Rough Volatility
Bergomi's model revisited
Variance swap
A variance swap with maturity is a contract which pays out the realized variance of the logarithmic total returns up to less a strike called the variance swap rate , determined in such a way that the contract has zero value today.
The annualized realized variance of a stock price process for the period with business days is usually defined as The constant denotes the number of trading days per year and is usually fixed to 252 so that . We assume the market is arbitrage-free and prices of traded instruments are represented as conditional expectations with respect to an equivalent pricing measure .
A standard result gives that as , we have
when is a continuous semimartingale.
Approximating the realized variance by the quadratic variation of the log returns works very well for variance swaps, but care should be taken in practise if we price short dated non-linear payoffs on realized variance. Denote by , the price at time of a variance swap with maturity . It is given under by
We define the forward variance curve as Note that, if we assume that the S&PX index follows a diffusion process, with a general stochastic volatility process, , the forward variance is given by It can be seen as the forward instantaneous variance for date , observed at . In particular
The current price of a variance swap, , is given in terms of the forward variances as The models used in practice are based on diffusion dynamics where forward variance curves are given as a functional of a finite-dimensional Markov-process: where the function and the m-dimensional Markov-process satisfy some consistency condition, which essentially ensures that for every fixed maturity , the forward variance is a martingale.
※ Pricing under rough volatility ※
ATM volatility skew
其中 是离到期日的时间, 是log-strike.在传统随机波动率模型中, 对短期时间是常数,对长时间与 成反比.经验上观测到 对某些 与 成比例.
forward variance curve
表示 时刻瞬时方差.则 forward variance curve 为:
Wick exponential
对零均值的 Gaussian R.V. ,其 Wick exponential 为
这里只作记号使用,不涉及其运算.
模型推导
Gatheral et al. (2014) 发现已实现方差(realized variance) 与如下模型一致
其中 是 fBm.This relationship was found to hold for all 21 equity indices in the Oxford-Man database, Bund futures, Crude Oil futures, and Gold futures. Perhaps this feature of the time series of volatility is universal?
考虑 fBm 的 Mandelbrot-Van Ness 表示
其中 , 这样选取是为了保证
将 (2)带入(1)并由 ,可以得到 基于 physical measure 的变化:
注意到 是 -可测,而 与 独立且是 Gaussian with mean zero and variance . 用如下记号: 和 有相同分布,仅仅方差变为 .记 则有 且 结合 Wick expenential 这里,由 1 式可知 依赖 的整个历史,所以 是 non-Markovian.而 2 式表示 the conditional distribution of depends on only through the instantaneous variance forecasts
总结,得到如下模型基于实际概率测度 : 其中,两个布朗运动 和 相关系数为 .
Pricing under Q
期权在 t 时刻的定价基于等价鞅测度 on s.t. 资产价格过程 在 下是一个鞅.
在固定的时间域 中,通过 Girsanov 变换, 使得
另一方面 由 而来,而 是一个布朗运动与 以如下关系相关, 其中 是一对独立的标准布朗运动.对第二项的一个标准的测度变换为 其中 ,for ,是一个合适的适应过程,称为波动率风险的市场价格.所以有 将其重写为 由 4 ,在 下, 特别的, 适应于由 生成的域流(和由 生成的域流一致).把上式重写为 指数中的最后一项明显改变了 的边缘分布.虽然 在 下的条件分布是对数正态的,它在 下不是对数正态.
rBergomi model
考虑最简单的测度变换, assuming for simplicity, resp. as a first approximation, 是关于 的确定性函数.则由 6 我们有 其中 .进一步有 forward variance curve
是如下两项的乘积: 依赖于驱动布朗运动的历史;另一项依赖于风险价格 .
模型 7 是 non-Markovian 因为 .
