
The owl of Minerva
spreads its wings
only with
the falling of the dusk
Markdown&LaTeX
python
pywin32
官方极简教程 PythonCOM Documentation Index
简单示例
from win32com.client import makepy
makepy.main() # 跳出窗口, 创建静态代理static proxy
win32com.client.constant.__d
HTML&CSS基础
本章极简地涵盖了html与CSS的基础知识, 内容来自html菜鸟教程.
一. HTML简介
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落.</p>
</body>
</html>
<!DOCTYPE html>声明为 HTML5 文档<html>元素是 HTML 页面的根元素<head>元素包含了文档的元(meta)数据,如 定义网页编码格式为 utf-8.<title>元素描述了文档的标题<body>元素包含了可见的页面内容<h1>元素定义一个大标题<p>元素定义一个段落 注:在浏览器的页面上使用键盘上的 F12 按键开启调试模式,就可以看到组成标签
什么是HTML
HTML 是用来描述网页的一种语言.
- HTML 指的是超文本标记语言: HyperText Markup Language
- HTML 不是一种编程语言,而是一种标记语言
- 标记语言是一套标记标签 (markup tag)
- HTML 使用标记标签来描述网页
- HTML 文档包含了HTML 标签及文本内容
- HTML文档也叫做 web 页面
HTML标签
HTML 标记标签通常被称为 HTML 标签 (HTML tag).
- HTML 标签是由尖括号包围的关键词,比如
- HTML 标签通常是成对出现的,比如 和
- 标签对中的第一个标签是开始标签,第二个标签是结束标签
- 开始和结束标签也被称为开放标签和闭合标签
HTML元素
"HTML 标签" 和 "HTML 元素" 通常都是描述同样的意思. 但是严格来讲, 一个 HTML 元素包含了开始标签与结束标签,如下实例:
HTML 元素:
<p>这是一个段落.</p>
<!DOCTYPE> 声明
声明有助于浏览器中正确显示网页.网络上有很多不同的文件,如果能够正确声明HTML的版本,浏览器就能正确显示网页内容. doctype 声明是不区分大小写的,以下方式均可:
<!DOCTYPE html>
<!DOCTYPE HTML>
<!doctype html>
<!Doctype Html>
通用声明
HTML5
<!DOCTYPE html>
HTML 4.01
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN"
"http://www.w3.org/TR/html4/loose.dtd">
XHTML 1.0
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
中文编码
目前在大部分浏览器中,直接输出中文会出现中文乱码的情况,这时候我们就需要在头部将字符声明为 UTF-8 或 GBK.
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>
页面标题</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落.</p>
</body>
</html>
二. HTML 属性
- HTML 元素可以设置属性
- 属性可以在元素中添加附加信息
- 属性一般描述于开始标签
- 属性总是以名称/值对的形式出现,比如:name="value".
属性实例
HTML 链接由 <a> 标签定义.链接的地址在 href 属性中指定:
<a href="http://www.runoob.com">这是一个链接</a>
HTML 属性常用引用属性值
属性值应该始终被包括在引号内.双引号是最常用的,不过使用单引号也没有问题.
提示: 在某些个别的情况下,比如属性值本身就含有双引号,那么您必须使用单引号,例如:
name='John "ShotGun" Nelson'
HTML 属性参考手册
查看完整的HTML属性列表: HTML 标签参考手册.
下面列出了适用于大多数 HTML 元素的属性:
| 属性 | 描述 |
|---|---|
| class | 为html元素定义一个或多个类名(classname)(类名从样式文件引入) |
| id | 定义元素的唯一id |
| style | 规定元素的行内样式(inline style) |
| title | 描述了元素的额外信息 (作为工具条使用) |
三. HTML元素
HTML <head> 元素
<head> 元素包含了所有的头部标签元素.在 <head>元素中你可以插入脚本(scripts), 样式文件(CSS),及各种meta信息.
可以添加在头部区域的元素标签为: <title>, <style>, <meta>, <link>, <script>, <noscript> 和 <base>.
HTML <title> 元素
<title> 标签定义了不同文档的标题.
<title> 在 HTML/XHTML 文档中是必需的.
<title> 元素:
- 定义了浏览器工具栏的标题
- 当网页添加到收藏夹时,显示在收藏夹中的标题
- 显示在搜索引擎结果页面的标题
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>文档标题</title>
</head>
<body>
文档内容......
</body>
</html>
HTML <base> 元素
<base> 标签描述了基本的链接地址/链接目标,该标签作为HTML文档中所有的链接标签的默认链接:
<head>
<base href="http://www.runoob.com/images/" target="_blank">
</head>
HTML <link> 元素
标签定义了文档与外部资源之间的关系.
标签通常用于链接到样式表:
<head>
<link rel="stylesheet" type="text/css" href="mystyle.css">
</head>
HTML <style> 元素
<style> 标签定义了HTML文档的样式文件引用地址.
在<style> 元素中你也可以直接添加样式来渲染 HTML 文档:
<head>
<style type="text/css">
body {
background-color:yellow;
}
p {
color:blue
}
</style>
</head>
HTML <meta> 元素
meta标签描述了一些基本的元数据.
<meta> 标签提供了元数据.元数据也不显示在页面上,但会被浏览器解析.
META 元素通常用于指定网页的描述,关键词,文件的最后修改时间,作者,和其他元数据.
元数据可以使用于浏览器(如何显示内容或重新加载页面),搜索引擎(关键词),或其他Web服务.
<meta> 一般放置于 <head> 区域
<meta> 标签- 使用实例
为搜索引擎定义关键词:
<meta name="keywords" content="HTML, CSS, XML, XHTML, JavaScript">
为网页定义描述内容:
<meta name="description" content="免费 Web & 编程 教程">
定义网页作者:
<meta name="author" content="Runoob">
每30秒钟刷新当前页面:
<meta http-equiv="refresh" content="30">
HTML <script> 元素
<script>标签用于加载脚本文件,如: JavaScript.
<script>元素在以后的章节中会详细描述.
HTML head 元素
| 标签 | 描述 |
|---|---|
<head> | 定义了文档的信息 |
<title> | 定义了文档的标题 |
<base> | 定义了页面链接标签的默认链接地址 |
<link> | 定义了一个文档和外部资源之间的关系 |
<meta> | 定义了HTML文档中的元数据 |
<script> | 定义了客户端的脚本文件 |
<style> | 定义了HTML文档的样式文件 |
四. HTML布局
HTML 布局 - 使用<div>元素
div 元素是用于分组 HTML 元素的块级元素. 下面的例子使用五个 div 元素来创建多列布局:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<div id="container" style="width:500px">
<div id="header" style="background-color:#FFA500;">
<h1 style="margin-bottom:0;">主要的网页标题</h1></div>
<div id="menu" style="background-color:#FFD700;height:200px;width:100px;float:left;">
<b>菜单</b><br>
HTML<br>
CSS<br>
JavaScript</div>
<div id="content" style="background-color:#EEEEEE;height:200px;width:400px;float:left;">
内容在这里</div>
<div id="footer" style="background-color:#FFA500;clear:both;text-align:center;">
版权 © runoob.com</div>
</div>
</body>
</html>
上面的 HTML 代码会产生如下结果:
主要的网页标题
HTML 布局 - 使用表格
使用 HTML <table> 标签是创建布局的一种简单的方式.
大多数站点可以使用 <div> 或者 <table> 元素来创建多列.CSS 用于对元素进行定位,或者为页面创建背景以及色彩丰富的外观.
下面的例子使用三行两列的表格 - 第一和最后一行使用 colspan 属性来横跨两列:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<table width="500" border="0">
<tr>
<td colspan="2" style="background-color:#FFA500;">
<h1>主要的网页标题</h1>
</td>
</tr>
<tr>
<td style="background-color:#FFD700;width:100px;">
<b>菜单</b><br>
HTML<br>
CSS<br>
JavaScript
</td>
<td style="background-color:#eeeeee;height:200px;width:400px;">
内容在这里</td>
</tr>
<tr>
<td colspan="2" style="background-color:#FFA500;text-align:center;">
版权 © runoob.com</td>
</tr>
</table>
</body>
</html>
主要的网页标题 |
|
|
菜单 HTML CSS JavaScript |
内容在这里 |
| 版权 © runoob.com | |
HTML 布局 - 有用的提示
- Tip: 使用 CSS 最大的好处是,如果把 CSS 代码存放到外部样式表中,那么站点会更易于维护.通过编辑单一的文件,就可以改变所有页面的布局.如需学习更多有关 CSS 的知识,请访问我们的CSS 教程.
- Tip: 由于创建高级的布局非常耗时,使用模板是一个快速的选项.通过搜索引擎可以找到很多免费的网站模板(您可以使用这些预先构建好的网站布局,并优化它们).
五. HTML其他
CSS基础
- CSS 指层叠样式表 (Cascading Style Sheets)
- 样式定义如何显示 HTML 元素
- 样式通常存储在样式表中
- 把样式添加到 HTML 4.0 中,是为了解决内容与表现分离的问题
- 外部样式表可以极大提高工作效率
- 外部样式表通常存储在 CSS 文件中
- 多个样式定义可层叠为一个
CSS 规则由两个主要的部分构成:选择器,以及一条或多条声明: 选择器通常是您需要改变样式的 HTML 元素,每条声明由一个属性和一个值组成. 属性(property)是您希望设置的样式属性(style attribute).每个属性有一个值. 属性和值被冒号分开.
CSS声明总是以分号;结束,声明总以大括号 {} 括起来, CSS注释以 /* 开始, 以 */ 结束
/*这是个注释*/
p
{
color:red;
/*这是另一个注释*/
text-align:center;
}
一. 基本操作
id 和 class 选择器
id 选择器可以为标有特定 id 的 HTML 元素指定特定的样式. HTML元素以id属性来设置id选择器,CSS 中 id 选择器以 "#" 来定义. 以下的样式规则应用于元素属性 id="para1":
#para1
{
text-align:center;
color:red;
}
class 选择器用于描述一组元素的样式,class 选择器有别于id选择器,class可以在多个元素中使用. class 选择器在 HTML 中以 class 属性表示, 在 CSS 中,类选择器以一个点 . 号显示:在以下的例子中,所有拥有 center 类的 HTML 元素均为居中.
.center {text-align:center;}
也可以指定特定的 HTML 元素使用 class. 在以下实例中, 所有的 p 元素使用 class="center" 让该元素的文本居中:
p.center {text-align:center;}
CSS创建
插入样式表的方法有三种:
- 外部样式表(External style sheet)
- 内部样式表(Internal style sheet)
- 内联样式(Inline style)
外部样式表
当样式需要应用于很多页面时,外部样式表将是理想的选择. 在使用外部样式表的情况下,可以通过改变一个文件来改变整个站点的外观. 每个页面使用 \<link\> 标签链接到样式表. \<link\> 标签在(文档的)头部:
<head>
<link rel="stylesheet" type="text/css" href="mystyle.css">
</head>
浏览器会从文件 mystyle.css 中读到样式声明,并根据它来格式文档.
外部样式表可以在任何文本编辑器中进行编辑. 文件不能包含任何的 html 标签. 样式表应该以 .css 扩展名进行保存. 下面是一个样式表文件的例子:
hr {color:sienna;}
p {margin-left:20px;}
body {background-image:url("/images/back40.gif");}
内部样式表
当单个文档需要特殊的样式时,就应该使用内部样式表. 你可以使用 \<style\> 标签在文档头部定义内部样式表,就像这样:
<head>
<style>
hr {color:sienna;}
p {margin-left:20px;}
body {background-image:url("images/back40.gif");}
</style>
</head>
内联样式
由于要将表现和内容混杂在一起,内联样式会损失掉样式表的许多优势. 请慎用这种方法,例如当样式仅需要在一个元素上应用一次时.
要使用内联样式,你需要在相关的标签内使用样式(style)属性. Style 属性可以包含任何 CSS 属性. 本例展示如何改变段落的颜色和左外边距:
<p style="color:sienna;margin-left:20px">这是一个段落。</p>
多重样式
如果某些属性在不同的样式表中被同样的选择器定义,那么属性值将从更具体的样式表中被继承过来.
例如,外部样式表拥有针对 h3 选择器的三个属性:
h3
{
color:red;
text-align:left;
font-size:8pt;
}
而内部样式表拥有针对 h3 选择器的两个属性:
h3
{
text-align:right;
font-size:20pt;
}
假如拥有内部样式表的这个页面同时与外部样式表链接,那么 h3 得到的样式是:
color:red;
text-align:right;
font-size:20pt;
即颜色属性将被继承于外部样式表,而文字排列(text-alignment)和字体尺寸(font-size)会被内部样式表中的规则取代.
多重样式优先级
样式表允许以多种方式规定样式信息. 样式可以规定在单个的 HTML 元素中,在 HTML 页的头元素中,或在一个外部的 CSS 文件中. 甚至可以在同一个 HTML 文档内部引用多个外部样式表。
一般情况下,优先级如下:
(内联样式)Inline style > (内部样式)Internal style sheet >(外部样式)External style sheet > 浏览器默认样式
<head>
<!-- 外部样式 style.css -->
<link rel="stylesheet" type="text/css" href="style.css"/>
<!-- 设置:h3{color:blue;} -->
<style type="text/css">
/* 内部样式 */
h3{color:green;}
</style>
</head>
<body>
<h3>显示绿色,是内部样式</h3>
</body>
注意:如果外部样式放在内部样式的后面,则外部样式将覆盖内部样式,实例如下:
<head>
<!-- 设置:h3{color:blue;} -->
<style type="text/css">
/* 内部样式 */
h3{color:green;}
</style>
<!-- 外部样式 style.css -->
<link rel="stylesheet" type="text/css" href="style.css"/>
</head>
<body>
<h3>显示蓝色,是外部样式</h3>
</body>
CSS背景
CSS 背景属性用于定义HTML元素的背景,CSS 属性定义背景效果:
background-colorbackground-imagebackground-repeatbackground-attachmentbackground-position
背景颜色
body {background-color:#b0c4de;}
CSS中,颜色值通常以以下方式定义:
- 十六进制:"#ff0000"
- RGB:"rgb(255,0,0)"
- 颜色名称:"red"
背景图像
默认情况下,背景图像进行平铺重复显示,以覆盖整个元素实体.
body {background-image:url('paper.gif');}
背景图像 - 水平或垂直平铺
默认情况下 background-image 属性会在页面的水平或者垂直方向平铺. 一些图像如果在水平方向与垂直方向平铺,这样看起来很不协调,如下所示:
body
{
background-image:url('gradient2.png');
}
如果图像只在水平方向平铺 (repeat-x)
body
{
background-image:url('gradient2.png');
background-repeat:repeat-x;
}
背景图像- 设置定位与不平铺
如果不想让图像平铺,可以使用 background-repeat 属性:
body
{
background-image:url('img_tree.png');
background-repeat:no-repeat;
}
以上实例中,背景图像与文本显示在同一个位置,为了让页面排版更加合理,不影响文本的阅读,我们可以改变图像的位置. 可以利用 background-position 属性改变图像在背景中的位置:
body
{
background-image:url('img_tree.png');
background-repeat:no-repeat;
background-position:right top;
}
CSS文本格式
文本颜色
body {color:red;}
h1 {color:#00ff00;}
h2 {color:rgb(255,0,0);}
文本的对齐方式
文本可居中或对齐到左或右,两端对齐. 当text-align设置为"justify",每一行被展开为宽度相等,左,右外边距是对齐(如杂志和报纸).
h1 {text-align:center;}
p.date {text-align:right;}
p.main {text-align:justify;}
文本修饰
text-decoration 属性用来设置或删除文本的装饰. 从设计的角度看 text-decoration属性主要是用来删除链接的下划线:
a {text-decoration:none;}
h1 {text-decoration:overline;}
h2 {text-decoration:line-through;}
h3 {text-decoration:underline;}
文本转换
文本转换属性是用来指定在一个文本中的大写和小写字母. 可用于所有字句变成大写或小写字母,或每个单词的首字母大写.
p.uppercase {text-transform:uppercase;}
p.lowercase {text-transform:lowercase;}
p.capitalize {text-transform:capitalize;}
文本缩进
文本缩进属性是用来指定文本的第一行的缩进。
p {text-indent:50px;}
CSS字体
CSS字型
在CSS中,有两种类型的字体系列名称:
- 通用字体系列 - 拥有相似外观的字体系统组合(如 "Serif" 或 "Monospace")
- 特定字体系列 - 一个特定的字体系列(如 "Times" 或 "Courier")
字体系列
font-family 属性设置文本的字体系列. font-family 属性应该设置几个字体名称作为一种"后备"机制,如果浏览器不支持第一种字体,他将尝试下一种字体.
多个字体系列是用一个逗号分隔指明:
p{font-family:"Times New Roman", Times, serif;}
字体样式
主要是用于指定斜体文字的字体样式属性. 这个属性有三个值:
- 正常 - 正常显示文本
- 斜体 - 以斜体字显示的文字
- 倾斜的文字 - 文字向一边倾斜(和斜体非常类似,但不太支持)
p.normal {font-style:normal;}
p.italic {font-style:italic;}
p.oblique {font-style:oblique;}
字体大小
font-size 属性设置文本的大小. 请务必使用正确的HTML标签,\<h1\> - \<h6\>表示标题和\<p\>表示段落:
字体大小的值可以是绝对或相对的大小
绝对大小:
- 设置一个指定大小的文本
- 不允许用户在所有浏览器中改变文本大小
- 确定了输出的物理尺寸时绝对大小很有用
相对大小:
- 相对于周围的元素来设置大小
- 允许用户在浏览器中改变文字大小
- Remark 如果你不指定一个字体的大小,默认大小和普通文本段落一样,是16像素(16px=1em)。
设置字体大小像素
设置文字的大小与像素,让您完全控制文字大小:
h1 {font-size:40px;}
h2 {font-size:30px;}
p {font-size:14px;}
用em来设置字体大小
为了避免Internet Explorer 中无法调整文本的问题,许多开发者使用 em 单位代替像素. em的尺寸单位由W3C建议. 1em和当前字体大小相等. 在浏览器中默认的文字大小是16px. 因此,1em的默认大小是16px. 可以通过下面这个公式将像素转换为em:px/16=em
h1 {font-size:2.5em;} /* 40px/16=2.5em */
h2 {font-size:1.875em;} /* 30px/16=1.875em */
p {font-size:0.875em;} /* 14px/16=0.875em */
在上面的例子,em的文字大小是与前面的例子中像素一样. 不过,如果使用 em 单位,则可以在所有浏览器中调整文本大小.
使用百分比和EM组合
在所有浏览器的解决方案中,设置
元素的默认字体大小的是百分比:body {font-size:100%;}
h1 {font-size:2.5em;}
h2 {font-size:1.875em;}
p {font-size:0.875em;}
CSS链接
链接样式
链接的样式,可以用任何CSS属性(如颜色,字体,背景等).特别的链接,可以有不同的样式,这取决于他们是什么状态.
这四个链接状态是:
- a:link - 正常,未访问过的链接
- a:visited - 用户已访问过的链接
- a:hover - 当用户鼠标放在链接上时
- a:active - 链接被点击的那一刻
a:link {color:#000000;} /* 未访问链接*/
a:visited {color:#00FF00;} /* 已访问链接 */
a:hover {color:#FF00FF;} /* 鼠标移动到链接上 */
a:active {color:#0000FF;} /* 鼠标点击时 */
当设置为若干链路状态的样式,也有一些顺序规则:
- a:hover 必须跟在 a:link 和 a:visited后面
- a:active 必须跟在 a:hover后面
常见的链接样式
根据上述链接的颜色变化的例子,看它是在什么状态. 让我们通过一些其他常见的方式转到链接样式:
文本修饰
text-decoration 属性主要用于删除链接中的下划线:
a:link {text-decoration:none;}
a:visited {text-decoration:none;}
a:hover {text-decoration:underline;}
a:active {text-decoration:underline;}
背景颜色
背景颜色属性指定链接背景色:
a:link {background-color:#B2FF99;}
a:visited {background-color:#FFFF85;}
a:hover {background-color:#FF704D;}
a:active {background-color:#FF704D;}
CSS列表
CSS 列表属性作用如下:
- 设置不同的列表项标记为有序列表
- 设置不同的列表项标记为无序列表
- 设置列表项标记为图像
列表
在 HTML中,有两种类型的列表:
- 无序列表
ul- 列表项标记用特殊图形(如小黑点、小方框等) - 有序列表
ol- 列表项的标记有数字或字母
使用 CSS,可以列出进一步的样式,并可用图像作列表项标记.
不同的列表项标记
list-style-type属性指定列表项标记的类型是:
ul.a {list-style-type: circle;}
ul.b {list-style-type: square;}
ol.c {list-style-type: upper-roman;}
ol.d {list-style-type: lower-alpha;}
作为列表项标记的图像
要指定列表项标记的图像,使用列表样式图像属性:
ul
{
list-style-image: url('sqpurple.gif');
}
CSS表格
表格边框
指定CSS表格边框,使用border属性. 下面的例子指定了一个表格的Th和TD元素的黑色边框:
table, th, td
{
border: 1px solid black;
}
请注意,在上面的例子中的表格有双边框. 这是因为表和th/ td元素有独立的边界. 为了显示一个表的单个边框,使用 border-collapse属性.
折叠边框
border-collapse 属性设置表格的边框是否被折叠成一个单一的边框或隔开:
table
{
border-collapse:collapse;
}
table, th, td
{
border: 1px solid black;
}
表格宽度和高度
Width和height属性定义表格的宽度和高度.
下面的例子是设置100%的宽度,50像素的th元素的高度的表格:
table
{
width:100%;
}
th
{
height:50px;
}
表格文字对齐
表格中的文本对齐和垂直对齐属性. `text-align 属性设置水平对齐方式,向左,右,或中心:
td
{
text-align:right;
}
垂直对齐属性设置垂直对齐,比如顶部,底部或中间:
td
{
height:50px;
vertical-align:bottom;
}
表格填充
如需控制边框和表格内容之间的间距,应使用td和th元素的填充属性:
td
{
padding:15px;
}
表格颜色
下面的例子指定边框的颜色,和th元素的文本和背景颜色:
table, td, th
{
border:1px solid green;
}
th
{
background-color:green;
color:white;
}
CSS 盒子模型(Box Model)
所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用. CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容. 盒模型允许我们在其它元素和周围元素边框之间的空间放置元素.
- Margin(外边距) - 清除边框外的区域,外边距是透明的
- Border(边框) - 围绕在内边距和内容外的边框
- Padding(内边距) - 清除内容周围的区域,内边距是透明的
- Content(内容) - 盒子的内容,显示文本和图像
元素的宽度和高度
重要: 当您指定一个 CSS 元素的宽度和高度属性时,你只是设置内容区域的宽度和高度. 要知道,完整大小的元素,你还必须添加内边距,边框和外边距.
div {
width: 300px;
border: 25px solid green;
padding: 25px;
margin: 25px;
}
300px (宽) + 50px (左 + 右填充) + 50px (左 + 右边框) + 50px (左 + 右边距) = 450px
div {
width: 220px;
padding: 10px;
border: 5px solid gray;
margin: 0;
}
最终元素的总宽度计算公式是这样的: 总元素的宽度=宽度+左填充+右填充+左边框+右边框+左边距+右边距
元素的总高度最终计算公式是这样的: 总元素的高度=高度+顶部填充+底部填充+上边框+下边框+上边距+下边距
CSS边框
边框样式
border-style值
none: 默认无边框dotted: 定义一个点线边框dashed: 定义一个虚线边框solid: 定义实线边框double: 定义两个边框,两个边框的宽度和border-width的值相同groove: 定义3d沟槽边框, 效果取决于边框的颜色值ridge: 定义3d脊边框, 效果取决于边框的颜色值inset:定义一个3D的嵌入边框, 效果取决于边框的颜色值outset: 定义一个3D突出边框, 效果取决于边框的颜色值
边框宽度
您可以通过 border-width 属性为边框指定宽度.
为边框指定宽度有两种方法:可以指定长度值,比如 2px 或 0.1em(单位为 px, pt, cm, em 等),或者使用 3 个关键字之一,它们分别是 thick 、medium(默认值) 和 thin.
注意:CSS 没有定义 3 个关键字的具体宽度,所以一个用户可能把 thick 、medium 和 thin 分别设置为等于 5px、3px 和 2px,而另一个用户则分别设置为 3px、2px 和 1px.
p.one
{
border-style:solid;
border-width:5px;
}
p.two
{
border-style:solid;
border-width:medium;
}
边框颜色
border-color属性用于设置边框的颜色. 可以设置的颜色:
- name - 指定颜色的名称,如 "red"
- RGB - 指定 RGB 值, 如 "rgb(255,0,0)"
- Hex - 指定16进制值, 如 "#ff0000"
p.one
{
border-style:solid;
border-color:red;
}
p.two
{
border-style:solid;
border-color:#98bf21;
}
边框-单独设置各边
在CSS中,可以指定不同的侧面不同的边框:
p
{
border-top-style:dotted;
border-right-style:solid;
border-bottom-style:dotted;
border-left-style:solid;
}
上面的例子也可以设置一个单一属性:
border-style:dotted solid;
border-style属性可以有1-4个值:
-
border-style:dotted solid double dashed;
- 上边框是 dotted
- 右边框是 solid
- 底边框是 double
- 左边框是 dashed
-
border-style:dotted solid double;
- 上边框是 dotted
- 左、右边框是 solid
- 底边框是 double
-
border-style:dotted solid;
- 上、底边框是 dotted
- 右、左边框是 solid
-
border-style:dotted;
- 四面边框是 dotted
上面的例子用了border-style. 然而,它也可以和border-width ,border-color一起使用
CSS轮廓(outline)
轮廓(outline)是绘制于元素周围的一条线,位于边框边缘的外围,可起到突出元素的作用. CSS outline 属性规定元素轮廓的样式、颜色和宽度.
所有CSS轮廓属性
| 属性 | 说明 | 值 |
|---|---|---|
| outline | 在一个声明中设置所有的轮廓属性 | outline-color outline-style outline-width inherit |
| outline-color | 设置轮廓的颜色 | color-name hex-number rgb-number invert inherit |
| outline-style | 设置轮廓的样式 | none dotted dashed solid double groove ridge inset outset inherit |
| outline-width | 设置轮廓的宽度 | thin medium thick length inherit |
CSS margin(外边距)
margin
margin 清除周围的(外边框)元素区域. margin 没有背景颜色,是完全透明的. margin 可以单独改变元素的上,下,左,右边距,也可以一次改变所有的属性.
可能的值
| 值 | 说明 |
|---|---|
| auto | 设置浏览器边距 这样做的结果会依赖于浏览器 |
| length | 定义一个固定的margin(使用像素,pt,em等) |
| % | 定义一个使用百分比的边距 |
Margin - 单边外边距属性
在CSS中,它可以指定不同的侧面不同的边距:
margin-top:100px;
margin-bottom:100px;
margin-right:50px;
margin-left:50px;
CSS padding(填充)
当元素的 padding(填充)内边距被清除时,所释放的区域将会受到元素背景颜色的填充,
length: 定义一个固定的填充(像素, pt, em,等)%: 使用百分比值定义一个填充
padding-top:25px;
padding-bottom:25px;
padding-right:50px;
padding-left:50px;
CSS 分组 和 嵌套 选择器
分组选择器
在样式表中有很多具有相同样式的元素
h1 {
color:green;
}
h2 {
color:green;
}
p {
color:green;
}
为了尽量减少代码,你可以使用分组选择器, 每个选择器用逗号分隔. 在下面的例子中,我们对以上代码使用分组选择器:
h1,h2,p
{
color:green;
}
嵌套选择器
它可能适用于选择器内部的选择器的样式,在下面的例子设置了四个样式:
p{ }: 为所有p元素指定一个样式.marked{ }: 为所有class="marked"的元素指定一个样式.marked p{ }: 为所有class="marked"元素内的p元素指定一个样式p.marked{ }: 为所有class="marked"的p元素指定一个样式
p
{
color:blue;
text-align:center;
}
.marked
{
background-color:red;
}
.marked p
{
color:white;
}
p.marked{
text-decoration:underline;
}
CSS 尺寸 (Dimension)
CSS 尺寸 (Dimension) 属性允许你控制元素的高度和宽度. 同样,它允许你增加行间距.
| 属性 | 描述 |
|---|---|
| height | 设置元素的高度 |
| line-height | 设置行高 |
| max-height | 设置元素最大高度 |
| max-width | 设置元素最大宽度 |
| min-height | 设置元素最小高度 |
| min-width | 设置元素最小宽度 |
| width | 设置元素宽度 |
CSS Display(显示) 与 Visibility(可见性)
display属性设置一个元素应如何显示,visibility属性指定一个元素应可见还是隐藏.
隐藏元素 - display:none或visibility:hidden
隐藏一个元素可以通过把display属性设置为"none",或把visibility属性设置为"hidden". 但是请注意,这两种方法会产生不同的结果.
visibility:hidden可以隐藏某个元素,但隐藏的元素仍需占用与未隐藏之前一样的空间. 也就是说,该元素虽然被隐藏了,但仍然会影响布局.
h1.hidden {visibility:hidden;}
display:none可以隐藏某个元素,且隐藏的元素不会占用任何空间. 也就是说,该元素不但被隐藏了,而且该元素原本占用的空间也会从页面布局中消失.
h1.hidden {display:none;}
CSS Display - 块和内联元素
块元素是一个元素,占用了全部宽度,在前后都是换行符.
块元素的例子:
<h1><p><div>
内联元素只需要必要的宽度,不强制换行.
内联元素的例子:
<span><a>
如何改变一个元素显示
可以更改内联元素和块元素,反之亦然,可以使页面看起来是以一种特定的方式组合,并仍然遵循web标准.
下面的示例把列表项显示为内联元素:
li {display:inline;}
下面的示例把span元素作为块元素:
span {display:block;}
注意:变更元素的显示类型看该元素是如何显示,它是什么样的元素. 例如:一个内联元素设置为display:block是不允许有它内部的嵌套块元素.
CSS Position(定位)
position 属性指定了元素的定位类型. position 属性的五个值:
staticrelativefixedabsolutesticky
元素可以使用的顶部,底部,左侧和右侧属性定位. 然而,这些属性无法工作,除非是先设定position属性. 他们也有不同的工作方式,这取决于定位方法.
static 定位
HTML 元素的默认值,即没有定位,遵循正常的文档流对象. 静态定位的元素不会受到 top, bottom, left, right影响.
div.static {
position: static;
border: 3px solid #73AD21;
}
fixed 定位
元素的位置相对于浏览器窗口是固定位置. 即使窗口是滚动的它也不会移动:
p.pos_fixed
{
position:fixed;
top:30px;
right:5px;
}
Fixed定位使元素的位置与文档流无关,因此不占据空间. Fixed定位的元素和其他元素重叠。
relative 定位
相对定位元素的定位是相对其正常位置.
h2.pos_left
{
position:relative;
left:-20px;
}
h2.pos_right
{
position:relative;
left:20px;
}
移动相对定位元素,但它原本所占的空间不会改变.
h2.pos_top
{
position:relative;
top:-50px;
}
相对定位元素经常被用来作为绝对定位元素的容器块.
absolute 定位
绝对定位的元素的位置相对于最近的已定位父元素,如果元素没有已定位的父元素,那么它的位置相对于<html>:
h2
{
position:absolute;
left:100px;
top:150px;
}
absolute 定位使元素的位置与文档流无关,因此不占据空间. absolute 定位的元素和其他元素重叠.
sticky 定位
sticky 英文字面意思是粘,粘贴,所以可以把它称之为粘性定位. position: sticky; 基于用户的滚动位置来定位. 粘性定位的元素是依赖于用户的滚动,在 position:relative 与 position:fixed 定位之间切换. 它的行为就像 position:relative; 而当页面滚动超出目标区域时,它的表现就像 position:fixed; 它会固定在目标位置. 元素定位表现为在跨越特定阈值前为相对定位,之后为固定定位.
这个特定阈值指的是 top, right, bottom 或 left 之一,换言之,指定 top, right, bottom 或 left 四个阈值其中之一,才可使粘性定位生效. 否则其行为与相对定位相同.
div.sticky {
position: -webkit-sticky; /* Safari */
position: sticky;
top: 0;
background-color: green;
border: 2px solid #4CAF50;
}
重叠的元素
元素的定位与文档流无关,所以它们可以覆盖页面上的其它元素. z-index属性指定了一个元素的堆叠顺序(哪个元素应该放在前面,或后面). 一个元素可以有正数或负数的堆叠顺序:
img
{
position:absolute;
left:0px;
top:0px;
z-index:-1;
}
具有更高堆叠顺序的元素总是在较低的堆叠顺序元素的前面.
注意: 如果两个定位元素重叠,没有指定z - index,最后定位在HTML代码中的元素将被显示在最前面.
CSS 布局 - Overflow
CSS overflow 属性用于控制内容溢出元素框时显示的方式. overflow 属性可以控制内容溢出元素框时在对应的元素区间内添加滚动条.
overflow属性有以下值:
| 值 | 描述 |
|---|---|
| visible | 默认值. 内容不会被修剪,会呈现在元素框之外 |
| hidden | 内容会被修剪,并且其余内容是不可见的 |
| scroll | 内容会被修剪,但是浏览器会显示滚动条以便查看其余的内容 |
| auto | 如果内容被修剪,则浏览器会显示滚动条以便查看其余的内容 |
| inherit | 规定应该从父元素继承 overflow 属性的值 |
注意:overflow 属性只工作于指定高度的块元素上. 默认情况下,overflow 的值为 visible, 意思是内容溢出元素框:
div {
width: 200px;
height: 50px;
background-color: #eee;
overflow: visible;
}
CSS Float(浮动)
CSS 的 Float(浮动),会使元素向左或向右移动,其周围的元素也会重新排列. Float(浮动),往往是用于图像,但它在布局时一样非常有用.
元素的水平方向浮动,意味着元素只能左右移动而不能上下移动. 一个浮动元素会尽量向左或向右移动,直到它的外边缘碰到包含框或另一个浮动框的边框为止. 浮动元素之后的元素将围绕它. 浮动元素之前的元素将不会受到影响. 如果图像是右浮动,下面的文本流将环绕在它左边:
img
{
float:right;
}
如果你把几个浮动的元素放到一起,如果有空间的话,它们将彼此相邻. 在这里,我们对图片廊使用 float 属性:
.thumbnail
{
float:left;
width:110px;
height:90px;
margin:5px;
}
清除浮动 - 元素浮动之后,周围的元素会重新排列,为了避免这种情况,使用 clear 属性.
clear 属性指定元素两侧不能出现浮动元素. 使用 clear 属性往文本中添加图片廊:
.text_line
{
clear:both;
}
CSS 布局 - 水平 & 垂直对齐
元素居中对齐
要水平居中对齐一个元素(如 <div>), 可以使用 margin: auto;. 设置到元素的宽度将防止它溢出到容器的边缘. 元素通过指定宽度,并将两边的空外边距平均分配:
.center {
margin: auto;
width: 50%;
border: 3px solid green;
padding: 10px;
}
注意: 如果没有设置 width 属性(或者设置 100%),居中对齐将不起作用.
文本居中对齐
如果仅仅是为了文本在元素内居中对齐,可以使用 text-align: center;
.center {
text-align: center;
border: 3px solid green;
}
图片居中对齐
要让图片居中对齐, 可以使用 margin: auto; 并将它放到 块 元素中:
img {
display: block;
margin: auto;
width: 40%;
}
左右对齐 - 使用定位方式
我们可以使用 position: absolute; 属性来对齐元素:
.right {
position: absolute;
right: 0px;
width: 300px;
border: 3px solid #73AD21;
padding: 10px;
}
注释:绝对定位元素会被从正常流中删除,并且能够交叠元素.
提示: 当使用 position 来对齐元素时, 通常 <body> 元素会设置 margin 和 padding . 这样可以避免在不同的浏览器中出现可见的差异.
body {
margin: 0;
padding: 0;
}
.container {
position: relative;
width: 100%;
}
.right {
position: absolute;
right: 0px;
width: 300px;
background-color: #b0e0e6;
}
左右对齐 - 使用 float 方式
我们也可以使用 float 属性来对齐元素:
.right {
float: right;
width: 300px;
border: 3px solid #73AD21;
padding: 10px;
}
当像这样对齐元素时,对 <body> 元素的外边距和内边距进行预定义是一个好主意. 这样可以避免在不同的浏览器中出现可见的差异.
注意:如果子元素的高度大于父元素,且子元素设置了浮动,那么子元素将溢出,这时候你可以使用 "clearfix(清除浮动)" 来解决该问题.
我们可以在父元素上添加 overflow: auto; 来解决子元素溢出的问题:
.clearfix {
overflow: auto;
}
body {
margin: 0;
padding: 0;
}
.right {
float: right;
width: 300px;
background-color: #b0e0e6;
}
垂直居中对齐 - 使用 padding
CSS 中有很多方式可以实现垂直居中对齐. 一个简单的方式就是头部顶部使用 padding:
.center {
padding: 70px 0;
border: 3px solid green;
}
如果要水平和垂直都居中,可以使用 padding 和 text-align: center:
.center {
padding: 70px 0;
border: 3px solid green;
text-align: center;
}
垂直居中 - 使用 line-height
.center {
line-height: 200px;
height: 200px;
border: 3px solid green;
text-align: center;
}
/* 如果文本有多行,添加以下代码: */
.center p {
line-height: 1.5;
display: inline-block;
vertical-align: middle;
}
垂直居中 - 使用 position 和 transform
除了使用 padding 和 line-height 属性外, 我们还可以使用 transform 属性来设置垂直居中:
.center {
height: 200px;
position: relative;
border: 3px solid green;
}
.center p {
margin: 0;
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
}
CSS 组合选择符
组合选择符说明了两个选择器之间的关系. CSS组合选择符包括各种简单选择符的组合方式. 在 CSS3 中包含了四种组合方式:
- 后代选择器(以空格
- 子元素选择器(以大于
>号分隔) - 相邻兄弟选择器(以加号
+分隔) - 普通兄弟选择器(以波浪号
~分隔)
后代选择器
后代选择器用于选取某元素的后代元素. 以下实例选取所有 <p> 元素插入到 <div> 元素中:
div p
{
background-color:yellow;
}
子元素选择器
与后代选择器相比,子元素选择器(Child selectors)只能选择作为某元素直接/一级子元素的元素. 以下实例选择了<div>元素中所有直接子元素 <p> :
div>p
{
background-color:yellow;
}
相邻兄弟选择器
相邻兄弟选择器(Adjacent sibling selector)可选择紧接在另一元素后的元素,且二者有相同父元素. 如果需要选择紧接在另一个元素后的元素,而且二者有相同的父元素,可以使用相邻兄弟选择器(Adjacent sibling selector). 以下实例选取了所有位于 <div> 元素后的第一个 <p> 元素:
div+p
{
background-color:yellow;
}
后续兄弟选择器
后续兄弟选择器选取所有指定元素之后的相邻兄弟元素. 以下实例选取了所有 <div> 元素之后的所有相邻兄弟元素 <p> :
div~p
{
background-color:yellow;
}
CSS 伪类(Pseudo-classes)
CSS伪类是用来添加一些选择器的特殊效果.
语法
伪类的语法:selector:pseudo-class {property:value;}
CSS类也可以使用伪类:selector.class:pseudo-class {property:value;}
anchor伪类
在支持 CSS 的浏览器中,链接的不同状态都可以以不同的方式显示
a:link {color:#FF0000;} /* 未访问的链接 */
a:visited {color:#00FF00;} /* 已访问的链接 */
a:hover {color:#FF00FF;} /* 鼠标划过链接 */
a:active {color:#0000FF;} /* 已选中的链接 */
注意: 在CSS定义中,a:hover 必须被置于 a:link 和 a:visited 之后,才是有效的
注意: 在 CSS 定义中,a:active 必须被置于 a:hover 之后,才是有效的
注意:伪类的名称不区分大小写
伪类和CSS类
伪类可以与 CSS 类配合使用:
a.red:visited {color:#FF0000;}
<a class="red" href="css-syntax.html">CSS 语法</a>
如果在上面的例子的链接已被访问,它会显示为红色.
CSS :first-child 伪类
您可以使用 :first-child 伪类来选择父元素的第一个子元素.
匹配第一个 <p> 元素
在下面的例子中,选择器匹配作为任何元素的第一个子元素的 <p> 元素:
p:first-child
{
color:blue;
}
匹配所有 <p> 元素中的第一个 <i> 元素
在下面的例子中,选择相匹配的所有<p>元素的第一个 <i> 元素:
p > i:first-child
{
color:blue;
}
匹配所有作为第一个子元素的 <p> 元素中的所有 <i> 元素
在下面的例子中,选择器匹配所有作为元素的第一个子元素的 <p> 元素中的所有 <i> 元素:
p:first-child i
{
color:blue;
}
CSS - :lang 伪类
:lang 伪类使你有能力为不同的语言定义特殊的规则
在下面的例子中,:lang 类为属性值为 no 的q元素定义引号的类型:
q:lang(no) {quotes: "~" "~";}
所有CSS伪类/元素
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| :checked | input:checked | 选择所有选中的表单元素 |
| :disabled | input:disabled | 选择所有禁用的表单元素 |
| :empty | p:empty | 选择所有没有子元素的p元素 |
| :enabled | input:enabled 选择所有启用的表单元素 | |
| :first-of-type | p:first-of-type | 选择的每个 p 元素是其父元素的第一个 p 元素 |
| :in-range | input:in-range | 选择元素指定范围内的值 |
| :invalid | input:invalid | 选择所有无效的元素 |
| :last-child | p:last-child | 选择所有p元素的最后一个子元素 |
| :last-of-type | p:last-of-type | 选择每个p元素是其母元素的最后一个p元素 |
| :not(selector) | :not(p) | 选择所有p以外的元素 |
| :nth-child(n) | p:nth-child(2) | 选择所有 p 元素的父元素的第二个子元素 |
| :nth-last-child(n) | p:nth-last-child(2) | 选择所有p元素倒数的第二个子元素 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 选择所有p元素倒数的第二个为p的子元素 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择所有p元素第二个为p的子元素 |
| :only-of-type | p:only-of-type | 选择所有仅有一个子元素为p的元素 |
| :only-child | p:only-child | 选择所有仅有一个子元素的p元素 |
| :optional | input:optional | 选择没有"required"的元素属性 |
| :out-of-range | input:out-of-range | 选择指定范围以外的值的元素属性 |
| :read-only | input:read-only | 选择只读属性的元素属性 |
| :read-write | input:read-write | 选择没有只读属性的元素属性 |
| :required | input:required | 选择有"required"属性指定的元素属性 |
| :root | root | 选择文档的根元素 |
| :target | #news:target | 选择当前活动#news元素(点击URL包含锚的名字) |
| :valid | input:valid | 选择所有有效值的属性 |
| :link | a:link | 选择所有未访问链接 |
| :visited | a:visited | 选择所有访问过的链接 |
| :active | a:active | 选择正在活动链接 |
| :hover | a:hover | 把鼠标放在链接上的状态 |
| :focus | input:focus | 选择元素输入后具有焦点 |
| :first-letter | p:first-letter | 选择每个<p> 元素的第一个字母 |
| :first-line | p:first-line | 选择每个<p> 元素的第一行 |
| :first-child | p:first-child | 选择器匹配属于任意元素的第一个子元素的 <p> 元素 |
| :before | p:before | 在每个<p>元素之前插入内容 |
| :after | p:after | 在每个<p>元素之后插入内容 |
| :lang(language) | p:lang(it) | 为<p>元素的lang属性选择一个开始值 |
CSS 伪元素
CSS 伪元素是用来添加一些选择器的特殊效果
伪元素的语法:
selector:pseudo-element {property:value;}
CSS类也可以使用伪元素:
selector.class:pseudo-element {property:value;}
:first-line 伪元素
"first-line" 伪元素用于向文本的首行设置特殊样式. 在下面的例子中,浏览器会根据 "first-line" 伪元素中的样式对 p 元素的第一行文本进行格式化:
p:first-line
{
color:#ff0000;
font-variant:small-caps;
}
注意:"first-line" 伪元素只能用于块级元素
注意: 下面的属性可应用于 "first-line" 伪元素:
font propertiescolor propertiesbackground propertiesword-spacingletter-spacingtext-decorationvertical-aligntext-transformline-heightclear
:first-letter 伪元素
"first-letter" 伪元素用于向文本的首字母设置特殊样式:
p:first-letter
{
color:#ff0000;
font-size:xx-large;
}
注意: "first-letter" 伪元素只能用于块级元素
注意: 下面的属性可应用于 "first-letter" 伪元素:
font propertiescolor propertiesbackground propertiesmargin propertiespadding propertiesborder propertiestext-decorationvertical-align(only if"float"is"none")text-transformline-heightfloatclear
伪元素和CSS类
伪元素可以结合CSS类:
p.article:first-letter {color:#ff0000;}
<p class="article">文章段落</p>
上面的例子会使所有 class 为 article 的段落的首字母变为红色。
多个伪元素
可以结合多个伪元素来使用. 在下面的例子中,段落的第一个字母将显示为红色,其字体大小为 xx-large. 第一行中的其余文本将为蓝色,并以小型大写字母显示. 段落中的其余文本将以默认字体大小和颜色来显示:
p:first-letter
{
color:#ff0000;
font-size:xx-large;
}
p:first-line
{
color:#0000ff;
font-variant:small-caps;
}
CSS - :before 伪元素
":before" 伪元素可以在元素的内容前面插入新内容. 下面的例子在每个 <h1>元素前面插入一幅图片:
h1:before
{
content:url(smiley.gif);
}
CSS - :after 伪元素
":after" 伪元素可以在元素的内容之后插入新内容. 下面的例子在每个 <h1> 元素后面插入一幅图片:
h1:after
{
content:url(smiley.gif);
}
所有CSS伪类/元素
| 选择器 | 示例 | 示例说明 |
|---|---|---|
| :link | a:link | 选择所有未访问链接 |
| :visited | a:visited | 选择所有访问过的链接 |
| :active | a:active | 选择正在活动链接 |
| :hover | a:hover | 把鼠标放在链接上的状态 |
| :focus | input:focus | 选择元素输入后具有焦点 |
| :first-letter | p:first-letter | 选择每个<p> 元素的第一个字母 |
| :first-line | p:first-line | 选择每个<p> 元素的第一行 |
| :first-child | p:first-child | 选择器匹配属于任意元素的第一个子元素的 <p> 元素 |
| :before | p:before | 在每个<p>元素之前插入内容 |
| :after | p:after | 在每个<p>元素之后插入内容 |
| :lang(language) | p:lang(it) | 为<p>元素的lang属性选择一个开始值 |
CSS 导航栏
使用CSS你可以转换成好看的导航栏而不是枯燥的HTML菜单.
导航栏=链接列表
在我们的例子中我们将建立一个标准的 HTML 列表导航栏. 导航条基本上是一个链接列表,所以使用 <ul> 和 <li>元素非常有意义:
<ul>
<li><a href="#home">主页</a></li>
<li><a href="#news">新闻</a></li>
<li><a href="#contact">联系</a></li>
<li><a href="#about">关于</a></li>
</ul>
现在,让我们从列表中删除边距和填充:
ul {
list-style-type: none;
margin: 0;
padding: 0;
}
例子解析:
list-style-type:none- 移除列表前小标志. 一个导航栏并不需要列表标记- 移除浏览器的默认设置将边距和填充设置为
0上面的例子中的代码是垂直和水平导航栏使用的标准代码.
垂直导航栏
上面的代码,我们只需要 <a>元素的样式,建立一个垂直的导航栏:
a
{
display:block;
width:60px;
}
示例说明:
display:block- 显示块元素的链接,让整体变为可点击链接区域(不只是文本),它允许我们指定宽度width:60px- 块元素默认情况下是最大宽度. 我们要指定一个60像素的宽度
注意: 请务必指定 <a>元素在垂直导航栏的的宽度. 如果省略宽度,IE6可能产生意想不到的效果.
垂直导航条实例
创建一个简单的垂直导航条实例,在鼠标移动到选项时,修改背景颜色:
ul {
list-style-type: none;
margin: 0;
padding: 0;
width: 200px;
background-color: #f1f1f1;
}
li a {
display: block;
color: #000;
padding: 8px 16px;
text-decoration: none;
}
/* 鼠标移动到选项上修改背景颜色 */
li a:hover {
background-color: #555;
color: white;
}
激活/当前导航条实例
在点击了选项后,我们可以添加 "active" 类来标注哪个选项被选中:
li a.active {
background-color: #4CAF50;
color: white;
}
创建链接并添加边框
可以在 <li> or <a>上添加 text-align:center 样式来让链接居中.
可以在 border <ul> 上添加 border 属性来让导航栏有边框. 如果要在每个选项上添加边框,可以在每个 <li> 元素上添加border-bottom :
ul {
border: 1px solid #555;
}
li {
text-align: center;
border-bottom: 1px solid #555;
}
li:last-child {
border-bottom: none;
}
全屏高度的固定导航条
接下来我们创建一个左边是全屏高度的固定导航条,右边是可滚动的内容.
ul {
list-style-type: none;
margin: 0;
padding: 0;
width: 25%;
background-color: #f1f1f1;
height: 100%; /* 全屏高度 */
position: fixed;
overflow: auto; /* 如果导航栏选项多,允许滚动 */
}
水平导航栏
有两种方法创建横向导航栏. 使用内联(inline)或浮动(float)的列表项. 这两种方法都很好,但如果你想链接到具有相同的大小,你必须使用浮动的方法.
内联列表项
建立一个横向导航栏的方法之一是指定元素, 下述代码是标准的内联:
li
{
display:inline;
}
实例解析:
display:inline;- 默认情况下,<li>元素是块元素. 在这里,我们删除换行符之前和之后每个列表项,以显示一行
浮动列表项
在上面的例子中链接有不同的宽度. 对于所有的链接宽度相等,浮动 <li>元素,并指定为 <a>元素的宽度:
li
{
float:left;
}
a
{
display:block;
width:60px;
}
实例解析:
float:left- 使用浮动块元素的幻灯片彼此相邻display:block- 显示块元素的链接,让整体变为可点击链接区域(不只是文本),它允许我们指定宽度width:60px- 块元素默认情况下是最大宽度. 我们要指定一个60像素的宽度
水平导航条实例
创建一个水平导航条,在鼠标移动到选项后修改背景颜色.
ul {
list-style-type: none;
margin: 0;
padding: 0;
overflow: hidden;
background-color: #333;
}
li {
float: left;
}
li a {
display: block;
color: white;
text-align: center;
padding: 14px 16px;
text-decoration: none;
}
/*鼠标移动到选项上修改背景颜色 */
li a:hover {
background-color: #111;
}
激活/当前导航条实例
在点击了选项后,我们可以添加 "active" 类来标准哪个选项被选中:
.active {
background-color: #4CAF50;
}
链接右对齐
将导航条最右边的选项设置右对齐 (float:right;):
<ul>
<li><a href="#home">主页</a></li>
<li><a href="#news">新闻</a></li>
<li><a href="#contact">联系</a></li>
<li style="float:right"><a class="active" href="#about">关于</a></li>
</ul>
添加分割线
<li> 通过 border-right 样式来添加分割线:
/* 除了最后一个选项(last-child) 其他的都添加分割线 */
li {
border-right: 1px solid #bbb;
}
li:last-child {
border-right: none;
}
固定导航条
可以设置页面的导航条固定在头部或者底部:
固定在头部
ul {
position: fixed;
top: 0;
width: 100%;
}
固定在底部
ul {
position: fixed;
bottom: 0;
width: 100%;
}
灰色水平导航条
ul {
border: 1px solid #e7e7e7;
background-color: #f3f3f3;
}
li a {
color: #666;
}
CSS 下拉菜单
使用 CSS 创建一个鼠标移动上去后显示下拉菜单的效果
<style>
.dropdown {
position: relative;
display: inline-block;
}
.dropdown-content {
display: none;
position: absolute;
background-color: #f9f9f9;
min-width: 160px;
box-shadow: 0px 8px 16px 0px rgba(0,0,0,0.2);
padding: 12px 16px;
}
.dropdown:hover .dropdown-content {
display: block;
}
</style>
<div class="dropdown">
<span>鼠标移动到我这!</span>
<div class="dropdown-content">
<p>菜鸟教程</p>
<p>www.runoob.com</p>
</div>
</div>
实例解析
HTML 部分:
我们可以使用任何的 HTML 元素来打开下拉菜单,如:<span>, 或 a <button> 元素.
使用容器元素 (如: <div>) 来创建下拉菜单的内容,并放在任何你想放的位置上.
使用 <div> 元素来包裹这些元素,并使用 CSS 来设置下拉内容的样式.
CSS 部分:
.dropdown 类使用 position:relative, 这将设置下拉菜单的内容放置在下拉按钮 (使用 position:absolute) 的右下角位置.
.dropdown-content 类中是实际的下拉菜单. 默认是隐藏的,在鼠标移动到指定元素后会显示. 注意 min-width 的值设置为 160px. 你可以随意修改它. 注意: 如果你想设置下拉内容与下拉按钮的宽度一致,可设置 width 为 100% ( overflow:auto 设置可以在小尺寸屏幕上滚动).
我们使用 box-shadow 属性让下拉菜单看起来像一个"卡片".
:hover 选择器用于在用户将鼠标移动到下拉按钮上时显示下拉菜单.
下拉菜单
创建下拉菜单,并允许用户选取列表中的某一项. 这个实例类似前面的实例,当我们在下拉列表中添加了链接,并设置了样式:
<style>
/* 下拉按钮样式 */
.dropbtn {
background-color: #4CAF50;
color: white;
padding: 16px;
font-size: 16px;
border: none;
cursor: pointer;
}
/* 容器 <div> - 需要定位下拉内容 */
.dropdown {
position: relative;
display: inline-block;
}
/* 下拉内容 (默认隐藏) */
.dropdown-content {
display: none;
position: absolute;
background-color: #f9f9f9;
min-width: 160px;
box-shadow: 0px 8px 16px 0px rgba(0,0,0,0.2);
}
/* 下拉菜单的链接 */
.dropdown-content a {
color: black;
padding: 12px 16px;
text-decoration: none;
display: block;
}
/* 鼠标移上去后修改下拉菜单链接颜色 */
.dropdown-content a:hover {background-color: #f1f1f1}
/* 在鼠标移上去后显示下拉菜单 */
.dropdown:hover .dropdown-content {
display: block;
}
/* 当下拉内容显示后修改下拉按钮的背景颜色 */
.dropdown:hover .dropbtn {
background-color: #3e8e41;
}
</style>
<div class="dropdown">
<button class="dropbtn">下拉菜单</button>
<div class="dropdown-content">
<a href="#">菜鸟教程 1</a>
<a href="#">菜鸟教程 2</a>
<a href="#">菜鸟教程 3</a>
</div>
</div>
下拉内容对齐方式
如果你想设置右浮动的下拉菜单内容方向是从右到左,而不是从左到右,可以添加以下代码 right: 0;
.dropdown-content {
right: 0;
}
CSS 提示工具(Tooltip)
提示工具在鼠标移动到指定元素后触发
基础提示框(Tooltip)
提示框在鼠标移动到指定元素上显示:
<style>
/* Tooltip 容器 */
.tooltip {
position: relative;
display: inline-block;
border-bottom: 1px dotted black; /* 悬停元素上显示点线 */
}
/* Tooltip 文本 */
.tooltip .tooltiptext {
visibility: hidden;
width: 120px;
background-color: black;
color: #fff;
text-align: center;
padding: 5px 0;
border-radius: 6px;
/* 定位 */
position: absolute;
z-index: 1;
}
/* 鼠标移动上去后显示提示框 */
.tooltip:hover .tooltiptext {
visibility: visible;
}
</style>
<div class="tooltip">鼠标移动到这
<span class="tooltiptext">提示文本</span>
</div>
实例解析
HTML-使用容器元素 (like <div>) 并添加 "tooltip" 类. 在鼠标移动到 <div> 上时显示提示信息.
提示文本放在内联元素上(如 <span>) 并使用class="tooltiptext"
CSS-tooltip 类使用 position:relative, 提示文本需要设置定位值 position:absolute. 注意: 接下来的实例会显示更多的定位效果.
tooltiptext 类用于实际的提示文本. 模式是隐藏的,在鼠标移动到元素显示. 设置了一些宽度、背景色、字体色等样式.
CSS3 border-radius 属性用于为提示框添加圆角.
:hover 选择器用于在鼠标移动到到指定元素 <div> 上时显示的提示.
定位提示工具
以下实例中,提示工具显示在指定元素的右侧(left:105%)
注意 top:-5px 同于定位在容器元素的中间. 使用数字 5 因为提示文本的顶部和底部的内边距(padding)是 5px. 如果你修改 padding 的值,top 值也要对应修改,这样才可以确保它是居中对齐的. 在提示框显示在左边的情况也是这个原理.
显示在右侧:
.tooltip .tooltiptext {
top: -5px;
left: 105%;
}
显示在左侧:
.tooltip .tooltiptext {
top: -5px;
right: 105%;
}
如果你想要提示工具显示在头部和底部, 我们需要使用 margin-left 属性,并设置为-60px. 这个数字计算来源是使用宽度的一半来居中对齐,即: width/2 (120/2 = 60).
显示在头部:
.tooltip .tooltiptext {
width: 120px;
bottom: 100%;
left: 50%;
margin-left: -60px; /* 使用一半宽度 (120/2 = 60) 来居中提示工具 */
}
显示在底部:
.tooltip .tooltiptext {
width: 120px;
top: 100%;
left: 50%;
margin-left: -60px; /* 使用一半宽度 (120/2 = 60) 来居中提示工具 */
}
添加箭头
我们可以用CSS 伪元素 ::after 及 content 属性为提示工具创建一个小箭头标志,箭头是由边框组成的,但组合起来后提示工具像个语音信息框. 以下实例演示了如何为显示在顶部的提示工具添加底部箭头:
顶部提示框/底部箭头:
.tooltip .tooltiptext::after {
content: " ";
position: absolute;
top: 100%; /* 提示工具底部 */
left: 50%;
margin-left: -5px;
border-width: 5px;
border-style: solid;
border-color: black transparent transparent transparent;
}
实例解析
在提示工具内定位箭头: top: 100% , 箭头将显示在提示工具的底部. left: 50% 用于居中对齐箭头.
注意:border-width 属性指定了箭头的大小. 如果你修改它,也要修改 margin-left 值. 这样箭头才能居中显示.
border-color 用于将内容转换为箭头. 设置顶部边框为黑色,其他是透明的. 如果设置了其他的也是黑色则会显示为一个黑色的四边形.
以下实例演示了如何在提示工具的头部添加箭头,注意设置边框颜色:
底部提示框/顶部箭头:
.tooltip .tooltiptext::after {
content: " ";
position: absolute;
bottom: 100%; /* 提示工具头部 */
left: 50%;
margin-left: -5px;
border-width: 5px;
border-style: solid;
border-color: transparent transparent black transparent;
}
以下两个实例是左右两边的箭头实例:
右侧提示框/左侧箭头:
.tooltip .tooltiptext::after {
content: " ";
position: absolute;
top: 50%;
right: 100%; /* 提示工具左侧 */
margin-top: -5px;
border-width: 5px;
border-style: solid;
border-color: transparent black transparent transparent;
}
左侧提示框/右侧箭头:
.tooltip .tooltiptext::after {
content: " ";
position: absolute;
top: 50%;
left: 100%; /* 提示工具右侧 */
margin-top: -5px;
border-width: 5px;
border-style: solid;
border-color: transparent transparent transparent black;
}
淡入效果
我们可以使用 CSS3 transition 属性及 opacity 属性来实现提示工具的淡入效果:
淡入效果:
.tooltip .tooltiptext {
opacity: 0;
transition: opacity 1s;
}
.tooltip:hover .tooltiptext {
opacity: 1;
}
CSS 图片廊
以下是使用 CSS 创建图片廊:
<div class="responsive">
<div class="img">
<a target="_blank" href="http://static.runoob.com/images/demo/demo1.jpg">
<img decoding="async" src="http://static.runoob.com/images/demo/demo1.jpg" alt="图片文本描述" width="300" height="200">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="http://static.runoob.com/images/demo/demo2.jpg">
<img decoding="async" loading="lazy" src="http://static.runoob.com/images/demo/demo2.jpg" alt="图片文本描述" width="300" height="200">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="http://static.runoob.com/images/demo/demo3.jpg">
<img decoding="async" loading="lazy" src="http://static.runoob.com/images/demo/demo3.jpg" alt="图片文本描述" width="300" height="200">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="http://static.runoob.com/images/demo/demo4.jpg">
<img decoding="async" loading="lazy" src="http://static.runoob.com/images/demo/demo4.jpg" alt="图片文本描述" width="300" height="200">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
使用 CSS3 的媒体查询来创建响应式图片廊:
<div class="responsive">
<div class="img">
<a target="_blank" href="img_fjords.jpg">
<img decoding="async" loading="lazy" src="http://www.runoob.com/wp-content/uploads/2016/04/img_fjords.jpg" alt="Trolltunga Norway" width="300" height="200">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="img_forest.jpg">
<img decoding="async" loading="lazy" src="http://www.runoob.com/wp-content/uploads/2016/04/img_forest.jpg" alt="Forest" width="600" height="400">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="img_lights.jpg">
<img decoding="async" loading="lazy" src="http://www.runoob.com/wp-content/uploads/2016/04/img_lights.jpg" alt="Northern Lights" width="600" height="400">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="responsive">
<div class="img">
<a target="_blank" href="img_mountains.jpg">
<img decoding="async" loading="lazy" src="http://www.runoob.com/wp-content/uploads/2016/04/img_mountains.jpg" alt="Mountains" width="600" height="400">
</a>
<div class="desc">这里添加图片文本描述</div>
</div>
</div>
<div class="clearfix"></div>
<div style="padding:6px;">
<h4>重置浏览器大小查看效果</h4>
</div>
CSS 图像透明/不透明
注意:CSS Opacity属性是W3C的CSS3建议的一部分.
实例1 - 创建一个透明图像
首先,展示如何用CSS创建一个透明图像.
img
{
opacity:0.4;
filter:alpha(opacity=40); /* IE8 及其更早版本 */
}
实例2 - 图像的透明度 - 悬停效果
img
{
opacity:0.4;
filter:alpha(opacity=40); /* IE8 及其更早版本 */
}
img:hover
{
opacity:1.0;
filter:alpha(opacity=100); /* IE8 及其更早版本 */
}
第一个CSS块是和例1中的代码类似. 此外,我们还增加了当用户将鼠标悬停在其中一个图像上时发生什么. 在这种情况下,当用户将鼠标悬停在图像上时,我们希望图片是清晰的.
此CSS是:opacity=1.
当鼠标指针远离图像时,图像将重新具有透明度.
实例3 - 透明的盒子中的文字
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<style>
div.background
{
width:500px;
height:250px;
background:url(https://www.runoob.com/images/klematis.jpg) repeat;
border:2px solid black;
}
div.transbox
{
width:400px;
height:180px;
margin:30px 50px;
background-color:#ffffff;
border:1px solid black;
opacity:0.6;
filter:alpha(opacity=60); /* IE8 及更早版本 */
}
div.transbox p
{
margin:30px 40px;
font-weight:bold;
color:#000000;
}
</style>
</head>
<body>
<div class="background">
<div class="transbox">
<p>这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。这些文本在透明框里。
</p>
</div>
</div>
</body>
</html>
首先,我们创建一个固定的高度和宽度的div元素,带有一个背景图片和边框. 然后我们在第一个div内部创建一个较小的div元素. 这个div也有一个固定的宽度,背景颜色,边框 - 而且它是透明的. 透明的div里面,我们在P元素内部添加一些文本.
CSS 图像拼合技术
图像拼合
图像拼合就是单个图像的集合. 有许多图像的网页可能需要很长的时间来加载和生成多个服务器的请求. 使用图像拼合会降低服务器的请求数量,并节省带宽.
图像拼合 - 简单实例
有了CSS,我们可以只显示我们需要的图像的一部分. 在下面的例子CSS指定显示 "img_navsprites.gif" 的图像的一部分:
img.home
{
width:46px;
height:44px;
background:url(img_navsprites.gif) 0 0;
}
实例解析:
<img class="home" src="img_trans.gif" />-因为不能为空,src属性只定义了一个小的透明图像. 显示的图像将是我们在CSS中指定的背景图像- 宽度:
46px;高度:44px; - 定义我们使用的那部分图像 background:url(img_navsprites.gif) 0 0;- 定义背景图像和它的位置(左0px,顶部0px)
这是使用图像拼合最简单的方法,现在我们使用链接和悬停效果.
图像拼合 - 创建一个导航列表
我们想使用拼合图像 ("img_navsprites.gif"),以创建一个导航列表. 我们将使用一个HTML列表,因为它可以链接,同时还支持背景图像:
#navlist{position:relative;}
#navlist li{margin:0;padding:0;list-style:none;position:absolute;top:0;}
#navlist li, #navlist a{height:44px;display:block;}
#home{left:0px;width:46px;}
#home{background:url('img_navsprites.gif') 0 0;}
#prev{left:63px;width:43px;}
#prev{background:url('img_navsprites.gif') -47px 0;}
#next{left:129px;width:43px;}
#next{background:url('img_navsprites.gif') -91px 0;}
实例解析:
#navlist{position:relative;}- 位置设置相对定位,让里面的绝对定位#navlist li{margin:0;padding:0;list-style:none;position:absolute;top:0;}-margin和padding设置为0,列表样式被删除,所有列表项是绝对定位#navlist li, #navlist a{height:44px;display:block;}- 所有图像的高度是44px
现在开始每个具体部分的定位和样式:
#home{left:0px;width:46px;}- 定位到最左边的方式,以及图像的宽度是46px#home{background:url(img_navsprites.gif) 0 0;}- 定义背景图像和它的位置(左0px,顶部0px)#prev{left:63px;width:43px;}- 右侧定位63px(#home宽46px+项目之间的一些多余的空间),宽度为43px#prev{background:url('img_navsprites.gif') -47px 0;}- 定义背景图像右侧47px(#home宽46px+分隔线的1px)#next{left:129px;width:43px;}- 右边定位129px(#prev63px+#prev宽是43px+ 剩余的空间), 宽度是43px.#next{background:url('img_navsprites.gif') no-repeat -91px 0;}- 定义背景图像右边91px(#home46px+1px的分割线+#prev宽43px+1px的分隔线)
图像拼合 - 悬停效果
现在,我们希望我们的导航列表中添加一个悬停效果. :hover 选择器用于鼠标悬停在元素上的显示的效果. :hover 选择器可以运用于所有元素. 我们的新图像 ("img_navsprites_hover.gif") 包含三个导航图像和三幅图像, 因为这是一个单一的图像,而不是6个单独的图像文件,当用户停留在图像上不会有延迟加载.
我们添加悬停效果只添加三行代码:
#home a:hover{background: url('img_navsprites_hover.gif') 0 -45px;}
#prev a:hover{background: url('img_navsprites_hover.gif') -47px -45px;}
#next a:hover{background: url('img_navsprites_hover.gif') -91px -45px;}
实例解析:
- 由于该列表项包含一个链接,我们可以使用
:hover伪类 #home a:hover{background: transparent url(img_navsprites_hover.gif) 0 -45px;}- 对于所有三个悬停图像,我们指定相同的背景位置,只是每个再向下45px
CSS 属性 选择器
具有特定属性的HTML元素样式不仅仅是class和id.
属性选择器
下面的例子是把包含标题(title)的所有元素变为蓝色:
[title]
{
color:blue;
}
属性和值选择器
下面的实例改变了标题title='runoob'元素的边框样式:
[title=runoob]
{
border:5px solid green;
}
属性和值的选择器 - 多值
下面是包含指定值的title属性的元素样式的例子,使用~分隔属性和值:
[title~=hello] { color:blue; }
下面是包含指定值的lang属性的元素样式的例子,使用|分隔属性和值:
[lang|=en] { color:blue; }
表单样式
属性选择器样式无需使用class或id的形式:
input[type="text"]
{
width:150px;
display:block;
margin-bottom:10px;
background-color:yellow;
}
input[type="button"]
{
width:120px;
margin-left:35px;
display:block;
}
CSS 表单
一个表单案例,我们使用 CSS 来渲染 HTML 的表单元素:
input[type=text], select {
width: 100%;
padding: 12px 20px;
margin: 8px 0;
display: inline-block;
border: 1px solid #ccc;
border-radius: 4px;
box-sizing: border-box;
}
input[type=submit] {
width: 100%;
background-color: #4CAF50;
color: white;
padding: 14px 20px;
margin: 8px 0;
border: none;
border-radius: 4px;
cursor: pointer;
}
input[type=submit]:hover {
background-color: #45a049;
}
div {
border-radius: 5px;
background-color: #f2f2f2;
padding: 20px;
}
输入框(input) 样式
使用 width 属性来设置输入框的宽度:
input {
width: 100%;
}
以上实例中设置了所有 <input> 元素的宽度为 100%,如果你只想设置指定类型的输入框可以使用以下属性选择器:
input[type=text]- 选取文本输入框input[type=password]- 选择密码的输入框input[type=number]- 选择数字的输入框- ...
输入框填充
使用 padding 属性可以在输入框中添加内边距.
input[type=text] {
width: 100%;
padding: 12px 20px;
margin: 8px 0;
box-sizing: border-box;
}
注意我们设置了 box-sizing 属性为 border-box. 这样可以确保浏览器呈现出带有指定宽度和高度的输入框是把边框和内边距一起计算进去的.
输入框(input) 边框
使用 border 属性可以修改 input 边框的大小或颜色,使用 border-radius 属性可以给 input 添加圆角:
input[type=text] {
border: 2px solid red;
border-radius: 4px;
}
如果你只想添加底部边框可以使用 border-bottom 属性:
input[type=text] {
border: none;
border-bottom: 2px solid red;
}
输入框(input) 颜色
可以使用 background-color 属性来设置输入框的背景颜色,color 属性用于修改文本颜色:
input[type=text] {
background-color: #3CBC8D;
color: white;
}
输入框(input) 聚焦
默认情况下,一些浏览器在输入框获取焦点时(点击输入框)会有一个蓝色轮廓. 我们可以设置 input 样式为 outline: none; 来忽略该效果.
使用 :focus 选择器可以设置输入框在获取焦点时的样式:
input[type=text]:focus {
background-color: lightblue;
}
input[type=text]:focus {
border: 3px solid #555;
}
输入框(input) 图标
如果你想在输入框中添加图标,可以使用 background-image 属性和用于定位的background-position 属性. 注意设置图标的左边距,让图标有一定的空间:
input[type=text] {
background-color: white;
background-image: url('searchicon.png');
background-position: 10px 10px;
background-repeat: no-repeat;
padding-left: 40px;
}
带动画的搜索框
以下实例使用了 CSS transition 属性,该属性设置了输入框在获取焦点时会向右延展.
input[type=text] {
-webkit-transition: width 0.4s ease-in-out;
transition: width 0.4s ease-in-out;
}
input[type=text]:focus {
width: 100%;
}
文本框(textarea)样式
注意: 使用 resize 属性来禁用文本框可以重置大小的功能(一般拖动右下角可以重置大小)
textarea {
width: 100%;
height: 150px;
padding: 12px 20px;
box-sizing: border-box;
border: 2px solid #ccc;
border-radius: 4px;
background-color: #f8f8f8;
resize: none;
}
下拉菜单(select)样式
select {
width: 100%;
padding: 16px 20px;
border: none;
border-radius: 4px;
background-color: #f1f1f1;
}
按钮样式
input[type=button], input[type=submit], input[type=reset] {
background-color: #4CAF50;
border: none;
color: white;
padding: 16px 32px;
text-decoration: none;
margin: 4px 2px;
cursor: pointer;
}
/* 提示: 使用 width: 100% 设置全宽按钮 */
响应式表单
响应式表单可以根据浏览器窗口的大小重新布局各个元素,我们可以通过重置浏览器窗口大小来查看效果:
* {
box-sizing: border-box;
}
input[type=text], select, textarea {
width: 100%;
padding: 12px;
border: 1px solid #ccc;
border-radius: 4px;
resize: vertical;
}
label {
padding: 12px 12px 12px 0;
display: inline-block;
}
input[type=submit] {
background-color: #4CAF50;
color: white;
padding: 12px 20px;
border: none;
border-radius: 4px;
cursor: pointer;
float: right;
}
input[type=submit]:hover {
background-color: #45a049;
}
.container {
border-radius: 5px;
background-color: #f2f2f2;
padding: 20px;
}
.col-25 {
float: left;
width: 25%;
margin-top: 6px;
}
.col-75 {
float: left;
width: 75%;
margin-top: 6px;
}
/* 清除浮动 */
.row:after {
content: "";
display: table;
clear: both;
}
/* 响应式布局 layout - 在屏幕宽度小于 600px 时, 设置为上下堆叠元素 */
@media screen and (max-width: 600px) {
.col-25, .col-75, input[type=submit] {
width: 100%;
margin-top: 0;
}
}
CSS 计数器
CSS 计数器通过一个变量来设置,根据规则递增变量.
使用计数器自动编号
CSS 计数器根据规则来递增变量. CSS 计数器使用到以下几个属性:
counter-reset- 创建或者重置计数器counter-increment- 递增变量content- 插入生成的内容counter()或counters()函数 - 将计数器的值添加到元素
要使用 CSS 计数器,得先用 counter-reset 创建:
以下实例在页面创建一个计数器 (在 body 选择器中),每个 <h2> 元素的计数值都会递增,并在每个 <h2> 元素前添加 "Section <计数值>:"
body {
counter-reset: section;
}
h2::before {
counter-increment: section;
content: "Section " counter(section) ": ";
}
嵌套计数器
以下实例在页面创建一个计数器,在每一个 <h1> 元素前添加计数值 "Section <主标题计数值>.", 嵌套的计数值则放在 <h2> 元素的前面,内容为 "<主标题计数值>.<副标题计数值>":
body {
counter-reset: section;
}
h1 {
counter-reset: subsection;
}
h1::before {
counter-increment: section;
content: "Section " counter(section) ". ";
}
h2::before {
counter-increment: subsection;
content: counter(section) "." counter(subsection) " ";
}
计数器也可用于列表中,列表的子元素会自动创建. 这里我们使用了 counters() 函数在不同的嵌套层级中插入字符串:
ol {
counter-reset: section;
list-style-type: none;
}
li::before {
counter-increment: section;
content: counters(section,".") " ";
}
CSS 计数器属性
| 属性 | 描述 |
|---|---|
| content | 使用 ::before 和 ::after 伪元素来插入自动生成的内容 |
| counter-increment | 递增一个或多个值 |
| counter-reset | 创建或重置一个或多个计数器 |
CSS 网页布局
头部区域
头部区域位于整个网页的顶部,一般用于设置网页的标题或者网页的 logo:
.header {
background-color: #F1F1F1;
text-align: center;
padding: 20px;
}
菜单导航区域
菜单导航条包含了一些链接,可以引导用户浏览其他页面:
/* 导航条 */
.topnav {
overflow: hidden;
background-color: #333;
}
/* 导航链接 */
.topnav a {
float: left;
display: block;
color: #f2f2f2;
text-align: center;
padding: 14px 16px;
text-decoration: none;
}
/* 链接 - 修改颜色 */
.topnav a:hover {
background-color: #ddd;
color: black;
}
内容区域
内容区域一般有三种形式:
- 1 列:一般用于移动端
- 2 列:一般用于平板设备
- 3 列:一般用于 PC 桌面设备
我们将创建一个 3 列布局,在小的屏幕上将会变成 1 列布局(响应式):
/* 创建三个相等的列 */
.column {
float: left;
width: 33.33%;
}
/* 列后清除浮动 */
.row:after {
content: "";
display: table;
clear: both;
}
/* 响应式布局 - 小于 600 px 时改为上下布局 */
@media screen and (max-width: 600px) {
.column {
width: 100%;
}
}
提示:要设置两列可以设置 width 为 50%. 创建 4 列可以设置为 25%
提示: 现在更高级的方式是使用 CSS Flexbox 来创建列的布局,但 Internet Explorer 10 及更早的版本不支持该方式, IE6-10 可以使用浮动方式
不相等的列
不相等的列一般是在中间部分设置内容区域,这块也是最大最主要的,左右两次侧可以作为一些导航等相关内容,这三列加起来的宽度是 100%.
.column {
float: left;
}
/* 左右侧栏的宽度 */
.column.side {
width: 25%;
}
/* 中间列宽度 */
.column.middle {
width: 50%;
}
/* 响应式布局 - 宽度小于600px时设置上下布局 */
@media screen and (max-width: 600px) {
.column.side, .column.middle {
width: 100%;
}
}
底部区域
底部区域在网页的最下方,一般包含版权信息和联系方式等.
.footer {
background-color: #F1F1F1;
text-align: center;
padding: 10px;
}
响应式网页布局
通过以上等学习我们来创建一个响应式等页面,页面的布局会根据屏幕的大小来调整:
* {
box-sizing: border-box;
}
body {
font-family: Arial;
padding: 10px;
background: #f1f1f1;
}
/* 头部标题 */
.header {
padding: 30px;
text-align: center;
background: white;
}
.header h1 {
font-size: 50px;
}
/* 导航条 */
.topnav {
overflow: hidden;
background-color: #333;
}
/* 导航条链接 */
.topnav a {
float: left;
display: block;
color: #f2f2f2;
text-align: center;
padding: 14px 16px;
text-decoration: none;
}
/* 链接颜色修改 */
.topnav a:hover {
background-color: #ddd;
color: black;
}
/* 创建两列 */
/* Left column */
.leftcolumn {
float: left;
width: 75%;
}
/* 右侧栏 */
.rightcolumn {
float: left;
width: 25%;
background-color: #f1f1f1;
padding-left: 20px;
}
/* 图像部分 */
.fakeimg {
background-color: #aaa;
width: 100%;
padding: 20px;
}
/* 文章卡片效果 */
.card {
background-color: white;
padding: 20px;
margin-top: 20px;
}
/* 列后面清除浮动 */
.row:after {
content: "";
display: table;
clear: both;
}
/* 底部 */
.footer {
padding: 20px;
text-align: center;
background: #ddd;
margin-top: 20px;
}
/* 响应式布局 - 屏幕尺寸小于 800px 时,两列布局改为上下布局 */
@media screen and (max-width: 800px) {
.leftcolumn, .rightcolumn {
width: 100%;
padding: 0;
}
}
/* 响应式布局 -屏幕尺寸小于 400px 时,导航等布局改为上下布局 */
@media screen and (max-width: 400px) {
.topnav a {
float: none;
width: 100%;
}
}
CSS !important 规则
什么是 !important
CSS 中的 !important 规则用于增加样式的权重. !important 与优先级无关,但它与最终的结果直接相关,使用一个 !important 规则时,此声明将覆盖任何其他声明.
#myid {
background-color: blue;
}
.myclass {
background-color: gray;
}
p {
background-color: red !important;
}
以上实例中,尽管 ID 选择器和类选择器具有更高的优先级,但三个段落背景颜色都显示为红色,因为 !important 规则会覆盖 background-color 属性.
重要说明
使用 !important 是一个坏习惯,应该尽量避免,因为这破坏了样式表中的固有的级联规则 使得调试找 bug 变得更加困难了. 当两条相互冲突的带有 !important 规则的声明被应用到相同的元素上时,拥有更大优先级的声明将会被采用.
以下实例我们在查看 CSS 源码时就不是很清楚哪种颜色最重要:
#myid {
background-color: blue !important;
}
.myclass {
background-color: gray !important;
}
p {
background-color: red !important;
}
使用建议:
- 一定要优先考虑使用样式规则的优先级来解决问题而不是
!important - 只有在需要覆盖全站或外部 CSS 的特定页面中使用
!important - 永远不要在你的插件中使用
!important - 永远不要在全站范围的 CSS 代码中使用
!important
何时使用 !important
如果要在你的网站上设定一个全站样式的 CSS 样式可以使用 !important.
比如我们要让网站上所有按钮的样式都一样:
.button {
background-color: #8c8c8c;
color: white;
padding: 5px;
border: 1px solid black;
}
如果我们将按钮放在另一个具有更优先级的元素中,按钮的外观就会发生变化,并且属性会发生冲突,如下实例:
.button {
background-color: #8c8c8c;
color: white;
padding: 5px;
border: 1px solid black;
}
#myDiv a {
color: red;
background-color: yellow;
}
如果想要设置所有按钮具有相同的外观,我们可以将 !important 规则添加到按钮的样式属性中,如下所示:
.button {
background-color: #8c8c8c !important;
color: white !important;
padding: 5px !important;
border: 1px solid black !important;
}
#myDiv a {
color: red;
background-color: yellow;
}
python爬虫_BeautifulSoup
获取浏览器模拟头部信息
- 浏览器输入网址
- F12 网络(network)
- 随便点一个,最下方请求标头‘User-Agent’部分
- 复制到脚本中head = {‘User-Agent’:xxxx}
# 查看头部
python正则表达式
正则表达式基础
语法
-
普通字符:
-
-
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
-
[ABC]:匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母
-
1:匹配除了 [...] 中字符的所有字符,例如 2 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母
-
[A-Z]:[A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母
-
. :匹配除换行符**(\n、\r)之外的任何单个字符,相等于[ ^\n\r]**
-
[\s\S]:匹配所有。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行
-
\w:匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
-
-
非打印字符:
-
-
非打印字符也可以是正则表达式的组成部分。下表列出了表示非打印字符的转义序列
-
\cx:匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符
-
\f:匹配一个换页符。等价于 \x0c 和 \cL
-
\n:匹配一个换行符。等价于 \x0a 和 \cJ
-
\r:匹配一个回车符。等价于 \x0d 和 \cM
-
\s:匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符
-
\S:匹配任何非空白字符。等价于 [ ^ \f\n\r\t\v]
-
\t:匹配一个制表符。等价于 \x09 和 \cI
-
\v:匹配一个垂直制表符。等价于 \x0b 和 \cK
-
-
特殊字符:
-
-
$:匹配输入字符串的结尾位置。要匹配 **** 字符本身,请使用 \$
-
( ):标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )
-
*****:匹配前面的子表达式零次或多次。要匹配 * 字符,请使用 *
-
+:匹配前面的子表达式一次或多次。要匹配 + 字符,请使用 +
-
. :匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 .
-
[:标记一个中括号表达式的开始。要匹配 [,请使用 [
-
?:匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 ?
-
\:将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "",而 '(' 则匹配 "("
-
^:匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配 ^ 字符本身,请使用 ^
-
{:标记限定符表达式的开始。要匹配 {,请使用 {
-
|:指明两项之间的一个选择。要匹配 |,请使用 |
-
-
限定符:
-
-
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配
-
:匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。**** 等价于 {0,}
-
+:匹配前面的子表达式一次或多次。例如,zo+ 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}
-
?:匹配前面的子表达式零次或一次。例如,do(es)? 可以匹配 "do" 、 "does"、 "doxy" 中的 "do" 。? 等价于 {0,1}
-
{n}:n 是一个非负整数。匹配确定的 n 次。例如,o{2} 不能匹配 "Bob" 中的 o,但是能匹配 "food" 中的两个 o
-
{n,}:n 是一个非负整数。至少匹配n 次。例如,o{2,} 不能匹配 "Bob" 中的 o,但能匹配 "foooood" 中的所有 o。o{1,} 等价于 o+。o{0,} 则等价于 o*
-
{n,m}:m 和 n 均为非负整数,其中 n <= m。最少匹配 n 次且最多匹配 m 次。例如,o{1,3} 将匹配 "fooooood" 中的前三个 o。o{0,1} 等价于 o?。请注意在逗号和两个数之间不能有空格
-
-
定位符:
-
- 定位符能够将正则表达式固定到行首或行尾。它们还能够创建这样的正则表达式,这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。
- ^:匹配输入字符串开始的位置
- ****:匹配输入字符串结尾的位置
- \b:匹配一个单词边界,即字与空格间的位置
- \B:非单词边界匹配
- 注意:不能将限定符与定位符一起使用。由于在紧靠换行或者单词边界的前面或后面不能有一个以上位置,因此不允许诸如 ^* 之类的表达式
-
选择:
-
- 用圆括号 () 将所有选择项括起来,相邻的选择项之间用 | 分隔
修饰符/标记
-
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。
标记不写在正则表达式里,标记位于表达式之外,格式如下
/pattern/flags -
i:ignore - 不区分大小写,
-
g:global - 全局匹配
-
m:multiline - 多行匹配
-
s:特殊字符圆点 . 中包含换行符 \n
元字符(重要)
下表包含了元字符的完整列表以及它们在正则表达式上下文中的行为
| 字符 | 描述 |
|---|---|
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 向后引用、或一个八进制转义符。例如,'n' 匹配字符 "n"。'\n' 匹配一个换行符。序列 '\' 匹配 "" 而 "(" 则匹配 "("。 |
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| ** 也匹配 '\n' 或 '\r' 之前的位置。 | |
| ***** | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符 (*, +, ?, {n}, {n,}, {n,m}) 后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串 "oooo",'o+?' 将匹配单个 "o",而 'o+' 将匹配所有 'o'。 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像"(.|\n)"的模式。 |
| (pattern) | 匹配 pattern 并获取这一匹配。所获取的匹配可以从产生的 Matches 集合得到,在VBScript 中使用 SubMatches 集合,在JScript 中则使用 9 属性。要匹配圆括号字符,请使用 '(' 或 ')'。 |
| (?:pattern) | 匹配 pattern 但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用 "或" 字符 (|) 来组合一个模式的各个部分是很有用。例如, 'industr(?:y|ies) 就是一个比 'industry|industries' 更简略的表达式。 |
| (?=pattern) | 正向肯定预查(look ahead positive assert),在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,"Windows(?=95|98|NT|2000)"能匹配"Windows2000"中的"Windows",但不能匹配"Windows3.1"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查(negative assert),在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如"Windows(?!95|98|NT|2000)"能匹配"Windows3.1"中的"Windows",但不能匹配"Windows2000"中的"Windows"。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?<=pattern) | 反向(look behind)肯定预查,与正向肯定预查类似,只是方向相反。例如,"(?<=95|98|NT|2000)Windows"能匹配"2000Windows"中的"Windows",但不能匹配"3.1Windows"中的"Windows"。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类似,只是方向相反。例如"(?<!95|98|NT|2000)Windows"能匹配"3.1Windows"中的"Windows",但不能匹配"2000Windows"中的"Windows"。 |
| x|y | 匹配 x 或 y。例如,'z|food' 能匹配 "z" 或 "food"。'(z|f)ood' 则匹配 "zood" 或 "food"。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| 3 | 负值字符集合。匹配未包含的任意字符。例如, '[ ^abc]' 可以匹配 "plain" 中的'p'、'l'、'i'、'n'。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,'[a-z]' 可以匹配 'a' 到 'z' 范围内的任意小写字母字符。 |
| 4 | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,'[ ^a-z]' 可以匹配任何不在 'a' 到 'z' 范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, 'er\b' 可以匹配"never" 中的 'er',但不能匹配 "verb" 中的 'er'。 |
| \B | 匹配非单词边界。'er\B' 能匹配 "verb" 中的 'er',但不能匹配 "never" 中的 'er'。 |
| \cx | 匹配由 x 指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [ ^0-9]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [ ^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
| \w | 匹配字母、数字、下划线。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配非字母、数字、下划线。等价于 '[ ^A-Za-z0-9_]'。 |
| \xn | 匹配 n,其中 n 为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,'\x41' 匹配 "A"。'\x041' 则等价于 '\x04' & "1"。正则表达式中可以使用 ASCII 编码。 |
| \num | 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。例如,'(.)\1' 匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用。否则,如果 n 为八进制数字 (0-7),则 n 为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果 \nm 之前至少有 nm 个获得子表达式,则 nm 为向后引用。如果 \nm 之前至少有 n 个获取,则 n 为一个后跟文字 m 的向后引用。如果前面的条件都不满足,若 n 和 m 均为八进制数字 (0-7),则 \nm 将匹配八进制转义值 nm。 |
| \nml | 如果 n 为八进制数字 (0-3),且 m 和 l 均为八进制数字 (0-7),则匹配八进制转义值 nml。 |
| \un | 匹配 n,其中 n 是一个用四个十六进制数字表示的 Unicode 字符。例如, \u00A9 匹配版权符号 (?)。 |
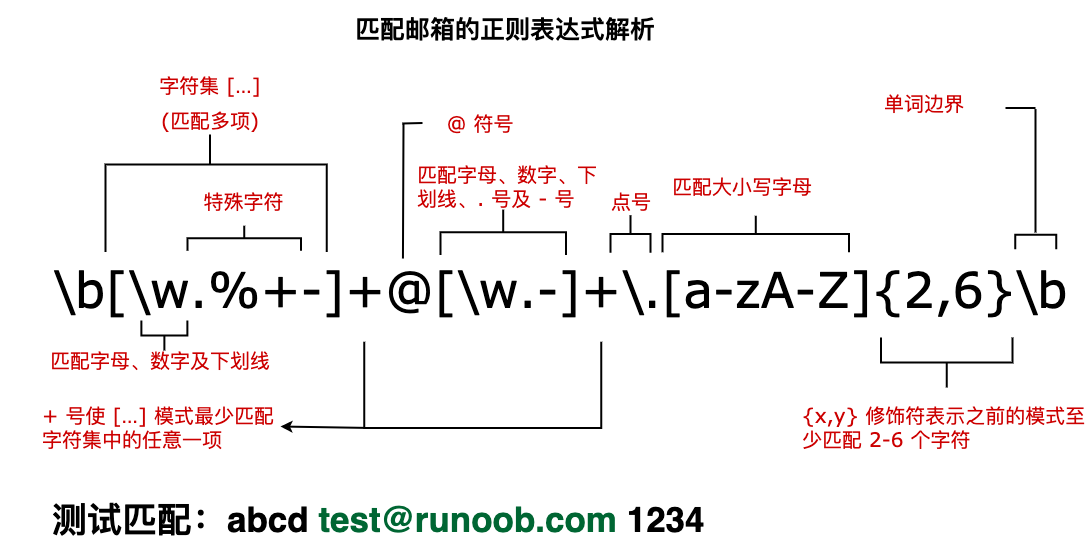
运算符优先级
下表从最高到最低说明了各种正则表达式运算符的优先级顺序
| 运算符 | 描述 |
|---|---|
| \ | 转义符 |
| (), (?:), (?=), [] | 圆括号和方括号 |
| *, +, ?, {n}, {n,}, {n,m} | 限定符 |
| ^, , \任何元字符、任何字符 | 定位点和序列(即:位置和顺序) |
| | | 替换,"或"操作字符具有高于替换运算符的优先级,使得"m|food"匹配"m"或"food"。若要匹配"mood"或"food",请使用括号创建子表达式,从而产生"(m|f)ood"。 |
匹配规则
基本模式匹配
一切从最基本的开始。模式,是正则表达式最基本的元素,它们是一组描述字符串特征的字符。模式可以很简单,由普通的字符串组成,也可以非常复杂,往往用特殊的字符表示一个范围内的字符、重复出现,或表示上下文。例如:
^once
这个模式包含一个特殊的字符 ^,表示该模式只匹配那些以 once 开头的字符串。例如该模式与字符串 "once upon a time" 匹配,与 "There once was a man from NewYork" 不匹配。正如如 ^ 符号表示开头一样,**** 符号用来匹配那些以给定模式结尾的字符串。
bucket$
这个模式与 "Who kept all of this cash in a bucket" 匹配,与 "buckets" 不匹配。字符 ^ 和 **
只匹配字符串 **"bucket"**。如果一个模式不包括 **^** 和 **$**,那么它与任何包含该模式的字符串匹配。例如模式:
once
与字符串
There once was a man from NewYork Who kept all of his cash in a bucket.
是匹配的。
在该模式中的字母 **(o-n-c-e)** 是字面的字符,也就是说,他们表示该字母本身,数字也是一样的。其他一些稍微复杂的字符,如标点符号和白字符(空格、制表符等),要用到转义序列。所有的转义序列都用反斜杠 **\\** 打头。制表符的转义序列是 **\t**。所以如果我们要检测一个字符串是否以制表符开头,可以用这个模式:
^\t
类似的,用 **\n** 表示**"新行"**,**\r** 表示回车。其他的特殊符号,可以用在前面加上反斜杠,如反斜杠本身用 **\\\\** 表示,句号 **.** 用 **\\.** 表示,以此类推。
#### 字符簇
在 INTERNET 的程序中,正则表达式通常用来验证用户的输入。当用户提交一个 FORM 以后,要判断输入的电话号码、地址、EMAIL 地址、信用卡号码等是否有效,用普通的基于字面的字符是不够的。
所以要用一种更自由的描述我们要的模式的办法,它就是字符簇。要建立一个表示所有元音字符的字符簇,就把所有的元音字符放在一个方括号里:
[AaEeIiOoUu]
这个模式与任何元音字符匹配,但只能表示一个字符。用连字号可以表示一个字符的范围,如:
[a-z] // 匹配所有的小写字母 [A-Z] // 匹配所有的大写字母 [a-zA-Z] // 匹配所有的字母 [0-9] // 匹配所有的数字 [0-9.-] // 匹配所有的数字,句号和减号 [ \f\r\t\n] // 匹配所有的白字符
同样的,这些也只表示一个字符,这是一个非常重要的。如果要匹配一个由一个小写字母和一位数字组成的字符串,比如 "z2"、"t6" 或 "g7",但不是 "ab2"、"r2d3" 或 "b52" 的话,用这个模式:
^[a-z][0-9]
尽管 **[a-z]** 代表 26 个字母的范围,但在这里它只能与第一个字符是小写字母的字符串匹配。
前面曾经提到^表示字符串的开头,但它还有另外一个含义。当在一组方括号里使用 **^** 时,它表示"**非**"或"**排除**"的意思,常常用来剔除某个字符。还用前面的例子,我们要求第一个字符不能是数字:
^[^0-9][0-9]
这个模式与 "&5"、"g7"及"-2" 是匹配的,但与 "12"、"66" 是不匹配的。下面是几个排除特定字符的例子:
4 //除了小写字母以外的所有字符 5 //除了()(/)(^)之外的所有字符 6 //除了双引号(")和单引号(')之外的所有字符
特殊字符 **.**(点,句号)在正则表达式中用来表示除了"新行"之外的所有字符。所以模式 **^.5$** 与任何两个字符的、以数字5结尾和以其他非"新行"字符开头的字符串匹配。模式 **.** 可以匹配任何字符串,**换行符(\n、\r)除外**。
PHP的正则表达式有一些内置的通用字符簇,列表如下:
| 字符簇 | 描述 |
| :----------- | :---------------------------------- |
| [[:alpha:]] | 任何字母 |
| [[:digit:]] | 任何数字 |
| [[:alnum:]] | 任何字母和数字 |
| [[:space:]] | 任何空白字符 |
| [[:upper:]] | 任何大写字母 |
| [[:lower:]] | 任何小写字母 |
| [[:punct:]] | 任何标点符号 |
| [[:xdigit:]] | 任何16进制的数字,相当于[0-9a-fA-F] |
#### 确定重复出现
到现在为止,你已经知道如何去匹配一个字母或数字,但更多的情况下,可能要匹配一个单词或一组数字。一个单词有若干个字母组成,一组数字有若干个单数组成。跟在字符或字符簇后面的花括号({})用来确定前面的内容的重复出现的次数。
| 字符簇 | 描述 |
| :--------------- | :------------------------------ |
| ^[a-zA-Z_]$ | 所有的字母和下划线 |
| ^[[:alpha:]]{3}$ | 所有的3个字母的单词 |
| ^a$ | 字母a |
| ^a{4}$ | aaaa |
| ^a{2,4}$ | aa,aaa或aaaa |
| ^a{1,3}$ | a,aa或aaa |
| ^a{2,}$ | 包含多于两个a的字符串 |
| ^a{2,} | 如:aardvark和aaab,但apple不行 |
| a{2,} | 如:baad和aaa,但Nantucket不行 |
| \t{2} | 两个制表符 |
| .{2} | 所有的两个字符 |
这些例子描述了花括号的三种不同的用法。一个数字 **{x}** 的意思是**前面的字符或字符簇只出现x次** ;一个数字加逗号 **{x,}** 的意思是**前面的内容出现x或更多的次数** ;两个数字用逗号分隔的数字 **{x,y}** 表示 **前面的内容至少出现x次,但不超过y次**。我们可以把模式扩展到更多的单词或数字:
^[a-zA-Z0-9_]{1,} // 所有的正整数 ^-{0,1}[0-9]{1,} // 所有的浮点数
最后一个例子不太好理解,是吗?这么看吧:以一个可选的负号 (**[-]?**) 开头 (**^**)、跟着1个或更多的数字(**[0-9]+**)、和一个小数点(**\.**)再跟上1个或多个数字**([0-9]+**),并且后面没有其他任何东西(**$**)。下面你将知道能够使用的更为简单的方法。
特殊字符 **?** 与 **{0,1}** 是相等的,它们都代表着: **0个或1个前面的内容** 或 **前面的内容是可选的** 。所以刚才的例子可以简化为:
^-?[0-9]{1,}.?[0-9]{1,} // 所有包含一个以上的字母、数字或下划线的字符串 ^[1-9][0-9]* // 所有的正整数 ^-?[0-9]+ // 所有的整数 ^[-]?[0-9]+(.[0-9]+)? // 所有的浮点数
当然这并不能从技术上降低正则表达式的复杂性,但可以使它们更容易阅读
## python re模块
```python
import re
re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none
re.match(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。参见:[正则表达式基础修饰符] |
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
import re
### match 实例
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
# 输出为
# (0, 3)
# None
### group 实例
line = "Cats are smarter than dogs"
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print "matchObj.group() : ", matchObj.group()
print "matchObj.group(1) : ", matchObj.group(1)
print "matchObj.group(2) : ", matchObj.group(2)
else:
print "No match!!"
# 输出为
# matchObj.group() : Cats are smarter than dogs
# matchObj.group(1) : Cats
# matchObj.group(2) : smarter
re.research 函数
re.search 扫描整个字符串并返回第一个成功的匹配
函数语法:
re.search(pattern, string, flags=0)
函数参数说明:
| 参数 | 描述 |
|---|---|
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.search方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象方法 | 描述 |
|---|---|
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
import re
# search实例
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
# 输出为
# (0, 3)
# (11, 14)
# group实例
line = "Cats are smarter than dogs";
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print "searchObj.group() : ", searchObj.group()
print "searchObj.group(1) : ", searchObj.group(1)
print "searchObj.group(2) : ", searchObj.group(2)
else:
print "Nothing found!!"
# 输出为
# searchObj.group() : Cats are smarter than dogs
# searchObj.group(1) : Cats
# searchObj.group(2) : smarter
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配
re.sub 检索和替换
语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
import re
phone = "2004-959-559 # 这是一个国外电话号码"
# 删除字符串中的 Python注释
num = re.sub(r'#.*', "", phone)
print "电话号码是: ", num
# 删除非数字(-)的字符串
num = re.sub(r'\D', "", phone)
print "电话号码是 : ", num
# 输出为
# 电话号码是: 2004-959-559
# 电话号码是 : 2004959559
repl 参数可以是一个函数
import re
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s))
# 输出为
# A46G8HFD1134
re.compile
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用,语法格式为
re.compile(pattern[, flags])
参数:
- pattern : 一个字符串形式的正则表达式
- flags : 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
- re.I 忽略大小写
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.M 多行模式
- re.S 即为 . 并且包括换行符在内的任意字符(. 不包括换行符)
- re.U 表示特殊字符集 \w, \W, \b, \B, \d, \D, \s, \S 依赖于 Unicode 字符属性数据库
- re.X 为了增加可读性,忽略空格和 # 后面的注释
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print m
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print m # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表
注意: match 和 search 是匹配一次 findall 匹配所有
参数:
- string : 待匹配的字符串
- pos : 可选参数,指定字符串的起始位置,默认为 0
- endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度
import re
pattern = re.compile(r'\d+') # 查找数字
result1 = pattern.findall('runoob 123 google 456')
result2 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
# 输出
# ['123', '456']
# ['88', '12']
XPath
XPath (全称:XML Path Language) 即 XML 路径语言,它是一门在 XML 文档中查找信息的语言,最初被用来搜寻 XML 文档,同时它也适用于搜索 HTML 文档。因此,在爬虫过程中可以使用 XPath 来提取相应的数据。
可以将 Xpath 理解为在XML/HTML文档中检索、匹配元素节点的工具。
Xpath 使用路径表达式来选取XML/HTML文档中的节点或者节点集。Xpath 的功能十分强大,它除了提供了简洁的路径表达式外,还提供了100 多个内建函数,包括了处理字符串、数值、日期以及时间的函数。因此 Xpath 路径表达式几乎可以匹配所有的元素节点。
Python 第三方解析库 lxml 对 Xpath 路径表达式提供了良好的支持,能够解析 XML 与 HTML 文档。
Xpath节点
XPath 提供了多种类型的节点,常用的节点有:元素、属性、文本、注释以及文档节点。如下所示:
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
<title lang="zh-CN">website name</title>
<name>编程帮</name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
上面的 XML 文档中的节点例子:
<website></website> (文档节点)
<name></name> (元素节点)
lang="zh-CN" (属性节点)
节点关系
XML 文档的节点关系和 HTML 文档相似,同样有父、子、同代、先辈、后代节点。如下所示:
<?xml version="1.0" encoding="utf-8"?>
<website>
<site>
<title lang="zh-CN">website name</title>
<name>编程帮</name>
<year>2010</year>
<address>www.biancheng.net</address>
</site>
</website>
上述示例分析后,会得到如下结果:
title name year address 都是 site 的子节点
site 是 title name year address 父节点
title name year address 属于同代节点
title 元素的先辈节点是 site website
website 的后代节点是 site title name year address
Xpath基本语法
1) 基本语法使用
Xpath 使用路径表达式在文档中选取节点,下表列出了常用的表达式规则:
| 表达式 | 描述 |
|---|---|
| node_name | 选取此节点的所有子节点 |
| / | 绝对路径匹配,从根节点选取 |
| // | 相对路径匹配,从所有节点中查找当前选择的节点,包括子节点和后代节点,其第一个 / 表示根节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性值,通过属性值选取数据。常用元素属性有 @id 、@name、@type、@class、@tittle、@href |
下面以下述代码为例讲解 Xpath 表达式的基本应用,代码如下所示:
<ul class="BookList">
<li class="book1" id="book_01" href="http://www.biancheng.net/">
<p class="name">c语言小白变怪兽</p>
<p class="model">纸质书</p>
<p class="price">80元</p>
<p class="color">红蓝色封装</p>
</li>
<li class="book2" id="book_02" href="http://www.biancheng.net/">
<p class="name">Python入门到精通</p>
<p class="model">电子书</p>
<p class="price">45元</p>
<p class="color">蓝绿色封装</p>
</li>
</ul>
路径表达式以及相应的匹配内容如下:
xpath表达式://li
匹配内容:
c语言小白变怪兽
纸质书
80元
红蓝色封装
Python入门到精通
电子书
45元
蓝绿色封装
xpath表达式://li/p[@class="name"]
匹配内容:
c语言小白变怪兽
Python入门到精通
xpath表达式://li/p[@class="model"]
匹配内容:
纸质书
电子书
xpath表达式://ul/li/@href
匹配内容:
http://www.biancheng.net/
http://www.biancheng.net/
xpath表达式://ul/li
匹配内容:
c语言小白变怪兽
纸质书
80元
红蓝色封装
Python入门到精通
电子书
45元
蓝绿色封装
注意:当需要查找某个特定的节点或者选取节点中包含的指定值时需要使用[]方括号。如下所示:
xpath表达式://ul/li[@class="book2"]/p[@class="price"]
匹配结果:45元
2) xpath通配符
Xpath 表达式的通配符可以用来选取未知的节点元素,基本语法如下:
|通配符|描述说| ||匹配任意元素节点| |@|匹配任意属性节点| |node()|匹配任意类型的节点|
示例如下:
xpath表达式://li/*
匹配内容:
c语言小白变怪兽
纸质书
80元
红蓝色封装
Python入门到精通
电子书
45元
蓝绿色封装
3) 多路径匹配
多个 Xpath 路径表达式可以同时使用,其语法如下:
xpath表达式1 | xpath表达式2 | xpath表达式3
示例应用:
表达式://ul/li[@class="book2"]/p[@class="price"]|//ul/li/@href
匹配内容:
45元
http://www.biancheng.net/
http://www.biancheng.net/
Xpath内建函数
Xpath 提供 100 多个内建函数,这些函数给我们提供了很多便利,比如实现文本匹配、模糊匹配、以及位置匹配等,下面介绍几个常用的内建函数。
| 函数名称 | xpath表达式示例 | 示例说明 |
|---|---|---|
| text() | ./text() | 文本匹配,表示值取当前节点中的文本内容 |
| contains() | //div[contains(@id,'stu')] | 模糊匹配,表示选择 id 中包含“stu”的所有 div 节点 |
| last() | //*[@class='web'][last()] | 位置匹配,表示选择@class='web'的最后一个节点 |
| position() | //*[@class='site'][position()<=2] | 位置匹配,表示选择@class='site'的前两个节点 |
| start-with() | "//input[start-with(@id,'st')]" | 匹配 id 以 st 开头的元素 |
| ends-with() | "//input[ends-with(@id,'st')]" | 匹配 id 以 st 结尾的元素 |
| concat(string1,string2) | concat('C语言中文网',.//*[@class='stie']/@href) | C语言中文与标签类别属性为"stie"的 href 地址做拼接 |
CSS选择器
下是一些常见的 CSS 选择器:
- 元素选择器(Element Selector):通过元素名称选择 HTML 元素
如下代码,p 选择器将选择所有 <p> 元素:
p {
color: blue;
}
- 类选择器(Class Selector):通过类别名称选择具有特定类别的 HTML 元素
类选择器以 . 开头,后面跟着类别名称。
如下代码,.highlight 选择器将选择所有具有类别为 "highlight" 的元素。
.highlight {
background-color: yellow;
}
- ID 选择器(ID Selector):通过元素的唯一标识符(ID)选择 HTML 元素。
ID 选择器以 # 开头,后面跟着 ID 名称。
如下代码,#runoob 选择器将选择具有 ID 为 "runoob" 的元素。
#runoob {
width: 200px;
}
- 属性选择器(Attribute Selector):通过元素的属性选择 HTML 元素。属性选择器可以根据属性名和属性值进行选择。
如下代码,input[type="text"] 选择器将选择所有 type 属性为 "text" 的 <input> 元素。
input[type="text"] {
border: 1px solid gray;
}
- 后代选择器(Descendant Selector):通过指定元素的后代关系选择 HTML 元素。
后代选择器使用空格分隔元素名称。
如下代码,div p 选择器将选择所有在 <div> 元素内的 <p> 元素。
div p {
font-weight: bold;
}
更多选择器参考下列表格:
| 选择器 | 示例 | 示例说明 | CSS |
|---|---|---|---|
.class | .intro | 选择所有class="intro"的元素 | 1 |
#id | #firstname | 选择所有id="firstname"的元素 | 1 |
* | * | 选择所有元素 | 2 |
element | p | 选择所有<p>元素 | 1 |
element,element | div,p | 选择所有<div>元素和 <p> 元素 | 1 |
element.class | p.hometown | 选择所有 class="hometown" 的 <p> 元素 | 1 |
element element | div p | 选择<div>元素内的所有<p>元素 | 1 |
element>element | div>p | 选择所有父级是 <div> 元素的 元素 | 2 |
element+element | div+p | 选择所有紧跟在 <div> 元素之后的第一个 <p> 元素 | 2 |
[attribute] | [target] | 选择所有带有target属性元素 | 2 |
[attribute=value] | [target=-blank] | 选择所有使用target="-blank"的元素 | 2 |
[attribute~=value] | [title~=flower] | 选择标题属性包含单词"flower"的所有元素 | 2 |
| `[attribute | =language]` | `[lang | =en]` |
:link | a:link | 选择所有未访问链接 | 1 |
:visited | a:visited | 选择所有访问过的链接 | 1 |
:active | a:active | 选择活动链接 | 1 |
:hover | a:hover | 选择鼠标在链接上面时 | 1 |
:focus | input:focus | 选择具有焦点的输入元素 | 2 |
:first-letter | p:first-letter | 选择每一个<p>元素的第一个字母 | 1 |
:first-line | p:first-line | 选择每一个<p>元素的第一行 | 1 |
:first-child | p:first-child | 指定只有当<p>元素是其父级的第一个子级的样式 | 2 |
:before | p:before | 在每个<p>元素之前插入内容 | 2 |
:after | p:after | 在每个<p>元素之后插入内容 | 2 |
:lang(language) | p:lang(it) | 选择一个lang属性的起始值="it"的所有<p>元素 | 2 |
element1~element2 | p~ul | 选择p元素之后的每一个ul元素 | 3 |
[attribute^=value] | a[src^="https"] | 选择每一个src属性的值以"https"开头的元素 | 3 |
[attribute$=value] | a[src$=".pdf"] | 选择每一个src属性的值以".pdf"结尾的元素 | 3 |
[attribute*=value] | a[src*="runoob"] | 选择每一个src属性的值包含子字符串"runoob"的元素 | 3 |
:first-of-type | p:first-of-type | 选择每个p元素是其父级的第一个p元素 | 3 |
:last-of-type | p:last-of-type | 选择每个p元素是其父级的最后一个p元素 | 3 |
:only-of-type | p:only-of-type | 选择每个p元素是其父级的唯一p元素 | 3 |
:only-child | p:only-child | 选择每个p元素是其父级的唯一子元素 | 3 |
:nth-child(n) | p:nth-child(2) | 选择每个p元素是其父级的第二个子元素 | 3 |
:nth-last-child(n) | p:nth-last-child(2) | 选择每个p元素的是其父级的第二个子元素,从最后一个子项计数 | 3 |
:nth-of-type(n) | p:nth-of-type(2) | 选择每个p元素是其父级的第二个p元素 | 3 |
:nth-last-of-type(n) | p:nth-last-of-type(2) | 选择每个p元素的是其父级的第二个p元素,从最后一个子项计数 | 3 |
:last-child | p:last-child | 选择每个p元素是其父级的最后一个子级 | 3 |
:root | :root | 选择文档的根元素 | 3 |
:empty | p:empty | 选择每个没有任何子级的p元素(包括文本节点) | 3 |
:target | #news:target | 选择当前活动的#news元素(包含该锚名称的点击的URL) | 3 |
:enabled | input:enabled | 选择每一个已启用的输入元素 | 3 |
:disabled | input:disabled | 选择每一个禁用的输入元素 | 3 |
:checked | input:checked | 选择每个选中的输入元素 | 3 |
:not(selector) | :not(p) | 选择每个并非p元素的元素 | 3 |
::selection | ::selection | 匹配元素中被用户选中或处于高亮状态的部分 | 3 |
:out-of-range | :out-of-range | 匹配值在指定区间之外的input元素 | 3 |
:in-range | :in-range | 匹配值在指定区间之内的input元素 | 3 |
:read-write | :read-write | 用于匹配可读及可写的元素 | 3 |
:read-only | :read-only | 用于匹配设置 "readonly"(只读) 属性的元素 | 3 |
:optional | :optional | 用于匹配可选的输入元素 | 3 |
:required | :required | 用于匹配设置了 "required" 属性的元素 | 3 |
:valid | :valid | 用于匹配输入值为合法的元素 | 3 |
:invalid | :invalid | 用于匹配输入值为非法的元素 | 3 |
Dash基础
本章介绍 Dash 的基本知识, 来自于官网教程
一. Dash Layout
Dash apps 由两部分组成,第一部分是 'Layout',决定了 app 的外观. 第二部分描述了 app 如何进行交互, 这在下一节进行介绍.
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, html, dcc
import plotly.express as px
import pandas as pd
app = Dash(__name__)
# assume you have a "long-form" data frame
# see https://plotly.com/python/px-arguments/ for more options
df = pd.DataFrame({
"Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"],
"Amount": [4, 1, 2, 2, 4, 5],
"City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"]
})
fig = px.bar(df, x="Fruit", y="Amount", color="City", barmode="group")
app.layout = html.Div(children=[
html.H1(children='Hello Dash'),
html.Div(children='''
Dash: A web application framework for your data.
'''),
dcc.Graph(
id='example-graph',
figure=fig
)
])
if __name__ == '__main__':
app.run_server(debug=True)
- Dash HTML 模组
dash.html对每个 HTML 标签都有对应的元件,html.H1(children='Hello Dash')为你的 app 生成了一个<h1>Hello Dash</h1>html标签. - 不是所有元件都是纯的 html. Dash Core Components 模组(
dash.dcc)包含了交互式高级元件, 它们是由 React.js 库通过 JavaScript, HTML, and CSS 生成的. - 每个元件完全由关键字属性进行定义
children是特殊的, 按照惯例,它永远是第一个属性,也就是说可以省略它,html.H1(children='Hello Dash')和html.H1('Hello Dash')是一样的. 它可以是一个字符串, 一个数字, 一个单独的元件或者一个元件列表.- 上述代码自己运行的 app 和官网上的字体看起来有所不一样, 因为官网上使用了本地的 CSS 风格. 具体使用 CSS 的教程
1.1 热重载
Dash支持热重载(hot-reloading), 这一特性可以通过设定app.run_server(debug=True)进行启用.
1.2 HTML 元件
Dash HTML Components(dash.html)对应每个HTML标签包含了一个元件类,以及对应每个HTML变量同样有关键词变量.
对上一节的代码进行修改
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, dcc, html
import plotly.express as px
import pandas as pd
app = Dash(__name__)
colors = {
'background': '#111111',
'text': '#7FDBFF'
}
# assume you have a "long-form" data frame
# see https://plotly.com/python/px-arguments/ for more options
df = pd.DataFrame({
"Fruit": ["Apples", "Oranges", "Bananas", "Apples", "Oranges", "Bananas"],
"Amount": [4, 1, 2, 2, 4, 5],
"City": ["SF", "SF", "SF", "Montreal", "Montreal", "Montreal"]
})
fig = px.bar(df, x="Fruit", y="Amount", color="City", barmode="group")
fig.update_layout(
plot_bgcolor=colors['background'],
paper_bgcolor=colors['background'],
font_color=colors['text']
)
app.layout = html.Div(style={'backgroundColor': colors['background']}, children=[
html.H1(
children='Hello Dash',
style={
'textAlign': 'center',
'color': colors['text']
}
),
html.Div(children='Dash: A web application framework for your data.', style={
'textAlign': 'center',
'color': colors['text']
}),
dcc.Graph(
id='example-graph-2',
figure=fig
)
])
if __name__ == '__main__':
app.run_server(debug=True)
本例中, 我们修改了通过style 属性修改了 html.Div和html.H1components的行内风格.
html.H1('Hello Dash', style={'textAlign': 'center', 'color': '#7FDBFF'})
上述代码在Dash app中被渲染为<h1 style="text-align: center; color: #7FDBFF">Hello Dash</h1>.
在 dash.html 和 HTML 属性间有几个重要不同
- HTML 中的
style是分号间隔的字符串, 而在Dash中, 可以仅写为一个字典 style字典中的键是**驼峰式(camelCased)**的, 所以text-align应该是textAlign- HEML
class属性在 Dash 中是类名 - HTML标签中的 children 通过关键词变量
children进行指定, 按照惯例这是第一个变量通常可以省略
1.3 可再用的元件
下面是一个例子,从 Pandas 的数据帧中生成一个 Table
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, html
import pandas as pd
df = pd.read_csv('https://gist.githubusercontent.com/chriddyp/c78bf172206ce24f77d6363a2d754b59/raw/c353e8ef842413cae56ae3920b8fd78468aa4cb2/usa-agricultural-exports-2011.csv')
def generate_table(dataframe, max_rows=10):
return html.Table([
html.Thead(
html.Tr([html.Th(col) for col in dataframe.columns])
),
html.Tbody([
html.Tr([
html.Td(dataframe.iloc[i][col]) for col in dataframe.columns
]) for i in range(min(len(dataframe), max_rows))
])
])
app = Dash(__name__)
app.layout = html.Div([
html.H4(children='US Agriculture Exports (2011)'),
generate_table(df)
])
if __name__ == '__main__':
app.run_server(debug=True)
1.4 更多可视化
Dash Core Components(dash.dcc) 包含了一个叫做 Graph 的元件.
Graph 通过开源的 plotly.js 图形库渲染出交互式可视化数据. Plotly.js 支持超过35类图形,并且可以渲染为矢量 SVG 或者 WebGL.
Graph 元件中使用的 figure 变量和开源 python 图形库 plotlt.py 中使用的 figure 是一样的.
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, dcc, html
import plotly.express as px
import pandas as pd
app = Dash(__name__)
df = pd.read_csv('https://gist.githubusercontent.com/chriddyp/5d1ea79569ed194d432e56108a04d188/raw/a9f9e8076b837d541398e999dcbac2b2826a81f8/gdp-life-exp-2007.csv')
fig = px.scatter(df, x="gdp per capita", y="life expectancy",
size="population", color="continent", hover_name="country",
log_x=True, size_max=60)
app.layout = html.Div([
dcc.Graph(
id='life-exp-vs-gdp',
figure=fig
)
])
if __name__ == '__main__':
app.run_server(debug=True)
1.5 Markdown
可以使用 Dash Core Components(dash.dcc) 中的 Markdown 元件来写
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, html, dcc
app = Dash(__name__)
markdown_text = '''
### Dash and Markdown
Dash apps can be written in Markdown.
Dash uses the [CommonMark](http://commonmark.org/)
specification of Markdown.
Check out their [60 Second Markdown Tutorial](http://commonmark.org/help/)
if this is your first introduction to Markdown!
'''
app.layout = html.Div([
dcc.Markdown(children=markdown_text)
])
if __name__ == '__main__':
app.run_server(debug=True)
1.6 核心元件
可以在Dash Core Components中查看所有的核心元件介绍
# Run this app with `python app.py` and
# visit http://127.0.0.1:8050/ in your web browser.
from dash import Dash, html, dcc
app = Dash(__name__)
app.layout = html.Div([
html.Div(children=[
html.Label('Dropdown'),
dcc.Dropdown(['New York City', 'Montréal', 'San Francisco'], 'Montréal'),
html.Br(),
html.Label('Multi-Select Dropdown'),
dcc.Dropdown(['New York City', 'Montréal', 'San Francisco'],
['Montréal', 'San Francisco'],
multi=True),
html.Br(),
html.Label('Radio Items'),
dcc.RadioItems(['New York City', 'Montréal', 'San Francisco'], 'Montréal'),
], style={'padding': 10, 'flex': 1}),
html.Div(children=[
html.Label('Checkboxes'),
dcc.Checklist(['New York City', 'Montréal', 'San Francisco'],
['Montréal', 'San Francisco']
),
html.Br(),
html.Label('Text Input'),
dcc.Input(value='MTL', type='text'),
html.Br(),
html.Label('Slider'),
dcc.Slider(
min=0,
max=9,
marks={i: f'Label {i}' if i == 1 else str(i) for i in range(1, 6)},
value=5,
),
], style={'padding': 10, 'flex': 1})
], style={'display': 'flex', 'flex-direction': 'row'})
if __name__ == '__main__':
app.run_server(debug=True)
二. 基本的Dash回调
本节将介绍如何使用回调函数(callback functions)来制作 Dash app, 当输入元件的属性改变时,Dash将自动调用回调函数,(作为输出)来更新另一个元件的某些属性.
2.1 简单的交互式 Dash app
from dash import Dash, dcc, html, Input, Output
app = Dash(__name__)
app.layout = html.Div([
html.H6("Change the value in the text box to see callbacks in action!"),
html.Div([
"Input: ",
dcc.Input(id='my-input', value='initial value', type='text')
]),
html.Br(),
html.Div(id='my-output'),
])
@app.callback(
Output(component_id='my-output', component_property='children'),
Input(component_id='my-input', component_property='value')
)
def update_output_div(input_value):
return f'Output: {input_value}'
if __name__ == '__main__':
app.run_server(debug=True)
- 'inputs' 和 'outputs' 在应用中描述为装饰器
@app.callback的变量 - 在Dash中,应用的 input 和 output 仅仅是特定元件的属性. 在上例中,input是元件的
'value'属性, 它有 ID'my-input',output是元件的'children'属性,它有ID'my-output'. - 只要一个 input 属性改变了,回调装饰器所包装的函数就会自动被调用. Dash 将新的 input 输入进这个回调函数中,并且将函数输出更新为 output 元件
component_id和component_property关键字是可选的- 不要混淆
dash.dependencies.Input和dcc.Input,前者只用在回调定义中,后者是是实际的元件 - 注意到我们在
layout的my-output元件中没有设置children属性. 当Dash app启动时,它会用输入元件的初始值来自动调用所有的回调函数,从而决定输出元件的初始状态. 在本例中,如果通过html.Div(id='my-output', children='Hello world')指定了 div 元件,在 app 启动时它会被覆盖
回忆每个元件是如何通过一组关键字变量来进行完全描述的,这些在Python中设定的变量成为了元件的属性. 通过 Dash 的交互式,我们可以使用回调函数来动态地更新这些属性,通常我们会更新 HTML 元件的children属性来展示新的文本,或者 dcc.Graph 元件的 figure 属性来展示新的数据,我们也可以更新一个元件的 style 甚至是一个 dcc.Dropdown 元件的可用'options'!
下述例子中 dcc.Slider 更新 dcc.Graph
from dash import Dash, dcc, html, Input, Output
import plotly.express as px
import pandas as pd
df = pd.read_csv('https://raw.githubusercontent.com/plotly/datasets/master/gapminderDataFiveYear.csv')
app = Dash(__name__)
app.layout = html.Div([
dcc.Graph(id='graph-with-slider'),
dcc.Slider(
df['year'].min(),
df['year'].max(),
step=None,
value=df['year'].min(),
marks={str(year): str(year) for year in df['year'].unique()},
id='year-slider'
)
])
@app.callback(
Output('graph-with-slider', 'figure'),
Input('year-slider', 'value'))
def update_figure(selected_year):
filtered_df = df[df.year == selected_year]
fig = px.scatter(filtered_df, x="gdpPercap", y="lifeExp",
size="pop", color="continent", hover_name="country",
log_x=True, size_max=55)
fig.update_layout(transition_duration=500)
return fig
if __name__ == '__main__':
app.run_server(debug=True)
2.2 多个输出的 Dash app
下面的例子中,一个回调函数绑定了5个输入,分别是两个 dcc.Dropdown 元件,两个 dcc.RadioItems 元件以及一个 dcc.Slider 元件的 value 属性,回调输出为一个 dcc.Graph 元件的 figure 属性.
from dash import Dash, dcc, html, Input, Output
import plotly.express as px
import pandas as pd
app = Dash(__name__)
df = pd.read_csv('https://plotly.github.io/datasets/country_indicators.csv')
app.layout = html.Div([
html.Div([
html.Div([
dcc.Dropdown(
df['Indicator Name'].unique(),
'Fertility rate, total (births per woman)',
id='xaxis-column'
),
dcc.RadioItems(
['Linear', 'Log'],
'Linear',
id='xaxis-type',
inline=True
)
], style={'width': '48%', 'display': 'inline-block'}),
html.Div([
dcc.Dropdown(
df['Indicator Name'].unique(),
'Life expectancy at birth, total (years)',
id='yaxis-column'
),
dcc.RadioItems(
['Linear', 'Log'],
'Linear',
id='yaxis-type',
inline=True
)
], style={'width': '48%', 'float': 'right', 'display': 'inline-block'})
]),
dcc.Graph(id='indicator-graphic'),
dcc.Slider(
df['Year'].min(),
df['Year'].max(),
step=None,
id='year--slider',
value=df['Year'].max(),
marks={str(year): str(year) for year in df['Year'].unique()},
)
])
@app.callback(
Output('indicator-graphic', 'figure'),
Input('xaxis-column', 'value'),
Input('yaxis-column', 'value'),
Input('xaxis-type', 'value'),
Input('yaxis-type', 'value'),
Input('year--slider', 'value'))
def update_graph(xaxis_column_name, yaxis_column_name,
xaxis_type, yaxis_type,
year_value):
dff = df[df['Year'] == year_value]
fig = px.scatter(x=dff[dff['Indicator Name'] == xaxis_column_name]['Value'],
y=dff[dff['Indicator Name'] == yaxis_column_name]['Value'],
hover_name=dff[dff['Indicator Name'] == yaxis_column_name]['Country Name'])
fig.update_layout(margin={'l': 40, 'b': 40, 't': 10, 'r': 0}, hovermode='closest')
fig.update_xaxes(title=xaxis_column_name,
type='linear' if xaxis_type == 'Linear' else 'log')
fig.update_yaxes(title=yaxis_column_name,
type='linear' if yaxis_type == 'Linear' else 'log')
return fig
if __name__ == '__main__':
app.run_server(debug=True)
2.3 多输出的Dassh app
from dash import Dash, dcc, html
from dash.dependencies import Input, Output
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
app.layout = html.Div([
dcc.Input(
id='num-multi',
type='number',
value=5
),
html.Table([
html.Tr([html.Td(['x', html.Sup(2)]), html.Td(id='square')]),
html.Tr([html.Td(['x', html.Sup(3)]), html.Td(id='cube')]),
html.Tr([html.Td([2, html.Sup('x')]), html.Td(id='twos')]),
html.Tr([html.Td([3, html.Sup('x')]), html.Td(id='threes')]),
html.Tr([html.Td(['x', html.Sup('x')]), html.Td(id='x^x')]),
]),
])
@app.callback(
Output('square', 'children'),
Output('cube', 'children'),
Output('twos', 'children'),
Output('threes', 'children'),
Output('x^x', 'children'),
Input('num-multi', 'value'))
def callback_a(x):
return x**2, x**3, 2**x, 3**x, x**x
if __name__ == '__main__':
app.run_server(debug=True)
2.4 链式回调(chained callbacks)的Dash app
一个回调函数的输出可以是另一个回调函数的输入,这可以用来创建动态的UI. 下面的例子中,一个输入元件会更新另一个元件的可用选项.
# -*- coding: utf-8 -*-
from dash import Dash, dcc, html, Input, Output
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
all_options = {
'America': ['New York City', 'San Francisco', 'Cincinnati'],
'Canada': [u'Montréal', 'Toronto', 'Ottawa']
}
app.layout = html.Div([
dcc.RadioItems(
list(all_options.keys()),
'America',
id='countries-radio',
),
html.Hr(),
dcc.RadioItems(id='cities-radio'),
html.Hr(),
html.Div(id='display-selected-values')
])
@app.callback(
Output('cities-radio', 'options'),
Input('countries-radio', 'value'))
def set_cities_options(selected_country):
return [{'label': i, 'value': i} for i in all_options[selected_country]]
@app.callback(
Output('cities-radio', 'value'),
Input('cities-radio', 'options'))
def set_cities_value(available_options):
return available_options[0]['value']
@app.callback(
Output('display-selected-values', 'children'),
Input('countries-radio', 'value'),
Input('cities-radio', 'value'))
def set_display_children(selected_country, selected_city):
return u'{} is a city in {}'.format(
selected_city, selected_country,
)
if __name__ == '__main__':
app.run_server(debug=True)
2.5 带状态(state)的 Dash app
某些情况下,不是实时根据用户的输入进行更新,而是等待输入完了所有的字符后再进行更新.
state 允许用户在不调用回调函数的情况下传递一些值. 下面例子中两个 dcc.Input 元件作为 state,一个新的按钮元件作为 Input(大写I,这是一个元件类型名).
# -*- coding: utf-8 -*-
from dash import Dash, dcc, html
from dash.dependencies import Input, Output, State
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
app.layout = html.Div([
dcc.Input(id='input-1-state', type='text', value='Montréal'),
dcc.Input(id='input-2-state', type='text', value='Canada'),
html.Button(id='submit-button-state', n_clicks=0, children='Submit'),
html.Div(id='output-state')
])
@app.callback(Output('output-state', 'children'),
Input('submit-button-state', 'n_clicks'),
State('input-1-state', 'value'),
State('input-2-state', 'value'))
def update_output(n_clicks, input1, input2):
return u'''
The Button has been pressed {} times,
Input 1 is "{}",
and Input 2 is "{}"
'''.format(n_clicks, input1, input2)
if __name__ == '__main__':
app.run_server(debug=True)
2.6 将元件传入回调函数,而不是ID
在第一个例子中,有id为'my-input'的dcc.Input元件和id为'my-output'的html.Div元件,
app.layout = html.Div([
html.H6("Change the value in the text box to see callbacks in action!"),
html.Div([
"Input: ",
dcc.Input(id='my-input', value='initial value', type='text')
]),
html.Br(),
html.Div(id='my-output'),
@app.callback(
Output(component_id='my-output', component_property='children'),
Input(component_id='my-input', component_property='value')
)
def update_output_div(input_value):
return f'Output: {input_value}'
也可以不带id,直接将元件作为输入或者输出,Dash为这些元件自动生成ID.
下面的例子就是第一个例子,在声明 app layout 之前,创建了两个元件并分别指派给一个变量,然后就可以在 layout 中直接引用这些变量并且直接将它们作为输入或者输出传给回调函数.
from dash import Dash, dcc, html, Input, Output, callback
app = Dash(__name__)
my_input = dcc.Input(value='initial value', type='text')
my_output = html.Div()
app.layout = html.Div([
html.H6("Change the value in the text box to see callbacks in action!"),
html.Div([
"Input: ",
my_input
]),
html.Br(),
my_output
])
@callback(
Output(my_output, component_property='children'),
Input(my_input, component_property='value')
)
def update_output_div(input_value):
return f'Output: {input_value}'
if __name__ == '__main__':
app.run_server(debug=True)
三. 交互式可视化
dcc.Graph 元件有四个可以在交互中改变的属性: hoverData, clickData, selectedData, relayoutData.
import json
from dash import Dash, dcc, html
from dash.dependencies import Input, Output
import plotly.express as px
import pandas as pd
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']
app = Dash(__name__, external_stylesheets=external_stylesheets)
styles = {
'pre': {
'border': 'thin lightgrey solid',
'overflowX': 'scroll'
}
}
df = pd.DataFrame({
"x": [1,2,1,2],
"y": [1,2,3,4],
"customdata": [1,2,3,4],
"fruit": ["apple", "apple", "orange", "orange"]
})
fig = px.scatter(df, x="x", y="y", color="fruit", custom_data=["customdata"])
fig.update_layout(clickmode='event+select')
fig.update_traces(marker_size=20)
app.layout = html.Div([
dcc.Graph(
id='basic-interactions',
figure=fig
),
html.Div(className='row', children=[
html.Div([
dcc.Markdown("""
**Hover Data**
Mouse over values in the graph.
"""),
html.Pre(id='hover-data', style=styles['pre'])
], className='three columns'),
html.Div([
dcc.Markdown("""
**Click Data**
Click on points in the graph.
"""),
html.Pre(id='click-data', style=styles['pre']),
], className='three columns'),
html.Div([
dcc.Markdown("""
**Selection Data**
Choose the lasso or rectangle tool in the graph's menu
bar and then select points in the graph.
Note that if `layout.clickmode = 'event+select'`, selection data also
accumulates (or un-accumulates) selected data if you hold down the shift
button while clicking.
"""),
html.Pre(id='selected-data', style=styles['pre']),
], className='three columns'),
html.Div([
dcc.Markdown("""
**Zoom and Relayout Data**
Click and drag on the graph to zoom or click on the zoom
buttons in the graph's menu bar.
Clicking on legend items will also fire
this event.
"""),
html.Pre(id='relayout-data', style=styles['pre']),
], className='three columns')
])
])
@app.callback(
Output('hover-data', 'children'),
Input('basic-interactions', 'hoverData'))
def display_hover_data(hoverData):
return json.dumps(hoverData, indent=2)
@app.callback(
Output('click-data', 'children'),
Input('basic-interactions', 'clickData'))
def display_click_data(clickData):
return json.dumps(clickData, indent=2)
@app.callback(
Output('selected-data', 'children'),
Input('basic-interactions', 'selectedData'))
def display_selected_data(selectedData):
return json.dumps(selectedData, indent=2)
@app.callback(
Output('relayout-data', 'children'),
Input('basic-interactions', 'relayoutData'))
def display_relayout_data(relayoutData):
return json.dumps(relayoutData, indent=2)
if __name__ == '__main__':
app.run_server(debug=True)
四. 在回调函数之间共享数据
暂时用不到
dash app 是设计在多用户的场景中的,一个用户修改全局变量会导致其他用户的崩溃,所以要用
dcc.store来储存共享数据
五. 实战:如何在已有的plotly图中手动添加曲线, 并根据曲线上的点进行计算?
通过drawmode手动画线
Interactive annotations and shape drawing in plotly figures and Dash apps
注意离线plot中无法正确显示模式按钮modeBarButtonsToAdd, 需要在终端中运行
import plotly.express as px
from skimage import data
img = data.chelsea() # or any image represented as a numpy array
fig = px.imshow(img)
# Define dragmode, newshape parameters, amd add modebar buttons
fig.update_layout(
dragmode='drawrect', # define dragmode
newshape=dict(line_color='cyan'))
# Add modebar buttons
fig.show(config={'modeBarButtonsToAdd':['drawline',
'drawopenpath',
'drawclosedpath',
'drawcircle',
'drawrect',
'eraseshape'
]})
也能够方便地与Dash进行互动
import dash
from dash.dependencies import Input, Output, State
import dash_html_components as html
import dash_core_components as dcc
import plotly.express as px
from skimage import data
import math
app = dash.Dash(__name__)
img = data.coins() # or any image represented as a numpy array
fig = px.imshow(img, color_continuous_scale='gray')
fig.update_layout(dragmode='drawline', newshape_line_color='cyan')
app.layout = html.Div(children=[
dcc.Graph(
id='graph',
figure=fig,
config={'modeBarButtonsToAdd':['drawline']}),
html.Pre(id='content', children='Length of lines (pixels) \n')
], style={'width':'25%'})
@app.callback(
dash.dependencies.Output('content', 'children'),
[dash.dependencies.Input('graph', 'relayoutData')],
[dash.dependencies.State('content', 'children')])
def shape_added(fig_data, content):
if fig_data is None:
return dash.no_update
if 'shapes' in fig_data:
line = fig_data['shapes'][-1]
length = math.sqrt((line['x1'] - line['x0']) ** 2 +
(line['y1'] - line['y0']) ** 2)
content += '%.1f'%length + '\n'
return content
if __name__ == '__main__':
app.run_server(debug=True)
pytorch
创建网络的一种快捷方法:Sequential
net = torch.nn.Sequential(
torch.nn.Linear(STATE_SIZE, HIDDEN_SIZE),
torch.nn.ReLU(),
torch.nn.Linear(HIDDEN_SIZE, ACTION_SIZE),
)
2.1 构造张量的函数
torch.tensor() torch.zeros(), torch.zeros_like() torch.ones(), torch.ones_like() torch.full(), torch.full_like() 全填充为指定值 torch.empty(), torch.empty_like() torch.eye() torch.arange(), torch.range(), torch.linspace() torch.logspace() 等比 torch.rand(), torch.rand_like() 标准均匀 torch.randn(), torch.randn_like(), torch.normal() 标准正态 torch.randint(), torch.randint_like() torch.bernoulli() 两点分布 torch.multinomial() torch.randperm() {0,1,2,3...,n-1}的随机排列
2.2 重排张量元素
以下三种不会改变张量的实际位置(浅拷贝)
- reshape()
- squeeze():消除张量中大小为 的维度,
t.squeeze() - unsqueeze():添加一个大小为 的维度,
t.unsqueeze(dim=2)
2.3 张量扩展和拼接
- repeat()
- cat():两个参数,第一个是要拼接的张量的列表,第二个是延哪一个维度
- stack():同上,不同在于 stack 要求拼接的张量大小完全一样,延一个新的维度拼接
2.4 求解优化问题
- 在构造用做自变量的 torch.Tensor 类实例时,应将参数 requires_grad 设置为 True
- 调用张量类实例的成员方法 backward() 可以求偏导,调用完后,自变量的属性 grad 就储存了偏导的数值
from math import pi
import torch
x = torch.tensor([ pi/3 , pi/6 ], requires_grad=True)
f = -((x.cos()**2).sum)**2
print(f'value = {f}')
f.backward()
print(f'grad = {x.grad}')
优化算法与torch.optim包
在梯度下降时,先调用优化器实例的方法 zero_grad() 清空优化器在上次迭代中储存的数据,然后调用 torch.tensor 类实例的方法 backward() 求梯度,最后使用优化器的方法 step() 更新自变量的值
optimizer.zero_grad()
f.backward()
optimizer.step()
使用 torch.optim.SGD 梯度下降的一个实例
from math import pi
import torch
import torch.optim
x = torch.tensor([ pi/3 , pi/6 ], requires_grad=True)
optimizer = torch.optim.SGD([x,], lr=0.1 ,momentum=0)
for step in range(11):
if step:
optimizer.zero_grad()
f.backward()
optimizer.step()
f = -((x.cos()**2).sum)**2
print(f'step {step}: x = {x.tolist()}, f(x) = {f}')
torch.nn子包与损失类
torch.nn.Module 类及其子类可有以下用途
- 表示一个神经网络.如:torch.nn.Sequential 类可以表示一个前馈神经网络
- 表示神经网络的一个层:如 torch.nn.Linear 线性层,torch.nn.ReLU 激活层
- 表示损失:torch.nn.MSELoss,torh.nn.CrossEntropyLoss 等
激活层中逐元素激活分为以下三类
- S 型激活:Sigmoid,Softsign,Tanh,Hardtanh,ReLU6
- 单侧激活:ReLU,LeakyReLU,PReLU,RReLU,Threshold,ELU,SELU,Softplus,LogSigmoid
- 褶皱激活:Hardshrinkage,Softshrinkage,Tanhshrinkage
非逐元素激活
- Softmax,Softmax2d,LogSoftmax
torch.nn 里的损失类都是 torch.nn.Module 类的子类
criterion = torch.nn.MSELoss()
pred = torch.arange(5, requires_grad=True)
y = torch.ones(5)
loss = criterion(pred, y)
loss.backward()
训练集、验证集与训练集
训练集用来计算参数,验证集来判定欠拟合或过拟合,测试机来评价最终结果
| 欠拟合 | 过拟合 | |
|---|---|---|
| 泛化差错主要来源 | 偏差差错 (bias) | 方差差错 (variance) |
| 模型复杂度 | 过低 | 过高 |
| 学习曲线和验证曲线特征 | 收敛到比较大的差错值 | 两条曲线之间差别大 |
| 解决方案 | 增加模型复杂度 | 减小模型复杂度或增大训练集 |
2.5 标准化
- 批标准化( batch normalization ):对同一通道使用相同的均值和方差进行归一化,更适用于特征提取这样的应用
- 实例标准化( instance normalization ):对同一通道使用不同的均值和方差进行归一化,更适用于生成数据这样的应用
| 标准化操作类型 | 维度 | 标准化类 | 输入输出张量维度 | 适用网络 |
|---|---|---|---|---|
| 批标准化 | 1 | torch.nn.BatchNorm1d | 前馈神经网络 | |
| 批标准化 | 2 | torch.nn.BatchNorm2d | 前馈神经网络 | |
| 批标准化 | 3 | torch.nn.BatchNorm3d | 前馈神经网络 | |
| 实例标准化 | 1 | torch.nn.InstanceNorm1d | 前馈神经网络 | |
| 实例标准化 | 2 | torch.nn.InstanceNorm2d | 前馈神经网络 | |
| 实例标准化 | 3 | torch.nn.InstanceNorm3d | 前馈神经网络 | |
| 层标准化 | 不限 | torch.nn.LayerNorm | 前馈神经网络 |
2.6 网络权重初始化
pytorch 中完成权重初始化需要 torch.nn.init 子包和 torch.nn.Module 类成员方法 apply().
| 函数名 | 元素分布 | 分布参数确定方法 |
|---|---|---|
| torch.nn.init.uniform_() | 均匀分布 | 传入表示最小值的参数 a (默认为 0 )和表示最大值的参数 b (默认为 1 ) |
| torch.nn.init.normal_() | 正态分布 | 传入表示均值的参数 mean (默认为 0 )和表示方差的参数 std (默认为 1 ) |
| torch.nn.init.constant_() | 常量 | 传入常量 vaL |
| torch.nn.init.xavier_uniform_() | 均匀分布 | 均值为 0 ,标准差 根据输入的张量大小和增益函数 gain 计算得到 |
| torch.nn.init.xavier_uniform_() | 均匀分布 | 均值为 0 ,标准差 根据输入的张量大小和增益函数 gain 计算得到 |
apply() 方法有一个参数,参数是一个 python 函数,这个函数的参数必须是 torch.nn.Module 类.
import torch.nn.init as init
def weights_init(m):
init.xavier_normal_(m.weight)
init.constant_(m.bias, 0)
2.7 卷积神经网络
对一维卷积,设 为输入张量,大小为 , 为卷积核,大小为 ,输出张量为 ,大小为 ,则有
补全 (pad) 运算
在补零后 (前后各补 ,) ,相应的张量维度为
核的膨胀(dilate),基本互相关中,每个权重连续对应着输入张量中的元素,此时可认为膨胀系数为 ,膨胀前后核大小关系为 图 8-4 给出了膨胀系数 的例子.膨胀前,核的大小为 ,膨胀后,

步幅(stride),基本互相关中,卷积核每次相对输入张量 向右移动一个元素的位置并得到一个输出张量,一共 个输出.将此输出大小记为 视为可以认为基本互相关操作的步幅 ,如果考虑更大步幅,则有
补全、步幅、膨胀可以综合使用.综合前文,输入大小 ,输出大小 ,核张量大小 ,两侧分别补全数 和 ,步幅 ,膨胀系数 之间的关系满足 将以上几式综合起来,可以得到
torch.nn 里的卷积层
| 运算类型 | 运算维度 | torch.nn.Module子类 | 类实例输入张量的大小 | 类实例输出张量的大小 |
|---|---|---|---|---|
| 互相关 | 1 | torch.nn.Conv1d | ||
| 互相关 | 2 | torch.nn.Conv2d | ||
| 互相关 | 3 | torch.nn.Conv3d |
为样本的计数, 表示数据的通道数,即一条数据有几个 维张量.卷积层的输出通道数表示最多支持的特征个数.因为每个通道使用相同的卷积核计算,每个卷积核只能提取一种特征.
conv = torch.nn.Conv2d(16, 33, kernel_size={3, 5}, stride={2, 1}, padding={4, 2}, dilation={3, 1})
inputs = torch.rand(20, 16, 50, 100) #20条样本,16个通道,每个通道大小为 50*100
outputs = conv(inputs)
outputs.size()
张量的池化
池化 (pooling),核不需要权重
- 最大池化(max pool):输出张量的每个元素都是若干个输入张量的最大值
- 平均池化(average pool):输出元素由若干个输入元素求平均得到
- 池化( pool):计算输入元素组合的 范数
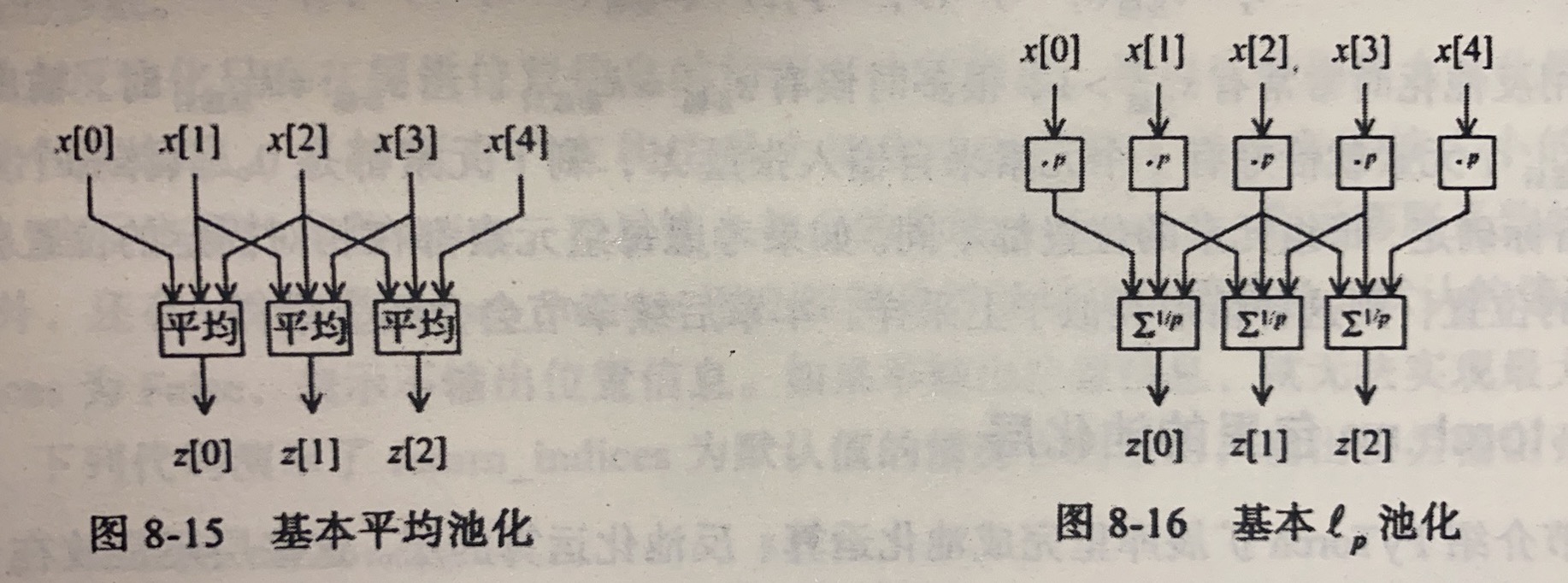
以下为不带“自适应”(adaptive)的版本,带自适应只需在 MaxPool1d 前加上 Adaptive,此时不能设置补全数等,他会自动帮你计算
| 运算类型 | 运算维度 | torch.nn.Module子类 | 类实例输入张量的大小 | 类实例输出张量的大小 |
|---|---|---|---|---|
| 最大池化 | 1 | torch.nn.MaxPool1d | ||
| 最大池化 | 2 | torch.nn.MaxPool2d | ||
| 最大池化 | 3 | torch.nn.MaxPool3d | ||
| 平均池化 | 1 | torch.nn.AvgPool1d | ||
| 平均池化 | 2 | torch.nn.AvgPool2d | ||
| 平均池化 | 3 | torch.nn.AvgPool3d | ||
| 池化 | 1 | torch.nn.LPPool1d | ||
| 池化 | 2 | torch.nn.LPPool2d | ||
| 最大反池化 | 1 | torch.nn.MaxUnpool1d | ||
| 最大反池化 | 2 | torch.nn.MaxUnpool2d | ||
| 最大反池化 | 3 | torch.nn.MaxUnpool3d |
张量的上采样
张量的上采样(up-sample),将输入张量的每个维度大小扩展若干倍.
- 最邻近上采样( nearest up-sample ):按照一个比例因子( scale factor )将每个元素重复若干次
- 线性插值上采样( linearup-sample )
pytorch 中上采样用的是 torch.nn 的子包 torch.nn.Unsample 类.
| 运算类型 | 运算维度 | torch.nn.Unsample类实例构造参数 | 类实例输入张量的大小 | 类实例输出张量的大小 |
|---|---|---|---|---|
| 最邻近上采样 | 1 | mode='nearest'(默认值) | ||
| 最邻近上采样 | 2 | mode='nearest'(默认值) | ||
| 最邻近上采样 | 3 | mode='nearest'(默认值) | ||
| 线性上采样 | 1 | mode='linear' | ||
| 线性上采样 | 2 | mode='bilinear' | ||
| 线性上采样 | 3 | mode='trilinear' |
张量的补全运算
- 常数补全( constant pad ):输入张量前后补上常数
- 重复补全( replication pad ):用最边上的值补全
- 反射补全( reflection pad ):以边界为对称轴补全
| 运算类型 | 运算维度 | torch.nn.Module子类 | 类实例输入张量的大小 | 类实例输出张量的大小 |
|---|---|---|---|---|
| 常数补全 | 2 | torch.nn.ConstantPad2d | ||
| 重复补全 | 2 | torch.nn.ReplicationPad2d | ||
| 反射补全 | 2 | torch.nn.ReflectionPad2d | ||
| 反射补全 | 3 | torch.nn.Reflection3d |
inputs = torch.arange(12).view(1, 1, 3, 4)
pad = nn.ConstantPad2d(padding=[1, 1, 1, 1], value=-1)
pad = nn.Replication2d(padding=[1, 1, 1, 1])
pad = nn.Reflection2d(padding=[1, 1, 1, 1])
例如实现下图的卷积网络,可以参考的构建网络方法:
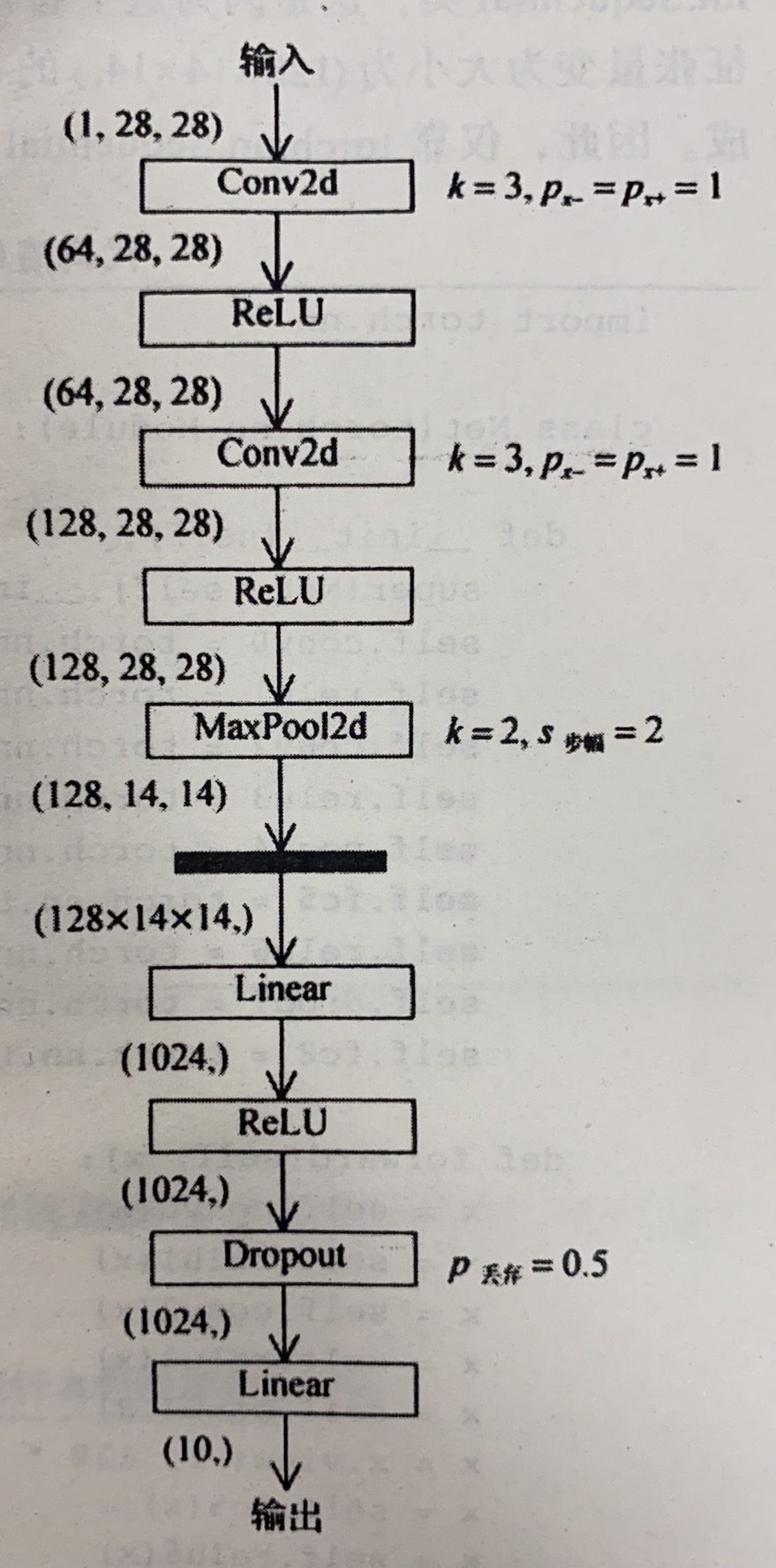
import torch.nn
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv0 = torch.nn.Conv2d(1, 64, kernel_size=3, padding=1)
self.relu1 = torch.nn.ReLU()
self.conv2 = torch.nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.relu3 = torch.nn.ReLU()
self.pool4 = torch.nn.MaxPool2d(stride=2, kernel_size=2)
self.fc5 = torch.nn.Linear(128*14*14, 1024)
self.relu6 = torch.nn.ReLU()
self.drop7 = torch.nn.Dropout(p=0.5)
self.fc8 = torch.nn.Linear(1024, 10)
def forward(self, x):
x = self.conv0(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.relu3(x)
x = self.pool4(x)
x = x.view(-1, 128 * 14 * 14)
x = self.fc5(x)
x = self.relu6(x)
x = self.drop7(x)
x = self.fc8(x)
return x
net = Net()
另外可用 sequential 方法
import torch.nn
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv = torch.nn.Sequential(
torch.nn.Conv2d(1, 64, kernel_size=3, padding=1)
torch.nn.ReLU()
torch.nn.Conv2d(64, 128, kernel_size=3, padding=1)
torch.nn.ReLU()
torch.nn.MaxPool2d(stride=2, kernel_size=2))
self.dense = torch.nn.Sequential(
torch.nn.Linear(128*14*14, 1024)
torch.nn.ReLU()
torch.nn.Dropout(p=0.5)
torch.nn.Linear(1024, 10))
def forward(self, x):
x = self.conv(x)
x = x.view(-1, 128 * 14 * 14)
x = self.dense(x)
return x
net = Net()
2.8 循环神经网络
TODO:循环神经网络
以下是 LSTM 示例
import torch.nn
class Net(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super(Net, self).__init__()
self.rnn = torch.nn.LSTM(input_size, hidden_size)
self.fc = torch.nn.Linear(hidden_size, 1)
def forward(self, x):
x = x[:, :, None]
x, _ = self.rnn(x)
x = self.fc(x)
x = x[:, :, 0]
return x
net = Net(input_size=1, hidden_size=5)
2.9 生成对抗网络
- 生成网络( generative network ):一般一条随机输入是一个有多个元素的张量 ,张量 的取值空间称为“潜在空间”( latent space ),张量 的元素个数称为“潜在大小”( latent size ).生成网络 可以将这条潜在张量样本 映射为一条数据张量 .
- 鉴别网络( discriminative network ):对生成网络生成的数据进行判定.
以 记交叉熵损失函数
目的:训练鉴别网络 使得 训练生成网络使得
以下是CIFAR-10图像生成的实例
'''读取数据'''
from torch.utils.data import DataLoader
from torchvision.datasets import CIFAR10
import torchvision.transforms as transforms
from torchvision.utils import save_image
dataset = CIFAR10(root='./data', download=True,
transform=transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
for batch_idx, data in enumerate(dataloader):
real_images, _ = data
batch_size = real_images.size(0)
print ('#{} has {} images.'.format(batch_idx, batch_size))
if batch_idx % 100 == 0:
path = './data/CIFAR10_shuffled_batch{:03d}.png'.format(batch_idx)
save_image(real_images, path, normalize=True)
'''生成网络与鉴别网络的搭建'''
import torch.nn as nn
# 搭建生成网络
latent_size = 64 # 潜在大小
n_channel = 3 # 输出通道数
n_g_feature = 64 # 生成网络隐藏层大小
gnet = nn.Sequential(
# 输入大小 = (64, 1, 1)
nn.ConvTranspose2d(latent_size, 4 * n_g_feature, kernel_size=4,
bias=False),
nn.BatchNorm2d(4 * n_g_feature),
nn.ReLU(),
# 大小 = (256, 4, 4)
nn.ConvTranspose2d(4 * n_g_feature, 2 * n_g_feature, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(2 * n_g_feature),
nn.ReLU(),
# 大小 = (128, 8, 8)
nn.ConvTranspose2d(2 * n_g_feature, n_g_feature, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(n_g_feature),
nn.ReLU(),
# 大小 = (64, 16, 16)
nn.ConvTranspose2d(n_g_feature, n_channel, kernel_size=4,
stride=2, padding=1),
nn.Sigmoid(),
# 图片大小 = (3, 32, 32)
)
print (gnet)
# 搭建鉴别网络
n_d_feature = 64 # 鉴别网络隐藏层大小
dnet = nn.Sequential(
# 图片大小 = (3, 32, 32)
nn.Conv2d(n_channel, n_d_feature, kernel_size=4,
stride=2, padding=1),
nn.LeakyReLU(0.2),
# 大小 = (64, 16, 16)
nn.Conv2d(n_d_feature, 2 * n_d_feature, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(2 * n_d_feature),
nn.LeakyReLU(0.2),
# 大小 = (128, 8, 8)
nn.Conv2d(2 * n_d_feature, 4 * n_d_feature, kernel_size=4,
stride=2, padding=1, bias=False),
nn.BatchNorm2d(4 * n_d_feature),
nn.LeakyReLU(0.2),
# 大小 = (256, 4, 4)
nn.Conv2d(4 * n_d_feature, 1, kernel_size=4),
# 对数赔率张量大小 = (1, 1, 1)
)
print(dnet)
'''网络初始化'''
import torch.nn.init as init
def weights_init(m): # 用于初始化权重值的函数
if type(m) in [nn.ConvTranspose2d, nn.Conv2d]:
init.xavier_normal_(m.weight)
elif type(m) == nn.BatchNorm2d:
init.normal_(m.weight, 1.0, 0.02)
init.constant_(m.bias, 0)
gnet.apply(weights_init)
dnet.apply(weights_init)
'''训练并输出图片'''
import torch
import torch.optim
# 损失
criterion = nn.BCEWithLogitsLoss()
# 优化器
goptimizer = torch.optim.Adam(gnet.parameters(),
lr=0.0002, betas=(0.5, 0.999))
doptimizer = torch.optim.Adam(dnet.parameters(),
lr=0.0002, betas=(0.5, 0.999))
# 用于测试的固定噪声,用来查看相同的潜在张量在训练过程中生成图片的变换
batch_size = 64
fixed_noises = torch.randn(batch_size, latent_size, 1, 1)
# 训练过程
epoch_num = 10
for epoch in range(epoch_num):
for batch_idx, data in enumerate(dataloader):
# 载入本批次数据
real_images, _ = data
batch_size = real_images.size(0)
# 训练鉴别网络
labels = torch.ones(batch_size) # 真实数据对应标签为1
preds = dnet(real_images) # 对真实数据进行判别
outputs = preds.reshape(-1)
dloss_real = criterion(outputs, labels) # 真实数据的鉴别器损失
dmean_real = outputs.sigmoid().mean()
# 计算鉴别器将多少比例的真数据判定为真,仅用于输出显示
noises = torch.randn(batch_size, latent_size, 1, 1) # 潜在噪声
fake_images = gnet(noises) # 生成假数据
labels = torch.zeros(batch_size) # 假数据对应标签为0
fake = fake_images.detach()
# 使得梯度的计算不回溯到生成网络,可用于加快训练速度.删去此步结果不变
preds = dnet(fake) # 对假数据进行鉴别
outputs = preds.view(-1)
dloss_fake = criterion(outputs, labels) # 假数据的鉴别器损失
dmean_fake = outputs.sigmoid().mean()
# 计算鉴别器将多少比例的假数据判定为真,仅用于输出显示
dloss = dloss_real + dloss_fake # 总的鉴别器损失
dnet.zero_grad()
dloss.backward()
doptimizer.step()
# 训练生成网络
labels = torch.ones(batch_size)
# 生成网络希望所有生成的数据都被认为是真数据
preds = dnet(fake_images) # 把假数据通过鉴别网络
outputs = preds.view(-1)
gloss = criterion(outputs, labels) # 真数据看到的损失
gmean_fake = outputs.sigmoid().mean()
# 计算鉴别器将多少比例的假数据判定为真,仅用于输出显示
gnet.zero_grad()
gloss.backward()
goptimizer.step()
# 输出本步训练结果
print('[{}/{}]'.format(epoch, epoch_num) +
'[{}/{}]'.format(batch_idx, len(dataloader)) +
'鉴别网络损失:{:g} 生成网络损失:{:g}'.format(dloss, gloss) +
'真数据判真比例:{:g} 假数据判真比例:{:g}/{:g}'.format(
dmean_real, dmean_fake, gmean_fake))
if batch_idx % 100 == 0:
fake = gnet(fixed_noises) # 由固定潜在张量生成假数据
save_image(fake, # 保存假数据
'./data/images_epoch{:02d}_batch{:03d}.png'.format(
epoch, batch_idx))
numpy
import numpy as np
基础
- 数组:np.array([[1,2,3],[4,5,6],...])
- 序列:np.arange(a,b,c) 初值a,终值b,步长c,不含终值
- 序列:np.linspace(a,b,c) 初值a,终值b,个数c,含终值
- 空数组:np.empty((a,b),np.int) shape&type
- 零数组:np.zeros((a,b),np.int)
- 单位阵:np.eye(N,M=None,k=0) 行数N,列数M,k为对角线上移(正)或下移(负)
- 全1阵:np.ones((a,b),np.int)
- 转置与内积:np.dot(A.T,A)
切片与索引
切片是视图而非副本,若要副本:arr[5:8].copy()
布尔型索引:data[data<0]=0, ~可用来反转条件
通用函数func
一元函数:np. f (arr)
- abs,fabs,sqrt开根,square平方
- exp,log,log10,log2
- sign,ceil向上取整,floor向下取整,rint四舍五入,modf拆成整数和小数
- isnan,isfinite,isinf
- cos,sin,cosh,sinh,tan,tanh
二元函数:np. f (arr)
- add,substract,multiply,divide,floor_divide 除后取整
- power,maximum,fmax,mod
- copysign 得到第二个数组的符号
- greater,greater_equal,less,less_equal,equal,not_equal返回布尔值
- meshgrid 接受两个一维数组,产生两个二维数组,对应所有(x,y)对
np.where()是 x if condition else y的矢量化版本 np.where(arr>2,2,-2) np.where(arr>2,2,arr)
数组统计方法
- sum,mean,std,var,min,max
- argmax,argmin 索引,cumsum,cumprod
- 查询数组中是否有true:all,any(示例:
(a=b).all())
排序
sort
集合运算,数字1
- unique(x)
- intersect1d(x,y) 交集
- union1d(x,y) 并集
- in1d(x,y) 包含于
- setdiff1d(x,y) 差集
- setxor1d(x,y) 对称差
常用numpy.linalg函数(npl)
- diag 对角阵和一维数组转化
- dot,trace,det
- eig 特征值特征向量
- inv 逆
- pinv Moore-Penrose 伪逆
- qr QR分解
- svd 奇异值分解
- solve 解Ax=b ,A方针
- lstsq Ax=b最小二乘解
部分numpy.random函数
- seed 确定随机数生成器种子
- permutation 返回新的打乱的x,x不变
- shuffle 原地打乱x
- rand 均匀分布
- randint 给定范围内随机取整数
- randn 标准正态分布
- binomial 二项分布
- normal 正态分布
- beta,gamma
- chisquare 卡方分布
- uniform [0,1)均匀分布
数组合并与拼接
- append(arr,values,axis=None)
Pandas
Series([1, 2, 3, 4], index=[a, b, c, d]) 查缺失数据 .isnull(), .notnull(), 返回同结构的布尔值 Series对象本身及其索引有个 name 属性
a = pd.Series([1 ,2 ,3 ,4], index=['a', 'b', 'c', 'd'])
a.name = 'series'
将序列作为 DataFrame 的一列时,name属性就变为那一列的列名
DataFrame
data = np.ones([3,4])
d = pd.DataFrame(data, index=['a','b','c'], columns=['a','b','c','d'])
.head() 取前五行,.tail() .del() 删除某一列,.drop()删除指定轴上某些项 .append() .difference() .intersection() .union()
索引 用标签名 data.loc['a',['c','d']] 不用标签名 data.iloc[2,[2,3]]
常用方法 .cumsum() .cumprod() .diff() .pct_change()
换指定列名 d=d.rename( index={1:'new'}, columns={'a':'shit'} )
matplotlib
import matplotlib.pyplot as plt
data1 = np.linspace(1,200,2000)
data2 = np.random.randn(2000)
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
plt.plot(data1, label='first')
plt.plot(data2,'.', label='second')
ax1.set_xticks([1,2,40])
ax1.legend(loc='best')
ax1.set_title('first plot')
ax1.set_xlabel('index')
ax2 = fig.add_subplot(2,2,2)
'-'实线 '--'短划线 '-.'点划线 ':'虚线 '.'点 'v'倒三角 等 color参数 'b'蓝 'g'绿 'r'红 'c'青 'm'品红 'y'黄 'k'黑 'w'白
从代码结构方面优化加速python
0. 代码优化原则
本文会介绍不少的 Python 代码加速运行的技巧。在深入代码优化细节之前,需要了解一些代码优化基本原则。
第一个基本原则是不要过早优化。很多人一开始写代码就奔着性能优化的目标,“让正确的程序更快要比让快速的程序正确容易得多”。因此,优化的前提是代码能正常工作。过早地进行优化可能会忽视对总体性能指标的把握,在得到全局结果前不要主次颠倒。
第二个基本原则是权衡优化的代价。优化是有代价的,想解决所有性能的问题是几乎不可能的。通常面临的选择是时间换空间或空间换时间。另外,开发代价也需要考虑。
第三个原则是不要优化那些无关紧要的部分。如果对代码的每一部分都去优化,这些修改会使代码难以阅读和理解。如果你的代码运行速度很慢,首先要找到代码运行慢的位置,通常是内部循环,专注于运行慢的地方进行优化。在其他地方,一点时间上的损失没有什么影响。
1. 避免全局变量
# 不推荐写法。代码耗时:26.8秒
import math
size = 10000
for x in range(size):
for y in range(size):
z = math.sqrt(x) + math.sqrt(y)
许多程序员刚开始会用 Python 语言写一些简单的脚本,当编写脚本时,通常习惯了直接将其写为全局变量,例如上面的代码。但是,由于全局变量和局部变量实现方式不同,定义在全局范围内的代码运行速度会比定义在函数中的慢不少。通过将脚本语句放入到函数中,通常可带来 15% - 30% 的速度提升。
# 推荐写法。代码耗时:20.6秒
import math
def main(): # 定义到函数中,以减少全部变量使用
size = 10000
for x in range(size):
for y in range(size):
z = math.sqrt(x) + math.sqrt(y)
main()
2. 避免.
2.1 避免模块和函数属性访问
# 不推荐写法。代码耗时:14.5秒
import math
def computeSqrt(size: int):
result = []
for i in range(size):
result.append(math.sqrt(i))
return result
def main():
size = 10000
for _ in range(size):
result = computeSqrt(size)
main()
每次使用.(属性访问操作符时)会触发特定的方法,如__getattribute__()和__getattr__(),这些方法会进行字典操作,因此会带来额外的时间开销。通过from import语句,可以消除属性访问。
# 第一次优化写法。代码耗时:10.9秒
from math import sqrt
def computeSqrt(size: int):
result = []
for i in range(size):
result.append(sqrt(i)) # 避免math.sqrt的使用
return result
def main():
size = 10000
for _ in range(size):
result = computeSqrt(size)
main()
在第 1 节中我们讲到,局部变量的查找会比全局变量更快,因此对于频繁访问的变量sqrt,通过将其改为局部变量可以加速运行。
# 第二次优化写法。代码耗时:9.9秒
import math
def computeSqrt(size: int):
result = []
sqrt = math.sqrt # 赋值给局部变量
for i in range(size):
result.append(sqrt(i)) # 避免math.sqrt的使用
return result
def main():
size = 10000
for _ in range(size):
result = computeSqrt(size)
main()
除了math.sqrt外,computeSqrt函数中还有.的存在,那就是调用list的append方法。通过将该方法赋值给一个局部变量,可以彻底消除computeSqrt函数中for循环内部的.使用。
# 推荐写法。代码耗时:7.9秒
import math
def computeSqrt(size: int):
result = []
append = result.append
sqrt = math.sqrt # 赋值给局部变量
for i in range(size):
append(sqrt(i)) # 避免 result.append 和 math.sqrt 的使用
return result
def main():
size = 10000
for _ in range(size):
result = computeSqrt(size)
main()
2.2 避免类内属性访问
# 不推荐写法。代码耗时:10.4秒
import math
from typing import List
class DemoClass:
def __init__(self, value: int):
self._value = value
def computeSqrt(self, size: int) -> List[float]:
result = []
append = result.append
sqrt = math.sqrt
for _ in range(size):
append(sqrt(self._value))
return result
def main():
size = 10000
for _ in range(size):
demo_instance = DemoClass(size)
result = demo_instance.computeSqrt(size)
main()
避免.的原则也适用于类内属性,访问self._value的速度会比访问一个局部变量更慢一些。通过将需要频繁访问的类内属性赋值给一个局部变量,可以提升代码运行速度。
# 推荐写法。代码耗时:8.0秒
import math
from typing import List
class DemoClass:
def __init__(self, value: int):
self._value = value
def computeSqrt(self, size: int) -> List[float]:
result = []
append = result.append
sqrt = math.sqrt
value = self._value
for _ in range(size):
append(sqrt(value)) # 避免 self._value 的使用
return result
def main():
size = 10000
for _ in range(size):
demo_instance = DemoClass(size)
demo_instance.computeSqrt(size)
main()
3. 避免不必要的抽象
# 不推荐写法,代码耗时:0.55秒
class DemoClass:
def __init__(self, value: int):
self.value = value
@property
def value(self) -> int:
return self._value
@value.setter
def value(self, x: int):
self._value = x
def main():
size = 1000000
for i in range(size):
demo_instance = DemoClass(size)
value = demo_instance.value
demo_instance.value = i
main()
任何时候当你使用额外的处理层(比如装饰器、属性访问、描述器)去包装代码时,都会让代码变慢。大部分情况下,需要重新进行审视使用属性访问器的定义是否有必要,使用getter/setter函数对属性进行访问通常是 C/C++ 程序员遗留下来的代码风格。如果真的没有必要,就使用简单属性。
# 推荐写法,代码耗时:0.33秒
class DemoClass:
def __init__(self, value: int):
self.value = value # 避免不必要的属性访问器
def main():
size = 1000000
for i in range(size):
demo_instance = DemoClass(size)
value = demo_instance.value
demo_instance.value = i
main()
4. 避免数据复制
4.1 避免无意义的数据复制
# 不推荐写法,代码耗时:6.5秒
def main():
size = 10000
for _ in range(size):
value = range(size)
value_list = [x for x in value]
square_list = [x * x for x in value_list]
main()
上面的代码中value_list完全没有必要,这会创建不必要的数据结构或复制。
# 推荐写法,代码耗时:4.8秒
def main():
size = 10000
for _ in range(size):
value = range(size)
square_list = [x * x for x in value] # 避免无意义的复制
main()
另外一种情况是对 Python 的数据共享机制过于偏执,并没有很好地理解或信任 Python 的内存模型,滥用 copy.deepcopy()之类的函数。通常在这些代码中是可以去掉复制操作的。
4.2 交换值时不使用中间变量
# 不推荐写法,代码耗时:0.07秒
def main():
size = 1000000
for _ in range(size):
a = 3
b = 5
temp = a
a = b
b = temp
main()
上面的代码在交换值时创建了一个临时变量temp,如果不借助中间变量,代码更为简洁、且运行速度更快。
# 推荐写法,代码耗时:0.06秒
def main():
size = 1000000
for _ in range(size):
a = 3
b = 5
a, b = b, a # 不借助中间变量
main()
4.3 字符串拼接用join而不是+
# 不推荐写法,代码耗时:2.6秒
import string
from typing import List
def concatString(string_list: List[str]) -> str:
result = ''
for str_i in string_list:
result += str_i
return result
def main():
string_list = list(string.ascii_letters * 100)
for _ in range(10000):
result = concatString(string_list)
main()
当使用a + b拼接字符串时,由于 Python 中字符串是不可变对象,其会申请一块内存空间,将a和b分别复制到该新申请的内存空间中。
# 推荐写法,代码耗时:0.3秒
import string
from typing import List
def concatString(string_list: List[str]) -> str:
return ''.join(string_list) # 使用 join 而不是 +
def main():
string_list = list(string.ascii_letters * 100)
for _ in range(10000):
result = concatString(string_list)
main()
5. 利用if条件的短路特性
# 不推荐写法,代码耗时:0.05秒
from typing import List
def concatString(string_list: List[str]) -> str:
abbreviations = {'cf.', 'e.g.', 'ex.', 'etc.', 'flg.', 'i.e.', 'Mr.', 'vs.'}
abbr_count = 0
result = ''
for str_i in string_list:
if str_i in abbreviations:
result += str_i
return result
def main():
for _ in range(10000):
string_list = ['Mr.', 'Hat', 'is', 'Chasing', 'the', 'black', 'cat', '.']
result = concatString(string_list)
main()
if 条件的短路特性是指对if a and b这样的语句, 当a为False时将直接返回,不再计算b;对于if a or b这样的语句,当a为True时将直接返回,不再计算b。因此, 为了节约运行时间,对于or语句,应该将值为True可能性比较高的变量写在or前,而and应该推后。
# 推荐写法,代码耗时:0.03秒
from typing import List
def concatString(string_list: List[str]) -> str:
abbreviations = {'cf.', 'e.g.', 'ex.', 'etc.', 'flg.', 'i.e.', 'Mr.', 'vs.'}
abbr_count = 0
result = ''
for str_i in string_list:
if str_i[-1] == '.' and str_i in abbreviations: # 利用 if 条件的短路特性
result += str_i
return result
def main():
for _ in range(10000):
string_list = ['Mr.', 'Hat', 'is', 'Chasing', 'the', 'black', 'cat', '.']
result = concatString(string_list)
main()
6. 循环优化
6.1 用for循环代替while循环
# 不推荐写法。代码耗时:6.7秒
def computeSum(size: int) -> int:
sum_ = 0
i = 0
while i < size:
sum_ += i
i += 1
return sum_
def main():
size = 10000
for _ in range(size):
sum_ = computeSum(size)
main()
Python 的for循环比while循环快不少。
# 推荐写法。代码耗时:4.3秒
def computeSum(size: int) -> int:
sum_ = 0
for i in range(size): # for 循环代替 while 循环
sum_ += i
return sum_
def main():
size = 10000
for _ in range(size):
sum_ = computeSum(size)
main()
6.2 使用隐式for循环代替显式for循环
针对上面的例子,更进一步可以用隐式for循环来替代显式for循环
# 推荐写法。代码耗时:1.7秒
def computeSum(size: int) -> int:
return sum(range(size)) # 隐式 for 循环代替显式 for 循环
def main():
size = 10000
for _ in range(size):
sum = computeSum(size)
main()
6.3 减少内层for循环的计算
# 不推荐写法。代码耗时:12.8秒
import math
def main():
size = 10000
sqrt = math.sqrt
for x in range(size):
for y in range(size):
z = sqrt(x) + sqrt(y)
main()
上面的代码中sqrt(x)位于内侧for循环, 每次训练过程中都会重新计算一次,增加了时间开销。
# 推荐写法。代码耗时:7.0秒
import math
def main():
size = 10000
sqrt = math.sqrt
for x in range(size):
sqrt_x = sqrt(x) # 减少内层 for 循环的计算
for y in range(size):
z = sqrt_x + sqrt(y)
main()
7. 使用numba.jit
我们沿用上面介绍过的例子,在此基础上使用numba.jit。 numba可以将 Python 函数 JIT 编译为机器码执行,大大提高代码运行速度。关于numba的更多信息见下面的主页:
http://numba.pydata.org/numba.pydata.org/
# 推荐写法。代码耗时:0.62秒
import numba
@numba.jit
def computeSum(size: float) -> int:
sum = 0
for i in range(size):
sum += i
return sum
def main():
size = 10000
for _ in range(size):
sum = computeSum(size)
main()
8. 选择合适的数据结构
Python 内置的数据结构如str, tuple, list, set, dict底层都是 C 实现的,速度非常快,自己实现新的数据结构想在性能上达到内置的速度几乎是不可能的。
list类似于 C++ 中的std::vector,是一种动态数组。其会预分配一定内存空间,当预分配的内存空间用完,又继续向其中添加元素时,会申请一块更大的内存空间,然后将原有的所有元素都复制过去,之后销毁之前的内存空间,再插入新元素。删除元素时操作类似,当已使用内存空间比预分配内存空间的一半还少时,会另外申请一块小内存,做一次元素复制,之后销毁原有大内存空间。因此,如果有频繁的新增、删除操作,新增、删除的元素数量又很多时,list的效率不高。此时,应该考虑使用collections.deque。collections.deque是双端队列,同时具备栈和队列的特性,能够在两端进行 O(1) 复杂度的插入和删除操作。
list的查找操作也非常耗时。当需要在list频繁查找某些元素,或频繁有序访问这些元素时,可以使用bisect维护list对象有序并在其中进行二分查找,提升查找的效率。
另外一个常见需求是查找极小值或极大值,此时可以使用heapq模块将list转化为一个堆,使得获取最小值的时间复杂度是 O(1) 。
下面的网页给出了常用的 Python 数据结构的各项操作的时间复杂度: TimeComplexity - Python WiKi
python之禅
print写法
name = 'ROSE'
country = 'China'
age = 20
print('hi, my name is {}. im from {}, and im {}'.format(name,country,age))
最简单写法
print(f'hi, my name is {name}, im from {country}, and im {age+1}')
for 循环时使用 enumerate 可返回两个参数,前一个是 index ,第二个是对应参数
for idx,step in enumerate(range(10))
@staticmethod
静态方法, 不强制要求传递参数
@classmethod
类方法, 不需要实例化, 不需要self参数, 但第一个参数需要是表示自身类的cls参数, 可以用来调用类的属性, 类的方法, 实例化对象等
### 类特殊方法
class Test():
def __init__():
pass
def __enter__():
'''使用with语句创建示例时会自动运行此方法'''
pass
‘’‘
with Test() as t:
pass
’‘’
def __exit__():
'''使用with语句创建实例, 在结束时自动调用该方法'''
pass
def __str__():
'''可print(实例)'''
return ‘我是Test类’
def __setattr__, __getattr__, __getattribute__, __delattr__:
'''对属性进行操作'''
pass
def __call__():
'''能让把实例化对象直接当做函数来调用'''
print(1)
'''
a = Test()
in: a()
out: 1
'''
def __contains__, __len__():
'''类作为容器'''
pass
# HDFStore`
with pd.HDFStore('iv_hv.h5') as store:
c = store.keys()
'''matplotlib
':' 点虚线
'-' 实线
'--' 破折线
'-.' 点划线
添加水平垂直线
plt.axhline(y=0,ls=":",c="yellow") 水平直线
plt.axvline(x=4,ls="-",c="green") 垂直直线
'''

自动发邮件
import smtplib
from smtplib import SMTP_SSL
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
from email.header import Header
from email.mime.application import MIMEApplication # 用于添加附件
host_server = 'smtp.qq.com' # qq邮箱smtp服务器
sender_qq = '359582058@qq.com' # 发件人邮箱
pwd = 'bglhxfrujynobhda'qq
pwd = 'EGGZASTFLHVGCBRU'163
receiver = '13918949838@163.com'
mail_title = 'Python自动发送邮件' # 邮件标题
# 邮件正文内容
mail_content = "您好"
msg = MIMEMultipart()
msg["Subject"] = Header(mail_title, 'utf-8')
msg["From"] = sender_qq
msg["To"] = Header("测试邮箱", "utf-8")
msg.attach(MIMEText(mail_content, 'html'))
attachment = MIMEApplication(open('复权.xlsx', 'rb').read())
attachment["Content-Type"] = 'application/octet-stream'
# 给附件重命名
basename = "复权.xlsx"
attachment.add_header('Content-Disposition', 'attachment',
filename=('utf-8', '', basename)) # 注意:此处basename要转换为gbk编码,否则中文会有乱码。
msg.attach(attachment)
try:
smtp = SMTP_SSL(host_server) # ssl登录连接到邮件服务器
smtp.set_debuglevel(1) # 0是关闭,1是开启debug
smtp.ehlo(host_server) # 跟服务器打招呼,告诉它我们准备连接,最好加上这行代码
smtp.login(sender_qq, pwd)
smtp.sendmail(sender_qq, receiver, msg.as_string())
smtp.quit()
print("邮件发送成功")
except smtplib.SMTPException:
print("无法发送邮件")
第一章 使用函数构建抽象
1.1 引言
计算机科学是一个极其宽泛的学科。全球的分布式系统、人工智能、机器人、图形、安全、科学计算,计算机体系结构和许多新兴的二级领域,每年都会由于新技术和新发现而扩展。计算机科学的快速发展广泛影响了人类生活。商业、通信、科学、艺术、休闲和政治都被计算机领域彻底改造。
计算机科学的巨大生产力可能只是因为它构建在一系列优雅且强大的基础概念上。所有计算都以表达信息、指定处理它所需的逻辑、以及设计管理逻辑复杂性的抽象作为开始。对这些基础的掌握需要我们精确理解计算机如何解释程序以及执行计算过程。
这些基础概念在伯克利长期教授,使用由Harold Abelson、Gerald Jay Sussman和Julie Sussman创作的经典教科书《计算机科学的构造与解释》(SICP)。这个讲义大量借鉴了这本书,原作者慷慨地使它可用于改编和复用。
我们的智力之旅一旦出发就不能回头了,我们也永远都不应该对此有所期待。
我们将要学习计算过程的概念。计算过程是计算机中的抽象事物。在演化中,过程操纵着叫做数据的其它事物。过程的演化由叫做程序的一系列规则主导。人们创造程序来主导过程。实际上,我们使用我们的咒语来凭空创造出计算机的灵魂。 我们用于创造过程的程序就像巫师的魔法。它们由一些古怪且深奥的编程语言中的符号表达式所组成,这些语言指定了我们想让过程执行的任务。 在一台工作正确的计算机上,计算过程准确且严谨地执行程序。所以,就像巫师的学徒那样,程序员新手必须学会理解和预测他们的魔法产生的结果。 --Abelson & Sussman, SICP (1993)
1.1.1 在Python中编程
语言并不是你学到的东西,而是你参与的东西。 --Arika Okrent
为了定义计算过程,我们需要一种编程语言,最好是一种许多人和大量计算机都能懂的语言。这门课中,我们将会使用Python语言。
Python是一种广泛使用的编程语言,并且在许多职业中都有它的爱好者:Web程序员、游戏工程师、科学家、学者,甚至新编程语言的设计师。当你学习Python时,你就加入到了一个数百万人的开发者社群。开发者社群是一个极其重要的组织:成员可以互相帮助来解决问题,分享他们的代码和经验,以及一起开发软件和工具。投入的成员经常由于他们的贡献而出名,并且收到广泛的尊重。也许有一天你会被提名为Python开发者精英。
Python语言自身就是一个大型志愿者社群的产物,并且为其贡献者的多元化而自豪。这种语言在20世纪80年代末由Guido van Rossum设计并首次实现。他的Python3教程的第一章解释了为什么Python在当今众多语言之中如此流行。
Python适用于作为教学语言,因为纵观它的历史,Python的开发者强调了Python代码对人类的解释性,并在Python之禅中美观、简约和可读的原则下进一步加强。Python尤其适用于课堂,因为它宽泛的特性支持大量的不同编程风格,我们将要探索它们。在Python中编程没有单一的解法,但是有一些习俗在开发者社群之间流传,它们可以使现有程序的阅读、理解,以及扩展变得容易。所以,Python的灵活性和易学性的组合可以让学生们探索许多编程范式,之后将它们新学到的知识用于数千个正在开发的项目中。
这些讲义通过使用抽象设计的技巧和严谨的计算模型,来快速介绍Python的特性。此外,这些讲义提供了Python编程的实践简介,包含一些高级语言特性和展示示例。通过这门课,学习Python将会变成自然而然的事情。
然而,Python是一门生态丰富的语言,带有大量特性和用法。我们讲到基本的计算机科学概念时,会刻意慢慢地介绍他们。对于有经验的学生,他们打算一口气学完语言的所有细节,我们推荐他们阅读Mark Pilgrim的书Dive Into Python 3,它在网上可以免费阅读。这本书的主题跟这门课极其不同,但是这本书包含了许多关于使用Python的宝贵的实用信息。事先告知:不像这些讲义,Dive Into Python 3需要一些编程经验。
开始在Python中编程的最佳方法就是直接和解释器交互。这一章会描述如何安装Python3,使用解释器开始交互式会话,以及开始编程。
1.1.2 安装Python3
就像所有伟大的软件一样,Python具有许多版本。这门课会使用Python3最新的稳定版本(本书编写时是3.2)。许多计算机都已经安装了Python的旧版本,但是它们可能不满足这门课。你应该可以在这门课上使用任何能安装Python3的计算机。不要担心,Python是免费的。
Dive Into Python 3拥有一个为所有主流平台准备的详细的安装指南。这个指南多次提到了Python3.1,但是你最好安装3.2(虽然它们的差异在这门课中非常微小)。EECS学院的所有教学机都已经安装了Python3.2。
1.1.3 交互式会话
在Python交互式会话中,你可以在提示符>>>之后键入一些Python代码。Python解释器读取并求出你输入的东西,并执行你的各种命令。
有几种开始交互式会话的途径,并且具有不同的特性。把它们尝试一遍来找出你最喜欢的方式。它们全部都在背后使用了相同的解释器(CPython)。
- 最简单且最普遍的方式就是运行Python3应用。在终端提示符后(Mac/Unix/Linux)键入
python3,或者在Windows上打开Python3应用。(译者注:Windows上设置完Python的环境变量之后,就可以在cmd或PowerShell中执行相同操作了。) - 有一个更加用户友好的应用叫做Idle3(
idle3),可用于学习这门语言。Idle会高亮你的代码(叫做语法高亮),弹出使用提示,并且标记一些错误的来源。Idle总是由Python自带,所以你已经安装它了。 - Emacs编辑器可以在它的某个缓冲区中运行交互式会话。虽然它学习起来有些挑战,Emacs是个强大且多功能的编辑器,适用于任何语言。请阅读61A的Emacs教程来开始。许多程序员投入大量时间来学习Emacs,之后他们就不再切换编辑器了。
在所有情况中,如果你看见了Python提示符>>>,你就成功开启了交互式会话。这些讲义使用提示符来展示示例,同时带有一些输入。
>>> 2 + 2
4
控制:每个会话都保留了你的历史输入。为了访问这些历史,需要按下<Control>-P(上一个)和<Control>-N(下一个)。<Control>-D会退出会话,这会清除所有历史。
1.1.4 第一个例子
想像会把不知名的事物用一种形式呈现出来,诗人的笔再使它们具有如实的形象,空虚的无物也会有了居处和名字。
--威廉·莎士比亚,《仲夏夜之梦》
为了介绍Python,我们会从一个使用多个语言特性的例子开始。下一节中,我们会从零开始,一步一步构建整个语言。你可以将这章视为即将到来的特性的预览。
Python拥有常见编程功能的内建支持,例如文本操作、显示图形以及互联网通信。导入语句
>>> from urllib.request import urlopen
为访问互联网上的数据加载功能。特别是,它提供了叫做urlopen的函数,可以访问到统一资源定位器(URL)处的内容,它是互联网上的某个位置。
**语句和表达式:**Python代码包含语句和表达式。广泛地说,计算机程序包含的语句
- 计算某个值
- 或执行某个操作
语句通常用于描述操作。当Python解释器执行语句时,它执行相应操作。另一方面,表达式通常描述产生值的运算。当Python求解表达式时,就会计算出它的值。这一章介绍了几种表达式和语句。
赋值语句
>>> shakespeare = urlopen('http://inst.eecs.berkeley.edu/~cs61a/fa11/shakespeare.txt')
将名称shakespeare和后面的表达式的值关联起来。这个表达式在URL上调用urlopen函数,URL包含了莎士比亚的37个剧本的完整文本,在单个文本文件中。
函数:函数封装了操作数据的逻辑。Web地址是一块数据,莎士比亚的剧本文本是另一块数据。前者产生后者的过程可能有些复杂,但是我们可以只通过一个表达式来调用它们,因为复杂性都塞进函数里了。函数是这一章的主要话题。
另一个赋值语句
>>> words = set(shakespeare.read().decode().split())
将名称words关联到出现在莎士比亚剧本中的所有去重词汇的集合,总计33,721个。这个命令链调用了read、decode和split,每个都操作衔接的计算实体:从URL读取的数据、解码为文本的数据、以及分割为单词的文本。所有这些单词都放在set中。
对象:集合是一种对象,它支持取交和测试成员的操作。对象整合了数据和操作数据的逻辑,并以一种隐藏其复杂性的方式。对象是第二章的主要话题。
表达式
>>> {w for w in words if len(w) >= 5 and w[::-1] in words}
{'madam', 'stink', 'leets', 'rever', 'drawer', 'stops', 'sessa',
'repaid', 'speed', 'redder', 'devil', 'minim', 'spots', 'asses',
'refer', 'lived', 'keels', 'diaper', 'sleek', 'steel', 'leper',
'level', 'deeps', 'repel', 'reward', 'knits'}
是一个复合表达式,求出正序或倒序出现的“莎士比亚词汇”集合。神秘的记号w[::-1]遍历单词中的每个字符,然而-1表明倒序遍历(::表示第一个和最后一个单词都使用默认值)。当你在交互式会话中输入表达式时,Python会在随后打印出它的值,就像上面那样。
解释器:复合表达式的求解需要可预测的过程来精确执行解释器的代码。执行这个过程,并求解复合表达式和语句的程序就叫解释器。解释器的设计与实现是第三章的主要话题。
与其它计算机程序相比,编程语言的解释器通常比较独特。Python在意图上并没有按照莎士比亚或者回文来设计,但是它极大的灵活性让我们用极少的代码处理大量文本。
最后,我们会发现,所有这些核心概念都是紧密相关的:函数是对象,对象是函数,解释器是二者的实例。然而,对这些概念,以及它们在代码组织中的作用的清晰理解,是掌握编程艺术的关键。
1.1.5 实践指南
Python正在等待你的命令。你应当探索这门语言,即使你可能不知道完整的词汇和结构。但是,要为错误做好准备。虽然计算机极其迅速和灵活,它们也十分古板。在斯坦福的导论课中,计算机的本性描述为
计算机的基本等式是:
计算机 = 强大 + 笨拙
计算机非常强大,能够迅速搜索大量数据。计算机每秒可以执行数十亿次操作,其中每个操作都非常简单。
计算机也非常笨拙和脆弱。它们所做的操作十分古板、简单和机械化。计算机缺少任何类似真实洞察力的事情...它并不像电影中的HAL 9000。如果不出意外,你不应被计算机吓到,就像它拥有某种大脑一样。它在背后非常机械化。
程序是一个人使用他的真实洞察力来构建出的一些实用的东西,它由这些简单的小操作所组成。
—Francisco Cai & Nick Parlante, 斯坦福 CS101
在你实验Python解释器的时候,你会马上意识到计算机的古板:即使最小的拼写和格式修改都会导致非预期的输出和错误。
学习解释错误和诊断非预期错误的原因叫做调试(debugging)。它的一些指导原则是:
- 逐步测试:每个写好的程序都由小型的组件模块组成,这些组件可以独立测试。尽快测试你写好的任何东西来及早捕获错误,并且从你的组件中获得自信。
- 隔离错误:复杂程序的输出、表达式、或语句中的错误,通常可以归于特定的组件模块。当尝试诊断问题时,在你能够尝试修正错误之前,一定要将它跟踪到最小的代码片段。
- 检查假设:解释器将你的指令执行为文字 -- 不多也不少。当一些代码不匹配程序员所相信的(或所假设的)行为,它们的输出就会是非预期的。了解你的假设,之后专注于验证你的假设是否整理来调试。
- 询问他人:你并不是一个人!如果你不理解某个错误信息,可以询问朋友、导师或者搜索引擎。如果你隔离了一个错误,但是不知道如何改正,可以让其它人来看一看。在小组问题解决中,会分享一大堆有价值的编程知识。
逐步测试、模块化设计、明确假设和团队作业是贯穿这门课的主题。但愿它们也能够一直伴随你的计算机科学生涯。
1.2 编程元素
编程语言是操作计算机来执行任务的手段,它也在我们组织关于过程的想法中,作为一种框架。程序用于在编程社群的成员之间交流这些想法。所以,程序必须为人类阅读而编写,并且仅仅碰巧可以让机器执行。
当我们描述一种语言时,我们应该特别注意这种语言的手段,来将简单的想法组合为更复杂的想法。每个强大的语言都拥有用于完成下列任务的机制:
- 基本的表达式和语句,它们由语言提供,表示最简单的构建代码块。
- 组合的手段,复杂的元素由简单的元素通过它来构建,以及
- 抽象的手段,复杂的元素可以通过它来命名,以及作为整体来操作。
在编程中,我们处理两种元素:函数和数据。(不久之后我们就会探索它们并不是真的非常不同。)不正式地说,数据是我们想要操作的东西,函数描述了操作数据的规则。所以,任何强大的编程语言都应该能描述基本数据和基本函数,并且应该拥有组合和抽象二者的方式。
1.2.1 表达式
在实验 Python 解释器之后,我们现在必须重新开始,按照顺序一步步地探索 Python 语言。如果示例看上去很简单,要有耐心 -- 更刺激的东西还在后面。
我们以基本表达式作为开始。一种基本表达式就是数值。更精确地说,是你键入的,由 10 进制数字表示的数值组成的表达式。
>>> 42
42
表达式表示的数值也许会和算数运算符组合,来形成复合表达式,解释器会求出它:
>>> -1 - -1
0
>>> 1/2 + 1/4 + 1/8 + 1/16 + 1/32 + 1/64 + 1/128
0.9921875
这些算术表达式使用了中缀符号,其中运算符(例如+、-、*、/)出现在操作数(数值)中间。Python包含许多方法来形成复合表达式。我们不会尝试立即将它们列举出来,而是在进行中介绍新的表达式形式,以及它们支持的语言特性。
1.2.2 调用表达式
最重要的复合表达式就是调用表达式,它在一些参数上调用函数。回忆代数中,函数的数学概念是一些输入值到输出值的映射。例如,max函数将它的输入映射到单个输出,输出是输入中的最大值。Python 中的函数不仅仅是输入输出的映射,它表述了计算过程。但是,Python 表示函数的方式和数学中相同。
>>> max(7.5, 9.5)
9.5
调用表达式拥有子表达式:运算符在圆括号之前,圆括号包含逗号分隔的操作数。运算符必须是个函数,操作数可以是任何值。这里它们都是数值。当求解这个调用表达式时,我们说max函数以参数 7.5 和 9.5 调用,并且返回 9.5。
调用表达式中的参数的顺序极其重要。例如,函数pow计算第一个参数的第二个参数次方。
>>> pow(100, 2)
10000
>>> pow(2, 100)
1267650600228229401496703205376
函数符号比中缀符号的数学惯例有很多优点。首先,函数可以接受任何数量的参数:
>>> max(1, -2, 3, -4)
3
不会产生任何歧义,因为函数的名称永远在参数前面。
其次,函数符号可以以直接的方式扩展为嵌套表达式,其中元素本身是复合表达式。在嵌套的调用表达式中,不像嵌套的中缀表达式,嵌套结构在圆括号中非常明显。
>>> max(min(1, -2), min(pow(3, 5), -4))
-2
(理论上)这种嵌套没有任何限制,并且 Python 解释器可以解释任何复杂的表达式。然而,人们可能会被多级嵌套搞晕。你作为程序员的一个重要作用就是构造你自己、你的同伴以及其它在未来可能会阅读你代码的人可以解释的表达式。
最后,数学符号在形式上多种多样:星号表示乘法,上标表示乘方,横杠表示除法,屋顶和侧壁表示开方。这些符号中一些非常难以打出来。但是,所有这些复杂事物可以通过调用表达式的符号来统一。虽然 Python 通过中缀符号(比如+和-)支持常见的数学运算符,任何运算符都可以表示为带有名字的函数。
1.2.3 导入库函数
Python 定义了大量的函数,包括上一节提到的运算符函数,但是通常不能使用它们的名字,这样做是为了避免混乱。反之,它将已知的函数和其它东西组织在模块中,这些模块组成了 Python 库。需要导入它们来使用这些元素。例如,math模块提供了大量的常用数学函数:
>>> from math import sqrt, exp
>>> sqrt(256)
16.0
>>> exp(1)
2.718281828459045
operator模块提供了中缀运算符对应的函数:
>>> from operator import add, sub, mul
>>> add(14, 28)
42
>>> sub(100, mul(7, add(8, 4)))
16
import语句标明了模块名称(例如operator或math),之后列出被导入模块的具名属性(例如sqrt和exp)。
Python 3 库文档列出了定义在每个模块中的函数,例如数学模块。然而,这个文档为了解整个语言的开发者编写。到现在为止,你可能发现使用函数做实验会比阅读文档告诉你更多它的行为。当你更熟悉 Python 语言和词汇时,这个文档就变成了一份有价值的参考来源。
1.2.4 名称和环境
编程语言的要素之一是它提供的手段,用于使用名称来引用计算对象。如果一个值被给予了名称,我们就说这个名称绑定到了值上面。
在 Python 中,我们可以使用赋值语句来建立新的绑定,它包含=左边的名称和右边的值。
>>> radius = 10
>>> radius
10
>>> 2 * radius
20
名称也可以通过import语句绑定:
>>> from math import pi
>>> pi * 71 / 223
1.0002380197528042
我们也可以在一个语句中将多个值赋给多个名称,其中名称和表达式由逗号分隔:
>>> area, circumference = pi * radius * radius, 2 * pi * radius
>>> area
314.1592653589793
>>> circumference
62.83185307179586
=符号在 Python(以及许多其它语言)中叫做赋值运算符。赋值是 Python 中的最简单的抽象手段,因为它使我们可以使用最简单的名称来引用复合操作的结果,例如上面计算的area。这样,复杂的程序可以由复杂性递增的计算对象一步一步构建,
将名称绑定到值上,以及随后通过名称来检索这些值的可能,意味着解释器必须维护某种内存来跟踪这些名称和值的绑定。这些内存叫做环境。
名称也可以绑定到函数。例如,名称max绑定到了我们曾经用过的max函数上。函数不像数值,不易于渲染成文本,所以 Python 使用识别描述来代替,当我们打印函数时:
>>> max
<built-in function max>
我们可以使用赋值运算符来给现有函数起新的名字:
>>> f = max
>>> f
<built-in function max>
>>> f(3, 4)
4
成功的赋值语句可以将名称绑定到新的值:
>>> f = 2
>>> f
2
在 Python 中,通过赋值绑定的名称通常叫做变量名称,因为它们在执行程序期间可以绑定到许多不同的值上面。
1.2.5 嵌套表达式的求解
我们这章的目标之一是隔离程序化思考相关的问题。作为一个例子,考虑嵌套表达式的求解,解释器自己会遵循一个过程:
为了求出调用表达式,Python 会执行下列事情:
- 求出运算符和操作数子表达式,之后
- 在值为操作数子表达式的参数上调用值为运算符子表达式的函数。
这个简单的过程大体上展示了一些过程上的重点。第一步表明为了完成调用表达式的求值过程,我们首先必须求出其它表达式。所以,求值过程本质上是递归的,也就是说,它会调用其自身作为步骤之一。
例如,求出
>>> mul(add(2, mul(4, 6)), add(3, 5))
208
需要应用四次求值过程。如果我们将每个需要求解的表达式抽出来,我们可以可视化这一过程的层次结构:
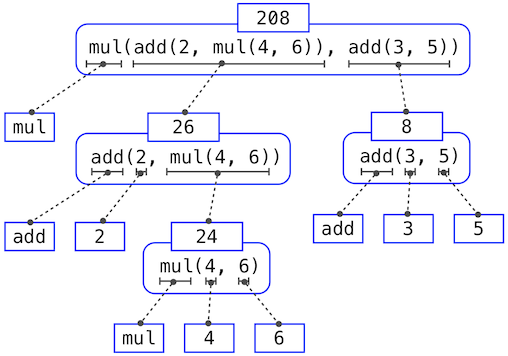
这个示例叫做表达式树。在计算机科学中,树从顶端向下生长。每一点上的对象叫做节点。这里它们是表达式和它们的值。
求出根节点,也就是整个表达式,需要首先求出枝干节点,也就是子表达式。叶子节点(也就是没有子节点的节点)的表达式表示函数或数值。内部节点分为两部分:表示我们想要应用的求值规则的调用表达式,以及表达式的结果。观察这棵树中的求值,我们可以想象操作数的值向上流动,从叶子节点开始,在更高的层上融合。
接下来,观察第一步的重复应用,这会将我们带到需要求值的地方,并不是调用表达式,而是基本表达式,例如数字(比如2),以及名称(比如add),我们需要规定下列事物来谨慎对待基本的东西:
- 数字求值为它标明的数值,
- 名称求值为当前环境中这个名称所关联的值
要注意环境的关键作用是决定表达式中符号的含义。Python 中,在不指定任何环境信息,来提供名称x(以及名称add)的含义的情况下,谈到这样一个表达式的值没有意义:
>>> add(x, 1)
环境提供了求值所发生的上下文,它在我们理解程序执行中起到重要作用。
这个求值过程并不符合所有 Python 代码的求解,仅仅是调用表达式、数字和名称。例如,它并不能处理赋值语句。
>>> x = 3
的执行并不返回任何值,也不求解任何参数上的函数,因为赋值的目的是将一个名称绑定到一个值上。通常,语句不会被求值,而是被执行,它们不产生值,但是会改变一些东西。每种语句或表达式都有自己的求值或执行过程,我们会在涉及时逐步介绍。
注:当我们说“数字求值为数值”的时候,我们的实际意思是 Python 解释器将数字求解为数值。Python 的解释器使编程语言具有了这个意义。假设解释器是一个固定的程序,行为总是一致,我们就可以说数字(以及表达式)自己在 Python 程序的上下文中会求解为值。
1.2.6 函数图解
当我们继续构建求值的形式模型时,我们会发现解释器内部状态的图解有助于我们跟踪求值过程的发展。这些图解的必要部分是函数的表示。
**纯函数:**具有一些输入(参数)以及返回一些输出(调用结果)的函数。内建函数
>>> abs(-2)
2
可以描述为接受输入并产生输出的小型机器。

abs是纯函数。纯函数具有一个特性,调用它们时除了返回一个值之外没有其它效果。
非纯函数:除了返回一个值之外,调用非纯函数会产生副作用,这会改变解释器或计算机的一些状态。一个普遍的副作用就是在返回值之外生成额外的输出,例如使用print函数:
>>> print(-2)
-2
>>> print(1, 2, 3)
1 2 3
虽然这些例子中的print和abs看起来很像,但它们本质上以不同方式工作。print的返回值永远是None,它是一个 Python 特殊值,表示没有任何东西。Python 交互式解释器并不会自动打印None值。这里,print自己打印了输出,作为调用中的副作用。
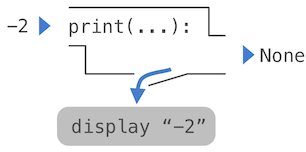
调用print的嵌套表达式会凸显出它的非纯特性:
>>> print(print(1), print(2))
1
2
None None
如果你发现自己不能预料到这个输出,画出表达式树来弄清为什么这个表达式的求值会产生奇怪的输出。
要当心print!它的返回值为None,意味着它不应该在赋值语句中用作表达式:
>>> two = print(2)
2
>>> print(two)
None
签名:不同函数具有不同的允许接受的参数数量。为了跟踪这些必备条件,我们需要以一种展示函数名称和参数名称的方式,画出每个函数。abs函数值接受一个叫作number的参数,向它提供更多或更少的参数会产生错误。print函数可以接受任意数量的参数,所以它渲染为print(...)。函数的可接受参数的描述叫做函数的签名。
1.3 定义新的函数
我们已经在 Python 中认识了一些在任何强大的编程语言中都会出现的元素:
- 数值是内建数据,算数运算是函数。
- 嵌套函数提供了组合操作的手段。
- 名称到值的绑定提供了有限的抽象手段。
现在我们将要了解函数定义,一个更加强大的抽象技巧,名称通过它可以绑定到复合操作上,并可以作为一个单元来引用。
我们通过如何表达“平方”这个概念来开始。我们可能会说,“对一个数求平方就是将这个数乘上它自己”。在 Python 中就是:
>>> def square(x):
return mul(x, x)
这定义了一个新的函数,并赋予了名称square。这个用户定义的函数并不内建于解释器。它表示将一个数乘上自己的复合操作。定义中的x叫做形式参数,它为被乘的东西提供一个名称。这个定义创建了用户定义的函数,并且将它关联到名称square上。
函数定义包含def语句,它标明了<name>(名称)和一列带有名字的<formal parameters>(形式参数)。之后,return(返回)语句叫做函数体,指定了函数的<return expression>(返回表达式),它是函数无论什么时候调用都需要求值的表达式。
def <name>(<formal parameters>):
return <return expression>
第二行必须缩进!按照惯例我们应该缩进四个空格,而不是一个Tab,返回表达式并不是立即求值,它储存为新定义函数的一部分,并且只在函数最终调用时会被求出。(很快我们就会看到缩进区域可以跨越多行。)
定义了square之后,我们使用调用表达式来调用它:
>>> square(21)
441
>>> square(add(2, 5))
49
>>> square(square(3))
81
我们也可以在构建其它函数时,将square用作构建块。列入,我们可以轻易定义sum_squares函数,它接受两个数值作为参数,并返回它们的平方和:
>>> def sum_squares(x, y):
return add(square(x), square(y))
>>> sum_squares(3, 4)
25
用户定义的函数和内建函数以同种方法使用。确实,我们不可能在sum_squares的定义中分辨出square是否构建于解释器中,从模块导入还是由用户定义。
1.3.1 环境
我们的 Python 子集已经足够复杂了,但程序的含义还不是非常明显。如果形式参数和内建函数具有相同名称会如何呢?两个函数是否能共享名称而不会产生混乱呢?为了解决这些疑问,我们必须详细描述环境。
表达式求值所在的环境由帧的序列组成,它们可以表述为一些盒子。每一帧都包含了一些绑定,它们将名称和对应的值关联起来。全局帧只有一个,它包含所有内建函数的名称绑定(只展示了abs和max)。我们使用地球符号来表示全局。
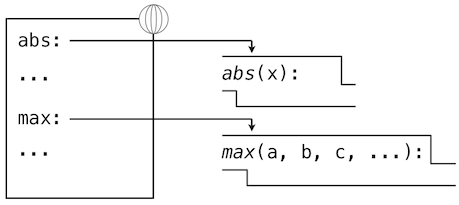
赋值和导入语句会向当前环境的第一个帧添加条目。到目前为止,我们的环境只包含全局帧。
>>> from math import pi
>>> tau = 2 * pi
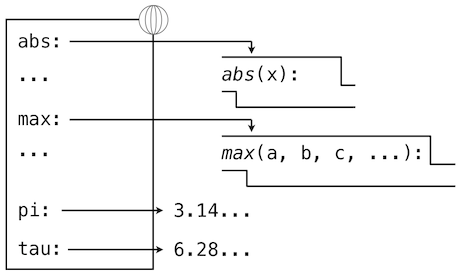
def语句也将绑定绑定到由定义创建的函数上。定义square之后的环境如图所示:
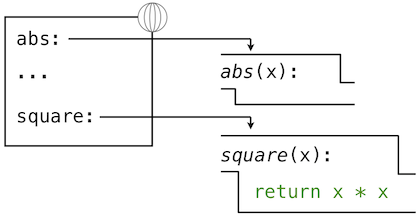
这些环境图示展示了当前环境中的绑定,以及它们所绑定的值(并不是任何帧的一部分)。要注意函数名称是重复的,一个在帧中,另一个是函数的一部分。这一重复是有意的,许多不同的名字可能会引用相同函数,但是函数本身只有一个内在名称。但是,在环境中由名称检索值只检查名称绑定。函数的内在名称不在名称检索中起作用。在我们之前看到的例子中:
>>> f = max
>>> f
<built-in function max>
名称max是函数的内在名称,以及打印f时我们看到的名称。此外,名称max和f在全局环境中都绑定到了相同函数上。
在我们介绍 Python 的附加特性时,我们需要扩展这些图示。每次我们这样做的时候,我们都会列出图示可以表达的新特性。
新的环境特性:赋值和用户定义的函数定义。
1.3.2 调用用户定义的函数
为了求出运算符为用户定义函数的调用表达式,Python 解释器遵循与求出运算符为内建函数的表达式相似的过程。也就是说,解释器求出操作数表达式,并且对产生的实参调用具名函数。
调用用户定义的函数的行为引入了第二个局部帧,它只能由函数来访问。为了对一些实参调用用户定义的函数:
- 在新的局部帧中,将实参绑定到函数的形式参数上。
- 在当前帧的开头以及全局帧的末尾求出函数体。
函数体求值所在的环境由两个帧组成:第一个是局部帧,包含参数绑定,之后是全局帧,包含其它所有东西。每个函数示例都有自己的独立局部帧。
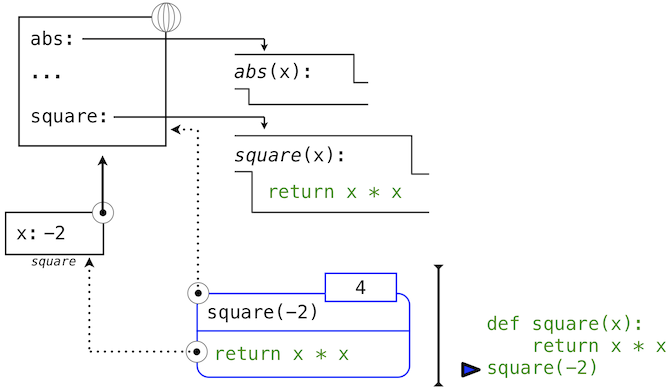
这张图包含两个不同的 Python 解释器层面:当前的环境,以及表达式树的一部分,它和要求值的代码的当前一行相关。我们描述了调用表达式的求值,用户定义的函数(蓝色)表示为两部分的圆角矩形。点线箭头表示哪个环境用于在每个部分求解表达式。
- 上半部分展示了调用表达式的求值。这个调用表达式并不在任何函数里面,所以他在全局环境中求值。所以,任何里面的名称(例如
square)都会在全局帧中检索。 - 下半部分展示了
square函数的函数体。它的返回表达式在上面的步骤1引入的新环境中求值,它将square的形式参数x的名称绑定到实参的值-2上。
环境中帧的顺序会影响由表达式中的名称检索返回的值。我们之前说名称求解为当前环境中与这个名称关联的值。我们现在可以更精确一些:
- 名称求解为当前环境中,最先发现该名称的帧中,绑定到这个名称的值。
我们关于环境、名称和函数的概念框架建立了求值模型,虽然一些机制的细节仍旧没有指明(例如绑定如何实现),我们的模型在描述解释器如何求解调用表示上,变得更准确和正确。在第三章我们会看到这一模型如何用作一个蓝图来实现编程语言的可工作的解释器。
新的环境特性:函数调用。
1.3.3 示例:调用用户定义的函数
让我们再一次考虑两个简单的定义:
>>> from operator import add, mul
>>> def square(x):
return mul(x, x)
>>> def sum_squares(x, y):
return add(square(x), square(y))
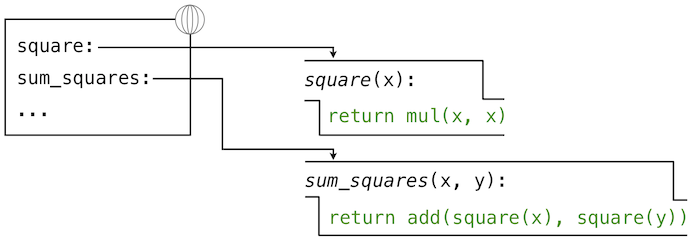
以及求解下列调用表达式的过程:
>>> sum_squares(5, 12)
169
Python 首先会求出名称sum_squares,它在全局帧绑定了用户定义的函数。基本的数字表达式 5 和 12 求值为它们所表达的数值。
之后,Python 调用了sum_squares,它引入了局部帧,将x绑定为 5,将y绑定为 12。
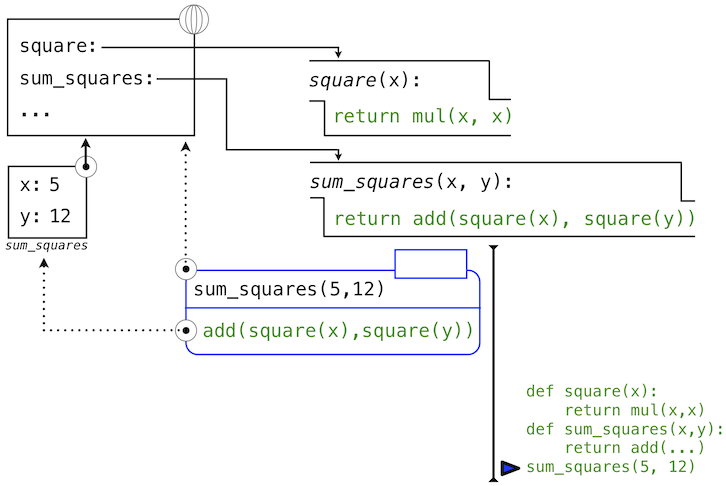
这张图中,局部帧指向它的后继,全局帧。所有局部帧必须指向某个先导,这些链接定义了当前环境中的帧序列。
sum_square的函数体包含下列调用表达式:
add ( square(x) , square(y) )
________ _________ _________
"operator" "operand 0" "operand 1"
全部三个子表达式在当前环境中求值,它开始于标记为sum_squares的帧。运算符字表达式add是全局帧中发现的名称,绑定到了内建的加法函数上。两个操作数子表达式必须在加法函数调用之前依次求值。两个操作数都在当前环境中求值,开始于标记为sum_squares的帧。在下面的环境图示中,我们把这一帧叫做A,并且将指向这一帧的箭头同时替换为标签A。
在使用这个局部帧的情况下,函数体表达式mul(x, x)求值为 25。
我们的求值过程现在轮到了操作数 1,y的值为 12。Python 再次求出square的函数体。这次引入了另一个局部环境帧,将x绑定为 12。所以,操作数 1 求值为 144。
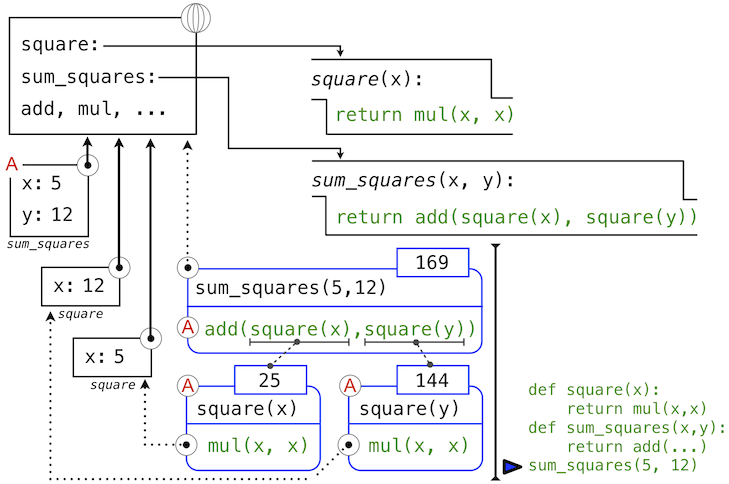
最后,对实参 25 和 144 调用加法会产生sum_squares函数体的最终值:169。
这张图虽然复杂,但是用于展示我们目前为止发展出的许多基础概念。名称绑定到值上面,它延伸到许多局部帧中,局部帧在唯一的全局帧之上,全局帧包含共享名称。表达式为树形结构,以及每次子表达式包含用户定义函数的调用时,环境必须被扩展。
所有这些机制的存在确保了名称在表达式中正确的地方解析为正确的值。这个例子展示了为什么我们的模型需要所引入的复杂性。所有三个局部帧都包含名称x的绑定。但是这个名称在不同的帧中绑定到了不同的值上。局部帧分离了这些名称。
1.3.4 局部名称
函数实现的细节之一是实现者对形式参数名称的选择不应影响函数行为。所以,下面的函数应具有相同的行为:
>>> def square(x):
return mul(x, x)
>>> def square(y):
return mul(y, y)
这个原则 -- 也就是函数应不依赖于编写者选择的参数名称 -- 对编程语言来说具有重要的结果。最简单的结果就是函数参数名称应保留在函数体的局部范围中。
如果参数不位于相应函数的局部范围中,square的参数x可能和sum_squares中的参数x产生混乱。严格来说,这并不是问题所在:不同局部帧中的x的绑定是不相关的。我们的计算模型具有严谨的设计来确保这种独立性。
我们说局部名称的作用域被限制在定义它的用户定义函数的函数体中。当一个名称不能再被访问时,它就离开了作用域。作用域的行为并不是我们模型的新事实,它是环境的工作方式的结果。
1.3.5 实践指南:选择名称
可修改的名称并不代表形式参数的名称完全不重要。反之,选择良好的函数和参数名称对于函数定义的人类可解释性是必要的。
下面的准则派生于 Python 的代码风格指南,可被所有(非反叛)Python 程序员作为指南。一些共享的约定会使社区成员之间的沟通变得容易。遵循这些约定有一些副作用,我会发现你的代码在内部变得一致。
- 函数名称应该小写,以下划线分隔。提倡描述性的名称。
- 函数名称通常反映解释器向参数应用的操作(例如
print、add、square),或者结果(例如max、abs、sum)。 - 参数名称应小写,以下划线分隔。提倡单个词的名称。
- 参数名称应该反映参数在函数中的作用,并不仅仅是满足的值的类型。
- 当作用非常明确时,单个字母的参数名称可以接受,但是永远不要使用
l(小写的L)和O(大写的o),或者I(大写的i)来避免和数字混淆。
周期性对你编写的程序复查这些准则,不用多久你的名称会变得十分 Python 化。
1.3.6 作为抽象的函数
虽然sum_squares十分简单,但是它演示了用户定义函数的最强大的特性。sum_squares函数使用square函数定义,但是仅仅依赖于square定义在输入参数和输出值之间的关系。
我们可以编写sum_squares,而不用考虑如何计算一个数值的平方。平方计算的细节被隐藏了,并可以在之后考虑。确实,在sum_squares看来,square并不是一个特定的函数体,而是某个函数的抽象,也就是所谓的函数式抽象。在这个层级的抽象中,任何能计算平方的函数都是等价的。
所以,仅仅考虑返回值的情况下,下面两个计算平方的函数是难以区分的。每个都接受数值参数并且产生那个数的平方作为返回值。
>>> def square(x):
return mul(x, x)
>>> def square(x):
return mul(x, x-1) + x
换句话说,函数定义应该能够隐藏细节。函数的用户可能不能自己编写函数,但是可以从其它程序员那里获得它作为“黑盒”。用户不应该需要知道如何实现来调用。Python 库拥有这个特性。许多开发者使用在这里定义的函数,但是很少有人看过它们的实现。实际上,许多 Python 库的实现并不完全用 Python 编写,而是 C 语言。
1.3.7 运算符
算术运算符(例如+和-)在我们的第一个例子中提供了组合手段。但是我们还需要为包含这些运算符的表达式定义求值过程。
每个带有中缀运算符的 Python 表达式都有自己的求值过程,但是你通常可以认为他们是调用表达式的快捷方式。当你看到
>>> 2 + 3
5
的时候,可以简单认为它是
>>> add(2, 3)
5
的快捷方式。
中缀记号可以嵌套,就像调用表达式那样。Python 运算符优先级中采用了常规的数学规则,它指导了如何解释带有多种运算符的复合表达式。
>>> 2 + 3 * 4 + 5
19
和下面的表达式的求值结果相同
>>> add(add(2, mul(3, 4)) , 5)
19
调用表达式的嵌套比运算符版本更加明显。Python 也允许括号括起来的子表达式,来覆盖通常的优先级规则,或者使表达式的嵌套结构更加明显:
>>> (2 + 3) * (4 + 5)
45
和下面的表达式的求值结果相同
>>> mul(add(2, 3), add(4, 5))
45
你应该在你的程序中自由使用这些运算符和括号。对于简单的算术运算,Python 在惯例上倾向于运算符而不是调用表达式。
1.4 实践指南:函数的艺术
函数是所有程序的要素,无论规模大小,并且在编程语言中作为我们表达计算过程的主要媒介。目前为止,我们讨论了函数的形式特性,以及它们如何使用。我们现在跳转到如何编写良好的函数这一话题。
- 每个函数都应该只做一个任务。这个任务可以使用短小的名称来定义,使用一行文本来标识。顺序执行多个任务的函数应该拆分在多个函数中。
- 不要重复劳动(DRY)是软件工程的中心法则。所谓的DRY原则规定多个代码段不应该描述重复的逻辑。反之,逻辑应该只实现一次,指定一个名称,并且多次使用。如果你发现自己在复制粘贴一段代码,你可能发现了一个使用函数抽象的机会。
- 函数应该定义得通常一些,准确来说,平方并不是在 Python 库中,因为它是
pow函数的一个特例,这个函数计算任何数的任何次方。
这些准则提升代码的可读性,减少错误数量,并且通常使编写的代码总数最小。将复杂的任务拆分为简洁的函数是一个技巧,它需要一些经验来掌握。幸运的是,Python 提供了一些特性来支持你的努力。
1.4.1 文档字符串
函数定义通常包含描述这个函数的文档,叫做文档字符串,它必须在函数体中缩进。文档字符串通常使用三个引号。第一行描述函数的任务。随后的一些行描述参数,并且澄清函数的行为:
>>> def pressure(v, t, n):
"""Compute the pressure in pascals of an ideal gas.
Applies the ideal gas law: http://en.wikipedia.org/wiki/Ideal_gas_law
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas
"""
k = 1.38e-23 # Boltzmann's constant
return n * k * t / v
当你以函数名称作为参数来调用help时,你会看到它的文档字符串(按下q来退出 Python 帮助)。
>>> help(pressure)
编写 Python 程序时,除了最简单的函数之外,都要包含文档字符串。要记住,代码只编写一次,但是会阅读多次。Python 文档包含了文档字符串准则,它在不同的 Python 项目中保持一致。
1.4.2 参数默认值
定义普通函数的结果之一就是额外参数的引入。具有许多参数的函数调用起来非常麻烦,也难以阅读。
在 Python 中,我们可以为函数的参数提供默认值。调用这个函数时,带有默认值的参数是可选的。如果它们没有提供,默认值就会绑定到形式参数的名称上。例如,如果某个应用通常用来计算一摩尔粒子的压强,这个值就可以设为默认:
>>> k_b=1.38e-23 # Boltzmann's constant
>>> def pressure(v, t, n=6.022e23):
"""Compute the pressure in pascals of an ideal gas.
v -- volume of gas, in cubic meters
t -- absolute temperature in degrees kelvin
n -- particles of gas (default: one mole)
"""
return n * k_b * t / v
>>> pressure(1, 273.15)
2269.974834
这里,pressure的定义接受三个参数,但是在调用表达式中只提供了两个。这种情况下,n的值通过def语句的默认值获得(它看起来像对n的赋值,虽然就像这个讨论暗示的那样,更大程度上它是条件赋值)。
作为准则,用于函数体的大多数数据值应该表示为具名参数的默认值,这样便于查看,以及被函数调用者修改。一些值永远不会改变,就像基本常数k_b,应该定义在全局帧中。
1.5 控制
我们现在可以定义的函数能力有限,因为我们还不知道一种方法来进行测试,并且根据测试结果来执行不同的操作。控制语句可以让我们完成这件事。它们不像严格的求值子表达式那样从左向右编写,并且可以从它们控制解释器下一步做什么当中得到它们的名称。这可能基于表达式的值。
1.5.1 语句
目前为止,我们已经初步思考了如何求出表达式。然而,我们已经看到了三种语句:赋值、def和return语句。这些 Python 代码并不是表达式,虽然它们中的一部分是表达式。
要强调的是,语句的值是不相干的(或不存在的),我们使用执行而不是求值来描述语句。
每个语句都描述了对解释器状态的一些改变,执行语句会应用这些改变。像我们之前看到的return和赋值语句那样,语句的执行涉及到求解所包含的子表达式。
表达式也可以作为语句执行,其中它们会被求值,但是它们的值会舍弃。执行纯函数没有什么副作用,但是执行非纯函数会产生效果作为函数调用的结果。
考虑下面这个例子:
>>> def square(x):
mul(x, x) # Watch out! This call doesn't return a value.
这是有效的 Python 代码,但是并不是想表达的意思。函数体由表达式组成。表达式本身是个有效的语句,但是语句的效果是,mul函数被调用了,然后结果被舍弃了。如果你希望对表达式的结果做一些事情,你需要这样做:使用赋值语句来储存它,或者使用return语句将它返回:
>>> def square(x):
return mul(x, x)
有时编写一个函数体是表达式的函数是有意义的,例如调用类似print的非纯函数:
>>> def print_square(x):
print(square(x))
在最高层级上,Python 解释器的工作就是执行由语句组成的程序。但是,许多有意思的计算工作来源于求解表达式。语句管理程序中不同表达式之间的关系,以及它们的结果会怎么样。
1.5.2 复合语句
通常,Python 的代码是语句的序列。一条简单的语句是一行不以分号结束的代码。复合语句之所以这么命名,因为它是其它(简单或复合)语句的复合。复合语句一般占据多行,并且以一行以冒号结尾的头部开始,它标识了语句的类型。同时,一个头部和一组缩进的代码叫做子句(或从句)。复合语句由一个或多个子句组成。
<header>:
<statement>
<statement>
...
<separating header>:
<statement>
<statement>
...
...
我们可以这样理解我们已经见到的语句:
- 表达式、返回语句和赋值语句都是简单语句。
def语句是复合语句。def头部之后的组定义了函数体。
为每种头部特化的求值规则指导了组内的语句什么时候以及是否会被执行。我们说头部控制语句组。例如,在def语句的例子中,我们看到返回表达式并不会立即求值,而是储存起来用于以后的使用,当所定义的函数最终调用时就会求值。
我们现在也能理解多行的程序了。
- 执行语句序列需要执行第一条语句。如果这个语句不是重定向控制,之后执行语句序列的剩余部分,如果存在的话。
这个定义揭示出递归定义“序列”的基本结构:一个序列可以划分为它的第一个元素和其余元素。语句序列的“剩余”部分也是一个语句序列。所以我们可以递归应用这个执行规则。这个序列作为递归数据结构的看法会在随后的章节中再次出现。
这一规则的重要结果就是语句顺序执行,但是随后的语句可能永远不会执行到,因为有重定向控制。
实践指南:在缩进代码组时,所有行必须以相同数量以及相同方式缩进(空格而不是Tab)。任何缩进的变动都会导致错误。
1.5.3 定义函数 II:局部赋值
一开始我们说,用户定义函数的函数体只由带有一个返回表达式的一个返回语句组成。实际上,函数可以定义为操作的序列,不仅仅是一条表达式。Python 复合语句的结构自然让我们将函数体的概念扩展为多个语句。
无论用户定义的函数何时被调用,定义中的子句序列在局部环境内执行。return语句会重定向控制:无论什么时候执行return语句,函数调用的流程都会中止,返回表达式的值会作为被调用函数的返回值。
于是,赋值语句现在可以出现在函数体中。例如,这个函数以第一个数的百分数形式,返回两个数量的绝对值,并使用了两步运算:
>>> def percent_difference(x, y):
difference = abs(x-y)
return 100 * difference / x
>>> percent_difference(40, 50)
25.0
赋值语句的效果是在当前环境的第一个帧上,将名字绑定到值上。于是,函数体内的赋值语句不会影响全局帧。函数只能操作局部作用域的现象是创建模块化程序的关键,其中纯函数只通过它们接受和返回的值与外界交互。
当然,percent_difference函数也可以写成一个表达式,就像下面这样,但是返回表达式会更加复杂:
>>> def percent_difference(x, y):
return 100 * abs(x-y) / x
目前为止,局部赋值并不会增加函数定义的表现力。当它和控制语句组合时,才会这样。此外,局部赋值也可以将名称赋为间接量,在理清复杂表达式的含义时起到关键作用。
新的环境特性:局部赋值。
1.5.4 条件语句
Python 拥有内建的绝对值函数:
>>> abs(-2)
2
我们希望自己能够实现这个函数,但是我们当前不能直接定义函数来执行测试并做出选择。我们希望表达出,如果x是正的,abs(x)返回x,如果x是 0,abx(x)返回 0,否则abs(x)返回-x。Python 中,我们可以使用条件语句来表达这种选择。
>>> def absolute_value(x):
"""Compute abs(x)."""
if x > 0:
return x
elif x == 0:
return 0
else:
return -x
>>> absolute_value(-2) == abs(-2)
True
absolute_value的实现展示了一些重要的事情:
条件语句:Python 中的条件语句包含一系列的头部和语句组:一个必要的if子句,可选的elif子句序列,和最后可选的else子句:
if <expression>:
<suite>
elif <expression>:
<suite>
else:
<suite>
当执行条件语句时,每个子句都按顺序处理:
- 求出头部中的表达式。
- 如果它为真,执行语句组。之后,跳过条件语句中随后的所有子句。
如果能到达else子句(仅当所有if和elif表达式值为假时),它的语句组才会被执行。
布尔上下文:上面过程的执行提到了“假值”和“真值”。条件块头部语句中的表达式也叫作布尔上下文:它们值的真假对控制流很重要,但在另一方面,它们的值永远不会被赋值或返回。Python 包含了多种假值,包括 0、None和布尔值False。所有其他数值都是真值。在第二章中,我们就会看到每个 Python 中的原始数据类型都是真值或假值。
布尔值:Python 有两种布尔值,叫做True和False。布尔值表示了逻辑表达式中的真值。内建的比较运算符,>、<、>=、<=、==、!=,返回这些值。
>>> 4 < 2
False
>>> 5 >= 5
True
第二个例子读作“5 大于等于 5”,对应operator模块中的函数ge。
>>> 0 == -0
True
最后的例子读作“0 等于 -0”,对应operator模块的eq函数。要注意 Python 区分赋值(=)和相等测试(==)。许多语言中都有这个惯例。
布尔运算符:Python 也内建了三个基本的逻辑运算符:
>>> True and False
False
>>> True or False
True
>>> not False
True
逻辑表达式拥有对应的求值过程。这些过程揭示了逻辑表达式的真值有时可以不执行全部子表达式而确定,这个特性叫做短路。
为了求出表达式<left> and <right>:
- 求出子表达式
<left>。 - 如果结果
v是假值,那么表达式求值为v。 - 否则表达式的值为子表达式
<right>。
为了求出表达式<left> or <right>:
- 求出子表达式
<left>。 - 如果结果
v是真值,那么表达式求值为v。 - 否则表达式的值为子表达式
<right>。
为了求出表达式not <exp>:
- 求出
<exp>,如果值是True那么返回值是假值,如果为False则反之。
这些值、规则和运算符向我们提供了一种组合测试结果的方式。执行测试以及返回布尔值的函数通常以is开头,并不带下划线(例如isfinite、isdigit、isinstance等等)。
1.5.5 迭代
除了选择要执行的语句,控制语句还用于表达重复操作。如果我们编写的每一行代码都只执行一次,程序会变得非常没有生产力。只有通过语句的重复执行,我们才可以释放计算机的潜力,使我们更加强大。我们已经看到了重复的一种形式:一个函数可以多次调用,虽然它只定义一次。迭代控制结构是另一种将相同语句执行多次的机制。
考虑斐波那契数列,其中每个数值都是前两个的和:
0, 1, 1, 2, 3, 5, 8, 13, 21, ...
每个值都通过重复使用“前两个值的和”的规则构造。为了构造第 n 个值,我们需要跟踪我们创建了多少个值(k),以及第 k 个值(curr)和它的上一个值(pred),像这样:
>>> def fib(n):
"""Compute the nth Fibonacci number, for n >= 2."""
pred, curr = 0, 1 # Fibonacci numbers
k = 2 # Position of curr in the sequence
while k < n:
pred, curr = curr, pred + curr # Re-bind pred and curr
k = k + 1 # Re-bind k
return curr
>>> fib(8)
13
要记住逗号在赋值语句中分隔了多个名称和值。这一行:
pred, curr = curr, pred + curr
具有将curr的值重新绑定到名称pred上,以及将pred + curr的值重新绑定到curr上的效果。所有=右边的表达式会在绑定发生之前求出来。
while子句包含一个头部表达式,之后是语句组:
while <expression>:
<suite>
为了执行while子句:
- 求出头部表达式。
- 如果它为真,执行语句组,之后返回到步骤 1。
在步骤 2 中,整个while子句的语句组在头部表达式再次求值之前被执行。
为了防止while子句的语句组无限执行,它应该总是在每次通过时修改环境的状态。
不终止的while语句叫做无限循环。按下<Control>-C可以强制让 Python 停止循环。
1.5.6 实践指南:测试
函数的测试是验证函数的行为是否符合预期的操作。我们的函数现在已经足够复杂了,我们需要开始测试我们的实现。
测试是系统化执行这个验证的机制。测试通常写为另一个函数,这个函数包含一个或多个被测函数的样例调用。返回值之后会和预期结果进行比对。不像大多数通用的函数,测试涉及到挑选特殊的参数值,并使用它来验证调用。测试也可作为文档:它们展示了如何调用函数,以及什么参数值是合理的。
要注意我们也将“测试”这个词用于if或while语句的头部中作为一种技术术语。当我们将“测试”这个词用作表达式,或者用作一种验证机制时,它应该在语境中十分明显。
断言:程序员使用assert语句来验证预期,例如测试函数的输出。assert语句在布尔上下文中只有一个表达式,后面是带引号的一行文本(单引号或双引号都可以,但是要一致)如果表达式求值为假,它就会显示。
>>> assert fib(8) == 13, 'The 8th Fibonacci number should be 13'
当被断言的表达式求值为真时,断言语句的执行没有任何效果。当它是假时,asset会造成执行中断。
为fib编写的test函数测试了几个参数,包含n的极限值:
>>> def fib_test():
assert fib(2) == 1, 'The 2nd Fibonacci number should be 1'
assert fib(3) == 1, 'The 3nd Fibonacci number should be 1'
assert fib(50) == 7778742049, 'Error at the 50th Fibonacci number'
在文件中而不是直接在解释器中编写 Python 时,测试可以写在同一个文件,或者后缀为_test.py的相邻文件中。
Doctest:Python 提供了一个便利的方法,将简单的测试直接写到函数的文档字符串内。文档字符串的第一行应该包含单行的函数描述,后面是一个空行。参数和行为的详细描述可以跟随在后面。此外,文档字符串可以包含调用该函数的简单交互式会话:
>>> def sum_naturals(n):
"""Return the sum of the first n natural numbers
>>> sum_naturals(10)
55
>>> sum_naturals(100)
5050
"""
total, k = 0, 1
while k <= n:
total, k = total + k, k + 1
return total
之后,可以使用 doctest 模块来验证交互。下面的globals函数返回全局变量的表示,解释器需要它来求解表达式。
>>> from doctest import run_docstring_examples
>>> run_docstring_examples(sum_naturals, globals())
在文件中编写 Python 时,可以通过以下面的命令行选项启动 Python 来运行一个文档中的所有 doctest。
python3 -m doctest <python_source_file>
高效测试的关键是在实现新的函数之后(甚至是之前)立即编写(以及执行)测试。只调用一个函数的测试叫做单元测试。详尽的单元测试是良好程序设计的标志。
1.6 高阶函数
我们已经看到,函数实际上是描述复合操作的抽象,这些操作不依赖于它们的参数值。在square中,
>>> def square(x):
return x * x
我们不会谈论特定数值的平方,而是一个获得任何数值平方的方法。当然,我们可以不定义这个函数来使用它,通过始终编写这样的表达式:
>>> 3 * 3
9
>>> 5 * 5
25
并且永远不会显式提及square。这种实践适合类似square的简单操作。但是对于更加复杂的操作会变得困难。通常,缺少函数定义会对我们非常不利,它会强迫我们始终工作在特定操作的层级上,这在语言中非常原始(这个例子中是乘法),而不是高级操作。我们应该从强大的编程语言索取的东西之一,是通过将名称赋为常用模式来构建抽象的能力,以及之后直接使用抽象的能力。函数提供了这种能力。
我们将会在下个例子中看到,代码中会反复出现一些常见的编程模式,但是使用一些不同函数来实现。这些模式也可以被抽象和给予名称。
为了将特定的通用模式表达为具名概念,我们需要构造可以接受其他函数作为参数的函数,或者将函数作为返回值的函数。操作函数的函数叫做高阶函数。这一节展示了高阶函数可用作强大的抽象机制,极大提升语言的表现力。
1.6.1 作为参数的函数
考虑下面三个函数,它们都计算总和。第一个,sum_naturals,计算截至n的自然数的和:
>>> def sum_naturals(n):
total, k = 0, 1
while k <= n:
total, k = total + k, k + 1
return total
>>> sum_naturals(100)
5050
第二个,sum_cubes,计算截至n的自然数的立方和:
>>> def sum_cubes(n):
total, k = 0, 1
while k <= n:
total, k = total + pow(k, 3), k + 1
return total
>>> sum_cubes(100)
25502500
第三个,计算这个级数中式子的和:
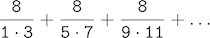
它会慢慢收敛于pi。
>>> def pi_sum(n):
total, k = 0, 1
while k <= n:
total, k = total + 8 / (k * (k + 2)), k + 4
return total
>>> pi_sum(100)
3.121594652591009
这三个函数在背后都具有相同模式。它们大部分相同,只是名字、用于计算被加项的k的函数,以及提供k的下一个值的函数不同。我们可以通过向相同的模板中填充槽位来生成每个函数:
def <name>(n):
total, k = 0, 1
while k <= n:
total, k = total + <term>(k), <next>(k)
return total
这个通用模板的出现是一个强有力的证据,证明有一个实用抽象正在等着我们表现出来。这些函数的每一个都是式子的求和。作为程序的设计者,我们希望我们的语言足够强大,便于我们编写函数来自我表达求和的概念,而不仅仅是计算特定和的函数。我们可以在 Python 中使用上面展示的通用模板,并且把槽位变成形式参数来轻易完成它。
>>> def summation(n, term, next):
total, k = 0, 1
while k <= n:
total, k = total + term(k), next(k)
return total
要注意summation接受上界n,以及函数term和next作为参数。我们可以像任何函数那样使用summation,它简洁地表达了求和。
>>> def cube(k):
return pow(k, 3)
>>> def successor(k):
return k + 1
>>> def sum_cubes(n):
return summation(n, cube, successor)
>>> sum_cubes(3)
36
使用identity 函数来返回参数自己,我们就可以对整数求和:
>>> def identity(k):
return k
>>> def sum_naturals(n):
return summation(n, identity, successor)
>>> sum_naturals(10)
55
我们也可以逐步定义pi_sum,使用我们的summation抽象来组合组件。
>>> def pi_term(k):
denominator = k * (k + 2)
return 8 / denominator
>>> def pi_next(k):
return k + 4
>>> def pi_sum(n):
return summation(n, pi_term, pi_next)
>>> pi_sum(1e6)
3.1415906535898936
1.6.2 作为一般方法的函数
我们引入的用户定义函数作为一种数值运算的抽象模式,便于使它们独立于涉及到的特定数值。使用高阶函数,我们开始寻找更强大的抽象类型:一些函数表达了计算的一般方法,独立于它们调用的特定函数。
尽管函数的意义在概念上扩展了,我们对于如何求解调用表达式的环境模型也优雅地延伸到了高阶函数,没有任何改变。当一个用户定义函数以一些实参调用时,形式参数会在最新的局部帧中绑定实参的值(它们可能是函数)。
考虑下面的例子,它实现了迭代改进的一般方法,并且可以用于计算黄金比例。迭代改进算法以一个方程的解的guess(推测值)开始。它重复调用update函数来改进这个推测值,并且调用test来检查是否当前的guess“足够接近”所认为的正确值。
>>> def iter_improve(update, test, guess=1):
while not test(guess):
guess = update(guess)
return guess
test函数通常检查两个函数f和g在guess值上是否彼此接近。测试f(x)是否接近于g(x)也是计算的一般方法。
>>> def near(x, f, g):
return approx_eq(f(x), g(x))
程序中测试相似性的一个常见方式是将数值差的绝对值与一个微小的公差值相比:
>>> def approx_eq(x, y, tolerance=1e-5):
return abs(x - y) < tolerance
黄金比例,通常叫做phi,是经常出现在自然、艺术、和建筑中的数值。它可以通过iter_improve使用golden_update来计算,并且在它的后继等于它的平方时收敛。
>>> def golden_update(guess):
return 1/guess + 1
>>> def golden_test(guess):
return near(guess, square, successor)
这里,我们已经向全局帧添加了多个绑定。函数值的描述为了简短而有所删节:
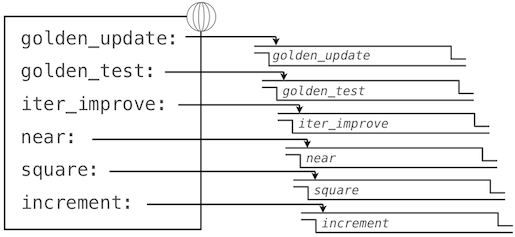
使用golden_update和golden_test参数来调用iter_improve会计算出黄金比例的近似值。
>>> iter_improve(golden_update, golden_test)
1.6180371352785146
通过跟踪我们的求值过程的步骤,我们就可以观察结果如何计算。首先,iter_improve的局部帧以update、test和guess构建。在iter_improve的函数体中,名称test绑定到golden_test上,它在初始值guess上调用。之后,golden_test调用near,创建第三个局部帧,它将形式参数f和g绑定到square和successor上。
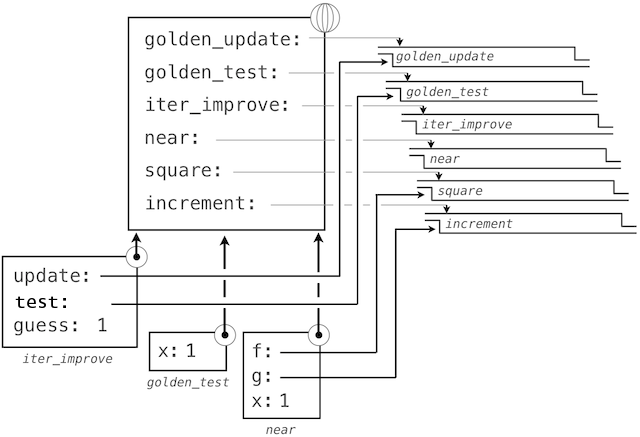
完成near的求值之后,我们看到golden_test为False,因为 1 并不非常接近于 2。所以,while子句代码组内的求值过程,以及这个机制的过程会重复多次。
这个扩展后的例子展示了计算机科学中两个相关的重要概念。首先,命名和函数允许我们抽象而远离大量的复杂性。当每个函数定义不重要时,由求值过程触发的计算过程是相当复杂的,并且我们甚至不能展示所有东西。其次,基于事实,我们拥有了非常通用的求值过程,小的组件组合在复杂的过程中。理解这个过程便于我们验证和检查我们创建的程序。
像通常一样,我们的新的一般方法iter_improve需要测试来检查正确性。黄金比例可以提供这样一个测试,因为它也有一个闭式解,我们可以将它与迭代结果进行比较。
>>> phi = 1/2 + pow(5, 1/2)/2
>>> def near_test():
assert near(phi, square, successor), 'phi * phi is not near phi + 1'
>>> def iter_improve_test():
approx_phi = iter_improve(golden_update, golden_test)
assert approx_eq(phi, approx_phi), 'phi differs from its approximation'
新的环境特性:高阶函数。
附加部分:我们在测试的证明中遗漏了一步。求出公差值e的范围,使得如果tolerance为e的near(x, square, successor)值为真,那么使用相同公差值的approx_eq(phi, x)值为真。
1.6.3 定义函数 III:嵌套定义
上面的例子演示了将函数作为参数传递的能力如何提高了编程语言的表现力。每个通用的概念或方程都能映射为自己的小型函数,这一方式的一个负面效果是全局帧会被小型函数弄乱。另一个问题是我们限制于特定函数的签名:iter_improve 的update参数必须只接受一个参数。Python 中,嵌套函数的定义解决了这些问题,但是需要我们重新修改我们的模型。
让我们考虑一个新问题:计算一个数的平方根。重复调用下面的更新操作会收敛于x的平方根:
>>> def average(x, y):
return (x + y)/2
>>> def sqrt_update(guess, x):
return average(guess, x/guess)
这个带有两个参数的更新函数和iter_improve不兼容,并且它只提供了一个介值。我们实际上只关心最后的平方根。这些问题的解决方案是把函数放到其他定义的函数体中。
>>> def square_root(x):
def update(guess):
return average(guess, x/guess)
def test(guess):
return approx_eq(square(guess), x)
return iter_improve(update, test)
就像局部赋值,局部的def语句仅仅影响当前的局部帧。这些函数仅仅当square_root求值时在作用域内。和求值过程一致,局部的def语句在square_root调用之前并不会求值。
词法作用域:局部定义的函数也可以访问它们定义所在作用域的名称绑定。这个例子中,update引用了名称x,它是外层函数square_root的一个形参。这种在嵌套函数中共享名称的规则叫做词法作用域。严格来说,内部函数能够访问定义所在环境(而不是调用所在位置)的名称。
我们需要两个对我们环境的扩展来兼容词法作用域。
- 每个用户定义的函数都有一个关联环境:它的定义所在的环境。
- 当一个用户定义的函数调用时,它的局部帧扩展于函数所关联的环境。
回到square_root,所有函数都在全局环境中定义,所以它们都关联到全局环境,当我们求解square_root的前两个子句时,我们创建了关联到局部环境的函数。在
>>> square_root(256)
16.00000000000039
的调用中,环境首先添加了square_root的局部帧,并且求出def语句update和test(只展示了update):
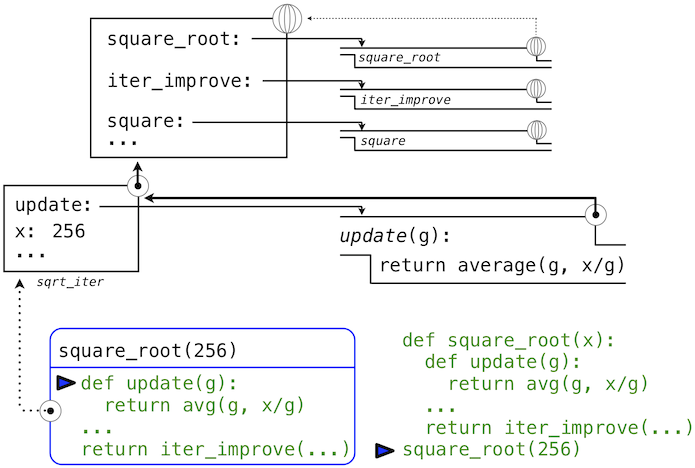
随后,update的名称解析到这个新定义的函数上,它是向iter_improve传入的参数。在iter_improve的函数体中,我们必须以初始值 1 调用update函数。最后的这个调用以一开始只含有g的局部帧创建了update的环境,但是之前的square_root帧上仍旧含有x的绑定。
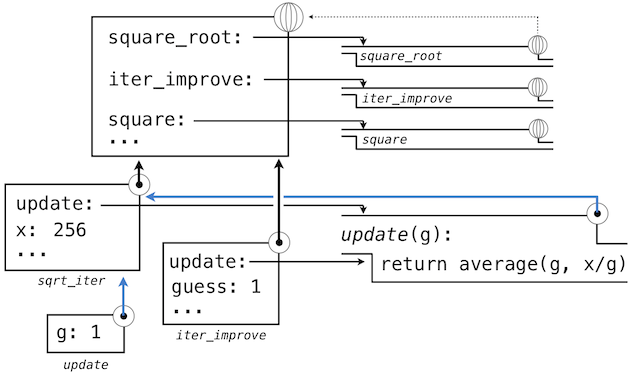
这个求值过程中,最重要的部分是函数所关联的环境变成了局部帧,它是函数求值的地方。这个改变在图中以蓝色箭头高亮。
以这种方式,update的函数体能够解析名称x。所以我们意识到了词法作用域的两个关键优势。
- 局部函数的名称并不影响定义所在函数外部的名称,因为局部函数的名称绑定到了定义处的当前局部环境中,而不是全局环境。
- 局部函数可以访问外层函数的环境。这是因为局部函数的函数体的求值环境扩展于定义处的求值环境。
update函数自带了一些数据:也就是在定义处环境中的数据。因为它以这种方式封装信息,局部定义的函数通常叫做闭包。
新的环境特性:局部函数定义。
1.6.4 作为返回值的函数
我们的程序可以通过创建返回值是它们本身的函数,获得更高的表现力。带有词法作用域的编程语言的一个重要特性就是,局部定义函数在它们返回时仍旧持有所关联的环境。下面的例子展示了这一特性的作用。
在定义了许多简单函数之后,composition是包含在我们的编程语言中的自然组合法。也就是说,提供两个函数f(x)和g(x),我们可能希望定义h(x) = f(g(x))。我们可以使用现有工具来定义复合函数:
>>> def compose1(f, g):
def h(x):
return f(g(x))
return h
>>> add_one_and_square = compose1(square, successor)
>>> add_one_and_square(12)
169
compose1中的1表明复合函数和返回值都只接受一个参数。这种命名惯例并不由解释器强制,1只是函数名称的一部分。
这里,我们开始观察我们在计算的复杂模型中投入的回报。我们的环境模型不需要任何修改就能支持以这种方式返回函数的能力。
1.6.5 Lambda 表达式
目前为止,每次我们打算定义新的函数时,我们都会给它一个名称。但是对于其它类型的表达式,我们不需要将一个间接产物关联到名称上。也就是说,我们可以计算a*b + c*d,而不需要给子表达式a*b或c*d,或者整个表达式来命名。Python 中,我们可以使用 Lambda 表达式凭空创建函数,它会求值为匿名函数。Lambda 表达式是函数体具有单个返回表达式的函数,不允许出现赋值和控制语句。
Lambda 表达式十分受限:它们仅仅可用于简单的单行函数,求解和返回一个表达式。在它们适用的特殊情形中,Lambda 表达式具有强大的表现力。
>>> def compose1(f,g):
return lambda x: f(g(x))
我们可以通过构造相应的英文语句来理解 Lambda 表达式:
lambda x : f(g(x))
"A function that takes x and returns f(g(x))"
一些程序员发现使用 Lambda 表达式作为匿名函数非常简短和直接。但是,复合的 Lambda 表达式非常难以辨认,尽管它们很简洁。下面的定义是是正确的,但是许多程序员不能很快地理解它:
>>> compose1 = lambda f,g: lambda x: f(g(x))
通常,Python 的代码风格倾向于显式的def语句而不是 Lambda 表达式,但是允许它们在简单函数作为参数或返回值的情况下使用。
这种风格规范不是准则,你可以想怎么写就怎么写,但是,在你编写程序时,要考虑某一天可能会阅读你的程序的人们。如果你可以让你的程序更易于理解,你就帮了人们一个忙。
Lambda 的术语是一个历史的偶然结果,来源于手写的数学符号和早期打字系统限制的不兼容。
使用 lambda 来引入过程或函数看起来是不正当的。这个符号要追溯到 Alonzo Church,他在 20 世纪 30 年代开始使用“帽子”符号;他把平方函数记为
ŷ . y × y。但是失败的打字员将这个帽子移到了参数左边,并且把它改成了大写的 lambda:Λy . y × y;之后大写的 lambda 就变成了小写,现在我们就会在数学书里看到λy . y × y,以及在 Lisp 里看到(lambda (y) (* y y))。 -- Peter Norvig (norvig.com/lispy2.html)
尽管它的词源不同寻常,Lambda 表达式和函数调用相应的形式语言,以及 Lambda 演算都成为了计算机科学概念的基础,并在 Python 编程社区广泛传播。当我们学习解释器的设计时,我们将会在第三章中重新碰到这个话题。
1.6.6 示例:牛顿法
最后的扩展示例展示了函数值、局部定义和 Lambda 表达式如何一起工作来简明地表达通常的概念。
牛顿法是一个传统的迭代方法,用于寻找使数学函数返回值为零的参数。这些值叫做一元数学函数的根。寻找一个函数的根通常等价于求解一个相关的数学方程。
- 16 的平方根是满足
square(x) - 16 = 0的x值。 - 以 2 为底 32 的对数(例如 2 与某个指数的幂为 32)是满足
pow(2, x) - 32 = 0的x值。
所以,求根的通用方法会向我们提供算法来计算平方根和对数。而且,我们想要计算根的等式只包含简单操作:乘法和乘方。
在我们继续之前有个注解:我们知道如何计算平方根和对数,这个事实很容易当做自然的事情。并不只是 Python,你的手机和计算机,可能甚至你的手表都可以为你做这件事。但是,学习计算机科学的一部分是弄懂这些数如何计算,而且,这里展示的通用方法可以用于求解大量方程,而不仅仅是内建于 Python 的东西。
在开始理解牛顿法之前,我们可以开始编程了。这就是函数抽象的威力。我们简单地将之前的语句翻译成代码:
>>> def square_root(a):
return find_root(lambda x: square(x) - a)
>>> def logarithm(a, base=2):
return find_root(lambda x: pow(base, x) - a)
当然,在我们定义find_root之前,现在还不能调用任何函数,所以我们需要理解牛顿法如何工作。
牛顿法也是一个迭代改进算法:它会改进任何可导函数的根的推测值。要注意我们感兴趣的两个函数都是平滑的。对于
f(x) = square(x) - 16(细线)f(x) = pow(2, x) - 32(粗线)
在二维平面上画出x对f(x)的图像,它展示了两个函数都产生了光滑的曲线,它们在某个点穿过了 0。
由于它们是光滑的(可导的),这些曲线可以通过任何点上的直线来近似。牛顿法根据这些线性的近似值来寻找函数的根。
想象经过点(x, f(x))的一条直线,它与函数f(x)的曲线在这一点的斜率相同。这样的直线叫做切线,它的斜率叫做f在x上的导数。
这条直线的斜率是函数值改变量与函数参数改变量的比值。所以,按照f(x)除以这个斜率来平移x,就会得到切线到达 0 时的x值。
我们的牛顿更新操作表达了跟随这条切线到零的计算过程。我们通过在非常小的区间上计算函数斜率来近似得到函数的导数。
>>> def approx_derivative(f, x, delta=1e-5):
df = f(x + delta) - f(x)
return df/delta
>>> def newton_update(f):
def update(x):
return x - f(x) / approx_derivative(f, x)
return update
最后,我们可以定义基于newton_update(我们的迭代改进算法)的find_root函数,以及一个测试来观察f(x)是否接近于 0。我们提供了一个较大的初始推测值来提升logarithm的性能。
>>> def find_root(f, initial_guess=10):
def test(x):
return approx_eq(f(x), 0)
return iter_improve(newton_update(f), test, initial_guess)
>>> square_root(16)
4.000000000026422
>>> logarithm(32, 2)
5.000000094858201
当你实验牛顿法时,要注意它不总是收敛的。iter_improve的初始推测值必须足够接近于根,而且函数必须满足各种条件。虽然具有这些缺陷,牛顿法是一个用于解决微分方程的强大的通用计算方法。实际上,非常快速的对数算法和大整数除法也采用这个技巧的变体。
1.6.7 抽象和一等函数
这一节的开始,我们以观察用户定义函数作为关键的抽象技巧,因为它们让我们能够将计算的通用方法表达为编程语言中的显式元素。现在我们已经看到了高阶函数如何让我们操作这些通用方法来进一步创建抽象。
作为程序员,我们应该留意识别程序中低级抽象的机会,在它们之上构建,并泛化它们来创建更加强大的抽象。这并不是说,一个人应该总是尽可能以最抽象的方式来编程;专家级程序员知道如何选择合适于他们任务的抽象级别。但是能够基于这些抽象来思考,以便我们在新的上下文中能使用它们十分重要。高阶函数的重要性是,它允许我们更加明显地将这些抽象表达为编程语言中的元素,使它们能够处理其它的计算元素。
通常,编程语言会限制操作计算元素的途径。带有最少限制的元素被称为具有一等地位。一些一等元素的“权利和特权”是:
- 它们可以绑定到名称。
- 它们可以作为参数向函数传递。
- 它们可以作为函数的返回值返回。
- 它们可以包含在数据结构中。
Python 总是给予函数一等地位,所产生的表现力的收益是巨大的。另一方面,控制结构不能做到:你不能像使用sum那样将if传给一个函数。
1.6.8 函数装饰器
Python 提供了特殊的语法,将高阶函数用作执行def语句的一部分,叫做装饰器。
>>> def trace1(fn):
def wrapped(x):
print('-> ', fn, '(', x, ')')
return fn(x)
return wrapped
>>> @trace1
def triple(x):
return 3 * x
>>> triple(12)
-> <function triple at 0x102a39848> ( 12 )
36
这个例子中,定义了高阶函数trace1,它返回一个函数,这个函数在调用它的参数之前执行print语句来输出参数。triple的def语句拥有一个注解,@trace1,它会影响def的执行规则。像通常一样,函数triple被创建了,但是,triple的名称并没有绑定到这个函数上,而是绑定到了在新定义的函数triple上调用trace1的返回函数值上。在代码中,这个装饰器等价于:
>>> def triple(x):
return 3 * x
>>> triple = trace1(triple)
附加部分:实际规则是,装饰器符号@可以放在表达式前面(@trace1仅仅是一个简单的表达式,由单一名称组成)。任何产生合适的值的表达式都可以。例如,使用合适的值,你可以定义装饰器check_range,使用@check_range(1, 10)来装饰函数定义,这会检查函数的结果来确保它们是 1 到 10 的整数。调用check_range(1,10)会返回一个函数,之后它会用在新定义的函数上,在新定义的函数绑定到def语句中的名称之前。感兴趣的同学可以阅读 Ariel Ortiz 编写的一篇装饰器的简短教程来了解更多的例子。
第二章 使用对象构建抽象
2.1 引言
在第一章中,我们专注于计算过程,以及程序设计中函数的作用。我们看到了如何使用原始数据(数值)和原始操作(算术运算),如何通过组合和控制来形成复合函数,以及如何通过给予过程名称来创建函数抽象。我们也看到了高阶函数通过操作通用计算方法来提升语言的威力。这是编程的本质。
这一章会专注于数据。数据允许我们通过使用已经获得的计算工具,表示和操作与世界有关的信息。脱离数据结构的编程可能会满足于探索数学特性,但是真实世界的情况,比如文档、关系、城市和气候模式,都拥有复杂的结构,它最好使用复合数据类型来表现。归功于互联网的高速发展,关于世界的大量结构信息可以免费从网上获得。
2.1.1 对象隐喻
在这门课的开始,我们区分了函数和数据:函数执行操作,而数据被操作。当我们在数据中包含函数值时,我们承认数据也拥有行为。函数可以像数据一样被操作,但是也可以被调用来执行计算。
在这门课中,对象作为我们对数据值的核心编程隐喻,它同样拥有行为。对象表示信息,但是同时和它们所表示的抽象概念行为一致。对象如何和其它对象交互的逻辑,和编码对象值的信息绑定在一起。在打印对象时,它知道如何以字母和数字把自己拼写出来。如果一个对象由几部分组成,它知道如何按照要求展示这些部分。对象既是信息也是过程,它们绑定在一起来展示复杂事物的属性、交互和行为。
Python 中所实现的对象隐喻具有特定的对象语法和相关的术语,我们会使用示例来介绍。日期(date)就是一种简单对象。
>>> from datetime import date
date的名字绑定到了一个类上面。类表示一类对象。独立的日期叫做这个类的实例,它们可以通过像函数那样在参数上调用这个类来构造,这些参数描述了实例。
>>> today = date(2011, 9, 12)
虽然today从原始数值中构造,它的行为就像日期那样。例如,将它与另一个日期相减会得到时间差,它可以通过调用str来展示为一行文本:
>>> str(date(2011, 12, 2) - today)
'81 days, 0:00:00'
对象拥有属性,它们是带有名字的值,也是对象的一部分。Python 中,我们使用点运算符来访问对象属性:
<expression> . <name>
上面的<expression>求值为对象,<name>是对象的某个属性名称。
不像我们之前见过的名称,这些属性名称在一般的环境中不可用。反之,属性名称是点运算符之前的对象实例的特定部分。
>>> today.year
2011
对象也拥有方法,它是值为函数的属性。在隐喻上,对象“知道”如何执行这些方法。方法从它们的参数和对象中计算出它们的结果。例如,today的strftime方法接受一个指定如何展示日期的参数(例如%A表示星期几应该以全称拼写)。
>>> today.strftime('%A, %B %d')
'Monday, September 12'
计算strftime的返回值需要两个输入:描述输出格式的字符串,以及绑定到today的日期信息。这个方法使用日期特定的逻辑来产生结果。我们从不会说 2011 年九月十二日是星期一,但是知道一个人的工作日是日期的一部分。通过绑定行为和信息,Python 对象提供了可靠、独立的日期抽象。
点运算符在 Python 中提供了另一种组合表达式。点运算符拥有定义好的求值过程。但是,点运算符如何求值的精确解释,要等到我们引入面向对象编程的完整范式,在几节之后。
即使我们还不能精确描述对象如何工作,我们还是可以开始将数据看做对象,因为 Python 中万物皆对象。
2.1.2 原始数据类型
Python 中每个对象都拥有一个类型。type函数可以让我们查看对象的类型。
>>> type(today)
<class 'datetime.date'>
目前为止,我们学过的对象类型只有数值、函数、布尔值和现在的日期。我们也碰到了集合和字符串,但是需要更深入地学习它们。有许多其它的对象类型 -- 声音、图像、位置、数据连接等等 -- 它们的多数可以通过组合和抽象的手段来定义,我们在这一章会研究它们。Python 只有一小部分内建于语言的原始或原生数据类型。
原始数据类型具有以下特性:
- 原始表达式可以计算这些类型的对象,叫做字面值。
- 内建的函数、运算符和方法可以操作这些对象。
像我们看到的那样,数值是原始类型,数字字面值求值为数值,算术运算符操作数值对象:
>>> 12 + 3000000000000000000000000
3000000000000000000000012
实际上,Python 包含了三个原始数值类型:整数(int)、实数(float)和复数(complex)。
>>> type(2)
<class 'int'>
>>> type(1.5)
<class 'float'>
>>> type(1+1j)
<class 'complex'>
名称float来源于实数在 Python 中表示的方式:“浮点”表示。虽然数值表示的细节不是这门课的话题,一些int和float对象的高层差异仍然很重要。特别是,int对象只能表示整数,但是表示得更精确,不带有任何近似。另一方面,float对象可以表示很大范围内的分数,但是不能表示所有有理数。然而,浮点对象通常用于近似表示实数和有理数,舍入到某个有效数字的数值。
扩展阅读:下面的章节介绍了更多的 Python 原始数据类型,专注于它们在创建实用数据抽象中的作用。Dive Into Python 3 中的原始数据类型一章提供了所有 Python 数据类型的实用概览,以及如何高效使用它们,还包含了许多使用示例和实践提示。你现在并不需要阅读它,但是要考虑将它作为宝贵的参考。
2.2 数据抽象
由于我们希望在程序中表达世界中的大量事物,我们发现它们的大多数都具有复合结构。日期是年月日,地理位置是精度和纬度。为了表示位置,我们希望程序语言具有将精度和纬度“粘合”为一对数据的能力 -- 也就是一个复合数据结构 -- 使我们的程序能够以一种方式操作数据,将位置看做单个概念单元,它拥有两个部分。
复合数据的使用也让我们增加程序的模块性。如果我们可以直接将地理位置看做对象来操作,我们就可以将程序的各个部分分离,它们根据这些值如何表示来从本质上处理这些值。将某个部分从程序中分离的一般技巧是一种叫做数据抽象的强大的设计方法论。这个部分用于处理数据表示,而程序用于操作数据。数据抽象使程序更易于设计、维护和修改。
数据抽象的特征类似于函数抽象。当我们创建函数抽象时,函数如何实现的细节被隐藏了,而且特定的函数本身可以被任何具有相同行为的函数替换。换句话说,我们可以构造抽象来使函数的使用方式和函数的实现细节分离。与之相似,数据抽象是一种方法论,使我们将复合数据对象的使用细节与它的构造方式隔离。
数据抽象的基本概念是构造操作抽象数据的程序。也就是说,我们的程序应该以一种方式来使用数据,对数据做出尽可能少的假设。同时,需要定义具体的数据表示,独立于使用数据的程序。我们系统中这两部分的接口是一系列函数,叫做选择器和构造器,它们基于具体表示实现了抽象数据。为了演示这个技巧,我们需要考虑如何设计一系列函数来操作有理数。
当你阅读下一节时,要记住当今编写的多数 Python 代码使用了非常高级的抽象数据类型,它们内建于语言中,比如类、字典和列表。由于我们正在了解这些抽象的工作原理,我们自己不能使用它们。所以,我们会编写一些不那么 Python 化的代码 -- 它并不是在语言中实现我们的概念的通常方式。但是,我们所编写的代码出于教育目的,它展示了这些抽象如何构建。要记住计算机科学并不只是学习如何使用编程语言,也学习它们的工作原理。
2.2.1 示例:有理数的算术
有理数可表示为整数的比值,并且它组成了实数的一个重要子类。类似于1/3或者17/29的有理数通常可编写为:
<numerator>/<denominator>
其中,<numerator>和<denominator>都是值为整数的占位符。有理数的值需要两部分来描述。
有理数在计算机科学中很重要,因为它们就像整数那样,可以准确表示。无理数(比如pi 或者 e 或者 sqrt(2))会使用有限的二元展开代替为近似值。所以在原则上,有理数的处理应该让我们避免算术中的近似误差。
但是,一旦我们真正将分子与分母相除,我们就会只剩下截断的小数近似值:
>>> 1/3
0.3333333333333333
当我们开始执行测试时,这个近似值的问题就会出现:
>>> 1/3 == 0.333333333333333300000 # Beware of approximations
True
计算机如何将实数近似为定长的小数扩展,是另一门课的话题。这里的重要概念是,通过将有理数表示为整数的比值,我们能够完全避免近似问题。所以出于精确,我们希望将分子和分母分离,但是将它们看做一个单元。
我们从函数抽象中了解到,我们可以在了解某些部分的实现之前开始编出东西来。让我们一开始假设我们已经拥有一种从分子和分母中构造有理数的方式。我们也假设,给定一个有理数,我们都有办法来提取(或选中)它的分子和分母。让我们进一步假设,构造器和选择器以下面三个函数来提供:
make_rat(n, d)返回分子为n和分母为d的有理数。numer(x)返回有理数x的分子。denom(x)返回有理数x的分母。
我们在这里正在使用一个强大的合成策略:心想事成。我们并没有说有理数如何表示,或者numer、denom和make_rat如何实现。即使这样,如果我们拥有了这三个函数,我们就可以执行加法、乘法,以及测试有理数的相等性,通过调用它们:
>>> def add_rat(x, y):
nx, dx = numer(x), denom(x)
ny, dy = numer(y), denom(y)
return make_rat(nx * dy + ny * dx, dx * dy)
>>> def mul_rat(x, y):
return make_rat(numer(x) * numer(y), denom(x) * denom(y))
>>> def eq_rat(x, y):
return numer(x) * denom(y) == numer(y) * denom(x)
现在我们拥有了由选择器函数numer和denom,以及构造器函数make_rat定义的有理数操作。但是我们还没有定义这些函数。我们需要以某种方式来将分子和分母粘合为一个单元。
2.2.2 元组
为了实现我们的数据抽象的具体层面,Python 提供了一种复合数据结构叫做tuple,它可以由逗号分隔的值来构造。虽然并不是严格要求,圆括号通常在元组周围。
>>> (1, 2)
(1, 2)
元组的元素可以由两种方式解构。第一种是我们熟悉的多重赋值:
>>> pair = (1, 2)
>>> pair
(1, 2)
>>> x, y = pair
>>> x
1
>>> y
2
实际上,多重赋值的本质是创建和解构元组。
访问元组元素的第二种方式是通过下标运算符,写作方括号:
>>> pair[0]
1
>>> pair[1]
2
Python 中的元组(以及多数其它编程语言中的序列)下标都以 0 开始,也就是说,下标 0 表示第一个元素,下标 1 表示第二个元素,以此类推。我们对这个下标惯例的直觉是,下标表示一个元素距离元组开头有多远。
与元素选择操作等价的函数叫做__getitem__,它也使用位置在元组中选择元素,位置的下标以 0 开始。
>>> from operator import getitem
>>> getitem(pair, 0)
1
元素是原始类型,也就是说 Python 的内建运算符可以操作它们。我们不久之后再来看元素的完整特性。现在,我们只对元组如何作为胶水来实现抽象数据类型感兴趣。
表示有理数:元素提供了一个自然的方式来将有理数实现为一对整数:分子和分母。我们可以通过操作二元组来实现我们的有理数构造器和选择器函数。
>>> def make_rat(n, d):
return (n, d)
>>> def numer(x):
return getitem(x, 0)
>>> def denom(x):
return getitem(x, 1)
用于打印有理数的函数完成了我们对抽象数据结构的实现。
>>> def str_rat(x):
"""Return a string 'n/d' for numerator n and denominator d."""
return '{0}/{1}'.format(numer(x), denom(x))
将它与我们之前定义的算术运算放在一起,我们可以使用我们定义的函数来操作有理数了。
>>> half = make_rat(1, 2)
>>> str_rat(half)
'1/2'
>>> third = make_rat(1, 3)
>>> str_rat(mul_rat(half, third))
'1/6'
>>> str_rat(add_rat(third, third))
'6/9'
就像最后的例子所展示的那样,我们的有理数实现并没有将有理数化为最简。我们可以通过修改make_rat来补救。如果我们拥有用于计算两个整数的最大公约数的函数,我们可以在构造一对整数之前将分子和分母化为最简。这可以使用许多实用工具,例如 Python 库中的现存函数。
>>> from fractions import gcd
>>> def make_rat(n, d):
g = gcd(n, d)
return (n//g, d//g)
双斜杠运算符//表示整数除法,它会向下取整除法结果的小数部分。由于我们知道g能整除n和d,整数除法正好适用于这里。现在我们的
>>> str_rat(add_rat(third, third))
'2/3'
符合要求。这个修改只通过修改构造器来完成,并没有修改任何实现实际算术运算的函数。
**扩展阅读。**上面的str_rat实现使用了格式化字符串,它包含了值的占位符。如何使用格式化字符串和format方法的细节请见 Dive Into Python 3 的格式化字符串一节。
2.2.3 抽象界限
在以更多复合数据和数据抽象的例子继续之前,让我们思考一些由有理数示例产生的问题。我们使用构造器make_rat和选择器numer和denom定义了操作。通常,数据抽象的底层概念是,基于某个值的类型的操作如何表达,为这个值的类型确定一组基本的操作。之后使用这些操作来操作数据。
我们可以将有理数系统想象为一系列层级。
平行线表示隔离系统不同层级的界限。每一层上,界限分离了使用数据抽象的函数(上面)和实现数据抽象的函数(下面)。使用有理数的程序仅仅通过算术函数来操作它们:add_rat、mul_rat和eq_rat。相应地,这些函数仅仅由构造器和选择器make_rat、numer和and denom来实现,它们本身由元组实现。元组如何实现的字节和其它层级没有关系,只要元组支持选择器和构造器的实现。
每一层上,盒子中的函数强制划分了抽象的边界,因为它们仅仅依赖于上层的表现(通过使用)和底层的实现(通过定义)。这样,抽象界限可以表现为一系列函数。
抽象界限具有许多好处。一个好处就是,它们使程序更易于维护和修改。很少的函数依赖于特定的表现,当一个人希望修改表现时,不需要做很多修改。
2.2.4 数据属性
我们通过实现算术运算来开始实现有理数,实现为这三个非特定函数:make_rat、numer和denom。这里,我们可以认为已经定义了数据对象 -- 分子、分母和有理数 -- 上的运算,它们的行为由这三个函数规定。
但是数据意味着什么?我们还不能说“提供的选择器和构造器实现了任何东西”。我们需要保证这些函数一起规定了正确的行为。也就是说,如果我们从整数n和d中构造了有理数x,那么numer(x)/denom(x)应该等于n/d。
通常,我们可以将抽象数据类型当做一些选择器和构造器的集合,并带有一些行为条件。只要满足了行为条件(比如上面的除法特性),这些函数就组成了数据类型的有效表示。
这个观点可以用在其他数据类型上,例如我们为实现有理数而使用的二元组。我们实际上不会谈论元组是什么,而是谈论由语言提供的,用于操作和创建元组的运算符。我们现在可以描述二元组的行为条件,二元组通常叫做偶对,在表示有理数的问题中有所涉及。
为了实现有理数,我们需要一种两个整数的粘合形式,它具有下列行为:
- 如果一个偶对
p由x和y构造,那么getitem_pair(p, 0)返回x,getitem_pair(p, 1)返回y。
我们可以实现make_pair和getitem_pair,它们和元组一样满足这个描述:
>>> def make_pair(x, y):
"""Return a function that behaves like a pair."""
def dispatch(m):
if m == 0:
return x
elif m == 1:
return y
return dispatch
>>> def getitem_pair(p, i):
"""Return the element at index i of pair p."""
return p(i)
使用这个实现,我们可以创建和操作偶对:
>>> p = make_pair(1, 2)
>>> getitem_pair(p, 0)
1
>>> getitem_pair(p, 1)
2
这个函数的用法不同于任何直观上的,数据应该是什么的概念。而且,这些函数满足于在我们的程序中表示复合数据。
需要注意的微妙的一点是,由make_pair返回的值是叫做dispatch的函数,它接受参数m并返回x或y。之后,getitem_pair调用了这个函数来获取合适的值。我们在这一章中会多次返回这个调度函数的话题。
这个偶对的函数表示并不是 Python 实际的工作机制(元组实现得更直接,出于性能因素),但是它可以以这种方式工作。这个函数表示虽然不是很明显,但是是一种足够完美来表示偶对的方式,因为它满足了偶对唯一需要满足的条件。这个例子也表明,将函数当做值来操作的能力,提供给我们表示复合数据的能力。
2.3 序列
序列是数据值的顺序容器。不像偶对只有两个元素,序列可以拥有任意(但是有限)个有序元素。
序列在计算机科学中是强大而基本的抽象。例如,如果我们使用序列,我们就可以列出伯克利的每个学生,或者世界上的每所大学,或者每所大学中的每个学生。我们可以列出上过的每一门课,提交的每个作业,或者得到的每个成绩。序列抽象让数千个数据驱动的程序影响着我们每天的生活。
序列不是特定的抽象数据类型,而是不同类型共有的一组行为。也就是说,它们是许多序列种类,但是都有一定的属性。特别地,
长度:序列拥有有限的长度。
元素选择:序列的每个元素都拥有相应的非负整数作为下标,它小于序列长度,以第一个元素的 0 开始。
不像抽象数据类型,我们并没有阐述如何构造序列。序列抽象是一组行为,它们并没有完全指定类型(例如,使用构造器和选择器),但是可以在多种类型中共享。序列提供了一个抽象层级,将特定程序如何操作序列类型的细节隐藏。
这一节中,我们开发了一个特定的抽象数据类型,它可以实现序列抽象。我们之后介绍实现相同抽象的 Python 内建类型。
2.3.1 嵌套偶对
对于有理数,我们使用二元组将两个整数对象配对,之后展示了我们可以同样通过函数来实现偶对。这种情况下,每个我们构造的偶对的元素都是整数。然而,就像表达式,元组可以嵌套。每个偶对的元素本身也可以是偶对,这个特性在实现偶对的任意一个方法,元组或调度函数中都有效。
可视化偶对的一个标准方法 -- 这里也就是偶对(1,2) -- 叫做盒子和指针记号。每个值,复合或原始,都描述为指向盒子的指针。原始值的盒子只包含那个值的表示。例如,数值的盒子只包含数字。偶对的盒子实际上是两个盒子:左边的部分(箭头指向的)包含偶对的第一个元素,右边的部分包含第二个。
嵌套元素的 Python 表达式:
>>> ((1, 2), (3, 4))
((1, 2), (3, 4))
具有下面的结构:
使用元组作为其它元组元素的能力,提供了我们编程语言中的一个新的组合手段。我们将这种将元组以这种方式嵌套的能力叫做元组数据类型的封闭性。通常,如果组合结果自己可以使用相同的方式组合,组合数据值的方式就满足封闭性。封闭性在任何组合手段中都是核心能力,因为它允许我们创建层次数据结构 -- 结构由多个部分组成,它们自己也由多个部分组成,以此类推。我们在第三章会探索一些层次结构。现在,我们考虑一个特定的重要结构。
2.3.2 递归列表
我们可以使用嵌套偶对来构建任意长度的元素列表,它让我们能够实现抽象序列。下面的图展示了四元素列表1, 2, 3, 4的递归表示:
这个列表由一系列偶对表示。每个偶对的第一个元素是列表中的元素,而第二个元素是用于表示列表其余部分的偶对。最后一个偶对的第二个元素是None,它表明列表到末尾了。我们可以使用嵌套的元组字面值来构造这个结构:
>>> (1, (2, (3, (4, None))))
(1, (2, (3, (4, None))))
这个嵌套的结构通常对应了一种非常实用的序列思考方式,我们在 Python 解释器的执行规则中已经见过它了。一个非空序列可以划分为:
- 它的第一个元素,以及
- 序列的其余部分。
序列的其余部分本身就是一个(可能为空的)序列。我们将序列的这种看法叫做递归,因为序列包含其它序列作为第二个组成部分。
由于我们的列表表示是递归的,我们在实现中叫它rlist,以便不会和 Python 内建的list类型混淆,我们会稍后在这一章介绍它。一个递归列表可以由第一个元素和列表的剩余部分构造。None值表示空的递归列表。
>>> empty_rlist = None
>>> def make_rlist(first, rest):
"""Make a recursive list from its first element and the rest."""
return (first, rest)
>>> def first(s):
"""Return the first element of a recursive list s."""
return s[0]
>>> def rest(s):
"""Return the rest of the elements of a recursive list s."""
return s[1]
这两个选择器和一个构造器,以及一个常量共同实现了抽象数据类型的递归列表。递归列表唯一的行为条件是,就像偶对那样,它的构造器和选择器是相反的函数。
- 如果一个递归列表
s由元素f和列表r构造,那么first(s)返回f,并且rest(s)返回r。
我们可以使用构造器和选择器来操作递归列表。
>>> counts = make_rlist(1, make_rlist(2, make_rlist(3, make_rlist(4, empty_rlist))))
>>> first(counts)
1
>>> rest(counts)
(2, (3, (4, None)))
递归列表可以按序储存元素序列,但是它还没有实现序列的抽象。使用我们已经定义的数据类型抽象,我们就可以实现描述两个序列的行为:长度和元素选择。
>>> def len_rlist(s):
"""Return the length of recursive list s."""
length = 0
while s != empty_rlist:
s, length = rest(s), length + 1
return length
>>> def getitem_rlist(s, i):
"""Return the element at index i of recursive list s."""
while i > 0:
s, i = rest(s), i - 1
return first(s)
现在,我们可以将递归列表用作序列了:
>>> len_rlist(counts)
4
>>> getitem_rlist(counts, 1) # The second item has index 1
2
两个实现都是可迭代的。它们隔离了嵌套偶对的每个层级,直到列表的末尾(在len_rlist中),或者到达了想要的元素(在getitem_rlist中)。
下面的一系列环境图示展示了迭代过程,getitem_rlist通过它找到了递归列表中下标1中的元素2。
while头部中的表达式求值为真,这会导致while语句组中的赋值语句被执行:
这里,局部名称s现在指向以原列表第二个元素开始的子列表。现在,while头中的表达式求值为假,于是 Python 会求出getitem_rlist最后一行中返回语句中的表达式。
最后的环境图示展示了调用first的局部帧,它包含绑定到相同子列表的s。first函数挑选出值2并返回了它,完成了getitem_rlist的调用。
这个例子演示了递归列表计算的常见模式,其中迭代的每一步都操作原列表的一个逐渐变短的后缀。寻找递归列表的长度和元素的渐进式处理过程需要一些时间来计算。(第三章中,我们会学会描述这种函数的计算时间。)Python 的内建序列类型以不同方式实现,它对于计算序列长度和获取元素并不具有大量的计算开销。
2.3.2 元组 II
实际上,我们引入用于形成原始偶对的tuple类型本身就是完整的序列类型。元组比起我们以函数式实现的偶对抽象数据结构,本质上提供了更多功能。
元组具有任意的长度,并且也拥有序列抽象的两个基本行为:长度和元素选择。下面的digits是一个四元素元组。
>>> digits = (1, 8, 2, 8)
>>> len(digits)
4
>>> digits[3]
8
此外,元素可以彼此相加以及与整数相乘。对于元组,加法和乘法操作并不对元素相加或相乘,而是组合和重复元组本身。也就是说,operator模块中的add函数(以及+运算符)返回两个被加参数连接成的新元组。operator模块中的mul函数(以及*运算符)接受整数k和元组,并返回含有元组参数k个副本的新元组。
>>> (2, 7) + digits * 2
(2, 7, 1, 8, 2, 8, 1, 8, 2, 8)
映射:将一个元组变换为另一个元组的强大手段是在每个元素上调用函数,并收集结果。这一计算的常用形式叫做在序列上映射函数,对应内建函数map。map的结果是一个本身不是序列的对象,但是可以通过调用tuple来转换为序列。它是元组的构造器。
>>> alternates = (-1, 2, -3, 4, -5)
>>> tuple(map(abs, alternates))
(1, 2, 3, 4, 5)
map函数非常重要,因为它依赖于序列抽象:我们不需要关心底层元组的结构,只需要能够独立访问每个元素,以便将它作为参数传入用于映射的函数中(这里是abs)。
2.3.4 序列迭代
映射本身就是通用计算模式的一个实例:在序列中迭代所有元素。为了在序列上映射函数,我们不仅仅需要选择特定的元素,还要依次选择每个元素。这个模式非常普遍,Python 拥有额外的控制语句来处理序列数据:for语句。
考虑一个问题,计算一个值在序列中出现了多少次。我们可以使用while循环实现一个函数来计算这个数量。
>>> def count(s, value):
"""Count the number of occurrences of value in sequence s."""
total, index = 0, 0
while index < len(s):
if s[index] == value:
total = total + 1
index = index + 1
return total
>>> count(digits, 8)
2
Python for语句可以通过直接迭代元素值来简化这个函数体,完全不需要引入index。例如(原文是For example,为双关语),我们可以写成:
>>> def count(s, value):
"""Count the number of occurrences of value in sequence s."""
total = 0
for elem in s:
if elem == value:
total = total + 1
return total
>>> count(digits, 8)
2
for语句按照以下过程来执行:
- 求出头部表达式
<expression>,它必须产生一个可迭代的值。 - 对于序列中的每个元素值,按顺序:
- 在局部环境中将变量名
<name>绑定到这个值上。 - 执行语句组
<suite>。
- 在局部环境中将变量名
步骤 1 引用了可迭代的值。序列是可迭代的,它们的元素可看做迭代的顺序。Python 的确拥有其他可迭代类型,但是我们现在只关注序列。术语“可迭代对象”的一般定义会在第四章的迭代器一节中出现。
这个求值过程的一个重要结果是,在for语句执行完毕之后,<name>会绑定到序列的最后一个元素上。这个for循环引入了另一种方式,其中局部环境可以由语句来更新。
序列解构:程序中的一个常见模式是,序列的元素本身就是序列,但是具有固定的长度。for语句可在头部中包含多个名称,将每个元素序列“解构”为各个元素。例如,我们拥有一个偶对(也就是二元组)的序列:
>>> pairs = ((1, 2), (2, 2), (2, 3), (4, 4))
下面的for语句的头部带有两个名词,会将每个名称x和y分别绑定到每个偶对的第一个和第二个元素上。
>>> for x, y in pairs:
if x == y:
same_count = same_count + 1
>>> same_count
2
这个绑定多个名称到定长序列中多个值的模式,叫做序列解构。它的模式和我们在赋值语句中看到的,将多个名称绑定到多个值的模式相同。
范围:range是另一种 Python 的内建序列类型,它表示一个整数范围。范围可以使用range函数来创建,它接受两个整数参数:所得范围的第一个数值和最后一个数值加一。
>>> range(1, 10) # Includes 1, but not 10
range(1, 10)
在范围上调用tuple构造器会创建与范围具有相同元素的元组,使元素易于查看。
>>> tuple(range(5, 8))
(5, 6, 7)
如果只提供了一个元素,它会解释为最后一个数值加一,范围开始于 0。
>>> total = 0
>>> for k in range(5, 8):
total = total + k
>>> total
18
常见的惯例是将单下划线字符用于for头部,如果这个名称在语句组中不会使用。
>>> for _ in range(3):
print('Go Bears!')
Go Bears!
Go Bears!
Go Bears!
要注意对解释器来说,下划线只是另一个名称,但是在程序员中具有固定含义,它表明这个名称不应出现在任何表达式中。
2.3.5 序列抽象
我们已经介绍了两种原生数据类型,它们实现了序列抽象:元组和范围。两个都满足这一章开始时的条件:长度和元素选择。Python 还包含了两种序列类型的行为,它们扩展了序列抽象。
成员性:可以测试一个值在序列中的成员性。Python 拥有两个操作符in和not in,取决于元素是否在序列中出现而求值为True和False。
>>> digits
(1, 8, 2, 8)
>>> 2 in digits
True
>>> 1828 not in digits
True
所有序列都有叫做index和count的方法,它会返回序列中某个值的下标(或者数量)。
切片:序列包含其中的子序列。我们在开发我们的嵌套偶对实现时观察到了这一点,它将序列切分为它的第一个元素和其余部分。序列的切片是原序列的任何部分,由一对整数指定。就像range构造器那样,第一个整数表示切片的起始下标,第二个表示结束下标加一。
Python 中,序列切片的表示类似于元素选择,使用方括号。冒号分割了起始和结束下标。任何边界上的省略都被当作极限值:起始下标为 0,结束下标是序列长度。
>>> digits[0:2]
(1, 8)
>>> digits[1:]
(8, 2, 8)
Python 序列抽象的这些额外行为的枚举,给我们了一个机会来反思数据抽象通常由什么构成。抽象的丰富性(也就是说它包含行为的多少)非常重要。对于使用抽象的用户,额外的行为很有帮助,另一方面,满足新类型抽象的丰富需求是个挑战。为了确保我们的递归列表实现支持这些额外的行为,需要一些工作量。另一个抽象丰富性的负面结果是,它们需要用户长时间学习。
序列拥有丰富的抽象,因为它们在计算中无处不在,所以学习一些复杂的行为是合理的。通常,多数用户定义的抽象应该尽可能简单。
扩展阅读:切片符号接受很多特殊情况,例如负的起始值,结束值和步长。Dive Into Python 3 中有一节叫做列表切片,完整描述了它。这一章中,我们只会用到上面描述的基本特性。
2.3.6 字符串
文本值可能比数值对计算机科学来说更基本。作为一个例子,Python 程序以文本编写和储存。Python 中原生的文本数据类型叫做字符串,相应的构造器是str。
关于字符串在 Python 中如何表示和操作有许多细节。字符串是丰富抽象的另一个示例,程序员需要满足一些实质性要求来掌握。这一节是字符串基本行为的摘要。
字符串字面值可以表达任意文本,被单引号或者双引号包围。
>>> 'I am string!'
'I am string!'
>>> "I've got an apostrophe"
"I've got an apostrophe"
>>> '您好'
'您好'
我们已经在代码中见过字符串了,在print的调用中作为文档字符串,以及在assert语句中作为错误信息。
字符串满足两个基本的序列条件,我们在这一节开始介绍过它们:它们拥有长度并且支持元素选择。
>>> city = 'Berkeley'
>>> len(city)
8
>>> city[3]
'k'
字符串的元素本身就是包含单一字符的字符串。字符是字母表中的任意单一字符,标点符号,或者其它符号。不像许多其它编程语言那样,Python 没有单独的字符类型,任何文本都是字符串,表示单一字符的字符串长度为 1、
就像元组,字符串可以通过加法和乘法来组合:
>>> city = 'Berkeley'
>>> len(city)
8
>>> city[3]
'k'
字符串的行为不同于 Python 中其它序列类型。字符串抽象没有实现我们为元组和范围描述的完整序列抽象。特别地,字符串上实现了成员性运算符in,但是与序列上的实现具有完全不同的行为。它匹配子字符串而不是元素。
>>> 'here' in "Where's Waldo?"
True
与之相似,字符串上的count和index方法接受子串作为参数,而不是单一字符。count的行为有细微差别,它统计字符串中非重叠字串的出现次数。
>>> 'Mississippi'.count('i')
4
>>> 'Mississippi'.count('issi')
1
多行文本:字符串并不限制于单行文本,三个引号分隔的字符串字面值可以跨越多行。我们已经在文档字符串中使用了三个引号。
>>> """The Zen of Python
claims, Readability counts.
Read more: import this."""
'The Zen of Python\nclaims, "Readability counts."\nRead more: import this.'
在上面的打印结果中,\n(叫做“反斜杠加 n”)是表示新行的单一元素。虽然它表示为两个字符(反斜杠和 n)。它在长度和元素选择上被认为是单个字符。
字符串强制:字符串可以从 Python 的任何对象通过以某个对象值作为参数调用str构造函数来创建,这个字符串的特性对于从多种类型的对象中构造描述性字符串非常实用。
>>> str(2) + ' is an element of ' + str(digits)
'2 is an element of (1, 8, 2, 8)'
str函数可以以任何类型的参数调用,并返回合适的值,这个机制是后面的泛用函数的主题。
方法:字符串在 Python 中的行为非常具有生产力,因为大量的方法都返回字符串的变体或者搜索其内容。一部分这些方法由下面的示例介绍。
>>> '1234'.isnumeric()
True
>>> 'rOBERT dE nIRO'.swapcase()
'Robert De Niro'
>>> 'snakeyes'.upper().endswith('YES')
True
扩展阅读:计算机中的文本编码是个复杂的话题。这一章中,我们会移走字符串如何表示的细节,但是,对许多应用来说,字符串如何由计算机编码的特定细节是必要的知识。Dive Into Python 3 的 4.1 ~ 4.3 节提供了字符编码和 Unicode 的描述。
2.3.7 接口约定
在复合数据的处理中,我们强调了数据抽象如何让我们设计程序而不陷入数据表示的细节,以及抽象如何为我们保留灵活性来尝试备用表示。这一节中,我们引入了另一种强大的设计原则来处理数据结构 -- 接口约定的用法。
接口约定使在许多组件模块中共享的数据格式,它可以混合和匹配来展示数据。例如,如果我们拥有多个函数,它们全部接受序列作为参数并且返回序列值,我们就可以把它们每一个用于上一个的输出上,并选择任意一种顺序。这样,我们就可以通过将函数链接成流水线,来创建一个复杂的过程,每个函数都是简单而专一的。
这一节有两个目的,来介绍以接口约定组织程序的概念,以及展示模块化序列处理的示例。
考虑下面两个问题,它们首次出现,并且只和序列的使用相关。
- 对前
n个斐波那契数中的偶数求和。 - 列出一个名称中的所有缩写字母,它包含每个大写单词的首字母。
这些问题是有关系的,因为它们可以解构为简单的操作,它们接受序列作为输入,并产出序列作为输出。而且,这些操作是序列上的计算的一般方法的实例。让我们思考第一个问题,它可以解构为下面的步骤:
enumerate map filter accumulate
----------- --- ------ ----------
naturals(n) fib iseven sum
下面的fib函数计算了斐波那契数(现在使用了for语句更新了第一章中的定义)。
>>> def fib(k):
"""Compute the kth Fibonacci number."""
prev, curr = 1, 0 # curr is the first Fibonacci number.
for _ in range(k - 1):
prev, curr = curr, prev + curr
return curr
谓词iseven可以使用整数取余运算符%来定义。
>>> def iseven(n):
return n % 2 == 0
map和filter函数是序列操作,我们已经见过了map,它在序列中的每个元素上调用函数并且收集结果。filter函数接受序列,并且返回序列中谓词为真的元素。两个函数都返回间接对象,map和filter对象,它们是可以转换为元组或求和的可迭代对象。
>>> nums = (5, 6, -7, -8, 9)
>>> tuple(filter(iseven, nums))
(6, -8)
>>> sum(map(abs, nums))
35
现在我们可以实现even_fib,第一个问题的解,使用map、filter和sum。
>>> def sum_even_fibs(n):
"""Sum the first n even Fibonacci numbers."""
return sum(filter(iseven, map(fib, range(1, n+1))))
>>> sum_even_fibs(20)
3382
现在,让我们思考第二个问题。它可以解构为序列操作的流水线,包含map和filter。
enumerate filter map accumulate
--------- ------ ----- ----------
words iscap first tuple
字符串中的单词可以通过字符串对象上的split方法来枚举,默认以空格分割。
>>> tuple('Spaces between words'.split())
('Spaces', 'between', 'words')
单词的第一个字母可以使用选择运算符来获取,确定一个单词是否大写的谓词可以使用内建谓词isupper定义。
>>> def first(s):
return s[0]
>>> def iscap(s):
return len(s) > 0 and s[0].isupper()
这里,我们的缩写函数可以使用map和filter定义。
>>> def acronym(name):
"""Return a tuple of the letters that form the acronym for name."""
return tuple(map(first, filter(iscap, name.split())))
>>> acronym('University of California Berkeley Undergraduate Graphics Group')
('U', 'C', 'B', 'U', 'G', 'G')
这些不同问题的相似解法展示了如何使用通用的计算模式,例如映射、过滤和累计,来组合序列的接口约定上的操作。序列抽象让我们编写出这些简明的解法。
将程序表达为序列操作有助于我们设计模块化的程序。也就是说,我们的设计由组合相关的独立片段构建,每个片段都对序列进行转换。通常,我们可以通过提供带有接口约定的标准组件库来鼓励模块化设计,接口约定以灵活的方式连接这些组件。
生成器表达式:Python 语言包含第二个处理序列的途径,叫做生成器表达式。它提供了与map和reduce相似的功能,但是需要更少的函数定义。
生成器表达式组合了过滤和映射的概念,并集成于单一的表达式中,以下面的形式:
<map expression> for <name> in <sequence expression> if <filter expression>
为了求出生成器表达式,Python 先求出<sequence expression>,它必须返回一个可迭代值。之后,对于每个元素,按顺序将元素值绑定到<name>,求出过滤器表达式,如果它产生真值,就会求出映射表达式。
生成器表达式的求解结果值本身是个可迭代值。累计函数,比如tuple、sum、max和min可以将返回的对象作为参数。
>>> def acronym(name):
return tuple(w[0] for w in name.split() if iscap(w))
>>> def sum_even_fibs(n):
return sum(fib(k) for k in range(1, n+1) if fib(k) % 2 == 0)
生成器表达式是使用可迭代(例如序列)接口约定的特化语法。这些表达式包含了map和filter的大部分功能,但是避免了被调用函数的实际创建(或者,顺便也避免了环境帧的创建需要调用这些函数)。
归约:在我们的示例中,我们使用特定的函数来累计结果,例如tuple或者sum。函数式编程语言(包括 Python)包含通用的高阶累加器,具有多种名称。Python 在functools模块中包含reduce,它对序列中的元素从左到右依次调用二元函数,将序列归约为一个值。下面的表达式计算了五个因数的积。
>>> from operator import mul
>>> from functools import reduce
>>> reduce(mul, (1, 2, 3, 4, 5))
120
使用这个更普遍的累计形式,除了求和之外,我们也可以计算斐波那契数列中奇数的积,将序列用作接口约定。
>>> def product_even_fibs(n):
"""Return the product of the first n even Fibonacci numbers, except 0."""
return reduce(mul, filter(iseven, map(fib, range(2, n+1))))
>>> product_even_fibs(20)
123476336640
与map、filter和reduce对应的高阶过程的组合会再一次在第四章出现,在我们思考多台计算机之间的分布式计算方法的时候。
2.4 可变数据
我们已经看到了抽象在帮助我们应对大型系统的复杂性时如何至关重要。有效的程序整合也需要一些组织原则,指导我们构思程序的概要设计。特别地,我们需要一些策略来帮助我们构建大型系统,使之模块化。也就是说,它们可以“自然”划分为可以分离开发和维护的各个相关部分。
我们用于创建模块化程序的强大工具之一,是引入可能会随时间改变的新类型数据。这样,单个数据可以表示独立于其他程序演化的东西。对象行为的改变可能会由它的历史影响,就像世界中的实体那样。向数据添加状态是这一章最终目标:面向对象编程的要素。
我们目前引入的原生数据类型 -- 数值、布尔值、元组、范围和字符串 -- 都是不可变类型的对象。虽然名称的绑定可以在执行过程中修改为环境中不同的值,但是这些值本身不会改变。这一章中,我们会介绍一组可变数据类型。可变对象可以在程序执行期间改变。
2.4.1 局部状态
我们第一个可变对象的例子就是局部状态。这个状态会在程序执行期间改变。
为了展示函数的局部状态是什么东西,让我们对从银行取钱的情况进行建模。我们会通过创建叫做withdraw的函数来实现它,它将要取出的金额作为参数。如果账户中有足够的钱来取出,withdraw应该返回取钱之后的余额。否则,withdraw应该返回消息'Insufficient funds'。例如,如果我们以账户中的$100开始,我们希望通过调用withdraw来得到下面的序列:
>>> withdraw(25)
75
>>> withdraw(25)
50
>>> withdraw(60)
'Insufficient funds'
>>> withdraw(15)
35
观察表达式withdraw(25),求值了两次,产生了不同的值。这是一种用户定义函数的新行为:它是非纯函数。调用函数不仅仅返回一个值,同时具有以一些方式修改函数的副作用,使带有相同参数的下次调用返回不同的结果。我们所有用户定义的函数,到目前为止都是纯函数,除非他们调用了非纯的内建函数。它们仍旧是纯函数,因为它们并不允许修改任何在局部环境帧之外的东西。
为了使withdraw有意义,它必须由一个初始账户余额创建。make_withdraw函数是个高阶函数,接受起始余额作为参数,withdraw函数是它的返回值。
>>> withdraw = make_withdraw(100)
make_withdraw的实现需要新类型的语句:nonlocal语句。当我们调用make_withdraw时,我们将名称balance绑定到初始值上。之后我们定义并返回了局部函数,withdraw,它在调用时更新并返回balance的值。
>>> def make_withdraw(balance):
"""Return a withdraw function that draws down balance with each call."""
def withdraw(amount):
nonlocal balance # Declare the name "balance" nonlocal
if amount > balance:
return 'Insufficient funds'
balance = balance - amount # Re-bind the existing balance name
return balance
return withdraw
这个实现的新奇部分是nonlocal语句,无论什么时候我们修改了名称balance的绑定,绑定都会在balance所绑定的第一个帧中修改。回忆一下,在没有nonlocal语句的情况下,赋值语句总是会在环境的第一个帧中绑定名称。nonlocal语句表明,名称出现在环境中不是第一个(局部)帧,或者最后一个(全局)帧的其它地方。
我们可以将这些修改使用环境图示来可视化。下面的环境图示展示了每个调用的效果,以上面的定义开始。我们省略了函数值中的代码,以及不在我们讨论中的表达式树。
我们的定义语句拥有平常的效果:它创建了新的用户定义函数,并且将名称make_withdraw在全局帧中绑定到那个函数上。
下面,我们使用初始的余额参数20来调用make_withdraw。
>>> wd = make_withdraw(20)
这个赋值语句将名称wd绑定到全局帧中的返回函数上:
所返回的函数,(内部)叫做withdraw,和定义所在位置即make_withdraw的局部环境相关联。名称balance在这个局部环境中绑定。在例子的剩余部分中,balance名称只有这一个绑定,这非常重要。
下面,我们求出以总数5调用withdraw的表达式的值:
>>> wd(5)
15
名称wd绑定到了withdraw函数上,所以withdraw的函数体在新的环境中求值,新的环境扩展自withdraw定义所在的环境。跟踪withdraw求值的效果展示了 Python 中nonlocal语句的效果。
withdraw的赋值语句通常在withdraw的局部帧中为balance创建新的绑定。由于nonlocal语句,赋值运算找到了balance定义位置的第一帧,并在那里重新绑定名称。如果balance之前没有绑定到值上,那么nonlocal语句会产生错误。
通过修改balance绑定的行为,我们也修改了withdraw函数。下次withdraw调用的时候,名称balance会求值为15而不是20。
当我们第二次调用wd时,
>>> wd(3)
12
我们发现绑定到balance的值的修改可在两个调用之间积累。
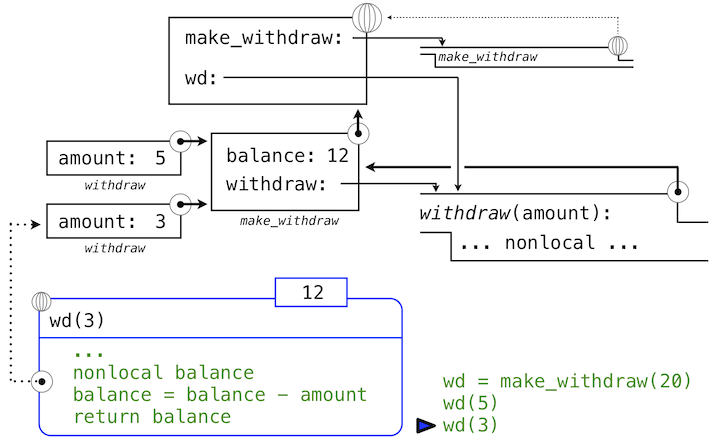
这里,第二次调用withdraw会创建第二个局部帧,像之前一样,但是,withdraw的两个帧都扩展自make_withdraw的环境,它们都包含balance的绑定。所以,它们共享特定的名称绑定,调用withdraw具有改变环境的副作用,并且会由之后的withdraw调用继承。
实践指南:通过引入nonlocal语句,我们发现了赋值语句的双重作用。它们修改局部绑定,或者修改非局部绑定。实际上,赋值语句已经有了两个作用:创建新的绑定,或者重新绑定现有名称。Python 赋值的许多作用使赋值语句的执行效果变得模糊。作为一个程序员,你应该用文档清晰记录你的代码,使赋值的效果可被其它人理解。
2.4.2 非局部赋值的好处
非局部赋值是将程序作为独立和自主的对象观察的重要步骤,对象彼此交互,但是各自管理各自的内部状态。
特别地,非局部赋值提供了在函数的局部范围中维护一些状态的能力,这些状态会在函数之后的调用中演化。和特定withdraw函数相关的balance在所有该函数的调用中共享。但是,withdraw实例中的balance绑定对程序的其余部分不可见。只有withdraw关联到了make_withdraw的帧,withdraw在那里被定义。如果make_withdraw再次调用,它会创建单独的帧,带有单独的balance绑定。
我们可以继续以我们的例子来展示这个观点。make_withdraw的第二个调用返回了第二个withdraw函数,它关联到了另一个环境上。
>>> wd2 = make_withdraw(7)
第二个withdraw函数绑定到了全局帧的名称wd2上。我们使用星号来省略了表示这个绑定的线。现在,我们看到实际上有两个balance的绑定。名称wd仍旧绑定到余额为12的withdraw函数上,而wd2绑定到了余额为7的新的withdraw函数上。
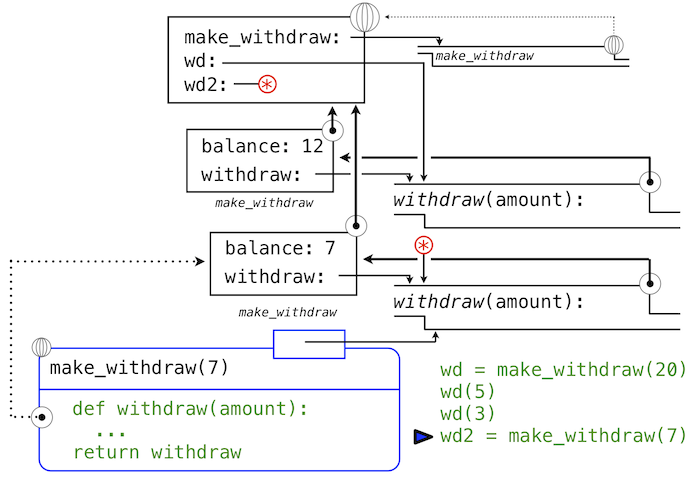
最后,我们调用绑定到wd2上的第二个withdraw函数:
>>> wd2(6)
1
这个调用修改了非局部名称balance的绑定,但是不影响在全局帧中绑定到名称wd的第一个withdraw。
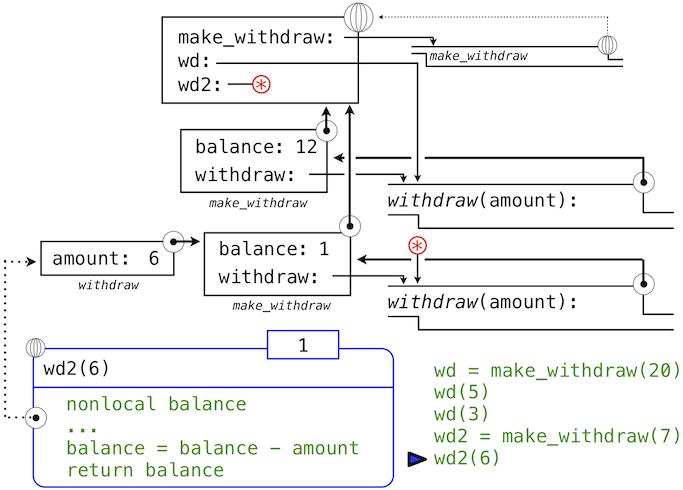
这样,withdraw的每个实例都维护它自己的余额状态,但是这个状态对程序中其它函数不可见。在更高层面上观察这个情况,我们创建了银行账户的抽象,它管理自己的内部状态,但以一种方式对真实世界的账户进行建模:它基于自己的历史提取请求来随时间变化。
2.4.3 非局部赋值的代价
我们扩展了我们的计算环境模型,用于解释非局部赋值的效果。但是,非局部复制与我们思考名称和值的方式有一些细微差异。
之前,我们的值并没有改变,仅仅是我们的名称和绑定发生了变化。当两个名称a和b绑定到4上时,它们绑定到了相同的4还是不同的4并不重要。我们说,只有一个4对象,并且它永不会改变。
但是,带有状态的函数不是这样的。当两个名称wd和wd2都绑定到withdraw函数时,它们绑定到相同函数还是函数的两个不同实例,就很重要了。考虑下面的例子,它与我们之前分析的那个正好相反:
>>> wd = make_withdraw(12)
>>> wd2 = wd
>>> wd2(1)
11
>>> wd(1)
10
这里,通过wd2调用函数会修改名称为wd的函数的值,因为两个名称都指向相同的函数。这些语句执行之后的环境图示展示了这个现象:
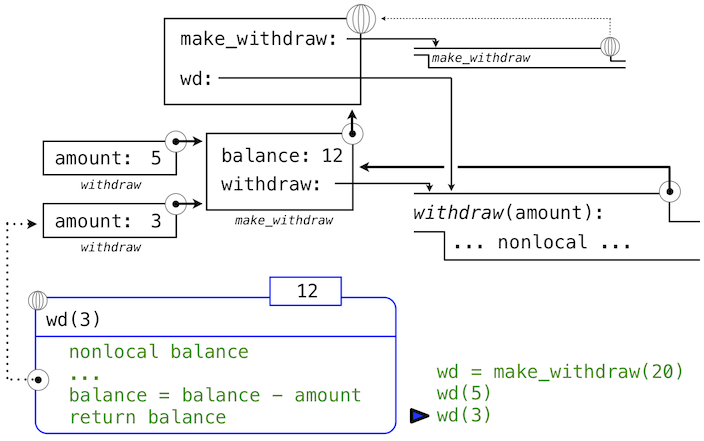
两个名称指向同一个值在世界上不常见,但我们程序中就是这样。但是,由于值会随时间改变,我们必须非常仔细来理解其它名称上的变化效果,它们可能指向这些值。
正确分析带有非局部赋值代码的关键是,记住只有函数调用可以创建新的帧。赋值语句始终改变现有帧中的绑定。这里,除非make_withdraw调用了两次,balance还是只有一个绑定。
变与不变:这些细微差别出现的原因是,通过引入修改非局部环境的非纯函数,我们改变了表达式的本质。只含有纯函数的表达式是引用透明(referentially transparent)的。如果我们将它的子表达式换成子表达式的值,它的值不会改变。
重新绑定的操作违反了引用透明的条件,因为它们不仅仅返回一个值。它们修改了环境。当我们引入任意重绑定的时候,我们就会遇到一个棘手的认识论问题:它对于两个相同的值意味着什么。在我们的计算环境模型中,两个分别定义的函数并不是相同的,因为其中一个的改变并不影响另一个。
通常,只要我们不会修改数据对象,我们就可以将复合数据对象看做其部分的总和。例如,有理数可以通过提供分子和分母来确定。但是这个观点在变化出现时不再成立了,其中复合数据对象拥有一个“身份”,不同于组成它的各个部分。即使我们通过取钱来修改了余额,某个银行账户还是“相同”的银行账户。相反,我们可以让两个银行账户碰巧具有相同的余额,但它们是不同的对象。
尽管它引入了新的困难,非局部赋值是个创建模块化编程的强大工具,程序的不同部分,对应不同的环境帧,可以在程序执行中独立演化。而且,使用带有局部状态的函数,我们就能实现可变数据类型。在这一节的剩余部分,我们介绍了一些最实用的 Python 内建数据类型,以及使用带有非局部赋值的函数,来实现这些数据类型的一些方法。
2.4.4 列表
list是 Python 中最使用和灵活的数据类型。列表类似于元组,但是它是可变的。方法调用和赋值语句都可以修改列表的内容。
我们可以通过一个展示(极大简化的)扑克牌历史的例子,来介绍许多列表编辑操作。例子中的注释描述了每个方法的效果。
扑克牌发明于中国,大概在 9 世纪。早期的牌组中有三个花色,它们对应钱的三个面额。
>>> chinese_suits = ['coin', 'string', 'myriad'] # A list literal
>>> suits = chinese_suits # Two names refer to the same list
扑克牌传到欧洲(也可能通过埃及)之后,西班牙的牌组(oro)中之只保留了硬币的花色。
>>> suits.pop() # Removes and returns the final element
'myriad'
>>> suits.remove('string') # Removes the first element that equals the argument
然后又添加了三个新的花色(它们的设计和名称随时间而演化),
>>> suits.append('cup') # Add an element to the end
>>> suits.extend(['sword', 'club']) # Add all elements of a list to the end
意大利人把剑叫做“黑桃”:
>>> suits[2] = 'spade' # Replace an element
下面是传统的意大利牌组:
>>> suits
['coin', 'cup', 'spade', 'club']
我们现在在美国使用的法式变体修改了前两个:
>>> suits[0:2] = ['heart', 'diamond'] # Replace a slice
>>> suits
['heart', 'diamond', 'spade', 'club']
也存在用于插入、排序和反转列表的操作。所有这些修改操作都改变了列表的值,它们并不创建新的列表对象。
共享和身份:由于我们修改了一个列表,而不是创建新的列表,绑定到名称chinese_suits上的对象也改变了,因为它与绑定到suits上的对象是相同的列表对象。
>>> chinese_suits # This name co-refers with "suits" to the same list
['heart', 'diamond', 'spade', 'club']
列表可以使用list构造函数来复制。其中一个的改变不会影响另一个,除非它们共享相同的结构。
>>> nest = list(suits) # Bind "nest" to a second list with the same elements
>>> nest[0] = suits # Create a nested list
在最后的赋值之后,我们只剩下下面的环境,其中列表使用盒子和指针的符号来表示:
根据这个环境,修改由suites指向的列表会影响nest第一个元素的嵌套列表,但是不会影响其他元素:
>>> suits.insert(2, 'Joker') # Insert an element at index 2, shifting the rest
>>> nest
[['heart', 'diamond', 'Joker', 'spade', 'club'], 'diamond', 'spade', 'club']
与之类似,在next的第一个元素上撤销这个修改也会影响到suit。
由于这个pop方法的调用,我们返回到了上面描述的环境。
由于两个列表具有相同内容,但是实际上是不同的列表,我们需要一种手段来测试两个对象是否相同。Python 引入了两个比较运算符,叫做is和is not,测试了两个表达式实际上是否求值为同一个对象。如果两个对象的当前值相等,并且一个对象的改变始终会影响另一个,那么两个对象是同一个对象。身份是个比相等性更强的条件。
译者注:两个对象当且仅当在内存中的位置相同时为同一个对象。CPython 的实现直接比较对象的地址来确定。
>>> suits is nest[0]
True
>>> suits is ['heart', 'diamond', 'spade', 'club']
False
>>> suits == ['heart', 'diamond', 'spade', 'club']
True
最后的两个比较展示了is和==的区别,前者检查身份,而后者检查内容的相等性。
列表推导式:列表推导式使用扩展语法来创建列表,与生成器表达式的语法相似。
例如,unicodedata模块跟踪了 Unicode 字母表中每个字符的官方名称。我们可以查找与名称对应的字符,包含这些卡牌花色的字符。
>>> from unicodedata import lookup
>>> [lookup('WHITE ' + s.upper() + ' SUIT') for s in suits]
['♡', '♢', '♤', '♧']
列表推导式使用序列的接口约定增强了数据处理的范式,因为列表是一种序列数据类型。
**扩展阅读。**Dive Into Python 3 的推导式一章包含了一些示例,展示了如何使用 Python 浏览计算机的文件系统。这一章介绍了os模块,它可以列出目录的内容。这个材料并不是这门课的一部分,但是推荐给任何想要增加 Python 知识和技巧的人。
实现:列表是序列,就像元组一样。Python 语言并不提供给我们列表实现的直接方法,只提供序列抽象,和我们在这一节介绍的可变方法。为了克服这一语言层面的抽象界限,我们可以开发列表的函数式实现,再次使用递归表示。这一节也有第二个目的:加深我们对调度函数的理解。
我们会将列表实现为函数,它将一个递归列表作为自己的局部状态。列表需要有一个身份,就像任何可变值那样。特别地,我们不能使用None来表示任何空的可变列表,因为两个空列表并不是相同的值(例如,向一个列表添加元素并不会添加到另一个),但是None is None。另一方面,两个不同的函数足以区分两个两个空列表,它们都将empty_rlist作为局部状态。
我们的可变列表是个调度函数,就像我们偶对的函数式实现也是个调度函数。它检查输入“信息”是否为已知信息,并且对每个不同的输入执行相应的操作。我们的可变列表可响应五个不同的信息。前两个实现了序列抽象的行为。接下来的两个添加或删除列表的第一个元素。最后的信息返回整个列表内容的字符串表示。
>>> def make_mutable_rlist():
"""Return a functional implementation of a mutable recursive list."""
contents = empty_rlist
def dispatch(message, value=None):
nonlocal contents
if message == 'len':
return len_rlist(contents)
elif message == 'getitem':
return getitem_rlist(contents, value)
elif message == 'push_first':
contents = make_rlist(value, contents)
elif message == 'pop_first':
f = first(contents)
contents = rest(contents)
return f
elif message == 'str':
return str(contents)
return dispatch
我们也可以添加一个辅助函数,来从任何内建序列中构建函数式实现的递归列表。只需要以递归顺序添加每个元素。
>>> def to_mutable_rlist(source):
"""Return a functional list with the same contents as source."""
s = make_mutable_rlist()
for element in reversed(source):
s('push_first', element)
return s
在上面的定义中,函数reversed接受并返回可迭代值。它是使用序列的接口约定的另一个示例。
这里,我们可以构造函数式实现的列表,要注意列表自身也是个函数。
>>> s = to_mutable_rlist(suits)
>>> type(s)
<class 'function'>
>>> s('str')
"('heart', ('diamond', ('spade', ('club', None))))"
另外,我们可以像列表s传递信息来修改它的内容,比如移除第一个元素。
>>> s('pop_first')
'heart'
>>> s('str')
"('diamond', ('spade', ('club', None)))"
原则上,操作push_first和pop_first足以对列表做任意修改。我们总是可以清空整个列表,之后将它旧的内容替换为想要的结果。
消息传递:给予一些时间,我们就能实现许多实用的 Python 列表可变操作,比如extend和insert。我们有一个选择:我们可以将它们全部实现为函数,这会使用现有的消息pop_first和push_first来实现所有的改变操作。作为代替,我们也可以向dispatch函数体添加额外的elif子句,每个子句检查一个消息(例如'extend'),并且直接在contents上做出合适的改变。
第二个途径叫做消息传递,它把数据值上面所有操作的逻辑封装在一个函数中,这个函数响应不同的消息。一个使用消息传递的程序定义了调度函数,每个函数都拥有局部状态,通过传递“消息”作为第一个参数给这些函数来组织计算。消息是对应特定行为的字符串。
可以想象,在dispatch的函数体中通过名称来枚举所有这些消息非常无聊,并且易于出现错误。Python 的字典提供了一种数据类型,会帮助我们管理消息和操作之间的映射,它会在下一节中介绍。
2.4.5 字典
字典是 Python 内建数据类型,用于储存和操作对应关系。字典包含了键值对,其中键和值都可以是对象。字典的目的是提供一种抽象,用于储存和获取下标不是连续整数,而是描述性的键的值。
字符串通常用作键,因为字符串通常用于表示事物名称。这个字典字面值提供了不同罗马数字的值。
>>> numerals = {'I': 1.0, 'V': 5, 'X': 10}
我们可以使用元素选择运算符,来通过键查找值,我们之前将其用于序列。
>>> numerals['X']
10
字典的每个键最多只能拥有一个值。添加新的键值对或者修改某个键的已有值,可以使用赋值运算符来完成。
>>> numerals['I'] = 1
>>> numerals['L'] = 50
>>> numerals
{'I': 1, 'X': 10, 'L': 50, 'V': 5}
要注意,'L'并没有添加到上面输出的末尾。字典是无序的键值对集合。当我们打印字典时,键和值都以某种顺序来渲染,但是对语言的用户来说,不应假设顺序总是这样。
字典抽象也支持多种方法,来从整体上迭代字典中的内容。方法keys、values和items都返回可迭代的值。
>>> sum(numerals.values())
66
通过调用dict构造函数,键值对的列表可以转换为字典。
>>> dict([(3, 9), (4, 16), (5, 25)])
{3: 9, 4: 16, 5: 25}
字典也有一些限制:
- 字典的键不能是可变内建类型的对象。
- 一个给定的键最多只能有一个值。
第一条限制被绑定到了 Python 中字典的底层实现上。这个实现的细节并不是这门课的主题。直觉上,键告诉了 Python 应该在内存中的哪里寻找键值对;如果键发生改变,键值对就会丢失。
第二个限制是字典抽象的结果,它为储存和获取某个键的值而设计。如果字典中最多只存在一个这样的值,我们只能获取到某个键的一个值。
由字典实现的一个实用方法是get,如果键存在的话,它返回键的值,否则返回一个默认值。get的参数是键和默认值。
>>> numerals.get('A', 0)
0
>>> numerals.get('V', 0)
5
字典也拥有推导式语法,和列表和生成器表达式类似。求解字典推导式会产生新的字典对象。
>>> {x: x*x for x in range(3,6)}
{3: 9, 4: 16, 5: 25}
实现:我们可以实现一个抽象数据类型,它是一个记录的列表,与字典抽象一致。每个记录都是两个元素的列表,包含键和相关的值。
>>> def make_dict():
"""Return a functional implementation of a dictionary."""
records = []
def getitem(key):
for k, v in records:
if k == key:
return v
def setitem(key, value):
for item in records:
if item[0] == key:
item[1] = value
return
records.append([key, value])
def dispatch(message, key=None, value=None):
if message == 'getitem':
return getitem(key)
elif message == 'setitem':
setitem(key, value)
elif message == 'keys':
return tuple(k for k, _ in records)
elif message == 'values':
return tuple(v for _, v in records)
return dispatch
同样,我们使用了传递方法的消息来组织我们的实现。我们已经支持了四种消息:getitem、setitem、keys和values。要查找某个键的值,我们可以迭代这些记录来寻找一个匹配的键。要插入某个键的值,我们可以迭代整个记录来观察是否已经存在带有这个键的记录。如果没有,我们会构造一条新的记录。如果已经有了带有这个键的记录,我们将这个记录的值设为新的值。
我们现在可以使用我们的实现来储存和获取值。
>>> d = make_dict()
>>> d('setitem', 3, 9)
>>> d('setitem', 4, 16)
>>> d('getitem', 3)
9
>>> d('getitem', 4)
16
>>> d('keys')
(3, 4)
>>> d('values')
(9, 16)
这个字典实现并不为快速的记录检索而优化,因为每个响应getitem消息都必须迭代整个records列表。内建的字典类型更加高效。
2.4.6 示例:传播约束
可变数据允许我们模拟带有变化的系统,也允许我们构建新的抽象类型。在这个延伸的实例中,我们组合了非局部赋值、列表和字典来构建一个基于约束的系统,支持多个方向上的计算。将程序表达为约束是一种声明式编程,其中程序员声明需要求解的问题结构,但是抽象了问题解决方案如何计算的细节。
计算机程序通常组织为单方向的计算,它在预先设定的参数上执行操作,来产生合理的输出。另一方面,我们通常希望根据数量上的关系对系统建模。例如,我们之前考虑过理想气体定律,它通过波尔兹曼常数k关联了理想气体的气压p,体积v,数量n以及温度t。
p * v = n * k * t
这样一个方程并不是单方向的。给定任何四个数量,我们可以使用这个方程来计算第五个。但将这个方程翻译为某种传统的计算机语言会强迫我们选择一个数量,根据其余四个计算出来。所以计算气压的函数应该不能用于计算温度,即使二者的计算通过相同的方程完成。
这一节中,我们从零开始设计线性计算的通用模型。我们定义了数量之间的基本约束,例如adder(a, b, c)会严格保证数学关系a + b = c。
我们也定义了组合的手段,使基本约束可以被组合来表达更复杂的关系。这样,我们的程序就像一种编程语言。我们通过构造网络来组合约束,其中约束由连接器连接。连接器是一种对象,它“持有”一个值,并且可能会参与一个或多个约束。
例如,我们知道华氏和摄氏温度的关系是:
9 * c = 5 * (f - 32)
这个等式是c和f之间的复杂约束。这种约束可以看做包含adder、multiplier和contant约束的网络。
这张图中,我们可以看到,左边是一个带有三个终端的乘法器盒子,标记为a,b和c。它们将乘法器连接到网络剩余的部分:终端a链接到了连接器celsius上,它持有摄氏温度。终端b链接到了连接器w上,w也链接到持有9的盒子上。终端c,被乘法器盒子约束为a和b的乘积,链接到另一个乘法器盒子上,它的b链接到常数5上,以及它的a连接到了求和约束的一项上。
这个网络上的计算会如下进行:当连接器被提供一个值时(被用户或被链接到它的约束器),它会唤醒所有相关的约束(除了刚刚唤醒的约束)来通知它们它得到了一个值。每个唤醒的约束之后会调查它的连接器,来看看是否有足够的信息来为连接器求出一个值。如果可以,盒子会设置这个连接器,连接器之后会唤醒所有相关的约束,以此类推。例如,在摄氏温度和华氏温度的转换中,w、x和y会被常量盒子9、5和32立即设置。连接器会唤醒乘法器和加法器,它们判断出没有足够的信息用于处理。如果用户(或者网络的其它部分)将celsis连接器设置为某个值(比如25),最左边的乘法器会被唤醒,之后它会将u设置为25 * 9 = 225。之后u会唤醒第二个乘法器,它会将v设置为45,之后v会唤醒加法器,它将fahrenheit连接器设置为77。
使用约束系统:为了使用约束系统来计算出上面所描述的温度计算,我们首先创建了两个具名连接器,celsius和fahrenheit,通过调用make_connector构造器。
>>> celsius = make_connector('Celsius')
>>> fahrenheit = make_connector('Fahrenheit')
之后,我们将这些连接器链接到网络中,这个网络反映了上面的图示。函数make_converter组装了网络中不同的连接器和约束:
>>> def make_converter(c, f):
"""Connect c to f with constraints to convert from Celsius to Fahrenheit."""
u, v, w, x, y = [make_connector() for _ in range(5)]
multiplier(c, w, u)
multiplier(v, x, u)
adder(v, y, f)
constant(w, 9)
constant(x, 5)
constant(y, 32)
>>> make_converter(celsius, fahrenheit)
我们会使用消息传递系统来协调约束和连接器。我们不会使用函数来响应消息,而是使用字典。用于分发的字典拥有字符串类型的键,代表它接受的消息。这些键关联的值是这些消息的响应。
约束是不带有局部状态的字典。它们对消息的响应是非纯函数,这些函数会改变所约束的连接器。
连接器是一个字典,持有当前值并响应操作该值的消息。约束不会直接改变连接器的值,而是会通过发送消息来改变,于是连接器可以提醒其他约束来响应变化。这样,连接器代表了一个数值,同时封装了连接器的行为。
我们可以发送给连接器的一种消息是设置它的值。这里,我们('user')将celsius的值设置为25。
>>> celsius['set_val']('user', 25)
Celsius = 25
Fahrenheit = 77.0
不仅仅是celsius的值变成了25,它的值也在网络上传播,于是fahrenheit的值也发生变化。这些变化打印了出来,因为我们在构造这两个连接器的时候命名了它们。
现在我们可以试着将fahrenheit设置为新的值,比如212。
>>> fahrenheit['set_val']('user', 212)
Contradiction detected: 77.0 vs 212
连接器报告说,它察觉到了一个矛盾:它的值是77.0,但是有人尝试将其设置为212。如果我们真的想以新的值复用这个网络,我们可以让celsius忘掉旧的值。
>>> celsius['forget']('user')
Celsius is forgotten
Fahrenheit is forgotten
连接器celsius发现了user,一开始设置了它的值,现在又想撤销这个值,所以celsius同意丢掉这个值,并且通知了网络的其余部分。这个消息最终传播给fahrenheit,它现在发现没有理由继续相信自己的值为77。于是,它也丢掉了它的值。
现在fahrenheit没有值了,我们就可以将其设置为212:
>>> fahrenheit['set_val']('user', 212)
Fahrenheit = 212
Celsius = 100.0
这个新值在网络上传播,并强迫celsius持有值100。我们已经使用了非常相似的网络,提供fahrenheit来计算celsius,以及提供celsius来计算fahrenheit。这个无方向的计算就是基于约束的网络的特征。
实现约束系统:像我们看到的那样,连接器是字典,将消息名称映射为函数和数据值。我们将要实现响应下列消息的连接器:
connector['set_val'](source, value)表示source请求连接器将当前值设置为该值。connector['has_val']()返回连接器是否已经有了一个值。connector['val']是连接器的当前值。connector['forget'](source)告诉连接器,source请求它忘掉当前值。connector['connect'](source)告诉连接器参与新的约束source。
约束也是字典,接受来自连接器的以下两种消息:
constraint['new_val']()表示连接到约束的连接器有了新的值。constraint['forget']()表示连接到约束的连接器需要忘掉它的值。
当约束收到这些消息时,它们适当地将它们传播给其它连接器。
adder函数在两个连接器上构造了加法器约束,其中前两个连接器必须加到第三个上:a + b = c。为了支持多方向的约束传播,加法器必须也规定从c中减去a会得到b,或者从c中减去b会得到a。
>>> from operator import add, sub
>>> def adder(a, b, c):
"""The constraint that a + b = c."""
return make_ternary_constraint(a, b, c, add, sub, sub)
我们希望实现一个通用的三元(三个方向)约束,它使用三个连接器和三个函数来创建约束,接受new_val和forget消息。消息的响应是局部函数,它放在叫做constraint的字典中。
>>> def make_ternary_constraint(a, b, c, ab, ca, cb):
"""The constraint that ab(a,b)=c and ca(c,a)=b and cb(c,b) = a."""
def new_value():
av, bv, cv = [connector['has_val']() for connector in (a, b, c)]
if av and bv:
c['set_val'](constraint, ab(a['val'], b['val']))
elif av and cv:
b['set_val'](constraint, ca(c['val'], a['val']))
elif bv and cv:
a['set_val'](constraint, cb(c['val'], b['val']))
def forget_value():
for connector in (a, b, c):
connector['forget'](constraint)
constraint = {'new_val': new_value, 'forget': forget_value}
for connector in (a, b, c):
connector['connect'](constraint)
return constraint
叫做constraint的字典是个分发字典,也是约束对象自身。它响应两种约束接收到的消息,也在对连接器的调用中作为source参数传递。
无论约束什么时候被通知,它的连接器之一拥有了值,约束的局部函数new_value都会被调用。这个函数首先检查是否a和b都拥有值,如果是这样,它告诉c将值设为函数ab的返回值,在adder中是add。约束,也就是adder对象,将自身作为source参数传递给连接器。如果a和b不同时拥有值,约束会检查a和c,以此类推。
如果约束被通知,连接器之一忘掉了它的值,它会请求所有连接器忘掉它们的值(只有由约束设置的值会被真正丢掉)。
multiplier与adder类似:
>>> from operator import mul, truediv
>>> def multiplier(a, b, c):
"""The constraint that a * b = c."""
return make_ternary_constraint(a, b, c, mul, truediv, truediv)
常量也是约束,但是它不会发送任何消息,因为它只包含一个单一的连接器,在构造的时候会设置它。
>>> def constant(connector, value):
"""The constraint that connector = value."""
constraint = {}
connector['set_val'](constraint, value)
return constraint
这三个约束足以实现我们的温度转换网络。
表示连接器:连接器表示为包含一个值的字典,但是同时拥有带有局部状态的响应函数。连接器必须跟踪向它提供当前值的informant,以及它所参与的constraints列表。
构造器make_connector是局部函数,用于设置和忘掉值,它响应来自约束的消息。
>>> def make_connector(name=None):
"""A connector between constraints."""
informant = None
constraints = []
def set_value(source, value):
nonlocal informant
val = connector['val']
if val is None:
informant, connector['val'] = source, value
if name is not None:
print(name, '=', value)
inform_all_except(source, 'new_val', constraints)
else:
if val != value:
print('Contradiction detected:', val, 'vs', value)
def forget_value(source):
nonlocal informant
if informant == source:
informant, connector['val'] = None, None
if name is not None:
print(name, 'is forgotten')
inform_all_except(source, 'forget', constraints)
connector = {'val': None,
'set_val': set_value,
'forget': forget_value,
'has_val': lambda: connector['val'] is not None,
'connect': lambda source: constraints.append(source)}
return connector
同时,连接器是一个分发字典,用于分发五个消息,约束使用它们来和连接器通信。前四个响应都是函数,最后一个响应就是值本身。
局部函数set_value在请求设置连接器的值时被调用。如果连接器当前并没有值,它会设置该值并将informant记为请求设置该值的source约束。之后连接器会提醒所有参与的约束,除了请求设置该值的约束。这通过使用下列迭代函数来完成。
>>> def inform_all_except(source, message, constraints):
"""Inform all constraints of the message, except source."""
for c in constraints:
if c != source:
c[message]()
如果一个连接器被请求忘掉它的值,它会调用局部函数forget_value,这个函数首先执行检查,来确保请求来自之前设置该值的同一个约束。如果是的话,连接器通知相关的约束来丢掉当前值。
对has_val消息的响应表示连接器是否拥有一个值。对connect消息的响应将source约束添加到约束列表中。
我们设计的约束程序引入了许多出现在面向对象编程的概念。约束和连接器都是抽象,它们通过消息来操作。当连接器的值由消息改变时,消息不仅仅改变了它的值,还对其验证(检查来源)并传播它的影响。实际上,在这一章的后面,我们会使用相似的字符串值的字典结构和函数值来实现面向对象系统。
2.5 面向对象编程
面向对象编程(OOP)是一种用于组织程序的方法,它组合了这一章引入的许多概念。就像抽象数据类型那样,对象创建了数据使用和实现之间的抽象界限。类似消息传递中的分发字典,对象响应行为请求。就像可变的数据结构,对象拥有局部状态,并且不能直接从全局环境访问。Python 对象系统提供了新的语法,更易于为组织程序实现所有这些实用的技巧。
但是对象系统不仅仅提供了便利;它也为程序设计添加了新的隐喻,其中程序中的几个部分彼此交互。每个对象将局部状态和行为绑定,以一种方式在数据抽象背后隐藏二者的复杂性。我们的约束程序的例子通过在约束和连接器之前传递消息,产生了这种隐喻。Python 对象系统使用新的途径扩展了这种隐喻,来表达程序的不同部分如何互相关联,以及互相通信。对象不仅仅会传递消息,还会和其它相同类型的对象共享行为,以及从相关的类型那里继承特性。
面向对象编程的范式使用自己的词汇来强化对象隐喻。我们已经看到了,对象是拥有方法和属性的数据值,可以通过点运算符来访问。每个对象都拥有一个类型,叫做类。Python 中可以定义新的类,就像定义函数那样。
2.5.1 对象和类
类可以用作所有类型为该类的对象的模板。每个对象都是某个特定类的实例。我们目前使用的对象都拥有内建类型,但是我们可以定义新的类,就像定义函数那样。类的定义规定了在该类的对象之间共享的属性和方法。我们会通过重新观察银行账户的例子,来介绍类的语句。
在介绍局部状态时,我们看到,银行账户可以自然地建模为拥有balance的可变值。银行账户对象应该拥有withdraw方法,在可用的情况下,它会更新账户余额,并返回所请求的金额。我们希望添加一些额外的行为来完善账户抽象:银行账户应该能够返回它的当前余额,返回账户持有者的名称,以及接受存款。
Account类允许我们创建银行账户的多个实例。创建新对象实例的动作被称为实例化该类。Python 中实例化某个类的语法类似于函数的调用语句。这里,我们使用参数'Jim'(账户持有者的名称)来调用Account。
>>> a = Account('Jim')
对象的属性是和对象关联的名值对,它可以通过点运算符来访问。属性特定于具体的对象,而不是类的所有对象,也叫做实例属性。每个Account对象都拥有自己的余额和账户持有者名称,它们是实例属性的一个例子。在更宽泛的编程社群中,实例属性可能也叫做字段、属性或者实例变量。
>>> a.holder
'Jim'
>>> a.balance
0
操作对象或执行对象特定计算的函数叫做方法。方法的副作用和返回值可能依赖或改变对象的其它属性。例如,deposit是Account对象a上的方法。它接受一个参数,即需要存入的金额,修改对象的balance属性,并返回产生的余额。
>>> a.deposit(15)
15
在 OOP 中,我们说方法可以在特定对象上调用。作为调用withdraw方法的结果,要么取钱成功,余额减少并返回,要么请求被拒绝,账户打印出错误信息。
>>> a.withdraw(10) # The withdraw method returns the balance after withdrawal
5
>>> a.balance # The balance attribute has changed
5
>>> a.withdraw(10)
'Insufficient funds'
像上面展示的那样,方法的行为取决于对象属性的改变。两次以相同参数对withdraw的调用返回了不同的结果。
2.5.2 类的定义
用户定义的类由class语句创建,它只包含单个子句。类的语句定义了类的名称和基类(会在继承那一节讨论),之后包含了定义类属性的语句组:
class <name>(<base class>):
<suite>
当类的语句被执行时,新的类会被创建,并且在当前环境第一帧绑定到<name>上。之后会执行语句组。任何名称都会在class语句的<suite>中绑定,通过def或赋值语句,创建或修改类的属性。
类通常围绕实例属性来组织,实例属性是名值对,不和类本身关联但和类的每个对象关联。通过为实例化新对象定义方法,类规定了它的对象的实例属性。
class语句的<suite>部分包含def语句,它们为该类的对象定义了新的方法。用于实例化对象的方法在 Python 中拥有特殊的名称,__init__(init两边分别有两个下划线),它叫做类的构造器。
>>> class Account(object):
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
Account的__init__方法有两个形参。第一个是self,绑定到新创建的Account对象上。第二个参数,account_holder,在被调用来实例化的时候,绑定到传给该类的参数上。
构造器将实例属性名称balance与0绑定。它也将属性名称holder绑定到account_holder上。形参account_holder是__init__方法的局部名称。另一方面,通过最后一个赋值语句绑定的名称holder是一直存在的,因为它使用点运算符被存储为self的属性。
定义了Account类之后,我们就可以实例化它:
>>> a = Account('Jim')
这个对Account类的“调用”创建了新的对象,它是Account的实例,之后以两个参数调用了构造函数__init__:新创建的对象和字符串'Jim'。按照惯例,我们使用名称self来命名构造器的第一个参数,因为它绑定到了被实例化的对象上。这个惯例在几乎所有 Python 代码中都适用。
现在,我们可以使用点运算符来访问对象的balance和holder。
>>> a.balance
0
>>> a.holder
'Jim'
身份:每个新的账户实例都有自己的余额属性,它的值独立于相同类的其它对象。
>>> b = Account('Jack')
>>> b.balance = 200
>>> [acc.balance for acc in (a, b)]
[0, 200]
为了强化这种隔离,每个用户定义类的实例对象都有个独特的身份。对象身份使用is和is not运算符来比较。
>>> a is a
True
>>> a is not b
True
虽然由同一个调用来构造,绑定到a和b的对象并不相同。通常,使用赋值将对象绑定到新名称并不会创建新的对象。
>>> c = a
>>> c is a
True
用户定义类的新对象只在类(比如Account)使用调用表达式被实例化的时候创建。
方法:对象方法也由class语句组中的def语句定义。下面,deposit和withdraw都被定义为Account类的对象上的方法:
>>> class Account(object):
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
def deposit(self, amount):
self.balance = self.balance + amount
return self.balance
def withdraw(self, amount):
if amount > self.balance:
return 'Insufficient funds'
self.balance = self.balance - amount
return self.balance
虽然方法定义和函数定义在声明方式上并没有区别,方法定义有不同的效果。由class语句中的def语句创建的函数值绑定到了声明的名称上,但是只在类的局部绑定为一个属性。这个值可以使用点运算符在类的实例上作为方法来调用。
每个方法定义同样包含特殊的首个参数self,它绑定到方法所调用的对象上。例如,让我们假设deposit在特定的Account对象上调用,并且传递了一个对象值:要存入的金额。对象本身绑定到了self上,而参数绑定到了amount上。所有被调用的方法能够通过self参数来访问对象,所以它们可以访问并操作对象的状态。
为了调用这些方法,我们再次使用点运算符,就像下面这样:
>>> tom_account = Account('Tom')
>>> tom_account.deposit(100)
100
>>> tom_account.withdraw(90)
10
>>> tom_account.withdraw(90)
'Insufficient funds'
>>> tom_account.holder
'Tom'
当一个方法通过点运算符调用时,对象本身(这个例子中绑定到了tom_account)起到了双重作用。首先,它决定了withdraw意味着哪个名称;withdraw并不是环境中的名称,而是Account类局部的名称。其次,当withdraw方法调用时,它绑定到了第一个参数self上。求解点运算符的详细过程会在下一节中展示。
2.5.3 消息传递和点表达式
方法定义在类中,而实例属性通常在构造器中赋值,二者都是面向对象编程的基本元素。这两个概念很大程度上类似于数据值的消息传递实现中的分发字典。对象使用点运算符接受消息,但是消息并不是任意的、值为字符串的键,而是类的局部名称。对象也拥有具名的局部状态值(实例属性),但是这个状态可以使用点运算符访问和操作,并不需要在实现中使用nonlocal语句。
消息传递的核心概念,就是数据值应该通过响应消息而拥有行为,这些消息和它们所表示的抽象类型相关。点运算符是 Python 的语法特征,它形成了消息传递的隐喻。使用带有内建对象系统语言的优点是,消息传递能够和其它语言特性,例如赋值语句无缝对接。我们并不需要不同的消息来“获取”和“设置”关联到局部属性名称的值;语言的语法允许我们直接使用消息名称。
点表达式:类似tom_account.deposit的代码片段叫做点表达式。点表达式包含一个表达式,一个点和一个名称:
<expression> . <name>
<expression>可为任意的 Python 有效表达式,但是<name>必须是个简单的名称(而不是求值为name的表达式)。点表达式会使用提供的<name>,对值为<expression>的对象求出属性的值。
内建的函数getattr也会按名称返回对象的属性。它是等价于点运算符的函数。使用getattr,我们就能使用字符串来查找某个属性,就像分发字典那样:
>>> getattr(tom_account, 'balance')
10
我们也可以使用hasattr测试对象是否拥有某个具名属性:
>>> hasattr(tom_account, 'deposit')
True
对象的属性包含所有实例属性,以及所有定义在类中的属性(包括方法)。方法是需要特别处理的类的属性。
方法和函数:当一个方法在对象上调用时,对象隐式地作为第一个参数传递给方法。也就是说,点运算符左边值为<expression>的对象,会自动传给点运算符右边的方法,作为第一个参数。所以,对象绑定到了参数self上。
为了自动实现self的绑定,Python 区分函数和绑定方法。我们已经在这门课的开始创建了前者,而后者在方法调用时将对象和函数组合到一起。绑定方法的值已经将第一个函数关联到所调用的实例,当方法调用时实例会被命名为self。
通过在点运算符的返回值上调用type,我们可以在交互式解释器中看到它们的差异。作为类的属性,方法只是个函数,但是作为实例属性,它是绑定方法:
>>> type(Account.deposit)
<class 'function'>
>>> type(tom_account.deposit)
<class 'method'>
这两个结果的唯一不同点是,前者是个标准的二元函数,带有参数self和amount。后者是一元方法,当方法被调用时,名称self自动绑定到了名为tom_account的对象上,而名称amount会被绑定到传递给方法的参数上。这两个值,无论函数值或绑定方法的值,都和相同的deposit函数体所关联。
我们可以以两种方式调用deposit:作为函数或作为绑定方法。在前者的例子中,我们必须为self参数显式提供实参。而对于后者,self参数已经自动绑定了。
>>> Account.deposit(tom_account, 1001) # The deposit function requires 2 arguments
1011
>>> tom_account.deposit(1000) # The deposit method takes 1 argument
2011
函数getattr的表现就像运算符那样:它的第一个参数是对象,而第二个参数(名称)是定义在类中的方法。之后,getattr返回绑定方法的值。另一方面,如果第一个参数是个类,getattr会直接返回属性值,它仅仅是个函数。
实践指南:命名惯例:类名称通常以首字母大写来编写(也叫作驼峰拼写法,因为名称中间的大写字母像驼峰)。方法名称遵循函数命名的惯例,使用以下划线分隔的小写字母。
有的时候,有些实例变量和方法的维护和对象的一致性相关,我们不想让用户看到或使用它们。它们并不是由类定义的一部分抽象,而是一部分实现。Python 的惯例规定,如果属性名称以下划线开始,它只能在方法或类中访问,而不能被类的用户访问。
2.5.4 类属性
有些属性值在特定类的所有对象之间共享。这样的属性关联到类本身,而不是类的任何独立实例。例如,让我们假设银行以固定的利率对余额支付利息。这个利率可能会改变,但是它是在所有账户中共享的单一值。
类属性由class语句组中的赋值语句创建,位于任何方法定义之外。在更宽泛的开发者社群中,类属性也被叫做类变量或静态变量。下面的类语句以名称interest为Account创建了类属性。
>>> class Account(object):
interest = 0.02 # A class attribute
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
# Additional methods would be defined here
这个属性仍旧可以通过类的任何实例来访问。
>>> tom_account = Account('Tom')
>>> jim_account = Account('Jim')
>>> tom_account.interest
0.02
>>> jim_account.interest
0.02
但是,对类属性的单一赋值语句会改变所有该类实例上的属性值。
>>> Account.interest = 0.04
>>> tom_account.interest
0.04
>>> jim_account.interest
0.04
属性名称:我们已经在我们的对象系统中引入了足够的复杂性,我们需要规定名称如何解析为特定的属性。毕竟,我们可以轻易拥有同名的类属性和实例属性。
像我们看到的那样,点运算符由表达式、点和名称组成:
<expression> . <name>
为了求解点表达式:
- 求出点左边的
<expression>,会产生点运算符的对象。 <name>会和对象的实例属性匹配;如果该名称的属性存在,会返回它的值。- 如果
<name>不存在于实例属性,那么会在类中查找<name>,这会产生类的属性值。 - 这个值会被返回,如果它是个函数,则会返回绑定方法。
在这个求值过程中,实例属性在类的属性之前查找,就像局部名称具有高于全局的优先级。定义在类中的方法,在求值过程的第三步绑定到了点运算符的对象上。在类中查找名称的过程有额外的差异,在我们引入类继承的时候就会出现。
赋值:所有包含点运算符的赋值语句都会作用于右边的对象。如果对象是个实例,那么赋值就会设置实例属性。如果对象是个类,那么赋值会设置类属性。作为这条规则的结果,对对象属性的赋值不能影响类的属性。下面的例子展示了这个区别。
如果我们向账户实例的具名属性interest赋值,我们会创建属性的新实例,它和现有的类属性具有相同名称。
>>> jim_account.interest = 0.08
这个属性值会通过点运算符返回:
>>> jim_account.interest
0.08
但是,类属性interest会保持为原始值,它可以通过所有其他账户返回。
>>> tom_account.interest
0.04
类属性interest的改动会影响tom_account,但是jim_account的实例属性不受影响。
>>> Account.interest = 0.05 # changing the class attribute
>>> tom_account.interest # changes instances without like-named instance attributes
0.05
>>> jim_account.interest # but the existing instance attribute is unaffected
0.08
2.5.5 继承
在使用 OOP 范式时,我们通常会发现,不同的抽象数据结构是相关的。特别是,我们发现相似的类在特化的程度上有区别。两个类可能拥有相似的属性,但是一个表示另一个的特殊情况。
例如,我们可能希望实现一个活期账户,它不同于标准的账户。活期账户对每笔取款都收取额外的 1,并且具有较低的利率。这里,我们演示上述行为:
>>> ch = CheckingAccount('Tom')
>>> ch.interest # Lower interest rate for checking accounts
0.01
>>> ch.deposit(20) # Deposits are the same
20
>>> ch.withdraw(5) # withdrawals decrease balance by an extra charge
14
CheckingAccount是Account的特化。在 OOP 的术语中,通用的账户会作为CheckingAccount的基类,而CheckingAccount是Account的子类(术语“父类”和“超类”通常等同于“基类”,而“派生类”通常等同于“子类”)。
子类继承了基类的属性,但是可能覆盖特定属性,包括特定的方法。使用继承,我们只需要关注基类和子类之间有什么不同。任何我们在子类未指定的东西会自动假设和基类中相同。
继承也在对象隐喻中有重要作用,不仅仅是一种实用的组织方式。继承意味着在类之间表达“is-a”关系,它和“has-a”关系相反。活期账户是(is-a)一种特殊类型的账户,所以让CheckingAccount继承Account是继承的合理使用。另一方面,银行拥有(has-a)所管理的银行账户的列表,所以二者都不应继承另一个。反之,账户对象的列表应该自然地表现为银行账户的实例属性。
2.5.6 使用继承
我们通过将基类放置到类名称后面的圆括号内来指定继承。首先,我们提供Account类的完整实现,也包含类和方法的文档字符串。
>>> class Account(object):
"""A bank account that has a non-negative balance."""
interest = 0.02
def __init__(self, account_holder):
self.balance = 0
self.holder = account_holder
def deposit(self, amount):
"""Increase the account balance by amount and return the new balance."""
self.balance = self.balance + amount
return self.balance
def withdraw(self, amount):
"""Decrease the account balance by amount and return the new balance."""
if amount > self.balance:
return 'Insufficient funds'
self.balance = self.balance - amount
return self.balance
CheckingAccount的完整实现在下面:
>>> class CheckingAccount(Account):
"""A bank account that charges for withdrawals."""
withdraw_charge = 1
interest = 0.01
def withdraw(self, amount):
return Account.withdraw(self, amount + self.withdraw_charge)
这里,我们引入了类属性withdraw_charge,它特定于CheckingAccount类。我们将一个更低的值赋给interest属性。我们也定义了新的withdraw方法来覆盖定义在Account对象中的行为。类语句组中没有更多的语句,所有其它行为都从基类Account中继承。
>>> checking = CheckingAccount('Sam')
>>> checking.deposit(10)
10
>>> checking.withdraw(5)
4
>>> checking.interest
0.01
checking.deposit表达式是用于存款的绑定方法,它定义在Account类中,当 Python 解析点表达式中的名称时,实例上并没有这个属性,它会在类中查找该名称。实际上,在类中“查找名称”的行为会在原始对象的类的继承链中的每个基类中查找。我们可以递归定义这个过程,为了在类中查找名称:
- 如果类中有带有这个名称的属性,返回属性值。
- 否则,如果有基类的话,在基类中查找该名称。
在deposit中,Python 会首先在实例中查找名称,之后在CheckingAccount类中。最后,它会在Account中查找,这里是deposit定义的地方。根据我们对点运算符的求值规则,由于deposit是在checking实例的类中查找到的函数,点运算符求值为绑定方法。这个方法以参数10调用,这会以绑定到checking对象的self和绑定到10的amount调用deposit方法。
对象的类会始终保持不变。即使deposit方法在Account类中找到,deposit以绑定到CheckingAccount实例的self调用,而不是Account的实例。
译者注:
CheckingAccount的实例也是Account的实例,这个说法是有问题的。
调用祖先:被覆盖的属性仍然可以通过类对象来访问。例如,我们可以通过以包含withdraw_charge的参数调用Account的withdraw方法,来实现CheckingAccount的withdraw方法。
要注意我们调用self.withdraw_charge而不是等价的CheckingAccount.withdraw_charge。前者的好处就是继承自CheckingAccount的类可能会覆盖支取费用。如果是这样的话,我们希望我们的withdraw实现使用新的值而不是旧的值。
2.5.7 多重继承
Python 支持子类从多个基类继承属性的概念,这是一种叫做多重继承的语言特性。
假设我们从Account继承了SavingsAccount,每次存钱的时候向客户收取一笔小费用。
>>> class SavingsAccount(Account):
deposit_charge = 2
def deposit(self, amount):
return Account.deposit(self, amount - self.deposit_charge)
之后,一个聪明的总经理设想了AsSeenOnTVAccount,它拥有CheckingAccount和SavingsAccount的最佳特性:支取和存入的费用,以及较低的利率。它将储蓄账户和活期存款账户合二为一!“如果我们构建了它”,总经理解释道,“一些人会注册并支付所有这些费用。甚至我们会给他们一美元。”
>>> class AsSeenOnTVAccount(CheckingAccount, SavingsAccount):
def __init__(self, account_holder):
self.holder = account_holder
self.balance = 1 # A free dollar!
实际上,这个实现就完整了。存款和取款都需要费用,使用了定义在CheckingAccount和SavingsAccount中的相应函数。
>>> such_a_deal = AsSeenOnTVAccount("John")
>>> such_a_deal.balance
1
>>> such_a_deal.deposit(20) # 2 fee from SavingsAccount.deposit
19
>>> such_a_deal.withdraw(5) # 1 fee from CheckingAccount.withdraw
13
就像预期那样,没有歧义的引用会正确解析:
>>> such_a_deal.deposit_charge
2
>>> such_a_deal.withdraw_charge
1
但是如果引用有歧义呢,比如withdraw方法的引用,它定义在Account和CheckingAccount中?下面的图展示了AsSeenOnTVAccount类的继承图。每个箭头都从子类指向基类。
对于像这样的简单“菱形”,Python 从左到右解析名称,之后向上。这个例子中,Python 按下列顺序检查名称,直到找到了具有该名称的属性:
AsSeenOnTVAccount, CheckingAccount, SavingsAccount, Account, object
继承顺序的问题没有正确的解法,因为我们可能会给某个派生类高于其他类的优先级。但是,任何支持多重继承的编程语言必须始终选择同一个顺序,便于语言的用户预测程序的行为。
扩展阅读:Python 使用一种叫做 C3 Method Resolution Ordering 的递归算法来解析名称。任何类的方法解析顺序都使用所有类上的mro方法来查询。
>>> [c.__name__ for c in AsSeenOnTVAccount.mro()]
['AsSeenOnTVAccount', 'CheckingAccount', 'SavingsAccount', 'Account', 'object']
这个用于查询方法解析顺序的算法并不是这门课的主题,但是 Python 的原作者使用一篇原文章的引用来描述它。
2.5.8 对象的作用
Python 对象系统为使数据抽象和消息传递更加便捷和灵活而设计。类、方法、继承和点运算符的特化语法都可以让我们在程序中形成对象隐喻,它能够提升我们组织大型程序的能力。
特别是,我们希望我们的对象系统在不同层面上促进关注分离。每个程序中的对象都封装和管理程序状态的一部分,每个类语句都定义了一些函数,它们实现了程序总体逻辑的一部分。抽象界限强制了大型程序不同层面之间的边界。
面向对象编程适合于对系统建模,这些系统拥有相互分离并交互的部分。例如,不同用户在社交网络中互动,不同角色在游戏中互动,以及不同图形在物理模拟中互动。在表现这种系统的时候,程序中的对象通常自然地映射为被建模系统中的对象,类用于表现它们的类型和关系。
另一方面,类可能不会提供用于实现特定的抽象的最佳机制。函数式抽象提供了更加自然的隐喻,用于表现输入和输出的关系。一个人不应该强迫自己把程序中的每个细微的逻辑都塞到类里面,尤其是当定义独立函数来操作数据变得十分自然的时候。函数也强制了关注分离。
类似 Python 的多范式语言允许程序员为合适的问题匹配合适的范式。为了简化程序,或使程序模块化,确定何时引入新的类,而不是新的函数,是软件工程中的重要设计技巧,这需要仔细关注。
2.6 实现类和对象
在使用面向对象编程范式时,我们使用对象隐喻来指导程序的组织。数据表示和操作的大部分逻辑都表达在类的定义中。在这一节中,我们会看到,类和对象本身可以使用函数和字典来表示。以这种方式实现对象系统的目的是展示使用对象隐喻并不需要特殊的编程语言。即使编程语言没有面向对象系统,程序照样可以面向对象。
为了实现对象,我们需要抛弃点运算符(它需要语言的内建支持),并创建分发字典,它的行为和内建对象系统的元素差不多。我们已经看到如何通过分发字典实现消息传递行为。为了完整实现对象系统,我们需要在实例、类和基类之间发送消息,它们全部都是含有属性的字典。
我们不会实现整个 Python 对象系统,它包含这篇文章没有涉及到的特性(比如元类和静态方法)。我们会专注于用户定义的类,不带有多重继承和内省行为(比如返回实例的类)。我们的实现并不遵循 Python 类型系统的明确规定。反之,它为实现对象隐喻的核心功能而设计。
2.6.1 实例
我们从实例开始。实例拥有具名属性,例如账户余额,它可以被设置或获取。我们使用分发字典来实现实例,它会响应“get”和“set”属性值消息。属性本身保存在叫做attributes的局部字典中。
就像我们在这一章的前面看到的那样,字典本身是抽象数据类型。我们使用列表来实现字典,我们使用偶对来实现列表,并且我们使用函数来实现偶对。就像我们以字典实现对象系统那样,要注意我们能够仅仅使用函数来实现对象。
为了开始我们的实现,我们假设我们拥有一个类实现,它可以查找任何不是实例部分的名称。我们将类作为参数cls传递给make_instance。
>>> def make_instance(cls):
"""Return a new object instance, which is a dispatch dictionary."""
def get_value(name):
if name in attributes:
return attributes[name]
else:
value = cls['get'](name)
return bind_method(value, instance)
def set_value(name, value):
attributes[name] = value
attributes = {}
instance = {'get': get_value, 'set': set_value}
return instance
instance是分发字典,它响应消息get和set。set消息对应 Python 对象系统的属性赋值:所有赋值的属性都直接储存在对象的局部属性字典中。在get中,如果name在局部attributes字典中不存在,那么它会在类中寻找。如果cls返回的value为函数,它必须绑定到实例上。
绑定方法值:make_instance中的get_value 使用get寻找类中的具名属性,之后调用bind_method。方法的绑定只在函数值上调用,并且它会通过将实例插入为第一个参数,从函数值创建绑定方法的值。
>>> def bind_method(value, instance):
"""Return a bound method if value is callable, or value otherwise."""
if callable(value):
def method(*args):
return value(instance, *args)
return method
else:
return value
当方法被调用时,第一个参数self通过这个定义绑定到了instance的值上。
2.6.2 类
类也是对象,在 Python 对象系统和我们这里实现的系统中都是如此。为了简化,我们假设类自己并没有类(在 Python 中,类本身也有类,几乎所有类都共享相同的类,叫做type)。类可以接受get和set消息,以及new消息。
>>> def make_class(attributes, base_class=None):
"""Return a new class, which is a dispatch dictionary."""
def get_value(name):
if name in attributes:
return attributes[name]
elif base_class is not None:
return base_class['get'](name)
def set_value(name, value):
attributes[name] = value
def new(*args):
return init_instance(cls, *args)
cls = {'get': get_value, 'set': set_value, 'new': new}
return cls
不像实例那样,类的get函数在属性未找到的时候并不查询它的类,而是查询它的base_class。类并不需要方法绑定。
实例化:make_class 中的new函数调用了init_instance,它首先创建新的实例,之后调用叫做__init__的方法。
>>> def init_instance(cls, *args):
"""Return a new object with type cls, initialized with args."""
instance = make_instance(cls)
init = cls['get']('__init__')
if init:
init(instance, *args)
return instance
最后这个函数完成了我们的对象系统。我们现在拥有了实例,它的set是局部的,但是get会回溯到它们的类中。实例在它的类中查找名称之后,它会将自己绑定到函数值上来创建方法。最后类可以创建新的(new)实例,并且在实例创建之后立即调用它们的__init__构造器。
在对象系统中,用户仅仅可以调用create_class,所有其他功能通过消息传递来使用。与之相似,Python 的对象系统由class语句来调用,它的所有其他功能都通过点表达式和对类的调用来使用。
2.6.3 使用所实现的对象
我们现在回到上一节银行账户的例子。使用我们实现的对象系统,我们就可以创建Account类,CheckingAccount子类和它们的实例。
Account类通过create_account_class 函数创建,它拥有类似于 Python class语句的结构,但是以make_class的调用结尾。
>>> def make_account_class():
"""Return the Account class, which has deposit and withdraw methods."""
def __init__(self, account_holder):
self['set']('holder', account_holder)
self['set']('balance', 0)
def deposit(self, amount):
"""Increase the account balance by amount and return the new balance."""
new_balance = self['get']('balance') + amount
self['set']('balance', new_balance)
return self['get']('balance')
def withdraw(self, amount):
"""Decrease the account balance by amount and return the new balance."""
balance = self['get']('balance')
if amount > balance:
return 'Insufficient funds'
self['set']('balance', balance - amount)
return self['get']('balance')
return make_class({'__init__': __init__,
'deposit': deposit,
'withdraw': withdraw,
'interest': 0.02})
在这个函数中,属性名称在最后设置。不像 Python 的class语句,它强制内部函数和属性名称之间的一致性。这里我们必须手动指定属性名称和值的对应关系。
Account类最终由赋值来实例化。
>>> Account = make_account_class()
之后,账户实例通过new消息来创建,它需要名称来处理新创建的账户。
>>> jim_acct = Account['new']('Jim')
之后,get消息传递给jim_acct ,来获取属性和方法。方法可以调用来更新账户余额。
>>> jim_acct['get']('holder')
'Jim'
>>> jim_acct['get']('interest')
0.02
>>> jim_acct['get']('deposit')(20)
20
>>> jim_acct['get']('withdraw')(5)
15
就像使用 Python 对象系统那样,设置实例的属性并不会修改类的对应属性:
>>> jim_acct['set']('interest', 0.04)
>>> Account['get']('interest')
0.02
继承:我们可以创建CheckingAccount子类,通过覆盖类属性的子集。在这里,我们修改withdraw方法来收取费用,并且降低了利率。
>>> def make_checking_account_class():
"""Return the CheckingAccount class, which imposes a $1 withdrawal fee."""
def withdraw(self, amount):
return Account['get']('withdraw')(self, amount + 1)
return make_class({'withdraw': withdraw, 'interest': 0.01}, Account)
在这个实现中,我们在子类的withdraw 中调用了基类Account的withdraw函数,就像在 Python 内建对象系统那样。我们可以创建子类本身和它的实例,就像之前那样:
>>> CheckingAccount = make_checking_account_class()
>>> jack_acct = CheckingAccount['new']('Jack')
它们的行为相似,构造函数也一样。每笔取款都会在特殊的withdraw函数中收费 1,并且interest也拥有新的较低值。
>>> jack_acct['get']('interest')
0.01
>>> jack_acct['get']('deposit')(20)
20
>>> jack_acct['get']('withdraw')(5)
14
我们的构建在字典上的对象系统十分类似于 Python 内建对象系统的实现。Python 中,任何用户定义类的实例,都有个特殊的__dict__属性,将对象的局部实例属性储存在字典中,就像我们的attributes字典那样。Python 的区别在于,它区分特定的特殊方法,这些方法和内建函数交互来确保那些函数能正常处理许多不同类型的参数。操作不同类型参数的函数是下一节的主题。
2.7 泛用方法
这一章中我们引入了复合数据类型,以及由构造器和选择器实现的数据抽象机制。使用消息传递,我们就能使抽象数据类型直接拥有行为。使用对象隐喻,我们可以将数据的表示和用于操作数据的方法绑定在一起,从而使数据驱动的程序模块化,并带有局部状态。
但是,我们仍然必须展示,我们的对象系统允许我们在大型程序中灵活组合不同类型的对象。点运算符的消息传递仅仅是一种用于使用多个对象构建组合表达式的方式。这一节中,我们会探索一些用于组合和操作不同类型对象的方式。
2.7.1 字符串转换
我们在这一章最开始说,对象值的行为应该类似它所表达的数据,包括产生它自己的字符串表示。数据值的字符串表示在类似 Python 的交互式语言中尤其重要,其中“读取-求值-打印”的循环需要每个值都拥有某种字符串表示形式。
字符串值为人们的信息交流提供了基础的媒介。字符序列可以在屏幕上渲染,打印到纸上,大声朗读,转换为盲文,或者以莫尔兹码广播。字符串对编程而言也非常基础,因为它们可以表示 Python 表达式。对于一个对象,我们可能希望生成一个字符串,当作为 Python 表达式解释时,求值为等价的对象。
Python 规定,所有对象都应该能够产生两种不同的字符串表示:一种是人类可解释的文本,另一种是 Python 可解释的表达式。字符串的构造函数str返回人类可读的字符串。在可能的情况下,repr函数返回一个 Python 表达式,它可以求值为等价的对象。repr的文档字符串解释了这个特性:
repr(object) -> string
Return the canonical string representation of the object.
For most object types, eval(repr(object)) == object.
在表达式的值上调用repr的结果就是 Python 在交互式会话中打印的东西。
>>> 12e12
12000000000000.0
>>> print(repr(12e12))
12000000000000.0
在不存在任何可以求值为原始值的表达式的情况中,Python 会产生一个代理:
>>> repr(min)
'<built-in function min>'
str构造器通常与repr相同,但是有时会提供更加可解释的文本表示。例如,我们可以看到str和repr对于日期的不同:
>>> from datetime import date
>>> today = date(2011, 9, 12)
>>> repr(today)
'datetime.date(2011, 9, 12)'
>>> str(today)
'2011-09-12'
repr函数的定义出现了新的挑战:我们希望它对所有数据类型都正确应用,甚至是那些在repr实现时还不存在的类型。我们希望它像一个多态函数,可以作用于许多(多)不同形式(态)的数据。
消息传递提供了这个问题的解决方案:repr函数在参数上调用叫做__repr__的函数。
>>> today.__repr__()
'datetime.date(2011, 9, 12)'
通过在用户定义的类上实现同一方法,我们就可以将repr的适用性扩展到任何我们以后创建的类。这个例子强调了消息传递的另一个普遍的好处:就是它提供了一种机制,用于将现有函数的职责范围扩展到新的对象。
str构造器以类似的方式实现:它在参数上调用了叫做__str__的方法。
>>> today.__str__()
'2011-09-12'
这些多态函数是一个更普遍原则的例子:特定函数应该作用于多种数据类型。这里举例的消息传递方法仅仅是多态函数实现家族的一员。本节剩下的部分会探索一些备选方案。
2.7.2 多重表示
使用对象或函数的数据抽象是用于管理复杂性的强大工具。抽象数据类型允许我们在数据表示和用于操作数据的函数之间构造界限。但是,在大型程序中,对于程序中的某种数据类型,提及“底层表示”可能不总是有意义。首先,一个数据对象可能有多种实用的表示,而且我们可能希望设计能够处理多重表示的系统。
为了选取一个简单的示例,复数可以用两种几乎等价的方式来表示:直角坐标(虚部和实部)以及极坐标(模和角度)。有时直角坐标形式更加合适,而有时极坐标形式更加合适。复数以两种方式表示,而操作复数的函数可以处理每种表示,这样一个系统确实比较合理。
更重要的是,大型软件系统工程通常由许多人设计,并花费大量时间,需求的主题随时间而改变。在这样的环境中,每个人都事先同意数据表示的方案是不可能的。除了隔离使用和表示的数据抽象的界限,我们需要隔离不同设计方案的界限,以及允许不同方案在一个程序中共存。进一步,由于大型程序通常通过组合已存在的模块创建,这些模块会单独设计,我们需要一种惯例,让程序员将模块递增地组合为大型系统。也就是说,不需要重复设计或实现这些模块。
我们以最简单的复数示例开始。我们会看到,消息传递在维持“复数”对象的抽象概念时,如何让我们为复数的表示设计出分离的直角坐标和极坐标表示。我们会通过使用泛用选择器为复数定义算数函数(add_complex,mul_complex)来完成它。泛用选择器可访问复数的一部分,独立于数值表示的方式。所产生的复数系统包含两种不同类型的抽象界限。它们隔离了高阶操作和低阶表示。此外,也有一个垂直的界限,它使我们能够独立设计替代的表示。

作为边注,我们正在开发一个系统,它在复数上执行算数运算,作为一个简单但不现实的使用泛用操作的例子。复数类型实际上在 Python 中已经内建了,但是这个例子中我们仍然自己实现。
就像有理数那样,复数可以自然表示为偶对。复数集可以看做带有两个正交轴,实数轴和虚数轴的二维空间。根据这个观点,复数z = x + y * i(其中i*i = -1)可以看做平面上的点,它的实数为x,虚部为y。复数加法涉及到将它们的实部和虚部相加。
对复数做乘法时,将复数以极坐标表示为模和角度更加自然。两个复数的乘积是,将一个复数按照另一个的长度作为因数拉伸,之后按照另一个的角度来旋转它的所得结果。
所以,复数有两种不同表示,它们适用于不同的操作。然而,从一些人编写使用复数的程序的角度来看,数据抽象的原则表明,所有操作复数的运算都应该可用,无论计算机使用了哪个表示。
**接口。**消息传递并不仅仅提供用于组装行为和数据的方式。它也允许不同的数据类型以不同方式响应相同消息。来自不同对象,产生相似行为的共享消息是抽象的有力手段。
像之前看到的那样,抽象数据类型由构造器、选择器和额外的行为条件定义。与之紧密相关的概念是接口,它是共享消息的集合,带有它们含义的规定。响应__repr__和__str__特殊方法的对象都实现了通用的接口,它们可以表示为字符串。
在复数的例子中,接口需要实现由四个消息组成的算数运算:real,imag,magnitude和angle。我们可以使用这些消息实现加法和乘法。
我们拥有两种复数的抽象数据类型,它们的构造器不同。
ComplexRI从实部和虚部构造复数。ComplexMA从模和角度构造复数。
使用这些消息和构造器,我们可以实现复数算数:
>>> def add_complex(z1, z2):
return ComplexRI(z1.real + z2.real, z1.imag + z2.imag)
>>> def mul_complex(z1, z2):
return ComplexMA(z1.magnitude * z2.magnitude, z1.angle + z2.angle)
术语“抽象数据类型”(ADT)和“接口”的关系是微妙的。ADT 包含构建复杂数据类的方式,以单元操作它们,并且可以选择它们的组件。在面向对象系统中,ADT 对应一个类,虽然我们已经看到对象系统并不需要实现 ADT。接口是一组与含义关联的消息,并且它可能包含选择器,也可能不包含。概念上,ADT 描述了一类东西的完整抽象表示,而接口规定了可能在许多东西之间共享的行为。
属性(Property):我们希望交替使用复数的两种类型,但是对于每个数值来说,储存重复的信息比较浪费。我们希望储存实部-虚部的表示或模-角度的表示之一。
Python 拥有一个简单的特性,用于从零个参数的函数凭空计算属性(Attribute)。@property装饰器允许函数不使用标准调用表达式语法来调用。根据实部和虚部的复数实现展示了这一点。
>>> from math import atan2
>>> class ComplexRI(object):
def __init__(self, real, imag):
self.real = real
self.imag = imag
@property
def magnitude(self):
return (self.real ** 2 + self.imag ** 2) ** 0.5
@property
def angle(self):
return atan2(self.imag, self.real)
def __repr__(self):
return 'ComplexRI({0}, {1})'.format(self.real, self.imag)
第二种使用模和角度的实现提供了相同接口,因为它响应同一组消息。
>>> from math import sin, cos
>>> class ComplexMA(object):
def __init__(self, magnitude, angle):
self.magnitude = magnitude
self.angle = angle
@property
def real(self):
return self.magnitude * cos(self.angle)
@property
def imag(self):
return self.magnitude * sin(self.angle)
def __repr__(self):
return 'ComplexMA({0}, {1})'.format(self.magnitude, self.angle)
实际上,我们的add_complex和mul_complex实现并没有完成;每个复数类可以用于任何算数函数的任何参数。对象系统不以任何方式显式连接(例如通过继承)这两种复数类型,这需要给个注解。我们已经通过在两个类之间共享一组通用的消息和接口,实现了复数抽象。
>>> from math import pi
>>> add_complex(ComplexRI(1, 2), ComplexMA(2, pi/2))
ComplexRI(1.0000000000000002, 4.0)
>>> mul_complex(ComplexRI(0, 1), ComplexRI(0, 1))
ComplexMA(1.0, 3.141592653589793)
编码多种表示的接口拥有良好的特性。用于每个表示的类可以独立开发;它们只需要遵循它们所共享的属性名称。这个接口同时是递增的。如果另一个程序员希望向相同程序添加第三个复数表示,它们只需要使用相同属性创建另一个类。
特殊方法:内建的算数运算符可以以一种和repr相同的方式扩展;它们是特殊的方法名称,对应 Python 的算数、逻辑和序列运算的运算符。
为了使我们的代码更加易读,我们可能希望在执行复数加法和乘法时直接使用+和*运算符。将下列方法添加到两个复数类中,这会让这些运算符,以及opertor模块中的add和mul函数可用。
>>> ComplexRI.__add__ = lambda self, other: add_complex(self, other)
>>> ComplexMA.__add__ = lambda self, other: add_complex(self, other)
>>> ComplexRI.__mul__ = lambda self, other: mul_complex(self, other)
>>> ComplexMA.__mul__ = lambda self, other: mul_complex(self, other)
现在,我们可以对我们的自定义类使用中缀符号。
>>> ComplexRI(1, 2) + ComplexMA(2, 0)
ComplexRI(3.0, 2.0)
>>> ComplexRI(0, 1) * ComplexRI(0, 1)
ComplexMA(1.0, 3.141592653589793)
扩展阅读:为了求解含有+运算符的表达式,Python 会检查表达式的左操作数和右操作数上的特殊方法。首先,Python 会检查左操作数的__add__方法,之后检查右操作数的__radd__方法。如果二者之一被发现,这个方法会以另一个操作数的值作为参数调用。
在 Python 中求解含有任何类型的运算符的表达值具有相似的协议,这包括切片符号和布尔运算符。Python 文档列出了完整的运算符的方法名称。Dive into Python 3 的特殊方法名称一章描述了许多用于 Python 解释器的细节。
2.7.3 泛用函数
我们的复数实现创建了两种数据类型,它们对于add_complex和mul_complex函数能够互相转换。现在我们要看看如何使用相同的概念,不仅仅定义不同表示上的泛用操作,也能用来定义不同种类、并且不共享通用结构的参数上的泛用操作。
我们到目前为止已定义的操作将不同的数据类型独立对待。所以,存在用于加法的独立的包,比如两个有理数或者两个复数。我们没有考虑到的是,定义类型界限之间的操作很有意义,比如将复数与有理数相加。我们经历了巨大的痛苦,引入了程序中各个部分的界限,便于让它们可被独立开发和理解。
我们希望以某种精确控制的方式引入跨类型的操作。便于在不严重违反抽象界限的情况下支持它们。在我们希望的结果之间可能有些矛盾:我们希望能够将有理数与复数相加,也希望能够使用泛用的add函数,正确处理所有数值类型。同时,我们希望隔离复数和有理数的细节,来维持程序的模块化。
让我们使用 Python 内建的对象系统重新编写有理数的实现。像之前一样,我们在较低层级将有理数储存为分子和分母。
>>> from fractions import gcd
>>> class Rational(object):
def __init__(self, numer, denom):
g = gcd(numer, denom)
self.numer = numer // g
self.denom = denom // g
def __repr__(self):
return 'Rational({0}, {1})'.format(self.numer, self.denom)
这个新的实现中的有理数的加法和乘法和之前类似。
>>> def add_rational(x, y):
nx, dx = x.numer, x.denom
ny, dy = y.numer, y.denom
return Rational(nx * dy + ny * dx, dx * dy)
>>> def mul_rational(x, y):
return Rational(x.numer * y.numer, x.denom * y.denom)
类型分发:一种处理跨类型操作的方式是为每种可能的类型组合设计不同的函数,操作可用于这种类型。例如,我们可以扩展我们的复数实现,使其提供函数用于将复数与有理数相加。我们可以使用叫做类型分发的机制更通用地提供这个功能。
类型分发的概念是,编写一个函数,首先检测接受到的参数类型,之后执行适用于这种类型的代码。Python 中,对象类型可以使用内建的type函数来检测。
>>> def iscomplex(z):
return type(z) in (ComplexRI, ComplexMA)
>>> def isrational(z):
return type(z) == Rational
这里,我们依赖一个事实,每个对象都知道自己的类型,并且我们可以使用Python 的type函数来获取类型。即使type函数不可用,我们也能根据Rational,ComplexRI和ComplexMA来实现iscomplex和isrational。
现在考虑下面的add实现,它显式检查了两个参数的类型。我们不会在这个例子中显式使用 Python 的特殊方法(例如__add__)。
>>> def add_complex_and_rational(z, r):
return ComplexRI(z.real + r.numer/r.denom, z.imag)
>>> def add(z1, z2):
"""Add z1 and z2, which may be complex or rational."""
if iscomplex(z1) and iscomplex(z2):
return add_complex(z1, z2)
elif iscomplex(z1) and isrational(z2):
return add_complex_and_rational(z1, z2)
elif isrational(z1) and iscomplex(z2):
return add_complex_and_rational(z2, z1)
else:
return add_rational(z1, z2)
这个简单的类型分发方式并不是递增的,它使用了大量的条件语句。如果另一个数值类型包含在程序中,我们需要使用新的语句重新实现add。
我们可以创建更灵活的add实现,通过以字典实现类型分发。要想扩展add的灵活性,第一步是为我们的类创建一个tag集合,抽离两个复数集合的实现。
>>> def type_tag(x):
return type_tag.tags[type(x)]
>>> type_tag.tags = {ComplexRI: 'com', ComplexMA: 'com', Rational: 'rat'}
下面,我们使用这些类型标签来索引字典,字典中储存了数值加法的不同方式。字典的键是类型标签的元素,值是类型特定的加法函数。
>>> def add(z1, z2):
types = (type_tag(z1), type_tag(z2))
return add.implementations[types](z1, z2)
add函数的定义本身没有任何功能;它完全地依赖于一个叫做add.implementations的字典去实现泛用加法。我们可以构建如下的字典。
>>> add.implementations = {}
>>> add.implementations[('com', 'com')] = add_complex
>>> add.implementations[('com', 'rat')] = add_complex_and_rational
>>> add.implementations[('rat', 'com')] = lambda x, y: add_complex_and_rational(y, x)
>>> add.implementations[('rat', 'rat')] = add_rational
这个基于字典的分发方式是递增的,因为add.implementations和type_tag.tags总是可以扩展。任何新的数值类型可以将自己“安装”到现存的系统中,通过向这些字典添加新的条目。
当我们向系统引入一些复杂性时,我们现在拥有了泛用、可扩展的add函数,可以处理混合类型。
>>> add(ComplexRI(1.5, 0), Rational(3, 2))
ComplexRI(3.0, 0)
>>> add(Rational(5, 3), Rational(1, 2))
Rational(13, 6)
数据导向编程:我们基于字典的add实现并不是特定于加法的;它不包含任何加法的直接逻辑。它只实现了加法操作,因为我们碰巧将implementations字典和函数放到一起来执行加法。
更通用的泛用算数操作版本会将任意运算符作用于任意类型,并且使用字典来储存多种组合的实现。这个完全泛用的实现方法的方式叫做数据导向编程。在我们这里,我们可以实现泛用加法和乘法,而不带任何重复的逻辑。
>>> def apply(operator_name, x, y):
tags = (type_tag(x), type_tag(y))
key = (operator_name, tags)
return apply.implementations[key](x, y)
在泛用的apply函数中,键由操作数的名称(例如add),和参数类型标签的元组构造。我们下面添加了对复数和有理数的乘法支持。
>>> def mul_complex_and_rational(z, r):
return ComplexMA(z.magnitude * r.numer / r.denom, z.angle)
>>> mul_rational_and_complex = lambda r, z: mul_complex_and_rational(z, r)
>>> apply.implementations = {('mul', ('com', 'com')): mul_complex,
('mul', ('com', 'rat')): mul_complex_and_rational,
('mul', ('rat', 'com')): mul_rational_and_complex,
('mul', ('rat', 'rat')): mul_rational}
我们也可以使用字典的update方法,从add中将加法实现添加到apply。
>>> adders = add.implementations.items()
>>> apply.implementations.update({('add', tags):fn for (tags, fn) in adders})
既然已经在单一的表中支持了 8 种不同的实现,我们可以用它来更通用地操作有理数和复数。
>>> apply('add', ComplexRI(1.5, 0), Rational(3, 2))
ComplexRI(3.0, 0)
>>> apply('mul', Rational(1, 2), ComplexMA(10, 1))
ComplexMA(5.0, 1)
这个数据导向的方式管理了跨类型运算符的复杂性,但是十分麻烦。使用这个一个系统,引入新类型的开销不仅仅是为类型编写方法,还有实现跨类型操作的函数的构造和安装。这个负担比起定义类型本身的操作需要更多代码。
当类型分发机制和数据导向编程的确能创造泛用函数的递增实现时,它们就不能有效隔离实现的细节。独立数值类型的实现者需要在编程跨类型操作时考虑其他类型。组合有理数和复数严格上并不是每种类型的范围。在类型中制定一致的责任分工政策,在带有多种类型和跨类型操作的系统设计中是大势所趋。
强制转换:在完全不相关的类型执行完全不相关的操作的一般情况中,实现显式的跨类型操作,尽管可能非常麻烦,是人们所希望的最佳方案。幸运的是,我们有时可以通过利用类型系统中隐藏的额外结构来做得更好。不同的数据类通常并不是完全独立的,可能有一些方式,一个类型的对象通过它会被看做另一种类型的对象。这个过程叫做强制转换。例如,如果我们被要求将一个有理数和一个复数通过算数来组合,我们可以将有理数看做虚部为零的复数。通过这样做,我们将问题转换为两个复数组合的问题,这可以通过add_complex和mul_complex由经典的方法处理。
通常,我们可以通过设计强制转换函数来实现这个想法。强制转换函数将一个类型的对象转换为另一个类型的等价对象。这里是一个典型的强制转换函数,它将有理数转换为虚部为零的复数。
>>> def rational_to_complex(x):
return ComplexRI(x.numer/x.denom, 0)
现在,我们可以定义强制转换函数的字典。这个字典可以在更多的数值类型引入时扩展。
>>> coercions = {('rat', 'com'): rational_to_complex}
任意类型的数据对象不可能转换为每个其它类型的对象。例如,没有办法将任意的复数强制转换为有理数,所以在coercions字典中应该没有这种转换的实现。
使用coercions字典,我们可以编写叫做coerce_apply的函数,它试图将参数强制转换为相同类型的值,之后仅仅调用运算符。coerce_apply 的实现字典不包含任何跨类型运算符的实现。
>>> def coerce_apply(operator_name, x, y):
tx, ty = type_tag(x), type_tag(y)
if tx != ty:
if (tx, ty) in coercions:
tx, x = ty, coercions[(tx, ty)](x)
elif (ty, tx) in coercions:
ty, y = tx, coercions[(ty, tx)](y)
else:
return 'No coercion possible.'
key = (operator_name, tx)
return coerce_apply.implementations[key](x, y)
coerce_apply的implementations仅仅需要一个类型标签,因为它们假设两个值都共享相同的类型标签。所以,我们仅仅需要四个实现来支持复数和有理数上的泛用算数。
>>> coerce_apply.implementations = {('mul', 'com'): mul_complex,
('mul', 'rat'): mul_rational,
('add', 'com'): add_complex,
('add', 'rat'): add_rational}
就地使用这些实现,coerce_apply 可以代替apply。
>>> coerce_apply('add', ComplexRI(1.5, 0), Rational(3, 2))
ComplexRI(3.0, 0)
>>> coerce_apply('mul', Rational(1, 2), ComplexMA(10, 1))
ComplexMA(5.0, 1.0)
这个强制转换的模式比起显式定义跨类型运算符的方式具有优势。虽然我们仍然需要编程强制转换函数来关联类型,我们仅仅需要为每对类型编写一个函数,而不是为每个类型组合和每个泛用方法编写不同的函数。我们所期望的是,类型间的合理转换仅仅依赖于类型本身,而不是要调用的特定操作。
强制转换的扩展会带来进一步的优势。一些更复杂的强制转换模式并不仅仅试图将一个类型强制转换为另一个,而是将两个不同类型强制转换为第三个。想一想菱形和长方形:每个都不是另一个的特例,但是两个都可以看做平行四边形。另一个强制转换的扩展是迭代的强制转换,其中一个数据类型通过媒介类型被强制转换为另一种。一个整数可以转换为一个实数,通过首先转换为有理数,接着将有理数转换为实数。这种方式的链式强制转换降低了程序所需的转换函数总数。
虽然它具有优势,强制转换也有潜在的缺陷。例如,强制转换函数在调用时会丢失信息。在我们的例子中,有理数是精确表示,但是当它们转换为复数时会变得近似。
一些编程语言拥有内建的强制转换函数。实际上,Python 的早期版本拥有对象上的__coerce__特殊方法。最后,内建强制转换系统的复杂性并不能支持它的使用,所以被移除了。反之,特定的操作按需强制转换它们的参数。运算符被实现为用户定义类上的特殊方法,比如__add__和__mul__。这完全取决于你,取决于用户来决定是否使用类型分发,数据导向编程,消息传递,或者强制转换来在你的程序中实现泛用函数。
第三章 计算机程序的构造和解释
3.1 引言
第一章和第二章描述了编程的两个基本元素:数据和函数之间的紧密联系。我们看到了高阶函数如何将函数当做数据操作。我们也看到了数据可以使用消息传递和对象系统绑定行为。我们已经学到了组织大型程序的技巧,例如函数抽象,数据抽象,类的继承,以及泛用函数。这些核心概念构成了坚实的基础,来构建模块化,可维护和可扩展的程序。
这一章专注于编程的第三个基本元素:程序自身。Python 程序只是文本的集合。只有通过解释过程,我们才可以基于文本执行任何有意义的计算。类似 Python 的编程语言很实用,因为我们可以定义解释器,它是一个执行 Python 求值和执行过程的程序。把它看做编程中最基本的概念并不夸张。解释器只是另一个程序,它确定编程语言中表达式的意义。
接受这一概念,需要改变我们自己作为程序员的印象。我们需要将自己看做语言的设计者,而不只是由他人设计的语言用户。
3.1.1 编程语言
实际上,我们可以将许多程序看做一些语言的解释器。例如,上一章的约束传播器拥有自己的原语和组合方式。约束语言是十分专用的:它提供了一种声明式的方式来描述数学关系的特定种类,而不是一种用于描述计算的完全通用的语言。虽然我们已经设计了某种语言,这章的材料会极大扩展我们可解释的语言范围。
编程语言在语法结构、特性和应用领域上差别很大。在通用编程语言中,函数定义和函数调用的结构无处不在。另一方法,存在不包含对象系统、高阶函数或类似while和for语句的控制结构的强大的编程语言。为了展示语言可以有多么不同,我们会引入Logo作为强大并且具有表现力的编程语言的例子,它包含非常少的高级特性。
这一章中,我们会学习解释器的设计,以及在执行程序时,它们所创建的计算过程。为通用语言设计解释器的想法可能令人畏惧。毕竟,解释器是执行任何可能计算的程序,取决于它们的输入。但是,典型的解释器拥有简洁的通用结构:两个可变的递归函数,第一个求解环境中的表达式,第二个在参数上调用函数。
这些函数都是递归的,因为它们互相定义:调用函数需要求出函数体的表达式,而求出表达式可能涉及到调用一个或多个函数。这一章接下来的两节专注于递归函数和数据结构,它们是理解解释器设计的基础。这一章的结尾专注于两个新的编程语言,以及为其实现解释器的任务。
3.2 函数和所生成的过程
函数是计算过程的局部演化模式。它规定了过程的每个阶段如何构建在之前的阶段之上。我们希望能够创建有关过程整体行为的语句,而过程的局部演化由一个或多个函数指定。这种分析通常非常困难,但是我们至少可以试图描述一些典型的过程演化模式。
在这一章中,我们会检测一些用于简单函数所生成过程的通用“模型”。我们也会研究这些过程消耗重要的计算资源,例如时间和空间的比例。
3.2.1 递归函数
如果函数的函数体直接或者间接自己调用自己,那么这个函数是递归的。也就是说,递归函数的执行过程可能需要再次调用这个函数。Python 中的递归函数不需要任何特殊的语法,但是它们的确需要一些注意来正确定义。
作为递归函数的介绍,我们以将英文单词转换为它的 Pig Latin 等价形式开始。Pig Latin 是一种隐语:对英文单词使用一种简单、确定的转换来掩盖单词的含义。Thomas Jefferson 据推测是先行者。英文单词的 Pig Latin 等价形式将辅音前缀(可能为空)从开头移动到末尾,并且添加-ay元音。所以,pun会变成unpay,stout会变成outstay,all会变成allay。
>>> def pig_latin(w):
"""Return the Pig Latin equivalent of English word w."""
if starts_with_a_vowel(w):
return w + 'ay'
return pig_latin(w[1:] + w[0])
>>> def starts_with_a_vowel(w):
"""Return whether w begins with a vowel."""
return w[0].lower() in 'aeiou'
这个定义背后的想法是,一个以辅音开头的字符串的 Pig Latin 变体和另一个字符串的 Pig Latin 变体相同:它通过将第一个字母移到末尾来创建。于是,sending的 Pig Latin 变体就和endings的变体(endingsay)相同。smother的 Pig Latin 变体和mothers的变体(othersmay)相同。而且,将辅音从开头移动到末尾会产生带有更少辅音前缀的更简单的问题。在sending的例子中,将s移动到末尾会产生以元音开头的单词,我们的任务就完成了。
即使pig_latin函数在它的函数体中调用,pig_latin的定义是完整且正确的。
>>> pig_latin('pun')
'unpay'
能够基于函数自身来定义函数的想法可能十分令人混乱:“循环”定义如何有意义,这看起来不是很清楚,更不用说让计算机来执行定义好的过程。但是,我们能够准确理解递归函数如何使用我们的计算环境模型来成功调用。环境的图示和描述pig_latin('pun')求值的表达式树展示在下面:
Python 求值过程的步骤产生如下结果:
pig_latin的def语句 被执行,其中:- 使用函数体创建新的
pig_latin函数对象,并且 - 将名称
pig_latin在当前(全局)帧中绑定到这个函数上。
- 使用函数体创建新的
starts_with_a_vowel的def语句类似地执行。- 求出
pig_latin('pun')的调用表达式,通过- 求出运算符和操作数子表达式,通过
- 查找绑定到
pig_latin函数的pig_latin名称 - 对字符串对象
'pun'求出操作数字符串字面值
- 查找绑定到
- 在参数
'pun'上调用pig_latin函数,通过- 添加扩展自全局帧的局部帧
- 将形参
w绑定到当前帧的实参'pun'上。 - 在以当前帧起始的环境中执行
pig_latin的函数体- 最开始的条件语句没有效果,因为头部表达式求值为
False - 求出最后的返回表达式
pig_latin(w[1:] + w[0]),通过- 查找绑定到
pig_latin函数的pig_latin名称 - 对字符串对象
'pun'求出操作数表达式 - 在参数
'unp'上调用pig_latin,它会从pig_latin函数体中的条件语句组返回预期结果。
- 查找绑定到
- 最开始的条件语句没有效果,因为头部表达式求值为
- 求出运算符和操作数子表达式,通过
就像这个例子所展示的那样,虽然递归函数具有循环特征,他仍旧正确调用。pig_latin函数调用了两次,但是每次都带有不同的参数。虽然第二个调用来自pig_latin自己的函数体,但由名称查找函数会成功,因为名称pig_latin在它的函数体执行前的环境中绑定。
这个例子也展示了 Python 的递归函数的求值过程如何与递归函数交互,来产生带有许多嵌套步骤的复杂计算过程,即使函数定义本身可能包含非常少的代码行数。
3.2.2 剖析递归函数
许多递归函数的函数体中都存在通用模式。函数体以基本条件开始,它是一个条件语句,为需要处理的最简单的输入定义函数行为。在pig_latin的例子中,基本条件对任何以元音开头的单词成立。这个时候,只需要返回末尾附加ay的参数。一些递归函数会有多重基本条件。
基本条件之后是一个或多个递归调用。递归调用有特定的特征:它们必须简化原始问题。在pig_latin的例子中,w中最开始辅音越多,就需要越多的处理工作。在递归调用pig_latin(w[1:] + w[0])中,我们在一个具有更少初始辅音的单词上调用pig_latin -- 这就是更简化的问题。每个成功的pig_latin调用都会更加简化,直到满足了基本条件:一个没有初始辅音的单词。
递归调用通过逐步简化问题来表达计算。与我们在过去使用过的迭代方式相比,它们通常以不同方式来解决问题。考虑用于计算n的阶乘的函数fact,其中fact(4)计算了4! = 4·3·2·1 = 24。
使用while语句的自然实现会通过将每个截至n的正数相乘来求出结果。
>>> def fact_iter(n):
total, k = 1, 1
while k <= n:
total, k = total * k, k + 1
return total
>>> fact_iter(4)
24
另一方面,阶乘的递归实现可以以fact(n-1)(一个更简单的问题)来表示fact(n)。递归的基本条件是问题的最简形式:fact(1)是1。
>>> def fact(n):
if n == 1:
return 1
return n * fact(n-1)
>>> fact(4)
24
函数的正确性可以轻易通过阶乘函数的标准数学定义来验证。
(n − 1)! = (n − 1)·(n − 2)· ... · 1
n! = n·(n − 1)·(n − 2)· ... · 1
n! = n·(n − 1)!
这两个阶乘函数在概念上不同。迭代的函数通过将每个式子,从基本条件1到最终的总数逐步相乘来构造结果。另一方面,递归函数直接从最终的式子n和简化的问题fact(n-1)构造结果。
将fact函数应用于更简单的问题实例,来展开递归的同时,结果最终由基本条件构建。下面的图示展示了递归如何向fact传入1而终止,以及每个调用的结果如何依赖于下一个调用,直到满足了基本条件。
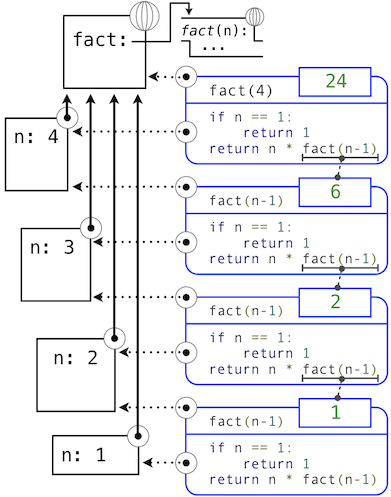
虽然我们可以使用我们的计算模型展开递归,通常把递归调用看做函数抽象更清晰一些。也就是说,我们不应该关心fact(n-1)如何在fact的函数体中实现;我们只需要相信它计算了n-1的阶乘。将递归调用看做函数抽象叫做递归的“信仰飞跃”(leap of faith)。我们以函数自身来定义函数,但是仅仅相信更简单的情况在验证函数正确性时会正常工作。这个例子中我们相信,fact(n-1)会正确计算(n-1)!;我们只需要检查,如果满足假设n!是否正确计算。这样,递归函数正确性的验证就变成了一种归纳证明。
函数fact_iter和fact也不一样,因为前者必须引入两个额外的名称,total和k,它们在递归实现中并不需要。通常,迭代函数必须维护一些局部状态,它们会在计算过程中改变。在任何迭代的时间点上,状态刻画了已完成的结果,以及未完成的工作总量。例如,当k为3且total为2时,就还剩下两个式子没有处理,3和4。另一方面,fact由单一参数n来刻画。计算的状态完全包含在表达式树的结果中,它的返回值起到total的作用,并且在不同的帧中将n绑定到不同的值上,而不是显式跟踪k。
递归函数可以更加依赖于解释器本身,通过将计算状态储存为表达式树和环境的一部分,而不是显式使用局部帧中的名称。出于这个原因,递归函数通常易于定义,因为我们不需要试着弄清必须在迭代中维护的局部状态。另一方面,学会弄清由递归函数实现的计算过程,需要一些练习。
3.2.3 树形递归
另一个递归的普遍模式叫做树形递归。例如,考虑斐波那契序列的计算,其中每个数值都是前两个的和。
>>> def fib(n):
if n == 1:
return 0
if n == 2:
return 1
return fib(n-2) + fib(n-1)
>>> fib(6)
5
这个递归定义和我们之前的尝试有很大关系:它准确反映了斐波那契数的相似定义。考虑求出fib(6)所产生的计算模式,它展示在下面。为了计算fib(6),我们需要计算fib(5)和fib(4)。为了计算fib(5),我们需要计算fib(4)和fib(3)。通常,这个演化过程看起来像一棵树(下面的图并不是完整的表达式树,而是简化的过程描述;一个完整的表达式树也拥有同样的结构)。在遍历这棵树的过程中,每个蓝点都表示斐波那契数的已完成计算。
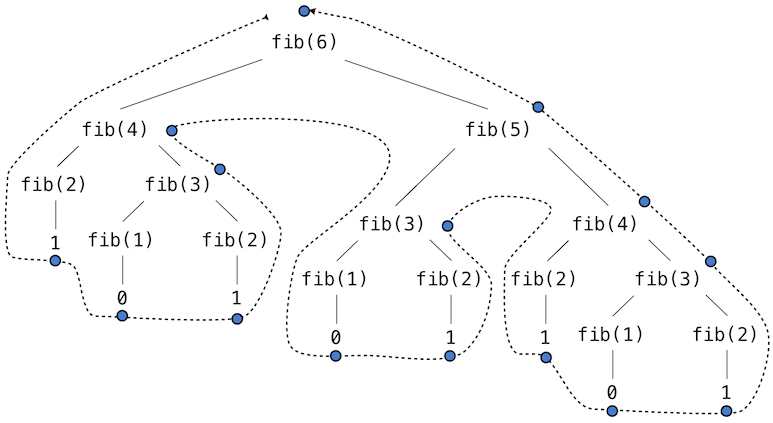
调用自身多次的函数叫做树形递归。以树形递归为原型编写的函数十分有用,但是用于计算斐波那契数则非常糟糕,因为它做了很多重复的计算。要注意整个fib(4)的计算是重复的,它几乎是一半的工作量。实际上,不难得出函数用于计算fib(1)和fib(2)(通常是树中的叶子数量)的时间是fib(n+1)。为了弄清楚这有多糟糕,我们可以证明fib(n)的值随着n以指数方式增长。所以,这个过程的步骤数量随输入以指数方式增长。
我们已经见过斐波那契数的迭代实现,出于便利在这里贴出来:
>>> def fib_iter(n):
prev, curr = 1, 0 # curr is the first Fibonacci number.
for _ in range(n-1):
prev, curr = curr, prev + curr
return curr
这里我们必须维护的状态由当前值和上一个斐波那契数组成。for语句也显式跟踪了迭代数量。这个定义并没有像递归方式那样清晰反映斐波那契数的数学定义。但是,迭代实现中所需的计算总数只是线性,而不是指数于n的。甚至对于n的较小值,这个差异都非常大。
然而我们不应该从这个差异总结出,树形递归的过程是没有用的。当我们考虑层次数据结构,而不是数值上的操作时,我们发现树形递归是自然而强大的工具。而且,树形过程可以变得更高效。
记忆:用于提升重复计算的递归函数效率的机制叫做记忆。记忆函数会为任何之前接受的参数储存返回值。fib(4)的第二次调用不会执行与第一次同样的复杂过程,而是直接返回第一次调用的已储存结果。
记忆函数可以自然表达为高阶函数,也可以用作装饰器。下面的定义为之前的已计算结果创建缓存,由被计算的参数索引。在这个实现中,这个字典的使用需要记忆函数的参数是不可变的。
>>> def memo(f):
"""Return a memoized version of single-argument function f."""
cache = {}
def memoized(n):
if n not in cache:
cache[n] = f(n)
return cache[n]
return memoized
>>> fib = memo(fib)
>>> fib(40)
63245986
由记忆函数节省的所需的计算时间总数在这个例子中是巨大的。被记忆的递归函数fib和迭代函数fib_iter都只需要线性于输入n的时间总数。为了计算fib(40),fib的函数体只执行 40 次,而不是无记忆递归中的 102,334,155 次。
空间:为了理解函数所需的空间,我们必须在我们的计算模型中规定内存如何使用,保留和回收。在求解表达式过程中,我们必须保留所有活动环境和所有这些环境引用的值和帧。如果环境为表达式树当前分支中的一些表达式提供求值上下文,那么它就是活动环境。
例如,当求值fib时,解释器按序计算之前的每个值,遍历树形结构。为了这样做,它只需要在计算的任何时间点,跟踪树中在当前节点之前的那些节点。用于求出剩余节点的内存可以被回收,因为它不会影响未来的计算。通常,树形递归所需空间与树的深度成正比。
下面的图示描述了由求解fib(3)生成的表达式树。在求解fib最初调用的返回表达式的过程中,fib(n-2)被求值,产生值0。一旦这个值计算出来,对应的环境帧(标为灰色)就不再需要了:它并不是活动环境的一部分。所以,一个设计良好的解释器会回收用于储存这个帧的内存。另一方面,如果解释器当前正在求解fib(n-1),那么由这次fib调用(其中n为2)创建的环境是活动的。与之对应,最开始在3上调用fib所创建的环境也是活动的,因为这个值还没有成功计算出来。
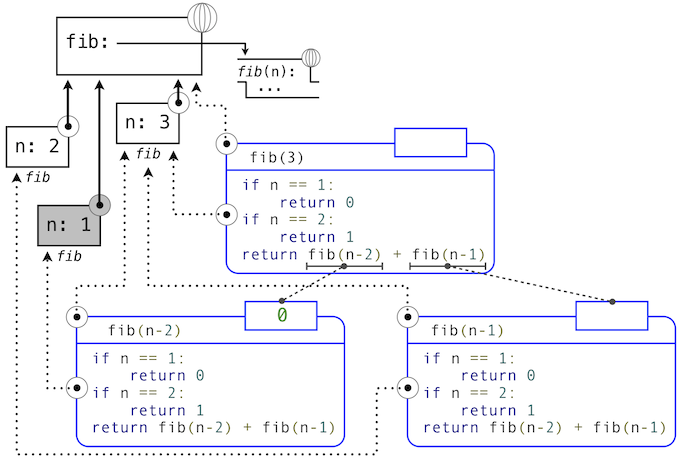
在memo的例子中,只要一些名称绑定到了活动环境中的某个函数上,关联到所返回函数(它包含cache)的环境必须保留。cache字典中的条目数量随传递给fib的唯一参数数量线性增长,它的规模线性于输入。另一方面,迭代实现只需要两个数值来在计算过程中跟踪:prev和curr,所以是常数大小。
我们使用记忆函数的例子展示了编程中的通用模式,即通常可以通过增加所用空间来减少计算时间,反之亦然。
3.2.4 示例:找零
考虑下面这个问题:如果给你半美元、四分之一美元、十美分、五美分和一美分,一美元有多少种找零的方式?更通常来说,我们能不能编写一个函数,使用一系列货币的面额,计算有多少种方式为给定的金额总数找零?
这个问题可以用递归函数简单解决。假设我们认为可用的硬币类型以某种顺序排列,假设从大到小排列。
使用n种硬币找零的方式为:
- 使用所有除了第一种之外的硬币为
a找零的方式,以及 - 使用
n种硬币为更小的金额a - d找零的方式,其中d是第一种硬币的面额。
为了弄清楚为什么这是正确的,可以看出,找零方式可以分为两组,不使用第一种硬币的方式,和使用它们的方式。所以,找零方式的总数等于不使用第一种硬币为该金额找零的方式数量,加上使用第一种硬币至少一次的方式数量。而后者的数量等于在使用第一种硬币之后,为剩余的金额找零的方式数量。
因此,我们可以递归将给定金额的找零问题,归约为使用更少种类的硬币为更小的金额找零的问题。仔细考虑这个归约原则,并且说服自己,如果我们规定了下列基本条件,我们就可以使用它来描述算法:
- 如果
a正好是零,那么有一种找零方式。 - 如果
a小于零,那么有零种找零方式。 - 如果
n小于零,那么有零种找零方式。
我们可以轻易将这个描述翻译成递归函数:
>>> def count_change(a, kinds=(50, 25, 10, 5, 1)):
"""Return the number of ways to change amount a using coin kinds."""
if a == 0:
return 1
if a < 0 or len(kinds) == 0:
return 0
d = kinds[0]
return count_change(a, kinds[1:]) + count_change(a - d, kinds)
>>> count_change(100)
292
count_change函数生成树形递归过程,和fib的首个实现一样,它是重复的。它会花费很长时间来计算出292,除非我们记忆这个函数。另一方面,设计迭代算法来计算出结果的方式并不是那么明显,我们将它留做一个挑战。
3.2.5 增长度
前面的例子表明,不同过程在花费的时间和空间计算资源上有显著差异。我们用于描述这个差异的便捷方式,就是使用增长度的概念,来获得当输入变得更大时,过程所需资源的大致度量。
令n为度量问题规模的参数,R(n)为处理规模为n的问题的过程所需的资源总数。在我们前面的例子中,我们将n看做给定函数所要计算出的数值。但是还有其他可能。例如,如果我们的目标是计算某个数值的平方根近似值,我们会将n看做所需的有效位数的数量。通常,有一些问题相关的特性可用于分析给定的过程。与之相似,R(n)可用于度量所用的内存总数,所执行的基本的机器操作数量,以及其它。在一次只执行固定数量操作的计算中,用于求解表达式的所需时间,与求值过程中执行的基本机器操作数量成正比。
我们说,R(n)具有Θ(f(n))的增长度,写作R(n)=Θ(f(n))(读作“theta f(n)”),如果存在独立于n的常数k1和k2,那么对于任何足够大的n值:
k1·f(n) <= R(n) <= k2·f(n)
也就是说,对于较大的n,R(n)的值夹在两个具有f(n)规模的值之间:
- 下界
k1·f(n),以及 - 上界
k2·f(n)。
例如,计算n!所需的步骤数量与n成正比,所以这个过程的所需步骤以Θ(n)增长。我们也看到了,递归实现fact的所需空间以Θ(n)增长。与之相反,迭代实现fact_iter 花费相似的步骤数量,但是所需的空间保持不变。这里,我们说这个空间以Θ(1)增长。
我们的树形递归的斐波那契数计算函数fib 的步骤数量,随输入n指数增长。尤其是,我们可以发现,第 n 个斐波那契数是距离φ^(n-2)/√5的最近整数,其中φ是黄金比例:
φ = (1 + √5)/2 ≈ 1.6180
我们也表示,步骤数量随返回值增长而增长,所以树形递归过程需要Θ(φ^n)的步骤,它的一个随n指数增长的函数。
增长度只提供了过程行为的大致描述。例如,需要n^2个步骤的过程和需要1000·n^2个步骤的过程,以及需要3·n^2+10·n+17个步骤的过程都拥有Θ(n^2)的增长度。在特定的情况下,增长度的分析过于粗略,不能在函数的两个可能实现中做出判断。
但是,增长度提供了实用的方法,来表示在改变问题规模的时候,我们应如何预期过程行为的改变。对于Θ(n)(线性)的过程,使规模加倍只会使所需的资源总数加倍。对于指数的过程,每一点问题规模的增长都会使所用资源以固定因数翻倍。接下来的例子展示了一个增长度为对数的算法,所以使问题规模加倍,只会使所需资源以固定总数增加。
3.2.6 示例:求幂
考虑对给定数值求幂的问题。我们希望有一个函数,它接受底数b和正整数指数n作为参数,并计算出b^n。一种方式就是通过递归定义:
b^n = b·b^(n-1)
b^0 = 1
这可以翻译成递归函数:
>>> def exp(b, n):
if n == 0:
return 1
return b * exp(b, n-1)
这是个线性的递归过程,需要Θ(n)的步骤和空间。就像阶乘那样,我们可以编写等价的线性迭代形式,它需要相似的步骤数量,但只需要固定的空间。
>>> def exp_iter(b, n):
result = 1
for _ in range(n):
result = result * b
return result
我们可以以更少的步骤求幂,通过逐次平方。例如,我们这样计算b^8:
b·(b·(b·(b·(b·(b·(b·b))))))
我们可以使用三次乘法来计算它:
b^2 = b·b
b^4 = b^2·b^2
b^8 = b^4·b^4
这个方法对于 2 的幂的指数工作良好。我们也可以使用这个递归规则,在求幂中利用逐步平方的优点:
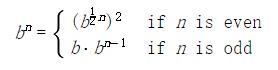
我们同样可以将这个方式表达为递归函数:
>>> def square(x):
return x*x
>>> def fast_exp(b, n):
if n == 0:
return 1
if n % 2 == 0:
return square(fast_exp(b, n//2))
else:
return b * fast_exp(b, n-1)
>>> fast_exp(2, 100)
1267650600228229401496703205376
fast_exp所生成的过程的空间和步骤数量随n以对数方式增长。为了弄清楚它,可以看出,使用fast_exp计算b^2n比计算b^n只需要一步额外的乘法操作。于是,我们能够计算的指数大小,在每次新的乘法操作时都会(近似)加倍。所以,计算n的指数所需乘法操作的数量,增长得像以2为底n的对数那样慢。这个过程拥有Θ(log n)的增长度。Θ(log n)和Θ(n)之间的差异在n非常大时变得显著。例如,n为1000时,fast_exp 仅仅需要14个乘法操作,而不是1000。
3.3 递归数据结构
在第二章中,我们引入了偶对的概念,作为一种将两个对象结合为一个对象的机制。我们展示了偶对可以使用内建元素来实现。偶对的封闭性表明偶对的每个元素本身都可以为偶对。
这种封闭性允许我们实现递归列表的数据抽象,它是我们的第一种序列类型。递归列表可以使用递归函数最为自然地操作,就像它们的名称和结构表示的那样。在这一节中,我们会讨论操作递归列表和其它递归结构的自定义的函数。
3.3.1 处理递归列表
递归列表结构将列表表示为首个元素和列表的剩余部分的组合。我们之前使用函数实现了递归列表,但是现在我们可以使用类来重新实现。下面,长度(__len__)和元素选择(__getitem__)被重写来展示处理递归列表的典型模式。
>>> class Rlist(object):
"""A recursive list consisting of a first element and the rest."""
class EmptyList(object):
def __len__(self):
return 0
empty = EmptyList()
def __init__(self, first, rest=empty):
self.first = first
self.rest = rest
def __repr__(self):
args = repr(self.first)
if self.rest is not Rlist.empty:
args += ', {0}'.format(repr(self.rest))
return 'Rlist({0})'.format(args)
def __len__(self):
return 1 + len(self.rest)
def __getitem__(self, i):
if i == 0:
return self.first
return self.rest[i-1]
__len__和__getitem__的定义实际上是递归的,虽然不是那么明显。Python 内建函数len在自定义对象的参数上调用时会寻找叫做__len__的方法。与之类似,下标运算符会寻找叫做__getitem__的方法。于是,这些定义最后会调用对象自身。剩余部分上的递归调用是递归列表处理的普遍模式。这个递归列表的类定义与 Python 的内建序列和打印操作能够合理交互。
>>> s = Rlist(1, Rlist(2, Rlist(3)))
>>> s.rest
Rlist(2, Rlist(3))
>>> len(s)
3
>>> s[1]
2
创建新列表的操作能够直接使用递归来表示。例如,我们可以定义extend_rlist函数,它接受两个递归列表作为参数并将二者的元素组合到新列表中。
>>> def extend_rlist(s1, s2):
if s1 is Rlist.empty:
return s2
return Rlist(s1.first, extend_rlist(s1.rest, s2))
>>> extend_rlist(s.rest, s)
Rlist(2, Rlist(3, Rlist(1, Rlist(2, Rlist(3)))))
与之类似,在递归列表上映射函数展示了相似的模式:
>>> def map_rlist(s, fn):
if s is Rlist.empty:
return s
return Rlist(fn(s.first), map_rlist(s.rest, fn))
>>> map_rlist(s, square)
Rlist(1, Rlist(4, Rlist(9)))
过滤操作包括额外的条件语句,但是也拥有相似的递归结构。
>>> def filter_rlist(s, fn):
if s is Rlist.empty:
return s
rest = filter_rlist(s.rest, fn)
if fn(s.first):
return Rlist(s.first, rest)
return rest
>>> filter_rlist(s, lambda x: x % 2 == 1)
Rlist(1, Rlist(3))
列表操作的递归实现通常不需要局部赋值或者while语句。反之,递归列表可以作为函数调用的结果来拆分和构造。所以,它们拥有步骤数量和所需空间的线性增长度。
3.3.2 层次结构
层次结构产生于数据的封闭特性,例如,元组可以包含其它元组。考虑这个数值1到4的嵌套表示。
>>> ((1, 2), 3, 4)
((1, 2), 3, 4)
这个元组是个长度为 3 的序列,它的第一个元素也是一个元组。这个嵌套结构的盒子和指针的图示表明,它可以看做拥有四个叶子的树,每个叶子都是一个数值。
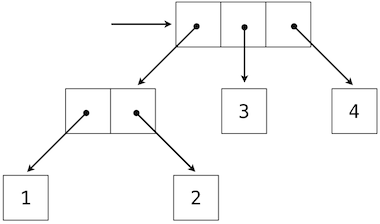
在树中,每个子树本身都是一棵树。作为基本条件,任何本身不是元组的元素都是一个简单的树,没有任何枝干。也就是说,所有数值都是树,就像在偶对(1, 2)和整个结构中那样。
递归是用于处理树形结构的自然工具,因为我们通常可以将树的操作降至枝干的操作,它会相应产生枝干的枝干的操作,以此类推,直到我们到达了树的叶子。例如,我们可以实现count_leaves函数,它返回树的叶子总数。
>>> t = ((1, 2), 3, 4)
>>> count_leaves(t)
4
>>> big_tree = ((t, t), 5)
>>> big_tree
((((1, 2), 3, 4), ((1, 2), 3, 4)), 5)
>>> count_leaves(big_tree)
9
正如map是用于处理序列的强大工具,映射和递归一起为树的操作提供了强大而通用的计算形式。例如,我们可以使用高阶递归函数map_tree 将树的每个叶子平方,它的结构类似于count_leaves。
>>> def map_tree(tree, fn):
if type(tree) != tuple:
return fn(tree)
return tuple(map_tree(branch, fn) for branch in tree)
>>> map_tree(big_tree, square)
((((1, 4), 9, 16), ((1, 4), 9, 16)), 25)
内部值:上面描述的树只在叶子上存在值。另一个通用的树形结构表示也在树的内部节点上存在值。我们使用类来表示这种树。
>>> class Tree(object):
def __init__(self, entry, left=None, right=None):
self.entry = entry
self.left = left
self.right = right
def __repr__(self):
args = repr(self.entry)
if self.left or self.right:
args += ', {0}, {1}'.format(repr(self.left), repr(self.right))
return 'Tree({0})'.format(args)
例如,Tree类可以为fib的递归实现表示表达式树中计算的值。fib函数用于计算斐波那契数。下面的函数fib_tree(n)返回Tree,它将第 n 个斐波那契树作为entry,并将所有之前计算出来的斐波那契数存入它的枝干中。
>>> def fib_tree(n):
"""Return a Tree that represents a recursive Fibonacci calculation."""
if n == 1:
return Tree(0)
if n == 2:
return Tree(1)
left = fib_tree(n-2)
right = fib_tree(n-1)
return Tree(left.entry + right.entry, left, right)
>>> fib_tree(5)
Tree(3, Tree(1, Tree(0), Tree(1)), Tree(2, Tree(1), Tree(1, Tree(0), Tree(1))))
这个例子表明,表达式树可以使用树形结构编程表示。嵌套表达式和树形数据结构的联系,在我们这一章稍后对解释器设计的讨论中起到核心作用。
3.3.3 集合
除了列表、元组和字典之外,Python 拥有第四种容器类型,叫做set。集合字面值遵循元素以花括号闭合的数学表示。重复的元素在构造中会移除。集合是无序容器,所以打印出来的顺序可能和元素在集合字面值中的顺序不同。
>>> s = {3, 2, 1, 4, 4}
>>> s
{1, 2, 3, 4}
Python 的集合支持多种操作,包括成员测试、长度计算和标准的交集并集操作。
>>> 3 in s
True
>>> len(s)
4
>>> s.union({1, 5})
{1, 2, 3, 4, 5}
>>> s.intersection({6, 5, 4, 3})
{3, 4}
除了union和intersection,Python 的集合还支持多种其它操作。断言isdisjoint、issubset和issuperset提供了集合比较操作。集合是可变的,并且可以使用add、remove、discard和pop一次修改一个元素。额外的方法提供了多元素的修改,例如clear和update。Python 集合文档十分详细并足够易懂。
实现集合:抽象上,集合是不同对象的容器,支持成员测试、交集、并集和附加操作。向集合添加元素会返回新的集合,它包含原始集合的所有元素,如果没有重复的话,也包含新的元素。并集和交集运算返回出现在任意一个或两个集合中的元素构成的集合。就像任何数据抽象那样,我们可以随意实现任何集合表示上的任何函数,只要它们提供这种行为。
在这章的剩余部分,我们会考虑三个实现集合的不同方式,它们在表示上不同。我们会通过分析集合操作的增长度,刻画这些不同表示的效率。我们也会使用这一章之前的Rlist和Tree类,它们可以编写用于集合元素操作的简单而优雅的递归解决方案。
作为无序序列的集合:一种集合的表示方式是看做没有出现多于一次的元素的序列。空集由空序列来表示。成员测试会递归遍历整个列表。
>>> def empty(s):
return s is Rlist.empty
>>> def set_contains(s, v):
"""Return True if and only if set s contains v."""
if empty(s):
return False
elif s.first == v:
return True
return set_contains(s.rest, v)
>>> s = Rlist(1, Rlist(2, Rlist(3)))
>>> set_contains(s, 2)
True
>>> set_contains(s, 5)
False
这个set_contains 的实现需要Θ(n)的时间来测试元素的成员性,其中n是集合s的大小。使用这个线性时间的成员测试函数,我们可以将元素添加到集合中,也是线性时间。
>>> def adjoin_set(s, v):
"""Return a set containing all elements of s and element v."""
if set_contains(s, v):
return s
return Rlist(v, s)
>>> t = adjoin_set(s, 4)
>>> t
Rlist(4, Rlist(1, Rlist(2, Rlist(3))))
那么问题来了,我们应该在设计表示时关注效率。计算两个集合set1和set2的交集需要成员测试,但是这次每个set1的元素必须测试set2中的成员性,对于两个大小为n的集合,这会产生步骤数量的平方增长度Θ(n^2)。
>>> def intersect_set(set1, set2):
"""Return a set containing all elements common to set1 and set2."""
return filter_rlist(set1, lambda v: set_contains(set2, v))
>>> intersect_set(t, map_rlist(s, square))
Rlist(4, Rlist(1))
在计算两个集合的并集时,我们必须小心避免两次包含任意一个元素。union_set 函数也需要线性数量的成员测试,同样会产生包含Θ(n^2)步骤的过程。
>>> def union_set(set1, set2):
"""Return a set containing all elements either in set1 or set2."""
set1_not_set2 = filter_rlist(set1, lambda v: not set_contains(set2, v))
return extend_rlist(set1_not_set2, set2)
>>> union_set(t, s)
Rlist(4, Rlist(1, Rlist(2, Rlist(3))))
作为有序元组的集合:一种加速我们的集合操作的方式是修改表示,使集合元素递增排列。为了这样做,我们需要一些比较两个对象的方式,使我们能判断哪个更大。Python 中,许多不同对象类型都可以使用<和>运算符比较,但是我们会专注于这个例子中的数值。我们会通过将元素递增排列来表示数值集合。
有序的一个优点会在set_contains体现:在检查对象是否存在时,我们不再需要扫描整个集合。如果我们到达了大于要寻找的元素的集合元素,我们就知道这个元素不在集合中:
>>> def set_contains(s, v):
if empty(s) or s.first > v:
return False
elif s.first == v:
return True
return set_contains(s.rest, v)
>>> set_contains(s, 0)
False
这节省了多少步呢?最坏的情况中,我们所寻找的元素可能是集合中最大的元素,所以步骤数量和无序表示相同。另一方面,如果我们寻找许多不同大小的元素,我们可以预料到有时我们可以在列表开头的位置停止搜索,其它情况下我们仍旧需要检测整个列表。平均上我们应该需要检测集合中一半的元素。所以,步骤数量的平均值应该是n/2。这还是Θ(n)的增长度,但是它确实会在平均上为我们节省之前实现的一半步骤数量。
我们可以通过重新实现intersect_set获取更加可观的速度提升。在无序表示中,这个操作需要Θ(n^2)的步骤,因为我们对set1的每个元素执行set2上的完整扫描。但是使用有序的实现,我们可以使用更加机智的方式。我们同时迭代两个集合,跟踪set1中的元素e1和set2中的元素e2。当e1和e2相等时,我们在交集中添加该元素。
但是,假设e1小于e2,由于e2比set2的剩余元素更小,我们可以立即推断出e1不会出现在set2剩余部分的任何位置,因此也不会出现在交集中。所以,我们不再需要考虑e1,我们将它丢弃并来到set1的下一个元素。当e2 < e1时,我们可以使用相似的逻辑来步进set2中的元素。下面是这个函数:
>>> def intersect_set(set1, set2):
if empty(set1) or empty(set2):
return Rlist.empty
e1, e2 = set1.first, set2.first
if e1 == e2:
return Rlist(e1, intersect_set(set1.rest, set2.rest))
elif e1 < e2:
return intersect_set(set1.rest, set2)
elif e2 < e1:
return intersect_set(set1, set2.rest)
>>> intersect_set(s, s.rest)
Rlist(2, Rlist(3))
为了估计这个过程所需的步骤数量,观察每一步我们都缩小了至少集合的一个元素的大小。所以,所需的步骤数量最多为set1和set2的大小之和,而不是无序表示所需的大小之积。这是Θ(n)而不是Θ(n^2)的增长度 -- 即使集合大小适中,它也是一个相当可观的加速。例如,两个大小为100的集合的交集需要 200步,而不是无序表示的 10000 步。
表示为有序序列的集合的添加和并集操作也以线性时间计算。这些实现都留做练习。
作为二叉树的集合:我们可以比有序列表表示做得更好,通过将几个元素重新以树的形式排列。我们使用之前引入的Tree类。树根的entry持有集合的一个元素。left分支的元素包括所有小于树根元素的元素。right分支的元素包括所有大于树根元素的元素。下面的图展示了一些树,它们表示集合{1, 3, 5, 7, 9, 11}。相同的集合可能会以不同形式的树来表示。有效表示所需的唯一条件就是所有left子树的元素应该小于entry,并且所有right子树的元素应该大于它。
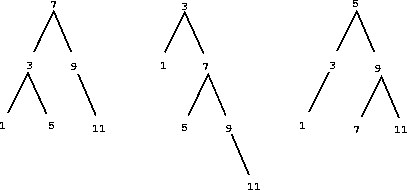
树形表示的优点是:假设我们打算检查v是否在集合中。我们通过将v于entry比较开始。如果v小于它,我们就知道了我们只需要搜索left子树。如果v大于它,我们只需要搜索right子树。现在如果树是“平衡”的,每个这些子树都约为整个的一半大小。所以,每一步中我们都可以将大小为n的树的搜索问题降至搜索大小为n/2的子树。由于树的大小在每一步减半,我们应该预料到,用户搜索树的步骤以Θ(log n)增长。比起之前的表示,它的速度对于大型集合有可观的提升。set_contains 函数利用了树形集合的有序结构:
>>> def set_contains(s, v):
if s is None:
return False
elif s.entry == v:
return True
elif s.entry < v:
return set_contains(s.right, v)
elif s.entry > v:
return set_contains(s.left, v)
向集合添加元素与之类似,并且也需要Θ(log n)的增长度。为了添加值v,我们将v与entry比较,来决定v应该添加到right还是left分支,以及是否已经将v添加到了合适的分支上。我们将这个新构造的分支与原始的entry和其它分支组合。如果v等于entry,我们就可以返回这个节点。如果我们被要求将v添加到空的树中,我们会生成一个Tree,它包含v作为entry,并且left和right都是空的分支。下面是这个函数:
>>> def adjoin_set(s, v):
if s is None:
return Tree(v)
if s.entry == v:
return s
if s.entry < v:
return Tree(s.entry, s.left, adjoin_set(s.right, v))
if s.entry > v:
return Tree(s.entry, adjoin_set(s.left, v), s.right)
>>> adjoin_set(adjoin_set(adjoin_set(None, 2), 3), 1)
Tree(2, Tree(1), Tree(3))
搜索该树可以以对数步骤数量执行,我们这个叙述基于树是“平衡”的假设。也就是说,树的左子树和右子树都拥有相同数量的相应元素,使每个子树含有母树一半的元素。但是我们如何确定,我们构造的树就是平衡的呢?即使我们以一颗平衡树开始,使用adjoin_set添加元素也会产生不平衡的结果。由于新添加的元素位置取决于如何将元素与集合中的已有元素比较,我们可以预测,如果我们“随机”添加元素到树中,树在平均上就会趋向于平衡。
但是这不是一个保证。例如,如果我们以空集开始,并向序列中添加 1 到 7,我们就会在最后得到很不平衡的树,其中所有左子树都是空的,所以它与简单的有序列表相比并没有什么优势。一种解决这个问题的方式是定义一种操作,它将任意的树转换为具有相同元素的平衡树。我们可以在每个adjoin_set操作之后执行这个转换来保证我们的集合是平衡的。
交集和并集操作可以在树形集合上以线性时间执行,通过将它们转换为有序的列表,并转换回来。细节留做练习。
Python 集合实现:Python 内建的set类型并没有使用上述任意一种表示。反之,Python 使用了一种实现,它的成员测试和添加操作是(近似)常量时间的,基于一种叫做哈希(散列)的机制,这是其它课程的话题。内建的 Python 集合不能包含可变的数据类型,例如列表、字典或者其它集合。为了能够嵌套集合,Python 也提供了一种内建的不可变frozenset 类,除了可变操作和运算符之外,它拥有和set相同的方法。
3.4 异常
程序员必须总是留意程序中可能出现的错误。例子数不胜数:一个函数可能不会收到它预期的信息,必需的资源可能会丢失,或者网络上的连接可能丢失。在设计系统时,程序员必须预料到可能产生的异常情况并且采取适当地措施来处理它们。
处理程序中的错误没有单一的正确方式。为提供一些持久性服务而设计的程序,例如 Web 服务器 应该对错误健壮,将它们记录到日志中为之后考虑,而且在尽可能长的时间内继续接受新的请求。另一方面,Python 解释器通过立即终止以及打印错误信息来处理错误,便于程序员在错误发生时处理它。在任何情况下,程序员必须决定程序如何对异常条件做出反应。
异常是这一节的话题,它为程序的错误处理提供了通用的机制。产生异常是一种技巧,终止程序正常执行流,发射异常情况产生的信号,并直接返回到用于响应异常情况的程序的封闭部分。Python 解释器每次在检测到语句或表达式错误时抛出异常。用户也可以使用raise或assert语句来抛出异常。
抛出异常:异常是一个对象实例,它的类直接或间接继承自BaseException类。第一章引入的assert语句产生AssertionError类的异常。通常,异常实例可以使用raise语句来抛出。raise语句的通用形式在 Python 文档中描述。raise的最常见的作用是构造异常实例并抛出它。
>>> raise Exception('An error occurred')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
Exception: an error occurred
当异常产生时,当前代码块的语句不会继续执行。除非异常被解决了(下面会描述),解释器会直接返回到“读取-求值-打印”交互式循环中,或者在 Python 以文件参数启动的情况下会完全终止。此外,解释器会打印栈回溯,它是结构化的文本块,描述了执行分支中的一系列嵌套的活动函数,它们是异常产生的位置。在上面的例子中,文件名称<stdin>表示异常由用户在交互式会话中产生,而不是文件中的代码。
处理异常:异常可以使用封闭的try语句来处理。try语句由多个子句组成,第一个子句以try开始,剩下的以except开始。
try:
<try suite>
except <exception class> as <name>:
<except suite>
...
当try语句执行时,<try suite>总是会立即执行。except子句组只在<try suite>执行过程中的异常产生时执行。每个except子句指定了需要处理的异常的特定类。例如,如果<exception class>是AssertionError,那么任何继承自AssertionError的类实例都会被处理,标识符<name> 绑定到所产生的异常对象上,但是这个绑定在<except suite>之外并不有效。
例如,我们可以使用try语句来处理异常,在异常发生时将x绑定为0。
>>> try:
x = 1/0
except ZeroDivisionError as e:
print('handling a', type(e))
x = 0
handling a <class 'ZeroDivisionError'>
>>> x
0
try语句能够处理产生在函数体中的异常,函数在<try suite>中调用。当异常产生时,控制流会直接跳到最近的try语句的能够处理该异常类型的<except suite>的主体中。
>>> def invert(x):
result = 1/x # Raises a ZeroDivisionError if x is 0
print('Never printed if x is 0')
return result
>>> def invert_safe(x):
try:
return invert(x)
except ZeroDivisionError as e:
return str(e)
>>> invert_safe(2)
Never printed if x is 0
0.5
>>> invert_safe(0)
'division by zero'
这个例子表明,invert中的print表达式永远不会求值,反之,控制流跳到了handler中的except子句组中。将ZeroDivisionError e强制转为字符串会得到由handler: 'division by zero'返回的人类可读的字符串。
3.4.1 异常对象
异常对象本身就带有属性,例如在assert语句中的错误信息,以及有关异常产生处的信息。用户定义的异常类可以携带额外的属性。
在第一章中,我们实现了牛顿法来寻找任何函数的零点。下面的例子定义了一个异常类,无论何时ValueError出现,它都返回迭代改进过程中所发现的最佳猜测值。数学错误(ValueError的一种)在sqrt在负数上调用时产生。这个异常由抛出IterImproveError处理,它将牛顿迭代法的最新猜测值储存为参数。
首先,我们定义了新的类,继承自Exception。
>>> class IterImproveError(Exception):
def __init__(self, last_guess):
self.last_guess = last_guess
下面,我们定义了IterImprove,我们的通用迭代改进算法的一个版本。这个版本通过抛出IterImproveError异常,储存最新的猜测值来处理任何ValueError。像之前一样,iter_improve接受两个函数作为参数,每个函数都接受单一的数值参数。update函数返回新的猜测值,而done函数返回布尔值,表明改进是否收敛到了正确的值。
>>> def iter_improve(update, done, guess=1, max_updates=1000):
k = 0
try:
while not done(guess) and k < max_updates:
guess = update(guess)
k = k + 1
return guess
except ValueError:
raise IterImproveError(guess)
最后,我们定义了find_root,它返回iter_improve的结果。iter_improve应用于由newton_update返回的牛顿更新函数。newton_update定义在第一章,在这个例子中无需任何改变。find_root的这个版本通过返回它的最后一个猜测之来处理IterImproveError。
>>> def find_root(f, guess=1):
def done(x):
return f(x) == 0
try:
return iter_improve(newton_update(f), done, guess)
except IterImproveError as e:
return e.last_guess
考虑使用find_root来寻找2 * x ** 2 + sqrt(x)的零点。这个函数的一个零点是0,但是在任何负数上求解它会产生ValueError。我们第一章的牛顿法实现会产生异常,并且不能返回任何零点的猜测值。我们的修订版实现在错误之前返回了最新的猜测值。
>>> from math import sqrt
>>> find_root(lambda x: 2*x*x + sqrt(x))
-0.030211203830201594
虽然这个近似值仍旧距离正确的答案0很远,一些应用更倾向于这个近似值而不是ValueError。
异常是另一个技巧,帮助我们将程序细节划分为模块化的部分。在这个例子中,Python 的异常机制允许我们分离迭代改进的逻辑,它在try子句组中没有发生改变,以及错误处理的逻辑,它出现在except子句中。我们也会发现,异常在使用 Python 实现解释器时是个非常实用的特性。
3.5 组合语言的解释器
运行在任何现代计算机上的软件都以多种编程语言写成。其中有物理语言,例如用于特定计算机的机器语言。这些语言涉及到基于独立储存位和原始机器指令的数据表示和控制。机器语言的程序员涉及到使用提供的硬件,为资源有限的计算构建系统和功能的高效实现。高阶语言构建在机器语言之上,隐藏了表示为位集的数据,以及表示为原始指令序列的程序的细节。这些语言拥有例如过程定义的组合和抽象的手段,它们适用于组织大规模的软件系统。
元语言抽象 -- 建立了新的语言 -- 并在所有工程设计分支中起到重要作用。它对于计算机编程尤其重要,因为我们不仅仅可以在编程中构想出新的语言,我们也能够通过构建解释器来实现它们。编程语言的解释器是一个函数,它在语言的表达式上调用,执行求解表达式所需的操作。
我们现在已经开始了技术之旅,通过这种技术,编程语言可以建立在其它语言之上。我们首先会为计算器定义解释器,它是一种受限的语言,和 Python 调用表达式具有相同的语法。我们之后会从零开始开发 Scheme 和 Logo 语言的解释器,它们都是 Lisp 的方言,Lisp 是现在仍旧广泛使用的第二老的语言。我们所创建的解释器,在某种意义上,会让我们使用 Logo 编写完全通用的程序。为了这样做,它会实现我们已经在这门课中开发的求值环境模型。
3.5.1 计算器
我们的第一种新语言叫做计算器,一种用于加减乘除的算术运算的表达式语言。计算器拥有 Python 调用表达式的语法,但是它的运算符对于所接受的参数数量更加灵活。例如,计算器运算符mul和add可接受任何数量的参数:
calc> add(1, 2, 3, 4)
10
calc> mul()
1
sub运算符拥有两种行为:传入一个运算符,它会对运算符取反。传入至少两个,它会从第一个参数中减掉剩余的参数。div运算符拥有 Python 的operator.truediv的语义,只接受两个参数。
calc> sub(10, 1, 2, 3)
4
calc> sub(3)
-3
calc> div(15, 12)
1.25
就像 Python 中那样,调用表达式的嵌套提供了计算器语言中的组合手段。为了精简符号,我们使用运算符的标准符号来代替名称:
calc> sub(100, mul(7, add(8, div(-12, -3))))
16.0
calc> -(100, *(7, +(8, /(-12, -3))))
16.0
我们会使用 Python 实现计算器解释器。也就是说,我们会编写 Python 程序来接受字符串作为输入,并返回求值结果。如果输入是符合要求的计算器表达式,结果为字符串,反之会产生合适的异常。计算器语言解释器的核心是叫做calc_eval的递归函数,它会求解树形表达式对象。
表达式树:到目前为止,我们在描述求值过程中所引用的表达式树,还是概念上的实体。我们从没有显式将表达式树表示为程序中的数据。为了编写解释器,我们必须将表达式当做数据操作。在这一章中,许多我们之前介绍过的概念都会最终以代码实现。
计算器中的基本表达式只是一个数值,类型为int或float。所有复合表达式都是调用表达式。调用表达式表示为拥有两个属性实例的Exp类。计算器的operator总是字符串:算数运算符的名称或符号。operands要么是基本表达式,要么是Exp的实例本身。
>>> class Exp(object):
"""A call expression in Calculator."""
def __init__(self, operator, operands):
self.operator = operator
self.operands = operands
def __repr__(self):
return 'Exp({0}, {1})'.format(repr(self.operator), repr(self.operands))
def __str__(self):
operand_strs = ', '.join(map(str, self.operands))
return '{0}({1})'.format(self.operator, operand_strs)
Exp实例定义了两个字符串方法。__repr__方法返回 Python 表达式,而__str__方法返回计算器表达式。
>>> Exp('add', [1, 2])
Exp('add', [1, 2])
>>> str(Exp('add', [1, 2]))
'add(1, 2)'
>>> Exp('add', [1, Exp('mul', [2, 3, 4])])
Exp('add', [1, Exp('mul', [2, 3, 4])])
>>> str(Exp('add', [1, Exp('mul', [2, 3, 4])]))
'add(1, mul(2, 3, 4))'
最后的例子演示了Exp类如何通过包含作为operands元素的Exp的实例,来表示表达式树中的层次结构。
求值:calc_eval函数接受表达式作为参数,并返回它的值。它根据表达式的形式为表达式分类,并且指导它的求值。对于计算器来说,表达式的两种句法形式是数值或调用表达式,后者是Exp的实例。数值是自求值的,它们可以直接从calc_eval中返回。调用表达式需要使用函数。
>>> def calc_eval(exp):
"""Evaluate a Calculator expression."""
if type(exp) in (int, float):
return exp
elif type(exp) == Exp:
arguments = list(map(calc_eval, exp.operands))
return calc_apply(exp.operator, arguments)
调用表达式首先通过将calc_eval函数递归映射到操作数的列表,计算出参数列表来求值。之后,在第二个函数calc_apply中,运算符会作用于这些参数上。
计算器语言足够简单,我们可以轻易地在单一函数中表达每个运算符的使用逻辑。在calc_apply中,每种条件子句对应一个运算符。
>>> from operator import mul
>>> from functools import reduce
>>> def calc_apply(operator, args):
"""Apply the named operator to a list of args."""
if operator in ('add', '+'):
return sum(args)
if operator in ('sub', '-'):
if len(args) == 0:
raise TypeError(operator + ' requires at least 1 argument')
if len(args) == 1:
return -args[0]
return sum(args[:1] + [-arg for arg in args[1:]])
if operator in ('mul', '*'):
return reduce(mul, args, 1)
if operator in ('div', '/'):
if len(args) != 2:
raise TypeError(operator + ' requires exactly 2 arguments')
numer, denom = args
return numer/denom
上面,每个语句组计算了不同运算符的结果,或者当参数错误时产生合适的TypeError。calc_apply函数可以直接调用,但是必须传入值的列表作为参数,而不是运算符表达式的列表。
>>> calc_apply('+', [1, 2, 3])
6
>>> calc_apply('-', [10, 1, 2, 3])
4
>>> calc_apply('*', [])
1
>>> calc_apply('/', [40, 5])
8.0
calc_eval的作用是,执行合适的calc_apply调用,通过首先计算操作数子表达式的值,之后将它们作为参数传入calc_apply。于是,calc_eval可以接受嵌套表达式。
>>> e = Exp('add', [2, Exp('mul', [4, 6])])
>>> str(e)
'add(2, mul(4, 6))'
>>> calc_eval(e)
26
calc_eval的结构是个类型(表达式的形式)分发的例子。第一种表达式是数值,不需要任何的额外求值步骤。通常,基本表达式不需要任何额外的求值步骤,这叫做自求值。计算器语言中唯一的自求值表达式就是数值,但是在通用语言中可能也包括字符串、布尔值,以及其它。
“读取-求值-打印”循环:和解释器交互的典型方式是“读取-求值-打印”循环(REPL),它是一种交互模式,读取表达式、对其求值,之后为用户打印出结果。Python 交互式会话就是这种循环的例子。
REPL 的实现与所使用的解释器无关。下面的read_eval_print_loop函数使用内建的input函数,从用户接受一行文本作为输入。它使用语言特定的calc_parse函数构建表达式树。calc_parse在随后的解析一节中定义。最后,它打印出对由calc_parse返回的表达式树调用calc_eval的结果。
>>> def read_eval_print_loop():
"""Run a read-eval-print loop for calculator."""
while True:
expression_tree = calc_parse(input('calc> '))
print(calc_eval(expression_tree))
read_eval_print_loop的这个版本包含所有交互式界面的必要组件。一个样例会话可能像这样:
calc> mul(1, 2, 3)
6
calc> add()
0
calc> add(2, div(4, 8))
2.5
这个循环没有实现终端或者错误处理机制。我们可以通过向用户报告错误来改进这个界面。我们也可以允许用户通过发射键盘中断信号(Control-C),或文件末尾信号(Control-D)来退出循环。为了实现这些改进,我们将原始的while语句组放在try语句中。第一个except子句处理了由calc_parse产生的SyntaxError异常,也处理了由calc_eval产生的TypeError和ZeroDivisionError异常。
>>> def read_eval_print_loop():
"""Run a read-eval-print loop for calculator."""
while True:
try:
expression_tree = calc_parse(input('calc> '))
print(calc_eval(expression_tree))
except (SyntaxError, TypeError, ZeroDivisionError) as err:
print(type(err).__name__ + ':', err)
except (KeyboardInterrupt, EOFError): # <Control>-D, etc.
print('Calculation completed.')
return
这个循环实现报告错误而不退出循环。发生错误时不退出程序,而是在错误消息之后重新开始循环可以让用户回顾他们的表达式。通过导入readline模块,用户甚至可以使用上箭头或Control-P来回忆他们之前的输入。最终的结果提供了错误信息报告的界面:
calc> add
SyntaxError: expected ( after add
calc> div(5)
TypeError: div requires exactly 2 arguments
calc> div(1, 0)
ZeroDivisionError: division by zero
calc> ^DCalculation completed.
在我们将解释器推广到计算器之外的语言时,我们会看到,read_eval_print_loop由解析函数、求值函数,和由try语句处理的异常类型参数化。除了这些修改之外,任何 REPL 都可以使用相同的结构来实现。
3.5.2 解析
解析是从原始文本输入生成表达式树的过程。解释这些表达式树是求值函数的任务,但是解析器必须提供符合格式的表达式树给求值器。解析器实际上由两个组件组成,词法分析器和语法分析器。首先,词法分析器将输入字符串拆成标记(token),它们是语言的最小语法单元,就像名称和符号那样。其次,语法分析器从这个标记序列中构建表达式树。
>>> def calc_parse(line):
"""Parse a line of calculator input and return an expression tree."""
tokens = tokenize(line)
expression_tree = analyze(tokens)
if len(tokens) > 0:
raise SyntaxError('Extra token(s): ' + ' '.join(tokens))
return expression_tree
标记序列由叫做tokenize的词法分析器产生,并被叫做analyze语法分析器使用。这里,我们定义了calc_parse,它只接受符合格式的计算器表达式。一些语言的解析器为接受以换行符、分号或空格分隔的多种表达式而设计。我们在引入 Logo 语言之前会推迟实现这种复杂性。
词法分析:用于将字符串解释为标记序列的组件叫做分词器(tokenizer ),或者词法分析器。在我们的视线中,分词器是个叫做tokenize的函数。计算器语言由包含数值、运算符名称和运算符类型的符号(比如+)组成。这些符号总是由两种分隔符划分:逗号和圆括号。每个符号本身都是标记,就像每个逗号和圆括号那样。标记可以通过向输入字符串添加空格,之后在每个空格处分割字符串来分开。
>>> def tokenize(line):
"""Convert a string into a list of tokens."""
spaced = line.replace('(',' ( ').replace(')',' ) ').replace(',', ' , ')
return spaced.split()
对符合格式的计算器表达式分词不会损坏名称,但是会分开所有符号和分隔符。
>>> tokenize('add(2, mul(4, 6))')
['add', '(', '2', ',', 'mul', '(', '4', ',', '6', ')', ')']
拥有更加复合语法的语言可能需要更复杂的分词器。特别是,许多分析器会解析每种返回标记的语法类型。例如,计算机中的标记类型可能是运算符、名称、数值或分隔符。这个分类可以简化标记序列的解析。
语法分析:将标记序列解释为表达式树的组件叫做语法分析器。在我们的实现中,语法分析由叫做analyze的递归函数完成。它是递归的,因为分析标记序列经常涉及到分析这些表达式树中的标记子序列,它本身作为更大的表达式树的子分支(比如操作数)。递归会生成由求值器使用的层次结构。
analyze函数接受标记列表,以符合格式的表达式开始。它会分析第一个标记,将表示数值的字符串强制转换为数字的值。之后要考虑计算机中的两个合法表达式类型。数字标记本身就是完整的基本表达式树。复合表达式以运算符开始,之后是操作数表达式的列表,由圆括号分隔。我们以一个不检查语法错误的实现开始。
>>> def analyze(tokens):
"""Create a tree of nested lists from a sequence of tokens."""
token = analyze_token(tokens.pop(0))
if type(token) in (int, float):
return token
else:
tokens.pop(0) # Remove (
return Exp(token, analyze_operands(tokens))
>>> def analyze_operands(tokens):
"""Read a list of comma-separated operands."""
operands = []
while tokens[0] != ')':
if operands:
tokens.pop(0) # Remove ,
operands.append(analyze(tokens))
tokens.pop(0) # Remove )
return operands
最后,我们需要实现analyze_token。analyze_token函数将数值文本转换为数值。我们并不自己实现这个逻辑,而是依靠内建的 Python 类型转换,使用int和float构造器来将标记转换为这种类型。
>>> def analyze_token(token):
"""Return the value of token if it can be analyzed as a number, or token."""
try:
return int(token)
except (TypeError, ValueError):
try:
return float(token)
except (TypeError, ValueError):
return token
我们的analyze实现就完成了。它能够正确将符合格式的计算器表达式解析为表达式树。这些树由str函数转换回计算器表达式。
>>> expression = 'add(2, mul(4, 6))'
>>> analyze(tokenize(expression))
Exp('add', [2, Exp('mul', [4, 6])])
>>> str(analyze(tokenize(expression)))
'add(2, mul(4, 6))'
analyze函数只会返回符合格式的表达式树,并且它必须检测输入中的语法错误。特别是,它必须检测表达式是否完整、正确分隔,以及只含有已知的运算符。下面的修订版本确保了语法分析的每一步都找到了预期的标记。
>>> known_operators = ['add', 'sub', 'mul', 'div', '+', '-', '*', '/']
>>> def analyze(tokens):
"""Create a tree of nested lists from a sequence of tokens."""
assert_non_empty(tokens)
token = analyze_token(tokens.pop(0))
if type(token) in (int, float):
return token
if token in known_operators:
if len(tokens) == 0 or tokens.pop(0) != '(':
raise SyntaxError('expected ( after ' + token)
return Exp(token, analyze_operands(tokens))
else:
raise SyntaxError('unexpected ' + token)
>>> def analyze_operands(tokens):
"""Analyze a sequence of comma-separated operands."""
assert_non_empty(tokens)
operands = []
while tokens[0] != ')':
if operands and tokens.pop(0) != ',':
raise SyntaxError('expected ,')
operands.append(analyze(tokens))
assert_non_empty(tokens)
tokens.pop(0) # Remove )
return elements
>>> def assert_non_empty(tokens):
"""Raise an exception if tokens is empty."""
if len(tokens) == 0:
raise SyntaxError('unexpected end of line')
信息丰富的语法错误在本质上提升了解释器的可用性。在上面,SyntaxError 异常包含所发生的问题描述。这些错误字符串也用作这些分析函数的定义文档。
这个定义完成了我们的计算器解释器。你可以获取单独的 Python 3 源码 calc.py来测试。我们的解释器对错误的处理能力很强,用户在calc>提示符后面的每个输入都会求值为数值,或者产生合适的错误,描述输入为什么不是符合格式的计算器表达式。
3.6 抽象语言的解释器
计算器语言提供了一种手段,来组合一些嵌套的调用表达式。然而,我们却没有办法定义新的运算符,将值赋给名称,或者表达通用的计算方法。总之,计算器并不以任何方式支持抽象。所以,它并不是特别强大或通用的编程语言。我们现在转到定义一种通用编程语言的任务中,这门语言通过将名称绑定到值以及定义新的操作来支持抽象。
我们并不是进一步扩展简单的计算器语言,而是重新开始,并且为 Logo 语言开发解释器。Logo 并不是为这门课发明的语言,而是一种经典的命令式语言,拥有许多解释器实现和自己的开发者社区。
上一章,我们将完整的解释器表示为 Python 源码,这一章使用描述性的方式。某个配套工程需要你通过构建完整的 Logo 函数式解释器来实现这里展示的概念。
3.6.1 Scheme 语言
Scheme 是 Lisp 的一种方言,Lisp 是现在仍在广泛使用的第二老(在 Fortran 之后)的编程语言。Scheme首次在 1975 年由 Gerald Sussman 和 Guy Steele 描述。Revised(4) Report on the Algorithmic Language Scheme 的引言中写道:
编程语言不应该通过堆砌特性,而是应该通过移除那些使额外特性变得必要的缺点和限制来设计。Scheme 表明,用于组成表达式的非常少量的规则,在没有组合方式的限制的情况下,足以组成实用并且高效的编程语言,它足够灵活,在使用中可以支持多数当今的主流编程范式。
我们将这个报告推荐给你作为 Scheme 语言的详细参考。我们这里只会涉及重点。下面的描述中,我们会用到报告中的例子。
虽然 Scheme 非常简单,但它是一种真正的编程语言,在许多地方都类似于 Python,但是“语法糖[1]”会尽量少。基本上,所有运算符都是函数调用的形式。这里我们会描述完整的 Scheme 语言的在报告中描述的可展示的子集。
[1] 非常遗憾,这对于 Scheme 语言的最新版本并不成立,就像 Revised(6) Report 中的那样。所以这里我们仅仅针对之前的版本。
Scheme 有多种可用的实现,它们添加了额外的过程。在 UCB,我们使用Stk 解释器的一个修改版,它也在我们的教学服务器上以stk提供。不幸的是,它并不严格遵守正式规范,但它可用于我们的目的。
**使用解释器。**就像 Python 解释器[2]那样,向 Stk 键入的表达式会由“读取-求值-打印”循环求值并打印:
>>> 3
3
>>> (- (/ (* (+ 3 7 10) (- 1000 8)) 992) 17)
3
>>> (define (fib n) (if (< n 2) n (+ (fib (- n 2)) (fib (- n 1)))))
fib
>>> '(1 (7 19))
(1 (7 19))
[2] 在我们的例子中,我们使用了和 Python 相同的符号
>>>和...,来表示解释器的输入行,和非前缀输出的行。实际上,Scheme 解释器使用不同的提示符。例如,Stk 以STk>来提示,并且不提示连续行。然而 Python 的惯例使输入和输出更加清晰。
Scheme 中的值:Scheme 中的值通常与 Python 对应。
布尔值
真值和假值,使用#t和#f来表示。Scheme 中唯一的假值(按照 Python 的含义)就是#f。
数值
这包括任意精度的整数、有理数、复数,和“不精确”(通常是浮点)数值。整数可用标准的十进制表示,或者通过在数字之前添加#o(八进制)、#x(十六进制)或#b(二进制),以其他进制表示。
符号
符号是一种字符串,但是不被引号包围。有效的字符包括字母、数字和:
! $ % & * / : < = > ? ^ _ ~ + - . @
在使用read函数输入时,它会读取 Scheme 表达式(也是解释器用于输入程序文本的东西),不区分符号中的大小写(在STk 实现中会转为小写)。两个带有相同表示的符号表示同一对象(并不是两个碰巧拥有相同内容的对象)。
偶对和列表
偶对是含有两个(任意类型)成员的对象,叫做它的car和cdr。car为A且cdr为B的偶对可表示为(A . B)。偶对(就像 Python 中的元组)可以表示列表、树和任意的层次结构。
标准的 Scheme 列表包含空的列表值(记为()),或者包含一个偶对,它的car是列表第一个元素,cdr是列表的剩余部分。所以,包含整数1, 2, 3的列表可表示为:
(1 . (2 . (3 . ())))
列表无处不在,Scheme 允许我们将(a . ())缩略为(a),将(a . (b ...))缩略为(a b ...)。所以,上面的列表通常写为:
(1 2 3)
过程(函数)
就像 Python 中一样,过程(或函数)值表示一些计算,它们可以通过向函数提供参数来调用。过程要么是原始的,由 Scheme 的运行时系统提供,要么从 Scheme 表达式和环境构造(就像 Python 中那样)。没有用于函数值的直接表示,但是有一些绑定到基本函数的预定义标识符,也有一些 Scheme 表达式,在求值时会产生新的过程值。
其它类型
Scheme 也支持字符和字符串(类似 Python 的字符串,除了 Scheme 区分字符和字符串),以及向量(就像 Python 的列表)。
**程序表示。**就像其它 Lisp 版本,Scheme 的数据值也用于表示程序。例如,下面的 Scheme 列表:
(+ x (* 10 y))
取决于如何使用,可表示为三个元素的列表(它的最后一个元素也是三个元素的列表),或者表达为用于计算x+10y的 Scheme 表达式。为了将 Scheme 值求值为程序,我们需要考虑值的类型,并按以下步骤求值:
- 整数、布尔值、字符、字符串和向量都求值为它们自己。所以,表达式
5求值为 5。 - 纯符号看做变量。它们的值由当前被求值环境来决定,就像 Python 那样。
- 非空列表以两种方式解释,取决于它们的第一个成员:
- 如果第一个成员是特殊形式的符号(在下面描述),求值由这个特殊形式的规则执行。
- 所有其他情况(叫做组合)中,列表的成员会以非特定的顺序(递归)求值。第一个成员必须是函数值。这个值会被调用,以列表中剩余成员的值作为参数。
- 其他 Scheme 值(特别是,不是列表的偶对)在程序中是错误的。
例如:
>>> 5 ; A literal.
5
>>> (define x 3) ; A special form that creates a binding for symbol
x ; x.
>>> (+ 3 (* 10 x)) ; A combination. Symbol + is bound to the primitive
33 ; add function and * to primitive multiply.
基本的特殊形式:特殊形式将东西表示为 Python 中的控制结构、函数调用或者类的定义:在调用时,这些结构不会简单地立即求值。
首先,一些通用的结构以这种形式使用:
EXPR-SEQ
只是表达式的序列,例如:
(+ 3 2) x (* y z)
当它出现在下面的定义中时,它指代从左到右求值的表达式序列,序列中最后一个表达式的值就是它的值。
BODY
一些结构拥有“主体”,它们是 EXPR-SEQ,就像上面一样,可能由一个或多个定义处理。它们的值就是 EXPR-SEQ 的值。这些定义的解释请见内部定义一节。
下面是这些特殊形式的代表性子集:
定义
定义可以出现在程序的顶层(也就是不包含在其它结构中)。
(define SYM EXPR)
求出EXPR并在当前环境将其值绑定到符号SYM上。
(define (SYM ARGUMENTS) BODY)
等价于(define SYM (lambda (ARGUMENTS) BODY))。
(lambda (ARGUMENTS) BODY)
求值为函数。ARGUMENTS 通常为(可能非空的)不同符号的列表,向函数提供参数名称,并且表明它们的数量。ARGUMENTS也可能具有如下形式:
(sym1 sym2 ... symn . symr)
(也就是说,列表的末尾并不像普通列表那样是空的,最后的cdr是个符号。)这种情况下,symr会绑定到列表的尾后参数值(后面的第 n+1 个参数)。
当产生的函数被调用时,ARGUMENTS在一个新的环境中绑定到形参的值上,新的环境扩展自lambda表达式求值的环境(就像 Python 那样)。之后BODY会被求值,它的值会作为调用的值返回。
(if COND-EXPR TRUE-EXPR OPTIONAL-FALSE-EXPR)
求出COND-EXPR,如果它的值不是#f,那么求出TRUE-EXPR,结果会作为if的值。如果COND-EXPR值为#f而且OPTIONAL-FALSE-EXPR存在,它会被求值为并作为if的值。如果它不存在,if值是未定义的。
(set! SYMBOL EXPR)
求出EXPR使用该值替换SYMBOL 的绑定。SYMBOL 必须已经绑定,否则会出现错误。和 Python 的默认情况不同,它会在定义它的第一个环境帧上替换绑定,而不总是最深处的帧。
(quote EXPR) 或 'EXPR
将 Scheme 数据结构用于程序表示的一个问题,是需要一种方式来表示打算被求值的程序文本。quote形式求值为EXPR自身,而不进行进一步的求值(替代的形式使用前导的单引号,由 Scheme 表达式读取器转换为第一种形式)。例如:
>>> (+ 1 2)
3
>>> '(+ 1 2)
(+ 1 2)
>>> (define x 3)
x
>>> x
3
>>> (quote x)
x
>>> '5
5
>>> (quote 'x)
(quote x)
派生的特殊形式
派生结构时可以翻译为基本结构的结构。它们的目的是让程序对于读取器更加简洁可读。在 Scheme 中:
(begin EXPR-SEQ)
简单地求值并产生EXPR-SEQ的值。这个结构是个简单的方式,用于在需要单个表达式的上下文中执行序列或表达式。
(and EXPR1 EXPR2 ...)
每个EXPR从左到右执行,直到碰到了#f,或遍历完EXPRs。值是最后求值的EXPR,如果EXPRs列表为空,那么值为#t。例如:
>>> (and (= 2 2) (> 2 1))
#t
>>> (and (< 2 2) (> 2 1))
#f
>>> (and (= 2 2) '(a b))
(a b)
>>> (and)
#t
(or EXPR1 EXPR2 ...)
每个EXPR从左到右求值,直到碰到了不为#f的值,或遍历完EXPRs。值为最后求值的EXPR,如EXPRs列表为空,那么值为#f。例如:
>>> (or (= 2 2) (> 2 3))
#t
>>> (or (= 2 2) '(a b))
#t
>>> (or (> 2 2) '(a b))
(a b)
>>> (or (> 2 2) (> 2 3))
#f
>>> (or)
#f
(cond CLAUSE1 CLAUSE2 ...)
每个CLAUSEi都依次处理,直到其中一个处理成功,它的值就是cond的值。如果没有子句处理成功,值是未定义的。每个子句都有三种可能的形式。
如果TEST-EXPR 求值为不为#f的值,(TEST-EXPR EXPR-SEQ)形式执行成功。这种情况下,它会求出EXPR-SEQ并产生它的值。EXPR-SEQ可以不写,这种情况下值为TEST-EXPR本身。
最后一个子句可为(else EXPR-SEQ)的形式,它等价于(#t EXPR-SEQ)。
最后,如果(TEST_EXPR => EXPR)的形式在TEST_EXPR求值为不为#f的值(叫做V)时求值成功。如果求值成功,cond结构的值是由(EXPR V)返回的值。也就是说,EXPR必须求值为单参数的函数,在TEST_EXPR的值上调用。
例如:
>>> (cond ((> 3 2) 'greater)
... ((< 3 2) 'less)))
greater
>>> (cond ((> 3 3) 'greater)
... ((< 3 3) 'less)
... (else 'equal))
equal
>>> (cond ((if (< -2 -3) #f -3) => abs)
... (else #f))
3
(case KEY-EXPR CLAUSE1 CLAUSE2 ...)
KEY-EXPR的求值会产生一个值K。之后将K与每个CLAUSEi一次匹配,直到其中一个成功,并且返回该子句的值。如果没有子句成功,值是未定义的。每个子句都拥有((DATUM1 DATUM2 ...) EXPR-SEQ)的形式。其中DATUMs是 Scheme 值(它们不会被求值)。如果K匹配了DATUM的值之一(由下面描述的eqv?函数判断),子句就会求值成功,它的EXPR-SEQ就会被求值,并且它的值会作为case的值。最后的子句可为(else EXPR-SEQ)的形式,它总是会成功,例如:
>>> (case (* 2 3)
... ((2 3 5 7) 'prime)
... ((1 4 6 8 9) 'composite))
composite
>>> (case (car '(a . b))
... ((a c) 'd)
... ((b 3) 'e))
d
>>> (case (car '(c d))
... ((a e i o u) 'vowel)
... ((w y) 'semivowel)
... (else 'consonant))
consonant
(let BINDINGS BODY)
BINDINGS是偶对的列表,形式为:
( (VAR1 INIT1) (VAR2 INIT2) ...)
其中VARs是(不同的)符号,而INITs是表达式。首先会求出INIT表达式,之后创建新的帧,将这些值绑定到VARs,再然后在新环境中求出BODY,返回它的值。换句话说,它等价于调用
((lambda (VAR1 VAR2 ...) BODY)
INIT1 INIT2 ...)
所以,任何INIT表达式中的VARs引用都指向这些符号在let结构外的定义(如果存在的话),例如:
>>> (let ((x 2) (y 3))
... (* x y))
6
>>> (let ((x 2) (y 3))
... (let ((x 7) (z (+ x y)))
... (* z x)))
35
(let* BINDINGS BODY)
BINDINGS 的语法和let相同。它等价于
(let ((VAR1 INIT1))
...
(let ((VARn INITn))
BODY))
也就是说,它就像let表达式那样,除了VAR1的新绑定对INITs子序列以及BODY中可见,VAR2与之类似,例如:
>>> (define x 3)
x
>>> (define y 4)
y
>>> (let ((x 5) (y (+ x 1))) y)
4
>>> (let* ((x 5) (y (+ x 1))) y)
6
(letrec BINDINGS BODY)
同样,语法类似于let。这里,首先会创建新的绑定(带有未定义的值),之后INITs被求值并赋给它们。如果某个INITs使用了某个VAR的值,并且没有为其赋初始值,结果是未定义的。这个形式主要用于定义互相递归的函数(lambda 本身并不会使用它们提到过的值;这只会在它们被调用时随后发生)。例如:
(letrec ((even?
(lambda (n)
(if (zero? n)
#t
(odd? (- n 1)))))
(odd?
(lambda (n)
(if (zero? n)
#f
(even? (- n 1))))))
(even? 88))
内部定义:当BODY以define结构的序列开始时,它们被看作“内部定义”,并且在解释上与顶层定义有些不同。特别是,它们就像letrec那样。
- 首先,会为所有由
define语句定义的名称创建绑定,一开始绑定到未定义的值上。 - 之后,值由定义来填充。
所以,内部函数定义的序列是互相递归的,就像 Python 中嵌套在函数中的def`语句那样:
>>> (define (hard-even? x) ;; An outer-level definition
... (define (even? n) ;; Inner definition
... (if (zero? n)
... #t
... (odd? (- n 1))))
... (define (odd? n) ;; Inner definition
... (if (zero? n)
... #f
... (even? (- n 1))))
... (even? x))
>>> (hard-even? 22)
#t
预定义函数:预定义函数有很多,都在全局环境中绑定到名称上,我们只会展示一小部分。其余的会在 Revised(4) Scheme 报告中列出。函数调用并不是“特殊的”,因为它们都使用相同的完全统一的求值规则:递归求出所有项目(包括运算符),并且之后在操作数的值上调用运算符的值(它必须是个函数)。
-
算数:Scheme 提供了标准的算数运算符,许多都拥有熟悉的表示,虽然它们统一出现在操作数前面:
>>> ; Semicolons introduce one-line comments. >>> ; Compute (3+7+10)*(1000-8) // 992 - 17 >>> (- (quotient (* (+ 3 7 10) (- 1000 8))) 17) 3 >>> (remainder 27 4) 3 >>> (- 17) -17与之相似,存在通用的数学比较运算符,为可接受多于两个参数而扩展:
>>> (< 0 5) #t >>> (>= 100 10 10 0) #t >>> (= 21 (* 7 3) (+ 19 2)) #t >>> (not (= 15 14)) #t >>> (zero? (- 7 7)) #t随便提一下,
not是个函数,并不是and或or的特殊形式,因为他的运算符必须求值,所以不需要特殊对待。 -
列表和偶对:很多操作用于处理偶对和列表(它们同样由偶对和空列表构建)。
>>> (cons 'a 'b) (a . b) >>> (list 'a 'b) (a b) >>> (cons 'a (cons 'b '())) (a b) >>> (car (cons 'a 'b)) a >>> (cdr (cons 'a 'b)) b >>> (cdr (list a b)) (b) >>> (cadr '(a b)) ; An abbreviation for (car (cdr '(a b))) b >>> (cddr '(a b)) ; Similarly, an abbreviation for (cdr (cdr '(a b))) () >>> (list-tail '(a b c) 0) (a b c) >>> (list-tail '(a b c) 1) (b c) >>> (list-ref '(a b c) 0) a >>> (list-ref '(a b c) 2) c >>> (append '(a b) '(c d) '() '(e)) (a b c d e) >>> ; All but the last list is copied. The last is shared, so: >>> (define L1 (list 'a 'b 'c)) >>> (define L2 (list 'd)) >>> (define L3 (append L1 L2)) >>> (set-car! L1 1) >>> (set-car! L2 2) >>> L3 (a b c 2) >>> (null? '()) #t >>> (list? '()) #t >>> (list? '(a b)) #t >>> (list? '(a . b)) #f -
相等性:
=运算符用于数值。通常对于值的相等性,Scheme 区分eq?(就像 Python 的is),eqv?(与之类似,但是和数值上的=一样),和equal?(比较列表结构或字符串的内容)。通常来说,除了在比较符号、布尔值或者空列表的情况中,我们都使用eqv?和equal?。>>> (eqv? 'a 'a) #t >>> (eqv? 'a 'b) #f >>> (eqv? 100 (+ 50 50)) #t >>> (eqv? (list 'a 'b) (list 'a 'b)) #f >>> (equal? (list 'a 'b) (list 'a 'b)) #t -
类型:每个值的类型都只满足一个基本的类型断言。
>>> (boolean? #f) #t >>> (integer? 3) #t >>> (pair? '(a b)) #t >>> (null? '()) #t >>> (symbol? 'a) #t >>> (procedure? +) #t -
输入和输出:Scheme 解释器通常执行“读取-求值-打印”循环,但是我们可以在程序控制下显式输出东西,使用与解释器内部相同的函数:
>>> (begin (display 'a) (display 'b) (newline)) ab于是,
(display x)与 Python 的print(str(x), end="")相似,并且
(newline)类似于print()。对于输入来说,
(read)从当前“端口”读取 Scheme 表达式。它并不会解释表达式,而是将其读作数据:>>> (read) >>> (a b c) (a b c) -
求值:
apply函数提供了函数调用运算的直接访问:>>> (apply cons '(1 2)) (1 . 2) >>> ;; Apply the function f to the arguments in L after g is >>> ;; applied to each of them >>> (define (compose-list f g L) ... (apply f (map g L))) >>> (compose-list + (lambda (x) (* x x)) '(1 2 3)) 14这个扩展允许开头出现“固定”参数:
>>> (apply + 1 2 '(3 4 5)) 15下面的函数并不在 Revised(4) Scheme 中,但是存在于我们的解释器版本中(警告:非标准的过程在 Scheme 的后续版本中并不以这种形式定义):
>>> (eval '(+ 1 2)) 3也就是说,
eval求解一块 Scheme 数据,它表示正确的 Scheme 表达式。这个版本在全局环境中求解表达式的参数。我们的解释器也提供了一种方式,来规定求值的特定环境:>>> (define (incr n) (lambda (x) (+ n x))) >>> (define add5 (incr 5)) >>> (add5 13) 18 >>> (eval 'n (procedure-environment add5)) 5
3.6.2 Logo 语言
Logo 是 Lisp 的另一种方言。它为教育用途而设计,所以 Logo 的许多设计决策是为了让语言对新手更加友好。例如,多数 Logo 过程以前缀形式调用(首先是过程名称,其次是参数),但是通用的算术运算符以普遍的中缀形式提供。Logo 的伟大之处是,它的简单亲切的语法仍旧为高级程序员提供了惊人的表现力。
Logo 的核心概念是,它的内建容器类型,也就是 Logo sentence (也叫作列表),可以轻易储存 Logo 源码,这也是它的强大表现力的来源。Logo 的程序可以编写和执行 Logo 表达式,作为求值过程的一部分。许多动态语言都支持代码生成,包括 Python,但是没有语言像 Logo 一样使代码生成如此有趣和易用。
你可能希望下载完整的 Logo 解释器来体验这个语言。标准的实现是 Berkeley Logo(也叫做 UCBLogo),由 Brian Harvey 和他的 Berkeley 学生开发。对于苹果用户,ACSLogo 兼容 Mac OSX 的最新版本,并带有一份介绍 Logo 语言许多特性的用户指南。
基础:Logo 设计为会话式。它的读取-求值循环的提示符是一个问号(?),产生了“我下面应该做什么?”的问题。我们自然想让它打印数值:
? print 5
5
Logo 语言使用了非标准的调用表达式语法,完全不带括号分隔符。上面,参数5转给了print,它打印了它的参数。描述 Logo 程序结构的术语有些不同于 Python。Logo 拥有过程而不是 Python 中等价的函数,而且过程输出值而不是返回值。和 python 类似,print过程总是输出None,但也打印出参数的字符串表示作为副作用。(过程的参数在 Logo 中也通常叫做输入,但是为了清晰起见,这篇文章中我们仍然称之为参数。)
Logo 中最常见的数据类型是单词,它是不带空格的字符串。单词用作可以表示数值、名称和布尔值的通用值。可以解释为数值或布尔值的记号,比如5,直接求值为单词。另一方面,类似five的名称解释为过程调用:
? 5
You do not say what to do with 5.
? five
I do not know how to five.
5和five以不同方式解释,Logo 的读取-求值循环也以不同方式报错。第一种情况的问题是,Logo 在顶层表达式不求值为 None 时报错。这里,我们看到了第一个 Logo 不同于计算器的结构;前者的接口是读取-解释循环,期待用户来打印结果。后者使用更加通用的读取-求值-打印循环,自动打印出返回值。Python 采取了混合的方式,非None的值使用repr强制转换为字符串并自动打印。
Logo 的行可以顺序包含多个表达式。解释器会一次求出每个表达式。如果行中任何顶层表达式不求值为None,解释器会报错。一旦发生错误,行中其余的表达式会被忽略。
? print 1 print 2
1
2
? 3 print 4
You do not say what to do with 3.
Logo 的调用表达式可以嵌套。在 Logo 的实现版本中,每个过程接受固定数量的参数。所以,当嵌套调用表达式的操作数完整时,Logo 解释器能够唯一地判断。例如,考虑两个过程sum和difference,它们相应输出两个参数的和或差。
? print sum 10 difference 7 3
14
我们可以从这个嵌套的例子中看到,分隔调用表达式的圆括号和逗号不是必须的。在计算器解释器中,标点符号允许我们将表达式树构建为纯粹的句法操作,没有任何运算符名称的判断。在 Logo 中,我们必须使用我们的知识,关于每个过程接受多少参数,来得出嵌套表达式的正确结构。下一节中,问题的细节会深入探讨。
Logo 也支持中缀运算符,例如+和*。这些运算符的优先级根据代数的标准规则来解析。乘法和除法优于加法和减法:
? 2 + 3 * 4
14
如何实现运算符优先级和前缀运算符来生成正确的表达式树的细节留做练习。对于下面的讨论,我们会专注于使用前缀语法的调用表达式。
引用:一个名称会被解释为调用表达式的开始部分,但是我们也希望将单词引用为数据。以双引号开始的记号解释为单词字面值。要注意单词字面值在 Logo 中并没有尾后的双引号。
? print "hello
hello
在 Lisp 的方言中(而 Logo 是它的方言),任何不被求值的表达式都叫做引用。这个引用的概念来自于事物之间的经典哲学。例如一只狗,它可以到处乱跑和叫唤,而单词“狗”只是用于指代这种事物的语言结构。当我们以引号使用“狗”的时候,我们并不是指特定的哪一只,而是这个单词。在语言中,引号允许我们谈论语言自身,Logo 中也一样。我们可以按照名称引用sum过程,而不会实际调用它,通过这样引用它:
? print "sum
sum
除了单词,Logo 包含句子类型,可以叫做列表。句子由方括号包围。print过程并不会打印方括号,以维持 Logo 的惯例风格,但是方括号可以使用show过程打印到输出:
? print [hello world]
hello world
? show [hello world]
[hello world]
句子也可以使用三个不同的二元过程来构造。sentence过程将参数组装为句子。它是多态过程,如果参数是单词,会将它的参数放入新的句子中;如果参数是句子,则会将拼接参数。结果通常是一个句子:
? show sentence 1 2
[1 2]
? show sentence 1 [2 3]
[1 2 3]
? show sentence [1 2] 3
[1 2 3]
? show sentence [1 2] [3 4]
[1 2 3 4]
list过程从两个元素创建句子,它允许用户创建层次数据结构:
? show list 1 2
[1 2]
? show list 1 [2 3]
[1 [2 3]]
? show list [1 2] 3
[[1 2] 3]
? show list [1 2] [3 4]
[[1 2] [3 4]]
最后,fput过程从第一个元素和列表的剩余部分创建列表,就像这一章之前的 Python RList构造器那样:
? show fput 1 [2 3]
[1 2 3]
? show fput [1 2] [3 4]
[[1 2] 3 4]
我们在 Logo 中可以调用sentence、list和fput句子构造器。在 Logo 中将句子解构为first和剩余部分(叫做butfirst)也非常直接,所以,我们也拥有一系列句子的选择器过程。
? print first [1 2 3]
1
? print last [1 2 3]
3
? print butfirst [1 2 3]
[2 3]
作为数据的表达式:句子的内容可以直接当做未求值的引用。所以,我们可以打印出 Logo 表达式而不求值:
? show [print sum 1 2]
[print sum 1 2]
将 Logo 表示表达式表示为句子的目的通常不是打印它们,而是使用run过程来求值。
? run [print sum 1 2]
3
通过组合引用和句子构造器,以及run过程,我们获得了一个非常通用的组合手段,它凭空构建 Logo 表达式并对其求值:
? run sentence "print [sum 1 2]
3
? print run sentence "sum sentence 10 run [difference 7 3]
14
最后一个例子的要点是为了展示,虽然sum和difference过程在 Logo 中并不是一等的构造器(它们不能直接放在句子中),它们的名称是一等的,并且run过程可以将它们的名称解析为所引用的过程。
将代码表示为数据,并且稍后将其解释为程序的一部分的功能,是 Lisp 风格语言的特性。程序可以重新编写自己来执行是一个强大的概念,并且作为人工智能(AI)早期研究的基础。Lisp 在数十年间都是 AI 研究者的首选语言。Lisp 语言由 John McCarthy 发明,他也发明了“人工智能”术语,并且在该领域的定义中起到关键作用。Lisp 方言的“代码即数据”的特性,以及它们的简洁和优雅,今天仍继续吸引着 Lisp 程序员。
海龟制图(Turtle graphics):所有 Logo 的实现都基于 Logo 海龟 来完成图形输出。这个海龟以画布的中点开始,基于过程移动和转向,并且在它的轨迹上画线。虽然海龟为鼓励青少年实践编程而发明,它对于高级程序员来说也是有趣的图形化工具。
在执行 Logo 程序的任意时段,Logo 海龟都在画布上拥有位置和朝向。类似于forward和right的一元过程能修改海龟的位置和朝向。常用的过程都有缩写:forward也叫作fd,以及其它。下面的嵌套表达式画出了每个端点带有小星星的大星星:
? repeat 5 [fd 100 repeat 5 [fd 20 rt 144] rt 144]
海龟过程的全部指令也内建于 Python 的turtle模块中。这些函数的有限子集也在这一章的配套项目中提供。
赋值:Logo 支持绑定名称和值。就像 Python 中那样,Logo 环境由帧的序列组成,每个帧中的某个名称都最多绑定到一个值上。名称使用make过程来绑定,它接受名称和值作为参数。
? make "x 2
任何以冒号起始的单词,例如:x都叫做变量。变量求值为其名称在当前环境中绑定的值。
make过程和 Python 的赋值语句具有不同的作用。传递给make的名称要么已经绑定了值,要么当前未绑定。
- 如果名称已经绑定,
make在找到它的第一帧中重新绑定该名称。 - 如果没有绑定,
make在全局帧中绑定名称。
这个行为与 Python 赋值语句的语义很不同,后者总是在当前环境中的第一帧中绑定名称。上面的第一条规则类似于遵循nonlocal语句的 Python 赋值。第二条类似于遵循global语句的全局赋值。
过程:Logo 支持用户使用以to关键字开始的定义来定义过程。定义是 Logo 中的最后一个表达式类型,在调用表达式、基本表达式和引用表达式之后。定义的第一行提供了新过程的名称,随后是作为变量的形参。下面的行是过程的主体,它可以跨越多行,并且必须以只包含end记号的一行结束。Logo 的读取-求值循环使用>连接符来提示用户输入过程体。用户定义过程使用output过程来输出一个值。
? to double :x
> output sum :x :x
> end
? print double 4
8
Logo 的用户定义过程所产生的调用过程和 Python 中的过程类似。在一系列参数上调用过程以使用新的帧扩展当前环境,以及将过程的形参绑定到实参开始,之后在开始于新帧的环境中求出过程体的代码行。
output的调用在 Logo 中与 Python 中的return语句有相同作用:它会中止过程体的执行,并返回一个值。Logo 过程可以通过调用stop来不带任何值返回。
? to count
> print 1
> print 2
> stop
> print 3
> end
? count
1
2
作用域:Logo 是动态作用域语言。类似 Python 的词法作用域语言并不允许一个函数的局部名称影响另一个函数的求值,除非第二个函数显式定义在第一个函数内。两个顶层函数的形参完全是隔离的。在动态作用域的语言中,没有这种隔离。当一个函数调用另一个函数时,绑定到第一个函数局部帧的名称可在第二个函数的函数体中访问:
? to print_last_x
> print :x
> end
? to print_x :x
> print_last_x
> end
? print_x 5
5
虽然名称x并没有在全局帧中绑定,而是在print_x的局部帧中,也就是首先调用的函数。Logo 的动态作用域规则允许函数print_last_x引用x,它被绑定到print_x的形式参数上。
动态作用域只需要一个对计算环境模型的简单修改就能实现。由用户函数调用创建的帧总是扩展自当前环境(调用处)。例如,上面的print_x调用引入了新的帧,它扩展自当前环境,当前环境中包含print_x的局部帧和全局帧。所以,在print_last_x的主体中查找x会发现局部帧中该名称绑定到5。与之相似,在 Python 的词法作用域下,print_last_x的帧只扩展自全局帧(定义处),而并不扩展自print_x的局部帧(调用处)。
动态作用域语言拥有一些好处,它的过程可能不需要接受许多参数。例如,print_last_x上面的过程没有接受参数,但是它的行为仍然由内层作用域参数化。
常规编程:我们的 Logo 之旅就到此为止了。我们还没有介绍任何高级特性,例如,对象系统、高阶过程,或者语句。学会在 Logo 中高效编程需要将语言的简单特性组合为有效的整体。
Logo 中没有条件表达式类型。过程if和ifelse使用调用表达式的求值规则。if的第一个参数是个布尔单词,True或者False。第二个参数不是输出值,而是一个句子,包含如果第一个参数为True时需要求值的代码行。这个设计的重要结果是,第二个函数的内容如果不被用到就不会全部求值。
? 1/0
div raised a ZeroDivisionError: division by zero
? to reciprocal :x
> if not :x = 0 [output 1 / :x]
> output "infinity
> end
? print reciprocal 2
0.5
? print reciprocal 0
infinity
Logo 的条件语句不仅仅不需要特殊语法,而且它实际上可以使用word和run实现。ifelse的基本过程接受三个函数:布尔单词、如果单词为True需要求值的句子,和如果单词为False需要求值的句子。通过适当命名形式参数,我们可以实现拥有相同行为的用户定义过程ifelse2。
? to ifelse2 :predicate :True :False
> output run run word ": :predicate
> end
? print ifelse2 emptyp [] ["empty] ["full]
empty
递归过程不需要任何特殊语法,它们可以和run、sentence、first和butfirst一起使用,来定义句子上的通用序列操作。例如,我们可以通过构建二元句子并执行它,来在参数上调用过程。如果参数是个单词,它必须被引用。
? to apply_fn :fn :arg
> output run list :fn ifelse word? :arg [word "" :arg] [:arg]
> end
下面,我们可以定义一个过程,它在句子:s上逐步映射函数:fn。
? to map_fn :fn :s
> if emptyp :s [output []]
> output fput apply_fn :fn first :s map_fn :fn butfirst :s
> end
? show map "double [1 2 3]
[2 4 6]
map_fn主体的第二行也可以使用圆括号编写,表明调用表达式的嵌套结构。但是,圆括号表示了调用表达式的开始和末尾,而不是包围在操作数和非运算符周围。
> (output (fput (apply_fn :fn (first :s)) (map_fn :fn (butfirst :s))))
圆括号在 Logo 中并不必须,但是它们通常帮助程序员记录嵌套表达式的结构。许多 Lisp 的方言都需要圆括号,所以就拥有了显式嵌套的语法。
作为最后一个例子,Logo 可以以非常紧凑的形式使用海龟制图来递归作图。谢尔宾斯基三角是个分形图形,它绘制每个三角形的同时还绘制邻近的三个三角形,它们的顶点是包含它们的三角形的边上的中点。它可以由这个 Logo 程序以有限的递归深度来绘制。
? to triangle :exp
> repeat 3 [run :exp lt 120]
> end
? to sierpinski :d :k
> triangle [ifelse :k = 1 [fd :d] [leg :d :k]]
> end
? to leg :d :k
> sierpinski :d / 2 :k - 1
> penup fd :d pendown
> end
triangle 过程是个通用方法,它重复三次绘制过程,并在每个重复之后左转。sierpinski 过程接受长度和递归深度。如果深度为1,它画出纯三角形,否则它画出由log的调用所组成的三角形。leg过程画出谢尔宾斯基递归三角型的一条边,通过递归调用sierpinski 填充这条边长度的上一半,之后将海龟移动到另一个顶点上。过程up和down通过将笔拿起并在之后放下,在海龟移动过程中停止画图。sierpinski和leg之间的多重递归产生了如下结果:
? sierpinski 400 6

3.6.3 结构
这一节描述了 Logo 解释器的通常结构。虽然这一章是独立的,它也确实引用了配套项目。完成这个项目会从零制造出这一章描述的解释器的有效实现。
Logo 的解释器可以拥有和计算器解释器相同的结构。解析器产生表达式数据结构,它们可由求值器来解释。求值函数检查表达式的形式,并且对于调用表达式,它在一些参数上调用函数来应用某个过程。但是,还是存在一些结构上的不同以适应 Logo 的特殊语法。
行:Logo 解析器并不读取一行代码,而是读取可能按序包含多个表达式的整行代码。它不返回表达式树,而是返回 Logo 句子。
解析器实际上只做微小的语法分析。特别是,解析工作并不会将调用表达式的运算符和操作数子表达式区分为树的不同枝干。反之,调用表达式的组成部分顺序排列,嵌套调用表达式表示为摊平的记号序列。最终,解析工作并不判断基本表达式,例如数值的类型,因为 Logo 没有丰富的类型系统。反之,每个元素都是单词或句子。
>>> parse_line('print sum 10 difference 7 3')
['print', 'sum', '10', 'difference', '7', '3']
解析器做了很微小的分析,因为 Logo 的动态特性需要求值器解析嵌套表达式的结构。
解析器并不会弄清句子的嵌套结构,句子中的句子表示为 Python 的嵌套列表。
>>> parse_line('print sentence "this [is a [deep] list]')
['print', 'sentence', '"this', ['is', 'a', ['deep'], 'list']]
parse_line的完整实现在配套项目的logo_parser.py中。
求值:Logo 一次求值一行。求值器的一个框架实现定义在配套项目的logo.py中。从parse_line返回的句子传给了eval_line函数,它求出行中的每个表达式。eval_line函数重复调用logo_eval,它求出行中的下一个完整的表达式,直到这一行全部求值完毕,之后返回最后一个值。logo_eval函数求出单个表达式。
![]()
logo_eval函数求出不同形式的表达式:基本、变量、定义、引用和调用表达式,我们已经在上一节中介绍过它们了。Logo 中多元素表达式的形式可以由检查第一个元素来判断。表达式的每个形式都有自己的求值规则。
- 基本表达式(可以解释为数值、
True或False的单词)求值为自身。 - 变量在环境中查找。环境会在下一节中详细讨论。
- 定义处理为特殊情况。用户定义过程也在下一节中详细讨论。
- 引用表达式求值为引用的文本,它是个去掉前导引号的字符串。句子(表示为 Python 列表)也看做引用,它们求值为自身。
- 调用表达式在当前环境中查找运算符名称,并且调用绑定到该名称的过程。
下面是logo_apply的简单实现。我们去掉了一些错误检查,以专注于我们的讨论。配套项目中有更加健壮的实现。
>>> def logo_eval(line, env):
"""Evaluate the first expression in a line."""
token = line.pop()
if isprimitive(token):
return token
elif isvariable(token):
return env.lookup_variable(variable_name(token))
elif isdefinition(token):
return eval_definition(line, env)
elif isquoted(token):
return text_of_quotation(token)
else:
procedure = env.procedures.get(token, None)
return apply_procedure(procedure, line, env)
上面的最后情况调用了第二个过程,表达为函数apply_procedure。为了调用由运算符记号命名的过程,这个运算符会在当前环境中查找。在上面的定义中,env是Environment 类的实例,会在下一节中描述。env.procedures属性是个储存运算符名称和过程之间映射的字典。在 Logo 中,环境拥有单词的这种映射,并且没有局部定义的过程。而且,Logo 为过程名称和变量名称维护分离的映射,叫做分离的命名空间。但是,以这种方式复用名称并不推荐。
过程调用:过程调用以调用apply_procedure函数开始,它被传入由logo_apply查找到的函数,并带有代码的当前行和当前环境。Logo 中过程调用的过程比计算器中的calc_apply更加通用。特别是,apply_procedure必须检查打算调用的过程,以便在求解n个运算符表达式之前,判断它的参数数量n。这里我们会看到,为什么 Logo 解析器不能仅仅由语法分析构建表达式树,因为树的结构由过程决定。
apply_procedure函数调用collect_args 函数,它必须重复调用logo_eval来求解行中的下n个表达式。之后,计算完过程的参数之后,apply_procedure调用了logo_apply,实际上这个函数在参数上调用过程。下面的调用图示展示了这个过程。
![]()
最终的函数 logo_apply接受两种参数:基本过程和用户定义的过程,二者都是Procedure的实例。Procedure是一个 Python 对象,它拥有过程的名称、参数数量、主体和形式参数作为实例属性。body属性可以拥有不同类型。基本过程在 Python 中已经实现,所以它的body就是 Python 函数。用户定义的过程(非基本)定义在 Logo 中,所以它的 body就是 Logo 代码行的列表。Procedure也拥有两个布尔值属性。一个用于表明是否是基本过程,另一个用于表明是否需要访问当前环境。
>>> class Procedure():
def __init__(self, name, arg_count, body, isprimitive=False,
needs_env=False, formal_params=None):
self.name = name
self.arg_count = arg_count
self.body = body
self.isprimitive = isprimitive
self.needs_env = needs_env
self.formal_params = formal_params
基本过程通过在参数列表上调用主体,并返回它的返回值作为过程输出来应用。
>>> def logo_apply(proc, args):
"""Apply a Logo procedure to a list of arguments."""
if proc.isprimitive:
return proc.body(*args)
else:
"""Apply a user-defined procedure"""
用户定义过程的主体是代码行的列表,每一行都是 Logo 句子。为了在参数列表上调用过程,我们在新的环境中求出主体的代码行。为了构造这个环境,我们向当前环境中添加新的帧,过程的形式参数在里面绑定到实参上。这个过程的重要结构化抽象是,求出用户定义过程的主体的代码行,需要递归调用eval_line。
求值/应用递归:实现求值过程的函数,eval_line 和logo_eval,以及实现函数应用过程的函数,apply_procedure、collect_args和logo_apply,是互相递归的。无论何时调用表达式被发现,求值操作都需要调用它。应用操作使用求值来求出实参中的操作数表达式,以及求出用户定义过程的主体。这个互相递归过程的通用结构在解释器中非常常见:求值以应用定义,应用又使用求值定义。
这个递归循环终止于语言的基本类型。求值的基本条件是,求解基本表达式、变量、引用表达式或定义。函数调用的基本条件是调用基本过程。这个互相递归的结构,在处理表达式形式的求值函数,和处理函数及其参数的应用之间,构成了求值过程的本质。
3.6.4 环境
既然我们已经描述了 Logo 解释器的结构,我们转而实现Environment 类,便于让它使用动态作用域正确支持赋值、过程定义和变量查找。Environment实例表示名称绑定的共有集合,可以在程序执行期间的某一点上访问。绑定在帧中组织,而帧以 Python 字典实现。帧包含变量的名称绑定,但不包含过程。运算符名称和Procedure实例之间的绑定在 Logo 中是单独储存的。在这个实现中,包含变量名称绑定的帧储存为字典的列表,位于Environment的_frames属性中,而过程名称绑定储存在值为字典的procedures属性中。
帧不能直接访问,而是通过两个Environment的方法:lookup_variable和set_variable_value。前者实现了一个过程,与我们在第一章的计算环境模型中引入的查找过程相同。名称在当前环境第一帧(最新添加)中与值匹配。如果它被找到,所绑定的值会被返回。如果没有找到,会在被当前帧扩展的帧中寻找。
set_variable_value 也会寻找与变量名称匹配的绑定。如果找到了,它会更新为新的值,如果没有找到,那么会在全局帧上创建新的绑定。这些方法的实现留做配套项目中的练习。
lookup_variable 方法在求解变量名称时由logo_eval调用。set_variable_value 由logo_make函数调用,它用作 Logo 中make基本过程的主体。
除了变量和make基本过程之外,我们的解释器支持它的第一种抽象手段:将名称绑定到值上。在 Logo 中,我们现在可以重复我们第一章中的第一种抽象步骤。
? make "radius 10
? print 2 * :radius
20
赋值只是抽象的一种有限形式。我们已经从这门课的开始看到,即使对于不是很大的程序,用户定义函数也是管理复杂性的关键工具。我们需要两个改进来实现 Logo 中的用户定义过程。首先,我们必须描述eval_definition的实现,如果当前行是定义,logo_eval会调用这个 Python 函数。其次,我们需要在logo_apply中完成我们的描述,它在一些参数上调用用户过程。这两个改动都需要利用上一节定义的Procedure类。
定义通过创建新的Procedure实例来求值,它表示用户定义的过程。考虑下面的 Logo 过程定义:
? to factorial :n
> output ifelse :n = 1 [1] [:n * factorial :n - 1]
> end
? print fact 5
120
定义的第一行提供了过程的名称factorial和形参n。随后的一些行组成了过程体。这些行并不会立即求值,而是为将来使用而储存。也就是说,这些行由eval_definition读取并解析,但是并不传递给eval_line。主体中的行一直读取,直到出现了只包含end的行。在 Logo 中,end并不是需要求值的过程,也不是过程体的一部分。它是个函数定义末尾的语法标记。
Procedure实例从这个过程的名称、形参列表以及主体中创建,并且在环境中的procedures的字典属性中注册。不像 Python,在 Logo 中,一旦过程绑定到一个名称,其它定义都不能复用这个名称。
logo_apply将Procedure实例应用于一些参数,它是表示为字符串的 Logo 值(对于单词),或列表(对于句子)。对于用户定义过程,logo_apply创建了新的帧,它是一个字典对象,键是过程的形参,值是实参。在动态作用域语言例如 Logo 中,这个新的帧总是扩展自过程调用处的当前环境。所以,我们将新创建的帧附加到当前环境上。之后,主体中的每一行都依次传递给eval_line 。最后,在主体完成求值后,我们可以从环境中移除新创建的帧。由于 Logo 并不支持高阶或一等过程,在程序执行期间,我们并不需要一次跟踪多于一个环境。
下面的例子演示了帧的列表和动态作用域规则,它们由调用这两个 Logo 用户定义过程产生:
? to f :x
> make "z sum :x :y
> end
? to g :x :y
> f sum :x :x
> end
? g 3 7
? print :z
13
由这些表达式的求值创建的环境分为过程和帧,它们维护在分离的命名空间中。帧的顺序由调用顺序决定。
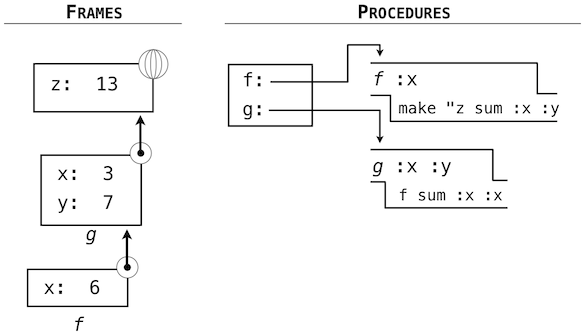
3.6.5 数据即程序
在思考求值 Logo 表达式的程序时,一个类比可能很有帮助。程序含义的一个可取观点是,程序是抽象机器的描述。例如,再次思考下面的计算阶乘的过程:
? to factorial :n
> output ifelse :n = 1 [1] [:n * factorial :n - 1]
> end
我们可以在 Python 中表达为等价的程序,使用传统的表达式。
>>> def factorial(n):
return 1 if n == 1 else n * factorial(n - 1)
我们可能将这个程序看做机器的描述,它包含几个部分,减法、乘法和相等性测试,并带有两相开关和另一个阶乘机器(阶乘机器是无限的,因为它在其中包含另一个阶乘机器)。下面的图示是一个阶乘机器的流程图,展示了这些部分是怎么组合到一起的。
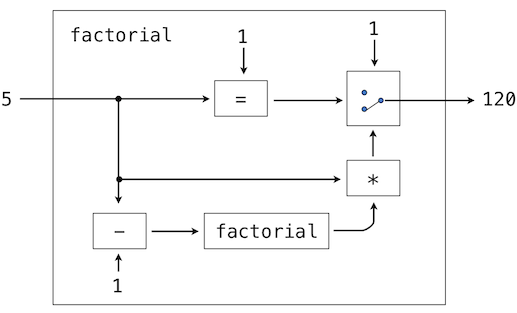
与之相似,我们可以将 Logo 解释器看做非常特殊的机器,它接受机器的描述作为输入。给定这个输入,解释器就能配置自己来模拟描述的机器。例如,如果我们向解释器中输入阶乘的定义,解释器就可以计算阶乘。
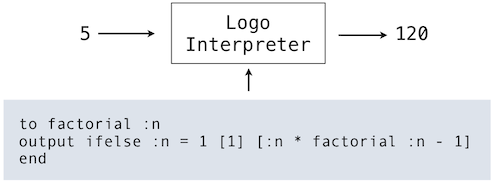
从这个观点得出,我们的 Logo 解释器可以看做通用的机器。当输入以 Logo 程序描述时,它就能模拟其它机器。它在由我们的编程语言操作的数据对象,和编程语言自身之间起到衔接作用。想象一下,一个用户在我们正在运行的 Logo 解释器中输入了 Logo 表达式。从用户的角度来看,类似sum 2 2的输入表达式是编程语言中的表达式,解释器应该对其求值。但是,从解释器的角度来看,表达式只是单词组成的句子,可以根据定义好的一系列规则来操作它。
用户的程序是解释器的数据,这不应该是混乱的原因。实际上,有时候忽略这个差异会更方便,以及让用户能够显式将数据对象求值为表达式。在 Logo 中,无论我们何时使用run 过程,我们都使用了这种能力。Python 中也存在相似的函数:eval函数会求出 Python 表达式,exec函数会求出 Python 语句,所以:
>>> eval('2+2')
4
和
>>> 2+2
4
返回了相同的结果。求解构造为指令的一部分的表达式是动态编程语言的常见和强大的特性。这个特性在 Logo 中十分普遍,很少语言是这样,但是在程序执行期间构造和求解表达式的能力,对任何程序员来说都是有价值的工具。
第四章 分布式和并行计算
4.1 引言
目前为止,我们专注于如何创建、解释和执行程序。在第一章中,我们学会使用函数作为组合和抽象的手段。第二章展示了如何使用数据结构和对象来表示和操作数据,以及向我们介绍了数据抽象的概念。在第三章中,我们学到了计算机程序如何解释和执行。结果是,我们理解了如何设计程序,它们在单一处理器上运行。
这一章中,我们跳转到协调多个计算机和处理器的问题。首先,我们会观察分布式系统。它们是互相连接的独立计算机,需要互相沟通来完成任务。它们可能需要协作来提供服务,共享数据,或者甚至是储存太大而不能在一台机器上装下的数据。我们会看到,计算机可以在分布式系统中起到不同作用,并且了解各种信息,计算机需要交换它们来共同工作。
接下来,我们会考虑并行计算。并行计算是这样,当一个小程序由多个处理器使用共享内存执行时,所有处理器都并行工作来使任务完成得更快。并发(或并行)引入了新的挑战,并且我们会开发新的机制来管理并发程序的复杂性。
4.2 分布式系统
分布式系统是自主的计算机网络,计算机互相通信来完成一个目标。分布式系统中的计算机都是独立的,并且没有物理上共享的内存或处理器。它们使用消息来和其它计算机通信,消息是网络上从一台计算机到另一台计算机传输的一段信息。消息可以用于沟通许多事情:计算机可以让其它计算机来执行一个带有特定参数的过程,它们可以发送和接受数据包,或者发送信号让其它计算机执行特定行为。
分布式系统中的计算机具有不同的作用。计算机的作用取决于系统的目标,以及计算机自身的硬件和软件属性。分布式系统中,有两种主要方式来组织计算机,一种叫客户端-服务端架构(C/S 架构),另一种叫做对等网络架构(P2P 架构)。
4.2.1 C/S 系统
C/S 架构是一种从中心来源分发服务的方式。只有单个服务端提供服务,多台客户端和服务器通信来消耗它的产出。在这个架构中,客户端和服务端都有不同的任务。服务端的任务就是响应来自客户端的服务请求,而客户端的任务就是使用响应中提供的数据来执行一些任务。
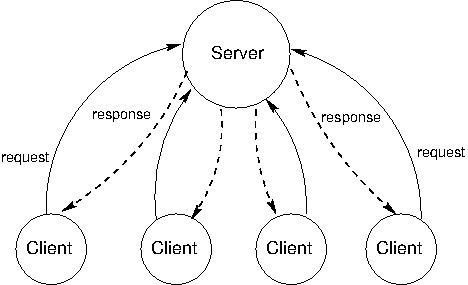
C/S 通信模型可以追溯到二十世纪七十年代 Unix 的引入,但这一模型由于现代万维网(WWW)中的使用而变得具有影响力。一个C/S 交互的例子就是在线阅读纽约时报。当www.nytimes.com上的服务器与浏览器客户端(比如 Firefox)通信时,它的任务就是发送回来纽约时报主页的 HTML。这可能涉及到基于发送给服务器的用户账户信息,计算个性化的内容。这意味着需要展示图片,安排视觉上的内容,展示不同的颜色、字体和图形,以及允许用户和渲染后的页面交互。
客户端和服务端的概念是强大的函数式抽象。服务端仅仅是一个提供服务的单位,可能同时对应多个客户端。客户端是消耗服务的单位。客户端并不需要知道服务如何提供的细节,或者所获取的数据如何储存和计算,服务端也不需要知道数据如何使用。
在网络上,我们认为客户端和服务端都是不同的机器,但是,一个机器上的系统也可以拥有 C/S 架构。例如,来自计算机输入设备的信号需要让运行在计算机上的程序来访问。这些程序就是客户端,消耗鼠标和键盘的输入数据。操作系统的设备驱动就是服务端,接受物理的信号并将它们提供为可用的输入。
C/S 系统的一个缺陷就是,服务端是故障单点。它是唯一能够分发服务的组件。客户端的数量可以是任意的,它们可以交替,并且可以按需出现和消失。但是如果服务器崩溃了,整个系统就会停止工作。所以,由 C/S 架构创建的函数式抽象也使它具有崩溃的风险。
C/S 系统的另一个缺陷是,当客户端非常多的时候,资源就变得稀缺。客户端增加系统上的命令而不贡献任何计算资源。C/S 系统不能随着不断变化的需求缩小或扩大。
4.2.2 P2P 系统
C/S 模型适合于服务导向的情形。但是,还有其它计算目标,适合使用更加平等的分工。P2P 的术语用于描述一种分布式系统,其中劳动力分布在系统的所有组件中。所有计算机发送并接受数据,它们都贡献一些处理能力和内存。随着分布式系统的规模增长,它的资源计算能力也会增长。在 P2P 系统中,系统的所有组件都对分布式计算贡献了一些处理能力和内存。
所有参与者的劳动力的分工是 P2P 系统的识别特征。也就是说,对等者需要能够和其它人可靠地通信。为了确保消息到达预定的目的地,P2P 系统需要具有组织良好的网络结构。这些系统中的组件协作来维护足够的其它组件的位置信息并将消息发送到预定的目的地。
在一些 P2P 系统中,维护网络健康的任务由一系列特殊的组件执行。这种系统并不是纯粹的 P2P 系统,因为它们具有不同类型的组件类型,提供不同的功能。支持 P2P 网络的组件就像脚手架那样:它们有助于网络保持连接,它们维护不同计算机的位置信息,并且它们新来者来邻居中找到位置。
P2P 系统的最常见应用就是数据传送和存储。对于数据传送,系统中的每台计算机都致力于网络上的数据传送。如果目标计算机是特定计算机的邻居,那台计算机就一起帮助传送数据。对于数据存储,数据集可以过于庞大,不能在任何单台计算机内装下,或者储存在单台计算机内具有风险。每台计算机都储存数据的一小部分,不同的计算机上可能会储存相同数据的多个副本。当一台计算机崩溃时,上面的数据可以由其它副本恢复,或者在更换替代品之后放回。
Skype,一个音频和视频聊天服务,是采用 P2P 架构的数据传送应用的示例。当不同计算机上的两个人都使用 Skype 交谈时,它们的通信会拆成由 1 和 0 构成的数据包,并且通过 P2P 网络传播。这个网络由电脑上注册了 Skype 的其它人组成。每台计算机都知道附近其它人的位置。一台计算机通过将数据包传给它的邻居,来帮助将它传到目的地,它的邻居又将它传给其它邻居,以此类推,直到数据包到达了它预定的目的地。Skype 并不是纯粹的 P2P 系统。一个超级节点组成的脚手架网络用于用户登录和退出,维护它们的计算机的位置信息,并且修改网络结构来处理用户进入和离开。
4.2.3 模块化
我们刚才考虑的两个架构 -- P2P 和 C/S -- 都为强制模块化而设计。模块化是一个概念,系统的组件对其它组件来说应该是个黑盒。组件如何实现行为应该并不重要,只要它提供了一个接口:规定了输入应该产生什么输出。
在第二章中,我们在调度函数和面向对象编程的上下文中遇到了接口。这里,接口的形式为指定对象应接收的信息,以及对象应如何响应它们。例如,为了提供“表示为字符串”的接口,对象必须回复__repr__和__str__信息,并且在响应中输出合适的字符串。那些字符串的生成如何实现并不是接口的一部分。
在分布式系统中,我们必须考虑涉及到多台计算机的程序设计,所以我们将接口的概念从对象和消息扩展为整个程序。接口指定了应该接受的输入,以及应该在响应中返回给输入的输出。
接口在真实世界的任何地方都存在,我们经常习以为常。一个熟悉的例子就是 TV 遥控器。你可以买到许多牌子的遥控器或者 TV,它们都能工作。它们的唯一共同点就是“TV 遥控器”的接口。只要当你按下电院、音量、频道或者其它任何按钮(输入)时,一块电路向你的 TV 发送正确的信号(输出),它就遵循“TV 遥控器”接口。
模块化给予系统许多好处,并且是一种沉思熟虑的系统设计。首先,模块化的系统易于理解。这使它易于修改和扩展。其次,如果系统中什么地方发生错误,只需要更换有错误的组件。再者,bug 或故障可以轻易定位。如果组件的输出不符合接口的规定,而且输入是正确的,那么这个组件就是故障来源。
4.2.4 消息传递
在分布式系统中,组件使用消息传递来互相沟通。消息有三个必要部分:发送者、接收者和内容。发送者需要被指定,便于接受者得知哪个组件发送了信息,以及将回复发送到哪里。接收者需要被指定,便于任何协助发送消息的计算机知道发送到哪里。消息的内容是最宝贵的。取决于整个系统的函数,内容可以是一段数据、一个信号,或者一条指令,让远程计算机来以一些参数求出某个函数。
消息传递的概念和第二章的消息传递机制有很大关系,其中,调度函数或字典会响应值为字符串的信息。在程序中,发送者和接受者都由求值规则标识。但是在分布式系统中,接受者和发送者都必须显式编码进消息中。在程序中,使用字符串来控制调度函数的行为十分方便。在分布式系统中,消息需要经过网络发送,并且可能需要存放许多不同种类的信号作为“数据”,所以它们并不始终编码为字符串。但是在两种情况中,消息都服务于相同的函数。不同的组件(调度函数或计算机)交换消息来完成一个目标,它需要多个组件模块的协作。
在较高层面上,消息内容可以是复杂的数据结构,但是在较低层面上,消息只是简单的 1 和 0 的流,在网络上传输。为了变得易用,所有网络上发送的消息都需要根据一致的消息协议格式化。
消息协议是一系列规则,用于编码和解码消息。许多消息协议规定,消息必须符合特定的格式,其中特定的比特具有固定的含义。固定的格式实现了固定的编码和解码规则来生成和读取这种格式。分布式系统中的所有组件都必须理解协议来互相通信。这样,它们就知道消息的哪个部分对应哪个信息。
消息协议并不是特定的程序或软件库。反之,它们是可以由大量程序使用的规则,甚至以不同的编程语言编写。所以,带有大量不同软件系统的计算机可以加入相同的分布式系统,只需要遵守控制这个系统的消息协议。
4.2.5 万维网上的消息
HTTP(超文本传输协议的缩写)是万维网所支持的消息协议。它指定了在 Web 浏览器和服务器之间交换的消息格式。所有 Web 浏览器都使用 HTTP 协议来请求服务器上的页面,而且所有 Web 服务器都使用 HTTP 格式来发回它们的响应。
当你在 Web 浏览器上键入 URL 时,比如 http://en.wikipedia.org/wiki/UC_Berkeley,你实际上就告诉了你的计算机,使用 "HTTP" 协议,从 "http://en.wikipedia.org/wiki/UC_Berkeley" 的服务器上请求 "wiki/UC_Berkeley" 页面。消息的发送者是你的计算机,接受者是 en.wikipedia.org,以及消息内容的格式是:
GET /wiki/UC_Berkeley HTTP/1.1
第一个单词是请求类型,下一个单词是所请求的资源,之后是协议名称(HTTP)和版本(1.1)。(请求还有其它类型,例如 PUT、POST 和 HEAD,Web 浏览器也会使用它们。)
服务器发回了回复。这时,发送者是 en.wikipedia.org,接受者是你的计算机,消息内容的格式是由数据跟随的协议头:
HTTP/1.1 200 OK
Date: Mon, 23 May 2011 22:38:34 GMT
Server: Apache/1.3.3.7 (Unix) (Red-Hat/Linux)
Last-Modified: Wed, 08 Jan 2011 23:11:55 GMT
Content-Type: text/html; charset=UTF-8
... web page content ...
第一行,单词 "200 OK" 表示没有发生错误。协议头下面的行提供了有关服务器的信息,日期和发回的内容类型。协议头和页面的实际内容通过一个空行来分隔。
如果你键入了错误的 Web 地址,或者点击了死链,你可能会看到类似于这个错误的消息:
404 Error File Not Found
它的意思是服务器发送回了一个 HTTP 协议头,以这样起始:
HTTP/1.1 404 Not Found
一系列固定的响应代码是消息协议的普遍特性。协议的设计者试图预料通过协议发送的常用消息,并且赋为固定的代码来减少传送大小,以及建立通用的消息语义。在 HTTP 协议中,200 响应代码表示成功,而 404 表示资源没有找到的错误。其它大量响应代码也存在于 HTTP 1.1 标准中。
HTTP 是用于通信的固定格式,但是它允许传输任意的 Web 页面。其它互联网上的类似协议是 XMPP,即时消息的常用协议,以及 FTP,用于在客户端和服务器之间下载和上传文件的协议。
4.3 并行计算
计算机每一年都会变得越来越快。在 1965 年,英特尔联合创始人戈登·摩尔预测了计算机将如何随时间而变得越来越快。仅仅基于五个数据点,他推测,一个芯片中的晶体管数量每两年将翻一倍。近50年后,他的预测仍惊人地准确,现在称为摩尔定律。
尽管速度在爆炸式增长,计算机还是无法跟上可用数据的规模。根据一些估计,基因测序技术的进步将使可用的基因序列数据比处理器变得更快的速度还要快。换句话说,对于遗传数据,计算机变得越来越不能处理每年需要处理的问题规模,即使计算机本身变得越来越快。
为了规避对单个处理器速度的物理和机械约束,制造商正在转向另一种解决方案:多处理器。如果两个,或三个,或更多的处理器是可用的,那么许多程序可以更快地执行。当一个处理器在做一些计算的一个切面时,其他的可以在另一个切面工作。所有处理器都可以共享相同的数据,但工作并行执行。
为了能够合作,多个处理器需要能够彼此共享信息。这通过使用共享内存环境来完成。该环境中的变量、对象和数据结构对所有的进程可见。处理器在计算中的作用是执行编程语言的求值和执行规则。在一个共享内存模型中,不同的进程可能执行不同的语句,但任何语句都会影响共享环境。
4.3.1 共享状态的问题
多个进程之间的共享状态具有单一进程环境没有的问题。要理解其原因,让我们看看下面的简单计算:
x = 5
x = square(x)
x = x + 1
x的值是随时间变化的。起初它是 5,一段时间后它是 25,最后它是 26。在单一处理器的环境中,没有时间依赖性的问题。x的值在结束时总是 26。但是如果存在多个进程,就不能这样说了。假设我们并行执行了上面代码的最后两行:一个处理器执行x = square(x)而另一个执行x = x + 1。每一个这些赋值语句都包含查找当前绑定到x的值,然后使用新值更新绑定。让我们假设x是共享的,同一时间只有一个进程读取或写入。即使如此,读和写的顺序可能会有所不同。例如,下面的例子显示了两个进程的每个进程的一系列步骤,P1和P2。每一步都是简要描述的求值过程的一部分,随时间从上到下执行:
P1 P2
read x: 5
read x: 5
calculate 5*5: 25 calculate 5+1: 6
write 25 -> x
write x-> 6
在这个顺序中,x的最终值为 6。如果我们不协调这两个过程,我们可以得到另一个顺序的不同结果:
P1 P2
read x: 5
read x: 5 calculate 5+1: 6
calculate 5*5: 25 write x->6
write 25 -> x
在这个顺序中,x将是 25。事实上存在多种可能性,这取决于进程执行代码行的顺序。x的最终值可能最终为 5,25,或预期值 26。
前面的例子是无价值的。square(x)和x = x + 1是简单快速的计算。我们强迫一条语句跑在另一条的后面,并不会失去太多的时间。但是什么样的情况下,并行化是必不可少的?这种情况的一个例子是银行业。在任何给定的时间,可能有成千上万的人想用他们的银行账户进行交易:他们可能想在商店刷卡,存入支票,转帐,或支付账单。即使一个帐户在同一时间也可能有活跃的多个交易。
让我们看看第二章的make_withdraw函数,下面是修改过的版本,在更新余额之后打印而不是返回它。我们感兴趣的是这个函数将如何并发执行。
>>> def make_withdraw(balance):
def withdraw(amount):
nonlocal balance
if amount > balance:
print('Insufficient funds')
else:
balance = balance - amount
print(balance)
return withdraw
现在想象一下,我们以 10 美元创建一个帐户,让我们想想,如果我们从帐户中提取太多的钱会发生什么。如果我们顺序执行这些交易,我们会收到资金不足的消息。
>>> w = make_withdraw(10)
>>> w(8)
2
>>> w(7)
'Insufficient funds'
但是,在并行中可以有许多不同的结果。下面展示了一种可能性:
P1: w(8) P2: w(7)
read balance: 10
read amount: 8 read balance: 10
8 > 10: False read amount: 7
if False 7 > 10: False
10 - 8: 2 if False
write balance -> 2 10 - 7: 3
read balance: 2 write balance -> 3
print 2 read balance: 3
print 3
这个特殊的例子给出了一个不正确结果 3。就好像w(8)交易从来没有发生过。其他可能的结果是 2,和'Insufficient funds'。这个问题的根源是:如果P2 在P1写入值前读取余额,P2的状态是不一致的(反之亦然)。P2所读取的余额值是过时的,因为P1打算改变它。P2不知道,并且会用不一致的值覆盖它。
这个例子表明,并行化的代码不像把代码行分给多个处理器来执行那样容易。变量读写的顺序相当重要。
一个保证执行正确性的有吸引力的方式是,两个修改共享数据的程序不能同时执行。不幸的是,对于银行业这将意味着,一次只可以进行一个交易,因为所有的交易都修改共享数据。直观地说,我们明白,让 2 个不同的人同时进行完全独立的帐户交易应该没有问题。不知何故,这两个操作不互相干扰,但在同一帐户上的相同方式的同时操作就相互干扰。此外,当进程不读取或写入时,让它们同时运行就没有问题。
4.3.2 并行计算的正确性
并行计算环境中的正确性有两个标准。第一个是,结果应该总是相同。第二个是,结果应该和串行执行的结果一致。
第一个条件表明,我们必须避免在前面的章节中所示的变化,其中在不同的方式下的交叉读写会产生不同的结果。例子中,我们从 10 美元的帐户取出了w(8)和w(7)。这个条件表明,我们必须始终返回相同的答案,独立于P1和P2的指令执行顺序。无论如何,我们必须以这样一种方式来编写我们的程序,无论他们如何相互交叉,他们应该总是产生同样的结果。
第二个条件揭示了许多可能的结果中哪个是正确的。例子中,我们从 10 美元的帐户取出了w(8)和w(7),这个条件表明结果必须总是余额不足,而不是 2 或者 3。
当一个进程在程序的临界区影响另一个进程时,并行计算中就会出现问题。这些都是需要执行的代码部分,它们看似是单一的指令,但实际上由较小的语句组成。一个程序会以一系列原子硬件指令执行,由于处理器的设计,这些是不能被打断或分割为更小单元的指令。为了在并行的情况下表现正确,程序代码的临界区需要具有原子性,保证他们不会被任何其他代码中断。
为了强制程序临界区在并发下的原子性,需要能够在重要的时刻将进程序列化或彼此同步。序列化意味着同一时间只运行一个进程 -- 这一瞬间就好像串行执行一样。同步有两种形式。首先是互斥,进程轮流访问一个变量。其次是条件同步,在满足条件(例如其他进程完成了它们的任务)之前进程一直等待,之后继续执行。这样,当一个程序即将进入临界区时,其他进程可以一直等待到它完成,然后安全地执行。
4.3.3 保护共享状态:锁和信号量
在本节中讨论的所有同步和序列化方法都使用相同的基本思想。它们在共享状态中将变量用作信号,所有过程都会理解并遵守它。这是一个相同的理念,允许分布式系统中的计算机协同工作 -- 它们通过传递消息相互协调,根据每一个参与者都理解和遵守的一个协议。
这些机制不是为了保护共享状态而出现的物理障碍。相反,他们是建立相互理解的基础上。和出现在十字路口的各种方向的车辆能够安全通行一样,是同一种相互理解。这里没有物理的墙壁阻止汽车相撞,只有遵守规则,红色意味着“停止”,绿色意味着“通行”。同样,没有什么可以保护这些共享变量,除非当一个特定的信号表明轮到某个进程了,进程才会访问它们。
锁:锁,也被称为互斥体(mutex),是共享对象,常用于发射共享状态被读取或修改的信号。不同的编程语言实现锁的方式不同,但是在 Python 中,一个进程可以调用acquire()方法来尝试获得锁的“所有权”,然后在使用完共享变量的时候调用release()释放它。当进程获得了一把锁,任何试图执行acquire()操作的其他进程都会自动等待到锁被释放。这样,同一时间只有一个进程可以获得一把锁。
对于一把保护一组特定的变量的锁,所有的进程都需要编程来遵循一个规则:一个进程不拥有特定的锁就不能访问相应的变量。实际上,所有进程都需要在锁的acquire()和release()语句之间“包装”自己对共享变量的操作。
我们可以把这个概念用于银行余额的例子中。该示例的临界区是从余额读取到写入的一组操作。我们看到,如果一个以上的进程同时执行这个区域,问题就会发生。为了保护临界区,我们需要使用一把锁。我们把这把锁称为balance_lock(虽然我们可以命名为任何我们喜欢的名字)。为了锁定实际保护的部分,我们必须确保试图进入这部分时调用acquire()获取锁,以及之后调用release()释放锁,这样可以轮到别人。
>>> from threading import Lock
>>> def make_withdraw(balance):
balance_lock = Lock()
def withdraw(amount):
nonlocal balance
# try to acquire the lock
balance_lock.acquire()
# once successful, enter the critical section
if amount > balance:
print("Insufficient funds")
else:
balance = balance - amount
print(balance)
# upon exiting the critical section, release the lock
balance_lock.release()
如果我们建立和之前一样的情形:
w = make_withdraw(10)
现在就可以并行执行w(8)和w(7)了:
P1 P2
acquire balance_lock: ok
read balance: 10 acquire balance_lock: wait
read amount: 8 wait
8 > 10: False wait
if False wait
10 - 8: 2 wait
write balance -> 2 wait
read balance: 2 wait
print 2 wait
release balance_lock wait
acquire balance_lock:ok
read balance: 2
read amount: 7
7 > 2: True
if True
print 'Insufficient funds'
release balance_lock
我们看到了,两个进程同时进入临界区是可能的。某个进程实例获取到了balance_lock,另一个就得等待,直到那个进程退出了临界区,它才能开始执行。
要注意程序不会自己终止,除非P1释放了balance_lock。如果它没有释放balance_lock,P2永远不可能获取它,而是一直会等待。忘记释放获得的锁是并行编程中的一个常见错误。
信号量:信号量是用于维持有限资源访问的信号。它们和锁类似,除了它们可以允许某个限制下的多个访问。它就像电梯一样只能够容纳几个人。一旦达到了限制,想要使用资源的进程就必须等待。其它进程释放了信号量之后,它才可以获得。
例如,假设有许多进程需要读取中心数据库服务器的数据。如果过多的进程同时访问它,它就会崩溃,所以限制连接数量就是个好主意。如果数据库只能同时支持N=2的连接,我们就可以以初始值N=2来创建信号量。
>>> from threading import Semaphore
>>> db_semaphore = Semaphore(2) # set up the semaphore
>>> database = []
>>> def insert(data):
db_semaphore.acquire() # try to acquire the semaphore
database.append(data) # if successful, proceed
db_semaphore.release() # release the semaphore
>>> insert(7)
>>> insert(8)
>>> insert(9)
信号量的工作机制是,所有进程只在获取了信号量之后才可以访问数据库。只有N=2个进程可以获取信号量,其它的进程都需要等到其中一个进程释放了信号量,之后在访问数据库之前尝试获取它。
P1 P2 P3
acquire db_semaphore: ok acquire db_semaphore: wait acquire db_semaphore: ok
read data: 7 wait read data: 9
append 7 to database wait append 9 to database
release db_semaphore: ok acquire db_semaphore: ok release db_semaphore: ok
read data: 8
append 8 to database
release db_semaphore: ok
值为 1 的信号量的行为和锁一样。
4.3.4 保持同步:条件变量
条件变量在并行计算由一系列步骤组成时非常有用。进程可以使用条件变量,来用信号告知它完成了特定的步骤。之后,等待信号的其它进程就会开始它们的任务。一个需要逐步计算的例子就是大规模向量序列的计算。在计算生物学,Web 范围的计算,和图像处理及图形学中,常常需要处理非常大型(百万级元素)的向量和矩阵。想象下面的计算:
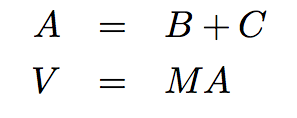
我们可以通过将矩阵和向量按行拆分,并把每一行分配到单独的线程上,来并行处理每一步。作为上面的计算的一个实例,想象下面的简单值:
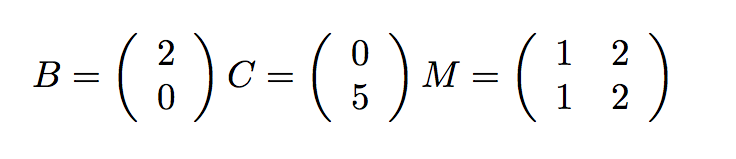
我们将前一半(这里是第一行)分配给一个线程,后一半(第二行)分配给另一个线程:
在伪代码中,计算是这样的:
def do_step_1(index):
A[index] = B[index] + C[index]
def do_step_2(index):
V[index] = M[index] . A
进程 1 执行了:
do_step_1(1)
do_step_2(1)
进程 2 执行了:
do_step_1(2)
do_step_2(2)
如果允许不带同步处理,就造成下面的不一致性:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
read M1: (1 2) read C2: 5
read A: (2 0) calculate 5+0: 5
calculate (1 2).(2 0): 2 write 5 -> A2
write 2 -> V1 read M2: (1 2)
read A: (2 5)
calculate (1 2).(2 5):12
write 12 -> V2
问题就是V直到所有元素计算出来时才会计算出来。但是,P1在A的所有元素计算出来之前,完成A = B+C并且移到V = MA。所以它与M相乘时使用了A的不一致的值。
我们可以使用条件变量来解决这个问题。
条件变量是表现为信号的对象,信号表示某个条件被满足。它们通常被用于协调进程,这些进程需要在继续执行之前等待一些事情的发生。需要满足一定条件的进程可以等待一个条件变量,直到其它进程修改了条件变量来告诉它们继续执行。
Python 中,任何数量的进程都可以使用condition.wait()方法,用信号告知它们正在等待某个条件。在调用该方法之后,它们会自动等待到其它进程调用了condition.notify()或condition.notifyAll()函数。notify()方法值唤醒一个进程,其它进程仍旧等待。notifyAll()方法唤醒所有等待中的进程。每个方法在不同情形中都很实用。
由于条件变量通常和决定条件是否为真的共享变量相联系,它们也提供了acquire()和release()方法。这些方法应该在修改可能改变条件状态的变量时使用。任何想要用信号告知条件已经改变的进程,必须首先使用acquire()来访问它。
在我们的例子中,在执行第二步之前必须满足的条件是,两个进程都必须完成了第一步。我们可以跟踪已经完成第一步的进程数量,以及条件是否被满足,通过引入下面两个变量:
step1_finished = 0
start_step2 = Condition()
我们在do_step_2的开头插入start_step_2().wait()。每个进程都会在完成步骤 1 之后自增step1_finished,但是我们只会在step_1_finished = 2时发送信号。下面的伪代码展示了它:
step1_finished = 0
start_step2 = Condition()
def do_step_1(index):
A[index] = B[index] + C[index]
# access the shared state that determines the condition status
start_step2.acquire()
step1_finished += 1
if(step1_finished == 2): # if the condition is met
start_step2.notifyAll() # send the signal
#release access to shared state
start_step2.release()
def do_step_2(index):
# wait for the condition
start_step2.wait()
V[index] = M[index] . A
在引入条件变量之后,两个进程会一起进入步骤 2,像下面这样:
P1 P2
read B1: 2
read C1: 0
calculate 2+0: 2
write 2 -> A1 read B2: 0
acquire start_step2: ok read C2: 5
write 1 -> step1_finished calculate 5+0: 5
step1_finished == 2: false write 5-> A2
release start_step2: ok acquire start_step2: ok
start_step2: wait write 2-> step1_finished
wait step1_finished == 2: true
wait notifyAll start_step_2: ok
start_step2: ok start_step2:ok
read M1: (1 2) read M2: (1 2)
read A:(2 5)
calculate (1 2). (2 5): 12 read A:(2 5)
write 12->V1 calculate (1 2). (2 5): 12
write 12->V2
在进入do_step_2的时候,P1需要在start_step_2之前等待,直到P2自增了step1_finished,发现了它等于 2,之后向条件发送信号。
4.3.5 死锁
虽然同步方法对保护共享状态十分有效,但它们也带来了麻烦。因为它们会导致一个进程等待另一个进程,这些进程就有死锁的风险。死锁是一种情形,其中两个或多个进程被卡住,互相等待对方完成。我们已经提到了忘记释放某个锁如何导致进程无限卡住。但是即使acquire()和release()调用的数量正确,程序仍然会构成死锁。
死锁的来源是循环等待,像下面展示的这样。没有进程能够继续执行,因为它们正在等待其它进程,而其它进程也在等待它完成。
作为一个例子,我们会建立两个进程的死锁。假设有两把锁,x_lock和y_lock,并且它们像这样使用:
>>> x_lock = Lock()
>>> y_lock = Lock()
>>> x = 1
>>> y = 0
>>> def compute():
x_lock.acquire()
y_lock.acquire()
y = x + y
x = x * x
y_lock.release()
x_lock.release()
>>> def anti_compute():
y_lock.acquire()
x_lock.acquire()
y = y - x
x = sqrt(x)
x_lock.release()
y_lock.release()
如果compute()和anti_compute()并行执行,并且恰好像下面这样互相交错:
P1 P2
acquire x_lock: ok acquire y_lock: ok
acquire y_lock: wait acquire x_lock: wait
wait wait
wait wait
wait wait
... ...
所产生的情形就是死锁。P1和P2每个都持有一把锁,但是它们需要两把锁来执行。P1正在等待P2释放y_lock,而P2正在等待P1释放x_lock。所以,没有进程能够继续执行。
第五章 序列和协程
5.1 引言
在这一章中,我们通过开发新的工具来处理有序数据,继续讨论真实世界中的应用。在第二章中,我们介绍了序列接口,在 Python 内置的数据类型例如tuple和list中实现。序列支持两个操作:获取长度和由下标访问元素。第三章中,我们开发了序列接口的用户定义实现,用于表示递归列表的Rlist类。序列类型具有高效的表现力,并且可以让我们高效访问大量有序数据集。
但是,使用序列抽象表示有序数据有两个重要限制。第一个是长度为n的序列的要占据比例为n的内存总数。于是,序列越长,表示它所占的内存空间就越大。
第二个限制是,序列只能表示已知且长度有限的数据集。许多我们想要表示的有序集合并没有定义好的长度,甚至有些是无限的。两个无限序列的数学示例是正整数和斐波那契数。无限长度的有序数据集也出现在其它计算领域,例如,所有推特状态的序列每秒都在增长,所以并没有固定的长度。与之类似,经过基站发送出的电话呼叫序列,由计算机用户发出的鼠标动作序列,以及飞机上的传感器产生的加速度测量值序列,都在世界演化过程中无限扩展。
在这一章中,我们介绍了新的构造方式用于处理有序数据,它为容纳未知或无限长度的集合而设计,但仅仅使用有限的内存。我们也会讨论这些工具如何用于一种叫做协程的程序结构,来创建高效、模块化的数据处理流水线。
5.2 隐式序列
序列可以使用一种程序结构来表示,它不将每个元素显式储存在内存中,这是高效处理有序数据的核心概念。为了将这个概念用于实践,我们需要构造对象来提供序列中所有元素的访问,但是不要事先把所有元素计算出来并储存。
这个概念的一个简单示例就是第二章出现的range序列类型。range表示连续有界的整数序列。但是,它的每个元素并不显式在内存中表示,当元素从range中获取时,才被计算出来。所以,我们可以表示非常大的整数范围。只有范围的结束位置才被储存为range对象的一部分,元素都被凭空计算出来。
>>> r = range(10000, 1000000000)
>>> r[45006230]
45016230
这个例子中,当构造范围示例时,并不是这个范围内的所有 999,990,000 个整数都被储存。反之,范围对象将第一个元素 10,000 与下标相加 45,006,230 来产生第 45,016,230 个元素。计算所求的元素值并不从现有的表示中获取,这是惰性计算的一个例子。计算机科学将惰性作为一种重要的计算工具加以赞扬。
迭代器是提供底层有序数据集的有序访问的对象。迭代器在许多编程语言中都是内建对象,包括 Python。迭代器抽象拥有两个组成部分:一种获取底层元素序列的下一个元素的机制,以及一种标识元素序列已经到达末尾,没有更多剩余元素的机制。在带有内建对象系统的编程语言中,这个抽象通常相当于可以由类实现的特定接口。Python 的迭代器接口会在下一节中描述。
迭代器的实用性来源于一个事实,底层数据序列并不能显式在内存中表达。迭代器提供了一种机制,可以依次计算序列中的每个值,但是所有元素不需要连续储存。反之,当下个元素从迭代器获取的时候,这个元素会按照请求计算,而不是从现有的内存来源中获取。
范围可以惰性计算序列中的元素,因为序列的表示是统一的,并且任何元素都可以轻易从范围的起始和结束位置计算出来。迭代器支持更广泛的底层有序数据集的惰性生成,因为它们不需要提供底层序列任意元素的访问途径。反之,它们仅仅需要按照顺序,在每次其它元素被请求的时候,计算出序列的下一个元素。虽然不像序列可访问任意元素那样灵活(叫做随机访问),有序数据序列的顺序访问对于数据处理应用来说已经足够了。
5.2.1 Python 迭代器
Python 迭代器接口包含两个消息。__next__消息向迭代器获取所表示的底层序列的下一个元素。为了对__next__方法调用做出回应,迭代器可以执行任何计算来获取或计算底层数据序列的下一个元素。__next__的调用让迭代器产生变化:它们向前移动迭代器的位置。所以多次调用__next__会有序返回底层序列的元素。在__next__的调用过程中,Python 通过StopIteration异常,来表示底层数据序列已经到达末尾。
下面的Letters类迭代了从a到d字母的底层序列。成员变量current储存了序列中的当前字母。__next__方法返回这个字母,并且使用它来计算current的新值。
>>> class Letters(object):
def __init__(self):
self.current = 'a'
def __next__(self):
if self.current > 'd':
raise StopIteration
result = self.current
self.current = chr(ord(result)+1)
return result
def __iter__(self):
return self
__iter__消息是 Python 迭代器所需的第二个消息。它只是简单返回迭代器,它对于提供迭代器和序列的通用接口很有用,在下一节会描述。
使用这个类,我们就可以访问序列中的字母:
>>> letters = Letters()
>>> letters.__next__()
'a'
>>> letters.__next__()
'b'
>>> letters.__next__()
'c'
>>> letters.__next__()
'd'
>>> letters.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 12, in next
StopIteration
Letters示例只能迭代一次。一旦__next__()方法产生了StopIteration异常,它就从此之后一直这样了。除非创建新的实例,否则没有办法来重置它。
迭代器也允许我们表示无限序列,通过实现永远不会产生StopIteration异常的__next__方法。例如,下面展示的Positives类迭代了正整数的无限序列:
>>> class Positives(object):
def __init__(self):
self.current = 0;
def __next__(self):
result = self.current
self.current += 1
return result
def __iter__(self):
return self
5.2.2 for语句
Python 中,序列可以通过实现__iter__消息用于迭代。如果一个对象表示有序数据,它可以在for语句中用作可迭代对象,通过回应__iter__消息来返回迭代器。这个迭代器应拥有__next__()方法,依次返回序列中的每个元素,最后到达序列末尾时产生StopIteration异常。
>>> counts = [1, 2, 3]
>>> for item in counts:
print(item)
1
2
3
在上面的实例中,counts列表返回了迭代器,作为__iter__()方法调用的回应。for语句之后反复调用迭代器的__next__()方法,并且每次都将返回值赋给item。这个过程一直持续,直到迭代器产生了StopIteration异常,这时for语句就终止了。
使用我们关于迭代器的知识,我们可以拿while、赋值和try语句实现for语句的求值规则:
>>> i = counts.__iter__()
>>> try:
while True:
item = i.__next__()
print(item)
except StopIteration:
pass
1
2
3
在上面,调用counts的__iter__方法所返回的迭代器绑定到了名称i上面,便于依次获取每个元素。StopIteration异常的处理子句不做任何事情,但是这个异常的处理提供了退出while循环的控制机制。
5.2.3 生成器和yield语句
上面的Letters和Positives对象需要我们引入一种新的字段,self.current,来跟踪序列的处理过程。在上面所示的简单序列中,这可以轻易实现。但对于复杂序列,__next__()很难在计算中节省空间。生成器允许我们通过利用 Python 解释器的特性定义更复杂的迭代。
生成器是由一类特殊函数,叫做生成器函数返回的迭代器。生成器函数不同于普通的函数,因为它不在函数体中包含return语句,而是使用yield语句来返回序列中的元素。
生成器不使用任何对象属性来跟踪序列的处理过程。它们控制生成器函数的执行,每次__next__方法调用时,它们执行到下一个yield语句。Letters迭代可以使用生成器函数实现得更加简洁。
>>> def letters_generator():
current = 'a'
while current <= 'd':
yield current
current = chr(ord(current)+1)
>>> for letter in letters_generator():
print(letter)
a
b
c
d
即使我们永不显式定义__iter__()或__next__()方法,Python 会理解当我们使用yield语句时,我们打算定义生成器函数。调用时,生成器函数并不返回特定的产出值,而是返回一个生成器(一种迭代器),它自己就可以返回产出的值。生成器对象拥有__iter__和__next__方法,每个对__next__的调用都会从上次停留的地方继续执行生成器函数,直到另一个yield语句执行的地方。
__next__第一次调用时,程序从letters_generator的函数体一直执行到进入yield语句。之后,它暂停并返回current值。yield语句并不破坏新创建的环境,而是为之后的使用保留了它。当__next__再次调用时,执行在它停留的地方恢复。letters_generator作用域中current和任何所绑定名称的值都会在随后的__next__调用中保留。
我们可以通过手动调用__next__()来遍历生成器:
>>> letters = letters_generator()
>>> type(letters)
<class 'generator'>
>>> letters.__next__()
'a'
>>> letters.__next__()
'b'
>>> letters.__next__()
'c'
>>> letters.__next__()
'd'
>>> letters.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
在第一次__next__()调用之前,生成器并不会开始执行任何生成器函数体中的语句。
5.2.4 可迭代对象
Python 中,迭代只会遍历一次底层序列的元素。在遍历之后,迭代器在__next__()调用时会产生StopIteration异常。许多应用需要迭代多次元素。例如,我们需要对一个列表迭代多次来枚举所有的元素偶对:
>>> def all_pairs(s):
for item1 in s:
for item2 in s:
yield (item1, item2)
>>> list(all_pairs([1, 2, 3]))
[(1, 1), (1, 2), (1, 3), (2, 1), (2, 2), (2, 3), (3, 1), (3, 2), (3, 3)]
序列本身不是迭代器,但是它是可迭代对象。Python 的可迭代接口只包含一个消息,__iter__,返回一个迭代器。Python 中内建的序列类型在__iter__方法调用时,返回迭代器的新实例。如果一个可迭代对象在每次调用__iter__时返回了迭代器的新实例,那么它就能被迭代多次。
新的可迭代类可以通过实现可迭代接口来定义。例如,下面的可迭代对象LetterIterable类在每次调用__iter__时返回新的迭代器来迭代字母。
>>> class LetterIterable(object):
def __iter__(self):
current = 'a'
while current <= 'd':
yield current
current = chr(ord(current)+1)
__iter__方法是个生成器函数,它返回一个生成器对象,产出从'a'到'd'的字母。
Letters迭代器对象在单次迭代之后就被“用完”了,但是LetterIterable对象可被迭代多次。所以,LetterIterable示例可以用于all_pairs的参数。
>>> letters = LetterIterable()
>>> all_pairs(letters).__next__()
('a', 'a')
5.2.5 流
流提供了一种隐式表示有序数据的最终方式。流是惰性计算的递归列表。就像第三章的Rlist类那样,Stream实例可以响应对其第一个元素和剩余部分的获取请求。同样,Stream的剩余部分还是Stream。然而不像RList,流的剩余部分只在查找时被计算,而不是事先存储。也就是说流的剩余部分是惰性计算的。
为了完成这个惰性求值,流会储存计算剩余部分的函数。无论这个函数在什么时候调用,它的返回值都作为流的一部分,储存在叫做_rest的属性中。下划线表示它不应直接访问。可访问的属性rest是个方法,它返回流的剩余部分,并在必要时计算它。使用这个设计,流可以储存计算剩余部分的方式,而不用总是显式储存它们。
>>> class Stream(object):
"""A lazily computed recursive list."""
def __init__(self, first, compute_rest, empty=False):
self.first = first
self._compute_rest = compute_rest
self.empty = empty
self._rest = None
self._computed = False
@property
def rest(self):
"""Return the rest of the stream, computing it if necessary."""
assert not self.empty, 'Empty streams have no rest.'
if not self._computed:
self._rest = self._compute_rest()
self._computed = True
return self._rest
def __repr__(self):
if self.empty:
return '<empty stream>'
return 'Stream({0}, <compute_rest>)'.format(repr(self.first))
>>> Stream.empty = Stream(None, None, True)
递归列表可使用嵌套表达式来定义。例如,我们可以创建RList,来表达1和5的序列,像下面这样:
>>> r = Rlist(1, Rlist(2+3, Rlist.empty))
与之类似,我们可以创建一个Stream来表示相同序列。Stream在请求剩余部分之前,并不会实际计算下一个元素5。
>>> s = Stream(1, lambda: Stream(2+3, lambda: Stream.empty))
这里,1是流的第一个元素,后面的lambda表达式是用于计算流的剩余部分的函数。被计算的流的第二个元素又是一个返回空流的函数。
访问递归列表r和流s中的元素拥有相似的过程。但是,5储存在了r之中,而对于s来说,它在首次被请求时通过加法来按要求计算。
>>> r.first
1
>>> s.first
1
>>> r.rest.first
5
>>> s.rest.first
5
>>> r.rest
Rlist(5)
>>> s.rest
Stream(5, <compute_rest>)
虽然 r 的 rest 是一个单元素递归列表,但 s 的其余部分包括一个计算其余部分的函数;它将返回空流的事实可能还没有被发现。
当构造一个 Stream 实例时,字段 self._computed 为 False ,表示 Stream 的 _rest 还没有被计算。当通过点表达式请求 rest 属性时,会调用 rest 方法,以 self._rest = self.compute_rest 触发计算。由于 Stream 中的缓存机制,compute_rest 函数只被调用一次。
compute_rest 函数的基本属性是它不接受任何参数,并返回一个 Stream。
惰性求值使我们能够用流来表示无限的顺序数据集。例如,我们可以从任意 first 开始表示递增的整数。
>>> def make_integer_stream(first=1):
def compute_rest():
return make_integer_stream(first+1)
return Stream(first, compute_rest)
>>> ints = make_integer_stream()
>>> ints
Stream(1, <compute_rest>)
>>> ints.first
1
当make_integer_stream首次被调用时,它返回了一个流,流的first是序列中第一个整数(默认为1)。但是,make_integer_stream实际是递归的,因为这个流的compute_rest以自增的参数再次调用了make_integer_stream。这会让make_integer_stream变成递归的,同时也是惰性的。
>>> ints.first
1
>>> ints.rest.first
2
>>> ints.rest.rest
Stream(3, <compute_rest>)
无论何时请求整数流的rest,都仅仅递归调用make_integer_stream。
操作序列的相同高阶函数 -- map和filter -- 同样可应用于流,虽然它们的实现必须修改来惰性调用它们的参数函数。map_stream在一个流上映射函数,这会产生一个新的流。局部定义的compute_rest函数确保了无论什么时候rest被计算出来,这个函数都会在流的剩余部分上映射。
>>> def map_stream(fn, s):
if s.empty:
return s
def compute_rest():
return map_stream(fn, s.rest)
return Stream(fn(s.first), compute_rest)
流可以通过定义compute_rest函数来过滤,这个函数在流的剩余部分上调用过滤器函数。如果过滤器函数拒绝了流的第一个元素,剩余部分会立即计算出来。因为filter_stream是递归的,剩余部分可能会多次计算直到找到了有效的first元素。
>>> def filter_stream(fn, s):
if s.empty:
return s
def compute_rest():
return filter_stream(fn, s.rest)
if fn(s.first):
return Stream(s.first, compute_rest)
return compute_rest()
map_stream和filter_stream展示了流式处理的常见模式:无论流的剩余部分何时被计算,局部定义的compute_rest函数都会对流的剩余部分递归调用某个处理函数。
为了观察流的内容,我们需要将其截断为有限长度,并转换为 Python list。
>>> def truncate_stream(s, k):
if s.empty or k == 0:
return Stream.empty
def compute_rest():
return truncate_stream(s.rest, k-1)
return Stream(s.first, compute_rest)
>>> def stream_to_list(s):
r = []
while not s.empty:
r.append(s.first)
s = s.rest
return r
这些便利的函数允许我们验证map_stream的实现,使用一个非常简单的例子,从3到7的整数平方。
>>> s = make_integer_stream(3)
>>> s
Stream(3, <compute_rest>)
>>> m = map_stream(lambda x: x*x, s)
>>> m
Stream(9, <compute_rest>)
>>> stream_to_list(truncate_stream(m, 5))
[9, 16, 25, 36, 49]
我们可以使用我们的filter_stream函数来定义素数流,使用埃拉托斯特尼筛法(sieve of Eratosthenes),它对整数流进行过滤,移除第一个元素的所有倍数数值。通过成功过滤出每个素数,所有合数都从流中移除了。
>>> def primes(pos_stream):
def not_divible(x):
return x % pos_stream.first != 0
def compute_rest():
return primes(filter_stream(not_divible, pos_stream.rest))
return Stream(pos_stream.first, compute_rest)
通过截断primes流,我们可以枚举素数的任意前缀:
>>> p1 = primes(make_integer_stream(2))
>>> stream_to_list(truncate_stream(p1, 7))
[2, 3, 5, 7, 11, 13, 17]
流和迭代器不同,因为它们可以多次传递给纯函数,并且每次都产生相同的值。素数流并没有在转换为列表之后“用完”。也就是说,在将流的前缀转换为列表之后,p1的第一个元素仍旧是2。
>>> p1.first
2
就像递归列表提供了序列抽象的简单实现,流提供了简单、函数式的递归数据结构,它通过高阶函数的使用实现了惰性求值。
5.3 协程
这篇文章的大部分专注于将复杂程序解构为小型、模块化组件的技巧。当一个带有复杂行为的函数逻辑划分为几个独立的、本身为函数的步骤时,这些函数叫做辅助函数或者子过程。子过程由主函数调用,主函数负责协调子函数的使用。
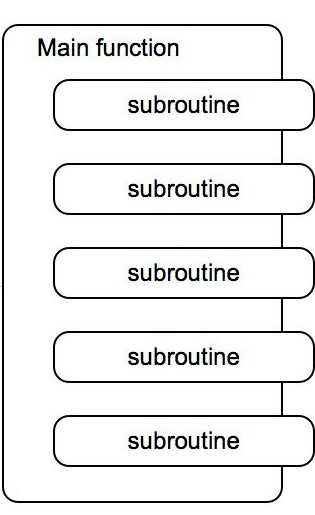
这一节中,我们使用协程,引入了一种不同的方式来解构复杂的计算。它是一种针对有序数据的任务处理方式。就像子过程那样,协程会计算复杂计算的一小步。但是,在使用协程时,没有主函数来协调结果。反之,协程会自发链接到一起来组成流水线。可能有一些协程消耗输入数据,并把它发送到其它协程。也可能有一些协程,每个都对发送给它的数据执行简单的处理步骤。最后可能有另外一些协程输出最终结果。
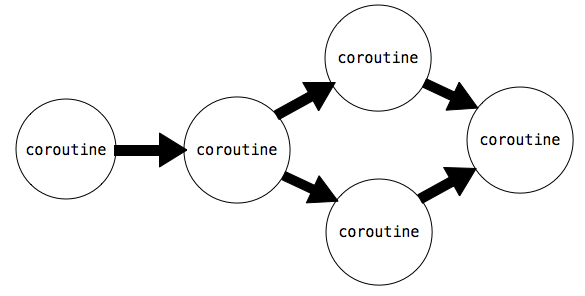
协程和子过程的差异是概念上的:子过程在主函数中位于下级,但是协程都是平等的,它们协作组成流水线,不带有任何上级函数来负责以特定顺序调用它们。
这一节中,我们会学到 Python 如何通过yield和send()语句来支持协程的构建。之后,我们会看到协程在流水线中的不同作用,以及协程如何支持多任务。
5.3.1 Python 协程
在之前一节中,我们介绍了生成器函数,它使用yield来返回一个值。Python 的生成器函数也可以使用(yield)语句来接受一个值。生成器对象上有两个额外的方法:send()和close(),创建了一个模型使对象可以消耗或产出值。定义了这些对象的生成器函数叫做协程。
协程可以通过(yield)语句来消耗值,向像下面这样:
value = (yield)
使用这个语法,在带参数调用对象的send方法之前,执行流会停留在这条语句上。
coroutine.send(data)
之后,执行会恢复,value会被赋为data的值。为了发射计算终止的信号,我们需要使用close()方法来关闭协程。这会在协程内部产生GeneratorExit异常,它可以由try/except子句来捕获。
下面的例子展示了这些概念。它是一个协程,用于打印匹配所提供的模式串的字符串。
>>> def match(pattern):
print('Looking for ' + pattern)
try:
while True:
s = (yield)
if pattern in s:
print(s)
except GeneratorExit:
print("=== Done ===")
我们可以使用一个模式串来初始化它,之后调用__next__()来开始执行:
>>> m = match("Jabberwock")
>>> m.__next__()
Looking for Jabberwock
对__next__()的调用会执行函数体,所以"Looking for jabberwock"会被打印。语句会一直持续执行,直到遇到line = (yield)语句。之后,执行会暂停,并且等待一个发送给m的值。我们可以使用send来将值发送给它。
>>> m.send("the Jabberwock with eyes of flame")
the Jabberwock with eyes of flame
>>> m.send("came whiffling through the tulgey wood")
>>> m.send("and burbled as it came")
>>> m.close()
=== Done ===
当我们以一个值调用m.send时,协程m内部的求值会在line = (yield)语句处恢复,这里会把发送的值赋给line变量。m中的语句会继续求值,如果匹配的话会打印出那一行,并继续执行循环,直到再次进入line = (yield)。之后,m中的求值会暂停,并在m.send调用后恢复。
我们可以将使用send()和yield的函数链到一起来完成复杂的行为。例如,下面的函数将名为text的字符串分割为单词,并把每个单词发送给另一个协程。
每个单词都发送给了绑定到next_coroutine的协程,使next_coroutine开始执行,而且这个函数暂停并等待。它在next_coroutine暂停之前会一直等待,随后这个函数恢复执行,发送下一个单词或执行完毕。
如果我们将上面定义的match和这个函数链到一起,我们就可以创建出一个程序,只打印出匹配特定单词的单词。
>>> text = 'Commending spending is offending to people pending lending!'
>>> matcher = match('ending')
>>> matcher.__next__()
Looking for ending
>>> read(text, matcher)
Commending
spending
offending
pending
lending!
=== Done ===
read函数向协程matcher发送每个单词,协程打印出任何匹配pattern的输入。在matcher协程中,s = (yield)一行等待每个发送进来的单词,并且在执行到这一行之后将控制流交还给read。
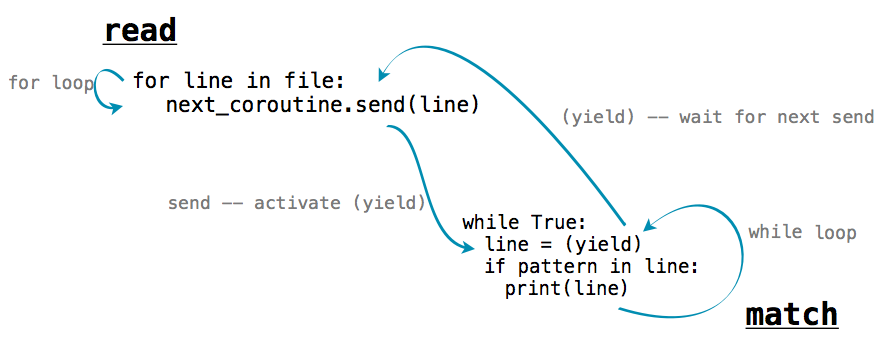
5.3.2 生产、过滤和消耗
协程基于如何使用yield和send()而具有不同的作用:
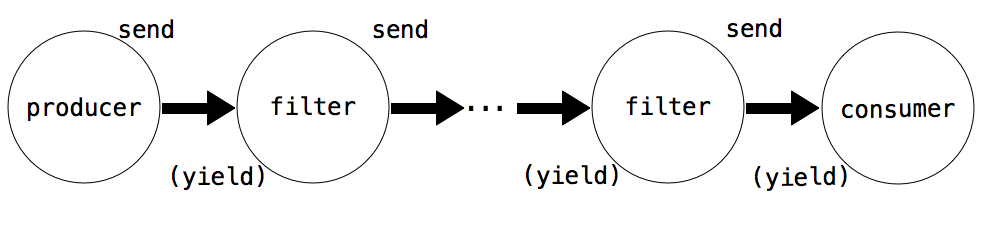
- 生产者创建序列中的物品,并使用
send(),而不是(yield)。 - 过滤器使用
(yield)来消耗物品并将结果使用send()发送给下一个步骤。 - 消费者使用
(yield)来消耗物品,但是从不发送。
上面的read函数是一个生产者的例子。它不使用(yield),但是使用send来生产数据。函数match是个消费者的例子。它不使用send发送任何东西,但是使用(yield)来消耗数据。我们可以将match拆分为过滤器和消费者。过滤器是一个协程,只发送与它的模式相匹配的字符串。
>>> def match_filter(pattern, next_coroutine):
print('Looking for ' + pattern)
try:
while True:
s = (yield)
if pattern in s:
next_coroutine.send(s)
except GeneratorExit:
next_coroutine.close()
消费者是一个函数,只打印出发送给它的行:
>>> def print_consumer():
print('Preparing to print')
try:
while True:
line = (yield)
print(line)
except GeneratorExit:
print("=== Done ===")
当过滤器或消费者被构建时,必须调用它的__next__方法来开始执行:
>>> printer = print_consumer()
>>> printer.__next__()
Preparing to print
>>> matcher = match_filter('pend', printer)
>>> matcher.__next__()
Looking for pend
>>> read(text, matcher)
spending
pending
=== Done ===
即使名称filter暗示移除元素,过滤器也可以转换元素。下面的函数是个转换元素的过滤器的示例。它消耗字符串并发送一个字典,包含了每个不同的字母在字符串中的出现次数。
>>> def count_letters(next_coroutine):
try:
while True:
s = (yield)
counts = {letter:s.count(letter) for letter in set(s)}
next_coroutine.send(counts)
except GeneratorExit as e:
next_coroutine.close()
我们可以使用它来计算文本中最常出现的字母,并使用一个消费者,将字典合并来找出最常出现的键。
>>> def sum_dictionaries():
total = {}
try:
while True:
counts = (yield)
for letter, count in counts.items():
total[letter] = count + total.get(letter, 0)
except GeneratorExit:
max_letter = max(total.items(), key=lambda t: t[1])[0]
print("Most frequent letter: " + max_letter)
为了在文件上运行这个流水线,我们必须首先按行读取文件。之后,将结果发送给count_letters,最后发送给sum_dictionaries。我们可以服用read协程来读取文件中的行。
>>> s = sum_dictionaries()
>>> s.__next__()
>>> c = count_letters(s)
>>> c.__next__()
>>> read(text, c)
Most frequent letter: n
5.3.3 多任务
生产者或过滤器并不受限于唯一的下游。它可以拥有多个协程作为它的下游,并使用send()向它们发送数据。例如,下面是read的一个版本,向多个下游发送字符串中的单词:
>>> def read_to_many(text, coroutines):
for word in text.split():
for coroutine in coroutines:
coroutine.send(word)
for coroutine in coroutines:
coroutine.close()
我们可以使用它来检测多个单词中的相同文本:
>>> m = match("mend")
>>> m.__next__()
Looking for mend
>>> p = match("pe")
>>> p.__next__()
Looking for pe
>>> read_to_many(text, [m, p])
Commending
spending
people
pending
=== Done ===
=== Done ===
首先,read_to_many在m上调用了send(word)。这个协程正在等待循环中的text = (yield),之后打印出所发现的匹配,并且等待下一个send。之后执行流返回到了read_to_many,它向p发送相同的行。所以,text中的单词会按照顺序打印出来。
现在滴王🤪
1~4基础
- 浮点运算的速度通常比整型运算慢,
对于标量运算float和double没有明显差别
对于矢量运算double比float慢得多
- 运算符重载(operator overloading):使用相同符号进行多种操作
1.C++内置重载 9/5 int ; 9L/5L long ; 9.0/5.0 double ; 9.0f/5.0f float
2.C++扩展运算符重载
- int guess(3.9832);结果:guess=3; 将浮点float转换为整型int时,采用截取(丢弃小数部分),而不是四舍五入
- 将一个值赋值给取值范围更大的类型通常不会导致什么问题,只是占用的字节更多而已。
- 列表初始化(使用大括号初始化)不允许窄缩(
float-->int)。 - (long)thorn; long(thron);强制类型转换不会改变thorn变量本身,而是创建一个新的,指定类型的值。
- auto让编译器能够根据初始值的类型推断变量的类型。
- C++的基本类型
- 整数值(内存量及有无符号): bool,char,signed char,unsigned char,short,unsigned short,int,unsigned int,long,unsigned long,(新)long long,unsigned long
- 浮点格式的值:float(32位),double(64位),long double(94~128位)
- 复合类型:数组;字符串:1.字符数组char array 2.string类;结构:struct;共同体:union;枚举:enum;指针:int* ,long*
数组(array)
short months[12];
int yamcosts[3]={20,30.5};
double earning[4]{1.2e4,1.6e4,1.4e4,1.7e4};
float balances[100]{};//初始化全部元素值为0
//字符串
char boss[8]="Bozo"//后面四个元素为"\0"空字符
using
- using namespace XXX;这是指示
引入名称空间内所有的名称:将XXX名称空间,所有成员变成可见,作用域和using声明一致;例:
using namespace std;
- using XXX;这是声明
引入名称空间或基类作用域内已经被声明的名称:一次只引入一个命名空间成员;
using std::cout;
类之于对象,类型之于变量
对象和变量都是用来描述一段内存的。
- 变量更强调的是变量名这个符号的含义,更强调名字与内存的联系,而不必关注这段内存是什么类型,有多少字节长度,只关注这个变量名a对应着某段内存。
- 而对象的描述更强调的是内存的类型而不在乎名字,也就是说,从对象的角度看内存,就需要清除这段内存的字节长度等信息,而不是关注这个对象在代码中是否有一个变量名来引用这段内存。
struct结构
- struct和class的区别 >struct能包含成员函数吗? 能! >struct能继承吗? 能!! >struct能实现多态吗? 能!!!
既然这些它都能实现,那它和class还能有什么区别? 最本质的一个区别就是默认的访问控制,体现在两个方面:默认继承访问权限和默认成员访问权限
- 1)默认的继承访问权限。struct是public的,class是private的。
- 2)struct作为数据结构的实现体,它默认的数据访问控制是public的,而class作为对象的实现体,它默认的成员变量访问控制是private的。
- 做个总结,从上面的区别,我们可以看出,struct更适合看成是一个数据结构的实现体,class更适合看成是一个对象的实现体。
共用体union
它能够存储不同的数据类型,但只能同时存储其中的一种类型。 这种特性使得当数据项使用两种或更多种格式(但不会同时使用)时,可节省空间。 使用场合:1.对内存的使用苛刻,如嵌入式系统编程 2.操作系统数据结构或硬件数据结构
枚举 enum
- 提供了一种创建符号常量的方式,这种方式可以替代const。
- 它还允许定义新的类型,但必须按严格的限制进行。
enum spectrum{red,orange,yellow,green,blue,violet,indigo,wltraciolet};//对应整数值0~7(声明定义)
//在不进行强制类型转换的情况下,只能将定义使用的枚举量赋给这种枚举的变量。
spectrum band;//声明定义
band = blue;//初始化(赋值)
//枚举量是整型,可提升为int型
int color = blue;
//设置枚举量的值;
enum bits{one=1,two=2,four=4,eight=8};
enum bigstep{first,second=100,third};//first=0,third=101
//枚举的取值范围
bits myflag;
myflag=bits(6);//强制类型转换(整数值),保证bits()输入的参数小于bits的上限,上限=(2^n-1)>max,max在bits中等于8
指针和自由存储空间
1.使用常规变量时,值是指定的量,而地址为派生量。
指针与C++基本原理 1.编译阶段:编译器将程序组合起来
2.运行阶段:程序正在运行时--》oop强调的是在运行阶段进行决策
- 考虑为数组分配内存的情况,C++采用的方法是:使用关键字new请求正确数量的内存以及使用指针来跟踪新分配内存的位置
2.处理存储数据的新策略刚好相反,将地址视为指定的量,将之视为派生量
*运算符被称为间接值运算符或叫解除引用运算符(对指针解除引用意味着获得指针指向的值)。
&地址运算符
注意:int * p1,p2;p1是指针,p2是int变量;对于每个指针变量名,都需要一个*
- 定义与初始化
int h = 5;
int *pt =& h;
//或
int *pt;
pt = &h;
应用*之前,一定要将指针初始化为一个确定的,适当的地址。就是说一定要初始化,否则*pt 将值会赋给一个未知内存。否则都还没引用,又怎么接触引用呢?
- 要将数字值作为地址来使用,应通过强制类型转换将数字转换为适当的地址类型。
pt=(int *)0×B8000000;
使用new来分配内存
变量:在编译时分配的有名称的内存。
指针的真正的用武之地在于,在运行阶段分配未命名的内存以及存储值,(C++中使用new运算符来实现)在这种情况下,只能通过指针来访问内存--->所以new的出现都会有指针。
typeName * pointer_name=new typeName;//使用new分配未命名的内存
* pointer_name=1000;//对该未去命名的内存赋值
-
new从被称为 堆(heap) 或 自由存储区(free store) 的内存区域分配内存。
delete pointer_name;释放指针pointer_name指向的内存。释放pointer_name指向的内存,但不会删除pointer_name指针本身。例如,可以将pointer_name重新指向另外一个新分配的内存块。不要创建两个指向同一内存块的指针 -
对于大型数据对象来说,使用new,如数组、字符串、结构。
- 1.静态联编(static binding)
如果通过声明来创建数组,则程序被编译时将为它分配内存空间,不管程序最终是否使用数组,数组都在那里。它占用了内存,所以必须指定数组长度。
- 2.动态联编(dynamic binding)
意味着数组是在程序运行时创建的,这种数组叫作动态数组。
使用new创建动态数组-->Vector模板类是替代品
//创建
int * psome =new int[10];
//释放
delete[] psome;//方括号告诉程序,应释放整个数组。
指针和数组等价的原因在于指针算术
将整数变量加1后,其值将增加1,
将指针变量加1后,增加的量等于它指向类型的字节数。
- 指针与数组之间的转换
数组:arrayname[i]等价于*(arrayname+i)
指针:pointername[i]等价于*(pointername+i)
因此,很多情况下,可以使用相同的方式使用数组名和指针名
const char *bird ='"wren"bird的值可以修改,但*bird值不可以修改。其实应该说是不能使用bird指针来修改!!!
- 常量指针:const修饰的是“char * bird”,里面的值是不可以改变的。可以使用指针bird访问字符串“wren”但不能修改字符串。
char * const p ="wren";
- 指针常量:const修饰的是指针“p”,指针的值是不能改变的。
使用new来创建动态结构
运行时创建数组(结构)由于编译时创建数组(结构)
创建一个未命名的inflatable类型,并将其地址赋给一个指针。
inflatable *ps=new inflatble
C++有三种管理数据内存的方式(不是说物理结构)
- 自动存储
- 静态存储
- 动态存储-->有时也叫自由存储空间或堆
- 线程存储(C++11新增-->第9章)
自动存储:自动变量(函数内部定义的常规变量)通常存储在栈中
--->随函数被调用生产,随该函数结束而消亡
--->自动变量是个局部变量,作用域为包含的代码块({...})
静态存储:使变量称为静态
- 1.在函数外面定义它
- 2.在声明变量是使用static关键字
static double free = 5650;
动态存储:使用new和delete(可能导致占用的自由存储区不连续)对数据的生命周期不完全受程序或函数的生存周期控制。
如果使用new运算符在自由存储(或堆)上创建变量后,没有调用delete,则即使包含指针的内存由于副作用或规则和对象生命周期的原因而被释放(将会无法访问自由存储空间中的结构,因为指向这些内存的指针无效。这将导致内存泄漏),在自由存储空间上动态内存分配的变量或结构也将继续存在。
类型组合
数组名是一个指针
- 要用指向成员运算符
a_y_e trio[3];
trio[0].year=2003;
(trio+1)->year=2004;
//创建指针数组
const a_y_e *arp[3]={&s01,&s02,&s03};
std::cout<<arp[1]->year<<std::endl;
//可创建指向上述收集自的指针:
const a_y_e **ppa =arp;//麻烦
//可以auto,让编译器自动推断
auto ppa=arps;
数组的替代品
- 1.模板类vector-->是一种动态数组-->可以在运行时设置长度-->它是使用new创建动态数组的替代品。
- vector类自动通过new和delete来管理内存。
vector<typeName> vt(n_elm);
typeName:类型, vt:对象名, n_elm:个数:整型常量/变量
- 2.模板类array(C++11)-->与数组一样,array对象长度也是固定的,也使用栈(静态内存分配),而不是自由存储去,因此其效率与数组相同,更方便,更安全。
array<int,5>ai;
array<double,4>ad={1.2,2.1,3.4,4.3};//列表初始化
C++的vector、array和数组的比较(都使用连续内存,而list内存空间是不连续的)
在C++11中,STL中提拱了一个新的容器std::array,该容器在某些程度上替代了之前版本的std::vector的使用,更可以替代之前的自建数组的使用。那针对这三种不同的使用方式,先简单的做个比较:
相同点:
-
三者均可以使用下标运算符对元素进行操作,即vector和array都针对下标运算符[ ]进行了重载
-
三者在内存的方面都使用连续内存,即在vector和array的底层存储结构均使用数组
不同点:
-
vector属于变长容器,即可以根据数据的插入删除重新构建容器容量;但array和数组属于定长容量。
-
vector和array提供了更好的数据访问机制,即可以使用front和back以及at访问方式,使得访问更加安全。而数组只能通过下标访问,在程序的设计过程中,更容易引发访问 错误。
-
vector和array提供了更好的遍历机制,即有正向迭代器和反向迭代器两种
-
vector和array提供了size和判空的获取机制,而数组只能通过遍历或者通过额外的变量记录数组的size
-
vector和array提供了两个容器对象的内容交换,即swap的机制,而数组对于交换只能通过遍历的方式,逐个元素交换的方式使用
-
array提供了初始化所有成员的方法fill
-
vector提供了可以动态插入和删除元素的机制,而array和数组则无法做到,或者说array和数组需要完成该功能则需要自己实现完成。但是vector的插入删除效率不高(从中间插入和删除会造成内存块的拷贝),但能进行高效的随机存储,list能高效地进行插入和删除,但随机存取非常没有效率遍历成本高。
-
由于vector的动态内存变化的机制,在插入和删除时,需要考虑迭代是否失效的问题。
基于上面的比较,在使用的过程中,可以将那些vector或者map当成数组使用的方式解放出来,可以直接使用array;也可以将普通使用数组但对自己使用的过程中的安全存在质疑的代码用array解放出来。
函数
函数---C++的编程模块(要提高编程效率,可更深入地学习STL和BOOST C++提供的功能)
- 1.提供函数定义 function definition
- 2.提供函数原型 function prototype
- 3.调用函数 function call
Void functionName(parameterlist)
{
statement(s)
teturn;
}
- parameterlist:指定了传递给函数的参数类型和数量
- void:没有返回值,对于有返回值的函数,必须有返回语句return
- 1.返回值类型:不能是数组,但可以是其他任何类型---整数,浮点数,指针,甚至可以是结构和对象。
- 2.函数通过将返回值复制到指定的CPU寄存器或内存单元中来将其返回。
为什么需要原型
原型描述了函数到编译器的接口,它将1.函数返回值类型(如果有的话)以及2.参数的类型和3.数量告诉编译器。(在原型的参数列表中,可以包含变量名,也可以不包含。原型中的变量名相当于占位符,因此不必与函数中的变量名相同)
- 确保:编译器正确处理1,编译器检查2,3
函数参数传递和按值传递
- 用于接收传递值的变量被称为形参(parameter),传递给函数的值被称为实参(argument)。
- 值传递:调用函数时,使用的是
实参的副本,而不是原来的数据。 - 在函数中声明的变量(局部变量(自动变量))(包括参数)是该函数私有的,函数调用时:计算机将为这些变量分配内存;函数结束时:计算机将释放这些变量使用的内存。
函数和数组
int sum_arr(int arr[],int n);//arr=arrayname.n=size
int sum_arr(int arr[],int n);//arr=arrayname.n=size
//两者是等价的
- const保护数组(输入数组原数据不能改变)
void show_array(const double ar[],int n);//声明形参时使用const关键字 - 该声明表明,指针or指向的是常量数据。这意味着不能使用or修改数据。这并不意味着原始数据必须是常量
- 如果该函数要修改数组的值,声明ar时不能使用const
- 1.对于处理数组的C++函数,必须将数组中的
1.数据类型 2.数组的起始位置 3.和数组元素中的数量提交给他
-
传统的C/C++方法是,将指向数组起始处的指针作为一个参数,将数组长度作为第二个参数(指针指出数组位置和数据类型)
-
2.第二种方法:指定元素区间(range) 通过传递两个指针来完成:一个指针表示数组的开头,另外一个指针表示数组的尾部。例子:
int sum_arr(const int *begun,const int *end)
{
const int *pt;
int total=0;
for(pt=begin;pt!=end;pt++)
total=toatl+*pt;
return total;
}
int cookies[ArSize]= {1,2,4,8,16,32,64,128};
int sum=sum_arr(cookies,cookies+ArSize);
函数与C风格字符串
假设要将字符串(实际传递的是字符串第一字符的地址)作为参数传递给函数,则表示字符串的方式有三种:
- 1.char数组
- 2.用字符串常量
- 3.被设置为字符串的地址的char指针。
函数和结构
涉及函数时,结构变量的行为更接近基于基本的单值变量
- 1.按值传递-->如果结构非常大,则复制结构将增加内存要求,且使用的是原始变量的副本
- 2.传递结构的地址,然后使用指针来访问结构的内容
rect rplace;
polar pplace;
void rect_to_polar(const rect*pxy,polar*pda)
{
...
}
rect_to_polar(&rplace,&pplace);
调用函数时,将结构的地址(&pplace)而不是结构本身(pplace)传递给它;将形参声明为指向polar的指针,即polar*类型。由于函数不应该修改结构,因此使用了const修饰符,由于形参是指针不是结构,因此应使用姐姐成员运算符(->),而不是成员运算符(.)。
- 3.按引传递用,传指针和传引用效率都高,一般主张是引用传递代码逻辑更加紧凑清晰。
递归---C++函数有一种有趣的特点--可以调用自己(除了main())
1.包含一个递归调用的递归
void recurs(argumentlist)
{
statement1
if(test)
recurs(arguments)
statement2
}
如果调用5次recurs就会运行5次statement1,运行1次statement2.
2.包含多个递归调用的递归
void recurs(argumentlist)
{
if(test)
return;
statement;
recurs(argumentlist1);
recurs(argumentlist2);
}
3.从1加到n
class Solution
{
public:
int Sum_Solution(int n){
int ans=n;
ans&&(ans+=Sum_Solution(n-1));
return ans;
}
};
//&&就是逻辑与,逻辑与有个短路特点,前面为假,后面不计算。
函数指针
函数也有地址---存储其机器语言代码的内存的开始地址
-
- 获取函数的地址,只要使用函数名(后面不跟参数)即可。
例如think()是个函数
process(think);//传递的是地址
thought(think());//传递的是函数返回值
//使用
double pam(int);//原始函数声明
double (*pf)(int);//函数指针声明
pf=pam;//使用指针指向pam函数
double x=pam(4);//使用函数名调用pam()
double y=(*pf)(5);//使用指针调用pam()
//也可以这样使用函数指针
double y=pf(5);
-
- 进阶 下面函数原型的特征表和返回类型相同
const double *f1(const double ar[],int n);
const double *f2(const dopuble [],int );
const double *f3(const double *,int );
//声明一个指针可以指向f1,f2,f3
const double * (*p1)(const double *,int );//返回类型相同,函数的特征标相同
//声明并初始化
const double * (*p1)(const double *,int )=f1;
//也可以使用自动类型推断
auto p2=f2;
-
- 使用for循环通过指针依次条用每个函数
例子:声明包含三个函数指针的数组,并初始化
const double * (*pa[3])(const double *,int)={f1,f2,f3};
问:为什么不使用自动类型推断?auto
答:因为自动类型推断只能用于单值初始化,而不能用初始化列表。
但可以声明相同类型的数组 auto pb=pa;
使用:
const double *px=pa[0](av.3);//两种表示法都可以
const double *py=pb[1](av.3);
//创建指向整个数组的指针。由于数组名pa是指向函数指针的指针
auto pc=&pa;//c++11
//等价于
const double * (*(*pd[3]))(const double *,int)=&pa;//C++98
- 除了auto外,其他简化声明的工具,typedef进行简化
点云库里常常用到,如:
typedef pcl::PointNormal PointNT
typedef const double * (*p_fun)(const double *,int );
p_fun p1=f1;
函数探幽
C++11新特性
- 函数内联
- 按引用传递变量
- 默认参数值
- 函数重载(多态)
- 模板函数
内联函数
c++内联函数-->提高程序运行速度:常规函数与内联函数的区别在于,C++编译器如何将它们组合到程序中
-
常规函数调用过程:
- 执行到函数调用指令程序在函数调用后立即存储该指令地址,并将函数参数复制到堆栈中(为此保留的代码),
- 跳到标记起点内存单元,
- 执行函数代码(也许将返回值放入寄存器中),
- 然后跳回地址被保存的指令处。来回跳跃并记录跳跃位置意味着以前使用函数时,需要一定的开销。
-
情况:函数代码执行时间很短---内联调用就可以节省非内联调用的大部分时间(节省时间绝对值并不大)
-
代价:需要占用更多的内存:如果程序在是个不同地方调用一个内联函数,则该函数将包含该函数代码的10个副本
-
使用:在函数声明前加上关键字inline;在函数定义前加上关键字inline;
通常的做法是省略原型,将整个定义(即函数头和所有代码),放在本应提供原型的地方。
- 内联函数不能递归
- 如果函数占用多行(假设没有冗长的标识符),将其作为内联函数不太合适.
内联与宏
C语言使用预处理语句#define来提供宏---内联代码的原始实现
# define SQUARE(X) X*X
- 这不是通过传递参数实现的,而是通过文本替换实现的---X是"参数"的符号标记。所以宏不能按值传递
故有时候会出现错误
c=10;
d=SQUARE(C++);is replaced by d=C++*c++=11X12=122
按引用传递变量
引用变量-->是复合类型
int & rodents =rats;其中int &是类型,该声明允许将rats和rodent互换---他们指向相同的值和内存单元。
- 必须在声明引用变量时进行初始化
- 引用更接近const指针(指向const数据的指针),必须在创建时进行初始化,一旦与某个变量关联起来就一直效忠于它。
int & rodents=rats;
//实际上是下述代码的伪装表示
int * const pr=&rats;
//引用rodents扮演的角色与*pr相同。
//*pr值是个地址,且该地址恒等于&rat-->rats的地址
引用的属性与特别之处
应该尽可能使用const
C++11新增了另外一种引用---右值引用。这种引用可指向右值,是使用&&声明的:
第十八章将讨论如何使用右值引用来实现移动语义(move semantics),以前的引用(使用&声明的引用)现在称为左值引用
-
- 右值引用是对临时对象的一种引用,它是在初始化时完成的,但右值引用不代表引用临时对象后,就不能改变右值引用所引用对象的值,仍然可以初始化后改变临时对象的值
-
- 右值短暂,右值只能绑定到临时对象。所引用对象将要销毁或没有其他用户
-
- 初始化右值引用一定要用一个右值表达式绑定。
例子:
double &&rref=std::sqrt(36.00);//在左值引用中不成立,即使用&来实现也是不允许的
double j=15.0;
double&& jref=2.0*j+18.5;//同样使用左值引用是不能实现的。
将引用用于结构
引用非常适合用于结构和类(C++用户定义类型)而不是基本的内置类型。
- 声明函数原型,在函数中将指向该结构的引用作为参数:
void set_pc(free_throws & tf);如果不希望函数修改传入的结构。可使用const;void display(free_throws & tf); - 返回引用:free_throws &accumlate(free_throws& traget,free_throws& source);为何要返回引用?如果accumlate()返回一个结构,如:dup=accumlate(team,five) 而不是指向结构的引用。这将把整个结构复制到一个临时位置,再将这个拷贝复制给dup。但在返回值为引用时,直接把team复制到dup,其效率更高,复制两次和复制一次的区别。
- 应避免返回函数终止时,不在存在的内存单元引用。为避免这种问题,最简单的方法是,返回一个作为参数传递给函数的引用。作为参数的引用指向调用函数使用的数据,因此返回引用也将指向这些数据。
free_throws& accumlate(free_throws& traget,free_throws& source)
{
traget.attempts+=source.attempts;
traget.mode+=source.mode;
set_pc(target);
return target;
}
- 另一种方法是用new来分配新的存储空间
const free_throws& clone(&three)
{
free_throws * pt;//创建无名的free_throws结构,并让指针pt指向该结构,因此*pt就是该结构,在不需要new分配的内存时,应使用delete来释放它们。
//auto_ptr模板以及unique_ptr可帮助程序员自动完成释放
* pt=ft;
return *pt;//实际上返回的是该结构的引用
}
将引用用于对象
和结构同理
对象继承和引用
使得能够将特性从一个类传递给另外一个类的语言被称为继承
ostream-->基类 ofstream-->派生类
基类引用可以指向派生类对象,而无需强制类型转换
时使用引用参数
使用引用参数到主要原因有两个:
(1)程序员能够修改调用函数中的数据对象。
(2)通过传递引用而不是整个数据对象,可以提高程序的运行速度。
当数据对象较大时(如结构和类对象),第二个原因最重要。这些也是使用指针参数的原因。这是有道理的,因为引用参数实际上是基于指针的代码的另一个接口。那么什么时候应该使用引用,什么时候应该使用指针呢?什么时候应该按值传递呢?下面是一些指导原则:
对于使用传递到值而不做修改到函数:
(1)如果数据对象很小,如内置数据类型或小型结构,则按值传递。 (2)如果数据对象是数组,则使用指针,因为这是唯一的选择,并将指针声明为指向const的指针。 (3)如果数据对象是较大的结构,则使用const指针或const引用,以提高程序的效率。这样可以节省复制结构所需要的时间和空间。 (4)如果数据对象是类对象,则使用const引用。类设计的语义常常要求使用引用,这是C++新增这项特性的主要原因。因此,传递类对象参数的标准方式是按引用传递。
对于修改调用函数中数据的函数:
(1)如果数据对象是内置数据类型,则使用指针。如果看到诸如fixit(&x)这样的代码(其中x是int),则很明显,该函数将修改x。 (2)如果数据对象是数组,则只能使用指针。 (3)如果数据对象是结构,则使用引用或指针。 (4)如果数据对象是类对象,则使用引用。
当然,这只是一些指导原则,很可能有充分到理由做出其他的选择。例如,对于基本类型,cin使用引用,因此可以使用cin>>n,而不是cin>>&n。
默认参数值---当函数调用中省略了实参时自动使用的一个值
如何设置默认值?必须通过函数原型
char* left(const char* str,int n=1);原型声明
定义长这样 char * left(const char* str,int n){...}
对于带参数列表的函数,必须从左向右添加默认值:下面代码错误,int j应该也设默认值
int chico(int n,int m=6,int j);//fault
- 通过默认参数,可以减少要定义的析构函数,方法以及方法重载的数量
函数重载
-
- 默认参数让你能够使用不同数目的参数调用的同一个函数。
-
- 而函数多态(函数重载)让你能够使用多个同名函数。
-
- 仅当函数基本上执行相同的任务,但使用不同形式的数据时,才应用函数重载
-
- C++使用名称修饰(名称矫正)来跟踪每一个重载函数
未经过修饰:long MyFunction(int,float);
名称修饰(内部转换):?MyFunctionFoo@@YAXH--->将对参数数目和类型进行编码
重载与多态的区别
- 重载:是指允许存在多个同名方法,而这些方法的参数不同(特征标不同)。重载的实现是:编译器根据方法不同的参数表,对同名方法的名称做修饰,对于编译器而言,这些同名方法就成了不同的方法。他们的调用地址在编译器就绑定了。**重载,是在编译阶段便已确定具体的代码,对同名不同参数的方法调用(静态联编)
- C++中,子类中若有同名函数则隐藏父类的同名函数,即子类如果有永明函数则不能继承父类的重载。
- 多态:是指子类重新定义父类的虚方法(virtual,abstract)。当子类重新定义了父类的虚方法后,父类根据赋给它的不同的子类,动态调用属于子类的方法,这样的方法调用在编译期间是无法确定的。(动态联编)。对于多态,只有等到方法调用的那一刻,编译器才会确定所要调用的具体方法。
重载与覆盖的区别
- 重载要求函数名相同,但是参数列列表必须不不同,返回值可以相同也可以不不同。 覆盖要求函数名、参数列列表、返回值必须相同。
- 在类中重载是同一个类中不同成员函数之间的关系 在类中覆盖则是⼦子类和基类之间不同成员函数之间的关系
- 重载函数的调用是根据参数列表来决定调用哪一个函数 覆盖函数的调用是根据对象类型的不不同决定调用哪一个
- 在类中对成员函数重载是不不能够实现多态 在子类中对基类虚函数的覆盖可以实现多态
模板函数---通用的函数描述
- 用于函数参数个数相同的类型不同的情况,如果参数个数不同,则不能那个使用函数模板
- 函数模板自动完成重载函数的过程。只需要使用泛型和具体算法来定义函数,编译器将为程序使用特定的参数类型生成正确的函数定义
- 函数模板允许以任意类型的方式来定义函数。例如,可以这样建立一个交换模板
template <typename AnyType>
void Swap(AnyType &a,AnyType &a)
{
AnyType temp;
temp=a;
a=b;
b=temp;
}
- 模板不会创建任何函数,而只是告诉编译器如何定义函数
- C++98没有关键字typename,使用的是
template<class AnyType>void Swap(AnyType &a,AnyType &a){...} - 函数模板不能缩短可执行程序,最终仍将由两个独立的函数定义,就像以手工方式定义了这些函数一样。最终的代码不包含任何模板,只包含了为程序生成的实际函。使用模板的寒除湿,它使生成多个函数定义更简单,更可靠更常见的情形是将模板放在头文件中,并在需要使用模板的文件中包含头文件
重载的模板
对多个不同类型使用同一种算法(和常规重载一样,被重载的模板的函数特征标必须不同)。
template <typename T>
void Swap(T& a,T& b);
template <typename T>
void Swap(T* a,T* b,int n);
- 模板的局限性:编写的模板很可能无法处理某些类型
如1.T为数组时,a=b不成立;T为结构时a>b不成立
- 解决方案:
- C++允许重载运算符,以便能够将其用于特定的结构或类
- 为特定类型提供具体化的模板定义
显式具体化(explicit specialization)
提供一个具体化函数定义,其中包含所需的代码,当编译器找到与函数调用匹配的具体化定义时,将使用该定义,不再寻找模板。
- 该内容在代码重用中有不再重复。
重载解析(overloading resolution)---编译器选择哪个版本的函数
对于函数重载,函数模板和函数模板重载,C++需要一个定义良好的策略,来决定为函数调用哪一个函数定义,尤其是有多个参数时
过程:
- 创建候选函数列表。其中包含与被调用函数的名称相同的函数和模板函数。
- 使用候选函数列表创建可行函数列表。这些都是参数数目正确的函数,为此有一个隐式的转换序列,其中包括实参类型与相应的形参类型完全匹配的情况。例如,使用float参数的函数调用可以将该参数转换为double,从而与double形参匹配,而模板可以为float生成一个实例。
- 确定是否有最佳的可行函数。如果有,则使用它,否则该函数调用出错。
最佳到最差的顺序:
- 完全匹配,但常规函数优先于模板
- 提升转换(例如,char和shorts自动转换为int ,float自动转换为double)。
- 标准转换(例如,int转换为char,long转换为double)。
- 用户定义的转换,如类声明中定义的转换。
完全匹配:完全匹配允许的无关紧要转换
| 从实参到形参 | 到实参 |
|---|---|
| Type | Type & |
| Type & | Type |
| Type[] | * Type |
| Type(argument-list) | Type( * )(argument-list) |
| Type | const Type |
| Type | volatile Type |
| Type* | const Type |
| Type* | volatile Type |
9内存模型和名称空间(4)
原来的程序分为三个部分
- 头文件:包含结构声明和使用这些结构的函数的原型//结构声明与函数原型
- 源代码文件:包含与结构有关的函数代码 //函数
- 源代码文件:包含调用与结构相关的函数的代码 //调用函数
这种组织方式也与oop方式一致。
- 一个文件(头文件)包含用户定义类型的定义;
- 另外一个文件包含操纵用户定义类型的函数代码;
这两个文件组成了一个软件包,可用于各种程序中。
- 请不要将函数定义或变量声明放在头文件中,如果其他文件都包含这个头文件,那么同一个函数就会有多次定义,变量也同理,会出错。
头文件中常包含的内容:
- 函数原型。
- 使用#define或const定义的符号常量(头文件中不可以创建变量)
- 结构声明=>因为它们不创建变量
- 模板声明=>模板声明不是将被编译的代码,他们指示编译器如何生成源代码中的函数调用相匹配的函数定义。
- 内联函数-->只有它可以在头文件定义函数。
被声明为const的数据和内联函数有特殊的链接属性
注意:在IDE中
- 不要将头文件加入到项目列表中
- 也不要在源代码文件中使用#include来包含其他源代码文件
在同一文件中只能将同一个头文件包含一次。-->使用预编译指令
#ifndef COORDIN_H_
...
#endif
- 但是这种方法并不能防止编译器将头文件包含两次,而只是让它忽略第一次包含之外的所有内容。大多数标注C和C++头文件都是用各种防护(guarding)方案。否则,可能在一个文件中定义同一个结构两次,这将导致编译错误。
编译
在UNIX系统中编译由多个文件组成的C++程序
- 编译两个源代码文件的UNIX命令: CC file1.cpp file2.cpp
- 预处理将包含的文件与源代码文件合并:
临时文件: temp1.cpp temp2.cpp
- 编译器创建每个源代码文件的目标代码文件:file1.o file2.o
- 链接程序将目标代码文件(file1.o file2.o)、库代码(Library code)和启动代码(startup code)合并,生成可执行文件:a.out
多个库的链接
- 由不同编译器创建的二进制模块(对象代码文件)很可能无法正确地链接。
- 原因:两个编译器为同一个函数生成不同的名称修饰
- 名称的不同将使链接器无法将一个编译器生成的函数调用与另外一个编译器生成的函数定义匹配。在链接编译模块时,请确保所有对象文件或库都是由同一编译器生成的。
- 链接错误解决的方法:如果有源代码,通常可以用自己的编译器重新编译来消除错误。
存储持续性,作用域与和链接性
C++中的四种存储方案
- 自动存储持续性 :在函数定义中声明的变量(包括函数参数)的存储持续性为自动的。它们在程序开始执行其所属的函数或代码块时被创建,在执行完函数或代码块时,它们使用的内存被释放。
- 静态存储持续性 :在函数定义外定义的变量和使用关键字static定义的变量的存储持续性都为静态。(请注意)它们在整个运行过程中都存在。
- 线程存储持续性(C++11) :当前,多核处理器很常见,这些CPU可同时处理多个执行任务。这让程序能够将计算放在可并行处理的不同线程中。如果变量是使用关键字thread_local声明的,则其生命周期与所属的线程一样长。
- 动态存储持续性 :用new运算符分配的内存将一直存在,直到使用delete运算符将其释放或程序结束为止。这种内存的存储持续性为动态,有时被称为自由存储(free store)或堆(heap)。
作用域和链接性
- 作用域(scope) 描述了名称在文件的多大范围内可见。例如,函数中定义的变量可在该函数中使用,但不能在其他函数中使用;而在文件中的函数定义之前定义的变量则可在所有函数中使用。
- 作用域:局部与全局-->(代码块/文件)
- 作用域为局部的变量只在定义它的代码块中可用。(代码块:由花括号括起的一系列语句,比如:函数体)
- 做英语为全局(也叫文件作用域)的变量在定义位置到文件结尾都可以用。
- 链接性(linkage) 描述了名称如何在不同单元间共享。链接性为外部的名称可在文件间共享,链接性为内部的名称只能由一个文件中的函数共享,自动变量的名称没有链接性,因为它们不能共享。
C++内存空间分布
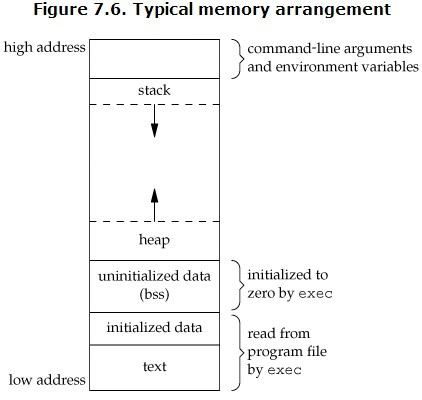
 1.命令行参数和环境变量
1.命令行参数和环境变量
shell在执行程序的时候调用exec函数将命令行参数传递给要执行的程序。
使程序了解进程环境,在执行时分配空间。
2.bss段(Block Start by Symbol)
存放未初始化的全局变量或者静态变量。
3.data段
存放具有明确初始值的全局变量或者静态变量。
存在于程序镜像文件中,由 exec 函数从程序镜像文件中读入内存。
4.text段
CPU执行的机器指令。
堆栈简要概述 栈:系统自动开辟空间,自动分配自动回收,在作用域运行完成后(函数返回时)就会被回收。
堆:由程序员自己申请空间,释放空间,不释放会出现内存泄漏。
栈
1.栈是连续的向下扩展的数据结构,总共只有1M或者2M的空间。空间不足就会异常提示栈溢出。
2.存储自动变量, 函数调用者信息, 包括函数参数(可变参数列表的压栈方向是从右向左), 函数内局部变量, 函数返回值, 函数调用时的返回地址。
堆
1.堆是不连续的向上扩展的数据结构,大小受限于计算机系统虚拟内存的大小。
2.操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。
对于大多数系统,会在这块内存空间中的首地址处(一般为一个字节的大小)记录本次分配的大小,这样,代码中的 delete语句才能正确的释放本内存空间。
由于找到的堆结点的空间大小可能大于申请的大小,系统会自动的将多余的那部分(即内存碎片)重新放入空闲链表中。这就涉及到申请效率的问题。
引入名称空间之前
下面列出5种变量存储方式(引用名称空间之前)
| 存储描述 | 持续性 | 作用域 | 链接性 | 如何声明 |
|---|---|---|---|---|
| 自动 | 自动 | 代码块 | 无 | 在代码块中 |
| 寄存器 | 自动 | 代码块 | 无 | 在代码块中,使用关键字register |
| 静态,无链接性 | 静态 | 代码块 | 无 | 在代码块中,使用关键字static |
| 静态,外部链接性 | 静态 | 文件 | 外部 | 不在任何函数内 |
| 静态,内部链接性 | 静态 | 文件 | 内部 | 不在任何函数内,使用关键字static |
- 自动存储持续性
在默认情况下,在函数中声明的函数参数和变量的存储持续性为自动,作用域为局部,没有链接性(自动变量不能共享)。
- 自动变量的初始化:可以使用任何声明时其值已知的表达式来初始化自动变量
int x=5;int y=2*x; - 自动变量和栈:自动变量的数目随函数的开始和结束而增减,因此程序必须在运行是对自动变量进行管理。常用方法是流出一段内存,并将其视为栈。程序使用两个指针来跟踪栈,一个指向栈底,栈的开始位置。另外一个指针指向栈顶,下一个可用内存单元。栈是LIFO(后进先出)的,即最后加入到栈中的变量首先被弹出。
- 寄存器变量-->旨在提高访问变量的速度
关键字register最初由C语言引入的,它建议编译器使用CPU寄存器来存储自动变量
register int count_fast;//request for a register variable
鉴于关键字register只能用于原来就是自动的变量,使用它的唯一原因是,指出程序员想使用一个自动变量,这个变量名可能与外部变量相同
- 静态持续变量
C++也为静态存储持续性提供了三种链接性
- 1.外部链接性(可在其他文件中访问)
- 2.内部链接性(只能在当前文件中访问)
- 3.无链接性(只能在当前函数或代码块中访问)
这三种链接性都在整个程序执行期间一直存在,与自动变量相比,他们的寿命更长。**由于静态变量的数目在程序运行期间是不变的,因此程序不需要使用特殊的装置(如栈)来管理它们,编译器将分配固定的内存块来存储所有的静态变量,这些变量在整个程序执行期间一直存在。另外,如果没有显示地初始化静态变量,编译器将把它设置为0。在默认情况下,静态数组和结构将每个元素或成员的所有位都设置为0。**被称为0初始化
- 例子:
int NUM_ZDS_GLOBAL = 80; //#1
static int NUM_ZDS_ONEFILE = 50; //#2
int main(){
…
}
void fun1(int n){
static int nCount = 0; //#3
int nNum = 0; //#4
}
void fun2(int q){
…
}
#1、#2、#3在整个程序运行期间都存在。在fun1中声明的#3的作用域为局部,没有链接性,这意味着只能在fun1函数中使用它,就像自动变量#4一样。但是,与#4不同的是,即使在fun1没有被执行的时候,#3也保留在内存中。
静态变量初始化
#include<cmath>
int x; //零初始化
int y=5; //常量表达式初始化
long z=13*13; //常量表达式初始化
const double pi=4.0*atan(1.0);//动态初始化,要初始化pi,必须调用函数atan(),这需要等到函数被链接上且程序执行时。(这也是常量表达式初始化)
//C++新增关键字constexpr,这增加了创建常量表达是的方式
1.静态持续性,外部链接性==>普通全局变量
链接性为外部的变量通常称为外部变量,它们的存储持续性为静态,作用域为整个文件。
外部变量是函数外部定义的,因此对所有函数而言都是外部的。
例如,可以在main()前面或头文件中定义他们。可以在文件中位于外部定义后面的任何函数中使用它。
因此外部变量也称为全局变量。
全局变量是在所有函数体的外部定义的,程序的所在部分(甚至其它文件中的代码)都可以使用。全局变量不受作用域的影响(也就是说,全局变量的生命期一直到程序的结束)。如果在一个文件中使用extern关键字来声明另一个文件中存在的全局变量,那么这个文件可以使用这个数据。
单定义规则
一方面,在每个使用外部变量的文件中,都必须声明它;另外一方面,C++有“单定义规则”,该规则指出,变量只有一次定义。
为满足这种需求,C++提供了两种变量声明。
-
- 一种是定义声明(defining declaration)或简称为定义(definition),它给变量分配存储空间。
-
- 一种是引用声明(referencing declaration)或简称为声明(declaration),它不给内存变量分配存储空间。
引用声明使用关键字extern,且不进行初始化;否则,声明未定义,导致分配内存空间:例
double up;//definition,up is 0 定义
extern int bllem;//blem defined elsewhere 声明,blem变量在某处定义了
extern char gr = 'z';//definition because initialized 定义
注意:
- 单定义规则并非意味着不能有多个变量名称相同
- 如果函数中声明了一个与外部变量同名的变量,结果将如何呢?
//external1.cpp 文件1
double warning=0.3;//warning defined 定义
//support.cpp 文件2
extern double warning;//use warning from another file 使用外部定义的变量warning
......
void update(double dt)
{
extern double warning;//optional redeclaration
......
}
void local()
{
//定义域全局变量名相同的局部变量都,局部变量将隐藏全局变量
double warning=0.8;//new variable hides external one
......
}
通常情况下,应使用局部变量,然而全局变量也有它们的用处。例如,可以让多个函数可以使用同一个数据块(如月份,名数组或原子量数组)。外部存储尤其适用于表示常量数据,因为这样可以使用关键字const来防止数据修改。
2.静态持续性,内部链接性==>Static全局变量
- 全局变量(外部变量)的说明之前再冠以static就构成了静态的全局变量。全局变量本身就是静态存储方式,静态全局变量当然也是静态存储方式。
- 这两者在存储方式上并无不同。这两者的区别在于非静态全局变量的作用域是整个源程序,当一个源程序由多个原文件组成时,非静态的全局变量在各个源文件中都是有效的。而静态全局变量则限制了其作用域,即只在定义该变量的源文件内有效,在同一源程序的其它源文件中不能使用它。
- 由于静态全局变量的作用域限于一个源文件内,只能为该源文件内的函数公用,因此可以避免在其他源文件中引起错误。 * static全局变量与普通的全局变量的区别是static全局变量只初始化一次,防止在其他文件单元被引用。
3.静态持续性,无链接性==>静态局部变量
这种变量是这样创建的,将static限定符用于代码块中定义的变量。
在两次函数调用之间,静态局部变量的值将保持不变,它同时拥有静态变量和局部变量的特性,即:
- 编译时自动初始化
- 会被放到静态内存的静态区
- 只能在局部被访问
作用:
有时候我们需要在两次调用之间对变量进行保存,通常的想法是定义一个全局变量来实现。但这样一来变量就不属于函数本身了,而受全局变量的控制。静态局部变量正好可以解决这个问题,静态局部变量保存在全局数据区,而不是保存在栈中,每次的值保持到下一次调用,直到下一次赋新值
说明符和限定符
存储说明符(storage class specifier)
- auto(在C++11中不再是说明符):在C++11之前,可以在声明中使用关键字auto来指出变量为自动变量;但在C++11中,auto用于自动类型推断。
- register:用于在声明中指示寄存器存储,在C++11中,它只是显式地指出变量是自动的。
- static:关键字static被用在作用域为整个文件的声明中时,表示内部链接性;被用于局部声明中,表示局部变量的存储持续性为静态的。
- thread_local(C++11新增):可以用static或extern结合使用,关键字thread_local指出变量持续性与其所属的持续性相同。thread_local变量之于线程,由于常规静态变量至于整个程序。
- mutable:关键字mutable的含义根据const来解释
mutable:可以用来指出,即使结构(或类)变量为const,其某个成员也可以被修改。
struct data
{
char name[30];
mutable int accesses;
...
}
const data veep={"claybourne clodde",0,...};
strcpy(veep.name,"ytttt"); //not allowed
veep.accessses++; //allowed
CV限定符(cv-qualifier)
- const:它表明,内存被初始化后,程序便不能再对他进行修改。
- volatile: volatile 关键字是一种类型修饰符,用它声明的类型变量表示可以被某些编译器未知的因素更改,比如:操作系统、硬件或者其它线程等遇到这个关键字声明的变量,编译器对访问该变量的代码就不再进行优化,从而可以提供对特殊地址的稳定访问
再谈const
- const限定对默认存储类型稍有影响。在默认情况下,全局变量的链接性为外部的,但const全局变量的链接性为内部的
const int fingers = 10;//same as static const init fingers=10;
int main(){
...
}
- 原因:C++这样子修改了常量类型的规则,让程序员更轻松
- 假如,假设将一组常量放在头文件中,并在同一程序的多个文件中使用该头文件。那么预处理器将头文件中的内容包含到每个源文件后,所有的源文件都将包含类似下面的定义:
const int fingers=10;
const char* warning ="wak!";
- **如果全局const声明的链接性像常规变量那样是外部的,则根据单定义规则,这将出错(二义性)。**也就是说只能有一个文件可以包含前面的声明,而其他文件必须使用extern关键字来提供引用声明。另外只有未使用extern关键字的生命才能进行初始化。
- 然而,由于外部定义的const数据的链接性为内部的,因此可以在所有文件中使用相同的声明。
- 内部链接性意味着每个文件都有自己一组常量,而不是所有文件共享一组常量。每个定义都是其所属文件所私有的,这就是能够将常量定义放在头文件中的原因。
函数和链接性
- 和C语言一样,C++不允许在一个函数中定义另外一个函数=>因此所有函数的存储持续性都自动为静态的,即整个程序执行期间都一直存在。
- 在默认情况喜爱,函数的链接性为外部的,即可以在文件间共享。
- 实际上可以使用extern关键字来指出函数是在另外一个文件中定义的,不过这是可选的。
- 使用关键字static将函数链接性改为内部链接性,使其只能在本文件中使用,必须在原型和函数定义中同时使用该关键字。
-
单定义规则也适用于非内联函数,因此对于每个非内联函数,程序只能包含一个定义。对于链接性味外部的函数来说,这意味着在多文件程序中,只能有一个文件包含该函数的定义,但使用该函数的每个文件都应包含其函数原型。
-
内联函数不受这种规则的约束,这允许程序员能够将内联函数的定义放在头文件中,这样包含了头文件的每个文件都有内联函数的定义。然而,C++要求同一个函数的所有内联定义都必须相同。
C++在哪里寻找函数?
假设在程序的某个文件中调用一个函数,C++将到哪里寻找函数定义?
- 如果该文件中的函数原型指出该函数是静态的,则编译器将只在该文件中查找函数定义;
- 否则,编译器(包括链接程序)将在所有文件中查找。
- 如果在程序文件中找不到,编译器将在库中搜索。这意味着,如果定义了一个与库函数同名的函数,编译器将使用程序员定义的版本,而不是库函数。
语言链接性
链接程序要求每个不同的函数都有不同的符号名。在C语言中,一个名词只对应一个函数,因此这很容易实现。为满足内部需要,C语言编译器可能将spiff这样的函数名翻译为_spiff。这种方法称为C语言链接性(C language linkage)。但在C++中,同一个名称可能对应多个函数,必须将这些函数翻译为不同的符号名称。因此,C++编译器执行名称纠正或名称修饰,为重载函数生成不同的符号名称。例如,spiff(int)转换为—_spiff_i,而将spiff(double, double)转换为_spiff_d_d。这种方法称为C++语言的链接性(C++ language linkage)。
如果要在C++程序中使用C语言预编译的函数,将出现什么情况呢?例如,假设有如下代码:spiff(22);它在C库文件中的符号名称为_spiff,但对于我们的C++链接程序来说,C++查询约定是查找符号民称_spiff_i。为解决这样的问题,可以用函数原型来指出要使用何种约定:
extern “C” void spiff(int);//使用C语言链接性
extern void spoff(int);//使用C++语言的链接性(通过默认方式指出)
extern “C++” void spaff(int);//使用C++语言的链接性(通过显式指出)
C和C++链接性是C++标准制定的说明符,但实现可以提供其他语言链接性说明符。
存储方案和动态分配
使用C++运算符new(或C函数malloc())分配的内存,这种内存被称为动态内存,动态内存由运算符new和delete控制,而不是由作用域和链接性规则控制。因此,可以在一个函数中分配动态内存,而在另外一个函数中将其释放。其分配方式要取决于new和delete在何时以何种方式被使用。通常编译器使用三块独立的内存:
- 一块用于静态变量(可能再细分)
- 一块用于自动变量
- 另外一块用于动态存储
- 虽然存储方案概念不是用于动态内存,但适用于用来跟踪动态内存的自动和静态指针变量(自动指针变量,静态指针变量),指针变量还是有作用域和链接性的
new运算符
如果要为内置的标量类型(int、double)分配存储空间并初始化,可在类型名后面加上初始值,并将其用括号括起。
int *pi = new int(6);
要初始化常规结构或数组,需要使用大括号的列表初始化,这要求编译器支持C++11。
struct where{double x, double y, double z};
where *one = new where{2.5, 5.3, 7.2};
int *ar = new int[4] {2, 4, 7, 6};
在C++11中,还可将初始化列表用于单值变量:
int *pin = new int {6};
new失败时
- 在最初的10年中,C++让new失败时返回空指针,但现在将引发std::bad_alloc异常。
new:运算符、函数和替换函数
运算符与函数:
//分配函数(allcation function);
void *operator new(std::size_t);//函数
void *operator new[](std::size_t);//函数
//释放函数(deallocation function);
void *operator delete(void *);//函数
void *operator delete[](void *);//函数
int *pi=new int;//运算符
int *pi=new(sizeof(int));//函数
int *pi=new int[40];//运算符
int *pi=new(40*sizeof(int));//函数
替换函数:
- 有趣的是,C++ 将这些函数(分配函数,释放函数) 称为可替换的(replaceable)。这意味着如果您有足够的知识和意愿,可为new和delete提供替换函数,并根据需要对其进行定制。例如,可定义作用域为类的替换函数,并对其进行定制,以满足该类的内存分配需求。在代码中,仍将使用new运算符,但它将调用您定义的new()函数。
定位new运算符
通常,new负责在堆(heap)中找到一个足以能够满足要求的内存块。new运算符还有另一种变体,被称为定位(placement)new运算符,它让您能够指定要使用的位置。程序员可能使用这种特性来设置其内存管理规程、处理需要通过特定地址进行访问的硬件或在特定位置创建对象。
要使用定位new特性,首先需要包含头文件new,它提供了这种版本的new运算符的原型;然后将new运算符用于提供了所需地址的参数。除需要指定参数外,句法与常规new运算符相同。具体地说,使用定位new运算符时,变量后面可以有方括号,也可以没有。下面的代码段演示了new运算符的4种用法:
#include <new>
char buffer1[50];//静态数组
char buffer2[500];
struct chaff
{
char dross[20];
int slag;
};
chaff *p1, *p2;
int *p3, *p4;
p1=new chaff; //place structure in heap
p3=new int[20]; //place int array in heap
p2=new (buffer1) chaff; //place structure in buffer1
p4=new (buffer2) int[20]; //place int array in buffer2
上述代码从buffer1中分配空间给结构chaff,从buffer2中分配空间给一个包含20个元素的int数组。
- 定位new运算符的其他形式 就像常规new调用一个接受一个参数的new函数一样,标准定位new调用一个接收两个参数的new函数。
int * p1=new int;//调用 new(sizeof(int))
int * p2=new(buffer) int;//调用 new(sizeof(int),buffer)
int * p3=new(buffer) int[40];//调用new(40*sizeof(int),buffer)
- 定位new运算符不可替换,但可重载。至少需要接收两个参数,其中第一个总是std::size_t,指定了请求的字节数。这样的重载函数都被定义为new。
名称空间
在C++中,名称可以是变量,函数,结构,枚举,类以及类的结构成员
两个概念:声明区域、潜在作用域
声明区域(declaration region)
可以在其中进行声明的区域
- 在函数外面声明全局变量=>对这种变量,其声明区域为其声明所在的文件。对于在函数声明的变量=>其声明区域为其声明所在的代码块。
潜在作用域(potential scope)
变量潜在作用域从声明点开始,到其声明区域的结尾。因此潜在作用域比声明区域小,这是由于变量必须定义后才能使用。
- 变量并非在其潜在作用域的任何位置都是可见的。
- 例如,它可能被另外一个嵌套声明区域中声明的同名变量隐藏
- 例如,在函数声明的局部变量(对于这种变量,声明区域为整个函数)将隐藏在同一文件中声明的全局变量(对于这种变量,声明区域为整个文件)。
- 变量对程序而言可见的范围被称为作用域(scope)。
新的名称空间(命名的名称空间)
即通过定义一种新的声明区域来创建命名的名称空间,这样做的目的之一是提供一个声明名称的区域。一个名称空间中的名称不会和另一个名称空间中的名称发生冲突,同时允许程序的其他部分使用该名称空间中声明的东西。
- 关键字namespace
- 名称空间可以是全局的,也可以位于另一个名称空间中,但是不能位于代码块中。因此在默认情况下,在名称空间中声明的名称的链接性为外部的(除非它引用了常量)。
- 除用户定义的名称空间,还存在另外一个名称空间全局名称空间(global namespace)。它对应文件级声明区域,因此前面所说的全局变量现在被描述为位于全局名称空间中
using 声明和using编译指令
- using声明使特定的标识符可用:
using std::cout;//将cout添加到它所属的声明区域中,即使得cout能够在main函数中直接使用
- using编译指令使整个名称空间可用:
using namespace std;//使得std空间中所有的名称都可以直接使用
using编译指令和using声明之比较
- 使用using声明时,就好像声明了相应的名称一样,如果某个名称已经在函数中声明了,则不能用using声明导入相同的名称。
- 然而,使用using编译指令时,将进行名称解析,就像在包含using声明和名称空间本身的最小声明区域中声明了名称一样。如果使用using编译指令倒入一个已经在函数中声明的名称,则局部名称将隐藏名称空间名,就像隐藏同名的全局变量一样。
一般来说,使用using声明要比使用using编译指令更加安全,这是由于它只能导入指定的名称,如果该名称与局部名称发生冲突,编译器将发出指示。
using编译指令导入所有的名称,包括可能并不需要的名称,如果与局部名称发生冲突,则局部名称将覆盖名称空间版本而编译器不发出警告! 另外,名称空间的开放性意味着名称空间的名称可能分散在多个地方,这使得难以准确知道添加了哪些名称。所以我们平时自己写程序时先怼一个using namespace std;上去可能并不是一个很好的决定。
10对象和类
- 类声明:以数据成员的方式描述数据部分,以成员函数(被称为方法)的方式描述公有接口-->C++程序员将接口(类定义)放在头文件中
- 类方法定义:描述如何实现成员函数-->并将实现(类方法代码)放在源代码文件中
细节:
- 使用#ifndef等来访问多次包含同一个文件
- 将类的首字母大写
- 控制访问关键字:private public protected
- C++对结构进行了扩展,使之具有与类相同的特性。他们之间唯一的区别是:结构的默认访问类型是public,类为private
- 通常,数据成员被放在私有部分中=>数据隐藏;成员函数被放在公有部分中=>公有接口
实现类成员方法
成员函数两个特殊的特征:
- 定义类成员函数时。使用作用域解析符(::)来标识函数所属的类;
- 类方法可以访问类的private组件。
class Stock
{
private:
char company[30];
int shares;
double share_val;
double total_val;
void set_tot(){total_val = shares * share_val;}
public:
Stock();
Stock(const char * co , int n = 0 , double pr = 0.0);
~Stock(){}
void buy(int num , double price);
void sell(int num , double price);
void update(double price);
void show() const;
const Stock & topval(const Stock & s) const;
};
- set_tot()只是实现代码的一种方式,而不是公有接口的组成部分,因此这个类将其声明为私有成员函数(即编写这个类的人可以使用它,但编写带来来使用这个类的人不能使用)。
- 内联方法,
- 其定义位于类声明中的函数都将自动成为内联函数。因此Stock::set_tot()是一个内联函数。
- 在类声明之外定义内联函数
class Stock
{
private:
...
void set_tot();
public:
...
};
inline void Stock::set_tot(){
total_val = shares * share_val;
}
- 内联函数有特殊规则,要求每个使用它们的文件都对其进行定义。确保内联定义对多个文件程序中的所有文件都可用的最简便方法是:将内联定义放在头文件中
- 如何将类方法应用于对象?(对象,数据和成员函数) 所创建的每个新对象都有自己的存储空间,用于存储其内部变量和类成员。但同一个类的所有对象共享一组类方法,即每种方法只有一个副本。
- 要使用类,要创建类对象,可以声明类变量,也可以使用new为类对象分配存储空间。
- 实现了一个使用stock00接口和实现文件的程序后,将其与stock00.cpp一起编译,并确保stock00.h位于当前文件夹中
- 类成员函数(方法)可通过类对象来调用。为此,需要使用成员运算符句点。
类的构造函数和析构函数
构造函数
原因:数据部分的访问状态是私有的,这意味着程序不能直接访问数据成员(私有部分数据)。程序只能通过成员函数来访问数据成员,因此需要设计合适的成员函数才能将对象初始化。---类构造函数
- 声明和定义构造函数
//construtor prototype with some default argument
Stock(const string &co,long n=0,double pr=0.0);//原型
原型声明位于类声明的公有部分。
构造函数可能的一种定义
Stock::Stock(const string &co,long n,double pr)
{
company = co;
if(n>0)
{
std::cerr<<"Number of shares can't be negative;"
<< company <<" shares set to 0.\n";
shares = 0;
}
else
shares=n;
share_val=pr;
set_tot();
}
- 注意“参数名co,n,pr不能与类成员相同.构造函数的参数表示不是类成员,而是赋给类成员的值。
- 区分参数名和类成员:一种常见的做法是在数据成员名中使用m_前缀 string m_company;;另外一种常见的做法是,在成员名中使用后缀_ string company_;
使用构造函数
- 显式调用
Stock food = Stock1("World cabbage",250,1.25);
- 隐式调用
Stock garment("Furry Mason",50,2.5);
//等价于
Stock garment= Stock("Furry Mason",50,2.5);
- 每次创建类对象(甚至使用new动态分配内存)时,C++都是用类结构函数。
Stock *pstock= new Stock("Electroshock Games",18,19.0);//对象没有名称,但可以使用指针来管理对象
默认构造函数
未提供显示初始值是,用来创建对象的构造函数。例:
Stock fluffy_the_cat;//use the default constructor
- 当且今当没有定义任何构造函数时,编译器才会提供默认构造函数。
- 为类定义了构造函数后,程序员就必须为它提供默认构造函数
- 如果提供了非默认构造函数(如Stock(const string &co,long n,double pr);),但没有提供构造函数,下面声明将出错(禁止创建未初始化对象)
Stock stock1;
如何定义默认构造函数:
方法1:给已有构造函数函数的所有参数提供默认值
Stock(const string &co="Error",int n=0,double pr=0.0);
方法2:通过函数重载来定义另外一个构造函数---一个没有参数的构造函数
Stock();
为Stock类提供一个默认构造函数:
//隐式初始化所有对象,提供初始值
Stock::Stock()
{
company = "no name";
shares = 0;
share_val = 0.0;
total_val = 0.0;
}
- 使用默认构造函数:
Stock first;//隐式地调用默认的构造函数
Stock first = Stock();//显式地
Stock * prelief=new Stock;//隐式地
- 然而不要被废默认构造函数的隐式形式所误导:
Stock first("Concrete Conglomerate");//调用构造函数
Stcok second(); //声明一个函数
Stock third; //调用默认构造函数
析构函数
- 对象过期是,程序将自动调用该特殊的成员函数。析构函数完成清理工作
- 如果构造函数使用new来分配内存,则析构函数将使用delete来释放这些内存。
什么时候调用析构函数?这由编译器决定,不应在代码中显示地调用析构函数
- 如果创建的是静态存储类对象,其析构函数将在程序结束时自动被调用。 2 .如果创建的是自动存储类对象,则其析构函数将在程序执行完代码块时(该对象是在其中定义的)自动被调用。
- 如果对象是通过new创建的,则它将驻留在栈内存或自由存储区中,当使用delete来释放内存时,其析构函数将自动被调用。 程序可以创建临时变量对象来完成特定操作,在这种情况下,程序将在结束对该对象的使用时自动调用其析构函数。
- 总的来说:**类对象过期时(需要被销毁时),析构函数将自动被调用。**因此必须有一个析构函数。如果程序员没有提供析构函数,编译器将隐式地声明一个默认构造函数。
C++列表初始化
只要提供与某个构造函数的参数列表匹配的内容,并用大括号将它们括起。
Stock hot_tip = {"Derivatives Plus Plus",100 ,45.0};//构造函数
Stock jock {"Sport Age Storage,Inc"};//构造函数
Stock temp{};//默认构造函数
前两个声明中,用大括号括起的列表与下面的构造函数匹配:
Stock(const string &co,long n=0,double pr=0.0);//原型
因此,用该构造函数来创建这两个对象。创建对象jock时,第二和第三个参数将默认值为0和0.0。第三个声明与默认构造函数匹配,因此将使用该构造函数创建对象temp。
const成员函数
void Stock::show() const;//promises not to change invoking object
以这种方式声明和定义的类成员函数被称为const成员函数。就像应景可能将const引用和指针作函数参数一样,只要类方法不修改调用对象,就应该将其声明为const
this指针
有的方法可能涉及两个对象,在这种情况下需要使用C++的this指针(比如运算符重载)
提出问题:如何实现:定义一个成员函数,查看两个Stocl对象,并返回股价高的那个对象的引用。
- 最直接的方法是,返回一个引用,该引用指向股价总值较高的对象,因此,用于比较的方法原型如下:
const Stock & topval(const Stock & s) const;//该函数隐式地访问一个对象,并返回其中一个对象
- 第一个const:由于返回函数返回两个const对象之一的引用,因此返回类型也应为const引用
- 第二个const:表明该函数不会修改被显式访问的对象
- 第三个const:表明该函数不会修改被隐式访问的对象
调用:
top = stock1.topval(stock2);//隐式访问stock1,显式访问stock2
- this 指针用来指向调用成员函数的对象(this被作为隐藏参数传递给方法)。
- 每个成员函数(包括构造函数和析构函数)都有一个this指针。this指针指向调用对象
- 如果方法需要引用整个调用对象,可一个使用表达式
*this。
实现:
const Stock & topval(const Stock & s) const
{
if(s.total_val>total_val)
return s;
else
return *this;
}
创建对象数组
Stock stocks[4]={
Stock("NanoSmart",12,20.0),
Stock("Boffo Objects",200,2.0),
Stock("Monolothic Obelisks",130,3.25),
Stock("Fleep Enterprises",60,6.5)
};
类作用域
回顾:
- 全局(文件)作用域,局部(代码块)作用域
- 可以在全局变量所属的任何地方使用它,而局部变量只能在其所属的代码块中使用。函数名称的作用域也可以是全局的,但不能是局部的。
类作用域
- 在类中定义的名称(如类数据成员和类成员函数名)的作用域为整个类。
- 类作用域意味着不能从外部直接访问类成员,公有函数也是如此。也就是说,要用调用公有成员函数,必须通过对象。
- 使用类成员名时,必须根据上下文使用,直接成员运算符(.),间接成员运算符(->)或者作用域解析符(::)
作用域为类的常量
下面是错误代码
class Bakery
{
private:
const int Months=12;//错误代码
double cots[Months];
}
- 这是行不通的,因为声明类只是描述了对象的形式,并没有创建对象。因此在创建对象之前,并没有用于存储值的空间。
解决:
- 方法一:使用枚举
class Bakery
{
private:
enum{Months=12};
double costs[Months];
}
- 这种方式声明枚举并不会创建类数据成员。也就是说,所有对象都不包含枚举。另外,Months只是一个符号名称,在作用域为整个类的代码中遇到他时,编译器将用12来替换它。
- 方法二:使用关键字static
class Bakery
{
private:
static const int Months=12;
double costs[Months];
}
- 这将创建一个名为Months的常量,**该常量与其他静态变量存储在一起,而不是存储在对象中。**因此,只有一个Months常量,被所有Bakery对象共享。
作用域内枚举(C++11)
传统的枚举存在一些问题,其中之一是两个枚举定义的枚举量可能发生冲突。
enum egg{Small,Medium,Large,XLarge};
enum t_shirt{Small,Medium,Large,Xlarge};
- 这将无法通过编译因为egg Small和t_shirt Small位于相同的作用域内,他们将发生冲突。
新枚举
enum class egg{Small,Medium,Large,XLarge};
enum class t_shirt{Small,Medium,Large,Xlarge};
- 作用域为类后,不同枚举定义的枚举量就不会发生冲突了。
- class也可以用关键字struct来代替
使用:
egg choice = egg::Large;
t_shirt Floyd=t_shirt::Large;
注意:作用域内枚举不能隐式地转换为整型,下面代码错误
int ring = Floyd;//错误
但是必要时可以进行显式转换
int Floyd = int(t_shirt::Small);
抽象数据类型ADT(Abstract Data Type)
- 以抽象的方式描述数据类型,而没有引入语言和细节
11使用类
运算符重载
- 运算符重载或函数多态---定义多个名称相同但特征标(参数列表)不同的函数
- 运算符重载---允许赋予运算符多种含义
运算符函数:operator op(argument-list)示例:
//有类方法:
Time Sum(const Time &t)const;
//定义:
Time Time::Sum(const Time & t)const
{
Time sum;
sum.minutes = minutes + t.minutes;
sum.hours = hours + t.hours + sum.minutes/60;
sum.minutes%=60;
retrun sum;
}
返回值是函数创建一个新的Time对象(sum),但由于sum对象是局部变量,在函数结束时将被删除,因此引用指向一个不存在的对象,返回类型Time意味着程序将在删除sum之前构造他的拷贝,调用函数将得到该拷贝
- 运算符重载,只需把上述函数名修改即可
Sum()的名称改为operator+()
//调用:
total=coding.Sum(fixing);
//运算符重载后调用
1. total=coding.operator+(fixing);
2. total=coding+fixing;
//t1,t2,t3,t4都是Time对象
t4=t1+t2+t3;
重载限制
下面是可重载的运算符列表:
| 运算符 | 分别 |
|---|---|
| 双目算术运算符 | + (加),-(减),*(乘),/(除),% (取模) |
| 关系运算符 | ==(等于),!= (不等于),< (小于),> (大于>,<=(小于等于),>=(大于等于) |
| 逻辑运算符 | ||(逻辑或),&&(逻辑与),!(逻辑非) |
| 单目运算符 | + (正),-(负),*(指针),&(取地址) |
| 自增自减运算符 | ++(自增),--(自减) |
| 位运算符 | | (按位或),& (按位与),~(按位取反),^(按位异或),,<< (左移),>>(右移) |
| 赋值运算符 | =, +=, -=, *=, /= , % = , &=, |=, ^=, <<=, >>= |
| 空间申请与释放 | new, delete, new[ ] , delete[] |
| 其他运算符 | ()(函数调用),->(成员访问),,(逗号),[](下标) |
下面是不可重载的运算符列表:
.:成员访问运算符.*,->*:成员指针访问运算符:::域运算符sizeof:长度运算符?::条件运算符
- 重载的运算符(有些例外情况)不必是成员函数,但必须至少有一个操作数是用户定义的类型.这防止用户标准类型重载运算符
- 使用运算符时不能违反运算符原来的语句法则,例如,不恩那个将秋末运算符(%)重载成一个操作数。
- 不能创建新的运算符
- 不能重载下面的运算符
sizeof:sizeof运算符.:成员运算符:::作用域解析运算符?::条件运算符typeid:一个RTTI运算符const_cast:强制类型转换运算符dynamic_cast:强制类型转换运算符static_cast:强制类型转换运算符reinterpret_cast:强制类型转换运算符
- 下面运算符只能通过成员运算符函数进行重载
=:赋值运算符():函数调用运算符[]:下标运算符->:通过指针访问类成员的运算符
友元函数
C++控制类对象私有部分的访问。通常,公有方法提供唯一的访问途径。
- C++提供了另外一种形式的访问权限:友元
- 友元函数
- 友元类(15章)
- 友元成员函数(15章)
- 友元函数:通过让函数成为类的友元,可以赋予该函数与类成员函数相同的访问权限。
- 问:为何需要友元?因为类重载二元运算符(带两个参数的运算符)常常需要友元函数。将Time对象乘以实数就属于这种情况之前我们有运算符重载:
A = B * 2.75;//Time operator*(double n)const;
如果要实现
A=2.75 * B;//不对应成员函数 cannot correspond to a member function
因为2.75不是TIme类型的对象。左侧应是调用对象 解决:
- 告知每个人(包括程序员自己),只能按 B * 2.75这种格式编写。
- 非成员函数(非成员函数来重载运算符),非成员函数不是由对象调用的,它所使用的所有值(包括对象)都是显式参数。
有函数原型:
Time operator * (double m,const Time &t);
使用:
A=2.75 * B;或 A=operator *(2.75,B);
- 问题:非成员函数不能访问类的私有数据,至少常规非成员函数不能访问
- 解决:友元函数(非成员函数,但其访问权限与成员函数相同。)
创建友元函数
将其原型放在类声明中,并在原型声明前加上关键字friend
- 声明:
friend Time operator * (double m,const Time & t);。该原型声明意味着下面两点:
- 虽然,operator* ()函数是在类中声明的,但它不是成员函数,因此不能使用成员运算符来调用;
- 虽然,operator* ()函数不是成员函数,但它与成员函数的访问权限相同。
- 定义:不要使用Time::限定符,不要再定义中使用关键字friend
Time operator*(double m,const Time & t)
{
Time result;
long totalminutes=t.hours*mult*60+t.minutes*mult;
resut.hours = totalminutes/60;
result.minutes=totalminutes%60;
return result;
}
- 注:不必是友元函数(不访问数据成员也能完成功能)
Time operator * (double m,const Time & t)
{
return t*m;//调用了Time operator*(double n)const
}
重载<<运算符
常用友元:重载座左移运算符
第一种重载版本
- 使用一个Time成员函数重载<<
trip<<cout;//(trip是Time对象)这样会让人困惑
- 通过使用友元函数,可以像下面这样重载运算符:
void operator<<(ostream & os,const Time& t)
{
os<<t.hours<<"hours"<<t.minutes<<"minute";
}
- 该函数成为Time类的一个友元函数(operator<<()直接访问Time对象的私有成员),但不是ostream类的友元(从始至终都将ostream对象作为一个整体来使用)
第二种重载版本
按照上面的定义,下面语句会出错:
cout<<"Trip Time:"<<trip<<"(Tuesday)\n"//不能这么做
应该修改友元函数返回ostream对象的引用即可:
ostream& operator<<(ostream & os,const Time& t)
{
os<<t.hours<<"hours"<<t.minutes<<"minute";
return os;
}
按照上面的定义,下面可以正常运行:
cout<<"Trip Time:"<<trip<<"(Tuesday)\n"//正常运行
类继承属性让ostream引用能指向ostream对象和ofstream对象
#include<fstream>
ofstram fout;
fout.open("Savetime.txt");
Time trip(12,40);
fout<<trip;//等价于operator<<(fout,trip);
类的自动类型转换和强制转换
有构造函数Stonewt(double lbs);可以编写下列代码:
stonewt mycat;//创建一个对象
mycat=19.6;//使用了Stonewt(double lbs)构造函数创意了一个临时对象
上面使用了一个Stonewt(double lbs)构造函数创建了一个临时对象,然后将该对象内容复制到了mycat中,这一过程(19.6利用构造函数变成类对象)需要隐式转换,因为是自动进行的,而不需要显式强制转换。
- --->只接受一个参数类型的构造函数定义了从参数类型到类类型的转换
注意:只有接受一个参数的构造函数才能作为转换函数,然而,如果第二个参数提供默认值,它便可用于转换int
Stonewt(int stn,double lbs=0);
explicit
这种自动特性并非总是合乎需要的,因为会导致意外的类型转换。
- 新增关键字explicit,用于关闭这种自动特性,也就是说,可以这样声明构造函数:
explicit Stonewt(double lbs);//关闭了上面的隐式转换,但允许显式转换,即显式强制类型转换
Stonewt mycat;
mycat =19.6;//错误代码
mycat = Stonewt(19.6);//这里是调用构造函数
mycat =(Stonewt)19.6;//这里是前置类型转换
总结
- 当构造函数只接受一个参数是,可以使用下面的格式来初始化类对象。
Stonewt incognito=2.75;
这等价于前面介绍过的另外两种格式:(这两种格式可用于接收多个参数的构造函数) Stonewt incognito(2.75); Stonewt incognito = Stonewt(2.75);
- 下面函数中,Stonewt和Stonewt&形参都与Stonewt实参匹配
void display(const Stonewt & st,int n)
{
for(int=0;i<n;i++)
{
cout<<"WOW!";
st>show_stn();
}
}
- 语句display(422,2);中
- 编译器先查找自动类型转换中42转Stone的构造函数
Stonewt(int) - 不存在
Stonewt(int)的话,Stonewt(double)构造函数满足这种要求因为,编译器将int转换为double
类的转换函数
- 构造函数只用于某种类型到类类型的转换,要进行相反的转换,必须用到特殊的C++运算符---转换函数
- 转换函数必定是类方法
- 用户定义的强制类型转换,可以向使用强制类型转换那样使用它们。
Stonewt wolf(285,7);
double host = double(wolfe);//格式1
double thinker=(double)wolfe;//格式2
- 也可以让编译器来决定如何做:
Stonewt wolf(20,3);
double star =wells;//隐式转换
创建转换函数
opeator typeName();
- 转换函数必定是类方法
- 转换函数不能指定返回类型
- 转换函数不能有参数
例如:转换函数为double类型的原型如下
operator double();//不要返回类型也不要参数
如何定义
- 头文件中声明:
operator int() const;
operator double() const;
- cpp文件中定义:
Stonewt::opeator int() const
{
return int (pounds+0.5);//四舍五入
}
Stonewt::opeator double() const
{
return pounds;//四舍五入
}
二义性
C++中,int和double值都可以被赋值给long变量,下面语句被编译器认为有二义性而拒绝了。
long gone = poppins;//注:poppins是Stonewt对象
//但是还是可以进行强制类型转换
long gone = (double)poppins;
long gone =int (poppins);
避免隐式转换
- 方法1:C++98中,关键字
explicit不能用于转换函数,但C++11消除了这种限制。因此,在C++11中,可将转换运算符声明为显示的:
class Stonewr
{
...
//conversion functions
explicit operator int() const;
explicit operator double() const;
};
有了这些声明后,需要前置转换时,将调用这些运算符。
- 方法2:用一个功能相同的非转换函数替换转换函数即可,但仅在被显式调用时,该函数才会执行。也就是说,可以将:
Stonewt::operator int(){return int(pounds+0.5);}
替换为
int Stonewt stone_to_int(){return int(pounds+0.5);}
这样下面语句为非法的:
int plb=popins;
需要转换时只能调用stone_to_int():
int plb =poppins.stone_to_int();
12类和动态内存分配
- 动态内存和类
- -->让程序运行时决定内存分配,而不是在编译时决定。
- ---->使用new和delete运算符来动态控制内存
- ------>在类中使用这些运算符将导致许多新的编程问题。这种情况下,析构函数将是必不可少的,而不再是可有可无的。
- -------->有时候还必须重载赋值运算符。
C++为类自动提供了下面这些成员函数
- 1.默认构造函数,如果没有定义构造函数;记得自己定义了构造函数时,编译器不会再提供默认构造函数,记得自己再定义一个默认构造函数。 带参数的构造函数也可以是默认构造函数,只要所有参数都有默认值。
- 2.默认析构函数,如果没有定义;用于销毁对象
- 3.复制(拷贝)构造函数,如果没有定义;用于将一个对象赋值到新创建的对象中(将一个对象初始化为另外一个对象)。用于初始化的过程中,而不是常规的赋值过程。
- 每当程序生成对象副本时(函数按值传递对象,函数返回对象时),编译器都将使用复制构造函数
- 编译器生成临时对象是,也将使用复制构造函数
默认的复制构造函数的功能--->逐个复制非静态成员(成员复制也叫浅复制,给两个对象的成员划上等号),复制的是成员的值;如果成员本身就是类对象,则将使用这个类的复制构造函数复制成员对象,静态成员变量不受影响,因为它们属于整个类,而不是各个对象
- 浅复制面对指针时会出现错误,在复制构造函数中浅复制的等价于sailor.len=sport.len;sailor.str=sport.str;前一个语句正确,后一个语句错误,因为成员char* str是指针,得到的是指向同一字符串的指针!!!
- 当出现动态内存分配时,要定义一个现实复制构造函数--->进行深度复制(deep copy)
StringBad::StringBad(const StringBad & st)
{
len=st.len;
str=new char[len+1];
std::strcpy(str,st.str);
}
- 4.赋值运算符,如果没有定义;赋值运算符只能由类成员函数重载的运算符之一。将已有的对象赋值给另外一个对象时(将一个对象复制给另外一个对象),使用赋值运算符。
原型:class_name & class_name::operator==(const class_name &);接受并返回一个指向类对象的引用。
- 与复制构造函数相似,赋值运算符的隐式实现也对成员进行逐个复制
- 解决:提供赋值运算符(进行深度复制)定义,其实现业余复制构造函数相似,但有一些差别
//代码1:先申请内存,再delete
CMyString& CMyString::operator=(const CMyString& str)
{
if(this==str)
{
char *temp_pData=new char[strlen(str.m_pData)+1)];
delete[]m_pData;
m_pData=temp_pData;
strcpy(m_pData,str.m_pData);
}
return *this;
}
//代码2:调用复制构造函数
CMyString& CMyString::operator=(const CMyString& str)
{
if(this==str)
{
CMyString strTemp(str);//复制构造函数创建临时对象,临时对象失效时会自动调用析构函数
char* pTemp=strTemp.m_pData;//创建一个指针指向临时对象的数据成员m_pData
strTemp.m_pData=m_pData;//交换
m_pData=pTemp;//交换
}
return *this;
}
- 5.地址运算符,如果没有定义;
- 6.移动构造函数(move construtor),如果没有定义;
- 7.移动赋值运算符(move assignment operator)。
静态类成员函数
- 1.静态函数:静态函数与普通函数不同,它只能在声明它的文件中可以见,不能被其他文件使用。定义静态函数的好处:静态函数不会被其他文件使用。其他文件中可以定义相同名字的函数,不会发生冲突。
- 2.静态类成员函数:与静态成员数据一样,我们可以创建一个静态成员函数,它为类的全部服务,而不是为某一个类的具体对象服务。静态成员函数与静态成员数据一样,都是在类的内部实现,属于类定义的一部分。普通成员函数一般都隐藏了一个this指针,this指针指向类的对象本身。
- 3.静态成员函数由于不是与任何对象相联系,因此不具有this指针,从这个意义上讲,它无法访问属于类对象的非静态数据成员,也无法访问非静态成员函数,它只能调用其余的静态成员函数
静态成员函数总结:
- 1.出现在类体外的函数不能指定关键字static;
- 2.静态成员之间可以互相访问,包括静态成员函数访问静态数据成员和访问静态成员函数;
- 3.非静态成员函数可以任意地访问静态成员函数和静态数据成员;
- 4.静态成员函数不能访问非静态成员函数和非静态数据成员
- 5.由于没有this指针的额外开销,因此静态成员函数与类的全局函数相比,速度上会有少许的增长
- 6.调用静态成员函数,可以用成员访问操作符(.)和(->)为一个类的对象或指向类对象的指调用静态成员函数。
构造函数中使用new时应注意的事项
- 1.如果构造函数中使用new来初始化指针成员,则应在析构函数中使用delete。
- 2.new和delete必须相互兼容,new对应于delete,new[]对应于delete[]
- 3.如果有多个构造函数,则必须以相同的方式使用new,要么中括号,要么都不带。因为只有一个析构函数,所有的构造函数都必须与它兼容。然而,可以在一个构造函数中使用new来初始化指针,而在另外一个构造函数中初始化为空(0或nullptr),这是因为delete(无论是带括号,还是不带括号)可以用于空指针。
- 4.应定义一个复制构造函数,通过深度复制将一个对象初始化为另外一个对象。
- 5.应当定义一个赋值运算符,通过深度复制将一个对象复制给另外一个对象。
有关返回对象的引用
- 1.首先,返回对象将调用复制构造函数(给新创建的临时对象复制(初始化)),而返回引用不会
- 2.其次,返回引用指向的对象因该在调用函数执行时存在。
- 3.返回作为参数输入的常量引用,返回类型必须为const,这样才匹配。
使用指向对象的指针
Class_name* ptr = new Class_name;调用默认构造函数
定位new运算符/常规new运算符
//使用new运算符创建一个512字节的内存缓冲区
char* buffer =new char[512];//地址:(void*)buffer=00320AB0
//创建两个指针;
JustTesting *pc1,*pc2;
//给两个指针赋值
pc1=new (buffer)JustTesting;//使用了new定位符,pc1指向的内存在缓冲区 地址:pc1=00320AB0
pc2=new JustTesting("help",20);//使用了常规new运算符,pc2指向的内存在堆中
//创建两个指针;
JustTesting *pc3,*pc4;
//给两个指针赋值
pc3=new (buffer)JustTesting("Bad Idea",6);//使用了new定位符,pc3指向的内存在缓冲区 地址:pc3=00320AB0
//创建时,定位new运算符使用一个新对象覆盖pc1指向的内存单元。
//问题1:显然,如果类动态地为其成员分配内存,该内存还没有释放,成员就没了,这将引发问题。
pc4=new JustTesting("help",10);//使用了常规new运算符,pc4指向的内存在堆中
//释放内存
delete pc2;//free heap1
delete pc4;//free heap2
delete[] buffer//free buffer
- 解决问题1,代码如下:
pc1=new (buffer)JustTesting;
pc3=new (buffer+sizeof(JustTesting))("Bad Idea",6);
- 问题2:
将delete用于pc2,pc4时,将自动调用为pc2和pc4指向的对象调用析构函数;问题2:然而,将的delete[]用于buffer时,不会为使用定位new运算符创建的对象调用析构函数
- 解决问题2:显式调用析构函数
pc3->~JustTesting;
pc1->~JustTesting;
嵌套结构和类
- 在类声明的结构、类或枚举被认为是被嵌套在类中,其作用域为整个类
- 这种声明不会创建数据对象,而是指定了可以在类中使用的类型。
- 1.如果声明是在类的私有部分进行的,则只能在这个类中使用被声明的类型。
- 2.如果声明是在公有部分进行的,则可以从类的外部通过作用域解析运算符使用被声明的类型 例如,如果Node是在Queue类的公有部分声明的,则可以在外部声明Queue::Node类型的变量。
默认初始化
a.内置类型的变量初始化
如果定义变量时没有指定初始值,则变量被默认初始化。默认值由变量类型和定义变量的位置决定。
- 如果是内置类型的变量未被显示初始化,它的值由定义位置决定。定义于任何函数体外的变量被初始化为0。
//不在块中
int i;//正确,i会被值初始化为0,也称为零初始化
- 定义于函数体内部的内置类型变量将不被初始化(uninitialized)。一个未被初始化的内置类型变量的值是未定义的,如果试图拷贝或其他形式的访问此类型将引发错误
1 {//在一个块中
2 int i;//默认初始化,不可直接使用
3 int j=0;//值初始化
4 j=1;//赋值
5 }
b.类类型的对象初始化
类通过一个或几个特殊的成员函数来控制其对象的初始化过程,这些函数叫做构造函数(constructor)。构造函数的任务是初始化类对象的数据成员。 由编译器提供的构造函数叫(合成的默认构造函数)。 合成的默认构造函数将按照如下规则初始化类的数据成员。
- 如果存在类内初始值(C++11新特性),用它来初始化成员。
class CC
{
public:
CC() {}
~CC() {}
private:
int a = 7; // 类内初始化,C++11 可用
}
- 否则,没有初始值的成员将被默认初始化。
成员列表初始化
- 使用成员初始化列表的构造函数将覆盖相应的类内初始化
- 对于简单数据成员,使用成员初始化列表和在函数体中使用复制没什么区别
- 对于本身就是类对象的成员来说,使用成员初始化列表的效率更高
如果Classy是一个类,而mem1,mem2,mem3都是这个类的数据成员,则类构造函数可以使用如下的语法来初始化数据成员。
Classy::Classy(int n,intm):mem1(n),mem2(0),men3(n*m+2)
{
//...
}
- 1.这种格式只能用于构造函数
- 2.必须用这种格式来初始化非静态const数据成员(至少在C++之前是这样的);
- 3.必须用这种格式来初始化引用数据成员
- 数据成员被初始化顺序与它们出现在类声明中的顺序相同,与初始化器中的排列顺序无关
13类继承
基类和派生类的特殊关系
- 1.派生类对象可以使用非私有的基类方法
- 2.基类指针(引用)可以在不进行显示转换的情况下指向(引用)派生类对象(反过来不行);基类指针或引用只能用来调用基类方法,不能用来调用派生类方法。
- 3.不可以将基类对象和地址赋给派生类对象引用和指针。
派生类构造函数要点
1.首先创建基类对象; 2.派生类构造函数应通过成员初始化列表将基类信息传递给基类构造函数。 3.派生类构造函数应初始化新增的数据成员。 注意:可以通过初始化列表语法知名指明要使用的基类构造函数,否则使用默认的基类构造函数。派生类对象过期时,程序将首先调用派生类的析构函数,然后在调用基类的析构函数。
RetedPlayer::RetedPlayer(unsigned int r,const string & fn,const string &ln, bool ht)//:TableTennisPlayer()等价于调用默认构造函数
{
rating = r;
}
虚方法
- 经常在基类中将派生类会重新定义的方法声明为虚方法。方法在基类中被声明为虚的后。它在派生类中将自动生成虚方法。然而,在派生类中使用关键字virtual来指出哪些函数是虚函数也不失为一个好方法。
- 如果要在派生类中重新定义基类的方法,通常将基类方法声明为虚。这样,程序根据对象类型而不是引用或指针类型来选择方法版本,为基类声明一个虚的析构函数也是一种惯例,为了确保释放派生类对象时,按正确的顺序调用析构函数。
- 虚函数的作用:基类指针(引用)指向(引用)派生类对象,会发生自动向上类型转换,即派生类升级为父类,虽然子类转换成了它的父类型,但却可正确调用属于子类而不属于父类的成员函数。这是虚函数的功劳。
派生类方法可以调用公有的基类方法
在派生类方法中,标准技术是使用作用域解析运算符来调用基类方法,如果没有使用作用域解析符,有可能创建一个不会终止的递归函数。如果派生类没有重新定义基类方法,那么代码不必对该方法是用作用域解析符(即该方法只有在基类中有)。
静态联编和动态联编
函数名联编(binding):将代码中的函数调用解释为执行特定的代码块。
- 在C语言中,这非常简单,因为每个函数名都对应一个不同的函数。
- 在C++中,由于函数重载的缘故,这个任务更繁杂,编译器必须查看函数参数以及函数名才能确定使用哪个函数。 >静态联编(static binding)
- 在编译过程中进行联编,又称为早期联编 >动态联编(dynamic binding)
- 编译器在程序运行时确定将要调用的函数,又称为晚期联编
什么时候使用静态联编,什么时候使用动态联编?
- 编译器对虚方法使用静态联编,因为方法是非虚的,可以根据指针类型关联到方法。
- 编译器对虚方法使用动态联编,因为方法是虚的,程序运行时才知道指针指向的对象类型,才来选择方法。(引用同理)
效率:为使程序能够在运行阶段进行决策,必须采取一些方法来跟踪基类指针和指向引用对象的对象类型,这增加了额外的处理开销
- 例如,如果类不会用作基类,则不需要动态联编。
- 同样,如果派生类不重新定义基类的任何方法,也不需要动态联编。
- 通常,编译器处理函数的方法是:给每个对象添加一个隐藏成员--指向函数地址数组的指针(vptr) >使用虚函数时,在内存和执行速度上有一定的成本,包括: a.每个对象为存储地址的空间; b.对于每个类,比那一期都将创建一个虚函数地址表(数组)vtbl; c.对于每个函数调用,都需要执行一项额外的操作,到表中查找地址。虽然非虚函数的效率比虚函数稍高,但不具有动态联编的功能
总结:
- 在基类方法的声明中使用关键字virtual可使该方法在基类以及所有的派生类(包括从派生类派生出来的类)中是虚的。
- 如果使用指向对象的引用或指针来调用虚方法,程序将使用为对象类型定义的方法,而不是用为引用或者指针类型定义的方法。这个成为动态联编或者晚期联编。这种行为非常重要。因为这样基类指针或引用可以指向派生类对象。
- 如果定义的类将被用作基类,则应该将那些在派生类中重新定义的类方法生命为虚的。
虚函数细节
- 1.构造函数不能是虚函数,派生类不能继承基类的构造函数,将类构造函数声明为虚没什么意义。
- 2.析构函数应当是虚函数,除非类不用作基类。
1.当子类指针指向子类是,析构函数会先调用子类析构再调用父类析构,释放所有内存。 2.当父类指针指向子类时,只会调用父类析构函数,子类析构函数不会被调用,会造成内存泄漏。(基类析构函数声明为虚,可以使得父类指针能够调用子类虚的析构函数)所以我们需要虚析构函数,将父类的析构函数定位为虚,那么父类指针会先调用子类的析构函数,再调用父类析构,使得内存得到释放。
- 3.友元不能是虚函数,因为友元不是类成员,只有类成员才是虚函数。
- 4.如果派生类没有重新定义函数。将使用该函数的基类版本。
- 5.重新定义将隐藏方法不会生成函数的两个重载版本,而是隐藏基类版本。如果派生类位于派生链中,则使用最新的虚函数版本,例外的情况是基类版本是隐藏的。总之,重新定义基本的方法并不是重载。如果重新定义派生类中的函数,将不只是使用相同的函数参数列表覆盖其基类声明,无论参数列表是否相同,该操作将隐藏所有的同名方法。
两条经验规则
- 1.如果重新定义继承的方法,应确保与原来的原型完全相同,但是如果返回类型是积累的引用或指针,则可以修改为指向派生类的引用或指针(只适用于返回值而不适用于参数),这种例外是新出现的。这种特性被称为返回类型协变(convariance of return type),因此返回类型是随类类型变化的。
//基类
class Dwelling
{
public:
virtual Dwelling & build(int n);
}
//派生类
class Hovel:public Dwelling
{
public:
virtual Hovel & build(int n);
}
- 2.如果基类声明被重载了,则应该在派生类中重新定义所有基类版本。
//基类
class Dwelling
{
public:
//三个重载版本的showperks
virtual void showperks(int a)const;
virtual void showperks(double a)const;
virtual void showperks( )const;
}
//派生类
class Hovel:public Dwelling
{
public:
//三个重新定义的的showperks
virtual void showperks(int a)const;
virtual void showperks(double a)const;
virtual void showperks( )const;
}
如果只重新定义一个版本,则另外两个版本将被隐藏,派生类对象将无法使用它们, 注意,如果不需要修改,则新定义可知调用基类版本:
void Hovel::showperk()const
{
Dwelling::showperks();
}
访问控制:protected
- 1.关键字protected与private相似,在类外,只能用公有类成员来访问protected部分中的类成员。
- 2.private和protected之间只有在基类派生的类才会表现出来。派生类的成员可以直接访问基类的保护成员,但是不能直接访问基类的私有成员。
提示:
- 1.最好对类的数据成员采用私有访问控制,不要使用保护访问控制。
- 2.对于成员函数来说,保护访问控制很有用,它让派生类能够访问公众不能使用的内部函数。
抽象基类(abstract base class)ABC->至少包含一个纯虚函数
- 在一个虚函数的声明语句的分号前加上 =0 ;就可以将一个虚函数变成纯虚函数,其中,=0只能出现在类内部的虚函数声明语句处。
- 纯虚函数只用声明,而不用定义,其存在就是为了提供接口,含有纯虚函数的类是抽象基类。我们不能直接创建一个抽象基类的对象,但可以创建其指针或者引用。
- 值得注意的是,你也可以为纯虚函数提供定义,不过函数体必须定义在类的外部。但此时哪怕在外部定义了,也是纯虚函数,不能构建对象。
- 派生类构造函数只直接初始化它的直接基类。多继承的虚继承除外。
抽象类应该注意的地方
- 抽象类不能实例化,所以抽象类中不能有构造函数。
- 纯虚函数应该在派生类中重写,否则派生类也是抽象类,不能实例化。
抽象基类的作用
- C++通过使用纯虚函数(pure virtual function)提供未实现的函数。纯虚函数声明的结尾处为=0,
virtual double Area() const=0;//=0指出类是一个抽象基类,在类中可以不定义该函数
- 可以将ABC看作是一种必须的接口。ABC要求具体派生类覆盖其纯虚函数---迫使派生类遵顼ABC设置的接口规则。简单来说是:因为在派生类中必须重写纯虚函数,否则不能实例化该派生类。所以,派生类中必定会有重新定义的该函数的接口。
- 从两个类(具体类concrete)(如:Ellipse和Circle类)中抽象出他们的共性,将这些特性放到一个ABC中。然后从该ABC派生出的Ellipse和Circle类。 这样,便可以使用基类指针数组同时管理Ellipse和Circle对象,即可以使用多态方法
友元
- 就像友元关系不能传递一样,友元关系同样不能继承,基类的友元在访问派生类成员时不具有特殊性,类似的,派生类的友元也不能随意访问基类的成员。
继承和动态内存分配(todo)
- 只有当一个类被用来做基类的时候才会把析构函数写成虚函数。
- 当基类和派生类都采用动态内存分配是,派生类的析构函数,复制构造函数,赋值运算符都必须使用相应的基类方法来处理基类
14C++中的代码重用(公有继承,包含对象的类,私有继承,多重继承,类模板)
包含(containment):包含对象成员的类
本身是另外一个类的对象。这种方法称为包含(containment),组合(composition),或层次化(laying)
私有继承(还是has-a关系)
基类的公有成员和保护成员都将成为派生类的私有成员。和公有继承一样,基类的私有成员是会被派生类继承但是不能被派生类访问。基类方法将不会成为派生类对象公有接口的一部分,但可以在派生类中使用它们。
- 1.初始化基类组件 >和包含不同,对于继承类的新版本的构造函数将使用成员初始化列表语法,它使用类名(std::string,std::valarry)而不是成员名来表示构造函数
//Student类私有继承两个类派生而来,本来包含的时候两个基类分别是name和score
class Student:private std::string,private std::valarry<double>
{
public:
......
};
//如果是包含的构造函数
Student(const char *str,const double *pd,int n):name(str),score(pd,n)
{
}
//继承类的构造函数
Student(const char *str,const double *pd,int n):std::string(str),std::valarry<double>(pd,n)
{
}
- 2.访问基类的方法
a.包含书用对象(对象名)来调用方法
b.私有继承时,将使用类名和作用域解析运算符来调用方法
double Student::Average() const
{
if(ArrayDb::size()>0)//ArrayDb typedef为std::valarry<double>
return ArrayDb::sum()/ArrayDb::size();
else
return 0;
}
- 3.访问基类对象
使用私有继承时,该string对象没有名称。那么,student类的代码如何访问内部string对象呢? 强制类型转换!
本来子到父自动类型提升,不需要强制类型转换。父到子才需要强制类型转换。但是下面是强制类型转换,原因在第4点那里写着。
由于Student类是从string类派生而来的,因此可以通过强制类型转换,将Student对象转换为S=string对象
//成员方法:打印出学生的名字
//因为不是包含,只能通过强制类型转换
const string & Student::Name()const
{
retrun (const string &) *this;
}
- 4.访问基类友的元函数
用类名显式地限定函数名不适合友元函数,因为友元不属于类。不能通过这种方法访问基类。
解决:通过显示地转换为基类来调用正确的函数
osstream & operator<<(ostream & os,const Student & stu)
{
os << "Score for "<<(const String &) stu <<":\n";//显式地将stu转换为string对象引用,进而调用基类方法
}
引用不会自动转换为string引用 原因:
- a.在私有继承中,未进行显示类型转换的派生类引用或指针,无法赋值给基类的引用或指针。
- b.即使这个例子使用的是公有继承,也必须使用显示类型转换。原因之一是,如果不使用类型转换,下述代码将无法与函数原型匹配从而导致递归调用,os<<stu
- c.由于这个类使用的是多重继承,编译器将无法确定应转换成哪个基类,如果两个基类都提供函数operator<<()。
- 5.使用包含还是私有继承? 通常,应使用包含来建立has-a关系;如果新需要访问原有的保护成员,或重新定义虚函数,则应使用私有继承。
- 6.保护继承 >* 基类的公有成员和保护成员都将成为派生类的保护成员。 >* 共同点:和私有继承一样,基类的接口在派生类中也是可用的,但在继承和结构之外是不可用的。 >* 区别:使用私有继承时,第三代类将不能使用基类的接口,这是因为公有方法在派生类中将变成私有方法;使用保护继承时,基类的公有方法在第二代将变成保护的,因此第三代派生类可以使用它们。
| 特征 | 公有继承 | 保护继承 | 私有继承 |
|---|---|---|---|
| 公有成员变成 | 派生类的公有成员 | 派生类的保护成员 | 派生类的私有成员 |
| 保护成员变成 | 派生类的保护成员 | 派生类的保护成员 | 派生类的私有成员 |
| 私有成员变成 | 只能通过基类接口访问 | 只能通过基类接口访问 | 只能通过基类接口访问 |
| 能否隐式向上转换 | 是 | 是(但只能在派生类中) | 否 |
- 7.使用using重新定义访问权限 使用派生或私有派生时,基类的公有成员将成为保护成员或私有成员,假设要让基类方法在派生类外面可用
- 方法1,定义一个使用该基类方法的派生类方法
double Student::sum() const
{
return std::valarray<double>::sum();
}
- 方法2,将函数调用包装在另外一个函数调用中,即使用一个using声明(就像空间名称一样)
class Student::private std::string,private std::valarray<double>
{
...
public:
using std::valarray<double>::min;
using std::valarray<double>::max;
}
//using声明只适用于继承,而不适用于包含 //using声明只使用成员名---没有圆括号,函数特征表和返回类型
多重继承
必须使用关键字public来限定每一个基类,这是因为,除非特别指出,否则编译器将认为是私有派生。(class 默认访问类型是私有,strcut默认访问类型是公有)
多重继承带来的两个主要问题:
- 1.从两个不同的基类继承同名方法。
- 2.从两个或更多相关的基类那里继承同一个类的多个实例。
class Singer:public Worker{...};
class Waiter:public Worker{...};
class SingerWaiter:public Singer,public Waiter{...};
- Singer和Waiter都继承一个Worker组件,因此SingerWaiter将包含两份Worker的拷贝-->通常可以将派生来对象的地址赋给基类指针,但是现在将出现二义性。(基类指针调用基类方法时不知道调用哪个基类方法),第二个问题:比如worker类中有一个对象成员,那么就会出现
虚基类(virtual base class)
- 虚基类使得从多个类(他们的基类相同)派生出的对象只继承一个基类对象。
class Singer:virtual public Worker{...};//virtual可以和public调换位置
class Waiter:public virtual Worker{...;
//然后将SingingWaiter定义为
class SingingWaiter:public Singer,public Waiter{...};
现在,SingingWaiter对象只包含Worker对象的一个副本
为什么不抛弃将基类声明为虚的这种方式,使虚行为成为MI的准则呢?(为什么不讲虚行为设为默认,而要手动设置)
- 第一,一些情况下,可能需要基类的多个拷贝;
- 第二,将基类作为虚的要求程序完成额外的计算,为不需要的工具付出代价是不应当的;
- 第三,这样做是有缺点的,为了使虚基类能够工作,需要对C++规则进行调整,必须以不同的方式编写一些代码。另外,使用虚基类还可能需要修改已有的代码
虚基类的构造函数(需要修改)
- 对于非虚基类,唯一可以出现在初始化列表的构造函数是即是基类构造函数。
- 对于虚基类,需要对类构造函数采用一种新的方法。
- 基类是虚的时候,禁止信息通过中间类自动传递给基类,因此向下面构造函数将初始化成员panache和voice,但wk参数中的信息将不会传递给子对象Waiter。然而,**编译器必须在构造派生对象之前构造基类对象组件;**在下面情况下,编译器将使用Worker的默认构造函数(即类型为Worker的参数没有用!而且调用了Worker的默认构造函数)
SingingWaiter(const Worker &wk,int p=0;int v=Singer:other):Waiter(wk,p),Singer(wk,v){}//flawed
- 如果不希望默认构造函数来构造虚基类对象,则需要显式地调用所需的基类构造函数。
SingingWaiter(const Worker &wk,int p=0;int v=Singer:other):Worker(wk),Waiter(wk,p),Singer(wk,v){}
- 上述代码将显式地调用构造函数worker(const Worker&)。请注意,这种调用是合法的,对于虚基类,必须这样做;但对于非虚基类,则是非法的。
有关MI的问题
- 多重继承可能导致函数调用的二义性。
假如每个祖先(Singer,waiter)都有Show()函数。那么如何调用
- 1.可以使用作用域解析符来澄清编程者的意图:
SingingWaiter newhire("Elise Hawks",2005,6,soprano);
newhire.Singer::Show();//using Singer Version
- 2.然而,更好的方法是在SingingWaiter中重新定义Show(),并指出要使用哪个show。
P559~P560
1.混合使用虚基类和非虚基类
- 如果基类是虚基类,派生类将包含基类的一个子对象;
- 如果基类不是虚基类,派生类将包含多个子对象
- 当虚基类和非虚基类混合是,情况将如何呢?
//有下面情况
class C:virtual public B{...};//B为虚基类
class D:virtual public B{...};//B为虚基类
class X: public B{...}; //B为非虚基类
class Y: public B{...}; //B为非虚基类
class M:public C,public D,public X,public Y{...};
- 这种情况下,类M从虚派生祖先C和D那里共继承了一个B类子对象,并从每一个非虚派生祖先X和Y分别继承了一个B类子对象。因此它(M)包含三个B类子对象。
- 当类通过多条虚途径和非虚途径继承了某个特定的基类时,该类包含一个表示所有的虚途径的基类子对象和分别表示各条非虚途径的多个基类子对象。(本例子中是1+2=3)
2.虚基类和支配(使用虚基类将改变C++解释二义性的方式)
- 使用非虚基类是,规则很简单,如果类从不同的类那里继承了两个或更多的同名函数(数据或方法),则使用该成员名是,如果没有用类名进行限定,将导致二义性。
- 但如果使用的是虚基类,则这样做不一定会导致二义性。这种情况下,如果某个名称**优先于(dominates)**其他所有名称,则使用它时,即使不使用限定符,也不会导致二义性。
class B
{
public:
short q();
...
};
class C:virtual public B
{
public:
long q();
int omg();
...
};
class D:public C
{
...
}
class E:virtual public B
{
private:
int omg();
...
};
class F: public D,public E
{
...
};
- 1.类C中的q()定义优先于类B中的q()定义,因为类C是从类B派生而来的。因此F中的方法可以使用q()来表示C::q().(父子类之间有优先级,子类大于父类)
- 2.任何一个omg()定义都不优先于其他omg()定义,因为C和E都不是对方的基类。所以,在F中使用非限定的omg()将导致二义性。
- 3.虚二义性规则与访问规则(pravite,public,protected)无关,也就是说即使E::omg是私有的,不能在F类中直接访问,但使用omg()仍将导致二义性。
类模板
类模板
- 类模板和模板函数都是以template开头(当然也可以使用class),后跟类型参数;类型参数不能为空,多个类型参数用逗号隔开。
template <typename 类型参数1,typename 类型参数2,typename 类型参数3>class 类名
{
//TODO
}
- 类模板中定义的类型参数可以用在函数声明和函数定义中,
- 类模板中定义的类型参数可以用在类型类声明和类实现中,
- 类模板的目的同样是将数据的类型参数化。
template <class Type>
class Stack
{
private:
enum {MAX=10};
Type items[MAX];
int top;
public:
Stack();
……
}
template <class Type>
Stack<Type>::Stack()
{
top=0;
}
- Type:泛型标识符,这里的type被称为类型参数。这意味着它们类似于变量,但赋给它们的不是数字,而只能是类型
- 相比于函数模板,类模板必须显式的提供所需的类型。
- 模板不是函数,它们不能单独编译。模板必须与特定的**模板实例化(instantiation)**请求一起使用,为此,最简单的方法是将所有模板信息放在一个文件中,并在要使用这些模板的文件中包含该头文件。
//类声明Stack<int>将使用int替换模板中所有的Type
Stack<int>kernels;
Stack<string>colonels;
深入探讨模板
模板具体化(instantiation)和实例化(specialization)
模板以泛型的方式描述类,而具体化是使用具体的类型生成类声明。
- 类模板具体化生成类声明
- 类实例化生成类对象
- 1.隐式实例化(implicit instantiation)
他们声明一个或多个对象,指出所需的类型,而编译器使用通用模板提供的处方生成具体的类定义;
Array<int,100>stuff;//隐式实例化
//在编译器处理对象之间,不会生成隐式实例化,如下
Array<double,30>*pt;//a pointer,no object needed yet
//下面语句导致编译器生成类定义,并根据该定义创建一个对象昂
pt=new Array<double,30>;
- 2.显式实例化(explicit instantiation)
当使用关键字template并指出所需类型来声明类时,编译器将生成类声明的实例化
template class ArrayTP<string,100>;
这种情况下,虽然没有指出创建或提及类对象,编译器也将生成类声明(包含方法定义)。和隐式实例化也将根据通用模板来生成具体化。
- 3.显式具体化(explicit specialization)---是特定类型(用于替换模板中的泛型)的定义
格式:template<>class Classname
{...}; 有时候,可能需要在特殊类型实例化是,对模板进行修改,使其行为不同。在这种情况下,可以创建显式实例化。
//原来的类模板
template <typename T>class sortedArray
{
...//details omitted
};
当具体化模板和通用模板都与实例化请求匹配时,编译器将使用具体化版本。
//新的表示法提供一个专供const char*类型使用的SortedArray模板
template<>class SortedArray<const char*>
{
...//details omitted
};
- 4.部分具体化(partical specialization)
部分限制模板的通用性
//general template 一般模板
template<class T1,class T2>class Pair{...};
//specialization with T2 set to int部分具体化
template<class T1>class Pair<T1,int>{...};
如果有多个模板可供选择,编译器将使用具体化程度最高的模板
Pair<double,double>p1;//使用了一般的Pair类模板
Pair<double,int>p2;//使用了部分具体化Pair<T1,int>
Pair<int,int>p3//使用了显式实例化Pair<int,int>
也可以通过为指针提供特殊版本来部分具体化现有模板:
template<class T>
class Feen{...};//一般版本的类模板
template<class T*>
class Feen{...};//部分具体化
将模板用作参数
template<template<typename T>class Thing>class Crab
模板类和友元
模板类声明也可以有友元。模板的友元分为3类:
- 非模板友元:
- 约束(bound)模板友元,即友元的类型取决于类被实例化时的类型;
- 非约束(unbund)模板友元,即友元的所有具体化都是类的每一个具体化的友元。
模板类的非模板友元函数
- 在模板类中奖一个常规函数声明为友元:
template <class T>
class HasFriend
{
public:
friend void counts();
...
};
上述声明指定counts()函数称为模板所有实例化的友元
- counts()函数不是通过对象调用(它是友元不是成员函数),也没有对象参数,那么如何访问HasFriend对象?
- 1.它可以访问全局对象
- 2.它可以使用全局指针访问非全局对象
- 3.可以创建自己的对象
- 4.可以访问独立于对象的模板类的静态成员函数
模板类的约束模板友元
- 1.首先,在类定义的前面声明每个模板函数
template
void counts(); template void report(T &);
- 2.然后,在函数中再次将模板声明为友元。这些语句根据类模板参数的类型声明
template<typename TT>
class HasFriendT
{
...
friend coid counts<TT>();
friend coid report<>(HasFriendT<TT> &);
};
- 3.为友元提供模板定义
模板类的非约束模板友元函数
- 前一节中的约束模板友元函数在类外面声明的模板的具体化。int类具体化获得int函数具体化,依此类推。通过类内部声明模板,可以创建非约束友元函数,即每个函数具体化都是每个类具体化的友元。对于非约束友元,友元模板类型参数与模板类类型参数是不同的:
template<typename T>
class ManyFriend
{
...
template<typename C,typename D>friend void show2(C &,D &);
};
模板别名(C++11)
- 1.如果能为类型指定别名,浙江爱你个很方便,在模板设计中尤为如此。可使用typedef为模板具体化指定别名
typedef std::array<double,12> arrd;
typedef std::array<int,12> arri;
typedef std::array<std::string,12> arrst;
//使用
arrd gallones;
arri days;
arrst months;
- 2.C++11新增了一项功能---使用模板提供一系列别名
template<typename T>
using arrtype=std::array<T,12>;//template aliases
这将arrtype定义为一个模板别名,可以用它来指定类型
arrtype<double> gallones;
arrtype<int> days;
arrtype<std::string> months;
- C++11允许将语法using=用于非模板。用于非模板是,这种语法与常规typedef等价:
typedef const char *pc1; //typedef syntax/ 常规typedef语法
using pc2=const char*; //using = syntax/ using =语法
可变参数模板(variadic template)18章
15友元、异常和其他
友元类
例子:模拟电视机和遥控器的简单程序
公有继承is-a关系并不适用。遥控器可以改变电视机的状态,这表明应将Remove类作为TV类的一个友元
- 友元声明 friend class Remote;--->友元声明可以位于公有、私有或保护部分,其所在的位置无关紧要。该声明让整个类成为友元并不需要前向(实现)声明,因为友元语句本身已经指出Remote是一个类。
- 友元Remove可以使用TV类的所有成员
- 大多类方法都被定义为内联。代码中,除构造函数外,所有Remove方法都将一个TV对象引用作为参数,这表明遥控器必须针对特定的电视机
- 同一个遥控器可以控制不同的电视机
TV S42;
TV S58(TV::ON);
Remote grey;
grey.set_chan(S42,10);
grey.set_chan(S58,28);
友元成员函数
- 某一个类的成员函数作为另外一个类的友元函数
例子:将TV成员中Remote方法Remote::set_chan(),成为另外一个类的成员
class TV
{
friend void Remote::set_chan(TV& t,int c);
...
};
- 问题1:在编译器在TV类声明中看到Remote的一个方法被声明为TV类的友元之前,应先看到Remote类的声明和set_chan()方法的声明。
//排列次序应如下:
class TV;//forward declaration
class Remote{...};
class TV{...};
- 问题2:Remote声明包含内联代码,例如:
void onoff(TV & t){t.onoff();}由于这将调用TV的一个方法,所以编译器此时必须看到一个TV的类声明,解决:使Remote声明中只包含方法声明,并将实际的定义放在TV类之后
#include<iostream>
class B
{
public :
B()
{
myValue=2;
std::cout<<"B init"<<std::endl;
}
~B()
{
std::cout<<"B end"<<std::endl;
}
//这样做可以
/*B operator+(const B av)
{
B a;
a.myValue=myValue+av.myValue;
return a;
}*/
//也可以这么做
friend B operator+(const B b1,const B b2);
//------------------------------------------------
int GetMyValue()
{
return myValue;
}
//重载<<
friend std::ostream& operator<<(std::ostream& os,B);
private :
int myValue;
};
B operator+(const B b1,const B b2)
{
B a;
a.myValue=b1.myValue+b2.myValue;
return a;
}
std::ostream& operator<<(std::ostream& os,B b)
{
return os<<"重载实现:"<<b.myValue<<std::endl;
}
int main()
{
B b1;
std::cout<<b1;
B b2;
B b3=b1+b2;
std::cout<<b3<<std::endl;
std::cin.get();
return 0;
}
- 内联函数的链接性是内部的,这意味着函数定义必须在使用函数的文件中,这个例子中内联定义位于头文件中,因此在使用函数的文件中包含头文件可确保将定义放在正确的地方。这可以将定义放在实现文件中,但必须删除关键字inline这样函数的链接性将是外部的
嵌套类
- 在另外一个类中声明的类被称为嵌套类(nested class)
- 包含类的成员函数可以创建和使用被嵌套的对象。而仅当声明位于公有部分,才能在包含类外面使用嵌套类,而且必须使用作用域解析运算符
- 访问权限:嵌套类、结构和美剧的作用域特征(三者相同)
| 声明位置 | 包含它的类是否可以使用它 | 从包含它的类派生而来的类是否可以使用它 | 在外部是否可以使用 |
|---|---|---|---|
| 私有部分 | 是 | 否 | 否 |
| 保护部分 | 是 | 是 | 否 |
| 公有部分 | 是 | 是 | 是,可以通过类限定符来使用 |
- 访问控制
- 1.类声明的位置决定了类的作用域或可见性
- 2.类可见后,访问控制规则(公有,保护,私有,友元)将决定程序对嵌套类成员的访问权限。
//在下面的程序中,我们创建了一个模板类用于实现Queue容器的部分功能,并且在模板类中潜逃使用了一个Node类。
// queuetp.h -- queue template with a nested class
#ifndef QUEUETP_H_
#define QUEUETP_H_
template <class Item>
class QueueTP
{
private:
enum {Q_SIZE = 10};
// Node is a nested class definition
class Node
{
public:
Item item;
Node * next;
Node(const Item & i) : item(i), next(0) {}
};
Node * front; // pointer to front of Queue
Node * rear; // pointer to rear of Queue
int items; // current number of items in Queue
const int qsize; // maximum number of items in Queue
QueueTP(const QueueTP & q) : qsize(0) {}
QueueTP & operator=(const QueueTP & q) { return *this; }
public:
QueueTP(int qs = Q_SIZE);
~QueueTP();
bool isempty() const
{
return items == 0;
}
bool isfull() const
{
return items == qsize;
}
int queuecount() const
{
return items;
}
bool enqueue(const Item &item); // add item to end
bool dequeue(Item &item); // remove item from front
};
// QueueTP methods
template <class Item>
QueueTP<Item>::QueueTP(int qs) : qsize(qs)
{
front = rear = 0;
items = 0;
}
template <class Item>
QueueTP<Item>::~QueueTP()
{
Node * temp;
while (front != 0) // while queue is not yet empty
{
temp = front;
front = front->next;
delete temp;
}
}
// Add item to queue
template <class Item>
bool QueueTP<Item>::enqueue(const Item & item)
{
if (isfull())
return false;
Node * add = new Node(item); // create node
// on failure, new throws std::bad_alloc exception
items ++;
if (front == 0) // if queue is empty
front = add; // place item at front
else
rear->next = add; // else place at rear
rear = add;
return true;
}
// Place front item into item variable and remove from queue
template <class Item>
bool QueueTP<Item>::dequeue(Item & item)
{
if (front == 0)
return false;
item = front->item; // set item to first item in queue
items --;
Node * temp = front; // save location of first item
front = front->next; // reset front to next item
delete temp; // delete former first item
if (items == 0)
rear = 0;
return true;
}
#endif // QUEUETP_H_
异常
- 意外情况
1.程序可能会试图打开一个不可用的文件 2.请求过多内存 3.遭遇不能容忍的值
1.调用abort()--原型在cstdlib(或stdlib.h)中
- 其典型实现是向标准错误流(即cerr使用的错误流)发送信息abnormalprogram termination(程序异常中止),然后终止程序。它返回一个随实现而异的值,告诉操作系统,处理失败。
- 调用abort()将直接终止程序(调用时,不进行任何清理工作)
- 使用方法:1.判断触发异常的条件 2.满足条件时调用abort()
- 1.exit(): 在调用时,会做大部分清理工作,但是决不会销毁局部对象,因为没有stack unwinding。 会进行的清理工作包括:销毁所有static和global对象,清空所有缓冲区,关闭所有I/O通道。终止前会调用经由atexit()登录的函数,atexit如果抛出异常,则调用terminate()。
- 2.abort():调用时,不进行任何清理工作。直接终止程序。
- 3.retrun:调用时,进行stack unwinding,调用局部对象析构函数,清理局部对象。如果在main中,则之后再交由系统调用exit()。
- return返回,可析构main或函数中的局部变量,尤其要注意局部对象,如不析构可能造成内存泄露。exit返回不析构main或函数中的局部变量,但执行收工函数, 故可析构全局变量(对象)。abort不析构main或函数中的局部变量,也不执行收工函数,故全局和局部对象都不析构。 所以,用return更能避免内存泄露,在C++中用abort和exit都不是好习惯。
2.返回错误代码
一种比异常终止更灵活的方法是,使用函数的返回值来指出问题
3.异常机制
- C++异常是对程序运行过程中发生的异常情况(例如被0除)的一种响应。异常提供了将控制权从程序的一个部分传递到另外一部分的途径
- 异常机制由三个部分组成
1.引发异常
double hmean(double a,double b)
{
if(a==-b)
throw "bad heam() arguments:a=-b not allowed";//throw关键字表示引发异常(实际上是跳转)
return 2.0*a*b/(a+b);
}
2.使用异常处理程序(exception handler)来捕获异常
3.使用try块:try块标识其中特定异常可能会被激活的代码,它后面跟一个或多个的catch块
- 例子:
#include <iostream>
using std::cout;
using std::cin;
using std::cerr;
int fun(int & a, int & b)
{
if(b == 0)
{
throw "hello there have zero sorry\n"; //引发异常
}
return a / b;
}
int main()
{
int a;
int b;
while(true)
{
cin >> a;
cin >> b;
try //try里面是可能引发异常代码块
{
cout << " a / b = "<< fun(a,b) << "\n";
}
catch(const char *str) 接收异常,处理异常
{
cout << str;
cerr <<"除数为0\n"; //cerr不会到输出缓冲中 这样在紧急情况下也可以使用
}
}
system("pause");
return 1;
}
1.try:try块标识符其中特定的异常可能被激活的代码块,他后面跟一个或者多个catch块.
2.catch:类似于函数定义,但并不是函数定义,关键字catch表明这是给一个处理程序,里面的
const cahr* str会接受throw传过来错误信息.
3.throw:抛出异常信息,类似于执行返回语句,因为它将终止函数的执行,但是它不是将控制权交给调用程序,而是导致程序沿着函数调用序列后退,知道找到包含try块的函数.
注意:
1.如果程序在try块外面调用fun(),将无法处理异常。
2.throw出的异常类型可以是字符串,或其他C++类型:通常为类类型
3.执行throw语句类似于执行返回语句,因为它也将终止函数的执行。
4.执行完try中的语句后,如果没有引发任何异常,则程序跳过try块后面的catch块,直接执行后面的第一条语句。
5.如果函数引发了异常,而没有try块或没有匹配处理程序时,将会发生什么情况。在默认情况下,程序最终调用abort()函数!
4.将对象用作异常类型 P622
5.栈解开(栈解退)stack unwind
- C++如何处理函数调用和返回的?
1.程序将**调用函数的地址(返回地址)**放入到栈中。当被调用的函数执行完毕后,程序将使用该地址来确定从哪里开始执行。
2.函数调用将函数参数放入到栈中。在栈中,这些函数参数被视为自动变量。如果被调用的函数创建的自动变量,则这些自动变量也将被添加到栈中
3.如果被调用的函数调用了另外一个函数,则后者的信息将被添加到栈中,依此类推。
- 假设函数出现异常(而不是返回)而终止,则程序也将释放栈中的内存,但不会释放栈中的第一个地址后停止,而是继续释放,直到找到一个位于try块中的返回地址。随后,控制权将转到块尾的异常处理程序,而不是函数调用后的第一条语句,这个过程被称为栈解退。
exception类(头文件exception.h/except.h第一了exception类)C++可以把它用作其他异常类的基类
- 1.stdexcept 异常类(头文件stdexcept定义了其他几个异常类。)
- 该文件定义了
1.logic_error类 2.runtime_error类他们都是以公有的方式从exception派生而来的。- 1.logic_error类错误类型(domain_error、invalid_argument、length_error、out_of_bounds)。每个类都有一个类似于logic_error的构造函数,让您能够提供一个供方法what()返回的字符串。
- 2.runtime_error类错误类型(range_error、overflow_error、underflow_error)。每个类都有一个类似于runtime_error的构造函数,让您能够提供一个供方法what()返回的字符串。
- 2.bad-alloc异常和new(头文件new)
对于使用new导致的内存分配问题,C++的最新处理方式是让new引发bad_alloc异常。头文件new包含bad_alloc类的生命,他是从exception类公有派生而来的。但在以前,当无法分配请求的内存量时,new返回一个空指针。
- 3.异常类和继承
1.可以像标准C++库所做的那样,从一个异常类派生出另外一个。
2.可以在类定义中嵌套异常类声明类组合异常。
3.这种嵌套声明本身可被继承,还可用作基类。
RTTI(运行阶段类型识别)(Run-Time Type Identification)
- 旨在为程序运行阶段确定对象的类型提供一种标准方式
RTTI的工作原理
C++有三个支持RTTI的元素
1.如果可能的话,dynamic_cast运算符将使用一个指向基类的指针来生成指向派生类的指针;否则,该运算符返回0---空指针。
2.typeid运算符返回指出对象类型的值
3.type_info结构存储了有关特定类型的信息。
- 1.dynamic_cast运算符是最常用的RTTI组件
他不能回答“指针指向的是哪类对象”这样的问题,但能回答“是否可以安全地将对象的地址赋给特定类型的指针”这样的问题
用法:Superb* pm = dynamic_cast<Super*>(pg);其中pg指向一个对象
提出这样的问题:指针pg类型是否可被安全地转换为Super* ?如果可以返回对象地址,否则返回一个空指针。
- 2.typeid运算符和type_info类。
typeid运算符使得能够确定两个对象是否为同类型,使用:如果pg指向的是一个Magnification对象,则下述表达式的结果为bool值true,否则为false;
typeid(Magnification)==typeid(*pg)
type_info类的实现岁厂商而异,但包含一个name()成员,该函数返回一个随实现而异的字符串;通常(但并非一定)是类的名称。例如下面的语句想爱你是指针pg指向的对象所属的类定义的字符串:
```C++
cout<<"Now Processing type"<<typeid(*pg).name()<<".\n";
类型转换运算符
4个类型转换运算符:dynamic_cast\const_cast\static_cast\reinterpret_cast
1.dynamic_cast<type_name>(expression)
- 该运算符的用途是,使得能够在类层次结构中进行向上转换(由于is-a关系,这样的类型转换是安全的),不允许其他转换。
2.const_cast<type_name>(expression)
- 该运算符用于执行只有一种用途的类型转换,即改变之const或volatile其语法与dynamic_cast运算符相同。
3.static_cast<type_name>(expression)
4.reinterpret_cast<type_name>(expression)
- 用于天生危险的类型转换。
未来滴王🤩
Rust相关
教程来自于Rust语言圣经
Rust基础知识
Rust基础知识
在线运行测试
fn main(){ println!("Hello, world!") }
安装rust(202302)
macOS
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
显示
Rust is installed now. Great!
则安装成功!
安装C语言编译器
$ xcode-select --install
Windows
先安装Microsoft C++ Build Tools, 勾选安装C++环境. 然后将Rust所需的msvc命令行程序手动添加到环境变量中, 其位于%Visual Studio 安装位置%\VC\Tools\MSVC\%version%\bin\Hostx64\x64下.
在RUSTUP-INIT下载系统对应的版本,
PS C:\Users\Hehongyuan> rustup-init.exe
......
Current installation options:
default host triple: x86_64-pc-windows-msvc
default toolchain: stable (default)
profile: default
modify PATH variable: yes
1) Proceed with installation (default)
2) Customize installation
3) Cancel installation
windows arm
rust other_installation aarch64-pc-windows-msvc
安装目录默认为C:\Program Files(x86)\Rust stable MSVC 1.67\
cargo
上面的命令使用 cargo new 创建一个项目,项目名是 world_hello, 该项目的结构和配置文件都是由 cargo 生成,意味着我们的项目被 cargo 所管理.
下面来看看创建的项目结构:
$ tree
.
├── .git
├── .gitignore
├── Cargo.toml
└── src
└── main.rs
运行项目
有两种方式可以运行项目:
-
cargo run -
手动编译和运行项目
首先来看看第一种方式,在之前创建的 world_hello 目录下运行:
$ cargo run
Compiling world_hello v0.1.0 (/Users/sunfei/development/rust/world_hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/world_hello`
Hello, world!
好了,你已经看到程序的输出:"Hello, world"。
如果你安装的 Rust 的 host triple 是 x86_64-pc-windows-msvc 并确认 Rust 已经正确安装,但在终端上运行上述命令时,出现类似如下的错误摘要 linking with `link.exe` failed: exit code: 1181,请使用 Visual Studio Installer 安装 Windows SDK。
上述代码,cargo run 首先对项目进行编译,然后再运行,因此它实际上等同于运行了两个指令,下面我们手动试一下编译和运行项目:
编译
$ cargo build
Finished dev [unoptimized + debuginfo] target(s) in 0.00s
运行
$ ./target/debug/world_hello
Hello, world!
行云流水,但谈不上一气呵成。在调用的时候,路径 ./target/debug/world_hello 中有一个明晃晃的 debug 字段,没错我们运行的是 debug 模式,在这种模式下,代码的编译速度会非常快,可是福兮祸所依,运行速度就慢了. 原因是,在 debug 模式下,Rust 编译器不会做任何的优化,只为了尽快的编译完成,让开发流程更加顺畅。
想要高性能的代码怎么办? 简单,添加 --release 来编译:
cargo run --releasecargo build --release
试着运行一下我们高性能的 release 程序:
$ ./target/release/world_hello
Hello, world!
cargo check
当项目大了后,cargo run 和 cargo build 不可避免的会变慢,那么有没有更快的方式来验证代码的正确性呢?
cargo check 是我们在代码开发过程中最常用的命令,它的作用很简单:快速的检查一下代码能否编译通过。因此该命令速度会非常快,能节省大量的编译时间。
$ cargo check
Checking world_hello v0.1.0 (/Users/sunfei/development/rust/world_hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.06s
Rust 虽然编译速度还行,但是还是不能与 Go 语言相提并论,因为 Rust 需要做很多复杂的编译优化和语言特性解析,甚至连如何优化编译速度都成了一门学问: 优化编译速度
Cargo.toml 和 Cargo.lock
Cargo.toml 和 Cargo.lock 是 cargo 的核心文件,它的所有活动均基于此二者。
-
Cargo.toml是cargo特有的项目数据描述文件。它存储了项目的所有元配置信息,如果 Rust 开发者希望 Rust 项目能够按照期望的方式进行构建、测试和运行,那么,必须按照合理的方式构建Cargo.toml。 -
Cargo.lock文件是cargo工具根据同一项目的toml文件生成的项目依赖详细清单,因此我们一般不用修改
什么情况下该把
Cargo.lock上传到 git 仓库里?很简单,当你的项目是一个可运行的程序时,就上传Cargo.lock,如果是一个依赖库项目,那么请把它添加到.gitignore中
现在用 VSCode 打开上面创建的"世界,你好"项目,然后进入根目录的 Cargo.toml 文件,可以看到该文件包含不少信息:
package 配置段落
package 中记录了项目的描述信息,典型的如下:
[package]
name = "world_hello"
version = "0.1.0"
edition = "2021"
name 字段定义了项目名称,version 字段定义当前版本,新项目默认是 0.1.0,edition 字段定义了使用的 Rust 大版本
定义项目依赖
使用 cargo 工具的最大优势就在于,能够对该项目的各种依赖项进行方便、统一和灵活的管理。
在 Cargo.toml 中,主要通过各种依赖段落来描述该项目的各种依赖项:
- 基于 Rust 官方仓库
crates.io,通过版本说明来描述 - 基于项目源代码的 git 仓库地址,通过 URL 来描述
- 基于本地项目的绝对路径或者相对路径,通过类 Unix 模式的路径来描述
这三种形式具体写法如下:
[dependencies]
rand = "0.3"
hammer = { version = "0.5.0"}
color = { git = "https://github.com/bjz/color-rs" }
geometry = { path = "crates/geometry" }
基本类型
Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
- 数值类型: 有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数 - 字符串:字符串字面量和字符串切片
&str - 布尔类型:
true和false - 字符类型: 表示单个 Unicode 字符,存储为 4 个字节
- 单元类型: 即
(),其唯一的值也是()
类型推导与标注
与 Python、JavaScript 等动态语言不同,Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 Rust 语言初印象中有过展示。
来看段代码:
#![allow(unused)] fn main() { let guess = "42".parse().expect("Not a number!"); }
先忽略 .parse().expect.. 部分,这段代码的目的是将字符串 "42" 进行解析,而编译器在这里无法推导出我们想要的类型:整数?浮点数?字符串?因此编译器会报错:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ consider giving `guess` a type
因此我们需要提供给编译器更多的信息,例如给 guess 变量一个显式的类型标注:let guess: i32 = ... 或者 "42".parse::<i32>()。
数值类型
Rust 使用一个相对传统的语法来创建整数(1,2,...)和浮点数(1.0,1.1,...)。整数、浮点数的运算和你在其它语言上见过的一致,都是通过常见的运算符来完成。
不仅仅是数值类型,Rust 也允许在复杂类型上定义运算符,例如在自定义类型上定义
+运算符,这种行为被称为运算符重载
整数类型
整数是没有小数部分的数字。之前使用过的 i32 类型,表示有符号的 32 位整数( i 是英文单词 integer 的首字母,与之相反的是 u,代表无符号 unsigned 类型)。下表显示了 Rust 中的内置的整数类型:
| 长度 | 有符号类型 | 无符号类型 |
|---|---|---|
| 8 位 | i8 | u8 |
| 16 位 | i16 | u16 |
| 32 位 | i32 | u32 |
| 64 位 | i64 | u64 |
| 128 位 | i128 | u128 |
| 视架构而定 | isize | usize |
类型定义的形式统一为:有无符号 + 类型大小(位数)。无符号数表示数字只能取正数,而有符号则表示数字既可以取正数又可以取负数。有符号数字以补码形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n - 1 - 1,其中 n 是该定义形式的位长度。因此 i8 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 u8 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
此外,isize 和 usize 类型取决于程序运行的计算机 CPU 类型: 若 CPU 是 32 位的,则这两个类型是 32 位的,同理,若 CPU 是 64 位,那么它们则是 64 位。
整形字面量可以用下表的形式书写:
| 数字字面量 | 示例 |
|---|---|
| 十进制 | 98_222 |
| 十六进制 | 0xff |
| 八进制 | 0o77 |
| 二进制 | 0b1111_0000 |
字节 (仅限于 u8) | b'A' |
这么多类型,有没有一个简单的使用准则?答案是肯定的, Rust 整型默认使用 i32. isize 和 usize 的主要应用场景是用作集合的索引。
整型溢出
假设有一个 u8 ,它可以存放从 0 到 255 的值。那么当你将其修改为范围之外的值,比如 256,则会发生整型溢出。关于这一行为 Rust 有一些有趣的规则:当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic(崩溃,Rust 使用这个术语来表明程序因错误而退出)。
在当使用 --release 参数进行 release 模式构建时,Rust 不检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping)的规则处理。简而言之,大于该类型最大值的数值会被补码转换成该类型能够支持的对应数字的最小值。比如在 u8 的情况下,256 变成 0,257 变成 1,依此类推。程序不会 panic,但是该变量的值可能不是你期望的值。依赖这种默认行为的代码都应该被认为是错误的代码。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
- 使用
wrapping_*方法在所有模式下都按照补码循环溢出规则处理,例如wrapping_add - 如果使用
checked_*方法时发生溢出,则返回None值 - 使用
overflowing_*方法返回该值和一个指示是否存在溢出的布尔值 - 使用
saturating_*方法使值达到最小值或最大值
下面是一个演示wrapping_*方法的示例:
fn main() { let a : u8 = 255; let b = a.wrapping_add(20); println!("{}", b); // 19 }
浮点类型
浮点类型数字 是带有小数点的数字,在 Rust 中浮点类型数字也有两种基本类型: f32 和 f64,分别为 32 位和 64 位大小。默认浮点类型是 f64,在现代的 CPU 中它的速度与 f32 几乎相同,但精度更高。
下面是一个演示浮点数的示例:
fn main() { let x = 2.0; // f64 let y: f32 = 3.0; // f32 }
浮点数根据 IEEE-754 标准实现。f32 类型是单精度浮点型,f64 为双精度。
浮点数陷阱
浮点数由于底层格式的特殊性,导致了如果在使用浮点数时不够谨慎,就可能造成危险,有两个原因:
-
浮点数往往是你想要数字的近似表达 浮点数类型是基于二进制实现的,但是我们想要计算的数字往往是基于十进制,例如
0.1在二进制上并不存在精确的表达形式,但是在十进制上就存在。这种不匹配性导致一定的歧义性,更多的,虽然浮点数能代表真实的数值,但是由于底层格式问题,它往往受限于定长的浮点数精度,如果你想要表达完全精准的真实数字,只有使用无限精度的浮点数才行 -
浮点数在某些特性上是反直觉的 例如大家都会觉得浮点数可以进行比较,对吧?是的,它们确实可以使用
>,>=等进行比较,但是在某些场景下,这种直觉上的比较特性反而会害了你。因为f32,f64上的比较运算实现的是std::cmp::PartialEq特征(类似其他语言的接口),但是并没有实现std::cmp::Eq特征,但是后者在其它数值类型上都有定义,说了这么多,可能大家还是云里雾里,用一个例子来举例:
Rust 的 HashMap 数据结构,是一个 KV 类型的 Hash Map 实现,它对于 K 没有特定类型的限制,但是要求能用作 K 的类型必须实现了 std::cmp::Eq 特征,因此这意味着你无法使用浮点数作为 HashMap 的 Key,来存储键值对,但是作为对比,Rust 的整数类型、字符串类型、布尔类型都实现了该特征,因此可以作为 HashMap 的 Key。
为了避免上面说的两个陷阱,你需要遵守以下准则:
- 避免在浮点数上测试相等性
- 当结果在数学上可能存在未定义时,需要格外的小心
来看个小例子:
fn main() { // 断言0.1 + 0.2与0.3相等 assert!(0.1 + 0.2 == 0.3); }
你可能以为,这段代码没啥问题吧,实际上它会 panic(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
那如果非要进行比较呢?可以考虑用这种方式 (0.1_f64 + 0.2 - 0.3).abs() < 0.00001 ,具体小于多少,取决于你对精度的需求。
讲到这里,相信大家基本已经明白了,为什么操作浮点数时要格外的小心,但是还不够,下面再来一段代码,直接震撼你的灵魂:
fn main() { let abc: (f32, f32, f32) = (0.1, 0.2, 0.3); let xyz: (f64, f64, f64) = (0.1, 0.2, 0.3); println!("abc (f32)"); println!(" 0.1 + 0.2: {:x}", (abc.0 + abc.1).to_bits()); println!(" 0.3: {:x}", (abc.2).to_bits()); println!(); println!("xyz (f64)"); println!(" 0.1 + 0.2: {:x}", (xyz.0 + xyz.1).to_bits()); println!(" 0.3: {:x}", (xyz.2).to_bits()); println!(); assert!(abc.0 + abc.1 == abc.2); assert!(xyz.0 + xyz.1 == xyz.2); }
运行该程序,输出如下:
abc (f32)
0.1 + 0.2: 3e99999a
0.3: 3e99999a
xyz (f64)
0.1 + 0.2: 3fd3333333333334
0.3: 3fd3333333333333
thread 'main' panicked at 'assertion failed: xyz.0 + xyz.1 == xyz.2',
➥ch2-add-floats.rs.rs:14:5
note: run with `RUST_BACKTRACE=1` environment variable to display
➥a backtrace
仔细看,对 f32 类型做加法时,0.1 + 0.2 的结果是 3e99999a,0.3 也是 3e99999a,因此 f32 下的 0.1 + 0.2 == 0.3 通过测试,但是到了 f64 类型时,结果就不一样了,因为 f64 精度高很多,因此在小数点非常后面发生了一点微小的变化,0.1 + 0.2 以 4 结尾,但是 0.3 以3结尾,这个细微区别导致 f64 下的测试失败了,并且抛出了异常。
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number)来处理这些情况。
所有跟 NaN 交互的操作,都会返回一个 NaN,而且 NaN 不能用来比较,下面的代码会崩溃:
fn main() { let x = (-42.0_f32).sqrt(); assert_eq!(x, x); }
出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN :
fn main() { let x = (-42.0_f32).sqrt(); if x.is_nan() { println!("未定义的数学行为") } }
数字运算
Rust 支持所有数字类型的基本数学运算:加法、减法、乘法、除法和取模运算。下面代码各使用一条 let 语句来说明相应运算的用法:
fn main() { // 加法 let sum = 5 + 10; // 减法 let difference = 95.5 - 4.3; // 乘法 let product = 4 * 30; // 除法 let quotient = 56.7 / 32.2; // 求余 let remainder = 43 % 5; }
这些语句中的每个表达式都使用了数学运算符,并且计算结果为一个值,然后绑定到一个变量上。
再来看一个综合性的示例:
fn main() { // 编译器会进行自动推导,给予twenty i32的类型 let twenty = 20; // 类型标注 let twenty_one: i32 = 21; // 通过类型后缀的方式进行类型标注:22是i32类型 let twenty_two = 22i32; // 只有同样类型,才能运算 let addition = twenty + twenty_one + twenty_two; println!("{} + {} + {} = {}", twenty, twenty_one, twenty_two, addition); // 对于较长的数字,可以用_进行分割,提升可读性 let one_million: i64 = 1_000_000; println!("{}", one_million.pow(2)); // 定义一个f32数组,其中42.0会自动被推导为f32类型 let forty_twos = [ 42.0, 42f32, 42.0_f32, ]; // 打印数组中第一个值,并控制小数位为2位 println!("{:.2}", forty_twos[0]); }
位运算
Rust的运算基本上和其他语言一样
| 运算符 | 说明 |
|---|---|
| & 位与 | 相同位置均为1时则为1,否则为0 |
| | 位或 | 相同位置只要有1时则为1,否则为0 |
| ^ 异或 | 相同位置不相同则为1,相同则为0 |
| ! 位非 | 把位中的0和1相互取反,即0置为1,1置为0 |
| << 左移 | 所有位向左移动指定位数,右位补0 |
| >> 右移 | 所有位向右移动指定位数,带符号移动(正数补0,负数补1) |
fn main() { // 二进制为00000010 let a:i32 = 2; // 二进制为00000011 let b:i32 = 3; println!("(a & b) value is {}", a & b); println!("(a | b) value is {}", a | b); println!("(a ^ b) value is {}", a ^ b); println!("(!b) value is {} ", !b); println!("(a << b) value is {}", a << b); println!("(a >> b) value is {}", a >> b); let mut a = a; // 注意这些计算符除了!之外都可以加上=进行赋值 (因为!=要用来判断不等于) a <<= b; println!("(a << b) value is {}", a); }
序列(Range)
Rust 提供了一个非常简洁的方式,用来生成连续的数值,例如 1..5,生成从 1 到 4 的连续数字,不包含 5 ;1..=5,生成从 1 到 5 的连续数字,包含 5,它的用途很简单,常常用于循环中:
#![allow(unused)] fn main() { for i in 1..=5 { println!("{}",i); } }
最终程序输出:
1
2
3
4
5
序列只允许用于数字或字符类型,原因是:它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。如下是一个使用字符类型序列的例子:
#![allow(unused)] fn main() { for i in 'a'..='z' { println!("{}",i); } }
有理数和复数
Rust 的标准库相比其它语言,准入门槛较高,因此有理数和复数并未包含在标准库中:
- 有理数和复数
- 任意大小的整数和任意精度的浮点数
- 固定精度的十进制小数,常用于货币相关的场景
好在社区已经开发出高质量的 Rust 数值库:num。
按照以下步骤来引入 num 库:
- 创建新工程
cargo new complex-num && cd complex-num - 在
Cargo.toml中的[dependencies]下添加一行num = "0.4.0" - 将
src/main.rs文件中的main函数替换为下面的代码 - 运行
cargo run
use num::complex::Complex; fn main() { let a = Complex { re: 2.1, im: -1.2 }; let b = Complex::new(11.1, 22.2); let result = a + b; println!("{} + {}i", result.re, result.im) }
总结
之前提到了过 Rust 的数值类型和运算跟其他语言较为相似,但是实际上,除了语法上的不同之外,还是存在一些差异点:
- Rust 拥有相当多的数值类型. 因此你需要熟悉这些类型所占用的字节数,这样就知道该类型允许的大小范围以及你选择的类型是否能表达负数
- 类型转换必须是显式的. Rust 永远也不会偷偷把你的 16bit 整数转换成 32bit 整数
- Rust 的数值上可以使用方法. 例如你可以用以下方法来将
13.14取整:13.14_f32.round(),在这里我们使用了类型后缀,因为编译器需要知道13.14的具体类型
字符、布尔、单元类型
这三个类型所处的地位比较尴尬,你说它们重要吧,确实出现的身影不是很多,说它们不重要吧,有时候也是不可或缺,而且这三个类型都有一个共同点:简单,因此我们统一放在一起讲。
字符类型(char)
字符,对于没有其它编程经验的新手来说可能不太好理解(没有编程经验敢来学 Rust 的绝对是好汉),但是你可以把它理解为英文中的字母,中文中的汉字。
下面的代码展示了几个颇具异域风情的字符:
fn main() { let c = 'z'; let z = 'ℤ'; let g = '国'; let heart_eyed_cat = '😻'; }
如果大家是从有年代感的编程语言过来,可能会大喊一声:这 XX 叫字符?是的,在 Rust 语言中这些都是字符,Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文、日文、韩文、emoji 表情符号等等,都是合法的字符类型。Unicode 值的范围从 U+0000 ~ U+D7FF 和 U+E000 ~ U+10FFFF。不过“字符”并不是 Unicode 中的一个概念,所以人在直觉上对“字符”的理解和 Rust 的字符概念并不一致。
由于 Unicode 都是 4 个字节编码,因此字符类型也是占用 4 个字节:
fn main() { let x = '中'; println!("字符'中'占用了{}字节的内存大小",std::mem::size_of_val(&x)); }
输出如下:
$ cargo run
Compiling ...
字符'中'占用了4字节的内存大小
注意,我们还没开始讲字符串,但是这里提前说一下,和一些语言不同,Rust 的字符只能用
''来表示,""是留给字符串的。
布尔(bool)
Rust 中的布尔类型有两个可能的值:true 和 false,布尔值占用内存的大小为 1 个字节:
fn main() { let t = true; let f: bool = false; // 使用类型标注,显式指定f的类型 if f { println!("这是段毫无意义的代码"); } }
使用布尔类型的场景主要在于流程控制,例如上述代码的中的 if 就是其中之一。
单元类型
单元类型就是 () ,对,你没看错,就是 () ,唯一的值也是 () ,一些读者读到这里可能就不愿意了,你也太敷衍了吧,管这叫类型?
只能说,再不起眼的东西,都有其用途,在目前为止的学习过程中,大家已经看到过很多次 fn main() 函数的使用吧?那么这个函数返回什么呢?
没错, main 函数就返回这个单元类型 (),你不能说 main 函数无返回值,因为没有返回值的函数在 Rust 中是有单独的定义的:发散函数( diverge function ),顾名思义,无法收敛的函数。
例如常见的 println!() 的返回值也是单元类型 ()。
再比如,你可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key。 这种用法和 Go 语言的 struct{} 类似,可以作为一个值用来占位,但是完全不占用任何内存。
语句和表达式
Rust 的函数体是由一系列语句组成,最后由一个表达式来返回值,例如:
#![allow(unused)] fn main() { fn add_with_extra(x: i32, y: i32) -> i32 { let x = x + 1; // 语句 let y = y + 5; // 语句 x + y // 表达式 } }
语句会执行一些操作但是不会返回一个值,而表达式会在求值后返回一个值,因此在上述函数体的三行代码中,前两行是语句,最后一行是表达式。
对于 Rust 语言而言,这种基于语句(statement)和表达式(expression)的方式是非常重要的,你需要能明确的区分这两个概念, 但是对于很多其它语言而言,这两个往往无需区分。基于表达式是函数式语言的重要特征,表达式总要返回值。
其实,在此之前,我们已经多次使用过语句和表达式。
语句
#![allow(unused)] fn main() { let a = 8; let b: Vec<f64> = Vec::new(); let (a, c) = ("hi", false); }
以上都是语句,它们完成了一个具体的操作,但是并没有返回值,因此是语句。
由于 let 是语句,因此不能将 let 语句赋值给其它值,如下形式是错误的:
#![allow(unused)] fn main() { let b = (let a = 8); }
错误如下:
error: expected expression, found statement (`let`) // 期望表达式,却发现`let`语句
--> src/main.rs:2:13
|
2 | let b = let a = 8;
| ^^^^^^^^^
|
= note: variable declaration using `let` is a statement `let`是一条语句
error[E0658]: `let` expressions in this position are experimental
// 下面的 `let` 用法目前是试验性的,在稳定版中尚不能使用
--> src/main.rs:2:13
|
2 | let b = let a = 8;
| ^^^^^^^^^
|
= note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information
= help: you can write `matches!(<expr>, <pattern>)` instead of `let <pattern> = <expr>`
以上的错误告诉我们 let 是语句,不是表达式,因此它不返回值,也就不能给其它变量赋值。但是该错误还透漏了一个重要的信息, let 作为表达式已经是试验功能了,也许不久的将来,我们在 stable rust 下可以这样使用。
表达式
表达式会进行求值,然后返回一个值。例如 5 + 6,在求值后,返回值 11,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中,6 就是一个表达式,它在求值后返回一个值 6(有些反直觉,但是确实是表达式)。
调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式:
fn main() { let y = { let x = 3; x + 1 }; println!("The value of y is: {}", y); }
上面使用一个语句块表达式将值赋给 y 变量,语句块长这样:
#![allow(unused)] fn main() { { let x = 3; x + 1 } }
该语句块是表达式的原因是:它的最后一行是表达式,返回了 x + 1 的值,注意 x + 1 不能以分号结尾,否则就会从表达式变成语句, 表达式不能包含分号。这一点非常重要,一旦你在表达式后加上分号,它就会变成一条语句,再也不会返回一个值,请牢记!
最后,表达式如果不返回任何值,会隐式地返回一个 () 。
fn main() { assert_eq!(ret_unit_type(), ()) } fn ret_unit_type() { let x = 1; // if 语句块也是一个表达式,因此可以用于赋值,也可以直接返回 // 类似三元运算符,在Rust里我们可以这样写 let y = if x % 2 == 1 { "odd" } else { "even" }; // 或者写成一行 let z = if x % 2 == 1 { "odd" } else { "even" }; }
函数
Rust 的函数我们在之前已经见过不少,跟其他语言几乎没有什么区别。因此本章的学习之路将轻松和愉快,骚年们,请珍惜这种愉快,下一章你将体验到不一样的 Rust。
在函数界,有一个函数只闻其名不闻其声,可以止小孩啼!在程序界只有 hello,world! 可以与之媲美,它就是 add 函数:
#![allow(unused)] fn main() { fn add(i: i32, j: i32) -> i32 { i + j } }
该函数如此简单,但是又是如此的五脏俱全,声明函数的关键字 fn ,函数名 add(),参数 i 和 j,参数类型和返回值类型都是 i32,总之一切那么的普通,但是又那么的自信,直到你看到了下面这张图:
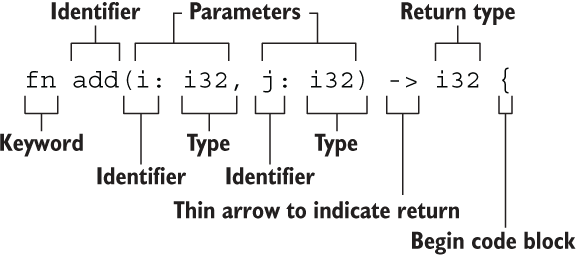
当你看懂了这张图,其实就等于差不多完成了函数章节的学习,但是这么短的章节显然对不起读者老爷们的厚爱,所以我们来展开下。
函数要点
- 函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() -> {} - 函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
- 每个函数参数都需要标注类型
函数参数
Rust 是强类型语言,因此需要你为每一个函数参数都标识出它的具体类型,例如:
fn main() { another_function(5, 6.1); } fn another_function(x: i32, y: f32) { println!("The value of x is: {}", x); println!("The value of y is: {}", y); }
another_function 函数有两个参数,其中 x 是 i32 类型,y 是 f32 类型,然后在该函数内部,打印出这两个值。这里去掉 x 或者 y 的任何一个的类型,都会报错:
fn main() { another_function(5, 6.1); } fn another_function(x: i32, y) { println!("The value of x is: {}", x); println!("The value of y is: {}", y); }
错误如下:
error: expected one of `:`, `@`, or `|`, found `)`
--> src/main.rs:5:30
|
5 | fn another_function(x: i32, y) {
| ^ expected one of `:`, `@`, or `|` // 期待以下符号之一 `:`, `@`, or `|`
|
= note: anonymous parameters are removed in the 2018 edition (see RFC 1685)
// 匿名参数在 Rust 2018 edition 中就已经移除
help: if this is a parameter name, give it a type // 如果y是一个参数名,请给予它一个类型
|
5 | fn another_function(x: i32, y: TypeName) {
| ~~~~~~~~~~~
help: if this is a type, explicitly ignore the parameter name // 如果y是一个类型,请使用_忽略参数名
|
5 | fn another_function(x: i32, _: y) {
| ~~~~
函数返回
在上一章节语句和表达式中,我们有提到,在 Rust 中函数就是表达式,因此我们可以把函数的返回值直接赋给调用者。
函数的返回值就是函数体最后一条表达式的返回值,当然我们也可以使用 return 提前返回,下面的函数使用最后一条表达式来返回一个值:
fn plus_five(x:i32) -> i32 { x + 5 } fn main() { let x = plus_five(5); println!("The value of x is: {}", x); }
x + 5 是一条表达式,求值后,返回一个值,因为它是函数的最后一行,因此该表达式的值也是函数的返回值。
再来看两个重点:
let x = plus_five(5),说明我们用一个函数的返回值来初始化x变量,因此侧面说明了在 Rust 中函数也是表达式,这种写法等同于let x = 5 + 5;x + 5没有分号,因为它是一条表达式,这个在上一节中我们也有详细介绍
再来看一段代码,同时使用 return 和表达式作为返回值:
fn plus_or_minus(x:i32) -> i32 { if x > 5 { return x - 5 } x + 5 } fn main() { let x = plus_or_minus(5); println!("The value of x is: {}", x); }
plus_or_minus 函数根据传入 x 的大小来决定是做加法还是减法,若 x > 5 则通过 return 提前返回 x - 5 的值,否则返回 x + 5 的值。
Rust 中的特殊返回类型
无返回值()
对于 Rust 新手来说,有些返回类型很难理解,而且如果你想通过百度或者谷歌去搜索,都不好查询,因为这些符号太常见了,根本难以精确搜索到。
例如单元类型 (),是一个零长度的元组。它没啥作用,但是可以用来表达一个函数没有返回值:
- 函数没有返回值,那么返回一个
() - 通过
;结尾的表达式返回一个()
例如下面的 report 函数会隐式返回一个 ():
#![allow(unused)] fn main() { use std::fmt::Debug; fn report<T: Debug>(item: T) { println!("{:?}", item); } }
与上面的函数返回值相同,但是下面的函数显式的返回了 ():
#![allow(unused)] fn main() { fn clear(text: &mut String) -> () { *text = String::from(""); } }
在实际编程中,你会经常在错误提示中看到该 () 的身影出没,假如你的函数需要返回一个 u32 值,但是如果你不幸的以 表达式; 的方式作为函数的最后一行代码,就会报错:
#![allow(unused)] fn main() { fn add(x:u32,y:u32) -> u32 { x + y; } }
错误如下:
error[E0308]: mismatched types // 类型不匹配
--> src/main.rs:6:24
|
6 | fn add(x:u32,y:u32) -> u32 {
| --- ^^^ expected `u32`, found `()` // 期望返回u32,却返回()
| |
| implicitly returns `()` as its body has no tail or `return` expression
7 | x + y;
| - help: consider removing this semicolon
还记得我们在语句与表达式中讲过的吗?只有表达式能返回值,而 ; 结尾的是语句,在 Rust 中,一定要严格区分表达式和语句的区别,这个在其它语言中往往是被忽视的点。
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverge function ),特别的,这种语法往往用做会导致程序崩溃的函数:
#![allow(unused)] fn main() { fn dead_end() -> ! { panic!("你已经到了穷途末路,崩溃吧!"); } }
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
#![allow(unused)] fn main() { fn forever() -> ! { loop { //... }; } }
变量绑定与解构
变量绑定
在其它语言中,我们用 var a = "hello world" 的方式给 a 赋值,也就是把等式右边的 "hello world" 字符串赋值给变量 a ,而在 Rust 中,我们这样写: let a = "hello world" ,同时给这个过程起了另一个名字:变量绑定。
为何不用赋值而用绑定呢(其实你也可以称之为赋值,但是绑定的含义更清晰准确)?这里就涉及 Rust 最核心的原则——所有权,简单来讲,任何内存对象都是有主人的,而且一般情况下完全属于它的主人,绑定就是把这个对象绑定给一个变量.
变量可变性
Rust 的变量在默认情况下是不可变的。前文提到,这是 Rust 团队为我们精心设计的语言特性之一,让我们编写的代码更安全,性能也更好。当然你可以通过 mut 关键字让变量变为可变的,让设计更灵活。
如果变量 a 不可变,那么一旦为它绑定值,就不能再修改 a:
fn main() { let x = 5; println!("The value of x is: {}", x); x = 6; println!("The value of x is: {}", x); }
在 Rust 中,可变性很简单,只要在变量名前加一个 mut 即可, 而且这种显式的声明方式还会给后来人传达这样的信息:嗯,这个变量在后面代码部分会发生改变。
fn main() { let mut x = 5; println!("The value of x is: {}", x); x = 6; println!("The value of x is: {}", x); }
如果创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告,因为这可能会是个 BUG。但是有时创建一个不会被使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头:
fn main() { let _x = 5; let y = 10; }
变量解构
let 表达式不仅仅用于变量的绑定,还能进行复杂变量的解构:从一个相对复杂的变量中,匹配出该变量的一部分内容:
fn main() { let (a, mut b): (bool,bool) = (true, false); // a = true,不可变; b = false,可变 println!("a = {:?}, b = {:?}", a, b); b = true; assert_eq!(a, b); }
解构式赋值
在Rust 1.59版本后,我们可以在赋值语句的左式中使用元组、切片和结构体模式了。
struct Struct { e: i32 } fn main() { let (a, b, c, d, e); (a, b) = (1, 2); // _ 代表匹配一个值,但是我们不关心具体的值是什么,因此没有使用一个变量名而是使用了 _ [c, .., d, _] = [1, 2, 3, 4, 5]; Struct { e, .. } = Struct { e: 5 }; assert_eq!([1, 2, 1, 4, 5], [a, b, c, d, e]); }
这种使用方式跟之前的 let 保持了一致性,但是 let 会重新绑定,而这里仅仅是对之前绑定的变量进行再赋值。
变量和常量之间的差异
变量的值不能更改可能让你想起其他另一个很多语言都有的编程概念:常量(constant)。与不可变变量一样,常量也是绑定到一个常量名且不允许更改的值,但是常量和变量之间存在一些差异:
- 常量不允许使用
mut。常量不仅仅默认不可变,而且自始至终不可变,因为常量在编译完成后,已经确定它的值。 - 常量使用
const关键字而不是let关键字来声明,并且值的类型必须标注。
常量可以在任意作用域内声明,包括全局作用域,在声明的作用域内,常量在程序运行的整个过程中都有效。
变量遮蔽(shadowing)
Rust 允许声明相同的变量名,在后面声明的变量会遮蔽掉前面声明的,如下所示:
fn main() { let x = 5; // 在main函数的作用域内对之前的x进行遮蔽 let x = x + 1; { // 在当前的花括号作用域内,对之前的x进行遮蔽 let x = x * 2; println!("The value of x in the inner scope is: {}", x); } println!("The value of x is: {}", x); }
这个程序首先将数值 5 绑定到 x,然后通过重复使用 let x = 来遮蔽之前的 x,并取原来的值加上 1,所以 x 的值变成了 6。第三个 let 语句同样遮蔽前面的 x,取之前的值并乘上 2,得到的 x 最终值为 12。
这和 mut 变量的使用是不同的,第二个 let 生成了完全不同的新变量,两个变量只是恰好拥有同样的名称,涉及一次内存对象的再分配
,而 mut 声明的变量,可以修改同一个内存地址上的值,并不会发生内存对象的再分配,性能要更好.
变量遮蔽的用处在于,如果你在某个作用域内无需再使用之前的变量(在被遮蔽后,无法再访问到之前的同名变量),就可以重复的使用变量名字,而不用绞尽脑汁去想更多的名字
所有权,引用与借用
所有权
所有的程序都必须和计算机内存打交道,如何从内存中申请空间来存放程序的运行内容,如何在不需要的时候释放这些空间,成了重中之重,在计算机语言不断演变过程中,出现了三种流派:
- 垃圾回收机制(GC),在程序运行时不断寻找不再使用的内存,典型代表:Java、Go
- 手动管理内存的分配和释放, 在程序中,通过函数调用的方式来申请和释放内存,典型代表:C++
- 通过所有权来管理内存,编译器在编译时会根据一系列规则进行检查
其中 Rust 选择了第三种,最妙的是,这种检查只发生在编译期,因此对于程序运行期,不会有任何性能上的损失。
一段不安全的代码
先来看看一段来自 C 语言的糟糕代码:
int* foo() {
int a; // 变量a的作用域开始
a = 100;
char *c = "xyz"; // 变量c的作用域开始
return &a;
} // 变量a和c的作用域结束
这段代码虽然可以编译通过,但是其实非常糟糕,变量 a 和 c 都是局部变量,函数结束后将局部变量 a 的地址返回,但局部变量 a 存在栈中,在离开作用域后,a 所申请的栈上内存都会被系统回收,从而造成了 悬空指针(Dangling Pointer) 的问题。这是一个非常典型的内存安全问题,虽然编译可以通过,但是运行的时候会出现错误, 很多编程语言都存在。再来看变量 c,c 的值是常量字符串,存储于常量区,可能这个函数我们只调用了一次,也可能我们不再会使用这个字符串,但 "xyz" 只有当整个程序结束后系统才能回收这片内存。
栈(Stack)与堆(Heap)
栈和堆的核心目标就是为程序在运行时提供可供使用的内存空间。
栈
栈按照顺序存储值并以相反顺序取出值,这也被称作后进先出。增加数据叫做进栈,移出数据则叫做出栈。
因为上述的实现方式,栈中的所有数据都必须占用已知且固定大小的内存空间,假设数据大小是未知的,那么在取出数据时,你将无法取到你想要的数据。
堆
与栈不同,对于大小未知或者可能变化的数据,我们需要将它存储在堆上。
当向堆上放入数据时,需要请求一定大小的内存空间。操作系统在堆的某处找到一块足够大的空位,把它标记为已使用,并返回一个表示该位置地址的指针, 该过程被称为在堆上分配内存,有时简称为 “分配”(allocating)。
接着,该指针会被推入栈中,因为指针的大小是已知且固定的,在后续使用过程中,你将通过栈中的指针,来获取数据在堆上的实际内存位置,进而访问该数据。
性能区别
写入方面:入栈比在堆上分配内存要快,因为入栈时操作系统无需分配新的空间,只需要将新数据放入栈顶即可。相比之下,在堆上分配内存则需要更多的工作,这是因为操作系统必须首先找到一块足够存放数据的内存空间,接着做一些记录为下一次分配做准备。
读取方面:得益于 CPU 高速缓存,使得处理器可以减少对内存的访问,高速缓存和内存的访问速度差异在 10 倍以上!栈数据往往可以直接存储在 CPU 高速缓存中,而堆数据只能存储在内存中。访问堆上的数据比访问栈上的数据慢,因为必须先访问栈再通过栈上的指针来访问内存。
因此,处理器处理和分配在栈上的数据会比在堆上的数据更加高效。
所有权与堆栈
当你的代码调用一个函数时,传递给函数的参数(包括可能指向堆上数据的指针和函数的局部变量)依次被压入栈中,当函数调用结束时,这些值将被从栈中按照相反的顺序依次移除。
因为堆上的数据缺乏组织,因此跟踪这些数据何时分配和释放是非常重要的,否则堆上的数据将产生内存泄漏 —— 这些数据将永远无法被回收。这就是 Rust 所有权系统为我们提供的强大保障。
对于其他很多编程语言,你确实无需理解堆栈的原理,但是在 Rust 中,明白堆栈的原理,对于我们理解所有权的工作原理会有很大的帮助。
所有权原则
理解了堆栈,接下来看一下关于所有权的规则,首先请谨记以下规则:
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
变量作用域
作用域是一个变量在程序中有效的范围, 假如有这样一个变量:
#![allow(unused)] fn main() { let s = "hello"; }
变量 s 绑定到了一个字符串字面值,该字符串字面值是硬编码到程序代码中的。s 变量从声明的点开始直到当前作用域的结束都是有效的:
#![allow(unused)] fn main() { { // s 在这里无效,它尚未声明 let s = "hello"; // 从此处起,s 是有效的 // 使用 s } // 此作用域已结束,s不再有效 }
简而言之,s 从创建伊始就开始有效,然后有效期持续到它离开作用域为止,可以看出,就作用域来说,Rust 语言跟其他编程语言没有区别。
简单介绍 String 类型
我们已经见过字符串字面值 let s ="hello",s 是被硬编码进程序里的字符串值(类型为 &str )。字符串字面值是很方便的,但是它并不适用于所有场景。原因有二:
- 字符串字面值是不可变的,因为被硬编码到程序代码中
- 并非所有字符串的值都能在编写代码时得知
例如,字符串是需要程序运行时,通过用户动态输入然后存储在内存中的,这种情况,字符串字面值就完全无用武之地。 为此,Rust 为我们提供动态字符串类型: String, 该类型被分配到堆上,因此可以动态伸缩,也就能存储在编译时大小未知的文本。
可以使用下面的方法基于字符串字面量来创建 String 类型:
#![allow(unused)] fn main() { let s = String::from("hello"); }
:: 是一种调用操作符,这里表示调用 String 中的 from 方法,因为 String 存储在堆上是动态的,你可以这样修改它:
#![allow(unused)] fn main() { let mut s = String::from("hello"); s.push_str(", world!"); // push_str() 在字符串后追加字面值 println!("{}", s); // 将打印 `hello, world!` }
变量绑定背后的数据交互
转移所有权
先来看一段代码:
#![allow(unused)] fn main() { let x = 5; let y = x; }
代码背后的逻辑很简单, 将 5 绑定到变量 x;接着拷贝 x 的值赋给 y,最终 x 和 y 都等于 5,因为整数是 Rust 基本数据类型,是固定大小的简单值,因此这两个值都是通过自动拷贝的方式来赋值的,都被存在栈中,完全无需在堆上分配内存。
这种拷贝不消耗性能吗?实际上,这种栈上的数据足够简单,而且拷贝非常非常快,只需要复制一个整数大小(i32,4 个字节)的内存即可,因此在这种情况下,拷贝的速度远比在堆上创建内存来得快的多。实际上,上一章我们讲到的 Rust 基本类型都是通过自动拷贝的方式来赋值的,就像上面代码一样。
然后再来看一段代码:
#![allow(unused)] fn main() { let s1 = String::from("hello"); let s2 = s1; }
对于基本类型(存储在栈上),Rust 会自动拷贝,但是 String 不是基本类型,而且是存储在堆上的,因此不能自动拷贝。
实际上, String 类型是一个复杂类型,由存储在栈中的堆指针、字符串长度、字符串容量共同组成,其中堆指针是最重要的,它指向了真实存储字符串内容的堆内存,至于长度和容量,如果你有 Go 语言的经验,这里就很好理解:容量是堆内存分配空间的大小,长度是目前已经使用的大小。
假定一个值可以拥有两个所有者,会发生什么呢?当变量离开作用域后,Rust 会自动调用 drop 函数并清理变量的堆内存。不过由于两个 String 变量指向了同一位置。这就有了一个问题:当 s1 和 s2 离开作用域,它们都会尝试释放相同的内存。这是一个叫做 二次释放(double free) 的错误,也是之前提到过的内存安全性 BUG 之一。两次释放(相同)内存会导致内存污染,它可能会导致潜在的安全漏洞。
因此,Rust 实际这样解决问题:当 s1 赋予 s2 后,Rust 认为 s1 不再有效,因此也无需在 s1 离开作用域后 drop 任何东西,这就是把所有权从 s1 转移给了 s2,s1 在被赋予 s2 后就马上失效了。
再来看看,在所有权转移后再来使用旧的所有者,会发生什么:
#![allow(unused)] fn main() { let s1 = String::from("hello"); let s2 = s1; println!("{}, world!", s1); }
回头看之前的规则
- Rust 中每一个值都被一个变量所拥有,该变量被称为值的所有者
- 一个值同时只能被一个变量所拥有,或者说一个值只能拥有一个所有者
- 当所有者(变量)离开作用域范围时,这个值将被丢弃(drop)
如果你在其他语言中听说过术语 浅拷贝(shallow copy) 和 深拷贝(deep copy),那么拷贝指针、长度和容量而不拷贝数据听起来就像浅拷贝,但是又因为 Rust 同时使第一个变量 s1 无效了,因此这个操作被称为 移动(move),而不是浅拷贝。上面的例子可以解读为 s1 被移动到了 s2 中。那么具体发生了什么,用一张图简单说明:
这样就解决了我们之前的问题,s1 不再指向任何数据,只有 s2 是有效的,当 s2 离开作用域,它就会释放内存。 相信此刻,你应该明白了,为什么 Rust 称呼 let a = b 为变量绑定了吧?
再来看一段代码:
fn main() { let x: &str = "hello, world"; let y = x; println!("{},{}",x,y); }
这段代码,大家觉得会否报错?如果参考之前的 String 所有权转移的例子,那这段代码也应该报错才是,但是实际上呢?
这段代码和之前的 String 有一个本质上的区别:在 String 的例子中 s1 持有了通过String::from("hello") 创建的值的所有权,而这个例子中,x 只是引用了存储在二进制中的字符串 "hello, world",并没有持有所有权。
因此 let y = x 中,仅仅是对该引用进行了拷贝,此时 y 和 x 都引用了同一个字符串。学习了 "引用与借用" 后,自然而言就会理解。
克隆(深拷贝)
首先,Rust 永远也不会自动创建数据的 “深拷贝”。因此,任何自动的复制都不是深拷贝,可以被认为对运行时性能影响较小。
如果我们确实需要深度复制 String 中堆上的数据,而不仅仅是栈上的数据,可以使用一个叫做 clone 的方法。
#![allow(unused)] fn main() { let s1 = String::from("hello"); let s2 = s1.clone(); println!("s1 = {}, s2 = {}", s1, s2); }
这段代码能够正常运行,因此说明 s2 确实完整的复制了 s1 的数据。
如果代码性能无关紧要,例如初始化程序时,或者在某段时间只会执行一次时,你可以使用 clone 来简化编程。但是对于执行较为频繁的代码(热点路径),使用 clone 会极大的降低程序性能,需要小心使用!
拷贝(浅拷贝)
浅拷贝只发生在栈上,因此性能很高,在日常编程中,浅拷贝无处不在。
再回到之前看过的例子:
#![allow(unused)] fn main() { let x = 5; let y = x; println!("x = {}, y = {}", x, y); }
但这段代码似乎与我们刚刚学到的内容相矛盾:没有调用 clone,不过依然实现了类似深拷贝的效果 —— 没有报所有权的错误。
原因是像整型这样的基本类型在编译时是已知大小的,会被存储在栈上,所以拷贝其实际的值是快速的。这意味着没有理由在创建变量 y 后使 x 无效(x、y 都仍然有效)。换句话说,这里没有深浅拷贝的区别,因此这里调用 clone 并不会与通常的浅拷贝有什么不同,我们可以不用管它(可以理解成在栈上做了深拷贝)。
Rust 有一个叫做 Copy 的特征,可以用在类似整型这样在栈中存储的类型。如果一个类型拥有 Copy 特征,一个旧的变量在被赋值给其他变量后仍然可用。
那么什么类型是可 Copy 的呢?可以查看给定类型的文档来确认,不过作为一个通用的规则: 任何基本类型的组合可以 Copy ,不需要分配内存或某种形式资源的类型是可以 Copy 的。如下是一些 Copy 的类型:
- 所有整数类型,比如
u32。 - 布尔类型,
bool,它的值是true和false。 - 所有浮点数类型,比如
f64。 - 字符类型,
char。 - 元组,当且仅当其包含的类型也都是
Copy的时候。比如,(i32, i32)是Copy的,但(i32, String)就不是。 - 不可变引用
&T,但是注意: 可变引用&mut T是不可以 Copy的
函数传值与返回
将值传递给函数,一样会发生 移动 或者 复制,就跟 let 语句一样,下面的代码展示了所有权、作用域的规则:
fn main() { let s = String::from("hello"); // s 进入作用域 takes_ownership(s); // s 的值移动到函数里 ... // ... 所以到这里不再有效 let x = 5; // x 进入作用域 makes_copy(x); // x 应该移动函数里, // 但 i32 是 Copy 的,所以在后面可继续使用 x } // 这里, x 先移出了作用域,然后是 s。但因为 s 的值已被移走, // 所以不会有特殊操作 fn takes_ownership(some_string: String) { // some_string 进入作用域 println!("{}", some_string); } // 这里,some_string 移出作用域并调用 `drop` 方法。占用的内存被释放 fn makes_copy(some_integer: i32) { // some_integer 进入作用域 println!("{}", some_integer); } // 这里,some_integer 移出作用域。不会有特殊操作
你可以尝试在 takes_ownership 之后,再使用 s,看看如何报错?例如添加一行 println!("在move进函数后继续使用s: {}",s);。
同样的,函数返回值也有所有权,例如:
fn main() { let s1 = gives_ownership(); // gives_ownership 将返回值 // 移给 s1 let s2 = String::from("hello"); // s2 进入作用域 let s3 = takes_and_gives_back(s2); // s2 被移动到 // takes_and_gives_back 中, // 它也将返回值移给 s3 } // 这里, s3 移出作用域并被丢弃。s2 也移出作用域,但已被移走, // 所以什么也不会发生。s1 移出作用域并被丢弃 fn gives_ownership() -> String { // gives_ownership 将返回值移动给 // 调用它的函数 let some_string = String::from("hello"); // some_string 进入作用域. some_string // 返回 some_string 并移出给调用的函数 } // takes_and_gives_back 将传入字符串并返回该值 fn takes_and_gives_back(a_string: String) -> String { // a_string 进入作用域 a_string // 返回 a_string 并移出给调用的函数 }
所有权很强大,避免了内存的不安全性,但是也带来了一个新麻烦: 总是把一个值传来传去来使用它。 传入一个函数,很可能还要从该函数传出去,结果就是语言表达变得非常啰嗦,幸运的是,Rust 提供了新功能解决这个问题。
引用与借用
上节中提到,如果仅仅支持通过转移所有权的方式获取一个值,那会让程序变得复杂。 Rust 能否像其它编程语言一样,使用某个变量的指针或者引用呢?答案是可以。
Rust 通过 借用(Borrowing) 这个概念来达成上述的目的,获取变量的引用,称之为借用(borrowing)。
引用与解引用
常规引用是一个指针类型,指向了对象存储的内存地址。在下面代码中,我们创建一个 i32 值的引用 y,然后使用解引用运算符*来解出 y 所使用的值:
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
变量 x 存放了一个 i32 值 5。y 是 x 的一个引用。可以断言 x 等于 5。然而,如果希望对 y 的值做出断言,必须使用 *y 来解出引用所指向的值(也就是解引用)。一旦解引用了 y,就可以访问 y 所指向的整型值并可以与 5 做比较。
相反如果尝试编写 assert_eq!(5, y);,则会得到如下编译错误:
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}` // 无法比较整数类型和引用类型
|
= help: the trait `std::cmp::PartialEq<&{integer}>` is not implemented for
`{integer}`
不允许比较整数与引用,因为它们是不同的类型。必须使用解引用运算符解出引用所指向的值。
不可变引用
下面的代码,我们用 s1 的引用作为参数传递给 calculate_length 函数,而不是把 s1 的所有权转移给该函数:
fn main() { let s1 = String::from("hello"); let len = calculate_length(&s1); println!("The length of '{}' is {}.", s1, len); } fn calculate_length(s: &String) -> usize { s.len() }
能注意到两点:
- 无需像上章一样:先通过函数参数传入所有权,然后再通过函数返回来传出所有权,代码更加简洁
calculate_length的参数s类型从String变为&String
这里,& 符号即是引用,它们允许你使用值,但是不获取所有权,如图所示:
通过 &s1 语法,我们创建了一个指向 s1 的引用,但是并不拥有它。因为并不拥有这个值,当引用离开作用域后,其指向的值也不会被丢弃。
同理,函数 calculate_length 使用 & 来表明参数 s 的类型是一个引用:
#![allow(unused)] fn main() { fn calculate_length(s: &String) -> usize { // s 是对 String 的引用 s.len() } // 这里,s 离开了作用域。但因为它并不拥有引用值的所有权, // 所以什么也不会发生 }
因此光借用满足不了我们,如果尝试修改借用的变量呢?
fn main() { let s = String::from("hello"); change(&s); } fn change(some_string: &String) { some_string.push_str(", world"); }
很不幸,修改错了:
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
7 | fn change(some_string: &String) {
| ------- help: consider changing this to be a mutable reference: `&mut String`
------- 帮助:考虑将该参数类型修改为可变的引用: `&mut String`
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
`some_string`是一个`&`类型的引用,因此它指向的数据无法进行修改
正如变量默认不可变一样,引用指向的值默认也是不可变的,没事,来一起看看如何解决这个问题。
可变引用
只需要一个小调整,即可修复上面代码的错误:
fn main() { let mut s = String::from("hello"); change(&mut s); } fn change(some_string: &mut String) { some_string.push_str(", world"); }
首先,声明 s 是可变类型,其次创建一个可变的引用 &mut s 和接受可变引用参数 some_string: &mut String 的函数。
可变引用同时只能存在一个
不过可变引用并不是随心所欲、想用就用的,它有一个很大的限制: 同一作用域,特定数据只能有一个可变引用:
#![allow(unused)] fn main() { let mut s = String::from("hello"); let r1 = &mut s; let r2 = &mut s; println!("{}, {}", r1, r2); }
以上代码会报错:
error[E0499]: cannot borrow `s` as mutable more than once at a time 同一时间无法对 `s` 进行两次可变借用
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here 首个可变引用在这里借用
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here 第二个可变引用在这里借用
6 |
7 | println!("{}, {}", r1, r2);
| -- first borrow later used here 第一个借用在这里使用
这段代码出错的原因在于,第一个可变借用 r1 必须要持续到最后一次使用的位置 println!,在 r1 创建和最后一次使用之间,我们又尝试创建第二个可变借用 r2。
对于新手来说,这个特性绝对是一大拦路虎,也是新人们谈之色变的编译器 borrow checker 特性之一,不过各行各业都一样,限制往往是出于安全的考虑,Rust 也一样。
这种限制的好处就是使 Rust 在编译期就避免数据竞争,数据竞争可由以下行为造成:
- 两个或更多的指针同时访问同一数据
- 至少有一个指针被用来写入数据
- 没有同步数据访问的机制
数据竞争会导致未定义行为,这种行为很可能超出我们的预期,难以在运行时追踪,并且难以诊断和修复。而 Rust 避免了这种情况的发生,因为它甚至不会编译存在数据竞争的代码!
很多时候,大括号可以帮我们解决一些编译不通过的问题,通过手动限制变量的作用域:
#![allow(unused)] fn main() { let mut s = String::from("hello"); { let r1 = &mut s; } // r1 在这里离开了作用域,所以我们完全可以创建一个新的引用 let r2 = &mut s; }
可变引用与不可变引用不能同时存在
下面的代码会导致一个错误:
#![allow(unused)] fn main() { let mut s = String::from("hello"); let r1 = &s; // 没问题 let r2 = &s; // 没问题 let r3 = &mut s; // 大问题 println!("{}, {}, and {}", r1, r2, r3); }
错误如下:
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
// 无法借用可变 `s` 因为它已经被借用了不可变
--> src/main.rs:6:14
|
4 | let r1 = &s; // 没问题
| -- immutable borrow occurs here 不可变借用发生在这里
5 | let r2 = &s; // 没问题
6 | let r3 = &mut s; // 大问题
| ^^^^^^ mutable borrow occurs here 可变借用发生在这里
7 |
8 | println!("{}, {}, and {}", r1, r2, r3);
| -- immutable borrow later used here 不可变借用在这里使用
注意,引用的作用域
s从创建开始,一直持续到它最后一次使用的地方,这个跟变量的作用域有所不同,变量的作用域从创建持续到某一个花括号}
NLL
对于这种编译器优化行为,Rust 专门起了一个名字 —— Non-Lexical Lifetimes(NLL),专门用于找到某个引用在作用域(})结束前就不再被使用的代码位置。
虽然这种借用错误有的时候会让我们很郁闷,但是你只要想想这是 Rust 提前帮你发现了潜在的 BUG,其实就开心了,虽然减慢了开发速度,但是从长期来看,大幅减少了后续开发和运维成本。
悬垂引用(Dangling References)
悬垂引用也叫做悬垂指针,意思为指针指向某个值后,这个值被释放掉了,而指针仍然存在,其指向的内存可能不存在任何值或已被其它变量重新使用。在 Rust 中编译器可以确保引用永远也不会变成悬垂状态:当你获取数据的引用后,编译器可以确保数据不会在引用结束前被释放,要想释放数据,必须先停止其引用的使用。
让我们尝试创建一个悬垂引用,Rust 会抛出一个编译时错误:
fn main() { let reference_to_nothing = dangle(); } fn dangle() -> &String { let s = String::from("hello"); &s }
这里是错误:
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime
|
5 | fn dangle() -> &'static String {
| ~~~~~~~~
仔细看看 dangle 代码的每一步到底发生了什么:
#![allow(unused)] fn main() { fn dangle() -> &String { // dangle 返回一个字符串的引用 let s = String::from("hello"); // s 是一个新字符串 &s // 返回字符串 s 的引用 } // 这里 s 离开作用域并被丢弃。其内存被释放。 // 危险! }
因为 s 是在 dangle 函数内创建的,当 dangle 的代码执行完毕后,s 将被释放, 但是此时我们又尝试去返回它的引用。这意味着这个引用会指向一个无效的 String,这可不对!
其中一个很好的解决方法是直接返回 String:
#![allow(unused)] fn main() { fn no_dangle() -> String { let s = String::from("hello"); s } }
这样就没有任何错误了,最终 String 的 所有权被转移给外面的调用者。
借用规则总结
总的来说,借用规则如下:
- 同一时刻,你只能拥有要么一个可变引用, 要么任意多个不可变引用
- 引用必须总是有效的
复合类型
顾名思义,复合类型是由其它类型组合而成的,最典型的就是结构体 struct 和枚举 enum。
来看一段代码,它使用我们之前学过的内容来构建文件操作:
#![allow(unused_variables)] type File = String; fn open(f: &mut File) -> bool { true } fn close(f: &mut File) -> bool { true } #[allow(dead_code)] fn read(f: &mut File, save_to: &mut Vec<u8>) -> ! { unimplemented!() } fn main() { let mut f1 = File::from("f1.txt"); open(&mut f1); //read(&mut f1, &mut vec![]); close(&mut f1); }
接下来我们的学习非常类似原型设计:有的方法只提供 API 接口,但是不提供具体实现。此外,有的变量在声明之后并未使用,因此在这个阶段我们需要排除一些编译器噪音(Rust 在编译的时候会扫描代码,变量声明后未使用会以 warning 警告的形式进行提示),引入 #![allow(unused_variables)] 属性标记,该标记会告诉编译器忽略未使用的变量,不要抛出 warning 警告,具体的常见编译器属性你可以在这里查阅:编译器属性标记。
read 函数也非常有趣,它返回一个 ! 类型,这个表明该函数是一个发散函数,不会返回任何值,包括 ()。unimplemented!() 告诉编译器该函数尚未实现,unimplemented!() 标记通常意味着我们期望快速完成主要代码,回头再通过搜索这些标记来完成次要代码,类似的标记还有 todo!(),当代码执行到这种未实现的地方时,程序会直接报错。你可以反注释 read(&mut f1, &mut vec![]); 这行,然后再观察下结果。
同时,从代码设计角度来看,关于文件操作的类型和函数应该组织在一起,散落得到处都是,是难以管理和使用的。而且通过 open(&mut f1) 进行调用,也远没有使用 f1.open() 来调用好,这就体现出了只使用基本类型的局限性:无法从更高的抽象层次去简化代码。
接下来,我们将引入一个高级数据结构 —— 结构体 struct,来看看复合类型是怎样更好的解决这类问题。 开始之前,先来看看 Rust 的重点也是难点:字符串 String 和 &str。
字符串
首先来看段很简单的代码:
fn main() { let my_name = "Pascal"; greet(my_name); } fn greet(name: String) { println!("Hello, {}!", name); }
greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解,你们猜猜,这段代码能否通过编译?
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error
Bingo,果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串.
在讲解字符串之前,先来看看什么是切片?
切片(slice)
它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
#![allow(unused)] fn main() { let s = String::from("hello world"); let hello = &s[0..5]; let world = &s[6..11]; }
hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
这就是创建切片的语法,使用方括号包括的一个序列:[开始索引..终止索引],其中开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置,也就是这是一个 右半开区间。在切片数据结构内部会保存开始的位置和切片的长度,其中长度是通过 终止索引 - 开始索引 的方式计算得来的。
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
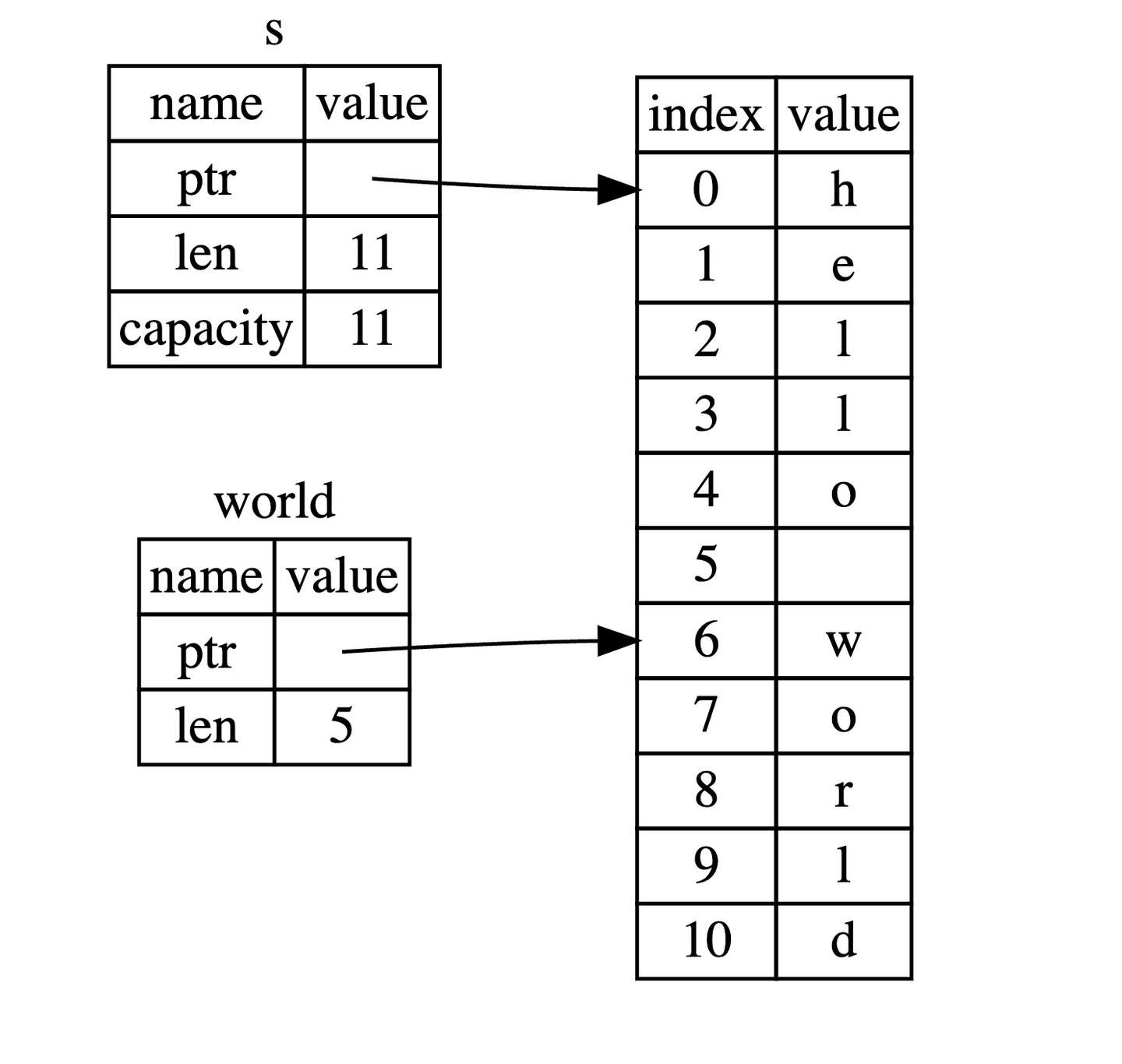
这两个是等效的:
#![allow(unused)] fn main() { let s = String::from("hello"); let slice = &s[0..2]; let slice = &s[..2]; }
同样的,如果你的切片想要包含 String 的最后一个字节,则可以这样使用:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[4..len]; let slice = &s[4..]; }
你也可以截取完整的 String 切片:
#![allow(unused)] fn main() { let s = String::from("hello"); let len = s.len(); let slice = &s[0..len]; let slice = &s[..]; }
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
#![allow(unused)] fn main() { let s = "中国人"; let a = &s[0..2]; println!("{}",a); }因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点
字符串切片的类型标识是 &str,因此我们可以这样声明一个函数,输入 String 类型,返回它的切片: fn first_word(s: &String) -> &str 。
有了切片就可以写出这样的代码:
fn main() { let mut s = String::from("hello world"); let word = first_word(&s); s.clear(); // error! println!("the first word is: {}", word); } fn first_word(s: &String) -> &str { &s[..1] }
编译器报错如下:
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
回忆一下借用的规则:当我们已经有了可变借用时,就无法再拥有不可变的借用。因为 clear 需要清空改变 String,因此它需要一个可变借用(利用 VSCode 可以看到该方法的声明是 pub fn clear(&mut self) ,参数是对自身的可变借用 );而之后的 println! 又使用了不可变借用,也就是在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
从上述代码可以看出,Rust 不仅让我们的 API 更加容易使用,而且也在编译期就消除了大量错误!
其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
#![allow(unused)] fn main() { let a = [1, 2, 3, 4, 5]; let slice = &a[1..3]; assert_eq!(slice, &[2, 3]); }
该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的.
字符串字面量是切片
之前提到过字符串字面量,但是没有提到它的类型:
#![allow(unused)] fn main() { let s = "Hello, world!"; }
实际上,s 的类型是 &str,因此你也可以这样声明:
#![allow(unused)] fn main() { let s: &str = "Hello, world!"; }
该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为 &str 是一个不可变引用。
了解完切片,可以进入本节的正题了。
什么是字符串?
顾名思义,字符串是由字符组成的连续集合,但是在上一节中我们提到过,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString, OsStr, CsString 和 CsStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
String 与 &str 的转换
在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
fn main() { let s = String::from("hello,world!"); say_hello(&s); say_hello(&s[..]); say_hello(s.as_str()); } fn say_hello(s: &str) { println!("{}",s); }
实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在Deref特征进行详细讲解。
字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
#![allow(unused)] fn main() { let s1 = String::from("hello"); let h = s1[0]; }
该代码会产生如下错误:
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
深入字符串内部
字符串的底层的数据存储格式实际上是[ u8 ],一个字节数组。对于 let hello = String::from("Hola"); 这行代码来说,Hola 的长度是 4 个字节,因为 "Hola" 中的每个字母在 UTF-8 编码中仅占用 1 个字节,但是对于下面的代码呢?
#![allow(unused)] fn main() { let hello = String::from("中国人"); }
如果问你该字符串多长,你可能会说 3,但是实际上是 9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是 3 个字节,因此这种情况下对 hello 进行索引,访问 &hello[0] 没有任何意义,因为你取不到 中 这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
字符串的不同表现形式
现在看一下用梵文写的字符串 “नमस्ते”, 它底层的字节数组如下形式:
#![allow(unused)] fn main() { [224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164, 224, 165, 135] }
长度是 18 个字节,这也是计算机最终存储该字符串的形式。如果从字符的形式去看,则是:
#![allow(unused)] fn main() { ['न', 'म', 'स', '्', 'त', 'े'] }
但是这种形式下,第四和六两个字母根本就不存在,没有任何意义,接着再从字母串的形式去看:
#![allow(unused)] fn main() { ["न", "म", "स्", "ते"] }
所以,可以看出来 Rust 提供了不同的字符串展现方式,这样程序可以挑选自己想要的方式去使用,而无需去管字符串从人类语言角度看长什么样。
还有一个原因导致了 Rust 不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是 O(1),然而对于 String 类型来说,无法保证这一点,因为 Rust 可能需要从 0 开始去遍历字符串来定位合法的字符。
字符串切片
前文提到过,字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
#![allow(unused)] fn main() { let hello = "中国人"; let s = &hello[0..2]; }
运行上面的程序,会直接造成崩溃:
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这里提示的很清楚,我们索引的字节落在了 中 字符的内部,这种返回没有任何意义。
因此在通过索引区间来访问字符串时,需要格外的小心,一不注意,就会导致你程序的崩溃!
操作字符串
由于 String 是可变字符串,下面介绍 Rust 字符串的修改,添加,删除等常用方法:
追加 (Push)
在字符串尾部可以使用 push() 方法追加字符 char,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() { let mut s = String::from("Hello "); s.push_str("rust"); println!("追加字符串 push_str() -> {}", s); s.push('!'); println!("追加字符 push() -> {}", s); }
代码运行结果:
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!
插入 (Insert)
可以使用 insert() 方法插入单个字符 char,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() { let mut s = String::from("Hello rust!"); s.insert(5, ','); println!("插入字符 insert() -> {}", s); s.insert_str(6, " I like"); println!("插入字符串 insert_str() -> {}", s); }
代码运行结果:
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!
替换 (Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用 replace() 方法。与替换有关的方法有三个。
1、replace
该方法可适用于 String 和 &str 类型。replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() { let string_replace = String::from("I like rust. Learning rust is my favorite!"); let new_string_replace = string_replace.replace("rust", "RUST"); dbg!(new_string_replace); }
代码运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!"
2、replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() { let string_replace = "I like rust. Learning rust is my favorite!"; let new_string_replacen = string_replace.replacen("rust", "RUST", 1); dbg!(new_string_replacen); }
代码运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!"
3、replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
fn main() { let mut string_replace_range = String::from("I like rust!"); string_replace_range.replace_range(7..8, "R"); dbg!(string_replace_range); }
代码运行结果:
string_replace_range = "I like Rust!"
删除 (Delete)
与字符串删除相关的方法有 4 个,他们分别是 pop(),remove(),truncate(),clear()。这四个方法仅适用于 String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None。
示例代码如下:
fn main() { let mut string_pop = String::from("rust pop 中文!"); let p1 = string_pop.pop(); let p2 = string_pop.pop(); dbg!(p1); dbg!(p2); dbg!(string_pop); }
代码运行结果:
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"
2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() { let mut string_remove = String::from("测试remove方法"); println!( "string_remove 占 {} 个字节", std::mem::size_of_val(string_remove.as_str()) ); // 删除第一个汉字 string_remove.remove(0); // 下面代码会发生错误 // string_remove.remove(1); // 直接删除第二个汉字 // string_remove.remove(3); dbg!(string_remove); }
代码运行结果:
string_remove 占 18 个字节
string_remove = "试remove方法"
3、truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() { let mut string_truncate = String::from("测试truncate"); string_truncate.truncate(3); dbg!(string_truncate); }
代码运行结果:
string_truncate = "测"
4、clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
示例代码如下:
fn main() { let mut string_clear = String::from("string clear"); string_clear.clear(); dbg!(string_clear); }
代码运行结果:
string_clear = ""
连接 (Concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 +, 必须传递切片引用类型。不能直接传递 String 类型。+ 和 += 都是返回一个新的字符串。所以变量声明可以不需要 mut 关键字修饰。
示例代码如下:
fn main() { let string_append = String::from("hello "); let string_rust = String::from("rust"); // &string_rust会自动解引用为&str let result = string_append + &string_rust; let mut result = result + "!"; result += "!!!"; println!("连接字符串 + -> {}", result); }
代码运行结果:
连接字符串 + -> hello rust!!!!
add() 方法的定义:
#![allow(unused)] fn main() { fn add(self, s: &str) -> String }
因为该方法涉及到更复杂的特征功能,因此我们这里简单说明下:
fn main() { let s1 = String::from("hello,"); let s2 = String::from("world!"); // 在下句中,s1的所有权被转移走了,因此后面不能再使用s1 let s3 = s1 + &s2; assert_eq!(s3,"hello,world!"); // 下面的语句如果去掉注释,就会报错 // println!("{}",s1); }
self 是 String 类型的字符串 s1,该函数说明,只能将 &str 类型的字符串切片添加到 String 类型的 s1 上,然后返回一个新的 String 类型,所以 let s3 = s1 + &s2; 就很好解释了,将 String 类型的 s1 与 &str 类型的 s2 进行相加,最终得到 String 类型的 s3。
由此可推,以下代码也是合法的:
#![allow(unused)] fn main() { let s1 = String::from("tic"); let s2 = String::from("tac"); let s3 = String::from("toe"); // String = String + &str + &str + &str + &str let s = s1 + "-" + &s2 + "-" + &s3; }
String + &str返回一个 String,然后再继续跟一个 &str 进行 + 操作,返回一个 String 类型,不断循环,最终生成一个 s,也是 String 类型。
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。这里涉及到所有权转移(Move)的相关知识。
2、使用 format! 连接字符串
format! 这种方式适用于 String 和 &str 。format! 的用法与 print! 的用法类似, 示例代码如下:
fn main() { let s1 = "hello"; let s2 = String::from("rust"); let s = format!("{} {}!", s1, s2); println!("{}", s); }
代码运行结果:
hello rust!
字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符。
fn main() { // 通过 \ + 字符的十六进制表示,转义输出一个字符 let byte_escape = "I'm writing \x52\x75\x73\x74!"; println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape); // \u 可以输出一个 unicode 字符 let unicode_codepoint = "\u{211D}"; let character_name = "\"DOUBLE-STRUCK CAPITAL R\""; println!( "Unicode character {} (U+211D) is called {}", unicode_codepoint, character_name ); // 换行了也会保持之前的字符串格式 let long_string = "String literals can span multiple lines. The linebreak and indentation here ->\ <- can be escaped too!"; println!("{}", long_string); }
当然,在某些情况下,可能你会希望保持字符串的原样,不要转义:
fn main() { println!("{}", "hello \\x52\\x75\\x73\\x74"); let raw_str = r"Escapes don't work here: \x3F \u{211D}"; println!("{}", raw_str); // 如果字符串包含双引号,可以在开头和结尾加 # let quotes = r#"And then I said: "There is no escape!""#; println!("{}", quotes); // 如果还是有歧义,可以继续增加,没有限制 let longer_delimiter = r###"A string with "# in it. And even "##!"###; println!("{}", longer_delimiter); }
操作 UTF-8 字符串
前文提到了几种使用 UTF-8 字符串的方式,下面来一一说明。
字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
#![allow(unused)] fn main() { for c in "中国人".chars() { println!("{}", c); } }
输出如下
中
国
人
字节
这种方式是返回字符串的底层字节数组表现形式:
#![allow(unused)] fn main() { for b in "中国人".bytes() { println!("{}", b); } }
输出如下:
228
184
173
229
155
189
228
186
186
获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 holla中国人नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。
你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。
字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行得过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
- 首先向操作系统请求内存来存放
String对象 - 在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的 String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
#![allow(unused)] fn main() { { let s = String::from("hello"); // 从此处起,s 是有效的 // 使用 s } // 此作用域已结束, // s 不再有效,内存被释放 }
与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数: 上面代码中,Rust 在结尾的 } 处自动调用 drop。
其实,在 C++ 中,也有这种概念: Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生
元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
可以通过以下语法创建一个元组:
fn main() { let tup: (i32, f64, u8) = (500, 6.4, 1); }
变量 tup 被绑定了一个元组值 (500, 6.4, 1),该元组的类型是 (i32, f64, u8).
可以使用模式匹配或者 . 操作符来获取元组中的值。
用模式匹配解构元组
fn main() { let tup = (500, 6.4, 1); let (x, y, z) = tup; println!("The value of y is: {}", y); }
上述代码首先创建一个元组,然后将其绑定到 tup 上,接着使用 let (x, y, z) = tup; 来完成一次模式匹配,因为元组是 (n1, n2, n3) 形式的,因此我们用一模一样的 (x, y, z) 形式来进行匹配,元组中对应的值会绑定到变量 x, y, z上。这就是解构:用同样的形式把一个复杂对象中的值匹配出来。
用 . 来访问元组
模式匹配可以让我们一次性把元组中的值全部或者部分获取出来,如果只想要访问某个特定元素,那模式匹配就略显繁琐,对此,Rust 提供了 . 的访问方式:
fn main() { let x: (i32, f64, u8) = (500, 6.4, 1); let five_hundred = x.0; let six_point_four = x.1; let one = x.2; }
和其它语言的数组、字符串一样,元组的索引从 0 开始。
元组的使用示例
元组在函数返回值场景很常用,例如下面的代码,可以使用元组返回多个值:
fn main() { let s1 = String::from("hello"); let (s2, len) = calculate_length(s1); println!("The length of '{}' is {}.", s2, len); } fn calculate_length(s: String) -> (String, usize) { let length = s.len(); // len() 返回字符串的长度 (s, length) }
calculate_length 函数接收 s1 字符串的所有权,然后计算字符串的长度,接着把字符串所有权和字符串长度再返回给 s2 和 len 变量。
在其他语言中,可以用结构体来声明一个三维空间中的点,例如 Point(10, 20, 30),虽然使用 Rust 元组也可以做到:(10, 20, 30),但是这样写有个非常重大的缺陷:
不具备任何清晰的含义,在下一章节中,会提到一种与元组类似的结构体,元组结构体,可以解决这个问题。
结构体
结构体跟元组有些相像:都是由多种类型组合而成。但是与元组不同的是,结构体可以为内部的每个字段起一个富有含义的名称。
结构体语法
定义结构体
一个结构体由几部分组成:
- 通过关键字
struct定义 - 一个清晰明确的结构体
名称 - 几个有名字的结构体
字段
例如, 以下结构体定义了某网站的用户:
#![allow(unused)] fn main() { struct User { active: bool, username: String, email: String, sign_in_count: u64, } }
该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 username 代表了用户名,是一个可变的 String 类型。
创建结构体实例
为了使用上述结构体,我们需要创建 User 结构体的实例:
#![allow(unused)] fn main() { let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; }
有几点值得注意:
- 初始化实例时,每个字段都需要进行初始化
- 初始化时的字段顺序不需要和结构体定义时的顺序一致
访问结构体字段
通过 . 操作符即可访问结构体实例内部的字段值,也可以修改它们:
#![allow(unused)] fn main() { let mut user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; user1.email = String::from("anotheremail@example.com"); }
需要注意的是,必须要将结构体实例声明为可变的,才能修改其中的字段,Rust 不支持将某个结构体某个字段标记为可变。
简化结构体创建
下面的函数类似一个构建函数,返回了 User 结构体的实例:
#![allow(unused)] fn main() { fn build_user(email: String, username: String) -> User { User { email: email, username: username, active: true, sign_in_count: 1, } } }
它接收两个字符串参数: email 和 username,然后使用它们来创建一个 User 结构体,并且返回。可以注意到这两行: email: email 和 username: username,非常的扎眼,因为实在有些啰嗦,如果你从 TypeScript 过来,肯定会鄙视 Rust 一番,不过好在,它也不是无可救药:
#![allow(unused)] fn main() { fn build_user(email: String, username: String) -> User { User { email, username, active: true, sign_in_count: 1, } } }
如上所示,当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟 TypeScript 中一模一样。
结构体更新语法
在实际场景中,有一种情况很常见:根据已有的结构体实例,创建新的结构体实例,例如根据已有的 user1 实例来构建 user2:
#![allow(unused)] fn main() { let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; }
好在 Rust 为我们提供了 结构体更新语法:
#![allow(unused)] fn main() { let user2 = User { email: String::from("another@example.com"), ..user1 }; }
因为 user2 仅仅在 email 上与 user1 不同,因此我们只需要对 email 进行赋值,剩下的通过结构体更新语法 ..user1 即可完成。
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
结构体更新语法跟赋值语句
=非常相像,因此在上面代码中,user1的部分字段所有权被转移到user2中:username字段发生了所有权转移,作为结果,user1无法再被使用。聪明的读者肯定要发问了:明明有三个字段进行了自动赋值,为何只有
username发生了所有权转移?仔细回想一下所有权那一节的内容,我们提到了
Copy特征:实现了Copy特征的类型无需所有权转移,可以直接在赋值时进行 数据拷贝,其中bool和u64类型就实现了Copy特征,因此active和sign_in_count字段在赋值给user2时,仅仅发生了拷贝,而不是所有权转移。值得注意的是:
username所有权被转移给了user2,导致了user1无法再被使用,但是并不代表user1内部的其它字段不能被继续使用,例如:
#[derive(Debug)] struct User { active: bool, username: String, email: String, sign_in_count: u64, } fn main() { let user1 = User { email: String::from("someone@example.com"), username: String::from("someusername123"), active: true, sign_in_count: 1, }; let user2 = User { active: user1.active, username: user1.username, email: String::from("another@example.com"), sign_in_count: user1.sign_in_count, }; println!("{}", user1.active); // 下面这行会报错 println!("{:?}", user1); }
结构体的内存排列
先来看以下代码:
#[derive(Debug)] struct File { name: String, data: Vec<u8>, } fn main() { let f1 = File { name: String::from("f1.txt"), data: Vec::new(), }; let f1_name = &f1.name; let f1_length = &f1.data.len(); println!("{:?}", f1); println!("{} is {} bytes long", f1_name, f1_length); }
上面定义的 File 结构体在内存中的排列如下图所示:
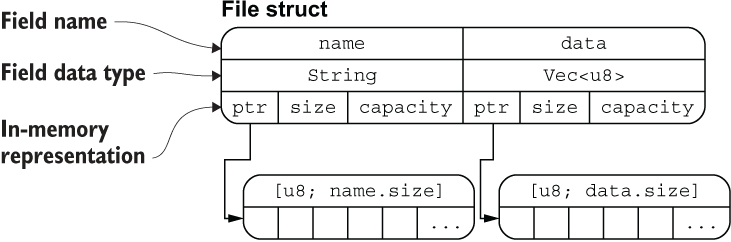
从图中可以清晰的看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
元组结构体(Tuple Struct)
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
#![allow(unused)] fn main() { struct Color(i32, i32, i32); struct Point(i32, i32, i32); let black = Color(0, 0, 0); let origin = Point(0, 0, 0); }
元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为:x, y, z。
单元结构体(Unit-like Struct)
如果你定义一个类型,但是不关心该类型的内容, 只关心它的行为时,就可以使用 单元结构体:
#![allow(unused)] fn main() { struct AlwaysEqual; let subject = AlwaysEqual; // 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征 impl SomeTrait for AlwaysEqual { } }
结构体数据的所有权
在之前的 User 结构体的定义中,有一处细节:我们使用了自身拥有所有权的 String 类型而不是基于引用的 &str 字符串切片类型。这是一个有意而为之的选择:因为我们想要这个结构体拥有它所有的数据,而不是从其它地方借用数据。
你也可以让 User 结构体从其它对象借用数据,不过这么做,就需要引入生命周期(lifetimes)这个新概念(也是一个复杂的概念),简而言之,生命周期能确保结构体的作用范围要比它所借用的数据的作用范围要小。
总之,如果你想在结构体中使用一个引用,就必须加上生命周期,否则就会报错:
struct User { username: &str, email: &str, sign_in_count: u64, active: bool, } fn main() { let user1 = User { email: "someone@example.com", username: "someusername123", active: true, sign_in_count: 1, }; }
编译器会抱怨它需要生命周期标识符:
error[E0106]: missing lifetime specifier
--> src/main.rs:2:15
|
2 | username: &str,
| ^ expected named lifetime parameter // 需要一个生命周期
|
help: consider introducing a named lifetime parameter // 考虑像下面的代码这样引入一个生命周期
|
1 ~ struct User<'a> {
2 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:3:12
|
3 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | username: &str,
3 ~ email: &'a str,
|
未来在生命周期中会讲到如何修复这个问题以便在结构体中存储引用,不过在那之前,我们会避免在结构体中使用引用类型。
使用 #[derive(Debug)] 来打印结构体的信息
在前面的代码中我们使用 #[derive(Debug)] 对结构体进行了标记,这样才能使用 println!("{:?}", s); 的方式对其进行打印输出,如果不加,看看会发生什么:
struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {}", rect1); }
首先可以观察到,上面使用了 {} 而不是之前的 {:?},运行后报错:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
提示我们结构体 Rectangle 没有实现 Display 特征,这是因为如果我们使用 {} 来格式化输出,那对应的类型就必须实现 Display 特征,以前学习的基本类型,都默认实现了该特征:
fn main() { let v = 1; let b = true; println!("{}, {}", v, b); }
上面代码不会报错,那么结构体为什么不默认实现 Display 特征呢?原因在于结构体较为复杂,例如考虑以下问题:你想要逗号对字段进行分割吗?需要括号吗?加在什么地方?所有的字段都应该显示?类似的还有很多,由于这种复杂性,Rust 不希望猜测我们想要的是什么,而是把选择权交给我们自己来实现:如果要用 {} 的方式打印结构体,那就自己实现 Display 特征。
接下来继续阅读报错:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
上面提示我们使用 {:?} 来试试,这个方式我们在本文的前面也见过,下面来试试:
#![allow(unused)] fn main() { println!("rect1 is {:?}", rect1); }
可是依然无情报错了:
error[E0277]: `Rectangle` doesn't implement `Debug`
好在,聪明的编译器又一次给出了提示:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
让我们实现 Debug 特征,Oh No,就是不想实现 Display 特征,才用的 {:?},怎么又要实现 Debug,但是仔细看,提示中有一行: add #[derive(Debug)] to Rectangle, 哦?这不就是我们前文一直在使用的吗?
首先,Rust 默认不会为我们实现 Debug,为了实现,有两种方式可以选择:
- 手动实现
- 使用
derive派生实现
后者简单的多,但是也有限制,这里我们就不再深入讲解,来看看该如何使用:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; println!("rect1 is {:?}", rect1); }
此时运行程序,就不再有错误,输出如下:
$ cargo run
rect1 is Rectangle { width: 30, height: 50 }
这个输出格式看上去也不赖嘛,虽然未必是最好的。这种格式是 Rust 自动为我们提供的实现,看上基本就跟结构体的定义形式一样。
当结构体较大时,我们可能希望能够有更好的输出表现,此时可以使用 {:#?} 来替代 {:?},输出如下:
rect1 is Rectangle {
width: 30,
height: 50,
}
此时结构体的输出跟我们创建时候的代码几乎一模一样了!当然,如果大家还是不满足,那最好还是自己实现 Display 特征,以向用户更美的展示你的私藏结构体。。
还有一个简单的输出 debug 信息的方法,那就是使用 dbg! 宏,它会拿走表达式的所有权,然后打印出相应的文件名、行号等 debug 信息,当然还有我们需要的表达式的求值结果。除此之外,它最终还会把表达式值的所有权返回!
dbg!输出到标准错误输出stderr,而println!输出到标准输出stdout
下面的例子中清晰的展示了 dbg! 如何在打印出信息的同时,还把表达式的值赋给了 width:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } fn main() { let scale = 2; let rect1 = Rectangle { width: dbg!(30 * scale), height: 50, }; dbg!(&rect1); }
最终的 debug 输出如下:
$ cargo run
[src/main.rs:10] 30 * scale = 60
[src/main.rs:14] &rect1 = Rectangle {
width: 60,
height: 50,
}
可以看到,我们想要的 debug 信息几乎都有了:代码所在的文件名、行号、表达式以及表达式的值,简直完美!
枚举
枚举(enum 或 enumeration)允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
#![allow(unused)] fn main() { enum PokerSuit { Clubs, Spades, Diamonds, Hearts, } }
扑克总共有四种花色,而这里我们枚举出所有的可能值,这也正是 枚举 名称的由来。
任何一张扑克,它的花色肯定会落在四种花色中,而且也只会落在其中一个花色上,这种特性非常适合枚举的使用,因为枚举值只可能是其中某一个成员。抽象来看,四种花色尽管是不同的花色,但是它们都是扑克花色这个概念,因此当某个函数处理扑克花色时,可以把它们当作相同的类型进行传参。
细心的读者应该注意到,我们对之前的 枚举类型 和 枚举值 进行了重点标注,这是容易被混淆的概念,总而言之:
枚举类型是一个类型,它会包含所有可能的枚举成员, 而枚举值是该类型中的具体某个成员的实例。
枚举值
现在来创建 PokerSuit 枚举类型的两个成员实例:
#![allow(unused)] fn main() { let heart = PokerSuit::Hearts; let diamond = PokerSuit::Diamonds; }
我们通过 :: 操作符来访问 PokerSuit 下的具体成员,从代码可以清晰看出,heart 和 diamond 都是 PokerSuit 枚举类型的,接着可以定义一个函数来使用它们:
fn main() { let heart = PokerSuit::Hearts; let diamond = PokerSuit::Diamonds; print_suit(heart); print_suit(diamond); } fn print_suit(card: PokerSuit) { println!("{:?}",card); }
print_suit 函数的参数类型是 PokerSuit,因此我们可以把 heart 和 diamond 传给它,虽然 heart 是基于 PokerSuit 下的 Hearts 成员实例化的,但是它是货真价实的 PokerSuit 枚举类型。
接下来,我们想让扑克牌变得更加实用,那么需要给每张牌赋予一个值:A(1)-K(13),这样再加上花色,就是一张真实的扑克牌了,例如红心 A。
目前来说,枚举值还不能带有值,因此先用结构体来实现:
enum PokerSuit { Clubs, Spades, Diamonds, Hearts, } struct PokerCard { suit: PokerSuit, value: u8 } fn main() { let c1 = PokerCard { suit: PokerSuit::Clubs, value: 1, }; let c2 = PokerCard { suit: PokerSuit::Diamonds, value: 12, }; }
这段代码很好的完成了它的使命,通过结构体 PokerCard 来代表一张牌,结构体的 suit 字段表示牌的花色,类型是 PokerSuit 枚举类型,value 字段代表扑克牌的数值。
可以吗?可以!好吗?说实话,不咋地,因为还有简洁得多的方式来实现:
enum PokerCard { Clubs(u8), Spades(u8), Diamonds(u8), Hearts(u8), } fn main() { let c1 = PokerCard::Spades(5); let c2 = PokerCard::Diamonds(13); }
直接将数据信息关联到枚举成员上,省去近一半的代码,这种实现是不是更优雅?
不仅如此,同一个枚举类型下的不同成员还能持有不同的数据类型,例如让某些花色打印 1-13 的字样,另外的花色打印上 A-K 的字样:
enum PokerCard { Clubs(u8), Spades(u8), Diamonds(char), Hearts(char), } fn main() { let c1 = PokerCard::Spades(5); let c2 = PokerCard::Diamonds('A'); }
回想一下,遇到这种不同类型的情况,再用我们之前的结构体实现方式,可行吗?也许可行,但是会复杂很多。
再来看一个来自标准库中的例子:
#![allow(unused)] fn main() { struct Ipv4Addr { // --snip-- } struct Ipv6Addr { // --snip-- } enum IpAddr { V4(Ipv4Addr), V6(Ipv6Addr), } }
这个例子跟我们之前的扑克牌很像,只不过枚举成员包含的类型更复杂了,变成了结构体:分别通过 Ipv4Addr 和 Ipv6Addr 来定义两种不同的 IP 数据。
从这些例子可以看出,任何类型的数据都可以放入枚举成员中: 例如字符串、数值、结构体甚至另一个枚举。
增加一些挑战?先看以下代码:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let m1 = Message::Quit; let m2 = Message::Move{x:1,y:1}; let m3 = Message::ChangeColor(255,255,0); }
该枚举类型代表一条消息,它包含四个不同的成员:
Quit没有任何关联数据Move包含一个匿名结构体Write包含一个String字符串ChangeColor包含三个i32
当然,我们也可以用结构体的方式来定义这些消息:
#![allow(unused)] fn main() { struct QuitMessage; // 单元结构体 struct MoveMessage { x: i32, y: i32, } struct WriteMessage(String); // 元组结构体 struct ChangeColorMessage(i32, i32, i32); // 元组结构体 }
由于每个结构体都有自己的类型,因此我们无法在需要同一类型的地方进行使用,例如某个函数它的功能是接受消息并进行发送,那么用枚举的方式,就可以接收不同的消息,但是用结构体,该函数无法接受 4 个不同的结构体作为参数。
而且从代码规范角度来看,枚举的实现更简洁,代码内聚性更强,不像结构体的实现,分散在各个地方。
同一化类型
最后,再用一个实际项目中的简化片段,来结束枚举类型的语法学习。
例如我们有一个 WEB 服务,需要接受用户的长连接,假设连接有两种:TcpStream 和 TlsStream,但是我们希望对这两个连接的处理流程相同,也就是用同一个函数来处理这两个连接,代码如下:
#![allow(unused)] fn main() { fn new (stream: TcpStream) { let mut s = stream; if tls { s = negotiate_tls(stream) } // websocket是一个WebSocket<TcpStream>或者 // WebSocket<native_tls::TlsStream<TcpStream>>类型 websocket = WebSocket::from_raw_socket( stream, ......) } }
此时,枚举类型就能帮上大忙:
#![allow(unused)] fn main() { enum Websocket { Tcp(Websocket<TcpStream>), Tls(Websocket<native_tls::TlsStream<TcpStream>>), } }
Option 枚举用于处理空值
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空,也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。
Tony Hoare,
null的发明者,曾经说过一段非常有名的话我称之为我十亿美元的错误。当时,我在使用一个面向对象语言设计第一个综合性的面向引用的类型系统。我的目标是通过编译器的自动检查来保证所有引用的使用都应该是绝对安全的。不过在设计过程中,我未能抵抗住诱惑,引入了空引用的概念,因为它非常容易实现。就是因为这个决策,引发了无数错误、漏洞和系统崩溃,在之后的四十多年中造成了数十亿美元的苦痛和伤害。
尽管如此,空值的表达依然非常有意义,因为空值表示当前时刻变量的值是缺失的。有鉴于此,Rust 吸取了众多教训,决定抛弃 null,而改为使用 Option 枚举变量来表述这种结果。
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。
Option<T> 枚举是如此有用以至于它被包含在了 prelude(prelude 属于 Rust 标准库,Rust 会将最常用的类型、函数等提前引入其中,省得我们再手动引入)之中,你不需要将其显式引入作用域。另外,它的成员 Some 和 None 也是如此,无需使用 Option:: 前缀就可直接使用 Some 和 None。
再来看以下代码:
#![allow(unused)] fn main() { let some_number = Some(5); let some_string = Some("a string"); let absent_number: Option<i32> = None; }
如果使用 None 而不是 Some,需要告诉 Rust Option<T> 是什么类型的,因为编译器只通过 None 值无法推断出 Some 成员保存的值的类型。
当有一个 Some 值时,我们就知道存在一个值,而这个值保存在 Some 中。当有个 None 值时,在某种意义上,它跟空值具有相同的意义:并没有一个有效的值。那么,Option<T> 为什么就比空值要好呢?
简而言之,因为 Option<T> 和 T(这里 T 可以是任何类型)是不同的类型,例如,这段代码不能编译,因为它尝试将 Option<i8>(Option<T>) 与 i8(T) 相加:
#![allow(unused)] fn main() { let x: i8 = 5; let y: Option<i8> = Some(5); let sum = x + y; }
如果运行这些代码,将得到类似这样的错误信息:
error[E0277]: the trait bound `i8: std::ops::Add<std::option::Option<i8>>` is
not satisfied
-->
|
5 | let sum = x + y;
| ^ no implementation for `i8 + std::option::Option<i8>`
|
很好!事实上,错误信息意味着 Rust 不知道该如何将 Option<i8> 与 i8 相加,因为它们的类型不同。当在 Rust 中拥有一个像 i8 这样类型的值时,编译器确保它总是有一个有效的值,我们可以放心使用而无需做空值检查。只有当使用 Option<i8>(或者任何用到的类型)的时候才需要担心可能没有值,而编译器会确保我们在使用值之前处理了为空的情况。
换句话说,在对 Option<T> 进行 T 的运算之前必须将其转换为 T。通常这能帮助我们捕获到空值最常见的问题之一:期望某值不为空但实际上为空的情况。
不再担心会错误的使用一个空值,会让你对代码更加有信心。为了拥有一个可能为空的值,你必须要显式的将其放入对应类型的 Option<T> 中。接着,当使用这个值时,必须明确的处理值为空的情况。只要一个值不是 Option<T> 类型,你就 可以 安全的认定它的值不为空。这是 Rust 的一个经过深思熟虑的设计决策,来限制空值的泛滥以增加 Rust 代码的安全性。
那么当有一个 Option<T> 的值时,如何从 Some 成员中取出 T 的值来使用它呢?Option<T> 枚举拥有大量用于各种情况的方法:你可以查看它的文档。熟悉 Option<T> 的方法将对你的 Rust 之旅非常有用。
总的来说,为了使用 Option<T> 值,需要编写处理每个成员的代码。你想要一些代码只当拥有 Some(T) 值时运行,允许这些代码使用其中的 T。也希望一些代码在值为 None 时运行,这些代码并没有一个可用的 T 值。match 表达式就是这么一个处理枚举的控制流结构:它会根据枚举的成员运行不同的代码,这些代码可以使用匹配到的值中的数据。
这里先简单看一下 match 的大致模样,在模式匹配中,我们会详细讲解:
#![allow(unused)] fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
plus_one 通过 match 来处理不同 Option 的情况。
数组
在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector,方便起见,我们称 array 为数组,Vector 为动态数组。
这两个数组的关系跟 &str 与 String 的关系很像,前者是长度固定的字符串切片,后者是可动态增长的字符串。其实,在 Rust 中无论是 String 还是 Vector,它们都是 Rust 的高级类型:集合类型,在后面章节会有详细介绍。
对于本章节,我们的重点还是放在数组 array 上。数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组。结合上面的内容,可以得出数组的三要素:
- 长度固定
- 元素必须有相同的类型
- 依次线性排列
这里再啰嗦一句,我们这里说的数组是 Rust 的基本类型,是固定长度的,这点与其他编程语言不同,其它编程语言的数组往往是可变长度的,与 Rust 中的动态数组 Vector 类似。
创建数组
在 Rust 中,数组是这样定义的:
fn main() { let a = [1, 2, 3, 4, 5]; }
数组语法跟 JavaScript 很像,也跟大多数编程语言很像。由于它的元素类型大小固定,且长度也是固定,因此数组 array 是存储在栈上,性能也会非常优秀。与此对应,动态数组 Vector 是存储在堆上,因此长度可以动态改变。当你不确定是使用数组还是动态数组时,那就应该使用后者。
举个例子,在需要知道一年中各个月份名称的程序中,你很可能希望使用的是数组而不是动态数组。因为月份是固定的,它总是只包含 12 个元素:
#![allow(unused)] fn main() { let months = ["January", "February", "March", "April", "May", "June", "July", "August", "September", "October", "November", "December"]; }
在一些时候,还需要为数组声明类型,如下所示:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; }
这里,数组类型是通过方括号语法声明,i32 是元素类型,分号后面的数字 5 是数组长度,数组类型也从侧面说明了数组的元素类型要统一,长度要固定。
还可以使用下面的语法初始化一个某个值重复出现 N 次的数组:
#![allow(unused)] fn main() { let a = [3; 5]; }
a 数组包含 5 个元素,这些元素的初始化值为 3,聪明的读者已经发现,这种语法跟数组类型的声明语法其实是保持一致的:[3; 5] 和 [类型; 长度]。
访问数组元素
因为数组是连续存放元素的,因此可以通过索引的方式来访问存放其中的元素:
fn main() { let a = [9, 8, 7, 6, 5]; let first = a[0]; // 获取a数组第一个元素 let second = a[1]; // 获取第二个元素 }
与许多语言类似,数组的索引下标是从 0 开始的。此处,first 获取到的值是 9,second 是 8。
越界访问
如果使用超出数组范围的索引访问数组元素,会怎么样?下面是一个接收用户的控制台输入,然后将其作为索引访问数组元素的例子:
use std::io; fn main() { let a = [1, 2, 3, 4, 5]; println!("Please enter an array index."); let mut index = String::new(); // 读取控制台的输出 io::stdin() .read_line(&mut index) .expect("Failed to read line"); let index: usize = index .trim() .parse() .expect("Index entered was not a number"); let element = a[index]; println!( "The value of the element at index {} is: {}", index, element ); }
使用 cargo run 来运行代码,因为数组只有 5 个元素,如果我们试图输入 5 去访问第 6 个元素,则会访问到不存在的数组元素,最终程序会崩溃退出:
Please enter an array index.
5
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 5', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这就是数组访问越界,访问了数组中不存在的元素,导致 Rust 运行时错误。程序因此退出并显示错误消息,未执行最后的 println! 语句。
当你尝试使用索引访问元素时,Rust 将检查你指定的索引是否小于数组长度。如果索引大于或等于数组长度,Rust 会出现 panic。这种检查只能在运行时进行,比如在上面这种情况下,编译器无法在编译期知道用户运行代码时将输入什么值。
这种就是 Rust 的安全特性之一。在很多系统编程语言中,并不会检查数组越界问题,你会访问到无效的内存地址获取到一个风马牛不相及的值,最终导致在程序逻辑上出现大问题,而且这种问题会非常难以检查。
数组元素为非基础类型
学习了上面的知识,很多朋友肯定觉得已经学会了Rust的数组类型,但现实会给我们一记重锤,实际开发中还会碰到一种情况,就是数组元素是非基本类型的,这时候大家一定会这样写。
#![allow(unused)] fn main() { let array = [String::from("rust is good!"); 8]; println!("{:#?}", array); }
然后你会惊喜的得到编译错误。
error[E0277]: the trait bound `String: std::marker::Copy` is not satisfied
--> src/main.rs:7:18
|
7 | let array = [String::from("rust is good!"); 8];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `std::marker::Copy` is not implemented for `String`
|
= note: the `Copy` trait is required because this value will be copied for each element of the array
有些还没有看过特征的小伙伴,有可能不太明白这个报错,不过这个目前可以不提,我们就拿之前所学的所有权知识,就可以思考明白,前面几个例子都是Rust的基本类型,而基本类型在Rust中赋值是以Copy的形式,let array=[3;5]底层就是不断的Copy出来的,但很可惜复杂类型都没有深拷贝,只能一个个创建。
正确的写法,应该调用std::array::from_fn
#![allow(unused)] fn main() { let array: [String; 8] = core::array::from_fn(|i| String::from("rust is good!")); println!("{:#?}", array); }
数组切片
在之前的章节,我们有讲到 切片 这个概念,它允许你引用集合中的部分连续片段,而不是整个集合,对于数组也是,数组切片允许我们引用数组的一部分:
#![allow(unused)] fn main() { let a: [i32; 5] = [1, 2, 3, 4, 5]; let slice: &[i32] = &a[1..3]; assert_eq!(slice, &[2, 3]); }
上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
- 切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
- 创建切片的代价非常小,因为切片只是针对底层数组的一个引用
- 切片类型[T]拥有不固定的大小,而切片引用类型&[T]则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此&[T]更有用,
&str字符串切片也同理
总结
最后,让我们以一个综合性使用数组的例子来结束本章:
fn main() { // 编译器自动推导出one的类型 let one = [1, 2, 3]; // 显式类型标注 let two: [u8; 3] = [1, 2, 3]; let blank1 = [0; 3]; let blank2: [u8; 3] = [0; 3]; // arrays是一个二维数组,其中每一个元素都是一个数组,元素类型是[u8; 3] let arrays: [[u8; 3]; 4] = [one, two, blank1, blank2]; // 借用arrays的元素用作循环中 for a in &arrays { print!("{:?}: ", a); // 将a变成一个迭代器,用于循环 // 你也可以直接用for n in a {}来进行循环 for n in a.iter() { print!("\t{} + 10 = {}", n, n+10); } let mut sum = 0; // 0..a.len,是一个 Rust 的语法糖,其实就等于一个数组,元素是从0,1,2一直增加到到a.len-1 for i in 0..a.len() { sum += a[i]; } println!("\t({:?} = {})", a, sum); } }
做个总结,数组虽然很简单,但是其实还是存在几个要注意的点:
- 数组类型容易跟数组切片混淆,[T;n]描述了一个数组的类型,而[T]描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用[T;n]的形式去描述
[u8; 3]和[u8; 4]是不同的类型,数组的长度也是类型的一部分- 在实际开发中,使用最多的是数组切片[T],我们往往通过引用的方式去使用
&[T],因为后者有固定的类型大小
流程控制
Rust 程序是从上而下顺序执行的,在此过程中,我们可以通过循环、分支等流程控制方式,更好的实现相应的功能。
使用 if 来做分支控制
if else 无处不在 -- 鲁迅
只要你拥有其它语言的编程经验,就一定会有以下认知:if else 表达式根据条件执行不同的代码分支:
#![allow(unused)] fn main() { if condition == true { // A... } else { // B... } }
该代码读作:若 condition 的值为 true,则执行 A 代码,否则执行 B 代码。
先看下面代码:
fn main() { let condition = true; let number = if condition { 5 } else { 6 }; println!("The value of number is: {}", number); }
以上代码有以下几点要注意:
if语句块是表达式,这里我们使用if表达式的返回值来给number进行赋值:number的值是5- 用
if来赋值时,要保证每个分支返回的类型一样(事实上,这种说法不完全准确,见这里),此处返回的5和6就是同一个类型,如果返回类型不一致就会报错
error[E0308]: if and else have incompatible types
--> src/main.rs:4:18
|
4 | let number = if condition {
| __________________^
5 | | 5
6 | | } else {
7 | | "six"
8 | | };
| |_____^ expected integer, found &str // 期望整数类型,但却发现&str字符串切片
|
= note: expected type `{integer}`
found type `&str`
使用 else if 来处理多重条件
可以将 else if 与 if、else 组合在一起实现更复杂的条件分支判断:
fn main() { let n = 6; if n % 4 == 0 { println!("number is divisible by 4"); } else if n % 3 == 0 { println!("number is divisible by 3"); } else if n % 2 == 0 { println!("number is divisible by 2"); } else { println!("number is not divisible by 4, 3, or 2"); } }
程序执行时,会按照自上至下的顺序执行每一个分支判断,一旦成功,则跳出 if 语句块,最终本程序会匹配执行 else if n % 3 == 0 的分支,输出 "number is divisible by 3"。
有一点要注意,就算有多个分支能匹配,也只有第一个匹配的分支会被执行!
如果代码中有大量的 else if 会让代码变得极其丑陋,不过不用担心,下一章的 match 专门用以解决多分支模式匹配的问题。
循环控制
在 Rust 语言中有三种循环方式:for、while 和 loop,其中 for 循环是 Rust 循环王冠上的明珠。
for 循环
for 循环是 Rust 的大杀器:
fn main() { for i in 1..=5 { println!("{}", i); } }
以上代码循环输出一个从 1 到 5 的序列,简单粗暴,核心就在于 for 和 in 的联动,语义表达如下:
#![allow(unused)] fn main() { for 元素 in 集合 { // 使用元素干一些你懂我不懂的事情 } }
注意,使用 for 时我们往往使用集合的引用形式,除非你不想在后面的代码中继续使用该集合(比如我们这里使用了 container 的引用)。如果不使用引用的话,所有权会被转移(move)到 for 语句块中,后面就无法再使用这个集合了):
#![allow(unused)] fn main() { for item in &container { // ... } }
对于实现了
copy特征的数组(例如 [i32; 10] )而言,for item in arr并不会把arr的所有权转移,而是直接对其进行了拷贝,因此循环之后仍然可以使用arr。
如果想在循环中,修改该元素,可以使用 mut 关键字:
#![allow(unused)] fn main() { for item in &mut collection { // ... } }
总结如下:
| 使用方法 | 等价使用方式 | 所有权 |
|---|---|---|
for item in collection | for item in IntoIterator::into_iter(collection) | 转移所有权 |
for item in &collection | for item in collection.iter() | 不可变借用 |
for item in &mut collection | for item in collection.iter_mut() | 可变借用 |
如果想在循环中获取元素的索引:
fn main() { let a = [4, 3, 2, 1]; // `.iter()` 方法把 `a` 数组变成一个迭代器 for (i, v) in a.iter().enumerate() { println!("第{}个元素是{}", i + 1, v); } }
有同学可能会想到,如果我们想用 for 循环控制某个过程执行 10 次,但是又不想单独声明一个变量来控制这个流程,该怎么写?
#![allow(unused)] fn main() { for _ in 0..10 { // ... } }
可以用 _ 来替代 i 用于 for 循环中,在 Rust 中 _ 的含义是忽略该值或者类型的意思,如果不使用 _,那么编译器会给你一个 变量未使用的 的警告。
两种循环方式优劣对比
以下代码,使用了两种循环方式:
#![allow(unused)] fn main() { // 第一种 let collection = [1, 2, 3, 4, 5]; for i in 0..collection.len() { let item = collection[i]; // ... } // 第二种 for item in collection { } }
第一种方式是循环索引,然后通过索引下标去访问集合,第二种方式是直接循环集合中的元素,优劣如下:
- 性能:第一种使用方式中
collection[index]的索引访问,会因为边界检查(Bounds Checking)导致运行时的性能损耗 —— Rust 会检查并确认index是否落在集合内,但是第二种直接迭代的方式就不会触发这种检查,因为编译器会在编译时就完成分析并证明这种访问是合法的 - 安全:第一种方式里对
collection的索引访问是非连续的,存在一定可能性在两次访问之间,collection发生了变化,导致脏数据产生。而第二种直接迭代的方式是连续访问,因此不存在这种风险(这里是因为所有权吗?是的话可能要强调一下)
由于 for 循环无需任何条件限制,也不需要通过索引来访问,因此是最安全也是最常用的,通过与下面的 while 的对比,我们能看到为什么 for 会更加安全。
continue
使用 continue 可以跳过当前当次的循环,开始下次的循环:
#![allow(unused)] fn main() { for i in 1..4 { if i == 2 { continue; } println!("{}", i); } }
上面代码对 1 到 3 的序列进行迭代,且跳过值为 2 时的循环,输出如下:
1
3
break
使用 break 可以直接跳出当前整个循环:
#![allow(unused)] fn main() { for i in 1..4 { if i == 2 { break; } println!("{}", i); } }
上面代码对 1 到 3 的序列进行迭代,在遇到值为 2 时的跳出整个循环,后面的循环不再执行,输出如下:
1
while 循环
如果你需要一个条件来循环,当该条件为 true 时,继续循环,条件为 false,跳出循环,那么 while 就非常适用:
fn main() { let mut n = 0; while n <= 5 { println!("{}!", n); n = n + 1; } println!("我出来了!"); }
该 while 循环,只有当 n 小于等于 5 时,才执行,否则就立刻跳出循环,因此在上述代码中,它会先从 0 开始,满足条件,进行循环,然后是 1,满足条件,进行循环,最终到 6 的时候,大于 5,不满足条件,跳出 while 循环,执行 我出来了 的打印,然后程序结束:
0!
1!
2!
3!
4!
5!
我出来了!
当然,你也可以用其它方式组合实现,例如 loop(无条件循环,将在下面介绍) + if + break:
fn main() { let mut n = 0; loop { if n > 5 { break } println!("{}", n); n+=1; } println!("我出来了!"); }
可以看出,在这种循环场景下,while 要简洁的多。
while vs for
我们也能用 while 来实现 for 的功能:
fn main() { let a = [10, 20, 30, 40, 50]; let mut index = 0; while index < 5 { println!("the value is: {}", a[index]); index = index + 1; } }
这里,代码对数组中的元素进行计数。它从索引 0 开始,并接着循环直到遇到数组的最后一个索引(这时,index < 5 不再为真)。运行这段代码会打印出数组中的每一个元素:
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
数组中的所有五个元素都如期被打印出来。尽管 index 在某一时刻会到达值 5,不过循环在其尝试从数组获取第六个值(会越界)之前就停止了。
但这个过程很容易出错;如果索引长度不正确会导致程序 panic。这也使程序更慢,因为编译器增加了运行时代码来对每次循环的每个元素进行条件检查。
for循环代码如下:
fn main() { let a = [10, 20, 30, 40, 50]; for element in a.iter() { println!("the value is: {}", element); } }
可以看出,for 并不会使用索引去访问数组,因此更安全也更简洁,同时避免 运行时的边界检查,性能更高。
loop 循环
对于循环而言,loop 循环毋庸置疑,是适用面最高的,它可以适用于所有循环场景(虽然能用,但是在很多场景下, for 和 while 才是最优选择),因为 loop 就是一个简单的无限循环,你可以在内部实现逻辑通过 break 关键字来控制循环何时结束。
当使用 loop 时,必不可少的伙伴是 break 关键字,它能让循环在满足某个条件时跳出:
fn main() { let mut counter = 0; let result = loop { counter += 1; if counter == 10 { break counter * 2; } }; println!("The result is {}", result); }
以上代码当 counter 递增到 10 时,就会通过 break 返回一个 counter * 2 的值,最后赋给 result 并打印出来。
这里有几点值得注意:
- break 可以单独使用,也可以带一个返回值,有些类似
return - loop 是一个表达式,因此可以返回一个值
模式匹配
match 和 if let
在 Rust 中,模式匹配最常用的就是 match 和 if let,本章节将对两者及相关的概念进行详尽介绍。
先来看一个关于 match 的简单例子:
enum Direction { East, West, North, South, } fn main() { let dire = Direction::South; match dire { Direction::East => println!("East"), Direction::North | Direction::South => { println!("South or North"); }, _ => println!("West"), }; }
这里我们想去匹配 dire 对应的枚举类型,因此在 match 中用三个匹配分支来完全覆盖枚举变量 Direction 的所有成员类型,有以下几点值得注意:
match的匹配必须要穷举出所有可能,因此这里用_来代表未列出的所有可能性match的每一个分支都必须是一个表达式,且所有分支的表达式最终返回值的类型必须相同- X | Y,类似逻辑运算符
或,代表该分支可以匹配X也可以匹配Y,只要满足一个即可
其实 match 跟其他语言中的 switch 非常像,_ 类似于 switch 中的 default。
match 匹配
首先来看看 match 的通用形式:
#![allow(unused)] fn main() { match target { 模式1 => 表达式1, 模式2 => { 语句1; 语句2; 表达式2 }, _ => 表达式3 } }
该形式清晰的说明了何为模式,何为模式匹配:将模式与 target 进行匹配,即为模式匹配,而模式匹配不仅仅局限于 match,后面我们会详细阐述。
match 允许我们将一个值与一系列的模式相比较,并根据相匹配的模式执行对应的代码,下面让我们来一一详解,先看一个例子:
#![allow(unused)] fn main() { enum Coin { Penny, Nickel, Dime, Quarter, } fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => { println!("Lucky penny!"); 1 }, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter => 25, } } }
value_in_cents 函数根据匹配到的硬币,返回对应的美分数值。match 后紧跟着的是一个表达式,跟 if 很像,但是 if 后的表达式必须是一个布尔值,而 match 后的表达式返回值可以是任意类型,只要能跟后面的分支中的模式匹配起来即可,这里的 coin 是枚举 Coin 类型。
接下来是 match 的分支。一个分支有两个部分:一个模式和针对该模式的处理代码。第一个分支的模式是 Coin::Penny,其后的 => 运算符将模式和将要运行的代码分开。这里的代码就仅仅是表达式 1,不同分支之间使用逗号分隔。
当 match 表达式执行时,它将目标值 coin 按顺序依次与每一个分支的模式相比较,如果模式匹配了这个值,那么模式之后的代码将被执行。如果模式并不匹配这个值,将继续执行下一个分支。
每个分支相关联的代码是一个表达式,而表达式的结果值将作为整个 match 表达式的返回值。如果分支有多行代码,那么需要用 {} 包裹,同时最后一行代码需要是一个表达式。
使用 match 表达式赋值
还有一点很重要,match 本身也是一个表达式,因此可以用它来赋值:
enum IpAddr { Ipv4, Ipv6 } fn main() { let ip1 = IpAddr::Ipv6; let ip_str = match ip1 { IpAddr::Ipv4 => "127.0.0.1", _ => "::1", }; println!("{}", ip_str); }
因为这里匹配到 _ 分支,所以将 "::1" 赋值给了 ip_str。
模式绑定
模式匹配的另外一个重要功能是从模式中取出绑定的值,例如:
#![allow(unused)] fn main() { #[derive(Debug)] enum UsState { Alabama, Alaska, // --snip-- } enum Coin { Penny, Nickel, Dime, Quarter(UsState), // 25美分硬币 } }
其中 Coin::Quarter 成员还存放了一个值:美国的某个州(因为在 1999 年到 2008 年间,美国在 25 美分(Quarter)硬币的背后为 50 个州印刷了不同的标记,其它硬币都没有这样的设计)。
接下来,我们希望在模式匹配中,获取到 25 美分硬币上刻印的州的名称:
#![allow(unused)] fn main() { fn value_in_cents(coin: Coin) -> u8 { match coin { Coin::Penny => 1, Coin::Nickel => 5, Coin::Dime => 10, Coin::Quarter(state) => { println!("State quarter from {:?}!", state); 25 }, } } }
上面代码中,在匹配 Coin::Quarter(state) 模式时,我们把它内部存储的值绑定到了 state 变量上,因此 state 变量就是对应的 UsState 枚举类型。
例如有一个印了阿拉斯加州标记的 25 分硬币:Coin::Quarter(UsState::Alaska), 它在匹配时,state 变量将被绑定 UsState::Alaska 的枚举值。
再来看一个更复杂的例子:
enum Action { Say(String), MoveTo(i32, i32), ChangeColorRGB(u16, u16, u16), } fn main() { let actions = [ Action::Say("Hello Rust".to_string()), Action::MoveTo(1,2), Action::ChangeColorRGB(255,255,0), ]; for action in actions { match action { Action::Say(s) => { println!("{}", s); }, Action::MoveTo(x, y) => { println!("point from (0, 0) move to ({}, {})", x, y); }, Action::ChangeColorRGB(r, g, _) => { println!("change color into '(r:{}, g:{}, b:0)', 'b' has been ignored", r, g, ); } } } }
运行后输出:
$ cargo run
Compiling world_hello v0.1.0 (/Users/sunfei/development/rust/world_hello)
Finished dev [unoptimized + debuginfo] target(s) in 0.16s
Running `target/debug/world_hello`
Hello Rust
point from (0, 0) move to (1, 2)
change color into '(r:255, g:255, b:0)', 'b' has been ignored
穷尽匹配
在文章的开头,我们简单总结过 match 的匹配必须穷尽所有情况,下面来举例说明,例如:
enum Direction { East, West, North, South, } fn main() { let dire = Direction::South; match dire { Direction::East => println!("East"), Direction::North | Direction::South => { println!("South or North"); }, }; }
我们没有处理 Direction::West 的情况,因此会报错:
error[E0004]: non-exhaustive patterns: `West` not covered // 非穷尽匹配,`West` 没有被覆盖
--> src/main.rs:10:11
|
1 | / enum Direction {
2 | | East,
3 | | West,
| | ---- not covered
4 | | North,
5 | | South,
6 | | }
| |_- `Direction` defined here
...
10 | match dire {
| ^^^^ pattern `West` not covered // 模式 `West` 没有被覆盖
|
= help: ensure that all possible cases are being handled, possibly by adding wildcards or more match arms
= note: the matched value is of type `Direction`
Rust 编译器清晰地知道 match 中有哪些分支没有被覆盖, 这种行为能强制我们处理所有的可能性,有效避免传说中价值十亿美金的 null 陷阱。
_ 通配符
当我们不想在匹配时列出所有值的时候,可以使用 Rust 提供的一个特殊模式,例如,u8 可以拥有 0 到 255 的有效的值,但是我们只关心 1、3、5 和 7 这几个值,不想列出其它的 0、2、4、6、8、9 一直到 255 的值。那么, 我们不必一个一个列出所有值, 因为可以使用特殊的模式 _ 替代:
#![allow(unused)] fn main() { let some_u8_value = 0u8; match some_u8_value { 1 => println!("one"), 3 => println!("three"), 5 => println!("five"), 7 => println!("seven"), _ => (), } }
通过将 _ 其放置于其他分支后,_ 将会匹配所有遗漏的值。() 表示返回单元类型与所有分支返回值的类型相同,所以当匹配到 _ 后,什么也不会发生。
然而,在某些场景下,我们其实只关心某一个值是否存在,此时 match 就显得过于啰嗦。
if let 匹配
有时会遇到只有一个模式的值需要被处理,其它值直接忽略的场景,如果用 match 来处理就要写成下面这样:
#![allow(unused)] fn main() { let v = Some(3u8); match v { Some(3) => println!("three"), _ => (), } }
我们只想要对 Some(3) 模式进行匹配, 不想处理任何其他 Some<u8> 值或 None 值。但是为了满足 match 表达式(穷尽性)的要求,写代码时必须在处理完这唯一的成员后加上 _ => (),这样会增加不少无用的代码。
俗话说“杀鸡焉用牛刀”,我们完全可以用 if let 的方式来实现:
#![allow(unused)] fn main() { if let Some(3) = v { println!("three"); } }
只要记住一点就好:当你只要匹配一个条件,且忽略其他条件时就用 if let ,否则都用 match。
matches!宏
Rust 标准库中提供了一个非常实用的宏:matches!,它可以将一个表达式跟模式进行匹配,然后返回匹配的结果 true or false。
例如,有一个动态数组,里面存有以下枚举:
enum MyEnum { Foo, Bar } fn main() { let v = vec![MyEnum::Foo,MyEnum::Bar,MyEnum::Foo]; }
现在如果想对 v 进行过滤,只保留类型是 MyEnum::Foo 的元素,你可能想这么写:
#![allow(unused)] fn main() { v.iter().filter(|x| x == MyEnum::Foo); }
但是,实际上这行代码会报错,因为你无法将 x 直接跟一个枚举成员进行比较。好在,你可以使用 match 来完成,但是会导致代码更为啰嗦,是否有更简洁的方式?答案是使用 matches!:
#![allow(unused)] fn main() { v.iter().filter(|x| matches!(x, MyEnum::Foo)); }
很简单也很简洁,再来看看更多的例子:
#![allow(unused)] fn main() { let foo = 'f'; assert!(matches!(foo, 'A'..='Z' | 'a'..='z')); let bar = Some(4); assert!(matches!(bar, Some(x) if x > 2)); }
变量覆盖
无论是 match 还是 if let,他们都可以在模式匹配时覆盖掉老的值,绑定新的值:
fn main() { let age = Some(30); println!("在匹配前,age是{:?}",age); if let Some(age) = age { println!("匹配出来的age是{}",age); } println!("在匹配后,age是{:?}",age); }
cargo run 运行后输出如下:
在匹配前,age是Some(30)
匹配出来的age是30
在匹配后,age是Some(30)
可以看出在 if let 中,= 右边 Some(i32) 类型的 age 被左边 i32 类型的新 age 覆盖了,该覆盖一直持续到 if let 语句块的结束。因此第三个 println! 输出的 age 依然是 Some(i32) 类型。
对于 match 类型也是如此:
fn main() { let age = Some(30); println!("在匹配前,age是{:?}",age); match age { Some(age) => println!("匹配出来的age是{}",age), _ => () } println!("在匹配后,age是{:?}",age); }
需要注意的是,match 中的变量覆盖其实不是那么的容易看出,因此要小心!
解构 Option
在枚举那章,提到过 Option 枚举,它用来解决 Rust 中变量是否有值的问题,定义如下:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
简单解释就是:一个变量要么有值:Some(T), 要么为空:None。
那么现在的问题就是该如何去使用这个 Option 枚举类型,根据我们上一节的经验,可以通过 match 来实现。
因为
Option,Some,None都包含在prelude中,因此你可以直接通过名称来使用它们,而无需以Option::Some这种形式去使用,总之,千万不要因为调用路径变短了,就忘记Some和None也是Option底下的枚举成员!
匹配 Option<T>
使用 Option<T>,是为了从 Some 中取出其内部的 T 值以及处理没有值的情况,为了演示这一点,下面一起来编写一个函数,它获取一个 Option<i32>,如果其中含有一个值,将其加一;如果其中没有值,则函数返回 None 值:
#![allow(unused)] fn main() { fn plus_one(x: Option<i32>) -> Option<i32> { match x { None => None, Some(i) => Some(i + 1), } } let five = Some(5); let six = plus_one(five); let none = plus_one(None); }
plus_one 接受一个 Option<i32> 类型的参数,同时返回一个 Option<i32> 类型的值(这种形式的函数在标准库内随处所见),在该函数的内部处理中,如果传入的是一个 None ,则返回一个 None 且不做任何处理;如果传入的是一个 Some(i32),则通过模式绑定,把其中的值绑定到变量 i 上,然后返回 i+1 的值,同时用 Some 进行包裹。
为了进一步说明,假设 plus_one 函数接受的参数值 x 是 Some(5),来看看具体的分支匹配情况:
传入参数 Some(5)
None => None,首先是匹配 None 分支,因为值 Some(5) 并不匹配模式 None,所以继续匹配下一个分支。
Some(i) => Some(i + 1),Some(5) 与 Some(i) 匹配吗?当然匹配!它们是相同的成员。i 绑定了 Some 中包含的值,因此 i 的值是 5。接着匹配分支的代码被执行,最后将 i 的值加一并返回一个含有值 6 的新 Some。
传入参数 None
接着考虑下 plus_one 的第二个调用,这次传入的 x 是 None, 我们进入 match 并与第一个分支相比较。
None => None,匹配上了!接着程序继续执行该分支后的代码:返回表达式 None 的值,也就是返回一个 None,因为第一个分支就匹配到了,其他的分支将不再比较。
模式适用场景
模式
模式是 Rust 中的特殊语法,它用来匹配类型中的结构和数据,它往往和 match 表达式联用,以实现强大的模式匹配能力。模式一般由以下内容组合而成:
- 字面值
- 解构的数组、枚举、结构体或者元组
- 变量
- 通配符
- 占位符
所有可能用到模式的地方
match 分支
#![allow(unused)] fn main() { match VALUE { PATTERN => EXPRESSION, PATTERN => EXPRESSION, PATTERN => EXPRESSION, } }
如上所示,match 的每个分支就是一个模式,因为 match 匹配是穷尽式的,因此我们往往需要一个特殊的模式 _,来匹配剩余的所有情况:
#![allow(unused)] fn main() { match VALUE { PATTERN => EXPRESSION, PATTERN => EXPRESSION, _ => EXPRESSION, } }
if let 分支
if let 往往用于匹配一个模式,而忽略剩下的所有模式的场景:
#![allow(unused)] fn main() { if let PATTERN = SOME_VALUE { } }
while let 条件循环
一个与 if let 类似的结构是 while let 条件循环,它允许只要模式匹配就一直进行 while 循环。下面展示了一个使用 while let 的例子:
#![allow(unused)] fn main() { // Vec是动态数组 let mut stack = Vec::new(); // 向数组尾部插入元素 stack.push(1); stack.push(2); stack.push(3); // stack.pop从数组尾部弹出元素 while let Some(top) = stack.pop() { println!("{}", top); } }
这个例子会打印出 3、2 接着是 1。pop 方法取出动态数组的最后一个元素并返回 Some(value),如果动态数组是空的,将返回 None,对于 while 来说,只要 pop 返回 Some 就会一直不停的循环。一旦其返回 None,while 循环停止。我们可以使用 while let 来弹出栈中的每一个元素。
你也可以用 loop + if let 或者 match 来实现这个功能,但是会更加啰嗦。
for 循环
#![allow(unused)] fn main() { let v = vec!['a', 'b', 'c']; for (index, value) in v.iter().enumerate() { println!("{} is at index {}", value, index); } }
这里使用 enumerate 方法产生一个迭代器,该迭代器每次迭代会返回一个 (索引,值) 形式的元组,然后用 (index,value) 来匹配。
let 语句
#![allow(unused)] fn main() { let PATTERN = EXPRESSION; }
是的, 该语句我们已经用了无数次了,它也是一种模式匹配:
#![allow(unused)] fn main() { let x = 5; }
这其中,x 也是一种模式绑定,代表将匹配的值绑定到变量 x 上。因此,在 Rust 中,变量名也是一种模式,只不过它比较朴素很不起眼罢了。
#![allow(unused)] fn main() { let (x, y, z) = (1, 2, 3); }
上面将一个元组与模式进行匹配(模式和值的类型必需相同!),然后把 1, 2, 3 分别绑定到 x, y, z 上。
模式匹配要求两边的类型必须相同,否则就会导致下面的报错:
#![allow(unused)] fn main() { let (x, y) = (1, 2, 3); }
#![allow(unused)] fn main() { error[E0308]: mismatched types --> src/main.rs:4:5 | 4 | let (x, y) = (1, 2, 3); | ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})` | | | expected a tuple with 3 elements, found one with 2 elements | = note: expected tuple `({integer}, {integer}, {integer})` found tuple `(_, _)` For more information about this error, try `rustc --explain E0308`. error: could not compile `playground` due to previous error }
对于元组来说,元素个数也是类型的一部分!
函数参数
函数参数也是模式:
#![allow(unused)] fn main() { fn foo(x: i32) { // 代码 } }
其中 x 就是一个模式,你还可以在参数中匹配元组:
fn print_coordinates(&(x, y): &(i32, i32)) { println!("Current location: ({}, {})", x, y); } fn main() { let point = (3, 5); print_coordinates(&point); }
&(3, 5) 会匹配模式 &(x, y),因此 x 得到了 3,y 得到了 5。
let 和 if let
对于以下代码,编译器会报错:
#![allow(unused)] fn main() { let Some(x) = some_option_value; }
因为右边的值可能不为 Some,而是 None,这种时候就不能进行匹配,也就是上面的代码遗漏了 None 的匹配。
类似 let , for和match 都必须要求完全覆盖匹配,才能通过编译( 不可驳模式匹配 )。
但是对于 if let,就可以这样使用:
#![allow(unused)] fn main() { if let Some(x) = some_option_value { println!("{}", x); } }
因为 if let 允许匹配一种模式,而忽略其余的模式( 可驳模式匹配 )。
全模式列表
我们已领略过许多不同类型模式的例子,本节的目标就是把这些模式语法都罗列出来,方便大家检索查阅(模式匹配在我们的开发中会经常用到)。
匹配字面值
#![allow(unused)] fn main() { let x = 1; match x { 1 => println!("one"), 2 => println!("two"), 3 => println!("three"), _ => println!("anything"), } }
这段代码会打印 one 因为 x 的值是 1,如果希望代码获得特定的具体值,那么这种语法很有用。
匹配命名变量
在 match中,我们有讲过变量覆盖的问题,这个在匹配命名变量时会遇到:
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(y) => println!("Matched, y = {:?}", y), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {:?}", x, y); }
让我们看看当 match 语句运行的时候发生了什么。第一个匹配分支的模式并不匹配 x 中定义的值,所以代码继续执行。
第二个匹配分支中的模式引入了一个新变量 y,它会匹配任何 Some 中的值。因为这里的 y 在 match 表达式的作用域中,而不是之前 main 作用域中,所以这是一个新变量,不是开头声明为值 10 的那个 y。这个新的 y 绑定会匹配任何 Some 中的值,在这里是 x 中的值。因此这个 y 绑定了 x 中 Some 内部的值。这个值是 5,所以这个分支的表达式将会执行并打印出 Matched,y = 5。
如果 x 的值是 None 而不是 Some(5),头两个分支的模式不会匹配,所以会匹配模式 _。这个分支的模式中没有引入变量 x,所以此时表达式中的 x 会是外部没有被覆盖的 x,也就是 None。
一旦 match 表达式执行完毕,其作用域也就结束了,同理内部 y 的作用域也结束了。最后的 println! 会打印 at the end: x = Some(5), y = 10。
如果你不想引入变量覆盖,那么需要使用匹配守卫(match guard)的方式,稍后在匹配守卫提供的额外条件中会讲解。
单分支多模式
在 match 表达式中,可以使用 | 语法匹配多个模式,它代表 或的意思。例如,如下代码将 x 的值与匹配分支相比较,第一个分支有 或 选项,意味着如果 x 的值匹配此分支的任何一个模式,它就会运行:
#![allow(unused)] fn main() { let x = 1; match x { 1 | 2 => println!("one or two"), 3 => println!("three"), _ => println!("anything"), } }
上面的代码会打印 one or two。
通过序列 ..= 匹配值的范围
在数值类型中我们有讲到一个序列语法,该语法不仅可以用于循环中,还能用于匹配模式。
..= 语法允许你匹配一个闭区间序列内的值。在如下代码中,当模式匹配任何在此序列内的值时,该分支会执行:
#![allow(unused)] fn main() { let x = 5; match x { 1..=5 => println!("one through five"), _ => println!("something else"), } }
如果 x 是 1、2、3、4 或 5,第一个分支就会匹配。这相比使用 | 运算符表达相同的意思更为方便;相比 1..=5,使用 | 则不得不指定 1 | 2 | 3 | 4 | 5 这五个值,而使用 ..= 指定序列就简短的多,比如希望匹配比如从 1 到 1000 的数字的时候!
序列只允许用于数字或字符类型,原因是:它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。
如下是一个使用字符类型序列的例子:
#![allow(unused)] fn main() { let x = 'c'; match x { 'a'..='j' => println!("early ASCII letter"), 'k'..='z' => println!("late ASCII letter"), _ => println!("something else"), } }
Rust 知道 'c' 位于第一个模式的序列内,所以会打印出 early ASCII letter。
解构并分解值
也可以使用模式来解构结构体、枚举、元组、数组和引用。
解构结构体
下面代码展示了如何用 let 解构一个带有两个字段 x 和 y 的结构体 Point:
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x: a, y: b } = p; assert_eq!(0, a); assert_eq!(7, b); }
这段代码创建了变量 a 和 b 来匹配结构体 p 中的 x 和 y 字段,这个例子展示了模式中的变量名不必与结构体中的字段名一致。不过通常希望变量名与字段名一致以便于理解变量来自于哪些字段。
因为变量名匹配字段名是常见的,同时因为 let Point { x: x, y: y } = p; 中 x 和 y 重复了,所以对于匹配结构体字段的模式存在简写:只需列出结构体字段的名称,则模式创建的变量会有相同的名称。下例与上例有着相同行为的代码,不过 let 模式创建的变量为 x 和 y 而不是 a 和 b:
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; let Point { x, y } = p; assert_eq!(0, x); assert_eq!(7, y); }
这段代码创建了变量 x 和 y,与结构体 p 中的 x 和 y 字段相匹配。其结果是变量 x 和 y 包含结构体 p 中的值。
也可以使用字面值作为结构体模式的一部分进行解构,而不是为所有的字段创建变量。这允许我们测试一些字段为特定值的同时创建其他字段的变量。
下文展示了固定某个字段的匹配方式:
struct Point { x: i32, y: i32, } fn main() { let p = Point { x: 0, y: 7 }; match p { Point { x, y: 0 } => println!("On the x axis at {}", x), Point { x: 0, y } => println!("On the y axis at {}", y), Point { x, y } => println!("On neither axis: ({}, {})", x, y), } }
首先是 match 第一个分支,指定匹配 y 为 0 的 Point;
然后第二个分支在第一个分支之后,匹配 y 不为 0,x 为 0 的 Point;
最后一个分支匹配 x 不为 0,y 也不为 0 的 Point。
在这个例子中,值 p 因为其 x 包含 0 而匹配第二个分支,因此会打印出 On the y axis at 7。
解构枚举
下面代码以 Message 枚举为例,编写一个 match 使用模式解构每一个内部值:
enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } fn main() { let msg = Message::ChangeColor(0, 160, 255); match msg { Message::Quit => { println!("The Quit variant has no data to destructure.") } Message::Move { x, y } => { println!( "Move in the x direction {} and in the y direction {}", x, y ); } Message::Write(text) => println!("Text message: {}", text), Message::ChangeColor(r, g, b) => { println!( "Change the color to red {}, green {}, and blue {}", r, g, b ) } } }
这里老生常谈一句话,模式匹配一样要类型相同,因此匹配 Message::Move{1,2} 这样的枚举值,就必须要用 Message::Move{x,y} 这样的同类型模式才行。
这段代码会打印出 Change the color to red 0, green 160, and blue 255。尝试改变 msg 的值来观察其他分支代码的运行。
对于像 Message::Quit 这样没有任何数据的枚举成员,不能进一步解构其值。只能匹配其字面值 Message::Quit,因此模式中没有任何变量。
对于另外两个枚举成员,就用相同类型的模式去匹配出对应的值即可。
解构嵌套的结构体和枚举
目前为止,所有的例子都只匹配了深度为一级的结构体或枚举。 match 也可以匹配嵌套的项!
例如使用下面的代码来同时支持 RGB 和 HSV 色彩模式:
enum Color { Rgb(i32, i32, i32), Hsv(i32, i32, i32), } enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(Color), } fn main() { let msg = Message::ChangeColor(Color::Hsv(0, 160, 255)); match msg { Message::ChangeColor(Color::Rgb(r, g, b)) => { println!( "Change the color to red {}, green {}, and blue {}", r, g, b ) } Message::ChangeColor(Color::Hsv(h, s, v)) => { println!( "Change the color to hue {}, saturation {}, and value {}", h, s, v ) } _ => () } }
match 第一个分支的模式匹配一个 Message::ChangeColor 枚举成员,该枚举成员又包含了一个 Color::Rgb 的枚举成员,最终绑定了 3 个内部的 i32 值。第二个,就交给亲爱的读者来思考完成。
解构结构体和元组
我们甚至可以用复杂的方式来混合、匹配和嵌套解构模式。如下是一个复杂结构体的例子,其中结构体和元组嵌套在元组中,并将所有的原始类型解构出来:
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } let ((feet, inches), Point {x, y}) = ((3, 10), Point { x: 3, y: -10 }); }
这种将复杂类型分解匹配的方式,可以让我们单独得到感兴趣的某个值。
解构数组
对于数组,我们可以用类似元组的方式解构,分为两种情况:
定长数组
#![allow(unused)] fn main() { let arr: [u16; 2] = [114, 514]; let [x, y] = arr; assert_eq!(x, 114); assert_eq!(y, 514); }
不定长数组
#![allow(unused)] fn main() { let arr: &[u16] = &[114, 514]; if let [x, ..] = arr { assert_eq!(x, &114); } if let &[.., y] = arr { assert_eq!(y, 514); } let arr: &[u16] = &[]; assert!(matches!(arr, [..])); assert!(!matches!(arr, [x, ..])); }
忽略模式中的值
有时忽略模式中的一些值是很有用的,比如在 match 中的最后一个分支使用 _ 模式匹配所有剩余的值。 你也可以在另一个模式中使用 _ 模式,使用一个以下划线开始的名称,或者使用 .. 忽略所剩部分的值。
使用 _ 忽略整个值
虽然 _ 模式作为 match 表达式最后的分支特别有用,但是它的作用还不限于此。例如可以将其用于函数参数中:
fn foo(_: i32, y: i32) { println!("This code only uses the y parameter: {}", y); } fn main() { foo(3, 4); }
这段代码会完全忽略作为第一个参数传递的值 3,并会打印出 This code only uses the y parameter: 4。
大部分情况当你不再需要特定函数参数时,最好修改签名不再包含无用的参数。在一些情况下忽略函数参数会变得特别有用,比如实现特征时,当你需要特定类型签名但是函数实现并不需要某个参数时。此时编译器就不会警告说存在未使用的函数参数,就跟使用命名参数一样。
使用嵌套的 _ 忽略部分值
可以在一个模式内部使用 _ 忽略部分值:
#![allow(unused)] fn main() { let mut setting_value = Some(5); let new_setting_value = Some(10); match (setting_value, new_setting_value) { (Some(_), Some(_)) => { println!("Can't overwrite an existing customized value"); } _ => { setting_value = new_setting_value; } } println!("setting is {:?}", setting_value); }
这段代码会打印出 Can't overwrite an existing customized value 接着是 setting is Some(5)。
第一个匹配分支,我们不关心里面的值,只关心元组中两个元素的类型,因此对于 Some 中的值,直接进行忽略。
剩下的形如 (Some(_),None),(None, Some(_)), (None,None) 形式,都由第二个分支 _ 进行分配。
还可以在一个模式中的多处使用下划线来忽略特定值,如下所示,这里忽略了一个五元元组中的第二和第四个值:
#![allow(unused)] fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, _, third, _, fifth) => { println!("Some numbers: {}, {}, {}", first, third, fifth) }, } }
老生常谈:模式匹配一定要类型相同,因此匹配 numbers 元组的模式,也必须有五个值(元组中元素的数量也属于元组类型的一部分)。
这会打印出 Some numbers: 2, 8, 32, 值 4 和 16 会被忽略。
使用下划线开头忽略未使用的变量
如果你创建了一个变量却不在任何地方使用它,Rust 通常会给你一个警告,因为这可能会是个 BUG。但是有时创建一个不会被使用的变量是有用的,比如你正在设计原型或刚刚开始一个项目。这时你希望告诉 Rust 不要警告未使用的变量,为此可以用下划线作为变量名的开头:
fn main() { let _x = 5; let y = 10; }
这里得到了警告说未使用变量 y,至于 x 则没有警告。
注意, 只使用 _ 和使用以下划线开头的名称有些微妙的不同:比如 _x 仍会将值绑定到变量,而 _ 则完全不会绑定。
#![allow(unused)] fn main() { let s = Some(String::from("Hello!")); if let Some(_s) = s { println!("found a string"); } println!("{:?}", s); }
s 是一个拥有所有权的动态字符串,在上面代码中,我们会得到一个错误,因为 s 的值会被转移给 _s,在 println! 中再次使用 s 会报错:
error[E0382]: borrow of partially moved value: `s`
--> src/main.rs:8:22
|
4 | if let Some(_s) = s {
| -- value partially moved here
...
8 | println!("{:?}", s);
| ^ value borrowed here after partial move
只使用下划线本身,则并不会绑定值,因为 s 没有被移动进 _:
#![allow(unused)] fn main() { let s = Some(String::from("Hello!")); if let Some(_) = s { println!("found a string"); } println!("{:?}", s); }
用 .. 忽略剩余值
对于有多个部分的值,可以使用 .. 语法来只使用部分值而忽略其它值,这样也不用再为每一个被忽略的值都单独列出下划线。.. 模式会忽略模式中剩余的任何没有显式匹配的值部分。
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, z: i32, } let origin = Point { x: 0, y: 0, z: 0 }; match origin { Point { x, .. } => println!("x is {}", x), } }
这里列出了 x 值,接着使用了 .. 模式来忽略其它字段,这样的写法要比一一列出其它字段,然后用 _ 忽略简洁的多。
还可以用 .. 来忽略元组中间的某些值:
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (first, .., last) => { println!("Some numbers: {}, {}", first, last); }, } }
这里用 first 和 last 来匹配第一个和最后一个值。.. 将匹配并忽略中间的所有值。
然而使用 .. 必须是无歧义的。如果期望匹配和忽略的值是不明确的,Rust 会报错。下面代码展示了一个带有歧义的 .. 例子,因此不能编译:
fn main() { let numbers = (2, 4, 8, 16, 32); match numbers { (.., second, ..) => { println!("Some numbers: {}", second) }, } }
如果编译上面的例子,会得到下面的错误:
error: `..` can only be used once per tuple pattern // 每个元组模式只能使用一个 `..`
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here // 上一次使用在这里
error: could not compile `world_hello` due to previous error ^^
Rust 无法判断,second 应该匹配 numbers 中的第几个元素,因此这里使用两个 .. 模式,是有很大歧义的!
匹配守卫提供的额外条件
匹配守卫(match guard)是一个位于 match 分支模式之后的额外 if 条件,它能为分支模式提供更进一步的匹配条件。
这个条件可以使用模式中创建的变量:
#![allow(unused)] fn main() { let num = Some(4); match num { Some(x) if x < 5 => println!("less than five: {}", x), Some(x) => println!("{}", x), None => (), } }
这个例子会打印出 less than five: 4。当 num 与模式中第一个分支匹配时,Some(4) 可以与 Some(x) 匹配,接着匹配守卫检查 x 值是否小于 5,因为 4 小于 5,所以第一个分支被选择。
相反如果 num 为 Some(10),因为 10 不小于 5 ,所以第一个分支的匹配守卫为假。接着 Rust 会前往第二个分支,因为这里没有匹配守卫所以会匹配任何 Some 成员。
模式中无法提供类如 if x < 5 的表达能力,我们可以通过匹配守卫的方式来实现。
在之前,我们提到可以使用匹配守卫来解决模式中变量覆盖的问题,那里 match 表达式的模式中新建了一个变量而不是使用 match 之外的同名变量。内部变量覆盖了外部变量,意味着此时不能够使用外部变量的值,下面代码展示了如何使用匹配守卫修复这个问题。
fn main() { let x = Some(5); let y = 10; match x { Some(50) => println!("Got 50"), Some(n) if n == y => println!("Matched, n = {}", n), _ => println!("Default case, x = {:?}", x), } println!("at the end: x = {:?}, y = {}", x, y); }
现在这会打印出 Default case, x = Some(5)。现在第二个匹配分支中的模式不会引入一个覆盖外部 y 的新变量 y,这意味着可以在匹配守卫中使用外部的 y。相比指定会覆盖外部 y 的模式 Some(y),这里指定为 Some(n)。此新建的变量 n 并没有覆盖任何值,因为 match 外部没有变量 n。
匹配守卫 if n == y 并不是一个模式所以没有引入新变量。这个 y 正是 外部的 y 而不是新的覆盖变量 y,这样就可以通过比较 n 和 y 来表达寻找一个与外部 y 相同的值的概念了。
也可以在匹配守卫中使用 或 运算符 | 来指定多个模式,同时匹配守卫的条件会作用于所有的模式。下面代码展示了匹配守卫与 | 的优先级。这个例子中看起来好像 if y 只作用于 6,但实际上匹配守卫 if y 作用于 4、5 和 6 ,在满足 x 属于 4 | 5 | 6 后才会判断 y 是否为 true:
#![allow(unused)] fn main() { let x = 4; let y = false; match x { 4 | 5 | 6 if y => println!("yes"), _ => println!("no"), } }
这个匹配条件表明此分支只匹配 x 值为 4、5 或 6 同时 y 为 true 的情况。
虽然在第一个分支中,x 匹配了模式 4 ,但是对于匹配守卫 if y 来说,因为 y 是 false,因此该守卫条件的值永远是 false,也意味着第一个分支永远无法被匹配。
下面的文字图解释了匹配守卫作用于多个模式时的优先级规则,第一张是正确的:
(4 | 5 | 6) if y => ...
而第二张图是错误的
4 | 5 | (6 if y) => ...
可以通过运行代码时的情况看出这一点:如果匹配守卫只作用于由 | 运算符指定的值列表的最后一个值,这个分支就会匹配且程序会打印出 yes。
@绑定
@(读作 at)运算符允许为一个字段绑定另外一个变量。下面例子中,我们希望测试 Message::Hello 的 id 字段是否位于 3..=7 范围内,同时也希望能将其值绑定到 id_variable 变量中以便此分支中相关的代码可以使用它。我们可以将 id_variable 命名为 id,与字段同名,不过出于示例的目的这里选择了不同的名称。
#![allow(unused)] fn main() { enum Message { Hello { id: i32 }, } let msg = Message::Hello { id: 5 }; match msg { Message::Hello { id: id_variable @ 3..=7 } => { println!("Found an id in range: {}", id_variable) }, Message::Hello { id: 10..=12 } => { println!("Found an id in another range") }, Message::Hello { id } => { println!("Found some other id: {}", id) }, } }
上例会打印出 Found an id in range: 5。通过在 3..=7 之前指定 id_variable @,我们捕获了任何匹配此范围的值并同时将该值绑定到变量 id_variable 上。
第二个分支只在模式中指定了一个范围,id 字段的值可以是 10、11 或 12,不过这个模式的代码并不知情也不能使用 id 字段中的值,因为没有将 id 值保存进一个变量。
最后一个分支指定了一个没有范围的变量,此时确实拥有可以用于分支代码的变量 id,因为这里使用了结构体字段简写语法。不过此分支中没有像头两个分支那样对 id 字段的值进行测试:任何值都会匹配此分支。
当你既想要限定分支范围,又想要使用分支的变量时,就可以用 @ 来绑定到一个新的变量上,实现想要的功能。
@前绑定后解构(Rust 1.56 新增)
使用 @ 还可以在绑定新变量的同时,对目标进行解构:
#[derive(Debug)] struct Point { x: i32, y: i32, } fn main() { // 绑定新变量 `p`,同时对 `Point` 进行解构 let p @ Point {x: px, y: py } = Point {x: 10, y: 23}; println!("x: {}, y: {}", px, py); println!("{:?}", p); let point = Point {x: 10, y: 5}; if let p @ Point {x: 10, y} = point { println!("x is 10 and y is {} in {:?}", y, p); } else { println!("x was not 10 :("); } }
@新特性(Rust 1.53 新增)
考虑下面一段代码:
fn main() { match 1 { num @ 1 | 2 => { println!("{}", num); } _ => {} } }
编译不通过,是因为 num 没有绑定到所有的模式上,只绑定了模式 1,你可能会试图通过这个方式来解决:
#![allow(unused)] fn main() { num @ (1 | 2) }
但是,如果你用的是 Rust 1.53 之前的版本,那这种写法会报错,因为编译器不支持。
至此,模式匹配的内容已经全部完结,复杂但是详尽,想要一次性全部记住属实不易,因此读者可以先留一个印象,等未来需要时,再来翻阅寻找具体的模式实现方式。
方法 Method
从面向对象语言过来的同学对于方法肯定不陌生,class 里面就充斥着方法的概念。在 Rust 中,方法的概念也大差不差,往往和对象成对出现:
#![allow(unused)] fn main() { object.method() }
例如读取一个文件写入缓冲区,如果用函数的写法 read(f, buffer),用方法的写法 f.read(buffer)。不过与其它语言 class 跟方法的联动使用不同(这里可能要修改下),Rust 的方法往往跟结构体、枚举、特征(Trait)一起使用,特征将在后面几章进行介绍。
定义方法
Rust 使用 impl 来定义方法,例如以下代码:
#![allow(unused)] fn main() { struct Circle { x: f64, y: f64, radius: f64, } impl Circle { // new是Circle的关联函数,因为它的第一个参数不是self,且new并不是关键字 // 这种方法往往用于初始化当前结构体的实例 fn new(x: f64, y: f64, radius: f64) -> Circle { Circle { x: x, y: y, radius: radius, } } // Circle的方法,&self表示借用当前的Circle结构体 fn area(&self) -> f64 { std::f64::consts::PI * (self.radius * self.radius) } } }
我们这里先不详细展开讲解,只是先建立对方法定义的大致印象。下面的图片将 Rust 方法定义与其它语言的方法定义做了对比:
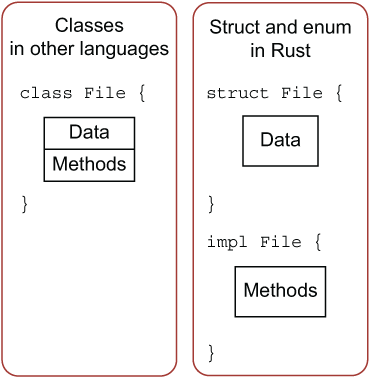
可以看出,其它语言中所有定义都在 class 中,但是 Rust 的对象定义和方法定义是分离的,这种数据和使用分离的方式,会给予使用者极高的灵活度。
再来看一个例子:
#[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50 }; println!( "The area of the rectangle is {} square pixels.", rect1.area() ); }
该例子定义了一个 Rectangle 结构体,并且在其上定义了一个 area 方法,用于计算该矩形的面积。
impl Rectangle {} 表示为 Rectangle 实现方法(impl 是实现 implementation 的缩写),这样的写法表明 impl 语句块中的一切都是跟 Rectangle 相关联的。
self、&self 和 &mut self
接下来的内容非常重要,请大家仔细看。在 area 的签名中,我们使用 &self 替代 rectangle: &Rectangle,&self 其实是 self: &Self 的简写(注意大小写)。在一个 impl 块内,Self 指代被实现方法的结构体类型,self 指代此类型的实例,换句话说,self 指代的是 Rectangle 结构体实例,这样的写法会让我们的代码简洁很多,而且非常便于理解:我们为哪个结构体实现方法,那么 self 就是指代哪个结构体的实例。
需要注意的是,self 依然有所有权的概念:
self表示Rectangle的所有权转移到该方法中,这种形式用的较少&self表示该方法对Rectangle的不可变借用&mut self表示可变借用
总之,self 的使用就跟函数参数一样,要严格遵守 Rust 的所有权规则。
回到上面的例子中,选择 &self 的理由跟在函数中使用 &Rectangle 是相同的:我们并不想获取所有权,也无需去改变它,只是希望能够读取结构体中的数据。如果想要在方法中去改变当前的结构体,需要将第一个参数改为 &mut self。仅仅通过使用 self 作为第一个参数来使方法获取实例的所有权是很少见的,这种使用方式往往用于把当前的对象转成另外一个对象时使用,转换完后,就不再关注之前的对象,且可以防止对之前对象的误调用。
简单总结下,使用方法代替函数有以下好处:
- 不用在函数签名中重复书写
self对应的类型 - 代码的组织性和内聚性更强,对于代码维护和阅读来说,好处巨大
方法名跟结构体字段名相同
在 Rust 中,允许方法名跟结构体的字段名相同:
impl Rectangle { fn width(&self) -> bool { self.width > 0 } } fn main() { let rect1 = Rectangle { width: 30, height: 50, }; if rect1.width() { println!("The rectangle has a nonzero width; it is {}", rect1.width); } }
当我们使用 rect1.width() 时,Rust 知道我们调用的是它的方法,如果使用 rect1.width,则是访问它的字段。
一般来说,方法跟字段同名,往往适用于实现 getter 访问器,例如:
pub struct Rectangle { width: u32, height: u32, } impl Rectangle { pub fn new(width: u32, height: u32) -> Self { Rectangle { width, height } } pub fn width(&self) -> u32 { return self.width; } } fn main() { let rect1 = Rectangle::new(30, 50); println!("{}", rect1.width()); }
用这种方式,我们可以把 Rectangle 的字段设置为私有属性,只需把它的 new 和 width 方法设置为公开可见,那么用户就可以创建一个矩形,同时通过访问器 rect1.width() 方法来获取矩形的宽度,因为 width 字段是私有的,当用户访问 rect1.width 字段时,就会报错。注意在此例中,Self 指代的就是被实现方法的结构体 Rectangle。
->运算符到哪去了?在 C/C++ 语言中,有两个不同的运算符来调用方法:
.直接在对象上调用方法,而->在一个对象的指针上调用方法,这时需要先解引用指针。换句话说,如果object是一个指针,那么object->something()和(*object).something()是一样的。Rust 并没有一个与
->等效的运算符;相反,Rust 有一个叫 自动引用和解引用的功能。方法调用是 Rust 中少数几个拥有这种行为的地方。他是这样工作的:当使用
object.something()调用方法时,Rust 会自动为object添加&、&mut或*以便使object与方法签名匹配。也就是说,这些代码是等价的:#![allow(unused)] fn main() { #[derive(Debug,Copy,Clone)] struct Point { x: f64, y: f64, } impl Point { fn distance(&self, other: &Point) -> f64 { let x_squared = f64::powi(other.x - self.x, 2); let y_squared = f64::powi(other.y - self.y, 2); f64::sqrt(x_squared + y_squared) } } let p1 = Point { x: 0.0, y: 0.0 }; let p2 = Point { x: 5.0, y: 6.5 }; p1.distance(&p2); (&p1).distance(&p2); }第一行看起来简洁的多。这种自动引用的行为之所以有效,是因为方法有一个明确的接收者————
self的类型。在给出接收者和方法名的前提下,Rust 可以明确地计算出方法是仅仅读取(&self),做出修改(&mut self)或者是获取所有权(self)。事实上,Rust 对方法接收者的隐式借用让所有权在实践中更友好。
带有多个参数的方法
方法和函数一样,可以使用多个参数:
impl Rectangle { fn area(&self) -> u32 { self.width * self.height } fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } fn main() { let rect1 = Rectangle { width: 30, height: 50 }; let rect2 = Rectangle { width: 10, height: 40 }; let rect3 = Rectangle { width: 60, height: 45 }; println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2)); println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3)); }
关联函数
现在大家可以思考一个问题,如何为一个结构体定义一个构造器方法?也就是接受几个参数,然后构造并返回该结构体的实例。其实答案在开头的代码片段中就给出了,很简单,参数中不包含 self 即可。
这种定义在 impl 中且没有 self 的函数被称之为关联函数: 因为它没有 self,不能用 f.read() 的形式调用,因此它是一个函数而不是方法,它又在 impl 中,与结构体紧密关联,因此称为关联函数。
在之前的代码中,我们已经多次使用过关联函数,例如 String::from,用于创建一个动态字符串。
#![allow(unused)] fn main() { #[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn new(w: u32, h: u32) -> Rectangle { Rectangle { width: w, height: h } } } }
Rust 中有一个约定俗成的规则,使用
new来作为构造器的名称,出于设计上的考虑,Rust 特地没有用new作为关键字
因为是函数,所以不能用 . 的方式来调用,我们需要用 :: 来调用,例如 let sq = Rectangle::new(3, 3);。这个方法位于结构体的命名空间中::: 语法用于关联函数和模块创建的命名空间。
多个 impl 定义
Rust 允许我们为一个结构体定义多个 impl 块,目的是提供更多的灵活性和代码组织性,例如当方法多了后,可以把相关的方法组织在同一个 impl 块中,那么就可以形成多个 impl 块,各自完成一块儿目标:
#![allow(unused)] fn main() { #[derive(Debug)] struct Rectangle { width: u32, height: u32, } impl Rectangle { fn area(&self) -> u32 { self.width * self.height } } impl Rectangle { fn can_hold(&self, other: &Rectangle) -> bool { self.width > other.width && self.height > other.height } } }
当然,就这个例子而言,我们没必要使用两个 impl 块,这里只是为了演示方便。
为枚举实现方法
枚举类型之所以强大,不仅仅在于它好用、可以同一化类型,还在于,我们可以像结构体一样,为枚举实现方法:
#![allow(unused)] enum Message { Quit, Move { x: i32, y: i32 }, Write(String), ChangeColor(i32, i32, i32), } impl Message { fn call(&self) { // 在这里定义方法体 } } fn main() { let m = Message::Write(String::from("hello")); m.call(); }
除了结构体和枚举,我们还能为特征(trait)实现方法,这将在下一章进行讲解,在此之前,先来看看泛型。
泛型与特征
泛型 Generics
Go 语言在 2022 年,就要正式引入泛型,被视为在 1.0 版本后,语言特性发展迈出的一大步,为什么泛型这么重要?到底什么是泛型?Rust 的泛型有几种?
我们在编程中,经常有这样的需求:用同一功能的函数处理不同类型的数据,例如两个数的加法,无论是整数还是浮点数,甚至是自定义类型,都能进行支持。在不支持泛型的编程语言中,通常需要为每一种类型编写一个函数:
fn add_i8(a:i8, b:i8) -> i8 { a + b } fn add_i32(a:i32, b:i32) -> i32 { a + b } fn add_f64(a:f64, b:f64) -> f64 { a + b } fn main() { println!("add i8: {}", add_i8(2i8, 3i8)); println!("add i32: {}", add_i32(20, 30)); println!("add f64: {}", add_f64(1.23, 1.23)); }
实际上,泛型就是一种多态。泛型主要目的是为程序员提供编程的便利,减少代码的臃肿,同时可以极大地丰富语言本身的表达能力,为程序员提供了一个合适的炮管。想想,一个函数,可以代替几十个,甚至数百个函数,是一件多么让人兴奋的事情:
fn add<T>(a:T, b:T) -> T { a + b } fn main() { println!("add i8: {}", add(2i8, 3i8)); println!("add i32: {}", add(20, 30)); println!("add f64: {}", add(1.23, 1.23)); }
将之前的代码改成上面这样,就是 Rust 泛型的初印象,这段代码虽然很简洁,但是并不能编译通过,我们会在后面进行详细讲解,现在只要对泛型有个大概的印象即可。
泛型详解
上面代码的 T 就是泛型参数,实际上在 Rust 中,泛型参数的名称你可以任意起,但是出于惯例,我们都用 T ( T 是 type 的首字母)来作为首选,这个名称越短越好,除非需要表达含义,否则一个字母是最完美的。
使用泛型参数,有一个先决条件,必需在使用前对其进行声明:
#![allow(unused)] fn main() { fn largest<T>(list: &[T]) -> T { }
该泛型函数的作用是从列表中找出最大的值,其中列表中的元素类型为 T。首先 largest<T> 对泛型参数 T 进行了声明,然后才在函数参数中进行使用该泛型参数 list: &[T] (还记得 &[T] 类型吧?这是数组切片。
总之,我们可以这样理解这个函数定义:函数 largest 有泛型类型 T,它有个参数 list,其类型是元素为 T 的数组切片,最后,该函数返回值的类型也是 T。
具体的泛型函数实现如下:
fn largest<T>(list: &[T]) -> T { let mut largest = list[0]; for &item in list.iter() { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {}", result); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest(&char_list); println!("The largest char is {}", result); }
运行后报错:
error[E0369]: binary operation `>` cannot be applied to type `T` // `>`操作符不能用于类型`T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- T
| |
| T
|
help: consider restricting type parameter `T` // 考虑对T进行类型上的限制 :
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T {
| ++++++++++++++++++++++
因为 T 可以是任何类型,但不是所有的类型都能进行比较,因此上面的错误中,编译器建议我们给 T 添加一个类型限制:使用 std::cmp::PartialOrd 特征(Trait)对 T 进行限制,特征在下一节会详细介绍,现在你只要理解,该特征的目的就是让类型实现可比较的功能。
还记得我们一开始的 add 泛型函数吗?如果你运行它,会得到以下的报错:
error[E0369]: cannot add `T` to `T` // 无法将 `T` 类型跟 `T` 类型进行相加
--> src/main.rs:2:7
|
2 | a + b
| - ^ - T
| |
| T
|
help: consider restricting type parameter `T`
|
1 | fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T {
| +++++++++++++++++++++++++++
同样的,不是所有 T 类型都能进行相加操作,因此我们需要用 std::ops::Add<Output = T> 对 T 进行限制:
#![allow(unused)] fn main() { fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T { a + b } }
进行如上修改后,就可以正常运行。
结构体中使用泛型
结构体中的字段类型也可以用泛型来定义,下面代码定义了一个坐标点 Point,它可以存放任何类型的坐标值:
struct Point<T> { x: T, y: T, } fn main() { let integer = Point { x: 5, y: 10 }; let float = Point { x: 1.0, y: 4.0 }; }
这里有两点需要特别的注意:
- 提前声明,跟泛型函数定义类似,首先我们在使用泛型参数之前必需要进行声明
Point<T>,接着就可以在结构体的字段类型中使用T来替代具体的类型 - x 和 y 是相同的类型
第二点非常重要,如果使用不同的类型,那么它会导致下面代码的报错:
struct Point<T> { x: T, y: T, } fn main() { let p = Point{x: 1, y :1.1}; }
错误如下:
error[E0308]: mismatched types //类型不匹配
--> src/main.rs:7:28
|
7 | let p = Point{x: 1, y :1.1};
| ^^^ expected integer, found floating-point number //期望y是整数,但是却是浮点数
当把 1 赋值给 x 时,变量 p 的 T 类型就被确定为整数类型,因此 y 也必须是整数类型,但是我们却给它赋予了浮点数,因此导致报错。
如果想让 x 和 y 既能类型相同,又能类型不同,就需要使用不同的泛型参数:
struct Point<T,U> { x: T, y: U, } fn main() { let p = Point{x: 1, y :1.1}; }
切记,所有的泛型参数都要提前声明:Point<T,U> ! 但是如果你的结构体变成这鬼样:struct Woo<T,U,V,W,X>,那么你需要考虑拆分这个结构体,减少泛型参数的个数和代码复杂度。
枚举中使用泛型
提到枚举类型,Option 永远是第一个应该被想起来的,在之前的章节中,它也多次出现:
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
Option<T> 是一个拥有泛型 T 的枚举类型,它第一个成员是 Some(T),存放了一个类型为 T 的值。得益于泛型的引入,我们可以在任何一个需要返回值的函数中,去使用 Option<T> 枚举类型来做为返回值,用于返回一个任意类型的值 Some(T),或者没有值 None。
对于枚举而言,卧龙凤雏永远是绕不过去的存在:如果是 Option 是卧龙,那么 Result 就一定是凤雏,得两者可得天下:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
这个枚举和 Option 一样,主要用于函数返回值,与 Option 用于值的存在与否不同,Result 关注的主要是值的正确性。
如果函数正常运行,则最后返回一个 Ok(T),T 是函数具体的返回值类型,如果函数异常运行,则返回一个 Err(E),E 是错误类型。例如打开一个文件:如果成功打开文件,则返回 Ok(std::fs::File),因此 T 对应的是 std::fs::File 类型;而当打开文件时出现问题时,返回 Err(std::io::Error),E 对应的就是 std::io::Error 类型。
方法中使用泛型
上一章中,我们讲到什么是方法以及如何在结构体和枚举上定义方法。方法上也可以使用泛型:
struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } fn main() { let p = Point { x: 5, y: 10 }; println!("p.x = {}", p.x()); }
使用泛型参数前,依然需要提前声明:impl<T>,只有提前声明了,我们才能在Point<T>中使用它,这样 Rust 就知道 Point 的尖括号中的类型是泛型而不是具体类型。需要注意的是,这里的 Point<T> 不再是泛型声明,而是一个完整的结构体类型,因为我们定义的结构体就是 Point<T> 而不再是 Point。
除了结构体中的泛型参数,我们还能在该结构体的方法中定义额外的泛型参数,就跟泛型函数一样:
struct Point<T, U> { x: T, y: U, } impl<T, U> Point<T, U> { fn mixup<V, W>(self, other: Point<V, W>) -> Point<T, W> { Point { x: self.x, y: other.y, } } } fn main() { let p1 = Point { x: 5, y: 10.4 }; let p2 = Point { x: "Hello", y: 'c'}; let p3 = p1.mixup(p2); println!("p3.x = {}, p3.y = {}", p3.x, p3.y); }
这个例子中,T,U 是定义在结构体 Point 上的泛型参数,V,W 是单独定义在方法 mixup 上的泛型参数,它们并不冲突,说白了,你可以理解为,一个是结构体泛型,一个是函数泛型。
为具体的泛型类型实现方法
对于 Point<T> 类型,你不仅能定义基于 T 的方法,还能针对特定的具体类型,进行方法定义:
#![allow(unused)] fn main() { impl Point<f32> { fn distance_from_origin(&self) -> f32 { (self.x.powi(2) + self.y.powi(2)).sqrt() } } }
这段代码意味着 Point<f32> 类型会有一个方法 distance_from_origin,而其他 T 不是 f32 类型的 Point<T> 实例则没有定义此方法。这个方法计算点实例与坐标(0.0, 0.0) 之间的距离,并使用了只能用于浮点型的数学运算符。
这样我们就能针对特定的泛型类型实现某个特定的方法,对于其它泛型类型则没有定义该方法。
const 泛型(Rust 1.51 版本引入的重要特性)
在之前的泛型中,可以抽象为一句话:针对类型实现的泛型,所有的泛型都是为了抽象不同的类型,那有没有针对值的泛型?可能很多同学感觉很难理解,值怎么使用泛型?不急,我们先从数组讲起。
在数组那节,有提到过很重要的一点:[i32; 2] 和 [i32; 3] 是不同的数组类型,比如下面的代码:
fn display_array(arr: [i32; 3]) { println!("{:?}", arr); } fn main() { let arr: [i32; 3] = [1, 2, 3]; display_array(arr); let arr: [i32;2] = [1,2]; display_array(arr); }
运行后报错:
error[E0308]: mismatched types // 类型不匹配
--> src/main.rs:10:19
|
10 | display_array(arr);
| ^^^ expected an array with a fixed size of 3 elements, found one with 2 elements
// 期望一个长度为3的数组,却发现一个长度为2的
结合代码和报错,可以很清楚的看出,[i32; 3] 和 [i32; 2] 确实是两个完全不同的类型,因此无法用同一个函数调用。
首先,让我们修改代码,让 display_array 能打印任意长度的 i32 数组:
fn display_array(arr: &[i32]) { println!("{:?}", arr); } fn main() { let arr: [i32; 3] = [1, 2, 3]; display_array(&arr); let arr: [i32;2] = [1,2]; display_array(&arr); }
很简单,只要使用数组切片,然后传入 arr 的不可变引用即可。
接着,将 i32 改成所有类型的数组:
fn display_array<T: std::fmt::Debug>(arr: &[T]) { println!("{:?}", arr); } fn main() { let arr: [i32; 3] = [1, 2, 3]; display_array(&arr); let arr: [i32;2] = [1,2]; display_array(&arr); }
也不难,唯一要注意的是需要对 T 加一个限制 std::fmt::Debug,该限制表明 T 可以用在 println!("{:?}", arr) 中,因为 {:?} 形式的格式化输出需要 arr 实现该特征。
通过引用,我们可以很轻松的解决处理任何类型数组的问题,但是如果在某些场景下引用不适宜用或者干脆不能用呢?你们知道为什么以前 Rust 的一些数组库,在使用的时候都限定长度不超过 32 吗?因为它们会为每个长度都单独实现一个函数,简直。。。毫无人性。难道没有什么办法可以解决这个问题吗?
好在,现在咱们有了 const 泛型,也就是针对值的泛型,正好可以用于处理数组长度的问题:
fn display_array<T: std::fmt::Debug, const N: usize>(arr: [T; N]) { println!("{:?}", arr); } fn main() { let arr: [i32; 3] = [1, 2, 3]; display_array(arr); let arr: [i32; 2] = [1, 2]; display_array(arr); }
如上所示,我们定义了一个类型为 [T; N] 的数组,其中 T 是一个基于类型的泛型参数,这个和之前讲的泛型没有区别,而重点在于 N 这个泛型参数,它是一个基于值的泛型参数!因为它用来替代的是数组的长度。
N 就是 const 泛型,定义的语法是 const N: usize,表示 const 泛型 N ,它基于的值类型是 usize。
在泛型参数之前,Rust 完全不适合复杂矩阵的运算,自从有了 const 泛型,一切即将改变。
const 泛型表达式
假设我们某段代码需要在内存很小的平台上工作,因此需要限制函数参数占用的内存大小,此时就可以使用 const 泛型表达式来实现:
// 目前只能在nightly版本下使用 #![allow(incomplete_features)] #![feature(generic_const_exprs)] fn something<T>(val: T) where Assert<{ core::mem::size_of::<T>() < 768 }>: IsTrue, // ^-----------------------------^ 这里是一个 const 表达式,换成其它的 const 表达式也可以 { // } fn main() { something([0u8; 0]); // ok something([0u8; 512]); // ok something([0u8; 1024]); // 编译错误,数组长度是1024字节,超过了768字节的参数长度限制 } // --- pub enum Assert<const CHECK: bool> { // } pub trait IsTrue { // } impl IsTrue for Assert<true> { // }
const fn
@todo
泛型的性能
在 Rust 中泛型是零成本的抽象,意味着你在使用泛型时,完全不用担心性能上的问题。
但是任何选择都是权衡得失的,既然我们获得了性能上的巨大优势,那么又失去了什么呢?Rust 是在编译期为泛型对应的多个类型,生成各自的代码,因此损失了编译速度和增大了最终生成文件的大小。
具体来说:
Rust 通过在编译时进行泛型代码的 单态化(monomorphization)来保证效率。单态化是一个通过填充编译时使用的具体类型,将通用代码转换为特定代码的过程。
编译器所做的工作正好与我们创建泛型函数的步骤相反,编译器寻找所有泛型代码被调用的位置并针对具体类型生成代码。
让我们看看一个使用标准库中 Option 枚举的例子:
#![allow(unused)] fn main() { let integer = Some(5); let float = Some(5.0); }
当 Rust 编译这些代码的时候,它会进行单态化。编译器会读取传递给 Option<T> 的值并发现有两种 Option<T>:一种对应 i32 另一种对应 f64。为此,它会将泛型定义 Option<T> 展开为 Option_i32 和 Option_f64,接着将泛型定义替换为这两个具体的定义。
编译器生成的单态化版本的代码看起来像这样:
enum Option_i32 { Some(i32), None, } enum Option_f64 { Some(f64), None, } fn main() { let integer = Option_i32::Some(5); let float = Option_f64::Some(5.0); }
我们可以使用泛型来编写不重复的代码,而 Rust 将会为每一个实例编译其特定类型的代码。这意味着在使用泛型时没有运行时开销;当代码运行,它的执行效率就跟好像手写每个具体定义的重复代码一样。这个单态化过程正是 Rust 泛型在运行时极其高效的原因。
特征 Trait
如果我们想定义一个文件系统,那么把该系统跟底层存储解耦是很重要的。文件操作主要包含四个:open 、write、read、close,这些操作可以发生在硬盘,可以发生在内存,还可以发生在网络IO。总之如果你要为每一种情况都单独实现一套代码,那这种实现将过于繁杂,而且也没那个必要。
要解决上述问题,需要把这些行为抽象出来,就要使用 Rust 中的特征 trait 概念。可能你是第一次听说这个名词,但是不要怕,如果学过其他语言,那么大概率你听说过接口,没错,特征跟接口很类似。
在之前的代码中,我们也多次见过特征的使用,例如 #[derive(Debug)],它在我们定义的类型(struct)上自动派生 Debug 特征,接着可以使用 println!("{:?}", x) 打印这个类型;再例如:
#![allow(unused)] fn main() { fn add<T: std::ops::Add<Output = T>>(a:T, b:T) -> T { a + b } }
通过 std::ops::Add 特征来限制 T,只有 T 实现了 std::ops::Add 才能进行合法的加法操作,毕竟不是所有的类型都能进行相加。
这些都说明一个道理,特征定义了一个可以被共享的行为,只要实现了特征,你就能使用该行为。
定义特征
如果不同的类型具有相同的行为,那么我们就可以定义一个特征,然后为这些类型实现该特征。定义特征是把一些方法组合在一起,目的是定义一个实现某些目标所必需的行为的集合。
例如,我们现在有文章 Post 和微博 Weibo 两种内容载体,而我们想对相应的内容进行总结,也就是无论是文章内容,还是微博内容,都可以在某个时间点进行总结,那么总结这个行为就是共享的,因此可以用特征来定义:
#![allow(unused)] fn main() { pub trait Summary { fn summarize(&self) -> String; } }
这里使用 trait 关键字来声明一个特征,Summary 是特征名。在大括号中定义了该特征的所有方法,在这个例子中是: fn summarize(&self) -> String。
特征只定义行为看起来是什么样的,而不定义行为具体是怎么样的。因此,我们只定义特征方法的签名,而不进行实现,此时方法签名结尾是 ;,而不是一个 {}。
接下来,每一个实现这个特征的类型都需要具体实现该特征的相应方法,编译器也会确保任何实现 Summary 特征的类型都拥有与这个签名的定义完全一致的 summarize 方法。
为类型实现特征
因为特征只定义行为看起来是什么样的,因此我们需要为类型实现具体的特征,定义行为具体是怎么样的。
首先来为 Post 和 Weibo 实现 Summary 特征:
#![allow(unused)] fn main() { pub trait Summary { fn summarize(&self) -> String; } pub struct Post { pub title: String, // 标题 pub author: String, // 作者 pub content: String, // 内容 } impl Summary for Post { fn summarize(&self) -> String { format!("文章{}, 作者是{}", self.title, self.author) } } pub struct Weibo { pub username: String, pub content: String } impl Summary for Weibo { fn summarize(&self) -> String { format!("{}发表了微博{}", self.username, self.content) } } }
实现特征的语法与为结构体、枚举实现方法很像:impl Summary for Post,读作“为 Post 类型实现 Summary 特征”,然后在 impl 的花括号中实现该特征的具体方法。
接下来就可以在这个类型上调用特征的方法:
fn main() { let post = Post{title: "Rust语言简介".to_string(),author: "Sunface".to_string(), content: "Rust棒极了!".to_string()}; let weibo = Weibo{username: "sunface".to_string(),content: "好像微博没Tweet好用".to_string()}; println!("{}",post.summarize()); println!("{}",weibo.summarize()); }
运行输出:
文章 Rust 语言简介, 作者是Sunface
sunface发表了微博好像微博没Tweet好用
说实话,如果特征仅仅如此,你可能会觉得花里胡哨没啥用,接下来就让你见识下 trait 真正的威力。
特征定义与实现的位置(孤儿规则)
上面我们将 Summary 定义成了 pub 公开的。这样,如果他人想要使用我们的 Summary 特征,则可以引入到他们的包中,然后再进行实现。
关于特征实现与定义的位置,有一条非常重要的原则:如果你想要为类型 A 实现特征 T,那么 A 或者 T 至少有一个是在当前作用域中定义的! 例如我们可以为上面的 Post 类型实现标准库中的 Display 特征,这是因为 Post 类型定义在当前的作用域中。同时,我们也可以在当前包中为 String 类型实现 Summary 特征,因为 Summary 定义在当前作用域中。
但是你无法在当前作用域中,为 String 类型实现 Display 特征,因为它们俩都定义在标准库中,其定义所在的位置都不在当前作用域,跟你半毛钱关系都没有,看看就行了。
该规则被称为孤儿规则,可以确保其它人编写的代码不会破坏你的代码,也确保了你不会莫名其妙就破坏了风马牛不相及的代码。
默认实现
你可以在特征中定义具有默认实现的方法,这样其它类型无需再实现该方法,或者也可以选择重载该方法:
#![allow(unused)] fn main() { pub trait Summary { fn summarize(&self) -> String { String::from("(Read more...)") } } }
上面为 Summary 定义了一个默认实现,下面我们编写段代码来测试下:
#![allow(unused)] fn main() { impl Summary for Post {} impl Summary for Weibo { fn summarize(&self) -> String { format!("{}发表了微博{}", self.username, self.content) } } }
可以看到,Post 选择了默认实现,而 Weibo 重载了该方法,调用和输出如下:
#![allow(unused)] fn main() { println!("{}",post.summarize()); println!("{}",weibo.summarize()); }
(Read more...)
sunface发表了微博好像微博没Tweet好用
默认实现允许调用相同特征中的其他方法,哪怕这些方法没有默认实现。如此,特征可以提供很多有用的功能而只需要实现指定的一小部分内容。例如,我们可以定义 Summary 特征,使其具有一个需要实现的 summarize_author 方法,然后定义一个 summarize 方法,此方法的默认实现调用 summarize_author 方法:
#![allow(unused)] fn main() { pub trait Summary { fn summarize_author(&self) -> String; fn summarize(&self) -> String { format!("(Read more from {}...)", self.summarize_author()) } } }
为了使用 Summary,只需要实现 summarize_author 方法即可:
#![allow(unused)] fn main() { impl Summary for Weibo { fn summarize_author(&self) -> String { format!("@{}", self.username) } } println!("1 new weibo: {}", weibo.summarize()); }
weibo.summarize() 会先调用 Summary 特征默认实现的 summarize 方法,通过该方法进而调用 Weibo 为 Summary 实现的 summarize_author 方法,最终输出:1 new weibo: (Read more from @horse_ebooks...)。
使用特征作为函数参数
之前提到过,特征如果仅仅是用来实现方法,那真的有些大材小用,现在我们来讲下,真正可以让特征大放光彩的地方。
现在,先定义一个函数,使用特征作为函数参数:
#![allow(unused)] fn main() { pub fn notify(item: &impl Summary) { println!("Breaking news! {}", item.summarize()); } }
impl Summary,只能说想出这个类型的人真的是起名鬼才,简直太贴切了,故名思义,它的意思是 实现了Summary特征 的 item 参数。
你可以使用任何实现了 Summary 特征的类型作为该函数的参数,同时在函数体内,还可以调用该特征的方法,例如 summarize 方法。具体的说,可以传递 Post 或 Weibo 的实例来作为参数,而其它类如 String 或者 i32 的类型则不能用做该函数的参数,因为它们没有实现 Summary 特征。
特征约束(trait bound)
虽然 impl Trait 这种语法非常好理解,但是实际上它只是一个语法糖:
#![allow(unused)] fn main() { pub fn notify<T: Summary>(item: &T) { println!("Breaking news! {}", item.summarize()); } }
真正的完整书写形式如上所述,形如 T: Summary 被称为特征约束。
在简单的场景下 impl Trait 这种语法糖就足够使用,但是对于复杂的场景,特征约束可以让我们拥有更大的灵活性和语法表现能力,例如一个函数接受两个 impl Summary 的参数:
#![allow(unused)] fn main() { pub fn notify(item1: &impl Summary, item2: &impl Summary) {} }
如果函数两个参数是不同的类型,那么上面的方法很好,只要这两个类型都实现了 Summary 特征即可。但是如果我们想要强制函数的两个参数是同一类型呢?上面的语法就无法做到这种限制,此时我们只能使特征约束来实现:
#![allow(unused)] fn main() { pub fn notify<T: Summary>(item1: &T, item2: &T) {} }
泛型类型 T 说明了 item1 和 item2 必须拥有同样的类型,同时 T: Summary 说明了 T 必须实现 Summary 特征。
多重约束
除了单个约束条件,我们还可以指定多个约束条件,例如除了让参数实现 Summary 特征外,还可以让参数实现 Display 特征以控制它的格式化输出:
#![allow(unused)] fn main() { pub fn notify(item: &(impl Summary + Display)) {} }
除了上述的语法糖形式,还能使用特征约束的形式:
#![allow(unused)] fn main() { pub fn notify<T: Summary + Display>(item: &T) {} }
通过这两个特征,就可以使用 item.summarize 方法,以及通过 println!("{}", item) 来格式化输出 item。
Where 约束
当特征约束变得很多时,函数的签名将变得很复杂:
#![allow(unused)] fn main() { fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {} }
严格来说,上面的例子还是不够复杂,但是我们还是能对其做一些形式上的改进,通过 where:
#![allow(unused)] fn main() { fn some_function<T, U>(t: &T, u: &U) -> i32 where T: Display + Clone, U: Clone + Debug {} }
使用特征约束有条件地实现方法或特征
特征约束,可以让我们在指定类型 + 指定特征的条件下去实现方法,例如:
#![allow(unused)] fn main() { use std::fmt::Display; struct Pair<T> { x: T, y: T, } impl<T> Pair<T> { fn new(x: T, y: T) -> Self { Self { x, y, } } } impl<T: Display + PartialOrd> Pair<T> { fn cmp_display(&self) { if self.x >= self.y { println!("The largest member is x = {}", self.x); } else { println!("The largest member is y = {}", self.y); } } } }
cmp_display 方法,并不是所有的 Pair<T> 结构体对象都可以拥有,只有 T 同时实现了 Display + PartialOrd 的 Pair<T> 才可以拥有此方法。
该函数可读性会更好,因为泛型参数、参数、返回值都在一起,可以快速的阅读,同时每个泛型参数的特征也在新的代码行中通过特征约束进行了约束。
也可以有条件地实现特征, 例如,标准库为任何实现了 Display 特征的类型实现了 ToString 特征:
#![allow(unused)] fn main() { impl<T: Display> ToString for T { // --snip-- } }
我们可以对任何实现了 Display 特征的类型调用由 ToString 定义的 to_string 方法。例如,可以将整型转换为对应的 String 值,因为整型实现了 Display:
#![allow(unused)] fn main() { let s = 3.to_string(); }
函数返回中的 impl Trait
可以通过 impl Trait 来说明一个函数返回了一个类型,该类型实现了某个特征:
#![allow(unused)] fn main() { fn returns_summarizable() -> impl Summary { Weibo { username: String::from("sunface"), content: String::from( "m1 max太厉害了,电脑再也不会卡", ) } } }
因为 Weibo 实现了 Summary,因此这里可以用它来作为返回值。要注意的是,虽然我们知道这里是一个 Weibo 类型,但是对于 returns_summarizable 的调用者而言,他只知道返回了一个实现了 Summary 特征的对象,但是并不知道返回了一个 Weibo 类型。
这种 impl Trait 形式的返回值,在一种场景下非常非常有用,那就是返回的真实类型非常复杂,你不知道该怎么声明时(毕竟 Rust 要求你必须标出所有的类型),此时就可以用 impl Trait 的方式简单返回。例如,闭包和迭代器就是很复杂,只有编译器才知道那玩意的真实类型,如果让你写出来它们的具体类型,估计内心有一万只草泥马奔腾,好在你可以用 impl Iterator 来告诉调用者,返回了一个迭代器,因为所有迭代器都会实现 Iterator 特征。
但是这种返回值方式有一个很大的限制:只能有一个具体的类型,例如:
#![allow(unused)] fn main() { fn returns_summarizable(switch: bool) -> impl Summary { if switch { Post { title: String::from( "Penguins win the Stanley Cup Championship!", ), author: String::from("Iceburgh"), content: String::from( "The Pittsburgh Penguins once again are the best \ hockey team in the NHL.", ), } } else { Weibo { username: String::from("horse_ebooks"), content: String::from( "of course, as you probably already know, people", ), } } } }
以上的代码就无法通过编译,因为它返回了两个不同的类型 Post 和 Weibo。
`if` and `else` have incompatible types
expected struct `Post`, found struct `Weibo`
报错提示我们 if 和 else 返回了不同的类型。如果想要实现返回不同的类型,需要使用下一章节中的特征对象。
修复上一节中的 largest 函数
还记得上一节中的例子吧,当时留下一个疑问,该如何解决编译报错:
#![allow(unused)] fn main() { error[E0369]: binary operation `>` cannot be applied to type `T` // 无法在 `T` 类型上应用`>`运算符 --> src/main.rs:5:17 | 5 | if item > largest { | ---- ^ ------- T | | | T | help: consider restricting type parameter `T` // 考虑使用以下的特征来约束 `T` | 1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> T { | ^^^^^^^^^^^^^^^^^^^^^^ }
在 largest 函数体中我们想要使用大于运算符(>)比较两个 T 类型的值。这个运算符是标准库中特征 std::cmp::PartialOrd 的一个默认方法。所以需要在 T 的特征约束中指定 PartialOrd,这样 largest 函数可以用于内部元素类型可比较大小的数组切片。
由于 PartialOrd 位于 prelude 中所以并不需要通过 std::cmp 手动将其引入作用域。所以可以将 largest 的签名修改为如下:
#![allow(unused)] fn main() { fn largest<T: PartialOrd>(list: &[T]) -> T {} }
但是此时编译,又会出现新的错误:
#![allow(unused)] fn main() { error[E0508]: cannot move out of type `[T]`, a non-copy slice --> src/main.rs:2:23 | 2 | let mut largest = list[0]; | ^^^^^^^ | | | cannot move out of here | help: consider using a reference instead: `&list[0]` error[E0507]: cannot move out of borrowed content --> src/main.rs:4:9 | 4 | for &item in list.iter() { | ^---- | || | |hint: to prevent move, use `ref item` or `ref mut item` | cannot move out of borrowed content }
错误的核心是 cannot move out of type [T], a non-copy slice,原因是 T 没有实现 Copy 特性,因此我们只能把所有权进行转移,毕竟只有 i32 等基础类型才实现了 Copy 特性,可以存储在栈上,而 T 可以指代任何类型(严格来说是实现了 PartialOrd 特征的所有类型)。
因此,为了让 T 拥有 Copy 特性,我们可以增加特征约束:
fn largest<T: PartialOrd + Copy>(list: &[T]) -> T { let mut largest = list[0]; for &item in list.iter() { if item > largest { largest = item; } } largest } fn main() { let number_list = vec![34, 50, 25, 100, 65]; let result = largest(&number_list); println!("The largest number is {}", result); let char_list = vec!['y', 'm', 'a', 'q']; let result = largest(&char_list); println!("The largest char is {}", result); }
如果并不希望限制 largest 函数只能用于实现了 Copy 特征的类型,我们可以在 T 的特征约束中指定 Clone 特征而不是 Copy 特征。并克隆 list 中的每一个值使得 largest 函数拥有其所有权。使用 clone 函数意味着对于类似 String 这样拥有堆上数据的类型,会潜在地分配更多堆上空间,而堆分配在涉及大量数据时可能会相当缓慢。
另一种 largest 的实现方式是返回在 list 中 T 值的引用。如果我们将函数返回值从 T 改为 &T 并改变函数体使其能够返回一个引用,我们将不需要任何 Clone 或 Copy 的特征约束而且也不会有任何的堆分配。尝试自己实现这种替代解决方式吧!
通过 derive 派生特征
在本书中,形如 #[derive(Debug)] 的代码已经出现了很多次,这种是一种特征派生语法,被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
例如 Debug 特征,它有一套自动实现的默认代码,当你给一个结构体标记后,就可以使用 println!("{:?}", s) 的形式打印该结构体的对象。
再如 Copy 特征,它也有一套自动实现的默认代码,当标记到一个类型上时,可以让这个类型自动实现 Copy 特征,进而可以调用 copy 方法,进行自我复制。
总之,derive 派生出来的是 Rust 默认给我们提供的特征,在开发过程中极大的简化了自己手动实现相应特征的需求,当然,如果你有特殊的需求,还可以自己手动重载该实现。
调用方法需要引入特征
在一些场景中,使用 as 关键字做类型转换会有比较大的限制,因为你想要在类型转换上拥有完全的控制,例如处理转换错误,那么你将需要 TryInto:
use std::convert::TryInto; fn main() { let a: i32 = 10; let b: u16 = 100; let b_ = b.try_into() .unwrap(); if a < b_ { println!("Ten is less than one hundred."); } }
上面代码中引入了 std::convert::TryInto 特征,但是却没有使用它,可能有些同学会为此困惑,主要原因在于如果你要使用一个特征的方法,那么你需要将该特征引入当前的作用域中,我们在上面用到了 try_into 方法,因此需要引入对应的特征。
但是 Rust 又提供了一个非常便利的办法,即把最常用的标准库中的特征通过 std::prelude模块提前引入到当前作用域中,其中包括了 std::convert::TryInto,你可以尝试删除第一行的代码 use ...,看看是否会报错。
几个综合例子
为自定义类型实现 + 操作
在 Rust 中除了数值类型的加法,String 也可以做加法,因为 Rust 为该类型实现了 std::ops::Add 特征,同理,如果我们为自定义类型实现了该特征,那就可以自己实现 Point1 + Point2 的操作:
use std::ops::Add; // 为Point结构体派生Debug特征,用于格式化输出 #[derive(Debug)] struct Point<T: Add<T, Output = T>> { //限制类型T必须实现了Add特征,否则无法进行+操作。 x: T, y: T, } impl<T: Add<T, Output = T>> Add for Point<T> { type Output = Point<T>; fn add(self, p: Point<T>) -> Point<T> { Point{ x: self.x + p.x, y: self.y + p.y, } } } fn add<T: Add<T, Output=T>>(a:T, b:T) -> T { a + b } fn main() { let p1 = Point{x: 1.1f32, y: 1.1f32}; let p2 = Point{x: 2.1f32, y: 2.1f32}; println!("{:?}", add(p1, p2)); let p3 = Point{x: 1i32, y: 1i32}; let p4 = Point{x: 2i32, y: 2i32}; println!("{:?}", add(p3, p4)); }
自定义类型的打印输出
在开发过程中,往往只要使用 #[derive(Debug)] 对我们的自定义类型进行标注,即可实现打印输出的功能:
#[derive(Debug)] struct Point{ x: i32, y: i32 } fn main() { let p = Point{x:3,y:3}; println!("{:?}",p); }
但是在实际项目中,往往需要对我们的自定义类型进行自定义的格式化输出,以让用户更好的阅读理解我们的类型,此时就要为自定义类型实现 std::fmt::Display 特征:
#![allow(dead_code)] use std::fmt; use std::fmt::{Display}; #[derive(Debug,PartialEq)] enum FileState { Open, Closed, } #[derive(Debug)] struct File { name: String, data: Vec<u8>, state: FileState, } impl Display for FileState { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { match *self { FileState::Open => write!(f, "OPEN"), FileState::Closed => write!(f, "CLOSED"), } } } impl Display for File { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "<{} ({})>", self.name, self.state) } } impl File { fn new(name: &str) -> File { File { name: String::from(name), data: Vec::new(), state: FileState::Closed, } } } fn main() { let f6 = File::new("f6.txt"); //... println!("{:?}", f6); println!("{}", f6); }
特征对象
在上一节中有一段代码无法通过编译:
#![allow(unused)] fn main() { fn returns_summarizable(switch: bool) -> impl Summary { if switch { Post { // ... } } else { Weibo { // ... } } } }
其中 Post 和 Weibo 都实现了 Summary 特征,因此上面的函数试图通过返回 impl Summary 来返回这两个类型,但是编译器却无情地报错了,原因是 impl Trait 的返回值类型并不支持多种不同的类型返回,那如果我们想返回多种类型,该怎么办?
再来考虑一个问题:现在在做一款游戏,需要将多个对象渲染在屏幕上,这些对象属于不同的类型,存储在列表中,渲染的时候,需要循环该列表并顺序渲染每个对象,在 Rust 中该怎么实现?
聪明的同学可能已经能想到一个办法,利用枚举:
#[derive(Debug)] enum UiObject { Button, SelectBox, } fn main() { let objects = [ UiObject::Button, UiObject::SelectBox ]; for o in objects { draw(o) } } fn draw(o: UiObject) { println!("{:?}",o); }
Bingo,这个确实是一个办法,但是问题来了,如果你的对象集合并不能事先明确地知道呢?或者别人想要实现一个 UI 组件呢?此时枚举中的类型是有些缺少的,是不是还要修改你的代码增加一个枚举成员?
总之,在编写这个 UI 库时,我们无法知道所有的 UI 对象类型,只知道的是:
- UI 对象的类型不同
- 需要一个统一的类型来处理这些对象,无论是作为函数参数还是作为列表中的一员
- 需要对每一个对象调用
draw方法
在拥有继承的语言中,可以定义一个名为 Component 的类,该类上有一个 draw 方法。其他的类比如 Button、Image 和 SelectBox 会从 Component 派生并因此继承 draw 方法。它们各自都可以覆盖 draw 方法来定义自己的行为,但是框架会把所有这些类型当作是 Component 的实例,并在其上调用 draw。不过 Rust 并没有继承,我们得另寻出路。
特征对象定义
为了解决上面的所有问题,Rust 引入了一个概念 —— 特征对象。
在介绍特征对象之前,先来为之前的 UI 组件定义一个特征:
#![allow(unused)] fn main() { pub trait Draw { fn draw(&self); } }
只要组件实现了 Draw 特征,就可以调用 draw 方法来进行渲染。假设有一个 Button 和 SelectBox 组件实现了 Draw 特征:
#![allow(unused)] fn main() { pub struct Button { pub width: u32, pub height: u32, pub label: String, } impl Draw for Button { fn draw(&self) { // 绘制按钮的代码 } } struct SelectBox { width: u32, height: u32, options: Vec<String>, } impl Draw for SelectBox { fn draw(&self) { // 绘制SelectBox的代码 } } }
此时,还需要一个动态数组来存储这些 UI 对象:
#![allow(unused)] fn main() { pub struct Screen { pub components: Vec<?>, } }
注意到上面代码中的 ? 吗?它的意思是:我们应该填入什么类型,可以说就之前学过的内容里,你找不到哪个类型可以填入这里,但是因为 Button 和 SelectBox 都实现了 Draw 特征,那我们是不是可以把 Draw 特征的对象作为类型,填入到数组中呢?答案是肯定的。
特征对象指向实现了 Draw 特征的类型的实例,也就是指向了 Button 或者 SelectBox 的实例,这种映射关系是存储在一张表中,可以在运行时通过特征对象找到具体调用的类型方法。
可以通过 & 引用或者 Box<T> 智能指针的方式来创建特征对象。
Box<T>在后面章节会详细讲解,大家现在把它当成一个引用即可,只不过它包裹的值会被强制分配在堆上
trait Draw { fn draw(&self) -> String; } impl Draw for u8 { fn draw(&self) -> String { format!("u8: {}", *self) } } impl Draw for f64 { fn draw(&self) -> String { format!("f64: {}", *self) } } // 若 T 实现了 Draw 特征, 则调用该函数时传入的 Box<T> 可以被隐式转换成函数参数签名中的 Box<dyn Draw> fn draw1(x: Box<dyn Draw>) { // 由于实现了 Deref 特征,Box 智能指针会自动解引用为它所包裹的值,然后调用该值对应的类型上定义的 `draw` 方法 x.draw(); } fn draw2(x: &dyn Draw) { x.draw(); } fn main() { let x = 1.1f64; // do_something(&x); let y = 8u8; // x 和 y 的类型 T 都实现了 `Draw` 特征,因为 Box<T> 可以在函数调用时隐式地被转换为特征对象 Box<dyn Draw> // 基于 x 的值创建一个 Box<f64> 类型的智能指针,指针指向的数据被放置在了堆上 draw1(Box::new(x)); // 基于 y 的值创建一个 Box<u8> 类型的智能指针 draw1(Box::new(y)); draw2(&x); draw2(&y); }
上面代码,有几个非常重要的点:
draw1函数的参数是Box<dyn Draw>形式的特征对象,该特征对象是通过Box::new(x)的方式创建的draw2函数的参数是&dyn Draw形式的特征对象,该特征对象是通过&x的方式创建的dyn关键字只用在特征对象的类型声明上,在创建时无需使用dyn
因此,可以使用特征对象来代表泛型或具体的类型。
继续来完善之前的 UI 组件代码,首先来实现 Screen:
#![allow(unused)] fn main() { pub struct Screen { pub components: Vec<Box<dyn Draw>>, } }
其中存储了一个动态数组,里面元素的类型是 Draw 特征对象:Box<dyn Draw>,任何实现了 Draw 特征的类型,都可以存放其中。
再来为 Screen 定义 run 方法,用于将列表中的 UI 组件渲染在屏幕上:
#![allow(unused)] fn main() { impl Screen { pub fn run(&self) { for component in self.components.iter() { component.draw(); } } } }
至此,我们就完成了之前的目标:在列表中存储多种不同类型的实例,然后将它们使用同一个方法逐一渲染在屏幕上!
再来看看,如果通过泛型实现,会如何:
#![allow(unused)] fn main() { pub struct Screen<T: Draw> { pub components: Vec<T>, } impl<T> Screen<T> where T: Draw { pub fn run(&self) { for component in self.components.iter() { component.draw(); } } } }
上面的 Screen 的列表中,存储了类型为 T 的元素,然后在 Screen 中使用特征约束让 T 实现了 Draw 特征,进而可以调用 draw 方法。
但是这种写法限制了 Screen 实例的 Vec<T> 中的每个元素必须是 Button 类型或者全是 SelectBox 类型。如果只需要同质(相同类型)集合,更倾向于这种写法:使用泛型和 特征约束,因为实现更清晰,且性能更好(特征对象,需要在运行时从 vtable 动态查找需要调用的方法)。
现在来运行渲染下咱们精心设计的 UI 组件列表:
fn main() { let screen = Screen { components: vec![ Box::new(SelectBox { width: 75, height: 10, options: vec![ String::from("Yes"), String::from("Maybe"), String::from("No") ], }), Box::new(Button { width: 50, height: 10, label: String::from("OK"), }), ], }; screen.run(); }
上面使用 Box::new(T) 的方式来创建了两个 Box<dyn Draw> 特征对象,如果以后还需要增加一个 UI 组件,那么让该组件实现 Draw 特征,则可以很轻松的将其渲染在屏幕上,甚至用户可以引入我们的库作为三方库,然后在自己的库中为自己的类型实现 Draw 特征,然后进行渲染。
在动态类型语言中,有一个很重要的概念:鸭子类型(duck typing),简单来说,就是只关心值长啥样,而不关心它实际是什么。当一个东西走起来像鸭子,叫起来像鸭子,那么它就是一只鸭子,就算它实际上是一个奥特曼,也不重要,我们就当它是鸭子。
在上例中,Screen 在 run 的时候,我们并不需要知道各个组件的具体类型是什么。它也不检查组件到底是 Button 还是 SelectBox 的实例,只要它实现了 Draw 特征,就能通过 Box::new 包装成 Box<dyn Draw> 特征对象,然后被渲染在屏幕上。
使用特征对象和 Rust 类型系统来进行类似鸭子类型操作的优势是,无需在运行时检查一个值是否实现了特定方法或者担心在调用时因为值没有实现方法而产生错误。如果值没有实现特征对象所需的特征, 那么 Rust 根本就不会编译这些代码:
fn main() { let screen = Screen { components: vec![ Box::new(String::from("Hi")), ], }; screen.run(); }
因为 String 类型没有实现 Draw 特征,编译器直接就会报错,不会让上述代码运行。如果想要 String 类型被渲染在屏幕上,那么只需要为其实现 Draw 特征即可,非常容易。
注意 dyn 不能单独作为特征对象的定义,例如下面的代码编译器会报错,原因是特征对象可以是任意实现了某个特征的类型,编译器在编译期不知道该类型的大小,不同的类型大小是不同的。
而 &dyn 和 Box<dyn> 在编译期都是已知大小,所以可以用作特征对象的定义。
#![allow(unused)] fn main() { fn draw2(x: dyn Draw) { x.draw(); } }
10 | fn draw2(x: dyn Draw) {
| ^ doesn't have a size known at compile-time
|
= help: the trait `Sized` is not implemented for `(dyn Draw + 'static)`
help: function arguments must have a statically known size, borrowed types always have a known size
特征对象的动态分发
回忆一下泛型章节我们提到过的,泛型是在编译期完成处理的:编译器会为每一个泛型参数对应的具体类型生成一份代码,这种方式是静态分发(static dispatch),因为是在编译期完成的,对于运行期性能完全没有任何影响。
与静态分发相对应的是动态分发(dynamic dispatch),在这种情况下,直到运行时,才能确定需要调用什么方法。之前代码中的关键字 dyn 正是在强调这一“动态”的特点。
当使用特征对象时,Rust 必须使用动态分发。编译器无法知晓所有可能用于特征对象代码的类型,所以它也不知道应该调用哪个类型的哪个方法实现。为此,Rust 在运行时使用特征对象中的指针来知晓需要调用哪个方法。动态分发也阻止编译器有选择的内联方法代码,这会相应的禁用一些优化。
下面这张图很好的解释了静态分发 Box<T> 和动态分发 Box<dyn Trait> 的区别:
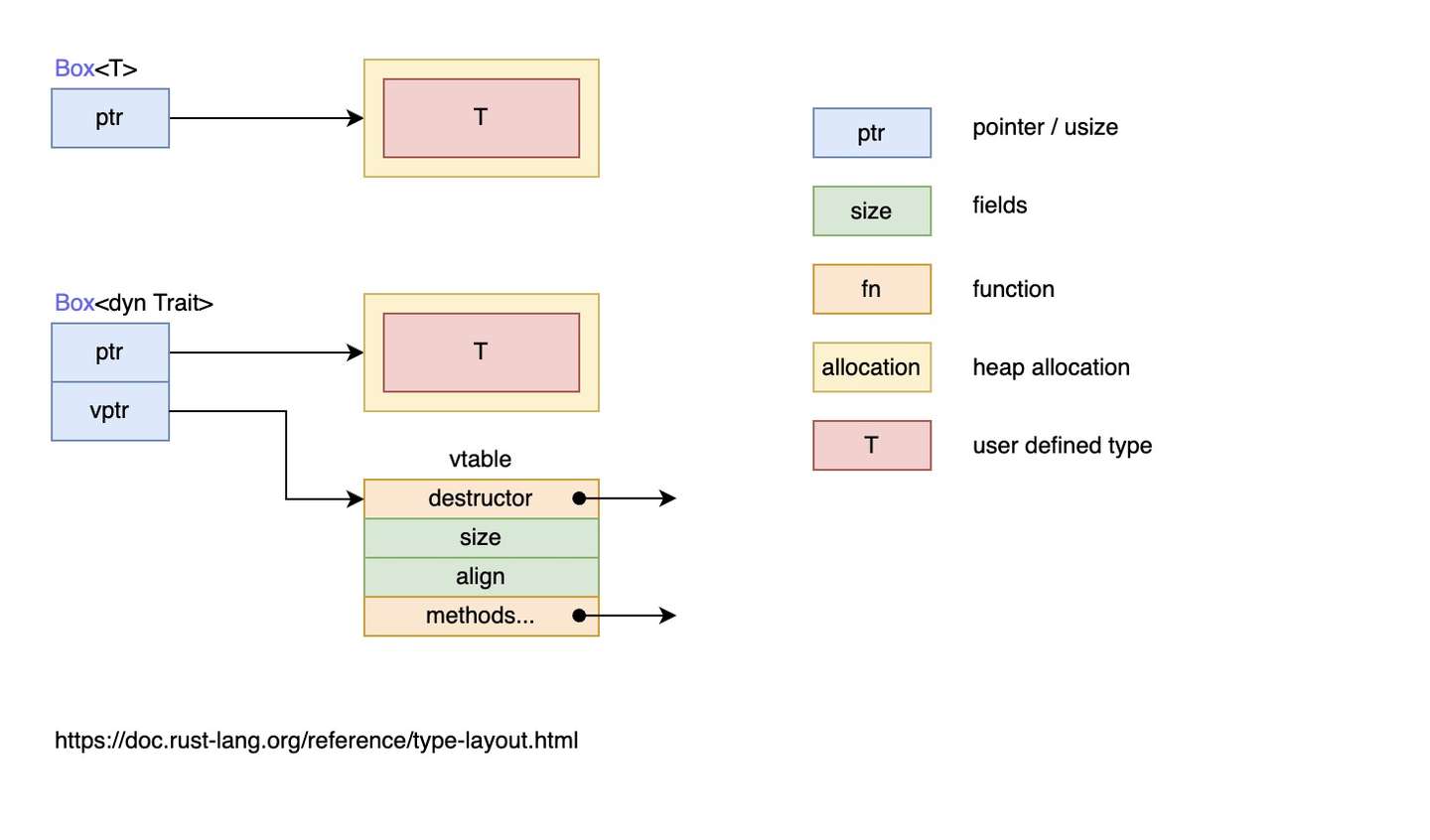
结合上文的内容和这张图可以了解:
- 特征对象大小不固定:这是因为,对于特征
Draw,类型Button可以实现特征Draw,类型SelectBox也可以实现特征Draw,因此特征没有固定大小 - 几乎总是使用特征对象的引用方式,如
&dyn Draw、Box<dyn Draw>- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
ptr和vptr),因此占用两个指针大小 - 一个指针
ptr指向实现了特征Draw的具体类型的实例,也就是当作特征Draw来用的类型的实例,比如类型Button的实例、类型SelectBox的实例 - 另一个指针
vptr指向一个虚表vtable,vtable中保存了类型Button或类型SelectBox的实例对于可以调用的实现于特征Draw的方法。当调用方法时,直接从vtable中找到方法并调用。之所以要使用一个vtable来保存各实例的方法,是因为实现了特征Draw的类型有多种,这些类型拥有的方法各不相同,当将这些类型的实例都当作特征Draw来使用时(此时,它们全都看作是特征Draw类型的实例),有必要区分这些实例各自有哪些方法可调用
- 虽然特征对象没有固定大小,但它的引用类型的大小是固定的,它由两个指针组成(
简而言之,当类型 Button 实现了特征 Draw 时,类型 Button 的实例对象 btn 可以当作特征 Draw 的特征对象类型来使用,btn 中保存了作为特征对象的数据指针(指向类型 Button 的实例数据)和行为指针(指向 vtable)。
一定要注意,此时的 btn 是 Draw 的特征对象的实例,而不再是具体类型 Button 的实例,而且 btn 的 vtable 只包含了实现自特征 Draw 的那些方法(比如 draw),因此 btn 只能调用实现于特征 Draw 的 draw 方法,而不能调用类型 Button 本身实现的方法和类型 Button 实现于其他特征的方法。也就是说,btn 是哪个特征对象的实例,它的 vtable 中就包含了该特征的方法。
Self 与 self
在 Rust 中,有两个self,一个指代当前的实例对象,一个指代特征或者方法类型的别名:
trait Draw { fn draw(&self) -> Self; } #[derive(Clone)] struct Button; impl Draw for Button { fn draw(&self) -> Self { return self.clone() } } fn main() { let button = Button; let newb = button.draw(); }
上述代码中,self指代的就是当前的实例对象,也就是 button.draw() 中的 button 实例,Self 则指代的是 Button 类型。
当理解了 self 与 Self 的区别后,我们再来看看何为对象安全。
特征对象的限制
不是所有特征都能拥有特征对象,只有对象安全的特征才行。当一个特征的所有方法都有如下属性时,它的对象才是安全的:
- 方法的返回类型不能是
Self - 方法没有任何泛型参数
对象安全对于特征对象是必须的,因为一旦有了特征对象,就不再需要知道实现该特征的具体类型是什么了。如果特征方法返回了具体的 Self 类型,但是特征对象忘记了其真正的类型,那这个 Self 就非常尴尬,因为没人知道它是谁了。但是对于泛型类型参数来说,当使用特征时其会放入具体的类型参数:此具体类型变成了实现该特征的类型的一部分。而当使用特征对象时其具体类型被抹去了,故而无从得知放入泛型参数类型到底是什么。
标准库中的 Clone 特征就不符合对象安全的要求:
#![allow(unused)] fn main() { pub trait Clone { fn clone(&self) -> Self; } }
因为它的其中一个方法,返回了 Self 类型,因此它是对象不安全的。
String 类型实现了 Clone 特征, String 实例上调用 clone 方法时会得到一个 String 实例。类似的,当调用 Vec<T> 实例的 clone 方法会得到一个 Vec<T> 实例。clone 的签名需要知道什么类型会代替 Self,因为这是它的返回值。
如果违反了对象安全的规则,编译器会提示你。例如,如果尝试使用之前的 Screen 结构体来存放实现了 Clone 特征的类型:
#![allow(unused)] fn main() { pub struct Screen { pub components: Vec<Box<dyn Clone>>, } }
将会得到如下错误:
error[E0038]: the trait `std::clone::Clone` cannot be made into an object
--> src/lib.rs:2:5
|
2 | pub components: Vec<Box<dyn Clone>>,
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `std::clone::Clone`
cannot be made into an object
|
= note: the trait cannot require that `Self : Sized`
这意味着不能以这种方式使用此特征作为特征对象。
深入了解特征
特征之于 Rust 更甚于接口之于其他语言,因此特征在 Rust 中很重要也相对较为复杂,我们决定把特征分为两篇进行介绍,第一篇在之前已经讲过,现在就是第二篇:关于特征的进阶篇,会讲述一些不常用到但是你该了解的特性。
关联类型
在方法一章中,我们讲到了关联函数,但是实际上关联类型和关联函数并没有任何交集,虽然它们的名字有一半的交集。
关联类型是在特征定义的语句块中,申明一个自定义类型,这样就可以在特征的方法签名中使用该类型:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; } }
以上是标准库中的迭代器特征 Iterator,它有一个 Item 关联类型,用于替代遍历的值的类型。
同时,next 方法也返回了一个 Item 类型,不过使用 Option 枚举进行了包裹,假如迭代器中的值是 i32 类型,那么调用 next 方法就将获取一个 Option<i32> 的值。
还记得 Self 吧?在之前的章节提到过, Self 用来指代当前调用者的具体类型,那么 Self::Item 就用来指代该类型实现中定义的 Item 类型:
impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { // --snip-- } } fn main() { let c = Counter{..} c.next() }
在上述代码中,我们为 Counter 类型实现了 Iterator 特征,变量 c 是特征 Iterator 的实例,也是 next 方法的调用者。 结合之前的黑体内容可以得出:对于 next 方法而言,Self 是调用者 c 的具体类型: Counter,而 Self::Item 是 Counter 中定义的 Item 类型: u32。
聪明的读者之所以聪明,是因为你们喜欢联想和举一反三,同时你们也喜欢提问:为何不用泛型,例如如下代码:
#![allow(unused)] fn main() { pub trait Iterator<Item> { fn next(&mut self) -> Option<Item>; } }
答案其实很简单,为了代码的可读性,当你使用了泛型后,你需要在所有地方都写 Iterator<Item>,而使用了关联类型,你只需要写 Iterator,当类型定义复杂时,这种写法可以极大的增加可读性:
#![allow(unused)] fn main() { pub trait CacheableItem: Clone + Default + fmt::Debug + Decodable + Encodable { type Address: AsRef<[u8]> + Clone + fmt::Debug + Eq + Hash; fn is_null(&self) -> bool; } }
例如上面的代码,Address 的写法自然远比 AsRef<[u8]> + Clone + fmt::Debug + Eq + Hash 要简单的多,而且含义清晰。
再例如,如果使用泛型,你将得到以下的代码:
#![allow(unused)] fn main() { trait Container<A,B> { fn contains(&self,a: A,b: B) -> bool; } fn difference<A,B,C>(container: &C) -> i32 where C : Container<A,B> {...} }
可以看到,由于使用了泛型,导致函数头部也必须增加泛型的声明,而使用关联类型,将得到可读性好得多的代码:
#![allow(unused)] fn main() { trait Container{ type A; type B; fn contains(&self, a: &Self::A, b: &Self::B) -> bool; } fn difference<C: Container>(container: &C) {} }
默认泛型类型参数
当使用泛型类型参数时,可以为其指定一个默认的具体类型,例如标准库中的 std::ops::Add 特征:
#![allow(unused)] fn main() { trait Add<RHS=Self> { type Output; fn add(self, rhs: RHS) -> Self::Output; } }
它有一个泛型参数 RHS,但是与我们以往的用法不同,这里它给 RHS 一个默认值,也就是当用户不指定 RHS 时,默认使用两个同样类型的值进行相加,然后返回一个关联类型 Output。
可能上面那段不太好理解,下面我们用代码来举例:
use std::ops::Add; #[derive(Debug, PartialEq)] struct Point { x: i32, y: i32, } impl Add for Point { type Output = Point; fn add(self, other: Point) -> Point { Point { x: self.x + other.x, y: self.y + other.y, } } } fn main() { assert_eq!(Point { x: 1, y: 0 } + Point { x: 2, y: 3 }, Point { x: 3, y: 3 }); }
上面的代码主要干了一件事,就是为 Point 结构体提供 + 的能力,这就是运算符重载,不过 Rust 并不支持创建自定义运算符,你也无法为所有运算符进行重载,目前来说,只有定义在 std::ops 中的运算符才能进行重载。
跟 + 对应的特征是 std::ops::Add,我们在之前也看过它的定义 trait Add<RHS=Self>,但是上面的例子中并没有为 Point 实现 Add<RHS> 特征,而是实现了 Add 特征(没有默认泛型类型参数),这意味着我们使用了 RHS 的默认类型,也就是 Self。换句话说,我们这里定义的是两个相同的 Point 类型相加,因此无需指定 RHS。
与上面的例子相反,下面的例子,我们来创建两个不同类型的相加:
#![allow(unused)] fn main() { use std::ops::Add; struct Millimeters(u32); struct Meters(u32); impl Add<Meters> for Millimeters { type Output = Millimeters; fn add(self, other: Meters) -> Millimeters { Millimeters(self.0 + (other.0 * 1000)) } } }
这里,是进行 Millimeters + Meters 两种数据类型的 + 操作,因此此时不能再使用默认的 RHS,否则就会变成 Millimeters + Millimeters 的形式。使用 Add<Meters> 可以将 RHS 指定为 Meters,那么 fn add(self, rhs: RHS) 自然而言的变成了 Millimeters 和 Meters 的相加。
默认类型参数主要用于两个方面:
- 减少实现的样板代码
- 扩展类型但是无需大幅修改现有的代码
之前的例子就是第一点,虽然效果也就那样。在 + 左右两边都是同样类型时,只需要 impl Add 即可,否则你需要 impl Add<SOME_TYPE>,嗯,会多写几个字:)
对于第二点,也很好理解,如果你在一个复杂类型的基础上,新引入一个泛型参数,可能需要修改很多地方,但是如果新引入的泛型参数有了默认类型,情况就会好很多,添加泛型参数后,使用这个类型的代码需要逐个在类型提示部分添加泛型参数,就很麻烦;但是有了默认参数(且默认参数取之前的实现里假设的值的情况下)之后,原有的使用这个类型的代码就不需要做改动了。
归根到底,默认泛型参数,是有用的,但是大多数情况下,咱们确实用不到,当需要用到时,大家再回头来查阅本章即可,手上有剑,心中不慌。
调用同名的方法
不同特征拥有同名的方法是很正常的事情,你没有任何办法阻止这一点;甚至除了特征上的同名方法外,在你的类型上,也有同名方法:
#![allow(unused)] fn main() { trait Pilot { fn fly(&self); } trait Wizard { fn fly(&self); } struct Human; impl Pilot for Human { fn fly(&self) { println!("This is your captain speaking."); } } impl Wizard for Human { fn fly(&self) { println!("Up!"); } } impl Human { fn fly(&self) { println!("*waving arms furiously*"); } } }
这里,不仅仅两个特征 Pilot 和 Wizard 有 fly 方法,就连实现那两个特征的 Human 单元结构体,也拥有一个同名方法 fly (这世界怎么了,非要这么卷吗?程序员何苦难为程序员,哎)。
既然代码已经不可更改,那下面我们来讲讲该如何调用这些 fly 方法。
优先调用类型上的方法
当调用 Human 实例的 fly 时,编译器默认调用该类型中定义的方法:
fn main() { let person = Human; person.fly(); }
这段代码会打印 *waving arms furiously*,说明直接调用了类型上定义的方法。
调用特征上的方法
为了能够调用两个特征的方法,需要使用显式调用的语法:
fn main() { let person = Human; Pilot::fly(&person); // 调用Pilot特征上的方法 Wizard::fly(&person); // 调用Wizard特征上的方法 person.fly(); // 调用Human类型自身的方法 }
运行后依次输出:
This is your captain speaking.
Up!
*waving arms furiously*
因为 fly 方法的参数是 self,当显式调用时,编译器就可以根据调用的类型( self 的类型)决定具体调用哪个方法。
这个时候问题又来了,如果方法没有 self 参数呢?稍等,估计有读者会问:还有方法没有 self 参数?看到这个疑问,作者的眼泪不禁流了下来,大明湖畔的关联函数,你还记得嘛?
但是成年人的世界,就算再伤心,事还得做,咱们继续:
trait Animal { fn baby_name() -> String; } struct Dog; impl Dog { fn baby_name() -> String { String::from("Spot") } } impl Animal for Dog { fn baby_name() -> String { String::from("puppy") } } fn main() { println!("A baby dog is called a {}", Dog::baby_name()); }
就像人类妈妈会给自己的宝宝起爱称一样,狗妈妈也会。狗妈妈称呼自己的宝宝为Spot,其它动物称呼狗宝宝为puppy,这个时候假如有动物不知道该如何称呼狗宝宝,它需要查询一下。
Dog::baby_name() 的调用方式显然不行,因为这只是狗妈妈对宝宝的爱称,可能你会想到通过下面的方式查询其他动物对狗狗的称呼:
fn main() { println!("A baby dog is called a {}", Animal::baby_name()); }
铛铛,无情报错了:
#![allow(unused)] fn main() { error[E0283]: type annotations needed // 需要类型注释 --> src/main.rs:20:43 | 20 | println!("A baby dog is called a {}", Animal::baby_name()); | ^^^^^^^^^^^^^^^^^ cannot infer type // 无法推断类型 | = note: cannot satisfy `_: Animal` }
因为单纯从 Animal::baby_name() 上,编译器无法得到任何有效的信息:实现 Animal 特征的类型可能有很多,你究竟是想获取哪个动物宝宝的名称?狗宝宝?猪宝宝?还是熊宝宝?
此时,就需要使用完全限定语法。
完全限定语法
完全限定语法是调用函数最为明确的方式:
fn main() { println!("A baby dog is called a {}", <Dog as Animal>::baby_name()); }
在尖括号中,通过 as 关键字,我们向 Rust 编译器提供了类型注解,也就是 Animal 就是 Dog,而不是其他动物,因此最终会调用 impl Animal for Dog 中的方法,获取到其它动物对狗宝宝的称呼:puppy。
言归正题,完全限定语法定义为:
#![allow(unused)] fn main() { <Type as Trait>::function(receiver_if_method, next_arg, ...); }
上面定义中,第一个参数是方法接收器 receiver (三种 self),只有方法才拥有,例如关联函数就没有 receiver。
完全限定语法可以用于任何函数或方法调用,那么我们为何很少用到这个语法?原因是 Rust 编译器能根据上下文自动推导出调用的路径,因此大多数时候,我们都无需使用完全限定语法。只有当存在多个同名函数或方法,且 Rust 无法区分出你想调用的目标函数时,该用法才能真正有用武之地。
特征定义中的特征约束
有时,我们会需要让某个特征 A 能使用另一个特征 B 的功能(另一种形式的特征约束),这种情况下,不仅仅要为类型实现特征 A,还要为类型实现特征 B 才行,这就是 supertrait (实在不知道该如何翻译,有大佬指导下嘛?)
例如有一个特征 OutlinePrint,它有一个方法,能够对当前的实现类型进行格式化输出:
#![allow(unused)] fn main() { use std::fmt::Display; trait OutlinePrint: Display { fn outline_print(&self) { let output = self.to_string(); let len = output.len(); println!("{}", "*".repeat(len + 4)); println!("*{}*", " ".repeat(len + 2)); println!("* {} *", output); println!("*{}*", " ".repeat(len + 2)); println!("{}", "*".repeat(len + 4)); } } }
等等,这里有一个眼熟的语法: OutlinePrint: Display,感觉很像之前讲过的特征约束,只不过用在了特征定义中而不是函数的参数中,是的,在某种意义上来说,这和特征约束非常类似,都用来说明一个特征需要实现另一个特征,这里就是:如果你想要实现 OutlinePrint 特征,首先你需要实现 Display 特征。
想象一下,假如没有这个特征约束,那么 self.to_string 还能够调用吗( to_string 方法会为实现 Display 特征的类型自动实现)?编译器肯定是不愿意的,会报错说当前作用域中找不到用于 &Self 类型的方法 to_string :
#![allow(unused)] fn main() { struct Point { x: i32, y: i32, } impl OutlinePrint for Point {} }
因为 Point 没有实现 Display 特征,会得到下面的报错:
error[E0277]: the trait bound `Point: std::fmt::Display` is not satisfied
--> src/main.rs:20:6
|
20 | impl OutlinePrint for Point {}
| ^^^^^^^^^^^^ `Point` cannot be formatted with the default formatter;
try using `:?` instead if you are using a format string
|
= help: the trait `std::fmt::Display` is not implemented for `Point`
既然我们有求于编译器,那只能选择满足它咯:
#![allow(unused)] fn main() { use std::fmt; impl fmt::Display for Point { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "({}, {})", self.x, self.y) } } }
上面代码为 Point 实现了 Display 特征,那么 to_string 方法也将自动实现:最终获得字符串是通过这里的 fmt 方法获得的。
在外部类型上实现外部特征(newtype)
在特征章节中,有提到孤儿规则,简单来说,就是特征或者类型必需至少有一个是本地的,才能在此类型上定义特征。
这里提供一个办法来绕过孤儿规则,那就是使用newtype 模式,简而言之:就是为一个元组结构体创建新类型。该元组结构体封装有一个字段,该字段就是希望实现特征的具体类型。
该封装类型是本地的,因此我们可以为此类型实现外部的特征。
newtype 不仅仅能实现以上的功能,而且它在运行时没有任何性能损耗,因为在编译期,该类型会被自动忽略。
下面来看一个例子,我们有一个动态数组类型: Vec<T>,它定义在标准库中,还有一个特征 Display,它也定义在标准库中,如果没有 newtype,我们是无法为 Vec<T> 实现 Display 的:
error[E0117]: only traits defined in the current crate can be implemented for arbitrary types
--> src/main.rs:5:1
|
5 | impl<T> std::fmt::Display for Vec<T> {
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^------
| | |
| | Vec is not defined in the current crate
| impl doesn't use only types from inside the current crate
|
= note: define and implement a trait or new type instead
编译器给了我们提示: define and implement a trait or new type instead,重新定义一个特征,或者使用 new type,前者当然不可行,那么来试试后者:
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {}", w); }
其中,struct Wrapper(Vec<String>) 就是一个元组结构体,它定义了一个新类型 Wrapper,代码很简单,相信大家也很容易看懂。
既然 new type 有这么多好处,它有没有不好的地方呢?答案是肯定的。注意到我们怎么访问里面的数组吗?self.0.join(", "),是的,很啰嗦,因为需要先从 Wrapper 中取出数组: self.0,然后才能执行 join 方法。
类似的,任何数组上的方法,你都无法直接调用,需要先用 self.0 取出数组,然后再进行调用。
当然,解决办法还是有的,要不怎么说 Rust 是极其强大灵活的编程语言!Rust 提供了一个特征叫 Deref,实现该特征后,可以自动做一层类似类型转换的操作,可以将 Wrapper 变成 Vec<String> 来使用。这样就会像直接使用数组那样去使用 Wrapper,而无需为每一个操作都添加上 self.0。
同时,如果不想 Wrapper 暴露底层数组的所有方法,我们还可以为 Wrapper 去重载这些方法,实现隐藏的目的。
集合类型
动态数组 Vector
动态数组类型用 Vec<T> 表示,事实上,在之前的章节,它的身影多次出现,我们一直没有细讲,只是简单的把它当作数组处理。
动态数组允许你存储多个值,这些值在内存中一个紧挨着另一个排列,因此访问其中某个元素的成本非常低。动态数组只能存储相同类型的元素,如果你想存储不同类型的元素,可以使用之前讲过的枚举类型或者特征对象。
总之,当我们想拥有一个列表,里面都是相同类型的数据时,动态数组将会非常有用。
创建动态数组
在 Rust 中,有多种方式可以创建动态数组。
Vec::new
使用 Vec::new 创建动态数组是最 rusty 的方式,它调用了 Vec 中的 new 关联函数:
#![allow(unused)] fn main() { let v: Vec<i32> = Vec::new(); }
这里,v 被显式地声明了类型 Vec<i32>,这是因为 Rust 编译器无法从 Vec::new() 中得到任何关于类型的暗示信息,因此也无法推导出 v 的具体类型,但是当你向里面增加一个元素后,一切又不同了:
#![allow(unused)] fn main() { let mut v = Vec::new(); v.push(1); }
此时,v 就无需手动声明类型,因为编译器通过 v.push(1),推测出 v 中的元素类型是 i32,因此推导出 v 的类型是 Vec<i32>。
如果预先知道要存储的元素个数,可以使用
Vec::with_capacity(capacity)创建动态数组,这样可以避免因为插入大量新数据导致频繁的内存分配和拷贝,提升性能
vec![]
还可以使用宏 vec! 来创建数组,与 Vec::new 有所不同,前者能在创建同时给予初始化值:
#![allow(unused)] fn main() { let v = vec![1, 2, 3]; }
同样,此处的 v 也无需标注类型,编译器只需检查它内部的元素即可自动推导出 v 的类型是 Vec<i32> (Rust 中,整数默认类型是 i32,在数值类型中有详细介绍)。
更新 Vector
向数组尾部添加元素,可以使用 push 方法:
#![allow(unused)] fn main() { let mut v = Vec::new(); v.push(1); }
与其它类型一样,必须将 v 声明为 mut 后,才能进行修改。
Vector 与其元素共存亡
跟结构体一样,Vector 类型在超出作用域范围后,会被自动删除:
#![allow(unused)] fn main() { { let v = vec![1, 2, 3]; // ... } // <- v超出作用域并在此处被删除 }
当 Vector 被删除后,它内部存储的所有内容也会随之被删除。目前来看,这种解决方案简单直白,但是当 Vector 中的元素被引用后,事情可能会没那么简单。
从 Vector 中读取元素
读取指定位置的元素有两种方式可选:
- 通过下标索引访问。
- 使用
get方法。
#![allow(unused)] fn main() { let v = vec![1, 2, 3, 4, 5]; let third: &i32 = &v[2]; println!("第三个元素是 {}", third); match v.get(2) { Some(third) => println!("第三个元素是 {third}"), None => println!("去你的第三个元素,根本没有!"), } }
和其它语言一样,集合类型的索引下标都是从 0 开始,&v[2] 表示借用 v 中的第三个元素,最终会获得该元素的引用。而 v.get(2) 也是访问第三个元素,但是有所不同的是,它返回了 Option<&T>,因此还需要额外的 match 来匹配解构出具体的值。
细心的同学会注意到这里使用了两种格式化输出的方式,其中第一种我们在之前已经见过,而第二种是后续新版本中引入的写法,也是更推荐的用法,具体介绍请参见格式化输出章节
下标索引与 .get 的区别
这两种方式都能成功的读取到指定的数组元素,既然如此为什么会存在两种方法?何况 .get 还会增加使用复杂度,这就涉及到数组越界的问题了,让我们通过示例说明:
#![allow(unused)] fn main() { let v = vec![1, 2, 3, 4, 5]; let does_not_exist = &v[100]; let does_not_exist = v.get(100); }
运行以上代码,&v[100] 的访问方式会导致程序无情报错退出,因为发生了数组越界访问。 但是 v.get 就不会,它在内部做了处理,有值的时候返回 Some(T),无值的时候返回 None,因此 v.get 的使用方式非常安全。
既然如此,为何不统一使用 v.get 的形式?因为实在是有些啰嗦,Rust 语言的设计者和使用者在审美这方面还是相当统一的:简洁即正义,何况性能上也会有轻微的损耗。
既然有两个选择,肯定就有如何选择的问题,答案很简单,当你确保索引不会越界的时候,就用索引访问,否则用 .get。例如,访问第几个数组元素并不取决于我们,而是取决于用户的输入时,用 .get 会非常适合。
同时借用多个数组元素
既然涉及到借用数组元素,那么很可能会遇到同时借用多个数组元素的情况,还记得在所有权和借用章节咱们讲过的借用规则嘛?如果记得,就来看看下面的代码 :)
#![allow(unused)] fn main() { let mut v = vec![1, 2, 3, 4, 5]; let first = &v[0]; v.push(6); println!("The first element is: {first}"); }
先不运行,来推断下结果,首先 first = &v[0] 进行了不可变借用,v.push 进行了可变借用,如果 first 在 v.push 之后不再使用,那么该段代码可以成功编译。
可是上面的代码中,first 这个不可变借用在可变借用 v.push 后被使用了,那么妥妥的,编译器就会报错:
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable 无法对v进行可变借用,因此之前已经进行了不可变借用
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here // 不可变借用发生在此处
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here // 可变借用发生在此处
7 |
8 | println!("The first element is: {}", first);
| ----- immutable borrow later used here // 不可变借用在这里被使用
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` due to previous error
其实,按理来说,这两个引用不应该互相影响的:一个是查询元素,一个是在数组尾部插入元素,完全不相干的操作,为何编译器要这么严格呢?
原因在于:数组的大小是可变的,当旧数组的大小不够用时,Rust 会重新分配一块更大的内存空间,然后把旧数组拷贝过来。这种情况下,之前的引用显然会指向一块无效的内存,这非常 rusty —— 对用户进行严格的教育。
若读者想要更深入的了解
Vec<T>,可以看看Rustonomicon,其中从零手撸一个动态数组,非常适合深入学习
迭代遍历 Vector 中的元素
如果想要依次访问数组中的元素,可以使用迭代的方式去遍历数组,这种方式比用下标的方式去遍历数组更安全也更高效(每次下标访问都会触发数组边界检查):
#![allow(unused)] fn main() { let v = vec![1, 2, 3]; for i in &v { println!("{i}"); } }
也可以在迭代过程中,修改 Vector 中的元素:
#![allow(unused)] fn main() { let mut v = vec![1, 2, 3]; for i in &mut v { *i += 10 } }
存储不同类型的元素
在本节开头,有讲到数组的元素必须类型相同,但是也提到了解决方案:那就是通过使用枚举类型和特征对象来实现不同类型元素的存储。先来看看通过枚举如何实现:
#[derive(Debug)] enum IpAddr { V4(String), V6(String) } fn main() { let v = vec![ IpAddr::V4("127.0.0.1".to_string()), IpAddr::V6("::1".to_string()) ]; for ip in v { show_addr(ip) } } fn show_addr(ip: IpAddr) { println!("{:?}",ip); }
数组 v 中存储了两种不同的 ip 地址,但是这两种都属于 IpAddr 枚举类型的成员,因此可以存储在数组中。
再来看看特征对象的实现:
trait IpAddr { fn display(&self); } struct V4(String); impl IpAddr for V4 { fn display(&self) { println!("ipv4: {:?}",self.0) } } struct V6(String); impl IpAddr for V6 { fn display(&self) { println!("ipv6: {:?}",self.0) } } fn main() { let v: Vec<Box<dyn IpAddr>> = vec![ Box::new(V4("127.0.0.1".to_string())), Box::new(V6("::1".to_string())), ]; for ip in v { ip.display(); } }
比枚举实现要稍微复杂一些,我们为 V4 和 V6 都实现了特征 IpAddr,然后将它俩的实例用 Box::new 包裹后,存在了数组 v 中,需要注意的是,这里必须手动地指定类型:Vec<Box<dyn IpAddr>>,表示数组 v 存储的是特征 IpAddr 的对象,这样就实现了在数组中存储不同的类型。
在实际使用场景中,特征对象数组要比枚举数组常见很多,主要原因在于特征对象非常灵活,而编译器对枚举的限制较多,且无法动态增加类型。
KV 存储 HashMap
和动态数组一样,HashMap 也是 Rust 标准库中提供的集合类型,但是又与动态数组不同,HashMap 中存储的是一一映射的 KV 键值对,并提供了平均复杂度为 O(1) 的查询方法,当我们希望通过一个 Key 去查询值时,该类型非常有用,以致于 Go 语言将该类型设置成了语言级别的内置特性。
Rust 中哈希类型(哈希映射)为 HashMap<K,V>,在其它语言中,也有类似的数据结构,例如 hash map,map,object,hash table,字典 等等。
创建 HashMap
跟创建动态数组 Vec 的方法类似,可以使用 new 方法来创建 HashMap,然后通过 insert 方法插入键值对。
使用 new 方法创建
#![allow(unused)] fn main() { use std::collections::HashMap; // 创建一个HashMap,用于存储宝石种类和对应的数量 let mut my_gems = HashMap::new(); // 将宝石类型和对应的数量写入表中 my_gems.insert("红宝石", 1); my_gems.insert("蓝宝石", 2); my_gems.insert("河边捡的误以为是宝石的破石头", 18); }
很简单对吧?跟其它语言没有区别,聪明的同学甚至能够猜到该 HashMap 的类型:HashMap<&str,i32>。
但是还有一点,你可能没有注意,那就是使用 HashMap 需要手动通过 use ... 从标准库中引入到我们当前的作用域中来,仔细回忆下,之前使用另外两个集合类型 String 和 Vec 时,我们是否有手动引用过?答案是 No,因为 HashMap 并没有包含在 Rust 的 prelude中(Rust 为了简化用户使用,提前将最常用的类型自动引入到作用域中)。
所有的集合类型都是动态的,意味着它们没有固定的内存大小,因此它们底层的数据都存储在内存堆上,然后通过一个存储在栈中的引用类型来访问。同时,跟其它集合类型一致,HashMap 也是内聚性的,即所有的 K 必须拥有同样的类型,V 也是如此。
跟
Vec一样,如果预先知道要存储的KV对个数,可以使用HashMap::with_capacity(capacity)创建指定大小的HashMap,避免频繁的内存分配和拷贝,提升性能
使用迭代器和 collect 方法创建
在实际使用中,不是所有的场景都能 new 一个哈希表后,然后悠哉悠哉的依次插入对应的键值对,而是可能会从另外一个数据结构中,获取到对应的数据,最终生成 HashMap。
例如考虑一个场景,有一张表格中记录了足球联赛中各队伍名称和积分的信息,这张表如果被导入到 Rust 项目中,一个合理的数据结构是 Vec<(String, u32)> 类型,该数组中的元素是一个个元组,该数据结构跟表格数据非常契合:表格中的数据都是逐行存储,每一个行都存有一个 (队伍名称, 积分) 的信息。
但是在很多时候,又需要通过队伍名称来查询对应的积分,此时动态数组就不适用了,因此可以用 HashMap 来保存相关的队伍名称 -> 积分映射关系。 理想很丰满,现实很骨感,如何将 Vec<(String, u32)> 中的数据快速写入到 HashMap<String, u32> 中?
一个动动脚趾头就能想到的笨方法如下:
fn main() { use std::collections::HashMap; let teams_list = vec![ ("中国队".to_string(), 100), ("美国队".to_string(), 10), ("日本队".to_string(), 50), ]; let mut teams_map = HashMap::new(); for team in &teams_list { teams_map.insert(&team.0, team.1); } println!("{:?}",teams_map) }
遍历列表,将每一个元组作为一对 KV 插入到 HashMap 中,很简单,但是……也不太聪明的样子,换个词说就是 —— 不够 rusty。
好在,Rust 为我们提供了一个非常精妙的解决办法:先将 Vec 转为迭代器,接着通过 collect 方法,将迭代器中的元素收集后,转成 HashMap:
fn main() { use std::collections::HashMap; let teams_list = vec![ ("中国队".to_string(), 100), ("美国队".to_string(), 10), ("日本队".to_string(), 50), ]; let teams_map: HashMap<_,_> = teams_list.into_iter().collect(); println!("{:?}",teams_map) }
代码很简单,into_iter 方法将列表转为迭代器,接着通过 collect 进行收集,不过需要注意的是,collect 方法在内部实际上支持生成多种类型的目标集合,因此我们需要通过类型标注 HashMap<_,_> 来告诉编译器:请帮我们收集为 HashMap 集合类型,具体的 KV 类型,麻烦编译器您老人家帮我们推导。
由此可见,Rust 中的编译器时而小聪明,时而大聪明,不过好在,它大聪明的时候,会自家人知道自己事,总归会通知你一声:
error[E0282]: type annotations needed // 需要类型标注
--> src/main.rs:10:9
|
10 | let teams_map = teams_list.into_iter().collect();
| ^^^^^^^^^ consider giving `teams_map` a type // 给予 `teams_map` 一个具体的类型
所有权转移
HashMap 的所有权规则与其它 Rust 类型没有区别:
- 若类型实现
Copy特征,该类型会被复制进HashMap,因此无所谓所有权 - 若没实现
Copy特征,所有权将被转移给HashMap中
例如我参选帅气男孩时的场景再现:
fn main() { use std::collections::HashMap; let name = String::from("Sunface"); let age = 18; let mut handsome_boys = HashMap::new(); handsome_boys.insert(name, age); println!("因为过于无耻,{}已经被从帅气男孩名单中除名", name); println!("还有,他的真实年龄远远不止{}岁", age); }
运行代码,报错如下:
error[E0382]: borrow of moved value: `name`
--> src/main.rs:10:32
|
4 | let name = String::from("Sunface");
| ---- move occurs because `name` has type `String`, which does not implement the `Copy` trait
...
8 | handsome_boys.insert(name, age);
| ---- value moved here
9 |
10 | println!("因为过于无耻,{}已经被除名", name);
| ^^^^ value borrowed here after move
提示很清晰,name 是 String 类型,因此它受到所有权的限制,在 insert 时,它的所有权被转移给 handsome_boys,所以最后在使用时,会遇到这个无情但是意料之中的报错。
如果你使用引用类型放入 HashMap 中,请确保该引用的生命周期至少跟 HashMap 活得一样久:
fn main() { use std::collections::HashMap; let name = String::from("Sunface"); let age = 18; let mut handsome_boys = HashMap::new(); handsome_boys.insert(&name, age); std::mem::drop(name); println!("因为过于无耻,{:?}已经被除名", handsome_boys); println!("还有,他的真实年龄远远不止{}岁", age); }
上面代码,我们借用 name 获取了它的引用,然后插入到 handsome_boys 中,至此一切都很完美。但是紧接着,就通过 drop 函数手动将 name 字符串从内存中移除,再然后就报错了:
handsome_boys.insert(&name, age);
| ----- borrow of `name` occurs here // name借用发生在此处
9 |
10 | std::mem::drop(name);
| ^^^^ move out of `name` occurs here // name的所有权被转移走
11 | println!("因为过于无耻,{:?}已经被除名", handsome_boys);
| ------------- borrow later used here // 所有权转移后,还试图使用name
查询 HashMap
通过 get 方法可以获取元素:
#![allow(unused)] fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); let team_name = String::from("Blue"); let score: Option<&i32> = scores.get(&team_name); }
上面有几点需要注意:
get方法返回一个Option<&i32>类型:当查询不到时,会返回一个None,查询到时返回Some(&i32)&i32是对HashMap中值的借用,如果不使用借用,可能会发生所有权的转移
还可以继续拓展下,上面的代码中,如果我们想直接获得值类型的 score 该怎么办,答案简约但不简单:
#![allow(unused)] fn main() { let score: i32 = scores.get(&team_name).copied().unwrap_or(0); }
这里留给大家一个小作业: 去官方文档中查询下 Option 的 copied 方法和 unwrap_or 方法的含义及该如何使用。
还可以通过循环的方式依次遍历 KV 对:
#![allow(unused)] fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert(String::from("Blue"), 10); scores.insert(String::from("Yellow"), 50); for (key, value) in &scores { println!("{}: {}", key, value); } }
最终输出:
Yellow: 50
Blue: 10
更新 HashMap 中的值
更新值的时候,涉及多种情况,咱们在代码中一一进行说明:
fn main() { use std::collections::HashMap; let mut scores = HashMap::new(); scores.insert("Blue", 10); // 覆盖已有的值 let old = scores.insert("Blue", 20); assert_eq!(old, Some(10)); // 查询新插入的值 let new = scores.get("Blue"); assert_eq!(new, Some(&20)); // 查询Yellow对应的值,若不存在则插入新值 let v = scores.entry("Yellow").or_insert(5); assert_eq!(*v, 5); // 不存在,插入5 // 查询Yellow对应的值,若不存在则插入新值 let v = scores.entry("Yellow").or_insert(50); assert_eq!(*v, 5); // 已经存在,因此50没有插入 }
具体的解释在代码注释中已有,这里不再进行赘述。
在已有值的基础上更新
另一个常用场景如下:查询某个 key 对应的值,若不存在则插入新值,若存在则对已有的值进行更新,例如在文本中统计词语出现的次数:
#![allow(unused)] fn main() { use std::collections::HashMap; let text = "hello world wonderful world"; let mut map = HashMap::new(); // 根据空格来切分字符串(英文单词都是通过空格切分) for word in text.split_whitespace() { let count = map.entry(word).or_insert(0); *count += 1; } println!("{:?}", map); }
上面代码中,新建一个 map 用于保存词语出现的次数,插入一个词语时会进行判断:若之前没有插入过,则使用该词语作 Key,插入次数 0 作为 Value,若之前插入过则取出之前统计的该词语出现的次数,对其加一。
有两点值得注意:
or_insert返回了&mut v引用,因此可以通过该可变引用直接修改map中对应的值- 使用
count引用时,需要先进行解引用*count,否则会出现类型不匹配
哈希函数
你肯定比较好奇,为何叫哈希表,到底什么是哈希。
先来设想下,如果要实现 Key 与 Value 的一一对应,是不是意味着我们要能比较两个 Key 的相等性?例如 "a" 和 "b",1 和 2,当这些类型做 Key 且能比较时,可以很容易知道 1 对应的值不会错误的映射到 2 上,因为 1 不等于 2。因此,一个类型能否作为 Key 的关键就是是否能进行相等比较,或者说该类型是否实现了 std::cmp::Eq 特征。
f32 和 f64 浮点数,没有实现
std::cmp::Eq特征,因此不可以用作HashMap的Key
好了,理解完这个,再来设想一点,若一个复杂点的类型作为 Key,那怎么在底层对它进行存储,怎么使用它进行查询和比较? 是不是很棘手?好在我们有哈希函数:通过它把 Key 计算后映射为哈希值,然后使用该哈希值来进行存储、查询、比较等操作。
但是问题又来了,如何保证不同 Key 通过哈希后的两个值不会相同?如果相同,那意味着我们使用不同的 Key,却查到了同一个结果,这种明显是错误的行为。
此时,就涉及到安全性跟性能的取舍了。
若要追求安全,尽可能减少冲突,同时防止拒绝服务(Denial of Service, DoS)攻击,就要使用密码学安全的哈希函数,HashMap 就是使用了这样的哈希函数。反之若要追求性能,就需要使用没有那么安全的算法。
高性能三方库
因此若性能测试显示当前标准库默认的哈希函数不能满足你的性能需求,就需要去 crates.io 上寻找其它的哈希函数实现,使用方法很简单:
#![allow(unused)] fn main() { use std::hash::BuildHasherDefault; use std::collections::HashMap; // 引入第三方的哈希函数 use twox_hash::XxHash64; // 指定HashMap使用第三方的哈希函数XxHash64 let mut hash: HashMap<_, _, BuildHasherDefault<XxHash64>> = Default::default(); hash.insert(42, "the answer"); assert_eq!(hash.get(&42), Some(&"the answer")); }
目前,
HashMap使用的哈希函数是SipHash,它的性能不是很高,但是安全性很高。SipHash在中等大小的Key上,性能相当不错,但是对于小型的Key(例如整数)或者大型Key(例如字符串)来说,性能还是不够好。若你需要极致性能,例如实现算法,可以考虑这个库:ahash
认识生命周期
生命周期,简而言之就是引用的有效作用域。在大多数时候,我们无需手动的声明生命周期,因为编译器可以自动进行推导,用类型来类比下:
- 就像编译器大部分时候可以自动推导类型 <-> 一样,编译器大多数时候也可以自动推导生命周期
- 在多种类型存在时,编译器往往要求我们手动标明类型 <-> 当多个生命周期存在,且编译器无法推导出某个引用的生命周期时,就需要我们手动标明生命周期
Rust 生命周期之所以难,是因为这个概念对于我们来说是全新的,没有其它编程语言的经验可以借鉴。当你觉得难的时候,不用过于担心,这个难对于所有人都是平等的,多点付出就能早点解决此拦路虎,同时本书也会尽力帮助大家减少学习难度(生命周期很可能是 Rust 中最难的部分)。
悬垂指针和生命周期
生命周期的主要作用是避免悬垂引用,它会导致程序引用了本不该引用的数据:
#![allow(unused)] fn main() { { let r; { let x = 5; r = &x; } println!("r: {}", r); } }
这段代码有几点值得注意:
let r;的声明方式貌似存在使用null的风险,实际上,当我们不初始化它就使用时,编译器会给予报错r引用了内部花括号中的x变量,但是x会在内部花括号}处被释放,因此回到外部花括号后,r会引用一个无效的x
此处 r 就是一个悬垂指针,它引用了提前被释放的变量 x,可以预料到,这段代码会报错:
error[E0597]: `x` does not live long enough // `x` 活得不够久
--> src/main.rs:7:17
|
7 | r = &x;
| ^^ borrowed value does not live long enough // 被借用的 `x` 活得不够久
8 | }
| - `x` dropped here while still borrowed // `x` 在这里被丢弃,但是它依然还在被借用
9 |
10 | println!("r: {}", r);
| - borrow later used here // 对 `x` 的借用在此处被使用
在这里 r 拥有更大的作用域,或者说活得更久。如果 Rust 不阻止该悬垂引用的发生,那么当 x 被释放后,r 所引用的值就不再是合法的,会导致我们程序发生异常行为,且该异常行为有时候会很难被发现。
借用检查
为了保证 Rust 的所有权和借用的正确性,Rust 使用了一个借用检查器(Borrow checker),来检查我们程序的借用正确性:
#![allow(unused)] fn main() { { let r; // ---------+-- 'a // | { // | let x = 5; // -+-- 'b | r = &x; // | | } // -+ | // | println!("r: {}", r); // | } // ---------+ }
这段代码和之前的一模一样,唯一的区别在于增加了对变量生命周期的注释。这里,r 变量被赋予了生命周期 'a,x 被赋予了生命周期 'b,从图示上可以明显看出生命周期 'b 比 'a 小很多。
在编译期,Rust 会比较两个变量的生命周期,结果发现 r 明明拥有生命周期 'a,但是却引用了一个小得多的生命周期 'b,在这种情况下,编译器会认为我们的程序存在风险,因此拒绝运行。
如果想要编译通过,也很简单,只要 'b 比 'a 大就好。总之,x 变量只要比 r 活得久,那么 r 就能随意引用 x 且不会存在危险:
#![allow(unused)] fn main() { { let x = 5; // ----------+-- 'b // | let r = &x; // --+-- 'a | // | | println!("r: {}", r); // | | // --+ | } // ----------+ }
根据之前的结论,我们重新实现了代码,现在 x 的生命周期 'b 大于 r 的生命周期 'a,因此 r 对 x 的引用是安全的。
通过之前的内容,我们了解了何为生命周期,也了解了 Rust 如何利用生命周期来确保引用是合法的,下面来看看函数中的生命周期。
函数中的生命周期
先来考虑一个例子 - 返回两个字符串切片中较长的那个,该函数的参数是两个字符串切片,返回值也是字符串切片:
fn main() { let string1 = String::from("abcd"); let string2 = "xyz"; let result = longest(string1.as_str(), string2); println!("The longest string is {}", result); }
#![allow(unused)] fn main() { fn longest(x: &str, y: &str) -> &str { if x.len() > y.len() { x } else { y } } }
这段 longest 实现,非常标准优美,就连多余的 return 和分号都没有,可是现实总是给我们重重一击:
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter // 参数需要一个生命周期
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is
borrowed from `x` or `y`
= 帮助: 该函数的返回值是一个引用类型,但是函数签名无法说明,该引用是借用自 `x` 还是 `y`
help: consider introducing a named lifetime parameter // 考虑引入一个生命周期
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ^^^^ ^^^^^^^ ^^^^^^^ ^^^
如果你仔细阅读,就会发现,其实主要是编译器无法知道该函数的返回值到底引用 x 还是 y ,因为编译器需要知道这些,来确保函数调用后的引用生命周期分析。
不过说来尴尬,就这个函数而言,我们也不知道返回值到底引用哪个,因为一个分支返回 x,另一个分支返回 y...这可咋办?先来分析下。
我们在定义该函数时,首先无法知道传递给函数的具体值,因此到底是 if 还是 else 被执行,无从得知。其次,传入引用的具体生命周期也无法知道,因此也不能像之前的例子那样通过分析生命周期来确定引用是否有效。同时,编译器的借用检查也无法推导出返回值的生命周期,因为它不知道 x 和 y 的生命周期跟返回值的生命周期之间的关系是怎样的(说实话,人都搞不清,何况编译器这个大聪明)。
因此,这时就回到了文章开头说的内容:在存在多个引用时,编译器有时会无法自动推导生命周期,此时就需要我们手动去标注,通过为参数标注合适的生命周期来帮助编译器进行借用检查的分析。
生命周期标注语法
生命周期标注并不会改变任何引用的实际作用域 -- 鲁迅
鲁迅说过的话,总是值得重点标注,当你未来更加理解生命周期时,你才会发现这句话的精髓和重要!现在先简单记住,标记的生命周期只是为了取悦编译器,让编译器不要难为我们,记住了吗?没记住,再回头看一遍,这对未来你遇到生命周期问题时会有很大的帮助!
在很多时候编译器是很聪明的,但是总有些时候,它会化身大聪明,自以为什么都很懂,然后去拒绝我们代码的执行,此时,就需要我们通过生命周期标注来告诉这个大聪明:别自作聪明了,听我的就好。
例如一个变量,只能活一个花括号,那么就算你给它标注一个活全局的生命周期,它还是会在前面的花括号结束处被释放掉,并不会真的全局存活。
生命周期的语法也颇为与众不同,以 ' 开头,名称往往是一个单独的小写字母,大多数人都用 'a 来作为生命周期的名称。 如果是引用类型的参数,那么生命周期会位于引用符号 & 之后,并用一个空格来将生命周期和引用参数分隔开:
#![allow(unused)] fn main() { &i32 // 一个引用 &'a i32 // 具有显式生命周期的引用 &'a mut i32 // 具有显式生命周期的可变引用 }
一个生命周期标注,它自身并不具有什么意义,因为生命周期的作用就是告诉编译器多个引用之间的关系。例如,有一个函数,它的第一个参数 first 是一个指向 i32 类型的引用,具有生命周期 'a,该函数还有另一个参数 second,它也是指向 i32 类型的引用,并且同样具有生命周期 'a。此处生命周期标注仅仅说明,这两个参数 first 和 second 至少活得和'a 一样久,至于到底活多久或者哪个活得更久,抱歉我们都无法得知:
#![allow(unused)] fn main() { fn useless<'a>(first: &'a i32, second: &'a i32) {} }
函数签名中的生命周期标注
继续之前的 longest 函数,从两个字符串切片中返回较长的那个:
#![allow(unused)] fn main() { fn longest<'a>(x: &'a str, y: &'a str) -> &'a str { if x.len() > y.len() { x } else { y } } }
需要注意的点如下:
- 和泛型一样,使用生命周期参数,需要先声明
<'a> x、y和返回值至少活得和'a一样久(因为返回值要么是x,要么是y)
该函数签名表明对于某些生命周期 'a,函数的两个参数都至少跟 'a 活得一样久,同时函数的返回引用也至少跟 'a 活得一样久。实际上,这意味着返回值的生命周期与参数生命周期中的较小值一致:虽然两个参数的生命周期都是标注了 'a,但是实际上这两个参数的真实生命周期可能是不一样的(生命周期 'a 不代表生命周期等于 'a,而是大于等于 'a)。
回忆下“鲁迅”说的话,再参考上面的内容,可以得出:在通过函数签名指定生命周期参数时,我们并没有改变传入引用或者返回引用的真实生命周期,而是告诉编译器当不满足此约束条件时,就拒绝编译通过。
因此 longest 函数并不知道 x 和 y 具体会活多久,只要知道它们的作用域至少能持续 'a 这么长就行。
当把具体的引用传给 longest 时,那生命周期 'a 的大小就是 x 和 y 的作用域的重合部分,换句话说,'a 的大小将等于 x 和 y 中较小的那个。由于返回值的生命周期也被标记为 'a,因此返回值的生命周期也是 x 和 y 中作用域较小的那个。
用一个例子来解释吧:
fn main() { let string1 = String::from("long string is long"); { let string2 = String::from("xyz"); let result = longest(string1.as_str(), string2.as_str()); println!("The longest string is {}", result); } }
在上例中,string1 的作用域直到 main 函数的结束,而 string2 的作用域到内部花括号的结束 },那么根据之前的理论,'a 是两者中作用域较小的那个,也就是 'a 的生命周期等于 string2 的生命周期,同理,由于函数返回的生命周期也是 'a,可以得出函数返回的生命周期也等于 string2 的生命周期。
现在来验证下上面的结论:result 的生命周期等于参数中生命周期最小的,因此要等于 string2 的生命周期,也就是说,result 要活得和 string2 一样久,观察下代码的实现,可以发现这个结论是正确的!
因此,在这种情况下,通过生命周期标注,编译器得出了和我们肉眼观察一样的结论,而不再是一个蒙圈的大聪明。
再来看一个例子,该例子证明了 result 的生命周期必须等于两个参数中生命周期较小的那个:
fn main() { let string1 = String::from("long string is long"); let result; { let string2 = String::from("xyz"); result = longest(string1.as_str(), string2.as_str()); } println!("The longest string is {}", result); }
Bang,错误冒头了:
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {}", result);
| ------ borrow later used here
在上述代码中,result 必须要活到 println!处,因为 result 的生命周期是 'a,因此 'a 必须持续到 println!。
在 longest 函数中,string2 的生命周期也是 'a,由此说明 string2 也必须活到 println! 处,可是 string2 在代码中实际上只能活到内部语句块的花括号处 },小于它应该具备的生命周期 'a,因此编译出错。
作为人类,我们可以很清晰的看出 result 实际上引用了 string1,因为 string1 的长度明显要比 string2 长,既然如此,编译器不该如此矫情才对,它应该能认识到 result 没有引用 string2,让我们这段代码通过。 Rust 编译器在调教上是非常保守的:当可能出错也可能不出错时,它会选择前者,抛出编译错误。
总之,显式的使用生命周期,可以让编译器正确的认识到多个引用之间的关系,最终帮我们提前规避可能存在的代码风险。
深入思考生命周期标注
使用生命周期的方式往往取决于函数的功能,例如之前的 longest 函数,如果它永远只返回第一个参数 x,生命周期的标注该如何修改(该例子就是上面的小练习结果之一)?
#![allow(unused)] fn main() { fn longest<'a>(x: &'a str, y: &str) -> &'a str { x } }
在此例中,y 完全没有被使用,因此 y 的生命周期与 x 和返回值的生命周期没有任何关系,意味着我们也不必再为 y 标注生命周期,只需要标注 x 参数和返回值即可。
函数的返回值如果是一个引用类型,那么它的生命周期只会来源于:
- 函数参数的生命周期
- 函数体中某个新建引用的生命周期
若是后者情况,就是典型的悬垂引用场景:
#![allow(unused)] fn main() { fn longest<'a>(x: &str, y: &str) -> &'a str { let result = String::from("really long string"); result.as_str() } }
上面的函数的返回值就和参数 x,y 没有任何关系,而是引用了函数体内创建的字符串,那么很显然,该函数会报错:
error[E0515]: cannot return value referencing local variable `result` // 返回值result引用了本地的变量
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
主要问题就在于,result 在函数结束后就被释放,但是在函数结束后,对 result 的引用依然在继续。在这种情况下,没有办法指定合适的生命周期来让编译通过,因此我们也就在 Rust 中避免了悬垂引用。
那遇到这种情况该怎么办?最好的办法就是返回内部字符串的所有权,然后把字符串的所有权转移给调用者:
fn longest<'a>(_x: &str, _y: &str) -> String { String::from("really long string") } fn main() { let s = longest("not", "important"); }
至此,可以对生命周期进行下总结:生命周期语法用来将函数的多个引用参数和返回值的作用域关联到一起,一旦关联到一起后,Rust 就拥有充分的信息来确保我们的操作是内存安全的。
结构体中的生命周期
不仅仅函数具有生命周期,结构体其实也有这个概念,只不过我们之前对结构体的使用都停留在非引用类型字段上。细心的同学应该能回想起来,之前为什么不在结构体中使用字符串字面量或者字符串切片,而是统一使用 String 类型?原因很简单,后者在结构体初始化时,只要转移所有权即可,而前者,抱歉,它们是引用,它们不能为所欲为。
既然之前已经理解了生命周期,那么意味着在结构体中使用引用也变得可能:只要为结构体中的每一个引用标注上生命周期即可:
struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); let i = ImportantExcerpt { part: first_sentence, }; }
ImportantExcerpt 结构体中有一个引用类型的字段 part,因此需要为它标注上生命周期。结构体的生命周期标注语法跟泛型参数语法很像,需要对生命周期参数进行声明 <'a>。该生命周期标注说明,结构体 ImportantExcerpt 所引用的字符串 str 必须比该结构体活得更久。
从 main 函数实现来看,ImportantExcerpt 的生命周期从第 4 行开始,到 main 函数末尾结束,而该结构体引用的字符串从第一行开始,也是到 main 函数末尾结束,可以得出结论结构体引用的字符串活得比结构体久,这符合了编译器对生命周期的要求,因此编译通过。
与之相反,下面的代码就无法通过编译:
#[derive(Debug)] struct ImportantExcerpt<'a> { part: &'a str, } fn main() { let i; { let novel = String::from("Call me Ishmael. Some years ago..."); let first_sentence = novel.split('.').next().expect("Could not find a '.'"); i = ImportantExcerpt { part: first_sentence, }; } println!("{:?}",i); }
观察代码,可以看出结构体比它引用的字符串活得更久,引用字符串在内部语句块末尾 } 被释放后,println! 依然在外面使用了该结构体,因此会导致无效的引用,不出所料,编译报错:
error[E0597]: `novel` does not live long enough
--> src/main.rs:10:30
|
10 | let first_sentence = novel.split('.').next().expect("Could not find a '.'");
| ^^^^^^^^^^^^^^^^ borrowed value does not live long enough
...
14 | }
| - `novel` dropped here while still borrowed
15 | println!("{:?}",i);
| - borrow later used here
生命周期消除
实际上,对于编译器来说,每一个引用类型都有一个生命周期,那么为什么我们在使用过程中,很多时候无需标注生命周期?例如:
#![allow(unused)] fn main() { fn first_word(s: &str) -> &str { let bytes = s.as_bytes(); for (i, &item) in bytes.iter().enumerate() { if item == b' ' { return &s[0..i]; } } &s[..] } }
该函数的参数和返回值都是引用类型,尽管我们没有显式的为其标注生命周期,编译依然可以通过。其实原因不复杂,编译器为了简化用户的使用,运用了生命周期消除大法。
对于 first_word 函数,它的返回值是一个引用类型,那么该引用只有两种情况:
- 从参数获取
- 从函数体内部新创建的变量获取
如果是后者,就会出现悬垂引用,最终被编译器拒绝,因此只剩一种情况:返回值的引用是获取自参数,这就意味着参数和返回值的生命周期是一样的。道理很简单,我们能看出来,编译器自然也能看出来,因此,就算我们不标注生命周期,也不会产生歧义。
实际上,在 Rust 1.0 版本之前,这种代码果断不给通过,因为 Rust 要求必须显式的为所有引用标注生命周期:
#![allow(unused)] fn main() { fn first_word<'a>(s: &'a str) -> &'a str { }
在写了大量的类似代码后,Rust 社区抱怨声四起,包括开发者自己都忍不了了,最终揭锅而起,这才有了我们今日的幸福。
生命周期消除的规则不是一蹴而就,而是伴随着 总结-改善 流程的周而复始,一步一步走到今天,这也意味着,该规则以后可能也会进一步增加,我们需要手动标注生命周期的时候也会越来越少,hooray!
在开始之前有几点需要注意:
- 消除规则不是万能的,若编译器不能确定某件事是正确时,会直接判为不正确,那么你还是需要手动标注生命周期
- 函数或者方法中,参数的生命周期被称为
输入生命周期,返回值的生命周期被称为输出生命周期
三条消除规则
编译器使用三条消除规则来确定哪些场景不需要显式地去标注生命周期。其中第一条规则应用在输入生命周期上,第二、三条应用在输出生命周期上。若编译器发现三条规则都不适用时,就会报错,提示你需要手动标注生命周期。
-
每一个引用参数都会获得独自的生命周期
例如一个引用参数的函数就有一个生命周期标注:
fn foo<'a>(x: &'a i32),两个引用参数的有两个生命周期标注:fn foo<'a, 'b>(x: &'a i32, y: &'b i32), 依此类推。 -
若只有一个输入生命周期(函数参数中只有一个引用类型),那么该生命周期会被赋给所有的输出生命周期,也就是所有返回值的生命周期都等于该输入生命周期
例如函数
fn foo(x: &i32) -> &i32,x参数的生命周期会被自动赋给返回值&i32,因此该函数等同于fn foo<'a>(x: &'a i32) -> &'a i32 -
若存在多个输入生命周期,且其中一个是
&self或&mut self,则&self的生命周期被赋给所有的输出生命周期拥有
&self形式的参数,说明该函数是一个方法,该规则让方法的使用便利度大幅提升。
规则其实很好理解,但是,爱思考的读者肯定要发问了,例如第三条规则,若一个方法,它的返回值的生命周期就是跟参数 &self 的不一样怎么办?总不能强迫我返回的值总是和 &self 活得一样久吧?! 问得好,答案很简单:手动标注生命周期,因为这些规则只是编译器发现你没有标注生命周期时默认去使用的,当你标注生命周期后,编译器自然会乖乖听你的话。
让我们假装自己是编译器,然后看下以下的函数该如何应用这些规则:
例子 1
#![allow(unused)] fn main() { fn first_word(s: &str) -> &str { // 实际项目中的手写代码 }
首先,我们手写的代码如上所示时,编译器会先应用第一条规则,为每个参数标注一个生命周期:
#![allow(unused)] fn main() { fn first_word<'a>(s: &'a str) -> &str { // 编译器自动为参数添加生命周期 }
此时,第二条规则就可以进行应用,因为函数只有一个输入生命周期,因此该生命周期会被赋予所有的输出生命周期:
#![allow(unused)] fn main() { fn first_word<'a>(s: &'a str) -> &'a str { // 编译器自动为返回值添加生命周期 }
此时,编译器为函数签名中的所有引用都自动添加了具体的生命周期,因此编译通过,且用户无需手动去标注生命周期,只要按照 fn first_word(s: &str) -> &str { 的形式写代码即可。
例子 2 再来看一个例子:
#![allow(unused)] fn main() { fn longest(x: &str, y: &str) -> &str { // 实际项目中的手写代码 }
首先,编译器会应用第一条规则,为每个参数都标注生命周期:
#![allow(unused)] fn main() { fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str { }
但是此时,第二条规则却无法被使用,因为输入生命周期有两个,第三条规则也不符合,因为它是函数,不是方法,因此没有 &self 参数。在套用所有规则后,编译器依然无法为返回值标注合适的生命周期,因此,编译器就会报错,提示我们需要手动标注生命周期:
error[E0106]: missing lifetime specifier
--> src/main.rs:1:47
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
| ------- ------- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
note: these named lifetimes are available to use
--> src/main.rs:1:12
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
| ^^ ^^
help: consider using one of the available lifetimes here
|
1 | fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &'lifetime str {
| +++++++++
不得不说,Rust 编译器真的很强大,还贴心的给我们提示了该如何修改,虽然。。。好像。。。。它的提示貌似不太准确。这里我们更希望参数和返回值都是 'a 生命周期。
方法中的生命周期
先来回忆下泛型的语法:
#![allow(unused)] fn main() { struct Point<T> { x: T, y: T, } impl<T> Point<T> { fn x(&self) -> &T { &self.x } } }
实际上,为具有生命周期的结构体实现方法时,我们使用的语法跟泛型参数语法很相似:
#![allow(unused)] fn main() { struct ImportantExcerpt<'a> { part: &'a str, } impl<'a> ImportantExcerpt<'a> { fn level(&self) -> i32 { 3 } } }
其中有几点需要注意的:
impl中必须使用结构体的完整名称,包括<'a>,因为生命周期标注也是结构体类型的一部分!- 方法签名中,往往不需要标注生命周期,得益于生命周期消除的第一和第三规则
下面的例子展示了第三规则应用的场景:
#![allow(unused)] fn main() { impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part(&self, announcement: &str) -> &str { println!("Attention please: {}", announcement); self.part } } }
首先,编译器应用第一规则,给予每个输入参数一个生命周期:
#![allow(unused)] fn main() { impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &str { println!("Attention please: {}", announcement); self.part } } }
需要注意的是,编译器不知道 announcement 的生命周期到底多长,因此它无法简单的给予它生命周期 'a,而是重新声明了一个全新的生命周期 'b。
接着,编译器应用第三规则,将 &self 的生命周期赋给返回值 &str:
#![allow(unused)] fn main() { impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'a str { println!("Attention please: {}", announcement); self.part } } }
Bingo,最开始的代码,尽管我们没有给方法标注生命周期,但是在第一和第三规则的配合下,编译器依然完美的为我们亮起了绿灯。
在结束这块儿内容之前,再来做一个有趣的修改,将方法返回的生命周期改为'b:
#![allow(unused)] fn main() { impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str { println!("Attention please: {}", announcement); self.part } } }
此时,编译器会报错,因为编译器无法知道 'a 和 'b 的关系。 &self 生命周期是 'a,那么 self.part 的生命周期也是 'a,但是好巧不巧的是,我们手动为返回值 self.part 标注了生命周期 'b,因此编译器需要知道 'a 和 'b 的关系。
有一点很容易推理出来:由于 &'a self 是被引用的一方,因此引用它的 &'b str 必须要活得比它短,否则会出现悬垂引用。因此说明生命周期 'b 必须要比 'a 小,只要满足了这一点,编译器就不会再报错:
#![allow(unused)] fn main() { impl<'a: 'b, 'b> ImportantExcerpt<'a> { fn announce_and_return_part(&'a self, announcement: &'b str) -> &'b str { println!("Attention please: {}", announcement); self.part } } }
Bang,一个复杂的玩意儿被甩到了你面前,就问怕不怕?
就关键点稍微解释下:
'a: 'b,是生命周期约束语法,跟泛型约束非常相似,用于说明'a必须比'b活得久- 可以把
'a和'b都在同一个地方声明(如上),或者分开声明但通过where 'a: 'b约束生命周期关系,如下:
#![allow(unused)] fn main() { impl<'a> ImportantExcerpt<'a> { fn announce_and_return_part<'b>(&'a self, announcement: &'b str) -> &'b str where 'a: 'b, { println!("Attention please: {}", announcement); self.part } } }
总之,实现方法比想象中简单:加一个约束,就能暗示编译器,尽管引用吧,反正我想引用的内容比我活得久,爱咋咋地,我怎么都不会引用到无效的内容!
静态生命周期
在 Rust 中有一个非常特殊的生命周期,那就是 'static,拥有该生命周期的引用可以和整个程序活得一样久。
在之前我们学过字符串字面量,提到过它是被硬编码进 Rust 的二进制文件中,因此这些字符串变量全部具有 'static 的生命周期:
#![allow(unused)] fn main() { let s: &'static str = "我没啥优点,就是活得久,嘿嘿"; }
这时候,有些聪明的小脑瓜就开始开动了:当生命周期不知道怎么标时,对类型施加一个静态生命周期的约束 T: 'static 是不是很爽?这样我和编译器再也不用操心它到底活多久了。
嗯,只能说,这个想法是对的,在不少情况下,'static 约束确实可以解决生命周期编译不通过的问题,但是问题来了:本来该引用没有活那么久,但是你非要说它活那么久,万一引入了潜在的 BUG 怎么办?
因此,遇到因为生命周期导致的编译不通过问题,首先想的应该是:是否是我们试图创建一个悬垂引用,或者是试图匹配不一致的生命周期,而不是简单粗暴的用 'static 来解决问题。
但是,话说回来,存在即合理,有时候,'static 确实可以帮助我们解决非常复杂的生命周期问题甚至是无法被手动解决的生命周期问题,那么此时就应该放心大胆的用,只要你确定:你的所有引用的生命周期都是正确的,只是编译器太笨不懂罢了。
总结下:
- 生命周期
'static意味着能和程序活得一样久,例如字符串字面量和特征对象 - 实在遇到解决不了的生命周期标注问题,可以尝试
T: 'static,有时候它会给你奇迹
事实上,关于
'static, 有两种用法:&'static和T: 'static
一个复杂例子: 泛型、特征约束
手指已经疲软无力,我好想停止,但是华丽的开场都要有与之匹配的谢幕,那我们就用一个稍微复杂点的例子来结束:
#![allow(unused)] fn main() { use std::fmt::Display; fn longest_with_an_announcement<'a, T>( x: &'a str, y: &'a str, ann: T, ) -> &'a str where T: Display, { println!("Announcement! {}", ann); if x.len() > y.len() { x } else { y } } }
依然是熟悉的配方 longest,但是多了一段废话: ann,因为要用格式化 {} 来输出 ann,因此需要它实现 Display 特征。
返回值和错误处理
Rust 中的错误主要分为两类:
- 可恢复错误,通常用于从系统全局角度来看可以接受的错误,例如处理用户的访问、操作等错误,这些错误只会影响某个用户自身的操作进程,而不会对系统的全局稳定性产生影响
- 不可恢复错误,刚好相反,该错误通常是全局性或者系统性的错误,例如数组越界访问,系统启动时发生了影响启动流程的错误等等,这些错误的影响往往对于系统来说是致命的
很多编程语言,并不会区分这些错误,而是直接采用异常的方式去处理。Rust 没有异常,但是 Rust 也有自己的卧龙凤雏:Result<T, E> 用于可恢复错误,panic! 用于不可恢复错误
panic 深入剖析
在正式开始之前,先来思考一个问题:假设我们想要从文件读取数据,如果失败,你有没有好的办法通知调用者为何失败?如果成功,你有没有好的办法把读取的结果返还给调用者?
panic! 与不可恢复错误
上面的问题在真实场景会经常遇到,其实处理起来挺复杂的,让我们先做一个假设:文件读取操作发生在系统启动阶段。那么可以轻易得出一个结论,一旦文件读取失败,那么系统启动也将失败,这意味着该失败是不可恢复的错误,无论是因为文件不存在还是操作系统硬盘的问题,这些只是错误的原因不同,但是归根到底都是不可恢复的错误(梳理清楚当前场景的错误类型非常重要)。
对于这些严重到影响程序运行的错误,触发 panic 是很好的解决方式。在 Rust 中触发 panic 有两种方式:被动触发和主动调用,下面依次来看看。
被动触发
先来看一段简单又熟悉的代码:
fn main() { let v = vec![1, 2, 3]; v[99]; }
心明眼亮的同学立马就能看出这里发生了严重的错误 —— 数组访问越界,在其它编程语言中无一例外,都会报出严重的异常,甚至导致程序直接崩溃关闭。
而 Rust 也不例外,运行后将看到如下报错:
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished dev [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
上面给出了非常详细的报错信息,包含了具体的异常描述以及发生的位置,甚至你还可以加入额外的命令来看到异常发生时的堆栈信息,这个会在后面详细展开。
总之,类似的 panic 还有很多,而被动触发的 panic 是我们日常开发中最常遇到的,这也是 Rust 给我们的一种保护,毕竟错误只有抛出来,才有可能被处理,否则只会偷偷隐藏起来,寻觅时机给你致命一击。
主动调用
在某些特殊场景中,开发者想要主动抛出一个异常,例如开头提到的在系统启动阶段读取文件失败。
对此,Rust 为我们提供了 panic! 宏,当调用执行该宏时,程序会打印出一个错误信息,展开报错点往前的函数调用堆栈,最后退出程序。
切记,一定是不可恢复的错误,才调用
panic!处理,你总不想系统仅仅因为用户随便传入一个非法参数就崩溃吧?所以,只有当你不知道该如何处理时,再去调用 panic!.
首先,来调用一下 panic!,这里使用了最简单的代码实现,实际上你在程序的任何地方都可以这样调用:
fn main() { panic!("crash and burn"); }
运行后输出:
thread 'main' panicked at 'crash and burn', src/main.rs:2:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
以上信息包含了两条重要信息:
main函数所在的线程崩溃了,发生的代码位置是src/main.rs中的第 2 行第 5 个字符(去除该行前面的空字符)- 在使用时加上一个环境变量可以获取更详细的栈展开信息:
- Linux/macOS 等 UNIX 系统:
RUST_BACKTRACE=1 cargo run - Windows 系统(PowerShell):
$env:RUST_BACKTRACE=1 ; cargo run
- Linux/macOS 等 UNIX 系统:
下面让我们针对第二点进行详细展开讲解。
backtrace 栈展开
在真实场景中,错误往往涉及到很长的调用链甚至会深入第三方库,如果没有栈展开技术,错误将难以跟踪处理,下面我们来看一个真实的崩溃例子:
fn main() { let v = vec![1, 2, 3]; v[99]; }
上面的代码很简单,数组只有 3 个元素,我们却尝试去访问它的第 100 号元素(数组索引从 0 开始),那自然会崩溃。
我们的读者里不乏正义之士,此时肯定要质疑,一个简单的数组越界访问,为何要直接让程序崩溃?是不是有些小题大作了?
如果有过 C 语言的经验,即使你越界了,问题不大,我依然尝试去访问,至于这个值是不是你想要的(100 号内存地址也有可能有值,只不过是其它变量或者程序的!),抱歉,不归我管,我只负责取,你要负责管理好自己的索引访问范围。上面这种情况被称为缓冲区溢出,并可能会导致安全漏洞,例如攻击者可以通过索引来访问到数组后面不被允许的数据。
说实话,我宁愿程序崩溃,为什么?当你取到了一个不属于你的值,这在很多时候会导致程序上的逻辑 BUG! 有编程经验的人都知道这种逻辑上的 BUG 是多么难被发现和修复!因此程序直接崩溃,然后告诉我们问题发生的位置,最后我们对此进行修复,这才是最合理的软件开发流程,而不是把问题藏着掖着:
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
好的,现在成功知道问题发生的位置,但是如果我们想知道该问题之前经过了哪些调用环节,该怎么办?那就按照提示使用 RUST_BACKTRACE=1 cargo run 或 $env:RUST_BACKTRACE=1 ; cargo run 来再一次运行程序:
thread 'main' panicked at 'index out of bounds: the len is 3 but the index is 99', src/main.rs:4:5
stack backtrace:
0: rust_begin_unwind
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/std/src/panicking.rs:517:5
1: core::panicking::panic_fmt
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/panicking.rs:101:14
2: core::panicking::panic_bounds_check
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/panicking.rs:77:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/slice/index.rs:184:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/slice/index.rs:15:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/alloc/src/vec/mod.rs:2465:9
6: world_hello::main
at ./src/main.rs:4:5
7: core::ops::function::FnOnce::call_once
at /rustc/59eed8a2aac0230a8b53e89d4e99d55912ba6b35/library/core/src/ops/function.rs:227:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
上面的代码就是一次栈展开(也称栈回溯),它包含了函数调用的顺序,当然按照逆序排列:最近调用的函数排在列表的最上方。因为咱们的 main 函数基本是最先调用的函数了,所以排在了倒数第二位,还有一个关注点,排在最顶部最后一个调用的函数是 rust_begin_unwind,该函数的目的就是进行栈展开,呈现这些列表信息给我们。
要获取到栈回溯信息,你还需要开启 debug 标志,该标志在使用 cargo run 或者 cargo build 时自动开启(这两个操作默认是 Debug 运行方式)。同时,栈展开信息在不同操作系统或者 Rust 版本上也有所不同。
panic 时的两种终止方式
当出现 panic! 时,程序提供了两种方式来处理终止流程:栈展开和直接终止。
其中,默认的方式就是 栈展开,这意味着 Rust 会回溯栈上数据和函数调用,因此也意味着更多的善后工作,好处是可以给出充分的报错信息和栈调用信息,便于事后的问题复盘。直接终止,顾名思义,不清理数据就直接退出程序,善后工作交与操作系统来负责。
对于绝大多数用户,使用默认选择是最好的,但是当你关心最终编译出的二进制可执行文件大小时,那么可以尝试去使用直接终止的方式,例如下面的配置修改 Cargo.toml 文件,实现在release模式下遇到 panic 直接终止:
#![allow(unused)] fn main() { [profile.release] panic = 'abort' }
线程 panic 后,程序是否会终止?
长话短说,如果是 main 线程,则程序会终止,如果是其它子线程,该线程会终止,但是不会影响 main 线程。因此,尽量不要在 main 线程中做太多任务,将这些任务交由子线程去做,就算子线程 panic 也不会导致整个程序的结束。
何时该使用 panic!
下面让我们大概罗列下何时适合使用 panic,也许经过之前的学习,你已经能够对 panic 的使用有了自己的看法,但是我们还是会罗列一些常见的用法来加深你的理解。
先来一点背景知识,在前面章节我们粗略讲过 Result<T, E> 这个枚举类型,它是用来表示函数的返回结果:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
当没有错误发生时,函数返回一个用 Result 类型包裹的值 Ok(T),当错误时,返回一个 Err(E)。对于 Result 返回我们有很多处理方法,最简单粗暴的就是 unwrap 和 expect,这两个函数非常类似,我们以 unwrap 举例:
#![allow(unused)] fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1".parse().unwrap(); }
上面的 parse 方法试图将字符串 "127.0.0.1" 解析为一个 IP 地址类型 IpAddr,它返回一个 Result<IpAddr, E> 类型,如果解析成功,则把 Ok(IpAddr) 中的值赋给 home,如果失败,则不处理 Err(E),而是直接 panic。
因此 unwrap 简而言之:成功则返回值,失败则 panic,总之不进行任何错误处理。
示例、原型、测试
这几个场景下,需要快速地搭建代码,错误处理会拖慢编码的速度,也不是特别有必要,因此通过 unwrap、expect 等方法来处理是最快的。
同时,当我们回头准备做错误处理时,可以全局搜索这些方法,不遗漏地进行替换。
你确切的知道你的程序是正确时,可以使用 panic
因为 panic 的触发方式比错误处理要简单,因此可以让代码更清晰,可读性也更加好,当我们的代码注定是正确时,你可以用 unwrap 等方法直接进行处理,反正也不可能 panic :
#![allow(unused)] fn main() { use std::net::IpAddr; let home: IpAddr = "127.0.0.1".parse().unwrap(); }
例如上面的例子,"127.0.0.1" 就是 ip 地址,因此我们知道 parse 方法一定会成功,那么就可以直接用 unwrap 方法进行处理。
当然,如果该字符串是来自于用户输入,那在实际项目中,就必须用错误处理的方式,而不是 unwrap,否则你的程序一天要崩溃几十万次吧!
可能导致全局有害状态时
有害状态大概分为几类:
- 非预期的错误
- 后续代码的运行会受到显著影响
- 内存安全的问题
当错误预期会出现时,返回一个错误较为合适,例如解析器接收到格式错误的数据,HTTP 请求接收到错误的参数甚至该请求内的任何错误(不会导致整个程序有问题,只影响该次请求)。因为错误是可预期的,因此也是可以处理的。
当启动时某个流程发生了错误,对后续代码的运行造成了影响,那么就应该使用 panic,而不是处理错误后继续运行,当然你可以通过重试的方式来继续。
上面提到过,数组访问越界,就要 panic 的原因,这个就是属于内存安全的范畴,一旦内存访问不安全,那么我们就无法保证自己的程序会怎么运行下去,也无法保证逻辑和数据的正确性。
panic 原理剖析
本来不想写这块儿内容,因为真的难写,但是转念一想,既然号称圣经,那么本书就得与众不同,避重就轻显然不是该有的态度。
当调用 panic! 宏时,它会
- 格式化
panic信息,然后使用该信息作为参数,调用std::panic::panic_any()函数 panic_any会检查应用是否使用了panic hook,如果使用了,该hook函数就会被调用(hook是一个钩子函数,是外部代码设置的,用于在panic触发时,执行外部代码所需的功能)- 当
hook函数返回后,当前的线程就开始进行栈展开:从panic_any开始,如果寄存器或者栈因为某些原因信息错乱了,那很可能该展开会发生异常,最终线程会直接停止,展开也无法继续进行 - 展开的过程是一帧一帧的去回溯整个栈,每个帧的数据都会随之被丢弃,但是在展开过程中,你可能会遇到被用户标记为
catching的帧(通过std::panic::catch_unwind()函数标记),此时用户提供的catch函数会被调用,展开也随之停止:当然,如果catch选择在内部调用std::panic::resume_unwind()函数,则展开还会继续。
还有一种情况,在展开过程中,如果展开本身 panic 了,那展开线程会终止,展开也随之停止。
一旦线程展开被终止或者完成,最终的输出结果是取决于哪个线程 panic:对于 main 线程,操作系统提供的终止功能 core::intrinsics::abort() 会被调用,最终结束当前的 panic 进程;如果是其它子线程,那么子线程就会简单的终止,同时信息会在稍后通过 std::thread::join() 进行收集。
可恢复的错误 Result
还记得上一节中,提到的关于文件读取的思考题吧?当时我们解决了读取文件时遇到不可恢复错误该怎么处理的问题,现在来看看,读取过程中,正常返回和遇到可以恢复的错误时该如何处理。
假设,我们有一台消息服务器,每个用户都通过 websocket 连接到该服务器来接收和发送消息,该过程就涉及到 socket 文件的读写,那么此时,如果一个用户的读写发生了错误,显然不能直接 panic,否则服务器会直接崩溃,所有用户都会断开连接,因此我们需要一种更温和的错误处理方式:Result<T, E>。
之前章节有提到过,Result<T, E> 是一个枚举类型,定义如下:
#![allow(unused)] fn main() { enum Result<T, E> { Ok(T), Err(E), } }
泛型参数 T 代表成功时存入的正确值的类型,存放方式是 Ok(T),E 代表错误时存入的错误值,存放方式是 Err(E),枯燥的讲解永远不及代码生动准确,因此先来看下打开文件的例子:
use std::fs::File; fn main() { let f = File::open("hello.txt"); }
以上 File::open 返回一个 Result 类型,那么问题来了:
如何获知变量类型或者函数的返回类型
有几种常用的方式,此处更推荐第二种方法:
- 第一种是查询标准库或者三方库文档,搜索
File,然后找到它的open方法- 推荐
VSCodeIDE 和rust-analyzer插件,如果你成功安装的话,那么就可以在VSCode中很方便的通过代码跳转的方式查看代码,同时rust-analyzer插件还会对代码中的类型进行标注,非常方便好用!- 你还可以尝试故意标记一个错误的类型,然后让编译器告诉你:
#![allow(unused)] fn main() { let f: u32 = File::open("hello.txt"); }
错误提示如下:
error[E0308]: mismatched types
--> src/main.rs:4:18
|
4 | let f: u32 = File::open("hello.txt");
| ^^^^^^^^^^^^^^^^^^^^^^^ expected u32, found enum
`std::result::Result`
|
= note: expected type `u32`
found type `std::result::Result<std::fs::File, std::io::Error>`
上面代码,故意将 f 类型标记成整形,编译器立刻不乐意了,你是在忽悠我吗?打开文件操作返回一个整形?来,大哥来告诉你返回什么:std::result::Result<std::fs::File, std::io::Error>,我的天呐,怎么这么长的类型!
别慌,其实很简单,首先 Result 本身是定义在 std::result 中的,但是因为 Result 很常用,所以就被包含在了prelude中(将常用的东东提前引入到当前作用域内),因此无需手动引入 std::result::Result,那么返回类型可以简化为 Result<std::fs::File,std::io::Error>,你看看是不是很像标准的 Result<T, E> 枚举定义?只不过 T 被替换成了具体的类型 std::fs::File,是一个文件句柄类型,E 被替换成 std::io::Error,是一个 IO 错误类型.
这个返回值类型说明 File::open 调用如果成功则返回一个可以进行读写的文件句柄,如果失败,则返回一个 IO 错误:文件不存在或者没有访问文件的权限等。总之 File::open 需要一个方式告知调用者是成功还是失败,并同时返回具体的文件句柄(成功)或错误信息(失败),万幸的是,这些信息可以通过 Result 枚举提供:
use std::fs::File; fn main() { let f = File::open("hello.txt"); let f = match f { Ok(file) => file, Err(error) => { panic!("Problem opening the file: {:?}", error) }, }; }
代码很清晰,对打开文件后的 Result<T, E> 类型进行匹配取值,如果是成功,则将 Ok(file) 中存放的的文件句柄 file 赋值给 f,如果失败,则将 Err(error) 中存放的错误信息 error 使用 panic 抛出来,进而结束程序,这非常符合上文提到过的 panic 使用场景。
好吧,也没有那么合理 :)
对返回的错误进行处理
直接 panic 还是过于粗暴,因为实际上 IO 的错误有很多种,我们需要对部分错误进行特殊处理,而不是所有错误都直接崩溃:
use std::fs::File; use std::io::ErrorKind; fn main() { let f = File::open("hello.txt"); let f = match f { Ok(file) => file, Err(error) => match error.kind() { ErrorKind::NotFound => match File::create("hello.txt") { Ok(fc) => fc, Err(e) => panic!("Problem creating the file: {:?}", e), }, other_error => panic!("Problem opening the file: {:?}", other_error), }, }; }
上面代码在匹配出 error 后,又对 error 进行了详细的匹配解析,最终结果:
- 如果是文件不存在错误
ErrorKind::NotFound,就创建文件,这里创建文件File::create也是返回Result,因此继续用match对其结果进行处理:创建成功,将新的文件句柄赋值给f,如果失败,则panic - 剩下的错误,一律
panic
失败就 panic: unwrap 和 expect
上一节中,已经看到过这两兄弟的简单介绍,这里再来回顾下。
在不需要处理错误的场景,例如写原型、示例时,我们不想使用 match 去匹配 Result<T, E> 以获取其中的 T 值,因为 match 的穷尽匹配特性,你总要去处理下 Err 分支。那么有没有办法简化这个过程?有,答案就是 unwrap 和 expect。
它们的作用就是,如果返回成功,就将 Ok(T) 中的值取出来,如果失败,就直接 panic,真的勇士绝不多 BB,直接崩溃。
use std::fs::File; fn main() { let f = File::open("hello.txt").unwrap(); }
如果调用这段代码时 hello.txt 文件不存在,那么 unwrap 就将直接 panic:
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:4:37
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
expect 跟 unwrap 很像,也是遇到错误直接 panic, 但是会带上自定义的错误提示信息,相当于重载了错误打印的函数:
use std::fs::File; fn main() { let f = File::open("hello.txt").expect("Failed to open hello.txt"); }
报错如下:
thread 'main' panicked at 'Failed to open hello.txt: Os { code: 2, kind: NotFound, message: "No such file or directory" }', src/main.rs:4:37
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
可以看出,expect 相比 unwrap 能提供更精确的错误信息,在有些场景也会更加实用。
传播错误
咱们的程序几乎不太可能只有 A->B 形式的函数调用,一个设计良好的程序,一个功能涉及十几层的函数调用都有可能。而错误处理也往往不是哪里调用出错,就在哪里处理,实际应用中,大概率会把错误层层上传然后交给调用链的上游函数进行处理,错误传播将极为常见。
例如以下函数从文件中读取用户名,然后将结果进行返回:
#![allow(unused)] fn main() { use std::fs::File; use std::io::{self, Read}; fn read_username_from_file() -> Result<String, io::Error> { // 打开文件,f是`Result<文件句柄,io::Error>` let f = File::open("hello.txt"); let mut f = match f { // 打开文件成功,将file句柄赋值给f Ok(file) => file, // 打开文件失败,将错误返回(向上传播) Err(e) => return Err(e), }; // 创建动态字符串s let mut s = String::new(); // 从f文件句柄读取数据并写入s中 match f.read_to_string(&mut s) { // 读取成功,返回Ok封装的字符串 Ok(_) => Ok(s), // 将错误向上传播 Err(e) => Err(e), } } }
有几点值得注意:
- 该函数返回一个
Result<String, io::Error>类型,当读取用户名成功时,返回Ok(String),失败时,返回Err(io:Error) File::open和f.read_to_string返回的Result<T, E>中的E就是io::Error
由此可见,该函数将 io::Error 的错误往上进行传播,该函数的调用者最终会对 Result<String,io::Error> 进行再处理,至于怎么处理就是调用者的事,如果是错误,它可以选择继续向上传播错误,也可以直接 panic,亦或将具体的错误原因包装后写入 socket 中呈现给终端用户。
但是上面的代码也有自己的问题,那就是太长了(优秀的程序员身上的优点极多,其中最大的优点就是懒),我自认为也有那么一点点优秀,因此见不得这么啰嗦的代码,下面咱们来讲讲如何简化它。
传播界的大明星: ?
大明星出场,必须得有排面,来看看 ? 的排面:
#![allow(unused)] fn main() { use std::fs::File; use std::io; use std::io::Read; fn read_username_from_file() -> Result<String, io::Error> { let mut f = File::open("hello.txt")?; let mut s = String::new(); f.read_to_string(&mut s)?; Ok(s) } }
看到没,这就是排面,相比前面的 match 处理错误的函数,代码直接减少了一半不止,但是,一山更比一山难,看不懂啊!
其实 ? 就是一个宏,它的作用跟上面的 match 几乎一模一样:
#![allow(unused)] fn main() { let mut f = match f { // 打开文件成功,将file句柄赋值给f Ok(file) => file, // 打开文件失败,将错误返回(向上传播) Err(e) => return Err(e), }; }
如果结果是 Ok(T),则把 T 赋值给 f,如果结果是 Err(E),则返回该错误,所以 ? 特别适合用来传播错误。
虽然 ? 和 match 功能一致,但是事实上 ? 会更胜一筹。何解?
想象一下,一个设计良好的系统中,肯定有自定义的错误特征,错误之间很可能会存在上下级关系,例如标准库中的 std::io::Error 和 std::error::Error,前者是 IO 相关的错误结构体,后者是一个最最通用的标准错误特征,同时前者实现了后者,因此 std::io::Error 可以转换为 std:error::Error。
明白了以上的错误转换,? 的更胜一筹就很好理解了,它可以自动进行类型提升(转换):
#![allow(unused)] fn main() { fn open_file() -> Result<File, Box<dyn std::error::Error>> { let mut f = File::open("hello.txt")?; Ok(f) } }
上面代码中 File::open 报错时返回的错误是 std::io::Error 类型,但是 open_file 函数返回的错误类型是 std::error::Error 的特征对象,可以看到一个错误类型通过 ? 返回后,变成了另一个错误类型,这就是 ? 的神奇之处。
根本原因是在于标准库中定义的 From 特征,该特征有一个方法 from,用于把一个类型转成另外一个类型,? 可以自动调用该方法,然后进行隐式类型转换。因此只要函数返回的错误 ReturnError 实现了 From<OtherError> 特征,那么 ? 就会自动把 OtherError 转换为 ReturnError。
这种转换非常好用,意味着你可以用一个大而全的 ReturnError 来覆盖所有错误类型,只需要为各种子错误类型实现这种转换即可。
强中自有强中手,一码更比一码短:
#![allow(unused)] fn main() { use std::fs::File; use std::io; use std::io::Read; fn read_username_from_file() -> Result<String, io::Error> { let mut s = String::new(); File::open("hello.txt")?.read_to_string(&mut s)?; Ok(s) } }
瞧见没? ? 还能实现链式调用,File::open 遇到错误就返回,没有错误就将 Ok 中的值取出来用于下一个方法调用,简直太精妙了,从 Go 语言过来的我,内心狂喜(其实学 Rust 的苦和痛我才不会告诉你们)。
不仅有更强,还要有最强,我不信还有人比我更短(不要误解):
#![allow(unused)] fn main() { use std::fs; use std::io; fn read_username_from_file() -> Result<String, io::Error> { // read_to_string是定义在std::io中的方法,因此需要在上面进行引用 fs::read_to_string("hello.txt") } }
从文件读取数据到字符串中,是比较常见的操作,因此 Rust 标准库为我们提供了 fs::read_to_string 函数,该函数内部会打开一个文件、创建 String、读取文件内容最后写入字符串并返回,因为该函数其实与本章讲的内容关系不大,因此放在最后来讲,其实只是我想震你们一下 :)
? 用于 Option 的返回
? 不仅仅可以用于 Result 的传播,还能用于 Option 的传播,再来回忆下 Option 的定义:
#![allow(unused)] fn main() { pub enum Option<T> { Some(T), None } }
Result 通过 ? 返回错误,那么 Option 就通过 ? 返回 None:
#![allow(unused)] fn main() { fn first(arr: &[i32]) -> Option<&i32> { let v = arr.get(0)?; Some(v) } }
上面的函数中,arr.get 返回一个 Option<&i32> 类型,因为 ? 的使用,如果 get 的结果是 None,则直接返回 None,如果是 Some(&i32),则把里面的值赋给 v。
其实这个函数有些画蛇添足,我们完全可以写出更简单的版本:
#![allow(unused)] fn main() { fn first(arr: &[i32]) -> Option<&i32> { arr.get(0) } }
有一句话怎么说?没有需求,制造需求也要上……大家别跟我学习,这是软件开发大忌。只能用代码洗洗眼了:
#![allow(unused)] fn main() { fn last_char_of_first_line(text: &str) -> Option<char> { text.lines().next()?.chars().last() } }
上面代码展示了在链式调用中使用 ? 提前返回 None 的用法, .next 方法返回的是 Option 类型:如果返回 Some(&str),那么继续调用 chars 方法,如果返回 None,则直接从整个函数中返回 None,不再继续进行链式调用。
新手用 ? 常会犯的错误
初学者在用 ? 时,老是会犯错,例如写出这样的代码:
#![allow(unused)] fn main() { fn first(arr: &[i32]) -> Option<&i32> { arr.get(0)? } }
这段代码无法通过编译,切记:? 操作符需要一个变量来承载正确的值,这个函数只会返回 Some(&i32) 或者 None,只有错误值能直接返回,正确的值不行,所以如果数组中存在 0 号元素,那么函数第二行使用 ? 后的返回类型为 &i32 而不是 Some(&i32)。因此 ? 只能用于以下形式:
let v = xxx()?;xxx()?.yyy()?;
带返回值的 main 函数
在了解了 ? 的使用限制后,这段代码你很容易看出它无法编译:
use std::fs::File; fn main() { let f = File::open("hello.txt")?; }
运行后会报错:
$ cargo run
...
the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
= help: the trait `FromResidual<Result<Infallible, std::io::Error>>` is not implemented for `()`
因为 ? 要求 Result<T, E> 形式的返回值,而 main 函数的返回是 (),因此无法满足,那是不是就无解了呢?
实际上 Rust 还支持另外一种形式的 main 函数:
use std::error::Error; use std::fs::File; fn main() -> Result<(), Box<dyn Error>> { let f = File::open("hello.txt")?; Ok(()) }
这样就能使用 ? 提前返回了,同时我们又一次看到了Box<dyn Error> 特征对象,因为 std::error:Error 是 Rust 中抽象层次最高的错误,其它标准库中的错误都实现了该特征,因此我们可以用该特征对象代表一切错误,就算 main 函数中调用任何标准库函数发生错误,都可以通过 Box<dyn Error> 这个特征对象进行返回.
至于 main 函数可以有多种返回值,那是因为实现了 std::process::Termination 特征,目前为止该特征还没进入稳定版 Rust 中,也许未来你可以为自己的类型实现该特征!
try!
在 ? 横空出世之前( Rust 1.13 ),Rust 开发者还可以使用 try! 来处理错误,该宏的大致定义如下:
#![allow(unused)] fn main() { macro_rules! try { ($e:expr) => (match $e { Ok(val) => val, Err(err) => return Err(::std::convert::From::from(err)), }); } }
简单看一下与 ? 的对比:
#![allow(unused)] fn main() { // `?` let x = function_with_error()?; // 若返回 Err, 则立刻返回;若返回 Ok(255),则将 x 的值设置为 255 // `try!()` let x = try!(function_with_error()); }
可以看出 ? 的优势非常明显,何况 ? 还能做链式调用。
总之,try! 作为前浪已经死在了沙滩上,在当前版本中,我们要尽量避免使用 try!。
包和模块
当工程规模变大时,把代码写到一个甚至几个文件中,都是不太聪明的做法,可能存在以下问题:
- 单个文件过大,导致打开、翻页速度大幅变慢
- 查询和定位效率大幅降低,类比下,你会把所有知识内容放在一个几十万字的文档中吗?
- 只有一个代码层次:函数,难以维护和协作,想象一下你的操作系统只有一个根目录,剩下的都是单层子目录会如何:
disaster - 容易滋生 Bug
同时,将大的代码文件拆分成包和模块,还允许我们实现代码抽象和复用:将你的代码封装好后提供给用户,那么用户只需要调用公共接口即可,无需知道内部该如何实现。
因此,跟其它语言一样,Rust 也提供了相应概念用于代码的组织管理:
- 项目(Packages):一个
Cargo提供的feature,可以用来构建、测试和分享包 - 包(Crate):一个由多个模块组成的树形结构,可以作为三方库进行分发,也可以生成可执行文件进行运行
- 模块(Module):可以一个文件多个模块,也可以一个文件一个模块,模块可以被认为是真实项目中的代码组织单元
下面,让我们一一来学习这些概念以及如何在实践中运用。
包和 Package
真实项目远比我们之前的 cargo new 的默认目录结构要复杂,好在,Rust 为我们提供了强大的包管理工具:
- 项目(Package):可以用来构建、测试和分享包
- 工作空间(WorkSpace):对于大型项目,可以进一步将多个包联合在一起,组织成工作空间
- 包(Crate):一个由多个模块组成的树形结构,可以作为三方库进行分发,也可以生成可执行文件进行运行
- 模块(Module):可以一个文件多个模块,也可以一个文件一个模块,模块可以被认为是真实项目中的代码组织单元
定义
其实项目 Package 和包 Crate 很容易被搞混,甚至在很多书中,这两者都是不分的,但是由于官方对此做了明确的区分,因此我们会在本章节中试图(挣扎着)理清这个概念。
包 Crate
对于 Rust 而言,包是一个独立的可编译单元,它编译后会生成一个可执行文件或者一个库。
一个包会将相关联的功能打包在一起,使得该功能可以很方便的在多个项目中分享。例如标准库中没有提供但是在三方库中提供的 rand 包,它提供了随机数生成的功能,我们只需要将该包通过 use rand; 引入到当前项目的作用域中,就可以在项目中使用 rand 的功能:rand::XXX。
同一个包中不能有同名的类型,但是在不同包中就可以。例如,虽然 rand 包中,有一个 Rng 特征,可是我们依然可以在自己的项目中定义一个 Rng,前者通过 rand::Rng 访问,后者通过 Rng 访问,对于编译器而言,这两者的边界非常清晰,不会存在引用歧义。
项目 Package
鉴于 Rust 团队标新立异的起名传统,以及包的名称被 crate 占用,库的名称被 library 占用,经过斟酌, 我们决定将 Package 翻译成项目,你也可以理解为工程、软件包。
由于 Package 就是一个项目,因此它包含有独立的 Cargo.toml 文件,以及因为功能性被组织在一起的一个或多个包。一个 Package 只能包含一个库(library)类型的包,但是可以包含多个二进制可执行类型的包。
二进制 Package
让我们来创建一个二进制 Package:
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
这里,Cargo 为我们创建了一个名称是 my-project 的 Package,同时在其中创建了 Cargo.toml 文件,可以看一下该文件,里面并没有提到 src/main.rs 作为程序的入口,原因是 Cargo 有一个惯例:src/main.rs 是二进制包的根文件,该二进制包的包名跟所属 Package 相同,在这里都是 my-project,所有的代码执行都从该文件中的 fn main() 函数开始。
使用 cargo run 可以运行该项目,输出:Hello, world!。
库 Package
再来创建一个库类型的 Package:
$ cargo new my-lib --lib
Created library `my-lib` package
$ ls my-lib
Cargo.toml
src
$ ls my-lib/src
lib.rs
首先,如果你试图运行 my-lib,会报错:
$ cargo run
error: a bin target must be available for `cargo run`
原因是库类型的 Package 只能作为三方库被其它项目引用,而不能独立运行,只有之前的二进制 Package 才可以运行。
与 src/main.rs 一样,Cargo 知道,如果一个 Package 包含有 src/lib.rs,意味它包含有一个库类型的同名包 my-lib,该包的根文件是 src/lib.rs。
易混淆的 Package 和包
看完上面,相信大家看出来为何 Package 和包容易被混淆了吧?因为你用 cargo new 创建的 Package 和它其中包含的包是同名的!
不过,只要你牢记 Package 是一个项目工程,而包只是一个编译单元,基本上也就不会混淆这个两个概念了:src/main.rs 和 src/lib.rs 都是编译单元,因此它们都是包。
典型的 Package 结构
上面创建的 Package 中仅包含 src/main.rs 文件,意味着它仅包含一个二进制同名包 my-project。如果一个 Package 同时拥有 src/main.rs 和 src/lib.rs,那就意味着它包含两个包:库包和二进制包,这两个包名也都是 my-project —— 都与 Package 同名。
一个真实项目中典型的 Package,会包含多个二进制包,这些包文件被放在 src/bin 目录下,每一个文件都是独立的二进制包,同时也会包含一个库包,该包只能存在一个 src/lib.rs:
.
├── Cargo.toml
├── Cargo.lock
├── src
│ ├── main.rs
│ ├── lib.rs
│ └── bin
│ └── main1.rs
│ └── main2.rs
├── tests
│ └── some_integration_tests.rs
├── benches
│ └── simple_bench.rs
└── examples
└── simple_example.rs
- 唯一库包:
src/lib.rs - 默认二进制包:
src/main.rs,编译后生成的可执行文件与Package同名 - 其余二进制包:
src/bin/main1.rs和src/bin/main2.rs,它们会分别生成一个文件同名的二进制可执行文件 - 集成测试文件:
tests目录下 - 基准性能测试
benchmark文件:benches目录下 - 项目示例:
examples目录下
这种目录结构基本上是 Rust 的标准目录结构,在 GitHub 的大多数项目上,你都将看到它的身影。
理解了包的概念,我们再来看看构成包的基本单元:模块。
模块 Module
在本章节,我们将深入讲讲 Rust 的代码构成单元:模块。使用模块可以将包中的代码按照功能性进行重组,最终实现更好的可读性及易用性。同时,我们还能非常灵活地去控制代码的可见性,进一步强化 Rust 的安全性。
创建嵌套模块
小旅馆,sorry,是小餐馆,相信大家都挺熟悉的,学校外的估计也没少去,那么咱就用小餐馆为例,来看看 Rust 的模块该如何使用。
使用 cargo new --lib restaurant 创建一个小餐馆,注意,这里创建的是一个库类型的 Package,然后将以下代码放入 src/lib.rs 中:
#![allow(unused)] fn main() { // 餐厅前厅,用于吃饭 mod front_of_house { mod hosting { fn add_to_waitlist() {} fn seat_at_table() {} } mod serving { fn take_order() {} fn serve_order() {} fn take_payment() {} } } }
以上的代码创建了三个模块,有几点需要注意的:
- 使用
mod关键字来创建新模块,后面紧跟着模块名称 - 模块可以嵌套,这里嵌套的原因是招待客人和服务都发生在前厅,因此我们的代码模拟了真实场景
- 模块中可以定义各种 Rust 类型,例如函数、结构体、枚举、特征等
- 所有模块均定义在同一个文件中
类似上述代码中所做的,使用模块,我们就能将功能相关的代码组织到一起,然后通过一个模块名称来说明这些代码为何被组织在一起。这样其它程序员在使用你的模块时,就可以更快地理解和上手。
模块树
在上一节中,我们提到过 src/main.rs 和 src/lib.rs 被称为包根(crate root),这个奇葩名称的来源(我不想承认是自己翻译水平太烂-,-)是由于这两个文件的内容形成了一个模块 crate,该模块位于包的树形结构(由模块组成的树形结构)的根部:
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
这颗树展示了模块之间彼此的嵌套关系,因此被称为模块树。其中 crate 包根是 src/lib.rs 文件,包根文件中的三个模块分别形成了模块树的剩余部分。
父子模块
如果模块 A 包含模块 B,那么 A 是 B 的父模块,B 是 A 的子模块。在上例中,front_of_house 是 hosting 和 serving 的父模块,反之,后两者是前者的子模块。
聪明的读者,应该能联想到,模块树跟计算机上文件系统目录树的相似之处。不仅仅是组织结构上的相似,就连使用方式都很相似:每个文件都有自己的路径,用户可以通过这些路径使用它们,在 Rust 中,我们也通过路径的方式来引用模块。
用路径引用模块
想要调用一个函数,就需要知道它的路径,在 Rust 中,这种路径有两种形式:
- 绝对路径,从包根开始,路径名以包名或者
crate作为开头 - 相对路径,从当前模块开始,以
self,super或当前模块的标识符作为开头
让我们继续经营那个惨淡的小餐馆,这次为它实现一个小功能: 文件名:src/lib.rs
#![allow(unused)] fn main() { mod front_of_house { mod hosting { fn add_to_waitlist() {} } } pub fn eat_at_restaurant() { // 绝对路径 crate::front_of_house::hosting::add_to_waitlist(); // 相对路径 front_of_house::hosting::add_to_waitlist(); } }
上面的代码为了简化实现,省去了其余模块和函数,这样可以把关注点放在函数调用上。eat_at_restaurant 是一个定义在包根中的函数,在该函数中使用了两种方式对 add_to_waitlist 进行调用。
绝对路径引用
因为 eat_at_restaurant 和 add_to_waitlist 都定义在一个包中,因此在绝对路径引用时,可以直接以 crate 开头,然后逐层引用,每一层之间使用 :: 分隔:
#![allow(unused)] fn main() { crate::front_of_house::hosting::add_to_waitlist(); }
对比下之前的模块树:
crate
└── eat_at_restaurant
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
可以看出,绝对路径的调用,完全符合了模块树的层级递进,非常符合直觉,如果类比文件系统,就跟使用绝对路径调用可执行程序差不多:/front_of_house/hosting/add_to_waitlist,使用 crate 作为开始就和使用 / 作为开始一样。
相对路径引用
再回到模块树中,因为 eat_at_restaurant 和 front_of_house 都处于包根 crate 中,因此相对路径可以使用 front_of_house 作为开头:
#![allow(unused)] fn main() { front_of_house::hosting::add_to_waitlist(); }
如果类比文件系统,那么它类似于调用同一个目录下的程序,你可以这么做:front_of_house/hosting/add_to_waitlist,嗯也很符合直觉。
绝对还是相对?
如果只是为了引用到指定模块中的对象,那么两种都可以,但是在实际使用时,需要遵循一个原则:当代码被挪动位置时,尽量减少引用路径的修改,相信大家都遇到过,修改了某处代码,导致所有路径都要挨个替换,这显然不是好的路径选择。
回到之前的例子,如果我们把 front_of_house 模块和 eat_at_restaurant 移动到一个模块中 customer_experience,那么绝对路径的引用方式就必须进行修改:crate::customer_experience::front_of_house ...,但是假设我们使用的相对路径,那么该路径就无需修改,因为它们两个的相对位置其实没有变:
crate
└── customer_experience
└── eat_at_restaurant
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
从新的模块树中可以很清晰的看出这一点。
再比如,其它的都不动,把 eat_at_restaurant 移动到模块 dining 中,如果使用相对路径,你需要修改该路径,但如果使用的是绝对路径,就无需修改:
crate
└── dining
└── eat_at_restaurant
└── front_of_house
├── hosting
│ ├── add_to_waitlist
不过,如果不确定哪个好,你可以考虑优先使用绝对路径,因为调用的地方和定义的地方往往是分离的,而定义的地方较少会变动。
代码可见性
让我们运行下面(之前)的代码:
#![allow(unused)] fn main() { mod front_of_house { mod hosting { fn add_to_waitlist() {} } } pub fn eat_at_restaurant() { // 绝对路径 crate::front_of_house::hosting::add_to_waitlist(); // 相对路径 front_of_house::hosting::add_to_waitlist(); } }
意料之外的报错了,毕竟看上去确实很简单且没有任何问题:
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ private module
错误信息很清晰:hosting 模块是私有的,无法在包根进行访问,那么为何 front_of_house 模块就可以访问?因为它和 eat_at_restaurant 同属于一个包根作用域内,同一个模块内的代码自然不存在私有化问题(所以我们之前章节的代码都没有报过这个错误!)。
模块不仅仅对于组织代码很有用,它还能定义代码的私有化边界:在这个边界内,什么内容能让外界看到,什么内容不能,都有很明确的定义。因此,如果希望让函数或者结构体等类型变成私有化的,可以使用模块。
Rust 出于安全的考虑,默认情况下,所有的类型都是私有化的,包括函数、方法、结构体、枚举、常量,是的,就连模块本身也是私有化的。在中国,父亲往往不希望孩子拥有小秘密,但是在 Rust 中,父模块完全无法访问子模块中的私有项,但是子模块却可以访问父模块、父父..模块的私有项。
pub 关键字
类似其它语言的 public 或者 Go 语言中的首字母大写,Rust 提供了 pub 关键字,通过它你可以控制模块和模块中指定项的可见性。
由于之前的解释,我们知道了只需要将 hosting 模块标记为对外可见即可:
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { fn add_to_waitlist() {} } } /*--- snip ----*/ }
但是不幸的是,又报错了:
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:12:30
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
哦?难道模块可见还不够,还需要将函数 add_to_waitlist 标记为可见的吗? 是的,没错,模块可见性不代表模块内部项的可见性,模块的可见性仅仅是允许其它模块去引用它,但是想要引用它内部的项,还得继续将对应的项标记为 pub。
在实际项目中,一个模块需要对外暴露的数据和 API 往往就寥寥数个,如果将模块标记为可见代表着内部项也全部对外可见,那你是不是还得把那些不可见的,一个一个标记为 private?反而是更麻烦的多。
既然知道了如何解决,那么我们为函数也标记上 pub:
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } /*--- snip ----*/ }
Bang,顺利通过编译,感觉自己又变强了。
使用 super 引用模块
在用路径引用模块中,我们提到了相对路径有三种方式开始:self、super和 crate 或者模块名,其中第三种在前面已经讲到过,现在来看看通过 super 的方式引用模块项。
super 代表的是父模块为开始的引用方式,非常类似于文件系统中的 .. 语法:../a/b
文件名:src/lib.rs
#![allow(unused)] fn main() { fn serve_order() {} // 厨房模块 mod back_of_house { fn fix_incorrect_order() { cook_order(); super::serve_order(); } fn cook_order() {} } }
嗯,我们的小餐馆又完善了,终于有厨房了!看来第一个客人也快可以有了。。。在厨房模块中,使用 super::serve_order 语法,调用了父模块(包根)中的 serve_order 函数。
那么你可能会问,为何不使用 crate::serve_order 的方式?额,其实也可以,不过如果你确定未来这种层级关系不会改变,那么 super::serve_order 的方式会更稳定,未来就算它们都不在包根了,依然无需修改引用路径。所以路径的选用,往往还是取决于场景,以及未来代码的可能走向。
使用 self 引用模块
self 其实就是引用自身模块中的项,也就是说和我们之前章节的代码类似,都调用同一模块中的内容,区别在于之前章节中直接通过名称调用即可,而 self,你得多此一举:
#![allow(unused)] fn main() { fn serve_order() { self::back_of_house::cook_order() } mod back_of_house { fn fix_incorrect_order() { cook_order(); crate::serve_order(); } pub fn cook_order() {} } }
是的,多此一举,因为完全可以直接调用 back_of_house,但是 self 还有一个大用处,在下一节中我们会讲。
结构体和枚举的可见性
为何要把结构体和枚举的可见性单独拎出来讲呢?因为这两个家伙的成员字段拥有完全不同的可见性:
- 将结构体设置为
pub,但它的所有字段依然是私有的 - 将枚举设置为
pub,它的所有字段也将对外可见
原因在于,枚举和结构体的使用方式不一样。如果枚举的成员对外不可见,那该枚举将一点用都没有,因此枚举成员的可见性自动跟枚举可见性保持一致,这样可以简化用户的使用。
而结构体的应用场景比较复杂,其中的字段也往往部分在 A 处被使用,部分在 B 处被使用,因此无法确定成员的可见性,那索性就设置为全部不可见,将选择权交给程序员。
模块与文件分离
在之前的例子中,我们所有的模块都定义在 src/lib.rs 中,但是当模块变多或者变大时,需要将模块放入一个单独的文件中,让代码更好维护。
现在,把 front_of_house 前厅分离出来,放入一个单独的文件中 src/front_of_house.rs:
#![allow(unused)] fn main() { pub mod hosting { pub fn add_to_waitlist() {} } }
然后,将以下代码留在 src/lib.rs 中:
#![allow(unused)] fn main() { mod front_of_house; pub use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); hosting::add_to_waitlist(); hosting::add_to_waitlist(); } }
so easy!其实跟之前在同一个文件中也没有太大的不同,但是有几点值得注意:
mod front_of_house;告诉 Rust 从另一个和模块front_of_house同名的文件中加载该模块的内容- 使用绝对路径的方式来引用
hosting模块:crate::front_of_house::hosting;
需要注意的是,和之前代码中 mod front_of_house{..} 的完整模块不同,现在的代码中,模块的声明和实现是分离的,实现是在单独的 front_of_house.rs 文件中,然后通过 mod front_of_house; 这条声明语句从该文件中把模块内容加载进来。因此我们可以认为,模块 front_of_house 的定义还是在 src/lib.rs 中,只不过模块的具体内容被移动到了 src/front_of_house.rs 文件中。
在这里出现了一个新的关键字 use,联想到其它章节我们见过的标准库引入 use std::fmt;,可以大致猜测,该关键字用来将外部模块中的项引入到当前作用域中来,这样无需冗长的父模块前缀即可调用:hosting::add_to_waitlist();,在下节中,我们将对 use 进行详细的讲解。
当一个模块有许多子模块时,我们也可以通过文件夹的方式来组织这些子模块。
在上述例子中,我们可以创建一个目录 front_of_house,然后在文件夹里创建一个 hosting.rs 文件,hosting.rs 文件现在就剩下:
#![allow(unused)] fn main() { pub fn add_to_waitlist() {} }
现在,我们尝试编译程序,很遗憾,编译器报错:
error[E0583]: file not found for module `front_of_house`
--> src/lib.rs:3:1
|
1 | mod front_of_house;
| ^^^^^^^^^^^^^^^^^^
|
= help: to create the module `front_of_house`, create file "src/front_of_house.rs" or "src/front_of_house/mod.rs"
是的,如果需要将文件夹作为一个模块,我们需要进行显示指定暴露哪些子模块。按照上述的报错信息,我们有两种方法:
- 在
front_of_house目录里创建一个mod.rs,如果你使用的rustc版本1.30之前,这是唯一的方法。 - 在
front_of_house同级目录里创建一个与模块(目录)同名的 rs 文件front_of_house.rs,在新版本里,更建议使用这样的命名方式来避免项目中存在大量同名的mod.rs文件( Python 点了个踩)。
而无论是上述哪个方式创建的文件,其内容都是一样的,你需要定义你的子模块(子模块名与文件名相同):
#![allow(unused)] fn main() { pub mod hosting; // pub mod serving; }
使用 use 及受限可见性
如果代码中,通篇都是 crate::front_of_house::hosting::add_to_waitlist 这样的函数调用形式,我不知道有谁会喜欢,也许靠代码行数赚工资的人会很喜欢,但是强迫症肯定受不了,悲伤的是程序员大多都有强迫症。。。
因此我们需要一个办法来简化这种使用方式,在 Rust 中,可以使用 use 关键字把路径提前引入到当前作用域中,随后的调用就可以省略该路径,极大地简化了代码。
基本引入方式
在 Rust 中,引入模块中的项有两种方式:绝对路径和相对路径,这两者在前面章节都有讲过,就不再赘述,先来看看使用绝对路径的引入方式。
绝对路径引入模块
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); hosting::add_to_waitlist(); hosting::add_to_waitlist(); } }
这里,我们使用 use 和绝对路径的方式,将 hosting 模块引入到当前作用域中,然后只需通过 hosting::add_to_waitlist 的方式,即可调用目标模块中的函数,相比 crate::front_of_house::hosting::add_to_waitlist() 的方式要简单的多,那么还能更简单吗?
相对路径引入模块中的函数
在下面代码中,我们不仅要使用相对路径进行引入,而且与上面引入 hosting 模块不同,直接引入该模块中的 add_to_waitlist 函数:
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } use front_of_house::hosting::add_to_waitlist; pub fn eat_at_restaurant() { add_to_waitlist(); add_to_waitlist(); add_to_waitlist(); } }
很明显,三兄弟又变得更短了,不过,怎么觉得这句话怪怪的。。
引入模块还是函数
从使用简洁性来说,引入函数自然是更甚一筹,但是在某些时候,引入模块会更好:
- 需要引入同一个模块的多个函数
- 作用域中存在同名函数
在以上两种情况中,使用 use front_of_house::hosting 引入模块要比 use front_of_house::hosting::add_to_waitlist; 引入函数更好。
例如,如果想使用 HashMap,那么直接引入该结构体是比引入模块更好的选择,因为在 collections 模块中,我们只需要使用一个 HashMap 结构体:
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert(1, 2); }
其实严格来说,对于引用方式并没有需要遵守的惯例,主要还是取决于你的喜好,不过我们建议:优先使用最细粒度(引入函数、结构体等)的引用方式,如果引起了某种麻烦(例如前面两种情况),再使用引入模块的方式。
避免同名引用
根据上一章节的内容,我们只要保证同一个模块中不存在同名项就行,模块之间、包之间的同名,谁管得着谁啊,话虽如此,一起看看,如果遇到同名的情况该如何处理。
模块::函数
#![allow(unused)] fn main() { use std::fmt; use std::io; fn function1() -> fmt::Result { // --snip-- } fn function2() -> io::Result<()> { // --snip-- } }
上面的例子给出了很好的解决方案,使用模块引入的方式,具体的 Result 通过 模块::Result 的方式进行调用。
可以看出,避免同名冲突的关键,就是使用父模块的方式来调用,除此之外,还可以给予引入的项起一个别名。
as 别名引用
对于同名冲突问题,还可以使用 as 关键字来解决,它可以赋予引入项一个全新的名称:
#![allow(unused)] fn main() { use std::fmt::Result; use std::io::Result as IoResult; fn function1() -> Result { // --snip-- } fn function2() -> IoResult<()> { // --snip-- } }
如上所示,首先通过 use std::io::Result 将 Result 引入到作用域,然后使用 as 给予它一个全新的名称 IoResult,这样就不会再产生冲突:
Result代表std::fmt::ResultIoResult代表std:io::Result
引入项再导出
当外部的模块项 A 被引入到当前模块中时,它的可见性自动被设置为私有的,如果你希望允许其它外部代码引用我们的模块项 A,那么可以对它进行再导出:
#![allow(unused)] fn main() { mod front_of_house { pub mod hosting { pub fn add_to_waitlist() {} } } pub use crate::front_of_house::hosting; pub fn eat_at_restaurant() { hosting::add_to_waitlist(); hosting::add_to_waitlist(); hosting::add_to_waitlist(); } }
如上,使用 pub use 即可实现。这里 use 代表引入 hosting 模块到当前作用域,pub 表示将该引入的内容再度设置为可见。
当你希望将内部的实现细节隐藏起来或者按照某个目的组织代码时,可以使用 pub use 再导出,例如统一使用一个模块来提供对外的 API,那该模块就可以引入其它模块中的 API,然后进行再导出,最终对于用户来说,所有的 API 都是由一个模块统一提供的。
使用第三方包
之前我们一直在引入标准库模块或者自定义模块,现在来引入下第三方包中的模块,关于如何引入外部依赖,这里直接给出操作步骤:
- 修改
Cargo.toml文件,在[dependencies]区域添加一行:rand = "0.8.3" - 此时,如果你用的是
VSCode和rust-analyzer插件,该插件会自动拉取该库,你可能需要等它完成后,再进行下一步(VSCode 左下角有提示)
好了,此时,rand 包已经被我们添加到依赖中,下一步就是在代码中使用:
use rand::Rng; fn main() { let secret_number = rand::thread_rng().gen_range(1..101); }
这里使用 use 引入了第三方包 rand 中的 Rng 特征,因为我们需要调用的 gen_range 方法定义在该特征中。
crates.io,lib.rs
Rust 社区已经为我们贡献了大量高质量的第三方包,你可以在 crates.io 或者 lib.rs 中检索和使用,从目前来说查找包更推荐 lib.rs,搜索功能更强大,内容展示也更加合理,但是下载依赖包还是得用crates.io。
你可以在网站上搜索 rand 包,看看它的文档使用方式是否和我们之前引入方式相一致:在网上找到想要的包,然后将你想要的包和版本信息写入到 Cargo.toml 中。
使用 {} 简化引入方式
对于以下一行一行的引入方式:
#![allow(unused)] fn main() { use std::collections::HashMap; use std::collections::BTreeMap; use std::collections::HashSet; use std::cmp::Ordering; use std::io; }
可以使用 {} 来一起引入进来,在大型项目中,使用这种方式来引入,可以减少大量 use 的使用:
#![allow(unused)] fn main() { use std::collections::{HashMap,BTreeMap,HashSet}; use std::{cmp::Ordering, io}; }
对于下面的同时引入模块和模块中的项:
#![allow(unused)] fn main() { use std::io; use std::io::Write; }
可以使用 {} 的方式进行简化:
#![allow(unused)] fn main() { use std::io::{self, Write}; }
self
上面使用到了模块章节提到的 self 关键字,用来替代模块自身,结合上一节中的 self,可以得出它在模块中的两个用途:
use self::xxx,表示加载当前模块中的xxx。此时self可省略use xxx::{self, yyy},表示,加载当前路径下模块xxx本身,以及模块xxx下的yyy
使用 * 引入模块下的所有项
对于之前一行一行引入 std::collections 的方式,我们还可以使用
#![allow(unused)] fn main() { use std::collections::*; }
以上这种方式来引入 std::collections 模块下的所有公共项,这些公共项自然包含了 HashMap,HashSet 等想手动引入的集合类型。
当使用 * 来引入的时候要格外小心,因为你很难知道到底哪些被引入到了当前作用域中,有哪些会和你自己程序中的名称相冲突:
use std::collections::*; struct HashMap; fn main() { let mut v = HashMap::new(); v.insert("a", 1); }
以上代码中,std::collection::HashMap 被 * 引入到当前作用域,但是由于存在另一个同名的结构体,因此 HashMap::new 根本不存在,因为对于编译器来说,本地同名类型的优先级更高。
在实际项目中,这种引用方式往往用于快速写测试代码,它可以把所有东西一次性引入到 tests 模块中。
受限的可见性
在上一节中,我们学习了可见性这个概念,这也是模块体系中最为核心的概念,控制了模块中哪些内容可以被外部看见,但是在实际使用时,光被外面看到还不行,我们还想控制哪些人能看,这就是 Rust 提供的受限可见性。
例如,在 Rust 中,包是一个模块树,我们可以通过 pub(crate) item; 这种方式来实现:item 虽然是对外可见的,但是只在当前包内可见,外部包无法引用到该 item。
所以,如果我们想要让某一项可以在整个包中都可以被使用,那么有两种办法:
- 在包根中定义一个非
pub类型的X(父模块的项对子模块都是可见的,因此包根中的项对模块树上的所有模块都可见) - 在子模块中定义一个
pub类型的Y,同时通过use将其引入到包根
#![allow(unused)] fn main() { mod a { pub mod b { pub fn c() { println!("{:?}",crate::X); } #[derive(Debug)] pub struct Y; } } #[derive(Debug)] struct X; use a::b::Y; fn d() { println!("{:?}",Y); } }
以上代码充分说明了之前两种办法的使用方式,但是有时我们会遇到这两种方法都不太好用的时候。例如希望对于某些特定的模块可见,但是对于其他模块又不可见:
#![allow(unused)] fn main() { // 目标:`a` 导出 `I`、`bar` and `foo`,其他的不导出 pub mod a { pub const I: i32 = 3; fn semisecret(x: i32) -> i32 { use self::b::c::J; x + J } pub fn bar(z: i32) -> i32 { semisecret(I) * z } pub fn foo(y: i32) -> i32 { semisecret(I) + y } mod b { mod c { const J: i32 = 4; } } } }
这段代码会报错,因为与父模块中的项对子模块可见相反,子模块中的项对父模块是不可见的。这里 semisecret 方法中,a -> b -> c 形成了父子模块链,那 c 中的 J 自然对 a 模块不可见。
如果使用之前的可见性方式,那么想保持 J 私有,同时让 a 继续使用 semisecret 函数的办法是将该函数移动到 c 模块中,然后用 pub use 将 semisecret 函数进行再导出:
#![allow(unused)] fn main() { pub mod a { pub const I: i32 = 3; use self::b::semisecret; pub fn bar(z: i32) -> i32 { semisecret(I) * z } pub fn foo(y: i32) -> i32 { semisecret(I) + y } mod b { pub use self::c::semisecret; mod c { const J: i32 = 4; pub fn semisecret(x: i32) -> i32 { x + J } } } } }
这段代码说实话问题不大,但是有些破坏了我们之前的逻辑,如果想保持代码逻辑,同时又只让 J 在 a 内可见该怎么办?
#![allow(unused)] fn main() { pub mod a { pub const I: i32 = 3; fn semisecret(x: i32) -> i32 { use self::b::c::J; x + J } pub fn bar(z: i32) -> i32 { semisecret(I) * z } pub fn foo(y: i32) -> i32 { semisecret(I) + y } mod b { pub(in crate::a) mod c { pub(in crate::a) const J: i32 = 4; } } } }
通过 pub(in crate::a) 的方式,我们指定了模块 c 和常量 J 的可见范围都只是 a 模块中,a 之外的模块是完全访问不到它们的。
限制可见性语法
pub(crate) 或 pub(in crate::a) 就是限制可见性语法,前者是限制在整个包内可见,后者是通过绝对路径,限制在包内的某个模块内可见,总结一下:
pub意味着可见性无任何限制pub(crate)表示在当前包可见pub(self)在当前模块可见pub(super)在父模块可见pub(in <path>)表示在某个路径代表的模块中可见,其中path必须是父模块或者祖先模块
一个综合例子
// 一个名为 `my_mod` 的模块 mod my_mod { // 模块中的项默认具有私有的可见性 fn private_function() { println!("called `my_mod::private_function()`"); } // 使用 `pub` 修饰语来改变默认可见性。 pub fn function() { println!("called `my_mod::function()`"); } // 在同一模块中,项可以访问其它项,即使它是私有的。 pub fn indirect_access() { print!("called `my_mod::indirect_access()`, that\n> "); private_function(); } // 模块也可以嵌套 pub mod nested { pub fn function() { println!("called `my_mod::nested::function()`"); } #[allow(dead_code)] fn private_function() { println!("called `my_mod::nested::private_function()`"); } // 使用 `pub(in path)` 语法定义的函数只在给定的路径中可见。 // `path` 必须是父模块(parent module)或祖先模块(ancestor module) pub(in crate::my_mod) fn public_function_in_my_mod() { print!("called `my_mod::nested::public_function_in_my_mod()`, that\n > "); public_function_in_nested() } // 使用 `pub(self)` 语法定义的函数则只在当前模块中可见。 pub(self) fn public_function_in_nested() { println!("called `my_mod::nested::public_function_in_nested"); } // 使用 `pub(super)` 语法定义的函数只在父模块中可见。 pub(super) fn public_function_in_super_mod() { println!("called my_mod::nested::public_function_in_super_mod"); } } pub fn call_public_function_in_my_mod() { print!("called `my_mod::call_public_funcion_in_my_mod()`, that\n> "); nested::public_function_in_my_mod(); print!("> "); nested::public_function_in_super_mod(); } // `pub(crate)` 使得函数只在当前包中可见 pub(crate) fn public_function_in_crate() { println!("called `my_mod::public_function_in_crate()"); } // 嵌套模块的可见性遵循相同的规则 mod private_nested { #[allow(dead_code)] pub fn function() { println!("called `my_mod::private_nested::function()`"); } } } fn function() { println!("called `function()`"); } fn main() { // 模块机制消除了相同名字的项之间的歧义。 function(); my_mod::function(); // 公有项,包括嵌套模块内的,都可以在父模块外部访问。 my_mod::indirect_access(); my_mod::nested::function(); my_mod::call_public_function_in_my_mod(); // pub(crate) 项可以在同一个 crate 中的任何地方访问 my_mod::public_function_in_crate(); // pub(in path) 项只能在指定的模块中访问 // 报错!函数 `public_function_in_my_mod` 是私有的 //my_mod::nested::public_function_in_my_mod(); // 试一试 ^ 取消该行的注释 // 模块的私有项不能直接访问,即便它是嵌套在公有模块内部的 // 报错!`private_function` 是私有的 //my_mod::private_function(); // 试一试 ^ 取消此行注释 // 报错!`private_function` 是私有的 //my_mod::nested::private_function(); // 试一试 ^ 取消此行的注释 // 报错! `private_nested` 是私有的 //my_mod::private_nested::function(); // 试一试 ^ 取消此行的注释 }
注释和文档
在之前的章节我们学习了包和模块如何使用,在此章节将进一步学习如何书写文档注释,以及如何使用 cargo doc 生成项目的文档,最后将以一个包、模块和文档的综合性例子,来将这些知识融会贯通。
注释的种类
在 Rust 中,注释分为三类:
- 代码注释,用于说明某一块代码的功能,读者往往是同一个项目的协作开发者
- 文档注释,支持
Markdown,对项目描述、公共 API 等用户关心的功能进行介绍,同时还能提供示例代码,目标读者往往是想要了解你项目的人 - 包和模块注释,严格来说这也是文档注释中的一种,它主要用于说明当前包和模块的功能,方便用户迅速了解一个项目
通过这些注释,实现了 Rust 极其优秀的文档化支持,甚至你还能在文档注释中写测试用例,省去了单独写测试用例的环节,我直呼好家伙!
代码注释
显然之前的刮目相看是打了引号的,想要去掉引号,该写注释的时候,就老老实实的,不过写时需要遵循八字原则:围绕目标,言简意赅,记住,洋洋洒洒那是用来形容文章的,不是形容注释!
代码注释方式有两种:
行注释 //
fn main() { // 我是Sun... // face let name = "sunface"; let age = 18; // 今年好像是18岁 }
如上所示,行注释可以放在某一行代码的上方,也可以放在当前代码行的后方。如果超出一行的长度,需要在新行的开头也加上 //。
当注释行数较多时,你还可以使用块注释
块注释/* ..... */
fn main() { /* 我 是 S u n ... 哎,好长! */ let name = "sunface"; let age = "???"; // 今年其实。。。挺大了 }
如上所示,只需要将注释内容使用 /* */ 进行包裹即可。
你会发现,Rust 的代码注释跟其它语言并没有区别,主要区别其实在于文档注释这一块,也是本章节内容的重点。
文档注释
当查看一个 crates.io 上的包时,往往需要通过它提供的文档来浏览相关的功能特性、使用方式,这种文档就是通过文档注释实现的。
Rust 提供了 cargo doc 的命令,可以用于把这些文档注释转换成 HTML 网页文件,最终展示给用户浏览,这样用户就知道这个包是做什么的以及该如何使用。
文档行注释 ///
本书的一大特点就是废话不多,因此我们开门见山:
#![allow(unused)] fn main() { /// `add_one` 将指定值加1 /// /// # Examples /// /// ``` /// let arg = 5; /// let answer = my_crate::add_one(arg); /// /// assert_eq!(6, answer); /// ``` pub fn add_one(x: i32) -> i32 { x + 1 } }
以上代码有几点需要注意:
- 文档注释需要位于
lib类型的包中,例如src/lib.rs中 - 文档注释可以使用
markdown语法!例如# Examples的标题,以及代码块高亮 - 被注释的对象需要使用
pub对外可见,记住:文档注释是给用户看的,内部实现细节不应该被暴露出去
咦?文档注释中的例子,为什看上去像是能运行的样子?竟然还是有 assert_eq 这种常用于测试目的的宏。 嗯,你的感觉没错,详细内容会在本章后面讲解,容我先卖个关子。
文档块注释 /** ... */
与代码注释一样,文档也有块注释,当注释内容多时,使用块注释可以减少 /// 的使用:
#![allow(unused)] fn main() { /** `add_two` 将指定值加2 Examples ``` let arg = 5; let answer = my_crate::add_two(arg); assert_eq!(7, answer); ``` */ pub fn add_two(x: i32) -> i32 { x + 2 } }
查看文档 cargo doc
锦衣不夜行,这是中国人的传统美德。我们写了这么漂亮的文档注释,当然要看看网页中是什么效果咯。
很简单,运行 cargo doc 可以直接生成 HTML 文件,放入target/doc目录下。
当然,为了方便,我们使用 cargo doc --open 命令,可以在生成文档后,自动在浏览器中打开网页,最终效果如图所示:

非常棒,而且非常简单,这就是 Rust 工具链的强大之处。
常用文档标题
之前我们见到了在文档注释中该如何使用 markdown,其中包括 # Examples 标题。除了这个标题,还有一些常用的,你可以在项目中酌情使用:
- Panics:函数可能会出现的异常状况,这样调用函数的人就可以提前规避
- Errors:描述可能出现的错误及什么情况会导致错误,有助于调用者针对不同的错误采取不同的处理方式
- Safety:如果函数使用
unsafe代码,那么调用者就需要注意一些使用条件,以确保unsafe代码块的正常工作
话说回来,这些标题更多的是一种惯例,如果你非要用中文标题也没问题,但是最好在团队中保持同样的风格 :)
包和模块级别的注释
除了函数、结构体等 Rust 项的注释,你还可以给包和模块添加注释,需要注意的是,这些注释要添加到包、模块的最上方!
与之前的任何注释一样,包级别的注释也分为两种:行注释 //! 和块注释 /*! ... */。
现在,为我们的包增加注释,在 src/lib.rs 包根的最上方,添加:
#![allow(unused)] fn main() { /*! lib包是world_hello二进制包的依赖包, 里面包含了compute等有用模块 */ pub mod compute; }
然后再为该包根的子模块 src/compute.rs 添加注释:
#![allow(unused)] fn main() { //! 计算一些你口算算不出来的复杂算术题 /// `add_one`将指定值加1 /// }
运行 cargo doc --open 查看下效果:
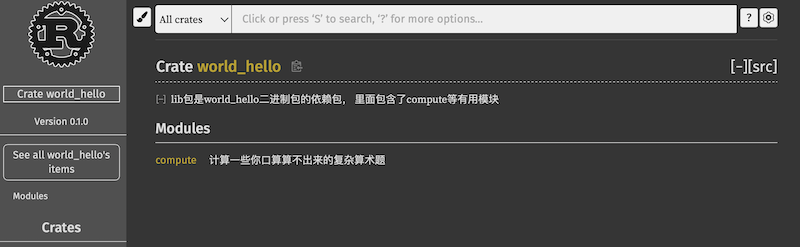
包模块注释,可以让用户从整体的角度理解包的用途,对于用户来说是非常友好的,就和一篇文章的开头一样,总是要对文章的内容进行大致的介绍,让用户在看的时候心中有数。
至此,关于如何注释的内容,就结束了,那么注释还能用来做什么?可以玩出花来吗?答案是Yes.
文档测试(Doc Test)
相信读者之前都写过单元测试用例,其中一个很蛋疼的问题就是,随着代码的进化,单元测试用例经常会失效,过段时间后(为何是过段时间?应该这么问,有几个开发喜欢写测试用例 =,=),你发现需要连续修改不少处代码,才能让测试重新工作起来。然而,在 Rust 中,大可不必。
在之前的 add_one 中,我们写的示例代码非常像是一个单元测试的用例,这是偶然吗?并不是。因为 Rust 允许我们在文档注释中写单元测试用例!方法就如同之前做的:
#![allow(unused)] fn main() { /// `add_one` 将指定值加1 /// /// # Examples11 /// /// ``` /// let arg = 5; /// let answer = world_hello::compute::add_one(arg); /// /// assert_eq!(6, answer); /// ``` pub fn add_one(x: i32) -> i32 { x + 1 } }
以上的注释不仅仅是文档,还可以作为单元测试的用例运行,使用 cargo test 运行测试:
Doc-tests world_hello
running 2 tests
test src/compute.rs - compute::add_one (line 8) ... ok
test src/compute.rs - compute::add_two (line 22) ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 1.00s
可以看到,文档中的测试用例被完美运行,而且输出中也明确提示了 Doc-tests world_hello,意味着这些测试的名字叫 Doc test 文档测试。
需要注意的是,你可能需要使用类如
world_hello::compute::add_one(arg)的完整路径来调用函数,因为测试是在另外一个独立的线程中运行的
造成 panic 的文档测试
文档测试中的用例还可以造成 panic:
#![allow(unused)] fn main() { /// # Panics /// /// The function panics if the second argument is zero. /// /// ```rust /// // panics on division by zero /// world_hello::compute::div(10, 0); /// ``` pub fn div(a: i32, b: i32) -> i32 { if b == 0 { panic!("Divide-by-zero error"); } a / b } }
以上测试运行后会 panic:
---- src/compute.rs - compute::div (line 38) stdout ----
Test executable failed (exit code 101).
stderr:
thread 'main' panicked at 'Divide-by-zero error', src/compute.rs:44:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
如果想要通过这种测试,可以添加 should_panic:
#![allow(unused)] fn main() { /// # Panics /// /// The function panics if the second argument is zero. /// /// ```rust,should_panic /// // panics on division by zero /// world_hello::compute::div(10, 0); /// ``` }
通过 should_panic,告诉 Rust 我们这个用例会导致 panic,这样测试用例就能顺利通过。
保留测试,隐藏文档
在某些时候,我们希望保留文档测试的功能,但是又要将某些测试用例的内容从文档中隐藏起来:
/// ``` /// # // 使用#开头的行会在文档中被隐藏起来,但是依然会在文档测试中运行 /// # fn try_main() -> Result<(), String> { /// let res = world_hello::compute::try_div(10, 0)?; /// # Ok(()) // returning from try_main /// # } /// # fn main() { /// # try_main().unwrap(); /// # /// # } /// ``` pub fn try_div(a: i32, b: i32) -> Result<i32, String> { if b == 0 { Err(String::from("Divide-by-zero")) } else { Ok(a / b) } }
以上文档注释中,我们使用 # 将不想让用户看到的内容隐藏起来,但是又不影响测试用例的运行,最终用户将只能看到那行没有隐藏的 let res = world_hello::compute::try_div(10, 0)?;:
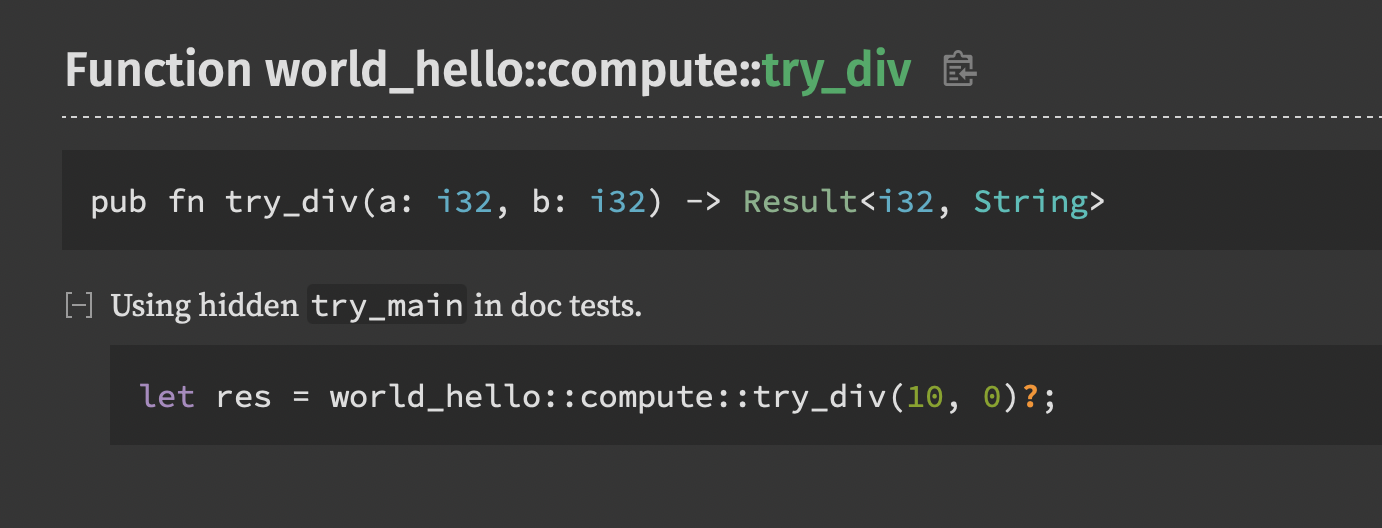
文档注释中的代码跳转
Rust 在文档注释中还提供了一个非常强大的功能,那就是可以实现对外部项的链接:
跳转到标准库
#![allow(unused)] fn main() { /// `add_one` 返回一个[`Option`]类型 pub fn add_one(x: i32) -> Option<i32> { Some(x + 1) } }
此处的 [Option] 就是一个链接,指向了标准库中的 Option 枚举类型,有两种方式可以进行跳转:
- 在 IDE 中,使用
Command + 鼠标左键(macOS),CTRL + 鼠标左键(Windows) - 在文档中直接点击链接
再比如,还可以使用路径的方式跳转:
#![allow(unused)] fn main() { use std::sync::mpsc::Receiver; /// [`Receiver<T>`] [`std::future`]. /// /// [`std::future::Future`] [`Self::recv()`]. pub struct AsyncReceiver<T> { sender: Receiver<T>, } impl<T> AsyncReceiver<T> { pub async fn recv() -> T { unimplemented!() } } }
使用完整路径跳转到指定项
除了跳转到标准库,你还可以通过指定具体的路径跳转到自己代码或者其它库的指定项,例如在 lib.rs 中添加以下代码:
#![allow(unused)] fn main() { pub mod a { /// `add_one` 返回一个[`Option`]类型 /// 跳转到[`crate::MySpecialFormatter`] pub fn add_one(x: i32) -> Option<i32> { Some(x + 1) } } pub struct MySpecialFormatter; }
使用 crate::MySpecialFormatter 这种路径就可以实现跳转到 lib.rs 中定义的结构体上。
同名项的跳转
如果遇到同名项,可以使用标示类型的方式进行跳转:
#![allow(unused)] fn main() { /// 跳转到结构体 [`Foo`](struct@Foo) pub struct Bar; /// 跳转到同名函数 [`Foo`](fn@Foo) pub struct Foo {} /// 跳转到同名宏 [`foo!`] pub fn Foo() {} #[macro_export] macro_rules! foo { () => {} } }
文档搜索别名
Rust 文档支持搜索功能,我们可以为自己的类型定义几个别名,以实现更好的搜索展现,当别名命中时,搜索结果会被放在第一位:
#![allow(unused)] fn main() { #[doc(alias = "x")] #[doc(alias = "big")] pub struct BigX; #[doc(alias("y", "big"))] pub struct BigY; }
结果如下图所示:
一个综合例子
这个例子我们将重点应用几个知识点:
- 文档注释
- 一个项目可以包含两个包:二进制可执行包和
lib包(库包),它们的包根分别是src/main.rs和src/lib.rs - 在二进制包中引用
lib包 - 使用
pub use再导出 API,并观察文档
首先,使用 cargo new art 创建一个 Package art:
Created binary (application) `art` package
系统提示我们创建了一个二进制 Package,根据之前章节学过的内容,可以知道该 Package 包含一个同名的二进制包:包名为 art,包根为 src/main.rs,该包可以编译成二进制然后运行。
现在,在 src 目录下创建一个 lib.rs 文件,同样,根据之前学习的知识,创建该文件等于又创建了一个库类型的包,包名也是 art,包根为 src/lib.rs,该包是是库类型的,因此往往作为依赖库被引入。
将以下内容添加到 src/lib.rs 中:
#![allow(unused)] fn main() { //! # Art //! //! 未来的艺术建模库,现在的调色库 pub use self::kinds::PrimaryColor; pub use self::kinds::SecondaryColor; pub use self::utils::mix; pub mod kinds { //! 定义颜色的类型 /// 主色 pub enum PrimaryColor { Red, Yellow, Blue, } /// 副色 #[derive(Debug,PartialEq)] pub enum SecondaryColor { Orange, Green, Purple, } } pub mod utils { //! 实用工具,目前只实现了调色板 use crate::kinds::*; /// 将两种主色调成副色 /// ```rust /// use art::utils::mix; /// use art::kinds::{PrimaryColor,SecondaryColor}; /// assert!(matches!(mix(PrimaryColor::Yellow, PrimaryColor::Blue), SecondaryColor::Green)); /// ``` pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor { SecondaryColor::Green } } }
在库包的包根 src/lib.rs 下,我们又定义了几个子模块,同时将子模块中的三个项通过 pub use 进行了再导出。
接着,将下面内容添加到 src/main.rs 中:
use art::kinds::PrimaryColor; use art::utils::mix; fn main() { let blue = PrimaryColor::Blue; let yellow = PrimaryColor::Yellow; println!("{:?}",mix(blue, yellow)); }
在二进制可执行包的包根 src/main.rs 下,我们引入了库包 art 中的模块项,同时使用 main 函数作为程序的入口,该二进制包可以使用 cargo run 运行:
Green
至此,库包完美提供了用于调色的 API,二进制包引入这些 API 完美的实现了调色并打印输出。
最后,再来看看文档长啥样:

总结
在 Rust 中,注释分为三个主要类型:代码注释、文档注释、包和模块注释,每个注释类型都拥有两种形式:行注释和块注释,熟练掌握包模块和注释的知识,非常有助于我们创建工程性更强的项目。
类型转换
Rust 是类型安全的语言,因此在 Rust 中做类型转换不是一件简单的事,这一章节我们将对 Rust 中的类型转换进行详尽讲解。
高能预警:本章节有些难,可以考虑学了进阶后回头再看
as转换
先来看一段代码:
fn main() { let a: i32 = 10; let b: u16 = 100; if a < b { println!("Ten is less than one hundred."); } }
能跟着这本书一直学习到这里,说明你对 Rust 已经有了一定的理解,那么一眼就能看出这段代码注定会报错,因为 a 和 b 拥有不同的类型,Rust 不允许两种不同的类型进行比较。
解决办法很简单,只要把 b 转换成 i32 类型即可,Rust 中内置了一些基本类型之间的转换,这里使用 as 操作符来完成: if a < (b as i32) {...}。那么为什么不把 a 转换成 u16 类型呢?
因为每个类型能表达的数据范围不同,如果把范围较大的类型转换成较小的类型,会造成错误,因此我们需要把范围较小的类型转换成较大的类型,来避免这些问题的发生。
使用类型转换需要小心,因为如果执行以下操作
300_i32 as i8,你将获得44这个值,而不是300,因为i8类型能表达的的最大值为2^7 - 1,使用以下代码可以查看i8的最大值:
#![allow(unused)] fn main() { let a = i8::MAX; println!("{}",a); }
下面列出了常用的转换形式:
fn main() { let a = 3.1 as i8; let b = 100_i8 as i32; let c = 'a' as u8; // 将字符'a'转换为整数,97 println!("{},{},{}",a,b,c) }
内存地址转换为指针
#![allow(unused)] fn main() { let mut values: [i32; 2] = [1, 2]; let p1: *mut i32 = values.as_mut_ptr(); let first_address = p1 as usize; // 将p1内存地址转换为一个整数 let second_address = first_address + 4; // 4 == std::mem::size_of::<i32>(),i32类型占用4个字节,因此将内存地址 + 4 let p2 = second_address as *mut i32; // 访问该地址指向的下一个整数p2 unsafe { *p2 += 1; } assert_eq!(values[1], 3); }
强制类型转换的边角知识
- 转换不具有传递性
就算
e as U1 as U2是合法的,也不能说明e as U2是合法的(e不能直接转换成U2)。
TryInto 转换
在一些场景中,使用 as 关键字会有比较大的限制。如果你想要在类型转换上拥有完全的控制而不依赖内置的转换,例如处理转换错误,那么可以使用 TryInto :
use std::convert::TryInto; fn main() { let a: u8 = 10; let b: u16 = 1500; let b_: u8 = b.try_into().unwrap(); if a < b_ { println!("Ten is less than one hundred."); } }
上面代码中引入了 std::convert::TryInto 特征,但是却没有使用它,可能有些同学会为此困惑,主要原因在于如果你要使用一个特征的方法,那么你需要引入该特征到当前的作用域中,我们在上面用到了 try_into 方法,因此需要引入对应的特征。但是 Rust 又提供了一个非常便利的办法,把最常用的标准库中的特征通过std::prelude模块提前引入到当前作用域中,其中包括了 std::convert::TryInto,你可以尝试删除第一行的代码 use ...,看看是否会报错。
try_into 会尝试进行一次转换,并返回一个 Result,此时就可以对其进行相应的错误处理。由于我们的例子只是为了快速测试,因此使用了 unwrap 方法,该方法在发现错误时,会直接调用 panic 导致程序的崩溃退出,在实际项目中,请不要这么使用,具体见panic部分。
最主要的是 try_into 转换会捕获大类型向小类型转换时导致的溢出错误:
fn main() { let b: i16 = 1500; let b_: u8 = match b.try_into() { Ok(b1) => b1, Err(e) => { println!("{:?}", e.to_string()); 0 } }; }
运行后输出如下 "out of range integral type conversion attempted",在这里我们程序捕获了错误,编译器告诉我们类型范围超出的转换是不被允许的,因为我们试图把 1500_i16 转换为 u8 类型,后者明显不足以承载这么大的值。
通用类型转换
虽然 as 和 TryInto 很强大,但是只能应用在数值类型上,可是 Rust 有如此多的类型,想要为这些类型实现转换,我们需要另谋出路,先来看看在一个笨办法,将一个结构体转换为另外一个结构体:
#![allow(unused)] fn main() { struct Foo { x: u32, y: u16, } struct Bar { a: u32, b: u16, } fn reinterpret(foo: Foo) -> Bar { let Foo { x, y } = foo; Bar { a: x, b: y } } }
简单粗暴,但是从另外一个角度来看,也挺啰嗦的,好在 Rust 为我们提供了更通用的方式来完成这个目的。
强制类型转换
在某些情况下,类型是可以进行隐式强制转换的,虽然这些转换弱化了 Rust 的类型系统,但是它们的存在是为了让 Rust 在大多数场景可以工作(说白了,帮助用户省事),而不是报各种类型上的编译错误。
首先,在匹配特征时,不会做任何强制转换(除了方法)。一个类型 T 可以强制转换为 U,不代表 impl T 可以强制转换为 impl U,例如下面的代码就无法通过编译检查:
trait Trait {} fn foo<X: Trait>(t: X) {} impl<'a> Trait for &'a i32 {} fn main() { let t: &mut i32 = &mut 0; foo(t); }
报错如下:
error[E0277]: the trait bound `&mut i32: Trait` is not satisfied
--> src/main.rs:9:9
|
9 | foo(t);
| ^ the trait `Trait` is not implemented for `&mut i32`
|
= help: the following implementations were found:
<&'a i32 as Trait>
= note: `Trait` is implemented for `&i32`, but not for `&mut i32`
&i32 实现了特征 Trait, &mut i32 可以转换为 &i32,但是 &mut i32 依然无法作为 Trait 来使用。
点操作符
方法调用的点操作符看起来简单,实际上非常不简单,它在调用时,会发生很多魔法般的类型转换,例如:自动引用、自动解引用,强制类型转换直到类型能匹配等。
假设有一个方法 foo,它有一个接收器(接收器就是 self、&self、&mut self 参数)。如果调用 value.foo(),编译器在调用 foo 之前,需要决定到底使用哪个 Self 类型来调用。现在假设 value 拥有类型 T。
再进一步,我们使用完全限定语法来进行准确的函数调用:
- 首先,编译器检查它是否可以直接调用
T::foo(value),称之为值方法调用 - 如果上一步调用无法完成(例如方法类型错误或者特征没有针对
Self进行实现,上文提到过特征不能进行强制转换),那么编译器会尝试增加自动引用,例如会尝试以下调用:<&T>::foo(value)和<&mut T>::foo(value),称之为引用方法调用 - 若上面两个方法依然不工作,编译器会试着解引用
T,然后再进行尝试。这里使用了Deref特征 —— 若T: Deref<Target = U>(T可以被解引用为U),那么编译器会使用U类型进行尝试,称之为解引用方法调用 - 若
T不能被解引用,且T是一个定长类型(在编译器类型长度是已知的),那么编译器也会尝试将T从定长类型转为不定长类型,例如将[i32; 2]转为[i32] - 若还是不行,那...没有那了,最后编译器大喊一声:汝欺我甚,不干了!
下面我们来用一个例子来解释上面的方法查找算法:
#![allow(unused)] fn main() { let array: Rc<Box<[T; 3]>> = ...; let first_entry = array[0]; }
array 数组的底层数据隐藏在了重重封锁之后,那么编译器如何使用 array[0] 这种数组原生访问语法通过重重封锁,准确的访问到数组中的第一个元素?
- 首先,
array[0]只是Index特征的语法糖:编译器会将array[0]转换为array.index(0)调用,当然在调用之前,编译器会先检查array是否实现了Index特征。 - 接着,编译器检查
Rc<Box<[T; 3]>>是否有实现Index特征,结果是否,不仅如此,&Rc<Box<[T; 3]>>与&mut Rc<Box<[T; 3]>>也没有实现。 - 上面的都不能工作,编译器开始对
Rc<Box<[T; 3]>>进行解引用,把它转变成Box<[T; 3]> - 此时继续对
Box<[T; 3]>进行上面的操作 :Box<[T; 3]>,&Box<[T; 3]>,和&mut Box<[T; 3]>都没有实现Index特征,所以编译器开始对Box<[T; 3]>进行解引用,然后我们得到了[T; 3] [T; 3]以及它的各种引用都没有实现Index索引(是不是很反直觉:D,在直觉中,数组都可以通过索引访问,实际上只有数组切片才可以!),它也不能再进行解引用,因此编译器只能祭出最后的大杀器:将定长转为不定长,因此[T; 3]被转换成[T],也就是数组切片,它实现了Index特征,因此最终我们可以通过index方法访问到对应的元素。
过程看起来很复杂,但是也还好,挺好理解,如果你现在不能彻底理解,也不要紧,等以后对 Rust 理解更深了,同时需要深入理解类型转换时,再来细细品读本章。
再来看看以下更复杂的例子:
#![allow(unused)] fn main() { fn do_stuff<T: Clone>(value: &T) { let cloned = value.clone(); } }
上面例子中 cloned 的类型是什么?首先编译器检查能不能进行值方法调用, value 的类型是 &T,同时 clone 方法的签名也是 &T : fn clone(&T) -> T,因此可以进行值方法调用,再加上编译器知道了 T 实现了 Clone,因此 cloned 的类型是 T。
如果 T: Clone 的特征约束被移除呢?
#![allow(unused)] fn main() { fn do_stuff<T>(value: &T) { let cloned = value.clone(); } }
首先,从直觉上来说,该方法会报错,因为 T 没有实现 Clone 特征,但是真实情况是什么呢?
我们先来推导一番。 首先通过值方法调用就不再可行,因为 T 没有实现 Clone 特征,也就无法调用 T 的 clone 方法。接着编译器尝试引用方法调用,此时 T 变成 &T,在这种情况下, clone 方法的签名如下: fn clone(&&T) -> &T,接着我们现在对 value 进行了引用。 编译器发现 &T 实现了 Clone 类型(所有的引用类型都可以被复制,因为其实就是复制一份地址),因此可以推出 cloned 也是 &T 类型。
最终,我们复制出一份引用指针,这很合理,因为值类型 T 没有实现 Clone,只能去复制一个指针了。
下面的例子也是自动引用生效的地方:
#![allow(unused)] fn main() { #[derive(Clone)] struct Container<T>(Arc<T>); fn clone_containers<T>(foo: &Container<i32>, bar: &Container<T>) { let foo_cloned = foo.clone(); let bar_cloned = bar.clone(); } }
推断下上面的 foo_cloned 和 bar_cloned 是什么类型?提示: 关键在 Container 的泛型参数,一个是 i32 的具体类型,一个是泛型类型,其中 i32 实现了 Clone,但是 T 并没有。
首先要复习一下复杂类型派生 Clone 的规则:一个复杂类型能否派生 Clone,需要它内部的所有子类型都能进行 Clone。因此 Container<T>(Arc<T>) 是否实现 Clone 的关键在于 T 类型是否实现了 Clone 特征。
上面代码中,Container<i32> 实现了 Clone 特征,因此编译器可以直接进行值方法调用,此时相当于直接调用 foo.clone,其中 clone 的函数签名是 fn clone(&T) -> T,由此可以看出 foo_cloned 的类型是 Container<i32>。
然而,bar_cloned 的类型却是 &Container<T>,这个不合理啊,明明我们为 Container<T> 派生了 Clone 特征,因此它也应该是 Container<T> 类型才对。万事皆有因,我们先来看下 derive 宏最终生成的代码大概是啥样的:
#![allow(unused)] fn main() { impl<T> Clone for Container<T> where T: Clone { fn clone(&self) -> Self { Self(Arc::clone(&self.0)) } } }
从上面代码可以看出,派生 Clone 能实现的根本是 T 实现了Clone特征:where T: Clone, 因此 Container<T> 就没有实现 Clone 特征。
编译器接着会去尝试引用方法调用,此时 &Container<T> 引用实现了 Clone,最终可以得出 bar_cloned 的类型是 &Container<T>。
当然,也可以为 Container<T> 手动实现 Clone 特征:
#![allow(unused)] fn main() { impl<T> Clone for Container<T> { fn clone(&self) -> Self { Self(Arc::clone(&self.0)) } } }
此时,编译器首次尝试值方法调用即可通过,因此 bar_cloned 的类型变成 Container<T>。
变形记(Transmutes)
前方危险,敬请绕行!
类型系统,你让开!我要自己转换这些类型,不成功便成仁!虽然本书大多是关于安全的内容,我还是希望你能仔细考虑避免使用本章讲到的内容。这是你在 Rust 中所能做到的真真正正、彻彻底底、最最可怕的非安全行为,在这里,所有的保护机制都形同虚设。
先让你看看深渊长什么样,开开眼,然后你再决定是否深入: mem::transmute<T, U> 将类型 T 直接转成类型 U,唯一的要求就是,这两个类型占用同样大小的字节数!我的天,这也算限制?这简直就是无底线的转换好吧?看看会导致什么问题:
- 首先也是最重要的,转换后创建一个任意类型的实例会造成无法想象的混乱,而且根本无法预测。不要把
3转换成bool类型,就算你根本不会去使用该bool类型,也不要去这样转换 - 变形后会有一个重载的返回类型,即使你没有指定返回类型,为了满足类型推导的需求,依然会产生千奇百怪的类型
- 将
&变形为&mut是未定义的行为- 这种转换永远都是未定义的
- 不,你不能这么做
- 不要多想,你没有那种幸运
- 变形为一个未指定生命周期的引用会导致无界生命周期
- 在复合类型之间互相变换时,你需要保证它们的排列布局是一模一样的!一旦不一样,那么字段就会得到不可预期的值,这也是未定义的行为,至于你会不会因此愤怒, WHO CARES ,你都用了变形了,老兄!
对于第 5 条,你该如何知道内存的排列布局是一样的呢?对于 repr(C) 类型和 repr(transparent) 类型来说,它们的布局是有着精确定义的。但是对于你自己的"普通却自信"的 Rust 类型 repr(Rust) 来说,它可不是有着精确定义的。甚至同一个泛型类型的不同实例都可以有不同的内存布局。 Vec<i32> 和 Vec<u32> 它们的字段可能有着相同的顺序,也可能没有。对于数据排列布局来说,什么能保证,什么不能保证目前还在 Rust 开发组的工作任务中呢。
你以为你之前凝视的是深渊吗?不,你凝视的只是深渊的大门。 mem::transmute_copy<T, U> 才是真正的深渊,它比之前的还要更加危险和不安全。它从 T 类型中拷贝出 U 类型所需的字节数,然后转换成 U。 mem::transmute 尚有大小检查,能保证两个数据的内存大小一致,现在这哥们干脆连这个也丢了,只不过 U 的尺寸若是比 T 大,会是一个未定义行为。
当然,你也可以通过裸指针转换和 unions (todo!)获得所有的这些功能,但是你将无法获得任何编译提示或者检查。裸指针转换和 unions 也不是魔法,无法逃避上面说的规则。
transmute 虽然危险,但作为一本工具书,知识当然要全面,下面列举两个有用的 transmute 应用场景 :)。
- 将裸指针变成函数指针:
#![allow(unused)] fn main() { fn foo() -> i32 { 0 } let pointer = foo as *const (); let function = unsafe { // 将裸指针转换为函数指针 std::mem::transmute::<*const (), fn() -> i32>(pointer) }; assert_eq!(function(), 0); }
- 延长生命周期,或者缩短一个静态生命周期寿命:
#![allow(unused)] fn main() { struct R<'a>(&'a i32); // 将 'b 生命周期延长至 'static 生命周期 unsafe fn extend_lifetime<'b>(r: R<'b>) -> R<'static> { std::mem::transmute::<R<'b>, R<'static>>(r) } // 将 'static 生命周期缩短至 'c 生命周期 unsafe fn shorten_invariant_lifetime<'b, 'c>(r: &'b mut R<'static>) -> &'b mut R<'c> { std::mem::transmute::<&'b mut R<'static>, &'b mut R<'c>>(r) } }
以上例子非常先进!但是是非常不安全的 Rust 行为!
格式化输出
提到格式化输出,可能很多人立刻就想到 "{}",但是 Rust 能做到的远比这个多的多,本章节我们将深入讲解格式化输出的各个方面。
满分初印象
先来一段代码,看看格式化输出的初印象:
#![allow(unused)] fn main() { println!("Hello"); // => "Hello" println!("Hello, {}!", "world"); // => "Hello, world!" println!("The number is {}", 1); // => "The number is 1" println!("{:?}", (3, 4)); // => "(3, 4)" println!("{value}", value=4); // => "4" println!("{} {}", 1, 2); // => "1 2" println!("{:04}", 42); // => "0042" with leading zeros }
可以看到 println! 宏接受的是可变参数,第一个参数是一个字符串常量,它表示最终输出字符串的格式,包含其中形如 {} 的符号是占位符,会被 println! 后面的参数依次替换。
print!,println!,format!
它们是 Rust 中用来格式化输出的三大金刚,用途如下:
print!将格式化文本输出到标准输出,不带换行符println!同上,但是在行的末尾添加换行符format!将格式化文本输出到String字符串
在实际项目中,最常用的是 println! 及 format!,前者常用来调试输出,后者常用来生成格式化的字符串:
fn main() { let s = "hello"; println!("{}, world", s); let s1 = format!("{}, world", s); print!("{}", s1); print!("{}\n", "!"); }
其中,s1 是通过 format! 生成的 String 字符串,最终输出如下:
hello, world
hello, world!
eprint!,eprintln!
除了三大金刚外,还有两大护法,使用方式跟 print!,println! 很像,但是它们输出到标准错误输出:
#![allow(unused)] fn main() { eprintln!("Error: Could not complete task") }
它们仅应该被用于输出错误信息和进度信息,其它场景都应该使用 print! 系列。
{} 与 {:?}
与其它语言常用的 %d,%s 不同,Rust 特立独行地选择了 {} 作为格式化占位符(说到这个,有点想吐槽下,Rust 中自创的概念其实还挺多的,真不知道该夸奖还是该吐槽-,-),事实证明,这种选择非常正确,它帮助用户减少了很多使用成本,你无需再为特定的类型选择特定的占位符,统一用 {} 来替代即可,剩下的类型推导等细节只要交给 Rust 去做。
与 {} 类似,{:?} 也是占位符:
{}适用于实现了std::fmt::Display特征的类型,用来以更优雅、更友好的方式格式化文本,例如展示给用户{:?}适用于实现了std::fmt::Debug特征的类型,用于调试场景
其实两者的选择很简单,当你在写代码需要调试时,使用 {:?},剩下的场景,选择 {}。
Debug 特征
事实上,为了方便我们调试,大多数 Rust 类型都实现了 Debug 特征或者支持派生该特征:
#[derive(Debug)] struct Person { name: String, age: u8 } fn main() { let i = 3.1415926; let s = String::from("hello"); let v = vec![1, 2, 3]; let p = Person{name: "sunface".to_string(), age: 18}; println!("{:?}, {:?}, {:?}, {:?}", i, s, v, p); }
对于数值、字符串、数组,可以直接使用 {:?} 进行输出,但是对于结构体,需要派生Debug特征后,才能进行输出,总之很简单。
Display 特征
与大部分类型实现了 Debug 不同,实现了 Display 特征的 Rust 类型并没有那么多,往往需要我们自定义想要的格式化方式:
#![allow(unused)] fn main() { let i = 3.1415926; let s = String::from("hello"); let v = vec![1, 2, 3]; let p = Person { name: "sunface".to_string(), age: 18, }; println!("{}, {}, {}, {}", i, s, v, p); }
运行后可以看到 v 和 p 都无法通过编译,因为没有实现 Display 特征,但是你又不能像派生 Debug 一般派生 Display,只能另寻他法:
- 使用
{:?}或{:#?} - 为自定义类型实现
Display特征 - 使用
newtype为外部类型实现Display特征
下面来一一看看这三种方式。
{:#?}
{:#?} 与 {:?} 几乎一样,唯一的区别在于它能更优美地输出内容:
// {:?}
[1, 2, 3], Person { name: "sunface", age: 18 }
// {:#?}
[
1,
2,
3,
], Person {
name: "sunface",
}
因此对于 Display 不支持的类型,可以考虑使用 {:#?} 进行格式化,虽然理论上它更适合进行调试输出。
为自定义类型实现 Display 特征
如果你的类型是定义在当前作用域中的,那么可以为其实现 Display 特征,即可用于格式化输出:
struct Person { name: String, age: u8, } use std::fmt; impl fmt::Display for Person { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!( f, "大佬在上,请受我一拜,小弟姓名{},年芳{},家里无田又无车,生活苦哈哈", self.name, self.age ) } } fn main() { let p = Person { name: "sunface".to_string(), age: 18, }; println!("{}", p); }
如上所示,只要实现 Display 特征中的 fmt 方法,即可为自定义结构体 Person 添加自定义输出:
大佬在上,请受我一拜,小弟姓名sunface,年芳18,家里无田又无车,生活苦哈哈
为外部类型实现 Display 特征
在 Rust 中,无法直接为外部类型实现外部特征,但是可以使用newtype解决此问题:
struct Array(Vec<i32>); use std::fmt; impl fmt::Display for Array { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "数组是:{:?}", self.0) } } fn main() { let arr = Array(vec![1, 2, 3]); println!("{}", arr); }
Array 就是我们的 newtype,它将想要格式化输出的 Vec 包裹在内,最后只要为 Array 实现 Display 特征,即可进行格式化输出:
数组是:[1, 2, 3]
至此,关于 {} 与 {:?} 的内容已介绍完毕,下面让我们正式开始格式化输出的旅程。
位置参数
除了按照依次顺序使用值去替换占位符之外,还能让指定位置的参数去替换某个占位符,例如 {1},表示用第二个参数替换该占位符(索引从 0 开始):
fn main() { println!("{}{}", 1, 2); // =>"12" println!("{1}{0}", 1, 2); // =>"21" // => Alice, this is Bob. Bob, this is Alice println!("{0}, this is {1}. {1}, this is {0}", "Alice", "Bob"); println!("{1}{}{0}{}", 1, 2); // => 2112 }
具名参数
除了像上面那样指定位置外,我们还可以为参数指定名称:
fn main() { println!("{argument}", argument = "test"); // => "test" println!("{name} {}", 1, name = 2); // => "2 1" println!("{a} {c} {b}", a = "a", b = 'b', c = 3); // => "a 3 b" }
需要注意的是:带名称的参数必须放在不带名称参数的后面,例如下面代码将报错:
#![allow(unused)] fn main() { println!("{abc} {1}", abc = "def", 2); }
#![allow(unused)] fn main() { error: positional arguments cannot follow named arguments --> src/main.rs:4:36 | 4 | println!("{abc} {1}", abc = "def", 2); | ----- ^ positional arguments must be before named arguments | | | named argument }
格式化参数
格式化输出,意味着对输出格式会有更多的要求,例如只输出浮点数的小数点后两位:
fn main() { let v = 3.1415926; // Display => 3.14 println!("{:.2}", v); // Debug => 3.14 println!("{:.2?}", v); }
上面代码只输出小数点后两位。同时我们还展示了 {} 和 {:?} 的用法,后面如无特殊区别,就只针对 {} 提供格式化参数说明。
接下来,让我们一起来看看 Rust 中有哪些格式化参数。
宽度
宽度用来指示输出目标的长度,如果长度不够,则进行填充和对齐:
字符串填充
字符串格式化默认使用空格进行填充,并且进行左对齐。
fn main() { //----------------------------------- // 以下全部输出 "Hello x !" // 为"x"后面填充空格,补齐宽度5 println!("Hello {:5}!", "x"); // 使用参数5来指定宽度 println!("Hello {:1$}!", "x", 5); // 使用x作为占位符输出内容,同时使用5作为宽度 println!("Hello {1:0$}!", 5, "x"); // 使用有名称的参数作为宽度 println!("Hello {:width$}!", "x", width = 5); //----------------------------------- // 使用参数5为参数x指定宽度,同时在结尾输出参数5 => Hello x !5 println!("Hello {:1$}!{}", "x", 5); }
数字填充:符号和 0
数字格式化默认也是使用空格进行填充,但与字符串左对齐不同的是,数字是右对齐。
fn main() { // 宽度是5 => Hello 5! println!("Hello {:5}!", 5); // 显式的输出正号 => Hello +5! println!("Hello {:+}!", 5); // 宽度5,使用0进行填充 => Hello 00005! println!("Hello {:05}!", 5); // 负号也要占用一位宽度 => Hello -0005! println!("Hello {:05}!", -5); }
对齐
fn main() { // 以下全部都会补齐5个字符的长度 // 左对齐 => Hello x ! println!("Hello {:<5}!", "x"); // 右对齐 => Hello x! println!("Hello {:>5}!", "x"); // 居中对齐 => Hello x ! println!("Hello {:^5}!", "x"); // 对齐并使用指定符号填充 => Hello x&&&&! // 指定符号填充的前提条件是必须有对齐字符 println!("Hello {:&<5}!", "x"); }
精度
精度可以用于控制浮点数的精度或者字符串的长度
fn main() { let v = 3.1415926; // 保留小数点后两位 => 3.14 println!("{:.2}", v); // 带符号保留小数点后两位 => +3.14 println!("{:+.2}", v); // 不带小数 => 3 println!("{:.0}", v); // 通过参数来设定精度 => 3.1416,相当于{:.4} println!("{:.1$}", v, 4); let s = "hi我是Sunface孙飞"; // 保留字符串前三个字符 => hi我 println!("{:.3}", s); // {:.*}接收两个参数,第一个是精度,第二个是被格式化的值 => Hello abc! println!("Hello {:.*}!", 3, "abcdefg"); }
进制
可以使用 # 号来控制数字的进制输出:
#b, 二进制#o, 八进制#x, 小写十六进制#X, 大写十六进制x, 不带前缀的小写十六进制
fn main() { // 二进制 => 0b11011! println!("{:#b}!", 27); // 八进制 => 0o33! println!("{:#o}!", 27); // 十进制 => 27! println!("{}!", 27); // 小写十六进制 => 0x1b! println!("{:#x}!", 27); // 大写十六进制 => 0x1B! println!("{:#X}!", 27); // 不带前缀的十六进制 => 1b! println!("{:x}!", 27); // 使用0填充二进制,宽度为10 => 0b00011011! println!("{:#010b}!", 27); }
指数
fn main() { println!("{:2e}", 1000000000); // => 1e9 println!("{:2E}", 1000000000); // => 1E9 }
指针地址
#![allow(unused)] fn main() { let v= vec![1, 2, 3]; println!("{:p}", v.as_ptr()) // => 0x600002324050 }
转义
有时需要输出 {和},但这两个字符是特殊字符,需要进行转义:
fn main() { // "{{" 转义为 '{' "}}" 转义为 '}' "\"" 转义为 '"' // => Hello "{World}" println!(" Hello \"{{World}}\" "); // 下面代码会报错,因为占位符{}只有一个右括号},左括号被转义成字符串的内容 // println!(" {{ Hello } "); // 也不可使用 '\' 来转义 "{}" // println!(" \{ Hello \} ") }
在格式化字符串时捕获环境中的值(Rust 1.58 新增)
在以前,想要输出一个函数的返回值,你需要这么做:
fn get_person() -> String { String::from("sunface") } fn main() { let p = get_person(); println!("Hello, {}!", p); // implicit position println!("Hello, {0}!", p); // explicit index println!("Hello, {person}!", person = p); }
问题倒也不大,但是一旦格式化字符串长了后,就会非常冗余,而在 1.58 后,我们可以这么写:
fn get_person() -> String { String::from("sunface") } fn main() { let person = get_person(); println!("Hello, {person}!"); }
是不是清晰、简洁了很多?甚至还可以将环境中的值用于格式化参数:
#![allow(unused)] fn main() { let (width, precision) = get_format(); for (name, score) in get_scores() { println!("{name}: {score:width$.precision$}"); } }
但也有局限,它只能捕获普通的变量,对于更复杂的类型(例如表达式),可以先将它赋值给一个变量或使用以前的 name = expression 形式的格式化参数。
目前除了 panic! 外,其它接收格式化参数的宏,都可以使用新的特性。对于 panic! 而言,如果还在使用 2015版本 或 2018版本,那 panic!("{ident}") 依然会被当成 正常的字符串来处理,同时编译器会给予 warn 提示。而对于 2021版本 ,则可以正常使用:
fn get_person() -> String { String::from("sunface") } fn main() { let person = get_person(); panic!("Hello, {person}!"); }
输出:
thread 'main' panicked at 'Hello, sunface!', src/main.rs:6:5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
构建一个简单命令行程序
在前往更高的山峰前,我们应该驻足欣赏下身后的风景,虽然是半览众山不咋小,但总比身在此山中无法窥全貌要强一丢丢。
在本章中,我们将一起构建一个命令行程序,目标是尽可能帮大家融会贯通之前的学到的知识。
linux 系统中的 grep 命令很强大,可以完成各种文件搜索任务,我们肯定做不了那么强大,但是假冒一个伪劣的版本还是可以的,它将从命令行参数中读取指定的文件名和字符串,然后在相应的文件中找到包含该字符串的内容,最终打印出来。
这里推荐一位大神写的知名 Rust 项目 ripgrep ,绝对是
grep真正的高替品,值得学习和使用
实现基本功能
无论功能设计的再怎么花里胡哨,对于一个文件查找命令而言,首先得指定文件和待查找的字符串,它们需要用户从命令行给予输入,然后我们在程序内进行读取。
接收命令行参数
国际惯例,先创建一个新的项目 minigrep ,该名字充分体现了我们的自信:就是不如 grep。
cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
首先来思考下,如果要传入文件路径和待搜索的字符串,那这个命令该长啥样,我觉得大概率是这样:
cargo run -- searchstring example-filename.txt
-- 告诉 cargo 后面的参数是给我们的程序使用的,而不是给 cargo 自己使用,例如 -- 前的 run 就是给它用的。
接下来就是在程序中读取传入的参数,这个很简单,下面代码就可以:
// in main.rs use std::env; fn main() { let args: Vec<String> = env::args().collect(); dbg!(args); }
首先通过 use 引入标准库中的 env 包,然后 env::args 方法会读取并分析传入的命令行参数,最终通过 collect 方法输出一个集合类型 Vector。
可能有同学疑惑,为啥不直接引入 args ,例如 use std::env::args ,这样就无需 env::args 来繁琐调用,直接args.collect() 即可。原因很简单,args 方法只会使用一次,啰嗦就啰嗦点吧,把相同的好名字让给 let args.. 这位大哥不好吗?毕竟人家要出场多次的。
不可信的输入
所有的用户输入都不可信!不可信!不可信!
重要的话说三遍,我们的命令行程序也是,用户会输入什么你根本就不知道,例如他输入了一个非 Unicode 字符,你能阻止吗?显然不能,但是这种输入会直接让我们的程序崩溃!
原因是当传入的命令行参数包含非 Unicode 字符时,
std::env::args会直接崩溃,如果有这种特殊需求,建议大家使用std::env::args_os,该方法产生的数组将包含OsString类型,而不是之前的String类型,前者对于非 Unicode 字符会有更好的处理。至于为啥我们不用,两个理由,你信哪个:1. 用户爱输入啥输入啥,反正崩溃了,他就知道自己错了 2.
args_os会引入额外的跨平台复杂性
collect 方法其实并不是std::env包提供的,而是迭代器自带的方法(env::args() 会返回一个迭代器),它会将迭代器消费后转换成我们想要的集合类型。
最后,代码中使用 dbg! 宏来输出读取到的数组内容,来看看长啥样:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
上面两个版本分别是无参数和两个参数,其中无参数版本实际上也会读取到一个字符串,仔细看,是不是长得很像我们的程序名,Bingo! env::args 读取到的参数中第一个就是程序的可执行路径名。
存储读取到的参数
在编程中,给予清晰合理的变量名是一项基本功,咱总不能到处都是 args[1] 、args[2] 这样的糟糕代码吧。
因此我们需要两个变量来存储文件路径和待搜索的字符串:
use std::env; fn main() { let args: Vec<String> = env::args().collect(); let query = &args[1]; let file_path = &args[2]; println!("Searching for {}", query); println!("In file {}", file_path); }
很简单的代码,来运行下:
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
输出结果很清晰的说明了我们的目标:在文件 sample.txt 中搜索包含 test 字符串的内容。
事实上,就算作为一个简单的程序,它也太过于简单了,例如用户不提供任何参数怎么办?因此,错误处理显然是不可少的,但是在添加之前,先来看看如何读取文件内容。
文件读取
既然读取文件,那么首先我们需要创建一个文件并给予一些内容,来首诗歌如何?"我啥也不是,你呢?"
I'm nobody! Who are you?
我啥也不是,你呢?
Are you nobody, too?
牛逼如你也是无名之辈吗?
Then there's a pair of us - don't tell!
那我们就是天生一对,嘘!别说话!
They'd banish us, you know.
你知道,我们不属于这里。
How dreary to be somebody!
因为这里属于没劲的大人物!
How public, like a frog
他们就像青蛙一样呱噪,
To tell your name the livelong day
成天将自己的大名
To an admiring bog!
传遍整个无聊的沼泽!
在项目根目录创建 poem.txt 文件,并写入如上的优美诗歌(可能翻译的很烂,别打我,哈哈,事实上大家写入英文内容就够了)。
接下来修改 main.rs 来读取文件内容:
use std::env; use std::fs; fn main() { // --省略之前的内容-- println!("In file {}", file_path); let contents = fs::read_to_string(file_path) .expect("Should have been able to read the file"); println!("With text:\n{contents}"); }
首先,通过 use std::fs 引入文件操作包,然后通过 fs::read_to_string 读取指定的文件内容,最后返回的 contents 是 std::io::Result<String> 类型。
运行下试试,这里无需输入第二个参数,因为我们还没有实现查询功能:
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
完美,虽然代码还有很多瑕疵,例如所有内容都在 main 函数,这个不符合软件工程,没有错误处理,功能不完善等。不过没关系,万事开头难,好歹我们成功迈开了第一步。
好了,是时候重构赚波 KPI 了,读者:are you serious? 这就开始重构了?
增加模块化和错误处理
但凡稍微没那么糟糕的程序,都应该具有代码模块化和错误处理,不然连玩具都谈不上。
梳理我们的代码和目标后,可以整理出大致四个改进点:
- 单一且庞大的函数。对于
minigrep程序而言,main函数当前执行两个任务:解析命令行参数和读取文件。但随着代码的增加,main函数承载的功能也将快速增加。从软件工程角度来看,一个函数具有的功能越多,越是难以阅读和维护。因此最好的办法是将大的函数拆分成更小的功能单元。 - 配置变量散乱在各处。还有一点要考虑的是,当前
main函数中的变量都是独立存在的,这些变量很可能被整个程序所访问,在这个背景下,独立的变量越多,越是难以维护,因此我们还可以将这些用于配置的变量整合到一个结构体中。 - 细化错误提示。 目前的实现中,我们使用
expect方法来输出文件读取失败时的错误信息,这个没问题,但是无论任何情况下,都只输出Should have been able to read the file这条错误提示信息,显然是有问题的,毕竟文件不存在、无权限等等都是可能的错误,一条大一统的消息无法给予用户更多的提示。 - 使用错误而不是异常。 假如用户不给任何命令行参数,那我们的程序显然会无情崩溃,原因很简单:
index out of bounds,一个数组访问越界的panic,但问题来了,用户能看懂吗?甚至于未来接收的维护者能看懂吗?因此需要增加合适的错误处理代码,来给予使用者给详细友善的提示。还有就是需要在一个统一的位置来处理所有错误,利人利己!
分离 main 函数
关于如何处理庞大的 main 函数,Rust 社区给出了统一的指导方案:
- 将程序分割为
main.rs和lib.rs,并将程序的逻辑代码移动到后者内 - 命令行解析属于非常基础的功能,严格来说不算是逻辑代码的一部分,因此还可以放在
main.rs中
按照这个方案,将我们的代码重新梳理后,可以得出 main 函数应该包含的功能:
- 解析命令行参数
- 初始化其它配置
- 调用
lib.rs中的run函数,以启动逻辑代码的运行 - 如果
run返回一个错误,需要对该错误进行处理
这个方案有一个很优雅的名字: 关注点分离(Separation of Concerns)。简而言之,main.rs 负责启动程序,lib.rs 负责逻辑代码的运行。从测试的角度而言,这种分离也非常合理: lib.rs 中的主体逻辑代码可以得到简单且充分的测试,至于 main.rs ?确实没办法针对其编写额外的测试代码,但是它的代码也很少啊,很容易就能保证它的正确性。
关于如何在 Rust 中编写测试代码,请参见如下章节:https://course.rs/test/intro.html
分离命令行解析
根据之前的分析,我们需要将命令行解析的代码分离到一个单独的函数,然后将该函数放置在 main.rs 中:
// in main.rs fn main() { let args: Vec<String> = env::args().collect(); let (query, file_path) = parse_config(&args); // --省略-- } fn parse_config(args: &[String]) -> (&str, &str) { let query = &args[1]; let file_path = &args[2]; (query, file_path) }
经过分离后,之前的设计目标完美达成,即精简了 main 函数,又将配置相关的代码放在了 main.rs 文件里。
看起来貌似是杀鸡用了牛刀,但是重构就是这样,一步一步,踏踏实实的前行,否则未来代码多一些后,你岂不是还要再重来一次重构?因此打好项目的基础是非常重要的!
聚合配置变量
前文提到,配置变量并不适合分散的到处都是,因此使用一个结构体来统一存放是非常好的选择,这样修改后,后续的使用以及未来的代码维护都将更加简单明了。
fn main() { let args: Vec<String> = env::args().collect(); let config = parse_config(&args); println!("Searching for {}", config.query); println!("In file {}", config.file_path); let contents = fs::read_to_string(config.file_path) .expect("Should have been able to read the file"); // --snip-- } struct Config { query: String, file_path: String, } fn parse_config(args: &[String]) -> Config { let query = args[1].clone(); let file_path = args[2].clone(); Config { query, file_path } }
值得注意的是,Config 中存储的并不是 &str 这样的引用类型,而是一个 String 字符串,也就是 Config 并没有去借用外部的字符串,而是拥有内部字符串的所有权。clone 方法的使用也可以佐证这一点。大家可以尝试不用 clone 方法,看看该如何解决相关的报错 :D
clone的得与失在上面的代码中,除了使用
clone,还有其它办法来达成同样的目的,但clone无疑是最简单的方法:直接完整的复制目标数据,无需被所有权、借用等问题所困扰,但是它也有其缺点,那就是有一定的性能损耗。因此是否使用
clone更多是一种性能上的权衡,对于上面的使用而言,由于是配置的初始化,因此整个程序只需要执行一次,性能损耗几乎是可以忽略不计的。总之,判断是否使用
clone:
- 是否严肃的项目,玩具项目直接用
clone就行,简单不好吗?- 要看所在的代码路径是否是热点路径(hot path),例如执行次数较多的显然就是热点路径,热点路径就值得去使用性能更好的实现方式
好了,言归正传,从 C 语言过来的同学可能会觉得上面的代码已经很棒了,但是从 OO 语言角度来说,还差了那么一点意思。
下面我们试着来优化下,通过构造函数来初始化一个 Config 实例,而不是直接通过函数返回实例,典型的,标准库中的 String::new 函数就是一个范例。
fn main() { let args: Vec<String> = env::args().collect(); let config = Config::new(&args); // --snip-- } // --snip-- impl Config { fn new(args: &[String]) -> Config { let query = args[1].clone(); let file_path = args[2].clone(); Config { query, file_path } } }
修改后,类似 String::new 的调用,我们可以通过 Config::new 来创建一个实例,看起来代码是不是更有那味儿了 :)
错误处理
回顾一下,如果用户不输入任何命令行参数,我们的程序会怎么样?
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'index out of bounds: the len is 1 but the index is 1', src/main.rs:27:21
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
结果喜闻乐见,由于 args 数组没有任何元素,因此通过索引访问时,会直接报出数组访问越界的 panic。
报错信息对于开发者会很明确,但是对于使用者而言,就相当难理解了,下面一起来解决它。
改进报错信息
还记得在错误处理章节,我们提到过 panic 的两种用法: 被动触发和主动调用嘛?上面代码的出现方式很明显是被动触发,这种报错信息是不可控的,下面我们先改成主动调用的方式:
#![allow(unused)] fn main() { // in main.rs // --snip-- fn new(args: &[String]) -> Config { if args.len() < 3 { panic!("not enough arguments"); } // --snip-- }
目的很明确,一旦传入的参数数组长度小于 3,则报错并让程序崩溃推出,这样后续的数组访问就不会再越界了。
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at 'not enough arguments', src/main.rs:26:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
不错,用户看到了更为明确的提示,但是还是有一大堆 debug 输出,这些我们其实是不想让用户看到的。这么看来,想要输出对用户友好的信息, panic 是不太适合的,它更适合告知开发者,哪里出现了问题。
返回 Result 来替代直接 panic
那只能祭出之前学过的错误处理大法了,也就是返回一个 Result:成功时包含 Config 实例,失败时包含一条错误信息。
有一点需要额外注意下,从代码惯例的角度出发,new 往往不会失败,毕竟新建一个实例没道理失败,对不?因此修改为 build 会更加合适。
#![allow(unused)] fn main() { impl Config { fn build(args: &[String]) -> Result<Config, &'static str> { if args.len() < 3 { return Err("not enough arguments"); } let query = args[1].clone(); let file_path = args[2].clone(); Ok(Config { query, file_path }) } } }
这里的 Result 可能包含一个 Config 实例,也可能包含一条错误信息 &static str,不熟悉这种字符串类型的同学可以回头看看字符串章节,代码中的字符串字面量都是该类型,且拥有 'static 生命周期。
处理返回的 Result
接下来就是在调用 build 函数时,对返回的 Result 进行处理了,目的就是给出准确且友好的报错提示, 为了让大家更好的回顾我们修改过的内容,这里给出整体代码:
use std::env; use std::fs; use std::process; fn main() { let args: Vec<String> = env::args().collect(); // 对 build 返回的 `Result` 进行处理 let config = Config::build(&args).unwrap_or_else(|err| { println!("Problem parsing arguments: {err}"); process::exit(1); }); println!("Searching for {}", config.query); println!("In file {}", config.file_path); let contents = fs::read_to_string(config.file_path) .expect("Should have been able to read the file"); println!("With text:\n{contents}"); } struct Config { query: String, file_path: String, } impl Config { fn build(args: &[String]) -> Result<Config, &'static str> { if args.len() < 3 { return Err("not enough arguments"); } let query = args[1].clone(); let file_path = args[2].clone(); Ok(Config { query, file_path }) } }
上面代码有几点值得注意:
- 当
Result包含错误时,我们不再调用panic让程序崩溃,而是通过process::exit(1)来终结进程,其中1是一个信号值(事实上非 0 值都可以),通知调用我们程序的进程,程序是因为错误而退出的。 unwrap_or_else是定义在Result<T,E>上的常用方法,如果Result是Ok,那该方法就类似unwrap:返回Ok内部的值;如果是Err,就调用闭包中的自定义代码对错误进行进一步处理
综上可知,config 变量的值是一个 Config 实例,而 unwrap_or_else 闭包中的 err 参数,它的类型是 'static str,值是 "not enough arguments" 那个字符串字面量。
运行后,可以看到以下输出:
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
终于,我们得到了自己想要的输出:既告知了用户为何报错,又消除了多余的 debug 信息,非常棒。可能有用户疑惑,cargo run 底下还有一大堆 debug 信息呢,实际上,这是 cargo run 自带的,大家可以试试编译成二进制可执行文件后再调用,会是什么效果。
分离主体逻辑
接下来可以继续精简 main 函数,那就是将主体逻辑( 例如业务逻辑 )从 main 中分离出去,这样 main 函数就保留主流程调用,非常简洁。
// in main.rs fn main() { let args: Vec<String> = env::args().collect(); let config = Config::build(&args).unwrap_or_else(|err| { println!("Problem parsing arguments: {err}"); process::exit(1); }); println!("Searching for {}", config.query); println!("In file {}", config.file_path); run(config); } fn run(config: Config) { let contents = fs::read_to_string(config.file_path) .expect("Should have been able to read the file"); println!("With text:\n{contents}"); } // --snip--
如上所示,main 函数仅保留主流程各个环节的调用,一眼看过去非常简洁清晰。
继续之前,先请大家仔细看看 run 函数,你们觉得还缺少什么?提示:参考 build 函数的改进过程。
使用 ? 和特征对象来返回错误
答案就是 run 函数没有错误处理,因为在文章开头我们提到过,错误处理最好统一在一个地方完成,这样极其有利于后续的代码维护。
#![allow(unused)] fn main() { //in main.rs use std::error::Error; // --snip-- fn run(config: Config) -> Result<(), Box<dyn Error>> { let contents = fs::read_to_string(config.file_path)?; println!("With text:\n{contents}"); Ok(()) } }
值得注意的是这里的 Result<(), Box<dyn Error>> 返回类型,首先我们的程序无需返回任何值,但是为了满足 Result<T,E> 的要求,因此使用了 Ok(()) 返回一个单元类型 ()。
最重要的是 Box<dyn Error>, 如果按照顺序学到这里,大家应该知道这是一个Error 的特征对象(为了使用 Error,我们通过 use std::error::Error; 进行了引入),它表示函数返回一个类型,该类型实现了 Error 特征,这样我们就无需指定具体的错误类型,否则你还需要查看 fs::read_to_string 返回的错误类型,然后复制到我们的 run 函数返回中,这么做一个是麻烦,最主要的是,一旦这么做,意味着我们无法在上层调用时统一处理错误,但是 Box<dyn Error> 不同,其它函数也可以返回这个特征对象,然后调用者就可以使用统一的方式来处理不同函数返回的 Box<dyn Error>。
明白了 Box<dyn Error> 的重要战略地位,接下来大家分析下,fs::read_to_string 返回的具体错误类型是怎么被转化为 Box<dyn Error> 的?其实原因在之前章节都有讲过,这里就不直接给出答案了,参见 ?-传播界的大明星。
运行代码看看效果:
$ cargo run the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: this `Result` may be an `Err` variant, which should be handled
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished dev [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
没任何问题,不过 Rust 编译器也给出了善意的提示,那就是 Result 并没有被使用,这可能意味着存在错误的潜在可能性。
处理返回的错误
fn main() { // --snip-- println!("Searching for {}", config.query); println!("In file {}", config.file_path); if let Err(e) = run(config) { println!("Application error: {e}"); process::exit(1); } }
先回忆下在 build 函数调用时,我们怎么处理错误的?然后与这里的方式做一下对比,是不是发现了一些区别?
没错 if let 的使用让代码变得更简洁,可读性也更加好,原因是,我们并不关注 run 返回的 Ok 值,因此只需要用 if let 去匹配是否存在错误即可。
好了,截止目前,代码看起来越来越美好了,距离我们的目标也只差一个:将主体逻辑代码分离到一个独立的文件 lib.rs 中。
分离逻辑代码到库包中
首先,创建一个 src/lib.rs 文件,然后将所有的非 main 函数都移动到其中。代码大概类似:
#![allow(unused)] fn main() { use std::error::Error; use std::fs; pub struct Config { pub query: String, pub file_path: String, } impl Config { pub fn build(args: &[String]) -> Result<Config, &'static str> { // --snip-- } } pub fn run(config: Config) -> Result<(), Box<dyn Error>> { // --snip-- } }
为了内容的简洁性,这里忽略了具体的实现,下一步就是在 main.rs 中引入 lib.rs 中定义的 Config 类型。
use std::env; use std::process; use minigrep::Config; fn main() { // --snip-- let args: Vec<String> = env::args().collect(); let config = Config::build(&args).unwrap_or_else(|err| { println!("Problem parsing arguments: {err}"); process::exit(1); }); println!("Searching for {}", config.query); println!("In file {}", config.file_path); if let Err(e) = minigrep::run(config) { // --snip-- println!("Application error: {e}"); process::exit(1); } }
很明显,这里的 mingrep::run 的调用,以及 Config 的引入,跟使用其它第三方包已经没有任何区别,也意味着我们成功的将逻辑代码放置到一个独立的库包中,其它包只要引入和调用就行。
呼,一顿书写猛如虎,回头一看。。。这么长的篇幅就写了这么点简单的代码??只能说,我也希望像很多国内的大学教材一样,只要列出定理和解题方法,然后留下足够的习题,就万事大吉了,但是咱们不行。
接下来,到了最喜(令)闻(人)乐(讨)见(厌)的环节:写测试代码,一起来开心吧。
测试驱动开发
开始之前,推荐大家先了解下如何在 Rust 中编写测试代码,这块儿内容不复杂,先了解下有利于本章的继续阅读
在之前的章节中,我们完成了对项目结构的重构,并将进入逻辑代码编程的环节,但在此之前,我们需要先编写一些测试代码,也是最近颇为流行的测试驱动开发模式(TDD, Test Driven Development):
- 编写一个注定失败的测试,并且失败的原因和你指定的一样
- 编写一个成功的测试
- 编写你的逻辑代码,直到通过测试
这三个步骤将在我们的开发过程中不断循环,知道所有的代码都开发完成并成功通过所有测试。
注定失败的测试用例
既然要添加测试,那之前的 println! 语句将没有大的用处,毕竟 println! 存在的目的就是为了让我们看到结果是否正确,而现在测试用例将取而代之。
接下来,在 lib.rs 文件中,添加 tests 模块和 test 函数:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn one_result() { let query = "duct"; let contents = "\ Rust: safe, fast, productive. Pick three."; assert_eq!(vec!["safe, fast, productive."], search(query, contents)); } } }
测试用例将在指定的内容中搜索 duct 字符串,目测可得:其中有一行内容是包含有目标字符串的。
但目前为止,还无法运行该测试用例,更何况还想幸灾乐祸的看其失败,原因是 search 函数还没有实现!毕竟是测试驱动、测试先行。
#![allow(unused)] fn main() { // in lib.rs pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> { vec![] } }
先添加一个简单的 search 函数实现,非常简单粗暴的返回一个空的数组,显而易见测试用例将成功通过,真是一个居心叵测的测试用例!
喔,这么复杂的代码,都用上生命周期了!嘚瑟两下试试:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 0.97s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... FAILED
failures:
---- tests::one_result stdout ----
thread 'main' panicked at 'assertion failed: `(left == right)`
left: `["safe, fast, productive."]`,
right: `[]`', src/lib.rs:44:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::one_result
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
太棒了!它失败了...
务必成功的测试用例
接着,改进型测试驱动的第二步了:编写注定成功的测试。当然,前提条件是实现我们的 search 函数。它包含以下步骤:
- 遍历迭代
contents的每一行 - 检查该行内容是否包含我们的目标字符串
- 若包含,则放入返回值列表中,否则忽略
- 返回匹配到的返回值列表
遍历迭代每一行
Rust 提供了一个很便利的 lines 方法将目标字符串进行按行分割:
#![allow(unused)] fn main() { // in lib.rs pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> { for line in contents.lines() { // do something with line } } }
这里的 lines 返回一个迭代器,关于迭代器在后续章节会详细讲解,现在只要知道 for 可以遍历取出迭代器中的值即可。
在每一行中查询目标字符串
#![allow(unused)] fn main() { // in lib.rs pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> { for line in contents.lines() { if line.contains(query) { // do something with line } } } }
与之前的 lines 函数类似,Rust 的字符串还提供了 contains 方法,用于检查 line 是否包含待查询的 query。
接下来,只要返回合适的值,就可以完成 search 函数的编写。
存储匹配到的结果
简单,创建一个 Vec 动态数组,然后将查询到的每一个 line 推进数组中即可:
#![allow(unused)] fn main() { // in lib.rs pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> { let mut results = Vec::new(); for line in contents.lines() { if line.contains(query) { results.push(line); } } results } }
至此,search 函数已经完成了既定目标,为了检查功能是否正确,运行下我们之前编写的测试用例:
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
测试通过,意味着我们的代码也完美运行,接下来就是在 run 函数中大显身手了。
在 run 函数中调用 search 函数
#![allow(unused)] fn main() { // in src/lib.rs pub fn run(config: Config) -> Result<(), Box<dyn Error>> { let contents = fs::read_to_string(config.file_path)?; for line in search(&config.query, &contents) { println!("{line}"); } Ok(()) } }
好,再运行下看看结果,看起来我们距离成功从未如此之近!
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
酷!成功查询到包含 frog 的行,再来试试 body :
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
完美,三行,一行不少,为了确保万无一失,再来试试查询一个不存在的单词:
cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
至此,章节开头的目标已经全部完成,接下来思考一个小问题:如果要为程序加上大小写不敏感的控制命令,由用户进行输入,该怎么实现比较好呢?毕竟在实际搜索查询中,同时支持大小写敏感和不敏感还是很重要的。
答案留待下一章节揭晓。
使用环境变量来增强程序
在上一章节中,留下了一个悬念,该如何实现用户控制的大小写敏感,其实答案很简单,你在其它程序中肯定也遇到过不少,例如如何控制 panic 后的栈展开? Rust 提供的解决方案是通过命令行参数来控制:
RUST_BACKTRACE=1 cargo run
与之类似,我们也可以使用环境变量来控制大小写敏感,例如:
IGNORE_CASE=1 cargo run -- to poem.txt
既然有了目标,那么一起来看看该如何实现吧。
编写大小写不敏感的测试用例
还是遵循之前的规则:测试驱动,这次是对一个新的大小写不敏感函数进行测试 search_case_insensitive。
还记得 TDD 的测试步骤嘛?首先编写一个注定失败的用例:
#![allow(unused)] fn main() { // in src/lib.rs #[cfg(test)] mod tests { use super::*; #[test] fn case_sensitive() { let query = "duct"; let contents = "\ Rust: safe, fast, productive. Pick three. Duct tape."; assert_eq!(vec!["safe, fast, productive."], search(query, contents)); } #[test] fn case_insensitive() { let query = "rUsT"; let contents = "\ Rust: safe, fast, productive. Pick three. Trust me."; assert_eq!( vec!["Rust:", "Trust me."], search_case_insensitive(query, contents) ); } } }
可以看到,这里新增了一个 case_insensitive 测试用例,并对 search_case_insensitive 进行了测试,结果显而易见,函数都没有实现,自然会失败。
接着来实现这个大小写不敏感的搜索函数:
#![allow(unused)] fn main() { pub fn search_case_insensitive<'a>( query: &str, contents: &'a str, ) -> Vec<&'a str> { let query = query.to_lowercase(); let mut results = Vec::new(); for line in contents.lines() { if line.to_lowercase().contains(&query) { results.push(line); } } results } }
跟之前一样,但是引入了一个新的方法 to_lowercase,它会将 line 转换成全小写的字符串,类似的方法在其它语言中也差不多,就不再赘述。
还要注意的是 query 现在是 String 类型,而不是之前的 &str,因为 to_lowercase 返回的是 String。
修改后,再来跑一次测试,看能否通过。
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished test [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ok,TDD的第二步也完成了,测试通过,接下来就是最后一步,在 run 中调用新的搜索函数。但是在此之前,要新增一个配置项,用于控制是否开启大小写敏感。
#![allow(unused)] fn main() { // in lib.rs pub struct Config { pub query: String, pub file_path: String, pub ignore_case: bool, } }
接下来就是检查该字段,来判断是否启动大小写敏感:
#![allow(unused)] fn main() { pub fn run(config: Config) -> Result<(), Box<dyn Error>> { let contents = fs::read_to_string(config.file_path)?; let results = if config.ignore_case { search_case_insensitive(&config.query, &contents) } else { search(&config.query, &contents) }; for line in results { println!("{line}"); } Ok(()) } }
现在的问题来了,该如何控制这个配置项呢。这个就要借助于章节开头提到的环境变量,好在 Rust 的 env 包提供了相应的方法。
#![allow(unused)] fn main() { use std::env; // --snip-- impl Config { pub fn build(args: &[String]) -> Result<Config, &'static str> { if args.len() < 3 { return Err("not enough arguments"); } let query = args[1].clone(); let file_path = args[2].clone(); let ignore_case = env::var("IGNORE_CASE").is_ok(); Ok(Config { query, file_path, ignore_case, }) } } }
env::var 没啥好说的,倒是 is_ok 值得说道下。该方法是 Result 提供的,用于检查是否有值,有就返回 true,没有则返回 false,刚好完美符合我们的使用场景,因为我们并不关心 Ok<T> 中具体的值。
运行下试试:
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished dev [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
看起来没有问题,接下来测试下大小写不敏感:
$ IGNORE_CASE=1 cargo run -- to poem.txt
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
大小写不敏感后,查询到的内容明显多了很多,也很符合我们的预期。
最后,给大家留一个小作业:同时使用命令行参数和环境变量的方式来控制大小写不敏感,其中环境变量的优先级更高,也就是两个都设置的情况下,优先使用环境变量的设置。
使用迭代器来改进我们的程序
本章节是可选内容,请大家在看完迭代器章节后,再来阅读
Rust 高级进阶
恭喜你,学会 Rust 基础后,金丹大道已在向你招手,大部分 Rust 代码对你来说都是家常便饭,简单得很。可是,对于一门难度传言在外的语言,怎么可能如此简单的就被征服,最难的生命周期,咱还没见过长啥样呢。
从本章开始,我们将进入 Rust 的进阶学习环节,与基础环节不同的是,由于你已经对 Rust 有了一定的认识,因此我们不会再对很多细节进行翻来覆去的详细讲解,甚至会一带而过。
总之,欢迎来到高级 Rust 的世界,全新的 Boss,全新的装备,你准备好了吗?
生命周期
何为高阶?一个字:难,二个字:很难,七个字:其实也没那么难。至于到底难不难,还是交给各位看官评判吧 :D
大家都知道,生命周期在 Rust 中是最难的部分之一,,因此相关内容被分成了两个章节:基础和进阶,其中基础部分已经在之前学习后,下面一起来看看真正的难字怎么写。
深入生命周期
其实关于生命周期的常用特性,在上一节中,我们已经概括得差不多了,本章主要讲解生命周期的一些高级或者不为人知的特性。对于新手,完全可以跳过本节内容,进行下一章节的学习。
不太聪明的生命周期检查
在 Rust 语言学习中,一个很重要的部分就是阅读一些你可能不经常遇到,但是一旦遇到就难以理解的代码,这些代码往往最令人头疼的就是生命周期,这里我们就来看看一些本以为可以编译,但是却因为生命周期系统不够聪明导致编译失败的代码。
例子 1
#[derive(Debug)] struct Foo; impl Foo { fn mutate_and_share(&mut self) -> &Self { &*self } fn share(&self) {} } fn main() { let mut foo = Foo; let loan = foo.mutate_and_share(); foo.share(); println!("{:?}", loan); }
上面的代码中,foo.mutate_and_share() 虽然借用了 &mut self,但是它最终返回的是一个 &self,然后赋值给 loan,因此理论上来说它最终是进行了不可变借用,同时 foo.share 也进行了不可变借用,那么根据 Rust 的借用规则:多个不可变借用可以同时存在,因此该代码应该编译通过。
事实上,运行代码后,你将看到一个错误:
error[E0502]: cannot borrow `foo` as immutable because it is also borrowed as mutable
--> src/main.rs:12:5
|
11 | let loan = foo.mutate_and_share();
| ---------------------- mutable borrow occurs here
12 | foo.share();
| ^^^^^^^^^^^ immutable borrow occurs here
13 | println!("{:?}", loan);
| ---- mutable borrow later used here
编译器的提示在这里其实有些难以理解,因为可变借用仅在 mutate_and_share 方法内部有效,出了该方法后,就只有返回的不可变借用,因此,按理来说可变借用不应该在 main 的作用范围内存在。
对于这个反直觉的事情,让我们用生命周期来解释下,可能你就很好理解了:
struct Foo; impl Foo { fn mutate_and_share<'a>(&'a mut self) -> &'a Self { &'a *self } fn share<'a>(&'a self) {} } fn main() { 'b: { let mut foo: Foo = Foo; 'c: { let loan: &'c Foo = Foo::mutate_and_share::<'c>(&'c mut foo); 'd: { Foo::share::<'d>(&'d foo); } println!("{:?}", loan); } } }
以上是模拟了编译器的生命周期标注后的代码,可以注意到 &mut foo 和 loan 的生命周期都是 'c。
还记得生命周期消除规则中的第三条吗?因为该规则,导致了 mutate_and_share 方法中,参数 &mut self 和返回值 &self 的生命周期是相同的,因此,若返回值的生命周期在 main 函数有效,那 &mut self 的借用也是在 main 函数有效。
这就解释了可变借用为啥会在 main 函数作用域内有效,最终导致 foo.share() 无法再进行不可变借用。
总结下:&mut self 借用的生命周期和 loan 的生命周期相同,将持续到 println 结束。而在此期间 foo.share() 又进行了一次不可变 &foo 借用,违背了可变借用与不可变借用不能同时存在的规则,最终导致了编译错误。
上述代码实际上完全是正确的,但是因为生命周期系统的“粗糙实现”,导致了编译错误,目前来说,遇到这种生命周期系统不够聪明导致的编译错误,我们也没有太好的办法,只能修改代码去满足它的需求,并期待以后它会更聪明。
例子 2
再来看一个例子:
#![allow(unused)] fn main() { use std::collections::HashMap; use std::hash::Hash; fn get_default<'m, K, V>(map: &'m mut HashMap<K, V>, key: K) -> &'m mut V where K: Clone + Eq + Hash, V: Default, { match map.get_mut(&key) { Some(value) => value, None => { map.insert(key.clone(), V::default()); map.get_mut(&key).unwrap() } } } }
这段代码不能通过编译的原因是编译器未能精确地判断出某个可变借用不再需要,反而谨慎的给该借用安排了一个很大的作用域,结果导致后续的借用失败:
error[E0499]: cannot borrow `*map` as mutable more than once at a time
--> src/main.rs:13:17
|
5 | fn get_default<'m, K, V>(map: &'m mut HashMap<K, V>, key: K) -> &'m mut V
| -- lifetime `'m` defined here
...
10 | match map.get_mut(&key) {
| - ----------------- first mutable borrow occurs here
| _________|
| |
11 | | Some(value) => value,
12 | | None => {
13 | | map.insert(key.clone(), V::default());
| | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ second mutable borrow occurs here
14 | | map.get_mut(&key).unwrap()
15 | | }
16 | | }
| |_________- returning this value requires that `*map` is borrowed for `'m`
分析代码可知在 match map.get_mut(&key) 方法调用完成后,对 map 的可变借用就可以结束了。但从报错看来,编译器不太聪明,它认为该借用会持续到整个 match 语句块的结束(第 16 行处),这便造成了后续借用的失败。
类似的例子还有很多,由于篇幅有限,就不在这里一一列举,如果大家想要阅读更多的类似代码,可以看看<<Rust 代码鉴赏>>一书。
无界生命周期
不安全代码(unsafe)经常会凭空产生引用或生命周期,这些生命周期被称为是 无界(unbound) 的。
无界生命周期往往是在解引用一个裸指针(裸指针 raw pointer)时产生的,换句话说,它是凭空产生的,因为输入参数根本就没有这个生命周期:
#![allow(unused)] fn main() { fn f<'a, T>(x: *const T) -> &'a T { unsafe { &*x } } }
上述代码中,参数 x 是一个裸指针,它并没有任何生命周期,然后通过 unsafe 操作后,它被进行了解引用,变成了一个 Rust 的标准引用类型,该类型必须要有生命周期,也就是 'a。
可以看出 'a 是凭空产生的,因此它是无界生命周期。这种生命周期由于没有受到任何约束,因此它想要多大就多大,这实际上比 'static 要强大。例如 &'static &'a T 是无效类型,但是无界生命周期 &'unbounded &'a T 会被视为 &'a &'a T 从而通过编译检查,因为它可大可小,就像孙猴子的金箍棒一般。
我们在实际应用中,要尽量避免这种无界生命周期。最简单的避免无界生命周期的方式就是在函数声明中运用生命周期消除规则。若一个输出生命周期被消除了,那么必定因为有一个输入生命周期与之对应。
生命周期约束 HRTB
生命周期约束跟特征约束类似,都是通过形如 'a: 'b 的语法,来说明两个生命周期的长短关系。
'a: 'b
假设有两个引用 &'a i32 和 &'b i32,它们的生命周期分别是 'a 和 'b,若 'a >= 'b,则可以定义 'a:'b,表示 'a 至少要活得跟 'b 一样久。
#![allow(unused)] fn main() { struct DoubleRef<'a,'b:'a, T> { r: &'a T, s: &'b T } }
例如上述代码定义一个结构体,它拥有两个引用字段,类型都是泛型 T,每个引用都拥有自己的生命周期,由于我们使用了生命周期约束 'b: 'a,因此 'b 必须活得比 'a 久,也就是结构体中的 s 字段引用的值必须要比 r 字段引用的值活得要久。
T: 'a
表示类型 T 必须比 'a 活得要久:
#![allow(unused)] fn main() { struct Ref<'a, T: 'a> { r: &'a T } }
因为结构体字段 r 引用了 T,因此 r 的生命周期 'a 必须要比 T 的生命周期更短(被引用者的生命周期必须要比引用长)。
在 Rust 1.30 版本之前,该写法是必须的,但是从 1.31 版本开始,编译器可以自动推导 T: 'a 类型的约束,因此我们只需这样写即可:
#![allow(unused)] fn main() { struct Ref<'a, T> { r: &'a T } }
来看一个使用了生命周期约束的综合例子:
#![allow(unused)] fn main() { struct ImportantExcerpt<'a> { part: &'a str, } impl<'a: 'b, 'b> ImportantExcerpt<'a> { fn announce_and_return_part(&'a self, announcement: &'b str) -> &'b str { println!("Attention please: {}", announcement); self.part } } }
上面的例子中必须添加约束 'a: 'b 后,才能成功编译,因为 self.part 的生命周期与 self的生命周期一致,将 &'a 类型的生命周期强行转换为 &'b 类型,会报错,只有在 'a >= 'b 的情况下,'a 才能转换成 'b。
闭包函数的消除规则
先来看一段简单的代码:
#![allow(unused)] fn main() { fn fn_elision(x: &i32) -> &i32 { x } let closure_slision = |x: &i32| -> &i32 { x }; }
乍一看,这段代码比古天乐还平平无奇,能有什么问题呢?来,拄拐走两圈试试:
error: lifetime may not live long enough
--> src/main.rs:39:39
|
39 | let closure = |x: &i32| -> &i32 { x }; // fails
| - - ^ returning this value requires that `'1` must outlive `'2`
| | |
| | let's call the lifetime of this reference `'2`
| let's call the lifetime of this reference `'1`
咦?竟然报错了,明明两个一模一样功能的函数,一个正常编译,一个却报错,错误原因是编译器无法推测返回的引用和传入的引用谁活得更久!
真的是非常奇怪的错误,学过上一节的读者应该都记得这样一条生命周期消除规则:如果函数参数中只有一个引用类型,那该引用的生命周期会被自动分配给所有的返回引用。我们当前的情况完美符合, function 函数的顺利编译通过,就充分说明了问题。
先给出一个结论:这个问题,可能很难被解决,建议大家遇到后,还是老老实实用正常的函数,不要秀闭包了。
对于函数的生命周期而言,它的消除规则之所以能生效是因为它的生命周期完全体现在签名的引用类型上,在函数体中无需任何体现:
#![allow(unused)] fn main() { fn fn_elision(x: &i32) -> &i32 {..} }
因此编译器可以做各种编译优化,也很容易根据参数和返回值进行生命周期的分析,最终得出消除规则。
可是闭包,并没有函数那么简单,它的生命周期分散在参数和闭包函数体中(主要是它没有确切的返回值签名):
#![allow(unused)] fn main() { let closure_slision = |x: &i32| -> &i32 { x }; }
编译器就必须深入到闭包函数体中,去分析和推测生命周期,复杂度因此极具提升:试想一下,编译器该如何从复杂的上下文中分析出参数引用的生命周期和闭包体中生命周期的关系?
由于上述原因(当然,实际情况复杂的多),Rust 语言开发者目前其实是有意针对函数和闭包实现了两种不同的生命周期消除规则。
用
Fn特征解决闭包生命周期之前我们提到了很难解决,但是并没有完全堵死(论文字的艺术- , -) 这不 @Ykong1337 同学就带了一个解决方法,为他点赞!
fn main() { let closure_slision = fun(|x: &i32| -> &i32 { x }); assert_eq!(*closure_slision(&45), 45); // Passed ! } fn fun<T, F: Fn(&T) -> &T>(f: F) -> F { f }
NLL (Non-Lexical Lifetime)
之前我们在引用与借用那一章其实有讲到过这个概念,简单来说就是:引用的生命周期正常来说应该从借用开始一直持续到作用域结束,但是这种规则会让多引用共存的情况变得更复杂:
fn main() { let mut s = String::from("hello"); let r1 = &s; let r2 = &s; println!("{} and {}", r1, r2); // 新编译器中,r1,r2作用域在这里结束 let r3 = &mut s; println!("{}", r3); }
按照上述规则,这段代码将会报错,因为 r1 和 r2 的不可变引用将持续到 main 函数结束,而在此范围内,我们又借用了 r3 的可变引用,这违反了借用的规则:要么多个不可变借用,要么一个可变借用。
好在,该规则从 1.31 版本引入 NLL 后,就变成了:引用的生命周期从借用处开始,一直持续到最后一次使用的地方。
按照最新的规则,我们再来分析一下上面的代码。r1 和 r2 不可变借用在 println! 后就不再使用,因此生命周期也随之结束,那么 r3 的借用就不再违反借用的规则,皆大欢喜。
再来看一段关于 NLL 的代码解释:
#![allow(unused)] fn main() { let mut u = 0i32; let mut v = 1i32; let mut w = 2i32; // lifetime of `a` = α ∪ β ∪ γ let mut a = &mut u; // --+ α. lifetime of `&mut u` --+ lexical "lifetime" of `&mut u`,`&mut u`, `&mut w` and `a` use(a); // | | *a = 3; // <-----------------+ | ... // | a = &mut v; // --+ β. lifetime of `&mut v` | use(a); // | | *a = 4; // <-----------------+ | ... // | a = &mut w; // --+ γ. lifetime of `&mut w` | use(a); // | | *a = 5; // <-----------------+ <--------------------------+ }
这段代码一目了然,a 有三段生命周期:α,β,γ,每一段生命周期都随着当前值的最后一次使用而结束。
在实际项目中,NLL 规则可以大幅减少引用冲突的情况,极大的便利了用户,因此广受欢迎,最终该规则甚至演化成一个独立的项目,未来可能会进一步简化我们的使用,Polonius:
Reborrow 再借用
学完 NLL 后,我们就有了一定的基础,可以继续学习关于借用和生命周期的一个高级内容:再借用。
先来看一段代码:
#[derive(Debug)] struct Point { x: i32, y: i32, } impl Point { fn move_to(&mut self, x: i32, y: i32) { self.x = x; self.y = y; } } fn main() { let mut p = Point { x: 0, y: 0 }; let r = &mut p; let rr: &Point = &*r; println!("{:?}", rr); r.move_to(10, 10); println!("{:?}", r); }
以上代码,大家可能会觉得可变引用 r 和不可变引用 rr 同时存在会报错吧?但是事实上并不会,原因在于 rr 是对 r 的再借用。
对于再借用而言,rr 再借用时不会破坏借用规则,但是你不能在它的生命周期内再使用原来的借用 r,来看看对上段代码的分析:
fn main() { let mut p = Point { x: 0, y: 0 }; let r = &mut p; // reborrow! 此时对`r`的再借用不会导致跟上面的借用冲突 let rr: &Point = &*r; // 再借用`rr`最后一次使用发生在这里,在它的生命周期中,我们并没有使用原来的借用`r`,因此不会报错 println!("{:?}", rr); // 再借用结束后,才去使用原来的借用`r` r.move_to(10, 10); println!("{:?}", r); }
再来看一个例子:
#![allow(unused)] fn main() { use std::vec::Vec; fn read_length(strings: &mut Vec<String>) -> usize { strings.len() } }
如上所示,函数体内对参数的二次借用也是典型的 Reborrow 场景。
那么下面让我们来做件坏事,破坏这条规则,使其报错:
fn main() { let mut p = Point { x: 0, y: 0 }; let r = &mut p; let rr: &Point = &*r; r.move_to(10, 10); println!("{:?}", rr); println!("{:?}", r); }
果然,破坏永远比重建简单 :) 只需要在 rr 再借用的生命周期内使用一次原来的借用 r 即可!
生命周期消除规则补充
在上一节中,我们介绍了三大基础生命周期消除规则,实际上,随着 Rust 的版本进化,该规则也在不断演进,这里再介绍几个常见的消除规则:
impl 块消除
#![allow(unused)] fn main() { impl<'a> Reader for BufReader<'a> { // methods go here // impl内部实际上没有用到'a } }
如果你以前写的impl块长上面这样,同时在 impl 内部的方法中,根本就没有用到 'a,那就可以写成下面的代码形式。
#![allow(unused)] fn main() { impl Reader for BufReader<'_> { // methods go here } }
'_ 生命周期表示 BufReader 有一个不使用的生命周期,我们可以忽略它,无需为它创建一个名称。
歪个楼,有读者估计会发问:既然用不到 'a,为何还要写出来?如果你仔细回忆下上一节的内容,里面有一句专门用粗体标注的文字:生命周期参数也是类型的一部分,因此 BufReader<'a> 是一个完整的类型,在实现它的时候,你不能把 'a 给丢了!
生命周期约束消除
#![allow(unused)] fn main() { // Rust 2015 struct Ref<'a, T: 'a> { field: &'a T } // Rust 2018 struct Ref<'a, T> { field: &'a T } }
在本节的生命周期约束中,也提到过,新版本 Rust 中,上面情况中的 T: 'a 可以被消除掉,当然,你也可以显式的声明,但是会影响代码可读性。关于类似的场景,Rust 团队计划在未来提供更多的消除规则,但是,你懂的,计划未来就等于未知。
一个复杂的例子
下面是一个关于生命周期声明过大的例子,会较为复杂,希望大家能细细阅读,它能帮你对生命周期的理解更加深入。
struct Interface<'a> { manager: &'a mut Manager<'a> } impl<'a> Interface<'a> { pub fn noop(self) { println!("interface consumed"); } } struct Manager<'a> { text: &'a str } struct List<'a> { manager: Manager<'a>, } impl<'a> List<'a> { pub fn get_interface(&'a mut self) -> Interface { Interface { manager: &mut self.manager } } } fn main() { let mut list = List { manager: Manager { text: "hello" } }; list.get_interface().noop(); println!("Interface should be dropped here and the borrow released"); // 下面的调用会失败,因为同时有不可变/可变借用 // 但是Interface在之前调用完成后就应该被释放了 use_list(&list); } fn use_list(list: &List) { println!("{}", list.manager.text); }
运行后报错:
error[E0502]: cannot borrow `list` as immutable because it is also borrowed as mutable // `list`无法被借用,因为已经被可变借用
--> src/main.rs:40:14
|
34 | list.get_interface().noop();
| ---- mutable borrow occurs here // 可变借用发生在这里
...
40 | use_list(&list);
| ^^^^^
| |
| immutable borrow occurs here // 新的不可变借用发生在这
| mutable borrow later used here // 可变借用在这里结束
这段代码看上去并不复杂,实际上难度挺高的,首先在直觉上,list.get_interface() 借用的可变引用,按理来说应该在这行代码结束后,就归还了,但是为什么还能持续到 use_list(&list) 后面呢?
这是因为我们在 get_interface 方法中声明的 lifetime 有问题,该方法的参数的生命周期是 'a,而 List 的生命周期也是 'a,说明该方法至少活得跟 List 一样久,再回到 main 函数中,list 可以活到 main 函数的结束,因此 list.get_interface() 借用的可变引用也会活到 main 函数的结束,在此期间,自然无法再进行借用了。
要解决这个问题,我们需要为 get_interface 方法的参数给予一个不同于 List<'a> 的生命周期 'b,最终代码如下:
struct Interface<'b, 'a: 'b> { manager: &'b mut Manager<'a> } impl<'b, 'a: 'b> Interface<'b, 'a> { pub fn noop(self) { println!("interface consumed"); } } struct Manager<'a> { text: &'a str } struct List<'a> { manager: Manager<'a>, } impl<'a> List<'a> { pub fn get_interface<'b>(&'b mut self) -> Interface<'b, 'a> where 'a: 'b { Interface { manager: &mut self.manager } } } fn main() { let mut list = List { manager: Manager { text: "hello" } }; list.get_interface().noop(); println!("Interface should be dropped here and the borrow released"); // 下面的调用可以通过,因为Interface的生命周期不需要跟list一样长 use_list(&list); } fn use_list(list: &List) { println!("{}", list.manager.text); }
至此,生命周期终于完结,两章超级长的内容,可以满足几乎所有对生命周期的学习目标。学完生命周期,意味着你正式入门了 Rust,只要再掌握几个常用概念,就可以上手写项目了。
&'static 和 T: 'static
Rust 的难点之一就在于它有不少容易混淆的概念,例如 &str 、str 与 String, 再比如本文标题那两位。不过与字符串也有不同,这两位对于普通用户来说往往是无需进行区分的,但是当大家想要深入学习或使用 Rust 时,它们就会成为成功路上的拦路虎了。
与生命周期的其它章节不同,本文短小精悍,阅读过程可谓相当轻松愉快,话不多说,let's go。
'static 在 Rust 中是相当常见的,例如字符串字面值就具有 'static 生命周期:
fn main() { let mark_twain: &str = "Samuel Clemens"; print_author(mark_twain); } fn print_author(author: &'static str) { println!("{}", author); }
除此之外,特征对象的生命周期也是 'static,例如这里所提到的。
除了 &'static 的用法外,我们在另外一种场景中也可以见到 'static 的使用:
use std::fmt::Display; fn main() { let mark_twain = "Samuel Clemens"; print(&mark_twain); } fn print<T: Display + 'static>(message: &T) { println!("{}", message); }
在这里,很明显 'static 是作为生命周期约束来使用了。 那么问题来了, &'static 和 T: 'static 的用法到底有何区别?
&'static
&'static 对于生命周期有着非常强的要求:一个引用必须要活得跟剩下的程序一样久,才能被标注为 &'static。
对于字符串字面量来说,它直接被打包到二进制文件中,永远不会被 drop,因此它能跟程序活得一样久,自然它的生命周期是 'static。
但是,&'static 生命周期针对的仅仅是引用,而不是持有该引用的变量,对于变量来说,还是要遵循相应的作用域规则 :
use std::{slice::from_raw_parts, str::from_utf8_unchecked}; fn get_memory_location() -> (usize, usize) { // “Hello World” 是字符串字面量,因此它的生命周期是 `'static`. // 但持有它的变量 `string` 的生命周期就不一样了,它完全取决于变量作用域,对于该例子来说,也就是当前的函数范围 let string = "Hello World!"; let pointer = string.as_ptr() as usize; let length = string.len(); (pointer, length) // `string` 在这里被 drop 释放 // 虽然变量被释放,无法再被访问,但是数据依然还会继续存活 } fn get_str_at_location(pointer: usize, length: usize) -> &'static str { // 使用裸指针需要 `unsafe{}` 语句块 unsafe { from_utf8_unchecked(from_raw_parts(pointer as *const u8, length)) } } fn main() { let (pointer, length) = get_memory_location(); let message = get_str_at_location(pointer, length); println!( "The {} bytes at 0x{:X} stored: {}", length, pointer, message ); // 如果大家想知道为何处理裸指针需要 `unsafe`,可以试着反注释以下代码 // let message = get_str_at_location(1000, 10); }
上面代码有两点值得注意:
&'static的引用确实可以和程序活得一样久,因为我们通过get_str_at_location函数直接取到了对应的字符串- 持有
&'static引用的变量,它的生命周期受到作用域的限制,大家务必不要搞混了
T: 'static
相比起来,这种形式的约束就有些复杂了。
首先,在以下两种情况下,T: 'static 与 &'static 有相同的约束:T 必须活得和程序一样久。
use std::fmt::Debug; fn print_it<T: Debug + 'static>( input: T) { println!( "'static value passed in is: {:?}", input ); } fn print_it1( input: impl Debug + 'static ) { println!( "'static value passed in is: {:?}", input ); } fn main() { let i = 5; print_it(&i); print_it1(&i); }
以上代码会报错,原因很简单: &i 的生命周期无法满足 'static 的约束,如果大家将 i 修改为常量,那自然一切 OK。
见证奇迹的时候,请不要眨眼,现在我们来稍微修改下 print_it 函数:
use std::fmt::Debug; fn print_it<T: Debug + 'static>( input: &T) { println!( "'static value passed in is: {:?}", input ); } fn main() { let i = 5; print_it(&i); }
这段代码竟然不报错了!原因在于我们约束的是 T,但是使用的却是它的引用 &T,换而言之,我们根本没有直接使用 T,因此编译器就没有去检查 T 的生命周期约束!它只要确保 &T 的生命周期符合规则即可,在上面代码中,它自然是符合的。
再来看一个例子:
use std::fmt::Display; fn main() { let r1; let r2; { static STATIC_EXAMPLE: i32 = 42; r1 = &STATIC_EXAMPLE; let x = "&'static str"; r2 = x; // r1 和 r2 持有的数据都是 'static 的,因此在花括号结束后,并不会被释放 } println!("&'static i32: {}", r1); // -> 42 println!("&'static str: {}", r2); // -> &'static str let r3: &str; { let s1 = "String".to_string(); // s1 虽然没有 'static 生命周期,但是它依然可以满足 T: 'static 的约束 // 充分说明这个约束是多么的弱。。 static_bound(&s1); // s1 是 String 类型,没有 'static 的生命周期,因此下面代码会报错 r3 = &s1; // s1 在这里被 drop } println!("{}", r3); } fn static_bound<T: Display + 'static>(t: &T) { println!("{}", t); }
static 到底针对谁?
大家有没有想过,到底是 &'static 这个引用还是该引用指向的数据活得跟程序一样久呢?
答案是引用指向的数据,而引用本身是要遵循其作用域范围的,我们来简单验证下:
fn main() { { let static_string = "I'm in read-only memory"; println!("static_string: {}", static_string); // 当 `static_string` 超出作用域时,该引用不能再被使用,但是数据依然会存在于 binary 所占用的内存中 } println!("static_string reference remains alive: {}", static_string); }
以上代码不出所料会报错,原因在于虽然字符串字面量 "I'm in read-only memory" 的生命周期是 'static,但是持有它的引用并不是,它的作用域在内部花括号 } 处就结束了。
总结
总之, &'static 和 T: 'static 大体上相似,相比起来,后者的使用形式会更加复杂一些。
至此,相信大家对于 'static 和 T: 'static 也有了清晰的理解,那么我们应该如何使用它们呢?
作为经验之谈,可以这么来:
- 如果你需要添加
&'static来让代码工作,那很可能是设计上出问题了 - 如果你希望满足和取悦编译器,那就使用
T: 'static,很多时候它都能解决问题
一个小知识,在 Rust 标准库中,有 48 处用到了 &'static ,112 处用到了
T: 'static,看来取悦编译器不仅仅是菜鸟需要的,高手也经常用到 :)
函数式编程
罗马不是一天建成的,编程语言亦是如此,每一门编程语言在借鉴前辈的同时,也会提出自己独有的特性,Rust 即是如此。当站在巨人肩膀上时,一个人所能看到的就更高更远,恰好,我们看到了函数式语言的优秀特性,例如:
- 使用函数作为参数进行传递
- 使用函数作为函数返回值
- 将函数赋值给变量
见猎心喜,我们忍不住就借鉴了过来,于是你能看到本章的内容,天下语言一大。。。跑题了。
关于函数式编程到底是什么的争论由来已久,本章节并不会踏足这个泥潭,因此我们在这里主要关注的是函数式特性:
- 闭包 Closure
- 迭代器 Iterator
- 模式匹配
- 枚举
其中后两个在前面章节我们已经深入学习过,因此本章的重点就是闭包和迭代器,这些函数式特性可以让代码的可读性和易写性大幅提升。对于 Rust 语言来说,掌握这两者就相当于你同时拥有了倚天剑屠龙刀,威力无穷。
闭包 Closure
闭包这个词语由来已久,自上世纪 60 年代就由 Scheme 语言引进之后,被广泛用于函数式编程语言中,进入 21 世纪后,各种现代化的编程语言也都不约而同地把闭包作为核心特性纳入到语言设计中来。那么到底何为闭包?
闭包是一种匿名函数,它可以赋值给变量也可以作为参数传递给其它函数,不同于函数的是,它允许捕获调用者作用域中的值,例如:
fn main() { let x = 1; let sum = |y| x + y; assert_eq!(3, sum(2)); }
上面的代码展示了非常简单的闭包 sum,它拥有一个入参 y,同时捕获了作用域中的 x 的值,因此调用 sum(2) 意味着将 2(参数 y)跟 1(x)进行相加,最终返回它们的和:3。
可以看到 sum 非常符合闭包的定义:可以赋值给变量,允许捕获调用者作用域中的值。
使用闭包来简化代码
传统函数实现
想象一下,我们要进行健身,用代码怎么实现(写代码什么鬼,健身难道不应该去健身房嘛?答曰:健身太累了,还是虚拟健身好,点到为止)?这里是我的想法:
use std::thread; use std::time::Duration; // 开始健身,好累,我得发出声音:muuuu... fn muuuuu(intensity: u32) -> u32 { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity } fn workout(intensity: u32, random_number: u32) { if intensity < 25 { println!( "今天活力满满,先做 {} 个俯卧撑!", muuuuu(intensity) ); println!( "旁边有妹子在看,俯卧撑太low,再来 {} 组卧推!", muuuuu(intensity) ); } else if random_number == 3 { println!("昨天练过度了,今天还是休息下吧!"); } else { println!( "昨天练过度了,今天干干有氧,跑步 {} 分钟!", muuuuu(intensity) ); } } fn main() { // 强度 let intensity = 10; // 随机值用来决定某个选择 let random_number = 7; // 开始健身 workout(intensity, random_number); }
可以看到,在健身时我们根据想要的强度来调整具体的动作,然后调用 muuuuu 函数来开始健身。这个程序本身很简单,没啥好说的,但是假如未来不用 muuuuu 函数了,是不是得把所有 muuuuu 都替换成,比如说 woooo ?如果 muuuuu 出现了几十次,那意味着我们要修改几十处地方。
函数变量实现
一个可行的办法是,把函数赋值给一个变量,然后通过变量调用:
use std::thread; use std::time::Duration; // 开始健身,好累,我得发出声音:muuuu... fn muuuuu(intensity: u32) -> u32 { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity } fn workout(intensity: u32, random_number: u32) { let action = muuuuu; if intensity < 25 { println!( "今天活力满满, 先做 {} 个俯卧撑!", action(intensity) ); println!( "旁边有妹子在看,俯卧撑太low, 再来 {} 组卧推!", action(intensity) ); } else if random_number == 3 { println!("昨天练过度了,今天还是休息下吧!"); } else { println!( "昨天练过度了,今天干干有氧, 跑步 {} 分钟!", action(intensity) ); } } fn main() { // 强度 let intensity = 10; // 随机值用来决定某个选择 let random_number = 7; // 开始健身 workout(intensity, random_number); }
经过上面修改后,所有的调用都通过 action 来完成,若未来声(动)音(作)变了,只要修改为 let action = woooo 即可。
但是问题又来了,若 intensity 也变了怎么办?例如变成 action(intensity + 1),那你又得哐哐哐修改几十处调用。
该怎么办?没太好的办法了,只能祭出大杀器:闭包。
闭包实现
上面提到 intensity 要是变化怎么办,简单,使用闭包来捕获它,这是我们的拿手好戏:
use std::thread; use std::time::Duration; fn workout(intensity: u32, random_number: u32) { let action = || { println!("muuuu....."); thread::sleep(Duration::from_secs(2)); intensity }; if intensity < 25 { println!( "今天活力满满,先做 {} 个俯卧撑!", action() ); println!( "旁边有妹子在看,俯卧撑太low,再来 {} 组卧推!", action() ); } else if random_number == 3 { println!("昨天练过度了,今天还是休息下吧!"); } else { println!( "昨天练过度了,今天干干有氧,跑步 {} 分钟!", action() ); } } fn main() { // 动作次数 let intensity = 10; // 随机值用来决定某个选择 let random_number = 7; // 开始健身 workout(intensity, random_number); }
在上面代码中,无论你要修改什么,只要修改闭包 action 的实现即可,其它地方只负责调用,完美解决了我们的问题!
Rust 闭包在形式上借鉴了 Smalltalk 和 Ruby 语言,与函数最大的不同就是它的参数是通过 |parm1| 的形式进行声明,如果是多个参数就 |param1, param2,...|, 下面给出闭包的形式定义:
#![allow(unused)] fn main() { |param1, param2,...| { 语句1; 语句2; 返回表达式 } }
如果只有一个返回表达式的话,定义可以简化为:
#![allow(unused)] fn main() { |param1| 返回表达式 }
上例中还有两点值得注意:
- 闭包中最后一行表达式返回的值,就是闭包执行后的返回值,因此
action()调用返回了intensity的值10 let action = ||...只是把闭包赋值给变量action,并不是把闭包执行后的结果赋值给action,因此这里action就相当于闭包函数,可以跟函数一样进行调用:action()
闭包的类型推导
Rust 是静态语言,因此所有的变量都具有类型,但是得益于编译器的强大类型推导能力,在很多时候我们并不需要显式地去声明类型,但是显然函数并不在此列,必须手动为函数的所有参数和返回值指定类型,原因在于函数往往会作为 API 提供给你的用户,因此你的用户必须在使用时知道传入参数的类型和返回值类型。
与函数相反,闭包并不会作为 API 对外提供,因此它可以享受编译器的类型推导能力,无需标注参数和返回值的类型。
为了增加代码可读性,有时候我们会显式地给类型进行标注,出于同样的目的,也可以给闭包标注类型:
#![allow(unused)] fn main() { let sum = |x: i32, y: i32| -> i32 { x + y } }
与之相比,不标注类型的闭包声明会更简洁些:let sum = |x, y| x + y,需要注意的是,针对 sum 闭包,如果你只进行了声明,但是没有使用,编译器会提示你为 x, y 添加类型标注,因为它缺乏必要的上下文:
#![allow(unused)] fn main() { let sum = |x, y| x + y; let v = sum(1, 2); }
这里我们使用了 sum,同时把 1 传给了 x,2 传给了 y,因此编译器才可以推导出 x,y 的类型为 i32。
下面展示了同一个功能的函数和闭包实现形式:
#![allow(unused)] fn main() { fn add_one_v1 (x: u32) -> u32 { x + 1 } let add_one_v2 = |x: u32| -> u32 { x + 1 }; let add_one_v3 = |x| { x + 1 }; let add_one_v4 = |x| x + 1 ; }
可以看出第一行的函数和后面的闭包其实在形式上是非常接近的,同时三种不同的闭包也展示了三种不同的使用方式:省略参数、返回值类型和花括号对。
虽然类型推导很好用,但是它不是泛型,当编译器推导出一种类型后,它就会一直使用该类型:
#![allow(unused)] fn main() { let example_closure = |x| x; let s = example_closure(String::from("hello")); let n = example_closure(5); }
首先,在 s 中,编译器为 x 推导出类型 String,但是紧接着 n 试图用 5 这个整型去调用闭包,跟编译器之前推导的 String 类型不符,因此报错:
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| ^
| |
| expected struct `String`, found integer // 期待String类型,却发现一个整数
| help: try using a conversion method: `5.to_string()`
结构体中的闭包
假设我们要实现一个简易缓存,功能是获取一个值,然后将其缓存起来,那么可以这样设计:
- 一个闭包用于获取值
- 一个变量,用于存储该值
可以使用结构体来代表缓存对象,最终设计如下:
#![allow(unused)] fn main() { struct Cacher<T> where T: Fn(u32) -> u32, { query: T, value: Option<u32>, } }
等等,我都跟着这本教程学完 Rust 基础了,为何还有我不认识的东东?Fn(u32) -> u32 是什么鬼?别急,先回答你第一个问题:骚年,too young too naive,你以为 Rust 的语法特性就基础入门那一些吗?太年轻了!如果是长征,你才刚到赤水河。
其实,可以看得出这一长串是 T 的特征约束,再结合之前的已知信息:query 是一个闭包,大概可以推测出,Fn(u32) -> u32 是一个特征,用来表示 T 是一个闭包类型?Bingo,恭喜你,答对了!
那为什么不用具体的类型来标注 query 呢?原因很简单,每一个闭包实例都有独属于自己的类型,即使于两个签名一模一样的闭包,它们的类型也是不同的,因此你无法用一个统一的类型来标注 query 闭包。
而标准库提供的 Fn 系列特征,再结合特征约束,就能很好的解决了这个问题. T: Fn(u32) -> u32 意味着 query 的类型是 T,该类型必须实现了相应的闭包特征 Fn(u32) -> u32。从特征的角度来看它长得非常反直觉,但是如果从闭包的角度来看又极其符合直觉,不得不佩服 Rust 团队的鬼才设计。。。
特征 Fn(u32) -> u32 从表面来看,就对闭包形式进行了显而易见的限制:该闭包拥有一个u32类型的参数,同时返回一个u32类型的值。
需要注意的是,其实 Fn 特征不仅仅适用于闭包,还适用于函数,因此上面的
query字段除了使用闭包作为值外,还能使用一个具名的函数来作为它的值
接着,为缓存实现方法:
#![allow(unused)] fn main() { impl<T> Cacher<T> where T: Fn(u32) -> u32, { fn new(query: T) -> Cacher<T> { Cacher { query, value: None, } } // 先查询缓存值 `self.value`,若不存在,则调用 `query` 加载 fn value(&mut self, arg: u32) -> u32 { match self.value { Some(v) => v, None => { let v = (self.query)(arg); self.value = Some(v); v } } } } }
上面的缓存有一个很大的问题:只支持 u32 类型的值,若我们想要缓存 &str 类型,显然就行不通了,因此需要将 u32 替换成泛型 E,该练习就留给读者自己完成,具体代码可以参考这里
捕获作用域中的值
在之前代码中,我们一直在用闭包的匿名函数特性(赋值给变量),然而闭包还拥有一项函数所不具备的特性:捕获作用域中的值。
fn main() { let x = 4; let equal_to_x = |z| z == x; let y = 4; assert!(equal_to_x(y)); }
上面代码中,x 并不是闭包 equal_to_x 的参数,但是它依然可以去使用 x,因为 equal_to_x 在 x 的作用域范围内。
对于函数来说,就算你把函数定义在 main 函数体中,它也不能访问 x:
fn main() { let x = 4; fn equal_to_x(z: i32) -> bool { z == x } let y = 4; assert!(equal_to_x(y)); }
报错如下:
error[E0434]: can't capture dynamic environment in a fn item // 在函数中无法捕获动态的环境
--> src/main.rs:5:14
|
5 | z == x
| ^
|
= help: use the `|| { ... }` closure form instead // 使用闭包替代
如上所示,编译器准确地告诉了我们错误,甚至同时给出了提示:使用闭包来替代函数,这种聪明令我有些无所适从,总感觉会显得我很笨。
闭包对内存的影响
当闭包从环境中捕获一个值时,会分配内存去存储这些值。对于有些场景来说,这种额外的内存分配会成为一种负担。与之相比,函数就不会去捕获这些环境值,因此定义和使用函数不会拥有这种内存负担。
三种 Fn 特征
闭包捕获变量有三种途径,恰好对应函数参数的三种传入方式:转移所有权、可变借用、不可变借用,因此相应的 Fn 特征也有三种:
FnOnce,该类型的闭包会拿走被捕获变量的所有权。Once顾名思义,说明该闭包只能运行一次:
fn fn_once<F>(func: F) where F: FnOnce(usize) -> bool, { println!("{}", func(3)); println!("{}", func(4)); } fn main() { let x = vec![1, 2, 3]; fn_once(|z|{z == x.len()}) }
仅实现 FnOnce 特征的闭包在调用时会转移所有权,所以显然不能对已失去所有权的闭包变量进行二次调用:
error[E0382]: use of moved value: `func`
--> src\main.rs:6:20
|
1 | fn fn_once<F>(func: F)
| ---- move occurs because `func` has type `F`, which does not implement the `Copy` trait
// 因为`func`的类型是没有实现`Copy`特性的 `F`,所以发生了所有权的转移
...
5 | println!("{}", func(3));
| ------- `func` moved due to this call // 转移在这
6 | println!("{}", func(4));
| ^^^^ value used here after move // 转移后再次用
|
这里面有一个很重要的提示,因为 F 没有实现 Copy 特征,所以会报错,那么我们添加一个约束,试试实现了 Copy 的闭包:
fn fn_once<F>(func: F) where F: FnOnce(usize) -> bool + Copy,// 改动在这里 { println!("{}", func(3)); println!("{}", func(4)); } fn main() { let x = vec![1, 2, 3]; fn_once(|z|{z == x.len()}) }
上面代码中,func 的类型 F 实现了 Copy 特征,调用时使用的将是它的拷贝,所以并没有发生所有权的转移。
true
false
如果你想强制闭包取得捕获变量的所有权,可以在参数列表前添加 move 关键字,这种用法通常用于闭包的生命周期大于捕获变量的生命周期时,例如将闭包返回或移入其他线程。
#![allow(unused)] fn main() { use std::thread; let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); }
FnMut,它以可变借用的方式捕获了环境中的值,因此可以修改该值:
fn main() { let mut s = String::new(); let update_string = |str| s.push_str(str); update_string("hello"); println!("{:?}",s); }
在闭包中,我们调用 s.push_str 去改变外部 s 的字符串值,因此这里捕获了它的可变借用,运行下试试:
error[E0596]: cannot borrow `update_string` as mutable, as it is not declared as mutable
--> src/main.rs:5:5
|
4 | let update_string = |str| s.push_str(str);
| ------------- - calling `update_string` requires mutable binding due to mutable borrow of `s`
| |
| help: consider changing this to be mutable: `mut update_string`
5 | update_string("hello");
| ^^^^^^^^^^^^^ cannot borrow as mutable
虽然报错了,但是编译器给出了非常清晰的提示,想要在闭包内部捕获可变借用,需要把该闭包声明为可变类型,也就是 update_string 要修改为 mut update_string:
fn main() { let mut s = String::new(); let mut update_string = |str| s.push_str(str); update_string("hello"); println!("{:?}",s); }
这种写法有点反直觉,相比起来前面的 move 更符合使用和阅读习惯。但是如果你忽略 update_string 的类型,仅仅把它当成一个普通变量,那么这种声明就比较合理了。
再来看一个复杂点的:
fn main() { let mut s = String::new(); let update_string = |str| s.push_str(str); exec(update_string); println!("{:?}",s); } fn exec<'a, F: FnMut(&'a str)>(mut f: F) { f("hello") }
这段代码非常清晰的说明了 update_string 实现了 FnMut 特征
Fn特征,它以不可变借用的方式捕获环境中的值 让我们把上面的代码中exec的F泛型参数类型修改为Fn(&'a str):
fn main() { let mut s = String::new(); let update_string = |str| s.push_str(str); exec(update_string); println!("{:?}",s); } fn exec<'a, F: Fn(&'a str)>(mut f: F) { f("hello") }
然后运行看看结果:
error[E0525]: expected a closure that implements the `Fn` trait, but this closure only implements `FnMut`
--> src/main.rs:4:26 // 期望闭包实现的是`Fn`特征,但是它只实现了`FnMut`特征
|
4 | let update_string = |str| s.push_str(str);
| ^^^^^^-^^^^^^^^^^^^^^
| | |
| | closure is `FnMut` because it mutates the variable `s` here
| this closure implements `FnMut`, not `Fn` //闭包实现的是FnMut,而不是Fn
5 |
6 | exec(update_string);
| ---- the requirement to implement `Fn` derives from here
从报错中很清晰的看出,我们的闭包实现的是 FnMut 特征,需要的是可变借用,但是在 exec 中却给它标注了 Fn 特征,因此产生了不匹配,再来看看正确的不可变借用方式:
fn main() { let s = "hello, ".to_string(); let update_string = |str| println!("{},{}",s,str); exec(update_string); println!("{:?}",s); } fn exec<'a, F: Fn(String) -> ()>(f: F) { f("world".to_string()) }
在这里,因为无需改变 s,因此闭包中只对 s 进行了不可变借用,那么在 exec 中,将其标记为 Fn 特征就完全正确。
move 和 Fn
在上面,我们讲到了 move 关键字对于 FnOnce 特征的重要性,但是实际上使用了 move 的闭包依然可能实现了 Fn 或 FnMut 特征。
因为,一个闭包实现了哪种 Fn 特征取决于该闭包如何使用被捕获的变量,而不是取决于闭包如何捕获它们。move 本身强调的就是后者,闭包如何捕获变量:
fn main() { let s = String::new(); let update_string = move || println!("{}",s); exec(update_string); } fn exec<F: FnOnce()>(f: F) { f() }
我们在上面的闭包中使用了 move 关键字,所以我们的闭包捕获了它,但是由于闭包对 s 的使用仅仅是不可变借用,因此该闭包实际上还实现了 Fn 特征。
细心的读者肯定发现我在上段中使用了一个 还 字,这是什么意思呢?因为该闭包不仅仅实现了 FnOnce 特征,还实现了 Fn 特征,将代码修改成下面这样,依然可以编译:
fn main() { let s = String::new(); let update_string = move || println!("{}",s); exec(update_string); } fn exec<F: Fn()>(f: F) { f() }
三种 Fn 的关系
实际上,一个闭包并不仅仅实现某一种 Fn 特征,规则如下:
- 所有的闭包都自动实现了
FnOnce特征,因此任何一个闭包都至少可以被调用一次 - 没有移出所捕获变量的所有权的闭包自动实现了
FnMut特征 - 不需要对捕获变量进行改变的闭包自动实现了
Fn特征
用一段代码来简单诠释上述规则:
fn main() { let s = String::new(); let update_string = || println!("{}",s); exec(update_string); exec1(update_string); exec2(update_string); } fn exec<F: FnOnce()>(f: F) { f() } fn exec1<F: FnMut()>(mut f: F) { f() } fn exec2<F: Fn()>(f: F) { f() }
虽然,闭包只是对 s 进行了不可变借用,实际上,它可以适用于任何一种 Fn 特征:三个 exec 函数说明了一切。强烈建议读者亲自动手试试各种情况下使用的 Fn 特征,更有助于加深这方面的理解。
关于第二条规则,有如下示例:
fn main() { let mut s = String::new(); let update_string = |str| -> String {s.push_str(str); s }; exec(update_string); } fn exec<'a, F: FnMut(&'a str) -> String>(mut f: F) { f("hello"); }
5 | let update_string = |str| -> String {s.push_str(str); s };
| ^^^^^^^^^^^^^^^ - closure is `FnOnce` because it moves the variable `s` out of its environment
| // 闭包实现了`FnOnce`,因为它从捕获环境中移出了变量`s`
| |
| this closure implements `FnOnce`, not `FnMut`
此例中,闭包从捕获环境中移出了变量 s 的所有权,因此这个闭包仅自动实现了 FnOnce,未实现 FnMut 和 Fn。再次印证之前讲的一个闭包实现了哪种 Fn 特征取决于该闭包如何使用被捕获的变量,而不是取决于闭包如何捕获它们,跟是否使用 move 没有必然联系。
如果还是有疑惑?没关系,我们来看看这三个特征的简化版源码:
#![allow(unused)] fn main() { pub trait Fn<Args> : FnMut<Args> { extern "rust-call" fn call(&self, args: Args) -> Self::Output; } pub trait FnMut<Args> : FnOnce<Args> { extern "rust-call" fn call_mut(&mut self, args: Args) -> Self::Output; } pub trait FnOnce<Args> { type Output; extern "rust-call" fn call_once(self, args: Args) -> Self::Output; } }
看到没?从特征约束能看出来 Fn 的前提是实现 FnMut,FnMut 的前提是实现 FnOnce,因此要实现 Fn 就要同时实现 FnMut 和 FnOnce,这段源码从侧面印证了之前规则的正确性。
从源码中还能看出一点:Fn 获取 &self,FnMut 获取 &mut self,而 FnOnce 获取 self。
在实际项目中,建议先使用 Fn 特征,然后编译器会告诉你正误以及该如何选择。
闭包作为函数返回值
看到这里,相信大家对于如何使用闭包作为函数参数,已经很熟悉了,但是如果要使用闭包作为函数返回值,该如何做?
先来看一段代码:
#![allow(unused)] fn main() { fn factory() -> Fn(i32) -> i32 { let num = 5; |x| x + num } let f = factory(); let answer = f(1); assert_eq!(6, answer); }
上面这段代码看起来还是蛮正常的,用 Fn(i32) -> i32 特征来代表 |x| x + num,非常合理嘛,肯定可以编译通过, 可惜理想总是难以照进现实,编译器给我们报了一大堆错误,先挑几个重点来看看:
fn factory<T>() -> Fn(i32) -> i32 {
| ^^^^^^^^^^^^^^ doesn't have a size known at compile-time // 该类型在编译器没有固定的大小
Rust 要求函数的参数和返回类型,必须有固定的内存大小,例如 i32 就是 4 个字节,引用类型是 8 个字节,总之,绝大部分类型都有固定的大小,但是不包括特征,因为特征类似接口,对于编译器来说,无法知道它后面藏的真实类型是什么,因为也无法得知具体的大小。
同样,我们也无法知道闭包的具体类型,该怎么办呢?再看看报错提示:
help: use `impl Fn(i32) -> i32` as the return type, as all return paths are of type `[closure@src/main.rs:11:5: 11:21]`, which implements `Fn(i32) -> i32`
|
8 | fn factory<T>() -> impl Fn(i32) -> i32 {
嗯,编译器提示我们加一个 impl 关键字,哦,这样一说,读者可能就想起来了,impl Trait 可以用来返回一个实现了指定特征的类型,那么这里 impl Fn(i32) -> i32 的返回值形式,说明我们要返回一个闭包类型,它实现了 Fn(i32) -> i32 特征。
完美解决,但是,在特征那一章,我们提到过,impl Trait 的返回方式有一个非常大的局限,就是你只能返回同样的类型,例如:
#![allow(unused)] fn main() { fn factory(x:i32) -> impl Fn(i32) -> i32 { let num = 5; if x > 1{ move |x| x + num } else { move |x| x - num } } }
运行后,编译器报错:
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:15:9
|
12 | / if x > 1{
13 | | move |x| x + num
| | ---------------- expected because of this
14 | | } else {
15 | | move |x| x - num
| | ^^^^^^^^^^^^^^^^ expected closure, found a different closure
16 | | }
| |_____- `if` and `else` have incompatible types
|
嗯,提示很清晰:if 和 else 分支中返回了不同的闭包类型,这就很奇怪了,明明这两个闭包长的一样的,好在细心的读者应该回想起来,本章节前面咱们有提到:就算签名一样的闭包,类型也是不同的,因此在这种情况下,就无法再使用 impl Trait 的方式去返回闭包。
怎么办?再看看编译器提示,里面有这样一行小字:
= help: consider boxing your closure and/or using it as a trait object
哦,相信你已经恍然大悟,可以用特征对象!只需要用 Box 的方式即可实现:
#![allow(unused)] fn main() { fn factory(x:i32) -> Box<dyn Fn(i32) -> i32> { let num = 5; if x > 1{ Box::new(move |x| x + num) } else { Box::new(move |x| x - num) } } }
至此,闭包作为函数返回值就已完美解决,若以后你再遇到报错时,一定要仔细阅读编译器的提示,很多时候,转角都能遇到爱。
迭代器 Iterator
如果你询问一个 Rust 资深开发:写 Rust 项目最需要掌握什么?相信迭代器往往就是答案之一。无论你是编程新手亦或是高手,实际上大概率都用过迭代器,虽然自己可能并没有意识到这一点:)
迭代器允许我们迭代一个连续的集合,例如数组、动态数组 Vec、HashMap 等,在此过程中,只需关心集合中的元素如何处理,而无需关心如何开始、如何结束、按照什么样的索引去访问等问题。
For 循环与迭代器
从用途来看,迭代器跟 for 循环颇为相似,都是去遍历一个集合,但是实际上它们存在不小的差别,其中最主要的差别就是:是否通过索引来访问集合。
例如以下的 JS 代码就是一个循环:
let arr = [1, 2, 3];
for (let i = 0; i < arr.length; i++) {
console.log(arr[i]);
}
在上面代码中,我们设置索引的开始点和结束点,然后再通过索引去访问元素 arr[i],这就是典型的循环,来对比下 Rust 中的 for:
#![allow(unused)] fn main() { let arr = [1, 2, 3]; for v in arr { println!("{}",v); } }
首先,不得不说这两语法还挺像!与 JS 循环不同,Rust中没有使用索引,它把 arr 数组当成一个迭代器,直接去遍历其中的元素,从哪里开始,从哪里结束,都无需操心。因此严格来说,Rust 中的 for 循环是编译器提供的语法糖,最终还是对迭代器中的元素进行遍历。
那又有同学要发问了,在 Rust 中数组是迭代器吗?因为在之前的代码中直接对数组 arr 进行了迭代,答案是 No。那既然数组不是迭代器,为啥咱可以对它的元素进行迭代呢?
简而言之就是数组实现了 IntoIterator 特征,Rust 通过 for 语法糖,自动把实现了该特征的数组类型转换为迭代器(你也可以为自己的集合类型实现此特征),最终让我们可以直接对一个数组进行迭代,类似的还有:
#![allow(unused)] fn main() { for i in 1..10 { println!("{}", i); } }
直接对数值序列进行迭代,也是很常见的使用方式。
IntoIterator 特征拥有一个 into_iter 方法,因此我们还可以显式的把数组转换成迭代器:
#![allow(unused)] fn main() { let arr = [1, 2, 3]; for v in arr.into_iter() { println!("{}", v); } }
迭代器是函数语言的核心特性,它赋予了 Rust 远超于循环的强大表达能力,我们将在本章中一一为大家进行展现。
惰性初始化
在 Rust 中,迭代器是惰性的,意味着如果你不使用它,那么它将不会发生任何事:
#![allow(unused)] fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); for val in v1_iter { println!("{}", val); } }
在 for 循环之前,我们只是简单的创建了一个迭代器 v1_iter,此时不会发生任何迭代行为,只有在 for 循环开始后,迭代器才会开始迭代其中的元素,最后打印出来。
这种惰性初始化的方式确保了创建迭代器不会有任何额外的性能损耗,其中的元素也不会被消耗,只有使用到该迭代器的时候,一切才开始。
next 方法
对于 for 如何遍历迭代器,还有一个问题,它如何取出迭代器中的元素?
先来看一个特征:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // 省略其余有默认实现的方法 } }
呦,该特征竟然和迭代器 iterator 同名,难不成。。。没错,它们就是有一腿。迭代器之所以成为迭代器,就是因为实现了 Iterator 特征,要实现该特征,最主要的就是实现其中的 next 方法,该方法控制如何从集合中取值,最终返回值的类型是关联类型 Item。
因此,之前问题的答案已经很明显:for 循环通过不停调用迭代器上的 next 方法,来获取迭代器中的元素。
既然 for 可以调用 next 方法,是不是意味着我们也可以?来试试:
fn main() { let arr = [1, 2, 3]; let mut arr_iter = arr.into_iter(); assert_eq!(arr_iter.next(), Some(1)); assert_eq!(arr_iter.next(), Some(2)); assert_eq!(arr_iter.next(), Some(3)); assert_eq!(arr_iter.next(), None); }
果不其然,将 arr 转换成迭代器后,通过调用其上的 next 方法,我们获取了 arr 中的元素,有两点需要注意:
next方法返回的是Option类型,当有值时返回Some(i32),无值时返回None- 遍历是按照迭代器中元素的排列顺序依次进行的,因此我们严格按照数组中元素的顺序取出了
Some(1),Some(2),Some(3) - 手动迭代必须将迭代器声明为
mut可变,因为调用next会改变迭代器其中的状态数据(当前遍历的位置等),而for循环去迭代则无需标注mut,因为它会帮我们自动完成
总之,next 方法对迭代器的遍历是消耗性的,每次消耗它一个元素,最终迭代器中将没有任何元素,只能返回 None。
例子:模拟实现 for 循环
因为 for 循环是迭代器的语法糖,因此我们完全可以通过迭代器来模拟实现它:
#![allow(unused)] fn main() { let values = vec![1, 2, 3]; { let result = match IntoIterator::into_iter(values) { mut iter => loop { match iter.next() { Some(x) => { println!("{}", x); }, None => break, } }, }; result } }
IntoIterator::into_iter 是使用完全限定的方式去调用 into_iter 方法,这种调用方式跟 values.into_iter() 是等价的。
同时我们使用了 loop 循环配合 next 方法来遍历迭代器中的元素,当迭代器返回 None 时,跳出循环。
IntoIterator 特征
其实有一个细节,由于 Vec 动态数组实现了 IntoIterator 特征,因此可以通过 into_iter 将其转换为迭代器,那如果本身就是一个迭代器,该怎么办?实际上,迭代器自身也实现了 IntoIterator,标准库早就帮我们考虑好了:
#![allow(unused)] fn main() { impl<I: Iterator> IntoIterator for I { type Item = I::Item; type IntoIter = I; #[inline] fn into_iter(self) -> I { self } } }
最终你完全可以写出这样的奇怪代码:
fn main() { let values = vec![1, 2, 3]; for v in values.into_iter().into_iter().into_iter() { println!("{}",v) } }
into_iter, iter, iter_mut
在之前的代码中,我们统一使用了 into_iter 的方式将数组转化为迭代器,除此之外,还有 iter 和 iter_mut,聪明的读者应该大概能猜到这三者的区别:
into_iter会夺走所有权iter是借用iter_mut是可变借用
其实如果以后见多识广了,你会发现这种问题一眼就能看穿,into_ 之类的,都是拿走所有权,_mut 之类的都是可变借用,剩下的就是不可变借用。
使用一段代码来解释下:
fn main() { let values = vec![1, 2, 3]; for v in values.into_iter() { println!("{}", v) } // 下面的代码将报错,因为 values 的所有权在上面 `for` 循环中已经被转移走 // println!("{:?}",values); let values = vec![1, 2, 3]; let _values_iter = values.iter(); // 不会报错,因为 values_iter 只是借用了 values 中的元素 println!("{:?}", values); let mut values = vec![1, 2, 3]; // 对 values 中的元素进行可变借用 let mut values_iter_mut = values.iter_mut(); // 取出第一个元素,并修改为0 if let Some(v) = values_iter_mut.next() { *v = 0; } // 输出[0, 2, 3] println!("{:?}", values); }
具体解释在代码注释中,就不再赘述,不过有两点需要注意的是:
.iter()方法实现的迭代器,调用next方法返回的类型是Some(&T).iter_mut()方法实现的迭代器,调用next方法返回的类型是Some(&mut T),因此在if let Some(v) = values_iter_mut.next()中,v的类型是&mut i32,最终我们可以通过*v = 0的方式修改其值
Iterator 和 IntoIterator 的区别
这两个其实还蛮容易搞混的,但我们只需要记住,Iterator 就是迭代器特征,只有实现了它才能称为迭代器,才能调用 next。
而 IntoIterator 强调的是某一个类型如果实现了该特征,它可以通过 into_iter,iter 等方法变成一个迭代器。
消费者与适配器
消费者是迭代器上的方法,它会消费掉迭代器中的元素,然后返回其类型的值,这些消费者都有一个共同的特点:在它们的定义中,都依赖 next 方法来消费元素,因此这也是为什么迭代器要实现 Iterator 特征,而该特征必须要实现 next 方法的原因。
消费者适配器
只要迭代器上的某个方法 A 在其内部调用了 next 方法,那么 A 就被称为消费性适配器:因为 next 方法会消耗掉迭代器上的元素,所以方法 A 的调用也会消耗掉迭代器上的元素。
其中一个例子是 sum 方法,它会拿走迭代器的所有权,然后通过不断调用 next 方法对里面的元素进行求和:
fn main() { let v1 = vec![1, 2, 3]; let v1_iter = v1.iter(); let total: i32 = v1_iter.sum(); assert_eq!(total, 6); // v1_iter 是借用了 v1,因此 v1 可以照常使用 println!("{:?}",v1); // 以下代码会报错,因为 `sum` 拿到了迭代器 `v1_iter` 的所有权 // println!("{:?}",v1_iter); }
如代码注释中所说明的:在使用 sum 方法后,我们将无法再使用 v1_iter,因为 sum 拿走了该迭代器的所有权:
#![allow(unused)] fn main() { fn sum<S>(self) -> S where Self: Sized, S: Sum<Self::Item>, { Sum::sum(self) } }
从 sum 源码中也可以清晰看出,self 类型的方法参数拿走了所有权。
迭代器适配器
既然消费者适配器是消费掉迭代器,然后返回一个值。那么迭代器适配器,顾名思义,会返回一个新的迭代器,这是实现链式方法调用的关键:v.iter().map().filter()...。
与消费者适配器不同,迭代器适配器是惰性的,意味着你需要一个消费者适配器来收尾,最终将迭代器转换成一个具体的值:
#![allow(unused)] fn main() { let v1: Vec<i32> = vec![1, 2, 3]; v1.iter().map(|x| x + 1); }
运行后输出:
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: iterators are lazy and do nothing unless consumed // 迭代器 map 是惰性的,这里不产生任何效果
如上述中文注释所说,这里的 map 方法是一个迭代者适配器,它是惰性的,不产生任何行为,因此我们还需要一个消费者适配器进行收尾:
#![allow(unused)] fn main() { let v1: Vec<i32> = vec![1, 2, 3]; let v2: Vec<_> = v1.iter().map(|x| x + 1).collect(); assert_eq!(v2, vec![2, 3, 4]); }
collect
上面代码中,使用了 collect 方法,该方法就是一个消费者适配器,使用它可以将一个迭代器中的元素收集到指定类型中,这里我们为 v2 标注了 Vec<_> 类型,就是为了告诉 collect:请把迭代器中的元素消费掉,然后把值收集成 Vec<_> 类型,至于为何使用 _,因为编译器会帮我们自动推导。
为何 collect 在消费时要指定类型?是因为该方法其实很强大,可以收集成多种不同的集合类型,Vec<T> 仅仅是其中之一,因此我们必须显式的告诉编译器我们想要收集成的集合类型。
还有一点值得注意,map 会对迭代器中的每一个值进行一系列操作,然后把该值转换成另外一个新值,该操作是通过闭包 |x| x + 1 来完成:最终迭代器中的每个值都增加了 1,从 [1, 2, 3] 变为 [2, 3, 4]。
再来看看如何使用 collect 收集成 HashMap 集合:
use std::collections::HashMap; fn main() { let names = ["sunface", "sunfei"]; let ages = [18, 18]; let folks: HashMap<_, _> = names.into_iter().zip(ages.into_iter()).collect(); println!("{:?}",folks); }
zip 是一个迭代器适配器,它的作用就是将两个迭代器的内容压缩到一起,形成 Iterator<Item=(ValueFromA, ValueFromB)> 这样的新的迭代器,在此处就是形如 [(name1, age1), (name2, age2)] 的迭代器。
然后再通过 collect 将新迭代器中(K, V) 形式的值收集成 HashMap<K, V>,同样的,这里必须显式声明类型,然后 HashMap 内部的 KV 类型可以交给编译器去推导,最终编译器会推导出 HashMap<&str, i32>,完全正确!
闭包作为适配器参数
之前的 map 方法中,我们使用闭包来作为迭代器适配器的参数,它最大的好处不仅在于可以就地实现迭代器中元素的处理,还在于可以捕获环境值:
#![allow(unused)] fn main() { struct Shoe { size: u32, style: String, } fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> { shoes.into_iter().filter(|s| s.size == shoe_size).collect() } }
filter 是迭代器适配器,用于对迭代器中的每个值进行过滤。 它使用闭包作为参数,该闭包的参数 s 是来自迭代器中的值,然后使用 s 跟外部环境中的 shoe_size 进行比较,若相等,则在迭代器中保留 s 值,若不相等,则从迭代器中剔除 s 值,最终通过 collect 收集为 Vec<Shoe> 类型。
实现 Iterator 特征
之前的内容我们一直基于数组来创建迭代器,实际上,不仅仅是数组,基于其它集合类型一样可以创建迭代器,例如 HashMap。 你也可以创建自己的迭代器 —— 只要为自定义类型实现 Iterator 特征即可。
首先,创建一个计数器:
#![allow(unused)] fn main() { struct Counter { count: u32, } impl Counter { fn new() -> Counter { Counter { count: 0 } } } }
我们为计数器 Counter 实现了一个关联函数 new,用于创建新的计数器实例。下面我们继续为计数器实现 Iterator 特征:
#![allow(unused)] fn main() { impl Iterator for Counter { type Item = u32; fn next(&mut self) -> Option<Self::Item> { if self.count < 5 { self.count += 1; Some(self.count) } else { None } } } }
首先,将该特征的关联类型设置为 u32,由于我们的计数器保存的 count 字段就是 u32 类型, 因此在 next 方法中,最后返回的是实际上是 Option<u32> 类型。
每次调用 next 方法,都会让计数器的值加一,然后返回最新的计数值,一旦计数大于 5,就返回 None。
最后,使用我们新建的 Counter 进行迭代:
#![allow(unused)] fn main() { let mut counter = Counter::new(); assert_eq!(counter.next(), Some(1)); assert_eq!(counter.next(), Some(2)); assert_eq!(counter.next(), Some(3)); assert_eq!(counter.next(), Some(4)); assert_eq!(counter.next(), Some(5)); assert_eq!(counter.next(), None); }
实现 Iterator 特征的其它方法
可以看出,实现自己的迭代器非常简单,但是 Iterator 特征中,不仅仅是只有 next 一个方法,那为什么我们只需要实现它呢?因为其它方法都具有默认实现,所以无需像 next 这样手动去实现,而且这些默认实现的方法其实都是基于 next 方法实现的。
下面的代码演示了部分方法的使用:
#![allow(unused)] fn main() { let sum: u32 = Counter::new() .zip(Counter::new().skip(1)) .map(|(a, b)| a * b) .filter(|x| x % 3 == 0) .sum(); assert_eq!(18, sum); }
其中 zip,map,filter 是迭代器适配器:
zip把两个迭代器合并成一个迭代器,新迭代器中,每个元素都是一个元组,由之前两个迭代器的元素组成。例如将形如[1, 2, 3, 4, 5]和[2, 3, 4, 5]的迭代器合并后,新的迭代器形如[(1, 2),(2, 3),(3, 4),(4, 5)]map是将迭代器中的值经过映射后,转换成新的值[2, 6, 12, 20]filter对迭代器中的元素进行过滤,若闭包返回true则保留元素[6, 12],反之剔除
而 sum 是消费者适配器,对迭代器中的所有元素求和,最终返回一个 u32 值 18。
enumerate
在之前的流程控制章节,针对 for 循环,我们提供了一种方法可以获取迭代时的索引:
#![allow(unused)] fn main() { let v = vec![1u64, 2, 3, 4, 5, 6]; for (i,v) in v.iter().enumerate() { println!("第{}个值是{}",i,v) } }
相信当时,很多读者还是很迷茫的,不知道为什么要这么复杂才能获取到索引,学习本章节后,相信你有了全新的理解,首先 v.iter() 创建迭代器,其次
调用 Iterator 特征上的方法 enumerate,该方法产生一个新的迭代器,其中每个元素均是元组 (索引,值)。
因为 enumerate 是迭代器适配器,因此我们可以对它返回的迭代器调用其它 Iterator 特征方法:
#![allow(unused)] fn main() { let v = vec![1u64, 2, 3, 4, 5, 6]; let val = v.iter() .enumerate() // 每两个元素剔除一个 // [1, 3, 5] .filter(|&(idx, _)| idx % 2 == 0) .map(|(idx, val)| val) // 累加 1+3+5 = 9 .fold(0u64, |sum, acm| sum + acm); println!("{}", val); }
迭代器的性能
前面提到,要完成集合遍历,既可以使用 for 循环也可以使用迭代器,那么二者之间该怎么选择呢,性能有多大差距呢?
理论分析不会有结果,直接测试最为靠谱:
#![allow(unused)] #![feature(test)] fn main() { extern crate rand; extern crate test; fn sum_for(x: &[f64]) -> f64 { let mut result: f64 = 0.0; for i in 0..x.len() { result += x[i]; } result } fn sum_iter(x: &[f64]) -> f64 { x.iter().sum::<f64>() } #[cfg(test)] mod bench { use test::Bencher; use rand::{Rng,thread_rng}; use super::*; const LEN: usize = 1024*1024; fn rand_array(cnt: u32) -> Vec<f64> { let mut rng = thread_rng(); (0..cnt).map(|_| rng.gen::<f64>()).collect() } #[bench] fn bench_for(b: &mut Bencher) { let samples = rand_array(LEN as u32); b.iter(|| { sum_for(&samples) }) } #[bench] fn bench_iter(b: &mut Bencher) { let samples = rand_array(LEN as u32); b.iter(|| { sum_iter(&samples) }) } } }
上面的代码对比了 for 循环和迭代器 iterator 完成同样的求和任务的性能对比,可以看到迭代器还要更快一点。
test bench::bench_for ... bench: 998,331 ns/iter (+/- 36,250)
test bench::bench_iter ... bench: 983,858 ns/iter (+/- 44,673)
迭代器是 Rust 的 零成本抽象(zero-cost abstractions)之一,意味着抽象并不会引入运行时开销,这与 Bjarne Stroustrup(C++ 的设计和实现者)在 Foundations of C++(2012) 中所定义的 零开销(zero-overhead)如出一辙:
In general, C++ implementations obey the zero-overhead principle: What you don’t use, you don’t pay for. And further: What you do use, you couldn’t hand code any better.
一般来说,C++的实现遵循零开销原则:没有使用时,你不必为其买单。 更进一步说,需要使用时,你也无法写出更优的代码了。 (翻译一下:用就完事了)
总之,迭代器是 Rust 受函数式语言启发而提供的高级语言特性,可以写出更加简洁、逻辑清晰的代码。编译器还可以通过循环展开(Unrolling)、向量化、消除边界检查等优化手段,使得迭代器和 for 循环都有极为高效的执行效率。
所以请放心大胆的使用迭代器,在获得更高的表达力的同时,也不会导致运行时的损失,何乐而不为呢!
深入类型
Rust 是强类型语言,同时也是强安全语言,这些特性导致了 Rust 的类型注定比一般语言要更深入也更困难。
本章将深入讲解一些进阶的 Rust 类型以及类型转换,希望大家喜欢。
深入 Rust 类型
弱弱地、不负责任地说,Rust 的学习难度之恶名,可能有一半来源于 Rust 的类型系统,而其中一半的一半则来自于本章节的内容。在本章,我们将重点学习如何创建自定义类型,以及了解何为动态大小的类型。
newtype
何为 newtype?简单来说,就是使用元组结构体的方式将已有的类型包裹起来:struct Meters(u32);,那么此处 Meters 就是一个 newtype。
为何需要 newtype?Rust 这多如繁星的 Old 类型满足不了我们吗?这是因为:
- 自定义类型可以让我们给出更有意义和可读性的类型名,例如与其使用
u32作为距离的单位类型,我们可以使用Meters,它的可读性要好得多 - 对于某些场景,只有
newtype可以很好地解决 - 隐藏内部类型的细节
一箩筐的理由~~ 让我们先从第二点讲起。
为外部类型实现外部特征
在之前的章节中,我们有讲过,如果在外部类型上实现外部特征必须使用 newtype 的方式,否则你就得遵循孤儿规则:要为类型 A 实现特征 T,那么 A 或者 T 必须至少有一个在当前的作用范围内。
例如,如果想使用 println!("{}", v) 的方式去格式化输出一个动态数组 Vec,以期给用户提供更加清晰可读的内容,那么就需要为 Vec 实现 Display 特征,但是这里有一个问题: Vec 类型定义在标准库中,Display 亦然,这时就可以祭出大杀器 newtype 来解决:
use std::fmt; struct Wrapper(Vec<String>); impl fmt::Display for Wrapper { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "[{}]", self.0.join(", ")) } } fn main() { let w = Wrapper(vec![String::from("hello"), String::from("world")]); println!("w = {}", w); }
如上所示,使用元组结构体语法 struct Wrapper(Vec<String>) 创建了一个 newtype Wrapper,然后为它实现 Display 特征,最终实现了对 Vec 动态数组的格式化输出。
更好的可读性及类型异化
首先,更好的可读性不等于更少的代码(如果你学过 Scala,相信会深有体会),其次下面的例子只是一个示例,未必能体现出更好的可读性:
use std::ops::Add; use std::fmt; struct Meters(u32); impl fmt::Display for Meters { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "目标地点距离你{}米", self.0) } } impl Add for Meters { type Output = Self; fn add(self, other: Meters) -> Self { Self(self.0 + other.0) } } fn main() { let d = calculate_distance(Meters(10), Meters(20)); println!("{}", d); } fn calculate_distance(d1: Meters, d2: Meters) -> Meters { d1 + d2 }
上面代码创建了一个 newtype Meters,为其实现 Display 和 Add 特征,接着对两个距离进行求和计算,最终打印出该距离:
目标地点距离你30米
事实上,除了可读性外,还有一个极大的优点:如果给 calculate_distance 传一个其它的类型,例如 struct MilliMeters(u32);,该代码将无法编译。尽管 Meters 和 MilliMeters 都是对 u32 类型的简单包装,但是它们是不同的类型!
隐藏内部类型的细节
众所周知,Rust 的类型有很多自定义的方法,假如我们把某个类型传给了用户,但是又不想用户调用这些方法,就可以使用 newtype:
struct Meters(u32); fn main() { let i: u32 = 2; assert_eq!(i.pow(2), 4); let n = Meters(i); // 下面的代码将报错,因为`Meters`类型上没有`pow`方法 // assert_eq!(n.pow(2), 4); }
不过需要偷偷告诉你的是,这种方式实际上是掩耳盗铃,因为用户依然可以通过 n.0.pow(2) 的方式来调用内部类型的方法 :)
类型别名(Type Alias)
除了使用 newtype,我们还可以使用一个更传统的方式来创建新类型:类型别名
#![allow(unused)] fn main() { type Meters = u32 }
嗯,不得不说,类型别名的方式看起来比 newtype 顺眼的多,而且跟其它语言的使用方式几乎一致,但是:
类型别名并不是一个独立的全新的类型,而是某一个类型的别名,因此编译器依然会把 Meters 当 u32 来使用:
#![allow(unused)] fn main() { type Meters = u32; let x: u32 = 5; let y: Meters = 5; println!("x + y = {}", x + y); }
上面的代码将顺利编译通过,但是如果你使用 newtype 模式,该代码将无情报错,简单做个总结:
- 类型别名仅仅是别名,只是为了让可读性更好,并不是全新的类型,
newtype才是! - 类型别名无法实现为外部类型实现外部特征等功能,而
newtype可以
类型别名除了让类型可读性更好,还能减少模版代码的使用:
#![allow(unused)] fn main() { let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi")); fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) { // --snip-- } fn returns_long_type() -> Box<dyn Fn() + Send + 'static> { // --snip-- } }
f 是一个令人眼花缭乱的类型 Box<dyn Fn() + Send + 'static>,如果仔细看,会发现其实只有一个 Send 特征不认识,Send 是什么在这里不重要,你只需理解,f 就是一个 Box<dyn T> 类型的特征对象,实现了 Fn() 和 Send 特征,同时生命周期为 'static。
因为 f 的类型贼长,导致了后面我们在使用它时,到处都充斥这些不太优美的类型标注,好在类型别名可解君忧:
#![allow(unused)] fn main() { type Thunk = Box<dyn Fn() + Send + 'static>; let f: Thunk = Box::new(|| println!("hi")); fn takes_long_type(f: Thunk) { // --snip-- } fn returns_long_type() -> Thunk { // --snip-- } }
Bang!是不是?!立刻大幅简化了我们的使用。喝着奶茶、哼着歌、我写起代码撩起妹,何其快哉!
在标准库中,类型别名应用最广的就是简化 Result<T, E> 枚举。
例如在 std::io 库中,它定义了自己的 Error 类型:std::io::Error,那么如果要使用该 Result 就要用这样的语法:std::result::Result<T, std::io::Error>;,想象一下代码中充斥着这样的东东是一种什么感受?颤抖吧。。。
由于使用 std::io 库时,它的所有错误类型都是 std::io::Error,那么我们完全可以把该错误对用户隐藏起来,只在内部使用即可,因此就可以使用类型别名来简化实现:
#![allow(unused)] fn main() { type Result<T> = std::result::Result<T, std::io::Error>; }
Bingo,这样一来,其它库只需要使用 std::io::Result<T> 即可替代冗长的 std::result::Result<T, std::io::Error> 类型。
更香的是,由于它只是别名,因此我们可以用它来调用真实类型的所有方法,甚至包括 ? 符号!
!永不返回类型
在函数那章,曾经介绍过 ! 类型:! 用来说明一个函数永不返回任何值,当时可能体会不深,没事,在学习了更多手法后,保证你有全新的体验:
fn main() { let i = 2; let v = match i { 0..=3 => i, _ => println!("不合规定的值:{}", i) }; }
上面函数,会报出一个编译错误:
error[E0308]: `match` arms have incompatible types // match的分支类型不同
--> src/main.rs:5:13
|
3 | let v = match i {
| _____________-
4 | | 0..3 => i,
| | - this is found to be of type `{integer}` // 该分支返回整数类型
5 | | _ => println!("不合规定的值:{}", i)
| | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected integer, found `()` // 该分支返回()单元类型
6 | | };
| |_____- `match` arms have incompatible types
原因很简单: 要赋值给 v,就必须保证 match 的各个分支返回的值是同一个类型,但是上面一个分支返回数值、另一个分支返回元类型 (),自然会出错。
既然 println 不行,那再试试 panic
fn main() { let i = 2; let v = match i { 0..=3 => i, _ => panic!("不合规定的值:{}", i) }; }
神奇的事发生了,此处 panic 竟然通过了编译。难道这两个宏拥有不同的返回类型?
你猜的没错:panic 的返回值是 !,代表它决不会返回任何值,既然没有任何返回值,那自然不会存在分支类型不匹配的情况。
Sized 和不定长类型 DST
在 Rust 中类型有多种抽象的分类方式,例如本书之前章节的:基本类型、集合类型、复合类型等。再比如说,如果从编译器何时能获知类型大小的角度出发,可以分成两类:
- 定长类型( sized ),这些类型的大小在编译时是已知的
- 不定长类型( unsized ),与定长类型相反,它的大小只有到了程序运行时才能动态获知,这种类型又被称之为 DST
首先,我们来深入看看何为 DST。
动态大小类型 DST
读者大大们之前学过的几乎所有类型,都是固定大小的类型,包括集合 Vec、String 和 HashMap 等,而动态大小类型刚好与之相反:编译器无法在编译期得知该类型值的大小,只有到了程序运行时,才能动态获知。对于动态类型,我们使用 DST(dynamically sized types)或者 unsized 类型来称呼它。
上述的这些集合虽然底层数据可动态变化,感觉像是动态大小的类型。但是实际上,这些底层数据只是保存在堆上,在栈中还存有一个引用类型,该引用包含了集合的内存地址、元素数目、分配空间信息,通过这些信息,编译器对于该集合的实际大小了若指掌,最最重要的是:栈上的引用类型是固定大小的,因此它们依然是固定大小的类型。
正因为编译器无法在编译期获知类型大小,若你试图在代码中直接使用 DST 类型,将无法通过编译。
现在给你一个挑战:想出几个 DST 类型。俺厚黑地说一句,估计大部分人都想不出这样的一个类型,就连我,如果不是查询着资料在写,估计一时半会儿也想不到一个。
先来看一个最直白的:
试图创建动态大小的数组
#![allow(unused)] fn main() { fn my_function(n: usize) { let array = [123; n]; } }
以上代码就会报错(错误输出的内容并不是因为 DST,但根本原因是类似的),因为 n 在编译期无法得知,而数组类型的一个组成部分就是长度,长度变为动态的,自然类型就变成了 unsized 。
切片
切片也是一个典型的 DST 类型,具体详情参见另一篇文章: 易混淆的切片和切片引用。
str
考虑一下这个类型:str,感觉有点眼生?是的,它既不是 String 动态字符串,也不是 &str 字符串切片,而是一个 str。它是一个动态类型,同时还是 String 和 &str 的底层数据类型。 由于 str 是动态类型,因此它的大小直到运行期才知道,下面的代码会因此报错:
#![allow(unused)] fn main() { // error let s1: str = "Hello there!"; let s2: str = "How's it going?"; // ok let s3: &str = "on?" }
Rust 需要明确地知道一个特定类型的值占据了多少内存空间,同时该类型的所有值都必须使用相同大小的内存。如果 Rust 允许我们使用这种动态类型,那么这两个 str 值就需要占用同样大小的内存,这显然是不现实的: s1 占用了 12 字节,s2 占用了 15 字节,总不至于为了满足同样的内存大小,用空白字符去填补字符串吧?
所以,我们只有一条路走,那就是给它们一个固定大小的类型:&str。那么为何字符串切片 &str 就是固定大小呢?因为它的引用存储在栈上,具有固定大小(类似指针),同时它指向的数据存储在堆中,也是已知的大小,再加上 &str 引用中包含有堆上数据内存地址、长度等信息,因此最终可以得出字符串切片是固定大小类型的结论。
与 &str 类似,String 字符串也是固定大小的类型。
正是因为 &str 的引用有了底层堆数据的明确信息,它才是固定大小类型。假设如果它没有这些信息呢?那它也将变成一个动态类型。因此,将动态数据固定化的秘诀就是使用引用指向这些动态数据,然后在引用中存储相关的内存位置、长度等信息。
特征对象
#![allow(unused)] fn main() { fn foobar_1(thing: &dyn MyThing) {} // OK fn foobar_2(thing: Box<dyn MyThing>) {} // OK fn foobar_3(thing: MyThing) {} // ERROR! }
如上所示,只能通过引用或 Box 的方式来使用特征对象,直接使用将报错!
总结:只能间接使用的 DST
Rust 中常见的 DST 类型有: str、[T]、dyn Trait,它们都无法单独被使用,必须要通过引用或者 Box 来间接使用 。
我们之前已经见过,使用 Box 将一个没有固定大小的特征变成一个有固定大小的特征对象,那能否故技重施,将 str 封装成一个固定大小类型?留个悬念先,我们来看看 Sized 特征。
Sized 特征
既然动态类型的问题这么大,那么在使用泛型时,Rust 如何保证我们的泛型参数是固定大小的类型呢?例如以下泛型函数:
#![allow(unused)] fn main() { fn generic<T>(t: T) { // --snip-- } }
该函数很简单,就一个泛型参数 T,那么如何保证 T 是固定大小的类型?仔细回想下,貌似在之前的课程章节中,我们也没有做过任何事情去做相关的限制,那 T 怎么就成了固定大小的类型了?奥秘在于编译器自动帮我们加上了 Sized 特征约束:
#![allow(unused)] fn main() { fn generic<T: Sized>(t: T) { // --snip-- } }
在上面,Rust 自动添加的特征约束 T: Sized,表示泛型函数只能用于一切实现了 Sized 特征的类型上,而所有在编译时就能知道其大小的类型,都会自动实现 Sized 特征,例如。。。。也没啥好例如的,你能想到的几乎所有类型都实现了 Sized 特征,除了上面那个坑坑的 str,哦,还有特征。
每一个特征都是一个可以通过名称来引用的动态大小类型。因此如果想把特征作为具体的类型来传递给函数,你必须将其转换成一个特征对象:诸如 &dyn Trait 或者 Box<dyn Trait> (还有 Rc<dyn Trait>)这些引用类型。
现在还有一个问题:假如想在泛型函数中使用动态数据类型怎么办?可以使用 ?Sized 特征(不得不说这个命名方式很 Rusty,竟然有点幽默):
#![allow(unused)] fn main() { fn generic<T: ?Sized>(t: &T) { // --snip-- } }
?Sized 特征用于表明类型 T 既有可能是固定大小的类型,也可能是动态大小的类型。还有一点要注意的是,函数参数类型从 T 变成了 &T,因为 T 可能是动态大小的,因此需要用一个固定大小的指针(引用)来包裹它。
Box<str>
在结束前,再来看看之前遗留的问题:使用 Box 可以将一个动态大小的特征变成一个具有固定大小的特征对象,能否故技重施,将 str 封装成一个固定大小类型?
先回想下,章节前面的内容介绍过该如何把一个动态大小类型转换成固定大小的类型: 使用引用指向这些动态数据,然后在引用中存储相关的内存位置、长度等信息。
好的,根据这个,我们来一起推测。首先,Box<str> 使用了一个引用来指向 str,嗯,满足了第一个条件。但是第二个条件呢?Box 中有该 str 的长度信息吗?显然是 No。那为什么特征就可以变成特征对象?其实这个还蛮复杂的,简单来说,对于特征对象,编译器无需知道它具体是什么类型,只要知道它能调用哪几个方法即可,因此编译器帮我们实现了剩下的一切。
来验证下我们的推测:
fn main() { let s1: Box<str> = Box::new("Hello there!" as str); }
报错如下:
error[E0277]: the size for values of type `str` cannot be known at compilation time
--> src/main.rs:2:24
|
2 | let s1: Box<str> = Box::new("Hello there!" as str);
| ^^^^^^^^ doesn't have a size known at compile-time
|
= help: the trait `Sized` is not implemented for `str`
= note: all function arguments must have a statically known size
提示得很清晰,不知道 str 的大小,因此无法使用这种语法进行 Box 进装,但是你可以这么做:
#![allow(unused)] fn main() { let s1: Box<str> = "Hello there!".into(); }
主动转换成 str 的方式不可行,但是可以让编译器来帮我们完成,只要告诉它我们需要的类型即可。
整数转换为枚举
在 Rust 中,从枚举到整数的转换很容易,但是反过来,就没那么容易,甚至部分实现还挺邪恶, 例如使用transmute。
一个真实场景的需求
在实际场景中,从枚举到整数的转换有时还是非常需要的,例如你有一个枚举类型,然后需要从外面传入一个整数,用于控制后续的流程走向,此时就需要用整数去匹配相应的枚举(你也可以用整数匹配整数-, -,看看会不会被喷)。
既然有了需求,剩下的就是看看该如何实现,这篇文章的水远比你想象的要深,且看八仙过海各显神通。
C 语言的实现
对于 C 语言来说,万物皆邪恶,因此我们不讨论安全,只看实现,不得不说很简洁:
#include <stdio.h>
enum atomic_number {
HYDROGEN = 1,
HELIUM = 2,
// ...
IRON = 26,
};
int main(void)
{
enum atomic_number element = 26;
if (element == IRON) {
printf("Beware of Rust!\n");
}
return 0;
}
但是在 Rust 中,以下代码:
enum MyEnum { A = 1, B, C, } fn main() { // 将枚举转换成整数,顺利通过 let x = MyEnum::C as i32; // 将整数转换为枚举,失败 match x { MyEnum::A => {} MyEnum::B => {} MyEnum::C => {} _ => {} } }
就会报错: MyEnum::A => {} mismatched types, expected i32, found enum MyEnum。
使用三方库
首先可以想到的肯定是三方库,毕竟 Rust 的生态目前已经发展的很不错,类似的需求总是有的,这里我们先使用num-traits和num-derive来试试。
在Cargo.toml中引入:
[dependencies]
num-traits = "0.2.14"
num-derive = "0.3.3"
代码如下:
use num_derive::FromPrimitive; use num_traits::FromPrimitive; #[derive(FromPrimitive)] enum MyEnum { A = 1, B, C, } fn main() { let x = 2; match FromPrimitive::from_i32(x) { Some(MyEnum::A) => println!("Got A"), Some(MyEnum::B) => println!("Got B"), Some(MyEnum::C) => println!("Got C"), None => println!("Couldn't convert {}", x), } }
除了上面的库,还可以使用一个较新的库: num_enums。
TryFrom + 宏
在 Rust 1.34 后,可以实现TryFrom特征来做转换:
#![allow(unused)] fn main() { use std::convert::TryFrom; impl TryFrom<i32> for MyEnum { type Error = (); fn try_from(v: i32) -> Result<Self, Self::Error> { match v { x if x == MyEnum::A as i32 => Ok(MyEnum::A), x if x == MyEnum::B as i32 => Ok(MyEnum::B), x if x == MyEnum::C as i32 => Ok(MyEnum::C), _ => Err(()), } } } }
以上代码定义了从i32到MyEnum的转换,接着就可以使用TryInto来实现转换:
use std::convert::TryInto; fn main() { let x = MyEnum::C as i32; match x.try_into() { Ok(MyEnum::A) => println!("a"), Ok(MyEnum::B) => println!("b"), Ok(MyEnum::C) => println!("c"), Err(_) => eprintln!("unknown number"), } }
但是上面的代码有个问题,你需要为每个枚举成员都实现一个转换分支,非常麻烦。好在可以使用宏来简化,自动根据枚举的定义来实现TryFrom特征:
#![allow(unused)] fn main() { #[macro_export] macro_rules! back_to_enum { ($(#[$meta:meta])* $vis:vis enum $name:ident { $($(#[$vmeta:meta])* $vname:ident $(= $val:expr)?,)* }) => { $(#[$meta])* $vis enum $name { $($(#[$vmeta])* $vname $(= $val)?,)* } impl std::convert::TryFrom<i32> for $name { type Error = (); fn try_from(v: i32) -> Result<Self, Self::Error> { match v { $(x if x == $name::$vname as i32 => Ok($name::$vname),)* _ => Err(()), } } } } } back_to_enum! { enum MyEnum { A = 1, B, C, } } }
邪恶之王 std::mem::transmute
这个方法原则上并不推荐,但是有其存在的意义,如果要使用,你需要清晰的知道自己为什么使用。
在之前的类型转换章节,我们提到过非常邪恶的transmute转换,其实,当你知道数值一定不会超过枚举的范围时(例如枚举成员对应 1,2,3,传入的整数也在这个范围内),就可以使用这个方法完成变形。
最好使用#[repr(..)]来控制底层类型的大小,免得本来需要 i32,结果传入 i64,最终内存无法对齐,产生奇怪的结果
#[repr(i32)] enum MyEnum { A = 1, B, C } fn main() { let x = MyEnum::C; let y = x as i32; let z: MyEnum = unsafe { std::mem::transmute(y) }; // match the enum that came from an int match z { MyEnum::A => { println!("Found A"); } MyEnum::B => { println!("Found B"); } MyEnum::C => { println!("Found C"); } } }
既然是邪恶之王,当然得有真本事,无需标准库、也无需 unstable 的 Rust 版本,我们就完成了转换!awesome!??
总结
本文列举了常用(其实差不多也是全部了,还有一个 unstable 特性没提到)的从整数转换为枚举的方式,推荐度按照出现的先后顺序递减。
但是推荐度最低,不代表它就没有出场的机会,只要使用边界清晰,一样可以大放光彩,例如最后的transmute函数.
智能指针
在各个编程语言中,指针的概念几乎都是相同的:指针是一个包含了内存地址的变量,该内存地址引用或者指向了另外的数据。
在 Rust 中,最常见的指针类型是引用,引用通过 & 符号表示。不同于其它语言,引用在 Rust 中被赋予了更深层次的含义,那就是:借用其它变量的值。引用本身很简单,除了指向某个值外并没有其它的功能,也不会造成性能上的额外损耗,因此是 Rust 中使用最多的指针类型。
而智能指针则不然,它虽然也号称指针,但是它是一个复杂的家伙:通过比引用更复杂的数据结构,包含比引用更多的信息,例如元数据,当前长度,最大可用长度等。总之,Rust 的智能指针并不是独创,在 C++ 或者其他语言中也存在相似的概念。
Rust 标准库中定义的那些智能指针,虽重但强,可以提供比引用更多的功能特性,例如本章将讨论的引用计数智能指针。该智能指针允许你同时拥有同一个数据的多个所有权,它会跟踪每一个所有者并进行计数,当所有的所有者都归还后,该智能指针及指向的数据将自动被清理释放。
引用和智能指针的另一个不同在于前者仅仅是借用了数据,而后者往往可以拥有它们指向的数据,然后再为其它人提供服务。
在之前的章节中,实际上我们已经见识过多种智能指针,例如动态字符串 String 和动态数组 Vec,它们的数据结构中不仅仅包含了指向底层数据的指针,还包含了当前长度、最大长度等信息,其中 String 智能指针还提供了一种担保信息:所有的数据都是合法的 UTF-8 格式。
智能指针往往是基于结构体实现,它与我们自定义的结构体最大的区别在于它实现了 Deref 和 Drop 特征:
Deref可以让智能指针像引用那样工作,这样你就可以写出同时支持智能指针和引用的代码,例如*TDrop允许你指定智能指针超出作用域后自动执行的代码,例如做一些数据清除等收尾工作
智能指针在 Rust 中很常见,我们在本章不会全部讲解,而是挑选几个最常用、最有代表性的进行讲解:
Box<T>,可以将值分配到堆上Rc<T>,引用计数类型,允许多所有权存在Ref<T>和RefMut<T>,允许将借用规则检查从编译期移动到运行期进行
Box<T> 堆对象分配
关于作者帅不帅,估计争议还挺多的,但是如果说 Box<T> 是不是 Rust 中最常见的智能指针,那估计没有任何争议。因为 Box<T> 允许你将一个值分配到堆上,然后在栈上保留一个智能指针指向堆上的数据。
之前我们在所有权章节简单讲过堆栈的概念,这里再补充一些。
Rust 中的堆栈
高级语言 Python/Java 等往往会弱化堆栈的概念,但是要用好 C/C++/Rust,就必须对堆栈有深入的了解,原因是两者的内存管理方式不同:前者有 GC 垃圾回收机制,因此无需你去关心内存的细节。
栈内存从高位地址向下增长,且栈内存是连续分配的,一般来说操作系统对栈内存的大小都有限制,因此 C 语言中无法创建任意长度的数组。在 Rust 中,main 线程的栈大小是 8MB,普通线程是 2MB,在函数调用时会在其中创建一个临时栈空间,调用结束后 Rust 会让这个栈空间里的对象自动进入 Drop 流程,最后栈顶指针自动移动到上一个调用栈顶,无需程序员手动干预,因而栈内存申请和释放是非常高效的。
与栈相反,堆上内存则是从低位地址向上增长,堆内存通常只受物理内存限制,而且通常是不连续的,因此从性能的角度看,栈往往比堆更高。
相比其它语言,Rust 堆上对象还有一个特殊之处,它们都拥有一个所有者,因此受所有权规则的限制:当赋值时,发生的是所有权的转移(只需浅拷贝栈上的引用或智能指针即可),例如以下代码:
fn main() { let b = foo("world"); println!("{}", b); } fn foo(x: &str) -> String { let a = "Hello, ".to_string() + x; a }
在 foo 函数中,a 是 String 类型,它其实是一个智能指针结构体,该智能指针存储在函数栈中,指向堆上的字符串数据。当被从 foo 函数转移给 main 中的 b 变量时,栈上的智能指针被复制一份赋予给 b,而底层数据无需发生改变,这样就完成了所有权从 foo 函数内部到 b 的转移。
堆栈的性能
很多人可能会觉得栈的性能肯定比堆高,其实未必。 由于我们在后面的性能专题会专门讲解堆栈的性能问题,因此这里就大概给出结论:
- 小型数据,在栈上的分配性能和读取性能都要比堆上高
- 中型数据,栈上分配性能高,但是读取性能和堆上并无区别,因为无法利用寄存器或 CPU 高速缓存,最终还是要经过一次内存寻址
- 大型数据,只建议在堆上分配和使用
总之,栈的分配速度肯定比堆上快,但是读取速度往往取决于你的数据能不能放入寄存器或 CPU 高速缓存。 因此不要仅仅因为堆上性能不如栈这个印象,就总是优先选择栈,导致代码更复杂的实现。
Box 的使用场景
由于 Box 是简单的封装,除了将值存储在堆上外,并没有其它性能上的损耗。而性能和功能往往是鱼和熊掌,因此 Box 相比其它智能指针,功能较为单一,可以在以下场景中使用它:
- 特意的将数据分配在堆上
- 数据较大时,又不想在转移所有权时进行数据拷贝
- 类型的大小在编译期无法确定,但是我们又需要固定大小的类型时
- 特征对象,用于说明对象实现了一个特征,而不是某个特定的类型
以上场景,我们在本章将一一讲解,后面车速较快,请系好安全带。
使用 Box<T> 将数据存储在堆上
如果一个变量拥有一个数值 let a = 3,那变量 a 必然是存储在栈上的,那如果我们想要 a 的值存储在堆上就需要使用 Box<T>:
fn main() { let a = Box::new(3); println!("a = {}", a); // a = 3 // 下面一行代码将报错 // let b = a + 1; // cannot add `{integer}` to `Box<{integer}>` }
这样就可以创建一个智能指针指向了存储在堆上的 3,并且 a 持有了该指针。在本章的引言中,我们提到了智能指针往往都实现了 Deref 和 Drop 特征,因此:
println!可以正常打印出a的值,是因为它隐式地调用了Deref对智能指针a进行了解引用- 最后一行代码
let b = a + 1报错,是因为在表达式中,我们无法自动隐式地执行Deref解引用操作,你需要使用*操作符let b = *a + 1,来显式的进行解引用 a持有的智能指针将在作用域结束(main函数结束)时,被释放掉,这是因为Box<T>实现了Drop特征
以上的例子在实际代码中其实很少会存在,因为将一个简单的值分配到堆上并没有太大的意义。将其分配在栈上,由于寄存器、CPU 缓存的原因,它的性能将更好,而且代码可读性也更好。
避免栈上数据的拷贝
当栈上数据转移所有权时,实际上是把数据拷贝了一份,最终新旧变量各自拥有不同的数据,因此所有权并未转移。
而堆上则不然,底层数据并不会被拷贝,转移所有权仅仅是复制一份栈中的指针,再将新的指针赋予新的变量,然后让拥有旧指针的变量失效,最终完成了所有权的转移:
fn main() { // 在栈上创建一个长度为1000的数组 let arr = [0;1000]; // 将arr所有权转移arr1,由于 `arr` 分配在栈上,因此这里实际上是直接重新深拷贝了一份数据 let arr1 = arr; // arr 和 arr1 都拥有各自的栈上数组,因此不会报错 println!("{:?}", arr.len()); println!("{:?}", arr1.len()); // 在堆上创建一个长度为1000的数组,然后使用一个智能指针指向它 let arr = Box::new([0;1000]); // 将堆上数组的所有权转移给 arr1,由于数据在堆上,因此仅仅拷贝了智能指针的结构体,底层数据并没有被拷贝 // 所有权顺利转移给 arr1,arr 不再拥有所有权 let arr1 = arr; println!("{:?}", arr1.len()); // 由于 arr 不再拥有底层数组的所有权,因此下面代码将报错 // println!("{:?}", arr.len()); }
从以上代码,可以清晰看出大块的数据为何应该放入堆中,此时 Box 就成为了我们最好的帮手。
将动态大小类型变为 Sized 固定大小类型
Rust 需要在编译时知道类型占用多少空间,如果一种类型在编译时无法知道具体的大小,那么被称为动态大小类型 DST。
其中一种无法在编译时知道大小的类型是递归类型:在类型定义中又使用到了自身,或者说该类型的值的一部分可以是相同类型的其它值,这种值的嵌套理论上可以无限进行下去,所以 Rust 不知道递归类型需要多少空间:
#![allow(unused)] fn main() { enum List { Cons(i32, List), Nil, } }
以上就是函数式语言中常见的 Cons List,它的每个节点包含一个 i32 值,还包含了一个新的 List,因此这种嵌套可以无限进行下去,Rust 认为该类型是一个 DST 类型,并给予报错:
error[E0072]: recursive type `List` has infinite size //递归类型 `List` 拥有无限长的大小
--> src/main.rs:3:1
|
3 | enum List {
| ^^^^^^^^^ recursive type has infinite size
4 | Cons(i32, List),
| ---- recursive without indirection
此时若想解决这个问题,就可以使用我们的 Box<T>:
#![allow(unused)] fn main() { enum List { Cons(i32, Box<List>), Nil, } }
只需要将 List 存储到堆上,然后使用一个智能指针指向它,即可完成从 DST 到 Sized 类型(固定大小类型)的华丽转变。
特征对象
在 Rust 中,想实现不同类型组成的数组只有两个办法:枚举和特征对象,前者限制较多,因此后者往往是最常用的解决办法。
trait Draw { fn draw(&self); } struct Button { id: u32, } impl Draw for Button { fn draw(&self) { println!("这是屏幕上第{}号按钮", self.id) } } struct Select { id: u32, } impl Draw for Select { fn draw(&self) { println!("这个选择框贼难用{}", self.id) } } fn main() { let elems: Vec<Box<dyn Draw>> = vec![Box::new(Button { id: 1 }), Box::new(Select { id: 2 })]; for e in elems { e.draw() } }
以上代码将不同类型的 Button 和 Select 包装成 Draw 特征的特征对象,放入一个数组中,Box<dyn Draw> 就是特征对象。
其实,特征也是 DST 类型,而特征对象在做的就是将 DST 类型转换为固定大小类型。
Box 内存布局
先来看看 Vec<i32> 的内存布局:
#![allow(unused)] fn main() { (stack) (heap) ┌──────┐ ┌───┐ │ vec1 │──→│ 1 │ └──────┘ ├───┤ │ 2 │ ├───┤ │ 3 │ ├───┤ │ 4 │ └───┘ }
之前提到过 Vec 和 String 都是智能指针,从上图可以看出,该智能指针存储在栈中,然后指向堆上的数组数据。
那如果数组中每个元素都是一个 Box 对象呢?来看看 Vec<Box<i32>> 的内存布局:
#![allow(unused)] fn main() { (heap) (stack) (heap) ┌───┐ ┌──────┐ ┌───┐ ┌─→│ 1 │ │ vec2 │──→│B1 │─┘ └───┘ └──────┘ ├───┤ ┌───┐ │B2 │───→│ 2 │ ├───┤ └───┘ │B3 │─┐ ┌───┐ ├───┤ └─→│ 3 │ │B4 │─┐ └───┘ └───┘ │ ┌───┐ └─→│ 4 │ └───┘ }
上面的 B1 代表被 Box 分配到堆上的值 1。
可以看出智能指针 vec2 依然是存储在栈上,然后指针指向一个堆上的数组,该数组中每个元素都是一个 Box 智能指针,最终 Box 智能指针又指向了存储在堆上的实际值。
因此当我们从数组中取出某个元素时,取到的是对应的智能指针 Box,需要对该智能指针进行解引用,才能取出最终的值:
fn main() { let arr = vec![Box::new(1), Box::new(2)]; let (first, second) = (&arr[0], &arr[1]); let sum = **first + **second; }
以上代码有几个值得注意的点:
- 使用
&借用数组中的元素,否则会报所有权错误 - 表达式不能隐式的解引用,因此必须使用
**做两次解引用,第一次将&Box<i32>类型转成Box<i32>,第二次将Box<i32>转成i32
Box::leak
Box 中还提供了一个非常有用的关联函数:Box::leak,它可以消费掉 Box 并且强制目标值从内存中泄漏,读者可能会觉得,这有啥用啊?
其实还真有点用,例如,你可以把一个 String 类型,变成一个 'static 生命周期的 &str 类型:
fn main() { let s = gen_static_str(); println!("{}", s); } fn gen_static_str() -> &'static str{ let mut s = String::new(); s.push_str("hello, world"); Box::leak(s.into_boxed_str()) }
在之前的代码中,如果 String 创建于函数中,那么返回它的唯一方法就是转移所有权给调用者 fn move_str() -> String,而通过 Box::leak 我们不仅返回了一个 &str 字符串切片,它还是 'static 生命周期的!
要知道真正具有 'static 生命周期的往往都是编译期就创建的值,例如 let v = "hello, world",这里 v 是直接打包到二进制可执行文件中的,因此该字符串具有 'static 生命周期,再比如 const 常量。
又有读者要问了,我还可以手动为变量标注 'static 啊。其实你标注的 'static 只是用来忽悠编译器的,但是超出作用域,一样被释放回收。而使用 Box::leak 就可以将一个运行期的值转为 'static。
使用场景
光看上面的描述,大家可能还是云里雾里、一头雾水。
那么我说一个简单的场景,你需要一个在运行期初始化的值,但是可以全局有效,也就是和整个程序活得一样久,那么就可以使用 Box::leak,例如有一个存储配置的结构体实例,它是在运行期动态插入内容,那么就可以将其转为全局有效,虽然 Rc/Arc 也可以实现此功能,但是 Box::leak 是性能最高的。
总结
Box 背后是调用 jemalloc 来做内存管理,所以堆上的空间无需我们的手动管理。与此类似,带 GC 的语言中的对象也是借助于 Box 概念来实现的,一切皆对象 = 一切皆 Box, 只不过我们无需自己去 Box 罢了。
其实很多时候,编译器的鞭笞可以助我们更快的成长,例如所有权规则里的借用、move、生命周期就是编译器在教我们做人,哦不是,是教我们深刻理解堆栈、内存布局、作用域等等你在其它 GC 语言无需去关注的东西。刚开始是很痛苦,但是一旦熟悉了这套规则,写代码的效率和代码本身的质量将飞速上升,直到你可以用 Java 开发的效率写出 Java 代码不可企及的性能和安全性,最终 Rust 语言所谓的开发效率低、心智负担高,对你来说终究不是个事。
因此,不要怪 Rust,它只是在帮我们成为那个更好的程序员,而这些苦难终究成为我们走向优秀的垫脚石。
Deref 解引用
在开始之前,我们先来看一段代码:
#![allow(unused)] fn main() { #[derive(Debug)] struct Person { name: String, age: u8 } impl Person { fn new(name: String, age: u8) -> Self { Person { name, age} } fn display(self: &mut Person, age: u8) { let Person{name, age} = &self; } } }
以上代码有一个很奇怪的地方:在 display 方法中,self 是 &mut Person 的类型,接着我们对其取了一次引用 &self,此时 &self 的类型是 &&mut Person,然后我们又将其和 Person 类型进行匹配,取出其中的值。
那么问题来了,Rust 不是号称安全的语言吗?为何允许将 &&mut Person 跟 Person 进行匹配呢?答案就在本章节中,等大家学完后,再回头自己来解决这个问题 :) 下面正式开始咱们的新章节学习。
何为智能指针?能不让你写出 ****s 形式的解引用,我认为就是智能: ),智能指针的名称来源,主要就在于它实现了 Deref 和 Drop 特征,这两个特征可以智能地帮助我们节省使用上的负担:
Deref可以让智能指针像引用那样工作,这样你就可以写出同时支持智能指针和引用的代码,例如*TDrop允许你指定智能指针超出作用域后自动执行的代码,例如做一些数据清除等收尾工作
先来看看 Deref 特征是如何工作的。
通过 * 获取引用背后的值
在正式讲解 Deref 之前,我们先来看下常规引用的解引用。
常规引用是一个指针类型,包含了目标数据存储的内存地址。对常规引用使用 * 操作符,就可以通过解引用的方式获取到内存地址对应的数据值:
fn main() { let x = 5; let y = &x; assert_eq!(5, x); assert_eq!(5, *y); }
这里 y 就是一个常规引用,包含了值 5 所在的内存地址,然后通过解引用 *y,我们获取到了值 5。如果你试图执行 assert_eq!(5, y);,代码就会无情报错,因为你无法将一个引用与一个数值做比较:
error[E0277]: can't compare `{integer}` with `&{integer}` //无法将{integer} 与&{integer}进行比较
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
// 你需要为{integer}实现用于比较的特征PartialEq<&{integer}>
智能指针解引用
上面所说的解引用方式和其它大多数语言并无区别,但是 Rust 中将解引用提升到了一个新高度。考虑一下智能指针,它是一个结构体类型,如果你直接对它进行 *myStruct,显然编译器不知道该如何办,因此我们可以为智能指针结构体实现 Deref 特征。
实现 Deref 后的智能指针结构体,就可以像普通引用一样,通过 * 进行解引用,例如 Box<T> 智能指针:
fn main() { let x = Box::new(1); let sum = *x + 1; }
智能指针 x 被 * 解引用为 i32 类型的值 1,然后再进行求和。
定义自己的智能指针
现在,让我们一起来实现一个智能指针,功能上类似 Box<T>。由于 Box<T> 本身很简单,并没有包含类如长度、最大长度等信息,因此用一个元组结构体即可。
#![allow(unused)] fn main() { struct MyBox<T>(T); impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox(x) } } }
跟 Box<T> 一样,我们的智能指针也持有一个 T 类型的值,然后使用关联函数 MyBox::new 来创建智能指针。由于还未实现 Deref 特征,此时使用 * 肯定会报错:
fn main() { let y = MyBox::new(5); assert_eq!(5, *y); }
运行后,报错如下:
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:12:19
|
12 | assert_eq!(5, *y);
| ^^
为智能指针实现 Deref 特征
现在来为 MyBox 实现 Deref 特征,以支持 * 解引用操作符:
#![allow(unused)] fn main() { use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.0 } } }
很简单,当解引用 MyBox 智能指针时,返回元组结构体中的元素 &self.0,有几点要注意的:
- 在
Deref特征中声明了关联类型Target,在之前章节中介绍过,关联类型主要是为了提升代码可读性 deref返回的是一个常规引用,可以被*进行解引用
之前报错的代码此时已能顺利编译通过。当然,标准库实现的智能指针要考虑很多边边角角情况,肯定比我们的实现要复杂。
* 背后的原理
当我们对智能指针 Box 进行解引用时,实际上 Rust 为我们调用了以下方法:
#![allow(unused)] fn main() { *(y.deref()) }
首先调用 deref 方法返回值的常规引用,然后通过 * 对常规引用进行解引用,最终获取到目标值。
至于 Rust 为何要使用这个有点啰嗦的方式实现,原因在于所有权系统的存在。如果 deref 方法直接返回一个值,而不是引用,那么该值的所有权将被转移给调用者,而我们不希望调用者仅仅只是 *T 一下,就拿走了智能指针中包含的值。
需要注意的是,* 不会无限递归替换,从 *y 到 *(y.deref()) 只会发生一次,而不会继续进行替换然后产生形如 *((y.deref()).deref()) 的怪物。
函数和方法中的隐式 Deref 转换
对于函数和方法的传参,Rust 提供了一个极其有用的隐式转换:Deref 转换。若一个类型实现了 Deref 特征,那它的引用在传给函数或方法时,会根据参数签名来决定是否进行隐式的 Deref 转换,例如:
fn main() { let s = String::from("hello world"); display(&s) } fn display(s: &str) { println!("{}",s); }
以上代码有几点值得注意:
String实现了Deref特征,可以在需要时自动被转换为&str类型&s是一个&String类型,当它被传给display函数时,自动通过Deref转换成了&str- 必须使用
&s的方式来触发Deref(仅引用类型的实参才会触发自动解引用)
连续的隐式 Deref 转换
如果你以为 Deref 仅仅这点作用,那就大错特错了。Deref 可以支持连续的隐式转换,直到找到适合的形式为止:
fn main() { let s = MyBox::new(String::from("hello world")); display(&s) } fn display(s: &str) { println!("{}",s); }
这里我们使用了之前自定义的智能指针 MyBox,并将其通过连续的隐式转换变成 &str 类型:首先 MyBox 被 Deref 成 String 类型,结果并不能满足 display 函数参数的要求,编译器发现 String 还可以继续 Deref 成 &str,最终成功的匹配了函数参数。
想象一下,假如 Rust 没有提供这种隐式转换,我们该如何调用 display 函数?
fn main() { let m = MyBox::new(String::from("Rust")); display(&(*m)[..]); }
结果不言而喻,肯定是 &s 的方式优秀得多。总之,当参与其中的类型定义了 Deref 特征时,Rust 会分析该类型并且连续使用 Deref 直到最终获得一个引用来匹配函数或者方法的参数类型,这种行为完全不会造成任何的性能损耗,因为完全是在编译期完成。
但是 Deref 并不是没有缺点,缺点就是:如果你不知道某个类型是否实现了 Deref 特征,那么在看到某段代码时,并不能在第一时间反应过来该代码发生了隐式的 Deref 转换。事实上,不仅仅是 Deref,在 Rust 中还有各种 From/Into 等等会给阅读代码带来一定负担的特征。还是那句话,一切选择都是权衡,有得必有失,得了代码的简洁性,往往就失去了可读性,Go 语言就是一个刚好相反的例子。
再来看一下在方法、赋值中自动应用 Deref 的例子:
fn main() { let s = MyBox::new(String::from("hello, world")); let s1: &str = &s; let s2: String = s.to_string(); }
对于 s1,我们通过两次 Deref 将 &str 类型的值赋给了它(赋值操作需要手动解引用);而对于 s2,我们在其上直接调用方法 to_string,实际上 MyBox 根本没有没有实现该方法,能调用 to_string,完全是因为编译器对 MyBox 应用了 Deref 的结果(方法调用会自动解引用)。
Deref 规则总结
在上面,我们零碎的介绍了不少关于 Deref 特征的知识,下面来通过较为正式的方式来对其规则进行下总结。
一个类型为 T 的对象 foo,如果 T: Deref<Target=U>,那么,相关 foo 的引用 &foo 在应用的时候会自动转换为 &U。
粗看这条规则,貌似有点类似于 AsRef,而跟 解引用 似乎风马牛不相及,实际里面有些玄妙之处。
引用归一化
Rust 编译器实际上只能对 &v 形式的引用进行解引用操作,那么问题来了,如果是一个智能指针或者 &&&&v 类型的呢? 该如何对这两个进行解引用?
答案是:Rust 会在解引用时自动把智能指针和 &&&&v 做引用归一化操作,转换成 &v 形式,最终再对 &v 进行解引用:
- 把智能指针(比如在库中定义的,Box、Rc、Arc、Cow 等)从结构体脱壳为内部的引用类型,也就是转成结构体内部的
&v - 把多重
&,例如&&&&&&&v,归一成&v
关于第二种情况,这么干巴巴的说,也许大家会迷迷糊糊的,我们来看一段标准库源码:
#![allow(unused)] fn main() { impl<T: ?Sized> Deref for &T { type Target = T; fn deref(&self) -> &T { *self } } }
在这段源码中,&T 被自动解引用为 T,也就是 &T: Deref<Target=T> 。 按照这个代码,&&&&T 会被自动解引用为 &&&T,然后再自动解引用为 &&T,以此类推, 直到最终变成 &T。
PS: 以下是 LLVM 编译后的部分中间层代码:
#![allow(unused)] fn main() { // Rust 代码 let mut _2: &i32; let _3: &&&&i32; bb0: { _2 = (*(*(*_3))) } }
几个例子
#![allow(unused)] fn main() { fn foo(s: &str) {} // 由于 String 实现了 Deref<Target=str> let owned = "Hello".to_string(); // 因此下面的函数可以正常运行: foo(&owned); }
#![allow(unused)] fn main() { use std::rc::Rc; fn foo(s: &str) {} // String 实现了 Deref<Target=str> let owned = "Hello".to_string(); // 且 Rc 智能指针可以被自动脱壳为内部的 `owned` 引用: &String ,然后 &String 再自动解引用为 &str let counted = Rc::new(owned); // 因此下面的函数可以正常运行: foo(&counted); }
#![allow(unused)] fn main() { struct Foo; impl Foo { fn foo(&self) { println!("Foo"); } } let f = &&Foo; f.foo(); (&f).foo(); (&&f).foo(); (&&&&&&&&f).foo(); }
三种 Deref 转换
在之前,我们讲的都是不可变的 Deref 转换,实际上 Rust 还支持将一个可变的引用转换成另一个可变的引用以及将一个可变引用转换成不可变的引用,规则如下:
- 当
T: Deref<Target=U>,可以将&T转换成&U,也就是我们之前看到的例子 - 当
T: DerefMut<Target=U>,可以将&mut T转换成&mut U - 当
T: Deref<Target=U>,可以将&mut T转换成&U
来看一个关于 DerefMut 的例子:
struct MyBox<T> { v: T, } impl<T> MyBox<T> { fn new(x: T) -> MyBox<T> { MyBox { v: x } } } use std::ops::Deref; impl<T> Deref for MyBox<T> { type Target = T; fn deref(&self) -> &Self::Target { &self.v } } use std::ops::DerefMut; impl<T> DerefMut for MyBox<T> { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.v } } fn main() { let mut s = MyBox::new(String::from("hello, ")); display(&mut s) } fn display(s: &mut String) { s.push_str("world"); println!("{}", s); }
以上代码有几点值得注意:
- 要实现
DerefMut必须要先实现Deref特征:pub trait DerefMut: Deref T: DerefMut<Target=U>解读:将&mut T类型通过DerefMut特征的方法转换为&mut U类型,对应上例中,就是将&mut MyBox<String>转换为&mut String
对于上述三条规则中的第三条,它比另外两条稍微复杂了点:Rust 可以把可变引用隐式的转换成不可变引用,但反之则不行。
如果从 Rust 的所有权和借用规则的角度考虑,当你拥有一个可变的引用,那该引用肯定是对应数据的唯一借用,那么此时将可变引用变成不可变引用并不会破坏借用规则;但是如果你拥有一个不可变引用,那同时可能还存在其它几个不可变的引用,如果此时将其中一个不可变引用转换成可变引用,就变成了可变引用与不可变引用的共存,最终破坏了借用规则。
总结
Deref 可以说是 Rust 中最常见的隐式类型转换,而且它可以连续的实现如 Box<String> -> String -> &str 的隐式转换,只要链条上的类型实现了 Deref 特征。
我们也可以为自己的类型实现 Deref 特征,但是原则上来说,只应该为自定义的智能指针实现 Deref。例如,虽然你可以为自己的自定义数组类型实现 Deref 以避免 myArr.0[0] 的使用形式,但是 Rust 官方并不推荐这么做,特别是在你开发三方库时。
Drop 释放资源
在 Rust 中,我们之所以可以一拳打跑 GC 的同时一脚踢翻手动资源回收,主要就归功于 Drop 特征,同时它也是智能指针的必备特征之一。
学习目标
如何自动和手动释放资源及执行指定的收尾工作
Rust 中的资源回收
在一些无 GC 语言中,程序员在一个变量无需再被使用时,需要手动释放它占用的内存资源,如果忘记了,那么就会发生内存泄漏,最终臭名昭著的 OOM 问题可能就会发生。
而在 Rust 中,你可以指定在一个变量超出作用域时,执行一段特定的代码,最终编译器将帮你自动插入这段收尾代码。这样,就无需在每一个使用该变量的地方,都写一段代码来进行收尾工作和资源释放。不禁让人感叹,Rust 的大腿真粗,香!
没错,指定这样一段收尾工作靠的就是咱这章的主角 - Drop 特征。
一个不那么简单的 Drop 例子
struct HasDrop1; struct HasDrop2; impl Drop for HasDrop1 { fn drop(&mut self) { println!("Dropping HasDrop1!"); } } impl Drop for HasDrop2 { fn drop(&mut self) { println!("Dropping HasDrop2!"); } } struct HasTwoDrops { one: HasDrop1, two: HasDrop2, } impl Drop for HasTwoDrops { fn drop(&mut self) { println!("Dropping HasTwoDrops!"); } } struct Foo; impl Drop for Foo { fn drop(&mut self) { println!("Dropping Foo!") } } fn main() { let _x = HasTwoDrops { two: HasDrop2, one: HasDrop1, }; let _foo = Foo; println!("Running!"); }
上面代码虽然长,但是目的其实很单纯,就是为了观察不同情况下变量级别的、结构体内部字段的 Drop,有几点值得注意:
Drop特征中的drop方法借用了目标的可变引用,而不是拿走了所有权,这里先设置一个悬念,后边会讲- 结构体中每个字段都有自己的
Drop
来看看输出:
Running!
Dropping Foo!
Dropping HasTwoDrops!
Dropping HasDrop1!
Dropping HasDrop2!
嗯,结果符合预期,每个资源都成功的执行了收尾工作,虽然 println! 这种收尾工作毫无意义 =,=
Drop 的顺序
观察以上输出,我们可以得出以下关于 Drop 顺序的结论
- 变量级别,按照逆序的方式,
_x在_foo之前创建,因此_x在_foo之后被drop - 结构体内部,按照顺序的方式,结构体
_x中的字段按照定义中的顺序依次drop
没有实现 Drop 的结构体
实际上,就算你不为 _x 结构体实现 Drop 特征,它内部的两个字段依然会调用 drop,移除以下代码,并观察输出:
#![allow(unused)] fn main() { impl Drop for HasTwoDrops { fn drop(&mut self) { println!("Dropping HasTwoDrops!"); } } }
原因在于,Rust 自动为几乎所有类型都实现了 Drop 特征,因此就算你不手动为结构体实现 Drop,它依然会调用默认实现的 drop 函数,同时再调用每个字段的 drop 方法,最终打印出:
Dropping HasDrop1!
Dropping HasDrop2!
手动回收
当使用智能指针来管理锁的时候,你可能希望提前释放这个锁,然后让其它代码能及时获得锁,此时就需要提前去手动 drop。
但是在之前我们提到一个悬念,Drop::drop 只是借用了目标值的可变引用,所以,就算你提前调用了 drop,后面的代码依然可以使用目标值,但是这就会访问一个并不存在的值,非常不安全,好在 Rust 会阻止你:
#[derive(Debug)] struct Foo; impl Drop for Foo { fn drop(&mut self) { println!("Dropping Foo!") } } fn main() { let foo = Foo; foo.drop(); println!("Running!:{:?}", foo); }
报错如下:
error[E0040]: explicit use of destructor method
--> src/main.rs:37:9
|
37 | foo.drop();
| ----^^^^--
| | |
| | explicit destructor calls not allowed
| help: consider using `drop` function: `drop(foo)`
如上所示,编译器直接阻止了我们调用 Drop 特征的 drop 方法,原因是对于 Rust 而言,不允许显式地调用析构函数(这是一个用来清理实例的通用编程概念)。好在在报错的同时,编译器还给出了一个提示:使用 drop 函数。
针对编译器提示的 drop 函数,我们可以大胆推测下:它能够拿走目标值的所有权。现在来看看这个猜测正确与否,以下是 std::mem::drop 函数的签名:
#![allow(unused)] fn main() { pub fn drop<T>(_x: T) }
如上所示,drop 函数确实拿走了目标值的所有权,来验证下:
fn main() { let foo = Foo; drop(foo); // 以下代码会报错:借用了所有权被转移的值 // println!("Running!:{:?}", foo); }
Bingo,完美拿走了所有权,而且这种实现保证了后续的使用必定会导致编译错误,因此非常安全!
细心的同学可能已经注意到,这里直接调用了 drop 函数,并没有引入任何模块信息,原因是该函数在std::prelude里。
Drop 使用场景
对于 Drop 而言,主要有两个功能:
- 回收内存资源
- 执行一些收尾工作
对于第二点,在之前我们已经详细介绍过,因此这里主要对第一点进行下简单说明。
在绝大多数情况下,我们都无需手动去 drop 以回收内存资源,因为 Rust 会自动帮我们完成这些工作,它甚至会对复杂类型的每个字段都单独的调用 drop 进行回收!但是确实有极少数情况,需要你自己来回收资源的,例如文件描述符、网络 socket 等,当这些值超出作用域不再使用时,就需要进行关闭以释放相关的资源,在这些情况下,就需要使用者自己来解决 Drop 的问题。
互斥的 Copy 和 Drop
我们无法为一个类型同时实现 Copy 和 Drop 特征。因为实现了 Copy 的特征会被编译器隐式的复制,因此非常难以预测析构函数执行的时间和频率。因此这些实现了 Copy 的类型无法拥有析构函数。
#![allow(unused)] fn main() { #[derive(Copy)] struct Foo; impl Drop for Foo { fn drop(&mut self) { println!("Dropping Foo!") } } }
以上代码报错如下:
error[E0184]: the trait `Copy` may not be implemented for this type; the type has a destructor
--> src/main.rs:24:10
|
24 | #[derive(Copy)]
| ^^^^ Copy not allowed on types with destructors
总结
Drop 可以用于许多方面,来使得资源清理及收尾工作变得方便和安全,甚至可以用其创建我们自己的内存分配器!通过 Drop 特征和 Rust 所有权系统,你无需担心之后的代码清理,Rust 会自动考虑这些问题。
我们也无需担心意外的清理掉仍在使用的值,这会造成编译器错误:所有权系统确保引用总是有效的,也会确保 drop 只会在值不再被使用时被调用一次。
Rc 与 Arc
Rust 所有权机制要求一个值只能有一个所有者,在大多数情况下,都没有问题,但是考虑以下情况:
- 在图数据结构中,多个边可能会拥有同一个节点,该节点直到没有边指向它时,才应该被释放清理
- 在多线程中,多个线程可能会持有同一个数据,但是你受限于 Rust 的安全机制,无法同时获取该数据的可变引用
以上场景不是很常见,但是一旦遇到,就非常棘手,为了解决此类问题,Rust 在所有权机制之外又引入了额外的措施来简化相应的实现:通过引用计数的方式,允许一个数据资源在同一时刻拥有多个所有者。
这种实现机制就是 Rc 和 Arc,前者适用于单线程,后者适用于多线程。由于二者大部分情况下都相同,因此本章将以 Rc 作为讲解主体,对于 Arc 的不同之处,另外进行单独讲解。
Rc<T>
引用计数(reference counting),顾名思义,通过记录一个数据被引用的次数来确定该数据是否正在被使用。当引用次数归零时,就代表该数据不再被使用,因此可以被清理释放。
而 Rc 正是引用计数的英文缩写。当我们希望在堆上分配一个对象供程序的多个部分使用且无法确定哪个部分最后一个结束时,就可以使用 Rc 成为数据值的所有者,例如之前提到的多线程场景就非常适合。
下面是经典的所有权被转移导致报错的例子:
fn main() { let s = String::from("hello, world"); // s在这里被转移给a let a = Box::new(s); // 报错!此处继续尝试将 s 转移给 b let b = Box::new(s); }
使用 Rc 就可以轻易解决:
use std::rc::Rc; fn main() { let a = Rc::new(String::from("hello, world")); let b = Rc::clone(&a); assert_eq!(2, Rc::strong_count(&a)); assert_eq!(Rc::strong_count(&a), Rc::strong_count(&b)) }
以上代码我们使用 Rc::new 创建了一个新的 Rc<String> 智能指针并赋给变量 a,该指针指向底层的字符串数据。
智能指针 Rc<T> 在创建时,还会将引用计数加 1,此时获取引用计数的关联函数 Rc::strong_count 返回的值将是 1。
Rc::clone
接着,我们又使用 Rc::clone 克隆了一份智能指针 Rc<String>,并将该智能指针的引用计数增加到 2。
由于 a 和 b 是同一个智能指针的两个副本,因此通过它们两个获取引用计数的结果都是 2。
不要被 clone 字样所迷惑,以为所有的 clone 都是深拷贝。这里的 clone 仅仅复制了智能指针并增加了引用计数,并没有克隆底层数据,因此 a 和 b 是共享了底层的字符串 s,这种复制效率是非常高的。当然你也可以使用 a.clone() 的方式来克隆,但是从可读性角度,我们更加推荐 Rc::clone 的方式。
实际上在 Rust 中,还有不少 clone 都是浅拷贝,例如迭代器的克隆。
观察引用计数的变化
使用关联函数 Rc::strong_count 可以获取当前引用计数的值,我们来观察下引用计数如何随着变量声明、释放而变化:
use std::rc::Rc; fn main() { let a = Rc::new(String::from("test ref counting")); println!("count after creating a = {}", Rc::strong_count(&a)); let b = Rc::clone(&a); println!("count after creating b = {}", Rc::strong_count(&a)); { let c = Rc::clone(&a); println!("count after creating c = {}", Rc::strong_count(&c)); } println!("count after c goes out of scope = {}", Rc::strong_count(&a)); }
有几点值得注意:
- 由于变量
c在语句块内部声明,当离开语句块时它会因为超出作用域而被释放,所以引用计数会减少 1,事实上这个得益于Rc<T>实现了Drop特征 a、b、c三个智能指针引用计数都是同样的,并且共享底层的数据,因此打印计数时用哪个都行- 无法看到的是:当
a、b超出作用域后,引用计数会变成 0,最终智能指针和它指向的底层字符串都会被清理释放
不可变引用
事实上,Rc<T> 是指向底层数据的不可变的引用,因此你无法通过它来修改数据,这也符合 Rust 的借用规则:要么存在多个不可变借用,要么只能存在一个可变借用。
但是实际开发中我们往往需要对数据进行修改,这时单独使用 Rc<T> 无法满足我们的需求,需要配合其它数据类型来一起使用,例如内部可变性的 RefCell<T> 类型以及互斥锁 Mutex<T>。事实上,在多线程编程中,Arc 跟 Mutex 锁的组合使用非常常见,它们既可以让我们在不同的线程中共享数据,又允许在各个线程中对其进行修改。
一个综合例子
考虑一个场景,有很多小工具,每个工具都有自己的主人,但是存在多个工具属于同一个主人的情况,此时使用 Rc<T> 就非常适合:
use std::rc::Rc; struct Owner { name: String, // ...其它字段 } struct Gadget { id: i32, owner: Rc<Owner>, // ...其它字段 } fn main() { // 创建一个基于引用计数的 `Owner`. let gadget_owner: Rc<Owner> = Rc::new(Owner { name: "Gadget Man".to_string(), }); // 创建两个不同的工具,它们属于同一个主人 let gadget1 = Gadget { id: 1, owner: Rc::clone(&gadget_owner), }; let gadget2 = Gadget { id: 2, owner: Rc::clone(&gadget_owner), }; // 释放掉第一个 `Rc<Owner>` drop(gadget_owner); // 尽管在上面我们释放了 gadget_owner,但是依然可以在这里使用 owner 的信息 // 原因是在 drop 之前,存在三个指向 Gadget Man 的智能指针引用,上面仅仅 // drop 掉其中一个智能指针引用,而不是 drop 掉 owner 数据,外面还有两个 // 引用指向底层的 owner 数据,引用计数尚未清零 // 因此 owner 数据依然可以被使用 println!("Gadget {} owned by {}", gadget1.id, gadget1.owner.name); println!("Gadget {} owned by {}", gadget2.id, gadget2.owner.name); // 在函数最后,`gadget1` 和 `gadget2` 也被释放,最终引用计数归零,随后底层 // 数据也被清理释放 }
以上代码很好的展示了 Rc<T> 的用途,当然你也可以用借用的方式,但是实现起来就会复杂得多,而且随着 Gadget 在代码的各个地方使用,引用生命周期也将变得更加复杂,毕竟结构体中的引用类型,总是令人不那么愉快,对不?
Rc 简单总结
Rc/Arc是不可变引用,你无法修改它指向的值,只能进行读取,如果要修改,需要配合后面章节的内部可变性RefCell或互斥锁Mutex- 一旦最后一个拥有者消失,则资源会自动被回收,这个生命周期是在编译期就确定下来的
Rc只能用于同一线程内部,想要用于线程之间的对象共享,你需要使用ArcRc<T>是一个智能指针,实现了Deref特征,因此你无需先解开Rc指针,再使用里面的T,而是可以直接使用T,例如上例中的gadget1.owner.name
多线程无力的 Rc<T>
来看看在多线程场景使用 Rc<T> 会如何:
use std::rc::Rc; use std::thread; fn main() { let s = Rc::new(String::from("多线程漫游者")); for _ in 0..10 { let s = Rc::clone(&s); let handle = thread::spawn(move || { println!("{}", s) }); } }
由于我们还没有学习多线程的章节,上面的例子就特地简化了相关的实现。首先通过 thread::spawn 创建一个线程,然后使用 move 关键字把克隆出的 s 的所有权转移到线程中。
能够实现这一点,完全得益于 Rc 带来的多所有权机制,但是以上代码会报错:
error[E0277]: `Rc<String>` cannot be sent between threads safely
表面原因是 Rc<T> 不能在线程间安全的传递,实际上是因为它没有实现 Send 特征,而该特征是恰恰是多线程间传递数据的关键,我们会在多线程章节中进行讲解。
当然,还有更深层的原因:由于 Rc<T> 需要管理引用计数,但是该计数器并没有使用任何并发原语,因此无法实现原子化的计数操作,最终会导致计数错误。
好在天无绝人之路,一起来看看 Rust 为我们提供的功能类似但是多线程安全的 Arc。
Arc
Arc 是 Atomic Rc 的缩写,顾名思义:原子化的 Rc<T> 智能指针。原子化是一种并发原语,我们在后续章节会进行深入讲解,这里你只要知道它能保证我们的数据能够安全的在线程间共享即可。
Arc 的性能损耗
你可能好奇,为何不直接使用 Arc,还要画蛇添足弄一个 Rc,还有 Rust 的基本数据类型、标准库数据类型为什么不自动实现原子化操作?这样就不存在线程不安全的问题了。
原因在于原子化或者其它锁虽然可以带来的线程安全,但是都会伴随着性能损耗,而且这种性能损耗还不小。因此 Rust 把这种选择权交给你,毕竟需要线程安全的代码其实占比并不高,大部分时候我们开发的程序都在一个线程内。
Arc 和 Rc 拥有完全一样的 API,修改起来很简单:
use std::sync::Arc; use std::thread; fn main() { let s = Arc::new(String::from("多线程漫游者")); for _ in 0..10 { let s = Arc::clone(&s); let handle = thread::spawn(move || { println!("{}", s) }); } }
对了,两者还有一点区别:Arc 和 Rc 并没有定义在同一个模块,前者通过 use std::sync::Arc 来引入,后者通过 use std::rc::Rc。
总结
在 Rust 中,所有权机制保证了一个数据只会有一个所有者,但如果你想要在图数据结构、多线程等场景中共享数据,这种机制会成为极大的阻碍。好在 Rust 为我们提供了智能指针 Rc 和 Arc,使用它们就能实现多个所有者共享一个数据的功能。
Rc 和 Arc 的区别在于,后者是原子化实现的引用计数,因此是线程安全的,可以用于多线程中共享数据。
这两者都是只读的,如果想要实现内部数据可修改,必须配合内部可变性 RefCell 或者互斥锁 Mutex 来一起使用。
Cell 和 RefCell
Rust 的编译器之严格,可以说是举世无双。特别是在所有权方面,Rust 通过严格的规则来保证所有权和借用的正确性,最终为程序的安全保驾护航。
但是严格是一把双刃剑,带来安全提升的同时,损失了灵活性,有时甚至会让用户痛苦不堪、怨声载道。因此 Rust 提供了 Cell 和 RefCell 用于内部可变性,简而言之,可以在拥有不可变引用的同时修改目标数据,对于正常的代码实现来说,这个是不可能做到的(要么一个可变借用,要么多个不可变借用)。
内部可变性的实现是因为 Rust 使用了
unsafe来做到这一点,但是对于使用者来说,这些都是透明的,因为这些不安全代码都被封装到了安全的 API 中
Cell
Cell 和 RefCell 在功能上没有区别,区别在于 Cell<T> 适用于 T 实现 Copy 的情况:
use std::cell::Cell; fn main() { let c = Cell::new("asdf"); let one = c.get(); c.set("qwer"); let two = c.get(); println!("{},{}", one, two); }
以上代码展示了 Cell 的基本用法,有几点值得注意:
- "asdf" 是
&str类型,它实现了Copy特征 c.get用来取值,c.set用来设置新值
取到值保存在 one 变量后,还能同时进行修改,这个违背了 Rust 的借用规则,但是由于 Cell 的存在,我们很优雅地做到了这一点,但是如果你尝试在 Cell 中存放String:
#![allow(unused)] fn main() { let c = Cell::new(String::from("asdf")); }
编译器会立刻报错,因为 String 没有实现 Copy 特征:
| pub struct String {
| ----------------- doesn't satisfy `String: Copy`
|
= note: the following trait bounds were not satisfied:
`String: Copy`
RefCell
由于 Cell 类型针对的是实现了 Copy 特征的值类型,因此在实际开发中,Cell 使用的并不多,因为我们要解决的往往是可变、不可变引用共存导致的问题,此时就需要借助于 RefCell 来达成目的。
我们可以将所有权、借用规则与这些智能指针做一个对比:
| Rust 规则 | 智能指针带来的额外规则 |
|---|---|
| 一个数据只有一个所有者 | Rc/Arc让一个数据可以拥有多个所有者 |
| 要么多个不可变借用,要么一个可变借用 | RefCell实现编译期可变、不可变引用共存 |
| 违背规则导致编译错误 | 违背规则导致运行时panic |
可以看出,Rc/Arc 和 RefCell 合在一起,解决了 Rust 中严苛的所有权和借用规则带来的某些场景下难使用的问题。但是它们并不是银弹,例如 RefCell 实际上并没有解决可变引用和引用可以共存的问题,只是将报错从编译期推迟到运行时,从编译器错误变成了 panic 异常:
use std::cell::RefCell; fn main() { let s = RefCell::new(String::from("hello, world")); let s1 = s.borrow(); let s2 = s.borrow_mut(); println!("{},{}", s1, s2); }
上面代码在编译期不会报任何错误,你可以顺利运行程序:
thread 'main' panicked at 'already borrowed: BorrowMutError', src/main.rs:6:16
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
但是依然会因为违背了借用规则导致了运行期 panic,这非常像中国的天网,它也许会被罪犯蒙蔽一时,但是并不会被蒙蔽一世,任何导致安全风险的存在都将不能被容忍,法网恢恢,疏而不漏。
RefCell 为何存在
相信肯定有读者有疑问了,这么做有任何意义吗?还不如在编译期报错,至少能提前发现问题,而且性能还更好。
存在即合理,究其根因,在于 Rust 编译期的宁可错杀,绝不放过的原则,当编译器不能确定你的代码是否正确时,就统统会判定为错误,因此难免会导致一些误报。
而 RefCell 正是用于你确信代码是正确的,而编译器却发生了误判时。
对于大型的复杂程序,也可以选择使用 RefCell 来让事情简化。例如在 Rust 编译器的ctxt结构体中有大量的 RefCell 类型的 map 字段,主要的原因是:这些 map 会被分散在各个地方的代码片段所广泛使用或修改。由于这种分散在各处的使用方式,导致了管理可变和不可变成为一件非常复杂的任务(甚至不可能),你很容易就碰到编译器抛出来的各种错误。而且 RefCell 的运行时错误在这种情况下也变得非常可爱:一旦有人做了不正确的使用,代码会 panic,然后告诉我们哪些借用冲突了。
总之,当你确信编译器误报但不知道该如何解决时,或者你有一个引用类型,需要被四处使用和修改然后导致借用关系难以管理时,都可以优先考虑使用 RefCell。
RefCell 简单总结
- 与
Cell用于可Copy的值不同,RefCell用于引用 RefCell只是将借用规则从编译期推迟到程序运行期,并不能帮你绕过这个规则RefCell适用于编译期误报或者一个引用被在多处代码使用、修改以至于难于管理借用关系时- 使用
RefCell时,违背借用规则会导致运行期的panic
选择 Cell 还是 RefCell
根据本文的内容,我们可以大概总结下两者的区别:
Cell只适用于Copy类型,用于提供值,而RefCell用于提供引用Cell不会panic,而RefCell会
性能比较
Cell 没有额外的性能损耗,例如以下两段代码的性能其实是一致的:
#![allow(unused)] fn main() { // code snipet 1 let x = Cell::new(1); let y = &x; let z = &x; x.set(2); y.set(3); z.set(4); println!("{}", x.get()); // code snipet 2 let mut x = 1; let y = &mut x; let z = &mut x; x = 2; *y = 3; *z = 4; println!("{}", x); }
虽然性能一致,但代码 1 拥有代码 2 不具有的优势:它能编译成功:)
与 Cell 的 zero cost 不同,RefCell 其实是有一点运行期开销的,原因是它包含了一个字大小的“借用状态”指示器,该指示器在每次运行时借用时都会被修改,进而产生一点开销。
总之,当非要使用内部可变性时,首选 Cell,只有你的类型没有实现 Copy 时,才去选择 RefCell。
内部可变性
之前我们提到 RefCell 具有内部可变性,何为内部可变性?简单来说,对一个不可变的值进行可变借用,但这个并不符合 Rust 的基本借用规则:
fn main() { let x = 5; let y = &mut x; }
上面的代码会报错,因为我们不能对一个不可变的值进行可变借用,这会破坏 Rust 的安全性保证,相反,你可以对一个可变值进行不可变借用。原因是:当值不可变时,可能会有多个不可变的引用指向它,此时若将修改其中一个为可变的,会造成可变引用与不可变引用共存的情况;而当值可变时,最多只会有一个可变引用指向它,将其修改为不可变,那么最终依然是只有一个不可变的引用指向它。
虽然基本借用规则是 Rust 的基石,然而在某些场景中,一个值可以在其方法内部被修改,同时对于其它代码不可变,是很有用的:
#![allow(unused)] fn main() { // 定义在外部库中的特征 pub trait Messenger { fn send(&self, msg: String); } // -------------------------- // 我们的代码中的数据结构和实现 struct MsgQueue { msg_cache: Vec<String>, } impl Messenger for MsgQueue { fn send(&self, msg: String) { self.msg_cache.push(msg) } } }
如上所示,外部库中定义了一个消息发送器特征 Messenger,它只有一个发送消息的功能:fn send(&self, msg: String),因为发送消息不需要修改自身,因此原作者在定义时,使用了 &self 的不可变借用,这个无可厚非。
我们要在自己的代码中使用该特征实现一个异步消息队列,出于性能的考虑,消息先写到本地缓存(内存)中,然后批量发送出去,因此在 send 方法中,需要将消息先行插入到本地缓存 msg_cache 中。但是问题来了,该 send 方法的签名是 &self,因此上述代码会报错:
error[E0596]: cannot borrow `self.msg_cache` as mutable, as it is behind a `&` reference
--> src/main.rs:11:9
|
2 | fn send(&self, msg: String);
| ----- help: consider changing that to be a mutable reference: `&mut self`
...
11 | self.msg_cache.push(msg)
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
在报错的同时,编译器大聪明还善意地给出了提示:将 &self 修改为 &mut self,但是。。。我们实现的特征是定义在外部库中,因此该签名根本不能修改。值此危急关头, RefCell 闪亮登场:
use std::cell::RefCell; pub trait Messenger { fn send(&self, msg: String); } pub struct MsgQueue { msg_cache: RefCell<Vec<String>>, } impl Messenger for MsgQueue { fn send(&self, msg: String) { self.msg_cache.borrow_mut().push(msg) } } fn main() { let mq = MsgQueue { msg_cache: RefCell::new(Vec::new()), }; mq.send("hello, world".to_string()); }
这个 MQ 功能很弱,但是并不妨碍我们演示内部可变性的核心用法:通过包裹一层 RefCell,成功的让 &self 中的 msg_cache 成为一个可变值,然后实现对其的修改。
Rc + RefCell 组合使用
在 Rust 中,一个常见的组合就是 Rc 和 RefCell 在一起使用,前者可以实现一个数据拥有多个所有者,后者可以实现数据的可变性:
use std::cell::RefCell; use std::rc::Rc; fn main() { let s = Rc::new(RefCell::new("我很善变,还拥有多个主人".to_string())); let s1 = s.clone(); let s2 = s.clone(); // let mut s2 = s.borrow_mut(); s2.borrow_mut().push_str(", on yeah!"); println!("{:?}\n{:?}\n{:?}", s, s1, s2); }
上面代码中,我们使用 RefCell<String> 包裹一个字符串,同时通过 Rc 创建了它的三个所有者:s、s1和s2,并且通过其中一个所有者 s2 对字符串内容进行了修改。
由于 Rc 的所有者们共享同一个底层的数据,因此当一个所有者修改了数据时,会导致全部所有者持有的数据都发生了变化。
程序的运行结果也在预料之中:
RefCell { value: "我很善变,还拥有多个主人, on yeah!" }
RefCell { value: "我很善变,还拥有多个主人, on yeah!" }
RefCell { value: "我很善变,还拥有多个主人, on yeah!" }
性能损耗
相信这两者组合在一起使用时,很多人会好奇到底性能如何,下面我们来简单分析下。
首先给出一个大概的结论,这两者结合在一起使用的性能其实非常高,大致相当于没有线程安全版本的 C++ std::shared_ptr 指针,事实上,C++ 这个指针的主要开销也在于原子性这个并发原语上,毕竟线程安全在哪个语言中开销都不小。
内存损耗
两者结合的数据结构与下面类似:
#![allow(unused)] fn main() { struct Wrapper<T> { // Rc strong_count: usize, weak_count: usize, // Refcell borrow_count: isize, // 包裹的数据 item: T, } }
从上面可以看出,从对内存的影响来看,仅仅多分配了三个usize/isize,并没有其它额外的负担。
CPU 损耗
从 CPU 来看,损耗如下:
- 对
Rc<T>解引用是免费的(编译期),但是*带来的间接取值并不免费 - 克隆
Rc<T>需要将当前的引用计数跟0和usize::Max进行一次比较,然后将计数值加 1 - 释放(drop)
Rc<T>需要将计数值减 1, 然后跟0进行一次比较 - 对
RefCell进行不可变借用,需要将isize类型的借用计数加 1,然后跟0进行比较 - 对
RefCell的不可变借用进行释放,需要将isize减 1 - 对
RefCell的可变借用大致流程跟上面差不多,但是需要先跟0比较,然后再减 1 - 对
RefCell的可变借用进行释放,需要将isize加 1
其实这些细节不必过于关注,只要知道 CPU 消耗也非常低,甚至编译器还会对此进行进一步优化!
CPU 缓存 Miss
唯一需要担心的可能就是这种组合数据结构对于 CPU 缓存是否亲和,这个我们无法证明,只能提出来存在这个可能性,最终的性能影响还需要在实际场景中进行测试。
总之,分析这两者组合的性能还挺复杂的,大概总结下:
- 从表面来看,它们带来的内存和 CPU 损耗都不大
- 但是由于
Rc额外的引入了一次间接取值(*),在少数场景下可能会造成性能上的显著损失 - CPU 缓存可能也不够亲和
通过 Cell::from_mut 解决借用冲突
在 Rust 1.37 版本中新增了两个非常实用的方法:
- Cell::from_mut,该方法将
&mut T转为&Cell<T> - Cell::as_slice_of_cells,该方法将
&Cell<[T]>转为&[Cell<T>]
这里我们不做深入的介绍,但是来看看如何使用这两个方法来解决一个常见的借用冲突问题:
#![allow(unused)] fn main() { fn is_even(i: i32) -> bool { i % 2 == 0 } fn retain_even(nums: &mut Vec<i32>) { let mut i = 0; for num in nums.iter().filter(|&num| is_even(*num)) { nums[i] = *num; i += 1; } nums.truncate(i); } }
以上代码会报错:
error[E0502]: cannot borrow `*nums` as mutable because it is also borrowed as immutable
--> src/main.rs:8:9
|
7 | for num in nums.iter().filter(|&num| is_even(*num)) {
| ----------------------------------------
| |
| immutable borrow occurs here
| immutable borrow later used here
8 | nums[i] = *num;
| ^^^^ mutable borrow occurs here
很明显,报错是因为同时借用了不可变与可变引用,你可以通过索引的方式来避免这个问题:
#![allow(unused)] fn main() { fn retain_even(nums: &mut Vec<i32>) { let mut i = 0; for j in 0..nums.len() { if is_even(nums[j]) { nums[i] = nums[j]; i += 1; } } nums.truncate(i); } }
但是这样就违背我们的初衷了,毕竟迭代器会让代码更加简洁,那么还有其它的办法吗?
这时就可以使用 Cell 新增的这两个方法:
#![allow(unused)] fn main() { use std::cell::Cell; fn retain_even(nums: &mut Vec<i32>) { let slice: &[Cell<i32>] = Cell::from_mut(&mut nums[..]) .as_slice_of_cells(); let mut i = 0; for num in slice.iter().filter(|num| is_even(num.get())) { slice[i].set(num.get()); i += 1; } nums.truncate(i); } }
此时代码将不会报错,因为 Cell 上的 set 方法获取的是不可变引用 pub fn set(&self, val: T)。
当然,以上代码的本质还是对 Cell 的运用,只不过这两个方法可以很方便的帮我们把 &mut [T] 类型转换成 &[Cell<T>] 类型。
总结
Cell 和 RefCell 都为我们带来了内部可变性这个重要特性,同时还将借用规则的检查从编译期推迟到运行期,但是这个检查并不能被绕过,该来早晚还是会来,RefCell 在运行期的报错会造成 panic。
RefCell 适用于编译器误报或者一个引用被在多个代码中使用、修改以至于难于管理借用关系时,还有就是需要内部可变性时。
从性能上看,RefCell 由于是非线程安全的,因此无需保证原子性,性能虽然有一点损耗,但是依然非常好,而 Cell 则完全不存在任何额外的性能损耗。
Rc 跟 RefCell 结合使用可以实现多个所有者共享同一份数据,非常好用,但是潜在的性能损耗也要考虑进去,建议对于热点代码使用时,做好 benchmark。
循环引用与自引用
实现一个链表是学习各大编程语言的常用技巧,但是在 Rust 中实现链表意味着····Hell,是的,你没看错,Welcome to hell。
链表在 Rust 中之所以这么难,完全是因为循环引用和自引用的问题引起的,这两个问题可以说综合了 Rust 的很多难点,难出了新高度,因此本书专门开辟一章,分为上下两篇,试图彻底解决这两个老大难。
本章难度较高,但是非常值得深入阅读,它会让你对 Rust 的理解上升到一个新的境界。
Weak 与循环引用
Rust 的安全性是众所周知的,但是不代表它不会内存泄漏。一个典型的例子就是同时使用 Rc<T> 和 RefCell<T> 创建循环引用,最终这些引用的计数都无法被归零,因此 Rc<T> 拥有的值也不会被释放清理。
何为循环引用
关于内存泄漏,如果你没有充足的 Rust 经验,可能都无法造出一份代码来再现它:
use crate::List::{Cons, Nil}; use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] enum List { Cons(i32, RefCell<Rc<List>>), Nil, } impl List { fn tail(&self) -> Option<&RefCell<Rc<List>>> { match self { Cons(_, item) => Some(item), Nil => None, } } } fn main() {}
这里我们创建一个有些复杂的枚举类型 List,这个类型很有意思,它的每个值都指向了另一个 List,此外,得益于 Rc 的使用还允许多个值指向一个 List:
如上图所示,每个矩形框节点都是一个 List 类型,它们或者是拥有值且指向另一个 List 的Cons,或者是一个没有值的终结点 Nil。同时,由于 RefCell 的使用,每个 List 所指向的 List 还能够被修改。
下面来使用一下这个复杂的 List 枚举:
fn main() { let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil)))); println!("a的初始化rc计数 = {}", Rc::strong_count(&a)); println!("a指向的节点 = {:?}", a.tail()); // 创建`b`到`a`的引用 let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a)))); println!("在b创建后,a的rc计数 = {}", Rc::strong_count(&a)); println!("b的初始化rc计数 = {}", Rc::strong_count(&b)); println!("b指向的节点 = {:?}", b.tail()); // 利用RefCell的可变性,创建了`a`到`b`的引用 if let Some(link) = a.tail() { *link.borrow_mut() = Rc::clone(&b); } println!("在更改a后,b的rc计数 = {}", Rc::strong_count(&b)); println!("在更改a后,a的rc计数 = {}", Rc::strong_count(&a)); // 下面一行println!将导致循环引用 // 我们可怜的8MB大小的main线程栈空间将被它冲垮,最终造成栈溢出 // println!("a next item = {:?}", a.tail()); }
这个类型定义看着复杂,使用起来更复杂!不过排除这些因素,我们可以清晰看出:
- 在创建了
a后,紧接着就使用a创建了b,因此b引用了a - 然后我们又利用
Rc克隆了b,然后通过RefCell的可变性,让a引用了b
至此我们成功创建了循环引用a-> b -> a -> b ····
先来观察下引用计数:
a的初始化rc计数 = 1
a指向的节点 = Some(RefCell { value: Nil })
在b创建后,a的rc计数 = 2
b的初始化rc计数 = 1
b指向的节点 = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
在更改a后,b的rc计数 = 2
在更改a后,a的rc计数 = 2
在 main 函数结束前,a 和 b 的引用计数均是 2,随后 b 触发 Drop,此时引用计数会变为 1,并不会归 0,因此 b 所指向内存不会被释放,同理可得 a 指向的内存也不会被释放,最终发生了内存泄漏。
下面一张图很好的展示了这种引用循环关系:
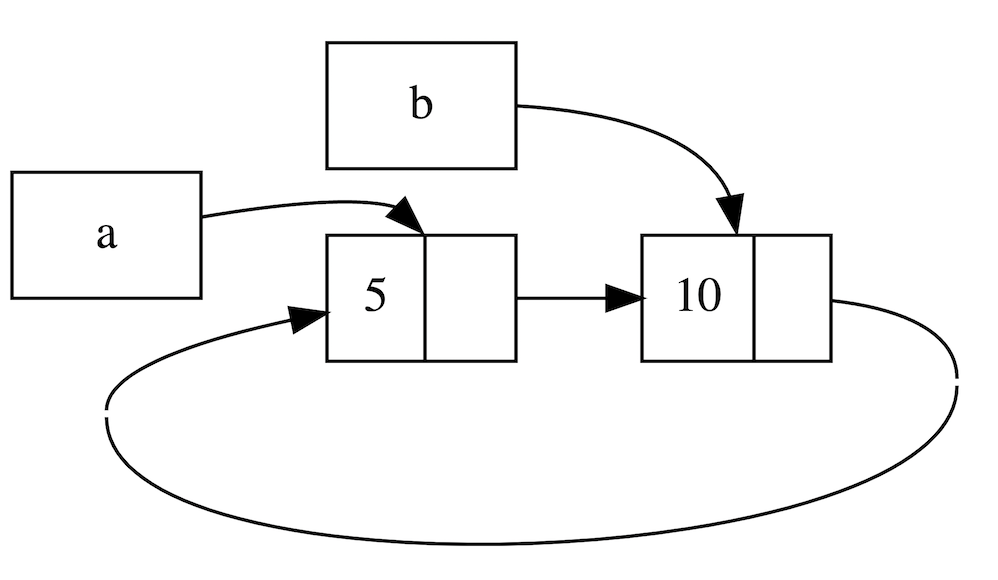
现在我们还需要轻轻的推一下,让塔米诺骨牌轰然倒塌。反注释最后一行代码,试着运行下:
RefCell { value: Cons(5, RefCell { value: Cons(10, RefCell { value: Cons(5, RefCell { value: Cons(10, RefCell { value: Cons(5, RefCell { value: Cons(10, RefCell {
...无穷无尽
thread 'main' has overflowed its stack
fatal runtime error: stack overflow
通过 a.tail 的调用,Rust 试图打印出 a -> b -> a ··· 的所有内容,但是在不懈的努力后,main 线程终于不堪重负,发生了栈溢出。
以上的代码可能并不会造成什么大的问题,但是在一个更加复杂的程序中,类似的问题可能会造成你的程序不断地分配内存、泄漏内存,最终程序会不幸OOM,当然这其中的 CPU 损耗也不可小觑。
总之,创建循环引用并不简单,但是也并不是完全遇不到,当你使用 RefCell<Rc<T>> 或者类似的类型嵌套组合(具备内部可变性和引用计数)时,就要打起万分精神,前面可能是深渊!
那么问题来了? 如果我们确实需要实现上面的功能,该怎么办?答案是使用 Weak。
Weak
Weak 非常类似于 Rc,但是与 Rc 持有所有权不同,Weak 不持有所有权,它仅仅保存一份指向数据的弱引用:如果你想要访问数据,需要通过 Weak 指针的 upgrade 方法实现,该方法返回一个类型为 Option<Rc<T>> 的值。
看到这个返回,相信大家就懂了:何为弱引用?就是不保证引用关系依然存在,如果不存在,就返回一个 None!
因为 Weak 引用不计入所有权,因此它无法阻止所引用的内存值被释放掉,而且 Weak 本身不对值的存在性做任何担保,引用的值还存在就返回 Some,不存在就返回 None。
Weak 与 Rc 对比
我们来将 Weak 与 Rc 进行以下简单对比:
Weak | Rc |
|---|---|
| 不计数 | 引用计数 |
| 不拥有所有权 | 拥有值的所有权 |
| 不阻止值被释放(drop) | 所有权计数归零,才能 drop |
引用的值存在返回 Some,不存在返回 None | 引用的值必定存在 |
通过 upgrade 取到 Option<Rc<T>>,然后再取值 | 通过 Deref 自动解引用,取值无需任何操作 |
通过这个对比,可以非常清晰的看出 Weak 为何这么弱,而这种弱恰恰非常适合我们实现以下的场景:
- 持有一个
Rc对象的临时引用,并且不在乎引用的值是否依然存在 - 阻止
Rc导致的循环引用,因为Rc的所有权机制,会导致多个Rc都无法计数归零
使用方式简单总结下:对于父子引用关系,可以让父节点通过 Rc 来引用子节点,然后让子节点通过 Weak 来引用父节点。
Weak 总结
因为 Weak 本身并不是很好理解,因此我们再来帮大家梳理总结下,然后再通过一个例子,来彻底掌握。
Weak 通过 use std::rc::Weak 来引入,它具有以下特点:
- 可访问,但没有所有权,不增加引用计数,因此不会影响被引用值的释放回收
- 可由
Rc<T>调用downgrade方法转换成Weak<T> Weak<T>可使用upgrade方法转换成Option<Rc<T>>,如果资源已经被释放,则Option的值是None- 常用于解决循环引用的问题
一个简单的例子:
use std::rc::Rc; fn main() { // 创建Rc,持有一个值5 let five = Rc::new(5); // 通过Rc,创建一个Weak指针 let weak_five = Rc::downgrade(&five); // Weak引用的资源依然存在,取到值5 let strong_five: Option<Rc<_>> = weak_five.upgrade(); assert_eq!(*strong_five.unwrap(), 5); // 手动释放资源`five` drop(five); // Weak引用的资源已不存在,因此返回None let strong_five: Option<Rc<_>> = weak_five.upgrade(); assert_eq!(strong_five, None); }
需要承认的是,使用 Weak 让 Rust 本来就堪忧的代码可读性又下降了不少,但是。。。真香,因为可以解决循环引用了。
使用 Weak 解决循环引用
理论知识已经足够,现在用两个例子来模拟下真实场景下可能会遇到的循环引用。
工具间的故事
工具间里,每个工具都有其主人,且多个工具可以拥有一个主人;同时一个主人也可以拥有多个工具,在这种场景下,就很容易形成循环引用,好在我们有 Weak:
use std::rc::Rc; use std::rc::Weak; use std::cell::RefCell; // 主人 struct Owner { name: String, gadgets: RefCell<Vec<Weak<Gadget>>>, } // 工具 struct Gadget { id: i32, owner: Rc<Owner>, } fn main() { // 创建一个 Owner // 需要注意,该 Owner 也拥有多个 `gadgets` let gadget_owner : Rc<Owner> = Rc::new( Owner { name: "Gadget Man".to_string(), gadgets: RefCell::new(Vec::new()), } ); // 创建工具,同时与主人进行关联:创建两个 gadget,他们分别持有 gadget_owner 的一个引用。 let gadget1 = Rc::new(Gadget{id: 1, owner: gadget_owner.clone()}); let gadget2 = Rc::new(Gadget{id: 2, owner: gadget_owner.clone()}); // 为主人更新它所拥有的工具 // 因为之前使用了 `Rc`,现在必须要使用 `Weak`,否则就会循环引用 gadget_owner.gadgets.borrow_mut().push(Rc::downgrade(&gadget1)); gadget_owner.gadgets.borrow_mut().push(Rc::downgrade(&gadget2)); // 遍历 gadget_owner 的 gadgets 字段 for gadget_opt in gadget_owner.gadgets.borrow().iter() { // gadget_opt 是一个 Weak<Gadget> 。 因为 weak 指针不能保证他所引用的对象 // 仍然存在。所以我们需要显式的调用 upgrade() 来通过其返回值(Option<_>)来判 // 断其所指向的对象是否存在。 // 当然,Option 为 None 的时候这个引用原对象就不存在了。 let gadget = gadget_opt.upgrade().unwrap(); println!("Gadget {} owned by {}", gadget.id, gadget.owner.name); } // 在 main 函数的最后,gadget_owner,gadget1 和 gadget2 都被销毁。 // 具体是,因为这几个结构体之间没有了强引用(`Rc<T>`),所以,当他们销毁的时候。 // 首先 gadget2 和 gadget1 被销毁。 // 然后因为 gadget_owner 的引用数量为 0,所以这个对象可以被销毁了。 // 循环引用问题也就避免了 }
tree 数据结构
use std::cell::RefCell; use std::rc::{Rc, Weak}; #[derive(Debug)] struct Node { value: i32, parent: RefCell<Weak<Node>>, children: RefCell<Vec<Rc<Node>>>, } fn main() { let leaf = Rc::new(Node { value: 3, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![]), }); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); { let branch = Rc::new(Node { value: 5, parent: RefCell::new(Weak::new()), children: RefCell::new(vec![Rc::clone(&leaf)]), }); *leaf.parent.borrow_mut() = Rc::downgrade(&branch); println!( "branch strong = {}, weak = {}", Rc::strong_count(&branch), Rc::weak_count(&branch), ); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); } println!("leaf parent = {:?}", leaf.parent.borrow().upgrade()); println!( "leaf strong = {}, weak = {}", Rc::strong_count(&leaf), Rc::weak_count(&leaf), ); }
这个例子就留给读者自己解读和分析,我们就不画蛇添足了:)
unsafe 解决循环引用
除了使用 Rust 标准库提供的这些类型,你还可以使用 unsafe 里的裸指针来解决这些棘手的问题,但是由于我们还没有讲解 unsafe,因此这里就不进行展开,只附上源码链接, 挺长的,需要耐心 o_o
虽然 unsafe 不安全,但是在各种库的代码中依然很常见用它来实现自引用结构,主要优点如下:
- 性能高,毕竟直接用裸指针操作
- 代码更简单更符合直觉: 对比下
Option<Rc<RefCell<Node>>>
总结
本文深入讲解了何为循环引用以及如何使用 Weak 来解决,同时还结合 Rc、RefCell、Weak 等实现了两个有实战价值的例子,让大家对智能指针的使用更加融会贯通。
至此,智能指针一章即将结束(严格来说还有一个 Mutex 放在多线程一章讲解),而 Rust 语言本身的学习之旅也即将结束,后面我们将深入多线程、项目工程、应用实践、性能分析等特色专题,来一睹 Rust 在这些领域的风采。
结构体自引用
结构体自引用在 Rust 中是一个众所周知的难题,而且众说纷纭,也没有一篇文章能把相关的话题讲透,那本文就王婆卖瓜,来试试看能不能讲透这一块儿内容,让读者大大们舒心。
平平无奇的自引用
可能也有不少人第一次听说自引用结构体,那咱们先来看看它们长啥样。
#![allow(unused)] fn main() { struct SelfRef<'a> { value: String, // 该引用指向上面的value pointer_to_value: &'a str, } }
以上就是一个很简单的自引用结构体,看上去好像没什么,那来试着运行下:
fn main(){ let s = "aaa".to_string(); let v = SelfRef { value: s, pointer_to_value: &s }; }
运行后报错:
let v = SelfRef {
12 | value: s,
| - value moved here
13 | pointer_to_value: &s
| ^^ value borrowed here after move
因为我们试图同时使用值和值的引用,最终所有权转移和借用一起发生了。所以,这个问题貌似并没有那么好解决,不信你可以回想下自己具有的知识,是否可以解决?
使用 Option
最简单的方式就是使用 Option 分两步来实现:
#[derive(Debug)] struct WhatAboutThis<'a> { name: String, nickname: Option<&'a str>, } fn main() { let mut tricky = WhatAboutThis { name: "Annabelle".to_string(), nickname: None, }; tricky.nickname = Some(&tricky.name[..4]); println!("{:?}", tricky); }
在某种程度上来说,Option 这个方法可以工作,但是这个方法的限制较多,例如从一个函数创建并返回它是不可能的:
#![allow(unused)] fn main() { fn creator<'a>() -> WhatAboutThis<'a> { let mut tricky = WhatAboutThis { name: "Annabelle".to_string(), nickname: None, }; tricky.nickname = Some(&tricky.name[..4]); tricky } }
报错如下:
error[E0515]: cannot return value referencing local data `tricky.name`
--> src/main.rs:24:5
|
22 | tricky.nickname = Some(&tricky.name[..4]);
| ----------- `tricky.name` is borrowed here
23 |
24 | tricky
| ^^^^^^ returns a value referencing data owned by the current function
其实从函数签名就能看出来端倪,'a 生命周期是凭空产生的!
如果是通过方法使用,你需要一个无用 &'a self 生命周期标识,一旦有了这个标识,代码将变得更加受限,你将很容易就获得借用错误,就连 NLL 规则都没用:
#[derive(Debug)] struct WhatAboutThis<'a> { name: String, nickname: Option<&'a str>, } impl<'a> WhatAboutThis<'a> { fn tie_the_knot(&'a mut self) { self.nickname = Some(&self.name[..4]); } } fn main() { let mut tricky = WhatAboutThis { name: "Annabelle".to_string(), nickname: None, }; tricky.tie_the_knot(); // cannot borrow `tricky` as immutable because it is also borrowed as mutable // println!("{:?}", tricky); }
unsafe 实现
既然借用规则妨碍了我们,那就一脚踢开:
#[derive(Debug)] struct SelfRef { value: String, pointer_to_value: *const String, } impl SelfRef { fn new(txt: &str) -> Self { SelfRef { value: String::from(txt), pointer_to_value: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.value; self.pointer_to_value = self_ref; } fn value(&self) -> &str { &self.value } fn pointer_to_value(&self) -> &String { assert!(!self.pointer_to_value.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.pointer_to_value) } } } fn main() { let mut t = SelfRef::new("hello"); t.init(); // 打印值和指针地址 println!("{}, {:p}", t.value(), t.pointer_to_value()); }
在这里,我们在 pointer_to_value 中直接存储裸指针,而不是 Rust 的引用,因此不再受到 Rust 借用规则和生命周期的限制,而且实现起来非常清晰、简洁。但是缺点就是,通过指针获取值时需要使用 unsafe 代码。
当然,上面的代码你还能通过裸指针来修改 String,但是需要将 *const 修改为 *mut:
#[derive(Debug)] struct SelfRef { value: String, pointer_to_value: *mut String, } impl SelfRef { fn new(txt: &str) -> Self { SelfRef { value: String::from(txt), pointer_to_value: std::ptr::null_mut(), } } fn init(&mut self) { let self_ref: *mut String = &mut self.value; self.pointer_to_value = self_ref; } fn value(&self) -> &str { &self.value } fn pointer_to_value(&self) -> &String { assert!(!self.pointer_to_value.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.pointer_to_value) } } } fn main() { let mut t = SelfRef::new("hello"); t.init(); println!("{}, {:p}", t.value(), t.pointer_to_value()); t.value.push_str(", world"); unsafe { (&mut *t.pointer_to_value).push_str("!"); } println!("{}, {:p}", t.value(), t.pointer_to_value()); }
运行后输出:
hello, 0x16f3aec70
hello, world!, 0x16f3aec70
上面的 unsafe 虽然简单好用,但是它不太安全,是否还有其他选择?还真的有,那就是 Pin。
无法被移动的 Pin
Pin 在后续章节会深入讲解,目前你只需要知道它可以固定住一个值,防止该值在内存中被移动。
通过开头我们知道,自引用最麻烦的就是创建引用的同时,值的所有权会被转移,而通过 Pin 就可以很好的防止这一点:
use std::marker::PhantomPinned; use std::pin::Pin; use std::ptr::NonNull; // 下面是一个自引用数据结构体,因为 slice 字段是一个指针,指向了 data 字段 // 我们无法使用普通引用来实现,因为违背了 Rust 的编译规则 // 因此,这里我们使用了一个裸指针,通过 NonNull 来确保它不会为 null struct Unmovable { data: String, slice: NonNull<String>, _pin: PhantomPinned, } impl Unmovable { // 为了确保函数返回时数据的所有权不会被转移,我们将它放在堆上,唯一的访问方式就是通过指针 fn new(data: String) -> Pin<Box<Self>> { let res = Unmovable { data, // 只有在数据到位时,才创建指针,否则数据会在开始之前就被转移所有权 slice: NonNull::dangling(), _pin: PhantomPinned, }; let mut boxed = Box::pin(res); let slice = NonNull::from(&boxed.data); // 这里其实安全的,因为修改一个字段不会转移整个结构体的所有权 unsafe { let mut_ref: Pin<&mut Self> = Pin::as_mut(&mut boxed); Pin::get_unchecked_mut(mut_ref).slice = slice; } boxed } } fn main() { let unmoved = Unmovable::new("hello".to_string()); // 只要结构体没有被转移,那指针就应该指向正确的位置,而且我们可以随意移动指针 let mut still_unmoved = unmoved; assert_eq!(still_unmoved.slice, NonNull::from(&still_unmoved.data)); // 因为我们的类型没有实现 `Unpin` 特征,下面这段代码将无法编译 // let mut new_unmoved = Unmovable::new("world".to_string()); // std::mem::swap(&mut *still_unmoved, &mut *new_unmoved); }
上面的代码也非常清晰,虽然使用了 unsafe,其实更多的是无奈之举,跟之前的 unsafe 实现完全不可同日而语。
其实 Pin 在这里并没有魔法,它也并不是实现自引用类型的主要原因,最关键的还是里面的裸指针的使用,而 Pin 起到的作用就是确保我们的值不会被移走,否则指针就会指向一个错误的地址!
使用 ouroboros
对于自引用结构体,三方库也有支持的,其中一个就是 ouroboros,当然它也有自己的限制,我们后面会提到,先来看看该如何使用:
use ouroboros::self_referencing; #[self_referencing] struct SelfRef { value: String, #[borrows(value)] pointer_to_value: &'this str, } fn main(){ let v = SelfRefBuilder { value: "aaa".to_string(), pointer_to_value_builder: |value: &String| value, }.build(); // 借用value值 let s = v.borrow_value(); // 借用指针 let p = v.borrow_pointer_to_value(); // value值和指针指向的值相等 assert_eq!(s, *p); }
可以看到,ouroboros 使用起来并不复杂,就是需要你去按照它的方式创建结构体和引用类型:SelfRef 变成 SelfRefBuilder,引用字段从 pointer_to_value 变成 pointer_to_value_builder,并且连类型都变了。
在使用时,通过 borrow_value 来借用 value 的值,通过 borrow_pointer_to_value 来借用 pointer_to_value 这个指针。
看上去很美好对吧?但是你可以尝试着去修改 String 字符串的值试试,ouroboros 限制还是较多的,但是对于基本类型依然是支持的不错,以下例子来源于官方:
use ouroboros::self_referencing; #[self_referencing] struct MyStruct { int_data: i32, float_data: f32, #[borrows(int_data)] int_reference: &'this i32, #[borrows(mut float_data)] float_reference: &'this mut f32, } fn main() { let mut my_value = MyStructBuilder { int_data: 42, float_data: 3.14, int_reference_builder: |int_data: &i32| int_data, float_reference_builder: |float_data: &mut f32| float_data, }.build(); // Prints 42 println!("{:?}", my_value.borrow_int_data()); // Prints 3.14 println!("{:?}", my_value.borrow_float_reference()); // Sets the value of float_data to 84.0 my_value.with_mut(|fields| { **fields.float_reference = (**fields.int_reference as f32) * 2.0; }); // We can hold on to this reference... let int_ref = *my_value.borrow_int_reference(); println!("{:?}", *int_ref); // As long as the struct is still alive. drop(my_value); // This will cause an error! // println!("{:?}", *int_ref); }
总之,使用这个库前,强烈建议看一些官方的例子中支持什么样的类型和 API,如果能满足的你的需求,就果断使用它,如果不能满足,就继续往下看。
只能说,它确实帮助我们解决了问题,但是一个是破坏了原有的结构,另外就是并不是所有数据类型都支持:它需要目标值的内存地址不会改变,因此 Vec 动态数组就不适合,因为当内存空间不够时,Rust 会重新分配一块空间来存放该数组,这会导致内存地址的改变。
类似的库还有:
- rental, 这个库其实是最有名的,但是好像不再维护了,用倒是没问题
- owning-ref,将所有者和它的引用绑定到一个封装类型
这三个库,各有各的特点,也各有各的缺陷,建议大家需要时,一定要仔细调研,并且写 demo 进行测试,不可大意。
rental 虽然不怎么维护,但是可能依然是这三个里面最强大的,而且网上的用例也比较多,容易找到参考代码
Rc + RefCell 或 Arc + Mutex
类似于循环引用的解决方式,自引用也可以用这种组合来解决,但是会导致代码的类型标识到处都是,大大的影响了可读性。
终极大法
如果两个放在一起会报错,那就分开它们。对,终极大法就这么简单,当然思路上的简单不代表实现上的简单,最终结果就是导致代码复杂度的上升。
学习一本书:如何实现链表
最后,推荐一本专门将如何实现链表的书(真是富有 Rust 特色,链表都能复杂到出书了 o_o),Learn Rust by writing Entirely Too Many Linked Lists
总结
上面讲了这么多方法,但是我们依然无法正确的告诉你在某个场景应该使用哪个方法,这个需要你自己的判断,因为自引用实在是过于复杂。
我们能做的就是告诉你,有这些办法可以解决自引用问题,而这些办法每个都有自己适用的范围,需要你未来去深入的挖掘和发现。
偷偷说一句,就算是我,遇到自引用一样挺头疼,好在这种情况真的不常见,往往是实现特定的算法和数据结构时才需要,应用代码中几乎用不到。
多线程并发编程
安全和高效的处理并发是 Rust 语言的主要目标之一。随着现代处理器的核心数不断增加,并发和并行已经成为日常编程不可或缺的一部分,甚至于 Go 语言已经将并发简化到一个 go 关键字就可以。
可惜的是,在 Rust 中由于语言设计理念、安全、性能的多方面考虑,并没有采用 Go 语言大道至简的方式,而是选择了多线程与 async/await 相结合,优点是可控性更强、性能更高,缺点是复杂度并不低,当然这也是系统级语言的应有选择:使用复杂度换取可控性和性能。
不过,大家也不用担心,本书的目标就是降低 Rust 使用门槛,这个门槛自然也包括如何在 Rust 中进行异步并发编程,我们将从多线程以及 async/await 两个方面去深入浅出地讲解,首先,从本章的多线程开始。
在本章,我们将深入讲解并发和并行的区别以及如何使用多线程进行 Rust 并发编程,那么先来看看何为并行与并发。
并发和并行
并发是同一时间应对多件事情的能力 - Rob Pike
并行和并发其实并不难,但是也给一些用户造成了困扰,因此我们专门开辟一个章节,用于讲清楚这两者的区别。
Erlang 之父 Joe Armstrong(伟大的异步编程先驱,开创一个时代的殿堂级计算机科学家,我还犹记得当年刚学到 Erlang 时的震撼,respect!)用一张 5 岁小孩都能看懂的图片解释了并发与并行的区别:

上图很直观的体现了:
- 并发(Concurrent) 是多个队列使用同一个咖啡机,然后两个队列轮换着使用(未必是 1:1 轮换,也可能是其它轮换规则),最终每个人都能接到咖啡
- 并行(Parallel) 是每个队列都拥有一个咖啡机,最终也是每个人都能接到咖啡,但是效率更高,因为同时可以有两个人在接咖啡
当然,我们还可以对比下串行:只有一个队列且仅使用一台咖啡机,前面哪个人接咖啡时突然发呆了几分钟,后面的人就只能等他结束才能继续接。可能有读者有疑问了,从图片来看,并发也存在这个问题啊,前面的人发呆了几分钟不接咖啡怎么办?很简单,另外一个队列的人把他推开就行了,自己队友不能在背后开枪,但是其它队的可以:)
在正式开始之前,先给出一个结论:并发和并行都是对“多任务”处理的描述,其中并发是轮流处理,而并行是同时处理。
CPU 多核
现在的个人计算机动辄拥有十来个核心(M1 Max/Intel 12 代),如果使用串行的方式那真是太低效了,因此我们把各种任务简单分成多个队列,每个队列都交给一个 CPU 核心去执行,当某个 CPU 核心没有任务时,它还能去其它核心的队列中偷任务(真·老黄牛),这样就实现了并行化处理。
单核心并发
那问题来了,在早期只有一个 CPU 核心时,我们的任务是怎么处理的呢?其实聪明的读者应该已经想到,是的,并发解君愁。当然,这里还得提到操作系统的多线程,正是操作系统多线程 + CPU 核心,才实现了现代化的多任务操作系统。
在 OS 级别,多线程负责管理我们的任务队列,你可以简单认为一个线程管理着一个任务队列,然后线程之间还能根据空闲度进行任务调度。我们的程序只会跟 OS 线程打交道,并不关心 CPU 到底有多少个核心,真正关心的只是 OS,当线程把任务交给 CPU 核心去执行时,如果只有一个 CPU 核心,那么它就只能同时处理一个任务。
相信大家都看出来了:CPU 核心对应的是上图的咖啡机,而多个线程的任务队列就对应的多个排队的队列,由于终受限于 CPU 核心数,每个队列每次只会有一个任务被处理。
和排队一样,假如某个任务执行时间过长,就会导致用户界面的假死(相信使用 Windows 的同学或多或少都碰到过假死的问题), 那么就需要 CPU 的任务调度了(真实 CPU 的调度很复杂,我们这里做了简化),有一个调度器会按照某些条件从队列中选择任务进行执行,并且当一个任务执行时间过长时,会强行切换该任务到后台中(或者放入任务队列,真实情况很复杂!),去执行新的任务。
不断这样的快速任务切换,对用户而言就实现了表面上的多任务同时处理,但是实际上最终也只有一个 CPU 核心在不停的工作。
因此并发的关键在于:快速轮换处理不同的任务,给用户带来所有任务同时在运行的假象。
多核心并行
当 CPU 核心增多到 N 时,那么同一时间就能有 N 个任务被处理,那么我们的并行度就是 N,相应的处理效率也变成了单核心的 N 倍(实际情况并没有这么高)。
多核心并发
当核心增多到 N 时,操作系统同时在进行的任务肯定远不止 N 个,这些任务将被放入 M 个线程队列中,接着交给 N 个 CPU 核心去执行,最后实现了 M:N 的处理模型,在这种情况下,并发与并行是同时在发生的,所有用户任务从表面来看都在并发的运行,但实际上,同一时刻只有 N 个任务能被同时并行的处理。
看到这里,相信大家已经明白两者的区别,那么我们下面给出一个正式的定义(该定义摘选自<<并发的艺术>>)。
正式的定义
如果某个系统支持两个或者多个动作的同时存在,那么这个系统就是一个并发系统。如果某个系统支持两个或者多个动作同时执行,那么这个系统就是一个并行系统。并发系统与并行系统这两个定义之间的关键差异在于 “存在” 这个词。
在并发程序中可以同时拥有两个或者多个线程。这意味着,如果程序在单核处理器上运行,那么这两个线程将交替地换入或者换出内存。这些线程是 同时“存在” 的——每个线程都处于执行过程中的某个状态。如果程序能够并行执行,那么就一定是运行在多核处理器上。此时,程序中的每个线程都将分配到一个独立的处理器核上,因此可以同时运行。
相信你已经能够得出结论——“并行”概念是“并发”概念的一个子集。也就是说,你可以编写一个拥有多个线程或者进程的并发程序,但如果没有多核处理器来执行这个程序,那么就不能以并行方式来运行代码。因此,凡是在求解单个问题时涉及多个执行流程的编程模式或者执行行为,都属于并发编程的范畴。
编程语言的并发模型
如果大家学过其它语言的多线程,可能就知道不同语言对于线程的实现可能大相径庭:
- 由于操作系统提供了创建线程的 API,因此部分语言会直接调用该 API 来创建线程,因此最终程序内的线程数和该程序占用的操作系统线程数相等,一般称之为1:1 线程模型,例如 Rust。
- 还有些语言在内部实现了自己的线程模型(绿色线程、协程),程序内部的 M 个线程最后会以某种映射方式使用 N 个操作系统线程去运行,因此称之为M:N 线程模型,其中 M 和 N 并没有特定的彼此限制关系。一个典型的代表就是 Go 语言。
- 还有些语言使用了 Actor 模型,基于消息传递进行并发,例如 Erlang 语言。
总之,每一种模型都有其优缺点及选择上的权衡,而 Rust 在设计时考虑的权衡就是运行时(Runtime)。出于 Rust 的系统级使用场景,且要保证调用 C 时的极致性能,它最终选择了尽量小的运行时实现。
运行时是那些会被打包到所有程序可执行文件中的 Rust 代码,根据每个语言的设计权衡,运行时虽然有大有小(例如 Go 语言由于实现了协程和 GC,运行时相对就会更大一些),但是除了汇编之外,每个语言都拥有它。小运行时的其中一个好处在于最终编译出的可执行文件会相对较小,同时也让该语言更容易被其它语言引入使用。
而绿色线程/协程的实现会显著增大运行时的大小,因此 Rust 只在标准库中提供了 1:1 的线程模型,如果你愿意牺牲一些性能来换取更精确的线程控制以及更小的线程上下文切换成本,那么可以选择 Rust 中的 M:N 模型,这些模型由三方库提供了实现,例如大名鼎鼎的 tokio。
在了解了并发和并行后,我们可以正式开始 Rust 的多线程之旅。
使用线程
放在十年前,多线程编程可能还是一个少数人才掌握的核心概念,但是在今天,随着编程语言的不断发展,多线程、多协程、Actor 等并发编程方式已经深入人心,同时多线程编程的门槛也在不断降低,本章节我们来看看在 Rust 中该如何使用多线程。
多线程编程的风险
由于多线程的代码是同时运行的,因此我们无法保证线程间的执行顺序,这会导致一些问题:
- 竞态条件(race conditions),多个线程以非一致性的顺序同时访问数据资源
- 死锁(deadlocks),两个线程都想使用某个资源,但是又都在等待对方释放资源后才能使用,结果最终都无法继续执行
- 一些因为多线程导致的很隐晦的 BUG,难以复现和解决
虽然 Rust 已经通过各种机制减少了上述情况的发生,但是依然无法完全避免上述情况,因此我们在编程时需要格外的小心,同时本书也会列出多线程编程时常见的陷阱,让你提前规避可能的风险。
创建线程
使用 thread::spawn 可以创建线程:
use std::thread; use std::time::Duration; fn main() { thread::spawn(|| { for i in 1..10 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
有几点值得注意:
- 线程内部的代码使用闭包来执行
main线程一旦结束,程序就立刻结束,因此需要保持它的存活,直到其它子线程完成自己的任务thread::sleep会让当前线程休眠指定的时间,随后其它线程会被调度运行(上一节并发与并行中有简单介绍过),因此就算你的电脑只有一个 CPU 核心,该程序也会表现的如同多 CPU 核心一般,这就是并发!
来看看输出:
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 4 from the main thread!
hi number 5 from the spawned thread!
如果多运行几次,你会发现好像每次输出会不太一样,因为:虽说线程往往是轮流执行的,但是这一点无法被保证!线程调度的方式往往取决于你使用的操作系统。总之,千万不要依赖线程的执行顺序。
等待子线程的结束
上面的代码你不但可能无法让子线程从 1 顺序打印到 10,而且可能打印的数字会变少,因为主线程会提前结束,导致子线程也随之结束,更过分的是,如果当前系统繁忙,甚至该子线程还没被创建,主线程就已经结束了!
因此我们需要一个方法,让主线程安全、可靠地等所有子线程完成任务后,再 kill self:
use std::thread; use std::time::Duration; fn main() { let handle = thread::spawn(|| { for i in 1..5 { println!("hi number {} from the spawned thread!", i); thread::sleep(Duration::from_millis(1)); } }); handle.join().unwrap(); for i in 1..5 { println!("hi number {} from the main thread!", i); thread::sleep(Duration::from_millis(1)); } }
通过调用 handle.join,可以让当前线程阻塞,直到它等待的子线程的结束,在上面代码中,由于 main 线程会被阻塞,因此它直到子线程结束后才会输出自己的 1..5:
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
以上输出清晰的展示了线程阻塞的作用,如果你将 handle.join 放置在 main 线程中的 for 循环后面,那就是另外一个结果:两个线程交替输出。
在线程闭包中使用 move
在闭包章节中,有讲过 move 关键字在闭包中的使用可以让该闭包拿走环境中某个值的所有权,同样地,你可以使用 move 来将所有权从一个线程转移到另外一个线程。
首先,来看看在一个线程中直接使用另一个线程中的数据会如何:
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(|| { println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); }
以上代码在子线程的闭包中捕获了环境中的 v 变量,来看看结果:
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {:?}", v);
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {:?}", v);
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
其实代码本身并没有什么问题,问题在于 Rust 无法确定新的线程会活多久(多个线程的结束顺序并不是固定的),所以也无法确定新线程所引用的 v 是否在使用过程中一直合法:
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(|| { println!("Here's a vector: {:?}", v); }); drop(v); // oh no! handle.join().unwrap(); }
大家要记住,线程的启动时间点和结束时间点是不确定的,因此存在一种可能,当主线程执行完, v 被释放掉时,新的线程很可能还没有结束甚至还没有被创建成功,此时新线程对 v 的引用立刻就不再合法!
好在报错里进行了提示:to force the closure to take ownership of v (and any other referenced variables), use the `move` keyword,让我们使用 move 关键字拿走 v 的所有权即可:
use std::thread; fn main() { let v = vec![1, 2, 3]; let handle = thread::spawn(move || { println!("Here's a vector: {:?}", v); }); handle.join().unwrap(); // 下面代码会报错borrow of moved value: `v` // println!("{:?}",v); }
如上所示,很简单的代码,而且 Rust 的所有权机制保证了数据使用上的安全:v 的所有权被转移给新的线程后,main 线程将无法继续使用:最后一行代码将报错。
线程是如何结束的
之前我们提到 main 线程是程序的主线程,一旦结束,则程序随之结束,同时各个子线程也将被强行终止。那么有一个问题,如果父线程不是 main 线程,那么父线程的结束会导致什么?自生自灭还是被干掉?
在系统编程中,操作系统提供了直接杀死线程的接口,简单粗暴,但是 Rust 并没有提供这样的接口,原因在于,粗暴地终止一个线程可能会导致资源没有释放、状态混乱等不可预期的结果,一向以安全自称的 Rust,自然不会砸自己的饭碗。
那么 Rust 中线程是如何结束的呢?答案很简单:线程的代码执行完,线程就会自动结束。但是如果线程中的代码不会执行完呢?那么情况可以分为两种进行讨论:
- 线程的任务是一个循环 IO 读取,任务流程类似:IO 阻塞,等待读取新的数据 -> 读到数据,处理完成 -> 继续阻塞等待 ··· -> 收到 socket 关闭的信号 -> 结束线程,在此过程中,绝大部分时间线程都处于阻塞的状态,因此虽然看上去是循环,CPU 占用其实很小,也是网络服务中最最常见的模型
- 线程的任务是一个循环,里面没有任何阻塞,包括休眠这种操作也没有,此时 CPU 很不幸的会被跑满,而且你如果没有设置终止条件,该线程将持续跑满一个 CPU 核心,并且不会被终止,直到
main线程的结束
第一情况很常见,我们来模拟看看第二种情况:
use std::thread; use std::time::Duration; fn main() { // 创建一个线程A let new_thread = thread::spawn(move || { // 再创建一个线程B thread::spawn(move || { loop { println!("I am a new thread."); } }) }); // 等待新创建的线程执行完成 new_thread.join().unwrap(); println!("Child thread is finish!"); // 睡眠一段时间,看子线程创建的子线程是否还在运行 thread::sleep(Duration::from_millis(100)); }
以上代码中,main 线程创建了一个新的线程 A,同时该新线程又创建了一个新的线程 B,可以看到 A 线程在创建完 B 线程后就立即结束了,而 B 线程则在不停地循环输出。
从之前的线程结束规则,我们可以猜测程序将这样执行:A 线程结束后,由它创建的 B 线程仍在疯狂输出,直到 main 线程在 100 毫秒后结束。如果你把该时间增加到几十秒,就可以看到你的 CPU 核心 100% 的盛况了-,-
多线程的性能
下面我们从多个方面来看看多线程的性能大概是怎么样的。
创建线程的性能
据不精确估算,创建一个线程大概需要 0.24 毫秒,随着线程的变多,这个值会变得更大,因此线程的创建耗时并不是不可忽略的,只有当真的需要处理一个值得用线程去处理的任务时,才使用线程,一些鸡毛蒜皮的任务,就无需创建线程了。
创建多少线程合适
因为 CPU 的核心数限制,当任务是 CPU 密集型时,就算线程数超过了 CPU 核心数,也并不能帮你获得更好的性能,因为每个线程的任务都可以轻松让 CPU 的某个核心跑满,既然如此,让线程数等于 CPU 核心数是最好的。
但是当你的任务大部分时间都处于阻塞状态时,就可以考虑增多线程数量,这样当某个线程处于阻塞状态时,会被切走,进而运行其它的线程,典型就是网络 IO 操作,我们可以为每一个进来的用户连接创建一个线程去处理,该连接绝大部分时间都是处于 IO 读取阻塞状态,因此有限的 CPU 核心完全可以处理成百上千的用户连接线程,但是事实上,对于这种网络 IO 情况,一般都不再使用多线程的方式了,毕竟操作系统的线程数是有限的,意味着并发数也很容易达到上限,而且过多的线程也会导致线程上下文切换的代价过大,使用 async/await 的 M:N 并发模型,就没有这个烦恼。
多线程的开销
下面的代码是一个无锁实现(CAS)的 Hashmap 在多线程下的使用:
#![allow(unused)] fn main() { for i in 0..num_threads { let ht = Arc::clone(&ht); let handle = thread::spawn(move || { for j in 0..adds_per_thread { let key = thread_rng().gen::<u32>(); let value = thread_rng().gen::<u32>(); ht.set_item(key, value); } }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } }
按理来说,既然是无锁实现了,那么锁的开销应该几乎没有,性能会随着线程数的增加接近线性增长,但是真的是这样吗?
下图是该代码在 48 核机器上的运行结果:
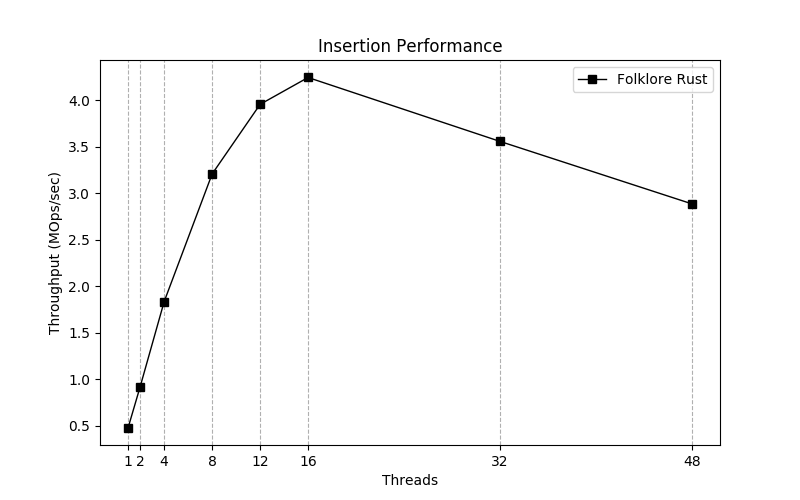
从图上可以明显的看出:吞吐并不是线性增长,尤其从 16 核开始,甚至开始肉眼可见的下降,这是为什么呢?
限于书本的篇幅有限,我们只能给出大概的原因:
- 虽然是无锁,但是内部是 CAS 实现,大量线程的同时访问,会让 CAS 重试次数大幅增加
- 线程过多时,CPU 缓存的命中率会显著下降,同时多个线程竞争一个 CPU Cache-line 的情况也会经常发生
- 大量读写可能会让内存带宽也成为瓶颈
- 读和写不一样,无锁数据结构的读往往可以很好地线性增长,但是写不行,因为写竞争太大
总之,多线程的开销往往是在锁、数据竞争、缓存失效上,这些限制了现代化软件系统随着 CPU 核心的增多性能也线性增加的野心。
线程屏障(Barrier)
在 Rust 中,可以使用 Barrier 让多个线程都执行到某个点后,才继续一起往后执行:
use std::sync::{Arc, Barrier}; use std::thread; fn main() { let mut handles = Vec::with_capacity(6); let barrier = Arc::new(Barrier::new(6)); for _ in 0..6 { let b = barrier.clone(); handles.push(thread::spawn(move|| { println!("before wait"); b.wait(); println!("after wait"); })); } for handle in handles { handle.join().unwrap(); } }
上面代码,我们在线程打印出 before wait 后增加了一个屏障,目的就是等所有的线程都打印出before wait后,各个线程再继续执行:
before wait
before wait
before wait
before wait
before wait
before wait
after wait
after wait
after wait
after wait
after wait
after wait
线程局部变量(Thread Local Variable)
对于多线程编程,线程局部变量在一些场景下非常有用,而 Rust 通过标准库和三方库对此进行了支持。
标准库 thread_local
使用 thread_local 宏可以初始化线程局部变量,然后在线程内部使用该变量的 with 方法获取变量值:
#![allow(unused)] fn main() { use std::cell::RefCell; use std::thread; thread_local!(static FOO: RefCell<u32> = RefCell::new(1)); FOO.with(|f| { assert_eq!(*f.borrow(), 1); *f.borrow_mut() = 2; }); // 每个线程开始时都会拿到线程局部变量的FOO的初始值 let t = thread::spawn(move|| { FOO.with(|f| { assert_eq!(*f.borrow(), 1); *f.borrow_mut() = 3; }); }); // 等待线程完成 t.join().unwrap(); // 尽管子线程中修改为了3,我们在这里依然拥有main线程中的局部值:2 FOO.with(|f| { assert_eq!(*f.borrow(), 2); }); }
上面代码中,FOO 即是我们创建的线程局部变量,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的 FOO 值彼此互不干扰。注意 FOO 使用 static 声明为生命周期为 'static 的静态变量。
可以注意到,线程中对 FOO 的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。
你还可以在结构体中使用线程局部变量:
use std::cell::RefCell; struct Foo; impl Foo { thread_local! { static FOO: RefCell<usize> = RefCell::new(0); } } fn main() { Foo::FOO.with(|x| println!("{:?}", x)); }
或者通过引用的方式使用它:
#![allow(unused)] fn main() { use std::cell::RefCell; use std::thread::LocalKey; thread_local! { static FOO: RefCell<usize> = RefCell::new(0); } struct Bar { foo: &'static LocalKey<RefCell<usize>>, } impl Bar { fn constructor() -> Self { Self { foo: &FOO, } } } }
三方库 thread-local
除了标准库外,一位大神还开发了 thread-local 库,它允许每个线程持有值的独立拷贝:
#![allow(unused)] fn main() { use thread_local::ThreadLocal; use std::sync::Arc; use std::cell::Cell; use std::thread; let tls = Arc::new(ThreadLocal::new()); // 创建多个线程 for _ in 0..5 { let tls2 = tls.clone(); thread::spawn(move || { // 将计数器加1 let cell = tls2.get_or(|| Cell::new(0)); cell.set(cell.get() + 1); }).join().unwrap(); } // 一旦所有子线程结束,收集它们的线程局部变量中的计数器值,然后进行求和 let tls = Arc::try_unwrap(tls).unwrap(); let total = tls.into_iter().fold(0, |x, y| x + y.get()); // 和为5 assert_eq!(total, 5); }
该库不仅仅使用了值的拷贝,而且还能自动把多个拷贝汇总到一个迭代器中,最后进行求和,非常好用。
用条件控制线程的挂起和执行
条件变量(Condition Variables)经常和 Mutex 一起使用,可以让线程挂起,直到某个条件发生后再继续执行:
use std::thread; use std::sync::{Arc, Mutex, Condvar}; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = pair.clone(); thread::spawn(move|| { let &(ref lock, ref cvar) = &*pair2; let mut started = lock.lock().unwrap(); println!("changing started"); *started = true; cvar.notify_one(); }); let &(ref lock, ref cvar) = &*pair; let mut started = lock.lock().unwrap(); while !*started { started = cvar.wait(started).unwrap(); } println!("started changed"); }
上述代码流程如下:
main线程首先进入while循环,调用wait方法挂起等待子线程的通知,并释放了锁started- 子线程获取到锁,并将其修改为
true,然后调用条件变量的notify_one方法来通知主线程继续执行
只被调用一次的函数
有时,我们会需要某个函数在多线程环境下只被调用一次,例如初始化全局变量,无论是哪个线程先调用函数来初始化,都会保证全局变量只会被初始化一次,随后的其它线程调用就会忽略该函数:
use std::thread; use std::sync::Once; static mut VAL: usize = 0; static INIT: Once = Once::new(); fn main() { let handle1 = thread::spawn(move || { INIT.call_once(|| { unsafe { VAL = 1; } }); }); let handle2 = thread::spawn(move || { INIT.call_once(|| { unsafe { VAL = 2; } }); }); handle1.join().unwrap(); handle2.join().unwrap(); println!("{}", unsafe { VAL }); }
代码运行的结果取决于哪个线程先调用 INIT.call_once (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 handle1 先,则输出 1,否则输出 2。
call_once 方法
执行初始化过程一次,并且只执行一次。
如果当前有另一个初始化过程正在运行,线程将阻止该方法被调用。
当这个函数返回时,保证一些初始化已经运行并完成,它还保证由执行的闭包所执行的任何内存写入都能被其他线程在这时可靠地观察到。
总结
Rust 的线程模型是 1:1 模型,因为 Rust 要保持尽量小的运行时。
我们可以使用 thread::spawn 来创建线程,创建出的多个线程之间并不存在执行顺序关系,因此代码逻辑千万不要依赖于线程间的执行顺序。
main 线程若是结束,则所有子线程都将被终止,如果希望等待子线程结束后,再结束 main 线程,你需要使用创建线程时返回的句柄的 join 方法。
在线程中无法直接借用外部环境中的变量值,因为新线程的启动时间点和结束时间点是不确定的,所以 Rust 无法保证该线程中借用的变量在使用过程中依然是合法的。你可以使用 move 关键字将变量的所有权转移给新的线程,来解决此问题。
父线程结束后,子线程仍在持续运行,直到子线程的代码运行完成或者 main 线程的结束。
线程间的消息传递
在多线程间有多种方式可以共享、传递数据,最常用的方式就是通过消息传递或者将锁和Arc联合使用,而对于前者,在编程界还有一个大名鼎鼎的Actor线程模型为其背书,典型的有 Erlang 语言,还有 Go 语言中很经典的一句话:
Do not communicate by sharing memory; instead, share memory by communicating
而对于后者,我们将在下一节中进行讲述。
消息通道
与 Go 语言内置的chan不同,Rust 是在标准库里提供了消息通道(channel),你可以将其想象成一场直播,多个主播联合起来在搞一场直播,最终内容通过通道传输给屏幕前的我们,其中主播被称之为发送者,观众被称之为接收者,显而易见的是:一个通道应该支持多个发送者和接收者。
但是,在实际使用中,我们需要使用不同的库来满足诸如:多发送者 -> 单接收者,多发送者 -> 多接收者等场景形式,此时一个标准库显然就不够了,不过别急,让我们先从标准库讲起。
多发送者,单接收者
标准库提供了通道std::sync::mpsc,其中mpsc是multiple producer, single consumer的缩写,代表了该通道支持多个发送者,但是只支持唯一的接收者。 当然,支持多个发送者也意味着支持单个发送者,我们先来看看单发送者、单接收者的简单例子:
use std::sync::mpsc; use std::thread; fn main() { // 创建一个消息通道, 返回一个元组:(发送者,接收者) let (tx, rx) = mpsc::channel(); // 创建线程,并发送消息 thread::spawn(move || { // 发送一个数字1, send方法返回Result<T,E>,通过unwrap进行快速错误处理 tx.send(1).unwrap(); // 下面代码将报错,因为编译器自动推导出通道传递的值是i32类型,那么Option<i32>类型将产生不匹配错误 // tx.send(Some(1)).unwrap() }); // 在主线程中接收子线程发送的消息并输出 println!("receive {}", rx.recv().unwrap()); }
以上代码并不复杂,但仍有几点需要注意:
tx,rx对应发送者和接收者,它们的类型由编译器自动推导:tx.send(1)发送了整数,因此它们分别是mpsc::Sender<i32>和mpsc::Receiver<i32>类型,需要注意,由于内部是泛型实现,一旦类型被推导确定,该通道就只能传递对应类型的值, 例如此例中非i32类型的值将导致编译错误- 接收消息的操作
rx.recv()会阻塞当前线程,直到读取到值,或者通道被关闭 - 需要使用
move将tx的所有权转移到子线程的闭包中
在注释中提到send方法返回一个Result<T,E>,说明它有可能返回一个错误,例如接收者被drop导致了发送的值不会被任何人接收,此时继续发送毫无意义,因此返回一个错误最为合适,在代码中我们仅仅使用unwrap进行了快速处理,但在实际项目中你需要对错误进行进一步的处理。
同样的,对于recv方法来说,当发送者关闭时,它也会接收到一个错误,用于说明不会再有任何值被发送过来。
不阻塞的 try_recv 方法
除了上述recv方法,还可以使用try_recv尝试接收一次消息,该方法并不会阻塞线程,当通道中没有消息时,它会立刻返回一个错误:
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { tx.send(1).unwrap(); }); println!("receive {:?}", rx.try_recv()); }
由于子线程的创建需要时间,因此println!和try_recv方法会先执行,而此时子线程的消息还未被发出。try_recv会尝试立即读取一次消息,因为消息没有发出,此次读取最终会报错,且主线程运行结束(可悲的是,相对于主线程中的代码,子线程的创建速度实在是过慢,直到主线程结束,都无法完成子线程的初始化。。):
receive Err(Empty)
如上,try_recv返回了一个错误,错误内容是Empty,代表通道并没有消息。如果你尝试把println!复制一些行,就会发现一个有趣的输出:
···
receive Err(Empty)
receive Ok(1)
receive Err(Disconnected)
···
如上,当子线程创建成功且发送消息后,主线程会接收到Ok(1)的消息内容,紧接着子线程结束,发送者也随着被drop,此时接收者又会报错,但是这次错误原因有所不同:Disconnected代表发送者已经被关闭。
传输具有所有权的数据
使用通道来传输数据,一样要遵循 Rust 的所有权规则:
- 若值的类型实现了
Copy特征,则直接复制一份该值,然后传输过去,例如之前的i32类型 - 若值没有实现
Copy,则它的所有权会被转移给接收端,在发送端继续使用该值将报错
一起来看看第二种情况:
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let s = String::from("我,飞走咯!"); tx.send(s).unwrap(); println!("val is {}", s); }); let received = rx.recv().unwrap(); println!("Got: {}", received); }
以上代码中,String底层的字符串是存储在堆上,并没有实现Copy特征,当它被发送后,会将所有权从发送端的s转移给接收端的received,之后s将无法被使用:
error[E0382]: borrow of moved value: `s`
--> src/main.rs:10:31
|
8 | let s = String::from("我,飞走咯!");
| - move occurs because `s` has type `String`, which does not implement the `Copy` trait // 所有权被转移,由于`String`没有实现`Copy`特征
9 | tx.send(s).unwrap();
| - value moved here // 所有权被转移走
10 | println!("val is {}", s);
| ^ value borrowed here after move // 所有权被转移后,依然对s进行了借用
各种细节不禁令人感叹:Rust 还是安全!假如没有所有权的保护,String字符串将被两个线程同时持有,任何一个线程对字符串内容的修改都会导致另外一个线程持有的字符串被改变,除非你故意这么设计,否则这就是不安全的隐患。
使用 for 进行循环接收
下面来看看如何连续接收通道中的值:
use std::sync::mpsc; use std::thread; use std::time::Duration; fn main() { let (tx, rx) = mpsc::channel(); thread::spawn(move || { let vals = vec![ String::from("hi"), String::from("from"), String::from("the"), String::from("thread"), ]; for val in vals { tx.send(val).unwrap(); thread::sleep(Duration::from_secs(1)); } }); for received in rx { println!("Got: {}", received); } }
在上面代码中,主线程和子线程是并发运行的,子线程在不停的发送消息 -> 休眠 1 秒,与此同时,主线程使用for循环阻塞的从rx迭代器中接收消息,当子线程运行完成时,发送者tx会随之被drop,此时for循环将被终止,最终main线程成功结束。
使用多发送者
由于子线程会拿走发送者的所有权,因此我们必须对发送者进行克隆,然后让每个线程拿走它的一份拷贝:
use std::sync::mpsc; use std::thread; fn main() { let (tx, rx) = mpsc::channel(); let tx1 = tx.clone(); thread::spawn(move || { tx.send(String::from("hi from raw tx")).unwrap(); }); thread::spawn(move || { tx1.send(String::from("hi from cloned tx")).unwrap(); }); for received in rx { println!("Got: {}", received); } }
代码并无太大区别,就多了一个对发送者的克隆let tx1 = tx.clone();,然后一个子线程拿走tx的所有权,另一个子线程拿走tx1的所有权,皆大欢喜。
但是有几点需要注意:
- 需要所有的发送者都被
drop掉后,接收者rx才会收到错误,进而跳出for循环,最终结束主线程 - 这里虽然用了
clone但是并不会影响性能,因为它并不在热点代码路径中,仅仅会被执行一次 - 由于两个子线程谁先创建完成是未知的,因此哪条消息先发送也是未知的,最终主线程的输出顺序也不确定
消息顺序
上述第三点的消息顺序仅仅是因为线程创建引起的,并不代表通道中的消息是无序的,对于通道而言,消息的发送顺序和接收顺序是一致的,满足FIFO原则(先进先出)。
由于篇幅有限,具体的代码这里就不再给出,感兴趣的读者可以自己验证下。
同步和异步通道
Rust 标准库的mpsc通道其实分为两种类型:同步和异步。
异步通道
之前我们使用的都是异步通道:无论接收者是否正在接收消息,消息发送者在发送消息时都不会阻塞:
use std::sync::mpsc; use std::thread; use std::time::Duration; fn main() { let (tx, rx)= mpsc::channel(); let handle = thread::spawn(move || { println!("发送之前"); tx.send(1).unwrap(); println!("发送之后"); }); println!("睡眠之前"); thread::sleep(Duration::from_secs(3)); println!("睡眠之后"); println!("receive {}", rx.recv().unwrap()); handle.join().unwrap(); }
运行后输出如下:
睡眠之前
发送之前
发送之后
//···睡眠3秒
睡眠之后
receive 1
主线程因为睡眠阻塞了 3 秒,因此并没有进行消息接收,而子线程却在此期间轻松完成了消息的发送。等主线程睡眠结束后,才姗姗来迟的从通道中接收了子线程老早之前发送的消息。
从输出还可以看出,发送之前和发送之后是连续输出的,没有受到接收端主线程的任何影响,因此通过mpsc::channel创建的通道是异步通道。
同步通道
与异步通道相反,同步通道发送消息是阻塞的,只有在消息被接收后才解除阻塞,例如:
use std::sync::mpsc; use std::thread; use std::time::Duration; fn main() { let (tx, rx)= mpsc::sync_channel(0); let handle = thread::spawn(move || { println!("发送之前"); tx.send(1).unwrap(); println!("发送之后"); }); println!("睡眠之前"); thread::sleep(Duration::from_secs(3)); println!("睡眠之后"); println!("receive {}", rx.recv().unwrap()); handle.join().unwrap(); }
运行后输出如下:
睡眠之前
发送之前
//···睡眠3秒
睡眠之后
receive 1
发送之后
可以看出,主线程由于睡眠被阻塞导致无法接收消息,因此子线程的发送也一直被阻塞,直到主线程结束睡眠并成功接收消息后,发送才成功:发送之后的输出是在receive 1之后,说明只有接收消息彻底成功后,发送消息才算完成。
消息缓存
细心的读者可能已经发现在创建同步通道时,我们传递了一个参数0: mpsc::sync_channel(0);,这是什么意思呢?
答案不急给出,先将0改成1,然后再运行试试:
睡眠之前
发送之前
发送之后
睡眠之后
receive 1
纳尼。。竟然得到了和异步通道一样的效果:根本没有等待主线程的接收开始,消息发送就立即完成了! 难道同步通道变成了异步通道? 别急,将子线程中的代码修改下试试:
#![allow(unused)] fn main() { println!("首次发送之前"); tx.send(1).unwrap(); println!("首次发送之后"); tx.send(1).unwrap(); println!("再次发送之后"); }
在子线程中,我们又多发了一条消息,此时输出如下:
睡眠之前
首次发送之前
首次发送之后
//···睡眠3秒
睡眠之后
receive 1
再次发送之后
Bingo,更奇怪的事出现了,第一条消息瞬间发送完成,没有阻塞,而发送第二条消息时却符合同步通道的特点:阻塞了,直到主线程接收后,才发送完成。
其实,一切的关键就在于1上,该值可以用来指定同步通道的消息缓存条数,当你设定为N时,发送者就可以无阻塞的往通道中发送N条消息,当消息缓冲队列满了后,新的消息发送将被阻塞(如果没有接收者消费缓冲队列中的消息,那么第N+1条消息就将触发发送阻塞)。
问题又来了,异步通道创建时完全没有这个缓冲值参数mpsc::channel(),它的缓冲值怎么设置呢? 额。。。都异步了,都可以无限发送了,都有摩托车了,还要自行车做啥子哦?事实上异步通道的缓冲上限取决于你的内存大小,不要撑爆就行。
因此,使用异步消息虽然能非常高效且不会造成发送线程的阻塞,但是存在消息未及时消费,最终内存过大的问题。在实际项目中,可以考虑使用一个带缓冲值的同步通道来避免这种风险。
关闭通道
之前我们数次提到了通道关闭,并且提到了当通道关闭后,发送消息或接收消息将会报错。那么如何关闭通道呢? 很简单:所有发送者被drop或者所有接收者被drop后,通道会自动关闭。
神奇的是,这件事是在编译期实现的,完全没有运行期性能损耗!只能说 Rust 的Drop特征 YYDS!
传输多种类型的数据
之前提到过,一个消息通道只能传输一种类型的数据,如果你想要传输多种类型的数据,可以为每个类型创建一个通道,你也可以使用枚举类型来实现:
use std::sync::mpsc::{self, Receiver, Sender}; enum Fruit { Apple(u8), Orange(String) } fn main() { let (tx, rx): (Sender<Fruit>, Receiver<Fruit>) = mpsc::channel(); tx.send(Fruit::Orange("sweet".to_string())).unwrap(); tx.send(Fruit::Apple(2)).unwrap(); for _ in 0..2 { match rx.recv().unwrap() { Fruit::Apple(count) => println!("received {} apples", count), Fruit::Orange(flavor) => println!("received {} oranges", flavor), } } }
如上所示,枚举类型还能让我们带上想要传输的数据,但是有一点需要注意,Rust 会按照枚举中占用内存最大的那个成员进行内存对齐,这意味着就算你传输的是枚举中占用内存最小的成员,它占用的内存依然和最大的成员相同, 因此会造成内存上的浪费。
新手容易遇到的坑
mpsc虽然相当简洁明了,但是在使用起来还是可能存在坑:
use std::sync::mpsc; fn main() { use std::thread; let (send, recv) = mpsc::channel(); let num_threads = 3; for i in 0..num_threads { let thread_send = send.clone(); thread::spawn(move || { thread_send.send(i).unwrap(); println!("thread {:?} finished", i); }); } // 在这里drop send... for x in recv { println!("Got: {}", x); } println!("finished iterating"); }
以上代码看起来非常正常,但是运行后主线程会一直阻塞,最后一行打印输出也不会被执行,原因在于: 子线程拿走的是复制后的send的所有权,这些拷贝会在子线程结束后被drop,因此无需担心,但是send本身却直到main函数的结束才会被drop。
之前提到,通道关闭的两个条件:发送者全部drop或接收者被drop,要结束for循环显然是要求发送者全部drop,但是由于send自身没有被drop,会导致该循环永远无法结束,最终主线程会一直阻塞。
解决办法很简单,drop掉send即可:在代码中的注释下面添加一行drop(send);。
mpmc 更好的性能
如果你需要 mpmc(多发送者,多接收者)或者需要更高的性能,可以考虑第三方库:
- crossbeam-channel, 老牌强库,功能较全,性能较强,之前是独立的库,但是后面合并到了
crossbeam主仓库中 - flume, 官方给出的性能数据某些场景要比 crossbeam 更好些
线程同步:锁、Condvar 和信号量
在多线程编程中,同步性极其的重要,当你需要同时访问一个资源、控制不同线程的执行次序时,都需要使用到同步性。
在 Rust 中有多种方式可以实现同步性。在上一节中讲到的消息传递就是同步性的一种实现方式,例如我们可以通过消息传递来控制不同线程间的执行次序。还可以使用共享内存来实现同步性,例如通过锁和原子操作等并发原语来实现多个线程同时且安全地去访问一个资源。
该如何选择
共享内存可以说是同步的灵魂,因为消息传递的底层实际上也是通过共享内存来实现,两者的区别如下:
- 共享内存相对消息传递能节省多次内存拷贝的成本
- 共享内存的实现简洁的多
- 共享内存的锁竞争更多
消息传递适用的场景很多,我们下面列出了几个主要的使用场景:
- 需要可靠和简单的(简单不等于简洁)实现时
- 需要模拟现实世界,例如用消息去通知某个目标执行相应的操作时
- 需要一个任务处理流水线(管道)时,等等
而使用共享内存(并发原语)的场景往往就比较简单粗暴:需要简洁的实现以及更高的性能时。
总之,消息传递类似一个单所有权的系统:一个值同时只能有一个所有者,如果另一个线程需要该值的所有权,需要将所有权通过消息传递进行转移。而共享内存类似于一个多所有权的系统:多个线程可以同时访问同一个值。
互斥锁 Mutex
既然是共享内存,那并发原语自然是重中之重,先来一起看看皇冠上的明珠: 互斥锁Mutex(mutual exclusion 的缩写)。
Mutex让多个线程并发的访问同一个值变成了排队访问:同一时间,只允许一个线程A访问该值,其它线程需要等待A访问完成后才能继续。
单线程中使用 Mutex
先来看看单线程中Mutex该如何使用:
use std::sync::Mutex; fn main() { // 使用`Mutex`结构体的关联函数创建新的互斥锁实例 let m = Mutex::new(5); { // 获取锁,然后deref为`m`的引用 // lock返回的是Result let mut num = m.lock().unwrap(); *num = 6; // 锁自动被drop } println!("m = {:?}", m); }
在注释中,已经大致描述了代码的功能,不过有一点需要注意:和Box类似,数据被Mutex所拥有,要访问内部的数据,需要使用方法m.lock()向m申请一个锁, 该方法会阻塞当前线程,直到获取到锁,因此当多个线程同时访问该数据时,只有一个线程能获取到锁,其它线程只能阻塞着等待,这样就保证了数据能被安全的修改!
m.lock()方法也有可能报错,例如当前正在持有锁的线程panic了。在这种情况下,其它线程不可能再获得锁,因此lock方法会返回一个错误。
这里你可能奇怪,m.lock明明返回一个锁,怎么就变成我们的num数值了?聪明的读者可能会想到智能指针,没错,因为Mutex<T>是一个智能指针,准确的说是m.lock()返回一个智能指针MutexGuard<T>:
- 它实现了
Deref特征,会被自动解引用后获得一个引用类型,该引用指向Mutex内部的数据 - 它还实现了
Drop特征,在超出作用域后,自动释放锁,以便其它线程能继续获取锁
正因为智能指针的使用,使得我们无需任何操作就能获取其中的数据。 如果释放锁,你需要做的仅仅是做好锁的作用域管理,例如上述代码的内部花括号使用,建议读者尝试下去掉内部的花括号,然后再次尝试获取第二个锁num1,看看会发生什么,友情提示:不会报错,但是主线程会永远阻塞,因为不幸发生了死锁。
use std::sync::Mutex; fn main() { let m = Mutex::new(5); let mut num = m.lock().unwrap(); *num = 6; // 锁还没有被 drop 就尝试申请下一个锁,导致主线程阻塞 // drop(num); // 手动 drop num ,可以让 num1 申请到下个锁 let mut num1 = m.lock().unwrap(); *num1 = 7; // drop(num1); // 手动 drop num1 ,观察打印结果的不同 println!("m = {:?}", m); }
多线程中使用 Mutex
单线程中使用锁,说实话纯粹是为了演示功能,毕竟多线程才是锁的舞台。 现在,我们再来看看,如何在多线程下使用Mutex来访问同一个资源.
无法运行的Rc<T>
use std::rc::Rc; use std::sync::Mutex; use std::thread; fn main() { // 通过`Rc`实现`Mutex`的多所有权 let counter = Rc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Rc::clone(&counter); // 创建子线程,并将`Mutex`的所有权拷贝传入到子线程中 let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } // 等待所有子线程完成 for handle in handles { handle.join().unwrap(); } // 输出最终的计数结果 println!("Result: {}", *counter.lock().unwrap()); }
由于子线程需要通过move拿走锁的所有权,因此我们需要使用多所有权来保证每个线程都拿到数据的独立所有权,恰好智能指针Rc<T>可以做到(上面代码会报错!具体往下看,别跳过-, -)。
以上代码实现了在多线程中计数的功能,由于多个线程都需要去修改该计数器,因此我们需要使用锁来保证同一时间只有一个线程可以修改计数器,否则会导致脏数据:想象一下 A 线程和 B 线程同时拿到计数器,获取了当前值1, 并且同时对其进行了修改,最后值变成2,你会不会在风中凌乱?毕竟正确的值是3,因为两个线程各自加 1。
可能有人会说,有那么巧的事情吗?事实上,对于人类来说,因为干啥啥慢,并没有那么多巧合,所以人总会存在巧合心理。但是对于计算机而言,每秒可以轻松运行上亿次,在这种频次下,一切巧合几乎都将必然发生,因此千万不要有任何侥幸心理。
如果事情有变坏的可能,不管这种可能性有多小,它都会发生! - 在计算机领域歪打正着的墨菲定律
事实上,上面的代码会报错:
error[E0277]: `Rc<Mutex<i32>>` cannot be sent between threads safely
// `Rc`无法在线程中安全的传输
--> src/main.rs:11:22
|
13 | let handle = thread::spawn(move || {
| ______________________^^^^^^^^^^^^^_-
| | |
| | `Rc<Mutex<i32>>` cannot be sent between threads safely
14 | | let mut num = counter.lock().unwrap();
15 | |
16 | | *num += 1;
17 | | });
| |_________- within this `[closure@src/main.rs:11:36: 15:10]`
|
= help: within `[closure@src/main.rs:11:36: 15:10]`, the trait `Send` is not implemented for `Rc<Mutex<i32>>`
// `Rc`没有实现`Send`特征
= note: required because it appears within the type `[closure@src/main.rs:11:36: 15:10]`
错误中提到了一个关键点:Rc<T>无法在线程中传输,因为它没有实现Send特征(在下一节将详细介绍),而该特征可以确保数据在线程中安全的传输。
多线程安全的 Arc<T>
好在,我们有Arc<T>,得益于它的内部计数器是多线程安全的,因此可以在多线程环境中使用:
use std::sync::{Arc, Mutex}; use std::thread; fn main() { let counter = Arc::new(Mutex::new(0)); let mut handles = vec![]; for _ in 0..10 { let counter = Arc::clone(&counter); let handle = thread::spawn(move || { let mut num = counter.lock().unwrap(); *num += 1; }); handles.push(handle); } for handle in handles { handle.join().unwrap(); } println!("Result: {}", *counter.lock().unwrap()); }
以上代码可以顺利运行:
Result: 10
内部可变性
在之前章节,我们提到过内部可变性,其中Rc<T>和RefCell<T>的结合,可以实现单线程的内部可变性。
现在我们又有了新的武器,由于Mutex<T>可以支持修改内部数据,当结合Arc<T>一起使用时,可以实现多线程的内部可变性。
简单总结下:Rc<T>/RefCell<T>用于单线程内部可变性, Arc<T>/Mutex<T>用于多线程内部可变性。
需要小心使用的 Mutex
如果有其它语言的编程经验,就知道互斥锁这家伙不好对付,想要正确使用,你得牢记在心:
- 在使用数据前必须先获取锁
- 在数据使用完成后,必须及时的释放锁,比如文章开头的例子,使用内部语句块的目的就是为了及时的释放锁
这两点看起来不起眼,但要正确的使用,其实是相当不简单的,对于其它语言,忘记释放锁是经常发生的,虽然 Rust 通过智能指针的drop机制帮助我们避免了这一点,但是由于不及时释放锁导致的性能问题也是常见的。
正因为这种困难性,导致很多用户都热衷于使用消息传递的方式来实现同步,例如 Go 语言直接把channel内置在语言特性中,甚至还有无锁的语言,例如erlang,完全使用Actor模型,依赖消息传递来完成共享和同步。幸好 Rust 的类型系统、所有权机制、智能指针等可以很好的帮助我们减轻使用锁时的负担。
另一个值的注意的是在使用Mutex<T>时,Rust 无法帮我们避免所有的逻辑错误,例如在之前章节,我们提到过使用Rc<T>可能会导致循环引用的问题。类似的,Mutex<T>也存在使用上的风险,例如创建死锁(deadlock):当一个操作试图锁住两个资源,然后两个线程各自获取其中一个锁,并试图获取另一个锁时,就会造成死锁。
死锁
在 Rust 中有多种方式可以创建死锁,了解这些方式有助于你提前规避可能的风险,一起来看看。
单线程死锁
这种死锁比较容易规避,但是当代码复杂后还是有可能遇到:
use std::sync::Mutex; fn main() { let data = Mutex::new(0); let d1 = data.lock(); let d2 = data.lock(); } // d1锁在此处释放
非常简单,只要你在另一个锁还未被释放时去申请新的锁,就会触发,当代码复杂后,这种情况可能就没有那么显眼。
多线程死锁
当我们拥有两个锁,且两个线程各自使用了其中一个锁,然后试图去访问另一个锁时,就可能发生死锁:
use std::{sync::{Mutex, MutexGuard}, thread}; use std::thread::sleep; use std::time::Duration; use lazy_static::lazy_static; lazy_static! { static ref MUTEX1: Mutex<i64> = Mutex::new(0); static ref MUTEX2: Mutex<i64> = Mutex::new(0); } fn main() { // 存放子线程的句柄 let mut children = vec![]; for i_thread in 0..2 { children.push(thread::spawn(move || { for _ in 0..1 { // 线程1 if i_thread % 2 == 0 { // 锁住MUTEX1 let guard: MutexGuard<i64> = MUTEX1.lock().unwrap(); println!("线程 {} 锁住了MUTEX1,接着准备去锁MUTEX2 !", i_thread); // 当前线程睡眠一小会儿,等待线程2锁住MUTEX2 sleep(Duration::from_millis(10)); // 去锁MUTEX2 let guard = MUTEX2.lock().unwrap(); // 线程2 } else { // 锁住MUTEX2 let _guard = MUTEX2.lock().unwrap(); println!("线程 {} 锁住了MUTEX2, 准备去锁MUTEX1", i_thread); let _guard = MUTEX1.lock().unwrap(); } } })); } // 等子线程完成 for child in children { let _ = child.join(); } println!("死锁没有发生"); }
在上面的描述中,我们用了"可能"二字,原因在于死锁在这段代码中不是必然发生的,总有一次运行你能看到最后一行打印输出。这是由于子线程的初始化顺序和执行速度并不确定,我们无法确定哪个线程中的锁先被执行,因此也无法确定两个线程对锁的具体使用顺序。
但是,可以简单的说明下死锁发生的必然条件:线程 1 锁住了MUTEX1并且线程2锁住了MUTEX2,然后线程 1 试图去访问MUTEX2,同时线程2试图去访问MUTEX1,就会死锁。 因为线程 2 需要等待线程 1 释放MUTEX1后,才会释放MUTEX2,而与此同时,线程 1 需要等待线程 2 释放MUTEX2后才能释放MUTEX1,这种情况造成了两个线程都无法释放对方需要的锁,最终死锁。
那么为何某些时候,死锁不会发生?原因很简单,线程 2 在线程 1 锁MUTEX1之前,就已经全部执行完了,随之线程 2 的MUTEX2和MUTEX1被全部释放,线程 1 对锁的获取将不再有竞争者。 同理,线程 1 若全部被执行完,那线程 2 也不会被锁,因此我们在线程 1 中间加一个睡眠,增加死锁发生的概率。如果你在线程 2 中同样的位置也增加一个睡眠,那死锁将必然发生!
try_lock
与lock方法不同,try_lock会尝试去获取一次锁,如果无法获取会返回一个错误,因此不会发生阻塞:
use std::{sync::{Mutex, MutexGuard}, thread}; use std::thread::sleep; use std::time::Duration; use lazy_static::lazy_static; lazy_static! { static ref MUTEX1: Mutex<i64> = Mutex::new(0); static ref MUTEX2: Mutex<i64> = Mutex::new(0); } fn main() { // 存放子线程的句柄 let mut children = vec![]; for i_thread in 0..2 { children.push(thread::spawn(move || { for _ in 0..1 { // 线程1 if i_thread % 2 == 0 { // 锁住MUTEX1 let guard: MutexGuard<i64> = MUTEX1.lock().unwrap(); println!("线程 {} 锁住了MUTEX1,接着准备去锁MUTEX2 !", i_thread); // 当前线程睡眠一小会儿,等待线程2锁住MUTEX2 sleep(Duration::from_millis(10)); // 去锁MUTEX2 let guard = MUTEX2.try_lock(); println!("线程1获取MUTEX2锁的结果: {:?}",guard); // 线程2 } else { // 锁住MUTEX2 let _guard = MUTEX2.lock().unwrap(); println!("线程 {} 锁住了MUTEX2, 准备去锁MUTEX1", i_thread); sleep(Duration::from_millis(10)); let guard = MUTEX1.try_lock(); println!("线程2获取MUTEX1锁的结果: {:?}",guard); } } })); } // 等子线程完成 for child in children { let _ = child.join(); } println!("死锁没有发生"); }
为了演示try_lock的作用,我们特定使用了之前必定会死锁的代码,并且将lock替换成try_lock,与之前的结果不同,这段代码将不会再有死锁发生:
线程 0 锁住了MUTEX1,接着准备去锁MUTEX2 !
线程 1 锁住了MUTEX2, 准备去锁MUTEX1
线程2获取MUTEX1锁的结果: Err("WouldBlock")
线程1获取MUTEX2锁的结果: Ok(0)
死锁没有发生
如上所示,当try_lock失败时,会报出一个错误:Err("WouldBlock"),接着线程中的剩余代码会继续执行,不会被阻塞。
一个有趣的命名规则:在 Rust 标准库中,使用
try_xxx都会尝试进行一次操作,如果无法完成,就立即返回,不会发生阻塞。例如消息传递章节中的try_recv以及本章节中的try_lock
读写锁 RwLock
Mutex会对每次读写都进行加锁,但某些时候,我们需要大量的并发读,Mutex就无法满足需求了,此时就可以使用RwLock:
use std::sync::RwLock; fn main() { let lock = RwLock::new(5); // 同一时间允许多个读 { let r1 = lock.read().unwrap(); let r2 = lock.read().unwrap(); assert_eq!(*r1, 5); assert_eq!(*r2, 5); } // 读锁在此处被drop // 同一时间只允许一个写 { let mut w = lock.write().unwrap(); *w += 1; assert_eq!(*w, 6); // 以下代码会panic,因为读和写不允许同时存在 // 写锁w直到该语句块结束才被释放,因此下面的读锁依然处于`w`的作用域中 // let r1 = lock.read(); // println!("{:?}",r1); }// 写锁在此处被drop }
RwLock在使用上和Mutex区别不大,需要注意的是,当读写同时发生时,程序会直接panic(本例是单线程,实际上多个线程中也是如此),因为会发生死锁:
thread 'main' panicked at 'rwlock read lock would result in deadlock', /rustc/efec545293b9263be9edfb283a7aa66350b3acbf/library/std/src/sys/unix/rwlock.rs:49:13
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
好在我们可以使用try_write和try_read来尝试进行一次写/读,若失败则返回错误:
Err("WouldBlock")
简单总结下RwLock:
- 同时允许多个读,但最多只能有一个写
- 读和写不能同时存在
- 读可以使用
read、try_read,写write、try_write, 在实际项目中,try_xxx会安全的多
Mutex 还是 RwLock
首先简单性上Mutex完胜,因为使用RwLock你得操心几个问题:
- 读和写不能同时发生,如果使用
try_xxx解决,就必须做大量的错误处理和失败重试机制 - 当读多写少时,写操作可能会因为一直无法获得锁导致连续多次失败(writer starvation)
- RwLock 其实是操作系统提供的,实现原理要比
Mutex复杂的多,因此单就锁的性能而言,比不上原生实现的Mutex
再来简单总结下两者的使用场景:
- 追求高并发读取时,使用
RwLock,因为Mutex一次只允许一个线程去读取 - 如果要保证写操作的成功性,使用
Mutex - 不知道哪个合适,统一使用
Mutex
需要注意的是,RwLock虽然看上去貌似提供了高并发读取的能力,但这个不能说明它的性能比Mutex高,事实上Mutex性能要好不少,后者唯一的问题也仅仅在于不能并发读取。
一个常见的、错误的使用RwLock的场景就是使用HashMap进行简单读写,因为HashMap的读和写都非常快,RwLock的复杂实现和相对低的性能反而会导致整体性能的降低,因此一般来说更适合使用Mutex。
总之,如果你要使用RwLock要确保满足以下两个条件:并发读,且需要对读到的资源进行"长时间"的操作,HashMap也许满足了并发读的需求,但是往往并不能满足后者:"长时间"的操作。
benchmark 永远是你在迷茫时最好的朋友!
三方库提供的锁实现
标准库在设计时总会存在取舍,因为往往性能并不是最好的,如果你追求性能,可以使用三方库提供的并发原语:
- parking_lot, 功能更完善、稳定,社区较为活跃,star 较多,更新较为活跃
- spin, 在多数场景中性能比
parking_lot高一点,最近没怎么更新
如果不是追求特别极致的性能,建议选择前者。
用条件变量(Condvar)控制线程的同步
Mutex用于解决资源安全访问的问题,但是我们还需要一个手段来解决资源访问顺序的问题。而 Rust 考虑到了这一点,为我们提供了条件变量(Condition Variables),它经常和Mutex一起使用,可以让线程挂起,直到某个条件发生后再继续执行,其实Condvar我们在之前的多线程章节就已经见到过,现在再来看一个不同的例子:
use std::sync::{Arc,Mutex,Condvar}; use std::thread::{spawn,sleep}; use std::time::Duration; fn main() { let flag = Arc::new(Mutex::new(false)); let cond = Arc::new(Condvar::new()); let cflag = flag.clone(); let ccond = cond.clone(); let hdl = spawn(move || { let mut m = { *cflag.lock().unwrap() }; let mut counter = 0; while counter < 3 { while !m { m = *ccond.wait(cflag.lock().unwrap()).unwrap(); } { m = false; *cflag.lock().unwrap() = false; } counter += 1; println!("inner counter: {}", counter); } }); let mut counter = 0; loop { sleep(Duration::from_millis(1000)); *flag.lock().unwrap() = true; counter += 1; if counter > 3 { break; } println!("outside counter: {}", counter); cond.notify_one(); } hdl.join().unwrap(); println!("{:?}", flag); }
例子中通过主线程来触发子线程实现交替打印输出:
outside counter: 1
inner counter: 1
outside counter: 2
inner counter: 2
outside counter: 3
inner counter: 3
Mutex { data: true, poisoned: false, .. }
信号量 Semaphore
在多线程中,另一个重要的概念就是信号量,使用它可以让我们精准的控制当前正在运行的任务最大数量。想象一下,当一个新游戏刚开服时(有些较火的老游戏也会,比如wow),往往会控制游戏内玩家的同时在线数,一旦超过某个临界值,就开始进行排队进服。而在实际使用中,也有很多时候,我们需要通过信号量来控制最大并发数,防止服务器资源被撑爆。
本来 Rust 在标准库中有提供一个信号量实现, 但是由于各种原因这个库现在已经不再推荐使用了,因此我们推荐使用tokio中提供的Semaphore实现: tokio::sync::Semaphore。
use std::sync::Arc; use tokio::sync::Semaphore; #[tokio::main] async fn main() { let semaphore = Arc::new(Semaphore::new(3)); let mut join_handles = Vec::new(); for _ in 0..5 { let permit = semaphore.clone().acquire_owned().await.unwrap(); join_handles.push(tokio::spawn(async move { // // 在这里执行任务... // drop(permit); })); } for handle in join_handles { handle.await.unwrap(); } }
上面代码创建了一个容量为 3 的信号量,当正在执行的任务超过 3 时,剩下的任务需要等待正在执行任务完成并减少信号量后到 3 以内时,才能继续执行。
这里的关键其实说白了就在于:信号量的申请和归还,使用前需要申请信号量,如果容量满了,就需要等待;使用后需要释放信号量,以便其它等待者可以继续。
总结
在很多时候,消息传递都是非常好用的手段,它可以让我们的数据在任务流水线上不断流转,实现起来非常优雅。
但是它并不能优雅的解决所有问题,因为我们面临的真实世界是非常复杂的,无法用某一种银弹统一解决。当面临消息传递不太适用的场景时,或者需要更好的性能和简洁性时,我们往往需要用锁来解决这些问题,因为锁允许多个线程同时访问同一个资源,简单粗暴。
除了锁之外,其实还有一种并发原语可以帮助我们解决并发访问数据的问题,那就是原子类型 Atomic,在下一章节中,我们会对其进行深入讲解。
线程同步:Atomic 原子类型与内存顺序
Mutex用起来简单,但是无法并发读,RwLock可以并发读,但是使用场景较为受限且性能不够,那么有没有一种全能性选手呢? 欢迎我们的Atomic闪亮登场。
从 Rust1.34 版本后,就正式支持原子类型。原子指的是一系列不可被 CPU 上下文交换的机器指令,这些指令组合在一起就形成了原子操作。在多核 CPU 下,当某个 CPU 核心开始运行原子操作时,会先暂停其它 CPU 内核对内存的操作,以保证原子操作不会被其它 CPU 内核所干扰。
由于原子操作是通过指令提供的支持,因此它的性能相比锁和消息传递会好很多。相比较于锁而言,原子类型不需要开发者处理加锁和释放锁的问题,同时支持修改,读取等操作,还具备较高的并发性能,几乎所有的语言都支持原子类型。
可以看出原子类型是无锁类型,但是无锁不代表无需等待,因为原子类型内部使用了CAS循环,当大量的冲突发生时,该等待还是得等待!但是总归比锁要好。
CAS 全称是 Compare and swap, 它通过一条指令读取指定的内存地址,然后判断其中的值是否等于给定的前置值,如果相等,则将其修改为新的值
使用 Atomic 作为全局变量
原子类型的一个常用场景,就是作为全局变量来使用:
use std::ops::Sub; use std::sync::atomic::{AtomicU64, Ordering}; use std::thread::{self, JoinHandle}; use std::time::Instant; const N_TIMES: u64 = 10000000; const N_THREADS: usize = 10; static R: AtomicU64 = AtomicU64::new(0); fn add_n_times(n: u64) -> JoinHandle<()> { thread::spawn(move || { for _ in 0..n { R.fetch_add(1, Ordering::Relaxed); } }) } fn main() { let s = Instant::now(); let mut threads = Vec::with_capacity(N_THREADS); for _ in 0..N_THREADS { threads.push(add_n_times(N_TIMES)); } for thread in threads { thread.join().unwrap(); } assert_eq!(N_TIMES * N_THREADS as u64, R.load(Ordering::Relaxed)); println!("{:?}",Instant::now().sub(s)); }
以上代码启动了数个线程,每个线程都在疯狂对全局变量进行加 1 操作, 最后将它与线程数 * 加1次数进行比较,如果发生了因为多个线程同时修改导致了脏数据,那么这两个必将不相等。好在,它没有让我们失望,不仅快速的完成了任务,而且保证了 100%的并发安全性。
当然以上代码的功能其实也可以通过Mutex来实现,但是后者的强大功能是建立在额外的性能损耗基础上的,因此性能会逊色不少:
Atomic实现:673ms
Mutex实现: 1136ms
可以看到Atomic实现会比Mutex快41%,实际上在复杂场景下还能更快(甚至达到 4 倍的性能差距)!
还有一点值得注意: 和Mutex一样,Atomic的值具有内部可变性,你无需将其声明为mut:
use std::sync::Mutex; use std::sync::atomic::{Ordering, AtomicU64}; struct Counter { count: u64 } fn main() { let n = Mutex::new(Counter { count: 0 }); n.lock().unwrap().count += 1; let n = AtomicU64::new(0); n.fetch_add(0, Ordering::Relaxed); }
这里有一个奇怪的枚举成员Ordering::Relaxed, 看上去很像是排序作用,但是我们并没有做排序操作啊?实际上它用于控制原子操作使用的内存顺序。
内存顺序
内存顺序是指 CPU 在访问内存时的顺序,该顺序可能受以下因素的影响:
- 代码中的先后顺序
- 编译器优化导致在编译阶段发生改变(内存重排序 reordering)
- 运行阶段因 CPU 的缓存机制导致顺序被打乱
编译器优化导致内存顺序的改变
对于第二点,我们举个例子:
static mut X: u64 = 0; static mut Y: u64 = 1; fn main() { ... // A unsafe { ... // B X = 1; ... // C Y = 3; ... // D X = 2; ... // E } }
假如在C和D代码片段中,根本没有用到X = 1,那么编译器很可能会将X = 1和X = 2进行合并:
#![allow(unused)] fn main() { ... // A unsafe { ... // B X = 2; ... // C Y = 3; ... // D ... // E } }
若代码A中创建了一个新的线程用于读取全局静态变量X,则该线程将无法读取到X = 1的结果,因为在编译阶段就已经被优化掉。
CPU 缓存导致的内存顺序的改变
假设之前的X = 1没有被优化掉,并且在代码片段A中有一个新的线程:
initial state: X = 0, Y = 1
THREAD Main THREAD A
X = 1; if X == 1 {
Y = 3; Y *= 2;
X = 2; }
我们来讨论下以上线程状态,Y最终的可能值(可能性依次降低):
Y = 3: 线程Main运行完后才运行线程A,或者线程A运行完后再运行线程MainY = 6: 线程Main的Y = 3运行完,但X = 2还没被运行, 此时线程 A 开始运行Y *= 2, 最后才运行Main线程的X = 2Y = 2: 线程Main正在运行Y = 3还没结束,此时线程A正在运行Y *= 2, 因此Y取到了值 1,然后Main的线程将Y设置为 3, 紧接着就被线程A的Y = 2所覆盖Y = 2: 上面的还只是一般的数据竞争,这里虽然产生了相同的结果2,但是背后的原理大相径庭: 线程Main运行完Y = 3,但是 CPU 缓存中的Y = 3还没有被同步到其它 CPU 缓存中,此时线程A中的Y *= 2就开始读取Y,结果读到了值1,最终计算出结果2
甚至更改成:
initial state: X = 0, Y = 1
THREAD Main THREAD A
X = 1; if X == 2 {
Y = 3; Y *= 2;
X = 2; }
还是可能出现Y = 2,因为Main线程中的X和Y被同步到其它 CPU 缓存中的顺序未必一致。
限定内存顺序的 5 个规则
在理解了内存顺序可能存在的改变后,你就可以明白为什么 Rust 提供了Ordering::Relaxed用于限定内存顺序了,事实上,该枚举有 5 个成员:
- Relaxed, 这是最宽松的规则,它对编译器和 CPU 不做任何限制,可以乱序
- Release 释放,设定内存屏障(Memory barrier),保证它之前的操作永远在它之前,但是它后面的操作可能被重排到它前面
- Acquire 获取, 设定内存屏障,保证在它之后的访问永远在它之后,但是它之前的操作却有可能被重排到它后面,往往和
Release在不同线程中联合使用 - AcqRel, 是 Acquire 和 Release 的结合,同时拥有它们俩提供的保证。比如你要对一个
atomic自增 1,同时希望该操作之前和之后的读取或写入操作不会被重新排序 - SeqCst 顺序一致性,
SeqCst就像是AcqRel的加强版,它不管原子操作是属于读取还是写入的操作,只要某个线程有用到SeqCst的原子操作,线程中该SeqCst操作前的数据操作绝对不会被重新排在该SeqCst操作之后,且该SeqCst操作后的数据操作也绝对不会被重新排在SeqCst操作前。
这些规则由于是系统提供的,因此其它语言提供的相应规则也大同小异,大家如果不明白可以看看其它语言的相关解释。
内存屏障的例子
下面我们以Release和Acquire为例,使用它们构筑出一对内存屏障,防止编译器和 CPU 将屏障前(Release)和屏障后(Acquire)中的数据操作重新排在屏障围成的范围之外:
use std::thread::{self, JoinHandle}; use std::sync::atomic::{Ordering, AtomicBool}; static mut DATA: u64 = 0; static READY: AtomicBool = AtomicBool::new(false); fn reset() { unsafe { DATA = 0; } READY.store(false, Ordering::Relaxed); } fn producer() -> JoinHandle<()> { thread::spawn(move || { unsafe { DATA = 100; // A } READY.store(true, Ordering::Release); // B: 内存屏障 ↑ }) } fn consumer() -> JoinHandle<()> { thread::spawn(move || { while !READY.load(Ordering::Acquire) {} // C: 内存屏障 ↓ assert_eq!(100, unsafe { DATA }); // D }) } fn main() { loop { reset(); let t_producer = producer(); let t_consumer = consumer(); t_producer.join().unwrap(); t_consumer.join().unwrap(); } }
原则上,Acquire用于读取,而Release用于写入。但是由于有些原子操作同时拥有读取和写入的功能,此时就需要使用AcqRel来设置内存顺序了。在内存屏障中被写入的数据,都可以被其它线程读取到,不会有 CPU 缓存的问题。
内存顺序的选择
- 不知道怎么选择时,优先使用
SeqCst,虽然会稍微减慢速度,但是慢一点也比出现错误好 - 多线程只计数
fetch_add而不使用该值触发其他逻辑分支的简单使用场景,可以使用Relaxed参考 Which std::sync::atomic::Ordering to use?
多线程中使用 Atomic
在多线程环境中要使用Atomic需要配合Arc:
use std::sync::Arc; use std::sync::atomic::{AtomicUsize, Ordering}; use std::{hint, thread}; fn main() { let spinlock = Arc::new(AtomicUsize::new(1)); let spinlock_clone = Arc::clone(&spinlock); let thread = thread::spawn(move|| { spinlock_clone.store(0, Ordering::SeqCst); }); // 等待其它线程释放锁 while spinlock.load(Ordering::SeqCst) != 0 { hint::spin_loop(); } if let Err(panic) = thread.join() { println!("Thread had an error: {:?}", panic); } }
Atomic 能替代锁吗
那么原子类型既然这么全能,它可以替代锁吗?答案是不行:
- 对于复杂的场景下,锁的使用简单粗暴,不容易有坑
std::sync::atomic包中仅提供了数值类型的原子操作:AtomicBool,AtomicIsize,AtomicUsize,AtomicI8,AtomicU16等,而锁可以应用于各种类型- 在有些情况下,必须使用锁来配合,例如上一章节中使用
Mutex配合Condvar
Atomic 的应用场景
事实上,Atomic虽然对于用户不太常用,但是对于高性能库的开发者、标准库开发者都非常常用,它是并发原语的基石,除此之外,还有一些场景适用:
- 无锁(lock free)数据结构
- 全局变量,例如全局自增 ID, 在后续章节会介绍
- 跨线程计数器,例如可以用于统计指标
以上列出的只是Atomic适用的部分场景,具体场景需要大家未来根据自己的需求进行权衡选择。
基于 Send 和 Sync 的线程安全
为何 Rc、RefCell 和裸指针不可以在多线程间使用?如何让裸指针可以在多线程使用?我们一起来探寻下这些问题的答案。
无法用于多线程的Rc
先来看一段多线程使用Rc的代码:
use std::thread; use std::rc::Rc; fn main() { let v = Rc::new(5); let t = thread::spawn(move || { println!("{}",v); }); t.join().unwrap(); }
以上代码将v的所有权通过move转移到子线程中,看似正确实则会报错:
error[E0277]: `Rc<i32>` cannot be sent between threads safely
------ 省略部分报错 --------
= help: within `[closure@src/main.rs:5:27: 7:6]`, the trait `Send` is not implemented for `Rc<i32>`
表面原因是Rc无法在线程间安全的转移,实际是编译器给予我们的那句帮助: the trait `Send` is not implemented for `Rc<i32>` (Rc<i32>未实现Send特征), 那么此处的Send特征又是何方神圣?
Rc 和 Arc 源码对比
在介绍Send特征之前,再来看看Arc为何可以在多线程使用,玄机在于两者的源码实现上:
#![allow(unused)] fn main() { // Rc源码片段 impl<T: ?Sized> !marker::Send for Rc<T> {} impl<T: ?Sized> !marker::Sync for Rc<T> {} // Arc源码片段 unsafe impl<T: ?Sized + Sync + Send> Send for Arc<T> {} unsafe impl<T: ?Sized + Sync + Send> Sync for Arc<T> {} }
!代表移除特征的相应实现,上面代码中Rc<T>的Send和Sync特征被特地移除了实现,而Arc<T>则相反,实现了Sync + Send,再结合之前的编译器报错,大概可以明白了:Send和Sync是在线程间安全使用一个值的关键。
Send 和 Sync
Send和Sync是 Rust 安全并发的重中之重,但是实际上它们只是标记特征(marker trait,该特征未定义任何行为,因此非常适合用于标记), 来看看它们的作用:
- 实现
Send的类型可以在线程间安全的传递其所有权 - 实现
Sync的类型可以在线程间安全的共享(通过引用)
这里还有一个潜在的依赖:一个类型要在线程间安全的共享的前提是,指向它的引用必须能在线程间传递。因为如果引用都不能被传递,我们就无法在多个线程间使用引用去访问同一个数据了。
由上可知,若类型 T 的引用&T是Send,则T是Sync。
没有例子的概念讲解都是耍流氓,来看看RwLock的实现:
#![allow(unused)] fn main() { unsafe impl<T: ?Sized + Send + Sync> Sync for RwLock<T> {} }
首先RwLock可以在线程间安全的共享,那它肯定是实现了Sync,但是我们的关注点不在这里。众所周知,RwLock可以并发的读,说明其中的值T必定也可以在线程间共享,那T必定要实现Sync。
果不其然,上述代码中,T的特征约束中就有一个Sync特征,那问题又来了,Mutex是不是相反?再来看看:
#![allow(unused)] fn main() { unsafe impl<T: ?Sized + Send> Sync for Mutex<T> {} }
不出所料,Mutex<T>中的T并没有Sync特征约束。
武学秘籍再好,不见生死也是花拳绣腿。同样的,我们需要通过实战来彻底掌握Send和Sync,但在实战之前,先来简单看看有哪些类型实现了它们。
实现Send和Sync的类型
在 Rust 中,几乎所有类型都默认实现了Send和Sync,而且由于这两个特征都是可自动派生的特征(通过derive派生),意味着一个复合类型(例如结构体), 只要它内部的所有成员都实现了Send或者Sync,那么它就自动实现了Send或Sync。
正是因为以上规则,Rust 中绝大多数类型都实现了Send和Sync,除了以下几个(事实上不止这几个,只不过它们比较常见):
- 裸指针两者都没实现,因为它本身就没有任何安全保证
UnsafeCell不是Sync,因此Cell和RefCell也不是Rc两者都没实现(因为内部的引用计数器不是线程安全的)
当然,如果是自定义的复合类型,那没实现那哥俩的就较为常见了:只要复合类型中有一个成员不是Send或Sync,那么该复合类型也就不是Send或Sync。
手动实现 Send 和 Sync 是不安全的,通常并不需要手动实现 Send 和 Sync trait,实现者需要使用unsafe小心维护并发安全保证。
至此,相关的概念大家已经掌握,但是我敢肯定,对于这两个滑不溜秋的家伙,大家依然会非常模糊,不知道它们该如何使用。那么我们来一起看看如何让裸指针可以在线程间安全的使用。
为裸指针实现Send
上面我们提到裸指针既没实现Send,意味着下面代码会报错:
use std::thread; fn main() { let p = 5 as *mut u8; let t = thread::spawn(move || { println!("{:?}",p); }); t.join().unwrap(); }
报错跟之前无二: `*mut u8` cannot be sent between threads safely, 但是有一个问题,我们无法为其直接实现Send特征,好在可以用newtype类型 :struct MyBox(*mut u8);。
还记得之前的规则吗:复合类型中有一个成员没实现Send,该复合类型就不是Send,因此我们需要手动为它实现:
use std::thread; #[derive(Debug)] struct MyBox(*mut u8); unsafe impl Send for MyBox {} fn main() { let p = MyBox(5 as *mut u8); let t = thread::spawn(move || { println!("{:?}",p); }); t.join().unwrap(); }
此时,我们的指针已经可以欢快的在多线程间撒欢,以上代码很简单,但有一点需要注意:Send和Sync是unsafe特征,实现时需要用unsafe代码块包裹。
为裸指针实现Sync
由于Sync是多线程间共享一个值,大家可能会想这么实现:
use std::thread; fn main() { let v = 5; let t = thread::spawn(|| { println!("{:?}",&v); }); t.join().unwrap(); }
关于这种用法,在多线程章节也提到过,线程如果直接去借用其它线程的变量,会报错:closure may outlive the current function,, 原因在于编译器无法确定主线程main和子线程t谁的生命周期更长,特别是当两个线程都是子线程时,没有任何人知道哪个子线程会先结束,包括编译器!
因此我们得配合Arc去使用:
use std::thread; use std::sync::Arc; use std::sync::Mutex; #[derive(Debug)] struct MyBox(*const u8); unsafe impl Send for MyBox {} fn main() { let b = &MyBox(5 as *const u8); let v = Arc::new(Mutex::new(b)); let t = thread::spawn(move || { let _v1 = v.lock().unwrap(); }); t.join().unwrap(); }
上面代码将智能指针v的所有权转移给新线程,同时v包含了一个引用类型b,当在新的线程中试图获取内部的引用时,会报错:
error[E0277]: `*const u8` cannot be shared between threads safely
--> src/main.rs:25:13
|
25 | let t = thread::spawn(move || {
| ^^^^^^^^^^^^^ `*const u8` cannot be shared between threads safely
|
= help: within `MyBox`, the trait `Sync` is not implemented for `*const u8`
因为我们访问的引用实际上还是对主线程中的数据的借用,转移进来的仅仅是外层的智能指针引用。要解决很简单,为MyBox实现Sync:
#![allow(unused)] fn main() { unsafe impl Sync for MyBox {} }
总结
通过上面的两个裸指针的例子,我们了解了如何实现Send和Sync,以及如何只实现Send而不实现Sync,简单总结下:
- 实现
Send的类型可以在线程间安全的传递其所有权, 实现Sync的类型可以在线程间安全的共享(通过引用) - 绝大部分类型都实现了
Send和Sync,常见的未实现的有:裸指针、Cell、RefCell、Rc等 - 可以为自定义类型实现
Send和Sync,但是需要unsafe代码块 - 可以为部分 Rust 中的类型实现
Send、Sync,但是需要使用newtype,例如文中的裸指针例子
实践应用:多线程Web服务器 todo
全局变量
在一些场景,我们可能需要全局变量来简化状态共享的代码,包括全局 ID,全局数据存储等等,下面一起来看看有哪些创建全局变量的方法。
首先,有一点可以肯定,全局变量的生命周期肯定是'static,但是不代表它需要用static来声明,例如常量、字符串字面值等无需使用static进行声明,原因是它们已经被打包到二进制可执行文件中。
下面我们从编译期初始化及运行期初始化两个类别来介绍下全局变量有哪些类型及该如何使用。
编译期初始化
我们大多数使用的全局变量都只需要在编译期初始化即可,例如静态配置、计数器、状态值等等。
静态常量
全局常量可以在程序任何一部分使用,当然,如果它是定义在某个模块中,你需要引入对应的模块才能使用。常量,顾名思义它是不可变的,很适合用作静态配置:
const MAX_ID: usize = usize::MAX / 2; fn main() { println!("用户ID允许的最大值是{}",MAX_ID); }
常量与普通变量的区别
- 关键字是
const而不是let - 定义常量必须指明类型(如 i32)不能省略
- 定义常量时变量的命名规则一般是全部大写
- 常量可以在任意作用域进行定义,其生命周期贯穿整个程序的生命周期。编译时编译器会尽可能将其内联到代码中,所以在不同地方对同一常量的引用并不能保证引用到相同的内存地址
- 常量的赋值只能是常量表达式/数学表达式,也就是说必须是在编译期就能计算出的值,如果需要在运行时才能得出结果的值比如函数,则不能赋值给常量表达式
- 对于变量出现重复的定义(绑定)会发生变量遮盖,后面定义的变量会遮住前面定义的变量,常量则不允许出现重复的定义
静态变量
静态变量允许声明一个全局的变量,常用于全局数据统计,例如我们希望用一个变量来统计程序当前的总请求数:
static mut REQUEST_RECV: usize = 0; fn main() { unsafe { REQUEST_RECV += 1; assert_eq!(REQUEST_RECV, 1); } }
Rust 要求必须使用unsafe语句块才能访问和修改static变量,因为这种使用方式往往并不安全,其实编译器是对的,当在多线程中同时去修改时,会不可避免的遇到脏数据。
只有在同一线程内或者不在乎数据的准确性时,才应该使用全局静态变量。
和常量相同,定义静态变量的时候必须赋值为在编译期就可以计算出的值(常量表达式/数学表达式),不能是运行时才能计算出的值(如函数)
静态变量和常量的区别
- 静态变量不会被内联,在整个程序中,静态变量只有一个实例,所有的引用都会指向同一个地址
- 存储在静态变量中的值必须要实现 Sync trait
原子类型
想要全局计数器、状态控制等功能,又想要线程安全的实现,原子类型是非常好的办法。
use std::sync::atomic::{AtomicUsize, Ordering}; static REQUEST_RECV: AtomicUsize = AtomicUsize::new(0); fn main() { for _ in 0..100 { REQUEST_RECV.fetch_add(1, Ordering::Relaxed); } println!("当前用户请求数{:?}",REQUEST_RECV); }
示例:全局 ID 生成器
来看看如何使用上面的内容实现一个全局 ID 生成器:
#![allow(unused)] fn main() { use std::sync::atomic::{Ordering, AtomicUsize}; struct Factory{ factory_id: usize, } static GLOBAL_ID_COUNTER: AtomicUsize = AtomicUsize::new(0); const MAX_ID: usize = usize::MAX / 2; fn generate_id()->usize{ // 检查两次溢出,否则直接加一可能导致溢出 let current_val = GLOBAL_ID_COUNTER.load(Ordering::Relaxed); if current_val > MAX_ID{ panic!("Factory ids overflowed"); } let next_id = GLOBAL_ID_COUNTER.fetch_add(1, Ordering::Relaxed); if next_id > MAX_ID{ panic!("Factory ids overflowed"); } next_id } impl Factory{ fn new()->Self{ Self{ factory_id: generate_id() } } } }
运行期初始化
以上的静态初始化有一个致命的问题:无法用函数进行静态初始化,例如你如果想声明一个全局的Mutex锁:
use std::sync::Mutex; static NAMES: Mutex<String> = Mutex::new(String::from("Sunface, Jack, Allen")); fn main() { let v = NAMES.lock().unwrap(); println!("{}",v); }
运行后报错如下:
error[E0015]: calls in statics are limited to constant functions, tuple structs and tuple variants
--> src/main.rs:3:42
|
3 | static NAMES: Mutex<String> = Mutex::new(String::from("sunface"));
但你又必须在声明时就对NAMES进行初始化,此时就陷入了两难的境地。好在天无绝人之路,我们可以使用lazy_static包来解决这个问题。
lazy_static
lazy_static是社区提供的非常强大的宏,用于懒初始化静态变量,之前的静态变量都是在编译期初始化的,因此无法使用函数调用进行赋值,而lazy_static允许我们在运行期初始化静态变量!
use std::sync::Mutex; use lazy_static::lazy_static; lazy_static! { static ref NAMES: Mutex<String> = Mutex::new(String::from("Sunface, Jack, Allen")); } fn main() { let mut v = NAMES.lock().unwrap(); v.push_str(", Myth"); println!("{}",v); }
当然,使用lazy_static在每次访问静态变量时,会有轻微的性能损失,因为其内部实现用了一个底层的并发原语std::sync::Once,在每次访问该变量时,程序都会执行一次原子指令用于确认静态变量的初始化是否完成。
lazy_static宏,匹配的是static ref,所以定义的静态变量都是不可变引用
可能有读者会问,为何需要在运行期初始化一个静态变量,除了上面的全局锁,你会遇到最常见的场景就是:一个全局的动态配置,它在程序开始后,才加载数据进行初始化,最终可以让各个线程直接访问使用
再来看一个使用lazy_static实现全局缓存的例子:
use lazy_static::lazy_static; use std::collections::HashMap; lazy_static! { static ref HASHMAP: HashMap<u32, &'static str> = { let mut m = HashMap::new(); m.insert(0, "foo"); m.insert(1, "bar"); m.insert(2, "baz"); m }; } fn main() { // 首次访问`HASHMAP`的同时对其进行初始化 println!("The entry for `0` is \"{}\".", HASHMAP.get(&0).unwrap()); // 后续的访问仅仅获取值,再不会进行任何初始化操作 println!("The entry for `1` is \"{}\".", HASHMAP.get(&1).unwrap()); }
需要注意的是,lazy_static直到运行到main中的第一行代码时,才进行初始化,非常lazy static。
Box::leak
在Box智能指针章节中,我们提到了Box::leak可以用于全局变量,例如用作运行期初始化的全局动态配置,先来看看如果不使用lazy_static也不使用Box::leak,会发生什么:
#[derive(Debug)] struct Config { a: String, b: String, } static mut CONFIG: Option<&mut Config> = None; fn main() { unsafe { CONFIG = Some(&mut Config { a: "A".to_string(), b: "B".to_string(), }); println!("{:?}", CONFIG) } }
以上代码我们声明了一个全局动态配置CONFIG,并且其值初始化为None,然后在程序开始运行后,给它赋予相应的值,运行后报错:
error[E0716]: temporary value dropped while borrowed
--> src/main.rs:10:28
|
10 | CONFIG = Some(&mut Config {
| _________-__________________^
| |_________|
| ||
11 | || a: "A".to_string(),
12 | || b: "B".to_string(),
13 | || });
| || ^-- temporary value is freed at the end of this statement
| ||_________||
| |_________|assignment requires that borrow lasts for `'static`
| creates a temporary which is freed while still in use
可以看到,Rust 的借用和生命周期规则限制了我们做到这一点,因为试图将一个局部生命周期的变量赋值给全局生命周期的CONFIG,这明显是不安全的。
好在Rust为我们提供了Box::leak方法,它可以将一个变量从内存中泄漏(听上去怪怪的,竟然做主动内存泄漏),然后将其变为'static生命周期,最终该变量将和程序活得一样久,因此可以赋值给全局静态变量CONFIG。
#[derive(Debug)] struct Config { a: String, b: String } static mut CONFIG: Option<&mut Config> = None; fn main() { let c = Box::new(Config { a: "A".to_string(), b: "B".to_string(), }); unsafe { // 将`c`从内存中泄漏,变成`'static`生命周期 CONFIG = Some(Box::leak(c)); println!("{:?}", CONFIG); } }
从函数中返回全局变量
问题又来了,如果我们需要在运行期,从一个函数返回一个全局变量该如何做?例如:
#[derive(Debug)] struct Config { a: String, b: String, } static mut CONFIG: Option<&mut Config> = None; fn init() -> Option<&'static mut Config> { Some(&mut Config { a: "A".to_string(), b: "B".to_string(), }) } fn main() { unsafe { CONFIG = init(); println!("{:?}", CONFIG) } }
报错这里就不展示了,跟之前大同小异,还是生命周期引起的,那么该如何解决呢?依然可以用Box::leak:
#[derive(Debug)] struct Config { a: String, b: String, } static mut CONFIG: Option<&mut Config> = None; fn init() -> Option<&'static mut Config> { let c = Box::new(Config { a: "A".to_string(), b: "B".to_string(), }); Some(Box::leak(c)) } fn main() { unsafe { CONFIG = init(); println!("{:?}", CONFIG) } }
标准库中的 OnceCell
在 Rust 标准库中提供 lazy::OnceCell 和 lazy::SyncOnceCell 两种 Cell,前者用于单线程,后者用于多线程,它们用来存储堆上的信息,并且具有最多只能赋值一次的特性。 如实现一个多线程的日志组件 Logger:
#![feature(once_cell)] use std::{lazy::SyncOnceCell, thread}; fn main() { // 子线程中调用 let handle = thread::spawn(|| { let logger = Logger::global(); logger.log("thread message".to_string()); }); // 主线程调用 let logger = Logger::global(); logger.log("some message".to_string()); let logger2 = Logger::global(); logger2.log("other message".to_string()); handle.join().unwrap(); } #[derive(Debug)] struct Logger; static LOGGER: SyncOnceCell<Logger> = SyncOnceCell::new(); impl Logger { fn global() -> &'static Logger { // 获取或初始化 Logger LOGGER.get_or_init(|| { println!("Logger is being created..."); // 初始化打印 Logger }) } fn log(&self, message: String) { println!("{}", message) } }
以上代码我们声明了一个 global() 关联函数,并在其内部调用 get_or_init 进行初始化 Logger,之后在不同线程上多次调用 Logger::global() 获取其实例:
Logger is being created...
some message
other message
thread message
可以看到,Logger is being created... 在多个线程中使用也只被打印了一次。
特别注意,目前 OnceCell 和 SyncOnceCell API 暂未稳定,需启用特性 #![feature(once_cell)]。
总结
在 Rust 中有很多方式可以创建一个全局变量,本章也只是介绍了其中一部分,更多的还等待大家自己去挖掘学习(当然,未来可能本章节会不断完善,最后变成一个巨无霸- , -)。
简单来说,全局变量可以分为两种:
- 编译期初始化的全局变量,
const创建常量,static创建静态变量,Atomic创建原子类型 - 运行期初始化的全局变量,
lazy_static用于懒初始化,Box::leak利用内存泄漏将一个变量的生命周期变为'static
错误处理
在之前的返回值和错误处理章节中,我们学习了几个重要的概念,例如 Result 用于返回结果处理,? 用于错误的传播,若大家对此还较为模糊,强烈建议回头温习下。
在本章节中一起来看看如何对 Result ( Option ) 做进一步的处理,以及如何定义自己的错误类型。
组合器
在设计模式中,有一个组合器模式,相信有 Java 背景的同学对此并不陌生。
将对象组合成树形结构以表示“部分整体”的层次结构。组合模式使得用户对单个对象和组合对象的使用具有一致性。–GoF <<设计模式>>
与组合器模式有所不同,在 Rust 中,组合器更多的是用于对返回结果的类型进行变换:例如使用 ok_or 将一个 Option 类型转换成 Result 类型。
下面我们来看看一些常见的组合器。
or() 和 and()
跟布尔关系的与/或很像,这两个方法会对两个表达式做逻辑组合,最终返回 Option / Result。
or(),表达式按照顺序求值,若任何一个表达式的结果是Some或Ok,则该值会立刻返回and(),若两个表达式的结果都是Some或Ok,则第二个表达式中的值被返回。若任何一个的结果是None或Err,则立刻返回。
实际上,只要将布尔表达式的 true / false,替换成 Some / None 或 Ok / Err 就很好理解了。
fn main() { let s1 = Some("some1"); let s2 = Some("some2"); let n: Option<&str> = None; let o1: Result<&str, &str> = Ok("ok1"); let o2: Result<&str, &str> = Ok("ok2"); let e1: Result<&str, &str> = Err("error1"); let e2: Result<&str, &str> = Err("error2"); assert_eq!(s1.or(s2), s1); // Some1 or Some2 = Some1 assert_eq!(s1.or(n), s1); // Some or None = Some assert_eq!(n.or(s1), s1); // None or Some = Some assert_eq!(n.or(n), n); // None1 or None2 = None2 assert_eq!(o1.or(o2), o1); // Ok1 or Ok2 = Ok1 assert_eq!(o1.or(e1), o1); // Ok or Err = Ok assert_eq!(e1.or(o1), o1); // Err or Ok = Ok assert_eq!(e1.or(e2), e2); // Err1 or Err2 = Err2 assert_eq!(s1.and(s2), s2); // Some1 and Some2 = Some2 assert_eq!(s1.and(n), n); // Some and None = None assert_eq!(n.and(s1), n); // None and Some = None assert_eq!(n.and(n), n); // None1 and None2 = None1 assert_eq!(o1.and(o2), o2); // Ok1 and Ok2 = Ok2 assert_eq!(o1.and(e1), e1); // Ok and Err = Err assert_eq!(e1.and(o1), e1); // Err and Ok = Err assert_eq!(e1.and(e2), e1); // Err1 and Err2 = Err1 }
除了 or 和 and 之外,Rust 还为我们提供了 xor ,但是它只能应用在 Option 上,其实想想也是这个理,如果能应用在 Result 上,那你又该如何对一个值和错误进行异或操作?
or_else() 和 and_then()
它们跟 or() 和 and() 类似,唯一的区别在于,它们的第二个表达式是一个闭包。
fn main() { // or_else with Option let s1 = Some("some1"); let s2 = Some("some2"); let fn_some = || Some("some2"); // 类似于: let fn_some = || -> Option<&str> { Some("some2") }; let n: Option<&str> = None; let fn_none = || None; assert_eq!(s1.or_else(fn_some), s1); // Some1 or_else Some2 = Some1 assert_eq!(s1.or_else(fn_none), s1); // Some or_else None = Some assert_eq!(n.or_else(fn_some), s2); // None or_else Some = Some assert_eq!(n.or_else(fn_none), None); // None1 or_else None2 = None2 // or_else with Result let o1: Result<&str, &str> = Ok("ok1"); let o2: Result<&str, &str> = Ok("ok2"); let fn_ok = |_| Ok("ok2"); // 类似于: let fn_ok = |_| -> Result<&str, &str> { Ok("ok2") }; let e1: Result<&str, &str> = Err("error1"); let e2: Result<&str, &str> = Err("error2"); let fn_err = |_| Err("error2"); assert_eq!(o1.or_else(fn_ok), o1); // Ok1 or_else Ok2 = Ok1 assert_eq!(o1.or_else(fn_err), o1); // Ok or_else Err = Ok assert_eq!(e1.or_else(fn_ok), o2); // Err or_else Ok = Ok assert_eq!(e1.or_else(fn_err), e2); // Err1 or_else Err2 = Err2 }
fn main() { // and_then with Option let s1 = Some("some1"); let s2 = Some("some2"); let fn_some = |_| Some("some2"); // 类似于: let fn_some = |_| -> Option<&str> { Some("some2") }; let n: Option<&str> = None; let fn_none = |_| None; assert_eq!(s1.and_then(fn_some), s2); // Some1 and_then Some2 = Some2 assert_eq!(s1.and_then(fn_none), n); // Some and_then None = None assert_eq!(n.and_then(fn_some), n); // None and_then Some = None assert_eq!(n.and_then(fn_none), n); // None1 and_then None2 = None1 // and_then with Result let o1: Result<&str, &str> = Ok("ok1"); let o2: Result<&str, &str> = Ok("ok2"); let fn_ok = |_| Ok("ok2"); // 类似于: let fn_ok = |_| -> Result<&str, &str> { Ok("ok2") }; let e1: Result<&str, &str> = Err("error1"); let e2: Result<&str, &str> = Err("error2"); let fn_err = |_| Err("error2"); assert_eq!(o1.and_then(fn_ok), o2); // Ok1 and_then Ok2 = Ok2 assert_eq!(o1.and_then(fn_err), e2); // Ok and_then Err = Err assert_eq!(e1.and_then(fn_ok), e1); // Err and_then Ok = Err assert_eq!(e1.and_then(fn_err), e1); // Err1 and_then Err2 = Err1 }
filter
filter 用于对 Option 进行过滤:
fn main() { let s1 = Some(3); let s2 = Some(6); let n = None; let fn_is_even = |x: &i8| x % 2 == 0; assert_eq!(s1.filter(fn_is_even), n); // Some(3) -> 3 is not even -> None assert_eq!(s2.filter(fn_is_even), s2); // Some(6) -> 6 is even -> Some(6) assert_eq!(n.filter(fn_is_even), n); // None -> no value -> None }
map() 和 map_err()
map 可以将 Some 或 Ok 中的值映射为另一个:
fn main() { let s1 = Some("abcde"); let s2 = Some(5); let n1: Option<&str> = None; let n2: Option<usize> = None; let o1: Result<&str, &str> = Ok("abcde"); let o2: Result<usize, &str> = Ok(5); let e1: Result<&str, &str> = Err("abcde"); let e2: Result<usize, &str> = Err("abcde"); let fn_character_count = |s: &str| s.chars().count(); assert_eq!(s1.map(fn_character_count), s2); // Some1 map = Some2 assert_eq!(n1.map(fn_character_count), n2); // None1 map = None2 assert_eq!(o1.map(fn_character_count), o2); // Ok1 map = Ok2 assert_eq!(e1.map(fn_character_count), e2); // Err1 map = Err2 }
但是如果你想要将 Err 中的值进行改变, map 就无能为力了,此时我们需要用 map_err:
fn main() { let o1: Result<&str, &str> = Ok("abcde"); let o2: Result<&str, isize> = Ok("abcde"); let e1: Result<&str, &str> = Err("404"); let e2: Result<&str, isize> = Err(404); let fn_character_count = |s: &str| -> isize { s.parse().unwrap() }; // 该函数返回一个 isize assert_eq!(o1.map_err(fn_character_count), o2); // Ok1 map = Ok2 assert_eq!(e1.map_err(fn_character_count), e2); // Err1 map = Err2 }
通过对 o1 的操作可以看出,与 map 面对 Err 时的短小类似, map_err 面对 Ok 时也是相当无力的。
map_or() 和 map_or_else()
map_or 在 map 的基础上提供了一个默认值:
fn main() { const V_DEFAULT: u32 = 1; let s: Result<u32, ()> = Ok(10); let n: Option<u32> = None; let fn_closure = |v: u32| v + 2; assert_eq!(s.map_or(V_DEFAULT, fn_closure), 12); assert_eq!(n.map_or(V_DEFAULT, fn_closure), V_DEFAULT); }
如上所示,当处理 None 的时候,V_DEFAULT 作为默认值被直接返回。
map_or_else 与 map_or 类似,但是它是通过一个闭包来提供默认值:
fn main() { let s = Some(10); let n: Option<i8> = None; let fn_closure = |v: i8| v + 2; let fn_default = || 1; assert_eq!(s.map_or_else(fn_default, fn_closure), 12); assert_eq!(n.map_or_else(fn_default, fn_closure), 1); let o = Ok(10); let e = Err(5); let fn_default_for_result = |v: i8| v + 1; // 闭包可以对 Err 中的值进行处理,并返回一个新值 assert_eq!(o.map_or_else(fn_default_for_result, fn_closure), 12); assert_eq!(e.map_or_else(fn_default_for_result, fn_closure), 6); }
ok_or() and ok_or_else()
这两兄弟可以将 Option 类型转换为 Result 类型。其中 ok_or 接收一个默认的 Err 参数:
fn main() { const ERR_DEFAULT: &str = "error message"; let s = Some("abcde"); let n: Option<&str> = None; let o: Result<&str, &str> = Ok("abcde"); let e: Result<&str, &str> = Err(ERR_DEFAULT); assert_eq!(s.ok_or(ERR_DEFAULT), o); // Some(T) -> Ok(T) assert_eq!(n.ok_or(ERR_DEFAULT), e); // None -> Err(default) }
而 ok_or_else 接收一个闭包作为 Err 参数:
fn main() { let s = Some("abcde"); let n: Option<&str> = None; let fn_err_message = || "error message"; let o: Result<&str, &str> = Ok("abcde"); let e: Result<&str, &str> = Err("error message"); assert_eq!(s.ok_or_else(fn_err_message), o); // Some(T) -> Ok(T) assert_eq!(n.ok_or_else(fn_err_message), e); // None -> Err(default) }
以上列出的只是常用的一部分,强烈建议大家看看标准库中有哪些可用的 API,在实际项目中,这些 API 将会非常有用: Option 和 Result。
自定义错误类型
虽然标准库定义了大量的错误类型,但是一个严谨的项目,光使用这些错误类型往往是不够的,例如我们可能会为暴露给用户的错误定义相应的类型。
为了帮助我们更好的定义错误,Rust 在标准库中提供了一些可复用的特征,例如 std::error::Error 特征:
#![allow(unused)] fn main() { use std::fmt::{Debug, Display}; pub trait Error: Debug + Display { fn source(&self) -> Option<&(Error + 'static)> { ... } } }
当自定义类型实现该特征后,该类型就可以作为 Err 来使用,下面一起来看看。
实际上,自定义错误类型只需要实现
Debug和Display特征即可,source方法是可选的,而Debug特征往往也无需手动实现,可以直接通过derive来派生
最简单的错误
use std::fmt; // AppError 是自定义错误类型,它可以是当前包中定义的任何类型,在这里为了简化,我们使用了单元结构体作为例子。 // 为 AppError 自动派生 Debug 特征 #[derive(Debug)] struct AppError; // 为 AppError 实现 std::fmt::Display 特征 impl fmt::Display for AppError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "An Error Occurred, Please Try Again!") // user-facing output } } // 一个示例函数用于产生 AppError 错误 fn produce_error() -> Result<(), AppError> { Err(AppError) } fn main(){ match produce_error() { Err(e) => eprintln!("{}", e), _ => println!("No error"), } eprintln!("{:?}", produce_error()); // Err({ file: src/main.rs, line: 17 }) }
上面的例子很简单,我们定义了一个错误类型,当为它派生了 Debug 特征,同时手动实现了 Display 特征后,该错误类型就可以作为 Err来使用了。
事实上,实现 Debug 和 Display 特征并不是作为 Err 使用的必要条件,大家可以把这两个特征实现和相应使用去除,然后看看代码会否报错。既然如此,我们为何要为自定义类型实现这两个特征呢?原因有二:
- 错误得打印输出后,才能有实际用处,而打印输出就需要实现这两个特征
- 可以将自定义错误转换成
Box<dyn std::error:Error>特征对象,在后面的归一化不同错误类型部分,我们会详细介绍
更详尽的错误
上一个例子中定义的错误非常简单,我们无法从错误中得到更多的信息,现在再来定义一个具有错误码和信息的错误:
use std::fmt; struct AppError { code: usize, message: String, } // 根据错误码显示不同的错误信息 impl fmt::Display for AppError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { let err_msg = match self.code { 404 => "Sorry, Can not find the Page!", _ => "Sorry, something is wrong! Please Try Again!", }; write!(f, "{}", err_msg) } } impl fmt::Debug for AppError { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!( f, "AppError {{ code: {}, message: {} }}", self.code, self.message ) } } fn produce_error() -> Result<(), AppError> { Err(AppError { code: 404, message: String::from("Page not found"), }) } fn main() { match produce_error() { Err(e) => eprintln!("{}", e), // 抱歉,未找到指定的页面! _ => println!("No error"), } eprintln!("{:?}", produce_error()); // Err(AppError { code: 404, message: Page not found }) eprintln!("{:#?}", produce_error()); // Err( // AppError { code: 404, message: Page not found } // ) }
在本例中,我们除了增加了错误码和消息外,还手动实现了 Debug 特征,原因在于,我们希望能自定义 Debug 的输出内容,而不是使用派生后系统提供的默认输出形式。
错误转换 From 特征
标准库、三方库、本地库,各有各的精彩,各也有各的错误。那么问题就来了,我们该如何将其它的错误类型转换成自定义的错误类型?总不能神鬼牛魔,同台共舞吧。。
好在 Rust 为我们提供了 std::convert::From 特征:
#![allow(unused)] fn main() { pub trait From<T>: Sized { fn from(_: T) -> Self; } }
事实上,该特征在之前的
?操作符章节中就有所介绍。大家都使用过
String::from函数吧?它可以通过&str来创建一个String,其实该函数就是From特征提供的
下面一起来看看如何为自定义类型实现 From 特征:
use std::fs::File; use std::io; #[derive(Debug)] struct AppError { kind: String, // 错误类型 message: String, // 错误信息 } // 为 AppError 实现 std::convert::From 特征,由于 From 包含在 std::prelude 中,因此可以直接简化引入。 // 实现 From<io::Error> 意味着我们可以将 io::Error 错误转换成自定义的 AppError 错误 impl From<io::Error> for AppError { fn from(error: io::Error) -> Self { AppError { kind: String::from("io"), message: error.to_string(), } } } fn main() -> Result<(), AppError> { let _file = File::open("nonexistent_file.txt")?; Ok(()) } // --------------- 上述代码运行后输出 --------------- Error: AppError { kind: "io", message: "No such file or directory (os error 2)" }
上面的代码中除了实现 From 外,还有一点特别重要,那就是 ? 可以将错误进行隐式的强制转换:File::open 返回的是 std::io::Error, 我们并没有进行任何显式的转换,它就能自动变成 AppError ,这就是 ? 的强大之处!
上面的例子只有一个标准库错误,再来看看多个不同的错误转换成 AppError 的实现:
use std::fs::File; use std::io::{self, Read}; use std::num; #[derive(Debug)] struct AppError { kind: String, message: String, } impl From<io::Error> for AppError { fn from(error: io::Error) -> Self { AppError { kind: String::from("io"), message: error.to_string(), } } } impl From<num::ParseIntError> for AppError { fn from(error: num::ParseIntError) -> Self { AppError { kind: String::from("parse"), message: error.to_string(), } } } fn main() -> Result<(), AppError> { let mut file = File::open("hello_world.txt")?; let mut content = String::new(); file.read_to_string(&mut content)?; let _number: usize; _number = content.parse()?; Ok(()) } // --------------- 上述代码运行后的可能输出 --------------- // 01. 若 hello_world.txt 文件不存在 Error: AppError { kind: "io", message: "No such file or directory (os error 2)" } // 02. 若用户没有相关的权限访问 hello_world.txt Error: AppError { kind: "io", message: "Permission denied (os error 13)" } // 03. 若 hello_world.txt 包含有非数字的内容,例如 Hello, world! Error: AppError { kind: "parse", message: "invalid digit found in string" }
归一化不同的错误类型
至此,关于 Rust 的错误处理大家已经了若指掌了,下面再来看看一些实战中的问题。
在实际项目中,我们往往会为不同的错误定义不同的类型,这样做非常好,但是如果你要在一个函数中返回不同的错误呢?例如:
use std::fs::read_to_string; fn main() -> Result<(), std::io::Error> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String, std::io::Error> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) }
上面的代码会报错,原因在于 render 函数中的两个 ? 返回的实际上是不同的错误:env::var() 返回的是 std::env::VarError,而 read_to_string 返回的是 std::io::Error。
为了满足 render 函数的签名,我们就需要将 env::VarError 和 io::Error 归一化为同一种错误类型。要实现这个目的有三种方式:
- 使用特征对象
Box<dyn Error> - 自定义错误类型
- 使用
thiserror
下面依次来看看相关的解决方式。
Box<dyn Error>
大家还记得我们之前提到的 std::error::Error 特征吧,当时有说:自定义类型实现 Debug + Display 特征的主要原因就是为了能转换成 Error 的特征对象,而特征对象恰恰是在同一个地方使用不同类型的关键:
use std::fs::read_to_string; use std::error::Error; fn main() -> Result<(), Box<dyn Error>> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String, Box<dyn Error>> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) }
这个方法很简单,在绝大多数场景中,性能也非常够用,但是有一个问题:Result 实际上不会限制错误的类型,也就是一个类型就算不实现 Error 特征,它依然可以在 Result<T, E> 中作为 E 来使用,此时这种特征对象的解决方案就无能为力了。
自定义错误类型
与特征对象相比,自定义错误类型麻烦归麻烦,但是它非常灵活,因此也不具有上面的类似限制:
use std::fs::read_to_string; fn main() -> Result<(), MyError> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String, MyError> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) } #[derive(Debug)] enum MyError { EnvironmentVariableNotFound, IOError(std::io::Error), } impl From<std::env::VarError> for MyError { fn from(_: std::env::VarError) -> Self { Self::EnvironmentVariableNotFound } } impl From<std::io::Error> for MyError { fn from(value: std::io::Error) -> Self { Self::IOError(value) } } impl std::error::Error for MyError {} impl std::fmt::Display for MyError { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { match self { MyError::EnvironmentVariableNotFound => write!(f, "Environment variable not found"), MyError::IOError(err) => write!(f, "IO Error: {}", err.to_string()), } } }
上面代码中有一行值得注意:impl std::error::Error for MyError {} ,只有为自定义错误类型实现 Error 特征后,才能转换成相应的特征对象。
不得不说,真是啰嗦啊。因此在能用特征对象的时候,建议大家还是使用特征对象,无论如何,代码可读性还是很重要的!
上面的第二种方式灵活归灵活,啰嗦也是真啰嗦,好在 Rust 的社区为我们提供了 thiserror 解决方案,下面一起来看看该如何简化 Rust 中的错误处理。
简化错误处理
对于开发者而言,错误处理是代码中打交道最多的部分之一,因此选择一把趁手的武器也很重要,它可以帮助我们节省大量的时间和精力,好钢应该用在代码逻辑而不是冗长的错误处理上。
thiserror
thiserror可以帮助我们简化上面的第二种解决方案:
use std::fs::read_to_string; fn main() -> Result<(), MyError> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String, MyError> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) } #[derive(thiserror::Error, Debug)] enum MyError { #[error("Environment variable not found")] EnvironmentVariableNotFound(#[from] std::env::VarError), #[error(transparent)] IOError(#[from] std::io::Error), }
如上所示,只要简单写写注释,就可以实现错误处理了,惊不惊喜?
error-chain
error-chain 也是简单好用的库,可惜不再维护了,但是我觉得它依然可以在合适的地方大放光彩,值得大家去了解下。
use std::fs::read_to_string; error_chain::error_chain! { foreign_links { EnvironmentVariableNotFound(::std::env::VarError); IOError(::std::io::Error); } } fn main() -> Result<()> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) }
喏,简单吧?使用 error-chain 的宏你可以获得:Error 结构体,错误类型 ErrorKind 枚举 以及一个自定义的 Result 类型。
anyhow
anyhow 和 thiserror 是同一个作者开发的,这里是作者关于 anyhow 和 thiserror 的原话:
如果你想要设计自己的错误类型,同时给调用者提供具体的信息时,就使用
thiserror,例如当你在开发一个三方库代码时。如果你只想要简单,就使用anyhow,例如在自己的应用服务中。
use std::fs::read_to_string; use anyhow::Result; fn main() -> Result<()> { let html = render()?; println!("{}", html); Ok(()) } fn render() -> Result<String> { let file = std::env::var("MARKDOWN")?; let source = read_to_string(file)?; Ok(source) }
关于如何选用 thiserror 和 anyhow 只需要遵循一个原则即可:是否关注自定义错误消息,关注则使用 thiserror(常见业务代码),否则使用 anyhow(编写第三方库代码)。
总结
Rust 一个为人津津乐道的点就是强大、易用的错误处理,对于新手来说,这个机制可能会有些复杂,但是一旦体会到了其中的好处,你将跟我一样沉醉其中不能自拔。
unsafe 简介
圣人论迹不论心,论心世上无圣人,对于编程语言而言,亦是如此。
虽然在本章之前,我们学到的代码都是在编译期就得到了 Rust 的安全保障,但是在其内心深处也隐藏了一些阴暗面,在这些阴暗面里,内存安全就存在一些变数了:当不娴熟的开发者接触到这些阴暗面,就可能写出不安全的代码,因此我们称这种代码为 unsafe 代码块。
为何会有 unsafe
几乎每个语言都有 unsafe 关键字,但 Rust 语言使用 unsafe 的原因可能与其它编程语言还有所不同。
过强的编译器
说来尴尬,unsafe 的存在主要是因为 Rust 的静态检查太强了,但是强就算了,它还很保守,这就会导致当编译器在分析代码时,一些正确代码会因为编译器无法分析出它的所有正确性,结果将这段代码拒绝,导致编译错误。
这种保守的选择确实也没有错,毕竟安全就是要防微杜渐,但是对于使用者来说,就不是那么愉快的事了,特别是当配合 Rust 的所有权系统一起使用时,有个别问题是真的棘手和难以解决。
举个例子,在之前的自引用章节中,我们就提到了相关的编译检查是很难绕过的,如果想要绕过,最常用的方法之一就是使用 unsafe 和 Pin。
好在,当遇到这些情况时,我们可以使用 unsafe 来解决。此时,你需要替代编译器的部分职责对 unsafe 代码的正确性负责,例如在正常代码中不可能遇到的空指针解引用问题在 unsafe 中就可能会遇到,我们需要自己来处理好这些类似的问题。
特定任务的需要
至于 unsafe 存在的另一个原因就是:它必须要存在。原因是计算机底层的一些硬件就是不安全的,如果 Rust 只允许你做安全的操作,那一些任务就无法完成,换句话说,我们还怎么跟 C++ 干架?
Rust 的一个主要定位就是系统编程,众所周知,系统编程就是底层编程,往往需要直接跟操作系统打交道,甚至于去实现一个操作系统。而为了实现底层系统编程,unsafe 就是必不可少的。
在了解了为何会有 unsafe 后,我们再来看看,除了这些必要性,unsafe 还能给我们带来哪些超能力。
unsafe 的超能力
使用 unsafe 非常简单,只需要将对应的代码块标记下即可:
fn main() { let mut num = 5; let r1 = &num as *const i32; unsafe { println!("r1 is: {}", *r1); } }
上面代码中, r1 是一个裸指针(raw pointer),由于它具有破坏 Rust 内存安全的潜力,因此只能在 unsafe 代码块中使用,如果你去掉 unsafe {},编译器会立刻报错。
言归正传, unsafe 能赋予我们 5 种超能力,这些能力在安全的 Rust 代码中是无法获取的:
- 解引用裸指针,就如上例所示
- 调用一个
unsafe或外部的函数 - 访问或修改一个可变的静态变量
- 实现一个
unsafe特征 - 访问
union中的字段
在本章中,我们将着重讲解裸指针和 FFI 的使用。
unsafe 的安全保证
曾经在 reddit 上有一个讨论还挺热闹的,是关于 unsafe 的命名是否合适,总之公有公理,婆有婆理,但有一点是不可否认的:虽然名称自带不安全,但是 Rust 依然提供了强大的安全支撑。
首先,unsafe 并不能绕过 Rust 的借用检查,也不能关闭任何 Rust 的安全检查规则,例如当你在 unsafe 中使用引用时,该有的检查一样都不会少。
因此 unsafe 能给大家提供的也仅仅是之前的 5 种超能力,在使用这 5 种能力时,编译器才不会进行内存安全方面的检查,最典型的就是使用裸指针(引用和裸指针有很大的区别)。
谈虎色变?
在网上充斥着这样的言论:千万不要使用 unsafe,因为它不安全,甚至有些库会以没有 unsafe 代码作为噱头来吸引用户。事实上,大可不必,如果按照这个标准,Rust 的标准库也将不复存在!
Rust 中的 unsafe 其实没有那么可怕,虽然听上去很不安全,但是实际上 Rust 依然提供了很多机制来帮我们提升了安全性,因此不必像对待 Go 语言的 unsafe 那样去畏惧于使用 Rust 中的 unsafe 。
大致使用原则总结如下:没必要用时,就不要用,当有必要用时,就大胆用,但是尽量控制好边界,让 unsafe 的范围尽可能小。
控制 unsafe 的使用边界
unsafe 不安全,但是该用的时候就要用,在一些时候,它能帮助我们大幅降低代码实现的成本。
而作为使用者,你的水平决定了 unsafe 到底有多不安全,因此你需要在 unsafe 中小心谨慎地去访问内存。
即使做到小心谨慎,依然会有出错的可能性,但是 unsafe 语句块决定了:就算内存访问出错了,你也能立刻意识到,错误是在 unsafe 代码块中,而不花大量时间像无头苍蝇一样去寻找问题所在。
正因为此,写代码时要尽量控制好 unsafe 的边界大小,越小的 unsafe 越会让我们在未来感谢自己当初的选择。
除了控制边界大小,另一个很常用的方式就是在 unsafe 代码块外包裹一层 safe 的 API,例如一个函数声明为 safe 的,然后在其内部有一块儿是 unsafe 代码。
忍不住抱怨一句,内存安全方面的 bug ,是真心难查!
五种兵器
古龙有一部小说,名为"七种兵器",其中每一种都精妙绝伦,令人闻风丧胆,而 unsafe 也有五种兵器,它们可以让你拥有其它代码无法实现的能力,同时它们也像七种兵器一样令人闻风丧胆,下面一起来看看庐山真面目。
解引用裸指针
裸指针(raw pointer,又称原生指针) 在功能上跟引用类似,同时它也需要显式地注明可变性。但是又和引用有所不同,裸指针长这样: *const T 和 *mut T,它们分别代表了不可变和可变。
大家在之前学过 * 操作符,知道它可以用于解引用,但是在裸指针 *const T 中,这里的 * 只是类型名称的一部分,并没有解引用的含义。
至此,我们已经学过三种类似指针的概念:引用、智能指针和裸指针。与前两者不同,裸指针:
- 可以绕过 Rust 的借用规则,可以同时拥有一个数据的可变、不可变指针,甚至还能拥有多个可变的指针
- 并不能保证指向合法的内存
- 可以是
null - 没有实现任何自动的回收 (drop)
总之,裸指针跟 C 指针是非常像的,使用它需要以牺牲安全性为前提,但我们获得了更好的性能,也可以跟其它语言或硬件打交道。
基于引用创建裸指针
下面的代码基于值的引用同时创建了可变和不可变的裸指针:
#![allow(unused)] fn main() { let mut num = 5; let r1 = &num as *const i32; let r2 = &mut num as *mut i32; }
as 可以用于强制类型转换,在之前章节中有讲解。在这里,我们将引用 &num / &mut num 强转为相应的裸指针 *const i32 / *mut i32。
细心的同学可能会发现,在这段代码中并没有 unsafe 的身影,原因在于:创建裸指针是安全的行为,而解引用裸指针才是不安全的行为 :
fn main() { let mut num = 5; let r1 = &num as *const i32; unsafe { println!("r1 is: {}", *r1); } }
基于内存地址创建裸指针
在上面例子中,我们基于现有的引用来创建裸指针,这种行为是很安全的。但是接下来的方式就不安全了:
#![allow(unused)] fn main() { let address = 0x012345usize; let r = address as *const i32; }
这里基于一个内存地址来创建裸指针,可以想像,这种行为是相当危险的。试图使用任意的内存地址往往是一种未定义的行为(undefined behavior),因为该内存地址有可能存在值,也有可能没有,就算有值,也大概率不是你需要的值。
同时编译器也有可能会优化这段代码,会造成没有任何内存访问发生,甚至程序还可能发生段错误(segmentation fault)。总之,你几乎没有好的理由像上面这样实现代码,虽然它是可行的。
如果真的要使用内存地址,也是类似下面的用法,先取地址,再使用,而不是凭空捏造一个地址:
use std::{slice::from_raw_parts, str::from_utf8_unchecked}; // 获取字符串的内存地址和长度 fn get_memory_location() -> (usize, usize) { let string = "Hello World!"; let pointer = string.as_ptr() as usize; let length = string.len(); (pointer, length) } // 在指定的内存地址读取字符串 fn get_str_at_location(pointer: usize, length: usize) -> &'static str { unsafe { from_utf8_unchecked(from_raw_parts(pointer as *const u8, length)) } } fn main() { let (pointer, length) = get_memory_location(); let message = get_str_at_location(pointer, length); println!( "The {} bytes at 0x{:X} stored: {}", length, pointer, message ); // 如果大家想知道为何处理裸指针需要 `unsafe`,可以试着反注释以下代码 // let message = get_str_at_location(1000, 10); }
以上代码同时还演示了访问非法内存地址会发生什么,大家可以试着去反注释这段代码试试。
使用 * 解引用
#![allow(unused)] fn main() { let a = 1; let b: *const i32 = &a as *const i32; let c: *const i32 = &a; unsafe { println!("{}", *c); } }
使用 * 可以对裸指针进行解引用,由于该指针的内存安全性并没有任何保证,因此我们需要使用 unsafe 来包裹解引用的逻辑(切记,unsafe 语句块的范围一定要尽可能的小,具体原因在上一章节有讲)。
以上代码另一个值得注意的点就是:除了使用 as 来显式的转换,我们还使用了隐式的转换方式 let c: *const i32 = &a;。在实际使用中,我们建议使用 as 来转换,因为这种显式的方式更有助于提醒用户:你在使用的指针是裸指针,需要小心。
基于智能指针创建裸指针
还有一种创建裸指针的方式,那就是基于智能指针来创建:
#![allow(unused)] fn main() { let a: Box<i32> = Box::new(10); // 需要先解引用a let b: *const i32 = &*a; // 使用 into_raw 来创建 let c: *const i32 = Box::into_raw(a); }
小结
像之前代码演示的那样,使用裸指针可以让我们创建两个可变指针都指向同一个数据,如果使用安全的 Rust,你是无法做到这一点的,违背了借用规则,编译器会对我们进行无情的阻止。因此裸指针可以绕过借用规则,但是由此带来的数据竞争问题,就需要大家自己来处理了,总之,需要小心!
既然这么危险,为何还要使用裸指针?除了之前提到的性能等原因,还有一个重要用途就是跟 C 语言的代码进行交互( FFI ),在讲解 FFI 之前,先来看看如何调用 unsafe 函数或方法。
调用 unsafe 函数或方法
unsafe 函数从外表上来看跟普通函数并无区别,唯一的区别就是它需要使用 unsafe fn 来进行定义。这种定义方式是为了告诉调用者:当调用此函数时,你需要注意它的相关需求,因为 Rust 无法担保调用者在使用该函数时能满足它所需的一切需求。
强制调用者加上 unsafe 语句块,就可以让他清晰的认识到,正在调用一个不安全的函数,需要小心看看文档,看看函数有哪些特别的要求需要被满足。
unsafe fn dangerous() {} fn main() { dangerous(); }
如果试图像上面这样调用,编译器就会报错:
error[E0133]: call to unsafe function is unsafe and requires unsafe function or block
--> src/main.rs:3:5
|
3 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
按照报错提示,加上 unsafe 语句块后,就能顺利执行了:
#![allow(unused)] fn main() { unsafe { dangerous(); } }
道理很简单,但一定要牢记在心:使用 unsafe 声明的函数时,一定要看看相关的文档,确定自己没有遗漏什么。
还有,unsafe 无需俄罗斯套娃,在 unsafe 函数体中使用 unsafe 语句块是多余的行为。
用安全抽象包裹 unsafe 代码
一个函数包含了 unsafe 代码不代表我们需要将整个函数都定义为 unsafe fn。事实上,在标准库中有大量的安全函数,它们内部都包含了 unsafe 代码块,下面我们一起来看看一个很好用的标准库函数:split_at_mut。
大家可以想象一下这个场景:需要将一个数组分成两个切片,且每一个切片都要求是可变的。类似需求在安全 Rust 中是很难实现的,因为要对同一个数组做两个可变借用:
fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = slice.len(); assert!(mid <= len); (&mut slice[..mid], &mut slice[mid..]) } fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = split_at_mut(r, 3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
上面代码一眼看过去就知道会报错,因为我们试图在自定义的 split_at_mut 函数中,可变借用 slice 两次:
error[E0499]: cannot borrow `*slice` as mutable more than once at a time
--> src/main.rs:6:30
|
1 | fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut slice[..mid], &mut slice[mid..])
| -------------------------^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*slice` is borrowed for `'1`
对于 Rust 的借用检查器来说,它无法理解我们是分别借用了同一个切片的两个不同部分,但事实上,这种行为是没任何问题的,毕竟两个借用没有任何重叠之处。总之,不太聪明的 Rust 编译器阻碍了我们用这种简单且安全的方式去实现,那只能剑走偏锋,试试 unsafe 了。
use std::slice; fn split_at_mut(slice: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) { let len = slice.len(); let ptr = slice.as_mut_ptr(); assert!(mid <= len); unsafe { ( slice::from_raw_parts_mut(ptr, mid), slice::from_raw_parts_mut(ptr.add(mid), len - mid), ) } } fn main() { let mut v = vec![1, 2, 3, 4, 5, 6]; let r = &mut v[..]; let (a, b) = split_at_mut(r, 3); assert_eq!(a, &mut [1, 2, 3]); assert_eq!(b, &mut [4, 5, 6]); }
相比安全实现,这段代码就显得没那么好理解了,甚至于我们还需要像 C 语言那样,通过指针地址的偏移去控制数组的分割。
as_mut_ptr会返回指向slice首地址的裸指针*mut i32slice::from_raw_parts_mut函数通过指针和长度来创建一个新的切片,简单来说,该切片的初始地址是ptr,长度为midptr.add(mid)可以获取第二个切片的初始地址,由于切片中的元素是i32类型,每个元素都占用了 4 个字节的内存大小,因此我们不能简单的用ptr + mid来作为初始地址,而应该使用ptr + 4 * mid,但是这种使用方式并不安全,因此.add方法是最佳选择
由于 slice::from_raw_parts_mut 使用裸指针作为参数,因此它是一个 unsafe fn,我们在使用它时,就必须用 unsafe 语句块进行包裹,类似的,.add 方法也是如此(还是那句话,不要将无关的代码包含在 unsafe 语句块中)。
部分同学可能会有疑问,那这段代码我们怎么保证 unsafe 中使用的裸指针 ptr 和 ptr.add(mid) 是合法的呢?秘诀就在于 assert!(mid <= len); ,通过这个断言,我们保证了裸指针一定指向了 slice 切片中的某个元素,而不是一个莫名其妙的内存地址。
再回到我们的主题:虽然 split_at_mut 使用了 unsafe,但我们无需将其声明为 unsafe fn,这种情况下就是使用安全的抽象包裹 unsafe 代码,这里的 unsafe 使用是非常安全的,因为我们从合法数据中创建了的合法指针。
与之对比,下面的代码就非常危险了:
#![allow(unused)] fn main() { use std::slice; let address = 0x01234usize; let r = address as *mut i32; let slice: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) }; println!("{:?}",slice); }
这段代码从一个任意的内存地址,创建了一个 10000 长度的 i32 切片,我们无法保证切片中的元素都是合法的 i32 值,这种访问就是一种未定义行为(UB = undefined behavior)。
zsh: segmentation fault
不出所料,运行后看到了一个段错误。
FFI
FFI(Foreign Function Interface)可以用来与其它语言进行交互,但是并不是所有语言都这么称呼,例如 Java 称之为 JNI(Java Native Interface)。
FFI 之所以存在是由于现实中很多代码库都是由不同语言编写的,如果我们需要使用某个库,但是它是由其它语言编写的,那么往往只有两个选择:
- 对该库进行重写或者移植
- 使用
FFI
前者相当不错,但是在很多时候,并没有那么多时间去重写,因此 FFI 就成了最佳选择。回到 Rust 语言上,由于这门语言依然很年轻,一些生态是缺失的,我们在写一些不是那么大众的项目时,可能会同时遇到没有相应的 Rust 库可用的尴尬境况,此时通过 FFI 去调用 C 语言的库就成了相当棒的选择。
还有在将 C/C++ 的代码重构为 Rust 时,先将相关代码引入到 Rust 项目中,然后逐步重构,也是不错的(为什么用不错来形容?因为重构一个有一定规模的 C/C++ 项目远没有想象中美好,因此最好的选择还是对于新项目使用 Rust 实现,老项目。。就让它先运行着吧)。
当然,除了 FFI 还有一个办法可以解决跨语言调用的问题,那就是将其作为一个独立的服务,然后使用网络调用的方式去访问,HTTP,gRPC 都可以。
言归正传,之前我们提到 unsafe 的另一个重要目的就是对 FFI 提供支持,它的全称是 Foreign Function Interface,顾名思义,通过 FFI , 我们的 Rust 代码可以跟其它语言的外部代码进行交互。
下面的例子演示了如何调用 C 标准库中的 abs 函数:
extern "C" { fn abs(input: i32) -> i32; } fn main() { unsafe { println!("Absolute value of -3 according to C: {}", abs(-3)); } }
C 语言的代码定义在了 extern 代码块中, 而 extern 必须使用 unsafe 才能进行进行调用,原因在于其它语言的代码并不会强制执行 Rust 的规则,因此 Rust 无法对这些代码进行检查,最终还是要靠开发者自己来保证代码的正确性和程序的安全性。
ABI
在 extern "C" 代码块中,我们列出了想要调用的外部函数的签名。其中 "C" 定义了外部函数所使用的应用二进制接口ABI (Application Binary Interface):ABI 定义了如何在汇编层面来调用该函数。在所有 ABI 中,C 语言的是最常见的。
在其它语言中调用 Rust 函数
在 Rust 中调用其它语言的函数是让 Rust 利用其他语言的生态,那反过来可以吗?其他语言可以利用 Rust 的生态不?答案是肯定的。
我们可以使用 extern 来创建一个接口,其它语言可以通过该接口来调用相关的 Rust 函数。但是此处的语法与之前有所不同,之前用的是语句块,而这里是在函数定义时加上 extern 关键字,当然,别忘了指定相应的 ABI:
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } }
上面的代码可以让 call_from_c 函数被 C 语言的代码调用,当然,前提是将其编译成一个共享库,然后链接到 C 语言中。
这里还有一个比较奇怪的注解 #[no_mangle],它用于告诉 Rust 编译器:不要乱改函数的名称。 Mangling 的定义是:当 Rust 因为编译需要去修改函数的名称,例如为了让名称包含更多的信息,这样其它的编译部分就能从该名称获取相应的信息,这种修改会导致函数名变得相当不可读。
因此,为了让 Rust 函数能顺利被其它语言调用,我们必须要禁止掉该功能。
访问或修改一个可变的静态变量
这部分我们在之前的全局变量章节中有过详细介绍,这里就不再赘述,大家可以前往此章节阅读。
实现 unsafe 特征
说实话,unsafe 的特征确实不多见,如果大家还记得的话,我们在之前的 Send 和 Sync章节中实现过 unsafe 特征 Send。
之所以会有 unsafe 的特征,是因为该特征至少有一个方法包含有编译器无法验证的内容。unsafe 特征的声明很简单:
unsafe trait Foo { // 方法列表 } unsafe impl Foo for i32 { // 实现相应的方法 } fn main() {}
通过 unsafe impl 的使用,我们告诉编译器:相应的正确性由我们自己来保证。
再回到刚提到的 Send 特征,若我们的类型中的所有字段都实现了 Send 特征,那该类型也会自动实现 Send。但是如果我们想要为某个类型手动实现 Send ,例如为裸指针,那么就必须使用 unsafe,相关的代码在之前的链接中也有,大家可以移步查看。
总之,Send 特征标记为 unsafe 是因为 Rust 无法验证我们的类型是否能在线程间安全的传递,因此就需要通过 unsafe 来告诉编译器,它无需操心,剩下的交给我们自己来处理。
访问 union 中的字段
截止目前,我们还没有介绍过 union ,原因很简单,它主要用于跟 C 代码进行交互。
访问 union 的字段是不安全的,因为 Rust 无法保证当前存储在 union 实例中的数据类型。
#![allow(unused)] fn main() { #[repr(C)] union MyUnion { f1: u32, f2: f32, } }
上从可以看出,union 的使用方式跟结构体确实很相似,但是前者的所有字段都共享同一个存储空间,意味着往 union 的某个字段写入值,会导致其它字段的值会被覆盖。
关于 union 的更多信息,可以在这里查看。
一些实用工具(库)
由于 unsafe 和 FFI 在 Rust 的使用场景中是相当常见的(例如相对于 Go 的 unsafe 来说),因此社区已经开发出了相当一部分实用的工具,可以改善相应的开发体验。
rust-bindgen 和 cbindgen
对于 FFI 调用来说,保证接口的正确性是非常重要的,这两个库可以帮我们自动生成相应的接口,其中 rust-bindgen 用于在 Rust 中访问 C 代码,而 cbindgen则反之。
下面以 rust-bindgen 为例,来看看如何自动生成调用 C 的代码,首先下面是 C 代码:
typedef struct Doggo {
int many;
char wow;
} Doggo;
void eleven_out_of_ten_majestic_af(Doggo* pupper);
下面是自动生成的可以调用上面代码的 Rust 代码:
#![allow(unused)] fn main() { /* automatically generated by rust-bindgen 0.99.9 */ #[repr(C)] pub struct Doggo { pub many: ::std::os::raw::c_int, pub wow: ::std::os::raw::c_char, } extern "C" { pub fn eleven_out_of_ten_majestic_af(pupper: *mut Doggo); } }
cxx
如果需要跟 C++ 代码交互,非常推荐使用 cxx,它提供了双向的调用,最大的优点就是安全:是的,你无需通过 unsafe 来使用它!
Miri
miri 可以生成 Rust 的中间层表示 MIR,对于编译器来说,我们的 Rust 代码首先会被编译为 MIR ,然后再提交给 LLVM 进行处理。
可以通过 rustup component add miri 来安装它,并通过 cargo miri 来使用,同时还可以使用 cargo miri test 来运行测试代码。
miri 可以帮助我们检查常见的未定义行为(UB = Undefined Behavior),以下列出了一部分:
- 内存越界检查和内存释放后再使用(use-after-free)
- 使用未初始化的数据
- 数据竞争
- 内存对齐问题
但是需要注意的是,它只能帮助识别被执行代码路径的风险,那些未被执行到的代码是没办法被识别的。
Clippy
官方的 clippy 检查器提供了有限的 unsafe 支持,虽然不多,但是至少有一定帮助。例如 missing_safety_docs 检查可以帮助我们检查哪些 unsafe 函数遗漏了文档。
需要注意的是: Rust 编译器并不会默认开启所有检查,大家可以调用 rustc -W help 来看看最新的信息。
Prusti
prusti 需要大家自己来构建一个证明,然后通过它证明代码中的不变量是正确被使用的,当你在安全代码中使用不安全的不变量时,就会非常有用。具体的使用文档见这里。
模糊测试(fuzz testing)
在 Rust Fuzz Book 中列出了一些 Rust 可以使用的模糊测试方法。
同时,我们还可以使用 rutenspitz 这个过程宏来测试有状态的代码,例如数据结构。
总结
至此,unsafe 的五种兵器已介绍完毕,大家是否意犹未尽?我想说的是,就算意犹未尽,也没有其它兵器了。
就像上一章中所提到的,unsafe 只应该用于这五种场景,其它场景,你应该坚决的使用安全的代码,否则就会像 actix-web 的前作者一样,被很多人议论,甚至被喷。。。
总之,能不使用 unsafe 一定不要使用,就算使用也要控制好边界,让范围尽可能的小,就像本章的例子一样,只有真的需要 unsafe 的代码,才应该包含其中, 而不是将无关代码也纳入进来。
进一步学习
内联汇编
Macro 宏编程
在编程世界可以说是谈“宏”色变,原因在于 C 语言中的宏是非常危险的东东,但并不是所有语言都像 C 这样,例如对于古老的语言 Lisp 来说,宏就是就是一个非常强大的好帮手。
那话说回来,在 Rust 中宏到底是好是坏呢?本章将带你揭开它的神秘面纱。
事实上,我们虽然没有见过宏,但是已经多次用过它,例如在全书的第一个例子中就用到了:println!("你好,世界"),这里 println! 就是一个最常用的宏,可以看到它和函数最大的区别是:它在调用时多了一个 !,除此之外还有 vec! 、assert_eq! 都是相当常用的,可以说宏在 Rust 中无处不在。
细心的读者可能会注意到 println! 后面跟着的是 (),而 vec! 后面跟着的是 [],这是因为宏的参数可以使用 ()、[] 以及 {}:
fn main() { println!("aaaa"); println!["aaaa"]; println!{"aaaa"} }
虽然三种使用形式皆可,但是 Rust 内置的宏都有自己约定俗成的使用方式,例如 vec![...]、assert_eq!(...) 等。
在 Rust 中宏分为两大类:声明式宏( declarative macros ) macro_rules! 和三种过程宏( procedural macros ):
#[derive],在之前多次见到的派生宏,可以为目标结构体或枚举派生指定的代码,例如Debug特征- 类属性宏(Attribute-like macro),用于为目标添加自定义的属性
- 类函数宏(Function-like macro),看上去就像是函数调用
如果感觉难以理解,也不必担心,接下来我们将逐个看看它们的庐山真面目,在此之前,先来看下为何需要宏,特别是 Rust 的函数明明已经很强大了。
宏和函数的区别
宏和函数的区别并不少,而且对于宏擅长的领域,函数其实是有些无能为力的。
元编程
从根本上来说,宏是通过一种代码来生成另一种代码,如果大家熟悉元编程,就会发现两者的共同点。
在附录 D中讲到的 derive 属性,就会自动为结构体派生出相应特征所需的代码,例如 #[derive(Debug)],还有熟悉的 println! 和 vec!,所有的这些宏都会展开成相应的代码,且很可能是长得多的代码。
总之,元编程可以帮我们减少所需编写的代码,也可以一定程度上减少维护的成本,虽然函数复用也有类似的作用,但是宏依然拥有自己独特的优势。
可变参数
Rust 的函数签名是固定的:定义了两个参数,就必须传入两个参数,多一个少一个都不行,对于从 JS/TS 过来的同学,这一点其实是有些恼人的。
而宏就可以拥有可变数量的参数,例如可以调用一个参数的 println!("hello"),也可以调用两个参数的 println!("hello {}", name)。
宏展开
由于宏会被展开成其它代码,且这个展开过程是发生在编译器对代码进行解释之前。因此,宏可以为指定的类型实现某个特征:先将宏展开成实现特征的代码后,再被编译。
而函数就做不到这一点,因为它直到运行时才能被调用,而特征需要在编译期被实现。
宏的缺点
相对函数来说,由于宏是基于代码再展开成代码,因此实现相比函数来说会更加复杂,再加上宏的语法更为复杂,最终导致定义宏的代码相当地难读,也难以理解和维护。
声明式宏 macro_rules!
在 Rust 中使用最广的就是声明式宏,它们也有一些其它的称呼,例如示例宏( macros by example )、macro_rules! 或干脆直接称呼为宏。
声明式宏允许我们写出类似 match 的代码。match 表达式是一个控制结构,其接收一个表达式,然后将表达式的结果与多个模式进行匹配,一旦匹配了某个模式,则该模式相关联的代码将被执行:
#![allow(unused)] fn main() { match target { 模式1 => 表达式1, 模式2 => { 语句1; 语句2; 表达式2 }, _ => 表达式3 } }
而宏也是将一个值跟对应的模式进行匹配,且该模式会与特定的代码相关联。但是与 match 不同的是,宏里的值是一段 Rust 源代码(字面量),模式用于跟这段源代码的结构相比较,一旦匹配,传入宏的那段源代码将被模式关联的代码所替换,最终实现宏展开。值得注意的是,所有的这些都是在编译期发生,并没有运行期的性能损耗。
简化版的 vec!
在动态数组 Vector 章节中,我们学习了使用 vec! 来便捷的初始化一个动态数组:
#![allow(unused)] fn main() { let v: Vec<u32> = vec![1, 2, 3]; }
最重要的是,通过 vec! 创建的动态数组支持任何元素类型,也并没有限制数组的长度,如果使用函数,我们是无法做到这一点的。
好在我们有 macro_rules!,来看看该如何使用它来实现 vec!,以下是一个简化实现:
#![allow(unused)] fn main() { #[macro_export] macro_rules! vec { ( $( $x:expr ),* ) => { { let mut temp_vec = Vec::new(); $( temp_vec.push($x); )* temp_vec } }; } }
简化实现版本?这也太难了吧!!只能说,欢迎来到宏的世界,在这里你能见到优雅 Rust 的另一面:) 标准库中的 vec! 还包含了预分配内存空间的代码,如果引入进来,那大家将更难以接受。
#[macro_export] 注释将宏进行了导出,这样其它的包就可以将该宏引入到当前作用域中,然后才能使用。可能有同学会提问:我们在使用标准库 vec! 时也没有引入宏啊,那是因为 Rust 已经通过 std::prelude的方式为我们自动引入了。
紧接着,就使用 macro_rules! 进行了宏定义,需要注意的是宏的名称是 vec,而不是 vec!,后者的感叹号只在调用时才需要。
vec 的定义结构跟 match 表达式很像,但这里我们只有一个分支,其中包含一个模式 ( $( $x:expr ),* ),跟模式相关联的代码就在 => 之后。一旦模式成功匹配,那这段相关联的代码就会替换传入的源代码。
由于 vec 宏只有一个模式,因此它只能匹配一种源代码,其它类型的都将导致报错,而更复杂的宏往往会拥有更多的分支。
虽然宏和 match 都称之为模式,但是前者跟后者的模式规则是不同的。如果大家想要更深入的了解宏的模式,可以查看这里。
模式解析
而现在,我们先来简单讲解下 ( $( $x:expr ),* ) 的含义。
首先,我们使用圆括号 () 将整个宏模式包裹其中。紧随其后的是 $(),跟括号中模式相匹配的值(传入的 Rust 源代码)会被捕获,然后用于代码替换。在这里,模式 $x:expr 会匹配任何 Rust 表达式并给予该模式一个名称:$x。
$() 之后的逗号说明在 $() 所匹配的代码的后面会有一个可选的逗号分隔符,紧随逗号之后的 * 说明 * 之前的模式会被匹配零次或任意多次(类似正则表达式)。
当我们使用 vec![1, 2, 3] 来调用该宏时,$x 模式将被匹配三次,分别是 1、2、3。为了帮助大家巩固,我们再来一起过一下:
$()中包含的是模式$x:expr,该模式中的expr表示会匹配任何 Rust 表达式,并给予该模式一个名称$x- 因此
$x模式可以跟整数1进行匹配,也可以跟字符串 "hello" 进行匹配:vec!["hello", "world"] $()之后的逗号,意味着1和2之间可以使用逗号进行分割,也意味着3既可以没有逗号,也可以有逗号:vec![1, 2, 3,]*说明之前的模式可以出现零次也可以任意次,这里出现了三次
接下来,我们再来看看与模式相关联、在 => 之后的代码:
#![allow(unused)] fn main() { { { let mut temp_vec = Vec::new(); $( temp_vec.push($x); )* temp_vec } }; }
这里就比较好理解了,$() 中的 temp_vec.push() 将根据模式匹配的次数生成对应的代码,当调用 vec![1, 2, 3] 时,下面这段生成的代码将替代传入的源代码,也就是替代 vec![1, 2, 3] :
#![allow(unused)] fn main() { { let mut temp_vec = Vec::new(); temp_vec.push(1); temp_vec.push(2); temp_vec.push(3); temp_vec } }
如果是 let v = vec![1, 2, 3],那生成的代码最后返回的值 temp_vec 将被赋予给变量 v,等同于 :
#![allow(unused)] fn main() { let v = { let mut temp_vec = Vec::new(); temp_vec.push(1); temp_vec.push(2); temp_vec.push(3); temp_vec } }
至此,我们定义了一个宏,它可以接受任意类型和数量的参数,并且理解了其语法的含义。
未来将被替代的 macro_rules
对于 macro_rules 来说,它是存在一些问题的,因此,Rust 计划在未来使用新的声明式宏来替换它:工作方式类似,但是解决了目前存在的一些问题,在那之后,macro_rules 将变为 deprecated 状态。
由于绝大多数 Rust 开发者都是宏的用户而不是编写者,因此在这里我们不会对 macro_rules 进行更深入的学习,如果大家感兴趣,可以看看这本书 “The Little Book of Rust Macros”。
用过程宏为属性标记生成代码
第二种常用的宏就是过程宏 ( procedural macros ),从形式上来看,过程宏跟函数较为相像,但过程宏是使用源代码作为输入参数,基于代码进行一系列操作后,再输出一段全新的代码。注意,过程宏中的 derive 宏输出的代码并不会替换之前的代码,这一点与声明宏有很大的不同!
至于前文提到的过程宏的三种类型(自定义 derive、属性宏、函数宏),它们的工作方式都是类似的。
当创建过程宏时,它的定义必须要放入一个独立的包中,且包的类型也是特殊的,这么做的原因相当复杂,大家只要知道这种限制在未来可能会有所改变即可。
事实上,根据这个说法,过程宏放入独立包的原因在于它必须先被编译后才能使用,如果过程宏和使用它的代码在一个包,就必须先单独对过程宏的代码进行编译,然后再对我们的代码进行编译,但悲剧的是 Rust 的编译单元是包,因此你无法做到这一点。
假设我们要创建一个 derive 类型的过程宏:
#![allow(unused)] fn main() { use proc_macro; #[proc_macro_derive(HelloMacro)] pub fn some_name(input: TokenStream) -> TokenStream { } }
用于定义过程宏的函数 some_name 使用 TokenStream 作为输入参数,并且返回的也是同一个类型。TokenStream 是在 proc_macro 包中定义的,顾名思义,它代表了一个 Token 序列。
在理解了过程宏的基本定义后,我们再来看看该如何创建三种类型的过程宏,首先,从大家最熟悉的 derive 开始。
自定义 derive 过程宏
假设我们有一个特征 HelloMacro,现在有两种方式让用户使用它:
- 为每个类型手动实现该特征,就像之前特征章节所做的
- 使用过程宏来统一实现该特征,这样用户只需要对类型进行标记即可:
#[derive(HelloMacro)]
以上两种方式并没有孰优孰劣,主要在于不同的类型是否可以使用同样的默认特征实现,如果可以,那过程宏的方式可以帮我们减少很多代码实现:
use hello_macro::HelloMacro; use hello_macro_derive::HelloMacro; #[derive(HelloMacro)] struct Sunfei; #[derive(HelloMacro)] struct Sunface; fn main() { Sunfei::hello_macro(); Sunface::hello_macro(); }
简单吗?简单!不过为了实现这段代码展示的功能,我们还需要创建相应的过程宏才行。 首先,创建一个新的工程用于演示:
$ cargo new hello_macro
$ cd hello_macro/
$ touch src/lib.rs
此时,src 目录下包含两个文件 lib.rs 和 main.rs,前者是 lib 包根,后者是二进制包根
接下来,先在 src/lib.rs 中定义过程宏所需的 HelloMacro 特征和其关联函数:
#![allow(unused)] fn main() { pub trait HelloMacro { fn hello_macro(); } }
然后在 src/main.rs 中编写主体代码,首先映入大家脑海的可能会是如下实现:
use hello_macro::HelloMacro; struct Sunfei; impl HelloMacro for Sunfei { fn hello_macro() { println!("Hello, Macro! My name is Sunfei!"); } } struct Sunface; impl HelloMacro for Sunface { fn hello_macro() { println!("Hello, Macro! My name is Sunface!"); } } fn main() { Sunfei::hello_macro(); }
但是这种方式有个问题,如果想要实现不同的招呼内容,就需要为每一个类型都实现一次相应的特征,Rust 不支持反射,因此我们无法在运行时获得类型名。
使用宏,就不存在这个问题:
use hello_macro::HelloMacro; use hello_macro_derive::HelloMacro; #[derive(HelloMacro)] struct Sunfei; #[derive(HelloMacro)] struct Sunface; fn main() { Sunfei::hello_macro(); Sunface::hello_macro(); }
简单明了的代码总是令人愉快,为了让代码运行起来,还需要定义下过程宏。就如前文提到的,目前只能在单独的包中定义过程宏,尽管未来这种限制会被取消,但是现在我们还得遵循这个规则。
宏所在的包名自然也有要求,必须以 derive 为后缀,对于 hello_macro 宏而言,包名就应该是 hello_macro_derive。在之前创建的 hello_macro 项目根目录下,运行如下命令,创建一个单独的 lib 包:
#![allow(unused)] fn main() { cargo new hello_macro_derive --lib }
至此, hello_macro 项目的目录结构如下:
hello_macro
├── Cargo.toml
├── src
│ ├── main.rs
│ └── lib.rs
└── hello_macro_derive
├── Cargo.toml
├── src
└── lib.rs
由于过程宏所在的包跟我们的项目紧密相连,因此将它放在项目之中。现在,问题又来了,该如何在项目的 src/main.rs 中引用 hello_macro_derive 包的内容?
方法有两种,第一种是将 hello_macro_derive 发布到 crates.io 或 GitHub 中,就像我们引用的其它依赖一样;另一种就是使用相对路径引入的本地化方式,修改 hello_macro/Cargo.toml 文件添加以下内容:
[dependencies]
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
# 也可以使用下面的相对路径
# hello_macro_derive = { path = "./hello_macro_derive" }
此时,hello_macro 项目就可以成功的引用到 hello_macro_derive 本地包了
另外,学习过程更好的办法是通过展开宏来阅读和调试自己写的宏,这里需要用到一个 cargo-expand 的工具,可以通过下面的命令安装
cargo install cargo-expand
接下来,就到了重头戏环节,一起来看看该如何定义过程宏。
定义过程宏
首先,在 hello_macro_derive/Cargo.toml 文件中添加以下内容:
[lib]
proc-macro = true
[dependencies]
syn = "1.0"
quote = "1.0"
其中 syn 和 quote 依赖包都是定义过程宏所必需的,同时,还需要在 [lib] 中将过程宏的开关开启 : proc-macro = true。
其次,在 hello_macro_derive/src/lib.rs 中添加如下代码:
#![allow(unused)] fn main() { extern crate proc_macro; use proc_macro::TokenStream; use quote::quote; use syn; use syn::DeriveInput; #[proc_macro_derive(HelloMacro)] pub fn hello_macro_derive(input: TokenStream) -> TokenStream { // 基于 input 构建 AST 语法树 let ast:DeriveInput = syn::parse(input).unwrap(); // 构建特征实现代码 impl_hello_macro(&ast) } }
这个函数的签名我们在之前已经介绍过,总之,这种形式的过程宏定义是相当通用的,下面来分析下这段代码。
首先有一点,对于绝大多数过程宏而言,这段代码往往只在 impl_hello_macro(&ast) 中的实现有所区别,对于其它部分基本都是一致的,例如包的引入、宏函数的签名、语法树构建等。
proc_macro 包是 Rust 自带的,因此无需在 Cargo.toml 中引入依赖,它包含了相关的编译器 API,可以用于读取和操作 Rust 源代码。
由于我们为 hello_macro_derive 函数标记了 #[proc_macro_derive(HelloMacro)],当用户使用 #[derive(HelloMacro)] 标记了他的类型后,hello_macro_derive 函数就将被调用。这里的秘诀就是特征名 HelloMacro,它就像一座桥梁,将用户的类型和过程宏联系在一起。
syn 将字符串形式的 Rust 代码解析为一个 AST 树的数据结构,该数据结构可以在随后的 impl_hello_macro 函数中进行操作。最后,操作的结果又会被 quote 包转换回 Rust 代码。这些包非常关键,可以帮我们节省大量的精力,否则你需要自己去编写支持代码解析和还原的解析器,这可不是一件简单的任务!
derive过程宏只能用在struct/enum/union上,多数用在结构体上,我们先来看一下一个结构体由哪些部分组成:
#![allow(unused)] fn main() { // vis,可视范围 ident,标识符 generic,范型 fields: 结构体的字段 pub struct User <'a, T> { // vis ident type pub name: &'a T, } }
其中type还可以细分,具体请阅读syn文档或源码
syn::parse 调用会返回一个 DeriveInput 结构体来代表解析后的 Rust 代码:
#![allow(unused)] fn main() { DeriveInput { // --snip-- vis: Visibility, generics: Generics ident: Ident { ident: "Sunfei", span: #0 bytes(95..103) }, // Data是一个枚举,分别是DataStruct,DataEnum,DataUnion,这里以 DataStruct 为例 data: Data( DataStruct { struct_token: Struct, fields: Fields, semi_token: Some( Semi ) } ) } }
以上就是源代码 struct Sunfei; 解析后的结果,里面有几点值得注意:
fields: Fields是一个枚举类型,FieldsNamed,FieldsUnnamed,FieldsUnnamed, 分别表示显示命名结构(如例子所示),匿名字段的结构(例如 struct A(u8);),和无字段定义的结构(例如 struct A;)ident: "Sunfei"说明类型名称为Sunfei,ident是标识符identifier的简写
如果想要了解更多的信息,可以查看 syn 文档。
大家可能会注意到在 hello_macro_derive 函数中有 unwrap 的调用,也许会以为这是为了演示目的,没有做错误处理,实际上并不是的。由于该函数只能返回 TokenStream 而不是 Result,那么在报错时直接 panic 来抛出错误就成了相当好的选择。当然,这里实际上还是做了简化,在生产项目中,你应该通过 panic! 或 expect 抛出更具体的报错信息。
至此,这个函数大家应该已经基本理解了,下面来看看如何构建特征实现的代码,也是过程宏的核心目标:
#![allow(unused)] fn main() { fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream { let name = &ast.ident; let gen = quote! { impl HelloMacro for #name { fn hello_macro() { println!("Hello, Macro! My name is {}!", stringify!(#name)); } } }; gen.into() } }
首先,将结构体的名称赋予给 name,也就是 name 中会包含一个字段,它的值是字符串 "Sunfei"。
其次,使用 quote! 可以定义我们想要返回的 Rust 代码。由于编译器需要的内容和 quote! 直接返回的不一样,因此还需要使用 .into 方法其转换为 TokenStream。
大家注意到 #name 的使用了吗?这也是 quote! 提供的功能之一,如果想要深入了解 quote,可以看看官方文档。
特征的 hell_macro() 函数只有一个功能,就是使用 println! 打印一行欢迎语句。
其中 stringify! 是 Rust 提供的内置宏,可以将一个表达式(例如 1 + 2)在编译期转换成一个字符串字面值("1 + 2"),该字面量会直接打包进编译出的二进制文件中,具有 'static 生命周期。而 format! 宏会对表达式进行求值,最终结果是一个 String 类型。在这里使用 stringify! 有两个好处:
#name可能是一个表达式,我们需要它的字面值形式- 可以减少一次
String带来的内存分配
在运行之前,可以显示用 expand 展开宏,观察是否有错误或是否符合预期:
$ cargo expand
struct Sunfei; impl HelloMacro for Sunfei { fn hello_macro() { { ::std::io::_print( ::core::fmt::Arguments::new_v1( &["Hello, Macro! My name is ", "!\n"], &[::core::fmt::ArgumentV1::new_display(&"Sunfei")], ), ); }; } } struct Sunface; impl HelloMacro for Sunface { fn hello_macro() { { ::std::io::_print( ::core::fmt::Arguments::new_v1( &["Hello, Macro! My name is ", "!\n"], &[::core::fmt::ArgumentV1::new_display(&"Sunface")], ), ); }; } } fn main() { Sunfei::hello_macro(); Sunface::hello_macro(); }
从展开的代码也能看出derive宏的特性,struct Sunfei; 和 struct Sunface; 都被保留了,也就是说最后 impl_hello_macro() 返回的token被加到结构体后面,这和类属性宏可以修改输入 的token是不一样的,input的token并不能被修改
至此,过程宏的定义、特征定义、主体代码都已经完成,运行下试试:
$ cargo run
Running `target/debug/hello_macro`
Hello, Macro! My name is Sunfei!
Hello, Macro! My name is Sunface!
Bingo,虽然过程有些复杂,但是结果还是很喜人,我们终于完成了自己的第一个过程宏!
下面来实现一个更实用的例子,实现官方的#[derive(Default)]宏,废话不说直接开干:
#![allow(unused)] fn main() { extern crate proc_macro; use proc_macro::TokenStream; use quote::quote; use syn::{self, Data}; use syn::DeriveInput; #[proc_macro_derive(MyDefault)] pub fn my_default(input: TokenStream) -> TokenStream { let ast: DeriveInput = syn::parse(input).unwrap(); let id = ast.ident; let Data::Struct(s) = ast.data else{ panic!("MyDefault derive macro must use in struct"); }; // 声明一个新的ast,用于动态构建字段赋值的token let mut field_ast = quote!(); // 这里就是要动态添加token的地方了,需要动态完成Self的字段赋值 for (idx,f) in s.fields.iter().enumerate() { let (field_id, field_ty) = (&f.ident, &f.ty); if field_id.is_none(){ //没有ident表示是匿名字段,对于匿名字段,都需要添加 `#field_idx: #field_type::default(),` 这样的代码 let field_idx = syn::Index::from(idx); field_ast.extend(quote! { field_idx: # field_ty::default(), }); }else{ //对于命名字段,都需要添加 `#field_name: #field_type::default(),` 这样的代码 field_ast.extend(quote! { field_id: # field_ty::default(), }); } } quote! { impl Default for # id { fn default() -> Self { Self { field_ast } } } }.into() } }
然后来写使用代码:
#[derive(MyDefault)] struct SomeData (u32,String); #[derive(MyDefault)] struct User { name: String, data: SomeData, } fn main() { }
然后我们先展开代码看一看
struct SomeData(u32, String); impl Default for SomeData { fn default() -> Self { Self { 0: u32::default(), 1: String::default(), } } } struct User { name: String, data: SomeData, } impl Default for User { fn default() -> Self { Self { name: String::default(), data: SomeData::default(), } } } fn main() {}
展开的代码符合预期,然后我们修改一下使用代码并测试结果
#[derive(MyDefault, Debug)] struct SomeData (u32,String); #[derive(MyDefault, Debug)] struct User { name: String, data: SomeData, } fn main() { println!("{:?}", User::default()); }
执行
$ cargo run
Running `target/debug/aaa`
User { name: "", data: SomeData(0, "") }
接下来,再来看看过程宏的另外两种类型跟 derive 类型有何区别。
类属性宏(Attribute-like macros)
类属性过程宏跟 derive 宏类似,但是前者允许我们定义自己的属性。除此之外,derive 只能用于结构体和枚举,而类属性宏可以用于其它类型项,例如函数。
假设我们在开发一个 web 框架,当用户通过 HTTP GET 请求访问 / 根路径时,使用 index 函数为其提供服务:
#![allow(unused)] fn main() { #[route(GET, "/")] fn index() { }
如上所示,代码功能非常清晰、简洁,这里的 #[route] 属性就是一个过程宏,它的定义函数大概如下:
#![allow(unused)] fn main() { #[proc_macro_attribute] pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream { }
与 derive 宏不同,类属性宏的定义函数有两个参数:
- 第一个参数时用于说明属性包含的内容:
Get, "/"部分 - 第二个是属性所标注的类型项,在这里是
fn index() {...},注意,函数体也被包含其中
除此之外,类属性宏跟 derive 宏的工作方式并无区别:创建一个包,类型是 proc-macro,接着实现一个函数用于生成想要的代码。
类函数宏(Function-like macros)
类函数宏可以让我们定义像函数那样调用的宏,从这个角度来看,它跟声明宏 macro_rules 较为类似。
区别在于,macro_rules 的定义形式与 match 匹配非常相像,而类函数宏的定义形式则类似于之前讲过的两种过程宏:
#![allow(unused)] fn main() { #[proc_macro] pub fn sql(input: TokenStream) -> TokenStream { }
而使用形式则类似于函数调用:
#![allow(unused)] fn main() { let sql = sql!(SELECT * FROM posts WHERE id=1); }
大家可能会好奇,为何我们不使用声明宏 macro_rules 来定义呢?原因是这里需要对 SQL 语句进行解析并检查其正确性,这个复杂的过程是 macro_rules 难以对付的,而过程宏相比起来就会灵活的多。
补充学习资料
- dtolnay/proc-macro-workshop,学习如何编写过程宏
- The Little Book of Rust Macros,学习如何编写声明宏
macro_rules! - syn 和 quote ,用于编写过程宏的包,它们的文档有很多值得学习的东西
- Structuring, testing and debugging procedural macro crates,从测试、debug、结构化的角度来编写过程宏
- blog.turbo.fish,里面的过程宏系列文章值得一读
- Rust 宏小册中文版,非常详细的解释了宏各种知识
总结
Rust 中的宏主要分为两大类:声明宏和过程宏。
声明宏目前使用 macro_rules 进行创建,它的形式类似于 match 匹配,对于用户而言,可读性和维护性都较差。由于其存在的问题和限制,在未来, macro_rules 会被 deprecated,Rust 会使用一个新的声明宏来替代它。
而过程宏的定义更像是我们平时写函数的方式,因此它更加灵活,它分为三种类型:derive 宏、类属性宏、类函数宏,具体在文中都有介绍。
虽然 Rust 中的宏很强大,但是它并不应该成为我们的常规武器,原因是它会影响 Rust 代码的可读性和可维护性,我相信没有几个人愿意去维护别人写的宏 :)
因此,大家应该熟悉宏的使用场景,但是不要滥用,当你真的需要时,再回来查看本章了解实现细节,这才是最完美的使用方式。
Rust 异步编程
在艰难的学完 Rust 入门和进阶所有的 70 个章节后,我们终于来到了这里。假如之前攀登的是珠穆朗玛峰,那么现在攀登的就是乔戈里峰( 比珠峰还难攀爬... )。
如果你想开发 Web 服务器、数据库驱动、消息服务等需要高并发的服务,那么本章的内容将值得认真对待和学习,将从以下方面深入讲解 Rust 的异步编程:
- Rust 异步编程的通用概念介绍
- Future 以及异步任务调度
- async/await 和 Pin/Unpin
- 异步编程常用的三方库
- tokio 库
- 一些示例
异步编程
接下来,我们将深入了解 async/await 的使用方式及背后的原理。
本章在内容上大量借鉴和翻译了原版英文书籍Asynchronous Programming In Rust, 特此感谢
Async 编程简介
众所周知,Rust 可以让我们写出性能高且安全的软件,那么异步编程这块儿呢?是否依然在高性能的同时保证了安全?
我们先通过一张 web 框架性能对比图来感受下 Rust 异步编程的性能:

上图并不能说 Rust 写的 actix 框架比 Go 的 gin 更好、更优秀,但是确实可以一定程度上说明 Rust 的异步性能非常的高!
简单来说,异步编程是一个并发编程模型,目前主流语言基本都支持了,当然,支持的方式有所不同。异步编程允许我们同时并发运行大量的任务,却仅仅需要几个甚至一个 OS 线程或 CPU 核心,现代化的异步编程在使用体验上跟同步编程也几无区别,例如 Go 语言的 go 关键字,也包括我们后面将介绍的 async/await 语法,该语法是 JavaScript 和 Rust 的核心特性之一。
async 简介
async 是 Rust 选择的异步编程模型,下面我们来介绍下它的优缺点,以及何时适合使用。
async vs 其它并发模型
由于并发编程在现代社会非常重要,因此每个主流语言都对自己的并发模型进行过权衡取舍和精心设计,Rust 语言也不例外。下面的列表可以帮助大家理解不同并发模型的取舍:
- OS 线程, 它最简单,也无需改变任何编程模型(业务/代码逻辑),因此非常适合作为语言的原生并发模型,我们在多线程章节也提到过,Rust 就选择了原生支持线程级的并发编程。但是,这种模型也有缺点,例如线程间的同步将变得更加困难,线程间的上下文切换损耗较大。使用线程池在一定程度上可以提升性能,但是对于 IO 密集的场景来说,线程池还是不够。
- 事件驱动(Event driven), 这个名词你可能比较陌生,如果说事件驱动常常跟回调( Callback )一起使用,相信大家就恍然大悟了。这种模型性能相当的好,但最大的问题就是存在回调地狱的风险:非线性的控制流和结果处理导致了数据流向和错误传播变得难以掌控,还会导致代码可维护性和可读性的大幅降低,大名鼎鼎的
JavaScript曾经就存在回调地狱。 - 协程(Coroutines) 可能是目前最火的并发模型,
Go语言的协程设计就非常优秀,这也是Go语言能够迅速火遍全球的杀手锏之一。协程跟线程类似,无需改变编程模型,同时,它也跟async类似,可以支持大量的任务并发运行。但协程抽象层次过高,导致用户无法接触到底层的细节,这对于系统编程语言和自定义异步运行时是难以接受的 - actor 模型是 erlang 的杀手锏之一,它将所有并发计算分割成一个一个单元,这些单元被称为
actor, 单元之间通过消息传递的方式进行通信和数据传递,跟分布式系统的设计理念非常相像。由于actor模型跟现实很贴近,因此它相对来说更容易实现,但是一旦遇到流控制、失败重试等场景时,就会变得不太好用 - async/await, 该模型性能高,还能支持底层编程,同时又像线程和协程那样无需过多的改变编程模型,但有得必有失,
async模型的问题就是内部实现机制过于复杂,对于用户来说,理解和使用起来也没有线程和协程简单,好在前者的复杂性开发者们已经帮我们封装好,而理解和使用起来不够简单,正是本章试图解决的问题。
总之,Rust 经过权衡取舍后,最终选择了同时提供多线程编程和 async 编程:
- 前者通过标准库实现,当你无需那么高的并发时,例如需要并行计算时,可以选择它,优点是线程内的代码执行效率更高、实现更直观更简单,这块内容已经在多线程章节进行过深入讲解,不再赘述
- 后者通过语言特性 + 标准库 + 三方库的方式实现,在你需要高并发、异步
I/O时,选择它就对了
async: Rust vs 其它语言
目前已经有诸多语言都通过 async 的方式提供了异步编程,例如 JavaScript ,但 Rust 在实现上有所区别:
- Future 在 Rust 中是惰性的,只有在被轮询(
poll)时才会运行, 因此丢弃一个future会阻止它未来再被运行, 你可以将Future理解为一个在未来某个时间点被调度执行的任务。 - Async 在 Rust 中使用开销是零, 意味着只有你能看到的代码(自己的代码)才有性能损耗,你看不到的(
async内部实现)都没有性能损耗,例如,你可以无需分配任何堆内存、也无需任何动态分发来使用async,这对于热点路径的性能有非常大的好处,正是得益于此,Rust 的异步编程性能才会这么高。 - Rust 没有内置异步调用所必需的运行时,但是无需担心,Rust 社区生态中已经提供了非常优异的运行时实现,例如大明星
tokio - 运行时同时支持单线程和多线程,这两者拥有各自的优缺点,稍后会讲
Rust: async vs 多线程
虽然 async 和多线程都可以实现并发编程,后者甚至还能通过线程池来增强并发能力,但是这两个方式并不互通,从一个方式切换成另一个需要大量的代码重构工作,因此提前为自己的项目选择适合的并发模型就变得至关重要。
OS 线程非常适合少量任务并发,因为线程的创建和上下文切换是非常昂贵的,甚至于空闲的线程都会消耗系统资源。虽说线程池可以有效的降低性能损耗,但是也无法彻底解决问题。当然,线程模型也有其优点,例如它不会破坏你的代码逻辑和编程模型,你之前的顺序代码,经过少量修改适配后依然可以在新线程中直接运行,同时在某些操作系统中,你还可以改变线程的优先级,这对于实现驱动程序或延迟敏感的应用(例如硬实时系统)很有帮助。
对于长时间运行的 CPU 密集型任务,例如并行计算,使用线程将更有优势。 这种密集任务往往会让所在的线程持续运行,任何不必要的线程切换都会带来性能损耗,因此高并发反而在此时成为了一种多余。同时你所创建的线程数应该等于 CPU 核心数,充分利用 CPU 的并行能力,甚至还可以将线程绑定到 CPU 核心上,进一步减少线程上下文切换。
而高并发更适合 IO 密集型任务,例如 web 服务器、数据库连接等等网络服务,因为这些任务绝大部分时间都处于等待状态,如果使用多线程,那线程大量时间会处于无所事事的状态,再加上线程上下文切换的高昂代价,让多线程做 IO 密集任务变成了一件非常奢侈的事。而使用async,既可以有效的降低 CPU 和内存的负担,又可以让大量的任务并发的运行,一个任务一旦处于IO或者其他等待(阻塞)状态,就会被立刻切走并执行另一个任务,而这里的任务切换的性能开销要远远低于使用多线程时的线程上下文切换。
事实上, async 底层也是基于线程实现,但是它基于线程封装了一个运行时,可以将多个任务映射到少量线程上,然后将线程切换变成了任务切换,后者仅仅是内存中的访问,因此要高效的多。
不过async也有其缺点,原因是编译器会为async函数生成状态机,然后将整个运行时打包进来,这会造成我们编译出的二进制可执行文件体积显著增大。
总之,async编程并没有比多线程更好,最终还是根据你的使用场景作出合适的选择,如果无需高并发,或者也不在意线程切换带来的性能损耗,那么多线程使用起来会简单、方便的多!最后再简单总结下:
若大家使用 tokio,那 CPU 密集的任务尤其需要用线程的方式去处理,例如使用
spawn_blocking创建一个阻塞的线程去完成相应 CPU 密集任务。至于具体的原因,不仅是上文说到的那些,还有一个是:tokio 是协作式地调度器,如果某个 CPU 密集的异步任务是通过 tokio 创建的,那理论上来说,该异步任务需要跟其它的异步任务交错执行,最终大家都得到了执行,皆大欢喜。但实际情况是,CPU 密集的任务很可能会一直霸占着 CPU,此时 tokio 的调度方式决定了该任务会一直被执行,这意味着,其它的异步任务无法得到执行的机会,最终这些任务都会因为得不到资源而饿死。
而使用
spawn_blocking后,会创建一个单独的 OS 线程,该线程并不会被 tokio 所调度( 被 OS 所调度 ),因此它所执行的 CPU 密集任务也不会导致 tokio 调度的那些异步任务被饿死
- 有大量
IO任务需要并发运行时,选async模型 - 有部分
IO任务需要并发运行时,选多线程,如果想要降低线程创建和销毁的开销,可以使用线程池 - 有大量
CPU密集任务需要并行运行时,例如并行计算,选多线程模型,且让线程数等于或者稍大于CPU核心数 - 无所谓时,统一选多线程
async 和多线程的性能对比
| 操作 | async | 线程 |
|---|---|---|
| 创建 | 0.3 微秒 | 17 微秒 |
| 线程切换 | 0.2 微秒 | 1.7 微秒 |
可以看出,async 在线程切换的开销显著低于多线程,对于 IO 密集的场景,这种性能开销累计下来会非常可怕!
一个例子
在大概理解async后,我们再来看一个简单的例子。如果想并发的下载文件,你可以使用多线程如下实现:
#![allow(unused)] fn main() { fn get_two_sites() { // 创建两个新线程执行任务 let thread_one = thread::spawn(|| download("https://course.rs")); let thread_two = thread::spawn(|| download("https://fancy.rs")); // 等待两个线程的完成 thread_one.join().expect("thread one panicked"); thread_two.join().expect("thread two panicked"); } }
如果是在一个小项目中简单的去下载文件,这么写没有任何问题,但是一旦下载文件的并发请求多起来,那一个下载任务占用一个线程的模式就太重了,会很容易成为程序的瓶颈。好在,我们可以使用async的方式来解决:
#![allow(unused)] fn main() { async fn get_two_sites_async() { // 创建两个不同的`future`,你可以把`future`理解为未来某个时刻会被执行的计划任务 // 当两个`future`被同时执行后,它们将并发的去下载目标页面 let future_one = download_async("https://www.foo.com"); let future_two = download_async("https://www.bar.com"); // 同时运行两个`future`,直至完成 join!(future_one, future_two); } }
此时,不再有线程创建和切换的昂贵开销,所有的函数都是通过静态的方式进行分发,同时也没有任何内存分配发生。这段代码的性能简直无懈可击!
事实上,async 和多线程并不是二选一,在同一应用中,可以根据情况两者一起使用,当然,我们还可以使用其它的并发模型,例如上面提到事件驱动模型,前提是有三方库提供了相应的实现。
Async Rust 当前的进展
简而言之,Rust 语言的 async 目前还没有达到多线程的成熟度,其中一部分内容还在不断进化中,当然,这并不影响我们在生产级项目中使用,因为社区中还有 tokio 这种大杀器。
使用 async 时,你会遇到好的,也会遇到不好的,例如:
- 收获卓越的性能
- 会经常跟进阶语言特性打交道,例如生命周期等,这些家伙可不好对付
- 一些兼容性问题,例如同步和异步代码、不同的异步运行时(
tokio与async-std) - 更昂贵的维护成本,原因是
async和社区开发的运行时依然在不停的进化
总之,async 在 Rust 中并不是一个善茬,你会遇到更多的困难或者说坑,也会带来更高的代码阅读成本及维护成本,但是为了性能,一切都值了,不是吗?
不过好在,这些进化早晚会彻底稳定成熟,而且在实际项目中,我们往往会使用成熟的三方库,例如tokio,因此可以避免一些类似的问题,但是对于本章的学习来说,async 的一些难点还是我们必须要去面对和征服的。
语言和库的支持
async 的底层实现非常复杂,且会导致编译后文件体积显著增加,因此 Rust 没有选择像 Go 语言那样内置了完整的特性和运行时,而是选择了通过 Rust 语言提供了必要的特性支持,再通过社区来提供 async 运行时的支持。 因此要完整的使用 async 异步编程,你需要依赖以下特性和外部库:
- 所必须的特征(例如
Future)、类型和函数,由标准库提供实现 - 关键字
async/await由 Rust 语言提供,并进行了编译器层面的支持 - 众多实用的类型、宏和函数由官方开发的
futures包提供(不是标准库),它们可以用于任何async应用中。 async代码的执行、IO操作、任务创建和调度等等复杂功能由社区的async运行时提供,例如tokio和async-std
还有,你在同步( synchronous )代码中使用的一些语言特性在 async 中可能将无法再使用,而且 Rust 也不允许你在特征中声明 async 函数(可以通过三方库实现), 总之,你会遇到一些在同步代码中不会遇到的奇奇怪怪、形形色色的问题,不过不用担心,本章会专门用一个章节罗列这些问题,并给出相应的解决方案。
编译和错误
在大多数情况下,async 中的编译错误和运行时错误跟之前没啥区别,但是依然有以下几点值得注意:
- 编译错误,由于
async编程时需要经常使用复杂的语言特性,例如生命周期和Pin,因此相关的错误可能会出现的更加频繁 - 运行时错误,编译器会为每一个
async函数生成状态机,这会导致在栈跟踪时会包含这些状态机的细节,同时还包含了运行时对函数的调用,因此,栈跟踪记录(例如panic时)将变得更加难以解读 - 一些隐蔽的错误也可能发生,例如在一个
async上下文中去调用一个阻塞的函数,或者没有正确的实现Future特征都有可能导致这种错误。这种错误可能会悄无声息的通过编译检查甚至有时候会通过单元测试。好在一旦你深入学习并掌握了本章的内容和async原理,可以有效的降低遇到这些错误的概率
兼容性考虑
异步代码和同步代码并不总能和睦共处。例如,我们无法在一个同步函数中去调用一个 async 异步函数,同步和异步代码也往往使用不同的设计模式,这些都会导致两者融合上的困难。
甚至于有时候,异步代码之间也存在类似的问题,如果一个库依赖于特定的 async 运行时来运行,那么这个库非常有必要告诉它的用户,它用了这个运行时。否则一旦用户选了不同的或不兼容的运行时,就会导致不可预知的麻烦。
性能特性
async 代码的性能主要取决于你使用的 async 运行时,好在这些运行时都经过了精心的设计,在你能遇到的绝大多数场景中,它们都能拥有非常棒的性能表现。
但是世事皆有例外。目前主流的 async 运行时几乎都使用了多线程实现,相比单线程虽然增加了并发表现,但是对于执行性能会有所损失,因为多线程实现会有同步和切换上的性能开销,若你需要极致的顺序执行性能,那么 async 目前并不是一个好的选择。
同样的,对于延迟敏感的任务来说,任务的执行次序需要能被严格掌控,而不是交由运行时去自动调度,后者会导致不可预知的延迟,例如一个 web 服务器总是有 1% 的请求,它们的延迟会远高于其它请求,因为调度过于繁忙导致了部分任务被延迟调度,最终导致了较高的延时。正因为此,这些延迟敏感的任务非常依赖于运行时或操作系统提供调度次序上的支持。
以上的两个需求,目前的 async 运行时并不能很好的支持,在未来可能会有更好的支持,但在此之前,我们可以尝试用多线程解决。
async/.await 简单入门
async/.await 是 Rust 内置的语言特性,可以让我们用同步的方式去编写异步的代码。
通过 async 标记的语法块会被转换成实现了Future特征的状态机。 与同步调用阻塞当前线程不同,当Future执行并遇到阻塞时,它会让出当前线程的控制权,这样其它的Future就可以在该线程中运行,这种方式完全不会导致当前线程的阻塞。
下面我们来通过例子学习 async/.await 关键字该如何使用,在开始之前,需要先引入 futures 包。编辑 Cargo.toml 文件并添加以下内容:
[dependencies]
futures = "0.3"
使用 async
首先,使用 async fn 语法来创建一个异步函数:
#![allow(unused)] fn main() { async fn do_something() { println!("go go go !"); } }
需要注意,异步函数的返回值是一个 Future,若直接调用该函数,不会输出任何结果,因为 Future 还未被执行:
fn main() { do_something(); }
运行后,go go go并没有打印,同时编译器给予一个提示:warning: unused implementer of Future that must be used,告诉我们 Future 未被使用,那么到底该如何使用?答案是使用一个执行器( executor ):
// `block_on`会阻塞当前线程直到指定的`Future`执行完成,这种阻塞当前线程以等待任务完成的方式较为简单、粗暴, // 好在其它运行时的执行器(executor)会提供更加复杂的行为,例如将多个`future`调度到同一个线程上执行。 use futures::executor::block_on; async fn hello_world() { println!("hello, world!"); } fn main() { let future = hello_world(); // 返回一个Future, 因此不会打印任何输出 block_on(future); // 执行`Future`并等待其运行完成,此时"hello, world!"会被打印输出 }
使用.await
在上述代码的main函数中,我们使用block_on这个执行器等待Future的完成,让代码看上去非常像是同步代码,但是如果你要在一个async fn函数中去调用另一个async fn并等待其完成后再执行后续的代码,该如何做?例如:
use futures::executor::block_on; async fn hello_world() { hello_cat(); println!("hello, world!"); } async fn hello_cat() { println!("hello, kitty!"); } fn main() { let future = hello_world(); block_on(future); }
这里,我们在hello_world异步函数中先调用了另一个异步函数hello_cat,然后再输出hello, world!,看看运行结果:
warning: unused implementer of `futures::Future` that must be used
--> src/main.rs:6:5
|
6 | hello_cat();
| ^^^^^^^^^^^^
= note: futures do nothing unless you `.await` or poll them
...
hello, world!
不出所料,main函数中的future我们通过block_on函数进行了运行,但是这里的hello_cat返回的Future却没有任何人去执行它,不过好在编译器友善的给出了提示:futures do nothing unless you `.await` or poll them,两种解决方法:使用.await语法或者对Future进行轮询(poll)。
后者较为复杂,暂且不表,先来使用.await试试:
use futures::executor::block_on; async fn hello_world() { hello_cat().await; println!("hello, world!"); } async fn hello_cat() { println!("hello, kitty!"); } fn main() { let future = hello_world(); block_on(future); }
为hello_cat()添加上.await后,结果立刻大为不同:
hello, kitty!
hello, world!
输出的顺序跟代码定义的顺序完全符合,因此,我们在上面代码中使用同步的代码顺序实现了异步的执行效果,非常简单、高效,而且很好理解,未来也绝对不会有回调地狱的发生。
总之,在async fn函数中使用.await可以等待另一个异步调用的完成。但是与block_on不同,.await并不会阻塞当前的线程,而是异步的等待Future A的完成,在等待的过程中,该线程还可以继续执行其它的Future B,最终实现了并发处理的效果。
一个例子
考虑一个载歌载舞的例子,如果不用.await,我们可能会有如下实现:
use futures::executor::block_on; struct Song { author: String, name: String, } async fn learn_song() -> Song { Song { author: "周杰伦".to_string(), name: String::from("《菊花台》"), } } async fn sing_song(song: Song) { println!( "给大家献上一首{}的{} ~ {}", song.author, song.name, "菊花残,满地伤~ ~" ); } async fn dance() { println!("唱到情深处,身体不由自主的动了起来~ ~"); } fn main() { let song = block_on(learn_song()); block_on(sing_song(song)); block_on(dance()); }
当然,以上代码运行结果无疑是正确的,但。。。它的性能何在?需要通过连续三次阻塞去等待三个任务的完成,一次只能做一件事,实际上我们完全可以载歌载舞啊:
use futures::executor::block_on; struct Song { author: String, name: String, } async fn learn_song() -> Song { Song { author: "曲婉婷".to_string(), name: String::from("《我的歌声里》"), } } async fn sing_song(song: Song) { println!( "给大家献上一首{}的{} ~ {}", song.author, song.name, "你存在我深深的脑海里~ ~" ); } async fn dance() { println!("唱到情深处,身体不由自主的动了起来~ ~"); } async fn learn_and_sing() { // 这里使用`.await`来等待学歌的完成,但是并不会阻塞当前线程,该线程在学歌的任务`.await`后,完全可以去执行跳舞的任务 let song = learn_song().await; // 唱歌必须要在学歌之后 sing_song(song).await; } async fn async_main() { let f1 = learn_and_sing(); let f2 = dance(); // `join!`可以并发的处理和等待多个`Future`,若`learn_and_sing Future`被阻塞,那`dance Future`可以拿过线程的所有权继续执行。若`dance`也变成阻塞状态,那`learn_and_sing`又可以再次拿回线程所有权,继续执行。 // 若两个都被阻塞,那么`async main`会变成阻塞状态,然后让出线程所有权,并将其交给`main`函数中的`block_on`执行器 futures::join!(f1, f2); } fn main() { block_on(async_main()); }
上面代码中,学歌和唱歌具有明显的先后顺序,但是这两者都可以跟跳舞一同存在,也就是你可以在跳舞的时候学歌,也可以在跳舞的时候唱歌。如果上面代码不使用.await,而是使用block_on(learn_song()), 那在学歌时,当前线程就会阻塞,不再可以做其它任何事,包括跳舞。
因此.await对于实现异步编程至关重要,它允许我们在同一个线程内并发的运行多个任务,而不是一个一个先后完成。若大家看到这里还是不太明白,强烈建议回头再仔细看一遍,同时亲自上手修改代码试试效果。
至此,读者应该对 Rust 的async/.await异步编程有了一个清晰的初步印象,下面让我们一起来看看这背后的原理:Future和任务在底层如何被执行。
底层探秘: Future 执行器与任务调度
异步编程背后到底藏有什么秘密?究竟是哪只幕后之手在操纵这一切?如果你对这些感兴趣,就继续看下去,否则可以直接跳过,因为本章节的内容对于一个 API 工程师并没有太多帮助。
但是如果你希望能深入理解 Rust 的 async/.await 代码是如何工作、理解运行时和性能,甚至未来想要构建自己的 async 运行时或相关工具,那么本章节终究不会辜负于你。
Future 特征
Future 特征是 Rust 异步编程的核心,毕竟异步函数是异步编程的核心,而 Future 恰恰是异步函数的返回值和被执行的关键。
首先,来给出 Future 的定义:它是一个能产出值的异步计算(虽然该值可能为空,例如 () )。光看这个定义,可能会觉得很空洞,我们来看看一个简化版的 Future 特征:
#![allow(unused)] fn main() { trait SimpleFuture { type Output; fn poll(&mut self, wake: fn()) -> Poll<Self::Output>; } enum Poll<T> { Ready(T), Pending, } }
在上一章中,我们提到过 Future 需要被执行器poll(轮询)后才能运行,诺,这里 poll 就来了,通过调用该方法,可以推进 Future 的进一步执行,直到被切走为止( 这里不好理解,但是你只需要知道 Future 并不能保证在一次 poll 中就被执行完,后面会详解介绍)。
若在当前 poll 中, Future 可以被完成,则会返回 Poll::Ready(result) ,反之则返回 Poll::Pending, 并且安排一个 wake 函数:当未来 Future 准备好进一步执行时, 该函数会被调用,然后管理该 Future 的执行器(例如上一章节中的block_on函数)会再次调用 poll 方法,此时 Future 就可以继续执行了。
如果没有 wake 方法,那执行器无法知道某个Future是否可以继续被执行,除非执行器定期的轮询每一个 Future ,确认它是否能被执行,但这种作法效率较低。而有了 wake,Future 就可以主动通知执行器,然后执行器就可以精确的执行该 Future。 这种“事件通知 -> 执行”的方式要远比定期对所有 Future 进行一次全遍历来的高效。
也许大家还是迷迷糊糊的,没事,我们用一个例子来说明下。考虑一个需要从 socket 读取数据的场景:如果有数据,可以直接读取数据并返回 Poll::Ready(data), 但如果没有数据,Future 会被阻塞且不会再继续执行,此时它会注册一个 wake 函数,当 socket 数据准备好时,该函数将被调用以通知执行器:我们的 Future 已经准备好了,可以继续执行。
下面的 SocketRead 结构体就是一个 Future:
#![allow(unused)] fn main() { pub struct SocketRead<'a> { socket: &'a Socket, } impl SimpleFuture for SocketRead<'_> { type Output = Vec<u8>; fn poll(&mut self, wake: fn()) -> Poll<Self::Output> { if self.socket.has_data_to_read() { // socket有数据,写入buffer中并返回 Poll::Ready(self.socket.read_buf()) } else { // socket中还没数据 // // 注册一个`wake`函数,当数据可用时,该函数会被调用, // 然后当前Future的执行器会再次调用`poll`方法,此时就可以读取到数据 self.socket.set_readable_callback(wake); Poll::Pending } } } }
这种 Future 模型允许将多个异步操作组合在一起,同时还无需任何内存分配。不仅仅如此,如果你需要同时运行多个 Future或链式调用多个 Future ,也可以通过无内存分配的状态机实现,例如:
#![allow(unused)] fn main() { trait SimpleFuture { type Output; fn poll(&mut self, wake: fn()) -> Poll<Self::Output>; } enum Poll<T> { Ready(T), Pending, } /// 一个SimpleFuture,它会并发地运行两个Future直到它们完成 /// /// 之所以可以并发,是因为两个Future的轮询可以交替进行,一个阻塞,另一个就可以立刻执行,反之亦然 pub struct Join<FutureA, FutureB> { // 结构体的每个字段都包含一个Future,可以运行直到完成. // 如果Future完成后,字段会被设置为 `None`. 这样Future完成后,就不会再被轮询 a: Option<FutureA>, b: Option<FutureB>, } impl<FutureA, FutureB> SimpleFuture for Join<FutureA, FutureB> where FutureA: SimpleFuture<Output = ()>, FutureB: SimpleFuture<Output = ()>, { type Output = (); fn poll(&mut self, wake: fn()) -> Poll<Self::Output> { // 尝试去完成一个 Future `a` if let Some(a) = &mut self.a { if let Poll::Ready(()) = a.poll(wake) { self.a.take(); } } // 尝试去完成一个 Future `b` if let Some(b) = &mut self.b { if let Poll::Ready(()) = b.poll(wake) { self.b.take(); } } if self.a.is_none() && self.b.is_none() { // 两个 Future都已完成 - 我们可以成功地返回了 Poll::Ready(()) } else { // 至少还有一个 Future 没有完成任务,因此返回 `Poll::Pending`. // 当该 Future 再次准备好时,通过调用`wake()`函数来继续执行 Poll::Pending } } } }
上面代码展示了如何同时运行多个 Future, 且在此过程中没有任何内存分配,让并发编程更加高效。 类似的,多个Future也可以一个接一个的连续运行:
#![allow(unused)] fn main() { /// 一个SimpleFuture, 它使用顺序的方式,一个接一个地运行两个Future // // 注意: 由于本例子用于演示,因此功能简单,`AndThenFut` 会假设两个 Future 在创建时就可用了. // 而真实的`Andthen`允许根据第一个`Future`的输出来创建第二个`Future`,因此复杂的多。 pub struct AndThenFut<FutureA, FutureB> { first: Option<FutureA>, second: FutureB, } impl<FutureA, FutureB> SimpleFuture for AndThenFut<FutureA, FutureB> where FutureA: SimpleFuture<Output = ()>, FutureB: SimpleFuture<Output = ()>, { type Output = (); fn poll(&mut self, wake: fn()) -> Poll<Self::Output> { if let Some(first) = &mut self.first { match first.poll(wake) { // 我们已经完成了第一个 Future, 可以将它移除, 然后准备开始运行第二个 Poll::Ready(()) => self.first.take(), // 第一个 Future 还不能完成 Poll::Pending => return Poll::Pending, }; } // 运行到这里,说明第一个Future已经完成,尝试去完成第二个 self.second.poll(wake) } } }
这些例子展示了在不需要内存对象分配以及深层嵌套回调的情况下,该如何使用 Future 特征去表达异步控制流。 在了解了基础的控制流后,我们再来看看真实的 Future 特征有何不同之处。
#![allow(unused)] fn main() { trait Future { type Output; fn poll( // 首先值得注意的地方是,`self`的类型从`&mut self`变成了`Pin<&mut Self>`: self: Pin<&mut Self>, // 其次将`wake: fn()` 修改为 `cx: &mut Context<'_>`: cx: &mut Context<'_>, ) -> Poll<Self::Output>; } }
首先这里多了一个 Pin ,关于它我们会在后面章节详细介绍,现在你只需要知道使用它可以创建一个无法被移动的 Future ,因为无法被移动,因此它将具有固定的内存地址,意味着我们可以存储它的指针(如果内存地址可能会变动,那存储指针地址将毫无意义!),也意味着可以实现一个自引用数据结构: struct MyFut { a: i32, ptr_to_a: *const i32 }。 而对于 async/await 来说,Pin 是不可或缺的关键特性。
其次,从 wake: fn() 变成了 &mut Context<'_> 。意味着 wake 函数可以携带数据了,为何要携带数据?考虑一个真实世界的场景,一个复杂应用例如 web 服务器可能有数千连接同时在线,那么同时就有数千 Future 在被同时管理着,如果不能携带数据,当一个 Future 调用 wake 后,执行器该如何知道是哪个 Future 调用了 wake ,然后进一步去 poll 对应的 Future ?没有办法!那之前的例子为啥就可以使用没有携带数据的 wake ? 因为足够简单,不存在歧义性。
总之,在正式场景要进行 wake ,就必须携带上数据。 而 Context 类型通过提供一个 Waker 类型的值,就可以用来唤醒特定的的任务。
使用 Waker 来唤醒任务
对于 Future 来说,第一次被 poll 时无法完成任务是很正常的。但它需要确保在未来一旦准备好时,可以通知执行器再次对其进行 poll 进而继续往下执行,该通知就是通过 Waker 类型完成的。
Waker 提供了一个 wake() 方法可以用于告诉执行器:相关的任务可以被唤醒了,此时执行器就可以对相应的 Future 再次进行 poll 操作。
构建一个定时器
下面一起来实现一个简单的定时器 Future 。为了让例子尽量简单,当计时器创建时,我们会启动一个线程接着让该线程进入睡眠,等睡眠结束后再通知给 Future 。
注意本例子还会在后面继续使用,因此我们重新创建一个工程来演示:使用 cargo new --lib timer_future 来创建一个新工程,在 lib 包的根路径 src/lib.rs 中添加以下内容:
#![allow(unused)] fn main() { use std::{ future::Future, pin::Pin, sync::{Arc, Mutex}, task::{Context, Poll, Waker}, thread, time::Duration, }; }
继续来实现 Future 定时器,之前提到: 新建线程在睡眠结束后会需要将状态同步给定时器 Future ,由于是多线程环境,我们需要使用 Arc<Mutex<T>> 来作为一个共享状态,用于在新线程和 Future 定时器间共享。
#![allow(unused)] fn main() { pub struct TimerFuture { shared_state: Arc<Mutex<SharedState>>, } /// 在Future和等待的线程间共享状态 struct SharedState { /// 定时(睡眠)是否结束 completed: bool, /// 当睡眠结束后,线程可以用`waker`通知`TimerFuture`来唤醒任务 waker: Option<Waker>, } }
下面给出 Future 的具体实现:
#![allow(unused)] fn main() { impl Future for TimerFuture { type Output = (); fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { // 通过检查共享状态,来确定定时器是否已经完成 let mut shared_state = self.shared_state.lock().unwrap(); if shared_state.completed { Poll::Ready(()) } else { // 设置`waker`,这样新线程在睡眠(计时)结束后可以唤醒当前的任务,接着再次对`Future`进行`poll`操作, // // 下面的`clone`每次被`poll`时都会发生一次,实际上,应该是只`clone`一次更加合理。 // 选择每次都`clone`的原因是: `TimerFuture`可以在执行器的不同任务间移动,如果只克隆一次, // 那么获取到的`waker`可能已经被篡改并指向了其它任务,最终导致执行器运行了错误的任务 shared_state.waker = Some(cx.waker().clone()); Poll::Pending } } } }
代码很简单,只要新线程设置了 shared_state.completed = true ,那任务就能顺利结束。如果没有设置,会为当前的任务克隆一份 Waker ,这样新线程就可以使用它来唤醒当前的任务。
最后,再来创建一个 API 用于构建定时器和启动计时线程:
#![allow(unused)] fn main() { impl TimerFuture { /// 创建一个新的`TimerFuture`,在指定的时间结束后,该`Future`可以完成 pub fn new(duration: Duration) -> Self { let shared_state = Arc::new(Mutex::new(SharedState { completed: false, waker: None, })); // 创建新线程 let thread_shared_state = shared_state.clone(); thread::spawn(move || { // 睡眠指定时间实现计时功能 thread::sleep(duration); let mut shared_state = thread_shared_state.lock().unwrap(); // 通知执行器定时器已经完成,可以继续`poll`对应的`Future`了 shared_state.completed = true; if let Some(waker) = shared_state.waker.take() { waker.wake() } }); TimerFuture { shared_state } } } }
至此,一个简单的定时器 Future 就已创建成功,那么该如何使用它呢?相信部分爱动脑筋的读者已经猜到了:我们需要创建一个执行器,才能让程序动起来。
执行器 Executor
Rust 的 Future 是惰性的:只有屁股上拍一拍,它才会努力动一动。其中一个推动它的方式就是在 async 函数中使用 .await 来调用另一个 async 函数,但是这个只能解决 async 内部的问题,那么这些最外层的 async 函数,谁来推动它们运行呢?答案就是我们之前多次提到的执行器 executor 。
执行器会管理一批 Future (最外层的 async 函数),然后通过不停地 poll 推动它们直到完成。 最开始,执行器会先 poll 一次 Future ,后面就不会主动去 poll 了,而是等待 Future 通过调用 wake 函数来通知它可以继续,它才会继续去 poll 。这种wake 通知然后 poll的方式会不断重复,直到 Future 完成。
构建执行器
下面我们将实现一个简单的执行器,它可以同时并发运行多个 Future 。例子中,需要用到 futures 包的 ArcWake 特征,它可以提供一个方便的途径去构建一个 Waker 。编辑 Cargo.toml ,添加下面依赖:
#![allow(unused)] fn main() { [dependencies] futures = "0.3" }
在之前的内容中,我们在 src/lib.rs 中创建了定时器 Future ,现在在 src/main.rs 中来创建程序的主体内容,开始之前,先引入所需的包:
#![allow(unused)] fn main() { use { futures::{ future::{BoxFuture, FutureExt}, task::{waker_ref, ArcWake}, }, std::{ future::Future, sync::mpsc::{sync_channel, Receiver, SyncSender}, sync::{Arc, Mutex}, task::{Context, Poll}, time::Duration, }, // 引入之前实现的定时器模块 timer_future::TimerFuture, }; }
执行器需要从一个消息通道( channel )中拉取事件,然后运行它们。当一个任务准备好后(可以继续执行),它会将自己放入消息通道中,然后等待执行器 poll 。
#![allow(unused)] fn main() { /// 任务执行器,负责从通道中接收任务然后执行 struct Executor { ready_queue: Receiver<Arc<Task>>, } /// `Spawner`负责创建新的`Future`然后将它发送到任务通道中 #[derive(Clone)] struct Spawner { task_sender: SyncSender<Arc<Task>>, } /// 一个Future,它可以调度自己(将自己放入任务通道中),然后等待执行器去`poll` struct Task { /// 进行中的Future,在未来的某个时间点会被完成 /// /// 按理来说`Mutex`在这里是多余的,因为我们只有一个线程来执行任务。但是由于 /// Rust并不聪明,它无法知道`Future`只会在一个线程内被修改,并不会被跨线程修改。因此 /// 我们需要使用`Mutex`来满足这个笨笨的编译器对线程安全的执着。 /// /// 如果是生产级的执行器实现,不会使用`Mutex`,因为会带来性能上的开销,取而代之的是使用`UnsafeCell` future: Mutex<Option<BoxFuture<'static, ()>>>, /// 可以将该任务自身放回到任务通道中,等待执行器的poll task_sender: SyncSender<Arc<Task>>, } fn new_executor_and_spawner() -> (Executor, Spawner) { // 任务通道允许的最大缓冲数(任务队列的最大长度) // 当前的实现仅仅是为了简单,在实际的执行中,并不会这么使用 const MAX_QUEUED_TASKS: usize = 10_000; let (task_sender, ready_queue) = sync_channel(MAX_QUEUED_TASKS); (Executor { ready_queue }, Spawner { task_sender }) } }
下面再来添加一个方法用于生成 Future , 然后将它放入任务通道中:
#![allow(unused)] fn main() { impl Spawner { fn spawn(&self, future: impl Future<Output = ()> + 'static + Send) { let future = future.boxed(); let task = Arc::new(Task { future: Mutex::new(Some(future)), task_sender: self.task_sender.clone(), }); self.task_sender.send(task).expect("任务队列已满"); } } }
在执行器 poll 一个 Future 之前,首先需要调用 wake 方法进行唤醒,然后再由 Waker 负责调度该任务并将其放入任务通道中。创建 Waker 的最简单的方式就是实现 ArcWake 特征,先来为我们的任务实现 ArcWake 特征,这样它们就能被转变成 Waker 然后被唤醒:
#![allow(unused)] fn main() { impl ArcWake for Task { fn wake_by_ref(arc_self: &Arc<Self>) { // 通过发送任务到任务管道的方式来实现`wake`,这样`wake`后,任务就能被执行器`poll` let cloned = arc_self.clone(); arc_self .task_sender .send(cloned) .expect("任务队列已满"); } } }
当任务实现了 ArcWake 特征后,它就变成了 Waker ,在调用 wake() 对其唤醒后会将任务复制一份所有权( Arc ),然后将其发送到任务通道中。最后我们的执行器将从通道中获取任务,然后进行 poll 执行:
#![allow(unused)] fn main() { impl Executor { fn run(&self) { while let Ok(task) = self.ready_queue.recv() { // 获取一个future,若它还没有完成(仍然是Some,不是None),则对它进行一次poll并尝试完成它 let mut future_slot = task.future.lock().unwrap(); if let Some(mut future) = future_slot.take() { // 基于任务自身创建一个 `LocalWaker` let waker = waker_ref(&task); let context = &mut Context::from_waker(&*waker); // `BoxFuture<T>`是`Pin<Box<dyn Future<Output = T> + Send + 'static>>`的类型别名 // 通过调用`as_mut`方法,可以将上面的类型转换成`Pin<&mut dyn Future + Send + 'static>` if future.as_mut().poll(context).is_pending() { // Future还没执行完,因此将它放回任务中,等待下次被poll *future_slot = Some(future); } } } } } }
恭喜!我们终于拥有了自己的执行器,下面再来写一段代码使用该执行器去运行之前的定时器 Future :
fn main() { let (executor, spawner) = new_executor_and_spawner(); // 生成一个任务 spawner.spawn(async { println!("howdy!"); // 创建定时器Future,并等待它完成 TimerFuture::new(Duration::new(2, 0)).await; println!("done!"); }); // drop掉任务,这样执行器就知道任务已经完成,不会再有新的任务进来 drop(spawner); // 运行执行器直到任务队列为空 // 任务运行后,会先打印`howdy!`, 暂停2秒,接着打印 `done!` executor.run(); }
执行器和系统 IO
前面我们一起看过一个使用 Future 从 Socket 中异步读取数据的例子:
#![allow(unused)] fn main() { pub struct SocketRead<'a> { socket: &'a Socket, } impl SimpleFuture for SocketRead<'_> { type Output = Vec<u8>; fn poll(&mut self, wake: fn()) -> Poll<Self::Output> { if self.socket.has_data_to_read() { // socket有数据,写入buffer中并返回 Poll::Ready(self.socket.read_buf()) } else { // socket中还没数据 // // 注册一个`wake`函数,当数据可用时,该函数会被调用, // 然后当前Future的执行器会再次调用`poll`方法,此时就可以读取到数据 self.socket.set_readable_callback(wake); Poll::Pending } } } }
该例子中,Future 将从 Socket 读取数据,若当前还没有数据,则会让出当前线程的所有权,允许执行器去执行其它的 Future 。当数据准备好后,会调用 wake() 函数将该 Future 的任务放入任务通道中,等待执行器的 poll 。
关于该流程已经反复讲了很多次,相信大家应该非常清楚了。然而该例子中还有一个疑问没有解决:
set_readable_callback方法到底是怎么工作的?怎么才能知道socket中的数据已经可以被读取了?
关于第二点,其中一个简单粗暴的方法就是使用一个新线程不停的检查 socket 中是否有了数据,当有了后,就调用 wake() 函数。该方法确实可以满足需求,但是性能着实太低了,需要为每个阻塞的 Future 都创建一个单独的线程!
在现实世界中,该问题往往是通过操作系统提供的 IO 多路复用机制来完成,例如 Linux 中的 epoll,FreeBSD 和 macOS 中的 kqueue ,Windows 中的 IOCP, Fuchisa中的 ports 等(可以通过 Rust 的跨平台包 mio 来使用它们)。借助 IO 多路复用机制,可以实现一个线程同时阻塞地去等待多个异步 IO 事件,一旦某个事件完成就立即退出阻塞并返回数据。相关实现类似于以下代码:
#![allow(unused)] fn main() { struct IoBlocker { /* ... */ } struct Event { // Event的唯一ID,该事件发生后,就会被监听起来 id: usize, // 一组需要等待或者已发生的信号 signals: Signals, } impl IoBlocker { /// 创建需要阻塞等待的异步IO事件的集合 fn new() -> Self { /* ... */ } /// 对指定的IO事件表示兴趣 fn add_io_event_interest( &self, /// 事件所绑定的socket io_object: &IoObject, event: Event, ) { /* ... */ } /// 进入阻塞,直到某个事件出现 fn block(&self) -> Event { /* ... */ } } let mut io_blocker = IoBlocker::new(); io_blocker.add_io_event_interest( &socket_1, Event { id: 1, signals: READABLE }, ); io_blocker.add_io_event_interest( &socket_2, Event { id: 2, signals: READABLE | WRITABLE }, ); let event = io_blocker.block(); // 当socket的数据可以读取时,打印 "Socket 1 is now READABLE" println!("Socket {:?} is now {:?}", event.id, event.signals); }
这样,我们只需要一个执行器线程,它会接收 IO 事件并将其分发到对应的 Waker 中,接着后者会唤醒相关的任务,最终通过执行器 poll 后,任务可以顺利的继续执行, 这种 IO 读取流程可以不停的循环,直到 socket 关闭。
定海神针 Pin 和 Unpin
在 Rust 异步编程中,有一个定海神针般的存在,它就是 Pin ,作用说简单也简单,说复杂也非常复杂,当初刚出来时就连一些 Rust 大佬都一头雾水,何况瑟瑟发抖的我。好在今非昔比,目前网上的资料已经很全,而我就借花献佛,给大家好好讲讲这个Pin。
在 Rust 中,所有的类型可以分为两类:
- 类型的值可以在内存中安全地被移动,例如数值、字符串、布尔值、结构体、枚举,总之你能想到的几乎所有类型都可以落入到此范畴内
- 自引用类型,大魔王来了,大家快跑,在之前章节我们已经见识过它的厉害
下面就是一个自引用类型
#![allow(unused)] fn main() { struct SelfRef { value: String, pointer_to_value: *mut String, } }
在上面的结构体中,pointer_to_value 是一个裸指针,指向第一个字段 value 持有的字符串 String 。很简单对吧?现在考虑一个情况, 若String 被移动了怎么办?
此时一个致命的问题就出现了:新的字符串的内存地址变了,而 pointer_to_value 依然指向之前的地址,一个重大 bug 就出现了!
灾难发生,英雄在哪?只见 Pin 闪亮登场,它可以防止一个类型在内存中被移动。再来回忆下之前在 Future 章节中,我们提到过在 poll 方法的签名中有一个 self: Pin<&mut Self> ,那么为何要在这里使用 Pin 呢?
为何需要 Pin
其实 Pin 还有一个小伙伴 UnPin ,与前者相反,后者表示类型可以在内存中安全地移动。在深入之前,我们先来回忆下 async/.await 是如何工作的:
#![allow(unused)] fn main() { let fut_one = /* ... */; // Future 1 let fut_two = /* ... */; // Future 2 async move { fut_one.await; fut_two.await; } }
在底层,async 会创建一个实现了 Future 的匿名类型,并提供了一个 poll 方法:
#![allow(unused)] fn main() { // `async { ... }`语句块创建的 `Future` 类型 struct AsyncFuture { fut_one: FutOne, fut_two: FutTwo, state: State, } // `async` 语句块可能处于的状态 enum State { AwaitingFutOne, AwaitingFutTwo, Done, } impl Future for AsyncFuture { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { loop { match self.state { State::AwaitingFutOne => match self.fut_one.poll(..) { Poll::Ready(()) => self.state = State::AwaitingFutTwo, Poll::Pending => return Poll::Pending, } State::AwaitingFutTwo => match self.fut_two.poll(..) { Poll::Ready(()) => self.state = State::Done, Poll::Pending => return Poll::Pending, } State::Done => return Poll::Ready(()), } } } } }
当 poll 第一次被调用时,它会去查询 fut_one 的状态,若 fut_one 无法完成,则 poll 方法会返回。未来对 poll 的调用将从上一次调用结束的地方开始。该过程会一直持续,直到 Future 完成为止。
然而,如果我们的 async 语句块中使用了引用类型,会发生什么?例如下面例子:
#![allow(unused)] fn main() { async { let mut x = [0; 128]; let read_into_buf_fut = read_into_buf(&mut x); read_into_buf_fut.await; println!("{:?}", x); } }
这段代码会编译成下面的形式:
#![allow(unused)] fn main() { struct ReadIntoBuf<'a> { buf: &'a mut [u8], // 指向下面的`x`字段 } struct AsyncFuture { x: [u8; 128], read_into_buf_fut: ReadIntoBuf<'what_lifetime?>, } }
这里,ReadIntoBuf 拥有一个引用字段,指向了结构体的另一个字段 x ,一旦 AsyncFuture 被移动,那 x 的地址也将随之变化,此时对 x 的引用就变成了不合法的,也就是 read_into_buf_fut.buf 会变为不合法的。
若能将 Future 在内存中固定到一个位置,就可以避免这种问题的发生,也就可以安全的创建上面这种引用类型。
Unpin
事实上,绝大多数类型都不在意是否被移动(开篇提到的第一种类型),因此它们都自动实现了 Unpin 特征。
从名字推测,大家可能以为 Pin 和 Unpin 都是特征吧?实际上,Pin 不按套路出牌,它是一个结构体:
#![allow(unused)] fn main() { pub struct Pin<P> { pointer: P, } }
它包裹一个指针,并且能确保该指针指向的数据不会被移动,例如 Pin<&mut T> , Pin<&T> , Pin<Box<T>> ,都能确保 T 不会被移动。

而 Unpin 才是一个特征,它表明一个类型可以随意被移动,那么问题来了,可以被 Pin 住的值,它有没有实现什么特征呢? 答案很出乎意料,可以被 Pin 住的值实现的特征是 !Unpin ,大家可能之前没有见过,但是它其实很简单,! 代表没有实现某个特征的意思,!Unpin 说明类型没有实现 Unpin 特征,那自然就可以被 Pin 了。
那是不是意味着类型如果实现了 Unpin 特征,就不能被 Pin 了?其实,还是可以 Pin 的,毕竟它只是一个结构体,你可以随意使用,但是不再有任何效果而已,该值一样可以被移动!
例如 Pin<&mut u8> ,显然 u8 实现了 Unpin 特征,它可以在内存中被移动,因此 Pin<&mut u8> 跟 &mut u8 实际上并无区别,一样可以被移动。
因此,一个类型如果不能被移动,它必须实现 !Unpin 特征。如果大家对 Pin 、 Unpin 还是模模糊糊,建议再重复看一遍之前的内容,理解它们对于我们后面要讲到的内容非常重要!
如果将 Unpin 与之前章节学过的 Send/Sync进行下对比,会发现它们都很像:
- 都是标记特征( marker trait ),该特征未定义任何行为,非常适用于标记
- 都可以通过
!语法去除实现 - 绝大多数情况都是自动实现, 无需我们的操心
深入理解 Pin
对于上面的问题,我们可以简单的归结为如何在 Rust 中处理自引用类型(果然,只要是难点,都和自引用脱离不了关系),下面用一个稍微简单点的例子来理解下 Pin :
#![allow(unused)] fn main() { #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } } }
Test 提供了方法用于获取字段 a 和 b 的值的引用。这里b 是 a 的一个引用,但是我们并没有使用引用类型而是用了裸指针,原因是:Rust 的借用规则不允许我们这样用,因为不符合生命周期的要求。 此时的 Test 就是一个自引用结构体。
如果不移动任何值,那么上面的例子将没有任何问题,例如:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); println!("a: {}, b: {}", test2.a(), test2.b()); }
输出非常正常:
a: test1, b: test1
a: test2, b: test2
明知山有虎,偏向虎山行,这才是我辈年轻人的风华。既然移动数据会导致指针不合法,那我们就移动下数据试试,将 test1 和 test2 进行下交换:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); println!("a: {}, b: {}", test2.a(), test2.b()); }
按理来说,这样修改后,输出应该如下:
#![allow(unused)] fn main() { a: test1, b: test1 a: test1, b: test1 }
但是实际运行后,却产生了下面的输出:
#![allow(unused)] fn main() { a: test1, b: test1 a: test1, b: test2 }
原因是 test2.b 指针依然指向了旧的地址,而该地址对应的值现在在 test1 里,最终会打印出意料之外的值。
如果大家还是将信将疑,那再看看下面的代码:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); test1.a = "I've totally changed now!".to_string(); println!("a: {}, b: {}", test2.a(), test2.b()); }
下面的图片也可以帮助更好的理解这个过程:
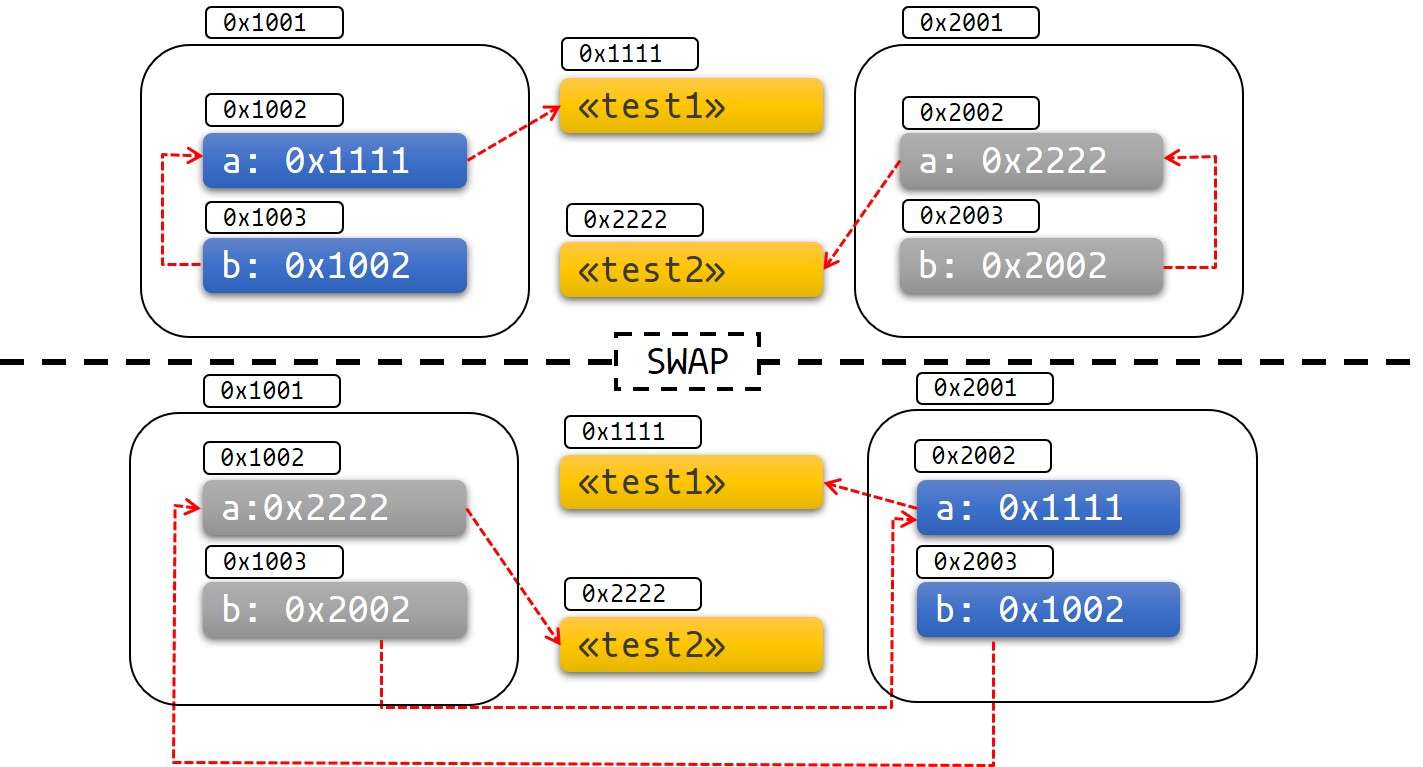
Pin 在实践中的运用
在理解了 Pin 的作用后,我们再来看看它怎么帮我们解决问题。
将值固定到栈上
回到之前的例子,我们可以用 Pin 来解决指针指向的数据被移动的问题:
#![allow(unused)] fn main() { use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, // 这个标记可以让我们的类型自动实现特征`!Unpin` } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } } }
上面代码中,我们使用了一个标记类型 PhantomPinned 将自定义结构体 Test 变成了 !Unpin (编译器会自动帮我们实现),因此该结构体无法再被移动。
一旦类型实现了 !Unpin ,那将它的值固定到栈( stack )上就是不安全的行为,因此在代码中我们使用了 unsafe 语句块来进行处理,你也可以使用 pin_utils 来避免 unsafe 的使用。
BTW, Rust 中的 unsafe 其实没有那么可怕,虽然听上去很不安全,但是实际上 Rust 依然提供了很多机制来帮我们提升了安全性,因此不必像对待 Go 语言的
unsafe那样去畏惧于使用 Rust 中的unsafe,大致使用原则总结如下:没必要用时,就不要用,当有必要用时,就大胆用,但是尽量控制好边界,让unsafe的范围尽可能小
此时,再去尝试移动被固定的值,就会导致编译错误 :
pub fn main() { // 此时的`test1`可以被安全的移动 let mut test1 = Test::new("test1"); // 新的`test1`由于使用了`Pin`,因此无法再被移动,这里的声明会将之前的`test1`遮蔽掉(shadow) let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); std::mem::swap(test1.get_mut(), test2.get_mut()); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); }
注意到之前的粗体字了吗?是的,Rust 并不是在运行时做这件事,而是在编译期就完成了,因此没有额外的性能开销!来看看报错:
error[E0277]: `PhantomPinned` cannot be unpinned
--> src/main.rs:47:43
|
47 | std::mem::swap(test1.get_mut(), test2.get_mut());
| ^^^^^^^ within `Test`, the trait `Unpin` is not implemented for `PhantomPinned`
需要注意的是固定在栈上非常依赖于你写出的
unsafe代码的正确性。我们知道&'a mut T可以固定的生命周期是'a,但是我们却不知道当生命周期'a结束后,该指针指向的数据是否会被移走。如果你的unsafe代码里这么实现了,那么就会违背Pin应该具有的作用!一个常见的错误就是忘记去遮蔽(shadow )初始的变量,因为你可以
drop掉Pin,然后在&'a mut T结束后去移动数据:fn main() { let mut test1 = Test::new("test1"); let mut test1_pin = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1_pin.as_mut()); drop(test1_pin); println!(r#"test1.b points to "test1": {:?}..."#, test1.b); let mut test2 = Test::new("test2"); mem::swap(&mut test1, &mut test2); println!("... and now it points nowhere: {:?}", test1.b); } use std::pin::Pin; use std::marker::PhantomPinned; use std::mem; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // This makes our type `!Unpin` _marker: PhantomPinned, } } fn init<'a>(self: Pin<&'a mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
固定到堆上
将一个 !Unpin 类型的值固定到堆上,会给予该值一个稳定的内存地址,它指向的堆中的值在 Pin 后是无法被移动的。而且与固定在栈上不同,我们知道堆上的值在整个生命周期内都会被稳稳地固定住。
use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Pin<Box<Self>> { let t = Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, }; let mut boxed = Box::pin(t); let self_ptr: *const String = &boxed.as_ref().a; unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr }; boxed } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { unsafe { &*(self.b) } } } pub fn main() { let test1 = Test::new("test1"); let test2 = Test::new("test2"); println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b()); println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b()); }
将固定住的 Future 变为 Unpin
之前的章节我们有提到 async 函数返回的 Future 默认就是 !Unpin 的。
但是,在实际应用中,一些函数会要求它们处理的 Future 是 Unpin 的,此时,若你使用的 Future 是 !Unpin 的,必须要使用以下的方法先将 Future 进行固定:
Box::pin, 创建一个Pin<Box<T>>pin_utils::pin_mut!, 创建一个Pin<&mut T>
固定后获得的 Pin<Box<T>> 和 Pin<&mut T> 既可以用于 Future ,又会自动实现 Unpin。
#![allow(unused)] fn main() { use pin_utils::pin_mut; // `pin_utils` 可以在crates.io中找到 // 函数的参数是一个`Future`,但是要求该`Future`实现`Unpin` fn execute_unpin_future(x: impl Future<Output = ()> + Unpin) { /* ... */ } let fut = async { /* ... */ }; // 下面代码报错: 默认情况下,`fut` 实现的是`!Unpin`,并没有实现`Unpin` // execute_unpin_future(fut); // 使用`Box`进行固定 let fut = async { /* ... */ }; let fut = Box::pin(fut); execute_unpin_future(fut); // OK // 使用`pin_mut!`进行固定 let fut = async { /* ... */ }; pin_mut!(fut); execute_unpin_future(fut); // OK }
总结
相信大家看到这里,脑袋里已经快被 Pin 、 Unpin 、 !Unpin 整爆炸了,没事,我们再来火上浇油下:)
- 若
T: Unpin( Rust 类型的默认实现),那么Pin<'a, T>跟&'a mut T完全相同,也就是Pin将没有任何效果, 该移动还是照常移动 - 绝大多数标准库类型都实现了
Unpin,事实上,对于 Rust 中你能遇到的绝大多数类型,该结论依然成立 ,其中一个例外就是:async/await生成的Future没有实现Unpin - 你可以通过以下方法为自己的类型添加
!Unpin约束:- 使用文中提到的
std::marker::PhantomPinned - 使用
nightly版本下的feature flag
- 使用文中提到的
- 可以将值固定到栈上,也可以固定到堆上
- 将
!Unpin值固定到栈上需要使用unsafe - 将
!Unpin值固定到堆上无需unsafe,可以通过Box::pin来简单的实现
- 将
- 当固定类型
T: !Unpin时,你需要保证数据从被固定到被 drop 这段时期内,其内存不会变得非法或者被重用
async/await 和 Stream 流处理
在入门章节中,我们简单学习了该如何使用 async/.await, 同时在后面也了解了一些底层原理,现在是时候继续深入了。
async/.await是 Rust 语法的一部分,它在遇到阻塞操作时( 例如 IO )会让出当前线程的所有权而不是阻塞当前线程,这样就允许当前线程继续去执行其它代码,最终实现并发。
有两种方式可以使用async: async fn用于声明函数,async { ... }用于声明语句块,它们会返回一个实现 Future 特征的值:
#![allow(unused)] fn main() { // `foo()`返回一个`Future<Output = u8>`, // 当调用`foo().await`时,该`Future`将被运行,当调用结束后我们将获取到一个`u8`值 async fn foo() -> u8 { 5 } fn bar() -> impl Future<Output = u8> { // 下面的`async`语句块返回`Future<Output = u8>` async { let x: u8 = foo().await; x + 5 } } }
async 是懒惰的,直到被执行器 poll 或者 .await 后才会开始运行,其中后者是最常用的运行 Future 的方法。 当 .await 被调用时,它会尝试运行 Future 直到完成,但是若该 Future 进入阻塞,那就会让出当前线程的控制权。当 Future 后面准备再一次被运行时(例如从 socket 中读取到了数据),执行器会得到通知,并再次运行该 Future ,如此循环,直到完成。
以上过程只是一个简述,详细内容在底层探秘中已经被深入讲解过,因此这里不再赘述。
async 的生命周期
async fn 函数如果拥有引用类型的参数,那它返回的 Future 的生命周期就会被这些参数的生命周期所限制:
#![allow(unused)] fn main() { async fn foo(x: &u8) -> u8 { *x } // 上面的函数跟下面的函数是等价的: fn foo_expanded<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a { async move { *x } } }
意味着 async fn 函数返回的 Future 必须满足以下条件: 当 x 依然有效时, 该 Future 就必须继续等待( .await ), 也就是说x 必须比 Future活得更久。
在一般情况下,在函数调用后就立即 .await 不会存在任何问题,例如foo(&x).await。但是,若 Future 被先存起来或发送到另一个任务或者线程,就可能存在问题了:
#![allow(unused)] fn main() { use std::future::Future; fn bad() -> impl Future<Output = u8> { let x = 5; borrow_x(&x) // ERROR: `x` does not live long enough } async fn borrow_x(x: &u8) -> u8 { *x } }
以上代码会报错,因为 x 的生命周期只到 bad 函数的结尾。 但是 Future 显然会活得更久:
error[E0597]: `x` does not live long enough
--> src/main.rs:4:14
|
4 | borrow_x(&x) // ERROR: `x` does not live long enough
| ---------^^-
| | |
| | borrowed value does not live long enough
| argument requires that `x` is borrowed for `'static`
5 | }
| - `x` dropped here while still borrowed
其中一个常用的解决方法就是将具有引用参数的 async fn 函数转变成一个具有 'static 生命周期的 Future 。 以上解决方法可以通过将参数和对 async fn 的调用放在同一个 async 语句块来实现:
#![allow(unused)] fn main() { use std::future::Future; async fn borrow_x(x: &u8) -> u8 { *x } fn good() -> impl Future<Output = u8> { async { let x = 5; borrow_x(&x).await } } }
如上所示,通过将参数移动到 async 语句块内, 我们将它的生命周期扩展到 'static, 并跟返回的 Future 保持了一致。
async move
async 允许我们使用 move 关键字来将环境中变量的所有权转移到语句块内,就像闭包那样,好处是你不再发愁该如何解决借用生命周期的问题,坏处就是无法跟其它代码实现对变量的共享:
#![allow(unused)] fn main() { // 多个不同的 `async` 语句块可以访问同一个本地变量,只要它们在该变量的作用域内执行 async fn blocks() { let my_string = "foo".to_string(); let future_one = async { // ... println!("{my_string}"); }; let future_two = async { // ... println!("{my_string}"); }; // 运行两个 Future 直到完成 let ((), ()) = futures::join!(future_one, future_two); } // 由于`async move`会捕获环境中的变量,因此只有一个`async move`语句块可以访问该变量, // 但是它也有非常明显的好处: 变量可以转移到返回的 Future 中,不再受借用生命周期的限制 fn move_block() -> impl Future<Output = ()> { let my_string = "foo".to_string(); async move { // ... println!("{my_string}"); } } }
当.await 遇见多线程执行器
需要注意的是,当使用多线程 Future 执行器( executor )时, Future 可能会在线程间被移动,因此 async 语句块中的变量必须要能在线程间传递。 至于 Future 会在线程间移动的原因是:它内部的任何.await都可能导致它被切换到一个新线程上去执行。
由于需要在多线程环境使用,意味着 Rc、 RefCell 、没有实现 Send 的所有权类型、没有实现 Sync 的引用类型,它们都是不安全的,因此无法被使用
需要注意!实际上它们还是有可能被使用的,只要在
.await调用期间,它们没有在作用域范围内。
类似的原因,在 .await 时使用普通的锁也不安全,例如 Mutex 。原因是,它可能会导致线程池被锁:当一个任务获取锁 A 后,若它将线程的控制权还给执行器,然后执行器又调度运行另一个任务,该任务也去尝试获取了锁 A ,结果当前线程会直接卡死,最终陷入死锁中。
因此,为了避免这种情况的发生,我们需要使用 futures 包下的锁 futures::lock 来替代 Mutex 完成任务。
Stream 流处理
Stream 特征类似于 Future 特征,但是前者在完成前可以生成多个值,这种行为跟标准库中的 Iterator 特征倒是颇为相似。
#![allow(unused)] fn main() { trait Stream { // Stream生成的值的类型 type Item; // 尝试去解析Stream中的下一个值, // 若无数据,返回`Poll::Pending`, 若有数据,返回 `Poll::Ready(Some(x))`, `Stream`完成则返回 `Poll::Ready(None)` fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>>; } }
关于 Stream 的一个常见例子是消息通道( futures 包中的)的消费者 Receiver。每次有消息从 Send 端发送后,它都可以接收到一个 Some(val) 值, 一旦 Send 端关闭(drop),且消息通道中没有消息后,它会接收到一个 None 值。
#![allow(unused)] fn main() { async fn send_recv() { const BUFFER_SIZE: usize = 10; let (mut tx, mut rx) = mpsc::channel::<i32>(BUFFER_SIZE); tx.send(1).await.unwrap(); tx.send(2).await.unwrap(); drop(tx); // `StreamExt::next` 类似于 `Iterator::next`, 但是前者返回的不是值,而是一个 `Future<Output = Option<T>>`, // 因此还需要使用`.await`来获取具体的值 assert_eq!(Some(1), rx.next().await); assert_eq!(Some(2), rx.next().await); assert_eq!(None, rx.next().await); } }
迭代和并发
跟迭代器类似,我们也可以迭代一个 Stream。 例如使用map,filter,fold方法,以及它们的遇到错误提前返回的版本: try_map,try_filter,try_fold。
但是跟迭代器又有所不同,for 循环无法在这里使用,但是命令式风格的循环while let是可以用的,同时还可以使用next 和 try_next 方法:
#![allow(unused)] fn main() { async fn sum_with_next(mut stream: Pin<&mut dyn Stream<Item = i32>>) -> i32 { use futures::stream::StreamExt; // 引入 next let mut sum = 0; while let Some(item) = stream.next().await { sum += item; } sum } async fn sum_with_try_next( mut stream: Pin<&mut dyn Stream<Item = Result<i32, io::Error>>>, ) -> Result<i32, io::Error> { use futures::stream::TryStreamExt; // 引入 try_next let mut sum = 0; while let Some(item) = stream.try_next().await? { sum += item; } Ok(sum) } }
上面代码是一次处理一个值的模式,但是需要注意的是:如果你选择一次处理一个值的模式,可能会造成无法并发,这就失去了异步编程的意义。 因此,如果可以的话我们还是要选择从一个 Stream 并发处理多个值的方式,通过 for_each_concurrent 或 try_for_each_concurrent 方法来实现:
#![allow(unused)] fn main() { async fn jump_around( mut stream: Pin<&mut dyn Stream<Item = Result<u8, io::Error>>>, ) -> Result<(), io::Error> { use futures::stream::TryStreamExt; // 引入 `try_for_each_concurrent` const MAX_CONCURRENT_JUMPERS: usize = 100; stream.try_for_each_concurrent(MAX_CONCURRENT_JUMPERS, |num| async move { jump_n_times(num).await?; report_n_jumps(num).await?; Ok(()) }).await?; Ok(()) } }
使用join!和select!同时运行多个 Future
招数单一,杀伤力惊人,说的就是 .await ,但是光用它,还真做不到一招鲜吃遍天。比如我们该如何同时运行多个任务,而不是使用.await慢悠悠地排队完成。
join!
futures 包中提供了很多实用的工具,其中一个就是 join!宏, 它允许我们同时等待多个不同 Future 的完成,且可以并发地运行这些 Future。
先来看一个不是很给力的、使用.await的版本:
#![allow(unused)] fn main() { async fn enjoy_book_and_music() -> (Book, Music) { let book = enjoy_book().await; let music = enjoy_music().await; (book, music) } }
这段代码可以顺利运行,但是有一个很大的问题,就是必须先看完书后,才能听音乐。咱们以前,谁又不是那个摇头晃脑爱读书(耳朵里偷偷塞着耳机,听的正 high)的好学生呢?
要支持同时看书和听歌,有些人可能会凭空生成下面代码:
#![allow(unused)] fn main() { // WRONG -- 别这么做 async fn enjoy_book_and_music() -> (Book, Music) { let book_future = enjoy_book(); let music_future = enjoy_music(); (book_future.await, music_future.await) } }
看上去像模像样,嗯,在某些语言中也许可以,但是 Rust 不行。因为在某些语言中,Future一旦创建就开始运行,等到返回的时候,基本就可以同时结束并返回了。 但是 Rust 中的 Future 是惰性的,直到调用 .await 时,才会开始运行。而那两个 await 由于在代码中有先后顺序,因此它们是顺序运行的。
为了正确的并发运行两个 Future , 我们来试试 futures::join! 宏:
#![allow(unused)] fn main() { use futures::join; async fn enjoy_book_and_music() -> (Book, Music) { let book_fut = enjoy_book(); let music_fut = enjoy_music(); join!(book_fut, music_fut) } }
Duang,目标顺利达成。同时join!会返回一个元组,里面的值是对应的Future执行结束后输出的值。
如果希望同时运行一个数组里的多个异步任务,可以使用
futures::future::join_all方法
try_join!
由于join!必须等待它管理的所有 Future 完成后才能完成,如果你希望在某一个 Future 报错后就立即停止所有 Future 的执行,可以使用 try_join!,特别是当 Future 返回 Result 时:
#![allow(unused)] fn main() { use futures::try_join; async fn get_book() -> Result<Book, String> { /* ... */ Ok(Book) } async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) } async fn get_book_and_music() -> Result<(Book, Music), String> { let book_fut = get_book(); let music_fut = get_music(); try_join!(book_fut, music_fut) } }
有一点需要注意,传给 try_join! 的所有 Future 都必须拥有相同的错误类型。如果错误类型不同,可以考虑使用来自 futures::future::TryFutureExt 模块的 map_err和err_info方法将错误进行转换:
#![allow(unused)] fn main() { use futures::{ future::TryFutureExt, try_join, }; async fn get_book() -> Result<Book, ()> { /* ... */ Ok(Book) } async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) } async fn get_book_and_music() -> Result<(Book, Music), String> { let book_fut = get_book().map_err(|()| "Unable to get book".to_string()); let music_fut = get_music(); try_join!(book_fut, music_fut) } }
join!很好很强大,但是人无完人,J 无完 J, 它有一个很大的问题。
select!
join!只有等所有 Future 结束后,才能集中处理结果,如果你想同时等待多个 Future ,且任何一个 Future 结束后,都可以立即被处理,可以考虑使用 futures::select!:
#![allow(unused)] fn main() { use futures::{ future::FutureExt, // for `.fuse()` pin_mut, select, }; async fn task_one() { /* ... */ } async fn task_two() { /* ... */ } async fn race_tasks() { let t1 = task_one().fuse(); let t2 = task_two().fuse(); pin_mut!(t1, t2); select! { () = t1 => println!("任务1率先完成"), () = t2 => println!("任务2率先完成"), } } }
上面的代码会同时并发地运行 t1 和 t2, 无论两者哪个先完成,都会调用对应的 println! 打印相应的输出,然后函数结束且不会等待另一个任务的完成。
但是,在实际项目中,我们往往需要等待多个任务都完成后,再结束,像上面这种其中一个任务结束就立刻结束的场景着实不多。
default 和 complete
select!还支持 default 和 complete 分支:
complete分支当所有的Future和Stream完成后才会被执行,它往往配合loop使用,loop用于循环完成所有的Futuredefault分支,若没有任何Future或Stream处于Ready状态, 则该分支会被立即执行
use futures::future; use futures::select; pub fn main() { let mut a_fut = future::ready(4); let mut b_fut = future::ready(6); let mut total = 0; loop { select! { a = a_fut => total += a, b = b_fut => total += b, complete => break, default => panic!(), // 该分支永远不会运行,因为`Future`会先运行,然后是`complete` }; } assert_eq!(total, 10); }
以上代码 default 分支由于最后一个运行,而在它之前 complete 分支已经通过 break 跳出了循环,因此default永远不会被执行。
如果你希望 default 也有机会露下脸,可以将 complete 的 break 修改为其它的,例如println!("completed!"),然后再观察下运行结果。
再回到 select 的第一个例子中,里面有一段代码长这样:
#![allow(unused)] fn main() { let t1 = task_one().fuse(); let t2 = task_two().fuse(); pin_mut!(t1, t2); }
当时没有展开讲,相信大家也有疑惑,下面我们来一起看看。
跟 Unpin 和 FusedFuture 进行交互
首先,.fuse()方法可以让 Future 实现 FusedFuture 特征, 而 pin_mut! 宏会为 Future 实现 Unpin特征,这两个特征恰恰是使用 select 所必须的:
Unpin,由于select不会通过拿走所有权的方式使用Future,而是通过可变引用的方式去使用,这样当select结束后,该Future若没有被完成,它的所有权还可以继续被其它代码使用。FusedFuture的原因跟上面类似,当Future一旦完成后,那select就不能再对其进行轮询使用。Fuse意味着熔断,相当于Future一旦完成,再次调用poll会直接返回Poll::Pending。
只有实现了FusedFuture,select 才能配合 loop 一起使用。假如没有实现,就算一个 Future 已经完成了,它依然会被 select 不停的轮询执行。
Stream 稍有不同,它们使用的特征是 FusedStream。 通过.fuse()(也可以手动实现)实现了该特征的 Stream,对其调用.next() 或 .try_next()方法可以获取实现了FusedFuture特征的Future:
#![allow(unused)] fn main() { use futures::{ stream::{Stream, StreamExt, FusedStream}, select, }; async fn add_two_streams( mut s1: impl Stream<Item = u8> + FusedStream + Unpin, mut s2: impl Stream<Item = u8> + FusedStream + Unpin, ) -> u8 { let mut total = 0; loop { let item = select! { x = s1.next() => x, x = s2.next() => x, complete => break, }; if let Some(next_num) = item { total += next_num; } } total } }
在 select 循环中并发
一个很实用但又鲜为人知的函数是 Fuse::terminated() ,可以使用它构建一个空的 Future ,空自然没啥用,但是如果它能在后面再被填充呢?
考虑以下场景:当你要在select循环中运行一个任务,但是该任务却是在select循环内部创建时,上面的函数就非常好用了。
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) { /* ... */ } async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let run_on_new_num_fut = run_on_new_num(starting_num).fuse(); let get_new_num_fut = Fuse::terminated(); pin_mut!(run_on_new_num_fut, get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // 定时器已结束,若`get_new_num_fut`没有在运行,就创建一个新的 if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // 收到新的数字 -- 创建一个新的`run_on_new_num_fut`并丢弃掉旧的 run_on_new_num_fut.set(run_on_new_num(new_num).fuse()); }, // 运行 `run_on_new_num_fut` () = run_on_new_num_fut => {}, // 若所有任务都完成,直接 `panic`, 原因是 `interval_timer` 应该连续不断的产生值,而不是结束 //后,执行到 `complete` 分支 complete => panic!("`interval_timer` completed unexpectedly"), } } } }
当某个 Future 有多个拷贝都需要同时运行时,可以使用 FuturesUnordered 类型。下面的例子跟上个例子大体相似,但是它会将 run_on_new_num_fut 的每一个拷贝都运行到完成,而不是像之前那样一旦创建新的就终止旧的。
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, FuturesUnordered, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) -> u8 { /* ... */ 5 } // 使用从 `get_new_num` 获取的最新数字 来运行 `run_on_new_num` // // 每当计时器结束后,`get_new_num` 就会运行一次,它会立即取消当前正在运行的`run_on_new_num` , // 并且使用新返回的值来替换 async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let mut run_on_new_num_futs = FuturesUnordered::new(); run_on_new_num_futs.push(run_on_new_num(starting_num)); let get_new_num_fut = Fuse::terminated(); pin_mut!(get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // 定时器已结束,若`get_new_num_fut`没有在运行,就创建一个新的 if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // 收到新的数字 -- 创建一个新的`run_on_new_num_fut` (并没有像之前的例子那样丢弃掉旧值) run_on_new_num_futs.push(run_on_new_num(new_num)); }, // 运行 `run_on_new_num_futs`, 并检查是否有已经完成的 res = run_on_new_num_futs.select_next_some() => { println!("run_on_new_num_fut returned {:?}", res); }, // 若所有任务都完成,直接 `panic`, 原因是 `interval_timer` 应该连续不断的产生值,而不是结束 //后,执行到 `complete` 分支 complete => panic!("`interval_timer` completed unexpectedly"), } } } }
一些疑难问题的解决办法
async 在 Rust 依然比较新,疑难杂症少不了,而它们往往还处于活跃开发状态,短时间内无法被解决,因此才有了本文。下面一起来看看这些问题以及相应的临时解决方案。
在 async 语句块中使用 ?
async 语句块和 async fn 最大的区别就是前者无法显式的声明返回值,在大多数时候这都不是问题,但是当配合 ? 一起使用时,问题就有所不同:
async fn foo() -> Result<u8, String> { Ok(1) } async fn bar() -> Result<u8, String> { Ok(1) } pub fn main() { let fut = async { foo().await?; bar().await?; Ok(()) }; }
以上代码编译后会报错:
error[E0282]: type annotations needed
--> src/main.rs:14:9
|
11 | let fut = async {
| --- consider giving `fut` a type
...
14 | Ok(1)
| ^^ cannot infer type for type parameter `E` declared on the enum `Result`
原因在于编译器无法推断出 Result<T, E>中的 E 的类型, 而且编译器的提示consider giving `fut` a type你也别傻乎乎的相信,然后尝试半天,最后无奈放弃:目前还没有办法为 async 语句块指定返回类型。
既然编译器无法推断出类型,那咱就给它更多提示,可以使用 ::< ... > 的方式来增加类型注释:
#![allow(unused)] fn main() { let fut = async { foo().await?; bar().await?; Ok::<(), String>(()) // 在这一行进行显式的类型注释 }; }
给予类型注释后此时编译器就知道Result<T, E>中的 E 的类型是String,进而成功通过编译。
async 函数和 Send 特征
在多线程章节我们深入讲过 Send 特征对于多线程间数据传递的重要性,对于 async fn 也是如此,它返回的 Future 能否在线程间传递的关键在于 .await 运行过程中,作用域中的变量类型是否是 Send。
学到这里,相信大家已经很清楚Rc无法在多线程环境使用,原因就在于它并未实现 Send 特征,那咱就用它来做例子:
#![allow(unused)] fn main() { use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); }
事实上,未实现 Send 特征的变量可以出现在 async fn 语句块中:
async fn bar() {} async fn foo() { NotSend::default(); bar().await; } fn require_send(_: impl Send) {} fn main() { require_send(foo()); }
即使上面的 foo 返回的 Future 是 Send, 但是在它内部短暂的使用 NotSend 依然是安全的,原因在于它的作用域并没有影响到 .await,下面来试试声明一个变量,然后让 .await的调用处于变量的作用域中试试:
#![allow(unused)] fn main() { async fn foo() { let x = NotSend::default(); bar().await; } }
不出所料,错误如期而至:
error: future cannot be sent between threads safely
--> src/main.rs:17:18
|
17 | require_send(foo());
| ^^^^^ future returned by `foo` is not `Send`
|
= help: within `impl futures::Future<Output = ()>`, the trait `std::marker::Send` is not implemented for `Rc<()>`
note: future is not `Send` as this value is used across an await
--> src/main.rs:11:5
|
10 | let x = NotSend::default();
| - has type `NotSend` which is not `Send`
11 | bar().await;
| ^^^^^^^^^^^ await occurs here, with `x` maybe used later
12 | }
| - `x` is later dropped here
提示很清晰,.await在运行时处于 x 的作用域内。在之前章节有提到过, .await 有可能被执行器调度到另一个线程上运行,而 Rc 并没有实现 Send,因此编译器无情拒绝了咱们。
其中一个可能的解决方法是在 .await 之前就使用 std::mem::drop 释放掉 Rc,但是很可惜,截止今天,该方法依然不能解决这种问题。
不知道有多少同学还记得语句块 { ... } 在 Rust 中其实具有非常重要的作用(特别是相比其它大多数语言来说时):可以将变量声明在语句块内,当语句块结束时,变量会自动被 Drop,这个规则可以帮助我们解决很多借用冲突问题,特别是在 NLL 出来之前。
#![allow(unused)] fn main() { async fn foo() { { let x = NotSend::default(); } bar().await; } }
是不是很简单?最终我们还是通过 Drop 的方式解决了这个问题,当然,还是期待未来 std::mem::drop 也能派上用场。
递归使用 async fn
在内部实现中,async fn被编译成一个状态机,这会导致递归使用 async fn 变得较为复杂, 因为编译后的状态机还需要包含自身。
#![allow(unused)] fn main() { // foo函数: async fn foo() { step_one().await; step_two().await; } // 会被编译成类似下面的类型: enum Foo { First(StepOne), Second(StepTwo), } // 因此recursive函数 async fn recursive() { recursive().await; recursive().await; } // 会生成类似以下的类型 enum Recursive { First(Recursive), Second(Recursive), } }
这是典型的动态大小类型,它的大小会无限增长,因此编译器会直接报错:
error[E0733]: recursion in an `async fn` requires boxing
--> src/lib.rs:1:22
|
1 | async fn recursive() {
| ^ an `async fn` cannot invoke itself directly
|
= note: a recursive `async fn` must be rewritten to return a boxed future.
如果认真学过之前的章节,大家应该知道只要将其使用 Box 放到堆上而不是栈上,就可以解决,在这里还是要称赞下 Rust 的编译器,给出的提示总是这么精确recursion in an `async fn` requires boxing。
就算是使用 Box,这里也大有讲究。如果我们试图使用 Box::pin 这种方式去包裹是不行的,因为编译器自身的限制限制了我们(刚夸过它。。。)。为了解决这种问题,我们只能将 recursive 转变成一个正常的函数,该函数返回一个使用 Box 包裹的 async 语句块:
#![allow(unused)] fn main() { use futures::future::{BoxFuture, FutureExt}; fn recursive() -> BoxFuture<'static, ()> { async move { recursive().await; recursive().await; }.boxed() } }
在特征中使用 async
在目前版本中,我们还无法在特征中定义 async fn 函数,不过大家也不用担心,目前已经有计划在未来移除这个限制了。
#![allow(unused)] fn main() { trait Test { async fn test(); } }
运行后报错:
error[E0706]: functions in traits cannot be declared `async`
--> src/main.rs:5:5
|
5 | async fn test();
| -----^^^^^^^^^^^
| |
| `async` because of this
|
= note: `async` trait functions are not currently supported
= note: consider using the `async-trait` crate: https://crates.io/crates/async-trait
好在编译器给出了提示,让我们使用 async-trait 解决这个问题:
#![allow(unused)] fn main() { use async_trait::async_trait; #[async_trait] trait Advertisement { async fn run(&self); } struct Modal; #[async_trait] impl Advertisement for Modal { async fn run(&self) { self.render_fullscreen().await; for _ in 0..4u16 { remind_user_to_join_mailing_list().await; } self.hide_for_now().await; } } struct AutoplayingVideo { media_url: String, } #[async_trait] impl Advertisement for AutoplayingVideo { async fn run(&self) { let stream = connect(&self.media_url).await; stream.play().await; // 用视频说服用户加入我们的邮件列表 Modal.run().await; } } }
不过使用该包并不是免费的,每一次特征中的async函数被调用时,都会产生一次堆内存分配。对于大多数场景,这个性能开销都可以接受,但是当函数一秒调用几十万、几百万次时,就得小心这块儿代码的性能了!
一个实践项目: Web 服务器
知识学得再多,不实际应用也是纸上谈兵,不是忘掉就是废掉,对于技术学习尤为如此。在之前章节中,我们已经学习了 Async Rust 的方方面面,现在来将这些知识融会贯通,最终实现一个并发 Web 服务器。
多线程版本的 Web 服务器
在正式开始前,先来看一个单线程版本的 Web 服务器,该例子来源于 Rust Book 一书。
src/main.rs:
use std::fs; use std::io::prelude::*; use std::net::TcpListener; use std::net::TcpStream; fn main() { // 监听本地端口 7878 ,等待 TCP 连接的建立 let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); // 阻塞等待请求的进入 for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // 从连接中顺序读取 1024 字节数据 let mut buffer = [0; 1024]; stream.read(&mut buffer).unwrap(); let get = b"GET / HTTP/1.1\r\n"; // 处理HTTP协议头,若不符合则返回404和对应的`html`文件 let (status_line, filename) = if buffer.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); // 将回复内容写入连接缓存中 let response = format!("{status_line}{contents}"); stream.write_all(response.as_bytes()).unwrap(); // 使用flush将缓存中的内容发送到客户端 stream.flush().unwrap(); }
hello.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
404.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
运行以上代码,并从浏览器访问 127.0.0.1:7878 你将看到一条来自 Ferris 的问候。
在回忆了单线程版本该如何实现后,我们也将进入正题,一起来实现一个基于 async 的异步 Web 服务器。
运行异步代码
一个 Web 服务器必须要能并发的处理大量来自用户的请求,也就是我们不能在处理完上一个用户的请求后,再处理下一个用户的请求。上面的单线程版本可以修改为多线程甚至于线程池来实现并发处理,但是线程还是太重了,使用 async 实现 Web 服务器才是最适合的。
首先将 handle_connection 修改为 async 实现:
#![allow(unused)] fn main() { async fn handle_connection(mut stream: TcpStream) { //<-- snip --> } }
该修改会将函数的返回值从 () 变成 Future<Output=()> ,因此直接运行将不再有任何效果,只用通过.await或执行器的poll调用后才能获取 Future 的结果。
在之前的代码中,我们使用了自己实现的简单的执行器来进行.await 或 poll ,实际上这只是为了学习原理,在实际项目中,需要选择一个三方的 async 运行时来实现相关的功能。 具体的选择我们将在下一章节进行讲解,现在先选择 async-std ,该包的最大优点就是跟标准库的 API 类似,相对来说更简单易用。
使用 async-std 作为异步运行时
下面的例子将演示如何使用一个异步运行时async-std来让之前的 async fn 函数运行起来,该运行时允许使用属性 #[async_std::main] 将我们的 fn main 函数变成 async fn main ,这样就可以在 main 函数中直接调用其它 async 函数,否则你得用之前章节的 block_on 方法来让 main 去阻塞等待异步函数的完成,但是这种简单粗暴的阻塞等待方式并不灵活。
修改 Cargo.toml 添加 async-std 包并开启相应的属性:
[dependencies]
futures = "0.3"
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
下面将 main 函数修改为异步的,并在其中调用前面修改的异步版本 handle_connection :
#[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); // 警告,这里无法并发 handle_connection(stream).await; } }
上面的代码虽然已经是异步的,实际上它还无法并发,原因我们后面会解释,先来模拟一下慢请求:
#![allow(unused)] fn main() { use async_std::task; async fn handle_connection(mut stream: TcpStream) { let mut buffer = [0; 1024]; stream.read(&mut buffer).unwrap(); let get = b"GET / HTTP/1.1\r\n"; let sleep = b"GET /sleep HTTP/1.1\r\n"; let (status_line, filename) = if buffer.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else if buffer.starts_with(sleep) { task::sleep(Duration::from_secs(5)).await; ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); let response = format!("{status_line}{contents}"); stream.write(response.as_bytes()).unwrap(); stream.flush().unwrap(); } }
上面是全新实现的 handle_connection ,它会在内部睡眠 5 秒,模拟一次用户慢请求,需要注意的是,我们并没有使用 std::thread::sleep 进行睡眠,原因是该函数是阻塞的,它会让当前线程陷入睡眠中,导致其它任务无法继续运行!因此我们需要一个睡眠函数 async_std::task::sleep,它仅会让当前的任务陷入睡眠,然后该任务会让出线程的控制权,这样线程就可以继续运行其它任务。
因此,光把函数变成 async 往往是不够的,还需要将它内部的代码也都变成异步兼容的,阻塞线程绝对是不可行的。
现在运行服务器,并访问 127.0.0.1:7878/sleep, 你会发现只有在完成第一个用户请求(5 秒后),才能开始处理第二个用户请求。现在再来看看该如何解决这个问题,让请求并发起来。
并发地处理连接
上面代码最大的问题是 listener.incoming() 是阻塞的迭代器。当 listener 在等待连接时,执行器是无法执行其它Future的,而且只有在我们处理完已有的连接后,才能接收新的连接。
解决方法是将 listener.incoming() 从一个阻塞的迭代器变成一个非阻塞的 Stream, 后者在前面章节有过专门介绍:
use async_std::net::TcpListener; use async_std::net::TcpStream; use futures::stream::StreamExt; #[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap(); listener .incoming() .for_each_concurrent(/* limit */ None, |tcpstream| async move { let tcpstream = tcpstream.unwrap(); handle_connection(tcpstream).await; }) .await; }
异步版本的 TcpListener 为 listener.incoming() 实现了 Stream 特征,以上修改有两个好处:
listener.incoming()不再阻塞- 使用
for_each_concurrent并发地处理从Stream获取的元素
现在上面的实现的关键在于 handle_connection 不能再阻塞:
#![allow(unused)] fn main() { use async_std::prelude::*; async fn handle_connection(mut stream: TcpStream) { let mut buffer = [0; 1024]; stream.read(&mut buffer).await.unwrap(); //<-- snip --> stream.write(response.as_bytes()).await.unwrap(); stream.flush().await.unwrap(); } }
在将数据读写改造成异步后,现在该函数也彻底变成了异步的版本,因此一次慢请求不再会阻止其它请求的运行。
使用多线程并行处理请求
聪明的读者不知道有没有发现,之前的例子有一个致命的缺陷:只能使用一个线程并发的处理用户请求。是的,这样也可以实现并发,一秒处理几千次请求问题不大,但是这毕竟没有利用上 CPU 的多核并行能力,无法实现性能最大化。
async 并发和多线程其实并不冲突,而 async-std 包也允许我们使用多个线程去处理,由于 handle_connection 实现了 Send 特征且不会阻塞,因此使用 async_std::task::spawn 是非常安全的:
use async_std::task::spawn; #[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap(); listener .incoming() .for_each_concurrent(/* limit */ None, |stream| async move { let stream = stream.unwrap(); spawn(handle_connection(stream)); }) .await; }
至此,我们实现了同时使用并行(多线程)和并发( async )来同时处理多个请求!
测试 handle_connection 函数
对于测试 Web 服务器,使用集成测试往往是最简单的,但是在本例子中,将使用单元测试来测试连接处理函数的正确性。
为了保证单元测试的隔离性和确定性,我们使用 MockTcpStream 来替代 TcpStream 。首先,修改 handle_connection 的函数签名让测试更简单,之所以可以修改签名,原因在于 async_std::net::TcpStream 实际上并不是必须的,只要任何结构体实现了 async_std::io::Read, async_std::io::Write 和 marker::Unpin 就可以替代它:
#![allow(unused)] fn main() { use std::marker::Unpin; use async_std::io::{Read, Write}; async fn handle_connection(mut stream: impl Read + Write + Unpin) { }
下面,来构建一个 mock 的 TcpStream 并实现了上面这些特征,它包含一些数据,这些数据将被拷贝到 read 缓存中, 然后返回 Poll::Ready 说明 read 已经结束:
#![allow(unused)] fn main() { use super::*; use futures::io::Error; use futures::task::{Context, Poll}; use std::cmp::min; use std::pin::Pin; struct MockTcpStream { read_data: Vec<u8>, write_data: Vec<u8>, } impl Read for MockTcpStream { fn poll_read( self: Pin<&mut Self>, _: &mut Context, buf: &mut [u8], ) -> Poll<Result<usize, Error>> { let size: usize = min(self.read_data.len(), buf.len()); buf[..size].copy_from_slice(&self.read_data[..size]); Poll::Ready(Ok(size)) } } }
Write的实现也类似,需要实现三个方法 : poll_write, poll_flush, 与 poll_close。 poll_write 会拷贝输入数据到 mock 的 TcpStream 中,当完成后返回 Poll::Ready。由于 TcpStream 无需 flush 和 close,因此另两个方法直接返回 Poll::Ready 即可。
#![allow(unused)] fn main() { impl Write for MockTcpStream { fn poll_write( mut self: Pin<&mut Self>, _: &mut Context, buf: &[u8], ) -> Poll<Result<usize, Error>> { self.write_data = Vec::from(buf); Poll::Ready(Ok(buf.len())) } fn poll_flush(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> { Poll::Ready(Ok(())) } fn poll_close(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> { Poll::Ready(Ok(())) } } }
最后,我们的 mock 需要实现 Unpin 特征,表示它可以在内存中安全的移动,具体内容在前面章节有讲。
#![allow(unused)] fn main() { use std::marker::Unpin; impl Unpin for MockTcpStream {} }
现在可以准备开始测试了,在使用初始化数据设置好 MockTcpStream 后,我们可以使用 #[async_std::test] 来运行 handle_connection 函数,该函数跟 #[async_std::main] 的作用类似。为了确保 handle_connection 函数正确工作,需要根据初始化数据检查正确的数据被写入到 MockTcpStream 中。
#![allow(unused)] fn main() { use std::fs; #[async_std::test] async fn test_handle_connection() { let input_bytes = b"GET / HTTP/1.1\r\n"; let mut contents = vec![0u8; 1024]; contents[..input_bytes.len()].clone_from_slice(input_bytes); let mut stream = MockTcpStream { read_data: contents, write_data: Vec::new(), }; handle_connection(&mut stream).await; let mut buf = [0u8; 1024]; stream.read(&mut buf).await.unwrap(); let expected_contents = fs::read_to_string("hello.html").unwrap(); let expected_response = format!("HTTP/1.1 200 OK\r\n\r\n{}", expected_contents); assert!(stream.write_data.starts_with(expected_response.as_bytes())); } }
Tokio 使用指南
在上一个章节中,我们提到了 Rust 异步编程的限制,其中之一就是你必须引入社区提供的异步运行时,其中最有名的就是 tokio。
在本章中,我们一起来看看 tokio 到底有什么优势,以及该如何使用它。
本章在内容上大量借鉴和翻译了 tokio 官方文档Tokio Tutorial, 但是重新组织了内容形式并融入了很多自己的见解和感悟,给大家提供更好的可读性和知识扩展性
tokio 概览
对于 Async Rust,最最重要的莫过于底层的异步运行时,它提供了执行器、任务调度、异步 API 等核心服务。简单来说,使用 Rust 提供的 async/await 特性编写的异步代码要运行起来,就必须依赖于异步运行时,否则这些代码将毫无用处。
异步运行时
Rust 语言本身只提供了异步编程所需的基本特性,例如 async/await 关键字,标准库中的 Future 特征,官方提供的 futures 实用库,这些特性单独使用没有任何用处,因此我们需要一个运行时来将这些特性实现的代码运行起来。
异步运行时是由 Rust 社区提供的,它们的核心是一个 reactor 和一个或多个 executor(执行器):
reactor用于提供外部事件的订阅机制,例如I/O、进程间通信、定时器等executor在上一章我们有过深入介绍,它用于调度和执行相应的任务(Future)
目前最受欢迎的几个运行时有:
tokio,目前最受欢迎的异步运行时,功能强大,还提供了异步所需的各种工具(例如 tracing )、网络协议框架(例如 HTTP,gRPC )等等async-std,最大的优点就是跟标准库兼容性较强smol, 一个小巧的异步运行时
但是,大浪淘沙,留下的才是金子,随着时间的流逝,tokio越来越亮眼,无论是性能、功能还是社区、文档,它在各个方面都异常优秀,时至今日,可以说已成为事实上的标准。
异步运行时的兼容性
为何选择异步运行时这么重要?不仅仅是它们在功能、性能上存在区别,更重要的是当你选择了一个,往往就无法切换到另外一个,除非异步代码很少。
使用异步运行时,往往伴随着对它相关的生态系统的深入使用,因此耦合性会越来越强,直至最后你很难切换到另一个运行时,例如 tokio 和 async-std ,就存在这种问题。
如果你实在有这种需求,可以考虑使用 async-compat,该包提供了一个中间层,用于兼容 tokio 和其它运行时。
结论
相信大家看到现在,心中应该有一个结论了。首先,运行时之间的不兼容性,让我们必须提前选择一个运行时,并且在未来坚持用下去,那这个运行时就应该是最优秀、最成熟的那个,tokio 几乎成了不二选择,当然 tokio 也有自己的问题:更难上手和运行时之间的兼容性。
如果你只用 tokio ,那兼容性自然不是问题,至于难以上手,Rust 这么难,我们都学到现在了,何况区区一个异步运行时,在本书的帮助下,这些都不再是问题:)
tokio 简介
tokio 是一个纸醉金迷之地,只要有钱就可以为所欲为,哦,抱歉,走错片场了。tokio 是 Rust 最优秀的异步运行时框架,它提供了写异步网络服务所需的几乎所有功能,不仅仅适用于大型服务器,还适用于小型嵌入式设备,它主要由以下组件构成:
- 多线程版本的异步运行时,可以运行使用
async/await编写的代码 - 标准库中阻塞 API 的异步版本,例如
thread::sleep会阻塞当前线程,tokio中就提供了相应的异步实现版本 - 构建异步编程所需的生态,甚至还提供了
tracing用于日志和分布式追踪, 提供console用于 Debug 异步编程
优势
下面一起来看看使用 tokio 能给你提供哪些优势。
高性能
因为快所以快,前者是 Rust 快,后者是 tokio 快。 tokio 在编写时充分利用了 Rust 提供的各种零成本抽象和高性能特性,而且贯彻了 Rust 的牛逼思想:如果你选择手写代码,那么最好的结果就是跟 tokio 一样快!
以下是一张官方提供的性能参考图,大致能体现出 tokio 的性能之恐怖:
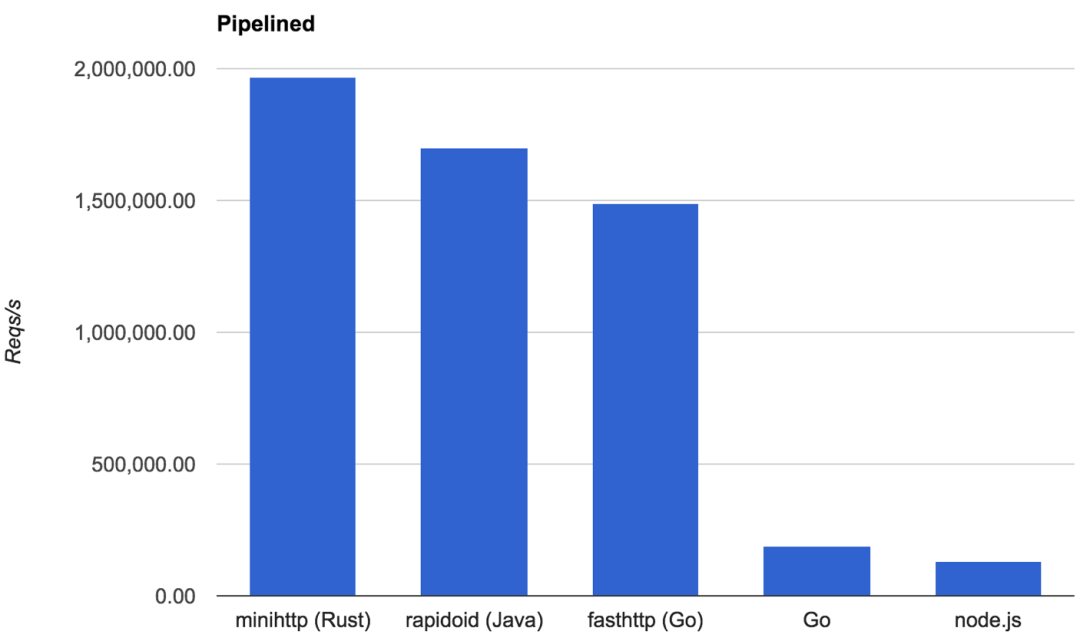
高可靠
Rust 语言的安全可靠性顺理成章的影响了 tokio 的可靠性,曾经有一个调查给出了令人乍舌的结论:软件系统 70%的高危漏洞都是由内存不安全性导致的。
在 Rust 提供的安全性之外,tokio 还致力于提供一致性的行为表现:无论你何时运行系统,它的预期表现和性能都是一致的,例如不会出现莫名其妙的请求延迟或响应时间大幅增加。
简单易用
通过 Rust 提供的 async/await 特性,编写异步程序的复杂性相比当初已经大幅降低,同时 tokio 还为我们提供了丰富的生态,进一步大幅降低了其复杂性。
同时 tokio 遵循了标准库的命名规则,让熟悉标准库的用户可以很快习惯于 tokio 的语法,再借助于 Rust 强大的类型系统,用户可以轻松地编写和交付正确的代码。
使用灵活性
tokio 支持你灵活的定制自己想要的运行时,例如你可以选择多线程 + 任务盗取模式的复杂运行时,也可以选择单线程的轻量级运行时。总之,几乎你的每一种需求在 tokio 中都能寻找到支持(画外音:强大的灵活性需要一定的复杂性来换取,并不是免费的午餐)。
劣势
虽然 tokio 对于大多数需要并发的项目都是非常适合的,但是确实有一些场景它并不适合使用:
- 并行运行 CPU 密集型的任务。
tokio非常适合于 IO 密集型任务,这些 IO 任务的绝大多数时间都用于阻塞等待 IO 的结果,而不是刷刷刷的单烤 CPU。如果你的应用是 CPU 密集型(例如并行计算),建议使用rayon,当然,对于其中的 IO 任务部分,你依然可以混用tokio - 读取大量的文件。读取文件的瓶颈主要在于操作系统,因为 OS 没有提供异步文件读取接口,大量的并发并不会提升文件读取的并行性能,反而可能会造成不可忽视的性能损耗,因此建议使用线程(或线程池)的方式
- 发送少量 HTTP 请求。
tokio的优势是给予你并发处理大量任务的能力,对于这种轻量级 HTTP 请求场景,tokio除了增加你的代码复杂性,并无法带来什么额外的优势。因此,对于这种场景,你可以使用reqwest库,它会更加简单易用。
若大家使用 tokio,那 CPU 密集的任务尤其需要用线程的方式去处理,例如使用
spawn_blocking创建一个阻塞的线程去完成相应 CPU 密集任务。原因是:tokio 是协作式的调度器,如果某个 CPU 密集的异步任务是通过 tokio 创建的,那理论上来说,该异步任务需要跟其它的异步任务交错执行,最终大家都得到了执行,皆大欢喜。但实际情况是,CPU 密集的任务很可能会一直霸着着 CPU,此时 tokio 的调度方式决定了该任务会一直被执行,这意味着,其它的异步任务无法得到执行的机会,最终这些任务都会因为得不到资源而饿死。
而使用
spawn_blocking后,会创建一个单独的 OS 线程,该线程并不会被 tokio 所调度( 被 OS 所调度 ),因此它所执行的 CPU 密集任务也不会导致 tokio 调度的那些异步任务被饿死
总结
离开三方开源社区提供的异步运行时, async/await 什么都不是,甚至还不如一堆破铜烂铁,除非你选择根据自己的需求手撸一个。
而 tokio 就是那颗皇冠上的夜明珠,也是值得我们投入时间去深入学习的开源库,它的设计原理和代码实现都异常优秀,在之后的章节中,我们将对其进行深入学习和剖析,敬请期待。
tokio 初印象
又到了喜闻乐见的初印象环节,这个环节决定了你心中的那 24 盏灯最终是全亮还是全灭。
在本文中,我们将看看本专题的学习目标、tokio该怎么引入以及如何实现一个 Hello Tokio 项目,最终亮灯还是灭灯的决定权留给各位看官。但我提前说好,如果你全灭了,但却找不到更好的,未来还是得回来真香 :P
专题目标
通过 API 学项目无疑是无聊的,因此我们采用一个与众不同的方式:边学边练,在本专题的最后你将拥有一个 redis 客户端和服务端,当然不会实现一个完整版本的 redis ,只会提供基本的功能和部分常用的命令。
mini-redis
redis 的项目源码可以在这里访问,本项目是从官方地址 fork 而来,在未来会提供注释和文档汉化。
再次声明:该项目仅仅用于学习目的,因此它的文档注释非常全,但是它完全无法作为 redis 的替代品。
环境配置
首先,我们假定你已经安装了 Rust 和相关的工具链,例如 cargo。其中 Rust 版本的最低要求是 1.45.0,建议使用最新版 1.58:
sunfei@sunface $ rustc --version
rustc 1.58.0 (02072b482 2022-01-11)
接下来,安装 mini-redis 的服务器端,它可以用来测试我们后面将要实现的 redis 客户端:
$ cargo install mini-redis
如果下载失败,也可以通过这个地址下载源码,然后在本地通过
cargo run运行。
下载成功后,启动服务端:
$ mini-redis-server
然后,再使用客户端测试下刚启动的服务端:
$ mini-redis-cli set foo 1
OK
$ mini-redis-cli get foo
"1"
不得不说,还挺好用的,先自我陶醉下 :) 此时,万事俱备,只欠东风,接下来是时候亮"箭"了:实现我们的 Hello Tokio 项目。
Hello Tokio
与简单无比的 Hello World 有所不同(简单?还记得本书开头时,湖畔边的那个多国语言版本的你好,世界嘛~~),Hello Tokio 它承载着"非常艰巨"的任务,那就是向刚启动的 redis 服务器写入一个 key=hello, value=world ,然后再读取出来,嗯,使用 mini-redis 客户端 :)
分析未到,代码先行
在详细讲解之前,我们先来看看完整的代码,让大家有一个直观的印象。首先,创建一个新的 Rust 项目:
$ cargo new my-redis
$ cd my-redis
然后在 Cargo.toml 中添加相关的依赖:
[dependencies]
tokio = { version = "1", features = ["full"] }
mini-redis = "0.4"
接下来,使用以下代码替换 main.rs 中的内容:
use mini_redis::{client, Result}; #[tokio::main] async fn main() -> Result<()> { // 建立与mini-redis服务器的连接 let mut client = client::connect("127.0.0.1:6379").await?; // 设置 key: "hello" 和 值: "world" client.set("hello", "world".into()).await?; // 获取"key=hello"的值 let result = client.get("hello").await?; println!("从服务器端获取到结果={:?}", result); Ok(()) }
不知道你之前启动的 mini-redis-server 关闭没有,如果关了,记得重新启动下,否则我们的代码就是意大利空气炮。
最后,运行这个项目:
$ cargo run
从服务器端获取到结果=Some("world")
Perfect, 代码成功运行,是时候来解释下其中蕴藏的至高奥秘了。
原理解释
代码篇幅虽然不长,但是还是有不少值得关注的地方,接下来我们一起来看看。
#![allow(unused)] fn main() { let mut client = client::connect("127.0.0.1:6379").await?; }
client::connect 函数由mini-redis 包提供,它使用异步的方式跟指定的远程 IP 地址建立 TCP 长连接,一旦连接建立成功,那 client 的赋值初始化也将完成。
特别值得注意的是:虽然该连接是异步建立的,但是从代码本身来看,完全是同步的代码编写方式,唯一能说明异步的点就是 .await。
什么是异步编程
大部分计算机程序都是按照代码编写的顺序来执行的:先执行第一行,然后第二行,以此类推(当然,还要考虑流程控制,例如循环)。当进行同步编程时,一旦程序遇到一个操作无法被立即完成,它就会进入阻塞状态,直到该操作完成为止。
因此同步编程非常符合我们人类的思维习惯,是一个顺其自然的过程,被几乎每一个程序员所喜欢(本来想说所有,但我不敢打包票,毕竟总有特立独行之士)。例如,当建立 TCP 连接时,当前线程会被阻塞,直到等待该连接建立完成,然后才往下继续进行。
而使用异步编程,无法立即完成的操作会被切到后台去等待,因此当前线程不会被阻塞,它会接着执行其它的操作。一旦之前的操作准备好可以继续执行后,它会通知执行器,然后执行器会调度它并从上次离开的点继续执行。但是大家想象下,如果没有使用 await,而是按照这个异步的流程使用通知 -> 回调的方式实现,代码该多么的难写和难读!
好在 Rust 为我们提供了 async/await 的异步编程特性,让我们可以像写同步代码那样去写异步的代码,也让这个世界美好依旧。
编译时绿色线程
一个函数可以通过async fn的方式被标记为异步函数:
#![allow(unused)] fn main() { use mini_redis::Result; use mini_redis::client::Client; use tokio::net::ToSocketAddrs; pub async fn connect<T: ToSocketAddrs>(addr: T) -> Result<Client> { // ... } }
在上例中,redis 的连接函数 connect 实现如上,它看上去很像是一个同步函数,但是 async fn 出卖了它。
async fn 异步函数并不会直接返回值,而是返回一个 Future,顾名思义,该 Future 会在未来某个时间点被执行,然后最终获取到真实的返回值 Result<Client>。
async/await 的原理就算大家不理解,也不妨碍使用
tokio写出能用的服务,但是如果想要更深入的用好,强烈建议认真读下本书的async/await异步编程章节,你会对 Rust 的异步编程有一个全新且深刻的认识。
由于 async 会返回一个 Future,因此我们还需要配合使用 .await 来让该 Future 运行起来,最终获得返回值:
async fn say_to_world() -> String { String::from("world") } #[tokio::main] async fn main() { // 此处的函数调用是惰性的,并不会执行 `say_to_world()` 函数体中的代码 let op = say_to_world(); // 首先打印出 "hello" println!("hello"); // 使用 `.await` 让 `say_to_world` 开始运行起来 println!("{}", op.await); }
上面代码输出如下:
hello
world
而大家可能很好奇 async fn 到底返回什么吧?它实际上返回的是一个实现了 Future 特征的匿名类型: impl Future<Output = String>。
async main
在代码中,使用了一个与众不同的 main 函数 : async fn main ,而且是用 #[tokio::main] 属性进行了标记。异步 main 函数有以下意义:
.await只能在async函数中使用,如果是以前的fn main,那它内部是无法直接使用async函数的!这个会极大的限制了我们的使用场景- 异步运行时本身需要初始化
因此 #[tokio::main] 宏在将 async fn main 隐式的转换为 fn main 的同时还对整个异步运行时进行了初始化。例如以下代码:
#[tokio::main] async fn main() { println!("hello"); }
将被转换成:
fn main() { let mut rt = tokio::runtime::Runtime::new().unwrap(); rt.block_on(async { println!("hello"); }) }
最终,Rust 编译器就愉快地执行这段代码了。
cargo feature
在引入 tokio 包时,我们在 Cargo.toml 文件中添加了这么一行:
tokio = { version = "1", features = ["full"] }
里面有个 features = ["full"] 可能大家会比较迷惑,当然,关于它的具体解释在本书的 Cargo 详解专题 有介绍,这里就简单进行说明。
Tokio 有很多功能和特性,例如 TCP,UDP,Unix sockets,同步工具,多调度类型等等,不是每个应用都需要所有的这些特性。为了优化编译时间和最终生成可执行文件大小、内存占用大小,应用可以对这些特性进行可选引入。
而这里为了演示的方便,我们使用 full ,表示直接引入所有的特性。
总结
大家对 tokio 的初印象如何?可否 24 灯全亮通过?
总之,tokio 做的事情其实是细雨润无声的,在大多数时候,我们并不能感觉到它的存在,但是它确实是异步编程中最重要的一环(或者之一),深入了解它对我们的未来之路会有莫大的帮助。
接下来,正式开始 tokio 的学习之旅。
创建异步任务
同志们,抓稳了,我们即将换挡提速,通向 mini-redis 服务端的高速之路已经开启。
不过在开始之前,先来做点收尾工作:上一章节中,我们实现了一个简易的 mini-redis 客户端并支持了 SET/GET 操作, 现在将该代码移动到 examples 文件夹下,因为我们这个章节要实现的是服务器,后面可以通过运行 example 的方式,用之前客户端示例对我们的服务器端进行测试:
$ mkdir -p examples
$ mv src/main.rs examples/hello-redis.rs
并在 Cargo.toml 里添加 [[example]] 说明。关于 example 的详细说明,可以在Cargo使用指南里进一步了解。
[[example]]
name = "hello-redis"
path = "examples/hello-redis.rs"
然后再重新创建一个空的 src/main.rs 文件,至此替换文档已经完成,提速正式开始。
接收 sockets
作为服务器端,最基础的工作无疑是接收外部进来的 TCP 连接,可以通过 tokio::net::TcpListener 来完成。
Tokio 中大多数类型的名称都和标准库中对应的同步类型名称相同,而且,如果没有特殊原因,Tokio 的 API 名称也和标准库保持一致,只不过用
async fn取代fn来声明函数。
TcpListener 监听 6379 端口,然后通过循环来接收外部进来的连接,每个连接在处理完后会被关闭。对于目前来说,我们的任务很简单:读取命令、打印到标准输出 stdout,最后回复给客户端一个错误。
use tokio::net::{TcpListener, TcpStream}; use mini_redis::{Connection, Frame}; #[tokio::main] async fn main() { // Bind the listener to the address // 监听指定地址,等待 TCP 连接进来 let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { // 第二个被忽略的项中包含有新连接的 `IP` 和端口信息 let (socket, _) = listener.accept().await.unwrap(); process(socket).await; } } async fn process(socket: TcpStream) { // `Connection` 对于 redis 的读写进行了抽象封装,因此我们读到的是一个一个数据帧frame(数据帧 = redis命令 + 数据),而不是字节流 // `Connection` 是在 mini-redis 中定义 let mut connection = Connection::new(socket); if let Some(frame) = connection.read_frame().await.unwrap() { println!("GOT: {:?}", frame); // 回复一个错误 let response = Frame::Error("unimplemented".to_string()); connection.write_frame(&response).await.unwrap(); } }
现在运行我们的简单服务器 :
cargo run
此时服务器会处于循环等待以接收连接的状态,接下来在一个新的终端窗口中启动上一章节中的 redis 客户端,由于相关代码已经放入 examples 文件夹下,因此我们可以使用 --example 来指定运行该客户端示例:
$ cargo run --example hello-redis
此时,客户端的输出是: Error: "unimplemented", 同时服务器端打印出了客户端发来的由 redis 命令和数据 组成的数据帧: GOT: Array([Bulk(b"set"), Bulk(b"hello"), Bulk(b"world")])。
生成任务
上面的服务器,如果你仔细看,它其实一次只能接受和处理一条 TCP 连接,只有等当前的处理完并结束后,才能开始接收下一条连接。原因在于 loop 循环中的 await 会导致当前任务进入阻塞等待,也就是 loop 循环会被阻塞。
而这显然不是我们想要的,服务器能并发地处理多条连接的请求,才是正确的打开姿势,下面来看看如何实现真正的并发。
关于并发和并行,在多线程章节中有详细的解释
为了并发的处理连接,需要为每一条进来的连接都生成( spawn )一个新的任务, 然后在该任务中处理连接:
use tokio::net::TcpListener; #[tokio::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); loop { let (socket, _) = listener.accept().await.unwrap(); // 为每一条连接都生成一个新的任务, // `socket` 的所有权将被移动到新的任务中,并在那里进行处理 tokio::spawn(async move { process(socket).await; }); } }
任务
一个 Tokio 任务是一个异步的绿色线程,它们通过 tokio::spawn 进行创建,该函数会返回一个 JoinHandle 类型的句柄,调用者可以使用该句柄跟创建的任务进行交互。
spawn 函数的参数是一个 async 语句块,该语句块甚至可以返回一个值,然后调用者可以通过 JoinHandle 句柄获取该值:
#[tokio::main] async fn main() { let handle = tokio::spawn(async { 10086 }); let out = handle.await.unwrap(); println!("GOT {}", out); }
以上代码会打印出GOT 10086。实际上,上面代码中.await 会返回一个 Result ,若 spawn 创建的任务正常运行结束,则返回一个 Ok(T)的值,否则会返回一个错误 Err:例如任务内部发生了 panic 或任务因为运行时关闭被强制取消时。
任务是调度器管理的执行单元。spawn生成的任务会首先提交给调度器,然后由它负责调度执行。需要注意的是,执行任务的线程未必是创建任务的线程,任务完全有可能运行在另一个不同的线程上,而且任务在生成后,它还可能会在线程间被移动。
任务在 Tokio 中远比看上去要更轻量,例如创建一个任务仅仅需要一次 64 字节大小的内存分配。因此应用程序在生成任务上,完全不应该有任何心理负担,除非你在一台没那么好的机器上疯狂生成了几百万个任务。。。
'static 约束
当使用 Tokio 创建一个任务时,该任务类型的生命周期必须是 'static。意味着,在任务中不能使用外部数据的引用:
use tokio::task; #[tokio::main] async fn main() { let v = vec![1, 2, 3]; task::spawn(async { println!("Here's a vec: {:?}", v); }); }
上面代码中,spawn 出的任务引用了外部环境中的变量 v ,导致以下报错:
error[E0373]: async block may outlive the current function, but
it borrows `v`, which is owned by the current function
--> src/main.rs:7:23
|
7 | task::spawn(async {
| _______________________^
8 | | println!("Here's a vec: {:?}", v);
| | - `v` is borrowed here
9 | | });
| |_____^ may outlive borrowed value `v`
|
note: function requires argument type to outlive `'static`
--> src/main.rs:7:17
|
7 | task::spawn(async {
| _________________^
8 | | println!("Here's a vector: {:?}", v);
9 | | });
| |_____^
help: to force the async block to take ownership of `v` (and any other
referenced variables), use the `move` keyword
|
7 | task::spawn(async move {
8 | println!("Here's a vec: {:?}", v);
9 | });
|
原因在于:默认情况下,变量并不是通过 move 的方式转移进 async 语句块的, v 变量的所有权依然属于 main 函数,因为任务内部的 println! 是通过借用的方式使用了 v,但是这种借用并不能满足 'static 生命周期的要求。
在报错的同时,Rust 编译器还给出了相当有帮助的提示:为 async 语句块使用 move 关键字,这样就能将 v 的所有权从 main 函数转移到新创建的任务中。
但是 move 有一个问题,一个数据只能被一个任务使用,如果想要多个任务使用一个数据,就有些强人所难。不知道还有多少同学记得 Arc,它可以轻松解决该问题,还是线程安全的。
在上面的报错中,还有一句很奇怪的信息function requires argument type to outlive `'static` , 函数要求参数类型的生命周期必须比 'static 长,问题是 'static 已经活得跟整个程序一样久了,难道函数的参数还能活得更久?大家可能会觉得编译器秀逗了,毕竟其它语言编译器也有秀逗的时候:)
先别急着给它扣帽子,虽然我有时候也想这么做。。原因是它说的是类型必须活得比 'static 长,而不是值。当我们说一个值是 'static 时,意味着它将永远存活。这个很重要,因为编译器无法知道新创建的任务将存活多久,所以唯一的办法就是让任务永远存活。
如果大家对于 '&static 和 T: 'static 较为模糊,强烈建议回顾下该章节。
Send 约束
tokio::spawn 生成的任务必须实现 Send 特征,因为当这些任务在 .await 执行过程中发生阻塞时,Tokio 调度器会将任务在线程间移动。
一个任务要实现 Send 特征,那它在 .await 调用的过程中所持有的全部数据都必须实现 Send 特征。当 .await 调用发生阻塞时,任务会让出当前线程所有权给调度器,然后当任务准备好后,调度器会从上一次暂停的位置继续执行该任务。该流程能正确的工作,任务必须将.await之后使用的所有状态保存起来,这样才能在中断后恢复现场并继续执行。若这些状态实现了 Send 特征(可以在线程间安全地移动),那任务自然也就可以在线程间安全地移动。
例如以下代码可以工作:
use tokio::task::yield_now; use std::rc::Rc; #[tokio::main] async fn main() { tokio::spawn(async { // 语句块的使用强制了 `rc` 会在 `.await` 被调用前就被释放, // 因此 `rc` 并不会影响 `.await`的安全性 { let rc = Rc::new("hello"); println!("{}", rc); } // `rc` 的作用范围已经失效,因此当任务让出所有权给当前线程时,它无需作为状态被保存起来 yield_now().await; }); }
但是下面代码就不行:
use tokio::task::yield_now; use std::rc::Rc; #[tokio::main] async fn main() { tokio::spawn(async { let rc = Rc::new("hello"); // `rc` 在 `.await` 后还被继续使用,因此它必须被作为任务的状态保存起来 yield_now().await; // 事实上,注释掉下面一行代码,依然会报错 // 原因是:是否保存,不取决于 `rc` 是否被使用,而是取决于 `.await`在调用时是否仍然处于 `rc` 的作用域中 println!("{}", rc); // rc 作用域在这里结束 }); }
这里有一个很重要的点,代码注释里有讲到,但是我们再重复一次: rc 是否会保存到任务状态中,取决于 .await 的调用是否处于它的作用域中,上面代码中,就算你注释掉 println! 函数,该报错依然会报错,因为 rc 的作用域直到 async 的末尾才结束!
下面是相应的报错,在下一章节,我们还会继续深入讨论该错误:
error: future cannot be sent between threads safely
--> src/main.rs:6:5
|
6 | tokio::spawn(async {
| ^^^^^^^^^^^^ future created by async block is not `Send`
|
::: [..]spawn.rs:127:21
|
127 | T: Future + Send + 'static,
| ---- required by this bound in
| `tokio::task::spawn::spawn`
|
= help: within `impl std::future::Future`, the trait
| `std::marker::Send` is not implemented for
| `std::rc::Rc<&str>`
note: future is not `Send` as this value is used across an await
--> src/main.rs:10:9
|
7 | let rc = Rc::new("hello");
| -- has type `std::rc::Rc<&str>` which is not `Send`
...
10 | yield_now().await;
| ^^^^^^^^^^^^^^^^^ await occurs here, with `rc` maybe
| used later
11 | println!("{}", rc);
12 | });
| - `rc` is later dropped here
使用 HashMap 存储数据
现在,我们可以继续前进了,下面来实现 process 函数,它用于处理进入的命令。相应的值将被存储在 HashMap 中: 通过 SET 命令存值,通过 GET 命令来取值。
同时,我们将使用循环的方式在同一个客户端连接中处理多次连续的请求:
#![allow(unused)] fn main() { use tokio::net::TcpStream; use mini_redis::{Connection, Frame}; async fn process(socket: TcpStream) { use mini_redis::Command::{self, Get, Set}; use std::collections::HashMap; // 使用 hashmap 来存储 redis 的数据 let mut db = HashMap::new(); // `mini-redis` 提供的便利函数,使用返回的 `connection` 可以用于从 socket 中读取数据并解析为数据帧 let mut connection = Connection::new(socket); // 使用 `read_frame` 方法从连接获取一个数据帧:一条redis命令 + 相应的数据 while let Some(frame) = connection.read_frame().await.unwrap() { let response = match Command::from_frame(frame).unwrap() { Set(cmd) => { // 值被存储为 `Vec<u8>` 的形式 db.insert(cmd.key().to_string(), cmd.value().to_vec()); Frame::Simple("OK".to_string()) } Get(cmd) => { if let Some(value) = db.get(cmd.key()) { // `Frame::Bulk` 期待数据的类型是 `Bytes`, 该类型会在后面章节讲解, // 此时,你只要知道 `&Vec<u8>` 可以使用 `into()` 方法转换成 `Bytes` 类型 Frame::Bulk(value.clone().into()) } else { Frame::Null } } cmd => panic!("unimplemented {:?}", cmd), }; // 将请求响应返回给客户端 connection.write_frame(&response).await.unwrap(); } } // main 函数在之前已实现 }
使用 cargo run 运行服务器,然后再打开另一个终端窗口,运行 hello-redis 客户端示例: cargo run --example hello-redis。
Bingo,在看了这么多原理后,我们终于迈出了小小的第一步,并获取到了存在 HashMap 中的值: 从服务器端获取到结果=Some(b"world")。
但是问题又来了:这些值无法在 TCP 连接中共享,如果另外一个用户连接上来并试图同时获取 hello 这个 key,他将一无所获。
共享状态
上一章节中,咱们搭建了一个异步的 redis 服务器,并成功的提供了服务,但是其隐藏了一个巨大的问题:状态(数据)无法在多个连接之间共享,下面一起来看看该如何解决。
解决方法
好在 Tokio 十分强大,上面问题对应的解决方法也不止一种:
- 使用
Mutex来保护数据的共享访问 - 生成一个异步任务去管理状态,然后各个连接使用消息传递的方式与其进行交互
其中,第一种方法适合比较简单的数据,而第二种方法适用于需要异步工作的,例如 I/O 原语。由于我们使用的数据存储类型是 HashMap,使用到的相关操作是 insert 和 get ,又因为这两个操作都不是异步的,因此只要使用 Mutex 即可解决问题。
在上面的描述中,说实话第二种方法及其适用的场景并不是很好理解,但没关系,在后面章节会进行详细介绍。
添加 bytes 依赖包
在上一节中,我们使用 Vec<u8> 来保存目标数据,但是它有一个问题,对它进行克隆时会将底层数据也整个复制一份,效率很低,但是克隆操作对于我们在多连接间共享数据又是必不可少的。
因此这里咱们新引入一个 bytes 包,它包含一个 Bytes 类型,当对该类型的值进行克隆时,就不再会克隆底层数据。事实上,Bytes 是一个引用计数类型,跟 Arc 非常类似,或者准确的说,Bytes 就是基于 Arc 实现的,但相比后者Bytes 提供了一些额外的能力。
在 Cargo.toml 的 [dependencies] 中引入 bytes :
bytes = "1"
初始化 HashMap
由于 HashMap 会在多个任务甚至多个线程间共享,再结合之前的选择,最终我们决定使用 Arc<Mutex<T>> 的方式对其进行包裹。
但是,大家先来畅想一下使用它进行包裹后的类型长什么样? 大概,可能,长这样:Arc<Mutex<HashMap<String, Bytes>>>,天哪噜,一不小心,你就遇到了 Rust 的阴暗面:类型大串烧。可以想象,如果要在代码中到处使用这样的类型,可读性会极速下降,因此我们需要一个类型别名( type alias )来简化下:
#![allow(unused)] fn main() { use bytes::Bytes; use std::collections::HashMap; use std::sync::{Arc, Mutex}; type Db = Arc<Mutex<HashMap<String, Bytes>>>; }
此时,Db 就是一个类型别名,使用它就可以替代那一大串的东东,等下你就能看到功效。
接着,我们需要在 main 函数中对 HashMap 进行初始化,然后使用 Arc 克隆一份它的所有权并将其传入到生成的异步任务中。事实上在 Tokio 中,这里的 Arc 被称为 handle,或者更宽泛的说,handle 在 Tokio 中可以用来访问某个共享状态。
use tokio::net::TcpListener; use std::collections::HashMap; use std::sync::{Arc, Mutex}; #[tokio::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:6379").await.unwrap(); println!("Listening"); let db = Arc::new(Mutex::new(HashMap::new())); loop { let (socket, _) = listener.accept().await.unwrap(); // 将 handle 克隆一份 let db = db.clone(); println!("Accepted"); tokio::spawn(async move { process(socket, db).await; }); } }
为何使用 std::sync::Mutex
上面代码还有一点非常重要,那就是我们使用了 std::sync::Mutex 来保护 HashMap,而不是使用 tokio::sync::Mutex。
在使用 Tokio 编写异步代码时,一个常见的错误无条件地使用 tokio::sync::Mutex ,而真相是:Tokio 提供的异步锁只应该在跨多个 .await调用时使用,而且 Tokio 的 Mutex 实际上内部使用的也是 std::sync::Mutex。
多补充几句,在异步代码中,关于锁的使用有以下经验之谈:
- 锁如果在多个
.await过程中持有,应该使用 Tokio 提供的锁,原因是.await的过程中锁可能在线程间转移,若使用标准库的同步锁存在死锁的可能性,例如某个任务刚获取完锁,还没使用完就因为.await让出了当前线程的所有权,结果下个任务又去获取了锁,造成死锁 - 锁竞争不多的情况下,使用
std::sync::Mutex - 锁竞争多,可以考虑使用三方库提供的性能更高的锁,例如
parking_lot::Mutex
更新 process()
process() 函数不再初始化 HashMap,取而代之的是它使用了 HashMap 的一个 handle 作为参数:
#![allow(unused)] fn main() { use tokio::net::TcpStream; use mini_redis::{Connection, Frame}; async fn process(socket: TcpStream, db: Db) { use mini_redis::Command::{self, Get, Set}; let mut connection = Connection::new(socket); while let Some(frame) = connection.read_frame().await.unwrap() { let response = match Command::from_frame(frame).unwrap() { Set(cmd) => { let mut db = db.lock().unwrap(); db.insert(cmd.key().to_string(), cmd.value().clone()); Frame::Simple("OK".to_string()) } Get(cmd) => { let db = db.lock().unwrap(); if let Some(value) = db.get(cmd.key()) { Frame::Bulk(value.clone()) } else { Frame::Null } } cmd => panic!("unimplemented {:?}", cmd), }; connection.write_frame(&response).await.unwrap(); } } }
任务、线程和锁竞争
当竞争不多的时候,使用阻塞性的锁去保护共享数据是一个正确的选择。当一个锁竞争触发后,当前正在执行任务(请求锁)的线程会被阻塞,并等待锁被前一个使用者释放。这里的关键就是:锁竞争不仅仅会导致当前的任务被阻塞,还会导致执行任务的线程被阻塞,因此该线程准备执行的其它任务也会因此被阻塞!
默认情况下,Tokio 调度器使用了多线程模式,此时如果有大量的任务都需要访问同一个锁,那么锁竞争将变得激烈起来。当然,你也可以使用 current_thread 运行时设置,在该设置下会使用一个单线程的调度器(执行器),所有的任务都会创建并执行在当前线程上,因此不再会有锁竞争。
current_thread 是一个轻量级、单线程的运行时,当任务数不多或连接数不多时是一个很好的选择。例如你想在一个异步客户端库的基础上提供给用户同步的 API 访问时,该模式就很适用
当同步锁的竞争变成一个问题时,使用 Tokio 提供的异步锁几乎并不能帮你解决问题,此时可以考虑如下选项:
- 创建专门的任务并使用消息传递的方式来管理状态
- 将锁进行分片
- 重构代码以避免锁
在我们的例子中,由于每一个 key 都是独立的,因此对锁进行分片将成为一个不错的选择:
#![allow(unused)] fn main() { type ShardedDb = Arc<Vec<Mutex<HashMap<String, Vec<u8>>>>>; fn new_sharded_db(num_shards: usize) -> ShardedDb { let mut db = Vec::with_capacity(num_shards); for _ in 0..num_shards { db.push(Mutex::new(HashMap::new())); } Arc::new(db) } }
在这里,我们创建了 N 个不同的存储实例,每个实例都会存储不同的分片数据,例如我们有a-i共 9 个不同的 key, 可以将存储分成 3 个实例,那么第一个实例可以存储 a-c,第二个d-f,以此类推。在这种情况下,访问 b 时,只需要锁住第一个实例,此时二、三实例依然可以正常访问,因此锁被成功的分片了。
在分片后,使用给定的 key 找到对应的值就变成了两个步骤:首先,使用 key 通过特定的算法寻找到对应的分片,然后再使用该 key 从分片中查询到值:
#![allow(unused)] fn main() { let shard = db[hash(key) % db.len()].lock().unwrap(); shard.insert(key, value); }
这里我们使用 hash 算法来进行分片,但是该算法有个缺陷:分片的数量不能变,一旦变了后,那之前落入分片 1 的key很可能将落入到其它分片中,最终全部乱掉。此时你可以考虑dashmap,它提供了更复杂、更精妙的支持分片的hash map。
在 .await 期间持有锁
在某些时候,你可能会不经意写下这种代码:
#![allow(unused)] fn main() { use std::sync::{Mutex, MutexGuard}; async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; do_something_async().await; } // 锁在这里超出作用域 }
如果你要 spawn 一个任务来执行上面的函数的话,会报错:
error: future cannot be sent between threads safely
--> src/lib.rs:13:5
|
13 | tokio::spawn(async move {
| ^^^^^^^^^^^^ future created by async block is not `Send`
|
::: /playground/.cargo/registry/src/github.com-1ecc6299db9ec823/tokio-0.2.21/src/task/spawn.rs:127:21
|
127 | T: Future + Send + 'static,
| ---- required by this bound in `tokio::task::spawn::spawn`
|
= help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::sync::MutexGuard<'_, i32>`
note: future is not `Send` as this value is used across an await
--> src/lib.rs:7:5
|
4 | let mut lock: MutexGuard<i32> = mutex.lock().unwrap();
| -------- has type `std::sync::MutexGuard<'_, i32>` which is not `Send`
...
7 | do_something_async().await;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^ await occurs here, with `mut lock` maybe used later
8 | }
| - `mut lock` is later dropped here
错误的原因在于 std::sync::MutexGuard 类型并没有实现 Send 特征,这意味着你不能将一个 Mutex 锁发送到另一个线程,因为 .await 可能会让任务转移到另一个线程上执行,这个之前也介绍过。
提前释放锁
要解决这个问题,就必须重构代码,让 Mutex 锁在 .await 被调用前就被释放掉。
#![allow(unused)] fn main() { // 下面的代码可以工作! async fn increment_and_do_stuff(mutex: &Mutex<i32>) { { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; } // lock在这里超出作用域 (被释放) do_something_async().await; } }
大家可能已经发现,很多错误都是因为
.await引起的,其实你只要记住,在.await执行期间,任务可能会在线程间转移,那么这些错误将变得很好理解,不必去死记硬背
但是下面的代码不工作:
#![allow(unused)] fn main() { use std::sync::{Mutex, MutexGuard}; async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock: MutexGuard<i32> = mutex.lock().unwrap(); *lock += 1; drop(lock); do_something_async().await; } }
原因我们之前解释过,编译器在这里不够聪明,目前它只能根据作用域的范围来判断,drop 虽然释放了锁,但是锁的作用域依然会持续到函数的结束,未来也许编译器会改进,但是现在至少还是不行的。
聪明的读者此时的小脑袋已经飞速运转起来,既然锁没有实现 Send, 那我们主动给它实现如何?这样不就可以顺利运行了吗?答案依然是不可以,原因就是我们之前提到过的死锁,如果一个任务获取了锁,然后还没释放就在 .await 期间被挂起,接着开始执行另一个任务,这个任务又去获取锁,就会导致死锁。
再来看看其它解决方法:
重构代码:在 .await 期间不持有锁
之前的代码其实也是为了在 .await 期间不持有锁,但是我们还有更好的实现方式,例如,你可以把 Mutex 放入一个结构体中,并且只在该结构体的非异步方法中使用该锁:
#![allow(unused)] fn main() { use std::sync::Mutex; struct CanIncrement { mutex: Mutex<i32>, } impl CanIncrement { // 该方法不是 `async` fn increment(&self) { let mut lock = self.mutex.lock().unwrap(); *lock += 1; } } async fn increment_and_do_stuff(can_incr: &CanIncrement) { can_incr.increment(); do_something_async().await; } }
使用异步任务和通过消息传递来管理状态
该方法常常用于共享的资源是 I/O 类型的资源时,我们在下一章节将详细介绍。
使用 Tokio 提供的异步锁
Tokio 提供的锁最大的优点就是:它可以在 .await 执行期间被持有,而且不会有任何问题。但是代价就是,这种异步锁的性能开销会更高,因此如果可以,使用之前的两种方法来解决会更好。
#![allow(unused)] fn main() { use tokio::sync::Mutex; // 注意,这里使用的是 Tokio 提供的锁 // 下面的代码会编译 // 但是就这个例子而言,之前的方式会更好 async fn increment_and_do_stuff(mutex: &Mutex<i32>) { let mut lock = mutex.lock().await; *lock += 1; do_something_async().await; } // 锁在这里被释放 }
消息传递
迄今为止,你已经学了不少关于 Tokio 的并发编程的内容,是时候见识下真正的挑战了,接下来,我们一起来实现下客户端这块儿的功能。
首先,将之前实现的 src/main.rs 文件中的服务器端代码放入到一个 bin 文件中,等下可以直接通过该文件来运行我们的服务器:
mkdir src/bin
mv src/main.rs src/bin/server.rs
接着创建一个新的 bin 文件,用于包含我们即将实现的客户端代码:
touch src/bin/client.rs
由于不再使用 main.rs 作为程序入口,我们需要使用以下命令来运行指定的 bin 文件:
#![allow(unused)] fn main() { cargo run --bin server }
此时,服务器已经成功运行起来。 同样的,可以用 cargo run --bin client 这种方式运行即将实现的客户端。
万事俱备,只欠代码,一起来看看客户端该如何实现。
错误的实现
如果想要同时运行两个 redis 命令,我们可能会为每一个命令生成一个任务,例如:
use mini_redis::client; #[tokio::main] async fn main() { // 创建到服务器的连接 let mut client = client::connect("127.0.0.1:6379").await.unwrap(); // 生成两个任务,一个用于获取 key, 一个用于设置 key let t1 = tokio::spawn(async { let res = client.get("hello").await; }); let t2 = tokio::spawn(async { client.set("foo", "bar".into()).await; }); t1.await.unwrap(); t2.await.unwrap(); }
这段代码不会编译,因为两个任务都需要去访问 client,但是 client 并没有实现 Copy 特征,再加上我们并没有实现相应的共享代码,因此自然会报错。还有一个问题,方法 set 和 get 都使用了 client 的可变引用 &mut self,由此还会造成同时借用两个可变引用的错误。
在上一节中,我们介绍了几个解决方法,但是它们大部分都不太适用于此时的情况,例如:
std::sync::Mutex无法被使用,这个问题在之前章节有详解介绍过,同步锁无法跨越.await调用时使用- 那么你可能会想,是不是可以使用
tokio::sync:Mutex,答案是可以用,但是同时就只能运行一个请求。若客户端实现了 redis 的 pipelining, 那这个异步锁就会导致连接利用率不足
这个不行,那个也不行,是不是没有办法解决了?还记得我们上一章节提到过几次的消息传递,但是一直没有看到它的庐山真面目吗?现在可以来看看了。
消息传递
之前章节我们提到可以创建一个专门的任务 C1 (消费者 Consumer) 和通过消息传递来管理共享的资源,这里的共享资源就是 client 。若任务 P1 (生产者 Producer) 想要发出 Redis 请求,首先需要发送信息给 C1,然后 C1 会发出请求给服务器,在获取到结果后,再将结果返回给 P1。
在这种模式下,只需要建立一条连接,然后由一个统一的任务来管理 client 和该连接,这样之前的 get 和 set 请求也将不存在资源共享的问题。
同时,P1 和 C1 进行通信的消息通道是有缓冲的,当大量的消息发送给 C1 时,首先会放入消息通道的缓冲区中,当 C1 处理完一条消息后,再从该缓冲区中取出下一条消息进行处理,这种方式跟消息队列( Message queue ) 非常类似,可以实现更高的吞吐。而且这种方式还有利于实现连接池,例如不止一个 P 和 C 时,多个 P 可以往消息通道中发送消息,同时多个 C,其中每个 C 都维护一条连接,并从消息通道获取消息。
Tokio 的消息通道( channel )
Tokio 提供了多种消息通道,可以满足不同场景的需求:
mpsc, 多生产者,单消费者模式oneshot, 单生产者单消费,一次只能发送一条消息broadcast,多生产者,多消费者,其中每一条发送的消息都可以被所有接收者收到,因此是广播watch,单生产者,多消费者,只保存一条最新的消息,因此接收者只能看到最近的一条消息,例如,这种模式适用于配置文件变化的监听
细心的同学可能会发现,这里还少了一种类型:多生产者、多消费者,且每一条消息只能被其中一个消费者接收,如果有这种需求,可以使用 async-channel 包。
以上这些消息通道都有一个共同点:适用于 async 编程,对于其它场景,你可以使用在多线程章节中提到过的 std::sync::mpsc 和 crossbeam::channel, 这些通道在等待消息时会阻塞当前的线程,因此不适用于 async 编程。
在下面的代码中,我们将使用 mpsc 和 oneshot, 本章节完整的代码见这里。
定义消息类型
在大多数场景中使用消息传递时,都是多个发送者向一个任务发送消息,该任务在处理完后,需要将响应内容返回给相应的发送者。例如我们的例子中,任务需要将 GET 和 SET 命令处理的结果返回。首先,我们需要定一个 Command 枚举用于代表命令:
#![allow(unused)] fn main() { use bytes::Bytes; #[derive(Debug)] enum Command { Get { key: String, }, Set { key: String, val: Bytes, } } }
创建消息通道
在 src/bin/client.rs 的 main 函数中,创建一个 mpsc 消息通道:
use tokio::sync::mpsc; #[tokio::main] async fn main() { // 创建一个新通道,缓冲队列长度是 32 let (tx, mut rx) = mpsc::channel(32); // ... 其它代码 }
一个任务可以通过此通道将命令发送给管理 redis 连接的任务,同时由于通道支持多个生产者,因此多个任务可以同时发送命令。创建该通道会返回一个发送和接收句柄,这两个句柄可以分别被使用,例如它们可以被移动到不同的任务中。
通道的缓冲队列长度是 32,意味着如果消息发送的比接收的快,这些消息将被存储在缓冲队列中,一旦存满了 32 条消息,使用send(...).await的发送者会进入睡眠,直到缓冲队列可以放入新的消息(被接收者消费了)。
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (tx, mut rx) = mpsc::channel(32); let tx2 = tx.clone(); tokio::spawn(async move { tx.send("sending from first handle").await; }); tokio::spawn(async move { tx2.send("sending from second handle").await; }); while let Some(message) = rx.recv().await { println!("GOT = {}", message); } }
你可以使用 clone 方法克隆多个发送者,但是接收者无法被克隆,因为我们的通道是 mpsc 类型。
当所有的发送者都被 Drop 掉后(超出作用域或被 drop(...) 函数主动释放),就不再会有任何消息发送给该通道,此时 recv 方法将返回 None,也意味着该通道已经被关闭。
在我们的例子中,接收者是在管理 redis 连接的任务中,当该任务发现所有发送者都关闭时,它知道它的使命可以完成了,因此它会关闭 redis 连接。
生成管理任务
下面,我们来一起创建一个管理任务,它会管理 redis 的连接,当然,首先需要创建一条到 redis 的连接:
#![allow(unused)] fn main() { use mini_redis::client; // 将消息通道接收者 rx 的所有权转移到管理任务中 let manager = tokio::spawn(async move { // Establish a connection to the server // 建立到 redis 服务器的连接 let mut client = client::connect("127.0.0.1:6379").await.unwrap(); // 开始接收消息 while let Some(cmd) = rx.recv().await { use Command::*; match cmd { Get { key } => { client.get(&key).await; } Set { key, val } => { client.set(&key, val).await; } } } }); }
如上所示,当从消息通道接收到一个命令时,该管理任务会将此命令通过 redis 连接发送到服务器。
现在,让两个任务发送命令到消息通道,而不是像最开始报错的那样,直接发送命令到各自的 redis 连接:
#![allow(unused)] fn main() { // 由于有两个任务,因此我们需要两个发送者 let tx2 = tx.clone(); // 生成两个任务,一个用于获取 key,一个用于设置 key let t1 = tokio::spawn(async move { let cmd = Command::Get { key: "hello".to_string(), }; tx.send(cmd).await.unwrap(); }); let t2 = tokio::spawn(async move { let cmd = Command::Set { key: "foo".to_string(), val: "bar".into(), }; tx2.send(cmd).await.unwrap(); }); }
在 main 函数的末尾,我们让 3 个任务,按照需要的顺序开始运行:
#![allow(unused)] fn main() { t1.await.unwrap(); t2.await.unwrap(); manager.await.unwrap(); }
接收响应消息
最后一步,就是让发出命令的任务从管理任务那里获取命令执行的结果。为了完成这个目标,我们将使用 oneshot 消息通道,因为它针对一发一收的使用类型做过特别优化,且特别适用于此时的场景:接收一条从管理任务发送的结果消息。
#![allow(unused)] fn main() { use tokio::sync::oneshot; let (tx, rx) = oneshot::channel(); }
使用方式跟 mpsc 很像,但是它并没有缓存长度,因为只能发送一条,接收一条,还有一点不同:你无法对返回的两个句柄进行 clone。
为了让管理任务将结果准确的返回到发送者手中,这个管道的发送端必须要随着命令一起发送, 然后发出命令的任务保留管道的发送端。一个比较好的实现就是将管道的发送端放入 Command 的数据结构中,同时使用一个别名来代表该发送端:
#![allow(unused)] fn main() { use tokio::sync::oneshot; use bytes::Bytes; #[derive(Debug)] enum Command { Get { key: String, resp: Responder<Option<Bytes>>, }, Set { key: String, val: Bytes, resp: Responder<()>, }, } /// 管理任务可以使用该发送端将命令执行的结果传回给发出命令的任务 type Responder<T> = oneshot::Sender<mini_redis::Result<T>>; }
下面,更新发送命令的代码:
#![allow(unused)] fn main() { let t1 = tokio::spawn(async move { let (resp_tx, resp_rx) = oneshot::channel(); let cmd = Command::Get { key: "hello".to_string(), resp: resp_tx, }; // 发送 GET 请求 tx.send(cmd).await.unwrap(); // 等待回复 let res = resp_rx.await; println!("GOT = {:?}", res); }); let t2 = tokio::spawn(async move { let (resp_tx, resp_rx) = oneshot::channel(); let cmd = Command::Set { key: "foo".to_string(), val: "bar".into(), resp: resp_tx, }; // 发送 SET 请求 tx2.send(cmd).await.unwrap(); // 等待回复 let res = resp_rx.await; println!("GOT = {:?}", res); }); }
最后,更新管理任务:
#![allow(unused)] fn main() { while let Some(cmd) = rx.recv().await { match cmd { Command::Get { key, resp } => { let res = client.get(&key).await; // 忽略错误 let _ = resp.send(res); } Command::Set { key, val, resp } => { let res = client.set(&key, val).await; // 忽略错误 let _ = resp.send(res); } } } }
有一点值得注意,往 oneshot 中发送消息时,并没有使用 .await,原因是该发送操作要么直接成功、要么失败,并不需要等待。
当 oneshot 的接受端被 drop 后,继续发送消息会直接返回 Err 错误,它表示接收者已经不感兴趣了。对于我们的场景,接收者不感兴趣是非常合理的操作,并不是一种错误,因此可以直接忽略。
本章的完整代码见这里。
对消息通道进行限制
无论何时使用消息通道,我们都需要对缓存队列的长度进行限制,这样系统才能优雅的处理各种负载状况。如果不限制,假设接收端无法及时处理消息,那消息就会迅速堆积,最终可能会导致内存消耗殆尽,就算内存没有消耗完,也可能会导致整体性能的大幅下降。
Tokio 在设计时就考虑了这种状况,例如 async 操作在 Tokio 中是惰性的:
#![allow(unused)] fn main() { loop { async_op(); } }
如果上面代码中,async_op 不是惰性的,而是在每次循环时立即执行,那该循环会立即将一个 async_op 发送到缓冲队列中,然后开始执行下一个循环,因为无需等待任务执行完成,这种发送速度是非常恐怖的,一秒钟可能会有几十万、上百万的消息发送到消息队列中。在其它语言编程中,相信大家也或多或少遇到过这种情况。
然后在 Async Rust 和 Tokio 中,上面的代码 async_op 根本就不会运行,也就不会往消息队列中写入消息。原因是我们没有调用 .await,就算使用了 .await 上面的代码也不会有问题,因为只有等当前循环的任务结束后,才会开始下一次循环。
#![allow(unused)] fn main() { loop { // 当前 `async_op` 完成后,才会开始下一次循环 async_op().await; } }
总之,在 Tokio 中我们必须要显式地引入并发和队列:
tokio::spawnselect!join!mpsc::channel
当这么做时,我们需要小心的控制并发度来确保系统的安全。例如,当使用一个循环去接收 TCP 连接时,你要确保当前打开的 socket 数量在可控范围内,而不是毫无原则的接收连接。 再比如,当使用 mpsc::channel 时,要设置一个缓冲值。
挑选一个合适的限制值是 Tokio 编程中很重要的一部分,可以帮助我们的系统更加安全、可靠的运行。
I/O
本章节中我们将深入学习 Tokio 中的 I/O 操作,了解它的原理以及该如何使用。
Tokio 中的 I/O 操作和 std 在使用方式上几无区别,最大的区别就是前者是异步的,例如 Tokio 的读写特征分别是 AsyncRead 和 AsyncWrite:
- 有部分类型按照自己的所需实现了它们:
TcpStream,File,Stdout - 还有数据结构也实现了它们:
Vec<u8>、&[u8],这样就可以直接使用这些数据结构作为读写器( reader / writer)
AsyncRead 和 AsyncWrite
这两个特征为字节流的异步读写提供了便利,通常我们会使用 AsyncReadExt 和 AsyncWriteExt 提供的工具方法,这些方法都使用 async 声明,且需要通过 .await 进行调用,
async fn read
AsyncReadExt::read 是一个异步方法可以将数据读入缓冲区( buffer )中,然后返回读取的字节数。
use tokio::fs::File; use tokio::io::{self, AsyncReadExt}; #[tokio::main] async fn main() -> io::Result<()> { let mut f = File::open("foo.txt").await?; let mut buffer = [0; 10]; // 由于 buffer 的长度限制,当次的 `read` 调用最多可以从文件中读取 10 个字节的数据 let n = f.read(&mut buffer[..]).await?; println!("The bytes: {:?}", &buffer[..n]); Ok(()) }
需要注意的是:当 read 返回 Ok(0) 时,意味着字节流( stream )已经关闭,在这之后继续调用 read 会立刻完成,依然获取到返回值 Ok(0)。 例如,字节流如果是 TcpStream 类型,那 Ok(0) 说明该连接的读取端已经被关闭(写入端关闭,会报其它的错误)。
async fn read_to_end
AsyncReadExt::read_to_end 方法会从字节流中读取所有的字节,直到遇到 EOF :
use tokio::io::{self, AsyncReadExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut f = File::open("foo.txt").await?; let mut buffer = Vec::new(); // 读取整个文件的内容 f.read_to_end(&mut buffer).await?; Ok(()) }
async fn write
AsyncWriteExt::write 异步方法会尝试将缓冲区的内容写入到写入器( writer )中,同时返回写入的字节数:
use tokio::io::{self, AsyncWriteExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut file = File::create("foo.txt").await?; let n = file.write(b"some bytes").await?; println!("Wrote the first {} bytes of 'some bytes'.", n); Ok(()) }
上面代码很清晰,但是大家可能会疑惑 b"some bytes" 是什么意思。这种写法可以将一个 &str 字符串转变成一个字节数组:&[u8;10],然后 write 方法又会将这个 &[u8;10] 的数组类型隐式强转为数组切片: &[u8]。
async fn write_all
AsyncWriteExt::write_all 将缓冲区的内容全部写入到写入器中:
use tokio::io::{self, AsyncWriteExt}; use tokio::fs::File; #[tokio::main] async fn main() -> io::Result<()> { let mut file = File::create("foo.txt").await?; file.write_all(b"some bytes").await?; Ok(()) }
以上只是部分方法,实际上还有一些实用的方法由于篇幅有限无法列出,大家可以通过 API 文档 查看完整的列表。
实用函数
另外,和标准库一样, tokio::io 模块包含了多个实用的函数或 API,可以用于处理标准输入/输出/错误等。
例如,tokio::io::copy 异步的将读取器( reader )中的内容拷贝到写入器( writer )中。
use tokio::fs::File; use tokio::io; #[tokio::main] async fn main() -> io::Result<()> { let mut reader: &[u8] = b"hello"; let mut file = File::create("foo.txt").await?; io::copy(&mut reader, &mut file).await?; Ok(()) }
还记得我们之前提到的字节数组 &[u8] 实现了 AsyncRead 吗?正因为这个原因,所以这里可以直接将 &u8 用作读取器。
回声服务( Echo )
就如同写代码必写 hello, world,实现 web 服务器,往往会选择实现一个回声服务。该服务会将用户的输入内容直接返回给用户,就像回声壁一样。
具体来说,就是从用户建立的 TCP 连接的 socket 中读取到数据,然后立刻将同样的数据写回到该 socket 中。因此客户端会收到和自己发送的数据一模一样的回复。
下面我们将使用两种稍有不同的方法实现该回声服务。
使用 io::copy()
先来创建一个新的 bin 文件,用于运行我们的回声服务:
touch src/bin/echo-server-copy.rs
然后可以通过以下命令运行它(跟上一章节的方式相同):
cargo run --bin echo-server-copy
至于客户端,可以简单的使用 telnet 的方式来连接,或者也可以使用 tokio::net::TcpStream,它的文档示例非常适合大家进行参考。
先来实现一下基本的服务器框架:通过 loop 循环接收 TCP 连接,然后为每一条连接创建一个单独的任务去处理。
use tokio::io; use tokio::net::TcpListener; #[tokio::main] async fn main() -> io::Result<()> { let listener = TcpListener::bind("127.0.0.1:6142").await?; loop { let (mut socket, _) = listener.accept().await?; tokio::spawn(async move { // 在这里拷贝数据 }); } }
下面,来看看重头戏 io::copy ,它有两个参数:一个读取器,一个写入器,然后将读取器中的数据直接拷贝到写入器中,类似的实现代码如下:
#![allow(unused)] fn main() { io::copy(&mut socket, &mut socket).await }
这段代码相信大家一眼就能看出问题,由于我们的读取器和写入器都是同一个 socket,因此需要对其进行两次可变借用,这明显违背了 Rust 的借用规则。
分离读写器
显然,使用同一个 socket 是不行的,为了实现目标功能,必须将 socket 分离成一个读取器和写入器。
任何一个读写器( reader + writer )都可以使用 io::split 方法进行分离,最终返回一个读取器和写入器,这两者可以独自的使用,例如可以放入不同的任务中。
例如,我们的回声客户端可以这样实现,以实现同时并发读写:
use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpStream; #[tokio::main] async fn main() -> io::Result<()> { let socket = TcpStream::connect("127.0.0.1:6142").await?; let (mut rd, mut wr) = io::split(socket); // 创建异步任务,在后台写入数据 tokio::spawn(async move { wr.write_all(b"hello\r\n").await?; wr.write_all(b"world\r\n").await?; // 有时,我们需要给予 Rust 一些类型暗示,它才能正确的推导出类型 Ok::<_, io::Error>(()) }); let mut buf = vec![0; 128]; loop { let n = rd.read(&mut buf).await?; if n == 0 { break; } println!("GOT {:?}", &buf[..n]); } Ok(()) }
实际上,io::split 可以用于任何同时实现了 AsyncRead 和 AsyncWrite 的值,它的内部使用了 Arc 和 Mutex 来实现相应的功能。如果大家觉得这种实现有些重,可以使用 Tokio 提供的 TcpStream,它提供了两种方式进行分离:
TcpStream::split会获取字节流的引用,然后将其分离成一个读取器和写入器。但由于使用了引用的方式,它们俩必须和split在同一个任务中。 优点就是,这种实现没有性能开销,因为无需Arc和Mutex。TcpStream::into_split还提供了一种分离实现,分离出来的结果可以在任务间移动,内部是通过Arc实现
再来分析下我们的使用场景,由于 io::copy() 调用时所在的任务和 split 所在的任务是同一个,因此可以使用性能最高的 TcpStream::split:
#![allow(unused)] fn main() { tokio::spawn(async move { let (mut rd, mut wr) = socket.split(); if io::copy(&mut rd, &mut wr).await.is_err() { eprintln!("failed to copy"); } }); }
使用 io::copy 实现的完整代码见此处。
手动拷贝
程序员往往拥有一颗手动干翻一切的心,因此如果你不想用 io::copy 来简单实现,还可以自己手动去拷贝数据:
use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; use tokio::net::TcpListener; #[tokio::main] async fn main() -> io::Result<()> { let listener = TcpListener::bind("127.0.0.1:6142").await?; loop { let (mut socket, _) = listener.accept().await?; tokio::spawn(async move { let mut buf = vec![0; 1024]; loop { match socket.read(&mut buf).await { // 返回值 `Ok(0)` 说明对端已经关闭 Ok(0) => return, Ok(n) => { // Copy the data back to socket // 将数据拷贝回 socket 中 if socket.write_all(&buf[..n]).await.is_err() { // 非预期错误,由于我们这里无需再做什么,因此直接停止处理 return; } } Err(_) => { // 非预期错误,由于我们无需再做什么,因此直接停止处理 return; } } } }); } }
建议这段代码放入一个和之前 io::copy 不同的文件中 src/bin/echo-server.rs , 然后使用 cargo run --bin echo-server 运行。
下面一起来看看这段代码有哪些值得注意的地方。首先,由于使用了 write_all 和 read 方法,需要先将对应的特征引入到当前作用域内:
#![allow(unused)] fn main() { use tokio::io::{self, AsyncReadExt, AsyncWriteExt}; }
在堆上分配缓冲区
在上面代码中,我们需要将数据从 socket 中读取到一个缓冲区 buffer 中:
#![allow(unused)] fn main() { let mut buf = vec![0; 1024]; }
可以看到,此处的缓冲区是一个 Vec 动态数组,它的数据是存储在堆上,而不是栈上(若改成 let mut buf = [0; 1024];,则存储在栈上)。
在之前,我们提到过一个数据如果想在 .await 调用过程中存在,那它必须存储在当前任务内。在我们的代码中,buf 会在 .await 调用过程中被使用,因此它必须要存储在任务内。
若该缓冲区数组创建在栈上,那每条连接所对应的任务的内部数据结构看上去可能如下所示:
#![allow(unused)] fn main() { struct Task { task: enum { AwaitingRead { socket: TcpStream, buf: [BufferType], }, AwaitingWriteAll { socket: TcpStream, buf: [BufferType], } } } }
可以看到,栈数组要被使用,就必须存储在相应的结构体内,其中两个结构体分别持有了不同的栈数组 [BufferType],这种方式会导致任务结构变得很大。特别地,我们选择缓冲区长度往往会使用分页长度(page size),因此使用栈数组会导致任务的内存大小变得很奇怪甚至糟糕:$page-size + 一些额外的字节。
当然,编译器会帮助我们做一些优化。例如,会进一步优化 async 语句块的布局,而不是像上面一样简单的使用 enum。在实践中,变量也不会在枚举成员间移动。
但是再怎么优化,任务的结构体至少也会跟其中的栈数组一样大,因此通常情况下,使用堆上的缓冲区会高效实用的多。
当任务因为调度在线程间移动时,存储在栈上的数据需要进行保存和恢复,过大的栈上变量会带来不小的数据拷贝开销
因此,存储大量数据的变量最好放到堆上
处理 EOF
当 TCP 连接的读取端关闭后,再调用 read 方法会返回 Ok(0)。此时,再继续下去已经没有意义,因此我们需要退出循环。忘记在 EOF 时退出读取循环,是网络编程中一个常见的 bug :
#![allow(unused)] fn main() { loop { match socket.read(&mut buf).await { Ok(0) => return, // ... 其余错误处理 } } }
大家不妨深入思考下,如果没有退出循环会怎么样?之前我们提到过,一旦读取端关闭后,那后面的 read 调用就会立即返回 Ok(0),而不会阻塞等待,因此这种无阻塞循环会最终导致 CPU 立刻跑到 100% ,并将一直持续下去,直到程序关闭。
解析数据帧
现在,鉴于大家已经掌握了 Tokio 的基本 I/O 用法,我们可以开始实现 mini-redis 的帧 frame。通过帧可以将字节流转换成帧组成的流。每个帧就是一个数据单元,例如客户端发送的一次请求就是一个帧。
#![allow(unused)] fn main() { use bytes::Bytes; enum Frame { Simple(String), Error(String), Integer(u64), Bulk(Bytes), Null, Array(Vec<Frame>), } }
可以看到帧除了数据之外,并不具备任何语义。命令解析和实现会在更高的层次进行(相比帧解析层)。我们再来通过 HTTP 的帧来帮大家加深下相关的理解:
#![allow(unused)] fn main() { enum HttpFrame { RequestHead { method: Method, uri: Uri, version: Version, headers: HeaderMap, }, ResponseHead { status: StatusCode, version: Version, headers: HeaderMap, }, BodyChunk { chunk: Bytes, }, } }
为了实现 mini-redis 的帧,我们需要一个 Connection 结构体,里面包含了一个 TcpStream 以及对帧进行读写的方法:
#![allow(unused)] fn main() { use tokio::net::TcpStream; use mini_redis::{Frame, Result}; struct Connection { stream: TcpStream, // ... 这里定义其它字段 } impl Connection { /// 从连接读取一个帧 /// /// 如果遇到EOF,则返回 None pub async fn read_frame(&mut self) -> Result<Option<Frame>> { // 具体实现 } /// 将帧写入到连接中 pub async fn write_frame(&mut self, frame: &Frame) -> Result<()> { // 具体实现 } } }
关于 Redis 协议的说明,可以看看官方文档,Connection 代码的完整实现见这里.
缓冲读取(Buffered Reads)
read_frame 方法会等到一个完整的帧都读取完毕后才返回,与之相比,它底层调用的TcpStream::read 只会返回任意多的数据(填满传入的缓冲区 buffer ),它可能返回帧的一部分、一个帧、多个帧,总之这种读取行为是不确定的。
当 read_frame 的底层调用 TcpStream::read 读取到部分帧时,会将数据先缓冲起来,接着继续等待并读取数据。如果读到多个帧,那第一个帧会被返回,然后剩下的数据依然被缓冲起来,等待下一次 read_frame 被调用。
为了实现这种功能,我们需要为 Connection 增加一个读取缓冲区。数据首先从 socket 中读取到缓冲区中,接着这些数据会被解析为帧,当一个帧被解析后,该帧对应的数据会从缓冲区被移除。
这里使用 BytesMut 作为缓冲区类型,它是 Bytes 的可变版本。
#![allow(unused)] fn main() { use bytes::BytesMut; use tokio::net::TcpStream; pub struct Connection { stream: TcpStream, buffer: BytesMut, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream, // 分配一个缓冲区,具有4kb的缓冲长度 buffer: BytesMut::with_capacity(4096), } } } }
接下来,实现 read_frame 方法:
#![allow(unused)] fn main() { use tokio::io::AsyncReadExt; use bytes::Buf; use mini_redis::Result; pub async fn read_frame(&mut self) -> Result<Option<Frame>> { loop { // 尝试从缓冲区的数据中解析出一个数据帧, // 只有当数据足够被解析时,才返回对应的帧 if let Some(frame) = self.parse_frame()? { return Ok(Some(frame)); } // 如果缓冲区中的数据还不足以被解析为一个数据帧, // 那么我们需要从 socket 中读取更多的数据 // // 读取成功时,会返回读取到的字节数,0 代表着读到了数据流的末尾 if 0 == self.stream.read_buf(&mut self.buffer).await? { // 代码能执行到这里,说明了对端关闭了连接, // 需要看看缓冲区是否还有数据,若没有数据,说明所有数据成功被处理, // 若还有数据,说明对端在发送帧的过程中断开了连接,导致只发送了部分数据 if self.buffer.is_empty() { return Ok(None); } else { return Err("connection reset by peer".into()); } } } } }
read_frame 内部使用循环的方式读取数据,直到一个完整的帧被读取到时,才会返回。当然,当远程的对端关闭了连接后,也会返回。
Buf 特征
在上面的 read_frame 方法中,我们使用了 read_buf 来读取 socket 中的数据,该方法的参数是来自 bytes 包的 BufMut。
可以先来考虑下该如何使用 read() 和 Vec<u8> 来实现同样的功能 :
#![allow(unused)] fn main() { use tokio::net::TcpStream; pub struct Connection { stream: TcpStream, buffer: Vec<u8>, cursor: usize, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream, // 4kb 大小的缓冲区 buffer: vec![0; 4096], cursor: 0, } } } }
下面是相应的 read_frame 方法:
#![allow(unused)] fn main() { use mini_redis::{Frame, Result}; pub async fn read_frame(&mut self) -> Result<Option<Frame>> { loop { if let Some(frame) = self.parse_frame()? { return Ok(Some(frame)); } // 确保缓冲区长度足够 if self.buffer.len() == self.cursor { // 若不够,需要增加缓冲区长度 self.buffer.resize(self.cursor * 2, 0); } // 从游标位置开始将数据读入缓冲区 let n = self.stream.read( &mut self.buffer[self.cursor..]).await?; if 0 == n { if self.cursor == 0 { return Ok(None); } else { return Err("connection reset by peer".into()); } } else { // 更新游标位置 self.cursor += n; } } } }
在这段代码中,我们使用了非常重要的技术:通过游标( cursor )跟踪已经读取的数据,并将下次读取的数据写入到游标之后的缓冲区中,只有这样才不会让新读取的数据将之前读取的数据覆盖掉。
一旦缓冲区满了,还需要增加缓冲区的长度,这样才能继续写入数据。还有一点值得注意,在 parse_frame 方法的内部实现中,也需要通过游标来解析数据: self.buffer[..self.cursor],通过这种方式,我们可以准确获取到目前已经读取的全部数据。
在网络编程中,通过字节数组和游标的方式读取数据是非常普遍的,因此 bytes 包提供了一个 Buf 特征,如果一个类型可以被读取数据,那么该类型需要实现 Buf 特征。与之对应,当一个类型可以被写入数据时,它需要实现 BufMut 。
当 T: BufMut ( 特征约束,说明类型 T 实现了 BufMut 特征 ) 被传给 read_buf() 方法时,缓冲区 T 的内部游标会自动进行更新。正因为如此,在使用了 BufMut 版本的 read_frame 中,我们并不需要管理自己的游标。
除了游标之外,Vec<u8> 的使用也值得关注,该缓冲区在使用时必须要被初始化: vec![0; 4096],该初始化会创建一个 4096 字节长度的数组,然后将数组的每个元素都填充上 0 。当缓冲区长度不足时,新创建的缓冲区数组依然会使用 0 被重新填充一遍。 事实上,这种初始化过程会存在一定的性能开销。
与 Vec<u8> 相反, BytesMut 和 BufMut 就没有这个问题,它们无需被初始化,而且 BytesMut 还会阻止我们读取未初始化的内存。
帧解析
在理解了该如何读取数据后, 再来看看该如何通过两个部分解析出一个帧:
- 确保有一个完整的帧已经被写入了缓冲区,找到该帧的最后一个字节所在的位置
- 解析帧
#![allow(unused)] fn main() { use mini_redis::{Frame, Result}; use mini_redis::frame::Error::Incomplete; use bytes::Buf; use std::io::Cursor; fn parse_frame(&mut self) -> Result<Option<Frame>> { // 创建 `T: Buf` 类型 let mut buf = Cursor::new(&self.buffer[..]); // 检查是否读取了足够解析出一个帧的数据 match Frame::check(&mut buf) { Ok(_) => { // 获取组成该帧的字节数 let len = buf.position() as usize; // 在解析开始之前,重置内部的游标位置 buf.set_position(0); // 解析帧 let frame = Frame::parse(&mut buf)?; // 解析完成,将缓冲区该帧的数据移除 self.buffer.advance(len); // 返回解析出的帧 Ok(Some(frame)) } // 缓冲区的数据不足以解析出一个完整的帧 Err(Incomplete) => Ok(None), // 遇到一个错误 Err(e) => Err(e.into()), } } }
完整的 Frame::check 函数实现在这里,感兴趣的同学可以看看,在这里我们不会对它进行完整的介绍。
值得一提的是, Frame::check 使用了 Buf 的字节迭代风格的 API。例如,为了解析一个帧,首先需要检查它的第一个字节,该字节用于说明帧的类型。这种首字节检查是通过 Buf::get_u8 函数完成的,该函数会获取游标所在位置的字节,然后将游标位置向右移动一个字节。
缓冲写入(Buffered writes)
关于帧操作的另一个 API 是 write_frame(frame) 函数,它会将一个完整的帧写入到 socket 中。 每一次写入,都会触发一次或数次系统调用,当程序中有大量的连接和写入时,系统调用的开销将变得非常高昂,具体可以看看 SyllaDB 团队写过的一篇性能调优文章。
为了降低系统调用的次数,我们需要使用一个写入缓冲区,当写入一个帧时,首先会写入该缓冲区,然后等缓冲区数据足够多时,再集中将其中的数据写入到 socket 中,这样就将多次系统调用优化减少到一次。
还有,缓冲区也不总是能提升性能。 例如,考虑一个 bulk 帧(多个帧放在一起组成一个 bulk,通过批量发送提升效率),该帧的特点就是:由于由多个帧组合而成,因此帧体数据可能会很大。所以我们不能将其帧体数据写入到缓冲区中,因为数据较大时,先写入缓冲区再写入 socket 会有较大的性能开销(实际上缓冲区就是为了批量写入,既然 bulk 已经是批量了,因此不使用缓冲区也很正常)。
为了实现缓冲写,我们将使用 BufWriter 结构体。该结构体实现了 AsyncWrite 特征,当 write 方法被调用时,不会直接写入到 socket 中,而是先写入到缓冲区中。当缓冲区被填满时,其中的内容会自动刷到(写入到)内部的 socket 中,然后再将缓冲区清空。当然,其中还存在某些优化,通过这些优化可以绕过缓冲区直接访问 socket。
由于篇幅有限,我们不会实现完整的 write_frame 函数,想要看完整代码可以访问这里。
首先,更新下 Connection 的结构体:
#![allow(unused)] fn main() { use tokio::io::BufWriter; use tokio::net::TcpStream; use bytes::BytesMut; pub struct Connection { stream: BufWriter<TcpStream>, buffer: BytesMut, } impl Connection { pub fn new(stream: TcpStream) -> Connection { Connection { stream: BufWriter::new(stream), buffer: BytesMut::with_capacity(4096), } } } }
接着来实现 write_frame 函数:
#![allow(unused)] fn main() { use tokio::io::{self, AsyncWriteExt}; use mini_redis::Frame; async fn write_frame(&mut self, frame: &Frame) -> io::Result<()> { match frame { Frame::Simple(val) => { self.stream.write_u8(b'+').await?; self.stream.write_all(val.as_bytes()).await?; self.stream.write_all(b"\r\n").await?; } Frame::Error(val) => { self.stream.write_u8(b'-').await?; self.stream.write_all(val.as_bytes()).await?; self.stream.write_all(b"\r\n").await?; } Frame::Integer(val) => { self.stream.write_u8(b':').await?; self.write_decimal(*val).await?; } Frame::Null => { self.stream.write_all(b"$-1\r\n").await?; } Frame::Bulk(val) => { let len = val.len(); self.stream.write_u8(b'$').await?; self.write_decimal(len as u64).await?; self.stream.write_all(val).await?; self.stream.write_all(b"\r\n").await?; } Frame::Array(_val) => unimplemented!(), } self.stream.flush().await; Ok(()) } }
这里使用的方法由 AsyncWriteExt 提供,它们在 TcpStream 中也有对应的函数。但是在没有缓冲区的情况下最好避免使用这种逐字节的写入方式!不然,每写入几个字节就会触发一次系统调用,写完整个数据帧可能需要几十次系统调用,可以说是丧心病狂!
write_u8写入一个字节write_all写入所有数据write_decimal由 mini-redis 提供
在函数结束前,我们还额外的调用了一次 self.stream.flush().await,原因是缓冲区可能还存在数据,因此需要手动刷一次数据:flush 的调用会将缓冲区中剩余的数据立刻写入到 socket 中。
当然,当帧比较小的时候,每写一次帧就 flush 一次的模式性能开销会比较大,此时我们可以选择在 Connection 中实现 flush 函数,然后将等帧积累多个后,再一次性在 Connection 中进行 flush。当然,对于我们的例子来说,简洁性是非常重要的,因此选了将 flush 放入到 write_frame 中。
深入 Tokio 背后的异步原理
在经过多个章节的深入学习后,Tokio 对我们来说不再是一座隐于云雾中的高山,它其实蛮简单好用的,甚至还有一丝丝的可爱!?
但从现在开始,如果想要进一步的深入 Tokio ,首先需要深入理解 async 的原理,其实我们在之前的章节已经深入学习过,这里结合 Tokio 再来回顾下。
Future
先来回顾一下 async fn 异步函数 :
#![allow(unused)] fn main() { use tokio::net::TcpStream; async fn my_async_fn() { println!("hello from async"); // 通过 .await 创建 socket 连接 let _socket = TcpStream::connect("127.0.0.1:3000").await.unwrap(); println!("async TCP operation complete"); // 关闭socket } }
接着对它进行调用获取一个返回值,再在返回值上调用 .await:
#[tokio::main] async fn main() { let what_is_this = my_async_fn(); // 上面的调用不会产生任何效果 // ... 执行一些其它代码 what_is_this.await; // 直到 .await 后,文本才被打印,socket 连接也被创建和关闭 }
在上面代码中 my_async_fn 函数为何可以惰性执行( 直到 .await 调用时才执行)?秘密就在于 async fn 声明的函数返回一个 Future。
Future 是一个实现了 std::future::Future 特征的值,该值包含了一系列异步计算过程,而这个过程直到 .await 调用时才会被执行。
std::future::Future 的定义如下所示:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; } }
代码中有几个关键点:
- 关联类型
Output是Future执行完成后返回的值的类型 Pin类型是在异步函数中进行借用的关键
和其它语言不同,Rust 中的 Future 不代表一个发生在后台的计算,而是 Future 就代表了计算本身,因此
Future 的所有者有责任去推进该计算过程的执行,例如通过 Future::poll 函数。听上去好像还挺复杂?但是大家不必担心,因为这些都在 Tokio 中帮你自动完成了 :)
实现 Future
下面来一起实现个五脏俱全的 Future,它将:1. 等待某个特定时间点的到来 2. 在标准输出打印文本 3. 生成一个字符串
use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; struct Delay { when: Instant, } // 为我们的 Delay 类型实现 Future 特征 impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { // 时间到了,Future 可以结束 println!("Hello world"); // Future 执行结束并返回 "done" 字符串 Poll::Ready("done") } else { // 目前先忽略下面这行代码 cx.waker().wake_by_ref(); Poll::Pending } } } #[tokio::main] async fn main() { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; // 运行并等待 Future 的完成 let out = future.await; // 判断 Future 返回的字符串是否是 "done" assert_eq!(out, "done"); }
以上代码很清晰的解释了如何自定义一个 Future,并指定它如何通过 poll 一步一步执行,直到最终完成返回 "done" 字符串。
async fn 作为 Future
大家有没有注意到,上面代码我们在 main 函数中初始化一个 Future 并使用 .await 对其进行调用执行,如果你是在 fn main 中这么做,是会报错的。
原因是 .await 只能用于 async fn 函数中,因此我们将 main 函数声明成 async fn main 同时使用 #[tokio::main] 进行了标注,此时 async fn main 生成的代码类似下面:
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; enum MainFuture { // 初始化,但永远不会被 poll State0, // 等待 `Delay` 运行,例如 `future.await` 代码行 State1(Delay), // Future 执行完成 Terminated, } impl Future for MainFuture { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { use MainFuture::*; loop { match *self { State0 => { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; *self = State1(future); } State1(ref mut my_future) => { match Pin::new(my_future).poll(cx) { Poll::Ready(out) => { assert_eq!(out, "done"); *self = Terminated; return Poll::Ready(()); } Poll::Pending => { return Poll::Pending; } } } Terminated => { panic!("future polled after completion") } } } } } }
可以看出,编译器会将 Future 变成状态机, 其中 MainFuture 包含了 Future 可能处于的状态:从 State0 状态开始,当 poll 被调用时, Future 会尝试去尽可能的推进内部的状态,若它可以被完成时,就会返回 Poll::Ready,其中还会包含最终的输出结果。
若 Future 无法被完成,例如它所等待的资源还没有准备好,此时就会返回 Poll::Pending,该返回值会通知调用者: Future 会在稍后才能完成。
同时可以看到:当一个 Future 由其它 Future 组成时,调用外层 Future 的 poll 函数会同时调用一次内部 Future 的 poll 函数。
执行器( Excecutor )
async fn 返回 Future ,而后者需要通过被不断的 poll 才能往前推进状态,同时该 Future 还能包含其它 Future ,那么问题来了谁来负责调用最外层 Future 的 poll 函数?
回一下之前的内容,为了运行一个异步函数,我们必须使用 tokio::spawn 或 通过 #[tokio::main] 标注的 async fn main 函数。它们有一个非常重要的作用:将最外层 Future 提交给 Tokio 的执行器。该执行器负责调用 poll 函数,然后推动 Future 的执行,最终直至完成。
mini tokio
为了更好理解相关的内容,我们一起来实现一个迷你版本的 Tokio,完整的代码见这里。
先来看一段基础代码:
use std::collections::VecDeque; use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; use futures::task; fn main() { let mut mini_tokio = MiniTokio::new(); mini_tokio.spawn(async { let when = Instant::now() + Duration::from_millis(10); let future = Delay { when }; let out = future.await; assert_eq!(out, "done"); }); mini_tokio.run(); } struct MiniTokio { tasks: VecDeque<Task>, } type Task = Pin<Box<dyn Future<Output = ()> + Send>>; impl MiniTokio { fn new() -> MiniTokio { MiniTokio { tasks: VecDeque::new(), } } /// 生成一个 Future并放入 mini-tokio 实例的任务队列中 fn spawn<F>(&mut self, future: F) where F: Future<Output = ()> + Send + 'static, { self.tasks.push_back(Box::pin(future)); } fn run(&mut self) { let waker = task::noop_waker(); let mut cx = Context::from_waker(&waker); while let Some(mut task) = self.tasks.pop_front() { if task.as_mut().poll(&mut cx).is_pending() { self.tasks.push_back(task); } } } }
以上代码运行了一个 async 语句块 mini_tokio.spawn(async {...}), 还创建了一个 Delay 实例用于等待所需的时间。看上去相当不错,但这个实现有一个 重大缺陷:我们的执行器永远也不会休眠。执行器会持续的循环遍历所有的 Future ,然后不停的 poll 它们,但是事实上,大多数 poll 都是没有用的,因为此时 Future 并没有准备好,因此会继续返回 Poll::Pending ,最终这个循环遍历会让你的 CPU 疲于奔命,真打工人!
鉴于此,我们的 mini-tokio 只应该在 Future 准备好可以进一步运行后,才去 poll 它,例如该 Future 之前阻塞等待的资源已经准备好并可以被使用了,就可以对其进行 poll。再比如,如果一个 Future 任务在阻塞等待从 TCP socket 中读取数据,那我们只想在 socket 中有数据可以读取后才去 poll 它,而不是没事就 poll 着玩。
回到上面的代码中,mini-tokio 只应该当任务的延迟时间到了后,才去 poll 它。 为了实现这个功能,我们需要 通知 -> 运行 机制:当任务可以进一步被推进运行时,它会主动通知执行器,然后执行器再来 poll。
Waker
一切的答案都在 Waker 中,资源可以用它来通知正在等待的任务:该资源已经准备好,可以继续运行了。
再来看下 Future::poll 的定义:
#![allow(unused)] fn main() { fn poll(self: Pin<&mut Self>, cx: &mut Context) -> Poll<Self::Output>; }
Context 参数中包含有 waker()方法。该方法返回一个绑定到当前任务上的 Waker,然后 Waker 上定义了一个 wake() 方法,用于通知执行器相关的任务可以继续执行。
准确来说,当 Future 阻塞等待的资源已经准备好时(例如 socket 中有了可读取的数据),该资源可以调用 wake() 方法,来通知执行器可以继续调用该 Future 的 poll 函数来推进任务的执行。
发送 wake 通知
现在,为 Delay 添加下 Waker 支持:
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::{Duration, Instant}; use std::thread; struct Delay { when: Instant, } impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { println!("Hello world"); Poll::Ready("done") } else { // 为当前任务克隆一个 waker 的句柄 let waker = cx.waker().clone(); let when = self.when; // 生成一个计时器线程 thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } waker.wake(); }); Poll::Pending } } } }
此时,计时器用来模拟一个阻塞等待的资源,一旦计时结束(该资源已经准备好),资源会通过 waker.wake() 调用通知执行器我们的任务再次被调度执行了。
当然,现在的实现还较为粗糙,等会我们会来进一步优化,在此之前,先来看看如何监听这个 wake 通知。
当 Future 会返回
Poll::Pending时,一定要确保wake能被正常调用,否则会导致任务永远被挂起,再也不会被执行器poll。忘记在返回
Poll::Pending时调用wake是很多难以发现 bug 的潜在源头!
再回忆下最早实现的 Delay 代码:
#![allow(unused)] fn main() { impl Future for Delay { type Output = &'static str; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<&'static str> { if Instant::now() >= self.when { // 时间到了,Future 可以结束 println!("Hello world"); // Future 执行结束并返回 "done" 字符串 Poll::Ready("done") } else { // 目前先忽略下面这行代码 cx.waker().wake_by_ref(); Poll::Pending } } } }
在返回 Poll::Pending 之前,先调用了 cx.waker().wake_by_ref() ,由于此时我们还没有模拟计时资源,因此这里直接调用了 wake 进行通知,这样做会导致当前的 Future 被立即再次调度执行。
由此可见,这种通知的控制权是在你手里的,甚至可以像上面代码这样,还没准备好资源,就直接进行 wake 通知,但是总归意义不大,而且浪费了 CPU,因为这种 执行 -> 立即通知再调度 -> 执行 的方式会造成一个非常繁忙的循环。
处理 wake 通知
下面,让我们更新 mint-tokio 服务,让它能接收 wake 通知:当 waker.wake() 被调用后,相关联的任务会被放入执行器的队列中,然后等待执行器的调用执行。
为了实现这一点,我们将使用消息通道来排队存储这些被唤醒并等待调度的任务。有一点需要注意,从消息通道接收消息的线程(执行器所在的线程)和发送消息的线程(唤醒任务时所在的线程)可能是不同的,因此消息( Waker )必须要实现 Send和 Sync,才能跨线程使用。
基于以上理由,我们选择使用来自于 crossbeam 的消息通道,因为标准库中的消息通道不是 Sync 的。在 Cargo.toml 中添加以下依赖:
crossbeam = "0.8"
再来更新下 MiniTokio 结构体:
#![allow(unused)] fn main() { use crossbeam::channel; use std::sync::Arc; struct MiniTokio { scheduled: channel::Receiver<Arc<Task>>, sender: channel::Sender<Arc<Task>>, } struct Task { // 先空着,后面会填充代码 } }
Waker 实现了 Sync 特征,同时还可以被克隆,当 wake 被调用时,任务就会被调度执行。
为了实现上述的目的,我们引入了消息通道,当 waker.wake() 函数被调用时,任务会被发送到该消息通道中:
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex}; struct Task { // `Mutex` 是为了让 `Task` 实现 `Sync` 特征,它能保证同一时间只有一个线程可以访问 `Future`。 // 事实上 `Mutex` 并没有在 Tokio 中被使用,这里我们只是为了简化: Tokio 的真实代码实在太长了 :D future: Mutex<Pin<Box<dyn Future<Output = ()> + Send>>>, executor: channel::Sender<Arc<Task>>, } impl Task { fn schedule(self: &Arc<Self>) { self.executor.send(self.clone()); } } }
接下来,我们需要让 std::task::Waker 能准确的找到所需的调度函数 关联起来,对此标准库中提供了一个底层的 API std::task::RawWakerVTable 可以用于手动的访问 vtable,这种实现提供了最大的灵活性,但是需要大量 unsafe 的代码。
因此我们选择更加高级的实现:由 futures 包提供的 ArcWake 特征,只要简单实现该特征,就可以将我们的 Task 转变成一个 waker。在 Cargo.toml 中添加以下包:
futures = "0.3"
然后为我们的任务 Task 实现 ArcWake:
#![allow(unused)] fn main() { use futures::task::{self, ArcWake}; use std::sync::Arc; impl ArcWake for Task { fn wake_by_ref(arc_self: &Arc<Self>) { arc_self.schedule(); } } }
当之前的计时器线程调用 waker.wake() 时,所在的任务会被推入到消息通道中。因此接下来,我们需要实现接收端的功能,然后 MiniTokio::run() 函数中执行该任务:
#![allow(unused)] fn main() { impl MiniTokio { // 从消息通道中接收任务,然后通过 poll 来执行 fn run(&self) { while let Ok(task) = self.scheduled.recv() { task.poll(); } } /// 初始化一个新的 mini-tokio 实例 fn new() -> MiniTokio { let (sender, scheduled) = channel::unbounded(); MiniTokio { scheduled, sender } } /// 在下面函数中,通过参数传入的 future 被 `Task` 包裹起来,然后会被推入到调度队列中,当 `run` 被调用时,该 future 将被执行 fn spawn<F>(&self, future: F) where F: Future<Output = ()> + Send + 'static, { Task::spawn(future, &self.sender); } } impl Task { fn poll(self: Arc<Self>) { // 基于 Task 实例创建一个 waker, 它使用了之前的 `ArcWake` let waker = task::waker(self.clone()); let mut cx = Context::from_waker(&waker); // 没有其他线程在竞争锁时,我们将获取到目标 future let mut future = self.future.try_lock().unwrap(); // 对 future 进行 poll let _ = future.as_mut().poll(&mut cx); } // 使用给定的 future 来生成新的任务 // // 新的任务会被推到 `sender` 中,接着该消息通道的接收端就可以获取该任务,然后执行 fn spawn<F>(future: F, sender: &channel::Sender<Arc<Task>>) where F: Future<Output = ()> + Send + 'static, { let task = Arc::new(Task { future: Mutex::new(Box::pin(future)), executor: sender.clone(), }); let _ = sender.send(task); } } }
首先,我们实现了 MiniTokio::run() 函数,它会持续从消息通道中接收被唤醒的任务,然后通过 poll 来推动其继续执行。
其次,MiniTokio::new() 和 MiniTokio::spawn() 使用了消息通道而不是一个 VecDeque 。当新任务生成后,这些任务中会携带上消息通道的发送端,当任务中的资源准备就绪时,会使用该发送端将该任务放入消息通道的队列中,等待执行器 poll。
Task::poll() 函数使用 futures 包提供的 ArcWake 创建了一个 waker,后者可以用来创建 task::Context,最终该 Context 会被传给执行器调用的 poll 函数。
注意,Task::poll 和执行器调用的 poll 是完全不同的,大家别搞混了
一些遗留问题
至此,我们的程序已经差不多完成,还剩几个遗留问题需要解决下。
在异步函数中生成异步任务
之前实现 Delay Future 时,我们提到有几个问题需要解决。Rust 的异步模型允许一个 Future 在执行过程中可以跨任务迁移:
use futures::future::poll_fn; use std::future::Future; use std::pin::Pin; #[tokio::main] async fn main() { let when = Instant::now() + Duration::from_millis(10); let mut delay = Some(Delay { when }); poll_fn(move |cx| { let mut delay = delay.take().unwrap(); let res = Pin::new(&mut delay).poll(cx); assert!(res.is_pending()); tokio::spawn(async move { delay.await; }); Poll::Ready(()) }).await; }
首先,poll_fn 函数使用闭包创建了一个 Future,其次,上面代码还创建一个 Delay 实例,然后在闭包中,对其进行了一次 poll ,接着再将该 Delay 实例发送到一个新的任务,在此任务中使用 .await 进行了执行。
在例子中,Delay:poll 被调用了不止一次,且使用了不同的 Waker 实例,在这种场景下,你必须确保调用最近一次 poll 函数中的 Waker 参数中的wake方法。也就是调用最内层 poll 函数参数( Waker )上的 wake 方法。
当实现一个 Future 时,很关键的一点就是要假设每次 poll 调用都会应用到一个不同的 Waker 实例上。因此 poll 函数必须要使用一个新的 waker 去更新替代之前的 waker。
我们之前的 Delay 实现中,会在每一次 poll 调用时都生成一个新的线程。这么做问题不大,但是当 poll 调用较多时会出现明显的性能问题!一个解决方法就是记录你是否已经生成了一个线程,然后只有在没有生成时才去创建一个新的线程。但是一旦这么做,就必须确保线程的 Waker 在后续 poll 调用中被正确更新,否则你无法唤醒最近的 Waker !
这一段大家可能会看得云里雾里的,没办法,原文就饶来绕去,好在终于可以看代码了。。我们可以通过代码来解决疑惑:
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::sync::{Arc, Mutex}; use std::task::{Context, Poll, Waker}; use std::thread; use std::time::{Duration, Instant}; struct Delay { when: Instant, // 用于说明是否已经生成一个线程 // Some 代表已经生成, None 代表还没有 waker: Option<Arc<Mutex<Waker>>>, } impl Future for Delay { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { // 若这是 Future 第一次被调用,那么需要先生成一个计时器线程。 // 若不是第一次调用(该线程已在运行),那要确保已存储的 `Waker` 跟当前任务的 `waker` 匹配 if let Some(waker) = &self.waker { let mut waker = waker.lock().unwrap(); // 检查之前存储的 `waker` 是否跟当前任务的 `waker` 相匹配. // 这是必要的,原因是 `Delay Future` 的实例可能会在两次 `poll` 之间被转移到另一个任务中,然后 // 存储的 waker 被该任务进行了更新。 // 这种情况一旦发生,`Context` 包含的 `waker` 将不同于存储的 `waker`。 // 因此我们必须对存储的 `waker` 进行更新 if !waker.will_wake(cx.waker()) { *waker = cx.waker().clone(); } } else { let when = self.when; let waker = Arc::new(Mutex::new(cx.waker().clone())); self.waker = Some(waker.clone()); // 第一次调用 `poll`,生成计时器线程 thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } // 计时结束,通过调用 `waker` 来通知执行器 let waker = waker.lock().unwrap(); waker.wake_by_ref(); }); } // 一旦 waker 被存储且计时器线程已经开始,我们就需要检查 `delay` 是否已经完成 // 若计时已完成,则当前 Future 就可以完成并返回 `Poll::Ready` if Instant::now() >= self.when { Poll::Ready(()) } else { // 计时尚未结束,Future 还未完成,因此返回 `Poll::Pending`. // // `Future` 特征要求当 `Pending` 被返回时,那我们要确保当资源准备好时,必须调用 `waker` 以通 // 知执行器。 在我们的例子中,会通过生成的计时线程来保证 // // 如果忘记调用 waker, 那等待我们的将是深渊:该任务将被永远的挂起,无法再执行 Poll::Pending } } } }
这着实有些复杂(原文。。),但是简单来看就是:在每次 poll 调用时,都会检查 Context 中提供的 waker 和我们之前记录的 waker 是否匹配。若匹配,就什么都不用做,若不匹配,那之前存储的就必须进行更新。
Notify
我们之前证明了如何用手动编写的 waker 来实现 Delay Future。 Waker 是 Rust 异步编程的基石,因此绝大多数时候,我们并不需要直接去使用它。例如,在 Delay 的例子中, 可以使用 tokio::sync::Notify 去实现。
该 Notify 提供了一个基础的任务通知机制,它会处理这些 waker 的细节,包括确保两次 waker 的匹配:
#![allow(unused)] fn main() { use tokio::sync::Notify; use std::sync::Arc; use std::time::{Duration, Instant}; use std::thread; async fn delay(dur: Duration) { let when = Instant::now() + dur; let notify = Arc::new(Notify::new()); let notify2 = notify.clone(); thread::spawn(move || { let now = Instant::now(); if now < when { thread::sleep(when - now); } notify2.notify_one(); }); notify.notified().await; } }
当使用 Notify 后,我们就可以轻松的实现如上的 delay 函数。
总结
在看完这么长的文章后,我们来总结下,否则大家可能还会遗忘:
- 在 Rust 中,
async是惰性的,直到执行器poll它们时,才会开始执行 Waker是Future被执行的关键,它可以链接起Future任务和执行器- 当资源没有准备时,会返回一个
Poll::Pending - 当资源准备好时,会通过
waker.wake发出通知 - 执行器会收到通知,然后调度该任务继续执行,此时由于资源已经准备好,因此任务可以顺利往前推进了
select!
在实际使用时,一个重要的场景就是同时等待多个异步操作的结果,并且对其结果进行进一步处理,在本章节,我们来看看,强大的 select! 是如何帮助咱们更好的控制多个异步操作并发执行的。
tokio::select!
select! 允许同时等待多个计算操作,然后当其中一个操作完成时就退出等待:
use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); tokio::spawn(async { let _ = tx1.send("one"); }); tokio::spawn(async { let _ = tx2.send("two"); }); tokio::select! { val = rx1 => { println!("rx1 completed first with {:?}", val); } val = rx2 => { println!("rx2 completed first with {:?}", val); } } // 任何一个 select 分支结束后,都会继续执行接下来的代码 }
这里用到了两个 oneshot 消息通道,虽然两个操作的创建在代码上有先后顺序,但在实际执行时却不这样。因此, select 在从两个通道阻塞等待接收消息时,rx1 和 rx2 都有可能被先打印出来。
需要注意,任何一个 select 分支完成后,都会继续执行后面的代码,没被执行的分支会被丢弃( dropped )。
取消
对于 Async Rust 来说,释放( drop )掉一个 Future 就意味着取消任务。从上一章节可以得知, async 操作会返回一个 Future,而后者是惰性的,直到被 poll 调用时,才会被执行。一旦 Future 被释放,那操作将无法继续,因为所有相关的状态都被释放。
对于 Tokio 的 oneshot 的接收端来说,它在被释放时会发送一个关闭通知到发送端,因此发送端可以通过释放任务的方式来终止正在执行的任务。
use tokio::sync::oneshot; async fn some_operation() -> String { // 在这里执行一些操作... } #[tokio::main] async fn main() { let (mut tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); tokio::spawn(async { // 等待 `some_operation` 的完成 // 或者处理 `oneshot` 的关闭通知 tokio::select! { val = some_operation() => { let _ = tx1.send(val); } _ = tx1.closed() => { // 收到了发送端发来的关闭信号 // `select` 即将结束,此时,正在进行的 `some_operation()` 任务会被取消,任务自动完成, // tx1 被释放 } } }); tokio::spawn(async { let _ = tx2.send("two"); }); tokio::select! { val = rx1 => { println!("rx1 completed first with {:?}", val); } val = rx2 => { println!("rx2 completed first with {:?}", val); } } }
上面代码的重点就在于 tx1.closed 所在的分支,一旦发送端被关闭,那该分支就会被执行,然后 select 会退出,并清理掉还没执行的第一个分支 val = some_operation() ,这其中 some_operation 返回的 Future 也会被清理,根据之前的内容,Future 被清理那相应的任务会立即取消,因此 some_operation 会被取消,不再执行。
Future 的实现
为了更好的理解 select 的工作原理,我们来看看如果使用 Future 该如何实现。当然,这里是一个简化版本,在实际中,select! 会包含一些额外的功能,例如一开始会随机选择一个分支进行 poll。
use tokio::sync::oneshot; use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; struct MySelect { rx1: oneshot::Receiver<&'static str>, rx2: oneshot::Receiver<&'static str>, } impl Future for MySelect { type Output = (); fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> { if let Poll::Ready(val) = Pin::new(&mut self.rx1).poll(cx) { println!("rx1 completed first with {:?}", val); return Poll::Ready(()); } if let Poll::Ready(val) = Pin::new(&mut self.rx2).poll(cx) { println!("rx2 completed first with {:?}", val); return Poll::Ready(()); } Poll::Pending } } #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); // 使用 tx1 和 tx2 MySelect { rx1, rx2, }.await; }
MySelect 包含了两个分支中的 Future,当它被 poll 时,第一个分支会先执行。如果执行完成,那取出的值会被使用,然后 MySelect 也随之结束。而另一个分支对应的 Future 会被释放掉,对应的操作也会被取消。
还记得上一章节中很重要的一段话吗?
当一个
Future返回Poll::Pending时,它必须确保会在某一个时刻通过Waker来唤醒,不然该Future将永远地被挂起
但是仔细观察我们之前的代码,里面并没有任何的 wake 调用!事实上,这是因为参数 cx 被传入了内层的 poll 调用。 只要内部的 Future 实现了唤醒并且返回了 Poll::Pending,那 MySelect 也等于实现了唤醒!
语法
目前来说,select! 最多可以支持 64 个分支,每个分支形式如下:
#![allow(unused)] fn main() { <模式> = <async 表达式> => <结果处理>, }
当 select 宏开始执行后,所有的分支会开始并发的执行。当任何一个表达式完成时,会将结果跟模式进行匹配。若匹配成功,则剩下的表达式会被释放。
最常用的模式就是用变量名去匹配表达式返回的值,然后该变量就可以在结果处理环节使用。
如果当前的模式不能匹配,剩余的 async 表达式将继续并发的执行,直到下一个完成。
由于 select! 使用的是一个 async 表达式,因此我们可以定义一些更复杂的计算。
例如从在分支中进行 TCP 连接:
use tokio::net::TcpStream; use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx, rx) = oneshot::channel(); // 生成一个任务,用于向 oneshot 发送一条消息 tokio::spawn(async move { tx.send("done").unwrap(); }); tokio::select! { socket = TcpStream::connect("localhost:3465") => { println!("Socket connected {:?}", socket); } msg = rx => { println!("received message first {:?}", msg); } } }
再比如,在分支中进行 TCP 监听:
use tokio::net::TcpListener; use tokio::sync::oneshot; use std::io; #[tokio::main] async fn main() -> io::Result<()> { let (tx, rx) = oneshot::channel(); tokio::spawn(async move { tx.send(()).unwrap(); }); let mut listener = TcpListener::bind("localhost:3465").await?; tokio::select! { _ = async { loop { let (socket, _) = listener.accept().await?; tokio::spawn(async move { process(socket) }); } // 给予 Rust 类型暗示 Ok::<_, io::Error>(()) } => {} _ = rx => { println!("terminating accept loop"); } } Ok(()) }
分支中接收连接的循环会一直运行,直到遇到错误才停止,或者当 rx 中有值时,也会停止。 _ 表示我们并不关心这个值,这样使用唯一的目的就是为了结束第一分支中的循环。
返回值
select! 还能返回一个值:
async fn computation1() -> String { // .. 计算 } async fn computation2() -> String { // .. 计算 } #[tokio::main] async fn main() { let out = tokio::select! { res1 = computation1() => res1, res2 = computation2() => res2, }; println!("Got = {}", out); }
需要注意的是,此时 select! 的所有分支必须返回一样的类型,否则编译器会报错!
错误传播
在 Rust 中使用 ? 可以对错误进行传播,但是在 select! 中,? 如何工作取决于它是在分支中的 async 表达式使用还是在结果处理的代码中使用:
- 在分支中
async表达式使用会将该表达式的结果变成一个Result - 在结果处理中使用,会将错误直接传播到
select!之外
use tokio::net::TcpListener; use tokio::sync::oneshot; use std::io; #[tokio::main] async fn main() -> io::Result<()> { // [设置 `rx` oneshot 消息通道] let listener = TcpListener::bind("localhost:3465").await?; tokio::select! { res = async { loop { let (socket, _) = listener.accept().await?; tokio::spawn(async move { process(socket) }); } Ok::<_, io::Error>(()) } => { res?; } _ = rx => { println!("terminating accept loop"); } } Ok(()) }
listener.accept().await? 是分支表达式中的 ?,因此它会将表达式的返回值变成 Result 类型,然后赋予给 res 变量。
与之不同的是,结果处理中的 res?; 会让 main 函数直接结束并返回一个 Result,可以看出,这里 ? 的用法跟我们平时的用法并无区别。
模式匹配
既然是模式匹配,我们需要再来回忆下 select! 的分支语法形式:
#![allow(unused)] fn main() { <模式> = <async 表达式> => <结果处理>, }
迄今为止,我们只用了变量绑定的模式,事实上,任何 Rust 模式都可以在此处使用。
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (mut tx1, mut rx1) = mpsc::channel(128); let (mut tx2, mut rx2) = mpsc::channel(128); tokio::spawn(async move { // 用 tx1 和 tx2 干一些不为人知的事 }); tokio::select! { Some(v) = rx1.recv() => { println!("Got {:?} from rx1", v); } Some(v) = rx2.recv() => { println!("Got {:?} from rx2", v); } else => { println!("Both channels closed"); } } }
上面代码中,rx 通道关闭后,recv() 方法会返回一个 None,可以看到没有任何模式能够匹配这个 None,那为何不会报错?秘密就在于 else 上:当使用模式去匹配分支时,若之前的所有分支都无法被匹配,那 else 分支将被执行。
借用
当在 Tokio 中生成( spawn )任务时,其 async 语句块必须拥有其中数据的所有权。而 select! 并没有这个限制,它的每个分支表达式可以直接借用数据,然后进行并发操作。只要遵循 Rust 的借用规则,多个分支表达式可以不可变的借用同一个数据,或者在一个表达式可变的借用某个数据。
来看个例子,在这里我们同时向两个 TCP 目标发送同样的数据:
#![allow(unused)] fn main() { use tokio::io::AsyncWriteExt; use tokio::net::TcpStream; use std::io; use std::net::SocketAddr; async fn race( data: &[u8], addr1: SocketAddr, addr2: SocketAddr ) -> io::Result<()> { tokio::select! { Ok(_) = async { let mut socket = TcpStream::connect(addr1).await?; socket.write_all(data).await?; Ok::<_, io::Error>(()) } => {} Ok(_) = async { let mut socket = TcpStream::connect(addr2).await?; socket.write_all(data).await?; Ok::<_, io::Error>(()) } => {} else => {} }; Ok(()) } }
这里其实有一个很有趣的题外话,由于 TCP 连接过程是在模式中发生的,因此当某一个连接过程失败后,它通过 ? 返回的 Err 类型并无法匹配 Ok,因此另一个分支会继续被执行,继续连接。
如果你把连接过程放在了结果处理中,那连接失败会直接从 race 函数中返回,而不是继续执行另一个分支中的连接!
还有一个非常重要的点,借用规则在分支表达式和结果处理中存在很大的不同。例如上面代码中,我们在两个分支表达式中分别对 data 做了不可变借用,这当然 ok,但是若是两次可变借用,那编译器会立即进行报错。但是转折来了:当在结果处理中进行两次可变借用时,却不会报错,大家可以思考下为什么,提示下:思考下分支在执行完成后会发生什么?
use tokio::sync::oneshot; #[tokio::main] async fn main() { let (tx1, rx1) = oneshot::channel(); let (tx2, rx2) = oneshot::channel(); let mut out = String::new(); tokio::spawn(async move { }); tokio::select! { _ = rx1 => { out.push_str("rx1 completed"); } _ = rx2 => { out.push_str("rx2 completed"); } } println!("{}", out); }
例如以上代码,就在两个分支的结果处理中分别进行了可变借用,并不会报错。原因就在于:select!会保证只有一个分支的结果处理会被运行,然后在运行结束后,另一个分支会被直接丢弃。
循环
来看看该如何在循环中使用 select!,顺便说一句,跟循环一起使用是最常见的使用方式。
use tokio::sync::mpsc; #[tokio::main] async fn main() { let (tx1, mut rx1) = mpsc::channel(128); let (tx2, mut rx2) = mpsc::channel(128); let (tx3, mut rx3) = mpsc::channel(128); loop { let msg = tokio::select! { Some(msg) = rx1.recv() => msg, Some(msg) = rx2.recv() => msg, Some(msg) = rx3.recv() => msg, else => { break } }; println!("Got {}", msg); } println!("All channels have been closed."); }
在循环中使用 select! 最大的不同就是,当某一个分支执行完成后,select! 会继续循环等待并执行下一个分支,直到所有分支最终都完成,最终匹配到 else 分支,然后通过 break 跳出循环。
老生常谈的一句话:select! 中哪个分支先被执行是无法确定的,因此不要依赖于分支执行的顺序!想象一下,在异步编程场景,若 select! 按照分支的顺序来执行会如何:若 rx1 中总是有数据,那每次循环都只会去处理第一个分支,后面两个分支永远不会被执行。
恢复之前的异步操作
async fn action() { // 一些异步逻辑 } #[tokio::main] async fn main() { let (mut tx, mut rx) = tokio::sync::mpsc::channel(128); let operation = action(); tokio::pin!(operation); loop { tokio::select! { _ = &mut operation => break, Some(v) = rx.recv() => { if v % 2 == 0 { break; } } } } }
在上面代码中,我们没有直接在 select! 分支中调用 action() ,而是在 loop 循环外面先将 action() 赋值给 operation,因此 operation 是一个 Future。
重点来了,在 select! 循环中,我们使用了一个奇怪的语法 &mut operation,大家想象一下,如果不加 &mut 会如何?答案是,每一次循环调用的都是一次全新的 action()调用,但是当加了 &mut operatoion 后,每一次循环调用就变成了对同一次 action() 的调用。也就是我们实现了在每次循环中恢复了之前的异步操作!
select! 的另一个分支从消息通道收取消息,一旦收到值是偶数,就跳出循环,否则就继续循环。
还有一个就是我们使用了 tokio::pin!,具体的细节这里先不介绍,值得注意的点是:如果要在一个引用上使用 .await,那么引用的值就必须是不能移动的或者实现了 Unpin,关于 Pin 和 Unpin 可以参见这里。
一旦移除 tokio::pin! 所在行的代码,然后试图编译,就会获得以下错误:
error[E0599]: no method named `poll` found for struct
`std::pin::Pin<&mut &mut impl std::future::Future>`
in the current scope
--> src/main.rs:16:9
|
16 | / tokio::select! {
17 | | _ = &mut operation => break,
18 | | Some(v) = rx.recv() => {
19 | | if v % 2 == 0 {
... |
22 | | }
23 | | }
| |_________^ method not found in
| `std::pin::Pin<&mut &mut impl std::future::Future>`
|
= note: the method `poll` exists but the following trait bounds
were not satisfied:
`impl std::future::Future: std::marker::Unpin`
which is required by
`&mut impl std::future::Future: std::future::Future`
虽然我们已经学了很多关于 Future 的知识,但是这个错误依然不太好理解。但是它不难解决:当你试图在一个引用上调用 .await 然后遇到了 Future 未实现 这种错误时,往往只需要将对应的 Future 进行固定即可: tokio::pin!(operation);。
修改一个分支
下面一起来看一个稍微复杂一些的 loop 循环,首先,我们拥有:
- 一个消息通道可以传递
i32类型的值 - 定义在
i32值上的一个异步操作
想要实现的逻辑是:
- 在消息通道中等待一个偶数出现
- 使用该偶数作为输入来启动一个异步操作
- 等待异步操作完成,与此同时监听消息通道以获取更多的偶数
- 若在异步操作完成前一个新的偶数到来了,终止当前的异步操作,然后接着使用新的偶数开始异步操作
async fn action(input: Option<i32>) -> Option<String> { // 若 input(输入)是None,则返回 None // 事实上也可以这么写: `let i = input?;` let i = match input { Some(input) => input, None => return None, }; // 这里定义一些逻辑 } #[tokio::main] async fn main() { let (mut tx, mut rx) = tokio::sync::mpsc::channel(128); let mut done = false; let operation = action(None); tokio::pin!(operation); tokio::spawn(async move { let _ = tx.send(1).await; let _ = tx.send(3).await; let _ = tx.send(2).await; }); loop { tokio::select! { res = &mut operation, if !done => { done = true; if let Some(v) = res { println!("GOT = {}", v); return; } } Some(v) = rx.recv() => { if v % 2 == 0 { // `.set` 是 `Pin` 上定义的方法 operation.set(action(Some(v))); done = false; } } } } }
当第一次循环开始时, 第一个分支会立即完成,因为 operation 的参数是 None。当第一个分支执行完成时,done 会变成 true,此时第一个分支的条件将无法被满足,开始执行第二个分支。
当第二个分支收到一个偶数时,done 会被修改为 false,且 operation 被设置了值。 此后再一次循环时,第一个分支会被执行,且 operation 返回一个 Some(2),因此会触发 return ,最终结束循环并返回。
这段代码引入了一个新的语法: if !done,在解释之前,先看看去掉后会如何:
thread 'main' panicked at '`async fn` resumed after completion', src/main.rs:1:55
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
'`async fn` resumed after completion' 错误的含义是:async fn 异步函数在完成后,依然被恢复了(继续使用)。
回到例子中来,这个错误是由于 operation 在它已经调用完成后依然被使用。通常来说,当使用 .await 后,调用 .await 的值会被消耗掉,因此并不存在这个问题。但是在这例子中,我们在引用上调用 .await,因此之后该引用依然可以被使用。
为了避免这个问题,需要在第一个分支的 operation 完成后禁止再使用该分支。这里的 done 的引入就很好的解决了问题。对于 select! 来说 if !done 的语法被称为预条件( precondition ),该条件会在分支被 .await 执行前进行检查。
那大家肯定有疑问了,既然 operation 不能再被调用了,我们该如何在有偶数值时,再回到第一个分支对其进行调用呢?答案就是 operation.set(action(Some(v)));,该操作会重新使用新的参数设置 operation。
spawn 和 select! 的一些不同
学到现在,相信大家对于 tokio::spawn 和 select! 已经非常熟悉,它们的共同点就是都可以并发的运行异步操作。
然而它们使用的策略大相径庭。
tokio::spawn 函数会启动新的任务来运行一个异步操作,每个任务都是一个独立的对象可以单独被 Tokio 调度运行,因此两个不同的任务的调度都是独立进行的,甚至于它们可能会运行在两个不同的操作系统线程上。鉴于此,生成的任务和生成的线程有一个相同的限制:不允许对外部环境中的值进行借用。
而 select! 宏就不一样了,它在同一个任务中并发运行所有的分支。正是因为这样,在同一个任务中,这些分支无法被同时运行。 select! 宏在单个任务中实现了多路复用的功能。
Stream
大家有没有想过, Rust 中的迭代器在迭代时能否异步进行?若不可以,是不是有相应的解决方案?
以上的问题其实很重要,因为在实际场景中,迭代一个集合,然后异步的去执行是很常见的需求,好在 Tokio 为我们提供了 stream,我们可以在异步函数中对其进行迭代,甚至和迭代器 Iterator 一样,stream 还能使用适配器,例如 map ! Tokio 在 StreamExt 特征上定义了常用的适配器。
要使用 stream ,目前还需要手动引入对应的包:
#![allow(unused)] fn main() { tokio-stream = "0.1" }
stream 没有放在
tokio包的原因在于标准库中的Stream特征还没有稳定,一旦稳定后,stream将移动到tokio中来
迭代
目前, Rust 语言还不支持异步的 for 循环,因此我们需要 while let 循环和 StreamExt::next() 一起使用来实现迭代的目的:
use tokio_stream::StreamExt; #[tokio::main] async fn main() { let mut stream = tokio_stream::iter(&[1, 2, 3]); while let Some(v) = stream.next().await { println!("GOT = {:?}", v); } }
和迭代器 Iterator 类似,next() 方法返回一个 Option<T>,其中 T 是从 stream 中获取的值的类型。若收到 None 则意味着 stream 迭代已经结束。
mini-redis 广播
下面我们来实现一个复杂一些的 mini-redis 客户端,完整代码见这里。
在开始之前,首先启动一下完整的 mini-redis 服务器端:
$ mini-redis-server
use tokio_stream::StreamExt; use mini_redis::client; async fn publish() -> mini_redis::Result<()> { let mut client = client::connect("127.0.0.1:6379").await?; // 发布一些数据 client.publish("numbers", "1".into()).await?; client.publish("numbers", "two".into()).await?; client.publish("numbers", "3".into()).await?; client.publish("numbers", "four".into()).await?; client.publish("numbers", "five".into()).await?; client.publish("numbers", "6".into()).await?; Ok(()) } async fn subscribe() -> mini_redis::Result<()> { let client = client::connect("127.0.0.1:6379").await?; let subscriber = client.subscribe(vec!["numbers".to_string()]).await?; let messages = subscriber.into_stream(); tokio::pin!(messages); while let Some(msg) = messages.next().await { println!("got = {:?}", msg); } Ok(()) } #[tokio::main] async fn main() -> mini_redis::Result<()> { tokio::spawn(async { publish().await }); subscribe().await?; println!("DONE"); Ok(()) }
上面生成了一个异步任务专门用于发布消息到 min-redis 服务器端的 numbers 消息通道中。然后,在 main 中,我们订阅了 numbers 消息通道,并且打印从中接收到的消息。
还有几点值得注意的:
into_stream会将Subscriber变成一个stream- 在
stream上调用next方法要求该stream被固定住(pinned),因此需要调用tokio::pin!
关于 Pin 的详细解读,可以阅读这篇文章
大家可以去掉 pin! 的调用,然后观察下报错,若以后你遇到这种错误,可以尝试使用下 pin!。
此时,可以运行下我们的客户端代码看看效果(别忘了先启动前面提到的 mini-redis 服务端):
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"two" })
got = Ok(Message { channel: "numbers", content: b"3" })
got = Ok(Message { channel: "numbers", content: b"four" })
got = Ok(Message { channel: "numbers", content: b"five" })
got = Ok(Message { channel: "numbers", content: b"6" })
在了解了 stream 的基本用法后,我们再来看看如何使用适配器来扩展它。
适配器
在前面章节中,我们了解了迭代器有两种适配器:
- 迭代器适配器,会将一个迭代器转变成另一个迭代器,例如
map,filter等 - 消费者适配器,会消费掉一个迭代器,最终生成一个值,例如
collect可以将迭代器收集成一个集合
与迭代器类似,stream 也有适配器,例如一个 stream 适配器可以将一个 stream 转变成另一个 stream ,例如 map、take 和 filter。
在之前的客户端中,subscribe 订阅一直持续下去,直到程序被关闭。现在,让我们来升级下,让它在收到三条消息后就停止迭代,最终结束。
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .take(3); }
这里关键就在于 take 适配器,它会限制 stream 只能生成最多 n 条消息。运行下看看结果:
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"two" })
got = Ok(Message { channel: "numbers", content: b"3" })
程序终于可以正常结束了。现在,让我们过滤 stream 中的消息,只保留数字类型的值:
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .filter(|msg| match msg { Ok(msg) if msg.content.len() == 1 => true, _ => false, }) .take(3); }
运行后输出:
got = Ok(Message { channel: "numbers", content: b"1" })
got = Ok(Message { channel: "numbers", content: b"3" })
got = Ok(Message { channel: "numbers", content: b"6" })
需要注意的是,适配器的顺序非常重要,.filter(...).take(3) 和 .take(3).filter(...) 的结果可能大相径庭,大家可以自己尝试下。
现在,还有一件事要做,咱们的消息被不太好看的 Ok(...) 所包裹,现在通过 map 适配器来简化下:
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .filter(|msg| match msg { Ok(msg) if msg.content.len() == 1 => true, _ => false, }) .map(|msg| msg.unwrap().content) .take(3); }
注意到 msg.unwrap 了吗?大家可能会以为我们是出于示例的目的才这么用,实际上并不是,由于 filter 的先执行, map 中的 msg 只能是 Ok(...),因此 unwrap 非常安全。
got = b"1"
got = b"3"
got = b"6"
还有一点可以改进的地方:当 filter 和 map 一起使用时,你往往可以用一个统一的方法来实现 filter_map。
#![allow(unused)] fn main() { let messages = subscriber .into_stream() .filter_map(|msg| match msg { Ok(msg) if msg.content.len() == 1 => Some(msg.content), _ => None, }) .take(3); }
想要学习更多的适配器,可以看看 StreamExt 特征。
实现 Stream 特征
如果大家还没忘记 Future 特征,那 Stream 特征相信你也会很快记住,因为它们非常类似:
#![allow(unused)] fn main() { use std::pin::Pin; use std::task::{Context, Poll}; pub trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; fn size_hint(&self) -> (usize, Option<usize>) { (0, None) } } }
Stream::poll_next() 函数跟 Future::poll 很相似,区别就是前者为了从 stream 收到多个值需要重复的进行调用。 就像在 深入async 章节提到的那样,当一个 stream 没有做好返回一个值的准备时,它将返回一个 Poll::Pending ,同时将任务的 waker 进行注册。一旦 stream 准备好后, waker 将被调用。
通常来说,如果想要手动实现一个 Stream,需要组合 Future 和其它 Stream。下面,还记得在深入async 中构建的 Delay Future 吗?现在让我们来更进一步,将它转换成一个 stream,每 10 毫秒生成一个值,总共生成 3 次:
#![allow(unused)] fn main() { use tokio_stream::Stream; use std::pin::Pin; use std::task::{Context, Poll}; use std::time::Duration; struct Interval { rem: usize, delay: Delay, } impl Stream for Interval { type Item = (); fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<()>> { if self.rem == 0 { // 去除计时器实现 return Poll::Ready(None); } match Pin::new(&mut self.delay).poll(cx) { Poll::Ready(_) => { let when = self.delay.when + Duration::from_millis(10); self.delay = Delay { when }; self.rem -= 1; Poll::Ready(Some(())) } Poll::Pending => Poll::Pending, } } } }
async-stream
手动实现 Stream 特征实际上是相当麻烦的事,不幸地是,Rust 语言的 async/await 语法目前还不能用于定义 stream,虽然相关的工作已经在进行中。
作为替代方案,async-stream 包提供了一个 stream! 宏,它可以将一个输入转换成 stream,使用这个包,上面的代码可以这样实现:
#![allow(unused)] fn main() { use async_stream::stream; use std::time::{Duration, Instant}; stream! { let mut when = Instant::now(); for _ in 0..3 { let delay = Delay { when }; delay.await; yield (); when += Duration::from_millis(10); } } }
嗯,看上去还是相当不错的,代码可读性大幅提升!
是不是发现了一个关键字 yield ,他是用来配合生成器使用的。详见原文
优雅的关闭
如果你的服务是一个小说阅读网站,那大概率用不到优雅关闭的,简单粗暴的关闭服务器,然后用户再次请求时获取一个错误就是了。但如果是一个 web 服务或数据库服务呢?当前的连接很可能在做着重要的事情,一旦关闭会导致数据的丢失甚至错误,此时,我们就需要优雅的关闭(graceful shutdown)了。
要让一个异步应用优雅的关闭往往需要做到 3 点:
- 找出合适的关闭时机
- 通知程序的每一个子部分开始关闭
- 在主线程等待各个部分的关闭结果
在本文的下面部分,我们一起来看看该如何做到这三点。如果想要进一步了解在真实项目中该如何使用,大家可以看看 mini-redis 的完整代码实现,特别是 src/server.rs 和 src/shutdown.rs。
找出合适的关闭时机
一般来说,何时关闭是取决于应用自身的,但是一个常用的关闭准则就是当应用收到来自于操作系统的关闭信号时。例如通过 ctrl + c 来关闭正在运行的命令行程序。
为了检测来自操作系统的关闭信号,Tokio 提供了一个 tokio::signal::ctrl_c 函数,它将一直睡眠直到收到对应的信号:
use tokio::signal; #[tokio::main] async fn main() { // ... spawn application as separate task ... // 在一个单独的任务中处理应用逻辑 match signal::ctrl_c().await { Ok(()) => {}, Err(err) => { eprintln!("Unable to listen for shutdown signal: {}", err); }, } // 发送关闭信号给应用所在的任务,然后等待 }
通知程序的每一个部分开始关闭
大家看到这个标题,不知道会想到用什么技术来解决问题,反正我首先想到的是,真的很像广播哎。。
事实上也是如此,最常见的通知程序各个部分关闭的方式就是使用一个广播消息通道。关于如何实现,其实也不复杂:应用中的每个任务都持有一个广播消息通道的接收端,当消息被广播到该通道时,每个任务都可以收到该消息,并关闭自己:
#![allow(unused)] fn main() { let next_frame = tokio::select! { res = self.connection.read_frame() => res?, _ = self.shutdown.recv() => { // 当收到关闭信号后,直接从 `select!` 返回,此时 `select!` 中的另一个分支会自动释放,其中的任务也会结束 return Ok(()); } }; }
在 mini-redis 中,当收到关闭消息时,任务会立即结束,但在实际项目中,这种方式可能会过于理想,例如当我们向文件或数据库写入数据时,立刻终止任务可能会导致一些无法预料的错误,因此,在结束前做一些收尾工作会是非常好的选择。
除此之外,还有两点值得注意:
- 将广播消息通道作为结构体的一个字段是相当不错的选择, 例如这个例子
- 还可以使用
watch channel实现同样的效果,与之前的方式相比,这两种方法并没有太大的区别
等待各个部分的结束
在之前章节,我们讲到过一个 mpsc 消息通道有一个重要特性:当所有发送端都 drop 时,消息通道会自动关闭,此时继续接收消息就会报错。
大家发现没?这个特性特别适合优雅关闭的场景:主线程持有消息通道的接收端,然后每个代码部分拿走一个发送端,当该部分结束时,就 drop 掉发送端,因此所有发送端被 drop 也就意味着所有的部分都已关闭,此时主线程的接收端就会收到错误,进而结束。
use tokio::sync::mpsc::{channel, Sender}; use tokio::time::{sleep, Duration}; #[tokio::main] async fn main() { let (send, mut recv) = channel(1); for i in 0..10 { tokio::spawn(some_operation(i, send.clone())); } // 等待各个任务的完成 // // 我们需要 drop 自己的发送端,因为等下的 `recv()` 调用会阻塞, 如果不 `drop` ,那发送端就无法被全部关闭 // `recv` 也将永远无法结束,这将陷入一个类似死锁的困境 drop(send); // 当所有发送端都超出作用域被 `drop` 时 (当前的发送端并不是因为超出作用域被 `drop` 而是手动 `drop` 的) // `recv` 调用会返回一个错误 let _ = recv.recv().await; } async fn some_operation(i: u64, _sender: Sender<()>) { sleep(Duration::from_millis(100 * i)).await; println!("Task {} shutting down.", i); // 发送端超出作用域,然后被 `drop` }
关于忘记 drop 本身持有的发送端进而导致 bug 的问题,大家可以看看这篇文章。
异步跟同步共存
一些异步程序例如 tokio 指南 章节中的绝大多数例子,它们整个程序都是异步的,包括程序入口 main 函数:
#[tokio::main] async fn main() { println!("Hello world"); }
在一些场景中,你可能只想在异步程序中运行一小部分同步代码,这种需求可以考虑下 spawn_blocking。
但是在很多场景中,我们只想让程序的某一个部分成为异步的,也许是因为同步代码更好实现,又或许是同步代码可读性、兼容性都更好。例如一个 GUI 应用可能想要让 UI 相关的代码在主线程中,然后通过另一个线程使用 tokio 的运行时来处理一些异步任务。
因此本章节的目标很纯粹:如何在同步代码中使用一小部分异步代码。
#[tokio::main] 的展开
在 Rust 中, main 函数不能是异步的,有同学肯定不愿意了,我们在之前章节..不对,就在开头,你还用到了 async fn main 的声明方式,怎么就不能异步了呢?
其实,#[tokio::main] 该宏仅仅是提供语法糖,目的是让大家可以更简单、更一致的去写异步代码,它会将你写下的async fn main 函数替换为:
fn main() { tokio::runtime::Builder::new_multi_thread() .enable_all() .build() .unwrap() .block_on(async { println!("Hello world"); }) }
注意到上面的 block_on 方法了嘛?在我们自己的同步代码中,可以使用它开启一个 async/await 世界。
mini-redis 的同步接口
在下面,我们将一起构建一个同步的 mini-redis ,为了实现这一点,需要将 Runtime 对象存储起来,然后利用上面提到的 block_on 方法。
首先,创建一个文件 src/blocking_client.rs,然后使用下面代码将异步的 Client 结构体包裹起来:
#![allow(unused)] fn main() { use tokio::net::ToSocketAddrs; use tokio::runtime::Runtime; pub use crate::client::Message; /// 建立到 redis 服务端的连接 pub struct BlockingClient { /// 之前实现的异步客户端 `Client` inner: crate::client::Client, /// 一个 `current_thread` 模式的 `tokio` 运行时, /// 使用阻塞的方式来执行异步客户端 `Client` 上的操作 rt: Runtime, } pub fn connect<T: ToSocketAddrs>(addr: T) -> crate::Result<BlockingClient> { // 构建一个 tokio 运行时: Runtime let rt = tokio::runtime::Builder::new_current_thread() .enable_all() .build()?; // 使用运行时来调用异步的连接方法 let inner = rt.block_on(crate::client::connect(addr))?; Ok(BlockingClient { inner, rt }) } }
在这里,我们使用了一个构造器函数用于在同步代码中执行异步的方法:使用 Runtime 上的 block_on 方法来执行一个异步方法并返回结果。
有一个很重要的点,就是我们还使用了 current_thread 模式的运行时。这个可不常见,原因是异步程序往往要利用多线程的威力来实现更高的吞吐性能,相对应的模式就是 multi_thread,该模式会生成多个运行在后台的线程,它们可以高效的实现多个任务的同时并行处理。
但是对于我们的使用场景来说,在同一时间点只需要做一件事,无需并行处理,多个线程并不能帮助到任何事情,因此 current_thread 此时成为了最佳的选择。
在构建 Runtime 的过程中还有一个 enable_all 方法调用,它可以开启 Tokio 运行时提供的 IO 和定时器服务。
由于
current_thread运行时并不生成新的线程,只是运行在已有的主线程上,因此只有当block_on被调用后,该运行时才能执行相应的操作。一旦block_on返回,那运行时上所有生成的任务将再次冻结,直到block_on的再次调用。如果这种模式不符合使用场景的需求,那大家还是需要用
multi_thread运行时来代替。事实上,在 tokio 之前的章节中,我们默认使用的就是multi_thread模式。
#![allow(unused)] fn main() { use bytes::Bytes; use std::time::Duration; impl BlockingClient { pub fn get(&mut self, key: &str) -> crate::Result<Option<Bytes>> { self.rt.block_on(self.inner.get(key)) } pub fn set(&mut self, key: &str, value: Bytes) -> crate::Result<()> { self.rt.block_on(self.inner.set(key, value)) } pub fn set_expires( &mut self, key: &str, value: Bytes, expiration: Duration, ) -> crate::Result<()> { self.rt.block_on(self.inner.set_expires(key, value, expiration)) } pub fn publish(&mut self, channel: &str, message: Bytes) -> crate::Result<u64> { self.rt.block_on(self.inner.publish(channel, message)) } } }
这代码看上去挺长,实际上很简单,通过 block_on 将异步形式的 Client 的方法变成同步调用的形式。例如 BlockingClient 的 get 方法实际上是对内部的异步 get 方法的同步调用。
与上面的平平无奇相比,下面的代码将更有趣,因为它将 Client 转变成一个 Subscriber 对象:
#![allow(unused)] fn main() { /// 下面的客户端可以进入 pub/sub (发布/订阅) 模式 /// /// 一旦客户端订阅了某个消息通道,那就只能执行 pub/sub 相关的命令。 /// 将`BlockingClient` 类型转换成 `BlockingSubscriber` 是为了防止非 `pub/sub` 方法被调用 pub struct BlockingSubscriber { /// 异步版本的 `Subscriber` inner: crate::client::Subscriber, /// 一个 `current_thread` 模式的 `tokio` 运行时, /// 使用阻塞的方式来执行异步客户端 `Client` 上的操作 rt: Runtime, } impl BlockingClient { pub fn subscribe(self, channels: Vec<String>) -> crate::Result<BlockingSubscriber> { let subscriber = self.rt.block_on(self.inner.subscribe(channels))?; Ok(BlockingSubscriber { inner: subscriber, rt: self.rt, }) } } impl BlockingSubscriber { pub fn get_subscribed(&self) -> &[String] { self.inner.get_subscribed() } pub fn next_message(&mut self) -> crate::Result<Option<Message>> { self.rt.block_on(self.inner.next_message()) } pub fn subscribe(&mut self, channels: &[String]) -> crate::Result<()> { self.rt.block_on(self.inner.subscribe(channels)) } pub fn unsubscribe(&mut self, channels: &[String]) -> crate::Result<()> { self.rt.block_on(self.inner.unsubscribe(channels)) } } }
由上可知,subscribe 方法会使用运行时将一个异步的 Client 转变成一个异步的 Subscriber,此外,Subscriber 结构体有一个非异步的方法 get_subscribed,对于这种方法,只需直接调用即可,而无需使用运行时。
其它方法
上面介绍的是最简单的方法,但是,如果只有这一种, tokio 也不会如此大名鼎鼎。
runtime.spawn
可以通过 Runtime 的 spawn 方法来创建一个基于该运行时的后台任务:
use tokio::runtime::Builder; use tokio::time::{sleep, Duration}; fn main() { let runtime = Builder::new_multi_thread() .worker_threads(1) .enable_all() .build() .unwrap(); let mut handles = Vec::with_capacity(10); for i in 0..10 { handles.push(runtime.spawn(my_bg_task(i))); } // 在后台任务运行的同时做一些耗费时间的事情 std::thread::sleep(Duration::from_millis(750)); println!("Finished time-consuming task."); // 等待这些后台任务的完成 for handle in handles { // `spawn` 方法返回一个 `JoinHandle`,它是一个 `Future`,因此可以通过 `block_on` 来等待它完成 runtime.block_on(handle).unwrap(); } } async fn my_bg_task(i: u64) { let millis = 1000 - 50 * i; println!("Task {} sleeping for {} ms.", i, millis); sleep(Duration::from_millis(millis)).await; println!("Task {} stopping.", i); }
运行该程序,输出如下:
Task 0 sleeping for 1000 ms.
Task 1 sleeping for 950 ms.
Task 2 sleeping for 900 ms.
Task 3 sleeping for 850 ms.
Task 4 sleeping for 800 ms.
Task 5 sleeping for 750 ms.
Task 6 sleeping for 700 ms.
Task 7 sleeping for 650 ms.
Task 8 sleeping for 600 ms.
Task 9 sleeping for 550 ms.
Task 9 stopping.
Task 8 stopping.
Task 7 stopping.
Task 6 stopping.
Finished time-consuming task.
Task 5 stopping.
Task 4 stopping.
Task 3 stopping.
Task 2 stopping.
Task 1 stopping.
Task 0 stopping.
在此例中,我们生成了 10 个后台任务在运行时中运行,然后等待它们的完成。作为一个例子,想象一下在图形渲染应用( GUI )中,有时候需要通过网络访问远程服务来获取一些数据,那上面的这种模式就非常适合,因为这些网络访问比较耗时,而且不会影响图形的主体渲染,因此可以在主线程中渲染图形,然后使用其它线程来运行 Tokio 的运行时,并通过该运行时使用异步的方式完成网络访问,最后将这些网络访问的结果发送到 GUI 进行数据渲染,例如一个进度条。
还有一点很重要,在本例子中只能使用 multi_thread 运行时。如果我们使用了 current_thread,你会发现主线程的耗时任务会在后台任务开始之前就完成了。因为在 current_thread 模式下,生成的任务只会在 block_on 期间才执行。
在 multi_thread 模式下,我们并不需要通过 block_on 来触发任务的运行,这里仅仅是用来阻塞并等待最终的结果。而除了通过 block_on 等待结果外,你还可以:
- 使用消息传递的方式,例如
tokio::sync::mpsc,让异步任务将结果发送到主线程,然后主线程通过.recv方法等待这些结果 - 通过共享变量的方式,例如
Mutex,这种方式非常适合实现 GUI 的进度条: GUI 在每个渲染帧读取该变量即可。
发送消息
在同步代码中使用异步的另一个方法就是生成一个运行时,然后使用消息传递的方式跟它进行交互。这个方法虽然更啰嗦一些,但是相对于之前的两种方法更加灵活:
#![allow(unused)] fn main() { use tokio::runtime::Builder; use tokio::sync::mpsc; pub struct Task { name: String, // 一些信息用于描述该任务 } async fn handle_task(task: Task) { println!("Got task {}", task.name); } #[derive(Clone)] pub struct TaskSpawner { spawn: mpsc::Sender<Task>, } impl TaskSpawner { pub fn new() -> TaskSpawner { // 创建一个消息通道用于通信 let (send, mut recv) = mpsc::channel(16); let rt = Builder::new_current_thread() .enable_all() .build() .unwrap(); std::thread::spawn(move || { rt.block_on(async move { while let Some(task) = recv.recv().await { tokio::spawn(handle_task(task)); } // 一旦所有的发送端超出作用域被 drop 后,`.recv()` 方法会返回 None,同时 while 循环会退出,然后线程结束 }); }); TaskSpawner { spawn: send, } } pub fn spawn_task(&self, task: Task) { match self.spawn.blocking_send(task) { Ok(()) => {}, Err(_) => panic!("The shared runtime has shut down."), } } } }
为何说这种方法比较灵活呢?以上面代码为例,它可以在很多方面进行配置。例如,可以使用信号量 Semaphore来限制当前正在进行的任务数,或者你还可以使用一个消息通道将消息反向发送回任务生成器 spawner。
抛开细节,抽象来看,这是不是很像一个 Actor ?
Cargo 使用指南
Rust 语言的名气之所以这么大,保守估计 Cargo 的贡献就占了三分之一。
Cargo 是包管理工具,可以用于依赖包的下载、编译、更新、分发等,与 Cargo 一样有名的还有 crates.io,它是社区提供的包注册中心:用户可以将自己的包发布到该注册中心,然后其它用户通过注册中心引入该包。
本章内容是基于 Cargo Book 翻译,并做了一些内容优化和目录组织上的调整
上手使用
Cargo 会在安装 Rust 的时候一并进行安装,无需我们手动的操作执行,安装 Rust 参见这里。
在开始之前,先来明确一个名词: Package,由于 Crate 被翻译成包,因此 Package 再被翻译成包就很不合适,经过斟酌,我们决定翻译成项目,你也可以理解为工程、软件包,总之,在本书中Package 意味着项目,而项目也意味着 Package 。
安装完成后,接下来使用 Cargo 来创建一个新的二进制项目,二进制意味着该项目可以作为一个服务运行或被编译成可执行文件运行。
#![allow(unused)] fn main() { $ cargo new hello_world }
这里我们使用 cargo new 创建一个新的项目 ,事实上该命令等价于 cargo new hello_world --bin,bin 是 binary 的简写,代表着二进制程序,由于 --bin 是默认参数,因此可以对其进行省略。
创建成功后,先来看看项目的基本目录结构长啥样:
$ cd hello_world
$ tree .
.
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
这里有一个很显眼的文件 Cargo.toml,一看就知道它是 Cargo 使用的配置文件,这个关系类似于: package.json 是 npm 的配置文件。
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[dependencies]
以上就是 Cargo.toml 的全部内容,它被称之为清单( manifest ),包含了 Cargo 编译程序所需的所有元数据。
下面是 src/main.rs 的内容 :
fn main() { println!("Hello, world!"); }
可以看出 Cargo 还为我们自动生成了一个 hello world 程序,或者说二进制包,对程序进行编译构建:
$ cargo build
Compiling hello_world v0.1.0 (file:///path/to/package/hello_world)
然后再运行编译出的二进制可执行文件:
$ ./target/debug/hello_world
Hello, world!
注意到路径中的 debug 了吗?它说明我们刚才的编译是 Debug 模式,该模式主要用于测试目的,如果想要进行生产编译,我们需要使用 Release 模式 cargo build --release,然后通过 ./target/release/hello_world 运行。
除了上面的编译 + 运行方式外,在日常开发中,我们还可以使用一个简单的命令直接运行:
$ cargo run
Fresh hello_world v0.1.0 (file:///path/to/package/hello_world)
Running `target/hello_world`
Hello, world!
cargo run 会帮我们自动完成编译、运行的过程,当然,该命令也支持 Release 模式: cargo run --release。
如果你的程序在跑性能测试 benchmark,一定要使用
Release模式,因为该模式下,程序会做大量性能优化
在快速了解 Cargo 的使用方式后,下面,我们将正式进入 Cargo 的学习之旅。
使用手册
在本章中,我们将学习 Cargo 的详细使用方式,例如 Package 的创建与管理、依赖拉取、Package 结构描述等。
为何会有 Cargo
根据之前学习的知识,Rust 有两种类型的包: 库包和二进制包,前者是我们经常使用的依赖包,用于被其它包所引入,而后者是一个应用服务,可以编译成二进制可执行文件进行运行。
包是通过 Rust 编译器 rustc 进行编译的:
#![allow(unused)] fn main() { $ rustc hello.rs $ ./hello Hello, world! }
上面我们直接使用 rustc 对二进制包 hello.rs 进行编译,生成二进制可执行文件 hello,并对其进行运行。
该方式虽然简单,但有几个问题:
- 必须要指定文件名编译,当项目复杂后,这种编译方式也随之更加复杂
- 如果要指定编译参数,情况将更加复杂
最关键的是,外部依赖库的引入也将是一个大问题。大部分实际的项目都有不少依赖包,而这些依赖包又间接的依赖了新的依赖包,在这种复杂情况下,如何管理依赖包及其版本也成为一个相当棘手的问题。
正是因为这些原因,与其使用 rustc ,我们可以使用一个强大的包管理工具来解决问题:欢迎 Cargo 闪亮登场。
Cargo
Cargo 解决了之前描述的所有问题,同时它保证了每次重复的构建都不会改变上一次构建的结果,这背后是通过完善且强大的依赖包版本管理来实现的。
总之,Cargo 为了实现目标,做了四件事:
- 引入两个元数据文件,包含项目的方方面面信息:
Cargo.toml和Cargo.lock - 获取和构建项目的依赖,例如
Cargo.toml中的依赖包版本描述,以及从crates.io下载包 - 调用
rustc(或其它编译器) 并使用的正确的参数来构建项目,例如cargo build - 引入一些惯例,让项目的使用更加简单
毫不夸张的说,得益于 Cargo 的标准化,只要你使用它构建过一个项目,那构建其它使用 Cargo 的项目,也将不存在任何困难。
下载并构建 Package
如果看中 GitHub 上的某个开源 Rust 项目,那下载并构建它将是非常简单的。
$ git clone https://github.com/rust-lang/regex.git
$ cd regex
如上所示,直接从 GitHub 上克隆下来想要的项目,然后使用 cargo build 进行构建即可:
$ cargo build
Compiling regex v1.5.0 (file:///path/to/package/regex)
该命令将下载相关的依赖库,等下载成功后,再对 package 和下载的依赖进行一同的编译构建。
这就是包管理工具的强大之处,cargo build 搞定一切,而背后隐藏的复杂配置、参数你都无需关心。
添加依赖
crates.io 是 Rust 社区维护的中心化注册服务,用户可以在其中寻找和下载所需的包。对于 cargo 来说,默认就是从这里下载依赖。
下面我们来添加一个 time 依赖包,若你的 Cargo.toml 文件中没有 [dependencies] 部分,就手动添加一个,并添加目标包名和版本号:
[dependencies]
time = "0.1.12"
可以看到我们指定了 time 包的版本号 "0.1.12",关于版本号,实际上还有其它的指定方式,具体参见指定依赖项章节。
如果想继续添加 regexp 包,只需在 time 包后面添加即可 :
[package]
name = "hello_world"
version = "0.1.0"
edition = "2021"
[dependencies]
time = "0.1.12"
regex = "0.1.41"
此时,再通过运行 cargo build 来重新构建,首先 Cargo 会获取新的依赖以及依赖的依赖, 接着对它们进行编译并更新 Cargo.lock:
$ cargo build
Updating crates.io index
Downloading memchr v0.1.5
Downloading libc v0.1.10
Downloading regex-syntax v0.2.1
Downloading memchr v0.1.5
Downloading aho-corasick v0.3.0
Downloading regex v0.1.41
Compiling memchr v0.1.5
Compiling libc v0.1.10
Compiling regex-syntax v0.2.1
Compiling memchr v0.1.5
Compiling aho-corasick v0.3.0
Compiling regex v0.1.41
Compiling hello_world v0.1.0 (file:///path/to/package/hello_world)
在 Cargo.lock 中包含了我们项目使用的所有依赖的准确版本信息。这个非常重要,未来就算 regexp 的作者升级了该包,我们依然会下载 Cargo.lock 中的版本,而不是最新的版本,只有这样,才能保证项目依赖包不会莫名其妙的因为更新升级导致无法编译。 当然,你还可以使用 cargo update 来手动更新包的版本。
此时,就可以在 src/main.rs 中使用新引入的 regexp 包:
use regex::Regex; fn main() { let re = Regex::new(r"^\d{4}-\d{2}-\d{2}$").unwrap(); println!("Did our date match? {}", re.is_match("2014-01-01")); }
运行后输出:
$ cargo run
Running `target/hello_world`
Did our date match? true
标准的 Package 目录结构
一个典型的 Package 目录结构如下:
.
├── Cargo.lock
├── Cargo.toml
├── src/
│ ├── lib.rs
│ ├── main.rs
│ └── bin/
│ ├── named-executable.rs
│ ├── another-executable.rs
│ └── multi-file-executable/
│ ├── main.rs
│ └── some_module.rs
├── benches/
│ ├── large-input.rs
│ └── multi-file-bench/
│ ├── main.rs
│ └── bench_module.rs
├── examples/
│ ├── simple.rs
│ └── multi-file-example/
│ ├── main.rs
│ └── ex_module.rs
└── tests/
├── some-integration-tests.rs
└── multi-file-test/
├── main.rs
└── test_module.rs
这也是 Cargo 推荐的目录结构,解释如下:
Cargo.toml和Cargo.lock保存在package根目录下- 源代码放在
src目录下 - 默认的
lib包根是src/lib.rs - 默认的二进制包根是
src/main.rs- 其它二进制包根放在
src/bin/目录下
- 其它二进制包根放在
- 基准测试 benchmark 放在
benches目录下 - 示例代码放在
examples目录下 - 集成测试代码放在
tests目录下
关于 Rust 中的包和模块,之前的章节有更详细的解释。
此外,bin、tests、examples 等目录路径都可以通过配置文件进行配置,它们被统一称之为 Cargo Target。
Cargo.toml vs Cargo.lock
Cargo.toml 和 Cargo.lock 是 Cargo 的两个元配置文件,但是它们拥有不同的目的:
- 前者从用户的角度出发来描述项目信息和依赖管理,因此它是由用户来编写
- 后者包含了依赖的精确描述信息,它是由
Cargo自行维护,因此不要去手动修改
它们的关系跟 package.json 和 package-lock.json 非常相似,从 JavaScript 过来的同学应该会比较好理解。
是否上传本地的 Cargo.lock
当本地开发时,Cargo.lock 自然是非常重要的,但是当你要把项目上传到 Git 时,例如 GitHub,那是否上传 Cargo.lock 就成了一个问题。
关于是否上传,有如下经验准则:
- 从实践角度出发,如果你构建的是三方库类型的服务,请把
Cargo.lock加入到.gitignore中。 - 若构建的是一个面向用户终端的产品,例如可以像命令行工具、应用程序一样执行,那就把
Cargo.lock上传到源代码目录中。
例如 axum 是 web 开发框架,它属于三方库类型的服务,因此源码目录中不应该出现 Cargo.lock 的身影,它的归宿是 .gitignore。而 ripgrep 则恰恰相反,因为它是一个面向终端的产品,可以直接运行提供服务。
那么问题来了,为何会有这种选择?
原因是 Cargo.lock 会详尽描述上一次成功构建的各种信息:环境状态、依赖、版本等等,Cargo 可以使用它提供确定性的构建环境和流程,无论何时何地。这种特性对于终端服务是非常重要的:能确定、稳定的在用户环境中运行起来是终端服务最重要的特性之一。
而对于三方库来说,情况就有些不同。它不仅仅被库的开发者所使用,还会间接影响依赖链下游的使用者。用户引入了三方库是不会去看它的 Cargo.lock 信息的,也不应该受这个库的确定性运行条件所限制。
还有个原因,在项目中,可能会有几个依赖库引用同一个三方库的同一个版本,那如果该三方库使用了 Cargo.lock 文件,那可能三方库的多个版本会被引入使用,这时就会造成版本冲突。换句话说,通过指定版本的方式引用一个依赖库是无法看到该依赖库的完整情况的,而只有终端的产品才会看到这些完整的情况。
假设没有 Cargo.lock
Cargo.toml 是一个清单文件( manifest )包含了我们 package 的描述元数据。例如,通过以下内容可以说明对另一个 package 的依赖 :
#![allow(unused)] fn main() { [package] name = "hello_world" version = "0.1.0" [dependencies] regex = { git = "https://github.com/rust-lang/regex.git" } }
可以看到,只有一个依赖,且该依赖的来源是 GitHub 上一个特定的仓库。由于我们没有指定任何版本信息,Cargo 会自动拉取该依赖库的最新版本( master 或 main 分支上的最新 commit )。
这种使用方式,其实就错失了包管理工具的最大的优点:版本管理。例如你在今天构建使用了版本 A,然后过了一段时间后,由于依赖包的升级,新的构建却使用了大更新版本 B,结果因为版本不兼容,导致了构建失败。
可以看出,确保依赖版本的确定性是非常重要的:
#![allow(unused)] fn main() { [dependencies] regex = { git = "https://github.com/rust-lang/regex.git", rev = "9f9f693" } }
这次,我们使用了指定 rev ( revision ) 的方式来构建,那么不管未来何时再次构建,使用的依赖库都会是该 rev ,而不是最新的 commit。
但是,这里还有一个问题:rev 需要手动的管理,你需要在每次更新包的时候都思考下 SHA-1,这显然非常麻烦。
当有了 Cargo.lock 后
当有了 Cargo.lock 后,我们无需手动追踪依赖库的 rev,Cargo 会自动帮我们完成,还是之前的清单:
#![allow(unused)] fn main() { [package] name = "hello_world" version = "0.1.0" [dependencies] regex = { git = "https://github.com/rust-lang/regex.git" } }
第一次构建时,Cargo 依然会拉取最新的 master commit,然后将以下信息写到 Cargo.lock 文件中:
#![allow(unused)] fn main() { [[package]] name = "hello_world" version = "0.1.0" dependencies = [ "regex 1.5.0 (git+https://github.com/rust-lang/regex.git#9f9f693768c584971a4d53bc3c586c33ed3a6831)", ] [[package]] name = "regex" version = "1.5.0" source = "git+https://github.com/rust-lang/regex.git#9f9f693768c584971a4d53bc3c586c33ed3a6831" }
可以看出,其中包含了依赖库的准确 rev 信息。当未来再次构建时,只要项目中还有该 Cargo.lock 文件,那构建依然会拉取同一个版本的依赖库,并且再也无需我们手动去管理 rev 的 SHA 信息!
更新依赖
由于 Cargo.lock 会锁住依赖的版本,你需要通过手动的方式将依赖更新到新的版本:
#![allow(unused)] fn main() { $ cargo update # 更新所有依赖 $ cargo update -p regex # 只更新 “regex” }
以上命令将使用新的版本信息重新生成 Cargo.lock ,需要注意的是 cargo update -p regex 传递的参数实际上是一个 Package ID, regex 只是一个简写形式。
测试和 CI
Cargo 可以通过 cargo test 命令运行项目中的测试文件:它会在 src/ 底下的文件寻找单元测试,也会在 tests/ 目录下寻找集成测试。
#![allow(unused)] fn main() { $ cargo test Compiling regex v1.5.0 (https://github.com/rust-lang/regex.git#9f9f693) Compiling hello_world v0.1.0 (file:///path/to/package/hello_world) Running target/test/hello_world-9c2b65bbb79eabce running 0 tests test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out }
从上面结果可以看出,项目中实际上还没有任何测试代码。
事实上,除了单元测试、集成测试,cargo test 还会编译 examples/ 下的示例文件以及文档中的示例。
CI
持续集成是软件开发中异常重要的一环,大家应该都听说过 Jenkins,它就是一个拥有悠久历史的持续集成工具。简单来说,持续集成会定期拉取同一个项目中所有成员的相关代码,对其进行自动化构建。
在没有持续集成前,首先开发者需要手动编译代码并运行单元测试、集成测试等基础测试,然后启动项目相关的所有服务,接着测试人员开始介入对整个项目进行回归测试、黑盒测试等系统化的测试,当测试通过后,最后再手动发布到指定的环境中运行,这个过程是非常冗长,且所有成员都需要同时参与的。
在有了持续集成后,只要编写好相应的编译、测试、发布配置文件,那持续集成平台会自动帮助我们完成整个相关的流程,期间无需任何人介入,高效且可靠。
GitHub Actions
关于如何使用 GitHub Actions 进行持续集成,在之前的章节已经有过详细的介绍,这里就不再赘述。
Travis CI
以下是 Travis CI 需要的一个简单的示例配置文件:
language: rust
rust:
- stable
- beta
- nightly
matrix:
allow_failures:
- rust: nightly
以上配置将测试所有的 Rust 发布版本,但是 nightly 版本的构建失败不会导致全局测试的失败,可以查看 Travis CI Rust 文档 获取更详细的说明。
Gitlab CI
以下是一个示例 .gitlab-ci.yml 文件:
stages:
- build
rust-latest:
stage: build
image: rust:latest
script:
- cargo build --verbose
- cargo test --verbose
rust-nightly:
stage: build
image: rustlang/rust:nightly
script:
- cargo build --verbose
- cargo test --verbose
allow_failure: true
这里将测试 stable 和 nightly 发布版本,同样的,nightly 下的测试失败不会导致全局测试的失败。查看 Gitlab CI 文档 获取更详细的说明。
Cargo 缓存
Cargo 使用了缓存的方式提升构建效率,当构建时,Cargo 会将已下载的依赖包放在 CARGO_HOME 目录下,下面一起来看看。
Cargo Home
默认情况下,Cargo Home 所在的目录是 $HOME/.cargo/,例如在 macos ,对应的目录是:
$ echo $HOME/.cargo/
/Users/sunfei/.cargo/
我们也可以通过修改 CARGO_HOME 环境变量的方式来重新设定该目录的位置。若你需要在项目中通过代码的方式来获取 CARGO_HOME ,home 包提供了相应的 API。
注意! Cargo Home 目录的内部结构并没有稳定化,在未来可能会发生变化
文件
config.toml是 Cargo 的全局配置文件credentials.toml为cargo login提供私有化登录证书,用于登录package注册中心,例如crates.io.crates.toml,.crates2.json这两个是隐藏文件,包含了通过cargo install安装的包的package信息,请不要手动修改!
目录
bin目录包含了通过cargo install或rustup下载的包编译出的可执行文件。你可以将该目录加入到$PATH环境变量中,以实现对这些可执行文件的直接访问git中存储了Git的资源文件:git/db,当一个包依赖某个git仓库时,Cargo会将该仓库克隆到git/db目录下,如果未来需要还会对其进行更新git/checkouts,若指定了git源和commit,那相应的仓库就会从git/db中checkout到该目录下,因此同一个仓库的不同checkout共存成为了可能性
registry包含了注册中心( 例如crates.io)的元数据 和packagesregistry/index是一个 git 仓库,包含了注册中心中所有可用包的元数据( 版本、依赖等 )registry/cache中保存了已下载的依赖,这些依赖包以gzip的压缩档案形式保存,后缀名为.crateregistry/src,若一个已下载的.crate档案被一个package所需要,该档案会被解压缩到registry/src文件夹下,最终rustc可以在其中找到所需的.rs文件
在 CI 时缓存 Cargo Home
为了避免持续集成时重复下载所有的包依赖,我们可以将 $CARGO_HOME 目录进行缓存,但缓存整个目录是效率低下的,原因是源文件可能会被缓存两次。
例如我们依赖一个包 serde 1.0.92,如果将整个 $CACHE_HOME 目录缓存,那么serde 的源文件就会被缓存两次:在 registry/cache 中的 serde-1.0.92.crate 以及 registry/src 下被解压缩的 .rs 文件。
因此,在 CI 构建时,出于效率的考虑,我们仅应该缓存以下目录:
bin/registry/index/registry/cache/git/db/
清除缓存
理论上,我们可以手动移除缓存中的任何一部分,当后续有包需要时 Cargo 会尽可能去恢复这些资源:
- 解压缩
registry/cache下的.crate档案 - 从
.git中checkout缓存的仓库 - 如果以上都没了,会从网络上重新下载
你也可以使用 cargo-cache 包来选择性的清除 cache 中指定的部分,当然,它还可以用来查看缓存中的组件大小。
构建时卡住:Blocking waiting for file lock ..
在开发过程中,或多或少我们都会碰到这种问题,例如你同时打开了 VSCode IDE 和终端,然后在 Cargo.toml 中刚添加了一个新的依赖。
此时 IDE 会捕捉到这个修改然后自动去重新下载依赖(这个过程可能还会更新 crates.io 使用的索引列表),在此过程中, Cargo 会将相关信息写入到 $HOME/.cargo/.package_cache 下,并将其锁住。
如果你试图在另一个地方(例如终端)对同一个项目进行构建,就会报错: Blocking waiting for file lock on package cache。
解决办法很简单:
- 既然下载慢,那就使用国内的注册服务,不再使用 crates.io
- 耐心等待持有锁的用户构建完成
- 强行停止正在构建的进程,例如杀掉 IDE 使用的 rust-analyer 插件进程,然后删除
$HOME/.cargo/.package_cache目录
构建( Build )缓存
cargo build 的结果会被放入项目根目录下的 target 文件夹中,当然,这个位置可以三种方式更改:设置 CARGO_TARGET_DIR 环境变量、build.target-dir 配置项以及 --target-dir 命令行参数。
target 目录结构
target 目录的结构取决于是否使用 --target 标志为特定的平台构建。
不使用 --target
若 --target 标志没有指定,Cargo 会根据宿主机架构进行构建,构建结果会放入项目根目录下的 target 目录中,target 下每个子目录中包含了相应的 发布配置profile的构建结果,例如 release、debug 是自带的profile,前者往往用于生产环境,因为会做大量的性能优化,而后者则用于开发环境,此时的编译效率和报错信息是最好的。
除此之外我们还可以定义自己想要的 profile ,例如用于测试环境的 profile: test,用于预发环境的 profile :pre-prod 等。
| 目录 | 描述 |
|---|---|
target/debug/ | 包含了 dev profile 的构建输出(cargo build 或 cargo build --debug) |
target/release/ | release profile 的构建输出,cargo build --release |
target/foo/ | 自定义 foo profile 的构建输出,cargo build --profile=foo |
出于历史原因:
dev和testprofile 的构建结果都存放在debug目录下release和benchprofile 则存放在release目录下- 用户定义的 profile 存在同名的目录下
使用 --target
当使用 --target XXX 为特定的平台编译后,输出会放在 target/XXX/ 目录下:
| 目录 | 示例 |
|---|---|
target/<triple>/debug/ | target/thumbv7em-none-eabihf/debug/ |
target/<triple>/release/ | target/thumbv7em-none-eabihf/release/ |
注意:,当没有使用
--target时,Cargo会与构建脚本和过程宏一起共享你的依赖包,对于每个rustc命令调用而言,RUSTFLAGS也将被共享。而使用
--target后,构建脚本、过程宏会针对宿主机的 CPU 架构进行各自构建,且不会共享RUSTFLAGS。
target 子目录说明
在 profile 文件夹中(例如 debug 或 release),包含编译后的最终成果:
| 目录 | 描述 |
|---|---|
target/debug/ | 包含编译后的输出,例如二进制可执行文件、库对象( library target ) |
target/debug/examples/ | 包含示例对象( example target ) |
还有一些命令会在 target 下生成自己的独立目录:
| 目录 | 描述 |
|---|---|
target/doc/ | 包含通过 cargo doc 生成的文档 |
target/package/ | 包含 cargo package 或 cargo publish 生成的输出 |
Cargo 还会创建几个用于构建过程的其它类型目录,它们的目录结构只应该被 Cargo 自身使用,因此可能会在未来发生变化:
| 目录 | 描述 |
|---|---|
target/debug/deps | 依赖和其它输出成果 |
target/debug/incremental | rustc 增量编译的输出,该缓存可以用于提升后续的编译速度 |
target/debug/build/ | 构建脚本的输出 |
依赖信息文件
在每一个编译成果的旁边,都有一个依赖信息文件,文件后缀是 .d。该文件的语法类似于 Makefile,用于说明构建编译成果所需的所有依赖包。
该文件往往用于提供给外部的构建系统,这样它们就可以判断 Cargo 命令是否需要再次被执行。
文件中的路径默认是绝对路径,你可以通过 build.dep-info-basedir配置项来修改为相对路径。
# 关于 `.d` 文件的一个示例 : target/debug/foo.d
/path/to/myproj/target/debug/foo: /path/to/myproj/src/lib.rs /path/to/myproj/src/main.rs
共享缓存
sccache 是一个三方工具,可以用于在不同的工作空间中共享已经构建好的依赖包。
为了设置 sccache,首先需要使用 cargo install sccache 进行安装,然后在调用 Cargo 之前将 RUSTC_WRAPPER 环境变量设置为 sccache。
- 如果用的
bash,可以将export RUSTC_WRAPPER=sccache添加到.bashrc中 - 也可以使用
build.rustc-wrapper配置项
进阶指南
进阶指南包含了 Cargo 的参考级内容,大家可以先看一遍了解下大概有什么,然后在后面需要时,再回来查询如何使用。
指定依赖项
我们的项目可以引用在 crates.io 或 GitHub 上的依赖包,也可以引用存放在本地文件系统中的依赖包。
大家可能会想,直接从前两个引用即可,为何还提供了本地方式?可以设想下,如果你要有一个正处于开发中的包,然后需要在本地的另一个项目中引用测试,那是将该包先传到网上,然后再引用简单,还是直接从本地路径的方式引用简单呢?答案显然不言而喻。
本章节,我们一起来看看有哪些方式可以指定和引用三方依赖包。
从 crates.io 引入依赖包
默认设置下,Cargo 就从 crates.io 上下载依赖包,只需要一个包名和版本号即可:
[dependencies]
time = "0.1.12"
字符串 "0.1.12" 是一个 semver 格式的版本号,符合 "x.y.z" 的形式,其中 x 被称为主版本major, y 被称为小版本 minor ,而 z 被称为补丁 patch,可以看出从左到右,版本的影响范围逐步降低,补丁的更新是无关痛痒的,并不会造成 API 的兼容性被破坏。
"0.1.12" 中并没有任何额外的符号,在版本语义上,它跟使用了 ^ 的 "^0.1.12" 是相同的,都是指定非常具体的版本进行引入。
但是 ^ 能做的更多。
npm 使用的就是
semver版本号,从JavaScript过来的同学应该非常熟悉。
^ 指定版本
与之前的 "0.1.12" 不同, ^ 可以指定一个版本号范围,然后会使用该范围内的最大版本号来引用对应的包。
只要新的版本号没有修改最左边的非零数字,那该版本号就在允许的版本号范围中。例如 "^0.1.12" 最左边的非零数字是 1,因此,只要新的版本号是 "0.1.z" 就可以落在范围内,而0.2.0 显然就没有落在范围内,因此通过 "^0.1.12" 引入的依赖包是无法被升级到 0.2.0 版本的。
同理,若是 "^1.0",则 1.1 在范围中,2.0 则不在。 大家思考下,"^0.0.1" 与哪些版本兼容?答案是:无,因为它最左边的数字是 1 ,而该数字已经退无可退,我们又不能修改 1,因此没有版本落在范围中。
^1.2.3 := >=1.2.3, <2.0.0
^1.2 := >=1.2.0, <2.0.0
^1 := >=1.0.0, <2.0.0
^0.2.3 := >=0.2.3, <0.3.0
^0.2 := >=0.2.0, <0.3.0
^0.0.3 := >=0.0.3, <0.0.4
^0.0 := >=0.0.0, <0.1.0
^0 := >=0.0.0, <1.0.0
以上是更多的例子,事实上,这个规则跟 SemVer 还有所不同,因为对于 SemVer 而言,0.x.y 的版本是没有其它版本与其兼容的,而对于 Rust,只要版本号 0.x.y 满足 : z>=y 且 x>0 的条件,那它就能更新到 0.x.z 版本。
~ 指定版本
~ 指定了最小化版本 :
#![allow(unused)] fn main() { ~1.2.3 := >=1.2.3, <1.3.0 ~1.2 := >=1.2.0, <1.3.0 ~1 := >=1.0.0, <2.0.0 }
* 通配符
这种方式允许将 * 所在的位置替换成任何数字:
#![allow(unused)] fn main() { * := >=0.0.0 1.* := >=1.0.0, <2.0.0 1.2.* := >=1.2.0, <1.3.0 }
不过 crates.io 并不允许我们只使用孤零零一个 * 来指定版本号 : *。
比较符
可以使用比较符的方式来指定一个版本号范围或一个精确的版本号:
#![allow(unused)] fn main() { >= 1.2.0 > 1 < 2 = 1.2.3 }
同时还能使用比较符进行组合,并通过逗号分隔:
#![allow(unused)] fn main() { >= 1.2, < 1.5 }
需要注意,以上的版本号规则仅仅针对 crate.io 和基于它搭建的注册服务(例如科大服务源) ,其它注册服务(例如 GitHub )有自己相应的规则。
从其它注册服务引入依赖包
为了使用 crates.io 之外的注册服务,我们需要对 $HOME/.cargo/config.toml (CARGO_HOME 下) 文件进行配置,添加新的服务提供商,有两种方式可以实现。
由于国内访问国外注册服务的不稳定性,我们可以使用科大的注册服务来提升下载速度,以下注册服务的链接都是科大的
首先是在 crates.io 之外添加新的注册服务,修改 .cargo/config.toml 添加以下内容:
[registries]
ustc = { index = "https://mirrors.ustc.edu.cn/crates.io-index/" }
对于这种方式,我们的项目的 Cargo.toml 中的依赖包引入方式也有所不同:
[dependencies]
time = { registry = "ustc" }
在重新配置后,初次构建可能要较久的时间,因为要下载更新 ustc 注册服务的索引文件,还挺大的...
注意,这一种使用方式最大的缺点就是在引用依赖包时要指定注册服务: time = { registry = "ustc" }。
而第二种方式就不需要,因为它是直接使用新注册服务来替代默认的 crates.io。
[source.crates-io]
replace-with = 'ustc'
[source.ustc]
registry = "git://mirrors.ustc.edu.cn/crates.io-index"
上面配置中的第一个部分,首先将源 source.crates-io 替换为 ustc,然后在第二部分指定了 ustc 源的地址。
注意,如果你要发布包到
crates.io上,那该包的依赖也必须在crates.io上
引入 git 仓库作为依赖包
若要引入 git 仓库中的库作为依赖包,你至少需要提供一个仓库的地址:
[dependencies]
regex = { git = "https://github.com/rust-lang/regex" }
由于没有指定版本,Cargo 会假定我们使用 master 或 main 分支的最新 commit 。你可以使用 rev、tag 或 branch 来指定想要拉取的版本。例如下面代码拉取了 next 分支上的最新 commit:
[dependencies]
regex = { git = "https://github.com/rust-lang/regex", branch = "next" }
任何非 tag 和 branch 的类型都可以通过 rev 来引入,例如通过最近一次 commit 的哈希值引入: rev = "4c59b707",再比如远程仓库提供的的具名引用: rev = "refs/pull/493/head"。
一旦 git 依赖被拉取下来,该版本就会被记录到 Cargo.lock 中进行锁定。因此 git 仓库中后续新的提交不再会被自动拉取,除非你通过 cargo update 来升级。需要注意的是锁定一旦被删除,那 Cargo 依然会按照 Cargo.toml 中配置的地址和版本去拉取新的版本,如果你配置的版本不正确,那可能会拉取下来一个不兼容的新版本!
因此不要依赖锁定来完成版本的控制,而应该老老实实的在 Cargo.toml 小心配置你希望使用的版本。
如果访问的是私有仓库,你可能需要授权来访问该仓库,可以查看这里了解授权的方式。
通过路径引入本地依赖包
Cargo 支持通过路径的方式来引入本地的依赖包:一般来说,本地依赖包都是同一个项目内的内部包,例如假设我们有一个 hello_world 项目( package ),现在在其根目录下新建一个包:
# 在 hello_world/ 目录下
cargo new hello_utils
新建的 hello_utils 文件夹跟 src、Cargo.toml 同级,现在修改 Cargo.toml 让 hello_world 项目引入新建的包:
[dependencies]
hello_utils = { path = "hello_utils" }
# 以下路径也可以
# hello_utils = { path = "./hello_utils" }
# hello_utils = { path = "../hello_world/hello_utils" }
但是,此时的 hello_world 是无法发布到 crates.io 上的。想要发布,需要先将 hello_utils 先发布到 crates.io 上,然后再通过 crates.io 的方式来引入:
[dependencies]
hello_utils = { path = "hello_utils", version = "0.1.0" }
注意!使用
path指定依赖的 package 将无法发布到crates.io,除非path存在于 [dev-dependencies] 中。当然,你还可以使用多种引用混合的方式来解决这个问题,下面将进行介绍
多引用方式混合
实际上,我们可以同时使用多种方式来引入同一个包,例如本地引入和 crates.io :
[dependencies]
# 本地使用时,通过 path 引入,
# 发布到 `crates.io` 时,通过 `crates.io` 的方式引入: version = "1.0"
bitflags = { path = "my-bitflags", version = "1.0" }
# 本地使用时,通过 git 仓库引入
# 当发布时,通过 `crates.io` 引入: version = "1.0"
smallvec = { git = "https://github.com/servo/rust-smallvec", version = "1.0" }
# N.B. 若 version 无法匹配,Cargo 将无法编译
这种方式跟下章节将要讲述的依赖覆盖类似,但是前者只会应用到当前声明的依赖包上。
根据平台引入依赖
我们还可以根据特定的平台来引入依赖:
[target.'cfg(windows)'.dependencies]
winhttp = "0.4.0"
[target.'cfg(unix)'.dependencies]
openssl = "1.0.1"
[target.'cfg(target_arch = "x86")'.dependencies]
native = { path = "native/i686" }
[target.'cfg(target_arch = "x86_64")'.dependencies]
native = { path = "native/x86_64" }
此处的语法跟 Rust 的 #[cfg] 语法非常相像,因此我们还能使用逻辑操作符进行控制:
[target.'cfg(not(unix))'.dependencies]
openssl = "1.0.1"
这里的意思是,当不是 unix 操作系统时,才对 openssl 进行引入。
如果你想要知道 cfg 能够作用的目标,可以在终端中运行 rustc --print=cfg 进行查询。当然,你可以指定平台查询: rustc --print=cfg --target=x86_64-pc-windows-msvc,该命令将对 64bit 的 Windows 进行查询。
聪明的同学已经发现,这非常类似于条件依赖引入,那我们是不是可以根据自定义的条件来决定是否引入某个依赖呢?具体答案参见后续的 feature 章节。这里是一个简单的示例:
[dependencies]
foo = { version = "1.0", optional = true }
bar = { version = "1.0", optional = true }
[features]
fancy-feature = ["foo", "bar"]
但是需要注意的是,你如果妄图通过 cfg(feature)、cfg(debug_assertions), cfg(test) 和 cfg(proc_macro) 的方式来条件引入依赖,那是不可行的。
Cargo 还允许通过下面的方式来引入平台特定的依赖:
[target.x86_64-pc-windows-gnu.dependencies]
winhttp = "0.4.0"
[target.i686-unknown-linux-gnu.dependencies]
openssl = "1.0.1"
自定义 target 引入
如果你在使用自定义的 target :例如 --target bar.json,那么可以通过下面方式来引入依赖:
[target.bar.dependencies]
winhttp = "0.4.0"
[target.my-special-i686-platform.dependencies]
openssl = "1.0.1"
native = { path = "native/i686" }
需要注意,这种使用方式在
stable版本的 Rust 中无法被使用,建议大家如果没有特别的需求,还是使用之前提到的 feature 方式
[dev-dependencies]
你还可以为项目添加只在测试时需要的依赖库,类似于 package.json( Nodejs )文件中的 devDependencies,可以在 Cargo.toml 中添加 [dev-dependencies] 来实现:
[dev-dependencies]
tempdir = "0.3"
这里的依赖只会在运行测试、示例和 benchmark 时才会被引入。并且,假设A 包引用了 B,而 B 通过 [dev-dependencies] 的方式引用了 C 包, 那 A 是不会引用 C 包的。
当然,我们还可以指定平台特定的测试依赖包:
[target.'cfg(unix)'.dev-dependencies]
mio = "0.0.1"
注意,当发布包到 crates.io 时,
[dev-dependencies]中的依赖只有指定了version的才会被包含在发布包中。况且,再加上测试稳定性的考虑,我们建议为[dev-dependencies]中的包指定相应的版本号
[build-dependencies]
我们还可以指定某些依赖仅用于构建脚本:
[build-dependencies]
cc = "1.0.3"
当然,平台特定的依然可以使用:
[target.'cfg(unix)'.build-dependencies]
cc = "1.0.3"
有一点需要注意:构建脚本( build.rs )和项目的正常代码是彼此独立,因此它们的依赖不能互通: 构建脚本无法使用 [dependencies] 或 [dev-dependencies] 中的依赖,而 [build-dependencies] 中的依赖也无法被构建脚本之外的代码所使用。
选择 features
如果你依赖的包提供了条件性的 features,你可以指定使用哪一个:
[dependencies.awesome]
version = "1.3.5"
default-features = false # 不要包含默认的 features,而是通过下面的方式来指定
features = ["secure-password", "civet"]
更多的信息参见 Features 章节
在 Cargo.toml 中重命名依赖
如果你想要实现以下目标:
- 避免在 Rust 代码中使用
use foo as bar - 依赖某个包的多个版本
- 依赖来自于不同注册服务的同名包
那可以使用 Cargo 提供的 package key :
[package]
name = "mypackage"
version = "0.0.1"
[dependencies]
foo = "0.1"
bar = { git = "https://github.com/example/project", package = "foo" }
baz = { version = "0.1", registry = "custom", package = "foo" }
此时,你的代码中可以使用三个包:
#![allow(unused)] fn main() { extern crate foo; // 来自 crates.io extern crate bar; // 来自 git repository extern crate baz; // 来自 registry `custom` }
有趣的是,由于这三个 package 的名称都是 foo(在各自的 Cargo.toml 中定义),因此我们显式的通过 package = "foo" 的方式告诉 Cargo:我们需要的就是这个 foo package,虽然它被重命名为 bar 或 baz。
有一点需要注意,当使用可选依赖时,如果你将 foo 包重命名为 bar 包,那引用前者的 feature 时的路径名也要做相应的修改:
[dependencies]
bar = { version = "0.1", package = 'foo', optional = true }
[features]
log-debug = ['bar/log-debug'] # 若使用 'foo/log-debug' 会导致报错
依赖覆盖
依赖覆盖对于本地开发来说,是很常见的,大部分原因都是我们希望在某个包发布到 crates.io 之前使用它,例如:
- 你正在同时开发一个包和一个项目,而后者依赖于前者,你希望能在该项目中对正在开发的包进行测试
- 你引入的一个依赖包在
master分支发布了新的代码,恰好修复了某个 bug,因此你希望能单独对该分支进行下测试 - 你即将发布一个包的新版本,为了确保新版本正常工作,你需要对其进行集成测试
- 你为项目的某个依赖包提了一个 PR 并解决了一个重要 bug,在等待合并到
master分支,但是时间不等人,因此你决定先使用自己修改的版本,等未来合并后,再继续使用官方版本
下面我们来具体看看类似的问题该如何解决。
上一章节中我们讲了如果通过多种引用方式来引入一个包,其实这也是一种依赖覆盖。
测试 bugfix 版本
假设我们有一个项目正在使用 uuid 依赖包,但是却不幸地发现了一个 bug,由于这个 bug 影响了使用,没办法等到官方提交新版本,因此还是自己修复为好。
我们项目的 Cargo.toml 内容如下:
[package]
name = "my-library"
version = "0.1.0"
[dependencies]
uuid = "0.8.2"
为了修复 bug,首先需要将 uuid 的源码克隆到本地,笔者是克隆到和项目同级的目录下:
git clone https://github.com/uuid-rs/uuid
下面,修改项目的 Cargo.toml 添加以下内容以引入本地克隆的版本:
[patch.crates-io]
uuid = { path = "../uuid" }
这里我们使用自己修改过的 patch 来覆盖来自 crates.io 的版本,由于克隆下来的 uuid 目录和我们的项目同级,因此通过相对路径 "../uuid" 即可定位到。
在成功为 uuid 打了本地补丁后,现在尝试在项目下运行 cargo build,但是却报错了,而且报错内容有一些看不太懂:
$ cargo build
Updating crates.io index
warning: Patch `uuid v1.0.0-alpha.1 (/Users/sunfei/development/rust/demos/uuid)` was not used in the crate graph.
Check that the patched package version and available features are compatible
with the dependency requirements. If the patch has a different version from
what is locked in the Cargo.lock file, run `cargo update` to use the new
version. This may also occur with an optional dependency that is not enabled.
具体原因比较复杂,但是仔细观察,会发现克隆下来的 uuid 的版本是 v1.0.0-alpha.1 (在 "../uuid/Cargo.toml" 中可以查看),然后我们本地引入的 uuid 版本是 0.8.2,根据之前讲过的 crates.io 的版本规则,这两者是不兼容的,0.8.2 只能升级到 0.8.z,例如 0.8.3。
既然如此,我们先将 "../uuid/Cargo.toml" 中的 version = "1.0.0-alpha.1" 修改为 version = "0.8.3" ,然后看看结果先:
$ cargo build
Updating crates.io index
Compiling uuid v0.8.3 (/Users/sunfei/development/rust/demos/uuid)
大家注意到最后一行了吗?我们成功使用本地的 0.8.3 版本的 uuid 作为最新的依赖,因此也侧面证明了,补丁 patch 的版本也必须遵循相应的版本兼容规则!
如果修改后还是有问题,大家可以试试以下命令,指定版本进行更新:
% cargo update -p uuid --precise 0.8.3
Updating crates.io index
Updating uuid v0.8.3 (/Users/sunfei/development/rust/demos/uuid) -> v0.8.3
修复 bug 后,我们可以提交 pr 给 uuid,一旦 pr 被合并到了 master 分支,你可以直接通过以下方式来使用补丁:
[patch.crates-io]
uuid = { git = 'https://github.com/uuid-rs/uuid' }
等未来新的内容更新到 crates.io 后,大家就可以移除这个补丁,直接更新 [dependencies] 中的 uuid 版本即可!
使用未发布的小版本
还是 uuid 包,这次假设我们要为它新增一个特性,同时我们已经修改完毕,在本地测试过,并提交了相应的 pr,下面一起来看看该如何在它发布到 crates.io 之前继续使用。
再做一个假设,对于 uuid 来说,目前 crates.io 上的版本是 1.0.0,在我们提交了 pr 并合并到 master 分支后,master 上的版本变成了 1.0.1,这意味着未来 crates.io 上的版本也将变成 1.0.1。
为了使用新加的特性,同时当该包在未来发布到 crates.io 后,我们可以自动使用 crates.io 上的新版本,而无需再使用 patch 补丁,可以这样修改 Cargo.toml:
[package]
name = "my-library"
version = "0.1.0"
[dependencies]
uuid = "1.0.1"
[patch.crates-io]
uuid = { git = 'https://github.com/uuid-rs/uuid' }
注意,我们将 [dependencies] 中的 uuid 版本提前修改为 1.0.1,由于该版本在 crates.io 尚未发布,因此 patch 版本会被使用。
现在,我们的项目是基于 patch 版本的 uuid 来构建,也就是从 gihtub 的 master 分支中拉取最新的 commit 来构建。一旦未来 crates.io 上有了 1.0.1 版本,那项目就会继续基于 crates.io 来构建,此时,patch 就可以删除了。
间接使用 patch
现在假设项目 A 的依赖是 B 和 uuid,而 B 的依赖也是 uuid,此时我们可以让 A 和 B 都使用来自 GitHub 的 patch 版本,配置如下:
[package]
name = "my-binary"
version = "0.1.0"
[dependencies]
my-library = { git = 'https://example.com/git/my-library' }
uuid = "1.0.1"
[patch.crates-io]
uuid = { git = 'https://github.com/uuid-rs/uuid' }
如上所示,patch 不仅仅对于 my-binary 项目有用,对于 my-binary 的依赖 my-library 来说,一样可以间接生效。
非 crates.io 的 patch
若我们想要覆盖的依赖并不是来自 crates.io ,就需要对 [patch] 做一些修改。例如依赖是 git 仓库,然后使用本地路径来覆盖它:
[patch."https://github.com/your/repository"]
my-library = { path = "../my-library/path" }
easy,轻松搞定!
使用未发布的大版本
现在假设我们要发布一个大版本 2.0.0,与之前类似,可以将 Cargo.toml 修改如下:
[dependencies]
uuid = "2.0"
[patch.crates-io]
uuid = { git = "https://github.com/uuid-rs/uuid", branch = "2.0.0" }
此时 2.0 版本在 crates.io 上还不存在,因此我们使用了 patch 版本且指定了 branch = "2.0.0"。
间接使用 patch
这里需要注意,与之前的小版本不同,大版本的 patch 不会发生间接的传递!,例如:
[package]
name = "my-binary"
version = "0.1.0"
[dependencies]
my-library = { git = 'https://example.com/git/my-library' }
uuid = "1.0"
[patch.crates-io]
uuid = { git = 'https://github.com/uuid-rs/uuid', branch = '2.0.0' }
以上配置中, my-binary 将继续使用 1.x.y 系列的版本,而 my-library 将使用最新的 2.0.0 patch。
原因是,大版本更新往往会带来破坏性的功能,Rust 为了让我们平稳的升级,采用了滚动的方式:在依赖图中逐步推进更新,而不是一次性全部更新。
多版本[patch]
在之前章节,我们介绍过如何使用 package key 来重命名依赖包,现在来看看如何使用它同时引入多个 patch。
假设,我们对 serde 有两个新的 patch 需求:
serde官方解决了一个bug但是还没发布到crates.io,我们想直接从git仓库的最新commit拉取版本1.*- 我们自己为
serde添加了新的功能,命名为2.0.0版本,并将该版本上传到自己的git仓库中
为了满足这两个 patch,可以使用如下内容的 Cargo.toml:
[patch.crates-io]
serde = { git = 'https://github.com/serde-rs/serde' }
serde2 = { git = 'https://github.com/example/serde', package = 'serde', branch = 'v2' }
第一行说明,第一个 patch 从官方仓库 main 分支的最新 commit 拉取,而第二个则从我们自己的仓库拉取 v2 分支,同时将其重命名为 serde2。
这样,在代码中就可以分别通过 serde 和 serde2 引用不同版本的依赖库了。
通过[path]来覆盖依赖
有时我们只是临时性地对一个项目进行处理,因此并不想去修改它的 Cargo.toml。此时可以使用 Cargo 提供的路径覆盖方法: 注意,这个方法限制较多,如果可以,还是要使用 [patch]。
与 [patch] 修改 Cargo.toml 不同,路径覆盖修改的是 Cargo 自身的配置文件 $Home/.cargo/config.toml:
paths = ["/path/to/uuid"]
paths 数组中的元素是一个包含 Cargo.toml 的目录(依赖包),在当前例子中,由于我们只有一个 uuid,因此只需要覆盖它即可。目标路径可以是相对的,也是绝对的,需要注意,如果是相对路径,那是相对包含 .cargo 的 $Home 来说的。
不推荐的[replace]
[replace]已经被标记为deprecated,并将在未来被移除,请使用[patch]替代
虽然不建议使用,但是如果大家阅读其它项目时依然可能会碰到这种用法:
[replace]
"foo:0.1.0" = { git = 'https://github.com/example/foo' }
"bar:1.0.2" = { path = 'my/local/bar' }
语法看上去还是很清晰的,[replace] 中的每一个 key 都是 Package ID 格式,通过这种写法可以在依赖图中任意挑选一个节点进行覆盖。
Cargo.toml 格式讲解
Cargo.toml 又被称为清单( manifest ),文件格式是 TOML,每一个清单文件都由以下部分组成:
cargo-features— 只能用于nightly版本的feature[package]— 定义项目(package)的元信息name— 名称version— 版本authors— 开发作者edition— Rust edition.rust-version— 支持的最小化 Rust 版本description— 描述documentation— 文档 URLreadme— README 文件的路径homepage- 主页 URLrepository— 源代码仓库的 URLlicense— 开源协议 License.license-file— License 文件的路径.keywords— 项目的关键词categories— 项目分类workspace— 工作空间 workspace 的路径build— 构建脚本的路径links— 本地链接库的名称exclude— 发布时排除的文件include— 发布时包含的文件publish— 用于阻止项目的发布metadata— 额外的配置信息,用于提供给外部工具default-run— [cargo run] 所使用的默认可执行文件( binary )autobins— 禁止可执行文件的自动发现autoexamples— 禁止示例文件的自动发现autotests— 禁止测试文件的自动发现autobenches— 禁止 bench 文件的自动发现resolver— 设置依赖解析器( dependency resolver)
- Cargo Target 列表: (查看 Target 配置 获取详细设置)
[lib]— Library target 设置.[[bin]]— Binary target 设置.[[example]]— Example target 设置.[[test]]— Test target 设置.[[bench]]— Benchmark target 设置.
- Dependency tables:
[dependencies]— 项目依赖包[dev-dependencies]— 用于 examples、tests 和 benchmarks 的依赖包[build-dependencies]— 用于构建脚本的依赖包[target]— 平台特定的依赖包
[badges]— 用于在注册服务(例如 crates.io ) 上显示项目的一些状态信息,例如当前的维护状态:活跃中、寻找维护者、deprecated[features]—features可以用于条件编译[patch]— 推荐使用的依赖覆盖方式[replace]— 不推荐使用的依赖覆盖方式 (deprecated).[profile]— 编译器设置和优化[workspace]— 工作空间的定义
下面,我们将对其中一些部分进行详细讲解。
[package]
Cargo.toml 中第一个部分就是 package,用于设置项目的相关信息:
[package]
name = "hello_world" # the name of the package
version = "0.1.0" # the current version, obeying semver
authors = ["Alice <a@example.com>", "Bob <b@example.com>"]
其中,只有 name 和 version 字段是必须填写的。当发布到注册服务时,可能会有额外的字段要求,具体参见发布到 crates.io。
name
项目名用于引用一个项目( package ),它有几个用途:
- 其它项目引用我们的
package时,会使用该name - 编译出的可执行文件(bin target)的默认名称
name 只能使用 alphanumeric 字符、 - 和 _,并且不能为空。
事实上,name 的限制不止如此,例如:
- 当使用
cargo new或cargo init创建时,name还会被施加额外的限制,例如不能使用 Rust 关键字名称作为name - 如果要发布到
crates.io,那还有更多的限制:name使用ASCII码,不能使用已经被使用的名称,例如uuid已经在crates.io上被使用,因此我们只能使用类如uuid_v1的名称,才能将项目发布到crates.io上
version
Cargo 使用了语义化版本控制的概念,例如字符串 "0.1.12" 是一个 semver 格式的版本号,符合 "x.y.z" 的形式,其中 x 被称为主版本major, y 被称为小版本 minor ,而 z 被称为补丁 patch,可以看出从左到右,版本的影响范围逐步降低,补丁的更新是无关痛痒的,并不会造成 API 的兼容性被破坏。
使用该规则,你还需要遵循一些基本规则:
- 使用标准的
x.y.z形式的版本号,例如1.0.0而不是1.0 - 在版本到达
1.0.0之前,怎么都行,但是如果有破坏性变更( breaking changes ),需要增加minor版本号。例如,为结构体新增字段或为枚举新增成员就是一种破坏性变更 - 在
1.0.0之后,如果发生破坏性变更,需要增加major版本号 - 在
1.0.0之后不要去破坏构建流程 - 在
1.0.0之后,不要在patch更新中添加新的api(pub声明),如果要添加新的pub结构体、特征、类型、函数、方法等对象时,增加minor版本号
如果大家想知道 Rust 如何使用版本号来解析依赖,可以查看这里。同时 SemVer 兼容性 提供了更为详尽的破坏性变更列表。
authors
[package]
authors = ["Sunfei <contact@im.dev>"]
该字段仅用于项目的元信息描述和 build.rs 用到的 CARGO_PKG_AUTHORS 环境变量,它并不会显示在 crates.io 界面上。
警告:清单中的
[package]部分一旦发布到crates.io就无法进行更改,因此对于已发布的包来说,authors字段是无法修改的
edition
可选字段,用于指定项目所使用的 Rust Edition。
该配置将影响项目中的所有 Cargo Target 和包,前者包含测试用例、benchmark、可执行文件、示例等。
[package]
# ...
edition = '2021'
大多数时候,我们都无需手动指定,因为 cargo new 的时候,会自动帮我们添加。若 edition 配置不存在,那 2015 Edition 会被默认使用。
rust-version
可选字段,用于说明你的项目支持的最低 Rust 版本(编译器能顺利完成编译)。一旦你使用的 Rust 版本比这个字段设置的要低,Cargo 就会报错,然后告诉用户所需的最低版本。
该字段是在 Rust 1.56 引入的,若大家使用的 Rust 版本低于该版本,则该字段会被自动忽略时。
[package]
# ...
edition = '2021'
rust-version = "1.56"
还有一点,rust-version 必须比第一个引入 edition 的 Rust 版本要新。例如 Rust Edition 2021 是在 Rust 1.56 版本引入的,若你使用了 edition = '2021' 的 [package] 配置,则指定的 rust version 字段必须要要大于等于 1.56 版本。
还可以使用 --ignore-rust-version 命令行参数来忽略 rust-version。
该字段将影响项目中的所有 Cargo Target 和包,前者包含测试用例、benchmark、可执行文件、示例等。
description
该字段是项目的简介,crates.io 会在项目首页使用该字段包含的内容,不支持 Markdown 格式。
[package]
# ...
description = "A short description of my package"
注意: 若发布
crates.io,则该字段是必须的
documentation
该字段用于说明项目文档的地址,若没有设置,crates.io 会自动链接到 docs.rs 上的相应页面。
[package]
# ...
documentation = "https://docs.rs/bitflags"
readme
readme 字段指向项目的 README.md 文件,该文件应该存在项目的根目录下(跟 Cargo.toml 同级),用于向用户描述项目的详细信息,支持 Markdown 格式。大家看到的 crates.io 上的项目首页就是基于该文件的内容进行渲染的。
[package]
# ...
readme = "README.md"
若该字段未设置且项目根目录下存在 README.md、README.txt 或 README 文件,则该文件的名称将被默认使用。
你也可以通过将 readme 设置为 false 来禁止该功能,若设置为 true ,则默认值 README.md 将被使用。
homepage
该字段用于设置项目主页的 URL:
[package]
# ...
homepage = "https://serde.rs/"
repository
设置项目的源代码仓库地址,例如 GitHub 链接:
[package]
# ...
repository = "https://github.com/rust-lang/cargo/"
license 和 license-file
license 字段用于描述项目所遵循的开源协议。而 license-file 则用于指定包含开源协议的文件所在的路径(相对于 Cargo.toml)。
如果要发布到 crates.io ,则该协议必须是 SPDX2.1 协议表达式。同时 license 名称必须是来自于 SPDX 协议列表 3.11。
SPDX 只支持使用 AND 、OR 来组合多个开源协议:
[package]
# ...
license = "MIT OR Apache-2.0"
OR 代表用户可以任选一个协议进行遵循,而 AND 表示用户必须要同时遵循两个协议。还可以通过 WITH 来在指定协议之外添加额外的要求:
MIT OR Apache-2.0LGPL-2.1-only AND MIT AND BSD-2-ClauseGPL-2.0-or-later WITH Bison-exception-2.2
若项目使用了非标准的协议,你可以通过指定 license-file 字段来替代 license 的使用:
[package]
# ...
license-file = "LICENSE.txt"
注意:crates.io 要求必须设置
license或license-file
keywords
该字段使用字符串数组的方式来指定项目的关键字列表,当用户在 crates.io 上搜索时,这些关键字可以提供索引的功能。
[package]
# ...
keywords = ["gamedev", "graphics"]
注意:
crates.io最多只支持 5 个关键字,每个关键字都必须是合法的ASCII文本,且需要使用字母作为开头,只能包含字母、数字、_和-,最多支持 20 个字符长度
categories
categories 用于描述项目所属的类别:
categories = ["command-line-utilities", "development-tools::cargo-plugins"]
注意:
crates.io最多只支持 5 个类别,目前不支持用户随意自定义类别,你所使用的类别需要跟 https://crates.io/category_slugs 上的类别精准匹配。
workspace
该字段用于配置当前项目所属的工作空间。
若没有设置,则将沿着文件目录向上寻找,直至找到第一个 设置了 [workspace] 的Cargo.toml。因此,当一个成员不在工作空间的子目录时,设置该字段将非常有用。
[package]
# ...
workspace = "path/to/workspace/root"
需要注意的是 Cargo.toml 清单还有一个 [workspace] 部分专门用于设置工作空间,若它被设置了,则 package 中的 workspace 字段将无法被指定。这是因为一个包无法同时满足两个角色:
- 该包是工作空间的根包(root crate),通过
[workspace]指定) - 该包是另一个工作空间的成员,通过
package.workspace指定
若要了解工作空间的更多信息,请参见这里。
build
build 用于指定位于项目根目录中的构建脚本,关于构建脚本的更多信息,可以阅读 构建脚本 一章。
[package]
# ...
build = "build.rs"
还可以使用 build = false 来禁止构建脚本的自动检测。
links
用于指定项目链接的本地库的名称,更多的信息请看构建脚本章节的 links
[package]
# ...
links = "foo"
exclude 和 include
这两个字段可以用于显式地指定想要包含在外或在内的文件列表,往往用于发布到注册服务时。你可以使用 cargo package --list 来检查哪些文件被包含在项目中。
[package]
# ...
exclude = ["/ci", "images/", ".*"]
[package]
# ...
include = ["/src", "COPYRIGHT", "/examples", "!/examples/big_example"]
尽管大家可能没有指定 include 或 exclude,但是任然会有些规则自动被应用,一起来看看。
若 include 没有被指定,则以下文件将被排除在外:
- 项目不是 git 仓库,则所有以
.开头的隐藏文件会被排除 - 项目是 git 仓库,通过
.gitignore配置的文件会被排除
无论 include 或 exclude 是否被指定,以下文件都会被排除在外:
- 任何包含
Cargo.toml的子目录会被排除 - 根目录下的
target目录会被排除
以下文件会永远被 include ,你无需显式地指定:
Cargo.toml- 若项目包含可执行文件或示例代码,则最小化的
Cargo.lock会自动被包含 license-file指定的协议文件
这两个字段很强大,但是对于生产实践而言,我们还是推荐通过
.gitignore来控制,因为这样协作者更容易看懂。如果大家希望更深入的了解include/exclude,可以参考下官方的Cargo文档
publish
该字段常常用于防止项目因为失误被发布到 crates.io 等注册服务上,例如如果希望项目在公司内部私有化,你应该设置:
[package]
# ...
publish = false
也可以通过字符串数组的方式来指定允许发布到的注册服务名称:
[package]
# ...
publish = ["some-registry-name"]
若 publish 数组中包含了一个注册服务名称,则 cargo publish 命令会使用该注册服务,除非你通过 --registry 来设定额外的规则。
metadata
Cargo 默认情况下会对 Cargo.toml 中未使用的 key 进行警告,以帮助大家提前发现风险。但是 package.metadata 并不在其中,因为它是由用户自定义的提供给外部工具的配置文件。例如:
[package]
name = "..."
# ...
# 以下配置元数据可以在生成安卓 APK 时使用
[package.metadata.android]
package-name = "my-awesome-android-app"
assets = "path/to/static"
与其相似的还有 [workspace.metadata],都可以作为外部工具的配置信息来使用。
default-run
当大家使用 cargo run 来运行项目时,该命令会使用默认的二进制可执行文件作为程序启动入口。
我们可以通过 default-run 来修改默认的入口,例如现在有两个二进制文件 src/bin/a.rs 和 src/bin/b.rs,通过以下配置可以将入口设置为前者:
[package]
default-run = "a"
[badges]
该部分用于指定项目当前的状态,该状态会展示在 crates.io 的项目主页中,例如以下配置可以设置项目的维护状态:
[badges]
# `maintenance` 是项目的当前维护状态,它可能会被其它注册服务所使用,但是目前还没有被 `crates.io` 使用: https://github.com/rust-lang/crates.io/issues/2437
#
# `status` 字段时必须的,以下是可用的选项:
# - `actively-developed`: 新特性正在积极添加中,bug 在持续修复中
# - `passively-maintained`: 目前没有计划去支持新的特性,但是项目维护者可能会回答你提出的 issue
# - `as-is`: 该项目的功能已经完结,维护者不准备继续开发和提供支持了,但是它的功能已经达到了预期
# - `experimental`: 作者希望同大家分享,但是还不准备满足任何人的特殊要求
# - `looking-for-maintainer`: 当前维护者希望将项目转移给新的维护者
# - `deprecated`: 不再推荐使用该项目,需要说明原因以及推荐的替代项目
# - `none`: 不显示任何 badge ,因此维护者没有说明他们的状态,用户需要自己去调查发生了什么
maintenance = { status = "..." }
[dependencies]
在之前章节中,我们已经详细介绍过 [dependencies] 、 [dev-dependencies] 和 [build-dependencies],这里就不再赘述。
[profile.*]
该部分可以对编译器进行配置,例如 debug 和优化,在后续的编译器优化章节有详细介绍。
Cargo Target
Cargo 项目中包含有一些对象,它们包含的源代码文件可以被编译成相应的包,这些对象被称之为 Cargo Target。例如之前章节提到的库对象 Library 、二进制对象 Binary、示例对象 Examples、测试对象 Tests 和 基准性能对象 Benches 都是 Cargo Target。
本章节我们一起来看看该如何在 Cargo.toml 清单中配置这些对象,当然,大部分时候都无需手动配置,因为默认的配置通常由项目目录的布局自动推断出来。
对象介绍
在开始讲解如何配置对象前,我们先来看看这些对象究竟是什么,估计还有些同学对此有些迷糊 :)
库对象(Library)
库对象用于定义一个库,该库可以被其它的库或者可执行文件所链接。该对象包含的默认文件名是 src/lib.rs,且默认情况下,库对象的名称跟项目名是一致的,
一个工程只能有一个库对象,因此也只能有一个 src/lib.rs 文件,以下是一种自定义配置:
# 一个简单的例子:在 Cargo.toml 中定制化库对象
[lib]
crate-type = ["cdylib"]
bench = false
二进制对象(Binaries)
二进制对象在被编译后可以生成可执行的文件,默认的文件名是 src/main.rs,二进制对象的名称跟项目名也是相同的。
大家应该还记得,一个项目拥有多个二进制文件,因此一个项目可以拥有多个二进制对象。当拥有多个对象时,对象的文件默认会被放在 src/bin/ 目录下。
二进制对象可以使用库对象提供的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
我们可以使用 cargo run --bin <bin-name> 的方式来运行指定的二进制对象,以下是二进制对象的配置示例:
# Example of customizing binaries in Cargo.toml.
[[bin]]
name = "cool-tool"
test = false
bench = false
[[bin]]
name = "frobnicator"
required-features = ["frobnicate"]
示例对象(Examples)
示例对象的文件在根目录下的 examples 目录中。既然是示例,自然是使用项目中的库对象的功能进行演示。示例对象编译后的文件会存储在 target/debug/examples 目录下。
如上所示,示例对象可以使用库对象的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
默认情况下,示例对象都是可执行的二进制文件( 带有 fn main() 函数入口),毕竟例子是用来测试和演示我们的库对象,是用来运行的。而你完全可以将示例对象改成库的类型:
[[example]]
name = "foo"
crate-type = ["staticlib"]
如果想要指定运行某个示例对象,可以使用 cargo run --example <example-name> 命令。如果是库类型的示例对象,则可以使用 cargo build --example <example-name> 进行构建。
与此类似,还可以使用 cargo install --example <example-name> 来将示例对象编译出的可执行文件安装到默认的目录中,将该目录添加到 $PATH 环境变量中,就可以直接全局运行安装的可执行文件。
最后,cargo test 命令默认会对示例对象进行编译,以防止示例代码因为长久没运行,导致严重过期以至于无法运行。
测试对象(Tests)
测试对象的文件位于根目录下的 tests 目录中,如果大家还有印象的话,就知道该目录是集成测试所使用的。
当运行 cargo test 时,里面的每个文件都会被编译成独立的包,然后被执行。
测试对象可以使用库对象提供的公共 API,也可以通过 [dependencies] 来引入外部的依赖库。
配置一个对象
我们可以通过 Cargo.toml 中的 [lib]、[[bin]]、[[example]]、[[test]] 和 [[bench]] 部分对以上对象进行配置。
大家可能会疑惑
[lib]和[[bin]]的写法为何不一致,原因是这种语法是TOML提供的数组特性,[[bin]]这种写法意味着我们可以在 Cargo.toml 中创建多个[[bin]],每一个对应一个二进制文件上文提到过,我们只能指定一个库对象,因此这里只能使用
[lib]形式
由于它们的配置内容都是相似的,因此我们以 [lib] 为例来说明相应的配置项:
[lib]
name = "foo" # 对象名称: 库对象、`src/main.rs` 二进制对象的名称默认是项目名
path = "src/lib.rs" # 对象的源文件路径
test = true # 能否被测试,默认是 true
doctest = true # 文档测试是否开启,默认是 true
bench = true # 基准测试是否开启
doc = true # 文档功能是否开启
plugin = false # 是否可以用于编译器插件(deprecated).
proc-macro = false # 是否是过程宏类型的库
harness = true # 是否使用libtest harness : https://doc.rust-lang.org/stable/rustc/tests/index.html
edition = "2015" # 对象使用的 Rust Edition
crate-type = ["lib"] # 生成的包类型
required-features = [] # 构建对象所需的 Cargo Features (N/A for lib).
name
对于库对象和默认的二进制对象( src/main.rs ),默认的名称是项目的名称( package.name )。
对于其它类型的对象,默认是目录或文件名。
除了 [lib] 外,name 字段对于其他对象都是必须的。
proc-macro
该字段的使用方式在过程宏章节有详细的介绍。
edition
对使用的 Rust Edition 版本进行设置。
如果没有设置,则默认使用 [package] 中配置的 package.edition,通常来说,这个字段不应该被单独设置,只有在一些特殊场景中才可能用到:例如将一个大型项目逐步升级为新的 edition 版本。
crate-type
该字段定义了对象生成的包类型。它是一个数组,因此为同一个对象指定多个包类型。
需要注意的是,只有库对象和示例对象可以被指定,因为其他的二进制、测试和基准测试对象只能是 bin 这个包类型。
默认的包类型如下:
| 对象 | 包类型 |
|---|---|
| 正常的库对象 | "lib" |
| 过程宏的库对象 | "proc-macro" |
| 示例对象 | "bin" |
可用的选项包括 bin、lib、rlib、dylib、cdylib、staticlib 和 proc-macro ,如果大家想了解更多,可以看下官方的参考手册。
required-features
该字段用于指定在构建对象时所需的 features列表。
该字段只对 [[bin]]、 [[bench]]、 [[test]] 和 [[example]] 有效,对于 [lib] 没有任何效果。
[features]
# ...
postgres = []
sqlite = []
tools = []
[[bin]]
name = "my-pg-tool"
required-features = ["postgres", "tools"]
对象自动发现
默认情况下,Cargo 会基于项目的目录文件布局自动发现和确定对象,而之前的配置项则允许我们对其进行手动的配置修改(若项目布局跟标准的不一样时)。
而这种自动发现对象的设定可以通过以下配置来禁用:
[package]
# ...
autobins = false
autoexamples = false
autotests = false
autobenches = false
只有在特定场景下才应该禁用自动对象发现。例如,你有一个模块想要命名为 bin,目录结构如下:
├── Cargo.toml
└── src
├── lib.rs
└── bin
└── mod.rs
这在默认情况下会导致问题,因为 Cargo 会使用 src/bin 作为存放二进制对象的地方。
为了阻止这一点,可以设置 autobins = false :
├── Cargo.toml
└── src
├── lib.rs
└── bin
└── mod.rs
工作空间 Workspace
一个工作空间是由多个 package 组成的集合,它们共享同一个 Cargo.lock 文件、输出目录和一些设置(例如 profiles : 编译器设置和优化)。组成工作空间的 packages 被称之为工作空间的成员。
工作空间的两种类型
工作空间有两种类型:root package 和虚拟清单( virtual manifest )。
根 package
若一个 package 的 Cargo.toml 包含了[package] 的同时又包含了 [workspace] 部分,则该 package 被称为工作空间的根 package。
换而言之,一个工作空间的根( root )是该工作空间的 Cargo.toml 文件所在的目录。
举个例子,我们现在有多个 package,它们的目录是嵌套关系,然后我们在最外层的 package,也就是最外层目录中的 Cargo.toml 中定义一个 [workspace],此时这个最外层的 package 就是工作空间的根。
再举个例子,大名鼎鼎的 ripgrep 就在最外层的 package 中定义了 [workspace] :
[workspace]
members = [
"crates/globset",
"crates/grep",
"crates/cli",
"crates/matcher",
"crates/pcre2",
"crates/printer",
"crates/regex",
"crates/searcher",
"crates/ignore",
]
那么最外层的目录就是 ripgrep 的工作空间的根。
虚拟清单
若一个 Cargo.toml 有 [workspace] 但是没有 [package] 部分,则它是虚拟清单类型的工作空间。
对于没有主 package 的场景或你希望将所有的 package 组织在单独的目录中时,这种方式就非常适合。
例如 rust-analyzer 就是这样的项目,它的根目录中的 Cargo.toml 中并没有 [package],说明该根目录不是一个 package,但是却有 [workspace] :
[workspace]
members = ["xtask/", "lib/*", "crates/*"]
exclude = ["crates/proc_macro_test/imp"]
结合 rust-analyzer 的目录布局可以看出,该工作空间的所有成员 package 都在单独的目录中,因此这种方式很适合虚拟清单的工作空间。
关键特性
工作空间的几个关键点在于:
- 所有的
package共享同一个Cargo.lock文件,该文件位于工作空间的根目录中 - 所有的
package共享同一个输出目录,该目录默认的名称是target,位于工作空间根目录下 - 只有工作空间根目录的
Cargo.toml才能包含[patch],[replace]和[profile.*],而成员的Cargo.toml中的相应部分将被自动忽略
[workspace]
Cargo.toml 中的 [workspace] 部分用于定义哪些 packages 属于工作空间的成员:
[workspace]
members = ["member1", "path/to/member2", "crates/*"]
exclude = ["crates/foo", "path/to/other"]
若某个本地依赖包是通过 path 引入,且该包位于工作空间的目录中,则该包自动成为工作空间的成员。
剩余的成员需要通过 workspace.members 来指定,里面包含了各个成员所在的目录(成员目录中包含了 Cargo.toml )。
members 还支持使用 glob 来匹配多个路径,例如上面的例子中使用 crates/* 匹配 crates 目录下的所有包。
exclude 可以将指定的目录排除在工作空间之外,例如还是上面的例子,crates/* 在包含了 crates 目录下的所有包后,又通过 exclude 中 crates/foo 将 crates 下的 foo 目录排除在外。
你也可以将一个空的 [workspace] 直接联合 [package] 使用,例如:
[package]
name = "hello"
version = "0.1.0"
[workspace]
此时的工作空间的成员包含:
- 根
package: "hello" - 所有通过
path引入的本地依赖(位于工作空间目录下)
选择工作空间
选择工作空间有两种方式:Cargo 自动查找、手动指定 package.workspace 字段。
当位于工作空间的子目录中时,Cargo 会自动在该目录的父目录中寻找带有 [workspace] 定义的 Cargo.toml,然后再决定使用哪个工作空间。
我们还可以使用下面的方法来覆盖 Cargo 自动查找功能:将成员包中的 package.workspace 字段修改为工作区间根目录的位置,这样就能显式地让一个成员使用指定的工作空间。
当成员不在工作空间的子目录下时,这种手动选择工作空间的方法就非常适用。毕竟 Cargo 的自动搜索是沿着父目录往上查找,而成员并不在工作空间的子目录下,这意味着顺着成员的父目录往上找是无法找到该工作空间的 Cargo.toml 的,此时就只能手动指定了。
选择 package
在工作空间中,package 相关的 Cargo 命令(例如 cargo build )可以使用 -p 、 --package 或 --workspace 命令行参数来指定想要操作的 package。
若没有指定任何参数,则 Cargo 将使用当前工作目录的中的 package 。若工作目录是虚拟清单类型的工作空间,则该命令将作用在所有成员上(就好像是使用了 --workspace 命令行参数)。而 default-members 可以在命令行参数没有被提供时,手动指定操作的成员:
[workspace]
members = ["path/to/member1", "path/to/member2", "path/to/member3/*"]
default-members = ["path/to/member2", "path/to/member3/foo"]
这样一来, cargo build 就不会应用到虚拟清单工作空间的所有成员,而是指定的成员上。
workspace.metadata
与 package.metadata 非常类似,workspace.metadata 会被 Cargo 自动忽略,就算没有被使用也不会发出警告。
这个部分可以用于让工具在 Cargo.toml 中存储一些工作空间的配置元信息。例如:
[workspace]
members = ["member1", "member2"]
[workspace.metadata.webcontents]
root = "path/to/webproject"
tool = ["npm", "run", "build"]
# ...
条件编译 Features
Cargo Feature 是非常强大的机制,可以为大家提供条件编译和可选依赖的高级特性。
[features]
Feature 可以通过 Cargo.toml 中的 [features] 部分来定义:其中每个 feature 通过列表的方式指定了它所能启用的其他 feature 或可选依赖。
假设我们有一个 2D 图像处理库,然后该库所支持的图片格式可以通过以下方式启用:
[features]
# 定义一个 feature : webp, 但它并没有启用其它 feature
webp = []
当定义了 webp 后,我们就可以在代码中通过 cfg 表达式来进行条件编译。例如项目中的 lib.rs 可以使用以下代码对 webp 模块进行条件引入:
#[cfg(feature = "webp")]
pub mod webp;
#[cfg(feature = "webp")] 的含义是:只有在 webp feature 被定义后,以下的 webp 模块才能被引入进来。由于我们之前在 [features] 里定义了 webp,因此以上代码的 webp 模块会被成功引入。
在 Cargo.toml 中定义的 feature 会被 Cargo 通过命令行参数 --cfg 传给 rustc,最终由后者完成编译:rustc --cfg ...。若项目中的代码想要测试 feature 是否存在,可以使用 cfg 属性或 cfg 宏。
之前我们提到了一个 feature 还可以开启其他 feature,举个例子,例如 ICO 图片格式包含 BMP 和 PNG 格式,因此当 ico 被启用后,它还得确保启用 bmp 和 png :
[features]
bmp = []
png = []
ico = ["bmp", "png"]
webp = []
对此,我们可以理解为: bmp 和 png 是开启 ico 的先决条件(注:开启 ico,会自动开启 bmp, png)。
Feature 名称可以包含来自 Unicode XID standard 定义的字母,允许使用 _ 或 0-9 的数字作为起始字符,在起始字符后,还可以使用 -、+ 或 . 。
但是我们还是推荐按照 crates.io 的方式来设置 Feature 名称 : crate.io 要求名称只能由 ASCII 字母数字、_、- 或 + 组成。
default feature
默认情况下,所有的 feature 都会被自动禁用,可以通过 default 来启用它们:
[features]
default = ["ico", "webp"]
bmp = []
png = []
ico = ["bmp", "png"]
webp = []
使用如上配置的项目被构建时,default feature 首先会被启用,然后它接着启用了 ico 和 webp feature,当然我们还可以关闭 default:
--no-default-features命令行参数可以禁用defaultfeaturedefault-features = false选项可以在依赖声明中指定
当你要去改变某个依赖库的
default启用的 feature 列表时(例如觉得该库引入的 feature 过多,导致最终编译出的文件过大),需要格外的小心,因为这可能会导致某些功能的缺失
可选依赖
当依赖被标记为 "可选 optional" 时,意味着它默认不会被编译。假设我们的 2D 图片处理库需要用到一个外部的包来处理 GIF 图片:
[dependencies]
gif = { version = "0.11.1", optional = true }
这种可选依赖的写法会自动定义一个与依赖同名的 feature,也就是 gif feature,这样一来,当我们启用 gif feature 时,该依赖库也会被自动引入并启用:例如通过 --feature gif 的方式启用 feature 。
注意:目前来说,
[feature]中定义的 feature 还不能与已引入的依赖库同名。但是在nightly中已经提供了实验性的功能用于改变这一点: namespaced features
当然,我们还可以通过显式定义 feature 的方式来启用这些可选依赖库,例如为了支持 AVIF 图片格式,我们需要引入两个依赖包,由于 avif 是通过 feature 引入的可选格式,因此它依赖的两个包也必须声明为可选的:
[dependencies]
ravif = { version = "0.6.3", optional = true }
rgb = { version = "0.8.25", optional = true }
[features]
avif = ["ravif", "rgb"]
之后,avif feature 一旦被启用,那这两个依赖库也将自动被引入。
注意:我们之前也讲过条件引入依赖的方法,那就是使用平台相关的依赖,与基于 feature 的可选依赖不同,它们是基于特定平台的可选依赖
依赖库自身的 feature
就像我们的项目可以定义 feature 一样,依赖库也可以定义它自己的 feature,也有需要启用的 feature 列表,当引入该依赖库时,我们可以通过以下方式为其启用相关的 features :
[dependencies]
serde = { version = "1.0.118", features = ["derive"] }
以上配置为 serde 依赖开启了 derive feature,还可以通过 default-features = false 来禁用依赖库的 default feature :
[dependencies]
flate2 = { version = "1.0.3", default-features = false, features = ["zlib"] }
这里我们禁用了 flate2 的 default feature,但又手动为它启用了 zlib feature。
注意:这种方式未必能成功禁用
default,原因是可能会有其它依赖也引入了flate2,并且没有对default进行禁用,那此时default依然会被启用。查看下文的 feature 同一化 获取更多信息
除此之外,还能通过下面的方式来间接开启依赖库的 feature :
[dependencies]
jpeg-decoder = { version = "0.1.20", default-features = false }
[features]
# Enables parallel processing support by enabling the "rayon" feature of jpeg-decoder.
parallel = ["jpeg-decoder/rayon"]
如上所示,我们定义了一个 parallel feature,同时为其启用了 jpeg-decoder 依赖的 rayon feature。
注意: 上面的 "package-name/feature-name" 语法形式不仅会开启指定依赖的指定 feature,若该依赖是可选依赖,那还会自动将其引入
在
nightly版本中,可以对这种行为进行禁用:weak dependency features
通过命令行参数启用 feature
以下的命令行参数可以启用指定的 feature :
--features FEATURES: 启用给出的 feature 列表,可以使用逗号或空格进行分隔,若你是在终端中使用,还需要加上双引号,例如--features "foo bar"。 若在工作空间中构建多个package,可以使用package-name/feature-name为特定的成员启用 features--all-features: 启用命令行上所选择的所有包的所有 features--no-default-features: 对选择的包禁用defaultfeature
feature 同一化
feature 只有在定义的包中才是唯一的,不同包之间的 feature 允许同名。因此,在一个包上启用 feature 不会导致另一个包的同名 feature 被误启用。
当一个依赖被多个包所使用时,这些包对该依赖所设置的 feature 将被进行合并,这样才能确保该依赖只有一个拷贝存在,这个过程就被称之为同一化。大家可以查看这里了解下解析器如何对 feature 进行解析处理。
这里,我们使用 winapi 为例来说明这个过程。首先,winapi 使用了大量的 features;然后我们有两个包 foo 和 bar 分别使用了它的两个 features,那么在合并后,最终 winapi 将同时启四个 features :
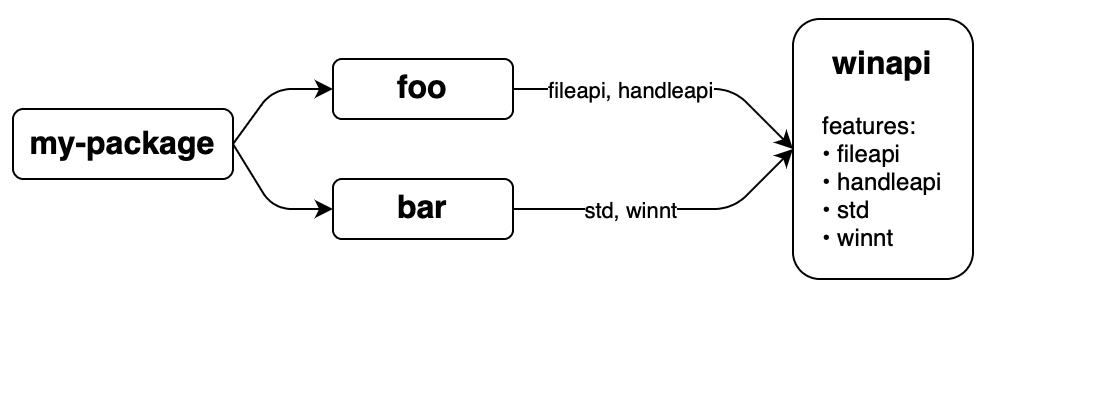
由于这种不可控性,我们需要让 启用feature = 添加特性 这个等式成立,换而言之,启用一个 feature 不应该导致某个功能被禁止。这样才能的让多个包启用同一个依赖的不同 features。
例如,如果我们想可选的支持 no_std 环境(不使用标准库),那么有两种做法:
- 默认代码使用标准库的,当
no_stdfeature 启用时,禁用相关的标准库代码 - 默认代码使用非标准库的,当
stdfeature 启用时,才使用标准库的代码
前者就是功能削减,与之相对,后者是功能添加,根据之前的内容,我们应该选择后者的做法:
#![allow(unused)] #![no_std] fn main() { #[cfg(feature = "std")] extern crate std; #[cfg(feature = "std")] pub fn function_that_requires_std() { // ... } }
彼此互斥的 feature
某极少数情况下,features 之间可能会互相不兼容。我们应该避免这种设计,因为如果一旦这么设计了,那你可能需要修改依赖图的很多地方才能避免两个不兼容 feature 的同时启用。
如果实在没有办法,可以考虑增加一个编译错误来让报错更清晰:
#[cfg(all(feature = "foo", feature = "bar"))]
compile_error!("feature \"foo\" and feature \"bar\" cannot be enabled at the same time");
当同时启用 foo 和 bar 时,编译器就会爆出一个更清晰的错误:feature foo 和 bar 无法同时启用。
总之,我们还是应该在设计上避免这种情况的发生,例如:
- 将某个功能分割到多个包中
- 当冲突时,设置 feature 优先级,cfg-if 包可以帮助我们写出更复杂的
cfg表达式
检视已解析的 features
在复杂的依赖图中,如果想要了解不同的 features 是如何被多个包多启用的,这是相当困难的。好在 cargo tree 命令提供了几个选项可以帮组我们更好的检视哪些 features 被启用了:
cargo tree -e features ,该命令以依赖图的方式来展示已启用的 features,包含了每个依赖包所启用的特性:
$ cargo tree -e features
test_cargo v0.1.0 (/Users/sunfei/development/rust/demos/test_cargo)
└── uuid feature "default"
├── uuid v0.8.2
└── uuid feature "std"
└── uuid v0.8.2
cargo tree -f "{p} {f}" 命令会提供一个更加紧凑的视图:
$ cargo tree -f "{p} {f}"
test_cargo v0.1.0 (/Users/sunfei/development/rust/demos/test_cargo)
└── uuid v0.8.2 default,std
cargo tree -e features -i foo,该命令会显示 features 会如何"流入"指定的包 foo 中:
$ cargo tree -e features -i uuid
uuid v0.8.2
├── uuid feature "default"
│ └── test_cargo v0.1.0 (/Users/sunfei/development/rust/demos/test_cargo)
│ └── test_cargo feature "default" (command-line)
└── uuid feature "std"
└── uuid feature "default" (*)
该命令在依赖图较为复杂时非常有用,使用它可以让你了解某个依赖包上开启了哪些 features 以及其中的原因。
大家可以查看官方的 cargo tree 文档获取更加详细的使用信息。
Feature 解析器 V2 版本
我们还能通过以下配置指定使用 V2 版本的解析器( resolver ):
[package]
name = "my-package"
version = "1.0.0"
resolver = "2"
V2 版本的解析器可以在某些情况下避免 feature 同一化的发生,具体的情况在这里有描述,下面做下简单的总结:
- 为特定平台开启的
features且此时并没有被构建,会被忽略 build-dependencies和proc-macros不再跟普通的依赖共享featuresdev-dependencies的features不会被启用,除非正在构建的对象需要它们(例如测试对象、示例对象等)
对于部分场景而言,feature 同一化确实是需要避免的,例如,一个构建依赖开启了 std feature,而同一个依赖又被用于 no_std 环境,很明显,开启 std 将导致错误的发生。
说完优点,我们再来看看 V2 的缺点,其中增加编译构建时间就是其中之一,原因是同一个依赖会被构建多次(每个都拥有不同的 feature 列表)。
由于此部分内容可能只有极少数的用户需要,因此我们并没有对其进行扩展,如果大家希望了解更多关于 V2 的内容,可以查看官方文档
构建脚本
构建脚本可以通过 CARGO_FEATURE_<name> 环境变量获取启用的 feature 列表,其中 <name> 是 feature 的名称,该名称被转换成大全写字母,且 - 被转换为 _。
required-features
该字段可以用于禁用特定的 Cargo Target:当某个 feature 没有被启用时,查看这里获取更多信息。
SemVer 兼容性
启用一个 feature 不应该引入一个不兼容 SemVer 的改变。例如,启用的 feature 不应该改变现有的 API,因为这会给用户造成不兼容的破坏性变更。 如果大家想知道哪些变化是兼容的,可以参见官方文档。
总之,在新增/移除 feature 或可选依赖时,你需要小心,因此这些可能会造成向后不兼容性。更多信息参见这里,简单总结如下:
- 在发布
minor版本时,以下通常是安全的: - 在发布
minor版本时,以下操作应该避免:
feature 文档和发现
将你的项目支持的 feature 信息写入到文档中是非常好的选择:
- 我们可以通过在
lib.rs的顶部添加文档注释的方式来实现。例如regex就是这么做的。 - 若项目拥有一个用户手册,那也可以在那里添加说明,例如 serde.rs。
- 若项目是二进制类型(可运行的应用服务,包含
fn main入口),可以将说明放在README文件或其他文档中,例如 sccache。
特别是对于不稳定的或者不该再被使用的 feature 而言,它们更应该被放在文档中进行清晰的说明。
当构建发布到 docs.rs 上的文档时,会使用 Cargo.toml 中的元数据来控制哪些 features 会被启用。查看 docs.rs 文档获取更多信息。
如何发现 features
若依赖库的文档中对其使用的 features 做了详细描述,那你会更容易知道他们使用了哪些 features 以及该如何使用。
当依赖库的文档没有相关信息时,你也可以通过源码仓库的 Cargo.toml 文件来获取,但是有些时候,使用这种方式来跟踪并获取全部相关的信息是相当困难的。
Features 示例
以下我们一起来看看一些来自真实世界的示例。
最小化构建时间和文件大小
如果一些包的部分特性不再启用,就可以减少该包占用的大小以及编译时间:
syn包可以用来解析 Rust 代码,由于它很受欢迎,大量的项目都在引用,因此它给出了非常清晰的文档关于如何最小化使用它包含的featuresregex也有关于 features 的描述文档,例如移除 Unicode 支持的 feature 可以降低最终生成可执行文件的大小winapi拥有众多 features,这些feature对用了各种 Windows API,你可以只引入代码中用到的 API 所对应的 feature.
行为扩展
serde_json 拥有一个 preserve_order feature,可以用于在序列化时保留 JSON 键值对的顺序。同时,该 feature 还会启用一个可选依赖 indexmap。
当这么做时,一定要小心不要破坏了 SemVer 的版本兼容性,也就是说:启用 feature 后,代码依然要能正常工作。
no_std 支持
一些包希望能同时支持 no_std 和 std 环境,例如该包希望支持嵌入式系统或资源紧张的系统,且又希望能支持其它的平台,此时这种做法是非常有用的,因为标准库 std 会大幅增加编译出来的文件的大小,对于资源紧张的系统来说,no_std 才是最合适的。
wasm-bindgen 定义了一个 std feature,它是默认启用的。首先,在库的顶部,它无条件的启用了 no_std 属性,它可以确保 std 和 std prelude 不会自动引入到作用域中来。其次,在不同的地方(示例 1,示例 2),它通过 #[cfg(feature = "std")] 启用 std feature 来添加 std 标准库支持。
对依赖库的 features 进行再导出
从依赖库再导出 features 在有些场景中会相当有用,这样用户就可以通过依赖包的 features 来控制功能而不是自己去手动定义。
例如 regex 将 regex_syntax 包的 features 进行了再导出,这样 regex 的用户无需知道 regex_syntax 包,但是依然可以访问后者包含的 features。
feature 优先级
一些包可能会拥有彼此互斥的 features(无法共存,上一章节中有讲到),其中一个办法就是为 feature 定义优先级,这样其中一个就会优于另一个被启用。
例如 log 包,它有几个 features 可以用于在编译期选择最大的日志级别,这里,它就使用了 cfg-if 的方式来设置优先级。一旦多个 features 被启用,那更高优先级的就会优先被启用。
过程宏包
一些包拥有过程宏,这些宏必须定义在一个独立的包中。但是不是所有的用户都需要过程宏的,因此也无需引入该包。
在这种情况下,将过程宏所在的包定义为可选依赖,是很不错的选择。这样做还有一个好处:有时过程宏的版本必须要跟父包进行同步,但是我们又不希望所有的用户都进行同步。
其中一个例子就是 serde ,它有一个 derive feature 可以启用 serde_derive 过程宏。由于 serde_derive 包跟 serde 的关系非常紧密,因此它使用了版本相同的需求来保证两者的版本同步性。
只能用于 nightly 的 feature
Rust 有些实验性的 API 或语言特性只能在 nightly 版本下使用,但某些使用了这些 API 的包并不想强制他们的用户也使用 nightly 版本,因此他们会通过 feature 的方式来控制。
若用户希望使用这些 API 时,需要启用相应的 feature ,而这些 feature 只能在 nightly 下使用。若用户不需要使用这些 API,就无需开启 相应的 feature,自然也不需要使用 nightly 版本。
例如 rand 包有一个 simd_support feature 就只能在 nightly 下使用,若我们不使用该 feature,则在 stable 下依然可以使用 rand。
实验性 feature
有一些包会提前将一些实验性的 API 放出去,既然是实验性的,自然无法保证其稳定性。在这种情况下,通常会在文档中将相应的 features 标记为实验性,意味着它们在未来可能会发生大的改变(甚至 minor 版本都可能发生)。
其中一个例子是 async-std 包,它拥有一个 unstable feature,用来标记一些新的 API,表示人们已经可以选择性的使用但是还没有准备好去依赖它。
发布配置 Profile
细心的同学可能发现了迄今为止我们已经为 Cargo 引入了不少新的名词,而且这些名词有一个共同的特点,不容易或不适合翻译成中文,因为难以表达的很准确,例如 Cargo Target, Feature 等,这不现在又多了一个 Profile。
默认的 profile
Profile 其实是一种发布配置,例如它默认包含四种: dev、 release、 test 和 bench,正常情况下,我们无需去指定,Cargo 会根据我们使用的命令来自动进行选择
- 例如
cargo build自动选择devprofile,而cargo test则是testprofile, 出于历史原因,这两个 profile 输出的结果都存放在项目根目录下的target/debug目录中,结果往往用于开发/测试环境 - 而
cargo build --release自动选择releaseprofile,并将输出结果存放在target/release目录中,结果往往用于生产环境
可以看出 Profile 跟 Nodejs 的 dev 和 prod 很像,都是通过不同的配置来为目标环境构建最终编译后的结果: dev 编译输出的结果用于开发环境,prod 则用于生产环境。
针对不同的 profile,编译器还会提供不同的优化级别,例如 dev 用于开发环境,因此构建速度是最重要的:此时,我们可以牺牲运行性能来换取编译性能,那么优化级别就会使用最低的。而 release 则相反,优化级别会使用最高,导致的结果就是运行得非常快,但是编译速度大幅降低。
初学者一个常见的错误,就是使用非
releaseprofile 去测试性能,例如cargo run,这种方式显然无法得到正确的结果,我们应该使用cargo run --release的方式测试性能
profile 可以通过 Cargo.toml 中的 [profile] 部分进行设置和改变:
[profile.dev]
opt-level = 1 # 使用稍高一些的优化级别,最低是0,最高是3
overflow-checks = false # 关闭整数溢出检查
需要注意的是,每一种 profile 都可以单独的进行设置,例如上面的 [profile.dev]。
如果是工作空间的话,只有根 package 的 Cargo.toml 中的 [profile] 设置才会被使用,其它成员或依赖包中的设置会被自动忽略。
另外,profile 还能在 Cargo 自身的配置文件中进行覆盖,总之,通过 .cargo/config.toml 或环境变量的方式所指定的 profile 配置会覆盖项目的 Cargo.toml 中相应的配置。
自定义 profile
除了默认的四种 profile,我们还可以定义自己的。对于大公司来说,这个可能会非常有用,自定义的 profile 可以帮助我们建立更灵活的工作发布流和构建模型。
当定义 profile 时,你必须指定 inherits 用于说明当配置缺失时,该 profile 要从哪个 profile 那里继承配置。
例如,我们想在 release profile 的基础上增加 LTO 优化,那么可以在 Cargo.toml 中添加如下内容:
[profile.release-lto]
inherits = "release"
lto = true
然后在构建时使用 --profile 来指定想要选择的自定义 profile :
$ cargo build --profile release-lto
与默认的 profile 相同,自定义 profile 的编译结果也存放在 target/ 下的同名目录中,例如 --profile release-lto 的输出结果存储在 target/release-lto 中。
选择 profile
- 默认使用
dev:cargo build,cargo rustc,cargo check, 和cargo run - 默认使用
test:cargo test - 默认使用
bench:cargo bench - 默认使用
release:cargo install,cargo build --release,cargo run --release - 使用自定义 profile:
cargo build --profile release-lto
profile 设置
下面我们来看看 profile 中可以进行哪些优化设置。
opt-level
该字段用于控制 -C opt-level 标志的优化级别。更高的优化级别往往意味着运行更快的代码,但是也意味着更慢的编译速度。
同时,更高的编译级别甚至会造成编译代码的改变和再排列,这会为 debug 带来更高的复杂度。
opt-level 支持的选项包括:
0: 无优化1: 基本优化2: 一些优化3: 全部优化- "s": 优化输出的二进制文件的大小
- "z": 优化二进制文件大小,但也会关闭循环向量化
我们非常推荐你根据自己的需求来找到最适合的优化级别(例如,平衡运行和编译速度)。而且有一点值得注意,有的时候优化级别和性能的关系可能会出乎你的意料之外,例如 3 比 2 更慢,再比如 "s" 并没有让你的二进制文件变得更小。
而且随着 rustc 版本的更新,你之前的配置也可能要随之变化,总之,为项目的热点路径做好基准性能测试是不错的选择,不然总不能每次都手动重写代码来测试吧 :)
如果想要了解更多,可以参考 rustc 文档,这里有更高级的优化技巧。
debug
debug 控制 -C debuginfo 标志,而后者用于控制最终二进制文件输出的 debug 信息量。
支持的选项包括:
0或false:不输出任何 debug 信息1: 行信息2: 完整的 debug 信息
split-debuginfo
split-debuginfo 控制 -C split-debuginfo 标志,用于决定输出的 debug 信息是存放在二进制可执行文件里还是邻近的文件中。
debug-assertions
该字段控制 -C debug-assertions 标志,可以开启或关闭其中一个条件编译选项: cfg(debug_assertions)。
debug-assertion 会提供运行时的检查,该检查只能用于 debug 模式,原因是对于 release 来说,这种检查的成本较为高昂。
大家熟悉的 debug_assert! 宏也是通过该标志开启的。
支持的选项包括 :
true: 开启false: 关闭
overflow-checks
用于控制 -C overflow-checks 标志,该标志可以控制运行时的整数溢出行为。当开启后,整数溢出会导致 panic。
支持的选项包括 :
true: 开启false: 关闭
lto
lto 用于控制 -C lto 标志,而后者可以控制 LLVM 的链接时优化( link time optimizations )。通过对整个程序进行分析,并以增加链接时间为代价,LTO 可以生成更加优化的代码。
支持的选项包括:
false: 只会对代码生成单元中的本地包进行"thin" LTO优化,若代码生成单元数为 1 或者opt-level为 0,则不会进行任何 LTO 优化true或"fat":对依赖图中的所有包进行"fat" LTO优化"thin":对依赖图的所有包进行"thin" LTO,相比"fat"来说,它仅牺牲了一点性能,但是换来了链接时间的可观减少off: 禁用 LTO
如果大家想了解跨语言 LTO,可以看下 -C linker-plugin-lto 标志。
panic
panic 控制 -C panic 标志,它可以控制 panic 策略的选择。
支持的选项包括:
"unwind": 遇到 panic 后对栈进行展开( unwind )"abort": 遇到 panic 后直接停止程序
当设置为 "unwind" 时,具体的栈展开信息取决于特定的平台,例如 NVPTX 不支持 unwind,因此程序只能 "abort"。
测试、基准性能测试、构建脚本和过程宏会忽略 panic 设置,目前来说它们要求是 "unwind",如果大家希望修改成 "abort",可以看看 panic-abort-tests 。
另外,当你使用 "abort" 策略且在执行测试时,由于上述的要求,除了测试代码外,所有的依赖库也会忽略该 "abort" 设置而使用 "unwind" 策略。
incremental
incremental 控制 -C incremental 标志,用于开启或关闭增量编译。开启增量编译时,rustc 会将必要的信息存放到硬盘中( target 目录中 ),当下次编译时,这些信息可以被复用以改善编译时间。
支持的选项包括:
true: 启用false: 关闭
增量编译只能用于工作空间的成员和通过 path 引入的本地依赖。
大家还可以通过环境变量 CARGO_INCREMENTAL 或 Cargo 配置 build.incremental 在全局对 incremental 进行覆盖。
codegen-units
codegen-units 控制 -C codegen-units 标志,可以指定一个包会被分隔为多少个代码生成单元。更多的代码生成单元会提升代码的并行编译速度,但是可能会降低运行速度。
对于增量编译,默认值是 256,非增量编译是 16。
r-path
用于控制 -C rpath标志,可以控制 rpath 的启用与关闭。
rpath 代表硬编码到二进制可执行文件或库文件中的运行时代码搜索(runtime search path),动态链接库的加载器就通过它来搜索所需的库。
默认 profile
dev
dev profile 往往用于开发和 debug,cargo build 或 cargo run 默认使用的就是 dev profile,cargo build --debug 也是。
注意:
devprofile 的结果并没有输出到target/dev同名目录下,而是target/debug,这是历史遗留问题
默认的 dev profile 设置如下:
[profile.dev]
opt-level = 0
debug = true
split-debuginfo = '...' # Platform-specific.
debug-assertions = true
overflow-checks = true
lto = false
panic = 'unwind'
incremental = true
codegen-units = 256
rpath = false
release
release 往往用于预发/生产环境或性能测试,以下命令使用的就是 release profile:
cargo build --releasecargo run --releasecargo install
默认的 release profile 设置如下:
[profile.release]
opt-level = 3
debug = false
split-debuginfo = '...' # Platform-specific.
debug-assertions = false
overflow-checks = false
lto = false
panic = 'unwind'
incremental = false
codegen-units = 16
rpath = false
test
该 profile 用于构建测试,它的设置是继承自 dev
bench
bench profile 用于构建基准测试 benchmark,它的设计默认继承自 release
构建本身依赖
默认情况下,所有的 profile 都不会对构建过程本身所需的依赖进行优化,构建过程本身包括构建脚本、过程宏。
默认的设置是:
[profile.dev.build-override]
opt-level = 0
codegen-units = 256
[profile.release.build-override]
opt-level = 0
codegen-units = 256
如果是自定义 profile,那它会自动从当前正在使用的 profile 继承相应的设置,但不会修改。
重写 profile
我们还可以对特定的包使用的 profile 进行重写(override):
# `foo` package 将使用 -Copt-level=3 标志.
[profile.dev.package.foo]
opt-level = 3
这里的 package 名称实际上是一个 Package ID,因此我们还可以通过版本号来选择: [profile.dev.package."foo:2.1.0"]。
如果要为所有依赖包重写(不包括工作空间的成员):
[profile.dev.package."*"]
opt-level = 2
为构建脚本、过程宏和它们的依赖重写:
[profile.dev.build-override]
opt-level = 3
注意:如果一个依赖同时被正常代码和构建脚本所使用,当
--target没有指定时,Cargo 只会构建该依赖一次。但是当使用了
build-override后,该依赖会被构建两次,一次为正常代码,一次为构建脚本,因此会增加一些编译时间
重写的优先级按以下顺序执行(第一个匹配获胜):
[profile.dev.package.name],指定名称进行重写[profile.dev.package."*"],对所有非工作空间成员的 package 进行重写[profile.dev.build-override],对构建脚本、过程宏及它们的依赖进行重写[profile.dev]- Cargo 内置的默认值
重写无法使用 panic、lto 或 rpath 设置。
通过 config.toml 对 Cargo 进行配置
Cargo 相关的配置有两种,第一种是对自身进行配置,第二种是对指定的项目进行配置,关于后者请查看 Cargo.toml 清单。对于普通用户而言第二种才是我们最常使用的。
本文讲述的是如何对 Cargo 相关的工具进行配置,该配置中的部分内容可能会覆盖掉 Cargo.toml 中对应的部分,例如关于 profile 的内容。
层级结构
在前面我们已经见识过如何为 Cargo 进行全局配置:$HOME/.cargo/config.toml,事实上,还支持在一个 package 内对它进行配置。
总体原则是:Cargo 会顺着当前目录往上查找,直到找到目标配置文件。例如我们在目录 /projects/foo/bar/baz 下调用 Cargo 命令,那查找路径如下所示:
/projects/foo/bar/baz/.cargo/config.toml/projects/foo/bar/.cargo/config.toml/projects/foo/.cargo/config.toml/projects/.cargo/config.toml/.cargo/config.toml$CARGO_HOME/config.toml默认是 :- Windows:
%USERPROFILE%\.cargo\config.toml - Unix:
$HOME/.cargo/config.toml
- Windows:
有了这种机制,我们既可以在全局中设置默认的配置,又可以每个包都设定独立的配置,甚至还能做版本控制。
如果一个 key 在多个配置中出现,那这些 key 只会保留一个:最靠近 Cargo 执行目录的配置文件中的 key 的值将被最终使用(因此, HOME 下的都是最低优先级)。需要注意的是,如果 key 的值是数组,那相应的值将被合并( join )。
对于工作空间而言,Cargo 的搜索策略是从 root 开始,对于内部成员中包含的 .cargo.toml 会自动忽略。例如一个工作空间拥有两个成员,每个成员都有配置文件: /projects/foo/bar/baz/mylib/.cargo/config.toml 和 /projects/foo/bar/baz/mybin/.cargo/config.toml,但是 Cargo 并不会读取它们而是从工作空间的根( /projects/foo/bar/baz/ )开始往上查找。
注意:Cargo 还支持没有
.toml后缀的.cargo/config文件。对于.toml的支持是从 Rust 1.39 版本开始,同时也是目前最推荐的方式。但若同时存在有后缀和无后缀的文件,Cargo 将使用无后缀的!
配置文件概览
下面是一个完整的配置文件,并对常用的选项进行了翻译,大家可以参考下:
paths = ["/path/to/override"] # 覆盖 `Cargo.toml` 中通过 path 引入的本地依赖
[alias] # 命令别名
b = "build"
c = "check"
t = "test"
r = "run"
rr = "run --release"
space_example = ["run", "--release", "--", "\"command list\""]
[build]
jobs = 1 # 并行构建任务的数量,默认等于 CPU 的核心数
rustc = "rustc" # rust 编译器
rustc-wrapper = "…" # 使用该 wrapper 来替代 rustc
rustc-workspace-wrapper = "…" # 为工作空间的成员使用 该 wrapper 来替代 rustc
rustdoc = "rustdoc" # 文档生成工具
target = "triple" # 为 target triple 构建 ( `cargo install` 会忽略该选项)
target-dir = "target" # 存放编译输出结果的目录
rustflags = ["…", "…"] # 自定义flags,会传递给所有的编译器命令调用
rustdocflags = ["…", "…"] # 自定义flags,传递给 rustdoc
incremental = true # 是否开启增量编译
dep-info-basedir = "…" # path for the base directory for targets in depfiles
pipelining = true # rustc pipelining
[doc]
browser = "chromium" # `cargo doc --open` 使用的浏览器,
# 可以通过 `BROWSER` 环境变量进行重写
[env]
# Set ENV_VAR_NAME=value for any process run by Cargo
ENV_VAR_NAME = "value"
# Set even if already present in environment
ENV_VAR_NAME_2 = { value = "value", force = true }
# Value is relative to .cargo directory containing `config.toml`, make absolute
ENV_VAR_NAME_3 = { value = "relative/path", relative = true }
[cargo-new]
vcs = "none" # 所使用的 VCS ('git', 'hg', 'pijul', 'fossil', 'none')
[http]
debug = false # HTTP debugging
proxy = "host:port" # HTTP 代理,libcurl 格式
ssl-version = "tlsv1.3" # TLS version to use
ssl-version.max = "tlsv1.3" # 最高支持的 TLS 版本
ssl-version.min = "tlsv1.1" # 最小支持的 TLS 版本
timeout = 30 # HTTP 请求的超时时间,秒
low-speed-limit = 10 # 网络超时阈值 (bytes/sec)
cainfo = "cert.pem" # path to Certificate Authority (CA) bundle
check-revoke = true # check for SSL certificate revocation
multiplexing = true # HTTP/2 multiplexing
user-agent = "…" # the user-agent header
[install]
root = "/some/path" # `cargo install` 安装到的目标目录
[net]
retry = 2 # 网络重试次数
git-fetch-with-cli = true # 是否使用 `git` 命令来执行 git 操作
offline = true # 不能访问网络
[patch.<registry>]
# Same keys as for [patch] in Cargo.toml
[profile.<name>] # profile 配置,详情见"如何在 Cargo.toml 中配置 profile" : https://course.rs/cargo/reference/profiles.html#profile设置
opt-level = 0
debug = true
split-debuginfo = '...'
debug-assertions = true
overflow-checks = true
lto = false
panic = 'unwind'
incremental = true
codegen-units = 16
rpath = false
[profile.<name>.build-override]
[profile.<name>.package.<name>]
[registries.<name>] # 设置其它的注册服务: https://course.rs/cargo/reference/specify-deps.html#从其它注册服务引入依赖包
index = "…" # 注册服务索引列表的 URL
token = "…" # 连接注册服务所需的鉴权 token
[registry]
default = "…" # 默认的注册服务名称: crates.io
token = "…"
[source.<name>] # 注册服务源和替换source definition and replacement
replace-with = "…" # 使用给定的 source 来替换当前的 source,例如使用科大源来替换crates.io源以提升国内的下载速度:[source.crates-io] replace-with = 'ustc'
directory = "…" # path to a directory source
registry = "…" # 注册源的 URL ,例如科大源: [source.ustc] registry = "git://mirrors.ustc.edu.cn/crates.io-index"
local-registry = "…" # path to a local registry source
git = "…" # URL of a git repository source
branch = "…" # branch name for the git repository
tag = "…" # tag name for the git repository
rev = "…" # revision for the git repository
[target.<triple>]
linker = "…" # linker to use
runner = "…" # wrapper to run executables
rustflags = ["…", "…"] # custom flags for `rustc`
[target.<cfg>]
runner = "…" # wrapper to run executables
rustflags = ["…", "…"] # custom flags for `rustc`
[target.<triple>.<links>] # `links` build script override
rustc-link-lib = ["foo"]
rustc-link-search = ["/path/to/foo"]
rustc-flags = ["-L", "/some/path"]
rustc-cfg = ['key="value"']
rustc-env = {key = "value"}
rustc-cdylib-link-arg = ["…"]
metadata_key1 = "value"
metadata_key2 = "value"
[term]
verbose = false # whether cargo provides verbose output
color = 'auto' # whether cargo colorizes output
progress.when = 'auto' # whether cargo shows progress bar
progress.width = 80 # width of progress bar
环境变量
除了 config.toml 配置文件,我们还可以使用环境变量的方式对 Cargo 进行配置。
配置文件的中的 key foo.bar 对应的环境变量形式为 CARGO_FOO_BAR,其中的.、- 被转换成 _,且字母都变成大写的。例如,target.x86_64-unknown-linux-gnu.runner key 转换成环境变量后变成 CARGO_TARGET_X86_64_UNKNOWN_LINUX_GNU_RUNNER。
就优先级而言,环境变量是比配置文件更高的。除了上面的机制,Cargo 还支持一些预定义的环境变量。
官方 Cargo Book 中本文的内容还有很多,但是剩余内容对于绝大多数用户都用不到,因此我们并没有涵盖其中。
发布到 crates.io
如果你想要把自己的开源项目分享给全世界,那最好的办法自然是 GitHub。但如果是 Rust 的库,那除了发布到 GitHub 外,我们还可以将其发布到 crates.io 上,然后其它用户就可以很简单的对其进行引用。
注意:发布包到
crates.io后,特定的版本无法被覆盖,要发布就必须使用新的版本号,代码也无法被删除!
首次发布之前
首先,我们需要一个账号:访问 crates.io 的主页,然后在右上角使用 GitHub 账户登陆,接着访问你的账户设置页面,进入到 API Tokens 标签页下,生成新的 Token,并使用该 Token 在终端中进行登录:
$ cargo login abcdefghijklmnopqrstuvwxyz012345
该命令将告诉 Cargo 你的 API Token,然后将其存储在本地的 ~/.cargo/credentials.toml 文件中。
注意:你需要妥善保管好 API Token,并且不要告诉任何人,一旦泄漏,请撤销( Revoke )并重新生成。
发布包之前
crates.io 上的包名遵循先到先得的方式:一旦你想要的包名已经被使用,那么你就得换一个不同的包名。
在发布之前,确保 Cargo.toml 中以下字段已经被设置:
你还可以设置关键字和类别等元信息,让包更容易被其他人搜索发现,虽然它们不是必须的。
如果你发布的是一个依赖库,那么你可能需要遵循相关的命名规范和 API Guidlines.
打包
下一步就是将你的项目进行打包,然后上传到 crates.io。为了实现这个目的,我们可以使用 cargo publish 命令,该命令执行了以下步骤:
- 对项目进行一些验证
- 将源代码压缩到
.crate文件中 - 将
.crate文件解压并放入到临时的目录中,并验证解压出的代码可以顺利编译 - 上传
.crate文件到crates.io - 注册服务会对上传的包进行一些额外的验证,然后才会添加它到注册服务列表中
在发布之前,我们推荐你先运行 cargo publish --dry-run (或 cargo package ) 命令来确保代码没有 warning 或错误。
$ cargo publish --dry-run
你可以在 target/package 目录下观察生成的 .crate 文件。例如,目前 crates.io 要求该文件的大小不能超过 10MB,你可以通过手动检查该文件的大小来确保不会无意间打包进一些较大的资源文件,比如测试数据、网站文档或生成的代码等。我们还可以使用以下命令来检查其中包含的文件:
$ cargo package --list
当打包时,Cargo 会自动根据版本控制系统的配置来忽略指定的文件,例如 .gitignore。除此之外,你还可以通过 exclude 来排除指定的文件:
[package]
# ...
exclude = [
"public/assets/*",
"videos/*",
]
如果想要显式地将某些文件包含其中,可以使用 include,但是需要注意的是,这个 key 一旦设置,那 exclude 就将失效:
[package]
# ...
include = [
"**/*.rs",
"Cargo.toml",
]
上传包
准备好后,我们就可以正式来上传指定的包了,在根目录中运行:
$ cargo publish
就是这么简单,恭喜你,完成了第一个包的发布!
发布已上传包的新版本
绝大多数时候,我们并不是在发布新包,而是发布已经上传过的包的新版本。
为了实现这一点,只需修改 Cargo.toml 中的 version 字段 ,但需要注意:版本号需要遵循 semver 规则。
然后再次使用 cargo publish 就可以上传新的版本了。
管理 crates.io 上的包
目前来说,管理包更多地是通过 cargo 命令而不是在线管理,下面是一些你可以使用的命令。
cargo yank
有的时候你会遇到发布的包版本实际上并不可用(例如语法错误,或者忘记包含一个文件等),对于这种情况,Cargo 提供了 yank 命令:
$ cargo yank --vers 1.0.1
$ cargo yank --vers 1.0.1 --undo
该命令并不能删除任何代码,例如如果你上传了一段隐私内容,你需要的是立刻重置它们,而不是使用 cargo yank。
yank 能做到的就是让其它人不能再使用这个版本作为依赖,但是现存的依赖依然可以继续工作。crates.io 的一个主要目标就是作为一个不会随着时间变化的永久性包存档,但删除某个版本显然违背了这个目标。
cargo owner
一个包可能会有多个主要开发者,甚至维护者 maintainer 都会发生变更。目前来说,只有包的 owner 才能发布新的版本,但是一个 owner 可以指定其它的用户为 owner:
$ cargo owner --add github-handle
$ cargo owner --remove github-handle
$ cargo owner --add github:rust-lang:owners
$ cargo owner --remove github:rust-lang:owners
命令中使用的 ownerID 必须是 GitHub 用户名或 Team 名。
一旦一个用户 B 通过 --add 被加入到 owner 列表中,他将拥有该包相关的所有权利。例如发布新版本、yank 一个版本,还能增加和移除 owner,包含添加 B 为 owner 的 A 都可以被移除!
因此,我们必须严肃的指出:不要将你不信任的人添加为 owner ! 免得哪天反目成仇后,他把你移除了 - , -
但是对于 Team 又有所不同,通过 -add 添加的 GitHub Team owner,只拥有受限的权利。它们可以发布或 yank 某个版本,但是他们不能添加或移除 owner!总之,Team 除了可以很方便的管理所有者分组的同时,还能防止一些未知的恶意。
如果大家在添加 team 时遇到问题,可以看看官方的相关文档,由于绝大多数人都无需此功能,因此这里不再详细展开。
构建脚本( Build Scripts)
一些项目希望编译第三方的非 Rust 代码,例如 C 依赖库;一些希望链接本地或者基于源码构建的 C 依赖库;还有一些项目需要功能性的工具,例如在构建之间执行一些代码生成的工作等。
对于这些目标,社区已经提供了一些工具来很好的解决,Cargo 并不想替代它们,但是为了给用户带来一些便利,Cargo 提供了自定义构建脚本的方式,来帮助用户更好的解决类似的问题。
build.rs
若要创建构建脚本,我们只需在项目的根目录下添加一个 build.rs 文件即可。这样一来, Cargo 就会先编译和执行该构建脚本,然后再去构建整个项目。
以下是一个非常简单的脚本示例:
fn main() { // 以下代码告诉 Cargo ,一旦指定的文件 `src/hello.c` 发生了改变,就重新运行当前的构建脚本 println!("cargo:rerun-if-changed=src/hello.c"); // 使用 `cc` 来构建一个 C 文件,然后进行静态链接 cc::Build::new() .file("src/hello.c") .compile("hello"); }
关于构建脚本的一些使用场景如下:
- 构建 C 依赖库
- 在操作系统中寻找指定的 C 依赖库
- 根据某个说明描述文件生成一个 Rust 模块
- 执行一些平台相关的配置
下面的部分我们一起来看看构建脚本具体是如何工作的,然后在下个章节中还提供了一些关于如何编写构建脚本的示例。
构建脚本的生命周期
在项目被构建之前,Cargo 会将构建脚本编译成一个可执行文件,然后运行该文件并执行相应的任务。
在运行的过程中,脚本可以使用之前 println 的方式跟 Cargo 进行通信:通信内容是以 cargo: 开头的格式化字符串。
需要注意的是,Cargo 也不是每次都会重新编译构建脚本,只有当脚本的内容或依赖发生变化时才会。默认情况下,任何文件变化都会触发重新编译,如果你希望对其进行定制,可以使用 rerun-if命令,后文会讲。
在构建脚本成功执行后,我们的项目就会开始进行编译。如果构建脚本的运行过程中发生错误,脚本应该通过返回一个非 0 码来立刻退出,在这种情况下,构建脚本的输出会被打印到终端中。
构建脚本的输入
我们可以通过环境变量的方式给构建脚本提供一些输入值,除此之外,构建脚本所在的当前目录也可以。
构建脚本的输出
构建脚本如果会产出文件,那么这些文件需要放在统一的目录中,该目录可以通过 OUT_DIR 环境变量来指定,构建脚本不应该修改该目录之外的任何文件!
在之前提到过,构建脚本可以通过 println! 输出内容跟 Cargo 进行通信:Cargo 会将每一行带有 cargo: 前缀的输出解析为一条指令,其它的输出内容会自动被忽略。
通过 println! 输出的内容在构建过程中默认是隐藏的,如果大家想要在终端中看到这些内容,你可以使用 -vv 来调用,以下 build.rs :
fn main() { println!("hello, build.rs"); }
将输出:
$ cargo run -vv
[study_cargo 0.1.0] hello, build.rs
构建脚本打印到标准输出 stdout 的所有内容将保存在文件 target/debug/build/<pkg>/output 中 (具体的位置可能取决于你的配置),stderr 的输出内容也将保存在同一个目录中。
以下是 Cargo 能识别的通信指令以及简介,如果大家希望深入了解每个命令,可以点击具体的链接查看官方文档的说明。
cargo:rerun-if-changed=PATH— 当指定路径的文件发生变化时,Cargo 会重新运行脚本cargo:rerun-if-env-changed=VAR— 当指定的环境变量发生变化时,Cargo 会重新运行脚本cargo:rustc-link-arg=FLAG– 将自定义的 flags 传给 linker,用于后续的基准性能测试 benchmark、 可执行文件 binary,、cdylib包、示例和测试cargo:rustc-link-arg-bin=BIN=FLAG– 自定义的 flags 传给 linker,用于可执行文件BINcargo:rustc-link-arg-bins=FLAG– 自定义的 flags 传给 linker,用于可执行文件cargo:rustc-link-arg-tests=FLAG– 自定义的 flags 传给 linker,用于测试cargo:rustc-link-arg-examples=FLAG– 自定义的 flags 传给 linker,用于示例cargo:rustc-link-arg-benches=FLAG– 自定义的 flags 传给 linker,用于基准性能测试 benchmarkcargo:rustc-cdylib-link-arg=FLAG— 自定义的 flags 传给 linker,用于cdylib包cargo:rustc-link-lib=[KIND=]NAME— 告知 Cargo 通过-l去链接一个指定的库,往往用于链接一个本地库,通过 FFIcargo:rustc-link-search=[KIND=]PATH— 告知 Cargo 通过-L将一个目录添加到依赖库的搜索路径中cargo:rustc-flags=FLAGS— 将特定的 flags 传给编译器cargo:rustc-cfg=KEY[="VALUE"]— 开启编译时cfg设置cargo:rustc-env=VAR=VALUE— 设置一个环境变量cargo:warning=MESSAGE— 在终端打印一条 warning 信息cargo:KEY=VALUE—links脚本使用的元数据
构建脚本的依赖
构建脚本也可以引入其它基于 Cargo 的依赖包,只需要在 Cargo.toml 中添加或修改以下内容:
[build-dependencies]
cc = "1.0.46"
需要这么配置的原因在于构建脚本无法使用通过 [dependencies] 或 [dev-dependencies] 引入的依赖包,因为构建脚本的编译运行过程跟项目本身的编译过程是分离的的,且前者先于后者发生。同样的,我们项目也无法使用 [build-dependencies] 中的依赖包。
大家在引入依赖的时候,需要仔细考虑它会给编译时间、开源协议和维护性等方面带来什么样的影响。如果你在 [build-dependencies] 和 [dependencies] 引入了同样的包,这种情况下 Cargo 也许会对依赖进行复用,也许不会,例如在交叉编译时,如果不会,那编译速度自然会受到不小的影响。
links
在 Cargo.toml 中可以配置 package.links 选项,它的目的是告诉 Cargo 当前项目所链接的本地库,同时提供了一种方式可以在项目构建脚本之间传递元信息。
[package]
# ...
links = "foo"
以上配置表明项目链接到一个 libfoo 本地库,当使用 links 时,项目必须拥有一个构建脚本,并且该脚本需要使用 rustc-link-lib 指令来链接目标库。
Cargo 要求一个本地库最多只能被一个项目所链接,换而言之,你无法让两个项目链接到同一个本地库,但是有一种方法可以降低这种限制,感兴趣的同学可以看看官方文档。
假设 A 项目的构建脚本生成任意数量的 kv 形式的元数据,那这些元数据将传递给 A 用作依赖包的项目的构建脚本。例如,如果包 bar 依赖于 foo,当 foo 生成 key=value 形式的构建脚本元数据时,那么 bar 的构建脚本就可以通过环境变量的形式使用该元数据:DEP_FOO_KEY=value。
需要注意的是,该元数据只能传给直接相关者,对于间接的,例如依赖的依赖,就无能为力了。
覆盖构建脚本
当 Cargo.toml 设置了 links 时, Cargo 就允许我们使用自定义库对现有的构建脚本进行覆盖。在 Cargo 使用的配置文件中添加以下内容:
[target.x86_64-unknown-linux-gnu.foo]
rustc-link-lib = ["foo"]
rustc-link-search = ["/path/to/foo"]
rustc-flags = "-L /some/path"
rustc-cfg = ['key="value"']
rustc-env = {key = "value"}
rustc-cdylib-link-arg = ["…"]
metadata_key1 = "value"
metadata_key2 = "value"
增加这个配置后,在未来,一旦我们的某个项目声明了它链接到 foo ,那项目的构建脚本将不会被编译和运行,替代的是这里的配置将被使用。
warning, rerun-if-changed 和 rerun-if-env-changed 这三个 key 在这里不应该被使用,就算用了也会被忽略。
构建脚本示例
下面我们通过一些例子来说明构建脚本该如何使用。社区中也提供了一些构建脚本的常用功能,例如:
- bindgen, 自动生成 Rust -> C 的 FFI 绑定
- cc, 编译 C/C++/汇编
- pkg-config, 使用
pkg-config工具检测系统库 - cmake, 运行
cmake来构建一个本地库 - autocfg, rustc_version, version_check,这些包提供基于
rustc的当前版本来实现条件编译的方法
代码生成
一些项目需要在编译开始前先生成一些代码,下面我们来看看如何在构建脚本中生成一个库调用。
先来看看项目的目录结构:
.
├── Cargo.toml
├── build.rs
└── src
└── main.rs
1 directory, 3 files
Cargo.toml 内容如下:
# Cargo.toml
[package]
name = "hello-from-generated-code"
version = "0.1.0"
接下来,再来看看构建脚本的内容:
// build.rs use std::env; use std::fs; use std::path::Path; fn main() { let out_dir = env::var_os("OUT_DIR").unwrap(); let dest_path = Path::new(&out_dir).join("hello.rs"); fs::write( &dest_path, "pub fn message() -> &'static str { \"Hello, World!\" } " ).unwrap(); println!("cargo:rerun-if-changed=build.rs"); }
以上代码中有几点值得注意:
OUT_DIR环境变量说明了构建脚本的输出目录,也就是最终生成的代码文件的存放地址- 一般来说,构建脚本不应该修改
OUT_DIR之外的任何文件 - 这里的代码很简单,但是我们这是为了演示,大家完全可以生成更复杂、更实用的代码
return-if-changed指令告诉 Cargo 只有在脚本内容发生变化时,才能重新编译和运行构建脚本。如果没有这一行,项目的任何文件发生变化都会导致 Cargo 重新编译运行该构建脚本
下面,我们来看看 main.rs:
// src/main.rs include!(concat!(env!("OUT_DIR"), "/hello.rs")); fn main() { println!("{}", message()); }
这里才是体现真正技术的地方,我们联合使用 rustc 定义的 include! 以及 concat! 和 env! 宏,将生成的代码文件( hello.rs ) 纳入到我们项目的编译流程中。
例子虽然很简单,但是它清晰地告诉了我们该如何生成代码文件以及将这些代码文件纳入到编译中来,大家以后有需要只要回头看看即可。
构建本地库
有时,我们需要在项目中使用基于 C 或 C++ 的本地库,而这种使用场景恰恰是构建脚本非常擅长的。
例如,下面来看看该如何在 Rust 中调用 C 并打印 Hello, World。首先,来看看项目结构和 Cargo.toml:
.
├── Cargo.toml
├── build.rs
└── src
├── hello.c
└── main.rs
1 directory, 4 files
# Cargo.toml
[package]
name = "hello-world-from-c"
version = "0.1.0"
edition = "2021"
现在,我们还不会使用任何构建依赖,先来看看构建脚本:
// build.rs use std::process::Command; use std::env; use std::path::Path; fn main() { let out_dir = env::var("OUT_DIR").unwrap(); Command::new("gcc").args(&["src/hello.c", "-c", "-fPIC", "-o"]) .arg(&format!("{}/hello.o", out_dir)) .status().unwrap(); Command::new("ar").args(&["crus", "libhello.a", "hello.o"]) .current_dir(&Path::new(&out_dir)) .status().unwrap(); println!("cargo:rustc-link-search=native={}", out_dir); println!("cargo:rustc-link-lib=static=hello"); println!("cargo:rerun-if-changed=src/hello.c"); }
首先,构建脚本将我们的 C 文件通过 gcc 编译成目标文件,然后使用 ar 将该文件转换成一个静态库,最后告诉 Cargo 我们的输出内容在 out_dir 中,编译器要在这里搜索相应的静态库,最终通过 -l static-hello 标志将我们的项目跟 libhello.a 进行静态链接。
但是这种硬编码的解决方式有几个问题:
gcc命令的跨平台性是受限的,例如 Windows 下就难以使用它,甚至于有些 Unix 系统也没有gcc命令,同样,ar也有这个问题- 这些命令往往不会考虑交叉编译的问题,如果我们要为 Android 平台进行交叉编译,那么
gcc很可能无法输出一个 ARM 的可执行文件
但是别怕,构建依赖 [build-dependencies] 解君忧:社区中已经有现成的解决方案,可以让这种任务得到更容易的解决。例如文章开头提到的 cc 包。首先在 Cargo.toml 中为构建脚本引入 cc 依赖:
[build-dependencies]
cc = "1.0"
然后重写构建脚本使用 cc :
// build.rs fn main() { cc::Build::new() .file("src/hello.c") .compile("hello"); println!("cargo:rerun-if-changed=src/hello.c"); }
不得不说,Rust 社区的大腿就是粗,代码立刻简洁了很多,最重要的是:可移植性、稳定性等头疼的问题也得到了一并解决。
简单来说,cc 包将构建脚本使用 C 的需求进行了抽象:
cc会针对不同的平台调用合适的编译器:windows 下调用 MSVC, MinGW 下调用 gcc, Unix 平台调用 cc 等- 在编译时会考虑到平台因素,例如将合适的标志传给正在使用的编译器
- 其它环境变量,例如
OPT_LEVEL、DEBUG等会自动帮我们处理 - 标准输出和
OUT_DIR的位置也会被cc所处理
如上所示,与其在每个构建脚本中复制粘贴相同的代码,将尽可能多的功能通过构建依赖来完成是好得多的选择。
再回到例子中,我们来看看 src 下的项目文件:
// src/hello.c
#include <stdio.h>
void hello() {
printf("Hello, World!\n");
}
// src/main.rs // 注意,这里没有再使用 `#[link]` 属性。我们把选择使用哪个 link 的责任交给了构建脚本,而不是在这里进行硬编码 extern { fn hello(); } fn main() { unsafe { hello(); } }
至此,这个简单的例子已经完成,我们学到了该如何使用构建脚本来构建 C 代码,当然又一次被构建脚本和构建依赖的强大所震撼!但控制下情绪,因为构建脚本还能做到更多。
链接系统库
当一个 Rust 包想要链接一个本地系统库时,如何实现平台透明化,就成了一个难题。
例如,我们想使用在 Unix 系统中的 zlib 库,用于数据压缩的目的。实际上,社区中的 libz-sys 包已经这么做了,但是出于演示的目的,我们来看看该如何手动完成,当然,这里只是简化版的,想要看完整代码,见这里。
为了更简单的定位到目标库的位置,可以使用 pkg-config 包,该包使用系统提供的 pkg-config 工具来查询库的信息。它会自动告诉 Cargo 该如何链接到目标库。
先修改 Cargo.toml:
# Cargo.toml
[package]
name = "libz-sys"
version = "0.1.0"
edition = "2021"
links = "z"
[build-dependencies]
pkg-config = "0.3.16"
这里的 links = "z" 用于告诉 Cargo 我们想要链接到 libz 库,在下文还有更多的示例。
构建脚本也很简单:
// build.rs fn main() { pkg_config::Config::new().probe("zlib").unwrap(); println!("cargo:rerun-if-changed=build.rs"); }
下面再在代码中使用:
#![allow(unused)] fn main() { // src/lib.rs use std::os::raw::{c_uint, c_ulong}; extern "C" { pub fn crc32(crc: c_ulong, buf: *const u8, len: c_uint) -> c_ulong; } #[test] fn test_crc32() { let s = "hello"; unsafe { assert_eq!(crc32(0, s.as_ptr(), s.len() as c_uint), 0x3610a686); } } }
代码很清晰,也很简洁,这里就不再过多介绍,运行 cargo build --vv来看看部分结果( 系统中需要已经安装 libz 库):
[libz-sys 0.1.0] cargo:rustc-link-search=native=/usr/lib
[libz-sys 0.1.0] cargo:rustc-link-lib=z
[libz-sys 0.1.0] cargo:rerun-if-changed=build.rs
非常棒,pkg-config 帮助我们找到了目标库,并且还告知了 Cargo 所有需要的信息!
实际使用中,我们需要做的比上面的代码更多,例如 libz-sys 包会先检查环境变量 LIBZ_SYS_STATIC 或者 static feature,然后基于源码去构建 libz,而不是直接去使用系统库。
使用其它 sys 包
本例中,一起来看看该如何使用 libz-sys 包中的 zlib 来创建一个 C 依赖库。
若你有一个依赖于 zlib 的库,那可以使用 libz-sys 来自动发现或构建该库。这个功能对于交叉编译非常有用,例如 Windows 下往往不会安装 zlib。
libz-sys 通过设置 include 元数据来告知其它包去哪里找到 zlib 的头文件,然后我们的构建脚本可以通过 DEP_Z_INCLUDE 环境变量来读取 include 元数据( 关于元数据的传递。
# Cargo.toml
[package]
name = "zuser"
version = "0.1.0"
edition = "2021"
[dependencies]
libz-sys = "1.0.25"
[build-dependencies]
cc = "1.0.46"
通过包含 libz-sys,确保了最终只会使用一个 libz 库,并且给了我们在构建脚本中使用的途径:
// build.rs fn main() { let mut cfg = cc::Build::new(); cfg.file("src/zuser.c"); if let Some(include) = std::env::var_os("DEP_Z_INCLUDE") { cfg.include(include); } cfg.compile("zuser"); println!("cargo:rerun-if-changed=src/zuser.c"); }
由于 libz-sys 帮我们完成了繁重的相关任务,C 代码只需要包含 zlib 的头文件即可,甚至于它还能在没有安装 zlib 的系统上找到头文件:
// src/zuser.c
#include "zlib.h"
// … 在剩余的代码中使用 zlib
条件编译
构建脚本可以通过发出 rustc-cfg 指令来开启编译时的条件检查。在本例中,一起来看看 openssl 包是如何支持多版本的 OpenSSL 库的。
openssl-sys 包对 OpenSSL 库进行了构建和链接,支持多个不同的实现(例如 LibreSSL )和多个不同的版本。它也使用了 links 配置,这样就可以给其它构建脚本传递所需的信息。例如 version_number ,包含了检测到的 OpenSSL 库的版本号信息。openssl-sys 自己的构建脚本中有类似于如下的代码:
#![allow(unused)] fn main() { println!("cargo:version_number={:x}", openssl_version); }
该指令将 version_number 的信息通过环境变量 DEP_OPENSSL_VERSION_NUMBER 的方式传递给直接使用 openssl-sys 的项目。例如 openssl 包提供了更高级的抽象接口,并且它使用了 openssl-sys 作为依赖。openssl 的构建脚本会通过环境变量读取 openssl-sys 提供的版本号的信息,然后使用该版本号来生成一些 cfg:
#![allow(unused)] fn main() { // (portion of build.rs) if let Ok(version) = env::var("DEP_OPENSSL_VERSION_NUMBER") { let version = u64::from_str_radix(&version, 16).unwrap(); if version >= 0x1_00_01_00_0 { println!("cargo:rustc-cfg=ossl101"); } if version >= 0x1_00_02_00_0 { println!("cargo:rustc-cfg=ossl102"); } if version >= 0x1_01_00_00_0 { println!("cargo:rustc-cfg=ossl110"); } if version >= 0x1_01_00_07_0 { println!("cargo:rustc-cfg=ossl110g"); } if version >= 0x1_01_01_00_0 { println!("cargo:rustc-cfg=ossl111"); } } }
这些 cfg 可以跟 cfg 属性 或 cfg 宏一起使用以实现条件编译。例如,在 OpenSSL 1.1 中引入了 SHA3 的支持,那么我们就可以指定只有当版本号为 1.1 时,才包含并编译相关的代码:
#![allow(unused)] fn main() { // (portion of openssl crate) #[cfg(ossl111)] pub fn sha3_224() -> MessageDigest { unsafe { MessageDigest(ffi::EVP_sha3_224()) } } }
当然,大家在使用时一定要小心,因为这可能会导致生成的二进制文件进一步依赖当前的构建环境。例如,当二进制可执行文件需要在另一个操作系统中分发运行时,那它依赖的信息对于该操作系统可能是不存在的!
日志和监控
这几年 AIOps 特别火,但是你要是逮着一个运维问一下,他估计很难说出个所以然来,毕竟概念和现实往往是脱节的,前者的发展速度肯定远快于后者。
好在我大概了解这块儿领域,可以说智能化运维的核心就在于日志和监控,换而言之?何为智能,不就是基于已有的海量数据分析后进行决策吗?当然,你要说以前的知识库类型的运维决策也是智能,我也没办法杠: D
总之,不仅仅是对于开发者,对于整个技术链条的参与者,甚至包括老板,日志和监控都是开发实践中最最重要的一环。
详解日志
相比起监控,日志好理解的多:在某个时间点向指定的地方输出一条信息,里面记录着重要性、时间、地点和发生的事件,这就是日志。
注意,本文和 Rust 无关,我们争取从一个中立的角度去介绍何为日志
日志级别和输出位置
日志级别
日志级别是对基本的“滚动文本”式日志记录的一个重要补充。每条日志消息都会基于其重要性或严重程度分配到一个日志级别。例如,对于某个程序,“你的电脑着火了”是一个非常重要的消息,而“无法找到配置文件”的重要等级可能就低一些;但对于另外一些程序,"无法找到配置文件" 可能才是最严重的错误,会直接导致程序无法正常启动,而“电脑着火”? 我们可能会记录为一条 Debug 日志(参见下文) :D。
至于到底该如何定义日志级别,这是仁者见仁的事情,并没有一个约定俗成的方式,就连很多大公司,都无法保证自己的开发者严格按照它所制定的规则来输出日志。而下面是我认为的日志级别以及相关定义:
-
Fatal: 程序发生致命错误,祝你好运。这种错误往往来自于程序逻辑的严重异常,例如之前提到的“无法找到配置文件”,再比如无法分配足够的硬盘空间、内存不够用等。遇到这种错误,建议立即退出或者重启程序,然后记录下相应的错误信息
-
Error: 错误,一般指的是程序级别的错误或者严重的业务错误,但这种错误并不会影响程序的运行。一般的用户错误,例如用户名、密码错误等,不使用 Error 级别
-
Warn: 警告,说明这条记录信息需要注意,但是不确定是否发生了错误,因此需要相关的开发来辨别下。或者这条信息既不是错误,但是级别又没有低到 info 级别,就可以用 Warn 来给出警示。例如某条用户连接异常关闭、无法找到相关的配置只能使用默认配置、XX秒后重试等
-
Info: 信息,这种类型的日志往往用于记录程序的运行信息,例如用户操作或者状态的变化,再比如之前的用户名、密码错误,用户请求的开始和结束都可以记录为这个级别
-
Debug: 调试信息,顾名思义是给开发者用的,用于了解程序当前的详细运行状况, 例如用户请求详细信息跟踪、读取到的配置信息、连接握手发包(连接的建立和结束往往是 Info 级别),就可以记录为 Debug 信息
可以看出,日志级别很多,特别是 Debug 日志,如果在生产环境中开启,简直就是一场灾难,每秒几百上千条都很正常。因此我们需要控制日志的最低级别:将最低级别设置为 Info 时,意味着低于 Info 的日志都不会输出,对于上面的分级来说,Debug 日志将不会被输出。
有些开发为了让特定的日志在控制上显示更明显,还会为不同的级别使用不同颜色的文字。
输出位置
通常来说,日志可以输出两个地方:终端控制台和文件。对于前者,我们还有一个称呼标准输出,例如使用 println! 打印到终端的信息就是输出到标准输出中。
如果没有日志持久化的需求,你只是为了调试程序,建议输出到控制台即可。悄悄的说一句,我们还可以为不同的级别设定不同的输出位置,例如 Debug 日志输出到控制台,既方便开发查看,但又不会占用硬盘,而 Info 和 Warning 日志可以输出到文件 info.log 中,至于 Error、Fatal 则可以输出到 error.log 中。
但是如果大家以为只有输出到文件才能持久化日志,那你就错了,在后面的日志采集我们会详细介绍,先来看看日志查看。
日志查看
关于如何查看日志,相信大家都非常熟悉了,常用的方式有三种(事实上,可能也只有这三种):
- 在控制台查看,即可以直接查看输出到标准输出的日志,还可以使用 tail、cat、grep 等命令从日志文件中搜索查询或者以实时滚动的方式查看最新的日志
- 最简单的,进入到日志文件中,进行字符串搜索,或者从头到尾、从尾到头进行逐行查看
- 在可视化界面上查看,但是这个往往要配合日志采集工具,将日志采集到 ElasticSearch 或者其它搜索平台、数据中,然后再通过 kibana、grafana 等图形化服务进行搜索、查看,最重要的是可以进行日志的聚合统计,例如可以很方便的在 kibana 中查询满足指定条件的日志在某段时间内出现了多少次。
大家现在知道了,可视化,首先需要将日志集中采集起来,那么该如何采集日志呢?
日志采集
之前我们提到,不是只有输出到文件才能持久化日志,事实上,输出到控制台也能持久化日志。
其中的秘诀就在于使用一个日志采集工具去从控制台的标准输出读取日志数据,然后将读取到的数据发送到日志存储平台,例如 ElasticSearch,进行集中存储。当然,在存储前,还需要进行日志格式、数据的处理,以便只保留我们需要的格式和日志数据。
最典型的就是容器或容器云环境的日志采集,基本都是通过上面的方式进行的:容器中的进程将日志输出到标准输出,然后一个单独的日志采集服务直接读取标准输出中的日志,再通过网络发送到日志处理、存储的平台。大家发现了吗?这个流程完全不会在应用运行的本地或宿主机上存储任何日志,所以特别适合容器环境!
目前常用的日志采集工具有 filebeat、vector( Rust 开发,功能强大,性能非常高 ) 等,它们都是以 agent 的形式运行在你的应用程序旁边( 在同一个 pod 或虚拟机上 ),提供贴心的服务。
中心化日志存储
最后,我们再来简单介绍下日志存储。提到存储,首先不得不提的就是日志使用方式。
其实,除了 Debug 的时候,我们使用日志基本都是基于某个关键字进行搜索的,将日志存储在各台主机上的硬盘文件中,然后逐个去查询显然是非常非常低效的,最好的方式就是将日志集中收集上来后,存储在一个搜索平台中,例如 ElasticSearch。
当然,存储的时候肯定也不是简单的一行一行存储,而是需要将一条日志的多个关键词切取出来,然后以关键词索引的方式进行存储( 简化模型 ),这样我们就可以在后续使用时,通过关键词来搜索日志了。
日志门面 log
就如同 slf4j 是 Java 的日志门面库,log 也是 Rust 的日志门面库( 这不是我自己编的,官方用语: logging facade ),它目前由官方积极维护,因此大家可以放心使用。
使用方式很简单,只要在 Cargo.toml 中引入即可:
[dependencies]
log = "0.4"
日志门面不是说排场很大的意思,而是指相应的日志 API 已成为事实上的标准,会被其它日志框架所使用。通过这种统一的门面,开发者就可以不必再拘泥于日志框架的选择,未来大不了再换一个日志框架就是
既然是门面,log 自然定义了一套统一的日志特征和 API,将日志的操作进行了抽象。
Log 特征
例如,它定义了一个 Log 特征:
#![allow(unused)] fn main() { pub trait Log: Sync + Send { fn enabled(&self, metadata: &Metadata<'_>) -> bool; fn log(&self, record: &Record<'_>); fn flush(&self); } }
enabled用于判断某条带有元数据的日志是否能被记录,它对于log_enabled!宏特别有用log会记录record所代表的日志flush会将缓存中的日志数据刷到输出中,例如标准输出或者文件中
日志宏
log 还为我们提供了一整套标准的宏,用于方便地记录日志。看到 trace!、debug!、info!、warn!、error!,大家是否感觉眼熟呢?是的,它们跟上一章节提到的日志级别几乎一模一样,唯一的区别就是这里乱入了一个 trace!,它比 debug! 的日志级别还要低,记录的信息还要详细。可以说,你如果想巨细无遗地了解某个流程的所有踪迹,它就是不二之选。
#![allow(unused)] fn main() { use log::{info, trace, warn}; pub fn shave_the_yak(yak: &mut Yak) { trace!("Commencing yak shaving"); loop { match find_a_razor() { Ok(razor) => { info!("Razor located: {}", razor); yak.shave(razor); break; } Err(err) => { warn!("Unable to locate a razor: {}, retrying", err); } } } } }
上面的例子使用 trace! 记录了一条可有可无的信息:准备开始剃须,然后开始寻找剃须刀,找到后就用 info! 记录一条可能事后也没人看的信息:找到剃须刀;没找到的话,就记录一条 warn! 信息,这条信息就有一定价值了,不仅告诉我们没找到的原因,还记录了发生的次数,有助于事后定位问题。
可以看出,这里使用日志级别的方式和我们上一章节所述基本相符。
除了以上常用的,log 还提供了 log! 和 log_enabled! 宏,后者用于确定一条消息在当前模块中,对于给定的日志级别是否能够被记录
#![allow(unused)] fn main() { use log::Level::Debug; use log::{debug, log_enabled}; // 判断能否记录 Debug 消息 if log_enabled!(Debug) { let data = expensive_call(); // 下面的日志记录较为昂贵,因此我们先在前面判断了是否能够记录,能,才继续这里的逻辑 debug!("expensive debug data: {} {}", data.x, data.y); } if log_enabled!(target: "Global", Debug) { let data = expensive_call(); debug!(target: "Global", "expensive debug data: {} {}", data.x, data.y); } }
而 log! 宏就简单的多,它是一个通用的日志记录方式,因此需要我们手动指定日志级别:
#![allow(unused)] fn main() { use log::{log, Level}; let data = (42, "Forty-two"); let private_data = "private"; log!(Level::Error, "Received errors: {}, {}", data.0, data.1); log!(target: "app_events", Level::Warn, "App warning: {}, {}, {}", data.0, data.1, private_data); }
日志输出在哪里?
我不知道有没有同学尝试运行过上面的代码,但是我知道,就算你们运行了,也看不到任何输出。
为什么?原因很简单,log 仅仅是日志门面库,它并不具备完整的日志库功能!,因此你无法在控制台中看到任何日志输出,这种情况下,说实话,远不如一个 println! 有用!
但是别急,让我们看看该如何让 log 有用起来。
使用具体的日志库
log 包这么设计,其实是有很多好处的。
Rust 库的开发者
最直接的好处就是,如果你是一个 Rust 库开发者,那你自己或库的用户肯定都不希望这个库绑定任何具体的日志库,否则用户想使用 log1 来记录日志,你的库却使用了 log2,这就存在很多问题了!
因此,作为库的开发者,你只要在库中使用门面库即可,将具体的日志库交给用户去选择和绑定。
#![allow(unused)] fn main() { use log::{info, trace, warn}; pub fn deal_with_something() { // 开始处理 // 记录一些日志 trace!("a trace log"); info!("a info long: {}", "abc"); warn!("a warning log: {}, retrying", err); // 结束处理 } }
应用开发者
如果是应用开发者,那你的应用运行起来,却看不到任何日志输出,这种场景想想都捉急。此时就需要去选择一个具体的日志库了。
目前来说,已经有了不少日志库实现,官方也推荐了一些 ,大家可以根据自己的需求来选择,不过 env_logger 是一个相当不错的选择。
log 还提供了 set_logger 函数用于设置日志库,set_max_level 用于设置最大日志级别,但是如果你选了具体的日志库,它往往会提供更高级的 API,无需我们手动调用这两个函数,例如下面的 env_logger 就是如此。
env_logger
修改 Cargo.toml , 添加以下内容:
# in Cargo.toml
[dependencies]
log = "0.4.0"
env_logger = "0.9"
在 src/main.rs 中添加如下代码:
use log::{debug, error, log_enabled, info, Level}; fn main() { // 注意,env_logger 必须尽可能早的初始化 env_logger::init(); debug!("this is a debug {}", "message"); error!("this is printed by default"); if log_enabled!(Level::Info) { let x = 3 * 4; // expensive computation info!("the answer was: {}", x); } }
在运行程序时,可以通过环境变量来设定日志级别:
$ RUST_LOG=error ./main
[2017-11-09T02:12:24Z ERROR main] this is printed by default
我们还可以为单独一个模块指定日志级别:
$ RUST_LOG=main=info ./main
[2017-11-09T02:12:24Z ERROR main] this is printed by default
[2017-11-09T02:12:24Z INFO main] the answer was: 12
还能为某个模块开启所有日志级别:
$ RUST_LOG=main ./main
[2017-11-09T02:12:24Z DEBUG main] this is a debug message
[2017-11-09T02:12:24Z ERROR main] this is printed by default
[2017-11-09T02:12:24Z INFO main] the answer was: 12
需要注意的是,如果文件名包含 -,你需要将其替换成下划线来使用,原因是 Rust 的模块和包名不支持使用 -。
$ RUST_LOG=my_app ./my-app
[2017-11-09T02:12:24Z DEBUG my_app] this is a debug message
[2017-11-09T02:12:24Z ERROR my_app] this is printed by default
[2017-11-09T02:12:24Z INFO my_app] the answer was: 12
默认情况下,env_logger 会输出到标准错误 stderr,如果你想要输出到标准输出 stdout,可以使用 Builder 来改变日志对象( target ):
#![allow(unused)] fn main() { use std::env; use env_logger::{Builder, Target}; let mut builder = Builder::from_default_env(); builder.target(Target::Stdout); builder.init(); }
默认
#![allow(unused)] fn main() { if cfg!(debug_assertions) { eprintln!("debug: {:?} -> {:?}", record, fields); } }
日志库开发者
对于这类开发者而言,自然要实现自己的 Log 特征咯:
#![allow(unused)] fn main() { use log::{Record, Level, Metadata}; struct SimpleLogger; impl log::Log for SimpleLogger { fn enabled(&self, metadata: &Metadata) -> bool { metadata.level() <= Level::Info } fn log(&self, record: &Record) { if self.enabled(record.metadata()) { println!("{} - {}", record.level(), record.args()); } } fn flush(&self) {} } }
除此之外,我们还需要像 env_logger 一样包装下 set_logger 和 set_max_level:
#![allow(unused)] fn main() { use log::{SetLoggerError, LevelFilter}; static LOGGER: SimpleLogger = SimpleLogger; pub fn init() -> Result<(), SetLoggerError> { log::set_logger(&LOGGER) .map(|()| log::set_max_level(LevelFilter::Info)) } }
更多示例
关于 log 门面库和具体的日志库还有更多的使用方式,详情请参见锈书的开发者工具一章。
使用 tracing 记录日志
严格来说,tracing 并不是一个日志库,而是一个分布式跟踪的 SDK,用于采集监控数据的。
随着微服务的流行,现在一个产品有多个系统组成是非常常见的,这种情况下,一条用户请求可能会横跨几个甚至几十个服务。此时再用传统的日志方式去跟踪这条用户请求就变得较为困难,这就是分布式追踪在现代化监控系统中这么炽手可热的原因。
关于分布式追踪,在后面的监控章节进行详细介绍,大家只要知道:分布式追踪的核心就是在请求的开始生成一个 trace_id,然后将该 trace_id 一直往后透穿,请求经过的每个服务都会使用该 trace_id 记录相关信息,最终将整个请求形成一个完整的链路予以记录下来。
那么后面当要查询这次请求的相关信息时,只要使用 trace_id 就可以获取整个请求链路的所有信息了,非常简单好用。看到这里,相信大家也明白为什么这个库的名称叫 tracing 了吧?
至于为何把它归到日志库的范畴呢?因为 tracing 支持 log 门面库的 API,因此,它既可以作为分布式追踪的 SDK 来使用,也可以作为日志库来使用。
在分布式追踪中,trace_id 都是由 SDK 自动生成和往后透穿,对于用户的使用来说是完全透明的。如果你要手动用日志的方式来实现请求链路的追踪,那么就必须考虑 trace_id 的手动生成、透传,以及不同语言之间的协议规范等问题
一个简单例子
开始之前,需要先将 tracing 添加到项目的 Cargo.toml 中:
[dependencies]
tracing = "0.1"
注意,在写作本文时,0.2 版本已经快要出来了,所以具体使用的版本请大家以阅读时为准。
下面的例子中将同时使用 log 和 tracing :
use log; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; fn main() { // 只有注册 subscriber 后, 才能在控制台上看到日志输出 tracing_subscriber::registry() .with(fmt::layer()) .init(); // 调用 `log` 包的 `info!` log::info!("Hello world"); let foo = 42; // 调用 `tracing` 包的 `info!` tracing::info!(foo, "Hello from tracing"); }
可以看出,门面库的排场还是有的,tracing 在 API 上明显是使用了 log 的规范。
运行后,输出如下日志:
2022-04-09T14:34:28.965952Z INFO test_tracing: Hello world
2022-04-09T14:34:28.966011Z INFO test_tracing: Hello from tracing foo=42
还可以看出,log 的日志格式跟 tracing 一模一样,结合上一章节的知识,相信聪明的同学已经明白了这是为什么。
那么 tracing 跟 log 的具体日志实现框架有何区别呢?别急,我们再来接着看。
异步编程中的挑战
除了分布式追踪,在异步编程中使用传统的日志也是存在一些问题的,最大的挑战就在于异步任务的执行没有确定的顺序,那么输出的日志也将没有确定的顺序并混在一起,无法按照我们想要的逻辑顺序串联起来。
归根到底,在于日志只能针对某个时间点进行记录,缺乏上下文信息,而线程间的执行顺序又是不确定的,因此日志就有些无能为力。而 tracing 为了解决这个问题,引入了 span 的概念( 这个概念也来自于分布式追踪 ),一个 span 代表了一个时间段,拥有开始和结束时间,在此期间的所有类型数据、结构化数据、文本数据都可以记录其中。
大家发现了吗? span 是可以拥有上下文信息的,这样就能帮我们把信息按照所需的逻辑性串联起来了。
核心概念
tracing 中最重要的三个概念是 Span、Event 和 Collector,下面我们来一一简单介绍下。
Span
相比起日志只能记录在某个时间点发生的事件,span 最大的意义就在于它可以记录一个过程,也就是在某一段时间内发生的事件流。既然是记录时间段,那自然有开始和结束:
use tracing::{span, Level}; fn main() { let span = span!(Level::TRACE, "my_span"); // `enter` 返回一个 RAII ,当其被 drop 时,将自动结束该 span let enter = span.enter(); // 这里开始进入 `my_span` 的上下文 // 下面执行一些任务,并记录一些信息到 `my_span` 中 // ... } // 这里 enter 将被 drop,`my_span` 也随之结束
Event 事件
Event 代表了某个时间点发生的事件,这方面它跟日志类似,但是不同的是,Event 还可以产生在 span 的上下文中。
use tracing::{event, span, Level}; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; fn main() { tracing_subscriber::registry().with(fmt::layer()).init(); // 在 span 的上下文之外记录一次 event 事件 event!(Level::INFO, "something happened"); let span = span!(Level::INFO, "my_span"); let _guard = span.enter(); // 在 "my_span" 的上下文中记录一次 event event!(Level::DEBUG, "something happened inside my_span"); }
2022-04-09T14:51:38.382987Z INFO test_tracing: something happened
2022-04-09T14:51:38.383111Z DEBUG my_span: test_tracing: something happened inside my_span
虽然 event 在哪里都可以使用,但是最好只在 span 的上下文中使用:用于代表一个时间点发生的事件,例如记录 HTTP 请求返回的状态码,从队列中获取一个对象,等等。
Collector 收集器
当 Span 或 Event 发生时,它们会被实现了 Collect 特征的收集器所记录或聚合。这个过程是通过通知的方式实现的:当 Event 发生或者 Span 开始/结束时,会调用 Collect 特征的相应方法通知 Collector。
tracing-subscriber
我们前面提到只有使用了 tracing-subscriber 后,日志才能输出到控制台中。
之前大家可能还不理解,现在应该明白了,它是一个 Collector,可以将记录的日志收集后,再输出到控制台中。
使用方法
span! 宏
span! 宏可以用于创建一个 Span 结构体,然后通过调用结构体的 enter 方法来开始,再通过超出作用域时的 drop 来结束。
use tracing::{span, Level}; fn main() { let span = span!(Level::TRACE, "my_span"); // `enter` 返回一个 RAII ,当其被 drop 时,将自动结束该 span let enter = span.enter(); // 这里开始进入 `my_span` 的上下文 // 下面执行一些任务,并记录一些信息到 `my_span` 中 // ... } // 这里 enter 将被 drop,`my_span` 也随之结束
#[instrument]
如果想要将某个函数的整个函数体都设置为 span 的范围,最简单的方法就是为函数标记上 #[instrument],此时 tracing 会自动为函数创建一个 span,span 名跟函数名相同,在输出的信息中还会自动带上函数参数。
use tracing::{info, instrument}; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; #[instrument] fn foo(ans: i32) { info!("in foo"); } fn main() { tracing_subscriber::registry().with(fmt::layer()).init(); foo(42); }
2022-04-10T02:44:12.885556Z INFO foo{ans=42}: test_tracing: in foo
关于 #[instrument] 详细说明,请参见官方文档。
in_scope
对于没有内置 tracing 支持或者无法使用 #instrument 的函数,例如外部库的函数,我们可以使用 Span 结构体的 in_scope 方法,它可以将同步代码包裹在一个 span 中:
#![allow(unused)] fn main() { use tracing::info_span; let json = info_span!("json.parse").in_scope(|| serde_json::from_slice(&buf))?; }
在 async 中使用 span
需要注意,如果是在异步编程时使用,要避免以下使用方式:
#![allow(unused)] fn main() { async fn my_async_function() { let span = info_span!("my_async_function"); // WARNING: 该 span 直到 drop 后才结束,因此在 .await 期间,span 依然处于工作中状态 let _enter = span.enter(); // 在这里 span 依然在记录,但是 .await 会让出当前任务的执行权,然后运行时会去运行其它任务,此时这个 span 可能会记录其它任务的执行信息,最终记录了不正确的 trace 信息 some_other_async_function().await // ... } }
我们建议使用以下方式,简单又有效:
#![allow(unused)] fn main() { use tracing::{info, instrument}; use tokio::{io::AsyncWriteExt, net::TcpStream}; use std::io; #[instrument] async fn write(stream: &mut TcpStream) -> io::Result<usize> { let result = stream.write(b"hello world\n").await; info!("wrote to stream; success={:?}", result.is_ok()); result } }
那有同学可能要问了,是不是我们无法在异步代码中使用 span.enter 了,答案是:是也不是。
是,你无法直接使用 span.enter 语法了,原因上面也说过,但是可以通过下面的方式来曲线使用:
#![allow(unused)] fn main() { use tracing::Instrument; let my_future = async { // ... }; my_future .instrument(tracing::info_span!("my_future")) .await }
span 嵌套
tracing 的 span 不仅仅是上面展示的基本用法,它们还可以进行嵌套!
use tracing::{debug, info, span, Level}; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; fn main() { tracing_subscriber::registry().with(fmt::layer()).init(); let scope = span!(Level::DEBUG, "foo"); let _enter = scope.enter(); info!("Hello in foo scope"); debug!("before entering bar scope"); { let scope = span!(Level::DEBUG, "bar", ans = 42); let _enter = scope.enter(); debug!("enter bar scope"); info!("In bar scope"); debug!("end bar scope"); } debug!("end bar scope"); }
INFO foo: log_test: Hello in foo scope
DEBUG foo: log_test: before entering bar scope
DEBUG foo:bar{ans=42}: log_test: enter bar scope
INFO foo:bar{ans=42}: log_test: In bar scope
DEBUG foo:bar{ans=42}: log_test: end bar scope
DEBUG foo: log_test: end bar scope
在上面的日志中,foo:bar 不仅包含了 foo 和 bar span 名,还显示了它们之间的嵌套关系。
对宏进行配置
日志级别和目标
span! 和 event! 宏都需要设定相应的日志级别,而且它们支持可选的 target 或 parent 参数( 只能二者选其一 ),该参数用于描述事件发生的位置,如果父 span 没有设置,target 参数也没有提供,那这个位置默认分别是当前的 span 和 当前的模块。
use tracing::{debug, info, span, Level,event}; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; fn main() { tracing_subscriber::registry().with(fmt::layer()).init(); let s = span!(Level::TRACE, "my span"); // 没进入 span,因此输出日志将不会带上 span 的信息 event!(target: "app_events", Level::INFO, "something has happened 1!"); // 进入 span ( 开始 ) let _enter = s.enter(); // 没有设置 target 和 parent // 这里的对象位置分别是当前的 span 名和模块名 event!(Level::INFO, "something has happened 2!"); // 设置了 target // 这里的对象位置分别是当前的 span 名和 target event!(target: "app_events",Level::INFO, "something has happened 3!"); let span = span!(Level::TRACE, "my span 1"); // 这里就更为复杂一些,留给大家作为思考题 event!(parent: &span, Level::INFO, "something has happened 4!"); }
记录字段
我们可以通过语法 field_name = field_value 来输出结构化的日志
#![allow(unused)] fn main() { // 记录一个事件,带有两个字段: // - "answer", 值是 42 // - "question", 值是 "life, the universe and everything" event!(Level::INFO, answer = 42, question = "life, the universe, and everything"); // 日志输出 -> INFO test_tracing: answer=42 question="life, the universe, and everything" }
捕获环境变量
还可以捕获环境中的变量:
#![allow(unused)] fn main() { let user = "ferris"; // 下面的简写方式 span!(Level::TRACE, "login", user); // 等价于: span!(Level::TRACE, "login", user = user); }
use tracing::{info, span, Level}; use tracing_subscriber::{fmt, layer::SubscriberExt, util::SubscriberInitExt}; fn main() { tracing_subscriber::registry().with(fmt::layer()).init(); let user = "ferris"; let s = span!(Level::TRACE, "login", user); let _enter = s.enter(); info!(welcome="hello", user); // 下面一行将报错,原因是这种写法是格式化字符串的方式,必须使用 info!("hello {}", user) // info!("hello", user); } // 日志输出 -> INFO login{user="ferris"}: test_tracing: welcome="hello" user="ferris"
字段名的多种形式
字段名还可以包含 . :
#![allow(unused)] fn main() { let user = "ferris"; let email = "ferris@rust-lang.org"; event!(Level::TRACE, user, user.email = email); // 还可以使用结构体 let user = User { name: "ferris", email: "ferris@rust-lang.org", }; // 直接访问结构体字段,无需赋值即可使用 span!(Level::TRACE, "login", user.name, user.email); // 字段名还可以使用字符串 event!(Level::TRACE, "guid:x-request-id" = "abcdef", "type" = "request"); // 日志输出 -> // TRACE test_tracing: user="ferris" user.email="ferris@rust-lang.org" // TRACE test_tracing: user.name="ferris" user.email="ferris@rust-lang.org" // TRACE test_tracing: guid:x-request-id="abcdef" type="request" }
?
? 符号用于说明该字段将使用 fmt::Debug 来格式化。
#![allow(unused)] fn main() { #[derive(Debug)] struct MyStruct { field: &'static str, } let my_struct = MyStruct { field: "Hello world!", }; // `my_struct` 将使用 Debug 的形式输出 event!(Level::TRACE, greeting = ?my_struct); // 等价于: event!(Level::TRACE, greeting = tracing::field::debug(&my_struct)); // 下面代码将报错, my_struct 没有实现 Display // event!(Level::TRACE, greeting = my_struct); // 日志输出 -> TRACE test_tracing: greeting=MyStruct { field: "Hello world!" } }
%
% 说明字段将用 fmt::Display 来格式化。
#![allow(unused)] fn main() { // `my_struct.field` 将使用 `fmt::Display` 的格式化形式输出 event!(Level::TRACE, greeting = %my_struct.field); // 等价于: event!(Level::TRACE, greeting = tracing::field::display(&my_struct.field)); // 作为对比,大家可以看下 Debug 和正常的字段输出长什么样 event!(Level::TRACE, greeting = ?my_struct.field); event!(Level::TRACE, greeting = my_struct.field); // 下面代码将报错, my_struct 没有实现 Display // event!(Level::TRACE, greeting = %my_struct); }
2022-04-10T03:49:00.834330Z TRACE test_tracing: greeting=Hello world!
2022-04-10T03:49:00.834410Z TRACE test_tracing: greeting=Hello world!
2022-04-10T03:49:00.834422Z TRACE test_tracing: greeting="Hello world!"
2022-04-10T03:49:00.834433Z TRACE test_tracing: greeting="Hello world!"
Empty
字段还能标记为 Empty,用于说明该字段目前没有任何值,但是可以在后面进行记录。
#![allow(unused)] fn main() { use tracing::{trace_span, field}; let span = trace_span!("my_span", greeting = "hello world", parting = field::Empty); // ... // 现在,为 parting 记录一个值 span.record("parting", &"goodbye world!"); }
格式化字符串
除了以字段的方式记录信息,我们还可以使用格式化字符串的方式( 同 println! 、format! )。
注意,当字段跟格式化的方式混用时,必须把格式化放在最后,如下所示
#![allow(unused)] fn main() { let question = "the ultimate question of life, the universe, and everything"; let answer = 42; event!( Level::DEBUG, question.answer = answer, question.tricky = true, "the answer to {} is {}.", question, answer ); // 日志输出 -> DEBUG test_tracing: the answer to the ultimate question of life, the universe, and everything is 42. question.answer=42 question.tricky=true }
文件输出
截至目前,我们上面的日志都是输出到控制台中。
针对文件输出,tracing 提供了一个专门的库 tracing-appender,大家可以查看官方文档了解更多。
一个综合例子
最后,再来看一个综合的例子,使用了 color-eyre 和 文件输出,前者用于为输出的日志加上更易读的颜色。
use color_eyre::{eyre::eyre, Result}; use tracing::{error, info, instrument}; use tracing_appender::{non_blocking, rolling}; use tracing_error::ErrorLayer; use tracing_subscriber::{ filter::EnvFilter, fmt, layer::SubscriberExt, util::SubscriberInitExt, Registry, }; #[instrument] fn return_err() -> Result<()> { Err(eyre!("Something went wrong")) } #[instrument] fn call_return_err() { info!("going to log error"); if let Err(err) = return_err() { // 推荐大家运行下,看看这里的输出效果 error!(?err, "error"); } } fn main() -> Result<()> { let env_filter = EnvFilter::try_from_default_env().unwrap_or_else(|_| EnvFilter::new("info")); // 输出到控制台中 let formatting_layer = fmt::layer().pretty().with_writer(std::io::stderr); // 输出到文件中 let file_appender = rolling::never("logs", "app.log"); let (non_blocking_appender, _guard) = non_blocking(file_appender); let file_layer = fmt::layer() .with_ansi(false) .with_writer(non_blocking_appender); // 注册 Registry::default() .with(env_filter) // ErrorLayer 可以让 color-eyre 获取到 span 的信息 .with(ErrorLayer::default()) .with(formatting_layer) .with(file_layer) .init(); // 安裝 color-eyre 的 panic 处理句柄 color_eyre::install()?; call_return_err(); Ok(()) }
总结 & 推荐
至此,tracing 的介绍就已结束,相信大家都看得出,它比上个章节的 log 及兄弟们要更加复杂一些,一方面是因为它能更好的支持异步编程环境,另一方面就是它还是一个分布式追踪的库,对于后者,我们将在后续的监控章节进行讲解。
如果你让我推荐使用哪个,那我的建议是:
- 对于简单的工程,例如用于 POC( Proof of Concepts ) 目的,使用
log即可 - 对于需要认真对待,例如生产级或优秀的开源项目,建议使用 tracing 的方式,一举解决日志和监控的后顾之忧
使用 tracing 输出自定义的 Rust 日志
在 tracing 包出来前,Rust 的日志也就 log 有一战之力,但是 log 的功能相对来说还是简单一些。在大名鼎鼎的 tokio 开发团队推出 tracing 后,我现在坚定的认为 tracing 就是未来!
截至目前,rust编译器团队、GraphQL 都在使用 tracing,而且 tokio 在密谋一件大事:基于 tracing 开发一套终端交互式 debug 工具: console!
基于这种坚定的信仰,我们决定将公司之前使用的 log 包替换成 tracing ,但是有一个问题:后者提供的 JSON logger 总感觉不是那个味儿。这意味着,对于程序员来说,最快乐的时光又要到来了:定制自己的开发工具。
好了,闲话少说,下面我们一起来看看该如何构建自己的 logger,以及深入了解 tracing 的一些原理,当然你也可以只选择来凑个热闹,总之,开始吧!
打地基(1)
首先,使用 cargo new --bin test-tracing 创建一个新的二进制类型( binary )的项目。
然后引入以下依赖:
# in cargo.toml
[dependencies]
serde_json = "1"
tracing = "0.1"
tracing-subscriber = "0.3"
其中 tracing-subscriber 用于订阅正在发生的日志、监控事件,然后可以对它们进行进一步的处理。serde_json 可以帮我们更好的处理格式化的 JSON,毕竟咱们要解决的问题就来自于 JSON logger。
下面来实现一个基本功能:设置自定义的 logger,并使用 info! 来打印一行日志。
// in examples/figure_0/main.rs use tracing::info; use tracing_subscriber::prelude::*; mod custom_layer; use custom_layer::CustomLayer; fn main() { // 设置 `tracing-subscriber` 对 tracing 数据的处理方式 tracing_subscriber::registry().with(CustomLayer).init(); // 打印一条简单的日志。用 `tracing` 的行话来说,`info!` 将创建一个事件 info!(a_bool = true, answer = 42, message = "first example"); }
大家会发现,上面引入了一个模块 custom_layer, 下面从该模块开始,来实现我们的自定义 logger。首先,tracing-subscriber 提供了一个特征 Layer 专门用于处理 tracing 的各种事件( span, event )。
#![allow(unused)] fn main() { // in examples/figure_0/custom_layer.rs use tracing_subscriber::Layer; pub struct CustomLayer; impl<S> Layer<S> for CustomLayer where S: tracing::Subscriber {} }
由于还没有填入任何代码,运行该示例比你打的水漂还无力 - 毫无效果。
捕获事件
在 tracing 中,当 info!、error! 等日志宏被调用时,就会产生一个相应的事件 Event。
而我们首先,就要为之前的 Layer 特征实现 on_event 方法。
// in examples/figure_0/custom_layer.rs where S: tracing::Subscriber, { fn on_event( &self, event: &tracing::Event<'_>, _ctx: tracing_subscriber::layer::Context<'_, S>, ) { println!("Got event!"); println!(" level={:?}", event.metadata().level()); println!(" target={:?}", event.metadata().target()); println!(" name={:?}", event.metadata().name()); for field in event.fields() { println!(" field={}", field.name()); } } }
从代码中可以看出,我们打印了事件中包含的事件名、日志等级以及事件发生的代码路径。运行后,可以看到以下输出:
$ cargo run --example figure_1
Got event!
level=Level(Info)
target="figure_1"
name="event examples/figure_1/main.rs:10"
field=a_bool
field=answer
field=message
但是奇怪的是,我们无法通过 API 来获取到具体的 field 值。还有就是,上面的输出还不是 JSON 格式。
现在问题来了,要创建自己的 logger,不能获取 filed 显然是不靠谱的。
访问者模式
在设计上,tracing 作出了一个选择:永远不会自动存储产生的事件数据( spans, events )。如果我们要获取这些数据,就必须自己手动存储。
解决办法就是使用访问者模式(Visitor Pattern):手动实现 Visit 特征去获取事件中的值。Visit 为每个 tracing 可以处理的类型都提供了对应的 record_X 方法。
#![allow(unused)] fn main() { // in examples/figure_2/custom_layer.rs struct PrintlnVisitor; impl tracing::field::Visit for PrintlnVisitor { fn record_f64(&mut self, field: &tracing::field::Field, value: f64) { println!(" field={} value={}", field.name(), value) } fn record_i64(&mut self, field: &tracing::field::Field, value: i64) { println!(" field={} value={}", field.name(), value) } fn record_u64(&mut self, field: &tracing::field::Field, value: u64) { println!(" field={} value={}", field.name(), value) } fn record_bool(&mut self, field: &tracing::field::Field, value: bool) { println!(" field={} value={}", field.name(), value) } fn record_str(&mut self, field: &tracing::field::Field, value: &str) { println!(" field={} value={}", field.name(), value) } fn record_error( &mut self, field: &tracing::field::Field, value: &(dyn std::error::Error + 'static), ) { println!(" field={} value={}", field.name(), value) } fn record_debug(&mut self, field: &tracing::field::Field, value: &dyn std::fmt::Debug) { println!(" field={} value={:?}", field.name(), value) } } }
然后在之前的 on_event 中来使用这个新的访问者: event.record(&mut visitor) 可以访问其中的所有值。
#![allow(unused)] fn main() { // in examples/figure_2/custom_layer.rs fn on_event( &self, event: &tracing::Event<'_>, _ctx: tracing_subscriber::layer::Context<'_, S>, ) { println!("Got event!"); println!(" level={:?}", event.metadata().level()); println!(" target={:?}", event.metadata().target()); println!(" name={:?}", event.metadata().name()); let mut visitor = PrintlnVisitor; event.record(&mut visitor); } }
这段代码看起来有模有样,来运行下试试:
$ cargo run --example figure_2
Got event!
level=Level(Info)
target="figure_2"
name="event examples/figure_2/main.rs:10"
field=a_bool value=true
field=answer value=42
field=message value=first example
Bingo ! 一切完美运行 !
构建 JSON logger
目前为止,离我们想要的 JSON logger 只差一步了。下面来实现一个 JsonVisitor 替代之前的 PrintlnVisitor 用于构建一个 JSON 对象。
#![allow(unused)] fn main() { // in examples/figure_3/custom_layer.rs impl<'a> tracing::field::Visit for JsonVisitor<'a> { fn record_f64(&mut self, field: &tracing::field::Field, value: f64) { self.0 .insert(field.name().to_string(), serde_json::json!(value)); } fn record_i64(&mut self, field: &tracing::field::Field, value: i64) { self.0 .insert(field.name().to_string(), serde_json::json!(value)); } fn record_u64(&mut self, field: &tracing::field::Field, value: u64) { self.0 .insert(field.name().to_string(), serde_json::json!(value)); } fn record_bool(&mut self, field: &tracing::field::Field, value: bool) { self.0 .insert(field.name().to_string(), serde_json::json!(value)); } fn record_str(&mut self, field: &tracing::field::Field, value: &str) { self.0 .insert(field.name().to_string(), serde_json::json!(value)); } fn record_error( &mut self, field: &tracing::field::Field, value: &(dyn std::error::Error + 'static), ) { self.0.insert( field.name().to_string(), serde_json::json!(value.to_string()), ); } fn record_debug(&mut self, field: &tracing::field::Field, value: &dyn std::fmt::Debug) { self.0.insert( field.name().to_string(), serde_json::json!(format!("{:?}", value)), ); } } }
#![allow(unused)] fn main() { // in examples/figure_3/custom_layer.rs fn on_event( &self, event: &tracing::Event<'_>, _ctx: tracing_subscriber::layer::Context<'_, S>, ) { // Covert the values into a JSON object let mut fields = BTreeMap::new(); let mut visitor = JsonVisitor(&mut fields); event.record(&mut visitor); // Output the event in JSON let output = serde_json::json!({ "target": event.metadata().target(), "name": event.metadata().name(), "level": format!("{:?}", event.metadata().level()), "fields": fields, }); println!("{}", serde_json::to_string_pretty(&output).unwrap()); } }
继续运行:
$ cargo run --example figure_3
{
"fields": {
"a_bool": true,
"answer": 42,
"message": "first example"
},
"level": "Level(Info)",
"name": "event examples/figure_3/main.rs:10",
"target": "figure_3"
}
终于,我们实现了自己的 logger,并且成功地输出了一条 JSON 格式的日志。并且新实现的 Layer 就可以添加到 tracing-subscriber 中用于记录日志事件。
下面再来一起看看如何使用tracing 提供的 period-of-time spans 为日志增加更详细的上下文信息。
何为 span
在之前我们多次提到 span 这个词,但是何为 span?
不知道大家知道分布式追踪不?在分布式系统中每一个请求从开始到返回,会经过多个服务,这条请求路径被称为请求跟踪链路( trace ),可以看出,一条链路是由多个部分组成,我们可以简单的把其中一个部分认为是一个 span。
跟 log 是对某个时间点的记录不同,span 记录的是一个时间段。当程序开始执行一系列任务时,span 就会开始,当这一系列任务结束后,span 也随之结束。
由此可见,tracing 其实不仅仅是一个日志库,它还是一个分布式追踪的库,可以帮助我们采集信息,然后上传给 jaeger 等分布式追踪平台,最终实现对指定应用程序的监控。
在理解后,再来看看该如何为自定义的 logger 实现 spans。
打地基(2)
先来创建一个外部 span 和一个内部 span,从概念上来说,spans 和 events 创建的东东类似以下嵌套结构:
- 进入外部 span
- 进入内部 span
- 事件已创建,内部 span 是它的父 span,外部 span 是它的祖父 span
- 结束内部 span
- 进入内部 span
- 结束外部 span
有些同学可能还是不太理解,你就把 span 理解成为监控埋点,进入 span == 埋点开始,结束 span == 埋点结束
在下面的代码中,当使用 span.enter() 创建的 span 超出作用域时,将自动退出:根据 Drop 特征触发的顺序,inner_span 将先退出,然后才是 outer_span 的退出。
// in examples/figure_5/main.rs use tracing::{debug_span, info, info_span}; use tracing_subscriber::prelude::*; mod custom_layer; use custom_layer::CustomLayer; fn main() { tracing_subscriber::registry().with(CustomLayer).init(); let outer_span = info_span!("outer", level = 0); let _outer_entered = outer_span.enter(); let inner_span = debug_span!("inner", level = 1); let _inner_entered = inner_span.enter(); info!(a_bool = true, answer = 42, message = "first example"); }
再回到事件处理部分,通过使用 examples/figure_0/main.rs 我们能获取到事件的父 span,当然,前提是它存在。但是在实际场景中,直接使用 ctx.event_scope(event) 来迭代所有 span 会更加简单好用。
注意,这种迭代顺序类似于栈结构,以上面的代码为例,先被迭代的是 inner_span,然后才是 outer_span。
当然,如果你不想以类似于出栈的方式访问,还可以使用 scope.from_root() 直接反转,此时的访问将从最外层开始: outer -> innter。
对了,为了使用 ctx.event_scope(),我们的订阅者还需实现 LookupRef。提前给出免责声明:这里的实现方式有些诡异,大家可能难以理解,但是..我们其实也无需理解,只要这么用即可。
译者注:这里用到了高阶生命周期 HRTB( Higher Ranke Trait Bounds ) 的概念,一般的读者无需了解,感兴趣的可以看看(这里)[https://doc.rust-lang.org/nomicon/hrtb.html]
#![allow(unused)] fn main() { // in examples/figure_5/custom_layer.rs impl<S> Layer<S> for CustomLayer where S: tracing::Subscriber, // 好可怕! 还好我们不需要理解它,只要使用即可 S: for<'lookup> tracing_subscriber::registry::LookupSpan<'lookup>, { fn on_event(&self, event: &tracing::Event<'_>, ctx: tracing_subscriber::layer::Context<'_, S>) { // 父 span let parent_span = ctx.event_span(event).unwrap(); println!("parent span"); println!(" name={}", parent_span.name()); println!(" target={}", parent_span.metadata().target()); println!(); // 迭代范围内的所有的 spans let scope = ctx.event_scope(event).unwrap(); for span in scope.from_root() { println!("an ancestor span"); println!(" name={}", span.name()); println!(" target={}", span.metadata().target()); } } } }
运行下看看效果:
$ cargo run --example figure_5
parent span
name=inner
target=figure_5
an ancestor span
name=outer
target=figure_5
an ancestor span
name=inner
target=figure_5
细心的同学可能会发现,这里怎么也没有 field 数据?没错,而且恰恰是这些 field 包含的数据才让日志和监控有意义。那我们可以像之前一样,使用访问器 Visitor 来解决吗?
span 的数据在哪里
答案是:No。因为 ctx.event_scope 返回的东东没有任何办法可以访问其中的字段。
不知道大家还记得我们为何之前要使用访问器吗?很简单,因为 tracing 默认不会去存储数据,既然如此,那 span 这种跨了某个时间段的,就更不可能去存储数据了。
现在只能看看 Layer 特征有没有提供其它的方法了,哦呦,发现了一个 on_new_span,从名字可以看出,该方法是在 span 创建时调用的。
#![allow(unused)] fn main() { // in examples/figure_6/custom_layer.rs impl<S> Layer<S> for CustomLayer where S: tracing::Subscriber, S: for<'lookup> tracing_subscriber::registry::LookupSpan<'lookup>, { fn on_new_span( &self, attrs: &tracing::span::Attributes<'_>, id: &tracing::span::Id, ctx: tracing_subscriber::layer::Context<'_, S>, ) { let span = ctx.span(id).unwrap(); println!("Got on_new_span!"); println!(" level={:?}", span.metadata().level()); println!(" target={:?}", span.metadata().target()); println!(" name={:?}", span.metadata().name()); // Our old friend, `println!` exploration. let mut visitor = PrintlnVisitor; attrs.record(&mut visitor); } } }
$ cargo run --example figure_6
Got on_new_span!
level=Level(Info)
target="figure_7"
name="outer"
field=level value=0
Got on_new_span!
level=Level(Debug)
target="figure_7"
name="inner"
field=level value=1
芜湖! 我们的数据回来了!但是这里有一个隐患:只能在创建的时候去访问数据。如果仅仅是为了记录 spans,那没什么大问题,但是如果我们随后需要记录事件然后去尝试访问之前的 span 呢?此时 span 的数据已经不存在了!
如果 tracing 不能存储数据,那我们这些可怜的开发者该怎么办?
自己存储 span 数据
何为一个优秀的程序员?能偷懒的时候绝不多动半跟手指,但是需要勤快的时候,也是自己动手丰衣足食的典型。
因此,既然 tracing 不支持,那就自己实现吧。先确定一个目标:捕获 span 的数据,然后存储在某个地方以便后续访问。
好在 tracing-subscriber 提供了扩展 extensions 的方式,可以让我们轻松地存储自己的数据,该扩展甚至可以跟每一个 span 联系在一起!
虽然我们可以把之前见过的 BTreeMap<String, serde_json::Value> 存在扩展中,但是由于扩展数据是被 registry 中的所有layers 所共享的,因此出于私密性的考虑,还是只保存私有字段比较合适。这里使用一个 newtype 模式来创建新的类型:
#![allow(unused)] fn main() { // in examples/figure_8/custom_layer.rs #[derive(Debug)] struct CustomFieldStorage(BTreeMap<String, serde_json::Value>); }
每次发现一个新的 span 时,都基于它来构建一个 JSON 对象,然后将其存储在扩展数据中。
#![allow(unused)] fn main() { // in examples/figure_8/custom_layer.rs fn on_new_span( &self, attrs: &tracing::span::Attributes<'_>, id: &tracing::span::Id, ctx: tracing_subscriber::layer::Context<'_, S>, ) { // 基于 field 值来构建我们自己的 JSON 对象 let mut fields = BTreeMap::new(); let mut visitor = JsonVisitor(&mut fields); attrs.record(&mut visitor); // 使用之前创建的 newtype 包裹下 let storage = CustomFieldStorage(fields); // 获取内部 span 数据的引用 let span = ctx.span(id).unwrap(); // 获取扩展,用于存储我们的 span 数据 let mut extensions = span.extensions_mut(); // 存储! extensions.insert::<CustomFieldStorage>(storage); } }
这样,未来任何时候我们都可以取到该 span 包含的数据( 例如在 on_event 方法中 )。
#![allow(unused)] fn main() { // in examples/figure_8/custom_layer.rs fn on_event(&self, event: &tracing::Event<'_>, ctx: tracing_subscriber::layer::Context<'_, S>) { let scope = ctx.event_scope(event).unwrap(); println!("Got event!"); for span in scope.from_root() { let extensions = span.extensions(); let storage = extensions.get::<CustomFieldStorage>().unwrap(); println!(" span"); println!(" target={:?}", span.metadata().target()); println!(" name={:?}", span.metadata().name()); println!(" stored fields={:?}", storage); } } }
功能齐全的 JSON logger
截至目前,我们已经学了不少东西,下面来利用这些知识实现最后的 JSON logger。
#![allow(unused)] fn main() { // in examples/figure_9/custom_layer.rs fn on_event(&self, event: &tracing::Event<'_>, ctx: tracing_subscriber::layer::Context<'_, S>) { // All of the span context let scope = ctx.event_scope(event).unwrap(); let mut spans = vec![]; for span in scope.from_root() { let extensions = span.extensions(); let storage = extensions.get::<CustomFieldStorage>().unwrap(); let field_data: &BTreeMap<String, serde_json::Value> = &storage.0; spans.push(serde_json::json!({ "target": span.metadata().target(), "name": span.name(), "level": format!("{:?}", span.metadata().level()), "fields": field_data, })); } // The fields of the event let mut fields = BTreeMap::new(); let mut visitor = JsonVisitor(&mut fields); event.record(&mut visitor); // And create our output let output = serde_json::json!({ "target": event.metadata().target(), "name": event.metadata().name(), "level": format!("{:?}", event.metadata().level()), "fields": fields, "spans": spans, }); println!("{}", serde_json::to_string_pretty(&output).unwrap()); } }
$ cargo run --example figure_9
{
"fields": {
"a_bool": true,
"answer": 42,
"message": "first example"
},
"level": "Level(Info)",
"name": "event examples/figure_9/main.rs:16",
"spans": [
{
"fields": {
"level": 0
},
"level": "Level(Info)",
"name": "outer",
"target": "figure_9"
},
{
"fields": {
"level": 1
},
"level": "Level(Debug)",
"name": "inner",
"target": "figure_9"
}
],
"target": "figure_9"
}
嗯,完美。
等等,你说功能齐全?
上面的代码在发布到生产环境后,依然运行地相当不错,但是我发现还缺失了一个功能: span 在创建之后,依然要能记录数据。
#![allow(unused)] fn main() { // in examples/figure_10/main.rs let outer_span = info_span!("outer", level = 0, other_field = tracing::field::Empty); let _outer_entered = outer_span.enter(); // Some code... outer_span.record("other_field", &7); }
如果基于之前的代码运行上面的代码,我们将不会记录 other_field,因为该字段在收到 on_new_span 事件时,还不存在。
对此,Layer 提供了 on_record 方法:
#![allow(unused)] fn main() { // in examples/figure_10/custom_layer.rs fn on_record( &self, id: &tracing::span::Id, values: &tracing::span::Record<'_>, ctx: tracing_subscriber::layer::Context<'_, S>, ) { // 获取正在记录数据的 span let span = ctx.span(id).unwrap(); // 获取数据的可变引用,该数据是在 on_new_span 中创建的 let mut extensions_mut = span.extensions_mut(); let custom_field_storage: &mut CustomFieldStorage = extensions_mut.get_mut::<CustomFieldStorage>().unwrap(); let json_data: &mut BTreeMap<String, serde_json::Value> = &mut custom_field_storage.0; // 使用我们的访问器老朋友 let mut visitor = JsonVisitor(json_data); values.record(&mut visitor); } }
终于,在最后,我们拥有了一个功能齐全的自定义的 JSON logger,大家快去尝试下吧。当然,你也可以根据自己的需求来定制专属于你的 logger,毕竟方法是一通百通的。
在以下 github 仓库,可以找到完整的代码: https://github.com/bryanburgers/tracing-blog-post
本文由 Rustt 提供翻译 原文链接: https://github.com/studyrs/Rustt/blob/main/Articles/%5B2022-04-07%5D%20在%20Rust%20中使用%20tracing%20自定义日志.md
监控
监控是一个很大的领域,大到老板、前端开发、后端开发理解的监控可能都不相同。
- 老板眼中的监控:业务大数据实时展示
- 前端眼中的监控:手机 APP 收集上来的异常、崩溃、用户操作日志等
- 后端眼中的监控:请求链路跟踪、一段时间内的请求错误率、QPS 过高、异常日志等
正是因为这些复杂性,导致很多同学难以准确的说出监控到底是什么。
下面,我们将试图解释清楚监控的概念,并引入一个全新的概念:可观测性。
可观测性
在监控章节的引言中,我们提到了老板、前端、后端眼中的监控是各不相同的,那么有没有办法将监控模型进行抽象、统一呢?
来简单分析一下:
- 业务指标实时展示,这是一个指标型的数据( metric )
- 手机 APP 上传的数据,包含了日志( log )和指标类型( metric ),如果考虑到 APP 作为一次 HTTP 请求的发起端,那还涉及到请求链路的跟踪( trace)
- 后端链路跟踪是 trace,请求错误率、QPS 是 metric,异常日志是 log
喔,好像线索很明显哎,我们貌似可以把监控模型分为三种:指标 metric、日志 log 和 链路 trace。
先别急,我们对总结出来的三种类型进行下对比,看看彼此之间是否存在关联性( 良好的模型设计,彼此之间应该是无关联的 ):
- 指标:用于表示在某一段时间内,一个行为出现的次数和分布
- 日志:记录在某一个时间点发生的一次事件
- 链路:记录一次请求所经过的完整的服务链路,可能会横跨线程、进程,也可能会横跨服务( 分布式、微服务 )
按照这个定义来看,三种类型几乎没有关联性,是不是意味着我们的监控模型非常成功?
恭喜你,刚才总结出的监控模型正是这几年非常火热的可观测性监控的三大基础:Metrics / Log / Trace。
各自为战的三种模型
但是如果按照这个模型,我们将监控分成三个部分开发,彼此没有关联,并且在使用之时,也带着孤立的观点去看待这些数据和功能,那可观测性就失去了其应有的意义。
例如要看指标趋势变化就使用 metrics,查看详细问题使用 log,要看请求链路、链路各部分的耗时、服务依赖都使用 trace,虽然看起来很美好,但是它们都在各自为战。
例如一个很常见的场景,现在我们通过 metrics 获得了一个告警,发现某个服务的 SLA 降低、错误率上升,此时该如何排查错误原因? 查看日志?你如何确保日志跟错误率上升有内在的联系呢?而且一个大型服务,它的各种类型的日志、错误都是非常频繁的,要大海捞针般地找出特定的日志,非常难。
由于缺乏数据模型上的关联,最后只能各自为战:发现了错误率上升,就人工去找日志和链路,运气好,就能很快地查明原因,运气不好?等待老板和用户的咆哮吧
这个过程很不美好,需要工程师们充分理解每一项数据的底层逻辑,而在大型微服务架构中,没有一个工程师可以清晰的知道所有的底层逻辑,此时就需要分工协作去排查,那问题处理的复杂度和挑战性最终会急剧增加。
模型纽带
看来,要解决这个问题,我们需要一个纽带,来把三个模型串联起来,目前来看,trace 是最适合的。
因为问题的跟踪和解决其实就是沿着数据的流向来的,我们只要在 trace 流动的过程中,在沿途把相关的 log 收集上来,然后再针对收到的各种 trace,根据其标签去统计相应的指标。
这样,是不是就成功地将三个模型关联在了一起?而且还不是强扭的瓜!
再回到之前假设的场景:当我们对某个 Metric 波动发生兴趣时,可以直接将造成此波动的 Trace 关联检索出来,然后查看这些 Trace 在各个微服务中的所有执行细节,最后发现是底层某个微服务在执行请求过程中发生了 Panic,这个错误不断向上传播导致了服务对外 SLA 下降。
如果可观测平台做得更完善一些,将微服务的变更事件数据也呈现出来,那么一个工程师就可以快速完成整个排障和根因定位的过程,甚至不需要人,通过机器就可以自动完成整个排障和根因定位过程。
看到这里,相信大家都已经明白了 trace 的重要性以及可观测性监控到底优秀在哪里。那么问题来了,该如何落地?
数据采集
首先,没有数据,就没有一切,因此我们需要先把监控数据采集上来。
除了跨服务的数据统一规范外,由于现在的微服务往往使用多种语言实现,我们的数据采集还要支持不同的语言,选择一个合适的数据采集 SDK 就成了重中之重。
目前来说,我们最推荐大家采用 OpenTelemetry 作为可观测性解决方案,它提供了完整的数据协议规范、API和多语言采集 SDK,我们将在下个章节进行详细介绍。
数据处理和存储
虽然在我们之前的模型设计完善后,数据彼此之间存在内在关联性,但是不代表它们就能够按照同样的格式来存储了,甚至都无法保证使用同一个数据库来存储。
就目前而言,对于三种模型的数据处理和存储推荐如下:
- Trace,使用 jaeger 接收采集上来的 trace 数据,经过处理后存储到一个分布式数据库中,例如 cassandra、scyllaDB 等
- Log,如果对日志的关键词索引有较高的要求,还是建议使用 ElasticeSearch,如果可以提前在日志中通过 kv 的形式打上标签,然后未来也只需要通过标签来索引,那可以考虑使用 loki
- Metrics,啥都不用说了,prometheus 走起,当然还可以使用 influxdb,后者正在使用 Rust 重写,期待未来的一飞冲天
数据查询和展示
大家知道可观测性现在为什么很多人搞不清楚吗?就是因为你怎么做都可以,比如之前的存储,就有很多解决方案,而且还都不错。
对于数据展示也是,你可以使用上面的 jaeger、prometheus 自带的 UI,也可以使用 grafana 这种统一性的 UI,而从我个人来说,更推荐使用 grafana,毕竟 UI 的统一性和内联性对于监控数据的查询是非常重要的。
再说了,grafana 的 UI 做的好看啊,没人能拒绝美好的事物吧 :D
好了,一篇口水文终于结束了,在后续章节我们将学习如何使用 OpenTelemetry + Jaeger + Prometheus + Grafana 搭建一套可用的监控服务,先来看看如何搭建和使用分布式追踪监控。
"tracing 呢?你这个监控服务怎么没有它的身影,日志章节口口声声的爱,现在就忘记了吗?"
"别急,我还记得呢,先卖个关子"
分布式追踪
附录 A:关键字
下面的列表包含 Rust 中正在使用或者以后会用到的关键字。因此,这些关键字不能被用作标识符(除了原生标识符),包括函数、变量、参数、结构体字段、模块、包、常量、宏、静态值、属性、类型、特征或生命周期。
目前正在使用的关键字
如下关键字目前有对应其描述的功能。
as- 强制类型转换,或use和extern crate包和模块引入语句中的重命名break- 立刻退出循环const- 定义常量或原生常量指针(constant raw pointer)continue- 继续进入下一次循环迭代crate- 链接外部包dyn- 动态分发特征对象else- 作为if和if let控制流结构的 fallbackenum- 定义一个枚举类型extern- 链接一个外部包,或者一个宏变量(该变量定义在另外一个包中)false- 布尔值falsefn- 定义一个函数或 函数指针类型 (function pointer type)for- 遍历一个迭代器或实现一个 trait 或者指定一个更高级的生命周期if- 基于条件表达式的结果来执行相应的分支impl- 为结构体或者特征实现具体功能in-for循环语法的一部分let- 绑定一个变量loop- 无条件循环match- 模式匹配mod- 定义一个模块move- 使闭包获取其所捕获项的所有权mut- 在引用、裸指针或模式绑定中使用,表明变量是可变的pub- 表示结构体字段、impl块或模块的公共可见性ref- 通过引用绑定return- 从函数中返回Self- 实现特征类型的类型别名self- 表示方法本身或当前模块static- 表示全局变量或在整个程序执行期间保持其生命周期struct- 定义一个结构体super- 表示当前模块的父模块trait- 定义一个特征true- 布尔值truetype- 定义一个类型别名或关联类型unsafe- 表示不安全的代码、函数、特征或实现use- 在当前代码范围内(模块或者花括号对)引入外部的包、模块等where- 表示一个约束类型的从句while- 基于一个表达式的结果判断是否继续循环
保留做将来使用的关键字
如下关键字没有任何功能,不过由 Rust 保留以备将来的应用。
abstractasyncawaitbecomeboxdofinalmacrooverrideprivtrytypeofunsizedvirtualyield
原生标识符
原生标识符(Raw identifiers)允许你使用通常不能使用的关键字,其带有 r# 前缀。
例如,match 是关键字。如果尝试编译如下使用 match 作为名字的函数:
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}会得到这个错误:
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
该错误表示你不能将关键字 match 用作函数标识符。你可以使用原生标识符将 match 作为函数名称使用:
文件名: src/main.rs
fn r#match(needle: &str, haystack: &str) -> bool { haystack.contains(needle) } fn main() { assert!(r#match("foo", "foobar")); }
此代码编译没有任何错误。注意 r# 前缀需同时用于函数名定义和 main 函数中的调用。
原生标识符允许使用你选择的任何单词作为标识符,即使该单词恰好是保留关键字。 此外,原生标识符允许你使用其它 Rust 版本编写的库。比如,try 在 Rust 2015 edition 中不是关键字,却在 Rust 2018 edition 是关键字。所以如果用 2015 edition 编写的库中带有 try 函数,在 2018 edition 中调用时就需要使用原始标识符语法,在这里是 r#try。
附录 B:运算符与符号
该附录包含了 Rust 目前出现过的各种符号,这些符号之前都分散在各个章节中。
运算符
表 B-1 包含了 Rust 中的运算符、上下文中的示例、简短解释以及该运算符是否可重载。如果一个运算符是可重载的,则该运算符上用于重载的特征也会列出。
下表中,expr 是表达式,ident 是标识符,type 是类型,var 是变量,trait 是特征,pat 是匹配分支(pattern)。
表 B-1:运算符
| 运算符 | 示例 | 解释 | 是否可重载 |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | 宏展开 | |
! | !expr | 按位非或逻辑非 | Not |
!= | var != expr | 不等比较 | PartialEq |
% | expr % expr | 算术求余 | Rem |
%= | var %= expr | 算术求余与赋值 | RemAssign |
& | &expr, &mut expr | 借用 | |
& | &type, &mut type, &'a type, &'a mut type | 借用指针类型 | |
& | expr & expr | 按位与 | BitAnd |
&= | var &= expr | 按位与及赋值 | BitAndAssign |
&& | expr && expr | 逻辑与 | |
* | expr * expr | 算术乘法 | Mul |
*= | var *= expr | 算术乘法与赋值 | MulAssign |
* | *expr | 解引用 | |
* | *const type, *mut type | 裸指针 | |
+ | trait + trait, 'a + trait | 复合类型限制 | |
+ | expr + expr | 算术加法 | Add |
+= | var += expr | 算术加法与赋值 | AddAssign |
, | expr, expr | 参数以及元素分隔符 | |
- | - expr | 算术取负 | Neg |
- | expr - expr | 算术减法 | Sub |
-= | var -= expr | 算术减法与赋值 | SubAssign |
-> | fn(...) -> type, |...| -> type | 函数与闭包,返回类型 | |
. | expr.ident | 成员访问 | |
.. | .., expr.., ..expr, expr..expr | 右半开区间 | PartialOrd |
..= | ..=expr, expr..=expr | 闭合区间 | PartialOrd |
.. | ..expr | 结构体更新语法 | |
.. | variant(x, ..), struct_type { x, .. } | “代表剩余部分”的模式绑定 | |
... | expr...expr | (不推荐使用,用..=替代) 闭合区间 | |
/ | expr / expr | 算术除法 | Div |
/= | var /= expr | 算术除法与赋值 | DivAssign |
: | pat: type, ident: type | 约束 | |
: | ident: expr | 结构体字段初始化 | |
: | 'a: loop {...} | 循环标志 | |
; | expr; | 语句和语句结束符 | |
; | [...; len] | 固定大小数组语法的部分 | |
<< | expr << expr | 左移 | Shl |
<<= | var <<= expr | 左移与赋值 | ShlAssign |
< | expr < expr | 小于比较 | PartialOrd |
<= | expr <= expr | 小于等于比较 | PartialOrd |
= | var = expr, ident = type | 赋值/等值 | |
== | expr == expr | 等于比较 | PartialEq |
=> | pat => expr | 匹配分支语法的部分 | |
> | expr > expr | 大于比较 | PartialOrd |
>= | expr >= expr | 大于等于比较 | PartialOrd |
>> | expr >> expr | 右移 | Shr |
>>= | var >>= expr | 右移与赋值 | ShrAssign |
@ | ident @ pat | 模式绑定 | |
^ | expr ^ expr | 按位异或 | BitXor |
^= | var ^= expr | 按位异或与赋值 | BitXorAssign |
| | pat | pat | 模式匹配中的多个可选条件 | |
| | expr | expr | 按位或 | BitOr |
|= | var |= expr | 按位或与赋值 | BitOrAssign |
|| | expr || expr | 逻辑或 | |
? | expr? | 错误传播 |
非运算符符号
表 B-2:独立语法
| 符号 | 解释 |
|---|---|
'ident | 生命周期名称或循环标签 |
...u8, ...i32, ...f64, ...usize, 等 | 指定类型的数值常量 |
"..." | 字符串常量 |
r"...", r#"..."#, r##"..."##, etc. | 原生字符串, 未转义字符 |
b"..." | 将 &str 转换成 &[u8; N] 类型的数组 |
br"...", br#"..."#, br##"..."##, 等 | 原生字节字符串,原生和字节字符串字面值的结合 |
'...' | Char 字符 |
b'...' | ASCII 字节 |
|...| expr | 闭包 |
! | 代表总是空的类型,用于发散函数(无返回值函数) |
_ | 模式绑定中表示忽略的意思;也用于增强整型字面值的可读性 |
表 B-3 展示了模块和对象调用路径的语法。
表 B-3:路径相关语法
| 符号 | 解释 |
|---|---|
ident::ident | 命名空间路径 |
::path | 从当前的包的根路径开始的相对路径 |
self::path | 与当前模块相对的路径(如一个显式相对路径) |
super::path | 与父模块相对的路径 |
type::ident, <type as trait>::ident | 关联常量、关联函数、关联类型 |
<type>::... | 不可以被直接命名的关联项类型(如 <&T>::...,<[T]>::..., 等) |
trait::method(...) | 使用特征名进行方法调用,以消除方法调用的二义性 |
type::method(...) | 使用类型名进行方法调用, 以消除方法调用的二义性 |
<type as trait>::method(...) | 将类型转换为特征,再进行方法调用,以消除方法调用的二义性 |
表 B-4 展示了使用泛型参数时用到的符号。
表 B-4:泛型
| 符号 | 解释 |
|---|---|
path<...> | 为一个类型中的泛型指定具体参数(如 Vec<u8>) |
path::<...>, method::<...> | 为一个泛型、函数或表达式中的方法指定具体参数,通常指双冒号(turbofish)(如 "42".parse::<i32>()) |
fn ident<...> ... | 泛型函数定义 |
struct ident<...> ... | 泛型结构体定义 |
enum ident<...> ... | 泛型枚举定义 |
impl<...> ... | 实现泛型 |
for<...> type | 高阶生命周期限制 |
type<ident=type> | 泛型,其一个或多个相关类型必须被指定为特定类型(如 Iterator<Item=T>) |
表 B-5 展示了使用特征约束来限制泛型参数的符号。
表 B-5:特征约束
| 符号 | 解释 |
|---|---|
T: U | 泛型参数 T需实现U类型 |
T: 'a | 泛型 T 的生命周期必须长于 'a(意味着该类型不能传递包含生命周期短于 'a 的任何引用) |
T : 'static | 泛型 T 只能使用声明周期为'static 的引用 |
'b: 'a | 生命周期'b必须长于生命周期'a |
T: ?Sized | 使用一个不定大小的泛型类型 |
'a + trait, trait + trait | 多个类型组成的复合类型限制 |
表 B-6 展示了宏以及在一个对象上定义属性的符号。
表 B-6:宏与属性
| 符号 | 解释 |
|---|---|
#[meta] | 外部属性 |
#![meta] | 内部属性 |
$ident | 宏替换 |
$ident:kind | 宏捕获 |
$(…)… | 宏重复 |
ident!(...), ident!{...}, ident![...] | 宏调用 |
表 B-7 展示了写注释的符号。
表 B-7:注释
| 符号 | 注释 |
|---|---|
// | 行注释 |
//! | 内部行(hang)文档注释 |
/// | 外部行文档注释 |
/*...*/ | 块注释 |
/*!...*/ | 内部块文档注释 |
/**...*/ | 外部块文档注释 |
表 B-8 展示了出现在使用元组时的符号。
表 B-8:元组
| 符号 | 解释 |
|---|---|
() | 空元组(亦称单元),即是字面值也是类型 |
(expr) | 括号表达式 |
(expr,) | 单一元素元组表达式 |
(type,) | 单一元素元组类型 |
(expr, ...) | 元组表达式 |
(type, ...) | 元组类型 |
expr(expr, ...) | 函数调用表达式;也用于初始化元组结构体 struct 以及元组枚举 enum 变体 |
expr.0, expr.1, etc. | 元组索引 |
表 B-9 展示了使用大括号的上下文。
表 B-9:大括号
| 符号 | 解释 |
|---|---|
{...} | 代码块表达式 |
Type {...} | 结构体字面值 |
表 B-10 展示了使用方括号的上下文。
表 B-10:方括号
| 符号 | 解释 |
|---|---|
[...] | 数组 |
[expr; len] | 数组里包含len个expr |
[type; len] | 数组里包含了len个type类型的对象 |
expr[expr] | 集合索引。 重载(Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | 集合索引,也称为集合切片,索引要实现以下特征中的其中一个:Range,RangeFrom,RangeTo 或 RangeFull |
附录 C:表达式
在语句与表达式章节中,我们对表达式有过介绍,下面对这些常用表达式进行一一说明。
基本表达式
#![allow(unused)] fn main() { let n = 3; let s = "test"; }
if 表达式
fn main() { let var1 = 10; let var2 = if var1 >= 10 { var1 } else { var1 + 10 }; println!("{}", var2); }
通过 if 表达式将值赋予 var2。
你还可以在循环中结合 continue 、break 来使用:
#![allow(unused)] fn main() { let mut v = 0; for i in 1..10 { v = if i == 9 { continue } else { i } } println!("{}", v); }
if let 表达式
#![allow(unused)] fn main() { let o = Some(3); let v = if let Some(x) = o { x } else { 0 }; }
match 表达式
#![allow(unused)] fn main() { let o = Some(3); let v = match o { Some(x) => x, _ => 0 }; }
loop 表达式
#![allow(unused)] fn main() { let mut n = 0; let v = loop { if n == 10 { break n } n += 1; }; }
语句块 {}
#![allow(unused)] fn main() { let mut n = 0; let v = { println!("before: {}", n); n += 1; println!("after: {}", n); n }; println!("{}", v); }
附录 D:派生特征 trait
在本书的各个部分中,我们讨论了可应用于结构体和枚举定义的 derive 属性。被 derive 标记的对象会自动实现对应的默认特征代码,继承相应的功能。
在本附录中,我们列举了所有标准库存在的 derive 特征,每个特征覆盖了以下内容
- 该特征将会派生什么样的操作符和方法
- 由
derive提供什么样的特征实现 - 实现特征对于类型意味着什么
- 你需要什么条件来实现该特征
- 特征示例
如果你希望不同于 derive 属性所提供的行为,请查阅 标准库文档 中每个特征的细节以了解如何手动实现它们。
除了本文列出的特征之外,标准库中定义的其它特征不能通过 derive 在类型上实现。这些特征不存在有意义的默认行为,所以由你负责以合理的方式实现它们。
一个无法被派生的特征例子是为终端用户处理格式化的 Display 。你应该时常考虑使用合适的方法来为终端用户显示一个类型。终端用户应该看到类型的什么部分?他们会找出相关部分吗?对他们来说最关心的数据格式是什么样的?Rust 编译器没有这样的洞察力,因此无法为你提供合适的默认行为。
本附录所提供的可派生特征列表其实并不全面:库可以为其内部的特征实现 derive ,因此除了本文列出的标准库 derive 之外,还有很多很多其它库的 derive 。实现 derive 涉及到过程宏的应用,这在宏章节中有介绍。
用于开发者输出的 Debug
Debug 特征可以让指定对象输出调试格式的字符串,通过在 {} 占位符中增加 :? 表明,例如println!("show you some debug info: {:?}", MyObject);.
Debug 特征允许以调试为目的来打印一个类型的实例,所以程序员可以在执行过程中看到该实例的具体信息。
例如,在使用 assert_eq! 宏时, Debug 特征是必须的。如果断言失败,这个宏就把给定实例的值打印出来,这样程序员就能看到两个实例为什么不相等。
等值比较的 PartialEq 和 Eq
PartialEq 特征可以比较一个类型的实例以检查是否相等,并开启了 == 和 != 运算符的功能。
派生的 PartialEq 实现了 eq 方法。当 PartialEq 在结构体上派生时,只有所有 的字段都相等时两个实例才相等,同时只要有任何字段不相等则两个实例就不相等。当在枚举上派生时,每一个成员都和其自身相等,且和其他成员都不相等。
例如,当使用 assert_eq! 宏时,需要比较一个类型的两个实例是否相等,则 PartialEq 特征是必须的。
Eq 特征没有方法, 其作用是表明每一个被标记类型的值都等于其自身。 Eq 特征只能应用于那些实现了 PartialEq 的类型,但并非所有实现了 PartialEq 的类型都可以实现 Eq。浮点类型就是一个例子:浮点数的实现表明两个非数字( NaN ,not-a-number)值是互不相等的。
例如,对于一个 HashMap<K, V> 中的 key 来说, Eq 是必须的,这样 HashMap<K, V> 就可以知道两个 key 是否一样。
次序比较的 PartialOrd 和 Ord
PartialOrd 特征可以让一个类型的多个实例实现排序功能。实现了 PartialOrd 的类型可以使用 <、 >、<= 和 >= 操作符。一个类型想要实现 PartialOrd 的前提是该类型已经实现了 PartialEq 。
派生 PartialOrd 实现了 partial_cmp 方法,一般情况下其返回一个 Option<Ordering>,但是当给定的值无法进行排序时将返回 None。尽管大多数类型的值都可以比较,但一个无法产生顺序的例子是:浮点类型的非数字值。当在浮点数上调用 partial_cmp 时, NaN 的浮点数将返回 None。
当在结构体上派生时, PartialOrd 以在结构体定义中字段出现的顺序比较每个字段的值来比较两个实例。当在枚举上派生时,认为在枚举定义中声明较早的枚举项小于其后的枚举项。
例如,对于来自于 rand 包的 gen_range 方法来说,当在一个大值和小值指定的范围内生成一个随机值时, PartialOrd trait 是必须的。
对于派生了 Ord 特征的类型,任何两个该类型的值都能进行排序。 Ord 特征实现了 cmp 方法,它返回一个 Ordering 而不是 Option<Ordering>,因为总存在一个合法的顺序。一个类型要想使用 Ord 特征,它必须要先实现 PartialOrd 和 Eq 。当在结构体或枚举上派生时, cmp 方法 和 PartialOrd 的 partial_cmp 方法表现是一致的。
例如,当在 BTreeSet<T>(一种基于有序值存储数据的数据结构)上存值时, Ord 是必须的。
复制值的 Clone 和 Copy
Clone 特征用于创建一个值的深拷贝(deep copy),复制过程可能包含代码的执行以及堆上数据的复制。查阅 通过 Clone 进行深拷贝获取有关 Clone 的更多信息。
派生 Clone 实现了 clone 方法,当为整个的类型实现 Clone 时,在该类型的每一部分上都会调用 clone 方法。这意味着类型中所有字段或值也必须实现了 Clone,这样才能够派生 Clone 。
例如,当在一个切片(slice)上调用 to_vec 方法时, Clone 是必须的。切片只是一个引用,并不拥有其所包含的实例数据,但是从 to_vec 中返回的 Vector 需要拥有实例数据,因此, to_vec 需要在每个元素上调用 clone 来逐个复制。因此,存储在切片中的类型必须实现 Clone。
Copy 特征允许你通过只拷贝存储在栈上的数据来复制值(浅拷贝),而无需复制存储在堆上的底层数据。查阅 通过 Copy 复制栈数据 的部分来获取有关 Copy 的更多信息。
实际上 Copy 特征并不阻止你在实现时使用了深拷贝,只是,我们不应该这么做,毕竟遵循一个语言的惯例是很重要的。当用户看到 Copy 时,潜意识就应该知道这是浅拷贝,复制一个值会非常快。
当一个类型的内部字段全部实现了 Copy 时,你就可以在该类型上派上 Copy 特征。 一个类型如果要实现 Copy 它必须先实现 Clone ,因为一个类型实现 Clone 后,就等于顺便实现了 Copy 。
总之, Copy 拥有更好的性能,当浅拷贝足够的时候,就不要使用 Clone ,不然会导致你的代码运行更慢,对于性能优化来说,一个很大的方面就是减少热点路径深拷贝的发生。
固定大小的值映射的 Hash
Hash 特征允许你使用 hash 函数把一个任意大小的实例映射到一个固定大小的值上。派生 Hash 实现了 hash 方法,对某个类型进行 hash 调用,其实就是对该类型下每个字段单独进行 hash 调用,然后把结果进行汇总,这意味着该类型下的所有的字段也必须实现了 Hash,这样才能够派生 Hash。
例如,在 HashMap<K, V> 上存储数据,存放 key 的时候, Hash 是必须的。
默认值的 Default
Default 特征会帮你创建一个类型的默认值。 派生 Default 意味着自动实现了 default 函数。 default 函数的派生实现调用了类型每部分的 default 函数,这意味着类型中所有的字段也必须实现了 Default,这样才能够派生 Default 。
Default::default 函数通常结合结构体更新语法一起使用,这在第五章的 结构体更新语法 部分有讨论。可以自定义一个结构体的一小部分字段而剩余字段则使用 ..Default::default() 设置为默认值。
例如,当你在 Option<T> 实例上使用 unwrap_or_default 方法时, Default 特征是必须的。如果 Option<T> 是 None 的话, unwrap_or_default 方法将返回 T 类型的 Default::default 的结果。
附录 E:prelude 模块
附录 F:Rust 版本发布
Rust 版本说明
早在第一章,我们见过 cargo new 在 Cargo.toml 中增加了一些有关 edition 的元数据。本附录将解释其意义!
与其它语言相比,Rust 的更新迭代较为频繁(得益于精心设计过的发布流程以及 Rust 语言开发者团队管理):
- 每 6 周发布一个迭代版本
- 2 - 3 年发布一个新的大版本:每一个版本会结合已经落地的功能,并提供一个清晰的带有完整更新文档和工具的功能包。新版本会作为常规的 6 周发布过程的一部分发布。
好处在于,可以满足不同的用户群体的需求:
- 对于活跃的 Rust 用户,他们总是能很快获取到新的语言内容,毕竟,尝鲜是技术爱好者的共同特点:)
- 对于一般的用户,edition 的发布会告诉这些用户:Rust 语言相比上次大版本发布,有了重大的改进,值得一看
- 对于 Rust 语言开发者,可以让他们的工作成果更快的被世人所知,不必锦衣夜行
在本文档编写时,Rust 已经有三个版本:Rust 2015、2018、2021。本书基于 Rust 2021 edition 编写。
Cargo.toml 中的 edition 字段表明代码应该使用哪个版本编译。如果该字段不存在,其默认为 2021 以提供后向兼容性。
每个项目都可以选择不同于默认的 Rust 2021 edition 的版本。这样,版本可能会包含不兼容的修改,比如新版本中新增的关键字可能会与老代码中的标识符冲突并导致错误。不过,除非你选择应用这些修改,否则旧代码依然能够被编译,即便你升级了编译器版本。
所有 Rust 编译器都支持任何之前存在的编译器版本,并可以链接任何支持版本的包。编译器修改只影响最初的解析代码的过程。因此,如果你使用 Rust 2021 而某个依赖使用 Rust 2018,你的项目仍旧能够编译并使用该依赖。反之,若项目使用 Rust 2018 而依赖使用 Rust 2021 亦可工作。
有一点需要明确:大部分功能在所有版本中都能使用。开发者使用任何 Rust 版本将能继续接收最新稳定版的改进。然而在一些情况,主要是增加了新关键字的时候,则可能出现了只能用于新版本的功能。只需切换版本即可利用新版本的功能。
请查看 Edition Guide 了解更多细节,这是一个完全介绍版本的书籍,包括如何通过 cargo fix 自动将代码迁移到新版本。
Rust 自身开发流程
本附录介绍 Rust 语言自身是如何开发的以及这如何影响作为 Rust 开发者的你。
无停滞稳定
作为一个语言,Rust 十分 注重代码的稳定性。我们希望 Rust 成为你代码坚实的基础,假如持续地有东西在变,这个希望就实现不了。但与此同时,如果不能实验新功能的话,在发布之前我们又无法发现其中重大的缺陷,而一旦发布便再也没有修改的机会了。
对于这个问题我们的解决方案被称为 “无停滞稳定”(“stability without stagnation”),其指导性原则是:无需担心升级到最新的稳定版 Rust。每次升级应该是无痛的,并应带来新功能,更少的 Bug 和更快的编译速度。
Choo, Choo! ~~ 小火车发布流程启动
开发 Rust 语言是基于一个火车时刻表来进行的:所有的开发工作在 Master 分支上完成,但是发布就像火车时刻表一样,拥有不同的时间,发布采用的软件发布列车模型,被用于思科 IOS 和等其它软件项目。Rust 有三个 发布通道(release channel):
- Nightly
- Beta
- Stable(稳定版)
大部分 Rust 开发者主要采用稳定版通道,不过希望实验新功能的开发者可能会使用 nightly 或 beta 版。
如下是一个开发和发布过程如何运转的例子:假设 Rust 团队正在进行 Rust 1.5 的发布工作。该版本发布于 2015 年 12 月,这个版本和时间显然比较老了,不过这里只是为了提供一个真实的版本。Rust 新增了一项功能:一个 master 分支的新提交。每天晚上,会产生一个新的 nightly 版本。每天都是发布版本的日子,而这些发布由发布基础设施自动完成。所以随着时间推移,发布轨迹看起来像这样,版本一天一发:
nightly: * - - * - - *
每 6 周时间,是准备发布新版本的时候了!Rust 仓库的 beta 分支会从用于 nightly 的 master 分支产生。现在,有了两个发布版本:
nightly: * - - * - - *
|
beta: *
大部分 Rust 用户不会主要使用 beta 版本,不过在 CI 系统中对 beta 版本进行测试能够帮助 Rust 发现可能的回归缺陷(regression)。同时,每天仍产生 nightly 发布:
nightly: * - - * - - * - - * - - *
|
beta: *
比如我们发现了一个回归缺陷。好消息是在这些缺陷流入稳定发布之前还有一些时间来测试 beta 版本!fix 被合并到 master,为此 nightly 版本得到了修复,接着这些 fix 将 backport 到 beta 分支,一个新的 beta 发布就产生了:
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
第一个 beta 版的 6 周后,是发布稳定版的时候了!stable 分支从 beta 分支生成:
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
好的!Rust 1.5 发布了!然而,我们忘了些东西:因为又过了 6 周,我们还需发布 新版 Rust 的 beta 版,Rust 1.6。所以从 beta 分支生成 stable 分支后,新版的 beta 分支也再次从 nightly 生成:
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
这被称为 “train model”,因为每 6 周,一个版本 “离开车站”(“leaves the station”),不过从 beta 通道到达稳定通道还有一段旅程。
Rust 每 6 周发布一个版本,如时钟般准确。如果你知道了某个 Rust 版本的发布时间,就可以知道下个版本的时间:6 周后。每 6 周发布版本的一个好的方面是下一班车会来得更快。如果特定版本碰巧缺失某个功能也无需担心:另一个版本很快就会到来!这有助于减少因临近发版时间而偷偷释出未经完善的功能的压力。
多亏了这个过程,你总是可以切换到下一版本的 Rust 并验证是否可以轻易的升级:如果 beta 版不能如期工作,你可以向 Rust 团队报告并在发布稳定版之前得到修复!beta 版造成的破坏是非常少见的,不过 rustc 也不过是一个软件,可能会存在 Bug。
不稳定功能
这个发布模型中另一个值得注意的地方:不稳定功能(unstable features)。Rust 使用一个被称为 “功能标记”(“feature flags”)的技术来确定给定版本的某个功能是否启用。如果新功能正在积极地开发中,其提交到了 master,因此会出现在 nightly 版中,不过会位于一个 功能标记 之后。作为用户,如果你希望尝试这个正在开发的功能,则可以在源码中使用合适的标记来开启,不过必须使用 nightly 版。
如果使用的是 beta 或稳定版 Rust,则不能使用任何功能标记。这是在新功能被宣布为永久稳定之前获得实用价值的关键。这既满足了希望使用最尖端技术的同学,那些坚持稳定版的同学也知道其代码不会被破坏。这就是无停滞稳定。
本书只包含稳定的功能,因为还在开发中的功能仍可能改变,当其进入稳定版时肯定会与编写本书的时候有所不同。你可以在网上获取 nightly 版的文档。
Rustup 和 Rust Nightly 的职责
安装 Rust Nightly 版本
Rustup 使得改变不同发布通道的 Rust 更为简单,其在全局或分项目的层次工作。其默认会安装稳定版 Rust。例如为了安装 nightly:
$ rustup install nightly
你会发现 rustup 也安装了所有的 工具链(toolchains, Rust 和其相关组件)。如下是一位作者的 Windows 计算机上的例子:
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
在指定目录使用 Rust Nightly
如你所见,默认是稳定版。大部分 Rust 用户在大部分时间使用稳定版。你可能也会这么做,不过如果你关心最新的功能,可以为特定项目使用 nightly 版。为此,可以在项目目录使用 rustup override 来设置当前目录 rustup 使用 nightly 工具链:
$ cd ~/projects/needs-nightly
$ rustup override set nightly
现在,每次在 *~/需要 nightly 的项目/*下(在项目的根目录下,也就是 Cargo.toml 所在的目录) 调用 rustc 或 cargo,rustup 会确保使用 nightly 版 Rust。在你有很多 Rust 项目时大有裨益!
RFC 过程和团队
那么你如何了解这些新功能呢?Rust 开发模式遵循一个 Request For Comments (RFC) 过程。如果你希望改进 Rust,可以编写一个提议,也就是 RFC。
任何人都可以编写 RFC 来改进 Rust,同时这些 RFC 会被 Rust 团队评审和讨论,他们由很多不同分工的子团队组成。这里是 Rust 官网 上所有团队的总列表,其包含了项目中每个领域的团队:语言设计、编译器实现、基础设施、文档等。各个团队会阅读相应的提议和评论,编写回复,并最终达成接受或回绝功能的一致。
如果功能被接受了,在 Rust 仓库会打开一个 issue,人们就可以实现它。实现功能的人可能不是最初提议功能的人!当实现完成后,其会合并到 master 分支并位于一个特性开关(feature gate)之后,正如不稳定功能 部分所讨论的。
在稍后的某个时间,一旦使用 nightly 版的 Rust 团队能够尝试这个功能了,团队成员会讨论这个功能在 nightly 中运行的情况,并决定是否应该进入稳定版。如果决定继续推进,特性开关会移除,然后这个功能就被认为是稳定的了!乘着“发布的列车”,最终在新的稳定版 Rust 中出现。
附录 G:Rust 更新版本列表
本目录包含了 Rust 历次版本更新的重要内容解读,需要注意,每个版本实际更新的内容要比这里记录的更多,全部内容请访问每节开头的官方链接查看。
1.58
1.59
1.60
1.61
1.62
1.63
1.64
1.65
1.66
1.67
官方readme
下面有任何有疑问的接口中的名称都直接去api文档中搜索
在Python中使用Rust
PyO3用来生成原生 Python 模块,最简单的方法是使用maturin,这是一个用最少配置发布基于 Rust 的 Python 包的工具。新建一个测试用的文件夹
# (replace string_sum with the desired package name)
$ mkdir string_sum
$ cd string_sum
$ pip install maturin
在上述string_sum文件夹中初始化maturin,
$ maturin init
✔ 🤷 What kind of bindings to use? · pyo3
✨ Done! New project created string_sum
可以看到生成了新包的source,最重要的文件时Cargo.toml和lib.rs,大约文件中看起来是这样的
Cargo.toml
[package]
name = "string_sum"
version = "0.1.0"
edition = "2021"
# See more keys and their definitions at https://doc.rust-lang.org/cargo/reference/manifest.html
[lib]
# The name of the native library. This is the name which will be used in Python to import the
# library (i.e. `import string_sum`). If you change this, you must also change the name of the
# `#[pymodule]` in `src/lib.rs`.
name = "string_sum"
# "cdylib" is necessary to produce a shared library for Python to import from.
#
# Downstream Rust code (including code in `bin/`, `examples/`, and `tests/`) will not be able
# to `use string_sum;` unless the "rlib" or "lib" crate type is also included, e.g.:
# crate-type = ["cdylib", "rlib"]
crate-type = ["cdylib"]
[dependencies]
pyo3 = "0.18.1"
src/lib.rs
#![allow(unused)] fn main() { use pyo3::prelude::*; /// Formats the sum of two numbers as string. #[pyfunction] fn sum_as_string(a: usize, b: usize) -> PyResult<String> { Ok((a + b).to_string()) } /// A Python module implemented in Rust. The name of this function must match /// the `lib.name` setting in the `Cargo.toml`, else Python will not be able to /// import the module. #[pymodule] fn string_sum(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(sum_as_string, m)?)?; Ok(()) } }
最后,终端输入maturin develop。这会创建一个 package 然后安装进当前的 Python 环境,然后这个 package 就能在 Python 里用了
$ maturin develop
# lots of progress output as maturin runs the compilation...
$ python
>>> import string_sum
>>> string_sum.sum_as_string(5, 20)
'25'
在Rust中使用Python
将 Python 嵌入为 Rust 二进制,你要确保你的 Python 安装包含了一个共享库(ensure that your Python installation contains a shared library?啥意思)。
用 cargo new 新建一个项目并像这样将 pyo3 加入到 Cargo.toml 中,
[dependencies.pyo3]
version = "0.18.1"
features = ["auto-initialize"]
下面的例子会输出 sys.version 的值以及当前用户名
use pyo3::prelude::*; use pyo3::types::IntoPyDict; fn main() -> PyResult<()> { Python::with_gil(|py| { let sys = py.import("sys")?; let version: String = sys.getattr("version")?.extract()?; let locals = [("os", py.import("os")?)].into_py_dict(py); let code = "os.getenv('USER') or os.getenv('USERNAME') or 'Unknown'"; let user: String = py.eval(code, None, Some(&locals))?.extract()?; println!("Hello {}, I'm Python {}", user, version); Ok(()) }) }
如果
cargo run后出现Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding,上面信息中应该还有PYTHONHOME: not set, PYTHONPATH: not set的信息,应该将使用的 Python 解释器路径加入到系统环境中,比如 Annconda 则将 Annaconda 文件夹路径创建为PYTHONHOME,其下的 python.exe 路径创建为PYTHONPATH。
工具和库
- maturin Build and publish crates with pyo3, rust-cpython or cffi bindings as well as rust binaries as python packages
- setuptools-rust Setuptools plugin for Rust support.
- pyo3-built Simple macro to expose metadata obtained with the
builtcrate as aPyDict - rust-numpy Rust binding of NumPy C-API
- dict-derive Derive FromPyObject to automatically transform Python dicts into Rust structs
- pyo3-log Bridge from Rust to Python logging
- pythonize Serde serializer for converting Rust objects to JSON-compatible Python objects
- pyo3-asyncio Utilities for working with Python's Asyncio library and async functions
- rustimport Directly import Rust files or crates from Python, without manual compilation step. Provides pyo3 integration by default and generates pyo3 binding code automatically.
例子
- autopy A simple, cross-platform GUI automation library for Python and Rust.
- Contains an example of building wheels on TravisCI and appveyor using cibuildwheel
- ballista-python A Python library that binds to Apache Arrow distributed query engine Ballista.
- bed-reader Read and write the PLINK BED format, simply and efficiently.
- Shows Rayon/ndarray::parallel (including capturing errors, controlling thread num), Python types to Rust generics, Github Actions
- cryptography Python cryptography library with some functionality in Rust.
- css-inline CSS inlining for Python implemented in Rust.
- datafusion-python A Python library that binds to Apache Arrow in-memory query engine DataFusion.
- deltalake-python Native Delta Lake Python binding based on delta-rs with Pandas integration.
- fastbloom A fast bloom filter | counting bloom filter implemented by Rust for Rust and Python!
- fastuuid Python bindings to Rust's UUID library.
- feos Lightning fast thermodynamic modeling in Rust with fully developed Python interface.
- forust A lightweight gradient boosted decision tree library written in Rust.
- html-py-ever Using html5ever through kuchiki to speed up html parsing and css-selecting.
- hyperjson A hyper-fast Python module for reading/writing JSON data using Rust's serde-json.
- inline-python Inline Python code directly in your Rust code.
- jsonschema-rs Fast JSON Schema validation library.
- mocpy Astronomical Python library offering data structures for describing any arbitrary coverage regions on the unit sphere.
- orjson Fast Python JSON library.
- ormsgpack Fast Python msgpack library.
- point-process High level API for pointprocesses as a Python library.
- polaroid Hyper Fast and safe image manipulation library for Python written in Rust.
- polars Fast multi-threaded DataFrame library in Rust | Python | Node.js.
- pydantic-core Core validation logic for pydantic written in Rust.
- pyheck Fast case conversion library, built by wrapping heck.
- Quite easy to follow as there's not much code.
- pyre Fast Python HTTP server written in Rust.
- ril-py A performant and high-level image processing library for Python written in Rust.
- river Online machine learning in python, the computationally heavy statistics algorithms are implemented in Rust.
- rust-python-coverage Example PyO3 project with automated test coverage for Rust and Python.
- tiktoken A fast BPE tokeniser for use with OpenAI's models.
- tokenizers Python bindings to the Hugging Face tokenizers (NLP) written in Rust.
- wasmer-python Python library to run WebAssembly binaries.
Articles and other media
- How Pydantic V2 leverages Rust's Superpowers - Feb 4, 2023
- Nine Rules for Writing Python Extensions in Rust - Dec 31, 2021
- Calling Rust from Python using PyO3 - Nov 18, 2021
- davidhewitt's 2021 talk at Rust Manchester meetup - Aug 19, 2021
- Incrementally porting a small Python project to Rust - Apr 29, 2021
- Vortexa - Integrating Rust into Python - Apr 12, 2021
- Writing and publishing a Python module in Rust - Aug 2, 2020
Python modules
可以用 #[pymodule] 创建一个模组
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } /// This module is implemented in Rust. #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
模组的名字会默认为 Rust 函数的名字(fn my_extenssion),如果要修改可以使用 #[pyo3(name = "custom_name")]
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } #[pymodule] #[pyo3(name = "custom_name")] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
模组的名字必须和 .so 或者 .pyd 一致。
注释
模组和其中函数都是在 #[pyfunction] 或 #[pymodule] 上方通过 ///加入。调用是通过 module_name.__doc__ 或者编辑器自动显示。
子模组
可以使用 PyModule.add_submodule()添加子模组
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn parent_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { register_child_module(py, m)?; Ok(()) } fn register_child_module(py: Python<'_>, parent_module: &PyModule) -> PyResult<()> { let child_module = PyModule::new(py, "child_module")?; child_module.add_function(wrap_pyfunction!(func, child_module)?)?; parent_module.add_submodule(child_module)?; Ok(()) } #[pyfunction] fn func() -> String { "func".to_string() } }
这并没有定义一个包,所以不支持直接通过from parent_module import child_module导入子模块,更多信息参考 #759和#1517。
Python functions
#[pyfunction]用来通过一个 Rust 函数定义 Python 函数。一旦定义了,需要通过 wrap_pyfunction! 宏来添加到一个 module 中。
下述例子定义了一个在 Python 模组 my_extension 中名为 double 的函数
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] fn double(x: usize) -> usize { x * 2 } #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
函数选项(Function options)
#[pyo3]属性可以用来改造生成的 Python 函数的性质。可以采用如下选项的任意组合
#[pyo3(name = "...")]:覆盖传递给 Python 的函数名,
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] #[pyo3(name = "no_args")] fn no_args_py() -> usize { 42 } #[pymodule] fn module_with_functions(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(no_args_py, m)?)?; Ok(()) } }
#[pyo3(signature = (...))]:定义 Python 中函数的签名,见本页 Function Signatures#[pyo3(text_signature = "...")]:覆盖在 Python 工具中可见的由 PyO3 生成的函数签名(例如通过inspect.signature)#[pyo3(pass_module)]:让 PyO3 将 "pass_module" 作为第一个变量传递给函数,那么就能够在函数体中使用该模组,该变量类型必须为&PyModule。下述例子将创建一个函数pyfunction_with_module,它会返回它包含的模组的名称(i.e.module_with_fn):
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyfunction] #[pyo3(pass_module)] fn pyfunction_with_module(module: &PyModule) -> PyResult<&str> { module.name() } #[pymodule] fn module_with_fn(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(pyfunction_with_module, m)?) } }
变量单独选项(Per-argument options)
#[pyo3]也可以用在单独的变量中来改变其性质,它可以是下述选项的任意组合:
#[pyo3(from_py_with = "...")]:将一个本地函数从 Python 形式转化为 Rust 形式的函数参数,取代使用默认的FromPyObject。函数签名必须为fn(&PyAny) -> PyResult<T>,其中T必须为 Rust 类型的变量。下述例子使用from_py_with将输入的 Python 对象转换为它的长度
#![allow(unused)] fn main() { use pyo3::prelude::*; fn get_length(obj: &PyAny) -> PyResult<usize> { let length = obj.len()?; Ok(length) } #[pyfunction] fn object_length( #[pyo3(from_py_with = "get_length")] argument: usize ) -> usize { argument } }
高级函数模式(Advanced function patterns)
在 Rust 中调用 Python 函数
可以将 Python 中定义的函数或者内置函数传递为 Rust 函数 (PyFunction-常规Python函数,PyCFunction-内置函数)repr()。
也可以使用 PyAny::is_callable 来检查是否有一个可调用的(callable) 对象。 is_callable会返回true若函数(包括 lambdas),方法和 objects 带有 __call__ 方法。可以用 PyAny::call 调用对象,args作为第一个参数,kwargs作为第二个参数。另外没参数时使用 PyAny::call0,只有 positional 参数时使用PyAny::call1。
在 Python 中调用 Rust 函数
将 Rust 函数转换为 Python 对象的方法取决于函数:
- Named functions,e.g.
fn foo():添加#[pyfunction]然后使用wrap_pyfunction!得到对应的PyCFunction - 匿名函数(Anonymous functions)或者闭包(closures)e.g.
foo: fn():- 使用
#[pyclass]结构将函数保存为一个域(field)并用__call__来调用保存的函数 - 使用
PyCFunction::new_closure来从函数直接创建
- 使用
获得FFI函数
为了使 Rust 函数在 Python 中可调用,PyO3生成一个外部的 "C" 函数,具体签名依赖于 Rust的签名。它将对于 Rust 的调用嵌入在这个 FFI-包装器(wrapper)函数中,这个包装器负责从输入PyObject中提取一般参数(regular argument)和关键字参数(keyword argument)。
wrap_pyfunction宏能用来根据给定的#[pyfunction]和一个PyModule: wrap_pyfunction!(rust_fun, module)直接得到一个PyCFunction。
#[pyfn]简写
有一种对#[pyfunction]和wrap_pymodule的简写:函数可以放置在模组的定义中并用#[pyfn]声明,但未来可能被移除
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { #[pyfn(m)] fn double(x: usize) -> usize { x * 2 } Ok(()) } }
#[pyfn(m)] 只是 #[pyfunction]的语法糖
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pymodule] fn my_extension(py: Python<'_>, m: &PyModule) -> PyResult<()> { #[pyfunction] fn double(x: usize) -> usize { x * 2 } m.add_function(wrap_pyfunction!(double, m)?)?; Ok(()) } }
函数签名(Function signatures)
#[pyfunction]同样也接受参数来控制生成的 Python 函数如何来接受参数。就像在 Python中一样,参数可以是 positional-only,keyword-only 或者同时是都有。*args 列表和 **kwargs字典也可以被接收。这些参数对下一章 Python Classes 中介绍的 [pyclassmethods] 也同样有效。
默认下,和 Python 一样,PyO3 接受所有参数作为 positional 或者 keyword 参数。大多数参数默认是需要的,除非结尾 Option<_> 参数,它会隐式的被给予一个 None。有两种方法改变这种模式:
#[pyo3(signature = (...))]允许用 Python 语法写一个签名- 额外的参数直接使用
#[pyfunction],见deprecated form(已弃用?)
使用#[pyo3(signature = (...))]
下述例子是一个函数可以接受任意的关键字参数(Python 语法中的**kwargs)并返回传入的参数量:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyDict; #[pyfunction] #[pyo3(signature = (**kwds))] fn num_kwds(kwds: Option<&PyDict>) -> usize { kwds.map_or(0, |dict| dict.len()) } #[pymodule] fn module_with_functions(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(num_kwds, m)?).unwrap(); Ok(()) } }
下述结构可以可以作为签名的一部分
/: 位置变量分隔符,每个定义在/前的变量都是一个位置(positionla-only)变量*: 每个定义在*后的变量是关键字(keyword-only)变量*args: var args,args parameter 的类型必须为&PyTuple**kwargs: 接受关键字变量,关键自变量的类型必须为Option<&PyDict>arg=Value: 有默认值的变量,如果arg在 var argments 后被定义,则被视为 keyword-only 变量
例子
#![allow(unused)] fn main() { use pyo3::types::{PyDict, PyTuple}; #[pymethods] impl MyClass { #[new] #[pyo3(signature = (num=-1))] fn new(num: i32) -> Self { MyClass { num } } #[pyo3(signature = (num=10, *py_args, name="Hello", **py_kwargs))] fn method( &mut self, num: i32, py_args: &PyTuple, name: &str, py_kwargs: Option<&PyDict>, ) -> String { let num_before = self.num; self.num = num; format!( "num={} (was previously={}), py_args={:?}, name={}, py_kwargs={:?} ", num, num_before, py_args, name, py_kwargs, ) } fn make_change(&mut self, num: i32) -> PyResult<String> { self.num = num; Ok(format!("num={}", self.num)) } } }
Python类型的变量不能是签名的一部分
#![allow(unused)] fn main() { #[pyfunction] #[pyo3(signature = (lambda))] pub fn simple_python_bound_function( py: Python<'_>, lambda: PyObject, ) -> PyResult<()> { Ok(()) } }
/和*变量的位置决定了系统如何处理位置和关键自变量,在 Python 中
import mymodule
mc = mymodule.MyClass()
print(mc.method(44, False, "World", 666, x=44, y=55))
print(mc.method(num=-1, name="World"))
print(mc.make_change(44, False))
输出如下
py_args=('World', 666), py_kwargs=Some({'x': 44, 'y': 55}), name=Hello, num=44
py_args=(), py_kwargs=None, name=World, num=-1
num=44
num=-1
使用关键字如
struct作为函数的变量,同时在签名和函数定义中使用 'raw identifier' 语法r#struct#![allow(unused)] fn main() { #[pyfunction(signature = (r#struct = "foo"))] fn function_with_keyword(r#struct: &str) { /* ... */ } }
尾随可选参数(Trailing optional arguments)
方便起见,没有#[pyo3(signature = (...))]的函数将末尾的Option<T>参数默认视为None,下述例子中,PyO3会创建 increment 函数带有签名 increment(x, amount=None)
#![allow(unused)] fn main() { use pyo3::prelude::*; /// Returns a copy of `x` increased by `amount`. /// /// If `amount` is unspecified or `None`, equivalent to `x + 1`. #[pyfunction] fn increment(x: u64, amount: Option<u64>) -> u64 { x + amount.unwrap_or(1) } }
要让末尾参数 Option<T> required,但仍然允许 None,添加一个#[pyo3(signature = (...))] 声明,在上述例子中,就是#[pyo3(signature = (x, amount))]:
#![allow(unused)] fn main() { #[pyfunction] #[pyo3(signature = (x, amount))] fn increment(x: u64, amount: Option<u64>) -> u64 { x + amount.unwrap_or(1) } }
为避免混淆,当 Option<T> 变量被不是 Option<T>的变量包围时,PyO3 需要 #[pyo3(signature = (...))]。
使函数签名对Python可用
函数签名对 Python 是可见的,通过__text_signature__属性。PyO3会自动为每个#[pyfunction]和#[pymethods]生成属性,会被#[pyo3(signature = (...))]覆盖。
这个仍有些缺点,未来有待改进
- 不包含变量的默认值,显示
... - 对
#[pyclass]中的#[new]方法不会生成
例子
#![allow(unused)] fn main() { use pyo3::prelude::*; /// This function adds two unsigned 64-bit integers. #[pyfunction] #[pyo3(signature = (a, b=0, /))] fn add(a: u64, b: u64) -> u64 { a + b } }
其签名在 Python 中是这样的
>>> pyo3_test.add.__text_signature__
'(a, b=..., /)'
>>> pyo3_test.add?
Signature: pyo3_test.add(a, b=Ellipsis, /)
Docstring: This function adds two unsigned 64-bit integers.
Type: builtin_function_or_method
替换生成的签名
#[pyo3(text_signature = "(<some signature>)")]可以用覆盖默认生成的签名,
#![allow(unused)] fn main() { use pyo3::prelude::*; /// This function adds two unsigned 64-bit integers. #[pyfunction] #[pyo3(signature = (a, b=0, /), text_signature = "(a, b=0, /)")] fn add(a: u64, b: u64) -> u64 { a + b } }
Python 中显示
>>> pyo3_test.add.__text_signature__
'(a, b=0, /)'
>>> pyo3_test.add?
Signature: pyo3_test.add(a, b=0, /)
Docstring: This function adds two unsigned 64-bit integers.
Type: builtin_function_or_method
错误处理(Error handling)
表示Python中错误
Rust 代码使用 Result<T, E>枚举来表示异常。错误类型 E 由代码作者指定。
PyO3 由 PyErr 类型来表示 Python 中的异常。如果 PyO3 API 可以抛出一个 Python 异常,那么那个 API 的返回类型会是 PyResult<T>,这是类型 Result<T, PyErr>的别名。
总的来说
- 当 Python 异常被抛出并被 PtO3 获取到,这个异常信息会被保存在
PyResult的Err变量中 - 通过 Rust 代码传递 Python 异常,然后使用通常的技术来处理(例如
?算子,PyErr作为错误类型) - 最后,当一个
PyResult从 Rust 通过 PyO3 返回到 Python 中时,如果结果是Err类型变量,那么其包含的异常会被抛出
在函数中抛出异常
如上所说,当一个 PyResult从 Rust 通过 PyO3 返回到 Python 中时,如果结果是Err类型变量,那么其包含的异常会被抛出。
那么,为了在一个#[pyfunction]中抛出异常,要把返回类型从T转为PyResult<T>。当函数返回一个Err,它会抛出一个 Python 异常。这对于#[pymethods]中的函数也有效。
例如,下述的 check_positive 函数当输入是负值时抛出一个 ValueError:
#![allow(unused)] fn main() { use pyo3::exceptions::PyValueError; use pyo3::prelude::*; #[pyfunction] fn check_positive(x: i32) -> PyResult<()> { if x < 0 { Err(PyValueError::new_err("x is negative")) } else { Ok(()) } } }
所有 Python 内置的异常类型都定义在 pyo3::exceptions 模块中,它们有一个 new_err 构造器来直接构造一个 PyErr。
Rust 错误类型
PyO3 自动将 #[pyfunction] 返回的 Result<T, E> 转换为 PyResult<T>,只要在 std::from::From<E> for PyErr 中有其实现。在 Rust 标准库中有许多这样定义的 From 转换的错误类型。
如果你处理的错误类型E来自第三方包,看本章的 foreign rust error types。
下述例子使用了 PyErr 的 From<ParseIntError>实现来抛出异常:parsing strings as integers
#![allow(unused)] fn main() { use std::num::ParseIntError; #[pyfunction] fn parse_int(x: &str) -> Result<usize, ParseIntError> { x.parse() } }
当传入一个不包含 floating-point number 的字符串,异常如下
>>> parse_int("bar")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: invalid digit found in string
用一个更复杂的例子,下述代码定义了一个 Rust 错误名为 CustomIOError。然后定义了一个 PyErr 下的 From<CustomIOError>,它会返回一个 PyErr 代表 Python 的 OSError。因此,可以直接在 #[pyfunction] 中使用这个错误。
use pyo3::exceptions::PyOSError; use pyo3::prelude::*; use std::fmt; #[derive(Debug)] struct CustomIOError; impl std::error::Error for CustomIOError {} impl fmt::Display for CustomIOError { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Oh no!") } } impl std::convert::From<CustomIOError> for PyErr { fn from(err: CustomIOError) -> PyErr { PyOSError::new_err(err.to_string()) } } pub struct Connection {/* ... */} fn bind(addr: String) -> Result<Connection, CustomIOError> { if &addr == "0.0.0.0" { Err(CustomIOError) } else { Ok(Connection{ /* ... */}) } } #[pyfunction] fn connect(s: String) -> Result<(), CustomIOError> { bind(s)?; // etc. Ok(()) } fn main() { Python::with_gil(|py| { let fun = pyo3::wrap_pyfunction!(connect, py).unwrap(); let err = fun.call1(("0.0.0.0",)).unwrap_err(); assert!(err.is_instance_of::<PyOSError>(py)); }); }
任何有 From 转换的错误 E 可以用在 ? 算子中。上述代码中 parse_int 的一个会返回 PyResult 的可选实现如下:
#![allow(unused)] fn main() { use pyo3::prelude::*; fn parse_int(s: String) -> PyResult<usize> { let x = s.parse()?; Ok(x) } }
第三方 Rust 错误类型(Foreign Rust error types)
The Rust compiler will not permit implementation of traits for types outside of the crate where the type is defined. (This is known as the "orphan rule".)
Given a type OtherError which is defined in third-party code, there are two main strategies available to integrate it with PyO3:
- Create a newtype wrapper, e.g.
MyOtherError. Then implementFrom<MyOtherError>forPyErr(orPyErrArguments), as well asFrom<OtherError>forMyOtherError. - Use Rust's Result combinators such as
map_errto write code freely to convertOtherErrorinto whatever is needed. This requires boilerplate at every usage however gives unlimited flexibility.
To detail the newtype strategy a little further, the key trick is to return Result<T, MyOtherError> from the #[pyfunction]. This means that PyO3 will make use of From<MyOtherError> for PyErr to create Python exceptions while the #[pyfunction] implementation can use ? to convert OtherError to MyOtherError automatically.
The following example demonstrates this for some imaginary third-party crate some_crate with a function get_x returning Result<i32, OtherError>:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::exceptions::PyValueError; use some_crate::{OtherError, get_x}; struct MyOtherError(OtherError); impl From<MyOtherError> for PyErr { fn from(error: MyOtherError) -> Self { PyValueError::new_err(error.0.message()) } } impl From<OtherError> for MyOtherError { fn from(other: OtherError) -> Self { Self(other) } } #[pyfunction] fn wrapped_get_x() -> Result<i32, MyOtherError> { // get_x is a function returning Result<i32, OtherError> let x: i32 = get_x()?; Ok(x) } }
Python classes
PyO3 提供许多 Rust 宏支持的属性来定义 Rust 结构的 Python 类。
主要的属性是 #[pyclass],放在一个 Rust 结构或者一个 fieldless 的枚举上面来为其生成一个 Python 类型。通常它们会有一个 #[pymethods]:用 impl 块注释的结构,用来定义 Python 方法和生成的 Python 类型的约束。(如果开启了 multiple-pymethods)特性,那么每个 #[pyclass]可以有多个 #[pymethods] 块。#[pymethods] 可以有类似 __str__ 的 Python 魔术方法的实现。
定义一个新类
定义一个 Python 类,需要在 Rust 结构或者 fieldless 枚举前加上 #[pyclass]
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Integer { inner: i32, } // A "tuple" struct #[pyclass] struct Number(i32); // PyO3 supports custom discriminants in enums #[pyclass] enum HttpResponse { Ok = 200, NotFound = 404, Teapot = 418, // ... } #[pyclass] enum MyEnum { Variant, OtherVariant = 30, // PyO3 supports custom discriminants. } }
限制
为了整合 Rust 类型与 Python,PyO3 需要对可以用 #[pyclass] 注释的类型加以限制。特别地,它们不能有生命周期的参数,不能有泛型参数,必须实现了 send。理由如下
没有生命周期
Rust 编译器为了内存安全使用生命周期,它们只在编译中使用,无法传输到 Python 这样的动态语言中。
没有泛型参数
一个带有泛型参数 T 的 Rust 结构 Foo<T> ,每次传入一个不同的具体类型的T时,会生成新的编译实现。这在 Python 中并不现实,因为 Python 中编译器只需要 Foo 的一个单独的实现。
必须要有Send
因为 Python 解释器中,Python 对象在线程中是免费共享的,不能保证哪个线程会最终丢弃这个对象。因此,每个用 #[pyclass] 注释的类型必须实现 Send(除非注释 #[pyclass(unsendable)])。
构造器(Constructor)
默认下是不可能通过 Python 代码创建一个自定义类的实例啊。为了声明一个构造器,需要定义一个方法并用 #[new] 属性注释它。只有 Python 的__new__ 方法可以,而__init__不可用。
#![allow(unused)] fn main() { #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Number(value) } } }
可选,如果你的 #[new] 可能会失败你可以返回 PyResult<Self>
#![allow(unused)] fn main() { #[pymethods] impl Nonzero { #[new] fn py_new(value: i32) -> PyResult<Self> { if value == 0 { Err(PyValueError::new_err("cannot be zero")) } else { Ok(Nonzero(value)) } } } }
如果没有声明含有 #[new] 的方法,那么只能由 Rust 创建实例,Python 无法创建。
将类添加到模组上
#![allow(unused)] fn main() { #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
PyCell and interior mutability
有时候需要将 pyclass 转换成一个 Python 对象然后在 Rust 代码中使用它,PyCell是主要的接口。
PyCell<T: PyClass>永远出现在 Python 语块中,所以 Rust 没有它的所有权。也就是说,Rust只能提取&PyCell<T>, not a 而不是PyCell<T>。
因此,想要安全地改变&PyCell后的数据,PyO3 采用例如 RefCell 这样的 Interior Mutability Pattern。
回忆Rust中借用的规则
- 在任意时刻,只能同时存在一个可变引用或者数个不可变引用
- 引用必须永远是有效的
PyCell,类似RefCell,通过在运行中跟踪引用来确保这些借用规则
#![allow(unused)] fn main() { #[pyclass] struct MyClass { #[pyo3(get)] num: i32, } Python::with_gil(|py| { let obj = PyCell::new(py, MyClass { num: 3 }).unwrap(); { let obj_ref = obj.borrow(); // Get PyRef assert_eq!(obj_ref.num, 3); // You cannot get PyRefMut unless all PyRefs are dropped assert!(obj.try_borrow_mut().is_err()); } { let mut obj_mut = obj.borrow_mut(); // Get PyRefMut obj_mut.num = 5; // You cannot get any other refs until the PyRefMut is dropped assert!(obj.try_borrow().is_err()); assert!(obj.try_borrow_mut().is_err()); } // You can convert `&PyCell` to a Python object pyo3::py_run!(py, obj, "assert obj.num == 5"); }); }
&PyCell<T>被限制了与 GILGuard 同样的生命周期。为了使对象存活更长(例如,在Rust中将它存在一个结构中),可以使用Py<T>,它可以将一个对象存储得比 GIL 更久,然后需要 Python<'_>来获取。
#![allow(unused)] fn main() { #[pyclass] struct MyClass { num: i32, } fn return_myclass() -> Py<MyClass> { Python::with_gil(|py| Py::new(py, MyClass { num: 1 }).unwrap()) } let obj = return_myclass(); Python::with_gil(|py| { let cell = obj.as_ref(py); // Py<MyClass>::as_ref returns &PyCell<MyClass> let obj_ref = cell.borrow(); // Get PyRef<T> assert_eq!(obj_ref.num, 1); }); }
自定义类
#[pyclass]可以使用如下参数
| 参数 | 描述 |
|---|---|
crate = "some::path" | 导入pyo3包的路径,如果::pyo3不可用 |
dict | 给予这个类的实例一个空的__dict__来存储自定义属性 |
extends = BaseType | 使用一个自定义的基类,默认为PyAny |
freelist = N | 实现一个大小为 N 的 free list,对那些经常要创建和删除的类型可以提升性能 |
frozen | 声明你的类是不可变的。会移除当检索到Rust结构的共享引用时的顶层借用检查,但同时无法再获取到一个可变的引用。 |
get_all | 为类的所有域生成 getter |
mapping | 告诉PyO3这个类是一个 mapping, |
module = "module_name" | Python中看到的类定义所在的模组名,默认为builtins |
name = "python_name" | Python看到的类名 |
sequence | 告诉PyO3这个类是一个 Sequence |
set_all | 为这类的所有域生成 setter |
subclass | 允许其他Python类或者#[pyclass]从这个类中继承,枚举无法被继承 |
text_signature = "(arg1, arg2, ...)" | 为Python类的 __new__ 方法设置文字签名 |
unsendable | 如果你的结构不是 Send的,如果使用了 unsendable,你的类会 panic 如果被另一个线程调用 |
weakref | 允许这个类为弱应用 |
所有这些参数可以直接通过#[pyclass(...)]注释传递,或者通过#[pyo3(...)]传递,e.g.:
#![allow(unused)] fn main() { // Argument supplied directly to the `#[pyclass]` annotation. #[pyclass(name = "SomeName", subclass)] struct MyClass {} // Argument supplied as a separate annotation. #[pyclass] #[pyo3(name = "SomeName", subclass)] struct MyClass {} }
返回类型
一般来说,#[new]方法必须返回T: Into<PyClassInitializer<Self>>或者PyResult<T>,其中T: Into<PyClassInitializer<Self>>。
对于可能失败的构造器,同样可以把返回类型包装进一个PyResult。
| 不可能失败 | 可能失败 | |
|---|---|---|
| 非继承 | T | PyResult<T> |
| 继承(T继承U) | (T, U) | PyResult<(T, U)> |
| 继承(一般情形) | PyClassInitializer<T> | PyResult<PyClassInitializer<T>> |
继承 Inheritance
默认情况下,object i.e. PyAny 被用作基本类。要覆盖这种默认,对pyclass使用 extends 参数,参数值为基类的完整路径。
方便起见,(T, U) 实现了Into<PyClassInitializer<T>>,其中U是T的基类。但是对更深的嵌套循环,还是必须明确地使用PyClassInitializer<T>。
要从一个子类获得其父类,对方法使用PyRef(而不是&self)或者PyRefMut(而不是&mut self)。这样就可以通过&Self::BaseClass的self_.as_ref()或者PyRef<Self::BaseClass>的self_.into_super()获取父类。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] struct BaseClass { val1: usize, } #[pymethods] impl BaseClass { #[new] fn new() -> Self { BaseClass { val1: 10 } } pub fn method(&self) -> PyResult<usize> { Ok(self.val1) } } #[pyclass(extends=BaseClass, subclass)] struct SubClass { val2: usize, } #[pymethods] impl SubClass { #[new] fn new() -> (Self, BaseClass) { (SubClass { val2: 15 }, BaseClass::new()) } fn method2(self_: PyRef<'_, Self>) -> PyResult<usize> { let super_ = self_.as_ref(); // Get &BaseClass super_.method().map(|x| x * self_.val2) } } #[pyclass(extends=SubClass)] struct SubSubClass { val3: usize, } #[pymethods] impl SubSubClass { #[new] fn new() -> PyClassInitializer<Self> { PyClassInitializer::from(SubClass::new()).add_subclass(SubSubClass { val3: 20 }) } fn method3(self_: PyRef<'_, Self>) -> PyResult<usize> { let v = self_.val3; let super_ = self_.into_super(); // Get PyRef<'_, SubClass> SubClass::method2(super_).map(|x| x * v) } } Python::with_gil(|py| { let subsub = pyo3::PyCell::new(py, SubSubClass::new()).unwrap(); pyo3::py_run!(py, subsub, "assert subsub.method3() == 3000") }); }
也可以继承类似PyDict的原生类型,只要它们实现了PySizedLayout。但是由于技术问题,现在还未向继承了原生类型的类型提供安全的 upcasting 方法。即使在这样的情况下,可以 unsafely get a base class by raw pointer conversion
#![allow(unused)] fn main() { #[cfg(not(Py_LIMITED_API))] { use pyo3::prelude::*; use pyo3::types::PyDict; use pyo3::AsPyPointer; use std::collections::HashMap; #[pyclass(extends=PyDict)] #[derive(Default)] struct DictWithCounter { counter: HashMap<String, usize>, } #[pymethods] impl DictWithCounter { #[new] fn new() -> Self { Self::default() } fn set(mut self_: PyRefMut<'_, Self>, key: String, value: &PyAny) -> PyResult<()> { self_.counter.entry(key.clone()).or_insert(0); let py = self_.py(); let dict: &PyDict = unsafe { py.from_borrowed_ptr_or_err(self_.as_ptr())? }; dict.set_item(key, value) } } Python::with_gil(|py| { let cnt = pyo3::PyCell::new(py, DictWithCounter::new()).unwrap(); pyo3::py_run!(py, cnt, "cnt.set('abc', 10); assert cnt['abc'] == 10") }); } }
如果 SubClass 没有提供基类的继承,编译会失败。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct BaseClass { val1: usize, } #[pyclass(extends=BaseClass)] struct SubClass { val2: usize, } #[pymethods] impl SubClass { #[new] fn new() -> Self { SubClass { val2: 15 } } } }
当创建了一个Python实例时,原生基类的__new__构造器会隐式地被调用。确保在(希望基类获得的)#[new]方法中接受参数,即使它们没有在那个fn中被使用:
#![allow(unused)] fn main() { #[allow(dead_code)] #[cfg(not(Py_LIMITED_API))] { use pyo3::prelude::*; use pyo3::types::PyDict; #[pyclass(extends=PyDict)] struct MyDict { private: i32, } #[pymethods] impl MyDict { #[new] #[pyo3(signature = (*args, **kwargs))] fn new(args: &PyAny, kwargs: Option<&PyAny>) -> Self { Self { private: 0 } } // some custom methods that use `private` here... } Python::with_gil(|py| { let cls = py.get_type::<MyDict>(); pyo3::py_run!(py, cls, "cls(a=1, b=2)") }); } }
这里,args和kwargs允许创建传递了初始 item 的实例,例如MyDict(item_sequence) 或 MyDict(a=1, b=2)。
对象性质
PyO3 支持两种方式来对#[pyclass]添加性质:
- 对简单的结构域,没有副作用,可以直接在
#[pyclass]的域定义中添加#[pyo3(get, set)]属性 - 对于需要计算(computation)的属性,可以在
#[pymethods]块中定义#[getter]和#[setter]函数
使用#[pyo3(get, set)]的对象性质
对于成员变量只是读取和填写(be read and written)的简单情形,可以用pyo3属性在#[pyclass]域中声明 getters 和 setters,下面是例子:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[pyo3(get, set)] num: i32, } }
上述代码使得 num 域可以作为一个self.num Python性质来读取和覆写。要将这个性质在另一个域可见,和其他选项(options)一起指明这个标注,e.g. #[pyo3(get, set, name = "custom_name")]。
通过单独使用 #[pyo3(get)] 或 #[pyo3(set)]可以使性质变为只读或者只写。
要使用这些标注,域类型必须实现一些转换特征:
- 对
get,域类型必须实现IntoPy<PyObject>和Clone - 对
set,域类型必须实现FromPyObject
使用#[getter]和#[setter]的对象属性
对于没有满足 #[pyo3(get, set)] 特征需求,或者需要副作用的情形,可以在一个#[pymethods] impl块中定义描述符方法(descriptor method)
通过使用 #[getter] 和 #[setter] 属性,下面是一个例子
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter] fn num(&self) -> PyResult<i32> { Ok(self.num) } } }
一个 getter 或 setter 的函数名默认用作属性名。有几种方法覆写这个名字。
如果 getter 和 setter 函数名分别以 get_ 和 set_ 开头,描述符的名字会变成这个前缀去掉后的名字。这对于像 type 的 Rust 关键字也有用(raw identifiers)。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter] fn get_num(&self) -> PyResult<i32> { Ok(self.num) } #[setter] fn set_num(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
这里,定义了性质 num,可以在 Python 中用 self.num 获取它。
#[getter] 和 #[setter] 都接收一个参数。如果参数被指定了,它将被用作性质的名字,i.e.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[getter(number)] fn num(&self) -> PyResult<i32> { Ok(self.num) } #[setter(number)] fn set_num(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
这里,定义了性质 number 并且在 Python 中可以用 self.number 获取它。
通过 #[setter] 或 #[pyo3(set)] 定义的属性永远会对 del 算子抛出 AttributeError,要自定义 del 参见#1778.
实例方法
要定义一个 Python 相容的方法,必须用 #[pymethods] 方法标注结构的 impl 块。PyO3 为所有在这个块里的函数生成与 Python 相容的包装器,像描述符,类方法,静态方法等等。
既然 Rust 允许任意数量的 impl 块,可以任意切分方法。但是要对同一结构同时标注多个 #[pymethods] 的 impl 块,必须使用PyO3的 multiple-pymethods 特性。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { fn method1(&self) -> PyResult<i32> { Ok(10) } fn set_method(&mut self, value: i32) -> PyResult<()> { self.num = value; Ok(()) } } }
对这些方法的调用受 GIL保护,所以 &self 和 &mut self 都可以使用。返回类型必须为 PyResult<T> 或者某个实现了 IntoPy<PyObject> 的 T,后者在方法不会抛出Python异常时是允许的。
一个 Python 参数可以作为方法签名的一部分被指定,此时 py 变量被方法包装器注入,e.g.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { fn method2(&self, py: Python<'_>) -> PyResult<i32> { Ok(10) } } }
从 Python 看来,这个例子中的 method2 不接受任何变量。
类方法
为一个自定义类创建一个类方法,需要对方法标注 #[classmethod] 属性。这和Python中的@classmethod是等价的。
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyType; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { #[classmethod] fn cls_method(cls: &PyType) -> PyResult<i32> { Ok(10) } } }
声明一个可被Python调用的类方法
- 第一个参数是方法被调用的类的类型对象
- 第一个参数隐式的是
&PyType类型 - 对于
parameter-list的细节,参见Method arguments章节 - 返回类型必须为
PyResult<T>或者某个实现了IntoPy<PyObject>的类型T
静态方法
要为自定义类创建一个静态方法,需要用 #[staticmethod] 属性标注该方法,返回类型必须为PyResult<T> 或者某个实现了 IntoPy<PyObject> 的类型 T
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { #[allow(dead_code)] num: i32, } #[pymethods] impl MyClass { #[staticmethod] fn static_method(param1: i32, param2: &str) -> PyResult<i32> { Ok(10) } } }
类属性
要创建一个类属性,也称为(class variable, classattr),可以用 #[classattr] 标注一个没有任何变量的方法。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[classattr] fn my_attribute() -> String { "hello".to_string() } } Python::with_gil(|py| { let my_class = py.get_type::<MyClass>(); pyo3::py_run!(py, my_class, "assert my_class.my_attribute == 'hello'") }); }
Note: 如果方法有一个
Result返回类型并且返回了Err,PyO3会在类创建过程中 panic
如果只用了 const 来定义类属性,也可以标注对应的常量:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[classattr] const MY_CONST_ATTRIBUTE: &'static str = "foobar"; } }
方法变量
类似#[pyfunction],可以用 #[pyo3(signature = (...))] 属性来指定 #[pymethods] 接收变量的方式,参见方法签名章节。
下述例子定义了一个具有method方法的类 MyClass。这个方法有一个签名,它为 num 和 name 设置了默认值,并且表明 py_args 会接收所有的位置变量,而 py_kwargs 会接收所有的关键字变量:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::{PyDict, PyTuple}; #[pyclass] struct MyClass { num: i32, } #[pymethods] impl MyClass { #[new] #[pyo3(signature = (num=-1))] fn new(num: i32) -> Self { MyClass { num } } #[pyo3(signature = (num=10, *py_args, name="Hello", **py_kwargs))] fn method( &mut self, num: i32, py_args: &PyTuple, name: &str, py_kwargs: Option<&PyDict>, ) -> String { let num_before = self.num; self.num = num; format!( "num={} (was previously={}), py_args={:?}, name={}, py_kwargs={:?} ", num, num_before, py_args, name, py_kwargs, ) } } }
而在Python中是这样子的
>>> import mymodule
>>> mc = mymodule.MyClass()
>>> print(mc.method(44, False, "World", 666, x=44, y=55))
py_args=('World', 666), py_kwargs=Some({'x': 44, 'y': 55}), name=Hello, num=44, num_before=-1
>>> print(mc.method(num=-1, name="World"))
py_args=(), py_kwargs=None, name=World, num=-1, num_before=44
使得类方法签名对Python可用
#[pyfunction] 的 text_signature = "..." 选项对类和方法也是可用的:
#![allow(dead_code)] use pyo3::prelude::*; use pyo3::types::PyType; // it works even if the item is not documented: #[pyclass(text_signature = "(c, d, /)")] struct MyClass {} #[pymethods] impl MyClass { // the signature for the constructor is attached // to the struct definition instead. #[new] fn new(c: i32, d: &str) -> Self { Self {} } // the self argument should be written $self #[pyo3(text_signature = "($self, e, f)")] fn my_method(&self, e: i32, f: i32) -> i32 { e + f } #[classmethod] #[pyo3(text_signature = "(cls, e, f)")] fn my_class_method(cls: &PyType, e: i32, f: i32) -> i32 { e + f } #[staticmethod] #[pyo3(text_signature = "(e, f)")] fn my_static_method(e: i32, f: i32) -> i32 { e + f } } fn main() -> PyResult<()> { Python::with_gil(|py| { let inspect = PyModule::import(py, "inspect")?.getattr("signature")?; let module = PyModule::new(py, "my_module")?; module.add_class::<MyClass>()?; let class = module.getattr("MyClass")?; if cfg!(not(Py_LIMITED_API)) || py.version_info() >= (3, 10) { let doc: String = class.getattr("__doc__")?.extract()?; assert_eq!(doc, ""); let sig: String = inspect .call1((class,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(c, d, /)"); } else { let doc: String = class.getattr("__doc__")?.extract()?; assert_eq!(doc, ""); inspect.call1((class,)).expect_err("`text_signature` on classes is not compatible with compilation in `abi3` mode until Python 3.10 or greater"); } { let method = class.getattr("my_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(self, /, e, f)"); } { let method = class.getattr("my_class_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(cls, e, f)"); } { let method = class.getattr("my_static_method")?; assert!(method.getattr("__doc__")?.is_none()); let sig: String = inspect .call1((method,))? .call_method0("__str__")? .extract()?; assert_eq!(sig, "(e, f)"); } Ok(()) }) }
注意到在abi3模式下编译时,类的 text_signature 只在 Python 3.10 或更高的版本相容。
#[pyclass]枚举
目前PyO3只支持 fieldless 枚举。PyO3对每个变量添加了类属性,所以你不用定义 #[new] 就可以在Python中获取它们。PyO3同样提供了 __richcmp__ 和 __int__ 的默认实现,所以它们可以用 == 来进行比较:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Variant, OtherVariant, } Python::with_gil(|py| { let x = Py::new(py, MyEnum::Variant).unwrap(); let y = Py::new(py, MyEnum::OtherVariant).unwrap(); let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, x y cls, r#" assert x == cls.Variant assert y == cls.OtherVariant assert x != y "#) }) }
也可以将枚举转换为 int:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Variant, OtherVariant = 10, } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); let x = MyEnum::Variant as i32; // The exact value is assigned by the compiler. pyo3::py_run!(py, cls x, r#" assert int(cls.Variant) == x assert int(cls.OtherVariant) == 10 assert cls.OtherVariant == 10 # You can also compare against int. assert 10 == cls.OtherVariant "#) }) }
PyO3 也为枚举提供了 __repr__
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum{ Variant, OtherVariant, } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); let x = Py::new(py, MyEnum::Variant).unwrap(); pyo3::py_run!(py, cls x, r#" assert repr(x) == 'MyEnum.Variant' assert repr(cls.OtherVariant) == 'MyEnum.OtherVariant' "#) }) }
PyO3定义的所有方法可以被覆写,例如想要覆写 __repr__:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] enum MyEnum { Answer = 42, } #[pymethods] impl MyEnum { fn __repr__(&self) -> &'static str { "42" } } Python::with_gil(|py| { let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, cls, "assert repr(cls.Answer) == '42'") }) }
枚举以及其变量也能使用 #[pyo3(name)] 来重命名:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(name = "RenamedEnum")] enum MyEnum { #[pyo3(name = "UPPERCASE")] Variant, } Python::with_gil(|py| { let x = Py::new(py, MyEnum::Variant).unwrap(); let cls = py.get_type::<MyEnum>(); pyo3::py_run!(py, x cls, r#" assert repr(x) == 'RenamedEnum.UPPERCASE' assert x == cls.UPPERCASE "#) }) }
不能使用枚举作为基类或者从其他类进行继承:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] enum BadBase { Var1, } }
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass(subclass)] struct Base; #[pyclass(extends=Base)] enum BadSubclass { Var1, } }
在Python中,#[pyclass] 枚举目前还不能与IntEnum 一起用。
实现的细节
#[pyclass]宏依赖许多 conditional code generation,每个 #[pyclass] 可以选择性地拥有一个 #[pymethods] 块。
To support this flexibility the
#[pyclass]macro expands to a blob of boilerplate code which sets up the structure for "dtolnay specialization". This implementation pattern enables the Rust compiler to use#[pymethods]implementations when they are present, and fall back to default (empty) definitions when they are not.This simple technique works for the case when there is zero or one implementations. To support multiple
#[pymethods]for a#[pyclass](in the [multiple-pymethods] feature), a registry mechanism provided by theinventorycrate is used instead. This collectsimpls at library load time, but isn't supported on all platforms. See inventory: how it works for more details.The
#[pyclass]macro expands to roughly the code seen below. ThePyClassImplCollectoris the type used internally by PyO3 for dtolnay specialization:
#![allow(unused)] fn main() { #[cfg(not(feature = "multiple-pymethods"))] { use pyo3::prelude::*; // Note: the implementation differs slightly with the `multiple-pymethods` feature enabled. struct MyClass { #[allow(dead_code)] num: i32, } unsafe impl pyo3::type_object::PyTypeInfo for MyClass { type AsRefTarget = pyo3::PyCell<Self>; const NAME: &'static str = "MyClass"; const MODULE: ::std::option::Option<&'static str> = ::std::option::Option::None; #[inline] fn type_object_raw(py: pyo3::Python<'_>) -> *mut pyo3::ffi::PyTypeObject { <Self as pyo3::impl_::pyclass::PyClassImpl>::lazy_type_object() .get_or_init(py) .as_type_ptr() } } impl pyo3::PyClass for MyClass { type Frozen = pyo3::pyclass::boolean_struct::False; } impl<'a, 'py> pyo3::impl_::extract_argument::PyFunctionArgument<'a, 'py> for &'a MyClass { type Holder = ::std::option::Option<pyo3::PyRef<'py, MyClass>>; #[inline] fn extract(obj: &'py pyo3::PyAny, holder: &'a mut Self::Holder) -> pyo3::PyResult<Self> { pyo3::impl_::extract_argument::extract_pyclass_ref(obj, holder) } } impl<'a, 'py> pyo3::impl_::extract_argument::PyFunctionArgument<'a, 'py> for &'a mut MyClass { type Holder = ::std::option::Option<pyo3::PyRefMut<'py, MyClass>>; #[inline] fn extract(obj: &'py pyo3::PyAny, holder: &'a mut Self::Holder) -> pyo3::PyResult<Self> { pyo3::impl_::extract_argument::extract_pyclass_ref_mut(obj, holder) } } impl pyo3::IntoPy<PyObject> for MyClass { fn into_py(self, py: pyo3::Python<'_>) -> pyo3::PyObject { pyo3::IntoPy::into_py(pyo3::Py::new(py, self).unwrap(), py) } } impl pyo3::impl_::pyclass::PyClassImpl for MyClass { const DOC: &'static str = "Class for demonstration\u{0}"; const IS_BASETYPE: bool = false; const IS_SUBCLASS: bool = false; type Layout = PyCell<MyClass>; type BaseType = PyAny; type ThreadChecker = pyo3::impl_::pyclass::ThreadCheckerStub<MyClass>; type PyClassMutability = <<pyo3::PyAny as pyo3::impl_::pyclass::PyClassBaseType>::PyClassMutability as pyo3::impl_::pycell::PyClassMutability>::MutableChild; type Dict = pyo3::impl_::pyclass::PyClassDummySlot; type WeakRef = pyo3::impl_::pyclass::PyClassDummySlot; type BaseNativeType = pyo3::PyAny; fn items_iter() -> pyo3::impl_::pyclass::PyClassItemsIter { use pyo3::impl_::pyclass::*; let collector = PyClassImplCollector::<MyClass>::new(); static INTRINSIC_ITEMS: PyClassItems = PyClassItems { slots: &[], methods: &[] }; PyClassItemsIter::new(&INTRINSIC_ITEMS, collector.py_methods()) } fn lazy_type_object() -> &'static pyo3::impl_::pyclass::LazyTypeObject<MyClass> { use pyo3::impl_::pyclass::LazyTypeObject; static TYPE_OBJECT: LazyTypeObject<MyClass> = LazyTypeObject::new(); &TYPE_OBJECT } } Python::with_gil(|py| { let cls = py.get_type::<MyClass>(); pyo3::py_run!(py, cls, "assert cls.__name__ == 'MyClass'") }); } }
魔术方法和值槽slots
Python的对象模型为不同的对象行为定义了数种协议(protocol),例如 sequence,mapping和 number。在Python中通过魔术方法实现这些协议,例如__str__,__repr__,也被称为双下划线方法(dunder methods)。
在基于 Python C-接口实现PyO3时,许多魔术方法必须放进类对象的值槽(slot)中。如果 #[pymethods] 中的一个函数被识别为魔术方法,它会被自动地放置进Python对象的正确值槽中。
PyO3处理的魔术方法和标准Python非常相像,它们是这里的值槽的子集。一些值槽没有Python中对应的魔术方法,它们需要一些额外的处理:
- 垃圾处理的魔术方法
- 缓存协议的魔术方法
当PyO3处理一个魔术方法时,和其他#[pymethods]有一些区别
- Rust的函数签名必须和魔术方法相匹配
- 不允许
#[pyo3(signature = (...)]和#[pyo3(text_signature = "...")]属性
下面列出所有PyO3处理的魔术方法
- 所有方法接受的第一个参数,显示为
<self>。可以是&self,&mut self或者是形如self_: PyRef<'_, Self>或self_: PyRefMut<'_, Self>的PyCell引用 - 永远允许可选参数
Python<'py>作为第一个参数 - 返回值可以选择被包装进
PyResult object意为任何类型都可以被一个Python对象提取(变量)或者被转换为一个Python对象(返回值)- 其他类型(若有)时必须匹配,例如
pyo3::basic::CompareOp作为__richcmp__的第二个参数 - 对于比较方法(comparison method)或者算数方法(arithmetic method),提取时的错误不表现为一个异常,而是返回一个
NotImplemented - 对一些魔术方法,返回值不受PyO3约束,但是会被Python解释器检查。例如,
__str__需要返回一个字符串对象。这由object(Python type)指明。
基本对象的自定义
__str__(<self>)->object (str)__repr__(<self>)->object (str)__hash__(<self>)->isize
objects that compare equal 必须有相同的哈希值。isize 处可能是返回任意到 64 bits 的类型,PyO3会自动地将其转换为一个 isize,
使Python默认的哈希失效
默认情况下,任何 `#[pyclass]` 类型在Python下有一个默认的哈希实现,不想要被哈希的类型需要替换`__hash__`为`None`。例如#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NotHashable {} #[pymethods] impl NotHashable { #[classattr] const __hash__: Option<PyObject> = None; } }
__richcmp__(<self>, object, pyo3::basic::CompareOp)->object
Overloads Python 的比较算子 (==, !=, <, <=, > 和 >=)。变量 CompareOp 表示这是一个比较算子。
注意到实现 __richcmp__ 会让Python不生成一个默认的 __hash__ 实现, 所以当实现 __richcmp__时考虑实现 __hash__ .
返回类型
返回类型通常是PyResult<bool>,但是其实可以返回任意的Python对象。如果第二个变量object不是在签名中指定的类型,生成的代码会自动返回NotImplemented。
可以使用CompareOp::matches来讲一个Rust的std::cmp::Ordering调整为需要的比较类型。
__getattr__(<self>, object)->object__getattribute__(<self>, object)->object
`__getattr__` 和 `__getattribute__`的区别
在Python中,只有当无法通过常规查找调用属性时会使用__getattr__。而__getattribute__可以通过任意属性方式调用。如果想要获取self中存在的属性,要特别小心不要引入无穷递归,并使用baseclass.__getattribute__()
__setattr__(<self>, value: object)->()__delattr__(<self>, object)->()
覆盖attribute access
__bool__(<self>)->bool
决定对象的真伪值
__call__(<self>, ...)->object- 可以对一般的pymethods定义任意变量列表
可迭代对象
可以用下述方法定义迭代器
__iter__(<self>) -> object__next__(<self>) -> Option<object> or IterNextOutput
在__next__中返回None则表示后面没有元素了。
例子:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyIterator { iter: Box<dyn Iterator<Item = PyObject> + Send>, } #[pymethods] impl MyIterator { fn __iter__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __next__(mut slf: PyRefMut<'_, Self>) -> Option<PyObject> { slf.iter.next() } } }
许多时候要区分迭代器和可迭代类型。事实上,可迭代对象只要实现__iter__(),而迭代器必须同时实现__iter__() 和 __next__()。例如:
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Iter { inner: std::vec::IntoIter<usize>, } #[pymethods] impl Iter { fn __iter__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __next__(mut slf: PyRefMut<'_, Self>) -> Option<usize> { slf.inner.next() } } #[pyclass] struct Container { iter: Vec<usize>, } #[pymethods] impl Container { fn __iter__(slf: PyRef<'_, Self>) -> PyResult<Py<Iter>> { let iter = Iter { inner: slf.iter.clone().into_iter(), }; Py::new(slf.py(), iter) } } Python::with_gil(|py| { let container = Container { iter: vec![1, 2, 3, 4] }; let inst = pyo3::PyCell::new(py, container).unwrap(); pyo3::py_run!(py, inst, "assert list(inst) == [1, 2, 3, 4]"); pyo3::py_run!(py, inst, "assert list(iter(iter(inst))) == [1, 2, 3, 4]"); }); }
更多信息见Python官方文档迭代器-类型。
在迭代中返回值
刚才讲了如何使用Option<T>在迭代中yield值。在Python中,生成器也可以返回值。PyO3提供了IterNextOutput枚举来同时Yield值和Return一个最终值。
Awaitable 对象
__await__(<self>)->object__aiter__(<self>)->object__anext__(<self>)->Option<object> or IterANextOutput
Mapping & Sequence类型
这一章中的魔术方法可以用来实现Python的容器(container)类型。Python中有两种主要的容器:"mappings"(例如字典)和 "sequences"(例如列表和元祖)。
PyO3所用的Python C-API 对于 sequence 和 mapping 有不同的值槽。在纯Python中书写时,实现的时候并没有这种区别,例如__getitem__的实现对这两种容器都会填充值槽。
mapping 类型不希望 sequence 值槽被填充,因为这会带来一些不想要结果,例如:
- mapping 类型会成功 cast to
PySequence]. - Python 会对 sequence 提供默认的
__iter__实现,它可以连续地用正整数调用__getitem__直到返回IndexError。
使用#[pyclass(mapping)]标注来指示PyO3只填充 mapping 值槽,保持 sequence值槽为空。这会应用到__getitem__, __setitem__ 和 __delitem__。
使用#[pyclass(sequence)]标注来指示PyO3用sq_length而不是mp_length来填充__len__。这可以帮助例如numpy的库将类识别为一个 sequence。
__len__(<self>)->usize
内置函数len()的实现
__contains__(<self>, object)->bool
Implements membership测试算子。会返回 true 若item 在 self中。对于没有定义__contains__()的对象,该测试对简单地遍历sequence直到找到匹配。
使Python默认的contain失效
默认情况下,所有带有__iter__方法的#[pyclass]类型支持默认的in算子的实现。不想要这个的类型可以将__contains__ 设置为 None。
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NoContains {} #[pymethods] impl NoContains { #[classattr] const __contains__: Option<PyObject> = None; } }
__getitem__(<self>, object)->object
实现取得self[a]元素
__setitem__(<self>, object, object)->()
实现分配(assign)self[a]元素,仅当元素可以被替换时进行实现
__delitem__(<self>, object)->()
实现删除元素
fn __concat__(&self, other: impl FromPyObject)->PyResult<impl ToPyObject>
通常使用+号,在尝试数值加法__add__ 和 __radd__后拼接两个sequence
fn __repeat__(&self, count: isize)->PyResult<impl ToPyObject>
通常使用*号,在尝试数值乘法__mul__ and __rmul__后重复sequence count次
fn __inplace_concat__(&self, other: impl FromPyObject)->PyResult<impl ToPyObject>
通常使用+=算子,在尝试数值加法__iadd__后相加两个sequence
fn __inplace_repeat__(&self, count: isize)->PyResult<impl ToPyObject>
通常使用*=算子,在尝试数值乘法__imul__后相乘两个sequence
描述符 Descriptors
__get__(<self>, object, object)->object__set__(<self>, object, object)->()__delete__(<self>, object)->()
数值类型
二元数值算子 (+, -, *, @, /, //, %, divmod(),
pow(), **, <<, >>, &, ^ 和 |)
(如果对象 object 不是在签名中指明的类型, 生成的代码会自动return NotImplemented.)
__add__(<self>, object)->object__radd__(<self>, object)->object__sub__(<self>, object)->object__rsub__(<self>, object)->object__mul__(<self>, object)->object__rmul__(<self>, object)->object__matmul__(<self>, object)->object__rmatmul__(<self>, object)->object__floordiv__(<self>, object)->object__rfloordiv__(<self>, object)->object__truediv__(<self>, object)->object__rtruediv__(<self>, object)->object__divmod__(<self>, object)->object__rdivmod__(<self>, object)->object__mod__(<self>, object)->object__rmod__(<self>, object)->object__lshift__(<self>, object)->object__rlshift__(<self>, object)->object__rshift__(<self>, object)->object__rrshift__(<self>, object)->object__and__(<self>, object)->object__rand__(<self>, object)->object__xor__(<self>, object)->object__rxor__(<self>, object)->object__or__(<self>, object)->object__ror__(<self>, object)->object__pow__(<self>, object, object)->object__rpow__(<self>, object, object)->object
占位分配算子(in-place assignment operator):(+=, -=, *=, @=, /=, //=, %=, **=, <<=, >>=, &=, ^=, |=):
__iadd__(<self>, object)->()__isub__(<self>, object)->()__imul__(<self>, object)->()__imatmul__(<self>, object)->()__itruediv__(<self>, object)->()__ifloordiv__(<self>, object)->()__imod__(<self>, object)->()__ipow__(<self>, object, object)->()__ilshift__(<self>, object)->()__irshift__(<self>, object)->()__iand__(<self>, object)->()__ixor__(<self>, object)->()__ior__(<self>, object)->()
一元算子(Unary operations):(-, +, abs() 和 ~):
__pos__(<self>)->object__neg__(<self>)->object__abs__(<self>)->object__invert__(<self>)->object
强制转换?Coercions:
__index__(<self>)->object (int)__int__(<self>)->object (int)__float__(<self>)->object (float)
缓存对象
__getbuffer__(<self>, *mut ffi::Py_buffer, flags)->()__releasebuffer__(<self>, *mut ffi::Py_buffer)->()
__releasebuffer__返回的错误会被传送到sys.unraiseablehook中。强烈建议永远不要从__releasebuffer__返回错误,__releasebuffer__不会被调用第二次,任何没有释放的东西会被泄露。
垃圾收集Garbage Collector Integration
如果类型有对其他Python对象的引用,需要使用Python的垃圾收集器来让GC识别这些引用。这需要实现__traverse__ 和 __clear__,对应于Python C API 中的值槽tp_traverse 和 tp_clear。每次引用另一个Python对象时,__traverse__ 必须调用 visit.call() 。__clear__ 必须清理其他Python对象的任意可变引用(来打破引用cycle)。不可变引用不是必须被清理,因为每个cycle必须包含至少一个可变引用。
__traverse__(<self>, pyo3::class::gc::PyVisit<'_>)->Result<(),pyo3::class::gc::PyTraverseError>__clear__(<self>)->()
例子
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::PyTraverseError; use pyo3::gc::PyVisit; #[pyclass] struct ClassWithGCSupport { obj: Option<PyObject>, } #[pymethods] impl ClassWithGCSupport { fn __traverse__(&self, visit: PyVisit<'_>) -> Result<(), PyTraverseError> { if let Some(obj) = &self.obj { visit.call(obj)? } Ok(()) } fn __clear__(&mut self) { // Clear reference, this decrements ref counter. self.obj = None; } } }
自定义基本对象
回忆上一章中的Number类
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Self(value) } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
目前Python可以导入这个模组,获取到这个类,并创建实例——没别的了。
from my_module import Number
n = Number(5)
print(n)
<builtins.Number object at 0x000002B4D185D7D0>
字符串表示String representations
它甚至不能打印一个用户可见的它自身的说明!我们可以在#[pymethods]块中加上__repr__ 和 __str__ 方法,用这个来获得Number中包含的值。methods inside a
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { // For `__repr__` we want to return a string that Python code could use to recreate // the `Number`, like `Number(5)` for example. fn __repr__(&self) -> String { // We use the `format!` macro to create a string. Its first argument is a // format string, followed by any number of parameters which replace the // `{}`'s in the format string. // // 👇 Tuple field access in Rust uses a dot format!("Number({})", self.0) } // `__str__` is generally used to create an "informal" representation, so we // just forward to `i32`'s `ToString` trait implementation to print a bare number. fn __str__(&self) -> String { self.0.to_string() } } }
哈希Hashing
接下来实现哈希。我们仅仅哈希i32,为此我们需要一个Hash,std提供的是DefaultHasher,使用的是SipHash算法。
#![allow(unused)] fn main() { use std::collections::hash_map::DefaultHasher; // Required to call the `.hash` and `.finish` methods, which are defined on traits. use std::hash::{Hash, Hasher}; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } } }
Note: 当实现
__hash__和比较时, 下属性质需要满足k1 == k2 -> hash(k1) == hash(k2)也就是说两个键值相等时,它们的哈希也要相等。 另外必须注意类的哈希不能在生命周期中改变。在这里的教程中,我们不让Python代码改变我们的
Number类,也就是说,它是不可变的。 默认情况下,所有#[pyclass]类型在Python中有一个默认的哈希实现。 不需要被哈希的类型需要改写__hash__为None#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct NotHashable {} #[pymethods] impl NotHashable { #[classattr] const __hash__: Option<Py<PyAny>> = None; } }
比较Comparisons
不像在Python中,PyO3不提供类似__eq__, __lt__的魔术比较方法。你需要通过__richcmp__一次性实现所有六个算子。
Unlike in Python, PyO3 does not provide the magic comparison methods you might expect like __eq__, 这个方法会根据算子的CompareOp值被调用
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } } }
如果通过比较两个Rust值获得了结果,可以采取一个捷径CompareOp::matches
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp) -> bool { op.matches(self.0.cmp(&other.0)) } } }
它会检查Rust的 Ord 中得到的 std::cmp::Ordering 是否匹配给定的CompareOp。
另外,如果想要保留一些算子不被实现,可以返回py.NotImplemented()
#![allow(unused)] fn main() { use pyo3::class::basic::CompareOp; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __richcmp__(&self, other: &Self, op: CompareOp, py: Python<'_>) -> PyObject { match op { CompareOp::Eq => (self.0 == other.0).into_py(py), CompareOp::Ne => (self.0 != other.0).into_py(py), _ => py.NotImplemented(), } } } }
真伪Truthyness
考虑Number是True如果它不是零
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __bool__(&self) -> bool { self.0 != 0 } } }
最终的代码
#![allow(unused)] fn main() { use std::collections::hash_map::DefaultHasher; use std::hash::{Hash, Hasher}; use pyo3::prelude::*; use pyo3::class::basic::CompareOp; #[pyclass] struct Number(i32); #[pymethods] impl Number { #[new] fn new(value: i32) -> Self { Self(value) } fn __repr__(&self) -> String { format!("Number({})", self.0) } fn __str__(&self) -> String { self.0.to_string() } fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } fn __bool__(&self) -> bool { self.0 != 0 } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } }
模拟数值类型
目前为止我们有了一个Number类但我们实际上不能做任何数学运算!
在继续前,我们先要考虑如何来处理溢出(overflows),有三种解决方式
- 可以像Python中的
int一样有无限的精确度,但这会非常无聊,我们在重复造轮子 - 我们可以在
Nmuber溢出时抛出异常,但这会使API很难用 - 我们可以按照
i32的边界进行包装,这也是下面将要做的。我们要沿着i32的wrapping方法
改造我们的构造器
现在来对付第一个溢出,在Number的构造器中
from my_module import Number
n = Number(1 << 1337)
Traceback (most recent call last):
File "example.py", line 3, in <module>
n = Number(1 << 1337)
OverflowError: Python int too large to convert to C long
除了靠默认的FromPyObject异常来语法分析变量,我们可以使用#[pyo3(from_py_with = "...")]属性来特别指定我们自己的异常函数。不幸的是,PyO3不能在 box 外包装 Python的整数,但我们可以做一个 Python 调用来掩饰它并把它传成一个i32
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; // 👇 This intentionally overflows! Ok(val as i32) } }
通过///和#[pyo3(text_signature = "...")]属性加上文档,都可以被Python用户看到
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; Ok(val as i32) } /// Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not. /// It's not a story C would tell you. It's a Rust legend. #[pyclass(module = "my_module")] #[pyo3(text_signature = "(int)")] struct Number(i32); #[pymethods] impl Number { #[new] fn new(#[pyo3(from_py_with = "wrap")] value: i32) -> Self { Self(value) } } }
有了这些,来实现几个算子
#![allow(unused)] fn main() { use std::convert::TryInto; use pyo3::exceptions::{PyZeroDivisionError, PyValueError}; use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __add__(&self, other: &Self) -> Self { Self(self.0.wrapping_add(other.0)) } fn __sub__(&self, other: &Self) -> Self { Self(self.0.wrapping_sub(other.0)) } fn __mul__(&self, other: &Self) -> Self { Self(self.0.wrapping_mul(other.0)) } fn __truediv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __floordiv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __rshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shr(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __lshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shl(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } } }
一元数值算子
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); #[pymethods] impl Number { fn __pos__(slf: PyRef<'_, Self>) -> PyRef<'_, Self> { slf } fn __neg__(&self) -> Self { Self(-self.0) } fn __abs__(&self) -> Self { Self(self.0.abs()) } fn __invert__(&self) -> Self { Self(!self.0) } } }
对内置函数 complex(), int() 和 float()的支持.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct Number(i32); use pyo3::types::PyComplex; #[pymethods] impl Number { fn __int__(&self) -> i32 { self.0 } fn __float__(&self) -> f64 { self.0 as f64 } fn __complex__<'py>(&self, py: Python<'py>) -> &'py PyComplex { PyComplex::from_doubles(py, self.0 as f64, 0.0) } } }
我们没有实现类似__iadd__的占位算子,因为我们不想让Number可变,同样的像__radd__的反射算子也没有实现
现在Python可以使用Number类了
from my_module import Number
def hash_djb2(s: str):
'''
A version of Daniel J. Bernstein's djb2 string hashing algorithm
Like many hashing algorithms, it relies on integer wrapping.
'''
n = Number(0)
five = Number(5)
for x in s:
n = Number(ord(x)) + ((n << five) - n)
return n
assert hash_djb2('l50_50') == Number(-1152549421)
最终代码
use std::collections::hash_map::DefaultHasher; use std::hash::{Hash, Hasher}; use std::convert::TryInto; use pyo3::exceptions::{PyValueError, PyZeroDivisionError}; use pyo3::prelude::*; use pyo3::class::basic::CompareOp; use pyo3::types::PyComplex; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let val = obj.call_method1("__and__", (0xFFFFFFFF_u32,))?; let val: u32 = val.extract()?; Ok(val as i32) } /// Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not. /// It's not a story C would tell you. It's a Rust legend. #[pyclass(module = "my_module")] #[pyo3(text_signature = "(int)")] struct Number(i32); #[pymethods] impl Number { #[new] fn new(#[pyo3(from_py_with = "wrap")] value: i32) -> Self { Self(value) } fn __repr__(&self) -> String { format!("Number({})", self.0) } fn __str__(&self) -> String { self.0.to_string() } fn __hash__(&self) -> u64 { let mut hasher = DefaultHasher::new(); self.0.hash(&mut hasher); hasher.finish() } fn __richcmp__(&self, other: &Self, op: CompareOp) -> PyResult<bool> { match op { CompareOp::Lt => Ok(self.0 < other.0), CompareOp::Le => Ok(self.0 <= other.0), CompareOp::Eq => Ok(self.0 == other.0), CompareOp::Ne => Ok(self.0 != other.0), CompareOp::Gt => Ok(self.0 > other.0), CompareOp::Ge => Ok(self.0 >= other.0), } } fn __bool__(&self) -> bool { self.0 != 0 } fn __add__(&self, other: &Self) -> Self { Self(self.0.wrapping_add(other.0)) } fn __sub__(&self, other: &Self) -> Self { Self(self.0.wrapping_sub(other.0)) } fn __mul__(&self, other: &Self) -> Self { Self(self.0.wrapping_mul(other.0)) } fn __truediv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __floordiv__(&self, other: &Self) -> PyResult<Self> { match self.0.checked_div(other.0) { Some(i) => Ok(Self(i)), None => Err(PyZeroDivisionError::new_err("division by zero")), } } fn __rshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shr(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __lshift__(&self, other: &Self) -> PyResult<Self> { match other.0.try_into() { Ok(rhs) => Ok(Self(self.0.wrapping_shl(rhs))), Err(_) => Err(PyValueError::new_err("negative shift count")), } } fn __xor__(&self, other: &Self) -> Self { Self(self.0 ^ other.0) } fn __or__(&self, other: &Self) -> Self { Self(self.0 | other.0) } fn __and__(&self, other: &Self) -> Self { Self(self.0 & other.0) } fn __int__(&self) -> i32 { self.0 } fn __float__(&self) -> f64 { self.0 as f64 } fn __complex__<'py>(&self, py: Python<'py>) -> &'py PyComplex { PyComplex::from_doubles(py, self.0 as f64, 0.0) } } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_class::<Number>()?; Ok(()) } const SCRIPT: &'static str = r#" def hash_djb2(s: str): n = Number(0) five = Number(5) for x in s: n = Number(ord(x)) + ((n << five) - n) return n assert hash_djb2('l50_50') == Number(-1152549421) assert hash_djb2('logo') == Number(3327403) assert hash_djb2('horizon') == Number(1097468315) assert Number(2) + Number(2) == Number(4) assert Number(2) + Number(2) != Number(5) assert Number(13) - Number(7) == Number(6) assert Number(13) - Number(-7) == Number(20) assert Number(13) / Number(7) == Number(1) assert Number(13) // Number(7) == Number(1) assert Number(13) * Number(7) == Number(13*7) assert Number(13) > Number(7) assert Number(13) < Number(20) assert Number(13) == Number(13) assert Number(13) >= Number(7) assert Number(13) <= Number(20) assert Number(13) == Number(13) assert (True if Number(1) else False) assert (False if Number(0) else True) assert int(Number(13)) == 13 assert float(Number(13)) == 13 assert Number.__doc__ == "Did you ever hear the tragedy of Darth Signed The Overfloweth? I thought not.\nIt's not a story C would tell you. It's a Rust legend." assert Number(12345234523452) == Number(1498514748) try: import inspect assert inspect.signature(Number).__str__() == '(int)' except ValueError: # Not supported with `abi3` before Python 3.10 pass assert Number(1337).__str__() == '1337' assert Number(1337).__repr__() == 'Number(1337)' "#; use pyo3::PyTypeInfo; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let globals = PyModule::import(py, "__main__")?.dict(); globals.set_item("Number", Number::type_object(py))?; py.run(SCRIPT, Some(globals), None)?; Ok(()) }) }
附录:写一些不安全的代码(unsafe code)
在这一章开始时我们说PyO3没有提供在box外包装Python整数的方法,其实并不完全对,虽然PyO3 API 不可以,但是有一个 Python C API 函数能做到:
unsigned long PyLong_AsUnsignedLongMask(PyObject *obj)
我们可以通过pyo3::ffi::PyLong_AsUnsignedLongMask调用这个函数,这是一个unsafe的函数,意味着我们必须使用一个 unsafe 块来调用它并对未保证其约束负责。回忆这些约束:
- 必须保证GIL,否则调用函数会引起数据竞争
- 指针必须是正当的,必须指向一个正当的 Python 对象
现在来创建那个帮助函数,签名必须是fn(&PyAny) -> PyResult<T>
&PyAny表示一个检查过的借用引用,所以指向它的指针是正当的- 每当我们在作用域中借用Python对象的引用时,必须保证GIL
#![allow(unused)] fn main() { #![allow(dead_code)] use std::os::raw::c_ulong; use pyo3::prelude::*; use pyo3::ffi; use pyo3::conversion::AsPyPointer; fn wrap(obj: &PyAny) -> Result<i32, PyErr> { let py: Python<'_> = obj.py(); unsafe { let ptr = obj.as_ptr(); let ret: c_ulong = ffi::PyLong_AsUnsignedLongMask(ptr); if ret == c_ulong::MAX { if let Some(err) = PyErr::take(py) { return Err(err); } } Ok(ret as i32) } } }
模拟可调用对象
如果类有称作 __call__的#[pymethod],那么它是可调用的。这允许类的实例表现得像函数一样。
这个方法的签名必须是__call__(<self>, ...) -> object
例子:实现一个可调用的计数器
下面的 pyclass 是一个基本的装饰器(构造器将一个Python对象作为参数,当被调用时调用该对象),本节最后有一个等价的Python实现的链接。
这里可以看到一个包含这个 pyclass 的示范包。
#![allow(unused)] fn main() { include ../../../examples/decorator/src/lib.rs }
Python code:
#include ../../../examples/decorator/tests/example.py
Output:
say_hello has been called 1 time(s).
hello
say_hello has been called 2 time(s).
hello
say_hello has been called 3 time(s).
hello
say_hello has been called 4 time(s).
hello
纯Python实现
一个和Rust版本类似的Python实现
class Counter:
def __init__(self, wraps):
self.count = 0
self.wraps = wraps
def __call__(self, *args, **kwargs):
self.count += 1
print(f"{self.wraps.__name__} has been called {self.count} time(s)")
self.wraps(*args, **kwargs)
注意到它也可以用高阶函数实现
def Counter(wraps):
count = 0
def call(*args, **kwargs):
nonlocal count
count += 1
print(f"{wraps.__name__} has been called {count} time(s)")
return wraps(*args, **kwargs)
return call
Cell 什么?
previous implementation使用了u64,这表示它需要一个&mut self接收者(receiver)来更新计数
#![allow(unused)] fn main() { #[pyo3(signature = (*args, **kwargs))] fn __call__(&mut self, py: Python<'_>, args: &PyTuple, kwargs: Option<&PyDict>) -> PyResult<Py<PyAny>> { self.count += 1; let name = self.wraps.getattr(py, "__name__")?; println!("{} has been called {} time(s).", name, self.count); // After doing something, we finally forward the call to the wrapped function let ret = self.wraps.call(py, args, kwargs)?; // We could do something with the return value of // the function before returning it Ok(ret) } }
这里的问题是&mut self这样的接收者意味着PyO3必须唯一地借用它,并在self.wraps.call(py, args, kwargs)调用中保持该借用。这个调用会将控制权返回给一个可以任意调用的Python代码,包括装饰器函数。如果这个发生了,PyO3就不能创建第二个唯一的借用并会抛出异常。
@Counter
def say_hello():
if say_hello.count < 2:
print(f"hello from decorator")
say_hello()
# RuntimeError: Already borrowed
本章给出的实现通过永远不做唯一的借用避免了这个错误,所有方法将&self作为接受者,all the methods take &self as receivers, of which multiple may exist simultaneously,这需要一个共享的计数器,而最简单的方式就是这里所使用的Cell。
这显示了运行任意Python代码的危险,
- Python 的异步执行器(asynchronous executor)可能在Python代码的中途挂起当前线程,即使是你在控制的Python代码,而运行其他Python代码
- 丢弃任意的Python对象可能会引起(invoke)在Python中通过
__del__methods定义的自毁器(destructor) - 调用Python的 C-API(绝大多数PyO3 api在内部调用了 C-API)可能会抛出异常,可能让信号处理器(signal handler)中的Python代码运行
所以在写 unsafe 的代码时要格外慎重
类型转换
这一章包括了PyO3支持的从Python类型到Rust类型的映射,以及表现他们之间转换的特征。
Rust类型到Python类型的映射
当编写在Python中可调用的函数时(例如#[pyfunction]或者#[pymethods]),函数的变量需要是特征FromPyObject,函数的返回值需要是IntoPy<PyObject>
变量类型
当接受一个函数变量时,可以使用 Rust 库的类型或者 PyO3 的 Python-原生类型
The table below contains the Python type and the corresponding function argument types that will accept them:
| Python | Rust | Rust (Python-native) |
|---|---|---|
object | - | &PyAny |
str | String, Cow<str>, &str, OsString, PathBuf | &PyUnicode |
bytes | Vec<u8>, &[u8], Cow<[u8]> | &PyBytes |
bool | bool | &PyBool |
int | Any integer type (i32, u32, usize, etc) | &PyLong |
float | f32, f64 | &PyFloat |
complex | num_complex::Complex1 | &PyComplex |
list[T] | Vec<T> | &PyList |
dict[K, V] | HashMap<K, V>, BTreeMap<K, V>, hashbrown::HashMap<K, V>2, indexmap::IndexMap<K, V>3 | &PyDict |
tuple[T, U] | (T, U), Vec<T> | &PyTuple |
set[T] | HashSet<T>, BTreeSet<T>, hashbrown::HashSet<T>2 | &PySet |
frozenset[T] | HashSet<T>, BTreeSet<T>, hashbrown::HashSet<T>2 | &PyFrozenSet |
bytearray | Vec<u8>, Cow<[u8]> | &PyByteArray |
slice | - | &PySlice |
type | - | &PyType |
module | - | &PyModule |
datetime.datetime | - | &PyDateTime |
datetime.date | - | &PyDate |
datetime.time | - | &PyTime |
datetime.tzinfo | - | &PyTzInfo |
datetime.timedelta | - | &PyDelta |
typing.Optional[T] | Option<T> | - |
typing.Sequence[T] | Vec<T> | &PySequence |
typing.Mapping[K, V] | HashMap<K, V>, BTreeMap<K, V>, hashbrown::HashMap<K, V>2, indexmap::IndexMap<K, V>3 | &PyMapping |
typing.Iterator[Any] | - | &PyIterator |
typing.Union[...] | #[derive(FromPyObject)] | - |
也有一些与 GIL 以及 Rust-defined #[pyclass]有关的特殊类型
| What | Description |
|---|---|
Python | A GIL token, used to pass to PyO3 constructors to prove ownership of the GIL |
Py<T> | A Python object isolated from the GIL lifetime. This can be sent to other threads. |
PyObject | Py<PyAny>的别名 |
&PyCell<T> | A #[pyclass] value owned by Python. |
PyRef<T> | A #[pyclass] borrowed immutably. |
PyRefMut<T> | A #[pyclass] borrowed mutably. |
Using Rust library types vs Python-native types
相比于 Python 原生类型,使用 Rust 库类型作为函数变量会导致转换成本。使用 Python 原生类型几乎是零成本的(它们只需要一个类似 Python 内建函数isinstance()的类型检查)。
然而,一旦支付了转换成本,Rust 标准库类型有下述的优点
- 可以编写原生 Rust 速度的代码
- 与 Rust 生态有更好的互动
- 可以使用
Python::allow_threads来解放 Python GIL,当你的 Rust 代码运行时使其他 Python 线程有更好的表现 - 可以有更严格的类型检查,比如指定
Vec<i32>后将只能接收一个包含整数的 Python 列表,而 Python 原生的等价物&PyList会接受包含任意类型的 Python 列表
绝大多数时间考虑到获得的收益,转换成本都是值得的!
返回 Rust 值到 Python 中
当从 Python 中调用函数返回值时,Python原生类型(&PyAny, &PyDict etc.)可以零成本使用。
因为这些类型是引用,在一些情况下 Rust 编译器会要求生命周期的标注。如果是这样,则需要Py<PyAny>, Py<PyDict> etc. 来代替,这同样是零成本的。对所有这些 Python原生类型T,Py<T>可以通过在T上用.into()转换来创建。
如果函数是易犯错的,则需要返回PyResult<T> 或 Result<T, E>,其中 E 是From<E> for PyErr的实现。如果返回了 Err 变量,这会抛出一个 Python 异常。
| Rust type | Resulting Python Type |
|---|---|
String | str |
&str | str |
bool | bool |
Any integer type (i32, u32, usize, etc) | int |
f32, f64 | float |
Option<T> | Optional[T] |
(T, U) | Tuple[T, U] |
Vec<T> | List[T] |
Cow<[u8]> | bytes |
HashMap<K, V> | Dict[K, V] |
BTreeMap<K, V> | Dict[K, V] |
HashSet<T> | Set[T] |
BTreeSet<T> | Set[T] |
&PyCell<T: PyClass> | T |
PyRef<T: PyClass> | T |
PyRefMut<T: PyClass> | T |
需要 num-complex optional feature.
需要 hashbrown optional feature.
需要 indexmap optional feature.
转换特征
PyO3提供了一些便利的特征来进行 Python 类型和 Rust 类型之间的转换。
.extract() 和 FromPyObject 特征
将 Python 对象转成一个 Rust 值最简单的方法是使用.extract()。如果转换失败了,它会返回一个类型错误PyResult,所以通常可以这样使用
use pyo3::prelude::*; use pyo3::types::PyList; fn main() -> PyResult<()> { Python::with_gil(|py| { let list = PyList::new(py, b"foo"); let v: Vec<i32> = list.extract()?; assert_eq!(&v, &[102, 111, 111]); Ok(()) }) }
这个方法对许多 Python 类型是可用的,并且可以产生许多 Rust 类型,可以在FromPyObject的实现列表中查看。对包装成 Python 对象的自己的 Rust 类型也有FromPyObject实现(见class章节)。为了同时操作可变引用并且满足 Rust 的无别名(non-aliasing)可变引用的规则,必须提取(extract)的 PyO3 引用包装器PyRef和PyRefMut。它们类似引用包装器std::cell::RefCell,确保了在运行时允许 Rust 借用。
提取(deriving)FromPyObject
FromPyObject 可以自动地由许多种的结构和枚举派生(derived),只要成员的类型实现了 FromPyObject。这甚至包含了泛型类型T: FromPyObject。
结构提取 FromPyObject
The derivation generates code that will attempt to access the attribute my_string on
the Python object, i.e. obj.getattr("my_string"), and call extract() on the attribute.
use pyo3::prelude::*; [derive(FromPyObject)] struct RustyStruct { my_string: String, } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let module = PyModule::from_code( py, "class Foo: def __init__(self): self.my_string = 'test'", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rustystruct: RustyStruct = instance.extract()?; assert_eq!(rustystruct.my_string, "test"); Ok(()) }) }
By setting the #[pyo3(item)] attribute on the field, PyO3 will attempt to extract the value by calling the get_item method on the Python object.
use pyo3::prelude::*; #[derive(FromPyObject)] struct RustyStruct { #[pyo3(item)] my_string: String, } use pyo3::types::PyDict; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let dict = PyDict::new(py); dict.set_item("my_string", "test")?; let rustystruct: RustyStruct = dict.extract()?; assert_eq!(rustystruct.my_string, "test"); Ok(()) }) }
传递给 getattr 和 get_item的变量也可以被配置:
use pyo3::prelude::*; [derive(FromPyObject)] struct RustyStruct { #[pyo3(item("key"))] string_in_mapping: String, #[pyo3(attribute("name"))] string_attr: String, } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.name = 'test' self['key'] = 'test2'", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rustystruct: RustyStruct = instance.extract()?; assert_eq!(rustystruct.string_attr, "test"); assert_eq!(rustystruct.string_in_mapping, "test2"); Ok(()) }) }
这尝试从一个带有键值key的mapping的属性name和string_in_mapping中提取string_attr。只要 item 能得到任意正当的实现了ToBorrowedObject的字面值,attribute的变量就被限制为非空字符串字面值。
元组结构提取 FromPyObject
元组结构支持但无法自定义提取(extraction)。永远假定输入是与 Rust 类型具有同样长度的 Python 元组。
use pyo3::prelude::*; [derive(FromPyObject)] struct RustyTuple(String, String); use pyo3::types::PyTuple; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let tuple = PyTuple::new(py, vec!["test", "test2"]); let rustytuple: RustyTuple = tuple.extract()?; assert_eq!(rustytuple.0, "test"); assert_eq!(rustytuple.1, "test2"); Ok(()) }) }
只有一个域的元组结构被处理为包装类型(下节讲),为了覆写这个特性以保证输入的是一个元组,需要指定结构为:
use pyo3::prelude::*; [derive(FromPyObject)] struct RustyTuple((String,)); use pyo3::types::PyTuple; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let tuple = PyTuple::new(py, vec!["test"]); let rustytuple: RustyTuple = tuple.extract()?; assert_eq!((rustytuple.0).0, "test"); Ok(()) }) }
包装类型(wrapper types)提取FromPyObject
pyo3(transparent)可以用在只有一个域的结构上,这导致了直接提取输入的对象,i.e. obj.extract(),而不是尝试获取一个 item 或者属性。
use pyo3::prelude::*; [derive(FromPyObject)] struct RustyTransparentTupleStruct(String); [derive(FromPyObject)] [pyo3(transparent)] struct RustyTransparentStruct { inner: String, } use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let s = PyString::new(py, "test"); let tup: RustyTransparentTupleStruct = s.extract()?; assert_eq!(tup.0, "test"); let stru: RustyTransparentStruct = s.extract()?; assert_eq!(stru.inner, "test"); Ok(()) }) }
枚举提取FromPyObject
枚举的FromPyObject提取会生成尝试按照域的顺序提取变量的代码,只要变量成功被提取,该变量会被返回。这使得能够从 Python 中提取如str|int的聚合类型(union type)。
结构提取中的自定义和限制对于枚举变量也是同样的,i.e. 一个元组变量假定输入是一个 Python 元组。transparent属性也能被应用到单域变量(single-field-variants)
代码有隐藏
use pyo3::prelude::*; #[derive(FromPyObject)] #[derive(Debug)] enum RustyEnum<'a> { Int(usize), // input is a positive int String(String), // input is a string IntTuple(usize, usize), // input is a 2-tuple with positive ints StringIntTuple(String, usize), // input is a 2-tuple with String and int Coordinates3d { // needs to be in front of 2d x: usize, y: usize, z: usize, }, Coordinates2d { // only gets checked if the input did not have `z` #[pyo3(attribute("x"))] a: usize, #[pyo3(attribute("y"))] b: usize, }, #[pyo3(transparent)] CatchAll(&'a PyAny), // This extraction never fails } use pyo3::types::{PyBytes, PyString}; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { { let thing = 42_u8.to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( 42, match rust_thing { RustyEnum::Int(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = PyString::new(py, "text"); let rust_thing: RustyEnum<'_> = thing.extract()?; assert_eq!( "text", match rust_thing { RustyEnum::String(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = (32_u8, 73_u8).to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( (32, 73), match rust_thing { RustyEnum::IntTuple(i, j) => (i, j), other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = ("foo", 73_u8).to_object(py); let rust_thing: RustyEnum<'_> = thing.extract(py)?; assert_eq!( (String::from("foo"), 73), match rust_thing { RustyEnum::StringIntTuple(i, j) => (i, j), other => unreachable!("Error extracting: {:?}", other), } ); } { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.x = 0 self.y = 1 self.z = 2", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rust_thing: RustyEnum<'_> = instance.extract()?; assert_eq!( (0, 1, 2), match rust_thing { RustyEnum::Coordinates3d { x, y, z } => (x, y, z), other => unreachable!("Error extracting: {:?}", other), } ); } { let module = PyModule::from_code( py, "class Foo(dict): def __init__(self): self.x = 3 self.y = 4", "", "", )?; let class = module.getattr("Foo")?; let instance = class.call0()?; let rust_thing: RustyEnum<'_> = instance.extract()?; assert_eq!( (3, 4), match rust_thing { RustyEnum::Coordinates2d { a, b } => (a, b), other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = PyBytes::new(py, b"text"); let rust_thing: RustyEnum<'_> = thing.extract()?; assert_eq!( b"text", match rust_thing { RustyEnum::CatchAll(i) => i.downcast::<PyBytes>()?.as_bytes(), other => unreachable!("Error extracting: {:?}", other), } ); } Ok(()) }) }
如果没有枚举变量匹配到,会返回一个包含着被测试变量名的PyTypeError。错误信息中报告的名字可以通过#[pyo3(annotation = "name")]属性自定义,e.g. 使用传统的 Python 类型名:
代码有折叠
use pyo3::prelude::*; #[derive(FromPyObject)] #[derive(Debug)] enum RustyEnum { #[pyo3(transparent, annotation = "str")] String(String), #[pyo3(transparent, annotation = "int")] Int(isize), } fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { { let thing = 42_u8.to_object(py); let rust_thing: RustyEnum = thing.extract(py)?; assert_eq!( 42, match rust_thing { RustyEnum::Int(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = "foo".to_object(py); let rust_thing: RustyEnum = thing.extract(py)?; assert_eq!( "foo", match rust_thing { RustyEnum::String(i) => i, other => unreachable!("Error extracting: {:?}", other), } ); } { let thing = b"foo".to_object(py); let error = thing.extract::<RustyEnum>(py).unwrap_err(); assert!(error.is_instance_of::<pyo3::exceptions::PyTypeError>(py)); } Ok(()) }) }
如果输入既不是 string 也不是 integer,则错误信息为 "'<INPUT_TYPE>' cannot be converted to 'str | int'"。
#[derive(FromPyObject)]容器属性
pyo3(transparent)- 直接从
obj.extract()对象中提取域,而不是get_item()或者getattr() - 每次默认中,新类型结构和元祖变量会被视为
transparent - 只对单域结构或者枚举变量有效
- 直接从
pyo3(annotation = "name")- 改变在失败时生成的错误信息中失败的变量的名字
- e.g.
pyo3("int")将变量类型报告为int - 只支持枚举变量
#[derive(FromPyObject)]域属性
pyo3(attribute),pyo3(attribute("name"))- 从一个属性中取回(retrieve)域,可能由变量指定一个自定义的名字
- 变量必须为字符串字面值
pyo3(item),pyo3(item("key"))- 从一个mapping取回(retrieve)域,可能由变量指定一个自定义的名字
- 可以是实现了
ToBorrowedObject的字面值
pyo3(from_py_with = "...")- 应用一个自定义的函数来 convert the field from Python the desired Rust type.
- 变量必须是函数名的 string
- 函数签名必须为
fn(&PyAny) -> PyResult<T>,其中T是 Rust 类型的变量
IntoPy<T>
这个特征定义了 Rust 类型的 to-python 转换,通常被实现为 IntoPy<PyObject> ,这是在从 #[pyfunction] 和 #[pymethods] 返回一个值时所需要的。
所有 PyO3 的类型实现了这个特征,一个没有使用 extends 的 #[pyclass] 也实现了。
偶尔在将自定义类型映射为没有独立(unique)类型的 Python 类型时会选择实现它。
#![allow(unused)] fn main() { use pyo3::prelude::*; struct MyPyObjectWrapper(PyObject); impl IntoPy<PyObject> for MyPyObjectWrapper { fn into_py(self, py: Python<'_>) -> PyObject { self.0 } } }
The ToPyObject trait
ToPyObject 是一个转变特征,它允许将各种对象转换为PyObject。IntoPy<PyObject>有同样的效果,除了它 consumes self。
Python 异常
定义一个新异常
可以使用create_exception!宏来定义一个新异常类型
#![allow(unused)] fn main() { use pyo3::create_exception; create_exception!(module, MyError, pyo3::exceptions::PyException); }
module是包含它的模组名MyError是新异常类型名
例如
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::create_exception; use pyo3::types::IntoPyDict; use pyo3::exceptions::PyException; create_exception!(mymodule, CustomError, PyException); Python::with_gil(|py| { let ctx = [("CustomError", py.get_type::<CustomError>())].into_py_dict(py); pyo3::py_run!( py, *ctx, "assert str(CustomError) == \"<class 'mymodule.CustomError'>\"" ); pyo3::py_run!(py, *ctx, "assert CustomError('oops').args == ('oops',)"); }); }
当使用 PyO3 来创建一个额外模组时,可以像这样在该模组上添加一个新异常,从而能在 Python 中导入它
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyModule; use pyo3::exceptions::PyException; pyo3::create_exception!(mymodule, CustomError, PyException); #[pymodule] fn mymodule(py: Python<'_>, m: &PyModule) -> PyResult<()> { // ... other elements added to module ... m.add("CustomError", py.get_type::<CustomError>())?; Ok(()) } }
抛出异常
像在函数/错误处理中说的那样,要从#[pyfunction] 或 #[pymethods]中抛出一个异常需要返回一个Err(PyErr)。PyO3 在返回这个结果给 Python 时会自动抛出这个异常。
也可以manually write and fetch errors in the Python interpreter's global state:
#![allow(unused)] fn main() { use pyo3::{Python, PyErr}; use pyo3::exceptions::PyTypeError; Python::with_gil(|py| { PyTypeError::new_err("Error").restore(py); assert!(PyErr::occurred(py)); drop(PyErr::fetch(py)); }); }
检查异常类型
Python 有一个isinstance方法来检查一个对象的类型。在 PyO3 中,每个对象都有具有同样效果的PyAny::is_instance 和 PyAny::is_instance_of方法。
#![allow(unused)] fn main() { use pyo3::Python; use pyo3::types::{PyBool, PyList}; Python::with_gil(|py| { assert!(PyBool::new(py, true).is_instance_of::<PyBool>().unwrap()); let list = PyList::new(py, &[1, 2, 3, 4]); assert!(!list.is_instance_of::<PyBool>().unwrap()); assert!(list.is_instance_of::<PyList>().unwrap()); }); }
要检查一个异常的类型,类似地可以
#![allow(unused)] fn main() { use pyo3::exceptions::PyTypeError; use pyo3::prelude::*; Python::with_gil(|py| { let err = PyTypeError::new_err(()); err.is_instance_of::<PyTypeError>(py); }); }
使用 Python 中定义的异常
可以用原生 Rust 类型来使用定义在 Python 代码中的异常。import_exception!宏允许导入一个特定的异常类型并为其定义一个 Rust 类型
#![allow(unused)] #![allow(dead_code)] fn main() { use pyo3::prelude::*; mod io { pyo3::import_exception!(io, UnsupportedOperation); } fn tell(file: &PyAny) -> PyResult<u64> { match file.call_method0("tell") { Err(_) => Err(io::UnsupportedOperation::new_err("not supported: tell")), Ok(x) => x.extract::<u64>(), } } }
Calling Python in Rust code
本章包含在 Rust 中与 Python 代码互动的几种方法
- 怎么调用 Python 函数
- 怎么执行现有的 Python 代码
Calling Python functions
任意 Python 原生的对象引用(例如&PyAny, &PyList 或 &PyCell<MyClass>)可以被用来调用 Python 函数。
PyO3 提供了两个 API 来进行函数调用
call:调用任何可调用的 Python 对象call_method:调用 Python 对象上的一个方法
这两个 API 接受args 和 kwargs 变量,有更简单形式的调用
call1和call_method1仅用位置变量args来进行调用call0和call_method0不需要变量进行调用
Both of these APIs take args and kwargs arguments (for positional and keyword arguments respectively). There are variants for less complex calls:
方便起见 Py<T> 智能指针也会 expose 六个 API 方法上,但是需要 Python 记号作为额外的第一个变量来显示 GIL 被占用。
下述例子调用了PyObject(aka Py<PyAny>)引用后的一个 Python 函数:
use pyo3::prelude::*; use pyo3::types::PyTuple; fn main() -> PyResult<()> { let arg1 = "arg1"; let arg2 = "arg2"; let arg3 = "arg3"; Python::with_gil(|py| { let fun: Py<PyAny> = PyModule::from_code( py, "def example(*args, **kwargs): if args != (): print('called with args', args) if kwargs != {}: print('called with kwargs', kwargs) if args == () and kwargs == {}: print('called with no arguments')", "", "", )? .getattr("example")? .into(); // call object without any arguments fun.call0(py)?; // call object with PyTuple let args = PyTuple::new(py, &[arg1, arg2, arg3]); fun.call1(py, args)?; // pass arguments as rust tuple let args = (arg1, arg2, arg3); fun.call1(py, args)?; Ok(()) }) }
创建关键字变量
对于 call 和 call_method API,kwargs可以是None或者 Some(&PyDict)。可以使用 IntoPyDict 特征来转换其他的 dict-like 容器,e.g. HashMap 或者 BTreeMap, 至多十个元素的元组和每个元素是一个二元元组的Vec。
use pyo3::prelude::*; use pyo3::types::IntoPyDict; use std::collections::HashMap; fn main() -> PyResult<()> { let key1 = "key1"; let val1 = 1; let key2 = "key2"; let val2 = 2; Python::with_gil(|py| { let fun: Py<PyAny> = PyModule::from_code( py, "def example(*args, **kwargs): if args != (): print('called with args', args) if kwargs != {}: print('called with kwargs', kwargs) if args == () and kwargs == {}: print('called with no arguments')", "", "", )? .getattr("example")? .into(); // call object with PyDict let kwargs = [(key1, val1)].into_py_dict(py); fun.call(py, (), Some(kwargs))?; // pass arguments as Vec let kwargs = vec![(key1, val1), (key2, val2)]; fun.call(py, (), Some(kwargs.into_py_dict(py)))?; // pass arguments as HashMap let mut kwargs = HashMap::<&str, i32>::new(); kwargs.insert(key1, 1); fun.call(py, (), Some(kwargs.into_py_dict(py)))?; Ok(()) }) }
执行已有的Python代码
如果有想在 Rust 中执行的 Python 代码,下面的 FAQS 可以帮助选择正确的 PyO3 功能
想要接入 Python API?PyModule::import
Pymodule::import 可以用来在 Rust 中处理 Python 模组。
use pyo3::prelude::*; fn main() -> PyResult<()> { Python::with_gil(|py| { let builtins = PyModule::import(py, "builtins")?; let total: i32 = builtins .getattr("sum")? .call1((vec![1, 2, 3],))? .extract()?; assert_eq!(total, 6); Ok(()) }) }
仅仅运行一个表达式(expressing)?使用eval
Python::eval 是执行Python 表达式的方法,返回一个 &PyAny 对象。
use pyo3::prelude::*; fn main() -> Result<(), ()> { Python::with_gil(|py| { let result = py .eval("[i * 10 for i in range(5)]", None, None) .map_err(|e| { e.print_and_set_sys_last_vars(py); })?; let res: Vec<i64> = result.extract().unwrap(); assert_eq!(res, vec![0, 10, 20, 30, 40]); Ok(()) }) }
想要运行语句(statement)?使用run
Python::run 是执行一个或多个Python语句的方法。这个方法不返回东西,但是可以通过locals字典去获取对象。
也可以使用其简写:py_run!宏。因为py_run!在异常时会panic,所以只推荐在测试异常时使用宏
use pyo3::prelude::*; use pyo3::{PyCell, py_run}; fn main() { #[pyclass] struct UserData { id: u32, name: String, } #[pymethods] impl UserData { fn as_tuple(&self) -> (u32, String) { (self.id, self.name.clone()) } fn __repr__(&self) -> PyResult<String> { Ok(format!("User {}(id: {})", self.name, self.id)) } } Python::with_gil(|py| { let userdata = UserData { id: 34, name: "Yu".to_string(), }; let userdata = PyCell::new(py, userdata).unwrap(); let userdata_as_tuple = (34, "Yu"); py_run!(py, userdata userdata_as_tuple, r#" assert repr(userdata) == "User Yu(id: 34)" assert userdata.as_tuple() == userdata_as_tuple "#); }) }
有一个Python文件或者代码片段?使用PyModule::from_code
PyModule::from_code可以用来生成能使用的Python模组,就像通过PyModule::import导入的。
Warning: 这会编译并执行代码,永远不要 传递不可信任的代码给这个函数
use pyo3::{prelude::*, types::{IntoPyDict, PyModule}}; fn main() -> PyResult<()> { Python::with_gil(|py| { let activators = PyModule::from_code(py, r#" def relu(x): """see https://en.wikipedia.org/wiki/Rectifier_(neural_networks)""" return max(0.0, x) def leaky_relu(x, slope=0.01): return x if x >= 0 else x * slope "#, "activators.py", "activators")?; let relu_result: f64 = activators.getattr("relu")?.call1((-1.0,))?.extract()?; assert_eq!(relu_result, 0.0); let kwargs = [("slope", 0.2)].into_py_dict(py); let lrelu_result: f64 = activators .getattr("leaky_relu")? .call((-1.0,), Some(kwargs))? .extract()?; assert_eq!(lrelu_result, -0.2); Ok(()) }) }
想在Rust中嵌入Python一个额外的模组?
Python 为所有导入的包保存了一个sys.modules字典。在Python中的导入包会首先在这个字典中进行查找,如果没有找到会尝试一些其他的办法。
append_to_inittab宏可以用来为嵌入的 Python 解释器添加额外的#[pymodule],这个宏必须在初始化Python前唤出。
例子,为嵌入的解释器添加foo模组
use pyo3::prelude::*; #[pyfunction] fn add_one(x: i64) -> i64 { x + 1 } #[pymodule] fn foo(_py: Python<'_>, foo_module: &PyModule) -> PyResult<()> { foo_module.add_function(wrap_pyfunction!(add_one, foo_module)?)?; Ok(()) } fn main() -> PyResult<()> { pyo3::append_to_inittab!(foo); Python::with_gil(|py| Python::run(py, "import foo; foo.add_one(6)", None, None)) }
如果append_to_inittab因为程序员因无法使用,可以使用PyModule::new创建一个模组并手动添加进sys.modules
use pyo3::prelude::*; use pyo3::types::PyDict; #[pyfunction] pub fn add_one(x: i64) -> i64 { x + 1 } fn main() -> PyResult<()> { Python::with_gil(|py| { // Create new module let foo_module = PyModule::new(py, "foo")?; foo_module.add_function(wrap_pyfunction!(add_one, foo_module)?)?; // Import and get sys.modules let sys = PyModule::import(py, "sys")?; let py_modules: &PyDict = sys.getattr("modules")?.downcast()?; // Insert foo into sys.modules py_modules.set_item("foo", foo_module)?; // Now we can import + run our python code Python::run(py, "import foo; foo.add_one(6)", None, None) }) }
包含许多Python文件
可以使用std::include_str宏在编译时包含一个文件.
或者在运行时通过std::fs::read_to_string函数加载一个文件。
许多Python文件可以作为模组被包含并加载。如果一个文件依赖于另一个文件,必须在声明PyModule时保持正确的顺序,
目录结构例子:
.
├── Cargo.lock
├── Cargo.toml
├── python_app
│ ├── app.py
│ └── utils
│ └── foo.py
└── src
└── main.rs
python_app/app.py:
from utils.foo import bar
def run():
return bar()
python_app/utils/foo.py:
def bar():
return "baz"
下面的例子说明了
- 怎样将
app.py和utils/foo.py的内容包含进你的Rust二进制中 - 怎么调用在
app.py中声明的函数run()(它需要从utils/foo.py导入的函数)
src/main.rs:
use pyo3::prelude::*; fn main() -> PyResult<()> { let py_foo = include_str!(concat!(env!("CARGO_MANIFEST_DIR"), "/python_app/utils/foo.py")); let py_app = include_str!(concat!(env!("CARGO_MANIFEST_DIR"), "/python_app/app.py")); let from_python = Python::with_gil(|py| -> PyResult<Py<PyAny>> { PyModule::from_code(py, py_foo, "utils.foo", "utils.foo")?; let app: Py<PyAny> = PyModule::from_code(py, py_app, "", "")? .getattr("run")? .into(); app.call0(py) }); println!("py: {}", from_python?); Ok(()) }
下面的例子说明了:
- 怎样在运行中导入
app.py的内容,让它自动解决其依赖 - 怎么调用在
app.py中声明的函数run()(它需要从utils/foo.py导入的函数)
建议使用绝对路径,从而你的二进制可以在任意位置运行只要你的 app.py 在预期的目录下(这个例子中,目录为/usr/share/python_app)
src/main.rs:
use pyo3::prelude::*; use pyo3::types::PyList; use std::fs; use std::path::Path; fn main() -> PyResult<()> { let path = Path::new("/usr/share/python_app"); let py_app = fs::read_to_string(path.join("app.py"))?; let from_python = Python::with_gil(|py| -> PyResult<Py<PyAny>> { let syspath: &PyList = py.import("sys")?.getattr("path")?.downcast()?; syspath.insert(0, &path)?; let app: Py<PyAny> = PyModule::from_code(py, &py_app, "", "")? .getattr("run")? .into(); app.call0(py) }); println!("py: {}", from_python?); Ok(()) }
需要在Rust中使用上下文管理器?
直接通过 __enter__ 和 __exit__ 使用上下文管理器
use pyo3::prelude::*; use pyo3::types::PyModule; fn main() { Python::with_gil(|py| { let custom_manager = PyModule::from_code(py, r#" class House(object): def __init__(self, address): self.address = address def __enter__(self): print(f"Welcome to {self.address}!") def __exit__(self, type, value, traceback): if type: print(f"Sorry you had {type} trouble at {self.address}") else: print(f"Thank you for visiting {self.address}, come again soon!") "#, "house.py", "house").unwrap(); let house_class = custom_manager.getattr("House").unwrap(); let house = house_class.call1(("123 Main Street",)).unwrap(); house.call_method0("__enter__").unwrap(); let result = py.eval("undefined_variable + 1", None, None); // If the eval threw an exception we'll pass it through to the context manager. // Otherwise, __exit__ is called with empty arguments (Python "None"). match result { Ok(_) => { let none = py.None(); house.call_method1("__exit__", (&none, &none, &none)).unwrap(); }, Err(e) => { house.call_method1( "__exit__", (e.get_type(py), e.value(py), e.traceback(py)) ).unwrap(); } } }) }
GIL lifetimes, mutability and Python object types
On first glance, PyO3 provides a huge number of different types that can be used to wrap or refer to Python objects. This page delves into the details and gives an overview of their intended meaning, with examples when each type is best used.
The Python GIL, mutability, and Rust types
Since Python has no concept of ownership, and works solely with boxed objects, any Python object can be referenced any number of times, and mutation is allowed from any reference.
The situation is helped a little by the Global Interpreter Lock (GIL), which ensures that only one thread can use the Python interpreter and its API at the same time, while non-Python operations (system calls and extension code) can unlock the GIL. (See the section on parallelism for how to do that in PyO3.)
In PyO3, holding the GIL is modeled by acquiring a token of the type
Python<'py>, which serves three purposes:
- It provides some global API for the Python interpreter, such as
eval. - It can be passed to functions that require a proof of holding the GIL,
such as
Py::clone_ref. - Its lifetime can be used to create Rust references that implicitly guarantee
holding the GIL, such as
&'py PyAny.
The latter two points are the reason why some APIs in PyO3 require the py: Python argument, while others don't.
The PyO3 API for Python objects is written such that instead of requiring a
mutable Rust reference for mutating operations such as
PyList::append, a shared reference (which, in turn, can only
be created through Python<'_> with a GIL lifetime) is sufficient.
However, Rust structs wrapped as Python objects (called pyclass types) usually
do need &mut access. Due to the GIL, PyO3 can guarantee thread-safe access
to them, but it cannot statically guarantee uniqueness of &mut references once
an object's ownership has been passed to the Python interpreter, ensuring
references is done at runtime using PyCell, a scheme very similar to
std::cell::RefCell.
Accessing the Python GIL
To get hold of a Python<'py> token to prove the GIL is held, consult PyO3's documentation.
Object types
PyAny
Represents: a Python object of unspecified type, restricted to a GIL
lifetime. Currently, PyAny can only ever occur as a reference, &PyAny.
Used: Whenever you want to refer to some Python object and will have the
GIL for the whole duration you need to access that object. For example,
intermediate values and arguments to pyfunctions or pymethods implemented
in Rust where any type is allowed.
Many general methods for interacting with Python objects are on the PyAny struct,
such as getattr, setattr, and .call.
Conversions:
For a &PyAny object reference any where the underlying object is a Python-native type such as
a list:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| -> PyResult<()> { let obj: &PyAny = PyList::empty(py); // To &PyList with PyAny::downcast let _: &PyList = obj.downcast()?; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = obj.into(); // To Py<PyList> with PyAny::extract let _: Py<PyList> = obj.extract()?; Ok(()) }).unwrap(); }
For a &PyAny object reference any where the underlying object is a #[pyclass]:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::{Py, Python, PyAny, PyResult}; #[pyclass] #[derive(Clone)] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let obj: &PyAny = Py::new(py, MyClass {})?.into_ref(py); // To &PyCell<MyClass> with PyAny::downcast let _: &PyCell<MyClass> = obj.downcast()?; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = obj.into(); // To Py<MyClass> with PyAny::extract let _: Py<MyClass> = obj.extract()?; // To MyClass with PyAny::extract, if MyClass: Clone let _: MyClass = obj.extract()?; // To PyRef<'_, MyClass> or PyRefMut<'_, MyClass> with PyAny::extract let _: PyRef<'_, MyClass> = obj.extract()?; let _: PyRefMut<'_, MyClass> = obj.extract()?; Ok(()) }).unwrap(); }
PyTuple, PyDict, and many more
Represents: a native Python object of known type, restricted to a GIL
lifetime just like PyAny.
Used: Whenever you want to operate with native Python types while holding
the GIL. Like PyAny, this is the most convenient form to use for function
arguments and intermediate values.
These types all implement Deref<Target = PyAny>, so they all expose the same
methods which can be found on PyAny.
To see all Python types exposed by PyO3 you should consult the
pyo3::types module.
Conversions:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| -> PyResult<()> { let list = PyList::empty(py); // Use methods from PyAny on all Python types with Deref implementation let _ = list.repr()?; // To &PyAny automatically with Deref implementation let _: &PyAny = list; // To &PyAny explicitly with .as_ref() let _: &PyAny = list.as_ref(); // To Py<T> with .into() or Py::from() let _: Py<PyList> = list.into(); // To PyObject with .into() or .to_object(py) let _: PyObject = list.into(); Ok(()) }).unwrap(); }
Py<T> and PyObject
Represents: a GIL-independent reference to a Python object. This can be a Python native type
(like PyTuple), or a pyclass type implemented in Rust. The most commonly-used variant,
Py<PyAny>, is also known as PyObject.
Used: Whenever you want to carry around references to a Python object without caring about a GIL lifetime. For example, storing Python object references in a Rust struct that outlives the Python-Rust FFI boundary, or returning objects from functions implemented in Rust back to Python.
Can be cloned using Python reference counts with .clone().
Conversions:
For a Py<PyList>, the conversions are as below:
#![allow(unused)] fn main() { use pyo3::prelude::*; use pyo3::types::PyList; Python::with_gil(|py| { let list: Py<PyList> = PyList::empty(py).into(); // To &PyList with Py::as_ref() (borrows from the Py) let _: &PyList = list.as_ref(py); let list_clone = list.clone(); // Because `.into_ref()` will consume `list`. // To &PyList with Py::into_ref() (moves the pointer into PyO3's object storage) let _: &PyList = list.into_ref(py); let list = list_clone; // To Py<PyAny> (aka PyObject) with .into() let _: Py<PyAny> = list.into(); }) }
For a #[pyclass] struct MyClass, the conversions for Py<MyClass> are below:
#![allow(unused)] fn main() { use pyo3::prelude::*; Python::with_gil(|py| { #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let my_class: Py<MyClass> = Py::new(py, MyClass { })?; // To &PyCell<MyClass> with Py::as_ref() (borrows from the Py) let _: &PyCell<MyClass> = my_class.as_ref(py); let my_class_clone = my_class.clone(); // Because `.into_ref()` will consume `my_class`. // To &PyCell<MyClass> with Py::into_ref() (moves the pointer into PyO3's object storage) let _: &PyCell<MyClass> = my_class.into_ref(py); let my_class = my_class_clone.clone(); // To Py<PyAny> (aka PyObject) with .into_py(py) let _: Py<PyAny> = my_class.into_py(py); let my_class = my_class_clone; // To PyRef<'_, MyClass> with Py::borrow or Py::try_borrow let _: PyRef<'_, MyClass> = my_class.try_borrow(py)?; // To PyRefMut<'_, MyClass> with Py::borrow_mut or Py::try_borrow_mut let _: PyRefMut<'_, MyClass> = my_class.try_borrow_mut(py)?; Ok(()) }).unwrap(); }); }
PyCell<SomeType>
Represents: a reference to a Rust object (instance of PyClass) which is
wrapped in a Python object. The cell part is an analog to stdlib's
RefCell to allow access to &mut references.
Used: for accessing pure-Rust API of the instance (members and functions
taking &SomeType or &mut SomeType) while maintaining the aliasing rules of
Rust references.
Like PyO3's Python native types, PyCell<T> implements Deref<Target = PyAny>,
so it also exposes all of the methods on PyAny.
Conversions:
PyCell<T> can be used to access &T and &mut T via PyRef<T> and PyRefMut<T> respectively.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let cell: &PyCell<MyClass> = PyCell::new(py, MyClass {})?; // To PyRef<T> with .borrow() or .try_borrow() let py_ref: PyRef<'_, MyClass> = cell.try_borrow()?; let _: &MyClass = &*py_ref; drop(py_ref); // To PyRefMut<T> with .borrow_mut() or .try_borrow_mut() let mut py_ref_mut: PyRefMut<'_, MyClass> = cell.try_borrow_mut()?; let _: &mut MyClass = &mut *py_ref_mut; Ok(()) }).unwrap(); }
PyCell<T> can also be accessed like a Python-native type.
#![allow(unused)] fn main() { use pyo3::prelude::*; #[pyclass] struct MyClass { } Python::with_gil(|py| -> PyResult<()> { let cell: &PyCell<MyClass> = PyCell::new(py, MyClass {})?; // Use methods from PyAny on PyCell<T> with Deref implementation let _ = cell.repr()?; // To &PyAny automatically with Deref implementation let _: &PyAny = cell; // To &PyAny explicitly with .as_ref() let _: &PyAny = cell.as_ref(); Ok(()) }).unwrap(); }
PyRef<SomeType> and PyRefMut<SomeType>
Represents: reference wrapper types employed by PyCell to keep track of
borrows, analog to Ref and RefMut used by RefCell.
Used: while borrowing a PyCell. They can also be used with .extract()
on types like Py<T> and PyAny to get a reference quickly.
Related traits and types
PyClass
This trait marks structs defined in Rust that are also usable as Python classes,
usually defined using the #[pyclass] macro.
PyNativeType
This trait marks structs that mirror native Python types, such as PyList.
Parallelism
CPython has the infamous Global Interpreter Lock, which prevents several threads from executing Python bytecode in parallel. This makes threading in Python a bad fit for CPU-bound tasks and often forces developers to accept the overhead of multiprocessing.
In PyO3 parallelism can be easily achieved in Rust-only code. Let's take a look at our word-count example, where we have a search function that utilizes the rayon crate to count words in parallel.
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; // These traits let us use `par_lines` and `map`. use rayon::str::ParallelString; use rayon::iter::ParallelIterator; /// Count the occurrences of needle in line, case insensitive fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } #[pyfunction] fn search(contents: &str, needle: &str) -> usize { contents .par_lines() .map(|line| count_line(line, needle)) .sum() } }
But let's assume you have a long running Rust function which you would like to execute several times in parallel. For the sake of example let's take a sequential version of the word count:
#![allow(unused)] fn main() { #![allow(dead_code)] fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } fn search_sequential(contents: &str, needle: &str) -> usize { contents.lines().map(|line| count_line(line, needle)).sum() } }
To enable parallel execution of this function, the Python::allow_threads method can be used to temporarily release the GIL, thus allowing other Python threads to run. We then have a function exposed to the Python runtime which calls search_sequential inside a closure passed to Python::allow_threads to enable true parallelism:
#![allow(unused)] fn main() { #![allow(dead_code)] use pyo3::prelude::*; fn count_line(line: &str, needle: &str) -> usize { let mut total = 0; for word in line.split(' ') { if word == needle { total += 1; } } total } fn search_sequential(contents: &str, needle: &str) -> usize { contents.lines().map(|line| count_line(line, needle)).sum() } #[pyfunction] fn search_sequential_allow_threads(py: Python<'_>, contents: &str, needle: &str) -> usize { py.allow_threads(|| search_sequential(contents, needle)) } }
Now Python threads can use more than one CPU core, resolving the limitation which usually makes multi-threading in Python only good for IO-bound tasks:
from concurrent.futures import ThreadPoolExecutor
from word_count import search_sequential_allow_threads
executor = ThreadPoolExecutor(max_workers=2)
future_1 = executor.submit(
word_count.search_sequential_allow_threads, contents, needle
)
future_2 = executor.submit(
word_count.search_sequential_allow_threads, contents, needle
)
result_1 = future_1.result()
result_2 = future_2.result()
Benchmark
Let's benchmark the word-count example to verify that we really did unlock parallelism with PyO3.
We are using pytest-benchmark to benchmark four word count functions:
- Pure Python version
- Rust parallel version
- Rust sequential version
- Rust sequential version executed twice with two Python threads
The benchmark script can be found here, and we can run nox in the word-count folder to benchmark these functions.
While the results of the benchmark of course depend on your machine, the relative results should be similar to this (mid 2020):
-------------------------------------------------------------------------------------------------- benchmark: 4 tests -------------------------------------------------------------------------------------------------
Name (time in ms) Min Max Mean StdDev Median IQR Outliers OPS Rounds Iterations
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
test_word_count_rust_parallel 1.7315 (1.0) 4.6495 (1.0) 1.9972 (1.0) 0.4299 (1.0) 1.8142 (1.0) 0.2049 (1.0) 40;46 500.6943 (1.0) 375 1
test_word_count_rust_sequential 7.3348 (4.24) 10.3556 (2.23) 8.0035 (4.01) 0.7785 (1.81) 7.5597 (4.17) 0.8641 (4.22) 26;5 124.9457 (0.25) 121 1
test_word_count_rust_sequential_twice_with_threads 7.9839 (4.61) 10.3065 (2.22) 8.4511 (4.23) 0.4709 (1.10) 8.2457 (4.55) 0.3927 (1.92) 17;17 118.3274 (0.24) 114 1
test_word_count_python_sequential 27.3985 (15.82) 45.4527 (9.78) 28.9604 (14.50) 4.1449 (9.64) 27.5781 (15.20) 0.4638 (2.26) 3;5 34.5299 (0.07) 35 1
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
You can see that the Python threaded version is not much slower than the Rust sequential version, which means compared to an execution on a single CPU core the speed has doubled.
Debugging
Macros
PyO3's attributes (#[pyclass], #[pymodule], etc.) are procedural macros, which means that they rewrite the source of the annotated item. You can view the generated source with the following command, which also expands a few other things:
cargo rustc --profile=check -- -Z unstable-options --pretty=expanded > expanded.rs; rustfmt expanded.rs
(You might need to install rustfmt if you don't already have it.)
You can also debug classic !-macros by adding -Z trace-macros:
cargo rustc --profile=check -- -Z unstable-options --pretty=expanded -Z trace-macros > expanded.rs; rustfmt expanded.rs
See cargo expand for a more elaborate version of those commands.
Running with Valgrind
Valgrind is a tool to detect memory management bugs such as memory leaks.
You first need to install a debug build of Python, otherwise Valgrind won't produce usable results. In Ubuntu there's e.g. a python3-dbg package.
Activate an environment with the debug interpreter and recompile. If you're on Linux, use ldd with the name of your binary and check that you're linking e.g. libpython3.7d.so.1.0 instead of libpython3.7.so.1.0.
Download the suppressions file for CPython.
Run Valgrind with valgrind --suppressions=valgrind-python.supp ./my-command --with-options
Getting a stacktrace
The best start to investigate a crash such as an segmentation fault is a backtrace. You can set RUST_BACKTRACE=1 as an environment variable to get the stack trace on a panic!. Alternatively you can use a debugger such as gdb to explore the issue. Rust provides a wrapper, rust-gdb, which has pretty-printers for inspecting Rust variables. Since PyO3 uses cdylib for Python shared objects, it does not receive the pretty-print debug hooks in rust-gdb (rust-lang/rust#96365). The mentioned issue contains a workaround for enabling pretty-printers in this case.
- Link against a debug build of python as described in the previous chapter
- Run
rust-gdb <my-binary> - Set a breakpoint (
b) onrust_panicif you are investigating apanic! - Enter
rto run - After the crash occurred, enter
btorbt fullto print the stacktrace
Often it is helpful to run a small piece of Python code to exercise a section of Rust.
rust-gdb --args python -c "import my_package; my_package.sum_to_string(1, 2)"
Features reference
PyO3 provides a number of Cargo features to customize functionality. This chapter of the guide provides detail on each of them.
By default, only the macros feature is enabled.
Features for extension module authors
extension-module
This feature is required when building a Python extension module using PyO3.
It tells PyO3's build script to skip linking against libpython.so on Unix platforms, where this must not be done.
See the building and distribution section for further detail.
abi3
This feature is used when building Python extension modules to create wheels which are compatible with multiple Python versions.
It restricts PyO3's API to a subset of the full Python API which is guaranteed by PEP 384 to be forwards-compatible with future Python versions.
See the building and distribution section for further detail.
The abi3-pyXY features
(abi3-py37, abi3-py38, abi3-py39, abi3-py310 and abi3-py311)
These features are extensions of the abi3 feature to specify the exact minimum Python version which the multiple-version-wheel will support.
See the building and distribution section for further detail.
generate-import-lib
This experimental feature is used to generate import libraries for Python DLL for MinGW-w64 and MSVC (cross-)compile targets.
Enabling it allows to (cross-)compile extension modules to any Windows targets without having to install the Windows Python distribution files for the target.
See the building and distribution section for further detail.
Features for embedding Python in Rust
auto-initialize
This feature changes Python::with_gil and Python::acquire_gil to automatically initialize a Python interpreter (by calling prepare_freethreaded_python) if needed.
If you do not enable this feature, you should call pyo3::prepare_freethreaded_python() before attempting to call any other Python APIs.
Advanced Features
experimental-inspect
This feature adds the pyo3::inspect module, as well as IntoPy::type_output and FromPyObject::type_input APIs to produce Python type "annotations" for Rust types.
This is a first step towards adding first-class support for generating type annotations automatically in PyO3, however work is needed to finish this off. All feedback and offers of help welcome on issue #2454.
macros
This feature enables a dependency on the pyo3-macros crate, which provides the procedural macros portion of PyO3's API:
#[pymodule]#[pyfunction]#[pyclass]#[pymethods]#[derive(FromPyObject)]
It also provides the py_run! macro.
These macros require a number of dependencies which may not be needed by users who just need PyO3 for Python FFI. Disabling this feature enables faster builds for those users, as these dependencies will not be built if this feature is disabled.
This feature is enabled by default. To disable it, set
default-features = falsefor thepyo3entry in your Cargo.toml.
multiple-pymethods
This feature enables a dependency on inventory, which enables each #[pyclass] to have more than one #[pymethods] block. This feature also requires a minimum Rust version of 1.62 due to limitations in the inventory crate.
Most users should only need a single #[pymethods] per #[pyclass]. In addition, not all platforms (e.g. Wasm) are supported by inventory. For this reason this feature is not enabled by default, meaning fewer dependencies and faster compilation for the majority of users.
See the #[pyclass] implementation details for more information.
nightly
The nightly feature needs the nightly Rust compiler. This allows PyO3 to use the auto_traits and negative_impls features to fix the Python::allow_threads function.
resolve-config
The resolve-config feature of the pyo3-build-config crate controls whether that crate's
build script automatically resolves a Python interpreter / build configuration. This feature is primarily useful when building PyO3
itself. By default this feature is not enabled, meaning you can freely use pyo3-build-config as a standalone library to read or write PyO3 build configuration files or resolve metadata about a Python interpreter.
Optional Dependencies
These features enable conversions between Python types and types from other Rust crates, enabling easy access to the rest of the Rust ecosystem.
anyhow
Adds a dependency on anyhow. Enables a conversion from anyhow’s Error type to PyErr, for easy error handling.
chrono
Adds a dependency on chrono. Enables a conversion from chrono's types to python:
- Duration ->
PyDelta - FixedOffset ->
PyDelta - Utc ->
PyTzInfo - NaiveDate ->
PyDate - NaiveTime ->
PyTime - DateTime ->
PyDateTime
eyre
Adds a dependency on eyre. Enables a conversion from eyre’s Report type to PyErr, for easy error handling.
hashbrown
Adds a dependency on hashbrown and enables conversions into its HashMap and HashSet types.
indexmap
Adds a dependency on indexmap and enables conversions into its IndexMap type.
num-bigint
Adds a dependency on num-bigint and enables conversions into its BigInt and BigUint types.
num-complex
Adds a dependency on num-complex and enables conversions into its Complex type.
serde
Enables (de)serialization of Py<T> objects via serde.
This allows to use #[derive(Serialize, Deserialize) on structs that hold references to #[pyclass] instances
#![allow(unused)] fn main() { #[cfg(feature = "serde")] #[allow(dead_code)] mod serde_only { use pyo3::prelude::*; use serde::{Deserialize, Serialize}; #[pyclass] #[derive(Serialize, Deserialize)] struct Permission { name: String, } #[pyclass] #[derive(Serialize, Deserialize)] struct User { username: String, permissions: Vec<Py<Permission>>, } } }
Memory management
Rust and Python have very different notions of memory management. Rust has a strict memory model with concepts of ownership, borrowing, and lifetimes, where memory is freed at predictable points in program execution. Python has a looser memory model in which variables are reference-counted with shared, mutable state by default. A global interpreter lock (GIL) is needed to prevent race conditions, and a garbage collector is needed to break reference cycles. Memory in Python is freed eventually by the garbage collector, but not usually in a predictable way.
PyO3 bridges the Rust and Python memory models with two different strategies for
accessing memory allocated on Python's heap from inside Rust. These are
GIL-bound, or "owned" references, and GIL-independent Py<Any> smart pointers.
GIL-bound memory
PyO3's GIL-bound, "owned references" (&PyAny etc.) make PyO3 more ergonomic to
use by ensuring that their lifetime can never be longer than the duration the
Python GIL is held. This means that most of PyO3's API can assume the GIL is
held. (If PyO3 could not assume this, every PyO3 API would need to take a
Python GIL token to prove that the GIL is held.) This allows us to write
very simple and easy-to-understand programs like this:
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); Ok(()) })?; Ok(()) }
Internally, calling Python::with_gil() or Python::acquire_gil() creates a
GILPool which owns the memory pointed to by the reference. In the example
above, the lifetime of the reference hello is bound to the GILPool. When
the with_gil() closure ends or the GILGuard from acquire_gil() is dropped,
the GILPool is also dropped and the Python reference counts of the variables
it owns are decreased, releasing them to the Python garbage collector. Most
of the time we don't have to think about this, but consider the following:
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { for _ in 0..10 { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); } // There are 10 copies of `hello` on Python's heap here. Ok(()) })?; Ok(()) }
We might assume that the hello variable's memory is freed at the end of each
loop iteration, but in fact we create 10 copies of hello on Python's heap.
This may seem surprising at first, but it is completely consistent with Rust's
memory model. The hello variable is dropped at the end of each loop, but it
is only a reference to the memory owned by the GILPool, and its lifetime is
bound to the GILPool, not the for loop. The GILPool isn't dropped until
the end of the with_gil() closure, at which point the 10 copies of hello
are finally released to the Python garbage collector.
In general we don't want unbounded memory growth during loops! One workaround is to acquire and release the GIL with each iteration of the loop.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { for _ in 0..10 { Python::with_gil(|py| -> PyResult<()> { let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); Ok(()) })?; // only one copy of `hello` at a time } Ok(()) }
It might not be practical or performant to acquire and release the GIL so many
times. Another workaround is to work with the GILPool object directly, but
this is unsafe.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { for _ in 0..10 { let pool = unsafe { py.new_pool() }; let py = pool.python(); let hello: &PyString = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello); } Ok(()) })?; Ok(()) }
The unsafe method Python::new_pool allows you to create a nested GILPool
from which you can retrieve a new py: Python GIL token. Variables created
with this new GIL token are bound to the nested GILPool and will be released
when the nested GILPool is dropped. Here, the nested GILPool is dropped
at the end of each loop iteration, before the with_gil() closure ends.
When doing this, you must be very careful to ensure that once the GILPool is
dropped you do not retain access to any owned references created after the
GILPool was created. Read the
documentation for Python::new_pool()
for more information on safety.
This memory management can also be applicable when writing extension modules.
#[pyfunction] and #[pymethods] will create a GILPool which lasts the entire
function call, releasing objects when the function returns. Most functions only create
a few objects, meaning this doesn't have a significant impact. Occasionally functions
with long complex loops may need to use Python::new_pool as shown above.
This behavior may change in future, see issue #1056.
GIL-independent memory
Sometimes we need a reference to memory on Python's heap that can outlive the
GIL. Python's Py<PyAny> is analogous to Arc<T>, but for variables whose
memory is allocated on Python's heap. Cloning a Py<PyAny> increases its
internal reference count just like cloning Arc<T>. The smart pointer can
outlive the "GIL is held" period in which it was created. It isn't magic,
though. We need to reacquire the GIL to access the memory pointed to by the
Py<PyAny>.
What happens to the memory when the last Py<PyAny> is dropped and its
reference count reaches zero? It depends whether or not we are holding the GIL.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { Python::with_gil(|py| -> PyResult<()> { let hello: Py<PyString> = py.eval("\"Hello World!\"", None, None)?.extract()?; println!("Python says: {}", hello.as_ref(py)); Ok(()) })?; Ok(()) }
At the end of the Python::with_gil() closure hello is dropped, and then the
GIL is dropped. Since hello is dropped while the GIL is still held by the
current thread, its memory is released to the Python garbage collector
immediately.
This example wasn't very interesting. We could have just used a GIL-bound
&PyString reference. What happens when the last Py<Any> is dropped while
we are not holding the GIL?
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program we want to access `hello`. Python::with_gil(|py| { println!("Python says: {}", hello.as_ref(py)); }); // Now we're done with `hello`. drop(hello); // Memory *not* released here. // Sometime later we need the GIL again for something... Python::with_gil(|py| // Memory for `hello` is released here. () ); Ok(()) }
When hello is dropped nothing happens to the pointed-to memory on Python's
heap because nothing can happen if we're not holding the GIL. Fortunately,
the memory isn't leaked. PyO3 keeps track of the memory internally and will
release it the next time we acquire the GIL.
We can avoid the delay in releasing memory if we are careful to drop the
Py<Any> while the GIL is held.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program: Python::with_gil(|py| { println!("Python says: {}", hello.as_ref(py)); drop(hello); // Memory released here. }); Ok(()) }
We could also have used Py::into_ref(), which consumes self, instead of
Py::as_ref(). But note that in addition to being slower than as_ref(),
into_ref() binds the memory to the lifetime of the GILPool, which means
that rather than being released immediately, the memory will not be released
until the GIL is dropped.
use pyo3::prelude::*; use pyo3::types::PyString; fn main() -> PyResult<()> { let hello: Py<PyString> = Python::with_gil(|py| { py.eval("\"Hello World!\"", None, None)?.extract() })?; // Do some stuff... // Now sometime later in the program: Python::with_gil(|py| { println!("Python says: {}", hello.into_ref(py)); // Memory not released yet. // Do more stuff... // Memory released here at end of `with_gil()` closure. }); Ok(()) }
Advanced topics
FFI
PyO3 exposes much of Python's C API through the ffi module.
The C API is naturally unsafe and requires you to manage reference counts, errors and specific invariants yourself. Please refer to the C API Reference Manual and The Rustonomicon before using any function from that API.
Memory management
PyO3's &PyAny "owned references" and Py<PyAny> smart pointers are used to
access memory stored in Python's heap. This memory sometimes lives for longer
than expected because of differences in Rust and Python's memory models. See
the chapter on memory management for more information.
Building and distribution
This chapter of the guide goes into detail on how to build and distribute projects using PyO3. The way to achieve this is very different depending on whether the project is a Python module implemented in Rust, or a Rust binary embedding Python. For both types of project there are also common problems such as the Python version to build for and the linker arguments to use.
The material in this chapter is intended for users who have already read the PyO3 README. It covers in turn the choices that can be made for Python modules and for Rust binaries. There is also a section at the end about cross-compiling projects using PyO3.
There is an additional sub-chapter dedicated to supporting multiple Python versions.
Configuring the Python version
PyO3 uses a build script (backed by the pyo3-build-config crate) to determine the Python version and set the correct linker arguments. By default it will attempt to use the following in order:
- Any active Python virtualenv.
- The
pythonexecutable (if it's a Python 3 interpreter). - The
python3executable.
You can override the Python interpreter by setting the PYO3_PYTHON environment variable, e.g. PYO3_PYTHON=python3.7, PYO3_PYTHON=/usr/bin/python3.9, or even a PyPy interpreter PYO3_PYTHON=pypy3.
Once the Python interpreter is located, pyo3-build-config executes it to query the information in the sysconfig module which is needed to configure the rest of the compilation.
To validate the configuration which PyO3 will use, you can run a compilation with the environment variable PYO3_PRINT_CONFIG=1 set. An example output of doing this is shown below:
$ PYO3_PRINT_CONFIG=1 cargo build
Compiling pyo3 v0.14.1 (/home/david/dev/pyo3)
error: failed to run custom build command for `pyo3 v0.14.1 (/home/david/dev/pyo3)`
Caused by:
process didn't exit successfully: `/home/david/dev/pyo3/target/debug/build/pyo3-7a8cf4fe22e959b7/build-script-build` (exit status: 101)
--- stdout
cargo:rerun-if-env-changed=PYO3_CROSS
cargo:rerun-if-env-changed=PYO3_CROSS_LIB_DIR
cargo:rerun-if-env-changed=PYO3_CROSS_PYTHON_VERSION
cargo:rerun-if-env-changed=PYO3_PRINT_CONFIG
-- PYO3_PRINT_CONFIG=1 is set, printing configuration and halting compile --
implementation=CPython
version=3.8
shared=true
abi3=false
lib_name=python3.8
lib_dir=/usr/lib
executable=/usr/bin/python
pointer_width=64
build_flags=
suppress_build_script_link_lines=false
The PYO3_ENVIRONMENT_SIGNATURE environment variable can be used to trigger rebuilds when its value changes, it has no other effect.
Advanced: config files
If you save the above output config from PYO3_PRINT_CONFIG to a file, it is possible to manually override the contents and feed it back into PyO3 using the PYO3_CONFIG_FILE env var.
If your build environment is unusual enough that PyO3's regular configuration detection doesn't work, using a config file like this will give you the flexibility to make PyO3 work for you. To see the full set of options supported, see the documentation for the InterpreterConfig struct.
Building Python extension modules
Python extension modules need to be compiled differently depending on the OS (and architecture) that they are being compiled for. As well as multiple OSes (and architectures), there are also many different Python versions which are actively supported. Packages uploaded to PyPI usually want to upload prebuilt "wheels" covering many OS/arch/version combinations so that users on all these different platforms don't have to compile the package themselves. Package vendors can opt-in to the "abi3" limited Python API which allows their wheels to be used on multiple Python versions, reducing the number of wheels they need to compile, but restricts the functionality they can use.
There are many ways to go about this: it is possible to use cargo to build the extension module (along with some manual work, which varies with OS). The PyO3 ecosystem has two packaging tools, maturin and setuptools-rust, which abstract over the OS difference and also support building wheels for PyPI upload.
PyO3 has some Cargo features to configure projects for building Python extension modules:
- The
extension-modulefeature, which must be enabled when building Python extension modules. - The
abi3feature and its version-specificabi3-pyXYcompanions, which are used to opt-in to the limited Python API in order to support multiple Python versions in a single wheel.
This section describes each of these packaging tools before describing how to build manually without them. It then proceeds with an explanation of the extension-module feature. Finally, there is a section describing PyO3's abi3 features.
Packaging tools
The PyO3 ecosystem has two main choices to abstract the process of developing Python extension modules:
maturinis a command-line tool to build, package and upload Python modules. It makes opinionated choices about project layout meaning it needs very little configuration. This makes it a great choice for users who are building a Python extension from scratch and don't need flexibility.setuptools-rustis an add-on forsetuptoolswhich adds extra keyword arguments to thesetup.pyconfiguration file. It requires more configuration thanmaturin, however this gives additional flexibility for users adding Rust to an existing Python package that can't satisfymaturin's constraints.
Consult each project's documentation for full details on how to get started using them and how to upload wheels to PyPI.
There are also maturin-starter and setuptools-rust-starter examples in the PyO3 repository.
Manual builds
To build a PyO3-based Python extension manually, start by running cargo build as normal in a library project which uses PyO3's extension-module feature and has the cdylib crate type.
Once built, symlink (or copy) and rename the shared library from Cargo's target/ directory to your desired output directory:
- on macOS, rename
libyour_module.dylibtoyour_module.so. - on Windows, rename
libyour_module.dlltoyour_module.pyd. - on Linux, rename
libyour_module.sotoyour_module.so.
You can then open a Python shell in the output directory and you'll be able to run import your_module.
If you're packaging your library for redistribution, you should indicated the Python interpreter your library is compiled for by including the platform tag in its name. This prevents incompatible interpreters from trying to import your library. If you're compiling for PyPy you must include the platform tag, or PyPy will ignore the module.
See, as an example, Bazel rules to build PyO3 on Linux at https://github.com/TheButlah/rules_pyo3.
Platform tags
Rather than using just the .so or .pyd extension suggested above (depending on OS), you can prefix the shared library extension with a platform tag to indicate the interpreter it is compatible with. You can query your interpreter's platform tag from the sysconfig module. Some example outputs of this are seen below:
# CPython 3.10 on macOS
.cpython-310-darwin.so
# PyPy 7.3 (Python 3.8) on Linux
$ python -c 'import sysconfig; print(sysconfig.get_config_var("EXT_SUFFIX"))'
.pypy38-pp73-x86_64-linux-gnu.so
So, for example, a valid module library name on CPython 3.10 for macOS is your_module.cpython-310-darwin.so, and its equivalent when compiled for PyPy 7.3 on Linux would be your_module.pypy38-pp73-x86_64-linux-gnu.so.
See PEP 3149 for more background on platform tags.
macOS
On macOS, because the extension-module feature disables linking to libpython (see the next section), some additional linker arguments need to be set. maturin and setuptools-rust both pass these arguments for PyO3 automatically, but projects using manual builds will need to set these directly in order to support macOS.
The easiest way to set the correct linker arguments is to add a build.rs with the following content:
fn main() {
pyo3_build_config::add_extension_module_link_args();
}Remember to also add pyo3-build-config to the build-dependencies section in Cargo.toml.
An alternative to using pyo3-build-config is add the following to a cargo configuration file (e.g. .cargo/config.toml):
[target.x86_64-apple-darwin]
rustflags = [
"-C", "link-arg=-undefined",
"-C", "link-arg=dynamic_lookup",
]
[target.aarch64-apple-darwin]
rustflags = [
"-C", "link-arg=-undefined",
"-C", "link-arg=dynamic_lookup",
]
Using the MacOS system python3 (/usr/bin/python3, as opposed to python installed via homebrew, pyenv, nix, etc.) may result in runtime errors such as Library not loaded: @rpath/Python3.framework/Versions/3.8/Python3. These can be resolved with another addition to .cargo/config.toml:
[build]
rustflags = [
"-C", "link-args=-Wl,-rpath,/Library/Developer/CommandLineTools/Library/Frameworks",
]
Alternatively, on rust >= 1.56, one can include in build.rs:
fn main() { println!( "cargo:rustc-link-arg=-Wl,-rpath,/Library/Developer/CommandLineTools/Library/Frameworks" ); }
For more discussion on and workarounds for MacOS linking problems see this issue.
Finally, don't forget that on MacOS the extension-module feature will cause cargo test to fail without the --no-default-features flag (see the FAQ).
The extension-module feature
PyO3's extension-module feature is used to disable linking to libpython on Unix targets.
This is necessary because by default PyO3 links to libpython. This makes binaries, tests, and examples "just work". However, Python extensions on Unix must not link to libpython for manylinux compliance.
The downside of not linking to libpython is that binaries, tests, and examples (which usually embed Python) will fail to build. If you have an extension module as well as other outputs in a single project, you need to use optional Cargo features to disable the extension-module when you're not building the extension module. See the FAQ for an example workaround.
Py_LIMITED_API/abi3
By default, Python extension modules can only be used with the same Python version they were compiled against. For example, an extension module built for Python 3.5 can't be imported in Python 3.8. PEP 384 introduced the idea of the limited Python API, which would have a stable ABI enabling extension modules built with it to be used against multiple Python versions. This is also known as abi3.
The advantage of building extension modules using the limited Python API is that package vendors only need to build and distribute a single copy (for each OS / architecture), and users can install it on all Python versions from the minimum version and up. The downside of this is that PyO3 can't use optimizations which rely on being compiled against a known exact Python version. It's up to you to decide whether this matters for your extension module. It's also possible to design your extension module such that you can distribute abi3 wheels but allow users compiling from source to benefit from additional optimizations - see the support for multiple python versions section of this guide, in particular the #[cfg(Py_LIMITED_API)] flag.
There are three steps involved in making use of abi3 when building Python packages as wheels:
- Enable the
abi3feature inpyo3. This ensurespyo3only calls Python C-API functions which are part of the stable API, and on Windows also ensures that the project links against the correct shared object (no special behavior is required on other platforms):
[dependencies]
pyo3 = { {{#PYO3_CRATE_VERSION}}, features = ["abi3"] }
-
Ensure that the built shared objects are correctly marked as
abi3. This is accomplished by telling your build system that you're using the limited API.maturin>= 0.9.0 andsetuptools-rust>= 0.11.4 supportabi3wheels. See the corresponding PRs for more. -
Ensure that the
.whlis correctly marked asabi3. For projects usingsetuptools, this is accomplished by passing--py-limited-api=cp3x(wherexis the minimum Python version supported by the wheel, e.g.--py-limited-api=cp35for Python 3.5) tosetup.py bdist_wheel.
Minimum Python version for abi3
Because a single abi3 wheel can be used with many different Python versions, PyO3 has feature flags abi3-py37, abi3-py38, abi3-py39 etc. to set the minimum required Python version for your abi3 wheel.
For example, if you set the abi3-py37 feature, your extension wheel can be used on all Python 3 versions from Python 3.7 and up. maturin and setuptools-rust will give the wheel a name like my-extension-1.0-cp37-abi3-manylinux2020_x86_64.whl.
As your extension module may be run with multiple different Python versions you may occasionally find you need to check the Python version at runtime to customize behavior. See the relevant section of this guide on supporting multiple Python versions at runtime.
PyO3 is only able to link your extension module to abi3 version up to and including your host Python version. E.g., if you set abi3-py38 and try to compile the crate with a host of Python 3.7, the build will fail.
Note: If you set more that one of these
abi3version feature flags the lowest version always wins. For example, with bothabi3-py37andabi3-py38set, PyO3 would build a wheel which supports Python 3.7 and up.
Building abi3 extensions without a Python interpreter
As an advanced feature, you can build PyO3 wheel without calling Python interpreter with the environment variable PYO3_NO_PYTHON set.
Also, if the build host Python interpreter is not found or is too old or otherwise unusable,
PyO3 will still attempt to compile abi3 extension modules after displaying a warning message.
On Unix-like systems this works unconditionally; on Windows you must also set the RUSTFLAGS environment variable
to contain -L native=/path/to/python/libs so that the linker can find python3.lib.
If the python3.dll import library is not available, an experimental generate-import-lib crate
feature may be enabled, and the required library will be created and used by PyO3 automatically.
Note: MSVC targets require LLVM binutils (llvm-dlltool) to be available in PATH for
the automatic import library generation feature to work.
Missing features
Due to limitations in the Python API, there are a few pyo3 features that do
not work when compiling for abi3. These are:
#[pyo3(text_signature = "...")]does not work on classes until Python 3.10 or greater.- The
dictandweakrefoptions on classes are not supported until Python 3.9 or greater. - The buffer API is not supported until Python 3.11 or greater.
- Optimizations which rely on knowledge of the exact Python version compiled against.
Embedding Python in Rust
If you want to embed the Python interpreter inside a Rust program, there are two modes in which this can be done: dynamically and statically. We'll cover each of these modes in the following sections. Each of them affect how you must distribute your program. Instead of learning how to do this yourself, you might want to consider using a project like PyOxidizer to ship your application and all of its dependencies in a single file.
PyO3 automatically switches between the two linking modes depending on whether the Python distribution you have configured PyO3 to use (see above) contains a shared library or a static library. The static library is most often seen in Python distributions compiled from source without the --enable-shared configuration option. For example, this is the default for pyenv on macOS.
Dynamically embedding the Python interpreter
Embedding the Python interpreter dynamically is much easier than doing so statically. This is done by linking your program against a Python shared library (such as libpython.3.9.so on UNIX, or python39.dll on Windows). The implementation of the Python interpreter resides inside the shared library. This means that when the OS runs your Rust program it also needs to be able to find the Python shared library.
This mode of embedding works well for Rust tests which need access to the Python interpreter. It is also great for Rust software which is installed inside a Python virtualenv, because the virtualenv sets up appropriate environment variables to locate the correct Python shared library.
For distributing your program to non-technical users, you will have to consider including the Python shared library in your distribution as well as setting up wrapper scripts to set the right environment variables (such as LD_LIBRARY_PATH on UNIX, or PATH on Windows).
Note that PyPy cannot be embedded in Rust (or any other software). Support for this is tracked on the PyPy issue tracker.
Statically embedding the Python interpreter
Embedding the Python interpreter statically means including the contents of a Python static library directly inside your Rust binary. This means that to distribute your program you only need to ship your binary file: it contains the Python interpreter inside the binary!
On Windows static linking is almost never done, so Python distributions don't usually include a static library. The information below applies only to UNIX.
The Python static library is usually called libpython.a.
Static linking has a lot of complications, listed below. For these reasons PyO3 does not yet have first-class support for this embedding mode. See issue 416 on PyO3's GitHub for more information and to discuss any issues you encounter.
The auto-initialize feature is deliberately disabled when embedding the interpreter statically because this is often unintentionally done by new users to PyO3 running test programs. Trying out PyO3 is much easier using dynamic embedding.
The known complications are:
-
To import compiled extension modules (such as other Rust extension modules, or those written in C), your binary must have the correct linker flags set during compilation to export the original contents of
libpython.aso that extensions can use them (e.g.-Wl,--export-dynamic). -
The C compiler and flags which were used to create
libpython.amust be compatible with your Rust compiler and flags, else you will experience compilation failures.Significantly different compiler versions may see errors like this:
lto1: fatal error: bytecode stream in file 'rust-numpy/target/release/deps/libpyo3-6a7fb2ed970dbf26.rlib' generated with LTO version 6.0 instead of the expected 6.2Mismatching flags may lead to errors like this:
/usr/bin/ld: /usr/lib/gcc/x86_64-linux-gnu/9/../../../x86_64-linux-gnu/libpython3.9.a(zlibmodule.o): relocation R_X86_64_32 against `.data' can not be used when making a PIE object; recompile with -fPIE
If you encounter these or other complications when linking the interpreter statically, discuss them on issue 416 on PyO3's GitHub. It is hoped that eventually that discussion will contain enough information and solutions that PyO3 can offer first-class support for static embedding.
Import your module when embedding the Python interpreter
When you run your Rust binary with an embedded interpreter, any #[pymodule] created modules won't be accessible to import unless added to a table called PyImport_Inittab before the embedded interpreter is initialized. This will cause Python statements in your embedded interpreter such as import your_new_module to fail. You can call the macro append_to_inittab with your module before initializing the Python interpreter to add the module function into that table. (The Python interpreter will be initialized by calling prepare_freethreaded_python, with_embedded_interpreter, or Python::with_gil with the auto-initialize feature enabled.)
Cross Compiling
Thanks to Rust's great cross-compilation support, cross-compiling using PyO3 is relatively straightforward. To get started, you'll need a few pieces of software:
- A toolchain for your target.
- The appropriate options in your Cargo
.configfor the platform you're targeting and the toolchain you are using. - A Python interpreter that's already been compiled for your target (optional when building "abi3" extension modules).
- A Python interpreter that is built for your host and available through the
PATHor setting thePYO3_PYTHONvariable (optional when building "abi3" extension modules).
After you've obtained the above, you can build a cross-compiled PyO3 module by using Cargo's --target flag. PyO3's build script will detect that you are attempting a cross-compile based on your host machine and the desired target.
When cross-compiling, PyO3's build script cannot execute the target Python interpreter to query the configuration, so there are a few additional environment variables you may need to set:
PYO3_CROSS: If present this variable forces PyO3 to configure as a cross-compilation.PYO3_CROSS_LIB_DIR: This variable can be set to the directory containing the target's libpython DSO and the associated_sysconfigdata*.pyfile for Unix-like targets, or the Python DLL import libraries for the Windows target. This variable is only needed when the output binary must link to libpython explicitly (e.g. when targeting Windows and Android or embedding a Python interpreter), or when it is absolutely required to get the interpreter configuration from_sysconfigdata*.py.PYO3_CROSS_PYTHON_VERSION: Major and minor version (e.g. 3.9) of the target Python installation. This variable is only needed if PyO3 cannot determine the version to target fromabi3-py3*features, or ifPYO3_CROSS_LIB_DIRis not set, or if there are multiple versions of Python present inPYO3_CROSS_LIB_DIR.PYO3_CROSS_PYTHON_IMPLEMENTATION: Python implementation name ("CPython" or "PyPy") of the target Python installation. CPython is assumed by default when this variable is not set, unlessPYO3_CROSS_LIB_DIRis set for a Unix-like target and PyO3 can get the interpreter configuration from_sysconfigdata*.py.
An experimental pyo3 crate feature generate-import-lib enables the user to cross-compile
extension modules for Windows targets without setting the PYO3_CROSS_LIB_DIR environment
variable or providing any Windows Python library files. It uses an external python3-dll-a crate
to generate import libraries for the Python DLL for MinGW-w64 and MSVC compile targets.
python3-dll-a uses the binutils dlltool program to generate DLL import libraries for MinGW-w64 targets.
It is possible to override the default dlltool command name for the cross target
by setting PYO3_MINGW_DLLTOOL environment variable.
Note: MSVC targets require LLVM binutils or MSVC build tools to be available on the host system.
More specifically, python3-dll-a requires llvm-dlltool or lib.exe executable to be present in PATH when
targeting *-pc-windows-msvc. The Zig compiler executable can be used in place of llvm-dlltool when the ZIG_COMMAND
environment variable is set to the installed Zig program name ("zig" or "python -m ziglang").
An example might look like the following (assuming your target's sysroot is at /home/pyo3/cross/sysroot and that your target is armv7):
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target armv7-unknown-linux-gnueabihf
If there are multiple python versions at the cross lib directory and you cannot set a more precise location to include both the libpython DSO and _sysconfigdata*.py files, you can set the required version:
export PYO3_CROSS_PYTHON_VERSION=3.8
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target armv7-unknown-linux-gnueabihf
Or another example with the same sys root but building for Windows:
export PYO3_CROSS_PYTHON_VERSION=3.9
export PYO3_CROSS_LIB_DIR="/home/pyo3/cross/sysroot/usr/lib"
cargo build --target x86_64-pc-windows-gnu
Any of the abi3-py3* features can be enabled instead of setting PYO3_CROSS_PYTHON_VERSION in the above examples.
PYO3_CROSS_LIB_DIR can often be omitted when cross compiling extension modules for Unix and macOS targets,
or when cross compiling extension modules for Windows and the experimental generate-import-lib
crate feature is enabled.
The following resources may also be useful for cross-compiling:
- github.com/japaric/rust-cross is a primer on cross compiling Rust.
- github.com/rust-embedded/cross uses Docker to make Rust cross-compilation easier.
Supporting multiple Python versions
PyO3 supports all actively-supported Python 3 and PyPy versions. As much as possible, this is done internally to PyO3 so that your crate's code does not need to adapt to the differences between each version. However, as Python features grow and change between versions, PyO3 cannot a completely identical API for every Python version. This may require you to add conditional compilation to your crate or runtime checks for the Python version.
This section of the guide first introduces the pyo3-build-config crate, which you can use as a build-dependency to add additional #[cfg] flags which allow you to support multiple Python versions at compile-time.
Second, we'll show how to check the Python version at runtime. This can be useful when building for multiple versions with the abi3 feature, where the Python API compiled against is not always the same as the one in use.
Conditional compilation for different Python versions
The pyo3-build-config exposes multiple #[cfg] flags which can be used to conditionally compile code for a given Python version. PyO3 itself depends on this crate, so by using it you can be sure that you are configured correctly for the Python version PyO3 is building against.
This allows us to write code like the following
#[cfg(Py_3_7)]
fn function_only_supported_on_python_3_7_and_up() {}
#[cfg(not(Py_3_8))]
fn function_only_supported_before_python_3_8() {}
#[cfg(not(Py_LIMITED_API))]
fn function_incompatible_with_abi3_feature() {}The following sections first show how to add these #[cfg] flags to your build process, and then cover some common patterns flags in a little more detail.
To see a full reference of all the #[cfg] flags provided, see the pyo3-build-cfg docs.
Using pyo3-build-config
You can use the #[cfg] flags in just two steps:
-
Add
pyo3-build-configwith theresolve-configfeature enabled to your crate's build dependencies inCargo.toml:[build-dependencies] pyo3-build-config = { {{#PYO3_CRATE_VERSION}}, features = ["resolve-config"] } -
Add a
build.rsfile to your crate with the following contents:fn main() { // If you have an existing build.rs file, just add this line to it. pyo3_build_config::use_pyo3_cfgs(); }
After these steps you are ready to annotate your code!
Common usages of pyo3-build-cfg flags
The #[cfg] flags added by pyo3-build-cfg can be combined with all of Rust's logic in the #[cfg] attribute to create very precise conditional code generation. The following are some common patterns implemented using these flags:
#[cfg(Py_3_7)]
This #[cfg] marks code that will only be present on Python 3.7 and upwards. There are similar options Py_3_8, Py_3_9, Py_3_10 and so on for each minor version.
#[cfg(not(Py_3_7))]
This #[cfg] marks code that will only be present on Python versions before (but not including) Python 3.7.
#[cfg(not(Py_LIMITED_API))]
This #[cfg] marks code that is only available when building for the unlimited Python API (i.e. PyO3's abi3 feature is not enabled). This might be useful if you want to ship your extension module as an abi3 wheel and also allow users to compile it from source to make use of optimizations only possible with the unlimited API.
#[cfg(any(Py_3_9, not(Py_LIMITED_API)))]
This #[cfg] marks code which is available when running Python 3.9 or newer, or when using the unlimited API with an older Python version. Patterns like this are commonly seen on Python APIs which were added to the limited Python API in a specific minor version.
#[cfg(PyPy)]
This #[cfg] marks code which is running on PyPy.
Checking the Python version at runtime
When building with PyO3's abi3 feature, your extension module will be compiled against a specific minimum version of Python, but may be running on newer Python versions.
For example with PyO3's abi3-py38 feature, your extension will be compiled as if it were for Python 3.8. If you were using pyo3-build-config, #[cfg(Py_3_8)] would be present. Your user could freely install and run your abi3 extension on Python 3.9.
There's no way to detect your user doing that at compile time, so instead you need to fall back to runtime checks.
PyO3 provides the APIs Python::version() and Python::version_info() to query the running Python version. This allows you to do the following, for example:
#![allow(unused)] fn main() { use pyo3::Python; Python::with_gil(|py| { // PyO3 supports Python 3.7 and up. assert!(py.version_info() >= (3, 7)); assert!(py.version_info() >= (3, 7, 0)); }); }
Logging
It is desirable if both the Python and Rust parts of the application end up logging using the same configuration into the same place.
This section of the guide briefly discusses how to connect the two languages'
logging ecosystems together. The recommended way for Python extension modules is
to configure Rust's logger to send log messages to Python using the pyo3-log
crate. For users who want to do the opposite and send Python log messages to
Rust, see the note at the end of this guide.
Using pyo3-log to send Rust log messages to Python
The pyo3-log crate allows sending the messages from the Rust side to Python's logging system. This is mostly suitable for writing native extensions for Python programs.
Use pyo3_log::init to install the logger in its default configuration.
It's also possible to tweak its configuration (mostly to tune its performance).
#![allow(unused)] fn main() { use log::info; use pyo3::prelude::*; #[pyfunction] fn log_something() { // This will use the logger installed in `my_module` to send the `info` // message to the Python logging facilities. info!("Something!"); } #[pymodule] fn my_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { // A good place to install the Rust -> Python logger. pyo3_log::init(); m.add_function(wrap_pyfunction!(log_something))?; Ok(()) } }
Then it is up to the Python side to actually output the messages somewhere.
import logging
import my_module
FORMAT = '%(levelname)s %(name)s %(asctime)-15s %(filename)s:%(lineno)d %(message)s'
logging.basicConfig(format=FORMAT)
logging.getLogger().setLevel(logging.INFO)
my_module.log_something()
It is important to initialize the Python loggers first, before calling any Rust functions that may log. This limitation can be worked around if it is not possible to satisfy, read the documentation about caching.
The Python to Rust direction
To have python logs be handled by Rust, one need only register a rust function to handle logs emitted from the core python logging module.
This has been implemented within the pyo3-pylogger crate.
use log::{info, warn}; use pyo3::prelude::*; fn main() -> PyResult<()> { // register the host handler with python logger, providing a logger target // set the name here to something appropriate for your application pyo3_pylogger::register("example_application_py_logger"); // initialize up a logger env_logger::Builder::from_env(env_logger::Env::default().default_filter_or("trace")).init(); // Log some messages from Rust. info!("Just some normal information!"); warn!("Something spooky happened!"); // Log some messages from Python Python::with_gil(|py| { py.run( " import logging logging.error('Something bad happened') ", None, None, ) }) }
Using async and await
If you are working with a Python library that makes use of async functions or wish to provide
Python bindings for an async Rust library, pyo3-asyncio
likely has the tools you need. It provides conversions between async functions in both Python and
Rust and was designed with first-class support for popular Rust runtimes such as
tokio and async-std. In addition, all async Python
code runs on the default asyncio event loop, so pyo3-asyncio should work just fine with existing
Python libraries.
In the following sections, we'll give a general overview of pyo3-asyncio explaining how to call
async Python functions with PyO3, how to call async Rust functions from Python, and how to configure
your codebase to manage the runtimes of both.
Quickstart
Here are some examples to get you started right away! A more detailed breakdown of the concepts in these examples can be found in the following sections.
Rust Applications
Here we initialize the runtime, import Python's asyncio library and run the given future to completion using Python's default EventLoop and async-std. Inside the future, we convert asyncio sleep into a Rust future and await it.
# Cargo.toml dependencies
[dependencies]
pyo3 = { version = "0.14" }
pyo3-asyncio = { version = "0.14", features = ["attributes", "async-std-runtime"] }
async-std = "1.9"
//! main.rs use pyo3::prelude::*; #[pyo3_asyncio::async_std::main] async fn main() -> PyResult<()> { let fut = Python::with_gil(|py| { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::async_std::into_future(asyncio.call_method1("sleep", (1.into_py(py),))?) })?; fut.await?; Ok(()) }
The same application can be written to use tokio instead using the #[pyo3_asyncio::tokio::main]
attribute.
# Cargo.toml dependencies
[dependencies]
pyo3 = { version = "0.14" }
pyo3-asyncio = { version = "0.14", features = ["attributes", "tokio-runtime"] }
tokio = "1.4"
//! main.rs use pyo3::prelude::*; #[pyo3_asyncio::tokio::main] async fn main() -> PyResult<()> { let fut = Python::with_gil(|py| { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::tokio::into_future(asyncio.call_method1("sleep", (1.into_py(py),))?) })?; fut.await?; Ok(()) }
More details on the usage of this library can be found in the API docs and the primer below.
PyO3 Native Rust Modules
PyO3 Asyncio can also be used to write native modules with async functions.
Add the [lib] section to Cargo.toml to make your library a cdylib that Python can import.
[lib]
name = "my_async_module"
crate-type = ["cdylib"]
Make your project depend on pyo3 with the extension-module feature enabled and select your
pyo3-asyncio runtime:
For async-std:
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["async-std-runtime"] }
async-std = "1.9"
For tokio:
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["tokio-runtime"] }
tokio = "1.4"
Export an async function that makes use of async-std:
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::async_std::future_into_py(py, async { async_std::task::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
If you want to use tokio instead, here's what your module should look like:
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::tokio::future_into_py(py, async { tokio::time::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
You can build your module with maturin (see the Using Rust in Python section in the PyO3 guide for setup instructions). After that you should be able to run the Python REPL to try it out.
maturin develop && python3
🔗 Found pyo3 bindings
🐍 Found CPython 3.8 at python3
Finished dev [unoptimized + debuginfo] target(s) in 0.04s
Python 3.8.5 (default, Jan 27 2021, 15:41:15)
[GCC 9.3.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import asyncio
>>>
>>> from my_async_module import rust_sleep
>>>
>>> async def main():
>>> await rust_sleep()
>>>
>>> # should sleep for 1s
>>> asyncio.run(main())
>>>
Awaiting an Async Python Function in Rust
Let's take a look at a dead simple async Python function:
# Sleep for 1 second
async def py_sleep():
await asyncio.sleep(1)
Async functions in Python are simply functions that return a coroutine object. For our purposes,
we really don't need to know much about these coroutine objects. The key factor here is that calling
an async function is just like calling a regular function, the only difference is that we have
to do something special with the object that it returns.
Normally in Python, that something special is the await keyword, but in order to await this
coroutine in Rust, we first need to convert it into Rust's version of a coroutine: a Future.
That's where pyo3-asyncio comes in.
pyo3_asyncio::into_future
performs this conversion for us.
The following example uses into_future to call the py_sleep function shown above and then await the
coroutine object returned from the call:
use pyo3::prelude::*; #[pyo3_asyncio::tokio::main] async fn main() -> PyResult<()> { let future = Python::with_gil(|py| -> PyResult<_> { // import the module containing the py_sleep function let example = py.import("example")?; // calling the py_sleep method like a normal function // returns a coroutine let coroutine = example.call_method0("py_sleep")?; // convert the coroutine into a Rust future using the // tokio runtime pyo3_asyncio::tokio::into_future(coroutine) })?; // await the future future.await?; Ok(()) }
Alternatively, the below example shows how to write a #[pyfunction] which uses into_future to receive and await
a coroutine argument:
#![allow(unused)] fn main() { #[pyfunction] fn await_coro(coro: &PyAny) -> PyResult<()> { // convert the coroutine into a Rust future using the // async_std runtime let f = pyo3_asyncio::async_std::into_future(coro)?; pyo3_asyncio::async_std::run_until_complete(coro.py(), async move { // await the future f.await?; Ok(()) }) } }
This could be called from Python as:
import asyncio
async def py_sleep():
asyncio.sleep(1)
await_coro(py_sleep())
If for you wanted to pass a callable function to the #[pyfunction] instead, (i.e. the last line becomes await_coro(py_sleep)), then the above example needs to be tweaked to first call the callable to get the coroutine:
#![allow(unused)] fn main() { #[pyfunction] fn await_coro(callable: &PyAny) -> PyResult<()> { // get the coroutine by calling the callable let coro = callable.call0()?; // convert the coroutine into a Rust future using the // async_std runtime let f = pyo3_asyncio::async_std::into_future(coro)?; pyo3_asyncio::async_std::run_until_complete(coro.py(), async move { // await the future f.await?; Ok(()) }) } }
This can be particularly helpful where you need to repeatedly create and await a coroutine. Trying to await the same coroutine multiple times will raise an error:
RuntimeError: cannot reuse already awaited coroutine
If you're interested in learning more about
coroutinesandawaitablesin general, check out the Python 3asynciodocs for more information.
Awaiting a Rust Future in Python
Here we have the same async function as before written in Rust using the
async-std runtime:
#![allow(unused)] fn main() { /// Sleep for 1 second async fn rust_sleep() { async_std::task::sleep(std::time::Duration::from_secs(1)).await; } }
Similar to Python, Rust's async functions also return a special object called a
Future:
#![allow(unused)] fn main() { let future = rust_sleep(); }
We can convert this Future object into Python to make it awaitable. This tells Python that you
can use the await keyword with it. In order to do this, we'll call
pyo3_asyncio::async_std::future_into_py:
#![allow(unused)] fn main() { use pyo3::prelude::*; async fn rust_sleep() { async_std::task::sleep(std::time::Duration::from_secs(1)).await; } #[pyfunction] fn call_rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::async_std::future_into_py(py, async move { rust_sleep().await; Ok(Python::with_gil(|py| py.None())) }) } }
In Python, we can call this pyo3 function just like any other async function:
from example import call_rust_sleep
async def rust_sleep():
await call_rust_sleep()
Managing Event Loops
Python's event loop requires some special treatment, especially regarding the main thread. Some of
Python's asyncio features, like proper signal handling, require control over the main thread, which
doesn't always play well with Rust.
Luckily, Rust's event loops are pretty flexible and don't need control over the main thread, so in
pyo3-asyncio, we decided the best way to handle Rust/Python interop was to just surrender the main
thread to Python and run Rust's event loops in the background. Unfortunately, since most event loop
implementations prefer control over the main thread, this can still make some things awkward.
PyO3 Asyncio Initialization
Because Python needs to control the main thread, we can't use the convenient proc macros from Rust
runtimes to handle the main function or #[test] functions. Instead, the initialization for PyO3 has to be done from the main function and the main
thread must block on pyo3_asyncio::run_forever or pyo3_asyncio::async_std::run_until_complete.
Because we have to block on one of those functions, we can't use #[async_std::main] or #[tokio::main]
since it's not a good idea to make long blocking calls during an async function.
Internally, these
#[main]proc macros are expanded to something like this:fn main() { // your async main fn async fn _main_impl() { /* ... */ } Runtime::new().block_on(_main_impl()); }Making a long blocking call inside the
Futurethat's being driven byblock_onprevents that thread from doing anything else and can spell trouble for some runtimes (also this will actually deadlock a single-threaded runtime!). Many runtimes have some sort ofspawn_blockingmechanism that can avoid this problem, but again that's not something we can use here since we need it to block on the main thread.
For this reason, pyo3-asyncio provides its own set of proc macros to provide you with this
initialization. These macros are intended to mirror the initialization of async-std and tokio
while also satisfying the Python runtime's needs.
Here's a full example of PyO3 initialization with the async-std runtime:
use pyo3::prelude::*; #[pyo3_asyncio::async_std::main] async fn main() -> PyResult<()> { // PyO3 is initialized - Ready to go let fut = Python::with_gil(|py| -> PyResult<_> { let asyncio = py.import("asyncio")?; // convert asyncio.sleep into a Rust Future pyo3_asyncio::async_std::into_future( asyncio.call_method1("sleep", (1.into_py(py),))? ) })?; fut.await?; Ok(()) }
A Note About asyncio.run
In Python 3.7+, the recommended way to run a top-level coroutine with asyncio
is with asyncio.run. In v0.13 we recommended against using this function due to initialization issues, but in v0.14 it's perfectly valid to use this function... with a caveat.
Since our Rust <--> Python conversions require a reference to the Python event loop, this poses a problem. Imagine we have a PyO3 Asyncio module that defines
a rust_sleep function like in previous examples. You might rightfully assume that you can call pass this directly into asyncio.run like this:
import asyncio
from my_async_module import rust_sleep
asyncio.run(rust_sleep())
You might be surprised to find out that this throws an error:
Traceback (most recent call last):
File "example.py", line 5, in <module>
asyncio.run(rust_sleep())
RuntimeError: no running event loop
What's happening here is that we are calling rust_sleep before the future is
actually running on the event loop created by asyncio.run. This is counter-intuitive, but expected behaviour, and unfortunately there doesn't seem to be a good way of solving this problem within PyO3 Asyncio itself.
However, we can make this example work with a simple workaround:
import asyncio
from my_async_module import rust_sleep
# Calling main will just construct the coroutine that later calls rust_sleep.
# - This ensures that rust_sleep will be called when the event loop is running,
# not before.
async def main():
await rust_sleep()
# Run the main() coroutine at the top-level instead
asyncio.run(main())
Non-standard Python Event Loops
Python allows you to use alternatives to the default asyncio event loop. One
popular alternative is uvloop. In v0.13 using non-standard event loops was
a bit of an ordeal, but in v0.14 it's trivial.
Using uvloop in a PyO3 Asyncio Native Extensions
# Cargo.toml
[lib]
name = "my_async_module"
crate-type = ["cdylib"]
[dependencies]
pyo3 = { version = "0.14", features = ["extension-module"] }
pyo3-asyncio = { version = "0.14", features = ["tokio-runtime"] }
async-std = "1.9"
tokio = "1.4"
#![allow(unused)] fn main() { //! lib.rs use pyo3::{prelude::*, wrap_pyfunction}; #[pyfunction] fn rust_sleep(py: Python<'_>) -> PyResult<&PyAny> { pyo3_asyncio::tokio::future_into_py(py, async { tokio::time::sleep(std::time::Duration::from_secs(1)).await; Ok(Python::with_gil(|py| py.None())) }) } #[pymodule] fn my_async_module(_py: Python<'_>, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(rust_sleep, m)?)?; Ok(()) } }
$ maturin develop && python3
🔗 Found pyo3 bindings
🐍 Found CPython 3.8 at python3
Finished dev [unoptimized + debuginfo] target(s) in 0.04s
Python 3.8.8 (default, Apr 13 2021, 19:58:26)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import asyncio
>>> import uvloop
>>>
>>> import my_async_module
>>>
>>> uvloop.install()
>>>
>>> async def main():
... await my_async_module.rust_sleep()
...
>>> asyncio.run(main())
>>>
Using uvloop in Rust Applications
Using uvloop in Rust applications is a bit trickier, but it's still possible
with relatively few modifications.
Unfortunately, we can't make use of the #[pyo3_asyncio::<runtime>::main] attribute with non-standard event loops. This is because the #[pyo3_asyncio::<runtime>::main] proc macro has to interact with the Python
event loop before we can install the uvloop policy.
[dependencies]
async-std = "1.9"
pyo3 = "0.14"
pyo3-asyncio = { version = "0.14", features = ["async-std-runtime"] }
//! main.rs use pyo3::{prelude::*, types::PyType}; fn main() -> PyResult<()> { pyo3::prepare_freethreaded_python(); Python::with_gil(|py| { let uvloop = py.import("uvloop")?; uvloop.call_method0("install")?; // store a reference for the assertion let uvloop = PyObject::from(uvloop); pyo3_asyncio::async_std::run(py, async move { // verify that we are on a uvloop.Loop Python::with_gil(|py| -> PyResult<()> { assert!(pyo3_asyncio::async_std::get_current_loop(py)?.is_instance( uvloop .as_ref(py) .getattr("Loop")? )?); Ok(()) })?; async_std::task::sleep(std::time::Duration::from_secs(1)).await; Ok(()) }) }) }
Additional Information
- Managing event loop references can be tricky with pyo3-asyncio. See Event Loop References in the API docs to get a better intuition for how event loop references are managed in this library.
- Testing pyo3-asyncio libraries and applications requires a custom test harness since Python requires control over the main thread. You can find a testing guide in the API docs for the
testingmodule
others
Com组件
如何查看本地的Com组件
oleview.exe是在 Windows SDK 中提供的应用程序,它显示计算机上安装的 COM 对象及其支持的接口。 可以使用此对象查看器查看类型库和接口。
OLE/COM 对象查看器应用位于 \Program Files (x86) \Windows Kits\10[version][architecture]\oleview.exe的 Windows SDK 中。
遇到程序调用的com,根据其id到注册表(win+r,regedit)中搜索,找到后复制其路径在oleview中进行搜索后即显示其com的method及event结构。
Introduction to COM - What It Is and How to Use It
本章目的是理解COM的基本概念,内容包括COM规范简介,重要的COM术语以及如何重用现有的COM组件。
COM即组件对象模型(Component Object Model),本章包括如下内容:
- COM――到底是什么?――COM标准的要点介绍,它被设计用来解决什么问题
- 基本元素的定义――COM术语以及这些术语的含义
- 使用和处理COM对象――如何创建、使用和销毁COM对象
- 基本接口――描述IUnknown基本接口及其方法
- 掌握串的处理――在COM代码中如何处理串
- 应用COM技术――例子代码,举例说明本章所讨论的所有概念
- 处理HRESULT――HRESULT类型描述,如何监测错误及成功代码
COM 到底是什么
简单地说,COM是一种跨应用和语言共享二进制代码的方法。与C++不同,它提倡源代码重用。ATL便是一个很好的例证。源码级重用虽然好,但只能用于C++。它还带来了名字冲突的可能性,更不用说不断拷贝重用代码而导致工程膨胀和臃肿。
Windows使用DLLs在二进制级共享代码。这也是Windows程序运行的关键――重用kernel32.dll, user32.dll等。但DLLs是针对C接口而写的,它们只能被C或理解C调用规范的语言使用。由编程语言来负责实现共享代码,而不是由DLLs本身。这样的话DLLs的使用受到限制。MFC引入了另外一种MFC扩展DLLs二进制共享机制。但它的使用仍受限制――只能在MFC程序中使用。
COM通过定义二进制标准解决了这些问题,即COM明确指出二进制模块(DLLs和EXEs)必须被编译成与指定的结构匹配。这个标准也确切规定了在内存中如何组织COM对象。COM定义的二进制标准还必须独立于任何编程语言(如C++中的命名修饰)。一旦满足了这些条件,就可以轻松地从任何编程语言中存取这些模块。由编译器负责所产生的二进制代码与标准兼容。这样使后来的人就能更容易地使用这些二进制代码。
在内存中,COM对象的这种标准形式在C++虚函数中偶尔用到,所以这就是为什么许多COM代码使用C++的原因。但是记住,编写模块所用的语言是无关的,因为结果二进制代码为所有语言可用。
基本元素的定义
接口只不过是一组函数。这些函数被称为方法。接口名字以大写的I开头,例如C++中的IShellLink,接口被设计成一个抽象基类,其中只有纯粹的虚拟函数。
接口可以从其它接口继承,这里所说的继承的原理就好像C++中的单继承。接口是不允许多继承的。
coclass(简称组件对象类――componentobject class)被包含在DLL或EXE中,并且包含着一个或者多个接口的代码。组件对象类(coclasss)实现这些接口。COM对象在内存中表现为组件对象类(coclasss)的一个实例。注意COM“类”和C++“类”是不相同的,尽管常常COM类实现的就是一个C++类。
COM服务器是包含了一个或多个coclass的二进制(DLL或EXE)。
注册(Registration)是创建注册表入口的一个过程,告诉Windows 操作系统COM服务器放在什么位置。取消注册(Unregistration)则相反――从注册表删除这些注册入口。
GUID(谐音为“fluid”,意思是全球唯一标示符――globally unique identifier)是个128位的数字。它是一种独立于COM编程语言的标示方法。每一个接口和coclass有一个GUID。因为每一个GUID都是全球唯一的,所以避免了名字冲突(只要你用COM API创建它们)。有时你还会碰到另一个术语UUID(意思也是全球唯一标示符――universally unique identifier)。UUIDs和GUIDs在实际使用时的用途是一样的。
类ID或者CLSID是命名coclass的GUID。接口ID或者IID是命名接口的GUID。
在COM中广泛地使用GUID有两个理由:
- GUIDs只是简单的数字,任何编程语言都可以对之进行处理;
- GUIDs可以在任何机器上被任何人创建,一旦完成创建,它就是唯一的。因此,COM开发人员可以创建自己特有的GUIDs而不会与其它开发人员所创建的GUIDs有冲突。这样就消除了集中授权发布GUIDs的必要。
HRESULT是COM用来返回错误和成功代码的整型数字,除此之外,别无它意,虽然以H作前缀,但没有句柄之意。
最后,COM库是在你使用COM时与你交互的操作系统的一部分,它常常指的就是COM本身。但是为了避免混淆才分开描述的。
使用和处理COM对象
每一种语言都有其自己处理对象的方式。例如,C++是在栈中创建对象,或者用new动态分配。因为COM必须独立于语言,所以COM库为自己提供对象管理例程。下面是对COM对象管理和C++对象管理所做的一个比较:
创建一个新对象
- C++中,用new操作符,或者在栈中创建对象。
- COM中,调用COM库中的API。
删除对象
- C++中,用delete操作符,或将栈对象踢出。
- COM中,所有的对象保持它们自己的引用计数。调用者必须通知对象什么时候用完这个对象。当引用计数为零时,COM对象将自己从内存中释放。
由此可见,对象处理的两个阶段:创建和销毁,缺一不可。当创建COM对象时要通知COM库使用哪一个接口。如果这个对象创建成功,COM库返回所请求接口的指针。然后通过这个指针调用方法,就像使用常规C++对象指针一样。
创建COM对象
为了创建COM对象并从这个对象获得接口,必须调用COM库的API函数,CoCreateInstance()。其原型如下:
HRESULT CoCreateInstance (
REFCLSID rclsid,
LPUNKNOWN pUnkOuter,
DWORD dwClsContext,
REFIID riid,
LPVOID* ppv );
参数解释:
- rclsid:coclass的CLSID,例如,可以传递CLSID_ShellLink创建一个COM对象来建立快捷方式。
- pUnkOuter:这个参数只用于COM对象的聚合,利用它向现有的coclass添加新方法。参数值为null表示不使用聚合。
- dwClsContext:表示所使用COM服务器的种类。本文使用的是最简单的COM服务器,一个进程内(in-process)DLL,所以传递的参数值为CLSCTX_INPROC_SERVER。注意这里不要随意使用CLSCTX_ALL(在ATL中,它是个缺省值),因为在没有安装DCOM的Windows95系统上会导致失败。
- riid:请求接口的IID。例如,可以传递IID_IShellLink获得IShellLink接口指针。
- ppv:接口指针的地址。COM库通过这个参数返回请求的接口。
当你调用CoCreateInstance()时,它负责在注册表中查找COM服务器的位置,将服务器加载到内存,并创建你所请求的coclass实例。以下是一个调用的例子,创建一个CLSID_ShellLink对象的实例并请求指向这个对象IShellLink接口指针。
HRESULT hr;
IShellLink* pISL;
hr = CoCreateInstance ( CLSID_ShellLink, //coclass 的CLSID
NULL, //不是用聚合
CLSCTX_INPROC_SERVER, //服务器类型
IID_IShellLink, //接口的IID
(void**)&pISL ); // 指向接口的指针
if ( SUCCEEDED ( hr ) )
{
// 用pISL调用方法
}
else
{
// 不能创建COM对象,hr 为出错代码
}
首先声明一个接受CoCreateInstance()返回值的HRESULT和IShellLink指针。调用CoCreateInstance()来创建新的COM对象。如果hr接受到一个表示成功的代码,则SUCCEEDED宏返回TRUE,否则返回FALSE。FAILED是一个与SUCCEEDED对应的宏用来检查失败代码。
删除COM对象
前面说过,你不用释放COM对象,只要告诉它们你已经用完对象。IUnknown是每一个COM对象必须实现的接口,它有一个方法,Release()。调用这个方法通知COM对象你不再需要对象。一旦调用了这个方法之后,就不能再次使用这个接口,因为这个COM对象可能从此就从内存中消失了。
如果你的应用程序使用许多不同的COM对象,因此在用完某个接口后调用Release()就显得非常重要。如果你不释放接口,这个COM对象(包含代码的DLLs)将保留在内存中,这会增加不必要的开销。如果你的应用程序要长时间运行,就应该在应用程序处于空闲期间调用CoFreeUnusedLibraries() API。这个API将卸载任何没有明显引用的COM服务器,因此这也降低了应用程序使用的内存开销。
继续用上面的例子来说明如何使用Release():
// 像上面一样创建COM 对象, 然后,
if ( SUCCEEDED ( hr ) )
{
// 用pISL调用方法
// 通知COM 对象不再使用它
pISL->Release();
}
基本接口IUnknow
每一个COM接口都派生于IUnknown。这个名字有点误导人,其中没有未知(Unknown)接口的意思。它的原意是如果有一个指向某COM对象的IUnknown指针,就不用知道潜在的对象是什么,因为每个COM对象都实现IUnknown。IUnknown有三个方法:
AddRef()―― 通知COM对象增加它的引用计数。如果你进行了一次接口指针的拷贝,就必须调用一次这个方法,并且原始的值和拷贝的值两者都要用到。在本文的例子中没有用到AddRef()方法;Release()―― 通知COM对象减少它的引用计数。参见前面的Release()示例代码段;QueryInterface()―― 从COM对象请求一个接口指针。当coclass实现一个以上的接口时,就要用到这个方法;
前面已经看到了Release()的使用,但如何使用QueryInterface()呢?当你用CoCreateInstance()创建对象的时候,你得到一个返回的接口指针。如果这个COM对象实现一个以上的接口(不包括IUnknown),你就必须用QueryInterface()方法来获得任何你需要的附加的接口指针。QueryInterface()的原型如下:
HRESULT IUnknown::QueryInterface (
REFIID iid,
void** ppv );
以下是参数解释:
- iid:所请求的接口的IID。
- ppv:接口指针的地址,
QueryInterface()通过这个参数在成功时返回这个接口。
让我们继续 shell link 的例子,它实现了IShellLink和IPersistFile接口。如果你已经有一个IShellLink指针,pISL,可以从COM对象请求IPersistFile接口:
HRESULT hr;
IPersistFile* pIPF;
hr = pISL->QueryInterface (IID_IPersistFile, (void**) &pIPF );
然后使用SUCCEEDED宏检查hr的值以确定QueryInterface()的调用情况,如果成功的话你就可以象使用其它接口指针那样使用新的接口指针,pIPF。但必须记住调用pIPF->Release()通知COM对象已经用完这个接口。
处理String
不管什么时候,只要COM方法返回一个串,这个串都是Unicode串(这里指的是写入COM规范的所有方法)。Unicode是一种字符编码集,类似ASCII,但用两个字节表示一个字符。如果你想更好地控制或操作串的话,应该将它转换成TCHAR类型串。
TCHAR和以_t开头的函数(如_tcscpy())被设计用来让你用相同的源代码处理Unicode和ANSI串。在大多数情况下编写的代码都是用来处理ANSI串和ANSI WindowsAPIs,所以在下文中,除非另外说明,我所说的字符/串都是指TCHAR类型。你应该熟练掌握TCHAR类型,尤其是当你阅读其他人写的有关代码时,要特别注意TCHAR类型。
当你从某个COM方法返回得到一个Unicode串时,可以用下列几种方法之一将它转换成char类型串:
- 调用 WideCharToMultiByte()API;
- 调用CRT 函数wcstombs();
- 使用CString 构造器或赋值操作(仅用于MFC );
- 使用ATL 串转换宏;
1.WideCharToMultiByte()
你可以用WideCharToMultiByte()将一个Unicode串转换成一个ANSI串。此函数的原型如下:
int WideCharToMultiByte (
UINT CodePage,
DWORD dwFlags,
LPCWSTR lpWideCharStr,
int cchWideChar,
LPSTR lpMultiByteStr,
int cbMultiByte,
LPCSTR lpDefaultChar,
LPBOOL lpUsedDefaultChar );
以下是参数解释:
-
CodePage:Unicode字符转换成的代码页。你可以传递CP_ACP来使用当前的ANSI代码页。代码页是256个字符集。字符0――127与ANSI编码一样。字符128――255与ANSI字符不同,它可以包含图形字符或者读音符号。每一种语言或地区都有其自己的代码页,所以使用正确的代码页对于正确地显示重音字符很重要。 -
dwFlags:dwFlags 确定Windows如何处理“复合” Unicode字符,它是一种后面带读音符号的字符。如è就是一个复合字符。如果这些字符在CodePage参数指定的代码页中,不会出什么事。否则,Windows必须对之进行转换。传递WC_COMPOSITECHECK使得这个API检查非映射复合字符。传递WC_SEPCHARS使得Windows将字符分为两段,即字符加读音,如e`。传递WC_DISCARDNS使得Windows丢弃读音符号。传递WC_DEFAULTCHAR使得Windows用lpDefaultChar参数中说明的缺省字符替代复合字符。缺省行为是WC_SEPCHARS。 -
lpWideCharStr要转换的Unicode串。 -
cchWideCharlpWideCharStr在Unicode 字符中的长度。通常传递-1,表示这个串是以0x00结尾。 -
lpMultiByteStr接受转换的串的字符缓冲 cbMultiBytelpMultiByteStr的字节大小。 -
lpDefaultChar可选――当dwFlags包含WC_COMPOSITECHECK | WC_DEFAULTCHAR并且某个Unicode字符不能被映射到同等的ANSI串时所传递的一个单字符ANSI串,包含被插入的“缺省”字符。可以传递NULL,让API使用系统缺省字符(一种写法是一个问号)。 -
lpUsedDefaultChar可选――指向BOOL类型的一个指针,设置它来表示是否缺省字符曾被插入ANSI串。可以传递NULL来忽略这个参数。
不搞清楚这些东西就很难搞清楚COM的串处理。何况文档中列出的比实际应用的要复杂得多。下面就给出了如何使用这个API的例子:
// 假设已经有了一个Unicode 串 wszSomeString...
char szANSIString[MAX_PATH];
WideCharToMultiByte (CP_ACP, //ANSI 代码页
WC_COMPOSITECHECK, // 检查重音字符
wszSomeString, //原Unicode 串
-1, //-1 意思是串以0x00结尾
szANSIString, //目的char字符串
sizeof(szANSIString), // 缓冲大小
NULL, //肥缺省字符串
NULL); //忽略这个参数
调用这个函数后,szANSIString将包含Unicode串的ANSI版本。调用这个函数后,szANSIString将包含Unicode串的ANSI版本。
2.wcstombs()
这个CRT函数wcstombs()是个简化版,但它终结了WideCharToMultiByte()的调用,所以最终结果是一样的。其原型如下:
size_t wcstombs (
char* mbstr,
const wchar_t* wcstr,
size_t count );
以下是参数解释:
mbstr:接受结果ANSI串的字符(char)缓冲。wcstr:要转换的Unicode串。count:mbstr参数所指的缓冲大小。
wcstombs()在它对WideCharToMultiByte()的调用中使用WC_COMPOSITECHECK | WC_SEPCHARS标志。用wcstombs()转换前面例子中的 Unicode串,结果一样:
wcstombs ( szANSIString, wszSomeString, sizeof(szANSIString));
3.CString
MFC中的CString包含有构造函数和接受Unicode串的赋值操作,所以你可以用CString来实现转换。例如:
// 假设有一个Unicode串wszSomeString...
CString str1 ( wszSomeString ); // 用构造器转换
CString str2;
str2 = wszSomeString; // 用赋值操作转换
4.ATL宏
ATL有一组很方便的宏用于串的转换。W2A()用于将Unicode串转换为ANSI串(记忆方法是“wide to ANSI”――宽字符到ANSI)。实际上使用OLE2A()更精确,“OLE”表示的意思是COM串或者OLE串。下面是使用这些宏的例子:
// 还是假设有一个Unicode串wszSomeString...
{
char szANSIString[MAX_PATH];
USES_CONVERSION; // 声明这个宏要使用的局部变量
lstrcpy ( szANSIString, OLE2A(wszSomeString));
}
OLE2A()宏“返回”转换的串的指针,但转换的串被存储在某个临时栈变量中,所以要用lstrcpy()来获得自己的拷贝。其它的几个宏是W2T()(Unicode 到 TCHAR)以及W2CT()(Unicode到常量TCHAR串)。
有个宏是OLE2CA()(Unicode到常量char串),可以被用到上面的例子中,OLE2CA()实际上是个更正宏,因为lstrcpy()的第二个参数是一个常量char*,关于这个问题本文将在以后作详细讨论。
另一方面,如果你不想做以上复杂的串处理,尽管让它还保持为Unicode串,如果编写的是控制台应用程序,输出/显示Unicode串时应该用全程变量std::wcout,如:
wcout << wszSomeString;
但是要记住,std::wcout只认Unicode,所以你要是“正常”串的话,还得用std::cout输出/显示。对于Unicode串文字量,要使用前缀L标示,如:
wcout << L"The Oraclesays..." << endl << wszOracleResponse;
如果保持串为Unicode,编程时有两个限制:
- 必须使用
wcsXXX()Unicode串处理函数,如wcslen(); - 在Windows 9x环境中不能在Windows API中传递Unicode串。要想编写能在9x和NT上都能运行的应用,必须使用TCHAR类型,详情请参考MSDN;
用例子总结上述内容
使用单接口COM对象
第一个例子展示的是单接口COM对象。这可能是你碰到得最简单的例子。它使用shell中的活动桌面组件对象类(CLSID_ActiveDesktop)来获得当前桌面墙纸的文件名。请确认系统中安装了活动桌面(Active Desktop)。以下是编程步骤:
- 初始化COM库。 (Initialize);
- 创建一个与活动桌面交互的COM对象,并取得
IActiveDesktop接口; - 调用COM对象的
GetWallpaper()方法; - 如果
GetWallpaper()成功,则输出/显示墙纸文件名; - 释放接口(
Release()); - 收回COM库(Uninitialize);
WCHAR wszWallpaper [MAX_PATH];
CString strPath;
HRESULT hr;
IActiveDesktop* pIAD;
// 1. 初始化COM库(让Windows加载DLLs)。通常是在程序的InitInstance()中调用
// CoInitialize ( NULL )或其它启动代码。MFC程序使用AfxOleInit()
CoInitialize ( NULL );
// 2. 使用外壳提供的活动桌面组件对象类创建COM对象。
// 第四个参数通知COM需要什么接口(这里是IActiveDesktop).
hr = CoCreateInstance(
CLSID_ActiveDesktop,
NULL,
CLSCTX_INPROC_SERVER,
IID_IActiveDesktop,
(void**) &pIAD );
if ( SUCCEEDED(hr) )
{
// 3. 如果COM对象被创建成功,则调用这个对象的GetWallpaper() 方法。
hr = pIAD->GetWallpaper ( wszWallpaper,MAX_PATH, 0 );
if ( SUCCEEDED(hr) )
{
// 4. 如果 GetWallpaper() 成功,则输出它返回的文件名字。
// 注意这里使用wcout 来显示Unicode 串wszWallpaper. wcout 是
// Unicode 专用,功能与cout.相同。
wcout << L"Wallpaper pathis:\n " << wszWallpaper<< endl << endl;
}
else
{
cout << _T("GetWallpaper()failed.") << endl << endl;
}
// 5. 释放接口。
pIAD->Release();
}
else
{
cout << _T("CoCreateInstanc()failed.") << endl << endl;
}
// 6. 收回COM库。MFC 程序不用这一步,它自动完成。
CoUninitialize();
在这个例子中,输出/显示Unicode 串 wszWallpaper用的是std::wcout。
使用多接口的COM对象
第二个例子展示了如何使用一个提供单接口的COM对象QueryInterface()函数。其中的代码用shell的Shell Link组件对象类创建我们在第一个例子中获得的墙纸文件的快捷方式。以下是编程步骤:
- 初始化 COM 库;
- 创建一个用于建立快捷方式的COM 对象并取得IShellLink 接口;
- 调用IShellLink 接口的
SetPath()方法; - 调用对象的
QueryInterface()函数并取得IPersistFile接口; - 调用IPersistFile 接口的
Save()方法; - 释放接口;
- 收回COM库;
CString sWallpaper = wszWallpaper; // 将墙纸路径转换为ANSI
IShellLink* pISL;
IPersistFile* pIPF;
// 1. 初始化COM库(让Windows 加载DLLs). 通常在InitInstance()中调用
// CoInitialize ( NULL )或其它启动代码。MFC 程序使用AfxOleInit()。
CoInitialize ( NULL );
// 2. 使用外壳提供的Shell Link组件对象类创建COM对象。.
// 第四个参数通知COM 需要什么接口(这里是IShellLink)。
hr = CoCreateInstance (
CLSID_ShellLink,
NULL,
CLSCTX_INPROC_SERVER,
IID_IShellLink,
(void**)&pISL
);
if ( SUCCEEDED(hr) )
{
// 3. 设置快捷方式目标(墙纸文件)的路径。
hr = pISL->SetPath ( sWallpaper );
if ( SUCCEEDED(hr) )
{
// 4. 获取这个对象的第二个接口(IPersistFile)。
hr = pISL->QueryInterface (IID_IPersistFile, (void**) &pIPF );
if ( SUCCEEDED(hr) )
{
// 5. 调用Save() 方法保存某个文件得快捷方式。第一个参数是
// Unicode 串。
hr = pIPF->Save (L"C:\\wallpaper.lnk", FALSE );
// 6a. 释放IPersistFile 接口。
pIPF->Release();
}
}
// 6. 释放IShellLink 接口。
pISL->Release();
}
// 输出错误信息部分这里省略。
// 7. 收回COM 库。MFC 程序不用这一步,它自动完成。
CoUninitialize();
处理HRESULT
这一部分准备用SUCCEEDED 和 FAILED宏进行一些简单的出错处理。主要是深入研究从COM方法返回的HRESULT,以便达到完全理解和熟练应用。
HRESULT是个32位符号整数,其非负值表示成功,负值表示失败。HRESULT有三个域:程度位(表示成功或失败),功能码和状态码。功能码表示HRESULT来自什么组件或程序。微软给不同的组件多赋予功能码,如:COM、任务调度程序等都有功能码。功能码是个16位的值,仅此而已,没有其它内在含义;它在数字和意义之间是随意关联的;类似GetLastError()返回的值。
如果你在winerror.h头文件中查找错误代码,会看到许多按照[功能]_[程度]_[描述]命名规范列出的HRESULT值,由组件返回的通用的 HRESULT(类似E_OUTOFMEMORY)在名字中没有功能码。如 :
REGDB_E_READREGDB:功能码 = REGDB, 指“注册表数据库(registry database)”;程度 = E 意思是错误(error);描述 = READREGDB 是对错误的描述(意思是不能读注册表数据库)。S_OK: 没有功能码――通用(generic)HRESULT;程度=S;表示成功(success);OK 是状态描述表示一切都好(everything''sOK)。
好在有一种比察看winerror.h文件更容易的方法来确定HRESULT的意思。使用VC提供的错误查找工具(Error Lookup)可以轻松查到为HRESULT内建功能码。例如,假设你在CoCreateInstance()之前忘了调用CoInitialize()。CoCreateInstance()返回的值是0x800401F0。你只要将这个值输入到错误查找工具按“Look Up”按钮,便可以看到错误信息描述“尚未调用CoInitialize”如下图所示:
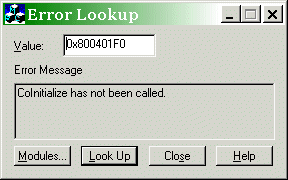
另外一种查找HRESULT描述的方法是在调试器中。假设有一个HRESULT变量是hres。在Watch窗口的左边框中输入“hres,hr”,表示想要看的值,“hr”便会通知VC显示HRESULT所描述的值。如下图所示:
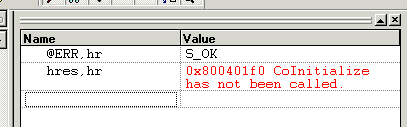
Cython 3.0 中文文档