※on deep calibration of rough sv model※
一.介绍
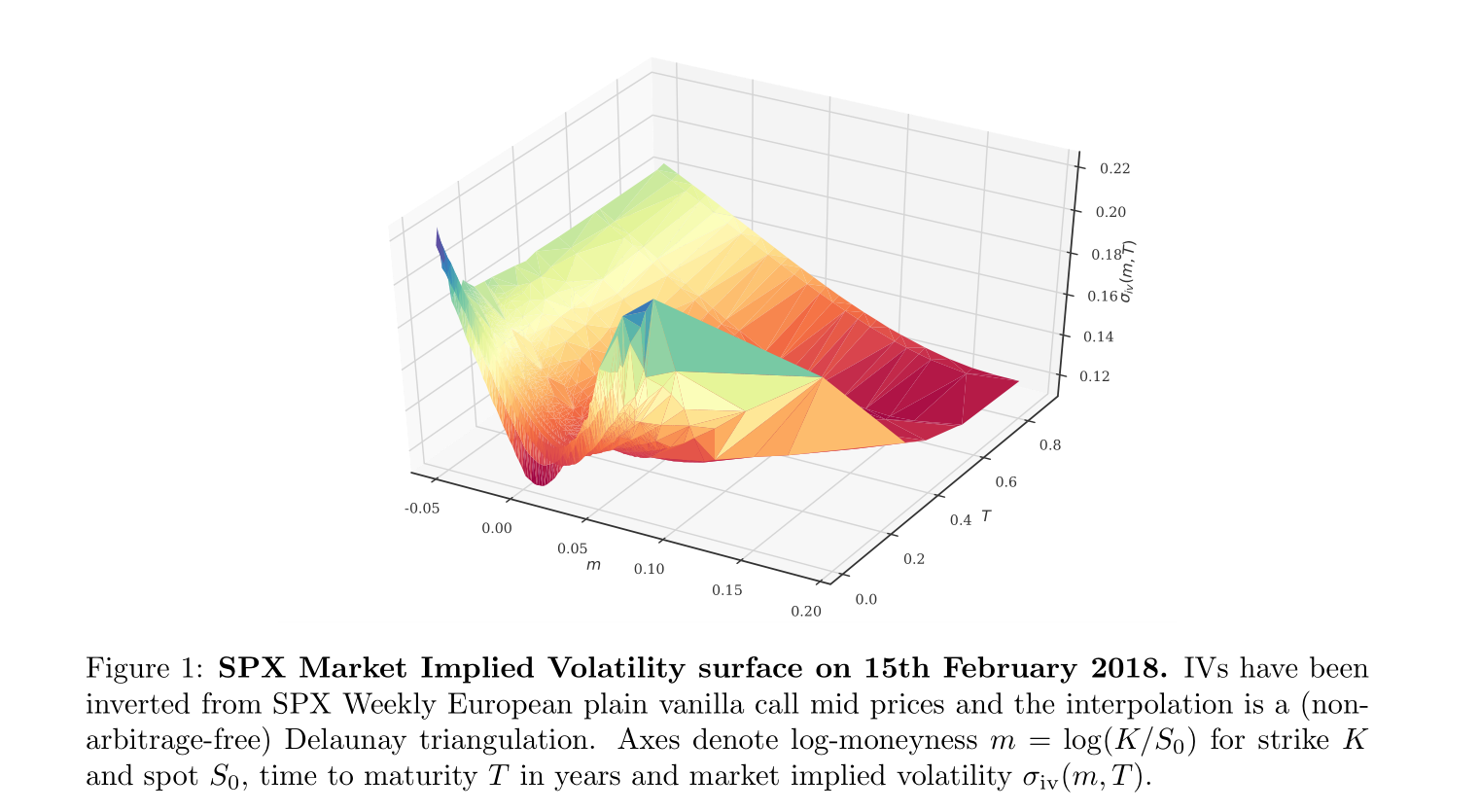
从隐含波动率按 moneyness 和 maturity 的变化可以观察到存在着著名的 smiles 和 at-the-money(ATM) skews 现象,与 BS 公式相悖.特别的,Bayer, Friz, and Gatheral 经验性地表明 ATM skew 符合如下形式:
其中 为 moneynessand , 为 time to maturity .
根据 Gatheral ,扩散的随机波动率模型不能复现当 time to maturity 趋于零时 volatility skew 的幂指数爆炸现象,反而表现为常数现象.
RSV 可定义为一族连续路径的随机波动率模型,其瞬时波动率由一个 Holder 正则性比布兰运动小的随机过程驱动,通常刻画为 Hurst 系数 H<1/2 的分形布朗运动.
这种范式转变的证据现在是 overwhelming ,一方面在物理测度下,时间序列分析表明对数已实现波动率的 Holder 正则为 0.1 阶;另一方面,在定价测度下经验性观察也表明在零附近由模型能够生成 power-law behaviour 的 volatility skew.
模型的一大难点来自于分形布朗运动的非马尔科夫性.
本文介绍两种方法
- one-step approach : 直接学习从隐含波动率曲面到模型参数的映射,
- two-step approach : 第一步学习从模型参数到期权价格的映射,然后根据实际市场价格校准模型.又分为 point-wise approach 和 grid-wise approach,前者将行权价和到期日作为输入,后者事先设定好这两项.
二.模型校准概述(未使用神经网络)
校准(calibration)意思是调整模型参数以使得模型曲面符合由欧式期权通过BS公式计算出的经验隐含波动率曲面.
假设模型有一个参数集 决定, i.e.,由 .进一步,我们假设期权由参数集 决定.E.g.,对看涨看跌期权我们有 ,分别为到期日和 log-moneyness.有些参数由市场观测得到,如现价、利率等,不在校准过程中.定价映射为 带参数 的模型中带参数 的期权的价格.我们通过 给定了有限子集 以及所有可能的期权参数对应的期权价格.校准是决定模型参数以使模型价格 和市场价格 在给定距离度量下最小,i.e.:
事实上,最常用的 是加权最小二乘: 这里的权重 反映了 对应期权的重要性以及 的可靠性.例如可以选择 bid-ask spread 的倒数.
只要模型参数比 少,此时就是超定(overdetermined)的非线性最小二乘问题,通常采用数值迭代的方法解决,如 Levenberg-Marquardt(LM)算法.
rBergomi :表示为 ,参数 ,例如可以设为 模型基于如下系统 其中 是 Hurst 系数,, 是 Wick exponential, 表示初始forward variance curve, 和 是以 相关的布朗运动.
三.深度校准
3.1 one-step approach
Hernandez A. Model calibration with neural networks[J]. Available at SSRN 2812140, 2016.
直接学习校准过程,即将模型参数视作市场价格(隐含波动率)的函数,i.e. 更具体地,训练神经网络基于标签数据 , 及其对应标签
3.2 two-step approach
首先学习定价映射,将模型参数映射为市场价格(或隐含波动率),然后使用标准校准方法进行校准.我们用 表示 是 的通过神经网络得到的近似.然后第二步我们进行校准
两步方法相较而言最大的好处如下:
- 神经网络只负责期权定价,所以能用人工数据来训练.
- 自然地将误差分为定价误差和模型误差.神经网络表现和模型对市场适应性做出的调整相互独立.
3.2.1 two-step approach: 逐点训练(pointwise)和基于网格(grid-based)训练
In this section, we examine its advantages and present an analysis of the objective function with the goal to enhance learning performance. Within this framework, the pointwise approach has the ability to asses the quality of using Monte Carlo or PDE methods, and indeed it is superior training in terms of robustness.
Pointwise learning
step 1:学习映射 即上述(2)式令 .在标准化期权(vanilla option,)情况下,我们可以直接学习隐含波动率映射 ,而不是期权定价的映射 .用 表示神经网络,最优化问题如下:
Step 2: 解决经典的模型校准步骤:
这里 或者 被替换成 step1 中的近似网络 .
第一步中,关键在于训练数据和网络结构的选择.训练数据在于选择 和 的‘先验’的、有实际意义的分布.
Implicit & grid-based learning
用 记关于到期日和行权价的网格.则
step 1:学习映射 ,输入是 ,输出是 这样的 网格. 取值在 中,其中 strikes maturities 最优化问题变为如下: 其中 . Step 2:
这里期权的参数 是固定了的,不再是学习的一部分.
3.2.2 pointwise versus grid-based
- 最大的不同在于 grid-based 在遇到不在网格上的 T,K 时需要手动插值
- grid-based 方法自然地有 reduction of variance ,
- pointwise 中对使样本符合实际金融数据的操作更简单,改变采样的分布.而 grid-wise 则是通过改变权重或者网格密度.
- grid-based 方法可以看做是一种降低维度的操作,将输入的维度转移到了输出的维度.
四.Pratical implementation
4.1 网络结构与训练
- 隐藏层为 3 层的全连接前馈神经网络,每层 30 个结点
- 输入维度记
- 输出维度为
- 总共有 个参数.
- 激活函数选择 Elu, ,梯度下降选择 Adam.
4.2 校准
使用第二节中讲的 LM 等算法.
五.数值实验
5.1定价近似网络的速度和精确度
※Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough)volatility models※
fBm的 Monte-Carlo 模拟
1.理论基础
Notations: 在单位区间 表示连续函数空间, 表示 -Hölder 连续函数空间, . 和 是 上连续可微和有界连续可微函数空间.
1.1. Hölder spaces and fractional operators
For , the -Hölder space , with the norm is a non-separable Banach space. Following the spirit of Riemann-Liouville fractional operators recalled in Appendix , we introduce the class of Generalised Fractional Operators (GFO). For any we introduce the intervals , and the space , for any
Definition 1.1. For any and , the GFO associated to is defined on as We shall further use the notation , for any . Of particular interest in mathematical finance are the following kernels and operators:
Proposition 1.2. For any and , the operator is continuous.
We develop here an approximation scheme for the following system, generalising the concept of rough volatility in the context of mathematical finance, where the process represents the dynamics of the logarithm of a stock price process: with , and the (strong) solution to the stochastic differential equation
where denotes the state space of the process , usually or The two Brownian motions and , defined on a common filtered probability space , are correlated by the parameter , and the functional is assumed to be smooth on This is enough to ensure that the first stochastic differential equation is well defined. It remains to formulate the precise definition for (Proposition 1.4) to fully specify the system (1.3) and clarify the existence of solutions. Existence and (strong) uniquess of a solution to the second in (1.4) is guaranteed by the following standard assumption :
Assumption 1.3. There exist such that, for all
Proposition 1.4. For any ,the equality holds almost surely for .