原文:Welcome to Cython's Documentation
起初就把事情做对是完全没必要的。但最后要把事情做对是绝对必要的。——Andrew Hunt & David Thomas
下载
Docker
docker pull apachecn0/cython-doc-zh
docker run -tid -p <port>:80 apachecn0/cython-doc-zh
# 访问 http://localhost:{port} 查看文档
PYPI
pip install cython-doc-zh
cython-doc-zh <port>
# 访问 http://localhost:{port} 查看文档
NPM
npm install -g cython-doc-zh
cython-doc-zh <port>
# 访问 http://localhost:{port} 查看文档
机器学习
机器学习(Machine Learning,ML)是指从有限的观测数据中学习(或“猜测”)出具有一般性的规律,并利用这些规律对未知数据进行预测的方法。 机器学习方法可以粗略地分为三个基本要素:模型、学习准则、优化算法.
- 模型:根据经验来假设一个函数集合 ℱ ,称为假设空间(Hypothesis Space),然后通过观测其在训练集 𝒟 上的特性,从中选择一个理想的假设(Hypothesis)𝑓∗∈ ℱ.通常分为线性&非线性.
- 学习准则:
- 损失函数:
- 风险最小化准则:经验风险最小化(Empirical Risk Minimization,ERM)准则与结构风险最小化(Structure Risk Minimization,SRM)准则. 前者是要求你对训练集的拟合,后者是保证泛化能力.
- 损失函数:
- 优化算法:在确定了训练集 𝒟 、假设空间 ℱ 以及学习准则后,如何找到最优的模型 𝑓(𝒙,𝜃∗) 就成了一个最优化(Optimization)问题.机器学习的训练过程其实就是最优化问题的求解过程.
传统的机器学习主要关注如何学习一个预测模型.一般需要首先将数据表示为一组特征(Feature),特征的表示形式可以是连续的数值、离散的符号或其他形式.然后将这些特征输入到预测模型,并输出预测结果.这类机器学习可以看作浅层学习(Shallow Learning).浅层学习的一个重要特点是不涉及特征学习,其特征主要靠人工经验或特征转换方法来抽取. 在实际任务中使用机器学习模型一般会包含以下几个步骤(如图1.2所示):
- 数据预处理:经过数据的预处理,如去除噪声等.比如在文本分类中,去除停用词等.
- 特征提取:从原始数据中提取一些有效的特征.比如在图像分类中,提取边缘、尺度不变特征变换(Scale Invariant Feature Transform,SIFT)特征等.
- 特征转换:对特征进行一定的加工,比如降维和升维.降维包括特征抽取(Feature Extraction)和特征选择(Feature Selection)两种途径.常用的特征转换方法有主成分分析(Principal Components Analysis,PCA)、线性判别分析(Linear Discriminant Analysis,LDA)等.
- 预测:机器学习的核心部分,学习一个函数并进行预测.

表示学习:为了提高机器学习系统的准确率,我们就需要将输入信息转换为有效的特征,或者更一般性地称为表示(Representation).如果有一种算法可以自动地学习出有效的特征,并提高最终机器学习模型的性能,那么这种学习就可以叫作表示学习(Representation Learning). 语义鸿沟:表示学习的关键是解决语义鸿沟(Semantic Gap)问题.即车这一概念是高层语义特征,轿车、自行车、卡车是底层特征,如何同不同车种提取出那个高层特征“车”呢?如果一个预测模型直接建立在底层特征之上,会导致对预测模型的能力要求过高.如果可以有一个好的表示在某种程度上能够反映出数据的高层语义特征,那么我们就能相对容易地构建后续的机器学习模型。
一. 绪论
1.1 机器学习的定义
正如我们根据过去的经验来判断明天的天气,吃货们希望从购买经验中挑选一个好瓜,那能不能让计算机帮助人类来实现这个呢?机器学习正是这样的一门学科,人的“经验”对应计算机中的“数据”,让计算机来学习这些经验数据,生成一个算法模型,在面对新的情况中,计算机便能作出有效的判断,这便是机器学习。
另一本经典教材的作者Mitchell给出了一个形式化的定义,假设:
- P:计算机程序在某任务类T上的性能。
- T:计算机程序希望实现的任务类。
- E:表示经验,即历史的数据集。
若该计算机程序通过利用经验E在任务T上获得了性能P的改善,则称该程序对E进行了学习。
1.2 机器学习的一些基本术语
假设我们收集了一批西瓜的数据,例如:(色泽=青绿;根蒂=蜷缩;敲声=浊响), (色泽=乌黑;根蒂=稍蜷;敲声=沉闷), (色泽=浅自;根蒂=硬挺;敲声=清脆)……每对括号内是一个西瓜的记录,定义:
- 所有记录的集合为:数据集。
- 每一条记录为:一个实例(instance)或样本(sample)。
- 例如:色泽或敲声,单个的特点为特征(feature)或属性(attribute)。
- 对于一条记录,如果在坐标轴上表示,每个西瓜都可以用坐标轴中的一个点表示,一个点也是一个向量,例如(青绿,蜷缩,浊响),即每个西瓜为:一个特征向量(feature vector)。
- 一个样本的特征数为:维数(dimensionality),该西瓜的例子维数为3,当维数非常大时,也就是现在说的“维数灾难”。
计算机程序学习经验数据生成算法模型的过程中,每一条记录称为一个“训练样本”,同时在训练好模型后,我们希望使用新的样本来测试模型的效果,则每一个新的样本称为一个“测试样本”。定义:
- 所有训练样本的集合为:训练集(trainning set),[特殊]。
- 所有测试样本的集合为:测试集(test set),[一般]。
- 机器学习出来的模型适用于新样本的能力为:泛化能力(generalization),即从特殊到一般。
西瓜的例子中,我们是想计算机通过学习西瓜的特征数据,训练出一个决策模型,来判断一个新的西瓜是否是好瓜。可以得知我们预测的是:西瓜是好是坏,即好瓜与差瓜两种,是离散值。同样地,也有通过历年的人口数据,来预测未来的人口数量,人口数量则是连续值。定义:
- 预测值为离散值的问题为:分类(classification)。
- 预测值为连续值的问题为:回归(regression)。
我们预测西瓜是否是好瓜的过程中,很明显对于训练集中的西瓜,我们事先已经知道了该瓜是否是好瓜,学习器通过学习这些好瓜或差瓜的特征,从而总结出规律,即训练集中的西瓜我们都做了标记,称为标记信息。但也有没有标记信息的情形,例如:我们想将一堆西瓜根据特征分成两个小堆,使得某一堆的西瓜尽可能相似,即都是好瓜或差瓜,对于这种问题,我们事先并不知道西瓜的好坏,样本没有标记信息。定义:
- 训练数据有标记信息的学习任务为:监督学习(supervised learning),容易知道上面所描述的分类和回归都是监督学习的范畴。
- 训练数据没有标记信息的学习任务为:无监督学习(unsupervised learning),常见的有聚类和关联规则。
二. 模型的评估与选择
2.1 误差与过拟合
我们将学习器对样本的实际预测结果与样本的真实值之间的差异成为:误差(error)。定义:
- 在训练集上的误差称为训练误差(training error)或经验误差(empirical error)。
- 在测试集上的误差称为测试误差(test error)。
- 学习器在所有新样本上的误差称为泛化误差(generalization error)。
显然,我们希望得到的是在新样本上表现得很好的学习器,即泛化误差小的学习器。因此,我们应该让学习器尽可能地从训练集中学出普适性的“一般特征”,这样在遇到新样本时才能做出正确的判别。然而,当学习器把训练集学得“太好”的时候,即把一些训练样本的自身特点当做了普遍特征;同时也有学习能力不足的情况,即训练集的基本特征都没有学习出来。我们定义:
- 学习能力过强,以至于把训练样本所包含的不太一般的特性都学到了,称为:过拟合(overfitting)。
- 学习能太差,训练样本的一般性质尚未学好,称为:欠拟合(underfitting)。
可以得知:在过拟合问题中,训练误差十分小,但测试误差教大;在欠拟合问题中,训练误差和测试误差都比较大。目前,欠拟合问题比较容易克服,例如增加迭代次数等,但过拟合问题还没有十分好的解决方案,过拟合是机器学习面临的关键障碍。
2.2 评估方法
在现实任务中,我们往往有多种算法可供选择,那么我们应该选择哪一个算法才是最适合的呢?如上所述,我们希望得到的是泛化误差小的学习器,理想的解决方案是对模型的泛化误差进行评估,然后选择泛化误差最小的那个学习器。但是,泛化误差指的是模型在所有新样本上的适用能力,我们无法直接获得泛化误差。
因此,通常我们采用一个“测试集”来测试学习器对新样本的判别能力,然后以“测试集”上的“测试误差”作为“泛化误差”的近似。显然:我们选取的测试集应尽可能与训练集互斥,下面用一个小故事来解释why:
假设老师出了10 道习题供同学们练习,考试时老师又用同样的这10道题作为试题,可能有的童鞋只会做这10 道题却能得高分,很明显:这个考试成绩并不能有效地反映出真实水平。回到我们的问题上来,我们希望得到泛化性能好的模型,好比希望同学们课程学得好并获得了对所学知识"举一反三"的能力;训练样本相当于给同学们练习的习题,测试过程则相当于考试。显然,若测试样本被用作训练了,则得到的将是过于"乐观"的估计结果。
2.3 训练集与测试集的划分方法
如上所述:我们希望用一个“测试集”的“测试误差”来作为“泛化误差”的近似,因此我们需要对初始数据集进行有效划分,划分出互斥的“训练集”和“测试集”。下面介绍几种常用的划分方法:
2.3.1 留出法
将数据集D划分为两个互斥的集合,一个作为训练集S,一个作为测试集T,满足D=S∪T且S∩T=∅,常见的划分为:大约2/3-4/5的样本用作训练,剩下的用作测试。需要注意的是:训练/测试集的划分要尽可能保持数据分布的一致性,以避免由于分布的差异引入额外的偏差,常见的做法是采取分层抽样。同时,由于划分的随机性,单次的留出法结果往往不够稳定,一般要采用若干次随机划分,重复实验取平均值的做法。
2.3.2 交叉验证法
将数据集D划分为k个大小相同的互斥子集,满足D=D1∪D2∪...∪Dk,Di∩Dj=∅(i≠j),同样地尽可能保持数据分布的一致性,即采用分层抽样的方法获得这些子集。交叉验证法的思想是:每次用k-1个子集的并集作为训练集,余下的那个子集作为测试集,这样就有K种训练集/测试集划分的情况,从而可进行k次训练和测试,最终返回k次测试结果的均值。交叉验证法也称“k折交叉验证”,k最常用的取值是10,下图给出了10折交叉验证的示意图。
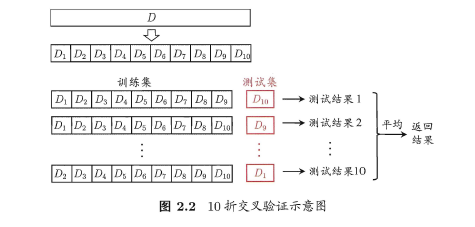
与留出法类似,将数据集D划分为K个子集的过程具有随机性,因此K折交叉验证通常也要重复p次,称为p次k折交叉验证,常见的是10次10折交叉验证,即进行了100次训练/测试。特殊地当划分的k个子集的每个子集中只有一个样本时,称为“留一法”,显然,留一法的评估结果比较准确,但对计算机的消耗也是巨大的。
2.3.3 自助法
我们希望评估的是用整个D训练出的模型。但在留出法和交叉验证法中,由于保留了一部分样本用于测试,因此实际评估的模型所使用的训练集比D小,这必然会引入一些因训练样本规模不同而导致的估计偏差。留一法受训练样本规模变化的影响较小,但计算复杂度又太高了。“自助法”正是解决了这样的问题。
自助法的基本思想是:给定包含m个样本的数据集D,每次随机从D 中挑选一个样本,将其拷贝放入D',然后再将该样本放回初始数据集D 中,使得该样本在下次采样时仍有可能被采到。重复执行m 次,就可以得到了包含m个样本的数据集D'。可以得知在m次采样中,样本始终不被采到的概率取极限为:
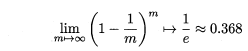
这样,通过自助采样,初始样本集D中大约有36.8%的样本没有出现在D'中,于是可以将D'作为训练集,D-D'作为测试集。自助法在数据集较小,难以有效划分训练集/测试集时很有用,但由于自助法产生的数据集(随机抽样)改变了初始数据集的分布,因此引入了估计偏差。在初始数据集足够时,留出法和交叉验证法更加常用。
2.4 调参
大多数学习算法都有些参数(parameter) 需要设定,参数配置不同,学得模型的性能往往有显著差别,这就是通常所说的"参数调节"或简称"调参" (parameter tuning)。
学习算法的很多参数是在实数范围内取值,因此,对每种参数取值都训练出模型来是不可行的。常用的做法是:对每个参数选定一个范围和步长λ,这样使得学习的过程变得可行。例如:假定算法有3 个参数,每个参数仅考虑5 个候选值,这样对每一组训练/测试集就有555= 125 个模型需考察,由此可见:拿下一个参数(即经验值)对于算法人员来说是有多么的happy。
最后需要注意的是:当选定好模型和调参完成后,我们需要使用初始的数据集D重新训练模型,即让最初划分出来用于评估的测试集也被模型学习,增强模型的学习效果。用上面考试的例子来比喻:就像高中时大家每次考试完,要将考卷的题目消化掉(大多数题目都还是之前没有见过的吧?),这样即使考差了也能开心的玩耍了~
2.5 性能度量
性能度量(performance measure)是衡量模型泛化能力的评价标准,在对比不同模型的能力时,使用不同的性能度量往往会导致不同的评判结果。本节除2.5.1外,其它主要介绍分类模型的性能度量。
2.5.1 最常见的性能度量
在回归任务中,即预测连续值的问题,最常用的性能度量是“均方误差”(mean squared error),很多的经典算法都是采用了MSE作为评价函数,想必大家都十分熟悉。

在分类任务中,即预测离散值的问题,最常用的是错误率和精度,错误率是分类错误的样本数占样本总数的比例,精度则是分类正确的样本数占样本总数的比例,易知:错误率+精度=1。
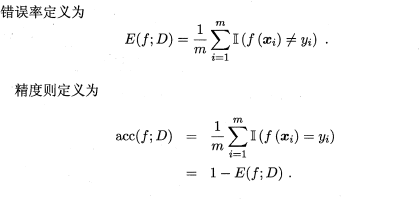

2.5.2 查准率/查全率/F1
错误率和精度虽然常用,但不能满足所有的需求,例如:在推荐系统中,我们只关心推送给用户的内容用户是否感兴趣(即查准率),或者说所有用户感兴趣的内容我们推送出来了多少(即查全率)。因此,使用查准/查全率更适合描述这类问题。对于二分类问题,分类结果混淆矩阵与查准/查全率定义如下:

初次接触时,FN与FP很难正确的理解,按照惯性思维容易把FN理解成:False->Negtive,即将错的预测为错的,这样FN和TN就反了,后来找到一张图,描述得很详细,为方便理解,把这张图也贴在了下边:
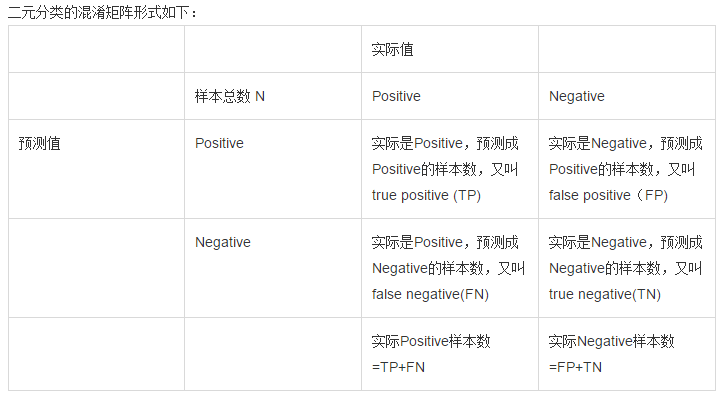
正如天下没有免费的午餐,查准率和查全率是一对矛盾的度量。例如我们想让推送的内容尽可能用户全都感兴趣,那只能推送我们把握高的内容,这样就漏掉了一些用户感兴趣的内容,查全率就低了;如果想让用户感兴趣的内容都被推送,那只有将所有内容都推送上,宁可错杀一千,不可放过一个,这样查准率就很低了。
“P-R曲线”正是描述查准/查全率变化的曲线,P-R曲线定义如下:根据学习器的预测结果(一般为一个实值或概率)对测试样本进行排序,将最可能是“正例”的样本排在前面,最不可能是“正例”的排在后面,按此顺序逐个把样本作为“正例”进行预测,每次计算出当前的P值和R值,如下图所示:
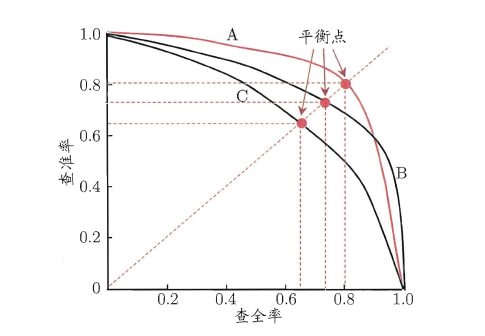
P-R曲线如何评估呢?若一个学习器A的P-R曲线被另一个学习器B的P-R曲线完全包住,则称:B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。但一般来说,曲线下的面积是很难进行估算的,所以衍生出了“平衡点”(Break-Event Point,简称BEP),即当P=R时的取值,平衡点的取值越高,性能更优。
P和R指标有时会出现矛盾的情况,这样就需要综合考虑他们,最常见的方法就是F-Measure,又称F-Score。F-Measure是P和R的加权调和平均,即:
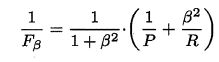
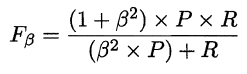
特别地,当β=1时,也就是常见的F1度量,是P和R的调和平均,当F1较高时,模型的性能越好。
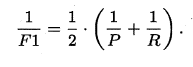

有时候我们会有多个二分类混淆矩阵,例如:多次训练或者在多个数据集上训练,那么估算全局性能的方法有两种,分为宏观和微观。简单理解,宏观就是先算出每个混淆矩阵的P值和R值,然后取得平均P值macro-P和平均R值macro-R,在算出Fβ或F1,而微观则是计算出混淆矩阵的平均TP、FP、TN、FN,接着进行计算P、R,进而求出Fβ或F1。
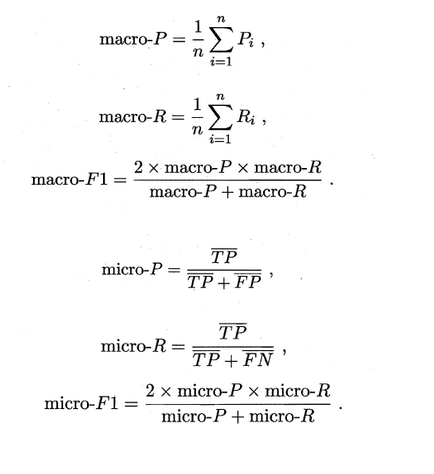
2.5.3 ROC与AUC
如上所述:学习器对测试样本的评估结果一般为一个实值或概率,设定一个阈值,大于阈值为正例,小于阈值为负例,因此这个实值的好坏直接决定了学习器的泛化性能,若将这些实值排序,则排序的好坏决定了学习器的性能高低。ROC曲线正是从这个角度出发来研究学习器的泛化性能,ROC曲线与P-R曲线十分类似,都是按照排序的顺序逐一按照正例预测,不同的是ROC曲线以“真正例率”(True Positive Rate,简称TPR)为横轴,纵轴为“假正例率”(False Positive Rate,简称FPR),ROC偏重研究基于测试样本评估值的排序好坏。

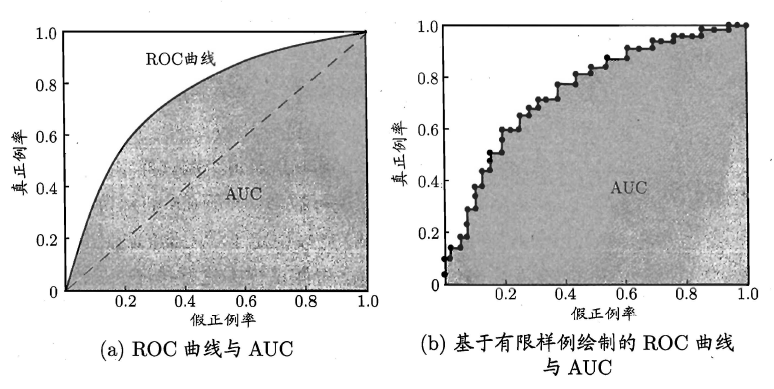
简单分析图像,可以得知:当FN=0时,TN也必须0,反之也成立,我们可以画一个队列,试着使用不同的截断点(即阈值)去分割队列,来分析曲线的形状,(0,0)表示将所有的样本预测为负例,(1,1)则表示将所有的样本预测为正例,(0,1)表示正例全部出现在负例之前的理想情况,(1,0)则表示负例全部出现在正例之前的最差情况。限于篇幅,这里不再论述。
现实中的任务通常都是有限个测试样本,因此只能绘制出近似ROC曲线。绘制方法:首先根据测试样本的评估值对测试样本排序,接着按照以下规则进行绘制。

同样地,进行模型的性能比较时,若一个学习器A的ROC曲线被另一个学习器B的ROC曲线完全包住,则称B的性能优于A。若A和B的曲线发生了交叉,则谁的曲线下的面积大,谁的性能更优。ROC曲线下的面积定义为AUC(Area Uder ROC Curve),不同于P-R的是,这里的AUC是可估算的,即AOC曲线下每一个小矩形的面积之和。易知:AUC越大,证明排序的质量越好,AUC为1时,证明所有正例排在了负例的前面,AUC为0时,所有的负例排在了正例的前面。
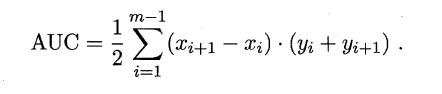
2.5.4 代价敏感错误率与代价曲线
上面的方法中,将学习器的犯错同等对待,但在现实生活中,将正例预测成假例与将假例预测成正例的代价常常是不一样的,例如:将无疾病-->有疾病只是增多了检查,但有疾病-->无疾病却是增加了生命危险。以二分类为例,由此引入了“代价矩阵”(cost matrix)。
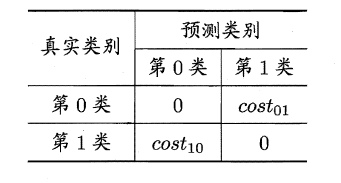
在非均等错误代价下,我们希望的是最小化“总体代价”,这样“代价敏感”的错误率(2.5.1节介绍)为:
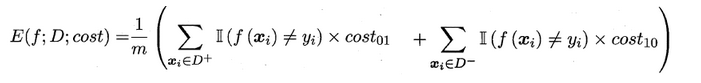
同样对于ROC曲线,在非均等错误代价下,演变成了“代价曲线”,代价曲线横轴是取值在[0,1]之间的正例概率代价,式中p表示正例的概率,纵轴是取值为[0,1]的归一化代价。
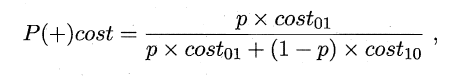
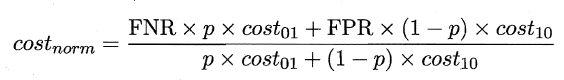
代价曲线的绘制很简单:设ROC曲线上一点的坐标为(TPR,FPR) ,则可相应计算出FNR,然后在代价平面上绘制一条从(0,FPR) 到(1,FNR) 的线段,线段下的面积即表示了该条件下的期望总体代价;如此将ROC 曲线土的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价,如图所示:
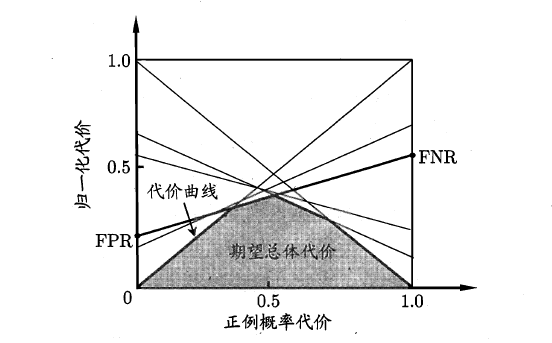
在此模型的性能度量方法就介绍完了,以前一直以为均方误差和精准度就可以了,现在才发现天空如此广阔~
2.6 比较检验
在比较学习器泛化性能的过程中,统计假设检验(hypothesis test)为学习器性能比较提供了重要依据,即若A在某测试集上的性能优于B,那A学习器比B好的把握有多大。 为方便论述,本篇中都是以“错误率”作为性能度量的标准。
2.6.1 假设检验
“假设”指的是对样本总体的分布或已知分布中某个参数值的一种猜想,例如:假设总体服从泊松分布,或假设正态总体的期望u=u0。回到本篇中,我们可以通过测试获得测试错误率,但直观上测试错误率和泛化错误率相差不会太远,因此可以通过测试错误率来推测泛化错误率的分布,这就是一种假设检验。

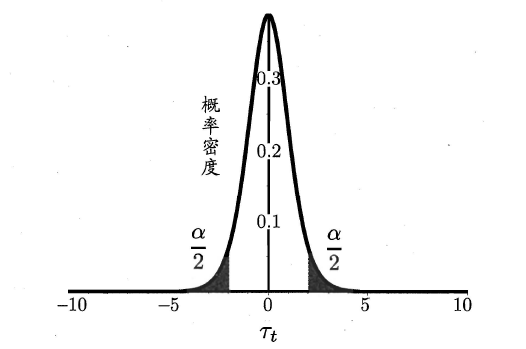
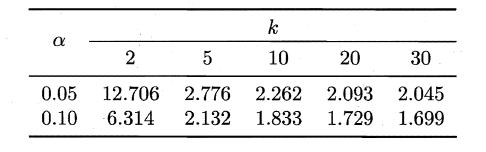
2.6.2 交叉验证t检验

2.6.3 McNemar检验
MaNemar主要用于二分类问题,与成对t检验一样也是用于比较两个学习器的性能大小。主要思想是:若两学习器的性能相同,则A预测正确B预测错误数应等于B预测错误A预测正确数,即e01=e10,且|e01-e10|服从N(1,e01+e10)分布。
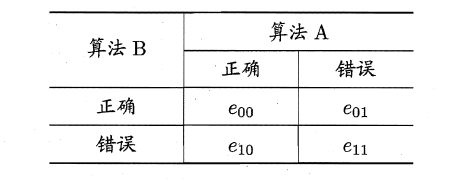
因此,如下所示的变量服从自由度为1的卡方分布,即服从标准正态分布N(0,1)的随机变量的平方和,下式只有一个变量,故自由度为1,检验的方法同上:做出假设-->求出满足显著度的临界点-->给出拒绝域-->验证假设。
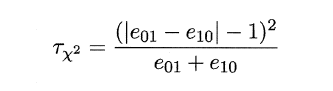
2.6.4 Friedman检验与Nemenyi后续检验
上述的三种检验都只能在一组数据集上,F检验则可以在多组数据集进行多个学习器性能的比较,基本思想是在同一组数据集上,根据测试结果(例:测试错误率)对学习器的性能进行排序,赋予序值1,2,3...,相同则平分序值,如下图所示:

若学习器的性能相同,则它们的平均序值应该相同,且第i个算法的平均序值ri服从正态分布N((k+1)/2,(k+1)(k-1)/12),则有:

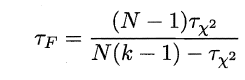
服从自由度为k-1和(k-1)(N-1)的F分布。下面是F检验常用的临界值:
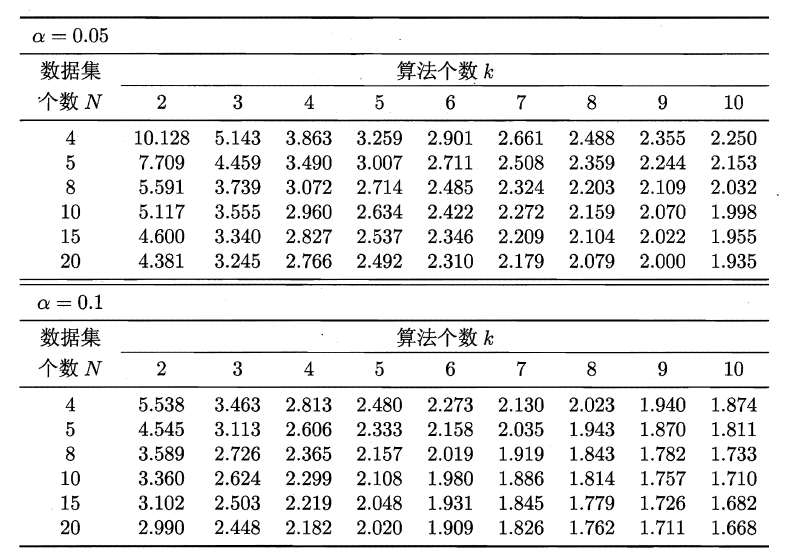
若“H0:所有算法的性能相同”这个假设被拒绝,则需要进行后续检验,来得到具体的算法之间的差异。常用的就是Nemenyi后续检验。Nemenyi检验计算出平均序值差别的临界值域,下表是常用的qa值,若两个算法的平均序值差超出了临界值域CD,则相应的置信度1-α拒绝“两个算法性能相同”的假设。
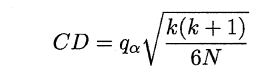
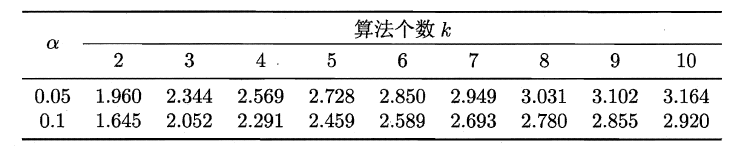
2.7 偏差与方差
偏差-方差分解是解释学习器泛化性能的重要工具。在学习算法中,偏差指的是预测的期望值与真实值的偏差,方差则是每一次预测值与预测值得期望之间的差均方。实际上,偏差体现了学习器预测的准确度,而方差体现了学习器预测的稳定性。通过对泛化误差的进行分解,可以得到:
- 期望泛化误差=方差+偏差
- 偏差刻画学习器的拟合能力
- 方差体现学习器的稳定性
易知:方差和偏差具有矛盾性,这就是常说的偏差-方差窘境(bias-variance dilamma),随着训练程度的提升,期望预测值与真实值之间的差异越来越小,即偏差越来越小,但是另一方面,随着训练程度加大,学习算法对数据集的波动越来越敏感,方差值越来越大。换句话说:在欠拟合时,偏差主导泛化误差,而训练到一定程度后,偏差越来越小,方差主导了泛化误差。因此训练也不要贪杯,适度辄止。
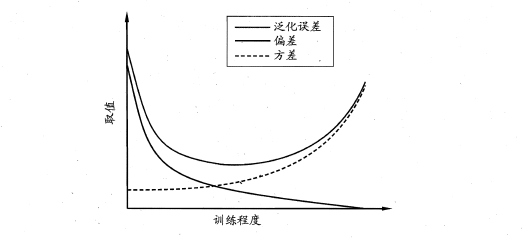
三. 线性模型
谈及线性模型,其实我们很早就已经与它打过交道,还记得高中数学必修3课本中那个顽皮的“最小二乘法”吗?这就是线性模型的经典算法之一:根据给定的(x,y)点对,求出一条与这些点拟合效果最好的直线y=ax+b,之前我们利用下面的公式便可以计算出拟合直线的系数a,b(3.1中给出了具体的计算过程),从而对于一个新的x,可以预测它所对应的y值。前面我们提到:在机器学习的术语中,当预测值为连续值时,称为“回归问题”,离散值时为“分类问题”。本篇先从线性回归任务开始,接着讨论分类和多分类问题。
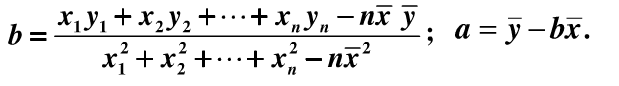
3.1 线性回归
线性回归问题就是试图学到一个线性模型尽可能准确地预测新样本的输出值,例如:通过历年的人口数据预测2017年人口数量。在这类问题中,往往我们会先得到一系列的有标记数据,例如:2000-->13亿...2016-->15亿,这时输入的属性只有一个,即年份;也有输入多属性的情形,假设我们预测一个人的收入,这时输入的属性值就不止一个了,例如:(学历,年龄,性别,颜值,身高,体重)-->15k。
有时这些输入的属性值并不能直接被我们的学习模型所用,需要进行相应的处理,对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;对于离散值的属性,可作下面的处理:
-
若属性值之间存在“序关系”,则可以将其转化为连续值,例如:身高属性分为“高”“中等”“矮”,可转化为数值:{1, 0.5, 0}。
-
若属性值之间不存在“序关系”,则通常将其转化为向量的形式,例如:性别属性分为“男”“女”,可转化为二维向量:{(1,0),(0,1)}。
(1)当输入属性只有一个的时候,就是最简单的情形,也就是我们高中时最熟悉的“最小二乘法”(Euclidean distance),首先计算出每个样本预测值与真实值之间的误差并求和,通过最小化均方误差MSE,使用求偏导等于零的方法计算出拟合直线y=wx+b的两个参数w和b,计算过程如下图所示:

(2)当输入属性有多个的时候,例如对于一个样本有d个属性{(x1,x2...xd),y},则y=wx+b需要写成:
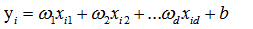
通常对于多元问题,常常使用矩阵的形式来表示数据。在本问题中,将具有m个样本的数据集表示成矩阵X,将系数w与b合并成一个列向量,这样每个样本的预测值以及所有样本的均方误差最小化就可以写成下面的形式:

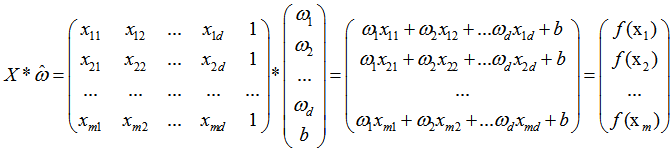
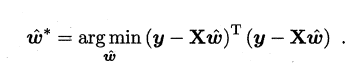
同样地,我们使用最小二乘法对w和b进行估计,令均方误差的求导等于0,需要注意的是,当一个矩阵的行列式不等于0时,我们才可能对其求逆,因此对于下式,我们需要考虑矩阵(X的转置*X)的行列式是否为0,若不为0,则可以求出其解,若为0,则需要使用其它的方法进行计算,书中提到了引入正则化,此处不进行深入。

另一方面,有时像上面这种原始的线性回归可能并不能满足需求,例如:y值并不是线性变化,而是在指数尺度上变化。这时我们可以采用线性模型来逼近y的衍生物,例如lny,这时衍生的线性模型如下所示,实际上就是相当于将指数曲线投影在一条直线上,如下图所示:
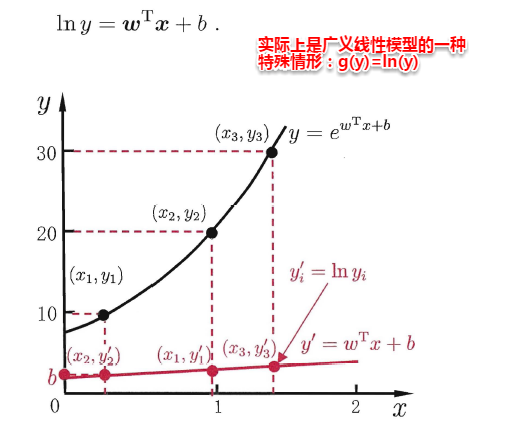
更一般地,考虑所有y的衍生物的情形,就得到了“广义的线性模型”(generalized linear model),其中,g(*)称为联系函数(link function)。
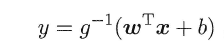
3.2 线性几率回归
回归就是通过输入的属性值得到一个预测值,利用上述广义线性模型的特征,是否可以通过一个联系函数,将预测值转化为离散值从而进行分类呢?线性几率回归正是研究这样的问题。对数几率引入了一个对数几率函数(logistic function),将预测值投影到0-1之间,从而将线性回归问题转化为二分类问题。
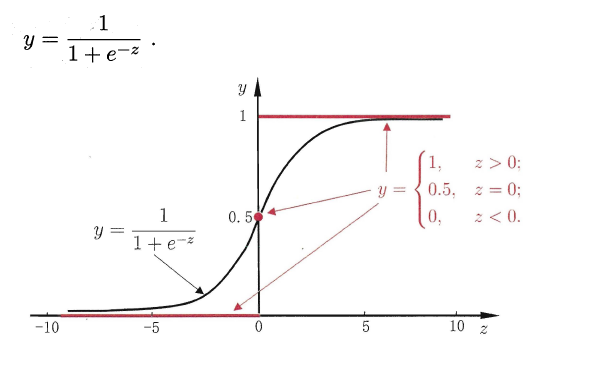

若将y看做样本为正例的概率,(1-y)看做样本为反例的概率,则上式实际上使用线性回归模型的预测结果器逼近真实标记的对数几率。因此这个模型称为“对数几率回归”(logistic regression),也有一些书籍称之为“逻辑回归”。下面使用最大似然估计的方法来计算出w和b两个参数的取值,下面只列出求解的思路,不列出具体的计算过程。
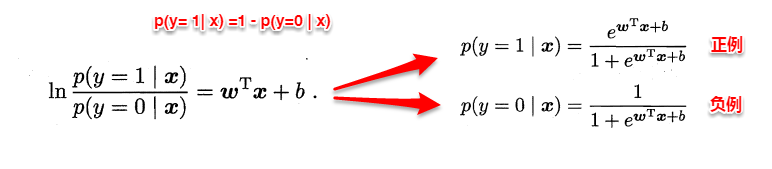

3.3 线性判别分析
线性判别分析(Linear Discriminant Analysis,简称LDA),其基本思想是:将训练样本投影到一条直线上,使得同类的样例尽可能近,不同类的样例尽可能远。如图所示:
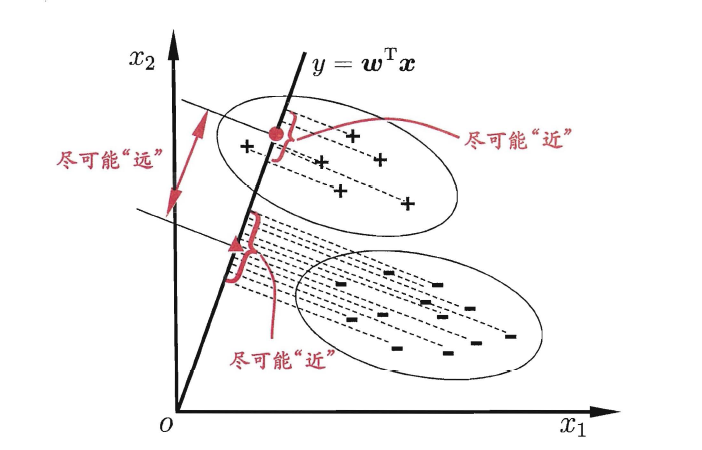

想让同类样本点的投影点尽可能接近,不同类样本点投影之间尽可能远,即:让各类的协方差之和尽可能小,不用类之间中心的距离尽可能大。基于这样的考虑,LDA定义了两个散度矩阵。
- 类内散度矩阵(within-class scatter matrix)
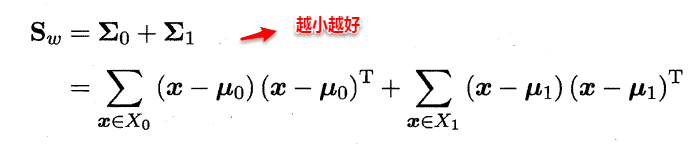
- 类间散度矩阵(between-class scaltter matrix)
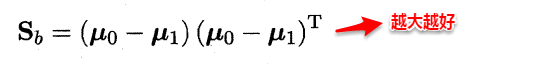
因此得到了LDA的最大化目标:“广义瑞利商”(generalized Rayleigh quotient)。
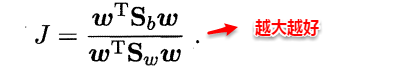
从而分类问题转化为最优化求解w的问题,当求解出w后,对新的样本进行分类时,只需将该样本点投影到这条直线上,根据与各个类别的中心值进行比较,从而判定出新样本与哪个类别距离最近。求解w的方法如下所示,使用的方法为λ乘子。

若将w看做一个投影矩阵,类似PCA的思想,则LDA可将样本投影到N-1维空间(N为类簇数),投影的过程使用了类别信息(标记信息),因此LDA也常被视为一种经典的监督降维技术。
3.4 多分类学习
现实中我们经常遇到不只两个类别的分类问题,即多分类问题,在这种情形下,我们常常运用“拆分”的策略,通过多个二分类学习器来解决多分类问题,即将多分类问题拆解为多个二分类问题,训练出多个二分类学习器,最后将多个分类结果进行集成得出结论。最为经典的拆分策略有三种:“一对一”(OvO)、“一对其余”(OvR)和“多对多”(MvM),核心思想与示意图如下所示。
-
OvO:给定数据集D,假定其中有N个真实类别,将这N个类别进行两两配对(一个正类/一个反类),从而产生N(N-1)/2个二分类学习器,在测试阶段,将新样本放入所有的二分类学习器中测试,得出N(N-1)个结果,最终通过投票产生最终的分类结果。
-
OvM:给定数据集D,假定其中有N个真实类别,每次取出一个类作为正类,剩余的所有类别作为一个新的反类,从而产生N个二分类学习器,在测试阶段,得出N个结果,若仅有一个学习器预测为正类,则对应的类标作为最终分类结果。
-
MvM:给定数据集D,假定其中有N个真实类别,每次取若干个类作为正类,若干个类作为反类(通过ECOC码给出,编码),若进行了M次划分,则生成了M个二分类学习器,在测试阶段(解码),得出M个结果组成一个新的码,最终通过计算海明/欧式距离选择距离最小的类别作为最终分类结果。
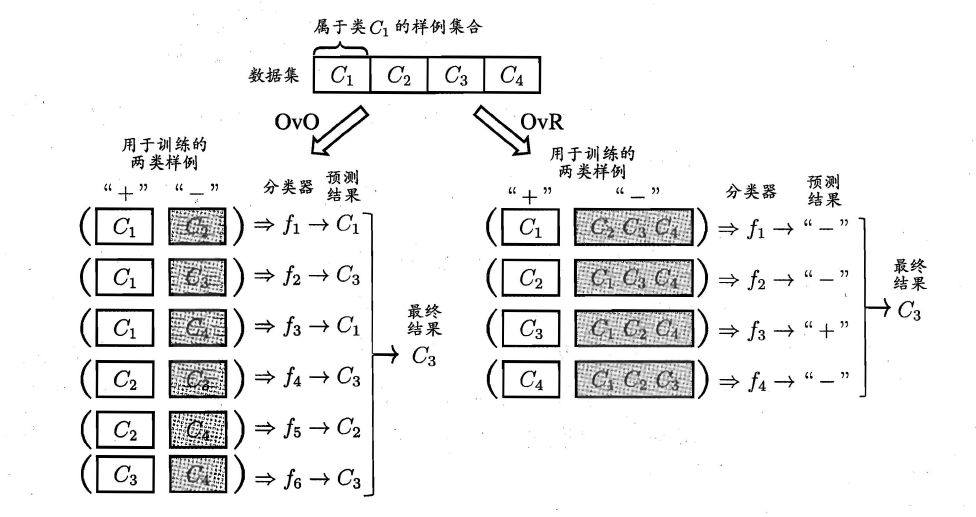
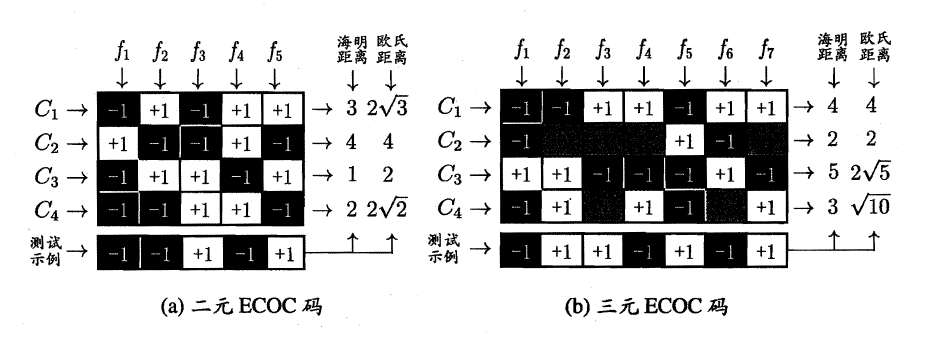
3.5 类别不平衡问题
类别不平衡(class-imbanlance)就是指分类问题中不同类别的训练样本相差悬殊的情况,例如正例有900个,而反例只有100个,这个时候我们就需要进行相应的处理来平衡这个问题。常见的做法有三种:
- 在训练样本较多的类别中进行“欠采样”(undersampling),比如从正例中采出100个,常见的算法有:EasyEnsemble。
- 在训练样本较少的类别中进行“过采样”(oversampling),例如通过对反例中的数据进行插值,来产生额外的反例,常见的算法有SMOTE。
- 直接基于原数据集进行学习,对预测值进行“再缩放”处理。其中再缩放也是代价敏感学习的基础。
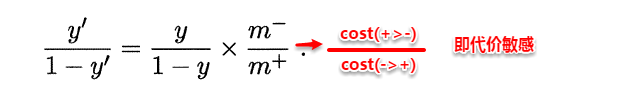
四. 决策树
4.1 决策树基本概念
顾名思义,决策树是基于树结构来进行决策的,在网上看到一个例子十分有趣,放在这里正好合适。现想象一位捉急的母亲想要给自己的女娃介绍一个男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的挑剔过程就是一个典型的决策树,即相当于通过年龄、长相、收入和是否公务员将男童鞋分为两个类别:见和不见。假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么使用下图就能很好地表示女孩的决策逻辑(即一颗决策树)。
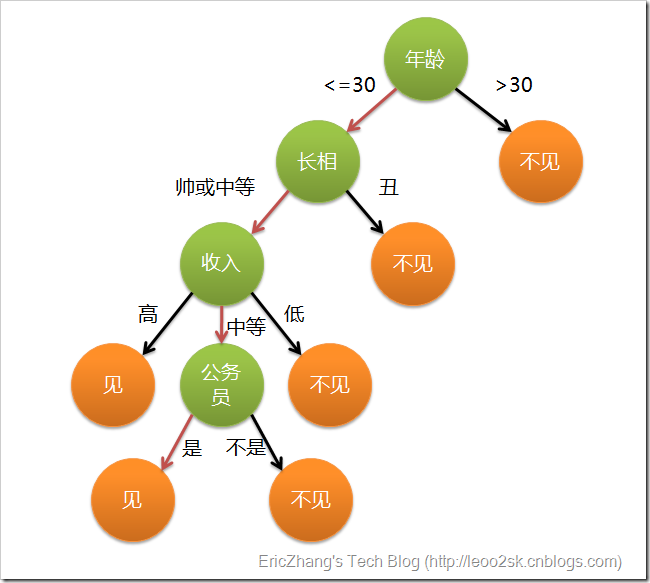
在上图的决策树中,决策过程的每一次判定都是对某一属性的“测试”,决策最终结论则对应最终的判定结果。一般一颗决策树包含:一个根节点、若干个内部节点和若干个叶子节点,易知:
- 每个非叶节点表示一个特征属性测试。
- 每个分支代表这个特征属性在某个值域上的输出。
- 每个叶子节点存放一个类别。
- 每个节点包含的样本集合通过属性测试被划分到子节点中,根节点包含样本全集。
4.2 决策树的构造
决策树的构造是一个递归的过程,有三种情形会导致递归返回:(1) 当前结点包含的样本全属于同一类别,这时直接将该节点标记为叶节点,并设为相应的类别;(2) 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分,这时将该节点标记为叶节点,并将其类别设为该节点所含样本最多的类别;(3) 当前结点包含的样本集合为空,不能划分,这时也将该节点标记为叶节点,并将其类别设为父节点中所含样本最多的类别。算法的基本流程如下图所示:

可以看出:决策树学习的关键在于如何选择划分属性,不同的划分属性得出不同的分支结构,从而影响整颗决策树的性能。属性划分的目标是让各个划分出来的子节点尽可能地“纯”,即属于同一类别。因此下面便是介绍量化纯度的具体方法,决策树最常用的算法有三种:ID3,C4.5和CART。
4.2.1 ID3算法
ID3算法使用信息增益为准则来选择划分属性,“信息熵”(information entropy)是度量样本结合纯度的常用指标,假定当前样本集合D中第k类样本所占比例为pk,则样本集合D的信息熵定义为:

假定通过属性划分样本集D,产生了V个分支节点,v表示其中第v个分支节点,易知:分支节点包含的样本数越多,表示该分支节点的影响力越大。故可以计算出划分后相比原始数据集D获得的“信息增益”(information gain)。
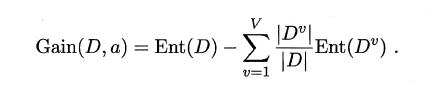
信息增益越大,表示使用该属性划分样本集D的效果越好,因此ID3算法在递归过程中,每次选择最大信息增益的属性作为当前的划分属性。
4.2.2 C4.5算法
ID3算法存在一个问题,就是偏向于取值数目较多的属性,例如:如果存在一个唯一标识,这样样本集D将会被划分为|D|个分支,每个分支只有一个样本,这样划分后的信息熵为零,十分纯净,但是对分类毫无用处。因此C4.5算法使用了“增益率”(gain ratio)来选择划分属性,来避免这个问题带来的困扰。首先使用ID3算法计算出信息增益高于平均水平的候选属性,接着C4.5计算这些候选属性的增益率,增益率定义为:
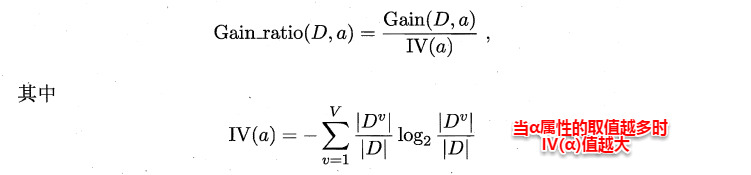
4.2.3 CART算法
CART决策树使用“基尼指数”(Gini index)来选择划分属性,基尼指数反映的是从样本集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小越好,基尼指数定义如下:
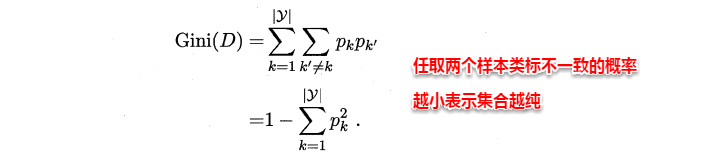
进而,使用属性α划分后的基尼指数为:
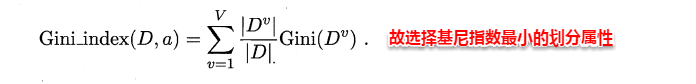
4.3 剪枝处理
从决策树的构造流程中我们可以直观地看出:不管怎么样的训练集,决策树总是能很好地将各个类别分离开来,这时就会遇到之前提到过的问题:过拟合(overfitting),即太依赖于训练样本。剪枝(pruning)则是决策树算法对付过拟合的主要手段,剪枝的策略有两种如下:
- 预剪枝(prepruning):在构造的过程中先评估,再考虑是否分支。
- 后剪枝(post-pruning):在构造好一颗完整的决策树后,自底向上,评估分支的必要性。
评估指的是性能度量,即决策树的泛化性能。之前提到:可以使用测试集作为学习器泛化性能的近似,因此可以将数据集划分为训练集和测试集。预剪枝表示在构造数的过程中,对一个节点考虑是否分支时,首先计算决策树不分支时在测试集上的性能,再计算分支之后的性能,若分支对性能没有提升,则选择不分支(即剪枝)。后剪枝则表示在构造好一颗完整的决策树后,从最下面的节点开始,考虑该节点分支对模型的性能是否有提升,若无则剪枝,即将该节点标记为叶子节点,类别标记为其包含样本最多的类别。
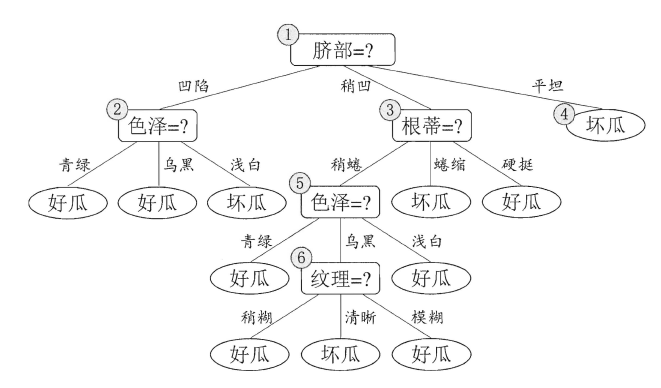
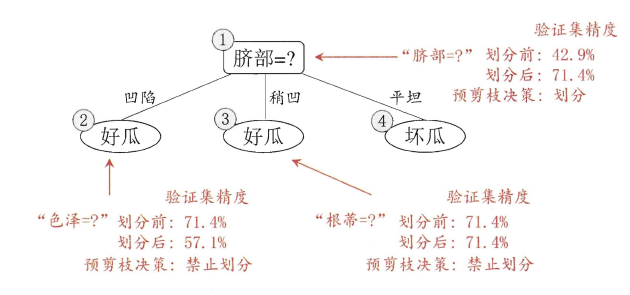
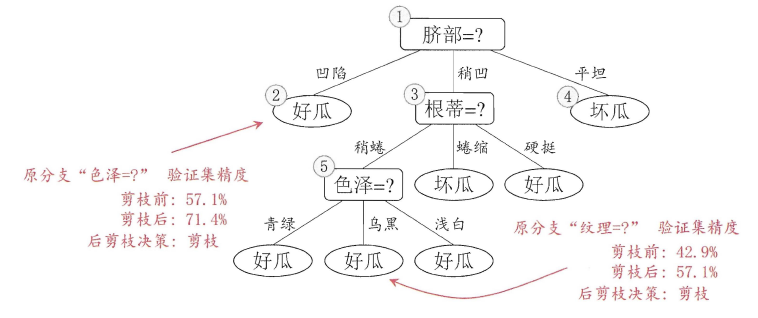
上图分别表示不剪枝处理的决策树、预剪枝决策树和后剪枝决策树。预剪枝处理使得决策树的很多分支被剪掉,因此大大降低了训练时间开销,同时降低了过拟合的风险,但另一方面由于剪枝同时剪掉了当前节点后续子节点的分支,因此预剪枝“贪心”的本质阻止了分支的展开,在一定程度上带来了欠拟合的风险。而后剪枝则通常保留了更多的分支,因此采用后剪枝策略的决策树性能往往优于预剪枝,但其自底向上遍历了所有节点,并计算性能,训练时间开销相比预剪枝大大提升。
4.4 连续值与缺失值处理
对于连续值的属性,若每个取值作为一个分支则显得不可行,因此需要进行离散化处理,常用的方法为二分法,基本思想为:给定样本集D与连续属性α,二分法试图找到一个划分点t将样本集D在属性α上分为≤t与>t。
- 首先将α的所有取值按升序排列,所有相邻属性的均值作为候选划分点(n-1个,n为α所有的取值数目)。
- 计算每一个划分点划分集合D(即划分为两个分支)后的信息增益。
- 选择最大信息增益的划分点作为最优划分点。
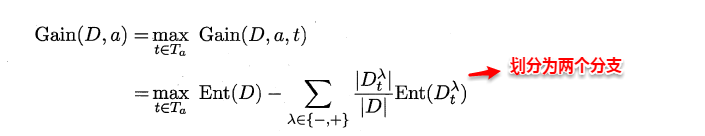
现实中常会遇到不完整的样本,即某些属性值缺失。有时若简单采取剔除,则会造成大量的信息浪费,因此在属性值缺失的情况下需要解决两个问题:(1)如何选择划分属性。(2)给定划分属性,若某样本在该属性上缺失值,如何划分到具体的分支上。假定为样本集中的每一个样本都赋予一个权重,根节点中的权重初始化为1,则定义:

对于(1):通过在样本集D中选取在属性α上没有缺失值的样本子集,计算在该样本子集上的信息增益,最终的信息增益等于该样本子集划分后信息增益乘以样本子集占样本集的比重。即:

对于(2):若该样本子集在属性α上的值缺失,则将该样本以不同的权重(即每个分支所含样本比例)划入到所有分支节点中。该样本在分支节点中的权重变为:

五. 神经网络
在机器学习中,神经网络一般指的是“神经网络学习”,是机器学习与神经网络两个学科的交叉部分。所谓神经网络,目前用得最广泛的一个定义是“神经网络是由具有适应性的简单单元组成的广泛并行互连的网络,它的组织能够模拟生物神经系统对真实世界物体所做出的交互反应”。
5.1 神经元模型
神经网络中最基本的单元是神经元模型(neuron)。在生物神经网络的原始机制中,每个神经元通常都有多个树突(dendrite),一个轴突(axon)和一个细胞体(cell body),树突短而多分支,轴突长而只有一个;在功能上,树突用于传入其它神经元传递的神经冲动,而轴突用于将神经冲动传出到其它神经元,当树突或细胞体传入的神经冲动使得神经元兴奋时,该神经元就会通过轴突向其它神经元传递兴奋。神经元的生物学结构如下图所示,不得不说高中的生化知识大学忘得可是真干净...
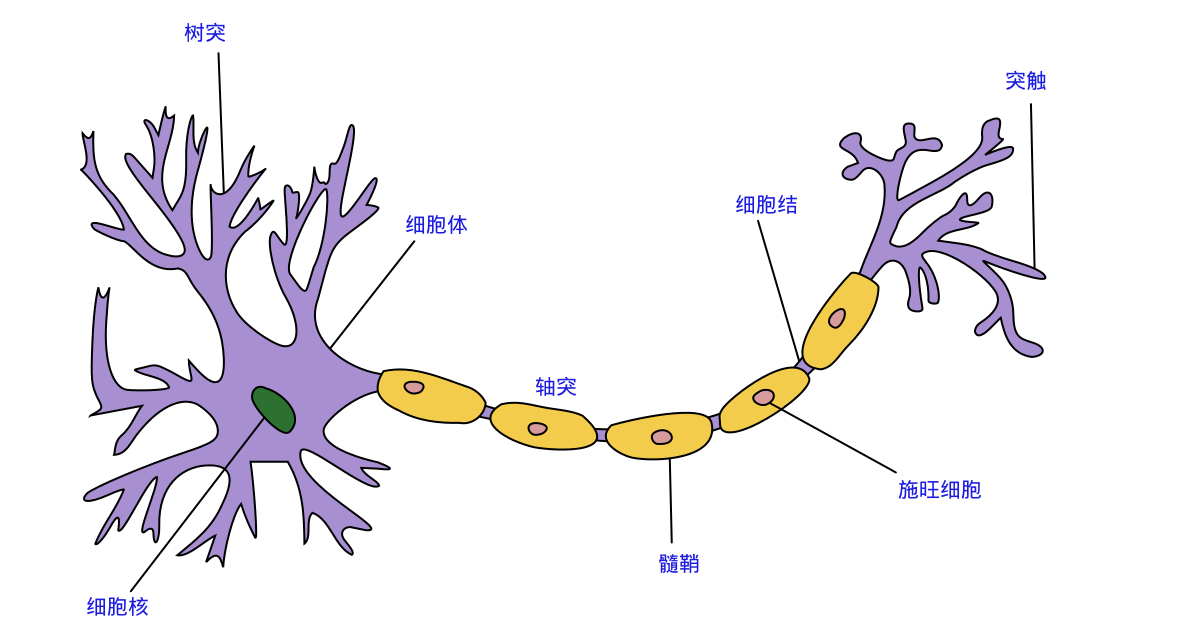
一直沿用至今的“M-P神经元模型”正是对这一结构进行了抽象,也称“阈值逻辑单元“,其中树突对应于输入部分,每个神经元收到n个其他神经元传递过来的输入信号,这些信号通过带权重的连接传递给细胞体,这些权重又称为连接权(connection weight)。细胞体分为两部分,前一部分计算总输入值(即输入信号的加权和,或者说累积电平),后一部分先计算总输入值与该神经元阈值的差值,然后通过激活函数(activation function)的处理,产生输出从轴突传送给其它神经元。M-P神经元模型如下图所示:
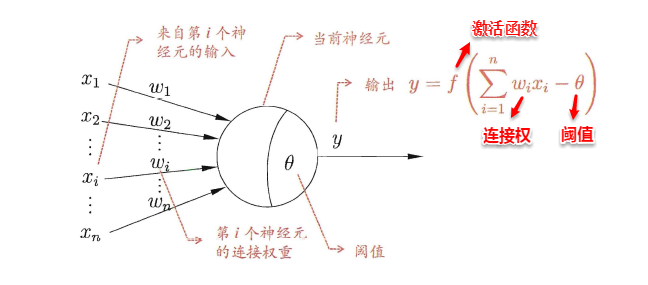
与线性分类十分相似,神经元模型最理想的激活函数也是阶跃函数,即将神经元输入值与阈值的差值映射为输出值1或0,若差值大于零输出1,对应兴奋;若差值小于零则输出0,对应抑制。但阶跃函数不连续,不光滑,故在M-P神经元模型中,也采用Sigmoid函数来近似, Sigmoid函数将较大范围内变化的输入值挤压到 (0,1) 输出值范围内,所以也称为挤压函数(squashing function)。
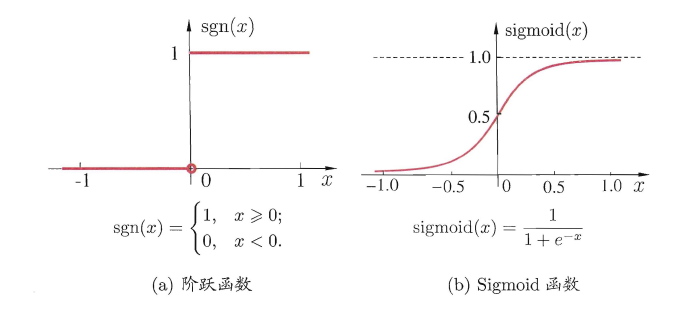
将多个神经元按一定的层次结构连接起来,就得到了神经网络。它是一种包含多个参数的模型,比方说10个神经元两两连接,则有100个参数需要学习(每个神经元有9个连接权以及1个阈值),若将每个神经元都看作一个函数,则整个神经网络就是由这些函数相互嵌套而成。
5.2 感知机与多层网络
感知机(Perceptron)是由两层神经元组成的一个简单模型,但只有输出层是M-P神经元,即只有输出层神经元进行激活函数处理,也称为功能神经元(functional neuron);输入层只是接受外界信号(样本属性)并传递给输出层(输入层的神经元个数等于样本的属性数目),而没有激活函数。这样一来,感知机与之前线性模型中的对数几率回归的思想基本是一样的,都是通过对属性加权与另一个常数求和,再使用sigmoid函数将这个输出值压缩到0-1之间,从而解决分类问题。不同的是感知机的输出层应该可以有多个神经元,从而可以实现多分类问题,同时两个模型所用的参数估计方法十分不同。
给定训练集,则感知机的n+1个参数(n个权重+1个阈值)都可以通过学习得到。阈值Θ可以看作一个输入值固定为-1的哑结点的权重ωn+1,即假设有一个固定输入xn+1=-1的输入层神经元,其对应的权重为ωn+1,这样就把权重和阈值统一为权重的学习了。简单感知机的结构如下图所示:
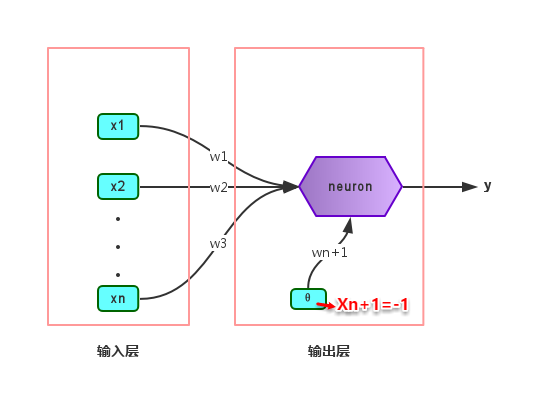
感知机权重的学习规则如下:对于训练样本(x,y),当该样本进入感知机学习后,会产生一个输出值,若该输出值与样本的真实标记不一致,则感知机会对权重进行调整,若激活函数为阶跃函数,则调整的方法为(基于梯度下降法):

其中 η∈(0,1)称为学习率,可以看出感知机是通过逐个样本输入来更新权重,首先设定好初始权重(一般为随机),逐个地输入样本数据,若输出值与真实标记相同则继续输入下一个样本,若不一致则更新权重,然后再重新逐个检验,直到每个样本数据的输出值都与真实标记相同。容易看出:感知机模型总是能将训练数据的每一个样本都预测正确,和决策树模型总是能将所有训练数据都分开一样,感知机模型很容易产生过拟合问题。
由于感知机模型只有一层功能神经元,因此其功能十分有限,只能处理线性可分的问题,对于这类问题,感知机的学习过程一定会收敛(converge),因此总是可以求出适当的权值。但是对于像书上提到的异或问题,只通过一层功能神经元往往不能解决,因此要解决非线性可分问题,需要考虑使用多层功能神经元,即神经网络。多层神经网络的拓扑结构如下图所示:
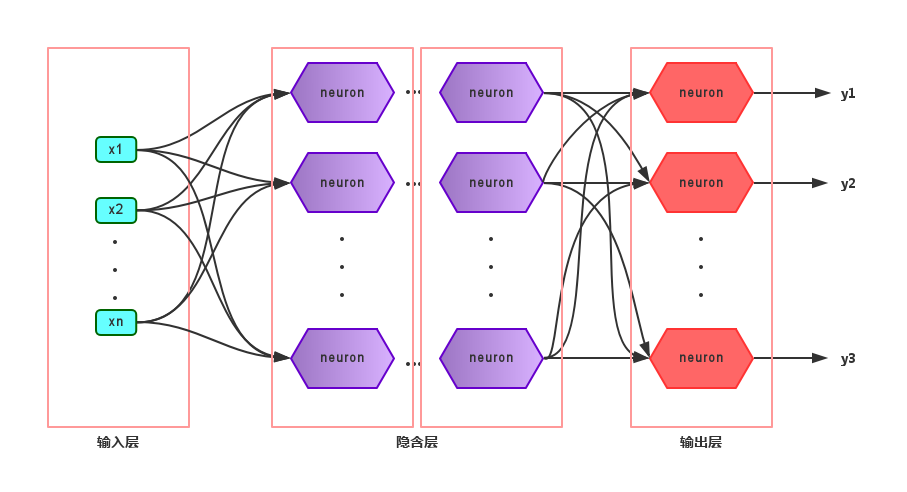
在神经网络中,输入层与输出层之间的层称为隐含层或隐层(hidden layer),隐层和输出层的神经元都是具有激活函数的功能神经元。只需包含一个隐层便可以称为多层神经网络,常用的神经网络称为“多层前馈神经网络”(multi-layer feedforward neural network),该结构满足以下几个特点:
- 每层神经元与下一层神经元之间完全互连
- 神经元之间不存在同层连接
- 神经元之间不存在跨层连接
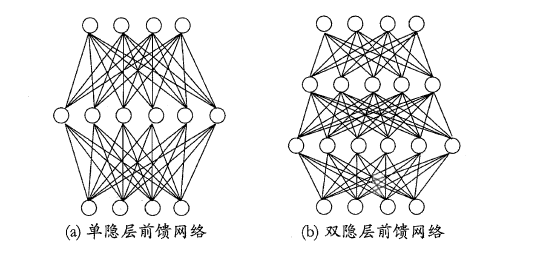
根据上面的特点可以得知:这里的“前馈”指的是网络拓扑结构中不存在环或回路,而不是指该网络只能向前传播而不能向后传播(下节中的BP神经网络正是基于前馈神经网络而增加了反馈调节机制)。神经网络的学习过程就是根据训练数据来调整神经元之间的“连接权”以及每个神经元的阈值,换句话说:神经网络所学习到的东西都蕴含在网络的连接权与阈值中。
5.3 BP神经网络算法
由上面可以得知:神经网络的学习主要蕴含在权重和阈值中,多层网络使用上面简单感知机的权重调整规则显然不够用了,BP神经网络算法即误差逆传播算法(error BackPropagation)正是为学习多层前馈神经网络而设计,BP神经网络算法是迄今为止最成功的的神经网络学习算法。
一般而言,只需包含一个足够多神经元的隐层,就能以任意精度逼近任意复杂度的连续函数[Hornik et al.,1989],故下面以训练单隐层的前馈神经网络为例,介绍BP神经网络的算法思想。
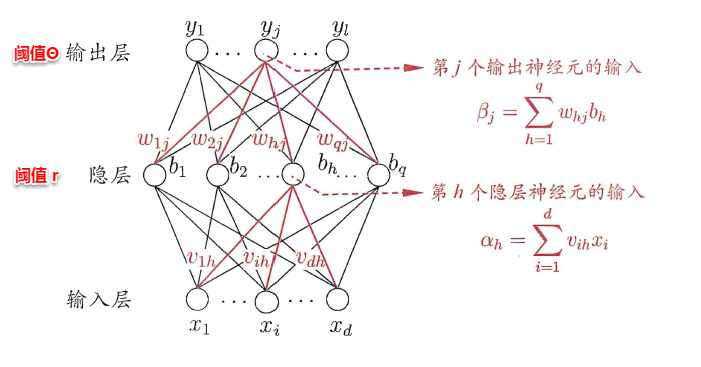
上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。BP算法基本的推导过程与感知机的推导过程原理是相同的,下面给出调整隐含层到输出层的权重调整规则的推导过程:

学习率η∈(0,1)控制着沿反梯度方向下降的步长,若步长太大则下降太快容易产生震荡,若步长太小则收敛速度太慢,一般地常把η设置为0.1,有时更新权重时会将输出层与隐含层设置为不同的学习率。BP算法的基本流程如下所示:

BP算法的更新规则是基于每个样本的预测值与真实类标的均方误差来进行权值调节,即BP算法每次更新只针对于单个样例。需要注意的是:BP算法的最终目标是要最小化整个训练集D上的累积误差,即:
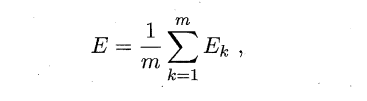
如果基于累积误差最小化的更新规则,则得到了累积误差逆传播算法(accumulated error backpropagation),即每次读取全部的数据集一遍,进行一轮学习,从而基于当前的累积误差进行权值调整,因此参数更新的频率相比标准BP算法低了很多,但在很多任务中,尤其是在数据量很大的时候,往往标准BP算法会获得较好的结果。另外对于如何设置隐层神经元个数的问题,至今仍然没有好的解决方案,常使用“试错法”进行调整。
前面提到,BP神经网络强大的学习能力常常容易造成过拟合问题,有以下两种策略来缓解BP网络的过拟合问题:
- 早停:将数据分为训练集与测试集,训练集用于学习,测试集用于评估性能,若在训练过程中,训练集的累积误差降低,而测试集的累积误差升高,则停止训练。
- 引入正则化(regularization):基本思想是在累积误差函数中增加一个用于描述网络复杂度的部分,例如所有权值与阈值的平方和,其中λ∈(0,1)用于对累积经验误差与网络复杂度这两项进行折中,常通过交叉验证法来估计。
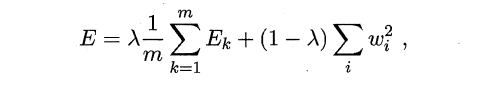
5.4 全局最小与局部最小
模型学习的过程实质上就是一个寻找最优参数的过程,例如BP算法试图通过最速下降来寻找使得累积经验误差最小的权值与阈值,在谈到最优时,一般会提到局部极小(local minimum)和全局最小(global minimum)。
- 局部极小解:参数空间中的某个点,其邻域点的误差函数值均不小于该点的误差函数值。
- 全局最小解:参数空间中的某个点,所有其他点的误差函数值均不小于该点的误差函数值。
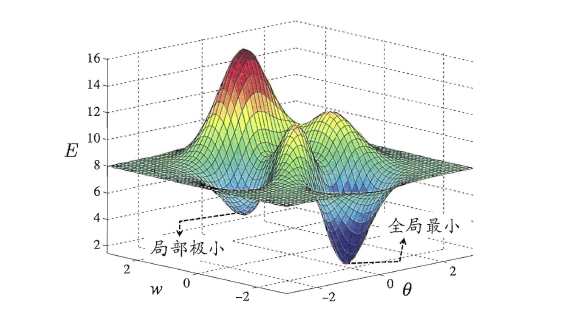
要成为局部极小点,只要满足该点在参数空间中的梯度为零。局部极小可以有多个,而全局最小只有一个。全局最小一定是局部极小,但局部最小却不一定是全局最小。显然在很多机器学习算法中,都试图找到目标函数的全局最小。梯度下降法的主要思想就是沿着负梯度方向去搜索最优解,负梯度方向是函数值下降最快的方向,若迭代到某处的梯度为0,则表示达到一个局部最小,参数更新停止。因此在现实任务中,通常使用以下策略尽可能地去接近全局最小。
- 以多组不同参数值初始化多个神经网络,按标准方法训练,迭代停止后,取其中误差最小的解作为最终参数。
- 使用“模拟退火”技术,这里不做具体介绍。
- 使用随机梯度下降,即在计算梯度时加入了随机因素,使得在局部最小时,计算的梯度仍可能不为0,从而迭代可以继续进行。
5.5 深度学习
理论上,参数越多,模型复杂度就越高,容量(capability)就越大,从而能完成更复杂的学习任务。深度学习(deep learning)正是一种极其复杂而强大的模型。
怎么增大模型复杂度呢?两个办法,一是增加隐层的数目,二是增加隐层神经元的数目。前者更有效一些,因为它不仅增加了功能神经元的数量,还增加了激活函数嵌套的层数。但是对于多隐层神经网络,经典算法如标准BP算法往往会在误差逆传播时发散(diverge),无法收敛达到稳定状态。
那要怎么有效地训练多隐层神经网络呢?一般来说有以下两种方法:
-
无监督逐层训练(unsupervised layer-wise training):每次训练一层隐节点,把上一层隐节点的输出当作输入来训练,本层隐结点训练好后,输出再作为下一层的输入来训练,这称为预训练(pre-training)。全部预训练完成后,再对整个网络进行微调(fine-tuning)训练。一个典型例子就是深度信念网络(deep belief network,简称DBN)。这种做法其实可以视为把大量的参数进行分组,先找出每组较好的设置,再基于这些局部最优的结果来训练全局最优。
-
权共享(weight sharing):令同一层神经元使用完全相同的连接权,典型的例子是卷积神经网络(Convolutional Neural Network,简称CNN)。这样做可以大大减少需要训练的参数数目。
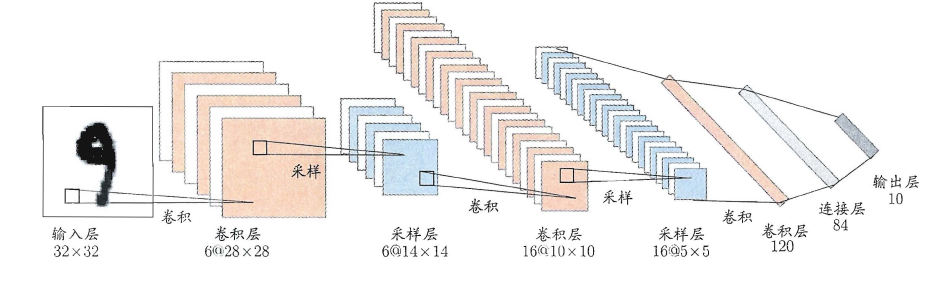
深度学习可以理解为一种特征学习(feature learning)或者表示学习(representation learning),无论是DBN还是CNN,都是通过多个隐层来把与输出目标联系不大的初始输入转化为与输出目标更加密切的表示,使原来只通过单层映射难以完成的任务变为可能。即通过多层处理,逐渐将初始的“低层”特征表示转化为“高层”特征表示,从而使得最后可以用简单的模型来完成复杂的学习任务。
传统任务中,样本的特征需要人类专家来设计,这称为特征工程(feature engineering)。特征好坏对泛化性能有至关重要的影响。而深度学习为全自动数据分析带来了可能,可以自动产生更好的特征。
六. 支持向量机
支持向量机是一种经典的二分类模型,基本模型定义为特征空间中最大间隔的线性分类器,其学习的优化目标便是间隔最大化,因此支持向量机本身可以转化为一个凸二次规划求解的问题。
6.1 函数间隔与几何间隔
对于二分类学习,假设现在的数据是线性可分的,这时分类学习最基本的想法就是找到一个合适的超平面,该超平面能够将不同类别的样本分开,类似二维平面使用ax+by+c=0来表示,超平面实际上表示的就是高维的平面,如下图所示:
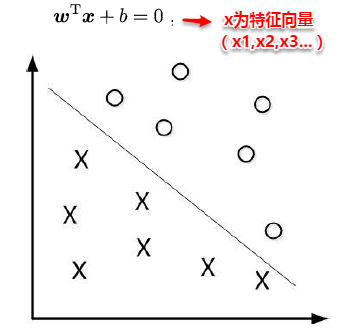
对数据点进行划分时,易知:当超平面距离与它最近的数据点的间隔越大,分类的鲁棒性越好,即当新的数据点加入时,超平面对这些点的适应性最强,出错的可能性最小。因此需要让所选择的超平面能够最大化这个间隔Gap(如下图所示), 常用的间隔定义有两种,一种称之为函数间隔,一种为几何间隔,下面将分别介绍这两种间隔,并对SVM为什么会选用几何间隔做了一些阐述。
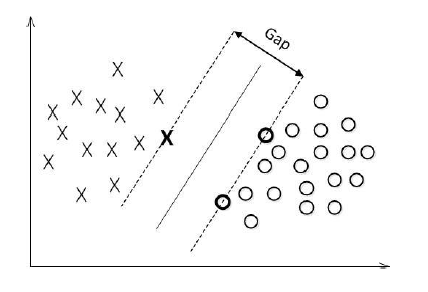
6.1.1 函数间隔
在超平面w'x+b=0确定的情况下,|w'x*+b|能够代表点x距离超平面的远近,易知:当w'x+b>0时,表示x在超平面的一侧(正类,类标为1),而当w'x+b<0时,则表示x在超平面的另外一侧(负类,类别为-1),因此(w'x+b)y* 的正负性恰能表示数据点x*是否被分类正确。于是便引出了函数间隔的定义(functional margin):
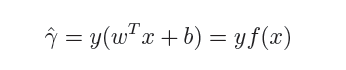
而超平面(w,b)关于所有样本点(Xi,Yi)的函数间隔最小值则为超平面在训练数据集T上的函数间隔:
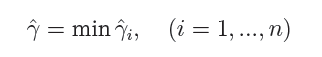
可以看出:这样定义的函数间隔在处理SVM上会有问题,当超平面的两个参数w和b同比例改变时,函数间隔也会跟着改变,但是实际上超平面还是原来的超平面,并没有变化。例如:w1x1+w2x2+w3x3+b=0其实等价于2w1x1+2w2x2+2w3x3+2b=0,但计算的函数间隔却翻了一倍。从而引出了能真正度量点到超平面距离的概念--几何间隔(geometrical margin)。
6.1.2 几何间隔
几何间隔代表的则是数据点到超平面的真实距离,对于超平面w'x+b=0,w代表的是该超平面的法向量,设x为超平面外一点x在法向量w方向上的投影点,x与超平面的距离为r,则有x=x-r(w/||w||),又x在超平面上,即w'x+b=0,代入即可得:
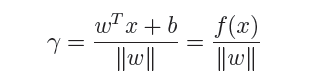
为了得到r的绝对值,令r呈上其对应的类别y,即可得到几何间隔的定义:
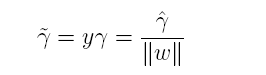
从上述函数间隔与几何间隔的定义可以看出:实质上函数间隔就是|w'x+b|,而几何间隔就是点到超平面的距离。
6.2 最大间隔与支持向量
通过前面的分析可知:函数间隔不适合用来最大化间隔,因此这里我们要找的最大间隔指的是几何间隔,于是最大间隔分类器的目标函数定义为:
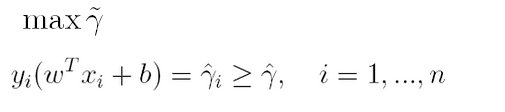
一般地,我们令r^为1(这样做的目的是为了方便推导和目标函数的优化),从而上述目标函数转化为:
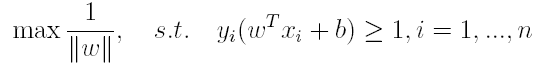
对于y(w'x+b)=1的数据点,即下图中位于w'x+b=1或w'x+b=-1上的数据点,我们称之为支持向量(support vector),易知:对于所有的支持向量,它们恰好满足y*(w'x*+b)=1,而所有不是支持向量的点,有y*(w'x*+b)>1。
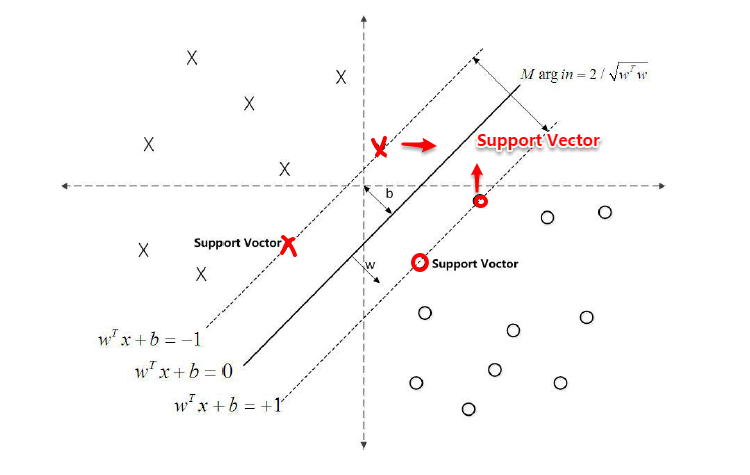
6.3 从原始优化问题到对偶问题
对于上述得到的目标函数,求1/||w||的最大值相当于求||w||^2的最小值,因此很容易将原来的目标函数转化为:
即变为了一个带约束的凸二次规划问题,按书上所说可以使用现成的优化计算包(QP优化包)求解,但由于SVM的特殊性,一般我们将原问题变换为它的对偶问题,接着再对其对偶问题进行求解。为什么通过对偶问题进行求解,有下面两个原因:
- 一是因为使用对偶问题更容易求解;
- 二是因为通过对偶问题求解出现了向量内积的形式,从而能更加自然地引出核函数。
对偶问题,顾名思义,可以理解成优化等价的问题,更一般地,是将一个原始目标函数的最小化转化为它的对偶函数最大化的问题。对于当前的优化问题,首先我们写出它的朗格朗日函数:
上式很容易验证:当其中有一个约束条件不满足时,L的最大值为 ∞(只需令其对应的α为 ∞即可);当所有约束条件都满足时,L的最大值为1/2||w||^2(此时令所有的α为0),因此实际上原问题等价于:
由于这个的求解问题不好做,因此一般我们将最小和最大的位置交换一下(需满足KKT条件) ,变成原问题的对偶问题:
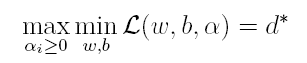
这样就将原问题的求最小变成了对偶问题求最大(用对偶这个词还是很形象),接下来便可以先求L对w和b的极小,再求L对α的极大。
(1)首先求L对w和b的极小,分别求L关于w和b的偏导,可以得出:
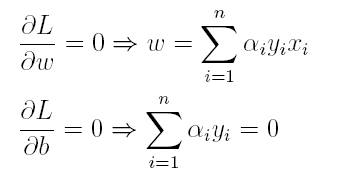
将上述结果代入L得到:
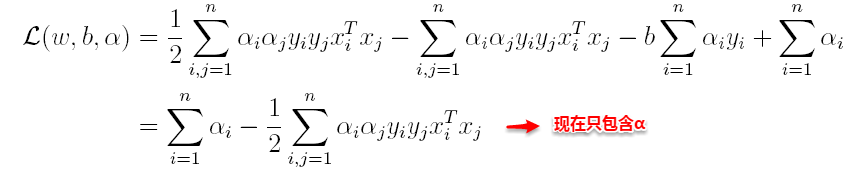
(2)接着L关于α极大求解α(通过SMO算法求解,此处不做深入)。
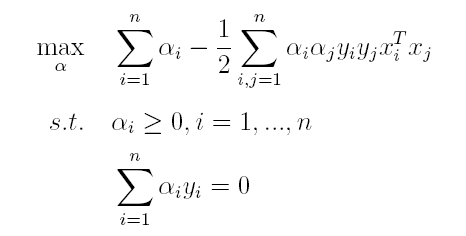
(3)最后便可以根据求解出的α,计算出w和b,从而得到分类超平面函数。
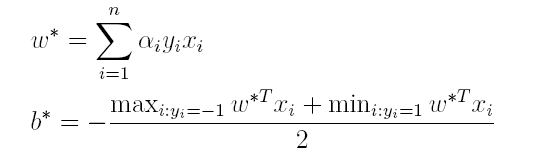
在对新的点进行预测时,实际上就是将数据点x*代入分类函数f(x)=w'x+b中,若f(x)>0,则为正类,f(x)<0,则为负类,根据前面推导得出的w与b,分类函数如下所示,此时便出现了上面所提到的内积形式。
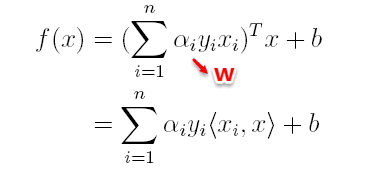
这里实际上只需计算新样本与支持向量的内积,因为对于非支持向量的数据点,其对应的拉格朗日乘子一定为0,根据最优化理论(K-T条件),对于不等式约束y(w'x+b)-1≥0,满足:
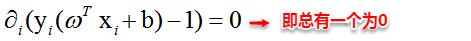
6.4 核函数
由于上述的超平面只能解决线性可分的问题,对于线性不可分的问题,例如:异或问题,我们需要使用核函数将其进行推广。一般地,解决线性不可分问题时,常常采用映射的方式,将低维原始空间映射到高维特征空间,使得数据集在高维空间中变得线性可分,从而再使用线性学习器分类。如果原始空间为有限维,即属性数有限,那么总是存在一个高维特征空间使得样本线性可分。若∅代表一个映射,则在特征空间中的划分函数变为:
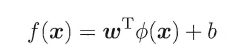
按照同样的方法,先写出新目标函数的拉格朗日函数,接着写出其对偶问题,求L关于w和b的极大,最后运用SOM求解α。可以得出:
(1)原对偶问题变为:
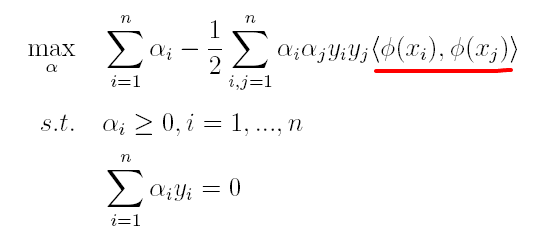
(2)原分类函数变为:
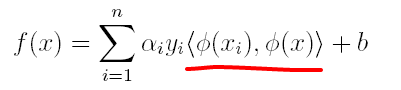
求解的过程中,只涉及到了高维特征空间中的内积运算,由于特征空间的维数可能会非常大,例如:若原始空间为二维,映射后的特征空间为5维,若原始空间为三维,映射后的特征空间将是19维,之后甚至可能出现无穷维,根本无法进行内积运算了,此时便引出了核函数(Kernel)的概念。

因此,核函数可以直接计算隐式映射到高维特征空间后的向量内积,而不需要显式地写出映射后的结果,它虽然完成了将特征从低维到高维的转换,但最终却是在低维空间中完成向量内积计算,与高维特征空间中的计算等效**(低维计算,高维表现)**,从而避免了直接在高维空间无法计算的问题。引入核函数后,原来的对偶问题与分类函数则变为:
(1)对偶问题:
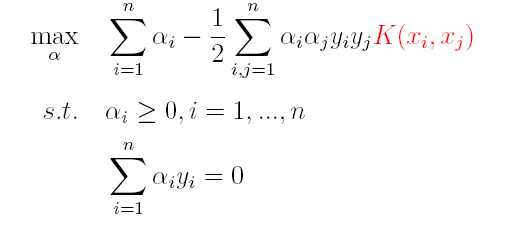
(2)分类函数:
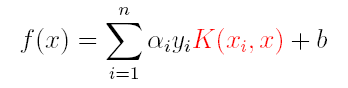
因此,在线性不可分问题中,核函数的选择成了支持向量机的最大变数,若选择了不合适的核函数,则意味着将样本映射到了一个不合适的特征空间,则极可能导致性能不佳。同时,核函数需要满足以下这个必要条件:

由于核函数的构造十分困难,通常我们都是从一些常用的核函数中选择,下面列出了几种常用的核函数:

6.5 软间隔支持向量机
前面的讨论中,我们主要解决了两个问题:当数据线性可分时,直接使用最大间隔的超平面划分;当数据线性不可分时,则通过核函数将数据映射到高维特征空间,使之线性可分。然而在现实问题中,对于某些情形还是很难处理,例如数据中有噪声的情形,噪声数据(outlier)本身就偏离了正常位置,但是在前面的SVM模型中,我们要求所有的样本数据都必须满足约束,如果不要这些噪声数据还好,当加入这些outlier后导致划分超平面被挤歪了,如下图所示,对支持向量机的泛化性能造成很大的影响。
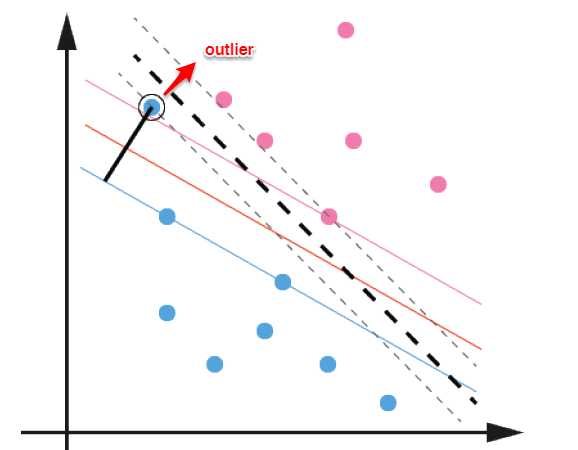
为了解决这一问题,我们需要允许某一些数据点不满足约束,即可以在一定程度上偏移超平面,同时使得不满足约束的数据点尽可能少,这便引出了**“软间隔”支持向量机**的概念
- 允许某些数据点不满足约束y(w'x+b)≥1;
- 同时又使得不满足约束的样本尽可能少。
这样优化目标变为:
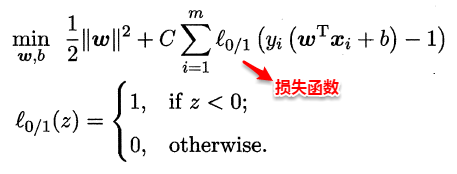
如同阶跃函数,0/1损失函数虽然表示效果最好,但是数学性质不佳。因此常用其它函数作为“替代损失函数”。
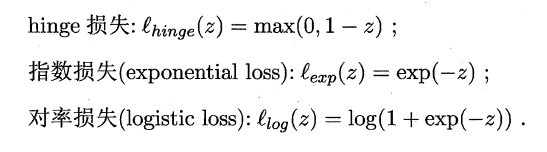
支持向量机中的损失函数为hinge损失,引入**“松弛变量”**,目标函数与约束条件可以写为:
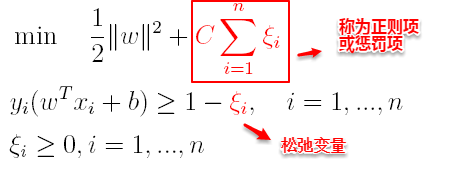
其中C为一个参数,控制着目标函数与新引入正则项之间的权重,这样显然每个样本数据都有一个对应的松弛变量,用以表示该样本不满足约束的程度,将新的目标函数转化为拉格朗日函数得到:
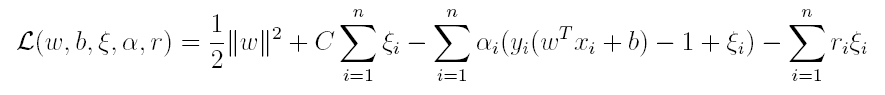
按照与之前相同的方法,先让L求关于w,b以及松弛变量的极小,再使用SMO求出α,有:
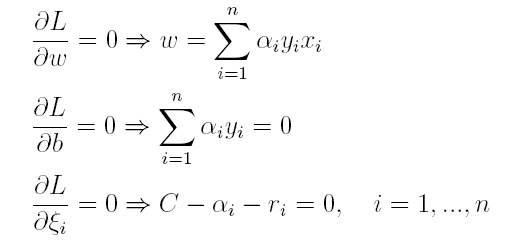
将w代入L化简,便得到其对偶问题:

将“软间隔”下产生的对偶问题与原对偶问题对比可以发现:新的对偶问题只是约束条件中的α多出了一个上限C,其它的完全相同,因此在引入核函数处理线性不可分问题时,便能使用与“硬间隔”支持向量机完全相同的方法。
七. 贝叶斯分类器
贝叶斯分类器是一种概率框架下的统计学习分类器,对分类任务而言,假设在相关概率都已知的情况下,贝叶斯分类器考虑如何基于这些概率为样本判定最优的类标。在开始介绍贝叶斯决策论之前,我们首先来回顾下概率论委员会常委--贝叶斯公式。

7.1 贝叶斯决策论
若将上述定义中样本空间的划分Bi看做为类标,A看做为一个新的样本,则很容易将条件概率理解为样本A是类别Bi的概率。在机器学习训练模型的过程中,往往我们都试图去优化一个风险函数,因此在概率框架下我们也可以为贝叶斯定义“条件风险”(conditional risk)。
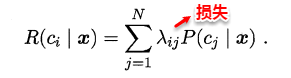
我们的任务就是寻找一个判定准则最小化所有样本的条件风险总和,因此就有了贝叶斯判定准则(Bayes decision rule):为最小化总体风险,只需在每个样本上选择那个使得条件风险最小的类标。
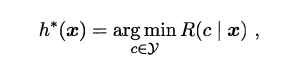
若损失函数λ取0-1损失,则有:
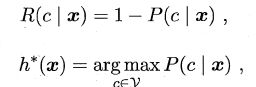
即对于每个样本x,选择其后验概率P(c | x)最大所对应的类标,能使得总体风险函数最小,从而将原问题转化为估计后验概率P(c | x)。一般这里有两种策略来对后验概率进行估计:
- 判别式模型:直接对 P(c | x)进行建模求解。例我们前面所介绍的决策树、神经网络、SVM都是属于判别式模型。
- 生成式模型:通过先对联合分布P(x,c)建模,从而进一步求解 P(c | x)。
贝叶斯分类器就属于生成式模型,基于贝叶斯公式对后验概率P(c | x) 进行一项神奇的变换,巴拉拉能量.... P(c | x)变身:
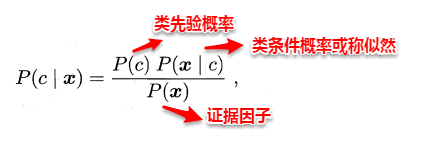
对于给定的样本x,P(x)与类标无关,P(c)称为类先验概率,p(x | c )称为类条件概率。这时估计后验概率P(c | x)就变成为估计类先验概率和类条件概率的问题。对于先验概率和后验概率,在看这章之前也是模糊了我好久,这里普及一下它们的基本概念。
- 先验概率: 根据以往经验和分析得到的概率。
- 后验概率:后验概率是基于新的信息,修正原来的先验概率后所获得的更接近实际情况的概率估计。
实际上先验概率就是在没有任何结果出来的情况下估计的概率,而后验概率则是在有一定依据后的重新估计,直观意义上后验概率就是条件概率。下面直接上Wiki上的一个例子,简单粗暴快速完事...

回归正题,对于类先验概率P(c),p(c)就是样本空间中各类样本所占的比例,根据大数定理(当样本足够多时,频率趋于稳定等于其概率),这样当训练样本充足时,p(c)可以使用各类出现的频率来代替。因此只剩下类条件概率p(x | c ),它表达的意思是在类别c中出现x的概率,它涉及到属性的联合概率问题,若只有一个离散属性还好,当属性多时采用频率估计起来就十分困难,因此这里一般采用极大似然法进行估计。
7.2 极大似然法
极大似然估计(Maximum Likelihood Estimation,简称MLE),是一种根据数据采样来估计概率分布的经典方法。常用的策略是先假定总体具有某种确定的概率分布,再基于训练样本对概率分布的参数进行估计。运用到类条件概率p(x | c )中,假设p(x | c )服从一个参数为θ的分布,问题就变为根据已知的训练样本来估计θ。极大似然法的核心思想就是:估计出的参数使得已知样本出现的概率最大,即使得训练数据的似然最大。

所以,贝叶斯分类器的训练过程就是参数估计。总结最大似然法估计参数的过程,一般分为以下四个步骤:
- 1.写出似然函数;
- 2.对似然函数取对数,并整理;
- 3.求导数,令偏导数为0,得到似然方程组;
- 4.解似然方程组,得到所有参数即为所求。
例如:假设样本属性都是连续值,p(x | c )服从一个多维高斯分布,则通过MLE计算出的参数刚好分别为:
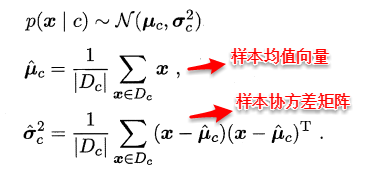
上述结果看起来十分合乎实际,但是采用最大似然法估计参数的效果很大程度上依赖于作出的假设是否合理,是否符合潜在的真实数据分布。这就需要大量的经验知识,搞统计越来越值钱也是这个道理,大牛们掐指一算比我们搬砖几天更有效果。
7.3 朴素贝叶斯分类器
不难看出:原始的贝叶斯分类器最大的问题在于联合概率密度函数的估计,首先需要根据经验来假设联合概率分布,其次当属性很多时,训练样本往往覆盖不够,参数的估计会出现很大的偏差。为了避免这个问题,朴素贝叶斯分类器(naive Bayes classifier)采用了“属性条件独立性假设”,即样本数据的所有属性之间相互独立。这样类条件概率p(x | c )可以改写为:
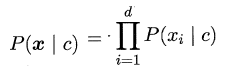
这样,为每个样本估计类条件概率变成为每个样本的每个属性估计类条件概率。

相比原始贝叶斯分类器,朴素贝叶斯分类器基于单个的属性计算类条件概率更加容易操作,需要注意的是:若某个属性值在训练集中和某个类别没有一起出现过,这样会抹掉其它的属性信息,因为该样本的类条件概率被计算为0。因此在估计概率值时,常常用进行平滑(smoothing)处理,拉普拉斯修正(Laplacian correction)就是其中的一种经典方法,具体计算方法如下:

当训练集越大时,拉普拉斯修正引入的影响越来越小。对于贝叶斯分类器,模型的训练就是参数估计,因此可以事先将所有的概率储存好,当有新样本需要判定时,直接查表计算即可。
八. EM算法
EM(Expectation-Maximization)算法是一种常用的估计参数隐变量的利器,也称为“期望最大算法”,是数据挖掘的十大经典算法之一。EM算法主要应用于训练集样本不完整即存在隐变量时的情形(例如某个属性值未知),通过其独特的“两步走”策略能较好地估计出隐变量的值。
8.1 EM算法思想
EM是一种迭代式的方法,它的基本思想就是:若样本服从的分布参数θ已知,则可以根据已观测到的训练样本推断出隐变量Z的期望值(E步),若Z的值已知则运用最大似然法估计出新的θ值(M步)。重复这个过程直到Z和θ值不再发生变化。
简单来讲:假设我们想估计A和B这两个参数,在开始状态下二者都是未知的,但如果知道了A的信息就可以得到B的信息,反过来知道了B也就得到了A。可以考虑首先赋予A某种初值,以此得到B的估计值,然后从B的当前值出发,重新估计A的取值,这个过程一直持续到收敛为止。

现在再来回想聚类的代表算法K-Means:【首先随机选择类中心=>将样本点划分到类簇中=>重新计算类中心=>不断迭代直至收敛】,不难发现这个过程和EM迭代的方法极其相似,事实上,若将样本的类别看做为“隐变量”(latent variable)Z,类中心看作样本的分布参数θ,K-Means就是通过EM算法来进行迭代的,与我们这里不同的是,K-Means的目标是最小化样本点到其对应类中心的距离和,上述为极大化似然函数。
8.2 EM算法数学推导
在上篇极大似然法中,当样本属性值都已知时,我们很容易通过极大化对数似然,接着对每个参数求偏导计算出参数的值。但当存在隐变量时,就无法直接求解,此时我们通常最大化已观察数据的对数“边际似然”(marginal likelihood)。
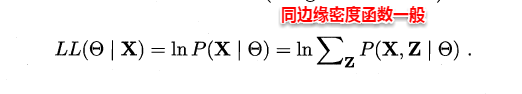
这时候,通过边缘似然将隐变量Z引入进来,对于参数估计,现在与最大似然不同的只是似然函数式中多了一个未知的变量Z,也就是说我们的目标是找到适合的θ和Z让L(θ)最大,这样我们也可以分别对未知的θ和Z求偏导,再令其等于0。
然而观察上式可以发现,和的对数(ln(x1+x2+x3))求导十分复杂,那能否通过变换上式得到一种求导简单的新表达式呢?这时候 Jensen不等式就派上用场了,先回顾一下高等数学凸函数的内容:
Jensen's inequality:过一个凸函数上任意两点所作割线一定在这两点间的函数图象的上方。理解起来也十分简单,对于凸函数f(x)''>0,即曲线的变化率是越来越大单调递增的,所以函数越到后面增长越厉害,这样在一个区间下,函数的均值就会大一些了。
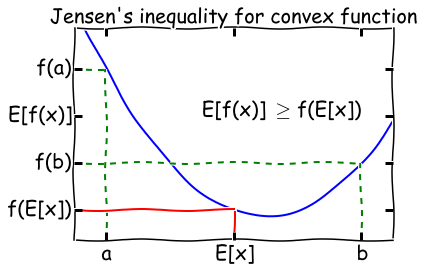
因为ln(*)函数为凹函数,故可以将上式“和的对数”变为“对数的和”,这样就很容易求导了。
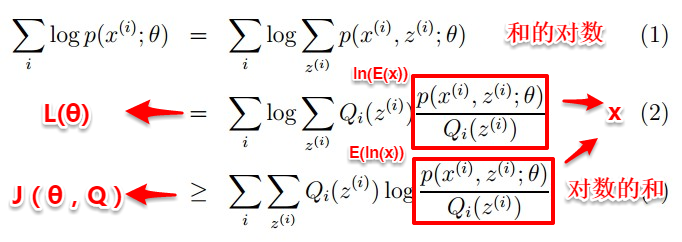
接着求解Qi和θ:首先固定θ(初始值),通过求解Qi使得J(θ,Q)在θ处与L(θ)相等,即求出L(θ)的下界;然后再固定Qi,调整θ,最大化下界J(θ,Q)。不断重复两个步骤直到稳定。通过jensen不等式的性质,Qi的计算公式实际上就是后验概率:
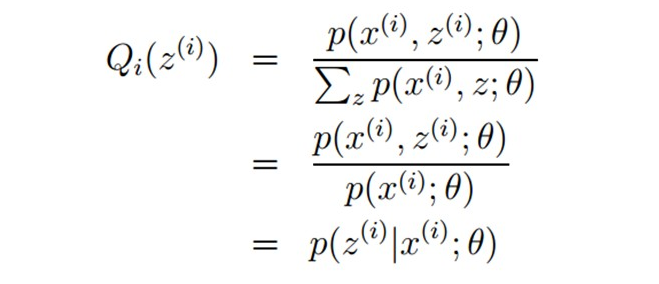
通过数学公式的推导,简单来理解这一过程:固定θ计算Q的过程就是在建立L(θ)的下界,即通过jenson不等式得到的下界(E步);固定Q计算θ则是使得下界极大化(M步),从而不断推高边缘似然L(θ)。从而循序渐进地计算出L(θ)取得极大值时隐变量Z的估计值。
EM算法也可以看作一种“坐标下降法”,首先固定一个值,对另外一个值求极值,不断重复直到收敛。这时候也许大家就有疑问,问什么不直接这两个家伙求偏导用梯度下降呢?这时候就是坐标下降的优势,有些特殊的函数,例如曲线函数z=y^2+x^2+x^2y+xy+...,无法直接求导,这时如果先固定其中的一个变量,再对另一个变量求极值,则变得可行。
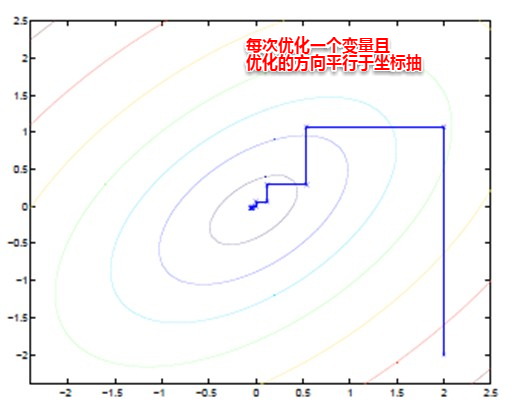
8.3 EM算法流程
看完数学推导,算法的流程也就十分简单了,这里有两个版本,版本一来自西瓜书,周天使的介绍十分简洁;版本二来自于大牛的博客。结合着数学推导,自认为版本二更具有逻辑性,两者唯一的区别就在于版本二多出了红框的部分.
版本一:

版本二:

九. 集成学习
顾名思义,集成学习(ensemble learning)指的是将多个学习器进行有效地结合,组建一个“学习器委员会”,其中每个学习器担任委员会成员并行使投票表决权,使得委员会最后的决定更能够四方造福普度众生~...~,即其泛化性能要能优于其中任何一个学习器。
9.1 个体与集成
集成学习的基本结构为:先产生一组个体学习器,再使用某种策略将它们结合在一起。集成模型如下图所示:
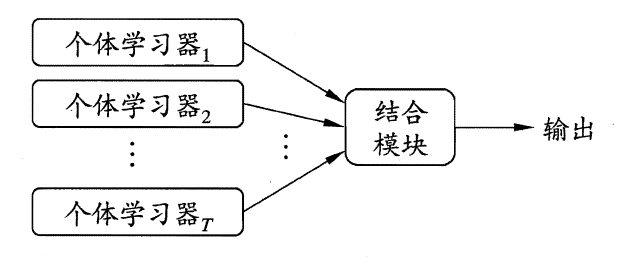
在上图的集成模型中,若个体学习器都属于同一类别,例如都是决策树或都是神经网络,则称该集成为同质的(homogeneous);若个体学习器包含多种类型的学习算法,例如既有决策树又有神经网络,则称该集成为异质的(heterogenous)。
同质集成:个体学习器称为“基学习器”(base learner),对应的学习算法为“基学习算法”(base learning algorithm)。 异质集成:个体学习器称为“组件学习器”(component learner)或直称为“个体学习器”。
上面我们已经提到要让集成起来的泛化性能比单个学习器都要好,虽说团结力量大但也有木桶短板理论调皮捣蛋,那如何做到呢?这就引出了集成学习的两个重要概念:准确性和多样性(diversity)。准确性指的是个体学习器不能太差,要有一定的准确度;多样性则是个体学习器之间的输出要具有差异性。通过下面的这三个例子可以很容易看出这一点,准确度较高,差异度也较高,可以较好地提升集成性能。

现在考虑二分类的简单情形,假设基分类器之间相互独立(能提供较高的差异度),且错误率相等为 ε,则可以将集成器的预测看做一个伯努利实验,易知当所有基分类器中不足一半预测正确的情况下,集成器预测错误,所以集成器的错误率可以计算为:

此时,集成器错误率随着基分类器的个数的增加呈指数下降,但前提是基分类器之间相互独立,在实际情形中显然是不可能的,假设训练有A和B两个分类器,对于某个测试样本,显然满足:P(A=1 | B=1)> P(A=1),因为A和B为了解决相同的问题而训练,因此在预测新样本时存在着很大的联系。因此,个体学习器的“准确性”和“差异性”本身就是一对矛盾的变量,准确性高意味着牺牲多样性,所以产生“好而不同”的个体学习器正是集成学习研究的核心。现阶段有三种主流的集成学习方法:Boosting、Bagging以及随机森林(Random Forest),接下来将进行逐一介绍。
9.2 Boosting
Boosting是一种串行的工作机制,即个体学习器的训练存在依赖关系,必须一步一步序列化进行。其基本思想是:增加前一个基学习器在训练训练过程中预测错误样本的权重,使得后续基学习器更加关注这些打标错误的训练样本,尽可能纠正这些错误,一直向下串行直至产生需要的T个基学习器,Boosting最终对这T个学习器进行加权结合,产生学习器委员会。
Boosting族算法最著名、使用最为广泛的就是AdaBoost,因此下面主要是对AdaBoost算法进行介绍。AdaBoost使用的是指数损失函数,因此AdaBoost的权值与样本分布的更新都是围绕着最小化指数损失函数进行的。看到这里回想一下之前的机器学习算法,不难发现机器学习的大部分带参模型只是改变了最优化目标中的损失函数:如果是Square loss,那就是最小二乘了;如果是Hinge Loss,那就是著名的SVM了;如果是log-Loss,那就是Logistic Regression了。
定义基学习器的集成为加权结合,则有:
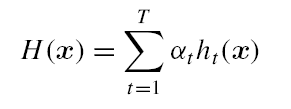
AdaBoost算法的指数损失函数定义为:
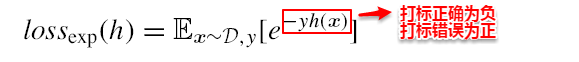
具体说来,整个Adaboost 迭代算法分为3步:
- 初始化训练数据的权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
- 训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
- 将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,使其在最终的分类函数中起着较大的决定作用,而降低分类误差率大的弱分类器的权重,使其在最终的分类函数中起着较小的决定作用。
整个AdaBoost的算法流程如下所示:

可以看出:AdaBoost的核心步骤就是计算基学习器权重和样本权重分布,那为何是上述的计算公式呢?这就涉及到了我们之前为什么说大部分带参机器学习算法只是改变了损失函数,就是因为大部分模型的参数都是通过最优化损失函数(可能还加个规则项)而计算(梯度下降,坐标下降等)得到,这里正是通过最优化指数损失函数从而得到这两个参数的计算公式,具体的推导过程此处不进行展开。
Boosting算法要求基学习器能对特定分布的数据进行学习,即每次都更新样本分布权重,这里书上提到了两种方法:“重赋权法”(re-weighting)和“重采样法”(re-sampling),书上的解释有些晦涩,这里进行展开一下:
重赋权法 : 对每个样本附加一个权重,这时涉及到样本属性与标签的计算,都需要乘上一个权值。 重采样法 : 对于一些无法接受带权样本的及学习算法,适合用“重采样法”进行处理。方法大致过程是,根据各个样本的权重,对训练数据进行重采样,初始时样本权重一样,每个样本被采样到的概率一致,每次从N个原始的训练样本中按照权重有放回采样N个样本作为训练集,然后计算训练集错误率,然后调整权重,重复采样,集成多个基学习器。
从偏差-方差分解来看:Boosting算法主要关注于降低偏差,每轮的迭代都关注于训练过程中预测错误的样本,将弱学习提升为强学习器。从AdaBoost的算法流程来看,标准的AdaBoost只适用于二分类问题。在此,当选为数据挖掘十大算法之一的AdaBoost介绍到这里,能够当选正是说明这个算法十分婀娜多姿,背后的数学证明和推导充分证明了这一点,限于篇幅不再继续展开。
9.3 Bagging与Random Forest
相比之下,Bagging与随机森林算法就简洁了许多,上面已经提到产生“好而不同”的个体学习器是集成学习研究的核心,即在保证基学习器准确性的同时增加基学习器之间的多样性。而这两种算法的基本思(tao)想(lu)都是通过“自助采样”的方法来增加多样性。
9.3.1 Bagging
Bagging是一种并行式的集成学习方法,即基学习器的训练之间没有前后顺序可以同时进行,Bagging使用“有放回”采样的方式选取训练集,对于包含m个样本的训练集,进行m次有放回的随机采样操作,从而得到m个样本的采样集,这样训练集中有接近36.8%的样本没有被采到。按照相同的方式重复进行,我们就可以采集到T个包含m个样本的数据集,从而训练出T个基学习器,最终对这T个基学习器的输出进行结合。
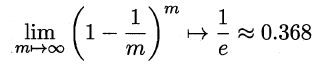
Bagging算法的流程如下所示:
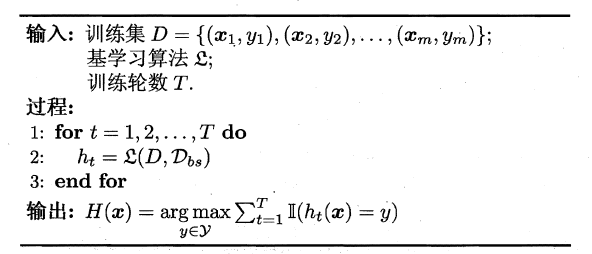
可以看出Bagging主要通过样本的扰动来增加基学习器之间的多样性,因此Bagging的基学习器应为那些对训练集十分敏感的不稳定学习算法,例如:神经网络与决策树等。从偏差-方差分解来看,Bagging算法主要关注于降低方差,即通过多次重复训练提高稳定性。不同于AdaBoost的是,Bagging可以十分简单地移植到多分类、回归等问题。总的说起来则是:AdaBoost关注于降低偏差,而Bagging关注于降低方差。
9.3.2 随机森林
随机森林(Random Forest)是Bagging的一个拓展体,它的基学习器固定为决策树,多棵树也就组成了森林,而“随机”则在于选择划分属性的随机,随机森林在训练基学习器时,也采用有放回采样的方式添加样本扰动,同时它还引入了一种属性扰动,即在基决策树的训练过程中,在选择划分属性时,RF先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性,一般推荐K=log2(d)。
这样随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,从而进一步提升了基学习器之间的差异度。相比决策树的Bagging集成,随机森林的起始性能较差(由于属性扰动,基决策树的准确度有所下降),但随着基学习器数目的增多,随机森林往往会收敛到更低的泛化误差。同时不同于Bagging中决策树从所有属性集中选择最优划分属性,随机森林只在属性集的一个子集中选择划分属性,因此训练效率更高。
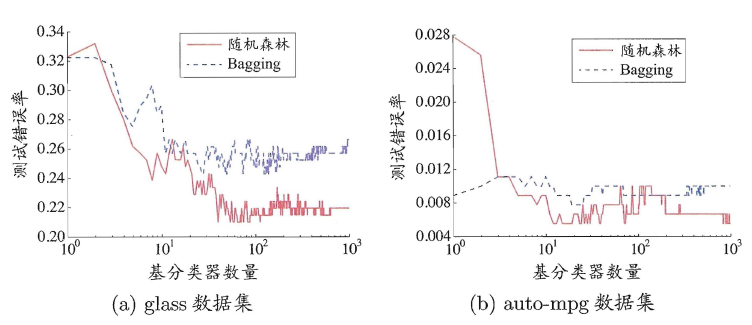
9.4 结合策略
结合策略指的是在训练好基学习器后,如何将这些基学习器的输出结合起来产生集成模型的最终输出,下面将介绍一些常用的结合策略:
9.4.1 平均法(回归问题)
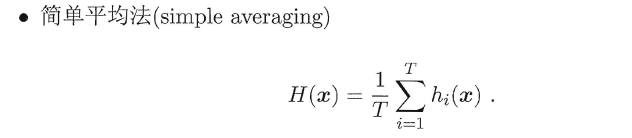
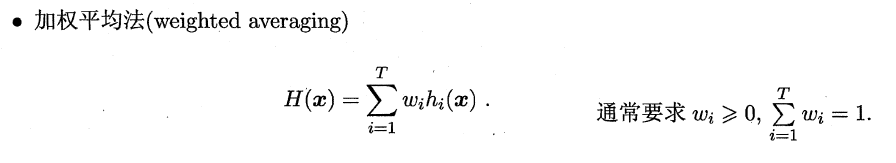
易知简单平均法是加权平均法的一种特例,加权平均法可以认为是集成学习研究的基本出发点。由于各个基学习器的权值在训练中得出,一般而言,在个体学习器性能相差较大时宜使用加权平均法,在个体学习器性能相差较小时宜使用简单平均法。
9.4.2 投票法(分类问题)

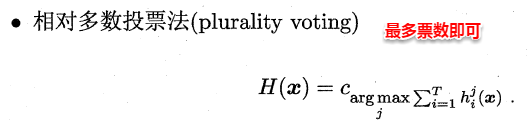
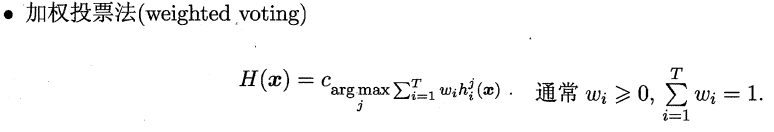
绝对多数投票法(majority voting)提供了拒绝选项,这在可靠性要求很高的学习任务中是一个很好的机制。同时,对于分类任务,各个基学习器的输出值有两种类型,分别为类标记和类概率。

一些在产生类别标记的同时也生成置信度的学习器,置信度可转化为类概率使用,一般基于类概率进行结合往往比基于类标记进行结合的效果更好,需要注意的是对于异质集成,其类概率不能直接进行比较,此时需要将类概率转化为类标记输出,然后再投票。
9.4.3 学习法
学习法是一种更高级的结合策略,即学习出一种“投票”的学习器,Stacking是学习法的典型代表。Stacking的基本思想是:首先训练出T个基学习器,对于一个样本它们会产生T个输出,将这T个基学习器的输出与该样本的真实标记作为新的样本,m个样本就会产生一个m*T的样本集,来训练一个新的“投票”学习器。投票学习器的输入属性与学习算法对Stacking集成的泛化性能有很大的影响,书中已经提到:投票学习器采用类概率作为输入属性,选用多响应线性回归(MLR)一般会产生较好的效果。

9.5 多样性(diversity)
在集成学习中,基学习器之间的多样性是影响集成器泛化性能的重要因素。因此增加多样性对于集成学习研究十分重要,一般的思路是在学习过程中引入随机性,常见的做法主要是对数据样本、输入属性、输出表示、算法参数进行扰动。
数据样本扰动,即利用具有差异的数据集来训练不同的基学习器。例如:有放回自助采样法,但此类做法只对那些不稳定学习算法十分有效,例如:决策树和神经网络等,训练集的稍微改变能导致学习器的显著变动。 输入属性扰动,即随机选取原空间的一个子空间来训练基学习器。例如:随机森林,从初始属性集中抽取子集,再基于每个子集来训练基学习器。但若训练集只包含少量属性,则不宜使用属性扰动。 输出表示扰动,此类做法可对训练样本的类标稍作变动,或对基学习器的输出进行转化。 算法参数扰动,通过随机设置不同的参数,例如:神经网络中,随机初始化权重与随机设置隐含层节点数。
十. 聚类算法
聚类是一种经典的无监督学习方法,无监督学习的目标是通过对无标记训练样本的学习,发掘和揭示数据集本身潜在的结构与规律,即不依赖于训练数据集的类标记信息。聚类则是试图将数据集的样本划分为若干个互不相交的类簇,从而每个簇对应一个潜在的类别。
聚类直观上来说是将相似的样本聚在一起,从而形成一个类簇(cluster)。那首先的问题是如何来度量相似性(similarity measure)呢?这便是距离度量,在生活中我们说差别小则相似,对应到多维样本,每个样本可以对应于高维空间中的一个数据点,若它们的距离相近,我们便可以称它们相似。那接着如何来评价聚类结果的好坏呢?这便是性能度量,性能度量为评价聚类结果的好坏提供了一系列有效性指标。
10.1 距离度量
谈及距离度量,最熟悉的莫过于欧式距离了,从年头一直用到年尾的距离计算公式:即对应属性之间相减的平方和再开根号。度量距离还有其它的很多经典方法,通常它们需要满足一些基本性质:

最常用的距离度量方法是**“闵可夫斯基距离”(Minkowski distance)**:
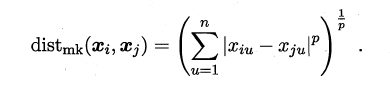
当p=1时,闵可夫斯基距离即曼哈顿距离(Manhattan distance):
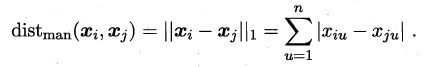
当p=2时,闵可夫斯基距离即欧氏距离(Euclidean distance):
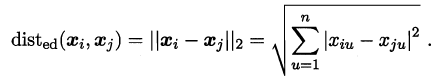
我们知道属性分为两种:连续属性和离散属性(有限个取值)。对于连续值的属性,一般都可以被学习器所用,有时会根据具体的情形作相应的预处理,例如:归一化等;而对于离散值的属性,需要作下面进一步的处理:
若属性值之间存在序关系,则可以将其转化为连续值,例如:身高属性“高”“中等”“矮”,可转化为{1, 0.5, 0}。 若属性值之间不存在序关系,则通常将其转化为向量的形式,例如:性别属性“男”“女”,可转化为{(1,0),(0,1)}。
在进行距离度量时,易知连续属性和存在序关系的离散属性都可以直接参与计算,因为它们都可以反映一种程度,我们称其为“有序属性”;而对于不存在序关系的离散属性,我们称其为:“无序属性”,显然无序属性再使用闵可夫斯基距离就行不通了。
对于无序属性,我们一般采用VDM进行距离的计算,例如:对于离散属性的两个取值a和b,定义:
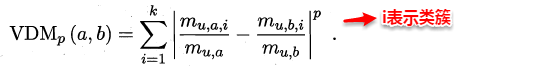
于是,在计算两个样本之间的距离时,我们可以将闵可夫斯基距离和VDM混合在一起进行计算:

若我们定义的距离计算方法是用来度量相似性,例如下面将要讨论的聚类问题,即距离越小,相似性越大,反之距离越大,相似性越小。这时距离的度量方法并不一定需要满足前面所说的四个基本性质,这样的方法称为:非度量距离(non-metric distance)。
10.2 性能度量
由于聚类算法不依赖于样本的真实类标,就不能像监督学习的分类那般,通过计算分对分错(即精确度或错误率)来评价学习器的好坏或作为学习过程中的优化目标。一般聚类有两类性能度量指标:外部指标和内部指标。
10.2.1 外部指标
即将聚类结果与某个参考模型的结果进行比较,以参考模型的输出作为标准,来评价聚类好坏。假设聚类给出的结果为λ,参考模型给出的结果是λ*,则我们将样本进行两两配对,定义:

显然a和b代表着聚类结果好坏的正能量,b和c则表示参考结果和聚类结果相矛盾,基于这四个值可以导出以下常用的外部评价指标:

10.2.2 内部指标
内部指标即不依赖任何外部模型,直接对聚类的结果进行评估,聚类的目的是想将那些相似的样本尽可能聚在一起,不相似的样本尽可能分开,直观来说:簇内高内聚紧紧抱团,簇间低耦合老死不相往来。定义:

基于上面的四个距离,可以导出下面这些常用的内部评价指标:

10.3 原型聚类
原型聚类即“基于原型的聚类”(prototype-based clustering),原型表示模板的意思,就是通过参考一个模板向量或模板分布的方式来完成聚类的过程,常见的K-Means便是基于簇中心来实现聚类,混合高斯聚类则是基于簇分布来实现聚类。
10.3.1 K-Means
K-Means的思想十分简单,首先随机指定类中心,根据样本与类中心的远近划分类簇,接着重新计算类中心,迭代直至收敛。但是其中迭代的过程并不是主观地想象得出,事实上,若将样本的类别看做为“隐变量”(latent variable),类中心看作样本的分布参数,这一过程正是通过EM算法的两步走策略而计算出,其根本的目的是为了最小化平方误差函数E:
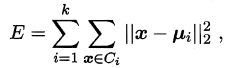
K-Means的算法流程如下所示:

10.3.2 学习向量量化(LVQ)
LVQ也是基于原型的聚类算法,与K-Means不同的是,LVQ使用样本真实类标记辅助聚类,首先LVQ根据样本的类标记,从各类中分别随机选出一个样本作为该类簇的原型,从而组成了一个原型特征向量组,接着从样本集中随机挑选一个样本,计算其与原型向量组中每个向量的距离,并选取距离最小的原型向量所在的类簇作为它的划分结果,再与真实类标比较。
若划分结果正确,则对应原型向量向这个样本靠近一些 若划分结果不正确,则对应原型向量向这个样本远离一些
LVQ算法的流程如下所示:

10.3.3 高斯混合聚类
现在可以看出K-Means与LVQ都试图以类中心作为原型指导聚类,高斯混合聚类则采用高斯分布来描述原型。现假设每个类簇中的样本都服从一个多维高斯分布,那么空间中的样本可以看作由k个多维高斯分布混合而成。
对于多维高斯分布,其概率密度函数如下所示:
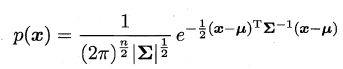
其中u表示均值向量,∑表示协方差矩阵,可以看出一个多维高斯分布完全由这两个参数所确定。接着定义高斯混合分布为:
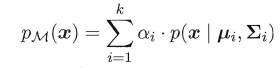
α称为混合系数,这样空间中样本的采集过程则可以抽象为:(1)先选择一个类簇(高斯分布),(2)再根据对应高斯分布的密度函数进行采样,这时候贝叶斯公式又能大展身手了:

此时只需要选择PM最大时的类簇并将该样本划分到其中,看到这里很容易发现:这和那个传说中的贝叶斯分类不是神似吗,都是通过贝叶斯公式展开,然后计算类先验概率和类条件概率。但遗憾的是:这里没有真实类标信息,对于类条件概率,并不能像贝叶斯分类那样通过最大似然法美好地计算出来,因为这里的样本可能属于所有的类簇,这里的似然函数变为:
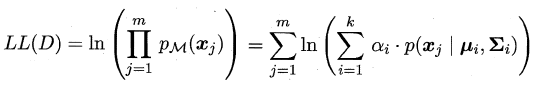
可以看出:简单的最大似然法根本无法求出所有的参数,这样PM也就没法计算。这里就要召唤出之前的EM大法,首先对高斯分布的参数及混合系数进行随机初始化,计算出各个PM(即γji,第i个样本属于j类),再最大化似然函数(即LL(D)分别对α、u和∑求偏导 ),对参数进行迭代更新。
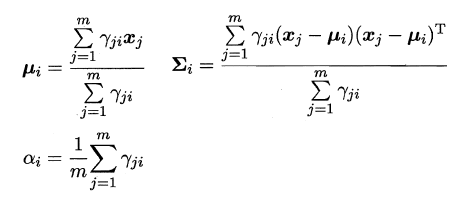
高斯混合聚类的算法流程如下图所示:

10.4 密度聚类
密度聚类则是基于密度的聚类,它从样本分布的角度来考察样本之间的可连接性,并基于可连接性(密度可达)不断拓展疆域(类簇)。其中最著名的便是DBSCAN算法,首先定义以下概念:

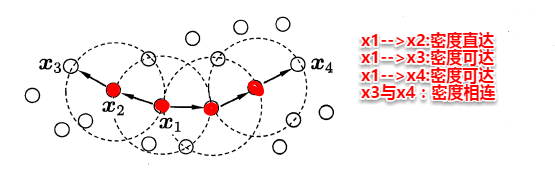
简单来理解DBSCAN便是:找出一个核心对象所有密度可达的样本集合形成簇。首先从数据集中任选一个核心对象A,找出所有A密度可达的样本集合,将这些样本形成一个密度相连的类簇,直到所有的核心对象都遍历完。DBSCAN算法的流程如下图所示:

10.5 层次聚类
层次聚类是一种基于树形结构的聚类方法,常用的是自底向上的结合策略(AGNES算法)。假设有N个待聚类的样本,其基本步骤是:
1.初始化-->把每个样本归为一类,计算每两个类之间的距离,也就是样本与样本之间的相似度; 2.寻找各个类之间最近的两个类,把他们归为一类(这样类的总数就少了一个); 3.重新计算新生成的这个类与各个旧类之间的相似度; 4.重复2和3直到所有样本点都归为一类,结束。
可以看出其中最关键的一步就是计算两个类簇的相似度,这里有多种度量方法:
-
单链接(single-linkage):取类间最小距离。
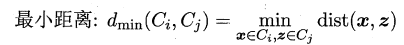
-
全链接(complete-linkage):取类间最大距离
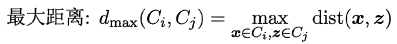
-
均链接(average-linkage):取类间两两的平均距离
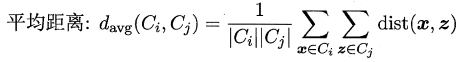
很容易看出:单链接的包容性极强,稍微有点暧昧就当做是自己人了,全链接则是坚持到底,只要存在缺点就坚决不合并,均连接则是从全局出发顾全大局。层次聚类法的算法流程如下所示:

在此聚类算法就介绍完毕,分类/聚类都是机器学习中最常见的任务,我实验室的大Boss也是靠着聚类起家,从此走上人生事业钱途...之巅峰,在书最后的阅读材料还看见Boss的名字,所以这章也是必读不可了...
十一. 降维与度量学习
样本的特征数称为维数(dimensionality),当维数非常大时,也就是现在所说的“维数灾难”,具体表现在:在高维情形下,数据样本将变得十分稀疏,因为此时要满足训练样本为“密采样”的总体样本数目是一个触不可及的天文数字,谓可远观而不可亵玩焉...训练样本的稀疏使得其代表总体分布的能力大大减弱,从而消减了学习器的泛化能力;同时当维数很高时,计算距离也变得十分复杂,甚至连计算内积都不再容易,这也是为什么支持向量机(SVM)使用核函数**“低维计算,高维表现”**的原因。
缓解维数灾难的一个重要途径就是降维,即通过某种数学变换将原始高维空间转变到一个低维的子空间。在这个子空间中,样本的密度将大幅提高,同时距离计算也变得容易。这时也许会有疑问,这样降维之后不是会丢失原始数据的一部分信息吗?这是因为在很多实际的问题中,虽然训练数据是高维的,但是与学习任务相关也许仅仅是其中的一个低维子空间,也称为一个低维嵌入,例如:数据属性中存在噪声属性、相似属性或冗余属性等,对高维数据进行降维能在一定程度上达到提炼低维优质属性或降噪的效果。
11.1 K近邻学习
k近邻算法简称kNN(k-Nearest Neighbor),是一种经典的监督学习方法,同时也实力担当入选数据挖掘十大算法。其工作机制十分简单粗暴:给定某个测试样本,kNN基于某种距离度量在训练集中找出与其距离最近的k个带有真实标记的训练样本,然后给基于这k个邻居的真实标记来进行预测,类似于前面集成学习中所讲到的基学习器结合策略:分类任务采用投票法,回归任务则采用平均法。接下来本篇主要就kNN分类进行讨论。
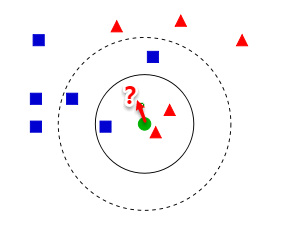
从上图【来自Wiki】中我们可以看到,图中有两种类型的样本,一类是蓝色正方形,另一类是红色三角形。而那个绿色圆形是我们待分类的样本。基于kNN算法的思路,我们很容易得到以下结论:
如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
可以发现:kNN虽然是一种监督学习方法,但是它却没有显式的训练过程,而是当有新样本需要预测时,才来计算出最近的k个邻居,因此kNN是一种典型的懒惰学习方法,再来回想一下朴素贝叶斯的流程,训练的过程就是参数估计,因此朴素贝叶斯也可以懒惰式学习,此类技术在训练阶段开销为零,待收到测试样本后再进行计算。相应地我们称那些一有训练数据立马开工的算法为“急切学习”,可见前面我们学习的大部分算法都归属于急切学习。
很容易看出:kNN算法的核心在于k值的选取以及距离的度量。k值选取太小,模型很容易受到噪声数据的干扰,例如:极端地取k=1,若待分类样本正好与一个噪声数据距离最近,就导致了分类错误;若k值太大, 则在更大的邻域内进行投票,此时模型的预测能力大大减弱,例如:极端取k=训练样本数,就相当于模型根本没有学习,所有测试样本的预测结果都是一样的。一般地我们都通过交叉验证法来选取一个适当的k值。
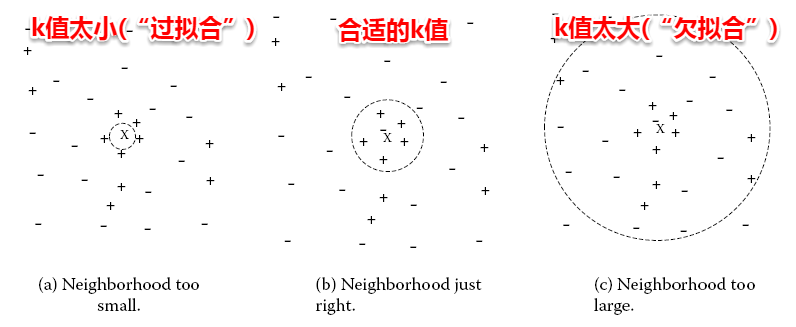
对于距离度量,不同的度量方法得到的k个近邻不尽相同,从而对最终的投票结果产生了影响,因此选择一个合适的距离度量方法也十分重要。在上一篇聚类算法中,在度量样本相似性时介绍了常用的几种距离计算方法,包括闵可夫斯基距离,曼哈顿距离,VDM等。在实际应用中,kNN的距离度量函数一般根据样本的特性来选择合适的距离度量,同时应对数据进行去量纲/归一化处理来消除大量纲属性的强权政治影响。
11.2 MDS算法
不管是使用核函数升维还是对数据降维,我们都希望原始空间样本点之间的距离在新空间中基本保持不变,这样才不会使得原始空间样本之间的关系及总体分布发生较大的改变。**“多维缩放”(MDS)**正是基于这样的思想,MDS要求原始空间样本之间的距离在降维后的低维空间中得以保持。
假定m个样本在原始空间中任意两两样本之间的距离矩阵为D∈R(m*m),我们的目标便是获得样本在低维空间中的表示Z∈R(d'*m , d'< d),且任意两个样本在低维空间中的欧式距离等于原始空间中的距离,即||zi-zj||=Dist(ij)。因此接下来我们要做的就是根据已有的距离矩阵D来求解出降维后的坐标矩阵Z。

令降维后的样本坐标矩阵Z被中心化,中心化是指将每个样本向量减去整个样本集的均值向量,故所有样本向量求和得到一个零向量。这样易知:矩阵B的每一列以及每一列求和均为0,因为提取公因子后都有一项为所有样本向量的和向量。
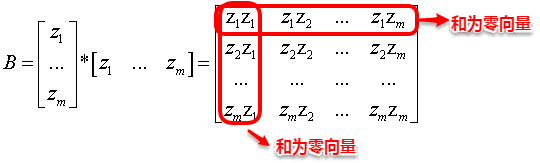
根据上面矩阵B的特征,我们很容易得到等式(2)、(3)以及(4):

这时根据(1)--(4)式我们便可以计算出bij,即bij=(1)-(2)(1/m)-(3)(1/m)+(4)*(1/(m^2)),再逐一地计算每个b(ij),就得到了降维后低维空间中的内积矩阵B(B=Z'*Z),只需对B进行特征值分解便可以得到Z。MDS的算法流程如下图所示:

11.3 主成分分析(PCA)
不同于MDS采用距离保持的方法,主成分分析(PCA)直接通过一个线性变换,将原始空间中的样本投影到新的低维空间中。简单来理解这一过程便是:PCA采用一组新的基来表示样本点,其中每一个基向量都是原来基向量的线性组合,通过使用尽可能少的新基向量来表出样本,从而达到降维的目的。
假设使用d'个新基向量来表示原来样本,实质上是将样本投影到一个由d'个基向量确定的一个超平面上(即舍弃了一些维度),要用一个超平面对空间中所有高维样本进行恰当的表达,最理想的情形是:若这些样本点都能在超平面上表出且这些表出在超平面上都能够很好地分散开来。但是一般使用较原空间低一些维度的超平面来做到这两点十分不容易,因此我们退一步海阔天空,要求这个超平面应具有如下两个性质:
最近重构性:样本点到超平面的距离足够近,即尽可能在超平面附近; 最大可分性:样本点在超平面上的投影尽可能地分散开来,即投影后的坐标具有区分性。
这里十分神奇的是:最近重构性与最大可分性虽然从不同的出发点来定义优化问题中的目标函数,但最终这两种特性得到了完全相同的优化问题:
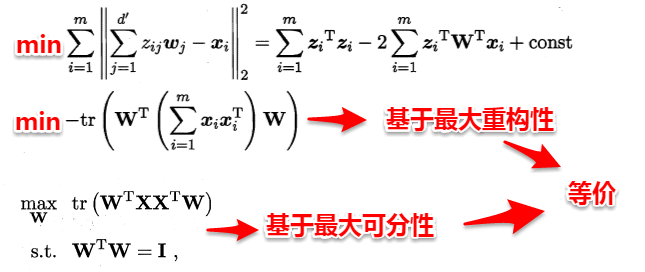
接着使用拉格朗日乘子法求解上面的优化问题,得到:

因此只需对协方差矩阵进行特征值分解即可求解出W,PCA算法的整个流程如下图所示:

另一篇博客给出更通俗更详细的理解:主成分分析解析(基于最大方差理论)
11.4 核化线性降维
说起机器学习你中有我/我中有你/水乳相融...在这里能够得到很好的体现。正如SVM在处理非线性可分时,通过引入核函数将样本投影到高维特征空间,接着在高维空间再对样本点使用超平面划分。这里也是相同的问题:若我们的样本数据点本身就不是线性分布,那还如何使用一个超平面去近似表出呢?因此也就引入了核函数,即先将样本映射到高维空间,再在高维空间中使用线性降维的方法。下面主要介绍**核化主成分分析(KPCA)**的思想。
若核函数的形式已知,即我们知道如何将低维的坐标变换为高维坐标,这时我们只需先将数据映射到高维特征空间,再在高维空间中运用PCA即可。但是一般情况下,我们并不知道核函数具体的映射规则,例如:Sigmoid、高斯核等,我们只知道如何计算高维空间中的样本内积,这时就引出了KPCA的一个重要创新之处:即空间中的任一向量,都可以由该空间中的所有样本线性表示。证明过程也十分简单:

这样我们便可以将高维特征空间中的投影向量wi使用所有高维样本点线性表出,接着代入PCA的求解问题,得到:

化简到最后一步,发现结果十分的美妙,只需对核矩阵K进行特征分解,便可以得出投影向量wi对应的系数向量α,因此选取特征值前d'大对应的特征向量便是d'个系数向量。这时对于需要降维的样本点,只需按照以下步骤便可以求出其降维后的坐标。可以看出:KPCA在计算降维后的坐标表示时,需要与所有样本点计算核函数值并求和,因此该算法的计算开销十分大。

11.5 流形学习
流形学习(manifold learning)是一种借助拓扑流形概念的降维方法,流形是指在局部与欧式空间同胚的空间,即在局部与欧式空间具有相同的性质,能用欧氏距离计算样本之间的距离。这样即使高维空间的分布十分复杂,但是在局部上依然满足欧式空间的性质,基于流形学习的降维正是这种**“邻域保持”的思想。其中等度量映射(Isomap)试图在降维前后保持邻域内样本之间的距离,而局部线性嵌入(LLE)则是保持邻域内样本之间的线性关系**,下面将分别对这两种著名的流行学习方法进行介绍。
11.5.1 等度量映射(Isomap)
等度量映射的基本出发点是:高维空间中的直线距离具有误导性,因为有时高维空间中的直线距离在低维空间中是不可达的。因此利用流形在局部上与欧式空间同胚的性质,可以使用近邻距离来逼近测地线距离,即对于一个样本点,它与近邻内的样本点之间是可达的,且距离使用欧式距离计算,这样整个样本空间就形成了一张近邻图,高维空间中两个样本之间的距离就转为最短路径问题。可采用著名的Dijkstra算法或Floyd算法计算最短距离,得到高维空间中任意两点之间的距离后便可以使用MDS算法来其计算低维空间中的坐标。
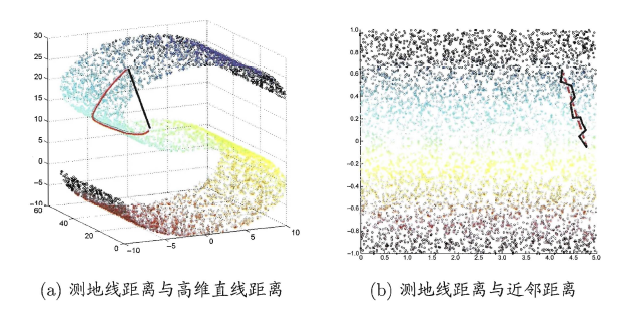
从MDS算法的描述中我们可以知道:MDS先求出了低维空间的内积矩阵B,接着使用特征值分解计算出了样本在低维空间中的坐标,但是并没有给出通用的投影向量w,因此对于需要降维的新样本无从下手,书中给出的权宜之计是利用已知高/低维坐标的样本作为训练集学习出一个“投影器”,便可以用高维坐标预测出低维坐标。Isomap算法流程如下图:

对于近邻图的构建,常用的有两种方法:一种是指定近邻点个数,像kNN一样选取k个最近的邻居;另一种是指定邻域半径,距离小于该阈值的被认为是它的近邻点。但两种方法均会出现下面的问题:
若邻域范围指定过大,则会造成“短路问题”,即本身距离很远却成了近邻,将距离近的那些样本扼杀在摇篮。 若邻域范围指定过小,则会造成“断路问题”,即有些样本点无法可达了,整个世界村被划分为互不可达的小部落。
11.5.2 局部线性嵌入(LLE)
不同于Isomap算法去保持邻域距离,LLE算法试图去保持邻域内的线性关系,假定样本xi的坐标可以通过它的邻域样本线性表出:
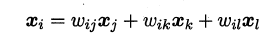
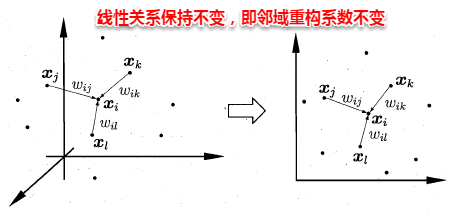
LLE算法分为两步走,首先第一步根据近邻关系计算出所有样本的邻域重构系数w:
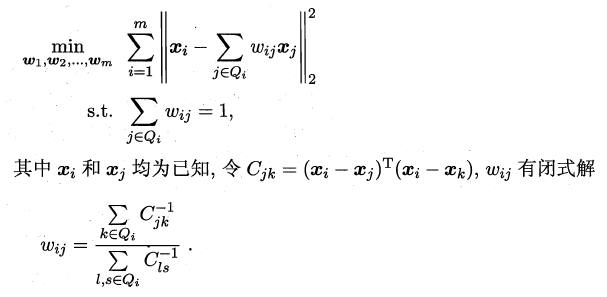
接着根据邻域重构系数不变,去求解低维坐标:
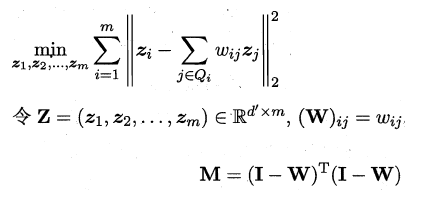
这样利用矩阵M,优化问题可以重写为:

M特征值分解后最小的d'个特征值对应的特征向量组成Z,LLE算法的具体流程如下图所示:

11.6 度量学习
本篇一开始就提到维数灾难,即在高维空间进行机器学习任务遇到样本稀疏、距离难计算等诸多的问题,因此前面讨论的降维方法都试图将原空间投影到一个合适的低维空间中,接着在低维空间进行学习任务从而产生较好的性能。事实上,不管高维空间还是低维空间都潜在对应着一个距离度量,那可不可以直接学习出一个距离度量来等效降维呢?例如:咋们就按照降维后的方式来进行距离的计算,这便是度量学习的初衷。
首先要学习出距离度量必须先定义一个合适的距离度量形式。对两个样本xi与xj,它们之间的平方欧式距离为:
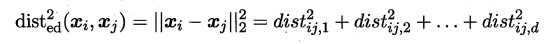
若各个属性重要程度不一样即都有一个权重,则得到加权的平方欧式距离:
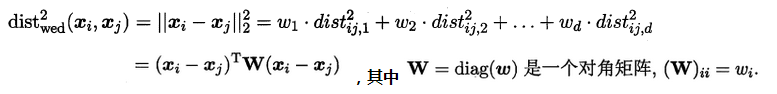
此时各个属性之间都是相互独立无关的,但现实中往往会存在属性之间有关联的情形,例如:身高和体重,一般人越高,体重也会重一些,他们之间存在较大的相关性。这样计算距离就不能分属性单独计算,于是就引入经典的马氏距离(Mahalanobis distance):
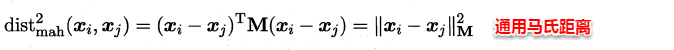
标准的马氏距离中M是协方差矩阵的逆,马氏距离是一种考虑属性之间相关性且尺度无关(即无须去量纲)的距离度量。
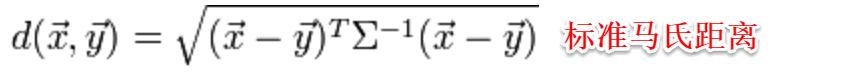
矩阵M也称为“度量矩阵”,为保证距离度量的非负性与对称性,M必须为(半)正定对称矩阵,这样就为度量学习定义好了距离度量的形式,换句话说:度量学习便是对度量矩阵进行学习。现在来回想一下前面我们接触的机器学习不难发现:机器学习算法几乎都是在优化目标函数,从而求解目标函数中的参数。同样对于度量学习,也需要设置一个优化目标,书中简要介绍了错误率和相似性两种优化目标,此处限于篇幅不进行展开。
在此,降维和度量学习就介绍完毕。降维是将原高维空间嵌入到一个合适的低维子空间中,接着在低维空间中进行学习任务;度量学习则是试图去学习出一个距离度量来等效降维的效果,两者都是为了解决维数灾难带来的诸多问题。也许大家最后心存疑惑,那kNN呢,为什么一开头就说了kNN算法,但是好像和后面没有半毛钱关系?正是因为在降维算法中,低维子空间的维数d'通常都由人为指定,因此我们需要使用一些低开销的学习器来选取合适的d',kNN这家伙懒到家了根本无心学习,在训练阶段开销为零,测试阶段也只是遍历计算了距离,因此拿kNN来进行交叉验证就十分有优势了~同时降维后样本密度增大同时距离计算变易,更为kNN来展示它独特的十八般手艺提供了用武之地。
十二. 特征选择与稀疏学习
最近在看论文的过程中,发现对于数据集行和列的叫法颇有不同,故在介绍本篇之前,决定先将最常用的术语罗列一二,以后再见到了不管它脚扑朔还是眼迷离就能一眼识破真身了~对于数据集中的一个对象及组成对象的零件元素:
统计学家常称它们为观测(observation)和变量(variable); 数据库分析师则称其为记录(record)和字段(field); 数据挖掘/机器学习学科的研究者则习惯把它们叫做样本/示例(example/instance)和属性/特征(attribute/feature)。
回归正题,在机器学习中特征选择是一个重要的“数据预处理”(data preprocessing)过程,即试图从数据集的所有特征中挑选出与当前学习任务相关的特征子集,接着再利用数据子集来训练学习器;稀疏学习则是围绕着稀疏矩阵的优良性质,来完成相应的学习任务。
12.1 子集搜索与评价
一般地,我们可以用很多属性/特征来描述一个示例,例如对于一个人可以用性别、身高、体重、年龄、学历、专业、是否吃货等属性来描述,那现在想要训练出一个学习器来预测人的收入。根据生活经验易知:并不是所有的特征都与学习任务相关,例如年龄/学历/专业可能很大程度上影响了收入,身高/体重这些外貌属性也有较小的可能性影响收入,但像是否是一个地地道道的吃货这种属性就八杆子打不着了。因此我们只需要那些与学习任务紧密相关的特征,特征选择便是从给定的特征集合中选出相关特征子集的过程。
与上篇中降维技术有着异曲同工之处的是,特征选择也可以有效地解决维数灾难的难题。具体而言:降维从一定程度起到了提炼优质低维属性和降噪的效果,特征选择则是直接剔除那些与学习任务无关的属性而选择出最佳特征子集。若直接遍历所有特征子集,显然当维数过多时遭遇指数爆炸就行不通了;若采取从候选特征子集中不断迭代生成更优候选子集的方法,则时间复杂度大大减小。这时就涉及到了两个关键环节:1.如何生成候选子集;2.如何评价候选子集的好坏,这便是早期特征选择的常用方法。书本上介绍了贪心算法,分为三种策略:
前向搜索:初始将每个特征当做一个候选特征子集,然后从当前所有的候选子集中选择出最佳的特征子集;接着在上一轮选出的特征子集中添加一个新的特征,同样地选出最佳特征子集;最后直至选不出比上一轮更好的特征子集。 后向搜索:初始将所有特征作为一个候选特征子集;接着尝试去掉上一轮特征子集中的一个特征并选出当前最优的特征子集;最后直到选不出比上一轮更好的特征子集。 双向搜索:将前向搜索与后向搜索结合起来,即在每一轮中既有添加操作也有剔除操作。
对于特征子集的评价,书中给出了一些想法及基于信息熵的方法。假设数据集的属性皆为离散属性,这样给定一个特征子集,便可以通过这个特征子集的取值将数据集合划分为V个子集。例如:A1={男,女},A2={本科,硕士}就可以将原数据集划分为2*2=4个子集,其中每个子集的取值完全相同。这时我们就可以像决策树选择划分属性那样,通过计算信息增益来评价该属性子集的好坏。

此时,信息增益越大表示该属性子集包含有助于分类的特征越多,使用上述这种子集搜索与子集评价相结合的机制,便可以得到特征选择方法。值得一提的是若将前向搜索策略与信息增益结合在一起,与前面我们讲到的ID3决策树十分地相似。事实上,决策树也可以用于特征选择,树节点划分属性组成的集合便是选择出的特征子集。
12.2 过滤式选择(Relief)
过滤式方法是一种将特征选择与学习器训练相分离的特征选择技术,即首先将相关特征挑选出来,再使用选择出的数据子集来训练学习器。Relief是其中著名的代表性算法,它使用一个“相关统计量”来度量特征的重要性,该统计量是一个向量,其中每个分量代表着相应特征的重要性,因此我们最终可以根据这个统计量各个分量的大小来选择出合适的特征子集。
易知Relief算法的核心在于如何计算出该相关统计量。对于数据集中的每个样例xi,Relief首先找出与xi同类别的最近邻与不同类别的最近邻,分别称为猜中近邻(near-hit)与猜错近邻(near-miss),接着便可以分别计算出相关统计量中的每个分量。对于j分量:
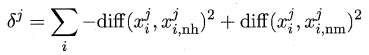
直观上理解:对于猜中近邻,两者j属性的距离越小越好,对于猜错近邻,j属性距离越大越好。更一般地,若xi为离散属性,diff取海明距离,即相同取0,不同取1;若xi为连续属性,则diff为曼哈顿距离,即取差的绝对值。分别计算每个分量,最终取平均便得到了整个相关统计量。
标准的Relief算法只用于二分类问题,后续产生的拓展变体Relief-F则解决了多分类问题。对于j分量,新的计算公式如下:
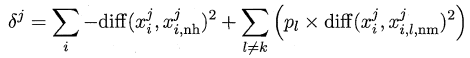
其中pl表示第l类样本在数据集中所占的比例,易知两者的不同之处在于:标准Relief 只有一个猜错近邻,而Relief-F有多个猜错近邻。
12.3 包裹式选择(LVW)
与过滤式选择不同的是,包裹式选择将后续的学习器也考虑进来作为特征选择的评价准则。因此包裹式选择可以看作是为某种学习器量身定做的特征选择方法,由于在每一轮迭代中,包裹式选择都需要训练学习器,因此在获得较好性能的同时也产生了较大的开销。下面主要介绍一种经典的包裹式特征选择方法 --LVW(Las Vegas Wrapper),它在拉斯维加斯框架下使用随机策略来进行特征子集的搜索。拉斯维加斯?怎么听起来那么耳熟,不是那个声名显赫的赌场吗?歪果仁真会玩。怀着好奇科普一下,结果又顺带了一个赌场:
蒙特卡罗算法:采样越多,越近似最优解,一定会给出解,但给出的解不一定是正确解; 拉斯维加斯算法:采样越多,越有机会找到最优解,不一定会给出解,且给出的解一定是正确解。
举个例子,假如筐里有100个苹果,让我每次闭眼拿1个,挑出最大的。于是我随机拿1个,再随机拿1个跟它比,留下大的,再随机拿1个……我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿100次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找较好的,但不保证是最好的。
而拉斯维加斯算法,则是另一种情况。假如有一把锁,给我100把钥匙,只有1把是对的。于是我每次随机拿1把钥匙去试,打不开就再换1把。我试的次数越多,打开(正确解)的机会就越大,但在打开之前,那些错的钥匙都是没有用的。这个试钥匙的算法,就是拉斯维加斯的——尽量找最好的,但不保证能找到。
LVW算法的具体流程如下所示,其中比较特别的是停止条件参数T的设置,即在每一轮寻找最优特征子集的过程中,若随机T次仍没找到,算法就会停止,从而保证了算法运行时间的可行性。

12.4 嵌入式选择与正则化
前面提到了的两种特征选择方法:过滤式中特征选择与后续学习器完全分离,包裹式则是使用学习器作为特征选择的评价准则;嵌入式是一种将特征选择与学习器训练完全融合的特征选择方法,即将特征选择融入学习器的优化过程中。在之前《经验风险与结构风险》中已经提到:经验风险指的是模型与训练数据的契合度,结构风险则是模型的复杂程度,机器学习的核心任务就是:在模型简单的基础上保证模型的契合度。例如:岭回归就是加上了L2范数的最小二乘法,有效地解决了奇异矩阵、过拟合等诸多问题,下面的嵌入式特征选择则是在损失函数后加上了L1范数。
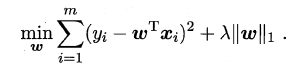
L1范数美名又约Lasso Regularization,指的是向量中每个元素的绝对值之和,这样在优化目标函数的过程中,就会使得w尽可能地小,在一定程度上起到了防止过拟合的作用,同时与L2范数(Ridge Regularization )不同的是,L1范数会使得部分w变为0, 从而达到了特征选择的效果。
总的来说:L1范数会趋向产生少量的特征,其他特征的权值都是0;L2会选择更多的特征,这些特征的权值都会接近于0。这样L1范数在特征选择上就十分有用,而L2范数则具备较强的控制过拟合能力。可以从下面两个方面来理解:
(1)下降速度:L1范数按照绝对值函数来下降,L2范数按照二次函数来下降。因此在0附近,L1范数的下降速度大于L2范数,故L1范数能很快地下降到0,而L2范数在0附近的下降速度非常慢,因此较大可能收敛在0的附近。
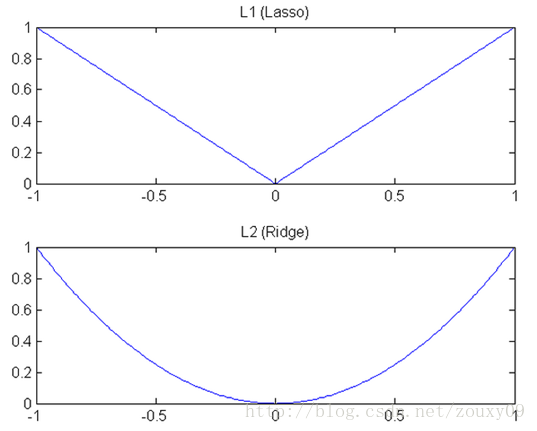
(2)空间限制:L1范数与L2范数都试图在最小化损失函数的同时,让权值W也尽可能地小。我们可以将原优化问题看做为下面的问题,即让后面的规则则都小于某个阈值。这样从图中可以看出:L1范数相比L2范数更容易得到稀疏解。
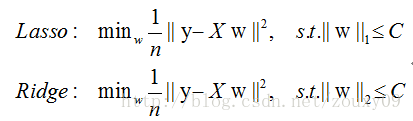
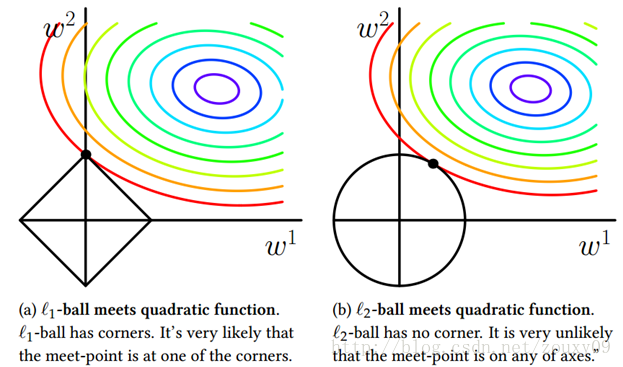
12.5 稀疏表示与字典学习
当样本数据是一个稀疏矩阵时,对学习任务来说会有不少的好处,例如很多问题变得线性可分,储存更为高效等。这便是稀疏表示与字典学习的基本出发点。稀疏矩阵即矩阵的每一行/列中都包含了大量的零元素,且这些零元素没有出现在同一行/列,对于一个给定的稠密矩阵,若我们能通过某种方法找到其合适的稀疏表示,则可以使得学习任务更加简单高效,我们称之为稀疏编码(sparse coding)或字典学习(dictionary learning)。
给定一个数据集,字典学习/稀疏编码指的便是通过一个字典将原数据转化为稀疏表示,因此最终的目标就是求得字典矩阵B及稀疏表示α,书中使用变量交替优化的策略能较好地求得解,深感陷进去短时间无法自拔,故先不进行深入...

12.6 压缩感知
压缩感知在前些年也是风风火火,与特征选择、稀疏表示不同的是:它关注的是通过欠采样信息来恢复全部信息。在实际问题中,为了方便传输和存储,我们一般将数字信息进行压缩,这样就有可能损失部分信息,如何根据已有的信息来重构出全部信号,这便是压缩感知的来历,压缩感知的前提是已知的信息具有稀疏表示。下面是关于压缩感知的一些背景:

十三. 计算学习理论
计算学习理论(computational learning theory)是通过“计算”来研究机器学习的理论,简而言之,其目的是分析学习任务的本质,例如:在什么条件下可进行有效的学习,需要多少训练样本能获得较好的精度等,从而为机器学习算法提供理论保证。
首先我们回归初心,再来谈谈经验误差和泛化误差。假设给定训练集D,其中所有的训练样本都服从一个未知的分布T,且它们都是在总体分布T中独立采样得到,即独立同分布(independent and identically distributed,i.i.d.),在《贝叶斯分类器》中我们已经提到:独立同分布是很多统计学习算法的基础假设,例如最大似然法,贝叶斯分类器,高斯混合聚类等,简单来理解独立同分布:每个样本都是从总体分布中独立采样得到,而没有拖泥带水。例如现在要进行问卷调查,要从总体人群中随机采样,看到一个美女你高兴地走过去,结果她男票突然冒了出来,说道:you jump,i jump,于是你本来只想调查一个人结果被强行撒了一把狗粮得到两份问卷,这样这两份问卷就不能称为独立同分布了,因为它们的出现具有强相关性。
回归正题,泛化误差指的是学习器在总体上的预测误差,经验误差则是学习器在某个特定数据集D上的预测误差。在实际问题中,往往我们并不能得到总体且数据集D是通过独立同分布采样得到的,因此我们常常使用经验误差作为泛化误差的近似。
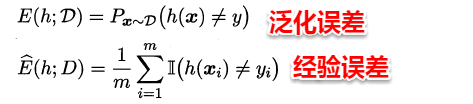
13.1 PAC学习
在高中课本中,我们将函数定义为:从自变量到因变量的一种映射;对于机器学习算法,学习器也正是为了寻找合适的映射规则,即如何从条件属性得到目标属性。从样本空间到标记空间存在着很多的映射,我们将每个映射称之为概念(concept),定义:
若概念c对任何样本x满足c(x)=y,则称c为目标概念,即最理想的映射,所有的目标概念构成的集合称为**“概念类”; 给定学习算法,它所有可能映射/概念的集合称为“假设空间”,其中单个的概念称为“假设”(hypothesis); 若一个算法的假设空间包含目标概念,则称该数据集对该算法是可分**(separable)的,亦称一致(consistent)的; 若一个算法的假设空间不包含目标概念,则称该数据集对该算法是不可分(non-separable)的,或称不一致(non-consistent)的。
举个简单的例子:对于非线性分布的数据集,若使用一个线性分类器,则该线性分类器对应的假设空间就是空间中所有可能的超平面,显然假设空间不包含该数据集的目标概念,所以称数据集对该学习器是不可分的。给定一个数据集D,我们希望模型学得的假设h尽可能地与目标概念一致,这便是概率近似正确 (Probably Approximately Correct,简称PAC)的来源,即以较大的概率学得模型满足误差的预设上限。




上述关于PAC的几个定义层层相扣:定义12.1表达的是对于某种学习算法,如果能以一个置信度学得假设满足泛化误差的预设上限,则称该算法能PAC辨识概念类,即该算法的输出假设已经十分地逼近目标概念。定义12.2则将样本数量考虑进来,当样本超过一定数量时,学习算法总是能PAC辨识概念类,则称概念类为PAC可学习的。定义12.3将学习器运行时间也考虑进来,若运行时间为多项式时间,则称PAC学习算法。
显然,PAC学习中的一个关键因素就是假设空间的复杂度,对于某个学习算法,若假设空间越大,则其中包含目标概念的可能性也越大,但同时找到某个具体概念的难度也越大,一般假设空间分为有限假设空间与无限假设空间。
13.2 有限假设空间
13.2.1 可分情形
可分或一致的情形指的是:目标概念包含在算法的假设空间中。对于目标概念,在训练集D中的经验误差一定为0,因此首先我们可以想到的是:不断地剔除那些出现预测错误的假设,直到找到经验误差为0的假设即为目标概念。但由于样本集有限,可能会出现多个假设在D上的经验误差都为0,因此问题转化为:需要多大规模的数据集D才能让学习算法以置信度的概率从这些经验误差都为0的假设中找到目标概念的有效近似。

通过上式可以得知:对于可分情形的有限假设空间,目标概念都是PAC可学习的,即当样本数量满足上述条件之后,在与训练集一致的假设中总是可以在1-σ概率下找到目标概念的有效近似。
13.2.2 不可分情形
不可分或不一致的情形指的是:目标概念不存在于假设空间中,这时我们就不能像可分情形时那样从假设空间中寻找目标概念的近似。但当假设空间给定时,必然存一个假设的泛化误差最小,若能找出此假设的有效近似也不失为一个好的目标,这便是不可知学习(agnostic learning)的来源。

这时候便要用到Hoeffding不等式:
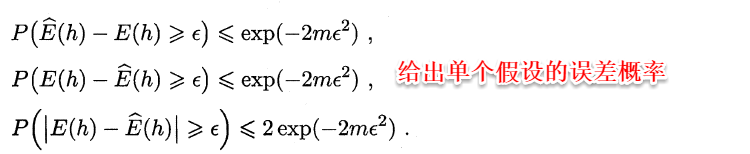
对于假设空间中的所有假设,出现泛化误差与经验误差之差大于e的概率和为:
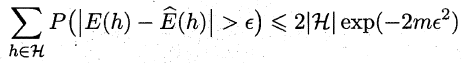
因此,可令不等式的右边小于(等于)σ,便可以求出满足泛化误差与经验误差相差小于e所需的最少样本数,同时也可以求出泛化误差界。
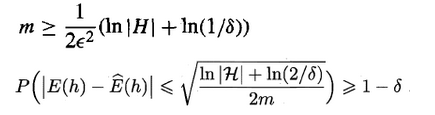
13.3 VC维
现实中的学习任务通常都是无限假设空间,例如d维实数域空间中所有的超平面等,因此要对此种情形进行可学习研究,需要度量假设空间的复杂度。这便是VC维(Vapnik-Chervonenkis dimension)的来源。在介绍VC维之前,需要引入两个概念:
增长函数:对于给定数据集D,假设空间中的每个假设都能对数据集的样本赋予标记,因此一个假设对应着一种打标结果,不同假设对D的打标结果可能是相同的,也可能是不同的。随着样本数量m的增大,假设空间对样本集D的打标结果也会增多,增长函数则表示假设空间对m个样本的数据集D打标的最大可能结果数,因此增长函数描述了假设空间的表示能力与复杂度。
打散:例如对二分类问题来说,m个样本最多有2^m个可能结果,每种可能结果称为一种**“对分”**,若假设空间能实现数据集D的所有对分,则称数据集能被该假设空间打散。
因此尽管假设空间是无限的,但它对特定数据集打标的不同结果数是有限的,假设空间的VC维正是它能打散的最大数据集大小。通常这样来计算假设空间的VC维:若存在大小为d的数据集能被假设空间打散,但不存在任何大小为d+1的数据集能被假设空间打散,则其VC维为d。
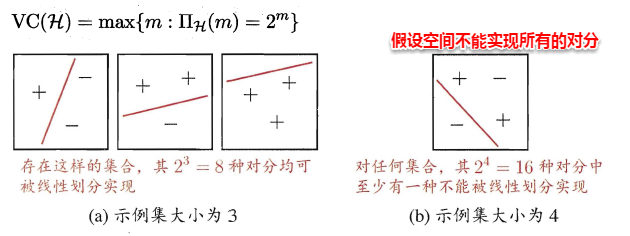
同时书中给出了假设空间VC维与增长函数的两个关系:
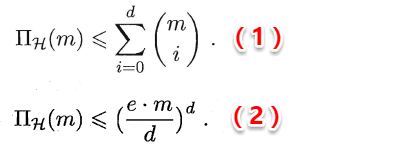
直观来理解(1)式也十分容易: 首先假设空间的VC维是d,说明当m<=d时,增长函数与2^m相等,例如:当m=d时,右边的组合数求和刚好等于2^d;而当m=d+1时,右边等于2^(d+1)-1,十分符合VC维的定义,同时也可以使用数学归纳法证明;(2)式则是由(1)式直接推导得出。
在有限假设空间中,根据Hoeffding不等式便可以推导得出学习算法的泛化误差界;但在无限假设空间中,由于假设空间的大小无法计算,只能通过增长函数来描述其复杂度,因此无限假设空间中的泛化误差界需要引入增长函数。


上式给出了基于VC维的泛化误差界,同时也可以计算出满足条件需要的样本数(样本复杂度)。若学习算法满足经验风险最小化原则(ERM),即学习算法的输出假设h在数据集D上的经验误差最小,可证明:任何VC维有限的假设空间都是(不可知)PAC可学习的,换而言之:若假设空间的最小泛化误差为0即目标概念包含在假设空间中,则是PAC可学习,若最小泛化误差不为0,则称为不可知PAC可学习。
13.4 稳定性
稳定性考察的是当算法的输入发生变化时,输出是否会随之发生较大的变化,输入的数据集D有以下两种变化:

若对数据集中的任何样本z,满足:
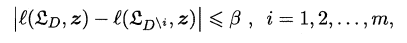
即原学习器和剔除一个样本后生成的学习器对z的损失之差保持β稳定,称学习器关于损失函数满足β-均匀稳定性。同时若损失函数有上界,即原学习器对任何样本的损失函数不超过M,则有如下定理:
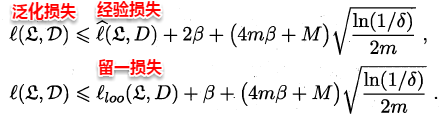
事实上,若学习算法符合经验风险最小化原则(ERM)且满足β-均匀稳定性,则假设空间是可学习的。稳定性通过损失函数与假设空间的可学习联系在了一起,区别在于:假设空间关注的是经验误差与泛化误差,需要考虑到所有可能的假设;而稳定性只关注当前的输出假设。
十四. 半监督学习
前面我们一直围绕的都是监督学习与无监督学习,监督学习指的是训练样本包含标记信息的学习任务,例如:常见的分类与回归算法;无监督学习则是训练样本不包含标记信息的学习任务,例如:聚类算法。在实际生活中,常常会出现一部分样本有标记和较多样本无标记的情形,例如:做网页推荐时需要让用户标记出感兴趣的网页,但是少有用户愿意花时间来提供标记。若直接丢弃掉无标记样本集,使用传统的监督学习方法,常常会由于训练样本的不充足,使得其刻画总体分布的能力减弱,从而影响了学习器泛化性能。那如何利用未标记的样本数据呢?
一种简单的做法是通过专家知识对这些未标记的样本进行打标,但随之而来的就是巨大的人力耗费。若我们先使用有标记的样本数据集训练出一个学习器,再基于该学习器对未标记的样本进行预测,从中挑选出不确定性高或分类置信度低的样本来咨询专家并进行打标,最后使用扩充后的训练集重新训练学习器,这样便能大幅度降低标记成本,这便是主动学习(active learning),其目标是使用尽量少的/有价值的咨询来获得更好的性能。
显然,主动学习需要与外界进行交互/查询/打标,其本质上仍然属于一种监督学习。事实上,无标记样本虽未包含标记信息,但它们与有标记样本一样都是从总体中独立同分布采样得到,因此它们所包含的数据分布信息对学习器的训练大有裨益。如何让学习过程不依赖外界的咨询交互,自动利用未标记样本所包含的分布信息的方法便是半监督学习(semi-supervised learning),即训练集同时包含有标记样本数据和未标记样本数据。
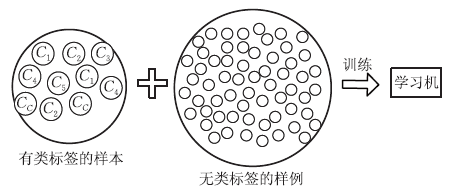
此外,半监督学习还可以进一步划分为纯半监督学习和直推学习,两者的区别在于:前者假定训练数据集中的未标记数据并非待预测数据,而后者假定学习过程中的未标记数据就是待预测数据。主动学习、纯半监督学习以及直推学习三者的概念如下图所示:
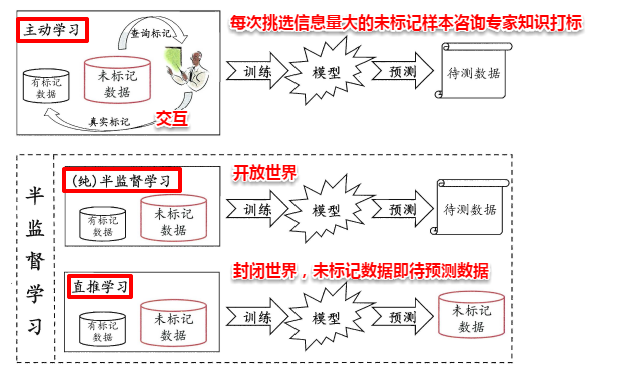
14.1 生成式方法
生成式方法(generative methods)是基于生成式模型的方法,即先对联合分布P(x,c)建模,从而进一步求解 P(c | x),此类方法假定样本数据服从一个潜在的分布,因此需要充分可靠的先验知识。例如:前面已经接触到的贝叶斯分类器与高斯混合聚类,都属于生成式模型。现假定总体是一个高斯混合分布,即由多个高斯分布组合形成,从而一个子高斯分布就代表一个类簇(类别)。高斯混合分布的概率密度函数如下所示:

不失一般性,假设类簇与真实的类别按照顺序一一对应,即第i个类簇对应第i个高斯混合成分。与高斯混合聚类类似地,这里的主要任务也是估计出各个高斯混合成分的参数以及混合系数,不同的是:对于有标记样本,不再是可能属于每一个类簇,而是只能属于真实类标对应的特定类簇。

直观上来看,基于半监督的高斯混合模型有机地整合了贝叶斯分类器与高斯混合聚类的核心思想,有效地利用了未标记样本数据隐含的分布信息,从而使得参数的估计更加准确。同样地,这里也要召唤出之前的EM大法进行求解,首先对各个高斯混合成分的参数及混合系数进行随机初始化,计算出各个PM(即γji,第i个样本属于j类,有标记样本则直接属于特定类),再最大化似然函数(即LL(D)分别对α、u和∑求偏导 ),对参数进行迭代更新。
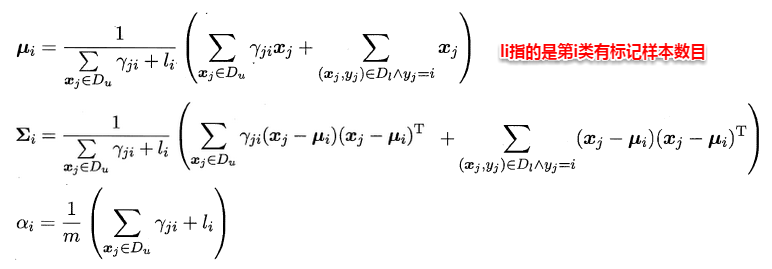
当参数迭代更新收敛后,对于待预测样本x,便可以像贝叶斯分类器那样计算出样本属于每个类簇的后验概率,接着找出概率最大的即可:
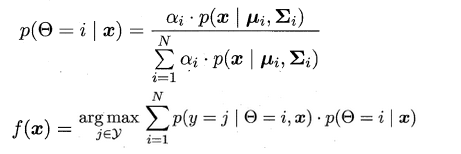
可以看出:基于生成式模型的方法十分依赖于对潜在数据分布的假设,即假设的分布要能和真实分布相吻合,否则利用未标记的样本数据反倒会在错误的道路上渐行渐远,从而降低学习器的泛化性能。因此,此类方法要求极强的领域知识和掐指观天的本领。
14.2 半监督SVM
监督学习中的SVM试图找到一个划分超平面,使得两侧支持向量之间的间隔最大,即“最大划分间隔”思想。对于半监督学习,S3VM则考虑超平面需穿过数据低密度的区域。TSVM是半监督支持向量机中的最著名代表,其核心思想是:尝试为未标记样本找到合适的标记指派,使得超平面划分后的间隔最大化。TSVM采用局部搜索的策略来进行迭代求解,即首先使用有标记样本集训练出一个初始SVM,接着使用该学习器对未标记样本进行打标,这样所有样本都有了标记,并基于这些有标记的样本重新训练SVM,之后再寻找易出错样本不断调整。整个算法流程如下所示:
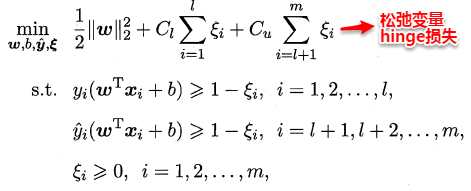

14.3 基于分歧的方法
基于分歧的方法通过多个学习器之间的**分歧(disagreement)/多样性(diversity)**来利用未标记样本数据,协同训练就是其中的一种经典方法。协同训练最初是针对于多视图(multi-view)数据而设计的,多视图数据指的是样本对象具有多个属性集,每个属性集则对应一个试图。例如:电影数据中就包含画面类属性和声音类属性,这样画面类属性的集合就对应着一个视图。首先引入两个关于视图的重要性质:
相容性:即使用单个视图数据训练出的学习器的输出空间是一致的。例如都是{好,坏}、{+1,-1}等。 互补性:即不同视图所提供的信息是互补/相辅相成的,实质上这里体现的就是集成学习的思想。
协同训练正是很好地利用了多视图数据的“相容互补性”,其基本的思想是:首先基于有标记样本数据在每个视图上都训练一个初始分类器,然后让每个分类器去挑选分类置信度最高的样本并赋予标记,并将带有伪标记的样本数据传给另一个分类器去学习,从而你依我侬/共同进步。
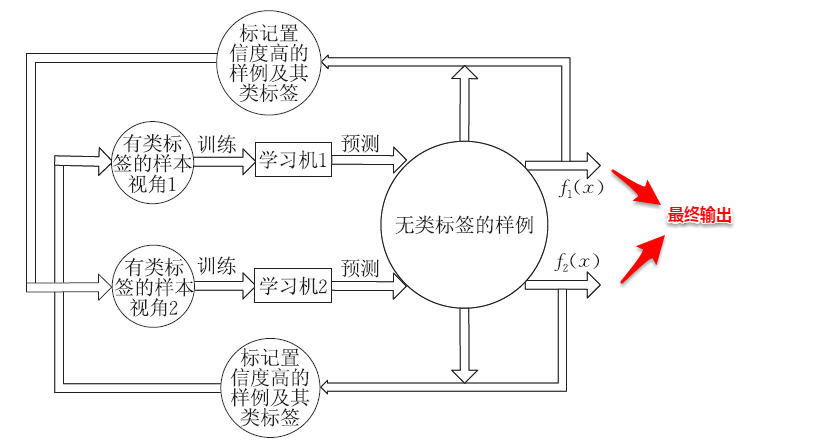

14.4 半监督聚类
前面提到的几种方法都是借助无标记样本数据来辅助监督学习的训练过程,从而使得学习更加充分/泛化性能得到提升;半监督聚类则是借助已有的监督信息来辅助聚类的过程。一般而言,监督信息大致有两种类型:
必连与勿连约束:必连指的是两个样本必须在同一个类簇,勿连则是必不在同一个类簇。 标记信息:少量的样本带有真实的标记。
下面主要介绍两种基于半监督的K-Means聚类算法:第一种是数据集包含一些必连与勿连关系,另外一种则是包含少量带有标记的样本。两种算法的基本思想都十分的简单:对于带有约束关系的k-均值算法,在迭代过程中对每个样本划分类簇时,需要检测当前划分是否满足约束关系,若不满足则会将该样本划分到距离次小对应的类簇中,再继续检测是否满足约束关系,直到完成所有样本的划分。算法流程如下图所示:

对于带有少量标记样本的k-均值算法,则可以利用这些有标记样本进行类中心的指定,同时在对样本进行划分时,不需要改变这些有标记样本的簇隶属关系,直接将其划分到对应类簇即可。算法流程如下所示:

十五. 概率图模型
现在再来谈谈机器学习的核心价值观,可以更通俗地理解为:根据一些已观察到的证据来推断未知,更具哲学性地可以阐述为:未来的发展总是遵循着历史的规律。其中基于概率的模型将学习任务归结为计算变量的概率分布,正如之前已经提到的:生成式模型先对联合分布进行建模,从而再来求解后验概率,例如:贝叶斯分类器先对联合分布进行最大似然估计,从而便可以计算类条件概率;判别式模型则是直接对条件分布进行建模。
概率图模型(probabilistic graphical model)是一类用图结构来表达各属性之间相关关系的概率模型,一般而言:图中的一个结点表示一个或一组随机变量,结点之间的边则表示变量间的相关关系,从而形成了一张“变量关系图”。若使用有向的边来表达变量之间的依赖关系,这样的有向关系图称为贝叶斯网(Bayesian nerwork)或有向图模型;若使用无向边,则称为马尔可夫网(Markov network)或无向图模型。
15.1 隐马尔可夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model,简称HMM)是结构最简单的一种贝叶斯网,在语音识别与自然语言处理领域上有着广泛的应用。HMM中的变量分为两组:状态变量与观测变量,其中状态变量一般是未知的,因此又称为“隐变量”,观测变量则是已知的输出值。在隐马尔可夫模型中,变量之间的依赖关系遵循如下两个规则:
1. 观测变量的取值仅依赖于状态变量; 2. 下一个状态的取值仅依赖于当前状态,通俗来讲:现在决定未来,未来与过去无关,这就是著名的马尔可夫性。
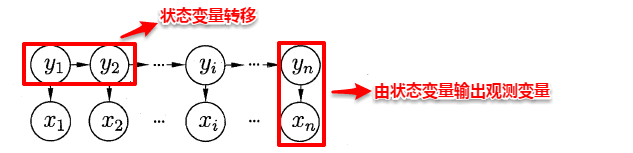
基于上述变量之间的依赖关系,我们很容易写出隐马尔可夫模型中所有变量的联合概率分布:
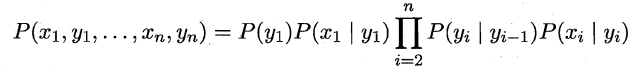
易知:欲确定一个HMM模型需要以下三组参数:

当确定了一个HMM模型的三个参数后,便按照下面的规则来生成观测值序列:

在实际应用中,HMM模型的发力点主要体现在下述三个问题上:

15.1.1 HMM评估问题
HMM评估问题指的是:给定了模型的三个参数与观测值序列,求该观测值序列出现的概率。例如:对于赌场问题,便可以依据骰子掷出的结果序列来计算该结果序列出现的可能性,若小概率的事件发生了则可认为赌场的骰子有作弊的可能。解决该问题使用的是前向算法,即步步为营,自底向上的方式逐步增加序列的长度,直到获得目标概率值。在前向算法中,定义了一个前向变量,即给定观察值序列且t时刻的状态为Si的概率:
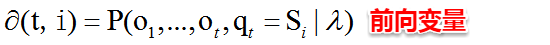
基于前向变量,很容易得到该问题的递推关系及终止条件:

因此可使用动态规划法,从最小的子问题开始,通过填表格的形式一步一步计算出目标结果。
15.1.2 HMM解码问题
HMM解码问题指的是:给定了模型的三个参数与观测值序列,求可能性最大的状态序列。例如:在语音识别问题中,人说话形成的数字信号对应着观测值序列,对应的具体文字则是状态序列,从数字信号转化为文字正是对应着根据观测值序列推断最有可能的状态值序列。解决该问题使用的是Viterbi算法,与前向算法十分类似地,Viterbi算法定义了一个Viterbi变量,也是采用动态规划的方法,自底向上逐步求解。
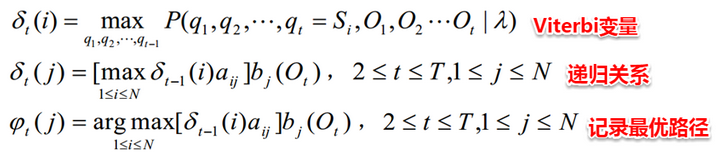
15.1.3 HMM学习问题
HMM学习问题指的是:给定观测值序列,如何调整模型的参数使得该序列出现的概率最大。这便转化成了机器学习问题,即从给定的观测值序列中学习出一个HMM模型,该问题正是EM算法的经典案例之一。其思想也十分简单:对于给定的观测值序列,如果我们能够按照该序列潜在的规律来调整模型的三个参数,则可以使得该序列出现的可能性最大。假设状态值序列也已知,则很容易计算出与该序列最契合的模型参数:

但一般状态值序列都是不可观测的,且即使给定观测值序列与模型参数,状态序列仍然遭遇组合爆炸。因此上面这种简单的统计方法就行不通了,若将状态值序列看作为隐变量,这时便可以考虑使用EM算法来对该问题进行求解:
【1】首先对HMM模型的三个参数进行随机初始化; 【2】根据模型的参数与观测值序列,计算t时刻状态为i且t+1时刻状态为j的概率以及t时刻状态为i的概率。

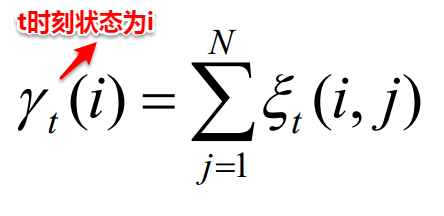
【3】接着便可以对模型的三个参数进行重新估计:

【4】重复步骤2-3,直至三个参数值收敛,便得到了最终的HMM模型。
15.2 马尔可夫随机场(MRF)
马尔可夫随机场(Markov Random Field)是一种典型的马尔可夫网,即使用无向边来表达变量间的依赖关系。在马尔可夫随机场中,对于关系图中的一个子集,若任意两结点间都有边连接,则称该子集为一个团;若再加一个结点便不能形成团,则称该子集为极大团。MRF使用势函数来定义多个变量的概率分布函数,其中每个(极大)团对应一个势函数,一般团中的变量关系也体现在它所对应的极大团中,因此常常基于极大团来定义变量的联合概率分布函数。具体而言,若所有变量构成的极大团的集合为C,则MRF的联合概率函数可以定义为:

对于条件独立性,马尔可夫随机场通过分离集来实现条件独立,若A结点集必须经过C结点集才能到达B结点集,则称C为分离集。书上给出了一个简单情形下的条件独立证明过程,十分贴切易懂,此处不再展开。基于分离集的概念,得到了MRF的三个性质:
全局马尔可夫性:给定两个变量子集的分离集,则这两个变量子集条件独立。 局部马尔可夫性:给定某变量的邻接变量,则该变量与其它变量条件独立。 成对马尔可夫性:给定所有其他变量,两个非邻接变量条件独立。
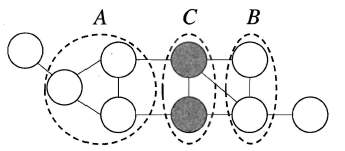
对于MRF中的势函数,势函数主要用于描述团中变量之间的相关关系,且要求为非负函数,直观来看:势函数需要在偏好的变量取值上函数值较大,例如:若x1与x2成正相关,则需要将这种关系反映在势函数的函数值中。一般我们常使用指数函数来定义势函数:

15.3 条件随机场(CRF)
前面所讲到的隐马尔可夫模型和马尔可夫随机场都属于生成式模型,即对联合概率进行建模,条件随机场则是对条件分布进行建模。CRF试图在给定观测值序列后,对状态序列的概率分布进行建模,即P(y | x)。直观上看:CRF与HMM的解码问题十分类似,都是在给定观测值序列后,研究状态序列可能的取值。CRF可以有多种结构,只需保证状态序列满足马尔可夫性即可,一般我们常使用的是链式条件随机场:
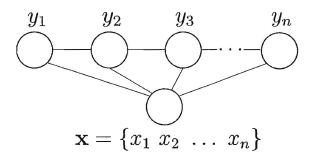
与马尔可夫随机场定义联合概率类似地,CRF也通过团以及势函数的概念来定义条件概率P(y | x)。在给定观测值序列的条件下,链式条件随机场主要包含两种团结构:单个状态团及相邻状态团,通过引入两类特征函数便可以定义出目标条件概率:
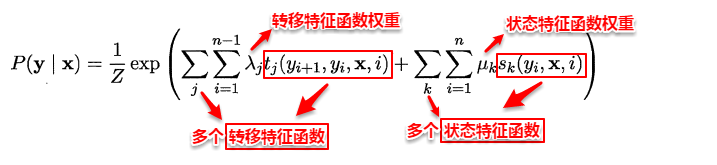
以词性标注为例,如何判断给出的一个标注序列靠谱不靠谱呢?转移特征函数主要判定两个相邻的标注是否合理,例如:动词+动词显然语法不通;状态特征函数则判定观测值与对应的标注是否合理,例如: ly结尾的词-->副词较合理。因此我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。也就是说,每一个特征函数(对应一种规则)都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。可以看出:特征函数是一些经验的特性。
15.4 学习与推断
对于生成式模型,通常我们都是先对变量的联合概率分布进行建模,接着再求出目标变量的边际分布(marginal distribution),那如何从联合概率得到边际分布呢?这便是学习与推断。下面主要介绍两种精确推断的方法:变量消去与信念传播。
15.4.1 变量消去
变量消去利用条件独立性来消减计算目标概率值所需的计算量,它通过运用乘法与加法的分配率,将对变量的积的求和问题转化为对部分变量交替进行求积与求和的问题,从而将每次的运算控制在局部,达到简化运算的目的。
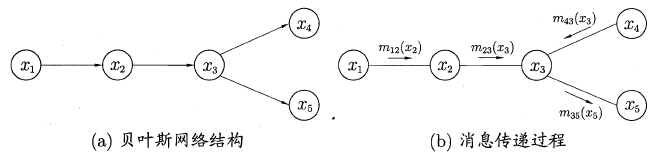
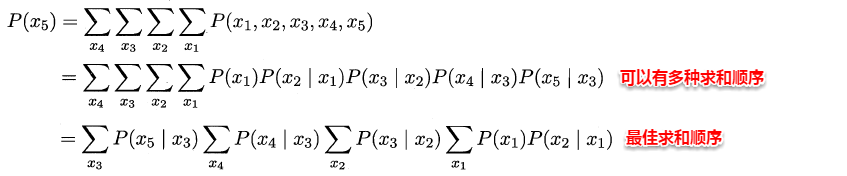
15.4.2 信念传播
若将变量求和操作看作是一种消息的传递过程,信念传播可以理解成:一个节点在接收到所有其它节点的消息后才向另一个节点发送消息,同时当前节点的边际概率正比于他所接收的消息的乘积:
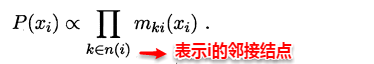
因此只需要经过下面两个步骤,便可以完成所有的消息传递过程。利用动态规划法的思想记录传递过程中的所有消息,当计算某个结点的边际概率分布时,只需直接取出传到该结点的消息即可,从而避免了计算多个边际分布时的冗余计算问题。
1.指定一个根节点,从所有的叶节点开始向根节点传递消息,直到根节点收到所有邻接结点的消息**(从叶到根); 2.从根节点开始向叶节点传递消息,直到所有叶节点均收到消息(从根到叶)**。
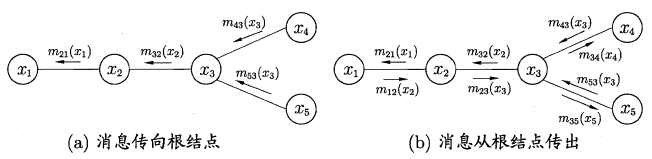
15.5 LDA话题模型
话题模型主要用于处理文本类数据,其中隐狄利克雷分配模型(Latent Dirichlet Allocation,简称LDA)是话题模型的杰出代表。在话题模型中,有以下几个基本概念:词(word)、文档(document)、话题(topic)。
词:最基本的离散单元; 文档:由一组词组成,词在文档中不计顺序; 话题:由一组特定的词组成,这组词具有较强的相关关系。
在现实任务中,一般我们可以得出一个文档的词频分布,但不知道该文档对应着哪些话题,LDA话题模型正是为了解决这个问题。具体来说:LDA认为每篇文档包含多个话题,且其中每一个词都对应着一个话题。因此可以假设文档是通过如下方式生成:

这样一个文档中的所有词都可以认为是通过话题模型来生成的,当已知一个文档的词频分布后(即一个N维向量,N为词库大小),则可以认为:每一个词频元素都对应着一个话题,而话题对应的词频分布则影响着该词频元素的大小。因此很容易写出LDA模型对应的联合概率函数:
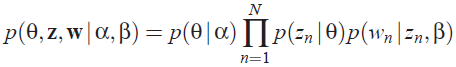
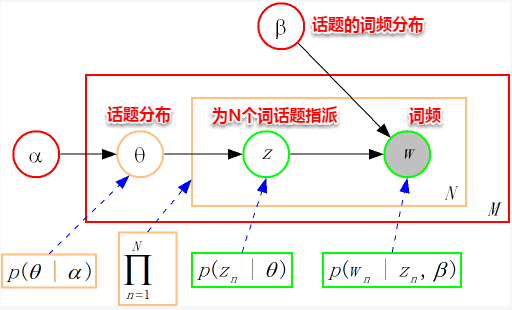
从上图可以看出,LDA的三个表示层被三种颜色表示出来:
corpus-level(红色): α和β表示语料级别的参数,也就是每个文档都一样,因此生成过程只采样一次。 document-level(橙色): θ是文档级别的变量,每个文档对应一个θ。 word-level(绿色): z和w都是单词级别变量,z由θ生成,w由z和β共同生成,一个单词w对应一个主题z。
通过上面对LDA生成模型的讨论,可以知道LDA模型主要是想从给定的输入语料中学习训练出两个控制参数α和β,当学习出了这两个控制参数就确定了模型,便可以用来生成文档。其中α和β分别对应以下各个信息:
α:分布p(θ)需要一个向量参数,即Dirichlet分布的参数,用于生成一个主题θ向量; β:各个主题对应的单词概率分布矩阵p(w|z)。
把w当做观察变量,θ和z当做隐藏变量,就可以通过EM算法学习出α和β,求解过程中遇到后验概率p(θ,z|w)无法直接求解,需要找一个似然函数下界来近似求解,原作者使用基于分解(factorization)假设的变分法(varialtional inference)进行计算,用到了EM算法。每次E-step输入α和β,计算似然函数,M-step最大化这个似然函数,算出α和β,不断迭代直到收敛。
十六. 强化学习
强化学习(Reinforcement Learning,简称RL)是机器学习的一个重要分支,前段时间人机大战的主角AlphaGo正是以强化学习为核心技术。在强化学习中,包含两种基本的元素:状态与动作,在某个状态下执行某种动作,这便是一种策略,学习器要做的就是通过不断地探索学习,从而获得一个好的策略。例如:在围棋中,一种落棋的局面就是一种状态,若能知道每种局面下的最优落子动作,那就攻无不克/百战不殆了~
若将状态看作为属性,动作看作为标记,易知:监督学习和强化学习都是在试图寻找一个映射,从已知属性/状态推断出标记/动作,这样强化学习中的策略相当于监督学习中的分类/回归器。但在实际问题中,强化学习并没有监督学习那样的标记信息,通常都是在尝试动作后才能获得结果,因此强化学习是通过反馈的结果信息不断调整之前的策略,从而算法能够学习到:在什么样的状态下选择什么样的动作可以获得最好的结果。
16.1 基本要素
强化学习任务通常使用马尔可夫决策过程(Markov Decision Process,简称MDP)来描述,具体而言:机器处在一个环境中,每个状态为机器对当前环境的感知;机器只能通过动作来影响环境,当机器执行一个动作后,会使得环境按某种概率转移到另一个状态;同时,环境会根据潜在的奖赏函数反馈给机器一个奖赏。综合而言,强化学习主要包含四个要素:状态、动作、转移概率以及奖赏函数。
状态(X):机器对环境的感知,所有可能的状态称为状态空间; 动作(A):机器所采取的动作,所有能采取的动作构成动作空间; 转移概率(P):当执行某个动作后,当前状态会以某种概率转移到另一个状态; 奖赏函数(R):在状态转移的同时,环境给反馈给机器一个奖赏。
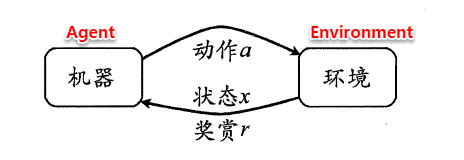
因此,强化学习的主要任务就是通过在环境中不断地尝试,根据尝试获得的反馈信息调整策略,最终生成一个较好的策略π,机器根据这个策略便能知道在什么状态下应该执行什么动作。常见的策略表示方法有以下两种:
确定性策略:π(x)=a,即在状态x下执行a动作; 随机性策略:P=π(x,a),即在状态x下执行a动作的概率。
一个策略的优劣取决于长期执行这一策略后的累积奖赏,换句话说:可以使用累积奖赏来评估策略的好坏,最优策略则表示在初始状态下一直执行该策略后,最后的累积奖赏值最高。长期累积奖赏通常使用下述两种计算方法:

16.2 K摇摆赌博机
首先我们考虑强化学习最简单的情形:仅考虑一步操作,即在状态x下只需执行一次动作a便能观察到奖赏结果。易知:欲最大化单步奖赏,我们需要知道每个动作带来的期望奖赏值,这样便能选择奖赏值最大的动作来执行。若每个动作的奖赏值为确定值,则只需要将每个动作尝试一遍即可,但大多数情形下,一个动作的奖赏值来源于一个概率分布,因此需要进行多次的尝试。
单步强化学习实质上是K-摇臂赌博机(K-armed bandit)的原型,一般我们尝试动作的次数是有限的,那如何利用有限的次数进行有效地探索呢?这里有两种基本的想法:
仅探索法:将尝试的机会平均分给每一个动作,即轮流执行,最终将每个动作的平均奖赏作为期望奖赏的近似值。 仅利用法:将尝试的机会分给当前平均奖赏值最大的动作,隐含着让一部分人先富起来的思想。
可以看出:上述两种方法是相互矛盾的,仅探索法能较好地估算每个动作的期望奖赏,但是没能根据当前的反馈结果调整尝试策略;仅利用法在每次尝试之后都更新尝试策略,符合强化学习的思(tao)维(lu),但容易找不到最优动作。因此需要在这两者之间进行折中。
16.2.1 ε-贪心
ε-贪心法基于一个概率来对探索和利用进行折中,具体而言:在每次尝试时,以ε的概率进行探索,即以均匀概率随机选择一个动作;以1-ε的概率进行利用,即选择当前最优的动作。ε-贪心法只需记录每个动作的当前平均奖赏值与被选中的次数,便可以增量式更新。

16.2.2 Softmax
Softmax算法则基于当前每个动作的平均奖赏值来对探索和利用进行折中,Softmax函数将一组值转化为一组概率,值越大对应的概率也越高,因此当前平均奖赏值越高的动作被选中的几率也越大。Softmax函数如下所示:


16.3 有模型学习
若学习任务中的四个要素都已知,即状态空间、动作空间、转移概率以及奖赏函数都已经给出,这样的情形称为“有模型学习”。假设状态空间和动作空间均为有限,即均为离散值,这样我们不用通过尝试便可以对某个策略进行评估。
16.3.1 策略评估
前面提到:在模型已知的前提下,我们可以对任意策略的进行评估(后续会给出演算过程)。一般常使用以下两种值函数来评估某个策略的优劣:
状态值函数(V):V(x),即从状态x出发,使用π策略所带来的累积奖赏; 状态-动作值函数(Q):Q(x,a),即从状态x出发,执行动作a后再使用π策略所带来的累积奖赏。
根据累积奖赏的定义,我们可以引入T步累积奖赏与r折扣累积奖赏:
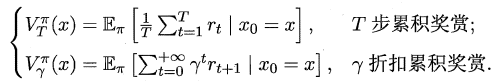
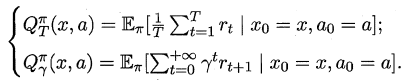
由于MDP具有马尔可夫性,即现在决定未来,将来和过去无关,我们很容易找到值函数的递归关系:

类似地,对于r折扣累积奖赏可以得到:
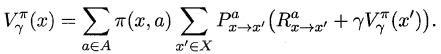
易知:当模型已知时,策略的评估问题转化为一种动态规划问题,即以填表格的形式自底向上,先求解每个状态的单步累积奖赏,再求解每个状态的两步累积奖赏,一直迭代逐步求解出每个状态的T步累积奖赏。算法流程如下所示:

对于状态-动作值函数,只需通过简单的转化便可得到:
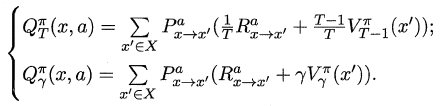
16.3.2 策略改进
理想的策略应能使得每个状态的累积奖赏之和最大,简单来理解就是:不管处于什么状态,只要通过该策略执行动作,总能得到较好的结果。因此对于给定的某个策略,我们需要对其进行改进,从而得到最优的值函数。
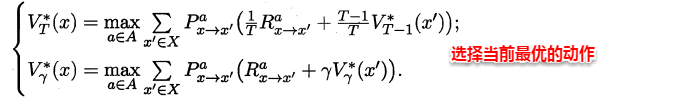
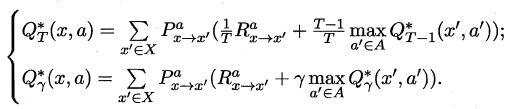
最优Bellman等式改进策略的方式为:将策略选择的动作改为当前最优的动作,而不是像之前那样对每种可能的动作进行求和。易知:选择当前最优动作相当于将所有的概率都赋给累积奖赏值最大的动作,因此每次改进都会使得值函数单调递增。
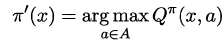
将策略评估与策略改进结合起来,我们便得到了生成最优策略的方法:先给定一个随机策略,现对该策略进行评估,然后再改进,接着再评估/改进一直到策略收敛、不再发生改变。这便是策略迭代算法,算法流程如下所示:

可以看出:策略迭代法在每次改进策略后都要对策略进行重新评估,因此比较耗时。若从最优化值函数的角度出发,即先迭代得到最优的值函数,再来计算如何改变策略,这便是值迭代算法,算法流程如下所示:

16.4 蒙特卡罗强化学习
在现实的强化学习任务中,环境的转移函数与奖赏函数往往很难得知,因此我们需要考虑在不依赖于环境参数的条件下建立强化学习模型,这便是免模型学习。蒙特卡罗强化学习便是其中的一种经典方法。
由于模型参数未知,状态值函数不能像之前那样进行全概率展开,从而运用动态规划法求解。一种直接的方法便是通过采样来对策略进行评估/估算其值函数,蒙特卡罗强化学习正是基于采样来估计状态-动作值函数:对采样轨迹中的每一对状态-动作,记录其后的奖赏值之和,作为该状态-动作的一次累积奖赏,通过多次采样后,使用累积奖赏的平均作为状态-动作值的估计,并引入ε-贪心策略保证采样的多样性。

在上面的算法流程中,被评估和被改进的都是同一个策略,因此称为同策略蒙特卡罗强化学习算法。引入ε-贪心仅是为了便于采样评估,而在使用策略时并不需要ε-贪心,那能否仅在评估时使用ε-贪心策略,而在改进时使用原始策略呢?这便是异策略蒙特卡罗强化学习算法。

16.5 AlphaGo原理浅析
本篇一开始便提到强化学习是AlphaGo的核心技术之一,刚好借着这个东风将AlphaGo的工作原理了解一番。正如人类下棋那般“手下一步棋,心想三步棋”,Alphago也正是这个思想,当处于一个状态时,机器会暗地里进行多次的尝试/采样,并基于反馈回来的结果信息改进估值函数,从而最终通过增强版的估值函数来选择最优的落子动作。
其中便涉及到了三个主要的问题:(1)如何确定估值函数(2)如何进行采样(3)如何基于反馈信息改进估值函数,这正对应着AlphaGo的三大核心模块:深度学习、蒙特卡罗搜索树、强化学习。
1.深度学习(拟合估值函数)
由于围棋的状态空间巨大,像蒙特卡罗强化学习那样通过采样来确定值函数就行不通了。在围棋中,状态值函数可以看作为一种局面函数,状态-动作值函数可以看作一种策略函数,若我们能获得这两个估值函数,便可以根据这两个函数来完成:(1)衡量当前局面的价值;(2)选择当前最优的动作。那如何精确地估计这两个估值函数呢?这就用到了深度学习,通过大量的对弈数据自动学习出特征,从而拟合出估值函数。
2.蒙特卡罗搜索树(采样)
蒙特卡罗树是一种经典的搜索框架,它通过反复地采样模拟对局来探索状态空间。具体表现在:从当前状态开始,利用策略函数尽可能选择当前最优的动作,同时也引入随机性来减小估值错误带来的负面影响,从而模拟棋局运行,使得棋盘达到终局或一定步数后停止。
3.强化学习(调整估值函数)
在使用蒙特卡罗搜索树进行多次采样后,每次采样都会反馈后续的局面信息(利用局面函数进行评价),根据反馈回来的结果信息自动调整两个估值函数的参数,这便是强化学习的核心思想,最后基于改进后的策略函数选择出当前最优的落子动作。
熵、交叉熵和KL散度
熵(Entropy)的介绍 我们以天气预报为例子,进行熵的介绍.
-
假如只有 2 种天气,sunny 和 rainy ,那么明天对于每一种天气来说,各有 50% 的可能性.
-
此时气象部门告诉你明天是rainy,他其实减少了你的不确定信息.
-
所以,天气部门给了你 1 bit的有效信息(因为此时只有两种可能性).
-
假如只有8种天气,每一种天气出现是等可能的.
-
此时气象部门告诉你明天是 Rainy ,他其实减少了你的不确定信息,也就是告诉了你有效信息.
-
所以,天气部门给了你 3 bit的有效信息(因为8种状态需要 2^3=8 ,需要 3 bit来表示.
-
所以,有效信息的计算可以使用 log 来进行计算,计算过程如下
-
上面所有的情况都是等概率出现的,假设各种情况出现的概率不是相等的.
-
例如有75%的可能性是Sunny,25%的可能性是Rainy.
-
如果气象部门告诉你明天是Rainy
- 我们会使用概率的倒数, (概率越小,有效信息越多)
- 接着计算有效信息, ,log的等价计算)
- 因为和本来的概率相差比较大,所以获得的有效信息比较多(本来是 Rainy 的可能性小)
-
如果气象部门告诉你明天是 Sunny
- 同样计算此时的有效信息,
- 因为和本来的概率相差比较小,所以获得的信息比较少(本来是 Sunny 的可能性大)
-
从气象部门获得的信息的平均值(这个就是熵
- 简单解释: 有 75% 的可能性是Sunny ,得到晴天的有效信息是 0.41 ,所以是
-
于是我们得到了熵的计算公式.
- 熵是用来衡量获取的信息的平均值,没有获取什么信息量,则 Entropy 接近 0 .
- 下面是熵的计算公式
交叉熵(Cross-Entropy)的介绍 对于交叉熵的介绍,我们还是以天气预报作为例子来进行讲解.
- 交叉熵(Cross-Entropy)可以理解为平均的 message length ,即平均信息长度.
- 现在有 8 种天气,于是每一种天气我们可以使用 3 bit 来进行表示(000,001,010,011...)
- 此时 average message length = 3 ,所以此时Cross-Entropy
现在假设你住在一个 sunny region ,出现晴天的可能性比较大(即每一种天气不是等可能出现的),下图是每一种天气的概率.