Example 1.5. This example is the rough Bergomi model introduced by Bayer, Friz and Gatheral, where with and is the Wick stochastic exponential. This corresponds exactly to with and
1.2 The approximation scheme
We now move on to the core of the project, namely an approximation scheme for the system (1.3). The basic ingredient to construct approximating sequences is a family of iid random variables, which satisfies the following assumption: Assumption 1.6. The family forms an iid sequence of centered random variables with finite moments of all orders and
Following Donsker and Lamperti, we first define, for any , the approximating sequence for the driving Brownian motion as As will be explained later, a similar construction holds to approximate the process : where and Here and satisfy Assumption , with appropriate correlation structure between the pairs that will be made precise later. We shall always use to denote the sequence generating and the one generating . Consequently, we deduce an approximating scheme (up to the interpolating term which decays to zero by Chebyshev's inequality) for as All the approximations above, as well as all the convergence statements below should be understood pathwise, but we omit the dependence in the notations for clarity. The main result here is a convergence statement about the approximating sequence . As usual in weak convergence analysis, convergence is stated in the Skorokhod space of càdlàg processes equipped with the Skorokhod topology. Theorem 1.7. The sequence converges weakly to in . The construction of the proof allows to extend the convergence to the case where is a -dimensional diffusion without additional work. The proof of the theorem requires a certain number of steps: we start with the convergence of the approximation in some Hölder space, which we translate, first into convergence of the stochastic integral in , then, by continuity of the mapping , into convergence of the sequence . All these ingredients are detailed in Section 1.3 below. Once this is achieved, the proof of the theorem itself is relatively straightforward.
1.3. Monte-Carlo.
Theorem 1.7 introduces the theoretical foundations of Monte-Carlo methods (in particular for path-dependent options) for rough volatility models. In this section we give a general and easy-to-understand recipe to implement the class of rough volatility models (1.3). For the numerical recipe to be as general as possible, we shall consider the general time partition on with .
Algorithm 1.8 (Simulation of rough volatility models). (1) Simulate two matrices and with ; (2) simulate M paths of viad and also compute (3) Simulate paths of the fractional driving process using The complexity of this step is in general of order (see Appendix for details). However, this step is easily implemented using discrete convolution with complexity (see Algorithm [B.4 in Appendix for details in the implementation). With the vectors and for , we can write , for , where represents the discrete convolution operator. (4) Use the forward Euler scheme to simulate the log-stock process, for all , as
Remark:
- When , we may skip step (2) and replace by on step (33).
- Step (3) may be replaced by the Hybrid scheme algorithm 11 only when .
Antithetic variates in Algorithm 1.8 are easy to implement as it suffices to consider the uncorrelated random vectors and , for Then and , for , constitute the antithetic variates, which significantly improves the performance of the Algorithm 1.8 by reducing memory requirements, reducing variance and accelerating execution by exploiting symmetry of the antithetic random variables.
1.3.1 Enhancing performance. A standard practice in Monte-Carlo simulation is to match moments of the approximating sequence with the target process. In particular, when the process is Gaussian, matching first and second moments suffices. We only illustrate this approximation for Brownian motion: the left-point approximation may be modified to match moments as where is chosen optimally. Since the kernel is deterministic, there is no confusion with the Stratonovich stochastic integral, and the resulting approximation will always converge to the Itô integral. The first two moments of read The first moment of the approximating sequence 1.8 is always zero, and the second moment reads Equating the theoretical and approximating quantities we obtain for , so that the optimal evaluation point can be computed as In the Riemann-Liouville fractional Brownian motion case, , and the optimal point can be computed in closed form as
1.3.2 Reducing Variance.
As Bayer, Friz and Gatheral, a major drawback in simulating rough volatility models is the very high variance of the estimators, so that a large number of simulations are needed to produce a decent price estimate. Nevertheless, the rDonsker scheme admits a very simple conditional expectation technique which reduces both memory requirements and variance while also admitting antithetic variates. This approach is best suited for calibrating European type options. We consider and the natural filtrations generated by the Brownian motions and In particular the conditional variance process is deterministic. As discussed by Romano and Touzi, and recently adapted to the rBergomi case by McCrickerd and Pakkanen, we can decompose the stock price process as and notice that Thus becomes log-normal and the Black-Scholes closed-form formulae are valid here (European, Barrier options, maximum,...). The advantage of this approach is that the orthogonal Brownian motion is completely unnecessary for the simulation, hence the generation of random numbers is reduced to a half, yielding proportional memory saving. Not only this, but also this simple trick reduces the variance of the Monte-Carlo estimate, hence fewer simulations are needed to obtain the same precision. We present a simple algorithm to implement the rDonsker with conditional expectation and assuming that .
Algorithm 1.9 (Simulation of rough volatility models with Brownian drivers). Consider the equidistant grid . (1) Draw a random matrix with unit variance, and create antithetic variates ; (2) Create a correlated matrix as above; (3) Simulate paths of the fractional driving process using discrete convolution: and store in memory for each (4) use the forward Euler scheme to simulate the log-stock process, for each , as (5) Finally, we have for we may compute any option using the Black-Scholes formula. For instance a Call option with strike would be given by for , where and Thus, the output of the model would be
The algorithm is easily adapted to the case of general diffusions as drivers of the volatility (see Algorithm 1.8 step 2). Algorithm 1.8 is obviously faster than 1.9, especially when using control variates. Nevertheless, with the same number of paths, Algorithm 1.9 remarkably reduces the Monte-Carlo variance, meaning in turn that fewer simulations are needed, making it very competitive for calibration.
2.传统cholesky分解法模拟
If you need to generate correlated Gaussian distributed random variables where is the vector you want to simulate, the vector of means and the given covariance matrix, 1.you first need to simulate a vector of uncorrelated Gaussian random variables, 2.then find a square root of , i.e. a matrix such that . Your target vector is given by A popular choice to calculate is the Cholesky decomposition.
而对于本 rBergomi 模型,
where is a Volterra processt with the scaling property . So far behaves just like . However, the dependence structure is different. Specifically, for where, for and with , where denotes the confluent hypergeometric function. Remark The dependence structure of the Volterra process is markedly different from that of with the MolchanGolosov kernel given by for some constant In particular, for small , correlations drop precipitously as the ratio moves away from 1 .
We also need covariances of the Brownian motion with the Volterra process . With , these are given by and where for future convenience, we have defined the constant, These two formulae may be conveniently combined as Lastly, of course, for . With the number of time steps and the number of simulations, our rBergomi model simulation algorithm may then be summarized as follows.
- Construct the joint covariance matrix for the Volterra process and the Brownian motion and compute its Cholesky decomposition.
- For each time, generate iid normal random vectors and multiply them by the lower triangular matrix obtained by the Cholesky decomposition to get a matrix of paths of and with the correct joint marginals.
- With these paths held in memory, we may evaluate the expectation under of any payoff of interest.
we simulate the process
import numpy as np
import matplotlib.pyplot as plt
import scipy.special as special
def fBm_path_chol(grid_points, M, H, T):
"""
@grid_points: # points in the simulation grid
@H: Hurst Index
@T: time horizon
@M: # paths to simulate
"""
assert 0<H<1.0
## Step1: create partition
X=np.linspace(0, 1, num=grid_points)
# get rid of starting point
X=X[1:grid_points]
## Step 2: compute covariance matrix
Sigma=np.zeros((grid_points-1,grid_points-1))
for j in range(grid_points-1):
for i in range(grid_points-1):
if i==j:
Sigma[i,j]=np.power(X[i],2*H)/2/H
else:
s=np.minimum(X[i],X[j])
t=np.maximum(X[i],X[j])
Sigma[i,j]=np.power(t-s,H-0.5)/(H+0.5)*np.power(s,0.5+H)*special.hyp2f1(0.5-H, 0.5+H, 1.5+H, -s/(t-s))
## Step 3: compute Cholesky decomposition
P=np.linalg.cholesky(Sigma)
## Step 4: draw Gaussian rv
Z=np.random.normal(loc=0.0, scale=1.0, size=[M,grid_points-1])
## Step 5: get V
W=np.zeros((M,grid_points))
for i in range(M):
W[i,1:grid_points]=np.dot(P,Z[i,:])
#Use self-similarity to extend to [0,T]
return W*np.power(T,H)
3.rDonker方法
def fBm_path_rDonsker(grid_points, M, H, T, kernel="optimal"):
"""
@grid_points: # points in the simulation grid
@H: Hurst Index
@T: time horizon
@M: # paths to simulate
@kernel: kernel evaluation point use "optimal" for momen-match or "naive" for left-point
"""
assert 0<H<1.0
## Step1: create partition
dt=1./(grid_points-1)
X=np.linspace(0, 1, num=grid_points)
# get rid of starting point
X=X[1:grid_points]
## Step 2: Draw random variables
dW = np.power(dt, H) *np.random.normal(loc=0, scale=1, size=[M, grid_points-1])
## Step 3: compute the kernel evaluation points
i=np.arange(grid_points-1) + 1
# By default use optimal moment-matching
if kernel=="optimal":
opt_k=np.power((np.power(i,2*H)-np.power(i-1.,2*H))/2.0/H,0.5)
# Alternatively use left-point evaluation
elif kernel=="naive" :
opt_k=np.power(i,H-0.5)
else:
raise NameError("That was not a valid kernel")
## Step 4: Compute the convolution
Y = np.zeros([M, n])
for i in range(int(M)):
Y[i, 1:n] = np.convolve(opt_k, dW[i, :])[0:n - 1]
#Use self-similarity to extend to [0,T]
return Y*np.power(T,H)
※使用GAN对LSV模型的校准※
This means parameterizing the model pool in a way which is accessible for machine learning techniques and interpreting the inverse problem as a training task of a generative network, whose quality is assessed by anadversary.We pursue this approach in the presentarticle and use as generative models so-called neural stochastic differential equations (SDE),which just means to parameterize the drift and volatility of an Itˆo-SDE by neural networks.
1.介绍
文中指的neural SDE即通过神经网络来对Ito-SDE的漂移项和波动率进行参数化.
这里考虑的某资产的折现后价格过程(discounted price process) :
其中 是某个 中取值的随机过程, 称为杠杆函数(Leverage function)取决于 和资产当前价格.
的选取非常重要,需要很好地校准市场上观测到的隐含波动率.故 需要满足如下条件:
其中 指 Dupire 的local volatility function.注意到(1.1)是 的隐式方程,因为 中需要 .故此时 满足的SDE也成为了一个McKean-Vlasov SDE.
本文采用了 fully data-driven 方法,规避了其他计算 Dupire 局部波动率的方法中必须的对波动率曲面插值的做法,即此方法只需离散数据.