我们来计算一下此时的熵(ntropy) ,计算的式子如下所示:
- 此时有效的信息是 2.23 bit.
- 所以再使用上面的编码方式(都使用 3 会有咒余.
- 也就是说我们每次发出 3 bit ,接收者有效信息为2.23 bit.
- 这时我们可以修改天气的 encode 的方式,可以给经常出现的天气比较小的 code 来进行表示,于是我们可以按照下图对每一种天气进行 encode .

此时的平均长度的计算如下所示(每一种天气的概率该天气code的长度): 此时的平均长度为 2.42 bit,可以看到比一开始的 3 bit有所减少.
如果我们使用相同的 code ,但是此时对应的天气的概率是不相同的,此时计算出的平均长度就会发生改变.此时每一种天气的概率如下图所示:

于是此时的信息的平均长度就是 4.58 bit ,比 Entropy 大很多 (如上图所示,我们给了概率很小的天 气的 code 也很小,概率很大的天气的 code 也很大,此时就会导致计算出的平均长度很大),下面是平均长度的计算的式子. 我们如何来理解我们给每一种天气的 code 呢,其实我们可以理解为这就是我们对每一种天气发生的可能性的预测,我们会给出现概率比较大的天气比较短的 code ,这里的概率是我们假设的,即我们有一个估计的概率,我们估计这个天气的概率比较大,所以给这个天气比较短的 code.
下图中可以表示出我们预测的q(predicted distribution)和真实分布p(true distribution).可以看到此时我们的预测概率 与真实分布 之间相差很大(此时计算出的交叉熵就会比较大)
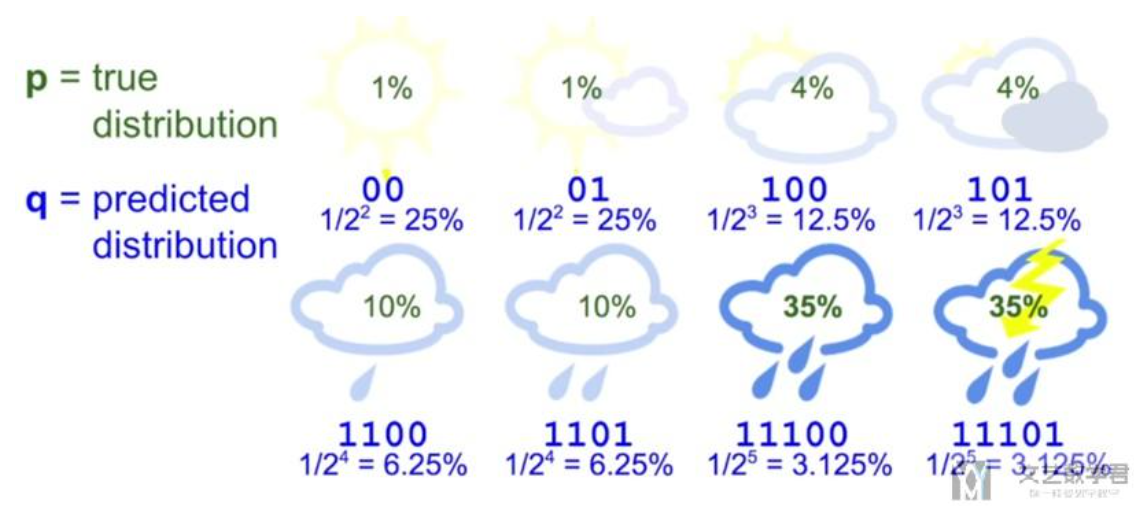
关于上面 code 长度与概率的转换,我们可以这么来进行理解,对于概率为 的信息,他的有效信息为 .若此时 code 长度为 ,我们问概率为多少的信息的有效信息为 n ,即求解 ,则 ,所以我们就可以求出 长度与概率的转换.此时,我们就可以定义交叉熵(Cross-Entropy),这里会有两个变量,分别是p(真实的分布)和 q(预测的概率): 这个交叉熵公式的意思就是在计算消息的平均长度,我们可以这样来进行理解.
- 是将预测概率转换为 code 的长度(这里看上面 code 长度与概率的转换)
- 接着我们再将 code 的长度 乘上出现的概率 真实的概率
我们简单说明一下熵(Entropy),和交叉熵(Cross-Entropy)的性质:
- 如果预测结果是好的,,那么 p 和 q 的分布是相似的,此时 Cross-Entropy 与 Entropy 是相似 的.
- 如果 p 和 q 有很大的不同,那么 Cross-Entropy 会比 Entropy 大.
- 其中 Cross-Entropy 比 Entropy 大的部分,我们称为 relative entropy ,或是Kullback- Leibler Divergence(KL Divergence),这个就是KL-散度,我们会在后面进行详细的介 绍.
- 也就是说,三者的关系为:Cross-Entropy=Entropy+ KL Divergence
在进行分类问题的时候,我们通常会将 loss 函数设置为交叉熵(Cross-Entropy),其实现在来看这个也是很好理解,我们会有我们预测的概率 q 和实际的概率 p ,若 p 和 q 相似,则交叉熵小,若 p 和 q 不相似,则交叉熵大.
有一个要注意的是,我们通常在使用的时候会使用 10 为底的 log ,但是这个不影响 ,因为 ,我们可以通过公式进行转换.
在 PyTorch 中,CrossEntropyLoss 不是直接按照上面进行计算的,他是包含了 Softmax 的步骤的.关于在 PyTorch 中 CrossEntropyLoss 的实际计算: 详细介绍:PyTorch中交叉熵的计算CrossEntropyLoss
交叉熵损失函数
交叉熵损失函数(Cross-Entropy Loss Function)一般用于分类问题.假设样本的标签 𝑦 ∈ {1,⋯,𝐶} 为离散的类别,模型 的输出为类别标签的条件概率分布,即 并满足 我们可以用一个 维的one-hot向量 来表示样本标签.假设样本的标签为 ,那么标签向量只有第 维的值为 1 ,其余元素的值都为 0 .标签向量 可以看作样本标签的真实条件概率分布 ,即第 维(记为 ) 是类别为 的真实条件概率.假设样本的类别为 ,那么它属于第 类的概率为 1 ,属于其他类的概率为 0 . 对于两个概率分布,一般可以用交叉熵来衡量它们的差异.标签的真实分布 和模型预测分布 之间的交叉熵为 比如对于三分类问题,一个样本的标签向量为,模型预测的标签分布为,则它们的交叉熵为. 因为 为one-hot向量,上式也可以写为 其中 可以看作真实类别 的似然函数.因此,交叉熵损失函数也就是负对数似然函数(Negative Log-Likelihood).
交叉熵最小值证明
为什么当 与 的分布一致时, 有最小值:
证明如下: 因为 为定义域上的凸函数 根据琴生不等式有 其中
将 代入则有: 所以 当 时, 等号成立.
神经网络
书可参考邱锡鹏:神经网络与深度学习
一. 神经元
时刻思考各个激活函数的特点,如合理性?梯度爆炸?梯度消失?
1. Sigmoid型函数
Sigmoid型函数是指一类S型曲线函数,为两端饱和函数.常用的Sigmoid型函数有Logistic函数和Tanh函数.
>对于函数 ,若 时,其导数 ,则称其为左饱和.若 时,其导数 ,则称其为右饱和.当同时满足左、右饱和时,就称为两端饱和.
1.1 Logistic型函数
1.2 Tanh函数
Tanh函数可以看作放大并平移的Logistic函数,其值域是(−1,1)
下图给出了Logistic函数和Tanh函数的形状.Tanh函数的输出是零中心化的(Zero-Centered),而Logistic函数的输出恒大于0.非零中心化的输出会使得其后一层的神经元的输入发生偏置偏移(Bias Shift),并进一步使得梯度下降的收敛速度变慢.
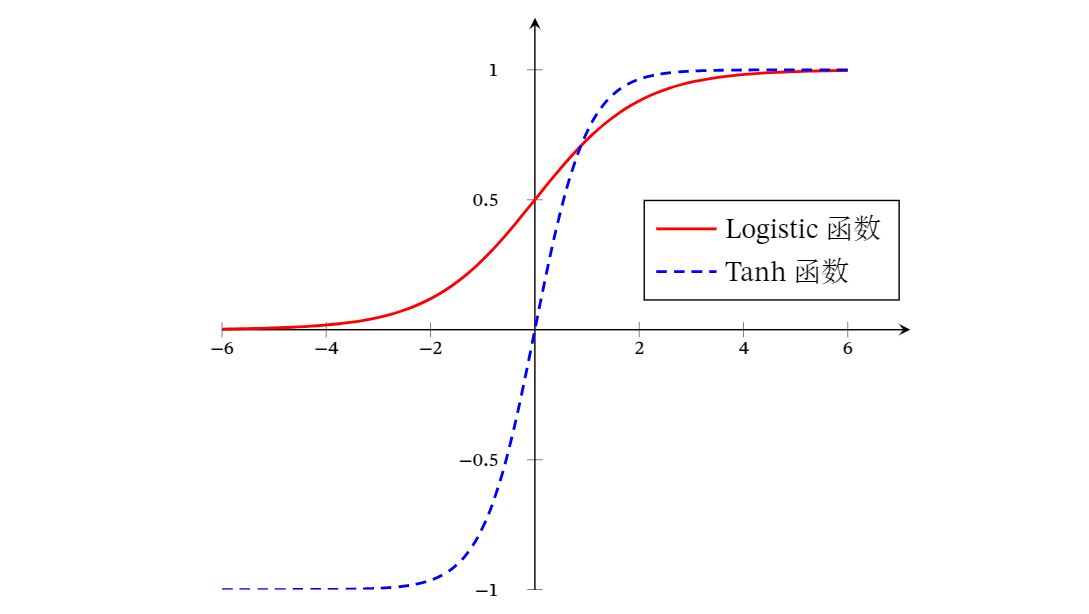
2. ReLU函数
ReLU(Rectified Linear Unit,修正线性单元),也叫Rectifier函数,是目前深度神经网络中经常使用的激活函数.ReLU实际上是一个斜坡(ramp)函数,定义为 ReLU神经元训练时比较容易“死亡”,在训练时,如果参数在一次不恰当的更新后,第一个隐藏层中的某个ReLU神经元在所有的训练数据上都不能被激活,那么这个神经元自身参数的梯度永远都会是0,在以后的训练过程中永远不能被激活.这种现象称为死亡ReLU问题(DyingReLU Problem).故有以下变种
2.1 带泄露的ReLU
带泄露的ReLU(Leaky ReLU)在输入 时,保持一个很小的梯度 .这样当神经元非激活时也能有一个非零的梯度可以更新参数,避免永远不能被激活.
2.2 带参数的ReLU
带参数的ReLU(Parametric ReLU,PReLU)引入一个可学习的参数,不同神经元可以有不同的参数[He et al.,2015].对于第𝑖个神经元,其PReLU的定义为
2.3 ELU函数
ELU(Exponential Linear Unit,指数线性单元)是一个近似的零中心化的非线性函数,其定义为 其中𝛾 ≥ 0是一个超参数,决定𝑥 ≤ 0时的饱和曲线,并调整输出均值在0附近.
2.4 Softplus函数
Softplus函数可以看作Rectifier函数的平滑版本,其定义为
Softplus函数其导数刚好是Logistic函数.Softplus函数虽然也具有单侧抑制、宽兴奋边界的特性,却没有稀疏激活性.
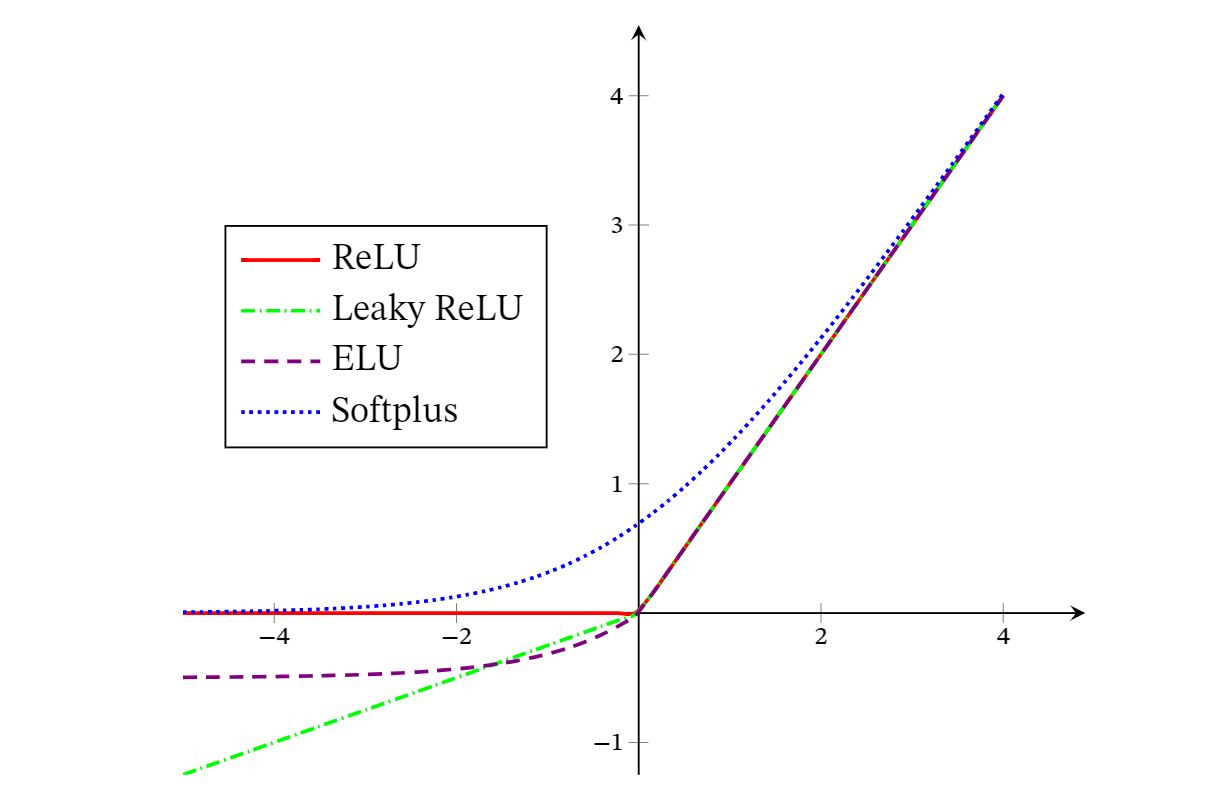
3. Swish函数
Swish函数是一种自门控(Self-Gated)激活函数,定义为
其中为Logistic函数, 为可学习的参数或一个固定超参数. 可以看作一种软性的门控机制.当 接近于1时,门处于“开”状态,激活函数的输出近似于𝑥本身;当 接近于0时,门的状态为“关”,激活函数的输出近似于0
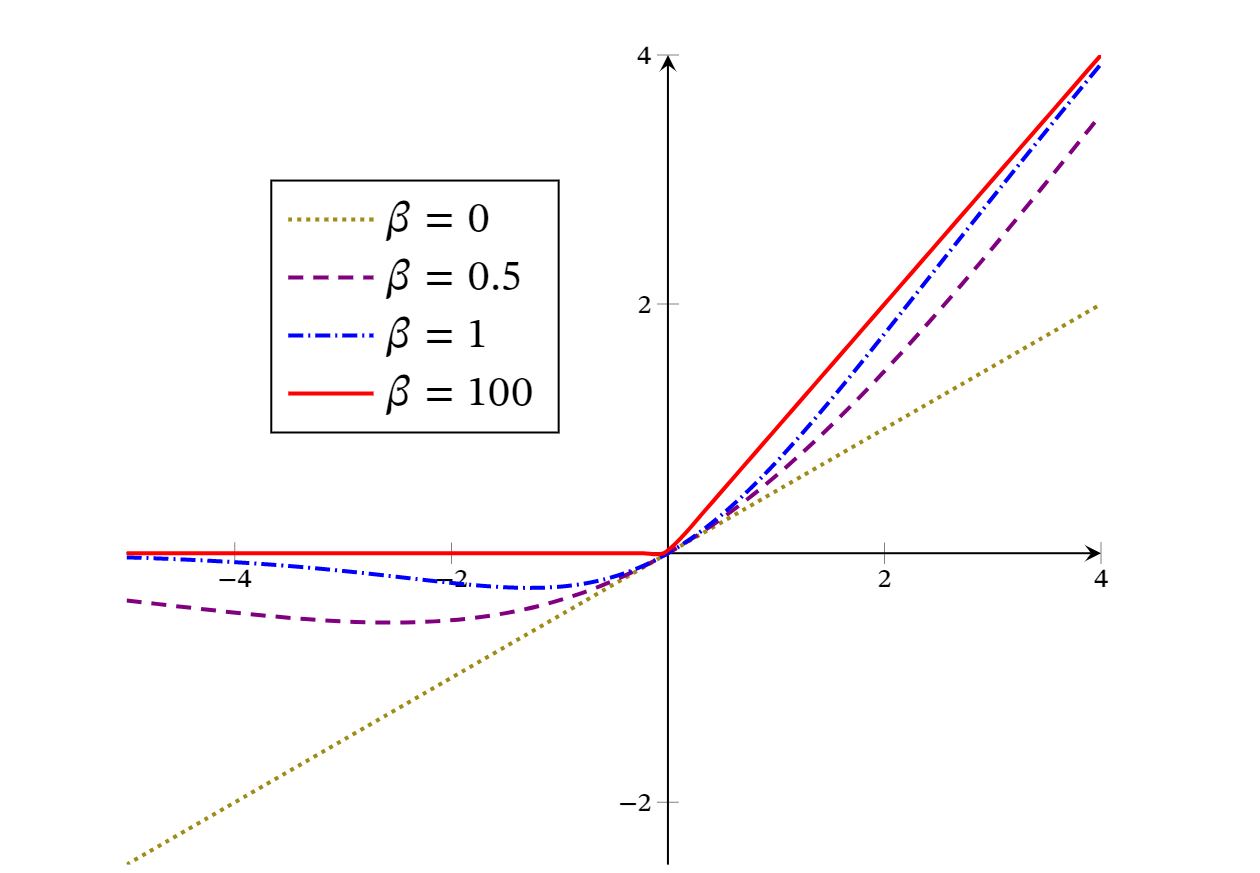
当 时,Swish函数变成线性函数 .当 时,Swish函数在 时近似线性,在 时近似饱和,同时具有一定的非单调性.当 时, 趋向于离散的0-1函数,Swish函数近似为ReLU函数.因此,Swish函数可以看作线性函数和ReLU函数之间的非线性插值函数,其程度由参数 控制.
4. GELU函数
TODO:GELU函数
5. Maxout单元
TODO:Maxout单元
二. 网络结构
1. 网络结构总述
目前为止,常用的神经网络有如下三种:
- 前馈网络:整个网络中的信息是朝一个方向传播,没有反向的信息传播,可以用一个有向无环路图表示.前馈网络包括全连接前馈网络和卷积神经网络等.前馈网络可以看作一个函数,通过简单非线性函数的多次复合,实现输入空间到输出空间的复杂映射.
- 记忆网络:也称为反馈网络,网络中的神经元不但可以接收其他神经元的信息,也可以接收自己的历史信息.和前馈网络相比,记忆网络中的神经元具有记忆功能,在不同的时刻具有不同的状态.记忆神经网络中的信息传播可以是单向或双向传递,因此可用一个有向循环图或无向图来表示.记忆网络包括循环神经网络、Hopfield网络、玻尔兹曼机、受限玻尔兹曼机等.记忆网络可以看作一个程序,具有更强的计算和记忆能力.为了增强记忆网络的记忆容量,可以引入外部记忆单元和读写机制,用来保存一些网络的中间状态,称为记忆增强神经网络(Memory Augmented NeuralNetwork,MANN),比如神经图灵机和记忆网络等.
- 图网络:实际应用中很多数据是图结构的数据,比如知识图谱、社交网络、分子(Molecular)网络等.图网络是定义在图结构数据上的神经网络.图中每个节点都由一个或一组神经元构成.节点之间的连接可以是有向的,也可以是无向的.每个节点可以收到来自相邻节点或自身的信息.图网络是前馈网络和记忆网络的泛化,包含很多不同的实现方式,比如图卷积网络(Graph Convolutional Network,GCN)、图注意力网络(Graph Attention Network,GAT)、消息传递神经网络(Message Passing Neural Network,MPNN)等.
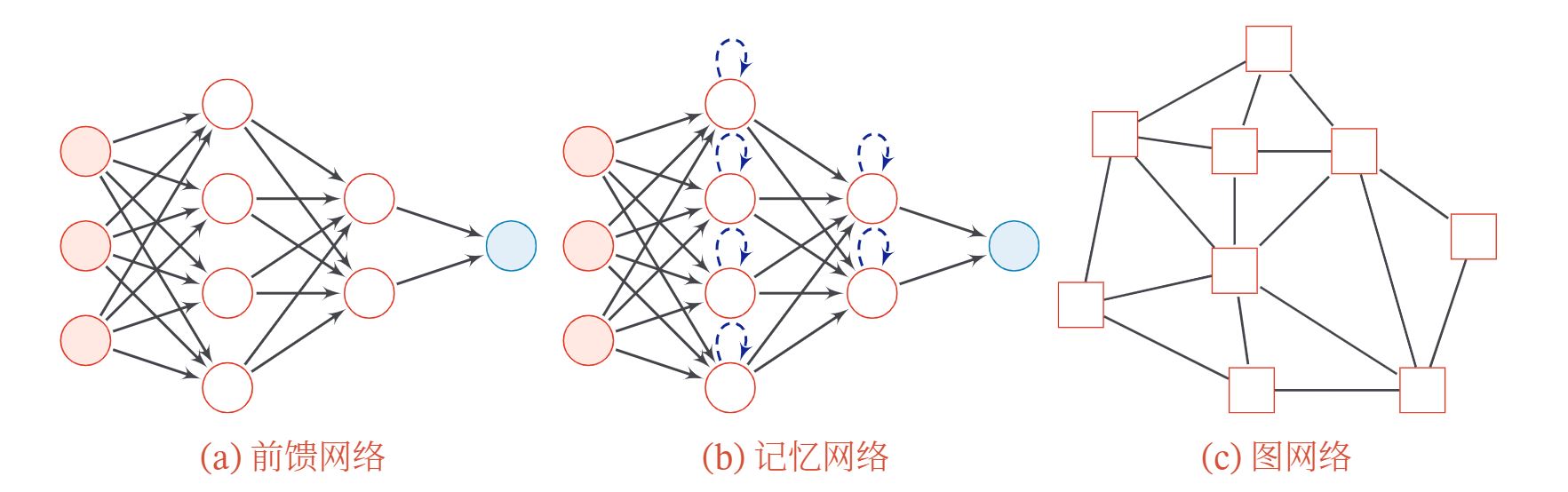
三. 小批量梯度下降
小批量梯度下降法(Mini-BatchGradient Descent).
令 表示一个深度神经网络, 为网络参数,在使用小批量梯度下降进行优化时,每次选取 个训练样本 .第 次迭代时损失函数关于参数 的偏导数为 其中 为可微分的损失函数, 为批量大小(batch size).
前馈神经网络
一. 前馈神经网络
前馈神经网络(Feedforward Neural Network,FNN)是最早发明的简单人工神经网络.前馈神经网络也经常称为多层感知器(Multi-Layer Perceptron,MLP).
在前馈神经网络中,各神经元分别属于不同的层.每一层的神经元可以接收前一层神经元的信号,并产生信号输出到下一层.第 0 层称为输入层,最后一层称为输出层,其他中间层称为隐藏层.整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示.
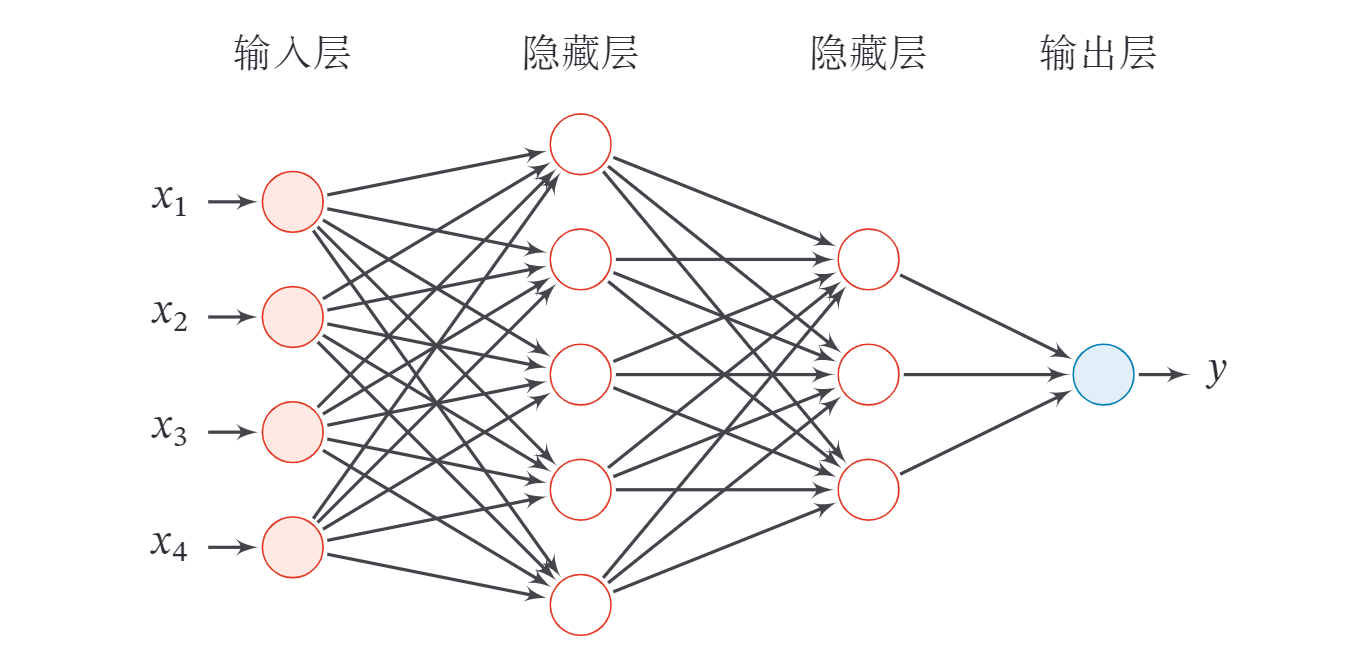
下面用到的记号:
- :神经网络的层数
- :第 层神经元的个数
- :第 层神经元的激活函数
- :第 层到第 层的权重矩阵
- :第 层神经元的净输入 净活性值
- :第 层神经元的输出 活性值
令 ,前馈神经网络通过不断迭代下面公式进行信息传播:
首先根据第 层神经元的活性值 ( Activation ) 计算出第 层神经元的净活性值 ( Net Activation ) ,然后经过一个激活函数得到第 层神经元的活性 值因此,我们也可以把每个神经层看作一个仿射变换 ( Affine Transformation ) 和一个非线性变换. 上述两式也可以合并写为: 或者
仿射变换:又称仿射映射,是指在几何中,一个向量空间进行一次线性变换并接上一个平移,变换为另一个向量空间.
这样, 前馈神经网络可以通过逐层的信息传递,得到网络最后的输出 .整个网络可以看作一个复合函数 ,将向量 作为第 1 层的输入 .将第 层的输出 作为整个函数的输出.
其中 表示网络中所有层的连接权重和偏置.
通用近似定理(Universal Approximation Theorem ) [Cy- benko, 1989; Hornik et al., 1989]: 令 是一个非常数、有界、单调递增的连续函数, 是一个 维的单位超立方体 是定义在 上的连续函数集合.对于任意给定的一个函数 ,存在一个整数 ,和一组实数 以及实数向量 ,以至于我 们可以定义函数 作为函数 的近似实现,即 其中 是一个很小的正数.
二. 反向传播
假设采用随机梯度下降进行神经网络参数学习,给定一个样本 ,将其输入到神经网络模型中,得到网络输出为 .假设损失函数为 ,要进行参数学习就需要计算损失函数关于每个参数的导数.
不失一般性,对第 层中的参数 和 计算偏导数.因为 的计算 涉及向量对矩阵的微分,十分繁銷,因此我们先计算 关于参数矩阵中每个元素的偏导数 .根据链式法则, 上式中的第二项都是目标函数关于第 层的神经元 的偏导数,称为误差项,可以一次计算得到,这样我们只需要计算三个偏导数, 分 别为 和 下面分别来计算这三个偏导数.
-
计算偏导数 因 ,偏导数 其中 为权重矩阵 的第 行, 表示第 个元素为 ,其余为 0 的行向量.
-
计算偏导数 因为 和 的函数关系为 ,因此偏导数 为 的单位矩阵.
-
计算偏导数 偏导数 表示第 层神经元对最终损失 的影响,也反映了最终损失对第 层神经元的敏感程度,因此一般称为第 层神经元的误差项,用 来表示.
误差项 也间接反映了不同神经元对网络能力的贡献程度,从而比较好地解决 了贡献度分配问题 ( Credit Assignment Problem, CAP ).
根据 ,有 根据 ,其中 为按位计算的函数,因此有 因此,根据链式法则,第 层的误差项为 其中 是向量的点积运算符,表示每个元素相乘.
从上式可以看出,第 层的误差项可以通过第 层的误差项计算得到,这就是误差的反向传播 ( BackPropagation, BP ).反向传播算法的含义是: 第 层的一个神经元的误差项 或敏感性 是所有与该神经元相连的第 层 的神经元的误差项的权重和.然后,再乘上该神经元激活函数的梯度.
在计算出上面三个偏导数之后,最初的式子可以写为 其中 相当于向量 和向量 的外积的第 个元素.上式可以进一步写为 因此, 关于第 层权重 的梯度为
同理, 关于第 层偏置 的梯度为 在计算出每一层的误差项之后,我们就可以得到每一层参数的梯度.因此,使用误差反向传播算法的前馈神经网络训练过程可以分为以下三步:
- 前馈计算每一层的净输入 和激活值 ,直到最后一层;
- 反向传播计算每一层的误差项 ;
- 计算每一层参数的偏导数,并更新参数.

三. 自动微分
自动微分(Automatic Differentiation,AD).
为简单起见,这里以一个神经网络中常见的复合函数的例子来说明自动微分的过程.令复合函数 为 其中 为输入标量, 和 分别为权重和偏置参数.
首先,我们将复合函数 分解为一系列的基本操作,并构成一个计算图 ( Computational Graph ).计算图是数学运算的图形化表示.计算图中的每个非叶子节点表示一个基本操作,每个叶子节点为一个输入变量或常量.下图给 出了当 时复合函数 的计算图,其中连边上的红色数字表示前向计算时复合函数中每个变量的实际取值.
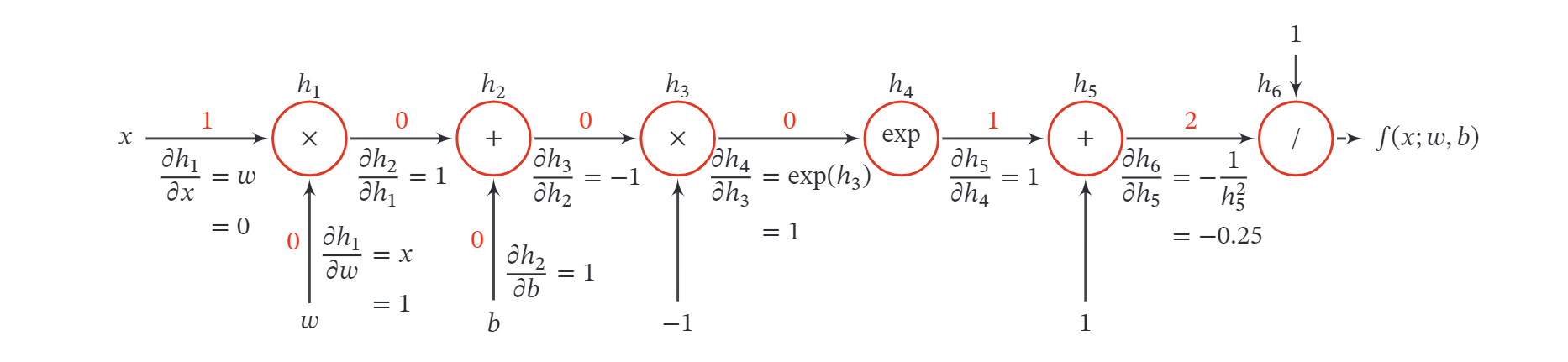
从计算图上可以看出,复合函数 由 6 个基本函数 组成.如下图所示,每个基本函数的导数都十分简单,可以通过规则来实现.

整个复合函数 关于参数 和 的导数可以通过计算图上的节点 与参数 和 之间路径上所有的导数连乘来得到,即 以 为例,当 时,可以得到 如果函数和参数之间有多条路径,可以将这多条路径上的导数再进行相加,得到最终的梯度.
按照计算导数的顺序,自动微分可以分为两种模式:前向模式和反向模式.
前向模式 前向模式是按计算图中计算方向的相同方向来递归地计算梯度.以 为例,当 时,前向模式的累积计算顺序如下: 反向模式 反向模式是按计算图中计算方向的相反方向来递归地计算梯度.以 为例,当 时,反向模式的累积计算顺序如下: 前向模式和反向模式可以看作应用链式法则的两种梯度累积方式.从反向模式的计算顺序可以看出,反向模式和反向传播的计算梯度的方式相同.对于一般的函数形式 ,前向模式需要对每一个输入变量都进行一遍遍历,共需要 遍.而反向模式需要对每一个输出都进行一个遍历,共需要 遍.当 时,反向模式更高效.在前馈神经网络的参数学习中,风险函数为 ,输出为标量,因此采用反向模式为最有效的计算方式,只需要一遍计算.
静态计算图和动态计算图计算图按构建方式可以分为静态计算图(StaticCom-putational Graph)和动态计算图(Dynamic Computational Graph).在目前深度学习框架里,Theano和Ten-sorflow采用的是静态计算图,而DyNet、Chainer和PyTorch采用的是动态计算图.Tensorflow 2.0也支持了动态计算图.静态计算图是在编译时构建计算图,计算图构建好之后在程序运行时不能改变,而动态计算图是在程序运行时动态构建.两种构建方式各有优缺点.静态计算图在构建时可以进行优化,并行能力强,但灵活性比较差.动态计算图则不容易优化,当不同输入的网络结构不一致时,难以并行计算,但是灵活性比较高.
四. 卷积神经网络
相关介绍还可看知乎:深度学习中不同类型卷积的综合介绍和原文
卷积神经网络(Convolutional Neural Network,CNN或ConvNet)是一种具有局部连接、权重共享等特性的深层前馈神经网络.卷积神经网络最早主要是用来处理图像信息.在用全连接前馈网络来处理图像时,会存在以下两个问题:
- 参数太多:如果输入图像大小为 100×100×3(即图像高度为 100 ,宽度为 100 以及RGB 3 个颜色通道),在全连接前馈网络中,第一个隐藏层的每个神经元到输入层都有 100 × 100 × 3 = 30000 个互相独立的连接,每个连接都对应一个权重参数.随着隐藏层神经元数量的增多,参数的规模也会急剧增加.这会导致整个神经网络的训练效率非常低,也很容易出现过拟合.
- 局部不变性特征:自然图像中的物体都具有局部不变性特征,比如尺度缩放、平移、旋转等操作不影响其语义信息.而全连接前馈网络很难提取这些局部不变性特征,一般需要进行数据增强来提高性能.
卷积神经网络是受生物学上感受野机制的启发而提出的.感受野(Recep-tive Field)机制主要是指听觉、视觉等神经系统中一些神经元的特性,即神经元只接受其所支配的刺激区域内的信号.在视觉神经系统中,视觉皮层中的神经细胞的输出依赖于视网膜上的光感受器.视网膜上的光感受器受刺激兴奋时,将神经冲动信号传到视觉皮层,但不是所有视觉皮层中的神经元都会接受这些信号.一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元.
目前的卷积神经网络一般是由卷积层、汇聚层和全连接层交叉堆叠而成的前馈神经网络.卷积神经网络有三个结构上的特性:局部连接、权重共享以及汇聚.这些特性使得卷积神经网络具有一定程度上的平移、缩放和旋转不变性.和前馈神经网络相比,卷积神经网络的参数更少.卷积神经网络主要使用在图像和视频分析的各种任务(比如图像分类、人脸识别、物体识别、图像分割等)上,其准确率一般也远远超出了其他的神经网络模型.近年来卷积神经网络也广泛地应用到自然语言处理、推荐系统等领域.
4.1 卷积
4.1.1 卷积的定义
卷积(Convolution),也叫褶积,是分析数学中一种重要的运算.在信号处理或图像处理中,经常使用一维或二维卷积.
4.1.1.1 一维卷积
一维卷积经常用在信号处理中,用于计算信号的延迟累积.假设一个信号发生器每个时刻 产生一个信号 ,其信息的衰减率为 ,即在 个时间步长后,信息为原来的 倍.假设 ,那么在时刻 收到的信号 为当前时刻产生的信息和以前时刻延迟信息的叠加. 我们把 称为滤波器 ( Filter ) 或卷积核 ( Convolution Kernel ).假设滤波器长度为 ,它和一个信号序列 的卷积为 为了简单起见,这里假设卷积的输出 的下标 从 开始.
信号序列 和滤波器 的卷积定义为 其中 表示卷积运算.一般情况下滤波器的长度 远小于信号序列 的长度.
我们可以设计不同的滤波器来提取信号序列的不同特征.比如,当令滤波器 时,卷积相当于信号序列的简单移动平均 窗口大小为 ;当令滤波器 时,可以近似实现对信号序列的二阶微分,即 下图给出了两个滤波器的一维卷积示例.可以看出,两个滤波器分别提取了输入序列的不同特征.滤波器 可以检测信号序列中的低频信息,而滤波器 可以检测信号序列中的高频信息.(高低频指信号变化的强烈程度)
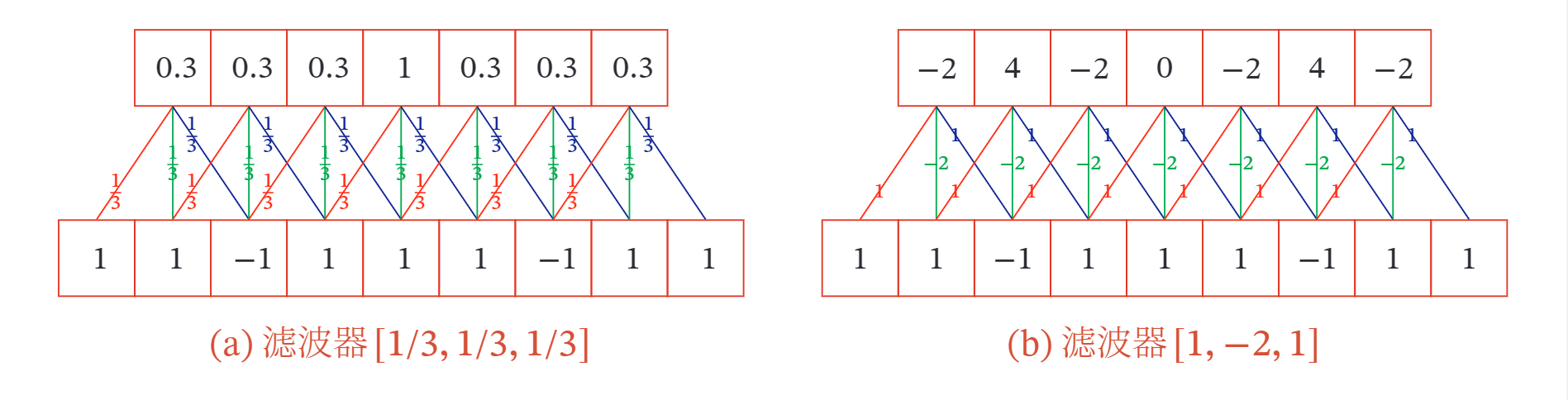
4.1.1.2 二维卷积
卷积也经常用在图像处理中.因为图像为一个二维结构,所以需要将一维卷积进行扩展.给定一个图像 和一个滤波器 ,一般 ,其卷积为 为了简单起见,这里假设卷积的输出 的下标 从 开始.
输入信息 和滤波器 的二维卷积定义为 其中*表示二维卷积运算. 下图给出了二维卷积示例.
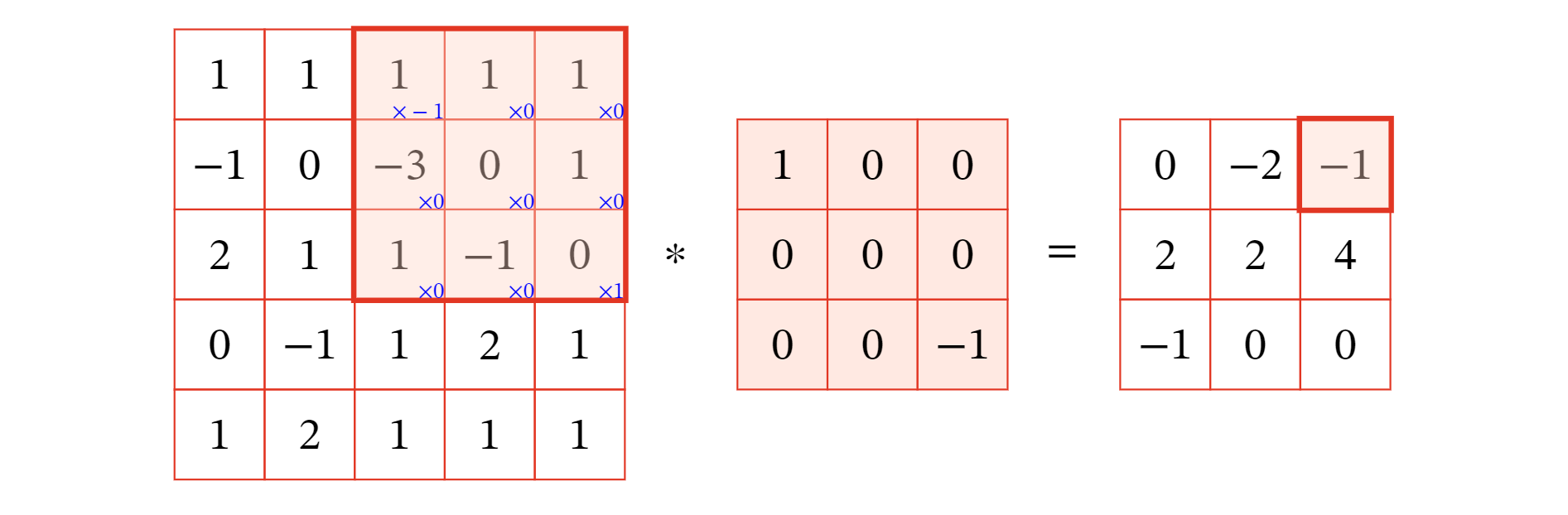
在图像处理中常用的均值滤波 ( Mean Filter ) 就是一种二维卷积,将当前位置的像素值设为滤波器窗口中所有像素的平均值,即 .
在图像处理中,卷积经常作为特征提取的有效方法.一幅图像在经过卷积操作后得到结果称为特征映射(Feature Map).下图给出在图像处理中几种常用的滤波器,以及其对应的特征映射.图中最上面的滤波器是常用的高斯滤波器,可以用来对图像进行平滑去噪;中间和最下面的滤波器可以用来提取边缘特征.

4.1.2 互相关
在机器学习和图像处理领域,卷积的主要功能是在一个图像 ( 或某种特征 ) 居滑动一个卷积核 ( 即滤波器 通过卷积操作得到一组新的特征.在计算卷积的过程中,需要进行卷积核翻转.在具体实现上,一般会以互相关操作来代替卷积,从而会减少一些不必要的操作或开销.互相关 ( Cross-Correlation ) 是一个 衡量两个序列相关性的函数,通常是用滑动窗口的点积计算来实现.给定一个图像 和卷积核 ,它们的互相关为 和公式 (4.1) 对比可知,互相关和卷积的区别仅仅在于卷积核是否进行翻转.因此互相关也可以称为不翻转卷积.
公式 (4.2) 可以表述为 其中 表示互相关运算, 表示旋转 180 度, 为输出 矩阵.
在神经网络中使用卷积是为了进行特征抽取,卷积核是否进行翻转和其特征抽取的能力无关.特别是当卷积核是可学习的参数时,卷积和互相关在能力上是等价的.因此,为了实现上 (或描述上 ) 的方便起见,我们用互相关来代替卷积.事实上,很多深度学习工具中卷积操作其实都是互相关操作.
4.1.3 卷积的变种
在卷积的标准定义基础上,还可以引入卷积核的滑动步长和零填充来增加卷积的多样性,可以更灵活地进行特征抽取.
- 步长(Stride)是指卷积核在滑动时的时间间隔.下图左给出了步长为2的卷积示例.(步长也可以小于1,即微步卷积)
- 零填充(Zero Padding)是在输入向量两端进行补零.下图右给出了输入的两端各补一个零后的卷积示例.
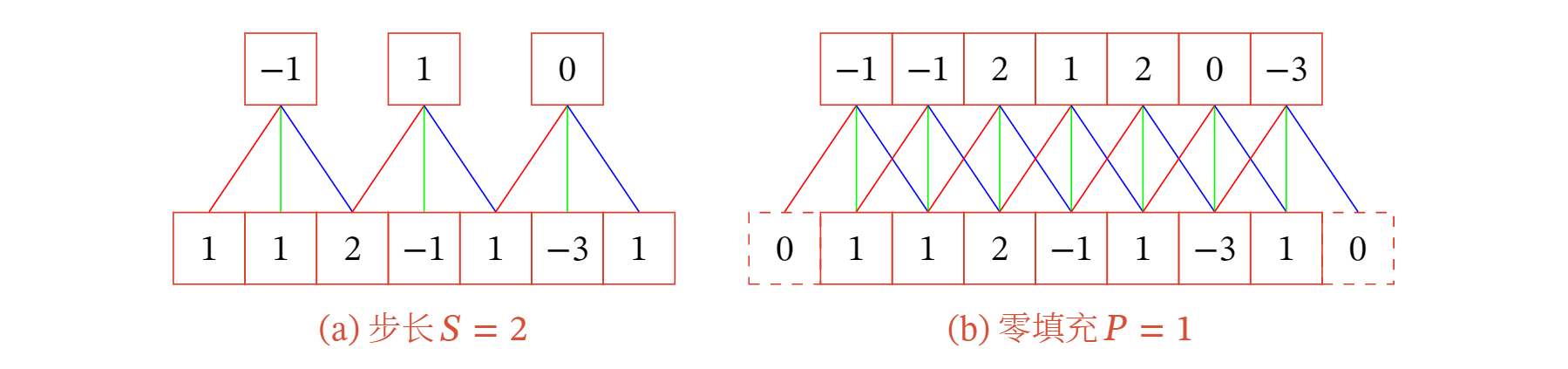
假设卷积层的输入神经元个数为 ,卷积大小为 ,步长为 ,在输入两端各填补 个 0 ( zero padding ) ,那么该卷积层的神经元数量为
一般常用的卷积有以下三类:
- 窄卷积 ( Narrow Convolution ) : 步长 ,两端不补零 ,卷积后输出长度为
- 宽卷积 ( Wide Convolution ) : 步长 ,两端补零 ,卷积后输出长度 . (3) 等宽卷积 ( Equal-Width Convolution ) 步长 ,两端补零 ,卷积后输出长度 .上图右就是一个等宽卷积示例.
4.1.4 卷积的数学性质
4.1.4.1 交换性
如果不限制两个卷积信号的长度,真正的翻转卷积是具有交换性的,即 .对于互相关的“卷积”,也同样具有一定的“交换性”.
我们先介绍宽卷积 ( Wide Convolution ) 的定义.给定一个二维图像 和一个二维卷积核 , 对图像 进行零填充,两端各补 和 个零,得到全填充 ( Full Padding 的图像 .图像 和卷积核 的宽卷积定义为 其中 表示宽卷积运算.当输入信息和卷积核有固定长度时,它们的宽卷积依然具有交换性,即 其中 表示旋转 180 度.
4.1.4.2 导数
假设 ,其中 ,函数 为一个标量函数,则 从上式可以看出, 关于 的偏导数为 和 的卷积 同理得到, 其中当 ,或 ,或 ,或 时, .即相当于对 进行了 的零填充.
从上式可以看出, 关于 的偏导数为 和 的宽卷积.上式中的卷积是真正的卷积而不是互相关,为了一致性,我们用互相关的“卷积”,即 其中 表示旋转 180 度.
4.2 卷积神经网络
卷积神经网络一般由卷积层、汇聚层和全连接层构成.
4.2.1 用卷积代替全连接
在全连接前馈神经网络中,如果第 层有 个神经元,第 层有 个神经元,连接边有 个,也就是权重矩阵有 个参数.当 和 都很大时,权重矩阵的参数非常多,训练的效率会非常低.
如果采用卷积来代替全连接,第 层的净输入 为第 层活性值 和卷积核 的卷积,即 其中卷积核 为可学习的权重向量, 为可学习的偏置.
根据卷积的定义,卷积层有两个很重要的性质 :
局部连接 在卷积层 假设是第 层 中的每一个神经元都只和下一层 第 层 ) 中某个局部窗口内的神经元相连,构成一个局部连接网络.如下图所示,卷积层和下一层之间的连接数大大减少,由原来的 个连接变为 个连接, 为卷积核大小.
权重共享 从上式可以看出,作为参数的卷积核 对于第 层的所有的神经元都是相同的.如下图中,所有的同颜色连接上的权重是相同的.权重共享可以理解为一个卷积核只捕捉输入数据中的一种特定的局部特征.因此,如果要提取多种特征就需要使用多个不同的卷积核.
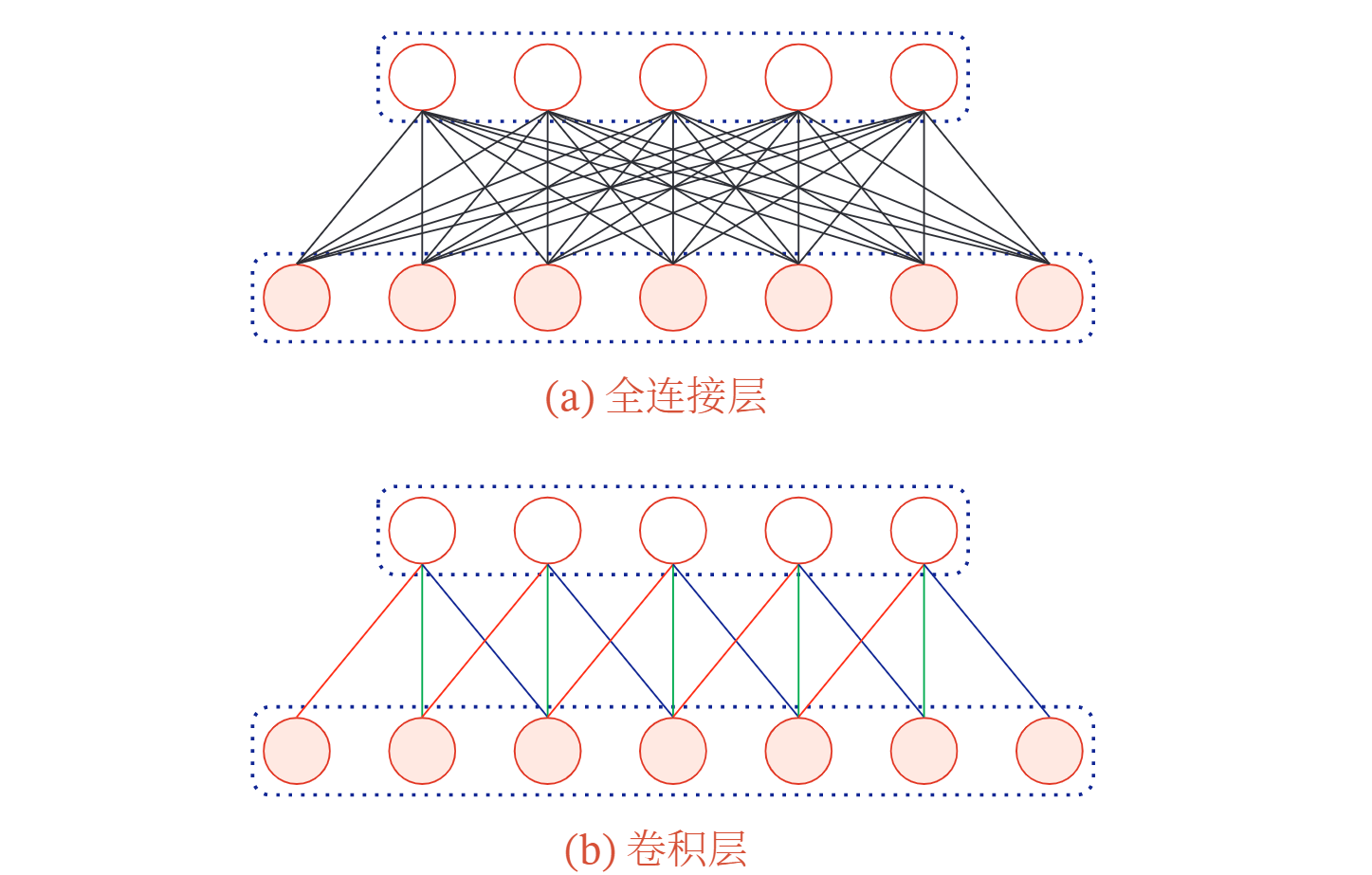
由于局部连接和权重共享,卷积层的参数只有一个 维的权重 和 1 维的偏置 ,共 个参数.参数个数和神经元的数量无关.此外,第 层的神经 元个数不是任意选择的,而是满足 .
4.2.2 卷积层
卷积层的作用是提取一个局部区域的特征,不同的卷积核相当于不同的特征提取器.上一节中描述的卷积层的神经元和全连接网络一样都是一维结构.由于卷积网络主要应用在图像处理上,而图像为二维结构,因此为了更充分地利用图像的局部信息,通常将神经元组织为三维结构的神经层,其大小为高度 宽 度 深度 ,由 个 大小的特征映射构成.
特征映射 ( Feature Map ) 为一幅图像 ( 或其他特征映射 ) 在经过卷积提取到的特征,每个特征映射可以作为一类抽取的图像特征.为了提高卷积网络的表示能力,可以在每一层使用多个不同的特征映射,以更好地表示图像的特征.
在输入层,特征映射就是图像本身.如果是灰度图像,就是有一个特征映射,输入层的深度 ;如果是彩色图像,分别有 三个颜色通道的特征映射,输入层的深度 .
不失一般性,假设一个卷积层的结构如下:
- 输入特征映射组: 为三维张量 ( Tensor ), 其中每个切 片 ( Slice ) 矩阵 为一个输入特征映射, ;
- 输出特征映射组: 为三维张量,其中每个切片矩阵 为一个输出特征映射, ;
- 卷积核: 为四维张量,其中每个切片矩阵 为一个二维卷积核, .
下图给出卷积层的三维结构表示.
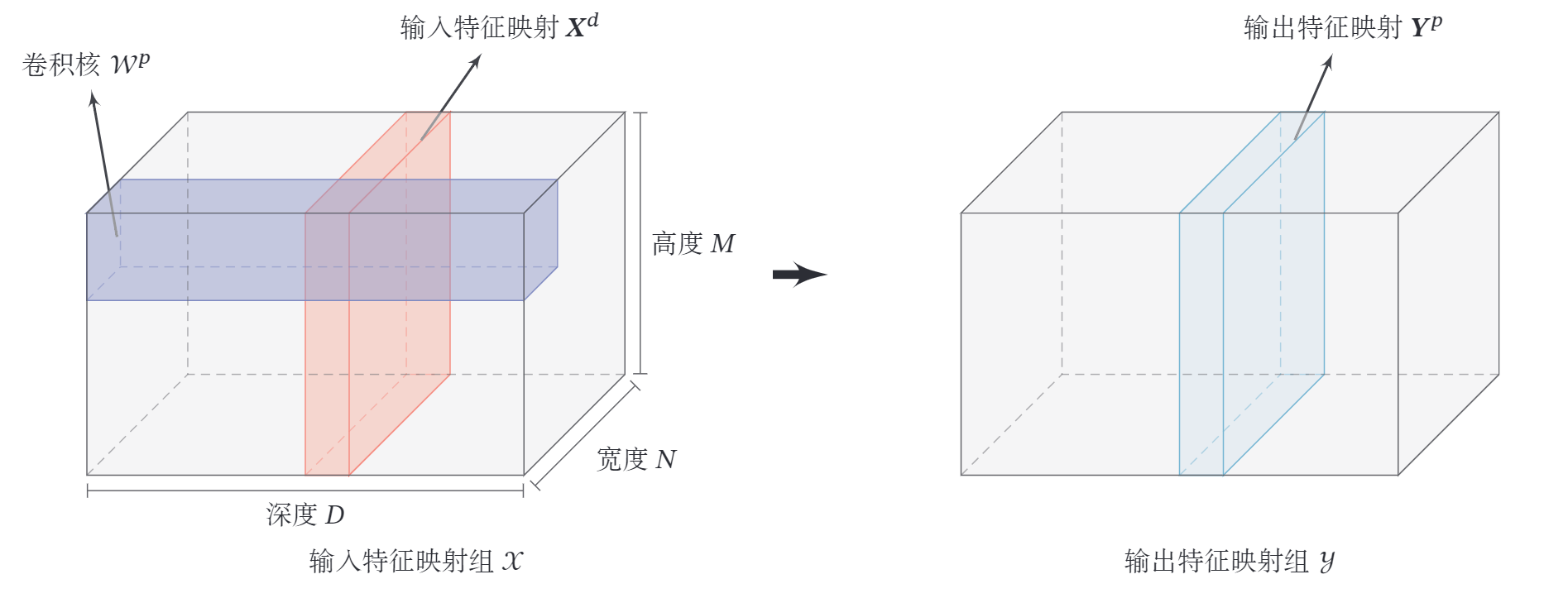
为了计算输出特征映射 ,用卷积核 分别对输入特征映射 进行卷积,然后将卷积结果相加,并加上一个标量偏置 得到卷积层的净输入 ,再经过非线性激活函数后得到输出特征映射 . 其中 为三维卷积核, 为非线性激活函数,一般用 函数.
整个计算过程如下图所示.如果希望卷积层输出 个特征映射,可以将上述计算过程重复 次,得到 个输出特征映射 .
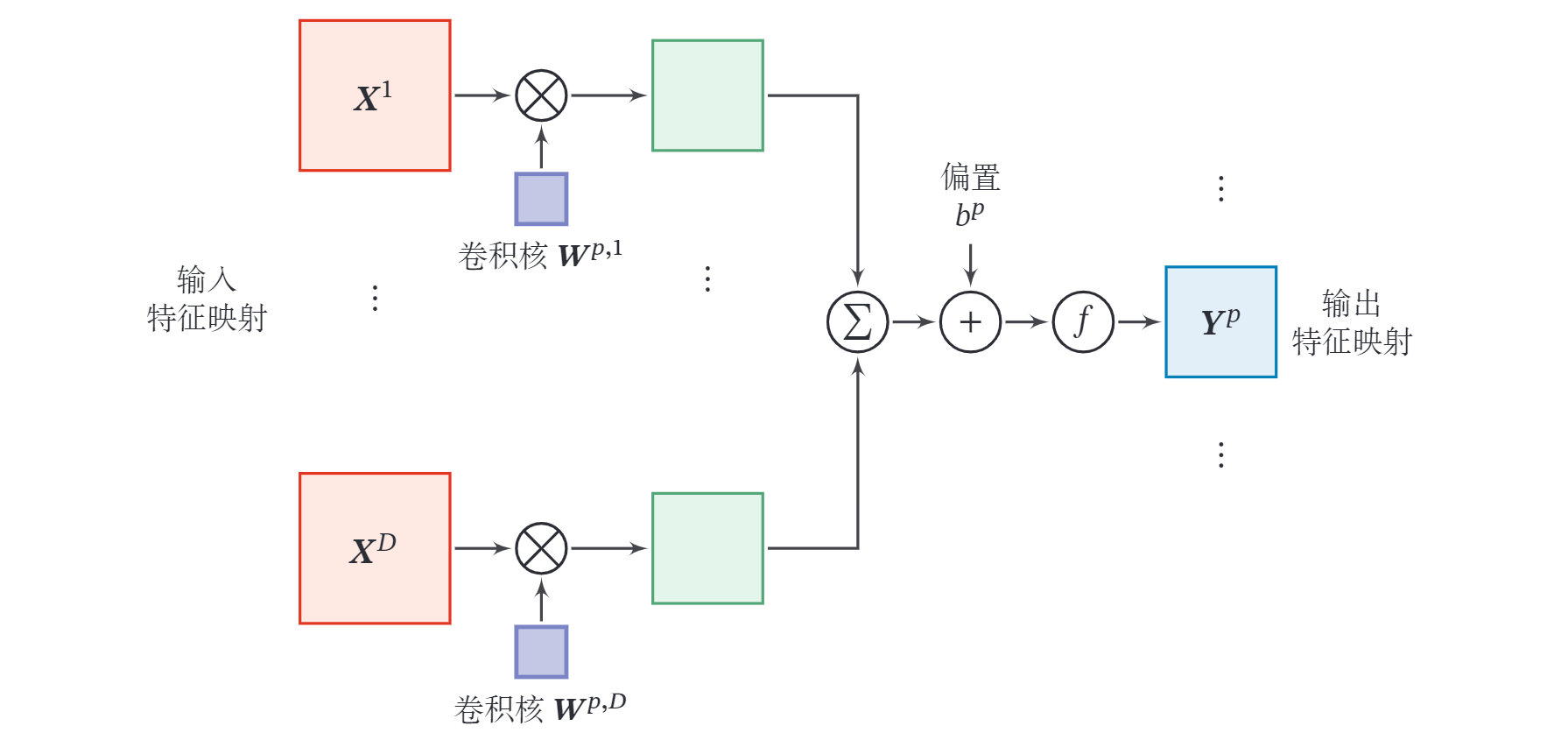
在输入为 ,输出为 的卷积层中,每一个输出特征映射都需要 个卷积核以及一个偏置.假设每个卷积核的大小为 ,那么 共需要 个参数.
4.2.3 汇聚层
汇聚层 ( Pooling Layer ) 也叫子采样层 ( Subsampling Layer ) ,其作用是进行特征选择,降低特征数量,从而减少参数数量.
卷积层虽然可以显著减少网络中连接的数量,但特征映射组中的神经元个数并没有显著减少.如果后面接一个分类,分类器的输入维数依然很高,很容易出现过拟合.为了解决这个问题,可以在卷积层之后加上一个汇聚层,从而降低特征维数,避免过拟合.
假设汇聚层的输入特征映射组为 ,对于其中每一个特征映射 ,将其划分为很多区域 ,这些区域可以重叠,也可以不重叠,汇聚 ( Pooling ) 是指对每个区域进行下采样 ( Down Sampling ) 得到一个值,作为这个区域的概括.
常用的汇聚函数有两种:
- 最大汇聚 ( Maximum Pooling 或 Max Pooling ) :对于一个区域 ,选择这个区域内所有神经元的最大活性值作为这个区域的表示,即 其中 为区域 内每个神经元的活性值.
- 平均汇聚 ( Mean Pooling ) :一般是取区域内所有神经元活性值的平均值,即 对每一个输入特征映射 的 个区域进行子采样,得到汇聚层的输出特征映射 .
下图给出了采样最大汇聚进行子采样操作的示例.可以看出,汇聚层不但可以有效地减少神经元的数量,还可以使得网络对一些小的局部形态改变保持不变性,并拥有更大的感受野.
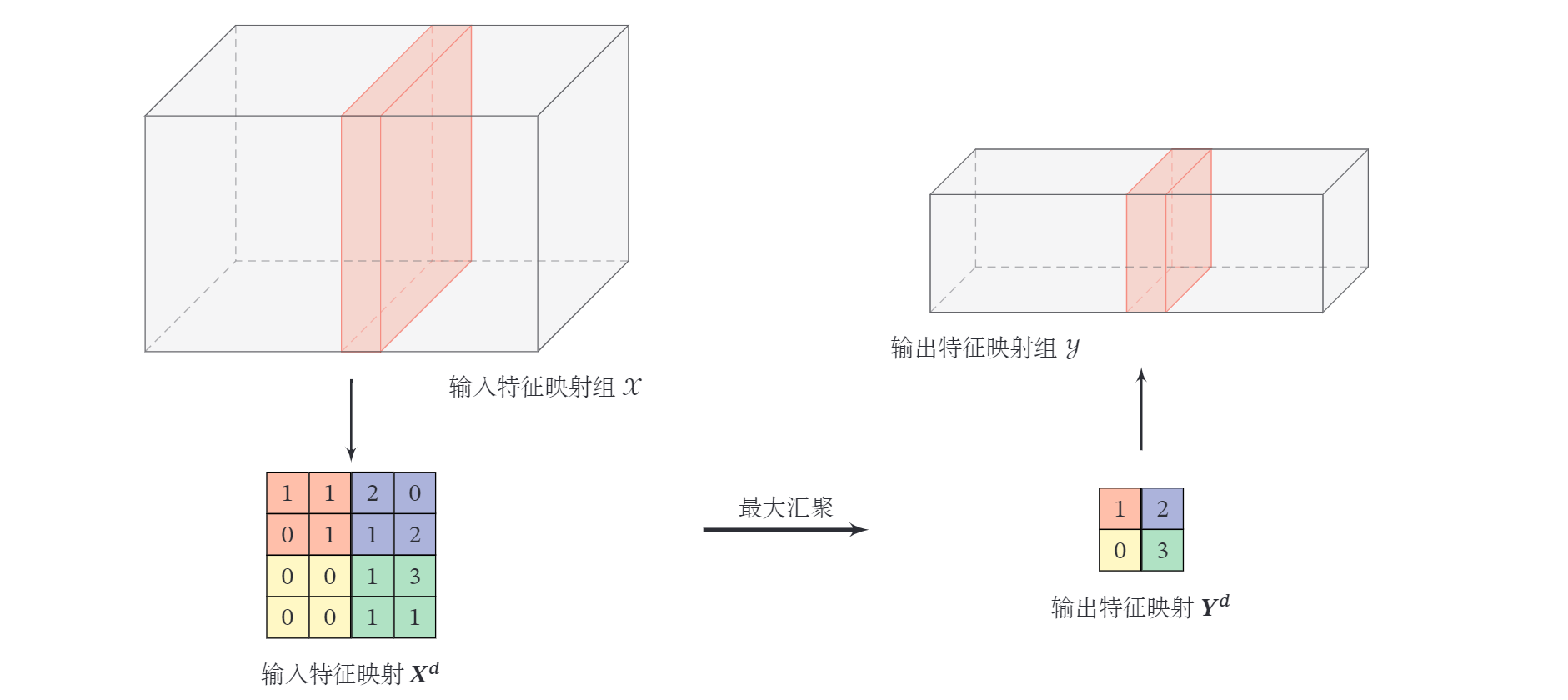
目前主流的卷积网络中,汇聚层仅包含下采样操作.但在早期的一些卷积网络 比如 LeNet-5 ) 中,有时也会在汇聚层使用非线性激活函数,比如 其中 为汇聚层的输出, 为非线性激活函数, 和 为可学习的标量权重和偏置.
典型的汇聚层是将每个特征映射划分为 大小的不重叠区域,然后使用最大汇聚的方式进行下采样.汇聚层也可以看作一个特殊的卷积层,卷积核大小 为 ,步长为 ,卷积核为 函数或 mean 函数.过大的采样区域会急剧减少神经元的数量,也会造成过多的信息损失.
4.2.4 卷积网络的整体结构
一个典型的卷积网络是由卷积层、汇聚层、全连接层交叉堆叠而成.目前常用的卷积网络整体结构如下图所示.一个卷积块为连续 个卷积层和 个汇聚层 通常设置为 为 0 或 1 ).一个卷积网络中可以堆叠 个连续的卷积块,然后在后面接着 个全连接层 的取值区间比较大,比如 或者更大; 一般为 ).
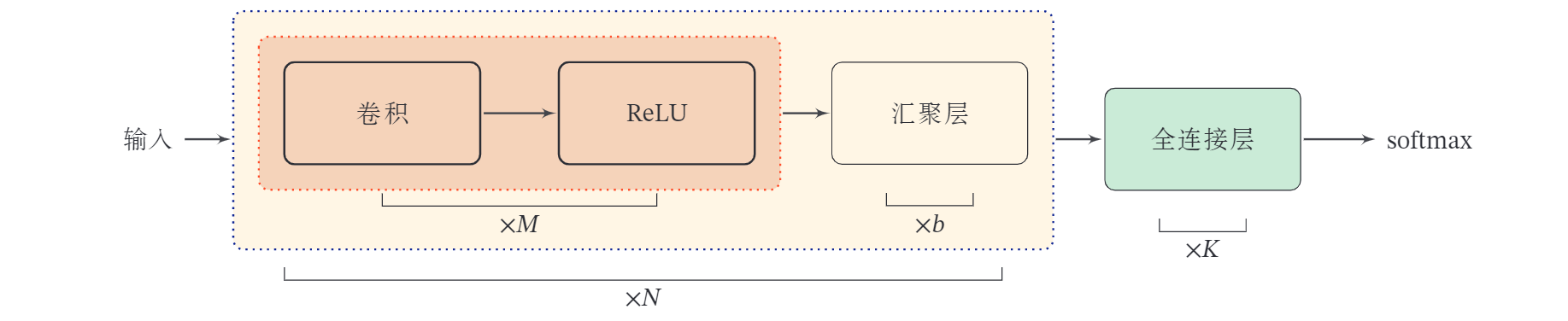
目前,卷积网络的整体结构趋向于使用更小的卷积核 比如 和 以及更深的结构 比如层数大于 50 ).此外,由于卷积的操作性越来越灵活 ( 比如不同的步长 ),汇聚层的作用也变得越来越小,因此目前比较流行的卷积网络中,汇聚层的比例正在逐渐降低,趋向于全卷积网络.
4.3 参数学习(卷积网络的反向传播)
在卷积网络中,参数为卷积核中权重以及偏置.和全连接前软网络类似,卷积网络也可以通过误差反向传播算法来进行参数学习.
在全连接前馈神经网络中,梯度主要通过每一层的误差项 进行反向传播,并进一步计算每层参数的梯度.
在卷积神经网络中,主要有两种不同功能的神经层:卷积层和汇聚层.而参数为卷积核以及偏置,因此只需要计算卷积层中参数的梯度.
不失一般性,对第 层为卷积层,第 层的输入特征映射为 ,通过卷积计算得到第 层的特征映射净输入 .第 层的第 个特征映射净输入 其中 和 为卷积核以及偏置.第 层中共有 个卷积核和 个偏 置,可以分别使用链式法则来计算其梯度.
根据上式,损失函数 关于第 层的卷积核 的偏 导数为 其中 为损失函数关于第 层的第 个特征映射净输入 的偏导数.
同理可得,损失函数关于第 层的第 个偏置 的偏导数为 在卷积网络中,每层参数的梯度依赖其所在层的误差项 .
4.3.1 卷积神经网络的反向传播算法
卷积层和汇聚层中误差项的计算有所不同,因此我们分别计算其误差项.
汇聚层 当第 层为汇聚层时,因为汇聚层是下采样操作, 层的每个神经元的误差项 对应于第 层的相应特征映射的一个区域. 层的第 个特征映射中的每个神经元都有一条边和 层的第 个特征映射中的一个神经元相连.根据链式法则,第 层的一个特征映射的误差项 ,只需要将 层对应特征映射的误差项 进行上采样操作 和第 层的大小一样 ,再和 层特征映射的激活值偏导数逐元素相乘,就得到了 .
第 层的第 个特征映射的误差项 的具体推导过程如下: 其中 为第 层使用的激活函数导数,up 为上采样函数 ( up sampling ),与汇聚层中使用的下采样操作刚好相反.如果下采样是最大汇聚,误差项 中每个值会直接传递到上一层对应区域中的最大值所对应的神经元,该区域中其他神经元的误差项都设为 .如果下采样是平均汇聚,误差项 中每个值会被平均分配到上一层对应区域中的所有神经元上.
卷积层 当 层为卷积层时,假设特征映射净输入 ,其中 第 个特征映射净输入 其中 和 为第 层的卷积核以及偏置.第 层中共有 个卷积核和 个偏置.
第 层的第 个特征映射的误差项 的具体推导过程如下: 其中 为宽卷积.
4.4 几种典型的卷积神经网络
4.4.1 LeNet-5
LeNet-5[LeCun et al., 1998 ] 虽然提出的时间比较早,但它是一个非常成功的神经网络模型.基于 LeNet-5 的手写数字识别系统在 20 世纪 90 年代被美国很多银行使用,用来识别支票上面的手写数字. LeNet-5的网络结构如下图所示.
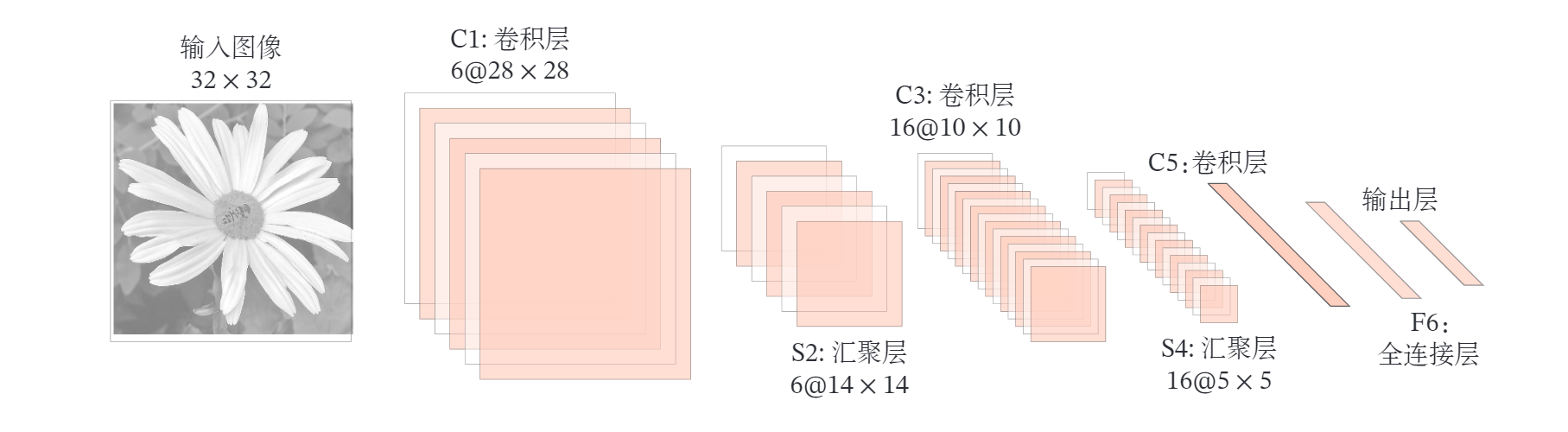
LeNet-5共有 7 层,接受输入图像大小为 ,输出对应 10 个类别的得分. LeNet-5中的每一层结构如下:
- C1 层是卷积层,使用 6 个 的卷积核,得到 6 组大小为 的特征映射.因此, 层的神经元数量为 , 可训练参数数量为 , 连接数为 (包括偏置在内,下同 ).
- S2层为汇聚层,采样窗口为 ,使用平均汇聚,并使用一个非线性函数.神经元个数为 , 可训练参数数量为 , 连接数为 .
- C3 层为卷积层. LeNet-5 中用一个连接表来定义输入和输出特征映 射之间的依赖关系,如图5.11所示,共使用 60 个 的卷积核,得到 16 组大 小为 的特征映射. 神经元数量为 , 可训练参数数量为 , 连接数为
- S4 层是一个汇聚层, 采样窗口为 , 得到 16 个 大小的特征映射, 可训练参数数量为 , 连接数为
- C5 层是一个卷积层, 使用 个 的卷积核, 得到 120 组大小为 的特征映射. 层的神经元数量为 120, 可训练参数数量为 , 连接数为
- F6层是一个全连接层,有 84 个神经元, 可训练参数数量为 1 ) 164. 连接数和可训练参数个数相同,为
- 输出层:输出层由 10 个径向基函数 ( Radial Basis Function, ) 组成.这里不再详述.
连接表 从公式可以看出, 卷积层的每一个输出特征映射都依赖于所有输入特征映射,相当于卷积层的输入和输出特征映射之间是全连接的关系. 实际上, 这种全连接关系不是必须的. 我们可以让每一个输出特征映射都依赖于少数几个输入特征映射. 定义一个连接表 ( Link Table ) 来描述输入和输出特征映射之间的连接关系. 在 LeNet-5 中, 连接表的基本设定如下图所示. C3层的第 0 -5 个特征映射依赖于S2层的特征映射组的每 3 个连续子集,第 6-11个特征映射依赖于 层的特征映射组的每 4 个连续子集, 第 12-14 个特征映射依赖于 S2 层的特征映射的每 4 个不连续子集,第 15 个特征映射依赖于 层的所有特征映射.
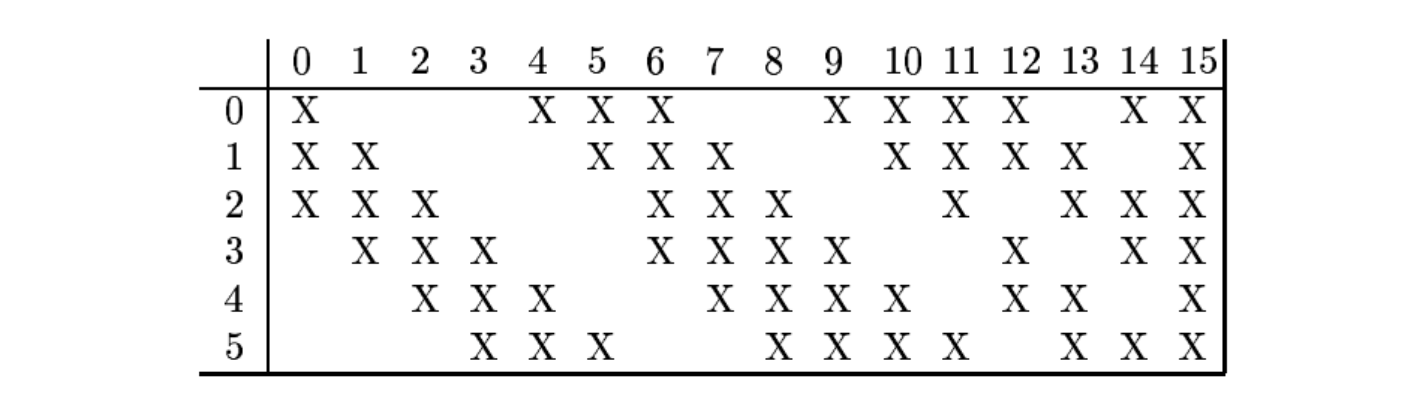
如果第 个输出特征映射依赖于第 个输入特征映射, 则 , 否则为 为其中 为 大小的连接表. 假设连接表 的非零个数为 , 每个卷积核的大小为 ,那么共需要 参数.
4.4.2 AlexNet
AlexNet[Krizhevsky et al., 2012 ] 是第一个现代深度卷积网络模型, 其首次使用了很多现代深度卷积网络的技术方法, 比如使用 进行并行训练, 采有了 作为非线性激活函数, 使用 Dropout 防止过拟合, 使用数据增强来提高 模型准确率等. AlexNet 赢得了 2012 年 ImageNet 图像分类竞赛的冠军.
AlexNet 的结构如下图所示,包括 5 个卷积层、3个汇聚层和 3 个全连接层(其中最后一层是使用 Softmax 函数的输出层).因为网络规模超出了当时的单个 GPU的内存限制, AlexNet 将网络拆为两半,分别放在两个 上, GPU间只 在某些层 比如第 3 层 进行通信.
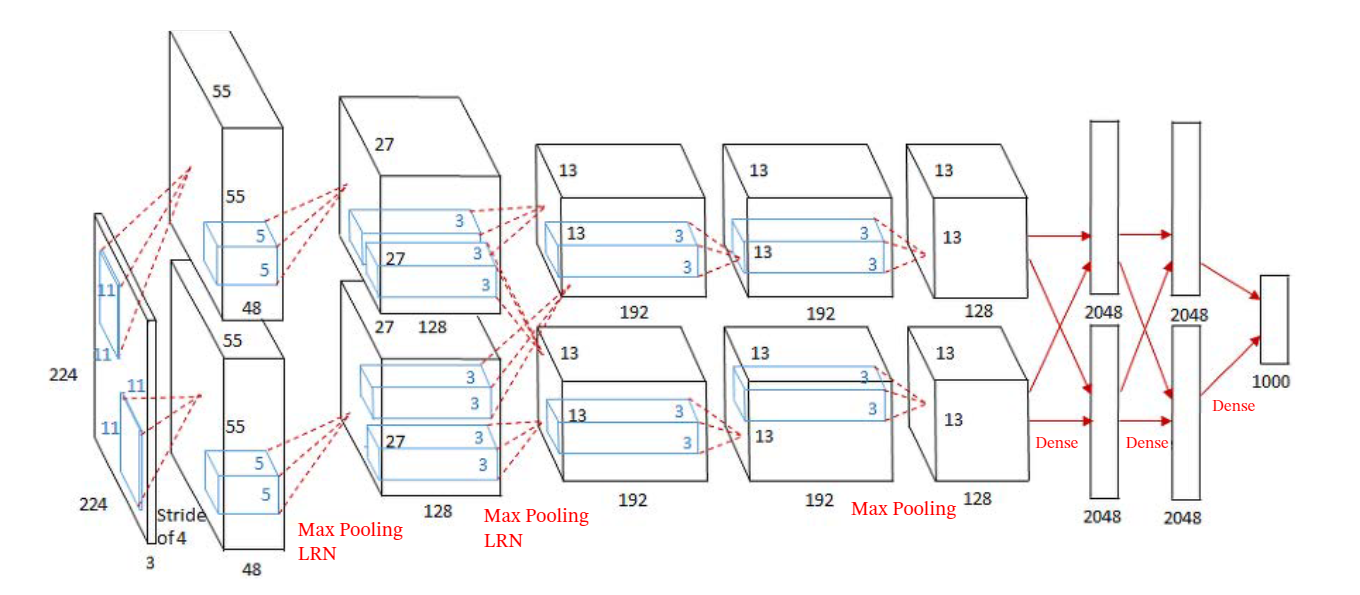
AlexNet 的输入为 的图像,输出为 1000 个类别的条件概率,具体结构如下:
- 第一个卷积层,使用两个大小为 的卷积核,步长 , 零填充 , 得到两个大小为 的特征映射组.
- 第一个汇聚层,使用大小为 的最大汇聚操作,步长 , 得到两个 的特征映射组.
- 第二个卷积层,使用两个大小为 的卷积核,步长 , 零填充 , 得到两个大小为 的特征映射组.
- 第二个汇聚层,使用大小为 的最大汇聚操作,步长 , 得到两个大小为 的特征映射组.
- 第三个卷积层为两个路径的融合,使用一个大小为 的卷积核, 步长 , 零填充 , 得到两个大小为 的特征映射组.
- 第四个卷积层, 使用两个大小为 的卷积核,步长 , 零填充 ,得到两个大小为 的特征映射组.
- 第五个卷积层, 使用两个大小为 的卷积核,步长 , 零填充 , 得到两个大小为 的特征映射组.
- 第三个汇聚层,使用大小为 的最大汇聚操作,步长 , 得到两个大小为 的特征映射组.
- 三个全连接层,神经元数量分别为 4096,4096 和 1000 .此外, AlexNet 还在前两个汇聚层之后进行了局部响应归一化 ( Local Re'nonse Normalization.LRN ) 以增强模型的泛化能力.
4.4.3 Inception网络
在卷积网络中,如何设置卷积层的卷积核大小是一个十分关键的问题. 在 Inception 网络中, 一个卷积层包含多个不同大小的卷积操作, 称为Inception 模块. Inception 网络是由有多个 Inception 模块和少量的汇聚层堆叠而成.
Inception 模块同时使用 等不同大小的卷积核, 并将得到的特征映射在深度上拼接 ( 堆叠 ) 起来作为输出特征映射.
下图给出了v1版本的 Inception 模块结构, 采用了 4 组平行的特征抽取方 式, 分别为 的卷积和 的最大汇聚. 同时, 为了提高计算效 率,减少参数数量, Inception 模块在进行 的卷积之前、 的最大汇聚之后,进行一次 的卷积来减少特征映射的深度. 如果输入特征映射之间存在冗余信息, 的卷积相当于先进行一次特征抽取.
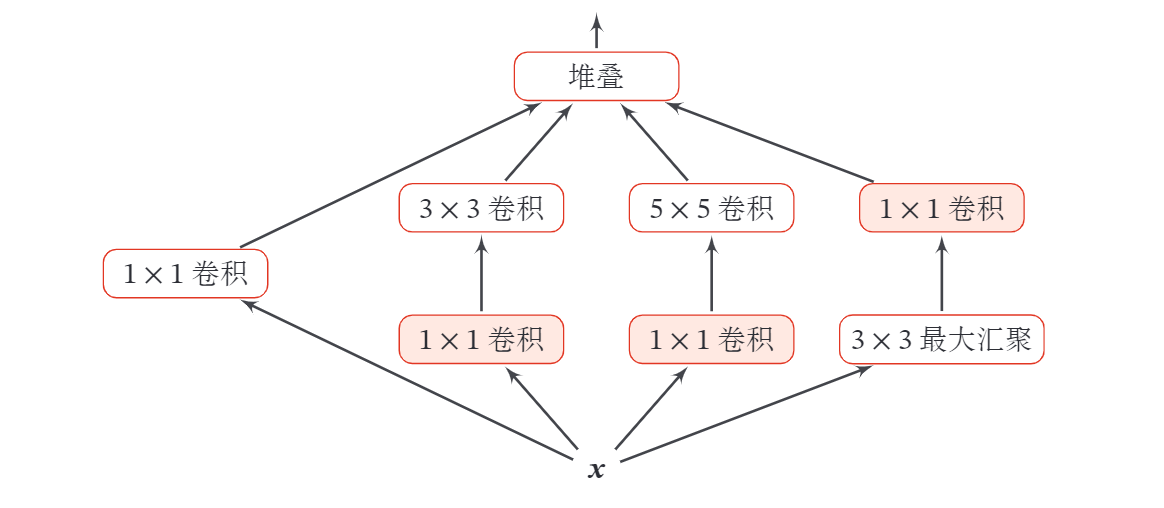
Inception 网络有多个版本, 其中最早的 Inception v1 版本就是非常著名的 GoogLeNet [Szegedy et al., 2015]. GoogLeNet 赢得了 2014年 ImageNet 图像分 类竞赛的冠军.
GoogLeNet 由 9 个 Inception v1 模块和 5 个汇聚层以及其他一些卷积层和全连接层构成, 总共为 22 层网络,如下图所示.
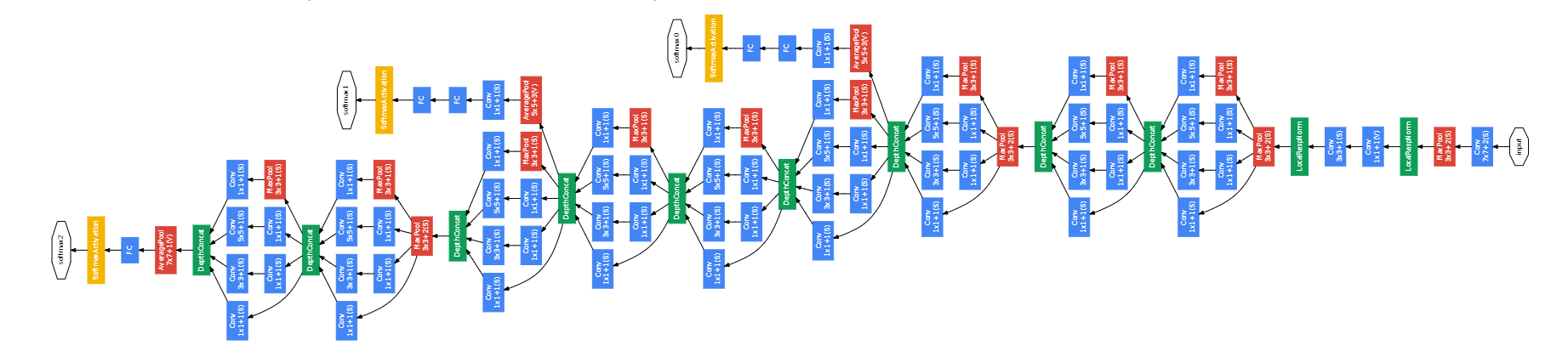
为了解决梯度消失问题, GoogLeNet 在网络中间层引入两个辅助分类器来加强监督信息.
Inception 网络有多个改进版本, 其中比较有代表性的有Inception v3网络[Szegedy et al., 2016]. Inception v3 网络用多层的小卷积核来替换大的卷积核,以减少计算量和参数量,并保持感受野不变. 具体包括 ) 使用两层 的卷积来替换 中的 的卷积; 2 ) 使用连续的 和 来替换 的卷积.
此外, Inception v3 网络同时也引入了标签平滑以及批量归一化等优化方法进行训练.
4.4.4 残差网络
残差网络 ( Residual Network, ResNet ) 通过给非线性的卷积层增加直连边 ( Shortcut Connection ) ( 也称为残差连接 ( Residual Connection ) ) 的方式来提高信息的传播效率.
假设在一个深度网络中,我们期望一个非线性单元 (可以为一层或多层的卷积层 去逼近一个目标函数为 .如果将目标函数拆分成两部分 : 恒等函数 ( Identity Function ) 和残差函数 ( Residue Function) . 根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习 [He et al., 2016].因此,原来的优化问题可以转换为:让非线性单元 去近似残差函数 , 并用 去逼近 .
下图给出了一个典型的残差单元示例.残差单元由多个级联的 ( 等宽 ) 卷积层和一个跨层的直连边组成,再经过 ReLU 激活后得到输出.
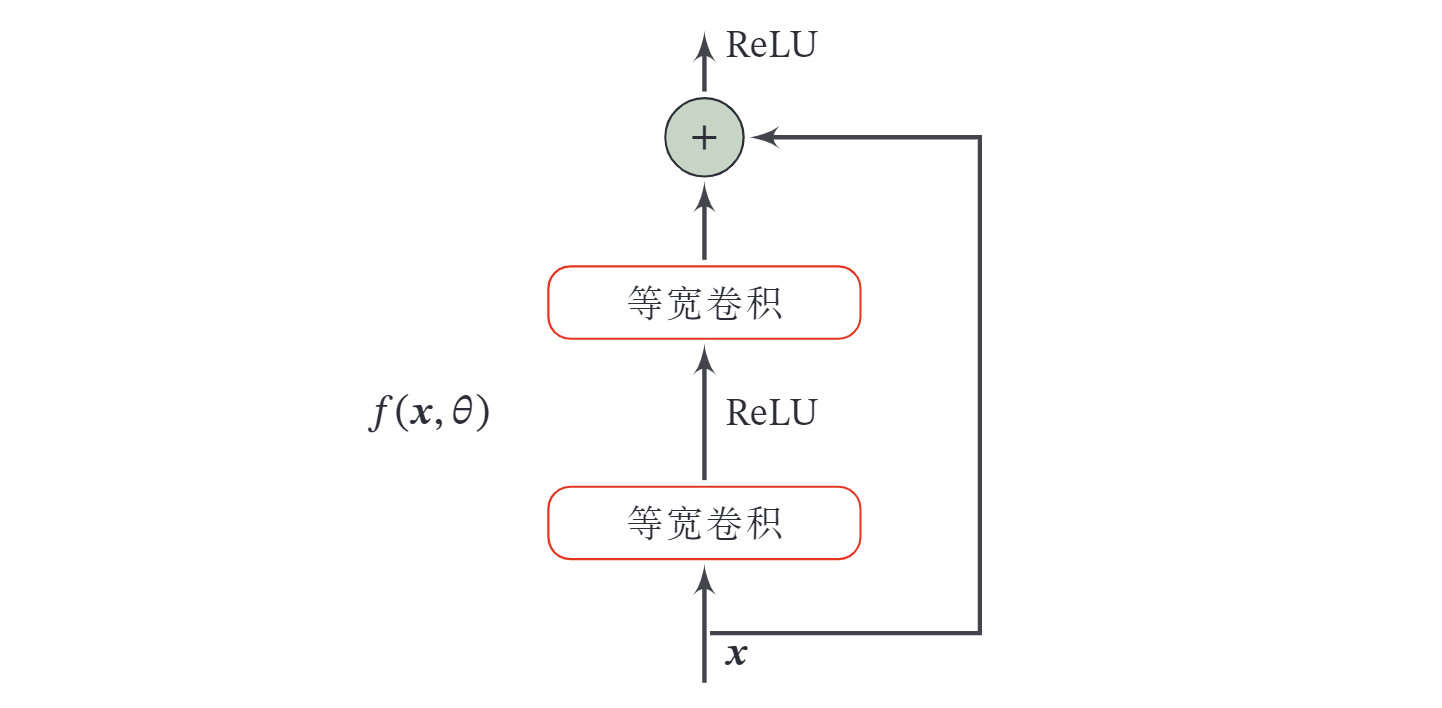
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络.和残差网络类似的还有 Highway Network[Srivastava et al., 2015].
4.5 其他卷积方式
在第4.1.3节中介绍了一些卷积的变种,可以通过步长和零填充来进行不同的卷积操作.本节介绍一些其他的卷积方式.
4.5.1 转置卷积
我们一般可以通过卷积操作来实现高维特征到低维特征的转换.比如在一维卷积中,一个 5 维的输入特征,经过一个大小为 3 的卷积核,其输出为 3 维特征.如果设置步长大于 1 ,可以进一步降低输出特征的维数.但在一些任务中,我们需要将低维特征映射到高维特征,并且依然希望通过卷积操作来实现.
假设有一个高维向量为 和一个低维向量为 .如果用仿射变换 ( Affine Transformation ) 来实现高维到低维的映射, 其中 为转换矩阵.我们可以很容易地通过转置 来实现低维到高维的反向映射,即 需要说明的是,上两式并不是逆运算,两个映射只是形式上 的转置关系.
在全连接网络中,忽略激活函数,前向计算和反向传播就是一种转置关系.比如前向计算时,第 层的净输入为 ,反向传播时,第 层的误差项为 .
卷积操作也可以写为仿射变换的形式.假设一个 5 维向量 ,经过大小为 3 的卷积核 进行卷积,得到 3 维向量 .卷积操作可以写为 其中 是一个稀疏矩阵,其非零元素来自于卷积核 中的元素.
如果要实现 3 维向量 到 5 维向量 的映射,可以通过仿射矩阵的转置来实现,即 其中 表示旋转 180 度.
可以看出,从仿射变换的角度来看两个卷积操作 和 也是形式上的转置关系.因此,我们将低维特征映射到高维特征的卷积操作称为转置卷积 ( Transposed Convolution ) [Dumoulin et al., 2016],也称为反卷积 ( Deconvolution ) [Zeiler et al., 2011].
在卷积网络中,卷积层的前向计算和反向传播也是一种转置关系.
对一个 维的向量 ,和大小为 的卷积核,如果希望通过卷积操作来映射到更高维的向量,只需要对向量 进行两端补零 ,然后进行卷积,可以得到 维的向量.
转置卷积同样适用于二维卷积.下图给出了一个步长 ,无零填充 的二维卷积和其对应的转置卷积.
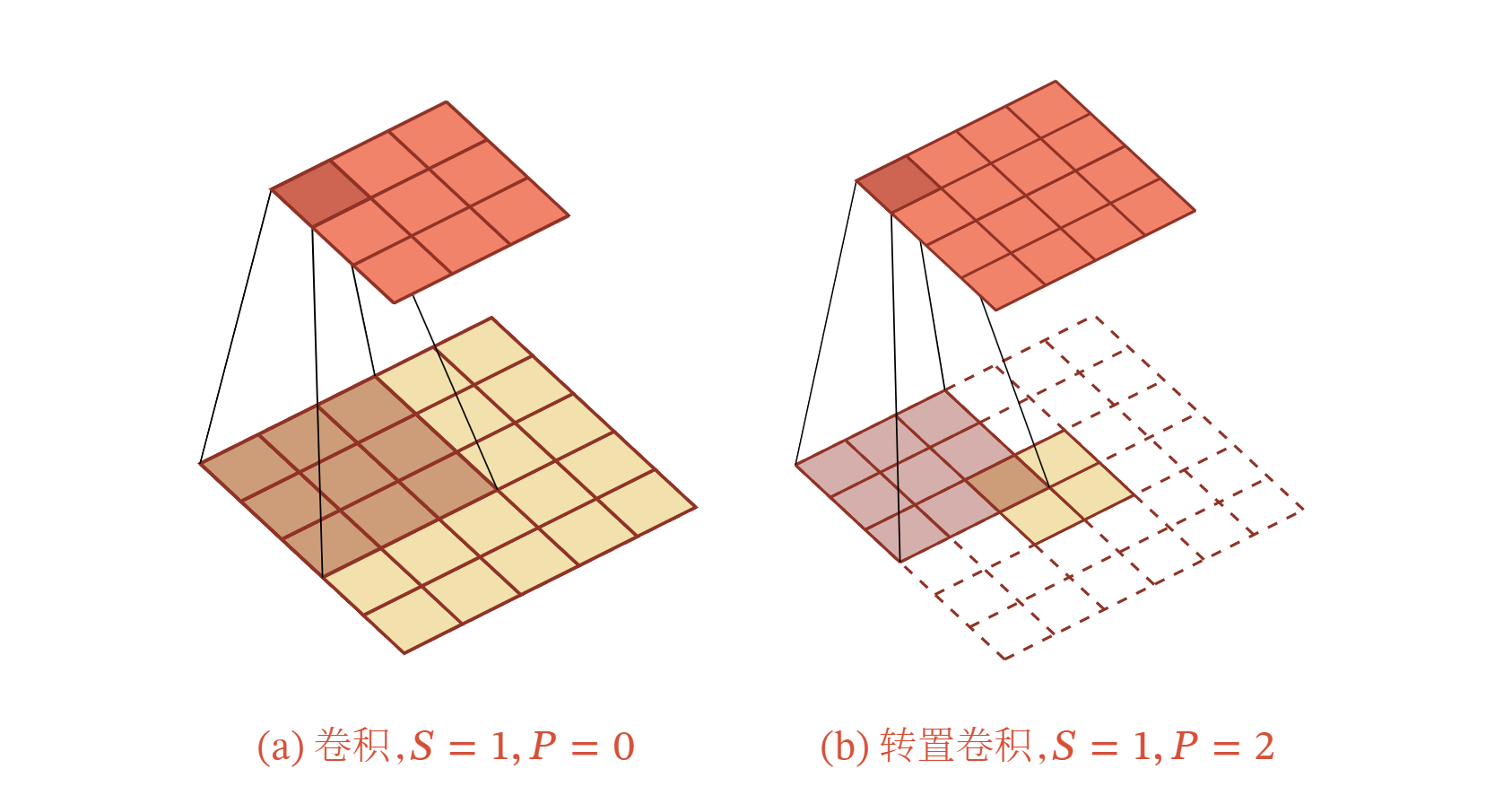
微步卷积 我们可以通过增加卷积操作的步长 来实现对输入特征的下采样操作,大幅降低特征维数.同样,我们也可以通过减少转置卷积的步长 来实现上采样操作,大幅提高特征维数.步长 的转置卷积也称为微步卷积 ( Fractionally-Strided Convolution ) [Long et al., 2015].为了实现微步卷积,我们可以在输入特征之间插入 0 来间接地使得步长变小.
如果卷积操作的步长为 ,希望其对应的转置卷积的步长为 ,需要在输入特征之间插入 个 0 来使得其移动的速度变慢.
以一维转置卷积为例, 对一个 维的向量 ,和大小为 的卷积核,通过对向量 进行两端补零 ,并且在每两个向量元素之间插入 个 0 ,然后进行步长为 1 的卷积,可以得到 维的向量.
下图给出了一个步长 ,无零填充 的二维卷积和其对应的转置卷积.
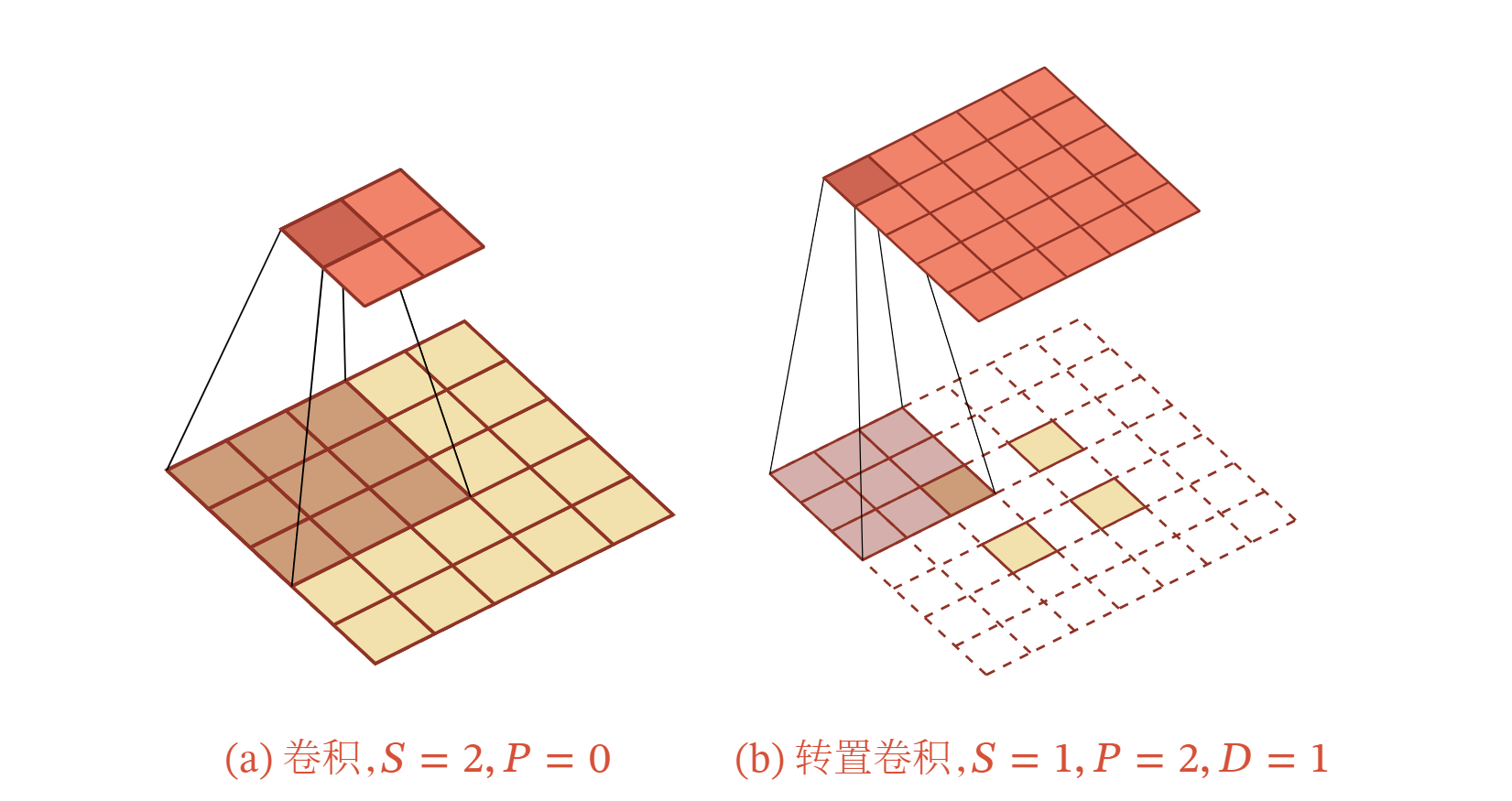
4.5.2 空洞卷积
对于一个卷积层,如果希望增加输出单元的感受野,一般可以通过三种方式实现: 1 )增加卷积核的大小; 2 ) 增加层数,比如两层 的卷积可以近似一层 卷积的效果 ; 3 ) 在卷积之前进行汇聚操作.前两种方式会增加参数数量,而第三种方式会丢失一些信息.
空洞卷积(Atrous Convolution ) 是一种不增加参数数量,同时增加输出单元感受野的一种方法,也称为膨胀卷积 ( Dilated Convolution ) [Chen et al. 2018; Yu et al., 2015.
空洞卷积通过给卷积核插入 “空洞”来变相地增加其大小.如果在卷积核的每两个元素之间插入 个空洞,卷积核的有效大小为 其中 称为膨胀率 ( Dilation Rate ).当 时卷积核为普通的卷积核.
下图给出了空洞卷积的示例.
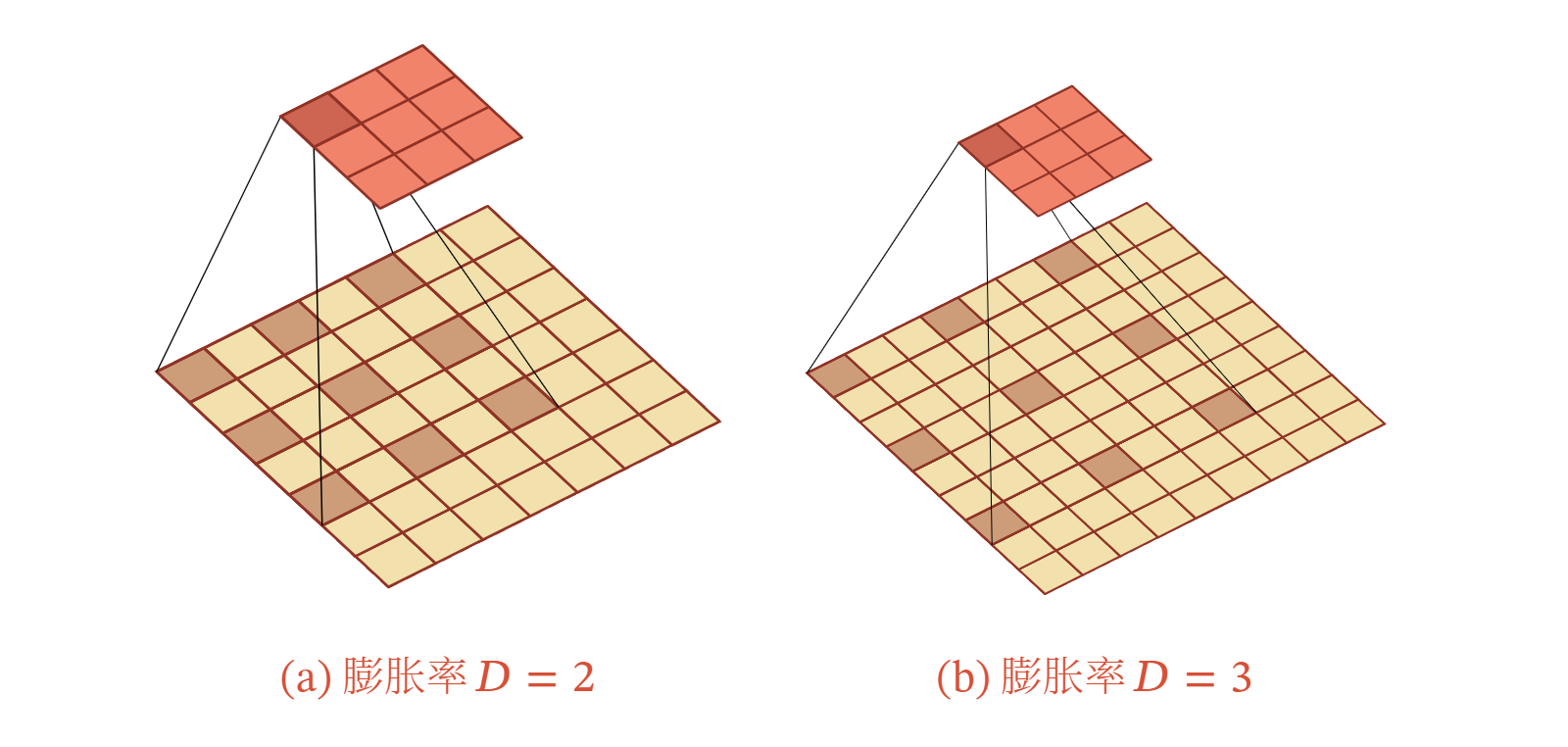
4.6 总结和深入阅读
卷积神经网络是受生物学上感受野机制启发而提出的.1959 年,[Hubel et al., 1959] 发现在猫的初级视觉皮层中存在两种细胞:简单细胞和复杂细胞.这两种细胞承担不同层次的视觉感知功能 [Hubel et al., 1962].简单细胞的感受野是狭长型的,每个简单细胞只对感受野中特定角度 ( orientation ) 的光带敏感,而复杂细胞对于感受野中以特定方向 ( direction ) 移动的某种角度 ( ori- entation ) 的光带敏感.受此启发,福岛邦彦 ( Kunihiko Fukushima ) 提出了一种带卷积和子采样操作的多层神经网络:新知机 ( Neocognitron ) [Fukushima, 1980].但当时还没有反向传播算法,新知机采用了无监督学习的方式来训练.[LeCun et al., 1989 ] 将反向传播算法引入了卷积神经网络,并在手写体数字识别上取得了很大的成功 [LeCun et al., 1998].
AlexNet[Krizhevsky et al., 2012 ] 是第一个现代深度卷积网络模型,可以说是深度学习技术在图像分类上真正突破的开端. AlexNet 不用预训练和逐层训练,首次使用了很多现代深度网络的技术,比如使用 GPU 进行并行训练,采用了 ReLU作为非线性激活函数,使用 Dropout 防止过拟合,使用数据增强来提高模型准确率等.这些技术极大地推动了端到端的深度学习模型的发展.
在 AlexNet 之后,出现了很多优秀的卷积网络,比如 VGG 网络 [Simonyan et al., 2014]、Inception v1,v2, v4 网络 [Szegedy et al., 2015, 2016, 2017] 、残差网 络 [He et al., 2016] 等.
目前,卷积神经网络已经成为计算机视觉领域的主流模型.通过引入跨层的直连边,可以训练上百层乃至上千层的卷积网络.随着网络层数的增加,卷积层越来越多地使用 和 大小的小卷积核,也出现了一些不规则的卷积操作,比如空洞卷积 [Chen et al., 2018; Yu et al., 2015] 可变形卷积 [Dai et al., 2017] 等.网络结构也逐渐趋向于全卷积网络 ( Fully Convolutional Network, FCN ) [Long et al., 2015],减少汇聚层和全连接层的作用.
各种卷积操作的可视化示例可以参考 [Dumoulin et al., 2016].
循环神经网络
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络.在循环神经网络中,神经元不但可以接受其他神经元的信息,也可以接受自身的信息,形成具有环路的网络结构.和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构.循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上.循环神经网络的参数学习可以通过随时间反向传播算法来学习.随时间反向传播算法即按照时间的逆序将错误信息一步步地往前传递.当输入序列比较长时,会存在梯度爆炸和消失问题,也称为长程依赖问题.为了解决这个问题,人们对循环神经网络进行了很多的改进,其中最有效的改进方式引入门控机制(Gating Mechanism).
此外,循环神经网络可以很容易地扩展到两种更广义的记忆网络模型:递归神经网络和图网络.
一. 循环神经网络
给定一个输入序列 ,循环神经网络通过下面公式更新带反馈边的隐藏层的活性值 :
其中 , 为一个非线性函数,可以是一个前馈网络.
给出了循环神经网络的示例,其中“延时器”为一个虚拟单元,记录神经元的最近一次(或几次)活性值.
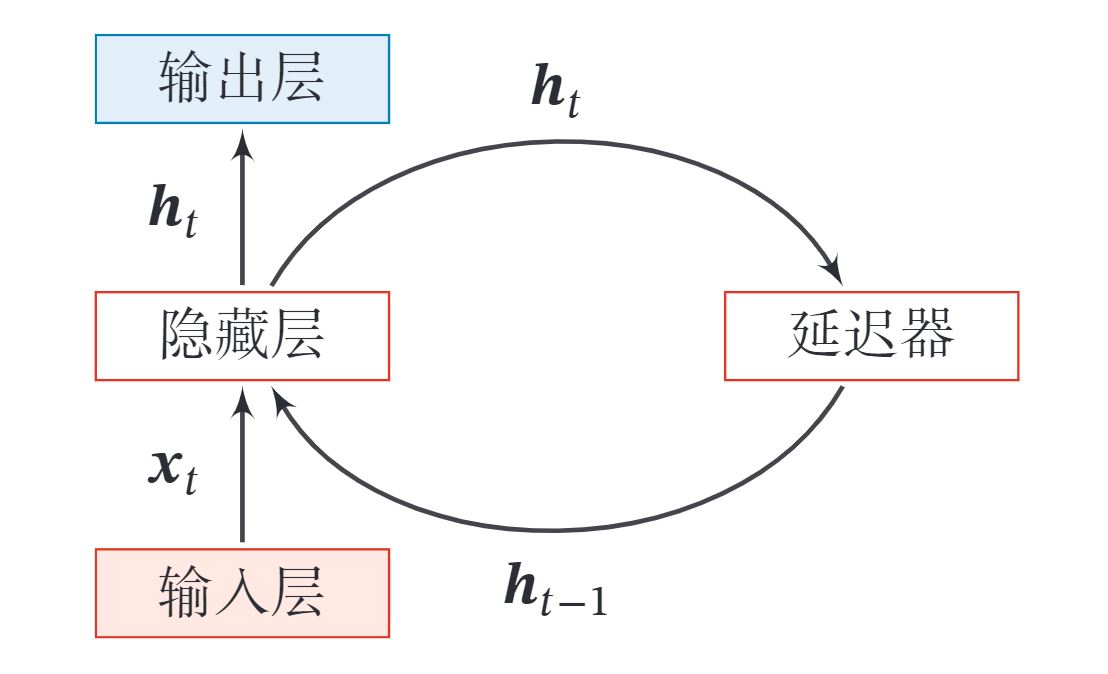
从数学上讲,上式可以看成一个动力系统.因此,隐藏层的活性值 在很多文献上也称为状态(State)或隐状态(Hidden State).由于循环神经网络具有短期记忆能力,相当于存储装置,因此其计算能力十分强大.理论上,循环神经网络可以近似任意的非线性动力系统.前馈神经网络可以模拟任何连续函数,而循环神经网络可以模拟任何程序.
二. 简单循环网络
简单循环网络(Simple Recurrent Network,SRN)只有一个隐藏层.在一个两层的前馈神经网络中,连接存在于相邻的层与层之间,隐藏层的节点之间是无连接的.而简单循环网络增加了从隐藏层到隐藏层的反馈连接.
令向量 表示在时刻 时网络的输入, 表示隐藏层状态(即隐藏层神经元活性值),则 不仅和当前时刻的输入 相关,也和上一个时刻的隐藏层状态 相关.简单循环网络在时刻 的更新公式为
其中 为隐藏层的净输入, 为状态-状态权重矩阵, 为状态-输入权重矩阵, 为偏置向量, 是非线性激活函数,通常为Logistic函数或Tanh函数.也经常直接写为
下图给出了按时间展开的循环神经网络:
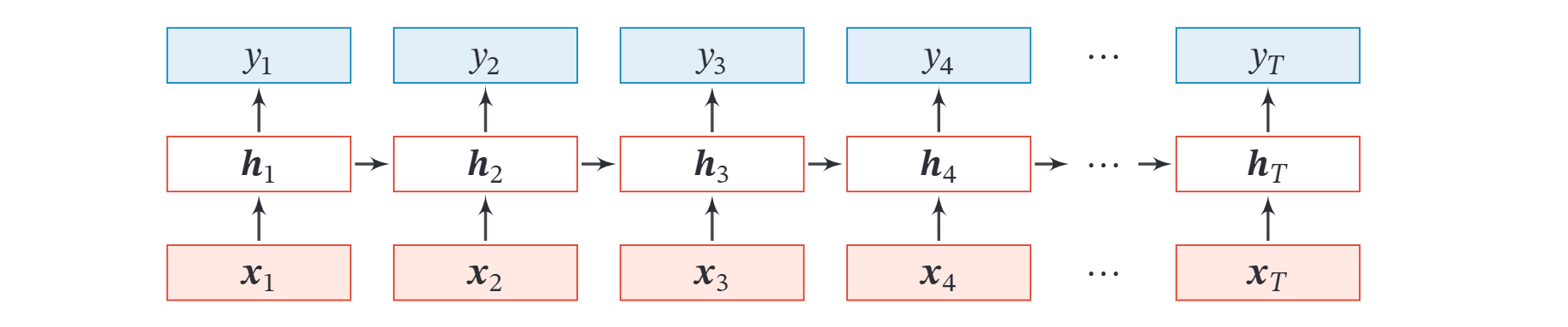
循环神经网络的通用近似定理
一个完全连接的循环网络是任何非线性动力系统的近似器.
定理:循环神经网络的通用近似定理[Haykin,2009]:如果一个完全连接的循环神经网络有足够数量的sigmoid型隐藏神经元,那么它可以以任意的准确率去近似任何一个非线性动力系统
其中 为每个时刻的隐状态, 是外部输入, 是可测的状态转换函数, 是连续输出函数,并且对状态空间的紧致性没有限制.
三. 参数学习
循环神经网络的参数可以通过梯度下降方法来进行学习.
以随机梯度下降为例,给定一个训练样本 ,其中 为长度是 的输入序列, 是长度为 的标签序列.即在每个时刻 ,都有一个监督信息 ,我们定义时刻 的损失函数为 其中 为第 时刻的输出, 为可微分的损失函数,比如交叉熵.那么整个序列的损失函数为 整个序列的损失函数 关于参数 的梯度为 即每个时刻损失 对参数 的偏导数之和.
循环神经网络中存在一个递归调用的函数 , 因此其计算参数梯度的方式和前馈神经网络不太相同.在循环神经网络中主要有两种计算梯度的方式:随 时间反向传播 ( BPTT ) 算法和实时循环学习 ( RTRL ) 算法.
3.1 随时间反向传播
随时间反向传播 ( BackPropagation Through Time, BPTT ) 算法的主要思想是通过类似前馈神经网络的错误反向传播算法 [Werbos, 1990]来计算梯度.
BPTT 算法将循环神经网络看作一个展开的多层前馈网络,其中“每一层”对应循环网络中的“每个时刻”.这样,循环神经网络就可以按照前馈网络中的反向传播算法计算参数梯度.在“展开”的前馈网络中,所有层的参数是共 享的,因此参数的真实梯度是所有“展开层”的参数梯度之和.
计算偏导数 先来计算第 时刻损失对参数 的偏导数 .
因为参数 和隐藏层在每个时刻 的净输入 有关,因此第 时刻的损失函数 关于参数 的梯度为: 其中 表示**“直接”偏导数**,即公式 中保持 不变,对 进行求偏导数,得到 其中 为第 时刻隐状态的第 维; 是除了第 行值为 外,其余都为 0 的行向量.
定义误差项 为第 时刻的损失对第 时刻隐藏神经层的净输入 的导数,则当 时 由上面三式得到 将上式写成矩阵形式为 下图给出了误差项随时间进行反向传播算法的示例.
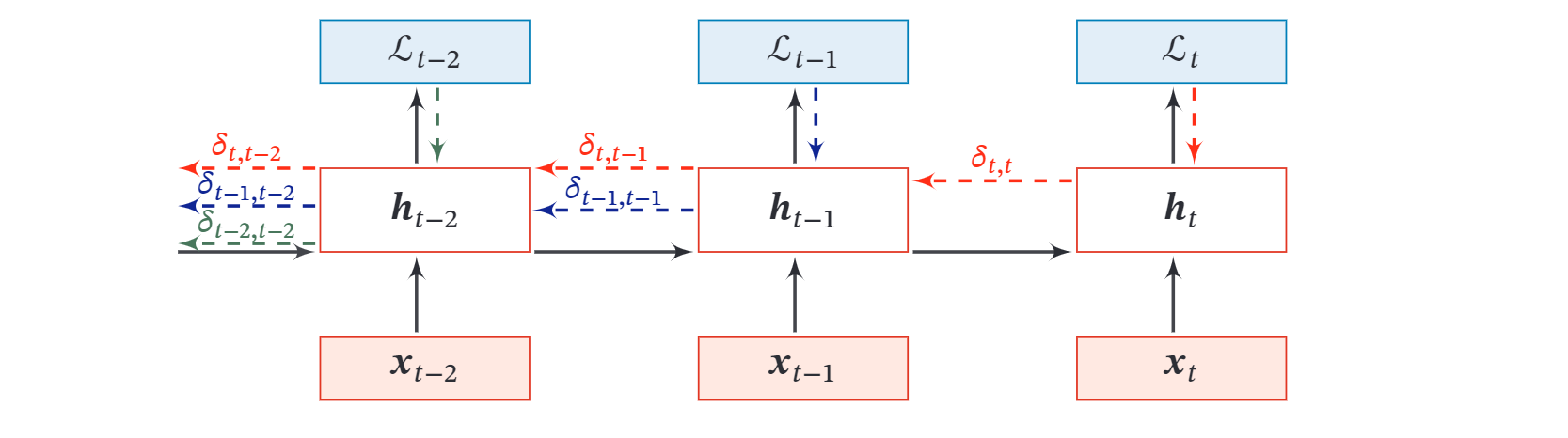
参数梯度 由几式,得到整个序列的损失函数 关于参数 的梯度 同理可得, 关于权重 和偏置 的梯度为 计算复杂度 在BPTT算法中,参数的梯度需要在一个完整的“前向”计算和“反向”计算后才能得到并进行参数更新.
3.2 实时循环学习
与反向传播的 BPTT 算法不同的是, 实时循环学习 ( Real-Time Recurrent Learning, RTRL ) 是通过前向传播的方式来计算梯度 [Williams et al., 1995].
假设循环神经网络中第 时刻的状态 为 其关于参数 的偏导数为 其中 是除了第 行值为 外,其余都为 0 的行向量.
RTRL 算法从第 1 个时刻开始,除了计算循环神经网络的隐状态之外,还利用上式依次前向计算偏导数 .
这样,假设第 个时刻存在一个监督信息,其损失函数为 ,就可以同时计 算损失函数对 的偏导数 这样在第 时刻,可以实时地计算损失 关于参数 的梯度,并更新参数.参数 和 的梯度也可以同样按上述方法实时计算.
两种算法比较 RTRL算法和 BPTT 算法都是基于梯度下降的算法,分别通过前向模式和反向模式应用链式法则来计算梯度.在循环神经网络中,一般网络输出维度远低于输入维度,因此 BPTT 算法的计算量会更小,但是 BPTT 算法需要保存所有时刻的中间梯度,空间复杂度较高.RTRL算法不需要梯度回传,因此非常 适合用于需要在线学习或无限序列的任务中.
四. 长程依赖问题
循环神经网络在学习过程中的主要问题是由于梯度消失或爆炸问题,很难建模长时间间隔 ( Long Range ) 的状态之间的依赖关系.
在 BPTT 算法中,将公式(6.36)展开得到 如果定义 ,则 若 ,当 时, .当间隔 比较大时,梯度也变得很大,会造成系统不稳定,称为梯度爆炸问题 ( Gradient Exploding Problem ).
相反,若 ,当 时, .当间隔 比较大时,梯度也变得非常小,会出现和深层前馈神经网络类似的梯度消失问题 ( Vanishing Gradient Problem ).
要注意的是,在循环神经网络中的梯度消失不是说 的梯度消失了,而是 的梯度消失了 (当间隔 比较大时 .也就是说,参数 的更新主要靠当前时刻 的几个相邻状态 来更新,长距离的状态对参数 没有影响.
由于循环神经网络经常使用非线性激活函数为 Logistic 函数或 Tanh 函数作为非线性激活函数,其导数值都小于 1 ,并且权重矩阵 也不会太大,因此如果时间间隔 过大, 会趋向于 0 ,因而经常会出现梯度消失问题.
虽然简单循环网络理论上可以建立长时间间隔的状态之间的依赖关系,但是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系.这样,如果时刻 的输出 依赖于时刻 的输入 ,当间隔 比较大时 ,简单神经网络很难建模这种长距离的依赖关系,称为长程依赖问题 ( Long-Term Dependencies Problem ).
4.1 改进方法
为了避免梯度爆炸或消失问题,一种最直接的方式就是选取合适的参数,同时使用非饱和的激活函数,尽量使得 ,这种方式需要足够的人 工调参经验,限制了模型的广泛应用.比较有效的方式是通过改进模型或优化方法来缓解循环网络的梯度爆炸和梯度消失问题.
梯度爆炸 一般而言,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断来避免.
权重衰减是通过给参数增加 或 范数的正则化项来限制参数的取值范围,从而使得 .梯度截断是另一种有效的启发式方法,当梯度的模大于一定阈值时,就将它截断成为一个较小的数.
梯度消失 梯度消失是循环网络的主要问题.除了使用一些优化技巧外,更有效的方式就是改变模型,比如让 ,同时令 为单位矩阵,即 其中 是一个非线性函数, 为参数. 公式(6.49)中, 和 之间为线性依赖关系,且权重系数为 1 ,这样就不存在梯度爆炸或消失问题.但是,这种改变也丢失了神经元在反馈边上的非线性 激活的性质,因此也降低了模型的表示能力.
为了避免这个缺点, 我们可以采用一种更加有效的改进策略: 这样 和 之间为既有线性关系,也有非线性关系,并且可以缓解梯度消失问题.但这种改进依然存在两个问题:
- 梯度爆炸问题:令 为在第 时刻函数 的输入,在计算公式(6.34)中的误差项 时,梯度可能会过大,从而导致梯度爆炸问题.
- 记忆容量 ( Memory Capacity ) 问题:随着 不断累积存储新的输入信息,会发生饱和现象.假设 为 Logistic 函数,则随着时间 的增长, 会变得越来越大,从而导致 变得饱和.也就是说,隐状态 可以存储的信息是有限的,随着记忆单元存储的内容越来越多,其丢失的信息也越来越多.
为了解决这两个问题,可以通过引入门控机制来进一步改进模型.
五. 基于门控的循环神经网络
为了改善循环神经网络的长程依赖问题,一种非常好的解决方案是在公式(6.50)的基础上引入门控机制来控制信息的累积速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息. 这一类网络可以称为基于门控的循环神经网络 ( Gated RNN ) . 本节中,主要介绍两种基于门控的循环神经网络:长短期记忆网络和门控循环单元网络.
5.1 长短期记忆网络
长短期记忆网络 ( Long Short-Term Memory Network, LSTM ) [Gers et al. 2000; Hochreiter et al., 1997] 是循环神经网络的一个变体,可以有效地解决简单 循环神经网络的梯度爆炸或消失问题.
在公式 的基础上,LSTM 网络主要改进在以下两个方面:
新的内部状态 LSTM 网络引入一个新的内部状态 ( internal state ) 专门进行线性的循环信息传递,同时 非线性地 输出信息给隐藏层的外部状态 .内部状态 通过下面公式计算; 其中 和 为三个门 gate 来控制信息传递的路径; 为向量元素乘积 为上一时刻的记忆单元 是通过非线性函数得到的候选状态: 在每个时刻 网络的内部状态 记录了到当前时刻为止的历史信息.
门控机制 在数字电路中,门 gate 为一个二值变量 代表关闭状态,不许任何信息通过 代表开放状态,允许所有信息通过
LSTM 网络引入门控机制 ( Gating Mechanism ) 来控制信息传递的路径. 公式 (4.1)中三个 "门"分别为输入门 遗忘门 和输出门 .这二个门的作用为
- 遗忘门 控制上一个时刻的内部状态 需要遗忘多少信息.
- 输入门 控制当前时刻的候选状态 有多少信息需要保存.
- 输出门 控制当前时刻的内部状态 有多少信息需要输出给外部状态
当 时,记忆单元将历史信息清空,并将候选状态向量 写入.但此时记忆单元 依然和上一时刻的历史信息相关.当 时,记忆单元将复制上一时刻的内容,不写入新的信息.
LSTM 网络中的“门”是一种“软”门,取值在 之间,表示以一定的比例允许信息通过.三个门的计算方式为: 其中 为 Logistic 函数,其输出区间为 为当前时刻的输入, 为上一时刻的外部状态.
下图给出了 LSTM 网络的循环单元结构,其计算过程为 ) 首先利用上一时刻的外部状态 和当前时刻的输入 ,计算出三个门,以及候选状态 ) 结合遗忘门 和输入门 来更新记忆单元 ) 结合输出门 ,将内部状态的信息传递给外部状态 .
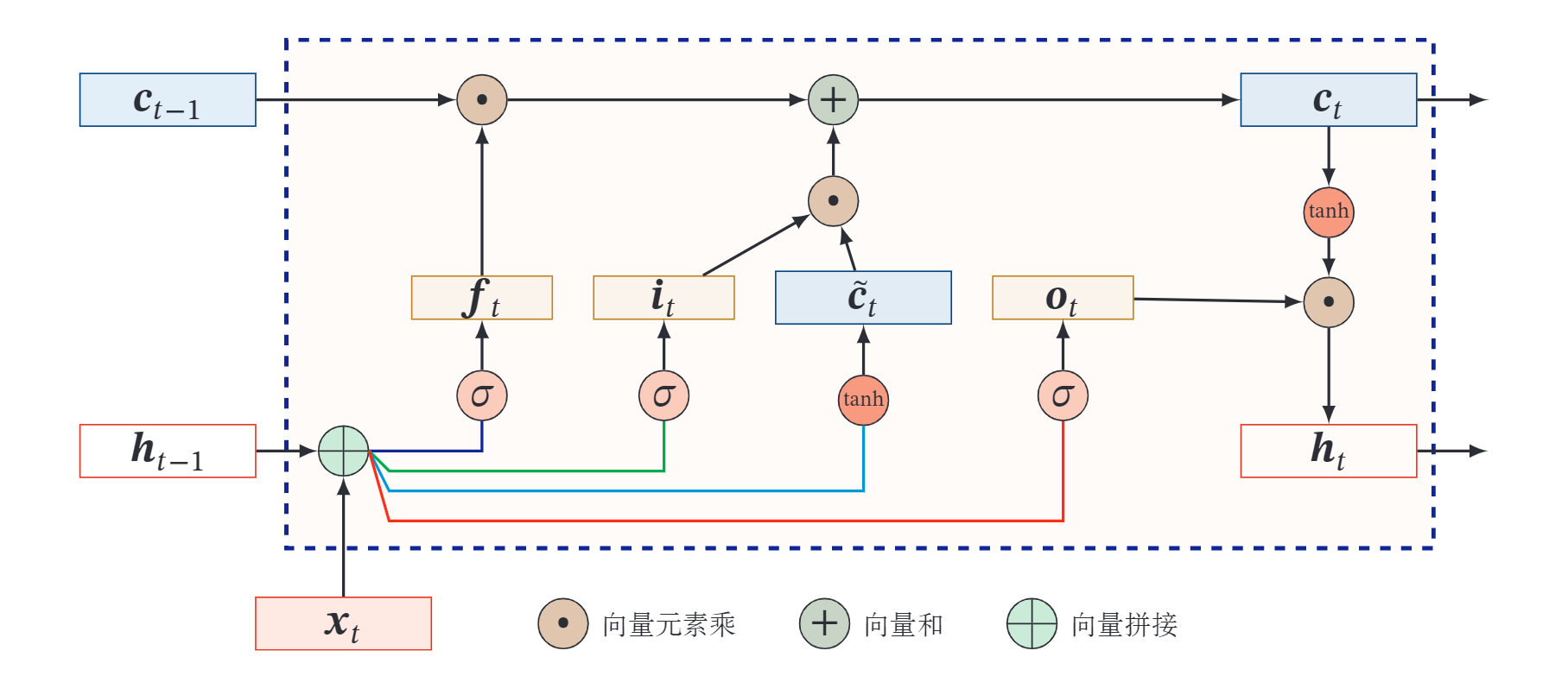
通过 循环单元,整个网络可以建立较长距离的时序依赖关系.公式可以简洁地描述为 其中 为当前时刻的输入, 和 为网络参数.
记忆 循环神经网络中的隐状态 存储了历史信息,可以看作一种记忆 ( Mem- ory ).在简单循环网络中,隐状态每个时刻都会被重写,因此可以看作一种短期记忆 ( Short-Term Memory ).在神经网络中,长期记忆 ( Long-Term Memory ) 可以看作网络参数,隐含了从训练数据中学到的经验,其更新周期要远远慢于短期记忆.而在 LSTM 网络中,记忆单元 可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔.记忆单元 中保存信息的生命周期要长于短期记忆 ,但又远远短于长期记忆,因此称为长短期记忆 ( Long Short-Term Memory ).
一般在深度网络参数学习时,参数初始化的值一般都比较小.但是在训练 LSTM 网络时,过小的值会使得遗忘门的值比较小.这意味着前一时刻的信息大部分都丢失了,这样网络很难捕捉到长距离的依赖信息.并且相邻时间间隔的梯度会非常小,这会导致梯度弥散问题.因此遗忘的参数初始值一般都设得比较大,其偏置向量 设为 1 或2.
5.2 LSTM网络的各种变体
目前主流的 LSTM 网络用三个门来动态地控制内部状态应该遗忘多少历史信息,输入多少新信息,以及输出多少信息.我们可以对门控机制进行改进并获得 LSTM 网络的不同变体.
无遗忘门的 LSTM 网络 [Hochreiter et al., 1997] 最早提出的 LSTM 网络是没有遗忘门的,其内部状态的更新为 如之前的分析,记忆单元 会不断增大.当输入序列的长度非常大时,记忆单元的容量会饱和,从而大大降低 LSTM 模型的性能. peephole 连接 另外一种变体是三个门不但依赖于输入 和上一时刻的隐状态 ,也依赖于上一个时刻的记忆单元 ,即 其中 和 为对角矩阵.
耦合输入门和遗忘门 LSTM 网络中的输入门和遗忘门有些互补关系,因此同时用两个门比较冗余.为了减少 LSTM 网络的计算复杂度,将这两门合并为一个 门.令 , 内部状态的更新方式为
5.3 门控循环单元网络
门控循环单元 ( Gated Recurrent Unit, GRU ) 网络 [Cho et al., 2014; Chung et al., 2014] 是一种比 LSTM 网络更加简单的循环神经网络.
GRU 网络引入门控机制来控制信息更新的方式.和 LSTM 不同,GRU 不引入额外的记忆单元, GRU 网络也是在公式 的基础上引入一个更新门 ( Up- date Gate ) 来控制当前状态需要从历史状态中保留多少信息 ( 不经过非线性变换 ) ,以及需要从候选状态中接受多少新信息,即 其中 为更新门 在 LSTM 网络中,输入门和遗忘门是互补关系,具有一定的咒余性.GRU 网络直接使用一个门来控制输入和遗忘之间的平衡.当 时,当前状态 和前一时刻的状态 之间为非线性函数关系;当 时, 和 之间为线性函数关系.
在 GRU 网络中,函数 的定义为 其中 表示当前时刻的候选状态, 为重置门 ( Reset Gate ) 用来控制候选状态 的计算是否依赖上一时刻的状态 . 当 时,候选状态 只和当前输入 相关,和历史 状态无关.当 时,候选状态 和当前输入 以及历史状态 相关,和简单循环网络一致.
综上,GRU网络的状态更新方式为 可以看出,当 时,GRU 网络退化为简单循环网络;若 时,当前状态 只和当前输入 相关,和历史状态 无关. 当 时,当前状态 等于上一时刻状态 ,和当前输入 无关.
下图给出了GRU 网络的循环单元结构.
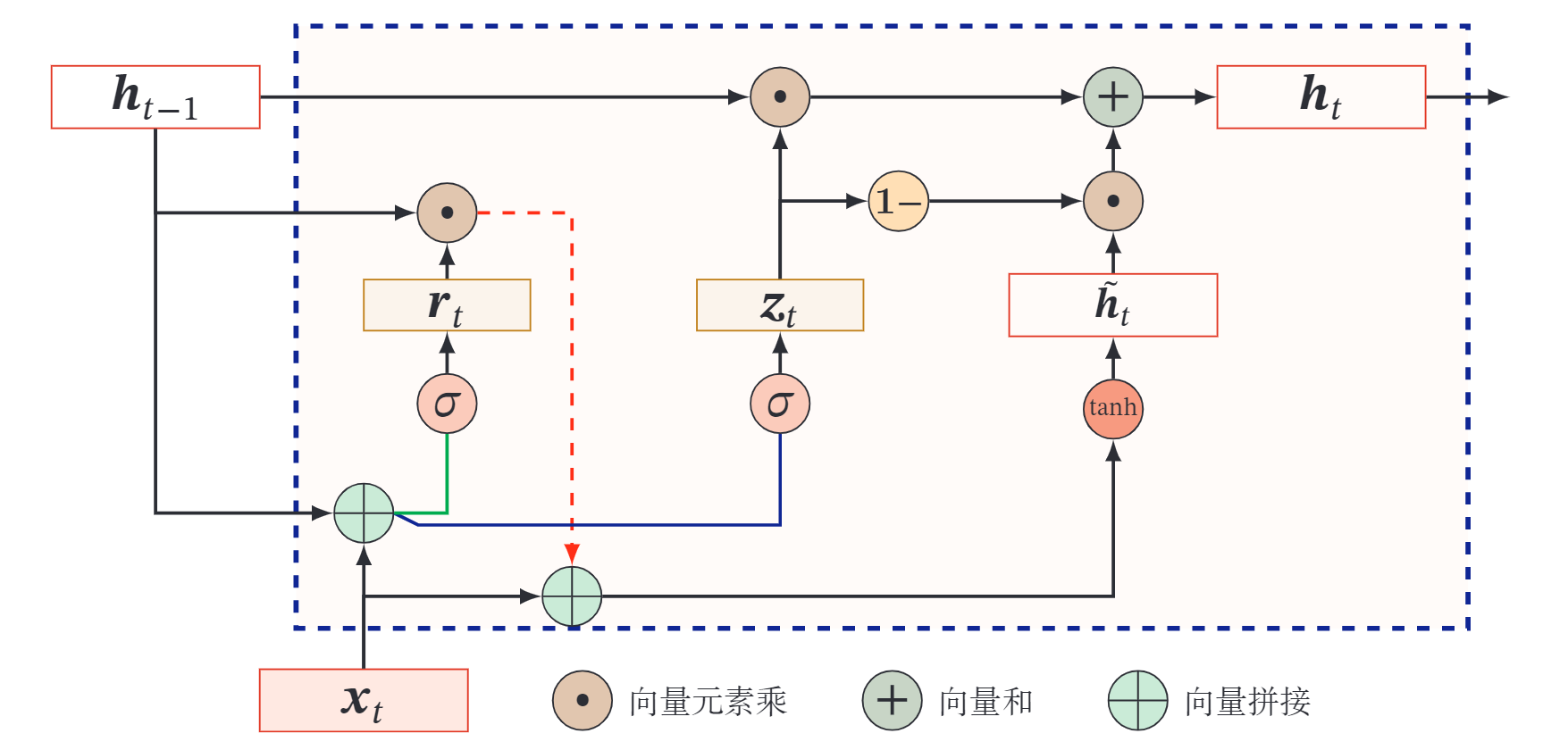
六. 深层循环神经网络
如果将深度定义为网络中信息传递路径长度的话,循环神经网络可以看作既“深”又“浅”的网络.一方面来说,如果我们把循环网络按时间展开,长时间间隔的状态之间的路径很长,循环网络可以看作一个非常深的网络.从另一方面来说,如果同一时刻网络输入到输出之间的路径 ,这个网络是非常浅的.
因此,我们可以增加循环神经网络的深度从而增强循环神经网络的能力.增加循环神经网络的深度主要是增加同一时刻网络输入到输出之间的路径 ,比如增加隐状态到输出 ,以及输入到隐状态 之间的路径的 深度.
6.1 堆叠循环神经网络
一种常见的增加循环神经网络深度的做法是将多个循环网络堆叠起来,称为堆叠循环神经网络 ( Stacked Recurrent Neural Network, SRNN ) .一个堆叠的简单循环网络 ( Stacked SRN ) 也称为循环多层感知器 ( Recurrent Multi-Layer Perceptron, RMLP ) [Parlos et al., 1991].
下图给出了按时间展开的堆肯循环神经网络.第 层网络的输入是第 层网络的输出.我们定义 为在时刻 时第 层的隐状态 其中 和 为权重矩阵和偏置向量,.
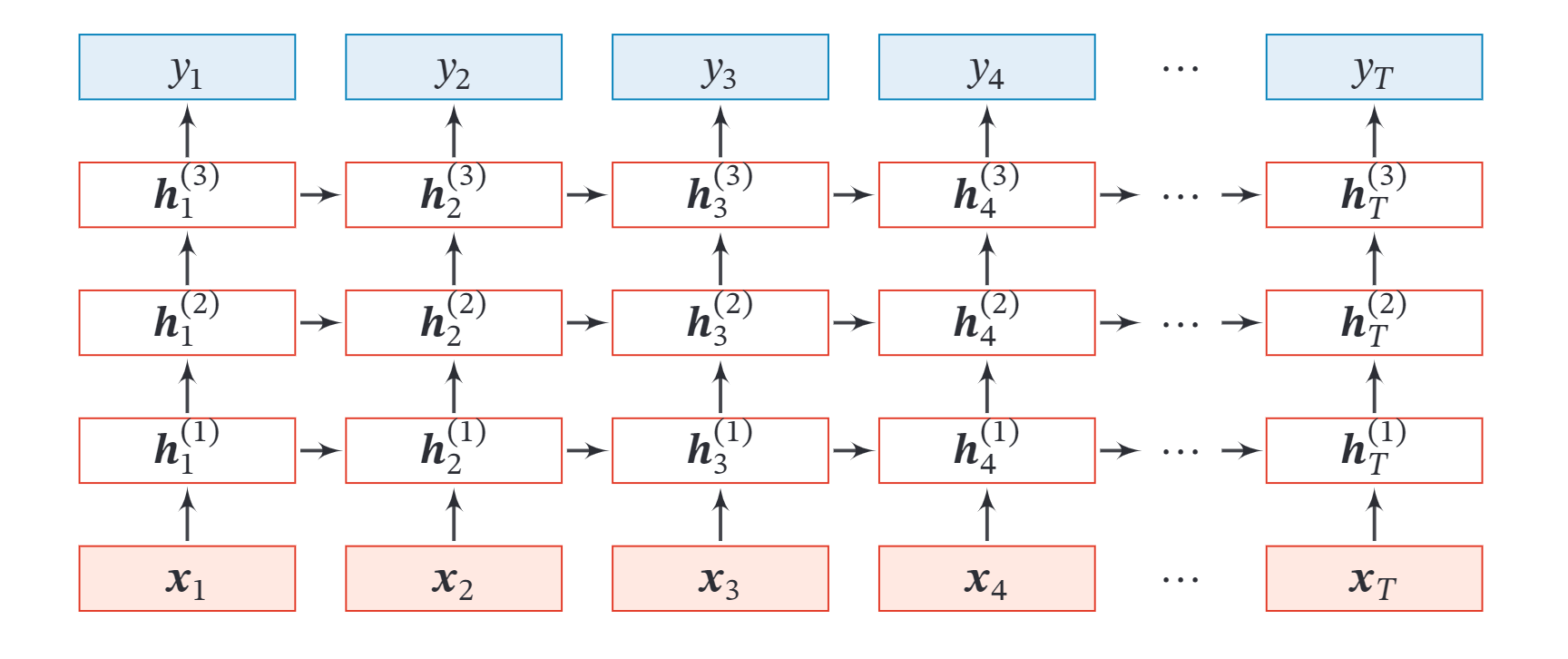
6.2 双向循环神经网络
在有些任务中,一个时刻的输出不但和过去时刻的信息有关,也和后续时刻的信息有关.比如给定一个句子,其中一个词的词性由它的上下文决定,即包含左右两边的信息.因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力.
双向循环神经网络 ( Bidirectional Recurrent Neural Network, Bi-RNN ) 由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同.
假设第 1 层按时间顺序,第 2 层按时间逆序,在时刻 时的隐状态定义为 和 , 则 其中 为向量拼接操作.
下图给出了按时间展开的双向循环神经网络.
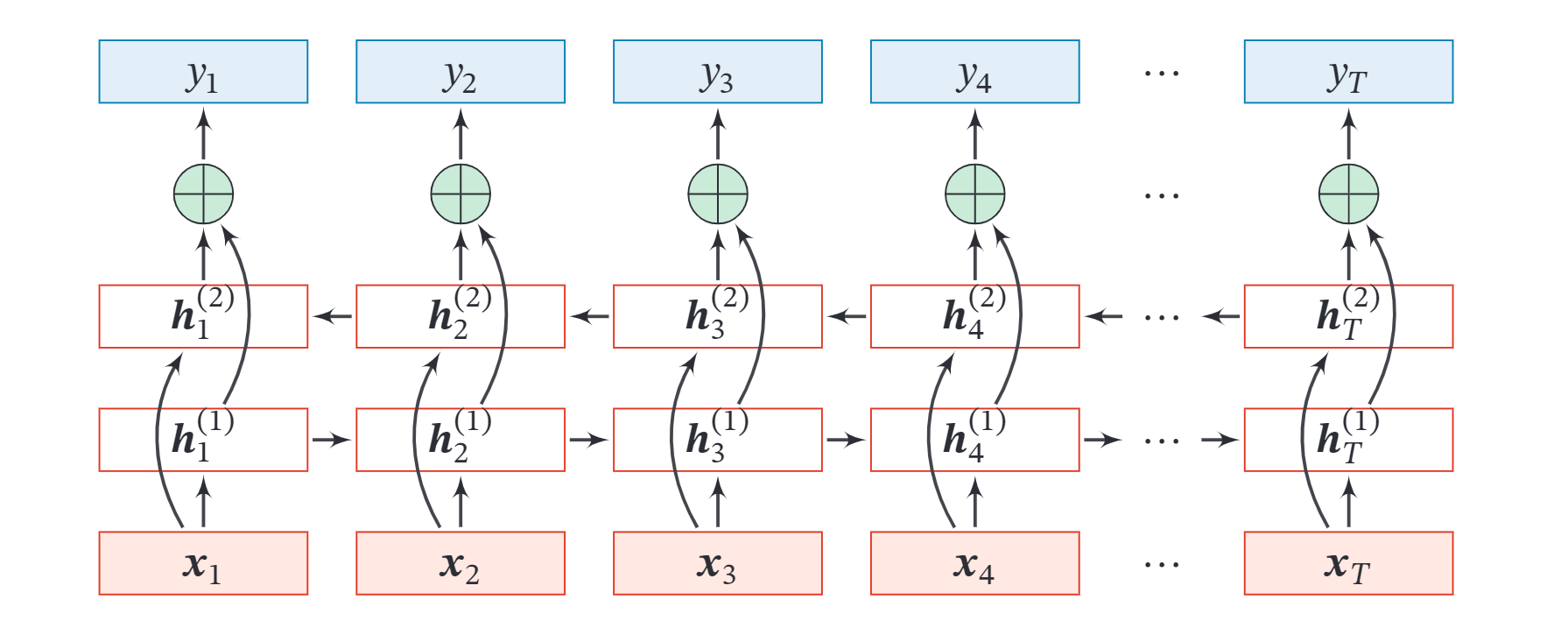
七. 扩展到图结构
如果将循环神经网络按时间展开,每个时刻的隐状态 看作一个节点,那么这些节点构成一个链式结构,每个节点 都收到其父节点的消息(Message),更新自己的状态,并传递给其子节点.而链式结构是一种特殊的图结构,我们可以比较容易地将这种消息传递 ( Message Passing ) 的思想扩展到任意的图结 构上.
7.1 递归神经网络
递归神经网络 ( Recursive Neural Network, ) 是循环神经网络在有向无循环图上的扩展 [Pollack, 1990].递归神经网络的一般结构为树状的层次结构,如下图左所示.
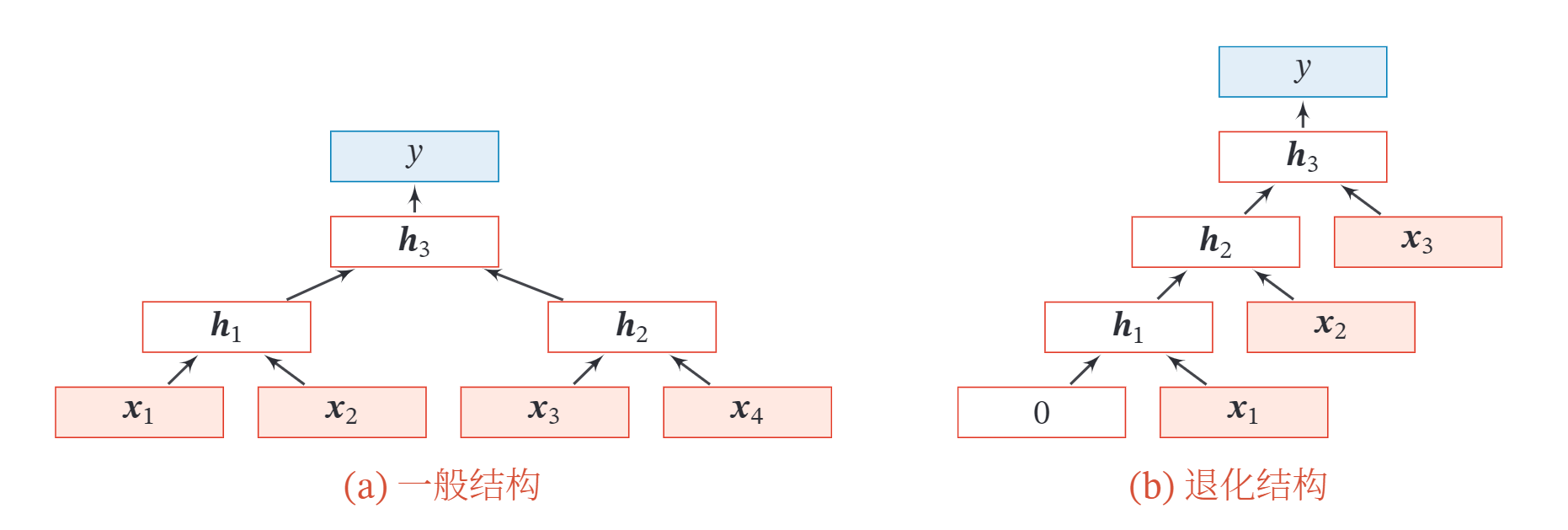
以上图左中的结构为例,有三个隐藏层 和 , 其中 由两个输入层 和 计算得到, 由另外两个输入层 和 计算得到, 由两个隐藏层 和 计算得到.
对于一个节点 ,它可以接受来自父节点集合 中所有节点的消息,并更新自己的状态. 其中 表示集合 中所有节点状态的拼接, 是一个和节点位置无关的非线性函数,可以为一个单层的前馈神经网络.比如上图左所示的递归神经网络具体可以写为 其中 表示非线性激活函数, 和 是可学习的参数.同样,输出层 可以为一个分类器,比如 其中 为分类器, 和 为分类器的参数.当递归神经网络的结构退化为线性序列结构 (上图右) 时,递归神经网络就等价于简单循环网络.
递归神经网络主要用来建模自然语言句子的语义[Socher et al., 2011,2013].给定一个句子的语法结构 ( 一般为树状结构 ),可以使用递归神经网络来按照句法的组合关系来合成一个句子的语义.句子中每个短语成分又可以分成一些子 成分,即每个短语的语义都可以由它的子成分语义组合而来,并进而合成整句的语义.
同样,我们也可以用门控机制来改进递归神经网络中的长距离依赖问题,比如树结构的长短期记忆模型 ( Tree-Structured LSTM ) [Tai et al., 2015; Zhu et al., 2015 ] 就是将 LSTM 模型的思想应用到树结构的网络中,来实现更灵活的组合函数.
7.2 图神经网络
在实际应用中,很多数据是图结构的,比如知识图谱、社交网络、分子网络等.而前馈网络和反馈网络很难处理图结构的数据.
图神经网络 ( Graph Neural Network, GNN ) 是将消息传递的思想扩展到图结构数据上的神经网络.
对于一个任意的图结构 ,其中 表示节点集合, 表示边集合.每条边表示两个节点之间的依赖关系.节点之间的连接可以是有向的,也可以是无向的.图中每个节点 都用一组神经元来表示其状态 , 初始状态可以为节点 的输入特征 .每个节点可以收到来自相邻节点的消息,并更新自己的状态. 其中 表示节点 的邻居, 表示在第 时刻节点 收到的信息, 为 边 上的特征.
上式是一种同步的更新方式,所有的结构同时接受信息并更新自己的状态.而对于有向图来说,使用异步的更新方式会更有效率,比如循环神经网络或递归神经网络,在整个图更新 次后,可以通过一个读出函数 ( Readout Function ) 来得到整个网络的表示:
八. 总结和深入阅读
循环神经网络可以建模时间序列数据之间的相关性.和延时神经网络[Lang et al., 1990; Waibel et al., 1989] 以及有外部输入的非线性自回归模型[Leontaritis et al., 1985 ]相比,循环神经网络可以更方便地建模长时间间隔的相关性.
常用的循环神经网络的参数学习算法是 BPTT算法 [Werbos, 1990],其计算时间和空间要求会随时间线性增长.为了提高效率,当输入序列的长度比较大时,可以使用带截断 ( truncated ) 的 BPTT算法[Williams et al., 1990],只计算固定时间间隔内的梯度回传.
一个完全连接的循环神经网络有着强大的计算和表示能力,可以近似任何非线性动力系统以及图灵机,解决所有的可计算问题.然而由于梯度爆炸和梯度消失问题,简单循环网络存在长期依赖问题[Bengio et al., 1994; Hochreiter et al., 2001].为了解决这个问题,人们对循环神经网络进行了很多的改进,其中最有效的改进方式为引入门控机制,比如 LSTM 网络 [Gers et al., 2000; Hochreiter et al., 1997]和GRU网络[Chung et al., 2014].当然还有一些其他方法,比如时钟循环神经网络 ( Clockwork RNN ) [Koutnik et al., 2014]、乘法RNN[Sutskever et al., 2011; Wu et al., 2016] 以及引入注意力机制等.
LSTM 网络是目前为止最成功的循环神经网络模型,成功应用在很多领域,比如语音识别、机器翻译 [Sutskever et al., 2014] 语音模型以及文本生成. LSTM 网络通过引入线性连接来缓解长距离依赖问题.虽然 LSTM 网络取得了很大的 成功,其结构的合理性一直受到广泛关注.人们不断尝试对其进行改进来寻找最优结构,比如减少门的数量、提高并行能力等.关于 LSTM 网络的分析可以参考文献 [Greff et al., 2017; Jozefowicz et al., 2015; Karpathy et al., 2015].
LSTM 网络的线性连接以及门控机制是一种十分有效的避免梯度消失问题的方法.这种机制也可以用在深层的前馈网络中,比如残差网络 [He et al., 2016] 和高速网络[Srivastava et al., 2015] 都通过引入线性连接来训练非常深的卷积网络.对于循环神经网格,这种机制也可以用在非时间维度上,比如 Gird LSTM 网络 [Kalchbrenner et al., 2015] 、Depth Gated RNN[Chung et al., 2015 等.
此外,循环神经网络可以很容易地扩展到更广义的图结构数据上,称为图网络[Scarselli et al., 2009].递归神经网络是一种在有向无环图上的简单的图网络.图网络是目前新兴的研究方向,还没有比较成熟的网络模型.在不同的网络结构以及任务上,都有很多不同的具体实现方式.其中比较有名的图网络模型包括图卷积网络 ( Graph Convolutional Network, GCN ) [Kipf et al., 2016]、图注意力网络 ( Graph Attention Network, GAT ) [Veličković et al., 2017] 消息传递神经网络 ( Message Passing Neural Network, MPNN ) [Gilmer et al., 2017] 等.关于图网络的综述可以参考文献 [Battaglia et al., 2018].
生成对抗网络
产生于2014年,论文地址 Ian J. Goodfellow
生动的白话例子:莫烦教程
又李宏毅课上举的例子:类似生物的拟态,枯叶蝶进化中不断地去模仿叶子的形态以逃避天敌的捕食.
简而言之,有两个网络,生成网络(generative network,即枯叶蝶自身形态的进化)和对抗网络(adversarial network,即天敌对它的分辨),生成网络负责生成样本(可能依据一个分布得到的随机数来生成),而对抗网络负责判断这个样本是真实样本还是生成样本,两个网络共同训练.
一. 概率生成模型
概率生成模型(Probabilistic Generative Model),简称生成模型,指一系列用于随机生成可观测数据的模型.假设在一个连续或离散的高维空间 中,存在一个随机向量 服从一个未知的数据分布 .生成模型是根据一些可观测的样本 来学习一个参数化的模型 来近似未知分布 ,并可以用这个模型来生成一些样本,使得“生成”的样本和“真实”的样本尽可能地相似.生成模型通常包含两个基本功能:概率密度估计和生成样本(即采样).
1.1 密度估计
给定一组数据 ,假设它们都是独立地从相同的概率密度函数为 的未知分布中产生的.密度估计(Density Estimation)是根据数据集 来估计其概率密度函数 .
直接建模 比较困难.因此,我们通常通过引入隐变量 来简化模型,这样密度估计问题可以转换为估计变量 的两个局部条件概率 和 .一般为了简化模型,假设隐变量 的先验分布为标准高斯分布 .隐变量 的每一维之间都是独立的.在这个假设下,先验分布 中没有参数.因此,密度估计的重点是估计条件分布 .
1.2 生成样本
生成样本就是给定一个概率密度函数为 的分布,生成一些服从这个分布的样本,也称为采样.
在得到两个变量的局部条件概率 和 之后,我们就可以生成数据 ,具体过程可以分为两步进行:
- 根据隐变量的先验分布 进行采样,得到样本 .
- 根据条件分布 进行采样,得到样本 .
为了便于采样,通常 不能太过复杂.因此,另一种生成样本的思想是从一个简单分布 ( 比如标准正态分布 ) 中采集一个样本 , 并利用一个深度神经网络 使得 服从 这样,我们就可以避免密度估计问题,并有效降低生成样本的难度,这正是生成对抗网络的思想.
1.3 生成对抗网络
一种无监督学习.注意到生成网络与真实样本是未接触的,判别网络根据真实样本来更新参数,而生成网络根据判别网络来更新参数.
1.3.1 显式密度模型和隐式密度模型
一些深度生成模型,比如变分自编码器、深度信念网络等,都是显示地构建出样本的密度函数 ,并通过最大似然估计来求解参数,称为显式密度模型(Explicit Density Model).
如果只是希望有一个模型能生成符合数据分布 的样本,那么可以不显式地估计出数据分布的密度函数.假设在低维空间 中有一个简单容易采样的 分布 通常为标准多元正态分布 .我们用神经网络构建一个映射函数 ,称为生成网络.利用神经网络强大的拟合能力,使得 服从分布 .这种模型就称为隐式密度模型 ( Implicit Density Model ).所谓隐式模型就是指并不显式地建模 ,而是建模生成过程.
1.3.2 网络分解
生成对抗网络(Generative Adversarial Networks,GAN)[Goodfellowet al.,2014]是通过对抗训练的方式来使得生成网络产生的样本服从真实数据分布.在生成对抗网络中,有两个网络进行对抗训练.一个是判别网络,目标是尽量准确地判断一个样本是来自于真实数据还是由生成网络产生;另一个是生成网络,目标是尽量生成判别网络无法区分来源的样本.

1.3.2.1 判别网络
判别网络 ( Discriminator Network ) 的目标是区分出一个样本 是来自于真实分布 还是来自于生成模型 ,因此判别网络实际上是一个二分类的分类器.用标签 来表示样本来自真实分布, 表示样本来自生成模型,判别网络 的输出为 属于真实数据分布的概率,即
则样本来自生成模型的概率为
.给定一个样本 表示其来自于 还是 .判别网络的
目标函数为最小化交叉嫡,即
假设分布 是由分布 和分布 等比例混合而成,即
,则上式等价于
其中 和 分别是生成网络和判别网络的参数.
>回忆交叉熵定义: ,其中 为真实值, 为以 为参数, 为输入的模型输出的估计值.
1.3.2.2 生成网络
生成网络(Generator Network)的目标刚好和判别网络相反,即让判别网络将自己生成的样本判别为真实样本.
上面的这两个目标函数是等价的.但是在实际训练时,一般使用前者,因为其梯度性质更好.我们知道,函数 在 接近 时的梯度要比接近 时的梯度小很多,接近“饱和”区间.这样,当判别网络 以很高的概率认为生成网络 产生的样本是“假”样本时, 即 , 目标函数关于 的 梯度反而很小,从而不利于优化.
1.3.2.3 训练
和单目标的优化任务相比,生成对抗网络的两个网络的优化目标刚好相反.因此生成对抗网络的训练比较难,往往不太稳定.一般情况下,需要平衡两个网络的能力.对于判别网络来说,一开始的判别能力不能太强,否则难以提升生成网络的能力.但是,判别网络的判别能力也不能太弱,否则针对它训练的生成网络也不会太好.在训练时需要使用一些技巧,使得在每次迭代中,判别网络比生成网络的能力强一些,但又不能强太多.
生成对抗网络的训练流程如下图所示.每次迭代时,判别网络更新 𝐾 次而生成网络更新一次,即首先要保证判别网络足够强才能开始训练生成网络.在实践中 𝐾 是一个超参数,其取值一般取决于具体任务.

1.3.2.4 难点
生成对抗网络训练的难点在于,不像一般的loss function,我们只要看loss收不收敛就知道训练效果.GAN中最后判断网络无法辨别样本来自真实网络还是生成网络,可能是由于生成网络训练得很好,但也可能是由于判别网络训练得太差,反之亦然.
DRL
DRL(deep reinforcement learning) 深度强化学习
强化学习基础
一. 有模型数值迭代
1.1 度量空间与压缩映射
1.1.1 度量空间及其完备性
度量 ( metric,又称距离 ),是定义在集合上的二元函数.对于集合 ,其上的度量 ,需要满足
- 非负性:对任意的 , 有
- 同一性:对任意的 , 如果 , 则
- 对称性:对任意的 , 有
- 三角不等式: 对任意的 , 有 .
有序对 又称为度量空间 (metric space).我们来看一个度量空间的例子.考虑有限 Markov 决策过程状态函数 ,其所有可能的取值组成集合 ,定义 如下: 可以证明, 是 上的一个度量.(证明: 非负性、同一性、对称性是显然的.由于 有 可得三角不等式.)所以, 是一个度量空间.对于一个度量空间,如果 Cauchy 序列都收敛在该空间内,则称这个度量空间是完备的(complete).对于度量空间 也是完备的.(证明: 考虑其中任意 Cauchy 列 ,即对任意的正实数 ,存在正整数 使得任意的 ,均有 对于 ,所以 是 Cauchy 列.由实数集的完备性,可以知道 收敛于某个实数,记这个实数为 .所以,对于 ,存在正整数 ,对于任意 ,有 取 ,有 ,所以 收敛于 ,而 ,完备性得证).
1.1.2 压缩映射与Bellman算子
本节介绍压缩映射的定义,并证明 Bellman 期望算子和 Bellman 最优算子是度量空间 上的压缩映射.
对于一个度量空间 和其上的一个映射 ,如果存在某个实数 ,使得对于任意的 ,都有 则称映射 是压缩映射 ( contraction mapping, 或 Lipschitzian mapping).其中的实数 被称为 Lipschitz 常数.
※ Bellman期望方程
用状态价值函数表示状态价值函数: 用动作价值函数表示动作价值函数:
※ Bellman最优方程
用最优状态价值函数表示最优状态价值函数: 用最优动作价值函数表示最优动作价值函数:
这两个方程都有用状态价值表示状态价值的形式.根据这个形式,我们可以为度量空间 定义 Bellman 期望算子 和 Bellman 最优算子.
给定策略 的 Bellman 期望算子 Bellman 最优算子 : 下面我们就来证明,这两个算子都是压缩映射.
首先来看 期望算子 .由 的定义可知,对任意的 ,有 所以 考虑到 是任取的,所以有 当 时, 就是压缩映射.接下来看 Bellman 最优算子 .要证明 是压缩映射,需要用到下列不等式: 其中 和 是任意的以 为自变量的函数。(证明: 设 , 则 同理可证 ,于是不等式得证. 利用这个不等 式,对任意的 ,有 进而易知 ,所以 是压缩映射.
1.1.3 Banach不动点定理
对于度量空间 上的映射 ,如果 使得 ,则称 是映射 的不动点 (fix point).
例如,策略 的状态价值函数 满足 Bellman 期望方程,是 Bellman 期望算子 的不动点.最优状态价值 满足 Bellman 最优方程,是 Bellman 最优算子 的不动点.
完备度量空间上的压缩映射有非常重要的结论: Banach 不动点定理. Banach 不动点定理(Banach fixed-point theorem, 又称压缩映射定理, compressed mapping theorem) 的内容是: 是非空的完备度量空间, 是一个压缩映射,则映射 在 内有且仅有一个不动点 .更进一步,这个不动点可以通过下列方法求出:从 内的任意一个元素 开始,定义迭代序列 ,这个序列收敛,且极限为 .
证明:考虑任取的 及其确定的列 ,我们可以证明它是 Cauchy 序列.对于任意的 且 ,用距离的三角不等式和非负性可知, 再反复利用压缩映射可知,对于任意的正整数 有 ,代人得: 由于 ,所以上述不等式右端可以任意小,得证.
Banach 不动点定理给出了求完备度量空间中压缩映射不动点的方法:从任意的起点开始,不断迭代使用压缩映射,最终就能收敛到不动点.并且在证明的过程中,还给出了收敛速度,即迭代正比于 的速度收敛 其中 是迭代次数).在 节我们已经证明 是完备的度量空间,而 节又证明了 Bellman 期望算子和 最优算子是压缩映射,那么就可以用迭代的方法求 Bellman 期望算子和 Bellman 最优算子的不动点.于 期望算子的不动点就是策略价值,Bellman 最优算子的不动点就是最优价值,所以这就意味着我们可以用迭代的方法求得策略的价值或最优价值.在后面的小节中,就来具体看看求解的算法.
1.2 有模型策略迭代
本节介绍在给定动力系统 的情况下的策略评估、策略改进和策略迭代.策略评估、策略改进和策略迭代分别指以下操作.
- 策略评估(policy evaluation): 对于给定的策略 ,估计策略的价值, 包括动作价值和状态价值
- 策略改进(policy improvement): 对于给定的策略 ,在已知其价值函数的情况 找到一个更优的策略
- 策略迭代(policy iteration): 综合利用策略评估和策略改进,找到最优策略
1.2.1 策略评估
本节介绍如何用迭代方法评估给定策略的价值函数.如果能求得状态价值函数,那么就能很容易地求出动作价值函数.由于状态价值函数只有 个自变量,而动作价值函数有 个自变量,所以存储状态价值函数比较节约空间.
用迭代的方法评估给定策略的价值函数的算法如算法 1-1 所示.算法 1-1 一开始初始化状态价值函数 ,并在后续的迭代中用 期望方程的表达式更新一轮所有状态的状态价值函数.这样对所有状态价值函数的一次更新又称为一次扫描(sweep).在第 次扫描时,用 的值来更新 的值,最终得到一系列的 .
算法 1-1:有模型策略评估迭代算法
输入: 动力系统 , 策略 输出:状态价值函数 的估计值 参数: 控制迭代次数的参数(如误差容忍度 或最大迭代次数
- (初始化) 对于 ,将 初始化为任意值 (比如 0 ).如果有终止状态,将终止状态初始化为 0,即
- (迭代) 对于 ,迭代执行以下步骤 2.1 对于 , 逐一更新 ,其中. 2.2 如果满足迭代终止条件 (如对 均有 ,或达到最大迭代次数 ,则跳出循环
值得一提的是,算法 1-1 没必要为每次捉描都重新分配一套空间来存储.一种优化的方法是,设置奇数次迭代的存储空间和偶数次迭代的存储空间,一开始初始化偶数次存储空间,当 是奇数时,用偶数次存储空间来更新奇数次存储空间; 当 是偶数时, 用奇数次存储空间来更新偶数次存储空间.这样,一共只需要两套存储空间就可以完成算法.
1.2.2 策略改进
对于给定的策略 ,如果得到该策略的价值函数,则可以用策略改进定理得到一个改进的策略.
策略改进定理的内容如下:对于策略 和 ,如果 则 ,即 在此基础上,如果存在状态使得第一式的不等号是严格小于号,那么就存在状态使得第二式中的不等号也是严格小于号.
证明: 考虑到第一个不等式等价于 其中的期望是针对用策略 生成的轨迹中,选取 的那些轨迹而言的.进而有 考虑到 所以 进而有 严格不等号的证明类似.
对于一个确定性策略 ,如果存在着 ,使得 ,那么我们可以构造一个新的确定策略 ,它在状态 做动作 ,而在除状态 以外的状态的动作都和策略一样.可以验证,策略 和 满足策略改进定理的条件.这样,我们就得到了一个比策略 更好的策略 .这样的策略更新算法可以用算法 1-2 来表示.
算法 1-2:有模型策略改进算法
输入: 动力系统 ,策略 及其状态价值函数 输出:改进的策略 ,或策略 已经达到最优的标志
- 对于每个状态 ,执行以下步骤: 1.1 为每个动作 ,求得动作价值函数 1.2 找到使得 最大的动作 ,即
- 如果新策略 和旧策略 相同,则说明旧策略巳是最优; 否则,输出改进的新策略
值得一提的是,在算法 1-2 中,旧策略 和新策略 只在某些状态上有不同的动作值, 新策略 可以很方便地在旧策略 的基础上修改得到.所以,如果在后续不需要使用旧策略的情况下,可以不为新策略分配空间.
1.2.3 策略迭代
策略迭代是一种综合利用策略评估和策略改进求解最优策略的迭代方法.
见算法 1-3 ,策略迭代从一个任意的确定性策略 开始,交替进行策略评估和策略改进.这里的策略改进是严格的策略改进,即改进后的策略和改进前的策略是不同的 对于状态空间和动作空间均有限的 Markov 决策过程,其可能的确定性策略数是有限的.由于确定性策略总数是有限的,所以在迭代过程中得到的策略序列 一定能收敛,使得到某个 ,有 (即对任意的 均有 .由于在 的情况下, ,进而 ,满足 Bellman 最优方程.因此, 就是最优策略.这样就证明了策略迭代能够收敛到最优策略.
算法 1-3:有模型策略迭代
输入: 动力系统 输出:最优策略
- (初始化)将策略 初始化为一个任意的确定性策略.
- (迭代) 对于 , 执行以下步骤 2.1 (策略评估)使用策略评估算法,计算策略 的状态价值函数 2.2 (策略更新)利用状态价值函数 改进确定性策略 ,得到改进的确定性策略 .如果 .(即对任意的 均有 ),则迭代完成,返回策略 为最终的最优策略.
策略迭代也可以通过重复利用空间来节约空间.为了节约空间,在各次迭代中用相同的空间 来存储状态价值函数,用空间 来存储确定性策略.
1.3 有模型价值迭代
价值迭代是一种利用迭代求解最优价值函数进而求解最优策略的方法.在 节介绍的策略评估中,迭代算法利用 Bellman 期望方程迭代求解给定策略的价值函数.与之相对,本节将利用 Bellman 最优方程迭代求解最优策略的价值函数,并进而求得最优策略.
与策略评估的情形类似,价值迭代算法有参数来控制迭代的终止条件,可以是误差容忍度 或是最大迭代次数 .
算法 1-4 给出了一个价值迭代算法.这个价值迭代算法中先初始化状态价值函数,然后用 Bellman 最优方程来更新状态价值函数.根据第 1.1 节的证明,只要迭代次数足够多,最终会收敘到最优价值函数.得到最优价值函数后,就能很轻易地给出确定性的最优策略.
算法 1-4: 有模型价值迭代算法
输入:动力系统 愉出:最优策略估计 参数:策略评估需要的参数
- (初始化) 任意值, .如果有终止状态,
- (迭代) 对于 ,执行以下步骤 2.1 对于 ,逐一更新 2.2 如果满足误差容忍度 (即对于 均有 或达到最大迭代次数 (即 ,则跳出循环
- (策略) 根据价值函数输出确定性策略 ,使得
与策略评估的迭代求解类似,价值迭代也可以在存储状态价值函数时重复使用空间.算法 1-5 给出了重复使用空间以节约空间的版本.
算法 1-5:有模型价值迭代 (节约空间的版本 )
输入: 动力系统 输出:最优策略 参数:策略评估需要的参数
- (初始化) 任意值, .如果有终止状态,
- (迭代) 对于 ,执行以下步骤
2.1 对于使用误差容忍度的情况,初始化本次迭代观测到的最大误差
2.2 对于 执行以下操作:
- 计算新状态价值
- 对于使用误差容忍度的情况,更新本次迭代观测到的最大误差
- 更新状态价值函数 2.3 如果满足误差容忍度(即 或达到最大迭代次数 即 ,则跳出循环
- (策略) 根据价值函数输出确定性策略:
二. 回合更新价值迭代
本章开始介绍无模型的机器学习算法.无模型的机器学习算法在没有环境的数学描述的情况下,只依靠经验(例如轨迹的样本) 学习出给定策略的价值函数和最优策略.在现实生活中,为环境建立精确的数学模型往往非常困难.因此,无模型的强化学习是强化学习的主要形式.
根据价值函数的更新时机,强化学习可以分为回合更新算法和时序差分更新算法这两类.回合更新算法只能用于回合制任务,它在每个回合结束后更新价值函数.本章将介绍回合更新算法,包括同策回合更新算法和异策回合更新算法.
2.1 同策回合更新
本节介绍同策回合更新算法.与有模型迭代更新的情况类似,我们也是先学习同策策略评估,再学习最优策略求解.
2.1.1 同策回合更新策略评估
本节考虑用回合更新的方法学习给定策略的价值函数.我们知道,状态价值和动作价值分别是在给定状态和状态动作对的情况下回报的期望值.回合更新策略评估的基本思路使用 Monte Carlo 方法来估计这个期望值.具体而言,在许多轨迹样本中,如果某个状态(或状态动作对) 出现了 次,其对应的回报值分别为 ,那么可以估计其状态价 (或动作价值) 为 .
无模型策略评估算法有评估状态价值函数和评估动作价值函数两种版本.在有模型情况下,状态价值和动作价值可以互相表示;但是在无模型的情况下,状态价值和动作价值并不能互相表示.我们已经知道,任意策略的价值函数满足 Bellman 期望方程.借助于动力 (某个状态转移分布)的表达式,我们可以用状态价值函数表示动作价值函数;借助于策略 的表达式,我们可以用动作价值函数表示状态价值函数.所以,对于无模型的策略评估, 的表达式未知,只能用动作价值表示状态价值,而不能用状态价值表示动作价值.另外,由于策略改进可以仅由动作价值函数确定,因此在学习问题中,动作价值函数往往更加重要.
在同一个回合中,多个步骤可能会到达同一个状态 (或状态动作对),即同一状态(或状态动作对)可能会被多次访问.对于不同次的访问,计算得到的回报样本值很可能不相 同.如果采用回合内全部的回报样本值更新价值函数, 则称为每次访问回合更新(every visit Monte Carlo update); 如果每个回合只采用第一次访问的回报样本更新价值函数,则称为首次访问回合更新( first visit Monte Carlo update).每次访问和首次访问在学习过程中的中间值并不相同,但是它们都能收敛到真实的价值函数.
首先来看每次访问回合更新策略评估算法.算法 2-1 给出了每次访问更新求动作价值的算法.我们来逐步看一下算法 2-1 .算法 2-1 首先对动作价值 进行初始化. 可以初始化为任意的值,因为在第一次更新后 的值就和初始化的值没有关系,所以将 初始化为什么数无关紧要.接着,算法 2-1 进行回合更新.与有模型迭代更新的情形类似,这里可以用参数来控制回合更新的回合数.例如,可以使用最大回合数 或者精度指标 .在生成好轨迹后,算法 2-1 采用逆序的方式更新 .这里采用逆序是为了使用 这一关系来更新 值,以减小计算复杂度.
算法 2-1:每次访问回合更新评估策略的动作价值
输入:环境(无数学描述),策略 输出:动作价值函数
- (初始化) 初始化动作价值估计 任意值, ,若更新价值需要使用计数 器,则初始化计数器 。
- (回合更新) 对于每个回合执行以下操作 2.1 (采样) 用策略 生成轨迹 2.2 (初始化回报) 2.3 (逐步更新)对 执行以下步骤 1. (更新回报) 2. (更新动作价值)更新 以减小 (如 , .
算法 2-1 在更新动作价值时,可以采用增量法来实现 Monte Carlo 方法.增量法的原理如下:如前 次观察到的回报样本是 ,则前 次价值函数的估计值为 ;如果第 次的回报样本是 ,则前 次价值函数的估计值为 可以证明, .所以,只要知道出现的次数 ,就可以用新的观测 把旧的平均值 更新为新的平均值 .因此,增量法不仅需要记录当前的价值估计 还需要记录状态动作对出现的次数 .在算法 2-1 中,状态动作对 的出现次数记录在 里,每次更新时将计数值加 1,再更新平均值 ,这样就实现了增量法.
求得动作价值后,可以用 Bellman 期望方程求得状态价值.状态价值也可以直接用回合更新的方法得到.算法 2-2 给出了每次访问回合更新评估策略的状态价值的算法.它与算法 2-1 的区别在于将 替换为了 ,计数也相应做了修改.
算法 4-2: 每次访问回合更新评估策略的状态价值
输入: 环境(无数学描述),策略 输出:状态价值函数
- (初始化)初始化状态价值估计 任意值, ,若更新价值时需要使用计数器则更新初始化计数器
- (回合更新)对于每个回合执行以下操作
2.1 (采样)用策略 生成轨迹
2.2 (初始化回报) 。
2.3 (逐步更新) 对 执行以下步骤 :
- (更新回报)
- (更新状态价值)更新 以减小 如 ,
首次访问回合更新策略评估是比每次访问回合更新策略评估更为历史悠久、更为全面研究的算法.算法 2-3 给出了首次访问回合更新求动作价值的算法.这个算法和算法 2-1 的区别在于,在每次得到轨迹样本后,先找出各状态分别在哪些步骤被首次访问.在后续的更新过程中,只在那些首次访问的步骤更新价值函数的估计值.
算法 2-3:首次访问回合更新评估策略的动作价值
输入: 环境(无数学描述),策略 输出:动作价值函数 .
- (初始化)初始化动作价值估计 任意值, ,若更新动作价值时需要计数器,则初始化计数器 .
- (回合更新)对于每个回合执行以下操作
2.1 (采样)用策略 生成轨迹
2.2 (初始化回报)
2.3 (初始化首次出现的步骤数)
2.4 (统计首次出现的步骤数)对于 ,执行以下步骤:如果 ,则
2.5 (逐步更新)对 ,执行以下步骤:
- (更新回报)
- (首次出现则更新)如果 ,则更新 以减小 如.
与每次访问的情形类似,首次访问也可以直接估计状态价值,见算法 2-4 .当然也可借助 Bellman 期望方程用动作价值求得状态价值.
算法 2-4:首次访问回合更新评估策略的状态价值
输入:环境(无数学描述),策略 输出:状态价值函数
- (初始化)初始化状态价值估计 任意值, ,若更新价值时需要使用计数器,更新初始化计数器
- (回合更新)对于每个回合执行以下操作
2.1 (采样)用策略 生成轨迹
2.2 (初始化回报)
2.3 (初始化首次出现的步骤数)
2.4 (统计首次出现的步骤数)对于 ,执行以下步骤:如果 ,则
2.5 (逐步更新)对 ,执行以下步骤 :
- (更新回报)
- (首次出现则更新)如果 ,则更新 以减小 如 ,.
TODO:起始探索与柔性策略
2.2 异策回合更新
本节考虑异策回合更新.异策算法允许生成轨迹的策略和正在被评估或被优化的策路不是同一策略.我们将引人异策算法中一个非常重要的概念——重要性采样,并用其进行 策略评估和求解最优策略.
2.2.1 重要性采样
在统计学上,重要性采样(importance sampling)是一种用一个分布生成的样本来估计另一个分布的统计量的方法.在异策学习中,将要学习的策略 称为目标策略(target policy),将用来生成行为的另一策略 称为行为策略(behavior policy ).重要性采样可以用行为策略生成的轨迹样本生成目标策略的统计量.
现在考虑从 开始的轨迹 .在给定 的条件下,采用 策略 和策略 生成这个轨迹的概率分别为: 我们把这两个概率的比值定义为重要性采样比率 (importance sample ratio): 这个比率只与轨迹和策略有关,而与动力无关.为了让这个比率对不同的轨迹总是有意义,我们需要使得任何满足 的 ,均有 这样的关系可以记为.
对于给定状态动作对 的条件概率也有类似的分析.在给定 的条件下,采用策略 和策略 生成这个轨迹的概率分别为: 其概率的比值为 回合更新总是使用 Monte Carlo 估计价值函数的值.同策回合更新得到 个回报 后,用平均值 来作为价值函数的估计.这样的方法实际上默认了这 个回报是等概率出现的.类似的是,异策回合更新用行为策略 得到 个回报 ,这个回报值对于行为策略 是等概率出现的.但是这 个回报值对于目标策略 不是等概率出现的.对于目标策略 而言,这 个回报值出现的概率正是各轨迹的重要性采样比率.这样,我们可以用加权平均来完成 Monte Carlo 估计.具体而言,若 是回报样本 对应的权重(即轨迹的重要性采样比率),可以有以下两种加权方法.
- 加权重要性采样(weighted importance sampling ), 即
- 普通重要性采样(ordinary importance sampling), 即
这两种方法的区别在于分母部分.对于加权重要性采样,如果某个权重 ,那么它不会让对应的 参与平均,并不影响整体的平均值;对于普通重要性采样,如果某个权重 ,那么它会让 0 参与平均,使得平均值变小.无论是加权重要性采样还是普通重要性采样,当回报样本数增加时,仍然可以用增量法将旧的加权平均值更新为新的加权平均值.对于加权重要性采样,需要将计数值替换为权重的和,以 的形式作更新.对于普通重要性采样而言,实际上就是对 加以平均,与直接没有加权情况下对 加以平均没有本质区别.它的更新形式为 :
2.2.2 异策回合更新策略评估
基于 2.2.1 节给出的重要性采样,算法 2-7 给出了每次访问加权重要性采样回合更新策略评估算法.这个算法在初始化环节初始化了权重和 与动作价值 ,然后进行回合更新.回合更新需要借助行为策略 .行为策略 可以每个回合都单独设计,也可以为整个算法设计一个行为策略,而在所有回合都使用同一个行为策略.用行为策略生成轨迹样本后,逆序更新回报、价值函数和权重值.一开始权重值 设为 1 ,以后会越来越小.如果某次权重值变为 0 (这往往是因为 ,那么以 后的权重值就都为 0 ,再循环下去没有意义.所以这里设计了一个检查机制.事实上,这个检查机制保证了在更新 时权重和 是必需的.如果没有检查机制,则可能在更新 时,更新前和更新后的 值都是 0 ,进而在更新 时出现除零错误.加这个检查机制避免了这样的错误.
算法 2-7: 每次访问加权重要性采样异策回合更新评估策略的动作价值
- (初始化)初始化动作价值估计 任意值, ,如果需要使用权重和,则初始化权重和
- (回合更新)对每个回合执行以下操作
2.1 (行为策略)指定行为策略 ,使得
2.2 (采样)用策略 生成轨迹:
2.3 (初始化回报和权重)
2.4 对于 执行以下操作:
- (更新回报)
- (更新价值)更新 以减小 如 ,
- (更新权重)
- (提前终止)如果 ,则结東步骤 2.4 的循环
在算法 2-7 的基础上略作修改,可以得到首次访问的算法、普通重要性采样的算法和估计状态价值的算法,此处略过.
2.2.3 异策回合更新最优策略求解
接下来介绍最优策略的求解.算法 2-8 给出了每次访问加权重要性采样异策回合最优策略求解算法.它和其他最优策略求解算法一样,都是在策略估计算法的基础上加上策略改进得来的.算法 2-8 的迭代过程中,始终让 是一个确定性策略.所以,在回合更新的过程中,任选一个策略 都满足 .这个柔性策略可以每个回合都分别选取,也可以整个程序共用一个.由于采用了确定性的策略,则对于每个状态 都有一个 使得 ,而其他 .算法 2-8 利用这一性质来更新权重并判断权重是否为 0 .如果 ,则意味着 ,更新后的权重为 0 ,需要退出循环以避免除零错误;若 ,则意味着 ,所以权重更新语句 就可以简化为 .
算法 2-8: 每次访问加权重要性采样异策回合更新最优策略求解
- (初始化)初始化动作价值估计 任意值, ,如果需要使用权重和,初始化权重和
- (回合更新)对每个回合执行以下操作
2.1 (柔性策略)指定 为任意柔性策略
2.2 (采样)用策略 生成轨迹:
2.3 (初始化回报和权重)
2.4 对
- (更新回报)
- (更新价值)更新 以减小 如 ,
- (策略更新)
- (提前终止)若 则退出步骤 2.4
- (更新权重)
算法 2-8 也可以修改得到首次访问的算法和普通重要性采样的算法,此处略过.
三. 时序差分价值迭代
本章介绍另外一种学习方法一时序差分更新.时序差分更新和回合更新都是直接采用经验数据进行学习,而不需要环境模型.时序差分更新与回合更新的区别在于,时序差 分更新汲取了动态规划方法中"自益"的思想,用现有的价值估计值来更新价值估计,不需要等到回合结束也可以更新价值估计.所以,时序差分更新既可以用于回合制任务,也可以用于连续性任务.
本章将介绍时序差分更新方法,包括同策时序差分更新方法和异策时序差分更新方法, 每种方法都先介绍简单的单步更新,再介绍多步更新.最后,本章会涉及基于资格迹的学习算法.
3.1 同策时序差分更新
本节考虑无模型同策时序差分更新.与无模型回合更新的情况相同,在无模型的情况下动作价值比状态价值更为重要,因为动作价值能够决定策略和状态价值,但是状态价值得不到动作价值.
本节考虑无模型同策时序差分更新。与无模型回合更新的情况相同,在无模型的情况下动作价值比状态价值更为重要,因为动作价值能够决定策略和状态价值,但是状态价值得不到动作价值。 从给定策略 的情况下动作价值的定义出发,我们可以得到下式: 在上一章的回合更新学习中,我们依据 ,用 Monte Carlo 方法来估计价值函数.为了得到回报样本,我们要从状态动作对 出发一直采样到回合结束.单步时序差分更新将依据 ,只需要采样一步,进而用 ,来估计回报样本的值.为了与由奖励直接计算得到的无偏回报样本 进行区别,本书用字母 表示使用自益得到的有偏回报样本.
基于以上分析,我们可以定义时序差分目标.时序差分目标可以针对动作价值定义,也可以针对状态价值定义.对于动作价值,其单步时序差分目标定义为 其中 的上标 表示是对动作价值定义的,下标 表示用 的估计值来估计 .如果 是终止状态,默认有 .这样的时序差分目标可以进一步扩展到多步的情况. n 步时序差分目标 定义为 在不强调步数的情况下, 可以简记为 或 .对于回合制任务,如果回合的步数 ,则我们可以强制让 这样,上述时序差分目标的定义式依然成立,实际上 达到了 的效果。本书后文都做这样的假设。类似的是,对于 状态价值,定义 步时序差分目标为 它也可以简记为 或 .
3.1.1 时序差分更新策略评估
本节考虑利用时序差分目标来评估给定策略的价值函数.回顾在同策回合更新策略评估中,我们用形如 的增量更新来学习动作价值函数,试图减小 .在这个式子中, 是回报样本.在时序差分中,这个量就对应着 .因此,只需在回合更新策略评估算法的基础上,将这个增量更新式中的回报 替换为时序差分目标 ,就可以得到时序差分策略评估算法了.
时序差分目标既可以是单步时序差分目标,也可以是多步时序差分目标.我们先来看单步时序差分目标.
算法 3-1 给出了用单步时序差分更新评估策略的动作价值的算法.这个算法有一个 ,它是一个正实数,表示学习率.在上一章的回合更新中,这个学习率往往是 ,它和状态动作对有关,并且不断减小.在时序差分更新中,也可以采用这样不断减小的学习率.不过,考虑到在时序差分算法执行的过程中价值函数会越来越准确,进而基于价值函数估计得到的价值函数也会越来越准确,因此估计值的权重可以越来越大.所以,算法 3-1 采用了一个固定的学习率 .这个学习率一般在 .当然,学习率也可以不是常数.在有些问题中,让学习率巧妙地变化能得到更好的效果.引入学习率 后,更新式可以表示为:
算法 3-1: 单步时序差分更新评估策略的动作价值
输入: 环境(无数学描述)、策略 输出:动作价值函数 参数:优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, .如果有终止状态,令 .
- (时序差分更新)对每个回合执行以下操作
2.1 (初始化状态动作对)选择状态 ,再根据输入策略 确定动作
2.2 如果回合未结東(例如未达到最大步数、S不是终止状态), 执行以下操作:
- (采样)执行动作 ,观测得到奖励 和新状态
- 用输入策略 确定动作
- (计算回报的估计值)
- (更新价值)更新 以减小 如
- .
在具体的更新过程中,除了学习率 和折扣因子 外,还有控制回合数和每个回合步数的参数.我们知道,时序差分更新不仅可以用于回合制任务,也可以用于非回合制任务.对于非回合制任务,我们可以自行将某些时段抽出来当作多个回合,也可以不划分回合当作只有一个回合进行更新.类似地,算法 3-2 给出了用单步时序差分方法评估策略状态价值的算法.
算法 3-2 单步时序差分更新评估策略的状态价值
输入:环境(无数学描述)、策略 输出:状态价值函数 参数:优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化) 任意值, .如果有终止状态,
- (时序差分更新)对每个回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结東(例如未达到最大步数、S不是终止状态),执行以下操作:
- 根据输入策略 确定动作
- (采样)执行动作 ,观测得到奖励 和新状态
- (计算回报的估计值)
- (更新价值)更新 以减小 如
在无模型的情况下,用回合更新和时序差分更新来评估策略都能渐近得到真实的价值函数.它们各有优劣.目前并没有证明某种方法就比另外一种方法更好.根据经验,学习 率为常数的时序差分更新常常比学习率为常数的回合更新更快收敛.不过时序差分更新对环境的 Markov 性要求更高.
我们通过一个例子来比较回合更新和时序差分更新.考虑某个 Markov 奖励过程,我们得到了它的 5 个轨迹样本如下(只显示状态和奖励): 使用回合更新得到的状态价值估计值为 ,而使用时序差分更新得到的状态价值估计值为 .这两种方法对 的估计是一样的,但是对于 的估计有明显不同:回合更新只考虑其中两个含有 的轨迹样本,用这两个轨迹样本回报来估计状态价值;时序差分更新认为状态 下一步肯定会到达状态 ,所以可以利用全部轨迹样本来估计 ,进而由 推出 .试想,如果这个环境真的是 Markov 决策过程,并且我们正确地识别出了状态空间 ,那么时序差分更新方法可以用更多的轨迹样本来帮助估计 的状态价值,这样可以更好地利用现有的样本得到更精确的估计.但是,如果这个环境其实并不是 Markov 决策过程,或是 并不是其真正的状态空间.那么也有可能 之后获得的奖励值其实和这个轨迹是否到达过 有关,例如如果达到过 则奖励总是为 0 .这种情况下,回合更新能够不受到这一错误的影响,只采用正确的信息,从而不受无关信息的干扰,得到正确的估计.这个例子比较了回合更新和时序差分更新的部分利弊。
接下来看如何用多步时序差分目标来评估策略价值.算法 3-3 和算法 3-4 分别给出了用多步时序差分评估动作价值和状态价值的算法.实际实现时,可以让 和 共享同一存储空间,这样只需要 份存储空间.
算法 3-3 步时序差分更新评估策略的动作价值
输入:环境(无数学描述)、策略 输出:动作价值估计 参数:步数 ,优化器 (隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化) 任意值 .如果有终止状态,令
- (时序差分更新)对每个回合执行以下操作
2.1 (生成 n 步)用策略 生成轨迹 (若遇到终止状态,则令后续奖励均为0,状态均为
2.2 对于 依次执行以下操作,直到 :
- 若 ,则根据 决定动作
- (更新时序差分目标)
- (更新价值)更新 以减小
- 若 ,则执行 ,得到奖励 和下一状态 ;若 ,
算法 3-4 步时序差分更新评估策略的状态价值
输入: 环境(无数学描述)、策略 输出:状态价值估计 参数:步数 ,优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化) 任意值, 如果有终止状态,令
- (时序差分更新) 对每个回合执行以下操作
2.1(生成 步)用策略 生成轨迹 (若遇到终止状态,则令后续奖励均为 0 ,状态均为 ).
2.2 对于 依次执行以下操作,直到 :
- (更新时序差分目标 )
- (更新价值)更新 以减小
- 若 ,则根据 决定动作 并执行,得到奖励 和下一状态 ;若 ,令 .
3.1.2 SARSA算法
本节我们采用同策时序差分更新来求解最优策略.首先我们来看 “状态 / 动作 / 奖励 状态 / 动作”(State-Action-Reward-State-Action, SARSA)算法.这个算法得名于更新涉及的随机变量 .该算法利用 得到单步时序差分目标 ,进而更新 .该算法的更新式为: 其中 是学习率.算法 3-5 给出了用 SARSA 算法求解最优策略的算法.SARSA 算法就是在单步动作价值估计的算法的基础上,在更新价值估计后更新策略.在算法 3-5 中,每当最优动作价值函数的估计 更新时,就进行策略改进,修改最优策略的估计 .策略的提升方法可以采用 贪心算法,使得 总是柔性策略.更新结束后,就得到最优动作价值估计和最优策略估计.
算法 3-5 SARSA 算法求解最优策略(显式更新策略)
与 Q-learning 区别在于,SARSA 每次算得的 在下一步会使用,也就是这一步通过 Q 函数预测得到的下一步采取的动作 也是在下一步更新时真正使用的,而 Q-learning 在下一步更新时的 是重新算的(用这一步更新后的 Q 函数算得)
输入:环境(无数学描述) 输出:最优策略估计 和最优动作价值估计 参数:优化器(隐含学习率 ),折扣因子 ,策略改进的参数(如 ),其他控制回合数和回合步数的参数
- (初始化) 任意值, .如果有终止状态,令 .用动作价值 确定策略 如使用 贪心策略
- (时序差分更新)对每个回合执行以下操作
2.1 (初始化状态动作对)选择状态 ,再用策略 确定动作
2.2 如果回合未结東(比如未达到最大步数、 不是终止状态),执行以下操作:
- (采样)执行动作 ,观测得到奖励 和新状态
- 用策略 确定动作
- (计算回报的估计值)
- (更新价值)更新 以减小 如
- (策略改进)根据 修改 如 贪心策略
其实,在同策迭代的过程中,最优策略也可以不显式存储.另外多步 SARSA 此处省略.
3.1.3 期望SARSA算法
SARSA 算法有一种变化一一期望 SARSA 算法(Expected SARSA).期望 SARSA算法与 SARSA 算法的不同之处在于,它在估计 时,不使用基于动作价值的时序差分目标 ,而使用基于状态价值的时序差分目标 .利用 Bellman 方程,这样的目标又可以表示为 与 SARSA 算法相比,期望 SARSA 需要计算 ,所以计算量比 SARSA 大.但是,这样的期望运算减小了 SARSA 算法中出现的个别不恰当决策.这样,可以避免在更新后期极个别不当决策对最终效果带来不好的影响.因此,期望 SARSA 常常有比 SARSA 更大的学习率.在很多情况下,期望 SARSA 的效果会比 SARSA 稍微好一些.
算法 3-6 给出了期望 SARSA 求解最优策略的算法,它可以视作在单步时序差分状态价值估计算法上修改得到的.期望 SARSA 对回合数和回合内步数的控制方法等都和 SARSA 相同,但是由于期望 SARSA 在更新 时不需要 ,所以其循环结构有所简化.算法中让 保持为 柔性策略.如果 很小,那么这个 柔性策略就很接近于确定性策略,则期望 SARSA 计算的 就很接近于 .
算法 3-6 期望 SARSA 求解最优策略
- (初始化) 任意值, .如果有终止状态,令 .用动作价值 确定策略 (如使用 贪心策略)
- (时序差分更新)对每个回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结東(比如未达到最大步数、S不是终止状态),执行以下操作:
- 用动作价值 确定的策略(如 贪心策略)确定动作
- (采样)执行动作 ,观测得到奖励 和新状态
- (用期望计算回报的估计值)
- (更新价值)更新 以减小 (如
3.2 异策时序差分更新
本节介绍异策时序差分更新.异策时序差分更新是比同策差分更新更加流行的算法.特别是 Q 学习算法,已经成为最重要的基础算法之一.
3.2.1 基于重要性采样的异策算法
时序差分策略评估也可以与重要性采样结合,进行异策的策略评估和最优策略求解.对于 步时序差分评估策略的动作价值和 SARSA 算法,其时序差分目标 依赖于轨迹 .在给定 的情况下,采用策略 和另外的行为策略 生成这个轨迹的概率分别为: 它们的比值就是重要性采样比率: 也就是说,通过行为策略 拿到的估计,在原策略 出现的概率是在策略 中出现概率的 倍.所以,在学习过程中,这样的时序差分目标的权重为 .将这个权重整合到时序差分策略评估动作价值算法或 SARSA算法中,就可以得到它们的重要性采样的版本.算法 3-7 给出了多步时序差分的版本,单步版本请自行整理.
算法 3-7: 步时序差分策略评估动作价值或 SARSA 算法
输入:环境(无数学描述)、策略 输出:动作价值函数 ,若是最优策略控制则还要输出策略 参数:步数 ,优化器 (隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化) 任意值, .如果有终止状态,令 .若是最优策略控制,还应该用 决定 (如 贪心策略)
- (时序差分更新)对每个回合执行以下操作
2.1 (行为策略)指定行为策略 ,使得
2.2 (生成 步)用策略 生成轨迹 (若遇到终止状态,则令后续奖励均为 0 , 状态均为 )
2.3 对于 依次执行以下操作,直到 :
- 若 ,则根据 决定动作
- (更新时序差分目标 )
- (计算重要性采样比率 )
- (更新价值)更新 以减小
- (更新策略)如果是最优策略求解算法,需要根据 修改
- 若 ,则执行 ,得到奖励 和下一状态 ;若 ,则令 .
我们可以用类似的方法将重要性采样运用于时序差分状态价值估计和期望 SARSA 算法中.具体而言,考虑从 开始的 步轨迹 .在给定 的条件下,采用策略 和策略 生成这个轨迹的概率分别为: 它们的比值就是时序差分状态评估和期望 SARSA 算法用到的重要性采样比率:
3.2.2 Q学习
3.1.3 节的期望 SARSA 算法将时序差分目标从 SARSA 算法的 改为 ,从而避免了偶尔出现的不当行为给整体结果带来的负面影响. Q 学习则是从改进后策略的行为出发,将时序差分目标改为 Q 学习算法认为,在根据 估计 时,与其使用 或 ,还不如使用根据 改进后的策略来更新,毕竟这样可以更接近最优价值.因此 Q 学习的更新式不是基于当前的策略,而是基于另外一个并不一定要使用的确定性策略来更新动作价值.从这个意义上看,Q 学习是一个异策算法.算法 3-8 给出了 Q 学习算法.Q 学习算法和期望 SARSA 有完全相同的程序结构,只是在更新最优动作价值的估计 时使用了不同的方法来计算目标.
算法 3-8: Q 学习算法求解最优策略
- (初始化) 任意值, .如果有终止状态,令
- (时序差分更新)对每个回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结東(例如未达到最大步数、S不是终止状态),执行以下操作:
- 用动作价值估计 确定的策略决定动作 如 贪心策略
- (采样)执行动作 ,观测得到奖励 和新状态
- (用改进后的策略计算回报的估计值)
- (更新价值和策略)更新 以减小 如
当然,Q学习也有多步的版本,其目标为: 具体省略
3.2.3 双重Q学习
上一节介绍的 Q 学习用 来更新动作价值,会导致“最大化偏差 (maximization bias),使得估计的动作价值偏大.
我们来看一个最大化偏差的例子.下所示的回合制任务中,Markov决策过程的状态空间为 ,回合开始时总是处在 状态,可以选择的动作空间 .如果选择动作 ,则可以到达状态 ,该步奖励为 0 ;如果选择动作 ,则可以达到终止状态并获得奖励 .从状态 出发,有很多可选的动作(例如有 1000 个可选的动作),但是这些动作都指向终止状态,并且奖励都服从均值为 0 、方差为 100 的正态分布.从理论上说,这个例子的最优价值函数为: , ,最优策略应当是 .但是,如果采用 Q 学习,在中间过程中会走一些弯路:在学习过程中,从 出发的某些动作会采样到比较大的奖励值,从而导致 会比较大,使得从 .这样的错误需要大量的数据才能纠正.为了解决这一问题,双重 Q 学习 ( Double Q Learning)算法使用两个独立的动作价值估计值 和 ,用 或 来 代替 Q 学习中的 .由于 和 是相互独立的估计,所以 ,其中 ,这样就消除了偏差.在双重学习的过程中, 和 都需要逐渐更新.所以,每步学习可以等概率选择以下两个更新 中的任意一个:
- 使用 来更新 以减小 和 之间的差别 (例如设定损失为 ,或采用 更新
- 使用 来更新 ,以减小 和 之间的差别 (例如设定损失为 ,或采用 更新
算法 3-9 给出了双重 Q 学习求解最优策略的算法.这个算法中最终输出的动作价值函数是 和 的平均值,即 .在算法的中间步骤,我们用这两个估计的和 来代替平均值 ,在略微简化的计算下也可以达到相同的效果.
算法 3-9: 双重 Q 学习算法求解最优策略
- (初始化) 任意值, .如果有终止状态,则令
- (时序差分更新)对每个回合执行以下操作.
2.1 (初始化状态)选择状态
2.2 如果回合未结束(比如未达到最大步数、 不是终止状态),执行以下操作:
- 用动作价值 确定的策略决定动作 (如 贪心策略)
- (采样)执行动作 ,观测得到奖励 和新状态
- (随机选择更新 或 )以等概率选择 或 中的一个动作价值函数作为更新对象,记选择的是
- (用改进后的策略更新回报的估计)
- (更新动作价值)更新 以减小 如
3.3 资格迹
资格迹是一种让时序差分学习更加有效的机制.它能在回合更新和单步时序差分更新之间折中,并且实现简单,运行有效.
3.3.1 回报
在正式介绍资格迹之前,我们先来学习 回报和基于 回报的离线 回报算法.给定 , 回报 return 是时序差分目标 按 加权平均的结果.对于连续性任务,有 对于回合制任务,则有 回报 可以看作是回合更新中的目标 和单步时序差分目标 的推广:当 时, 就是回合更新的回报;当 时, 就是单步时序差分目标.
离线 回报算法( offline -return algorithm )则是在更新价值(如动作价值 或状态价值 时,用 作为目标,试图减小 或 .它与回合更新算法相比,只是将更新的目标从 换为了 .对于回合制任务,在回合结束后为每一步 计算 ,并统一更新价值.因此,这样的算法称为离线算法( offline algorithm ).对于连续性任务,没有办法计算 ,所以无法使用离线 算法.
由于离线 回报算法使用的目标在 和 间做了折中,所以离线 回报算法的效果可能比回合更新和单步时序差分更新都要好.但是,离线 回报算法也有明显的缺点: 其一,它只能用于回合制任务,不能用于连续性任务;其二,在回合结束后要计算 ,计算量巨大.在下一节我们将采用资格迹来弥补这两个缺点.
3.3.2 TD()
TD () 是历史上具有重要影响力的强化学习算法,在离线 回报算法的基础上改进而来.以基于动作价值的算法为例,在离线 回报算法中,对任意的 ,在更新 或 时,时序差分目标 的权重是 .虽然需要等到回合结束才能计算 ,但是在知道 后就能计算 .所以我们在知道 后,就可 以用 去更新所有的 ,并且更新的权重与 成正比.
据此,给定轨迹 ,可以引入资格迹 来表示第 步的状态动作对 的单步自益结果 对每个状态动作对 需要更新的权重.资格迹(eligibility)用下列递推式定义:当 时, 当 时, 其中 是事先给定的参数.资格迹的表达式应该这么理解:对于历史上的某个状念动作对 ,距离第 步间隔了 步, 在 回报 中的权重为 ,并且 ,所以 是以 的比率折算到 中.间隔的步数每增加一步,原先的资格迹大致需要衰减为 倍.对当前最新出现的状态动作对 ,大的更新权重则要进行某种强化.强化的强度 常有以下取值:
- , 这时的资格迹称为累积迹(accumulating trace)
- (其中 是学习率),这时的资格迹称为荷兰迹(dutch trace)
- ,这时的资格迹称为替换迹(replacing trace).
当 时,直接将其资格迹加 1 ;当 时,资格迹总是取值在 范围内,所以让其资格迹直接等于 1 也实现了增加,只是增加的幅度没有 时那么大;当 时,增加的幅度在 和 之间.

利用资格迹,可以得到 策略评估算法.算法 3-10 给出了用 评估动作价值的算法.它是在单步时序差分的基础上,加入资格迹来实现的.资格迹也可以和最优策略求解算法结合,例如和 算法结合得到 算法.算法 3-10 中如果没有策略输入,在选择动作时按照当前动作价值来选择最优动作,就是 算法.
算法 3-10 的动作价值评估或 学习
输入:环境(无数学描述),若评估动作价值则需输入策略 . 输出:动作价值估计 参数:资格迹参数 ,优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化)初始化价值估计 任意值, .如果有终止状态,令
- 对每个回合执行以下操作:
2.1 (初始化资格迹)
2.2 (初始化状态动作对)选择状态 ,再根据输入策略 确定动作
2.3 如果回合未结東(比如未达到最大步数、S不是终止状态),执行以下操作:
- (采样)执行动作 ,观测得到奖励 和新状态
- 根据输入策略 或是迭代的最优价值函数 确定动作
- (更新资格迹)
- (计算回报的估计值)
- (更新价值)
- 若 ,则退出 2.2 步;否则 .
资格迹也可以用于状态价值.给定轨迹 ,资格迹 来表示第 步的状态动作对 对的单步自益结果 对每个状态 需要更新的权重,其定义为:当 时, 当 时, 算法 3-11 给出了用资格迹评估策略状态价值的算法.
算法 5-14 更新评估策略的状态价值
输入:环境(无数学描述)、策略 输出:状态价值函数 参数:资格迹参数 ,优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化)初始化价值 任意值, .如果有终止状态,
- 对每个回合执行以下操作:
2.1 (初始化资格迹)
2.2 (初始化状态)选择状态 S.
2.3 如果回合未结東(比如未达到最大步数、 不是终止状态),执行以下操作:
- 根据输入策略 确定动作
- (采样)执行动作 ,观测得到奖励 和新状态
- (更新资格迹)
- (计算回报的估计值)
- (更新价值)
算法与离线 回报算法相比,具有三大优点:
- 算法既可以用于回合制任务,又可以用于连续性任务
- 算法在每一步都更新价值估计,能够及时反映变化
- 算法在每一步都有均匀的计算,而且计算量都较小
四. 函数近似方法
第 章中介绍的有模型数值迭代算法、回合更新算法和时序差分更新算法,在每次更新价值函数时都只更新某个状态(或状态动作对)下的价值估计.但是,在有些任务中,状态和动作的数目非常大,甚至可能是无穷大,这时,不可能对所有的状态 (或状态动作对) 逐一进行更新.函数近似方法用参数化的模型来近似整个状态价值函数(或动作价值函数),并在每次学习时更新整个函数.这样,那些没有被访问过的状态(或状态动作对)的价值估计也能得到更新.本章将介绍函数近似方法的一般理论,包括策略评估和最优策略求解的一般理论.再介绍两种最常见的近似函数:线性函数和人工神经网络.后者将深度学习和强化学习相结合,称为深度 Q 学习,是第一个深度强化学习算法,也是目前的热门算法.
4.1 函数近似原理
本节介绍用函数近似(function approximation)方法来估计给定策略 的状态价值函数 或动作价值函数 .要评估状态价值,我们可以用一个参数为 的函数 来近似状态价值;要评估动作价值,我们可以用一个参数为 的函数 来近似动作价值.在动作集 有限的情况下,还可以用一个矢量函数一个动作,而整个矢量函数除参数外只用状态作为输人.这里的函数 、 形式不限,可以是线性函数,也可以是神经网络.但是,它们的形式要事先给定,在学习过程中只更新参数 .一旦参数 完全确定,价值估计就完全给定.所以,本节将介绍如何更新参数 .更新参数的方法既可以用于策略价值评估,也可以用于最优策略求解.
4.1.1 随机梯度下降
本节来看同策回合更新价值估计.将同策回合更新价值估计与函数近似方法相结合,可以得到函数近似回合更新价值估计算法(算法 4-1 ).这个算法与第 2 章中回合更新算法的区别就是在价值更新时更新的对象是函数参数,而不是每个状态或状态动作对的价值估计.
算法 6-1: 随机梯度下降函数近似评估策略的价值
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (采样)用环境和策略 生成轨迹样本
2.2 (初始化回报)
2.3 (逐步更新)对 ,执行以下步骤
- (更新回报)
- (更新价值)若评估的是动作价值则更新 以减小 (如 若评估的是状态价值则更新 以减小 .
如果我们用算法 4-1 评估动作价值,则更新参数时应当试图减小每一步的回报估计 和动作价值估计 的差别.所以,可以定义每一步损失为 ,而整个回合的损失为 .如果我们沿着 对 的梯度的反方向更新策略参数 ,就有机会减小损失.这样的方法称为随机梯度下降( stochastic gradient-descent, SGD )算法.对于能支持自动梯度计算的软件包,往往自带根据损失函数更新参数的功能.如果不使用现成的参数更新软件包,也可以自己计算得到 的 梯度 ,然后利用下式进行更新 : 对于状态价值函数,也有类似的分析.定义每一步的损失为 ,整个回合的损失为 .可以在自动梯度计算并更新参数的软件包中定义这个损失来更新参数 , 也可以用下式更新: 相应的回合更新策略评估算法与算法 4-1 类似,此处从略.
将策略改进引入随机梯度下降评估策略,就能实现随机梯度下降最优策略求解.算法 4-2 给出了随机梯度下降最优策略求解的算法.它与第 2 章回合更新最优策略求解算法的区别也仅仅在于迭代的过程中不是直接修改价值估计,而是更新价值参数 .
算法 4-2: 随机梯度下降求最优策略
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (采样)用环境和当前动作价值估计 导出的策略(如 柔性策略)生成轨迹样
本
2.2 (初始化回报)
2.3 (逐步更新)对 ,执行以下步骤:
- (更新回报)
- (更新动作价值函数)更新参数 以减小 如 .
4.1.2 半梯度下降
动态规划和时序差分学习都用了“自益”来估计回报,回报的估计值与 有关,是存在偏差的.例如,对于单步更新时序差分估计的动作价值函数,回报的估计为 ,而动作价值的估计为 ,这两个估计都与权重 有关.在试图减小每一步的回报估计 和动作价值估计 的差别时,可以定义每一步损失为 ,而整个回合的损失为 .在更新参数 以减小损失时,应当注意不对回报的估计 求梯度,只对动作价值的估计 求关于 的梯度,这就是半梯度下降(semi-gradient descent)算法.半梯度下降算法同样既可以用于策略评估,也可以用于求解最优策略(见算法 4-3 和算法 4-4 ).
算法 4-3: 半梯度下降算法估计动作价值或 算法求最优策略
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (初始化状态动作对)选择状态 .如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,则用当前动作价值估计 导出的策略 如 柔性策略 确定动作
2.2 如果回合未结東,执行以下操作:
- (采样)执行动作 ,观测得到奖励 和新状态
- 如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,则用当前动作价值估计 导出的策略 如 柔性策略)确定动作
- (计算回报的估计值)
- (更新动作价值函数)更新参数 以减小 如 .注意此步不可以重新计算
算法 4-4: 半梯度下降估计状态价值或期望 SARSA 算法或 学习
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结束,执行以下操作
- 如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,则用当前动作价值估计 导出的策略(如 柔性策略)确定动作
- (采样)执行动作 ,观测得到奖励 和新状态
- (计算回报的估计值)如果是状态价值评估,则 .如果是期望 SARSA 算法,则 ,其中 是 确定的策略(如 柔性策略)若是 学习则
- (更新动作价值函数)若是状态价值评估则更新 以减小 (如 ,若是期望 算法或 学习则更新参数 以减小 如 .注意此步不可以重新计算
- .
如果采用能够自动计算微分并更新参数的软件包来减小损失,则务必注意不能对回报的估计求梯度.有些软件包可以阻止计算过程中梯度的传播,也可以在计算回报估计的表达式时使用阻止梯度传播的功能.还有一种方法是复制一份参数 ,在计算回报估计的表达式时用这份复制后的参数 来计算回报估计,而在自动微分时只对原来的参数进行微分,这样就可以避免对回报估计求梯度.
4.1.3 带资格迹的半梯度下降
在第 3 章中,我们学习了资格迹算法.资格迹可以在回合更新和单步时序差分更新之间进行折中,可能获得比回合更新或单步时序差分更新都更好的结果.回顾前文,在资格迹算法中,每个价值估计的数值都对应着一个资格迹参数,这个资格迹参数表示这个价值估计数值在更新中的权重.最近遇到的状态动作对(或状态)的权重大,比较久以前遇到的状态动作对(或状态)的权重小,从来没有遇到过的状态动作对(或状态)的权重为 0 .每次更新时,都可以更新整条轨迹上的资格迹,再利用资格迹作为权重,更新整条轨迹上的价值估计.
资格迹同样可以运用在函数近似算法中,实现回合更新和单步时序差分的折中.这时,资格迹对应价值参数 .具体而言,资格迹参数 和价值参数 具有相同的形状大小,并且逐元素一一对应.资格迹参数中的每个元素表示了在更新价值参数对应元素时应当使用的权重乘以价值估计对该分量的梯度.也就是说,在更新价值参数 的某个分量 对应着资格迹参数 中的某个分量 时,那么在更新 时应当使用以下迭代式更新: 对价值参数整体而言,就有 当选取资格迹为累积迹时,资格迹的递推定义式如下:当 时 当 时 资格迹的递推式由 2 项组成.递推式的第一项是对前一次更新时使用的资格迹衰减而来,衰减系数是 ,这是一个 0 到 1 之间的数.可以通过改变 的值,决定衰减的速度. 当 接近 0 时,衰减快;当 接近 1 时,衰减慢.递推式的第二项是加强项,它由动作价值的梯度值决定.动作价值的梯度值事实上确定了价值参数对总体价值估计的影响.对总体价值估计影响大的那些价值参数分量是当前比较重要的分量,应当加强它的资格迹.不过,梯度的分量值不一定是正数或 0 ,也可能是负数.所以,更新后的资格迹分量也可能是负值.当资格迹的某些分量是负值时,对应价值参数分量的权重值就是负值.进一步而言,在价值参数更新时,面对相同的时序差分误差,会出现价值参数的某些分量增大而另一些 分量减小的情况. 算法 4-5 和算法 4-6 给出了使用资格迹的价值估计和最优策略求解算法.这两个算法都 使用了累积迹.
算法 6-5 算法估计动作价值或 算法
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (初始化状态动作对)选择状态 如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,则用当前动作价值估计 导出的策略(如 柔性策略 确定动作
2.2 如果回合未结東,执行以下操作
- (采样)执行动作 ,观测得到奖励 和新状态
- 如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,用当前动作价值估计 导出的策略 如 柔性策略 确定动作 ;
- (计算回报的估计值)
- (更新资格迹)
- (更新动作价值函数)
- .
算法 4-6 TD(\lambda) 估计状态价值或期望 SARSA(\lambda) 算法或 学习
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (初始化资格迹)
2.2 (初始化状态)选择状态 S
2.3 如果回合未结束,执行以下操作
- 如果是策略评估,则用输入策略 确定动作 ;如果是寻找最优策略,用当前动作价值估计 导出的策略 如 柔性策略 确定动作
- (采样)执行动作 ,观测得到奖励 和新状态
- (计算回报的估计值)如果是状态价值评估,则 .如果是期望 SARSA 算法,则 ,其中 是 确定的策略 (如 柔性策略 .若是 学习则
- (更新资格迹)若是状态价值评估,则 ;若是期望 法或 学习,则
- (更新动作价值函数)若是状态价值评估,则 ;若是期望 算法或 学习,则
- .
TODO:线性近似
TODO:4.3函数近似的收敛性
4.4 深度Q学习
本节介绍一种目前非常热门的函数近似方法——深度 Q 学习.深度 Q 学习将深度学习和强化学习相结合,是第一个深度强化学习算法.深度 Q 学习的核心就是用一个人工神经网络 来代替动作价值函数.由于神经网络具有强大的表达能力,能够自动寻找特征,所以采用神经网络有潜力比传统人工特征强大得多.最近基于深度 Q 网络的深度强化学习算法有了重大的进展,在目前学术界有非常大的影响力.当同时出现异策、自益和函数近似时,无法保证收敛性,会出现训练不稳定或训练困难等问题.针对出现的各种问题,研究人员主要从以下两方面进行了改进.
- 经验回放(experience replay): 将经验(即历史的状态、动作、奖励等)存储起来,再在存储的经验中按一定的规则采样.
- 目标网络(target network): 修改网络的更新方式,例如不把刚学习到的网络权重马上用于后续的自益过程.
本节后续内容将从这两条主线出发,介绍基于深度 Q 网络的强化学习算法.
4.4.1 经验回放
V. Mnih 等在 2013 年发表文章《Playing Atari with deep reinforcement learning 》,提出了基于经验回放的深度 Q 网络,标志着深度 Q 网络的诞生,也标志着深度强化学习的诞生.在 4.2 节中我们知道,采用批处理的模式能够提供稳定性.经验回放就是一种让经验的概率分布变得稳定的技术,它能提高训练的稳定性.经验回放主要有“存储”和“采样回放”两大关键步骤.
- 存储:将轨迹以 等形式存储起来;
- 采样回放:使用某种规则从存储的 中随机取出一条或多条经验
算法 4-8 给出了带经验回放的 Q 学习最优策略求解算法
算法 6-8 带经验回放的 学习最优策略求解
- (初始化)任意初始化参数
- 逐回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结東,执行以下操作
- (采样)根据 选择动作 并执行,观测得到奖励 和新状态
- (存储)将经验 存入经验库中
- (回放)从经验库中选取经验
- (计算回报的估计值)
- (更新动作价值函数)更新 以减小 (如
经验回放有以下好处.
- 在训练 网络时,可以消除数据的关联,使得数据更像是独立同分布的(独立同分布是很多有监督学习的证明条件)这样可以减小参数更新的方差,加快收敛.
- 能够重复使用经验,对于数据获取困难的情况尤其有用.
从存储的角度,经验回放可以分为集中式回放和分布式回放.
- 集中式回放:智能体在一个环境中运行,把经验统一存储在经验池中.
- 分布式回放:智能体的多份拷贝(worker) 同时在多个环境中运行,并将经验统一存储于经验池中.由于多个智能体拷贝同时生成经验,所以能够在使用更多资源的同 时更快地收集经验
从采样的角度,经验回放可以分为均匀回放和优先回放.
- 均匀回放:等概率从经验集中取经验,并且用取得的经验来更新最优价值函数
- 优先回放(Prioritized Experience Replay, PER):为经验池里的每个经验指定一个优先级,在选取经验时更倾向于选择优先级高的经验.
T. Schaul 等于 2016 年发表文章 《Prioritized experience replay》,提出了优先回放.优先回放的基本思想是为经验池里的经验指定一个优先级,在选取经验时更倾向于选择优先级高的经验.一般的做法是,如果某个经验(例如经验 )的优先级为 ,那么选取该经验的概率为 经验值有许多不同的选取方法,最常见的选取方法有成比例优先和基于排序优先.
- 成比例优先(proportional priority):第 个经验的优先级为 .其中 是时序差分误差 定义为 或 是预先选择 的一个小正数, 是正参数.
- 基于排序优先(rank-based priority): 第 个经验的优先级为 .其中 是第 个经验从大到小排序的排名,排名从 1 开始.
D. Horgan 等在 2018 发表文章 《 Distributed prioritized experience replay》,将分布式经 签回放和优先经验回放相结合,得到分布式优先经验回放(distributed prioritized experience replay).
4.4.2 带目标网络的深度Q学习
对于基于自益的 Q 学习,其回报的估计和动作价值的估计都和权重 有关.当权重值变化时,回报的估计和动作价值的估计都会变化.在学习的过程中,动作价值试图追逐一个变化的回报,也容易出现不稳定的情况.在 4.1.2 节中给出了半梯度下降的算法来解决 这个问题.在半梯度下降中,在更新价值参数 时,不对基于自益得到的回报估计 求梯 度.其中一种阻止对 求梯度的方法就是将价值参数复制一份得到 ,在计算 时用 计算.基于这一方法,V. Mnih 等在 2015 年发表了论文《Human-level control through deep reinforcement learning》,提出了目标网(target network)这一概念.目标网络是在原有的神经网络之外再搭建一份结构完全相同的网络.原先就有的神经网络称为评估网络(evaluation network).在学习的过程中,使用目标网络来进行自益得到回报的评估值,作为学习的目标.在权重更新的过程中,只更新评估网络的权重,而不更新目标网络的权重.这样,更新权重时针对的目标不会在每次迭代都变化,是一个固定的目标.在完成一定次数的更新后,再将评估网络的权重值赋给目标网络,进而进行下一批更新.这样,目标网络也能得到更新.由于在目标网络没有变化的一段时间内回报的估计是相对固定的,目标网络的引入增加了学习的稳定性.所以,目标网络目前已经成为深度 Q 学习的主流做法.
算法 4-9 给出了带目标网络的深度 Q 学习算法.算法开始时将评估网络和目标网络初始化为相同的值.为了得到好的训练效果,应当按照神经网络的相关规则仔细初始化神经网络的参数.
算法 4-9 带经验回放和目标网络的深度 学习最优策略求解
- (初始化)初始化评估网络 的参数 ;目标网络 的参数
- 逐回合执行以下操作
2.1 (初始化状态)选择状态
2.2 如果回合未结束,执行以下操作:
- (采样)根据 选择动作 并执行,观测得到奖励 和新状态
- (经验存储)将经验 存入经验库 中
- (经验回放)从经验库 中选取一批经验
- (计算回报的估计值)
- (更新动作价值函数)更新 以减小 (如
- (更新目标网络)在一定条件下(例如访问本步若千次)更新目标网络的权重
在更新目标网络时,可以简单地把评估网络的参数直接赋值给目标网络 即 ,也可以引人一个学习率 把旧的目标网络参数和新的评估网络参数直接做加权平均后的值赋值给目标网络 即 .事实上,直接赋值的版本是带学习率版本在 时的特例.对于分布式学习的情形,有很多独立的拷贝(worker)同时会修改目标网络,则就更常用学习率 .
4.4.3 双重深度Q学习
第 3 章曾提到 学习会带来最大化偏差,而双重 学习却可以消除最大化偏差.基于查找表的双重 Q 学习引入了两个动作价值的估计 和 ,每次更新动作价值时用其中的一个网络确定动作,用确定的动作和另外一个网络来估计回报.
对于深度 Q 学习也有同样的结论.Deepmind 于 2015 年发表论文 《 Deep reinforcement learning with double Q-learning 》,将双重 Q 学习用于深度 Q 网络,得到了双重深度 Q 网络(Double Deep Q Network, Double ).考虑到深度 Q 网络已经有了评估网络和目标网络两个网络,所以双重深度 Q 学习在估计回报时只需要用评估网络确定动作,用目标网络确定回报的估计即可.所以,只需要将算法 4-10 中的 更换为 就得到了带经验回放的双重深度 Q 网络算法.
4.4.4 对偶深度 Q 网络
Z. Wang 等在 2015 年发表论文《Dueling network architectures for deep reinforcement learning 》,提出了一种神经网络的结构——对偶网络( duel network).对偶网络理论利用动作价值函数和状态价值函数之差定义了一个新的函数——优势函数(advantage function): 对偶 网络仍然用 来估计动作价值,只不过这时候 是状态价值估计 和优 势函数估计 的叠加,即 其中 和 可能都只用到了 中的部分参数.在训练的过程中, 和 是共 同训练的,训练过程和单独训练普通深度 Q 网络并无不同之处.不过,同一个 事实上存在着无穷多种分解为 和 的方式.如果某个 可以分解为某个 和 ,那么它也能分解为 和 ,其中 是任意一个只和状态 有关的函数.为了不给训练带来不必要的麻烦,往往可以通过增加一个由优势函数导出的量,使得等效的优势函数满足固定的特征,使得分解唯一.常见的方法有以下两种:
- 考虑优势函数的最大值,令 使得等效优势函数 满足
- 考虑优势函数的平均值,令 使得等效优势函数 满足
五. 回合更新策略梯度方法
本书前几章的算法都利用了价值函数,在求解最优策略的过程中试图估计最优价值函数,所以那些算法都称为最优价值算法(optimal value algorithm).但是,要求解最优策略不一定要估计最优价值函数.本章将介绍不直接估计最优价值函数的强化学习算法,它们试图用含参函数近似最优策略,并通过迭代更新参数值.由于迭代过程与策略的梯度有关,所以这样的迭代算法又称为策略梯度算法(policy gradient algorithm).
5.1 策略梯度算法的原理
基于策略的策略梯度算法有两大核心思想:
- 用含参函数近似最优策略
- 用策略梯度优化策略参数
本节介绍这两部分内容.
5.1.1 函数近似与动作偏好
用函数近似方法估计最优策略 的基本思想是用含参函数 来近似最优策略.由于任意策略 都需要满足对于任意的状态 ,均有 ,我们也希望 满足对于任意的状态 ,均有 .为此引入动作偏好函数(action preference function) ,其 softmax 的值为 ,即 在第 3~4 章中,从动作价值函数导出最优策略估计往往有特定的形式 (如 贪心策 略).与之相比,从动作偏好导出的最优策略的估计不拘泥于特定的形式,其每个动作都可以有不同的概率值,形式更加灵活.如果采用迭代方法更新参数 ,随着迭代的进行, 可以自然而然地逼近确定性策略,而不需要手动调节 等参数.
动作偏好函数可以具有线性组合、人工神经网络等多种形式.在确定动作偏好的形式中,只需要再确定参数 的值,就可以确定整个最优状态估计.参数 的值常通过基于梯度的迭代算法更新,所以,动作偏好函数往往需要对参数 可导.
5.1.2 策略梯度定理
策略梯度定理给出了期望回报和策略梯度之间的关系,是策略梯度方法的基础.本节学习策略梯度定理.
在回合制任务中,策略 期望回报可以表示为 .策略梯度定理(policy gradient theorem) 给出了它对策略参数 的梯度为 其等式右边是和的期望,求和的 中,只有 显式含有参数 .
策略梯度定理告诉我们,只要知道了 的值,再配合其他一些容易获得的 值(如 和 ,就可以得到期望回报的梯度.这样,我们也可以顺着梯度方向改变 以增大期望回报.
接下来我们来证明这个定理.回顾,策略 满足 期望方程,即 将以上两式对 求梯度,有 将 的表达式代人 的表达式中,有 在策略 下,对 求上式的期望,有 这样就得到了从 到 的递推式.注意到最终关注的梯度值就是 所以有 考虑到 所以 又由于 ,所以 得证.
5.2 同策回合更新策略梯度算法
策略梯度定理告诉我们,沿着 的方向改变策略参数 的值,就有机会增加期望回报.基于这一结论,可以设计策略梯度算法.本节考虑同策更新算法
5.2.1 简单的策略梯度算法
在每一个回合结束后,我们可以就回合中的每一步用形如 的迭代式更新参数 .这样的算法称为简单的策略梯度算法(Vanilla Policy Gradient, VPG).
R Willims 在文章《Simple statistical gradient-following algorithms for connectionist reinforcement learning 》中给出了该算法,并称它为“REward Increment = Nonnegative Factor Offset Reinforcement Characteristic Eligibility” ( ,表示增量 是由三个部分的积组成的.这样迭代完这个回合轨迹就实现了 在具体的更新过程中,不一定要严格采用这样的形式.当采用 TensorFlow 等自动微分的软件包来学习参数时,可以定义单步的损失为 ,让软件包中的优化器减小整个回合中所有步的平均损失,就会沿着 的梯度方向改变 的值.
简单的策略梯度算法见算法 5-1.
算法 5-1: 简单的策略梯度算法求解最优策略
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ),折扣因子 ,控制回合数和回合内步数的参数
- (初始化) 任意值
- (回合更新)对每个回合执行以下操作
2.1 (采样)用策略 生成轨迹
2.2 (初始化回报)
2.3 对 ,执行以下步骤:
- (更新回报)
- (更新策略)更新 以减小
5.2.2 带基线的简单策略梯度算法
本节介绍简单的策略梯度算法的一种改进一带基线的简单的策略梯度算法(REINFOCE with baselines).为了降低学习过程中的方差,可以引人基线函数 .基线函数 可以是任意随机函数或确定函数,它可以与状态 有关,但是不能和动作 有关.满足这样的条件后,基线函数 自然会满足 证明如下:由于 与 无关,所以 进而 得证. 基线函数可以任意选择,例如以下情况
- 选择基线函数为由轨迹确定的随机变量 ,这时 ,梯度的形式为
- 选择基线函数为 ,这时梯度的形式 为
但是,在实际选择基线时,应当参照以下两个思想.
- 基线的选择应当有效降低方差.一个基线函数能不能降低方差不容易在理论上判别, 往往需要通过实践获知.- 基线函数应当是可以得到的.例如我们不知道最优价值函数,但是可以得到最优价值函数的估计.价值函数的估计也可以随着迭代过程更新.
一个能有效降低方差的基线是状态价值函数的估计.算法 5-2 给出了用状态价值函数的估计作为基线的算法.这个算法有两套参数 和 ,分别是最优策略估计和最优状态价值函数估计的参数.每次迭代时,它们都以各自的学习算法进行学习.算法 5-2 采用了随机梯度下降法来更新这两套参数(事实上也可以用其他算法),在更新过程中都用到了 ,可以在更新前预先计算以减小计算量.
算法 5-2: 带基线的简单策略梯度算法求解最优策略
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值.
- (回合更新)对每个回合执行以下操作:
2.1 (采样)用策略 生成轨迹
2.2 (初始化回报)
2.3 对 ,执行以下步骤:
- (更新回报)
- (更新价值)更新 以减小 如
- (更新策略)更新 以减小 如
接下来,我们来分析什么样的基线函数能最大程度地减小方差.考虑 的方差为 其对 求偏导数为 (求偏导数时用到了 ).令这个偏导数为 0 ,并假设 可知 这意味着,最佳的基线函数应当接近回报 以梯度 为权重加权平均的结果.但是,在实际应用中,无法事先知道这个值,所以无法使用这样的基线函数.
值得一提的是,当策略参数和价值参数同时需要学习的时候,算法的收敛性需要通过双时间轴 Robbins-Monro 算法(two timescale Robbins-Monro algorithm)来分析.
5.3 异策回合更新策略梯度算法
在简单的策略梯度算法的基础上引入重要性采样,可以得到对应的异策算法.记行为策略为 ,有 即 所以,采用重要性采样的离线算法,只需要把用在线策略采样得到的梯度方向 改为用行为策略 采样得到的梯度方向 即可.这就意味着,在更新参数 时可以试图增大 .
算法5-3: 重要性采样简单策略梯度求解最优策略
- (初始化) 任意值
- (回合更新)对每个回合执行以下操作:
2.1 (行为策略)指定行为策略 ,使得
2.2 (采样)用策略 生成轨迹:
2.3 (初始化回报和权重)
2.4 对 ,执行以下步骤:
- (更新回报)
- (更新策略)更新参数 以减小 如
重要性采样使得我们可以利用其他策略的样本来更新策略参数,但是可能会带来较大的偏差,算法稳定性比同策算法差.
5.4 策略梯度更新和极大似然估计的关系
至此,本章已经介绍了各种各样的策略梯度算法.这些算法在学习的过程中,都是通过更新策略参数 以试图增大形如 的目标(考虑单个条目则为 ,其中 可取 等值.将这一学习过程与下列有监督学习最大似然问题的过程进行比较,如果已经有一个表达式未知的策略 ,我们要用策略 来近似它,这时可以考虑用最大似然的方法来估计策略参数 .具体而言,如果已经用未知策略 生成了很多样本,那么这些样本对于策略 的对数似然值正比于 .用这些样本进行有监督学习,需要更新策略参数 以增大 (考虑单个条目则为 .可以看出, 可以通过 中取 得到,在形式上具有相似性.策略梯度算法在学习的过程中巧妙地利用观测到的奖励信号决定每步对数似然值 对策略奖励的贡献,为其加权 (这里的 可能是正数,可能是负数,也可 能是 0 ),使得策略 能够变得越来越好.注意,如果取 ,在整个回合中是不变的(例如 ,那么在单一回合中的 就是对整个回合的对数似然值进行加权后对策略的贡献,使得策略 能够变得越来越好.试想,如果有的回合表现很好 (比如 是很大的正数 ),在策略梯度更新的时候这个回合的似然值 就会有一个比较大的权重 例如 ,这样这个表现比较好的回合就会更倾向于出现;如果有的回合表现很差(比如 是很小的负数,即绝对值很大的负数)则策略梯度更新时这个回合的似然值就会有比较小的权重,这样这个表现较差的回合就更倾向于不出现.
六. 执行者/评论者方法
本章介绍带自益的策略梯度算法.这类算法将策略梯度和自益结合了起来:一方面,用一个含参函数近似价值函数,然后利用这个价值函数的近似值来估计回报值;另一方面,利用估计得到的回报值估计策略梯度,进而更新策略参数.这两方面又常常被称为评论者 (critic) 和执行者(actor).所以,带自益的策略梯度算法被称为执行者 / 评论者算法(actorcritic algorithm).
6.1 执行者 / 评论者算法
同样用含参函数 表示偏好,用其 运算的结果 来近似最优策略.在更新参数 时,执行者 / 评论者算法依然也是根据策略梯度定理,取 为梯度方向迭代更新.其中, Schulman 等在文章《 High-dimensional continuous control using generalized advantage estimation 》中指出, 并不拘泥于以上形式. 可以是以下几种形式:
- (动作价值)
- (优势函数)
- (时序差分)
在以上形式中,往往用价值函数来估计回报.例如,由于 ,而且 也表征期望方向,所以 ,相当于用 表示期望.再例如,对于 ,就相当于在回报 的基础上减去基线 以减小方差.对于时序差分 ,也是用 代表回报,再减去基线 以减小方差.
不过在实际使用时,真实的价值函数是不知道的.但是,我们可以去估计这些价值函数.具体而言,我们可以用函数近似的方法,用含参函数 或 来近似 和 .在上一章中,带基线的简单策略梯度算法已经使用了含参函数 作为基线函数.我们可以在此基础上进一步引人自益的思想,用价值的估计 来代替 中表示回报的部分.例如,对于时序差分,用估计来代替价值函数可以得到 .这里的估计值 就是评论者,这样的算法就是执行者 / 评论者算法. >注意:只有采用了自益的方法,即用价值估计来估计回报,并引入了偏差,才是执行者 / 评论者算法.用价值估计来做基线并没有带来偏差(因为基线本来就可以任意选择).所以,带基线的简单策略梯度算法不是执行者 / 评论者算法.
6.1.1 动作价值执行者 / 评论者算法
根据前述分析,同策执行者 / 评论者算法在更新策略参数 时也应该试图减小 ,只是在计算 时采用了基于自益的回报估计.算法 6-1 给出了在回报估计为 ,并取 时的同策算法,称为动作价值执行者 / 评论者算法.算法一开始初始化了策略参数和价值参数.虽然算法中写的是可以将这个参数初始化为任意值,但是如果它们是神经网络的参数,还是应该按照神经网络的要求来初始化参数.在迭代过程中有个变量 ,用来存储策略梯度的表达式中的折扣因子 .在同一回合中,每一步都把这个折扣因子乘上 ,所以第 步就是 .
算法 6-1: 动作价值同策执行者 / 评论者算法
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化累积折扣)
2.2 (决定初始状态动作对)选择状态 ,并用 得到动作
2.3 如果回合未结束,执行以下操作:
- (采样)根据状态 和动作 得到奖励 和下一状态
- (执行)用 得到动作
- (估计回报)
- (策略改进)更新 以减小 如
- (更新价值)更新 以减小 如
- (更新累积折扣)
- (更新状态) .
6.1.2 优势执行者 / 评论者算法
在基本执行者 / 评论者算法中引入基线函数 ,就会得到 ,其中, 是优势函数的估计.这样,我们就得到了优势执行者 评论者算法.不过,如果采用 这样形式的优势函数估计值,我们就需搭建两个函数分别表示 和 .为了避免这样的麻烦,这里用了 做目标,这样优势函数的估计就变为单步时序差分的形式 .
如果优势执行者 / 评论者算法在执行过程中不是每一步都更新参数,而是在回合结束后用整个轨迹来进行更新,就可以把算法分为经验搜集和经验使用两个部分.这样的分隔可以让这个算法同时有很多执行者在同时执行.例如,让多个执行者同时分别收集很多经验,然后都用自己的那些经验得到一批经验所带来的梯度更新值.每个执行者在一定的时机更新参数,同时更新策略参数 和价值参数 .每个执行者的更新是异步的.所以,这样的并行算法称为异步优势执行者 / 评论者算法( Asynchronous Advantage Actor-Critic, ).异步优势执行者 / 评论者算法中的自益部分,不仅可以采用单步时序差分,也可以使用多步时序差分.另外,还可以对函数参数的访问进行控制,使得所有执行者统一更新参数.这样的并行算法称为优势执行者 / 评论者算法(Advantage Actor-Critic, ).算法 给出了异步优势执行者 / 评论者算法.异步优势执行者 / 评论者算法可以有许多执行者 (或称多个线程 ),所以除了有全局的价值参数 和策略参数 外,每个线程还可能有自己维护的价值参数 和 .执行者执行时,先从全局同步参数,然后再自己学习,最后统一同步全局参数.
算法 6-2: 优势执行者 / 评论者算法
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值.
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化累积折扣)
2.2 (决定初始状态)选择状态
2.3 如果回合未结束,执行以下操作:
- (采样)用 得到动作
- (执行)执行动作 ,得到奖励 和观测
- (估计回报)
- (策略改进)更新 以减小 如
- (更新价值)更新 以减小 如
- (更新累积折扣)
- (更新状态).
算法 6-3: 异步优势执行者 / 评论者算法 (演示某个线程的行为)
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ,折扣因子 ,控制回合数和回合内步数的参数
- (同步全局参数)
- 逐回合执行以下过程:
2.1 用策略 生成轨迹 ,直到回合结束或执行步数达
到上限
2.2 为梯度计算初始化:
- (初始化目标 )若 是终止状态,则 ;否则
- (初始化梯度) 2.3 (异步计算梯度)对 ,执行以下内容:
- (估计目标)计算
- (估计策略梯度方向)
- (估计价值梯度方向)
- (同步更新)更新全局参数 3.1 (策略更新)用梯度方向 更新策略参数 如 3.2 (价值更新)用梯度方向 更新价值参数 如 .
6.1.3 带资格迹的执行者 / 评论者方法
执行者 / 评论者算法引入了自益,那么它也就可以引入资格迹.算法 6-4 给出了带资格迹的优势执行者 / 评论者算法.这个算法里有两个资格迹 和 ,它们分别与策略参数 和价值参数 对应,并可以分别有自己的 和 .具体而言, 与价值参数 对应,运用梯度为 ,参数为 的累积迹; 与策略参数 对应,运用的梯度是 参数为 的累积迹,在运用中可以将折扣 整合到资格迹中.
算法 6-4: 带资格迹的优势执行者 / 评论者算法
输入:环境(无数学描述) 输出:最优策略的估计 参数:资格迹参数 ,学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值.
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化资格迹和累积折扣)
2.2 (决定初始状态)选择状态
2.3 如果回合未结束,执行以下操作:
- (采样)用 得到动作
- (执行)执行动作 ,得到奖励 和观测
- (估计回报)
- (更新策略资格迹)
- (策略改进)
- (更新价值资格迹)
- (更新价值)
- (更新累积折扣)
- (更新状态) .
6.2 基于代理优势的同策算法
本节介绍面向代理优势的执行者 / 评论者算法.这些算法在迭代的过程中并没有直接优化期望目标,而是试图优化期望目标近似一代理优势.在很多问题上,这些算法会比简单的执行者 / 评论者算法得到更好的性能.
6.2.1 代理优势
考虑采用迭代的方法更新策略 .在某次迭代后,得到了策略 .接下来我们希望得到一个更好的策略 .Kakade 等在文章 《 Approximately optimal approximate reinforcement learning 》中证明了策略 和策略 的期望回报满足性能差别引理 (Performance Difference Lemma): (证明: 得证.)
所以,要最大化 ,就是要最大化优势的期望 .这个期望是对含参策略而言的.要优化这样的期望,可以利用以下形式的重采样,将其中对 求期望转化为对 求期望: 但是,对 求期望无法进一步转化.代理优势( surrogate advantage)就是在上述重采样的基础上,将对 求期望近似为对 求期望: 这样得到了 的近似表达式 ,其中 可以证明, 和 在 处有相同的值 和梯度.
虽然 没有直接的表达式而很难直接优化,但是只要沿着它的梯度方向改进策略参数,就有机会增大它.由于 和 在 处有着相同的值和梯度方向, 和代理优势有着相同的梯度方向.所以,沿着 的梯度方向就有机会改进 .据此,我们可以得到以下结论:通过优化代理优势,有希望找到更好的策略.
6.2.2 邻近策略优化
我们已经知道代理优势与真实的目标相比,在 处有相同的值和梯度.但是,如果 和 差别较远,则近似就不再成立.所以针对代理优势的优化不能离原有的策略太远.基于这一思想,J. Schulman 等在文章 《 Proximal policy optimization algorithms 》中提出了邻近策略优化 (Proximal Policy Optimization) 算法,将优化目标设计为 其中 是指定的参数.采用这样的优化目标后,优化目标至多比 大 ,所以优化问题就没有动力让代理优势 变得非常大,可以避免迭代后的策略与迭代前的策略差距过大.
算法 6-5 给出了邻近策略优化算法的简化版本.
算法 6-5: 邻近策略优化算法 (简化版本 )
输入:环境(无数学描述) 输出:最优策略的估计 参数:策略更新时目标的限制参数 ,优化器,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值
- (时序差分更新)对每个回合执行以下操作: 2.1 用策略 生成轨迹 2.2 用生成的轨迹由 确定的价值函数估计优势函数 如 2.3 (策略更新)更新 以增大 2.4 (价值更新)更新 以减小价值函数的误差(如最小化
在实际应用中,常常加人经验回放.具体的方法是,每次更新策略参数 和价值参数 前得到多个轨迹,为这些轨迹的每一步估计优势和价值目标,并存储在经验库 中.接着多次执行以下操作:从经验库 中抽取一批经验 ,并利用这批经验回放并学习,即从经验库中随机抽取一批经验并用这批经验更新策略参数和价值参数.
注意:邻近策略优化算法在学习过程中使用的经验都是当前策略产生的经验,所以使用了经验回放的邻近策略优化依然是同策学习算法.
6.3 信任域算法
信任域方法(Trust Region Method, TRM)是求解非线性优化的常用方法,它将一个复杂的优化问题近似为简单的信任域子问题再进行求解.
本节将介绍三种同策执行者 / 评论者算法:
- 自然策略梯度算法
- 信任域策略优化算法
- Kronecker 因子信任域执行者 / 评论者算法
这三个算法十分接近,它们都是以试图通过优化代理优势,迭代更新策略参数,进而找到最优策略的估计.在优化的过程中,也需要让新的策略和旧的策略不能相差太远.和上节介绍的邻近策略优化相比,它们在代理优势的基础上可以进一步引入信任域,要求新的策略在一个信任域内.本节将介绍信任域的定义(包括用来定义信任域的 散度的定义),再介绍如何利用信任域实现这些算法.
6.3.1 KL 散度
我们先来看 散度的定义.回顾重要性采样的章节,我们知道,如果两个分布 和 ,满足对于任意的 ,均有 ,则称分布 对 分布 绝对连续,记为 .在这种情况下,我们可以定义从分布 到分布 的 KL 散度 (Kullback-Leibler divergence): 当 和 是离散分布时, 当 和 是连续分布时, 散度有个性质:相同分布的 散度为 0 ,即 .
TODO:信任域A-C算法
重要性采样异策执行者 / 评论者算法
执行者 / 评论者算法可以和重要性采样结合,得到异策执行者 / 评论者算法.本节介绍基于重要性采样的异策执行者 / 评论者算法.
6.4.1 基本的异策算法
本节介绍基于重要性采样的异策的执行者/评论者算法(Off-Policy Actor-Critic, OffPAC ).
用 表示行为策略,则梯度方向可由 变为 .这时,更新策略参数 时就应该试图减小 .据此,可以得到异策执行者 / 评论者算法,见算法 6-10.
算法 8-10: 异策动作价值执行者 / 评论者算法
输入:环境(无数学描述) 输出:最优策略的估计 参数:优化器(隐含学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化累积折扣)
2.2 (初始化状态动作对)选择状态 ,用行为策略 得到动作
2.3 如果回合未结束,执行以下操作:
- (采样)根据状态 和动作 得到采样 和下一状态
- (执行)用 得到动作
- (估计回报)
- (策略改进)更新 以减小 如
- (更新价值)更新 以减小 如
- (更新累积折扣)
- (更新状态)
6.4.2 带经验回放的异策算法
本节介绍 Wang 等在文章 《 Sample efficient actor-critic with experience replay》中提出的带经验回放的执行者 / 评论者算法 ( Actor-Critic with Experiment Replay, .如果说 节介绍的基本异策执行者 / 评论者算法是 节介绍的基本同策执行者 / 评论者算法的异策版本,那么本节介绍的带经验回放的异策执行者 / 评论者算法就相当于 节介绍的 算法的异策版本.它同样可以支持多个线程的异步学习:每个线程在执行前先同步全局参数,然后独立执行和学习,再利用学到的梯度方向进行全局更新.
6.1.2 节中介绍的执行者 / 评论者算法是基于整个轨迹进行更新的.对于引入行为策略和重采样后,对于目标 的重采样系数变为 , 其中 .在这个表达式中,每个 都有比较大的方差,最终乘积得到的方差会特别大.一种限制方差的方法是控制重采样比例的范围,例如给定一个常数 ,将重采样比例截断为 .但是,如果直接将梯度方向中的重采样系数进行截断(例如从 修改为 ),会带来偏差.这时候我们可以再加一项来弥补这个偏差.利用恒等式 ,我们可以把梯度 拆成以下两项: 期望针对行为策略 ,此项方差是可控的; 即 采用针对原有目标策略 的期望后, 也是有界的 (即 ).
采用这样的拆分后,两项的方差都是可控的.但是,这两项中其中一项针对的是行为策略,另外一项针对的是原策略,这就要求在执行过程中兼顾这两种策略.
得到梯度方向后,我们希望对这个梯度方向做修正,以免超出范围.为此,用 散度增加了约束。记在迭代过程中策略参数的指数滑动平均值为 ,对应的平均策略为 .我 们可以希望迭代得到的新策略参数不要与这个平均策略 参数差别太大.所以,可以限定这两个策略在当前状态 下的动作分布不要差别太大.考虑到 KL 散度可以刻画两个分布直接的差别,所以可以限定新得到的梯度方向(记为 ) 与 的内积不要太大.值得一提的是, 实际上有和重采样比例类似的形式: 至此,我们可以得到一个确定新的梯度方向的优化问题.记新的梯度方向为 ,定义 我们一方面希望新的梯度方向 要和 尽量接近,另外一方面要满足 ,不超过一个给定的参数 .这样这个优化问题为 接下来求解这个优化问题.使用 Lagrange 乘子法,构造函数: 将前式代人后式可得 .由于 Lagrange 乘子应大等于 0 ,所以,Lagrange 乘子应为 ,优化问题的最优解为 这个方向才是我们真正要用的梯度方向.综合以上分析,我们可以得到带经验回放的执行者 / 评论者算法的一个简化版本.这个算法可以有一个回放因子,可以控制每次运行得到的经验可以回放多少次.算法 6-11 给出了经验回放的线程的算法.对于经验回放的线程所回放的经验是从其他线程已经执行过的线程生成并存储的,这个过程在算法 6-11 中没有展示,但是是这个算法必需的.在存储和回放的时候,不仅要存储和回放状态 , 动作 、奖励 等,还需要存储和回放在状态 产生动作 的概率 .有了这个概率值,才能计算重采样系数.在价值网络的设计方面,只维护动作价值网络.在需要状态价值的估计时,由动作价值网络计算得到.
算法 6-11: 带经验回放的执行者 / 评 论者算法 (异策简化版本)
参数: 学习率 ,指数滑动平均系数 ,重采样因子截断系数 ,折扣因子 ,控制回合数和回合内步数的参数.
- (同步全局参数)
- (经验回放)回放存储的经验轨迹 ,以及经验对应的行为策略概率
- 梯度估计
3.1 为梯度计算初始化:
- (初始化目标 )若 是终止状态,则 ;否则
- (初始化梯度) 3.2 (异步计算梯度) 对 ,执行以下内容:
- (估计目标)计算
- (估计价值梯度方向)
- (估计策略梯度方向)计算动作价值 ,重采样系数 以及
- (更新回溯目标)
- (同步更新)更新全局参数. 4.1 (价值更新) 4.2 (策略更新) 4.3 (更新平均策略)
TODO:柔性A-C
七. 连续动作空间的确定性策略
简单易懂:b站搬运ShuSenWang教程
如何理解:两个网络:策略网络与价值函数网络( 函数 ) , 时刻,先利用策略时序差分地更新价值函数,再更新策略网络,策略网络的梯度下降想法是:参数朝着使 函数增大的方向走,即 函数关于策略网络的参数求梯度,所以最后推得的关系式策略网络的更新式形式为连式法则的样子 .
本章介绍在连续动作空间里的确定性执行者 / 评论者算法.在连续的动作空间中,动作的个数是无穷大的.如果采用常规方法,需要计算 .而对于无穷多的动作,最大值往往很难求得.为此,D. Silver 等人在文章《 Deterministic Policy Gradient Algorithms 》中提出了确定性策略的方法,来处理连续动作空间情况.本章将针对连续动作空间,推导出确定性策略的策略梯度定理,并据此给出确定性执行者 / 评论者算法.
7.1 同策确定性算法
对于连续动作空间里的确定性策略, 并不是一个通常意义上的函数,它对策略参数 的梯度. 也不复存在.所以,第 6 章介绍的执行者 / 评论者算法就不再适用.幸运的是,曾提到确定性策略可以表示为 .这种表示可以绕过由于 并不是通常意义上的函数而带来的困难.
本节介绍在连续空间中的确定性策略梯度定理,并据此给出基本的同策确定性执行者 / 评论者算法.
7.1.1 策略梯度定理的确定性版本
当策略是一个连续动作空间上的确定性的策略 时,策略梯度定理为 (证明:状态价值和动作价值满足以下关系 以上两式对 求梯度,有 将 的表达式代人 的表达式中,有 对上式求关于 的期望,并考虑到 (其中 任取),有 这样就得到了从 到 的递推式.注意,最终关注的梯度值就是 所以有 就得到和之前梯度策略定理类似的形式 ).
对于连续动作空间中的确定性策略,更常使用的是另外一种形式: 其中的期望是针对折扣的状态分布 (discounted state distribution) 而言的。(证明: 得证.)
7.1.2 基本的同策确定性执行者 / 评论者算法
根据策略梯度定理的确定性版本,对于连续动作空间中的确定性执行者 / 评论者算法,梯度的方向变为 确定性的同策执行者 评论者算法还是用 来近似 .这时, 近似为 所以,与随机版本的同策确定性执行者 / 评论者算法相比,确定性同策执行者 / 评论者算法在更新策略参数 时试图减小 .迭代式可以是 算法 7-1 给出了基本的同策确定性执行者 / 评论者算法.对于同策的算法,必须进行探索.连续性动作空间的确定性算法将每个状态都映射到一个确定的动作上,需要在动作空间添加扰动实现探索.具体而言,在状态 下确定性策略 指定的动作为 ,则在同策算法中使用的动作可以具有 的形式,其中 是扰动量.在动作空间无界的情况下(即没有限制动作有最大值和最小值),常常假设扰动量 满足正态分布.在动作空间有界的情况下,可以用 clip 函数进一步限制加扰动后的范围(如 ,其中 和 是动作的最小取值和最大取值),或用 sigmoid 函数将对加扰动后的动作变换到合适的区间里 如 .
算法 7-1: 基本的同策确定性执行者 / 评论者算法
输入: 环境(无数学描述) 输出:最优策略的估计 参数:学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值,任意值
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化累积折扣)
2.2 (初始化状态动作对)选择状态 ,对 加扰动进而确定动作 (如用正态分布随机变量扰动)
2.3 如果回合未结束,执行以下操作:
- (采样)根据状态 和动作 得到采样 和下一状态
- (执行)对 加扰动进而确定动作
- (估计回报)
- (更新价值)更新 以减小 如
- (策略改进)更新 以减小 如
- (更新累积折扣)
- (更新状态) .
在有些任务中,动作的效果经过低通滤波器处理后反映在系统中,而独立同分布的 Gaussian 噪声不能有效实现探索.例如,在某个任务中,动作的直接效果是改变一个质点的加速度.如果在这个任务中用独立同分布的 Gaussian 噪声叠加在动作上,那么对质点位置的整体效果是在没有噪声的位置附近移动.这样的探索就没有办法为质点的位置提供持续的偏移,使得质点到比较远的位置.在这类任务中,常常用 Ornstein Uhlenbeck 过 程作为动作噪声.Ornstein Uhlenbeck 过程是用下列随机微分方程定义的 (以一维的情况为例 ) 其中 是参数 是标准 Brownian 运动.当初始扰动是在原点的单点分布(即限定 ),并且 时,上述方程的解为 (证明:将 代入 化简可得 .将此式从 0 积到 ,得 .当 且 时化简可得结果).
这个解的均值为 0 ,方差为 ,协方差为 (证明:由于均值为 0 ,所以 .另外,Ito Isometry 告诉我们 ,所以 ,进一步化简可得结果.)
对于 总有 ,所以 .据此可知,使用 Ornstein Uhlenbeck 过程让相邻扰动正相关,进而让动作向相近的方向偏移.
7.2 异策确定性算法
对于连续的动作空间,我们希望能够找到一个确定性策略,使得每条轨迹的回报最大.同策确定性算法利用策略 生成轨迹,并在这些轨迹上求得回报的平均值,通过让平均回报最大,使得每条轨迹上的回报尽可能大.事实上,如果每条轨迹的回报都要最大,那么对于任意策略 采样得到的轨迹,我们都希望在这套轨迹上的平均回报最大.所以异策确定性策略算法引入确定性行为策略 ,将这个平均改为针对策略 采样得到的轨迹,得到异策确定性梯度为 这个表达式与同策的情形相比,期望运算针对的表达式相同.所以,异策确定性算法的迭代式与同策确定性算法的迭代式相同.
异策确定性算法可能比同策确定性算法性能好的原因在于,行为策略可能会促进探索,用行为策略采样得到的轨迹能够更加全面的探索轨迹空间.这时候,最大化对轨迹分布的平均期望时能够同时考虑到更多不同的轨迹,使得在整个轨迹空间上的所有轨迹的回报会更大.
7.2.1 基本的异策确定性执行者 / 评论者算法
基于上述分析,我们可以得到异策确定性执行者 / 评论者算法 (Off-Policy Deterministic Actor-Critic, ),见算法 7-2 .
值得一提的是,虽然异策算法和同策算法有相同形式的迭代式,但是在算法结构上并不完全相同.在同策算法迭代更新时,目标策略的动作可以在运行过程中直接得到;但是在异策算法迭代更新策略参数时,对环境使用的是行为策略决定的动作,而不是目标策略决定的动作,所以需要额外计算目标策略的动作.在更新价值函数时,采用的是 学习,依然需要计算目标策略的动作.
算法 9-2: 基本的异策确定性执行者 / 评论者算法
输入:环境(无数学描述) 输出:最优策略的估计 参数:学习率 ,折扣因子 ,控制回合数和回合内步数的参数.
- (初始化) 任意值, 任意值.
- (带自益的策略更新)对每个回合执行以下操作:
2.1 (初始化累积折扣)
2.2 (初始化状态)选择状态
2.3 如果回合未结束,执行以下操作:
- (执行)用 得到动作
- (采样)根据状态 和动作 得到采样 和下一状态
- (估计回报)
- (更新价值)更新 以减小 如
- (策略改进)更新 以减小 (如
- (更新累积折扣)
- (更新状态) .
7.2.2 深度确定性策略梯度算法
深度确定性策略梯度算法(Deep Deterministic Policy Gradient, )将基本的异策 确定性执行者 / 评论者算法和深度 Q 网络中常用的技术结合.具体而言,确定性深度策略梯度算法用到了以下技术.
- 经验回放:执行者得到的经验 收集后放在一个存储空间中,等更新参数时批量回放,用批处理更新.
- 目标网络:在常规价值参数 和策略参数 外再使用一套用于估计目标的目标价值参数 和目标策略参数 在更新目标网络时,为了避免参数更新过快,还引入了目标网络的学习率
算法 7-3 给出了深度确定性策略梯度算法.
算法 7-3: 深度确定性策略梯度算法 (假设 总是在动作空间内)
输入:环境(无数学描述) 输出:最优策略的估计 参数:学习率 ,折扣因子 ,控制回合数和回合内步数的参数,目标网络学习率
- (初始化) 任意值, 任意值,
- 循环执行以下操作:
2.1 (累积经验)从起始状态 出发,执行以下操作,直到满足终止条件:
- 用对 加扰动进而确定动作 (如用正态分布随机变量扰动)
- 执行动作 ,观测到收益 和下一状态
- 将经验 存储在经验存储空间 2.2 (更新)在更新的时机,执行一次或多次以下更新操作:
- (回放)从存储空间 采样出一批经验
- (估计回报)为经验估计回报
- (价值更新)更新 以减小
- (策略更新)更新 以减小 (如
- (更新目标)在恰当的时机更新目标网络和目标策略, .
7.2.3 双重延迟深度确定性策略梯度算法
S. Fujimoto 等人在文章 《 Addressing function approximation error in actor-critic methods》 中给出了双重延迟深度确定性策略梯度算法(Twin Delay Deep Deterministic Policy Gradient, TD3 ),结合了深度确定性策略梯度算法和双重 Q 学习.
回顾前文,双重 学习可以消除最大偏差.基于查找表的双重 Q 学习用了两套动作价值函数 和 ,其中一套动作价值函数用来计算最优动作(如 ,另外一套价值函数用来估计回报(如 ;双重 网络则考虑到有了目标网络后已经有了两套价值函数的参数 和 所以用其中一套参数 计算最优动作(如 ),再用目标网络的参数 估计目标 (如 ). 但是对于确定性策略梯度算法,动作已经由含参策略 决定了 (如 ),双重网络则要由双重延迟深度确定性策略梯度算法维护两份学习过程的价值网络参数 和目标网络参数 .在估计目标时,选取两个目标网络得到的结果中较小的那个,即 .
算法 7-4 给出了双重延迟深度确定性策略梯度算法.
算法 7-4 :双重延迟深度确定性策略梯度
输入: 环境(无数学描述) 榆出:最优策略的估计 参数:学习率 ,折扣因子 ,控制回合数和回合内步数的参数,目标网络学习率 .
- (初始化) 任意值, 任意值,
- 循环执行以下操作:
2.1 (累积经验)从起始状态 出发,执行以下操作,直到满足终止条件:
- 用对 加扰动进而确定动作 (如用正态分布随机变量扰动)
- 执行动作 ,观测到收益 和下一状态
- 将经验 存储在经验存储空间 2.2 (更新)一次或多次执行以下操作:
- (回放)从存储空间 采样出一批经验
- (扰动动作)为目标动作 加受限的扰动,得到动作
- (估计回报)为经验估计回报
- (价值更新)更新 以减小
- (策略更新)在恰当的时机,更新 以减小 如
- (更新目标)在恰当的时机,更新目标网络和目标策略, .
TODO:AlphaZero算法
RL 在金融中的应用
参见Modern Perspectivs on RL in Finance和RL in economics and finance 2021.
本来应该通过动态规划方法解这些问题.用动态规划解优化问题通常需要下述三个条件:
- 明确知道模型的状态转移概率
- 有足够的算力来求解DP
- Markov性质
RL,结合了DP,蒙特卡洛模拟,函数近似和机器学习.
RL在金融中主要有以下三个应用方向:
- 衍生品定价/对冲
- 投资组合/资产配置
- 做市
一. RL for Risk Management
通常而言,学术中对衍生品定价和对冲都是基于随机环境下的有模型决策(model-driven decision rules in a stochastic environment),常规对冲策略都会用到希腊值 Greeks,代表模型对不同参数风险定价的敏感程度.
这种方法在高维情况时通常缺少有效的数值模拟方法.
Deep Hedging
参考Deep Hedging, Buehler et al.
市场摩擦(market frictions):指金融资产在交易中存在的难度,如手续费(transaction costs)、买卖价差(bid/ask spread)、流动性约束(liquidity constraints)等.
本文中的对冲的对象是对冲掉一些衍生品的投资组合.
把 trading decision 建模成一个网络,特征不仅仅有价格,还有交易信号,新闻分析(news analytics),过去对冲决策等等.
算法是完全 model-free,不依赖对应市场的动力.我们只需确定下来市场的状态生成(scenario generator),损失函数,市场摩擦和交易行为(trading instruments).所以此方法 lends itself to a statistically driven market dynamics,我们不需要像传统方法那样计算单个衍生品的希腊值,应将建模的精力花在实现真实的市场动力和样本外表现.
建模:带市场摩擦的离散市场
考虑有限时域的离散金融市场 和交易时刻 . 固定一个有限概率空间 和一个概率测度 s.t. 对所有的 . 定义所有 上的实值随机变量 .
记 在 available 的新市场数据, including market costs and mid-prices of liquid instruments-typically quoted in auxiliary terms such as implied volatilities-news, balance sheet information, any trading signals, risk limits etc. 过程 生成域流 , i.e. 表示到 时刻所有可用的信息. 注意到每个 可测的随机变量可以写成 的函数.
市场有 个hedging instruments with mid-prices 取值于 -valued -adapted 随机过程 . 即可以用来做对冲的资产.
衍生品的投资组合即负债(liability)是一个 可测的随机变量 . 到期日 是所有衍生品种最大的那一个.此为想要对冲掉的东西.
即 用.
想要在 对冲掉 , 我们要用 -valued -adapted stochastic process with 来交易 . 表示智能体在 时刻对第 个资产的持有. 同样定义 .
记 是这样的交易策略的无约束集合. 但是每个 有其交易约束. 可能来自 liquidity, asset availability or trading restrictions. They are also used to restrict trading in a particular option prior to its availability. In the example above of an option which is listed in , the respective trading constraints would be until the point. 所以我们假定 受 约束,由一个连续 可测映射给出 , i.e.
对无约束策略 , 我们定义它在 的有约束投影 .记 为受约束的交易策略相应的非空集.
EXAMPLE 1 Assume that are a range of options and that computes the Black-Scholes Vega of each option using the various market parameters available at time . The overall Vega traded with is then A liquidity limit of a maximum tradable Vega of could then be implemented by the map:
对冲
交易是自融资的.不带交易费用的 时刻最终财富为 , 其中 当考虑交易费用时,在 时刻买入 的 股票a产生费用 . 策略总的交易费用为 回忆 .所以智能体总的花费变为
DRL
DRL(deep reinforcement learning) 深度强化学习
ChatGPT历史简介
本段历史截止至2023年5月
AGI(Artificial general intelligence)指通用人工智能, 以下是 wiki 第一段:
An artificial general intelligence (AGI) is a type of hypothetical(假设的) intelligent agent. The AGI concept is that it can learn to accomplish any intellectual task that human beings or other animals can perform. Alternatively, AGI has been defined as an autonomous(自洽的) system that surpasses(超过) human capabilities in the majority of economically valuable tasks. Creating AGI is a primary goal of some artificial intelligence research and companies such as OpenAI, DeepMind, and Anthropic. AGI is a common topic in science fiction and futures studies.
OpenAI的成立
2014年1月26日, 谷歌宣布以5亿美元收购 DeepMind. 2015年, DeepMind 的 AlphaGo横空出世(AlphaGo论文--Mastering the game of Go with deep neural networks and tree search, AlphaGo Zero论文--Mastering the game of Go without human knowledge). 此时外界看来 DeepMind 有可能最先完成 AGI, 而谷歌就会垄断这一技术. 硅谷的互联网公司决定投资成立一个对抗 DeepMind 的实验室.
2015年12月11日, OpenAI成立.
Sam Altman, Greg Brockman, Reid Hoffman, Jessica Livingston, Peter Thiel, Elon Musk, Amazon Web Services (AWS), Infosys, and YC Research announced the formation of OpenAI and pledged over 1 billion to the venture.
- Sam Altman, 山姆·阿尔特曼1985年4月22日出生于美国伊利诺伊州的芝加哥, 后被斯坦福大学录取, 开始研究人工智能和计算机科学. 2005年从大学辍学, 同好友合作创办社交媒体公司. 被媒体称为ChatGPT之父, 现为Y Combinator 总裁、人工智能实验室OpenAI首席执行官.
- Peter Thiel, 彼得·蒂尔出生于1964年, 于1996年创办了Thiel资产管理公司(Thiel Capital Management), 并在2002年更名为 Clarium Capital Management. 该公司管理总值超过50亿美元的资产. 蒂尔曾在1998联合创办了PayPal, 并在2002年以15亿美元出售给eBay. 蒂尔是国际象棋天才, 12岁时就在全美排名第七.
- Reid Hoffman, 里德·霍夫曼, 1967年8月5日出生. LinkedIn联合创始人, 曾经担任过PayPal高级副总裁. 是硅谷最有名的天使投资者之一, 曾经投资过60多家创业公司, 包括Facebook和 Digg.
- Elon Reeve Musk, 埃隆·里夫·马斯克, 1971年6月28日出生于南非的行政首都比勒陀利亚, 兼具美国、南非、加拿大三重国籍, 企业家、工程师、发明家、慈善家、特斯拉(TESLA)创始人和首席执行官、太空探索技术公司(SpaceX)首席执行官和首席技术官、太阳城公司(SolarCity)董事会主席、推特首席执行官、OpenAI联合创始人、美国国家工程院院士、英国皇家学会院士, 本科毕业于宾夕法尼亚大学经济学和物理学双专业. 1995年至2002年, 马斯克与合伙人先后办了三家公司, 分别是在线内容出版软件“Zip2”、电子支付“X.com”和“PayPal”.2002年6月, 马斯克投资1亿美元成立太空探索技术公司(Space X), 出任首席执行官兼首席技术官. 2004年, 马斯克向马丁·艾伯哈德(Martin Eberhard)创立的特斯拉公司投资630万美元, 并担任该公司的董事长. 2006年, 马斯克投资1000万美元联合创办了光伏发电企业太阳城公司. 2018年9月29日, 卸任特斯拉董事长, 但继续担任特斯拉首席执行官.
- Ilya Sutskever, 伊尔亚·苏茨克维, 现担任OpenAI首席科学家, 多伦多大学计算机本硕博, AI大牛图灵奖获得者Geoffrey Hinton的学生, Andrew Ng的博后, 前Google研究科学家, AlphaGo的研发者之一





OpenAI截止到ChatGPT前的时间线
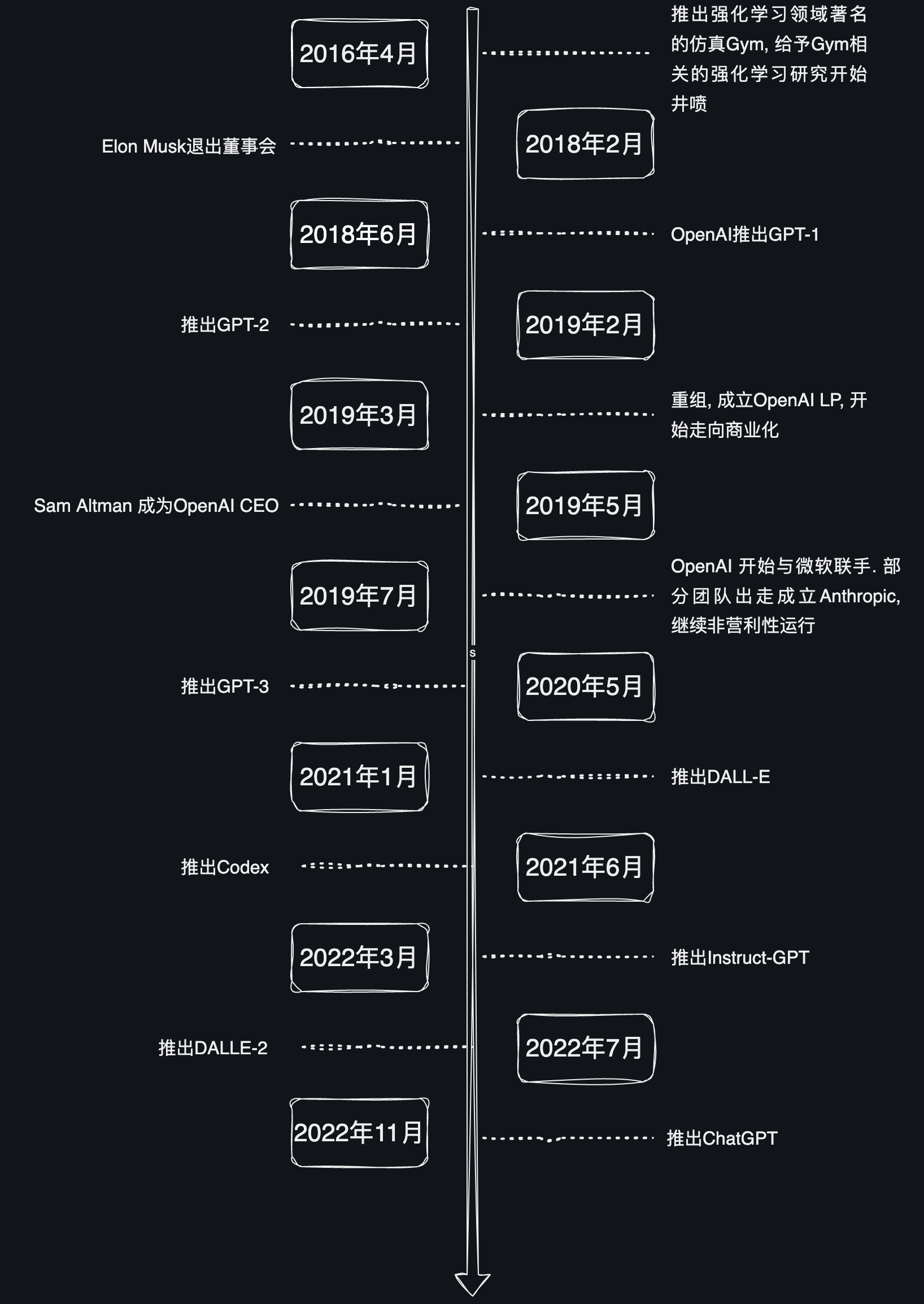
Chatgpt历代版本
2017年6月, 谷歌大脑团队(Google Brain)在神经信息处理系统大会(NeurlPS)上发表了《Attention is all you need》, 提出了基于注意力机制的 Transformer 模型, 用于自然语言处理(NLP).
2018年6月, OpenAI推出有1.7亿参数的GPT-1, 论文为Improving Language Understanding by Generative Pre-training.
GPT-1得出发点是解决之前模型的主要2个问题:
- 有监督学习需要大量的标注数据, 但是高质量的标注数据很难获得
- 根据一个任务训练的模型, 很难泛化和应用到其它任务中, 无法做到通用
GPT-1的思想是先通过在无标签的数据上学习一个生成式的语言模型, 然后再根据特定任务进行微调, 处理的有监督任务包括:
- 自然语言推理:判断两个句子是关系(包含、矛盾、中立);
- 问答和常识推理:类似于多选题, 输入一个文章, 一个问题以及若干个候选答案, 输出为每个答案的预测概率;
- 语义相似度:判断两个句子是否语义上市是相关的;
- 分类:判断输入文本是指定的哪个类别
GPT-1采用的数据集来自于NLP领域里面有名的BooksCorpus dataset(大型书籍训练集), 包括7000本不同体裁的未出版的书籍数据.
2019年2月, OpenAI发布15亿参数的GPT-2, 论文为Language Models are Unsupervised Multitask Learners. 相较于GPT-1, GPT-2只使用了更多的网络参数与更大的数据集:最大模型共计48层.
GPT-2的训练数据WebText, 爬取了来自著名的社交媒体平台Reddit约4500万个网络链接, 抽取对应的网络文字. 800万篇文章, 共40G.
GPT-2可以基于embedding应用不同的规模. GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型可迁移到其它类别任务中, 而不需要额外的训练. GPT-2基于WebText数据训练, 测试迁移到其它8个语言任务中, 能有7个实现SOTA.
2020年5月, OpenAI发布1750亿参数的GPT-3, 论文为Language Models are Few-Shot Learners
GPT-3是在GPT-2上的延伸. 训练好的GPT-3无需进一步训练和调整可以迁移到其它任务,实现聊好的表现,比如翻译,问题回答互动等. GPT-3的模型架构和GPT-2一样. 为了控制变量,研究模型规模对模型表现的影响,OpenAI训练了8个不同规模的GPT-3,从1.25亿参数到1750亿参数.
2022年3月, OpenAI发布13亿参数的 Instruct GPT, 论文为Training language models to follow instructions with human feedback, InstructGPT的目标是生成清晰、简洁且易于遵循的自然语言文本. 通过收集了一批带标签的语言标记数据,通过引入了强化学习(reinforcement learning)基于人们的反馈,来进行有监督的调优. InstructGPT在真实性,错误性等上面相比GPT-3有更好的表现.
CHATGPT前置论文:
- RLHF(Augmenting Reinforcement Learning with Human Feedback), 人类反馈强化学习
- TAMER(Training an Agent Manually via Evaluative Reinforcement), 评估式强化人工训练处理
- PPO(Proximal Policy Optimization Algorithms), 近端策略优化
AlphaGO论文:Mastering the game of Go with deep neural networks and tree search
AlphaGO ZERO论文:Mastering the game of Go without human knowledge
注意力机制论文:Attention is all you need
In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.
MODEL ARCHITECTURE
大多数优秀的神经序列转导模型(neural sequence transduction model)有一个 encoder-decoder 结构. encoder 将输入的序列 \left(x_1, \ldots, x_n\right)\mathbf{z}=\left(z_1, \ldots, z_n\right)\mathbf{z}\left(y_1, \ldots, y_m\right). 每一步模型都是自回归的(auto-regressive,即在生成文本时将前一次生成的信号作为额外的输入).
Transformer 遵循了该基本的结构,另外同时对 encoder 和 decoder 使用了 stacked self-attention(栈式的自注意力?) 和点点的全连接层. 如下图所示
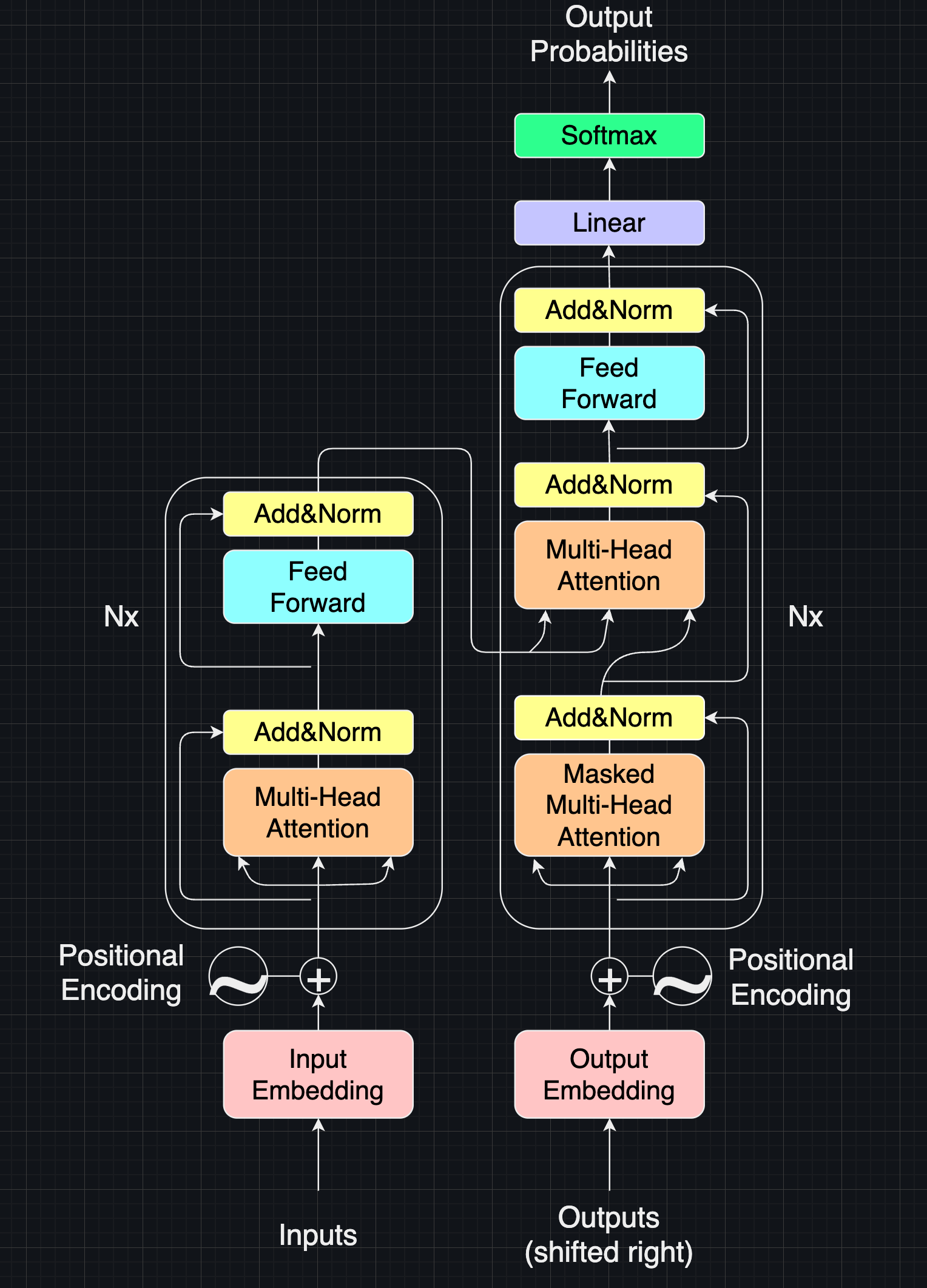
Encoder and Decoder Stacks
- Encoder: encoder 由 N=6N=6 相同层组成. 除了在每个 encoder 层中的两个子层, decoder 插入了第三个子层, 它在 encoder 的输出后面作为 multi-head 注意力
Attention
一个 attention 函数可以描述为将一个请求(query)和一组 key-value pairs 映射为一个输出向量.
Scaled Dot-Product Attention
我们将该特殊的 Attention 称为 Scaled Dot-Product Attention, 输入由请求和 d_kd_v\sqrt{d_k}QKV\frac{1}{\sqrt{d_k}} 的 scaling 部分.
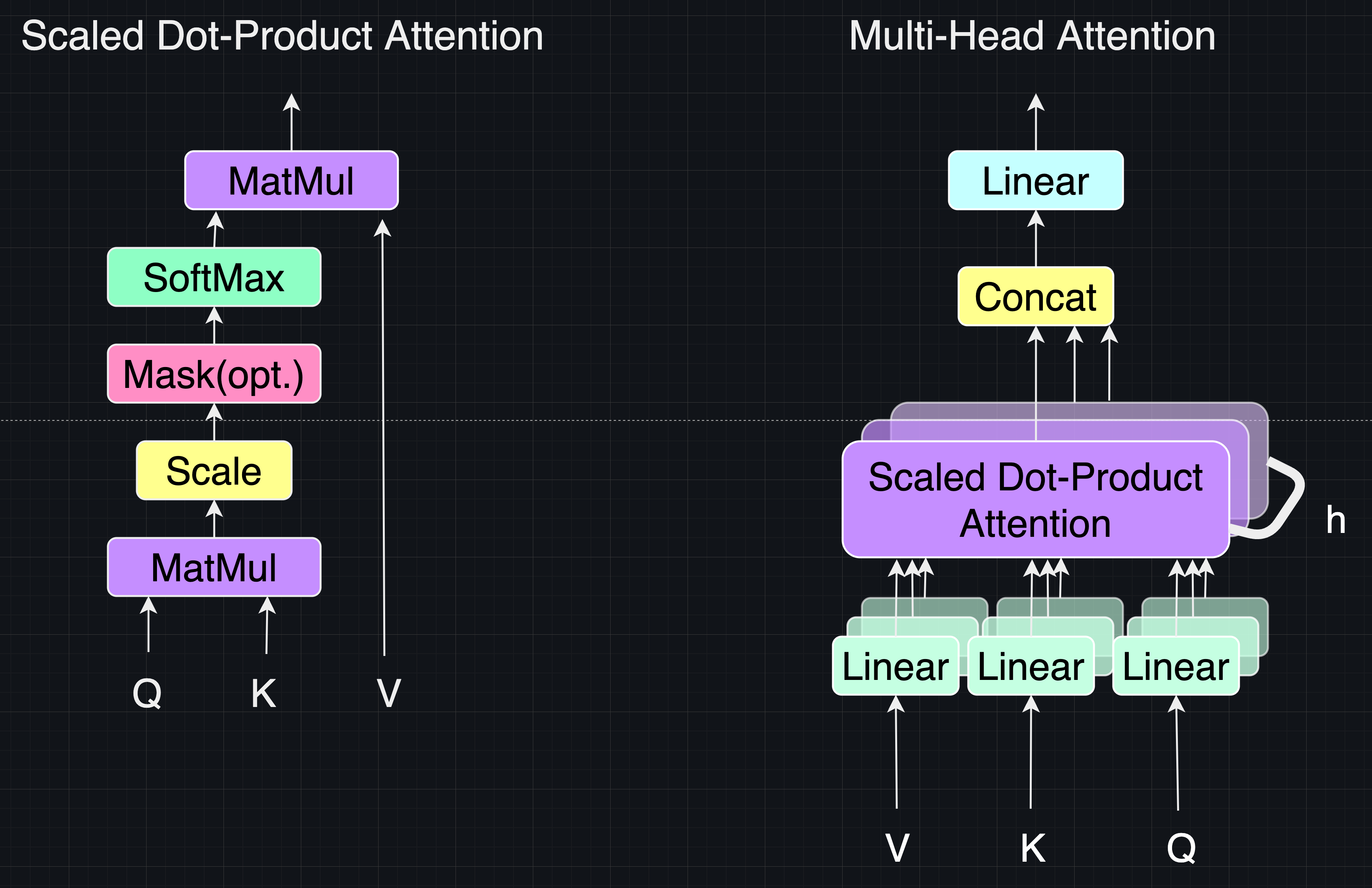
Multi-Head Attention
除了对 d_{\text {model}}d_{\text {model}}hd_k, d_kd_vd_vW_i^Q \in \mathbb{R}^{d_{\text {model }} \times d_k}, W_i^K \in \mathbb{R}^{d_{\text {model }} \times d_k}, W_i^V \in \mathbb{R}^{d_{\text {model }} \times d_v}W^O \in \mathbb{R}^{h d_v \times d_{\text {model }}}h=8d_k=d_v=d_{\text {model }} / h=64. Due to the reduced dimension of each head, the total computational cost is similar to that of single-head attention with full dimensionality.
GPT-1论文:Improving Language Understanding by Generative Pre-training
GPT-2论文:Language Models are Unsupervised Multitask Learners
GPT-3论文:Language Models are Few-Shot Learners
Instruct GPT论文:Training language models to follow instructions with human feedback
PPO论文:Proximal Policy Optimization Algorithms
期权
期权基础知识
一.基础概念
1.1 BS公式(Delta对冲下)
BS部分参考知乎专栏:Black-Scholes 模型学习框架
假设股价满足 自融资资产组合(此处为期权价格的一个复制)价值变化为 对 ( 时刻衍生品的价值)做Ito公式,比较项的系数得到Delta 对冲下 的 BS 偏微分方程 (在比较系数过程中会使用到替换为,即为持有的债券份额为自融资总份额减去持有的标的份额,标的的持有量已经使用为) 终值条件(看涨期权)为 解即为 BS 公式 注意到 的漂移项 对期权定价没有影响.
BS公式解法(欧式call)
有考虑边界条件
注意到这是一个 Cauchy-Euler 方程,能通过下述变量代换将其转化为一个扩散方程 The solution of the PDE gives the value of the option at any earlier time, Black-Scholes PDE 变为一个扩散方程: 终值条件 现在变为了初值条件 其中 是 Heaviside 阶梯函数,
使用解给定了初值函数 的扩散方程的标准卷积法,得到 经过处理,得到: 其中 N 为正态分布累计密度函数,
BS model给出了期权价格的函数,作为一个波动率的函数.可以通过这个公式在给定期权价格时计算隐含波动率(implied volatility).但事实是 BS 波动率强烈依赖于欧式期权的到期日和行权价.
波动率微笑是指给定到期日下,隐含波动率与行权价(maturity)的关系.
1.2 Delta对冲
我们现在考虑用衍生品 和其标的资产 构建一个“无风险组合”,考虑这样的自融资组合 ,即每一单位的空头衍生品,我们用 单位多头的股票对其进行对冲 (Hedging),由于其自融资的特性,根据定义,我们有 ,将股价的 SDE 和上一节中通过伊藤-德布林公式求出的 带入这个式子,我们可以得到: 因为要使资产组合为无风险的, >一个自融资组合 如果是无风险的,则可以表示为 ,且 . 1式即 Delta 对冲法则,将 带入2式我们再次得到 BlackScholes 偏微分方程: .
1.3 BS公式(风险中性定价下)
1.3.1 鞅
定义 在 上的随机过程 , ,称其是关于域流 的鞅,如果满足:
- 是 -适应的 (adapted);
- ;
- 对于 ,有 .
1.3.2 Radon-Nikodym导数
定义 设 和 为 上的等价测度,若 ,a.s.,且有 , 则称 是 关于 的 Radon-Nikodym 导数,记作: .
,即 ,其中 表示在测度 下的期望.进一步的,可以用条件期望定义R-N导数过程: .用鞅和RN导数过程的定义,可以简单的证明,R-N导数过程 是一个 -鞅.
1.3.3 资产的现值
用 表示风险资产的价值过程.首先要知道,在 模型的假设下,市场是完备 (Complete) 的,即任意资产 都可以被风险资产 和无风险资产 构成的组合所复制,即对任意一个 ,我们可以把它表示 为一个自融资组合: 可以看到该组合的收益率部分由组合的时间价值 与风险资产的超额收益 构成.我们考虑该资产的折现价值过程
1.3.4 鞅表示
定理(鞅表示) 设 是 上的布朗运动,而 为 -鞅, 且满足 ,则存在一个 适应的过程 ,使得 .
可以看到,如果 是鞅,那么 可以被表示为一个伊藤积分的形式,即没有 项而仅仅只有 项.再看我们的折现价值过程 ,如果想让它只有 项从而变成一个鞅,我们貌似只需要做变换: ,这样折现价值过程就可以被表示为:
但是,鞅表示定理有个非常非常重要的前提,就是你需要保证 这玩意儿是个伊藤积分,即 需要是一个布朗运动. 我们知道是布朗运动,但是经过这样变换过后的 还是布朗运动么,或者说我们需要如何选择新的测度, 来保证经过变换之后的 仍然是个布朗运动?
1.3.5 Girsanov定理
定理(Grisanov) 设 是 上的布朗运动. 为一个相适应的过程, 定义指数鞅过程,.其中 是初值 的相适应的过程, 表示二次变差.则可以定义新的概率测度 .如果在概率测度 下 是一个布朗运动,那么: 在新的概率测度 下也是一个布朗运动.
这样一来, 我们就找到了新的测度和两个测度之下布朗运动之间的关系.我们看新定义的这个布朗运动:,它的实质是把资产的风险溢价项给消除了.风险溢价是什么?是对承担单位风险的补偿,在新的测度下风险溢价是没有补偿的,所以说在这个世界里,风险是中性的,因此我们把这样定义的新测度 称为风险中性测度,并且用 来表示.
1.3.6 风险定价公式
现在我们知道了变换公式 ,那么在风险中性测度 下,风险资产 所满足的 SDE 也需要进行相应的变化: 由此可见,在风险中性世界里,风险资产 (例如股票) 的收益率完全等于无风险收益率.
此时任意资产的折现价值过程可以被表示为: .我们知道 在 下是一个鞅,那么由鞅的性贡我们可以知道: .常利率假设下有: .
假设我们需要对一个欧式看涨期权进行定价,我们知道该期权在到期日 的价值为 ,则有: 其中: 与PDE方法一致.
我们来总结一下 Risk-neutral Pricing 的几个步骤:
- 找到资产的折现价值过程;
- 作测度变换令这个折现价值在新的测度下为鞅;
- 用 Girsanov 定理找到新的变换;
- 利用鞅性质得到风险中性定价公式。
二.波动率价差
2.1 各种形式
2.1.1 跨式期权
跨式期权(straddle)由一个看涨期权和一个看跌期权组成,这两个期权具有相同的行权价格和到期日.在跨式期权中,这两个期权要么同时买入(跨式期权多头),要么同时卖出(跨式期权空头).
2.1.2 宽跨式期权
与跨式期权一样,宽跨式期权(straggle)由一个看涨期权和一个看跌期权组成,且两个期权的到期时间相同.但在宽跨式期权中,两个期权的行权价格不同.
为了避免混淆,通常假设宽跨式期权由虚值期权组成.如果当前标的市场价格为 100,而交易者想买入 3 月行权价格为 90/110 的宽跨式期权,这意味着他想买入 1 份 3 月行权价格为 90 的看跌期权和 1 份 3 月行权价格为 110 的看涨期权.
2.1.3 蝶式期权
蝶式期权(butterfly)通常就是一个由相同类型(要么都是看涨,要么都看跌)并具有相同到期时间,且合约间行权价格间距相等的 3 份期货合约组成的三腿价差.蝶式期权多头中,买入外部行权价格的期权合约,卖出内部行权价格的期权合约.构成比例固定不变:都为 1x2x1 .
为何买外卖内算作蝶式的多头? 根据损益图,如果不考虑期权费,买外卖内的损益总不小于零,故必须付出一定金额,所以称为多头.
跨式期权潜在收益或风险都是无限的,而蝶式都是有限的.
2.1.4 鹰式期权
鹰式期权(condor)由 4 份期权组成,2 个内部行权价格和两个外部行权价格.构成比例总是 1x1x1x1 ,尽管两个内部行权价格的差额可以变化,但是 2 个最低行权价格的差额一定要与 2 个最高行权价格的差额相等(why?).与蝶式期权一样,鹰式期权中所有期权的到期时间和类型都相同.买入两个外部行权价格的期权,卖出两个内部行权价格的期权就构成了鹰式期权多头.
上述四个策略对标的市场的变动方向没有偏好,损益图为对称的.
2.1.5 比例价差
在波动率价差中,交易者不能完全不关心标的市场的变动方向.交易者可能认为向一个方向变动的可能性要大于向另一个方向变动的可能性.鉴于这个原因,交易者可能希望构建一个当标的向一个方向而不是另一个方向变动时能最大化收益或最小化损失的价差策略.为了实现这个目标,交易者可以构建一个比例价差(ratio spread)——买入并卖出不同数量的期权,所有期权都是同一类型的,且具有相同的到期时间.和其他波动率头寸一样,比例价差也是典型的 Delta 中性策略.
三.希腊值的含义
序:各种希腊值特性
delta
call 的价值变化:标的相对于行权价的变化
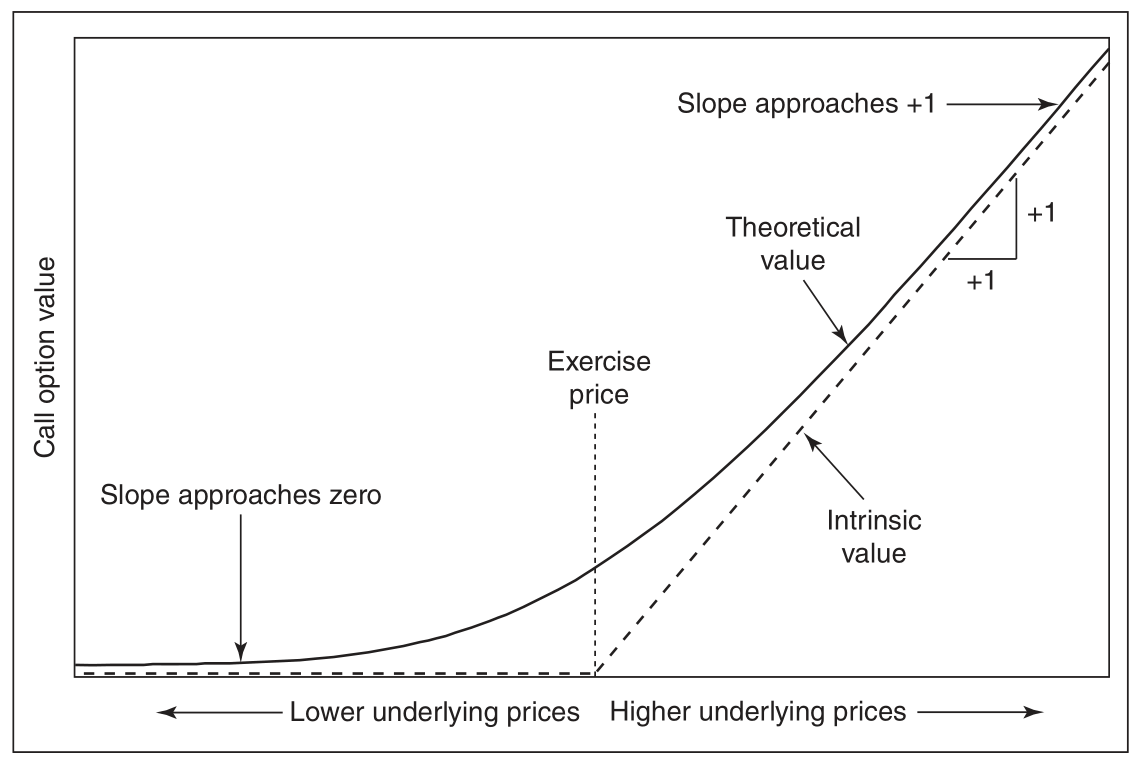
put 的价值变化:标的相对于行权价的变化
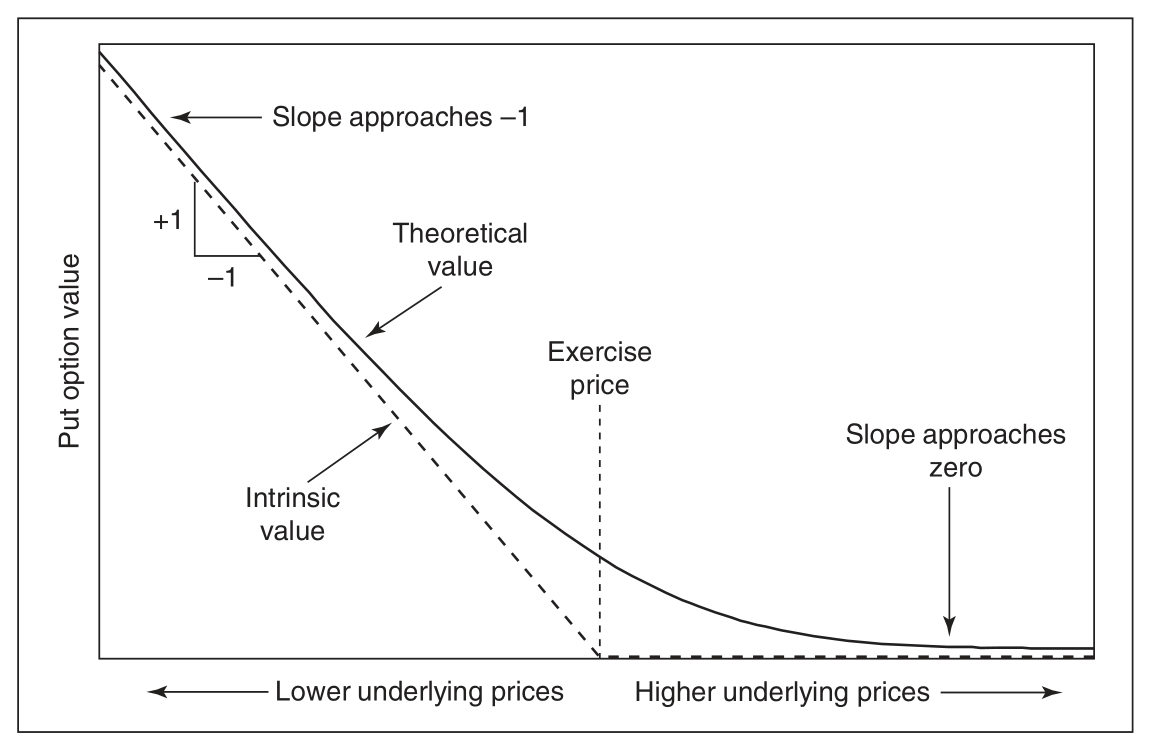
delta 随标的的变化
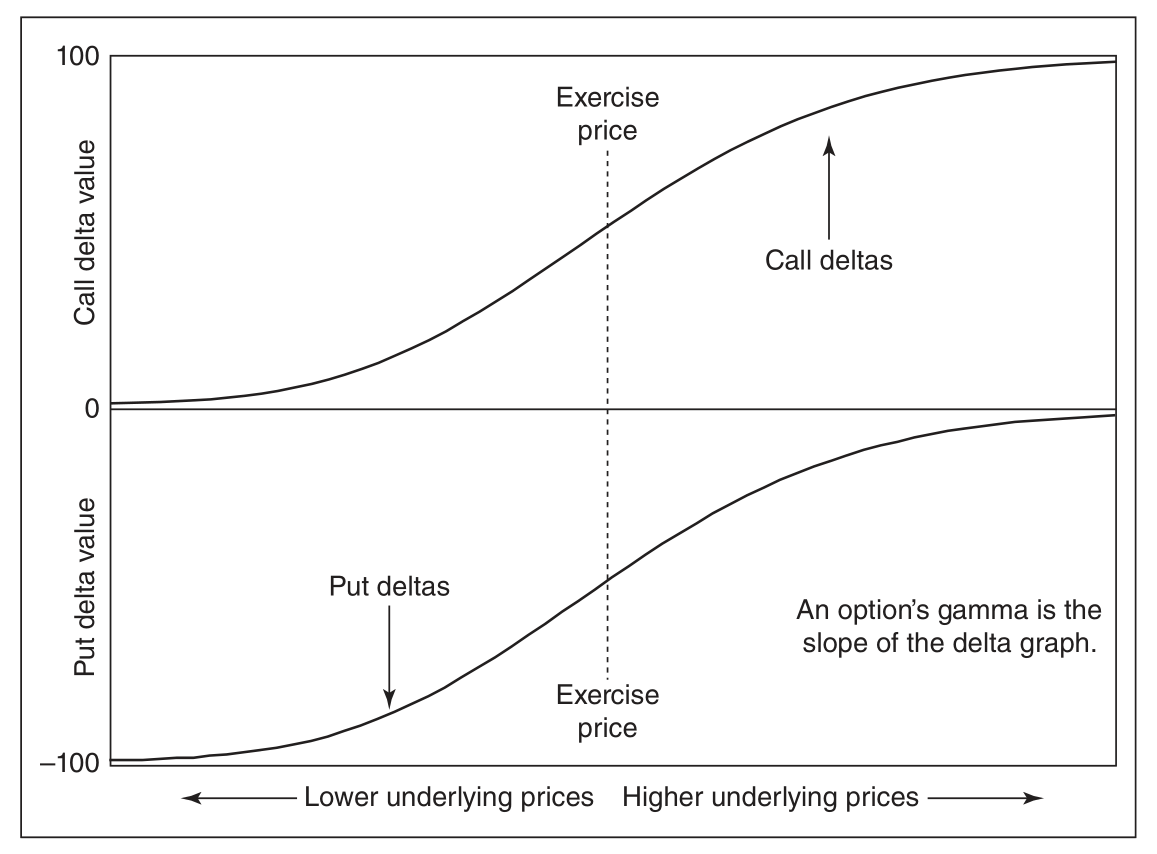
call_delta 随 volatility 的变化
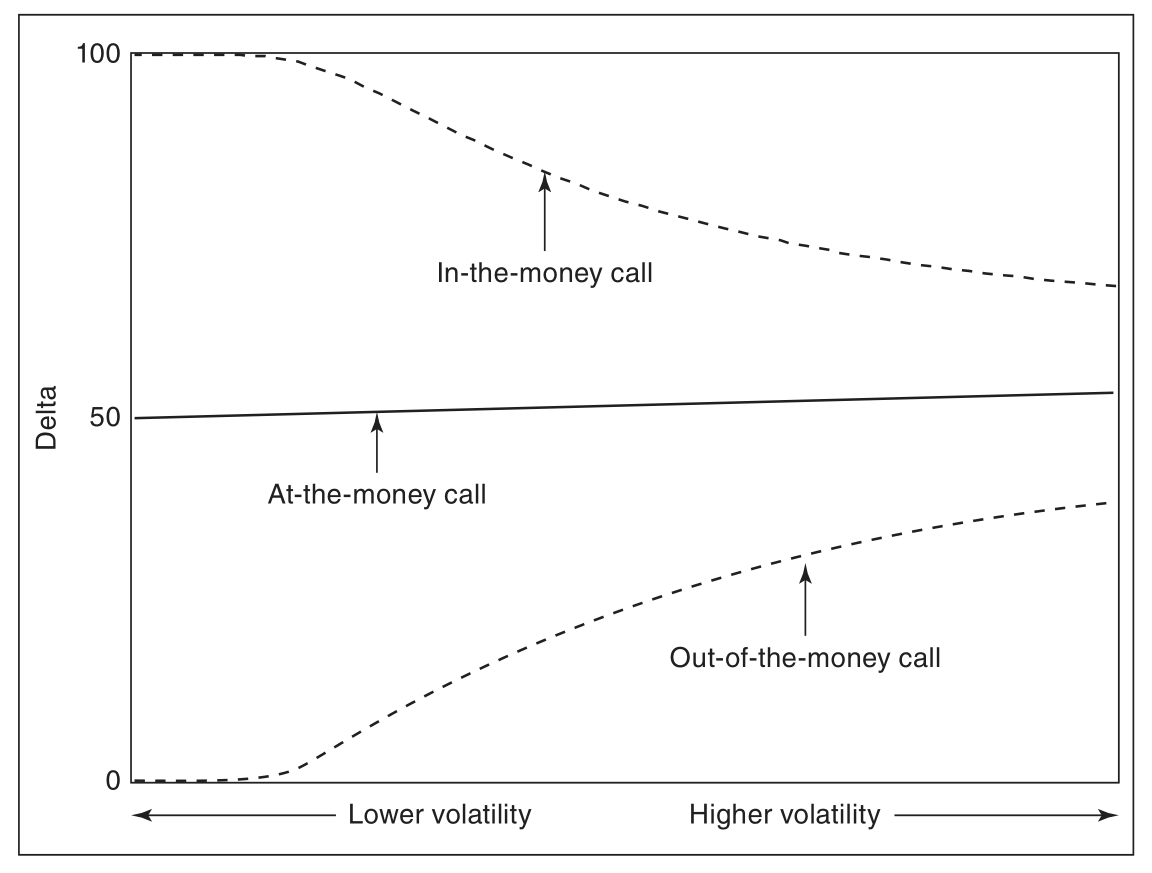
put_delta 随 volatility 的变化
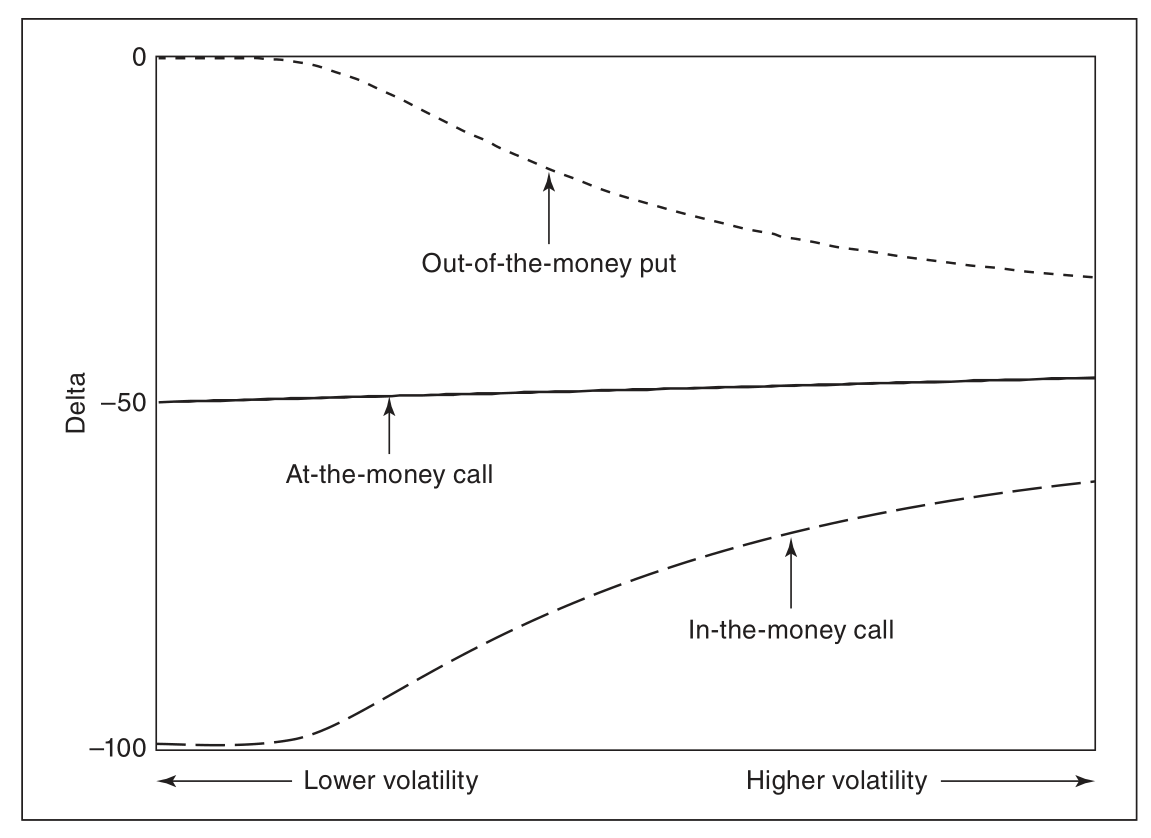
call_delta 随到期时间变化
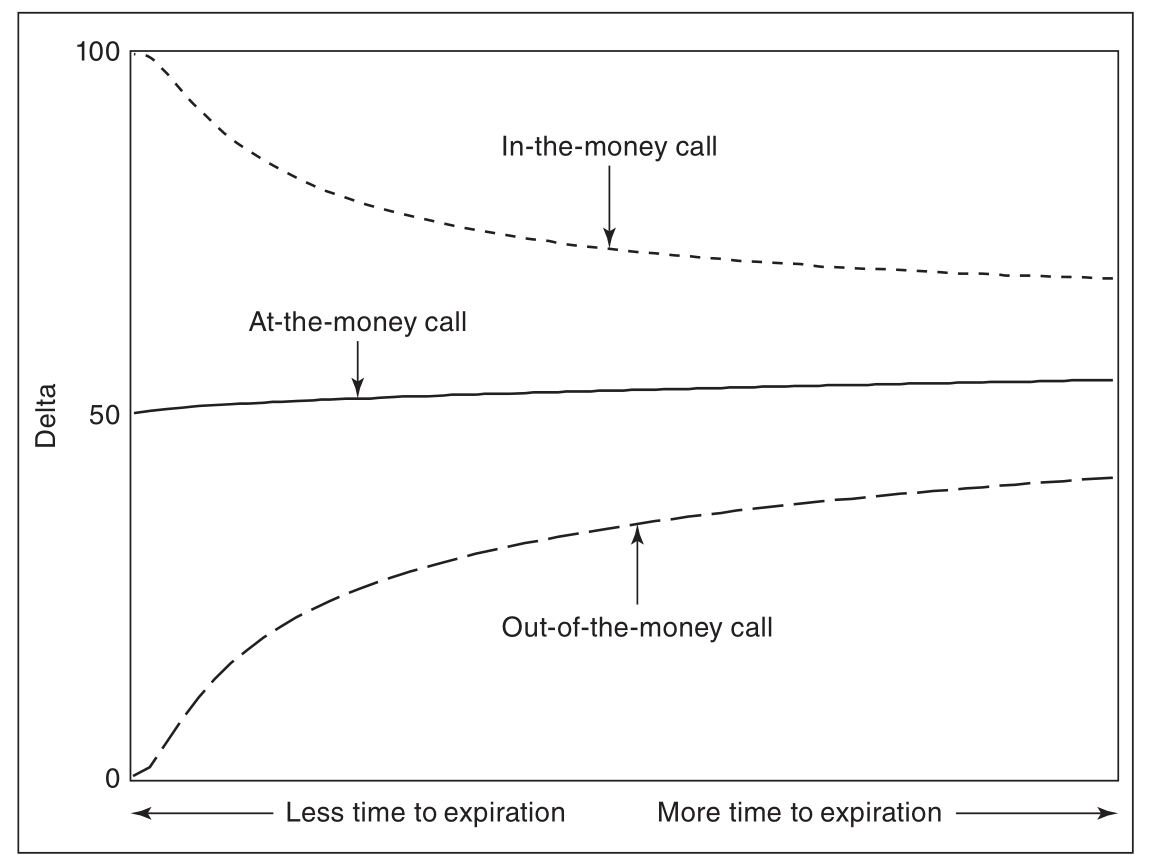
put_delta 随到期时间变化
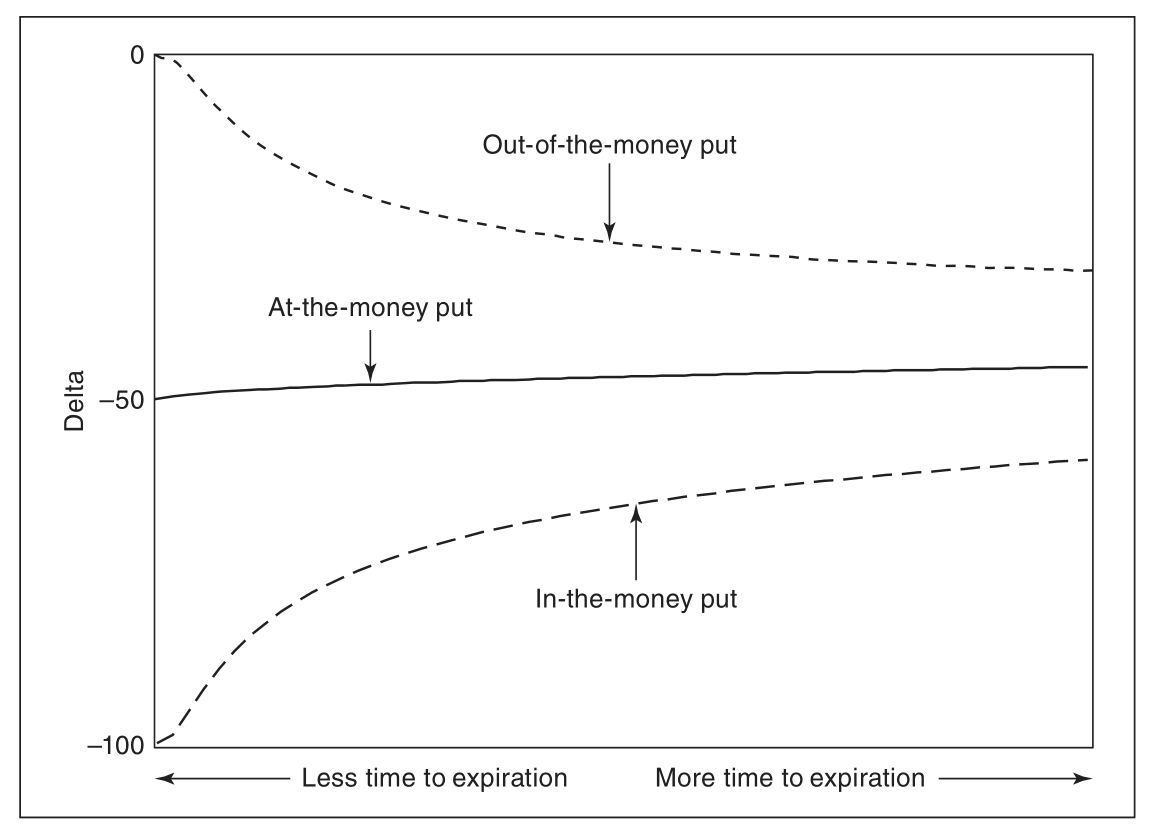
call_delta 随着时间推移或者波动率下降的变化
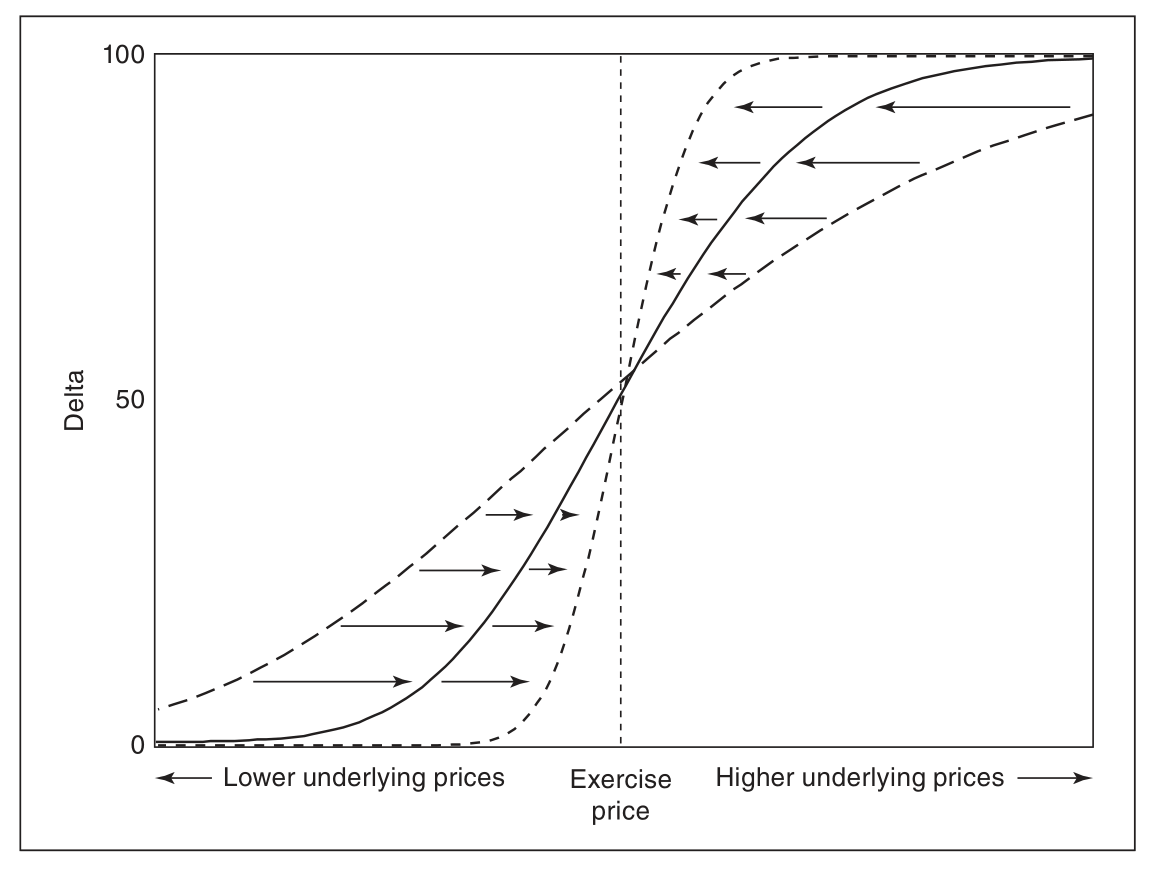
Vanna
Vanna:作为 Delta 对波动率的偏导,或者 Vega 对标的价格的偏导.
theta
theta:期权价格随着标的价格变化,此处取了绝对值(call 与 put 一样,都是负的!跟恒正 GAMMA 比较)
vega
gamma
恒正的 GAMMA:
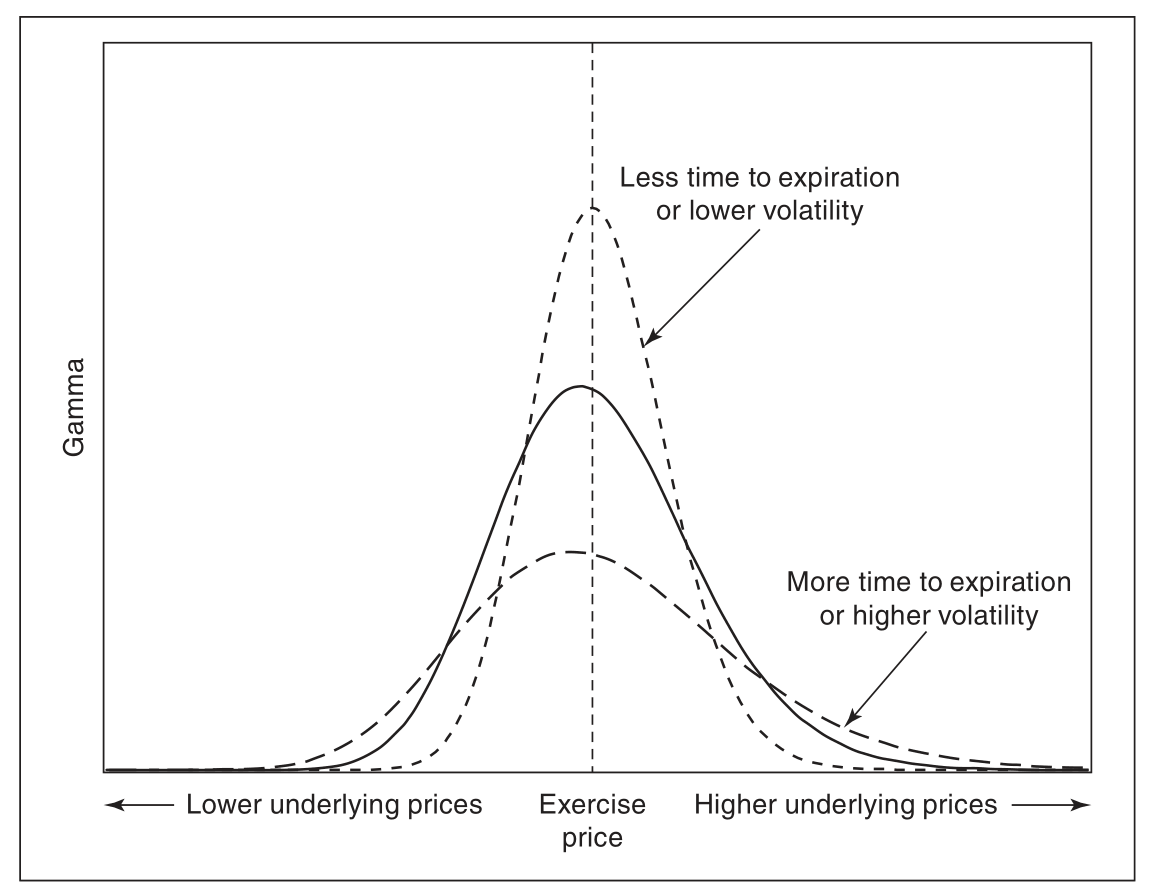
其中
3.0 随机分析几大基础定理
3.0.1 Radon–Nikodym
3.0.1.1 Radon-Nikodym 定理
测度空间 上定义有两个 -有限测度: 和 .定理表明:如果 (i.e. 关于 绝对连续),则存在一个 -可测函数 s.t. 可测集,
-有限: 是一个测度空间, 是上面一测度. 称为其上一个 -有限测度若 可以写成至多可列个有限测度集合的无交并.
绝对连续:实线上 Borel 子集上的测度 称为关于 Lebesgue 测度 绝对连续若对任何 的可测集 有 .记为 .
等价测度: 和 称为等价测度若 且 .
3.0.1.2 Radon-Nikodym 导数
上述函数 在几乎处处意义下唯一,通常写为 ,通常称为 Radon-Nikodym 导数.
3.0.2 Girsanov 定理
二次变差(quadratic variation):,,计算公式为 .
是 Wiener 概率空间 上的 Wiener 过程.令 是适应于 Wiener 过程生成的自然域流 的可测过程,.
定义 关于 的 Doléans-Dade exponential 如下: 其中 是 的二次变差.若 是严格正的鞅,那么可以定义 上的概率测度 s.t. 有 Radon-Nikodym 导数: 则对每个 , 限制在未扩充的 -域 上和 限制在 是等价的.进一步,若 是 下的局部鞅,那么过程 是 下的在 上的局部鞅.
推论:若 是连续过程, 是 下的布朗运动,那么: 是 下的布朗运动.
3.1 BS公式含义
Moneyness 指的是标的现价相对于行权价格的关系.下面考虑的是远期 F,
进行标准化后为:
下面我们记 ,故
标准的 moneyness 为如下均值: 大小关系为: 每级相差 ,这几项都在单位标准差内,所以把这几项转换成百分数,用标准正态的累计密度函数来评估.对这几个量的解释很精细(subtle),与风险中性测度有关.简单来说,有如下解释:
- 是二项 call option 的未来价值,或者风险中性下期权会在价内行权的可能性,with numéraire cash(风险中性资产)
- 是标准化的货币价值的百分比(概率?)
- 是 Delta,或者风险中性下期权会在价内行权的可能性,with numéraire asset(注意与上面的不同之处,cash 与 asset,债券与标的资产)
These have the same ordering, asis monotonic (since it is a CDF): 因为 是单调的(是一个CDF),他们有大小关系
3.2 计价单位的变换
wiki 概述:
在证券交易的金融市场中,计价单位的变换可以用来对资产定价.例如,若 exp 是 时刻投资在货币市场的 元在 时刻的价格,那么以货币市场定价的所有资产(记作 )在风险测度(记作 )下是鞅: 现在假定 是另一个严格正的交易资产(因此在货币市场的定价下是一个鞅),那么我们能根据 Radon-Nikodym 导数定义一个新的概率测度: 根据贝叶斯定理可以证明 关于新的计价单位 在 下是一个鞅:
知乎总结:
3.2.1 概述
在探讨计价单位变换之前,我们先来粗略的看一下这个公式长什么样子: ,这里 是一个计价单位 (Numéraire).乍一看,这个式子和风险中性定价公式 长得一模一样,只不过是将债券 替换为了另一个东西 ,然后从 测度下的期望变成了在 下的期望.
直观上来理解,就是这个意思,风险中性定价公式其实是以债券为计价单位,从而得出的资产的期望价值,那在某些情况下,我们也可以用其他资产作为计价单位,来对某些资产进行定价,或者是进行计算上的简化,这就是计价单位变换的动机所在.
其实可以看到,计价单位变换的本质,就是从一个 测度转化为另一个 测度,所以这个公式的核心,是找到连接两个测度的 Radon-Nikodym 导数 .
3.2.2 计价单位变换公式的推导
3.2.2.1 RN 导数的存在
这里我们想到的第一个问题是,对于任意一个给出的计价单位 ,存在这样的 RN 导数来定义测度 么?
这里我们需要注意的是,计价单位变换公式中,要求 是任意一个价格严格为正的资产,由先前的知识可以知道,这样的资产以债券计价时 (或者说以货币账户计价时) 是一个鞅,即 在测度 下是一个鞅,这样良好的性质,保证了 RN 导数 的存在性. >定理( 的存在性). 设测度 与 为 上的等价摡率测度,则存在 ,满足 ,且 .
根据这个定理,我们可以找到那个存在的 .可以验证,这样定义的 严格为正,且有 ,满足上述定理: 定义 RN 导数过程 ,可以证明 在原本的测度 下是一个 -鞅: (鞅性质).
3.2.2.2 RN 导数的性质
这里设 是由上一节中的定义 给出.
则在两个测度下期望的运算之间,可以用 RN 导数过程来联系.
设 为 -可测的随机变量.给定 ,则无条件期望之间的关系: 给出简单的证明: 更进一步的,给定 ,则条件期望之间的关系: 这里的其实是贝叶斯定理 (Abstract Bayes' Theorem) 的结论.
定理 (Abstract Bayes). 设 为 上的随机变量, 是 上由 导数 定义的测度.设 为 -代数且 ,则有: .
3.2.2.3 计价单位变换公式
首先我们有风险中性定价公式 ,接着根据定义的 RN 导数 ,可以得到:
对于 conditional on 的公式,根据 Abstract Bayes' Theorem 有:
3.2.2.4 新测度下的股价
根据这个计价单位变换公式,在实际运用时我们首先需要找到合适的计价单位 ,然后将风险中性定价公式中的 替换为 ,接着求一个在测度 下的期望 就可以了.
但要求出 ,我们还需要知道某个随机变量在 下的分布,或者说需要知道它新的 dynamics 是什么,此时还需要 Girsanov 定理来帮助我们找到 下的布朗运动 和 下的布朗运动之间的关系 .
定理 (Grisanov). 设 是 上的布朗运动, 为一个相适应的过程,定义指数鞅过程:,其中 是初值 的相适应的过程, 表示二次变差.则可以定义新的概率测度 .如果在概率测度 下 是一个布朗运动,那么: 在新的概率测度 下也是一个布朗运动.
我们这里以股价 为计价单位来运用 Girsanov 定理,找到 与 之间的关系.根据 的定义,有: 根据 Girsanov 定理,可以得到 ,于是在 下,对数价格 的 SDE 为:
3.2.3 一些栗子
根据风险中性公式, 0 时刻欧式看涨期权的价值应为: 此时,如果我们不想计算一个比较复杂的期望,则可以用 作为计价单位处理第一项,得到: 可以看到,我们其实是将原式转化为求事件 分别在 和 下的概率.
由上一节可以知道,在 下有 ,则:
此时可以很快的得到欧式看矤期权的定价公式:
上述推导也说明了, 表示在 下事件 的概率,即代表了在风险中性世界 中,该看涨期权在到期日被执行的概率,而 表示在 下事件 的概率,即 在以股价为计价单位的世界中,该看涨期权在到期日被执行的概率.
日内交易要点
杀伐果断!
- 时刻关注自己的仓位结构,行情有大变动时,根据当前的iv结构考虑是否进行移仓(有edge的话),例如已做买左卖右(负vanna),若行情向下走(iv此时涨)则迅速卖更左的put并挂单成交已有的左边put
- 标的走势表现出一定的趋势性时,(负gamma时)总delta保持与趋势同一方向,而不是被动的防守型delta,即如果趋势性上涨则保持一定的正delta而非保护性的负delta,因为趋势性上涨时保持正delta相当于先于行情布仓,符合我们顺势而为的思路
- 日内如果单向顺着行情做了一些vega,如果发现iv有掉头的趋势则应迅速平掉日内做的部分(大部分甚至全部)
- 接上条,如果已有昨仓,但是日内行情单项大幅变动,例如已有部分负vega,但是日内标的大跌iv大涨,则应立刻将vega买回,
- 极强负(正)相关时不要硬做正(负)vanna,
- 2023.4.20铁矿石,左边分位值很高,右边分位值很低,但是超强负相关,此时不能做正vanna,(如果要做应该做买左卖中偏左的负vanna?待重播)
- 临近到期时如果要买,先比较vega和theta,看预计的波动涨幅是否能够弥补theta亏损
- 临近到期时虚值多单可以卖掉
期权模型
随机波动率摘要
一. BS公式(Delta对冲下
BS部分参考知乎专栏:Black-Scholes 模型学习框架
假设股价满足 自融资资产组合(此处为期权价格的一个复制)价值变化为 对 ( 时刻衍生品的价值)做Ito公式,比较项的系数得到Delta 对冲下 的 BS 偏微分方程 (在比较系数过程中会使用到替换为,即为持有的债券份额为自融资总份额减去持有的标的份额,标的的持有量已经使用为) 终值条件(看涨期权)为 解即为 BS 公式 注意到 的漂移项 对期权定价没有影响.
BS公式解法(欧式call)
有考虑边界条件
注意到这是一个 Cauchy-Euler 方程,能通过下述变量代换将其转化为一个扩散方程 The solution of the PDE gives the value of the option at any earlier time, Black-Scholes PDE 变为一个扩散方程: 终值条件 现在变为了初值条件 其中 是 Heaviside 阶梯函数,
使用解给定了初值函数 的扩散方程的标准卷积法,得到 经过处理,得到: 其中 N 为正态分布累计密度函数,
BS model给出了期权价格的函数,作为一个波动率的函数.可以通过这个公式在给定期权价格时计算隐含波动率(implied volatility).但事实是 BS 波动率强烈依赖于欧式期权的到期日和行权价.
波动率微笑是指给定到期日下,隐含波动率与行权价(maturity)的关系.
二. Delta对冲
我们现在考虑用衍生品 和其标的资产 构建一个“无风险组合”,考虑这样的自融资组合 ,即每一单位的空头衍生品,我们用 单位多头的股票对其进行对冲 (Hedging),由于其自融资的特性,根据定义,我们有 ,将股价的 SDE 和上一节中通过伊藤-德布林公式求出的 带入这个式子,我们可以得到:
因为要使资产组合为无风险的,
>一个自融资组合 如果是无风险的,则可以表示为 ,且 .
1式即 Delta 对冲法则,将 带入2式我们再次得到 BlackScholes 偏微分方程: .
三. BS公式(风险中性定价下)
3.1 鞅
定义 在 上的随机过程 , ,称其是关于域流 的鞅,如果满足:
- 是 -适应的 (adapted);
- ;
- 对于 ,有 .
3.2 Radon-Nikodym导数
定义 设 和 为 上的等价测度,若 ,a.s.,且有 , 则称 是 关于 的 Radon-Nikodym 导数,记作: .
,即 ,其中 表示在测度 下的期望.进一步的,可以用条件期望定义R-N导数过程: .用鞅和RN导数过程的定义,可以简单的证明,R-N导数过程 是一个 -鞅.
3.3 资产的现值
用 表示风险资产的价值过程.首先要知道,在 模型的假设下,市场是完备 (Complete) 的,即任意资产 都可以被风险资产 和无风险资产 构成的组合所复制,即对任意一个 ,我们可以把它表示 为一个自融资组合: 可以看到该组合的收益率部分由组合的时间价值 与风险资产的超额收益 构成.我们考虑该资产的折现价值过程
3.4 鞅表示
定理(鞅表示) 设 是 上的布朗运动,而 为 -鞅, 且满足 ,则存在一个 适应的过程 ,使得 .
可以看到,如果 是鞅,那么 可以被表示为一个伊藤积分的形式,即没有 项而仅仅只有 项.再看我们的折现价值过程 ,如果想让它只有 项从而变成一个鞅,我们貌似只需要做变换: ,这样折现价值过程就可以被表示为: 但是,鞅表示定理有个非常非常重要的前提,就是你需要保证 这玩意儿是个伊藤积分,即 需要是一个布朗运动. 我们知道是布朗运动,但是经过这样变换过后的 还是布朗运动么,或者说我们需要如何选择新的测度, 来保证经过变换之后的 仍然是个布朗运动?
3.5 Girsanov定理
定理(Grisanov) 设 是 上的布朗运动 为一个相适应的过程, 定义指数鞅过程, 其中 是初值 的相适应的过程, 表示二次变差.则可以定义新的概率测度 .如果在概率测度 下 是一个布朗运动,那么: 在新的概率测度 下也是一个布朗运动.
这样一来, 我们就找到了新的测度和两个测度之下布朗运动之间的关系.我们看新定义的这个布朗运动:,它的实质是把资产的风险溢价项给消除了.风险溢价是什么?是对承担单位风险的补偿,在新的测度下风险溢价是没有补偿的,所以说在这个世界里,风险是中性的,因此我们把这样定义的新测度 称为风险中性测度,并且用 来表示.
3.6 风险定价公式
现在我们知道了变换公式 ,那么在风险中性测度 下,风险资产 所满足的 SDE 也需要进行相应的变化: 由此可见,在风险中性世界里,风险资产 (例如股票) 的收益率完全等于无风险收益率.
此时任意资产的折现价值过程可以被表示为: .我们知道 在 下是一个鞅,那么由鞅的性贡我们可以知道: . 常利率假设下有: .
假设我们需要对一个欧式看涨期权进行定价,我们知道该期权在到期日 的价值为 ,则有: 其中: 与PDE方法一致.
我们来总结一下 Risk-neutral Pricing 的几个步骤:
- 找到资产的折现价值过程;
- 作测度变换令这个折现价值在新的测度下为鞅;
- 用 Girsanov 定理找到新的变换;
- 利用鞅性质得到风险中性定价公式。
四. SDE WITH ANN
定价模型很重要的一点是能快速地根据现有或者历史价格校准模型.
四. 局部波动率
4.1 Dupire 的工作1994
局部波动率基于如下: 其中, 是 和 的确定性函数, 是固定的参数.在风险中性测度时, 下. 一旦 给定,那么模型也就定了.
Dupire(1994)证明了当给定了关于 (行权价) 和 (到期日) 的期权价格函数 时,局部波动率 是唯一确定的.
令 是如下定义的 的转移密度函数(transitional density function): >转移密度函数: at at ,指在 时刻 条件下在 时刻时 的分布 其中 代表风险中性测度.众所周知 满足倒向的 Fokker-Planck 方程: 其中 一维情形,Fokker-Planck 方程有两个参数,一是拓扑参数 ,另一是扩散
又可证它也满足前向的 Fokker-Planck 方程 其中 且 下面可推导 Dupire 方程,看涨期权的价格满足 其中 是 的风险中性测度.对(4.1)关于 做一次和二次微分,有
已知 满足前向 Fokker-Planck 方程 (4.1)对 微分,有 这里我们假设 与 无关,故我们得到了 Dupire 方程: Dupire 方程最大的优点是把局部波动率函数用期权价格和他们的微分表示出来了 以上结果扩展到了时间依赖的利率,我们只要将 替换为 即可.
局限性
- 可用的观测值是很少的
- 数值微分不可靠,二阶的更甚
确定方程的传统做法是二元样条插值,再对模型进行校准(calibration).
局部波动率作为瞬时方差的条件期望
考虑如下形式的一般的随机波动率模型 其中 远期价格 资产价格过程变为 考虑到 , 欧式看涨期权的 -forward 价格为 上式两端对 求微分 >其中 是 Heaviside函数, 是Dirac函数, , .
对最终的支付应用 Ito 公式并令 有 两侧取条件期望 ,有 上式用到了 鞅的性质.接下来 第二个等式是条件期望公式的一个推广: 或者 因为 故有 进行比较,可知对应的局部波动率模型为 也就是说,局部方差是以最终股票价格 等于行权价 为条件的瞬时方差的风险中性期望.
五. 随机局部波动率模型
5.1 Jex的随机局部波动率模型1999
其中 和 应该是无风险利率减股息收益, 是随机波动率部分, 是波动率的均值回复的平衡点. >Heston随机波动率模型:,.或者()
注意到如果没有 这一项,模型即为Heston模型,而当 为 时模型即为Dupire.
5.2 GAN基于LOCAL_STOCHASTIC_VOLATILITY
This means parameterizing the model pool in a way which is accessible for machine learning techniques and interpreting the inverse problem as a training task of a generative network, whose quality is assessed by anadversary.We pursue this approach in the presentarticle and use as generative models so-called neural stochastic differential equations (SDE),which just means to parameterize the drift and volatility of an Itˆo-SDE by neural networks.
文中指的neural SDE即通过神经网络来对Ito-SDE的漂移项和波动率进行参数化.
这里考虑的某资产的折现后价格过程(discounted price process) :
其中 是某个 中取值的随机过程, 称为杠杆函数(Leverage function)取决于 和资产当前价格.
的选取非常重要,需要很好地校准市场上观测到的隐含波动率.故 需要满足如下条件:
其中 指 Dupire 的local volatility function.注意到(1.1)是 的隐式方程,因为 中需要 .故此时 满足的SDE也成为了一个McKean-Vlasov SDE.
本文采用了 an alternative,fully data-driven 方法,规避了其他计算 Dupire 局部波动率的方法中必须的对波动率曲面插值的做法,即此方法只需离散数据.
令 , 为不同期权的到期日.使用神经网络族 将杠杆函数参数化,参数为 ,i.e.
于是有了neural SDE的生成模型组(generative model class),即使用带参数 的神经网络来参数化漂移项 和波动率项 ,i.e.
本文中,没有漂移项,波动率项如下所示:
依次对每个到期日,参数优化采用如下的校准法则: 其中 是期权的数目, 和 是模型与市场分别的价格.
对固定的 , 是非线性非负凸函数满足 且 对 ,衡量模型和市场价的距离. 某种权重,参数 扮演了对抗(adversarial)的部分,注意到 和 都受 控制.
Rough Volatility
Bergomi's model revisited
Variance swap
A variance swap with maturity is a contract which pays out the realized variance of the logarithmic total returns up to less a strike called the variance swap rate , determined in such a way that the contract has zero value today.
The annualized realized variance of a stock price process for the period with business days is usually defined as The constant denotes the number of trading days per year and is usually fixed to 252 so that . We assume the market is arbitrage-free and prices of traded instruments are represented as conditional expectations with respect to an equivalent pricing measure .
A standard result gives that as , we have
when is a continuous semimartingale.
Approximating the realized variance by the quadratic variation of the log returns works very well for variance swaps, but care should be taken in practise if we price short dated non-linear payoffs on realized variance. Denote by , the price at time of a variance swap with maturity . It is given under by
We define the forward variance curve as Note that, if we assume that the S&PX index follows a diffusion process, with a general stochastic volatility process, , the forward variance is given by It can be seen as the forward instantaneous variance for date , observed at . In particular
The current price of a variance swap, , is given in terms of the forward variances as The models used in practice are based on diffusion dynamics where forward variance curves are given as a functional of a finite-dimensional Markov-process: where the function and the m-dimensional Markov-process satisfy some consistency condition, which essentially ensures that for every fixed maturity , the forward variance is a martingale.
※ Pricing under rough volatility ※
ATM volatility skew
其中 是离到期日的时间, 是log-strike.在传统随机波动率模型中, 对短期时间是常数,对长时间与 成反比.经验上观测到 对某些 与 成比例.
forward variance curve
表示 时刻瞬时方差.则 forward variance curve 为:
Wick exponential
对零均值的 Gaussian R.V. ,其 Wick exponential 为
这里只作记号使用,不涉及其运算.
模型推导
Gatheral et al. (2014) 发现已实现方差(realized variance) 与如下模型一致
其中 是 fBm.This relationship was found to hold for all 21 equity indices in the Oxford-Man database, Bund futures, Crude Oil futures, and Gold futures. Perhaps this feature of the time series of volatility is universal?
考虑 fBm 的 Mandelbrot-Van Ness 表示
其中 , 这样选取是为了保证
将 (2)带入(1)并由 ,可以得到 基于 physical measure 的变化:
注意到 是 -可测,而 与 独立且是 Gaussian with mean zero and variance . 用如下记号: 和 有相同分布,仅仅方差变为 .记 则有 且 结合 Wick expenential 这里,由 1 式可知 依赖 的整个历史,所以 是 non-Markovian.而 2 式表示 the conditional distribution of depends on only through the instantaneous variance forecasts
总结,得到如下模型基于实际概率测度 : 其中,两个布朗运动 和 相关系数为 .
Pricing under Q
期权在 t 时刻的定价基于等价鞅测度 on s.t. 资产价格过程 在 下是一个鞅.
在固定的时间域 中,通过 Girsanov 变换, 使得
另一方面 由 而来,而 是一个布朗运动与 以如下关系相关, 其中 是一对独立的标准布朗运动.对第二项的一个标准的测度变换为 其中 ,for ,是一个合适的适应过程,称为波动率风险的市场价格.所以有 将其重写为 由 4 ,在 下, 特别的, 适应于由 生成的域流(和由 生成的域流一致).把上式重写为 指数中的最后一项明显改变了 的边缘分布.虽然 在 下的条件分布是对数正态的,它在 下不是对数正态.
rBergomi model
考虑最简单的测度变换, assuming for simplicity, resp. as a first approximation, 是关于 的确定性函数.则由 6 我们有 其中 .进一步有 forward variance curve
是如下两项的乘积: 依赖于驱动布朗运动的历史;另一项依赖于风险价格 .
模型 7 是 non-Markovian 因为 .
※on deep calibration of rough sv model※
一.介绍
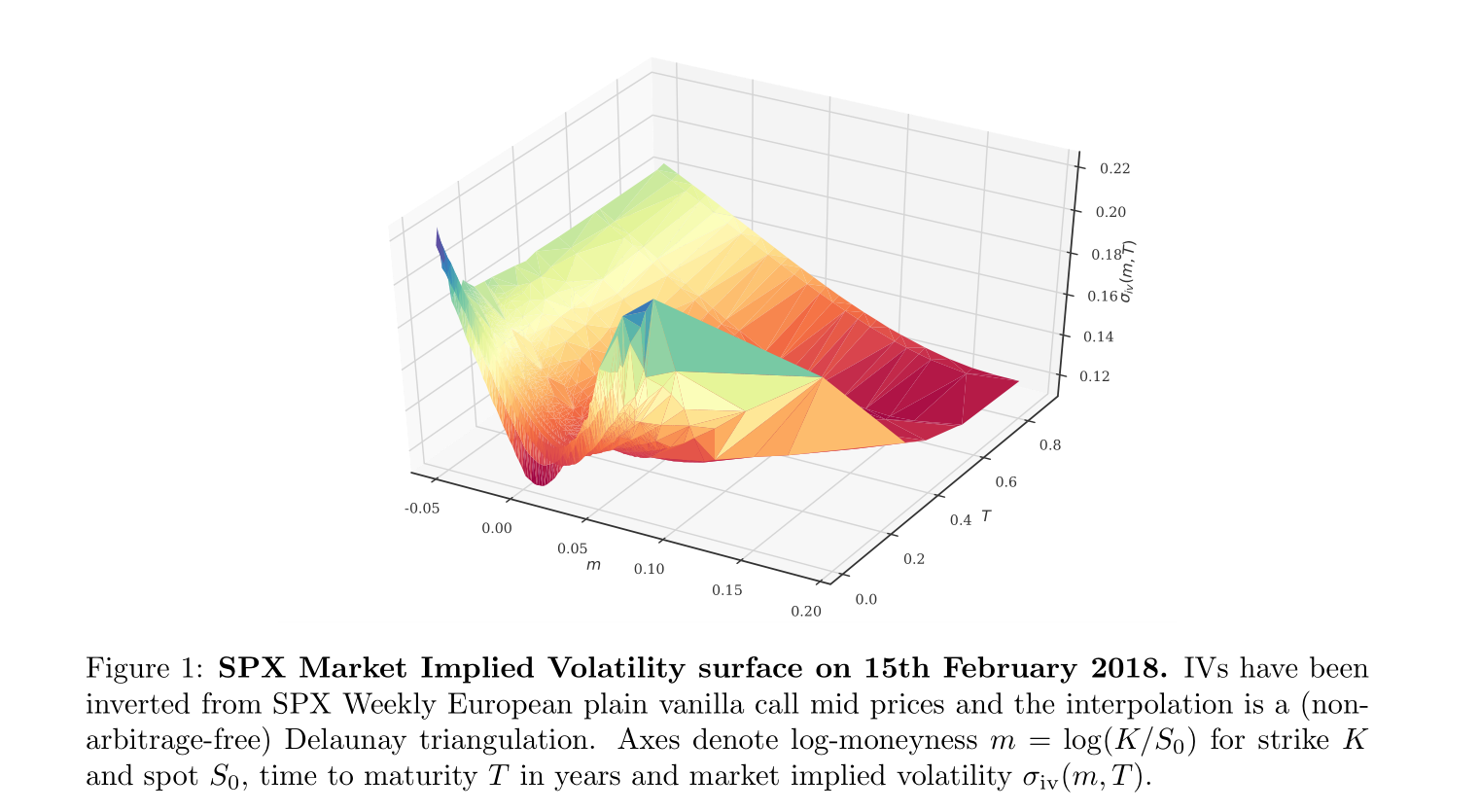
从隐含波动率按 moneyness 和 maturity 的变化可以观察到存在着著名的 smiles 和 at-the-money(ATM) skews 现象,与 BS 公式相悖.特别的,Bayer, Friz, and Gatheral 经验性地表明 ATM skew 符合如下形式:
其中 为 moneynessand , 为 time to maturity .
根据 Gatheral ,扩散的随机波动率模型不能复现当 time to maturity 趋于零时 volatility skew 的幂指数爆炸现象,反而表现为常数现象.
RSV 可定义为一族连续路径的随机波动率模型,其瞬时波动率由一个 Holder 正则性比布兰运动小的随机过程驱动,通常刻画为 Hurst 系数 H<1/2 的分形布朗运动.
这种范式转变的证据现在是 overwhelming ,一方面在物理测度下,时间序列分析表明对数已实现波动率的 Holder 正则为 0.1 阶;另一方面,在定价测度下经验性观察也表明在零附近由模型能够生成 power-law behaviour 的 volatility skew.
模型的一大难点来自于分形布朗运动的非马尔科夫性.
本文介绍两种方法
- one-step approach : 直接学习从隐含波动率曲面到模型参数的映射,
- two-step approach : 第一步学习从模型参数到期权价格的映射,然后根据实际市场价格校准模型.又分为 point-wise approach 和 grid-wise approach,前者将行权价和到期日作为输入,后者事先设定好这两项.
二.模型校准概述(未使用神经网络)
校准(calibration)意思是调整模型参数以使得模型曲面符合由欧式期权通过BS公式计算出的经验隐含波动率曲面.
假设模型有一个参数集 决定, i.e.,由 .进一步,我们假设期权由参数集 决定.E.g.,对看涨看跌期权我们有 ,分别为到期日和 log-moneyness.有些参数由市场观测得到,如现价、利率等,不在校准过程中.定价映射为 带参数 的模型中带参数 的期权的价格.我们通过 给定了有限子集 以及所有可能的期权参数对应的期权价格.校准是决定模型参数以使模型价格 和市场价格 在给定距离度量下最小,i.e.:
事实上,最常用的 是加权最小二乘: 这里的权重 反映了 对应期权的重要性以及 的可靠性.例如可以选择 bid-ask spread 的倒数.
只要模型参数比 少,此时就是超定(overdetermined)的非线性最小二乘问题,通常采用数值迭代的方法解决,如 Levenberg-Marquardt(LM)算法.
rBergomi :表示为 ,参数 ,例如可以设为 模型基于如下系统 其中 是 Hurst 系数,, 是 Wick exponential, 表示初始forward variance curve, 和 是以 相关的布朗运动.
三.深度校准
3.1 one-step approach
Hernandez A. Model calibration with neural networks[J]. Available at SSRN 2812140, 2016.
直接学习校准过程,即将模型参数视作市场价格(隐含波动率)的函数,i.e. 更具体地,训练神经网络基于标签数据 , 及其对应标签
3.2 two-step approach
首先学习定价映射,将模型参数映射为市场价格(或隐含波动率),然后使用标准校准方法进行校准.我们用 表示 是 的通过神经网络得到的近似.然后第二步我们进行校准
两步方法相较而言最大的好处如下:
- 神经网络只负责期权定价,所以能用人工数据来训练.
- 自然地将误差分为定价误差和模型误差.神经网络表现和模型对市场适应性做出的调整相互独立.
3.2.1 two-step approach: 逐点训练(pointwise)和基于网格(grid-based)训练
In this section, we examine its advantages and present an analysis of the objective function with the goal to enhance learning performance. Within this framework, the pointwise approach has the ability to asses the quality of using Monte Carlo or PDE methods, and indeed it is superior training in terms of robustness.
Pointwise learning
step 1:学习映射 即上述(2)式令 .在标准化期权(vanilla option,)情况下,我们可以直接学习隐含波动率映射 ,而不是期权定价的映射 .用 表示神经网络,最优化问题如下:
Step 2: 解决经典的模型校准步骤:
这里 或者 被替换成 step1 中的近似网络 .
第一步中,关键在于训练数据和网络结构的选择.训练数据在于选择 和 的‘先验’的、有实际意义的分布.
Implicit & grid-based learning
用 记关于到期日和行权价的网格.则
step 1:学习映射 ,输入是 ,输出是 这样的 网格. 取值在 中,其中 strikes maturities 最优化问题变为如下: 其中 . Step 2:
这里期权的参数 是固定了的,不再是学习的一部分.
3.2.2 pointwise versus grid-based
- 最大的不同在于 grid-based 在遇到不在网格上的 T,K 时需要手动插值
- grid-based 方法自然地有 reduction of variance ,
- pointwise 中对使样本符合实际金融数据的操作更简单,改变采样的分布.而 grid-wise 则是通过改变权重或者网格密度.
- grid-based 方法可以看做是一种降低维度的操作,将输入的维度转移到了输出的维度.
四.Pratical implementation
4.1 网络结构与训练
- 隐藏层为 3 层的全连接前馈神经网络,每层 30 个结点
- 输入维度记
- 输出维度为
- 总共有 个参数.
- 激活函数选择 Elu, ,梯度下降选择 Adam.
4.2 校准
使用第二节中讲的 LM 等算法.
五.数值实验
5.1定价近似网络的速度和精确度
※Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough)volatility models※
fBm的 Monte-Carlo 模拟
1.理论基础
Notations: 在单位区间 表示连续函数空间, 表示 -Hölder 连续函数空间, . 和 是 上连续可微和有界连续可微函数空间.
1.1. Hölder spaces and fractional operators
For , the -Hölder space , with the norm is a non-separable Banach space. Following the spirit of Riemann-Liouville fractional operators recalled in Appendix , we introduce the class of Generalised Fractional Operators (GFO). For any we introduce the intervals , and the space , for any
Definition 1.1. For any and , the GFO associated to is defined on as We shall further use the notation , for any . Of particular interest in mathematical finance are the following kernels and operators:
Proposition 1.2. For any and , the operator is continuous.
We develop here an approximation scheme for the following system, generalising the concept of rough volatility in the context of mathematical finance, where the process represents the dynamics of the logarithm of a stock price process: with , and the (strong) solution to the stochastic differential equation
where denotes the state space of the process , usually or The two Brownian motions and , defined on a common filtered probability space , are correlated by the parameter , and the functional is assumed to be smooth on This is enough to ensure that the first stochastic differential equation is well defined. It remains to formulate the precise definition for (Proposition 1.4) to fully specify the system (1.3) and clarify the existence of solutions. Existence and (strong) uniquess of a solution to the second in (1.4) is guaranteed by the following standard assumption :
Assumption 1.3. There exist such that, for all
Proposition 1.4. For any ,the equality holds almost surely for .
Example 1.5. This example is the rough Bergomi model introduced by Bayer, Friz and Gatheral, where with and is the Wick stochastic exponential. This corresponds exactly to with and
1.2 The approximation scheme
We now move on to the core of the project, namely an approximation scheme for the system (1.3). The basic ingredient to construct approximating sequences is a family of iid random variables, which satisfies the following assumption: Assumption 1.6. The family forms an iid sequence of centered random variables with finite moments of all orders and
Following Donsker and Lamperti, we first define, for any , the approximating sequence for the driving Brownian motion as As will be explained later, a similar construction holds to approximate the process : where and Here and satisfy Assumption , with appropriate correlation structure between the pairs that will be made precise later. We shall always use to denote the sequence generating and the one generating . Consequently, we deduce an approximating scheme (up to the interpolating term which decays to zero by Chebyshev's inequality) for as All the approximations above, as well as all the convergence statements below should be understood pathwise, but we omit the dependence in the notations for clarity. The main result here is a convergence statement about the approximating sequence . As usual in weak convergence analysis, convergence is stated in the Skorokhod space of càdlàg processes equipped with the Skorokhod topology. Theorem 1.7. The sequence converges weakly to in . The construction of the proof allows to extend the convergence to the case where is a -dimensional diffusion without additional work. The proof of the theorem requires a certain number of steps: we start with the convergence of the approximation in some Hölder space, which we translate, first into convergence of the stochastic integral in , then, by continuity of the mapping , into convergence of the sequence . All these ingredients are detailed in Section 1.3 below. Once this is achieved, the proof of the theorem itself is relatively straightforward.
1.3. Monte-Carlo.
Theorem 1.7 introduces the theoretical foundations of Monte-Carlo methods (in particular for path-dependent options) for rough volatility models. In this section we give a general and easy-to-understand recipe to implement the class of rough volatility models (1.3). For the numerical recipe to be as general as possible, we shall consider the general time partition on with .
Algorithm 1.8 (Simulation of rough volatility models). (1) Simulate two matrices and with ; (2) simulate M paths of viad and also compute (3) Simulate paths of the fractional driving process using The complexity of this step is in general of order (see Appendix for details). However, this step is easily implemented using discrete convolution with complexity (see Algorithm [B.4 in Appendix for details in the implementation). With the vectors and for , we can write , for , where represents the discrete convolution operator. (4) Use the forward Euler scheme to simulate the log-stock process, for all , as
Remark:
- When , we may skip step (2) and replace by on step (33).
- Step (3) may be replaced by the Hybrid scheme algorithm 11 only when .
Antithetic variates in Algorithm 1.8 are easy to implement as it suffices to consider the uncorrelated random vectors and , for Then and , for , constitute the antithetic variates, which significantly improves the performance of the Algorithm 1.8 by reducing memory requirements, reducing variance and accelerating execution by exploiting symmetry of the antithetic random variables.
1.3.1 Enhancing performance. A standard practice in Monte-Carlo simulation is to match moments of the approximating sequence with the target process. In particular, when the process is Gaussian, matching first and second moments suffices. We only illustrate this approximation for Brownian motion: the left-point approximation may be modified to match moments as where is chosen optimally. Since the kernel is deterministic, there is no confusion with the Stratonovich stochastic integral, and the resulting approximation will always converge to the Itô integral. The first two moments of read The first moment of the approximating sequence 1.8 is always zero, and the second moment reads Equating the theoretical and approximating quantities we obtain for , so that the optimal evaluation point can be computed as In the Riemann-Liouville fractional Brownian motion case, , and the optimal point can be computed in closed form as
1.3.2 Reducing Variance.
As Bayer, Friz and Gatheral, a major drawback in simulating rough volatility models is the very high variance of the estimators, so that a large number of simulations are needed to produce a decent price estimate. Nevertheless, the rDonsker scheme admits a very simple conditional expectation technique which reduces both memory requirements and variance while also admitting antithetic variates. This approach is best suited for calibrating European type options. We consider and the natural filtrations generated by the Brownian motions and In particular the conditional variance process is deterministic. As discussed by Romano and Touzi, and recently adapted to the rBergomi case by McCrickerd and Pakkanen, we can decompose the stock price process as and notice that Thus becomes log-normal and the Black-Scholes closed-form formulae are valid here (European, Barrier options, maximum,...). The advantage of this approach is that the orthogonal Brownian motion is completely unnecessary for the simulation, hence the generation of random numbers is reduced to a half, yielding proportional memory saving. Not only this, but also this simple trick reduces the variance of the Monte-Carlo estimate, hence fewer simulations are needed to obtain the same precision. We present a simple algorithm to implement the rDonsker with conditional expectation and assuming that .
Algorithm 1.9 (Simulation of rough volatility models with Brownian drivers). Consider the equidistant grid . (1) Draw a random matrix with unit variance, and create antithetic variates ; (2) Create a correlated matrix as above; (3) Simulate paths of the fractional driving process using discrete convolution: and store in memory for each (4) use the forward Euler scheme to simulate the log-stock process, for each , as (5) Finally, we have for we may compute any option using the Black-Scholes formula. For instance a Call option with strike would be given by for , where and Thus, the output of the model would be
The algorithm is easily adapted to the case of general diffusions as drivers of the volatility (see Algorithm 1.8 step 2). Algorithm 1.8 is obviously faster than 1.9, especially when using control variates. Nevertheless, with the same number of paths, Algorithm 1.9 remarkably reduces the Monte-Carlo variance, meaning in turn that fewer simulations are needed, making it very competitive for calibration.
2.传统cholesky分解法模拟
If you need to generate correlated Gaussian distributed random variables where is the vector you want to simulate, the vector of means and the given covariance matrix, 1.you first need to simulate a vector of uncorrelated Gaussian random variables, 2.then find a square root of , i.e. a matrix such that . Your target vector is given by A popular choice to calculate is the Cholesky decomposition.
而对于本 rBergomi 模型,
where is a Volterra processt with the scaling property . So far behaves just like . However, the dependence structure is different. Specifically, for where, for and with , where denotes the confluent hypergeometric function. Remark The dependence structure of the Volterra process is markedly different from that of with the MolchanGolosov kernel given by for some constant In particular, for small , correlations drop precipitously as the ratio moves away from 1 .
We also need covariances of the Brownian motion with the Volterra process . With , these are given by and where for future convenience, we have defined the constant, These two formulae may be conveniently combined as Lastly, of course, for . With the number of time steps and the number of simulations, our rBergomi model simulation algorithm may then be summarized as follows.
- Construct the joint covariance matrix for the Volterra process and the Brownian motion and compute its Cholesky decomposition.
- For each time, generate iid normal random vectors and multiply them by the lower triangular matrix obtained by the Cholesky decomposition to get a matrix of paths of and with the correct joint marginals.
- With these paths held in memory, we may evaluate the expectation under of any payoff of interest.
we simulate the process
import numpy as np
import matplotlib.pyplot as plt
import scipy.special as special
def fBm_path_chol(grid_points, M, H, T):
"""
@grid_points: # points in the simulation grid
@H: Hurst Index
@T: time horizon
@M: # paths to simulate
"""
assert 0<H<1.0
## Step1: create partition
X=np.linspace(0, 1, num=grid_points)
# get rid of starting point
X=X[1:grid_points]
## Step 2: compute covariance matrix
Sigma=np.zeros((grid_points-1,grid_points-1))
for j in range(grid_points-1):
for i in range(grid_points-1):
if i==j:
Sigma[i,j]=np.power(X[i],2*H)/2/H
else:
s=np.minimum(X[i],X[j])
t=np.maximum(X[i],X[j])
Sigma[i,j]=np.power(t-s,H-0.5)/(H+0.5)*np.power(s,0.5+H)*special.hyp2f1(0.5-H, 0.5+H, 1.5+H, -s/(t-s))
## Step 3: compute Cholesky decomposition
P=np.linalg.cholesky(Sigma)
## Step 4: draw Gaussian rv
Z=np.random.normal(loc=0.0, scale=1.0, size=[M,grid_points-1])
## Step 5: get V
W=np.zeros((M,grid_points))
for i in range(M):
W[i,1:grid_points]=np.dot(P,Z[i,:])
#Use self-similarity to extend to [0,T]
return W*np.power(T,H)
3.rDonker方法
def fBm_path_rDonsker(grid_points, M, H, T, kernel="optimal"):
"""
@grid_points: # points in the simulation grid
@H: Hurst Index
@T: time horizon
@M: # paths to simulate
@kernel: kernel evaluation point use "optimal" for momen-match or "naive" for left-point
"""
assert 0<H<1.0
## Step1: create partition
dt=1./(grid_points-1)
X=np.linspace(0, 1, num=grid_points)
# get rid of starting point
X=X[1:grid_points]
## Step 2: Draw random variables
dW = np.power(dt, H) *np.random.normal(loc=0, scale=1, size=[M, grid_points-1])
## Step 3: compute the kernel evaluation points
i=np.arange(grid_points-1) + 1
# By default use optimal moment-matching
if kernel=="optimal":
opt_k=np.power((np.power(i,2*H)-np.power(i-1.,2*H))/2.0/H,0.5)
# Alternatively use left-point evaluation
elif kernel=="naive" :
opt_k=np.power(i,H-0.5)
else:
raise NameError("That was not a valid kernel")
## Step 4: Compute the convolution
Y = np.zeros([M, n])
for i in range(int(M)):
Y[i, 1:n] = np.convolve(opt_k, dW[i, :])[0:n - 1]
#Use self-similarity to extend to [0,T]
return Y*np.power(T,H)
※使用GAN对LSV模型的校准※
This means parameterizing the model pool in a way which is accessible for machine learning techniques and interpreting the inverse problem as a training task of a generative network, whose quality is assessed by anadversary.We pursue this approach in the presentarticle and use as generative models so-called neural stochastic differential equations (SDE),which just means to parameterize the drift and volatility of an Itˆo-SDE by neural networks.
1.介绍
文中指的neural SDE即通过神经网络来对Ito-SDE的漂移项和波动率进行参数化.
这里考虑的某资产的折现后价格过程(discounted price process) :
其中 是某个 中取值的随机过程, 称为杠杆函数(Leverage function)取决于 和资产当前价格.
的选取非常重要,需要很好地校准市场上观测到的隐含波动率.故 需要满足如下条件:
其中 指 Dupire 的local volatility function.注意到(1.1)是 的隐式方程,因为 中需要 .故此时 满足的SDE也成为了一个McKean-Vlasov SDE.
本文采用了 fully data-driven 方法,规避了其他计算 Dupire 局部波动率的方法中必须的对波动率曲面插值的做法,即此方法只需离散数据.
令 , 为不同期权的到期日.使用神经网络族 将杠杆函数参数化,参数为 ,i.e.
于是有了neural SDE的生成模型组(generative model class),即使用带参数 的神经网络来参数化漂移项 和波动率项 ,i.e.
本文中,没有漂移项,波动率项如下所示:
依次对每个到期日,参数优化采用如下的校准法则: 其中 是期权的数目, 和 是模型与市场分别的价格.
对固定的 , 是非线性非负凸函数满足 且 对 ,衡量模型和市场价的距离. 某种权重,参数 扮演了对抗(adversarial)的部分,注意到 和 都受 控制.本文中 采用的是 Cont R, Ben Hamida S. Recovering volatility from option prices by evolutionary optimization[J]. 2004.中的 vega-type.
2.VARIANCE REDUCTION FOR PRICING AND CALIBRATION VIA HEDGING AND DEEP HEDGING
介绍在蒙特卡洛定价和校准中利用对冲投资组合作为控制变量的方差缩减技术.在 LSV 校准中非常重要.
考虑有限时域 ,已折现的市场中有 个交易中的金融产品 ,它是在某个概率空间 上在 中取值的随机变量. 是风险中性测度, 假设是右连续的.特别的,假设 是有右连左极路径的 维平方可积鞅.
令 是 可测的随机变量,表示表示某个欧式期权在到期日 的支付.那么通常的对这个期权价格的 Monte Carlo 估计是: 其中, 是以分布 , i.i.d 的.可以简单改造这个估计,加上关于 的随机积分.考虑一个策略 和某个常数 .用 记关于 的随机积分,考虑如下估计: 其中, 是以分布 i.i.d 的.则对于任意的 和 ,这个估计仍是期权价格的无偏估计,因为随机积分的期望消失了.记 则 的方差为: 在以下取法下达到最小 此时 特别地,在沿路径完美对冲的情形下, a.s.,有 和 ,此时 因此,找到一个好的近似对冲投资组合使得 大是很重要的.
2.1 Black&Scholes Delta Hedge
In many cases, of local stochastic volatility models as of form (1.1) and options depending only on the terminal value of the price process, a Delta hedge of the BlackâĂŞScholes model works well.
令 , 是 BS 模型下 时刻的价格.对冲策略为:
2.2 Hedging Strategies as Neural Networks-Deep Hedging
在对冲产品数很多等情况下时,可以将对冲策略用神经网络参数化.令期权的支付是对冲产品最终价值的函数,i.e.,.在马尔科夫模型中,可以用函数表示对冲策略: 对应这样一个神经网络:. 是网络参数.根据Buehler H, Gonon L, Teichmann J, et al. Deep hedging[J]. Quantitative Finance, 2019, 19(8): 1271-1291. 给定 的最优对冲可以如下计算 是凸的损失函数.
为了解决这个最优问题,采用随机梯度下降,随机目标函数 为: 记最优的参数 和最优对冲策略 .
假定激活函数和凸损失函数是光滑的.下面要证明 的梯度是: i.e.,我们可以把梯度移到随机积分中.为此,我们要使用下述定理.
定理 2.1:,令 是
Theorem 2.1. For ling, let be a solution of a stochastic differential equation as described in Theorem with drivers , functionally Lipschitz operators , and a process , which is here for all simply for some constant vector , i.e. Let be a map, such that the bounded càglàd process converges to , then holds true.
推论 2.2:,令 为对冲产品过程 的离散,使得定理 2.1 中的条件都满足.对应的对冲策略 由神经网络 给出,其中网络的激活函数有界 ,且导数有界.那么
(i) 随机积分在 点关于 导数 满足
(ii) 若当 时, ucp 收敛到 ,则离散积分的方向导数,i.e. 随着离散刻度 收敛到
ucp means uniform convergence on compacts in probability,i.e.,if for all . The notation is sometimes used, and is said to converge ucp to .
3. LSV的校准
考虑定义在某个概率空间 上的(1.1)LSV模型, 是风险中性测度.假定随机过程 固定.所以实际中我们可以先令 来近似校准其他参数并固定他们.
主要目标是确定符合市场数据的杠杆函数 ,根据通用近似定理(universal approximation properties),对其参数化.令 为欧式看涨期权的到期日.将 用如下神经网络近似 其中 , .方便起见,通常省略 .当我们写 时, 表示 时刻前所有的参数 .
训练过程中,我们需要计算 LSV 过程关于 的导数.以下结果可以看做 对应的链式法则.从附录 A 推导而来.
定理 3.1:令 为(3.1)形式,神经网络 有界且 ,导数有界且 Lipschitz 连续.则关于 在 点处的导数满足: 初值为 0.这个可以通过常数变易来解,i.e. 其中 表示随机指数(stochastic exponential).
Remark
(i) 只看存在唯一性的话, 为 (3.1) 形式,那么神经网络 有界以及 Lipschitz 足够了,.
(ii) 公式 (3.3) 可以用来倒向传播.
定理 3.1 保证了导数过程的存在唯一性.这也保证了基于梯度搜索的学习算法的建立.
下面叙述如何具体优化.为了记号方便,省略权重 和损失函数 对应的参数 .对每个到期日 ,我们假定有 个期权,行权价为 .对第 个到期日,校准函数的形式为 回忆 指的是对应到期日 和行权价 的模型期权价格. 是某个非负非线性凸的损失函数满足 对 . 是权重.
我们通过迭代地计算最优化问题(3.5),从 和 出发,计算 ,然后解决对应 的(3.5).为了简便记号,去掉 ,考虑一般的到期日 ,(3.5)变为 模型价格由下式给出 我们有 ,其中 那么校准问题变为寻找最小的 因为 是非线性函数,不是 B.1 中的期望形式,标准的随机梯度下降方法不能直接用.我们通过第二节中讲的对冲控制变量 (hedge control variates) 解决这个问题.
3.1 极小化校准方程
考虑标准的对(3.8) 的 Monte-Carlo 模拟: 对 i.i.d 的样本 .Monte-Carlo 误差以 递减.模拟次数 必须很大 .因为由于 非线性,随机梯度下降不能直接使用,所以看起来要计算整个函数 的梯度来最小化(3.9).但 ,这一做法计算成本太大且不稳定,因为要计算 项的和的导数.
一个方便的做法是应用对冲控制变量来降低方差,可以将 Monte-Carlo 的样本数 降为大约 .
假定我们有 个对冲产品(包含价格过程 ),用 表示,为 下的平方可积鞅,在 下取值.对 ,策略 使得 , 为常数,定义 则校准函数(3.8)和(3.9)可以通过替换 为 来定义,变为最小化 对此,我们应用如下梯度下降的变种:从初始猜测 出发,迭代计算 对某个学习率 ,i.i.d 样本 .其中 是基于梯度待确定的量,样本在每次迭代中可以一样,可以另取.本文中另取.
最简单情形下,可以令
注意到(3.10)中随机积分项的导数计算通常是昂贵的.我们进行下述改造.令 定义 : 然后令 注意到基于倒向传播,这一项计算起来是很简单的.Moreover, leaving the stochastic integral away in the inner derivative is justified by its vanishing expectation. During the forward pass, the stochastic integral terms are included in the computation; however the contribution to the gradient (during the backward pass) is partly neglected, which can e.g. be implemented via the tensorflow stop_gradient function.
关于对冲策略的选择,我们可以按照 2.2 节中的方法将其用神经网络参数化,并通过下式计算最优的权重 : 对 i.i.d 样本 和损失函数 .此处 这意味着迭代两个优化步骤,i.e.,优化(3.11)中的 (固定 ) 和(3.14)中的 (固定 ).
4. 数值实验流程
实际使用的 SABR-LSV 模型如下 参数为 ,初值有 . 和 是两个相关的布朗运动.
Remark:一般使用的是关于 的对数价格 .故模型也可写为: 注意到 是一个几何布朗运动,也就是说它有表达式:
生成样本
在已有文献中,有推荐的局部波动率函数族 如下: 其中 且参数满足如下约束: 令 , 如下定义: 文中作者修改为: 其中 注意到 与 有关.所以在做 Monte Carlo 模拟时,我们将 替换为 , 是 Monte Carlo 模拟的时间间隔. What is left to be specified are the parameters 模型变为: 上式是用来生成人工市场价格样本的.
所以我们实际的做法是随机对 中的 采样再根据 (1) 计算出价格,然后对 SABR-LSV 模型进行校准,i.e. 寻找使模型符合上述价格的参数 , 以及 .
到期日 ,每个到期日 对应行权价为 .用 Monte-Carlo 模拟以 间隔计算价格.
具体如下:
- 在 下对 以给定分布进行模拟.
- 对每个 ,根据(1)式计算 and strikes for and 对应的欧式期权的价格.每个 分别使用不同的 条布朗运动轨道.
- 保存这些价格数据
准备做的工作(弃案)
寻找最适合市场波动率曲面的“复合”模型,即假设市场波动率曲面实际是由一些波动率模型的凸组合决定的.
回忆:波动率曲面即隐含波动率以 :time to maturity 和 :log-moneyness 为自变量构成的曲面. 例如,我们可以假设当前 ,其中 .
大致做法
记号:分别以 、 记 Heston 和 rough 模型的参数集,以 、 记该两者通过神经网络训练得到的从模型参数到市场价格(隐含波动率)的映射,、 为前述凸组合系数.
我们这里考虑直接通过神经网络来学习市场波动率曲面 到凸组合系数 的映射.
我们对两个模型的参数以及 分别均匀采样,然后根据两者的模型分别模拟出不同凸组合下两者的复合波动率曲面,但要注意的是两者采用同一个参数 (即两个标准布朗运动的相关系数)并且一个凸组合下两模型使用同一条 Monte-Carlo 轨道.这时,忽略掉模型的参数,我们有了带有 标签的许多波动率曲面样本,我们利用前述 grid-based 的方法通过神经网络学习从波动率曲面到凸组合系数的映射.
知道了 后,如何校准出两个模型分别的参数?
LSV-ROUGH 模型的校准
模型:
杠杆函数:
主要共有两个神经网络,一个负责 Rough 的部分,一个负责 LSV 的部分.
一方面,Rough 部分的网络对应的即 Bayer 提出的 two-step 校准方法,即如下模型 ((1.1)中 时): 对应的从模型参数到模型对应价格的映射的网络.只需用人工模拟数据训练一次后,网络就固定住了,在校准等步骤中是不会再变动的.
回忆:用 记关于到期日和行权价的网格.则 step 1:学习映射 ,输入是 ,输出是 这样的 网格. 取值在 中,其中 strikes maturities 最优化问题变为如下: 其中 . Step 2:
另一方面,我们将 这个函数用网络近似,这个网络中的参数是随着校准不断变动的.具体地,令 为欧式看涨期权的到期日.将 用如下神经网络近似 其中 , .
为了记号方便,省略权重 和损失函数 对应的参数 .对每个到期日 ,我们假定有 个期权,行权价为 .对第 个到期日,校准函数的形式为 回忆 指的是对应到期日 和行权价 的模型期权价格. 是某个非负非线性凸的损失函数满足 对 . 是权重.
我们通过迭代地计算最优化问题(1.3),从 和 出发,计算 ,然后解决对应 的(1.3).为了简便记号,去掉 ,考虑一般的到期日 ,(1.3)变为 模型价格由下式给出 我们有 ,其中 那么校准问题变为寻找最小的 我们通过第二节中讲的对冲控制变量 (hedge control variates) 解决这个问题.
考虑标准的对(3.8) 的 Monte-Carlo 模拟: 对 i.i.d 的样本 .Monte-Carlo 误差以 递减.模拟次数 必须很大 .因为由于 非线性,随机梯度下降不能直接使用,所以看起来要计算整个函数 的梯度来最小化(3.9).但 ,这一做法计算成本太大且不稳定,因为要计算 项的和的导数.
一个方便的做法是应用对冲控制变量来降低方差,可以将 Monte-Carlo 的样本数 降为大约 .
假定我们有 个对冲产品(包含价格过程 ),用 表示,为 下的平方可积鞅,在 下取值.对 ,策略 使得 , 为常数,定义 则校准函数(3.8)和(3.9)可以通过替换 为 来定义,变为最小化
算法1:模型的校准步骤
-
# 初始化网络参数
-
-
# 定义初始模拟轨道数和初始步骤值
-
-
# 定义时间离散间隔和误差容忍度
-
-
:
-
-
# 计算此次切片的初始正规化权重
-
-
-
-
-
-
-
-
-
-
-
-
-
-
算法2:超参的更新
附录
证明:
首先定理 A.2 暗示了 的解存在唯一性.这里驱动过程是一维的 .事实上,若 有界,对 左极右连,对 Lipschitz 连续以一个与 无关的 Lipschitz 常数. 为 functionally Lipschitz,得到结论.这些条件由 的形式和 的条件保证.
为了证明导数过程的形式,我们对如下系统应用定理 A.3: 和 以及 在定理 A.3 中,. 为 ucp 收敛到 事实上,, 等度连续.因此,点点收敛暗示对 的一致连续.This together with being piecewise constant in yields: whence ucp convergence of the first term in (3.4). The convergence of term two is clear. The one of term three follows again from the fact that the family is equicontinuous, which is again a consequence of the form of the neural networks.
By the assumptions on the derivatives, is functionally Lipschitz. Hence Theorem A.2 yields the existence of a unique solution to (3.2) and Theorem A.3 implies convergence.
Proof. Consider the extended system and where we obtain existence, uniqueness and stability for the second equation by Theorem A.3, and from where we obtain ucp convergence of the integrand of the first equation: since stochastic integration is continuous with respect to the ucp topology we obtain the result.
文献
- 首次在波动率校准中运用神经网络 Hernandez A. Model calibration with neural networks[J]. Available at SSRN 2812140, 2016.
- rough波动率模型的神经网络校准 Bayer C, Horvath B, Muguruza A, et al. On deep calibration of (rough) stochastic volatility models[J]. arXiv preprint arXiv:1908.08806, 2019.和 Horvath B, Muguruza A, Tomas M. Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough) volatility models[J]. Quantitative Finance, 2021, 21(1): 11-27. Github 代码
- LSV模型GAN校准 Cuchiero C, Khosrawi W, Teichmann J. A generative adversarial network approach to calibration of local stochastic volatility models[J]. Risks, 2020, 8(4): 101. Github 代码
- 损失函数中不同期权权重取法 Cont R, Ben Hamida S. Recovering volatility from option prices by evolutionary optimization[J]. 2004.
- fBm的MC模拟 Horvath B, Jacquier A J, Muguruza A. Functional central limit theorems for rough volatility[J]. Available at SSRN 3078743, 2017. Github 代码
- rBergomi提出 Bayer C, Friz P, Gatheral J. Pricing under rough volatility[J]. Quantitative Finance, 2016, 16(6): 887-904.
wing model
一. 模型建立
波动率模型 Wing Model(知乎, maomao.run)
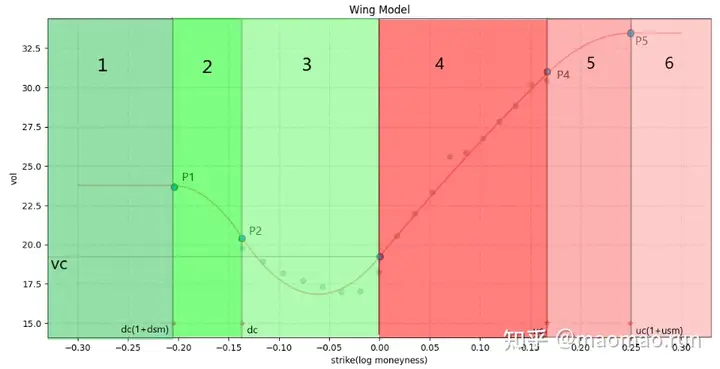
Wing Model是期权交易中常见的一种对波动率进行建模的方法. 它通过调整参数, 将市场中一个系列的期权的隐含波动率拟合到一个曲线上. Wing Model 把隐含波动率曲线分为 6 个区域, 以 ATM Forward(期权对应标的远期价)为中心, 左边区域 1, 2, 3 构成 Put Wing, 右边区域 4, 5, 6 构成 Call Wing. 其中, 区域 1, 6 为常数波动率部分, 区域 3, 4 为抛物线部分, 区域 2, 5 则为过渡部分(其实也是抛物线). x 轴为期权的行权价(或者对数化行权价), y 轴为期权波动率.
| 名称 | 参数 | 描述 |
|---|---|---|
| atm forward | atm | 期权对应合成期货价 |
| volatility reference | vr(vc) | 中心点参考波动率 |
| slope reference | sr(sc) | 中心点参考斜率,也是 Put Wing3 和 Call Wing4 抛物线共同的一次项系数 |
| put curvature | pc | Put Wing3 抛物线的二次项系数 |
| call curvature | cc | Call Wing4 抛物线的二次项系数 |
| down cutoff | dc | Put Wing 2和3 交界点 x 值, dc<0 |
| up cutoff | uc | Call Wing 4和5 交界点 x 值, uc>0 |
| down smoothing range | dsm | Put Wing 用来计算 1 和 2 交界点 x 值的参数 |
| up smoothing range | usm | Call Wing 用来计算 5 和 6 交界点 x 值的参数 |
| skew swimmingness rate | ssr | 斜率游离系数, 取值范围 , 在计算合成期货价格时, 该参数用来调节 atm 和 ref 的比例 |
| volatility change rate | vcr | 波动率变化系数 |
| slope change rate | scr | 斜率变化系数 |
| reference price | ref | ssr<100 时, 需要定义 ref 用来描述 vcr 和 scr 对中心点波动率和中心点斜率的影响 |
其中,atm已知,dc、dsm、uc、usm一般为经验值,vcr、scr、ssr一般使用默认值0、0、100,vc、sc、pc、cc待拟合.
代码中取的几个默认参数是:dc=-0.2, uc=0.2, dsm=0.5, usm=0.5.
- 以50etf为例,当前2022-12-13 13:12近月合成期货为2.682,那么中间两个区域边界分别为;
- 以300etf为例,当前2022-12-13 13:12近月合成期货为4.012,那么中间两个区域边界分别为;
如果 dc=-0.15, uc=0.15 , 50中间区域边界为 [2.31, 3.12], 300中间区域边界为 [3.45, 4.66].
除了上述参数, 还需要一些中间参数以便于表示最终函数. 其中,
合成期货价格: 是中心点波动率: 为中心点斜率: 在常规使用的时候,下列参数一般取默认值: 将默认值带入中间参数公式,可得: 因此我们平常使用,只需要 这9个参数就 够了. 依照参数的定义, 我们可以定义出区域之间的 5 个分隔点的 x 坐标, 从左到右依次为: 把这个五个点对数化,即: 其中 为原 坐标, 为合成期货价格. 对数化后我们重新定义出 5 个分隔点新的 x 坐标, 从左到右依次为:
函数求解
区域 3 和区域 4 的抛物线函数是由参数确定的: 根据各区域连接处导数一致列方程即可求出其他区域的表达式:
二. 根据无套利进行推导
Wing-Model Volatility Skew Manager, 子非鱼根据Jim Gatheral 在Arbitrage-free SVI volatility surfaces 提到的无套利观点和算法对 wing-model 进行公式推导分析,在拟合的基础上进一步根据按定义域分 6 块给出 6 个约束条件判断拟合曲线无蝶式套利.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2020/5/22 11:12 PM
# @Author : 稻草人
# @contact : dybeta2021@163.com
# @File : wing_model.py
# @Desc : orc wing model
from functools import partial
from numpy import ndarray, array, arange, zeros, ones, argmin, minimum, maximum, clip
from numpy.linalg import norm
from numpy.random import normal
from scipy.interpolate import interp1d
from scipy.optimize import minimize
class WingModel(object):
def skew(moneyness: ndarray, vc: float, sc: float, pc: float, cc: float, dc: float, uc: float, dsm: float,
usm: float) -> ndarray:
"""
:param moneyness: converted strike, moneyness
:param vc:
:param sc:
:param pc:
:param cc:
:param dc:
:param uc:
:param dsm:
:param usm:
:return:
"""
assert -1 < dc < 0
assert dsm > 0
assert 1 > uc > 0
assert usm > 0
assert 1e-6 < vc < 10 # 数值优化过程稳定
assert -1e6 < sc < 1e6
assert dc * (1 + dsm) <= dc <= 0 <= uc <= uc * (1 + usm)
# volatility at this converted strike, vol(x) is then calculated as follows:
vol_list = []
for x in moneyness:
# volatility at this converted strike, vol(x) is then calculated as follows:
if x < dc * (1 + dsm):
vol = vc + dc * (2 + dsm) * (sc / 2) + (1 + dsm) * pc * pow(dc, 2)
elif dc * (1 + dsm) < x <= dc:
vol = vc - (1 + 1 / dsm) * pc * pow(dc, 2) - sc * dc / (2 * dsm) + (1 + 1 / dsm) * (
2 * pc * dc + sc) * x - (pc / dsm + sc / (2 * dc * dsm)) * pow(x, 2)
elif dc < x <= 0:
vol = vc + sc * x + pc * pow(x, 2)
elif 0 < x <= uc:
vol = vc + sc * x + cc * pow(x, 2)
elif uc < x <= uc * (1 + usm):
vol = vc - (1 + 1 / usm) * cc * pow(uc, 2) - sc * uc / (2 * usm) + (1 + 1 / usm) * (
2 * cc * uc + sc) * x - (cc / usm + sc / (2 * uc * usm)) * pow(x, 2)
elif uc * (1 + usm) < x:
vol = vc + uc * (2 + usm) * (sc / 2) + (1 + usm) * cc * pow(uc, 2)
else:
raise ValueError("x value error!")
vol_list.append(vol)
return array(vol_list)
def loss_skew(cls, params: [float, float, float], x: ndarray, iv: ndarray, vega: ndarray, vc: float, dc: float,
uc: float, dsm: float, usm: float):
"""
:param params: sc, pc, cc
:param x:
:param iv:
:param vega:
:param vc:
:param dc:
:param uc:
:param dsm:
:param usm:
:return:
"""
sc, pc, cc = params
vega = vega / vega.max()
value = cls.skew(x, vc, sc, pc, cc, dc, uc, dsm, usm)
return norm((value - iv) * vega, ord=2, keepdims=False)
def calibrate_skew(cls, x: ndarray, iv: ndarray, vega: ndarray, dc: float = -0.2, uc: float = 0.2, dsm: float = 0.5,
usm: float = 0.5, is_bound_limit: bool = False,
epsilon: float = 1e-16, inter: str = "cubic"):
"""
:param x: moneyness
:param iv:
:param vega:
:param dc:
:param uc:
:param dsm:
:param usm:
:param is_bound_limit:
:param epsilon:
:param inter: cubic inter
:return:
"""
vc = interp1d(x, iv, kind=inter, fill_value="extrapolate")([0])[0]
# init guess for sc, pc, cc
if is_bound_limit:
bounds = [(-1e3, 1e3), (-1e3, 1e3), (-1e3, 1e3)]
else:
bounds = [(None, None), (None, None), (None, None)]
initial_guess = normal(size=3)
args = (x, iv, vega, vc, dc, uc, dsm, usm)
residual = minimize(cls.loss_skew, initial_guess, args=args, bounds=bounds, tol=epsilon, method="SLSQP")
assert residual.success
return residual.x, residual.fun
def sc(sr: float, scr: float, ssr: float, ref: float, atm: ndarray or float) -> ndarray or float:
return sr - scr * ssr * ((atm - ref) / ref)
def loss_scr(cls, x: float, sr: float, ssr: float, ref: float, atm: ndarray, sc: ndarray) -> float:
return norm(sc - cls.sc(sr, x, ssr, ref, atm), ord=2, keepdims=False)
def fit_scr(cls, sr: float, ssr: float, ref: float, atm: ndarray, sc: ndarray,
epsilon: float = 1e-16) -> [float, float]:
init_value = array([0.01])
residual = minimize(cls.loss_scr, init_value, args=(sr, ssr, ref, atm, sc), tol=epsilon, method="SLSQP")
assert residual.success
return residual.x, residual.fun
def vc(vr: float, vcr: float, ssr: float, ref: float, atm: ndarray or float) -> ndarray or float:
return vr - vcr * ssr * ((atm - ref) / ref)
def loss_vc(cls, x: float, vr: float, ssr: float, ref: float, atm: ndarray, vc: ndarray) -> float:
return norm(vc - cls.vc(vr, x, ssr, ref, atm), ord=2, keepdims=False)
def fit_vcr(cls, vr: float, ssr: float, ref: float, atm: ndarray, vc: ndarray,
epsilon: float = 1e-16) -> [float, float]:
init_value = array([0.01])
residual = minimize(cls.loss_vc, init_value, args=(vr, ssr, ref, atm, vc), tol=epsilon, method="SLSQP")
assert residual.success
return residual.x, residual.fun
def wing(cls, x: ndarray, ref: float, atm: float, vr: float, vcr: float, sr: float, scr: float, ssr: float,
pc: float, cc: float, dc: float, uc: float, dsm: float, usm: float) -> ndarray:
"""
wing model
:param x:
:param ref:
:param atm:
:param vr:
:param vcr:
:param sr:
:param scr:
:param ssr:
:param pc:
:param cc:
:param dc:
:param uc:
:param dsm:
:param usm:
:return:
"""
vc = cls.vc(vr, vcr, ssr, ref, atm)
sc = cls.sc(sr, scr, ssr, ref, atm)
return cls.skew(x, vc, sc, pc, cc, dc, uc, dsm, usm)
class ArbitrageFreeWingModel(WingModel):
def calibrate(cls, x: ndarray, iv: ndarray, vega: ndarray, dc: float = -0.2, uc: float = 0.2, dsm: float = 0.5,
usm: float = 0.5, is_bound_limit: bool = False, epsilon: float = 1e-16, inter: str = "cubic",
level: float = 0, method: str = "SLSQP", epochs: int = None, show_error: bool = False,
use_constraints: bool = False) -> ([float, float, float], float):
"""
:param x:
:param iv:
:param vega:
:param dc:
:param uc:
:param dsm:
:param usm:
:param is_bound_limit:
:param epsilon:
:param inter:
:param level:
:param method:
:param epochs:
:param show_error:
:param use_constraints:
:return:
"""
vega = clip(vega, 1e-6, 1e6)
iv = clip(iv, 1e-6, 10)
# init guess for sc, pc, cc
if is_bound_limit:
bounds = [(-1e3, 1e3), (-1e3, 1e3), (-1e3, 1e3)]
else:
bounds = [(None, None), (None, None), (None, None)]
vc = interp1d(x, iv, kind=inter, fill_value="extrapolate")([0])[0]
constraints = dict(type='ineq', fun=partial(cls.constraints, args=(x, vc, dc, uc, dsm, usm), level=level))
args = (x, iv, vega, vc, dc, uc, dsm, usm)
if epochs is None:
if use_constraints:
residual = minimize(cls.loss_skew, normal(size=3), args=args, bounds=bounds, constraints=constraints,
tol=epsilon, method=method)
else:
residual = minimize(cls.loss_skew, normal(size=3), args=args, bounds=bounds, tol=epsilon, method=method)
if residual.success:
sc, pc, cc = residual.x
arbitrage_free = cls.check_butterfly_arbitrage(sc, pc, cc, dc, dsm, uc, usm, x, vc)
return residual.x, residual.fun, arbitrage_free
else:
epochs = 10
if show_error:
print("calibrate wing-model wrong, use epochs = 10 to find params! params: {}".format(residual.x))
if epochs is not None:
params = zeros([epochs, 3])
loss = ones([epochs, 1])
for i in range(epochs):
if use_constraints:
residual = minimize(cls.loss_skew, normal(size=3), args=args, bounds=bounds,
constraints=constraints,
tol=epsilon, method="SLSQP")
else:
residual = minimize(cls.loss_skew, normal(size=3), args=args, bounds=bounds, tol=epsilon,
method="SLSQP")
if not residual.success and show_error:
print("calibrate wing-model wrong, wrong @ {} /10! params: {}".format(i, residual.x))
params[i] = residual.x
loss[i] = residual.fun
min_idx = argmin(loss)
sc, pc, cc = params[min_idx]
loss = loss[min_idx][0]
arbitrage_free = cls.check_butterfly_arbitrage(sc, pc, cc, dc, dsm, uc, usm, x, vc)
return (sc, pc, cc), loss, arbitrage_free
def constraints(cls, x: [float, float, float], args: [ndarray, float, float, float, float, float],
level: float = 0) -> float:
"""蝶式价差无套利约束
:param x: guess values, sc, pc, cc
:param args:
:param level:
:return:
"""
sc, pc, cc = x
moneyness, vc, dc, uc, dsm, usm = args
if level == 0:
pass
elif level == 1:
moneyness = arange(-1, 1.01, 0.01)
else:
moneyness = arange(-1, 1.001, 0.001)
return cls.check_butterfly_arbitrage(sc, pc, cc, dc, dsm, uc, usm, moneyness, vc)
"""蝶式价差无套利约束条件
"""
def left_parabolic(sc: float, pc: float, x: float, vc: float) -> float:
"""
:param sc:
:param pc:
:param x:
:param vc:
:return:
"""
return pc - 0.25 * (sc + 2 * pc * x) ** 2 * (0.25 + 1 / (vc + sc * x + pc * x * x)) + (
1 - 0.5 * x * (sc + 2 * pc * x) / (vc + sc * x + pc * x * x)) ** 2
def right_parabolic(sc: float, cc: float, x: float, vc: float) -> float:
"""
:param sc:
:param cc:
:param x:
:param vc:
:return:
"""
return cc - 0.25 * (sc + 2 * cc * x) ** 2 * (0.25 + 1 / (vc + sc * x + cc * x * x)) + (
1 - 0.5 * x * (sc + 2 * cc * x) / (vc + sc * x + cc * x * x)) ** 2
def left_smoothing_range(sc: float, pc: float, dc: float, dsm: float, x: float, vc: float) -> float:
a = - pc / dsm - 0.5 * sc / (dc * dsm)
b1 = -0.25 * ((1 + 1 / dsm) * (2 * dc * pc + sc) - 2 * (pc / dsm + 0.5 * sc / (dc * dsm)) * x) ** 2
b2 = -dc ** 2 * (1 + 1 / dsm) * pc - 0.5 * dc * sc / dsm + vc + (1 + 1 / dsm) * (2 * dc * pc + sc) * x - (
pc / dsm + 0.5 * sc / (dc * dsm)) * x ** 2
b2 = (0.25 + 1 / b2)
b = b1 * b2
c1 = x * ((1 + 1 / dsm) * (2 * dc * pc + sc) - 2 * (pc / dsm + 0.5 * sc / (dc * dsm)) * x)
c2 = 2 * (-dc ** 2 * (1 + 1 / dsm) * pc - 0.5 * dc * sc / dsm + vc + (1 + 1 / dsm) * (2 * dc * pc + sc) * x - (
pc / dsm + 0.5 * sc / (dc * dsm)) * x ** 2)
c = (1 - c1 / c2) ** 2
return a + b + c
def right_smoothing_range(sc: float, cc: float, uc: float, usm: float, x: float, vc: float) -> float:
a = - cc / usm - 0.5 * sc / (uc * usm)
b1 = -0.25 * ((1 + 1 / usm) * (2 * uc * cc + sc) - 2 * (cc / usm + 0.5 * sc / (uc * usm)) * x) ** 2
b2 = -uc ** 2 * (1 + 1 / usm) * cc - 0.5 * uc * sc / usm + vc + (1 + 1 / usm) * (2 * uc * cc + sc) * x - (
cc / usm + 0.5 * sc / (uc * usm)) * x ** 2
b2 = (0.25 + 1 / b2)
b = b1 * b2
c1 = x * ((1 + 1 / usm) * (2 * uc * cc + sc) - 2 * (cc / usm + 0.5 * sc / (uc * usm)) * x)
c2 = 2 * (-uc ** 2 * (1 + 1 / usm) * cc - 0.5 * uc * sc / usm + vc + (1 + 1 / usm) * (2 * uc * cc + sc) * x - (
cc / usm + 0.5 * sc / (uc * usm)) * x ** 2)
c = (1 - c1 / c2) ** 2
return a + b + c
def left_constant_level() -> float:
return 1
def right_constant_level() -> float:
return 1
def _check_butterfly_arbitrage(cls, sc: float, pc: float, cc: float, dc: float, dsm: float, uc: float, usm: float,
x: float, vc: float) -> float:
"""检查是否存在蝶式价差套利机会,确保拟合time-slice iv-curve 是无套利(无蝶式价差静态套利)曲线
:param sc:
:param pc:
:param cc:
:param dc:
:param dsm:
:param uc:
:param usm:
:param x:
:param vc:
:return:
"""
# if x < dc * (1 + dsm):
# return cls.left_constant_level()
# elif dc * (1 + dsm) < x <= dc:
# return cls.left_smoothing_range(sc, pc, dc, dsm, x, vc)
# elif dc < x <= 0:
# return cls.left_parabolic(sc, pc, x, vc)
# elif 0 < x <= uc:
# return cls.right_parabolic(sc, cc, x, vc)
# elif uc < x <= uc * (1 + usm):
# return cls.right_smoothing_range(sc, cc, uc, usm, x, vc)
# elif uc * (1 + usm) < x:
# return cls.right_constant_level()
# else:
# raise ValueError("x value error!")
if dc < x <= 0:
return cls.left_parabolic(sc, pc, x, vc)
elif 0 < x <= uc:
return cls.right_parabolic(sc, cc, x, vc)
else:
return 0
def check_butterfly_arbitrage(cls, sc: float, pc: float, cc: float, dc: float, dsm: float, uc: float, usm: float,
moneyness: ndarray, vc: float) -> float:
"""
:param sc:
:param pc:
:param cc:
:param dc:
:param dsm:
:param uc:
:param usm:
:param moneyness:
:param vc:
:return:
"""
con_arr = []
for x in moneyness:
con_arr.append(cls._check_butterfly_arbitrage(sc, pc, cc, dc, dsm, uc, usm, x, vc))
con_arr = array(con_arr)
if (con_arr >= 0).all():
return minimum(con_arr.mean(), 1e-7)
else:
return maximum((con_arr[con_arr < 0]).mean(), -1e-7)
最简单情形的自动对冲
简介
本自动对冲是与策略下单相互独立,策略下单所需要的下单中保持对冲会集成在策略下单的代码中,本章的自动对冲适用于在未触发策略信号时的额外对冲操作,如果有其他自动交易的策略触发时,应该停止对应的合约的自动对冲操作。
选用近月或次月(可选)离合成期货最近的行权价对应的合成期货对作为对冲合约; 手动填入本次的目标$delta以及可以接受的一个上下范围区间,对冲必须要达到目标$delta一次后才会考虑上下范围; 例子:当前实际$delta为5%,目标$delta为20%,给定的上下容忍范围为10%,那么刚开始对冲的情形下,$delta必须到达一次20%才停止进入等待状态,后续才会判断$delta出了目标$delta20%上下10%去做对冲,也就是低于10%或高于30%.
$vega方面,不同于$delta我们给定的是目标$delta,$vega我们会给一个本次$vega,$vega我们会实时计算从本次对冲开始下的单对应的$vega,该$vega未到设定的本次要做的$vega前我们只用call或者put去做对冲,在该$vega达到本次要做的$vega后我们只会用合成期货去进行对冲;下的单对应的$vega到过一次本次要做的$vega后就再也不考虑$vega这一希腊值了
TODO:追价类型目前是'aT|b|c|M/C'的形式, 后续希望能够有更多的自定义操作,如作为买方时每次以min(对手价+2T, 前一笔+2T)的价格进行追价,待讨论
流程图
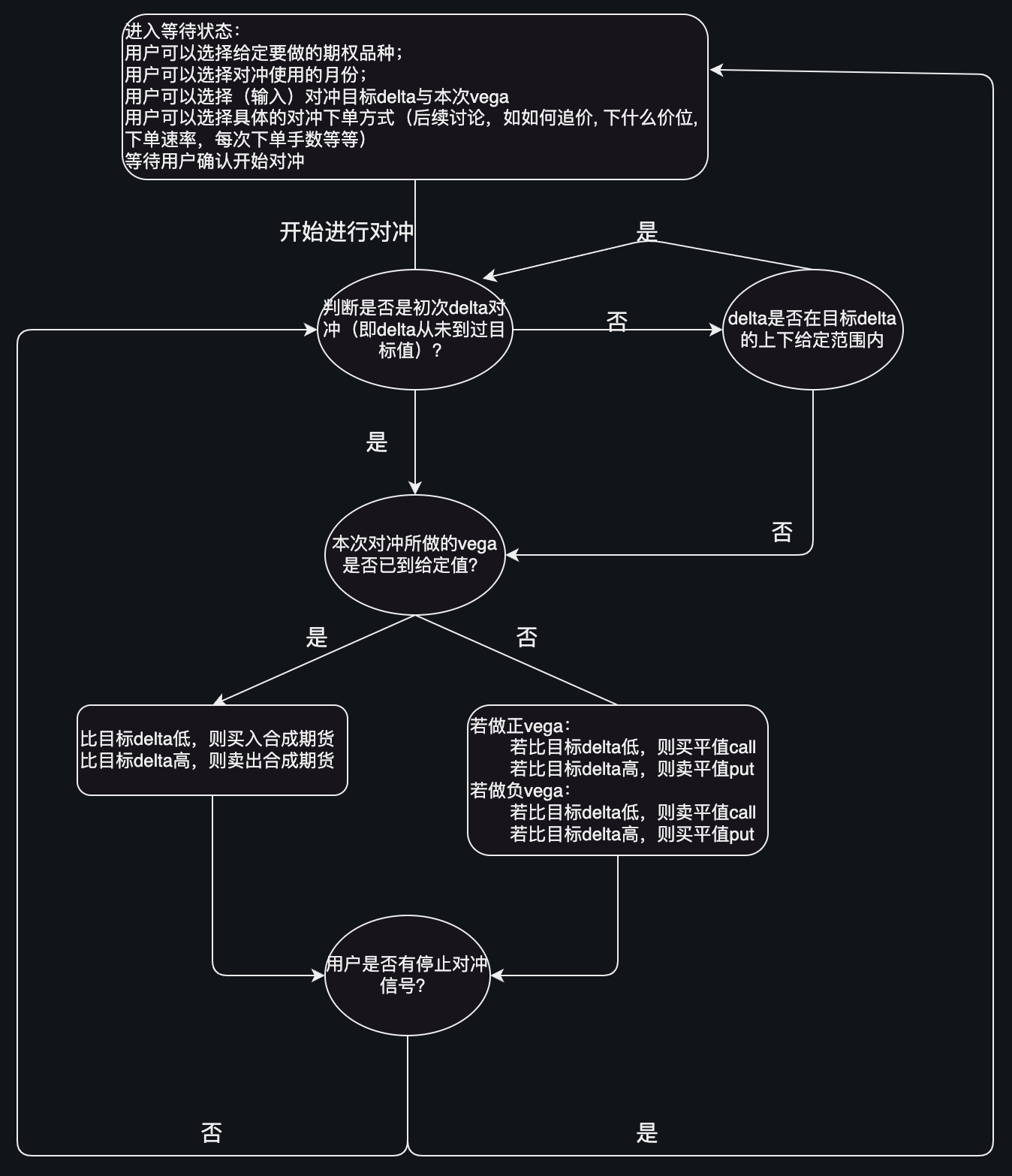
GUI代码部分
需要模块 icetcore, loguru
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : hedger_vanilla.py
@Time : 2023/02/15 20:55:33
@Author : DingWenjie
@Contact : 359582058@qq.com
@Desc : ### 独立自动对冲模块 ###
对冲合约: 平值合成期货
需要输入: 对冲月份: 近月/次月
目标delta: 百分值
目标delta容忍范围: 正百分值
本次对冲vega: 万分值
下单模式: 可选 本方价+1/对手价-1/中间价
相邻单间隔: int,秒
追价模式:
每笔单数: int
### 对冲逻辑 ###
以目标delta为主, 首次对冲(first_time)必须delta达到目标delta,
非首次时delta必须达到目标delta的容忍范围内,
vega则是以本次对冲为准, 不看总仓位的vega, 未达到本次对冲vega时,
只买(卖)不卖(买), 到达本次对冲vega后, 使用合成期货对冲
'''
import warnings
import datetime
import os
from loguru import logger
from tkinter import ttk, Tk, Label, Entry, StringVar, Button
from copy import deepcopy
from icetcore import TCoreAPI, QuoteEvent, TradeEvent, OrderStruct
from functools import partial
from threading import Thread
from time import sleep
now = datetime.datetime.now()
TODAY_STR = datetime.date.today().strftime('%Y%m%d')
if not os.path.exists('log'):
os.mkdir('log')
warnings.simplefilter('ignore')
logger.add(f"log/runtime_{now.strftime('%Y%m%d_%H_%M_%S')}.log")
type_list = ['本方+1', '中间价', '对手-1']
interval_list = ['1秒', '2秒', '3秒', '4秒', '5秒', '6秒',
'7秒', '8秒', '9秒', '10秒', '15秒', '20秒', '30秒']
qty_list = [str(i+1) for i in range(30)]
chase_list = ['1T|1|2|M', '1T|2|2|M', '2T|1|2|M', '2T|2|2|M', '1T|2|10|M']
class APIEvent(TradeEvent, QuoteEvent):
def __init__(self):
super().__init__()
def onconnected(self, apitype: str):
pass
def ondisconnected(self, apitype: str):
pass
def ongreeksreal(self, datatype, symbol, data):
global greeks_dict
try:
greeks_dict[data['Symbol']] = data
except:
return
def onbar(self, datatype, interval, symbol, data, isreal):
pass
def onfilledreportreal(self, data):
global filled_report_dict
temp_key = '.'.join(data['Symbol'].split('.')[
2:4])
if 'A' in temp_key:
temp_key = temp_key[:-1]
filled_report_dict[temp_key][data['Symbol'].split(
'.')[4]][data['DetailReportID']] = data
def onmargin(self, accmask, data):
global cash
global initial_cash
cash = data[0]['MarketPremium']
if not cash:
try:
cash = initial_cash
except NameError:
return
def onATM(self, datatype, symbol, data):
global atm_dict
try:
if data['ATM'] == '.'.join(data['OTM-1C'].split('.')[6:]):
atm_dict['.'.join(data['Symbol'].split('.')[2:5])] = {
'call': data['OTM-1C'],
'put': '.'.join(data['OTM-1C'].split('.')[:5])+'.P.'+data['ATM']
}
else:
atm_dict['.'.join(data['Symbol'].split('.')[2:5])] = {
'put': data['OTM-1P'],
'call': '.'.join(data['OTM-1P'].split('.')[:5])+'.C.'+data['ATM']
}
except:
return
def onpositionmoniter(self, data):
global und_list
global position_dict
try:
und_list
except:
return
try:
position_dict[und_list[0]]
except:
for und in und_list:
position_dict[und] = {
'Total': {'delta': 0, 'vega': 0},
month_list[0]: {'delta': 0, 'vega': 0},
month_list[1]: {'delta': 0, 'vega': 0}
}
for und in und_list:
for position in data:
if und in position['Symbol']:
position_dict[und][position['SubKey']
]['delta'] = position['$Delta']
position_dict[und][position['SubKey']
]['vega'] = position['$Vega']
class HedgerVanilla():
def __init__(self, account, brokerid):
self.account = account
self.brokerid = brokerid
logger.warning(f'当前登录的账户为{self.account},请确认后再继续!')
global cash
global initial_cash
cash = 0
while not cash:
cash = api.getaccmargin(
self.brokerid+'-'+self.account)['MarketPremium']
initial_cash = cash
@staticmethod
def _get_0and1_symbols_and_quote():
'''根据und_list订阅该标的对应的近月次月合约greeks及atm
'''
global und_list
global greeks_dict
global atm_dict
global symbol_dict
global month_list
atm_dict = {}
greeks_dict = {}
symbol_dict = {}
for und in und_list:
all_symbol = api.getallsymbol('OPT', und.split('.')[0])
symbol_dict[und] = all_symbol
month_list = list(set([int(symbol.split('.')[4])
for symbol in all_symbol]))
month_list.sort()
month_list = [str(month) for month in month_list[:2]]
for month in month_list:
api.subATM('TC.O.'+und+'.'+month+'.GET.ATM')
for symbol in all_symbol:
if und in symbol and (month_list[0] in symbol or month_list[1] in symbol):
api.subgreeksreal(symbol)
@staticmethod
def _calculate_cashvega_given_und(und, month):
'''根据已成交的单计算给定标的本次对冲(not vega_done)已做的cashvega
'''
global filled_report_dict
vega = 0
temp_symbol = {}
for order, data in filled_report_dict[und][month].items():
if data['Symbol'] not in temp_symbol:
temp_symbol[data['Symbol']] = int(
(data['Side']*(-2)+3)*data['MatchedQty'])
else:
temp_symbol[data['Symbol']
] += int((data['Side']*(-2)+3)*data['MatchedQty'])
for symbol, data in temp_symbol.items():
try:
vega += data*greeks_dict[symbol]['Vega']*10000
except TypeError:
print(f'data:{data}')
print('vega:', greeks_dict[symbol]['Vega']*10000)
print('\n'*50)
continue
return vega/cash*10000
@staticmethod
def _get_order_given_side_and_type(order, side, type_):
'''根据买卖方向和价格类型给出order_obj
'''
global order_obj
order_obj = deepcopy(order)
order_obj.Side = side
if side == 1:
if type_ == '本方+1':
order_obj.Price = 'BID+1T'
elif type_ == '对手-1':
order_obj.Price = 'ASK-1T'
else:
order_obj.OrderType = 15
order_obj.Synthetic = 1
else:
if type_ == '本方+1':
order_obj.Price = 'ASK-1T'
elif type_ == '对手-1':
order_obj.Price = 'BID+1T'
else:
order_obj.OrderType = 15
order_obj.Synthetic = 1
return order_obj
def _do_hedging_thread(self, und, month):
'''进行对冲子线程
'''
global hedging_state_dict
global filled_report_dict
global done_vega_dict
global atm_dict
global order_type_dict
global order_interval_dict
global order_qty_dict
global chase_type_dict
done_vega_dict[und][month] = 0
logger.debug(f'当前开始{und}_{month}的对冲子线程')
if globals()['delta_entry'].get() == '':
globals()[f'warning_tag_{month}']['text'] = '请输入目标delta!'
logger.debug(f'{und}_{month}对冲子线程因未输入终止')
hedging_state_dict[und][month] = 0
return
target_delta = float(globals()['delta_entry'].get())
if globals()['delta_tol'].get() == '':
globals()[f'warning_tag_{month}']['text'] = '请输入delta范围!'
logger.debug(f'{und}_{month}对冲子线程因未输入终止')
hedging_state_dict[und][month] = 0
return
delta_tol = float(globals()['delta_tol'].get())
if globals()[f'vega_entry_{month}'].get() == '':
globals()[f'warning_tag_{month}']['text'] = '请输入本次vega!'
logger.debug(f'{und}_{month}对冲子线程因未输入终止')
hedging_state_dict[und][month] = 0
return
globals()[f'warning_tag_{month}']['text'] = ''
target_vega = float(globals()[f'vega_entry_{month}'].get())
vega_done = False
first_time = True
delta_direction_for_first_time = 0
filled_report_dict[und][month] = {}
while hedging_state_dict[und][month]:
try:
temp_order_type = order_type_dict[und][month]
temp_order_interval = int(
order_interval_dict[und][month].split('秒')[0])
temp_order_qty = int(order_qty_dict[und][month])
temp_chase_type = chase_type_dict[und][month]
logger.debug(f'当前在{und}_{month}的对冲子线程中')
logger.debug(
f'目标delta为{target_delta}, 容忍范围是{delta_tol}, 要做的vega是{target_vega}, 月份为{month}, 下单间隔为{temp_order_interval}, 每笔手数为{temp_order_qty}, 下单类型为{temp_order_type}')
temp_delta = position_dict[und]['Total']['delta']
logger.debug(
f'当前{month}月份temp_delta为{temp_delta:.0f}, 当前目标delta为{target_delta/100*cash}')
hedger_symbol_call = atm_dict[und+'.'+month]['call']
hedger_symbol_put = atm_dict[und+'.'+month]['put']
if not vega_done: # 之前未做到过vega, 则先判断当前vega是否已到
done_vega_dict[und][month] = self._calculate_cashvega_given_und(
und, month)
logger.info(
f'当前已做的vega为 {done_vega_dict[und][month]: .1f}')
if abs(done_vega_dict[und][month]) >= abs(target_vega):
logger.success('当前首次到达目标vega, 后续做合成期货!')
vega_done = True
if first_time: # 若未到达过目标delta, 则判断所做delta方向(首次)/当前是否到达目标delta
if not delta_direction_for_first_time:
if temp_delta > target_delta/100*cash >= 0 or (temp_delta > target_delta/100*cash and 0 >= target_delta):
delta_direction_for_first_time = -1
else:
delta_direction_for_first_time = 1
logger.debug(
f'初次对冲, 判断对冲方向为{delta_direction_for_first_time}')
elif (temp_delta-target_delta/100*cash)*delta_direction_for_first_time > 0:
logger.info(
f'当前first_time,当前delta与目标delta之差为{temp_delta-target_delta/100*cash}')
first_time = False
continue
order_obj = OrderStruct(Account=self.account,
BrokerID=self.brokerid,
OrderQty=temp_order_qty,
OrderType=2, # 默认限价单
Symbol='',
Side=1,
TimeInForce=1,
PositionEffect=4,
SelfTradePrevention=3,
ChasePrice=temp_chase_type)
if (first_time and temp_delta < target_delta/100*cash) or (not first_time and temp_delta < (target_delta-delta_tol)/100*cash): # 做正delta
logger.info('判断本次做正delta')
if not vega_done: # 买call or 卖put
if target_vega > 0: # 买call
order = self._get_order_given_side_and_type(
order=order_obj, side=1, type_=temp_order_type)
order.Symbol = hedger_symbol_call
else: # 卖put
order = self._get_order_given_side_and_type(
order=order_obj, side=2, type_=temp_order_type)
order.Symbol = hedger_symbol_put
order_response, _ = api.neworder(order)
else: # 买合成期货
order_call = self._get_order_given_side_and_type(
order=order_obj, side=1, type_=temp_order_type)
order_call.Symbol = hedger_symbol_call
order_put = self._get_order_given_side_and_type(
order=order_obj, side=2, type_=temp_order_type)
order_put.Symbol = hedger_symbol_put
order_response_call, _ = api.neworder(order_call)
order_response_put, _ = api.neworder(order_put)
elif (first_time and temp_delta > target_delta/100*cash) or (not first_time and temp_delta > (target_delta+delta_tol)/100*cash): # 做负delta
logger.info('判断本次做负delta')
if not vega_done: # 卖call or 买put
if target_vega < 0: # 卖call
order = self._get_order_given_side_and_type(
order=order_obj, side=2, type_=temp_order_type)
order.Symbol = hedger_symbol_call
else: # 买put
order = self._get_order_given_side_and_type(
order=order_obj, side=1, type_=temp_order_type)
order.Symbol = hedger_symbol_put
order_response, _ = api.neworder(order)
else: # 卖合成期货
order_call = self._get_order_given_side_and_type(
order=order_obj, side=2, type_=temp_order_type)
order_call.Symbol = hedger_symbol_call
order_put = self._get_order_given_side_and_type(
order=order_obj, side=1, type_=temp_order_type)
order_put.Symbol = hedger_symbol_put
order_response_call, _ = api.neworder(order_call)
order_response_put, _ = api.neworder(order_put)
else:
logger.debug('当前delta满足要求, 不做对冲')
sleep(temp_order_interval)
except Exception as error:
logger.exception(error)
hedging_state_dict[und][month] = 0
logger.success(f'{und}对冲子线程已结束!')
filled_report_dict[und][month] = {}
done_vega_dict[und][month] = '-'
def _do_hedging(self, month):
'''tk.Button绑定开始对冲按键
'''
global hedging_state_dict
if hedging_state_dict[csd_und][month]:
logger.warning(f'{csd_und}_{month}已在对冲中')
return
global target_delta_dict
global target_delta_tol_dict
global target_vega_dict
global order_type_dict
global order_interval_dict
global order_qty_dict
global chase_type_dict
target_delta_dict[csd_und] = globals()['delta_entry'].get()
target_delta_tol_dict[csd_und] = globals()['delta_tol'].get()
target_vega_dict[csd_und][month] = globals()[
f'vega_entry_{month}'].get()
order_type_dict[csd_und][month] = globals(
)[f'csd_order_type_{month}'].get()
order_interval_dict[csd_und][month] = globals(
)[f'csd_order_interval_{month}'].get()
order_qty_dict[csd_und][month] = globals(
)[f'csd_order_qty_{month}'].get()
chase_type_dict[csd_und][month] = globals(
)[f'csd_chase_type_{month}'].get()
logger.debug(f'开始对冲{csd_und}-{month}')
hedging_state_dict[csd_und][month] = 1
globals()[f'hedging_subprocess_{csd_und}_{month}'] = Thread(
target=self._do_hedging_thread, args=(csd_und, month), daemon=True)
globals()[f'hedging_subprocess_{csd_und}_{month}'].start()
def _stop_hedging(self, month):
'''tk.Button绑定停止对冲按键
'''
global hedging_state_dict
if not hedging_state_dict[csd_und][month]:
logger.warning(f'{csd_und}_{month}未在对冲')
return
global target_delta_dict
global target_delta_tol_dict
global target_vega_dict
target_delta_dict[csd_und] = ''
target_delta_tol_dict[csd_und] = ''
target_vega_dict[csd_und][month] = ''
hedging_state_dict[csd_und][month] = 0
logger.debug(f'停止对冲{csd_und}_{month}')
def main_window(self):
'''GUI窗口
'''
def go(*args):
pass
global position_dict
global und_list
global month_list
global hedging_state_dict
global hedging_state_list
global done_vega_dict
global filled_report_dict
global order_report_dict
global csd_und
global target_delta_dict
global target_vega_dict
global target_delta_tol_dict
global order_type_dict
global order_interval_dict
global order_qty_dict
global chase_type_dict
chase_type_dict = {}
order_qty_dict = {}
order_interval_dict = {}
order_type_dict = {}
target_delta_tol_dict = {}
target_vega_dict = {}
target_delta_dict = {}
csd_und = und_list[0]
order_report_dict = {}
filled_report_dict = {}
done_vega_dict = {}
hedging_state_list = ['未运行', '对冲中']
hedging_state_dict = {}
position_dict = {}
self._get_0and1_symbols_and_quote()
sleep(3)
window = Tk()
window.title('ETF期权自动对冲初版')
account_tag = Label(text='当前账户:')
account_tag.grid(row=0, column=0)
account_tag_ = Label(text=self.account)
account_tag_.grid(row=0, column=1)
cash_tag = Label(text='当前资金:')
cash_tag.grid(row=1, column=0)
cash_tag_ = Label(text=f'{cash:.2f}')
cash_tag_.grid(row=1, column=1)
for i, und in enumerate(und_list):
order_report_dict[und] = {}
done_vega_dict[und] = {
month_list[0]: '',
month_list[1]: ''
}
hedging_state_dict[und] = {
month_list[0]: 0,
month_list[1]: 0
}
filled_report_dict[und] = {
month_list[0]: {},
month_list[1]: {}
}
target_delta_dict[und] = ''
target_delta_tol_dict[und] = ''
target_vega_dict[und] = {
month_list[0]: '',
month_list[1]: ''
}
order_type_dict[und] = {
month_list[0]: 1,
month_list[1]: 1
}
order_interval_dict[und] = {
month_list[0]: 1,
month_list[1]: 1,
}
order_qty_dict[und] = {
month_list[0]: 1,
month_list[1]: 1,
}
chase_type_dict[und] = {
month_list[0]: 0,
month_list[1]: 0,
}
crt_row = 2
text_tag = Label(text='当前总体$delta(百分之):')
text_tag.grid(row=crt_row, column=0)
try:
globals()['crt_delta_total'] = Label(
text=str(round(position_dict[csd_und]['Total']['delta']/cash*100, 1)), width=9)
except KeyError:
globals()['crt_delta_total'] = Label(
text=str('-'), width=8)
globals()['crt_delta_total'].grid(row=crt_row, column=1)
text_tag = Label(text='', width=8)
text_tag.grid(row=crt_row, column=2)
crt_row += 1
crt_vega = Label(text='当前总体$vega(万分之):')
crt_vega.grid(row=crt_row, column=0)
try:
globals()['crt_vega_total'] = Label(
text=str(round(position_dict[csd_und]['Total']['vega']/cash*10000, 1)), width=9)
except KeyError:
globals()['crt_vega_total'] = Label(
text=str('-'), width=8)
globals()['crt_vega_total'].grid(row=crt_row, column=1)
crt_row += 1
def choose_und(*args):
global csd_und
global target_delta_dict
global target_delta_tol_dict
global target_vega_dict
global order_type_dict
global order_interval_dict
global order_qty_dict
global chase_type_dict
csd_und = globals()['choose_csd_und'].get()
globals()['delta_entry'].delete(0, 5)
globals()['delta_entry'].insert(0, str(target_delta_dict[csd_und]))
globals()['delta_tol'].delete(0, 5)
globals()['delta_tol'].insert(
0, str(target_delta_tol_dict[csd_und]))
for month in month_list:
globals()[f'vega_entry_{month}'].delete(0, 5)
globals()[f'vega_entry_{month}'].insert(
0, str(target_vega_dict[csd_und][month]))
if hedging_state_dict[csd_und][month]:
globals()[f'csd_order_type_{month}'].current(
type_list.index(order_type_dict[csd_und][month]))
globals()[f'csd_order_interval_{month}'].current(
interval_list.index(order_interval_dict[csd_und][month]))
globals()[f'csd_order_qty_{month}'].current(
qty_list.index(order_qty_dict[csd_und][month]))
globals()[f'csd_chase_type_{month}'].current(
chase_list.index(chase_type_dict[csd_und][month]))
text_tag = Label(text='选择对冲合约:')
text_tag.grid(row=crt_row, column=0)
globals()['choose_csd_und'] = ttk.Combobox(
window, textvariable=StringVar(), width=11)
globals()['choose_csd_und']['values'] = und_list
globals()['choose_csd_und'].current(0)
globals()['choose_csd_und'].bind('<<ComboboxSelected>>', choose_und)
globals()['choose_csd_und'].grid(row=crt_row, column=1)
crt_row += 1
text_tag = Label(text='')
text_tag.grid(row=crt_row, column=0)
crt_row += 1
text_tag = Label(text='对冲设置')
text_tag.grid(row=crt_row, column=0)
fixed_row_num = crt_row
col_num = 4
for i, month in enumerate(month_list):
crt_row = fixed_row_num
text_tag = Label(text='考虑月份')
text_tag.grid(row=crt_row, column=i*col_num)
text_tag = Label(text=month, fg='red')
text_tag.grid(row=crt_row, column=i*col_num+1)
crt_row += 1
text_tag = Label(text='该月$delta(百分之):')
text_tag.grid(row=crt_row, column=i*col_num)
try:
globals()[f'crt_delta_{month}'] = Label(
text=str(round(position_dict[csd_und][month]['delta']/cash*100, 1)), width=9)
except KeyError:
globals()[f'crt_delta_{month}'] = Label(
text=str('-'), width=8)
globals()[f'crt_delta_{month}'].grid(
row=crt_row, column=1+i*col_num)
text_tag = Label(text='', width=8)
text_tag.grid(row=crt_row, column=2+i*col_num)
crt_row += 1
crt_vega = Label(text='该月$vega(万分之):')
crt_vega.grid(row=crt_row, column=i*col_num)
try:
globals()[f'crt_vega_{month}'] = Label(
text=str(round(position_dict[csd_und][month]['vega']/cash*10000, 1)), width=9)
except KeyError:
globals()[f'crt_vega_{month}'] = Label(
text=str('-'), width=8)
globals()[f'crt_vega_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
globals()[f'warning_tag_{month}'] = Label(text='', fg='red')
globals()[f'warning_tag_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
if not i:
text_tag = Label(text='目标总delta(百分之):')
text_tag.grid(row=crt_row, column=i*col_num)
globals()['delta_entry'] = Entry(window, width=10)
globals()['delta_entry'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
if not i:
text_tag = Label(text='delta范围(百分之):')
text_tag.grid(row=crt_row, column=i*col_num)
globals()['delta_tol'] = Entry(window, width=10)
globals()['delta_tol'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='本次vega(万分之):')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'vega_entry_{month}'] = Entry(window, width=10)
globals()[f'vega_entry_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='选择对冲下单模式:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'csd_order_type_{month}'] = ttk.Combobox(
window, textvariable=StringVar(), width=7)
globals()[f'csd_order_type_{month}']['values'] = type_list
globals()[f'csd_order_type_{month}'].current(0)
globals()[f'csd_order_type_{month}'].bind(
'<<ComboboxSelected>>', go)
globals()[f'csd_order_type_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='选择下单相邻间隔:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'csd_order_interval_{month}'] = ttk.Combobox(
window, textvariable=StringVar(), width=7)
globals()[f'csd_order_interval_{month}']['values'] = interval_list
globals()[f'csd_order_interval_{month}'].current(1)
globals()[f'csd_order_interval_{month}'].bind(
'<<ComboboxSelected>>', go)
globals()[f'csd_order_interval_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='对冲每笔下单单数:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'csd_order_qty_{month}'] = ttk.Combobox(
window, textvariable=StringVar(), width=7)
globals()[f'csd_order_qty_{month}']['values'] = qty_list
globals()[f'csd_order_qty_{month}'].current(0)
globals()[f'csd_order_qty_{month}'].bind(
'<<ComboboxSelected>>', go)
globals()[f'csd_order_qty_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='选择对冲追价方式:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'csd_chase_type_{month}'] = ttk.Combobox(
window, textvariable=StringVar(), width=7)
globals()[f'csd_chase_type_{month}']['values'] = chase_list
globals()[f'csd_chase_type_{month}'].current(3)
globals()[f'csd_chase_type_{month}'].bind(
'<<ComboboxSelected>>', go)
globals()[f'csd_chase_type_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='')
text_tag.grid(row=crt_row, column=i*col_num)
crt_row += 1
text_tag = Label(text='当前对冲状态:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'hedging_state_{month}'] = Label(
text=hedging_state_list[hedging_state_dict[und][month]], fg='red')
globals()[f'hedging_state_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
text_tag = Label(text='当前已做vega:')
text_tag.grid(row=crt_row, column=i*col_num)
globals()[f'done_vega_{month}'] = Label(text='0')
globals()[f'done_vega_{month}'].grid(
row=crt_row, column=1+i*col_num)
crt_row += 1
Button(window, text="开始对冲", width=10, command=partial(
self._do_hedging, month)).grid(row=crt_row, column=i*col_num, padx=1, pady=1)
crt_row += 1
Button(window, text="停止对冲", width=10, command=partial(
self._stop_hedging, month)).grid(row=crt_row, column=i*col_num, padx=1, pady=1)
crt_row += 1
text_tag = Label(text='')
text_tag.grid(row=crt_row, column=0)
crt_row += 1
text_tag = Label(text='注意事项:', fg='red')
text_tag.grid(row=crt_row, column=0)
crt_row += 1
text_tag = Label(
text='目标delta, delta范围, 本次vega三个输出栏不可在对冲中进行更改!(待更改)', fg='red')
text_tag.grid(row=crt_row, column=0, columnspan=6)
crt_row += 1
text_tag = Label(
text='追价方式参数为"递增tick|追几次|每次几秒|M"', fg='red')
text_tag.grid(row=crt_row, column=0, columnspan=5)
def update():
while True:
sleep(0.5)
cash_tag_['text'] = f'{cash:.2f}'
try:
globals()['crt_delta_total']['text'] = str(
round(position_dict[csd_und]['Total']['delta']/cash*100, 1))
except KeyError:
globals()['crt_delta_total']['text'] = str('-')
try:
globals()['crt_vega_total']['text'] = str(
round(position_dict[csd_und]['Total']['vega']/cash*10000, 1))
except KeyError:
globals()['crt_vega_total']['text'] = str('-')
for month in month_list:
try:
globals()[f'crt_delta_{month}']['text'] = str(
round(position_dict[csd_und][month]['delta']/cash*100, 1))
except KeyError:
globals()[f'crt_delta_{month}']['text'] = str('-')
try:
globals()[f'crt_vega_{month}']['text'] = str(
round(position_dict[csd_und][month]['vega']/cash*10000, 1))
except KeyError:
globals()[f'crt_vega_{month}']['text'] = str('-')
globals()[
f'hedging_state_{month}']['text'] = hedging_state_list[hedging_state_dict[csd_und][month]]
try:
globals()[f'done_vega_{month}']['text'] = str(
round(done_vega_dict[csd_und][month], 1))
except TypeError:
globals()[f'done_vega_{month}']['text'] = '-'
if hedging_state_dict[csd_und][month]:
order_type_dict[csd_und][month] = globals(
)[f'csd_order_type_{month}'].get()
order_interval_dict[csd_und][month] = globals(
)[f'csd_order_interval_{month}'].get()
order_qty_dict[csd_und][month] = globals(
)[f'csd_order_qty_{month}'].get()
chase_type_dict[csd_und][month] = globals(
)[f'csd_chase_type_{month}'].get()
def monitor(window):
window.after(100, update())
update_thread = Thread(
target=update, daemon=True, name='update_thread')
monitor_thread = Thread(
target=monitor, args=(window), daemon=True, name='monitor_thread')
update_thread.start()
monitor_thread.start()
window.mainloop()
if __name__ == '__main__':
api = TCoreAPI(APIEvent)
re = api.connect()
account_info = api.getaccountlist()
account = account_info[0]['Account']
brokerid = account_info[0]['BrokerID']
global und_list
und_list = ['SSE.510050', 'SSE.510300', 'SSE.510500', 'SZSE.159915']
hedger = HedgerVanilla(account=account, brokerid=brokerid)
hedger.main_window()
记录哲学学习过程
西方哲学史: 从苏格拉底到萨特及其后
作者: 塞缪尔·以诺·斯图姆夫 (Samuel Enoch Stumpf)
第一部分 古希腊哲学/Ancient Greek Philisophy
第零章 古希腊年表
- 公元前776年,第一届奥林匹克运动会举办,成为后来希腊世界很多历史事件确定时间的基础。
- 约公元前740—公元前720年,第一次美塞尼亚战争。斯巴达取胜,占领美赛尼亚人大部分国土。
- 公元前735年,科林斯人建立希腊人在西西里的第一个城邦纳克索斯;公元前734年,科林斯人在西西里建立叙拉古城邦。
- 公元前8—公元前7世纪,诗人希西阿德在世,希腊此时称为“希西阿德时期”。
- 公元前725年,斯巴达人建成希腊第一座石制神庙阿尔忒弥斯神庙。
- 公元前683年,雅典执政官改为一年一任,日后雅典国家文件常用名年执政官纪年。
- 公元前664年,普萨美提克一世开始招募希腊雇佣兵,希腊人开始渗入埃及。
- 约公元前7世纪中期,重步兵战术开始在希腊传播,深刻影响希腊世界的作战方式。
- 公元前660—公元前645年,第二次美塞尼亚战争,斯巴达占领美塞尼亚人的全部领土,奴役全部美塞尼亚人。
- 公元前650年,希腊人开始向黑海地区殖民。
- 公元前638年,梭伦出生于雅典。

-
公元前630年,希腊人在利比亚建立昔兰尼城邦。
-
公元前630年,女诗人萨福出生列斯波斯岛。萨福是有史可查的古希腊第一位女诗人。

-
公元前624年,米利都学派创始人泰勒斯出生于米利都。

- 公元前621年,雅典执政官德拉古颁布古希腊第一部成文法典。
- 公元前610年,米利都学派哲学家阿那克西曼德出生于米利都。他首次在哲学史上提出“本原”的概念。

- 公元前595—公元前586年,为争夺德尔菲的控制权而爆发第一次神圣战争。
- 公元前594年,梭伦改革。雅典开始民主化进程。
- 公元前590—公元前560年,斯巴达-提吉亚战争。斯巴达取胜,提吉亚被迫成为斯巴达的“盟邦”。
- 公元前580年,雅典建立第一座雅典娜神庙。
- 约公元前580年,毕达哥拉斯出生于萨摩斯岛。他最早提出地球是球形的思想。

- 公元前560年—公元前527年,庇西特拉图在雅典反复建立僭主政治,促进了雅典民主的建立。
- 公元前544年,爱菲斯学派创始人、哲学家赫拉克利特出生于爱菲斯。列宁称其为“辩证法的奠基人”。

- 公元前540年,阿拉里亚海战,希腊人向地中海西部的扩张被迦太基人和爱特鲁里亚人阻止。
- 公元前534年,雅典第一部悲剧在酒神节中上演。
- 公元前525年,“悲剧之父”埃斯库罗斯出生于阿提卡的埃琉西斯。

- 公元前525—公元前523年,斯巴达人扩张到萨摩斯。伯罗奔尼撒同盟逐渐形成。
- 公元前510年,雅典僭主希庇阿斯被驱逐,雅典僭主制结束。
- 公元前508年,克里斯提尼改革,雅典民主政治基本建立,雅典国家正式形成。
- 约公元前500年,雅典十将军制度确立。
- 公元前499年,波斯统治下的伊奥尼亚人暴动。
- 公元前496年,悲剧作家索福克勒斯出生于雅典。
- 公元前494年,波斯军攻陷并洗劫米利都。
- 公元前490年,5月,雅典在海战中败于埃及那;波斯军出征希腊本土;9月,马拉松战役,希腊联军大胜。
- 约公元前490—公元前480年,智者学派代表人物普罗塔哥拉出生于阿布德拉。

- 公元前487年,雅典首次实施“陶片放逐法”。同年第一部喜剧上演。
- 公元前486年,雅典执政官开始实行抽签选举。
- 约公元前484年,历史学家希罗多德出生于哈利卡纳苏。

- 公元前482年,雅典人在劳里昂发现银矿,并利用银矿的收入发展海军。
- 公元前481年,波斯军攻陷雅典,雅典人全部登上舰船;10月,在斯巴达组建希腊同盟。
- 公元前480年,9月,温泉关战役;同月,萨拉米海战,希腊联军大胜,波斯军大部撤军。

- 公元前480年,悲剧作家欧里庇得斯出生于阿提卡的佛利亚乡。
- 普拉提亚战役,希腊联军大胜,波斯驻希腊陆军统帅玛尔多纽斯阵亡;米卡列战役。

- 公元前478年,提洛同盟成立。
- 公元前469年,苏格拉底出生于雅典。

- 约公元前468年,攸里梅敦河战役,客蒙率领提洛同盟军大胜波斯军。
- 约公元前464—公元前453年,第三次美塞尼亚战争,美塞尼亚人获得了解放。
- 公元前462年,雅典厄菲阿尔特改革,民主程度加强。
- 公元前460—公元前446年,以雅典为首的城邦集团与以斯巴达为首的城邦集团交战(又称“第一次伯罗奔尼撒战争”)。
- 公元前460年,历史学家修昔底德出生于雅典;医学家希波克拉底出生于科斯岛;哲学家德谟克利特出生于色雷斯,他提出了“原子论”。


- 公元前459—公元前454年,雅典人远征埃及,最终全军覆没。
- 公元前454年,提洛同盟金库转移至雅典,雅典帝国初步形成;罗马派遣考察团前往希腊考察法律。
- 公元前449—公元前448年,第二次神圣战争。
- 公元前447年,帕特农神庙开始修建。
- 公元前446年,喜剧作家阿里斯托芬出生于阿提卡;优卑亚暴动。
- 公元前445年,雅典人与伯罗奔尼撒人签订三十年和约。
- 公元前443年,雅典人在南意大利建立图里伊城邦。
- 公元前442—公元前429年,伯利克里连续当选将军,雅典民主政治进入黄金时代。

- 约公元前440年,历史学家色诺芬出生于雅典。
- 公元前438年,帕特农神庙竣工。
- 公元前437年,雅典人在色雷斯建立安菲波利斯城邦。
- 公元前433年,雅典与科基拉结盟,援助科基拉与科林斯作战。此事是伯罗奔尼撒战争的导火索之一。
- 公元前431年,伯罗奔尼撒战争爆发,斯巴达国王阿奇达慕斯率军入侵阿提卡。

- 公元前430—公元前427年,雅典大瘟疫。
- 公元前427年,柏拉图出生于雅典;西西里的高尔基亚出使雅典,修辞学开始在希腊本土传播。

- 公元前424年,伯罗奔尼撒同盟军攻克安菲波利斯,史学家修昔底德因救援不利而被放逐。
- 公元前422年,克里昂、伯拉西达战死,伯罗奔尼撒战争双方主和派占上风。
- 公元前421年,雅典与斯巴达签订“尼基阿斯和约”。
- 公元前418年,斯巴达在曼丁尼亚战役中大败阿尔戈斯同盟军。
- 公元前416年,雅典在西西里的盟友爱吉斯泰与赛林努斯发生冲突。
- 公元前415年,雅典公民大会通过远征西西里的决议,任命亚西比德、尼基阿斯、拉马库斯为远征军指挥;赫尔墨斯神像案,远征进行时公民大会决议逮捕亚西比德回国,亚西比德潜逃至斯巴达。
- 公元前413年,雅典军在西西里惨败,损失战舰200艘以上。从此雅典不再有赢得伯罗奔尼撒战争的可能。
- 公元前411年,6月,雅典四百人政府执政;9月,雅典五千人政府执政;年底,亚西比德指挥雅典军在库诺赛马和阿卑多斯取胜。
- 公元前410年,雅典五千人政府被推翻,恢复了民主制。
- 公元前407年,亚西比德会到雅典,成为全权将军;吕山德成为斯巴达海军统帅。
- 公元前406年,3月,斯巴达于诺提昂海战击败雅典;8月,雅典在阿吉努塞海战大胜斯巴达,但8名将军中有6名被判处死刑。
- 公元前405年,羊河海战,雅典战败,失去几乎全部海上力量。
- 公元前404年,雅典投降,拆毁比雷埃夫斯长城,建立三十寡头政府,其暴政引起雅典人普遍不满。伯罗奔尼撒战争结束。
- 公元前403年,雅典三十寡头政府被推翻,民主制恢复。
- 公元前401—公元前400年,希腊万人雇佣军参与小居鲁士与其兄阿尔塔薛西斯二世争夺王位的战争。色诺芬《长征记》记载了此内容。
- 公元前399年,苏格拉底被判处死刑。
- 公元前396—公元前394年,斯巴达进军小亚。
- 公元前395年,科林斯战争爆发;雅典开始重修长城。
- 公元前394年,克多尼斯海战,科浓作为雇佣军将领率波斯海军大败斯巴达舰队,斯巴达失去海上霸权。
- 公元前393年,雅典重修长城竣工。

- 公元前390年,雅典名将伊菲克拉特首次率轻盾兵击败斯巴达重步兵。
- 公元前387年,柏拉图创建阿卡德米学园。
- 公元前386年,《大王和约》签订,波斯从此能合法介入希腊事务。
- 公元前384年,亚里士多德出生于色雷斯的希腊殖民地斯塔基拉。


- 公元前382年,斯巴达军攻占底比斯卫城。
- 公元前378年,雅典与底比斯结盟;第二雅典海上同盟成立。
- 公元前376年,纳克索斯海战,雅典重新掌握爱琴海制海权。
- 公元前371年,留克特拉战役,底比斯军大败斯巴达军,底比斯开始称霸希腊。
- 公元前369年,雅典与斯巴达结盟,抵抗正在崛起的底比斯。
- 公元前362年,曼丁尼亚战役,底比斯惨胜反底比斯联军,底比斯名将伊巴密浓达战死。
- 公元前359年,马其顿的腓力摄政,雅典与马其顿结盟。
- 公元前356—公元前346年,第三次神圣战争。
- 公元前340年,德摩斯梯尼组织反马其顿同盟。
- 公元前338年,喀罗尼亚战役,希腊诸邦联军惨败于马其顿;第一次科林斯会议。
- 公元前337年,第二次科林斯会议,组建以马其顿为首的希腊同盟,并向波斯宣战。
- 公元前336年,马其顿的亚历山大二世继位。
- 公元前335年,亚里士多德在吕凯昂建立学园。
- 公元前334年,亚历山大征服小亚。
- 公元前333年,伊苏斯战役,波斯军大败。
- 公元前331年,亚历山大里亚建城;高加米拉战役。
- 公元前327年,亚历山大进入印度。
- 公元前323年,亚历山大去世。
- 公元前323—公元前322年,拉米亚战争,希腊反马其顿联盟惨败。
第一章 苏格拉底的前辈
希腊哲学诞生在与雅典隔爱琴海相望的港口城市米利都,它坐落于小亚细亚伊奥尼亚地区的西海岸。由于他们所处的地理位置,第一批希腊哲学家就被称作米利都学派或伊奥尼亚学派。