令 , 为不同期权的到期日.使用神经网络族 将杠杆函数参数化,参数为 ,i.e.
于是有了neural SDE的生成模型组(generative model class),即使用带参数 的神经网络来参数化漂移项 和波动率项 ,i.e.
本文中,没有漂移项,波动率项如下所示:
依次对每个到期日,参数优化采用如下的校准法则: 其中 是期权的数目, 和 是模型与市场分别的价格.
对固定的 , 是非线性非负凸函数满足 且 对 ,衡量模型和市场价的距离. 某种权重,参数 扮演了对抗(adversarial)的部分,注意到 和 都受 控制.本文中 采用的是 Cont R, Ben Hamida S. Recovering volatility from option prices by evolutionary optimization[J]. 2004.中的 vega-type.
2.VARIANCE REDUCTION FOR PRICING AND CALIBRATION VIA HEDGING AND DEEP HEDGING
介绍在蒙特卡洛定价和校准中利用对冲投资组合作为控制变量的方差缩减技术.在 LSV 校准中非常重要.
考虑有限时域 ,已折现的市场中有 个交易中的金融产品 ,它是在某个概率空间 上在 中取值的随机变量. 是风险中性测度, 假设是右连续的.特别的,假设 是有右连左极路径的 维平方可积鞅.
令 是 可测的随机变量,表示表示某个欧式期权在到期日 的支付.那么通常的对这个期权价格的 Monte Carlo 估计是: 其中, 是以分布 , i.i.d 的.可以简单改造这个估计,加上关于 的随机积分.考虑一个策略 和某个常数 .用 记关于 的随机积分,考虑如下估计: 其中, 是以分布 i.i.d 的.则对于任意的 和 ,这个估计仍是期权价格的无偏估计,因为随机积分的期望消失了.记 则 的方差为: 在以下取法下达到最小 此时 特别地,在沿路径完美对冲的情形下, a.s.,有 和 ,此时 因此,找到一个好的近似对冲投资组合使得 大是很重要的.
2.1 Black&Scholes Delta Hedge
In many cases, of local stochastic volatility models as of form (1.1) and options depending only on the terminal value of the price process, a Delta hedge of the BlackâĂŞScholes model works well.
令 , 是 BS 模型下 时刻的价格.对冲策略为:
2.2 Hedging Strategies as Neural Networks-Deep Hedging
在对冲产品数很多等情况下时,可以将对冲策略用神经网络参数化.令期权的支付是对冲产品最终价值的函数,i.e.,.在马尔科夫模型中,可以用函数表示对冲策略: 对应这样一个神经网络:. 是网络参数.根据Buehler H, Gonon L, Teichmann J, et al. Deep hedging[J]. Quantitative Finance, 2019, 19(8): 1271-1291. 给定 的最优对冲可以如下计算 是凸的损失函数.
为了解决这个最优问题,采用随机梯度下降,随机目标函数 为: 记最优的参数 和最优对冲策略 .
假定激活函数和凸损失函数是光滑的.下面要证明 的梯度是: i.e.,我们可以把梯度移到随机积分中.为此,我们要使用下述定理.
定理 2.1:,令 是
Theorem 2.1. For ling, let be a solution of a stochastic differential equation as described in Theorem with drivers , functionally Lipschitz operators , and a process , which is here for all simply for some constant vector , i.e. Let be a map, such that the bounded càglàd process converges to , then holds true.
推论 2.2:,令 为对冲产品过程 的离散,使得定理 2.1 中的条件都满足.对应的对冲策略 由神经网络 给出,其中网络的激活函数有界 ,且导数有界.那么
(i) 随机积分在 点关于 导数 满足
(ii) 若当 时, ucp 收敛到 ,则离散积分的方向导数,i.e. 随着离散刻度 收敛到
ucp means uniform convergence on compacts in probability,i.e.,if for all . The notation is sometimes used, and is said to converge ucp to .
3. LSV的校准
考虑定义在某个概率空间 上的(1.1)LSV模型, 是风险中性测度.假定随机过程 固定.所以实际中我们可以先令 来近似校准其他参数并固定他们.
主要目标是确定符合市场数据的杠杆函数 ,根据通用近似定理(universal approximation properties),对其参数化.令 为欧式看涨期权的到期日.将 用如下神经网络近似 其中 , .方便起见,通常省略 .当我们写 时, 表示 时刻前所有的参数 .
训练过程中,我们需要计算 LSV 过程关于 的导数.以下结果可以看做 对应的链式法则.从附录 A 推导而来.
定理 3.1:令 为(3.1)形式,神经网络 有界且 ,导数有界且 Lipschitz 连续.则关于 在 点处的导数满足: 初值为 0.这个可以通过常数变易来解,i.e. 其中 表示随机指数(stochastic exponential).
Remark
(i) 只看存在唯一性的话, 为 (3.1) 形式,那么神经网络 有界以及 Lipschitz 足够了,.
(ii) 公式 (3.3) 可以用来倒向传播.
定理 3.1 保证了导数过程的存在唯一性.这也保证了基于梯度搜索的学习算法的建立.
下面叙述如何具体优化.为了记号方便,省略权重 和损失函数 对应的参数 .对每个到期日 ,我们假定有 个期权,行权价为 .对第 个到期日,校准函数的形式为 回忆 指的是对应到期日 和行权价 的模型期权价格. 是某个非负非线性凸的损失函数满足 对 . 是权重.
我们通过迭代地计算最优化问题(3.5),从 和 出发,计算 ,然后解决对应 的(3.5).为了简便记号,去掉 ,考虑一般的到期日 ,(3.5)变为 模型价格由下式给出 我们有 ,其中 那么校准问题变为寻找最小的 因为 是非线性函数,不是 B.1 中的期望形式,标准的随机梯度下降方法不能直接用.我们通过第二节中讲的对冲控制变量 (hedge control variates) 解决这个问题.
3.1 极小化校准方程
考虑标准的对(3.8) 的 Monte-Carlo 模拟: 对 i.i.d 的样本 .Monte-Carlo 误差以 递减.模拟次数 必须很大 .因为由于 非线性,随机梯度下降不能直接使用,所以看起来要计算整个函数 的梯度来最小化(3.9).但 ,这一做法计算成本太大且不稳定,因为要计算 项的和的导数.
一个方便的做法是应用对冲控制变量来降低方差,可以将 Monte-Carlo 的样本数 降为大约 .
假定我们有 个对冲产品(包含价格过程 ),用 表示,为 下的平方可积鞅,在 下取值.对 ,策略 使得 , 为常数,定义 则校准函数(3.8)和(3.9)可以通过替换 为 来定义,变为最小化 对此,我们应用如下梯度下降的变种:从初始猜测 出发,迭代计算 对某个学习率 ,i.i.d 样本 .其中 是基于梯度待确定的量,样本在每次迭代中可以一样,可以另取.本文中另取.
最简单情形下,可以令
注意到(3.10)中随机积分项的导数计算通常是昂贵的.我们进行下述改造.令 定义 : 然后令 注意到基于倒向传播,这一项计算起来是很简单的.Moreover, leaving the stochastic integral away in the inner derivative is justified by its vanishing expectation. During the forward pass, the stochastic integral terms are included in the computation; however the contribution to the gradient (during the backward pass) is partly neglected, which can e.g. be implemented via the tensorflow stop_gradient function.
关于对冲策略的选择,我们可以按照 2.2 节中的方法将其用神经网络参数化,并通过下式计算最优的权重 : 对 i.i.d 样本 和损失函数 .此处 这意味着迭代两个优化步骤,i.e.,优化(3.11)中的 (固定 ) 和(3.14)中的 (固定 ).
4. 数值实验流程
实际使用的 SABR-LSV 模型如下 参数为 ,初值有 . 和 是两个相关的布朗运动.
Remark:一般使用的是关于 的对数价格 .故模型也可写为: 注意到 是一个几何布朗运动,也就是说它有表达式:
生成样本
在已有文献中,有推荐的局部波动率函数族 如下: 其中 且参数满足如下约束: 令 , 如下定义: 文中作者修改为: 其中 注意到 与 有关.所以在做 Monte Carlo 模拟时,我们将 替换为 , 是 Monte Carlo 模拟的时间间隔. What is left to be specified are the parameters 模型变为: 上式是用来生成人工市场价格样本的.
所以我们实际的做法是随机对 中的 采样再根据 (1) 计算出价格,然后对 SABR-LSV 模型进行校准,i.e. 寻找使模型符合上述价格的参数 , 以及 .
到期日 ,每个到期日 对应行权价为 .用 Monte-Carlo 模拟以 间隔计算价格.
具体如下:
- 在 下对 以给定分布进行模拟.
- 对每个 ,根据(1)式计算 and strikes for and 对应的欧式期权的价格.每个 分别使用不同的 条布朗运动轨道.
- 保存这些价格数据
准备做的工作(弃案)
寻找最适合市场波动率曲面的“复合”模型,即假设市场波动率曲面实际是由一些波动率模型的凸组合决定的.
回忆:波动率曲面即隐含波动率以 :time to maturity 和 :log-moneyness 为自变量构成的曲面. 例如,我们可以假设当前 ,其中 .
大致做法
记号:分别以 、 记 Heston 和 rough 模型的参数集,以 、 记该两者通过神经网络训练得到的从模型参数到市场价格(隐含波动率)的映射,、 为前述凸组合系数.
我们这里考虑直接通过神经网络来学习市场波动率曲面 到凸组合系数 的映射.
我们对两个模型的参数以及 分别均匀采样,然后根据两者的模型分别模拟出不同凸组合下两者的复合波动率曲面,但要注意的是两者采用同一个参数 (即两个标准布朗运动的相关系数)并且一个凸组合下两模型使用同一条 Monte-Carlo 轨道.这时,忽略掉模型的参数,我们有了带有 标签的许多波动率曲面样本,我们利用前述 grid-based 的方法通过神经网络学习从波动率曲面到凸组合系数的映射.
知道了 后,如何校准出两个模型分别的参数?