由于他们所处的地理位置,第一批希腊哲学家就被称作米利都学派或伊奥尼亚学派。大约公元前 585 年,当米利都学派的哲学家们开始他们系统的哲学工作时,米利都巴经成为一个海洋贸易和各地思想的汇聚之地。早先伊奥尼亚就诞生过创作了《伊利亚特 》和《奥德塞》Odyssey)的荷马(约公元前700年)。
1.1 什么东西是持存的
泰勒斯
对于米利都的泰勒斯我们知道的并不多,而我们所知道的那些还不如说是一些逸闻。泰勒斯没有留下任何作品。他是希腊国王克洛素斯和执政官梭伦的同代人,他生活的年代大概是在公元前624年到公元前546年之间。 他开启了一个全新的思想领域, 由此,也赢得了西方文明“第一个哲学家”的称号。
泰勒斯全新的问题是关子事物的本质的。事物是由什么构成的呢?或者,哪种”物质”构成了万事万物?泰勒斯提出这些问题,试图解释这样一个事实,即存在着各种不同的事物, 例如士壤、云和海洋,有时这些事物中的一些转变成另一些事物,不过它们在某些方面依然类似。泰勒斯对思想的独特贡献在于他的如下思想,即不论事物之间有多大的差异,它们之间依然存在着根本的相似。多通过一而相互关联。他假定某种单一的元素,某种“物质”包含了自身活动和变化的原则,它是所有物理实在的基础。对泰勒斯来说,这个一,这种物质,就是水。
他的问题为一种新的研究创造了条件,这种研究就其本性而言是允许争论的,在进一步的分析中它可能得到证实,也可能被驳倒。
阿那克西曼德
阿那克西曼德是比泰勒斯年轻一些的同代人,也是泰勒斯的学生。他同意老师的看法.认为存在着某种单一的基本物质,事物就是由它构成的。但是, 阿那克西曼德不同于泰勒斯,他说,这种基本的物质既不是水,也不是其他任何特殊的元素。他认为,所有这些物质都来自最原始的本质,它就是一个不定的或无限制的实在。
他另外还提出了人是由鱼演化而来的演化论,绘制了第一幅全球地图,认识到天体环绕北极星运转提出天空是一个完整的球体等等。
阿那克西米尼
阿那克西米尼(约公元前585年——公元前528年),他是阿那克西曼德的年轻同伴。阿那克西米尼试图沟通他的两个前辈的不同观点,他提出气是万物由之而产生的原初物质。就像泰勒斯提出的水的思想,气也是一种确定的物质,我们可以很有理由的把它看作是所有事物的基础。例如,虽然气是不可见的,但是我们只有在可以呼吸时才能存活,“就像我们的灵魂——它是气——把我们凝聚为一体,气息和气也包围了整个世界。”就像阿那克西曼德 提出的无限制者处于持续的运动中这种看法一样,气弥漫于所有的地方——虽然不像无限制者,它是一种特殊的、可以被实实在在把握到而加以识别的物质实体。此外,气的运动也是一个比阿那克西曼德的“分离”更加特殊的过程。为了解释气是如何作为万物本原的,阿那克西米尼指出,事物之成为它们所是的那个样子,取决于组成这些东西的气在多大程度上凝聚和扩张。在这样说的时候,他已经提出了一种重要的新思想:质上的差异,原因在于量上的差异。
米利都学派真正的意义在于他们第一次提出了事物的最终本性的问题,并且第一次迟疑不决地但却是直接地探究了自然实际上是由什么构成的。
1.2 万物的数学基础
毕达哥拉斯
爱琴海中有一座与米利都一水之隔的小岛——萨摩斯岛。它就是智薏非凡的毕达哥拉斯(约公元前570年——公元前497年)的出生地。亚里士多德告诉我们,毕达哥拉斯派"致力于数学研究,他们是最先推动这项研究的,由于长期浸淫其中,他们进而认为数的原则就是所有事物的原则。“与米利都学派形成对照的是, 毕达哥拉斯学派认为,事物是由数构成的。
像毕达哥拉斯学派那样说所有事物都是数,就意味着在他们看来所有具有形状和大小的事物都有一个数的基础。他们以这种方式从算术转到了几何,然后再转到实在的结构。对数的这种理解使毕达哥拉斯学派形成了他们最重要的哲学观念,即形式的概念。米利都学派已经形成了原初物质或质料的观念,所有的事物都是由它构成的,但是特殊事物是如何从这个单一的原初物质中分化出来的?他们对此却没有一个连贯的概念。他们都谈到了一种无限定的物质,不论它是水、气,还是不确定的无限制者,都以之来意指某种原初的物质。毕达哥拉斯学派现在提出了形式的概念。在他们看来,形式意味着限定(limit),而限定尤其要通过数来加以理解。
毕达哥拉斯及其追随者的辉煌在某种程度上体现在他们对后来的哲学家尤其是柏拉图的影响上。柏拉图哲学的许多内容在毕达哥拉斯的教导中已经得到了表述,包括灵魂的重要性和它的三重区分,还有数学的重要性,因为它关系到形式或“理念”的概念。
1.3 解释变化的尝试
赫拉克利特
早先的哲学家们试图描述我们周围世界的构成要素。来自爱菲索的贵族赫拉克利特(约公元前540年-公元前480年)把注意力转向一个新的问题,即变化的问题。他的主要思想是“一切都处于流变之中”,他用如下的话表达了永恒变化的思想:“我们不能两次踏进同一条河流“。这种流变的思想不仅适用于河流,而且适用于一切事物,包括人类的灵魂。赫拉克利特指出,在这许多形式和那单一的持存元素之间,在多和一之间,必定存在着某种基本的统一性。他的说理方式富有想象力,因此他的许多说法在后来柏拉图和斯多噶派的哲学中有着重要的位置;在近几个世纪里,他则深为黑格尔与尼采所激赏。
流变与火 为了把变化描述为多样性中的统一,赫拉克利特认定必定存在着某种在变化的东西,他说这个东西就是火。但是他并不只是简单地用火这个元素取代素勒斯的水或者阿那克西米尼的气。赫拉克利特之所以认定火是万物的基本元素,是因为火的活动方式提示出了变化过程是如何进行的。火在同一时刻既是一种不足,又是一种过剩:它必须不停地加人(燃料),它也不停地释放出某些东西一热、烟或者灰烬。火是一个转化的过程,于是在这一过程中,添加进火里去的东西转化成其他的东西。
除了火的概念外,赫拉克利特还提出了另外一个很有意义的思想,这就是作为普遍规律的理性的思想。
作为普遍规律的理性 变化的过程不是杂乱无章的运动,而是神的普遍理性(逻各斯,logos)的产物。理性的观念来源于赫拉克利特的宗教信仰,他相信最实在的东西是灵魂,而灵魂最独特最重要的属性是智慧或思想。但是当他谈到神和灵魂时,却并未想到独立的人格实体。对他而言,只存在一种基本的实在,这就是火,赫拉克利特将火这个物质实体称作一或神。因此,赫拉克利特是一个泛神论者,即认为神就是宇宙中万物的总体。在赫拉克利特看来,一切事物都是火/神。既然火/神存在于一切事物之中,所以甚至人的灵魂也是火/神的一部分。
巴门尼德
巴门尼德是比赫拉克利特年轻一些的同代人。他大约出生在公元前510年,他的一生大部分时间是在埃利亚度过的。这座城市位于意大利的西南部,是由希腊的流亡者们建造的。居于此城时,巴门尼德在多个领域卓有建树,他为埃利亚的人们制定了法律,建立了一个新的哲学学派即埃利亚学派。巴门尼德对他的前辈们的哲学观点深感不满,他提出了一种非常引人注目的理论:整个的宇宙只有一个东西,它从不变化,没有任何部分,永远不可毁灭。他把这个单一的东西称作一(One)。在巴门尼德看来,所有这些变化和多样性都只是一个幻觉。不管现象是怎样的,存在的只能是一个单一的、不变的、永恒的东西。为什么巴门尼德要提出一个与现象截然相反的理论呢?原因就在于他更加信服于逻辑推理而不是眼睛看到的东西。
巴门尼德的理路从如下一个简单的陈述开始,要么存在者存在,要么存在者不存在。例如,母牛存在,但是独角兽不存在。经过进一步的考虑,巴门尼德认识到我们只能断言上面这个陈述的前半部分,即存在者存在。因为我们只能对存在的东西形成概念并言说之,而对不存在的东西则不能。因此,在巴门尼德看来,我们必须拒斥任何暗含着存在者不存在的观点。巴门尼德随后揭示了这个观点的几个隐含的意思。首先,他指出不存在变化。赫拉克利特认为一切都处在持续不断的变化之中;而巴门尼德侧持完全相反的观点。我们通常观察到事物通过产生和消失而变化着。虽然事物如此这般地呈现在我们眼前,但是巴门尼德指出,这个所谓的变化过程在逻辑上是有缺陷的。我们先是说树不存在,然后又说它存在,接着我们再一次说它不存在。这里我们在开始和最后都说到了存在者不存在这个不可能成立的观点。于是从逻辑上来说,我们不得不拒斥这个所谓的变化过程,把它看作一个巨大的幻象。因此,没有什么东西是变化的。
与此类似,巴门尼德指出,世界是由一个不可分的东西构成的。不过我们通常也观察到世界包含许多不同的东西。例如,假设我看到一只猫坐在地毯上。对此,我通常所知觉到的是,猫和地毯是不同的东西,而不仅仅是一团没有分别的物质。但是这种通常的物理差别的观点在逻辑上也是有缺陷的。我其实是在说在猫爪子的下面不存在猫,而从它的爪子到头才存在猫,在猫的头顶之上又不存在猫。因而当我划分猫的物理界限时,我在开始和最后都说到了存在者不存在这个不可能的观点。因此我必须拒斥所谓的物理差异的事实,把它也看作一个幻象。简而言之,只有一个不可分的东西存在。
巴门尼德运用类似的逻辑指出一必定是不动的:如果它运动的话,它在它原来的地方将不存在,这包含了存在者不存在这样一个不合逻辑的断言。巴门尼德还指出一必定是一个完满的球体。如果它在任何一个方向上是不规则的一就像保龄球上钻有三个洞,这将在保龄球里边产生一个不存在的区域。这也会错误地断言某物不存在。
即使我们承认巴门尼德论证的逻辑力量,我们也很难抛弃我们的常识观点,即世界呈现出变化和多样性。但是巴门尼德拒斥这些通常的思想,坚持在现象与实在之间作出区分。他说,变化和多样性混淆了现象和实在。在现象与实在的区分之后的是巴门尼德另外一个同样重要的区分,即意见与真理之间的区分。现象只能产生意见,而实在是真理的基础。常识告诉我们,事物似乎处在流变之中,因此处在个持续的变化过程之中。然而巴门尼德说,这个建基于感性的意见必须被理性的活动所取代。理性能够辨别出关于事物的真理,它告诉我们如果存在着一个单一的实体,而且所有东西都是由它构成的,那么就不可能存在运动或变化。当泰勒斯说一切都来源于水的时候,他在某种程度上也提出了这个观点。泰勒斯暗示说,事物的现象并没有向我们展示实在的构成物质。但是巴门尼德明确地强调这些区分,它们在柏拉图的哲学中产生了决定性的作用。柏拉图接受了巴门尼德关于存在的不变性的根本思想,由此进一步提出他的真理的理智世界和意见的可见世界之间的区分。
巴门尼德在65岁时由他主要的学生芝诺陪同前往雅典。传说他与年轻的苏格拉底进行了对话。巴门尼德关于变化和多样性的极端观点不可避免地招致了人们的质疑和嘲笑。捍卫这些观点、反击其论敌的任务落在了巴门尼德的学生芝诺的上。
芝诺
芝诺大约在公元前489年出生在埃利亚。当他陪同巴门尼德访问雅典时已经40岁了。芝诺为巴门尼德进行辩护的主要策略是揭示关于世界的所谓常识会导致比巴门尼德的观点更荒唐的结论。例如,毕达哥拉斯学派拒斥巴门尼德所接受的一个基本的假设,这就是实在是一。相反他们相信事物的复多性——存在着大量分离的互相区别的事物——因而运动和变化是实在的。他们的观点似乎更能得到常识和感官的验证。但是芝诺所追随的埃利亚学派要求在现象与实在之间作出区。
芝诺强烈地感到我们的感官没有为我们提供关于实在的任何线索,它只是为我们提供了关于现象的线索。所以我们的感官没有给我们提供可靠的知识,而只是提供了意见。他举了一个黍米种子的例子来说明这一点。如果我们把一粒黍米的种子扔到地上,是不会发出声响的。但是如果我们把半蒲式尔的种子倒到地上,就会有声音了。芝诺由此下结论说,我们的感官欺骗了我们。因为要么哪怕只有一粒种子落下时也有声音,要么即使许多种子落下时也没有声音,二者必居其一。所以要想达到事物的真理,思想之路要比感觉之路更为可靠。
芝诺的四个悖论 为了回击对巴门尼德的批评,芝诺把他的论证构造成悖论的形式。关于世界的常识观点采用了两个主要的假设:(1)变化在时间中发生,以及(2)各种不同的事物延伸在空间之中。芝诺追随巴门尼德,他当然也拒斥这两个假设。为了反驳常识观点,芝诺暂时先接受上面的两个假设,然后揭示出从中产生的悖论。这样得到的结果实际上如此荒唐,以至于常识的观点再也不是表面上看来那么符合常理了。两相对比之下,巴门尼德关于一的观点似乎倒是对世界更合理的解释了。芝诺提出了四个主要的悖论。
1.运动场恃论 根据运动的这个悖论,一个奔跑者从跑道的起点到终点要穿越一系列的距离单位。根据毕达哥拉斯学派的假设,跑步者要跑完全程必须在有限数量的时间内穿越无限数量的点。但关键问题是,一个人如何能够在有限的时间里穿过无限数重的点呢?跑步者要达到跑道的终点,就必须首先达到跑道的中点:但是从起点到中点又可以分成两半,要想达到中间点,跑步者必须首先达到那个四分之一点。同样从起点到四分之一点之间的距离也是可分的,这个分割的过程必定可以无限进行下去,因为分割后总是有剩余,而剩余的部分还是可分的。所以,如果跑步者不首先到达某个点之前的一个中间点,他就不能到达那个点,而如果有无数的点,那么他就不可能在有限的时间里穿越无限数量的点。因此芝诺下结论说,运动并不存在。
2.阿基里斯追🐢的恃论 这个悖论与运动场悖论很类似。让我们想象在迅捷的阿基里斯和缓慢的乌龟之间举行一场赛跑。由于阿基里斯是位运动健将,假设之下,阿基里斯永远也追不上乌龟。
3.飞失恃论 当射手瞄准一个靶子射出箭时,那支箭运动吗?毕达哥拉斯学派承认空间的实在性与可分性,他们会说,运动的箭在每一刻都占据了空间中的一个特定位置。但是如果一支箭在空间中占据了和它的长度相等的一个位置,那么这正是我们说一支箭不动时所表达的意思。由于飞矢必定总是在空间中占据这样一个等于它的长度的位置,它必定总是处于静止状态。此外,正如我们在运动场的例子中看到的,任何量都是无限可分的。因此,飞矢占据的空间是无限的,这样它就必须与所有其他的事物相重合,在此情况下,所有事物都必定是一而不是多。因此运动只是一个幻象。
4.运动的相对性恃论 想象三辆相同长度的大客车,它们在相互平行的道路上行驶,每辆车的一边都有8个窗户。一辆车静止不动,其他两辆车以相同的速度朝相反的方向运动。芝诺主要的观点就是运动没有清晰的定义,它是一个相对的概念。
在所有这些论证中,芝诺仅仅是在对巴门尼德的反对者的观点进行驳难,他严格遵循他们对复多性世界——例如其中一条线或者时间是可分的世界——的假设。通过把这些假设推导到它们的逻辑结论,芝诺试图证明复多性世界的思想将使人陷人不可解决的荒谬和悖论之中。因此,他重申了巴门尼德的论题:变化和运动乃是幻象,只有一个存在者,它是连续的、物质的、不动的。芝诺的努力尽管勇气非凡,但是关于世界的常识观点依然存在,它促使后来的哲学家们采取一种不同的方式来解决变化与恒常的关系问题。
恩培多克勒
恩培多克勒在他的家乡西西里岛的阿格里琴托是个引人注目的人物,他在那里大概从公元前490年活到了公元前430年。他的兴趣和活动覆盖了从政治学和医学到宗教和哲学的泛领域。传说为了让人们永远对他奉若神明,恩培多克勒跳进埃特纳火山口结束了自已的生命,这样他的身体就不留下任何痕迹,人们便会以为他升天了。恩培多克勒认为承认与否认运动变化的论证都有各自的价值。由此他发现了一种协调的方式,使得我们既可以说存在着变化,同时也可以断言实在从根本上来讲是不变的。
恩培多克勒在如下的观点上是同意巴门尼德的,即存在是永生的、不可毁灭的,它仅仅只存在着。他写道:“从绝对没有实存的东西不可能产生任何存在;而存在的毁灭也是完全不能实现也不可想象的:因为它将一直存在下去,不论什么人把它放在什么条件下,都是如此。”但是,恩培多克勒不像巴门尼德,他不同意说实存之物仅仅由“一”构成。我们要接受那个“一”的概念就必须否认运动的实在性,可是对于恩培多克勒来说,运动的现象如此显而易见、引人注目因而是不容否认的。因此他拒斥了“一”的观念。恩培多克勒同意巴门尼德的存在是永生的且不可毁灭的观点,但是他认为,存在不是一而是多。不变的、永恒的东西是多。
在恩培多克勒看来,我们看到和经验到的物体事实上是有成也有毁的。但是这样的变化和运动之所以可能,是因为物体是由许多物质微粒组成的。因此,虽然物体能够变化,就像赫拉克利特说的那样,但是它们由之构成的微粒是不变的,就像巴门尼德谈论的一那样。但是这些微粒包括什么呢?恩培多克勒认为这些微粒包括四种永恒的物质元素,即土、气、火、水。他相信这四种元素是不变的、永恒的,永远也不能转化为其他的东西。用来解释我们看到的物体中的变化的,是四种元素的混合,而不是它们的转化。他写道,“只存在混合以及混合之物的相互交换。”土、气、火、水是不变的微粒,它们混合在一起形成物体,这就使得我们在日常经验中看到的变化成为可能。
恩培多克勒对土、气、火、水的解释只是他的理论的第一个部分。第二个部分是对推动变化过程的特殊的力的解释。伊奥尼亚学派假定自然物质自身就转化为各种各样的物体。只有阿那克西米尼试图用气的稠密和膨胀的理论来具体地分析变化的过程。恩培多克勒则与之形成鲜明对照,他假定在自然中存在着两种力,他称之为爱和恨(也可以说和谐与争执)。它们就是导致四种元素互相混合后来又互相分离的力。爱的力导致元素相互吸引,形成某种特殊的形式或者某个特殊的人。恨的力导致事物的解体。
阿那克萨戈拉
阿那克萨戈拉(公元前500年-公元前428年)出生在一个叫克拉左美奈的海滨小城,它现在土耳其境内。后来他来到雅典伴随执政官伯里克利左右。他主要的哲学贡献是提出了心灵(奴斯,nous)概念,他把它和物质区分开来。阿那克萨戈拉同意恩培多克勒的观点,所有存在的产生和消灭都仅仅在于已经存在的物质的混合与分离。但是他不接受恩培多克勒认为各种事物都是由爱与恨形成的那种含糊不清甚至带有神话色彩的思想。在阿那克萨戈拉看来,这个世界和世上的一切事物都是井然有序而且具有复杂精妙的结构的;所以,必定存在着某个有知识有力量的存在者把物质世界组织成这个样子。
根据阿那克萨戈拉的看法,实在的本质最好被理解为是由心灵和物质构成的。在心灵影响物质的形状和行为之前,物质就已经存在了,它是各种各样物质实体的混合,而这些物质实体都是不生不灭的。即使当这种物质原料被分成实际的物体时,分出的每个部分也还是包含着其他所有元素“种子”的微粒。例如雪就既包含了黑又包含了白,而它之所以被称作白的只不过是因为白在其中居于主导地位。所以在某种意义上,实在的每个部分都和实在的全体有同样的成分,因为,每个部分之中都含有每种元素的“一份”。
根据阿那克萨戈拉的看法,原始物质形成各种事物是通过分离的过程,这个分离是由心灵的力量促其发生的。具体说来,心灵首先产生了一个旋转运动,形成了一个漩涡,它扩展开来,使得越来越多的原初物质卷入进来。这迫使各种物质“分离”开来。这个漩祸运动最初将物质分成两大部分,其中的一部分包含热、光明、稀薄和干燥的物质,另一部分则包含冷、黑暗、稠密和潮湿的物质。这个分离的过程是连续的,是永不间断地进行下去的。特定的事物总是由诸物质结合而成的,在其中某种特定的物质占了统治地位。例如,水中是潮湿的元素占主导地位,但也存在所有其他的元素。
虽然阿那克萨戈拉把心灵作为宇宙中和人的身体中的推动力或控制力,但是他对心灵实际作用的解释是有其局限的。一方面,心灵不是物质的创造者,因为他认为物质是永恒的。此外,他在心灵中没有看到自然世界的任何目的。那种主要用“分离”过程来说明心灵在特殊事物起源中的作用的办法,看来是一个机械论的解释。事物是物质原因的产物,而心灵除了予以最初的推动外,似乎就没有任何别的特殊作用了。
亚里士多德后来区分了不同种类的原因,他对阿那克萨戈拉的观点的评价有褒有贬。他把阿那克萨戈拉和他的前辈作了比较,那些前辈把事物的起源归结为自发性和随机。根据亚里士多德的观点,阿那克萨戈拉说,“理性在动物中,也在全部的自然中作为秩序和一切安排的原因而出现时,他看起来头脑冷静,截然不同于他的前辈。”但是,亚里士多德又说,阿那克萨戈拉对心灵概念的运用是“远不充分的”。他的批评是,“阿那克萨戈拉让理性作为一具神奇的机器来制造世界。当他说不清楚某事物必然存在的原因何在时,他就会把理性拉进来,但在其他一切情况下他都把事物的原因归于理性之外的东西。”阿那克萨戈拉似乎只是解释了物质如何能发生漩涡运动,自然秩序的其余内容测不过是这个运动的产物而已。
然而,阿那克萨戈拉关于理性的说法在哲学史上产生了深远的影响,因为他由此把一种抽象的原则引入了事物的本质之中。他区分了心灵和物质.他或许还没有将心灵描述为完全非物质的,但是他将心灵和它要与之打交道的物质区分了开来。他宜称,心灵不像物质,“它不与其他任何东西相混合,是单独的、自在的”。心灵不同于物质的地方在于它是“所有事物中最精细的、最纯的,它拥有对每件事物的一切知识,具有最大的力量”。因而,物质是复合的,而心灵则是单一的。但是阿那克萨戈拉并没有区分两个不同的世界一心灵的世界和物质的世界一而是将它们看作总是相互关联的。所以他写道,心灵存在于“每一个事物存在的地方”。虽然阿那克萨戈拉没有展开他的心灵概念的所有可能性,但是这个概念注定会对此后的希腊哲学产生巨大的影响。
1.4 原子论者
留基波和德谟克利特建立了一种关于事物的本质的理论,它与某些当代的科学观点有着惊人的相似。然而今天我们很难把留基波和德谟克利特各自对这个理论的贡献区分开。他们的作品绝大部分都佚失了,但是我们至少知道留基波是原子论学派的创立者,对此理论的详尽阐述则来自德谟克利特。留基波与恩培多克勒(公元前490年-公元前430年)是同时代的人,但是除此之外我们对他的生平几乎一无所知。德谟克利特出生在色雷斯的阿布德拉,据说他活了100岁,生于公元前460年,卒于公元前360年。他学识广博,力求对他那抽象的原子理论进行清晰的表述,这些自然都让留基波相形见绌。不过我们还是得肯定,是留基波提出了原子论的主要观点,即所有事物都是由运动在虚空中的原子构成的。
原子和虚空
根据亚里士多德的描述,原子论的产生是想要克服埃利亚学派拒斥空间的逻辑结果。巴门尼德否认存在任何独立的事物,因为到处都是存在,在这种情况下整个的存在是一。尤其是他否认非存在或虚空(空的空间)的存在,因为说存在着虚空就是说虚空是某种存在。他认为,我们不可能说存在着无。留基波建立他的新理论,正是为了反对埃利亚学派对空间或虚空的处理方式。
留基波肯定了空间的实在性,从而为一种关于运动和变化的连贯理论的提出准备了条件。使巴门尼德的空间概念陷入困境的是,他认为任何存在的东西都必须是物质的,因此如果空间存在,那么它也必定是物质的。而留基波则认为,我们可以肯定空间的存在,同时无须说空间是物质的。所以他把空间描述为一个容器,它可以在某个地方是空的,而在另一个地方被充满。空间或虚空作为一个容器可以是物体移动的场所,留基波认为,很显然我们没有任何理由否认空间的这一特性。要是没有这样一种空间概念,留基波和德谟克利特就不可能提出他们的万物都是由原子构成的观点。
在留基波和德谟克利特看来,事物的本质在于无限数量的微粒或单元,称为“原子”。留基波和德谟克利特赋予这些原子两个主要的特性——这也是巴门尼德认为“一”所具有的——即不可毁灭性和永恒性。巴门尼德说过,实在是个单一的“一”,而原子论者现在说,存在着无限多的原子,每一个原子自身是绝对致密的。这些原子不包含任何的虚空,因此是不可入、不可分的。它们存在于空间之中,并且在形状和大小上相互区别。由于它们太过微小,所以是不可见的。因为这些原子是永恒的,所以它们不是被创造的。因此,自然只包含两种东西:空间(它是真空)和原子。原子在空间中运动,它们的运动使它们形成了我们所经验到的物体。
原子论者认为无须解释原子最初是如何在空间中运动起来的。他们认为这些原子最初的运动类似于灰尘在光线中向各个方向的飞速运动,即使没有风推动它们,灰尘也会这样。最初原子在空间中运动着,它们是单个的单元。它们不可避免地相互碰撞。在有些情况下,它们的形状使它们能够结合在一起,形成团。在这点上,原子论者和认为事物都是数的毕达哥拉斯学派有近似之处。事物就像数一样是由可以相互结合的单元构成的;对于原子论者来说,事物仅仅是各种不同原子的结合。数学的形体和物理的形体是类似的。原子一开始就存在于空间中。每个原子就像巴门尼德的一,但是,虽然它们是不可毁灭的,却永远处于运动之中。原子论者把土、气、火、水描述为本身不变的原子所形成的各种不同的聚集一这些聚集产生于最初单一的原子的运动。这四种元素并不像早先的哲学家所认为的那样是所有其他事物的最初根源,它们本身也是绝对原初的物质——原子——的产物。
原子论者对事物的本质提出了一个机械论的概念。对他们来说,所有事物都是在空间中运动的原子相互碰撞的结果。他们认为没有必要解释原子的来源,也没有必要解释推动原子的最初运动。因为这些起源的问题总是可以问下去,甚至对于上帝我们也可以这么问:赋予物质的原子以永恒的存在似乎并不比其他任何解释更令人感到不满。
留基波和德谟克利特设想的原子理论在历史上造成了长久而深远的影响。这一理论的生命力十分顽强,虽然在中世纪曾一度式微,但到了文艺复兴时期又东山再起,并且为接下来几个世纪里的科学工作提供了模式。伊萨克·牛顿(1642-1727)在写作著名的《数学原理》(Principia Mathematica)时依然用原子论的术语进行思考。在这部著作里他推导出了行星、彗星、月球和海洋的运动;他在1686年写道:
我希望我们能够用从机械原理得出的相同的推理揭示出自然的其他现象,因为有许多原因促使我猜测它们或许都依赖于某些力,凭借这些力,由于某种目前还不清楚的原因,这些物体的微粒互相吸引,形成规则的形状,或者互相排斥而彼此远离。
虽然牛顿假设是上帝椎动了事物运动起来,他对自然的物理分析却仅限于在空间中运动的物质的机械原则。在牛顿之后原子论一直占据支配地位,直到量子理论和爱因斯坦为当代科学提供了一种新的物质概念,它否认了原子有不可毁灭性。
知识理论和伦理学
除了描述自然的结构,德谟克利特还关注其他两个哲学问题:知识问题和人类行为问题。德谟克利特是个彻底的唯物主义者,他认为思想也可以用解释其他现象的方式来解释,即它也是原子的运动。他区分了两种不同的知觉,一种是感性知觉,一种是理性知觉,它们都是物理过程。当我们的眼晴看到某个东西时,它其实是由物体造成的“影响”,是物体的原子的流射,从而形成了一个“影像”。这些事物的原子影像进人眼晴和其他感觉器官,对灵魂产生了影响,而灵魂自身也是由原子构成的。
德谟克利特进一步区分了两种认识事物的方式:“存在着两种形式的知识,真实的知识和暗昧的知识。属于后者的是视觉、听觉、嗅觉、味觉和触觉。但是真实的知识与这完全不同。”区别这两种思想的东西是,“真实的”知识仅仅依赖于对象,而“暗昧的”知识则受到那个人特定身体条件的影响。例如两个人都会同意他们品尝的是苹果(真实的知识)。但是他们可能对苹果的味道意见不一(暗昧的知识)。所以根据德谟克利特的看法,“我们通过感官不能知道任何确切的真理,我们所知道的只是那些按照我们身体的倾向以及进入身体或者抵抗身体的东西的倾向而变化的东西。”不过德谟克利特还是承认,感觉和思想是相同类型的机械式的过程。
关于伦理学,德谟克利特为人类行为提出了一套雄心勃勃的规则。总的来说,他认为生活最令人向往的目标是快乐,我们最好是通过在一切事务上的节制有度和文化上的教养来获得它。随着伦理学成为哲学最关注的问题,哲学也走到了它的一个主要分水岭前,哲学的第一个时期结束了,这一时期的主要问题是自然的秩序。现在人们提出了许多更富有挑战性的问题来探讨他们应该如何行动。
第二章 智者派与苏格拉底
第一批哲学家关注的是自然;而智者派和苏格拉底则将哲学的关注点转到了对人类的研究。他们不去问“事物的终极原则是什么”等一些关于宇宙的大问題,而是提出一些与道德行为有着更直接关系的问題。哲学由主要关注科学问题转而关注基本的伦理问题,这一转向能在下述事实中得到部分解释:前苏格拉底哲学家们彼此之间并没有能达成任何一种统一的宇宙概念。他们对自然提出了各不相同的解释,这些解释彼此似乎无法调和。例如,赫拉克利特说自然由多种实体构成,所有事物都处于持续的变化过程中。巴门尼德则持完全相反的观点,他论证实在是单一的、静止的实体,是“一〞,运动和变化只是由事物的現象投射于我们的感官而引起的幻觉。如果这些相互矛盾的宇宙论在破解自然之迷时所遇到的巨大困难产生的仅仅是人们的一种理智的疲倦,那么哲学也许就会在这里止步不前了。确实,关于事物终极原則的爭论导致了一种怀疑主义的傾向:人类理性是否有能力发现自然的真理?但是这种怀疑主义为哲学转向一个新方向提供了推动力,因为怀疑主义自身成了被加以认真考虑的主題。哲学家们现在不再就各种自然理论争论不休,他们现在想解决有关人类知识的问題,问道:我们有没有可能发现普遍的真理?各个种族和社群的文化差异使这个问题越发显得突出。结果,关于真的问题与关于善的问题深深地纠缠在了一起。如果人们没有能力认识到任何普遍的真理,那么还能够存在一个普通的善的概念吗?这场新爭论的主要参与方是智者派和苏格拉底。
2.1 智者派
在公元前5世纪前后,雅典出现三个最为杰出的智者,他们是普罗泰戈拉、高尔吉亚和塞拉西马柯。他们这群人或者是作为游历教师来到雅典的,或者是像埃利斯的希庇亚的情况那样,作为使节来到雅典的。他们给自己加上“智者”或者“有知识的人”的特别称号。他们的文化背景各异:普罗泰戈拉来自色雷斯的阿布德拉,高尔吉亚来自南西西里岛的林地尼,塞拉西马柯侧来自卡尔亚冬。他们对雅典人的思想和习俗进行了一番新的审视,提出了一些追根究底的问题。特别是,他们使雅典人不得不考虑自己的观念和习俗是基于真理还是仅仅基于惯常的行为方式。雅典人在希腊人与野蛮人之间,以及在主人与奴隶之间作出的区分是有充足的根据还是仅仅基于偏见?智者们对不同文化的广博知识使他们怀疑获得任何让社会能借以对人们生活进行规范的绝对真理的可能性。他们迫使富有思想的雅典人考虑希腊文化是建基于人为的规侧(nomos)还是建基于自然(physis)。他们令雅典人追问自己的宗教和道德规范是约定俗成的从而也是可变的,还是自然的从而也是永恒的。毫无疑问,智者们为更加深人细致地思考人类本性开辟了道路——尤其是我们如何获得知识以及我们如何规范自己的行为。
智者派主要是一些有实际经验的人,他们尤其善于语法、写作和公开辩说。这些技能使他们成了惟一有能力满足雅典社会中一种特殊社会需要的人。在执政官伯里克利(公元前490年-公元前429年)的领导下,雅典旧有的贵族政体被民主制取代了。由于自由民可以参与政治讨论并担任领导职务,人们的政治生活得到了强化。但是旧有的贵族教育体系主要建基于家庭传统,无法使人们适应民主社会生活中的新情况。在宗教、语法领域以及对诗歌的细致解释方面,还没有严格的理论训练。智者们进入这一文化真空,他们在教育上的实践兴趣满足了这个迫切的需要。他们成为广受欢迎的讲师,是新式教育的主要提供者。使他们特别受人追捧的首先是他们自称能教授修辞术——即令人信服地演说。在民主的雅典,说服力对任何一个想要爬到领导层的人都是政治上所必需的。
智者派的声誉最初是很好的。他们为训练人们清晰有力地表述自己的思想而做了大量工作。但是修辞术有些像一把刀,既可为善,也可作恶。修辞术的运用从令人赞许变为令人遗憾,这其中智者派所固有的怀疑主义起了极大的推动作用。没有多久,智者派的怀疑主义和相对主义使他们受到了怀疑。他们的形象已经不同于早期哲学家那种不带任何经济考虑而从事哲学的公正无偏的思想家形象。智者派为他们的教学索取费用,而且刻意找那些付得起费的有钱人来教。苏格拉底曾在智者门下学习,可是因为穷,他只上得起他们提供的“短期课程”。这种收费教学的行为使得柏拉图将他们讥为“销售灵魂食品的商人”。
普罗泰戈拉
在来到雅典的诸多智者当中,阿布德拉的普罗泰戈拉(约公元前490年-公元前420年)是年纪最长的,在许多方面他也是最有影响的。他因下面的这一陈述而广为人知,“人是万物的尺度,是存在者存在的尺度,也是不存在者不存在的尺度。”就是说,每个个人是他或她作出的所有判断的最终标准。这意味着任何我可能达到的关于事物的知识都受到我作为人的能力的限制。普罗泰戈拉不考虑任何神学的探讨,他说,“关于神,我既不能认识到他们是否存在,也不能认识到他们是什么样子的;因为阻碍我的认识的因素有很多:问题的晦涩,人生的短暂。”普罗泰戈拉说,知识受到我们各种知觉的限制,这些知觉是因人而异的。如果两个人观察同一个对象,他们的感觉会各不相同,因为每个人相对于这个对象的位置不一样。与此相似,同一阵风吹向两个人,一个人会觉得凉,一个人则会觉得暖。因而,说一个人是所有事物的尺度就是说我们的知识被自己的知觉所限制。如果在我们内部的某个东西使我们以与别人不同的方式知觉事物,那么就不存在什么标准来检验是不是某个人的知觉是对的而另一个人的是错的。普罗泰戈拉认为,我们通过自己各种各样的感官知觉到的对象必定具有不同的人各自知觉到的属于它们的所有属性。由于这一原因,我们不可能发现一个事物的“真正”本质是什么;一个事物有多少感知它的人就有多少特性。这样,我们就没有办法区分一个事物的现象和它的实在。基于这一知识理论,我们不可能获得任何绝对的科学知识,因为不同的观察者之间存在着固有的差异,这使我们每个人对事物的观察各不相同。普罗泰戈拉总结道,知识对每个人而言都是相对的。
当普罗泰戈拉谈到伦理学时,他认为道德判断也是相对的。他乐意承认法律观念反映了存在于每一种文化中的想在所有人中建立道德秩序的普遍愿望。但是,他拒绝承认存在着任何适合于所有人类行为的统一的、所有人在任何地方都可以发现的自然法律。他区分了自然和习俗,他说法律和道德规范不是基于自然,而是基于习俗。每个社会都有它自己的法律和道德规则,没有什么方法来断定这个社会的法律和道德规范的对错。但是普罗泰戈拉没有将这一道德相对主义推到极端,他并不认为每个个人都能够仅凭自已就断定对他或她而言什么是道德。相反,他持一种保守的观点,认为城邦制定法律,而每个人应该接受它们,因为这些法律是能够制定出的最好的法律。其他的社群或许有不同的法律,这个城邦里的个人或许想到不同的法律,但是在这两种情况下,并不是说它们就是更好的法律:它们只不过是不同的法律而已。因而,为了社会和平有序,人们应该尊重和支持自己的传统精心发展出的习俗、法律和道德规范。在宗教问题上,普罗泰戈拉持类似的观点:我们不能确定地知道诸神的存在及其本质,不过这并不妨碍我们对神的崇拜。普罗泰戈拉相对主义有趣的结果是他保守的结论,年轻人应该被教育接受和支持自己的社会的传统,这不是因为此传统是正确的,而是因为它使一个稳定的社会成为可能。尽管如此,毫无疑问,普罗泰戈拉的相对主义严重地打击了人们对有可能发现真知的信心。他的怀疑主义招致了苏格拉底和柏拉图的严厉批评。
高尔吉亚
高尔吉亚(公元前5世纪后期)于公元前427年作为使节从他的母邦利昂提尼来到雅典。他对真理所持的观点如此极端,以至最终他放弃了哲学,而转向了修辞术的实践与教学。他的极端观点不同于普罗泰戈拉的观点,因为普罗泰戈拉说,相对于不同的观众,一切都是真的;而高尔吉亚侧拒绝承认任何真理的存在。高尔吉亚极其繁琐地运用埃利亚哲学家巴门尼德和芝诺所使用的推理类型,提出了一系列非同寻常的观点:(1)无物存在,(2)如果有某物存在,它也无法被认识,(3)即使它可以被认识,也不能被传达。以第三个观点为例,他论证说,我们用语言进行交流,但是语言只是符号或标记,符号与它所代表的事物是绝不相同的。因此,知识就不能被传达。通过这种推理,高尔吉亚认为他能够证明上述全部的观点,至少他的推理与和他意见相左者的推理一样严密。他确信不存在任何可靠的知识,当然也不存在任何真理。
高尔吉亚放弃哲学之后转向了修辞学,他试图将之作为说服的技术加以完善。在修辞学和说服术的这种结合中,传统认为他运用心理学和暗示的力量发展了欺骗术。
塞拉西马柯
在柏拉图的《理想国》(Republic)中,塞拉西马柯被刻画为智者,他断言不正义比正义的生活更可取。他并不把不正义看成性格的缺陷。相反,塞拉西马柯将不正义的人看作在性格和智力上更优越的人。他说,事实上,不正义不只是在小偷这种可怜的水平上令人“获利”(虽然在这里也会有利可图),而且尤其对那些将不正义推行到登峰造极之境的人有利,并使他们成为城邦或国家的首领。只有傻子才追求正义,正义只能导致软弱。塞拉西马柯主张,人们应该以一种事实上是毫无顾忌地自作主张的方式去肆意追求他们自己的利益。他将正义看作较强者的利益,他相信“有力即有理”。他说,法律是由统治集团为了自己的利益而制定的,这些法律规定了什么是正确的。所有的国家都一样,“正当”的观念意味着同一个东西,因为“正当”仅仅是以权力建立起来的,反映了把持权力的集团的利益。所以,塞拉西马柯说,“合理的结论就是‘正当'的东西在任何地方都是一样的:都是更强大的集团的利益。”
这里有一个从道德到权力的还原。这是智者派的怀疑主义不可避免的结果,这种怀疑主义使得他们对真理和伦理抱有相对主义的态度。而揭示智者派的逻辑矛盾,重建某种真理概念,为道德判断建立某种牢固的基础,这些就是苏格拉底主要考虑的问题了。
2.2 苏格拉底
许多雅典人误把苏格拉底看作智者,事实上苏格拉底是智者派最尖锐的批判者之一。苏格拉底之所以被人们混同于智者,部分地是因为他对任何主题的不带感情的分析——智者们也运用了这一技术。然而在苏格拉底与智者派之间存在着一个根本的差异。智者派挖空心思钻牛角尖,以表明对于一个问题的任何一面都可以作出同样好的论证。他们是怀疑主义者,不相信有任何确定的或可靠的知识。此外,他们还得出结论说,既然所有知识都是相对的,那么道德标准也是相对的。相反,苏格拉底坚持不懈地进行论辩却是怀着不同的动机。他坚定地追求真理,认为自己的任务就是为确定的知识寻找基础。他也试图发现善的生活的基础。苏格拉底在履行自己的使命时,发明了一种达到真理的方法:他将知和行联系起来,所以认识善就是行善,在这个意义上,“知识就是美德”。所以,与智者派不同,苏格拉底致力于进行讨论是为了获得对真理和善的实质性概念。
苏格拉底的生平
苏格拉底于公元前470年出生在雅典。历史上很少有某时某地像此时的雅典这样出现了如此众多的天才人物。这个时候,刷作家埃斯库罗斯已经完成了他的几部戏剧杰作。欧里庇得斯和索福克勒斯这两位剧作家此时还是小孩子,他们以后将要创作的伟大悲剧苏格拉底很有可能是到剧场看过的。这时伯里克利还是个年轻小伙,他将会开创一个政治民主、艺术繁荣的伟大时代。苏格拉底有可能看过帕特农神庙和菲狄亚斯的雕塑,它们就是完成于他生活的那个年代的。这个时候,波斯已经被打败,雅典已经成为海上期主,基本上控制了爱琴海。雅典达到了前所未有的强大和辉煌。虽然苏格拉底成长于一个黄金时代,但在垂暮之年,他目睹了雅典在战争中的失败,而他自己的生命也在狱中结束。公元前399年,也就是苏格拉底71岁时,他遵从法庭对他的判决喝下了毒药。
苏格拉底没有写下文字作品。我们所知道的关于他的绝大部分事情都是由他的三个著名的年轻的同代人记载下来的,他们是阿里斯托芬、色诺芬以及三人中最重要的一位——柏拉图。从这些资料里看,苏格拉底天资过人,不仅思维严谨超乎群伦,为人也热情友善,秉性幽默。他体格健壮,颇能吃苦耐劳。阿里斯托芬在他的喜剧《云》里把苏格拉底描绘得像一只自负的水鸟,取笑他转跟珠的习惯,俏皮地提到他的“学徒们”及“思想的作坊”。而色诺芬所描绘的则是一位忠诚的战士,他充满激情地探讨着道德的要求,对那些想在他这里得到指点的年轻人有着难以抗拒的吸引力。柏拉图肯定了对苏格拉底的这个总的写照,并进一步把苏格拉底描绘为一个有着深沉的使命感和绝对的道德纯洁性的人。在《会饮篇》中,柏拉图讲述了一位美少年阿尔西比亚德斯是如何希望赢得苏格拉底的爱情的,他想方设法要和苏格拉底单独相处。但是,阿尔西比亚德斯说,“从来就没有出现过这种情况:他只愿意用他通常的方式和我交谈,和我呆了一整个白天后,他就会离开我,自顾自走了。”苏格拉底在从军征战时比其他任何人都更能忍饥挨饿。其他人都“小心翼翼地”把自己包得严严实实,用“毡子加羊毛”裹在鞋子外面,以抵御冬日的严寒。而苏格拉底,阿尔西比亚德斯说,“就穿着他平常穿的一件外套在那样的天气里出门,他光着脚在冰面上行走比我们穿着鞋走还要轻快。”
苏格拉底的注意力能长时间地高度集中。在一次战役中,他曾经站着沉思了一天一夜,“直到黎明来临,太阳升起;在向着太阳做了一次铸告之后,他才走开”。他经常从一个神秘的“声音”那里获得信息或警告,他称这个声音为自己的灵异(daimon)。虽然这种“超自然的”征兆从小就侵扰着他的思想,但对此最合理的解释应该是苏格拉底具有“宗教梦幻式”的气质,尤其是具有对人类行为的道德品质的敏感,正是这些道德品质赋予生活以价值。他对早期希腊街学家们的自然科学必定是非常熟悉的,虽然在柏拉图的《申辩篇》中,他说过,“事情的真相就是如此,雅典人、我与对自然的思索没有任何关系。”对他而言,这样的思索已经让位于那些更紧迫的问题,即人的本性、真理和善。一个决定性的事件确认了苏格拉底的使命是做一个道德哲学家,这就是德尔斐神庙的神谕。故事是这样的,一个名叫凯勒丰的虔信宗教的青年到德尔斐附近的阿波罗神庙去问,这世上是否还有人比苏格拉底更聪明;女祭司回答说没有。苏格拉底认为这个回答的意思是,他之所以是最聪明的,是因为他意识到并且承认自己的无知。苏格拉底就是以这样的态度开始了他对不可动摇的真理和智慧的探求。
作为哲学家的苏格拉底
由于苏格拉底自己没有留下文字作品,究竟哪些哲学思想可以确认是他的,现在还是有争议的。关于他的思想,我们所拥有的最全面丰富的资料来源是柏拉图的《对话集》,他是这些对话中的主角。但是长期以来一直存在的一个问题是,这里柏拉图所描绘的是苏格拉底确实教导过的东西,还是在假托苏格拉底的形象来表达他自己的思想。有些人认为柏拉图《对话集》中的苏格拉底就是历史上的那个苏格拉底。这将意味着这些对话中包含的创造性的哲学工作全都要归功于苏格拉底。要是这样看的话,柏拉图就不过是发明了一种文学体裁,使苏格拉底的思想能够保存下来并得到详尽阐述、准确表达和文字上的润色。可是,亚里士多德对苏格拉底和柏拉图的哲学贡献作出了区分。亚里士多德将“归纳论证和普遍定义”归功于苏格拉底,而将理念论——普遍的原型独立于特殊事物而存在,特殊事物只是它们的具体化——的提出归功于柏拉图。其实,争论就在于是苏格拉底还是柏拉图提出了理念论。因为亚里士多德自己对这个问题特别感兴趣,在学园里已经和柏拉图对之进行过详尽的讨论,因此似乎有理由认为他对苏格拉底和柏拉图的思想的区分是准确的。同时,柏拉图的一些早期对话似乎体现了苏格拉底自己的思想,比如《申辩篇》、《欧绪弗洛篇》。因此,对此问题最合理的解决方法就是把两种观点各采纳一部分。这样我们就可以认为,柏拉图早期的很多对话都是对苏格拉底哲学活动的描述,而柏拉图后期的对话则主要代表了他自己的哲学发展,包括系统地提出具有形而上意义的理念论。在这个基础上,我们就应当把苏格拉底看作是一个原创性的哲学家,他提出了一种新方法来进行理智的探究。
要想成功地克服智者派的相对主义和怀疑主义,苏格拉底就必须为知识的大厦找到一个稳固的基础。苏格拉底在人之中,而不是在外部世界的种种事实中,发现了这个稳固的基础。苏格拉底说,内在生活是一种独特活动即认知活动发生的场所,这一活动导致实践活动,也就是行为。为了描述这一活动,苏格拉底提出了灵魂或心灵(psyche)的概念。对他而言,灵魂不是任何特殊的官能,也不是任何一种特别的实体。相反,它是理智和性格的能力;它是一个人有意识的人格。苏格拉底进一步表述了他的灵魂概念的意义,灵魂是在“我们之中的,我们由于它而被断定是聪明的还是愚意的,是好的还是坏的”。通过这样的描述,苏格拉底是把灵魂等同于理智和性格的正常能力,而不是什么幽灵般的实体。灵魂是人格的结构。虽然苏格拉底很难确切地描述灵魂究竟是什么,但他还是确信灵魂的活动乃是去认识和影响甚至指引和支配一个人的日常行为。虽然对苏格拉底而言灵魂不是一个事物(thing),他还是可以说,我们最应该关心的就是去照料我们的灵魏,“使灵魂尽可能地善”。当我们理解了事实与幻想的区别从而将我们的思想建基于对人类生活的真实状况的知识上时,我们就最好地照料了我们的灵魂。由于获得了这样的知识,那些在思想中照料好了自己灵魂的人也将根据他们对真实的道德价值的知识而采取相应的行动。简而言之,苏格拉底主要关注的是善的生活,而不是纯粹的沉思。
对苏格拉底而言,这种灵魂概念的要点涉及到我们对一些词语的意义的清醒意识。认识到一些事物与另一些事物相矛盾——比如,正义不能意味着伤害别人——就是一个典型的例子,灵魂仅仅通过运用自己的认知能力就可以发现它。因而当我们在行动中违抗这种知识的时——例如当我们伤害一个人而同时又十分清楚这一行为违背了我们关于正义的知识的时候——就会破坏我们自己作为人的本性。苏格拉底确信人可以获得可靠的知识,而且只有这样的知识小能成为道德的正当基础。因而他的首要任务就是为他自己和他的追随者澄清一个人是如何得到可靠的知识的。
苏格拉底的知识理论:思想的助产术
苏格拉底确信,得到可靠知识的最可靠的方法就是通过受到规训的对话,这种对话所起的作用就像一名思想的助产士。他称这个方法为辩证法(dialectic)。不管面对什么问题,这方法总是先讨论它的最显而易见的方面。在对话的过程中,交谈的各方将不得不澄清他们的观点,最终的结论将是一个意义清晰的陈述。虽然这套方法表面上看很简单,但当苏格拉底将之运用到别人身上时,不管是谁,不久都会感受到它那极其严密的力量,也会因苏格拉底的讽刺而感到难堪。柏拉图的早期对话就展示了这种方法,苏格拉底假装对某个主题一无所知,然后设法从其他人的言谈中抽引出他们关于这一主题所能有的最完满的知识。他认为通过对不全面或不确切的思想进行一步步的修正,就可以诱导任何人得出真理。他常常揭示出潜藏在对方观,点之下的矛盾——这种技术被称作“问答法”(elenchus)——从而迫使那人放弃自己误人歧途的观点。如果有些东西是人类的心灵所认识不了的,苏格拉底也要把这点论证出来。因此他相信,没有经过仔细审视的观念是不值得拥有的,正如没有经过仔细审视的生活是不值得过的一样。有些对话的结尾没有结论,因为苏格拉底关心的不是提出一套教条式的思想强加给他的听众,而是引导他们去经历一个有条不紊的思想过程。
我们在柏拉图写的对话《欧绪弗洛篇》中发现了苏格拉底方法的一个很好的例子。对话发生在阿卡翁国王的宫邸前,苏格拉底等在那里想看看是谁指控他不虔敬,这可是一项死罪。年轻的欧绪弗洛赶到那里向他解释说,他想指控自己的父亲不虔敬。苏格拉底表示对不虔敬的含义一无所知,他要欧绪弗洛解释它的意思,因为欧绪弗洛就是以这个罪名指控他的父亲的。欧绪弗洛作出了回答,他将虔敬定义为“起诉犯罪的人”,而不虔敬就是不起诉他。苏格拉底对此回答说,“我没有要你从无数虔敬的行为中举出一两样来;我是要你告诉我虔敬的概念是什么,正是它使得一切虔敬的行为成为虔敬的。”由于他的第一个定义并不令人满意,欧绪弗洛再次尝试说,“凡是令诸神喜悦的就是虔敬的”。但是苏格拉底指出,诸神也相互争吵,这表明诸神之间对于什么是更好的和什么是更糟的意见不一。因而,同一个行动可能令一些神感到喜悦却并不令另一些神喜悦。所以欧绪弗洛的第二个定义也不充分。饮绪弗洛试图修正,他提出了一个新的定义,“虔敬就是诸神全都喜爱的,而不虔敬就是诸神全都痛恨的”。但是苏格拉底问,“诸神是因为一个行动是虔敬的而喜爱它,还是因为诸神喜欢这个行动它才是虔敬的?”简而言之,虔敬的本质是什么?欧绪弗洛再次尝试说,虔敬乃是“正义的一部分,它与对诸神给予其应得的侍奉有关”。苏格拉底再次问,诸神应得的侍奉是怎样的,以迫使欧绪弗洛作出一个更加清晰的定义。这个时候,欧绪弗洛已经陷入了无法摆脱的犹疑不定之中,苏格拉底告诉他,“你不能起诉你年迈的父亲,除非你确切地知道什么是虔敬和不虔敬。”当苏格拉底迫使他再一次作出一个更清晰的定义时,欧绪弗洛回答说,“下次吧…苏格拉底。我现在很忙,我得走了。”
这篇对话对于有关虔敬的话题没有得出结论。但它是苏格拉底辩证方法的一个生动例子,是他关于哲学生活的概念的一个写照。特别是它表现出了苏格拉底对定义的独特关注,定义乃是清晰思想的工具。
定义的重要性 苏格拉底求知方法的再清楚不过的体现是在他寻求定义的过程中。也正是通过对定义的强调,他对智者派进行了最有决定意义的反驳:名词术语都有确定的意义,这就从根本上动摇了相对主义。对他来说,一个定义是一个清晰而确定的概念。苏格拉底深刻地意识到这样一个事实:虽然特殊的事件或事物在某些方面变化或消逝着,它们里面却有某种东西是同一的,从不变化,从不消逝。这就是它们的定义、它们的本性。当苏格拉底追问“那使得一切虔敬的行为成为虔敬的虔敬概念”时,他想要欧绪弗洛给出的就是这个永恒的意义。苏格拉底以一种相似的方法寻求正义的概念,由于它,一个行为才成为正义的;寻求美的概念,由于它,特殊的事物才可以被称作美的;寻求善的概念,由于它,我们才认为一个人的行动是善的。例如,没有什么特殊的事物是完全地美的:它之所以美只是因为它分有了更大的美的概念。此外,当一个美的事物消逝了,美的概念却依然存在。苏格拉底所看重的是我们对一般观念而不仅仅是特殊事物的思考能力。
他认为无论我们思考什么东西,某种意义上我们都是在思考着两种不同的对象。一朵美的花首先是这一朵特殊的花,同时它又是美的一般或普遍意义的一个例子或分有者。对苏格拉底而言,定义包含一个过程,通过这一过程我们的心灵能够区分思想的这两种对象,即特殊(这一个特殊的花朵)和一般或普遍(美的概念,这朵花由于分有了它才是美的)。如果苏格拉底问,“什么是一朵美的花?”或者“什么是一个虔诚的行动?”他一定不会满足于你向他指出这朵花或这个行动。因为虽然美以某种方式与一个特定的事物相关联,但这个事物既不等于也没有穷尽美的概念。此外,虽然各种美的事物互不相同,但不论它们是花还是人,都被称作美的,这是因为它们不管彼此有何差别,都一样分有使它们被称为美的那种要素。只有通过严格的定义过程,我们才能最终把握一个特殊的事物(这一朵美的花)和一个普遍的观念(美或美的)之间的区别。定义的过程,正如苏格拉底所展示的,是一个达到清晰确定的概念的过程。
运用这种定义的方法,苏格拉底表明了真知识不仅仅是简单地考察事实,知识相关于我们在事实中发现那些永恒要素的能力,这些要素在这些事实消逝之后也依然存在。玫瑰花凋谢了,美依然存在。对心灵来说,一个不完美的三角形暗示了那个三角形(的概念),不完美的圆则被看作近似于那个完美的圆(的概念),完美的圆的定义产生了清晰确定的圆的概念。事实可以产生许多不同的观念,因为没有两朵花是相同的。同样也没有两个人或两种文化是相同的。如果我们将我们的知识仅仅限于罗列未经解释的事实,我们的结论将是所有的事物都各不相同,不存在普遍的相似之处。智者派就是这么做的,他们搜集其他文化的一些事实,然后论证说,有关正义和善的所有观念都是相对的。但是苏格拉底不愿接受这个结论。在他看来,人们之间事实上的差异——例如他们的身高、体力和智力的差异——并没有抹杀他们都是人这个同样确定的事实。他通过定义的过程,透过具体的人显而易见的实际差异,发现了是什么东西使每个人尽管有这些差异,却仍然是一个人。他的清晰的人的概念为他对人的思考提供了一个牢靠的基础。与此相似,虽然存在着文化上的差异,存在着实际的法律和道德规则上的差异,苏格拉底认为,法律、正义和善的概念依然可以像人的概念一样被严格地定义。面对我们周围变异的事实,苏格拉底并不认为我们周围的多样性的事实一定会导向怀疑主义和相对主义,相反地,他相信,只要我们运用分析和定义的方法,这些事实就能够产生出清晰而确定的概念。
于是苏格拉底相信,在事实世界的后面,在事物之中,存在着一个我们可以发现的秩序。这使得他在哲学中引入了一种考察宇宙万物的方法,即对事物的一种目的论的概念——它认为每个事物都有一个功能或目标,都朝向善。例如,说一个人有一个可定义的本质,也就是说有某种行为是适合于他或她的本质的。如果人是理性的存在者,那么理性地行动就是适合于他的本质的行为。这差不多也就等于说人们应该理性地行动。通过发现每个事物的本性,苏格拉底相信他也可以在事物中发现可理解的秩序。从这个观点看,事物不仪有它自己特殊的本质和功能,而且这些功能在所有事物的整体安排中还有某种另外的目的。宇宙中存在着许多种事物,这不是由于偶然的混合,而是每个事物都各尽其职,所有的事物共同构成了有序的宇宙。很明显,苏格拉底可以区分出两个层次的知识,一个层次是基于对事实的观察(inspection),另一个层次则是基于对事实的解释(interpretation)。换言之,一个是基于特殊的事物,一个是基于一般的或普遍的概念。
在话语中总是使用诸如美、直线、三角形、人等普遍概念,这个事实表明它们的使用实际上存在着某种实在的基础。重要的是,这些普遍的概念是否是指某种像特殊的世界那样存在着的实在?如果约翰这个词是指存在于一个特定地方的一个人,那么人这个概念是否也指存在于某处的实在?苏格拉底是否处理了这个普遍意义上的形而上学问题,这得看我们认为是柏拉图还是苏格拉底是理念论的创立者。柏拉图确确实实教导说,这些概念化的理念是最实在的存在者,它们独立于我们看到的特殊事物而存在,特殊事物只是分有了这些理念。亚里士多德则拒斥主张理念单独存在的理论,他论证说,某种意义上普遍的形式只存在于我们经验到的实际事物之中。他也表明,苏格拉底并没有把这些理念和事物“分离开来”。即使苏格拉底不是见于柏拉图对话中的理念论的创立者,隐藏于可见世界背后的可理解秩序观念,却依然是由他创建的。
苏格拉底的道德思想
对苏格拉底而言,知识和德性是同一个东西。如果德性与“使灵魂尽可能地善”有关,那么我们首先就有必要知道什么使灵魂善。因此善和知识密切相关。但是苏格拉底对于道德所说的不只于此。他实际上将善与知识等同起来,他说,认识善就是行善,知识就是德性。通过将知识和德性等同起来,苏格拉底也就认为恶行或恶乃是缺乏知识。正如知识就是德性,恶行也就是无知。这个推理的结论使苏格拉底确信没有人会作恶无度或者明知故犯地行恶。他说,做错事总是不自觉的,是无知的结果。
把德性与知识、恶行与无知分别划上等号,这似乎有悖于我们关于人的最基本的经验。常识告诉我们,经常有这样的情况:即使我们知道一个行为错了,我们还是会拼命去做,因此我们是故意而自愿地做错事的。苏格拉底承认我们会做坏事。但是他不认为人们是明知故犯。苏格拉底说,当人们做坏事时,他们总是以为这些事在某种意义上是好事。
当苏格拉底把德性和知识等同起来时,他头脑中考虑的德性概念有着特殊的含义。对他而言,德性意味着履行一个人的功能。作为一个理性的存在者,一个人的功能就是理性地行事。同时,每个人都不可避免地为其灵魂追求幸福或好的生活。这一内在的好的生活,“使灵魂尽可能地善”,只有通过某种合适的行为方式才能达到。因为我们有着对幸福的渴求,我们就会对我们的行动有所选择,希望它们能带来幸福。哪种行动或者什么行为可以带来幸福?苏格拉底认识到,有些行动表面上带来了幸福,但实际上并非如此。因此我们常常选择那些本身很成问题的行动,却以为它们可以带来幸福。小偷或许知道偷窃本身是错误的,但是他们依然行窃,希望以此获得幸福。与之类似,我们追求权力、肉体愉悦和财富,以为它们是成功和幸福的标志,却混滑了幸福的真正基础。
不管怎么说,把恶行和无知等同其实并不是那么违背常识的,因为苏格拉底所说的无知是对一个行动产生幸福的能力的无知,而不是对行动自身的无知。这是对一个人的灵魂的无知,即不知道怎么办才可以“使灵魂尽可能地善”。因此过错就是对某些行为不确切的估计造成的后果。这种不确切的预期以为某些事物或愉悦能带来幸福。因而,过错之所以是无知的产物,就是因为人们在做错事的时候指望它会产生其产生不了的结果。无知即在于看不到某些行为并不能产生幸福。要有对人类本性的真知识,才能知道什么才是幸福所必需的。还要有对事物和行为类型的真知识,才能知道它们是否能实现人们对幸福的要求。这就要求我们的知识能够区分:什么东西表面看上去能带来幸福,什么东西确实能带来幸福。
所以,说恶行是无知,是不自愿的,就是说没有人会故意选择损害、破坏或者毁灭自己的人性。甚至当我们选择痛苦时,我们也是希望这种痛苦能够带来德性,实现我们人的本性——这个本性追求着它自己的好的生活。我们总是认为我们的所作所为是正当的。但是我们的行为是否正当则依赖于它们是否与真的人性相和谐,而这是一个真知的问题。此外,因为苏格拉底相信人性的基本结构是恒常的,所以他相信有德性的行为也是恒常的。这就是他得以克服智者派的怀疑主义和相对主义的基础。苏格拉底为道德哲学所设定的方向,是道德哲学在整个西方文明史中一直遵循的。他的思想得到了柏拉图、亚里士多德和基督教神学家们的修正,但它依然是理智和道德方面万变不离其宗的主导性传统。
苏格拉底的审判与死亡
苏格拉底确信我们最该关心的就是照料我们的灵魂,所以他把一生大部分的时间都用在审视他自己的生活和其他雅典人的生活和思想上。当雅典在伯里克利统治下是一个稳定而强大的民主社会时,苏格拉底可以履行他作为一只“牛虻”的使命而没有招致严重的反对。他不留情面地在人们无序的行为之下追寻稳定恒常的道德秩序。这一追寻要么令人愤怒,要么令人愉快,这也为他带来从事于悖论的智者这个名声。更增糕的是,人们认为他的思想太没有拘束,对于那些雅典人认为不容置疑的敏感问题也进行追问。然而,在雅典经济和军事上还强大的时候,苏格拉底还是可以随其所好去进行追问而不受惩罚。但是,随着雅典的社会大势走向危机和挫折,苏格拉底就再也不能免于受到追究了。他在上层社会的年轻人中发展辩证技能的努力一尤其是对道德习俗、宗教和政治行为的刨根问底的技巧一已经引起了人们的疑虑。但是直到雅典与斯巴达交战期间,他的行为才终于被认为是具有明显的、迫在眉睫的危险性的。
与这场战争有关的一系列的事件最终导致了对苏格拉底的审判和处死。其中之一是阿尔西比亚德斯的叛国行为,他是苏格拉底的学生。阿尔西比亚德斯的确去了斯巴达并在对雅典的作战中为斯巴达人提出了颇有价值的建议。这就难免让许多雅典人认为苏格拉底在某种程度上应该为阿尔西比亚德斯的行为负责。此外,苏格拉底发现自己与五百人会议分歧严重,他是其中的一个成员。他们面临的问题是有8位军事指挥官被指控在亚吉努撤群岛附近的一次海战中玩忽职守。雅典军队虽然最终赢得了这场战争,但是他们也付出了高昂的代价,损失了25艘战舰和4000名士兵。8位卷人这场损失惨重的战役的将领被要求受审判。但是,五百人会议不是一个一个地确定每一位将军的罪责,而是被命令-次性投票表决这8个人全体是否有罪。起先会议抵制这一动议,认为它违反了正常的法律程序。但是当检举人威胁说除了将军们还要起诉会议成员时,就只有苏格拉底还坚持原来的意见,其他会议成员都屈服了。将军们后来被认定有罪,其中已经被监禁起来的6人被立即执行了死刑。这些事件发生在公元前406年。在公元前404年,随着雅典的衰落,苏格拉底再一次发现他面临着强大的反对势力。在斯巴达胜利者的压力下,雅典成立了一个30人团为雅典的新政府起草法律。但是这个30人团很快蜕变成-一个横暴的寡头统治集忧.他们专断地迫害以前拥护伯里克利民主秩序的人,为自己聚敛财富。仪仅过了一年,这个寡头集团就被暴力推翻了,雅典重新建立起了民主秩序。但是很不幸,被推翻的寡头集团里有一些人是苏格拉底的好友,尤其是克里提亚斯和查米德斯。这是他又一次因株连而获罪,如同在先前阿尔西比亚德斯的案件中他因为是叛徒的老师而被判入狱一样。到这个时候,人们对苏格拉底的愤怒已经发展到对他的不信任。大概在公元前399年,苏格拉底被控受审,据第欧根尼·拉尔修记载,他被指控的罪名是:“(1)对于城邦所崇拜的神不虔敬,而是引人新的陌生的宗教惯例;(2)更有甚者,腐蚀青年。指控者要求判处苏格拉底死刑。”
苏格拉底听到对他的指控后本来可以选择自愿流放。但是他依然留在雅典,在法庭上为自己辩护。法庭的陪审团由大约500人组成。柏拉图的《申辩篇》记载了苏格拉底为自己的辩护,这是对他理智能力的光辉证明。它有力地揭露了原告们的动机和他们指控根据的不充分。他强调自己对雅典的毕生忠诚,他提到了他的军旅生涯和在审判将领们的事件中对法律程序的维护。他的辩护是强有力论证的典范,完全建立在引用事实和要求讲理的基础上。当他被判有罪时,他还有机会提议给自己定什么刑。苏格拉底不但坚信自己无罪,而且坚信他这样的生活和教导对雅典是有价值的,他提议雅典人应该让他得到应得的奖赏。苏格拉底把他自己和“在奥林匹克比赛中赛马、赛车夺冠的人”作了比较,他说,“这样的人只是让你们表面上快乐,而我是令你们真正地快乐。”因此他说,他的奖赏应该是“由城邦出钱在名人院里奉养他”,这个礼遇是只有声名显赫的雅典人、将军、奥林匹克冠军和其他杰人士才能荣享的。陪审团在他的傲慢面前颜面扫地,最后判处他死刑。
最后,他的朋友们试图提供机会让他越狱逃跑,但是苏格拉底坚决不从。正如他拒绝在陪审团面前提及他的妻子和年幼的孩子们来打动他们一样,现在他也没有为他的学生克里托的恳求所动,克里托曾说,他不想自己也得想想他的孩子们。他如何能够收回他曾经教导别人的东西,抛弃自己对真理永远忠贞不渝的信念?苏格拉底相信,逃跑就是违抗并损害雅典和雅典的法制,那将是在追求一个错误的目标。法律对他的审判和死刑并无责任;有责任的是那些误入歧途的原告们,是阿尼图斯和美勒托,是他们犯了错误。因此,他服从法庭对他的判决,以此证明他对法制的尊重。
柏拉图在他的《斐多篇》中描绘了苏格拉底喝下毒药后的最后时刻,“苏格拉底摸了一下自己,说等药力抵达心脏,他就完了。他已经开始变冷…说出了最后的话,‘克里托,我还欠阿斯克勒比俄斯一只公鸡;千万别忘了替我还上’…这就是我们这位朋友的结局,我认为他是他的时代所有人中最优秀、最睿智、最公正的人。”
第三章 🐮柏拉图ψ(`∇´)ψ
柏拉图对知识的全面论述是如此有力,以至于他的哲学成为西方思想史中最有影响的流派之一。他的前辈们关注单个的重大问题,而柏拉图则把人类思想所关注的主要问题都综合进了一个连贯的知识体系中。最早的希腊哲学家即米利都学派的学者们关注的主要是物质自然的构造,而不是道德的基础。同样,埃利亚学派哲学家巴门尼德和芝诺的主要兴趣是论证实在是不变的、单一的,是一。另一方面,赫拉克利特和毕达哥拉斯则将实在描述为总是变化的,充满流变,只有许多不同的东西构成的。苏格拉底和智者派则对物质自然不甚关心,而是将哲学引入道德领域。柏拉图的巨大影响源于他将所有这些不同的哲学关注点置入一个统一的思想体系之中的方式。
3.1 柏拉图的生平
柏拉图于公元前428/427年生于雅典,这是伯里克利去世的第二年,这一年苏格拉底大概42岁。雅典文化欣欣向荣,柏拉图的家庭也是雅典的名门望族,他幼时接受的教育包括雅典文化在艺术、政治和哲学各方面的丰富内容。他父亲把自己家族的世系追溯到雅典古代的君王们,并继续往上追溯到波塞冬神。他的母亲珀里克提俄涅是查米底斯的姐姐、克里提亚斯的表妹,这两个人都是伯罗奔尼撒战争中随着雅典的衰落而出现的短暂的寡头统治时期的领导者。在柏拉图幼年时期,他的父亲就去世了,他的母亲改嫁给了皮里兰佩,此人曾是伯里克利的-一个好朋友。尤其是在他母亲这一边的先辈中曾有一位是立法者梭伦的一个朋友,而她家族的另一个远亲侧是公元前644年的执政官。
在这样一个家庭环境中,柏拉图学到了很多有关社会政治生活的东西,并在早年就培养了一种为公共政治服务的责任感。但柏拉图在伯罗奔尼撒战争最后阶段的亲身见闻影响了他对雅典民主政治的态度。他看到这种民主制产生不了伟大的领导者,他也看到了它如何对待雅典城邦最伟大的公民苏格拉底。苏格拉底受审时柏拉图在场,并且愿意为苏格拉底的罚金作担保。雅典的衰败和他的老师苏格拉底被判死刑,这些很可能导致了他对民主制的绝望,转而开始构想新的政治统治概念,在这种概念中,权威和知识适当地结合在一起。柏拉图总结说,如同在一艘船上,领航员的权力是建基于他的航海知识上的,国家这艘船也应该由某个具备充分知识的人来领航。他在《理想国》中详细论述了这一主题。
公元前387年柏拉图大概40岁的时候,他在雅典建立了学园。在某种意义上,这是西欧历史上出现的第一所大学,柏拉图掌管学园前后凡20年。学园的主要目标是通过原创性的研究追求科学知识。虽然柏拉图尤其关注于对未来统治者的教育,不过他确信他们的教育必须包括严格的理智活动一这里他是指包括数学、天义学和声学在内的科学研究。学园对科学的强调和柏拉图同时代的伊索克拉底形成鲜明对照,后者采用了更加实用的方法来训练青年们参与社会政治生活。科学在伊索克拉底那里几乎没有用武之地,因为他认为纯粹的研究没有丝毫的实际价值或人文意义。但是柏拉图将数学纳入课程安排的核心,他认为,为那些将掌握政治权力的人所做的最好的准备是对真理或科学知识超功利的追求。一群出色的学者加盟学园造成了超出以前毕达哥拉斯学派的数学知识的重大的进步,这也使得著名数学家欧多克索率领他的学派从西西索斯赶来与柏拉图在雅典的学同合并。
苏格拉底被处死使柏拉图对政治的幻想从内心深处破灭了,使他个人从积极的公共活动中退出来。不过柏拉图继续教导说,严格的知识必须被用来对统治者进行正确的训练。他由于这一观点而声名远播,他受邀至少去了叙拉古三次以教导年轻的僭主狄奥尼索斯二世。他的努力没能获得成功,因为他对这个学生的教育开始得太晚了,而此人性格也太软弱。柏拉图此后继续从事著述,直到公元前348/347年于80岁去世时,他依然在学园里积极工作。
柏拉图在学园授课时是不用任何笔记的。因为他的讲授从来没有讲稿,它们也从来没有出版,虽然他的学生们记的笔记被人们传阅着。例如亚里士多德于公元前367年在他18岁进入学园时,他就对柏拉图的讲授作了笔记。不过柏拉图创作了20多部哲学对话,最长的一部有200多页。学者们对这些对话创作的先后年代争论不休,但是现在一般都把它们分为二组。第一组是早期作品,由于它们对伦理问题的关注而通常被称为苏格拉底对话。这其中包括《申辩篇》、《克里托篇》、《卡尔米德篇》、《拉凯斯篇》、《欧绪弗洛篇》、《欧绪德谟篇》、《克拉底鲁篇》、《普罗泰戈拉篇》和《高尔吉亚篇》。第二组包括《美诺篇》、《会饮篇》、《斐多篇》、《理想国》以及《斐德若篇》,在这些作品中,理念论和形而上学理论得到了详细的说明。柏拉图在其晚年创作了一些方法上更成熟的对话,它们时常展示出一种不断加深的宗教信念;这些对话包括《泰阿泰德篇》、《巴门尼德篇》、《智者篇》、《政治家篇》、《斐莱布篇》、《蒂迈欧篇》和《法律篇》。我们找不到任何一部作品可以为我们提供柏拉图思想的图解式的布局。不同的对话处理着不同的问题,而他的许多处理方式由于时间前后不同而是有变化的。但不管怎样,在这些对话中还是存在着一些最重要的主题,下面我们就来加以介绍。
3.2 知识理论
柏拉图哲学的基础是他对知识的论述。我们已经看到,智者派对我们获得知识的能力持怀疑的观点。他们相信,人类知识以社会习惯和个人感觉为基础。文化不同,个体不同,“知识”也就随之而摇摆不定。然而,柏拉图坚决反对这种观点。他确信,存在着人类理性可以把握的不变的普遍真理。在他的对话《理想国》里,柏拉图用洞穴的寓言和分割线段的隐喻对其观,点进行了生动的例证。
洞穴
柏拉图让我们想象一些人住在一个巨大的洞穴中,从小就被锁链锁住了颈项和腿脚而动弹不得。因为他们甚至没法扭头,所以只能看到他们前面的东西。在他们后面是一块高地,隆起于这些人被囚系的地面之上。在这个高地上有另外一些人,他们缸着人造的东西来来回回地走动,那些人造物包括用木头、石头和其他各种材料做成的动物和人的形象。在这些走动的人后面是一团火,再后面是洞穴的出口。那些被锁住的人只能往他们前方洞穴尽头的洞壁方向看,既看不见彼此,也看不见那些走动的人及其后面的火。闪徒们惟一能看见的是他们前面洞壁上的影子,这些影子是人们在火前走动时被火光投射到洞壁上的。闪徒们从来没有看见过扛着东西的人和那些东西。他们也没有意识到那些影子只是其他东西的影子。当他们看到一个影子并听到从洞壁传来的某个人的回声时,就认为声音来自那个影子,因为他们没有意识到其他任何东西的存在。如此一来,这些囚徒所认作实在的只是在洞壁上形成的影子 。 柏拉图问道,如果其中有个囚徒被解除了锁链,被强迫站起来,转过身去,向前走并抬眼看那火光,那么将会发生什么事情?假定他被迫看着那些被搬动的物体和它们在洞壁上投下的他熟悉的影子。他岂不会发现这些真实的物体既不如那些影子悦目,也不如它们有意义吗?如果他直视火光本身,他的眼晴岂不会疼吗?此刻毫无疑问他会努力逃离那释效他的人,想回到那些他能清楚地看见的东西那里去,他确信那些影子要比他被迫在火光中看见的物体更清楚。
假定这个囚徒不能回转,而是被强拖着沿着陡峭崎岖的通道走到洞口,直到已经被带到阳光下他才被放开。阳光刺激得他眼睛发痛,他将不能看见他现在被告知是真实的任何东西。要过一段时间他的眼睛才能适应洞穴外的世界。他将首先认出一些影子,他将会觉得它们很熟悉。如果是一个人的影子,他先前在洞穴的墙壁上就已经看过。然后,他将看到人们与各种东西在水中的倒影,这将代表他在知识上的一个巨大进步。因为对那曾经只知道是黑乎乎的模糊的东西,现在他能够看到线条和色彩这些更精确的细节。关于花实际上是什么样子,花的影子所能告诉我们的很少。但是花在水中的倒影为我们的眼睛提供了每片花瓣和它的各种色彩的更清晰的影像。然后他将看到花本身。当他抬眼向空中看时,他首先发现更容易看到夜晚的天体,看着月亮和星星而不是看着白天的太阳。最终,他将直视天空中的太阳而不是它在其他任何东西上的反射。
这次非凡的经历将逐渐使这个被解放的囚徒得出结论说,是太阳使得事物能被看见。太阳也可以解释一年四季的原因,因此太阳也是春天里的生命的原因。现在他理解了他和他的闪徒伙伴们在洞壁上所看到的东西一一影子和倒影是如何不同于可见世界中实际存在的东西的,他也会明白,何以没有太阳就没有可见的世界。这个人对他先前的洞穴中的生活将作何感想?他将回想他和他的囚徒伙伴在洞穴里认作智慧的东西。他将回想起,对把来来往往的影子看得最清、把这些影子的前后顺序记得最准的那个人,他们曾如何交口称赞。这个被释放的囚徒还会认为这种称赞是值得拥有的吗?他还会羡慕那些在洞穴中得 到赞誉的人们吗?一点也不羡慕,相反,他只会觉得这些人可悲可怜。
如果他重回到他先前在洞穴中待的地方,他首先会觉得非常不适应,因为从光天化日下突然进人洞穴将使他眼前一片漆黑。在这种情形下,他不能和别的囚徒在分辨洞壁上的影子上一较高低。当他的“洞中视力”还很微弱而且不稳定的时候,那些一直待在黑暗中的囚徒们在与他的比赛中可以每回都赢。他们首先会发现这种情况很有趣,他们奚落他说,他的视力在离开洞穴之前还很好,而现在他回来时视力却坏了。他们的结论将是,离开洞穴实属徒劳尤益。事实上,柏拉图说,“如果他们抓到那企图释放他们并带他们出洞的人,非把他杀了不可。”
这个寓言暗示我们绝大多数人都居住在祠穴的黑暗之中,我们的思想都是与模糊不清的影子的世界相适应的。教育的作用就是引导人们离开洞穴进人光明的世界。教育不等于将知识灌输给本来没有知识的灵魂,正如视觉不等于将景象置入本来失明的眼睛。知识就像视觉一样需要一个对其有接受能力的器官。囚徒不得不把他整个的身体转过来以使他的眼睛能看见光明而不是黑暗。与此相类,我们也必须彻底地摆脱这个充满了变化和欲望,使得理智变得育目的似真实幻的世界。所以,教育乃是一种转变——从现象世界到实在世界的彻底转向。“灵魂的转变,”柏拉图说,不是“将看的能力置人灵魂之眼中,灵魂已经拥有它了;而是保证它没有看向错误的方向,而朝向它应该朝向的方向。”即使是“秉性最为高贵的人”也并不总是想向那个方向看,因此柏拉图说,统治者必须“义不容辞地肩负起责任”,从黑暗上升到光明。同样,当那些从洞穴中被解放出来的人达到最高的知识时,他们必定不被允许逗留在较高的沉思世界。相反,他们须返回洞穴中参与囚徒们的生活与劳作。
通过论证存在着两个世界,黑暗的洞穴世界和光明的世界,柏拉图抵制了智者派的怀疑主义。对柏拉图来说,知识不仅是可能的,而且它事实上也是确实可靠的。知识之所以确实可靠,是因为它以最实在的东西为基础。影子、映像和真实的物体之间显著的差别与人类能被教化的不同程度相对应。智者派对真知识的怀疑是因为他们对我们经验到的各种各样的变化印象深刻,它们因人而异。柏拉图承认,如果我能够知道的全都只是影子,那么我们的确永远也不会有可靠的知识。因为这些影子由于实在事物的不为我们所知的运动,总是在大小和形状上不断变化着。然而柏拉图确信,我们可以发现在各种影子后面的实在对象,并由此获得真知识。
线段
在线段的隐喻中,柏拉图更详细地来描述所能获得的知识的层级。在发现真知的过程中,我们依次经历四个发展段,在每一个阶段,事物都对应于一种它使之可能的思想。这些事物以及与它们相对应的思想类型可以用下图表示:

在上图中,连结×和y的一条垂直线是整个图形的核心。这条线分为四段,每段分别代表不同的思想类型。这条线是一条连续线,暗示在每一点上都有某种程度的知识。但是随着这条线从实在的最低形态走向最高形态,相应地真理也从其最低级发展到最高级。
首先,这条线被分为两个不相等的部分,上面更大的部分代表了理智世界,下面较小的部分代表可见世界。这个不平均的分割象征着在可见世界中发现的低级的实在和真理与在理智世界中发现的更大的实在和真理的对比。这两个部分又分别以与整个线段同样的比例再次分割,这样产生了四个部分,每个部分都代表了比下面一部分更清晰更确定的思想类型。联想到前面说的洞穴寓言,我们就可以认为,这条线始于x处黑暗的影子般的世界,直到y处的光明。从x走到y代表我们理智启蒙的连续过程。在每一个水平上向我们呈现的事物并非四种不同的实在对象;毋宁说,它们代表了观看同一个对象的四种不同的方式。
想象 精神活动最肤浅的形式,处于线段的最底端。这里我们遇到影像,遇到最不实在的东西。当然,想象这个词有可能意味着超越了对事物的简单现象而进人到它们更深的实在。但是这里柏拉图用想象仅仅是指对现象的感性经验,而我们在这种经验中把现象当成了真正的实在。一个明显的例子是可能被误认为某种实在之物的一个影子。其实,影子确实是某种实在的东西;它是一个实实在在的影子。但是想象之所以成为认识的最低形态,是因为在这一阶段它还不知道它面对的是一个影子或一个影像。如果一个人知道它是影子,他将不再处于想象或幻觉的阶段。洞穴中的囚徒们陷于最深的无知,就是因为他们没有意识到他们看见的是影子。
除了影子,还有其他种类的形象,柏拉图认为它们也是不可靠的,这就是由艺术家和诗人虚构的形象。艺术家呈现的形象至少和实在隔了两层。假设一个艺术家画一幅苏格拉底的肖像。苏格拉底代表了理念中的人的一个特殊的或具体的变体。而肖像则仅仅代表艺术家自己对苏格拉底的观察。那么在这里实在的二个层次就是:(1)人的理念,(2)这个理念在苏格拉底这里的具体化,以及(3)在画布上再现的苏格拉底的形象。柏拉图对艺术的批评是,它造出了影像,这影像又在观者那里引起了虚幻的观念。和上面提到的情形一样,当影像被认为等于实在之物的本来面貌时,就产生了幻象。通常我们知道一个艺术 家描绘到画布上的是他(她)自己观看一个主体的方式。然而艺术形象确实能够影响人们的思想,如果人们将他们对事物的理解限制在这些带有各种歪曲和夸大的影像上,就的确会对事物的真实状况缺乏理解。
柏拉图最关心的是通过运用语词的艺术而虚构出来的形象。诗艺与修辞术对他来说是为害最严重的幻象来源。语词具有在我们心中创造形象的力量,诗人和修辞学家在使用语词创造这样的形象上有着高超的技巧。柏拉图特别批评了智者派,他们的影响力就是来月这种使用语词的技巧。他们能使得一个论题的正反两面看起来似乎一样有根据。
信念 想象之后下一个阶段是信念。我们或许会奇怪,柏拉图使用“相信”而不是“知道”来描述由看见真实的物体所导致的心灵状态。当我们观察到看得见,摸得着的东西时,我们容易很强烈地感到一种确定性。然而对柏拉图来说,看见只会形成信念,因为可见事物的许多性质还要取决于它们周围的背景条件。看见给予了我们某种程度的确定性,但这不是绝对的确定性。如果地中海的水从岸边看上去是蓝的,而当从海里取出时,就变得透明了,我们对它的颜色或成分的确定就至少是可以质疑的了。所有物体都有重量,这似乎是确定的,因为我们看到它们下落。但对我们视觉所给出的这个验证若是碰到了物体在空间中的一定高度上会失重的事实,也必须作出某种修改。因此柏拉图说,信念即使是以目睹为基础,也仍然处于意见的阶段。可见事物所引起的心灵状态很明显处于一个比想象更高的水平上,因为它以实在的一种更高的形态为基础。但是虽然实际的事物比它们的影子具有更大的实在性,它们也不是自身就能给予我们所想获得的关于它们的全部知识的。事物的属性不论是色彩、重量,还是其他性质,都是在特定的背景条件下被我们经验到的。因此,我们关于它们的知识就要受这些特定条件的限制。但是我们不满足于这种知识,因为我们知道,如果背景条件发生改变,这种知识的确定性就很有可能被动摇。因此真正的科学家不愿将他们的理解局限于这些特殊情况,而是要寻找事物表象之后的原则。
思想 当我们从信念转到思想时,我们就从可见世界转到了理智世界,从意见领域转到了知识领域。柏拉图称为思想的心灵状态尤其是科学家的特性。科学家们并非仅仅根椐他们对于可见事物的视觉来对这些事物加以探讨。对科学家来说,可见的东西象征着可思想但不可见的实在。柏拉图以数学为例来说明这种知识。数学家从事“抽象”活动,从可见事物中抽出其所象征的东西。当数学家看到一个二角形的图形时,他们思想“三角形”或“三角形自身”。他们区分可见的三角形和可理解(只能用智力了解的)的三角形。通过把可见事物当成象征物来使用,科学提供了从可见世界通向理智世界的一座桥梁。科学迫使我们去思想,因为科学家们总是在寻找规律或原则。虽然科学家或许会观察特殊的事物——一个三角形或一个大脑——但是他们超越了这个特殊的三角形或大脑而去思想三角形本身或大脑本身。科学要求我们“摆脱"我们的诸感官而诉诸我们的理智。不论是两个什么东西,我们的心灵都知道2加2等于4。它也知道不论一个等边三角形有多大,它的各个角都相等。因而思想代表了我们的心灵从可见事物中抽象出一种性质的能力,这种性质在那一类事物中的所有个体中都是一样的,不论这个事物事实上还有什么其他不同的性质。简言之,不论我们观察的人是小的、大的、黑的、白的、年轻的或年老的,我们还是可以思想“人”的理念。
思想的特性不仅在于它将可见事物看作表征物,也在于它从假说出发进行推理。柏拉图用“假说”指一个被认作自明的但依赖于某种更高真理的真理。“你知道,”柏拉图说,“学习诸如几何和算术这些学科的学生是从假定奇偶数、各种符号以及三种角等开始的…他们把这些东西看作是已知的,将之作为假定来运用,他们并不觉得有必要对自己或其他任何人进行说明,而是把它们当作‘自明'的东西来对待。”使用这些假设,或者“从这些假定出发,他们不断前进,直到通过一系列连续的步骤最终达到他们要研究的结论。”这样,对柏拉图来说,一个假说的含义并不意味着它仅仅是字面意义上的一个假设。不如说,柏拉图用这个词指一个确定不变的真理,只不过它与一个更大的背景相关。特殊科学和数学把它们的课题当作独立真理来处理。在这里柏拉图说的是,如果能看到一切事物的本来面貌,我们会发现所有事物都相互关联。从假设出发的思想或推理给予了我们关于真理的知识,但它仍然带有自己的局限:它将某些真理与其他真理隔离开来,这就使我们的心灵依然要追问为什么某个特定的真理是真的。
完善的理智 只要我们还要追求对事物的更完满的解释,我们就永不会满足。但是拥有完善的知识将要求我们把握所有事物相互之间的关系一也就是看到实在之整体的统一性。有了完善的理智我们就彻底地摆脱了感性事物的束缚。在这个层次上,我们直接和理念打交道。理念是理智的对象,例如“三角形”和“人”,它们是从实际的事物中抽象出来的。我们把握这些纯粹的理念而无须任何可见事物——哪怕只是其象征性特征——介人其间。这里我们也不再运用假说,它只代表有限的、孤立的真理。我们在多大程度上超越假说的限制而达到了所有理念的统一,也就在多大程度上达到了最高层次的知识。通过辩证的理智能力,我们迈向它的最高目标,这包括直接看见知识的所有部分之间相互关系的能力。因而,完善的理智意味着对实在的统一的观点,而这对柏拉图而言则意味着知识的统一。
柏拉图用下面一段概括性的陈述总结了他关于线段的讨论,“现在你可以把心灵的这四种状态对应于四个部分:最高级的是理智,第二是思想,第三是信念,最低级的是想象。你可以按照这种关系在一种比例中排列它们,每一个都配以与它们的对象拥有真理和实在的程度相应的清晰度和确定性。”他说,较之影子、倒影和可见事物,最高程度的实在是理念。我们现在就来更详细地探讨他所说的理念的含义。
理念论
柏拉图的理念论是他最有意义的哲学贡献。简言之,理念乃是那些不变的、永恒的、非物质的本质或原型,我们所看见的实际的可见事物仅仅是这些原型的拙劣的摹本。存在着三角形的理念,我们所看到的所有三角形都只是这个理念的幕本。关于理念至少可以提出五个问题。虽然这些问题难以精确地给出答案,但在柏拉图各篇对话中所找到的种种回答使我们仍然能够掌握他关于理念的总的理论。
理念是什么?说我们所见事物仅仪是理念的摹本底下的永恒原型的时候,我们已经暗示了柏拉图对此问题的回答。一个美的人是美的一个摹本。我们可以说一个人是美的,因为我们知道美的理念并且认识到这个人或多或少地分有了这个理念。在《会饮篇》中柏拉图指出,我们通常首先在一个特殊的事物或人身上领会到美。但是在这个有限的形态中发现了美之后,我们很快就“觉察到一种形态的美和另一种形态的美是类似的”,因此我们从一个特殊形体的美转向了美“在每种形态中都是同一的”这一认识。所有类型的美都具有某种相似性——这一发现使我们不再局限于美的事物,而是由美的有形之物转向美的概念。柏拉图说,当一个人发现了这个美的一般本质时,“他对那个特定事物的狂热的爱将会减轻,他将把它视为微不足道的东西,他将成为一个所有形态的美的爱好者;在下一个阶段,他将认为心灵的美比外表形态的美更荣耀。”然后,“把美的汪洋大海尽收眼底,凝神观照,在对智慧无限的爱中,他将创造出许多美好崇高的思想;直达精力弥漫的顶点,最终在他面前展示出一个单一科学的前景,它是一切美的科学。”这就是说,各种各样美的事物都指向一个美本身,每个事物都是由之而得到它们的美的。但是这个“美”不仅仅是一个概念:“美”有其客观实在性。“美”是一个理念。事物成为美的,而美本身却是永存的。所以美的存在独立于那些不断变成美的或不美的事物。
在《理想国》中,柏拉图指出,真正的哲学家想要知道事物的本质。当他问什么是正义或美时,他并不是想要公正的或美的具体事例。意见与知识的差别正在于:处于意见层次的人们可以认出一个正义的行为,但不能告诉你为什么它是正义的。他们不知道正义的本质,而特殊的行为之所以是正义的正是因为分有了这个本质。知识并非仅仅包含转瞬即逝的事实和现象——即并不只是“变成如此这般”的领域。知识追寻真正“实有”的东西;它所关心的是存在。实有的东西、拥有存在的东西,是事物的本质。这些本质是诸如美、善那样永恒的理念,它们使我们断定事物为美的或善的成为可能。除了美、善,还有许多其他理念。柏拉图在某处提到了床的理念,我们所看到的各式各样的床只是它的基本。但是这里就产生了一个问题:是否有多少本质就有多少理念呢?虽然柏拉图并没有肯定存在着狗、水,以及其他一些东西的理念,但他在《巴门尼德篇》中指出“必定没有”淤泥或污物的理念。很明显,如果在事物的所有种类后面都有理念,那么就有一个双重的世界。我们若企图详细说明有多少理念、有些什么理念,困难还会越来越多。但不管怎么说,柏拉图用理念所表示的意思是足够清晰的,他将它们认作事物的本质原型,有着永恒的存在,被我们的心灵而不是感官所把握。
理念存在于何处? 如果理念真是实在的,那么它们似乎总得在某个地方。但是非物质性的理念如何能占有一个位置?我们几乎不能说它们处于空间中。关于这个问题,柏拉图最明确的提法就是:理念与具体的事物是“分离的”,它们“脱离”我们所看见的事物而存在。“分离”或“脱离”肯定只能意味着,理念有其独立的存在;即使特殊的事物灭亡了,它们也依然持存着。理念没有空间维度,关于它们的位置的问题乃是我们语言的结果,我们的语言说理念是某种东西,这暗示着它必定在空间中有一个位置。关于它们的位置,我们能说的或许仅仅是下面这个事实:理念有着独立的存在。而柏拉图以另外三种方式强调了这一点。第一,柏拉图认为,在我们的心灵与身体结合之前,我们的灵魂在一个精神领域里就已经存在了;在那个状态下,我们的灵魂熟悉了理念。第二,柏拉图认为,在创造万物的过程中,神用理念来塑造特殊的事物;这意味着理念先于其在事物中的具体化而存在。第三,这些理念似乎最初是存在于“神的心灵”中或理性的最高原则中的。在对柏拉图的线喻的论述中,我们指出了柏拉图对心灵历程的追溯如何从最低层次的影像达到最高层次,在这个层次上,善的理念包含有最完满的实在。
正如在洞穴寓言中,太阳同时是光和生命的源泉一样,柏拉图说,善的理念也是“所有美的、公正的事物的万能创造者,是这个世界的光明之母、光明之主,是另一个世界中真理和理性的源泉。”理念是否真的存在于神的心灵中,这是个问题,但理念是理性原则在宇宙中普遍运作的一种机能,这似乎就是柏拉图的意思。
理念与事物的关系是什么?一个理念可以以三种方式与一个事物相关联(事实上,可以说它们只是言说同一个事物的三种方式)。首先,理念乃是一个事物之本质的原因。其次,一个事物可以说分有了一个理念。最后,一个事物可以说模仿了个理念,是这个理念的摹本。以上每种情形中,柏拉图都暗示了虽然理念与事物是相分离的——人的理念不同于苏格拉底——然而,每一个具体的、实际的事物的存在还是要在某种意义上归于一个理念。它在某种程度上分有了它所从属的这个类的完美的原型,是对原型的一个模仿或摹本。后来,亚里土多德会说,形式与质料是不可分的,我们只能在实实在在的事物中发现真实的善或美。但是,柏拉图只允许用分有和模仿来解释事物与它们的理念之间的关系。为了强调这一点,他指出,正是通过理念,秩序才被带进了混沌之中,这表明形式和质料确实是互相分离的。亚里士多德对柏拉图观点的批评是难以对付的,因为似乎没有什么办法能把脱离了实际事物的理念前后一致地解释通。然而,柏拉图会问他:如果我们的心灵除了不完善的事物就再也不可能达到其他任何东西,那么是什么使我们得以判断一个事物是不完善的呢?
诸理念之间的相互关系是什么? 柏拉图说:“只有把各种理念编结在一起,我们才能进行言谈。”思想和言谈大都是在高于特殊事物的层面上进行的。我们是针对本质或普遍的共相进行言说的,特殊事物是对它们的例证;于是,我们谈论王后、狗和木匠。这些都是对事物的规定,这些规定本身是共相或理念。当然,我们也会提到我们经验中的具体事物,例如黑的、美丽的和人,但我们的语言揭示出,我们其实是把理念和理念连接在一起的。有动物的理念,在其中还有次一级的动物类别,如人和马。因而理念作为种和属就相互关联。就这样,诸理念即使在保持它们各自的统一性时,也倾向于互相结合。动物的理念似乎也在马的理念中出现,于是一个理念就分有了另一个。因此,存在着不同理念所构成的一个等级结构,它代表了实在的结构,而可见世界只是对它的一个反映。在这个理念的等级中我们达到的层次“越低”,离可见事物越近,我们的知识普遍性也就“更少”,比如当我们说“红苹果”时,就是这样。反过来说,我们达到的层次越高,或者说理念越抽象,例如当我们说一般的“苹果”时,我们的知识就越有广度。科学的论说是最抽象的,这正是因为它已经最大程度地独立于特殊情形、特殊事物。对柏拉图而言,它具有知识的最高形式。一个植物学家从这朵玫瑰花进展到玫瑰花,再进展到花,他就达到了柏拉图这里所思考的对特殊事物的抽象或独立。然而这并不意味着柏拉图就认为所有理念都可以相互关联。他只是想说,每个有意义的陈述都需要运用某些理念,而知识就在于对适当理念之间的相互关系的理解。
我们如何认识理念? 关于我们的心灵如何发现理念,柏拉图至少提到三种不同的方法。第一是回忆。我们的灵魂在与我们的身体结合之前,就熟悉了诸理念。现在,人们在对他们的灵魂在自己的前世存在中已经认识到的东西进行回忆,而可见事物提醒他们记起他们先前知道的本质,教育实际上乃是一个回忆的过程。第二,人们通过辩证法的活动达到对于诸理念的知识,辩证法是将事物的本质抽象出来,发现知识各部分相互关系的力量。第三是欲求、爱(爱欲)的能力,正如柏拉图在《会饮篇》中所描绘的,它引导人们一步步地从美的事物达到美的思想,再达到美的本质自身。
虽然理念论解决了关于人类知识的许多问题,它也还有许多问题没有回答。柏拉图的语言给我们这样一个印象,存在着两个互相区别的世界,但这两个世界之间的关系是很难设想的。诸理念与相应于它们的事物之间的关系也不是我们期望的那么清晰。即使这样,他的论说仍是极富启发性的,这尤其是因为,他试图说明我们作出价值判断的能力。说一个东西较好或较坏,这暗示了某种标准,很明显,这标准本身并不存在于正在被评价的事物中。理念论也使科学知识成为可能,因为很明显科学家“不去管”实际可见的特殊的东西,而是和本质的东西或普遍的东西即“规律”打交道。科学家系统地阐述“规律”,这些规律提供给我们的情况是关于所有事物而不仅仅是暂时的、特殊的事物。虽然整个的理念论都建基于柏拉图的形而上学观点——最终的实在是非物质的——但是对于一个更简单的事实,即我们可能如何进行日常对话,所作的解释是很深人的。看起来,人们相互之间的任何言谈都印证了我们对于特殊事物的独立性。柏拉图会说,对话是将我们引向诸理念的线索,因为对话所涉及的不止是看见东西。我们的眼睛只能看见特殊的事物,但是当我们的思想给对话注人了活力,而当它“看到”(see)普遍的理念时,它就离开了具体的事物。归根到底,柏拉图的理论中有着一种持久的魅力,虽然它最终并没有得出定论。
3.3 道德哲学
从柏拉图的理念论自然就会推进到他的伦理学说。如果我们有可能被自然物理世界的各种现象所欺骗,那么,我们同样有可能被道德领域内的各种现象所欺骗。存在着一种特殊的知识,它帮助我们区分影子、映像和可见世界中实在的事物。我们也正需要这样一种知识来区分真正好的生活的影子和映像。柏拉图相信,如果我们的知识仅限于可见事物,那么就不可能有物理科学。与此类似,如果我们仅仅限于我们所拥有的对特定文化的经验,那么就不存在关于一个普遍的善的理念的知识。对于苏格拉底和柏拉图来说,为人所熟知的智者派的怀疑主义就是知识与道德之间这种联系的例证。智者派相信所有的知识都是相对的,因而他们否认人们能够发现任何不变的、普遍的道德标准。智者派的怀疑主义使他们不可避免地得出一些关于道德的结论。第一,他们认为道德规则是由每个社群刻意制造出来的,只针对特定地方的居民,也只对他们有效力。第二,智者派相信,道德规则是非自然的,而人们遵守这些规侧仅仅是迫于奥论的压力。他们认为,如果人们的行为是私下里发生的,那么即使是我们中的那些“好人”也不会遵从道德规则。第三,他们认为,正义的本质是权力,或者说“有力即有理”。第四,在回答“什么是好的生活”这一基本问题时,智者派认为那是愉悦的生活。针对智者派这些令人感到难以反驳的教导,柏拉图提出了苏格拉底式的思想——“知识即美德”。柏拉图对苏格拉底的道德观点作了详细的说明,他强调(1)灵魂概念和(2)作为其机能的德性概念。
灵魂概念
在《理想国》中,柏拉图描述灵魂有三个部分,他称之为理性、精神和欲望。他这种把灵魂一分为三的概念,是建立在一切人都有过内心困惑和冲突的共同经验上的。当他分析这一冲突的本质时,他发现在一个人身上发生着三种不同的活动。第一,存在着一种对目的或价值的意识,而这是理性的活动。第二,存在着激发行动的驱动力——精神——它本来是中立的,但对理性的指示作出响应。最后,存在着对物质的东西的欲望。他将这些活动归于灵魂,是因为他认为:灵魂是生命和运动的原则。物体自身则是无生命的,因而,当它活动或运动时,它一定是被生命的原则即灵魂所推动的。有可能发生这样的情况:我们的理性为行为指出一个目的,但最后却被感官欲望所压倒,而精神的力量就被这些感官欲求随便拉向什么方向。柏拉图在《斐德若篇》中举例说明了人们面临的折中情况,其中他描绘了一个驾驶着两匹马拉的车的驭手。柏拉图说,一匹马是好的,“不需要动鞭子,而只需言语和告诫来引导”,另一匹马是坏的,是个“桀骜不驯的同伴…马鞭和马刺都很难让它就范”。虽然驭手对于将去往哪里看得很清楚,并且好马是循着正确路线在跑,但是坏马“乱跳乱跑,给它的同伴和驭手造成了各种各样的麻烦”。
柏拉图以这一图景为例生动地展示了对秩序的破坏:两匹马跑向相反的方向,而驭手站在那里无计可施,他的命令也无人理睬。由于驭手是掌握缰绳的人,所以他有责任、权力和能力引导和控制马。同样地,灵魂的理性部分有权支配精神和欲望的部分。诚然,驭手没有这两匹马就哪儿也去不了,因此这三者是关联在一起的,它们要达到它们的目标必须共同努力。灵魂的理性部分与其他两个部分有着和上面同样的关系,因为欲望和精神的力量对于生命本身是必不可少的。理性作用于精神和欲望,而这两者也推动和影响着理性。但是理性与精神和欲望的关系被理性之所是决定:理性是一种追求目的并对目的进行权衡的能力。当然,情欲也从事于对目的的追求,因为它们不断地追求愉悦。愉悦是一个合理的生活目标。然而,情欲仅仅趋向于能带来愉悦的事物。这样的话,情欲就并不能将那些能带来更高的或持续更长时间的愉悦的东西和那些只是貌似能提供这些愉悦的东西区分开来。
追求人类生活的真正目标,这乃是灵魂的理性部分的功能,要做到这一点,它就要根据事物真实的本性来估量其价值。激情或者欲望或许会将我们引向一个幻相的世界,诱骗我们相信某种愉悦将带给我们幸福。这样,识破幻相的世界并发现真实的世界,从而将激情引导到那些能够产生真正愉悦和真正幸福的爱的对象上去,就成了理性独有的任务。当我们将现象混同于实在时,我们会遇到不幸,并且会经历人类灵魂的全局混乱。这种混淆主要发生在我们的激情压倒我们的理性时。正是因为这个原因,所以柏拉图要争辩说——正如苏格拉底此前说过的——道德上的恶乃是无知的后果。只有驭手能够控制住马匹时,取手与马匹之间才能有秩序。类似地,只有我们的理性部分能控制住我们精神和欲望的部分时,人类灵魂才能安宁有序。
在对人类的道德经验的分析中,柏拉图始终在对我们德性能力的乐观看法与怀疑我们能否将我们德性潜能付诸实现的否定性意见之间摇摆着。这种双重态度是以柏拉图关于道德上的恶的理论为根据的。我们已经了解了苏格拉底的观点,恶或恶行是由无知导致的——就是说,是由错误的知识导致的。当我们的理性受情欲的影响,而以为那似乎会带来幸福的东西真的会带来幸福(而事实上它并不能做到)的时候,错误的知识就出现了。我的欲望于是压倒了我的理性,这时我的灵魂的统一就受到了有害的影响。尽管这时存在着一个统一,但我的灵魂的这个新的统一是颠倒的!因为现在是我的理性服从于我的欲望,理性已经失去了它的合法地位。是什么原因使这一错乱的统一能够发生?或者说,是什么原因使错误的知识变为可能的?简言之,道德上的恶的原因是什么呢?
恶的原因:无知或遗忘
在灵魂的本性中,在灵魂与身体的关系中,我们发现了恶的原因。柏拉图说,灵魂在进人身体之前有一个前世的存在。正如我们已经知道的,灵魂有两大部分,理性的部分和非理性的部分。这个非理性的部分又由两个小部分组成,即精神和欲望。两个大的部分分别有着不同的来源。灵魂的理性部分是由造物主德穆革(Demiurge).创造的;与之相对的是,非理性部分是由天神们创造的,这些天神也创造了身体。这样,甚至在进人身体之前,灵魂的成分就有了两个不同的来源。在灵魂前世的存在中,理性部分对诸理念和真理有着清晰的认识。然而同时,精神和欲望出于其本性已经有堕落的倾向了。如果我们问为什么灵魂下降到一个身体里,柏拉图会说,这纯粹是由于非理性部分一灵魂中不完善的那一部分——有不服管束并要将灵魂拉向尘世的倾向。柏拉图说:“当其羽翼丰满之时,她(灵魂)向上高飞…而那不完善的灵魂,失去了她的翅膀,在飞行中最后坠落到坚硬的地面一在这里,她发现了一个家,接受了一个尘世的构形…灵魂与身体的这一结合被称作一个有生命的、有死的被造物。”这样,灵魂“坠落”了,它就这样进人了身体。但是关键在于甚至在灵魂进人身体之前,它的非理性部分中就有着难以控制的恶的本性。于是,在某种意义上,恶的原因甚至在灵魂的先前状态中就已出现了。灵魂还在“天上”时就已经在对诸理念或真理的观照与对这观照的“遗忘”之间摇摆,于是它的堕落就开始了。从这个观点看,恶不是一个实在的东西,毋宁说,它是灵魂的某种特性,这种特性使灵魂有“可能”发生遗忘。只有那些确实忘记了真理的灵魂才堕落,才被地上的事物吸引而下坠。因此,灵魂就其本性而言是完善的,但它的本性的一个方面则是陷人错乱的这种可能性,因为灵魂也同其他的被造物一样,也包含了不完善的原则。然而,一旦进入身体,灵魂所处的困境就比以前大得多了。
柏拉图相信,是身体刺激灵魂的非理性部分去颠覆理性的统治地位。因此,灵魂进人身体是灵魂错乱或者说灵魂各部分之和谐受到破坏的更进一步的原因。一方面,当灵魂离开理念的王国而进人身体时,它就从一的王国进人到了多的王国。现在灵魂在杂多事物光怪陆离的大海上漂浮,并且受这些事物似是而非的性质的蒙蔽而犯下各种错误。此外,身体也让饮食男女之类的欲望膨胀起来,刺激灵魂的非理性部分一味追求享乐。这反过来又成了贪欲。灵魂在身体中体验着欲望、愉悦、痛苦,还有恐惧与愤怒。当然,这里也还存在着一种对极其多样的各种对象的爱:从对能满足某种口味的一点粗茶淡饭的喜好,到对纯粹的、永恒的真理或美的爱。这些都暗示:身体对灵魂来说乃是一个惰性的累赘,而灵魂中的精神和欲望尤其容易受到身体作用的影响。这样,我们的身体就破坏了灵魂的和谐。因为我们的身体使灵魂暴露于各种刺激之下,使我们的理性偏离了真知识,或者说阻碍了我们的理性回忆起我们曾经知道的真理。
在人世间,只要一个社会有着错误的价值观,并使个体将这些错误价值观认同为他们自己的,那么错误就将一直被沿袭下去。每个社会必然像一位导师一样对其成员产生影响,因此,社会的价值观也将成为个体的价值观。此外,社会很容易承袭前一代人的过恶。柏拉图强调了这一思想,并且他提出,除了对恶的社会性传承之外,人的灵魂也可以通过转世而重新出现,并将它们早先的错误和价值判断带到一个新的身体里。归根结底,身体才是导致无知、鲁莽、贪欲的原因。因为身体把灵魂暴露在洪水般的感官刺激之下,破坏了理性、精神和欲望有条不紊的运作。
回顾柏拉图对人类道德状况的解释,我们已经了解到,他的出发点是独立于身体而存在的灵魂概念。在此状态中,灵魂的理性部分和非理性部分之间有一种根本性的和谐,此时理性通过它对真理的知识而控制着精神和欲望。但是由于灵魂的非理性部分有着不完善的可能性,因此当它由于欲望而被较低级的领域所吸引,还拉上了精神和理性一起堕落时,就把这种可能性表现出来了。在进入身体时,灵魂各部分之间最初的和谐受到了进一步破坏,先前的知识被遗忘,而身体的惰性又阻碍了这一知识的恢复。
恢复失去的道德
对柏拉图来说,道德就在于恢复我们已经失去了的内在和谐。它意味着将那个我们的理性为欲望和肉体刺激所征服的过程颠倒过来。无论人们做什么,他们总是认为这些行为会在某些方面给他们带来愉悦和幸福。柏拉图说,没有人明知道一个行为对他有害还会选择去做。我们或许会做出“错误”的行为,例如谋杀或撒谎,甚至还会承认这些行为是错误的。但是我们总是以为可以从中得到某种好处。这是错误的知识——一种无知——人们必须克服它,成为道德的人。因而,说“知识即美德”,就意味着必须以对事物或行为及其价值的正确估计来取代错误的知识。
在我们能够从错误知识走向真知识之前,我们必须对我们处于无知状态这一点有所意识。这就像我们必须被从“无知的沉睡”中唤醒一样。我们可以被发生在我们内心或外部的事情唤醒,也可以被别人唤醒。与此类似,就知识尤其是道德知识来说,人类也有这样三种被唤醒的方式。柏拉图认为知识深藏于心灵的记忆中,这一潜在的知识会不时地进人意识的表层。灵魂曾经知道的东西通过回忆的过程上升到当下意识。回忆首先开始于我们的心灵由于感性经验之间的明显矛盾而感到困感的时候。当我们努力在杂多事物中寻找意义时,我们开始“超越”事物自身而通向理念,我们心灵的这一行为是由我们对于一个需要解决的问题的经验来推动的。柏拉图认为,除了这个内部原因外,唤醒也可以由一位导师来完成。在他的洞穴寓言中,柏拉图描绘了人们如何从黑暗走向光明,从无知走向有知。不过在这个寓言中,他写出了囚徒们当中的那种自满态度:他们不知道他们是囚徒,不知道他们被错误的知识所束缚,不知道他们处在无知的黑暗之中。唤醒他们必须通过一位导师。就像柏拉图说的,“他们从锁链中被解脱,愚味被消除”是由于他们“被猛然地强迫站起来,转过身…抬眼看着光明走”。就是说,必须有某个人打碎囚徒的锁链并使他转过身。在被强制释放之后,他接着才能被一步一步引导着走出洞穴。苏格拉底讽刺的力量和对辩证法的坚持,使其成为历史上将人们从无知的沉睡中唤醒的最有影响力的人。但是除了唤醒我们或打碎我们的锁链,这位有影响力的老师还必须使我们转过身,好让我们将他的目光从影子转到实在世界。
作为功能之实现的德性
在对道德的探讨中,柏拉图始终将善的生活视为内心和谐、健康、幸福的生活。他经常把善的生活比作事物功能的有效实现。他说,当一把刀能够有效地切割东西时,就是说当它实现了自己的功能时,它就是好的。当医生们实现了诊治的功能时,我们就说他们是好 的。同样,当音乐家们实现了其艺术功能时,他们是好的。柏拉图接着问,“灵魂是否具有一种其他任何东西都完成不了的功能呢?”他说,生活如同一门艺术,灵魂独有的功能就是生活的艺术。在对音乐艺术与生活艺术的比较中,柏拉图看到了一种密切的相似性,在这两种情况下,艺术都需要承认并服从界限和尺度的要求。当音乐家校准他们的乐器时,他们知道每一根弦都应该上得恰到好处,不能太紧也不能太松,因为每一根弦都有它自己的音调。因而音乐家的艺术就在于承认一个界限,一根弦不应紧得超出这个界限;也在于演奏他们的乐器时遵守音程之间的“尺度”。同样,雕塑家们也须清晰地意识到尺度和界限,因为当他们用锤子和凿刀工作时,他们必须根据他们所要完成的形象而控制每一击的力量。在开始剔除大理石的较大部分时,他们的敲击将很重。但当他们开始蔽凿雕像的头部时,他们必须对界限有一个清晰的认识,他们的凿刀千万不能超出这些界限,当他们塑造面部的精细线条时,他们的敲击必须很轻。
与之相类,生活的艺术也需要界限和尺度的知识。灵魂有各种功能,但这些功能必须在由知识或理智设立的界限之内运行。因为灵魂有许多不同的部分,每一个部分都有一个特殊的功能。既然德性就是功能的实现,那么有多少种功能就有多少种德性。与灵魂的三个部分相对应,也就有三种德性。当这三部分各自都实现了它们的功能时,也就达到了这三种德性。欲望必须被控制在界限和尺度之内,避免纵欲,这样它们就不会侵占灵魂其他部分的位置。在愉悦的欲望中,这种适度就产生了节制之德。源于灵魂的精神部分的意志力量也需要被控制在界限之内,避免鲁莽的或冒失的行动,而成为在进攻和防御行动中的一种值得信赖的力量。通过这样做我们就达到了勇敢之德。当理性保持在没有被欲望的急流所烦扰的状态下,不管日常生活中经验到的持续的变化而仍能看到真实的诸理念时,理性就达到了智慧之德。这三种德性相互之间又有着关联,节制乃是对欲望的理性控制,勇敢乃是对精神的理性规范。同时,灵魂的每个部分也有它自身的功能,而当每一个部分事实上都实现了其特殊的功能时,就达到了第四种德性,正义,因为正义意味着让每个部分各得其所。这样,正义就是一个全面的德性,它反映一个人达到了健全与内在的和谐,也只有当灵魂的每个部分都实现了其真正的功能时,一个人才能达到正义。
3.4 政治哲学
在柏拉图的思想中,政治理论与道德哲学有紧密的联系。在《理想国》中,他说国家的不同等级就像一个人灵魂的不同部分。同样,国家的不同类型以及它们独有的德和恶与人的不同类型以及他们的德和恶是相类的。在这两种情况下,我们应该根据各等级或各部分是否很好地履行了其功能,彼此间是否有着适当的关系来分析国家或个人是否健全。事实上,柏拉图认为国家就像一个巨人。正义是有德之人的全面德性,因此它也是好的社会的标志。在《理想国》中,柏拉图论证说,要理解什么是正义的人,最好的办法是分析国家的本质。他说:“我们应该从探讨在一个国家中正义意味着什么开始。接下来我们就可以在个人之中寻找它的具体而微的对应物。”
巨人般的国家
对柏拉图来说,国家是从个人的本性中发展出来的,因此个人在逻辑上先于国家。柏拉图说,国家是一个自然的机构——之所以是自然的,是因为它反映了人类本性的结构。国家的起源反映了人们的经济需要,柏拉图说,国家的出现是因为任何个人都不是自足的;我们都有多种多样的需要。我们的多种需要就要求多种技能来满足,没有哪个个人能具备生产粮食、住所、衣物及创造各种艺术所需的所有技能。因而劳动分工是必需的,因为“当每个人不再为其他事物所累,只是适时地去做适合他的本性的惟一一件事的时候,人们就能生产出更多的东西,工作就会变得更容易,完成得更好”。我们的需要并不局限于物质需求,因为我们的目标并非仅仅是存活,而是一种高于动物的生活。然而,健全的国家很快就会受到一大堆欲望的影响,并且“由于一大批无关乎基本生活需要的职业而膨胀起来”。于是有了“猎人和渔夫…雕塑家、画家、音乐家:诗人以及由此而伴生的职业吟诵者、演员、舞者、舞台监督;各种日用品包括妇女装饰品的制造者。我们会需要更多的服务人员…侍奉女士的丫环、理发师、厨师、糖果商。”
得寸进尺的欲望很快就会耗尽社会的资源,柏拉图认为,不久,“我们将不得不割占我们邻邦的领地…他们也会图谋我们的领地。”照这样下去,邻国之间不可避免地要陷人战争。战争“源于欲望,欲望对个人和国家来说都是最能产生恶的源泉。”由于战争的不可避免,就必须“有一支完整的军队去抵御任何人侵者,保卫本邦的财产和公民”。这样就出现了国家的保卫者,他们首先是代表那些能击退入侵者并维护内部秩序的精壮之士。现在,人群中出现了两个不同的等级,那些从事各种技艺的人——农夫、工匠、商人——和那些保卫这个社会的人。从后边这个等级中,又挑选出经过最好训练的保卫者,他们将成为这个国家的统治者,代表第三个等级即精英阶层。
个体与国家的关系现在就一清二楚了:国家的三个等级是灵魂的三个部分的延伸。劳动者或工匠作为一个社会等级,代表了灵魂的最低部分,即欲望。保卫者则是灵魂的精神要素的体现。而最高等级,统治者,则代表了理性的成分。到此为止,这个分析看起来似乎还是合情合理的,因为我们无须花费多少想象力就能看到这样一些联系:(1)个人的欲望与满足这些欲望的劳动者阶层之间的联系,(2)人群之中的精神要素和这种能动力量在军事机构中的大量体现之间的联系,以及(3)理性要素和统治者独有的领导职能之间的联系。但是柏拉图意识到,要想说服人们接受国家的这种等级体系并不容易,尤其是当他们发现自已处于他们一旦有选择余地时也许就不会选择的那个等级之中时。
只有通过广泛的训练,才能把所有人都安排到他们各自的等级中,只有那些能接受训练服从安排的人才能上升到更高层次。虽然理论上人们都有达到最高层次的机会,但事实上他们将止步于他们的自然桌赋所能达到的那个层次。为了使他们所有人都满足于自己的命运,柏拉图认为有必要利用一个“方便的虚构…一个纯属大胆想象的捏造”。他写道:“我应该努力首先使统治者和军人相信,然后使整个社会都相信,我们给予他们的抚养和教育对他们来说,只是如同梦境一般的貌似真实的经历而已。实际上,他们一直都处于大地深处,被塑造、被赋形…直到最后他们被塑造完成后,大地才把他们从子宫中生出,送到光天化日之下。”
这个“高尚的谎言”也会说,那塑造了所有人的神,在那些将会当统治者的人的成分中混人了金,而在“将成为战士的人的成分中加人了银,在农民、工匠的成分中加人了铁和铜”。这意味着一些人天生就是统治者,另一些人天生就是工匠,而这也将为一个有着完善的等级分化的社会奠定基础。但是欧洲后来的社会却认为出生于这样一个等级社会的孩子将一直处于他们所出身的等级,而柏拉图承认孩子们并不总是与他们的父母具有相同的质。因此他说,在上天给统治者领下的命令之中,“没有哪一道命令执行起来像关于孩子们灵魂的合金这一道这样,希要如此小心仔细的观察,如果统治者自己的孩子天生就是铁或铜的合金,他们必须毫不怜惜地将他送到与他的本性相符合的地方去,将他扔到农民和工匠之中。”同样,如果金质的或银质的孩子出身于工匠家庭,“他们将根据他的价值提升他”。最为重要的是,柏拉图认为,在谁做统治者以及为何要服从统治者这两点上,人们的意见应该取得一致。
哲学王
柏拉图相信,能力应该是当权者的资格证明。国家的统治者应该具有履行其职能的特别能力。导致国家混乱与导致个人失调的都是同样的情形,即较低级的要素试图篡夺较高级的要素的地位。无论在个人还是在国家中,欲望和肆意妄为都将导致内部的失控状态。在这两个层面上,理性要素都必须处于支配地位。谁应该成为一艘船的船长——应该是一个“最受欢迎的”人还是一个懂得航海技术的人?谁该统治国家一是一个受过战争训练的人还是受过商业训圳练的人?柏拉图说,统治者应该是一个受到全面教育从而理解了可见世界与理智世界一意见领域与知识领域,现象与实在一之间的区别的人。简言之,哲学王所接受的教育已经引导他一步一步通过线段之喻中层层上升的知识等级而达到了对善的知识的把握,达到了对所有真理之间的相互关系的提纲率领的洞察。
要达到这一点,哲学王要通过许多教育阶段。到18岁为止,他将受到文学、音乐和初等数学的圳练。他接触的文学要受到审查,因为柏拉图指责一些诗人进行公然的欺骗并对诸神的行为加以不虔敬的描述。音乐也要加以规定,那些诱人堕落的音乐将被各种更有教益的音乐取代。在此后的几年中,他将受到广泛的体能和军事圳练。在20岁时将从中选拔一些人学习数学的高级课程。在30岁时,将开始为期5年的辩证法和道德哲学的训练。接下来的15年将通过公共服务来积累实践经验。最后,在50岁时,最有能力的人将达到最高层次的知识即对善的洞察,这样他就能胜任治国之责了。
国家中的德性
柏拉认为,在一个国家之中能否达到正义要看哲学的要素能否在社会中取得统治地位。他写道:“我不能不称赞道,正确的哲学提供了一个高瞻远瞩的位置,由此我们能够在一切情形中辨别出对社会和个人来说什么才是正义的。”他也相信,“要么那些真心实意并且正确无误地遵从哲学的人获得了政治权力,要么在城邦中有权力的阶层为神的干预所引导而成为真正的哲学家,舍此二途,人类就不能摆脱恶。”但是正如我们已经了解到的,正义是一个全面的德性。它意味着所有的部分都实现了它们各自特殊的功能,达到了它们各自的德性。国家中的正义只有在三个等级都实现了他们各自的功能时才能达到。
既然匠人们体现了欲望的要素,他们也将反映节制的德性。节制并不仪仅限于匠人们,而是适合所有阶层的,因为做到节制就表明较低级者情愿被较高级者统治。然而节制尤其适合匠人,因为匠人是最低阶级、必须服从于其他两个较高阶级的。
那些保卫国家的武士则表现了勇敢的德性。为了保证这些武士能一直履行其职能,要对他们加以特别的训练和供给。匠人们各自结婚并各月拥有财产,武士们则不同,他们的财产和妻子都是共有的。柏拉图认为,要让武士们获得真正的勇气,这些安排就是必要的,因为勇敢就是知道该害怕什么、不该害怕什么。对武士来说惟一真正应该害怕的东两应该是道德的恶。他绝不能害怕贫困或匮乏,而由于这一原因他的生活方式应该与财产无关。虽然妻子是共有的,但这并不意味着一种对女性的歧视。相反,柏拉图相信,男性和女性在某些事情上是平等的,例如,“如果一个男子和一个女子都有当医生的才能,那他们就有相同的本性。”如果情况真是如此,只要他们拥有适当的才能,他们就该被指派同样的工作。由于这一原因,柏拉图相信女性也可以像男性一样成为保卫国家的武士。
为了维持保卫者阶层成员的统一,长期的个体家庭将被禁止,而整个等级将成为一个单一的大家庭。柏拉图在这里的考虑是,武士们不仅必须免受发财的诱惑,而且必须免受置家庭利益于国家利益之上的诱惑。此外,他认为在繁育赛狗、赛马上费尽心力,同时在生育国家的保卫者和统治者上却完全放任自流,听天由命,实属不智。因此,性关系也要严格控制,限制在特许的婚配节日期间进行。这些节日有固定日期,伴侣们以为他们是通过抽签配对,而事实上抽签是被统治者操纵的,以保证最大可能地做到优生优育。柏拉图的确说过,“在战争和执行其他任务中表现出色的年轻人,除了得到其他奖赏和特权外,还应被给予更多机会和一个妻子同房,”但这只是出于实用的目的,“这样就有了很好的由头让这样的父亲可以生出尽量多的孩子。”武士们的孩子一出生,就会为了这个目的而由指定的官员负责管理,他们将在位于城市的某个特殊区域中的保育学校里得到抚养。柏拉图认为,有了这些条件,保卫者将最有可能履行好他们保卫国家的真正职能,而不受到其他事情的干扰,从而达到他们恰如其分的勇敢的德性。
因此,国家的正义和个人的正义就是一样的。它是人们各安其所、各司其职的结果。正义是节制、勇敢、智慧这三种德性的和谐。既然国家是由个人组成的,那么每个人也都有必要拥有所有这些德性,例如,即使是匠人也必须有智慧的德性,这不仪是为了让他们能监督自己的欲望,而且也为了让他们懂得安于现状并遵纪守法。同样,正如我们已经看到的,为了知道什么是该害怕的、什么是不该害怕的,保卫者也必须具有足够的智慧,这样他们才能培养出真正的勇敢。最重要的是,统治者必须尽力获得有关善的知识,因为国家的健全发达有赖于统治者的知识和品质。
理想国的衰败
柏拉图认为,如果说国家是一个巨人,那么它将反映出这个社会中的人们成为了什么样的类型。他头脑中所想的是,虽然人的本性是固定的,但因为所有人都有一个二分的灵魂,那么人们成为什么类型的人,就要看他们所达到的内在和谐的程度。因而,国家将会反映出人类品质的这些不同变化。由于这一原因,柏拉图表明,“国之组织形式并非木石所能造就,它们必定源于某种占主导地位的品质,这种品质吸引着社会中其他人紧随其后。所以如果有五种政体形式,则在个人中间必定有五种类型的心理构造。”这五种政体形式是:贵族政体、荣誉政体、寡头政体、民主政体和专制政体。
柏拉图把从贵族政体到专制政体的变化看作是相应于统治者和公民在道德品质上逐渐堕落的国家性质的逐渐衰败。他的理想国家是贵族政体,在其中,体现为哲学王的理性要素居于至高无上的地位,而人们的理性也控制着他们的欲望。柏拉图强调,这种政体虽然只是一个理想,但却是一个值得追求的很有意义的目标。他对政治有着很清醒的认识,这尤其是因为雅典人处死苏格拉底的情形以及他们保证不了好的领袖能够后继有人。“当我凝视公共生活的漩涡时,”他说,“我清楚地看到所有现存国家的政体都是坏的,无一例外。”不过对一个国家来说,贵族政体是模范政体,因为在这个形式中我们发现了所有阶级之间的那种正当的从属关系。
但是即使我们建成了这个理想的国家,它依然有可能发生变化,因为没有什么是恒久不变的,贵族政体首先会下降为荣誉政体。这体现了一种退化,因为这个政体代表了对荣誉的爱,由于统治阶级那些野心勃勃的成员们爱他们自己的荣誉胜过爱公共的善,他们灵魂的精神部分就篡夺了理性的地位。虽然这只是灵魂结构上一个很小的裂隙,但它的确使非理性部分开始非分地要求越来越重要的地位。从对荣誉的爱到对财富的欲望只有一小步,而后者意味着让欲望来进行统治。
即使在一个以荣誉至上为宗旨的政体里,也将开始出现私有财产制度,这种对财富的欲望为被称为寡头统治的政体铺平了道路,在这个政体里,权力落在主要关心财富的人的手里。柏拉图说:“由于在社会评价中富人们被抬高,结果有道德的人受到了贬低。”对柏拉图来说,寡头统治的恶劣之处在于,它使统一的国家分裂成两个互相争斗的阶层——富人和穷人。此外,财阀寡头们是商品的消费者,当他们用光了他们的钱时,他们会变得很危险,因为他们想要更多的东西,他们要这些东西已经成了习惯。富豪就像一个追求永久享乐的人。但享乐的本性就在于它是暂时的,因而必须被不断重复。追求享乐不可能有完全满足的时候;一个追求享乐的人永远也不会满足,就像一个漏桶永远也填不满一样。不过寡头们还是知道如何区分三种欲望:(1)必需的,(2)不必需的,以及(3)不合法的;于是他在许多欲望之间左右为难。“他较好的欲望通常能克制住较坏的欲望”,所以柏拉图认为,寡头们“表现得要比许多人体面”。
柏拉图说,民主政体是进一步的退化,因为它的平等和自由的原则反映了人类品质的退化:人性的一切欲望都可以被同样自由地去追求。诚然,柏拉图的民主概念以及对它的批评是基于他对雅典城邦中特定的民主形式的亲身经验。这里民主是直接的,因为所有的公民都有权参与统治。至少从理论上讲,雅典公民大会包括所有18岁以上的成年公民。所以在柏拉图的头脑里还没有现代的自由和代议民主。他在那个年代所看到的只是直接的大众民主,而它明显违背了他的如下观念:一个国家应该处在有着特殊才能并受过专门训练的人的统治之下。
导致这一平等精神的是在寡头统治之下,寡头们那些比父辈更不知自制的子孙们把一切欲望都逐渐合法化了,人生的目标就变成了尽可能地发财致富。柏拉图说,“这种贪得无厌的狂热欲望将导致向民主制的转变”,因为“一个社会不可能既以财富为荣,同时又在它的公民中建立起自我控制”。在民主政体中,即使一只狗也会在大街上拒不给人让路以展现平等和独立。其实,当富人和穷人发现他们在寡头统治之下处于争夺状态时,就已经到了一个转折点,因为“当穷人赢了的时候,结果就是民主制”。这样,“自由与自由言论到处盛行,每个人爱做什么就做什么。”现在,“你不再有什么权威…也不必服从任何统治,如果你不喜欢的话。”所有这些政治平等和自由都源于一个秩序被破坏了的灵魂。这个灵魂的一切欲望现在完全是平等自由的了,它像一个充满激情的暴民一样行事。自由与平等的生活口号是,“所有的欲望都一样好,它们必须拥有平等的权利。”
但是欲望的持续放纵不可避免地将把我们带到这样一个境地,一种起主宰作用的强烈欲望将最终奴役灵魂。我们不会屈从于任何一个渴望,除非最终不得不屈从于最强烈、最持久的激情。在这一点上,我们说我们处于主宰性欲望的专制之下。类似地,在国家中,追求金钱和享乐的强烈欲望导致大众劫掠富人。富人们抵抗时,大众就推举出一个强人作为他们的首领。但是这个人要求并且获得了绝对权力,奴役人们,直到此时人们才意识到他们为人臣虏的程度之深。这是个不正义的社会,是不正义的灵魂的扩展。民主政体的自然结果就是专制政体。
3.5 宇宙观
虽然柏拉图最一贯的思想集中在道德哲学与政治哲学,但他也将他的注意力转向科学。他的自然理论或物理学主要见于他的《蒂迈欧篇》。根据一些学者的研究,这篇对话是柏拉图在大约70岁时写的。柏拉图并非故意把这个专题的研究押后,也不是刻意置促进科学发展于不顾而专事于道德问题。相反,他那个时代的科学已经步人迷途,科学领域中似乎看不出有什么有研究前途的方向。根据柏拉图的说法,早先苏格拉底曾经“抱有宏愿,想弄懂被称为自然研究的哲学分支,想知道事物的原因”。然而,阿那克西曼德、阿那克西米尼、留基波和德漠克利特,以及其他人提出的相互冲突的回答和理论使苏格拉底的幻想破灭了。此外,随着他自己的哲学的形成,他的某些关于实在的理论也对一种严格精确的科学知识的可能性提出了怀疑。他认为物理学永远都只是“姑妄言之”。尤其是他的理念论使得科学作为一种确切的知识成为不可能。他说,实在的世界是诸理念的世界。而可见世界充满了变化和不完善。但科学正是要努力囿绕着可见世界的事物来建立其理论。如果一个研究对象自身是不完善的、充满了变化,我们如何能形成对它的精确的、可信的、永恒的知识?同时,柏拉图清楚地意识到,他的理念论——以及关于道德、恶和真理的观点——要求有一种能把他的思想的所有要素连贯地结合起来的宇宙观。这样,虽然柏拉图承认他对物质世界的解释只是“姑妄言之的说法”,或者最多只是可能的知识,但他还是确信,他关于世界不得不说的东西的精确性已经达到了这个话题本身所能允许的极限。
柏拉图关于世界的第一个思想是,虽然世界充满了变化和不完善,它依然展现出秩序和目的。他拒绝德谟克利特给出的万物产生于原子间的偶然碰撞的解释。例如,当柏拉图考虑行星的运行轨道时,他观察到,它们是精确地按照几何级数的间隔排列的,通过适当的计算,可以发现这种间隔就是和谐音阶的基础。柏拉图大量运用了毕达哥拉斯派的数学知识来描述世界。但是,他不像毕达哥拉斯那样说事物是数,他说的是,事物分有数,并且对它们可以给出一个数学的解释。事物的这一数学特性令柏拉图想到在事物背后必定存在着思想和目的,而不仅仅是偶然性和随之而来的机械结构。因此,宇宙必定是理智的作品,因为安排万物的正是理智。人性和世界之间有着某种相似性,首先,它们都包含一个理智的永恒要素;其次;它们都包含一个可感的可毁灭的要素。这种二元结构在人之中是通过灵魂和身体的结合表现出来的。与此类似,世界是一个灵魂,在其中事物被安置为我们所知道的那个样子。
虽然柏拉图说心灵安排了每一个事物,但他并没有提出一种创世论。创世论认为事物是从无中被创造出来的。但是柏拉图对可见世界之起源的解释并不会导致创世论。毫无疑问,柏拉图的确说过“生成的东西必定是通过某个原因的作用而生成的”。但是,他称为天工或德穆革的那个行动主体,并没有产生什么新的东西,而只是碰到了己经在混沌状态中存在的东西并对之加以安排而已。这样一来,我们所想到的就是一个手头有着要加工的材料的工匠的形象。因此为了解释如我们所知的可见世界中的事物的起源,柏拉图预设了事物所有要素的存在,即:那些构成事物的原料的存在,作为工匠的德穆革的存在,和事物依其来创造的诸理念或类型的存在。
柏拉图不同于唯物主义者,唯物主义者认为所有事物都来源于某种原初的物质,不论物质的形态是土、气、火,还是水。柏拉图没有接受物质是基本实在这一思想。柏拉图说,应该对物质自身加以更精致的解释,不能说物质又是某种更精细的物质构成的,而应该说物质是由不同于物质的东西构成的。我们称之为物质的东西,不论其形态是土还是水,都是一种理念的反映,这些理念是通过一种介质表现出来的。事物产生于柏拉图称作容受者(receptacle)的东西,柏拉图认为它是“所有生成的东西的培养基”。这个容受者是一种“基体”,或者说,是一种没有任何结构但能够接受德穆革加之于它的结构的介质。柏拉图用来形容容受者的另外一个词是空间,他说,空间是“永恒存在的、不可毁坏的,为所有生成的事物提供了一个位置,但我们对它自身的把握却不是通过感官,而是通过一种非法的推理,它很难成为信念的一个对象。”对这个容受者的来源没有任何解释,因为按柏拉图的想法,它并不是由别的东西产生的,正如理念和德穆革也不是由别的东西产生的一样。容受者就是事物出现和消亡的地方。
在一个不反思的人看来,土和水或许就是固定不变的物质形态。但是柏拉图说它们在不断地变化着,因而并没有足够长时间的稳定性,它们不能“被描述为‘这个'或‘那个’,也不能用任何将它们说成具有永恒存在的语词来描述”。当诸感官对土和水这些元素加以把握时,它们所认作“质料”或“物质”的只是一些性质。而这些性质是通过容受者的媒介而表现出来的,“所有这些性质都是在这个容受者中形成、出现,然后又消失的”。物质的东西是由非物质的东西复合而成的。当柏拉图在此论证说有形物体可以根据它们的各个面而用几何关系来加以规定时,他又是受毕达哥拉斯派观点的影响。他说,任何一个面都可以分解成三角形,而任何一个三角形又可以分解成直角三角形。这些形状、这些三角形是不可还原的,因而必定是合成所谓物质的基本要素。例如,最简单的立体将是由四个三角形构成的锥体。类似地,一个立方体是由六个正方形构成的,每个正方形都是由两个“半正方形”即两个三角形构成的。我们通常所谓的有形物体所包含的仅仅是“面”,因此我们可以说“物体”或者“微粒”都是几何形体。事实上,整个宇宙都可以根据它的几何图解来思考——宇宙可以被简单地定义为在空间中发生的一切,或者反映了各种形式的空间。柏拉图特别想确立这样的思想:物质只是体现某种更基本的东西的现象。
如果各种不同的三角形代表了所有事物的基本要素,那么我们怎样才能既解释清事物的稳定性又解释清事物的变化呢?简言之,是什么使如我们所知这般的世界和宇宙成为可能呢?这里柏拉图不得不又一次假定,一切事物都由心灵安排,宇宙就是世界灵魂——也就是有生命的宇宙的灵魂——的活动。具体事物的世界是现象(phenomena,就是希腊文的“现象”一词)的世界。呈现于我们的知觉的是多种多样的现象事物,一分析就可以发现这些现象事物是由几何组成的。再说一遍,这些面是基本的、不可还原的,它们在容受者中作为“原材料”要求某种组织者将它们先排列成三角形再排列成现象。这所有的活动都是由世界灵魂完成的。世界灵魂是永恒的,虽然有时柏拉图说它是德穆革的创造。虽然世界灵魂是永恒的,但是现象世界却充满了变化,这就像在人类这里灵魂体现了永恒的要素,而身体却包含了变化的原则一样。物质和身体世界的变化是因为它是合成的,总是趋向于回复到它的那些基本构成要素,在空间中“进进出出”。但世界灵魂是永恒的,因此尽管我们的经验世界有着种种变化,还是可以说世界有着稳定而永恒的要素,有着一个结构,而宇宙也是可以理解的。
柏拉图说,世界中存在着恶是因为在德穆革的创造之途中有障碍。虽然德穆革力求尽可能地将世界造得像它的原型那么好,但这个世界依然是不完善的。虽然德穆革代表了塑造宇宙秩序的神圣理性和力量,但“这个宇宙的创生,”柏拉图说,“是必然性与理性相互结合、共同作用的结果。”在这里,必然性的意思是不愿意变化,而在容受者中的“原材料”上,它表现为一种对拒不接受心灵命令的固执。在这个意义上,必然性是世界中的恶的条件之一,因为恶是目的的失效,而目的则是心灵的特性。这样,让心灵作用失效的那一切因素就造成了秩序的缺失,而这正是恶的含义。这就暗示了,在人类生活中,一旦不受心灵的控制,桀骜不驯的身体和灵魂较低部分也会成为产生恶的条件。必然性表现为各种形态,例如惰性、不可逆性,而理性,甚至神的理性,在试图根据某种明确的目的来安排世界时,都必须妥善处理这些阻碍。
最后,还有一个关于时间的问题。在柏拉图看来,只有现象产生之后,时间才存在。直到有了如我们所知的那些东西、那些不完善的和变化的东西之后,才能有时间。在此之前,根据定义来说,无论什么东西都是永恒的。时间的意思恰恰就是变化,因而没有变化就没有时间。尽管理念是永恒的,但它们的各种基本不断地在容受者中“进进出出”,这种“进进出出”就是变化的过程,而变化就是时间的原因。然而,时间代表了时间和永恒性在宇宙中的双重显现;宇宙的秩序既然得自心灵,则宇宙就包含有永恒的要素;而宇宙是由各个面的暂时结合而构成的,它也就包含了变化和时间的要素。而既然变化不是杂乱无章的而是有规律的,那么变化的过程本身就正好昭示了永恒心灵的存在。变化的这种规律性,如同恒星和行星有条不紊的变化和运行所展示的那样,使得对变化的度量成为可能,也使得“报时”成为可能。
所以,柏拉图关于宇宙的“姑妄言之”就是对德穆革如何以理念为原型、从容受者中塑造出事物的解说。世界灵魂是由德穆革产生的,是容受者中能动的活动,它创造了在我们看来是物质实体或有形事物的东西——虽然实际上它只是由几何面的排列而产生的诸多性质。这样一来,恶和时间是不完善性和变化的产物。我们所知的世界有赖于一个能动者和在我们所知的物理世界中找不到的“原材料”,这个能动者就是心灵,而这种原材料则主要得用数学来解释。
此时,我们或许会想要对柏拉图庞大的哲学体系进行一种经得起推敲的批判性评价。但是在某种意义上,哲学史恰好就表现为这样一场大规模的对话,在这场对话中思想家们起来赞同或反对柏拉图的思想。他为哲学事业所铸造的模式具有强大的影响力,以至于后来许多世纪里,他的观点在思想界占据了支配地位。事实上,阿尔弗雷德·诺思·怀特海曾经评论说:“对欧洲哲学传统特点的最可靠的总概括就是,它是由一系列对柏拉图的注释所构成的。”我们可以加上一句,这些注释的许多部分是由柏拉图的杰出继承者亚里士多德写就的。我们接下来就要谈他。
第四章 🐮亚里士多德( ̄3 ̄)a
4.1 亚里士多德的生平
亚里士:多德于公元前384年生于色雷斯东北海滨的小城斯塔吉拉。他的父亲是马其顿国王的医生。很有可能亚里士多德对生物学和一般科学的兴趣在他幼年时代就得到了培养。在他17岁的时候,亚里士多德前往雅典进入柏拉图学园。他作为一位学生和学派的一个成员,在那里一直待了20年。亚里士多德在学园里有“博览群书”之称并被誉为“学园的头脑”。虽然为了形成他自己对于一些哲学问题的看法,亚里士多德最终与柏拉图哲学分道扬镳了,但是柏拉图的思想和人格还是深深地影响了他。他在学园的时候写了大量的柏拉图风格的对话,他的同代人称这些对话是流淌着他们滔滔雄辩的“金色河流”。在他的《优台谟》(Eude mus)中,亚里士多德甚至再次肯定了柏拉图思想中极其核心的理念论,虽然他后来严厉批评了这一理论。
我们现在没有办法确定亚里士多德的思想是什么时候摆脱柏拉图思想的。我们必须记住,当亚里士多德在学园时,柏拉图自己的思想也是处于变化之中的。事实上,学界认为,亚里士多德是在柏拉图晚年时跟随他学习的,而这个时候柏拉图的兴趣已经转向了数学、分类法和自然科学。在这一时期,医学、人类学、考古学等学科的专家们来到了学园。这意昧着亚里土多德泛接触了大量的经验事实,由于他有着自己的全盘考虑,他发现这些事实对于从事研究以及形成科学的概念是非常有用的。因此,很有可能是学园的学术氛围——它们体现在柏拉图暮年所关心的几个主要课题上,也体现在具体领域里收集到的有用材料——为亚里士多德提供了和他的科学气质相契合的一个哲学方向。
亚里士多德所采取的新方向最终导致他背离了柏拉图的一些理论,虽然要弄清他们之间的差异程度有多大还需要进行细心的解读阐释。但是即使他们都还在学园时,某些气质上的差异必定已经显现出来。比如,亚里士多德对数学不像柏拉图那么感兴趣,他更感兴趣的是经验材料。而且,随着时间的推移,亚里士多德对具体自然过程的关注愈加坚定了,以至于他认为他那些抽象的科学概念的栖身之所就在这活生生的自然界之内。与此相反,柏拉图将思想世界从流变的事物世界中分离出来,将真正的实在归于理念,他认为这些理念脱离了自然事物而有其存在。因此,我们可以说,亚里士多德的思想指向动态的生成(becoming)领域,而柏拉图的思想则更多地关注于静态的无时间性的存在(being)领域。不论在这两位伟大思想家之间有什么样的差异,事实上亚里士多德在个人关系上从来没有和柏拉图决裂,直到柏拉图去世他一直都留在学园。另外,尽管亚里士多德后来的主要论文有其独到的阐述和独特的风格,我们在其中还是处处可以发现柏拉图思想确凿无疑的影响。但是随着柏拉图的故去,亚里士多德具有鲜明的“柏拉图主义色彩”的那一时期也就结束了。这以后,学园的领导权落入了柏拉图的侄子斯彪西波之手,他对数学的过分强调不合亚里士多德的想法。再加上其他一些原因,亚里士多德退出学园并离开了雅典。
在公元前348-347年间,亚里士多德离开了学园,接受了赫尔米亚的邀请,来到特洛伊附近的亚索斯城。赫尔米亚以前是学园的学生,现在是亚索斯的统治者。他有点像个哲学王,在自已的宫廷里聚集了一小批思想家。此后的3年亚里士多德就在这里写作、教学并开展研究。就是在赫尔米亚的宫廷里,他与这个统治者的侄女也是养女皮提亚结婚并育有一女。他们回到雅典后,皮提亚去世,接着亚里士多德和一个叫赫尔普利斯的女子同居。虽然没有正式结婚,但他们结下的是一桩情深意笃、白头到老的美满姻缘,并且生有一子,名为尼各马可,亚里士多德的《尼各马可伦理学》就是以他的名字命名的。在亚索斯待了3年之后,亚里士多德移居到了毗邻的列斯堡岛上,在米底勒尼住了一段时间,在那里他从事教学并继续他的生物学研究,特别是对许多种海洋生物的研究。在这里,他也因力主希腊统一而闻名,他极力主张,这样一个联合体将比各自为政的诸城邦更能成功地抵御波斯势力的入侵。在公元前343-342年间,马其顿的腓力国王邀请亚里士多德给他时年13岁的儿子亚历山大做私人教师。作为一个未来的统治者的家庭教师,亚里士多德关注的东西包括政治学,很有可能他就是在马其顿产生了搜集并比较各种政体的念头,后来他实施了这一计划,收集了希腊158个城邦的政体情况的摘要。腓力去世后亚历山大登基,亚里士多德作为家庭教师的任务告一段落,他在自己的家乡斯塔吉拉小住后又回到了雅典。
亚里士多德于公元前335-334年间回到雅典,他一生中最多产的时期从此开始了。在马其顿执政官安提珀特的庇护之下,亚里士多德建立了他自己的学园。这个学园被称作“日克昂”,它得名于苏格拉底过去经常到那里思考问题的一片园林,这片园林也是供奉吕克欧的阿波罗神的圣地。在这里,亚里士多德和他的学生们在林荫道上一边漫步一边讨论哲学,由于这一原因,他的学园被称作“逍遥学派”——意思是“漫步”。除了这些漫步时的探讨之外,还有讲座,有些比较专业的内容是针对少数听众的,有些较通俗的内容则是针对大众的。传统上人们一直认为,亚里士多德还建立了第一个大图书馆,他收集了成百上千的手稿、地图和标本,并在自己的演讲中将它们用作例证。此外,他的学园制定了许多正式的活动程序,按这些程序,学园是由其成员轮流主持的。亚里士多德为这些程序作出了一些规定,例如,他规定一月一次的聚餐讨论如何进行。在这些活动场合,一个成员被指定为某个哲学观点辩护,反驳其他成员批评性的反对意见。亚里士多德作为日克昂的领导在这里教学和演讲,共计十二三年之久。但最重要的是,他在这里形成了自己对科学分类的主要思想,建立了全新的逻辑科学,也写下了他对哲学和科学的每个主要领域的卓越见解,这一切都展示了他超乎群伦的渊博学识。
当亚历山大于公元前323年去世的时候,兴起了一股反对马其顿的浪潮,由于和马其顿关系密切,亚里士多德在雅典的处境变得岌岌可危了。照苏格拉底的老例,亚里士多德又被指控为“不虔敬”,但是他离开了吕克昂,逃到了卡尔西斯,据传他说这是“为了不让雅典人再次对哲学犯罪”。公元前322年他在那里死于一种长期的消化道疾病。亚里士多德在他的遗嘱中表现出了他的人情味,慷慨周济自己的亲戚,不让出售自己的奴隶,并嘱咐要释放一些奴隶。就像苏格拉底和柏拉图一样,亚里士多德的思想有着具有决定意义的力量,影响了此后好些世纪的哲学。我们将从他的哲学所涉及的广阔领域里选出他的逻辑学、形而上学、伦理学、政治学和美学的一些部分来加以考察。
4.2 逻辑学
亚里士多德发明了形式逻辑,他也提出了分门别类的诸科学的思想在他看来,逻辑和科学有密切的联系,这是因为他把逻辑看作一种工具,能用来在分析某门科学所涉及的问题时,对语言加以正确的组织。
范畴和推理的起点
在能够逻辑地演示或证明出什么之前,我们必须为我们的推理找到一个清晰的起点。首先,我们必须确定我们所讨论的对象——我们正在处理的那种特殊的事物。除此之外,我们还得加上那些与这种事物相关的属性和原因。在这样一种联系中,亚里士多德提出了范畴的思想,这一思想解释了我们对事物的思考方式。只要我们想到某个特殊的对象,我们就想到一个主词和它的谓词,也就是说,想到了某个实体和它的偶性。我们思考“人”这个词,也将“高”和“有能力”这样一些谓词和“人”这个词联系起来。“人”这个词在这里是一个实体,亚里士多德说,大概存在着九种能与一个实体相关联的范畴(就是谓词),包括量(例如“六英尺高”)、质(例如“口齿清楚的”)、关系(例如“两倍的”)、处所(例如“在学校里”)、时间(例如“上个星期”)、状态(例如“站着”)、所有(例如“穿着衣服”)、活动(例如“服务”),以及遭受(例如“接受服务”)。我们可以将实体自身当作一个范畴,因为比如我们说“他是一个人”,“人”(一个实体)在此就成了一个谓词。在亚里士多德看来,这些范畴代表了对科学知识所使用的概念进行的分类。它们代表了任何存在的东西存在或被认识到的特定方式。我们在思考时按这些范畴对事物加以整理,把这些范畴分为属(genera)、种(species)和个体事物。我们把个别的东西看作种中的一员,而把这个种看作是与属相关的。亚里士多德并不认为这些范畴或类别是心灵作出的人为创造。他认为它们在心灵之外、在事物之中有其实际的存在。他认为事物是由于它们自身的本性而从属于各种类别的,我们之所以将它们认作一个种或属的成员,是因为它们的确是那样的。亚里士多德认为,思想与事物存在的方式有关,而这是逻辑学和形而上学之间密切关系的基础。思想总是关涉某种具体的个别事物即一个实体的。但一个事物并不光是存在而已;它总有其存在的方式和存在的根据。
有了主词(实体)就总是会有与之相关的谓词(范畴)。有些谓词是一个事物所固有的。这样的谓词或范畴属于一个事物,仅仅因为它就是其所是。我们认为一匹马有一些谓词,因为它是一匹马;它和其他的马一样,都有这些谓词。它也有其他的谓词,不是这样固有的,而是“偶然的”,诸如颜色、处所、大小和其他影响着它和其他物体关系的规定性。亚里士多德想要强调的是,存在着一个通向科学的次序。这一次序首先是事物的存在以及它们的过程:第二是我们对事物及其表现的思想:最后是将我们关于事物的思想转换为语词。语言是形成科学思想的工具。逻辑是语言的分析,是推理的过程,是语言和推理相关于实在的方式。
三段论
亚里土多德提出的逻辑系统是以三段论为基础的,他将之定义为“一段论说,其中已经陈述了某些事实,而其他陈述可以由已知陈述中必然地推导出来。”三段论的一个经典的例子是:
- 大前提:所有人都是要死的。
- 小前提:苏格拉底是人。
- 结论:因此苏格拉底是要死的。
前两个陈述是前提,它们是第三个陈述的依据,而第三个陈述是结论。那么我们如何确定一个结论是由它的前提得出的呢?答案就在于有效的三段论论证的基本结构,亚里士多德创立了一套规侧来确定什么时候结论能够由它们的前提正确地推导出来。直到19世纪,哲学家们还相信,亚里士多德对三段论的解释已经把逻辑学要谈的内容囊括无余了。此后的几十年间,才出现了另外一些逻辑体系,取代了亚里士多德的解释。虽然亚里士多德的三段论理论是确定前提与结论之间关系的有效操作手段,但他的目标是为科学论证提供工具。由于这一原因,他再一次强调了逻辑与形而上学之间的关系一我们认识事物的方式和事物是什么以及它们所表现出的性质状态之间的关系。就是说,他认为各种语词与命题互相关联是因为语言所反映的事物也是互相关联的。由此,亚里士多德认识到,前后一贯地运用三段论却不必然达到科学真理,这是完全可能的。如果前提并没有建立在正确假设的基础上——就是说如果它们没有反映实在一就会发生上述情况。亚里士多德区分了三种推理,每一种都可以运用三段论的工具,但是却得出了不同的结果。这三种推理是,第一,辩证的推理,它从“被普遍接受的意见”出发进行推理;第二,诡辩的推理,它从看起来像被普遍接受的,但实际并非如此的意见出发;第三,亚里土多德称之为演证的推理,其中推理由之开始的前提是真的、初始的。这样,三段论推理的价值在亚里士多德看来就依赖于前提的正确。如果要想达到真的科学知识,我们所使用的前提就必须不能只是意见,甚至不能只是或然的真理。演证推理将结论回湖到构成结论之必然起点的前提。当我们说“所有人都是要死的”时,我们事实上回到了那些在动物中构成其必死性的原因和性质。接着,我们通过将人包括进动物类中而把这些性质与人联系起来。演证推理因此必须抓住可靠的前提,亚里士多德又称之为第一原理(archai)——即任一事物、种类或者一个主题之任何特定领域的被精确定义的性质。有效推理因此就预设了真实的第一原理的发现,结论可以由之推导出来。
我们如何达到这些第一原理呢?亚里士多德回答说:我们通过观察和归纳得到它们。当我们多次观察到某些事实时,“其中的普遍性就是显而易见的了”。无论何时只要我们观察到任何特定的“那一个”,我们就将之贮存在记忆中。在观察到许多类似的“那一个”之后,我们就从所有这些特定的“那一个”中得出了一个有一般意义的一般术语。我们通过归纳过程在特殊之中发现了普遍,这一过程最终使我们在被观察的特殊的“那一个”中发现了更多的意义。
如果我们再追问我们是否以及如何能够知道第一原理是真的,亚里士多德会回答说,我们之所以知道它们是真的,就是因为我们的心灵在某些事实的作用下活动起来,“认出”了或者说“看到”了它们的真。这些第一原理不再需要被演证。如果必须对每一个前提都进行演证,那将导致无穷后退,因为每一个在先的前提也需要被证明,这样知识就永远不可能开始。亚里士多德说:“并非所有的知识都是演证性的:相反,对于直接前提的知识就不依赖于演证。”他在此指的就是第一原理。他说,科学知识的基础是一种并不依赖科学结论所依赖的那种证明的知识。所以,“除了科学知识之外,还存在着科学知识原初的源泉,它使得我们能够认出那些定义。
这里亚里土多德使用了“认出”这个词来解释我们如何认识到某些真理;这与柏拉图所使用的语词“回忆”或“记起”形成了鲜明对照。“认出”一个真理就是对之有一个直接的直观把握,就像我们认识到2加2等于4时的情况。“认出”这一算术真理的诱因可能是把砖块或石头之类的特殊事物相加的行动。尽管如此,从这些特殊的场合中我们还是“看到”或“认出”了如下真理:特定的事物属于某个种或属,它们之间有着特定的关系,例如2加2等于4。于是,亚里士多德认为,科学建基于初始前提,我们通过理智直观(nous)而达到它们。一旦把握了这些初始的前提和事物根本性质的定义,我们接下去就能够进行演证的推理。
4.3 形而上学
在他题为《形而上学》(Metaphysics)的著作中,亚里士多德阐发了一种他称之为第一哲学的科学。“形而上学”这个术语的起源不是很清楚,但至少在亚里士多德的语境中,它部分地表明了这部作品相对于他的其他作品的地位,就是说它是超越于(beyond)或者说后于(after)他的物理学著作的。亚里士多德在《形而上学》中始终都在探讨一种他认为应该被最恰当不过地称作智慧的知识。这一著作以如下陈述为出发点:“求知是人类的本性。”亚里士多德说,这一内在欲望不仪仪是为了做事情或造东西而去求知。除了这些实用的动机之外,在我们身上还有着一种纯粹是为了认知而去认知某些事情的欲望。亚里士多德认为,“我们在感觉中体验到的快乐”就说明了这一点;“撇开感觉的实际用处不说,感觉自身就是为人们所喜爱的”,因为我们的观看“能使我们认识事物,能揭示出事物之间的许多差别”。
存在着不同层次的知识。有些人只知道他们通过其感官所经验到的东西,例如当他们认识到火是热的时候的情形。但是亚里士多德说,我们并不把通过感官所认识到的东西称作智慧。相反,智慧类似于科学家们所拥有的知识。它们由对某些事物的观察开始,然后重复这些感性经验,最终通过思考经验对象的原因而超越感性经验。有多少种可定义的研究领域就有多少种科学,亚里士多德研究了其中的许多种,包括物理学、伦理学、政治学和美学。除了这些特殊的科学,还存在着另外一门科学——第一哲学,我们现在称之为形而上学,它超越了其他所有科学的研究对象而考虑关于真正实在的知识。
界定形而上学的问题
各门科学力求发现特定种类的事物的第一原则和原因,诸如物体、人体、国家、诗,等等。不同于具体的科学追问“如此这般的某事物是什么以及它为什么是这样?”,形而上学与这些科学不同,它追问一个更加一般的问题——每一门科学最终必定也会考虑这样一个问题,即“是任何一个东西,这是什么意思?”简言之,“是”是什么意思?亚里士多德在《形而上学》中所考虑的就是这个问题,这使得形而上学对他而言成为“研究存在者(existent)之为存在者的一门科学”。因此,形而上学的问题如他所理解的,就是对存在(Being)及其“诸原则”和“诸原因”的研究。亚里士多德的形而上学在相当大的程度上是他的逻辑学观点和他对生物学的兴趣的结果。从他的逻辑观点看,“是”的意思就是可以被精确地规定,因而可以成为谈论的对象的某个东西。从他对生物学的兴趣这方面看,他倾向于将“是”理解为被包含在一个动态过程中的某个东西。在亚里士多德看来,“是”总是意味着是某个东西。因此,所有的存在都是个别的,都有着特定的本质。亚里士多德在他的逻辑著作中处理的所有范畴(或谓词)诸如质、关系、姿态、处所等一预设了某种这些谓词能够运用于其上的主词。所有范畴运用于其上的这个主词,亚里士多德称之为实体(ousia)。“是”因此就是一种特定的实体。“是”也意味着是一个作为动态过程的产物的实体。这样,形而上学思考的就是存在(即存在着的实体)和它的原因(即实体由之而形成的过程)。
作为事物的首要本质的实体
亚里士多德相信,我们认识一个事物的方式为弄清实体究竞意味着什么提供了一条主要线索。亚里土多德再一次考虑到了范畴或谓词,并说,当我们知道一个东西是什么时,我们对它的了解,要比我们知道它的颜色、大小或姿态更多。我们将一个东西同它所有的性质区分开来,我们只专注于一个东西实际上是什么,专注于它本然的性质。亚里士多德在这里区分了事物的本然性质和偶然性质。例如说一个人有一头红发就是描述了某种偶然的东西,因为一个人并不必然或本然地有一头红发一甚或任何一种颜色的头发。但是就我作为人来说,我是会死的却是本然的。与此类似,我们也认为所有人都是人,不论他们的身材、肤色和年龄如何。在每一个彼此有具体差异的个人身上有某种东西,使得他或她成为一个人,尽管是一些独一无二的特性使得他或她成为这个特殊的个人。在这一点上,亚里土多德会倾向于同意这些特殊的性质(范畴、谓词)也存在着,也有某种“是”。但这些性质的是并不是形而上学探讨的核心对象。
形而上学的核心问题是对实体——即一个事物本然性质的研究。从这个角度看,实体就是“不陈述一个主体,而其他一切东西都陈述它的东西”。实体是我们所知道的作为某个东西基础的东西,有了实体,我们才能言说与它有关的其他东西。无论何时只要我们对某事物加以定义——比如我们要谈论一张大桌子或一个健康的人,在我们能够谈论关于它的任何东西之前,我们都得先把握它的本质(essence)。这里我们是根据它们的“本质”来理解桌子和人——是什么使它们成为一张桌子或一个人的,然后我们才能够将它们理解为大的或健康的。千真万确,我们所能认识的只是具体的确定的事物——实际存在的个别的桌子或人。同时,一个桌子或一个人的本质或实体拥有自己在特征上区别于其范畴或性质的存在。但这并不意味着我们可以发现一个实体在事实上能够脱离它的性质而存在。然而亚里士多德相信,我们能够知道一个东西的本质,比如“桌子性”,它区别于其圆的、小的和褐色的这些特殊性质。于是他说,必定存在着桌子的一个普遍本质,无论我们在哪里看到一张桌子都能在其中发现这一本质,这一本质或实体必定独立于它的特殊性质,因为尽管每张实际存在的桌子性质各异,桌子的本质却是一样的。亚里士多德的观点是,一个东西不仅仅是它的特定性质的总和。在所有这些性质“之下”(substance)存在着某种东西。这样,一方面任何一个特定的东西就是许多性质的结合,而另一方面,有一个这些性质归于其上的基底(substratum)。有了这些区分,亚里士多德于是就像柏拉图那样,开始考虑这些本质或普遍的东西是如何与特殊事物发生关系的。简言之,使得一个实体成为实体的是什么东西——是作为基底的质料,还是形式?
质料和形式
虽然亚里士多德区分了质料和形式,但是他说在自然界中我们永远也不能发现无形式的质料或无质料的形式。每一个存在的事物都是某种具体的个别的东西,每个事物都是质料和形式的统一。因此实体总是质料与形式的合成物。让我们回忆一下柏拉图的论述,他说,像人本身、桌子本身这样的理念都有一种独立的存在,特殊的事物,比如我们眼前的桌子是通过分有这些理念而获得它们的本质的。亚里士多德反对柏拉图对普遍理念的解释,他尤其批评这样一个论点:理念脱离了个别的事物还有其独立的存在。当然,亚里士多德认同普遍共相的存在,同意诸如人本身、桌子本身这样一些共相不仅仅是主观的思想。事实上,亚里士多德承认,没有关于共相的理论,就不可能有科学的知识,因为如果是那样的话,我们就无法对涉及一个特定种类的所有成员的事情加以谈论了。
科学知识之所以有效,是因为它确定了对象的类(比如人类的某种疾病),所以只要一个个体被归入这个类,我们就能够设想其他的事实也与之相关。这样,这些种类就不仅仅是头脑的想象,而是在事实上也有其客观的实在性。但是亚里士多德说,这些类的实在性是只能在个体事物本身中发现的。他问,认为普遍的理念有独立存在,这能起什么作用呢?如果说真有什么作用的话,那就是使事情更加复杂化了,因为每个事物——不仅是个别事物,还包括它们的关系——都得在理念的世界里又被复制一遍。此外,亚里士多德不相信柏拉图的理念论能够帮助我们更好地认识事物,“它们对于认识其他事物毫无帮助。”因为这些理念据说是不动的,所以亚里士多德认为,它们不能帮助我们理解我们所知道的那样一些总是在运动的事物。由于它们是非物质的,所以也不能解释我们对之有着感性印象的对象。还有,非物质的理念如何能够与一个特定的事物发生关系呢?像柏拉图那样,说事物分有理念,这并不是一个令人满意的解释:“说它们是原型,而其他事物分有了它们,这只是在说些空话,打些诗意的比方而已。
当我们使用质料和形式这些语词描述任何具体事物的时候,我们似乎是在考虑事物由以构成的东西与这东西所构成的东西之间的区别。这又使得我们倾向于认为,质料事物由之构成的东西——一开始就存在于一种没有形式的状态中,直到它被制作成为一个东西才具备了形式。但是亚里士多德再次强调,我们无论在哪儿都找不到“原初质料”即无形式的质料这样的东西。设想一个将要用大理石雕刻维纳斯雕像的雕刻家,他或她永远也不能找到没有某种形式的大理石。它将总是这一块大理石或那一块大理石,一块方形的或不规则形状的大理石。而他或她将总是在形式和质料已经结合在一起的一块大理石上工作。至于说雕刻家将赋予它一个不同的形式,这就是另外一个问题了。这个问题就是:一个东西是如何成为另一个东西的?简言之,变化的本质是什么?
变化的过程:四因
在我们周围的世界里,我们看到事物是不断变化着的,变化是我们经验的基本事实之一。对亚里士多德而言,变化这个词有很多意思,包括运动、生长、死亡、进化、衰落。这些变化中有一些是自然的,而另外一些则是人工技术的结果。事物总是呈现新的形式:新的生命诞生了,新的雕像造好了。因为变化总是涉及到事物获得新的形式,所以我们可以就变化的过程问几个问题。对于任何事物,我们都可以问四个问题,即(1)它是什么?(2)它是拿什么做成的?(3)它是被什么造成的?(4)它是为什么目的而做的?对于这些问题的四种回答,代表亚里士多德的四种原因,虽然如今人们使用原因这个词主要是指先于一个结果的事件,但在亚里士多德那里,它是指一种解释。因此他的四个原因就代表了对于一切事物进行总体解释的具有广泛效力的原型或结构。以一个艺术品为例,它的四个原因可能是:(1)它是一座雕像,(2)由大理石做成,(3)由一个雕刻家制作,(4)是为了装饰。除了人工技术制作出的事物之外,还有自然产生的事物。根据亚里士多德的看法,虽然自然在“动机”的意义上没有什么“意图”,但在有其内在的活动方式这个意义上,自然的确在任何地方总是有其“目的”。由于这一原因,种子发芽,根部向下生长(不是向上!),而长出植物。在这个变化过程中,植物朝向其“目的”即它们的各种不同的功能和存在方式运动。在自然中,变化也将涉及同样的四个要素。亚里士多德的四因因此就是:(1)形式因,它规定了一个事物是什么,(2)质料因,一个事物是由什么构成的,(3)动力因,一个事物是被什么造成的,(4)目的因,它是为了什么“目的”而构成的。
亚里土多德以一个生物学家的眼光考察生命。对他来说,自然就是生命。所有事物都处于运动之中一处于生成和消亡的过程之中。在他看来,繁殖的过程就是一个非常清楚的例子,说明所有的生物都有内在的力量能产生变化,纂衍后代。亚里士多德总结他的诸因说,“所有生成的事物都是受某种力量支配而从某种事物生成为某物的。”亚里士多德从这个生物学的观点出发,详细阐述了形式和质料从不分离存在的思想。在自然中,新一代的生命首先需要一个具有某种具体形式的个体,后代也会具有这个形式(父本)。然后还得有能够作为这个形式载体的质料(这个质料是由母本提供的)。最终,一个有着同样的具体形式的新个体由此而形成。亚里士多德用这个例子来说明,变化并不是将无形式的质料和无质料的形式结合到一起。恰恰相反,变化总是发生在形式和质料已经结合在一起的事物中,这事物正在成为新的或不同的东西。
潜能和现实
亚里士多德说,一切事物都处于一个变化过程之中。每个事物都有一种力量,使它要成为它的形式已经设定为其目的的东西。所有事物中都有一种努力要追求它们“目的”的动力。这种努力有些是指向外在对象的,比如某人建造一座房屋的时候。但还有另外一种努力,是要达到属于一个人的内在本质的目的,例如我们通过进行思考而实现我们作为一个人的本质。这一自身所含目的(self-contained end)的思想使亚里士多德考虑潜能与现实之间的区别。他使用这一区分来解释变化和发展的过程。如果一粒橡子的目的是成为一棵树,那么在某种意义上橡子只是潜在地是一棵树,而不是当下就现实地是一棵树。因此变化的一个基本类型是从潜能到现实的变化。而这一区分的主要意义在于,亚里士多德以此论证现实相对于潜能的优先性。就是说,虽然一个现实的事物是从潜能而来的,但如果不是首先有某种现实,那么就不可能有从潜在到现实的运动。一个小孩潜在的是一个成人,但在有这一潜能的孩子能够存在之前,必须先存在着一个现实的成人。
因为自然界所有的事物都类似于孩子与成人的关系,或者橡子与橡树的关系,亚里士多德进而在自然中发现了存在的不同层次。如果所有事物都处于变化中一处于产生和衰亡之中一那么所有事物都将具有潜能。但是正如我们已经看到的,要有某种潜在的东西就必须已经有某种现实的东西。为了解释潜在事物的世界的存在,亚里士多德认为有必要设定某种高于潜在的或可毁灭的事物的现实性。这导致了一种纯粹现实的存在的思想,这种存在不具有任何的潜在性,处于存在的最高层次。由于变化是一种运动,所以亚里士多德将可见世界看作是由处于运动中的事物构成的。但是运动作为一种变化涉及潜能。事物潜在的处于运动中,但是它们必须被现实地处于运动中的某种东西所推动。
不被推动的推动者
对于亚里士多德来说,不被推动的推动者是自然界中所有变化的最终原因。然而,这一概念与第一推动者并不完全相同,好像运动可以被回湖到一个运动开始的时刻似的。他也没有将不动的推动者理解为后来神学意义上的造物主。亚里士多德从他对潜能与现实的区分得出结论,解释变化或运动如何可能发生的惟一途径,就是假定某种现实的东西逻辑地先于任何潜在的东西。变化的事实暗示了某种现实性的东西的存在,这个东西没有任何潜能的混杂而是纯粹地现实的。根据亚里士多德的说法,这个推动者不是一个正在发挥其威力的强大力量这种意义上的动力因。那样的活动将意味着潜能,就像我们说上帝“曾经想要”创造世界一样。这就会意味着在上帝创造世界之前,他曾经潜在的能够或想要创造世界。
亚里士多德关于不被推动的推动者的思想的核心在于,它是对运动这一事实进行解释的一种方法。自然界充满了努力实现它们的特定目的的事物。每一事物都想要完善地实现自身的可能性和目的,也就是要成为一棵完善的树、一个完美的好人,等等。所有这些努力的总和构成了世界秩序的宏大进程。这样,所有的实在都处在一个变化过程中,从其潜能和可能性出发向这些潜能的最终完善运动。为了解释这个包罗万象的总的运动,亚里士多德把不被推动的推动者当作运动的“理由”或“原则”。因此不被推动的推动者代表了运动的现实的——因为这里没有任何潜在性一和永恒的原则。因为对运动的这一解释暗示了一个永恒的活动,所以决不可能有过一个不断变化的事物世界本身还不存在的“时刻”。出于这个原因,亚里士多德也不承认时间中有什么“创世”。
为了谈论一个不被推动的推动者,亚里士多德不得不使用一种隐喻式的语言。在解释一个不被推动的推动者如何能够“导致”运动时,他将之比作一个被爱着的人,此人仅仅作为爱的对象,发出吸引力而不是靠强力“推动”着爱他的人。亚里士多德还有一种更巧妙的解释方式,把不被推动的推动者看作形式而把世界看成实体。根据他的四因的观点,亚里士多德认为这个不被推动的推动者是目的因,就像成人的形式就在孩子之中那样,它指引着变化的方向朝向一个最终的目的——一个确定的、恰当的目的。作为目的因,不被推动的推动者也就成了世界的动力因。它以其吸力激励事物努力追求它们的自然目的。虽然亚里士多德的不被推动的推动者是作为运动的科学原则和世界的内在形式而发挥作用的,但它的弦外之音的确带有某种宗教意味。许多世纪之后——尤其是在13世纪的阿奎那手里——这一思想被改造为对基督教上帝的哲学描述。
4.4 人的地位:物理学、生物学和心理学
在等级分明的自然界中,亚里士多德把人置于一个迥然不同于无生命事物和动物的地位上。在自然序列中,首先有简单的物体、植物和动物。与椅子、桌子这些人造物不同,自然事物是这样的一些事物,“它们中每一个都在自身中有运动和静止的原则”。这种内在的运动是事物中起关键作用的一方面,因为亚里士多德以这种运动解释了事物生成和毁败的整个过程。
物理学
如果我们只限于谈在自然界中各种事物是如何产生的,那么对此亚里士多德思考的起点是原初质料的概念。我们已经说过,亚里士多德否认纯粹的形式和纯粹的质料能够独立存在。并不存在独立自在的原初质料。亚里士多德用“原初质料”是指存在于事物中的、能够变化、能够成为其他实体或事物、能够呈现出新的形式的基底。因此自然的过程就是质料从一个形式到另一个形式的持续转化。当雕刻家制作一个雕像时,他的材料,比如说大理石,已经有了某种形式,接着他就要对之加以改变。同样,亚里士多德说,也存在着自然由之造出各种事物的某种原材料,他把这些原料称作简单物体,也就是气、火、土、水。他说,所有的事物都能以这样或那样的方式被归结为这几样东西。而这些物体互相结合,就形成新的实体。但与雕像不同的是,这些新形式的起源是自然本身的产物,因为这些物体自身之中含有“运动和静止的原则”。由于这一原因,火倾向于上升而成为气,水倾向于下降而成为土。固体倾向于成为液体,潮湿的倾向于成为于燥的。无论如何,说事物变化,就是说这些基本的简单物体由于它们内在的运动原则和其他事物的推动,在持续不断地转化为各种事物。
生物学
是什么赋予了某些种类的物体以生命?亚里士多德通过对灵魂本质的思考,解释了从无机物到有机物的转变。他说,所有的物体都是由基本的元素结合而成的,但有些物体有生命而另一些则没有。亚里士多德所说的生命是指“自我营养、自我生长(也包括与之相关的衰亡)”。质料并非生命的原则,因为物质实体只是潜在的有生命。质料只是潜在性,形式才是现实性。一个现实的有生命的物体是从现实性即从形式获得它的生命的。灵魂就是个有机体的形式。不论是灵魂还是身体都不能离开对方而存在,但它们也不是同一的,“所以我们完全无须考虑灵魂和身体是否同一:这样的问题就如同问蜡和印在它上面的形状是否是同一的一样,是没有意义的。”亚里士多德将灵魂定义为“一个自然有机体最起码的现实性”。一旦一个物体成为了“有机的”,它的各部分就会自己设定自己的运动,因此在一株植物中,“叶子的作用就是保护果皮,果皮的作用就是保护果实,而根的作用就类似于动物的嘴…起吸收养分的作用”。灵魂乃是“决定一个事物本质的结构”。只要一个特定种类的物体——即那种“在自身中含有令自已自动地运动和静止的力量”的物体一存在,灵魂就存在。灵魂和身体不是两个分离的东西,而是同一个统一体的质料(身体)和形式(灵魂)。“由此我们可以很清楚地看到,灵魂与身体是不能相分离的。”没有身体,灵魂也不存在,就像没有了眼睛就没有视力一样。
为了说明身体可以被有机地组织起来的三种方式,亚里土多德区分了三种灵魂。他称之为营养灵魂、感觉灵魂和理性灵魂。它们代表了身体活动的各种能力。第一种仅仅具有生存活动的能力,第二种既有生存能力又有感知能力,第三种则兼具生存、感知和思想能力。
心理学
我们在动物这一层次上就可以发现感觉灵魂。它主要的特点在于具有吸收事物的性质和形式而无须摄入它们的质料的能力。这与更低级的营养灵魂形成对照,后者摄人质料(例如食物)但是却不能够吸收它的形式。基本的感觉是触觉,它可以吸收所有的物体都共同具有的东西。而其他的感觉,亚里士多德说,“每一种感觉都有一种它辨别的对象,从不会弄不清在它面前的是色彩还是声音。”此外,感觉灵魂只吸收形式而不吸收质料,“就像一块蜡上只留下戒指的印子而不会留下铁或金…类似地,感觉受到有色彩、有味道、有声音的东西的影响,它却不关心每种情况下的那种基质是什么”。
亚里士多德使用了潜能的概念来解释感觉灵魂是如何感知事物的。感觉器官必定能够感知各种不同的形式。因此,它们必定有能适应任何性质的潜能。例如眼睛必定是由这样的质料构成的,它潜在的能够成为蓝色的,而且事实上当看到某种对象时,它就的确变成了蓝色。眼睛的这种中性的质料必定潜在的具有一切色彩和形状。我们其他的各感官都有着针对其他性质的类似的潜能。此外,五官还以某种方式将各自获得的信息结合成为一个整体,反映出一个单一的客体或世界,而那些“可感内容”就是来自这个客体或世界。甚至在我们不再直接知觉一个对象时,我们所感知到的性质也能继续保持下去。亚里士多德用记忆和想象来解释这一现象。我们所记得的许多东西都能让我们联想起其他事物,这表明,不论是感知还是记忆都不是随意乱来的行为,而是要复现出的确在现实世界中存在的东西。从记忆和想象的能力中最终产生了更高级的灵魂,即人的灵魂或理性灵魂。
人的理性 人的灵魂包括其他所有较低级的灵魂形式——营养灵魂和感觉灵魂——除了这些之外,它还有理性灵魂。理性灵魂具有科学思维能力。我们的理性能够对不同种类的事物加以区分,这就是分析的能力,它理解事物相互之间的关系。除了科学思维,理性灵魂还能够深思熟虑。我们在此不仅能发现自然界的真理,还能找到人类行为的指南。
此外,在亚里士多德看来,灵魂是身体的确定形式。没有身体,灵魂既无法存在,也无从发挥其功能。亚里士多德说,身体和灵魂共同构成了一个实体。这与柏拉图认为身体是灵魂的囚牢的说法形成了鲜明的对照。柏拉图将灵魂和身体分离开来,所以他可以谈论灵魂的前世存在。他也可以将认知或学习描述成一个灵魂回忆起它在前世存在中已经知道的东西的过程。还有,柏拉图可以谈论个体灵魂的不朽。与之相反,亚里士多德则认为灵魂与身体是密不可分的,所以如果身体死亡了,灵魂这个身体的组织原则也就随之消亡。
人们的理性灵魂就像感觉灵魂一样,是以具有潜能为其特征的。眼睛有能力看见一个红的物体,但只有在确实遇到了一个红的物体时,眼睛才真的看到了它。我们的理性灵魂也正如此,它有能力理解事物的真正本性。但是理性只是潜在的具有知识;它必须椎导出它的结论。简而言之,人的思维是一种可能性,而不是一种连续不断的现实性,这是因为,如果说人类心灵有可能获得知识,那么它也同样有可能得不到知识。因此人类思想就在现实地知道和潜在的知道之间陆续交替。真理在人类理智中永远不可能连续不断地出现。
世界的连续性暗示了真理的连续性。作为潜在知识而为人类心灵所拥有的东西,必定在某种心灵中是完善的、连续不断的知识。亚里士多德谈到了不被推动的推动者,认为他是世界的灵魂(奴斯)和可理解的原侧。在他的《论灵魂》中,亚里士多德谈到了积极理智。他说,“奴斯并非在此一时活动,在彼一时就不活动了。”这里他似乎把个体的人的理智(它只能断断续续地进行认知)和积极理智(它在某种意义上独立于特定的人,并且是永恒的)相比较。如果这个理智确实是纯粹积极的,那么它就不具有任何潜在性。而亚里士多德在前面就正好是把不被推动的推动者描述成这样的东西。不动的推动者的独特活动就是纯粹的活动,这是与实在整体的真理完全吻合的心灵活动。于是,作为一切事物的可理解结构而被把握的整个形式系统,就必定构成不动的推动者或积极理智所拥有的连续知识。这个理智是不朽的,而根据我们消极的潜在的理智对任一真理的认知程度,消极理智也在一定程度上具有积极理智一直都知道的东西。在我们死后依然不朽的东西就属于积极理智,但是由于这并不是我们所具有的部分,因此,随着身体这个质料的死亡,我们的个体灵魂作为身体的形式也就消亡了。只有纯粹的活动是永恒的,而我们的实体则因为混杂有潜在性,而不能免于一死。
4.5 伦理学
亚里士多德的道德理论是围绕着他的如下信念而展开的:人类和自然界中所有其他事物一样,也要达到自己与众不同的日的,实现自己的功能。他的《尼各马可伦理学》开篇即说,“一切技术、一切研究,以及一切实践和选择,都以某种善为目标。”如果情况确实如他所说,那么伦理学的问题就是,“人类行为所追求的那个善是什么?”柏拉图已经回答了这个问题,他说,人类追求的是对善的理念的知识。在他看来,这一善的最高原则是与经验世界、与个体事物相分离的;我们通过从可见世界上升到理智世界而达到它。而在亚里士多德看来正好相反,善与正当的原则植根于每一个人的内心。并且,这一原则可以通过研究人的本性而发现,也可以通过日常生活中的实际行为来达到。不过,亚里士多德提醒他的读者,在伦理学的讨论中不要指望太大的精确性,以致超出了“这一主题所能达到的限度”。话说回来,虽然在这个主题上很容易出现“变化和错误”,但这并不意味着正当和不当的观念“只是作为约定俗成的东西而存在,并不存在于事物的本质之中”。亚里士多德就是抱着这样的看法,开始着手在人类本性的结构中寻找道德的基础。
“目的”的类型
亚里士多德预先用了一个例证来说明他的伦理理论的基本构架。他已经指出,所有行动都是要达到某个目的,现在他要区分两种主要的目的:(1)工具性目的(其行动是作为达到其他目的的手段)和(2)内在目的(其行动以自身为目的)。这两种类型的目的可以在比如与战争有关的行动中得到例释。亚里士多德认为,当我们一步一步地考虑整个战争行动涉及到什么时,我们发现,其中有一系列特殊种类的行动。首先有马勒制造者的技术。马勒做好后,他就实现了他作为马勒制作者的目的。而马勒对于骑兵来说又是一种用来在战斗中驾驭马匹的工具。还有,木匠建造一座兵营,建造完工时,他也实现了自己作为木匠的功能。而兵营在为士兵们提供了住所时也实现了它的功能。但是这里由木匠和建筑物所实现的那些目的不是在它们自身中的内在目的,而只是工具性的目的,是为了安顿好士兵直到他们采取下一步行动。同样,在船只成功地出航时,造船者实现了他的功能,但是这个目的又只是一个手段,是要把士兵们运送到战场。一个医生维护了士兵的健康,在此意义上他实现了自己的功能。但在这个例子中,健康的“目的”是要成为“手段”以利于有效地作战。在战斗中指挥官的目的是胜利,但是胜利是和平的手段。虽然和平有时被误以为本身就是战争的最终目的,但它其实是创造某些条件的一种手段,有了这些条件,人们才能够实现他们作为人的功能。当我们发现人们的目的不是当木匠、医生或者将军,而是要成为人的时候,我们就达到了一种以白身为日的的行动,其他所有行动对它来说都只是一种手段,亚里士多德说,这个目的“必定是人性的善”。
我们应该如何理解善这个词呢?就像柏拉图先前的做法一样,亚里士多德将“善”这个词与一个事物的特殊功能联系起来。一把锤子如果能够做到人们期望一把锤子能够做到的事情,它就是善的。如果一个木匠实现了他作为一个建造者的功能,那么他就是善的。这对于所有的技能和职业而言都是对的。但是亚里士多德将一个人的技能和职业与他作为一个人的活动区分了开来。例如,亚里士多德感到做一个好医生与做一个好人并不是一回事。我可以是一个好医生同时并不是一个好人,而是一个邪恶的人。这里有两种不同的功能:医疗的功能和作为一个人而行动的功能。亚里士多德说,要发现一个人应该朝向的善,我们就必须发现人类本性的各种功能。根据亚里士多德的看法,一个善的人就是这样一个人,他实现了他作为一个人的功能。
人的功能
亚里士多德问.“我们是否得假设,木匠和鞋匠都有特定的工作和行为方式,而作为人本身的人却没有,而是被自然遗弃在无所作为的状态?”或者说,如果“眼睛、手、脚——总之,身体的每一个部分——显然都有一种功能,我们是否可以认为,人也有一种不同于所有这些功能的功能呢?”人当然也有一种独特类型的活动,但它是什么呢?为了找到人的独特的活动,亚里士多德分析了人的本性。首先,人的目的“不仅仅是生存”,因为很显然连植物都会这样,而亚里士多德说,“我们想要知道的是人类特有的东西。”其次,人类还有着能进行感觉的生命,“但是很明显马、牛及任何动物也一样有”。现在就只剩下了“属于某个要素的一种主动的生命,这个要素具有一个理性的原则”。他进一步主张,“如果人的功能就是灵魂的活动(这种活动遵循着或意味着一个理性的原则)…那么人类的善当然就是与德性相一致的灵魂活动。”
既然一个人作为人的功能就是灵魂的正当运作,亚里士多德就试图描述灵魂的本质。人的灵魂是人的身体的形式。这样一来,灵魂关系到的就是一整个人。因此,亚里士多德说,灵魂有两个部分,非理性的部分和理性的部分。非理性的部分是由两个更小的部分构成的。首先,像植物一样,它有一个营养的部分,使我们能够吸收营养维持生理的生命。其 次,像动物一样,它又有一个欲望的部分,使我们能够感受欲望,复义推动我们四处活动以满足这些欲望。灵魂的这两个非理性的部分都有反对和抵抗理性部分的倾向。人的理性成分与非理性成分的冲突导致了关于道德的问题。
道德必然涉及行动。因此亚里士多德说,“在奥林匹克比赛中,赢得桂冠的并不是最健壮的人,而是那些参加了比赛的人,因为获奖者是从这些参赛者中产生出来的。在生活中也是如此,在那些可敬而善良的人们中,能当之无愧地获得奖赏的,是那些身体力行的人。”而这种特殊类型的行动在此意味着灵魂的理性部分对非理性部分的支配和引导。不仅如此,一个人行善于一时一地,并不成其为一个善人。善人必须终其一生都是善的,“一燕之来或一日之晴都不足以成春,同样,一个人也不是只凭着朝夕之功就可以成为一个幸福的人的。”
作为目的的幸福
人类行为应该指向正当的目标。人们无处不在追求愉悦、财富和荣誉。虽然这些目标有某种价值,但它们不是人所应追求的首要的善。要成为一个终极目的,一个行动必须是自足的、终极的,“是自身就值得欲求的,决不是因为要追求他物而值得欲求”,而且它必须能够被人们追求到。亚里士多德确信,所有人都会同意,惟有幸福这一目的可以完全满足对人类行动的终极目的的一切要求。事实上,我们之所以选择愉悦、财富和荣誉就是因为我们认为“以它们为手段可以获得幸福”。幸福就是善的代名词,因为幸福和善一样是我们独特功能的实现。正如亚里士多德所说,“幸福…就是灵魂按照美德或德性活动。”
灵魂如何得到幸福呢?道德的普遍规则是“根据正当的理性去行动。”这就意味着灵魂的理性部分应该控制非理性的部分。很明显,考虑到灵魂的非理性部分的构成及其运作机制,它有必要被加以引导。当考察我们的欲望时,我们首先发现它受到了自我之外的人或物的影响。灵魂的这个欲望的部分以两种基本的方式对这些外部因素作出反应——这就是爱(沉迷于情欲的激情)与恨(暴躁的激情)。爱使我们对事物或人产生欲求,而恨则使我们躲避或者破坏他们。很明显,这种爱和恨的激情如果放任不管,很容易就会“失去控制”。它们在自身之中并不包含任何权衡的原则。一个人应该欲求什么?欲求多少?在何种情况下才可做如此欲求?我们该如何处理我们与各种事物、财富、荣誉,以及他人的关系?
在这些事情上我们并不是自动地就正确地行动的。正如亚里士多德所说,“没有什么道德上的品性是一生下来就出现在我们身上的;因为没有什么天生就有的东西可以形成一个与它的天生本性相反的习惯。”道德与习惯的形成有关,这些习惯是正确思考的习惯、正确选择的习惯和正确行动的习惯。
作为中道的德性
人的激情可以激起从不足到过度的各种各样的行为。且看我们对于食物的欲望。一方面我们有可能由饕餮无度任意摆布。另一方面我们也可能食欲不振直到饿死。恰当的行为方式——也就是符合德性的行为方式——是过度和不足之间的中间状态或者叫中道。我们应该找出我们所有激情的这个中间状态,例如害怕、自信、情欲、愤怒、怜悯、快乐和痛苦的中间状态。在我们没有达到这一中间状态时,我们就会陷入过分或不足的过恶中。我们通过灵魂的理性力量来控制我们的激情,形成各种符合德性的习惯,这些习惯自动地引导我们遵从中间路线。例如,勇敢的德性是两种缺点——怯懦(不足)和鲁莽(过度)——之间的中道。德性乃是一种存在的状态,“这种状态倾向于深思熟虑的选择,处于相对的中道,由理性来作出决定,就像一个有实践智慧的人那样作出决定”。因此,德性就是根据中道来进行选择的习惯。
对于不同的人来说.中道是不一样的,对不同的行为来说也是如此。由于每个人所处条件不同,中道对每个人来说是相对的。以吃饭为例,适当的食量对一个成年运动员和一个蹒跚学步的小孩来说显然是不一样的。但是,对每个人来说依然存在着一个符合比例的或者说相对的中道,这就是节制(temperance)的德性。它处于两种极端的缺点之间,即暴饮暴食(过度)和饥饿(不足)之间。与此类似,当我们花钱时,大方就是有德性的中庸,它处于挥霍和吝啬的缺点之间。至于花多少钱才是大方,并不存在一个固定的数目;钱数要视我们的资产而定。虽然有大量的德性处于两个极端的过恶之间,但是也还有一些行动无任何中道可言。它们的本质已经意味着恶,例如轻侮、嫉妒、通奸、盗窃和谋杀。这些行为本身——而不是它们的过度或不足——就是坏的。所以如果我们做这些事就总是错误的。
因此,道德品性就在于培养会自动地使我们按中间路线行动的习惯——或者就是不去做偷盗、谋杀之类的坏事。柏拉图曾经列举出四种主要的德性(后来被称作“基本的”德性),亚里士多德也认可它们,这就是勇敢、节制、正义和智慧。除了这些,亚里士多德还讨论了慷慨、宽宏、友爱和自尊的德性。
审慎和选择
在理性灵魂中存在着两种理性。第一种是理论理性,它给予我们关于确定原则或哲学智慧的知识。另一种就是实践理性,它为我们在自己所处的特定情况下的道德行为提供理性指导,这就是实践智慧。理性所起作用的重要性在于,如果没有了这一理性的要素,那么我们将没有任何道德能力。此外,亚里士多德强调,虽然我们有着正确行动的自然能力,但是我们并不是天生地就能正确地行动。我们的生活有着无数种可能性。善在我们身上只是潜在地存在。一棵橡树会结出橡子,这几乎有一种机械的必然性。但是对于人来说,我们要认识到我们必须做什么,对之深思熟虑,并实实在在地作出选择去行动,这样才能将我们潜在的东西转变成现实。柏拉图和苏格拉底认为,认识到善就足以去行善。亚里士多德侧不同,他意识到,除了有知识,还必须有深思熟虑的选择。因此,亚里士多德说,“道德行动的起源——它的致动因而不是目的因——乃是选择,而选择(的起源)乃是带有一个目的考虑的欲望和理性。”
自由选择和人类义务之间有着重要联系。例如,假设你的头脑里长有一个肿瘤,使你产生不可遏制的暴力冲动。如果你的暴力行为真的是你无法控制的,那么你对你的行为并不负有道德责任。因此,亚里士多德——还有其他许多道德哲学家们——主张,人们要对自己的行为负责,从而也主张,道德行为乃是自愿的。但是并非我们所有的行动都是自愿的。存在着一些例外,因为亚里士多德说过,“对于自愿的行为我们可以赞扬和指责,而对于非自愿的行为,我们只能宽容,有时它们只能令人怜悯。”对亚里士多德而言,自愿行为和非自愿行为的主要区别在于:非自愿的行为是一个人无须为之负责的行为,因为他们这么做(1)是出于特定情况下的无知,(2)是外部强迫的结果,或者(3)是为了避免更大的恶。而自愿的行为是一个人要对之负责的行为,因为当他这么做时,上述三种情有可原的情况并未发生。
沉思
对亚里士多德而言,人类本性不仅仅在于理性,它涵盖了植物灵魂、欲求灵魂和理性灵魂。德性并不意味着否定或排斥这些自然能力中的任何一种。道德的人运用他身体的和心灵的所有能力。与人类本性的这两大部分相对应,理性也有着两种功能,道德的功能和理智的功能,它们有着各自的德性。我们已经了解了亚里士多德对道德德性的解释,这就是那些有助于我们在面对自然欲望时遵循中道的习惯。与之相对照,理智的德性关注我们理智的本性而不是身体的本性;理智德性种最主要的是哲学智慧(sophia),它包括科学知识和把握第一原理的能力。
亚里士多德在他的伦理学主要著作的最后讨论了哲学智慧和沉思理智真理的活动。如果说幸福是我们根据自己独特的本性行动的结果,那么我们很有理由认为,当我们按照自己最高本性行动时,也就是在沉思时,我们是最幸福的。亚里士多德说,这个活动是最好的,“因为不但理性在我们身上是最好的,而且理性的对象也是可以知道的对象里最好的”。不仅如此,沉思“是最持久的,因为我们可以比作任何事情都更长久地沉思真理”。最后,我们认为幸福伴有愉悦,但是哲学智慧的活动毫无疑问是最令人愉悦的有德性的活动。
4.6 政治学
亚里士多德在《政治学》(Politics)中就像在《伦理学》(Ethics)中一样强调目的这一要素。就像人一样,国家自然地就被赋予了某种独特的功能。亚里士多德将这两种思想结合了起来,说,“很明显,国家是自然的产物,而人则天生就是政治的动物。”人类本性和国家密切相关,所以“一个不能生活在社会中的人,或者一个由于自足而无需他人的人,要么是头野兽.要么是个神”。不仅人的本性使我们倾向于生活在一个国家,而且国家就像任何别的社群一样,“是出于一种要达到某种善的考虑而建立”、为了某个目的而存在的。家庭的存在主要是为了延续生命。国家的出现起初是为了延续家庭和村社的生命,家庭和村社从长远来看是不能光靠自身存在下去的。但是国家的功能还在于确保人民的最高利益,即我们的道德的和理智的生活。
与柏拉图不同,亚里士多德没有描绘出一个理想国家的蓝图。虽然亚里士多德把国家看作使人民能够达到他们作为人的终极目标的机构,他还是意识到关于国家的任何理论都必须注意几个实际的问题。例如,我们必须确定“什么样的政体适用于一个特定的国家”,哪怕一个最好的国家通常是达不到的。还有,我们必须确定“如何在既定的条件下组建一个国家”,如何维护它。在亚里士多德看来,“政治学家们虽然有着出色的思想,但他们却通常并不务实。”由于这些原因,他很难接受柏拉图那些非常极端的思想。他嘲笑柏拉图废除保卫者阶层的家庭并把他们的后代交由公共抚养的主张。在亚里士多德看来,如果采取这种主张,“那么所谓的父亲就没有任何理由照顾儿子,儿子也没有任何理由照顾父亲,兄弟之间也是如此”。财产的公有同样也会破坏人们的一些基本享受,还会产生低下的效率和无尽的纷争。
国家类型
亚里士多德承认,在适当的条件下,一个社会可以把自己组织成三种形态的政体。它们之间最基本的差异是每种政体的统治者的数目。一种政体的统治者数目可以是一个、少数几个或许多个。但是其中每一种政体又都分别可以有一种常态或一种变态。当一种政体运作正常时,它是为了所有人的共同利益而进行统治。当政府的统治者只谋求自己私人的利益时,这个政体是反常的。亚里士多德认为,各种政体常态分别是君主政体(一人统治)、贵族政体(少数人统治)和共和政体(许多人统治)。与它们相应的变态政体分别是僭主政体(一人统治)、寡头政体(少数人统治)和民主政体(许多人统治)。亚里士多德自己最推崇的是贵族政体,这主要是因为就算我们再努力,杰出的人总还是少数。在一个贵族政体中,统治者是一群这样的人,他们优秀的程度、他们的成就和拥有的财富使他们有责任心、能干,领导有方。
差异与不平等
由于亚里士多德严重依赖对事物的那种逸闻轶事式的观察,所以他不可避免地犯了一些错误。最明显不过的例子就是他关于奴隶的观点。他观察到奴隶都是强壮魁梧的,于是就下结论道,奴隶制是自然的产物。亚里士多德说,“很明显,有些人天生自由,而有些人天生就是奴隶,对那些天生为奴的人来说,奴隶制既是有益的又是合理的。”当然,亚里士多德非常注意区分那些天生就是奴隶的人和那些由于军事征服而沦为奴隶的人,他接受前一种人为奴而反对后一种人为奴。亚里士多德反对通过征服而沦落为奴隶的理由相当充分:征服了别人并不意味着我们在本性上就高他们一等。此外,强力的使用究竟有无正当理由也很难说,这样一来,成为奴隶很有可能是一个非正义的行动的结果。同时,谈到“对奴隶的正当对待”时,他提议,“鉴于他们提供的服务,应该可以随时给他们以自由,这是很有好处的。”事实上,在他的遗嘱中,亚里士多德提出要释放他的一些奴隶。
亚里土多德也相信公民权是不平等的。他认为获得公民权的基本资格在于一个人所具有的参与统治和服从统治的能力。一个公民有权力也有义务参与正义的管理。既然公民们必须出席会议、参与法庭审理,那么他们就必须既要有充足的时间又要有适当的性情和品格。由于这一原因,亚里士多德不相信劳动者可以成为公民,因为他们既没有时间,心智 也没有得到适当的发展,况且参政的过程对他们并无益处。
好的政体和革命
亚里士多德一再强调国家的存在是为了每个人道德和理智的完善。他说,“国家的存在是为了好的生活,而决不仅仅是为了生活。”类似地,“国家是家庭和村社在一种完满自足的生活中的联合,这是一种幸福高尚的生活。”最后,“我们的结论就是,政治组织的存在是为了高尚的活动,而不仅仅是为了交朋结党。”然而,一个国家是否带来了好的生活,这要取决于它的统治者如何行事。我们已经看到,亚里士多德区分了政体的变态和常态,好的统治者力求为所有人谋利益,而变态政体中的统治者则为他们自己谋私利。
不论政府采取哪种形式,它都建立在某种正义观念和相称的平等观念的基础之上。但是这些正义的概念可能引起纷争,并最后导致革命。亚里士多德认为,民主政体就产生于这样一个假设,那些在某个方面平等的人在所有方面都是平等的:“因为人们在自由上是平等的,他们就宜称他们是绝对平等的。”另一方面,亚里士多德说,寡头政体是基于如下思想,“那些在某个方面不平等的人在所有方面都是不平等的。”因此,“由于他们在财产上不平等,他们就以为他们是绝对不平等的。”由于这些原因,只要民主政府或寡头政府落到了少数人手里,而责任政府的执政原则“并不符合它们先前设想的理念,(他们)就会激起革命…这时革命就如同山洪一般爆发了。”
亚里上多德的结论是,“革命情绪普遍的和主要的原因是要求平等,人们要求与那些拥有的资源比自己多的人平等。”他没有忽略其他一些原因,诸如蛮横、贪婪,以及恐惧和蔑视。亚里士多德说,针对这些革命的原因,每种形式的政府都可以采取一些预防步骤。例如,君主必须避免独断专行,贵族政府应该避免由少数富人为了富裕阶级的利益来进行统治,一个共和政府应该让那些更能干的成员有更多时间来参与统治。亚里士多德大声疾呼,最重要的是,“没有什么东西比守法的精神更值得加以精心维护的了”。归根结底,人们在一个国家中的生活条件使他们能够达到幸福,达到他们认为的好的生活时,他们才不会批评这个国家。
4.7 艺术哲学
亚里士多德对艺术有比柏拉图更加同情的关注。不论柏拉图还是亚里上多德都认为,艺术在本质上就是是对自然的模仿。柏拉图认为艺术作品至少与真理隔着三层,所以他对某些艺术门类很轻视。人类真正的实在是人的永恒理念。这一理念的拙劣摹本就是任何一个具体的人——比如说苏格拉底。苏格拉底的雕像或画像就是基本的基本。柏拉图特别关心艺术的认知方面,他感到艺术会歪曲知识,因为它与实在隔了好几层。而亚里士多德则相信普遍的形式只存在具体的事物中,他感到,当艺术研究事物并将它们转化为艺术的形式时,艺术直接地就是在和普遍的东西打交道。因此,亚里士多德肯定了艺术的认知价值,他说既然艺术的确模仿自然,那么它也传达了关于自然的信息。
在《诗学》中,亚里士多德通过比较诗歌与历史强调了诗歌认知的方面。历史学家只关心特定的人或事件,诗人却不是这样,他们处理的是基本的人性,因而是普遍的经验。它们之间真正的区别在于:历史考虑的是已经发生的事情,而诗歌考虑的则是可能发生的事情。“因此诗歌比历史更富有哲学性,比历史更高;因为诗歌力图表现普遍的东西,而历史表现的侧是特殊的东西。”亚里士多德所谓普遍性的意思是“根据可能性或必然性的规律,一个属于某种类型的人在某个场合会有怎样的言行”。“诗歌的目标就是达到这种普遍性。”
在亚里士多德看来,艺术除了认知的价值外还有可观的心理意义。一方面艺术反映了人类本性中使人区别于动物的深层方面,这就是人类天生的模仿本能。事实上,人从婴幼儿时期起就通过模仿来学习。除了这个本能,当人们面对艺术作品时也能感到愉悦。因此,“人们乐意看见真实东西的拟似物,其原因就在于,人们在沉思它时发现自己是在进行学习或推断,并且或许会说:‘哈,这就是他。’”
亚里士多德对史诗、悲剧和喜剧进行了细致的分析,分别指出了它们的构成和功能。他对悲剧的论述在后代人的思想中引起的共鸣尤为强烈。他特别强调悲刷的情感方面,其论述的核心是关于净化(catharsis)一对不愉快情感的清洗一的思想。亚里士多德说:
悲剧就是对一个严肃行动的模仿,这一行动有一定长度,因而自身是完整的:带有一些令人愉悦的对语言的附属修饰,各种修饰分别适用于作品的不同部分;它的表达形式是戏剧性的而非叙述性的;它带着能够引起怜悯和恐惧的情节,以此来完成它对这些感情的净化作用。
“净化”一语是否暗示,我们通过悲剧“去除”了我们的感情?或者,它是否意味着给了我们一个机会以一种间接的方式来表达或释放我们内心深处的情感?不论是哪种情况,亚里士多德的意思似乎是说,对深重痛苦的艺术再现在观众心中唤起了真实的恐惧和怜悯,也就由此在某种意义上净化了观众的精神。因此,亚里士多德说:“悲制是对一个行动的模 仿…通过怜悯和恐惧使这些情感得到了真正的净化。”
第二部分 希腊化时期和中世纪的哲学
第五章 亚里士多德以后的古代哲学
在亚里士多德完成了他的宏大的思辨体系之后,哲学转向了一个新的发展方向。四个哲学家群体对形成这种新的研究方向起了推进作用,这四个哲学家群体分别是伊壁鸠鲁学派、斯多噶学派、怀疑论学派和新柏拉图主义。当然,他们都受到其先行者的巨大影响。因此,我们看到:伊壁鸠鲁学派依据的是德漠克利特的原子论的自然理论。斯多噶学派运用了赫拉克利特的渗透万物的火的实体概念。怀疑论学派建立了某种基于苏格拉底式的怀疑形式的问答方法,而普罗提诺则大量地吸收了柏拉图的思想。然而,使得他们的哲学不同于前人的与其说是哲学的主题,不如说是哲学的取向和重点。他们哲学的重点是实践的,而其取向则是以个体为中心的。由于强调生存技艺,哲学的实践性加强了。当然,这些新的思想运动中的每一个都确实包含了对宇宙构造的思辩性描述。与柏拉图、亚里士多德详细拟定理想社会之蓝图,而且使个人顺应大的社会和政治组织的做法不同,这些新哲学家引导人们首先去思考其自身,思考作为个体他们如何才能在更大的自然系统中获得令人最为满意的个人生活。
这些新的哲学取向在很大程度上是历史条件的产物。在伯罗奔尼撒战争和雅典陷落之后,古希腊文明也随之衰落了。随着小的希腊城邦的崩渍,作为个体的公民丧失了那种认为自己拥有重要地位的感觉,对把握自己的社会和政治命运也感到无能为力。因为他们被吸收到不断壮大的罗马帝国之中,人们更日益感受到个人无力支配自己在共同体中的生活。当希腊成为只不过是罗马的一个行省时,人们对探求有关理想社会的思辩问题失去了兴趣。人们所需要的是一种能在不断改变的环境中对人们的生活给予指导的实践哲学。在诸多事变让人们疲于应付的时代,想要改变历史似乎是徒劳的。然而,即使人类控制不了历史,但是他们至少还能在某种程度上成功地经营自己的生活。所以,哲学转到了新的方向,日益关注属于个体的那个更加直接的世界。
伊壁鸠鲁主义者致力于一种他们所谓的“不动心”(ataraxia))——或者说灵魂宁静——的生活的理想;斯多噶学派试图控制他们对不可避免的事件的反应:怀疑论者则希望通过对那些其真理性值得怀疑的理想不作任何基本的承诺来保持个人的自由;最后,普罗提诺则在一种与神的神秘结合中允诺拯救世界。他们都希望哲学提供一种人的生存意义的根据。而且毫不奇怪的是:他们的哲学,特别是斯多噶学派的哲学,后来和宗教一起竞相要求人们效忠。他们希望找到使个体的人能够在一个并不友好且到处充满了诸多陷阱的世界中成功地获得幸福和满足的道路。在寻求意义的过程中,当时一些被称为“调和派”的哲学家吸收了几个不同学派的观点。每种方法都给出了对人的本性的深刻洞见,不论这些洞见被理解为是针对个人的还是针对集体的。
5.1 伊壁鸠鲁主义
伊壁鸠鲁大约于柏拉图去世后的五六年——当时亚里士多德42岁——即公元前342或341年出生在爱琴海上的萨摩斯岛上。十几岁时,他接触到德谟克利特的著作,后者有关自然的思想对他自已的哲学有着持久的影响。当雅典人被赶出萨摩斯时,他来到了小亚细亚。在小亚细亚,他在几个学校任教。大约在公元前306年,他迁到了雅典,并在那里建立起他自己的学园,学园集会的地方是他的院子。当时他的学园和柏拉图的学园、亚里士多德的吕克昂学园以及芝诺的柱廊齐名,成为古代有影响的学园之一。在那里伊壁鸠鲁吸引了一个由友人组成的关系密切的团体。这些人都因为对伊壁鸠鲁怀有深厚情感和敬意而追随他,互相之间也因为深爱有教养的谈话而倾心相与。尽管他的大量的富有创造力的著述流失了,然而,从这个学园中仍然产生出一种明确的探讨哲学的方法,这方法并未因伊壁鸠鲁在公元前270年逝世而随之消亡。伊壁鸠鲁思想持久的影响力表现在这种影响力在雅典不断显示并向罗马传播。在罗马,诗人卢克莱修(公元前98年-公元前55年)在他的名诗《物性论》(De Rerum Natura)中生动地表达了伊壁鸠鲁的主要思想,该书存留到现在。
伊壁鸠鲁是一位实践哲学家。他认为,观念对生活的控制作用理当与医药对于身体健康的作用一样大。实际上,他把哲学看成是灵魂的医药。他没有探讨那些像“世界是由什么构成的?”之类的问题,受德谟克利特影响,他认为万物都是由虚空中的叫做“原子”的微粒所构成的。伊壁鸠鲁所考虑的是:如果这些东西就是构成世界的东西,那么能由之引出些什么与人类行为有关的结论来呢?
对伊壁鸠鲁来说,人类生活的主要目的是快乐。但是,令人啼笑皆非的是,直到现在人们还把他的名字与那种放纵吃喝的人联系在一起。因为没有什么比把快乐等同于吃、喝及作乐这个三一式的说法离伊壁鸠鲁的学说更远的了。相反,伊壁鸠鲁却煞费苦心地对快乐的各种类型作了区分。例如,有些快乐是强烈而不持久的,有些快乐虽然不那么强烈但却是天长日久的,有一些快乐带来痛苦的后果,而另一些快乐则给人一种宁静而安祥的感觉。他试图把快乐原则提升为行为的基础。
物理学与伦理学
使伊壁鸩鲁转向快乐原则的是来自德谟克利特的“科学”或物理学。这种科学对于神创万物以及人的行为应当遵守源自神的原则等思想具有消解作用。基于这种“原子论”,伊壁鸠鲁断定,存在着的万物必定是由永恒不变的原子所构成,而原子是一些细小的,不可毁坏的,坚硬的物质微粒。除了这些原子团外,没有别的东西存在。这就意味着如果上帝或诸神存在,他们也必定是些物质的存在物。最为重要的是,神不是任何事物的来源或创造者,自身反而倒是一种无目的的随机事件的结果。
伊壁鸠鲁用原子没有开端这种思想来解释万物的起源。原子永远存在于空间之中,像雨滴一样,它们同一时间分别从空间中下落,而且由于它们没有避遇到阴碍,所以它们相互之间总是保持着相同的距离。在这种垂直的下落中,伊壁鸠鲁认为,有一个原子离开了完全直线的下降路径而产生些微的朝向一边的松动,一也就是某种侧向的“偏斜”。于是,这个原子运动到了迎面而来的原子的轨道上与之发生碰撞,结果这种碰撞迫使这些原子都进入别的原子的轨道之中,因而在运动中造成了整个一连串的碰撞,直到这些原子形成许多个原子团。而这些原子团或原子的排列就是我们一直到现在所看到的事物,包括岩石、花朵、动物、人类,简言之,整个世界。由于有无限多的原子,所以必定有无限多的世界。无论如何,人类不是由神来产生或支配的、被创造出的有目的的秩序的一个环节,而是原子碰撞的偶然产物。
神和死亡
根据对人类起源的这种解释——以及他对包括“神圣的存在者”在内的所有存在者构成的物质的解释——伊壁鸠鲁认为:他把人们从对神和对死亡的恐惧中解放了出来。我们不再被迫害怕神了,因为神并不控制自然或人类的命运,而且它也无力干预人们的生活。至于说到死亡,伊壁鸠鲁说,它不会使任何人感到烦恼,因为只有活着的人才有痛苦或快乐的感觉,人死了之后,就没有感觉了。这是因为构成我们的身体和心灵的原子散开了,也就是说不再有这个特殊的身体和心灵了,有的只是大量的各不相同的原子而已。这些原子回复到物质的原初存在,继续进行新的构成物的循环之中。只有物质存在。而且,在人的生命中,我们所知的一切只不过是这种肉体以及这种经验的当下一刻。人的本质的成分包括各种大小和形状的原子。那些较大的原子构成了我们的身体,而那些较小的,较光滑的和较敏捷的原子则解释了感觉和思想的存在。要解释人的本性,无须任何别的本原,也无须神,当然也就无须来世。把人从对神和死亡的恐惧中解放出来,这为那种完全处于个人自己控制之下的生活方式铺平了道路。
这是道德哲学中的一种新取向,因为它把注意力集中到了个人及其对肉体的和精神的快乐的直接渴望上,而不是集中在正当行为的抽象原则上,或者是对神的命令的思考上。正如他的物理学理论使个体的原子成为一切存在的终极基础一样,伊壁鸠鲁也拣选出个体的人作为道德事业的活动场所。
快乐原则
伊壁鸠鲁以一种机械论的方式描述了万物的起源,而且他把人安排到万物的体系中,使人就好像是另一台其本性引导我们去追求快乐的小机器一样。然而,伊壁鸠鲁为人们保留了调整我们的欲望的大小和方向的能力和责任。虽然伊壁鸠鲁把人们从对神的天命的恐惧中解放出来,但他却无意借此打开情欲和放纵的闸门,他确信快乐是善的标准,然而他同样确信并非一切快乐都具有同等的价值。
如果我们问伊壁鸠鲁,他怎么知道快乐是善的标准,他将简单地回答说:所有人都能直接感受到快乐与痛苦之间的区别,也都能直接感受到,快乐是令人称心如意的。他写到:“我们认识到快乐是我们之中与生俱来的第一位的善。我们对行为的取舍,其出发点和归宿都是快乐。”伊壁鸠鲁说,感受(feeling)是善与恶的直截了当的试金石,正如感觉(sensation)是真理的判断标准一样。对于我们的感官来说,痛苦总是坏的,快乐总是好的,正如观察告知我们某个东西是否在我们跟前一样。
进而,为了把人们引向最幸福的生活,伊壁鸠鲁强调各种快乐之间的区别。很显然,有些欲望既是自然的,又是必要的,比如对食物的欲望;有一些欲望是自然的,但是不必要的,就像在某些类型的性快感的情况中那样;还有一些欲望既非自然得到的,又非必要的,例如,无论何种奢侈或名望。正是因为他可以对这些做出明确的区分,所以他得出结论说:
当我们坚持认为快乐是目的时,我们并不是指挥霍浪费的快乐,或肉体享受的快乐,像那些无知或不赞成或不理解我们的人所设想的那样,我们所说的快乐指的是身体的无痛苦和心灵的无纷扰。快乐不是连续不断地饮酒作乐,也不是淫欲的满足,更不是盛宴中的鱼和别的美食佳馔的享用。快乐源自冷静地推理,这种推理会寻求取舍的动机,并且排除那些导致精神纷扰的意见。
伊壁鸠鲁并非要谴责肉体快乐,相反,他的意思只不过是强调,对这些快乐的过度关心既是不自然的,也毫无疑问会导致不幸和痛苦。某些种类的肉体快乐永远也不可能得到充分满足。而且,如果这种快乐要求连续不断地放纵的生活,那么就会导致追求这些快乐的人必定永远得不到满足,也就会不断地道受某种痛苦。例如,如果他们想要更多的金钱,或者更多的公众的喝彩,或者是更难吃到的食物,或者是更高的地位,他们就会永远不满足于他们现有的状况,就会道受某种内心的痛苦。但与此相反,一个聪明的人,是能够确定什么是他或她的本性所需要的最低限度的东西,而且能够轻而易举地很快满足这些需要的。当这些需要得到满足时,一个人的体质就处于均衡状态之中。聪明人的粗茶淡饭的饮食,比起讲究吃喝的人的过量的高档食品似乎可以带来多得多的幸福。因为聪明人不仅学会了消费少而且需要得少——后者是关键所在。
人的本性所寻求的终极的快乐是宁静(repose)。伊壁鸠鲁所说的宁静指的是身体的无痛苦和心灵的淡泊松弛。这种意义上的宁静可以通过减少我们的欲望,克服无用的恐惧,尤其重要的是通过转向精神上的快乐——因为这种快乐具有最高等级的持久性——最为成功地得到。在某种意义上,这些心灵上的快乐也是身体的快乐,因为它们具有防止在肉体的事情上的放纵从而防止随之而来的痛苦的作用。
快乐和社会主义
伊壁鸠鲁以对个人快乐的考虑为出发点,并将其推而广之来解释社会交往和社会正义。伊壁鸠鲁尽力想让自己摆脱和别人的牵连,特别是和那些缺这缺那,困境重重的穷人的牵连,正如他力图摆脱和那些享用山珍海味的僭主的牵连一样。然而,我们不可避免地要和别人打交道,这也会对我们的幸福产生实实在在的不可忽视的影响。首先,友谊的建立是我们的幸福的一个关键要素,尤其是当我们的朋友与我们趣味相投且富于思想魅力的时候。其次,文明社会的一个主要功能就是制止那些要把痛苦施加给个人的人。伊壁鸠鲁的物理学理论排除了像我们在柏拉图的理念论里发现的那种支配事物的更高的理性秩序,但是,他的趋乐避苦的思想还是蕴含着建立自然正义的一个牢固基础:人们同意不彼此伤害。他写道:“从来就没有什么绝对正义之类的东西,只有人们在不同时间不同地点经过互相协商达成的约定,其中规定禁止折磨和伤害。”这种社会约定的具体细目是因地制宜,各不相同的,但伊壁鸠鲁认为这种社会约定的作用是显而易见的,因此各种社会无一例外地都会加以采用。
5.2 斯多噶主义
斯多噶主义作为一种哲学学派,包括了一些最卓越的知识分子。斯多噶学派是由基提翁城的芝诺(Zeno of Citium,公元前334年-公元前262年)所创立。他让他的学派在斯多亚(stoa)(这是希腊文的柱廊一词,因而有斯多噶学派一说)集会,这一哲学运动吸引了雅典的克莱安西斯(Cleanthes,公元前303年-公元前233年)和阿里斯顿(Aristo)。后来,在罗马,它又吸引了诸如西赛罗(Cicero,公元前106年-公元前43年)、爱比克泰德(Epictetus,60-117)、赛涅卡(Seneca,公元前4年-65年),以及罗马皇帝马尔库斯·奥勒留(Marcus Aurelius,121-l80)这样的拥护者。这种影响有助于把斯多噶哲学的压倒一切的重点锁定在伦理学上,虽然斯多噶学派论述了由亚里士多德学园所构建的哲学的三大部分,即逻辑学、物理学和伦理学。
相对于快乐的智慧和控制
在他们的道德哲学中,斯多噶学派的目标也在于幸福。但是与伊壁鸠鲁派不同,他们并没有期望在快乐中找到幸福。相反,斯多噶学派通过智慧去寻求幸福。这是一种对人类力所能及范围内的事情则加以支配,对无可奈何的事情则以一种不失体面的顺应来加以接受的智慧。芝诺在年轻时就被从容无畏地面对死亡的苏格拉底的伦理学说和生活激励。苏格拉底的这种面对着对自己的存在的极度威胁——死亡的威胁时极好地控制情感的榜样,为斯多噶学派的生活提供了一个真正的模范。几个世纪之后,斯多噶学派的爱比克泰德说:“我不能逃避死亡,难道我还不能逃避对死亡的惧怕吗?”他以一种更一般的形式发展这一论题。他说:“不要要求事情像你所希望的那样发生,而要希望它们像实际发生的那样发生,这样你就会好好过下去。”我们不可能控制所有的事情,但是我们能够控制我们对所发生的事情的态度。害怕未来会发生的事情,这是毫无用处的,因为它们无论如何都是要发生的。然而,通过意志的活动去控制我们的害怕却是可以做到的。所以,我们不应当害怕事情发生——在某种真正的意义上,我们“除了害怕本身之外,没有什么可害怕的”。
这种道德哲学具有一种朴实简洁的特点,然而它毕竞还是一种思想精英的哲学。“控制我们的态度”这目标是足够简单的了。然而,斯多噶学派到底是如何以哲学的方法达到这一目标的呢?他们是通过创造一种关于世界必定是什么样子,以及人类如何顺应这个世界的精神图像来做到这一点的。他们说,世界是一种有序的安排,在世界中,人和自然事物按照目的原则而活动。他们在全部自然中到处都看到了理性与法测的作用。斯多噶学派依靠一种特殊的神的规念去解释这种世界观,因为他们认为神是一种理性的实体,它并不存在于某个地方,而是存在于整个自然之中,存在于万物之中。正是斯多噶学派所说的这种神——理性的一种无处不在的实体性形式,而这种理性控制和安排了自然的整体结构——决定了事件的发展过程,而道德哲学的基础就在这里。但是斯多噶学派的思想在其中椎进这些主题的取向,则是被他们关于知识的理论所设定的。
斯多噶学派的知识论
斯多噶学派以非常详细的方式解释了我们是如何能够获得知识的。尽管他们的说明并不完全成功,但是他们关于知识的理论却仍然是重要的。这至少有两个理由:第一,这种知识理论为他们的唯物主义的自然理论打下了基础;第二,这种关于知识的理论也为他们的真理或确定性的观念提供了基础。
斯多噶学派知识论的结论,全都源自他们对观念起源的说明。他们说,语词是表达思想的,而思想则是由于某些对象影响心灵的结果。心灵在出生时是一片空白的,当它受到对象的影响时,它建构起观念的存储器。这些对象通过感官的渠道在我们的心灵上留下印象,例如,一棵树,通过视觉器官把它的形象印在了我们的心灵之上。就像一封印章把它的印迹留在了蜡上一样。正是一次又一次地暴露在由事物构成的世界面前,增加了印象的数量,发展了我们的记忆,而且给了我们形成超越我们直接面对的对象的更一般的观念的能力。
斯多噶学派真正面对的难题是如何解释这最后一点的问题,也就是如何解释我们的诸如善和美的一般观念的问题。为此他们必须揭示出我们的思想是如何和我们的感觉相关联的。证明我们关于树的观念来自我们关于树的视觉,这是一回事,但是,我们又如何能够说明那些涉及到我们的感觉之外的事物的一般观念呢?斯多噶学派答复说,一切思想都以某种方式和感觉相联系,即使是那些表达判断和推理的思想也是如此。一种关于某物是好的或真的判断或推理,是印象的机械性过程的产物。我们的一切形式的思想都开始于印象,而我们的思想中有一些是基于那种开始于我们之中的印象的,例如身体感觉就是这种印象。所以,身体感觉可以给我们知识,它们是“不可抗拒的知觉”的来源,这种不可抗拒的知觉又是我们的确定性意识的基础。正如怀疑论者后来指出的,这种解释或许不能把我们提出的反对它的所有批评意见都顶回去。但是不管怎么说,通过这种理论,斯多噶学派不仅在其中建立了真理的基础,而且还赋予了他们的一般哲学一种独特的倾向。正如他们所做的那样,论证所有的思想都源于对象对感官的冲击,就是断言除了具有某种物质形式的东西之外,没有什么东西真正存在。斯多噶学派的逻辑把斯多噶学派的哲学塑造成了唯物主义的的形态。
作为一些实在之基础的物质
这种唯物论给斯多噶主义提供了一种具有独创性的关于物理世界和人类本性的观念。斯多噶学派勾画出来的关于物理自然的广阔图景得自于他们的这样一种观点,即一切实在的东西都是物质的,因此,整个宇宙中的每一事物都是物质的某种形式,然而世界并不就是惰性的或被动的物质的堆积——世界是一种能动的、变化着的、结构性的和有序的安排。除了惰性的物质,还有动力或能力,它们在自然中都代表着主动定形和建立秩序的要素。这种主动的能力或动力不是不同于物质的东西,而是物质的另一种形式。它是一种永恒运动着的精巧的东西,像气流或呼吸那样。斯多噶学派说它就是火,这火蔓延到所有的事物,赋予它们以活力。这种物质的火具有合理性的属性,而且由于它是存在的最高形式,所以,斯多噶学派把这种合理性的力理解为神。
万物中的神
斯多噶主义的核心思想是“神在每一事物之中”。当我们说神在每一事物之中——像火,或者力,或者逻各斯,或者合理性一样一我们指的是自然中的一切都充满了理性的原则。斯多噶学派以某种更详细的方式说到物质的可渗透性,他们这样说的意思是,各种不同类型的物质被混合在一起。他们说,神的物质性实体和那些本来不会运动的物质混合在一起,物质以这种方式活动,是因为在它之中存在着理性的原则。自然律就是物质按照这一原理的连续活动,它是事物本性的法则或原则。因此,对斯多噶学派来说,自然有它在神一切事物的温暖的、火的母体——中的起源,并且万物都直接被打上神的建构性理性的印记。万物就一直按照它们被安排的样子活动下去,由此我们可以看到斯多噶学派是如何发展出他们有关命运和天意的概念来的。
命运和天意
对斯多噶学派来说,天意意味着事情以它们应有的方式发生,因为一切事物和一切人都处在逻各斯或者说神的支配之下。整个世界的秩序是基于它的所有部分的统一,而使物质的整体结构形成一体的东西是火的实体,这种火的实体渗透到一切事物之中。在宇宙中没有什么会“格格作响”,因为没有什么东西是松动的。最后,斯多噶学派在这种完全被控制的物质世界背景的基础上建构了他们的道德哲学。
人的本性
斯多噶学派知道,要建构一种道德哲学,必须对“人的本性是什么”这个问题有一个清晰的看法。他们把那些曾用于描述自然整体的观念径直搬用到对人类的研究之中,形成了他们的关于人的本性的观点。正如世界是一种被称之为理性或神的火的实体所渗透的物质体系一样,一个人也是一种被这同样的火实体所渗透的物质存在。斯多噶学派正是由于说人自身中包含了一分神性而闻名于世。他们这样说的意思是:在一种实在的意义上,人包含了神的实体的一部分。神是世界的灵魂,而每一个人的灵魂是神的一部分。这点神性是一种渗透到一个人的肉体之中,使它运动并具有一切感觉能力的精细纯粹的物质实体。这种纯粹的物质性的灵魂通过身体方面的途径被父母转移到孩子的身上。斯多噶学派认为,灵魂之中心在心脏,具体来讲,它是通过血流而循环的。灵魂加在身体上的东西是说话的能力和繁殖的能力,以及五官的精巧装置。但是,由于神是理性的逻各斯,而人的灵魂植根在理性之中,因而人的人格(个性)在它的理性中找到它的惟一的表达。然而,对斯多噶学派而言,人的理性并非仅仅意味着人能够对事物加以思想或者进行推理。正相反,人的理性意味着人的本性参与到理性的结构和整个自然的秩序之中。人的理性代表了我们对事物的实际秩序以及我们在这种秩序中的地位的意识,它使我们意识到,万物都遵循法则。斯多噶学派的道德哲学主要关心的就是把人的行为和法的秩序联系起来。
伦理学和人的戏剧
根据爱比克泰德的说法,道德哲学以一种简单的洞见为基础,按这种见解,每个人都是一出戏剧中的一位演员。当爱比克泰德运用这样一个比喻时,他的意思是说:一个演员不能选择某个角色,相反,是戏剧的作者或导演选人去扮演各种角色。在世界这出戏剧中,正是神,或者理性的原则,决定每个人将会成为什么样的人,以及他或者她将在历史中处于何种地位。斯多噶学派说,人的智慧在于认识到在这部戏剧中我们的角色是什么,并把这个角色扮演好。有些人只是“跑跑龙套”,而另一些人则被分派演主角。“不论神高兴你扮演一个穷人,或扮演一个残疾人,一个统治者还是一个普通公民,你都一定要演好。因为扮演好给你的角色是你的本分。”演员要学会不去操心那些他或者她不能控制的事,例如,舞台布景的样子和形式,别的演员将会如何,等等。演员尤其无法控制戏剧故事或者说它的情节。但是,有一样东西演员可以控制,那就是他们的态度和情绪。我们可以因为扮演一个小角色而闷闷不乐,或者当别人被挑选扮演主角时因嫉妒而耗精劳神,或者因为化妆师给你一个特别丑陋的鼻子而感觉蒙受奇耻大辱。但是,生气、嫉炉以及自感受辱都绝不可能改变我们是演小角色,而不是演主角,并且必须戴上那个丑陋的鼻子这一事实。这些感情只不过是剥夺了演员的幸福而已。如果我们能不受这些感情的困扰,或者能够达到斯多噶学派称之为“不动心”的那种状态,那么我们将会得到作为一个聪明人的标志的宁静和幸福,聪明的人是知道他或她的角色是什么并欣然接受的人。
自由的问题
在斯多噶学派的道德哲学中,还存留着一个问题,这个问题关系到人的自由的本性。我们]可以很容易地理解斯多噶学派关于自然被上帝的理性所固定和安排的看法,特别是当我们把这宏大的设计想象为一出宇宙戏剧时。演员可能确实不能挑选他们的角色,但是挑选你在戏剧中的角色是一个方面,而选择你的态度则是另一个方面,在这两者之间有什么区别呢?如果你在选择其一时是不自由的,那么你在作别样选择时又怎么可能是自由的呢?神很可能不仅选择让你做个穷人,而且还分派你当一个特别不满意的穷人。难道态度会自由地漂浮在四周等着鱼贯而过的人们去加以选择吗?或者它们像眼晴的颜色一样是人的一部分吗?
斯多噶学派顽强地坚持他们的看法,认为态度是我们可以控制的。而且坚持认为,通过意志的活动我们可以决定我们将如何对事件做出反应。但是他们从未对这样的事实提出一个令人满意的解释,即既然天意支配一切,那么为什么天意却并不同时支配我们的态度呢?他们最接近一种解释的说法,是暗示虽然在整个世界中一切事物都是遵照神的法则而行动,但根据他们对法则的认知而行动却是人类的一大特点。例如,水由于太阳的加热而蒸发,后来又以雨的形式凝结并落了下来。但是一滴水决不会对另一滴水说:“我们又回到这里来了”,就好像对自己被迫与大海脱离流露出抱怨一样。当我们开始衰老并面对死亡时,我们经历了一个同样的变化过程。然而,除了衰老这个机械过程,我们还知道我们正在发生着什么变化。增加再多的知识也改变不了这样的事实,即人总是要死的。不过,斯多噶学派把他们的整个道德哲学建立在这样一种确信上:如果我们懂得了严格的律法而且理解到我们不可避免要担任我们的角色,我们就不会拼命去反对这种必然性,而是会欣然跟随着历史的步伐前进。幸福与其说是选择的产物,不如说是存在的一种性质,幸福产生于对不得不如此的事情的接受。所以自由不是改变我们命运的力量,它只不过是没有情绪上的纷扰而已。
世界主义和正义
斯多噶学派还发展了一种强有力的世界主义的思想——也就是所有人都是同一个人类共同体的公民。把世界的进程看成是一部戏剧,也就是允许每一个人在其中都扮演一个角色。斯多噶学派把人的相互关系看成是具有最大意义的事,因为人都带有一点神性。使人们相互联系起来的东西是每一个人都有一种共同的成分这一事实。这就好比说,逻各斯是一根主要的电话线路,而所有的人都在开一个电话会议,这样就把神和所有的人连贯起来前所有的人之间又相互联系,或者像西赛罗所说的:
因为理性既存在于人之中也存在于神之中,人和神共同具有的第一个东西就是理性。但是那些具有共同理性的人也必定具有共同的正当理性。而且由于正当理性就是法,所以我们必须相信,人和神一起共同具有法。进而,那些分有法的人还必定分有正义,而且那些分有这些东西的人应当被视为同一个共同体的成员。
四海之内皆兄弟和关于正义的普遍的自然法的理论是斯多噶学派对西方思想所作出的令人印象最为深刻的贡献之一。他们把这些基本的论题注人到思想的河流中去,以致它们在即将到来的世纪,特别是在中世纪的哲学中产生了决定性的影响。
虽然斯多噶主义与伊壁鸠鲁哲学有着许多共同的特点,但是它也作出了某些重要的创新。和伊壁鸠鲁派一样,斯多噶学派把他们的主要重点放在了属于伦理学的实践问题上,把自我控制看成是伦理学的中心;以唯物论的观点来看待自然中的一切,并且把追求幸福作为目的。斯多噶学派注人的最有意义的变化是:他们把世界不是看作偶然事件的产物,而是看作建立秩序的心灵的产物,或者说是理性的产物。这种观点使斯多噶学派对人类智慧能达到的可能性持高度乐观的态度。然而,正是对关于智意的这种论断——即认为我们能够详尽认知世界运行的诸多细节的论断一的反对,产生出了怀疑论派的批判哲学。
5.3 怀疑主义
我们今天所说的怀疑主义者指的是这样一些人,他们的基本态度是怀疑的态度。但是在古希腊的语词中,skeptics是从skeptikoi派生出来的心,这词有很不同的意义,是指“探求者”或“研究者”。怀疑论学派也确实是一些怀疑者。他们不相信柏拉图和亚里士多德已经成功地发现了世界的真理。他们也同样怀疑伊壁鸠鲁和斯多噶学派在这方面的成就,但是尽管怀疑这怀疑那,他们仍然是一些探求者,探求一种获得平静生活的方法。埃利斯的皮罗(Pyπho of Elis,公元前361年-公元前270年)是怀疑派这个特殊学派的创始人,这个学派对后来的许多世纪的哲学都具有某种特殊的意义以及深远的影响。他的这一特别的观点以他的名字命名为“皮罗主义”而流传于世。在皮罗引来他的追随者的同时,一个与之相竞争的怀疑主义学派产生于柏拉图的学园之中,此学派的崛起,要特别归功于阿凯西劳斯(Arcesilaus,公元前316年-公元前241年)的领导,他是学园的领袖,大概比柏拉图晚一两代。他们有“学园派”之名,但却拒绝柏拉图的形而上学,而且复活了苏格拉底的辩证的方法,他们用这种方法来悬置判断。皮罗没有写什么东西,其思想主要是通过第二手的历史资料和论述才得以存留下来。古希腊怀疑主义残存下来的主要的文本是通过塞克斯都·恩披里可(Sextus Empiricus,.200),一个皮罗主义传统的追随者留下的。在他的《皮罗主义纲要》(Outlines of Pyrrhonism)的开篇中,塞克斯都对怀疑主义观点的目的和意义给出了一个富有启发性的说明。
寻求心灵的安宁
是什么导致怀疑主义?塞克斯都说,怀疑主义起源于对获得精神上的平和或宁静的期望。他说人们曾经被事物中的矛盾所纷扰,被他们到底应当相信对立观点中的哪一个所困扰。一个哲学家告诉我们一个东西,另一个哲学家则告诉我们正好与之相反的东西。那么在怀疑派看来,如果他们能够通过研究排除错误确定真理,那么他们也就可以得到精神上的宁静。然而,怀疑派注意到,不同的哲学家提出的真理概念是不同的。他们还注意到,那些寻求真理的人们可被分为这样三种:(1)那些认为他们已经发现真理的人们(怀疑派称这些人为独断主义者),(2)那些承认他们没有发现真理且断言真理不可能被发现的人们(怀疑派认为这也是一种独断论的观点),以及(3)那些坚持不懈地寻求真理的人们。和前两种人不同,塞克斯都说,“怀疑派坚持不断的探索”,怀疑主义并不否认找到真理的可能性,也不否认人类经验的基本事实,它不如说是一种持续研究的过程。在这个过程中,对经验的每一种解释都要受到相反经验的检验。塞克斯都说,怀疑主义的基本原则是每个命题都有一个与之相当的相反命题。他说,这个原则的结果就是,“我们以消除独断而结束”。
怀疑派对这样的事实印象极为深刻,那就是,同样的“现象”在那些经验它们的人中产生出各种各样不同的解释。塞克斯都说,他们发现,相互反对的论证似乎同样有力。也就是说,不同的解释似乎有着不相上下的正确几率。因此,怀疑派被导向悬置判断,避免否定或肯定任何东西。他们希望由这种对判断的悬置而获得一种无干扰的、宁静的心态。
明显的事情和不明显的事情
显然,怀疑派并没有放弃富有活力的思考和辩论的事业,他们也没有否认明显的生活事实——例如,人们会有饥渴,如果走近悬崖,处境会很危险。怀疑派认为人们显然应该在行动中小心仔细。他们并不怀疑他们生活在一个“真实的”世界之中,他们只是想知道这个世界是否已经得到了正确的描述。塞克斯都说,没有人会质疑对象有这种或那种现象,问题是“对象实际上是否像它们表现出来的那样”。所以,虽然怀疑论拒绝独断式的生活,但是他们也并不否认与经验有关的明显事实。塞克斯都说,“我们对现象给予了应有的尊重。”对怀疑派来说,日常生活似乎要求小心地认知四个方面的问题,塞克斯都称这四方面问题为:(1)本性的引导,(2)感觉的制约,(3)法和习惯的传统,(4)技艺的教育,这四个方面中的每一个都对成功而宁静的生活作出了贡献。而且对它们中的娜一个都无须作任何独断的解释或评价,只须加以接受就是。于是,正是通过本性的引导,我们才本能地具有感觉和思想的能力;也正是通过我们的感觉的力量,饥饿驱使我们去进食,干渴促使我们去饮水。而正是法和习惯的传统在日常生活中约束我们,使我们相信虔诚是善,不虔诚是恶。最后,塞克斯都说,正是借助于技艺的教育,我们从事那些我们选择参与其中的技艺。
因此,毫无疑义,怀疑论者决不否认感性知觉到的明显事实。塞克斯都说,确实,那些说怀疑派否定现象的人们“似乎并不熟悉我们学派的说法”。他们质疑的不是现象而只是“对现象的解释”。塞克斯都举例说,蜂蜜表面上似乎是甜的,而且“我们同意这一点,是因为我们通过感官知觉到它是甜的”,但问题是它是否真的在本质上是甜的。因此,怀疑派阐述自己关于现象的论证,不是要否定现象的实在性,而是为了指出“独断论者”的轻率。塞克斯都从这种关于感官对象的论述中得到的教训是:如果人的理性可以如此容易地被现象所欺骗的话,“如果理性是这样的一个骗子,以致他几乎能从我们眼皮底下提走现象”,那么在那些并不明显的事情上,为了不草率行事,我们遵循起理性来岂不更是要特别小心吗?
那些并不明显的事情在柏拉图、亚里士多德和斯多噶派的宏大哲学体系中占有中心地位。怀疑派在此发现了许多精心建构的理论,特别是关于自然事物之本性的理论。然而物理学理论——它是对不明显的事情的一种研究——又何以能够给我们可靠的真理呢?怀疑派对物理学研究采取了一种双重态度。一方面他们拒绝对物理学加以这样的理论化:仿佛要这样来发现“对物理理论中任何事物的牢固而坚定的观点,以支撑起坚定不移的理论”似的。然而,他们“为了让每一种论证都有一个与之相反的同等论证,也为了精神宁静的目的”,又确确实实谈及了物理学。他们对关于伦理学和逻辑学的问题的看法是与此相似的。无论在哪种情况下,他们对精神宁静的追求都不是一种消极的方法,也不是一种拒绝思考的做法,而是一种积极的方法。他们的“悬置判断”的方法要求在对立面中设定事物的积极性。正如塞克斯都说的,“我们用现象反对现象,或者用思想反对思想,或者用现象反对思想。”
因而,塞克斯都区分了两种类型的研究,也就是涉及明显事情的研究和涉及不明显事情的研究。那些明显的事情,比如现在究竟是白天还是黑夜,是不会产生知识方面的严重问题的。为达到社会和个人安宁的那些明显的要求,也是属于这个范畴的,因为我们知道,是习俗和法维持着社会的团结统一。而不明显的事情,例如,自然的元素是否由原子或某种火的实体所构成这类事情,则会产生理智上的争论。只要我们一走出那些人的经验中显而易见的东西的范围之外,我们对知识的探寻就只能在创造性怀疑的影响下继续。因此,如果我们问:我们是何以知道世界是什么样的?怀疑派就会回答说:我们尚不知道。他们说,人们或许可以获得真理,但是他们也可能陷人错误,而我们不能确定他们到底是得到了真理还是处在错误之中,因为我们没有一个可靠的标准去确定不明显事情中的真相。
感觉是靠不住的 塞克斯都论证说,如果我们的知识来自经验或感觉印象,那么就更有理由怀疑所有知识的恰当性。因为事实是:在不同的时间和不同的环境之下,对同一对象我们的感觉给我们不同的信息。例如,隔着某个距离看过去,一座方形的建筑物好像是圆的,一处风景在一天中不同的时间去看也显得不同,蜂蜜让某些人觉得是苦的,剧场上的绘景让人觉得真的有门窗在那儿,其实那只不过是画在平面上的一些线条。我们拥有印象,这是确确实实的,例如,我们确实是“看到”了水中的一支弯曲的桨,但是我们永远不能确定的是:事实上这桨是否是弯的。虽然我们可以把桨拿出水面,而且发现知觉的错误,但是,并非每一种知觉都有这样一种简单易行的办法来检验其精确性和真实性。我们大部分知识都是基于知觉的,但是我们对这些知觉却没有判断真假的标准,怀疑论的结论是:我们不可能确定我们关于事物本性的知识是真的还是假的。
道德法则产生怀疑 和自然物体一样,道德概念也是怀疑的对象。不同社会的民众有着不同的关于什么是善和正当的观念。每个社会的习惯和法都不同。就是同一个社会,时代不同习惯和法也不同。斯多噶派学说,有某种为所有人共同具备的普遍理性,它引导所有人达成关于人的权利的普遍共识。怀疑派在理论和事实上都对此加以质疑,他们说,没有证据证明所有人都能够赞同普遍道德原则之真理。进而,他们论证说,也设有证据说明民众在实际上显示过这种普遍同意。事实是:民众的意见是各不相同的。再说,那些看法不同的人们全都可以用同样强有力的论证来支持他们自己的观点。在道德问题上,没有绝对的知识,只有意见。斯多噶学派曾论证说,在某些问题上,检验真理的标准是“不可抗拒的知觉”。怀疑派则答复说,可悲的是,一种意见无论多么强硬地坚持,它毕竟还只不过是一种意见。而且我们也可以用与它同样多的证据去支持一个与它正好相反的意见。当人们采取了独断论的立场时,他们的结论在他们自己看来总是不可抗拒的。但是这并不能保证他们的结论是真实的。
这种对我们关于事物本性的知识以及我们关于道德真理的知识的怀疑态度,其结果就是我们有权怀疑这种知识的有效性。由于我们没有确定的知识,那么最好的办法就是不要对道德的真实本性作出判断。然而伦理学实在是一个人们很难对之不下判断的领域。当一个关系到行动的问题摆在我们面前时,我们总会想知道做什么样的事情才是正当的,而这就需要关于“正当”的知识。所以,批判怀疑派的人会认为:怀疑论者已经使伦理学成为不可能,而且使人们的行为失去了指导。
没有理智确定性道德是可能的 然而怀疑派认为,要明智地行动,无须具有知识。他们说,只要有合乎理性的自信就足够了,或者只要有他们所说的或然性也就足够了。从来没有什么绝对的确定性,但只要我们的观念有极大可能把我们引向一种幸福而宁静的生活,那么我们信从这些观念就是合理的。我们从日常的经验出发就能够区分出不清晰的观念和具有高度清晰性的观念。当有关正当的观念有某种高度的清晰性时,它们就在我们之中产生出一种强大的信念,相信它们是对的,而要引导我们去行动,这就足矣。由于这个原因,习惯、国家的法律以及我们基本的欲望,大体来说就是可靠的指导。然而就是在此怀疑派也还是要求保留一种谨慎态度,这样我们才不会错把现象当成实在,尤其是能避免狂信和独断论。虽然我们即便没有一个真理的标准也可以满怀热情去行动,但是我们心理上的安全要求我们让研究的渠道保持敞开。应当采取的惟一安全的态度是,怀疑包括道德信念在内的任何观念的绝对真理性。一个能够在这种怀疑态度下保持冷静的人才最有可能获得幸福的生活。
如果我们问怀疑派是否有一个“体系”,塞克斯都回答说,如果我们所说的“体系”指的是“对一定数量的既相互信赖又依赖于现象的教条的坚持”一这里我们用“教条”一词指“对一个没有证据的命题的同意”一的话,那么怀疑派“没有体系”。但是,如果我们说的体系指的是“某种程序,它和现象相一致,遵循一定的推理路线,并指出如何可能过上看起来正当的生活”,那么怀疑论也确实有一个体系。因为塞克斯都说:“我们遵循一条推理的路线,这条路线为我们指出一种生活,这种生活和我们国家的习惯,它的法律和制度,也和我们自己本能的感觉相一致。”
5.4 普罗提诺
站在古代哲学顶点的是普罗提诺(Plotinus,204-270)这样一位有影响的人物。他生活的时代,没有哪一种令人信服的哲学理论能满足人们对那个年代的特殊问题的关切。极其繁多的宗教派别的出现,说明罗马帝国开国后的第二和第三世纪里人们在不顾一切地想要拳握一种对生活和命运的解释。这是一个各种学说融合的时代。这个时代的观念来自各种不同的起源,合在一起就形成了各种哲学和宗教。对埃及的伊希斯的信仰把希腊和埃 及的诸神的观念结合在一起;罗马人发展了帝国的信仰而且崇拜他们的无论是活着还是死去的皇帝。密特拉教的信徒们崇拜太阳,弗利吉亚人则崇拜诸神之母。基督教这时仍然被视为一个小宗派,虽然某些基督教的思想家已经产生,诸如殉教士查士丁(Justin Martyr,100-l65)、亚历山大的克雷芒(Clement of Alexandria,150-220)、德尔图良(Tenullian,160-230),以及奥利根(0igen,185-254)。他们都希望让基督教信仰系统化并具有理智上的基础。奥利根试图为基督教提供一种柏拉图主义和斯多噶主义的理论构架,此前,克雷芒也试图把基督教的思想和哲学思想结合起来。但是,直到奥古斯丁使基督教与柏拉图思想的混合成形,基督教神学才算是羽翼丰满了。在古代哲学和奥古斯丁之间的关键性过渡是普罗提诺的著述。但是普罗提诺的著作中并没有提到过基督教。他的创造性的贡献包含了柏拉图哲学的一种新形式,并因此而被称为新柏拉图主义。
普罗提诺大约于204年出生在埃及,他是亚历山大里亚的阿摩尼乌斯·萨卡斯(Ammonius Saccas)的学生。这时亚历山大里亚是古代世界各种思想的荟萃之所。在这里普罗提诺潜心钻研了包括毕达哥拉斯、柏拉图、亚里土多德、伊壁鸠鲁,以及斯多噶学派的思想在内的古代哲学。在这许多的哲学流派之中,他选择了柏拉图主义作为真理最可靠的起源,并且以他对柏拉图思想的理解作为标准对别的哲学进行了批判。在40岁时,他从亚历山大里亚到了罗马,那时罗马在道德和宗教上正是一片混乱,在社会和政治上也动荡不安。在罗马,他开办了自己的学校,把城市里的一些精英吸引到学校中来,其中包括皇帝和他的妻子。他一度计划建立一个基于柏拉图《理想国》的理论之上的城邦,称之为“柏拉图城邦”。但是这个计划从未实现过。他写了54篇论文,这些文章没有一定的先后次序,其文风也没有他在说话时那么精彩雄辩。这些论文在普罗提诺死后由他最能干的学生波斐利(Porphyry)收集在一起,他把这些文章编排成九章,每章六篇,这也就是现在人们所说的《儿章集》(Enneads)。普罗提诺是一个才华横溢的演说家,同时还是崇尚精神的理想主义者。确实,他那与理智上的严密性结合在一起的道德的和精神的力量,不仅影响了他同时代的人,而且还特别影响了奥古斯丁。奥古斯丁后来说,普罗提诺只要改动少数几个语词就会成为一名基督教徒。不管怎么说,普罗提诺的思想成了大多数中世纪哲学中的主流思想。
普罗提诺哲学不同于他人之处在于,他把对实在的思辨性描述和关于救赎的宗教理论结合在一起。他不仪描述了世界,而且说明了它的起源,还说明了我们在世界上的地位以及我们如何在其中克服道德上和精神上的困难。简而言之,普罗提诺发展了一种认为神是万物之起源也是人的必然归宿的理论。在构建他自己的思想时,普罗提诺先后分析和驳斥了斯多噶学派、伊壁鸠鲁学派、毕达哥拉斯学派以及亚里士多德的观点,认为它们都不完善。他对这些思想流派的驳难中有一条在于他确信:他们不理解灵魂的真正本性。斯多噶学派把灵魂描述成一种物体——一种物质性的“气息”。普罗提诺论证说,同为唯物主义者的斯多噶学派和伊壁鸠鲁学派,都没有理解灵魂对物质性身体的独立性。同样,毕达哥拉斯学派的人,他们说灵魂是身体的“和谐”,所以他们不得不承认:当身体不是处在和谐状态时,它就没有灵魂。最后,普罗提诺驳斥了亚里士多德的思想。亚里士多德认为,灵魂是身体的形式,因而没有身体灵魂就不能存在。普罗提诺认为,照此看来,如果身体的某部分失去了它的形式,这将意味着在某种程度上灵魂也会受损,而这将使身体成为首要的了。因而,普罗提诺说,灵魂才是首要的,而且是它给了作为整体的身体以生命。普罗提诺认为,一切都取决于对人的本质的准确理解。
为了理解人的本性,普罗提诺奉行柏拉图在他那些生动的神话和寓言中建立起来的思想路线。他被柏拉图的关于实在的全面论述所打动,其中包括柏拉图关于造物主德穆革用物质铸造世界的解释,关于善的理念犹如从太阳中射出的光线的理论,以及柏拉图关于灵魂在进人肉体之前就已经存在,它是身体中的囚徒,努力想挣脱这种囚困,返回到它的起源的思想,最后,还有柏拉图对我们只能在精神世界而不是物质世界中发现真正实在的确信。普罗提诺采用了这些基本的思想,特别是作为核心的柏拉图关于只有精神是真实存在的思想,他把柏拉图的这些思想重构成一种新型的柏拉图主义。
作为太一的神
普罗提诺认为,有着多种多样事物的物质世界,不可能是真正的实在,因为物质世界总是在不断地变化。真正不变的实在是神。关于神,除了他是绝对地超越于或存在于世界万物之上这一点外,无法对其进行具体的描述。因此,神不是物质的,也不是有限的或可分的,它没有特殊的形式——也就是说,既不是物质、灵魂,也不是心灵——这些东西中的每一个都处于变化之中。神不可能被限制在理智的任何一个或多个观念之中,而且因此也不可能在任何人类语言中得到表达。他不为任何感官所感知而只能在一种神秘的迷狂中接近,而这种神秘的迷狂是独立于任何理性的或感觉的经验的。由于这个原因,普罗提诺把神说成是太一(One),以此意指在神之中是绝对不存在任何复合的,而且神确实是绝对的一。进一步说,太一意味着神是不变的。神是不可见的、单一的、不被创造的,而且是绝对不可变更的。
普罗提诺认为,太一不可能是特殊事物的总汇,因为正是这些有限存在的东西籍要解释和起源。因此,太一“不可能是任何存在着的事物,而是先于任何存在物的”。对于太一来说,不存在任何我们可以加以描述的肯定的属性。因为我们关于属性的观念都是产生于有限的自然事物。因而,说神是这样而不是那样,是不可能的,因为这种做法就给神加上了限制。因而,说神是一就是肯定神存在而且超越于世界之上。这就是说,他是单纯的、没有任何二元性、潜在性或者物质的有限性,而且他超越于一切差别之上。在这种意义上,神也不可能从事任何自我意识的活动,因为那就会意味着由于思考先后出现的特殊思想而具有复合性,也因此而意味着变化。神决不和人相类似,他确实是单纯的太一,绝对的一。
流溢的隐喻
如果神是太一,他就不可能创造,因为创造是一种活动,而活动意味着变化。那么我们怎么能够说明世界中的许多事物呢?为了前后一贯地坚持神是太一这个思想,普罗提诺是通过这样一种说法来解释事物的起源的。他说,事物来自神,但不是通过自由的创造活动,而是通过必然性。为了表达出他所说的“必然性”是什么意思,普罗提诺运用了一些隐喻,特别是关于流溢的隐喻。事物流溢——它们从神那里流溢出来——的方式就像光线从太阳那里射出来一样,或者水从泉眼里流出来一样。太阳是永远不会枯竭的,而且它不“做”任何事,它只是存在。而且太阳因为是其所是,就必然发射出光来。神就以这样的方式成了一切事物的起源,而且一切事物都体现了神。但是没有什么东西和神是同等的。任何流溢物都落在了纯存在(也就是神本身)和完全的非存在之间的区域内。因而,普罗提诺并不像一个严格意义上的泛神论者——即主张神和作为整体的自然同一的人。虽然整个世界由神和它的流溢所构成,不过在自然中也还存在着一种等级安排,正如离太阳最近的光也就最亮一样,存在的最高形式也就是第一次流溢。普罗提诺把这种从太一中出来的第一次流溢描述为心灵(奴斯),它最像太一,但它又不是绝对的,因而可以说有某种具体属性或特征。这种奴斯是思想或普遍理智,而且它代表着作为世界之基础的合理性。这种合理性从本质上讲是不受时间和空间的限制的。不过合理性确实暗含了多样性,因为思想中包含了关于一切具体事物的观念。
世界灵魂 正如光从太阳中发射出来后其强度逐渐减弱一样,流溢物离神越远其完满性程度也越低。然而,每一个接着发生的流溢物都是下一个更低的流溢物的原因,就好像有某种原则在起作用,要求每一种本质都要产生比它低一级的东西一样。这样一来,奴斯就又是下一种流溢物的原因了。普罗提诺把这下一种流溢物称之为灵魂。世界的灵魂有两种朝向,向上看,它似乎朝向奴斯或纯粹理性,这时灵魂努力沉思万物的永恒观念;向下看,它又进一步地每次流溢出一种事物,并为自然之全体提供生命的原则。因而它跨越了事物(在奴斯中)的观念和自然世界的领域之间的鸿沟。灵魂的活动说明了时间的现象,因为现在有事物出现了,事物的相互联系就造成了事件,而事件是一个接着一个发生的,而事件之间的这种相继关系,就是我们所说的时间。确实,太一奴斯以及世界灵魂都是永恒共在的,所以它们都在时间之外。在世界灵魂之下的有自然和特殊事物的领域,它通过时间来反映变化着的永恒观念。
人的灵魂 人的灵魂是一种来自世界灵魂的流溢物。像世界灵魂一样,它也有两个朝向。朝上看,人的灵魂分有奴斯或普遍理性;朝下看,人的灵魂和肉体相联系——但不是相同一。在此,普罗提诺重申了柏拉图的人的灵魂预先存在的理论。他相信,灵魂与肉体的结合是一种“堕落”的产物。而且,肉体死后人的灵魂还活着,并且可以想象它进人到了从一个肉体到另一个肉体的不断轮回之中。由于它是精神性的从而是真实的存在,人的灵魂并没有被消灭,而是再次和所有别的灵魂一起进入到世界灵魂之中。而在肉体中,正是人的灵魂提供了理性的力量、感觉以及生命的能力。
物质的世界 在存在等级的最低层次上,也就是说,在离太一最远的地方的是物质。在流溢物中,有某种原则在起作用,它要求较高级的存在的流滋要与下一个可能性的领域一致。因而,在观念和灵魂之后,就有一个物质性的物体的世界,它显示出某种机械的秩序。这个秩序的运作或运动是理性在发挥作用,它使所有的物体都服从原因与结果的法则或规侧。物质世界又表现出一个较高的和一个较低的方面,其较高的成分是它对运动的法测的敏感性,而较低的方面也就是它的赤棵棵的物质本性,它是感觉迟钝的物质的黑暗世界,它带着惰性的不和谐,无目的地朝着冲撞和灭绝运动。普罗提诺把物质比作是光的最暗淡和最遥远的区域——光的末端的边界——其实就是黑暗。显然,黑暗是光明的反面。同样,物质是精神的反面,因而也是太一的反面。强调一下,就物质存在于和精神——无论这种精神是个人的灵魂还是世界的灵魂——的结合中而言,在这个范围内物质还不是完全黑暗的。但是正如光最终总要射到完全黑暗的地方一样,物质因而也就处在无的边缘上,并在那里向着非存在消逝。
造成恶的原因
通过流溢理论,普罗提诺论证说,神为了尽可能多地分出他的完满性而流溢出来。由于神不可能完满地复制他自身,所以,他这样做的惟一可能的方式就是说借助流溢物来代表完满性的所有可能的等级。这就必然不仅有奴斯,而且有最低层次的存在,也就是物质。然而,在这最低层次中,我们发现各种各样的恶:痛苦、持续不断的情欲的冲突,最后还有死亡和悲哀。万物归根到底是流溢自太一的,而完满的太一又怎么能够允许这种不完满存 在于人类之中呢?普罗提诺以各种不同的方式解释了恶的问题。他说,一方面,恶以自己的方式在完满性的等级中占有一个地位。如果没有恶,在万物的体系中就会缺少某种东西。恶就像一幅肖像的阴影部分,它极大地增强了这个形象的美。另外,像斯多噶学派早先所论述的那样,一切事件的发生都有严格的必然性,因而好人不把它们看成是恶,而坏人则可以把这看做是正义的惩罚。但是,普罗提诺发现对恶的最好的解释还是在他对物质的说明之中。
对于普罗提诺来说,物质是必然的,而且是从太一而来的流溢物的终极界限。正如我们曾经看到的那样,流溢物的本性是高层次必然向低层次运动,太一生成奴斯,而最终个体灵魂生成物质肉体。然而,赤裸裸的物质仍然在继续着流溢的过程,就好像阳光离太阳越远就越暗那样,离太一也越来越远。因而物质有一种脱离灵魂活动——或者是使自己与灵魂活动相分离——的倾向,以及进行某种不受理性支配的运动的倾向。再者,当物质仰面朝上时,它看到灵魂和理性的原则。对于自然中的物体而言,这表现为它们井然有序的运动,对于个人而言,它意味着身体在理性、感受性、欲望以及活力各层面上都是响应着灵魂的活动的。但是物质的本能倾向是俯身向下,这是由于流溢物的向下的惰性所致。由于自已有向下的趋势,物质碰到了黑暗本身,正是在这一点上,物质与合理性相分离。
灵魂和物质身体的结合为解释道德上的恶的问题提供了线索。尽管灵魂有理性的特征,它还是必须和肉体作斗争。而肉体的物质本性使得它向下运动而且摆脱理性的控制。当肉体到达低于合理性的层次时,它就陷入有无数种可能方式的运动。正是情感的作用使得身体对各种欲望作出回应。因而恶也就是在灵魂的正确意向与它的实际行为之间的不一致。这就是灵肉soul-boby安排上的不完满性,这种不完满性的原因主要被归结为物质身体的非理性的运动。
在物质是流溢的边缘这个意义上,物质或肉体是恶的原则,理性的缺失在此导致了无形式和完满性的最低程度。然而由于在一切都源自太一流溢的意义上,物质也是源自神的,所以可以认为,神是恶的来源。而且,在普罗提诺看来,恶并非是一种有肯定性存在的破坏性力量。它并不是一个“魔鬼”,或者与善神斗争的敌对的神柢,像某些琐罗亚斯德教的哲学家所认为的那样,是具有同等力量的光明与黑暗之间的竞争。在普罗提诺看来,恶只不过是某种东西的缺乏。它是完满性的缺乏,是物质肉体的形式的缺乏,而物质肉体本身实质上却并不是恶。所以,一个人所进行的道德上的斗争不是一场反对某种外部力量的斗争,而是一场反对内部的败坏、无序和情欲失控等倾向的斗争。而且恶不是事物,而是秩序的缺乏。肉体本身并不是恶,恶是物质缺少形式,就像黑暗是缺少光明一样。在整个分析中,普罗提诺试图既论证灵魂要为它的活动负责,又认为所有事件都是被决定的。只不过这两种观点怎么能够一致起来,这一点却并不十分清楚。同时,普罗提诺的感染力有很大部分来自他对救赎的承诺,他认为他的哲学能提供这种承诺。
得救
普罗提诺由对流溢的哲学分析进而提出宗教色彩浓厚的神秘的关于得救的设想。他那个时代的神秘崇拜让个人想和神结合在一起的愿望立即就得到满足。相反,普罗提诺把灵魂上升到与神的合一描述为一种困难和充满痛苦的使命。这种上升要求一个人要依次发展出伦理的和理智的德性。由于肉体和自然世界本身并未被看成是恶,所以无须一味排斥它们。普罗提诺的核心看法是:世界上的物理事物决不应使灵魂偏离它的更高目的。我们应当放弃世俗生活以便推进灵魂上升到理智活动,就像在哲学和科学中那样。我们必须在严格和正确的思维中锻炼我们自已。这种思维提升了我们,使我们超越了自己的个体性,而且一日有了关于事物的广博知识,我们就很容易把自我和世界的整体安排联系起来。这个知识阶梯上的所有台阶引导人们最终在一种迷狂状态中达到自我与太一的合一,在那里不再有任何与神相分离的自我意识。这种狂喜是正当行动、正确思考,以及恰当处置感情的最后结果。
普罗提诺意识到:达到这种结合可能要求每个灵魂多次投生。最终灵魂在爱中得到提炼和净化,而且,像柏拉图在他的《会饮篇》中所说的那样,要能够最彻底地交出自我。在这一点上,流溢的过程被完全颠倒过来了,而自我再一次融合在太一之中。对于许多人来说,普罗提诺的新柏拉图主义具有宗教的全部力量,而且相当于是基督教的一个强有力的替代物。虽然新柏拉图主义错综复杂的思想体系妨碍了它的广泛传播,但它给当时正在产生的基督教神学以相当大的影响。奥古斯丁在普罗提诺的《九章集》中发现了一种对恶以及由于有序的爱而得救的问题的崭新解释。通过奥古斯丁的中介,新柏拉图主义成为了中世纪对基督教信仰进行理智表达的一个关键要素。
第六章 奥古斯丁
6.1 奥古斯丁的生平
奥古斯丁十分关注自己的个人命运,这为他的哲学活动提供了椎动力。从很小时候开始,他就苦于一种道德上的深刻的困扰。这种困扰激发了他内心对智慧和精神上的宁静的毕生追求。354年,他出生在非洲努米底亚省的塔加斯特城。虽然他父亲不是基督徒,但是他母亲莫尼卡却是这个新信仰的虔诚信徒。16岁时,奥古斯丁在迦太基开始学习修辞学。迦太基是一个生活放浪成风的港口城市。虽然他母亲向他灌输了一些基督教思想和行为的传统,但是他抛弃了这种宗教信仰和道德,而且在这时与一位女子同居,和她生活了十年,还生了一个儿子。同时,强烈的求知欲推动着他严谨治学,并在修辞学的研习上成绩斐然。
他个人的一系列经历把他引上了一条研究哲学的独特途径。奥古斯丁在19岁时读了西塞罗的《霜滕修斯》,该书是一本倡导获取哲学智慧的读物。西塞罗的话语激发了他从事研究的热情,但是他陷入了一个难题:在何处才能找到理智的确定性呢?他的基督教的思想似乎不能使他感到满足。他尤其为一直挥之不去的道德上恶的问题所困扰。我们如何才能解释人类经验中恶的存在?基督徒说上帝是万物的创造者,而且上帝是善的。那么,一个由全善的上帝所创造的世界又怎么能产生出恶来呢?因为奥古斯丁从年轻时所学到的基督教中找不到答案,所以他转向了一个名为摩尼教的团体。摩尼教徒对基督教的很多看法是同情的,但由于自认为在理智上更胜一筹,他们不接受旧约中的基本的一神论理论,以及人类的创造者和救赎者是同一个神的观点。相反,摩尼教教导一种二元论的理论,根据这种理论,在世界中有两个基本本原,一个是光明或善的本原,另一个是黑暗和恶的本原。他们认为这两个本原同样是永恒的,而且相互之间是永远冲突的。他们相信,这种冲突在人的生活之中,就表现为由光明所构成的灵魂和由黑暗所构成的肉体的冲突。乍看起来,这种二元论的理论似乎对恶的问题提供了一个完满的回答,它克服了在一个善的上帝所创造的世界中却存在着恶这一矛盾。奥古斯丁现在可以把他的感性的欲望归为外在的黑暗的力量所致。
虽然这种二元论似乎解决了神创世界中关于恶的矛盾,但是它引起了新的问题。其一,我们如何理解自然中会有两个相互冲突的本原?如果不能给出令人信服的理由,理智的确定性又何以可能?更加严重的是,奥古斯丁意识到,说恶全都是由某种外在的力量所产生无助于解决他在道德上的困扰。强烈情欲的存在并没有因为对它的“谴责”被转向了某种它自身之外的东西而不再令人困扰而起先曾经把他吸引到摩尼教去的是他们夸口可以给他以能够讨论并能变得明白易懂的真理,这种真理无须像基督那样“先信仰而后理解”。因此,他与摩尼教断绝了关系。他认为,“那些被称为学园派(也就是怀疑派)的哲学家,比起其他的哲学家来更为明智,因为他们认为我们应当怀疑一切,而且没有可以为人类所理解的真理。”他这时被怀疑论所吸引,虽然同时他也保留了某种对上帝的信仰。他坚持了一种关于事物的唯物论观点,而且据此怀疑非物质实体的存在以及灵魂的不朽。
因为想在修辞学方面取得更大的成就,奥古斯丁离开了非洲来到罗马,很快又到了米兰。384年他成为米兰市的一位修辞学教授。在此,他受到安布罗斯的深刻影响。安布罗斯当时是米兰的主教,让奥古斯丁有些始料未及的是,从安布罗斯那里他得到的主要的不是修辞学的技巧,而是对基督教的更大的认同。在米兰期间,奥古斯丁喜欢上了另一位女子,而他已经把他的第一个情人留在了非洲。也正是在米兰,奥古斯丁接触到某些形式的柏拉图主义,尤其是在普罗提诺的《九章集》中建立起来的新柏拉图主义。在新柏拉图主义中有许多引起他注意的东西,其中首先有新柏拉图主义关于非物质世界是一个和物质世界完全分离的世界的观点。其次是有关人们具有某种能使他们认识神和非物质世界的精神性知觉的思想。第三是从普罗提诺那里奥古斯丁得到了恶不是肯定的实在,而是一种缺乏(也就是善的缺乏)的思想。最重要的是,新柏拉图主义克服了奥古斯丁先前的怀疑主义、唯物主义以及二元论思想。通过柏拉图的思想,奥古斯丁可以理解到并非所有活动都是物理活动,精神的实在和物理的实在一样,也是存在的。他看到了世界的统一性而无须设想在灵魂和肉体的背后有两个本原。因此他信从普罗提诺对实在的描绘,把实在看成是一个单一的等级系统,在其中物质只不过是处在最低层次上。
从理智上看,新柏拉图主义提供了奥古斯丁曾经寻求的东西,但是也留给他有待解决的道德问题。他现在需要的是与他的理智上的洞见相配的道德力量。他在安布罗斯的布道中找到了这种力量。新柏拉图主义最终使得基督教在他看来成了合理的东西,而且现在他也能践行信仰的活动,由此而得到了精神力量而并不感到自己正陷人某种迷信之中。他的戏剧性的皈依发生在386年,那时他“真正同意”放弃修辞学教席的前途,把他的生命完全献给哲学的追求,而对他来说,这种哲学意味着关于上帝的知识。他现在认为柏拉图主义和基督教事实上是一个东西。在新柏拉图主义中他看到了基督教的哲学表达,所以他说,“我确信,在柏拉图主义者中我将找到和我们的宗教不相反对的教导。”所以,他着手从事他称之为获取智慧的“我的整个计划”。他说,“从这一刻开始,我决心永不脱离耶稣基督的权威,因为我发现没有什么比这一权威更强大了。”不过,他依然强调说:“我必须以最大的理性精密性来追随这种权威。”
奥古斯丁著述之丰简直令人难以置信,由于成了天主教会的著名领袖,他作为信仰的捍卫者和异端的反对者而埋头写作。396年,他成为希波主教,希波是邻近他的出生地塔加斯特的一个海港城市。裴拉鸠(Pelagius)是他的许多反对者中的一个,奥古斯丁和他展开了一场著名的争论。裴拉鸠认为,所有的人都具有获得某种正当生活的自然能力,因而否认关于原罪的观念。原罪的观念认为,人的本性生来就是堕落的。奥古斯丁认为,裴拉鸠错误地理解了人的本性,因为他设想我们人的意志靠自身就能得到拯救,因而把神恩的作用贬低到了无以复加的地步。
这一争论完全昭示了奥古斯丁的思想方法,因为这场争论再次表明,他坚持认为,所有关于一切问题的知识,除了运用哲学的视角之外,必须顾及到《圣经》的启示真理。因为一切知识的目的都在于帮助人们理解上帝,这种宗教的维度在他的反思中显然占有优先地位。因此后来阿奎那这样谈起他:“奥古斯丁对柏拉图主义者的学说烂熟于心,一旦在他们的著作中找到任何和信仰相一致的东西时,他就予以采纳,而凡是他发现与信仰相反之处,就予以修正。”但不管怎么说,正是柏拉图主义把奥古斯丁从怀疑论中拯救出来,使得基督教信仰对他来说成了合乎理性的东西,而且激发了他的著述活动,这些著述堪称哲学和神学的伟大成就之一。430年,当汪达尔人兵围希波城时,奥古斯丁去世,享年75岁,死时还保持着诵忏悔诗的姿态一整个这一幕仿佛正象征着他动荡不宁的一生。
6.2 人类知识
信仰和理性
奥古斯丁与贯穿中世纪始终的有关信仰与理性的关系的长期争论有密切关系。这里的中心议题是要判定:重要的哲学和宗教信念究竟是建立在信仰还是理性的权威之上,抑或建立在两者的某种结合之上?以宇宙的起源为例,关于这个问题,无论哲学家还是神学家们,都是从古以来就提出了各种不同的观点:也许世界是自然而然地产生于原始物质的漩涡运动;也许它是原子的偶然碰撞的结果;也许它是由一个或许多神创造的。在一归纳这些可能性的时候,我们所倚为向导的究竟是信仰还是理性呢?选择信仰,就需要抱一种建立在天启基础上的信任态度;选择理性则反是,它所需要的信念要以有条不紊的演证为基础。
在讨论信仰和理性的问题时,早期的基督教神学家德尔图良坚决地倒向了信仰一边,这可以从他的两句名言里看出来。首先,他运用借代手法,问道:“雅典和耶路撒冷究竟有什么关系?”——他的意思是,理性(雅典)和信仰(耶路撒冷)全不相干。其次,在面对基督教道成肉身概念的矛盾时,德尔图良说:“正因为它荒谬,我才相信。”——他的意思是:信仰是如此截然不同于理性,以致成了非理性的。他争论道,宗教信仰不但反乎理性,而且高于理性。奥古斯丁在信仰与理性关系问题上的立场要温和得多,但他仍然认为信仰先于理性。对他而言,信仰照耀着理性,没有信仰就没有理解。《旧约》里的先知以赛亚声称:“除非你信,否则不会理解。”而受他的启发的奥古斯丁的观点可以概括为“信仰寻求理解”(fdesquaerens intellectum).
奥古斯丁认为,没有信仰和理性以这种方式的结合,就无法设想真正的哲学。要理解人类存在的具体状况,我们就必须从基督教信仰的角度对我们自己加以考虑,而这也就会要求从信仰的更高角度来考虑整个世界。在奥古斯丁看来,神学和哲学之间不可能有什么判然划分。事实上,他相信除非我们人类的意志已经得到转化,否则我们是无法进行正确的哲学思考的,而且清晰的思想只有蒙上帝的神恩才是可能的。所以,讨论奥古斯丁的哲学不可能不同时考虑他的神学观点。事实上,奥古斯丁并没有写过现代意义上的纯哲学著作。在这个意义上,奥古斯丁为中世纪基督智慧确立了主导方向和主要风格。
克服怀疑论
奥古斯丁曾一度认真地接受了怀疑派的思想——特别是学园派的怀疑论——而且同意他们的“人类不可能理解任何真理”这一观点。但是,在他皈依基督教以后,他的问题就不再是人们是否能够获得确定性的问题,而是人们如何能够获得它的问题了。因而,奥古斯丁力求回答怀疑派的问题。为此,他首先揭示出人的理性确实拥有关于各种事物的确定性,尤其是人的理性对矛盾律的认识是绝对确定的。我们都知道,一个东西不可能同时既在又不在。运用这个原侧,我们可以确定这样一些事情:比方说,要么有一个世界,要么有多个世界:如果有多个世界,那么它们的数量要么是有限的,要么是无限的。我们在此所知道的只不过是两个相反的东西不可能同时都是真的,而这并非什么实质性的知识。但是,对于奥古斯丁来说,这意味着我们并没有毫无希望地彻底迷失在不确定性中。我们不仅知道两个相反的东西不可能同时为真,我们还知道事情永远是如此。再者,他说,就是怀疑派也不得不承认怀疑活动本身就是某种形式的确定性,因为一个怀疑的人是确信他在怀疑的。于是就会有另一种确定性——我存在的确定性。因为如果我怀疑,我必存在。不论我如何怀疑一切,但我总不能怀疑我在怀疑。怀疑派认为,一个人可能睡着了,而且仅仅是梦见他看到某些东西或者是意识到自己。然而对奥古斯丁来说,这不是一个可怕的论证。因为他回答说,“无论他是睡着了还是醒着”,任何有意识的人都确定他自己存在着,他活着,而且他能思想。奥古斯丁说,“因为我们存在着,而且我们知道我们存在,我们还热爱我们的存在和我们关于它的知识。这些真理可以毫无惧色地直面(怀疑主义的)学园派的争辩。”17世纪,笛卡尔在他的经典命题“我思故我在”中,构造了一个相似的论证,接下来还把它作为他的哲学体系的基础。然而奥古斯丁则仅仅满足于用它来驳斥怀疑派的基本观点。奥古斯丁不像笛卡尔那样去证明外界事物的存在,而是设定这些事物是存在的,他谈及这些事物主要是为了描述我们是如何获得有关事物的知识的。
知识和感觉
当我们感知物体时,我们从感觉活动中获得了某种知识。但是根据奥古斯丁的说法,这种感觉方面的信息是最低层次的认知。不错,感觉确实给了我们某种知识。但是,由于感性知识给予我们的确定性是最少的,所以它处于认知的最低层次。这种缺乏确定性的情况有两个原因。第一,感觉对象总是在变化之中;第二,感觉器官也会变化。因此,感觉不仅因时异,而且因人而异。同样一个东西,一个人尝起来觉得甜,另一个人觉得苦,一个人觉得暖和,另一个人却觉得冷。不过,奥古斯丁相信感觉本身是准确的。他说,希望或者要求从感觉中得到比它们所能提供的更多的东西,这是不公正的。例如,当水中的桨在我们看来变弯了的时候,我们的感官并没有什么错。相反,如果那桨看起来是直的,那倒是有点问题了,因为在这种情况下桨就应该看起来是弯的。问题是出现在我们不得不对桨的实际情况作出某种判断的时候。如果我们同意说桨在实际上是弯的,那我们就上当了。奥古斯丁说,为了避免这种错误,“除了赞同现象的事实之外,不要说更多的东西,这样你就不会被欺骗了。”奥古斯丁就这样既肯定了感觉的可靠性,同时也认识到它们的局限性。至于感觉如何给我们以知识,奥古斯丁则是通过分析感觉的本性或机制的方式来加以解释的。
当我们感知一个对象时,究竟发生了什么?奥古斯丁依靠他对人的本性的柏拉图式的解释来回答这个问题:人是灵魂和肉体的结合。他甚至暗示肉体是灵魂的监狱。但是,当他描述灵魂是如何获得知识时,他却离开了柏拉图的回忆说的理论。他认为,知识不是一种回忆的活动,它是灵魂自身的一种活动。当我们看到一个物体时,灵魂(心灵)在它自己的实体中形成一个物体的图像。由于灵魂是精神性的而不是物质性的,物体不可能在心灵上形成一个物理的“印象”,像戒指留在蜡上的痕迹那样。因此,正是心灵本身产生了一个图像。不仪如此,当我们看见一个物体时,我们不仅感知到了一个图像,而且作出了一个判断。假如我们看到一个人而且说她很漂亮,那么在这种判断活动中,我不仅用我的感官看到了这个人,而且把她和一个标准进行了比较,而我的心灵能在其中得到这个标准的这个领域,是不同于我在其中感觉到那个人的那个领域的。
因而,感觉给我们某种知识,但是它的主要特征是它必然指向感觉对象之外的东西。我们被推动着从对一支桨的感觉出发去思考直和曲:从对一个非常漂亮的人的感觉出发,我们想到一般而言的美;从对小孩的感觉出发,我们想到了关于数的永恒真理。关于我们人的本性的问题也一再随着这些推理而被提出来,因为对感觉机制的解释,导致了对肉体和灵魂之间的区分。就为了感知事物需要某种肉体器官而育,感觉必然涉及到身体,然而,和动物不同的是,人并不是仅仅感觉事物,而且还具有某种关于事物的理性知识,并且作出关于它们的理性判断。当有理性的人作出这种判断时,他们不再仅仅依靠感觉,而是使他们的心灵指向别的对象,比如说美和数学的真理。所以,细致的分析表明:人的感觉活动至少包括了四种要素,它们是:(1)被感觉的对象;(2)感觉所依靠的身体器官;(3)在形成物体图像的过程中心灵的活动;(4)非物质的对象,也就是像美这类对象,心灵在形成有关被感知对象的判断时要用到它们。从这种分析中可以看出,人类在感觉活动中遇到两种不同类型的对象,也就是说,身体感觉的对象和心灵的对象。运用身体的眼睛人们可以看见事物,而运用心灵我们可以把握永恒的真理。这些不同的对象说明了不同等级的理智确定性。当我们使我们的可变的感觉器官指向变化的物理对象时,我们将难以有可靠的知识。相反,当我们不依赖感官而沉思永恒的真理时,知识将会更加可靠。感觉只是达到知识之路的开端,这条道路最终会导向发生在我们之中的一种活动,而不是导向我们之外的东西。知识从被感知的事物的层次出发,推进到一般真理的较高层次。在奥古斯丁看来,知识的最高层次是关于上帝的知识。感觉在获得这种知识的过程中起到了它自己的作用,它指引我们的心灵向上运动。因此,奥古斯丁说,我们“从外在向内在,从低级向高级”,而走向上帝。
光照论
在他对感觉和知识之间联系的说明中,奥古斯丁还有一个问题没有解决,那就是:我们的心灵何以能够作出涉及永恒必然真理的判断?在这点上,究竞为什么还会有问题呢?这问题就在于,迄今为止他对人类知识所作的说明中,知识所涉及的所有要素都是可变的或不完满的,因而也是有限的而非永恒的。被感知的对象是可变的,身体的感觉器官也是要变化的,心灵本身是一个被造物因而也是有限的而非完满的。那么,这些东西以某种方式安排后怎么就可以产生出高于它们自身之不完满性和可变性的东西,并揭示那些我们对之毫不怀疑的永恒真理呢?这种永恒真理使我们面对确实性的难以抗拒的力量,它们大大优越于我们的心灵仅凭自己的力量所能产生出来的东西,以致我们必须去适应它们或者和它们相一致。柏拉图在回答这个问题时运用了他的知识通过回忆获得的理论,即,灵魂通过回忆而记起它在进人肉体之前曾经知道的东西。相反,亚里士多德则主张,永恒的普遍的观念是理智从特殊事物中抽象出来的。这两种解决办法奥古斯丁都不接受。但是,他确实遵循了柏拉图的另一种见解,即关于可见世界中的太阳和理智世界中善的理念之间的类比的思想。
较之观念的起源问题,奥古斯丁更关注的是对我们的某些观念的确定性的意识。由于拒绝了回忆说和某种形式的天赋观念,奥古斯丁的思想更接近于关于抽象说。奥古斯丁说,实际上,人本身的构造方式决定了:当我们用肉眼去看一个物体时,只要物体是沐浴在光照之下,我们就能对这个物体形成图像。同样,只要永恒的对象也沐浴在与它们相适合的光照之下,那么我们的心灵也可以“看到”永恒的对象。正如奥古斯丁所说,我们应当相信,“理智心灵的本性就是这样的:通过月然而然地从属于只能用理智理解的世界,根据造物主的安排,它就能在某种惟一的非物质性的光中看见这些真理(例如数学的真理)。就像肉限在有形的光线之下看见周围的东西一样。”简言之,如果人的心灵想“看见”永恒的和必然的真理的话,它就需要光照。没有光照我们不能“看见”理智理解的对象或理智的真理。就像没有阳光我们不能看见世界上的事物一样。
当奥古斯丁说“在‘我们'之中存在着永恒的理性之光,在这种光中我们可以看到不变的真理"时,他以简洁的方式陈述了他的光照论。他通过这一理论所要说的东西并不十分清楚。然而对奥古斯丁来说很明显的是,光照来自上帝,这就像光由太阳发射出来一样。如果我们严格地运用这种类比的话,那么神圣之光必定会照亮某种已经存在于那里的东西。通过太阳光,我们可以看到树和房子,如果神圣之光起同样的作用,那么这种光也必定照亮某种东西——我们的规念。这种光与其说是我们观念的来源,还不如说是我们据以认识到真理的特质和我们观念中的永恒性的条件。简言之,神圣光照不是一种把观念的内容灌输进我们心灵之中的过程,相反,正是我们判断的这种光照使得我们能够看出某些规念包含着必然的和永恒的真理。上帝,作为这种光的来源,是完满的和永恒的,而人的理智是在上帝的永恒观念的影响下运作。这不是说我们人类的心灵可以认识上帝,但是这的确意味着,神圣光照允许我们去克服由自然物体的可变性和我们心灵的有限性所造成的知识的局限。因而,运用这种理论,奥古斯丁自感满意地解决了关于人类理智何以能够超出感觉对象之外并作出关于必然的和永恒的真理的判断的问题。
6.3 上帝
奥古斯丁对关于上帝存在的单纯神学思辨并不感兴趣。他关于上帝的哲学反思是他强烈追求智慧和精神之宁静的产物。他那沉溺于感官快乐之中的经历戏剧性地证明了灵魂不可能在肉体的快乐或感觉中找到宁静。同样,在他对知识确定性的追求中,他发现,由事物所构成的世界是充满变化和暂时性的。他还发现,他的心灵是不完满的,因为它有犯错误的可能。与此同时,他有认知某些确定而永恒的真理的经验,他能够把沉思真理的经验和享有快乐和感觉的经验加以比较。在这两种经验中他发现,精神的活动能够提供更持久程度也更深的宁静。他考虑到了一个技术性问题:有限的人的心灵何以能够获得超出其心灵能力的知识?他得出的结论是:这种知识不可能来自他之外的有限事物,也不能完全由他自己的心灵所产生。因为这种他能够获得的知识是永恒的,因此不能来自他的受限制的或有限的心灵,于是他被引向这样的信念:不变的真理必定在上帝中有其起源。人的知识的某些特征和上帝的属性之间的某种相似性使他得出这个结论,而这两者的相似性就在于它们都是永恒的和真实的。某些永恒真理(some eternal truths)的存在对奥占斯丁来说意味着永恒真理本身(the Eternal Truth)的存在,这种永恒真理本身也就是上帝。奥古斯丁就这样通过各种不同层次的个人经验和精神追求走向了那种等于是对上帝存在之“证明”的东西。
由于上帝是真理,因而在某种意义上,上帝是在我们之中。但是由于上帝是永恒的,他又超越于我们。然而,通过描述的方式,一个人对上帝还能说些什么呢?实际上,和普罗提诺一样,奥古斯丁发现,说上帝不是什么比界定他是什么要容易得多。然而,说上帝超越于有限事物毕竞是迈出了最主要的一步。按照《圣经》所说,上帝报给摩西的名,也就是:“我是自有永有的”,奥古斯丁对此的解读是:这意味着上帝就是存在自身。而这样的上帝就是最高存在。这和普罗提诺的没有存在的太一不是一回事。相反,“它是某种无与伦比的最好和最崇高地存在的东西”——这句话在几个世纪后影响到安瑟伦,使他提出他的本体论证明。作为最高存在,上帝是完满的存在。这意味着他是自在的、不变的、永恒的存在。因为完满,他也是“单纯的”,无论把何种复多的属性归之于他,结果都是同一的。这也就是说,他的知识、智慧、善和力量全都是一,而且构成他的本质。进而,奥古斯丁还推论说:日常事物所构成的世界反映了上帝的存在和活动。虽然我们看到的事物都会逐渐消亡因而都是可变的,然而只要它们存在,它们就有某种确定的形式,而这种形式本身是永恒的,而且是对上帝的反映。的的确确,奥古斯丁是把上帝视为整个存在之源泉,只要各种事物毕竟还有任何存在的话。
但是,正如奥古斯丁所说,上帝不同于世界上的事物,他“并不存在于空间的区间或范围之中”,同样也“不存在于时间的区间或范围之中”。简言之,奥古斯丁把上帝描述成纯粹的或最高的存在,这就暗示了,在上帝之中既没有从非存在到存在的变化,也没有从存在到非存在的变化。上帝是“自有永有的”。再次提醒一下,这条思想路线的基本力量在于它与解决奥古斯丁关于精神方面的问题有关——虽然奥古斯丁确信这种推理具有充分的哲学上的严密性。作为存在和真理的源泉和纯一的永恒实在,上帝对奥古斯丁来说,现在成了思想和情感两者的正当对象。由于上帝,心灵得到了启迪,意志获得了力量。并且,由于上帝是真理的标准,所有别的知识才是可能的。上帝的本质就是存在,存在也就是活动,活动也就是认知。由于是永恒的和全知的,上帝总是知道在创世过程中对自己加以反映的所有途径。因此,世界得以被形成的各种形式总是作为理想的样本存在于上帝之中,所以万物都是上帝永恒思想的有限反映。如果说上帝的思想是“永恒的”,那么当人们说到上帝“预知”将要发生的事时,在我们的语言中就会产生困难。然而对奥古斯丁来说,重要的是世界和上帝是密切相联的,而且世界反映了上帝的永恒思想,虽然上帝并不与世界同——而是超越于世界的。因为存在着上帝和世界之间的这种联系,所以知道了其一,也就在某种程度上知道了其二,这就是为什么奥古斯丁要如此确信:对上帝知之最多的人可以最为深刻地理解世界的真实本性,特别是人的本性和人的命运。
6.4 被造世界
奥古斯丁得出结论说:上帝是思想和感情最合适的对象,而物质世界不可能给我们真正的知识和精神上的宁静。但尽管他强调精神王国,他对物质世界还是给予了相当的注意。毕竞,我们必须生活在自然界,所以为了建立自己和自然界的恰当联系,我需要理解这个世界。从他已经提出的有关知识的本性和关于上帝的种种说法中,可以看出,奥古斯丁相信世界是上帝的创造。在他的《仟悔录》中,奥古斯丁说,无论我们朝哪儿看,万物都在说,“我们没有创造自身,是永生的他(He)创造了我们。”也就是说,有限的东西要求应当有某种永久的存在来解释它们何以能够开始存在。在他独特的创世论中,奥古斯丁所解释的就是上帝是如何与世界相关联的问题。
从无中创世
奥古斯丁独树一帜的理论是:上帝从无中(ex nihilo)创造万物。这和柏拉图对世界的说明相反。柏拉图认为,世界不是“创造出来的”,而是造物主把理念和容受者(receptacle)结合在一起而产生的,而这两个东西本身是永恒独立存在着的。奥古斯丁也离开了普罗提诺的新柏拉图主义,普罗提诺把世界解释成源自神的流溢物。普罗提诺说:在神之中有一种流溢的自然必然性,因为至善必然要扩散自身。而且,普罗提诺的理论还认为,就世界只不过是神的扩展而言,在神和世界之间有某种连续性。奥古斯丁反对所有这些思想,他强调:世界是上帝自由行为的产物。他从无中创造出构成世界的万物。因而,万物的存在都归因于上帝。然而,在上帝和他所创造的事物之间是有明显的区别的。普罗提诺把世界看作是神的流溢物因此也是神的延续,而奥古斯丁却说上帝创造了存在物,也就是创造了以前末曾存在过的东西。上帝不能从某种已经存在的物质中创造世界,因为物质,即使是在其最原始的形式中,也已经是某种东西了。说无形式的质料实际上就是指无。实际上,根据奥古斯丁的说法,每一事物,包括物质,都是上帝创造性活动的产物。即使是有某些无形式的而可以被赋予形式的质料,它们也必定在上帝之中有它们的起源,而且也必定是被上帝从无中创造出来的。物质从本质上看实际上是善,因为它是由上帝创造出来的,而且上帝不可能创造任何恶的东西。正如我们将会看到的,物质的本质上的善在奥古斯丁的道德理论中起了十分重要的作用。
种质(the seminal principles)
奥古斯丁特别注意到这样一个事实,即在自然的各个不同的物种中从未产生过新物种。马生马,花生花,就人而言,也是人的父母生人的子女。这一切之所以深深吸引住了奥古斯丁,是因为它和一般的因果性问题有关。虽然在某种意义上父母是子女的原因,老花是新花的原因,但是这些东西都不能把新的形式引进到自然之中。在被造物的秩序中,存在着的事物只能促使已经存在着的形式变成完成了的存在。奥古斯丁从这一事实(在这点上他显然没有决定性的经验支持)中得到一个结论,即万物形成的背后的原因是上帝的理智,在事物中没有初始的作为原因的力量能够形成新的形式。那么,事物、动物以及人又何以产生出任何东西呢?奥古斯丁的回答是:在创世活动中,上帝已经把种质(rationes seminles)植于物质之中,因而也就把所有会出现的物种的潜能安放在了自然之中。这些种质是事物的胚芽,它们是看不见的,但具有作为原因的力量。因而所有的物种都携有一种看不见的和潜在的能力,这种能力能够使它们成为它们现在尚不是的东西。当物种开始存在时,它们的种质——也就是它们的潜能——就得到了实现。现实的种子也就是这样把固定物种的延续从潜能转化为现实。一开始,上帝在一次完满的创造行动中就已经给所有物种提供了发育的本原。
奥古斯丁用这种理论解释了物种的起源,把它们的原因放在了上帝的心灵之中,种质就来自上帝的心灵。奥古斯丁认为,种质论还可以解决《圣经》上的一个难题。在《圣经》“创世纪”这一章中说,上帝在六天中侧造世界,它似乎和奥古斯丁关于上帝的观点不一致,因为奥古斯丁认为上帝应该是逐步创造出事物的。而且关于“六天”在此意味着什么也是一个问题,特别是,太阳是直到第四天才被“创造”出来的。种质论使得奥古斯丁能够说,上帝是一次创造所有事物的,这也意味着他把种质同时植人了所有物种之中。但是,由于这些胚芽是潜在性的本原,它们是那些将要存在的然而尚未“发育成熟”的事物的载体。因此,虽然所有的物种都是一次创造的,但是它们并不以充分成形的状态同时存在,它们依照时间点的顺序依次实现它们的每一个潜能。
6.5 道德哲学
由奥古斯丁发挥出来的每一哲学思想,都以这种或那种方式指向人的道德状况的问题。所以,对他来说,道德理论并不是某种特殊的或孤立的主题。每一事物在道德中达到了顶点,道德阐明了达到幸福的必由之路,而幸福则是人的行为的终极目标。于是在形成他的道德观点的过程中,奥古斯丁花了很大精力说明了他关于人的知识的本性、上帝的本性,以及创世的理论的主要观点。依托这些观点,他集中探讨了人的道德结构的问题。
我们人类的道德追求是一种特殊的和具体的条件的结果。这个条件就是:我们被创造出来的方式决定了我们要追求幸福。虽然古希腊人也曾把幸福看成是善的生活的顶点,但是奥古斯丁的理论对什么是真正的幸福以及如何才能得到幸福的问题提出了一种新的看法。其他哲学家也曾主张幸福是我们生活的目标,比如亚里士多德就说,当人们通过和谐有序的生活而实现了他们的自然功能时,他们就获得了幸福。然而,奥古斯丁则主张,真正的幸福要求我们越出自然之外达到超自然的东西。他以宗教的和哲学的两种语言来表达这一观点。在《忏悔录》中他写道:“上帝啊,你为了你自己创造了我们,以致我们的心不得安宁,直到它们在你之中找到了它们的安宁。”他还用更有哲学性的语言表达了同样的观点:人的本性是如此地被造成的,以致“它自己不能成为使它幸福的善”。简言之,没有纯粹的“自然”的人。奥古斯丁说,之所以没有完全自然的人的原因在于:自然并不产生人,人是上帝创造的。因此,人的本性总是带有被造的标记。这就意味着,和别的事物一样,在人和上帝之间存在着某些永恒的联系。我们追求幸福,这并非是偶然的,相反这是我们的不完满性和有限性的必然结果。我们只有在上帝之中才能找到幸福,这也决不是偶然的,而是因为上帝使得我们只能在上帝中找到幸福。通过爱的理论,奥古斯丁详尽阐述了人的本性这个方面。
爱的作用
根据奥古斯丁的看法,我们不可避免地爱。爱就是走出我们自身之外,而且把我们的感情加之于某个爱的对象之上。也正是我们的不完满性促使我们去爱。人们可以选择的爱的对象具有一个很宽广的范围,它反映了人们是以各种不同的方式成为不完满的。我们可以爱(1)自然物体,(2)其他的人,或者甚至是(3)自己。所有这些事物都会给我们以某种程度的满足和幸福。而且,在某种意义上,所有这些事物都是爱的正当对象。因为没有什么东西本身是恶的——正如我们已经知道的,恶不是一种肯定的东西,而是某种东西的缺乏。我们的道德问题主要并不在于爱或我们爱的对象上。真正的问题在于我们依恋这些爱的对象的方式,以及我们对这种爱的结果的期望。每个人都希望获得幸福,希望从爱中得到满足。然而我们却是痛苦的、不幸的、不安的。为什么会是这样?奥古斯丁将之归咎于“失序的”爱——即我们对具体事物的爱的程度超出了这种爱所应有的程度,而同时,我们没有把最终的爱奉献给上帝。
恶与失序的爱
奥古斯丁相信,我们人有不同的需要,这些需要产生不同的爱的行动。实际上,在人的不同需要和能够满足它们的对象之间有某种相互联系。爱是使这些需要和它们的对象和谐一致的一种活动。除了那些促使我去爱事物,爱他人和爱自己的世俗需要之外,我们还有一种促使我们去爱上帝的精神需要。奥古斯丁对这个问题的详细论述多少用到了定量的方式,每个爱的对象都只能提供如此多的满足而不能是更多。人的每一种需要也同样具有可以量度的量。显然,满意和幸福要求爱的对象包含足量的用来实现和满足特别需要的东西,我们爱食物,而且我们消费与我们的饥饿程度相当的东西。但我们的需要并非都是这种原始意义上的物质需要。我们爱艺术的对象,是因为它们能够给我们审美的满足。在一个更高的层次上,我们需要人们之间的爱。其实,这种感情层次的爱所提供的快乐和幸福比起对纯物质的东西的爱所能提供的数量要更多,质量也更好。由此可以明白,人的某些需要的满足不可能通过替代物来得到。例如,我们对人类友谊的深切需要除了通过和别人的联系之外不可能由任何别的方式来满足。物不可能是人的替代物,因为物本身并不包含人的个性的独特成分。
因此,虽然每个事物都是爱的正当对象,但是,除了它特有的本性所能提供的之外,我们一定不要希望从它那里得到更多的东西。对我们的精神需要来说尤其是如此。奥古斯丁说,上帝造人就是让人去爱上帝,而上帝是无限的。因而,我们以某种方式被造,以致只有上帝这个无限者,才能给我们最终的满足和幸福。奥古斯丁说:“当作为居间物的善的意志坚守着不变的善时,…人们就在其中发现了幸福的生活。”因为“幸福的生活就是爱上帝。”因而,爱上帝是幸福生活不可或缺的要求,因为只有无限的上帝才能满足我们心中实际上是对无限的特殊需要。如果说爱的对象是不可替换的——例如,物不能代替人——那么任何有限的事物或人也都不可能替代上帝。然而我们全都满怀信心地期望,我们只限于爱物品、爱他人、爱自己就可以获得真正的幸福。这些东西都是有限的爱的正当对象,然而当我们为了寻求终极幸福去爱这些东西的时候,我们对它们的爱就是失序的。所谓“失序的爱”就在于我们期望从一个爱的对象那里得到的东西超过了它所能提供的限度,而这一点导致了人类行为中的各种反常现象。正常的自爱变成了骄傲,而骄傲则是让人的行为的方方面面都受到影响的最主要罪过。骄做的本质是认为人是自足的。
然而,人的本性的不变事实恰恰是我们无论物质上、情感上还是精神上都不是自足的。我们的骄做使我们背离上帝,把我们引向各种形式的放纵,因为我们试图用有限的存在物去满足无限的需要。因此,我们对那些事物的爱已经超出了正当的限度,这个限度本来是取决于这些事物本身所能起到的作用的大小的。我们对他人的爱有可能变成实际上对他人有害的东西,因为我们总是试图从那种友谊中得到比它所能提供的更多的东西。欲望纷出,激情迭起,结果人们就不顾一切地想通过满足所有欲望来获得宁静。我们变得失常,从而表现出嫉妒、贪婪、猜忌、诡计、恐慌,以及一种无法摆脱的不安。不需多长时间这失序的爱就会产生一个失序的个人,而失序的人又会产生一个失序的社会。不重构每一个人而想重构一个有序的或安定的社会或家庭是不可能的。严峻且不变的事实是:个人的重构和得救只有通过对爱进行重新整理(reordering love)才有可能——也就是说,只有通过恰当的方式去爱恰当的事物才可能。事实上,奥古斯丁认为:只有首先爱上帝,我们才能恰当地爱一个人,因为惟有如此我们方能不期望从人类的爱中得到那种只有从我们对上帝的爱中才能得到的东西。同样,只有当我们把自己放在上帝之下时,我们才能恰当地爱我们自已,因为没有其他办法来克服由骄傲所造成的破坏性后果,除非消灭骄傲本身。
作为恶的原因和自由意志
奥古斯丁不赞同柏拉图所说的恶的原因仪仅是无知的说法。确实,在有些情况下,我们不知道终极的善,因而也没有意识到上帝。不过奥古斯丁还是认为,“即使是不信神的人”也有“对人类行为中的各种事情加以恰当的赞扬或谴责的能力。”在此最重要的事实是:在日常行为中我们之所以懂得赞扬和谴责,仅仅是因为我们已经知道我们有某种责任做值得赞扬之事,不做应受谴责之事。在这些情况下,我们的境况就不是无知的,而是面临着选择的可能性。我们必须选择是转向上帝还是背离上帝。简言之,我们是自由的。我们无论选择何种道路,都是怀着追求幸福的希望。我们有能力指导我们的感情仅仅朝向有限的事物、他人或者我们自己,并且因此而背离上帝。奥古斯丁说,“这种背离和转向都不是被迫的,是自愿的行为。”
根据奥古斯丁的看法,恶或者罪,是意志的产物。它不像柏拉图说的那样是无知,也不像摩尼教徒所说的是渗透到身体之中的黑暗本原的作用。尽管有原罪,我们仍然具有意志的自由,然而这种意志的自由(liberum)和精神的自由(Libertas)不是一回事。因为真正的精神自由在今生是不可能完全得到的。今生我们可以运用自由意志作出错误的选择。但是,奥占斯丁认为,即使当我们做出正确选择时,我们也不具有去做我们所选择的善事的精神力量。我们必须有上帝神恩的帮助。尽管恶是由自由意志的活动所造成,德性却是上帝神恩的产物而不是我们意志的产物。道德法则告诉我们必须做什么,而归根到底它真正揭示给我们的是我们不能靠自己力量去做的事。因此,奥古斯丁得出结论说:“律法的建立是为了使人追求神恩;有了神恩,律法就可以实现。”
6.6 正义
对奥古斯丁而言,公共的或政治的生活和一个人的个体的或个人的生活是受同样的道德法则支配的。对于这两个领域来说,其真理的来源只有一个。而且他认为这个真理是“完整的、不容破坏的,而且不受人类生活中的变化的影响”。所有的人都认识到这个真理,而且都认为它就是自然法或自然正义。奥古斯丁把自然法看成是我们的理智对上帝真理的分有,也就是对上帝的永恒法的分有。奥古斯丁对永恒法的看法在斯多噶学派那里已经有了先声。那是在他们说到理性原则贯穿于自然中的一切时说的。这样一来,他们就赋予了这种理性以支配万物的作用和力量。他们的理论是:心灵(奴斯)作为理性的原则,构成了自然法。所以,斯多噶学派是把自然法看成是世界中理性原则的非人格化力量的作用,而奥古斯丁则把永恒法解释为一个人格化的上帝的理性和意志。他写道:“永恒法是上帝
6.7 历史和两座城
奥古斯丁使对上帝的爱成为核心的道德原则。他也通过他的失序的爱的理论来解释恶。由此他得出结论,人可以分成两类:一类是那些爱上帝的人,另一类是那些爱他们自身以及俗世的人。由于有两种根本不同的爱,因而也就有两种相反的社会。奥古斯丁把那些爱上帝的人称为“上帝之城”,把那些爱自己和爱万物的人称为“世俗之城”。
奥古斯丁并没有把这两个城分别等同于教会和国家。他强调,构成一个社会的决定性因素是它的成员的占主导地位的爱,然后他指出,那些爱俗世的人既可以在国家中找到,也可以在教会中找到。但并能不因此而得出结论说,教会包含了被称为上帝之城的那整个社会。同样,在国家之中也有爱上帝的人。所以这两个城在教会和国家之中都是交错在一起的,同时,又以某种看不见的方式有它们自身的独立存在。因此,凡是那些爱上帝的人存在的地方就会有上帝之城。凡是存在爱俗世的人的地方就会有世俗之城。
在两个城之间的冲突中,奥古斯丁看到了通往一种历史哲学的线索。他所说的历史“哲学”指的是历史具有某种意义。希腊早期的历史学家除了王国的兴衰以及不断重复的历史循环之外,看不出人类事务中还有别的模式。大家可以回顾一下,亚里士多德曾认为历史几乎不可能教给人们任何有关人性的重要知识。根据亚里士多德的说法,历史不同于戏剧,它所涉及的是个别的人、国家以及事件,而戏剧所涉及的则是普遍的状况和问题。但是奥古斯丁认为,所有戏剧中最伟大的戏剧是人类历史。在很大程度上的确如此,因为历史的作者是上帝。历史开始于创世,中间点缀着许多重要事件,诸如人类的堕落,以及上帝的道成肉身等等。现在历史则陷入到上帝之城和世俗之城之间的紧张状态之中。没有任何事情的发生是与上帝的最终天命无关的。奥古斯丁认为:他自己那个时代的政治事件尤其如此。
当野蛮的哥特人于410年洗劫了罗马时,许多非基督徒据此谴责基督徒,说他们过分强调了爱上帝和服务于上帝,淡化了爱国主义而且削弱了国家的防卫。为了回答这种指责和许多别的指责,奥古斯丁于413年写了他的著作《上帝之城》(The City of God)。在书中他论证说,罗马的衰落并非因为基督徒的颠覆活动。相反,是因为整个帝国中无处不有的猖獗恶行,而基督教的信仰和对上帝的爱可以防止这种恶。罗马的衰落在奥古斯丁看来恰好是上帝有目的地干预历史的另一个例证,他以此来力求建立上帝之城以限制世俗之城。奥古斯丁相信,我们全都能发现历史戏剧中的现实意义,因为我们人类的命运不可避免地和这两座城以及上帝的活动联系在一起。对人的存在和世界来说,有一种囊括一切(all-embracing)的命运,而且它将在上帝认为合适时和对上帝的爱占统治地位时实现。奥古斯丁用这些观点来理解他认为不如此理解就纯属杂乱无章的人和事,而且给这些人和事某种总体意义、某种“历史哲学”。
第七章 中世纪早期的哲学
罗马帝国在476年的崩渍,宣告了一个理智的黑暗时期的到来。摧毁罗马政治权力的野蛮人也捣毁了西欧的文化制度。学术研究陷于停滞,因为实际上整个古代文献都流失了。在接下来的的五六个世纪里,哲学得以维系是靠着基督教的学者们,他们成了古希腊著作传到西方的渠道。早期三个有影响的思想家是波埃修、伪狄奥尼修斯和约翰·司各脱·爱留根纳。
9世纪,神圣罗马帝国的查理大帝雄心勃勃地打算复兴古典学术。而且随着爱留根纳的系统性巨著《自然的区分》(The Division of Nature)的问世,我们本可以期望哲学在这个思想压抑的时期产生出来,而且重新在整个西欧繁荣光大起来。然而这个早先曾经出现过的持续复兴的前景,由于几个历史事件的发生而没能及时变成现实。在查理大帝死后,帝国也就分裂为几个封建邦国。罗马教皇的统治进入了一个道德上和精神上的衰弱时期。而且僧侣们在他们专有的教育和学术领域里没能进行有效的领导。而蒙古人、撒拉逊人以及斯堪的纳维亚人的入侵加大了这种阻碍力量,促成了文化的黑暗。在几乎100年的时间里,也就是10世纪的大多数时间里,几乎没有进行什么哲学活动。然而哲学确实在下一个世纪复兴起来,而且从 1000年到1200年它集中讨论了共相、上帝存在之证明、信仰和理性的关系等问题,在对这些问题进行讨论的过程中,哲学的几个源头都被发掘出来,希腊的、基督教的、犹太的和移斯林的思想被结合到了一起。
7.1 波埃修
中世纪早期最著名的哲学人物之一是意大利的罗马和帕维亚的安尼修斯·曼留斯·塞伏林·波埃修(Anicius Manlius Severinus Boethius,480-524)。他生长在基督徒狄奥多里克(Theodoric)的王国里。早年他被送到雅典,在那里他掌握了希腊语,并接触到了亚里士多德主义、新柏拉图主义和斯多噶主义。510年,他被提升到狄奥多里克宫廷宰相的位置上,后来也备极尊荣。然而,尽管声望素著,官阶显赫,他还是因严重的谋逆罪嫌疑而被剥夺了各种荣誉,受到了长期监禁,最后在524年被处以死刑。波埃修是中世纪早期把希腊思想特别是亚里士多德的某些著作传到西方的最重要的中介者。因为对希腊语学有所成,波埃修最初厂算把柏拉图和亚里士多德的著作翻译成拉丁文,而且揭示出他们之间表面上的差异何以能被调和起来。虽然这个雄心勃勃的计划未能实现,但他确实留下了很可观的哲学遗产,其中包括亚里士多德某些著作的译文,以及对这些著作以及被菲利(Porphyry)和西塞罗(Cicero)的著作的评注。此外,他还写了神学著作和论述所谓四种人文学术——算术、几何、天文和音乐——的论文。他把这四门学科称为四大高级学科(quadrivium),以区别于另外三门人文学术即中世纪学校中的三学科(trivium)——语法、逻辑和修辞学。在他自己原创的论文中,波埃修引证了许多作者的著作,表现出他对柏拉图、亚里士多德、斯多噶学派、普罗提诺、奥古斯丁以及其他哲学家都很熟悉,不过很显然,对他起了最重要影响的还是亚里士多德。他的著作获得了经典的地位,而且后来被包括托马斯·阿奎那(Thomas Aquiuas)在内的重要哲学家作为阐释古代作家和基本哲学问题的权威著作来引用。
哲学的慰藉
在帕维亚监中服刑期间,波埃修写出了他的名作《哲学的慰籍》。这本书在中世纪广为流传,而且影响持久,连乔叟也翻译了此书,而且他的《坎特伯雷故事集》有一部分就是以此书为蓝本的。《哲学的慰藉》是一本对话集,是作者自己和一个作为哲学之化身的人之间的对话。对话涉及到上帝、命运、自由,以及恶这些主题。在该书的头几页中,波埃修对哲学作了一个寓言式的描绘,这个描绘我们如今仍然能在欧洲的许多大教堂的雕刻门面上看到。他之所以用这种寓言性的方式看待哲学,最初起因是当他在狱中饱受煎熬时,试图靠写诗来克服他的优郁。这时,他自己凭借巨大的想象力所制定的新的哲学形象让他深受触动。哲学现身为一位贵妇人向他走来,这个女人有着一双极其敏锐的眼睛,暗示哲学有着高于人的本性的力量;这女人给人的印象是看不出她的具体年龄,这表示哲学是青春常驻的;在她的长袍上能看见一个希腊字母字,象征着实践哲学;还有一个字,象征着理论哲学。在它们中间有一架梯子表示向智慧攀登的阶梯。当波埃修从哲学发现,世俗的善和快乐决不能给他真正的幸福,一个人必须转向最高的善,而哲学是引向这种善的学问时,他就从哲学那里得到了安慰。但是,除了这种寓言性的解释外,波埃修还给哲学下了一个更专门的定义,称哲学为“对智慧的爱”。“智慧”这个词负载了这个定义的整个内容,对波埃修来说智慧意味着一种实在,某种自身存在的东西,智慧是产生万物的有生命的思想。在爱智慧的过程当中,我们爱的是思想和产生万物的原因。归根到底,对智慧的爱也就是对上帝的爱。在他的《哲学的慰藉》中,他没有谈到基督教,而是系统地表述了一种基于人类理性自身能够提供的东西之上的自然神学。
共相的问题
共相的问题,决非一个新的问题。它之所以作为一个基本问题对中世纪思想家产生深刻影响,乃是因为根据他们的判断,思想的事业很大程度上有赖于对这一问题的解决。这个问题的核心在于如何把人类思想的对象和存在于心灵之外的对象联系起来。心灵之外的对象是个别的和杂多的,而心灵之中的对象则是单一的和普遍的。例如,在通常的讨论中,我们使用“树”和“人”这样的词,但是这些词指的是我们用感官感觉到的实际的、具体的树和人。看见一棵树是一回事,思想它则是另一回事。我们看见的是特殊,而我们思考的则是普遍。当我们看到一个特殊事物时,我们把它放到某个种或属之中。我们从未看到过“树”或“人”,只看到“这棵栎树”或“约翰”这个人。树在我们的语言中代表所有实际存在的树,包括栎树、榆树等,而“人”也包括约翰、珍妮以及其他每个具体的人。那么,在这些一般语词和这些具体的树和人之间的联系是什么呢?“树”仅仅是一个词,还是指存在于某处的某个东西?如果“树”这个词指的是在这棵具体的栎树中的某种属于所有树的东西,那么这个词就是指普遍的东西。因而,共相也就是一般性名词。而存在于我们的心灵之外的对象则是单个的或特殊的和具体的。如果共相仅仅是在我们心灵中的观念,那么我们思想的方式与我们心灵之外实际存在的特殊对象之间是什么关系呢?我的心灵又是如何着手形成一个普遍概念的呢?在心灵之外有任何与我的心灵中的普遍观念相应的东西吗?
波埃修翻译了波菲利的《亚里士多德“范畴篇”导论》(Introduction to Aristotle's Categories),在该书中他发现了依据波菲利提出的某些问题而进行的关于共相问题的讨论。这些问题探讨的中心是一般观念和具体观念之间的关系。简言之,类和具体对象之间的关系是什么?波菲利提出这样三个问题:(1)类在自然中是真的存在,抑或仪仅是我们心灵的构想?(2)如果它们是实在的,那么它们是物质的还是非物质的?(3)它们是脱离可感事物而存在,还是以某种方式存在于它们之中?然而波菲利并没有回答他自己的问题,而波埃修则主要依据亚里士多德对这个问题的看法对此提出了系统的解答。
波埃修意识到这个问题的巨大难度。如果问题在于要发现人类思想是否符合我们心灵之外的实在,那么我们很快就会发现,在我们心中的有些观念并无与之对应的外部对象。我们可以想到半人半马的怪物,但是这种人和马的结合物并不存在。或者我们也可以想到一条如几何学家所设想的那样的线,但是我们在任何地方也找不到这样的线。半人半马的怪物的观念和线的观念之间有什么不同呢?人们会说,关于半人半马的怪物的观念是虚假的,而关于线的观念则是真实的。波被埃修在此要说明的是:我们形成概念有两种基本不同的方式,即组合(把马和人拼凑到一起)与抽象(从一个特殊的对象中抽出它的某种属性)。他想说的是,普遍的观念,例如类,是被心灵从实际的个别的事物中抽象出来的,因此是真实的观念。
关于共相是从个别事物中抽象出来的说法使得波埃修得出这样的结论:类存在于个别事物之中,而且当我们思想它们时,它们就变成共相了。共相以这种方式同时存在于对象之中和我们心灵中——在事物中实存,在我们的心灵中被思想。虽然波埃修把他的分析仅限于类,但这种共相不仪包含类,而且还有别的性质,诸如公正、善、美等。两棵树之所以都成为树,是因为作为对象,它们由于包含使它们存在的普遍基础而互相类似。同时,我们可以把它们两者都想象成树,因为我们的心灵发现在它们之中有同样的普遍要素。因而,这就是波埃修对第一个问题——即共相存在于自然中还是仅仅存在于我们心中这个问题——的回答。在他看来,它们是既存在于事物之中又存在于我们的心灵之中的。对第二个问题——共相是物质的还是非物质的——他现在可以说,它们既是具体地存在于事物之中,又是非物质地或抽象地存在于我们的心灵之中。同样,他对第三个问题即共相是和个别对象分离开来还是在它们之中被现实化的回答是,它们是既在事物之中,又和事物分离开来而存在于我们的心灵之中。
7.2 伪狄奥尼修斯
大约在500年左右,一部新柏拉图主义的著作集在西欧流传,这个集子被认为是使徒保罗在1世纪时的一位名叫狄奥尼修斯的弟子所作。他是古希腊雅典最高法院的法官。然而,因为这些著作收录了由较晚的思想家普罗克洛(Proclus,410-485)所发挥的思想,学者们现在认为这些论文大概写于接近500年的叙利亚,而作者用的是一个化名。因此,这些著作的作者被冠以“伪狄奥尼修斯”这个名字。伪狄奥尼修斯的论文试图系统地把基督教思想与新柏拉图主义联系起来。这些著作由《神圣名称》、《天国等级》、《教会等级》、《神秘神学》以及《书信十札》所组成。它们频频被译成拉丁文,而且有人为它们写了一些评注。在整个中世纪,伪狄奥尼修斯的影响是非常大的。关注完全不同的问题的哲学家和神学家们相当大量地使用了他的著作。神秘主义者对他关于存在物之等级的精巧理论大加利用,因为它为描述灵魂上升到上帝的过程提供了丰富的思想资源。阿奎那说明巨大的存在之链以及人类与上帝之间的类比关系时也运用了他的理论。最重要的是,他是最有力的新柏拉图主义思想来源之一,影响了对世界的起源、上帝的知识,以及恶的本性等问题的哲学思考。
对上帝的知识
伪狄奥尼修斯对世界和上帝的关系给出了一个说明,在其中他把新柏拉图主义的流溢论和基督教的侧世说结合到了一起。他希望避免潜在于新柏拉图主义理论中的泛神论思想,因为新柏拉图主义认为,万物都是由上帝流溢出来的。与此同时,他又希望确立凡是存在的东西都来自上帝的思想。虽然他显然也没有认为上帝的创世活动是一种自由意志的活动的明确观念。但是伪狄奥尼修斯仍然论证说:世界是上帝天意的产物。上帝在他自己和人类之间设置了一个存在物的实质性的阶梯或等级,这些阶梯或等级被称之为天使(heavenly spirits)。从存在物的最低等级到最高等级——上帝处在顶峰——有各种存在的等级。因为这种连续的存在阶梯或链条,伪狄奥尼修斯确实接近于泛神论和一元论了。他有时把这种阶梯描述为一束光线,他还以此来反对关于事物的多元论观点。上帝是所有被造物的目标,他以他的善和他所激起的爱把万物吸引到他自身那里去。
伪狄奥尼修斯认为,我们可以以两种方式达到对上帝的知识:一种是肯定的方式,一种是否定的方式。当我们采用肯定的方式时,我们把通过研究被造物所发现的所有完满的属性归之于上帝。我们可以把善、光、存在、统一、智慧以及生命这些名目给予神圣的东西。伪狄奥尼修斯说,这些名目在它们的完满情况下都是属于上帝的。仅仅只是在某种派生的意义上才根据被造物分有这些完满性的程度而属于人类。伪狄奥尼修斯认为,在一种十分严格的意义上,这些属性是存在于上帝之中的,因为上帝毫无疑问就是善,是生命,是智慧,等等。与之相比,人类只能在较低的程度上具有这些属性。但不管怎么说,上帝毕竞是更像人而不是更像比如石头那样的东西,因为对石头我们不能说它是善的、智慧的和有生命的。
虽然我们确实可以通过肯定的方式获得关于上帝的知识,但是伪狄奥尼修斯认为,否定的方式更为重要。伪狄奥尼修斯意识到:人们不可避免地会提出关于上帝的拟人化的观点,因此他着手从上帝那里除去所有被造物的属性。在他看来,很显然,上帝的特点正在于他没有有限被造物的那些属性。他一步一步地从上帝的概念中除去我们用来言说被造物的一切东西。以否定的方式,我们通过否定那些最不可能和上帝相容的东西——比如“迷醉和狂怒”——来考察上帝的本性。然后我们通过“排除”的方法,把各种范畴的属性从上帝的概念中除去。因为我们所知道的一切都是属于被造物世界的,所以“排除”的否定性方法,不是把我们引向一个关于上帝的清晰的概念,而是仅仪引向一种“无知的黑暗”。这种方法的惟一的肯定方面是:它能够确保我们知道上帝不是什么样子。因为上帝决不是对象,那他就是超越于可知事物的。这种观点对后来的神秘主义者有很大的影响,这些神秘主义者相信,当人上升到接近上帝时,人类通常形式的知识就被过强的上帝之光所造成的失明所湮灭。
根据新柏拉图主义的思想,伪狄奥尼修斯否认恶的积极的存在。如果恶是某种积极的东西,有某种实体性的存在,我们就会被迫沿着它追溯到上帝,把上帝当作恶的原因,因为所有的存在物都源自上帝。对于伪狄奥尼修斯来说,存在和善是一个意思,因为凡是存在的东西都是善的,而且如果某物是善的,它显然首先必须存在。在上帝之中,善和存在是完全同一的,因此,凡是来自上帝的东西都是善的。但是,这种说法的推论即恶和非存在是同义的却并非必然为真,不过,存在的缺乏会造成恶,因为它意味着善的缺乏。恶人在他们拥有积极存在的所有意义上都是善的,只是在不论哪方面缺乏某种形式的存在的情况下才是恶的,特别是在运用他们意志的过程中。在物质自然中,丑陋和疾病被称为恶和道德领域里的行为被称为恶都是出于同样的理由,即,它们在形式上有缺陷或者缺乏某种存在。失明是光的缺乏,非某种恶的力量的出现。
7.3 约翰·司各脱·爱留根纳
约翰·司各脱·爱留根纳的生平
在波埃修和伪狄奥尼修斯的时代过去3个世纪之后,西方义出现了另一位哲学大家。此人是一位不同凡响的爱尔兰僧侣,名叫约翰·司各脱·爱留根纳,他建立了中世纪第一个完备的哲学体系。810年他出生在爱尔兰,在一个修道院上的学,是他那个时代少有的几个掌握了希腊文的学者之一。无论从何种标准看,约翰·司各脱·爱留根纳都是一个才华出众的希腊学者。他可以随心所欲地运用他那时的哲学资料,由于有了这个条件,他所写的系统著作使他脱颖而出,成为他那个世纪最杰出的思想家。
大约在851年,爱留根纳离开爱尔兰而出现在秃头查理的官廷之中。那时候,他主要是投身于对拉丁文作者,特别是奥古斯丁和波埃修的研究。他为波埃修的《哲学的慰藉》写了一本评注。应秃头查理的要求,爱留根纳于858年将希腊文本的伪狄奥尼修斯的著作翻译成拉丁文,而且还为这些著述写了评注。他还翻译了早期神学家忏悔者马克西姆斯(Maximus)和尼斯的格利高里(Gregory of Nyssa)的著作。在翻译了这些著作之后,爱留根纳写作了他自己的名著《自然的区分》(The Divisionof Nature)。这本以对话形式写作的书大约写于864年。在这本书中,他承担了一个复杂的任务,那就是根据伪狄奥尼修斯的新柏拉图主义来表述基督教的思想和奥古斯丁的哲学观点。虽然这本书成为中世纪思想中划时代的著作,但是它却未能引起爱留根纳同时代人的注意。而许多后来的著作家则求助于这本书去印证异端理论,比如泛神论。这导致在1225年2月25日教皇洪诺留三世(PopHonorius?Ⅲ)对爱留根纳的《自然的区分》进行谴责,并下令将该书焚毁。尽管如此,还是有一些手抄本存留到现在。
自然的区分
爱留根纳的《自然的区分》一书中的复杂论证是围绕着他对该书书名中的两个关键词的特殊理解进行的。首先,爱留根纳认为“自然”一词指的是“存在着的一切”。在这个意义上,自然包括了上帝和被造物。其次,当他说到自然的“区分”时,他考虑的是对整个实在——上帝和被造物——加以区分的一些方法。此外,区分这个词还有一种特殊意义。爱留根纳说,有两种理解实在之结构的方法:一个是通过区分,另一个是通过分析。区分的意思是从较普遍的东西推进到普遍性少一些的东西。例如当一个人把实体区分为有形的和无形的时候就是如此。再往下,无形的又分为有生命的和无生命的,如此等等。另一方面,分析则是把区分的过程颊倒过来,让从实体中区分出的要素又回到统一的实体之中去。作为爱留根纳区分的和分析的方法之根基的是他对我们心灵的活动与形而上学的实在相一致的确信。当我们在作“区分”和“分析”时我们的心灵并非仅仅在和概念打交道,我们正在描述事物是如何现实地存在和活动的。如果上帝是终极的统一,那么事物和世界就是这个作为基础的统一所区分出的各部分。而分析侧是事物又返回到上帝那里去的过程。根据爱留根纳的说法,思想的法则是和实在的法则相一致的。
根据心灵中的这些区分,爱留根纳论证说:仅仅只有一个真实的实在,所有别的事物都依靠它,而且都返回到它那里去。这个实在就是上帝。在自然的全部实在中,可以做出四重区分,即:(1)创造的而非被造的自然;(2)被造的而且创造的自然;(3)被造的而非创造的自然;(4)既非创造也非被造的自然。
创造的而非被造的自然 爱留根纳的这种自然指的是上帝。他是万物的原因而他自身却无须被任何原因所产生。他无中生有地创造了所有被造物。按照伪狄奥尼修斯所作的区分,我们关于上帝的知识是否定性的,这是因为我们从经验对象中得到的属性,在严格意义上都不适用于上帝,上帝以他的无限性而具有一切完满性。为了确保即使像智慧和真理这样仿佛很适合上帝的属性未经认可也不能归到上帝身上,爱留根纳在它们之上都加上了一个“超”字,因此我们在说到上帝时,要说他是超智慧的、超真理的。亚里士多德的谓词或范畴都不适用于上帝,因为这些谓词都假设了某种形式的实体——例如,“量”意味着范围——而上帝并不存在一个可以限定的地方。爱留根纳沿着奥古斯丁的思路讨论了几个问题,诸如上帝的本性和由无中创世的思想等。然而当他继续讨论上帝与被造物的关系这个问题时,他的新柏拉图主义思想似乎占据了支配地位。而且对爱留根纳来说,很难不得出在上帝和被造物之间没有清晰的区别的结论。爱留根纳说:“当我们听说上帝创造万物时,我们只应当理解为,上帝存在于万物之中。”之所以这么说,是因为只有上帝才是“真实存在”,因此,凡是存在于事物中的都是上帝。
被造的而且创造的自然 这种划分指的是神圣的理念(divine Forms)"。它们是所有被造物的原型。它们是所有被造物所模仿的原因。根据爱留根纳的说法,说它们是被造的,并不是说它们自某一时间点开始存在。他所考虑的是一个逻辑的而非时间先后的顺序。在上帝之中,有关于万物的知识,包括万物原始原因的知识。这些原始原因就是神圣的理念和事物的原型。在所有的被造物都“分有”它们这个意义上,这些理念也进行着创造的活动。例如,人类智慧分有超智慧。虽然他在此用了创造这个词,但起决定作用的还是他的新柏拉图主义思想,这尤其是因为,在爱留根纳看来,创造并不是发生在时间之中,而是上帝的理念和被造物之间的一种永恒的联系。
被造的而非创造的自然 这是我们经验到的事物的世界。如果用学术名词来表述,它指的是原始原因的外在结果的集合。这些结果,无论是无形体的(如天使或理智),还是有形体的(如人和物),都是对神圣理念的分有。爱留根纳强调:这些事物——存在物的这种完备的等级排列——包含了作为其本质的上帝,尽管具体事物给人们以它们是个体事物的印象。他把事物的这种表面上的复多性比作光在孔雀毛上的各种反光。每一种颜色都是实在的,但是它却依赖于羽毛,因此,归根到底颜色不是一种独立的实在。在被造的世界中,每一个体之成为实在的,都是凭着它的原始原因,原始原因存在于上帝的心灵之中。然而上帝如果是什么东西的话,他就是一个统一体,而说理念、原型以及范型都在他心中也只是一种比喻的说法,因为这些东西一起构成一个统一体。由于这个原因,世界也是一个统一体,就像孔雀的羽毛一样,而世界和上帝又构成一个更加包罗万象的统一体,因为上帝是在万物之中。在爱留根纳看来,神圣理念处在上帝和被造物之间,就好像它们能够向“上”仰视上帝,向“下”俯视这些被外在化了的理念一样。但到最后,他的新柏拉图主义导致他抹去了理念、上帝和被造物之间的空间,把它们全都融合成一个统一体,而且最终成为了一种泛神论。
既非创造也非被造的自然 这最后的一重区分指的还是上帝,不过这时的上帝是作为被造物秩序的目标或目的的上帝。由于万物产生于上帝,它们也全都回归于上帝。运用亚里士多德的比喻,爱留根纳把上帝比作一个被爱者,他没有运动,但却吸引着爱他的人们。凡是从某种本原开始的东西都将再次回归到这同一本原,而这样一来,万物的原因把由它产生的各种事物都引向它自身。由于这种回归,所有的恶都将有一个终结,而人们也将找到他们与上帝的结合。
7.4 解决共相问题的新方法
正如我们看到的,中世纪关于共相的问题最初是由波菲利详细论述,而由波埃修加以回答的。这个问题在将近500年后又被讨论,而且造成了接下来持续几个世纪的激烈争论。虽然对这些问题的讨论颇受局限而且似乎显得不那么重要,但是参与者意识到一些重要的哲学的和神学的结论都要依争议的结果而定。关于共相的问题,至少有三个主要观点被提了出来,它们是:极端实在论、唯名论和概念论。
奥多和威廉姆:极端实在论
共相问题后来集中为一个简单的问题,即共相到底是不是一种实在事物的问题。那些认为共相实际上:是实在事物的人们被称为极端实在论者。这些人说,类概念是真实存在,而个别事物侧分有这些共相。然而,他们并没有走得像柏拉图那样远,柏拉图认为共相是理念,而且是脱离个体事物而存在的。实际上,实在论者认为,例如,“人”存在,但是它存在于许多人之中。
这种形式的实在论为什么会显得如此重要?我们在陶奈的奥多(Odo of Taurnai)的著作中找到了答案。奥多是一位著名的思想家,他曾任教于图尔的天主教经院。该经院建立在圣·马丁修道院中。奥多是坎布雷的主教,1113年死于安钦修道院。在他看来,实在论是某种传统神学教义的基础。例如,根据他的说法,原罪说要求对人的本性进行实在论的描述。实在论认为,存在着某种普遍的实体,它被包含在某一物种的每一个成员之中。他说,如果我们想准确理解人类本性的状况,我们就必须认识到:在亚当和夏娃的罪中,“人”的普遍实体被感染,以致所有的后代都继承了他们行为的后果。如果我们否认实在论,那么亚当夏娃所做的事就会仅仅属于他们自己,如果情况是这样,那么原罪概念所具有的力量就会丧失。
另一个极端的实在论者是威廉姆·香浦(Guillaume de Champeaux,1070-1121),他详细论述了两种不同的观点。起初,在他的同一性理论中,他认为,共相在它的所有成员中都是同一的,比如说“人”这个共相,在所有的人中是同一的。这个共相的全部实在性都包含在每一个人之中。区分珍妮和约翰的东西只不过是他们的本质或实体的次一级的或偶然的变形。阿伯拉尔(Abelard,1079-1142)对这条推理路线加以嘲笑说,如果每个人都是整个“人”的种,那么“人”也就存在于罗马的苏格拉底和雅典的柏拉图之中了。如果苏格拉底出现在凡是有“人”的本质的地方,而“人”的本质既在罗马又在雅典,那么苏格拉底就必须既在罗马同时又在雅典。阿伯拉尔说,这不仅荒谬,而且还导致泛神论。由于这种以及别的批评,威廉姆被迫采取了第二种理论,也就是“不区分论”(indifferentism),也就是一种反实在论的观点。根据他的新观点,一个物种的许多个体之所以是同种东西,不是由于它们的共同本质,而是因为在某些方面它们并无区别(not different),也就是说它们“不显区分”(indifferent)。
洛色林:唯名论
对极端实在论的一个最难以对付的批评是洛色林(Roscellinus或Roscelin)的批评。他出生在贡比涅,而且曾到英国、罗马以及图尔去游历。他在塔谢、贡比涅以及贝桑松任过教,是阿伯拉尔的老师。他的核心论点是:自然中只存在个体事物,类概念不是实在的事物。像“人”这样的类概念并不指示任何东西,它只是一个词(voces).或一个名称(nomen),由字母所组成而且表现为一种声音的传播,所以,只不过是空气而已。由于这个原因,关于共相的讨论成了关于语词而不是关于实在事物的讨论。洛色林希望从他的论证中引出一些明显的结论,尤其是三位一体中的三个位格是三个相互分离的存在,他们所共有的是一个词而非任何真正实质性的东西,因而他们可以被看成是三个神。因为这些观点,他被1092年举行的索松宗教会议指控犯了三神论的错误。当受到被革出教会的威胁时,他否认了这一学说。尽管这样,洛色林在关于共相问题的历史中仍起到了至关重要的作用。特别重要的是,他拒斥极端实在论,拒斥把共相变成一个事物的企图。
阿伯拉尔:概念论或温和实在论
洛色林在他的唯名论中似乎和另一方在实在论中一样,也是在走极端。这两者都属于极端的观点。阿伯拉尔所提出的观点则是力图避免这两种极端。1079年,他出生在巴莱的一个军人家庭。在他动荡的一生中,他和他的老师进行争论,和爱洛伊丝有过一段有名的罗曼史,他是布列塔尼修道院的院长,在巴黎则是一个著名的讲师,因为他的异端学说而受到英诺森二世的谴责,最后在克吕尼隐居,并于1142年在那里去世。
在共相问题上,阿伯拉尔说,普遍性必须首先归于语词。当一个词被用于许多个体时它就是一个共相。“苏格拉底”这个词不是共相,因为它只能用于一个人。而“人”这个词是共相,因为它可以用于所有的人。阿伯拉尔说,一个普遍性名词的功能在于它以特殊的方式指称个别事物。于是问题就在于:我们是如何构想出这些普遍性名词的?阿伯拉尔对此的回答是:一定的个体事物,由于它们存在的方式,使得任何观察到它们的人都会认为在所有这些个体事物中有某种相似性。这种所谓的相似性不是实在论者称之为“本质”或“实体”的东西,它的意义仅仅在于:事物在这些相似的方面是一致的。当我们经验一个个体事物时,我们既看它,也思考它或理解它。和眼睛不同,眼睛需要对象,而我们的心灵并不需要一个物质对象,因为它能够形成概念。因此,我们的心灵有做两件事的能力,其中一件就是形成关于个别事物的概念,比如“柏拉图”或“苏格拉底”,另一件就是形成共相的概念,比如“人”。关于个体事物的概念是清晰的,而关于共相的概念是模糊的。即使我们事实上知道共相指的是什么,我们也不可能清晰地把注意力集中在共相的精确意义上。作为心灵的概念,共相是和个体可感事物分离而存在的。但是作为被用于那些个体事物的语词,它们仅仅存在于这些物体之中。同一个词能够同时被用于好些个体,是因为每个个体已经以这样一种方式存在,使得它和别的与它相似的个体能够以同样的方式被设想。因此,共相是从个体中抽象出来的。这种抽象的过程告诉我们应当如何理解共相,却没有告诉我们共相是如何实存的。只要我们从事物中抽象出那些它们确实具有的属性,我们就恰当地理解了事物。因此阿伯拉尔得出结论说,共相是一个语词和概念,它代表了某种为该概念提供依据的实在。这依据指的是类似的事物存在并触动我们心灵的方式。就此而言,共相有一个客观的基础,但这个基础不是像实在论者所认为的那样是某种像事物一样实在的东西。阿伯拉尔也不同意极端唯名论者所说的,共相仅仅是一个没有客观依据的主观的观念或语词。阿伯拉尔关于共相的理论战胜了极端实在论和极端唯名论,赢得了时人的赞同。
7.5 🐮安瑟伦的本体论证明ψ(`∇´)ψ
安瑟伦在思想史上之所以著名,主要是因为他对上帝存在的证明。它在近几个世纪以来被称为“本体论证明”。安瑟伦l033年出生于皮埃蒙特(Piedmont),后来加入本尼迪克特僧团,最后成为坎特伯雷的大主教,并于1109年在此逝世。对于安瑟伦来说,哲学与神学之间没有清晰的界线。与在他之前的奥古斯丁一样,他特别关心为基督教教义提供理性支持,而且他已经把这些教义当作信仰的事接受下来了。他确信:信仰和理性会得出相同的结论。安瑟伦还相信,人的理性可以创立一种自然神学或形而上学,这种学说具有理性的一致性,而且并不依靠除理性之外的任何别的权威,然而这并不意味着安瑟伦否认自然神学和信仰之间的联系。正相反,他的观点是:自然神学在于给被信仰的东西以一种理性的说法。这方面他是彻头彻尾的奥古斯丁主义,说他并不企图单凭理性去发现关于上帝的真理,而是希望运用理性去理解他一直信仰的东西。所以,他的方法是“信仰寻求理解”。“我并非为了相信而去理解,”他说,“而是为了理解而相信。”他更是一清二楚:倘若他不是已经相信了上帝,他证明上帝存在的那桩事业是无从开始的。安瑟伦承认,人的心灵不可能参透上帝的奥秘。然而,从对上帝存在的理性证明来看,安瑟伦怀着一个有限的期望:“我仅仅希望对我的心灵所相信和热爱的真理有些许的理解。”
安瑟伦的实在论
在他设计出现在他的《宣讲》一书中的本体论证明之前,在更早的一本名为《独白》的书中,他系统地表述了另外三种证明。这三个论证反映了他的总体哲学取向,也就是他接受实在论,拒绝唯名论。他的实在论思想表露在他的这样一种信念中,他相信:语词不仅仅是声音或语法习惯,而是代表我们心外的实在的事物。简而言之,他的早期的三个论证是:(1)人们力图享有他们认为是善的东西。因为我们可以对那些多少具有善的事物加以相互比较,而这些事物必定分有一个且是同一个善。这个善必定是自身为善的,而且因此就是最高的善。人们可以以同样的方法去论证伟大。因此必定存在着某种在所有善和伟大中最善和最伟大的东西:(2)每一存在着的事物,要么由于某物而存在,要么由于无而存在。显然,它不能产生于无,因此,剩下的选择就只能是二者之一:一个事物要么是被某种别的事物所产生,要么是被它自己所产生。它不可能被它自己所产生,因为在它存在之前它是无。说它被某种别的东西所产生,将会意味着事物之间相互产生,但这也是荒谬的。因此,必定有惟一一个是来自自身且使其他万物得以存在的东西,而这就是上帝;(3)有各种等级或层次的存在,因而动物有比植物更高的存在,人比动物又有更高的存在。用类似于第一条论证的推理线索,安瑟伦提出结论说:如果我们不想继续向上运动到经过无限多的层次的话,我们就必定达到一种最高和最完满的存在,没有比它更完满的存在了。
所有这三个论证都是从一个存在着的有限物出发,然后沿着一个等级序列上溯,直到它们达到存在序列的顶点。安瑟伦的实在论在这里很明显的是受到柏拉图和奥古斯丁的影响。他自始至终设想:当一个有限事物分有了我们的语言称之为“善”、“伟大”、“原因”、“存在”等的东西时,这些语词指的就是某种存在着的实在。因此,有限的事物不仅分有个语词,而且分有了存在。而这种存在以其最大的完满性而存在于某处。和极端实在论者奥多和威廉姆一样,安瑟伦也感觉到,实在论的问题具有重要的神学含义——特别是对三位一体教义来说。如果我们否认一个具有同一性的实体存在于几个成员之中,那么三位一体说就会成为三神论,每一个成员就会是一个完全独立、互不相同的存在。按照安瑟伦的说法,“谁不能理解许多人何以会在种上是一个惟一的人,他也不可能理解几个位格的每一个都是上帝,加在一起又是惟一的一个上帝。”
本体论证明
安瑟伦意识到:他的上述三个关于上帝存在的证明都不具有数学证明的那种明晰性和力量。而且,他的修道士同仁们都想知道他是否能够把这些论证加以简化。因此,在对这问题作了深思熟虑后,安瑟伦说,他已经发现一个单一的、清晰的、堪称完美无缺的证明方式。他把这种证明发表在他的《宣讲,或信仰寻求理解》之中。关于这个证明,值得注意的第一件事是:安瑟伦的思想产生于他的心灵内部,而并不从这样一种假设出发,即每一种证明都必须开始于某种经验的证据,而心灵从这种经验证据出发方能合乎逻辑地推出上帝。安瑟伦追随奥古斯丁的神圣光照说。这种学说给了他直接通向某些真理的捷径。确实,在开始本体论证明之前,安瑟伦要求读者“进人到你心灵的内室之中”,而且“把那些除上帝以及有助于追寻上帝的东西之外的一切全都关在外面”,显然,安瑟伦在开始他的证明之前,是确信上帝存在的,因为他的说法是“除非我信,我将不会理解”。
这个证明本身的推理是简洁利落的。安瑟伦说,我们相信,上帝是“无法设想比他更伟大的存在的存在。”——或者更简洁地说,上帝是可以想象得到的最伟大的存在。那么,问题就在于:可以想象得到的最伟大的存在是真实地存在着的吗?有些人否认上帝的存在。安瑟伦引用了“诗篇”第14节第1行的话,“愚顽人心里说:没有上帝。”“愚顽”这个词在这段话中是什么意思?它指的是:那个否定上帝存在的人陷入了一种明显的矛盾之中。因为当这个愚顽人听到“可以设想的最伟大的存在”时,他理解了他所听到的,而且他所理解的东西可以认为是存在于他的理智之中的。但是对某种东西存在于理智之中是一回事,把它理解成某种实际存在的东西是另一回事。例如,一个画家,事先想到他打算画的东西。这时,在他的理智中有了对他要画的东西的一种理解。但不是把那幅还没被画出来的画理解为实际存在的。但是,当他后来画好了这画时,他就既在他的理智中有了这幅画,而且把这幅他画好了的画理解为实际存在着的。根据安瑟伦的看法,这里所证明的是,某物甚至能够在我们知道它实际存在之前就存在于我们的理智之中。所以,在愚顽人的理智之中有对“可以设想的最伟大的存在”这句话所指的东西的理解,即使这个愚顽人未必理解到这种存在确实存在。它存在于他的理智之中,因为当这个愚顽人听到这句话时,他便理解了它,而凡是我们理解了的东西都因此而存在于我们的理解之中。因而,即使是愚顽人也知道:至少在他的理智之中有一个可以设想的最伟大的存在。
这就把安瑟伦带到他的证明的要点上来了。我们将问我们自己下面这两个概念哪一个更伟大一些。(a)一个“可以设想的最伟大的在现实中存在的存在”;(b)一个“可以设想的仅仅存在于我们心中的最伟大的存在”。答案必定是(a),因为根据安瑟伦的看法,对于任何给定的存在来说,实在地存在比起想象的存在要伟大一些。现在,上帝被定义为“可以设想的最伟大的存在”。如果上帝仅仅存在于我们心灵之中,他就还可以成为更伟大的,也就是说,上帝就会成为“可以成为更伟大的最伟大的可能存在”,而这种说法就是一个矛盾。因此,为了避免这个矛盾,“可以设想的最伟大的存在”必定在现实中存在。在一个作为结论的析祷中,安瑟伦感谢上帝:“因为通过你的神圣光照,你丰盛的礼物,我现在才真正理解了我先前所相信的东西。”
高尼罗的反驳
在靠近图尔的马蒙梯尔(Marmontier)修道院中,另一位本尼迪克特派的僧侣高尼罗,出面为“愚顽人”进行了辩护。高尼罗并非要否认上帝的存在,只是想证明安瑟伦并没有构造出一个充足的证明。一方面,高尼罗论证说,“证明”的第一部分是不可能获得的。它要求在理解中有一个上帝的观念,这样愚顽人在听到这个语词的时候就能得到一个“无与伦比的伟大的东西”的概念。但是高尼罗说,愚顽人不可能形成这样一种存在的概念,因为在他经验到的别的实在中,不存在能从中形成这种概念的东西。确实,安瑟伦自己已经证明没有像上帝那样的实在。实际上,如果人的心灵能形成这样一个概念,那就没有证明的必要了。因为如果那样的话我们就已经把存在联系到一个完满存在物的某一方面了。高尼罗的另一个主要反驳是:我们常常想到某些实际上并不存在的东西,例如,我们能够想象一个“可以设想的无与伦比的最大岛屿”,但无法证明这样一个岛屿的存在。
安瑟伦对高尼罗的回答
安瑟伦作出了两点回答。第一,他说:我们,包括愚顽人在内,可以形成一个“可以设想的无与伦比的伟大存在”的概念。只要我们比较事物中的不同程度的完满性,而且上升到最大的完满性,即那种没有比它更完满的东西,我们就能做到这一点。第二,他认为高尼罗提出个完满的岛屿的说法表明他误解了这个论证的要点所在。“可以设想的无与伦比的岛屿”的整个概念作为概念来说是有缺陷的。这是因为“岛屿”根据它的本性是有限的或被限定了的,因此它不可能以无限(或“可以想象的无与伦比的伟大”)的方式存在。只有“存在”的概念才能在实际上超越有限的界限而以“可以想象的无与伦比的伟大”的方式存在。我们不妨说在这一点上安瑟伦胜了:在本质上有限的“岛屿”和潜在的无限的“存在”之间不存在真正的可比性。因而,本体论的论证经受得住高尼罗的批评,它有待后来各个世纪的哲学家来提出更加确实可信的批评。
7.6 穆斯林和犹太思想中的信仰和理性
大多数中世纪的思想都试图调和哲学和神学两大领域一也就是说,调和理性和信仰两大领域。而起主导作用的作者是基督徒,他们的著作在神学中混合着哲学。他们的宗教取问源于基督教传统的主流,因此大体而言是一致的。然而,他们的哲学取向则十分歧异,因为在不同的时代和不同的地方,他们受到不同哲学家的影响。就是在他们依托同个哲学家——例如,亚里士多德——时,他们也受到对其著作的不同阐释的影响。穆斯林的哲学家在中世纪是十分重要的,因为他们撰写的对亚里士多德著作的评注产生了重大的影响,许多基督教的著作家正是凭借这些评注来理解亚里士多德的思想的。结果,这些对亚里士多德思想的穆斯林解释不仅提供了关于亚里士多德的许多知识,而且也导致了协调信仰和理性两大领域时的许多严重困难。
在穆罕默德(570-632)的领导下,曾建立了一个庞大的穆斯林帝国,而其文化中心在波斯和西班牙,9世纪-12世纪期间,在那里发生了具有重大意义的哲学活动。在这几个世纪中,穆斯林世界关于希腊哲学、科学以及数学方面的知识远远超过基督教世界。而且,穆斯林世界比西欧早几个世纪得到亚里士多德的主要著作。许多希腊哲学家的文献被翻译成了阿拉伯文。而后来西方的拉丁文译本都是从这里来的。到了833年,巴格达的哲学已经名声大振,在那里还建立了一座经院,既是为翻译希腊哲学和科学的手抄本文献,也是为了进行创造性的学术活动。一代又一代卓越的思想家在这里工作,尤其是阿维森纳(Avicenna,980-1037)。穆斯林文化的另一个集中地是西班牙的科尔多瓦。在那里,另一位最重要的穆斯林哲学家阿威罗伊(Averroes,1126-1198)写下了他的许多哲学著作。虽然阿维森纳和阿威罗伊用阿拉伯文写作,而且是穆斯林,但是他们不是阿拉伯人。阿维森纳是波斯人,而阿威罗伊则是西班牙人。
阿维森纳和阿威罗伊都写下了对亚里士多德哲学的重要评注,而某些基督教作者把这些解释作为亚里士多德自己的观点接受了下来。因为这些阐释表现出亚里士多德学说与基督教的教义不符,有些中世纪的作者,例如波那文都(Bonaventura),认为必须拒斥亚里士多德的学说以避免谬误。因此,穆斯林哲学家有双重意义:一方面他们是把亚里士多德和别的希腊思想家的思想传到西方的传播者;另一方面,他们也是对亚里士多德加以解释的著作家,而这些解释成为中世纪哲学争论的基础。
阿维森纳
阿维森纳980年生于波斯,是一位了不起的学者。他学习了几何学、逻辑学、法理学、《古兰经》、物理学、神学和医学,16岁时就开业行医。他写了许多著作,虽然他的思想以亚里士多德为核心,但是他也表现出受到新柏拉图主义的影响,并能创造性地阐述问题。
阿维森纳对创世说的系统表述是特别重要的。在这个问题上,他把亚里士多德主义和新柏拉图主义的观点结合到一起,得出了一种在13世纪引起热烈争论的理论。阿维森纳首先给出一个对上帝存在的证明,他说:凡是开始存在的东西(就像我们经验到的一切事物那样)必定有一个原因。需要一个原因的事物被称之为可能的存在。原因如果也是可能的存在,那它肯定也是被先前的存在所产生的,而这先前的存在也必定有一个原因。但是不可能有这样的一个无限的原因系列。所以,必定有一个第一原因,其存在不是可能的而是必然的,他的存在在他自身之中而不是来自于一个原因,而这种存在也就是上帝。阿奎那后来大力运用了这种推理路线。
上帝处于存在的顶峰,没有开端,永远处在活动之中(也就是说永远在表达他的完满存在),因此,他总是在创造。因而根据阿维森纳的说法,创世既是必然的也是永恒的。这个结论在3世纪时让波那文都大吃一惊,认为这是一个严重谬误,而且还和《圣经》中的创世学说相冲突。根据波那文都的说法,创世的两个主要特点就是:它是上帝自由意志的产物,不是必然的;另外,创世发生在某一时间点上,不是永远都在进行的。
如果阿维森纳的形而上学使基督教哲学家遭受困难是因为他的创世理论的话,那么他的心理学甚至引起了更严重的关切。在他的心理学中,阿维森纳特别希望说明人类的理智活动。他的理论的核心是关于可能的理智和主动的理智的区分的问题。为了说明这种区分,阿维森纳运用了他的新柏拉图主义的存在物等级性的观点。他把人置于最低层次的有天使性质的存在物或者理智之下。也就是说,上帝创造了一个单一的结果,这个结果被称为理智,这种理智是最高的天使,但这种理智又产生出较低的理智。在这一下降的序列中有九个这样的理智,每一个都创造(1)一个低于它的理智,以及(2)相继领域的灵魂。因而第九个理智创造第十个也是最后一个理智,即主动理智,正是这个主动理智创造了世界的四元素以及人的个体灵魂。主动理智不仅创造人的灵魂或心灵,它还向这些被造的心灵“发射形式”。
阿维森纳在此所说的是,由于一个人的心灵有一个开端,所以它是一种可能的存在。所以,一个人具有一种可能的理智。在此,阿维森纳在存在和本质之间作出了明确的区别,他说那是在被造物中的两种不同的东西。也就是说,因为我的本质不同于我的存在,我的本质不是自动实现的,它并不因自身而获得存在。人的心灵的本质是认知,但是它并不总是知道。理智有认知的能力,它的本质是认知。但是它的认知仅仅是可能的。理智被创造时不具有任何知识,而是具有获得知识的本质或可能性。知识在人理智中的存在需要两个要素,也就是(1)我们借以能够向外知觉到可感事物的身体感官,以及在记忆和想象中内在地保存物体印象的能力;(2)在个体事物中通过抽象能力发现本质或共相的能力。但是——这也是阿维森纳的独特观点——这种抽象不是由人的理智而是由主动理智来进行的。主动理智照亮我们人的心灵使我们能够去认知,因而它也就把存在加在了我们心灵的本质之上。因为主动理智是所有人的灵魂的创造者,又是人类知识中的能动力量。所以,在全体人之中只有一个主动理智,它为全体人所分有。
波那文都也反对阿维森纳的心理学理论,理由是它威胁到每个人的分离的个体性的概念。阿维森纳的本意不是要做这样的推论,因为他实际上有一种每个个体灵魂不死的学说,也就是说,每个灵魂都将何归到它的来源之处,即回归到主动理智中去。但是,基督教的作者们往往容易在主动理智学说中看出个体灵魂的毁灭。他们还批评说,这种理论从根本上把人和上帝分离开了,因为是主动理智而不是上帝给人类理智以光照。个体的人的存在只是就物质被塑成肉体,灵魂成为肉体的形式而言的。然而,理智的主动的部分不是属于他们的。阿维森纳以这些方式给中世纪哲学注人了某些引起争议的论题。它包括:(1)创世的永恒性和必然性;(2)一种存在物的等级序列的分等和流溢;(3)关于那种既创造人类灵魂,又照亮可能理智的主动理智的学说;(4)与可能存在和必然存在相关联的本质与存在的区分。
阿威罗伊
和他之前的阿维森纳一样,阿威罗伊是一位极其渊博的学者。他于1126年出生在西班牙的科尔多瓦,在那里,他学习了哲学、数学、法理学、医学和神学。在和他父亲一样当了一阵法官之后,他成为了一名医生,但是他花了许多时间去写他那著名的评注。由于这个原因,在中世纪他被称为“评注者”。他在摩洛哥度过了他的晚年,并于1198年在此去世,享年72岁。
阿威罗伊认为亚里士多德是所有哲学家中最伟大的,甚至说自然之所以产生亚里士多德是为了树立一个人类之完满性的典范。由于这个原因,阿威罗伊围绕着亚里士多德的文本和观点来建构他的所有著作。在某些方面他不同意阿维森纳。一方面,虽然阿维森纳认为创世是永恒的和必然的,阿威罗伊却全然否认创世的思想。他说,哲学可不知道这种说法,这种说法只不过是一种宗教的信条。阿威罗伊也拒绝在本质和存在之间作出区分,认为在它们之间没有实在的区分(而这种区分导致阿维森纳作出了可能的理智和主动的理智的区分):相反,在本质和存在之间只有一种为了进行分析而作的逻辑上的区分。而且,阿威罗伊认为:一个人的形式是灵魂,然而灵魂是一种物质的而非精神的形式。因此,物质的灵魂和肉体一样是有死的,所以死后没有什么东西能活下来。而人之拥有不同于其他动物的特殊地位,是因为与低等的动物不同,人类通过知识与主动理智结合起来。我们已经看到,阿维森纳说,每个个体都有一种可能理智,因此都有一种独特的精神力量,然而对于所有的人来说,他们只有一个且是同一个主动理智。阿威罗伊否认人有分离的可能理智。因此,他明确认为人类知识就在在普遍的主动理智中,而且否认灵魂不朽的学说。毫不奇怪,基督教的思想家认为他的学说是不虔诚的,但是他的影响是巨大的,阿奎那常常引用他的著作。阿威罗伊不怎么看重神学,而且不遗余力地去区分哲学和神学、信仰和理性 各自的领域。
阿威罗伊学说中“最恶名昭彰”的是后人所称的“双重真理说”。此说的最极端形态认为两个互不相容的断言——比如,关于宇宙创生的互不相容的宗教和科学断言——可以同时为真。尽管阿威罗伊可能并不持这种极端看法,他的批评者们还是把这观点归到他名下。其实他的真正立场的出发点倒是够清白的。阿威罗伊说,哲学和神学各自都有其功能,这是因为有它们分别为之服务的各种不同类型的人。他设想有二种人:(1)靠想象而不是靠理性生活的大多数人,他们奉行道德是由于雄辩的传教士所灌输的恐惧心理。相反,哲学家不需要受到威胁,他们的行为是出于他们的知识。虽然宗教和哲学一般说来是为了同一个目的而发挥作用,但是它们所传达的是不同的内容,从而在这个意义上传达的也是不同的真理。这些真理并不必然相互矛盾,它们仪仅属于不同的种类而已。因此,第一群人是由那些更多地被激动人心的观念支配而不是被理性支配的人们所组成的。(2)第二群人由神学家所组成。他们不同于第一群人的地方只在于,虽然他们有着与第一群人同样的宗教信仰,但他们打算为了他们的称义而谋求理智的支持。但是,由于他们把思想置于一些僵化的假设之上,而使思想有失公允,所以即便他们对理性的力量有所认识,也还是不能达到真理。(3)第三群人也是最高的一群人由哲学家所组成。他们只是极少数。他们能够欣赏那些笃信宗教的人们和理性的神学家所追寻的真理,但是他们看不出有什么理由非得通过拐弯抹角的宗教视角去领略这种真理。哲学家是直接地认知真理的。实际上,阿威罗伊认为,宗教具有某种社会功能,因为它们使哲学真理能够进入到那些不具哲学思维能力的头脑里去。然而,他认为,神学家和一般民众比起来应当更加明智,不要把繁复深奥的推理能力运用到宗教这样的主题上,而宗教的本性是与理性相编离的,虽然它并不一定与理性相反。
摩西·迈蒙尼德
摩西·迈蒙尼德1135年出生于科尔多瓦,和阿威罗伊是同时代的人,而且阿威罗伊也出生在那里。后来他被迫离开西班牙,先去了摩洛哥,后来去了埃及,在埃及以行医为业。1204年,他死于开罗,享年69岁。他的主要著作是他的名为《迷途指津》的书。在这本书中,他着手来证明,犹太教义与哲学思想是一致的,并且《圣经》的思想提供了某些单凭理性不能发现的确凿见解。为了达到这个目的,迈蒙尼德引用了数量惊人的文献,不过,主要是亚里士多德的著作。
除了陈述那些别人也研究和教导过的亚里士多德观点,迈蒙尼德还提出了某些独特的看法,我们在此列举其中的几个。第一,迈蒙尼德相信在神学、哲学和科学之间——也就是信仰和理性之间——不可能有根本冲突。他的《迷途指津》基本上是向那些研究过哲学家的科学而被宗教的律法(Torh)字面含义给弄糊涂了的信教的犹太人宣讲的。他认为,哲学是一类不同于来自宗教律法的知识。虽然这两者并不冲突,但是它们的范围和内容还是不同的。由于这个原因,并非每一种宗教学说都会有一种理性的或哲学的解释。
第二,创世的学说是一个宗教信仰的问题。虽然亚里士多德的哲学暗示了世界是永恒存在的——没有时间中的创世——迈蒙尼德却指出:在这个问题上,哲学的证明并无决定性的力量,也就是说,从哲学上证明和反对创世学说是同样有力的。
第三,迈蒙尼德认为,信仰和理性之间的冲突产生于两个原因,即,宗教的拟人化的语言和思想糊涂的人用来讨论信仰问题的混乱方法。我们必须一步步从数学和自然科学推进到对律法的研究,然后进到形而上学或专门的哲学神学。有了这种方法论的训练,就更容易理解圣经中大量说法的寓言性质。但要发现宗教语言中的这种拟人化要素,人们还必须受到科学范畴和哲学概念方面的训练。
第四,迈蒙尼德同意阿维森纳关于人的本性的结构的说法。像阿维森纳一样,他接受了主动理智是一个人的实质性知识的来源的理论。每个个体都只有一个可能的或被动的理智,这个理智只属于他或她。每个人都获得一个能动理智,它要么就是一种主动理智,要么按照每个人优越性的程度而在不同程度上来自主动理智。到死的时候,作为肉体形式的人的灵魂也就消灭了,惟一存留下来的要素是能动理智这一部分,它来自主动理智而且现在又复归于它。如果这是一种灵魂不死的学说,那么在这样的一种学说中每个个体的独一无二的特征已经被大大削弱了。
第五,迈蒙尼德提出了几种对上帝存在的证明。他利用亚里士多德形而上学和物理学中的某些部分,证明了第一推动者的存在,一个必然存在物的存在(这也是建立在阿维森纳的基础上)以及一个第一原因的存在。迈蒙尼德认为,无论世界是从无中创造出来的,还是永恒存在的,都不影响自然神学的事业。但是在证明了上帝存在之后,迈蒙尼德否认了言说上帝是什么样子的可能性。没有任何肯定的属性能被归于上帝,只能说上帝不是什么样子,从而把否定的属性归于他。
第六,人类生活的日标是获得专属于人类的完满性。迈蒙尼德说,哲学家已经弄清楚,一个人能够获得的完满性有四种。按照上升的次序排列,它们分别是:(1)占有的完满性,(2)身体结构和形状的完满性,(3)道德德性的完满性,最后是(4)最高的完满性,即理性德性的获得。迈蒙尼德说,所谓理性德性,“我指的是可知事物的概念,它所教导的是有关神圣事物的真实看法。那是真的实在中的终极目的,因而是给个人以真正完满性的东西。”这种对人类完满性的理性的说明在信仰中也有它的对应物,因为迈蒙尼德得出结论说:“先知也曾经解释了自身同一(self-same)的概念——就像哲学家已经对它们作过了解释一样。”信仰和理性是协调一致的。
第八章 阿奎那和他中世纪晚期的继承者
托马斯·阿奎那(Tomas Aquinas,1225-1274)的伟大成就在于他将古学和基督教神学的各种洞见结合起来了。虽然他从柏拉图和斯多噶主义那里吸收了古典哲学的论题,但阿奎那哲学之所以出类拔萃,还是在于它以亚里士多德为根基。阿奎那也意识到基督教作者们所造就的宏大思想视野,还有穆斯林和犹太哲学家所作的贡献。到他开始从事著述的时候,柏拉图和亚里士多德的大部分著作在西欧已经可以得到了。奥古斯丁曾经系统地建构了哲学与神学的早期结合,这种结合是把基督教信仰和他在新柏拉图主义者普罗提诺的著作中发现的柏拉图思想的一些因素结合在一起。奥古斯丁之后不久,波埃修(480-524)在6世纪第一次用拉丁文译介了亚里士多德的部分著作,因而再次引发了哲学的思辨。大约从7世纪到13世纪,有好几条思想发展的线索导致了柏拉图主义者和亚里士多德主义者之间的歧义和争论。
这种冲突以奥古斯丁主义者和托马斯主义者(托马斯·阿奎那的追随者)之间的争论的形式延续到13世纪之后,这是因为奥古斯丁和阿奎那是分别围绕着柏拉图和亚里士多德来建立各自的思想的。在这两派形成的这些世纪中,中世纪的思想家们殚精竭虑于哲学与神学的关系问题,他们将之表述为信仰和理性的关系问题。此外还有共相的问题。共相问题不仅反映出柏拉图和亚里士多德的不同观点,而且还为基督教信仰带来了许多重要的纠葛。通过厘清所涉及的问题,承认由不同的权威所提供的解决办法,回答对他的亚里士多德——基督教的解决办法的主要诘难,阿奎那对所有这些问题的讨论都产生了决定性的影响。以这种方式,阿奎那完善了“经院哲学的方法”。
这里所说的“经院哲学”这个词来源于在中世纪大教堂的学院中进行的理智活动,其倡导者被称为“经院博士”。后来经院哲学演变为专指那些经院博士创立的最有影响力的思想体系以及他们教授哲学时所运用的特殊方法。经院哲学企图把传统思想组合成一个首尾一贯的体系,而不是追求真正的创见。这种体系的内容大多是基督救神学和希腊哲学——柏拉图特别是亚里士多德的哲学——的融合。在经院哲学中,特色最鲜明的是它的方法。这种方法是这样一种进程:它主要依靠严格的逻辑推演,呈现为一种复杂的系统并以一种辩证的或辩论的形式加以表达,而在这种辩论中神学支配着哲学。另外,阿奎那完善了波埃修——“第一个经院学者”——作为关于神学主题的“学术性的”观点而建立起来的东西。波埃修极力主张“你应当尽可能地把信仰和理性结合起来”,而阿奎那则把信仰和理性的结合提升到了它的最高形式。在接受启示和传统神学真理的同时,他力图提供理性的论证以使这些启示的真理成为可以理解的。
8.1 阿奎那的生平
阿伞那于1225年出生在那不勒斯附近。他的父亲是阿奎诺(Aquino)的一位伯爵,他希望他的儿子有一天会取得基督教会中的高级职位。因此,阿奎那5岁时就被送到蒙蒂·卡西(Monte Cassino)诺修道院去当修童。在随后的9年中,他在这个属于本尼迪克特教团的修道院中进修他的学业。14岁时,他进入那不勒斯大学,然而在这个城市中,阿奎那被附近一个修道院中的某些多米尼克僧团的修道士的生活所强烈吸引住了,而且决定加入他们的修会。因为多米尼克僧团的成员特别专注于教学,所以,阿奎那在加入他们这个僧团之后,就决心献身于宗教和教学事业。4年之后,也就是1245年,他进人巴黎大学,在那里他受到一位杰出学者的影响,这位学者借凭自己巨大的理智上的成就而赢得了“大阿尔伯特”和“全能导师”的美称。在巴黎和科隆两地,在长期和亲密协助阿尔伯特的过程中,阿奎那的思想在各个关键的方面形成了。
阿尔伯特认识到哲学对于确立基督教信仰之基础和发展人类心灵的能力方面的重大意义。在别的神学家以孤疑的目光看待世俗学术的时候,阿尔伯特就得出结论说:基督教思想家必须掌握各类哲学和科学知识。他尊重所有的理智活动,而且他的著作表明他学养深厚且广博多样。可以说他熟知所有古代的、基督教的、犹太的以及穆斯林的著作家。然而他的头脑是百科全书式的而不是创造性的。不过,正是阿尔伯特认识到哲学和神学之间的根本区别,比他的先行者更加准确鲜明地划清了它们二者之间的界限。阿尔伯特认为,像安瑟伦和阿伯拉尔这样的一些学者把太多的能力归之于理性,而没有认识到,严格说起来,他们归之于理性的东西,大多实际上是属于信仰的问题。阿尔伯特特别想让亚里士多德学说成为所有欧洲人能够清楚理解的东西,希望把亚里士多德的所有著作都翻译成拉丁文,他把亚里士多德看成是所有哲学家中最伟大的哲学家,亚里士多德思想在13世纪能占统治地位,很大程度上要归功于他。正是在这样的氛围中,他的学生阿奎那也将看到,在亚里士多德的学说中有着对基督教神学最有意义的哲学支持。
阿尔伯特对他所引用的哲学家的著作未做任何的改变,阿奎那则不同,他对亚里士多德哲学的运用更富创造性和系统性,而且对亚里士多德思想和基督教信仰之间的一致性有着更为具体的认识。1259年到1268年间他中断了教学活动而托庇于罗马教廷,后来,阿奎那重返巴黎,并卷入了一场与阿威罗伊的追随者们的著名争论。1274年,罗马教皇格利高里五世召他到里昂去参加一个宗教会议。途中,他在那不勒斯和罗马之间的一个修道院里去世,时年49岁。
阿奎那留下了大量的论著,如果我们想到,它们全是在短短20年时间中写成的时候,这些著作的数量之巨就更加突出了。在他的基本著作中,有对亚里士多德许多著作的评注,还有辩驳希腊人和阿威罗伊主义者谬误的细心论证,早期的一部论本质和存在的卓越著作,一部论统治者的政治论文集,然而他最有声望的著作成就却是他的两部主要的神学著作,它们是:《反异教大全》和《神学大全》。
波那文都和巴黎大学
要想理解推动阿奎那哲学的那些争论,重要的是先要理解他在其中写作的中世纪大学的背景情况。第一批大学源自所谓的“大教堂学院”。巴黎大学就是由圣母(Notre Dame)大教堂学院发展而来的,其正式的组织和运作制度是1215年由教皇的代表加以批准的。起初,像所有早期的大学一样,巴黎大学由教师和学生构成,丝毫没有我们今天一想到大学就联想起的那些特殊的建筑或别的特征,例如图书馆和基金一这些是在14世纪和15世纪才添上去的东西。但是在那里并不缺最重要的要素:具有求知热情的教师和学生。既然本来就是教会机构,大学就和教会一样有着神学上的地位。这也意昧着,四大专科——神学、法学、医学和艺术——中的神学学科具有无可争议的最高地位。
除了以神学为主导之外,巴黎大学兼收并蓄了广泛的知识。这也就解释了亚里士多德哲学之所以在巴黎被逐渐接受和取得胜利的原因。然而,很明显,亚里土多德主义的引入将会给正统派的学说造成难题。这里不仅有对亚里士多德哲学冲击基督教思想的忧虑,而且还有一个严重问题,就是穆斯林哲学家对亚里士多德的解释是否忠实和准确。此外,奥古斯丁和柏拉图主义在牛津取得了胜利。这种思想虽然在巴黎并未占据支配地位,然而在此时的巴黎,与阿奎那同时代的波那文都强烈地表现了这种思想。波那文都批评亚里士多德学说,他认为,由于否定柏拉图的理念论,亚里士多德的思想一旦被结合到神学中去,就会导致严重的谬误。例如,否定柏拉图的理念就会意味着上帝在自身内并不具有万物的理念,因而对具体的和特殊的世界是无知的。接下去,这也会否定上帝的天意或者说他对世界的支配。这还意味着事件的发生要么靠机遇,要么通过机械的必然性。
更为严重的是波那文都指责说,如果上帝不思想世界的理念,他就不可能创造这个世界。在这个问题上,阿奎那和教会的权威们后来都退到严重的困难,因为根据亚里士多德的学说,阿奎那发现没有决定性的理由否认如下观点:世界是永恒存在的,而不是在某一时刻被创造的。但是,波那文都说如果世界是永恒存在的,那必定有无限多的人存在过,这样的话,要么就有无限多的灵魂,要么像阿威罗伊认为的,只有一个灵魂或理智,它为一切人所共有。如果阿威罗伊的这种论证被接受,它将取消个人灵魂不朽的理论。这种观点为13世纪主要的阿威罗伊主义者西格尔所极力主张。他说:仅仅只有一个永恒的理智,而且当个别的人出生和死亡时,这个理智依然保持着,而且总是找到别的人,在其中去完成它的组织身体和进行认知的功能,简言之,只有一个理智,它为所有的人所共有。
波那文都反对亚里士多德哲学,认为它引起所有这些错误,故而对基督教信仰构成了威胁。他提出奥古斯丁和柏拉图主义的观点与之对抗。然而,因为亚里士多德的思想是如此难以应付、如此具有系统性,特别是在关于自然和科学的问题上,所以它的向前推进是不可抗拒的,而且它的胜利最终也是不可避免的。如果大学中的大部分人都倾向于亚里士多德的思想,那么神学家们也不可能不向这位不朽的思想家让步。如果亚里士多德被接受,神学家们的特殊使命就是使他的哲学和基督教相协调。也就是说,使亚里士多德“基督教化”,而这正是阿奎那打算去做的事,同时他还要和波那文都的奥古斯丁主义和西格尔的阿威罗伊主义进行论争。
8.2 哲学与神学
阿奎那是作为一个基督徒来思考和写作的,他首先是一个神学家。与此同时,在写作他的神学著作时,他义在极大程度上要仰仗亚里士多德的哲学。他把哲学和神学集合在一起,这并不意味着他混淆这两种学科,正相反,他的观点是,在我们寻求其理的过程中,哲学和神学所起的作用是相互补充的。像他的老师大阿尔伯特一样,阿奎那花费极大力气去描述信仰和理性之间的界限,指明哲学和神学各自能提供什么和不能提供什么。13世纪思想中占支配地位的宗教取向涉及我们的上帝知识的重要性,阿奎那把哲学和宗教的洞见结合起来处理这个问题。关于上帝的正确知识之所以如此至关重要,是因为在这个主题上的任何基本的错误都可能影响一个人的生活方向——引导一个人或者朝向、或者背离上帝,而上帝是我们的终极目的。哲学产生于被人类理性所发现的原则,而神学则是对得自权威启示的原侧所作的理性整理,并被认作是信仰的问题。阿奎那的哲学大部分包含在他认为可以得到理性论证的那部分神学之中——这种神学也就是后来几个世纪的哲学家所说的自然神学。
信仰与理性
阿奎那看到了哲学与神学一理性与信仰之间的具体区别。一方面,哲学开始于感觉经验的直接对象,通过推理而上升到更一般的概念,最后,像在亚里士多德那里一样,我们把握住最高的原侧或存在的第一原因,最终达到上帝的概念。另一方面,神学则开始于对上帝的信仰,而且把万物说成是上帝的创造物。在此有一个方法上的根本差异,因为哲学家是从他们对事物之本质的理性描述中得出他们的结论的。相反,神学家则把他们的证明放在启示知识的权威的基础之上。神学和哲学两者并不相互矛盾。然而,并非哲学所讨论的一切对于一个人的宗教目的而言都是有意义的。神学所涉及的是人们为了得救所需的知识,而且为了确保这种知识,这种知识必须能通过启示而得到。有些启示的真理永远不可能通过自然理性被发现。而启示真理中别的部分,虽然单独通过理性就可以得知,但是为了确保我们真正熟悉这些真理,还是要靠启示。
由于这个原因,在哲学和神学之间就有某种重叠。但大体而言,哲学与神学是两门相互分离的独立学科。凡是理性有能力认知某物的地方,严格说来就不需要信仰,而只有信仰通过启示才能认知的东西,单靠自然理性也是不可能认识的。哲学与神学都涉及上帝。但是哲学家只能推断出上帝存在而不能通过对感觉对象的反思去理解上帝的本质属性。然而,在哲学和神学的目的之间还是有着某种联系,因为它们都和真理有关。亚里土多德曾认为哲学的对象是对第一原则和原因的研究,是对存在及其原因的研究。这就会引向一位第一推动者,他把这种第一推动者理解为宇宙中真理的基础。这就是以哲学的方式去述说神学家设定为他的知识对象的东西,也就是上帝的存在,以及由此而启示出的关于被造世界的真理。为了发现阿可奎那哲学的主要方面,我们必须从他的大量神学著作中选取那些在其中他试图以纯理性的方式来证明真理的部分。他的哲学方法在他试图论证上帝存在的过程中是特别明显易见的。
8.3 上帝存在的证明
阿啊奎那系统地阐述了论证上帝存在的五种证明或方法。这些证明表面看似很简短,每一个只有一段话。然而,某些重要的假设隐藏在它们的简洁性的背后。更为重要的是,他的方法是和安瑟伦的本体论证明相反的。安瑟伦是从“可以想象的无与伦比的伟大存在”的观念开始的,由此他推论出那个存在的实存。然而阿奎那说:所有的知识都必须开始于我们对感觉对象的经验。他不是从具有完满性的天赋观念开始,相反,他的五种证明全都以那些我们凭着感官经验到的日常对象的观念为基础。
从运动、致动因以及必然存在出发的证明
前三个证明都运用了同一种策略,这些证明后来被称为“宇宙论证明”。它们都以在世界中观察到的某个事实为起点,然后沿着所有的联系环节一直追湖到这个事实的最初来源。这个联系的链条很显然不能被追溯到无限远的过去,于是这个链条一定有一个最初的开端,我们便称之为上帝。
第一个证明是从运动出发的。阿奎那认为,我们能确定世界上有事物在运动,因为这对我们的感官来说是显而易见的。同样清楚的是,一切运动之物都是被他物所推动的。如果一物处于静止状态,那么除非被他物推动,否则它是不会运动的。当一物静止的时候,它只是潜在的处于运动状态。当潜在的处于运动中的一物受到推动而现实地处于运动中时,运动就发生了,因此运动是潜在性向现实性的转化。可以想象一列彼此相接的多米诺骨牌:当它们成列而立的时候,我们可以说它们是潜在的处于运动状态,虽然是现实地处于静止状态。现在考虑其中的某张骨牌,它的潜在性就在于,直到被相邻的骨牌推倒之前它是不会运动的:唯有被现实地在运动的某物推动时,它才会运动。阿奎那由此推出一个普遍结论:任何事物都不可能在一个同样仅仅处于潜在状态的事物的推动下走出潜在状态——正如一块骨牌不可能被另一块直立不动的骨牌所碰倒。潜在性意味着某种东西的缺乏,所以潜在性是“无”。因此,一块骨牌的潜在的运动不能推动相邻的骨牌,因为潜在的运动是“无”,而我们不能从不运动中得出运动。这正如阿奎那所说的:“一切事物除非受一个处于某种现实性状态的事物作用,否则是不能被还原到现实性的。”此外,同一个东西——例如一块骨牌——不可能同时既在运动的潜在性中又在运动的现实性中:现实地处于静止中的东西不可能同时又在运动。这就意味着一块骨牌不可能既被推动而同时又是那个推动者。潜在的处于运动中的某物不可能自己推动自已,被推动者都一定是被他物所推动的,最后一块倒下的骨牌原先是潜在的处于运动中的,但倒数第二块原先也是如此。每块骨牌都是被前一块骨牌推动之后,自己才成为推动者的。我们在此碰到了阿奎那的关键论点:要解释运动,我们就不能采取无穷回湖的办法。要是我们说,这个序列中的每个推动者原来又是被先前的推动者所推动的,那我们就永远不能找到运动的始源,因为那样一来,每个推动者就都只是潜在的处于运动中了。就算这个序列可以无穷回溯,每个运动者也仍然只是潜在的,从中绝不可能发生现实的运动。然而,事实却是,的确存在运动。所以,必然存在一个能够推动他物而无需被他物推动的推动者,这个推动者,阿奎那说,“每个人都把他理解为上帝。”
关于这个证明有两点应加以注意。首先,阿奎那的运动概念并不限于多米诺骨牌之类的东西,也就是说,并不限于位置移动。他所想到的是运动的最广义,也包括“生成“和“创造”的概念。其次,对阿奎那来说,第一推动者并不就是一个漫长的原因序列的第一个原因,仿佛这样一个推动者与其他的推动者是一样的,唯一的区别就是它是第一个而已。很显然,其实不是这么回事,因为这样的话这个推动者也就会只是潜在的处于运动中了。所以第一推动者必须是毫无潜在性的纯粹的现实性,因此它不是处于那个序列中,而是处在现实性中。
第二个证明是从致动因出发。我们经验到各种各样的结果,而且在每一种情况中我们对每种结果都归因于一个致动因。一座雕像的致动因是雕刻师的工作,如果我们取消了雕刻师的活动,就不会有作为结果的雕像。然而有一个致动因的秩序:雕刻师的父母又是雕刻师的致动因:采石场的工人是这块大理石之所以能被提供给雕刻师的致动因。总之,有一个可以在序列中加以追期的错综复杂的原因秩序。之所以需要这样一个原因序列,是因为没有什么事情能成为它本身的原因:雕刻师不能产生他自己,雕像也不能产生它自已。原因先于结果,这样,就没有什么东西能先于它自己,于是万事都需要一个在先的原因。每个在先的原因一定有它自己的原因,就像父母一定有自己的父母一样。但是不可能无穷后退,因为这一序列里的所有原因都依赖于一个使其他所有原因成为现实的原因的第一致动因。于是就一定有一个第一致动因,这个第一致动因“每个人都称之为上帝”。
第三个证明是从必然存在出发。在自然界中我们发现万物都是既可能存在,也可能不存在的。这些事物是可能的或者说偶然的,是因为它们并不是一直都存在而是有成有毁的。例如,曾经有某段时间一棵树不存在,然后这棵树存在,最后它又会不再存在。说这棵树的存在是可能的,必然意味着它不存在也是可能的。这个树不存在的可能性有两方面:其一,这棵树可能从来就没有开始其存在;其二,一旦这棵树存在了,它也就有将来不再存在的可能性。于是,说某事物是可能的,就必然意味着在其存在的两端——即它存在之前以及消亡之后——它是不存在的。可能的存在有这么一个根本特点,即它们有可能不存在。它不存在的可能不仪是在它已经存在之后,更重要的,是在它被创生、引起或推动之前。因此,某个有可能不存在的可能事物,事实上“在某个时候的确不存在”。所以,一切可能的事物,在某个时候的确都曾经不存在,它们将存在一段时间,最后又不再存在。“一旦可能事物开始存在,它们就会导致其他类似的可能事物产生出来,就好像父母生出儿女等情形一样。但是阿奎那作出了如下论证:可能事物自身中或其本质中并不含有其存在:而如果现实中的一切事物都只是可能的——也就是说,如果我们对每个事物都能说:在它存在之前和之后它都是可能不存在的——那么就会有某个时候任何事物都不存在。但如果有一个什么东西都不存在的时候,那么什么东西也都无法开始其存在了,甚至直到现在也不会有任何东西存在,“因为不存在的东西只有通过某种已经存在着的东西才能开始存在。”但既然我们的经验已经清清楚楚地向我们昭示了各种事物的存在,这就必然意味着:并非所有的存在物都只不过是可能的。阿奎那由此得出结论,“一定存在着某物,其存在是必然的。”于是他说,我们就必须承认,“某个自身就具有其自身的必然性,并且不是从他物那里得到这必然性,而是在他物中产生这必然性的存在者的存在。这个存在者所有人都称之为上帝。”
从完满性和秩序出发的证明
后面的两个证明建立在不同的策略之上。阿奎那的第四个证明是从我们在事物中看到的完满性等级出发的证明。我们在经验中发现,有些事物更善、更真、更高贵,有些事物则不那么真、善和高贵。但是,对事物进行比较的这种和那种方式仅仅是因为事物以不同的方式相似于某种极限的东西才成为可能的。必定存在某种最真、最高贵、最好的东西。同样,关于事物,我们可以说它们有或多或少的存在,或低或高的存在形式,就像我们在比较一块石头和一种理性的创造物时那样。因此,也必定有“某种最多存在的东西”。因而阿奎那论证说,在任何属中,体现最大值的东西是那个属中的每一事物的原因。就像火,火是最大的热,是所有热的东西的原因。由此出发,阿奎那得出结论说,“也必定有某种东西,对于所有的存在物来说,它是它们存在的原因,它们的善的原因,以及别的完满性的原因,而这种东西我们称之为上帝。”
最后,阿奎那构造了一个基于我们在世界中看到的秩序而提出的对上帝存在的证明。我们看到那些作为自然界之一部分的事物,或者是作为人的身体器官的事物,它们并不具有理智,然而它们却以某种有序的方式活动。它们以特有的和可以预言的方式去实现某些目的或功能。但是,这些缺乏理智的事物,像耳朵或肺这样的东西,如果没有得到某种具有理智的东西的指导,是不可能完成某种功能的,这正如一枝箭射向何方要由弓箭手决定一样。阿奎那得出结论说,“有某种理智的存在物存在,所有的自然事物都依靠它指导而朝向它们的目的,而这种存在我们称之为上帝。”
对证明的评价
阿奎那的五种证明,是一种实质性的理智成就,也属于西方哲学中最著名的那些论证之列。然而他的论证力量只取决于它们所建立于其上的那些假设。头三个证明在这一点上显得特别容易受到责难。这是因为,和阿奎那的看法相反,今天我们通过无限性来追溯一个无限的原因链条,这在逻辑上完全可以没有任何问题。与头三个证明有关的另一个问题是:即使这种证明成功了,它们也不导致一个有意识的和人格的上帝的观念。然而,这些证明阿奎那认为是宗教的上帝观的哲学确证,而且我们必须记住,它们是在他的神学任务的背景上构成的。不过,尽管头三个证明有这些问题,他的证明还是把阿维森纳的证明向前推进了。此外,当后来几个世纪的哲学家改进关于上帝的因果证明时,他们所依靠的就是阿奎那论证的修正形式。
第四个证明也是可以提出质疑的,这是因为它假设例如火是最大的热——亚里士多德是这一观点的始作俑者。而现代科学拒绝这种主张。至于最后一个证明——这是一个基于自然目的的证明——情况则有所不同。自阿奎那以后的几个世纪,哲学家们相信,基于世界中的自然秩序的现象,我们可以明确地证明上帝的存在。他们论证说,事实上,世界展现出设计的特征,而且对此的最合理的解释是:一个宇宙的设计者产生出对我们周周的自然的设计,对这种证明的最大挑战是产生于19世纪的进化论,达尔文和别的理论家提供了一个可供选择的完全自然化的解释来说明我们在自然界所看到的明显的设计现象。至少神学家们再也不能说一个宇宙的设计者是对设计现象的惟一可能的解释了。
8.4 对上帝本性的认识
对上帝存在的证明并没有确定地告诉我们上帝是什么。传统的神学都说:在人类知识能力与上帝本性的无限性之间有一道巨大的鸿沟。阿奎那时常意识到这道实质上不可逾越的鸿沟。他说:“神圣的实在是超乎人们对它的所有概念的。”然而这五种证明中的每一个都把某种东西加在了上帝的概念之中。作为第一推动者,上帝被看成是不变的因而是永恒的。作为第一因,上帝被看成是有无所不能的创造力的。说上帝是一种必然的存在而非可能的存在,也就是说上帝是纯粹的现实性。作为终极真理和善,上帝是自身完满的。作为宇宙的安排者和设计者,上帝是支配事物的最高理智。
否定的方式(Via Negativa}
虽然五种证明给了我们某种有关上帝的信息,但这些知识与其说是直接的,不如说是间接的。我们知道,我们所知的关于上帝的知识仪仅是以一种否定的方式得到的,也就是通过知道上帝不是什么而得到的。这种证明只不过表示:上帝是不被推动的,因此他必定是不会变化的。这必定意味着:上帝不在时间之中,因而是永恒的。同样,为了说明运动,就必须有某种不具有潜能的东西——具有潜能的是具体物质——所以,在上帝之中不存在物质性的东西。上帝是纯粹的活动,是非物质性的,因为在上帝之中既没有物质也没有潜能,所以他是单纯的,没有任何复合。这种上帝的单纯性的观念不是通过我们直接领悟而得到的,而是通过否定的方式得到的,通过这种方式我们把复合性、物质性等观念从上帝概念中除去。从哲学上看,上帝的单纯性意味着和那种既具有潜能又具有实在性的被造物不同,上帝只不过是纯粹的活动。因而,一个被造物有其存在,而上帝则就是其存在。在被造物中,存在和本质是两个东西,而上帝的存在就是他的本质。然而即便是上帝的这些听起来像是肯定性的属性,归根到底也是在说上帝不是什么,即,上帝不同于被造物。
类比的知识
人类所有的语言都不可避免地来自我们对我们已经感知到的世界中的事物的经验。由于这个原因,就像阿奎那已经认识到的,我们用于上帝身上的那些名目,和我们描述人类以及事物的名目是一样的。这些名目,如智慧或爱,一方面用于有限的人,另一方面用于无限的上帝时,确实不可能指的是同样的东西。然而,如果这些名目和语词在我们把它们分别用于描述被造物和上帝时,对我们来说指的是不同的东西的话,那么关键问题就是:从我们关于被造物的知识中我们到底能否得知任何属于上帝的东西。
阿奎那区分了我们人的词汇与上帝的联系的三种可能的方式。第一种可能的联系方式是单义的。在这种情况中,像智慧这样的语词,用于上帝和用于人类将会是指完全相同的东西,而且这暗示了上帝和人在本性上是相同的,这显然不是事实,因为上帝和人是不相同的,上帝是无限的,而人类是有限的。第二种可能的联系方式是阿奎那所说的多义的联系。在这种联系中,词语在运用于上帝和运用于人类时,各自指的是完全不同的东西,这意味着上帝和人是根本不相同的。这样的话,我们关于人的知识将不会给我们带来任何关于上帝的知识。然而,阿奎那坚持认为,由于我们是上帝的创造物,所以我们必定在某种程度上哪怕是不完满地反映了上帝的本性。第三种也是最后一种可能的联系方式是人和上帝既非完全相同,又非完全不相同。他们的联系是一种类比的联系,在这个意义上,它是单义和多义之间的中间道路。当智慧这样的词用于描述上帝和人时,并不是说上帝和人之为智慧的意义是完全相同的,也不是说他们之为智慧的意义是完全不同的。
对阿奎那来说,“类比”是一个本体论术语——也就是说,是一个与事物之存在或本性有关的词。“类比”这个概念指的是存在于上帝之中,也存在于人类之中的。这就不止是单纯的隐喻或直喻关系了。说在上帝和我们之间有一种类比关系,也就是说我们与上帝相似,“相似”在这里的意思是:我们在某种程度上是只有上帝才是的东西。例如,阿奎那说,人有某种程度的存在,而另一方面,上帝就是存在。因而,形成上帝和我们之间的类比关系的,是这样的事实,即我们是由与上帝共有的属性而和上帝联系起来的。人的本性从上帝那里获得其存在。这个事实说明在上帝和人之中有共同的要素。当我们使用诸如“智慧”这样的词的时候,我们指的是在上帝之中得到完满实现(对此我们并不完全理解),而在人类之中只得到部分实现的一种属性。智慧是某种既存在于上帝之中也存在于我们之中的东西。人的智慧的不同之处在于,我们的心灵居于我们的物质身体之中,而且要依赖我们的感官,当我们思考、言语时,我们一次只能说出一个语词或想到一个观念,因此是零碎散乱的。作为纯粹活动的上帝没有物质性的实体,他同时知道万物。所以在这里“类比”就意味着,我们知道上帝所知道的东西,但并非知道上帝所知道的一切事物,也不是以上帝知道它们的方式知道。再说一遍,这种类比关系之所以可能,是因为上帝的创造物具有与上帝的相似性。类比意味着我们同时既像上帝又不像上帝。认知到人是什么样子,也就是具有了某种程度的关于上帝的知识。由于这个原因,人们首先造出来人的那些名目和语词在运用于上帝时也有某种意义,只是在每种场合中的意义都要加以调整,以反映那种把上帝和人区分开来的不同存在等级和存在类型。
8.5 创世
在阿奎那对上帝存在的证明和上帝本性的整个讨论中,他都以创世的概念作为先决条件。根据对上帝存在的五种证明,我们的感觉对象不可能从它们自身中得到存在,而必须从第一推动者、第一原因、必然存在、完满存在以及宇宙的安排者那里得到其存在。然而,阿奎那看出了创世论中的特有的哲学问题。
被创造的秩序是永恒的吗?
根据《圣经》的启示,创世发生在某一时间点。然而,哲学的推理又何以能支持这种信条呢?阿奎那认为,不可能以一种哲学的方式去确定世界到底是永恒存在的还是在某一时刻创造出来的。世界是被创造的,这一点必然是我们由启示而知的上帝本性所决定的。作为纯粹的活动和自由,上帝愿意进行创造。阿奎那区分了作为自由活动的创造和像普罗提诺所说的那样一种必然的流溢。然而,由于上帝是一种纯粹的活动,所以他可以实施在永恒中创造世界的活动。简言之,说上帝创世和说上帝永恒地创世并没有矛盾。如果我们认为上帝在时间中创世的话,就有一个会引起矛盾的更加严重的问题,因为这可能意味着上帝中的潜能——也就是说,上帝在创世之前他就潜在的是一个创世者。阿奎那在这点上有些不确定,这导致了对他的学说之正统性的质疑。然而他坚持认为,亚里士多德认为上帝是从永恒中创世的,这是无可反驳的观点,尽管波那文都想加以反驳。最后,阿奎那接受启示的权威来解决这个问题,他得出结论说,这两种解决方法中的任何一种从哲学上看都是可能的。
无中创世
说上帝从无(ex nihilo)中创世,是什么意思?再者,阿奎那认为,如果上帝是万物的起源,那么就不可能有任何别的存在之起源。简言之,在这点上把上帝和一个艺术家相提并论是没有用的。艺术家是重新安排已经存在的物质,就像一个雕刻家雕刻一座雕像时一样。创世之前只有上帝存在,上帝不是在任何已经存在的物质的基础上行动的,因为不存在这样的原初物质。最初只有上帝存在,而且开始存在的东西是从上帝那里得到它的存在的。因而,每个事物都是上帝的创造物,因为它最终来自上帝,而且除了上帝之外没有别的独立的产生存在的来源。
这是最好的可能世界吗?
哲学家们经常沉思,现在的世界是否确实是上帝所能创造的所有可能世界中最好的世界?根据阿奎那的看法,要回答这个问题,我们需要在心里记住两件事。第一,和无限的上帝不一样,我们是有限的,所以我们的完满性将不及上帝的完满性。第二,宇宙不可能比被造物依据其本性所能成为的东西更好,或者说与后者不一样。在整个这种讨论中,阿奎那强调,整个宇宙之中必然到处都有某种限定,这只不过是因为创造某种类型的存在就限制了别的存在,世界只是在这样的意义上是最好的,那就是世界包含了那些已经被创造的事物的可能的最好安排。
作为缺乏的恶
如果上帝是全能的和善的,那为什么还有苦难发生?这个问题在我们考虑到一切事物的存在都是来自上帝时变得更加突出。因为在世界上存在着恶,那么恶似乎也得来自上帝。然而,阿奎那接近于奥古斯丁对恶的问题所提出的解决办法,即是说恶不是任何肯定意义上的东西。上帝不是恶的原因,因为恶不是一个事物,自然的恶也就是由自然力所产生的苦难所表现出来的在某种东西中的缺席(或缺乏),而这种东西若不是因为有了这种缺乏,其本身是善的。例如,失明在于视力的缺乏,同样,道德上的恶——也就是具有意志的人的选择所造成的苦难——也包含某种缺乏,因而不是一种肯定意义上的东西。在这个意义上,缺乏是由一类不适宜的行为所构成,虽然这种行为本身不是恶。阿奎那说,通奸者的行为是恶的,不在于这行为的肉体方面,而在于使它成为通奸的东西,也就是说在于恰当的行为的缺乏。但是,在道德领域中,好像有些人选择了纵情去做那些明显是邪恶的行为。阿奎那像柏拉图那样论证说,就对自己行为的意愿而言,人们总是希望他们的行为产生出某种善来,不论这些行为看起来会是多么穷凶极恶。通奸者决不愿意他或她的行为完全是一种恶,而是认为这种行为的某一方面是善的而且带来快乐。
被创造的存在的等级排列:存在之链
阿奎那把宇宙描述成包含着一个由事物构成的完备的序列,或者等级系统——就好像存在着一个巨大的存在之链。在种上和存在等级上,这些存在物都相互区别。存在物的这种完备的序列是必需的,所以上帝的完满性才能被最恰当地表现在全部被造的秩序之中,因为单个的被造物不可能恰当地反映出上帝的完满性。上帝创造了许多层次的存在,它们叠合在一起,在存在的结构上没有间隙。因而,低于上帝的是天使的等级,阿奎那称他们为理智,而且说他们是非物质的。我们之所以能够知道他们的存在,既是由于理性,也是由于天启。为了说明存在物从最低到最高的完备的连续性而不留任何不可解释的空隙,理性也要求他们的存在。低于这些天使的是人的存在,人的本性既包括物质的也包括精神的方面。再往下就是动物、植物,最终是气、土、火、水四元素。至于说到启示,《圣经》中以各种不同的语词说到这些天使,诸如本原、力量以及撤拉弗。
阿奎那指出,在各种层次的存在物之间没有间隙,它们像一条链子上的环一样联结在一起。例知,动物中最低的物种和最高形式的植物重叠在一起。而最高形式的动物相当于最低形式的人的本性,而人中的最高成分(理智)则与构成天使的独特成分是一致的。区分所有这些层次的存在物的是它们特有的复合本性,或者是它们的形式与质料的联结方式。在一个人中,灵魂是形式,而身体是物质性的实体。天使没有物质性的实体,而因为它们不具有这类质料——即那种把特定的属性归属于特定的个体的质料,所以每个天使就是它自已的种。因而,每个天使在存在的等级制中占有一个独立的等级,在它的存在的等级或量上不同于别的天使。最高级的天使是最靠近上帝的天使,而最低级的天使则最接近于人。低于我们人的是动物、植物以及单个的元素,这些等级全体表现了被造物的完备的序列。
8.6 道德与自然法
道德的构成
阿奎那的道德学说是建立在亚里士多德的伦理理论之上的。与亚里士多德一样,他把伦理学看成是对幸福的一种追求。进而,遵循亚里士多德的榜样,阿奎那论证说,幸福是和我们的目标或日的紧密联系在一起的。为了得到幸福,我们必须实现我们的目标。然而,亚里士多德设想的却是一种自然主义的道德,根据这种道德,人们可以通过实现他们的自然能力或目的而获得德性与幸福。阿奎那则在此之上增加了他关于人的超自然日的的概念。作为一个基督徒,阿奎那认为人的本性在上帝之中既有它的起源,又有最后的归宿。由于这个原因,人的本性之内并不包含它自己的实现标准。对我们来说,为了得到完满的幸福,仅仅作为人以及仅仅实践我们的自然功能和能力是不够的。而亚里土多德则认为这样的一种自然主义的伦理学是可能的。阿奎那同意这种说法的大部分内容,只是进一步指出,亚里士多德的伦理学是不完备的。所以阿奎那认为,对于道德而言,有一种双重的层次,它对应于我们的自然目的和超自然目的。
我们的道德经验的要素是由人的本性所提供的。一方面,我们具有身体的事实使我们倾向于某些类型的活动。我们的感官成为欲望和情感的工具。我们的感官也提供某种程度的关于可感对象的知识,以致我们被吸引到某些对象之上,这是因为我们认知到这些对象是可以使人愉快的和有好处的(爱欲);我们也抵制某些对象,这也是因为我们认知到这些对象是有害的、痛苦的,或者是坏的(恶欲)。这种吸引和拒绝是我们的爱和快乐、根和惧怕等能力的基础。
在动物中,这些恶欲和爱欲直接支配和引导它们的行为。然而,在人类中,意志要在理性的共同作用下,完成人的活动。意志是使一个人倾向于获得善的力量。也就是说,我们的所有欲望都寻求得到满足,而满足过程要求我们在可供选择的对象之间作出取舍。我们必须在理性的指导之下通过意志作出这种选择。如果我们作出了正确的选择,那么我们就获得了快乐,但是并非每一种选择都是正确的选择。由于这个原因,意志凭自己不可能总是作出正确的行为选择;而必须导之以理智。理智也不是知识的终极来源,因为我们的超自然目的要求上帝的神恩以及启示的真理。不过,意志仍然代表着我们对善和正当的欲求,而理智则具有理解什么是善的一般的或普遍意义的功能和能力。理智是我们的最高的能力,而自然目的要求理智以及别的能力追求它的适当对象。理智的适当对象是真理,而完全的真理是上帝,当理智指导意志时,它帮助意志选择善。然而,理智知道,有某种善的等级,而且有些善是有限的,一定不能将其误解为是我们最适当的和终极的善。财富、快乐、权力以及知识都是善,而且是欲望的正当的对象。但是它们不能使我们得到最深远的幸福,因为它们并不具有我们灵魂所追求的普遍的善的特征。完满的幸福在被造物中是找不到的,只能存在于上帝之中,而上帝则是最高的善。
道德的构成包括感觉、欲望、意志和理性。赋予一个人道德属性的是一些作为自由行动的组成成分的要素。如果我被我的欲望以某种机械的或严格决定的方式所推动,那么我的行为就不是自由的,而且不可能从道德的角度来加以考察。自由不仅是一个被看做是道德行为的先决条件,而且阿奎那还认为,一个行为只有当它是自由的时,它才是人的行为。因为只有有了对可选择行为的知识以及进行选择的意志能力,才可能有自由。德性或者善,就在于作出正确的选择,也就是在极端之间的中府。阿奎那同意亚里士多德的这种看法:当欲望被意志和理性所恰当地控制时,自然人的德性也就达到了。占支配地位的或“主要的”自然德性是勇敢、节制、正义以及审慎,除了这些特殊的德性之外,我们的自然目的通过我们关于自然法的也就是道德律的知识而得以进一步实现。
自然法
道德,如阿奎那所认为的,并非是任意的一套行为法则。毋宁说,道德责任的基础首先是在人的本性(nature)中找到的。各种倾向,诸如维持生命的倾向,繁殖物种的倾向,以及因为人是有理性的,所以还有追求真理的倾向,都是人的本性之中的部分。基本的道德真理只不过是“行善避恶”。作为一个理性存在,我有维持我的生命和健康的基本的自然责任,自杀和不爱护自己都是错误的。第二,繁殖物种的自然倾向形成了夫妇结合的基础,而对于这种关系来说,任何别的基础都是错误的。第三,因为我们追求真理,所以,我们只有和所有别的也致力于此的人在社会中和平共处,才能把这件事做好。为了确保一个有序的社会,人类制定了祛律,以便指导共同体的行为。在人类法律管辖之下的所有维持生命、繁殖物种、形成有序社会的活动,再加上对真理的追求——所有这一切都与我们本性的层次相关。道德律是建立在人的本性之上,建立在朝向特定类型的行为的自然倾向之上,也是建立在辨别行为的正确方向的理性的能力之上的。因为人的本性有某些固定的特征,所以对应于这些特征的行为规则被称为自然法(natural law)。
亚里士多德已经在很大程度上建立了这种自然法的理论,在他的《伦理学》中,亚里士多德区分了自然正义和约定正义。他说,某些形式的行为,只是在规范这样的行为的法律己经制定之后才是错误的。例如,以某种速度开车是错误的,只是因为限制速度的法规已经设立,但是在自然中并不存在要车辆以某种速度行驶的要求。所以,这样的法律不是自然的,而是约定的。因为在该法律被通过之前,以超出现在所限的速度行驶并无什么错误可言。另一方面,有些法律是源于自然的,所以它们所规范的行为总是错的,谋杀就是一个例子。但是阿奎那并没有把他对自然法的论述仅仅限制在这样的看法上,即人的理性以某种方式能够发现人类行为的自然基础。相反,他推论说:如果人的存在和本性只有在理解了和上帝的关系时才能被充分地理解,那么,自然法就必须以哲学的和神学的方式来加以描述,就像斯多噶学派和奥古斯丁曾经做过的那样。
阿奎那说,法律首先和理性有关,人类的理性是我们行动的标准。因为指导我们的整个行为去达成我们的目的,这是理性的事。法律由人类行为的这些规侧和尺度所构成,因而它是基于理性的。但是,阿奎那认为,因为上帝创造了万物,所以人的本性和自然法最好理解为上帝的智慧或理性的产物,从这种立场出发,阿奎那区分了四种法。
永恒法 这个法指的是这样的事实:“整个宇宙的共同体都被神的理性所支配,因此,在宇宙的统治者上帝之中,支配事物的思想就具有了法的本质。而且,由于神的理性所具有的事物概念不受时间影响,而是永恒的…所以这种类型的法必须被称之为永恒的。”
自然法 对阿奎那来说,自然法是永恒法专属于人的那部分。他的推理是:“万物由于印记在它们之上的永恒法,而在某种程度上分有永恒法…”,万物由此“得到它们各自的倾向性,倾向于它们的恰当行为和目的。”这点特别适用于人,因为我们的理性能力“也分有永恒理性的一部分,因而它有一种自然的倾向,倾向于它恰当的行为和目的”。阿奎那还说,“这种在理性的被造物中对永恒法的分有被称为自然法”,而且他强调“自然法无非就是理性被造物对永恒法的分有”。我们已经提到过,自然法的基本准侧是保存生命,繁殖和教育子女,追求真理和一个和平的社会。因此,自然法由大量的一般原则所构成,这些原则反映了上帝在创世时为人所作的打算。
人为法 这指的是政府的具体法令。这些法令或人为法派生于自然法的一般准则。正如“我们从本能地知道的不证自明的原则中得出各种科学的结论”一样,“从自然法的准则出发…人的理性也需要继续推进到关于特定问题的更为具体的决定上去”。而“这些由人的理性所制定的具体决定,被称为人为法。”人为法这个概念的深远意义在于:它驳斥了这样一种看法,即认为法之所以为法仅仅是因为统治者颁布了它。阿奎那认为,给一条规则以法的特征的是它的道德维度,它和自然法准则的相符,以及它与道德律的一致。阿奎那采纳了奥古斯丁的“凡是不正义的东西,根本就不像个法的样子”的说法,他说:“每种人为法在多大程度上来自自然法,就在多大程度上具有自然法的性质。”但是,他又说,“如果它在任何一点上偏离了自然法,那么它就不再是法,而是对法的歪曲。”像这样的法当然也就不再具有良心上的约束力了,而人们有时也遵守它,只是为了防止某种更大的恶。阿奎那比那种简单地对人为法所具有的违反自然道德法的特征加以否认的说法要进了一步,他说,这样的一个法令,不应当被遵守。他说,某些法“可能是由于和神的善相违背而是不公正的:这些就是导致偶像崇拜,或者导致和神法相违背的任何别的东西的暴君之法”。他得出结论说:“这种法一定不能遵守,因为…我们更应当服从神而不是服从人。”
神法 阿奎那说,神法的功能是指导人达到他们的恰当目的。因为我们注定除了世俗的幸福之外,还要达到永恒幸福的目的,所以,必定有一种法能够引导我们达到这种超自然的目的。阿奎那在此与亚里士多德分道扬镳了,因为亚里士多德只知道我们的自然目的和目标,而且对于这种目的而言,人类理性所认知的自然法被视为一种足以胜任的引导。但是人也被规定要达到永恒的幸福,而阿奎那说,这种永恒的幸福“是与一个人的自然能力成比例的”。所以“除了自然法和人为法之外,人应当由神所给予的法来指导其达到他们的目的,这是完全必要的。”因而,神法对我们来说,是通过启示而得到的,而且它也可以在《圣经》中找到,它不是人的理性的产物,而是由上帝的神恩给予我们的。这种神恩保证我们全都知道我们必须去做什么事,从而既实现我们的自然目的,更要实现我们的超自然的目的。自然法与神法之间的不同正是在于这样一点:自然法代表的是我们关于善的理性知识,通过这种知识,理智指导我们的意志去控制我们的欲望和情感,而这又引导我们通过获得正义、节制、勇敢和审慎这些基本美德去实现我们的自然目的。另一方面,神法则通过启示直接来自上帝,而且是上帝神恩所赠,通过它,我们被指导去达到我们超自然的目的,从而获得信、望、爱的神学德性。这些德性是由上帝的神恩注人人的本性之中的,它不是我们自然能力的结果。阿奎那以这种方式完成了而且超越了亚里士多德的自然主义伦理学。他揭示了人的想认知上帝的自然欲望何以是确实无疑的,以及启示何以成为理性的向导。他还描述了我们的最高本性如何被上帝的神恩所完善。
8.7 国家
阿奎那说,国家是一种自然的机构,它来自人的本性。在这点上,阿奎那与亚里土多德的政治理论是一致的,从亚里士多德那里,他接受了这样的说法:“人天生是社会的动物。”但是因为阿奎那对人的本性有不同的看法,所以他必定会有一种多少有些不同的政治哲学。这种不同表现在对国家的作用或任务的两种看法上。亚里士多德设想:国家可以为所有的人提供人们所需要的东西,因为他只知道我们人的自然需要。而阿奎那相信,除了我们的物质的或自然的需要之外,我们还有一个超自然的目的。国家并不是为了处理这种更为终极的目标而准备的。指导我们去达到这个目标的是教会。但是阿奎那并没有简单地把人类事务的这两个领域划分出来,一归国家,一归教会。相反,他从上帝创世这方面来考察国家并说明它的起源。
根据这种观点,国家是上帝所意愿的,有上帝所赋予的功能,这种功能涉及人性的社会成分。对阿奎那来说,国家不是像奥古斯丁所认为的那样,是人的罪性的产物。相反,阿奎那说,即使是“在无罪的情况下,人也应当生活在社会之中”。然而即便如此,“一种共同的生活也只有处在某个关注共同的善的人掌控之下,才能存在。”国家的作用在于通过种种途径来保障共同的善:维护和平,组织公民们的活动使他们的追求相互协调,还提供维持生命的资源,尽可能防止对善的生活的妨害。这最后一项即关系到对善的生活的威胁,它不仅给了国家一种和我们人的最终目的相关联的功能,而且也说明了在和教会的联系中国家的地位。
国家是从属于教会的,这样说并不意味着阿奎那把教会看成是一种超级国家。阿奎那看到,说国家有一个在其中它有其正当功能的领域,同时说国家必须使自已从属于教会,这两种说法之间并没有矛盾。在它自己的领域内,国家是自主的,但是人类生活中还存在带有超自然目的的方面,所以国家决不能恣意设置障碍来妨碍我们的精神生活。教会并不挑战国家的自主权。它只是说国家并不是绝对自主的,在它自己的领域内,国家是阿奎那称之为“完满的社会”的东西,有它自己的目的和达到目的的手段。但是国家像一个个人,无论是国家还是个人都不是只有一个自然的目的。按阿奎那的说法,我们人的精神性目的“不能依靠人的力量,只有依靠神的力量”才能达到。此外,像阿奎那讲的那样,由于我们的命运是和精神上的幸福联系在一起的,国家必须认识到人类事务的这一方面。在提供公民的共同善的过程中,统治者必须带着对我们的精神目的的意识去追求共同体的目的。在这种状况下,国家并不是变成教会,而只是说,统治者“应当安排那些引导到天堂至福的事,并尽可能防止那些与之相反的事。”阿奎那以这种方式肯定了国家的合法性以及它在自己的领域内的自主性。国家只是在为了保证我们最终的精神目的得到考虑这方面应当服从教会。
出于国家通过法律规范其公民的行为,因而国家被公正法律的要求所限制。阿奎那在描述制定人为法或成文法的标准时,最清楚明白地阐明了他对国家绝对自主权的反对。我们已经分析过法的不同类型:永恒的、自然的、人为的和神的。国家尤其是人为法的来源。每一个政府都面临这样的任务:即根据它自己所处的时间和空间上的具体条件,来制定规范它的公民行为的具体法律。然而,法律的制定决不应是一种任意的行为,而必须在自然法的影响下进行,而自然法就包含着人对上帝的永恒法的分有。人所制定的法必须由来自自然法的一般原则的特殊法则所构成。任何违反自然法的人为法都失去了法的特征而成为对“法的歪曲”,而不再具有对人类良心的约束力。立法者立法的权威来自上帝,而且对上帝负责,如果统治者违背上帝的神法制定了一种不公正的法,那么,根据阿奎那的说法,这种法“一定不能遵守”。
政治统治者具有来自上帝的这种权威,而且这种权威的目的是提供共同的善。权威决不能被当作目的本身或者为了自私的目的而运用。但共同善也决不能被解释为:在集体的整体性中我们忽视了个人。共同善必须是具体的人们的善。因此,阿奎那说:“法的恰当作用就是引导服从法律的人达到他们恰当的德性,…使这些人具有法律向他们所领布的那种善。”立法者惟一的“真正立足点”是确保“共同善按照神的正义得到规定”的意图,因此“法的作用是使人为善”。所以,共同善这个词对于阿奎那来说,除了造成个人善的结果之外没有别的意义。与此同时,阿奎那说,“任何部分的善都会在与整体的比较中加以考 察。由于每一个人都是国家的一部分,除非和共同善相适应,否则一个人想成为善的是不可能的。”社会的整个框架,以及它的法律都是以其中的理性成分为其特色的。阿奎那说,“法律本身是一种为了共同善的理性的法令,它由关心共同体的统治者所制定和颁布。”因此,虽然统治者有权威和权力,但是法律绝不能毫无节制地去反映这种权力,而应受理性的教化,并以共同善为其目标。
8.8 人的本性的知识
人的本性
阿奎那对人的本性有一个明确的概念。他说,人的本性是一种有形的实体。使得这个概念之所以有其独到之处的是阿奎那坚持人的本性的统一性。柏拉图曾经说,灵魂是被囚禁在肉体之中的。同样,奥古斯丁认为,灵魂是一种精神实体。亚里士多德认为灵魂是肉体的形式,但却没有像阿奎那那样认为人的灵魂对肉体的依赖程度和肉体对灵魂的依赖程度是一样的。像阿奎那那样说一个人是一个有形实体,也就是强调了人的本性的实体统一性。人是一个身心统一体,没有灵魂,肉体将没有形式;没有肉体,灵魂将没有它获得知识所需要的感觉器官。作为一个有形实体,我们是由灵魂和肉体组合而成。天使是纯粹的理智,他们没有肉体,人虽然也是理性的被造物,但是我们特有的属性却在于:只有当灵魂和肉体结合在一起时,我们才作为人而存在并发挥功能。因为灵魂授予我们的肉体以形式,所以正是灵魂给我们人以生命、理解力,以及特殊的物理特征。灵魂也解释了我们人的感觉能力和理智与意志的能力。我们人的最高能力就在理智之中,它使得我们成为理性的动物,并授予我们对上帝进行沉思的方法。
知识
阿奎那遵循亚里士多德的知识论,而给他最深刻印象的是亚里士多德对那些怀疑我们人类心灵能够在任何问题上获得确定性的人们的回答。有些古代哲学家论证说,由于人类知识被限制在感性知觉的范围内,而可感世界中的物体处在流变之中,所以不可能有确定性。柏拉图同意对感性知识的这种评价,说感性知识不能给我们确定性。但是柏拉图设定有一个分离的世界、理智的世界,把它和可见世界相对照,来避免理智上的悲观主义。在柏拉图看来,存在着具有永恒存在而且为知识提供基础的理念。奥古斯丁调整了柏拉图的理念论以适应基督教思想,认为理念存在于上帝的心灵中,由于这些理念通过神圣之光照亮了我们的心灵,所以人类具有了认知真理的能力。然而,阿奎那接受了亚里士多德的观点,认为人的心灵在与实际具体对象的遭遇中,知道自己在做什么。我们的心灵能够把握可感事物中的不变的和稳定的东西。当我们感知到了物或人时,我们知道它们的本质,例如,树的本质和人的本质——即使它们处在变化的过程之中。这些事物确实是处在流变之中的,但是我们并不怀疑它们是什么。因而,我们的理智在特殊的事物中看到了普遍的东西,我们从特殊的东西中抽象出普遍的东西。和亚里士多德一样,阿奎那称这种精神能力为主动理智。
阿奎那否认共相与特殊的具体的对象相分离而存在。例如,不存在与个体的人相分离的“人”。有的只是为我们的主动理智所把握的抽象概念,但它不是独立存在的理念。所以在阿奎那看来,没有感性经验,我们就不可能有知识,因为凡是存在于理智之中的,无不首先存在于感觉之中(nihil in intellectu quod prius non fuerit in sensu),大体而言,阿奎那在关于共相的问题上是一个温和的实在论者。和阿维森纳和阿伯拉尔一样,他认为共相存在于(1)事物之外(ante rem),但仅仅作为神圣概念存在于上帝的心灵之中;(2)事物之中(inre),即作为具体的个别的本质而存在于一个种的所有成员之中:(3)心灵之中(post rem),即作为从个别事物中抽象出来的普遍概念而存在于心灵之中。关于共相的问题在中世纪还有一种论述,那就是在这一时期由奥康的威廉提出的一种不同的解答。
8.9 司各脱、奥康以及艾克哈特
阿奎那最重要的成就是把神学和哲学融合到一起。到下个世纪,对他的著作最有意义的反应是来自那些企图把神学与哲学再次分离开来的人们。在此,关键的人物是约翰·邓司·司各脱(John Duns Scotus,1265-1308)、奥康的威(William of Ockham,1280-1349)以及约翰·艾克哈特(Johannes Eckhart,1260-1327)。这些思想家并非对阿奎那所说的全都不同意。其实,在许多问题上他们大体上还是一致的。然而,他们中的每一个人都提出了一种基本的批评。这种批评使得哲学与神学——信仰与理性——之间出现了裂隙。为了反对阿奎那关于理性的最高地位的思想,司各脱论证了上帝的意志(而不是上帝的理性)的至上性。这种学说被称为唯意志论。为了反对阿奎那关于共相至少有某种实际存在的思想,奥康论证说共相仅仅只是语词,这种观点被称为唯名论。为了反对阿奎那对宗教观念的高度理性的和学术化的表述,艾克哈特认为宗教篇要一种通过神秘主义的精神活动而达到与上帝更直接的相遇。
唯意志论
为什么这三种新的思想会起到分离哲学与神学的作用?当我们考察唯意志论的某些结论时,这个问题就变得清楚明白了。阿奎那论证说,对于人和上帝来说,意志都是服从理智的,理性引导或决定意志。司各脱不接受这种说法。如果上帝的意志服从于他的理性,或者为永恒其理所限制,那么上帝自身也会受到限制。这样一来,上帝就不可能想做什么就做什么,因为某种隐约出现在他之上的在先的理性标准就会束缚他或者决定他的行动。所以,如果上帝的自由有任何意义的话,那么他必定有一种绝对自由的意志。所以,上帝的支配能力在于他的意志而不是他的理性。19世纪,这种观点根据拉丁文voluntas(意思是“意志")而被叫做“唯意志论(voluntarism)”。
说上帝的意志是第一位的,超过他的理智,这就有一个重要的道德结论:上帝的活动和道德命令是意志的行动,因而本身是非理性的。上帝的道德法则并不反映他坚持理性的标准,而是反映他不受强制的意志。因此,上帝可以意愿任何他所选择的道德法则。严格地说,即便谋杀和通奸,如果上帝愿意它们是道德的,它们也会成为善的行为。直截了当地说,道德似乎就是由上帝作出的任意选择的结果。而且,如果道德标准是出自上帝的任意命令,那么,对上帝而言,由于我们违反了这些命令而惩罚我们或宜判我们下地狱,也将同样是任意的。如果上帝是绝对自由的,那么,他就可以挑选任何行为来加以奖赏或惩罚。对可各脱来说,道德的基础不是在理性之中而是在意志之中。所以,道德不可能是理性与哲学研究的课题,而仅仅是信仰和接受的问题。
唯意志论的一个意义更广泛的结论是:不可能有自然神学,而正是依靠自然神学,人类理性才发现了神对宇宙的一切理性命令。也就是说,根据这种观点,我们不能发现在经验世界和上帝之间的任何理性联系,上帝存在的证明充其量不过是或然的证明,而上帝存在的问题成了一个信仰的问题,而不是一个哲学发现的问题。所以,理性知识只限于经验世界,一般来说,宗教知识成了神圣光照或启示的产物。这样一来,哲学和神学的主题就分离开了。
除了唯意志论,还可以选择一种被称之为唯智主义的观点一这种观点认为,上帝的理性比他的意志重要,而且上帝的选择实际上是被理性的标准所指导的。当阿奎那说我们是通过我们通常保存在良心中的自然之光而认识道德原则时,他所持的就是这种观点。根据这种观点,由于善的原则能够被理性地发现,所以道德能对人进行理智的训练。而且,从一个更广泛的视角看来,上帝创造的整个宇宙实际上都反映了上帝的理性心灵和选择。作为哲学家,我们可以看到创世中的理性秩序,而且可以做出有关上帝存在及其本性的逻辑上可靠的推论。司各脱以后的几个世纪,最伟大的神学家和哲学家都要在唯意志论——唯理智论的争论中采取某种立场。
唯名论
和司各脱一样,奥康也是一个唯意志论者,他的某些关于此主题的更加激进的说法在天主教会的教阶组织中给他带来了麻烦。但奥康最为人所铭记的或许是他的唯名论学说。这种观点认为,普遍性的名词例如“人”是单纯的符号或名称,这些符号或名称所指的是一些我们在观察特殊事物时形成的思想概念。此外,关于共相的核心问题是:像“人”这样的名词是否指除了具体的人如詹姆斯和约翰之外的任何实在?除了指那些特殊的人之外,还有一个为普遍名词“人”所指的实体存在吗?对奥康来说,只有具体的个别事物存在,而且当我们运用普遍名词时,我们只不过是在以一种有序的方式思想特殊的事物。像“人”这样的普遍的名词既指詹姆斯,同样又指约翰,但并不是因为有某种为詹姆斯和约翰参与或分有的“人”的真实实体存在,而是因为作为詹姆斯的本性和作为约翰的本性是相似的。因而人的理性被限制在个别事物的世界之中。奥康的观点是货真价实的经验论。他说,我们的心灵只能认识个别事物和它们的属性,虽然我们能够运用普遍概念,但这些概念只不过是个别事物的类别名称。最重要的是,普遍的概念并不是指具体个别事物的世界之外的一个实在领域。奥康关于唯名论的论证之——是基于一种被称为“奥康的剃刀”的简单化原则的:“能用较少的原则解释的,就无须更多的原则。”这样一来,我们在一个存在领域就够了的情况下,便无须假设有两个存在领域。实在论者实际上提出了三个存在领域:(1)个别事物,(2)它们所共同具有的独立存在的属性,(3)我们关于这些的思想概念。而根据奥康的说明,只有两个存在领域,(1)个别事物,(2)我们用语言表达的关于这些事物的思想概念。
和阿奎那关于共相问题的论述相比较,这种看法有什么不同呢?在大部分问题上,他们的观点之间并不冲突。阿奎那说,共相是在特殊事物中发现的(in re);是从事物中抽象出来的(post rem),是在我们对它们的经验之后。然而,阿奎那相信,共相存在于上帝的心灵之中(ante rem),因而具有相对于个别事物的形而上的优先地位。如果共相存在于上帝的心灵之中,那么,两个人之所以是相像的,就是因为他们共同分有了这个上帝心中的形而上的实在。当我们思想共相时,我们的心灵也以某种方式分有上帝的思想,而这正是奥康和阿奎那分道扬镳之处。他也拒绝了司各脱曾经拒绝的神圣的理念的理论,理由和司各脱一样:上帝的意志是高于上帝的理性的。人之所以成为人,是因为上帝选择使他们成为那个样子,而不是因为他们反映了存在于上帝心中的永恒的原型。
如果我们的思想被限制在经验中的个别事物中,那么,我们关于这些事物的知识就不会引向经验之外的任何实在。实在论者相信,普遍的词项指向个别事物之外的某种东西,因而他们认为,我们对这些词项的运用给了我们关于超出经验背景的实在的知识。而且如果我们进一步设想:共相是上帝心中的观念,那么我们就可以得出结论说,关于个别事物的哲学推理可以引向各种神学真理,因此,就可以有某种自然神学存在。但是奥康对共相的精确解释产生了使哲学与形而上学分离的结果,而从哲学中得出了某种更像是科学的东西。神学和宗教的真理不可能通过哲学和科学获得。实际上,他的观点引出了“双重真理”说:种真理可以通过科学或哲学得到;另一种真理则通过启示获得。第一种真理是人类理性的产物,而另一种真理侧是信仰的事情。而且,一种真理不可能影响另一种真理。双重真理论的最终结果是:神学的真理和哲学的真理不仅是各自独立的,而且也不能相互派生,相反,这两种不同的真理甚至可能相互矛盾。这就是为阿威罗伊的追随者所坚持的明确的看法。例如,他们论证说,没有个人的灵魂不死,这在哲学上是真的,然而对于神学来说,这种理论则是错误的。在分离信仰和理性方面,奥康并没有走得那么远。然而他为思考经验事实的经验的和科学的方法开辟了道路。他的唯名论产生了分离科学与形而上学的结果,对自然事物的研究变得越来越独立于形而上学和神学的解释了。
神秘主义
由于受到新柏拉图主义的强烈影响,艾克哈特提出了一种处理神学的神秘主义方法。这种方法把重点从理性转移到感情。阿奎那在我们对有限事物的经验的基础上建构他的上帝存在的证明,艾克哈特却力主人们超越感性知识,因为这种知识毕竟是被限制在物质对象之中的。虽然他极为详尽地考察了诸如关于上帝本性、创世以及人的本性等许多传统神学问题,但他基本上是一个神秘主义者,希望和别人一起分享他的与上帝合一的丰富经验。他相信,这种结合,只有通过把自己从世间万物中解放出来才有可能达到。然而他相信,和上帝的结合不能通过人的努力来达到,相反,只有通过上帝的神恩和光照这种结合才能圆满实现,而且只有在我们灵魂所及的最深之处,我们才能充分地领会上帝。艾克哈特说,当这种情形发生时,人就和上帝合二为一了,因为“我们完全被转化为神,而且是以与圣餐中面包转化为基督肉身同样的方式转化为神”。我们与上帝的神秘的结合是一种超理性的体验,而且艾克哈特感到只能用“旷野”和“黑暗”这样的词来表达这种神秘的结合。他相信,上帝既超越存在物,也超越知识,因此,人们惯常的概念和范畴不适用于上帝。因此,我们必须求助于对上帝的隐喻的描述以及我们对他的体验。
艾克哈特的神秘主义并没有取代阿奎那所提倡的更为理性的神学方法。然而,他以一种新的方式表达了伪狄奥尼修斯等人的较早的新柏拉图主义观点,而且给了他之后的神秘主义传统以巨大的影响。
第三部分 近代早期的哲学
第九章 文艺复兴时期的哲学
9.1 中世纪的结束
对于中世纪的大多数哲学家来说,天宇低垂,暗示着天国和人世的密切结合,也就是哲学与神学的结合。在这个时期,哲学实际上是神学的婢女,它为神学的各种教条提供了一种由推理得出的说明。柏拉图和亚里士多德以前曾关注过人的日常事务何以能够且应当与实在的永恒不变的结构以及神发生联系的问题。但是,中世纪神学与哲学的融合是一种不牢固的融合。一方面,在亚里士多德的非一神论哲学和基督教对人格化的上帝的信仰之间的相容性上存在着一些严重的问题。此外,亚里士多德的许多思想在这段时期是通过穆斯林的思想家才为人所知,而这些思想家理解亚里上多德的方式很难为基督徒所接受。阿珂奎那试图重新解释亚里士多德的思想并使之基督教化,以克服这种不相容性。然而,哲学现在发现,在很大程度上它正在做着一件它起初并不打算做的事,那就是为启示的宗教提供一种理智的和形上学的根据。哲学以前也没有受到过一个像中世纪教会那样的机构的压制。当然,就算是那些最早的哲学家,在他们的学说威胁到现状时,也曾身陷道德上的风险之中,毕竞,苏格拉底就是因为这个原因而被处以死刑的,而亚里士多德离开雅典也就是为了不让他的同胞们“第二次对哲学犯罪”。但不管怎么说,古代哲学还是或多或少自由地向真理的追求引导它去的任何地方推进。由于仅仅把自己限于进行人的推理活动,哲学就可以仔细研究人的本性、伦理、宇宙、上帝以及政治权威等方面的问题。相比之下,中世纪哲学精神突出的不同点则在于:它的出发点牢牢地固定在基督教神学教义上,而且整个文化氛围都受到教会统治的影响。
中世纪末期,宗教与哲学之间的中世纪的联姻变得紧张起来,而在文艺复兴时期,这二者之间出现了决定性的分裂。文艺复兴——字面上的意思是“再生”——是指发生在15世纪和16世纪的古希腊学术的复兴。许多古代哲学家和别的伟大著作家的著作再一次成为人们能够得到的东西。中世纪的学者往往只是间接地熟知像柏拉图这样的古希腊的思想家,他们是在普罗提诺和奥古斯丁的著作中读到有关这些希腊思想家的内容的。然而,在文艺复兴时期,希腊文原稿被从雅典带到了意大利,于是这些文本现在可以直接接触到了。例如,在佛罗伦萨,美第奇少建立了一个学园,柏拉图的哲学在那里成了主要的研究科目。这种学术的影响力,被那不勒斯和罗马的类似的学园所增强,进一步削弱了亚里士多德思想和经院哲学方法论的支配地位。对文本的直接接触也产生了一种对语言的深深热爱。
古希腊和罗马文献的发现产生了一个结果,那就是鼓励了一种新的写作风格,这种文风风没有中世纪作者的文本那么正规,而且它的表达日益以本国语言的形式出现。随着本国语言的运用,这些文献变得越来越成为民众的财产。威克里夫把《圣经》翻译成本国语言的做法中于使民众得以直接接触《圣经》的内容,终于在宗教思想中造成了广泛影响。谷登堡的活字印刷术的发明最为有力地促成了文化的广泛传播。它使书籍成为容易得到的了,变得更小、更容易携带,价钱也便宜了。印刷厂很快在巴黎、伦敦、马德里以及意大利的苏比亚科(Subiaco)修道院出现了。书籍的制作和本国语言的运用不可避免地影响到哲学写作的方式,隐含在这些活动之中的解放的意义导致哲学家们更多地去进行原创性的思想构建而不是仅仅对权威思想家的思想加以评注。最后,近代的折学家们将以他们自己民族的语言来撰写他们的论著,因而洛克和休谟用英语写作,伏尔泰和卢梭用法语写作,康德则用德语写作。
随着对柏拉图哲学重新开始关注,人们也重新燃起了对伊壁鸠鲁、斯多噶主义甚至怀疑论的兴趣。一种新的哲学也诞生了,这就是人文主义哲学,它着重研究古典著作家以及人的理性在发现真理和构成社群方面的核心作用。人文主义哲学家并不拒绝宗教,而只是断言,通过并非直接得自宗教的方法和假设,可以对人的本性进行卓有成效的研究。文艺复兴期间发生在思想方面的其他变化也影响到哲学。欧洲许多国家开始进行一场反对罗马天主教会统治的宗教改革运动。科学家从一种非宗教的观点出发研究物理世界的构成。在这一章中,我们将探讨人文主义、宗教改革、怀疑主义和科学革命等方面的哲学主题。
9.2 人文主义和意大利文艺复兴运动
义艺复兴运动最初是在意大利开始的一种艺术运动。整个中世纪时期的艺术为宗教象征主义所充斥,它通常被看成主要是对那些不识字的教区居民宣讲圣经故事和教义的一种工具。绘画和雕塑远不是对它们题材的真实写照。中世纪早期的艺术几乎不传达任何现实的意义,相反却试图唤起某种来世的精神品质。中世纪后期艺术逐渐转向对世界的精确的描绘,吸收了三维艺术的技巧和对人体解剖学的研究。这就推进了向文艺复兴艺术作品的过渡,这些作品通过对风景和人体形象的精确描绘高扬了自然。我们在当时意大利最著名的两个艺术家的作品中可以看到这一点。米开朗基罗(1475-1564)虽然用他的艺术天才服务于教会,但仍然强有力地表现了栩栩如生的形象。他在西斯廷教堂所画的亚当是一幅关于人体美和力量的震撼人心的作品。达·芬奇(1452-1519)透过表层的美而注意到人体解剖的更加具体而微的要素,我们在他的《蒙娜丽莎》中就能看到这一点。
和艺术作品一样,意大利文艺复兴的文学也对人性给予了特别的关注。一个主要的代表人物是诗人和历史学家彼特拉克(1304-1374),他常常被认为是人文主义运动的奠基者。他的诗作着重表现了我们日常体验到的作为人的欢乐和悲伤。作为古典学术的翘楚,他在历史方面的著作试图鲜明生动地展现古罗马的历史事件。在他的其他著作中,他抨击了中世纪的亚里士多德主义传统,而提出了一种斯多噶主义的生活观。他的著作《论好的和坏的命运之疗救》强调了节制的重要性,以及避免观看角力之类的无意义的消遭活动。
皮科
文艺复兴时期人文主义特色最鲜明的代表人物或许是皮科(Pico della Mirandola,1463-1494)。早年,皮科接受了所有可以想象得到的古典学科方面的教育,其中包括希腊的、穆斯林的以及基督教的传统教育,甚至还有犹太人的神秘主义的教育,而他的哲学著作则把所有这些成分结合在了一起。他最著名的作品是《关于人的尊严的演讲》,这是他在1486年撰写的一篇简短的演讲。这一讨论的哲学背景是“伟大的存在之链”的经典理论。从亚里士多德到整个中世纪的哲学家们都相信在世界中有一个事物的自然等级系统。在这个存在之链的最底端是岩石以及别的无生命的物质。在它们之上是植物,然后是简单的动物种类,例如蠕虫和飞虫,在此后有老鼠那样的小动物,以及像马那样的大动物,进一步问链条的上方去的是人,人之上是天使,接着是上帝。在这个等级系统背后,是中世纪时的一种设想:所有的事物都被固定在它们特定的位置之上,而且正如亚里士多德所主张的,自然事物的目的是根据它在这个体系中的所占的位置来确定的。
皮科的《演讲》以这样一个提问开始:是什么使得人如此特殊呢?对这个问题的一个典型的回答是:因为上帝把我们放在了存在之链的独一无二的位置上,它恰好在动物之上,天使之下。在这个位置上,我们可以经验到我们周围的物质世界,同时我们也能把握永恒天国的精神真理。尽管这个答案听起来冠冕堂皇,但是皮科对它并不满意。为了提出可以替代这种说法的理论,皮科沉思了上帝创世时的意图:“他把生气勃勃的灵魂赋予天体。他以各种动物来填充作为残余部分的下界。”事实上,上帝在存在之链中的每一个可以想象的合适位置上都填充了某种被造物,然后,到了创造人类的时候,上帝就发现每一个空隙都被某种东西占满了。于是上帝的解决办法就是允许人类在伟大的存在之链中选择一个属于他们自己的位置。上帝告诉亚当说:“你可以堕落到低等动物的形式之中,或者通过你的灵魂的理性攀升到一个更高的神圣的本性上去。”那么,到底是什么使人如此特殊?答案是:我们有一种独一无二的选择自己命运的能力,而且和动物甚至天使不同的是,我们并没有被限制在任何界限之内。皮科的看法确实是真知灼见。实际上,人可以不顾他们的理性和教养而堕入最低层次的动物式生存,在犯罪行为中我们对此是屡见不鲜的。然而,人也可以养成道德上无私忘我的最高境界,像甘地所做的那样,或者把科学知识推进到它的最高极限。所以,根据皮科的说法,我们并没有像他的中世纪前辈们所假定的那样,被僵硬地固定在预先规定好的人的存在的概念之中。皮科说,我们应当以拥有选择我们作为人的命运的能力而骄傲,而且把它运用到最好。
马基雅维利
尼科洛·马基雅维利(NiccolòMachiavelli,1469-1527)虽然不能从学术上说他是一个人文主义者,但是他仍然是意大利文艺复兴的产儿。他是一位意大利律师的儿子,当伟大的传教士萨伏那洛拉在佛罗伦萨的影响力如日中天时,马基雅维利是一个年仅20岁的青年人。萨伏那洛拉在佛罗伦萨曾建立起一个非常成功的民主政府。但是,尽管他素有懿行美政,他还是与政教官员们产生不和,最终被处以死刑。这样一位有影响的人物落得这样一个悲惨下场,这件事给马基雅维利上了最初的一课,使他认识到社会中善恶力量的对比。当他自己在政府和外交部门工作时,他花了相当多的时间去思考政治行为的规则或原则。他的这些思考记录在两本书中,一本是《论李维的前十书》,另一本是《君主论》。两本都写作于1513年,而且都是在他死后出版。在《论李维的前十书》中,马基雅维利赞扬了罗马共和制,表达了他对自治和自由的热情。然而,在《君主论》中,他却强调,需要一个有绝对权力的君主。
理解马基雅维利思想的一个关键在于:弄清是什么理由导致了他在这两本书中明显的不一致。虽然在《君主论》中他表达了对专制君主的一种偏向,但他并不想否认他在《论李维的前十书》中如此赞赏的自治政府是值得追求的。毋宁说,他感到当时意大利在道德上的腐化不允许有以罗马共和国为典范的那种民众的政府。马基雅维利认为,人的恶实在是显而易见的。他在政治和宗教当局的每个层面上都看到腐败的现象。甚至当时的教皇都恶名昭彰,以致马基雅维利这样写道:“我们意大利人之所以变得如此不虔诚、如此道德败坏,应当归咎于罗马教会,归咎于它的那些神父们。”一个从根子上都腐败了的社会需要一个强有力的政府。他相信,君主专制——或者说一个人的统治——是一种最可取的政府形式,因为共和制很少建立起良好的秩序。
使得《君主论》千古留名的,是它建议统治者应当掌握欺诈之术,并且只要是维持自已的政治生命所必需的事情,可以无所不为——哪怕是背弃传统道德美德也在所不惜。他相信,只有那种最精明和最狡猾的人,才能成功运用灵活多变的统治术。他的思想以对同时代人的实际行为的切实考察为基础,所以他很快就得出结论说:把政治行为当成道德的事情,就是把自己暴露在聪明的敌手所制造的全部危险之下。因此之故,对关于道德的主张,他漠然置之。基督教的道德强调谦恭和谦卑,而古希腊罗马的宗教道德却强调“灵魂的崇高”和“身体的强键”。他对基督教伦理学的主要批评是它使人变得软弱,而且使他们很容易牺牲在那些有恶意的人手下。马基雅维利设想了一种双重的行为标准:一重是对统治者而言的,另一重侧是对民众而言的。他相信:大众需要遵循基督教伦理,这是作为一种保障社会和平的必要手段。马基雅维利提出的是一种实用主义的宗教观,只考虑宗教的社会效用而不考虑它的真理性,在后来的几个世纪中,许多哲学家都将采纳这种观点。
他认为,和一般大众的道德相反,统治者必须能自由地调整他们的行为以适应任何情况的需要,而不受任何客观的道德法则的束缚。马基雅维利认为,民众的态度是在不断变化的,而这种不一致性要靠统治者的精明和敏捷的适应能力才能应付得了。他写道:“人是忘恩负义的、反复无常的、虚伪的、胆小懦弱的、贪婪的,一且你获得成功,他们就都完全服从于你。”但是,当统治者真正需要他们帮助时,“他们马上转过来反对你”。因此,马基雅维利厌恶一切要求对统治者进行道德教化的思想。他认识到,并没有像阿奎那所宣杨的那种更高的法律,而极力主张要有一种完全世俗的探讨政治学的方法。他认为,诡计的价值高于道德信念;统治者应当只选择那些能确保实际达到目标的手段。考虑到人是不道德的和自私自利的,如果统治者要想成功的话,道德必须让位于纯粹的权力。只有当讲道德能实现统治者的最大利益时,他才应该讲道德。然而,就是在统治者为了生存而背弃传统道德的时候,他也必须“把这一点加以精心掩盖,要演技高超,伪装有术”。因此,尽管统治者无须具有所有德性,“他也必须看起来具有这些德性”。甚至残忍无情也有它的一席之地,而且马基雅维利为此提供了一个例证。博尔吉亚(Caesar Borgia)是意大利北部地区罗曼吉那的一位专制君主,由于他的属下奥尔科(Ramiro d'Orco)所制定的不得人心的政策而有失去其臣民支持的危险。为了克服这种损害,博尔吉亚处死了奥尔科,且将其暴尸于城里的广场,“斩首用的垫头木和血淋淋的刀子就放在他身边”。根据马基雅维利的说法,“这种惨状所表现出来的残忍很快使民众感到既满意又惊愕”。
这里有一个问题,即《君主论》是否在任何意义上是作为一种政治哲学而写出来的。由于它产生于马基雅维利那个时代的特殊环境,人们也许可以说,它主要是活动在当时的统治者们的一种实用的行动方案。然而,在这部著作中好像含有一种更具普遍意义的信息,那就是,最有用的行动路线实际上也就是正当的行动路线。他的观点影响如此之大,以致“马基雅维利主义”这个术语很快就成为了政治学语汇中的一部分。所谓马基亚维利主义,就是指这样的观点:为了得到政治权力,领导人可以无可非议地运用无论多么不道德的手段。
9.3 宗教改革
1517年10月31日,当一位名叫马丁·路德(1483-1546)的德国神父把一份抗议书钉在了维腾堡大教堂(Wittenberg Castle)的门上时,也就发动了新教宗教改革运动。令路德感到愤怒的是罗马天主教许多产生于中世纪、到文艺复兴时期已经成为主流的政策。他相信,教皇的权威已经失控无度。为了筹钱,教皇按例签署了售卖赎罪券的文件。一个人可以为自己买,也可以代表已经死去进了炼狱的所爱的人买。多年来路德以外交手段来抗议这种权力的滥用。当这种努力失败之后,路德在德国教会内领导了一场完全断绝与罗马天主教教阶制联系的运动。这个运动蔓延到别的欧洲国家,因而一个“新教”的基督教教会团体由此诞生。宗教改革对哲学产生了深远的影响,特别是在这些新教国家中。许多新教哲学家除了抛弃天主教的权威之外,也抛弃了天主教的整个中世纪思想传统,代之以复兴了的古希腊理论,以及他们自己创造的新的哲学。
路德
马丁·路德受到两个伟大的中世纪哲学家的深刻影响。这两个哲学家是奥古斯丁和奥康。奥古斯丁认为罪基于人的意志的束缚,而不在于无知或理性不发达。所以能超越我们的罪性的是信仰而不是理性。事实上,路德说:“信仰的特性就是要拧断理性的脖子。”所以,在理性看来不可能的事情对信仰来说却是可能的。奥康认为我们要发现上帝不可能单凭运用理性和对上帝存在的所谓证明。毋宁说,我们对上帝的知识是通过信仰得到的,信仰是上帝自己的神恩给我们的赠礼。路德毫无保留地接受了这种立场。除了拒绝阿奎那的自然神学之外,他还谴责了亚里士多德全部的形而上学体系。说到这位伟大的哲学家时,他认为,“因为我们的罪,上帝把他作为一种瘟疫送给我们。”
根据路德的思想,人类理性的困难在于:理性作为有限的东西,倾向于把一切都归之于它自己的有限的视野之下。当自然理性去沉思上帝的本性和能力的时候,尤其如此。因为在这种情况下,人的理性把上帝限制在人关于上帝是什么以及能够做什么的严格评价上。路德尤其被亚伯拉罕所面对的理智困境所打动。这种困境是在上帝许诺他会让其不孕的妻子萨拉给他生下子女时发生的。“毫无疑问,”路德说,“关于这件事,信仰和理性在亚伯拉罕的心中相互恶斗,然而最后是信仰占了上风,战胜和扼杀了理性——这个上帝的最残忍和最致命的敌人。”
路德关于基督徒生活的看法不仅起到挑战中世纪经院神学体系的作用,而且也挑战了那种认为个人和社会的完满在于善业的乐观主义观点。路德说:“所有形式的事功,哪怕是沉思默想和灵魂所能做的一切事,都毫无用处。”对于正直、自由和基督徒的生活来说,只有一件东西是必须的,“这就是上帝最神圣的话语”。如果有人问:“那么,上帝的话语是什么呢?由于上帝的话语如此之多,我们又如何用它呢?”路德回答说:“使徒在《罗马书》的第一章第17节中解释说‘义人必因信得生’…那么很显然,基督徒在其信仰中就有他所需要的一切,而不需要称义的事功。”
路德在宗教事务上对信仰的强调在他的政治思想中有其相应的部分。在路德看来,政府是由上帝设立的。由于这个原因,政府的主要功能就是“维护和平”。我们有罪的本性使我们狂妄悖逆,而这又导致需要一个强有力的统治者:“上帝使他们服从于刀剑,以便即使他们想作恶,他们也不能将其付诸实践。”对路德来说,在政治领域中的忠顺在许多方面与宗教领域中的信仰的功能相似。不管统治者发出何种命令,个人都必须服从,因为统治者的意见总是指向维护和平和秩序的。如果没有统治者的权力,以自我为中心的民众将产生出无政府状态,“而世界因此将退回到一片混乱的状态”。如果我们处在一个腐败残忍的暴君的统治之下,那么我们又该怎么办呢?我们是否有反抗的权利?在路德看来,答案是“没有”。尘世的生活不是我们最重要的考量,最重要的是我们灵魂的得救。一个统治者或最高权力者无论做什么,都不可能损害到人的灵魂,只能损害到肉体和财产。而且对上帝来说,“世俗权力只是区区小事”。因此,我们也不会被统治者烦扰到要去违抗他们的程度。在路德看来,“受到不公正待遇并不会毁坏我们的灵魂,而且它还会改善我们的灵魂,虽然它使我们的肉体和财产受到损失。”这公开表达了与托马斯·阿奎那所系统阐述的中世纪观点不同的看法。阿奎那认为,如果人为法曲解了自然法,我们就无须遵守国家的人为法。
伊拉斯谟
伊拉斯谟(Desiderius Erasmus,1466-1536)是一个重要的人物。他既是一个人文主义者,又是一个宗教改革家。他于1466年出生在鹿特丹,是一个神父的私生子。他虽然是中世纪经院哲学的反对者,但却无意拒绝基督教的信仰。凭着他的人文主义学养特别是他对希腊语言的精通,他企图揭示出基督教纯粹的和简单的要素,因为他认为这些要素已经被经院学说的过度理性主义所掩盖和模糊了。他最早的教育是在一个名叫“共同生活教友会”的学校中接受的。后来从那里进人到斯特恩的奥古斯丁派的修道院。对伊拉斯谟来说修道院里的生活是痛苦的。因为无论在精神上、肉体上,还是在气质上,他都对那种不提供任何肉体上的快乐和事实上没有理智自由的制度感到不适。由于好运,他应坎布雷主教的邀请成为他的拉丁文秘书。主教又送他到巴黎的孟太古学院学习了一阵。在那里,他只能再次对经院的教育方法产生蔑视。然而,也正是在那里,他对古典文献的热情被激发起来,并且开始了他第一部著作的写作。该书后来成为他的多卷著作之一,那是一本名为《千年谚语集》(A dagiorum Chiliades)的箴言类的著作。1499年,伊拉斯谟访问了英国,在英国,他很快受到约翰·科利特——此人是一位研究《圣经》的学者——以及托马斯·莫尔(ThomasMo)的影响。令他感到惊奇的是:没有希腊文的知识,科利特却讲授《圣经》。所以,他着手熟悉和精通这种语言,最后出版了一本为人们广泛接受并附有拉丁文译文的希腊文《新约全书》。1511年,伊拉斯谟第二次访问英国时,他成为了剑桥学术团体的成员之一。在剑桥,他被委任为玛格丽特夫人的教授。他不那么尊敬他的同事,所以称他们为“淫荡的公牛和食粪者"(Cyprian bulls and dung-eaters):他对英国的啤酒和天气也没说什么好话。几年之后,他来到巴塞尔定居,于1536年在此去世,享年70岁。
伊拉斯谟对文艺复兴的精神作出了多种贡献。他对古典文献的热情在当时有着决定性的影响。他意识到:随着印刷术的发明,通过大量生产有知识的读者能够买得起的价格低廉的读物,古代经典的普及已经成为可能。这些书籍展现了古典学术的新世界,而这些古典学术在中世纪是得不到的。伊拉斯谟不仅仅是一个编纂者,虽然他在普及希腊文和拉丁文版本的经典这方面所做的工作也足以确保他在思想史上的名望和地位了。更重要的是,他为发展一种新的文字表达风格方面所作的贡献。伊拉斯谟喜欢语词,他花了大量工夫去选择正确的语词或短语来表达他的看法。就像画家会展示他在色彩运用上的天才一样,作为毫无生气的经院话语的长期死敌,在形成一种以处处措辞优雅为标志的新的纯净文风的过程中,伊拉斯谟得到了极大的快乐和自由。
伊拉斯谟之所以批评经院式的行话,不仅仅是因为它不优雅,更重要的是因为它让福音的真正教导变得模糊不清了。在伊拉斯谟看来,伟大的古典作家的思想和福音书基本上是一致的。他特别注意到了柏拉图哲学与耶稣教导之间的密切相似性。他意识到在耶稣的朴实教导和罗马教廷的奢华与自大之间的深深的不一致。这促使他写作了讽刺作品《拒绝尤里乌斯》(Julius Exclusus)。在其中,教皇尤里乌斯二世被圣彼得禁止进人天堂的大门。他自己早年在修道院的生活经历推动他写了一本批评教士的著作,名为《愚人颂》(Praise of Folly),路德在他和教会的决定性的论战中就用了其中许多内容。但是,伊拉斯谟既不是一个宗教怀疑论者,也没有成为路德教派的一员。他与天主教会的争论是善意地为了天主教好,主要是希望教会的教义能够和新的人文主义的学说相一致。
伊拉斯谟的《愚人颂》是一部既尖锐讽刺又严肃论述了制度化了的宗教和学术中的各种愚人的著作。他首先抨击的是神父,反对他们对灵魂居住在炼狱中的精确时间的错综复杂的椎测。他嘲笑神学家们之间的纷争,这些人就道成肉身、三位一体以及圣餐中的化体等教条而奋力争斗。他主要的指责是,宗教的整体观点已经丧失,重点被过多地放在了琐碎的和不相干的细节上,特别是在修道院中,穿着的问题以及教规的细枝末节,使人们偏离了基督教的核心目的。在想象这些教士们将如何在最后审判面前炫耀他们的所有善功而谋求进入天堂时,伊拉斯谟再也按捺不住要痛加斥责了,他描写道,一位教士强调了“祈祷者大量的供奉,另一方面却夸口说,如果不戴至少两双手套,他是不会碰一分钱的”。对于所有这些,耶稣基督回答说,“我只留给你一条命令,那就是相亲相爱,我没有听到任何人声明他已经忠实地尽到了这条义务。”与这种对修道院生活的批评密切相关的,是伊拉斯谟对经院学说吹毛求疵的逻辑的长期不满。与这些他加以谴责的教士中的愚人相反,他赞扬了那单纯信仰的所谓愚人。他认为,真正的宗教是一件属于心而不属于脑的事情。这种观点是新教改革者所持的核心观点。而且这种观点后来又由帕斯卡再次作了强有力的表达,他写道:“人心具有理性并不知道的道理。”
如果说路德成为了一个富有激情的改革者的话,伊拉斯谟则始终只是一位批判者。在他温和的《论自由意志》(Essay on Free Will)一书中,伊拉斯谟表达了文艺复兴的一种思想,即我们有完善道德的巨大能力。路德在对该书的回应中把他看作是一个“胡言乱语”的人,一个“怀疑论者”,或者“来自伊壁鸠鲁猪圈里的另一头猪”而不屑一顾。在这场争论中,伊拉斯谟是文艺复兴精神的伟大倡导者。因为抱定了乐观主义的态度,他一直相信,教育最终会战胜愚昧和无知。他对古典文献和哲学的兴趣并没有使他去系统阐述一种新的经院哲学,或者使基督教信仰从属于柏拉图哲学。不如说,他是用他的古典语言知识去发现福音书的真正含义。他说,“如果有任何新希腊文要掌握,我宁可当掉我的大衣也不愿得不到它。特别是如果它是某种属于基督教的东西,就像希腊文的赞美诗或福音书那样的话。”
如果说伊拉斯谟回顾旧物是为了发掘古典文化的宝藏,那么宗教改革者们,特别是路德,回顾原始基督教团体则是为了寻找基督教本原的精神。这样,文艺复兴和宗教改革都集中体现了对过去的复兴。伊拉斯谟和路德在他们的相互攻击中却可以对16世纪的基督教现状中的诸多问题取得一致意见。然而,尽管伊拉斯谟能够平衡古典人文主义学说和基督倍仰,但路德对信仰的高扬导致的结果却是,人类理性引领人类得救的能力受到了严重的怀疑。
9.4 怀疑论和信仰
文艺复兴时期最重要的哲学进展之一是古希腊怀疑主义的复兴,特别是皮罗的怀疑主义传统的复兴,这种怀疑主义被塞克斯都·恩披里柯(Sextus Empiricus,公元前200年)所提炼并加以系统化。在文艺复兴时期,塞克斯都的著作到处都可以得到,而且许多读者都感受到了他所鼓吹的怀疑主义式宁静的魅力。也有些人反感塞克斯都对人类理性的攻击,不得不起而抨击他的观点。因此,在以后的几个世纪中,哲学的很大部分都陷入到了怀疑主义和非怀疑主义的思想较量中。
蒙田
在著名的《论文集》(Essays)中,米歇尔·蒙田(Michel de Montaigne,1533-1592)表述了一种令人倾倒的古典怀疑论观点。在古代怀疑论的著作中,蒙田发现了一种观察日常生活的新方法。“怀疑论”这个词经过了许多世纪,一直以来,主要是指某种怀疑的态度,它常常伴随着对生活事件动向的漠不关心。但是,这些并不是古典怀疑主义或蒙田思想的主要特征。古典怀疑主义的核心是与过一种完善的、值得仿效的人类生活的欲望结合起来的探索氛围。这也是蒙田主要关心的东西。他特别为这样一种生活方式所吸引,即在允许他不断地发现新的视野的同时,又可以享受到他作为一个人所具有的一切力量。蒙田写道:“皮罗并没有希望把自已变成一块石头,他希望使他自己成为一个活生生的人,一个在谈话、推理、享受一切快乐和自然之趣,在有条不紊地、恰当地运用他所有的肉体和精神的器官的人。”
蒙田把自已看成是“一个无意而成的哲学家”——一个在理智上没有为他的思想和生活必须在其中得以表达的那一套僵硬观念所限制的人。如果他专心致力于他的理论的话,他过一种幸福牛活的愿望就不可能实现,因为人们可以对他的理论提出某种完全合理的诘难。他意识到有许多问题并没有明确的解答。这指的是有关事物之本性的问题。它们是前苏格拉底哲学如此专心致力解决的问题。蒙田接受了怀疑论者的判断。怀疑论者说:存在的状况可能是:“这不是真的,那也不是真的。”然而这种怀疑论的公式并不是想否认常识告诉我们的是事实。对蒙田来说,怀疑主义是一种解放的力量,使他摆脱了别的哲学体系的僵硬理论。而且,特别吊诡的是,怀疑论使他摆脱怀疑论本身!要真正成为怀疑论者,那么我们必须怀疑我们正在从事的怀疑的过程,因而避免被它自己的理论的力量所动摇。我们永远不应形成对任何理论的持续不变的信仰,相反只能永远采取一种询问的姿态。蒙田说,只有在我们获得了一种心灵的宁静时,我们才有可能感到满意。搅乱我们的这种宁静的东西是那种想超越我们日常经验而洞察事物的内在本性的企图。所有这些情况中最可悲的情况是:我们发现有些人正在系统地阐述着他们对某些问题的终极答案,而这些问题因为过于微妙易变,是不能这样来处理的。这种企图最终导致的愚行是狂信和独断的态度。
蒙田深知狂信的可怕结果。他一生中看到过战争和残酷的宗教迫害。他写道,他的“邻人长这么大一直都处在动乱之中”,所以他怀疑他的杜会能否继续维持不瓦解。他写道:“我看到了如此残暴的司空见惯的行为,特别是在暴行和背叛中,以致我一想起这些就会吓得脸色惨白,”他把这种情况归咎于狂信的凶焰。他意识到:心灵宁静的丧失将会迅速表现为社会动乱。蒙田真诚地相信,建设性的怀疑主义态度可以防止残酷行为的大爆发。在真正的怀疑主义的态度下,人的活力将被引导到他们可以驾驭的问题和目的上,而不是在那些关于宇宙及其命运的莫名其妙的事情上相互斗争。蒙田愿意劝导人们通过反思身边的事情来开始他们的生活哲学。
蒙田说,一个好的起点,是从一个人的个人经验开始思考:“每一个人在其自身之中都带有人性状况的整体。”由于这个原因,蒙田确信,凡是证明了对一个人自己有用的也可能对别人有用。秉持着文艺复兴的真精神,蒙田寻求某种对人的最自然的和正常的行为的公开明白的表达,反对专业行话的模糊不清。他写道:“我的助手和人做爱,而且知道他自己在做什么。可你要是给他读埃伯勒或者菲其诺的书,虽然这些书中说到爱的行为和思想,他对此却完全不知所云。”蒙田埋怨说:“当我日常所做的大多数的事出现在亚里士多德的书里时,我不明白它们是怎么回事。为了便利那些学究,它们被另一层外衣掩饰起来或遮蔽起来了。”蒙田认为,我们所要求的是“像使艺术成为自然的那样,付出同样多的努力使自然成为艺术的。”他说:“生活的艺术就是认识到做人意味着什么,因为,没有什么事情会比恰如其分地演好人这个角色更让人赏心悦目了。在我们所有的弊病中,最坏的就是轻视我们自己的存在。”没有什么比自高自大更损害人的本性了。凡是这种情况发生时,蒙田说:“我总是看到了高到天外的观念和低到地下的行为之间奇特的一致。”凡是人“不肯面对自己和逃避做人时,(他们)就是在做蠢事。他们没有使自己变成天使,相反倒是使自已变成了禽兽。”
对于蒙田来说,怀疑主义也不是指作为一种态度或行为规则的悲观主义。正相反,他在怀疑主义中看到了对人类生活的所有方面的积极肯定的源泉。虽然他看到了技术理性能力的严重局限性,但是他却褒扬了人类的批判性判断的能力。他认为,在最深层意义上,做人也就是要具有充分自觉的经验——根据这种经验,我们自觉地权衡各种选择并判断来控制我们的行为。他用这样一个公式表达了古典怀疑论的看法:“我停了下来——我进行考察——我以世道常情和感觉经验为我的向导。”我们的感觉给了我们足够可靠的关于我们自己以及外部世界的信息,它确保了我们的肉体生存和真正的快乐。而世道常情不管它们客观上的正当性或真理性如何,也都具有价值。法律和宗教是有关世界的确定的事实,否认和拒绝这些事实实际上就像说一个人站在悬崖边上没有危险一样。至于说到政治学,好的判断要求我们接受各自国家的国情和组织形式,而且通过对我们周围的观察,我们是能够区分那些对我们生活限制是恰当还是不恰当的。怀疑主义不应把我们引导到革命或无政府主义的行为上去。蒙田自己就是一个地道的政治保守主义者,他相信,社会变化决不应是突然的。由于没有绝对的真理,也就不存在社会必须被迫达到的特定终点。因此,习惯就获得了很强的力量,要求民众在政治上的忠诚。在宗教的问题上也是如此,一个具有良好判断力的人将会尊重传统的权威,因为他看到,在有组织的宗教共同体中具有进行持续探究的条件,而这在无政府状态下将会成为不可能。
因此,蒙田想提醒他同时代的人,智慧就在于接受生活的本来面貌并认识到确切地认知任何事物是何等的困难。他特别希望人们注意到人类生活的丰富性,而正是对人类能力的尊重与接受使这种丰富性成为可能。在这方面,他是文艺复兴主要思潮的真正代表。
帕斯卡
帕斯卡(Blaise Pascal,1623-1662)是受到当时复兴的怀疑主义强烈影响的另一位思想家。虽然他正式地表明他与怀疑论学派保持距离,但是他仍然相信:人的理性是不可能获得最重要的人生真理的。帕斯卡是作为一位数学家和自然科学家而出名的。他奠定了微积分的基础。1639年,在他16岁时候,他就写了一篇关于圆锥截面的论文,不久他发明了加法器——一种机械计算器。他还试图证明托里切利(Evangelista Torricelli,.16O8-1647)关于真空的实验性发现。
当帕斯卡31岁的时候,他经历了一场深刻的宗教体验,这种体验影响到他作为思想家的后半生。虽然他一心一意地信仰上帝,但这没有使得他放弃对科学的兴趣。帕斯卡并不把科学活动看得过于世俗化,因而认为比起宗教来它们没什么意义,而是把这两种活动看成虽然并非总是在同一层次上,却是相辅相成的工作,虽然它们并非总是在同等的层次上。在他的名言“心灵具有理性并不理解的道理”中,我们发现他对新的思想方法的表述。看来帕斯卡是以感性或情感的要素取代理性或严密的思考。因此,对于帕斯卡来说,真理的向导是心灵。他对什么是“心灵”没有做出精确的界定,但是从他运用这个语词的各种方式来看,很清楚,帕斯卡所说的“心灵”指的是直觉的力量。他确信,在我们的思想中某些基本的命题是不可能加以证明的,我们是通过一种特殊的洞察达到这些原则的。事物的真假取决于我们观察它们时的背景和视角。因而“我们不仅通过理性,也通过心灵去认识真理。”正是通过心灵,我们才知道梦境和醒来时的生活之间的区别。在此,“心灵”这个词指的是:“对真理的、直觉的、直接的、无须推理的领悟。”在几何学中,我们对原理有一种直接的领悟。在伦理学中,我们对正确与错误有某种自发的和直觉的领悟。在宗教中,信徒对上帝有一种爱的领悟,这种领悟决非依靠自然神学的理性证明。
尽管别的哲学家提出通过理性论证来证明上帝的存在,帕斯卡却要求我们设想从赌徒的观点来看待上帝存在的问题。他说,每个赌徒都是为了某种不确定的获利而冒险。如果在两边有同样多的机会,你赌的就是同样的赔率。这时,你拿来赌的东西的确定性和你有可能赢得的东西的不确定性相等。生活中,你用来下注或者拿来冒险的东西是你永生和幸福,和它们相比较的是你有限的生命和痛苦。当我们说有某种永生时,这就是一种承认上帝存在的方式。然而,我们是如何知道上帝存在的呢?我们只能说不知道,因而这个问题就成了一次赌局。打赌可能出现四种情况,它们具有完全不同的结果:(1)如果上帝存在,而且我们相信他,那么我们所得回报,将会是无限大的;(2)如果上帝存在,而我们不信上帝,那么这无限的回报我们就会全部损失;(3)如果上帝不存在,而我们信仰他,那么我们无所得也无所失;(4)如果上帝不存在,我们也不信上帝,那么我们仍然是无所得失。通过衡量这些结果,帕斯卡认为,从心理学的角度看,我们将被迫信仰上帝,因为它许诺了更大的可能的奖赏。帕斯卡并不认为我们可以从数学上计算出我们确信宗教信仰的方法,而是认为,我们的计算至少会使我们开始走上信仰之路。我们可能通过无意识地压制我们的情感开始去接受宗教的德性以及遵循宗教的习惯。他坚持认为,在我们沉浸于宗教传统中后,一种真正的对信仰的献身精神就会自然地形成。
9.5 科学革命
文艺复兴时期开始了一场科学革命。它实际上对知识的各个分支都发生了势不可挡的和持续的冲击。与中世纪的思想家大多都是从事对传统文本的阅读不同,近代早期的科学家最为看重的是观察和假说的建构。观察的方法意味着两种东西:第一,对于自然的传统解释应当从经验上加以证实,因为这些解释很可能是错误的;第二,如果他们能够深入到事物表面现象的背后,这些科学家就可以得到新的信息。人们现在开始以新的态度考察天体,他们不仅希望找到对《圣经》中所说的神的创世的确证,而且也希望发现描述物体运动的原则和规律。观察不仅指向星体,而且要循着相反的方向指向物质实体的最小的组成成分。
新的发现和新的方法
科学革命来有两个突出的要素:即(1)新的科学发现和(2)进行科学研究的新方法。为了提高观察的精确性,科学家们发明了各种科学仪器。1590年,第一台复合显微镜问世,1608年发明了望远镜。托里切利发明了气压计,居里克(0 tto von Guericke,l602-1686)发明了空气泵。空气泵能形成真空,其巨大重要性在于,它从经验上证明了所有的物体,不论它们的重量和大小,在没有空气阻力的情况下,都是以同样的速度下落的。运用这些仪器以及富有想象力的假说,新的知识开始呈现出来了。伽利略(Galileo Galilei,1564-1642)发现了环绕木星的卫星,而列文虎克(Anton Leeuwenhoek,1632-1723)发现了精子、原生动物和细菌,哈维(William Harvey,1578-1657)发现了血液循环。吉尔伯特(William Gilbert,1540-1603)写作了论磁石的专门著作。而化学之父玻意耳(Robert Boyle,1627-1691),则系统阐述了他著名的关于温度、体积和大气压的关系的规律。
那个时代更戏剧性的发现是新的天文学的概念。中世纪的天文学家相信,人是上帝创世活动的焦点,因此,上帝确实是把我们放在严格意义上的宇宙中心。文艺复兴时期的天文学家把这种观点打得落花流水。波兰天文学家尼古拉·哥白尼(Nicolaus Copernicus,1473-1543)在他的《天体运行》(Revolutions of the Heienly Spheres,1543)一书中阐述了新的假说,该书说到:太阳是宇宙的中心,地球每日自转,而且每年围绕太阳公转一次。哥白尼是一名忠实的基督徒,他从未想反对任何传统的圣经教义。他的著作不如说是表达了他建立一种与已有证据相符合的天体理论的难以抑制的欲望。第谷·布拉赫(Tycho Brahe,1546-1601)作出了进一步的和经过校准的观察,而且他的年轻的助手刻卜勒(Johannes Kepler,1571-1630)系统地阐述了行星运转的三条重要规律。其中他加上了数学方程式来支持单纯的观察。为新的天文学提供了最大的理论精确性的是伽利略,在这一努力的过程中,他系统地阐述了加速度和动力学的重要规律。
科学革命的第二个贡献主要是新的科学方法的提出。中世纪的科学方法是基于亚里士多德的演绎逻辑。有几个文艺复兴时期和近代早期的科学家们提出了一些体系来替代它,而这些体系相互之间又往往大不相同。我们现今所遵循的科学方法在许多方面是对这些早期理论的直接继承,特别是对弗朗西斯·培根(Francis Bacon,1561-l626)方法的继承,培根的方法强调了观察和归纳推论的重要性。当数学的新领域被开拓出来时,科学方法论取得了新进展。哥白尼运用了双重的方法:第一,对运动物体进行观察的方法:第二,对空间中的物体运动的数学计算方法。
由哥白尼所开始的工作后来被刻卜勒,特别是被伽利略所改进。伽利略强调了直接观察的重要性,而避免使用仅仅从传统和书本中的那些彼此对立的推测而得到的第二手信息。这使得他发现围绕着木星的许多卫星。他写道:“为了向我的反对者证明我的结论的真理性,我曾不得不用各种实验去证明它们。”在给刻卜勒的一封信中,他反思了他那个时代的旧派天文学家们的顽固态度:“我亲爱的刻卜勒,在此你应当对那些学者们说些什么呢?他们满脑子毒蛇般的顽固,就是不肯用望远镜去看上一眼。对此我们该做些什么?我们到底是该笑还是该哭?”除了对观察的强调之外,伽利略还希望给天文学以几何学的精确性。由于把几何学的模式用于他对天文学的推理,所以他认为,只要他能够制定一些能演绎出结论的基本公理,就像人们在几何学中那样,他就可以证明他的结论的精确性。进而,他还设想,经验事实是和几何学的公理相对应的,或者说,思想所系统阐述的公理对应于可以观察到的运动物的实际特征。依据几何学去思想,也就是去认识事物是如何实际活动的。特别需要指出的是,伽利略第一次系统地给出了物体运动和它们的加速度的几何表达。
科学研究中的数学成分被牛顿(Isaac Newton,1642-1727)以及莱布尼茨(Gottfried Wilhelm Leibniz,1646-1716)所进一步发展。他们各自独立地发明了微积分。当时,观察以及数学运算的方法成为近代科学的标志。这些思想家中的大多数都有这样的共识:任何在他们的研究工作中运用了适当方法的人都可以得到有关事物的本性知识。无须回顾传统或者古代权威的证言,个人就可以直接得到关于自然的真理:把握通过观察而得到的信息,并将之组织到一个公理系统之中,这是发现真理最可靠的途径。
近代原子论
在这个时代的科学家和哲学家中,一个正在成熟的设想是这样一种观点:宇宙以及它所包含的一切都是由物质实体所组成的。根据这种想法,每个事物都以有序的和可以预见的方式活动。在上的天体和在下的最小分子全都展示出同样的运动法则,这表明一切事物都遵循某种机械模式。进而,哲学家们还试图以机械的方式来解释人的思想和行为,而这些思想和行为被较早的伦理学家描述为自由意志的产物。
早在公元前5世纪,德谟克利特就把宇宙中所有的事物都还原为运动中的原子——也就是说,还原为物质。后来卢克来修(Lucretius,公元前98年-公元前55年)揭示了假象何以能够存在。他描述了这样一种现象:一个站在山谷这一边的人何以可能把山谷那边的东西看成好像是一片白云,而只有走过去才会发现这所谓的“云”只不过是一群羊而已。同样,伽利略也强调了现象与实在之间的不同。现象是由第二性质形成的,而实在则由第一性质所构成。他相信,我们不能希望把现象当作是达到真理的可靠途径。例如,我们基于现象的观念把我们领向一个错误的结论——太阳围绕着地球旋转。同样,一棵树或一块岩石看起来是一个单一的固体,但是实际上它们是由大量的原子所组成。对我们来说,可以得到的最精确的知识产生于对运动物体的数学分析,不仅天文学是如此,近在手边的物理学也是如此。
考察过第一和第二性质之间的区别之后,伽利略确实给了人们一个深刻的印象:只有那些属于物体或物质的性质才具有真正的实在性。第一性质,诸如大小、位置、运动以及密度是真正实在的,因为它们能够以数学的方法加以处理。相反,第二性质,诸如颜色、气味、情感以及声音,就“仅仅存在于意识之中;如果有生命的被造物没有了,那么,所有这些性质也都一扫而光不复存在了”。一个人可以被界定为一个具有物质器官的身体。然而当一个人被界定为一个个人时,结果,他之成为个人的大多数特征都是由第二性质来体现的。这将意味着,要么这些第二性质也必须以数学的方式来加以解释——就像在物质的第一性质的情况中那样——要么第二性质在实在的领域里根本没有一席之地。在这两种情况的任何一种中,人独一无二的尊严、价值或者在自然中人所特有的地位都被严重削弱了。
牛顿接受了自然是由“微粒和物体”所组成的观点。他表达了这样的愿望,即所有的自然现象都能“由源自机械论原理的同一种推理来解释。因为我有许多理由怀疑它们全都来自某种力量、分子和物体…要么被这种力量推动并凝聚在一个规则的形状之中,要么就被其推动而相互远离”。因此,牛顿在他的巨著《数学原理》Principia Mathematica,l687)中完善了有关运动法则的早期阐述。这部著作对以后的几代人产生了巨大的影响。虽然牛顿仍然认为上帝是白然这个机器的创造者,但是在解释自然现象时,却越来越不必借助上帝了。新的科学方法的整体趋势朝向一个关于人、自然和整个人类知识机制的新概念前进。
正如宇宙现在被看成是运动中的物体的一个系统一样,自然之中所有别的方面现在也都被描述成运动中的物体。人的本性和人的思想不久也被以机械论的方式来看待。如果所有的东西都是由运动中的物体所构成,那么,对这种机械活动据说就必定能够作出数学的描述。因此,产生于文艺复义时期的观察和数学的运用又成为了科学思维的新方法的组成部分。人们认为:运用这种方法就能发现新的知识。文艺复兴时期的科学家的观点是:中世纪的思想家仅仅是为我们已知的东西弄出了一套解释体系,并没有为发现新的信息而提供方法。这种发现精神生动地体现在哥伦布对新大陆的发现中,也体现在艺术、文学和 人的尚未运用的官能和能力中对新天地的发现,现在在推动着科学家们去揭示自然结构中的新世界中。而且,正是这种新的科学态度对近代哲学的发展起着最直接的影响,尤其是对弗朗西斯·培根和托马斯·霍布斯的哲学,我们现在就着手来论述他们。
9.6 弗朗西斯·培根
弗朗西斯·培根为他自己规定的任务是复兴他那个时代的哲学和科学,他最主要的批评是认为学术已经停滞不前了。科学已被等同于学术,而学术则是指对古代文本的阅读。例如,研究医学,主要是研究书本,而且是由诗人、修辞学家以及教士们来做,他们之所以有从事这种工作的资格,在于他们有引用希波克拉底和盖伦的话语的能力。哲学仍然被柏拉图和亚里士多德所统治,而他们的学说被培根斥为“灯影”和“幽灵”。虽然培根说过“知识就是力量”的名言,他却尤其忿忿于传统学术的“无用”。这种学术之所以不行,是因为科学与“迷信”、与毫无头绪的思辨以及神学混在了一起。培根反对这种搞科学的方法,批评它不适于作为发现自然及其运行的真相的方法。他真心尊敬的一个古代思想家是德谟克利特,并采纳了其唯物论的思想。然而,他把中世纪经院学者的学说看成是亚里士多德哲学的“退化了的”变种。他们的著作不是从事物的实际本性中获得实质证据,而是在那里制作他们自己的想象物。他们像蜘蛛,它们生产出“学术的蜘蛛网,蛛丝和工艺的细致足可博 得欣赏,但毫无实质内容或益处”。
培根主张用一种新的方法来整理和解释事实,把人类的知识推倒重来。他确信他已经发现了这种方法,它将揭开自然的所有秘密。他知道别人纠正传统学术之不足的尝试,尤其是吉尔伯特、哥白尼和伽利略修正亚里士多德的物理学的尝试。然而,他印象最为深刻的是伽利略对望远镜的设计和运用。他把这个事件看成是天文学史上最重要的事件之一,因为它使得学术的真正进展成为可能。例如,古代人并不知道“银河”的构成,而望远镜证明它是遥远的星球的集合。培根把心灵视为一块玻璃或一面镜子,它被情感的自然倾向和传统学术的谬误弄得粗糙不平。在这种情况下,心灵不可能精确地反映真理。培根的方法,以及他的希望,使心灵的镜面变得清晰平滑,而且提供给它新的管用的工具,以便它能精确地观察和理解宇宙。为了达到这个目的,他不得不让科学摆脱根深蒂固的传统学术。这意味着把科学的真理和神学启示的真理分离开来,而且形成一种建立于对自然的新的观察方法和新的解释的基础上的新哲学。
培根的生平
由于出身和教养,培根命定以某种适合于上层社会的方式去生活、工作和思考。他1561年出生,是尼古拉斯·培根的儿子,尼古拉斯后来成了掌玺大臣。培根12岁进入剑桥大学。I6岁时被允许以一个相当高的地位进人到格雷英(Gray'slnn)法学界。随后的几年,他被伊丽莎白女王和詹姆斯一世任命为英国下议院议员、上议院议员,同时成为司法部副部长、掌玺大臣,最后成为大法官。考虑到培根要全身心地投人到法律和政治生涯中,我们就更加叹赏他的哲学天才了。他的哲学著作是意义深远的,而且也是不朽的。这些著作中最著名的是《学术的进展》(Advancement of Learning)和《新工具》(New Organon)。他意识到他的政治生活影响到他成为思想家的首要目标,说“我认识到,当我一直忽视能够使我自己成为一个有益的人的东西时,我绝不是在履行自己的义务。”他的晚年愈加的不幸,在被命名为大法官后不久,他就被控收受贿烙,并因此被判罚款和短期监禁,而且永远不能再担任政府官员。1626年他的生命走到了尽头,当时,出于对实验的热情,为了弄清冰冻是否能使鲜肉不腐,他在大冷天到室外,把雪填充到鸡肚子里去。由于受寒严重,几天之后他就去世了,享年65岁。
培根的基本目标,如他所说,是“对科学、艺术和人类所有的知识进行全面重建”,他称之为他的“伟大的复兴”。但是在他能够着手从事他的创造性工作之前,他要针对牛津、剑桥和一般大学进行猛烈的批评,也要针对占统治地位的哲学学派加以批评,指责他们食古不化。因此他号召与亚里士多德哲学的绵延不断的影响相决裂。
学术的病状
培根攻击了过去的思维方式,把它们称之为“学术的病状”并给这种病状开出了一个处方。他把这些学术命名为三种:异想天开的学术、好争辩的学术,以及脆弱不堪的学术。在异想天开的学术中人们参与争论,强调文本、语言和风格,而且“对文字的探求超过对问题的探求,对用词造句的探求…超过对问题重要性的探求”。他说,好争辩的学术甚至是更坏的学术,因为它以以前思想家的固定立场或观点为起点,在争论中这些观点总是被作为出发点来加以运用。最后还有脆弱不堪的学术,其中著作家声称自己拥有的知识比能够证明的知识多,而读者也就当他们真有他们自称的那么多知识而接受下来。例如,亚里士多德就是被作为科学的“独裁者”来接受的。他说:为了让心灵摆脱它们所产生的谬误,这三种弊病必须加以治疗。
心灵的假象
同样,人的思维是被假相所败坏的。培根指出有四种假相,他以隐喻的方式称这四种假相为:种族假相、洞穴假相、市场假相以及剧场假相。这些假相,或者说“虚假的幽灵”,是心灵的扭曲,就像从一个不平的镜子反射回来的光线的扭曲一样。“因为从一面清洁平整的镜子反射回来,其中事物的光束就应当根据它们真实的入射角来反射,现在这面镜子则大为不同,毋宁说是一面魔镜,其中充满了迷信和欺诈。”要纠正这种任意妄为的思想,办法只有一个,那就是通过观察和实验——也就是通过归纳的方法。这些假相,或者说“虚假的意见”、“教条”、“迷信”以及“谬误”,以各种不同的方式歪曲着知识。
种族假相包含我们的一些偏见,它们来自“人的感觉是事物的尺度这一错误的论断”。在此培根想要说明的是,单纯观看事物是不能保证我们看到事物的本来面目的,我们把我们的希望、恐惧、偏见以及焦虑都带到事物之中,因而影响了对事物的理解。洞穴假相是培根取自柏拉图的比喻,并再次暗示了没有经过圳练的心灵的局限性。心灵被封闭在由它自己的习惯和意见背景所构成的洞穴之中,它反映了一个人所读的各种书籍、一个人看重的各种观念,以及一个人所服从的理智权威。
第三种假相被恰当地称之为市场假相。因为它象征着人们在日常生活的交际活动中所使用的语词,这些语词就是日常交际中的通用货币。尽管语词有其用处,但语词也可以削弱知识,因为它们创造得并不准确精密,而是为了让普通人能理解它们的用法。就连哲学家也被这些假相所误导,因为他们经常给那些仅仅存在于想象之中的东西取名字。此外,他们还为一些抽象的东西造一些名称,诸如“火元素”或者沉重、珍奇或密集这样一些“性质”。最后,剧场假相是指庞大的系统化了的冗长的哲学论著的教条。这些教条表现了他们“模仿一种不真实的布景模型而创造的世界”。培根在此指的不仅有完整的体系,而且包括由于传说、轻信和疏忽而被接受下来的科学中的诸多原理和公理。
归纳的方法
在适当瞥告了他同时代的人们,说人的理解力有可能被这些假相所扭曲之后,培根描述了获取知识的新方法。他说,“为了深人到自然的内部和深层”,我们必须“以一种更加确定的和有保障的方式”从事物那里得到我们的观点。这种方法包括除掉我们自己的偏见和考察事物的本来面貌。“我们必须把人们引导到特殊事物本身上去。”为了给我们的观察以帮助,我们必须纠正我们的错误,“与其说是用仪器不如说是用实验。因为实验的精巧是远远超过感觉本身的”。培根的实验概念和他的观察方法是基于归纳的概念之上,也就是基于从对特殊之物及其系列和秩序的简单观察中得到的“规律”之上的。他所严厉批评的与此相左的观点是亚里士多德的演绎。亚里士多德关于演绎论证的经典例证是:(1)所有的人都是有死的;(2)苏格拉底是人;(3)所以苏格拉底是有死的。培根认为这种方法的问题在于,我们所推出来的结论只不过使已经包含在前提之中的错误永远维持下去而已。而我们需要的是一种给我们新信息的论证策略,我们能够根据这些新的信息推出新的结论。归纳所要做的正是这件事。
培根知道“简单枚举法”的局限性,例如,由于所数到的18匹马都是黑色的,就得出结论说所有的马都是黑色的。培根相信,解决之道是寻找作为基础的本质或“形式”,我们在我们所观察的特殊物中发现这些东西的体现。他给他的归纳法所提出的例子是发现热的本质。第一步是列一个我们能在其中看到热的所有例证的表,诸如“太阳的光”,他把这个表称之为“本质与存在表”。第二步我们必须编制另一个表,这个表包括那些和第一个表中的那些情况相似,但却不具有热的例子,“月亮和星星的光”。第二个表被称为“差异表”。第三是“比较表”,是一种通过分析在不同事物中发现的热的不同程度来发现热的性质的进一步的企图。“例如,烧红着的铁就比酒精的火焰要热得多,毁灭的力量亦大得多。”
第四步是排除的过程。也就是动手开始“归纳的工作”。我们试图发现某种“本质”,即凡是有热它就存在、凡是无热它就不存在的本性。热的原因是光吗?不是,因为月亮是明亮的却无热。这种排除的过程是培根科学方法的核心,而且他把这个过程称之为“真正归纳的基础”。他设想:“一个事物的形式应该在事物本身必定在其中被发现的每一个以及所有的例证中发现。”把这个设定运用到关于热的问题上,培根得出结论说:“热本身,它的本质和精髓不是别的,就是运动。”对“本质”的强调有一种亚里士多德的意味,而且暗示了培根与亚里士多德的决裂并不彻底。不过,这最后一步却有一种近代特性,因为培根希望通过与他的表中的所有项目相对照来验证他的结论。
培根方法的主要弱点是:他没有把握被近代科学家称为“假说”的东西。培根以为,只要我们观察了足够多的事实,一个假说就会自动出现。然而当代的科学家认识到,在我们考察事实之前,必须先有一个假说。这种假说在与实验相关的事实的选择中起向导作用。培根也低估了数学对科学的重要性。然而,他永久解除了经院思想的控制,为哲学科学化提供了动力。
9.7 托马斯·霍布斯
霍布斯的生平
托马斯·霍布斯一生的91年一从1588年到1679年—都是多事之秋。他出生在英国马默斯伯利附近的威斯波特(Westport),父亲是一名教区牧师。他在牛津所受的教育激起他对古代文献的强烈爱好。然而亚里士多德逻辑学的灌输使他厌倦。1608年,他离开牛津大学,而且十分幸运地成为了德文郡伯爵(Earl of Devonshire)威廉·卡文迪什(William Cavendish)的家庭教师。与卡文迪什家族的关系对霍布斯后来的发展有很大影响。因为它为霍布斯提供了周游欧洲大陆列国,和许多著名思想家及当代名士会面的机会。在意大利,他会见了伽利略,在巴黎他和笛卡尔的敬慕者梅森(Mersenne),以及笛卡尔的反对者伽桑第建立了终生友谊。他是否会见过笛卡尔本人,这还存在疑问,不过他经过细致推理的对《沉思》的洁难,显示霍布斯对笛卡尔哲学是非常熟悉的。在英国,大法官培根十分欣赏霍布斯。他喜欢和霍布斯谈话,而且“在戈兰伯利的美妙的散步过程中”把他的思想讲给霍布斯听。霍布斯早年对古典文献的兴趣使他去翻译修昔底德的著作。在他40来岁时,他的兴趣转向了数学和分析。这是由于他发现了欧几里得的《几何原本》(Elements)。“这本书使他爱上了几何学。”在他思想发展的下一阶段——这一阶段包括他整个后半生——他看到了自己卓越的哲学著作的出版,其中最著名的是他的《利维坦》(Leviathan)。
几何学对霍布斯思想的影响
虽然《利维坦》基本上是一本关于社会和政治哲学的著作,但是霍布斯却无意将他的注意力限制在这个主题之上。由于置身方兴未艾的科学发现大潮之中,霍布斯被科学的精确性,尤其是被科学知识的确定性所深深打动。16世纪和17世纪的思想氛围已经经历了一个彻底的改变,各个研究领域一个接一个地转而采用科学的探究方法。霜布斯抓住了这种时代精神。霍布斯最初对数学的迷恋源自他与欧几里得学说的遭遇。他加入到人数不多但很雄辩的思想家的团伙之中,这些人在几何学中看到了研究自然的钥匙。由于他的智力极其敏锐,又由于一种激情使他夸大了这种方法的可能性,霍布斯开始着手凭着他的单一方法来重塑知识的全部领域。霍布斯认为,不管研究的对象是什么,通过观察的方法以及从公理出发进行演绎推理的方法(公理也来自观察),他就能获得精确的知识。因此,他制定了一个雄心勃勃的计划,这个计划将改造对自然本性的研究、对人类本性的研究,以及对社会的研究,而且全都用同样的方法来进行。1642年他出版了《论公民》(De Cive);1655年出版了《论物体》(De Corpore);l658年出版了《论人》(De Homine)。最后,正是他的政治哲学使他闻名于世,因为正是在政治哲学中,他的严密逻辑和科学方法的运用产生了惊人的新成果。
作为一名政治哲学家,霍布斯常常被称为近代极权主义之父,虽然这样说不是很准确。他的著作《论公民》和《利维坦》,读起来像是关于服从的入门初阶一样。他以这样极端的语词来描述公民和统治者之间的关系,无怪乎会给他自己招来如此广泛的批评。霍布斯之所以如此阐述他独特的政治义务理论,主要有两种考虑:第一是他那个时代的政治动乱,此时,克伦威尔准备把他的民众引向残酷的国内战争之中。这种暴力的经历产生于对政治问题的深刻分歧,在霍布斯的心中,这种情况与人们在数学和科学问题上很快达成一致意见的情况形成鲜明对比。第二,霍布斯把政治哲学看成是物理科学的变型。他设想:从一种彻底的唯物主义的人性观出发——在这种人性观中,人的行为可以仅仅依据运动中的物体来加以解释——就能够形成一种精确的政治哲学。他希望:如果政治理论能够以逻辑的严密性来加以系统阐述,人们之间就更有可能达成一致意见,因此也就可以达到霍布斯最渴望得到的和平与秩序了。至于霍布斯在他系统的政治哲学中是否在逻辑上首尾一贯,这还存在问题,而且他认为人们在相互关系中能保持有序,仅仅是因为他们得到了一个协调行动的逻辑方案,这一设想甚至存在更大的问题。但无论如何,他关于人和社会的理论实现了一个新的转向,这主要是因为他按照机械论的模式建构了它,这种模式的主要成分是运动中的物体。由于霍布斯的政论理论如此多地依赖于他独特的知识理论和他关于实在的数学模式,所以我们应当把他的哲学的这些方面看成是其政治共同体观点的背景而加以详细考察。
运动中的物体:思想的对象
根据霍布斯的看法,哲学主要关心的是物体的原因和特性。有二种主要类型的物体:自然物体,如石头;人体;以及政治物体。哲学和这三种类型的物体都有关系,它考察它们的原因和特性。有一种基本的特性是所有物体共有的,单单这种特性使得理解它们如何得以存在、如何活动成为可能,这种特性就是运动。在霍布斯的思想中,运动是一个关键概念。同样重要的是霍布斯认定,只有物体存在着,可知的实在仅仅由物体所构成。他不愿承认天使或上帝之类事物的存在,如果这些名词指的是一些没有形体的存在物,或者是精神性的存在物的话。关于上帝的存在,霍布斯写道:“通过世上可见的事物及它们值得赞赏的秩序,一个人可以设想有一个有关它们的原因,人们就把这个原因称之为上帝。然而在他的心中并没有一个关于上帝的观念和形象。”霍布斯愿意承认上帝的存在,但认为人们并不知道上帝是什么。说可能存在某种具有非物质性实体的东西,就像神学家们描述上帝一样,这对霍布斯来说是没有意义的。他认为,实体,只能是有形的,而且由于这个原因上帝应当具有某种形式的身体。但是霍布斯无心探讨神学的精义。他在此论及上帝的性质,仅仅是为了阐明一个更一般的观点,即凡是存在的都是有形的。哲学的范围被限制在对运动中的物体的研究上。
霍布斯企图把物质的和精神的事件都解释为只不过是运动中的物体而已。霍布斯说:“运动就是连续不断地放弃一个位置得到另一个位置。”任何运动的事物都是在不断地改变它的位置。同样,凡是被推动的东西也都改变它的位置。如果某物是静止的,它就总是处在静止状态,除非有某种东西推动它。只有一个运动着的物体才能使一个静止的物体运动。因为运动的物体“通过努力进入静止物的位置而使它不再保持静止状态”。同样,一个运动着的物体,除非它以外的别的物体阻止它动,它就倾向于永远运动。对运动的这种说明好像只限于位移。因为像惯性、力、动力、阻力以及努力这些概念——这是霍布斯用来描述运动的概念——似乎全都是适用于在空间中占有或改变其位置的事物的。但是,由于霍布斯是从只有物体存在这个前提出发的,他就必然借助于运动的物体来解释所有的实在和所有的过程。因此,运动不仅仅是简单意义上的位移,而且也是我们看作是变化过程的东西,事物之所以变得不一样,是因为在它们之中的什么东西被别的东西所推动,而且这不仅仅是指物理的变动,也指精神的变动。
霍布斯指出两种专属于动物或人的运动:那就是生命的运动和自发的运动。生命的运动开始于出生的过程,并在整个一生之中持续。它包括这样一些运动,如脉动、营养、排泄、血液流动和呼吸的过程。“这些运动是无须借助想象力的。”而自发的运动,如走动、说话以及我们的肢体有意的运动等。首先是我们心灵的运动,而且“因为走动、说话以及类似的自发运动总是依赖于对是否做、以何种方式做,以及做什么的预先思考,所以很明显,想象是所有自发的运动最初的内在开端。”想象是月发运动的原因,但想象本身以及我们称之为思想的人类活动也被解释为在先原因的结果——解释为先前运动的结果。
关于人的思想的机械论观点
人的心灵以各种方式进行活动,从感知、想象、记忆到思想。所有这些类型的精神活动基本上都是同一种活动,因为它们全都是在我们身体之中的活动。对霍布斯来说,尤其显而易见的是:感知、想象和记忆都是相似的。所谓感知,他指的是我们“感觉”事物的能力,是我们基本的心灵活动,而其他的活动都是“从这个原初的活动派生出来的”。人类思维的整个结构和过程被解释为运动中的物体,而且精神活动的变化由于循着一条可描述的因果链条而指明每种类型的精神活动的位置而得到说明。因此,当一个外在于我们的物体运动起来并造成我们内部的运动时,思想的过程就开始了。就像我们看见一棵树那样,看见树就是知觉或感觉。当我们观察一个对象时,我们也就看到蛋布斯称之为影像的东西。一个影像也就是外在于我们的对象所形成的内在于我们之中的映像。知觉并不是对运动的感觉,或者是对一个对象实际具有的精确性质的感觉。我们看到绿色的树,但是绿色和树是两个影像——一种性质和一个对象——而且这些表象是我们经验到由外在于我们的物体所形成的运动的方式。一个外在对象对我们所造成的最初印象,不仅产生我们的直接感觉,而且也产生更为持久的后果,正如在海上,风停而“浪不止”一样。而“这种情况也发生在人内部器官中的运动中,就是在对象已经不在,或者眼睛已经闭上之后,我们仍然保留着已看到的东西的映像,虽然比起我们看见它时要模糊一些。”这种在对象已经消除以后保留在我们之中的映像,就是霍布斯所说的想象。因此,想象是一种带后的——或者是如霍布斯所说的衰减的——感觉。到后来当我们希望表达这种衰减,以及揭示出这种感觉正在淡忘时,我们称它为记忆,“所以想象和记忆只不过是一个东西,因为从各种考虑出发就会有各种不同的名称。”
就像我们互相交谈时那样,思想看来是某种完全不同于感觉和记忆的东西。在感觉中,我们心灵中的映像的次序是由发生在我们身外的事物所决定的,而在思想中,我们以什么方式把观念放在一起似乎是随心所欲的。然而,运用他的机械论的模式,霍布斯以和他解释感觉时同样的说法来解释思想,以致对他来说,思想只不过是感觉的变形。思想中观念前后相继,是因为一开始在感觉中它们就是前后相继的。因为“那些在感觉中相互直接接续发生的运动,在感觉之后也同样是连在一起的”。我们的观念相互之间有一种稳定的联系,因为在任何形式的连续运动中——思想也是这样一种运动——“由于内聚力,所以一部分紧随着另一部分”。但是思想的机械论并非全都那么完满,而且人们总是以某种并非精确反映他们过去感觉的方式进行思考。霍布斯意识到这一点,但是他试图解释说这种连续的打破是由于更占优势的感觉侵人到想象和记忆的潮流中的结果。例如,关于国内战争的思想可能使他想起一种个人经历,因而也就打破了他的记忆中国内战争的那些事件的链条。他希望确定这样一种观点:发生在思想中的东西,无不可以通过感觉和记忆来加以解释。
然而,在动物的心灵和人的心灵之间有某种不同,虽然两者之中都有感觉和记忆。使他们相互区别的东西是人能够形成符号或名称去标示他们的感觉。通过这些名称我们可以回忆起有关它们的感觉。进一步说,科学和哲学之所以可能,乃是因为人具有系统构造语词和句子的能力。因而,知识采取了两种不同的形式:一种是关于事实的知识,另一种是关于结果的知识。关于事实的知识只不过是对过去事件的记忆,而关于结果的知识则是假定的或有条件的知识,但仍然是基于经验的。因为这种知识肯定,如果A是真的,B也应当是真的——或者用霍布斯的例证来说:“如果展示出来的图形是一个圆,那么通过圆心的任何一条直线都将把圆分成相等的两半。”科学知识或广义上的哲学之所以是可能的,乃是因为人有运用文字和语言的能力。虽然霍布斯认为符号和名称是一些“随口说出的用来作为标记的语词”,但是这些词表达了我们的经验,语词和句子指出了事物活动的方式。因此,用语词进行推理就不同于语词游戏。因为一旦语词的意义被确定,关于它们如何运用就会有确定的结果,这些结果反映出在它们的帮助下我们的想象所回忆起来的实在。
因此,说一个人是一个有生命的被造物这种说法是一个真命题,有两个理由:第一,“人”这个词已经包含了有生命的观念;第二,“人”这个词是我们看见一个实在的人时所得到的感觉的标记。语词相互之间的关系是以语词作为表象所代表的事件之间的关系为基础的。因而,推理“只不过是计算——也就是加减,亦即对一般名词的结果进行加减”。即使“人”这个词并不是指任何一般的或普遍的实在,而仅仅是指特殊的人,霍布斯也仍然坚持认为,我们有可靠的知识,虽然经验“并不能下普遍的结论”,但是基于经验的科学却的确可以“下普遍的结论”。这集中体现了霍布斯的唯名论思想,这种思想导致他说像“人”这样的普遍语词只不过是语词而并不指向一般的实在。这也表现出他的经验论,这种经验论导致他论证说:由于我们在经验中对某些人的认识,我们就能认知有关所有人的情况。
政治哲学和道德
当我们转向霍布斯的政治哲学时,我们发现他在这个主题上尽可能多地运用了他的关于运动的理论和逻辑,以及几何学的方法。正如他试图用运动和物体的概念去描述人的本性——特别是描述人类知识——一样,他也借助运动着的物体来分析国家的结构和本性。而且,他对国家的说明是他的哲学思想中令人印象最为深刻的例证。因为如果哲学是一种“计算的事情,也就是说是一般名词结果的加减”,那么在他的政治哲学中,他所展示出来的运用语词的意义的技巧和严密性是十分卓越的。
霍布斯的国家理论给我们造成的首要印象是:他不是从历史的观点出发,而是从逻辑和分析这种居高临下的位置出发去探讨这个主题。他并没有问:“公民社会是何时产生的?”而是问:“你如何解释社会的产生?”他希望发现公民社会产生的原因,而且为了要和他的一般方法相一致。他通过描述物体的运动来着手解释国家产生的原因。他关于政治哲学的思想与几何学方法的相似性仅仅在于,他从类似公理的前提中演绎出它的政治理论的所有结果或结论,而且这些前提大多数以他关于人类本性的观念为核心。
自然状态
首先,霍布斯描述了出现在他所谓的“自然状态”之中的人。自然状态是存在于任何国家或公民社会之前的人的状态。在这种自然状态中,所有的人都是平等的,而且他们也平等地对他们看来是他们生存所必需的东西拥有权利。在这里,平等指的仅仅是人们具有伤害其邻人,以及为了自保想拿什么就拿什么的能力。力量上的差异早晚会被克服,而且弱者也可以毁灭强者。在自然状态中通行的“所有人对所有人的权利”并不是指一个人有某种权利,别的人就有与之相应的义务。在赤棵棵的自然状态中,“权利”这个词是指一个人“做他想做的事,反对他认为应当反对的人,占有、利用和享受他想要的一切,或者他可以得到的一切”的自由。驱动一个人的力量是生存的意愿,蔓延在所有人之中的心理状态是恐惧——对死亡的恐惧,特别是对暴力造成死亡的恐惧。在自然状态中,每个人都毫不留情地为确保他们的安全而无所不为。我们所得到的关于这种自然状态的图景是人们做相互反对的运动——都是运动中的物体——或者是霍布斯所说的“一切人反对一切人的战争”的无政府状态。
为什么人们以这种方式行动?霍布斯分析了人的动机,他说,每个人都有两种动力,那就是欲望和厌恶。这两种动力解释了我们趋向或远离他人或对象的活动,而且这两种动力具有和“爱”以及“恨”这样的语词相同的含义。人们被吸引向那些他们认为将有助于他们生存的东西,他们恨那些他们判断对他们构成威胁的东西。善恶这两个词具有人想要给予它们的任何含义,人们会把他们喜欢的任何东西称之为善,把他们憎恨的任何东西称之为恶,“没有什么东西是单纯和绝对地善或恶的”。我们从根本上说利已主义的,因为我们所关心的主要是我们自己的生存,并把善等同于我们自己的欲望。因此,似乎对人们来说,在自然状态中没有尊重他人的义务,或者说没有在传统意义上的善和正义方面的道德。一旦给定了这种利己主义人性观,我们也就似乎没有创造一种有序的与和平的社会的能力了。
但是,霍布斯论证说,有一些逻辑结果或结论可以从我们对我们生存的关心中演绎出来,在这些结果中就有霍布斯称之为自然法的东西。即使在自然状态之中,人们也知道这些自然法,它们在逻辑上与我们对自身安全的极大关切是相一致的。霍布斯说,自然法“是一种准则或一般的法则,是通过理性发现出来的”,它告诉我们应当做什么和不应当做什么。如果大前提是我要生存,那么即使在自然状态中,我也可以从逻辑上演绎出某些有助于我生存的行为法则来。因此,第一条自然法则是每个人都应当“寻求和平、信守和平”。这条迫使我去寻求和平的法则是自然的,因为它是关心我们的生存的一个逻辑上的延伸。很显然,如果我出力创造一个和平的环境,那么我将有更好的生存机会。因此,我对生存的渴望,将推动我去寻求和平。从自然法的这个首要的和基本的法则中派生出第二条法则,这条法则说,“在别人也愿意这样做的条件下,当一个人为了和平与自卫的目的认为必要时,他愿意放弃对一切事物之权利,而仅仅满足于他对别人所拥有的自由和他允许别人对他所拥有的自由一样多。”简单一点说,那就是如果别人放弃反对我们的权利,我们也愿意放弃反对别人的权利。
自然状态中的义务
如果我们认识到自然状态中的这些和那些自然法,我们是否就有遵守它们的义务呢?霍布斯回答说,这些法则是永远具有约束力的,无论是在自然状态中还是在公民社会中。但是他区分了自然法适用于自然状态的两种方式。他说:“自然法在内心范围中(in foro interno)是有约束力的,也就是说,它们只要出现便对一种欲望有约束力。但在外部范围中(in foro externo),也就是把它们付诸行动时,就并非永远如此了。"因此,并不是说,在自然状态中似乎就没有义务了,而只是说,在自然状态中并不总是能出现让人们遵循自然法而生活的条件。人们在自然状态中对一切具有权利并非因为没有义务,而是因为如果一个人谦恭、温顺且守其诺言,那么“在别的人并不这样做的时候和场舍(他)就只能使自己成为别人的捕获物,使他自己遭受毁灭。这是违背一切自然法的基础的,因为自然法倾向于自然的保存。”而在我们为了保存我们自己而行动时,我们也并没有摆脱理性的自然法,因为甚至在自然状态下我们也应该根据一个好的信念而行动,即“如果任何人自称某物必然有助于他的自我保存,但连他自己都并不确信如此,他就可能违背自然法。”
霍布斯意识到:无政府状态是那些只考虑自己如何最好地生存的利己主义的个人必然产生的逻辑结果。在这种状态中将出现一种可怕的情况,即:“没有艺术,没有文学,没有社会,最糟糕的是人们总是处于死于暴力的恐惧和危险之中。人的生活孤独,贫困,卑污,残忍而短寿。”因此,我们应当在力所能及的范围内避免这种无政府状态。导致这种状态的主要原因是那些利己主义的个人判断间的冲突。通过遵循自然法的命令,我们将寻求和平,放弃我们的某些权利或自由,进入到一种社会契约之中。因此,我们将创造一种人造的人——伟大的利维坦——它被称为公民社会或者国家。
社会契约
我们避免自然状态和进人公民社会的契约是一种个人之间的协议,“就好像每一个人对每一个人说,我承认并放弃我支配自己的权利,把它授予这个人或这些人的会议。但条件是:你也放弃你的权利,也把它授予他,而且以同样的方式认可他的一切行为。”在这个契约中,有两点是很突出的:第一,订立契约的各方是相互许诺放弃他们自己支配自己的权利,把它交给主权者,它不是主权者和公民之间的契约。主权者具有绝对的支配权,而且决不服从于公民。第二,霍布斯清楚地说明,主权者要么是“这个人”,要么是“这个集体”。这暗示,至少在理论上,他关于主权的观点并不等同于任何一种具体形式的政府。这很可能是因为,他偏爱具有绝对权力的单个人的统治,然而他又认识到他的统治权的理论有可能和民主制相协调。但是,无论最高主权者采取何种形式,很明显,霍布斯确保了统治权从人民手中转移到了绝对的不可改变的主权者的手中。
霍布斯特别急于以逻辑的严格性来证明主权是不可分割的。由于已经揭示出在自然状态中无政府状态是独立的个人判断的逻辑结果,他得出结论说:克服这种无政府状态的惟一办法就是把多个公民团体形成为一个单一的团体。这惟一的方法就是把多数人的意志转变为一个单一的意志,这也就是承认最高统治者的单一的意志和判断代表了所有公民的意志和判断。实际上,这就是在人们同意放弃他们支配自己的权利时契约所要说的东西。现在,主权者的行为不仅代表了公民,而且似乎也体现了公民的意志——这就肯定了主权者的意志和公民的意志之间的同一性。一个公民反抗主权者的做法在两方面是不合逻辑的。首先,这种反抗将等于是反对他自己;其次,这种反抗也就是要退回到独立判断的原始状态,也就是退回到自然状态或无政府状态。因此,为了确保秩序、和平和法律,主权者的权力必须是绝对的。
民法对自然法
法律仅仅开始于有主权者存在的时候,这在逻辑上是不言而喻的。因为在司法意义上,法律被定义为主权者的命令。这就得出这样的结论:没有主权者的地方就没有法律。的确,霍布斯肯定:即使在自然状态下,人们也有关于自然法的知识,而且在某种特定意义上,自然法甚至在自然状态中也一直有着约束力。但是,只有在有了主权者之后,才可能有某种法律秩序,因为只有到那时才有法律机关。在这种法律机关中,强制性权力是核心。霍布斯说,没有强制性权力,契约也就是“一纸空文”。霍布斯把法律与主权者的命令相等同,他还补充一点说:“不可能有不公正的法律。”
在主张不可能有不公正的法律的时候,霍布斯极端独裁主义的思想以最令人震惊的方式表现了出来。看起来正义和道德开始于主权者,而且没有先于且限制主权者行为的正义和道德原则。霍布斯在一段名文中断言了这一点:“制定一个好的法律是主权者所关心的事。但是,什么是好的法律?我所说的好的法律,不是指一个公正的法律,因为没有不公正的法律。”之所以说没有不公正的法律,霍布斯提出了两条理由:第一,因为正义就意味着遵守法律,而且正义只是在法律制定之后才存在,它自身不可能成为法律的标准。第二,当主权者制定一个法律时,这也就像是民众自己在制定法律一样,而民众所同意的东西不可能是不正义的。确实,霍布斯所说的第三条自然法则说的就是:“人们应当履行他们订立的契约”,而且他还说这是“正义的基础”。因而,信守你同意的服从最高统治者的契约,这就是霍布斯哲学所说的正义的本质。
很明显,霍布斯强迫读者认真对待他的每一句话,而且“断定”所有的“结论”都能由之推演出来。如果法律指的是主权者的命令,如果正义就意味着遵守法律,那么就不可能有不正义的法律。但是,可以有坏的法律。因为霍布斯又吸收了足够的亚里士多德思想,他认识到主权者具有确定的目的,“正是因为这个目的,他被委以统治的权力,也就是说他被委派来保证民众的安全。自然法责成他负有此项义务,对此他要向上帝作出交代。”但是,即使在主权者已经制定了一个“坏的”法律的情况下,这种判断也不是公民们能作的,也不能以此证明他们可以对这个法律不予遵守。只有主权者才有对什么是有助于民众安全的事作出判断的权力。如果民众不同意统治者,他们就会回到无政府状态中去。如果统治者从事不公正的行为,这是统治者与上帝之间的事,而不是公民与统治者之间的事。出自对无政府状态和无序的深深恐惧,霍布斯把他的服从的逻辑推进到这样的地步:使宗教和教会服从于国家。对那些认为主权者的命令违背了上帝的律法的基督徒,霍布斯没有给予任何的安慰,而是坚持认为,如果这种人不能服从主权者,那么他就必须“去为耶稣基督殉道”。
由于这些大胆的做法,霍布斯改变了哲学的方向。他是首先把科学方法运用于研究人的本性的人之一,他对人类知识和道德行为提出了新的解释,并把它们和中世纪的自然概念区分了开来,最终达到了一种高度独裁的主权观念。虽然霍布斯在他那个时代没有赢得广泛的赞同,在他的哲学中甚至还有许多值得怀疑和批评的地方,然而他对哲学问题系统阐述的严密性保证了他的哲学的持久影响力。
第十章 大陆理性主义
虽然哲学很少以极其突然的方式改变自己的方向,但有因为新的关注和新的重心而把自己与刚刚过去的时代清晰地区别开来的时候。这就是17世纪大陆理性主义的情况,它的剑立者是笛卡尔,而它的新方案开始了所谓的近代哲学。在一定意义上,大陆理性主义者想做的很多事情都已经由中世纪哲学和培根与霍布斯尝试过了。但笛卡尔、斯宾诺莎和莱布尼茨形成了一种新的哲学观点。由于受到科学进步的影响,他们试图给哲学以数学的精确性:他们企图制定能够组织进入一个真理系统中去的清晰的理性原则,从其中能够推演出有关世界的精确信息。他们强调人的心灵的理性能力,他们把这种能力看作既是有关人的本性的,也是有关世界的真理的源泉。虽然他们并不拒斥宗教的断言,但他们的确认为哲学的推理是某种独立于超自然的启示的东西。他们认为主观感觉和激情作为发现真理的手段没有多少价值。相反,他们相信遵循适当的方法,就可以发现宇宙的本质。这是对于人的理性的乐观主义观点,这种观点与那些复活古代怀疑论的近代企图,特别是在蒙田那里这种企图是针锋相对的。理性主义者认定凡是他们能够以他们的心智清晰地思考的,就是现实地存在于他们的心智之外的世界中的。笛卡尔和莱布尼茨甚至论证说,某些观念内在于人心,并且如果给以适当的诱发,经验就会使这些内在的真理变得自明起来。理性主义的这种高度乐观主义的方案并没有完全成功,它的那些主要倡导者们的观点众说纷绘,就表明了这一点。的确,所有的理性主义者都认为一切自然事件都是决定论的,对自然界按照物理学的机械论模式加以解释。但笛卡尔把实在描述为一种由两种基本实体——即思维和广延——所构成的二元结构。斯宾诺莎提出了一种一元论,说唯有一个单一的实体——那就是自然。菜布尼茨是一个多元论者,他认为存在着许多不同种类的基本实体,它们组成了世界。
10.1 笛卡尔
笛卡尔的生平
勒内·笛卡尔(RenéDescartes)1596年生于托莱。他的父亲约阿西姆·笛卡尔是布里坦的地方议会的议员。自1604年到1612年,幼小的笛卡尔在耶稣会的拉弗来施公学学习,他在那里所受的教育包括数学、逻辑和哲学。在这几年给他印象最深的是数学的确定性和精密性,与之形成对照的则是传统哲学,它一律导致怀疑和争辩。有一段时间他曾是巴伐利亚的马克西米廉军队中的一名军人。游遍了欧洲之后,他在1628年决定移居荷兰,在这里笛卡尔写出了他基本的哲学著作,包括《方法谈》(Method,1637)、《第一哲学沉思集》(Meditations on First P%iloSophy,l641)、《哲学原理》(Principles of Philosophy,1644)和《心灵的激情(The Passions of the Soul,1649)。1649年他应克利斯蒂娜女王的邀请去瑞典,女王希望笛卡尔在哲学上给她以指导。由于女王只能在早上5点钟接见他,在这个时刻所受到的酷寒所带来的不适应轻而易举地使他成为了疾病的牺牲品。几个月内他受到发烧的折磨,在1650年2月逝世,终年54岁。
对确定性的追求
笛卡尔最关心的是理智的确定性问题。如他所说的,他是“在欧洲最著名的学校之一中受教育的”,然而他还是发现自己为“许多怀疑和错误”所困扰。回顾他的学习,他认为古典文献给他提供了诱人的故事,这些故事对他的心灵有激励作用。但这并不能引导他的行动,因为这些故事所描绘的那些人类行为的典范完全是超出人的行动力量的。他亲切地谈到了诗歌,他说诗人是用“想象的力量”带给我们知识,甚至让真理比在哲学家那里“放射出更多的光彩”。然而,诗是心灵的一种天赋而不是学习的成果;因此它给予我们的不是有意识地揭示真理的方法。虽然他尊重神学,但他断言神学的“启示的真理”完全是超越人的理智的,并且如果我们要有成效地思考它,“那就必须从高处得到某种超凡的援助,而不仅仅只是一个人。”他并不想否认这种真理,因为他直到最后显然还是一个虔诚的天主教徒。然而,他并没有在神学中发现一种方法,可以使这些真理全凭人的理性能力而达到。他在学校里所学的哲学对于这一点也没有任何更多的帮助,因为“在其中发现不了任何一个没有争端的问题和不容置疑的结论。”
笛卡尔对确定性的追求把他从所读的书本转而引向了“世界这本大书”,在那里他通过旅行遇到了“各种不同气质和身份的人”,并收集到“各种各样的经验”。他的想法是,通过和世人广泛接触,他将发现更多精确的推理,因为实际的生活中与学术活动不同,对推理错误会有很严重的后果。但是他说,他在实践的人们中发现了如同在哲学家们之间同样多的意见分歧。从读“世界这本大书”的这种经验中,笛卡尔决定“不再过于相信我仅仅通过榜样和习惯所确信的任何东西”。他执意继续自己对确定性的追寻,并且在一个值得纪念的夜晚,1619年11月10日,做了三个梦,这三个梦使他确信,他必须把真知识的体系惟一地建构在人的理性能力之上。
笛卡尔与过去决裂并给了哲学一个新的起点。特别是,由于他的真理体系必须从他自己的理性能力中引申出来,他的思想就不应当再依赖过去的哲学家,也不应当仅仅因为是由某个权威人士说出来的就把任何思想当作真理接受下来。无论是亚里士多德巨大声望的权威还是教会的权威都不足以产生出他所追求的那种确定性。笛卡尔决定在他自己的理性中发现理智确定性的基础。因此,他由于只使用那些他通过自己的力量能够当作其他一切知识的基础来知晓的真理,而给哲学提供了一个新起点。他完全意识到他在哲学史上独一无二的地位,他写道:“虽然在我的原理中分门别类的所有这些真理是一切时代和一切人都知晓的,但据我所知,直到现在还没有一个人采用它们作为哲学的原理…作为关于世上的一切其他事物的知识的源泉。这就说明了,为什么还得由我来证明它们是这样的原理。”
他的理想是达到这样一个思想体系,它的各条不同的原理不仅仅是真的,而且以这样一种清晰的方式联结起来,以致我们能够很容易地从一条真实的原理推进到另一条真实的原理。但为了得到这样一套有机联系起来的真理,笛卡尔感到他必须使这些真理“遵守一个合理的规划”。借助于这个规划,他就不仅能够使现有的知识组织起来,而且能够“指导我们的理性去发现那些我们所不知道的真理”。所以他的第一个任务就是要制定出他的“理性的规划”——这就是他的方法。
笛卡尔的方法
笛卡尔的方法在于利用一套特殊的规则来驾驭心灵的各种能力。他坚决主张方法要有必然性,要系统地和有序地进行思维。他对那些漫无目的地追求真理的经院学者感到吃惊,并且把他们比作这样一些人,他们“满心燃烧着利令智昏的寻宝欲望,不停地在大街上徘徊,想拾到一个过路人没准儿会掉下的什么东西”。他接着说:“非常肯定的是,这一类毫无章法的探讨和混乱的反思只会惑乱自然之光并蒙蔽我们心智的力量。”但仅凭我们内心的能力也有可能把我们引人歧途,除非这些能力受到悉心规范。所以方法就在于能够指导我们的直觉和推理能力有序运作的那样一些规则。
数学的例证 笛卡尔把数学看作清楚精密的思维的最好例证。他写道:“我的方法包括所有把确定性给予算术规则的东西。”实际上,笛卡尔是想把一切知识都做成一种“普遍数学”。他确信数学的确定性是一种特别的思维方式的结果。如果他能够发现这种方式,他将会得到一种方法来发现“处于我的能力范围内的对任何事物的”真知识。数学本身并不是方法,它只是展示了笛卡尔所要寻求的方法。他说,几何与算术只是他的新方法的“例证”和“外部包装”而非“构成要素”。那么,数学中究竞有什么东西引导笛卡尔在其中找到他自己的方法基础呢?
笛卡尔在数学中发现了有关心智活动的某些基础性的东西。特别是,他紧紧抓住了心智对直接的和清楚可靠的基本真理的领会能力。他不太关注对于我们如何从经验中形成观念的这种机制作出解释。相反,他想断言的是这样一件事情:我们的心智有能力以绝对的清楚和分明来知晓某些观念。此外,数学的推理表明了我们如何按照一种有序的方法从我们所知道的东西前进到我们所不知道的东西。例如,在几何学中我们从线和角的概念开始,并从中发现了那些更复杂的概念,像一个角的角度之类。为什么我们不能把这同一种推理方法也运用到别的领域中去呢?笛卡尔确信我们能够这样做,他还声称这种方法包含“人类理性的根本基础”,而且他可以借此引出“不论在哪个领域中的真理”。以他的眼光看来,所有各种不同的科学都只不过是同一个推理能力和同一种方法被运用的不同方式而已。在任何场合下这都是对直观和演绎的有序运用。
直观和演绎 笛卡尔把知识的全部大厦都置于直观和演绎的基础之上,他说:“这两种方法就是获得知识的最可靠的路线。”他还说,任何其他的进路都将“因有错误和危险之嫌而遭拒斥”。简言之,直观给我们提供了基本的概念,而演绎则从我们的直观中引出了更多的信息。笛卡尔把直观描述为一种理智的活动,或是一种如此清晰以至于在内心中不容怀疑的眼光。我们感觉的动摇不定的证据和我们想象的不完善的创造物都让我们陷入混乱;而直观却给我们提供了“一颗不受蒙蔽的专注的心如此周到而分明地给予我们的概念,以至于我们完全摆脱了对我们所理解的东西的怀疑”。直观不但给了我们清楚的概念,也给了我们一些有关实在的真理,例如“我思”,“我在”,以及“一个球体只有一个面”——这些都是基本的、单纯的、不可化约的真理。此外,我们凭借直观还把握了一个真理和另一个真理之间的关联——比如这个公式:“如果A=B,并且C=B,那么A=C。”
笛卡尔把演绎描述为“从确定地知道的事实中作出的任何必然性推断”。使直观和演绎相似的是,这两者都涉及到真理。通过直观,我们完整而直接地把握到一种简单的真理;而通过演绎,我们经过一个过程,即一个“连续而不间断的心灵活动”,而达到真理。由于如此紧密地把演绎和直观联系起来,笛卡尔对直到他那个时代仍被人们与名为三段论的推理类型等同起来的演绎给出了一种新的解释。按照笛卡尔的描述,演绎是不同于三段论的。一个三段论涉及概念之间的相互关系,而演绎在笛卡尔看来则涉及真理之间的相互关系。像在三段论中那样从前提进结论是一回事,但从一个不容置疑的事实中推出有关那个事实的结论,即笛卡尔所说的我们必须凭演绎来做的结论,则是另一回事。笛卡尔强调的是出自一个事实的推理和出自一个前提的推理两者之间的差异,因为他的方法的核心之点全系于此。笛卡尔对以前哲学和神学的批评在于,其结论是根据三段论要么从不真实的前提,要么从仅仅基于权威的前提中推理出来的。然而,如果我们从事实出发,那么通过恰当的演绎,我们结论的真理性就有了保证。笛卡尔想要把知识建立于一个在个体自己心目中具有绝对可靠性的出发点上。所以知识要求运用直观和演绎,在这里,“第一原理是单独由直觉给出的,而间接结论则…仅仅由演绎所提供。”而这也就是笛卡尔方法的关键成分。他的方法的另一个成分包括指导直观和演绎的规则。
方法的诸规则 笛卡尔的规则的主要之点就是为心灵的运作准备一套清楚而有序的步骤。他所确信的是:“方法完全在于我们精神的眼光如果想找到任何真理都必须指向的那些客体的秩序和特性。”我们必须从一种简单的和绝对清楚的真理开始,并且必须一步步不失清晰性和可靠性地沿着这条路推进。笛卡尔花费了许多年来完成制定具体规则的任务。在其《指导心灵的规则》中可以找到21条规则,下面是其中一些最重要的:
规则3,如果我们打算研究一个主体,“我们的研讨就不应当指向别人思考过的东西,也不应当指向我们自己所猜测的东西,而应当指向我们能够清楚明白地看到并可靠地推演出来的东西。”
规则4,这是一条要求其他规则都必须严格服从的规则,因为“如果一个人严格地遵守它,他就永远也不会把本是虚假的东西当作真实的,并且永远也不会把自己的心思花费在无意义的事情上。”
规则5:我们应当精确地遵照这个方法来做,如果我们“把复杂的和晦涩的命题逐步化归成那些更简单的命题,然后从对所有这些绝对简单的命题的直观领会出发,试图遵循严格相似的步骤上升到一切其他的知识的话。”
规则8:如果在有待考察的事情上我们到达了这一步,我们的理解能力尚不足以对这一步所属的那个序列形成一个直观的认识,那么我们就必须在那里止步。”
以类似的方式,笛卡尔在他的《方法谈》中制定了四条准则,他相信这四条准则是完全够用了的,“只要我立下坚定不移的决心,决不在任何情况下不遵守它们。”用笛卡尔自己的话说,这些规训是:
第一,决不把任何我还没有清楚地认识其为真的东西当作真的而接受下来;在我的判断中不包含别的任何东西,只包含清楚明白地呈现在我心灵之前,让我根本无从怀疑的东西。第二,把所考察的每个难题分解成尽可能多的部分,直到可以必然地使这些难题得到适当的解决。第三,按照这样一种次序引导我的思想,以便我从可以最简单也最容易知悉的对象开始,一点一点地,也就是逐步地上升到更为复杂的知识。最后,无论何时都要尽量列举出一切情况,尽量普遍地加以审视,以至我可以确信无一遗漏。
比起培根和霍布斯来,笛卡尔的方法甚少重视在获得知识时的感觉经验和实验。笛卡尔问道,那么,我们又将如何知道那些本质的属性,例如蜡块的本质属性呢?蜡块有时候是硬的,有一定的形状、颜色、体积和香气。但当我们把它凑近火焰时,它的硬度就消融了,它的香味就消失了,它的形状颜色也失去了,而它的体积则增大了。在蜡中还留下什么让我们仍然可以认为它是蜡的东西呢?笛卡尔认为,“这不可能是任何我凭借感觉所觉察到的东西,因为一切尝到的、闻到的、看到的、摸到的和听到的都已经变化了,然而蜡却还是那块蜡。”所以“只是我用以设想它的理解力…只是单凭我的心灵所进行的考察”就使我能够知道蜡的真实属性了。并且,笛卡尔还说,“凡是我在这里关于蜡所说的话也可以适用于一切在我之外的其他事物。”他几乎总是依靠包含于心灵中的真理,“(不要把真理从另外的源头中引出来,而要从天然存在于我们心灵中的真理发源地中引出来。”笛卡尔认为在这种意义上,即在我们“生来有某种确立它们的气质或倾向”这种意义上,我们具有确定可靠的天赋观念。由于我们能够知道这些真理,我们就可以有保证地为我们的演绎奠定可信赖的基础。笛卡尔相信他能够从这个开端出发,通过仅仅诉诸他自己的理性能力并根据他的规则引导这些能力,而反思和重建全部哲学。因此他试图表明,他不仪能够拥有关于数学概念的知识的可靠性,而且还拥有关于实在本质的知识的可靠性。
作为方法的怀疑
笛卡尔运用怀疑的方法来为建构我们的知识找到一个绝对可靠的出发点。由于他在自己的规侧中宣称我们决不能接受我们能够对之抱有怀疑的任何东西,于是笛卡尔试图怀疑每件事情。他说,“因为我希望彻底献身于对真理的追求,我认为对于我来说有必要对任何我可以设想有哪怕再小不过的一点理由加以怀疑的东西都当作绝对错误的而加以拒绝。”他的意图很明显,因为他就是要清除自己以前的一切观点,“好让这些观点以后要么被另外的更好的观点所接替,要么还是被同样的观点所接替,但我们已经使这同样的观点与理性规划的齐一性相一致了。”
凭借这种怀疑的方法,笛卡尔表明我们的知识,哪怕对那些看来最明显不过的事情的知识都是如何地不可靠。有什么能比“我在这里,坐在火炉边…在我手里拿着这张纸”更清楚的呢?但是,当我睡着了,我也会梦见我坐在火炉边,而这就使我意识到,没有什么最终的标志能够借以使清醒时的生活与睡眠区别开来。我也不能肯定物的存在,因为我说不清究竟我何时在想象、何时在认知现实:“我懂得了(我的)感官有时会误导我”。但算术、几何或那些涉及各种事物的科学肯定是必须包含某种可靠性的,因为“不论我醒着还是睡着了,2加3总会得出5这个数来。”在这里笛卡尔用到了他长期保持的信念,即有一个能够做任何事的上帝。但是,他追问他如何能够肯定上帝没有“造成既没有地,也没有天,也没有有广延的物体的情况呢?”不论他关于他周围世界的印象如何自明,有这样一种可能性——不管这种可能性多么小——即这一切都是神性干预的幻觉。或许他所经验的每件事都是上帝在欺骗他!
这时,笛卡尔说:“如果我有足够的幸运能找到哪怕一条确定的不可怀疑的真理”,那就会足以推翻怀疑并建立起一种哲学来。就像阿基米德只要求一个不动的支点以推动地球离开其轨道,笛卡尔也在寻求他的惟一的真理,而且正是在怀疑的行动中找到了它。我怀疑我的身体的存在,或是怀疑我醒着,简言之,怀疑一切都是幻觉或假相。但还是留下了一件我根本不可能对它加以怀疑的事情,这就是我存在。笛卡尔在哲学史上最著名的篇章之一中阐述了这个论点:
但我曾被说服相信在整个世界中无物存在,没有天,没有地,既没有心灵也没有任何物体:那么,我不是也同样被说服了相信我不存在吗?根本不是;我自己的确存在,因为是我说服我自己相信些什么东西。但是有某个欺骗者或一个另外的极强大极狡猾者不断地在用他的足智多谋欺骗着我。那么即使在他欺骗我的时候我也无疑是存在的,并且他尽可以任意欺骗我,但只要我想到我是某种东西,他却永远不可能使我什么也不是。
在笛卡尔看来,即使上帝以任何可能的方式欺骗我,我也由此知道我存在,因为我通过怀疑的这种完全是精神性的活动而肯定了我自已的存在。笛卡尔用这样一句话来表达这一点:“我思,故我在”(拉丁文为cogito ergo sum)。
首先,由“我思,故我在”这一真理而得到证实的只是我的思维的存在,而不是别的。对我自己的身体的存在和除了我的思维以外的其他任何东西,我仍然保留着怀疑。说“我思,故我在”,就是肯定我的存在:“但究竟什么是我?一个进行思维的东西。什么是进行思维的东西?这就是一个在怀疑、在理解、在肯定、在否定、在意愿、在拒绝,并且也在想象和感觉的东西。”笛卡尔始终认定:因为思维是一个事实,所以也就必须有一个思维者,“一个在思维的东西”。这个“东西”不是身体,因为“我知道我是一个其全部本性都是思维的实体,而且它的存在不需要任何位置,它也不依赖于任何物质的东西。”于是看起来可以绝对肯定的是,我,一个自我,存在着,“因为没有任何思维能够离开一个进行思维的东西而存在,这一点是肯定的。”但这样一来,思维者就是一个孤独的鲁滨逊,被封闭在自己的观念中了。
上帝和外部事物的存在
笛卡尔为了超越他自己作为一个思维之物而存在的确定性,又问道,我们如何知道某物是真的?他问:“在一个命题中为了成为真的和可靠的需要什么?”是什么使得命题“我思,故我在”成为可靠的?“我得出了这样的结论,即我可以把‘凡是我十分清楚和分明地想到的东西全都是真的'设想为一条普遍的规则。”在这一语境中,“清楚”意味着“它出现了,并且对于关注的心灵是显而易见的”,就好像物体清楚地呈现给我们的眼晴一样。“分明'”则是指“那种如此精确且如此区别于一切其他对象的东西,以至于它在自身中只包含清楚的东西。”于是“我思,故我在”这一命题为真的的理由就纯粹在于它对于我的心灵来说是清楚分明的。这也是数学命题为真的的理由,因为数学命题是如此清楚分明,以至于我不得不接受它们。但是,为了保证我们清楚分明的观念的真理性,笛卡尔必须证明上帝的存在,以及上帝并不是一个使我们把虚假的事物想成是真的骗子。
笛卡尔不能利用阿奎那对上帝存在的证明,因为这些证明都是建立在仍然遭到笛卡尔怀疑的那些事实之上的,也就是建立在像自然事物中的运动和原因这样一些外部世界的事实之上的。相反,笛卡尔必须完全凭着对他自己的存在与内部思想的合理意识来证明上帝的存在。因此他通过考察经过他的心灵的各种观念而开始他的证明。
关于这些观念,他注意到了两点:(1)这些观念是有原因的以及(2)按照其内容它们相互之间是有明显区别的。这些观念是些结果,而它们的原因则必须去发现。我们的观念中有些看起来是“与生俱来的”,有些是由我“制造出来的”,而另外一些却“来自于外部”。我们的理性告诉我们,“无不能生有”,而且“较完满的东西…不可能是…较不完满的东西的结果”。我们的观念具有不同的实在性程度,“但自然之光表明,在起作用的总体的原因中的实在性至少必须与结果中的一样多”。我们的有些观念按其实在性程度来看,可以在我们自身中有其起源。但上帝的观念包含如此多的“客观实在性”,以至于怀疑我能否由自身中产生出这一观念。因为“在上帝的名下我理解到一个实体是无限的、自主的、全知的、全能的,并且我自己和任何别的东西——如果任何别的东西存在的话——都是由它创造出来的”。我这样一个有限的实体如何能够产生出一个无限实体的观念来呢?事实上,除非我能够把自己与一个完满存在的观念相比较,否测我怎么能知道自己是有限的呢?这个完满性的观念是如此清楚和分明,以至于我确信它不可能出自我的不完满的本性。即使我潜在地是完满的,完满性的观念也不可能来自那种潜在性,因为一个现实的结果必须出自一个现实存在的存在者。于是,笛卡尔认为:(1)观念具有其原因;(2)原因必须至少具有与结果一样多的实在性;(3)他是有限的和不完满的。由这三点他就得出结论说,他关于一个完满的和无限的存在者的观念来自他的外部一来自一个存在着的完满的存在者,来自上帝。另外,笛卡尔得出结论,上帝不会是一个骗子,“因为自然之光告诉我们,欺诈和蒙骗必然出自某种缺陷”,这种缺陷根本不可能归之于一个完满的存在者。
除了这个他借以证明上帝存在的出自因果性的证明之外,笛卡尔还步安瑟伦的后尘,提出了他的本体论证明的翻版。笛卡尔在这个证明中试图通过探讨上帝观念中所隐含的意义来论证上帝的存在。他说,如果“我所清楚分明地知道的一切与这个对象有关的东西实际上确实是属于这个对象的,难道我就不可能从中引出一个证明来论证上帝的存在吗?”如何可能从对一个观念的分析中推出上帝存在的确定性呢?
笛卡尔说,我们的有些观念是如此清楚分明,以至于我们立即就察觉到它们包含着什么。例如,我们不可能思考一个三角形而不同时思考它的边和角。虽然我们不可能思考一个三角形而不同时思考它的边和角的属性,这却并不必然得出思考一个三角形就意味着这个三角形存在。正知一个三角形的观念包含着某些属性一样,上帝的观念也包含有一些属性,特别是存在这个属性。上帝的观念是指一个完满的存在者。但正是这个完满性的观念包含着存在。谈论一个不存在的完满性必然会陷人矛盾之中。我们不可能前后一贯地设想一个存在者在一切方面都是最大完满的而同时却又不存在。笛卡尔说,正如我们不可能思考一个三角形的观念而不同时意识到它的属性,同样我们也不可能思考上帝的观念而不意识到这个观念清楚地包含着存在属性。笛卡尔认为,“我们清楚分明地理解到的那个属于任何事物的不变的真实本性的东西,即它的本质或形式,事实上都可以肯定属于那个事物。但既然我们以充分的精确性考察了上帝的本性,我们就清楚而分明地理解到存在应属于上帝的真正本性。因此我们可以真实地断啻上帝存在。”笛卡尔的批评者伽桑第(Gassendi)反对这种推理方式,他说,完满性并不包含存在,因为存在并不是完满性的一个必要的属性。他认为,缺乏存在并不包含对完满性的损害,它只意味着缺乏实在性。正如我们将会看到的,康德更详细地批评了这些证明上帝存在的企图。
笛卡尔由他自已的存在证明了上帝的存在。按照这种方式他也确立了真理的标准,并以此为数学思维和一切理性活动提供了基础。现在,笛卡尔又来考察物理世界,考察他自己的身体和别的事物了,并询问他是否能肯定它们的存在。我是一个思维者,这本身并不证明我的身体存在,因为我的思维本身“是完全和绝对地不同于我的身体的,并且可以没有身体而存在。”那么,我如何能够知道我的身体和其他自然事物的存在呢?
笛卡尔回答说,我们对改变自己位置、四处运动以及各种活动,都有着清楚分明的经验,这些经验暗示着有一个身体或者他所称的“一个有广延的实体”。我们也接受到视觉、声音、触觉的感官印象——甚至往往违背我们的意志,而这些印象引得我们相信它们来自不同于我们自己的物体。而这样一种相信这些印象“是由物质客体传达给我”的不可抗拒的倾向必然来自于上帝;否则,“如果这些观念是由不同于物质客体的原因所产生的,上帝就不可能免于行骗的指责。所以我们必须承认物质客体存在。”于是在笛卡尔看来,对自我的知识先于对上帝的知识,而自我和上帝这两者又先于我们对外部世界的知识。
心灵和身体
笛卡尔现在推翻了他的一切怀疑,并使自已绝对地相信他自己、事物和上帝的存在了。他作出结论说,存在着思维的东西和有广延、有维度的东西。既然一个人既有心灵又有身体,那就还有一个确定身体和心灵如何相互联系的问题等着笛卡尔来回答。笛卡尔思想的全部要旨都在于这种二元论倾向——即在自然中有两种不同种类的实体这一观点。我们知道一个实体是通过它的属性,而既然我们清楚分明地知道两种完全不同的属性,即思维和广延,则必然也有两种不同的实体,即精神和物质、心和身。因为笛卡尔把实体定义为“一个除了自身存在之外什么也不需要的存在之物”,他就把每个实体都看作是完全独立于另一个实体的。所以,为了对心灵有所认识,我们不必涉及到身体,同样肉体也可以不对心灵有任何涉及而被彻底地理解。这种二元论的结果之一是,笛卡尔借此把神学和科学分离开来了,并认为在它们之间不必有什么冲突。科学对物理自然的研究将与其他训诫了无干系,因为物质实体拥有自己的活动领域,并能够按自己的规律得到理解。
如果思维和广延是如此不同并且互相分离,我们又如何能够解释有生命之物呢?笛卡尔推论道,因为生命体具有广延,它们就是物质世界的…部分。所以生命体按照支配物质秩序中的其他事物的同一个机械和数学规律来活动。例如说到动物,笛卡尔认为它们是一些自动机,他说,“我们从幼年时代保留下来的一切成见中最大的成见就是相信兽类能思维。”他认为,我们之所以以为动物思维,只是因为我们看到它们偶尔会做出人那样的行为,比如,狗会演杂技。因为人有两条推动原则,一条是物质的,而另一条是精神的,我们就设想当动物做出了类似于人的行为时,它们的身体运动是由它们的精神能力所导致的。但笛卡尔看不出把精神能力赋予动物的理由,因为它们的一切活动或行为都能单凭机械论上的考虑就得到说明。这是因为,是“自然在它们中按照它们器官的特性而活动,正如一只仅仅由齿轮和钟摆组成的钟样”。所以动物是机器或自动机。但人又如何呢?
笛卡尔说,人的身体的许多活动都像动物的活动一样是机械的。这些身体行为如呼吸、血液循环和消化都是自动的。他认为人的身体的作用可以被还原为物理学。每件身体的事情都可以由对机械原因或者亚里土多德所说的“动力因”的考虑而得到恰当的说明;在描述身体的自然过程时就不需要考虑目的因了。此外,笛卡尔相信宇宙中运动的总量保持不变。这导致他断言人的身体的运动不可能源自人的心灵或灵魂:他认为灵魂只能影响或改变身体中某些因素和部分的运动方向。心灵如何能够做到这一点?这就很难作出准确的解释了,因为思维和广延——心灵和身体——在笛卡尔看来是彼此迥异且相互分离的实体。他争辩说心灵不是直接推动身体的那些不同部分的,相反,“灵魂的主要原则在大脑里”,即在松果腺中,它首先与“生命的精气”相接触,而灵魂通过它们与肉体互相作用。显然,笛卡尔试图给人的身体个机械的解释,而同时义想保持灵魂通过意志活动对人的行为发生影响的可能性。因此,人与动物不同,他是能够进行好些种类的活动的。我们能够从事纯粹的思想,我们的心灵能够受身体感觉和知觉的影响,我们的身体可以由我们的心灵支配,而我们的身体又是由纯粹的机械力所推动的。
但是笛卡尔严格的二元论在描述精神和肉体如何能够相互作用上给他造成了困难。如果每个实体都是完全相互独立的,那么心灵居住在身体中,就必然会像珍珠在珠蚌中一样,或者用笛卡尔自己的比喻说,如同领港员在船里一样。经院哲学曾把人描述为一个统一体,在其中精神是形式,而肉体是质料,并且说没有其一就不可能有其二。霍布斯曾把精神归结为运动的物体并以这种方式达到了人的统一。但笛卡尔却以他对“思维”的新定义加剧了心灵和身体的分裂。这是因为,他把传统上一直被归于身体的某些经验,即感官知觉的全部范围,例如“身体感觉”,都包括进思维活动中了。当笛卡尔把“我所是的东西”定义为“一个进行思维的东西”时,他并没有提及身体,因为对他来说一切实质性的东西都被包括在“思维”中了。一个进行思维的东西就是一个进行怀疑、理解、肯定、否定、意愿、拒绝的东西,也就是进行想象和感觉的东西。这个自我想必可以不需要身体而感觉到热。但显而易见,笛卡尔在此不可能完全接受他自已的二元论。他承认,“自然也通过痛苦、饥饿、口渴等这些感觉来教导我说,我并没有像一艘船的领港员一样住在我的身体里,相反,我是非常紧密地联系在身体上的,并且可以说,是如此的与身体混为一体,以至于我似乎是与它组成了一个整体。”虽然他企图把心灵定位于松果腺中,但也还是留下了关于相互作用的技术难题。如果有相互作用,也就必须有接触,而这样心灵也就必须是有广延的。在这个问题上,他的方法规则并没有把他引向任何清楚分明的结论。
10.2 斯宾诺莎
巴鲁赫·斯宾诺莎(Baruch Spinoza)是最伟大的犹太哲学家之一。他的思想的原创性是受到他因自己的非正统观点而被阿姆斯特丹犹太教堂所驱逐的激发。他拒绝接受海德堡大学的哲学教授席位,这进一步表明他渴望保持追求自己的思想的自由,无论这种对真理的追求会把他引向何处。虽然他甘于过简朴的生活,通过磨透镜来清寒度日,他作为思想家的名声却广泛传播,既激起了赞美也引起了谴责。斯宾诺莎1632年在阿姆斯特丹出生于一个从西班牙的宗教迫害中逃出来的葡萄牙犹太人家庭中。他受的是《旧约圣经》和塔木德研究的训练,并且通晓犹太哲学家迈蒙尼德的著作。1663年他被迫离开阿姆斯特丹而去到海牙(The Hague),在那里进行著述活动,其中《伦理学》(Ethics)是他登峰造极的著作。1677年他死于肺结核,终年45岁。
斯宾诺莎受到笛卡尔的理性主义、他的方法和他对哲学主要问题的选择的影响。但他们的兴趣甚至术语上的相似性并不说明斯宾诺莎就是笛卡尔的一个追随者。在许多观点上斯宾诺莎给笛卡尔所开创的大陆理性主义带来了新的东西。
斯宾诺莎的方法
与笛·卡尔一样,斯宾诺莎认为我们遵循几何学的方法就能获得有关实在的精确知识。笛卡尔制定了这种哲学方法的基本形式,他从清楚分明的那些第一原理出发并试图从中推演出全部知识内容。斯宾诺莎对笛卡尔的方法所增添的东西是对各种原理和公理的一个高度系统化的整理。如果说笛卡尔的方法是简单的,那么斯宾诺莎则几乎是打算写出一部地地道道的哲学几何学,就是说,一整套完备的公理或定理(大约共有250条),它们将以几何学解释事物的关系和运动的方式来解释实在的整个体系。在几何学中结论是推演出来的,而斯宾诺莎相信我们关于实在的本性的理论也能够被推演出来。霍布斯怀疑斯宾诺莎通过把他的大量公理和定理整理为一个知识系统是否能有任何成效。蛋布斯认为,从公理中引出许多彼此一贯的结论的确是可能的,但由于构成这个公理的无非是任意的定义,它们并不能告诉我们关于实在的什么东西。斯宾诺莎则不会同意说这些定义是任意的,因为他像笛卡尔一样相信我们的理性官能有能力形成反映事物的真实本性的观念。斯宾诺莎说:“每个定义或清楚分明的观念都是真的。”于是,这就必然会得出,对真观念的一个完备而系统的安排将给我们提供一个真实的实在图景,因为“观念的秩序和关联与事物的秩序和关联是一样的”。
事物的这种秩序也为哲学家应该用来整理他的题材的那个秩序提供范本。至为重要的是,如果我们必须精确理解自然的各个方面的话,我们就要小心地遵守这种秩序。例如,如果我们认为事物出于其本性而依赖于上帝,那么我们在能够理解事物之前必须首先尽我们所能地知道有关上帝的一切。由于这个原因,在斯宾诺莎看来,弗兰西斯·培根的方法没有多少价值,这种方法是由对可见事物的观察材料加以列举以及从这些观察材料中通过归纳引出结论而构成的。他也不会去利用阿奎那的方法,即通过首先分析我们对事物和人的日常经验的本性来为上帝存在说明理由。在这一点上斯宾诺莎还拒绝了笛卡尔的做法。笛卡尔从他自己存在的清楚分明的观念和“我思,故我在”的公式出发,继而推演出他的哲学的其他部分。而斯宾诺莎则由于在事物的真实本性中上帝是先于任何其他事物的,就相信哲学必须首先阐述有关上帝的观念。然后,关于上帝的观念又会具体落实到影响我们所引出的那些关于人的本性、行为的方式和心物关系之类问题的推论。而由于斯宾诺莎关于上帝说了这样一些新的东西,他就不可避免地也会对人的本性说出新的东西来。因此,斯宾诺莎是从上帝的本性和存在这个问题开始他的哲学的。
上帝:实体和属性
斯宾诺莎提出了一个惊人的独一无二的上帝概念,在其中他把上帝和整个宇宙看作同一的——一个我们现在称作“泛神论”的观点。他的著名的公式是上帝或自然(Deus sive Natura),就好像说这两个词是可以互换的。我们也许会在《圣经》对上帝的这些描述中找到泛神论的暗示,即“我们活在上帝里面,行在上帝里面,并在他里面有我们的生命”。然而,斯宾诺莎通过强调上帝和人之间的根本统一性而不是它们之间的关系,而剥除了以往意义的上帝观念。他说:“不论什么都在上帝中,而且任何东西都不可能在上帝之外存在或被设想。”理解斯宾诺莎独一无二的上帝概念的线索是在他的如下定义中找到的:“上帝,我理解为一个绝对无限的存在,就是说,一个包含无限属性的实体,这些属性中的每一个都表达了永恒无限的本质。”斯宾诺莎的特殊的思想就是围绕着实体和实体的属性这两个观念而展开的。
通过一系列复杂的连续论证,斯宾诺莎得出了实在的最终本性就是单一的实体的结论。他把实体定义为“在本身中并且通过本身而被设想的东西:我指的是这样一种东西,它的概念的形成不依赖于任何别的事物的概念”。因此,实体并不具有外部的原因,而是在自身中有自身的原因。到此为止,实体还只是一个概念,一个自因的无限实体的观念。然而,这个观念所包含的不仅是这个实体是怎么样的,而且也包含着它存在。这个实体观念本身包含着实体的存在,是因为“存在属于实体”,并且,“因此从实体的单纯定义中实体的存在可以被推论出来”。这就类似于安瑟伦的本体论证明,而且又引起了和本体论证明同样的问题。但斯宾诺莎仍然确信我们可以有把握地从我们关于这个完善的实体的观念进到它的存在,他说:“如果有人说他有一个关于实体的清楚分明的、也就是真的观念,同时却怀疑这样一个实体是否存在,这就像一个人说他有一个真观念却怀疑这个观念是否是假的一样。”从斯宾诺莎为实体所给出的前述定义中推出的是:这个实体是一,并且是无限的。因此存在着一个具有无限属性的单一实体。
斯宾诺莎说:属性是“被理智理解为构成实体的本质的东西。”如果上帝被定义为一个“由无限属性所构成的实体”,那么上帝的本质就会有无限多的方面了。然而,由于我们是从我们人类的有限视角来考察上帝的,所以我们只能理解上帝这一实体的两种属性,即思维和广延。笛卡尔认为这两种属性显示的是两种截然不同的实体的存在,这就把他引向了对身心二元论的肯定。然而斯宾诺莎把这两种属性看作表现单一实体的活动的两种不同方式。因此,上帝就是被理解为无限思维和无限广延的实体。由于无限地存在,上帝包含任何事物。
世界作为上帝属性的样式
斯宾诺莎并没有把上帝和世界对立起来,仿佛它们是像原因和结果那样是有区别的且截然不同的——仿佛上帝是非物质的原因而世界是物质性的结果那样。他已经确立的是,只有一个实体,并且“上帝”这个词和“白然”这个词是可以互换的。但是斯宾诺莎确实区分了自然的两个方面,为此他采用了两个表达方式:“创造自然的自然”和“被自然所创造的自然”。第一个短语“创造自然的自然”,是指上帝中的能动与生命的原则,有了这个原则,他就能通过他的各种属性的活动而产生变化。而那个伴生的概念“被自然所创造的自然”,则是一个被动的概念,指的是上帝已经创造了的东西。这个关于上帝的被动概念中包含了世界上存在的一切“样式”或特性一包括静止和运动等的普遍自然规律,以及石头、树木、人等单个事物。
由于世界是由上帝属性的诸样式组成的,所以这个世界中的每件事物都是按照必然性而活动的——就是说,每件事物都是被决定的。所以,思维和广延借以取得在这个世界上的形式的那些样式是由上帝的实体所决定的。如斯宾诺莎说的,这些样式体现了“从上帝本性的必然性中随之而来的一切东西”。斯宾诺莎给我们提供了一幅严密的宇宙图景,在这里每件事情都按它发生的惟一可能的方式而展开。他写道:“在事物的本性中没有什么可以被承认为偶然的,而是一切事物都被神的本性的必然性所决定,从而按照一定方式存在和发生作用。”上帝是自由的,这有一种特别的意义:虽然他必须创造的正是他所创造的东西,他却不是被某种外在的原因强迫做这件事的,而只是凭他自己的本性。另一方面,人则连这种自由也没有,因为我们是被决定去存在并按照上帝的实体而行动的,人性就是实体属性的一个样式。上帝属性的一切样式都是以来所固定了的,因为“事物本来就不可能被上帝以任何不同于它们已被产生的那种方式或秩序而产生出来”。我们所经验到的一切事物“都无非是上帝(自然)属性的变形,或是这些属性以某种确定的和被决定了的方式得以表现出来的样式”。因此,任何事物都是紧密相关的,无限实体规定了一种贯穿万物的的连续性。那些特殊的事物只不过是上帝的属性的各种变形或各种样式。
因为每件事物永远都是它必然是的那个样子,又因为特殊事物只不过是实体的有限变形,所以就不存在事物运动所趋向的方向。没有目标,没有意图,没有目的因。从我们人类较高的观点出发,我们试图把事情解释为某种历史目的要么实现要么受挫的过程。斯宾诺莎说,目的的观念源自我们按照所确定的目标来行动的倾向。由于这种习惯,我们倾向于把宇宙看作似乎也有某种目的。但这是一种看待字宙的错误方式,实际上也是看待我们自己的行为的错误方式。因为不论是宇宙还是人都并不追求什么目标;它们只是在做它们必然要做的事。这个“真理也许永远不会被人们所知——如果不是数学不管什么目的因,而只管事物的本质,从而给人们提供了另一种真理标准的话。”而真相则是,一切事情都是单纯存在着的永恒实体之各种变形的一个连续的和必然的系列。于是斯宾诺莎把生物学的东西归结为数学的东西。
知识、心灵和身体
斯宾诺莎如何能够宜称知道实在的最终本性?他区分了知识的三个层次,并描述了我们是如何从最低的层次推进到最高的层次的。我们是从我们最熟悉的事物开始的,并且斯宾诺莎说,“我们越是更多地理解个别事物,就越是更多地理解上帝。”通过将我们关于事物的知识加以提炼,我们可以从(1)想象椎进到(2)椎理,最后再推进到(3)直观。
在想象的层次上,我们的观念是从感觉中发源的,就像我们看到另一个人时那样。在这时我们的观念是非常具体而特殊的,而且心灵是被动的。虽然我们的观念在这个层次上是特殊的,但它们却是模糊不清的和不充分的,因为我们只是凭着事物影响我们感官的方式而认识它们。例如,我知道我看见了一个人,但此时我凭单纯的看还不知道什么是这个人的本质。我通过看到几个人可以形成像“人”这样一个一般的观念,从经验中形成的这种观念对于日常生活是很有用的,但它们并不能给我以真知识。
知识的第二个层次超越想象而达到了推理,这就是科学的知识。每个人都可以分有这种知识,因为这正是凭借分享实体的属性即上帝的思维和广延才成为可能的。凡是在一切事物中有的在人性中都有,并且既然这些共同特征之一是理智,人的心灵也就分享着那种整理事物的理智。在这一层次上人的心灵可以超出直接的特殊物之上而处理抽象的观念,就像它在数学和物理学中所做的那样。知识在这个层次上是充分的和真的。如果我们问斯宾诺莎,我们怎么知道理性和科学的这些观念是真的,他实际上会回答说,真理证实自身,因为“一个拥有真观念的人,他同时就会知道他拥有真观念,他也不可能怀疑这件事的真实性”。
第三个、也是最高的知识层次就是直观。通过直观我们可以把握自然的整个体系。在这个层次上,我们能够以新的方式理解我们在第一个层次上所遇到的那些特殊的事物,因为在那个最初的层次上我们把别的物体看成彼此分离的,而现在我们把它看作这个完整系统的一部分了。这种认识是“从有关上帝确定属性之形式本质的充分观念出发而进到事物本质的充分知识的”。一旦我们达到这一层次,我们就获得了越来越多的对上帝的意识,并从此更为完善和有福,因为通过这种眼光我们把握到了自然的整个体系,并看到了我们在其中的位置,这给我们带来一种对自然即上帝的完满秩序的理智的爱恋。
笛卡尔留下了一个困难的问题,即解释心灵如何与身体相互作用。这个问题在他那里实际上是无法解决的,因为他断定心灵和肉体代表两个截然不同的实体。然而对斯宾诺莎来说,这根本就不是个问题,因为他把心灵和肉体看作单一实体的两个属性。只存在一个自然秩序,身与心两者都隶属于它。人构成了一个单一的样式。我们谈及身体,这只是因为我们能够把人看作广延的一个样式,或者我们谈及心灵,这也只是因为我们能够把人看作思维的一个样式。这里不可能有心灵和身体的分裂,因为它们是同一事物的两个方面。每个身体都有相应的观念,而总的来说斯宾诺莎认为,心灵是身体的观念,这就是他描述心灵对身体的关系的方式。心灵和身体在其中运作的这个结构是同一个结构。所以,人的存在就是上帝的有限的变体,因为它是思维和广延这两种上帝属性的一个样式。对人和上帝两者的这种解释为斯宾诺莎的独特伦理学理论提供了舞台。
伦理学
斯宾诺莎对人类行为的描述的核心特点是,他把人当作自然的一个不可或缺的部分来对待。斯宾诺莎认为他看待“人的行动和欲望就像处理线、面、体那样精确”。他的观点是,人的行为可以像任何其他自然现象一样精密地用原因和结果以及数学的关系来解释。虽然人们认为他们是自由的并且能够作出选择,但他们都上了幻觉的当,或者说,只有人的无知才允许我们认为我们具有意志自由。人们喜欢认为他们以某种特殊的方式而置身于原因和结果的严格控制之外——即虽然他们的意志可以成为行动的原因,他们的意志本身却不受先前原因的影响。但斯宾诺莎却主张全部自然的统一性,人也是自然的一个内在部分。因此,斯宾诺莎发展出了一种自然主义的伦理学,其中一切人的行为,不管是精神行为还是身体行为,都被说成是由在先的原因所决定了的。
作为其本性的一部分,所有的人都具有继续和保持他们自己的生存的动力,这种动力斯宾诺莎称之为自然倾向(conatus)。当这种自然倾向涉及到心灵和身体时,它就叫做欲望(appetite),而当欲望被意识到时,就叫做愿望(desire)。当我们意识到更高程度的自保和完善性时,我们就体验到愉快,而由于这种完善性的减少,我们就体验到痛苦。我们的善恶观念是与我们对愉快和痛苦的理解相关的。如同斯宾诺莎说的,“我在这里用善来理解各种愉快,不论它是由什么导致的,尤其用来理解那种满足我们的强烈愿望的东西,不论它会是什么。我用恶来理解各种痛苦,尤其用来理解那种阻碍我们的愿望的东西。”这就不存在固定的善或恶。当我们愿望某物时我们就把它称为善的,而当我们讨厌某物时就把它称为恶的。善和恶反映了一种主观的评价。但因为我们的愿望是被决定了的,所以我们的判断也是被决定了的。
如果我们的一切愿望和行动都是被外部力量所决定了的,那么怎么还可能有任何谈道德的余地呢?在这里斯宾诺莎类似于斯多噶学派,后者也认为一切事件都是被决定了的。斯多噶学派提倡顺从和认同事件的发展趋势,他们说,虽然我们不能够支配事件,但我们可以支配我们自己的态度。以类似的方式,斯宾诺莎告诉我们说,我们通过自己关于上帝的知识可以达到“最大可能的精神认同”。因此,构成道德的是通过从混乱和不充分的观念层次朝直观的第三层次的提升而对我们知识的改进,这时我们就有了关于一切事物在上帝中的永恒完善的安排的清楚分明的观念。只有知识能够引导我们达到幸福,因为只有通过知识我们才能够从我们的激情的束缚中解脱出来。当我们的愿望被系于易朽的事物,而我们又没有充分理解我们的情感时,我们就被激情所奴役。我们越是理解我们的情感,我们的欲望和愿望就越是不会过分。并且,“当心灵把一切事物都理解为必然的时,它就有更大的力量克服情感而越少受其束缚。”
我们不仅要研究我们的情感,而且必须研究整个的自然秩序,因为只有从永恒的角度看我们才能真正理解我们自己的具体的生活,因为这样一来我们就通过作为原因的上帝观念来看待一切事件了。斯宾诺莎说,精神上的不健康总是可以追溯到我们“对某些东西的过分爱好,这些东西受许多变化因素的影响,而我们永远也不可能做它们的主人”。但我们本性上就具有获得更高程度完善性的愿望和能力,而且我们凭借我们理智的机能来达到完善性的各种层次。激情只有当我们缺乏知识时才奴役我们。但“从这种知识中必然会产生对上帝的理智的爱。从这种知识中会产生由作为原因的上帝观念所伴随的愉快,就是说,对上帝的爱;这并不是因为我们把上帝想象为就在面前,而是因为我们理解到上帝是永恒的;这就是我称为对上帝的理智之爱的东西。”这种对上帝的爱当然不是对一个神圣人格的爱。相反,这更接近于当我们理解了一条数学公式或是一项科学工作时所感到的精神上的愉快。斯宾诺莎愿意承认,这里所描述的这种达到道德的途径是“极其艰难的”,但他补充说,“一切优秀的事物有多么珍贵就有多么困难。”
10.3 莱布尼兹
莱布尼兹的生平
从幼年时代起,哥特弗里德·威廉·莱布尼茨就明显崭露出一颗灿烂的思想明星的迹象。他13岁时就像其他孩子读小说一样轻松地阅读经院学者的艰深的论文了。他提出了无穷小的微积分算法,并且他发表自己的成果比伊萨克·牛顿爵士将他的手稿付梓早三年,而后者宣称自己第一个做出了这项发现。莱布尼茨是一个世故的人,取悦于宫廷并得到知名人士的庇护。他与斯宾诺莎有私交,后者的哲学给他以深刻的印象,虽然他断然与斯宾诺莎的观念分道扬镳了。莱布尼茨与哲学家、神学家和文人们进行着广泛的通信交往。在他的宏大计划中曾尝试达成新教和天主教之间的一个和解以及基督教国家之间的联合,这种联合在他那个时代将意味着欧洲联邦。他还做过后来成为普鲁士科学院的柏林科学协会的第一任会长。
莱布尼茨1646年出生于莱比锡,并且15岁就进人了那里的大学。在莱比锡大学他学习哲学,接着到耶拿学习数学。后来到阿尔多夫,在那里他修完了法学课程,并在21岁获得了法学博士学位。他以超乎寻常的精力积极地活跃于行动和思维这两个世界中。他是一系列意义深远的著作的作者。他的《人类理解新论》(New Essays on Human Understanding)系统地审查了洛克的《人类理解论》。他的《神正论》(Essays in Theodicy)讨论了恶的问题。他也写了一些短篇的哲学作品,包括《关于形而上学的对话》(Discourse on Metaphysics)、《自然新系统和实体的交互作用》(The New System of Nature and the Interaction),以及《单子论》(The Monadology)。他曾服务于汉诺威宫廷,但当乔治一世成为英格兰国王时,莱布尼茨没有被邀请同去,也许是由于他与牛顿的争端。他的公众影响力下降了,而在1716年,他在无人注意,甚至被他所创立的学会忽视的情况下去世,终年70岁。
实体
莱布尼茨不满于笛卡尔和斯宾诺莎描述实体本性的方式,因为他感到他们歪曲了我们对人的本性、自由和上帝的本性的理解。像笛卡尔所做的那样说有两个相互独立的实体——思维和广延——这就必然在解释作为身体和心灵的这两个实体无论在人中还是在上帝中如何可能相互作用时,陷入不可能摆脱的进退维谷的困境。斯宾诺莎试图通过主张只有一个实体、但带有两个可以认知的属性即思维和广延这种说法来解决这一困难。但是把一切实在性都归结为单个实体,这就会失去自然中各种不同要素之间的差异性。的确,斯宾诺莎谈到了世界由许多样式所组成,在这些样式中表现了思维和广延的属性。然而,斯宾诺莎的一元论是一种泛神论,在其中上帝是每一个事物,而每一个事物都是其他每个事物的组成部分。对莱布尼茨而言,这种实体概念是不充分的,因为它抹杀了上帝、人和自然之间的差异,而莱布尼茨想让这三者彼此都保持分离。
广延相对于力 莱布尼茨向笛卡尔和斯宾诺赖以建立自己的实体理论的基本假定,即广延包含有三维量度和形状的假定提出了挑战。笛卡尔认为广延是指一个在空间中扩延着的、并且不可分割为更基本的东西的物质实体。斯宾诺莎也认为广延是上帝或自然的某种不可还原的物质属性。莱布尼茨则不同意。由于观察到我们通过感官所看到的物体或事物都是可以分割为更小的部分的,莱布尼茨问道:为什么我们不能认为一切事物都是复合的或聚合起来的呢?他说:“既然有复合的实体,则必定有单纯的实体,因为复合的东西只不过是单纯实体的集合或聚合。”
单子 说事物必须由单纯实体所构成,这里面并没有什么新东西,因为德谟克利特和伊壁鸠鲁在许多世纪以前就论证过一切事物都由原子构成的观点了。但莱布尼茨拒绝了这种原子的概念,因为德谟克利特把这些原子描述为有广延的物体,即不可分解的物质微粒。这样一种物质微粒必然会被认为是无生命的和惰性的,并且必须从自己外部的某种东西得到自己的动力。莱布尼茨拒绝了原始物质的观念,认为真正单纯的实体就是单子,单子是“自然的真正原子…事物的基本要素”。单子与原子的不同在于,原子被看作有广延的物体,而莱布尼茨则把单子描述为非三维性的力或能。所以莱布尼茨说,物质不是事物的原始组成部分。相反,单子连同其力的要素构成了事物的本质性实体。
莱布尼茨想要强调实体必须包含有生命或一种动力。如果说德谟克利特的物质原子必然会靠从自身外部而来的推动以便运动起来或成为一个更大集团的一部分的话,那么莱布尼茨则认为,单纯实体,即单子,是“有活动能力的”。他补充说:“复合实体是单子的集合。单子(Monas)是一个希腊词,它代表单一体,或者那种作为一的东西…简单实体、生命、灵魂、精神都是单一体。所以全部自然都是充满生命的。”
单子是无广延的.它没有形状和大小。一个单子是一个点,不是数学或物理学的点,而是形而上学地存在的点。每个单子都独立于另一个单子,而且单子相互也没有任何因果关系。很难想象一个不具有任何形状或大小的点,但菜布尼茨想说的正是这样的点,以便把单子与物质原子区分开来。实际上他在这里的思想类似于那种把物理粒子归结为能量、认为粒子是能量的特殊形式的现代观点。实质上莱布尼茨说的是,单子是逻辑上先于任何有形实在的形式的。所以真正的实体是单子,而这些单子莱布尼茨也称之为灵魂,以强调它们的非物质本性。每个单子都和其他单子不同,而每个单子都具有自已的活动原则和自己的力。莱布尼茨说:“有某种充分性使单子成为了它们内部活动的源泉,并且可以说,使它们成为了非有形实在的自动机。”单子不只是互相独立互相区别的,它们也在自身中包含有它们的主动性的源泉。此外,为了强调宇宙的其余部分不影响单子的行动,莱布尼茨说单子“没有窗口”。但在组成宇宙的所有单子之间必须有某种关系——必须有某种对它们的有秩序的活动的解释。这种解释莱布尼茨在他的前定和谐的观念中找到了。
前定和谐 每个单子都按照它自己被造的目的而行动。这些没有窗口的,各自都遵循着自己的目的的单子形成了这个有秩序的宇宙的统一体。虽说每个单子都是与另一个单子相互孤立的,它们的目的却形成了一个巨大规模的和谐。这就如同几个不同的时钟因为它们精准无误的走时而全都在同一时刻敲响。莱布尼茨把所有这些单子比作“各自分开进行表演,并且被安排得相互看不见甚至听不见的几支乐队或合唱队”。莱布尼茨接着说,然而他们“由于每个人都注意他自己的音符而保持着完美的配合,以这样一种方式使倾听这个全体的人在其中发现一种和谐,它妙不可言,而且比在他们中有任何联通的情况要更加令人震撼得多”。所以,每个单子都是一个分离的世界,但是每个单子的所有这些活动却在与其他单子活动的和谐中发生。以这种方式,我们就能够说每个单子都反映着整个宇宙——但却是从各自独特的视角。如果任何事物“被去掉或是认为是另一个样子,这个世界上的一切事物就都会不同于它们现在的这个样子。这里这样一种和谐不可能是单子的某种偶然协调的产物,而必定是上帝活动的结果,因此这种和谐就是前定的。
上的的存在
在莱布尼茨看来,一切事物的普遍和谐这个事实提供了“关于上帝存在的一个新的证据”。他在很大程度上接受了以前证明上帝存在的那些尝试。他谈到这些尝试时说:“几乎一切曾用来证明上帝存在的手段都是好的,也都是可以用的,如果我们将它们完善的话,”但特别给他以深刻印象的是“如此众多的相互没有交往的实体的这种完美的和谐”。他相信这种和谐以“令人惊奇的清晰性”指示了上帝的存在,因为许多没有窗子的实体的和谐“只可能来白一个共同的原因”。这就类似于设计论论证和第一因论证,虽然莱布尼茨用他的充足理由原则对这种出自原因的论证作了修正。
充足理由律 莱布尼茨认为,任何事件都可以援引在先的原因来解释。但这个在先的原因本身又仍然必须援引更早的原因来解释。所以理论上说,我们可以找到一个各种有限原因的组成的、追溯至无限的连续链条。那么,当我们追寻任何事件的最终原因时,在这个无限链条中挑出任何个别原因来是无济于事的,因为总是会有另一个原因在它的前面。在莱布尼茨看来,解决办法是要认识到有某种原因是存在于这个因果序列之外的。就是说,它必须存在于宇宙本身的复杂组织之外。这个原因必定就是一个其存在是必然的实体,它的存在不需要理由或进一步的解释,它是一个存在者,“其本质包含存在,因为这就是一个必然存在者的东西所意味着的东西”。因此我们在事实世界中所经验到的日常事物的这个充足理由处于一个在明显原因系列之外的存在者中——处于一个其一切本性或本质都是他自己存在的充足理由的存在者中,它不需要一个在先的原因,而这个存在者就是上帝。
恶和一切可能世界中最好的世界 这个世界的和谐引导莱布尼茨去论证的不只是上帝预先规定了它,而且是上帝在做这件事时创造了一切可能世界中最好的世界。要么这个世界是最好的,要么甚至连一个好的世界都是成问题的,因为其中有无序和恶。实际上,19世纪的德国哲学家叔本华认为,如果世界还是个什么东西的话,那么这个世界是一切可能世界中最坏的世界,所以我们最终并没有理由证明上帝存在或这个世界连同它一切的恶都是某个善的上帝的创造。莱布尼茨意识到恶和无序的事实,但他认为这是可以与一个仁慈的创造者的概念相容的。上帝在他的完善的知识中能够考虑到他所能创造的一切可能种类的世界,但他的选择必须与道德的需要相一致,即这个世界应当包含善的最大可能的总量。这样一个世界将不会是没有不完美之处的。正相反,这个创造出来的世界包含有限的和不完美的事物,“因为上帝不可能把一切都给被造物,除非他把被造物变成上帝:所以必然也需要有…一切的局限性。”恶的来源不是上帝,而毋宁是上帝所创造的那些事物的本性,因为这些事物是有限的或受限制的,所以它们是不完满的。所以恶不是什么实体性的东西,而只是完满的缺乏。对莱布尼茨来说,恶是缺乏。这就是为什么莱布尼茨能够说“上帝要把善作为前件而要把至善作为后件”,因为上帝所能够做得最多的就是创造这个最好的可能世界,不管他多么善意。最终,莱布尼茨承认,如果我们仅仅只考虑个别的恶的事物或事件的话,我们就不可能有权利评价恶。有些本身显得是恶的事物结果证明是善的必要条件,如“甜的东西如果我们不吃任何别的东西的话就变得无味了;辣的、酸的甚至苦的东西必须和它结合起来,这样才刺激口味。”再者,我们生活中的事件如果单就其本身来看,并不是一个恰当的角度。莱布尼茨问道:“如果你去看一幅很美的图画,它全部都被覆盖起来只留下一个很小的部分,那么无论你如何彻底地审视这个部分,它呈现给你的,除了一大堆混乱的色彩毫无选择毫无技巧地涂在上面之外,又还有什么呢?然而如果你移开这覆盖物,并从正确的视角来看这整幅画,你将会发现那本来显得是漫不经心地乱涂在画布上的东西其实是画家用极其了不起的艺术创作出来的。”
自由 在莱布尼茨所描绘的,上帝通过将特殊目的注人各个单子而预先定下一种秩序安排的这个被决定了的世界中,如何能够有任何自由呢?每个单子都必须按其被置入的目的而发展,而“一个单纯实体的每个当前状态自然都是它的在先状态的结果,这种方式使它的当前也包含着它的将来”。每个人的同一性都集中围绕在一个支配单子,他或她的灵魂必须从这样一个机械的角度来展开一种一开始就定好了的生命。然而,由于这样一个人的基本本性是思维,他或她一生的发展历程就在于克服混乱思想而达到真观念,这种真观念以含混的潜能形式存在于我们所有人之中,同时又追求成为现实的。当我们的潜能成为现实的,我们就会把事物看作它们实在地所是的那样,而莱布尼茨说,所谓“成为自由的”就是这个意思。在他看来自由并不意味着意志自决力——选择的权力——而毋宁说意味着自身发展。这样,虽然我被决定了以特殊的方式行动,这却是我自己内在的本性决定我的行为而非外在力量。自由在这种意义上是无阻碍地成为我被注定要成为的东西的能力。它也意味着我的知识借以从混乱而达到清晰的那种存在的性质。我在多大程度上知道为什么我做我所做的事,我就在多大程度上是自由的。沿着这条思路,莱布尼茨认为他成功地使他的自然决定论观点和自由相调和了。
莱布尼茨是否成功地调和了他的单子世界和自由概念,这当然是可以质疑的。虽然他在一方面用“我们意志的选择”这种术语谈论自由,并说“自由与意志自愿是指同一件事”,但他主要强调的似乎还是在决定论这方面——在一个机械式的宇宙概念或一种精神机器方面。实际上,莱布尼茨在描述宇宙时并没有使用机械论的模式,因为如果他这样做,他就不得不说这个宇宙的各个不同的部分是按照每个其他部分而行动的,就像一个钟的各部分影响每个其他部分的运动一样。在某种意义上,莱布尼茨的解释甚至比机械论模式的主张更加具有严格的决定论色彩。因为他的单子全都是互相独立的,并且互不发生影响,但却按照它们从一开始就通过上帝的创造而接受到的原始目的而行动。这种决定论之所以更严格,是因为它不依赖外部因果联系的变化莫测,而是依赖每个单子被给定的并且是永远固定的内部本性。
知识和自然
这种自然决定论的观点在莱布尼茨的知识论那里进一步得到了支持。例如,一个人在莱布尼茨看来相当于一个语法意义上的“主词”。对于任何真句子或命题来说,谓词已经被包含在主词中了。所以,知道主词就等于已经知道一定的谓词了。“一切人都是要死的”是一个真命题,因为谓词“要死的”已经包含在“人”的概念之中了。因此莱布尼茨说,在任何真命题中“我都发现每个谓词,不论是必然的还是偶然的,是过去的、现在的还是将来的,都包括在主词的概念中了”。同样,在事物的本性中,一切实体都可以说是主词,而它们的一切所作所为则是它们的谓词。正如语法上的主词包含它们的谓词一样,存在着的实体也已经包含着它们将来的活动。于是莱布尼茨得出结论道:“当说到亚当的个体性概念包含着将要对他发生的一切事情时,我的意思不是别的,只是一切哲学家在他们说谓词就在个真命题的主词之中时所指的意思。”莱布尼茨的实体论和形而上学是按照他的知识论或逻辑的模式而构建的。处于他论证的核心的是他对真理概念的特殊处理方式。
莱布尼茨区分了推理的真理和事实的真理。我们知道推理的真理纯粹是凭借逻辑,而我们知道事实的真理则是凭借经验。对推理的真理的检验是矛盾律,而对事实真理的检验则是充足理由律。一个推理的真理是一个必然真理,因为否定了它就必然会陷入矛盾。另一方面,事实的真理是偶然的,而它的对立面是可能的。一个推理的真理之所以是必然的真理,是因为所用术语的真正意义和那种类型的人类理智都要求某些东西是真的。例如一个三角形有三条边,这是真的,因为有三条边是一个三角形所意指的。说一个三角形有四条边则很明显会陷人矛盾。2加2得4,A等于A,A不是非A,热的就是不冷的——所有这些命题都是真的,因为否定它们的真理性将会自相矛盾。推理的真理是同义反复,因为在这样一些命题中谓词纯粹是重复着已经包含在主词中的东西。一旦主词被清楚地理解了,关于谓词的真理性的进一步的证明也就不需要了。推理的真理并不要求或断言命题的主词存在。例如说,一个三角形有三条边,这是真的,哪怕并不涉及到任何具体存在的三角形。推理的真理告诉我们什么东西在任何涉及某个主词(在这里就是三角形)的情况下都将是真的。这些真理处理的是可能性的领域。一个三角形是方的,这是不可能的和自相矛盾的,所以不能是真的。
数学是推理的真理的一个很明显的范例,因为它的命题一旦通过了矛盾律的检验,就是真的。所以莱布尼茨说:“数学的伟大基础是矛盾原则…就是说,一个命题不可能同时既是真的又是假的。”他下结论说:“这个单一的原则足够推演出算术和几何的每个部分。”简言之,推理的真理就是自明的真理。它们都是分析命题,其谓词已经包含于主词之中,并且否定谓词就必然陷人矛盾。
事实的真理又怎么样呢?这些真理是通过经验而知道的。它们不是必然的命题。它们的反面可以被认为是无矛盾的、可能的,并且由于这个理由,它们的真理是偶然的。“玛丽存在”这个陈述不是一个推理的真理;它的真实性不是先天的。在主词“玛丽”中没有什么是必然含有,或是可能让我们推演出谓词存在的。我们只是通过后天——就是说,按照经验——才知道她“存在”这个谓词。这个事实的真理,和一切事实的真理一样,是建立在充足理由律之上的,这条规律说:“没有任何事物的发生是没有它为什么要这样而不是那样发生的理由的。”如果这一点成立,“玛丽存在”这一命题是偶然的,就取决于一些充分理由。在缺乏任何充足理由时,说“玛丽不存在”也就会正好同样是真的。如果现在有一个充足理由,则另一个命题也有真理性的基础,所以我们说“如果A,那么B”。A的这一假说性质表明,虽然在A和B之间可能会有一种必然的关联,A存在这一点却不是绝对必然的。A的存在是偶然的,就是说,是可能的。它事实上是否会存在取决于为了它的存在是有还是将会有一个充足的理由。对于我们所接受的每一个事实的真理,我们都可以看出它们的对立面是可能的、没有矛盾的。
当我们考虑到有关事实的命题所暗含的一切可能性时,一种限制性原则就浮现出来了。虽然某些事件纯粹作为另一些事件的对立面来说,可以被看作可能的,但是,当另一些可能的事件成为现实时它们就不能是可能的了。就是说,有些可能的东西是与某些事件共可能的,虽然与另外一些事件不是这样。所以莱布尼茨说:“虽然字宙如此伟大,但并非一切可能的种都是共同可能地存在于字宙中的,而且这不仅对同时存在的那些事物成立,也对有关事物的整个先后系列成立。”
事实的宇宙,据我们所知只不过是某些共同可能的东西的集合,就是说,一切存在的可能东西的集合。可能的东西可以有不同于我们这个现实的宇宙所包含的联合方式的另外的联合方式。各种不同的可能东西的相互关系要求我们理解这种把每个事件与另一个事件联系起来的充足理由。然而,自然科学与数学不同,不可能是一个演绎的学科。数学的真理是分析的。但在有关事实的命题中,主词并不包含谓词。支配着事实真理的充足理由律要求这些真理被证实。但这种证实总是部分的,因为事件的因果之链中每个在前的事件也必须得到证实。然而,没有人能够说明原因的无限序列。如果A的原因是B,那么又必须要说明B的原因,并且要回湖到如此之远,直到开端。关于字宙的第一个事实正像任何其他事实一样:就人的分析能力所能够发现的限度而言,并不包含任何明显必然的谓词。要认识它的真理,就要求我们发现它所是的那种存在的充足理由。
莱布尼茨说,对世界的最终的解释就是:“为什么某些事物而不是另外一些事物存在的真正理由,是来自神圣意志的自由天命。”事物像它们存在那样存在是因为上帝意愿它们以那种方式存在。通过意愿某些事物是它们之所是,上帝限定了其他可能的东西的数目,并决定哪些事件是共可能的。上帝本来可以愿意有另外的宇宙,以及可能东西的另外的联合。但他既已意愿了这个宇宙,现在就在特殊的事件中存在着某些必然的关联。虽然从人的理性的角度来看,有关事实世界的那些命题都是综合的,或者说,如果我们想知道它们的真理性,那就要求有经验和证实;但从上帝的角度来看,这些命题都是分析的。只有上帝能够推导任何实体的一切谓词。而且只是因为我们的无知,我们才不能在任何具体的人那里看到与那个人相关的一切谓词。归根到底,事实的真理在莱布尼茨看来也是分析的。一个人已经包含了他或她的一切谓词,所以如果我们真正领会了一个人的完备概念,我们就能够推导出这些谓词,例如“附属于亚历山大大帝身上的国王性质”。
所以,对莱布尼茨来说,逻辑是形而上学的一把钥匙。从命题的语法规则中他推论出了有关实在世界的结论。归根到底,他主张一切真命题都是分析的。由于这个理由,莱布尼茨认为实体和人格与一个分析命题的主词是可以等量齐观的,他说它们实在地包含着它们的一切谓词。他还把连续律运用于他的实体概念,以便进一步证实他的这个理论,即每个实体都以有序的和(从上帝的角度看来)可预见的方式来展开自己的诸谓词。连续律宣称“自然不作飞跃”。在被创造的事物中,每个可能的位置都被占据了,以至于一切变化都是连续的。按照连续律,静止和运动都是对方的一个方面,通过无限小的变化而融入对方,“所以静止的法则应当被看作运动的法则的一个特例。”所以没有窗口的单子在自身中包含着它未来的一切活动。并且由于每个单子都是这样,所以已经被包含在这个世界中的那些事件的一切联合和可能性也包含了这个世界的整个未来,而这个秩序的充足理由就是“那至上的理由,它以最完满的方式做出了每一件事”。虽然人的心灵不可能像上帝那样知道全部实在,但莱布尼茨说,我们知道某些天赋的观念、自明的真理。一个孩子并不是一下子就知道这些真理,而必须等到时机成熟,等到经验中特殊的机缘把这些观念唤起的时候。这些观念只是在实质上是天赋的“,因为我们要靠特殊的机缘才知道它们。然而,这个天赋观念的学说仍然与莱布尼茨对逻辑与实在的关系的一般论述一道,带有理性主义传统的鲜明特征。他乐观地评价理性认知实在的能力,并认为我们能够从天赋自明的真理中推演出可观的知识。
第十一章 英国经验主义
虽然经验主义学派是以不事张扬的方出场的,但它还是注定要改变近代哲学的航向和关注点。如果说培根的目的是“一切人类知识的…整体重建”的话,英国经验主义哲学的奠基人洛克所定的目标则更为审慎,即“做一点地基的清理工作,并且扫除一些挡在知识道路上的垃圾。”但在“清理”和“扫除”的过程中,洛克却弄出了一种对心灵如何运作的大胆而独创的解释,并据此描述了我们可以从心智中期望的知识的种类和范围。
洛克说,我们知识的范围被限制在我们的经验中。这并不是一个新见解,因为在他之前有其他人已经说过差不多同样的话。培根和霍布斯曾极力主张知识应当建立在观察的基础上,并且就此而言他们也应该被称作经验主义者。但不论是培根还是霍布斯都没有对人类的理智能力提出批判性的疑问。他们两位都揭露并拒斥那些在他们看来是无用和谬误的思想类型。然而,他们却不加怀疑地接受了这样一个总的观点,即:只要我们运用适当的方法,我们就能获得确定的知识。同样,笛卡尔也认为,如果运用了正确的方法,就没有人类理性不能解决的问题。这就是那个被洛克纳入到批判性的疑问中来的假定,亦即:相信人的心灵有能力做到使人发现字宙的真实本性。大卫·休谟进一步推进了这个批判性的观点,并质问任何可靠的知识在根本上是否可能。英国经验主义者——洛克、贝克莱和休谟——以各自不同的方式,不仅向他们的英国先驱者们,而且也向大陆理性主义者们提出了挑战,后者以对我们理性能力的乐观主义观点开创了近代哲学,但这种观点却是经验主义者所不能接受的。
11.1 洛克
洛克的生平
约翰·洛克(John Locke)1632年生于威灵领的萨姆塞特,于1704年去世。他是在清教徒的家庭长大的,培养了勤劳的美德和对朴素的爱。在威斯敏斯特学校受到全面的古典教育之后,洛克成了一名牛津大学的学生,在那里取得了学士和硕士学位,并被委任为高级研究生,继而是道德哲学方面的学监。他一生中有30年是在牛津市度过的。虽然他继续着他的关于亚里士多德逻辑和形而上学的研究,他却逐渐被吸引到了实验科学新近的发展上,在这方面,他尤其受到罗伯特·玻意耳(Rokert Boyle)的影响。他的科学兴趣引导他从事医学研究,1674年取得了医学学位并获得了行医执照。当他考虑他的职业将朝向什么方向时,在当医生和当牛津导师的考虑上又加上了一个选择:外交官。他实际上从事过多种工作,最后成了伦敦的政要之一莎夫茨伯利伯爵的私人医生和枢密顾问。但早先所受的那些影响——其中包括他在牛津时对笛卡尔著作的研读——更坚定了他把自己的创造力都用于为闲扰着他这一代人的某些问题制定一种哲学理解方式的愿望。他写作的主题如此多种多样,如《基督教的合理性,一篇关于信仰自由的论文》(The Reasonableness of Christianity,An Essay concerning Toleration)和《降低利率和抬高币值的后果》(The Consequences of the Lowering of Interest and Raising the Value of Money),显示了他对他那个时代的公共事务的积极参与。
1690年,当他57岁时,他出版了两本将给他带来哲学家和政治理论家名声的书:《人类理解论》(An Essay concerning Human Understanding)和《关于国民政府的两篇论文》(To Treatises)。虽然在他之前的其他哲学家也写过关于人类知识的书,洛克却是第一个对人类心灵的范围和限度进行了一种全面详尽的探究的人。同样,别的人也写过关于政治理论的重要著作,但洛克的《两篇论文》的第二篇来得正是时侯候,使得它能够塑造一个时代的思想并影响了后来事件的进程。《两篇论文》和《理解论》展示了洛克是如何把实践上和理论上的兴趣和能力结合起来的。《两篇论文》是为了阐明1688年革命的正当性而特意写的。其中有些思想对后世产生了强有力的影响,以致书中的一些提法——例如,我们大家“都是平等和独立的”并且具有对“生命、健康、自由和财产”的自然权利——被写进了《独立宣言》并对美国宪法产生了影响。至于他的《理解论》,他告诉我们这本书产生于在距出版差不多20年的一次经历。那一回,五六个朋友聚在一起讨论一个哲学观点,不久他们就地陷入了无可救药的混乱,而“丝毫也没有接近于解决这些困惑着我们的疑难。”洛克确信这场讨论走错了方向。在我们能够谈论道德和启示宗教的那些原则以前,我们首先需要去“考察我们自己的能力,并且看清什么样的对象是我们的理智宜于或不宜于处理的。”根据这种考察,洛克最后写成了他的《人类理解论》,该书成为了英国经验主义的奠基之作。
洛克的知识理论
洛克开始“探讨人类知识的起源、确定性和范围”。他认为,如果他能够描述知识由什么组成又是如何获得的,他就能够规定知识的界限并判定是什么构成了理智的确定性。他的结论是,知识是被限定在观念(idas)上的——不是理性主义者的天赋观念,而是由我们所经验的对象所产生出来的观念。在洛克看来,我们的一切观念无一例外地都是通过某种经验而给予我们的。这就意味着每个人的心灵在一开始都像一张白纸,随后只有经验能够在它上面写下知识。在他能够详尽发挥这个结论之前,洛克感到他必须先驳倒天赋观念论,这种观点认为,在某种意义上我们与生俱来就都有一套内置于心灵的观念。
反天赋观念 很明显,如果洛克打算说一切观念都来自经验,他就必须拒绝天赋理论。他指出,“在有些人中有一种牢固的观点,认为在理智中存在着某些天赋的原则,…在人的心灵上打上了印记,它是灵魂一开始就接受下来了的,并且是与生俱来的。”洛克对此不仅是作为非真理而加以拒绝,而且他认为这种学说在那些可能会误用它的人的手中是一种危险的工具。如果一位有手腕的统治者能够使人民相信有某些原则是天赋的,这就可能“使他们脱离对他们自己的理性和判断的运用,把他们椎给信仰,使他们保持信任而无作进一步的解释。”并且,“在这种肓目轻信的状态中他们就可以更容易统治了。”但有些对天赋观念论感兴趣的人并不是这样心存歹念的。
拉尔夫·卡德沃思(Ralph Cudworth,1617-1688)就是这种情况。他是所谓剑桥柏拉图主义思想学派的成员,这个学派追随柏拉图,坚持理性是知识的最终标准。卡德沃思在l678年出版了他的《宇宙的真实的理智系统》(True Intellectual System of the Universe),这恰好是在洛克试图清理他在这个问题上的思想的时候。卡德沃思采取了这样的立场:对上帝存在的推演依赖于一个前提,即某些原则是天赋于人的心灵中的。他进一步争论说,那条著名的经验论公式:“凡是存在理智中的无不先在感觉之中”会导致无神论。在卡德沃思看来,如果知识单由在心灵之外的对象提供给心灵的信息所构成,外部世界就是在有知识以前就存在着的。在这种情况下,知识就不可能是这个世界的原因。洛克不同意这种观点,他说,实际上有可能不求助于天赋原则的概念而证明上帝的存在。他特别关心的是揭示天赋观念的主张没有根据,以便在偏见、激情和臆断这方面与知识这方面之间划定清楚的界限。因此,他开始进行一系列的论证来反对这种天赋观念的主张。
那些为天武观念论辩护的人这样做的根据在于,人们普遍接受各种理性原则的真理性。其中就有“存在者存在”这条同一性原则,以及“同一事物既存在又不存在是不可能的”这条不矛盾原则。但这些原则是天赋的吗?洛克否认它们是天赋的,虽然他并不怀疑它们的可靠性。这些原则之所以可靠并不是由于它们是天赋的,而是因为只要我们考虑到事物如其所是的那个本性,我们的心灵就不会让我们以别的方式思维。并且,即使这些原则被每个人所接受,这也并不证明它们就是天赋的,假如能为这种普遍的赞同提供一种另外的解释的话。此外,他还论证说,是否存在着有关这些原则的普遍的知识也是成问题的。洛克说,这样一种普遍的原则“在印第安人的小屋里是很少提及的,在儿童们的思想中就更少见了。”如果可以争辩说,这样一些原则只有在心智成熟以后才能够被领会,那么,为什么把它们称作天赋的?如果它们真的是天赋的,它们就必须从来就是已知的,因为“没有什么命题可以被说成存在于心灵中,却从来也没有被心灵所知悉、从来也没有被心灵意识到。”照洛克对这个问题的看法,天赋观念说是多余的,因为它不包含任何他不能用他对观念起源的经验性解释加以说明的东西。
简单观念和复杂观念 洛克认为知识可以通过发现它由以造成的原初材料而得到说明。关于这些材料,他是这样说的:“那么让我们设想心灵像我们所说的是一张白纸,不带任何记号,没有任何观念:它是如何获得那些观念的呢?…它是从何处获得理性和知识的全部材料的呢?对此我用一句话来答复:是从经验中得来。”经验给我们提供了观念的两个来源:感觉和反省。从感觉中我们接受到我们心灵中来的是各种不同的知觉,借此我们熟悉了我们之外的对象。这就是我们为什么会拥有黄、白、热、冷、软、硬、苦、甜和一切其他可感性质的观念的原因。感觉是“我们所拥有的大部分观念的巨大源泉”。经验的另一方面是反省,即心灵的一种活动,它通过注意先前由感觉提供的观念而产生出一些观念来。反省包含有知觉、思考、怀疑、信念、推理、认识、意愿和所有这些心灵活动,它们所产生的观念与我们从影响感官的外部物体所获得的那些观念同样分明。我们所有的一切观念都可以追溯到感觉或反省,而且这些观念要么是简单的,要么就是复杂的。
简单观念构成了我们的知识由以形成的那些原材料的主要来源。这些观念是心灵通过我们的感官而被动接受下来的。当我们看到一个对象时,各种观念就单纯不杂地依次进入我们的心灵。甚至当一个对象拥有各种混杂在一起的不同性质时也是如此。例如,一朵白色的百合花不可分离地拥有白色和芳香的性质。我们的心灵却是分离地接受白色和芳香的观念的,因为每个观念都是分别通过一个不同的感官,也就是视觉和嗅觉而进来的。有时候不同的性质也通过同一个感官进来,例如冰的硬和冷都是通过触觉而来的。在这种场合下,我们的心灵在它们之间作出区分,因为这里实际上涉及到两种不同的性质。所以,简单观念首先发源于感官。但有些简单观念也发源于反省。就像我们的感官受到对象的影响一样,我们的心灵也以同样的方式意识到我们所获得的这些观念。与通过感觉所获得的这些观念相联系,我们的心灵也能够通过推理和判断来得到另外的简单观念。这样,反省的简单观念可以是愉快或痛苦,或者是由观察自然事物相互作用而获得的因果性力量的观念。
另一方面,复杂观念不是被动地接受下来的,毋宁说是被我们的心灵作为简单观念的复合而集合到一起来的。在这里强调的是我们心灵的主动性,它采取了三种形式:心灵(1)联结观念,(2)把观念放到一起但保持其分离状态,(3)进行抽象。于是,我的心灵就把白、硬和甜联结而形成了糖块的复杂观念。我的心灵也把这些观念放到一起,但保持着它们的分离状态以思考各种关系,例如当我们说草比树更绿时,就是这样。最后,我的心灵能够把一些观念“与在这些观念的实际存在中总是与之伴随的所有其他观念”分离开来,如当我们把“人”的观念与约翰和彼得分离开来时那样。以这种抽象的方式,“就形成了观念的一切普遍规律”。
第一性的质和第二性的质 为了更详细地描述我们是如何得到观念的,洛克转而关注观念如何与产生它们的那些对象发生关系这个问题。我们的观念是精确地复制我们所感到的对象的吗?例如,如果我们考虑一个雪球,那么这个雪球在我们心中所造成的观念和这个雪球的真实本性之间是什么关系呢?我们有圆的、运动的、硬的、白的和冷的这样一些观念。为了说明这些观念的原因,洛克说对象具有各种性质,并且他把性质定义为“(一个对象中的)在我们心中产生任何观念的能力。”所以,这个雪球具有一些性质,它们具有在我们心中产生观念的能力。
洛克在这里作出了对两类不同性质的重要区分,以回答观念如何与对象相联系这个问题。他把这些性质分别称为第一性的质和第二性的质。第一性的质是“真正存在于物体本身中的质”。所以我们由第一性的质所引起的观念是严格相似于这些不可分地属于对象的性质的。雪球看起来是圆的,并且确实是圆的,显得在运动,并且确实是在运动。另一方面,第二性的质在我们心中产生的观念在对象中并没有精确的对应物。当我们接触雪球时我们有冷的观念,当我们看它时我们有白的观念。但在雪球中并没有冷性或白性。存在于雪球中的都是性质,是在我们中引起冷和白的观念的能力。所以第一性的质是指坚固性、广延、形状、运动或静止及数量一或者说,一切属于对象的性质。第二性的质像颜色、声音、味道和气味,它们不属于也不构成物体,而只是在我们中产生这些观念的能力。
洛克对第一性的质和第二性的质之区分的重要性在于,通过这种区分,他试图在现象和实在之间作出划分。这种区分不是洛克首创的。德谟克利特早就表示过类似的意思了,他说,无色的原子是基本的实在,而颜色、味道和气味则是这些原子的特殊组合的结果。笛卡尔也把第二性的质与他称之为广延的基本实体划分开来。洛克的区分反映了他对新物理学的兴趣以及“明断的牛顿先生无与伦比的书”给他的思想造成的影响。牛顿把白的现象解释为看不见的微小粒子的运动。所以实在并不存在于仅仅只是一个结果的白性之中,而只存在于作为原因的某个东西的运动之中。洛克关于第一性的质和第二性的质的讨论始终认定了,存在着能够具有这些性质的某个东西,而他把这个东西称作实体。
实体 洛克是从他认为是常识的那种观点出发来处理实体问题的。不假定有某种东西——某种实体——是这些性质固存于其中的,我们又如何能够具有关于性质的观念呢?如果我们问是什么东西具有形状和颜色,我们的回答是某种固体的和有广延的东西。固体的和有广延的都是第一性的质。而如果我们问它们固存于什么里面,洛克的回答是:实体。无论实体的观念对常识来说是如何地不可避免,洛克却无法对它作精确的描述。他承认,“如果任何一个人想在涉及自己的一般纯粹实体的概念方面检查一下自己,他就会发现他根本就不具有关于实体的别的观念,而只有一个假定,即对一个他所不知道的支撑着能在我们之中产生出简单观念来的那些性质的东西的假定。”但洛克仍然在实体概念中找到了对感觉的解释,他说感觉是由实体引起的。同样,是实体包含着给我们的观念以规则性和一致性的能力。最后,洛克坚持是实体构成了感性知识的对象。洛克是被事情的这种简单逻辑所推动的:如果有运动,则必须有某种运动的东西。各种性质绝不可能没有某种东西把它们保持在一起而到处漂浮。我们有物质的观念和思维的规念,但“我们永远也不能知道是否有某种单纯物质的存在者在思维着。”但如果有思维,则必定有某种思维着的东西。我们也有关于上帝的观念,它正如一般实体观念一样并不是清楚和分明的。然而,“如果我们考察我们所拥有的关于不可理解的至上存在者的观念,我们将发现我们是以同样的方式得到它的,我们所拥有的不论是关于上帝的还是关于分离的精神的复杂观念都是由我们从反省中所获得的简单观念造成的。”上帝的观念正如实体的观念一样是从其他简单观念中推断出来的,并且不是直接观察的产物,而是推演的产物。然而实体这个“我不知道它是什么的某物”的观念却对洛克提出了一个问题,即我们的知识能扩展到多远并且具有多大的有效性。
知识的各种等级 在洛克看来,我们的知识扩展到多远及具有多大的有效性取决于我们的观念相互之间所具有的关系。事实上,洛克最后把知识定义为不外是“对我们的任何观念之间的联系与符合或是不符合与相冲突的知觉”。我们的观念依次进人我们心中,但一旦它们进来了,它们就可能以多种方式发生相互关系。我们的观念所具有的某些相互关系取决于我们所经验到的对象。在别的时候,我们的想象有可能重新整理我们的简单或复杂的观念来适应我们的幻想。我们的知识是幻想出来的还是确实有效的,这取决于我们对我们的观念相互之间的关系的知觉。有三类知觉,即直观的、推演的和感性的,而每一种都引导我们达到对实在的知识的不同等级。
直观的知识是直接性的,不会让人怀疑的,并且是“人类的微薄力量所能达到的最清楚最确定的知识”。这样一种知识“就像阳光迫使心灵一旦把自已的目光转向那个方向就直接地觉察到它。”我们立刻就知道圆不是方,或6不是8,因为我们能够觉察到这些观念相互的冲突。但除了这些形式的和数学的真理以外,直观还可以把我们引向关于存在的东西的知识。由直观我们知道我们存在:“所以经验使我们确信,我们拥有关于我们自己存在的直观知识,以及关于我们存在的内在的确定无误的知觉。”
推演的知识出现在我们的心灵试图通过唤起对另外一些的观念的注意来发现某些观念间的一致或不一致的时候。在理想情况下,推演的每一步都必须有直观的确定性。在数学中尤其是这样,但洛克又认为推演是知觉的一种类型,它引导心灵获得对某些形式的存在着的实在的知识。所以“人们借助于直观的确定性知道,纯粹的虚无是不能产生任何实在的存在的,就如同纯粹的虚无不能等于两个直角一样。”洛克从这个出发点来论证,既然实际上有存在着的、在时间中开始和结束的事物,既然“一个非存在不可能产生出任何实在的存在,则一个自明的推论就是,自无始以来就有某种东西存在。”通过以这类方式推理,他得出结论说,这个无始以来的存在者就是“最有知识的”和“最有力量的”,并且“在我看来很明白的是,我们对于上帝的存在的知识要比对于我们的感官没有直接向我们揭示的任何东西的知识更加确定。
感性的知识不是严格意义上的知识;它只是“以知识的名义出现而已”。洛克并不怀疑我们之外的事物存在,因为要不是这样的话,我们又从何处获得我们的简单观念呢?但感性的知识并不给予我们可靠性,而且也不能推广得很远。我们感觉到我们看到了另外一个人,而且并不怀疑他的存在,但当他离开我们时,我们就不再能确定他的存在了。“因为如果我看到像通常被称之为人的这样一个诸简单观念的集合体在一分钟以前还和我一起存在,而现在却只有我一人了,我就不能确定同一个人现在还存在,因为他一分钟以前的存在与他现在的存在之间没有任何必然的关联。”因此,“当我一个人写下这件事的时候,我对此并没有我们严格意义上称作知识的那种知识;尽管它的极大可能性可以让我忽略我的怀疑。"既然经验只是让我们觉察到那些性质,所以我们对这些性质之间的关联是没有把握的。尤其要指出,感性的知识并不能向我们保证那些看起来是相关的性质实际上是必然关联着的。我们只是感觉到事物像它们所是的那样,而正如我们永远也感觉不到实体一样,我们从感觉中永远也不知道事物实际上是怎么关联着的。不过,感觉的知识还是给我们提供了某种程度的知识,只是不能提供确定性。直观的知识给我们提供了我们存在的确定性,推演的知识表明了上帝的存在,而感性的知识使我们确信别的自我和事物的存在,但只是如同我们经验到它们时它们所是的那样。
洛克的道德和政治理论
伦理和法律 洛克把我们有关道德的思想置于推演的知识的范围内。在他看来道德能够具有数学的精密性。他写道:“我大胆地认为道德是能够推演的,正如数学也能够推演一样:因为道德语词所代表的事物的精确的实在本质是人们能够完全地知道的,因而那些事物本身之间的一致或不一致是可以完全地发现出来的。”伦理学中的关键词即“善”是能够被完全地理解的,因为每个人都知道“善”这个词代表着什么:“事物是善的还是恶的只涉及愉快或痛苦。我们称之为善的那种东西容易引起或增加愉快,或是减少我们的痛苦。”某些行为会带给我们愉快,而另一些侧会带给我们痛苦。所以,道德与对善的选择或意愿有关。
作为对伦理学的进一步的规定,洛克认为:“道德上的善或恶因而就只是我们的自愿的行为与某种法则的一致或不一致。”他谈到了三种法则,即意见的法则,国民的法则和神的法则。这里的实质性的问题在于追问洛克如何知道这些法则存在,以及他如何看待所有这三者之间的相互关系。要记住,在洛克看来,推演出上帝存在是毫无困难的,所以他现在想从这种推演的知识中进一步引出一些推论:
一个在力量、善意和智慧方面都无限的至高存在者,我们都是他的作品并都依赖于他、他的观念和我们自己作为理智的理性存在者的观念,对我们来说都是清清楚楚的,如果适当地对之加以考虑和探求的话,我料想将会为我们的行动的责任和规则提供这样一个基础,使道德可以像各门科学一样成为能够进行推演的一门科学:我毫不怀疑,在这门科学中,从和数学中一样无可争辩的自明原理出发,通过同样无可争辩的必然推论,判断正确和错误的标准将会明白地呈现给任何一个把他在研究其他科学时所运用的那种一视同仁的和全神贯注的态度运用于自己身上的人。
洛克在此暗示,通过自然之光,也就是通过我们的理性,我们能够发现符合上帝法则的道德规则。他没有把这个计划详细发挥为一个伦理学体系,但他的确暗示了这些不同种类的法则应当具有什么样的相互关系。意见的法则代表了一个社会对什么样的行动将导致幸福所作的判断。对这条法则的符合就叫做善(virtue),虽然必须注意不同的社会对于善所包含的东西有不同的观念。国民法则是由全体国民建立起来的,并且是由法庭强制施行的。这条法则倾向于遵循第一条法则,因为在大多数社会中法庭施行的这些法则都体现了人民的意见。神的法则是我们要么通过我们自己的理性,要么通过启示而可以知道的,它是人的行为的真实的法规。洛克写道:“上帝提供了一条人们应当据以进行自我管理的法规,我想没有人在这里会愚蠢到否认这一点。”而“这就是道德正直的惟一真正的试金石。”因此,从长远看,意见的法则以及国民法则都应当成为与神的法则这个“道德正直的试金石”相一致的。在这三种法则之间有某种不一致,其原因就是人们任何时候都倾向于选择当下的愉快,而不是选择那些具有更持久的价值的愉快。无论这个道德理论在我们看来显得多么含糊不清,洛克却相信这些道德法则是永远为真的,并且依靠从神的法则中引出的那些洞见,他建立了自己的自然权利理论。
自然状态 在《关于政府的第二篇论文》中,洛克像霜布斯所做的那样,以对“自然状态”的论述来开始自己的政治理论。但是他以完全不同的方式来描述这种状态,甚至拿霍布斯作为他评论的靶子。在洛克看来,自然状态并不像霍布斯的“一切人对一切人的战争”的情况。相反,洛克认为“人们相互按照理性来生活,在地上没有一个具有权威的共同主宰在他们之间进行裁判,这才是真正的自然状态。”按照洛克的知识理论,人们甚至在自然状态中也能够知道道德法则。他说,“理性就是那样的法则,它教导一切唯愿听从理性的人类:一切人都是平等和独立的,没有人有权损害另一个人的生命、健康、自由和财产。”这种自然的道德法则不是单纯利已主义的自保法则,而是积极承认每个个体由于他或她作为上帝造物的身份而来的德性都具有作为人格的价值。这种自然法则包含着带有相应责任的自然权利,而在这些权利中洛克特别强调的就是私有财产权。
私有财产 在霍布斯看来,一种财产权只能是按照法定秩序建立起来的。洛克则认为,私有财产权先于国民法测,因为它是基于自然的道德法则之中的。私人所有制的正当理由是劳动。既然一个人的劳动是他自己的,无论他通过他自己的劳动而把那些最初的劳动条件转换成了什么,那都成为了他的,因为这种劳动现在已经与这些东西结合在一起了。正是通过他的劳动与某种东西的这种结合,一个人占据了原先是共同财产的东西,并使之成为了他的私有财产。所以,也就有了对一个人所能积累的财产总量的某种限制,就是说,“任何人有多少能够用来促进生活而不是危害生活的东西,他就可以用自己的劳动占有一笔多大的财产。”洛克还认为,一个人可以继承财产,这也是自然权利,因为“每个人生来就具有…一种权利,先于任何其他人而与自己的兄弟一起继承父亲的财物。”
国民政府 如果人们具有自然权利并且也知道道德法则,为什么他们会愿意告别自然状态呢?对这个问题洛克的回答是,“人们联合成国家并促使自己服从政府的最大的和主要的目的是保护他们的财产。”洛克用“财产”(property)这个术语所指的是人们的“生命、自由权和产业,我用一个总的名称叫做财产”。的确,人们在自然状态中知道道德法则,或不如说,如果他们用心考虑这个问题的话,他们就能够知道。但是由于冷漠和疏忽他们并不总是去发扬这种知识。此外,当争论发生时,人们倾向于以他们自己的偏好来作出判定。因此,就应该有一套成文法并且有一个独立的判决者来对争端进行决断。为了达到这些目的,人们创立了一个政治的社会。
洛克最为强调的是人权的不可剥夺的性质,而这一点引导他去证明,政治社会必须以人们的同意为基础来建立,因为“所有人都是生而自由、平等和独立的,不经同意,任何人都不能被剥夺财产和被迫使屈从于他人的政治权力。”但人们同意的是什么呢?他们同意由社会制定和施行法律,但是由于“没有一个理性的被造物能够被设想为具有使自已的状况变得更糟的意向”,所以法律的制定是为了保障人们生而具有的权利。他们也同意受到多数的约束,因为“物体应当运动到更大的力把它推向的那个方向,这是必然的,而这就是多数的同意。”由于这个原因,洛克认为绝对君主制“根本就不是任何一种国民政府”。我们是否在事实上在某个时候订立了一种契约,这在洛克看来是无足轻重的,因为重要是,从逻辑上看,我们的行为表明我们已经表示了自己的同意,这就是洛克所谓的“默许”。因为如果我们享受着公民身份的权利,占有和交换着财产,信赖警察和法庭,那我们实际上也就认可了公民身份的责任并同意了接受大多数人的统治。一个人尽可以离开本国前往异邦,却还是留在自己的国家里,这一事实进一步证实了他的同意。国家主权洛克给了我们一幅不同于我们在霍布斯那里看到的关于社会中的主权的图景。霍布斯的主权者是有绝对权力的。洛克承认必须有一个“至高无上的权力”,但他小心地把这个权力置于立法机关的手中,实际上也就等于置于大多数人的手中。他强调分权的重要性,主要是为了保证执法和司法者不要也来制定法律,因为“他们也许会使自己免于服从他们所制定的法律,并在立法和执法过程中让法律服务于他们的私利。”因此执法机关要被“置于法律管辖之下”。甚至立法机关也不是有绝对权力的,虽然它是“至高无上的”,因为立法的权力是由一种信托,因而只是一种受委托的权力。所以,“在人民手中还保有一种至高无上的权力来撤销或变更立法者,如果他们发现立法者的行为与被寄托于他的信任相冲突的话。”洛克决不同意说人民自己的权力转移给了主权者就不可收回了。起义的权利被保留了,虽然起义只有在政府瓦解时才是正当的。在洛克看来,政府瓦解不仅仅是在它被外部敌人所推翻时,而且也在内部发生了立法机关的变故时。主权的立法部门可能会被改变,例如,如果执法者用自己的法律代替立法者的法律,或是立法者拒不执行正式法律;在这些情况下起义反对就是正当的。如果说霍布斯把主权置于上帝的裁断之下的话,洛克则宣称“人民会作出裁断”。
11.2 贝克莱
贝克莱的生平
乔治·贝克莱1685年生于爱尔兰。他在15岁时进入都柏林的三一学院(Trinity College),在那里他学习数学、逻辑、语言和哲学。他在取得文学学士学位后没几年就成为了这个学院的研究员,并且还被任命为英国教会的牧师,1734年成为主教。20岁出头他便开始了其负有盛名的著述生涯,他最重要的哲学著作包括他的《视觉新论》(Essay towards a New Theory of Vision,l709)、《人类知识原理》(A Treatise concerning the Principles of Human Knowledge,l710)和《西利斯和斐罗诺斯的三篇对话》(Three Dialogues between Hylas and Philonus,1713)。他到过法国和意大利去旅行,并且在伦敦成为斯梯尔、阿底松和斯威夫特的朋友。在伦敦时他曾试图说服国会支持他在百慕大创建一个学院的计划,这个计划旨在“改革英国人在我们的西半球种植园的作风,并在美洲野蛮人中传播福音。”1728年,他带着新婚的妻子航行到美洲,并在纽伯特的罗德岛待了三年,为他的学院制订规划。由于他的学院的资金始终没有筹集到,贝克莱回到伦敦,通过与约拿丹·爱德华的频繁联系在美洲的哲学中留下了他的影响。在那以后不久,他回到爱尔兰,在那里当了18年的克莱因主教。在65岁时他偕妻子与全家定居牛津;一年后的1753年他去世了,被莽于牛津基督教教堂墓地。
存在的本质
具有讽刺意味的是,洛克对哲学的常识立场竟然影响贝克莱去制定一种初看起来是如此违背常识的哲学主张。由于否认在每个人看来最明显的东西,他成了人们严厉批判和嘲笑的对象。贝克莱企图否定物质的存在。萨缪尔·约翰逊曾踢了一块大石头一脚,并且说到贝克莱:“我这就是反驳他。”这想必是表达了许多人对贝克莱的反应。
贝克莱的令人震惊和带有挑衅性的公式是“存在就是被感知”(esse est percipi)。显然,这将意味着如果有某物没有被感知,它将不存在。贝克莱完全意识到他这个公式中潜在包含着的荒谬之处,因为他说:“这并不能说成是我取消了存在。我只是宣示了我所理解到的这个词的意义。”但不管怎么说,当说到某物的存在依赖于它的被感知时,这的的确确就向我们提出了一个问题,即它在没有被感知时是否存在。在贝克莱那里这全部的问题都在于我们如何解释或理解存在这个词:“我说我写字的这张桌子存在,这就是说,我看见它并摸到它;而如果我走出我的书房,我还会说它存在,这话的意思是如果我在我的书房中我就会感知到它,或是某种另外的精神在现实地感知到它。”在这里贝克莱认为,存在这个词无非意味着包含在他的公式里的那个意思,再没有别的,因为我们找不到任何一个场合,在其中我们使用“存在”这个词而不同时设定有一个心灵在感知着某物。对于那些主张物质事物不与其被感知发生任何关系也有某种绝对存在的人,贝克莱答复说:“这在我看来是难以理解的。”他认为,的确,“和以前一样,马在马厩里,书在书房中,甚至我不在那儿时也是如此。但既然我们不知道有任何不被感知而事物也存在的例子,则桌子、马和书,甚至当我没有感知它们时也存在,就是因为有某个感知者确实在感知它们。
贝克莱怎么会提出这个新观点来呢?在《视觉新论》中他论证说,我们的一切知识实际上都依赖于视觉和其他的感官经验。贝克莱具体论证道:我们从来也没有感到空间和体积;当我们从不同的视角来看事物时,我们所有的不过是对事物的不同视觉或感知。我们也没有看到距离,对象的距离是由我们的经验所暗示的。所有我们看到的东西都是我们的视觉机能能够感觉到的对象的性质。我们没有看到一个对象的“近”,我们只是在向它移动或者远离它时,对它具有不同的视觉。贝克莱越是考虑我们自己心灵的活动并对他的观念如何与他心灵之外的对象发生关系感到不解,就越是肯定,他绝不可能发现任何不依赖于他的观念的对象。他说:“当我们尽全力去想象外部物体的存在时,其实一直都在沉思我们自己的观念。”想象公园里有树,书橱里有书而并没有人看见它们,这对我们来说好象是冉容易不过的了。但贝克莱说,这一切其实不过就是“在你的心灵中制定出某些你称之为书和树的观念。…但这时不正是你自己一直都在感知它们或思考它们吗?”他下结论说,除非想象它们与某个心灵发生关系,否则对任何事物的思考都是不可能的。我们从来也没有经验过像我们的“近”或“远”的观念所可能暗示的存在于我们之外并与我们分离的某物。在“外面”没有什么我们并不对之有所感知的东西。
物质和实体
正是洛克的哲学导致贝克莱对事物的独立存在——对物质的实在性——提出了怀疑。洛克并没有能够把他自己的知识理论推进到贝克莱视为不可避免的结论。当洛克说实体是“我们不知道是什么的东西”的时候,他离贝克莱明确说出的“实体是无”就只有一步之遥了。洛克在处理观念和事物之间的关系时,是认为在第一性的质和第二性的质——对象的体积、形状等为一方面,颜色、味道和气味等为另一方面——这两方面之间有着实在的差别。他认为一方面颜色只作为观念存在于心灵之中,另一方面体积却与对象的实体有关。而“实体”在洛克看来就是在像颜色这样的第二性的质的“后面”或“底下”存在着的实在,因而是独立于心灵的。
然而,贝克莱论证说,“从一切性质中抽象出来的”体积、形状和运动“是不可设想的”。例如,什么是樱桃?它是软的、红的、圆的、甜的和香的。所有这些性质就是樱桃有能力通过感官在心灵中所产生的观念。这样,我们就摸到了它的软性,看到了它的颜色,既摸到又看到了它的圆性,尝到了它的甜味,并闻到了它的芳香。而这一切性质的存在都在于它们被感知。而除去这些性质,则没有被感到的实在——简言之,再没有任何东西。因此,楼桃就是由我们所感知的所有性质所组成的:樱桃(以及一切事物)代表了诸感觉的一种复合。假设我坚持有某些第一性的质不能被感官所感知到,如体积和形状之类,贝克莱就会回答,甚至把形状和体积设想为不依赖于感知因而不依赖于第二性的质的,这也是不可能的。他问道:难道“哪怕是在思想中”可以把第一性的质和第二性的质分开吗?他又说,“那我就可以同样容易地把一个事物和这个事物自己分离开来,…实际上,对象和感觉就是同一个事物,因而是不可能把一个从另一个中抽出来的。所以,一个事物就是它的被感知的性质的总和,正是因为这个理由,贝克莱才认为,存在就是被感知。既然实体或物质是永远也不被感知或感觉到的,所以不能说它们存在。如果实体不存在,如果只有被感觉到的性质是实在的,那么就只有思想或如贝克莱所说的精神性的存在者存在。
除了把洛克的经验论哲学引向他认为是显而易见的结论之外,贝克莱还不得不处理一系列的疑难问题。在他的《人类知识原理》中,他把这些作为“在科学中的错误和困难的主要原因,连同怀疑论、无神论和反宗教的根据…来展开考察。”引起一切困难的正是那个物质概念。因为如果一种惰性的物质实体被承认为实在地存在的,那么在这样一个宇宙中哪里会有精神性的或非物质的实体的存在余地呢?而且,一种基于从事物的活动中引出的一般观念的科学知识,不是会给我们提供一种不需要上帝观念的完备哲学并导致那“可恶的无神论学说”吗?这并不是要说,贝克莱因为这些神学上的后果而武断地谴责物质观念。相反,他提供了附加的理由来坚持他相信本身就是正确的观点。
物质是一个无意义的术语 洛克曾说实体或物质支撑着我们所感到的性质,或者说是它们之下的一种“基质”。在贝克莱的《西利斯和斐罗诺斯的第一篇对话》中,西利斯表达了洛克的观点:“我发现必须假设一个物质的基质,没有它就不能设想(性质)是存在的。”斐罗诺斯回答说,“基质”这个词的含义对他来说是不清楚地,他想知道“你在这个词中所指的是什么意思,不论是字面上的意思还是非字面的意思。”但西利斯承认他不可能对“基质”这个词指定任何确切的意义,他说:“我承认我不知道该说什么。”由此引出的结论是:“无思想的(物质的)事物的绝对存在是无意义的说法。”这并不是说感性事物不具有实在性,而只是说感性事物只有当它们被感知时才存在。这其中的应有之义是只有观念存在,但贝克莱又说:“我希望把一个事物称作‘观念'不会减少其实在性。”
贝克莱意识到他的唯心主义可能会遭到嘲笑。他写道:“那么太阳、月亮和星辰会变成什么呢?我们必须怎样思考房屋、河流、山脉、树木、石头,甚至我们自己的身体呢?所有这些难道是些幻想出来的怪物或假象么?”他说,根据他的那些原理,“我们并没有因此而失去自然中的任何一个事物。我们看到、摸到、听到,或是以任何方式的想到和理解到的一切,都与以往一样可靠、一样实在。这里有的是一种‘自然事实'(rerum natura),而实在的东西和怪物的区别仍保留着它的全部效力。”如果是这样的话,为什么又说只有观念存在而不是事物存在呢?贝克莱说,为了消除物质这个无用的概念,“我并没有要反对任何一个我们能够加以领悟的事物的存在,无论是通过感觉还是通过反省来领悟,…我否定其存在的惟一事物是哲学家称之为物质或有形实体的事物。而这么做对其他人并没有造成任何损失,而我敢说,人们是决不会不理解这一点的。”
科学和抽象观念 因为当时的科学,特别是物理学的情况是如此的倚重物质概念,贝克莱不得不与科学的那些假设和方法打交道。科学假定我们能够也必须把现象与实在区别开来。大海看上去是蓝的但实际上不是。贝克莱对科学家提出质疑,要求他们看看是否有任何不同于可感世界的实在。在这一分析中贝克莱遵循的是经验主义的原则并试图使这一原则精致化。他说,物理学家由于在他们的理论中容纳了形而上学,结果把科学的面貌弄得模糊不清了。他们使用这样一些词如“力”、“吸引力”、“重力”,并且认为它们指向某些实在的物理实体。甚至谈论那些以其运动引起了颜色性质的微粒,这就必须进行理性分析而不是经验分析。最使贝克莱不满的是科学家们使用那些一般的或抽象的术语,仿佛这些术语确实归于实在的实体,特别是归于一个作为基础的物质实体一样。贝克莱坚持认为,我们任何地方都不会遇到这样的实体,因为实体是一种抽象的观念。只有被感觉到的性质是真实存在的,实体的概念则是从被观察到的性质中误推出来的:“由于观察到好几个这种性质彼此相随,它们就被用一个名称来标记,于是就被称为一个‘事物'。这样,例如一定的颜色、味道、气味、形状和坚硬性就被一起观察到了,这就被认为是一个独特的事物,用“苹果'这个名称来表示:另外一些观念的集合构成了一块石头、一棵树、一本书和诸如此类的可感事物。”同样,当科学家们观察到事物的活动时,他们运用“力”或“重力”这样一些术语,就好像它们就是事物或在事物中有某种实在的存在似的。但“力”只不过是描述我们对事物的活动的感觉的一个词,给我们的知识并不超出感觉和反省所给予我们的。
贝克莱的意思并不是要摧毁科学,同样,他也不想否认“事物本性”的存在。他真正所想要做的就是澄清科学语言是怎么回事。像“力”、“重力”和“原因”这样一些术语所涉及的只不过是我们的心灵从感觉中所获得的一束束观念。我们经验到热使蜡融化了,但我们从这一经验中所知道的一切只是:我们称之为“在融化的蜡”的东西总是与我们称之为“热”的东西相伴随。我们并没有关于“原因”这个词所代表的任何单个事物的知识。其实,我们惟一拥有的知识就是关于个别经验的知识。但尽管我们不具有关于一切事物的原因的第一手知识,我们的确还是知道这些事物的秩序。我们经验到A由B所跟随着这一秩序,虽然我们并没有经验到这为什么会发生。科学给我们提供了一个关于物理作用的描述,而许多力学的原理都可以从我们的观察中精确地形成,这对于作出预测是有用的。于是贝克莱愿意让科学原封不动,但他却要澄清科学的语言,这样就没有人会认为科学给了我们比我们从可感世界中所能获得的还要多的知识了。而这个可感世界展示给我们的既没有实体也没有因果性。
上帝及事物的存在 既然贝克莱没有否定事物的存在或它们在自然中的秩序,那么对他来说就必须解释事物怎样在我们的心灵之外存在——甚至在我们没有知觉到它们时也如此,以及它们是怎样得到它们的秩序的。于是,通过详尽地阐述他的“存在就是被感知”这一主题,贝克莱认为“当我否定可感事物在心灵之外的存在时,我指的并不是我这个特殊的心灵,而是一切心灵。现在很清楚,它们有一个在我的心灵之外的存在,因为我通过经验发现它们是独立于我的心灵的。因此在我没有感知它们的这段时间中,就有它们存在于其中的另外的心灵。”而因为一切人类的心灵都会间歇性地离开事物,所以“就有一个无所不在的永恒的心灵,他知道和理解一切事物,并以这样一种方式,即按照他自己制定的这样一些规律把它们显示在我们的眼前,这些规律被我们称之为自然法则。”因此事物的存在就依赖于上帝的存在,上帝是自然中的事物的有序性的原因。
再说一遍,贝克莱并不想否认,例如甚至当他离开房间时,蜡烛仍然会在那里,而当他经过一段时间转回来时,蜡烛可能已经烧完了。但这在贝克莱只不过意味着经验有一定的规则性,使得我们有可能预测我们将来的经验会是什么样子。说蜡烛甚至当我不在房间里时还在燃烧,这并不证明物质实体独立于一个心灵而存在。对贝克莱而言,说我能够知道蜡烛的情况只是因为我现实地经验到对错烛的感知,这似乎是一个常识问题。同样我知道我自己存在,因为我意识到我自己的心灵活动。
那么,如果我试图以我的经验来描述和解释实在,我首先就会达到这样一个结论,即存在着像我一样具有心灵的其他人。由此就可以设想,就像我拥有观念一样,另外的人同样也拥有观念。除了我的有限的心灵和别人的有限的心灵,还有一个类似于我的更伟大的心灵,这就是上帝的心灵。上帝的观念构成了自然的有规则的秩序。存在于我们心灵中的那些观念就是上帝的观念,是上帝传达给我们这些观念,所以我们在日常经验中所感知到的对象或事物并不是由物质或实体引起的,而是由上帝引起的。上帝也使一切有限心灵的经验协调起来,保证经验中的规则性和可靠性,这种规则性和可靠性又使我们能够以“自然法则”的形式来思考。于是,观念在上帝的心灵中的这种有序安排就被传达给了人的有限心灵或精神——当然,还得考虑到神的心灵和有限的心灵之间在能力上的差别。所以,那种终极的实在就是精神的(上帝),而不是物质的,而对象在我们没有感知它们时的继续存在,是由上帝对它们的持续感知来解释的。
如同贝克莱那样说人的观念来自上帝,这暗含着对因果关系的一种特殊的解释。强调一下,贝克莱并没有否认我们对因果关系有某种洞察:他只是坚持说,我们的感觉材料并没有向我们揭示一种独特的因果力量。例如,当考虑水如何并且为什么会结冰时,我们并没有在寒冷中发现任何迫使水成为固体的力量。然而,我们的的确确通过我们的心理活动来理解因果关系。例如,我们意识到我们的意志力:我们可以有意移动我们的手臂,或者,这一点在此更为重要,我们可以在我们]心中产生想象的观念。我们产生这种观念的能力暗示被感知的那些观念也是由精神的力量所导致的。但想象出来的观念是由有限的心灵所产生的,而被感知的观念却是由无限的心灵创造出来并使之存在于我们心中的。
贝克莱确信,通过他对“存在就是被感知(esse est percipi)”这一公式的讨论,他已经有效地打击了哲学唯物主义和宗教怀疑主义的立足点。洛克的经验主义,就他坚持知识建立在感性经验之上而隐藏在现象之后的实体或实在永远不可知而言,不可避免地包含着怀疑主义。贝克莱为上帝的和精神存在者的实在性所作出的论证是否成功地反驳了唯物主义和怀疑主义,仍然是成问题的,因为他的论证包含有与他在唯物主义者身上所抓到的一样的破绽。但他的影响仍然是意义深远的,只不过对后世产生持久影响的是他的经验主义而不是他的唯心主义。贝克莱在洛克经验论的基础上阐明了这样一个关键论点,即人的心灵仅仅是并且永远是就特殊的感性经验进行推理一抽象的观念并不指向与之对等的实在。休谟这位将让经验主义得到最充分表达的人,曾说贝克莱是“一个伟大的哲学家,(他)质疑了被接受到这种个别性中来的意见,并断言一切普遍观念都无非是个别观念。…我把这看作是近年来在学术界中作出的最伟大和最有价值的发现之一。”
11.3 休谟
休谟的生平
大卫·休谟汲取了洛克和贝克莱哲学中的纯正的经验主义要素,而从他们的思想中排除了残留的形而上学,并且给了经验主义以最清楚最严格的系统阐述。他1711年生于爱丁堡,父母都是苏格兰人。他的早年兴趣是文学,这种兴趣不久就向他家里表明,他不会按照他们为他制定的计划成为一名律师。虽然他上了爱丁堡大学,他却没有毕业。他是一位性情温和但很有主见的人,对“增进我们文学才干以外的日的都不屑一顾”,并且“除了对哲学和一般学问的探求之外,对每件事情都感到一种不可克服的厌恶。”他1734-1737年在法国漫游,在“节衣缩食”的条件下写成了他的《人性论》(Treatise of Human Nature)。当他的书在1739年出版时,休谟对它所受到的冷遇颇感失望,后来他评论说:“没有任何著述的尝试比这更倒霉的了”,因为这本书“从印刷机上一下来就是个死胎”。他的下一本书《道德政治论》(Essays Moral and Political)出版于1741-1742年,是较为成功的。接着休谟修改了他的《人性论》中的主题并且以《人类理智研究》(Enquiry concerning Human Understandg)为题将它出版。除了他关于英国历史的、内容广博的著作之外,休谟还写了三本其他的可以使他名声远扬的书,这就是《道德原则研究》(An Enquiry concerning the Principles of Mors,1751)、《政治论文集》(Political Discourses,1752),和在他身后出版的《自然宗教对话录》(Dialogues concerning Natural Religion,IT99)。
休漠还参加政治生活,1763年他作为英国大使的秘书到了法国。他的书让他在欧洲大陆声名广播,而他在欧洲大陆的朋友之一就是哲学家让-雅克·卢梭。1767年到1769年他担任副国务大臣,1769年回到爱丁堡,他家成了当时社会名流的聚会中心。这时他“十分富足”,所以往来于朋友和仰慕者——其中就有经济学家亚当·斯密——之间,过着宁静而怡然的生活。1776年他在爱丁堡逝世。
休谟想运用物理学的方法建立一门人性科学。他对文学的广泛了解向他表明,读者是何其频繁地在一切问题上碰到相互冲突的观点。他认为这种观点的冲突兆示着一个严重的哲学问题:我们如何能够知道事物的真正本性?如果手段高明的作者能够引导读者接受有关道德、宗教和物理实在的真实本性的那些互相冲突的观念,那么,究竞是这些观念同样为真,还是有一些方法可以用来发现这些观念互相冲突的理由呢?休谟同样有他那个时代的乐观想法,这种乐观主义在科学方法中看到了解决世界上一切问题的手段。他相信这样一种方法能够引导我们达到对人的本性尤其是对人的心灵活动的清楚理解。
结果,休谟发现,对使用科学方法来描述人的思想机制的可能性的这种乐观看法不可能有合理的根据。他早先对理性的信仰最终导致了怀疑主义。因为当他追湖观念在心灵中形成的过程时,他大吃一惊地发现人的思维的范围是多么的有限。洛克和贝克莱两人都已经走到了这一点,但他们谁都没有足够严格地采用自己对观念起源的解释从而把自己的整个认识论都置于这一基础之上。他们仍然求助于人的“常识”信念,这种信念是他们不愿意完全放弃的。虽然他们认为我们的一切观念都来自于经验,但他们还是确信,经验可以在很多题材上给我们以知识的确定性。相反,休谟的结论却是,如果我们严格地接受这个前提即我的一切观念都来自经验的话,我们就必然会承认把这种对观念的解释迫使我们接受的那种知识的有限性,而不管我们的习惯性信念会说些什么。
休谟的知识理论
休谟认为,要解决在“晦涩问题”上的争执和玄想引起的难题,只有一种方法,那就是“严格探究人类理智的本性,并从对人的力量和能力的精确分析中表明,没有什么办法使它适合于如此陌生和晦涩的主题。”据此,休谟仔细地分析了一系列引他达到怀疑论的结论的主题,而这始于他对心灵内容的一种说明。
心灵的内容 休谟说,没有什么看起来比人的思维更加无拘无束的了。虽然我们的身体被束缚于一个星球上,我们的心灵却能够到字宙中最遥远的地方去漫游。心灵似乎也不受自然或实在的界限束缚,因为想象力能够毫无困难地设想最离奇古怪和最不合情理的幻象,如飞马和金山之类。但是,虽然心灵看来具有这种广阔的自由,休谟却认为,它“实际上却被限制在非常狭窄的界限之内”。归根到底,心灵的内涵全部都可以被归结为由感官和经验所给予我们的材料,这些材料休谟称之为“知觉”。心灵的知觉有两种形式,休谟将其区分为“印象”和“观念”。
印象和观念构成了心灵的全部内容。思想的原始素材就是印象(感觉或情感),而观念则只是印象的摹本。在休谟看来,一个印象和一个观念的区别只是它们的鲜明程度不同而已。原始的知觉就是印象,如当我们听、看、触、爱、恨、欲求和意愿时。这些印象在我们拥有它们时是“生动的”和清晰的。当我们思考这些印象时,我们就有了关于它们的观念,而这些观念是对原始印象不那么生动的翻版。感到痛是一个印象,而对这个印象的回忆就是一个观念了。在任何具体情况下,印象与其相应的观念都是相似的,区别只在于它们的鲜明程度。
除了在印象和观念之间作出区分,休谟还认为没有印象就不可能有观念。因为如果一个观念只不过是一个印象的摹本,那么结论就是,有一个观念,就必须有一个在先的印象。然而,并不是每个观念都反映了一个与之精确相应的印象,因为我们从来也没有见到过一匹飞马或一座金山,尽管我们有它们的观念。但休谟把这样一些观念解释为心灵“对感觉和经验提供给我们的材料进行组合、变换或削减的机能”的产物。当我们思考一匹飞马时,我们的想象力结合了两个观念,即翅膀和马,这两个观念我们原来是通过我们的感觉而作为印象得到的。休谟说,如果我们怀疑一个哲学术语的使用是没有意义或没有思想内容的,我们“只需查问一下:那个被假定的观念来自什么印象?而如果不可能指给它任何印象,这就足以证实我们的怀疑了。”休谟甚至也以此来检验上帝的观念,并且得出结论说它是由于我们对自己心灵活动的反省把我们从人那里经验到的善与智慧等品质作了“无限的推论”而产生的。但如果我们的一切观念都来自印象,我们如何能够解释我们称之为“思维”的事情,或解释观念用来把自己集合在我们心灵中的那些模式呢?
观念的联想 我们的观念相互发生关系并不完全是凑巧。休谟说,必定有“某种结合的纽带、某种联想的性质,由此一个观念才自然而然地引出另一个观念”。休谟将之称为“一种经常占优势的温和的力量,它向每个人指出最适于结合成一个复杂观念的那些简单观念。”这并不是心灵把一个观念与另一个观念联结起来的一种特殊的机能,因为休谟并不具有对心灵的构造性装置的印象。但是根据对我们实际思维方式的观察和对我们观念的集合的分析,休谟认为他发现了对观念的联想的一种解释。他的解释是:只要观念中具有确定的性质,这些观念就是相互被联想的。这些性质分为三类:相似、在时间和空间中的接近,以及原因和结果。休谟相信一切观念相互之间的联系都能够由这一种性质来解释,并提供了如下例子来解释它们如何起作用:“一幅画自然而然地引导我们想到那个原件(相似);提及一个建筑物中的一个房间自然而然地就引导人们去考察…另一个房间(接近):而且如果我们想到一个伤口,我们几乎不可避免地反省到由它所带来的痛苦(原因和结果)。”心灵没有任何活动原则上是不同于观念联想的这二个例子之一的。但其中,原因和结果的概念又被休谟看作是知识的核心要素。他采取的立场是,因果律是一切知识的有效性所赖以成立的基础。如果因果律有任何缺陷,则我们就不可能有知识的确定性了。
因果性 休谟最具独创性和影响力的思想是关于因果性问题的。洛克也好,贝克莱也好,都没有挑战因果律这一基础。虽然贝克莱说我们不能发现结果在事物中的致动因,他的意图却是追寻现象的原因,从而在上帝的活动中追寻可预测的自然秩序。
在休谟那里,因果性的整个概念都是可疑的,而他探讨这个问题是通过发问:“因果观念的来源是什么?”既然观念是印象的摹本,休谟就是问什么印象给了我们因果性观念。他的回答是,并没有与这个观念相应的印象。那么,这个因果性观念义是如何在心灵中产生的呢?休谟说,肯定是这样,即因果性观念是在我们经验到对象之间的一定的关系时在我们心灵中产生出来的。当我们谈论原因和结果时,我们的意思是说A引起了B。然而,是怎样一种关系造成了A和B之间的这样一种现象呢?经验提供给我们两种关系:(1)接近关系,因为A和B总是紧密靠在一起的;(2)时间中的在先性,因为A这个“原因”总是先于B这个“结果”的。但还有另外一种关系是因果观念提供给常识的,就是在A和B之间有一种“必然的关联”。但无论是接近也好还是在先也好,都并不包含对象之间的“必然”关联。休谟说,如果我们个别地考虑各种对象的话,没有什么对象包含有另一个对象的存在。对氧气无论观察多少次都不能告诉我们当它与氢混合时就必然会给我们带来水。我们知道这一点只是在我们看到它们在一起之后:“因此我们能够从一个对象推断出来另一个对象的存在,这只是通过经验。”虽然我们的确拥有接近的、在先的和经久联结的印象,我们却并不具有任何必然关联的印象。所以,因果性并不是我们所观察到的对象中的性质,毋宁是一种由于A和B的随时重复而在心灵中产生的“联想的习惯”。
由于休谟认定因果律是一切知识的核心,他对这一原则的攻击破坏了一切知识的合理性。他看不出有什么理由可以把“无论什么存在者要存在都必须有一个存在的原因”作为一条直观的或是可演证的原则而接受下来。最后,休谟把思维或推理看作“一种特殊的感觉”,而作为这样一种感觉,我们的思维是不可能扩展到超出我们的直接经验之外的。
什么存在与我们之外?
休谟的极端经验论导致他认为,物体或思维在我们之外具有连续的和独立的存在是没有理性合法性的。我们的日常经验使人想到,在我们之外的事物是存在的。但如果我们严格接受我们的观念是印象的基本这一看法,哲学的结论就必然会是:我们所知道的一切都是印象。印象是内部主观的状态而不是对外部实在的清晰的证据。可以肯定,我们总是那样行动,好像的确有一个实在的外部的事物的世界似的,而且休谟愿意“以我们的一切理性承认”事物当然是存在的。但他想要探讨的是我们为什么会认为有一个外部世界的理由。
我们的感官并没有告诉我们事物独立于我们而存在,因为,我们如何知道甚至当我们中断了我们对它们的感觉时它们还继续存在呢?并且甚至当我们感觉某物时,我们也决不具备一种我们能够借以把事物与我们对事物的印象区别开来的双重眼光;我们所有的只有印象。心灵没有任何办法超越印象和印象使之成为可能的那些观念:“把我们的想象推移到天边,或是一直到宇宙的尽头;我们永远也不会超出我们自己一步,除了已经显现在那个狭窄范围内的知觉,我们也不可能构想出任何别的存在。这就是想象的宇宙,除了在这个宇宙中产生出来的观念,我们也再没有任何别的观念。”
恒定性和一贯性 休谟认为,我们相信事物在我们之外存在,是我们的想象力在处理我们的印象的两种特殊性质时的产物。从印象中,我们的想象力意识到恒定性和一贯性。事物的排列有恒定性,例如,当我向我的窗外看去时:那里有山、房子、树。如果我闭上我的眼腈或是转身离开,然后再来看同一片景色,那排列还是一样的,而正是我的印象内容中的这种恒定性导致我的想象力断言说,不论我想到还是没想到它们,山、房子和树都存在着。同样,我在离开房间之前放一根木柴在火炉上,而当我转回来时它已经几乎烧成了灰。但是虽然在火炉中已发生了巨大的变化,我却习惯于在类似的情况下发现这类变化:“这种…在其变化中的一贯性是外部对象的特征之一。”在山的例子中,有我们的诸印象的一种恒定性,而在火炉的例子中,我们的印象与变化过程有一种一贯性的关系。由于这些原因,想象力引得我们相信某些事物是连续地具有外在于我们的独立存在的。但这是一种信念而不是一种理性的证明,因为假定我们的印象与事物相关联“是没有任何推理为基础的”。休谟把这种怀疑论的推理思路推广到对象和事物以外,而去考虑自我、实体和上帝的存在。
自我 休谟否定我们对“自我”有任何观念。如果“我”说我并不拥有一个对我自己的观念,这看起来好像是悖谬的。然而在这里休谟又要考察一下我们所说的“自我”是什么意思,他问道:“从何种印象中能够产生出这个观念来?”有任何能产生我们对自我的观念的连续而同一的实在吗?我们有任何一个印象不变地与我们的自我观念联结着吗?休谟说,“当我最亲切地体会我所谓的我自已时,我总是会碰到这个或那个特殊的知觉,如热或冷、爱或恨、苦或乐。任何时候我总不能抓住一个没有知觉的我自己,除了知觉之外我也不能观察到任何事物。”休谟否认连续的自我同一性的存在,并且说,自我“除了一束或一堆不同知觉之外什么也不是。”那么,我们如何解释我们认为是自我的东西呢?这就是我们的记忆的力量,它提供给我们连续同一性的印象。不过,休谟认为,心灵是“一种舞台,各个知觉在这个舞台上相继出现”然后又消失。
实体 导致休谟否定以某种方式保持着自己在时间中的同一性的连续性自我存在的,就是他对任何形式的实体的存在的彻底否定。洛克还保留了作为那种具有颜色或形状和其他性质的某种东西的实体观念,虽然他把它们说成是“某种我们不知道是什么的东西”。贝克莱否认作为各种性质的基础的实体,但却保留了精神实体的观念。休谟否认了实体以任何形式存在或具有任何连贯的意义。如果“自我”所意味的东西是某种形式的实体,那么休谟认为没有这样一种实体能够来源于我们的感官印象。如果实体的观念是通过我们的感官而被传达给我们的,休谟问道:“是哪种感官,并且按照何种方式?如果是通过眼睛的知觉,那它必定是有颜色的;如果是通过耳朵,那就有声音;如果是通过味觉,就有滋味…因此我们不具有与特殊性质的集合的观念不同的实体观念。”
上帝 休谟的“我们的观念超不出我们的经验”这一严格前提不可避免地会使他对上帝的存在提出怀疑论的质疑。大多数推演上帝存在的尝试都依赖于某种形式的因果性。其中,设计论论证一直有力地影响着宗教信徒们。休谟意识到这一论证的力量,但他敏锐地区分开了这个问题的各个要素,让这一证明减少了它通常所具有的力量。
由设计论论证而来的证明开始于对自然界美丽秩序的观察。这种秩序与人的心灵能够加之于无思想的物质之上的那种秩序相似。从这一预备性的观察出发,我们就推断不能思想的物质自身中并不包含有秩序的原则:“把大量的铁片扔在一起,没有形状或形式,它们永远也不会自行组成一只表。”所以人们认为,秩序需要某种心灵即某个安排者的活动。我们的经验告诉我们,一只表也好,一栋房子也好,离开钟表匠或建筑师,是不可能形成的。由此推出,自然秩序类似于人为形成的秩序,并且,正如表需要一个进行安排的原因,宇宙的自然秩序同样也需要一个这样的原因。但休谟说,这样一个推断“是不可靠的;因为这件事完全超出了人的经验范围。”
如果这全部设计论论证都基于“宇宙中的秩序的那个或那些原因很可能带有某种与人的理智的间接的类似性”这一命题,那么,休谟认为,这个论证所能证明的东西就没有它声称的那么多。休谟对因果性观念的批判在这里有着特别的力量。我们从对两个事物的多次重复的观察中引出了原因观念。那么,当我们根本没有把宇宙作为与我们可能认作原因的任何事物相关的来经验到时,我们怎么能够为宇宙指定一个原因呢?运用类比不能解决问题,因为在一只表和宇宙之间的类比是不精确的。为什么不把宇宙看作植物生长过程的产物而要看作有理性的设计者的产物呢?并且,即使宇宙的原因是某种类似于理智的东西,又怎么能把道德特性归之于这样一个存在者呢?此外,如果必须运用类比,应当挑选哪一个类比?房子和船通常是由一群设计者设计出来的:我们应当说有许多上帝吗?实验模型的建造有时是在不具备对最终完成的形式的现成知识时进行的:宇宙是一种试验模型还是最终的设计?借助于这条探索的思路,休谟希望强调的是,宇宙的秩序只是一个经验的事实,我们不可能从它去推断上帝的存在。这并不必然导致无神论——虽然休谟本人看起来像一个无神论者。他只是像检验我们的自我观念和实体观念一样,用同一种严格经验主义的方式,来检验我们的上帝观念。他最终的确是一个怀疑论者,但他最后吐露的观点却意味深长:“无论一个人把他的思辨原则推进到多远,他都必须和其他人一样行动和交谈…要保持彻底的怀疑论,或者把怀疑论体现到行动中去哪怕只是几个钟点,都是他不可能做到的。”
伦理学
休谟的怀疑论并没有妨碍他严肃地对待伦理学。正相反,在他的《人性论》第三卷的开篇中,休谟写道:“道德是一个比一切其他事物都更让我们感兴趣的主题。”他对伦理学的兴趣是如此强烈,以至于他希望为这个主题做伽利略和牛顿为自然科学所做的事。为了这个目的,他在其《道德原则研究》的第一节中说:“道德哲学的处境正如…哥白尼时代以前的天文学一样。”旧的科学连同其抽象一般的假说必须让位给一种更具实验性的方法。于是这样一个时代也就来到了,休谟写道,这时哲学家们“应该尝试在一切道德探究中作一种类似的改革,并拒绝一切不是建立在事实和观察之上的伦理学体系,无论它们如何精妙和新颖。”
在休谟看来,伦理学的核心事实是,道德判断不仅仅是凭理性而形成的,而是要通过情感。无疑,理性在我们讨论道德决定时起了相当重要的作用。但休谟认为,理性“并不足以单独产生出任何道德谴责和道德认可”。限制理性在伦理学中的作用的是,理性作出的判断是涉及经验性的“事实的事情”和分析性的“观念的关系”的真假。道德评价不是有关任何事情的真假判断。相反,道德评价是情感反应。
例如,为什么我们判断谋杀是一桩罪恶呢?或者用休谟的话来说,“哪里有我们在这里称作罪恶的那种事实的东西?”假定你描述这个行为,它发生的准确时间,所使用的武器,简言之,你搜集了有关这件事的一切细节资料。但理性的机能仍然不能挑出那件可以贴上“罪恶”标签的事实。毕竟,这个行为不可能总是并且在一切情况下都被看作一桩罪恶。同样的行为可以被称为自我防卫或明正典刑。作出善或恶的判断,是在一切事实都已知“之后”。一个行为的善或恶并不是一件由理性所发现或推演出来的新事实。道德评价也并不和数学判断相似。从有关一个三角形或圆形的少数事实中就可以推断出另外的事实和关系。但善就像美一样,并不是由理性推断或演绎出来的一个另外的事实。休谟说:“欧几里德完备地解释了圆的一切性质,但在任何一个命题中都对它的美不置一词。理由很清楚。美不是圆的一种性质。美并不处于其每一部分都与一个共同中心等距的一条线的任何一部分中。美只是那个图形在心灵上产生的效果,心灵特有的组织结构使其易于受这种情感的影响。”
为了强调这点,休谟请我们“看看是否能发现那种你称之为‘恶'的事实性东西或实在的存在”,他认为:“不论你以何种方式理解它,你只能发现某些欲望、动机、意志和思想。在这件事中没有别的事实性的东西。…你永远不可能发现它,直到你转而反省自己的内心,并发现在你心中产生了对这种行为的不认可的感情为止。这里有一种事实的东西;但它是感情的对象,而不是理性的对象。它处在你自己之中,而不是在对象之中。”
在休谟看来,道德评价涉及对我们在观察到某个人的行为的后果时所经验到的愉快和痛苦的同情感。例如,如果我的邻居遭到了抢劫,我会为他感到同情的痛苦,而这种痛苦就构成了我对抢劫犯的行为的道德谴责。如果我看到某人帮助一位老妇人过街,我就会为这位老妇人感到同情的偷快,而这种愉快就构成了对于那位帮助她的人的道德认可。休谟意识到,把伦理学体系建立在情感能力上必须冒着将伦理学归结为趣味问题的风险,那样道德判断就成了主观的和相对的了。此外,把情感或感情指为赞赏和谴责的根源就意味着我们的道德判断来自于我们对自利和自爱的一种算计。休谟拒绝了这些假设,他肯定道德感情是一切人心中都可以发现的,人们赞赏或谴责的是同样一些行为,而这些赞赏或谴责并不来源于狭隘的自爱。休漠写道:“由敌方所做出的一种仁慈、勇敢、高尚的行为使我们不得不认可;而就其后果而论,这种行为也许被认为是对我们的特殊利益有损害的。”而且,我们所经验到的同情感并不限于我们眼前所看到的事。相反,我们把一种“对道德行为加以赞扬”的本能的能力“运用于离我们非常遥远的时代和国度;在那里想象力再怎么细致也不会发现任何自身利益的迹象,或发现我们现有的幸福及安全与离我们如此遥远的事件有任何关联。”
在人身上究竟有哪些性质会触发我们对道德赞同的同情感呢?按照休谟的意思,这些性质一或德性—包括“给观者带来愉快的认同情感的一切精神活动或性质;恶则相反”。这些性质包括“判断力、谨慎、进取心、勤劳、节俭、机智、精明和洞察力”。他还认为,甚至在最玩世不恭的人中,对“节制、清醒、容忍、坚定、周密、沉着、思维敏捷和措辞得体的优点时,事实上也有普遍的赞许。”这些引起我们赞赏的性质是怎样一些性质呢?休谟说,这些性质是有用的和令人惬意的。但对什么有用?休谟回答说:“肯定是对某些人的利益。究竞对谁的利益呢?不仅是对我们自己的:因为我们的认可经常扩展得更远。所以这必定是那些被赞赏的特性或行为所服务的人的利益。”
休谟在这里的方法是彻底经验主义的。首先,经验告诉我们道德评价涉及情感,而本身不是理性判断。其次,经验告诉我们,我们在对人们拥有的许多道德品质作出反应时,有对愉快和痛苦的同情感。最后,经验告诉我们,所有这些道德品质都有一个共同点:它们对那些受到我们行为影响的人来说是有用的或惬意的。在对道德评价的这种经验主义的分析中,我们发现在休谟心里有一个清晰的道德判断标准:道德的行为就是对这些行为所影响的人有用或使之惬意的行动。用休谟的话来说,“一个人的优点完全在于拥有对他自己或对别人有用或使之惬意的精神性质。”
休谟对道德的经验主义态度有其直言不讳的批评者。许多人认为,道德需要被确定为永恒的和绝对的,而休谟却把道德的整个规划都建立在人的不稳固的机能和情感中。此外,批评者们还认为,我们在休谟的描述中完全找不到上帝的作用。所以,他的全部立场都站不住脚,而且是无神论的。然而,休谟理论的那些让批评者感到不安的特色,也正是对另一些人的吸引力所在。在读完休谟的道德理论后,杰里米·边沁写道:“我感到仿佛眼中的弱障去掉了一样。”边沁自己在对道德作非宗教立场的探讨,道德被建立在经验事实的基础上,而不是神秘的理性直觉上。边沁很注意休谟的这个论点,即我们评价行为是基于它们的有用性一或者像休谟也曾表述的那样:它们的“效用”。这一点成为了边沁和其他许多思想家所拥护的、持续了整个19世纪并一直延续至今的功利主义道德理论的基础。
第十二章 启蒙哲学
欧洲在18世纪经历了一场被称为“启蒙”的思想运动,这一运动发出了振奋人心的呼声:人类在致力于包括科学、政治、宗教、美学和哲学等在内的一切领域时,都应该以理性为指导。科学的飞速进步让启蒙思想家们深受鼓舞,他们自信通过对理性的运用,就能揭开宇宙的奥秘,使社会走上斯的高度进步的发展方向。这种对理性的信念在文艺复兴中就已经有所体现,它迎来了科学的革命和人们对古希腊思想家们几乎被遗忘的著作所重新焕发出的兴趣。同样,17世纪那些理性主义的大哲学家们——笛卡尔、斯宾诺莎、莱布尼茨——也鼓励人们运用理性去破解关于人性和周图世界的那些亘古之谜。然而,启蒙运动之强调理性,有其独特之处,即:它关于伦理、政府权成和人类心理的理论都具有毫不掩饰的世俗性,而与带有宗教色彩的各种传统人性观分道扬籁了。洛克认为人心生下来是一块白板,由于通过感官接受了经验才形成观念,这大大地促进了启蒙运动的人性观念的建立。休谟则以怀疑主义对上帝、奇迹、来世生活等信念发起攻击,进一步推动了启蒙的进程。本章中我们将探讨其他一些对启蒙哲学居功至伟的关键人物,即:自然神论者、让一雅克·卢梭和托马斯·锐德。
12.1 自然神论和无神论
自然神论是指这样一种观点:上帝创造了世界,但此后就听其自然了。按这种观念,上帝并不通过天启来干预这个世界:那些异象、奇迹、预言、藉神启而写下的经书,通通都是子虚乌有。上帝很像个钟表匠,制造了一台精密的机器,使之能自动维持其运行,一俟钟表售出,这匠人就退居幕后,不再拨动指针了。我们对上帝和我们彼此之间道德责任的知识,都是通过运用人的理性而得之于我们自身的。有些自然神论者仍然相信有来世生活,那时上帝将根据我们的所作所为对我们施以赏罚,但即便这一点也是我们通过理性发现的,而不是通过启示。
英国自然神论
大不列颠自然神论之父是切尔布利的爱德华·赫伯特(Edwad Herbert of Cherbury,1583-1648)。他是个贵族,从过军,也当过外交官。在其最有名的著作《论真理》(On Truth,1624)中,赫伯特阐明了一个哲学体系,它以这样一种理论为基础:我们的心灵包含本能的、普遍为真的“共同观念”。这些观念有的使得我们对周围世界如此这般地进行感知,有的使得我们在科学问题上如此这般地进行推理。而有一组共计五个这样的共同观念则构成了宗教的基础:(1)有一个最高的神;(2)我们应当崇拜他;(3)敬神的最好形式是正当的道德行为;(4)我们应该为我们不道德的行为而忏悔,以及(5)来世我们将因此生的作为而受赏或受罚。以上列出的这几条本身并不包含什么可争议的内容,而它之所以具有颠覆性意义,是因为赫伯特坚称,这些原则就是真正的宗教的惟一基础。没有什么天启的经书:神的真正训示就是以这五条原则的形式,通过自然的理性传达给我们所有人的。要是我们发现一种宗教的任何教义超出了这五条,那就应当把那些无关乎这五条的教义视作教主们为谋取私利而编造出来的东西。进而言之,基督教作为一种宗教也并没有什么天然的优越性,因为我们在世界上其他的宗教体系中也能发现这五条原则。
后来赫伯特又有--部题为《一位教师与学生的对话》(A Dialogue between a Tutor and His Pupil)的著作,他在其中讲到了我们如果要反对像基督教那样占统治地位的宗教的教主,将会面临何等的挑战。这篇对话里的学生相信,宗教问题取决于理性而不是信仰,但让他感到祖丧的是,“我们的神学家们想让我首先信仰,然后再开始运用理性。”老师赞同他的观点,认为宗教如无理性基础而全凭信仰,则“价值甚微,或许会被认为不过是有关圣迹的传奇故事或是寓言化了的历史”。赫伯特接着说道,不幸的是,教主们“无处不在叫我们要摒弃除他们的以外的一切信仰,由此还想让我们把一切他们所不曾教给我们的教义一下子全都忘掉。”赫伯特认为,这种做法明显是不合理的,尤其是因为即使占统治地位的宗教,也有很多教义是疑点重重的。教主们还急于诅咒有其他信仰的信徒们下地狱,但我们不应被这些威肋所吓倒。如果我们从严格理性的角度来考察这个问题,就会发现真正的宗教的基础就只在于那五条原则。所以,倘若“任何国家的神学家要你拒绝其他一切信仰,只信他的”,这时,老师认为,这学生就应当回答,这种限制是“专横而不义的”,因为这妨碍了他发现真理。
赫伯特告诉我们,要探求宗教的真谛,就得在这五条原则在一切信仰中出现时把它们发现出来,对那些与此无关的教义则不予理会:
你不妨注意一下流传在异邦人士中的所有虔诚的信条——只要它们也以普遍理性为基础,也包含我们的教会所教导的那种对(道德上)善的生活的观念。然而它们那种不可思议的讲道方式也许会让你产生疑虑。不过,要是所讲的教义被加上了与虔诚和德性不符的东西,或者加上了有可能是教士为谋私利而编造出来的东西,那我就希望你先把它撒开,直到你所受的教诲足以让你分辨数真孰伪以及可信度的大小。
照赫伯特看来,伊斯兰教就是一个明显的例证,说明异国的宗教也反映出这五条原则。当然,也会有一些宗教彻头彻尾是教主们臆造出来的。即便如此,按赫伯特的解释,这些人也并未被神所抛弃。此时,神便另辟蹊径,通过它们的哲学家和立法者来把宗教的真理传播到这些文化中,而这些人是在他们自身以及他们所处的自然界的范围以内发现宗教的那些原则的。
追随赫伯特自然神论观点的英国著作家不乏其人,马修·廷德尔(Matthew Tindal,1657-1733)是其中恶名最著者之一。赫伯特还小心翼翼地避免直接攻击基督教,甚至不提“基督教”这个名称,而廷德尔的说法就没那么拐弯抹角了。他最著名的那部作品,其题目本身就是在发难:《与创世一样古老的基督教,或作为自然宗教之再现的福音书》(Christianity as Old as Creation,or the Gospel,a Republication of the Religion of Noture,1730).这本书里廷德尔认为:基督教的一切要素已经出现在年代要早于《圣经》成书的自然宗教中。赫伯特得出自然神论还要以“天赋观念”为基础,廷德尔采用的则是洛克的更有经验论特点的方法,把人的经验用作论证自然宗教的手段。廷德尔写道:“有了‘自然宗教',我就理解了关于上帝存在的信念,也理解了我们对所担负的那些义务的认识和践履,这一切都来自我们通过理性而获得的(1)关于他和他的完满性的知识;(2)关于我们自身和我们的不完满性的知识;以及(3)关于我们与他以及与其他被造物的关系的知识。于是,自然宗教便把一切建立在理性和事物本性基础上的东西都包括在内了。”在廷德尔看来,基督教的目的应该是把迷信从宗教中清除出去,重新成为一种纯粹的、自然的宗教。要做到这一点,我们就应当服从理性的指导,而不是经书的权威。
法国哲人派
英国自然神论者激进的宗教观在法国后继有人,受到一个名为哲人派(philosophes)的独特的思想家群体的热烈欢迎。他们发表的多是些离经叛道的观点,对有关宗教、政府和道德的传统思想提出挑战。由于相信人的理性是人生最可靠的指导,他们提出:“理性之于哲人,恰如神恩之于基督徒。”那名为《百科全书》(Encyclopedie,1751-1780)的杰作即是以此为主题的,其中包含了一望而知属于哲人派的那些思想。这部宏伟巨著由丹尼斯·狄德罗(Denis Diderot,1713-1784)和让·勒隆·达朗贝尔(Jean Le Rond d'Alembert)主编,到1780年已经出版了35卷。在“百科全书”一章中,狄德罗写道:“只有在一个哲学的时代,人们才会有心去编纂一套百科全书”,原因在于“这样的著作所需要的胆识之大,远非在爱好平庸的年代里所能有的。一切都要毫无例外地、毫不带感情色彩地加以考察、论证和研究。”那些古老的小儿之见应当置之不理,那些羁绊理性的障碍应当打翻在地。狄德罗继续写道:“我们对一个理性时代的需要已非一日,那时人们要探求法则将不再引经据典,而会去考察自然。”《百科全书》的很大部分是关于各门技艺和行当的“怎么做”的条目。这些技术指南到今天当然是不足为奇了,然而在当时的社会,把业内人士喝力保守的绝学秘技公之于众,却堪称革命性的创举。狄德罗写道:“有的时候,工匠们对自己的一身家数守口如瓶,要把它们学到手,最便捷的办法是由自己或者托心腹人出面,去向他们拜师学徒。”狄德罗确信自己对全人类负有责任,应当使那些机巧秘学广为人知,使全世界人民的生活都得以改善。
因为要与审书吏反复周旋,《百科全书》中哲学怀疑论的成分被冲淡了,但这部著作还是立志要与迷信、不宽容以及教条主义进行斗争。不仅如此,许多撰稿人还表达了唯物主义和决定论的世界观,这些观点在他们自己的著作中得到了更充分的论述。
《百科全书》的一位更著名的撰稿人是弗朗索瓦-玛利·阿鲁埃(Frangois-Marie Arout)——人们更为熟知的是他的笔名——伏尔泰(Voltaire,1694-1778)。1765年,他出版了一部名为《哲学辞典》的著作,发展了哲人派的许多伦理和宗教观点。这本书里的一个特别有煽动性的条目是“无神论与自然神论”,该条目批评了无神论,而对自然神论表示赞赏。伏尔泰承认,无神论者多为饱学之士,但他们并不专治哲学,因此他们就创世、恶的起源以及导致他们认为上帝并不存在的其他事情所作的推理都并不高明。不过,伏尔泰认为,导致无神论者否定信仰的,归根到底不是别人,而恰恰是那些宗教信徒们自己,即“那些统治我们灵魂的唯利是图的暴君,他们耍尽花招,令人生厌,使得那些意志不坚者放弃了对上帝的信仰。”这些信徒们想叫我们相信“驴说了话;鱼吞下了一个人,而且三天之后又把他毫发无伤地扔到了岸上;主宰宇宙的上帝会叫一位犹太先知吃下粪便——我们对此也得深信不疑。”伏尔泰声称,这些观点是如此荒诞不经以致令人作呕,也无怪乎那些意志薄弱者会得出结论说上帝并不存在了。但伏尔泰相信上帝确实存在,并且他还认为,相信上帝存在对于文明社会来说实在是至关重要,所以即便真的不存在上帝,那也得造出一个来。他认为,所幸的是,自然本身已经清清楚楚地向我们昭示了上帝的存在。传统的宗教体系是基于对启示的迷信观念的,我们应该加以拒斥,但同时我们也应该接受自然神论的观点。伏尔泰写道,“自然神论者坚决相信有一个既是善的又是强有力的最高存在者,他创造了一切有广延的,能认识、能思想的存在;他使他们的种族得以延续,他膺惩罪恶但不失之于残酷,奖掖德性而必佐之以良善。”要而言之,自然神论就是没有被启示所误导的健全理智,其他宗教虽然本来也是健全理智,但其中已经充斥着迷信。
《百科全书》的另一位重要撰稿人是保尔-亨利·迪特利希(Paul-Henri Dietrich),也就是人们熟知的霍尔巴赫(Barond'Holbach,1723-1789)。他为《百科全书》撰写了376个条目,其中大多是有关科学方面的课题的。在他的《自然的体系》(A System of Nature,l770)和《健全的思想》(Common Sense,1772)两书中,蛋尔巴赫把法国怀疑论哲学推到了极致。霍尔巴赫不同于提倡自然神论的伏尔泰,他彻底否认上帝的存在,认为关于一个神的存在的观念是不可理解的:“我们真能设想自己诚心诚意地相信有那么一个其本来面目我们不得而知,其自身为我们的感官所不能及,其性质我们又绝对无法捉摸的存在物吗?”他认为,宗教是在古时候产生于那些野蛮蒙昧的族群的,后来那些掌权人物发现它是对人们加以控制的便利途径,于是通过制造恐惧心理来加强其威力。于是,宗教信仰就父子相传,代代相袭了:“人的大脑,尤其是幼年时期的大脑,就像一块软蜡,无论压上什么印记,它接受起来都是愉快的。”这样一来,父母的宗教观点也就牢牢地占据了他们子女的心灵。
按霍尔巴赫的看法,自然的真正体系,与各种宗教迷信毫无瓜葛,而完全是物质性的:是那些确定的自然规律在支配着物质的运动和结构。人类也是在地球上事物发展的自然进程中出现的,并且,尽管霍尔巴赫不愿去玄想人类究竟是怎么来的,他仍然坚持认为:人类并没有高于其他生物的特权。所有的生物都是靠着各自物种所特有的“精气”(energies)来生息繁衍的。如果我们人类自以为在自然界占据了一个独一无二的尊荣地位,那不过是由于我们受了无知和自恋的误导而已。
霍尔巴赫认为,我们的物理性的身体和心理性的机能作为自然的产物,也都完全是由物质材料构成的,而关于人的非物质的精神的概念是无法令人理解的。他写道:“像现在这般的关于精神性实在的教条,给出的都是些模糊不清的思想,或者不如说根本毫无思想。这个精神实在除了一个我们的感官决不能让我们对其性质有所认识的实体外,还能让我们想到什么吗?说实在的,我们真能把自己想象成一个既无大小又无组成部分,既要作用于物体,却又与之毫无联系、绝不类似的存在者吗?”一旦认识到我们完全是由物质材料所构成的,很快就能推出:我们的一切行动都是被决定的。我们的每个动作都是产生于自然向它所统辖的万物颁布的不可更易的规律。每个人“的出生都是不经他自己同意的。他的身体组织也不是他自己决定的。他的念头也是不由自主地产生的。他的习惯则是由那些使他产生这些习惯的因素的力量所支配的。他不断地为或显或隐的原因所改变,这些他都无法控制,并且这些决定了他的思维方式,决定了他的行为表现。”于是照霍尔巴赫的看法,我们在生命中的任何一刻都不是自由行动的,要看清这一点,最好是去考察那促使我们产生出某种行为的特定动机:我们总会发现这些动机是我们不能控制的。只是因为个人的能力有限,“无法把他自己这台机器的复杂运动过程分析清楚,才导致有人以为自己是自由的行动者。”
12.2 卢梭
卢梭的生平
当让-雅克·卢梭(Jean-Jacques Rousseau)踏人法国哲人们生气勃勃的思想氛围中时,他所拥有的资历让他看起来在学界将难以立足。然而,尽管卢梭几乎没有受过正规教育,他提出的关于人性的思想却有着动人心魄的力量,最后终于胜过了当时那些最伟大的思想家。
卢梭于1712年出生在日内瓦。他出生才几天,母亲就去世了,10岁那年,当钟表匠的父亲也远走他乡,把卢梭托给姑妈抚养。他先在一所寄宿学校上了两年学,后来他在自传《忏悔录》(Confessions)中说,在这里“我们得把被冠以教育之名的毫无意义的垃圾货色都学个遍”,之后在他12岁时,卢梭被领回到姑妈家里,他所受的正规教育也就到此结束了。后来,他又跟着一个给钟表匣子雕花的工匠学徒,没多久,他就离开了日内瓦到处流浪,途中他遇到的有些人对他施以援手,让他能粗茶淡饭勉强度日,有的则把他引见给那些能指望上的资助人。一路上他读书不辍,并且培养了自己的音乐技能。最后,他漫游到法国,受到一位贵族妇女德·华伦夫人的关照,这位夫人想让他继续接受正规教育,结果以失败告终,于是设法为他安排工作。他干得最久的工作是抄写乐谱,但也在里昂市长德·马布利侯爵那里为他的孩子们当过家庭教师,后来还当过法国驻威尼斯大使的秘书。卢梭早慧,很小就开始读书。到了二十几岁时,他已读了柏拉图、维吉尔、贺拉斯、蒙田、帕斯卡尔、伏尔泰的部分经典著作,这些著作内容宏富,对他的想象力产生了强烈影响。他带着马布利家的介绍停,离开里昂来到巴黎,遇到了一些在京城里最有影响力的人物。在巴黎,富有的贵族和劳苦的工匠,巍峨壮观的大教堂和读着伏尔泰的异端思想的主教,沙龙里的轻快情调和拉辛剧作的悲剧主题——这些鲜明对比都让卢梭铭记在心。尽管他结识了狄德罗等许多名流,出人法国上流社会圈子也愈加频繁,卢梭却一直保持着童年时代的那种腼腆——尤其是对女性,他最后在1746年和一位叫特勒丝·勒瓦瑟尔的没念过书的女仆结成了终身伴侣,并在1768年娶她为妻。
卢梭的著述生涯始于他的获奖论文“论艺术与科学"(Discourse on the Arts and Sciences,1750)。文中他以强烈的情感力量指出,道德腐化是因为科学代替了宗教,因为艺术中的感官快乐,因为文学中的秽淫放荡,因为牺性了情感来鼓吹逻辑。这篇文章让卢梭一举成名,以致狄德罗说“像这样的成功,真是史无前例”。接着在1752年他写了一出歌剧《山村卜者》(Le Devin du village)——此剧曾在枫丹白露宫为国王及其朝臣演出——还有一出喜刷《纳西斯》(Narcisse),在法兰西剧院上演。1755年他有两部重要著作面世,即:《论人间不平等的起源一这种状况是天经地义的吗?》(What Is the Origin of the Inequality among Men,and Is It Authorized by Natural Law?)以及载于《百科全书》中的《论政治经济学》(Discourse on Political Economy)。1761年卢梭出版了一部爱情小说《新爱洛伊丝》(ulie,ou La Nouvelle Heloise),此书跻身18世纪最著名的小说作品之列。他在1762年出版的《爱弥儿》(Emi)一书详尽地提出了一种新的教育方式,其中的“萨伏依牧师关于信仰的忏悔”颇令人为之一振,因为此节即使在极力倡言宗教对人类的重要性之际,仍不忘对教会体制下的宗教予以抨击。同年,卢梭出版了他最负盛名的著作《社会契约论》(ThSocial Contract),在本书中他力图对从“自然状态”发展到文明状态的过程加以描述,并阐明支配着人的那些律则为什么是正当的。
由于健康恶化并罹患妄想症,卢梭的晚年十分不幸。教会和政府当局严厉抨击他的著作,以致下令要“把卢梭逮送到高等法院监狱[the Concierge prison in the Palace(of Justice)]法办。”卢梭成了逃犯,期间曾接受休谟的邀请到英国去拜访他,在英国逗留了16个月。由于感到他的敌人密谋诋毁自己,卢梭又回到了法国。当有人告诉他伏尔泰已在弥留之际的时候,他说:“我们生命是连在一块儿的,我也多活不了几时了。”1778年7月,卢梭逝世,终年66岁。在他身后,出版了他以非凡的坦率写下的详尽自传——《忏悔录》。
学问的悖论
当卢梭读到第戎科学院(the Academy of Dijon)就“艺术与科学的复兴是否有助于敦风化俗”进行征文,并将给最优者颁奖的启事时,想到要做这样一篇文章,他不禁激情澎湃。他在回顾这一刻时说:“只觉有千道璀璨光芒炫我心目。成群结队的鲜活思想涌入我的脑海,强烈有力,又彼此纠结,令我沉浸到一种不可名状的激动中。”他那时已38岁,已经博览了古今典籍;游历了瑞士、意大利和法国;考察了不同文化的模式;在巴黎的社交界也历练有时,但对这个机心重重的社会圈子,他除了蔑视,别无感情。他接着说道,“只要我能把自己所见所感的写出四分之一,那对我们社会制度中的矛盾都会是一个多么鲜明的揭露!”他力图揭示“人的本性是善的,只是我们的社会体制败坏了他”。这最终成了卢梭此后的著作所包含的基本主题。但在此文中,对这个主题的处理还欠准确和清晰,原因在于,就像卢梭白已承认的,“尽管充满了力量和火样的激情,(这第一篇论文)却无疑是逻辑不严、次序凌乱的…是我写的作品中推理最薄弱的一篇。”因此,卢梭的《论艺术和科学》极易招致批评。他那种认为文明导致不幸,研习艺术和科学使社会腐化的议论,也看似不经之谈,殊难令读者接受。
卢梭的论文一开头先对人类理性的成就高唱赞歌,说:“人类任一己之力,一无所傍而卓然鹄立,以理性之光,将人类生而蒙蔽于其中之重重阴霾,尽行驱散一此等景象,真是雄奇瑰美,蔚为壮观。”仅仅几句话之后,他就笔锋一转,开始对艺术、文学和科学大张挞伐了,他说,这些东西“抛掷花环于人类所戴枷锁之上,终致人类”在日常生活中“不堪重负”,而且“窒塞人心,将人类生而追求之本真自由感加以扼杀”。卢梭清楚,人类的本性在过去一点也不比现在更好,但他提出:艺术和科学带来了一些值得注意的变化,这些变化使人们变坏了。卢梭认为,当艺术和文学还没有对我们的行为造成重大影响,还没有让我们的激情学会一种矫揉造作的表达方式的时候,我们的道德尽管粗鲁,却不失自然。而现代的教养使得每个人的言谈举止、穿着打扮都互相雷同,只是追随潮流而不是出自本性,于是我们都不再有勇气以真面目示人。芸芸众生,所作所为都难分彼此,结果我们即使与友人相处,也不知究竞在与何人来往。现今的人际关系充满尔虞我诈,而过去人们彼此一看就透,使得很多恶行止于未发。
卢梭也把攻击的矛头指向奢华之风和那些把政治中的经济层面拿来大讲特讲的政要们。他提醒时人“古之为政者,其言终不离道义与美德二事;今之为政者,舍通商、财利之外无以为辞。”他反对奢华的理由是,奢华能使社会光鲜一时,却决难长久,因为虽然金钱“可致万物,但唯独道德与公民非金钱所能收买。”艺术家与音乐家如果追求奢华,就会把他们的才华降低到一时流俗的水平,以取宠于当下。这就是研习艺术和科学带来的恶果,其时道德再也没有正当的地位,趣味也受到腐化。卢梭谈及了这个问题的一个解决之道,那就是要重视女性的作用,因为“男子之为何状,盖由女子择而使为之。故欲男子高贵有德,必先使女子知灵魂之伟,德性之宏。”但卢梭又说,人们关心的已经不再是一个男子是否诚实,而是他是否机灵,不在于一本书是否有用,而在于它写得好不好。人们对才智不吝奖赏,对美德却不以尊荣加之。
卢梭援引史实来佐证他关于艺术和科学的进步会使道德败坏社会衰朽的观点。他说,埃及乃“哲学和艺术之母;旋即为冈比西斯所征服,后又相继臣服于希腊人、罗马人、阿拉伯人,最终落人土耳其人之手。”与此相似,曾经英雄辈出的希腊,如今“未尝一日无学,未尝一日不美,亦未尝一日不为奴,虽屡历鼎革,所得无非新主代旧主而已。”以此之故,如今在希腊“即使倾狄摩西尼之口才,亦万难令此元气已为奢华与艺术淘尽之身重现生机。”当罗马是一个蛮夫武卒组成的民族时,她开创了一个庞大的帝国,但当她废弛了斯多噶式的纪律,而沉湎于伊壁鸠鲁式的淫乐时,就招致了他国的讥笑,甚至被蛮族所嘲弄。行文到此,卢梭于是把爱国主义尊为至上美德,把对艺术、艺术家、科学和学者都加以排斥的斯巴达作为最理想的国家。
看到卢梭在启蒙运动的高潮中竟然对无知加以褒扬,不免令人大感惊异。但他的意思并不是说哲学和科学毫无价值。他颇有同感地引用了也赞扬过无知的苏格拉底的话雅典的智者、诗人、演说家和艺术家都夸说自己有知识,但他们其实所知甚少,而苏格拉底说:“我至少确知自己无知。”卢梭担心的是,意见相左、众说交难所引起的思想混乱会对伦理和杜会形成威胁。要是让每个人都去形成自已有关道德的思想——甚或哪怕是有关科学真理的思想——势必会造成严重的意见分歧。如果人们发现到处都是不同见解,那么用不了多久,深重的怀疑主义思潮就会在全体人民中泛滥开来。
一个稳定的社会是建立在一套被大多数人奉为思想和行为规范的见解——或称价值观——的基础上的。卢梭认为,有好几个原因使这些为人们所坚信的见解受到了哲学和科学的破坏。一方面,任何社会都是独特的,而其独特性就在于它的一套价值观具有本地的特色。但科学和哲学力图发现普遍真理。对这种普遍真理的追求使得那种带地方性的观点在真理面前相形见绌,权威受损。更有甚者,科学极力要求给出证明过程和证据,而在最至关重要的问题上,主流意见是不可能得到确凿无疑的论证的,因而对人们失去了约束力。此外,科学要求一种怀疑的态度,而这与那种乐于接受某种观点的心态是截然相反的。能凝聚社会的是信仰而不是知识,而科学家和哲学家在对知识的追求中都把信仰搁置起来。这种把信仰束之高阁的做法,如果仅限于少数几人,危害倒还不大,但令卢梭感到不安的是,这种怀疑精神如流布于全体人民,将造成破坏性后果,而它发展到顶点,就成了怀疑主义。从怀疑主义滑向纲常废弛,又不可避免地导致公德削弱,而公德照卢梭的理解,主要就是爱国主义。正是科学精神本身将危及爱国主义,因为科学家极易成为世界主义者,而爱国主义者则对他自己所属的社群怀有强烈的依恋。为了不让社会走向分崩离析,强有力的政府是必不可少的,而这在卢梭看来,将为专制暴政扫清道路。
归根到底,卢梭所非议的,与其说是哲学与科学自身,不如说是在人民中普及这些学科的企图。对培根、笛卡尔和牛顿,他都极为崇敬,认为他们是人类的伟大导师。但是,他说:“人类学术之光荣丰碑,其树立之任,唯少数人可当之。”所以,让某些人专攻艺术和科学是无可非议的。他的矛头所向,是那些为了使知识迎合大众,而不惜对其加以曲解的人,即那些“贸然毁破科学之门,引无能治学之众擅人科学殿堂之编纂家辈。”卢梭说,人们得明白,“自然护佑众民,不使接触科学,犹如为人母者不容伤人利器操于儒子之手。”普通人应该把幸福建立在那些“我们见之于本心”的道理之上。卢梭认为,美德乃是“素朴心灵之崇高科学”,因为真正的哲学就在于“听命于良知。”
社会契约
虽然卢梭把“自然状态”中的自然的人与文明社会中作为公民的人作了比较,但他承认,从前一种情况向后一种情况的转变是如何发生的,他无法予以具体的说明。因而他的《社会契约论》一书不是要描述我们是如何脱离自然状态而转变为政治社会成员的过程,而是要解答这样一个问题:为什么人们应该遵守政府的法律。所以卢梭这本书的开头就是他的这样一句名言:“人生而自由,但无往不在枷锁之中。”他接着说:“这个变化是怎么发生的?我不知道。这个变化为什么是合理的?这才是我认为自己能够回答的问题。”
在自然状态中,人人都活得快乐,这不是因为他们是天使,而是因为每个人都完全是为了他/她自己而活着,故而拥有绝对的独立地位。卢梭拒不接受有关原罪的教义,相反却认为,恶的起源要到人类社会发展的较晚阶段去找。卢梭认为,在自然状态中,人们的所作所为是发自“一种自然情感,这种情感使动物都知道要自我保持,而在人群中,它则受理性和同情心的引导而产生人性和美德。”相反,当人们发明社会契约时,他们也发明了种种恶行,因为现在人们的所作所为是发自“一种在社会中产生的非自然情感,这种情感使得他们都想更充分地成就自己,而超过一切他人”,而且“这种情感在人们当中激起了他们永无休止地加诸彼此的一切邪恶”,其中包括追逐名利的激烈争斗,也包括嫉妒、敌意、虚荣、傲慢和轻侮。归根结底,人不可能离群索居,因为卢梭认为,最初很有可能正是人口的稳定增长使得人们结成社会的。那么,人生而具有的独立性和人们结群而处的必然性将如何协调呢?卢梭认为,问题在于“要找到一种联合的方式,既能举众人之力来保卫每个成员的人身和利益,又能使其中的每个人在与他人联合之际,仍然只服从他自己。”解决这个问题的办法,是“每个成员把他自己连同他的一切权利都完全交给社会全体。”虽然这样的做法表面看来像是要搞专制,但卢梭确信,这是通向自由之路。
“社会契约”的思想似乎意味着:这样一个契约是在历史上的某个时候形成的。卢梭对社会契约并不是从历史角度来看的,因为他承认,无法找到证据来证实发生过这样的历史事件。对他来说,社会契约是活生生的现实,凡是有合法政府的地方就有社会契约。这种发生着效力的社会契约,乃是一个政治联合体赖以奠立的根本原则;这条原则有助于克服绝对放任自流所导致的无法无天的状态,因为人们将自愿地调整自己的行为,以与他人合法的自由权利相谐调。有了社会契约,人们失去了“天然自由”和对一切事物的无限制权利;而他们之所得,则是“公民自由”和对他们所据有的东西的财产权。社会契约的实质照卢梭看来,就在于“我们每个人都一致把自己的人身和全部权力置于公意的最高指导之下,并在我们共同的容纳范围内,把每个成员都接受为一个整体的不可分割的一部分。”社会契约中暗示,任何不服从“公意”的人,社会全体都会强迫他服从之;一句话,“这意味着,他将被强迫而成为自由的。”
公民能“被强迫而自由”,这样说的合理性何在呢?法律归根到底是“公意”的产物,而卢梭认为“公意”是“主权者”的意志。对卢梭来说,“主权者”由特定社会的全体公民组成。于是,主权者的公意就是反映了所有个体公民的意志之总和的单一的意志。公民们的众多意志之所以能被看作一个公意,乃是因为全体人民作为社会契约的各订约方(每个公民都是订约者)都已经同意对自己的行为加以引导以实现公共利益。所有公民出于对自身利益的考虑,都会认识到不应该做出那些会导致他人以自己为敌并伤害自己的行为。这样,所有公民都意识到,他们各白的利益、他们各自的自由都是和公共利益息息相关的。于是,最理想的情况就是,每个个体的意志都与每个其他个体的意志完全是同一的,因为它们都指向同一个目标,即公共利益。由于在这种理想情况下所有个体的意志都是同一的,或者至少是一致的,所以也可以说,这时只存在着一个意志,即公意。因此也可以说,如果法律是产生于主权者的公意的,那么每个个体实际上都是法律的制定者;从这个意义上说,人服从法律就是服从他自己。只有当某些人拒不守法的时候,暴力和强制的因素才会在卢梭的公式中起作用。
卢梭区分了“公意”与“众意”,他说:“在普遍公意与所有人的‘众意'之间往往存在极大的差异。”这两种形式的集体意志的区别在于各自想要实现的目的。如果“众意”的目的和“公意”一样,也是公共利益或正义,那么这两者将并无差别。但卢梭认为,当“众”指的是某个群体中的选民时,“众意”所追求的目标往往会与“公意”不同——哪怕他们碰巧就是大多数。这种背离公意的目的反映的是与公共利益相反的特殊的或私人的利益。这种情形下,社会就不再有“公意”,而是有多少群体或“派别”就有多少种意志。所以,公意要得以表达,国家内部就不能有任何派别或党派集团。卢梭确信,只要人们得到足够的信息并有条件去进行深思熟虑,即便他们彼此并不沟通,每个人都只想自己所想,他们最后也是会达成公意的。他们会选择以实现公共利益或正义为目标的道路,只有实现公共利益才能为实现每个公民最大限度的自由创造条件。
这时,可能会有人作出不遵守法律的选择。如果法律的制定是以公共利益或正义为念,而不是为了实现特殊利益,那法律就确实是表达了公意。投票反对法律或者选择不遵守法律的人就是在犯错误:“如果与我相反的意见因此而压倒了我的意见,那就恰好说明是我错了,说明我本以为是公意的东西其实并不是公意。”提出一项法律叫人们表决,与其说是让人们去决定对这法律是赞成还是反对,不如说是让人们来判断这法律是否与公意也就是公共利益或正义相一致。只有这样看问题,我们才能说“计票而知公意。”只有具备了这些条件,强迫任何人守法才有合理性可言。其实,这些被强迫而守法的人如果准确理解了公共利益的要求是会心甘情愿地服从法律的,因为唯有公共利益的实现能给他们以最大限度的自由。”卢梭认为,惟其如此,说“他们被强迫而自由”才是合理的。
卢梭一点也不幻想在现代世界中能轻而易举地准备好全部条件来制定公正的法律。一方面,他的许多思想反映的是他的故国日内瓦的情况,那是一个小城市,公民们参与政治可以采用较为直接的方式。此外,他的看法中包含某些假设,要求人们得有相当高的德性。如果想要每一个人都守法,那就得让每一个人都有权参与对这些法律的决策。在立法过程中,这些参与决策的人必须超越特殊利益和派别之见,而以公共利益为念。卢梭还认为,所有公民都应该平等地参与立法,法律哪怕由代表来制定也是不行的,因为“即使人们愿意,他们也不可能放弃自己所拥有的这一不可交换的权利。”可是,因为现代社会规模不断增大,结构也日趋复杂——卢梭在他的时代已经看到了这个发展趋势——他提出那些实现正义社会的假设和条件,看来更多地是具有一种理想的色彩而不是能见之于当下的可能性。
整个说来,卢梭的著作抨击了启蒙运动,通过对情感的强调而触发了浪漫主义运动,并为教育提出了新的发展方向。他也鼓舞了法国革命,并在政治哲学中留下了独特影响。伟大的德国哲学家伊曼努尔·康德对卢梭有着深刻印象,将其画像挂在了自己书房的墙上,深信卢梭就是道德领域里的牛顿。
12.3 锐德
锐德的生平
和卢梭一样,苏格兰哲学家托马斯·锐德(Thomas Reid,1710-1796)既是启蒙运动的产儿,同时又是这一运动最严厉的批评者之一。在他进行著述的那个时代,大不列颠的许多最有影响的作家——哲学家、史学家、诗人、散文家——都来自苏格兰:这些作家的高产,使得这个时期被称为“苏格兰启蒙运动”。在不列颠的哲学家中,锐德的影响力仅次于他的苏格兰同胞一大卫•休谟,而且他们二人许多年间一直都保持着友好的书信往来。锐德身兼苏格兰两所著名大学的教授,而他的主要著作都是由他课堂讲授的内容整理而成的。他的哲学有两大最重要的主题,其一是批判性的:笛卡尔以来的哲学越来越走向怀疑主义,甚至到了其主要理论都完全沦为无稽之谈的境地。其二是建设性的:哲学的正当方法是引自理性的常识原则,这些原则是我们与生俱来的,并且塑造了我们心中关于世界的各种观念。随着他的第一部书《根据常识原则对人类心灵的研究》(An Inquiry into the Humanllind,On the Principles of Common Sense,I767)的出版,锐德声名鹊起,并且另外几位苏格兰哲学家也采用了他的方法,由此形成了一个被称为“苏格兰常识哲学”的学派。
对观念论的批判
锐德认为现代哲学的历史呈现出每况愈下的趋势。这一趋势开始于笛卡尔,他出于寻求确定性的需要,而探讨了人格同一性问题。不幸的是,他的解决方法却是先怀疑他自己的存在,然后又试图通过“我思故我在”让自己来个起死回生。但是锐德认为,“一个不相信自己存在的人,就像一个相信自己是玻璃做成的人一样,完全是不可理喻的。”锐德认为,很显然,笛卡尔绝不可能当真怀疑他自己的存在,他的整套论证方法都是站不住脚的。洛克也试图解构人格同一性观念,他认为,我们是通过心灵的记忆机能而在时间中保持我们自身的同一性的。也就是说,今天的我和昨天的我是同一个人,乃是因为我具有对昨天发生的事情的记忆。但在锐德看来,这就意味着每当我忘掉什么事情的时候,我就丧失了人格同一性。贝克莱断言物质客体并不存在,也不可能成为我们心灵中有关外界事物的观念的来源,这就对心灵作了进一步的解构。于是休谟把贝克莱的推理引向了极端的结论,根本否认我们有任何能在时间中持续的实实在在的同一性;照休谟看来,我们的有意识的心灵不过是些转瞬即逝的知觉。然而,锐德指出,休谟自己承认,他无法一面否认自己的人格同一性,一面又在现实世界中生存。
锐德认为,这不仅仅是人格同一性理论的问题。事实上,有依照笛卡尔思路进行的对人类心灵的研究都“不可避免地让人一头栽进怀疑论的深渊。”笛卡尔本人“还没来得及在这一领域进行深究,怀疑主义就已经布置停当,要让他半途而废了。”笛卡尔的方法有一些内在的缺陷使得怀疑主义孕育其中。这问题的根源就在于锐德所说的“观念论”,它误以为我们所感知的不是真实客体的本来面目,而只是得到了对那些客体的心灵影像。假设我看着一把放在我面前的地板上的椅子,那么根据观念论,我真正看到的不是真实的椅子,而是它在我心灵中的一个复本,这复本就好像呈现在我的心灵之眼前的这张椅子的照片。这心象有可能与真实的椅子相似,但根据观念论,它们只是相似而已,我不能把两者混为 一谈。
锐德坚持认为,笛卡尔以来的每个现代哲学家都采取了观念论的立场;甚至休谟也在他的《人类理智研究》中明确地表示赞同观念论,说“除了影像或知觉就再没有别的东西呈现给心灵了,感官不过是这些影像传入的通道。”
这种观念论究竟有什么重大缺陷呢?不管怎么说,它难道不是对两个人为何会对同一事物产生不同感知的最佳解释吗?假设鲍勃和我都在看一个苹果,在我看来,苹果是红色的,在他看来却是蓝色的,那么根据观念论,苹果虽然是同个,我们的心象却由于我们的视觉“摄影机”输入了这苹果的不同图像而各不相同。这个解释看上去很有说服力,但在锐德看来,正是这个假设让我们不可避免地走向了怀疑主义。个中缘由在于,这一理论摧毁了我们接近外部世界的一切途径:我们所知的一切都是我们的心象,而不是客体自身。据称我们只能拥有完全被自己的视觉摄影机所产生的知识,至于任何事物的本来面目——无论是一个苹果、一把椅子,甚至就连我们自身的人格同一性——都是我们没法指望能感知到的。这样一来,我所有的整个现实就不过是一套心灵照片,我对世界所抱有的一切信念都来自对这些照片的比较。无论我们视觉或听觉的“摄影机”拍摄了多少外界事物的“相片”;无论我们的心灵将这些感觉影像进行了多少组合、分解和联结,结果都是一样:我无法说事物本身。我的心灵所构建出的现实就像一座被施了魔法的城堡,与外部世界没有任何联系。因此,我陷人了彻底的怀疑主义。
常识信念与直接实在论
锐德对当时哲学家们的怀疑主义倾向的批评可以用一句话概括:他们违背了由人性所决定的常识信念所指示的真理。锐德写道:
如果正像我所认为的那样,确有一些原则是我们的本质结构使得我们要相信的,并且是我们在日常生活中认为理所当然而无须给出任何理由的,那么这些原则就是我称之为常识原则的东西;而明显违反这些原则的东西,我们就称之为荒谬。
哲学在锐德看来需要与牢牢扎根于我们思维过程中的常识原则相一致。如果在哲学理论中不顾这些原则,那么我们不仅是在赞同不实之词,而且会滑入哲学上的怀疑主义,这会使得我们陷入否认外部世界存在之类的荒谬见解中。
锐德认为,常识在许多方面都对我们的信念加以指导,我们在感官知觉、人格同一性、上帝、自由意志等方面的各种信念都是例证。但锐德的意思不是说我们每个人都有一份清单,上面都是我们可以凭着记忆一一开列出来的经过了精确定义的本能信念。比方说,我们的脑子里并没有细小的声音在念叨着一套套的诸如“外部世界存在”、“看起来是红的东西确实是红的”、“上帝是宇宙的终极原因”之类的倍念。事实上,我们常识信念的知识不是那么容易察觉的。锐德认为,我们首先要考察我们在交谈时所用的语词,因为语言反映了我们日常的思维方式。所以,表明我们拥有常识信念的、主要是这样一个事实.即这些信念在我们自然的说话方式中是根深蒂固的。例如,一切语言都有表示“硬”、“软”、“重”、“轻”等概念的语词,这就说明这些概念是我们人类心灵的固定成分。这不是一个绝对的证明,但不失为一个强有力的证据。锐德坚信,随着我们在语言中把常识信念一个个辨认出来,我们会发现它们彼此之间是相容的。也就是说,如果今天我发现一个常识信念表明“外部世界存在”,我就不会在明天又发现一个信念说“外部世界不存在”。
对锐德来说,常识信念的一个显而易见的好处就在于,有了它就可以打发掉那些骇人听闻的怀疑主义理论。哪怕支持一个怀疑主义理论的推理过程听起来头头是道.我们也得拒斥这一理论,因为它反乎常识。常识信念的第二个好处就是,它们组成了人类心灵运作过程的基本构架,能帮助我们解决困扰了从笛卡尔直到休谟以后的现代哲学家们的那些难题。确切说来,锐德是这样处理我们如何感知外界事物这一哲学难题的:据笛卡尔等人提出的错误理论,感官知觉中涉及三种要素——首先是外界事物,例如一棵树:其次是我关于这棵树的心灵影像或“照片”;最后还有我对这幅照片的觉察——而在锐德看来,我们的常识对知觉的理解只有两个要素,即这棵真实的树和我对这颗树的觉察。这也就是说,我直接感知到其实的树而无须心灵影像作为中介者。所以,当我感知一棵树的形状和颜色的时候,我是在直接觉察这棵真实的树的内在特征。因此,锐德的知觉理论就被称为“直接实在论”。
虽然锐德坚持我们直接感知外界事物的理论,但他意识到,我们并不是毫厘不爽地按照事物的本来面目去感知它们的。比如我看着一棵树并感知树叶的绿时,常识并不会迫使我下结论说:那绿的颜色确确实实就在树本身之内。我知道,我对颜色的知觉依赖于光照条件和许多其他因素。但常识确实会令我不能不相信叶子中确有某种性质使我能将它们感知为绿色的。于是,我对绿色叶子的感知,实际上是对那棵树中能引起我的绿色感觉的性质的直接觉察。
第四部分 近代晚期和19世纪哲学
第十三章 康德
13.1 康德的生平
伊曼努尔·康德(Immanuel Kant,1724-1804)活了80岁,一生都是在东普鲁士的哥尼斯堡城度过的。他的父母都不是有钱人,他们受自虔信派熏陶的宗教精神对康德的思想和个人生活产生了终生影响。他在当地的腓特烈学校开始接受教育,这个学校的校长也是个虔信派教徒。1740年,康德进入哥尼斯堡大学,在这所大学里,他学习了古代经典、物理学和哲学。这一时期德国大学的哲学讲坛被哲学家克里斯蒂安·冯·沃尔夫(Christian von Wolff、1679-1754)所统治,他沿着莱布尼茨理性主义和形而上学的路线发展出了个包罗万象的哲学体系,从而推进了哲学的发展。康德在哥尼斯堡大学的导师马丁·克努真也受到了沃尔夫-莱布尼茨这条哲学路线的影响,所以康德所受的大学教育也就势必非常强调人类理性在形上学领域里按照确定性推进的能力。虽然克努真使康德的早期思想倾向于大陆理性主义的传统,但是,他也激发了康德对牛顿物理学的兴趣,而这种兴趣在康德独创的批判哲学的发展中起了非常重要的作用。在完成了大学学业之后,康德做了将近8年的家庭教师。1755年他成为哥尼斯堡大学的一名讲师,1770年被任命接替克努真的哲学教席。
虽然康德的个人生活中没有任何值得一提的大事件,因为他既没有外出游历过,也没有任何引人注日的社会或政治关系,然而,他的讲师当得是很城功的。他是一个非常风趣、健谈的人,是一个很有魅力的主人。通常他被刻画为一个老单身汉,每一个行动都经过精确的计划,以至于当他每天下午4点半走出他的屋子,在他家附近的小路上来回走上8次时,他的邻居都可以以此来调校他们的钟表了。但是,要不是这样循规蹈矩,他也很难写出一系列出类拔萃的名著,例如他那部不朽的《纯粹理性批判》(Critique of Pure Reason,.1781)、《未来形而上学导论》(Prolegomena to Any Future Metaphysis,l783)、《道德形而上学原理》(Principles of the Metaphysis of Morals,l785)、《自然科学的形而:学基础》(Metaphysical First Principles of Natural Science,1786)、《纯粹理性批判》(第2版,1787)、《实践理性批判》(Critique of片actical Reason,1788)、《判断力批判》(Critique of Judgment,.1790)、《单纯理性限度内的宗教》(Religion within the Limits of Pure Reason,1793),以及小册子《论永久和平》(Perpetual Peace,l795)。
13.2 康德问题的形成
康德对近代哲学进行了一次革命。促成这次革命的是他对同时代的哲学无法成功地处理的个问题的深刻关切。他自己的一句名言提示出了他的问题:“有两样东西,我们愈经常愈持久地加以思索,它们就愈使心灵充满有加无已的景仰和敬畏:这就是我们头顶的星空和心中的道德法侧。”对他而言,头顶的星空提醒我们,这个世界如同早先被霍布斯和牛顿所刻画的,是一个处于运动中的物体组成的系统。同时,所有人都体会到道德责任感,这暗示人类不同于自然的其他要素,它在其行动中拥有自由。因此,问题就在于如何调解对事情的两个似乎相互矛盾的解释——一个解释认为所有事件都是必然性的产物,另一个则认为在人类行为的某些方面存在着自由。
当康德考察科学思想的发展趋势时,他在其中看到了一种想要囊括全体实在的企图,想要将人类本性囊括在其机械模式中,这将意味着所有事物都只是一个统一的机械装置的一部分,都可以根据因果性得到解释。此外,这一科学的方法将把任何不适于其方法的元素排除出考虑之列。科学的方法非常强调将知识限制在实际的感性经验领域,限制于对可以通过这些经验归纳出来的东西的概括。遵循着这一方法,科学将无须自由和上帝这样的概念,也无须解释这样的概念。
科学知识的显著成功和持续进步给康德留下了深刻的印象。在康德看来,牛顿物理学的成功,引起了关系到他那个时代哲学的适当性的一些严重的问题。他那个时代的两个主要传统是大陆理性主义和英国经验主义,而牛顿的物理学却独立于这两个哲学体系。因为大陆理性主义建基于数学模式之上,所以这种哲学强调观念相互之间的关系,因此与事物实际的情况没有什么明确的联系。理性主义不能够产生牛顿物理学所表述的知识,而由于这一原因,它对超经验的实在的形而上学思辨就被认为是独断的。康德谈到克里斯蒂安·冯·沃尔夫(他的菜布尼茨式形而上学影响了康德的早期思想)时说,他是“最大的独断论哲学家”。理性主义和科学之间这种鲜明的对照向康德提出了一个问题,形而上学能否像科学那样增加我们的知识?通过形而上学家们在其各自的思想体系中得出的结论的多样性,例如笛卡尔、斯宾诺莎和莱布尼茨之间的差异,形而上学的独断论特性很清楚地表现了出来。但是问题的核心在于,科学家们在揭示实在的本质的同时,却越来越少关注于自由、上帝和道德真理的可能性这样一些形而上学的概念。
同时,科学的进展也独立于康德时代的另一个哲学传统,即英国经验主义。休谟最惊人的哲学论证是对传统因果性观念的攻击。既然我们所有的知识都来白于经验,而我们又并没有经验到因果性,因此我们就不能够从自己当下的经验中推断或者预言任何未来将发生的事件。休谟说,我们所谓因果性的东西,仅仅是由于我们经验到两个事件的共同发生,就将它们联结在一起的一种习惯,但是这并没有证明这些事件之间有任何必然关联的结论。因此休谟否定归纳推理。然而,科学正是建立在因果性观念和归纳推理的基础上的。因为它假定,我们关于当下特殊事件的知识给予了我们关于未来大量类似事件的可靠知 识,休谟经验主义的逻辑结论就是,不存在任何科学的知识,而这就导致了哲学上的怀疑论。因此,康德对于科学抱有极大的崇敬,却由于理性主义的独断论和经验主义的怀疑论而面对着哲学上的严重问题。
虽然牛顿物理学给康德留下了深刻的印象,但科学自身也为他提出了两个主要的问题,第一个问题我们前面已经提到过,就是科学方法被应用于对全体实在的研究时,道德、自由和上帝这些观念就有被纳入一个机械宇宙中的危险。科学向康德提出的第二个问题是如何解释,或者说如何说明科学知识的合理性。就是说,科学家就“什么使他对自然的理解成为可能”这问题给出允分的解释了吗?最终人们可以看到,这两个问题是密切相关的。正如康德所发现的,科学知识和形而上学知识是很相似的,因此,对于科学思想的证明或解释和对有关自由及道德的形而上学思想的证明或解释就是同一的。于是康德拯救了形而上学,而又没有攻击科学。不论是在科学中还是在形而上学中,我们的心灵都从某种给定事实出发,这种事实在我们的理性中产生了一个判断。因此,康德说,“形而上学真正的方法和牛顿引入自然科学并在其中产生了累累硕果的方法,从根本上说是一样的。”通过对科学和道德思想的这一解释,康德给了哲学一种新的功能和新的生命。康德的主要著作《纯粹理性批判》这一书名就暗示了这一功能,因为哲学现在的任务变成了对人类理性能力进行批判性的评价。在履行这新的批判功能时,康德完成了他所谓哲学中的哥白尼革命。
13.3 康德的批判哲学和他的哥白尼革命
康德思想发展的转折点是他和休谟怀疑主义的遭遇。他告诉我们,“我坦率地承认,是休谟的意见在许多年前首先打破了我独断论的迷梦,并且给我对思辨哲学的研究中指出了一个完全不同的方向。”休谟认为,我们所有的知识都源于经验,因此,我们不能够拥有关于任何超出我们经验的实在的知识。这一论点正击中了理性主义的基础。理性主义者自信地认为,人类理性可以像人们在数学中所做的那样,仅仅通过从一个观念推进到另一个观念,就能得出关于超出经验的实在的知识。理性主义者对上帝存在的证明就是一个能说明问题的例子,斯宾诺莎和莱布尼茨对于实在的结构的解释则是另外一个这样的例子。康德最终抛弃了理性主义者的形而上学,他称之为“腐朽的独断论”,但是他也没有接受休谟的全部论点,他说,“我对他可远没有言听计从到同意他所达到的那些结论的地步。”
康德拒绝全盘遵循休谟的道路,这不仅仅是因为它将导致怀疑主义,而且还因为康德觉得,虽然休谟的思路是对的,但是他并没有完成解释我们如何获得知识这一任务。康德也不希望放弃与理性主义形而上学相关的一些主题,如自由、上帝,对于这些我们是不可能“漠不关心”的,虽然他会说,我们不能够拥有关于超出我们经验的对象的演证的知识。所以,康德就试图吸收他认为的理性主义和经验主义中有意义的东西,而拒斥这些系统中那些不能够得到辩护的东西。他并不是仅仅将他的前辈们的洞见结合起来,而是踏上了一条他称之为“批判哲学”的崭新道路。
批判哲学的方法
康德的批判哲学包括对人类理性构成要素的分析,他这个分析是指“根据所有独立于任何经验可以努力达到的知识而对理性能力进行的一个批判性的探究”。因此,批判哲学的方法就是追问这样一个问题:“独立于任何经验,知性和理性能够认识什么,又能够认识多少?”以前的形而上学家们不断地就最高存在者之本性以及其他带着他们超越直接经验领域的主题进行一场场争论。而康德追问的则是这样一个根本问题:人类理性是否具有从事这样一个探究的能力?站在这一立场上,康德认为,形而上学家们在还没有确定我们是否单凭纯粹理性就能够把握没有在经验中给予我们的东西之前,就想建立起知识的体系,这是非常愚蠢的。因此,对康德而言,批判哲学并非是对形而上学的否定,而是对它的预备。如果形而上学与理性独自建立起来的——即先于经验的,或先天的——知识有关,那么关键的问题就在于,这样的先天知识是如何可能的?
先天知识的本质
康德肯定我们拥有一种能够无须诉诸任何经验就可以获得知识的能力。在下面这一点上他赞同经验主义者,即我们的知识始于经验,但是他补充说,“虽然我们的一切知识都开始于经验,它却并不因此就都来源于经验。”而这一点正是休谟所忽略的,因为休谟说过,我们的一切知识都是由一系列的印象组成的,这些印象是我们通过我们的感官而获得的。然而我们显然拥有一种不来源于经验的知识,即便它也是开始于经验的。例如,我们并没有经验和感受到因果性,在这一点上:休谟是正确的。但是康德不同意休谟把因果性仅仅解释为将我们称为原因和结果的两个事件联系起来的心理习惯。相反,康德相信我们拥有关于因果性的知识,而且我们不是从感性经验中而是直接从理性判断的能力中,因此是先天地获得这一知识的。
更明确地说,什么是先天知识?康德回答道,“如果我们想要从科学中举出一个例子,那么我们只要看看数学中的任何一个命题,如果我们想要从知性最普通的运作中举一个例子,那么‘每一个变化都必须有一个原因'这一命题就可以满足我们的目的。”是什么使得一个数学命题,或者“一切变化皆有原因”这个命题成为先天知识的?康德说,这是由于这种知识不能够由经验推导出来。经验不能够向我们表明每一个变化都必有一个原因,因为我们还没有经验到每一个变化,经验也不能够向我们表明事件之间的关联是必然的;经验惟一能告诉我们的是“一个事件是这样的,但是不能够告诉我们它不能是别样的”。因此,经验不能够给予我们关于必然性关联或命题之普遍性的知识。但是,事实上我们拥有这种因果性和普遍性的知识,因为这些正是刻画数学和科学知识之特性的概念。我们自信地说,所有有重量的东西在空间中都会下落,或者5加7在所有情况下都等于12。存在着这样的先天知识,这是很明显的,不过康德所关心的是这样的知识如何能够得到解释。简言之,我们如何回应休谟的怀疑主义?不过这不仅仅是一个先天知识如何可能的问题,而是一个“先天综合判断”如何可能的问题。要回答这一问题,康德得先搞清楚是什么构成了一个先天综合判断。
先天综合判断
康德区分了两种判断:分析的判断和综合的判断。他说,一个判断是我们借以将主词和谓词联结起来的思想活动,在这里,谓词以某种方式规定了主词。当我说“那座建筑物很高”时,我们就作了一个判断,因为心灵能够理解主词和谓词之间的一个联结。主词和谓词的联结方式有两种,因此我们作出的判断也有两种。
在分析判断中,谓词已经被包含在主词的概念之中了。“所有三角形都有三个角”这一判断就是一个分析判断。因为谓词已经被暗含在一个分析判断的主词中了,所以这个谓词并没有给予我们关于这个主词的任何新知识。再举一个例子,“所有物体都是有广延的”这个判断是分析的.因为“广延”的概念已经被包含在“物体”这一概念中。一个分析判断之所以是真的,仅仅是由于主词和谓词的逻辑关系。否认一个分析判断将陷人逻辑矛盾。
一个综合判断不同于分析判断之处在于,它的谓词并没有被包含在主词之中。因此在一个综合判断中谓词对主词的概念增加了一些新的东西。说“苹果是红的”,就将两个独立的概念连接了起来,因为“苹果”这一概念并没有包含“红”这一概念。同样,康德认为,“所有物体都是有重量的”也是一个综合判断的例子,因为重量这一概念并没有被包含在物体这一概念中,就是说,谓词并没有被包含在主词之中。
在此康德进行了进一步的区分,这一次是在先天判断与后天判断之间作出的区分。所有的分析判断都是先天的:它们的意义并不依赖于我们对任何特定情况或事件的经验,因为它就像在数学中那样,不依赖于任何观察。由于“必然性和严格的普遍性是先天知识的可靠标志”,康德毫无困难地指明分析判断表述了先天知识。另一方面,综合判断绝大部分都是后天的;就是说它们是在一个经验观察之后产生的。例如,说X校所有的男生都是6英尺高,这就是一个后天综合判断,因为这个关于他们身高的命题是偶然的,它对于所有当前或未来那个学校的成员来说并不必然是真的。没有关于这个学校特定细节的经验是不能作出这一判断的。因此,所有的分析判断都是先天的,而绝大多数综合判断则是后天的。
然而,在先天分析判断和后天综合判断之外,还存在着另外一种判断,这就是先天综合判断。这是康德最关心的一种判断,因为他确信我们作着这种判断,然而始终存在一个问题:这样的判断是如何可能的?这一问题之所以产生,是因为综合判断被定义为是建基于经验的,如果情况是这样的话,它们又如何能被称为先天的呢——因为先天暗示了它不依赖于经验?不过康德指出,在数学、物理学、伦理学和形而上学中,我们的确在作着一些不仅是先天的而且是综合的判断。例如,7加5等于12这一判断,当然是先天的,因为它包含着必然性和普遍性的标志;就是说,7加5必定等于12,而且总是等于12。同时,这一判断又是综合的而非分析的,因为通过对7和5这两个数字的单纯分析并不能够得出12。为了达到7、5和“加”这些概念的综合,直观行为是必须的。
康德表明,在几何学的命题中,虽然主词和谓词间有着一个必然的、普遍的关联,但是谓词也没有被包含在主词中。因此几何命题就既是先天的义是综合的。例如,康德说,“两点之间直线最短,就是一个综合命题。因为直线的概念并没有包含任何量的概念,而仅仅是质的概念,最短这个概念因此完全是加上去的一个东西,它不能够通过对直线概念的任何分析得出。因此在这里必须借助于直观,只有凭借直观这一综合才是可能的。”在物理学中我们也发现了先天综合判断;康德说,“自然科学在其自身中包含了先天综合判断作为原侧。”“在物质世界的所有变化中,物质的总量保持不变”这一命题是先天的,因为我们在经验所有变化之前就作出了这一判断,它也是综合的,因为永恒这一概念在物质概念中是发现不了的。在形而上学中,我们认为我们扩展或增加了自己的知识。如果情况是这样的话,那么诸如“人类可以自由作出选择”这样一些形而上学的命题,就必定是综合的,因为这里谓问给主词概念增加了新的知识。同时这一形而上学判断也是先天的,因为自由这一 谓词甚至在我们经验到所有人之前就和所有人的概念相关联。
康德通过这些例子想要指出的是,我们不仅在形而上学中,而且在数学和物理学中都作着先天综合判断。如果这些判断在形而上学中产生了困难.它们在数学和物理学中也会产生同样的闲难。因此康德相信,如果先天综合判断可以在数学和物理学中得到解释和证明,那么它们也会在形而上学中得到证明。
康德的哥白尼革命
通过在心灵与其对象的关系上采用一个新假说取代以往的假说,康德解决了先天综合判断的问题。在他看来,很显然,如果我们如同休谟那样假设心灵在形成它的概念时必定符合它的对象,那么这一问题就是无法解决的。休谟的理论仅仅对我们实际经验到的事物的观念有效,但是这些都是后天的判断。如果我问,“我是如何知道椅子是棕色的呢?”我的问答是我能够看到它;如果我的断言受到了质疑,我将诉诸于我的经验。因此,当我诉诸于我的经验时,就解决了这个问题,因为我们都同意经验给予了我们一种符合事物的本性的知识。但是一个先天综合判断不能够通过经验被确证:例如,如果我说,两点之间直线最短,我当然不能够说我已经经验到了每一条可能的直线。是什么使我在事件发生之前,就能够作出普遍真的、总是可以被证实的判断?如果心灵如同休谟所相信的那样是被动的,仅仅从对象接受信息,那么心灵将只会拥有关于那个特定对象的信息。但是心灵作出的判断是关于所有对象的,甚至是那些它还没有经验到的对象,而且对象事实上在未来的活动的确是与这些判断一致的。这种科学知识为我们提供了关于事物之本性的可靠信息。但是,由于这一知识既是综合的又是先天的,它不能够由心灵符合对象这一假设得到解释。康德不得不尝试在心灵和对象关系上提出一个新假说。
根据康德的新假说,是对象符合心灵的运作,而不是相反。他有意识地仿照哥白尼的例子,以一种实验的精神达到这一假设。哥白尼在“假定全部星体周绕观测者旋转时,对天体运动的解释无法令人满意地进行下去,于是他试着让观测者自己旋转,而让星体停留在静止中,看这样是否有可能取得更好的成绩。”康德看到了哥白尼和他月己的问题有某种相似性,他说:
向来人们都认为,我们的一切知识都必须符合对象;但是在这个假定下,想要通过概念先天地构成有关这些对象的东西以扩展我们的知识的一切尝试都失败了。因此我们不妨试试,当我们假定我们的对象必须符合我们的知识时,我们在形而上学的任务中是否会有更好的进展…如果直观必须依照对象的性状,那么我就看不出来,我们如何能先天地对对象有所认识;但是如果对象(作为感宫的客体)必须依照我们直观能力的性状,那么我倒是完全可以想象这种可能性。
康德的意思并不是说心灵创造对象,也不是说心灵拥有天赋的观念,他的哥白尼革命毋宁说在于心灵给其所经验的对象带去一些东西。康德在如下一点上是同意休谟的,即我们的知识开始于经验,但不同于休谟的是,康德将心灵看作一种主动的力量,对它所经验到的对象有着作用。康德说,心灵构造就是如此,它将自己认知对象的方式加于它的对象之上。心灵由于其本质,主动地整理我们的经验。这就是说,思维不仅包括通过我们的感官接受印象,而且也包括对我们所经验到的东西作判断。如同一个戴着有色眼镜的人看到的每一个东西都具有这种颜色,每一个有着思维机能的人,都不避免地按照心灵的自然构造来思考事物。
13.4 理性思想的结构
康德说,“人类知识有着两个来源,它们或许都来源于一个共同的但不为我们所知的根源,它们就是感性和知性。通过前者,对象被给予我们;通过后者,它们被思想。”因此,知识就是认知者和认知对象共同作用的事情。但是,虽然我可以将作为一个认知者的我自己和认知对象区分开来,我却永远也不能知道事物自身是怎样的,因为当我认知它的时候,我仅仅是按照我有着特定结构的心灵允许的那样认知它。如果有色眼镜永远戴在我的眼腈上,我将水远透过那种颜色去看事物,永远无法摆脱那些镜片给我的视觉施加的限制。同样,我的心灵总是将思想的特定方式带给事物,而这总是会影响我对它们的理解。心灵将什么带给了那给定的、未经加工的经验材料呢?
思想范畴和直观形式
心灵独特的活动是综合并统一我们的经验。它完成这个统一首先是给各种各样处于“感性杂多”中的经验加上特定的直观形式,即空间和时间。我们不可避免地将事物知觉为存在于空间和时间中。但是空间和时间不是由我们所经验到的事物推导出来的观念,它们也不是概念。空间和时间是在直观中直接遭遇到的,同时它们又是先天的,打个比方,它们就像透镜,我们总是透过它们才看到经验对象的。
除了专门和感知事物的方式发生关系的空间和时间外,还有一些思想范畴,它们更加专门地处理心灵统一或综合我们经验的方式。心灵通过在我们从事于解释感性世界的活动时作出各种各样的判断来完成这一统一活动。我们凭借某些固定的概念形式如“量”、“质”、“关系”和“模态”等而对我们各种各样的经验或者说“经验杂多”作出判断,当我们断言“量”的时候,我们在头脑中想的是一或者多;当我们作出一个质的判断时,我们作的是一个要么肯定要么否定的陈述;当我们作出一个关系判断时,我们所考虑的一方面是原因和结果,另外一方面是主词和谓词的关系;而当我们作出一个模态判断的时候,我们头脑中所考虑的是某些事物或者是可能的或者是不可能的。所有这些思想的方式就是构成综合的行为,通过这些行为心灵从感性印象的杂多中建立了一个一致的单一世界。
自我和经验的统一
是什么使我们对周围世界的一个统一把握成为可能?在分析我们的心灵活动方式的基础上,康德回答说,是心灵把给予我们感官的未经加工整理的材料转变为一个一贯的相互联系的要素集合。这使得康德说,我们经验的统一必定暗示了自我的统一,因为除非在心灵的诸活动之间存在着一个统一,否则不可能有经验知识。要想拥有这样的知识,就需要处于不同次序中的感性、想象、记忆及直观综合的能力。因此,必定是同一个自我感知一个对象,记住它的特性,并加之以空间和时间形式以及因果范畴。所有这些活动必定发生在某个单一的主体中。否则就不存在知识,因为如果一个主体只拥有感性,另外一个只拥有记忆…像这样的话,感性杂多就不可能被统一。
完成这个统一活动的单一主体在哪里?它又是什么呢?康德称之为“统觉的先验统一”——我们称之为“自我”。他使用“先验的”这一术语是指,即使这样一个统一或自我通过我们实际的经验得到了暗示,我们也不能够直接地经验到它。于是,这个自我的观念就是我们拥有的关于统一的自然界的知识的一个先天的必要条件。在统一经验的所有要素这个活动中,我们意识到自己的统一,这样我们对于一个统一的经验世界的意识和我们自己的自我意识就同时发生了。然而,我们的自我意识也受到了影响着我们对外部世界的知觉的同一机能的影响。我将同样的一套构件带到了关于自我的知识中,因此,我用同样的“透镜”来看作为知识对象的自我。正如我不知道事物离开了感知形式会是什么样子,我也不知道这个“统觉的先验统一”的本质,而只能说我意识到我拥有对经验领域的统一性的知识。我所能确信的是,任何经验知识都暗示着一个统一的自我。
现象实在和本体实在
康德批判哲学的一个主要方面就在于他坚持认为人类知识永远被限制在它自己的范围内。这一限制有两种形式。首先,知识被限制于经验世界。其次,我们的知识被自己的知觉能力和组织经验原材料的思想方式所限制。康德毫不怀疑:向我们所呈现的世界并不是最终的实在。他在现象实在(我们所经验到的世界)和本体实在(纯粹理智的,即非感性的实在)之间作出区分。在我们经验一个东西的时候,我们不可避免地是通过我们思想的先天范畴“透镜”知觉它的。但是,当一个东西未被知觉时,它是什么样子呢?物自体是什么?很明显,我们永远也不能拥有一个非感性的知觉经验。我们所认识的所有对象都是感性的对象。然而,我们知道我们经验世界的存在不是心灵的产物。毋宁说,心灵把它的观念加于经验杂多之上,这些经验杂多源于物自体世界。这意味着存在着一个外在于我们并且不依赖于我们的实在,而我们只知道它向我们所呈现的,以及被我们整理之后的样子。一个物自体的概念并没有增加我们的知识,而只是提醒我们知识的界限。
作为调节性概念的纯粹理性的先验理念
除了本体领域这一一般概念之外,还有三个调节性理念是我们倾向于加以思考的,它们引导我们超越感性经验,但由于我们不可避免的想要统一所有经验的倾向,我们不可能对它们无动于衷。它们是自我、宇宙和上帝的理念。它们是先验的,因为在我的经验中没有相应的对象。它们不是由直观,而是由纯粹理性单独产生的,然而在如下的意义上它们也是被经验所激发的:我们在对我们的经验完成一个综合的尝试中思考到这些理念。康德说,
“第一个(调节性的)理念是‘我'本身,它被仅仅看作思考着的本质或灵魂…尽可能地将存在于一个单一的个体中的所有规定性、所有力量,表象为源于一个单一的基础,将所有的变化都表象为属于同一个永恒存在的不同状态,将空间中的所有现象都表现为完全不同于思想活动的东西。”
我们的纯粹理性以这种方式试图将我们所意识到的各种各样的心理活动综合成一个统一体,它通过形成自我这一理念而做到这一点。与此类似,纯粹理性通过形成世界理念,试图产生经验中的诸多事件的一个综合。这样,
纯粹思辨理性的第二个调节性理念是一般的世界理念…诸条件序列的绝对整体…一个在理性的经验运用中永远也不能被完全认识的理念,但是它作为一个规定了我们在处理这样的序列时应该如何继续进行的规则而起作用…宇宙论的理念不是别的,它仅仅是调节性的原则,它远远不是…这种序列的一个实际的整体。
康德继续说,
纯粹理性的第三个理念包含着一个对作为宇宙中所有序列惟一充足的原因的存在者的相应假定,这就是上帝理念。我们没有任何根据绝对地假定这个理念的对象…很明显,这样一个存在者的理念就像所有的思辨理念一样,只是阐明了理性的要求,世界中的所有联系都是根据这些综合统一的原则而得到考察的——似乎所有这些联系都源于一个单一的无所不包的存在者,它就是最高的充足的原因。
康德对这些调节性理念的运用就是他调和独断的理性主义和怀疑的经验主义的例子。康德同意经验主义者们的如下看法,我们不能够拥有关于超越了经验的实在的知识。自我、宇宙和上帝的理念不能够给予我们任何关于相应于这些理念的实在的理论知识。这些理念的功能仅仅是调节性的。作为调节性的理念,它们为我们提供了一个处理形而上学中一直不断重现的那个问题的合理方式。在这一限度内,康德承认理性主义主题的有效性。但是,他对人类理性范围的批判分析使他发现以前的理性主义者错误地将先验理念当作有关现实存在的观念来进行处理。康德强调,“在作为一个对象而绝对地给予我的理性的东西与仅仅作为观念中的对象而给予我的理性的东西之间有着巨大的差别。在前一种情况下,我们的概念被用来规定(超验的)对象:在后一种情况下,只有一个图型,它不对应于任何直接被给予的哪怕是假定的对象,甚至一个假定的对象,它只是使我们能够以一种间接的方式,即通过它们与这个理念的关系而将其他对象在其系统统一中呈现给我们自己。于是我说,最高理智的概念仅仅是一个(先验的)理念。”
二律背反和理性的限度
因为调节性的理念没有指向任何我们能对之拥有知识的客观实在,所以我们必须将这些理念看作纯粹理性的产物。因而我们不能够将时间、空间或因果范畴这些先天形式运用于这些理念,因为它们只能被运用于感性经验的杂多。科学之所以可能,是因为所有人都拥有同样的心灵结构,都会时时处处以同样的方式来整理感性经验事物。就是说,我们都同样地将相同的知性整理能力加于被给予的感性经验之上。但是并不存在形而上学的科学,因为当我们考虑自我、宇宙和上帝理念时,并没有当我们考虑“两点之间最短距离”时那样的被给予之物。在形而上学中被给予的是想要完成对经验中各种极为不同的事件的综合的一种被感到需要,要不断将这些各种各样的事件综合于一个更高的水平,不断发现现象领域的一个更普遍的解释。
对康德而言,先天的或理论的科学知识与思辨的形而上学之间存在着一个区别。这就是我们能够拥有关于现象的科学知识,但是不能够拥有关于本体领域的科学知识,或者说,我们不能够拥有关于超验领域的知识。康德认为,我们想要完成一个形而上学的“科学”的企图注定是要失败的。我们试图讨论自我、宇宙或者上帝,仿佛它们是经验对象一样,但是心灵对这一点的绝对无能为力通过我们所陷入的康德所谓“二律背反”表现了出来。这四个二律背反向我们表明,当我们超越了经验探讨世界的本质时,我们可以用同等有力的论证来证明不同命题的两个相反方面,具体来说,即:(1)世界在时间和空间上是有限的,或者它是无限的;(2)每一个复合的实体都是由单纯的部分构成的,或者在世界上没有什么复合的东西是由单纯的东西构成的;(3)除了根据自然律的因果性之外,还存在着另外一种因果性即自由,或者不存在自由,因为世界中每一个事物都只是根据自然规律而发生的;(4)存在着一个绝对必然的存在者,作为世界之部分或作为它的原因,或者一个绝对必然的存在者在任何地方都是不存在的。
这些二律背反反映了由独断论的形而上学产生的不一致。这种不一致的发生仅仅是因为它们基于“无意义”的东西——就是说,它们想要对一个我们没有而且不可能拥有感性经验的实在进行描述。但是康德相信这些二律背反也有积极的价值。尤其是它们为下面的说法提供了一个额外证明:时空世界只是现象世界,在这个世界里,自由是一个无矛盾的一贯的理念。这是因为如果世界是一个物自体,那么它在广延和可分性上就要么是有限的,要么是无限的。但是二律背反指出,对于这两个命题的对错没有任何演证的证据。在这个意义上,因为世界仅仅是现象的,所以我们就有理由对道德自由和人类责任加以肯定。
作为调节性的理念,自我、世界和上帝的理念有一个合法的功能,它们帮助我们综合自己的经验。而谈论一个本体的领域或者物自体的领域,也是对某些被给予的经验和我们思想的倾向作出的反应。由于这一原因,我们可以以两种不同的方式来思考一个人:作为一个现象的人和作为一个本体的人。作为一个现象的人,他可以被作为一个处在时空以及因果背景之中的存在者来进行科学的研究。同时,我们道德责任的经验也暗示了,一个人的本体本质——他超越于我们对他的感性知觉之外的样子——的特点是自由。在这一情况下,自由概念如同自我或上帝概念,是一个调节性的理念。对于人是自由的或上帝是存在的,永远也不会有任何演证的证据,因为这些理念让我们去超越我们的感性经验,在那里心灵的诸范畴没有任何材料可以进行加工。
上帝存在的证明
有了这个对人类理性能力和范围的批判性评价,康德不可避免地要拒斥对于上帝存在的传统证明,即本体论的、字宙论的和目的论的证明。他反对本体论的证明的论证是,它只是在操弄语词。这一证明的本质就是断言,既然我们拥有最完善的存在的观念,那么,如果否认这样一个存在者的存在就会导致矛盾。这种否认之所以会是矛盾的,是因为一个完善的存在者的概念必定包含着“存在”这一谓词。也就是说,一个不存在的存在者很难被认为是一个完善的存在者。但是康德论证说,这一推理的过程“源于判断而不是源于事物和它们的存在”,上帝观念仅仅是通过把“存在”包括在一个完善的存在者的概念中的这个方式而简单地形成的概念,由此它断言上帝概念具有存在这一谓词。这一论证丝毫没有表明为什么我们必然拥有上帝这个主词。如果一个完善的存在者的确存在,而我们拒斥这样一个存在者的全能,那会导致矛盾。但是,我们通过同意一个最高的存在者的全能而避免这一矛盾,其自身并没有表明这样一个存在者的存在。此外,否认上帝的存在并不仅仅是否认一个谓词,而是抛弃这一主词从而也抛弃所有伴随它的谓词,“如果我们同样地取消主词和谓词,就没有什么矛盾了;因为再没有什么东西能够与之相矛盾了。”因此,康德概括说,“笛卡尔派(本体论的)对最高存在者存在的著名论证所作的艰辛劳作都是徒劳的。一个人希望通过单纯理念来丰富自已的知识,就如同一个商人希望通过在自己的账本上添加一些零来增加自己的财富一样不可能。”
本体论的证明从一个(完善的存在者的)观念开始,而宇宙论的证明“以经验为立足点”。因为它说,“我存在,因此一个绝对的必然存在者存在”,这是基于如下设定:如果任何东西存在的话,那么一个绝对的存在者也必然存在。根据康德的看法,这一论证的错误在于,虽然它是从经验开始的,但是很快它就超越了经验。在感性经验的领域,为每个事件推导出一个原因是合法的,但是,“因果性的原则除在可感世界中外,其应用都是没有意义、没有标准的”。这里是康德批判方法的一个直接运用,因为他论证说,我们不能够运用心灵的先天范畴来尝试描述超越感性经验的实在。因而宇宙论的证明并不能成功地将我们导向一个所有事物的第一原因,我们从自己对事物的经验中能够得出的充其量也只是一个调节性的上帝理念。事实上是否真有这样一个存在者、一个所有偶然事物的根据,这引起了和通过本体论的证明所引起的同样一个问题,即我们是否能够成功地跨越我们的一个完善存在者的观念和它存在的演证的证据之间的鸿沟。
同样,目的论的证明从一个很有说服力的东西开始,因为它说,“在世界中我们到处都可以发现根据一个确定的目的而安排的迹象…如果不同的事物没有被一个与潜在的理念相符合的安排的理性原则所选择和设计,它们自身不可能以如此多样的方式协同运作,从而实现确定的最终目的。”康德对于这一论证的回答是,我们对宇宙中秩序的经验很有可能暗示了一个安排者,但是世界中的秩序并没有证明世界的物质材料没有这个安排者就不存在。这一论证从设计能证明的最多只是“一个总是被自己劳作的物质材料绊手绊脚的建筑师,而不是一个让所有事物都服从于他的观念的创世者”。要证明一个创造者的存在,这会把我们引回宇宙论的证明及其因果性观念。但是既然我们不能够将因果性范畴作超越经验事物的运用,我们就只剩下了一个第一原因或者创造者的观念,这就将我们带回到本体论的证明,但它是无效的。所以康德的结论是,我们不能够使用先验观念或理论原则来证明上帝的存在,它们不能运用于超越感性经验的领域。
然而,康德对“诸论证”批判性评论的结果必然是,我们不能够证明上帝存在,同样也不能够证明上帝不存在。仅仅通过纯粹理性,我们既不能够证明,也不能够否证上帝的存在。因此如果上帝的存在不能够被理论理性有效处理,那么理性的某些其他方面就必定会被认为是上帝理念的源泉。这样,上帝的理念在康德的哲学中就还是有其重要性的,其他 的调节性理念也一样。
13.5 实践理性
除了“头顶的星空”之外,使康德充满惊奇的还有“心中的道德律”。他意识到,人类不仅注视着一个事物的世界,而且也是行动世界中的参与者。因而理性交替地关注关于事物的理论和实践行为——即道德行为。但是康德说,“最终只有同一个理性,它根据其运用被区分开来”,理性的目标,“第一个是理论理性知识,第二个是实践理性知识”。康德解释纯粹理论理性范围和能力的方式使他对实践理性的解释成为可能。
在康德的时代,科学思想的趋势是把实在等同于我们可以从感觉经验中、从现象中获知的东西。如果这是对实在的一个真的解释,那么知识将只包含被理解为由于因果性而相互严格地关联着的事物的各种感性经验。从而实在将被视为一个巨大的机械结构,它惟一的活动乃是先前原因的产物,而人类也将被视为这个机械的一部分。如果事实是这样,康德说,“我就不能够…没有明显矛盾地谈论同一个东西如人的灵魂,说它的意志既是自由的,然而又服从自然的必然性,从而又是不自由的。”康德指出,一个人的现象自我或我们能够观察到的自我是服从于自然的必然性或因果性的,但是本体自我作为一个自在之物拥有自由。这么一来,康德就避免了上面所说的矛盾。康德以消极的方式,通过将理论理性的范围限制于感性杂多,而开辟了实践理性的积极运用:“(就)我们的批判限制了思辨理性(而言),它确实是消极的,但是因为它由此扫除了实践理性运用道路上的障碍,而不是威胁破坏它,所以实际上它有一个积极的而且非常重要的运用。”
道德之所以成为可能的,是因为即使我们不能知道那些自在之物或本体领域的对象,“我们却至少可以将它们作为自在之物来思考;不然我们将陷入这样一个荒唐的结论:有现象却没有任何东西显现。”但是,“对象(如一个人)被看作具有双重意义,即作为现象和作为自在之物,如果我们的批判在这一点上没有错的话,…那么下面这一假定就没有矛盾了:同一个意志在现象中,即在可观察的行动中,必然地服从自然律,是不自由的;而作为属于一个自在之物的东西,它不服从自然律,因而是自由的。”诚然,灵魂不能够被思辨理性作为一个自在之物而认识,“但是虽然我不能够认识自由,我还是可以思考它。”所以,康德已经为道德和宗教的探讨提供了基础。具体说来,他区分了两种实在——现象实在与本体实在:然后他将科学限制于现象实在,从而证明了与本体世界相关联的实践理性的运用。
道德知识的基础
据康德说,道德哲学的任务是发现我们如何能够达到那些约束所有人的行为的原则。他确信仅仅研究人们实际的行为是不能发现这些原则的,因为虽然这样的研究将为我们提供关于人们实际如何行动的一些有趣的人类学信息,但它还是不能够告诉我们应该如何行动。但是,我们确实在做着道德判断——例如当我们说我们应该讲真话时,问题在于我们是如何达到这一行为规则的。在康德看来,“我们应该讲真话”这一道德判断在原则上与“每一个变化都有其原因”这个科学判断是一样的。使这两个判断相似的是,它们都来自我们的理性,而不是来自我们的经验对象。正如我们的理论理性将因果范畴加于可观察的对象,并以此解释变化过程一样,实践理性将责任或“应该”的概念加于任何一种特定的道德情况。我们在科学中和在道德哲学中都运用了一些概念,它们超出了我们在任何时候经验到的特殊事实。在这两种情况下,经验都是触发心灵以普遍的方式思考的机缘。当我们经验到一个特定变化的例子时,我们的心灵将因果性范畴加于这一事件。这就使得不仅在这种情况下,而且在所有变化的情况下,解释因果关系成为可能。同样.在人类关系的情景中,实践理性不仅能够断定在这个时候我们应该如何行动,而且能够断定在任何时候都应该作为我们行动原则的是什么。如同科学知识一样,道德知识也基于先天判断。康德此前发现,科学知识之所以可能是由于心灵加于经验的诸先天范畴。这里他同样说道,“责任的基础不能在人的本性中,或是在人性被置于其中的世界诸条件中寻求,它先天地就在理性的概念中。”
因而对康德而言,道德是理性的一个方面,它与我们对行动规则或“规律”的意识有关,我们认为这些规则或“规律”既是普遍的又是必然的。普遍性和必然性的性质是先天判断的标志,而这也进一步证明了康德的以下观点:行为诸原则源于先天实践理性。康德不是在我们行动的后果中寻找“善”的性质,而是集中考察我们的行为的理性方面。
道德和理性
作为一个理性的存在者,我不仅问“我可以做什么”这样的问题,而且我也意识到自己必须以某种特定方式行动的责任,我“应该”做什么。这些理性的活动反映了实践理性的能力,而且我可以假定,所有理性的存在者都意识到同样的问题。因而当我考虑我必须做什么时,我也在考虑所有理性的存在者必须做什么。因为如果一个道德规律或规则对作为一个理性的存在者的我而言是有效的话,它也必定对所有理性的存在者都有效。因而一个道德善行的主要检验方法之一就是看它的原则是否能够被应用于所有理性的存在者,是否能够被一贯地运用。道德哲学就是探究适用于所有理性的存在者并导致我们称之为善的行为的这些原则的。
被定义为善良意志的“善”
康德说,“在这个世界上乃至世界外,没有任何东西能有资格被思考为或称作‘善’,除了善良意志。”当然他承认其他的事情也可以被认为是善的,例如对激情的节制,“但是我们很难称它们是普遍地善的…因为若没有一个善良意志的原侧,它们实际上或许会成为邪恶的。一个恶棍的冷血不仅使他更危险得多,也直接使他比自己如果不冷血的时候显得更加卑劣。”康德的主要观点是,道德善行的本质是一个人意愿一个行动时所确认的原则:“善良意志之所以是善的,不是由于它所导致或完成的东西,也不是它对达到某个预定目标的效用,而仅仅是因为这个意愿,就是说,它自身就是善的。”
一个理性的存在者努力去做他应该做的事情,康德将之与出于爱好或自身利益的行动区分开来。我们可以比较这些动机中的差异,因为无论是出于爱好还是出于自身利益的行动,对我们而言都显得与出于道德律的责任的行动不在同一个道德水平上。康德作出一个引人注目的断言,“善良意志之所以是善的,绝非由于它所完成的东西。”他这样说是要强调意志在道德中的支配地位。我们行为的后果符合道德律还不够;真正道德的行为是为了道德律,“因为所有这些结果——甚至是对他人幸福的促进——都可能由于其他原因而达到,所以为了这些结果本来并不需要一个理性存在者的意志。”道德价值的所在是意志,善良意志是出于责任意识而行动的意志;“出于责任的行动必定完全排除了爱好以及任何意志对象的影响,这样,能够决定意志的就只有客观的规律和对这一实践规律主观的纯粹尊重。”
责任暗示我们处于某种义务——一个道德律之中。康德说,当义务以一个命令的形式出现时,作为理性存在者的我们就意识到它。不是所有的命令都相关于道德,因为它们并不是在每个情况中都指向所有人,因而它们缺乏一个道德规则要求的普遍性。例如,存在着一些技术的命令或技巧的规则,它们要求我们做特定的事情,如果我们想要达到某个特定的目的的话。例如,如果我们想要建造一座跨河大桥,那么我们必须要使用具有一定强度的材料。但是我们并非绝对有必要造一座桥。我们可以建造一条过河隧道或使用水上交通工具到河对岸去。同样,存在着一些出于审慎的命令,例如,如果我想让自己受到某些人的欢迎,我就必须去说或做一些事情。但是我受欢迎依然不是绝对必然的。技术的和审慎的命令因而只是假言的命令,因为只有我们决定进入其运作领域时,它们才命令我们。
定言命令
不同于那些其本质仅仅是假言的技术性命令和审慎的命令,真正的道德命令是定言的。这一定言命令适用于所有人,要求“无须涉及其他目的,其自身就是必然的一个行动,即一个客观必然的行动。”它直接要求某种行动,无须任何其他意图作为条件。实际上,定言命令要求一个形成了特定选择的基础的规律。它是定言的,因为它同时适用于所有理性的存在者,它是命令,因为它是我们应该依其行动的原则。定言命令的基本表达式是,“只按照你同时也希望它成为普遍规律的准则行动。”康德曾说过,“自然界的所有事物都根据规律运作。唯有理性的存在者有根据对规律的设想而行动的能力。”他想表明定言命令是我们对有关人的行为的自然律的设想,因而康德以另外一种方式表述了责任命令,“这样行动,仿佛你的行动的准则要成为一条普遍的自然律一样。”
很明显,定言命令并没有为我们提供具体的行动规则,因为它仅仅是作为一个抽象的公式而出现的。然而按康德的想法,这正是道德哲学为指导我们的道德行为而应该为我们提供的东西。因为我们一旦理解了道德律的基本原则,我们就能够将之运用于各种具体情况。为了表明定言命令是如何使我们发现自己的道德责任的,康德举了下面这个例子:
(一个人)在困难的逼迫下觉得需要借钱。他很清楚自己无力偿还,但事情却明摆着,如果他不明确地答应在一定期限内偿还,他就什么也借不到。他想要做这样的承诺,但他还良知未泯,扪心自问:用这种手段来摆脱困境不是太不合情理、太不负责任了吗?假定他还是要这样做,那么他的行为准则可以被表述如下:在我需要钱的时候我就去借,并且答应如期偿还,尽管我知道是永远偿还不了的。这样一条自私或利已原则也许永远都会占便宜;但现在的问题是,这样做对吗?我要把这样的自私变成一条普遍规律,问题就可以这样提出:若是我的准则成为一条普遍的原则,事情会怎样呢?我立刻可以看出,这一准则永远也不可能被当作普遍的自然规律而不同时必然陷入自相矛盾。因为,如果一个人认为自己在困难的时候可以把随便做不负责任的诺言变成一条普遍规律,那么诺言自身就成为不可能的了,人们再也不会相信向他所做的任何保证,会嘲笑所有这样的表白,将之看作欺人之谈。
如果我们还是要问为什么他必须说真话?或者他为什么应该避免虚假承诺所包含的矛盾呢?康德回答说,存在着关于人的一些东西使我们反对和憎恶自己被作为一个物而不是作为一个人来对待。人之为人就在于他的理性,作为一个人或一个理性的存在者,自身就是一个目的。当某个人把我们当作实现一个其他目的的工具时,比如当他向我们说谎时,我们就成为了一个物。但是不论对我们的利用有时是多么必要,我们都把自己认作具有绝对固有价值的人。个体拥有绝对价值,这成为最高道德原则的基础:
这一原则的根据是:理性的本质作为一个自在的目的实存着。所有人都和我一样想要被作为人而不是作为物来对待,这一对个体绝对价值的断言导致定言命令的第二个表达式:你的行动要把你自己人身中的人性和其他人身中的人性,在任何时候都同样看作是目的,永远不能只看作是手段。
绝对命令还有第三个表达式,前两个表达式已经暗示了它,但是康德想要使之更明晰。这就是,我们应该“这样行动,意志可以将自身当作同时是在以它自己的准则制定着普遍的法律。”这里康德说到了意志的自律,每个人通过他自己意志的行动制定着道德律。康德区分了自律和他律,他律是由其他人或其他事物而不是自己作出的(一个法律或行动的)规定。这样一个他律的意志会被欲望或喜好所影响甚至决定。相反,一个自律的意志是自由的、独立的,因此是“道德的最高原则”。意志自律概念的核心是自由理念,它是至关紧要的调节性理念,康德以之区分科学的世界和道德的世界——现象世界和本体世界。他说,“意志是有生命的东西的一种因果性,如果这些东西是有理性的,而自由则是这种因果性所固有的性质,它不受外来原因的限制,而独立地起作用,正如自然必然性是一切无理性东西的因果性所固有的性质,它们的活动在外来原因影响下被规定一样。”此外,他还说,“我主张,我们必须承认每个具有意志的有理性的存在者都是自由的,并且依从自由观念而行动。我们想,在这样的东西里有种理性,这就是实践理性,具有与其对象相关的因果性的理性。”因此,定言命令所说的就是道德律的普遍性,它确认了每一个理性的人的最髙价值,并赋予意志以自由或自主。对康德来说,我们对道德律的经验暗示了某些进一步的洞见,它们相关于自由、不朽和上帝的悬设。
道德悬设
康德认为我们不可能证明或演证上帝存在以及人类意志自由。自由是由于我们对道德责任的经验而必须要假设的一个理念——就是说,“因为我必须,所以我能够”。虽然我们不能演证我们的意志是自由的,但是从理智上讲,我们不得不假定这样的自由,因为自由和道德“不可分割地联系在一起,我们可以将实践的自由规定为意志独立于任何东西而仅仅遵从道德律”。如果人们不能够或者不是自由地实现他们对道德命令的责任或响应,他们如何可能是有责任或有义务的呢?自由必须被假定,这就是第一个道德悬设。
康德的第二个道德悬设是不朽。康德是通过一系列推理而达到不朽悬设的。这个推理始于对至善(the summum bonum)的设想。虽然德性是可设想的最高的善,但是只有当在德性和幸福之间存在着一个统一时,作为理性存在者的我们才会完全满意。虽然事实上并非总是如此,我们都还是认为德性应该产生幸福。康德严峻地坚持说,道德律命令我们去行动,并不是我们因此会获得幸福,而是因为这样做我们的行为会是正当的(合法的)。不过一个理性存在者的完满实现要求我们将至善思考为既包含德性也包含幸福。可是我们的经验表明,在德性与幸福之间并不存在必然的关联。如果我们将人类经验限制于此世,那么要完全达到至善看起来就是不可能的了。不过道德律的确命令我们为完满的善而努力,这就暗示了一个朝向这一理想的无限过程,“但这个无尽的过程只有在下面假设的基础上才有可能,即同一个理性存在者的存在和人格是无尽地持续的,这被称为灵魂不朽。”
道德的世界也使我们不得不悬设上帝的存在,它作为德性与幸福之间的必然关联的基础。如果我们所说的幸福是指“现世中一个理性存在者的这样一种状态,对他来说在自己的一生中一切都按照愿望和意志而发生”,那么幸福就暗示了个人意志与物理自然之间的一种和谐。但是人不是世界的创造者,他或她也没有能力命令自然达到德性与幸福的必然关联。但是我们的确从至善概念中得出结论说德性与幸福必须相伴随。所以我们必须悬设“整个自然的一个原因的存在,它不同于自然,并包含了这一关联的基础,即幸福与道德完全和谐的基础。”这样,“假定上帝的存在在道德上就是必须的。”这不是说没有宗教就不可能有道德,因为康德已经说,没有上帝的理念,一个人也能够认识到他的道德责任,他必定仅仅是出于对道德律的敬重而服从它——“为义务而义务”。但是康德的确说过,“通过至善理念这一纯粹实践理性的对象和最终目标,道德律通向了宗教,也就是认识到所有的责任都是神圣的命令。它们不是约束或者说一个外在意志的任意命令…而是每一个自由意志自身的本质性规律。不过这必须被看作最高存在者的命令,因为只有从一个道德完备并且是全能的意志那里…我们才能指望达到最高的善,道德律使我们的责任将这最高的善作为我们努力的日标。”
不论康德是否成功地达到了他为自己新的批判哲学所设定的目标,他的成就都是不朽的。在这条道路上他所犯下的错误很可能比绝大多数人取得的成功更加重要,而毫无疑问的是,虽然我们不必接受康德说的每一句话,但是在今天我们如果不考虑他的观点,就很难进行哲学讨论。
13.6 美学:美
正如我们已经了解到的,康德提出了一套具体的道德规侧,我们可以通过它判断一个行动能否被正当地(合法地)称作“善的”。这些规则适用于所有人,所以衡量道德上善的行为有一个普遍的或客观的标准。同样,康德论证说,人类心灵能够建立起可靠的科学知识,自然必定被认作是完全统一的,科学规律对所有人来讲都必定是有效的或“真的”。然而,当他转向美学问题时,康德说“不存在任何规则让某个人根据它而必然地将一个东西认作美的。”康德说,不存在什么原因或原则表示一件衣服、一座房屋或一朵花是美的。然而,我们的确谈论着美的事物,而且我们喜欢认为,自己称作美的东西也会被别人称作美的。最后康德指出,尽管我们的审美判断是基于我们的主观感受的,美的定义却是“令人普遍感到愉悦的东西”。从我们对美的主观感受推进到美是令人普遍地感到愉悦的东西这个结论的过程,为我们提供了康德对审美经验之本质的一些关键性洞见。
美是不带任何利害而令人愉悦的东西
发现我们的审美判断之本质的第一步是将之看作一个主观鉴赏的问题。当我们表达一个对象是美的这个判断时,它是主观的,因为在经验到对象的基础上,把我们对对象的感觉归于作为主体的我们,归于我们愉悦或不愉悦的感受。这一愉悦或不愉悦的感受并没有指示对象中的任何东西,它仅仅是对象影响我们的方式。康德这里的核心观点是,鉴赏判断不是关涉到概念知识的逻辑的事情。如果我想说一个对象是“善的”,我必须知道该对象是被意欲成为什么东西。就是说,我必须有一个它的概念。但是对我来说,要在对象中看到美,我却并没有必要有一个关于对象的概念。例如,“花朵、随意的图案、杂乱交织的线条,这些我们称作建筑物上的叶饰的东西没有任何的意指,它们不依赖于任何确定的概念,但依然是令人愉悦的。”我的审美判断、我的鉴赏只是静观的(contemplative),就是说我无须知道关于对象的任何东西,只要知道它的特性是如何影响我愉悦或不愉悦的感受的。一个审美判断不是一个认知判断;就是说,它既不以理论知识,也不以实践知识为根据。
康德坚持认为,一个审美判断若要是“纯粹的”,它必须独立于任何特殊的利害;它必须是“无利害的”。无利害当然不是无趣,它的意思是,一个对象是美的这个判断不是对一个对象赞成或反对的偏好。一座房子是不是美的必须独立于我对房屋大小的偏好以及我想拥有它的愿望。纯粹审美判断确认的是,对象的形式无关乎任何我可能在其中具有的利害而令人愉悦。当然我对一个对象可能有某种利害关系或欲望。但它是美的这一判断是无关于这个利害或欲望的。由于这个原因,康德将美定义如下,“鉴赏是通过不带任何利害的愉悦或不愉悦而对一个对象或一个表象方式作出评判的能力。这样一个愉悦的对象就被称作美的。”
美是普遍愉悦的对象
如果一个对象是美的这个判断无关乎我个人的任何利害或偏好,那么它也不依赖于任何其他的利害,同样也不受它们的影响。我的判断是“自由的”,这时,首先我表达了一个对象是美的这样一个观点,其次我意识到,当我这样做的时候,我不依赖于任何其他的利害,也不受它们的影响——不论它们是一种嗜好、一个欲望,还是一种偏爱。因为没有任何我的个人的或特别的偏好影响我的判断,所以我有充足的理由相信像这般摆脱了他们的个人利害的其他人,也会达到同样一个美的判断。审美判断是普遍的。康德意识到,并非鉴赏这个词的所有使用都指向普遍的审美判断。有可能不同的人在对同一个东西的鉴赏上意见并不一致。一个人会说,“加纳利香槟是令人快适的”,但是他的朋友会提醒他应该说,“是令我快适的”。对一个人来说紫色是温柔可爱的:但对另一个人来说它是沉闷暗淡的。一个人喜欢管乐声,另一个人喜爱弦乐声。的确,在这些事情上,关于一个东西是否“令我们快适”,“每个人都有着自己独特的品味。”但是“快适”绝对不能被混同于美。因为如果一个东西只对某一个人是快适甚或愉悦的,他或她并不能将之称为美的。如康德所说,许多东西都对我们很有吸引力,令我们快适。但是如果我们把一个东西当作不一般的,并称之是美的,这就暗示我们期待所有人都会作出同样的判断,所有人在对象中都会有同样的愉快。那些作出不同判断的人可能会受到批评,会被认为没有鉴赏力。在这个意义上康德说,“我们不能说:每个人都有自己独特的鉴赏。这种说法将等于说,不存在任何鉴赏;就是说,没有任何可以合法地(正当地)要求每个人都同意的审美判断。”
“鉴赏”这个词含混的用法通过感官的鉴赏和反思的或静观的鉴赏之间的区分而得到了澄清。例如对食物和饮品的品味就是感官的鉴赏,它们通常仅仅是个人的。但是包含一个审美判断的鉴赏则暗示了普遍的赞同。这一审美判断并不基于逻辑,因为它没有涉及我们认知的能力;它只涉及所有主体中愉悦或不愉悦的感受。美的判断不依赖于任何概念,而是依赖于感受。因而康德以另一种方式将美定义如下:“美是那没有概念而普遍地令人愉悦的东西。”
美的对象中的目的与合目的性
有两种美:(1)自由的美与(2)仅仅是依存的美。自由美没有预设某个对象应该是什么的一个概念。相反,依存美预设了对象应该是什么的一个概念,有了这个概念我们就能确定这个对象是不是完善。
一朵花的美是白由美。只要看到它我们就能够说它是不是美的。我们无须拥有关于它的更多知识。没有关联于花的任何其他诸如目的之类的概念帮助我们确定它是否是美的。花朵向我们呈现自身的方式就是合目的的。如我们所看到的花朵的形式就体现了它的“合目的性”,这一合目的性为对它的美的判断提供了基础。在我们作出这一判断时,我们的意识和知性当然有着某种活动,但这里是我们的情感力量而不是理性力重处于支配地位。因此康德说,“一个判断被称作是审美的,严格来讲正是因为它的规定性基础不是一个概念,而是对心灵诸能力活动之和谐的感受,只要它能够在感受中被经验到。”诚然,植物学家对花朵可以知道很多东西,但是这些概念与花朵是否漂亮这个判断没有任何关系。与此类似,在绘画、雕塑、园艺,甚至音乐中,构思都是根本性的东西,因而,通过其形式而使人愉悦的东西是鉴赏的基本先决条件。
但是一个男人、女人或孩子的美,一座教堂或一个凉亭的美,所有这些都预设了一个“目的”的概念,它规定着此物应当是什么。我们可以说一个人或一座建筑是美的。但是这里我们对美的判断考虑到了目的或意图的概念。此外,美的判断变得依赖于所讨论对象的适当目的是否实现。这里我们不是在作仅仅基于感受的纯粹的审美判断。相反,这里是一个概念知识的综合,它牵涉到一个人的本质或目的,或一座建筑的目的或功能。例如,某个人可能判断说一座建筑并不令人愉悦,因为它的形式(虽然非常精致)对一座教堂来说并不合适。一个人或许被判断是美的,因为他或她以道德的方式行事,在这个情况下,审美判断被混同于或至少是混合了善的判断,后者是一个认知判断。如果我们关于一个人或一座建筑是美的这样的判断依赖于人类本质的目的或建筑的目的,那么我们的判断就被置于一个限制之下,不再是一个自由和纯粹的鉴赏判断。所以,康德以第三种方式将美定义如下:“美是一个对象和目的的形式,如果这个形式是没有一个目的的表象而在对象身上被知觉到的话。”
必然性、共通感和美
有一些关于美的东西导致它“和愉悦(快乐)方面的某种必然关系”。康德说,这并不意味着我能够提前知道“每个人在我称之为美的那个对象上:实际地感到这种愉悦”。联结审美判断与愉悦的必然性既不是理论的必然性,也不是实践的必然性。虽然我可以断言我的审美判断是普遍的,但我不能够认定每个人都会实际上同意它。事实上,因为我甚至不能够清楚地形成一个规则,它可以根据概念来规定美,所以我只有自己的美的感受,它包括我的快乐或愉悦。审美判断中要提到我的快乐,这并不意味着快乐这个要素是从美的概念中逻辑地推演出来的。康德认为,快乐被包含在美的经验之中这一“必然性”是“一种特殊的必然性”。在审美判断中被思考的必然性“只能被称作示范性的(exemplary)”。它是“一切人对于一个被看作某种无法指明的普遍规则之实例的判断加以赞同的必然性”。简言之,我的判断是一个关于美的普遍规则的示例。
如果我不能够以理性的或认知的方式形成美的原则,那么我是如何可能与他人交流审美判断的那些必然性成分的呢?2乘2对每个人而言都必然等于4。审美判断如何也能够包含必然性的要素?康德说,我必须有“一个主观的原则,它仅仅通过情感而不通过概念就规定了什么是令人愉悦或不愉悦的,但仍然是普遍有效的。”由于这个原因,鉴赏判断就依赖于我们存在着共通感这一预设。只有在这样一个共通感的预设之下,我才能够作出一个鉴赏判断。这并不意味着每个人都会同意我的判断,而是意味着每个人应该同意它。我们可以认为,当我们说2加2等于4时其他人也能够甚至必定理解这个判断的普遍正确——虽然在这个例子里我们是在处理一个客观原则。因此我们也可以假定在所有人中都存在着一种共通感,出于它我们可以交流主规的审美判断。由此康德对美下了第四个定义,“美是没有概念而被认作一个必然愉悦的对象的东西。”
如同他在《判断力批判》的前言中指出的,康德自己意识到,“解决一个问题的困难是如此地纠缠在这个问题的本质之中,这可以用来为我在解决这问题时有某些不能完全避免的模糊性作出辩解。”尽管有着康德这个坦言,黑格尔在康德的美学理论中还是发现了“有关美的第一句合理的话”。
第十四章 德国唯心主义
14.1 康德对德国思想的影响
紧随康德批判哲学之后的是19世纪德国唯心主义思潮。作为一种形而上学的理论,通常的唯心主义是指这样一个观点,字宙仅仅是由心灵的——或精神性的——东西构成的,在实在中不存在物质的东西。例如,18世纪的英国经验主义者乔治·贝克莱就认为,只存在精神性的心灵,我对这个所谓物理世界的知觉只是上帝置入我的精神性心灵的一个内心感觉之流。唯心主义在德国的道路以康德的哲学为起点。康德在理论上并没有否认物理世界的存在。但是他主张物自体的真正本质对我们而言永远是不可知的。我们心灵的构造方式使我们永远也不能超越感性经验的领域,即现象的领域。进而言之,我们对于经验世界的解释永远都被我们的心灵施加于经验的诸范畴所限定。康德相信这些范畴——诸如原因和结果,实存性和否定性,等等——是我们的心灵先于经验就拥有的概念,它们在与对象的关系中被应用,而知识之所以可能正在于此。
虽然我们被封闭在一种受到我们的感性经验和心灵结构限制的世界观之中,但是康德仍然相信存在着一个物自体的本体领域,即使我们永远也不能达到它。例如,我们只是经验到红苹果的现象——已经被我们心灵的知觉能力整理过的感性信息。但是在苹果的这个红之后必定存在着红色与之相联系的东西,或某种能够具有红色的东西,即自在的苹果自身。但是对康德而言,事实依然是我们不能够认识任何这种自在之物,因为我们的心灵范畴只适用于现象世界。
约翰·哥特利勃·费希特(Johann Gottlieb Fichte,1762-l814)是最先认识到在康德的论点中存在的明显矛盾的人之一。说某个东西存在而我们对之却一无所知,这怎么可能呢?当我们说一个东西存在时,我们不是已经知道了关于它的某些事了吗?而且,康德为了解释我们的感性经验,断言了物自体的存在,这实际上就是说,物自体是任何被给予的感觉的“原因”。但是,他已经明明白白地主张说,心灵的诸范畴,例如原因和结果,不能够用来得出关于本体世界的知识。这样,当康德说物自体是我们感觉的原因时,他就与他自己将范畴的运用限制于我们对感性经验对象的判断这一规则相矛盾了。
甚至说物自体实存也超越了康德为知识设下的限度。因为“实存”是在心灵以连贯的方式组织我们的感性经验时起作用的一个范畴。事实上,康德反对先前的形而上学家的一个最有力的论点就是指出他们错误地将实存归于超越了感性经验的所谓存在者和实在。现在从他关于物自体的学说看,似乎康德保留的正是他的批判哲学应该消除的东西。不仅在康德的理论中不可能将实存范畴运用于物自体,而且,说一个东西不可知而它却可能实存,这是一个很明显的矛盾。当然,我们可以区分暂时不被知道的东西(但潜在地它们是可知的)和永远也不可能被知道的东西。但是说一个东西永远也不可能被知道,这是自相矛盾的,因为这样一个陈述暗示我们已经知道了有这个东西,在这个限度内它是可知的。这样,康德的物自体概念就崩遗了。
费希特提出针锋相对的命题:任何东西都是可知的。同时,费希特并没有企图回复到康德已经驳斥了的那种形而上学。他认为康德在哲学上取得了真实的进展,而试图将康德开启的东西继续向前推进。因此费希特试图做的是,运用康德的方法——其中去掉了不可知的物自体的概念——将康德的批判唯心主义转化成形而上学的唯心主义。这就是说,费希特接受康德的如下理论,心灵把它的范畴加于经验,并且他将这一点转化为这样一个理论:每一个对象,从而整个宇宙都是心灵的一个产物。
其他的德国哲学家也加入了这个将康德的批判哲学转化为形而上学的唯心主义的事业,其中最突出的是乔治·威廉·弗里德里希·黑格尔(Georg Wilhelm Friedrich Hegel,1770-1831)、弗里德里希·威廉·约瑟夫·冯·谢林(Friedrich Wilhelm Joseph von Schelling,1775-1854)和奥瑟·叔本华(Arthur Schopenhauer,1788-1860)。每一个哲学家都以自己各不相同的方式推进了这一事业。但是他们都认为不存在康德所假定的不可知的物自体。此外,康德相信物自体是我们感性经验的最终根源。唯心主义者则主张,恰恰相反,我们的经验知识乃是心灵的产物。在这一章里我们将考察两个德国唯心主义者的观点——黑格尔和叔本华。
14.2 黑格尔
黑格尔的生平
黑格尔的历史意义在于,他以出色的、体系化的彻底性完成了此前不久还被康德宣称是不可能被完成的事情。康德认为形而上学是不可能的,人类心灵是不可能达到对实在全体的理论认识的。而黑格尔则提出了这样一个普遍命题,“凡是合理的都是实在的,凡是实在的都是合理的”,由此得出结论,一切东西都是可知的。这是一种复杂详尽的形而上学,它为思考实在的结构及其在道德、法律、宗教、艺术、历史中以及最重要的,在思想自身中的体现提供了一个新的基础。或许可以说,黑格尔哲学最后的衰落与其说是由于遭到了学术上的抨击,不如说是被抛弃了——更像放弃一座大厦而非攻克一个据点。但是若以为黑格尔的继承者们只是对他精致的形而上学体不屑一顾,这就错误地判断了他的思想对紧随其后的一代代人的影响和支配。黑格尔思想的影响力可以拿这样一个事实来衡量,大多数现代哲学家都代表了修正或者拒斥他的绝对唯心主义的某些方面的各种方式。
乔治·威廉·弗里德里希·黑格尔1770年生于斯图加特,他生活于德国精神生活最辉煌的时期。这一年,贝多芬刚刚出生,而“集整个文明于一身”的诗人——科学家歌德这一年也正好20岁。康德时年46岁,还没有创作其经典的哲学著作。英国人华兹华斯也出生在这一年,他的诗歌后来成为浪漫主义的一部分,而浪漫主义也和德国唯心主义有一些共同立场。黑格尔在早年的岁月里深受了古希腊作家们的影响,最终他逐渐相信,柏拉图和亚里士多德不仅是哲学的源泉,而且甚至直到现在也是给予哲学以生命的根基。黑格尔在斯图加特的学校里是一个普普通通的学生,在18岁的时候,他被录取进人图宾根大学神学院就读。在这里,他与荷尔德林和谢林成为好友,他对于谈论法国大革命这一话题特别感兴趣。在图宾根的5年岁月里,他的兴趣逐渐转向哲学与神学的关系。他对哲学的兴趣最终成熟旺盛起来,是在他离开大学以后。他在伯尔尼和法兰克福做了6年的家庭教师。在这些年里他写作了一些较小的作品,但它们包含了后来成为他的哲学的核心的一些重大问题的萌芽。
唯心主义在这个时候已经在费希特和谢林那里得到了有影响力的表达。1801年,当黑格尔被任命为耶拿大学的教员时,他出版了他的第一本著作《论费希特与谢林哲学体系的差异》(Differenle between the Philosophical System of Fichte and Schelling),在这本书里他表达了对费希特的反感。虽然在这些早年的岁月里他更倾向于谢林,但不久以后,他独立的、原创的哲学探索在其第一部主要著作《精神现象学》(The Phenomenology of Mind)中公诸于世了,据他自己说,这本书完成于1807年耶拿战役的前夜。这场战役导致了耶拿大学的关闭,黑格尔为了维持他和妻子的生计(他们于1811年结婚),做了纽伦堡中学的校长,他在那里一直待到1816年。他在这里完成了极有影响的《逻辑学》(Science of Logic),这本书为他带来几所大学的邀请函。1816年,他到海德堡大学任教,1817年,他在这儿出版了《哲学全书纲要》(Encyclo Pedia of the P%ilosophical Sciences in Outline),黑格尔在这本书里展现了他宏大的哲学结构的二部分:逻辑学、自然哲学和精神哲学。两年之后黑格尔被授予柏林大学的哲学教席,他在那里一直工作到1831年因霍乱逝世,享年61岁。黑格尔在柏林写出了大量的作品,许多是在他身后才出版的。他在这一时期的著作包括《法哲学原理》(Philosophy of Right),以及身后出版的一系列演讲,《历史哲学》(Philosophy of History)、《美学》(Aesthetics)、《宗教哲学》(Philosophy of Religion)和《哲学史讲演录》(History of Philosophy)。
绝对精神
前面已经提到,德国唯心主义主张知识最终的源泉和内容是心灵,而不是物理对象或者什么神秘的物自体。正如黑格尔所表达的,凡是实在都是合理的,凡是合理的都是实在的。但是哪一种“心灵”实际上产生了我们的知识?我们的确经验到了一个外在于我们的事物世界。我们将之认作独立于我们而存在,而不是我们的创造。如果我们所有知识的对象都是心灵——但并不是我们的心灵——的产物,那么就必定认为它们是一个不同于有限的个别心灵的理智的产物。黑格尔和其他的唯心主义者下结论说,知识的所有对象、因而所有对象、事实上整个宇宙,都是一个绝对的主体、一个绝对精神的产物。
在康德看来,心灵的诸范畴仅仅使知识成为可能。但是对黑格尔而,诸范畴还有某种独立于任何个别心灵的存在。另外,对康德而言,诸范畴代表了一个个体的心灵活动过程,为康德提供了对人类知识的类型及其限度的解释。他说,范畴是在人心灵中的概念——是心灵带给经验的东西,心灵通过它们才能够理解经验世界。与康德不同,黑格尔不仅仅将范畴考虑为心灵过程,而且考虑为不依赖于进行思考的个人而存在的客观实在。更具体地讲,黑格尔认为,范畴的存在是基于绝对精神。但是正如我们将看到的,黑格尔并不是说一方面存在着范畴,另一方面存在着诸如椅子、苹果之类的事物。这样一个区分将意味着观念和事物有着相互分离的存在——正如柏拉图从事物中分离出理念一样。黑格尔不像柏拉图,他并没有将任何独立的存在归于范畴。他是说它们不依赖于个人的心灵或思想而有其实存。黑格尔想要说的是实在的世界不仅仅是人们心灵的主观概念,同时他要说的是实在就是理性或思想。
以一把椅子为例。什么是一把椅子,或者说,椅子是由什么构成的?黑格尔说,如果我们接受不可能有不可知的物自体这一结论,那么一把椅子必定是由我们对之能够拥有的观念的总和构成的。在这一基础上,一把椅子必定是由当我们经验它时在其中所发现的所有普遍的东西构成的。我们说椅子是硬的、褐色的、圆的和小的。这些都是普遍的观念,当它们以这种方式相互关联时,它们就是一把椅子。这些普遍的东西在椅子中有其存在;普遍的东西或范畴从没有单独的或独立的存在。既然椅子中不存在不可知的方面,即除了我们经验到的那些性质之外再无别的东西,那么,椅子就是我们关于它所知道的东西,我们所知道的是,它是由普遍的东西或观念的结合所构成的。这样,说范畴和普遍的东西有客观的状态,就是说它们独立于认知主体而有其存在。同时正如椅子的例子所显示的,黑格尔说思想的对象首先在于思想自身。他说,在认识与存在之间有着同一性。认识和存在只是同一枚硬币的两个面。固然黑格尔承认存在着一个主体和一个客体、一个人和这个世界。但是他的唯心主义的本质在于他的这样一个思想:我们意识的对象——我们经验和思想的事物——自身就是思想。最后黑格尔形成了这样一个见解,实在将在绝对理念中被发现。
到目前为止,我们已经提出了黑格尔的论述中的两个主要观点,即(1)我们必须拒斥一个不可知的物自体的观念,以及(2)实在的本质是思想、理性,最终的实在是绝对理念。为了指出黑格尔达到实在是思想这一结论的一些步骤,我们下面转向他的复杂的哲学体系中的几个基本要素。
实在的本质
黑格尔将世界看作一个有机的过程。我们已经了解到,对他而言真正实在的东西就是他所说的绝对。用神学的术语说,这个绝对被称作上帝。但是黑格尔想要表明的是,这里他不是指一个脱离了自然界甚至脱离了个体的人的“存在(Being)”。柏拉图在现象与实在之间作出了严格的区分,黑格尔实际上认为现象就是实在。黑格尔说,没有什么东西是不处在关系中的。因此,基于仔细的反思,我们经验为孤立事物的任何一个东西都会把我们引向与之相关的事物。最后辩证思想的过程将以对绝对的知识而告终。然而绝对并不是孤立事物的统一。黑格尔拒斥唯物主义,唯物主义主张存在着个别的、有限的和坚固的物质微粒,它们以不同的方式被组织,构成了所有事物的全部本质。黑格尔也不接受由古代世界的巴门尼德和近代的斯宾诺莎分别提出的极端的理论,即一切是一,即一个有着各种各样的类型和属性的单一本体。黑格尔将绝对描述为一个动态过程,描述为一个有着诸多部分 但是被统一进一个复杂系统的有机体。因而绝对不是某种脱离了世界的实体,而就是以一种特殊的方式观察到的世界。
黑格尔相信绝对的内在本质是人类理性可以达到的,因为绝对在自然中和人类心灵的运作中同样得到了展现。联结绝对、自然和心灵这三者的是思想自身。一个人的思想方式是并且总是被自然的结构,被事物实际的活动方式所限定的。然而,事物之所以那样活动,是因为绝对在通过自然的结构表达它自身。这样,一个人就是在以绝对在自然中表现自身的方式思考自然。正如绝对和自然是一个动态的过程一样,人类思想也是一个过程——一个辩证的过程。
逻辑与辩证过程 黑格尔非常强调逻辑。事实上,他将逻辑理解为与形而上学其实是同一个东西。这尤其是因为他相信认识与存在是一致的。不过黑格尔的观点是,通过一步步逻辑的进展并在此过程中避免自相矛盾,我们就能够认识到实在的本质。笛卡尔主张一种类似的方法,按这方法,知识中的确定性将随着从一个清晰的观念到另一个清晰观念的推进而获得。但与笛卡尔(他重点强调的是观念相互之间的关系)不同,黑格尔认为,思想必须遵从实在自身的内在逻辑。这就是说,既然黑格尔已经将理性的东西与现实的东西同一了,因此他的结论就是逻辑以及逻辑关联必定是在现实的东西之中,而不是在什么“空洞的推理”中发现的。他认为,“由于哲学是对理性的东西的探究,因此它就是对显现的、现实的东西的理解,而不是对一个上帝才知道它在什么地方的超越之物的设立。”于是,逻辑就是一个过程,我们通过它而从我们对现实的东西的经验中推演出描述了绝对的诸范畴。这一推演的过程在黑格尔辩证哲学中处于核心地位。
黑格尔的辩证法过程展示了一个三段式的运动。辩证法的这种三段式的结构通常被描述为一个从正题到反题最后到合题的运动过程。在这个过程之后,合题成为一个新的正题。这一过程一直持续下去直到它终结于绝对理念。黑格尔在他的辩证逻辑中强调的是思想是运动的。矛盾并没有使知识中断,而是在人的推理中作为一个积极的推动力量起作用。
为了展示黑格尔的辩证方法,我们就以他逻辑学的第一个基本的三段式即存在、无、变易为例。黑格尔说心灵必然总是从较普遍抽象的东西推进到特殊的具体的东西。我们对事物能形成的最普遍的概念是它们存在。虽然各种各样的事物具有特殊的、各不相同的性质,但它们都有一个共同点,即它们的存在。因此存在就是心灵能够形成的最普遍的概念。而且存在必定逻辑地先于任何特殊事物,因为特殊事物体现了那一开始没有任何特性的东西的规定或形态。于是,逻辑学(以及实在)就从无规定性开始,从“先于一切规定的原始的无规定性开始。这就是我们所说的存在。”因此黑格尔的体系是从存在概念开始的,这是正题。现在的问题是,思想如何能从这样一个抽象概念运动到任何别的概念?更为重要的是,如何能够从存在这样一个普遍的概念推演出一个别的概念呢?
黑格尔相信他在这里已经发现了一些关于思想的本质的新东西。自亚里士多德以来,逻辑学家们认为从一个范畴中不能推演出任何没有被包含在这个范畴中的东西。从A中推演出B,要求B已经以某种方式被包含在A中。黑格尔接受了这一点。但他拒斥的是亚里士多德逻辑学中这样一个假定,即没有任何东西可以从一个普遍的项中推演出来。例如,亚里士多德论证说每个事物都是一个独特的东西,因此逻辑学只向我们提供特殊的普遍项,由之不能推导出其他普遍项。比如说,要么是蓝色,要么是非蓝色;我们无法从蓝色推演出其他任何颜色。如果蓝色是蓝色的,你不能同时说它是其他什么东西,一个非蓝色。这个不矛盾律在任何形式逻辑中都很重要。然而黑格尔相信,说一个普遍的东西不包含另一个概念,这是不对的。回到存在概念,黑格尔说,这里我们有一个观念,它并不包含许多具有存在的事物的任何特殊性质。存在的观念没有任何内容,当你赋予它某种内容时,它就不再是纯存在概念而是某个东西的概念。但是不同于亚里士多德,黑格尔相信从这一存在的概念能够推演出另一个概念。他论证说,因为纯存在是纯粹的抽象,因此它是绝对的否定。就是说,由于存在概念完全没有被规定,它就演变成非存在概念。只要我们试图思考没有任何特殊性质的存在,心灵就从存在过渡到非存在。当然这意味着存在与非存在在某种意义上是一样的。黑格尔意识到且并不讳言“存在与无是同一的,这个命题在想象力和知性看来是如此悖谬,以致它或许只被当作是句玩笑话。”事实上,黑格尔说,将存在和无理解为同一的,“是思想期望自身所能做的最困难的事情之一”。不过黑格尔的观点是,无是由存在推演出来的。同时无的概念很容易地将心灵引导回到存在的概念。当然黑格尔并非在暗示我们可以这样来说具体事物,说它们同时也是无。他的论证仅仅限于纯存在概念,他说,它包含了无的观念。这样,他就从存在概念推演出了无的概念。反题无被包含在正题存在中。在黑格尔的逻辑中,反题总是由正题推演出来,因为它已经被包含在正题中了。
心灵从存在到无的运动产生了第三个范畴,即变易。变易概念的形成,是因为心灵由于上述原因而理解到,存在与无是同一的。黑格尔说,变易是“存在与无的统一”。它是“‘一个'观念”。因此变易就是存在与无的合题。如果我们问一个东西如何能够既存在又不存在,黑格尔会回答说,当一个东西变易时,它就能既存在又不存在。
黑格尔将逻辑学的这一辩证方法运用于他的整个庞大而错综复杂的体系。在每一个阶段,他提出一个正题,由之推演出一个反题;这个正题和反题在其统一中发现了一个更高的合题。最后,黑格尔达到了绝对理念这一概念,他根据自己的辩证方法将之描述为变易——描述为一个自我发展的过程。这样,从处于知识之最低水平的对特殊事物之性质及特性的感觉开始,黑格尔通过发现所有事物不断拓展的相互联系而努力扩展知识的领域。就这样,我们的心灵严格按照从一个概念向另一个概念的推演而运动着,而这些概念我们是作为现实中的范畴发现出来的。在黑格尔看来,单个的事实是不合理的,只有当这样的单个事实被看作整体的一个方面时,它们才成为合理的。思想由于事实所产生的每个概念的本性而被推动着从一个事实运动到另一个事实。例如考虑一台引擎的各个部分。一个火花塞就自身而言没有合理性的特性;给予它合理性的是它与引擎其他部分的关系。这样,要发现火花塞的本质,就是要发现其他部分的、最终是整个发动机的真理。于是,人类心灵辩证地运动着,持续地容纳不断增加的实在领域,只有在发现一个事物与整体的关系即它与那理念的关系之后,才发现了这个事物的真理。
黑格尔所说的理念在他的逻辑学中是通过从存在中产生变易的同一种方法而推导出来的。主观性范畴是从如下事实推演出来的,一个人能够拥有一个事物的观念,作出关于它的判断,能够推出诸多逻辑关联。但是从主观性我们可以推演出它的对立面,即客观性。这就是说主观性的观念已经包含了客观性的观念。说我是一个自我(主观性)就暗示了存在着一个非自我(客观性)。主观性在包含了在其形式意义上的思想。另一方面,客观性可以说是外在于其自身的、在事物之中的思想。描述一个人的观念的客观特性,黑格尔说,这包括机械性、化学性和目的性。例如,一个主体关于自然所知道的机械规律,客体在其行为中都表现了出来。主观的东西与客观的东西的合题是它们在理念中的统一。就是说,在理念中,主观的东西(形式的东西)和客观的东西(质料的东西)是统一在一起的。但是理念包含自己的辩证过程,即生命、认识和绝对理念。这样,理念乃是自我意识的范畴;它在其对象中认识自身。因此黑格尔逻辑学的整个发展趋势就是从最初的存在概念不断运动最终直到理念概念。但是这个理念也必须被理解为处于一个动态的过程中,如此理念自身就处于一个朝向自我完善而不断自我发展的连续过程。
自然哲学 从理念我们导出了自然的领域。如黑格尔所表述的,自然表现了“外在于其自身的”理念。这一表述容易导致误解,因为它暗示理念独立于世界而存在。此外,黑格尔将“绝对自由"赋予理念,因为“它把它自己自由地外化为自然”。但是,回想到黑格尔的前提即实在的是合理的,这儿必然得出自然只是处于外在形态中的理性或理念,这类似于钟表匠的观念在外在于他的钟表中被发现。但是黑格尔的观点比钟表匠对钟表的关系所暗示的要更复杂微妙。因为黑格尔并不是真的指两种各自存在的事物,理念和自然。最终的实在是一个单一的有机体和整个的动态过程。黑格尔在所有事物“之后”的逻辑理念与自然之间作出的区分,其实只是想区分自身同一的实在的“内在的”和“外在的”两个方面。简言之,自然是理性理念(正题)的对立面(反题)。我们的思想辩证地从理性的东西(理念)运动到非理性的东西(自然)。自然的概念将我们的思想最终导向由在新的“精神”概念中理念与自然的统一所体现的新的合题。驱使我们的思想从自然返回到精神的,是在自然概念中的辩证运动。正如逻辑学始于最抽象的概念存在,自然哲学也始于最抽象的概念,黑格尔认为,这就是空间。空间是空的(正如存在是无规定的)。这样一来,在一端自然触及到了空无。在另一端,它深入到了精神。在空间与精神之间是具有多样性的特殊事物,这就是自然。自然展示了力学、物理学和有机体的规律。黑格尔将自然的所有这些方面又分析为它的诸辩证环节。
黑格尔关于自然所说的很多东西都被自他的时代开始的科学的发展超越了。但他的意图并非取代科学家的工作。他更关注于通过自然哲学发现一个在所有实在中的理性结构和模式。同时他试图表明自由与必然之间的差异,他说自然是必然的王国而精神是自由的。黑格尔说,自然“被视为一个诸多发展阶段的体系,这个体系的一个阶段是由另一个阶段必然的发展而来。”另一方面,自由是精神的活动。这样,在精神与自然之间、自由与必然之间就存在着一个辩证的对立。事实上,实在的“历程”、历史的目的论的运动,就体现了精神、自由的理念逐步而连续的展开。
精神哲学在逻辑理念和自然哲学之后,黑格尔体系的第三部分就是精神或心灵哲学。这里黑格尔再次提出了其辩证法的各个要素,其中正题是主观精神,反题是客观精神,合题是绝对精神。他极其详尽地把一个个二段式叠加起来,展示了绝对乃是精神,并且这个精神在个体心灵中,在家庭、市民社会、国家的社会制度中,最终在艺术、宗教和哲学中找到了它的表现。主观精神指人类心灵的内在运作,客观精神代表了外在地体现在社会和政治制度中的心灵。知识的顶峰则是艺术、宗教和哲学,它们是绝对精神的成就。
令黑格尔哲学出名的,很大程度上是它围绕客观精神概念发展出的那部分思想。这里我们看到了黑格尔思想的统一,他试图将他的道德、社会和政治思想与他的体系的其余部分连接起来。人类行为——包括个体的和集体的——的整个领域,被他描述为现实的一部分,因而从根本上是理性的。此外,作为现实的一个部分,精神的这一客观的方面被视作包含在辩证过程之中。人类行为和社会与政治组织包含或体现了精神,正如自然是绝对理念的客观体现一样。由于这一原因,黑格尔将制度不仅仅看作人类的创造,而且也看作历史辩证运动的产物,看作理性实在的客观显现。例如,谈到他的法哲学,黑格尔说它“可以说包含了关于国家的科学,它只是努力将国家作为一个本质上理性的事物来加以把握和描绘。作为一种哲学工作,它必须与那种建构一个应然国家的尝试拉开距离。”认为现实的国家与其实在的这种真正的根据是同一的,这使得黑格尔的政治理论对于那些希望以极权主义的或至少是非民主的观点思考国家的人有着蛊惑性的影响力。下面我们就转入辩证过程中的一些“环节”,黑格尔想要通过这些过程展示从个体的法的概念到国家凌驾于社会之上的权威的自然运动。这里基本的三段式运动是从法(正题)到道德(反题),再到社会伦理(合题)。
伦理和政治
法的概念 我们必须首先将人类行为理解为个体的活动。黑格尔说,个体意识到自由。我们表达我们的自由的最具体的形式是通过意志的行为。黑格尔将意志和理性看作实质上是同义的,他说,“只有作为思想着的理智,意志才是自由意志。”我们主要地是在与物质事物的关系中表达自由的,我们占有它们、使用它们、交换它们。黑格尔说,“占有实际上只是通过证明事物不是自身完成的,没有任何它们自身的意图,从而表明了我们意志对于它们的权力。”对黑格尔而言,财产权的基础是个体在占有行动中的自由意志。但是自由的人们会由于财产而“异化”他们自己,而这是我们通过“契约”做到的。一个契约是两个自由意志同意交换财产的产物。它也表明了义务的提出,契约的条款体现的就是义务。黑格尔在这里的核心观点是,在个体理性地行动的情况下,我们的自由行动与普遍的理性相符合。我们的个体意志与普遍意志相和谐。但是在自由的人们之中,诸个体意志的和谐是不稳定的。这样,就总是存在着法的对立面的可能性;对法的否定在暴力与欺诈中得到例证。“不法”在于对个体意志与普遍意志之间和谐的破坏。“法”与“不法”之间的辩证关系就在“犯罪的”意志的行动方式与意志为了成为普遍的而应该采取的行动方式,即理性的方式之间产生了一种张力。法和不法之间的这种张力或冲突产生了道德。
黑格尔说,道德根本上是一个在人类伦理生活中的目的和意图的问题。换句话说,“善”不只是服从法律和信守契约。道德与那些人们自己可以对之负责的事情有关。只有一个人所意图的以及构成他或她的行动的目的的那些后果,才能影响这一行为的善或恶。于是黑格尔似乎认为,道德的本质是内在地在一个人的意图和目的中发现的。这样道德责任就始于那些能够被归于一个自由意志(一个意欲进行这一行动的意志)的行动。但是,黑格尔认为,行动的这一主观方面并未穷尽道德的全部领域。毕竟人类行为总是在一个关联(context)中,尤其是在他人从而在其他意志的关联中发生的。因此,道德义务或责任就比个体的关注和意图更为广泛。道德义务源于使个人意志与普遍意志相同一这一要求。虽然关注自身的幸福和福利对于人们是完全合法的,但是理性原则要求我们必须以如下方式行使我们自己的意志:其他人的意志也自由地行动,也能达到他们自己的幸福和福利。道德因而就是辩证过程中的一个要素:正题是每个个体的抽象法(权利);反题是道德,因为道德代表了普遍意志作为限定而对个体意志提出的义务。这两种意志的关系是自由与义务、主观与客观的关系。在这一伦理领域中辩证过程持续地朝向主观与客观更大的和谐运动,正是考虑到这一点,黑格尔将善描述为“自由和世界最终的绝对目的的现实化”。但对黑格尔而言,自由的现实化必须在义务的限度内发生。在这个意义上,最自由的人就是最完全地实现了他或她的义务的人。因此,黑格尔势必要在人类的具体组织中,特别是国家中找到这两方面——一方面是个体自由与法(权利),另一方面是普遍意志——的合题了。
国家 在黑格尔看来,在个体与国家之间有两个辩证的阶段:家庭和社会。家庭可以说是客观意志的第一阶段。在婚姻中,两个人为了成为一个人而在某种程度上放弃他们的个体意志。因为家庭是个单一的单元,所以它的财产成了共同所有的,尽管由于法律的原因可以说财产归丈夫所有。此外,家庭是由感情或爱的纽带联合起来的,它在逻辑上构成了普遍意志具体化的第一个环节。同时,家庭包含着它自己的反题,即那些最终将长大,离开家庭的个体,他们将进入与自己类似的诸多个体的一个更大的关联(它被称为市民社会)中。这些个体现在规划他们自已的生活,有着他们自己的目的。此时,我们需要记住,这里黑格尔是在分析国家的辩证发展,而不是对它的出现给予历史的解释。国家是家庭和市民社会的合题。家庭在这种分折中代表着体现出来的普遍性,而市民社会代表着特殊性,这是因为市民社会的每个个体不同于家庭成员,而是设立着他或她自己的目标。这两个要素,普遍性和特殊性,不能够独立存在,因为它们互相包含;因而它们的统一是在国家中被发现的,国家是普遍性与特殊性的合题。国家是一个处于差异中的统一。这似乎并不是一个真正的推导,但是黑格尔的确总结说,普遍的东西与特殊的东西的合题在于个别的东西之中。在这种情况下,国家被构想为一个个体,真正的个体,一个诸多个别的个体的有机统一体。
黑格尔没有将国家构想为一个从外部强加于个体的权威。他也不认为国家是公意或大多数人意志的产物。黑格尔说,国家“是绝对的理性——实体性的意志”,此外,“国家是伦理理念的现实性。”黑格尔赋予国家以一个人的特性,说它代表了普遍的自我意识。他说,一个特殊的个体,在其是这个更大的自我的一部分的情况下,意识到他的自身。黑格尔说,“因为国家是客观化了的精神,因此个体只有作为国家的一个成员时,自身才有客观性、真正的个体性和伦理的生活。”一个人的精神实在也是在国家中找到的,因为如黑格尔所说,一个人的“精神实在在于他自己的本质——理性被客观地展现给他,在于它对他而言具有客观的、直接的存在”。考虑到黑格尔无意构造一个理想国家的理论,他对“现实的”国家的描述就更引人注目了,关于现实存在的国家,他说“国家是理性自由的体现”,而最引人注目的是,“国家是存在于地上的神圣理念”。
所有这些村国家溢美之词使得黑格尔看上去是在拥护极权主义的国家。但是他的确坚持国家应保护个体的自由,我们是凭借这种自由才成为市民社会的成员的。国家既没有毁灭家庭,也没有毁灭市民社会;它们继续存在于国家之内。国家的法律以及——一般来说——国家的立法和执行机关并不是武断地颁布法令的。法律是普遍的规则,它们在涉及到个体的个案中有其运用,此外,法律必须是理性的而且是针对理性的人的。之所以有法律是因为人们具有自由选择的能力,他们有能力选择对他人有害的结果。当他们的行动伤害了他人时,他们这些行动就是非理性的。因此,法律的功能就是将理性带人行动之中。一个行动之所以是理性的,乃在于它同时既达到了个人的利益又达到了公共的利益。只有一个理性的行动者才能够获得自由,因为只有理性的行动在社会中才被允许,因为只有理性的行动才能避免社会危害。因此国家的功能就不是通过颁布任意的,因而是非理性的命令来解决个人的伤害或痛苦,而是通过它的法律增加理性行为的总和。因而国家就是一个有机体,它就如同其每个个体成员一样,力求把自由理念发展到最大限度并求得客观的自由。这样,国家的法律与其说是任意的,不如说是个体若理性地行动就会自己选择的理性的行动规则。理性所允许的对个体意志所作的惟一限制就是由于其他意志的存在而要求的限制。统治者以普遍意志、理性的名义行动,而不是任意武断地行动。于是,国家“就是处于人类意志和自由的外在显现中的精神理念”。
谈到国家之间的关系,黑格尔强调每个国家的自治和绝对的主权。在黑格尔看来,两个国家之间的关系不同于市民社会中两个人之间的关系。当两个人有分歧时,国家是解决这一纷争的更高权威。但如果两个国家有分歧,就不存在解决这一矛盾的更高的权力了。每一个国家,黑格尔说,“都是实体性的理性的精神,并有其直接的现实性,因而都是地上的绝对权力”。由于这一原因,“每个国家相对于其邻国都是拥有主权的和自治的。国际法的基本主张是闲家之间的义务应该保留。”但是黑格尔说,“国与国在相互关系中是处于自然状态中的”,因此不存在任何约束它们的普遍意志。“国家的法只是在它的特殊意志中”,在没有凌驾于它们之上的组织力量的情况下,“才得以现实化”,在国家之间不存在任何仲裁者。
我们不清楚黑格尔为什么不继续他的辩证法运动到下一阶段,在这一阶段个别国家将被联合为一个国家共同体。他当然意识到康德已有通过国家联盟调解纷争以维护“永久和平”的思想。但是黑格尔说,这样一个安排是不会起作用的,因为那仍然会需要每个国家都愿意服从国际法庭。但是一个国家总是会以它自己的利益为意愿。事实上,黑格尔说,“利益是支配国与国之间关系的最高法律”。不存在对国家的道德限制,因为国家是“伦理实体”。于是,“如果国家间有分歧,并且它们的特殊意志不可能互相协调的话,那么问题就只有通过战争来解决。”
世界历史 在黑格尔的观点中,世界的历史就是民族国家(nations)的历史,历史的动态展开表现了“自由意识的进展”。这一过程不完全是偶然的,而是一个理性的过程,黑格尔说,“理性支配着世界…世界历史因而是个理性的过程。”国家在某种特定意义上是理性的载体,因此黑格尔曾经说国家是具有外在形式的“精神理念”,是“存在于地上的神圣理念”。但是历史过程的辩证法在于国家之间的对立。每个国家都表现了一种民族精神,并在其集体的意识中表达出世界精神。诚然只有个体心灵能够有意识。但是一群特定人民的心灵发展出一个统一的精神,因此我们可以说某种“民族的精神”,每个民族精神都代表了世界精神发展中的一个环节,民族精神之间的相互影响体现了历史的辩证法。
由于历史过程是实在的内容,是自由理念的逐步展现,因而民族之间的冲突是不可避免的。诸民族被历史的大潮推动,所以在每一个时代,都会有一个特定的民族是“这个时代世界历史中占支配地位的民族。”一个民族不能选择它何时强大,因为“它能够引人注目的时刻只有一次。”黑格尔说,特定的世界历史性的人物在历史的关键性时刻作为世界精神的代表出现。这些人把国家带向一个发展和完善的新高度。黑格尔认为,对这样的个人的 评断几乎不能根据一个国家正在从中走出的那个时代的道德来进行。相反,这样的人的价值在于他们对自由理念的展开作出的创造性的响应。
在黑格尔看来,历史的时间过程同时也是辩证的逻辑过程。历史朝向一个有目的的终点即自由而运动。为了展示历史的辩证法,黑格尔举了很多民族的例子,他认为它们显示了自由发展中的三个环节。他认为,亚洲人对自由一无所知,只知道君主一个人能够为所欲为。虽然古希腊人和古罗马人知道公民权的概念,但他们只将之赋予一小部分人,而把其他人视作天生的奴隶。日耳曼民族在基督教的影响下形成了人是自由的这一洞见。于是,黑格尔说,“东方人过去只知道,现在依然也只知道一个人是自由的;希腊人和罗马人知道一些人是白由的;日耳曼世界知道一切人都是自由的。”我们已经了解到,在黑格尔看来,当个体根据整个社会普遍的、理性的意志行动时,最高的自由就出现了。
绝对精神
黑格尔的哲学在我们对绝对的知识中达到了顶点。在辩证过程中,对绝对的知识是主观精神与客观精神的合题。因为实在是理性(思想、理念),那么在黑格尔看来,我们关于绝对的知识实际上是绝对通过人类的有限精神认识到自身。黑格尔在辩证法的最后阶段描述了绝对的自我意识这一环节是如何在人们的精神中发生的。
黑格尔说,我们依次经过从艺术到宗教,最后到哲学这三个阶段,就达到了对绝对的意识。艺术通过给予我们感性对象而提供了“理念的感性显现”。在艺术的对象中,心灵将绝对把握为美。此外,艺术对象也是精神的创造,从而包含了理念的某个方面。我们从亚细亚的象征艺术推进到希腊古典艺术,最后是基督教浪漫艺术时,这是一个对绝对的不断深入的洞察。
艺术超越自身而达到宗教。宗教不同于艺术,它是一个思想的活动,而一个审美经验则基本上是情感的问题。虽然艺术能够引导意识朝向绝对,但宗教肯定要离绝对更近,因为绝对乃是思想。同时,黑格尔说,宗教思想是表象的思想。在早期的宗教中,这一表象的要素所占比重很大。例如“希腊的神是质朴直观与感性想象的对象。它的形象因而就是人形的。”宗教的顶点是基督教,它是精神的宗教。
黑格尔把基督教看作哲学的表象性体现。他相信哲学与宗教有着同样的主题,相信它们都代表了“关于永恒的东西的知识,关于上帝是什么以及由它的本质产生了什么的知识”,这样,“宗教与哲学考虑的就是同样的事情”。哲学抛开宗教的表象形式而上升到纯粹思想的层次。但是哲学并不提供绝对在任何特定的环节中的知识,因为这样的知识是辩证过程的产物。哲学自身有其历史,是一个辩证的运动,哲学的主要阶段和体系不是杂乱无章地发展的。这些哲学史上的体系代表了理念前进展开所要求的必然的思想演进。因而在黑格尔看来,哲学史就是绝对的自我意识在人的心灵中的发展。
14.3 叔本华
叔本华是黑格尔同时代的人,但他不承认黑格尔是康德的合适的或者当之无愧的继承者。叔本华十分瞧不上黑格尔,以他说:“在康德和我自已之间的这段时间里没有哲学;只有大学里假充内行的伎俩。”他对黑格尔的这一抨击与下面的评论是一脉相承的,“我们从休谟著作的任何一页所学到的东西,都比从黑格尔的全部哲学著作中学到的东西要多。”但是黑格尔并不是叔本华尖刻批评的惟一靶子。在下面的判断中他表达了范围更广的轻蔑:“我倒要看看,有谁能自称他的那批同代人比我更遭受困顿。”在别人看来是妄自尊大的说法,对叔本华来说,只是意味着他认识到了自己无与伦比的天禀,正如他说的,一个人对自己比一般人是更高还是更矮,是心知肚明的。因此他毫不犹豫地说,“我比以前任何一个人都更高地掀起了真理的面纱。”
叔本华的生平
奥瑟·叔本华(Arthur Schopenhauer)于l788年生于但泽。虽然他的祖先是荷兰人,但很早之前他们家族就定居在这座德国城市了,这一家族有着古老的传统,与汉萨同盟有着许多商业往来。他的祖先地位显赫、家资富有。当俄罗斯的彼得大帝和凯瑟琳皇后访问但泽时,他们就下榻在叔本华曾祖父的住所。他的父亲是个富有的商人,希望叔本华跟着自己也做个商人。叔本华小的时候就跟着父母做了很多旅行,这使他见识到了形形色色的文化和习俗,也使他形成了一种鲜明的世界主义的视角。虽然他从在法国、意大利、英国、比利时和德国的这些旅行中获得了很多东西,但他早期系统的教育也因此被中断了。不过他的学习能力极强,使他得以很快弥补上正规教育的不足。
叔本华9岁时在法国开始上学;两年之后他回到了德国,在德国他受到的教育主要集中在经商的技能方面,很少把经典著作作为要务。但是叔本华很快就显示出很强的哲学兴趣,这令他的父亲很不高兴。他的父亲担心搞哲学只会导致贫困。在英格兰和瑞士做了更多的旅行和学习之后,叔本华回到但泽,当了一个商人的办公室职员。此后不久他父亲就去世了。他17岁的时候就独立生活,和母亲关系既不密切,也很少互相照顾。他和他母亲的脾气截然相反,她生性十分乐观,喜欢享乐,而叔本华在童年就有悲观主义的倾向。两个人之间的这种差异使得他们不可能生活在一起。后来,他的母亲移居到魏玛,她写信给叔本华谈到耶拿战争和魏玛沦陷说,“我可以说些令你毛骨悚然的事情,但是我忍住了,因为我知道你是多么喜欢在任何一件事情上为人类的不幸而焦虑。
到21岁的时候,叔本华已经充分弥补了他早年所受教育之不完全的状况,他开始对古典作品有了深入的研究。他在语言方面的出色天赋使他自如地学习了希腊文、拉丁文、历史,他也没有忽略数学。现在他准备从事一项新的事业,1809年他被哥廷根大学医学院录取了。不过第二年他就转到了哲学系,他被“神圣的”柏拉图和“非凡的康德”所吸引。叔本华完成了规定课程的学习,为了拿到耶拿大学的博士学位,他写了一本题为《论充足理由律的四重根》(On the Fourfold Root of the Principle of Sufficient Reason)的书,于l813年出版。诗人歌德对此书曾有好评;但是它在读者中间几乎没有引起什么注意,卖不出去。在歌德的建议下,叔本华开始研究光的问题。歌德和牛顿对光学进行探讨的观点是很不 一样的。叔本华通过研究写出了一本小册子,名为《论视觉与色彩》(On Vision and Colours),倾向于支持歌德的观点。
《作为意志和表象的世界》(The World as Will and Idea)是叔本华的代表作,这本书是他在1814年到1818年幽居德累斯顿时写的,出版于1819年。这本书仍然没有引起什么注意,销量甚少。它包含了叔本华完整的哲学体系。他确信在这本书中自己已经作出了最具特色的贡献,并且相信自己找到了许多长期存在的哲学问题的答案。他写道,“我的哲学是在人类知识的限度之内对世界之谜的真正解答。”他似乎已经准备好面对肤浅的批判以至粗暴的蔑视,他写道,“一个完成了不朽著作的人是不会由于公众对它接受与否或批评家的意见如何而受到伤害的,正如一个健全人在疯人院里不会为精神病人的谴责所影响一样。”
叔本华从德累斯顿前往柏林,开始在柏林大学授课。他期望人们接受或者至少认识到他的哲学体系。他的努力失败了,这部分是由于学术界对他的观点持续的漠视,也是由于他过于自信地把自己授课的时间恰好排在伟大的黑格尔授课的同一时间。1831年,叔本华为了躲避霍乱——这场霍乱就夺去了黑格尔的生命——而离开了柏林。他定居在美茵河畔的法兰克福,写了一些书,进一步探讨并论证了《作为意志和表象的世界》的基本思想。其中有《自然界中的意志》(On the Will in Nature,1836),在这本书里他试图为他的形而上学理论提供科学知识上的支持。1838年他因“意识的证据能否证明自由意志”一文而获得了挪威的一个科学协会授予的奖金。还有一篇关于道德之起源或基础的论文也是应征丹麦皇家科学院的作品。但即使叔本华是惟一一个提交论文的人,他还是没有赢得这笔奖金。不过这两篇文章在l841年以《伦理学的两个基本问题》(The Two Fundamental Problem.s of Ethics)为题出版。1851年他出版了另一本主要的著作《附录和补遗》(Parerga and Paralipomena),它是一部涉及许多主题的论文集,包括“论女人”、“论宗教”、“论伦理学”、“论美学”、“论自杀”、“论世界的苦难”和“论存在的空虚”。从这本书起,他开始广为人知。
我们发现叔本华的哲学既来源于他所专注学习的东西,同样也来源于他悲观主义的个人气质。在叔本华早年,他的一个老师建议他把自己的哲学研究集中于柏拉图和康德,我们可以在他所有的主要著作中发现这两位哲学巨擘的影响。此外,叔本华还为他的形而上学理论洞见发现了另一个强有力的然而有些不可思议的来源,即印度经典《奥义书》(Upanishads)。是一个叫弗里德里克·迈耶尔的研究亚洲的学者引起叔本华对这本书的关注的,这个学者写了一部《梵天或印度宗教》(Brahma,or the Religion of the Hindus)。这种亚洲州哲学为叔本华由他的理智和气质的结合而得出的如下结论提供了支持:我们所经验到的仅仅只是现象。“这就是一切吗?”“这就是生活吗?”答案是一个悲观主义的“是”。叔本华的悲观主义当然是他气质的问题。但是他力图在如下两者之间作出区分:一方面是他的悲观主义,他认为这是他基于对“愚妄的客观认识”而下的成熟判断所导致的结果,另一方面是“坏人的恶毒”。他称自己的悲观主义是“一种高尚的悲情,完全是来自一种更好的本性,这种本性在起而对抗不可预料的邪恶。”他补充说,他这样的悲观主义不仅仅是针对特殊的个体的,而且是“针对所有人的,每个人都只是一个例子。”我们甚至可以说,叔本华的形而上学体系绝不仅仅是处理形而上学问题的另一种方式,毋宁说它是对生命和实在的悲观见解所作的精致的形而上学辩护。
充足理由律
和许多原创性思想家一样,叔本华在其早年就获得了他主要的哲学洞见。在他25岁时写的博士论文《论充足理由律的四重根》中,叔本华思想体系的基础就已经形成了。在这本书中.他试图回答“我能知道什么?”以及“事物的本质是什么?”如果这听起来有些大而无当的话,那么可以说,他是想对整个实在领域给出一个不折不扣的彻底说明。他是借助于充足理由律来达到这一目标的。
用最简单的形式表述,充足理由律就是,“没有什么东西是没有理由(原因或根据)的。”这一原则最明显的运用是在科学领域中,科学中物理对象的活动和相互关系以一种足以满足理性要求的方式得到了解释。但是叔本华发现,充足理由律除了科学的形式之外,还有其他多种形式。他说,这是因为除了科学所处理的对象之外,还存在着其他一些对象,它们要求这一支配性原则的独特形式来处理。
叔本华一共提出了充足理由律的四种基本形式,它们分别对应于四种不同的表象。这些思想涵盖了整个人类思想领域。存在着四种对象,它们引起了四种不同表象。
1.物理对象 它们在时空之中实存并发生因果关系,我们通过对事物的日常经验而知道它们。它们也提供了诸如物理学之类的物质科学的研究题材。在这一点上,叔本华紧紧追随着康德的基本理论,即知识从经验开始,但不像休谟设想的那样被限于经验性地被给予或呈现给我们的东西。相反,经验的要素被我们人类的心灵所整理。我们的心灵把空间、时间、因果性这些先天范畴加于经验,这些范畴就像一些透镜,我们是透过它们来观察对象的。在这一属于现象的领域里,充足理由原则解释生成或变化。
2.抽象概念 这些对象具有我们从其他概念抽取出来的结论的形式,比如当我们运用推理或推论的规侧时所做的那样。概念与它们推出或蕴涵的结论之间的关系服从充足理由律。这是逻辑的领域,充足理由律在这里被运用于认知的方式。
3.数学的对象 在这儿我们遇到了例如算术与几何学之类的科学,它们与空间和时间相关。几何学建基于支配着空间各部分诸多不同位置的原则。而算术则涉及时间的诸部分,因为如叔本华所说,“所有计数都基于时间各部分的连接。”他总结说,“时空各部分根据一个规律而互相规定,我称这个规律为存在的充足理由律。”
4.自我 “自我如何能够成为一个对象?”叔本华说,自我是意愿的主体,这个意愿主体是“认知主体的对象”。我们可以称之为自我意识。支配我们对于自我和它的意愿行动之关系的知识的原则,是“行动的充足理由律,更简洁地说,是动机的规律。”
由充足理由原则的这四种形式,叔本华得出如下引人注目的结论,必然性或决定论无处不在。他在整个对象领域中都强调必然性的事实,不管它们是物理对象、逻辑的抽象概念,数学对象还是作为认知主体之对象的自我。这样我们就遇到了物理必然、逻辑必然、数学必然和道德必然。事物之本质中的这一必然性要素使得叔本华认为,人们在日常生活中的行为受到必然性的支配。我们只是对由我们的性格所产生的动机作出反应,而不管我们是否能改变这些动机的特性。必然性的无处不在在叔本华心里引起了一种深刻的悲观主义感受,他所有关于人的生存的著作都充满着这种感觉。一旦考虑到他对人在宇宙中地位的解释,他的这种悲观主义就是可以理解的了。这一解释是他的主要著作所关注的中心间题。
作为意志和表象的世界
叔本华的名著《作为意志和表象的世界》一开篇就是一句惊人之语:“世界是我的表象。”这句话令人震惊的地方在于,它的每个字和这本书题目中的每个字一样,如果被赋予其普通的日常含义的话,就会传达出一种奇特的印象。叔本华用“世界”这个词所表示的意思,他对“意志”的定义和赋予它的作用,以及他对“表象”的解释,都给这些词带来了独一无二的意义,从而构成了其形而上学理论的主要洞见。
世界 对叔本华而言,“世界”这个词有着它所能具有的最广泛意义。它包括人类、动物、树木、恒星、月亮、地球、行星,事实上它包括整个宇宙。但为什么称之为我的表象?为什么不简单地说世界“外在于那里”?此前,英国哲学家乔治·贝克莱已经阐明了这样一个命题,存在就是被感知。如果一个东西要存在就得被感知,那么当你没有在知觉它时,这个东西又将如何?如果你走出图书馆,馆里的书籍还在那儿吗?但是叔本华坚持认为,一个对自己关于世界的经验进行了细致反思的人会发现,“他所认识到的并不是太阳或是地球,而永远只是眼睛,是眼睛看见太阳,永远只是手,是手触及大地。他会发现自己周围的世界只是作为表象而存在着。”叔本华说,这意味着“对于认识而言所存在的一切,因而整个世界,都只是与主体相关联的对象,是感知者的感知,一句话,都只是表象。”
作为表象的世界 “观念(idea)”这个英文词并没有传达出叔本华使用的德文词Vorstellung的意义,这两个词义的差别有助于解释为什么“世界是我的表象”这句话在我们听来会显得很奇怪。叔本华所使用的“表象”这个词照字面意思讲,是指一个“摆在面前”或“置于面前”的东西,是一个“显现”之物。它指任何一个被呈现于或被置于我们的意识或知性之前的东西,因而“作为表象”的世界或“我的表象”就不仅仅是指我们想到的东西(狭义上的观念),而同样也指我们听到、触到或以其他各种方式知觉到的东西。除了我们知觉到的东西,不存在其他什么客体,或者就如叔本华所说的,“整个现实的世界乃是被知性规定为现实的,舍此无物存在。”世界呈现自身于人就如一个客体呈现于一个主体,而作为主体的我们只知道我们所知觉的世界,因而,“整个的对象世界是并且一直是表象,从而完全地,也永远地被主体所决定。
有可能没有人对世界的表象是完善的,因而“我的表象”会与“你的表象”不尽相同。但由于这样一个简单的原因——即除了我知觉到的东西或被置于我的知性之前的东西,其他我一无所知——每个人都可以说“世界是我的表象”。此外,即使我不再存在了,“世界’也无疑会继续存在。但是,除了知觉到的这个世界,我并不知道一个更实在的世界。知觉是知识的基础。除了知觉之外我们还能形成抽象概念。这些抽象概念,例如“树”和“房子”的概念,有着非常实用的功能。叔本华写道,“借助于这些抽象概念,知识的原材料就更容易被加以把握、勘察和整理。”抽象概念因而决不仅仅是不着边际的空想。叔本华认为,事实上,抽象概念的价值取决于它们是否建基于原始的知觉,或者说是否是从这些原始知觉“抽象”而来的(原始的知觉就是实际的经验),因为“概念和抽象如果最终并不指向知觉就会像林中那些并不通往森林外的小路一样。”因此,说“世界是我的表象”并未暗示我对世界的表象是一个抽象的概念,除非这个概念牢牢地建基于知觉。那么,世界之所以是我的表象,是因为它是一种客观的或经验性的呈现,呈现给作为知性主体的我。
作为意志的世界 在需要对叔本华所用的语言加以澄清的种种场合中,最重要的莫过于他对“意志”一词的使用。通常,我们用“意志”指有意识地、深思熟虑地选择某种行为方式。我们将它认作一个有理性的人的属性或能力。毫无疑问,意志受到理性的影响。但这一解释并不足以使我们理解叔本华对“意志”这个术语的用法——他的这个用法别出心裁而意义重大,构成了叔本华哲学体系的核心主题或本质。
叔本华的意志概念表现出他对康德物自体理论的主要异议。康德说我们永远也不可能知道自在的事物是什么样子。我们始终在事物之外,永远也不能洞察事物自身的内在本质。但是叔本华认为他已经发现了“惟一一扇通向真理的窄门”。他说,在我们永远都处在事物之外这一点上,存在着一个重要的例外,这就是“我们每个人都有的,对于自已的意志活动”的体验或认识。我们身体的行动通常被认为是意志活动的产物。不过在叔本华看来意志活动和行动不是两个不同的东西,而是同一个东西。“身体的活动不是别的,只是客体化了的意志活动…说意愿和行为不同,这只是一种反思。”在我们的意识中,我们对自己所知道的是,“我们不仅是一个认知的主体,从另一方面看,我们自己也属于要被认识的内在本性。”他的结论是,“我们自己就是物自体。”而这个物自体就是意志,或者像叔本华说的,“意志的行动…是物自体最贴切最分明的表现。”这样,通向真理的惟一窄门就是发现意志是每一个人的本质。虽然我们永远在其他事物之外,我们自己却属于能被认识的内在本质。这使叔本华得出结论,“从‘我们自己'内部出发的这条道路实际上是为我们通向物自体所属的内在本性而散开着的”,因而“在这个意义上我教导说,所有事物的内在本性就是意志。”而既然“所有事物”构成了世界,所以叔本华就认为,我们必须将世界看作意志。
对叔本华来说,意志不仪仅属于有理性的人。在所有事物中——在动物中,甚至在无生命的事物中——都可以发现意志。事实上只有一个意志,每个事物都只是那个意志的特殊显现。叔本华将意志的作用归于一切实在,他说,“意志是所有事物中内在的、无意识的身体功能的承担者,有机体自身不是别的,只是意志。在所有的自然力中,积极的推动力就是意志。在所有我们发现有任何自发的运动或基本的力量的情形中,我们都必须将最内在的本质看作意志。意志在一棵橡树中展现自身和在一百万棵橡树中呈现的一样完全。”这样,整个自然界都存在着一种到处弥漫的力、能,或叔本华所谓的“一种育目而持续的冲动”。此外,他还谈到意志是“无尽的努力”,这种冲动在整个自然中发生作用而“不自知”,而归根到底,它是“生存意志”。
悲观主义的基础
这里我们看到了叔本华悲观主义的理由。他的意志概念将整个自然系统描绘为在所有事物中的驱动力的作用下不断运动的状态。所有事物就像“受其内部的发条驱动的”玩偶。最低级的存在物(如变形虫)或最高级的存在物(一个人),都被同一种力——意志所驱动。那产生人类行为的盲目意志“和使植物生长的意志是同一个意志”。每个个体身上都带有“被强迫状态”的印记。所以叔本华拒斥如下假设:由于动物只被本能支配而人是理性的存在者,因而人比动物高级。他说,理智是被普遍意志造成的,所以,人类理智就和动物本能处于同一水平。此外,人类的理智和意志不能被认为是两种各自独立的能力。相反,在叔本华看来,理智是意志的一种属性;它是第二性的,或者在哲学的意义上说,它是偶性。理智只能在短时间里维持其活动。它会的力量会衰弱,并且需要休息,归根到底,它只是身体的一种功能。相反,意志则持续不间断地延续下来并支撑着生命。在无梦的睡眠期间,理智并不起作用,而身体的有机功能则继续着。这些有机功能是意志的显现。叔本华说,其他思想家谈论着意志的自由,而“我证明了它的全能”。
意志在所有自然物中的全能对人类来说有着悲观意味。如叔本华所说,“人类只是表面上被前面的东西牵引:他们实际上被后面的东西推动;决不是生命诱使他们前进,是必然性驱使他们向前。”整个自然界中最基本的驱动力是生殖。生存意志的目的只是为了维持生命的循环。叔本华将自然领域描述为一场惨烈的斗争,在这里生存意志不可避免地导致持续的矛盾和破坏。生存意志为了自然中某个成分的生存,就要对其他成分或其他参与方加以破坏。这一冲突并没有违背任何意图或目的:意志的根本驱动力必然会出现这一结果。叔本华谈到一个关于爪哇的报道,那里一眼望去都是骨骼,令人恍如置身战场。它们是大海龟的骨骼,这种大海龟有5英尺长、3英尺宽、3英尺高。它们爬上岸产海龟蛋。这样一来它们会受到野狗的攻击,这些野狗扑到它们的背上,剥去它们的硬壳,活生生地吃掉它们。叔本华说,“这一悲剧年复一年地重演了千万遍。那些海龟就是为此而出生的…这里生存意志把它自身客观化了。”
如果我们从动物世界转到人类,叔本华承认问题变得更为复杂,“但基本的特征是不变的”。个体的人对自然而言没有任何价值,因为“自然所关心的不是个体而是类”。人的生命因此就决不是用来享受的天赐赠礼,“而是一个任务,一个要完成的苦役”。成千上万的人被统一为各个民族,争取着共同的利益,但千百人为了它而倒下去成为牺牲品。“是无意义的幻觉而不是引人入胜的政见激发他们去互相争斗的…在和平时期,工商业活跃,各种发明产生奇迹般的效果,大海通航,从世界的各个角落搜罗来山珍海味。”但是叔本华问,所有这些努力的目的是什么?他回答说,“是为了在短暂的一段时间内维持那些转瞬即逝又痛苦不堪的个体生存。”
叔本华说,生命是一桩得不偿失的事情。人遵遇的困难和所得的回报之间不成比例,就是说,生命“为了一些没有价值的东西”而耗尽了我们的全部力量。“除了食欲和性本能的满足,或者不管什么情况下的一点点片刻的舒适”,未来是没有任何盼头的。他的结论是,“生命是一场交易,它的收益远远抵不上损耗。”没有什么真正的幸福,因为幸福不过是人的痛苦的暂时间歇。痛苦又是由欲望和需求引起的,而大多数的欲望是永远也不可能得到满足的。归根结底,人的生命“是毫无目的的努力”。“每个个体的生命…实际上总是一个悲剧,但是仔细考察,它有着喜剧的特征。”
有可能摆脱意志吗
一个人如何可能摆脱那压倒一切的意志力量(它遍布于整个宇宙)呢?叔本华提出,至少有两条出路,一是通过伦理学,一是通过美学。从道德角度看,我们可以拒斥激情和欲望:从美学的立场看,我们可以静观艺术的美。当然,这里有一个问题,即普遍意志的力量是否强大到了这样的地步,以致无论如何摆脱它,都只能是暂时的。
使一个人的生命变得复杂并引起他的痛苦的,是持续的生存意志。生存意志以无尽欲望的形式表达它自身。欲望产生了侵略、争斗、毁坏和自我中心。如果有什么办法能让人的欲望不那么强烈,一个人就可能至少达到片刻的幸福。诚然,叔本华总是提醒我们,“人实际上是一个可怕的野生动物…决不次于老虎和土狼。”不过我们可以不时地上升到超出事物领域的思想和意识的层次。当我们对事物和他人产生欲望时,就会出现问题,因为这些欲望的对象在食色之欲的层次上刺微了我们内在的生命意志。但是当这些生物性的机能得到满足时,人还有着反抗暴力和征服以维持肉体生存的目的。叔本华说,一个人甚至还能够超越这一层次而理解他所欲望的个别特殊对象和某些普遍一般对象之间的区别。就是说,我们不仅能够认识约翰、玛丽这些个体,还能够认识普遍的人性。这会使我们能够从对一个人的强然欲望转向对全人类的同情。在此范围内,欲望就让位于一种更无偏私的爱。这时,我们认识到我们所有人都有着同样的本质,这一意识可以产生一种温和的伦理学。或者像叔本华说的,“我真正的内部存在在每个生物中和在我自已的意识中一样都是直接实存的。承认这一点就会产生同情,所有无私的德性都是建基于此的,它的实践表现就是善行。对温和、爱、怜悯的呼唤都指向这一信念;因为这些让我]想起了使我们成为同类的那种东西。”
美的愉悦也能以类似的方式让我们的注意力离开那些激发我们侵略性的生存意志的对象.而集中于无关乎激情和欲望的静观的对象。当我们静观一件艺术品时,我们就成了一个纯粹的认知主体——与一个意愿主体恰恰相反。我们在艺术中,不论是在绘画还是在音乐中,所观察到的都是一般的或普遍的要素。我们在一幅人像画中看到的并不是一个特殊的人,而是我们都拥有的人性的某些方面的表象。这里叔本华所表达的思想与柏拉图的“理念”概念很类似,也表明他受到印度哲学的强烈影响。叔本华的伦理学和美学在这里也有着类似的功能,它们都试图将我们的意识从充斥着情欲的世俗奋斗提升到超越意志活动的层次。在这个层次上,最高的活动是悠闲的静观。
尽管叔本华试图借助伦理学和美学来摆脱普遍意志的限制和引导力量,但叔本华确实并没有在人类中找到一种真正自由的个体意志,他对人类行为主体的最后一言是:“我们个体的行动…决不是自由的…所以每个个体…不多不少只能做出他在那个特定时刻做了的那些事情,决不可能做出别的事情。”
第十五章 功利主义和实证主义
康德、黑格尔和叔本华的观点代表了19世纪哲学为回应早先的理性主义者和经验主义者之间的争论所采取的一个方向,也就是唯心主义的方向。按照康德和他的德国同仁们的看法,传统理性主义忽视了感性印象形成我们观念的内容这一明显事实。可是,传统的经验主义者也忽视了塑造我们的经验的我们固有的精神结构。于是,康德和德国唯心主义者们强调心灵在组织经验时所起的核心作用;这种作用事实上是如此具有核心性,以至于唯心主义者们认为心灵既是我们的感性经验的来源,也是这些经验的塑造者。然而,19世纪还有另外一种不取唯心主义路线的哲学思路。有些哲学家相信,经验主义者的观点大体上是正确的,而哲学的任务是要对经验主义的方法论进行提炼。在大不列颠就有两位这样的领军人物杰里米·边沁(leremy Bentham,1748-1832)和约翰·斯图亚特·密尔(John Stuart Mill,1806-1873)。边沁和密尔两人都不承认理性直观在我们探索知识的过程中的作用,相反,他们使整理和评价感性经验的技术精致化了。他们在这一点上最值得铭记的贡献是在伦理学领域,特别是功利主义的理论。按照这种理论,道德的行为就是为最大多数人产生最大的善的行为。在法国,奥古斯特·孔德(Auguste Comte,1798-1857)作出了类似的努力来对经验主义进行提炼,并建立了名为实证主义的哲学路径。按照实证主义,我们应当拒斥任何不是建立在直接观察之上的研究。
边沁和密尔的道德和政治观点戏剧性地影响了西方哲学的方向。很少有一种思维方式像他们的功利主义理论那样如此完全地吸引了好几代人的想象力。吸引人们的是这种理论的简单性和对我们大多数人已经相信的东西——即每个人都追求快乐和幸福——的证明方式。从这一简单的事实出发,边沁和密尔论证说,道德的善包含为最大多数人实现最大量的快乐——以及减少最大量的痛苦的意思。
对道德善的这样一种直截了当的说明不仅因其简单性而可取,而且在边沁和密尔看来还具有科学的精密性这一优点。以往的伦理学理论或是以上帝的诫命,或是以理性的命令,或是以实现人性的目的,或是以服从定言命令的义务,来理解道德的善。这一切引起了一个聚讼纷纭的问题:这些诚命、命令、目的和绝对命令包含着些什么东西?然而,功利的原则却是用每个人都知道的标准即快乐来衡量每个行为。为了绕开神学的道德教诲和柏拉图、亚里士多德的古典理论以及新近的康德的规范伦理学,边沁和密尔沿着他们自己的同胞英国经验主义者的哲学足迹前进。
霍布斯已经想要构建一种人性的科学,并且背离了传统的道德思想,转而强调人对自己的快乐的自利性考虑。休谟也摒弃了传统的哲学和神学的纠缠不清的麻烦,而围绕个人建立了自己的思想休系,否定人除了能认识普遍的物理规律之外还能够对普遍的道德律有任何认识。在休谟看来,整个伦理学都与我们对同情和愉快的体验能力有关,这是所有人都具有的一种能力,我们用它来“拨动一根所有人都与之共鸣的弦”。因此,边沁和密尔在道德哲学中并没有什么创新,因为他们的先驱者们已经以一般的形式阐明了功利主义的原则。使边沁和密尔成为最著名的功利主义者的是,他们在把功利原则和他们时代的许多问题联系起来这方面,比其他人做得更有成效。为此目的他们为19世纪的英国提供了不仅是道德思想上而且也是实践变革上的哲学基础。
15.1 边沁
边沁的生平
边礼沁1748年出生于伦敦汉底奇区红狮街,他很早就崭露出超凡的智力。还只有4岁时,他就已经在学习拉丁语法,八岁他就被送到威斯敏斯特学校,他后来说,那里的教育“惨不忍睹”。他12岁时进入了牛津的女王学院。在那里度过了并不特别愉快的三年之后——因为他看不惯他的同学们的腐化堕落——他于1763年获得了文学士学位并进入了林肯协会(Lincoln'slnn)m,按照他父亲的希望,为法律职业生涯作准备。同年他回到牛津,结果成了他的智力生涯中具有决定性意义的经历之一,因为他去听了威廉·布莱克斯通的法律讲座。这个事件之所以如此重要,是因为当他全神贯注地倾听这些讲座时,他说他“直接觉察到布莱克斯通重视自然权利这一谬见”,而这一经历使他自己的法律理论明确化了,他在这一理论中把“自然权利”的理论当作“夸夸其谈的胡说”而加以拒斥。他于1776年获得文学硕士学位,并且又返回到伦敦,但他对法律职业从来没有产生任何好感,并且决定不当律师。相反,他投身于一种生气勒勃的著述生涯,他认为法律和由于此法律而成为可能的社会现实处于一种可悲的状态,他试图对之加以改进,使之具有秩序和道德上的可辩护性。
因此,边沁主要是一个改革家。大体而言,他的哲学方向是建立在英国经验主义基础上的。洛克开明而自由的思想给了边沁有力的武器来反对那些基于偏见的观念。边沁读休谟的《人性论》(Treatise on Human Nature)大有收获,以至于他说这本书从他看待道德哲学的眼中“就像去掉了翳障一样”。他的第一本书《政府片论》(A Fragment on Goverment)出版于1776年,是抨击布莱克斯通的。这部《片论》也与发表于同一年的另一篇文献,即《独立宣言》,形成了对照。边沁认为《独立宜言》是一篇混乱而荒谬的语词大杂烩,它毫无根据地预设了自然权利的概念。他后来的作品有《为高利贷一辩》(Defense of Usury,1787)、著名的《道德和立法原则导论》(Introduction to the Principles of Morals and Legislation,1789)、《为宪法请愿》(A Plea for the Constitution,l803)和《关于议会改革的问答手册》(Catechism of Parliamentary Reform,1809)。由于这些著作,以及他个人对当时的社会政治问题的介入,边礼在其漫长一生中的大部分时间里都是一个富有影响力的公众人物,直到他1832年84岁时逝世。
功利原则
边沁以这句经典名言开始了他的《道德和立法原则导论》:“自然把人类置于两个最高主人的统治之下:痛苦和快乐。只有它们才能够指出什么是我们应当做的,也才能规定什么是我们将要做的。”受快乐和痛苦的支配是我们大家都承认的一个事实,我们力图趋乐避苦也是一个事实。然后他提出了他的功利原则,即“这样一条原则,它无论赞成或反对任何行为,所依据的都是哪些行为所表现出来的可能增长或减少…幸福的倾向。”边沁意识到他并没有证明幸福是“善”或“正当”的基础,但这并不是一个疏忽。他认为,功利原则的全部本性毋宁说正在于,一个人不可能推演出这种原则的合法性:“它能被用任何方式证明吗?看来它不能,因为被用来证明每个其他东西的原则自身是不可能被证明的;一个证明的链条必须在某个地方有它的开端。给出这样一个证明,既不可能,又无必要。”
但如果说边沁不能够证明功利原则的合法性,那么他倒觉得他至少可以拒绝那些所谓的“更高的”理论。在边沁看来,这些理论要么可以归结为功利原则,要么就比功利原则还要差,因为它们不具有清晰的意义,或者不可能被一贯地遵循。边沁举出了《社会契约论》及它对我们服从法律的义务的解释为例。首先,这里有一个困难,就是要确定是否曾经有过这样一个契约或协定。其次,甚至契约论本身也依赖于功利原则,因为它实际上是说,最大多数人的最大幸福只有当我们服从法律时才能达成。当其他一些人说善是由我们的道德感,或知性,或健全理性,或上帝意志的神学原则所决定的时候,情况也是一样的。边沁说,所有这些都是相互类似的,并且都可以被归结到功利原则。例如,“神学原则把每件事都归因为上帝悦乐这样。但什么是上帝的悦乐?上帝不会,而且显然现在也没有说给我们听或写给我们看。那么我们怎么能够知道他悦乐的是什么呢?通过观察什么是我们自已的悦乐,并且断言这就是他的悦乐。”因此,只有快乐和痛苦给了我们行为的真实价值。在私人的和公共的生活中,归根结底,我们大家关心的都是幸福的最大化。
约束 正如快乐和痛苦提供了行为的真实评价,同样,它们也构成了我们行动的原因。边沁区分了快乐和痛苦得以产生的四个根源,并且认为这些根源就是我们行动的原因,称之为约束。一个约束就是提供控制力量给行为规则或法律的东西,他把这四种约束称之为物理的、政治的、道德的和宗教的约束。他对它们解释如下:
一个人的财产或容貌被毁于火灾。如果这事发生在他身上是由于被称为偶然的事故,这就是一场灾难;如果是由于他自己的不小心(例如由于他忘了熄灭他的蜡烛),这就可以称作物理约束的惩罚;如果这事发生在他身上是由于地方司法官员的判决,就是属于政治约束的惩罚;而那种人们通常称作“惩罚”的东西,如果是因为无人施救,因为他的邻居由于厌恶他的道德品质而拒绝给他帮助,就是一种道德约束的惩罚:如果是由于上帝生气而直接采取的行动,表明是因为他所犯下的某种罪恶…那就是一种宗教约束的惩罚。
因此,在所有这些领域内,促成行动的原因都是痛苦的威胁。在公共生活中,立法者懂得,人们只有在一定的行动带有与这些行为有关的清楚的约束时,才会感到有如此行事的义务。这种约束当公民违背立法者规定的行为模式时,就是由某种导致痛苦的形式所构成的。因此,立法者所主要关心的问题,是必须确定什么样的行为模式会有利于增进社会的幸福,而什么样的约束最有可能带来这种增进。所以边沁的约束概念给义务一词提供了具体的含义。因为义务现在并不意味着某种不加界定的责任,而是意味着当一个人不服从道德和法律的规则时将会遭受的痛苦。康德认为一个行为的道德性依据在于拥有正确的动机而不是行为的结果。边沁却采取了对立的立场,认为道德性直接依赖于结果。他承认有些动机比其他的动机更有可能增进幸福。但仍然是快乐而不是动机赋予行动以道德的性质。此外,边沁采取了这种立场:一般说来法律只能惩罚那些现实地带来了痛苦的人,无论他们的动机是什么。边沁相信道德与法律的义务在这点上以前是相似的,因为在这两种情况下,行动的外在结果都比它背后的动机更重要。
苦乐计算 每个个体和每个立法者所考虑的都是避苦和趋乐。但快乐和痛苦也各有不同,因而有不同的价值。边沁谈到快乐和痛苦的单位——或者他称之为份额,想以此来达到数学的精密性。他建议在我们行动以前,我们应当计算一下这些份额的值。它们的值就自身来看是大还是小,在边沁看来取决于快乐的强烈性、持久性、可靠性,以及它的临近性。如果我们不只是就快乐本身来考虑它,而是考虑它导致什么结果的话,我们就必须计算另外的情况。这些情况包括快乐的多产性,或者说它有更多快乐伴随而来的机会,以及它的纯粹性,或者说快乐将会有某种痛苦伴随而来的机会。第七种情况就是快乐的广泛性,就是说,它所扩展到或由这一行动所影响到的人数。
在边沁看来,我们“一方面在计算一切快乐的总值,另一方面在计算一切痛苦的总值。如果在快乐方面有结余,这种结余就会给行为带来好的趋向…如果在痛苦方面有结余,这就会带来坏的趋向。”这种计算表明,边沁感兴趣的主要是快乐的量的方面,所以,如果所有的行为都能产生同样数量的快乐,那它们就是同等程度地善的。我们是否真的在进行这样一种计算,这是边沁预料到的一个问题,他的回答是:
也许有些人…会认为对这些规则进行那么精确的调整,完全是白费力气:因为他们会说,粗俗无知的人永远也不会为各种法则而烦恼,而激情也从不计算。但无知的危害可以矫正:并且…当痛苦和快乐这样重要的问题处于千钧一发时,如果这种痛苦和快乐达到最高程度的话,谁还会不去计算一番呢?人们确实在计算,有些计算得不那么精确,而有些较为精确:但一切人都计算。
法律和惩罚
边沁把功利主义原则运用于法律和惩罚方面,这令人印象特别深刻。既然立法者的职能是制止一些行为并鼓励另一些行为,我们应该如何把应该阻止的那些行为归入与应该鼓励的那些行为泾渭分明的一个类别呢?
法律的目的 边沁的立法方式是首先衡量“一个行为的损害”,这种损害在于后果,也就是在于由该行为所造成的痛苦或危害,而这种产生危害的行为必须被制止。边沁说,立法者所关心的既有原生的危害也有次生的危害。强盗把危害加于受害者,受害者失去了自己的财物,这就是原生的危害的例子。但抢劫也造成了次生的危害,因为成功的抢劫传递了一个信息:盗窃是容易的。这种暗示是危害性的,因为它们削弱了对财产的尊重,而财产就成了更不安全的了。站在立法者的角度看,次生的危害往往还比原生的危害更重要。因为,还是举抢劫的例子,受害者的实际损失也许远不如整个社会在稳定和安全上的损失那么大。
法律所考虑的是增进社会的总体幸福,而且它必须通过阻止那些可能产生危害性结果的行为来做到这一点。一个犯罪行为按照定义就是一个明显有损于社会幸福的行为。大多数情况下,政府会通过惩罚那些干出了被功利原则确定为有危害的违法行为的人,来完成自己促进社会幸福的职责。边沁认为政府在决定何种行为应被看作“违法行为”时只应当运用功利原则。如果他们这样做了,那么他那个时代的许多非法的行为就都会由此而变成只不过是私人道德问题了。所以功利主义的作用在于要求对行为重新进行分类,以确定什么行为是或者不是适合于由政府来规范的东西。此外,功利原则给边沁提供了一个新的而且简单的惩罚理论——这个理论在他看来比起旧的理论来不仅更容易被证明正当,而且能够更为有效地达到惩罚的目的。
惩罚 边沁写道:“一切惩罚本身都是危害”,因为它使人遭受损失和痛苦。同时,“一切法律共同的目的是增进社会的总体幸福。”如果我们要从功利的观点证明惩罚是合法的,我们就必须表明由惩罚招致的痛苦会以某种方式防止某些更大的痛苦。因此惩罚必须是在达到某种更大的总体幸福上“有用”的,而如果它的效果只是徒然给这个社会增加更多的痛苦单位或份额,它就不具有合法性。功利原则将明确要求排除纯粹的“果报”或报复,因为没有什么有用的目的是靠在社会所遭受的整个损失上再徒然加上更多的痛苦来达到的。这并不是说功利主义摒弃惩罚。这只是意味着功利原则,尤其是边沁的功利原侧,要求重新追问为什么社会要惩罚罪犯的问题。
在边沁看来,在四种具体情况下,不应施加惩罚。(1)如果惩罚是无根据的,它就不应当施加。例如这种情况:已经同意就一种违法行为进行赔偿,而这种赔偿的及时兑现又确有保障。(2)如果惩罚是无效的,它也不应当被施加。这里的情况是,惩罚不能够防止一种损害行为,比如一项法律已经制定但还没有颁布的时候。涉案的如果是未成年人、精神失常者或醉汉,惩罚也是无效的。(3)如果惩罚没有益处或花费太大,也不应当施加,“这时它造成的损害会比它所防止的损害更大。”(4)最后,如果惩罚是不必要的,也不应当施加,“这时损害可以在不施加惩罚的情况下得到防止或自行停止:这样代价就更小。”尤其在那些“在义务问题上散布有害的行为准则”的案件中是如此,因为在这些情况下说服比强迫要更有效果。
某种特定的行为是否应当留给私人伦理而不是成为立法的对象,这个问题边沁仅仅凭借援引功利原则就作出了回答。如果立法程序和惩罚机关参与其事的整个过程所造成的损失比好处还多的话,这个问题就应当留给私人伦理处理。他确信,试图规范两性关系上的不检点行为将是特别无益的,因为这将需要进行十分繁复的监视。还有某些过犯也是同样的情况,如“忘恩负义或粗野,在这些事情上因为定义模糊,所以做不到放心地向法官委以惩戒之权。”我们自己对自己负有的责任很难为法律和惩罚所关注,我们更不必被强迫去乐善好施,虽然我们也可能在某些特定场合下有义务对弱者施以援手。但法律主要关心的是鼓励那些可能导致社会最大幸福的行为。于是,对惩罚的一种合法性辩护就是,通过惩罚,最大多数人的最大利益最有效地得到了保障。
除了为惩罚提供理论依据外,功利原则也给我们提供了一些线索来思考惩罚包括些什么。边沁考虑到“惩罚和违法行为之间的比例”而描述了惩罚的每个单位或份额的适当性质。为此目的,他提出了如下规则。(1)惩罚必须足够重,超过罪犯可能由他的罪行中所获得的好处。(2)罪行越大,惩罚也越重:对较大罪行的惩罚必须足以导致一个人在两种罪行的权衡中宁可选择较小的罪行。(3)惩罚应当具有可变性和适应性,以适合各种特殊情况,虽然每个罪犯为同一罪行将得到同样的惩罚。(4)惩罚的力度决不应大于使之生效所需要的最小量。(5)一个罪犯越是不容易被抓住,惩罚就应当越大。(6)如果一个罪行是属于惯犯,惩罚就必须不仅是超过这一直接罪行的所获,而且也超过那些未被发现的罪行的所获。这些规则导致边沁作出结论说,惩罚应当是可变的,以适应具体的情况。它应当是一视同仁的,以使类似的罪行遭受同样的痛苦。它应当是可通约的,以使对不同种类的罪的惩罚是合乎比例的。它应当特点鲜明,好让那些潜在的罪犯一想起来就深受震慑。它应当有节制,以防止滥施无度。惩罚应当意在改过,以纠正错误行为。惩罚应当剥夺犯罪能力,以威慑今后的罪犯。惩罚应当对受害者有所补偿。为了不带来新的问题,惩罚应当让大众觉得可以接受,并且理由充分的话,可以予以减免。
边沁的激进主义
边沁很快就发现,英国的法律和一般社会结构的诸要素与功利原则所提出的要求并不适合。他想要立法程序严格按照功利原则来运行,就好像行星服从万有引力定律一样。这就是说,他希望给系统思维的概念加上系统行动的概念。所以凡是在他发现在现实的法律及社会秩序与功利原则不一致的地方,他都强烈地要求改革。他把这个法律体系中的大部分恶都追溯到那些法官,他指责说,这些法官“制定了普遍的法律。你知道他们怎么制定的吗?就像一个人给他的狗立法一样。如果你的狗做任何你想阻止它做的事,你就等着它做出来然后打它…法官们为你我立法的情形,便是如此。”在揭露了一个又一个巨大的弊端之后,边沁积极地尝试改革这些弊端,并且为此参加了一个由有类似思想的功利主义者组成的以“哲学激进派”闻名的团体。
边沁谴责当时的贵族社会败坏了功利原则。为什么即使在他推演出新的确定的行为模式能够产生“最大多数人的最大幸福”之后,社会的恶和法律体系的恶依然故我呢?他认为,答案就是,那些掌权的人不想要“最大多数人的最大幸福”。统治者考虑更多的是他们自己的利益。然而,从功利主义的角度看,每当这些掌权的人只代表一个阶级或一小群人时,他们自己的利益就会与政府的正当目的发生冲突。解决这种冲突的方式是把政府交到人民的手中。如果在统治者和被统治者之间有同一性,他们的利益就会是相同的,而最大多数人的最大幸福也就有了保障。这种利益的同一性很显然不可能在君主制下达到。君主的行为是为了他或她自己的利益,或者最好也不过是以他或她身边的那个特殊阶级的幸福为目标。而在民主制中,最大多数人的最大幸福是最容易得到实现的,因为统治者就是人民,而人民的代表恰恰是因为他们承诺要服务于这个最大利益才被选出来的。在边沁看来,功利原则的应用明确要求摒弃君主制连同其一切必然的后果。这就是说,他的国家应当不要国王、上议院和国教会,而要按照美国的模式建立一种民主秩序取而代之。因为“所有的政府都是一种巨大的恶”,那么政府存在的惟一的合法理由是,必须运用恶以防止或排除某种更大的恶。
15.2 约翰·斯图亚特·密尔
pass
15.3 孔德
pass
第十六章 克尔凯廓尔、马克思与尼采
在整个19世纪,康德、黑格尔和其他德国唯心主义者的观点对哲学、宗教、美学以及新的学术领域——心理学都有强烈的影响。这些哲学家们设计出精致的思想体系,引入复杂的哲学词汇,当时,许多哲学家信奉他们的观点,然而,有三位哲学家对这一潮流完全持批判的态度,他们是索伦·克尔恺廓尔(Soren Kierkegaard, 1813-1855)、卡尔·马克思(Karl Marx, 1818-1883)和弗里德里希·尼采(Friedrich Nietzsche,1844-1900)。尽管他们在自己的时代并不怎么出名,但是,他们每一个人都对下一个世纪的思想产生了深远的影响。克尔凯廓尔反对黑格尔的体系构建方法,认为对真理的追求是基于宗教信仰的,并且要求个人选择。马克思反对德国哲学的唯心主义方向和他那个时代的整个资本主义经济结构。他认为支配物质世界的规律最终会以共产主义社会制度取代资本主义。尼采既反对宗教价值体系又反对理性价值体系,而提出一种以个人选择为基础的道德取而代之。这三位哲学家在上帝存在之类的重要问题上观点互不相同。但是,他们有一个共同的信念,即19世纪的欧洲文化严重地功能失调。并且他们都认为,只有与主流的文化立场根本决裂,我们才能达到对人类生存和社会的正确理解。
16.1 克尔凯廓尔
克尔凯廓尔的生平
克尔恺廓尔于1813年出生在哥本哈根,他短暂的一生都奉献给了著述事业,成果辉煌。1855年42岁他去世之前,写下了大量著作。尽管他的著作在他去世后很快就被遗忘了,但是,在20世纪早期,他的著作被一些德国学者重新发现时,就开始产生巨大影响。在哥本哈根大学,克尔恺廓尔接受了黑格尔哲学的训练,但并没有对它产生好印象。当他在柏林听到谢林对黑格尔进行批评的讲座时,克尔恺廓尔同意对德国最伟大思辨思想家的这种抨击。克尔恺廓尔写道,“如果黑格尔在写完了他的全部逻辑学之后说…这仅仅是一种思想实验,那么,他无疑是最伟大的思想家。但现在,他只是一个滑稽演员。”在克尔恺廓尔看来,使黑格尔显得滑稽的是,这位伟大的哲学家试图在他的思想体系中抓住全部实在,但是,在这一过程中,却丢失了最重要的要素即存在。克尔恺廓尔用存在(existence)这一术语专门指人类的个体存在他说,存在,意味着某种个体,一个在进行奋斗、考虑不同可能性,作出选择,作出决定——最重要的是承担责任的个体。事实上,所有这些行为都没有包括进黑格尔的哲学。克尔恺廓尔的一生都可以看作是在自觉地反抗抽象思想,努力实践费尔巴哈的忠告:“不要希望成为一位哲学家而不是成为一个人…不要像思想家那样思想…要像一个活生生的、真实的存在者那样思想,…在存在中思想。”
人的存在
对克尔恺廓尔来说,从存在的角度进行思考意味着认识到我们面临着个人选择。因此,我们的思想应该处理我们自已的个人处境以及我们必须作出的重大决定。黑格尔哲学歪曲了人们对实在的理解,因为它把关注的焦点从具体个人转移到普遍概念。他要求个体去思想而不是去存在——去思考绝对思想而不是做决定和承担责任。克尔恺廓尔把旁观者和行动者区别开来,认为只有行动者置身于存在。当然,我们可以说旁观者存在,但是,存在这一术语严格说来并不属于惰性的或不活跃的事物,无论它们是旁观者还是石头。他通过比较四轮马车中的两种人来说明这种区别。一种人手里拿着缰绳却在睡觉,另一种人则是完全清醒的。在第一种情况中,马沿着熟悉的路走,不从沉睡着的人那里获得任何指令;在另一种情形中,那个人则是一位真正的驾驭者。当然,在某种意义上,我们可以说两个人都存在,但是,克尔恺廓尔坚持认为,存在必须是指个体的这样一种性质,即他有意识地参与到行动中。只有有意识的驾驭者才存在。同样,个人只有参与到有意识的意志行动和选择中,才能真正说得上是存在。因此,虽然旁观者和行动者在某种意义上都存在,但只有行动者才置身于存在。
克尔恺廓尔对理性知识的批评是非常严厉的。他厌恶古希腊思想中对理性的强调,指责这种精神充斥了后来的哲学和基督教神学。他的具体观点是,古希腊人高度敬重数学,这一点对古希腊哲学影响过甚。尽管他不想反对数学和科学的恰当运用,但是,他拒绝这一假设,即科学所特有的思想类型可以成功地应用于理解人类本性。数学和科学中没有人类个体的位置,它的价值仅仅是针对一般和共相的。同样,柏拉图的哲学强调共相、形式、真、善。柏拉图的整个设想是,如果我们知道了善,我们就会行善。克尔恺廊尔认为,这样一种伦理学思路歪曲了人们的真实困境。相反,克尔恺廓尔强调,即使在我们获得知识的时候,我们仍然处于不得不作出决定的困境。最终,各种哲学体系的那些宏大表述只是绕了一个更大的弯子,除非重新关注个体,否则这些体系终将一无所获。数学和科学无疑能够解决一些问题.正如伦理学和形而上学能够解决一些问题一样。但是,生活——每一个人的生活——与这种一般的或普遍的问题形成鲜明对照,它在对我们提出要求。在这些关键时刻,抽象思想是起不了作用的。
克尔恺廓尔从《圣经》有关亚伯拉罕的故事中看到了人类的典型处境:亚伯拉罕与他的妻子撒拉求嗣多年,终于生下一个孩子以撒,得偿夙愿。然后,上帝向亚伯拉罕提出,让他杀死他的儿子,作为人牲来进献。有什么知识能帮助亚伯拉罕决定是否服从上帝意旨呢?生命中最痛苦的时刻是个人的,在这些时刻,我们意识到我们自己是一个主体。理性思想模糊甚至否定这种主观因素,因为它只考虑我们的客观特性——那些所有人都共同具有的特性。但是,主观性是构成我们每个人的独一无二存在的东西。因此,客观性不能提供关于我们的个体自我的全部真理。理性的、数学的和科学的思想之所以不能够指导我们到达本真存在,原因即在于此。
作为主观性的真理
克尔恺廓尔说,真理是主观性。这一奇怪命题的意思是,对于做选择的人们而言,并没有预先构造好的真理“外在地在那儿”。正如美国哲学家威廉·詹姆斯讲的类似观点:真理是由意志行动“制造的”。在克尔恺廓尔看来,“外在地在那儿”的只是“一个客观的不确定性”。无论他如何批评柏拉图,但他的确从苏格拉底的自称无知中找到了这种真理概念的一个好例子。他据此说,“因而苏格拉底式的无知正是这一原则的表达,即永恒真理是与存在着的个体相关的,而苏格拉底始终以他个人经验的全部热情坚持这一信念。”这表明智力的培养并不是生活中惟一重要或关键的事情。更为重要的是我们的人格的发展和成熟。
在描述人类境况时,克尔恺廓尔区分了“我们现在是”与“我们应该是”。即有一个从我们的本质到我们的存在的运动。在发展这一观念时,他吸收了传统神学概念的内容,即我们的罪把我们与上帝分开。我们固有的人类本性包含一种与上帝的关系,我们的存在状况是我们从上帝异化的结果。如果我的罪恶行动驱使我更进一步远离上帝,那么我的异化和绝望就会更加深重。由于认识到我们的不安全性和有限性,我们试图“做一些事情”来克服我们的有限性,但是,我们的所作所为不过是在使问题恶化,加重我们的罪恶和绝望,使我们更加焦虑。例如,我们也许会投身于人群之中,想这样来为我们的生命找到某种意义,这个群体可能是一个政治联合体,还可以是教堂里的会众。克尔恺廓尔说,无论何种情况,“本来意义上的人群都是不真实的,因为事实是,它使个体完全不知悔过和不负责任,或者至少是把个体变成一块碎屑,从而削弱他的责任感。”在人群中只会消解我们的自我,从而毁坏我们的本性。在克尔恺廓尔看来,真正的出路是把我们与上帝联系起来,而不是与人群联系起来。惟有当我做到这一点时,我们的生命才不会充满焦虑。但是,转向上帝,常A常不是能一蹴而就的,克尔恺廓尔以“生命历程的三阶段”来描述这一过程。
美学阶段
克尔恺廓尔对“三阶段”的分析,与黑格尔关于人的自我意识的连续发展的理论形成鲜明对照。黑格尔把心灵的辩证发展过程说成是,我们通过思维的过程,从精神意识的一个阶段发展到另一阶段。克尔恺廓尔则把自我从存在的一个层次到另一个层次的发展说成是通过选择行动。黑格尔的辩证法逐渐走向对普遍的知识,克尔恺廓尔的辩证法则包含个体的逐渐实现。黑格尔用概念活动来超越反题,而克尔恺廓尔则是通过个人的承担来超越反题。
克尔恺廓尔说,这一辩证过程的第一阶段是美学阶段,在这一阶段,我根据我的本能冲动和情感行事。尽管在这一阶段我并不完全就是感性的,但是,我大体上是受我的感官支配的。因此,我对任何普遍的道德标准一无所知,没有明确的宗教信仰。我的主要动机就是要享受最丰富多样的感官快乐。我的生活除了自己的趣味以外再不受其他原则限制。我憎恶任何限制我的无限选择自由的东西。在这一阶段,我能够存在,只是因为我有意识地选择做一个感性的人。但是,在这一阶段,尽管我能达到某种存在,却是一种品质很低的存在。即使我也许会完全陷入感性生活方式中不能自拔,我仍然意识到我的生命应该包含比这更多的东西。
根据克尔恺廓尔的看法,我们必须区别我们的精神能力和我们的感性能力。他认为我们的精神能力建立在感性能力之上。能够对其他人做这种区分是一回事,但是,当我们在自已身上发觉这两种可能性时,就引发了我们自身中的辩证运动。感性冲动的反题是精神的诱导。在经验中,当我们发现我们事实上正生活在感性的“洞穴”中而且这一阶段的生命不可能达到真实的存在时,这种冲突就会导致焦虑和绝望。现在,我面临一次非此即彼的抉择:要么停留在有着致命诱惑和内在局限的美学阶段,要么就前进到下一阶段。克尔恺廓尔坚持认为,我不能单单通过思想来完成这种转变,而必须通过一种意志行动来做出一种承担。
伦理阶段
第二个阶段是伦理阶段。美学的人没有普遍的标准,只有他们自己的趣味。伦理的人则不同,他认识到并且接受理性所制定的行为准则。在这一阶段,道德准则赋予我的生命以形式和一致性这些要紫。并且,作为一个伦理的人,我接受道德责任对我的生活所施加的限制。克尔恺廓尔以各自对性行为的态度为例说明了美学的人与伦理的人的不同。在任何地方,只要有性吸引,美学的人就听任本能冲动的摆布,而伦理的人则接受婚姻的责任,把它视为一种对理性的表达。如果说,唐·璜是美学的人的典型,那么,苏格拉底就是伦理的人的范例,或普遍道德律至上的范例。
作为一个伦理的人,我持有道德自足的态度。在道德问题上,我持有坚定的立场,并且我像苏格拉底所主张的那样认定,知善就是行善。大体说来,我把道德上的恶看作要么是无知要么是意志薄弱的结果。但是,克尔恺廓尔说,辩证的过程终将要开始在伦理的人的意识中起作用。我开始认识到,我所陷入的是比对道德律知识不充分或意志力不足在层次上要更深的问题。我正在做的是比单纯的犯错误更严重的事情。我最终逐渐认识到,我实际上没有能力满足道德律的要求,甚至还故意违反道德律。于是,我意识到了我的过和罪。克尔恺廓尔说,罪过成了一个辩证的反题,它让我面临着一个新的非此即彼的选择。现在,我必须要么停留在伦理阶段,并且努力满足道德律,要么对我的新发现作出回应。这尤其包括发现我自己的有限性以及我正在远离那个我所从属并且从中获得力量的上帝。同样,我从伦理阶段向下一阶段的进展不能单单通过思想来完成,而是要通过承担的行为——即信仰的飞跃。
宗教阶段
当我们到达第三阶段即宗教阶段时,信仰与理性的差别尤为显著。我从美学阶段进展到伦理阶段要求一种选择和承担行为。它把我引到理性面前,因为道德律是对普遍理性的表达。但是,从伦理阶段进展到宗教阶段就大不一样了,信仰的飞跃并没有把我带到这样一个上帝的面前,似乎我可以理性而客观地把它描述为绝对并且可知的真理。正相反,我是站在一个主体的面前。因此,我不能以一种“客观的方式”探求上帝,或“客观地揭示上帝”。克尔恺廓尔说,这“永远是不可能的,因为上帝是主体,因此,在本质上只为主观性而存在。”在伦理阶段,我可能为了我理性地加以理解的伦理规律而牺牲自己的生命,正如苏格拉底所做的那样。但是,一旦碰到我与上帝的关系问题,我便没有关于这种关系的理性的或客观的知识了。
上帝与每一个个体的关系是一种独特的和主观的经验。绝不可能先于现实的关系而获得关于它的知识。任何企图获得关于这种关系的客观知识的努力都只能做到接近它。只有信仰行为才能确保我与上帝的个人关系。一旦我发现我在美学阶段和伦理阶段的存在是不充分的,在上帝那里实现自我的愿望就对我变得清晰起来了。我通过绝望和罪过,而被带入了生命中的关键时刻,遭遇到信仰上的非此即彼的最后抉择。我体验到我的自我异化,从中领悟到上帝的存在。当我看到上帝在一个有限的人类个体即耶稣的身上显现自已的时候,一个信仰悖论就出现了。说上帝这一无限者显身于耶稣这一有限者,这实际上是对人类理性的大不敬。克尔恺廓尔写道,这一悖论“在犹太人,会被认作障碍,在希腊人,则被认作愚妄。”然而,在克尔恺廓尔看来,要跨越人类与上帝之间的距离——一种在“时间与永恒之间的无限的质的差别”——别无他途:这不是通过思辨的理性——甚至也不是通过黑格尔的思辨理性;相反,是通过信仰,而信仰是一个主观的问题和承担的结果,并且它总是需要进行某种冒险。
克尔恺廓尔的哲学可以用他自己的话来总结,“每一个人的存在都必须通过本质地占有本质上属于人的存在东西来承担。”因此,“主体思想者的任务是把自己转变为一个工具,以在存在中清晰明确地表达一切本质上是属人的东西。”总之,每一个人都拥有一个他或她应当加以实现的本质自我。这一本质自我的确定正是由于这一事实,即人类必然无可逃避地与上帝相联系。当然,在生命历程的三阶段的任一阶段,我们都可以存在。但是,对绝望和有罪的体验,使我们产生了一种对不同类型的存在之间的性质差异的认识。我们还认识到,人的某些类型的存在要比另一些更加本真。但是,达到本真存在并不是一个理智的问题,相反,它是一个信仰和承担的问题,是一个在各种非此即彼的抉择面前不断进行选择的过程。
16.2 马克思
20世纪后半叶,马克思主义为世界上至少三分之一的人提供了官方哲学观点。若是考虑到,马克思成年以后的生活很大部分是在默默无闻中度过的,那么,他的观点对几代人产生如此巨大的影响,就更是非同一般了。他很少公开讲话,当他讲话时,也没有表现出演讲家的任何魅力和特质。他主要是一位思想家,完全潜心于阐述他的理论的复杂细节,而这一理论的大纲要目,是他还在二十几岁年纪轻轻的时候,就已经掌握了的。他很少与大众来往,虽然大众的状况是他的理论所关注的中心。虽然他著述甚丰,但是,他的著作在他生前并没有广大的读者。例如,在与他同时代的著名思想家约翰·斯图亚特·密尔的社会政治著作中,就没有对马克思的引述。马克思的观点也不是完全原创性的。马克思经济思想的很多东西可以在李嘉图的著作中找到。他的哲学可以在黑格尔和费尔巴哈的著作中找到某些前提和注脚,他的历史决定于社会阶级冲突的观点是来自圣西门,劳动价值理论则来源于洛克。马克思的原创在于,他从所有这些来源中提炼出了一个统一的思想框架,将其打造成了社会分析和社会革命的有力工具。
马克思的生平和影响
卡尔·亨利希·马克思,1818年出生在德国的特里尔,是一位犹太律师的长子,祖上世代都是犹太教拉比。尽管他有犹太血统,但在他的父亲出于实际考虑而非宗教信仰而成了一名路德教教徒之后,他也就被作为一名新教徒来数养了。老马克思以其理性和人道主义倾向而强烈地影响了他儿子的思想发展。青年马克思还受到路德维希·冯·威斯特华伦的影响,威斯特华伦是他家的邻居,一位杰出的普鲁士政府官员,也是他未来的岳父。他激起 了马克思对文学的兴趣,还有终生对古希腊诗人以及但丁和莎士比亚的崇敬。在特里尔的高中毕业后,马克思于1835年来到波恩大学,17岁时开始学习法律。一年后,他转到柏林大学,放弃法律而开始学习哲学。1841年,23岁的马克思获得耶拿大学的博士学位,博士论文题目是《论德谟克利特和伊壁鸠鲁的自然哲学的差别》。
在柏林大学,有着主导性影响力的是黑格尔哲学,马克思深受黑格尔的唯心主义以及他关于历史的动态观点的影响。他成为激进的青年黑格尔派的一员,该学派在黑格尔的哲学观点中发现了对人类本性、世界和历史的新理解的关键。黑格尔的思想是以精神(Spirit or Mind)概念为中心的。对他来说,绝对精神是上帝。上帝是实在的整体。上帝与全部自然是同一的,因而,上帝也存在于文化和文明的结构之中。历史就在于上帝按时间顺序逐渐的自我实现。自然之所以可知,是因为它的本质是精神。精神为了以完美的形式实现自己而进行着不断的斗争,这就产生了历史。因此,上帝和世界是同一的。于是,基本的实在是精神。并且,黑格尔主张,现实的政治维度——理念(the Idea),处于一个按其完善程度由低级到高级持续展开的过程中,而这就是我们所知道的历史的过程。历史是一个以三段模式运动的辩证过程,从正题(thesis)到反题(antithesis),最后到合题(synthesis)。
马克思是否曾全盘接受过黑格尔的唯心主义,尚无定论。但是,黑格尔把上帝与自然或世界同一起来的方法对他产生了强烈影响。黑格尔说,“精神(上帝)就是实在。它是世界的内在存在,它本质上就存在并且本来就存在(that which essentially is and is per se)。”无论存在着什么,无论有什么被认知,它都是作为自然的世界存在。在世界及其历史以外,没有任何存在。这种观点反对那种把上帝与世界分开的旧神学,内容新颖而意义重大,使马克思为之心动。尽管黑格尔并不想以他的观点摧毁宗教的基础,但是,柏林大学激进的青年黑格尔学派却对福音书进行了“更高层次的批判”。大卫·斯特劳斯(David Strauss)写了一本批判性的著作《耶稣传》(L证osus),他在书中认为,耶稣的许多教义完全是神话虚构,尤其是那些关于来世的部分。布鲁诺·鲍威尔(Bruno Bauer)则更进一步,干脆否认耶稣在历史上存在过。这些激进作家运用黑格尔上帝与世界同一的方法,摧毁了对福音书语言的字面解释,认为它的惟一价值在于它的形象化的力量而不是真实性。黑格尔主义的必然趋势是把上帝与人类同一起来,因为在自然中的所有事物,以一种独特方式体现着精神的要素。因此,这离哲学无神论只有一步之遥,黑格尔本人并没有走到这一步,但是,马克思等人则迈出了这一步。
黑格尔哲学的三种成分对马克思有直接的影响。第一是这样的思想:只存在惟一的一种实在性,而且它可以被作为世界中的理性之体现揭示出来。第二是认定,历史是一种在全部实在中,包括在物质自然界、社会和政治生活和人类思想中,由较不完善到较完善形式的发展和变化。第三是设定:任何特定时代和地方的人的思想和行为是由一个同一的精神——特定时代的时代精神——在他们中的作用引起的。尽管这些都是黑格尔主义在马克思思想中看来发生了刺激作用的一般主题,但其他一些作家的影响却使他对黑格尔哲学的某些部分加以拒斥或重新解释。例如,在马克思完成他的博士论文后不久,费尔巴哈著作的出版对激进的青年黑格尔学派尤其是马克思产生了决定性的影响。
费尔巴哈使黑格尔的观点推到极端的结论,由此批判了黑格尔主义自身的基础。为此他拒斥黑格尔的唯心主义,代之以基本的实在是物质这一观点。总之,费尔巴哈复活了哲学唯物主义,而马克思立即感到,它对人类思想和行为的解释要比黑格尔的唯心主义好得多。黑格尔把特定时代的思想和行为看作是同一的精神在所有人中的作用。相反,费尔巴哈则主张,形成人的思想的影响力是来自特定历史时期的物质条件的总和。因此,费尔巴哈不接受黑格尔精神第一性的看法,而代之以物质秩序的第一性。在《基督教的本质》(Essence of Christianity)一书中,他特别有力地阐发了这一点。他认为,人类而非上帝才是基本的实在。他说,我们分析我们的上帝观念时,发现我们并没有任何超乎人的感情与需求的上帝观念。一切有关上帝的所谓知识只不过是有关人的知识。因此,上帝就是人性。我们的各种上帝观念只是简单地反映了人类存在的不同类型。费尔巴哈就这样颠倒了黑格尔的唯心主义,所得出的唯物主义结论在马克思那里擦燃了一团火焰,为马克思哲学提供了最关键和最富特色的要素。
现在,马克思承认费尔巴哈是哲学中的关键人物。最重要的是,费尔巴哈把历史发展的焦点从上帝转移到了人。也就是说,黑格尔认为,精神在历史中逐步实现它自己,费尔巴哈却说,实际上是人正在努力实现他们自己。是人而不是上帝以某种方式从自身发生异化,而历史与我们努力克服自我异化有关。马克思认为,如果这就是实际的人类状况,那么,显然就应该改变世界以促进人类的自我实现。正是一点使得马克思说,迄今为止,“哲学家们只是以各种不同的方式解释世界:但问题在于改变世界。”这样,马克思把他的思想置于两个主要洞见的基础之上,即(1)黑格尔的辩证的历史观与(2)费尔巴哈对物质秩序第一性的强调。现在,他准备把这些观念铸造成一个全面的社会分析工具,而最重要的是,制定出一套切实有力的行动规划。
25岁那年,马克思离开了柏林来到巴黎,和一些朋友在那里出版激进期刊《德法年鉴》(Deutsch--Franzosiche Jahrbuicher)。在巴黎,马克思遇到了许多激进分子、革命者和乌托邦思想家,从而接触到像傅立叶、普鲁东、圣西门和巴枯宁这样一些人的观点。具有深远意义的是与一位德国纺织品制造商的儿子弗里德里希·恩格斯的会见,马克思与他保持着长久而亲密的交往。在巴黎期间,除了通过他的新闻事业逐渐深入到实际的社会行动中外,马克思还非常关注法国革命为何失败的问题。他想要知道是否可能发现可靠的历史规律,以便在将来的革命行动中避免错误。就这一主题他博览群书,发现了几个颇令人期待的答案。他尤为重视圣西门对阶级斗争的论述,这使得马克思把研究集中在阶级上,并认为阶级不仅是互相斗争的派别,而且体现了决定各个阶级的生活的物质和经济实在。马克思开始看到,如果革命仅仅是一些浪漫的想法,而忽视了物质秩序的现实状况,那就不会成功。但是,马克思来到巴黎仅仅一年之后就被驱逐出了这个城市。在接下来的时间里,从1845年到1848年,马克思和他的家人居住在布鲁塞尔。在那里,他帮助组建德国工人联盟。1847年在伦敦的一次会议上,该团体与欧洲一些类似的组织联合组成了国际共产主义者同盟,第一任书记是恩格斯。同盟要求马克思起草一份原则宜言。该文于1848年发表,题为《共产党宜言》(Manifesto of the Communist Party)。
马克思从布鲁塞尔返回巴黎呆了一阵,参加革命活动,但是再次被勒令离开。这一次,1849年秋,他去了伦敦,直到逝世都生活在那里。那个时候的英国还没有进行革命活动的成熟条件,因为工人群众还没有广泛地组织起来。马克思自己也成了一位与世隔绝的人物,以惊人的勤奋进行研究和写作。他每天到大英博物馆的阅览室,从早晨九点钟工作到晚上七点钟,然后回到他在伦敦梭霍廉租区的一套阴冷的两居室公寓里,继续工作几个小时。他的贫穷状况令人难堪。但是,他一心一意地要写出他的鸿篇巨著,他不能偏离这个目标而去为他的家庭提供更充足的供养。除了贫穷以外,他又害了肝病,并为痈疽所苦。在这种环境中,他六岁的儿子死去了,他美丽的妻子身体也垮了。恩格斯给了他一些接济,还有一些收入是来自他定期为《纽约每日论坛》撰写关于欧洲事务的文章所得的稿酬。
在这些令人难以置信的条件下,马克思写出了许多有名的著作,包括他称之为《政治经济学批判》(Critique of Political Economy,1859)的,他的第一部系统的经济学著作。这些著作中最重要的是他的巨著《资本论》(Das Kapital),第一卷于1867年由他自己出版,第二卷和第三卷是在他去世后由恩格斯从他的手稿中搜集整理而成,并分别于1885年和1894年出版。虽然马克思为共产主义运动提供了理论基础,但他却越来越少地实际参与其所极力主张的运动。尽管如此,他仍然怀着一个强烈的希望:大革命将要到来,他关于资本主义崩遗的预言将变成事实。但是,当他在生命的最后十年里变得闻名于世的时候,他的创作力却不如以前了。1883年3月14日,在他妻子去世后两年,他大女儿去世仪仅两个月后,卡尔·马克思在伦敦死于胸膜炎,终年65岁。
马克思经常宣称他不是“马克思主义者”,并不是所有世界共产主义使用的观念和策略都可以恰当地归因于他。但是,马克思主义有一个思想核心,它构成了马克思主义哲学的本质,这个核心是马克思在19世纪中期欧洲高度激昂的思想氛围——他是其中一分子——中构想出来的。马克思主义思想的这个核心是对四个基本要素的分析,即(1)历史的主要时期,(2)物质秩序的因果力量,(3)劳动的异化,(4)观念的来源和作用。我们将依次考察这些要素。
历史的诸阶段:马克思的辩证法
在《共产党宣言》中,马克思阐述了他的基本理论,他认为这一理论在很多方面是原创性的。他说:“我所做的是证明:(1)阶级的存在只是与生产发展的特定历史阶段相联系,(2)阶级斗争必然导致无产阶级专政,(3)专政本身只是构成向废除所有阶级的无阶级社会的过渡。”后来,在伦敦期间,他努力作出了极其详细的论证,他认为这一证明为他在《共产党宜言》中更具普遍性的论断提供了科学支持。因此,他在《资本论》的序言中说道:“这本著作的最终目标是揭示现代社会运动的经济规律。"这一运动规律就成了他的辩证唯物主义理论。
五个时期 马克思指明,阶级斗争是与“特定历史阶段紧密相连的”。他区分了五个这样的阶段或时期。它们是:(1)原始公社阶段,(2)奴隶杜会阶段,(3)封建社会阶段,(4)资本主义社会阶段,以及他预言即将到来的(5)社会主义和共产主义阶段。这大部分是对西方社会历史主要时期的一种传统的划分。但是,马克思想要做的是揭示“运动的规律”。这就不仅要说明历史已经展现出这些不同的时期,还要说明这些特定的时期如它们已经展示出来的那样发展的理由。如果他能够发现历史的运动规律,那么,他就不仅能够说明过去还能够预言未来。他想和分析物理学、生物学对象一样来分析个人和社会的行为。他认为经济学的商品和价值产品“类似于微观解剖学所处理的对象(微观要素)”。在分析每一个历史时期的结构时,他把这些结构看作是社会阶级之间冲突的结果。最后,对这种冲突本身也必须进行更仔细的分析。现在,他把历史看作是冲突的结果,并在很大程度上依赖黑格尔的辩证法概念来对之加以说明。
马克思当然是反对黑格尔的唯心主义的,但他接受黑格尔提出的历史辩证运动的一般理论。黑格尔认为,观念通过思想的运动和反动以辩证的方式发展。他把这一辩证过程描述为从正题到反题,再到合题的运动,而合题又成为新的正题,并让这一过程不断继续下去。另外,黑格尔认为,外部社会、政治和经济世界不过是人们(和上帝)的观念的体现。外部世界的发展或运动是观念先行发展的结果。马克思同样把黑格尔的辩证法概念看作是理解历史的一个最重要的工具。但是,由于费尔巴哈的巨大影响,马克思为这一辩证法加进了一个唯物主义的基础。因此,马克思说,“我的辩证方法不仅仅与黑格尔的不同,而且正好与它相反。在黑格尔看来,思维的过程…是现实世界的创造者。”但是,在马克思看来,“观念的东西不外是由人的头脑所反映并转化为思想形式的物质世界而已。”照马克思的看法,我们应把历史看作是由物质秩序中的冲突引起的运动,因此,历史学就是一种辩证唯物主义。
变化:量变与质变 历史显示,社会与经济秩序处于一个变化的过程之中。马克思的辩证唯物主义进一步主张,物质秩序是第一位的,因为物质是真实实在的基础。他反对那种认为存在永久不变的实在结构或“永恒的真实性”的看法。相反地,任何事物都处于辩证的变化过程之中。他认为,自然界“从最小的事物到最大的事物,从一粒沙子到太阳…到人,都处于…永不休止的运动和变化之中。”历史是按照严格无情的历史运动规律从一个阶段到另一个阶段的变化过程。
在马克思看来,变化与单纯的成长并不相同。社会的成熟并不能同小孩长大成人等量齐观。自然界也不是简单地以一个永远不变、周而复始的轨迹运动。它经历着一种真正的历史。变化意味着出现新的结构和前所未有的形式。引起变化的仅仅是事物量的改变,量的改变就产生了具有新的质的东西。例如,当我增加水的温度时,水不仅变得热起来,并且最终达到沸点,这时,这一量的变化使它从液体变成气体。反过来,当我逐渐降低水温时,我最后会把它从液体转变成固态的冰。同样,我可以震动一大块玻璃,震动的幅度随着我施加在上面的力量的增加而增加。但最终,进一步地增加力量将不再增加震动的幅度,而是导致质的变化——玻璃破碎。马克思认为,历史也展现着这种变化,经济秩序中某些量的因素最终会促使社会结构发生质的变化。正是这一过程推动历史从原始公社阶段发展到奴隶社会阶段,再依次发展到封建社会阶段和资本主义阶段。
马克思关于资本主义秩序将要崩溃的预言是基于以下观念的:资本主义中量的因素的变化将不可避免地摧毁资本主义。他不动声色地描述以上五个时期的发展,就好像在描述水是如何随着加热的过程而化为水蒸气一样。他在《资本论》中写到,“随着资本家所有者在数量上逐渐减少,贫穷、奴役、衰落、剥削,当然就会有相应的增加,但是,这同时也稳步地增强了工人阶级的作用。”于是,“生产资料的集中与劳动的社会化达到这种程度,证明它们与资本主义外壳的矛盾已不可调和。这个外壳就会炸毁了。私有财产的丧钟就会敲响了,剥夺者就会被剥夺了。”这在社会层面上就是马克思所讲的量的飞跃,“跳跃到一个新的结合状态…结果量在这里就转变成质。”
决定论或铁的规律 实验室里的水到水蒸气的转变,与社会从资本主义到社会主义的发展之间有一个基本的差别。这个差别就是我可以选择增加还是不增加水温。但是,历史却不具备这种可假设性质。我可以说“如果升高温度”,马克思却不能说“如果社会秩序如此这般”。马克思主义主张“事物本质中的基本矛盾”引起辩证的运动。虽然可以延缓或加速这种事物本质的内在运动,但是,不可能阻止它的最终展开。所有事物都是互相有因果联系的,全无约束放任自流的东西是没有的。因此,无论在物质自然界,还是在人类行为中从而在历史中,都没有孤立的事件。在马克思看来,有一种确定无情的运动变化过程在起着作用,产生“历史”,就如自然界是存在的这一显而易见的事实一样,是确定无疑的。
当我们像马克思那样宣称所有事物都是依据规律性与可预言性的原则行动的时候,我们应该做一个重要的区分。例如,物理学规律描述“机械的决定论”,而历史揭示的也是决定论的规律,但不是在严格机械论的意义上。一只台球被另一只台球撞击而运动是机械决定论的典型例子。如果我们能够确定一个物体的空间位置并测量它与另一个物体的距离,并且,另一物体的速度也是可测量的,那么,就可能预言相撞的时间以及随后的运动轨迹和速率。这种机械决定论很难运用到像社会秩序这样复杂的现象,社会秩序并没有这种空间和时间上的位置。但是,社会仍然是必然因果关系和决定论作用的结果,它的新形式是可以预测的,正如虽然关于具体的粒子只有“或然”的预测,但亚微观粒子在量子力学中仍然是被决定的一样。因此,尽管不可能高度精确地预言具体个人的特殊历史,但是,我们可以精确地描述社会秩序的未来状况。马克思认为他在对各种历史时期的分析中,发现了物质世界变化的内在规律——一种事物发展的铁的内在逻辑——它导致历史以一种无情的决定论的方式,从一个时期发展到另一个时期。基于这种观点,他预言资本主义必然会被未来的社会大潮所改变,并最终被性质上根本不同的社会主义与共产主义社会所取代。
历史的终结 在马克思看来,社会主义,以及最终共产主义的出现就是历史的终结。在这里,他再次把黑格尔的理论颠倒过来加以遵循。黑格尔认为,当自由的观念完全实现时,辩证过程将到达一个终点。毫无疑问,这将意味着一切冲突与斗争的结束。而马克思认为,对立面的辩证斗争是发生在物质秩序尤其是阶级间的斗争之中的。一且阶级之间的内在矛盾得到解决,运动与变化的主要原因将不复存在。于是将出现一个无阶级的社会,所有的力量和利益将达到完满的平衡,并且,这种平衡将是永久的。因此历史将不会有更进一步的发展,因为将不再会有任何推动历史向未来时代发展的冲突。
马克思的五个历史时期辩证发展的理论是以物质实在秩序与人类思想秩序之间的紧密联系为基础的。他确信,获得对历史的现实的理解从而在实际的革命活动计划中避免错误的惟一途径,是恰当地评价物质秩序与人类思想秩序的作用。因此,马克思在社会基础与上层建筑之间作了严格的区分。基础是物质秩序,包含着推动历史的动力,而上层建筑是人们的观念,只是物质秩序结构的反映。
基础:物质秩序
根据马克思的看法,物质世界包括全部的自然环境,这在他看来包括全部的无机自然界、有机世界、社会生活和人的意识。马克思与德谟克利特不同,德谟克利特用不可还原的微小原子来定义物质,马克思则把物质定义为“存在于人类意识之外的客观实在”。另外,德谟克利特把原子看作是“宇宙的砖头”,马克思主义的唯物主义并不接受这一观点,并不试图在所有事物中找到某种单一物质形式。马克思主义的唯物主义的主要特征是,它在物质世界中认识到广泛的多样性,而并不把这种多样性还原为某一种物质形式。物质秩序包括存在于我们意识之外的自然界中的所有事物。认为有精神实在如上帝作为超自然的东西存在于我们的意识之外,这种看法是为马克思主义的唯物主义所否定的。人类具有意识,仅仅表示有机物质已经发展到这样一种程度,大脑皮层已经成为能够进行复杂的反射行为过程的器官,这种复杂的反射行为过程就是人的思维。并且,人类意识受到作为社会存在的人类劳动的制约。因此,基于达尔文的人类进化论,马克思主义肯定物质秩序的第一性,而把精神活动看作是物质产生的第二位的副产品。最早的生命并没有精神活动,直到人类的祖先开始运用他们的前肢,学会直立行走,开始使用自然物体作为工具来获取食物和保护自己,这才有了精神活动。从动物到人类的大转变带来了制造和使用工具以及控制某些自然力如火的能力。这反过来又使食物的多样化和大脑的进一步发展成为可能。即使在今天,复杂的物质秩序仍是基本的实在,而精神领域则是派生的东西。具体地讲,物质秩序由(1)生产要素和(2)生产关系构成。
生产要素 人类生活的一个基本事实是,为了生存,人们必须保障自己的吃、穿、住。为了获得这些物质资料,人们就必须把它们生产出来。有人类社会的地方,就能发现各种生产要素,即原材料、生产工具和熟练的劳动技能,人们通过这些生产出东西来维持生命。但是,这些生产要素或生产力主要是代表着人们与这些物质东西的联系方式。更加重要的东西是在生产过程中我们相互联系的方式。马克思强调,生产总是作为一种社会活动而发生的,人们并不是作为个体,而是形成群体或社会来与自然斗争,利用自然。因而,在马克思看来,对生产要素的静态分析不如对作为一种进行生产的社会的人们之间的相互关系的动态分析重要。当然,马克思感到,生产要素会影响生产关系。例如,原材料的匮乏对生产过程中人们相互联系的方式有着相当的影响。总之,马克思关于物质秩序的分析集中在人们从事生产活动的方式即生产关系上。
生产关系 马克思认为,他对生产关系的解析是他的社会分析的核心。正是在这里,他认为他找到了辩证过程的动力。生产关系的关键是财产状况或它的所有权。这就是说,决定人们在生产过程中如何相互联系的是他们与财产的关系。例如,在奴隶社会,奴隶主拥有生产资料,甚至拥有并买卖奴隶。奴隶制是辩证过程的必然产物,因为它产生于先进的生产工具使得更稳定持久的农业生产以及劳动分工成为可能的时候。但是,在奴隶社会时期以及后来的社会时期,劳动者是“被剥削的”,因为他们既不拥有生产资料的所有权,也不享有劳动果实。阶级之间的基本矛盾在奴隶制社会已经出现。因为财产所有权把社会分为有财产者和无财产者两部分。在封建制度下,封建主拥有生产资料。农奴的地位要高于以前的奴隶,他拥有一部分生产工具的所有权,但仍然为封建主劳动,并且按马克思的说法,他感觉自已受到剥削并与剥削者进行斗争。比起奴隶和农奴,资本主义社会里的工人是自由的,但是,他们不拥有生产资料,为了生存,他们必须把他们的劳动力出卖给资本家。
从奴隶制的到封建的再到资本主义的生产关系的转变,不是理性设计的结果,而是物质秩序的内在运动和逻辑的产物。具体说来,求生的动力驱使人们创造出工具,然后,创造出的各种工具又影响人们相互联系的方式。所以,有些工具如弓和箭,允许独立自存,而犁则理所当然地意味着劳动分工。同样,家用纺车可以在家庭或小作坊中使用,而大机器则要求有大工厂和专门集中起来的大量工人。这一过程以决定论的方式进行,受到经济动力的驱动,其方向则是由当时的技术发展的要求所确定的。所有人的思想和行为都是由他们的相互关系以及他们与生产资料的关系所决定的。尽管在所有时期都存在不同阶级间的冲突和斗争,但在资本主义制度下,阶级斗争尤为剧烈。
在资本主义制度下,阶级斗争至少有二个特征。第一,阶级减少到基本上只剩下两个了,即所有者(资产阶级)和工人(无产阶级)。第二,阶级之间的相互关系基于这样一个基本矛盾,即,尽管两个阶级都参与了生产活动,但是,生产成果的分配模式与各阶级在生产过程中所作的贡献却是不一致的。这种不一致是因为在资本主义制度下,供给和需求的力量决定劳动力的价格,工人的大量供给使工资下降到仅仅能维持生存的水平。但是,劳动创造的产品能够以高于雇用劳动力费用的价格卖出。马克思的分析以劳动价值理论为前提,即认为产品的价值产生于注入其中的劳动量。从这一基本观点出发,由于劳动产品能够以高于劳动成本的价格卖出,资本家才从这种差价中获利,马克思把这种差价叫做剩余价值。在马克思看来,剩余价值的存在构成了资本主义制度的矛盾。因此,马克思认为,在资本主义制度中,剥削并不是某个地方、某一时间的孤立事件,而是出由于铁的工资规律的作用而总是存在,处处存在。然而马克思并没有对这一状况作任何道德评断,他认为,如果准则就是通过劳动的供求关系来确定工资,那么事实上工人获得的就正是他所值的。他说,“劳动力维持一天只费半个工作日,而劳动力却能劳动一整天,因此,劳动力使用一天所创造的价值比劳动力自身一天的价值大一倍。这种情况对买者是一种特别的幸运,对卖者(工人)也绝不是不公平。”
在某种意义上,马克思并没有为这种局面而“谴责”资本家。这些不如说是历史中的物质力量的结果。劳动成为了一种集团组织,只是因为大规模机器要求大型的工厂,而被要求来操作这些机器的工人群众突然发现他们紧密地生活在一起。历史产生了资本主义制度是一回事,而它基于一个矛盾是另一回事。因此,马克思为资本家辩解。但是,为了科学的原因,他不得不说,由剩余价值引起的阶级冲突将推动辩证运动发展到下一个历史阶段,即社会主义和最终的共产主义。
这种阶级斗争的第三个特征是,资本主义中工人的状况会逐渐变得越来越悲惨。穷人将越来越贫穷,且数量上越来越多,同时富人将越来越富有,且数量上将越来越少,直到工人群众接管所有生产资料。只要生产资料仍然掌握在少数人手里,阶级斗争就会无情地继续进行下去,直到矛盾解决,结束这个辩证运动。同时,由于马克思所称的“劳动异化”,工人的生活将会变得极度非人化。
劳动异化
还在二十几岁的时候,马克思就完成了他的一系列短篇手稿一《1844年经济学和哲学手稿》(Economic and Philosophical Manuscripts of1844),这些手稿于1932年首次出版。这些手稿的关键概念就是异化——一个贯穿于马克思整个思想体系的主题。虽然马克思决不是第一个提出异化理论的人,但是,他关于这一主题的观点是独特的,因为这些观点是以其独特的经济学和哲学假设为基础的,这些假设构成他资本主义批判的基础。
如果人被异化了,即被疏远或被分离了——那么,他们必定是从某种东西中被异化出来的。在基督教神学里,人由于原罪和亚当的堕落而从上帝那里被异化出来。在法律意义上,异化意味着卖出或让渡某些东西,或如康德讲的,“某人的财产转移给别人就是财产的异化。”随着时间的推移,几乎所有的东西都成了可买卖的东西。正如巴尔扎克所讽刺的,“就连圣灵在证券交易所也有报价哩。”在马克思看来,在我们的人性中有某种至关重要的东西,是我们可以从中被异化的,这种东西就是我们的劳动。
马克思描述了异化的四个方面。我们(1)从自然中异化,(2)从我们自己异化,(3)从我们的类存在中异化,(4)从他人中异化。他首先探讨工人与他们的劳动产品的基本关系。本来,我们与我们的劳动产品的关系是非常紧密的。我们从物质世界获取材料,然后加以制作,使它们成为我们自己的。然而,资本主义迫使工人为了交换金钱而丧失他们的劳动产品,从而打破了这种关系。在生产过程中,人的劳动变成了与被加工的物质材料一样的东西,因为劳动现在是可以买卖的。我们生产的物品越多,我们个人能占有的就越少,因此,我们丧失的就越多。我本是体现在我的劳动之中的,从这一意义上讲,我与我工作于其中的自然世界相异化了。马克思说,“工人把他的生命注人对象,然后他的生命就不再属于他自己,而是属于这对象了。”而这一对象为其他人所窃取和占有。人与自然的本来关系就这样被打破了。
其次,通过参与资本主义的劳动,我们从我们自己异化了。其所以如此,是因为劳动是外在于我们的,而不是我们本性的一部分。不是自愿的而是强加给我们的。我们感到痛苦而不是幸福。我们不是实现自己,而是不得不否定自己。我们不是自由地发展我们的身心能力,而是体力耗尽,精神贬低。结果,我们只是在空闲时间才感觉自已像人。最重要的是,我们从我们的劳动中异化了,因为它不是我们自己的劳动,而是为别人劳动。在这个意义上,工人并不属于他们自己,而是属于别人,我们或多或少成了出卖自已的人。结果工人“只是在他的动物机能——吃、喝和生殖上,或者最多还有在居家和个人打扮上——感觉自己是自由行动的,而在他的人的机能方面,他被降低为动物。”尽管吃、喝和生殖是真正人的机能,但当与它们被与其他的人类机能分离开来的时候,这些机能就变成了动物机能。
其三,在另一层次上,人与他们的类存在相异化,即与他们的真正人类的本性相异化。任何物种的特征存在于它表现出的活动类型中。人类的类特征是“自由、有意识的活动”。与之相反,动物不能区别自己和自己的活动。动物就是它的活动。但是,马克思说,人“使它的生命活动本身成为他的意志和意识的对象。”的确,动物也可以筑巢建窝,就像蜜蜂、妈蚁和河狸那样。但是,它们建造这些东西决不超出它们或它们的幼体的直接需要的限度。我们则以普遍的方式生产,即以一种能适用于所有人类并为所有人类理解的方式生产。另外,动物只是迫于具体的生理需要才进行生产,我们却只有在不受我们的生理需要驱使的时候,才生产我们最独特的产品。动物只再生产他们白己,而我们能生产整个世界,一个艺术、科学和文学的世界。动物的活动以它们所属物种的标准为限。我们则知道如何根据所有物种的标准来进行生产。因此,我们劳动的全部目标就是把我们的类生活——我们的自由、自发和创造性的活动施加给自然界。我们就是这样在我们创造的事物中再生产我们自己,不仅在观念领域进行精神的再生产,而且能动地在我们创造的物质世界上看到我们自己的反映。当我们的劳动被异化时,这一人类生活独有的特征就丧失了。随着我与我的劳动对象相分离,我的自由自发的能动性和创造性也被剥夺了。现在,我的意识偏离了我的创造性,而成了不过是针对着维持我的个体生存的一种手段。
这导致我与他人相异化。我与他人关系的瓦解与我从我的劳动对象的异化是类似的。在一个劳动被异化的环境中,我从工人的观点来看待他人。我把其他工人看作其劳动被买卖的对象,而不是看作完整的人类成员。于是,说我的类本质从我自己中异化了或疏离了就意味着我与他人疏离了。
马克思问道,“如果劳动产品对我是异己的…那么,它属于谁呢?”在远古时代,当人们在占埃及与印度建造庙宇的时候,人们认为产品属于众神。但是,马克思说,异化了的劳动产品只能属于某些人。如果它不属于工人,那么,它必定属于某个不是工人的人。于是,作为异化劳动的一个结果,工人在他们自己与他人之间建立了一种新的关系,而这个他人就是资本家。异化劳动的最后产物就是私有财产。私有财产以资本主义企业的形式既是异化劳动的产物又是使劳动异化的工具。在私有财产所必然产生的工资制度中,劳动发现它自己不是目的而是工资的奴仆。工资的被迫增加,并不会恢复工人及其工作的人的意义和价值。作为一个最终解放的陈述,马克思总结道,社会从私有财产中解放出来包含了工人的解放,它反过来又会导致全人类的解放。
他确信,这一辩证过程不可避免地包括悲剧性的冲突。他在历史上看到了不相容力量之间深刻的紧张状态,每一种势力都竭尽全力战胜对方。革命的暴力很难避免,但是,暴力并不能让人们想要的任何一种空想性的制度成为现实。只有物质秩序的内在逻辑正在以一种决定论的方式向其推进的那种生产关系,才能成为革命的目标。即使一个社会意识到了它的最终方向,这个杜会“仍然既不能通过大胆跃进来扫清,也不能通过制定法律来排除它正常发展阶段上的障碍。”那么,工人阶级革命活动的作用是什么呢?马克思说,是“缩短或减轻分娩的阵痛”。
马克思显然通过这种关于阶级斗争的严格观点而赋予物质基础以在历史的辩证发展中最重要的意义。那么,人的思想的地位和作用是什么?观念是否具有力量和重要性?在马克思看来,观念只是代表了对基本物质实在的反映,因此,他把人的思想活动描述为上层建筑。
上层建筑:观念的来源和作用
马克思说,每一个时代都有该时代占统治地位的观念。人们在宗教、道德和法律领域建构起观念。黑格尔认为,人们在宗教、道德和法律思想上大体是一致的,因为在他们中有一种普遍精神即绝对观念在起作用。相反,马克思说,每一时代的观念产生于并且反映该历史时期的实际物质条件。因此,在物质秩序已经影响了人们的精神后,思想才出现。用马克思的话来说,“不是人们的意识决定人们的存在,而是他们的社会存在决定他们的意识。”
观念的来源在于物质秩序。诸如正义、善甚至宗教的拯救观念都仅仅是各种使现存秩序合理化的方法。正义大体上表现了经济上处于支配地位的阶级的意志,以及他想要“固定”现存生产关系的愿望。在早年还是法学学生的时候,马克思对法理学家萨维尼的教导印象非常深刻,萨维尼把法律定义为每一时代的“精神”。萨维尼认为,法律和语言一样,在每一个社会都是不一样的。马克思和萨维尼一样反对那种认为有普遍永恒的正义规范的思想。实际上,马克思认为如果观念仅仅反映生产关系的内在秩序,那么,每一个相继的时代将会有它自己的一套观念和占统治地位的哲学。
社会内部在某个时代的观念冲突是因为经济秩序的动态性质。辩证过程是对立面的斗争,既有物质的方面,又有意识形态的方面。社会的成员通过属于不同的阶级而与辩证过程相联系,他们的利益不同,因此他们的观念也是对立的。并且,根据马克思的看法,人们最大的错误是没有认识到,在较早的时期正确地反映物质秩序的观念不再是正确的,因为实在的基础发生了变化。那些持有旧观念的人错误地以为实在仍然未变,与旧的观念是一致的。于是,他们要求颠倒事物的秩序来适合他们的观念,从而成为“反动分子”。另一方面,敏锐的观察者能够发现历史运动的方向,并且调整他们的思想和行为来适应历史发展的方向。马克思说,事实上,辩证过程必然使一些事物消亡,使新的事物产生。这就是为什么一个时代灭亡,另一个时代产生的原因,而这一过程是不可阻挡的。那些认为正义、善和公正原则有永恒的实在性的人没有认识到,这种观念是不可能适用于实在的,因为物质秩序是惟一的实在,而它处于不断的变化之中。马克思说,“全部生产关系的总和构成社会的经济结构——它是有法律的和政治的上层建筑竖立于其上的现实基础…它决定社会、政治和精神生活过程的一般特征。”
由于马克思认为观念主要是物质秩序的反映,因此,他认为观念的作用和功能是有限的。当观念与经济实在无关时,它们就尤其无用。马克思对改革者、改良家和空想家强烈不满。他认为观念不能决定历史的方向,只能延缓或加速确定不移的辩证过程。因此,马克思认为,他自己关于资本主义的观念并不构成一种道德谴责。他并不说资本主义是邪恶的或是由于人的愚蠢而导致的。它只是由“社会运动的规律产生的”。归根到底,马克思认为他是作为一名科学家来进行他的分析的,他认为他只思考客观实在,并从中抽象出运动规律。
16.3 尼采
尼采逝世于1900年8月25日,终年55岁,留下了光辉的著作,这些著作直到20世纪才产生冲击和影响。他的一生充满了尖锐的对照。他是两任路德教教长的儿子和孙子,但他又是发布“上帝死了”这一断言的人,并且进行了一场“反道德的战斗”。他是在一个完全由女性支配的环境中被抚养大的,但是,他的超人哲学决没有丝毫温情。他以权力意志的名义,要求充分表达人的生命力,然而却相信升华和克制是真正人的特征。他的著作写得很清晰,然而他却在绝望的精神错乱中结束了他的生命。
尼采的生平
尼采的名字是照当时普鲁士国王的名字起的。1844年10月15日弗里德里希·威廉·尼采出生于萨克森省的勒肯镇。在他4岁的时候父亲就去世了,他是在一个由母亲、妹妹、祖母和两个未婚姨妈组成的家庭中长大的。14岁的时候,他被送到普佛塔的著名寄宿学校学习。在那里,他接受了六年的严格教育,在古典文学、宗教和德国文学上尤其出色。正是在那里,他受到古希腊思想魅力的影响,尤其在埃斯库罗斯和柏拉图那里发现了古希腊思想。1864年10月,他来到波恩大学,但是,在那里只待了一年,因为他感觉他的同学的才能一般。他决定追随他的杰出古典文学和语文学老师弗里德里希·里奇尔,里奇尔接受了莱比锡大学的教授席位。在莱比锡大学,尼采偶然发现了叔本华的主要著作,他的无神论和反理性主义在一段时间里深深地影响了尼采,更加坚定了他对当代欧洲文化的反叛,他开始把欧洲文化酃夷为颓废文化。也正是在这里,尼采受到瓦格纳音乐的影响。他后来说,“没有瓦格纳的音乐,我就不可能熬过我的青年时代。当一个人想要摆脱难以忍受的重压时,他需要大麻。唔,我需要瓦格纳。”
当巴塞尔大学物色哲学教授人选的时候,尼采的名字已经特别引人注目了。他当时还没有完成博士学位学习.但是,他已发表的一些论文因其出色的学术水平而受到关注。有了这些,再加上他的老师的热情推荐,尼采在24岁时就被聘为大学教授。在巴塞尔大学批准对他的任命后,莱比锡大学未经考试就授予尼采博士学位。1869年5月,尼采发表了他的就职讲稿“荷马与古典语文学”。在巴塞尔时期,尼采频繁地到位于卢塞恩湖畔的瓦格纳别墅造访理查德·瓦格纳。虽然这种友谊注定不会长久,但是,瓦格纳影响了尼采第一部著作《悲剧从音乐精神中诞生》(The Birth of Tragedyfrom the Spirit of Music,1872)中的思想。尼采与他的老同事,著名历史学家雅克布·布克哈特的友谊持续了很长时间,他与布克哈特都醉心于古希腊和文艺复兴时期的意大利。尼采身体很差,又讨厌大学里的各种职责,所以在1879年34岁时辞去了教授职位。在接下来的十年里,他在意大利、瑞士和德国漫游,寻找能使他恢复健康的地方。尽管他的身体不好,但他还是在1881年至1887年的六年间写了几本著作,包括《黎明》(The Dawn of Day)、《快乐的智慧》(Joyful Wisdom)、著名的《查拉图斯特拉如是说》(Thus Spake Zarathustra)、《超越善恶》(Beyond Good and Evil)和《道德的谱系》(A Genealogy of Morals)。
1888年,当他44岁的时候,他病了好,好了又病的长期循环中,出现了一个短暂的间欺时期。在六个月的时间里,他写出了五本著作,它们是:《瓦格纳事件》(The Case of Wagner)、《偶像的黄昏》(The Twilight of the Idols)、《反基督者》(Antichrist)、《瞧这个人!》(Ecce Homo)、《尼采驳瓦格纳》(Nietzsche contra Wagner)。此后不久,在1889年元月,尼采在都灵的街上病倒了。他被带回到巴塞尔的诊所治疗。然后又从那里送到耶拿的精神病院,最后回到他母亲和妹妹那里,由她们照顾。在他生命的最后十一年,尼采由于脑部感染,完全疯藏了,因此,无法完成他计划的主要著作《重估一切价值》(Revaluation of All Values)。尼采的著作风格异常生动活泼,充满着强烈的激情。尽管他后期的一些著作表现出一些即将发生的精神问题的征兆,但学者们普遍认为,我们不应该因为他后来的精神崩遗而低估他的著作。
“上帝死了”
尼采写作哲学著作,更多的是考虑如何激发起严肃的思想,而不是拿出一本正经的答案来回答问题。在这一点上,他更像苏格拉底和柏拉图而不是斯宾诺莎、康德或黑格尔。他没有构造形式上的体系,因为他认为,要构造体系就得假设我们已经有一些自明的真理,然后才能在其上构造体系。他认为,建造体系是不诚实的行为,因为诚实的思想正是要质疑那些被大多数体系倚为基础的自明真理。我们必须参与辩证的过程,在适当时候要心甘情愿地公开反对自己以前所持的意见。大多数哲学体系构造者企图充当“解答宇宙之谜的人”,一次解决所有问题。尼采认为,哲学家应该少一点自命不凡,多关注人的价值问题,而不是抽象的体系。哲学家应该不受他所处文化的主流价值的束缚,以一种勇于尝试的态度,关注当下的人的问题。尼采在许多重要问题上都采取了各种不同的立场,因此人们很容易以互相矛盾的方式阐释他的观点。并且他主要是以格言警句而不是细致地分析来表达他对问题的看法,这给人一种含糊不清、模棱两可的感觉。尽管如此,尼采还是提出了许多与众不同的观点,这些观点相当清晰地从他的著作中显露出来。
当其他人在19世纪的欧洲看到权力与安全的象征的时候,尼采却以预言家的洞察力,看到现代人所信守的传统价值支撑即将倒塌。普鲁士军队使德国成为欧洲大陆的一大强国,而科学上的惊人进步愈加激起了乐观情绪。但是,尼采却大胆地预言,强权政治和血腥战争已经注定要发生。他感觉到一个虚无主义的时代正在到来,其种子已经播下。他的预言并不是以德国军事力量或正在进一步发展的科学为根据,相反,他是这样受到一个无可争辩的事实的触动,即对基督教上帝的信仰已经完全衰落,以致他可以自信地说“上帝死了”。
尽管尼采是一位无神论者,他仍然是带着复杂的心理来思考上帝之“死”的。一旦所有人都充分地认识到上帝之死的含义,随之而来的后果令他胆寒。他既考虑到宗教信仰的衰落,又看到对达尔文物种进化的无情思想的信仰正方兴未艾。这两者结合起来让他看到了人与动物的基本差别的泯灭。如果这就是我们被要求信仰的东西,那么,当未来带给我们前所未见的巨大战争灾难时,我们就不应该感到惊讶。同时,上帝之死对于尼采而言,意味着一个新时代的开始——本质上否定生命的基督教伦理会被一种肯定生命的哲学所取代。“最后,”他说道,“海洋,我们的海洋,展开在我们面前,也许从来没有如此展开的海洋。”对上帝之死的虚无主义后果的矛盾心理,使尼采转向人类价值的中心问题。在为这个上帝已经不再是人类行为的目标和界限的时代寻找新的价值基础的过程中,尼采认为,美学最有希望替代宗教,成为新的价值基础。他认为,只有作为一种美学现象,人类存在和世界才能被永远证明是合理的。古希腊人从最初就发现了人类所作所为的真实意义。他起初是从古希腊关于日神阿波罗和酒神狄俄尼索斯的观念中提取出他关于人性的基本洞见的。
阿波罗精神与狄俄尼索斯精神
尼采认为,美学价值产生于两个原则的融合,这两个原则分别由两个古希腊神祇——阿波罗与狄俄尼索斯代表。狄俄尼索斯象征动态的生命之流,它不受任何约束和阻碍,不顾一切限制。狄俄尼索斯的崇拜者会陷入迷狂,从而在更广大的生命海洋中失去自我的同一性。另一方面,阿波罗是秩序、节制和形式的象征。如果狄俄尼索斯的态度在某些类型的音乐中使放纵的激情得到了最好的表现,那么,阿波罗那种赋形的力量则在古希腊的雕塑中找到了它的最高表现。于是,狄俄尼索斯象征人性与生命的统一,个体性被吸纳进生命力量的更大实在。阿波罗则是“个性化的原则”——这种力量控制和约束着生命的动态过程,以便创造出有形的艺术作品或得到控制的人格特征。从另一个方面看,狄俄尼索斯代表灵魂中否定的和毁灭的黑暗力量,如果不受限制的话,它就会“荒淫残暴到登峰造极的地步,浑如最凶残的野兽。”阿波罗则与此相反,它代表一种对这种强大生命能量的涌动加以调处的力量,它能驾驭毁灭性的力量,并把这些力量转化成有创造性的行动。
照尼采看来,古希腊悲剧是伟大的艺术作品。它表现了阿波罗对狄俄尼索斯的征服。但是,尼采由这一阐释得出的结论是:人们并不面临在狄俄尼索斯与阿波罗之间的选择。认为我们居然会面临这样的选择是误解了人类境况的真实性质。事实是,人的生命必然包含黑暗的汹涌的情欲力量。尼采认为,古希腊悲剧表明,对这些驱动力的意识——而不是放任自己的本能、冲动和情欲泛滥——成了创作艺术作品的契机。无论是通过节制形成我们自己的性格,还是通过把形式加到那些不易驾驭的材料上来形成文学或艺术作品,情况都是这样。尼采把悲制的诞生——即艺术的创造——看作是人的基本健康因素即阿波罗精神,对狄俄尼索斯精神的病态迷狂的挑战所作的应答。根据这种看法,没有狄俄尼索斯的刺激,就不会有艺术出现。同时,如果把狄俄尼索斯看作是人性中的惟一因素或主导因素,我们就很可能陷于绝望,最后逐渐对生命持否定态度。但是,在尼采看来,古希腊雕塑把狄俄尼索斯因素与阿波罗因素协调起来,体现了人性的最高成就。19世纪的文化否认狄俄尼索斯因素在生命中有其正当地位。然而在尼采看来,这只不过是推迟了生命力量不可避免的爆发而已,而生命力的表达是不可能永远被抑制的。要问是生命应该主宰知识还是知识应该主宰生命,就是在问这两者中哪一个是更高和更具决定性的力量。尼采认为,毫无疑问,生命是更高和更具决定性的力量,但是,原始的生命力最终是毁灭生命的。因此,尼采寄希望于古希腊的做法——融合狄俄尼索斯因素与阿波罗因素——人类生活通过这种途径而转变为美学现象。尼采认为,在这样一个时代,宗教信仰不能给出一种令人信服的对人类命运的洞见,而古希腊的这一个方案,能够为现代文化提供一个切实可行的行为准则。尼采认为,宗教信仰之所以再也做不到这一点,正是因为基督教伦理本质上的那种否定生命的消极性。
主人道德与奴隶道德
尼采反对那种认为有一个普遍的、绝对的每个人都同样要遵守的道德体系的观念。人是各种各样的,把道德设想为普遍的,就忽视了个体之间的基本差异。那种认为只有一种人类性质,它的趋向能够以一套规则来规定的想法,这是一种不切实际的想法。每当我们设想一种普遍的道德规则的时候,我们总是试图不让我们的基本生命能量得到充分表达。在这方面,犹太教与基督教所犯的罪过是最严重的。他认为,犹太教与基督教伦理与我们的本性是背道而驰,因此它的反自然的道德让人性变得衰弱,只能产生一些“等而下之的”生命。
人类怎么会搞出这样一些不自然的伦理体系呢?尼采说,有“一种双重善恶标准的早期历史”,这一历史显示了两种主要道德类型的发展,即主人道德与奴隶道德。在主人道德中,“善”总是意味着“高贵”,“有着高级的灵魂”。相反,“恶”则意味着“粗鄙”和“下等”。高贵的人把自己看作是价值的创造者和决定者。他们并不从自身之外寻求任何对他们行动的认可。他们自己对自已下判断。他们的道德是一种自我尊崇的道德。这些高贵人的行动是出自他们总是要充溢而出的权力感。他们帮助不幸的人,但并不是出于怜悯,而是出于一种由权力丰溢而产生的神动。他们以各种形式的权力为荣,乐于经历严酷与困苦。他们也尊崇一切艰难困苦。与此相反,奴隶道德起源于社会的最低阶层:被虐待者、被压迫者、奴隶和那些把握不了自己的人。对奴隶而言,“善”代表所有那些能够有助于减轻受害者痛苦的品质,诸如“同情、善意的援助之手、热心肠、耐心、勤奋、谦卑、友善”。尼采认为,奴隶道德本质上是功利性的道德,因为道德的善包括任何对那些虚弱无力的人有益的东西。在奴隶道德看来,引起畏惧的人是“恶”人,但是,在主人道德看来,实际上,“善”人正是能引起畏惧的人。
奴隶报复的方式是把贵族的美德说成是恶。尼采强烈抗议西方主流道德,认为它抬高了“畜群”的平庸价值观,“畜群”“对于积聚大力而发的壮观冲动毫无所知,而这种冲动是高贵的东西,或许是一切事物的标准。”令人难以置信的是,通过成功地使所有高贵的品质看似罪恶,并让所有羸弱的品质看似美德,“畜群精神”最终竟战胜了主人道德。主人道德对生命的积极肯定被弄得似乎是“恶的”,是人们应该对之有“负罪”感的东西。尼采说,事实是:
那些仍然具有自然本性的人,那些十足可怕的名副其实的野蛮人,那些劫掠者,仍然具有完整的意志力量和权力欲望,他们扑向那些更软弱、更讲道德、更爱和平的种族…一开始,高贵等级总是野蛮等级:他们的优越性首先并不在于他们的身体力量,而是在于他们的心理力量一他们是完全的人。
但是,由于心理力量遭到削弱,主人种族的权力已经被摧毁。为了不让自然的冲动施展其攻击力,赢弱种族精心建立了一道道心理防线。和平与平等之类的新的价值和新的理想,被伪装成“社会基本原则”而提了出来。尼采说,不难看出,这其实是表现了弱者想要削弱强者权力的愿望。弱者建立了一种消极性的心理态度来对付人类最自然的生活动力。尼采说,奴隶道德是“一种导致否定生命的意志,是一种导致解体与衰朽的原则。”但他继续说道,从心理学上对畜群的愤恨心理及他们对强者意志进行报复的欲望进行精密分析,能告诉我们该做什么。这就是,我们必须“抵制一切多愁善感的虚弱:生命本质上就是对异己者和弱者的占用、伤害和征服,是各种不同形式的压制、施暴和强迫…用最婉转的话讲,至少也是利用。”
权力意志
剥削在尼采看来并不是人类固有的退化行为。相反,“它是生物本性中的一项根本机能。”剥削是“内在的权力意志的结果,权力意志正是生命意志——全部历史的一个基本事实。”权力意志是人类本性中支配环境的一个核心动力,它不仅仅是要活下去的意志,而是一种要强有力地肯定我们个体力量的冲动。正如尼采说的,“最强有力的和最高的生命意志并不在可怜的生存斗争中寻求其表达,而是在战争意志中寻求其表达。哪里有权力意志,哪里就有进行征服的意志!”
欧洲道德否认权力意志的核心作用,并且是以一种不诚实的方式来否认的。尼采把这归咎于基督教的奴隶道德。他写道,“我把基督教看作是古往今来一切谎言中最致命的和最能蛊惑人心的——也是最大的和最不虔诚的谎言。”让他惊骇的是,整个欧洲竟要服从于耶稣周围的一小撮可怜的社会渣滓的道德。他说,试想一下,“无足轻重的猥琐之徒的道德竟然成了衡量一切事物的标准。”他把这看作是“文明所带来的最令人反感的堕落”。在《新约全书》中,“最没有资格的人…在书中对最重大的存在问题指手画脚。”这对尼采来讲简直是难以置信的。基督教要求我们去爱我们的敌人,这与我们的本性相矛盾,因为我们的本性命令我们去恨我们的敌人。并且基督教否定道德的自然起源,因为它要求我们在爱任何事物之前首先要爱上帝。我们把上帝注入到我们的感情中,颠覆了要求肯定生命直接而自然的道德标准。我们把思想转向上帝,冲淡了我们最强大的活力。尼采承认,基督教的“精神的”人通过对受苦人提供安慰和鼓励,对欧洲起了不可估量的作用。但是达到基督教博爱的代价是什么?尼采写到,代价是“欧洲人种的退化”。那时他们必然要颠倒所有的价值评价——这正是他们不得不做的事情!摧毁强者,破坏伟大的希望,怀疑对美的喜好,瓦解一切自主的、阳刚的、征服性的和威严的东西。于是,基督教成功地颠倒了“对现世的爱和现世的至上性,把它们转变为对现世和世俗事物的恨…”
尼采乐意虚弱的畜群有他们自己的道德,只要他们不把他们的道德强加给更高等的人类。具有巨大创造力的人为什么要降低到畜群的庸庸碌碌的层次呢?尼采讲超越“善恶”,他的意思是要超越他那个时代占支配地位的畜群道德。他构想了一个新时代,那时,真正完全的人将再次达到一个新的创造水平,从而成为一种更高类型的人——超人(bermensch)。这种新人并不拒绝道德,而只是拒绝消极的畜群道德。并且,尼采认为,以权力意志为基础的道德是唯一最诚实的道德,奴隶道德则小心翼翼地掩盖这种道德。尼采说,如果超人是“残忍的”,那么我们必须认识到,实际上,几乎所有我们称为“更高级文化”的东西,仅仅是残忍性在精神上的强化。他说,“这就是我的论题,‘野兽'根本没有被杀死,它活着而且繁荣滋茂,只是改头换面了而已。”例如,古罗马人从刀光剑影的角斗中取乐。基督徒在十字架像上体验到狂喜。西班牙人兴高采烈地观赏鲜血淋漓的斗牛场面。法国工人迫不及待地渴望流血革命、这些都是残忍性的表现。
从主人道德的更高观点看,残忍一词不过是指与基本的权力意志,它是力量的种有然表现。人被区分为不同的等级,正是权力的多少决定和区别人所属的等级。因此,像政治与社会平等这样的理想是无意义的。在事实上存在权力差别的地方,是不可能有平等的。平等只能意味着把每一个人都降低到畜群的平庸水平。尼采想要保持两种类型的人之间的自然差别,即在“代表向上的生命类型和代表堕落、衰败和虚弱的生命类型”之间的差别。当然,一种较高级的文化总是需要平庸的畜群,但这只是使超人的出现和发展成为可能。如果要有超人,那他就必须超越低等人所信奉的善恶。
重估一切道德
尼采认为传统的道德无疑正在走向死亡,那么他想以什么来取代传统道德的呢?他肯定性的建议不如他的批判性分析那么清楚。但是,从他对奴隶道德的拒绝中,我们]可以推想出他的新价值的许多内容。如果奴隶道德产生于愤恨与复仇,那就必定会再次出现对所有价值的重估。尼采的重估并不是要创造一套新的道德价值表,而是向当前已被接受的那些价值宣战,就像苏格拉底那样“用解剖刀对时代的美德进行活体解剖。”由于传统道德是对原来的自然道德的一种颠倒,所以重估必须是以追求诚实和准确的名义拒绝传统道德。重估意味着,所有那些“更强烈的冲动仍然存在,但是,它们现在是在以虚假的名义出现在虚假的评价之下,还没有获得自觉。”没必要创立新的价值,只需要把价值再次颠倒过来正如“基督教是一切对古代价值的重估”一样,现在,也必须以扬我们原初的最深刻本性,拒斥今天的主流价值。因此尼采重估价值的设想,实质上就是对现代人类理想的批判性分析。他揭示,现代人称作“善”的根本就不是美德。他们的所谓真理是披上了伪装的自私和羸弱,他们的宗教是在精心创造一种心理武器,道德的侏儒凭着这一武器来驯服自然的巨人。一旦把这种伪装从现代道德上除掉,真实的价值就会显露出来。
归根到底,道德价值必须以我们真实的人类本性和环境为基础来建立。达尔文在描述物种的进化时强调外部环境,与达尔文不同,尼采关注个人的内在力量,这种力量能够决定并制造出事件——这是“一种开发和利用环境的权力”。尼采的宏大假说认为,在任何地方任何事情中,都是权力意志在寻求自我表达。他说,“世界就是权力意志——别无他物。”生命本身是多种力量,“是维持各种力量的各种过程的一种永久形式”。人的心理结构显示,我们对快乐和痛苦的关注反映了一种努力增强权力的趋向。痛苦刺激我们动用权力来克服障碍,而快乐则伴有一种权力增加的感觉。
超人
尼采的权力意志概念在超人的态度和行为中是表现得最清楚不过的了。我们已经看到,尼采拒绝平等的概念。他还表示,道德必须适合不同等级。即使在重估一切价值后,“平庸的畜群”也没有能力在思想上达到“自由精神”的高度。总之,不可能有“普遍的善”。尼采说,有伟大之人方能有伟大之事,“有非凡之人方能有非凡之事”。超人将是非凡的,但它是人类演化的下一阶段。历史并不是走向某种抽象的发达的“人性”,而是走向杰出人物的出现:超人就是历史的日标。但是,超人不会是机械的进化过程的产物。当只有较高级的人有勇气重估一切价值,自由地回应他们内在的权力意志时,历史的下一个阶段才会到来。人类需要被超越,而正是超人将代表身体、智力和情感力量发展和表现的最高水平。超人将是真正自由的人,对他而言,除了妨碍权力意志的行为要被禁止之外,没有任何禁忌。超人将体现对生命的自发肯定。
尼采并不认为他的超人将会是一个暴君。当然,在超人身上将会有很多狄俄尼索斯的成分。但是,这些激情会受到控制,动物本性与智力会由此得到协调,他或她的行为也就有了一定之规。我们不应该把这种超人与极权主义的恶棍混为一谈。尼采想到的超人模型是他心目中的英雄歌德和“拥有基督灵魂的罗马恺撒”。在尼采的思想成熟后,他的理想人物必须达到狄俄尼索斯因素和阿波罗因素的和谐统一。起先,当他的思想受到瓦格纳和叔本华影响时,尼采批评苏格拉底导致西方思想错误地转向理性。后来,他对理性有了更多的肯定。但是,即使在最后,他仍然认为,理性必须用来为生命服务,决不能牺牲生命来换取知识。苏格拉底之所以在历史上那么重要,正是因为他把人们从自我毁灭中拯救出来。他说,对生命的强烈渴望将会导致毁灭性的战争。光靠狄俄尼索斯因素自身,会导致悲观主义和毁灭。因此,有必要对人们的本能进行驾驭,而这就需要苏格拉底提供的这种影响力。尽管理性的阿波罗因素有彻底摧毁充满生机的生命之流的危险,但尼采仍然认为,没有某些理性指导来赋予形式的话,我们是无法生活的。苏格拉底在尼采那里之所以重要,正是因为这位古代哲学家第一个看到了思想与生活之间的恰当关系。苏格拉底认识到,思想服务于生活,而以前的哲学家则认为,生活服务于思想和知识。于是,尼采的理想人格是:能控制其激情的充满激情的人。
第五部分 20世纪和当代哲学
第十七章 实用主义和过程哲学
17.1 实用主义
17.2 皮尔士
皮尔士的生平
意义理论
信念的地位
方法的要素
17.3 詹姆斯
詹姆斯的生平
作为方法的实用主义
实用主义的真理论
自由意志
相信的意志
17.4 杜威
杜伟的生平
旁观者与经验
习惯、智力和学习
事实世界里的价值
17.5 过程哲学
17.6 柏格森
17.7 怀特海
怀特海的生平
简单定位的错误
自我意识
把握
永恒客体
第十八章 分析哲学
18.1 伯特兰·怀素
怀素的任务
逻辑原子主义
逻辑主义主义的困难
18.2 逻辑实证主义
证实原则
卡尔纳普的逻辑分析
逻辑实证主义的疑难
18.3 维特根斯坦
维特根斯坦的哲学之路
新的维特根斯坦
语言游戏和遵守规则
澄清形而上学的语言
18.4 约翰·奥斯汀
奥斯汀的独特方法
“辩解”的概念
日常语言的优点
第十九章 现象学和存在主义
19.1 埃德蒙德·胡塞尔
胡塞尔的生平及影响
欧洲科学的危机
笛卡尔和意向性
现象和现象学的加括号
生活世界
19.2 马丁·海德格尔
海德格尔的生平
作为在世的存在
作为操心的存在
19.3 宗教存在主义
雅思贝尔斯的生存哲学
马塞尔的存在主义
19.4 让·保罗·萨特
萨特的生平
存在先于本质
自由和责任
虚无和坏的信仰
人的意识
马克思主义和重新检讨自由
19.5 莫里斯·梅洛·庞蒂
梅洛·庞蒂的生平
知觉的第一性
认识的相对性
知觉与政治
纯粹理性批判
全书除了序言和一个总的导言外,分为“先验要素论”和“先验方法论”,前者占全书约4/5的篇幅,是全书的主体部分,讨论人类认识能力中的先天要素;后者讨论在这些先天要素基础上建立形而上学体系的形式条件。人类认识能力由作为接受性的直观能力的感性和作为自发性的思维能力的理性这样两类原则上不同而又彼此联系的认识能力构成,因而“先验要素论”就区分为讨论感性的先天要素的“先验感性论”和讨论(广义的)理性的先天要素的“先验逻辑”。由于人类的思维能力有知性、判断力和(狭义的)理性这样三个彼此不同而又相互联结的环节,因而“先验逻辑”就区分为讨论知性和判断力的先天要素的“先验分析论”(“真理的逻辑”)一其中讨论知性的先天概念(范畴)的称为“概念分析论”,讨论判断力的法规即知性的先天原理的称为“原理分析论”——和讨论理性的先验理念和先验幻相的“先验辩证论”(“幻相的逻辑”)。
导言提出了全书的总纲:纯粹理性批判的总任务是要解决“先天综合判断”即具有普遍性和必然性而又扩展了知识内容的真正科学知识是“如何可能”的问题,并将这个总问题分解为如下四个依次回答的问题:数学知识如何可能?自然科学如何可能?形而上学作为自然的倾向如何可能?形而上学作为科学如何可能?
先验感性论阐明,只有通过人的感性认识能力(接受能力)所先天具有的直观形式即空间和时间去整理由自在之物刺激感官而引起的感觉材料,才能获得确定的感性知识,空间和时间的先天直观形式是数学知识的普遍必然性的根据和条件。
先验逻辑的导言阐明感性必须与知性结合,直观必须与思维结合,才能产生关于对象的知识即自然科学知识,因而必须有一门不同于形式逻辑的先验逻辑来探讨知性的结构及其运用于经验对象时的各种原理,包括这种运用的限度。先验逻辑立足于知识与对象的关系,即知识的内容,而不是单纯的思维形式,这标志着辩证逻辑在近代的萌芽。
先验分析论(真理的逻辑)中阐明了知性的先天概念和先天原理是自然科学知识之所以可能的根据和条件。在概念分析论中,通过对知性在判断中的逻辑机能(形式逻辑中一般判断形式的分类)的分析,康德发现了知性的十二个(对)先天的纯粹概念即范畴;通过对范畴的“先验演绎”则阐明了,知性从自我意识的先验统一出发,运用范畴去综合感性提供的经验材料,这是一切可能的经验和经验对象之所以可能的条件,从而证明了范畴在经验即现象的范畴内的普遍必然的有效性。原理分析论主要阐明了知性指导判断力把范畴运用于现象的法规:判断力是用普遍(规则)去统摄特殊(事例)的能力;范畴运用于现象必须以时间图型为中介;通过时间图型把先天感性要素统摄于范畴之下所产生的先天综合判断就是知性的先天原理,亦即判断力的法规。依照范畴表,知性先天原理的体系由“直观的公理”、“知觉的预测”、“经验的类比”和“一般经验思维的公设”所构成,而经验的类比中的“实体的持存性原理”、“按照因果律的时间相继的原理”和“按照交互作用律(在空间中)并存的原理”是作为自然科学的最根本的基础的三条最普遍的原理,也就是自然界(作为现象)的三条最普遍的规律。知性的先天原理只是对现象有效,对超越现象的自在之物或本体则无效,严格划分可知的现象和可思而不可知的本体的界限是“纯粹理性批判”的最根本的要求。
先验辩证论(幻相的逻辑)主要阐明了理性不可避免地要超越现象去认识超验的本体,由此产生的作为自然倾向的形而上学只不过是一些先验的幻相,而不可能是真正的科学。康德在这部分的导言中指出,理性这种推理的能力由于要从有条件者出发通过推论去认识无条件者,这种自然倾向就成了先验幻相的来源和所在地,即它把由于推论的主观需要而产生的有关无条件者的概念看作了有客观实在的对象与之相应的实体概念了。先验的理念就是理性关于这类无条件者(如灵魂、世界整体和上帝)的概念,这样三个先验的理念起着一种为知识的经验认识提供可望而不可及的目标以引导其不断前进、并达到越来越大的统一的调节性(范导性)的作用。纯粹理性的辩证推论就是理性力图运用只对经验、现象有效的范畴来认识上述三个无条件者即超验对象的推论,这样的推论相应地有三种:关于灵魂作了含有“四名词”错误的“谬误推理”,关于世界整体陷入了由两组截然相反的判断彼此对立冲突的“二律背反”,关于上帝则推出了一些无客观实在性的“先验理想”。所有这些都只不过是一些属于先验幻相的假知识而已。
先验方法论首先阐明,纯粹理性的经验使用虽然有正确使用的法规(知性的先天原理),但其理论的(思辨的、先验的)使用却没有法规可言,因而必须对其先验使用的方法(从定义出发的独断论方法、从正反两方争辩并互相证伪的怀疑论方法、还有假设和证明的方法等四个方面)加以“训练”,确立一些“消极的”规则,以限制纯粹理性扩充到可能经验之外的倾向,从而为建立一种有关经验或现象的“内在的”自然形而上学准备了方法论的原则。其次阐明,与纯粹理性的理论的使用相反,其实践的使用则是有正确使用的法规的,这就是道德法测;那些理论理性所不能认识的超验的对象如自由意志、灵魂不朽和上帝,可以成为实践理性所追求的对象,因而对它们有“实践的知识”,即信念或信仰,这就为人类道德生活和幸福的和谐统一从而达到“至善”提供了前提,这就说明一种超验的道德形而上学是可能的。此外,康德还从“纯粹理性的建筑术”出发,说明了作为科学出现的未来形而上学的总体构成(以“批判”为导论,以自然形而上学和道德形而上学为主体),特别是自然形而上学的总体构成。