LSV-ROUGH 模型的校准
模型:
杠杆函数:
主要共有两个神经网络,一个负责 Rough 的部分,一个负责 LSV 的部分.
一方面,Rough 部分的网络对应的即 Bayer 提出的 two-step 校准方法,即如下模型 ((1.1)中 时): 对应的从模型参数到模型对应价格的映射的网络.只需用人工模拟数据训练一次后,网络就固定住了,在校准等步骤中是不会再变动的.
回忆:用 记关于到期日和行权价的网格.则 step 1:学习映射 ,输入是 ,输出是 这样的 网格. 取值在 中,其中 strikes maturities 最优化问题变为如下: 其中 . Step 2:
另一方面,我们将 这个函数用网络近似,这个网络中的参数是随着校准不断变动的.具体地,令 为欧式看涨期权的到期日.将 用如下神经网络近似 其中 , .
为了记号方便,省略权重 和损失函数 对应的参数 .对每个到期日 ,我们假定有 个期权,行权价为 .对第 个到期日,校准函数的形式为 回忆 指的是对应到期日 和行权价 的模型期权价格. 是某个非负非线性凸的损失函数满足 对 . 是权重.
我们通过迭代地计算最优化问题(1.3),从 和 出发,计算 ,然后解决对应 的(1.3).为了简便记号,去掉 ,考虑一般的到期日 ,(1.3)变为 模型价格由下式给出 我们有 ,其中 那么校准问题变为寻找最小的 我们通过第二节中讲的对冲控制变量 (hedge control variates) 解决这个问题.
考虑标准的对(3.8) 的 Monte-Carlo 模拟: 对 i.i.d 的样本 .Monte-Carlo 误差以 递减.模拟次数 必须很大 .因为由于 非线性,随机梯度下降不能直接使用,所以看起来要计算整个函数 的梯度来最小化(3.9).但 ,这一做法计算成本太大且不稳定,因为要计算 项的和的导数.
一个方便的做法是应用对冲控制变量来降低方差,可以将 Monte-Carlo 的样本数 降为大约 .
假定我们有 个对冲产品(包含价格过程 ),用 表示,为 下的平方可积鞅,在 下取值.对 ,策略 使得 , 为常数,定义 则校准函数(3.8)和(3.9)可以通过替换 为 来定义,变为最小化
算法1:模型的校准步骤
-
# 初始化网络参数
-
-
# 定义初始模拟轨道数和初始步骤值
-
-
# 定义时间离散间隔和误差容忍度
-
-
:
-
-
# 计算此次切片的初始正规化权重
-
-
-
-
-
-
-
-
-
-
-
-
-
-
算法2:超参的更新
附录
证明:
首先定理 A.2 暗示了 的解存在唯一性.这里驱动过程是一维的 .事实上,若 有界,对 左极右连,对 Lipschitz 连续以一个与 无关的 Lipschitz 常数. 为 functionally Lipschitz,得到结论.这些条件由 的形式和 的条件保证.
为了证明导数过程的形式,我们对如下系统应用定理 A.3: 和 以及 在定理 A.3 中,. 为 ucp 收敛到 事实上,, 等度连续.因此,点点收敛暗示对 的一致连续.This together with being piecewise constant in yields: whence ucp convergence of the first term in (3.4). The convergence of term two is clear. The one of term three follows again from the fact that the family is equicontinuous, which is again a consequence of the form of the neural networks.
By the assumptions on the derivatives, is functionally Lipschitz. Hence Theorem A.2 yields the existence of a unique solution to (3.2) and Theorem A.3 implies convergence.
Proof. Consider the extended system and where we obtain existence, uniqueness and stability for the second equation by Theorem A.3, and from where we obtain ucp convergence of the integrand of the first equation: since stochastic integration is continuous with respect to the ucp topology we obtain the result.
文献
- 首次在波动率校准中运用神经网络 Hernandez A. Model calibration with neural networks[J]. Available at SSRN 2812140, 2016.
- rough波动率模型的神经网络校准 Bayer C, Horvath B, Muguruza A, et al. On deep calibration of (rough) stochastic volatility models[J]. arXiv preprint arXiv:1908.08806, 2019.和 Horvath B, Muguruza A, Tomas M. Deep learning volatility: a deep neural network perspective on pricing and calibration in (rough) volatility models[J]. Quantitative Finance, 2021, 21(1): 11-27. Github 代码
- LSV模型GAN校准 Cuchiero C, Khosrawi W, Teichmann J. A generative adversarial network approach to calibration of local stochastic volatility models[J]. Risks, 2020, 8(4): 101. Github 代码
- 损失函数中不同期权权重取法 Cont R, Ben Hamida S. Recovering volatility from option prices by evolutionary optimization[J]. 2004.
- fBm的MC模拟 Horvath B, Jacquier A J, Muguruza A. Functional central limit theorems for rough volatility[J]. Available at SSRN 3078743, 2017. Github 代码
- rBergomi提出 Bayer C, Friz P, Gatheral J. Pricing under rough volatility[J]. Quantitative Finance, 2016, 16(6): 887-904.